
Abstract
Policy formulation and implementation generate large volumes of text. However, since reading all relevant sources is often impossible, evaluators must navigate the complexities of selecting the appropriate technology to efficiently extract meaningful information from growing amounts of unstructured text. Text mining blends interpretative and statistical methods to generate novel insights, potentially contributing to evidence-based policy-making. At the same time, biases, a potential lack of accuracy, explainability, and transparency create ethical concerns and make it necessary to combine natural language processing and human judgment to avoid over-reliance on the capabilities of these methods and, in particular, large language models. This article provides practical guidance on how evaluators can use natural language processing to convert unstructured data from text to structured data. It presents a decision framework that accounts for the characteristics of the data, the nature of the task, and the expected results, facilitating the selection of the appropriate technique.
Introduction
The availability of organized and formatted data greatly facilitates valid, efficient, and replicable evaluation. An example of a resulting push for an increase in structured data is the global indicator framework to monitor and evaluate the 2030 Agenda for Sustainable Development. Databases and spreadsheets make it easier to monitor progress in areas such as poverty, hunger, health, education, gender equality, clean water, and climate action. Consequently, greater availability of structured data promises better evidence-based decision-making.
However, while the global indicator framework exemplifies the importance of structured data, much of the information relevant to evaluation remains unstructured, that is, is not organized in a tabular format or according to predefined fields. Examples of development evaluation include the documentation around development interventions such as proposals and progress reports, evaluations providing evidence on what works, and press and social media that reflect public opinion on development cooperation. Although these documents are structured into sections and the text has a syntactical and semantic structure, the data cannot be directly queried according to a consistent data model. Instead, making unstructured data accessible for evaluation requires more sophisticated methods to efficiently store, process, and analyze these large document collections, as well as to detect patterns and extract meaning.
Natural language processing (NLP) describes methods that enable computers to interpret or generate human language. The recent development and scaling of the transformer architecture combined with large-scale training on massive datasets has led to the emergence of sophisticated capabilities (Maslej et al., 2024b). Transformer-based language models are a specific type of neural network representing words contextually. These contextual representations enable the computer to gain a deep understanding of language for tasks such as text generation, classification, and summarization. This advancement, as well as the ability of transformers for parallel processing, has led to the development of large language models (LLMs), that is, systems trained on vast amounts of diverse text sources. However, using LLMs involves substantial costs, necessitating extensive resources or service-based hosting, which in turn impacts transparency and privacy. Consequently, classical robust NLP techniques remain valuable.
The use of NLP and data mining techniques to access and extract knowledge from text is known as text mining (TM). This involves applications that identify patterns and relationships within large volumes of text. They often use additional statistical methods and machine learning (ML) algorithms to automate tasks that were previously manual. Consequently, these advances allow evaluators to uncover insights that would otherwise be too time-consuming or difficult to find manually.
This article provides a practical guide to applying TM in evaluation, focusing on the process to convert unstructured text to structured data. As technological innovation rapidly reshapes the field, ensuring scientific rigor and practical usability poses a challenge. Striking a balance, we focus on well-established tools that have proven reliable, while at the same time recognizing promising opportunities of recent innovations. For example, recent developments such as retrieval-augmented generation (RAG) (Lewis et al., 2020), the Language Model Query Language (Beurer-Kellner et al., 2023) and Open Prompt (Ding et al., 2022) have significantly improved the usability of LLMs for evaluation. These tools enable the development of tailored language models for document collections and the integration of external knowledge sources, enhancing information retrieval tasks and usability. At the same time, they require substantial computational resources and careful oversight. Evaluation of model-generated output remains an open challenge, as scientific standards to assess their validity and reliability are still evolving and require further discussion within the scientific community. Privacy issues, such as the potential for unauthorized access to sensitive data, remain a significant concern when using language model services.
Another example is the easily accessible generative AI tools. They might appear as a one-stop solution for NLP tasks. Mostly, usage of these models relies on a chat interface for interaction, delivering answers within this framework. While practical for daily work—they excel at generating human-like responses—these tools are not optimized for specific quantitative NLP tasks and may lack the consistency required for annotation tasks or content-based empirical assessment. For instance, extracting topics from text using an LLM in a chat interface appears superior to using complex model approaches like BERTopic (Grootendorst, 2022). However, these interfaces do not provide topic distributions or scaled content annotation over large text collections. Instead, leveraging these models for complex TM tasks typically involves using API interfaces, such as that of OpenAI, within custom software applications. Therefore, we introduce the usage of LLMs, from a current perspective, as a foundational model for custom-developed procedures.
The applications of ML to evaluation are rapidly developing and are relevant for all aspects of evaluation. Head et al. (2023) estimate that more than two thirds of evaluation activities are affected by LLM, specifically the phases of evaluation design and analysis. The advent of LLMs holds great opportunities. At the same time, there are ethical concerns regarding their use such as low interpretability of outputs, the reproduction and amplification of inequity, and potential harm due to biases (Bommasani et al., 2021).
Ultimately, harnessing the potential of NLP and LLM to generate insights from unstructured text in evaluations can improve evidence-based policy-making. Similar to evidence-based medicine, where guidelines derived from extensive text-based reviews are developed with significant effort and increasingly supported by NLP (Nazi and Peng, 2024), the evidence-based process in policy-making, which also relies on the review of numerous texts, has the potential to be enhanced by NLP. First, by providing policy makers with more timely recommendations through improved efficiency. Second, by broadening the evidence base to include larger volumes of diverse textual information reflecting a wider range of perspectives.
The field of evaluation has been slow in adapting to new technologies (Nielsen et al., 2025a). In this article, we describe where NLP and LLMs can contribute to evaluation, that is, data collection, analysis, and reporting. Yet, we are still far away from fully automated evaluations where humans remain “outside-the-loop.” Such evaluations are currently neither feasible nor advisable. Consequently, current NLP methods are not a panacea and will not replace evaluators.
Unstructured text for descriptive and causal analysis
Innovations in TM and NLP have proven their practical utility in automatic content analysis. But the key challenge is turning the vast amounts of unstructured text into insights that can inform policy decisions. As the volume of data continues to grow, the role of TM and NLP in processing and interpreting this information will become increasingly indispensable to provide policymakers and the public with information on “what works” but also “why it works” and “under what circumstances.”
Digitization has significantly enhanced access to documents and increased the ability to store and handle data on an unprecedented scale. Building on this foundation, TM efforts usually begin by identifying relevant text sources and compiling them into a collection known as corpus.
Figure 1 presents a generalized workflow for utilizing unstructured data in evaluation. Starting with a corpus, the workflow typically consists of the following steps:
Preprocessing: Preprocess the corpus with appropriate NLP procedures. This includes optical character recognition (OCR) to convert scanned documents to machine-readable text, layout detection for tabular data, and the splitting of text into smaller word or subword units (tokenization).
Transformation: Apply NLP methods to transform unstructured data into a numerical representation. This involves feature engineering or embedding techniques and allows algorithms to process the data efficiently.
NLP and ML: Apply NLP or machine-learning methods to aggregate, categorize, or group the data. For example, this might involve frequencies of key terms over time, or the clustering of documents based on their topics.
Descriptive data analysis: Describe the information using quantitative or qualitative methods. This involves descriptive summaries of data, visualizations or statistical analyses. This step helps inform the subsequent stages through building or refining a theoretical model, formulating hypotheses, or selecting cases.
Theory: To enable causal inference, researchers need to make assumptions based on theoretical arguments and qualitative and quantitative evidence. These assumptions extend beyond empirical evidence, relying on inferences or interpretations that cannot be directly observed. They describe how variables are directly causally connected and, more importantly, which are not. These assumptions can be depicted in a causal graph.
Inferential analysis: The causal model, paired with data, allows causal inference. This ultimately enables effect estimation, counterfactual reasoning, prediction, and testing of causal mechanisms.
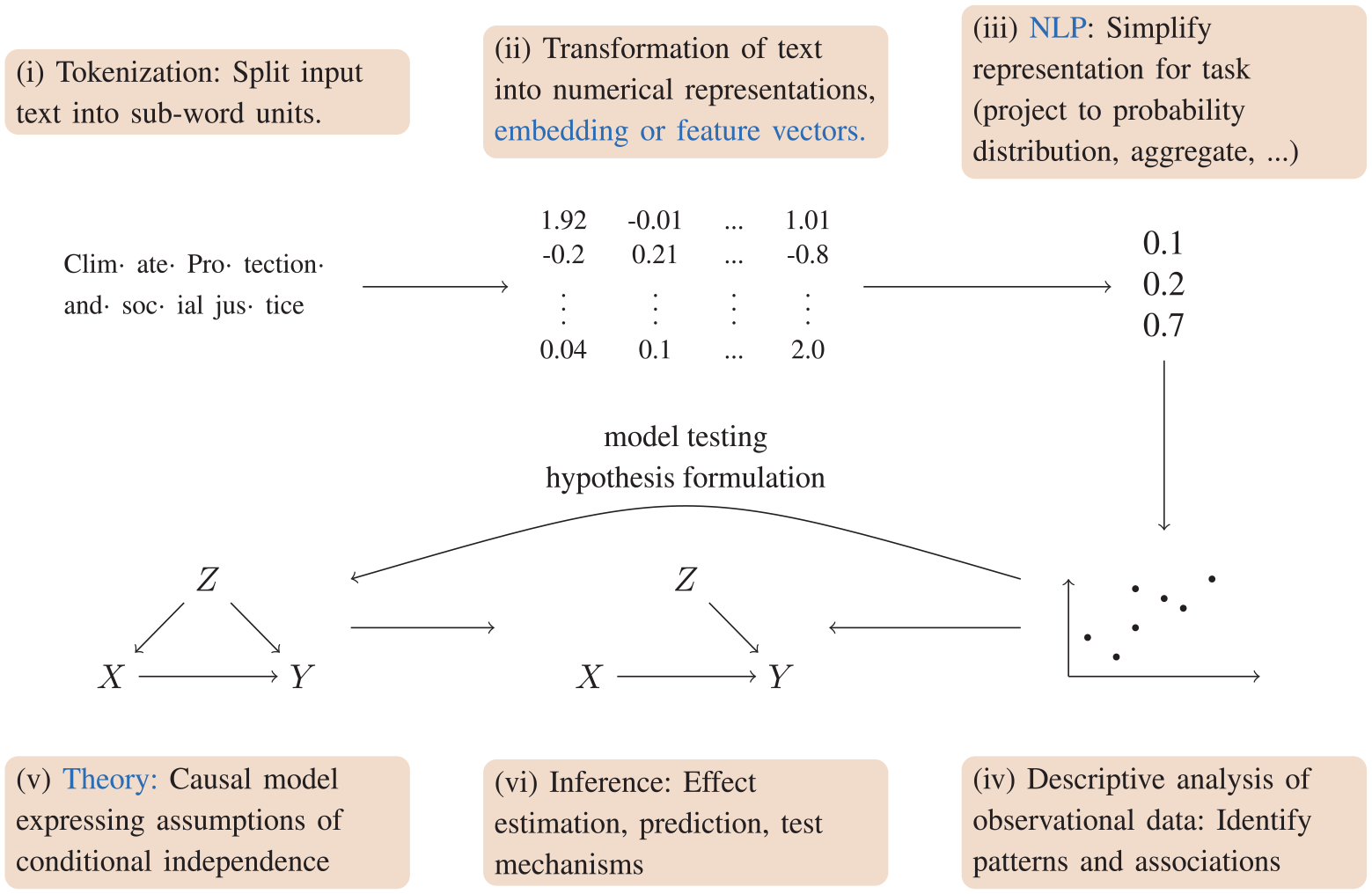
The figure illustrates the typical workflow to convert unstructured text to structured data and to put the data to use in descriptive and causal analysis.
This paper introduces a decision tree, based on academic research and practical experience, to guide the selection of methods for processing unstructured text data. The decision tree guides users through the implementation process, aiming to ensure that the chosen approach aligns with the characteristics of the data and the epistemic interest of evaluators. In addition, this paper outlines validation procedures and quality assurance. Practical examples demonstrate the application and we conclude with implications and future research directions for the evaluation community.
Related work
A growing body of literature on the intersection of computational techniques and text analysis demonstrates the transformative potential of text as data for evaluation and other disciplines. Grimmer et al. (2022) introduced the concept of “text as data” as a foundational approach in computational social science, emphasizing the potential of text analysis for understanding political behavior, communication patterns, and social trends. Treating text as a source of quantitative data, Grimmer et al. highlight how computational techniques could be applied to large text corpora, enabling researchers to extract patterns, categorize content, and generate insights unattainable through manual qualitative methods.
Other scholars have expanded on this framework. For example, Wiedemann (2016) describes methods for combining qualitative and quantitative approaches in TM, demonstrating their application in social science research. Furthermore, the Handbook of Computational Social Science (Engel et al., 2022) provides comprehensive insights into how these techniques are reshaping research methodologies. More recently, Dell (2024) provides an overview of deep learning methods for classification, document digitization, and data exploration in large text and image corpora.
The recent debate on the use of LLMs and NLP in the field of evaluation highlights potentials and challenges. An anthology by Nielsen et al. (2025b) discusses the impact of AI on program evaluation. Individual contributions examine the potential and risks associated with digital technologies in real-world evaluation scenarios. In a similar vein, a recent special issue (Mason and Montrosse-Moorhead, 2023) reflects on the impact of AI on evaluation theory and practice. Contributions in the field of evaluation have highlighted ethical and methodological challenges regarding biases, accuracy, explainability (Bouyousfi and Ouedraogo, 2024; Head et al., 2023).
At the same time, NLP has already shown its added value in policy evaluation. Gatto and Bundi (2025) discuss the use of quantitative text analysis in evaluations focusing primarily on a single method (Wordfish), which uses word frequencies to estimate the position of documents on a latent scale. They also discuss steps to transform text to data and present another way to systematize the field of quantitative text analysis methods. In contrast, our approach provides a comprehensive overview, focusing on general principles rather than in-depth examinations of specific techniques.
LLMs can assist in systematic literature reviews by efficiently extracting evidence from large amounts of unstructured texts such as journal articles (Marshall and Wallace, 2019; van de Schoot et al., 2020) rivaling human performance (Khraisha et al., 2024). LLMs have made it possible to make independent assessments of official reporting by allowing huge amounts of reporting data to be examined. Examples include the assessment of the transparency of climate finance reporting (Borst et al., 2023; Toetzke et al., 2022). Sentiment analysis allows the identification of attitudes from interview transcripts (Roy and Rambo-Hernandez, 2021) or Twitter messages (Rinaldi et al., 2025). Named Entity Recognition (NER), a technique for identifying and categorizing entities such as names and locations in text, enables geographical information to be extracted from evaluation reports and then used to locate projects for a more accurate and valid evaluation (Wencker and Verspohl, 2019). In addition, ML techniques allow the development and monitoring of target values for result indicators (Bonfiglio et al., 2023). Together, these examples highlight the growing importance of NLP and ML in improving the accuracy and efficiency of policy evaluation.
Core methods for processing unstructured text data
This section outlines the core methods of converting unstructured text into structured information. The presented methods automate code assignment to categorize and interpret data, transforming unstructured text into measurable sets of meaningful categories (Palanivinayagam et al., 2023).
ML
ML encompasses a variety of techniques for data analysis. Many state-of-the-art ML techniques, particularly in NLP, utilize deep learning, a subset of ML. Deep learning employs multilayered Neural Networks to automatically learn hierarchical representations from data (Rothman, 2023). This approach excels in tasks with complex patterns, such as image recognition and NLP, but requires substantial computational resources and large datasets. Effective ML, especially deep learning, demands significant computational resources, including graphics or tensor processing units, large datasets, and optimized algorithms.
The explainability of ML results differs between classical and deep learning methods (Miller, 2019). Classical ML algorithms, such as decision trees or linear regression, are easier to interpret because they provide clear and often intuitive decision rules or weightings linking input features directly to outputs. This allows researchers and practitioners to understand and explain how predictions are made. In contrast, deep learning models, particularly those involving deep Neural Networks, operate as black boxes due to their complex architectures and multiple layers of abstraction. While deep learning achieves superior performance on tasks involving high-dimensional and unstructured data, the intricate interplay of millions or billions of parameters within these models makes it challenging to trace how decisions are reached. This lack of transparency raises concerns in critical applications where understanding the decision-making process is as important as the accuracy of the predictions. Therefore, while deep learning offers advanced capabilities, it presents significant challenges in interpretability and explainability compared to classical ML methods.
Resource demands and differences in explainability necessitate careful decision-making when selecting ML methods, as these factors must align with the context and requirements. These considerations are systematically addressed in the decision tree presented below.
TM
TM is an interdisciplinary field that combines NLP, ML, and data mining to extract insights from unstructured text (Grimmer et al., 2022; Macanovic, 2022). The TM process begins with the application of NLP techniques to prepare and linguistically process the raw text (see Figure 1). This involves tasks such as tokenization (word separation), part-of-speech tagging (word class prediction, e.g. verb, noun), and syntactic parsing (inference of grammatical sentence structures), which convert the text into a structured format suitable for further analysis.
NLP leverages linguistic knowledge including syntactic structures, semantic relationships, and pragmatic rules to process language. This provides the foundation for features, e.g. word embeddings, n-grams, or part-of-speech tags, that are used in subsequent ML algorithms. These algorithms benefit from linguistic knowledge integration, enabling effective learning from textual content and transforming unstructured text into actionable insights that support decision-making and knowledge discovery across various domains.
LLMs
Pre-trained language models represent a breakthrough in NLP. Pre-trained models such as BERT (Devlin et al., 2019) and RoBERTa (Liu et al., 2019) consistently achieve top results on downstream classification tasks (He et al., 2023; Yang et al., 2019). LLMs, such as GPT-3 (Brown et al., 2020), have expanded possibilities by enabling previously infeasible tasks. Further finetuning of these LLMs to follow instructions (Ouyang et al., 2022; Taori et al., 2023) has resulted in the development of modern chatbot interfaces and conversational LLM systems.
Unlike traditional models, which required extensive preprocessing and feature engineering, and suffered from vocabulary limitations, LLMs are mostly independent of these challenges. This allows them to automatically handle diverse languages, dialects, and domain-specific jargon. Pretraining on vast and varied datasets encodes deep language understanding directly into the model, allowing LLMs to generalize across a wide range of tasks with minimal task-specific training. This often eliminates the need for elaborate preprocessing or large volumes of labeled data.
The emergence of instruction-tuned models—fine-tuned to generate responses based on input prompts—further enhances the flexibility of LLMs. These models produce precise context-aware responses in various applications, thanks to their ability to dynamically adapt to specific instructions. This combination of comprehensive language understanding, flexibility, and reduced dependence on manual preprocessing, all while achieving top scores, solidifies LLMs as powerful tools in modern NLP.
Decision framework for processing unstructured data in evaluation
Processing and evaluation of unstructured data require a carefully designed decision process that takes into account the specific characteristics of the data, the nature of the task, and the expected outcomes. Prior knowledge of these aspects is essential to select the most appropriate methods and approaches. This section introduces a decision framework that aids in systematically navigating these choices, ensuring that the analysis is both effective and aligned with the research objectives.
The decision tree presented in Figure 2 serves as a structured guide for analyzing unstructured text data with the goal of investigating specific concepts of interest. These concepts may include identifying geographic positions mentioned in a text, detecting topics, or analyzing the sentiment expressed in social media posts.
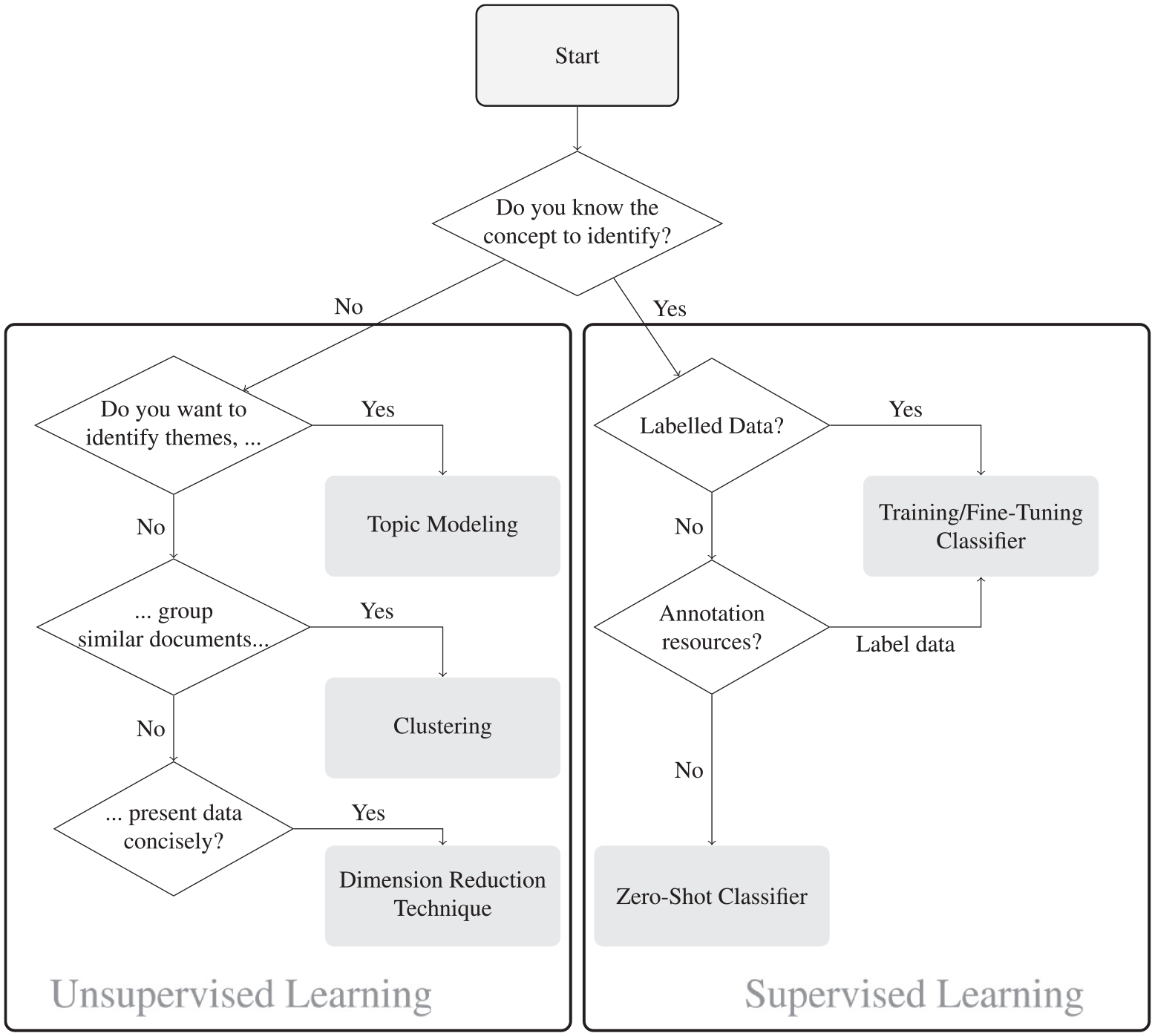
This decision tree guides the selection of appropriate techniques for analyzing unstructured text data. It includes unsupervised learning methods for exploratory analysis and supervised learning techniques for identifying known concepts within unstructured text.
Do you know the concept to identify?
Evaluation usually starts with questions that then guide the selection of data and methods. However, evaluation questions may not include specific concepts to investigate, e.g. when evaluators are interested in identifying potential explanatory factors of an outcome. In this case, the factors are not yet known. Hence, the first decision when approaching data is to ask “Do I have a specific concept in mind that I am investigating?”.
If we know this concept (e.g. a specific code, class, or context) supervised learning techniques are appropriate. Otherwise, unsupervised learning techniques allow the identification of patterns in text.
Unsupervised learning
Unsupervised learning, particularly clustering, involves grouping data without predefined labels. Algorithms detect patterns based solely on the inherent similarities of data points, making them useful for exploratory data analysis where the structure of underlying distributions is unknown. In these cases, a text (e.g. a document, article, or paragraph) can be converted into a numerical representation, known as an embedding (Figure 1). Embeddings map text to a point in a high-dimensional vector space, where each dimension corresponds to a specific text feature, such as sentiment. The text’s position in this space reflects its characteristics, enabling the clustering of similar documents or the identification of topics within texts through comparison of their positions. The grouped data can then be summarized through various methods, such as keyword representations, to understand the meaning and context of detected groups.
Use for evaluation
Unsupervised learning is well suited to identify patterns in data that are unknown and not immediately apparent to human readers and to use them to generate hypotheses. This step is illustrated by the curved arrow in Figure 1.
However, evaluators should avoid jumping from regularities to premature conclusions or judgments about causal relations and policy advice. This is because causal inference relies on assumptions that cannot be deduced from observational data (Pearl and Bareinboim, 2014). Hence, unsupervised learning techniques are insufficient for causal or counterfactual reasoning, such as in attribution or contribution analyses.
At the same time, the discovery of causal relations often begins with an identified regularity or correlation. Thus, unsupervised learning is well suited as an initial step in creating causal models of evaluands, as seen in theories of change. Uncovering patterns in text can inform reverse causal questions (Gelman and Imbens, 2013), theoretical models, and hypotheses.
However, unsupervised learning can also be useful in later stages of an evaluation to test and refine existing causal models. For example, unsupervised learning can identify additional potentially confounding variables.
Do you want to identify themes?
In the early phases of an evaluation, evaluators may want to detect latent themes in large unstructured text data for exploratory purposes. Topic Modeling is a suitable method for this. Topic Models are statistical tools that uncover hidden topics in a collection of documents by modeling each document as a mixture of topics, where the topics themselves are represented as distributions over words (Blei et al., 2003; Roberts et al., 2019). This approach reflects how documents may cover multiple topics in varying proportions, with each word associated with one of those latent topics. For instance, a document might be 40 percent about sports and 60 percent about technology, and the words in the document will be drawn based on these proportions. Through this probabilistic process, Topic Models help identify recurring themes in documents without requiring prior knowledge of their content.
Recently, language models have contributed new approaches to the Topic Modeling paradigm. Unlike probabilistic models, BERTopic transforms documents into dense vectors using BERT embeddings and applies clustering algorithms to group similar document embeddings (Grootendorst, 2022). These clusters represent topics, described by frequently occurring words, enabling flexible, data-driven topic discovery. By capturing word context and disambiguating meanings, BERTopic generates more coherent and semantically meaningful topics than probabilistic models (e.g. Latent Dirichlet allocation).
Use for evaluation
Topic Modeling can be applied to support theorizing by investigating potential causes of successful policy interventions. The automated extraction of topics from evaluations and scientific research facilitates the development of causal models including the identification of relevant variables, potential relations among these variables, and hypothesis formulation (see step iv in Figure 1). For instance, Kumar and Ng (2022) identify topics related to growth in global renewable energy projects.
In contrast to qualitative comparative research, Topic Models facilitate the efficient exploration of large collections of evaluation reports, scientific studies, and other relevant documents by extracting references to influential topics such as political institutions or economic performance. Cintron and Montrosse-Moorhead (2022) illustrate how Topic Modeling allows for integration of big data in evaluation.
Do you want to group similar documents?
The grouping of similar texts is another important task in early stages of evaluations. While Topic Modeling regards documents as mixtures of topics, clustering partitions text data into mutually exclusive subsets. Text clustering groups similar documents based on shared patterns, such as common entities, topics, or geographic references, allowing for a coherent organization of documents before assessing their contents.
Unlike Topic Modeling, which uncovers latent topics, clustering focuses on identifying overall document similarity. This can be based on features such as shared named entities, topics, or contextual similarities. BERTopic, for example, leverages BERT embeddings to cluster documents based on their dense vector representations, capturing deeper semantic relationships and word context. The clusters can then be analyzed to understand the overarching themes or characteristics of the grouped documents. Text clustering is a well-established technique and has been explored in various domains to improve information retrieval and document classification systems (Aggarwal and Zhai, 2012). This approach enables more nuanced analysis, such as clustering documents by common geopolitical references or similar events, enhancing content exploration and organization.
We can differentiate between partitional clustering and hierarchical clustering. In partitional clustering, a set number of clusters is created, while hierarchical clustering arranges data in a tree-like structure. This enables clustering at different levels of similarity, with broader clusters at the top and more specific clusters at the bottom. This approach enables the analysis of relationships between data points at varying degrees of similarity, offering flexibility in exploring broad groupings or more detailed sub-clusters based on the desired granularity.
Use for evaluation
Raveh et al. (2020) used clustering to uncover trends within audit reports, allowing evaluators to focus on specific groups of reports. This approach improves the efficiency of the evaluation process. It also improves the representativeness of the findings by supporting stratified sampling across different clusters of reports.
Do you want to present data concisely?
The primary goal of dimensionality reduction is to project high-dimensional data, such as document embeddings, into a lower-dimensional space (e.g. from hundreds of dimensions to two or three) while preserving the structure and relationships within the data as much as possible, making it especially useful for visualization (Waggoner, 2021). Techniques such as Uniform Manifold Approximation and Projection (UMAP) and t-Distributed Stochastic Neighbor Embedding (t-SNE) reveal patterns, clusters, or separations that may not be visible in high dimensions (McInnes et al., 2020).
The outcome of these methods is a low-dimensional projection that visually explores the data by showing relationships between points (e.g. documents) in an easily interpretable way. However, these projections do not assign explicit cluster labels; the visual clusters that emerge are based on proximity in the reduced space but do not strictly correspond to clusters in the original high-dimensional space. These algorithms focus on preserving local structure, that is, relationships between neighboring points, rather than performing clustering. As a result, visual similarity in UMAP or t-SNE can help assess relationships between topics or document clusters, but the analysis should account for the fact that visual groupings reflect structure rather than precise clustering.
Dimensionality reduction is therefore ideal for exploring and analyzing complex data, particularly when checking for patterns or relationships that would be difficult to discern in higher dimensions.
Use for evaluation
Dimensionality reduction is particularly useful early in the evaluation process. It can be a pragmatic tool to make large volumes of text data more comprehensible to evaluators. For instance, evaluators might be interested in investigating social media posts pertaining to a certain policy. Dimensionality reduction might visually reveal patterns of similar posts and outliers with unique or extreme perspectives. While some information is necessarily lost (e.g. subtle differences in sentiments of posts), dimensionality reduction techniques can reveal patterns in the data that were previously unnoticed. Dimensionality reduction is an initial exploratory technique in evaluation, and thus typically a preliminary step before moving on to other techniques like clustering, classification, or causal analysis.
Supervised learning
Supervised learning focuses on assigning labels from a predefined set of classes to text. Assigning labels to paragraphs and documents is known as text classification. Labels can also be applied to specific words or word spans in a text. This is token classification with the most prominent example being NER. If a set of manually labeled items is available, supervised learning typically involves ML algorithms that adapt to these examples.
The current best-performing approach for supervised learning is fine-tuning pre-trained Neural Networks, such as language models (Devlin et al., 2019; Howard and Ruder, 2018; Yang et al., 2019). Fine-tuning involves adapting the parameters of a pre-trained model using labeled data to suit a specific task. This requires some expertise and depends on the right choice of soft- and hardware (which will be discussed in a later section). Neural Networks have consistently outperformed traditional ML algorithms (Kim, 2014), and fine-tuning has consistently outperformed earlier Neural Network approaches in NLP (Akbik et al., 2018; Liu et al., 2019; Peters et al., 2018). To achieve optimal performance in text classification, fine-tuning language models is currently the most effective method, with a variety of base models available (Wolf et al., 2020).
Use for evaluation
Supervised learning is particularly useful for extending analyses from samples to entire datasets. An evaluation of climate finance reporting provides an example. To assess the credibility of reported figures, researchers used to manually read through a sample of project descriptions to re-evaluate their climate relevance. Borst et al. (2023) then used supervised learning to train a classifier to re-evaluate more than 1.5 million project descriptions. The application of supervised learning greatly expanded assessments of reporting credibility that previously relied on small, manually evaluated samples.
Is labeled data available?
The first step in deciding on an appropriate approach to classification with supervised learning is determining whether labeled data is available. In ML, a label is a specific identifier or category assigned to data instances, providing contextual information about them. Labels link unstructured text data to structured data and serve as the ground truth in supervised learning, where each piece of unstructured text data is associated with a corresponding label that indicates its class or category.
If labeled data exists, it can be used to train a model, extending learned patterns to the broader dataset. If labeled data is not existent, evaluators must assess whether resources are available for manual annotation, as discussed in the next section.
Do I have the resources for annotation
If no labeled data is available, evaluators should consider creating such a dataset. Classifiers trained on task-specific data are currently the most effective way to achieve high performance (Bucher and Martini, 2024).
In manual labeling, annotators associate each text sample with the correct category or class. Although resource-intensive and time-consuming, this method is highly accurate and allows for precise control over the labeling process. Manual labeling is often used when high-quality training data is essential.
Tools such as Doccano and Argilla streamline the annotation process by providing user-friendly platforms for annotation. Doccano is an open-source text annotation tool designed for tasks such as text classification, NER, and sequence labeling (Nakayama et al., 2018). It features a web-based interface for labeling large datasets and supports collaborative labeling. The tool allows data export in formats compatible with common ML frameworks, facilitating the integration of labeled data into the model training pipeline.
Argilla is another open-source tool that supports text annotation and provides active learning and model-assisted labeling features. Argilla enables annotation for text classification, NER, and other NLP tasks, while integrating ML models to suggest labels or highlight uncertain cases, increasing the efficiency of the labeling process. This active learning approach reduces manual effort by focusing on the most informative examples. Argilla also offers APIs for integration with Python workflows, automating parts of the annotation process, and integrating it with existing ML pipelines.
Use in evaluation
Ziulu et al. (2025) describe the use of supervised learning to identify World Bank projects that reference the World Bank’s Doing Business report or indicators. The evaluators first manually labeled a set of 372 projects and then used this set to classify over 5000 projects, thereby broadening the evidence base of the evaluation. The example also illustrates the resource-intensive process of creating a high-quality training dataset through manual labeling when the evaluand is complex.
Active learning
When fully annotating large datasets is infeasible, compromises are necessary in the amount and process of annotating training data. Active learning is an iterative process in which a model is trained on a small set of labeled data and then used to identify the most informative or uncertain samples from a larger pool of unlabeled data. These selected samples are then labeled by human annotators and added to the training set, refining the performance of the model with minimal labeling effort (Schröder and Niekler, 2020). This approach reduces the labeling burden and improves the model’s performance with fewer labeled examples. For instance, the small-text Python library (Schröder et al., 2023) is a specialized tool designed to facilitate active learning workflows in NLP tasks, particularly text classification.
Few-shot learning
Few-shot learning involves finetuning a pre-trained model with a minimal amount of labeled data, sometimes as few as a handful of examples per class (Brown et al., 2020; Muller et al., 2022; Perez et al., 2021). Leveraging the vast knowledge encoded in pre-trained LLMs, few-shot learning can achieve high accuracy with very limited labeled data, making it a practical approach when collecting large datasets is not feasible.
Few-shot learning can be effectively implemented using Hugging Face or the OpenAI API. With Hugging Face (Wolf et al., 2020), few-shot learning involves selecting a pre-trained model, preparing a small dataset with a few labeled examples per class, and fine-tuning the model using the Trainer API. Despite limited data, the model leverages pre-trained knowledge for effective generalization. Alternatively, when using generative classifiers, few-shot learning is achieved by constructing prompts that include a few labeled examples and passing them to the model. The model then uses these examples to classify new inputs. In the case of OpenAI’s GPT model, this can be achieved via an API call. Both approaches enable efficient task performance with minimal labeled data.
External data
In some cases, existing labeled datasets from related domains can supplement the training process. This may involve techniques such as transfer learning (Pan and Yang, 2010) or distant supervision (Mintz et al., 2009). These paradigms leverage similar datasets or larger amounts of unlabeled data to improve performance when only a small task-specific dataset is available. Using such external resources can significantly reduce the need for manual labeling while still providing relevant knowledge to the classifier.
These approaches provide diverse pathways to address the challenge of training data scarcity. Whether leveraging advanced techniques like few-shot learning or combining manual and automated strategies, these methods enable the development of effective classifiers that can operate with limited labeled data.
Zero-shot classification
Finally, in scenarios where labeled data is unavailable and generating new data or training models is impractical or impossible, zero-shot classification offers a possible solution to text classification, provided the set of classes is predefined, unlike in unsupervised classification.
Zero-shot classification enables models to assign categories to text without needing specific labeled examples for those categories. This approach leverages the transferable knowledge encoded in pre-trained language models. Approaches include reusing models trained for other classification tasks (Muller et al., 2022; Schick and Schutze, 2021; Yin et al., 2019), predicting labels using generative foundation models like GPT-3 (Brown et al., 2020) or describing the task to instruction-following models such as Llama (Touvron et al., 2023) or OpenAI’s GPT. These models can recognize relationships between input text and target labels, even without prior exposure to task-specific examples.
While zero-shot text classification remains an active area of research (Kumar et al., 2024; Sinha and Singh, 2024), generative models, such as GPT-4 variants, have recently outperformed other zero-shot methods (Bubeck et al., 2023; Gilardi et al., 2023; OpenAI, 2023). If a closed-system black-box classifier is inadequate for a specific task, a wide range of open-source solutions is now available (Chiang et al., 2023; Jiang et al., 2023; Touvron et al., 2023).
However, when performing text classification without labeled datasets, it is essential to develop a robust strategy to build an effective and accurate classifier. Evaluating the performance of zero-shot models presents unique challenges. Traditional metrics like accuracy or precision may not fully capture the model’s ability to generalize across diverse and unseen categories. The lack of labeled ground truth complicates evaluation, and relying on proxy tasks or human judgment can introduce subjectivity and bias, making a robust assessment difficult.
Use in evaluation
Zero-shot classification represents the cutting edge of NLP research. Thus, its performance and reliability in practical applications are still under active discussion (Ma et al., 2021; Reiss, 2023). Consequently, applications of zero-shot classification techniques in high-stakes environments, such as evaluation and policy advice, are still rare. Trajanov et al. (2023) compare ChatGPT as a zero-shot classifier with ClimateBERT (Webersinke et al., 2022), a text classification model that detects relevance to climate aspects in texts. Gilardi et al. (2023) demonstrate that GPT 3.5turbo outperforms manual annotators in text annotation, a classification task. Auzepy et al. (2023) analyze climate-related disclosures from banks that endorsed the recommendations on climate-related financial disclosures using zero-shot text classification. Luo et al. (2024) explore the feasibility of using zero-shot classification to automate the extraction of preventive care criteria, risk factors, and services from clinical guidelines for potential integration with Electronic Health Records (EHRs). However, these studies mostly present evaluations of zero-shot performance and feasibility studies.
Key considerations for practical method implementation and evaluation
The practical implementation of text analysis requires attention to three considerations. First, an iterative mixed-method research approach that integrates both qualitative and quantitative methods is essential to capture the complexity of phenomena. Second, a thorough assessment of the validity and reliability of the results ensures that the findings are credible and consistent. It requires careful, independent verification to ensure that the integration of qualitative and quantitative insights has yielded reliable and meaningful outcomes that can be confidently interpreted. Third, the choice of hardware and software is crucial for the efficiency and feasibility of applying the chosen method.
Qualitative and quantitative methods: Epistemic considerations
TM is an iterative mixed-methods approach combining quantitative and qualitative reasoning. Qualitative content analysis examines non-numerical data theory-driven to understand patterns, themes, and meanings (Bhattacherjee et al., 2019), while TM, especially in social and political science, emphasizes empirical recognition of language patterns and reasoning (McEnery and Brookes, 2024), highlighting a fundamental epistemological difference. Critics argue that TM methods produce limited scientific contributions to the social and political sciences due to their positivist approach (Angouri, 2018; Baxter, 2018; McEnery and Brookes, 2024).
Integrating a theory-driven, mixed-methods approach enhances TM’s applicability to critical analysis. Combining qualitative validation with rigorous quantitative measurement strengthens the reliability and depth of research findings. Sequentially applied, TM identifies patterns, while subsequent manual reading and coding validates and interprets findings to ensure nuanced meanings and complex relationships are accurately captured. In contrast, integrating TM methods into qualitative research offers a promising avenue for automating aspects of the coding process, enhancing efficiency (Rutkowski et al., 2022). By blending automation with manual expertise, researchers can manage large-scale qualitative data while maintaining the richness of interpretation.
With the advent of ML and LLMs, the distinction between qualitative content analysis and quantitative text analysis has become blurry. LLMs use contextual embeddings, interpreting text in a more context-aware manner. As a result, the gap in understanding text between human readers and ML approaches has significantly narrowed. However, quantitative models may still miss nuances, especially in transfer learning, where models are applied to contexts other than those they were trained on.
Validity and reliability of results
Randomness and reliability in model training, evaluation, and results
Stochastic processes play an inherent role in the training and inference phases of Neural Network-based ML algorithms, introducing random variability that influences outcomes (Goodfellow et al., 2016).
Training Neural Networks is a random process, and two instances of the same model with identical hyperparameters can yield different results. However, fine-tuned classification models produce deterministic predictions. The same input consistently produces the same output (Guo et al., 2017). This behavior changes when transitioning to generative models which generate the next token through probabilistic sampling. For example, methods such as zero-shot classification require prompting LLMs, thus using generative paradigms. The inference algorithms for Topic Models are another example of non-deterministic results (Grootendorst, 2022; Maier et al., 2018).
These differences have implications for model evaluation. In fine-tuning tasks, the availability of labeled data allows deterministic evaluation using metrics such as the F1 score, precision, and recall (Christen et al., 2024). Non-deterministic outputs complicate evaluation (Holtzman et al., 2020), affecting scientific reproducibility (Pineau et al., 2021). For example, two researchers using the same model and data may obtain slightly different results, even with identical prompts. Some of these issues can be mitigated by setting random seeds, though this approach is not always sufficient, particularly for large-scale models (Melis et al., 2018).
Both supervised and unsupervised learning can utilize either deterministic or non-deterministic algorithms. This is crucial for understanding algorithm behavior. Evaluating the reliability of these algorithms involves checking if their results are consistent and stable. Just as in content analysis, where the reliability of human-created annotations is assessed (Krippendorff, 2004), the reliability of non-deterministic algorithms must also be evaluated. This can be achieved through repeated experiments, quantifying deviations with stability measures, or conducting qualitative checks. Cross-validation strategies and ensemble learners (Zhang and Shafiq, 2024) are effective methods to ensure reliability. In contrast, more traditional approaches, such as fine-tuning language models or using traditional classification tasks, are easier to validate making them preferable in certain research contexts.
Transparency and fairness
Transparency and fairness in AI are closely related to the field of interpretable AI, often referred to as algorithmic transparency, which aims to make the decision-making processes of AI systems more understandable. Research has identified political (Motoki et al., 2024) and religious (Abid et al., 2021) biases in large-language models. However, transparency introduces additional complexities, including concerns about data privacy, socioeconomic factors, and legal and ethical considerations (Haresamudram et al., 2023; Larsson and Heintz, 2020). The deployment of LLMs in diverse environments and the presence of unforeseen biases pose significant challenges to ensuring transparency in AI applications and human−computer interaction (Liao and Vaughan, 2023). It has been suggested that transparency, with a particular focus on ethical concerns, should be integrated into the evaluation process of all LLMs (Bommasani et al., 2023; Liang et al., 2023). However, proprietary technologies that dominate many LLM deployments are recognized as major barriers to transparency (Liao and Vaughan, 2023). In addition, public understanding of what these models can and cannot do is often misaligned with reality (Liao and Vaughan, 2023). Furthermore, there is a persistent trade-off between transparency and performance, with some systems prioritizing performance over openness (Maslej et al., 2024a).
Explainability
Explainability is a critical consideration in TM, particularly when assessing ML decisions, as its importance varies depending on the application and the analyst’s needs. Modern LLMs based on deep learning and transformers operate as “black boxes” with highly complex internal representations that are difficult to interpret. While these models excel in performance and can capture nuanced language patterns, they do not readily offer transparency regarding how decisions are made. If explainability is not a priority, these models are well-suited for tasks requiring high accuracy and flexibility.
Conversely, classical ML approaches, such as logistic regression, Naive Bayes, linear Support Vector Machines (SVMs), and decision trees, provide a clear understanding of the parameters and features that lead to specific outcomes. These models allow analysts to trace decisions back to specific inputs, making them ideal when transparency and interpretability are necessary. For instance, a decision tree’s structure explicitly shows the decision path, while regression models provide coefficients that quantify the impact of each feature. In SVMs, each feature is assigned a weight that reflects its importance in classification. Features with high positive weights are associated with one class, while those with high negative weights are associated with the opposite class. Analysts can examine these weights to understand which features influence the classification.
However, when explainability requires a qualitative approach rather than purely statistical analysis, LLMs can still provide valuable insights. Ongoing research is focused on making the decisions of these models more interpretable (Molnar, 2019). Post hoc explanations for model outputs can be explored at different levels. At the mathematical level, explanations may focus on activations and weights (Shrikumar et al., 2017; Simonyan et al., 2013), while at the engineering level, they often target features (Du et al., 2019; Molnar, 2019). In addition, in generative models, user-friendly textual explanations or a chain of thought may clarify a model’s decisions (Bubeck et al., 2023; Wei et al., 2022). Thus, the choice of model in TM depends on the trade-off between the need for interpretability and the benefits of more advanced, though opaque, models.
Model performance evaluation
Model performance evaluation in TM is crucial for ensuring the reliability, validity, and utility of individual steps or models. Model evaluation in TM can be broadly divided into quantitative and qualitative evaluations, both of which play distinct, yet complementary roles in assessing performance and the quality of outputs. Unlike a mixed-method approach, the focus here is on evaluating the model’s performance rather than directly answering the research question.
Quantitative evaluation typically involves statistical measures that assess a model’s accuracy, precision, and overall performance. Common metrics include precision, recall, and the F1 score, which balances precision and recall, providing a single metric reflecting both aspects of performance. In classification tasks, these metrics assess how well the model distinguishes between different categories.
In unsupervised tasks, such as clustering, evaluation might focus on metrics like the silhouette score or intra-cluster distance, which assess the cohesion of clusters by measuring how close data points within the same cluster are, compared to those in different clusters. These metrics assess how effectively the procedure groups the data and how distinct the resulting clusters are.
Qualitative evaluation, on the other hand, involves manual inspection of the model’s outputs to assess their contextual relevance, interpretability, and identify systematic errors. Identifying and fixing these errors helps refine the model by correcting biases and improving interpretation. For instance, in NER, qualitative checks might verify that the model does not incorrectly infer locations based on prepositions or systematically overlook domain-specific names.
Another aspect of qualitative evaluation is plausibility, particularly in time series or trend analysis. Here, quantitative results are cross-referenced with known events or expected outcomes to validate the predictive capabilities of the model. For instance, if a model predicts a surge in online discussions about a specific topic, this surge should align with real-world events. This can be achieved by qualitatively reviewing relevant text samples to confirm whether the increase in mentions is accurately identified or reflects a false bias.
In summary, a rigorous evaluation process in TM integrates both quantitative and qualitative approaches. Quantitative metrics provide objective measures of model performance on test samples, while qualitative assessments ensure that the model’s outputs are meaningful, relevant, and plausible. By combining these approaches, models can be more comprehensively refined and validated, ultimately leading to more reliable and actionable insights.
Choice of software and hardware
We have presented how to start implementing TM for evaluation, which involves selecting methods using the proposed decision framework based on the nature of the data, goals, and the need for explainability or automation. The process starts with collecting and processing text data into an analyzable format and involves further application of NLP, ML and statistics. Scripting languages like Python and R are standard tools for those tasks due to their flexibility and extensive libraries. Python is favored for text processing and ML, while R is effective in statistical analysis. GUI tools, for example, RapidMiner and KNIME (Bartschat et al., 2019), also offer user-friendly environments for TM, but still require a solid understanding of the underlying ML and language models for effective use. Educating evaluators in scripting languages like Python and R, or involving external experts, is the key to integrating TM into evaluation processes. Given the widespread use and accessibility of resources, we would argue that it is realistic to include this skill requirement in the training curriculum for evaluation professionals.
However, processing large volumes of text data on a laptop or local machine may be limited by computing power, especially with LLMs or complex analyses. In such cases, access to high-performance computing resources, such as computing centers or cloud-based solutions, becomes essential.
For organizations without in-house expertise, cloud-based services such as Amazon Comprehend, Google Cloud NLP, and OpenAI provide robust alternatives. These platforms offer powerful APIs accessible via Python, allowing seamless integration into workflows. In addition, their GUI-based interfaces simplify certain tasks, though a fundamental understanding of ML and NLP remains essential.
When using cloud-based services, organizations must actively ensure that data storage and processing align with legal frameworks. For instance, server location can impact compliance with data protection requirements such as the General Data Protection Regulation. Moreover, the provision of an AI system or its use in the EU might require registration in EU databases under the EU Artificial Intelligence Act.
Discussion and concluding remarks
The expanding body of research combining computational techniques with text analysis underscores the significant impact of using text as data across various disciplines, including evaluation. Modern methods for analyzing unstructured text enable both descriptive and causal analyses. These approaches rely on ML, LLMs, NLP, and TM, each with its own implications for validity, applicability, and specific use cases. In response, we propose a decision process to guide the processing of unstructured text, particularly in the context of evaluation. We hope this process will be useful for experts with limited experience in these techniques, helping them navigate the complexities of selecting the appropriate technology or algorithm for working with large text datasets.
The proposed approach aims to simplify the decision-making process by breaking down requirements into identifiable and actionable questions. In addition to the choice of algorithm, it is crucial to consider other constraints, such as result validity and resource requirements. Automated text analysis in domain-specific tasks like evaluation not only demands quantitative rigor but also requires methodological checks for qualitative measures, ensuring the accuracy of the data and addressing concerns about bias.
We consider this paper to be a small step toward supporting the uptake of NLP in evaluation. As the field of NLP is rapidly evolving, the decision tree might need regular updates to incorporate methodological innovations. This pertains less to the tasks than to the proposed methods. A possible future modification is to include methods that have the potential to assist humans in causal inference (steps v–vi in Figure 1) (Kıcıman et al., 2024).
Evaluations serve the key functions of ensuring accountability and improving decision-making through learning. Stakeholder involvement is often key to providing useful and actionable evidence. Using text as data, evaluators can more effectively fulfill these functions with modern methods of text analysis. NLP enables the analysis of large amounts of data, such as policy documents, interviews, or social media, far more quickly and often with human-like accuracy, generating more comprehensive insights and better-informed recommendations. Once implemented, these methods also enable faster reporting, which is particularly important as datasets grow larger and the number of documents to be reviewed increases in standardized evaluation processes.
In this context, TM facilitates a more inclusive and stakeholder-oriented evaluation. Increased availability of digital text through digitization makes it necessary to go beyond close reading of sources by humans. In addition, TM promises to generate more complex and comprehensive recommendations while streamlining accountability reporting for organizations. These methods not only address the growing need to process unstructured datasets more efficiently but also enhance the depth and cost-effectiveness of evaluation processes. By leveraging automation, the entire process – from comprehensiveness to cost-effectiveness – can be significantly improved.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.