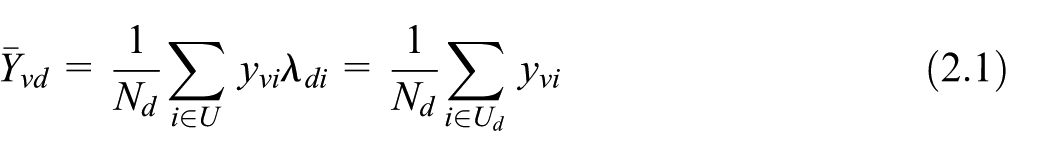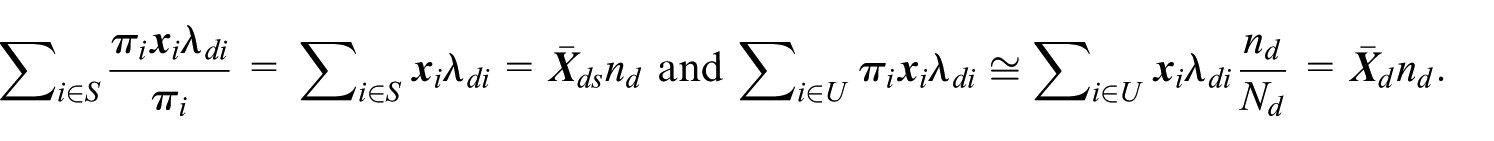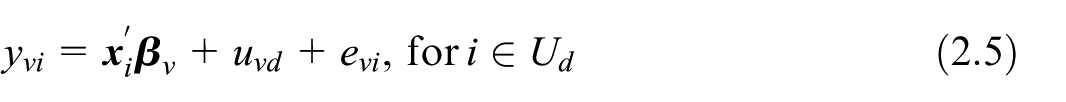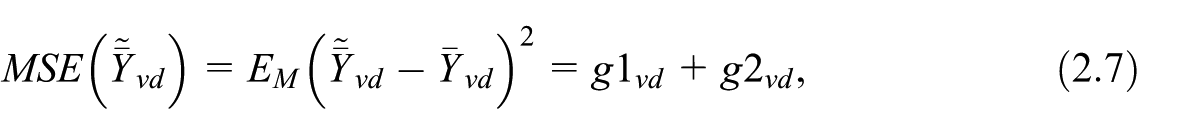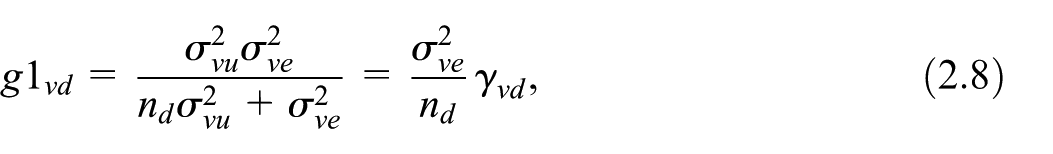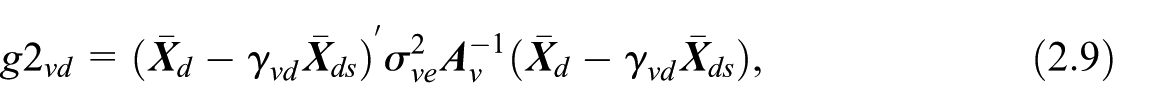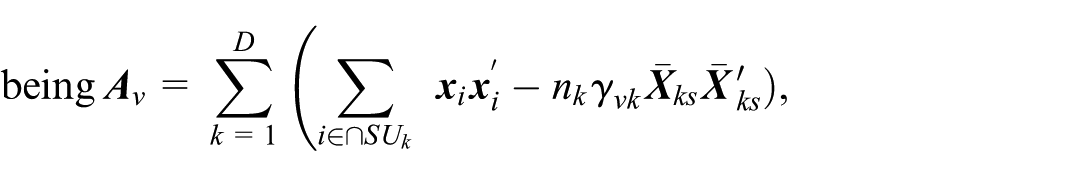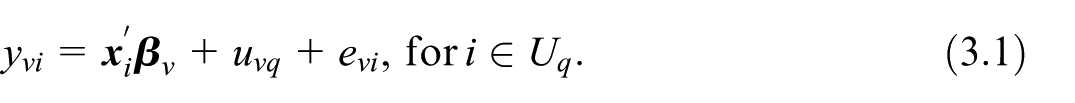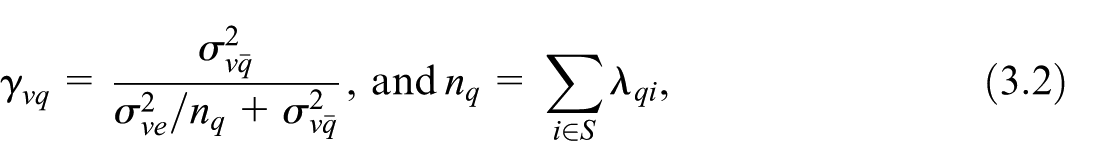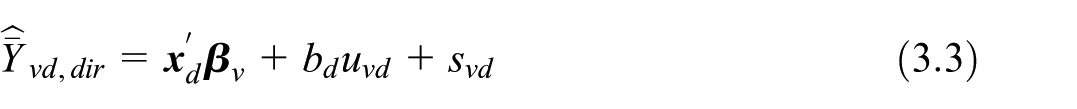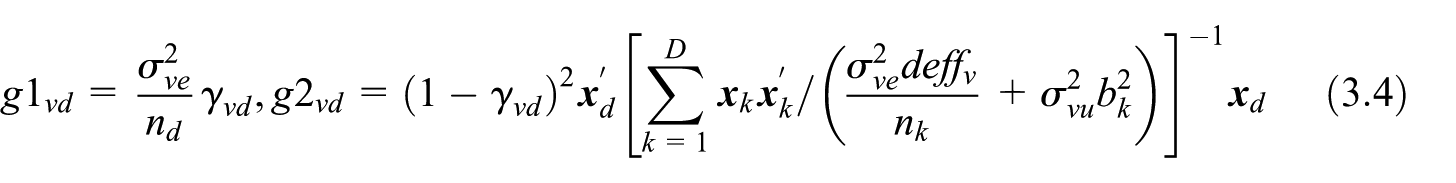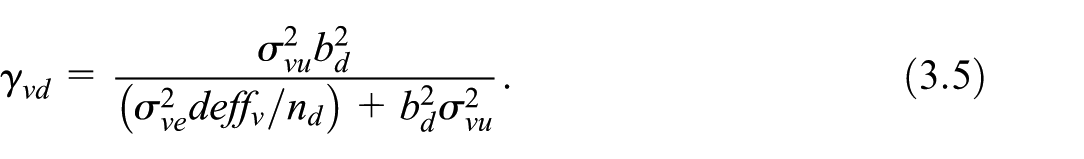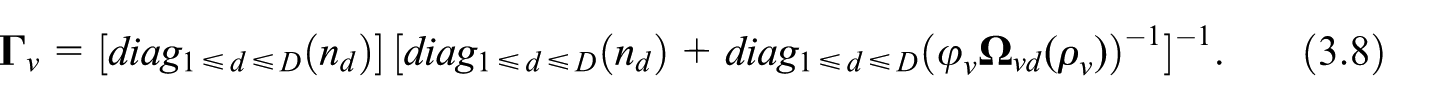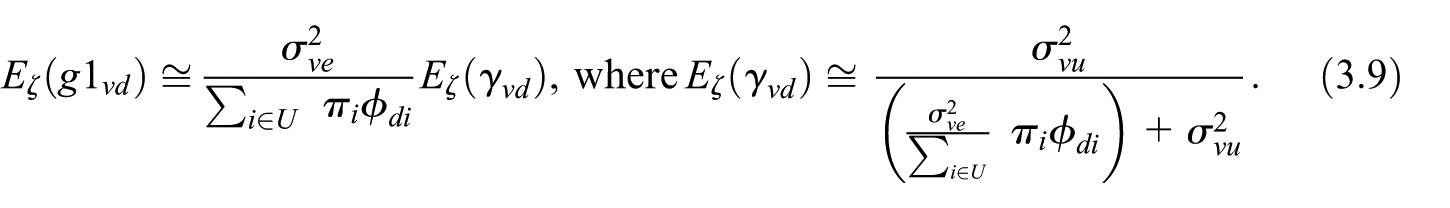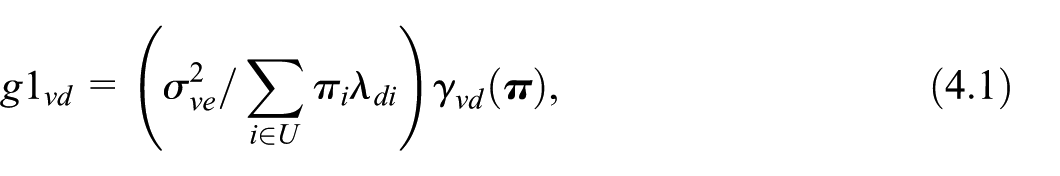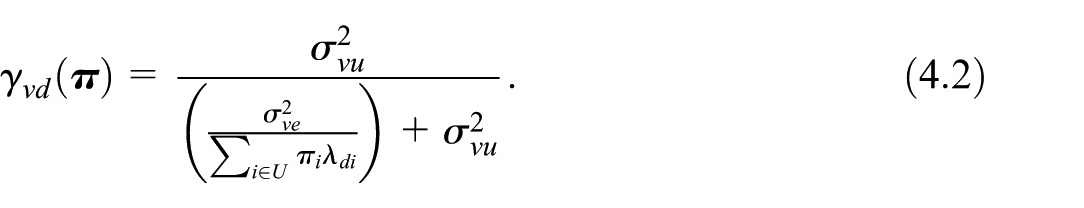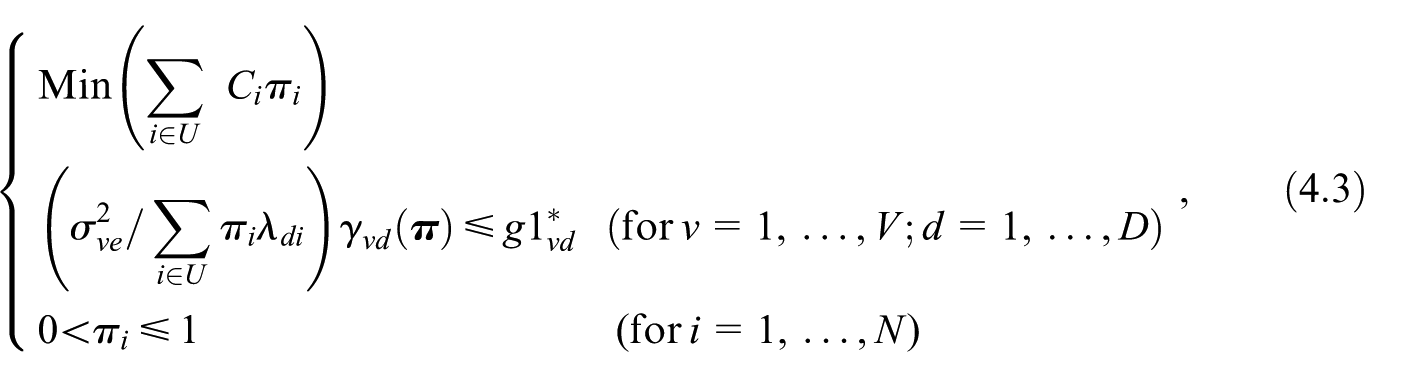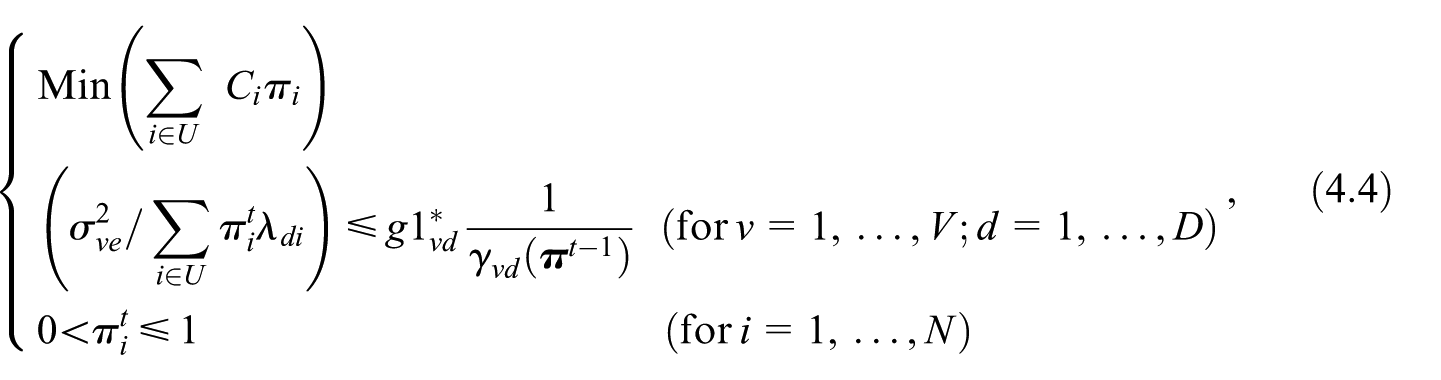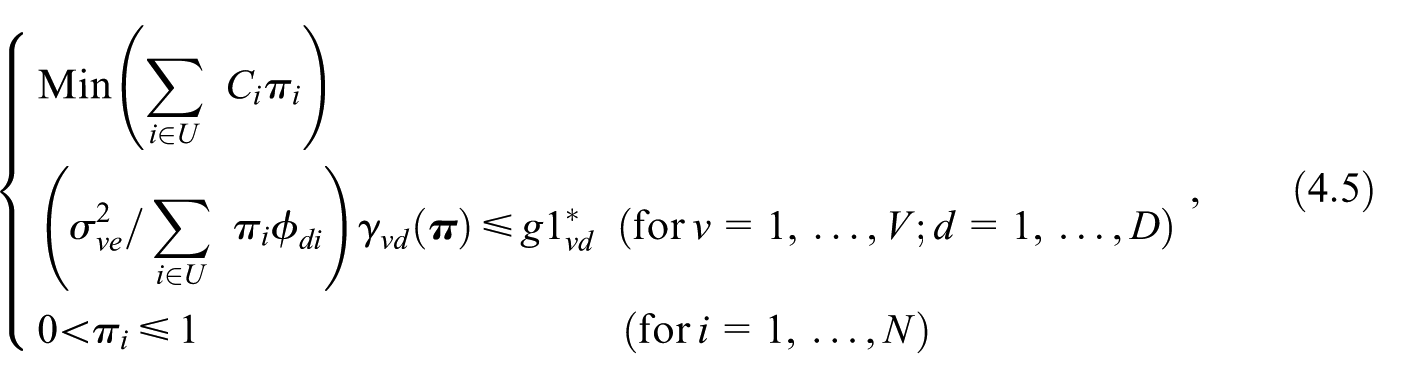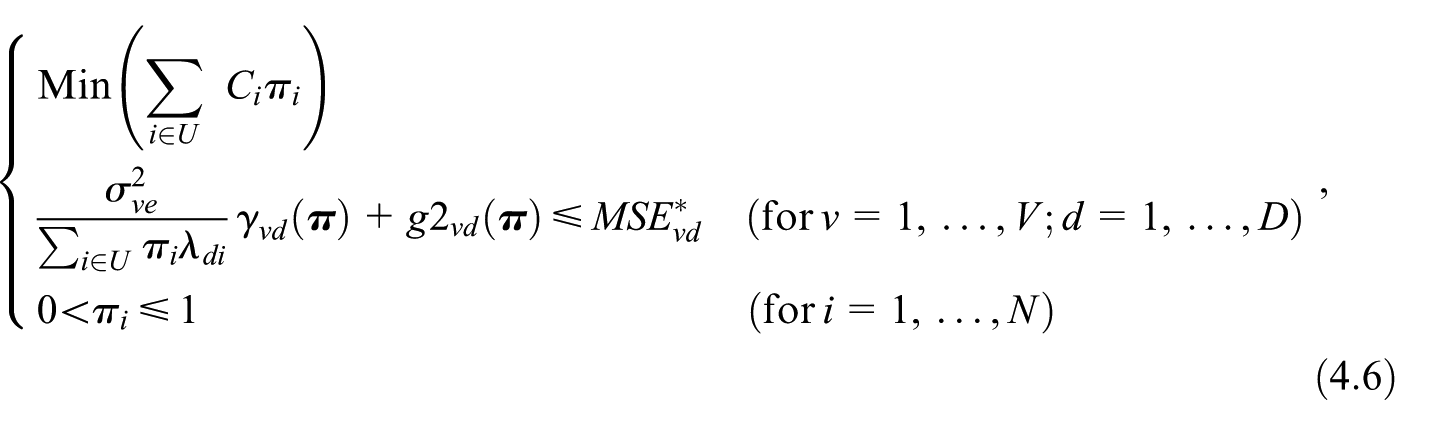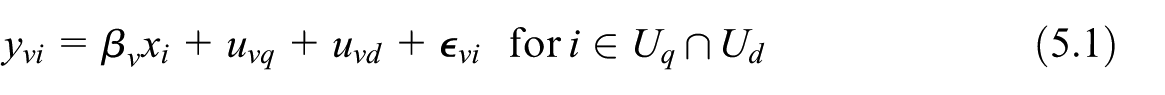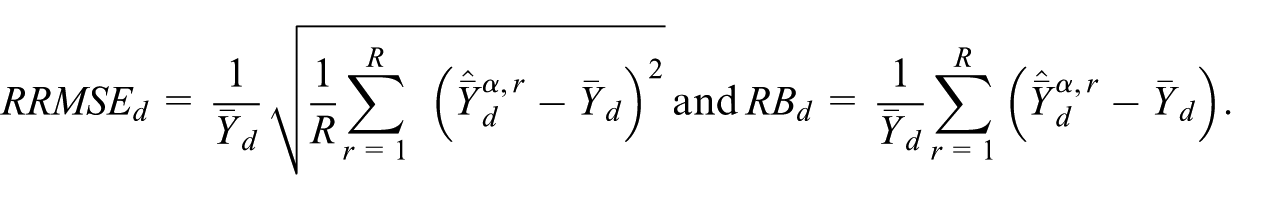The paper sketches a proper statistical setting necessary to define the sampling design for Small Area Estimation (SAE). Since SAE techniques are commonly used in official statistics, relying on appropriate sampling designs to improve the quality of estimates becomes crucial. The sampling design is based on both allocation and sampling selection. The allocation step solves a non-standard problem necessary for finding the minimum-cost solution that controls the accuracy of the model-based small area estimator. The sampling selection ensures the planned sample sizes for each level of random effects affecting the variables of interest.
The paper outlines a proper statistical setting necessary to define the sampling design for Small Area Estimation (SAE). An area (or domain) is considered small if a direct estimator based on the sampling design, for example, the Horvitz-Thompson estimator (Särndal et al. 1992), produces unreliable estimates. Let us imagine that we do not observe a domain in the sample. In this case, we cannot compute the direct estimate since the applicability of the estimator depends on the presence of sampling units in the domain of interest (Lehtonen et al. 2003; Lehtonen and Veijanen 2009; Rao and Molina 2015). According to a model-based approach, we usually treat the SAE problem via indirect estimation exploiting the values of the variable of interest also from different areas or the same area but using data from previous survey occasions (Rao and Molina 2015). This approach does not consider sampling design issues.
In this paper, we use another approach and investigate the issues of how to define a random sampling design and selecting the sample units in the case where we estimate the characteristics of interest at the domain level with SAE techniques developed under a model-based approach to inference (Chambers and Clark 2012). We try to define a random sampling strategy consistent with the adopted estimation method. In essence, the strategy we propose seeks to plan and select the sample in the best possible way to guarantee, within the available budget, predefined levels of accuracy for model-based estimates by domain. In our approach, we propose controlling the sample size at each level of the random effects considered in the SAE model used for estimation. For instance, if the SAE model includes a random effect for each small area of interest, the sampling design could specify a targeted sample size for each small area. Conversely, if the model assumes random effects only at the level of broader macro-areas, the sampling design should be adjusted to allocate sample sizes appropriately for those macro-areas. This approach ensures more accurate model-based estimates compared to scenarios where some levels are not observed in the sample. This condition provides more accurate model-based estimates than the situation where we do not observe some levels in the sample. A significant result we provide is the definition and the algorithmic solutions to the non-standard problem for identifying the inclusion probabilities as the result of a minimum cost problem, ensuring predefined thresholds for the accuracy of small area estimates.
Dealing with the problem of defining the sampling design when using the SAE techniques may sound strange, given that these techniques were created to overcome the insufficient sample sizes of the domains that were not planned at the moment of the survey design. However, in the last few decades, a growing number of national statistical institutes and other statistical organizations worldwide have recognized the value of regularly producing small-area statistics and using them to provide information for policy-making decisions (Kordos 2014). Some small-area estimates have been recognized as official national statistics. Two examples refer to the United Kingdom (Tzavidis et al. 2018) include the annual set of unemployment estimates for unitary authorities and local authority districts, broken down by gender and age group, and the average income estimates for electoral wards. In more than 20 developing countries, the World Bank has used SAE techniques to create poverty maps (Bedi et al. 2007). Another relevant example is the yearly dissemination of employment and unemployment statistics at a municipality level for the Italian Permanent Population Census (UNECE 2018). Furthermore, Article 9 of “Regulation (EU) 2019/1700 of the European Parliament and of the Council of 10 October 2019” includes SAE methods, intended to cover the territorial diversity, provided that they fulfill the prefixed precision requirements. In synthesis, official statistics organizations regularly disseminate estimates for small areas using SAE techniques. Therefore, it becomes relevant to develop the suggestion by Singh et al. (1994), as they noted a need to create an overall strategy that deals with the SAE problem, involving planning sample design and estimation aspects.
A consolidated approach (see Chambers and Clark 2012; Dorfman and Valliant 2005; Valliant et al. 2000) to construct the overall strategy recommends selecting a random sample and using the models to predict values for the non-sampled units of the population. Indeed, in such model-based inference, it is crucial to guard against problems arising from model failure.
Marker (2001) first contributed to defining a sampling design as it urged spreading the sample design across potential small areas to improve their estimation. It also provided examples of requiring the sample to be selected from each small area known in advance. An easily practicable way to control the sample at the level of the small areas known in advance is to adopt stratified designs where the intersection of the small areas and other design variables defines the layers. We call these cross-stratified designs. However, in many practical situations, this design is unsuitable since it requires selecting a huge number of sampling units as large as the product of the number of categories of the stratification variables (Cochran 1977, 124). Falorsi and Righi (2008) and Falorsi and Righi (2015) overcame the weakness of the cross-classified stratified design, introducing the use of the incomplete stratified design. This approach controls the sample sizes for the marginal strata, corresponding to the domain partitions, while the sample size in the cross-classified strata is a random variable. The proposed strategy uses a balanced selection technique (Deville and Tillé 2004). The sample allocation specifies the sample sizes in the marginal strata to ensure that the sampling errors of the domain estimators are lower than pre-specified thresholds. Moreover, in Falorsi and Righi (2015), a GREG-type estimator is adopted (Lehtonen et al. 2003; Lehtonen and Veijanen 2009). Furthermore, Falorsi and Righi (2008) extended this strategy to synthetic estimators and, more generally, to model-based estimation. Burgard et al. (2014) and Friedrich et al. (2018) focused on a topic related to optimal SAE sampling. In both papers, the authors highlight the need to provide samples at the domain levels and a variety of subclasses. The use of cross-classified stratified design leads to a too-detailed stratification of the population. Optimizing the accuracy of design-based estimator for stratified random samples requires incorporating many strata at various levels of aggregation. Considering several variables of interest for the optimization yields a multivariate optimal sampling allocation. In particular, Burgard et al. (2014) studied the effect of some SAE sampling designs for business data and suggest considering the box-constraint optimal allocation proposed by Gabler et al. (2012). Rao and Molina (2015, Section 2.6) advocate for effective sampling designs to improve small area estimation. Their key proposals include minimizing clustering to enhance effective sample size, using stratification to create smaller strata for better data quality, and implementing compromise sample allocations for reliability across small and large areas. They also suggest employing dual-frame surveys and harmonizing questions across surveys to increase effective sample sizes. Keto et al. (2018) recommended a sampling allocation based on multi-objective optimization using a small-area model and estimation method introduced by Falorsi and Righi (2008). Breidt and Chauvet (2012) review balanced sampling and the cube algorithm, proposing an implementation that allows the selection of penalized balanced samples. Such samples can lessen or even remove the need for linear mixed model weight adjustments and yield highly efficient Horvitz–Thompson estimators when responses are well captured by a linear mixed model with auxiliary information. Finally, at the end of this short bibliographic review, the work of Pfeffermann and Ben-Hur (2019) is worth mentioning as well. They contributed to the topic of joint use of random sampling and model-based inference by proposing a hybrid inferential approach to estimating the design-based mean squared error of model-dependent small area predictors. Having adequate and general measures of the mean squared errors in this context is important in order to be able to produce accurate measures of the quality level of the estimates produced.
Our proposed solution addresses the SAE problem through three key steps: (1) defining a budget-aligned SAE working model that balances complexity and feasibility, (2) optimizing inclusion probabilities for cost-effective allocation while maintaining model-based accuracy, and (3) employing balanced sample selection techniques to account for random effects and auxiliary variables. This comprehensive strategy enhances SAE estimate accuracy through an improved sampling design. Additionally, we introduce an algorithm to solve the optimization problem and demonstrate its practical implementation with a case study based on real data and a simulated dataset.
The article is organized as follows. Section 2 formalizes the statistical and mathematical aspects of the problem at hand. Section 3 shows traditional small area estimation models that could be implemented in line with our proposal. Section 4 proposes a formulation for the sampling optimization problem. Section 5 presents empirical evidence based on a simulated and real datasets. Finally, Section 6 offers some concluding remarks.
2. Statistical Setting
2.1. Parameters of Interest
Let be a population of size , and let be a particular sub-population of of size . The target parameters are the domain-level means of one or more variables of interest
where indicates the value of the variable of interest in the -th unit of the population and is the domain membership variable, where if , and otherwise. Equation (2.1) identifies a multivariate-multi-domain schema. Indeed, there are (variables (domains) target means. Finally, let be a vector of auxiliary variables known for all population units.
2.2. Sampling
We assume for now that the domain membership variables are available in the sampling frame and observable without measurement error. We observe the variables of interest on a random sample of fixed size selected from the population with the vector of inclusion probabilities. Let be the subset of sample units belonging to the population . is the number of units in .
We select the sample with the Cube algorithm (Deville and Tillé 2004), respecting, at least approximately, the following balancing equations:
where is a vector of auxiliary variables for the unit . We define the variables such that precisely units are selected in each sample selection, where is an integer.
Let be a known column vector of entries. Deville and Tillé (2004, 895 and 905) demonstrate that if , is a vector if integers, and we define the balancing variables in Equation (2.2) as
then Equation (2.2) is fully satisfied and the sampling selection ensures the planned sample sizes, for each domain. A rounding problem must be solved to ensure that the vector is a vector of integers. Deville and Tillé (2005, 577) and Tillé and Favre (2005, 168) have shown that several customary sampling designs may be considered as special cases of balanced sampling, by properly defining the vectors and .
Let , and be the domain means of auxiliary variables respectively for the sample and the whole population. Consider the case where the values of the inclusion probabilities for the units of domain are sufficiently homogeneous among each other and approximately equal to . In that case, if the balancing variables in Equation (2.2) are defined as
then the selected sample respects the planned sample sizes , and, at least approximately, the conditions . Indeed, we have
Finally, we note that the Local Cube method (Grafström and Lundström 2013; Grafström et al. 2012) is a helpful enhancement to the Cube algorithm in our setting since it enables the selection of samples that are balanced on several auxiliary variables and, at the same time, is well-spread for some variables, which can be geographical coordinates.
The proposed design employs unequal inclusion probabilities but is noninformative for the model based on the selected sample. According to Särndal et al. (1992, Section 2.4.4), Chambers and Clark (2012, Section 1.4), and Rao and Molina (2015, Section 7.6.3) this means that once we condition on the sample , the same superpopulation model that applies to the entire population is also valid for the sample units. More formally, the joint conditional distribution of the sample values, given the population values of , is equivalent to the population distribution of given the population values of . This equivalence holds because the design values—which consist of the domain membership variables and possibly the values—are the same basis upon which model inference is established.
2.3. Estimation
The estimation of is based on the super-population small-area model that connects the sampled values to the available covariate vectors . The basic unit-level model (Rao 2003, Section 7.2.1) is the simplest model we are considering in this case:
where is the regression coefficient vector, indicates a random domain effect, and is a random noise. The random domain effects are independently and identically distributed with model-expectation and variance given by and . The random individual effects are also independently and identically distributed with , and . Under the model in Equation (2.5), it is assumed that domain random effects and individual random effects are mutually independent. With negligible , and assuming that the variance components and , are known, the Best Linear Unbiased Predictor (BLUP) of is given by:
where is the Best Linear Unbiased Estimate (BLUE) of , is the BLUP of (Rao and Molina 2015). The model mean-squared error of is
where
where
where the index in the previous equation represents the generic domain, which ranges from 1 to .
The component in the MSE decomposition refers to the model-based variance of the predictor , assuming that all model parameters (like , , and ) are known. Specifically, reflects the uncertainty that arises within the structure of the model itself, due to both the area-specific random effects and the individual-level errors. It corresponds to the variance of the BLUP and does not account for additional variability introduced by estimating the model parameters. In this sense, represents the ideal or baseline MSE of the predictor, capturing the prediction error that would remain even under perfect knowledge of the model’s parameters.
is the dominant component of (Chambers and Clark 2012, 171). It is of order . In contrast, is of order . Under specification Equation (2.3) of the balancing equations, we have . Upon substituting for in Equations (2.8) and (2.10), we observe that is a function of the probability of inclusion . The term depends on both the inclusion probabilities and the values of auxiliary variables for the domain in the population and the selected sample. After data collection, we can estimate the components and based on sampling data. We can therefore obtain the EBLUP estimator of , where the estimates of variance components and substitute the unknown values and . The MSE of the EBLUP estimator, , in this case, is equal to Equation (2.7) with the addition of the term . This latter incremental variability term arises from the need to estimate the variance components and (see Rao 2003, 104). Then, we have , where the term , like , is of a lower order than the dominant term .
At the end of this Subsection, we note that the selection of auxiliary variables impacts the estimation of residual variance components (). The allocation algorithm, which will be introduced later, will automatically account for the variance components resulting from the selected variables.
2.4. Remark 2.1. Domain Membership Variables
In some cases, domain membership variables are available in the sampling frame, particularly for business statistics where extensive data is available. This hypothesis may also apply to household surveys in European countries where population registries have demographic data attached to each person. However, in Subsections 3.2.4 and 4.2.4, we will remove this assumption to consider a more general setting. This setting is applicable to many household surveys where uncertainty exists regarding the domain membership of the population units.
2.5. Better Specification of the Objectives of the Paper
The primary objective of this article is to determine the optimal value of the inclusion probabilities vector , which guarantees a minimum-cost solution while ensuring that the values of remain below the predefined error thresholds. By doing so, we aim to control the dominant part of the MSE. The optimality characteristics of the sampling design are driven by the employed model-based estimator. The statistical framework we propose in the following sections guarantees the consistency of the estimation phase with the planned sampling design. In our developments, we will consider the and variance components as known. As in the case of Neyman’s optimal allocation, this approach is typically adopted when defining the sample optimality in the sampling design phase. Cochran (1977, Ch. 5) observes, in the case of stratified sampling, that the optimal solution is scarcely influenced by minor deviations of the starting variances. This case also occurs in the simulation developed in Section 5, in which the MSE of the EBLUP calculated in the estimation phase is slightly higher than the MSE defined in the planning phase of the sampling design. In actual survey situations, the and variances can be estimated either from previous surveys or pilot surveys.
3. Super-Population Models
Following the framework proposed by Tzavidis et al. (2018, 928), the model choice should be guided by the principle of parsimony: “one should be looking to use the simplest possible method that achieves acceptable precision. Parsimony may be defined in terms of a hierarchy of estimation methods in increasing order of complexity.” The principle of parsimony suggests that during the sampling design stage, it is difficult to define complex models without actually observing the selected sample. Hence, it is best to aim for an efficient sampling design based on elementary models. Advanced models can be specified after data collection, which will help increase the efficiency defined during the sampling design stage.
In Section 3.1, we follow the principle of parsimony and discuss the basic unit-level model Equation (2.5). This model provides a reasonable basis for defining the essential aspects of the sampling design. Equation (2.5) is applicable in situations where the areas are small geographic areas. In such cases, the model allows for units in the same geographic location to be correlated through the random effect . Later, in Section 3.2, we will discuss other small-area models. We do not intend to cover all the available cases, but we want to illustrate how the problem of defining the model at the sampling design stage can be approached in some situations that may arise in the reality of sample surveys.
3.1. The Basic Unit-Level Model
The value taken by gives rise to two different situations depending on whether or .
In the first case where the value of is zero, we can only calculate the synthetic part of the estimator, which is . This component may be significantly biased. The term matches the quadratic model bias and becomes . Assuming that the model in Equation (2.5) is true, is greater than the term of the BLUP estimator defined by Equation (2.8). In fact, by dividing both terms and by we obtain , since . Also, the term takes its maximum value being .
In the second scenario where is greater than zero, the mean value is unbiased according to Equation (2.5). As the value of increases, the terms and decrease. Moreover, we can observe that when a fixed value of is set, the minimum value of , which is denoted as , is achieved when and .
3.2. Other Models
3.2.1. Model with Random Intercept at the Macro-Domain Level for Addressing Cases Where Budget Constraints Prevent Sample Coverage in All Small Areas
In certain situations, limited survey budgets permit direct observation only in a subset of the small areas . For instance, consider a social survey where the total budget allows for only 100 interviews, but estimates are needed for 200 domains (). In such cases, it is advisable to adopt a sampling design based on a model other than Equation (2.5). Otherwise, estimates for too many domains could be based solely on the synthetic part of the estimator, resulting in a higher mean squared error. In this context, we can consider macro-domains for which the sample sizes can be controlled in the design’s planning phase. Below, we propose valuable models for a two-step strategy representing a good compromise between accuracy and feasibility. First, we identify macro-areas by grouping the domains that are supposed not to have very different values of the random effects. Then, we control the sample at the macro-domain level so that one can reduce the model MSE at that level. We can carry out the aggregation step with different statistical techniques (Royle and Dorazio 2006). A similar approach is proposed by Haslett et al. (2010) from a mass imputation perspective. The authors adopt a random effects model, where the effects are defined at an aggregate level relative to the micro-domains that are the target of estimation. The U.S. Census gives an example of this approach, where they control the sample at the Division level (with nine Divisions) rather than for each of the fifty states.
Having defined the macro-domains , it is possible to define a model with the random intercept at the macro-domain level as
The random domain effects are supposed to be independently and identically distributed with model-expectation and variance and , where the symbol has been used to distinguish it from the symbol and to indicate that the variance component is calculated at the -domain level instead of at the -domain level. Taking the use of symbology for granted, we denote by the BLUP of . All the domains belonging to a given macro area will have the same value of the term and equal that of the macro area, say , to which they belong, where:
where
where if , and 0 otherwise. Let’s consider a scenario where the actual model is expressed as Equation (2.5), but we have chosen to use the model in Equation (3.1) to manage the errors, at least at a broader level. In this situation, the quadratic model bias would be . This highlights the importance of defining macro-areas in a way that the value of is minimal for the domains included in .
3.2.2. Area Level Model
The area-level model is appropriate when auxiliary information is available only at the aggregate (area) level, and unit-level covariates are either unavailable or not accessible. Below, we describe the basic version of this model as outlined in Rao (2003, Section 7.1.1):
where is a direct estimator of , are the covariates for area , is a known positive constant, and are the domain random effects and sampling errors. We have independent of the sampling error with a known variance . The BLUP of is . Assuming that the variance can be modeled as , where is the variance of the random individual effects of the model in Equation (2.5) and is the design effect (Kish 1995), the components and of BLUP are:
where
3.2.3. General Linear Mixed Effects Model
Equations (2.5), (3.1) and (3.3) are particular cases of the general linear mixed-effects model with a block diagonal covariance structure. We introduce this model with the symbols given in Rao (2003, Sections 6.2 and 6.3):
where , , , , and , being , , , and . and are known and matrices of full rank, and are independently distributed with mean 0 and covariance matrices and depending on some variance parameters . We suppose that belongs to a specified subset of the Euclidean space such that , is non-singular for all belonging to the subset. For instance, in a model that considers the correlation between different units within the same domain (D’Alò et al. 2023), , being . The structure of is known unless the variance components and of . The MSE of the BLUP estimate of can still be expressed as the sum of the two addenda and in which the component is a decreasing function of (Falorsi et al. 2023)
where is the element on the main diagonal of where:
As in the previous cases, is a minor order term whose expression, given in still depends of the values of the selected sample (Falorsi et al. 2023).
3.2.4. Uncertainty on the Domain Membership Variables
Suppose quantities are not available in the sampling frame. However, using some auxiliary variables, we can define a model on the probability that unit belongs to the domain : , with . Assuming model independence between and , the expected value of can be linearly approximated as
4. Sampling Optimization
4.1. The Basic Unit Level Model
4.1.1. The Optimization Problem
We look for the vector so as to obtain the expected minimum cost sampling design, ensuring that the terms are lower than pre-fixed thresholds . If the sample is selected with the cube method under specification in Equation (2.3) of the balancing variables, the component given in Equation (2.8), can be formulated as function of the inclusion probabilities
where
Based on Equations (4.1) and (4.2), the vector can be obtained as the solution of the following Optimization Problem (OP) based on inequality constraints and with unknowns, :
where is the unit cost of collecting data on the unit. The second row of OP Equation (4.3) represents the constraints on the maximum values that the terms can attain, and the third row identifies the constraints on the field of variation of the values. The variances and are treated as known; in practice, they must be estimated. Equation (4.3) can be solved with the fixed-point algorithm illustrated below.
4.1.2. Fixed-Point Algorithm
Let denote the iteration number, and let be the vector at iteration . The value of at iteration , denoted as , is calculated using Equation (4.2), by substituting the vector with .
Step 0. Initialization. We determine the vector where is a fixed scalar.
Step 1. Calculus. At iteration , we solve the following OP
Step 2. Fixed-point iteration. Assigning a small value (e.g., ), if
the iterations stop. Otherwise, we update the values and iterate step 1 for , until convergence. Appendix in Falorsi et al. (2023) demonstrates that under certain approximations, the algorithm converges to a fixed-point solution for model 2.5.
4.2. Other Models
We briefly delve below into how to specify the OP and run the fixed-point algorithm for the other models illustrated in Subsection 3.2.
4.2.1. Model with Random Intercept at the Macro-Domain Level for Addressing Cases Where Budget Constraints Prevent Sample Coverage in All Small Areas: Equation (3.1)
In this case, we can control the sample size only at the macro area level. Therefore, the OP considers only constraints on the maximum values the terms can take. The OP can be defined similarly to Equation (4.3) by substituting the terms given in Equation (3.2) instead of the values defined by Equation (2.7). The updating of the values is defined consequently.
The OP is defined by Equation (4.3), where the term is given in Equation (3.5). The fixed-point iteration is updated consequently. To run the fixed-point algorithm, the values should be known or estimated.
4.2.3. General Linear Mixed Effects Model: Equation (3.6)
The OP is defined by Equation (4.3), where the term is the element on the main diagonal of the matrix given in Equation (3.8). The fixed-point iteration is updated consequently. To run the fixed-point algorithm, the elements of the variance vectors should be known or estimated.
4.2.4. Uncertainty on the Domain Membership Variables
where is given in Equation (3.9), the probabilities are considered as known, even if they are estimated in actual situations. The specification of the corresponding fixed-point algorithm is trivial.
4.3. Some Computational Aspects
This Section briefly discusses some computational aspects, referring to Appendices A.2, A.3, and A4 for the more technical aspects.
4.3.1. Powell’s Algorithm
Powell (1994) proposed an algorithm for nonlinearly constrained optimization that can solve almost all OP illustrated in Section 3 except for Model in Equation (3.6). It is based on an iterative approach without using derivatives. The algorithm is available in the software library NLopt for non-linear optimization (http://github.com/stevengj/nlopt). In Section 5.2, we see that based on the actual data analyzed in the empirical experiment we conducted, the fixed point algorithm finds a better optimal solution than Powell’s algorithm. However, in Falorsi et al. (2023), we see that Powell’s algorithm reaches convergence faster. Moreover, the fixed-point algorithm applies to all models illustrated in Section 3.2.
4.3.2. Computational Simplification
OP Equation (4.3) is computationally complex since there are unknown values. We can simplify the OP by partitioning the population in strata such that we can obtain each domain as a union of entire strata and defining a uniform inclusion probability at the stratum level. Under the two above conditions, we have a Stratified Simple Random Sampling Without Replacement (SSRSWOR) design. For instance, consider the case in which the domains of interest are the regions and the classes of the NACE code (https://ec.europa.eu/competition/mergers/cases/index/nace_all.html) separately. In this case, we may individuate strata by cross-classifying the modalities of the two variables region and NACE-code. Let be the generic stratum of units, where and . Moreover, we have , and , where if and, otherwise. We use square brackets to denote strata in the introduced notation to avoid confusing domains with strata. We assign a uniform inclusion probability to units in stratum , for , where is the sample size of stratum . With a SSRSWOR design, since , we can define an OP (see Appendix A2), which is computationally much more straightforward than OP Equation (4.3) because it considers only unknown values that are the proportions .
4.3.3. OP That Considers HT Estimates in Larger Domains and SAE Estimates in Smaller Domains
Let us consider the case where there are larger domains in which sample estimates are calculated using the HT estimator. At the same time, we use model-based estimates for smaller domains. Let us illustrate this case for the SSRSWOR design just introduced to avoid too many complexities. Furthermore, suppose we can define the strata, such as each domain (large or small) can be obtained by aggregating entire strata. Let be a large domain, where , and , where if and, otherwise. The same notation holds for all the small domains . In this setting, as illustrated in Appendix A3, we can define an OP that finds the minimum cost solution guaranteeing the accuracy for both the large and small domains, where the accuracy for the small domains is based on the model. In contrast, the large domain’s accuracy is defined in terms of the sampling variance of the HT estimator.
4.3.4. Including the Term g2 in the Optimization
Suppose the sample is selected using the Cube algorithm, with the balancing variables defined by Equation (2.4). In this case, the sample selection ensures that the following two conditions are met, at least approximately . Hence, may by defined as a function of the vector , as . We can include the term in the optimization by defining the following OP
As illustrated in Appendix A4, OP Equation (4.6) can be solved under some approximations with an algorithm based on two nested fixed-point iterations.
4.3.5. Two-Stage Sampling
OP Equation (4.3) can be easily extended to other sampling designs. We illustrate here the case of a two-stage design. Let be a population of clusters. In order to avoid introducing too many new symbols, the index will be used to denote the cluster rather than the generic unit. The cluster has final units. Suppose that the probability of belonging to is quite uniform for the ultimate sampling units of the cluster and approximately equal to . A first-stage sample, , of size is selected without replacement from , with varying inclusion probabilities . Suppose the cluster is included in the sample . In that case, a fixed number, , final units are selected without replacement and with equal probabilities out of the , final units of the cluster. Under Equation (2.5), we can define where . The objective function of the OP is This type of sampling design is commonly used in household surveys conducted by national statistical offices, such as those carried out by ISTAT (the Italian National Institute of Statistics). Typically, a two-stage design is applied within strata that group primary sampling units according to geographical domains. When the inclusion probabilities of the first-order units are approximately proportional to the size of the population, this sampling design ensures final inclusion probabilities for all the final sampling units within the stratum, which leads to optimality properties as it significantly reduces the variability of the final sampling weights.
5. Experimental Study
The proposed methodology underwent rigorous testing on both simulated data generated by a superpopulation model and actual open data from a survey conducted by the ISTAT.
In addition to the nature of data generation, the two experiments differ significantly. In the first experiment, we examined one continuous variable where there is a relatively high value of the variance of the domain effects . In the second experiment, we examined the case of a multidimensional variable where the variances have a relatively slight impact.
Considering a model-generated population allowed us to control the various factors influencing the results. On the other hand, actual data examination revealed some weaker results.
Both experiments unequivocally underscore the paramount importance of a well-defined sampling design in enhancing the accuracy of SAE estimates. This key finding not only validates our research but also amplifies its relevance in the field.
Cadamuro (2023) conducted other experimental studies using synthetic open data derived from the Australian Agricultural and Grazing Industries Survey that are congruent with those given in this section and confirms the relevance of the sampling design when producing small area estimates.
A reader of the following Section 5 might be somewhat confused as to why different data are used and why the same outputs are not applied across examples. It is worth noting that in both experiments—on simulated and real data—we followed the same methodological steps; however, when presenting the results, we chose to emphasize the aspects most relevant for the reader.
5.1. Simulatated Population
5.1.1. Data Generation
Let be a population of size . Let be a small domain of interest, where the set of the 100 domains defines a partition of the population. We first randomly assign the 10,000 units to the D domains. Furthermore, let be a large domain. We assumed the first ten small domains form the first large domain, the following ten the second large domain and so on.
We generated a single response variable, , for the finite population , according to the model
where , and , in which , , and are independent of one another. Variances are fixed as , and . In the experimental setup, several parameter sets were evaluated, and the configuration that most clearly produced the scenario with a relatively high variance of the domain effects was retained. Although other configurations yielded comparable outcomes, this choice was made to ensure clarity and conciseness in the exposition.
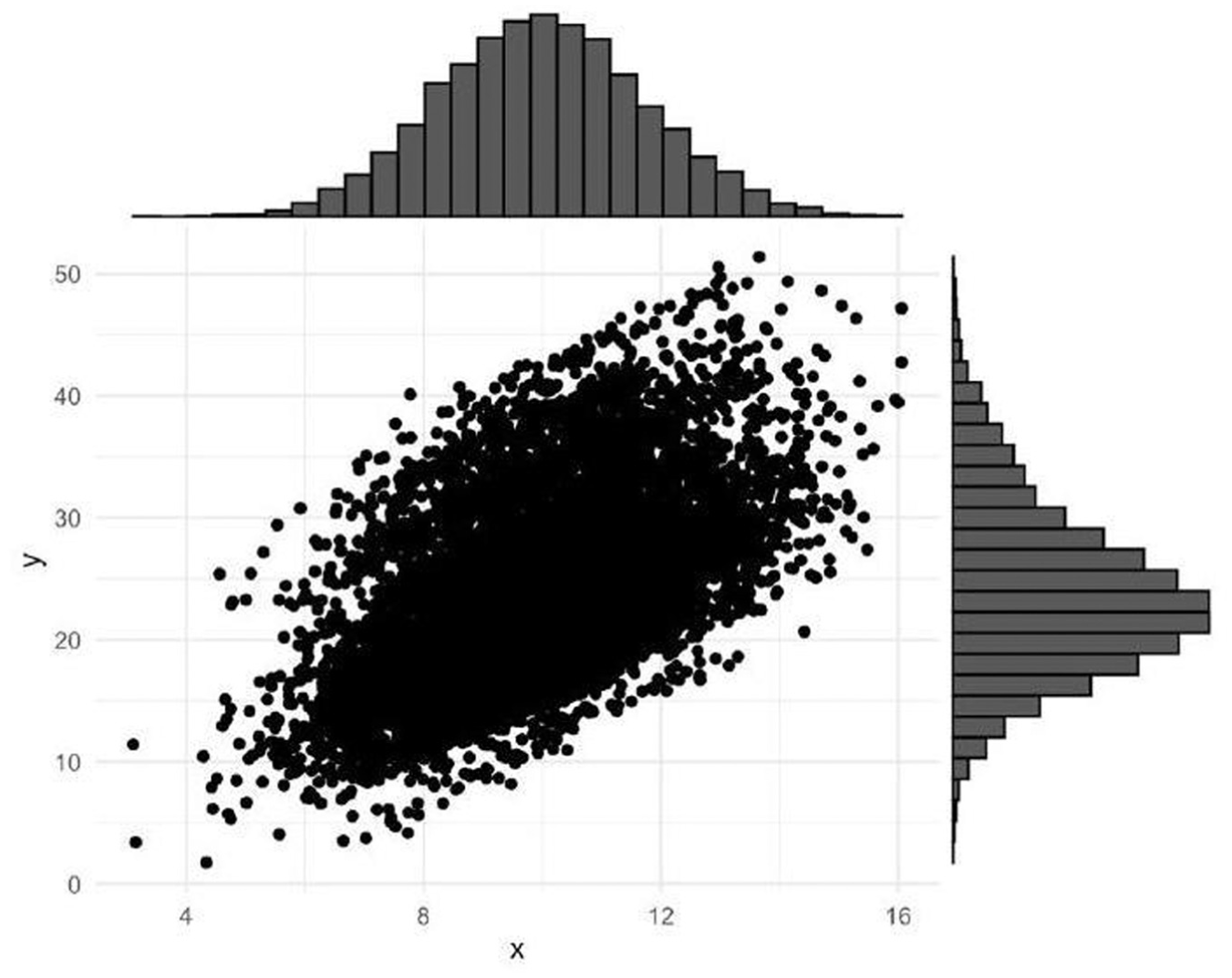
We first generated the 110 random area values and . Then for each unit , we generated the 10,000 and random values. The final values are then obtained by adding the fixed value and the random components , , and . The joint density of the overall generated data has a normal distribution (Figure 1). The domains have different population sizes and variability of the target variable as shown in Figure 2.
Joint density distribution of generated data.
Min-max range of the generated data by domains.
5.1.2. The Sample Allocation
We have a budget for a maximum of 150 interviews, which means we can expect to conduct 1.5 interviews per domain. To determine our sampling strategy, we will use a small area indirect estimator based on the following working model:
where with reference to the model in Equation (5.1), we have . The model in Equation (5.2) is simpler than the model in Equation (5.1) which generated the population data. This case reflects a realistic situation for the sampling design stage where the knowledge one has about the data is only approximate.
We performed the sampling allocation based on the computational simplification illustrated in Subsection 4.3.2. We partioned the population in strata such that each small domain corresponds to a stratum . Moreover, we defined a uniform inclusion probability and a uniform cost at the stratum level. To render expressive the variance threshold, we defined them as relative errors given by . We tune the values equal to 0.035 in all areas, thus achieving an overall sample size of 144 units. Even if the threshold , defined in relative terms, is fixed as equal in all the domains, the threshold defined in terms of totals, varies among the domains since increasing the values, the has to grow as well to fix the relative error . In our experiment the totals are known. In actual applications, is unknown. Therefore, if we want to define the error threshold in relative terms, we must replace in the relative error threshold with an estimated value (for instance, from a previous survey). From now on, we denote this allocation as opt.
We compared the opt sample allocation and the Proportional to the Population Size Allocation (PPSA) method. The latter is the expected allocation in a sampling strategy using a Simple Random Sampling Without Replacement (SRSWOR) design.
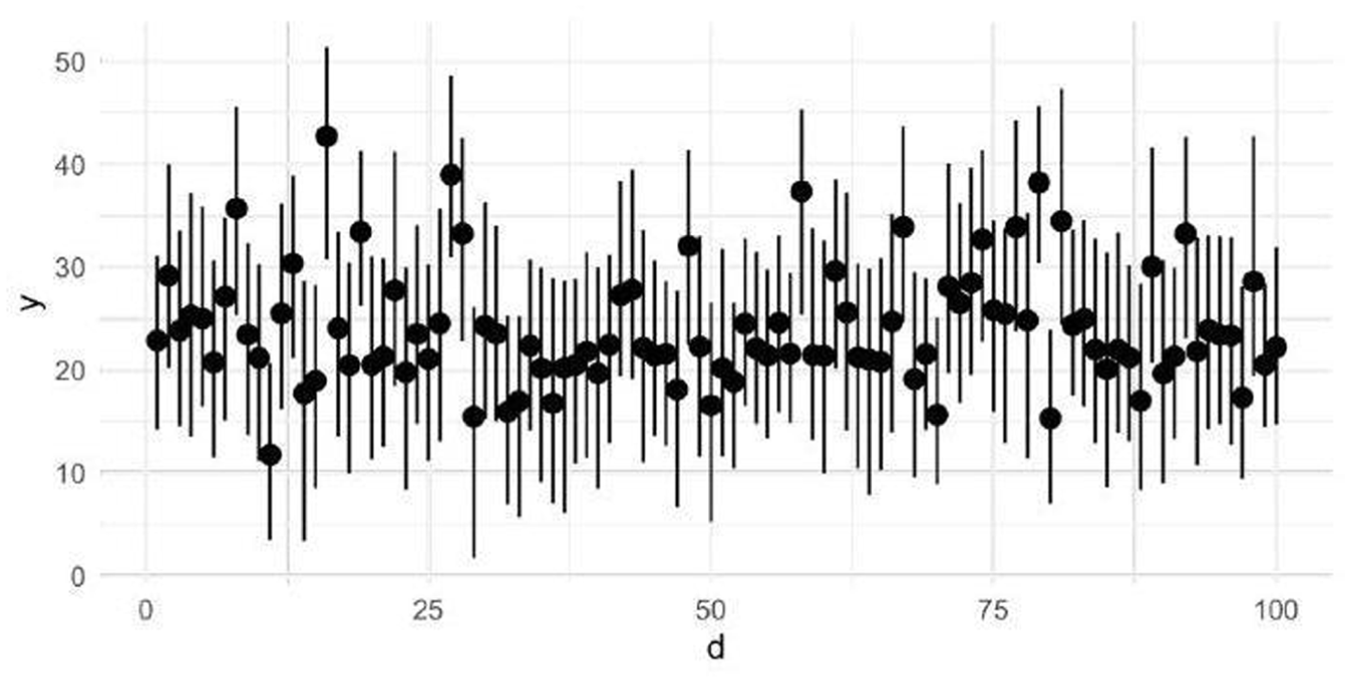
Figure 3 shows the expected sampling error for the 100 domains for the fixed population generated, as illustrated in Subsection 5.1.1. The horizontal axis considers the Coefficient of Variation of the actual domain values, where , being . The vertical axis shows the ratio between the value of g1, calculated according to the allocation (with and PPSA) and the threshold value . A value of of 1 means that exactly the sample required to achieve the desired accuracy is allocated to the domain. Conversely, a value less than 1 means too much of the sample is allocated to the domain concerning the desired precision. If the value is greater than 1, it indicates that the sample allocated is not sufficient to achieve the desired precision. In such cases, more sample units should be allocated in the domain. It can be observed that the ratio of the opt solution is always 1 for every domain, which is an expected outcome. If there is only one target variable and there are non-overlapping domains, then the constraints on the terms of of OP are satisfied by equality. Falorsi et al. (2023) have illustrated another experimental situation where the study domains intersect. In that experiment, the opt allocation always leads to solutions where many values are lower than 1, which ensures the constraints on accuracy. However, in some domains, the values of the ratio are equal to 1, while other domains need to be oversampled to guarantee the desired accuracy.
Domain ratios and versus domain values.
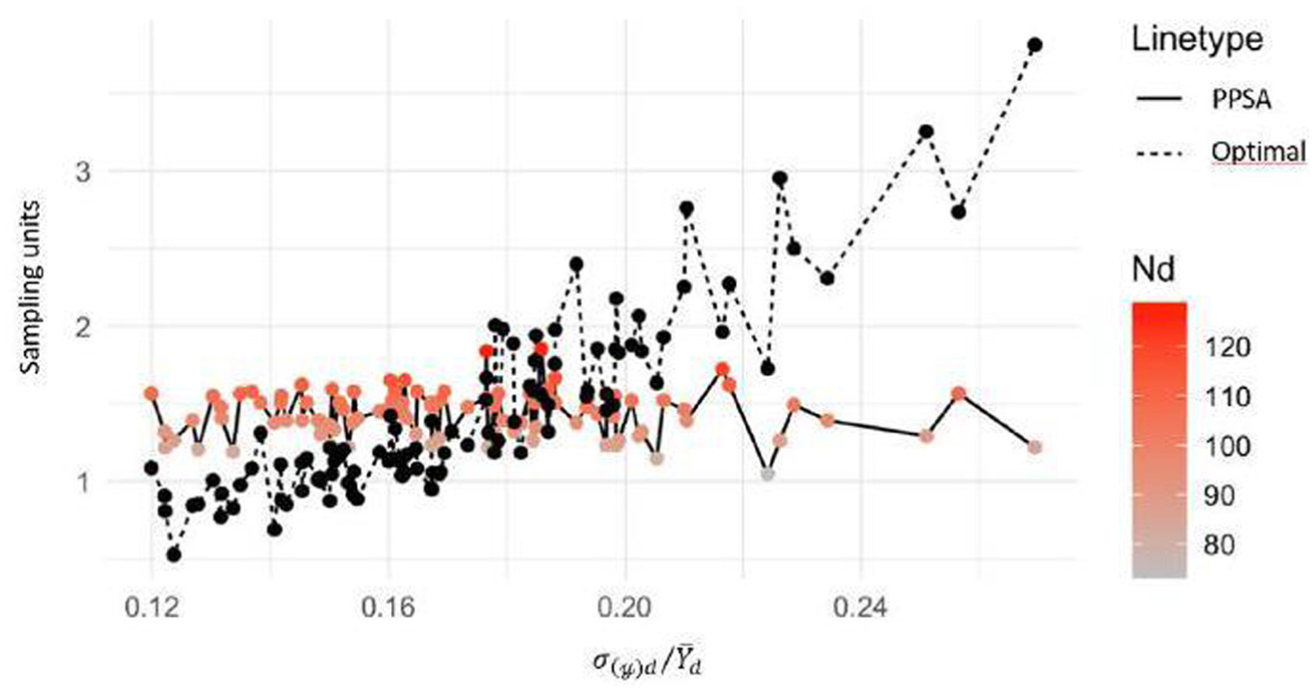
In contrast, the ratio values of the PPSA allocation show that the values are larger or smaller than 1. We note that two elements affect the domain estimates’ variance: the coefficient of variation of the actual domain values ( and the population size. The PPSA does not consider the domain , so with larger , we have a more significant sampling error with a given sample size. This issue is well depicted in Figure 3 by the increasing trend of the graph of . The domain population size explains the irregularities of the trend. Two domains with similar but different population sizes have different expected sampling errors since the PPSA gives a number of sample units proportional to the size. Large domains have smaller sampling errors. The color of the dots in the PPSA graph shows the different population sizes. Optimal allocation is a compromise solution between the one driven by domain size and that derived from variability expressed in . It gives more sampling units when and/or , as shown in Figure 4.
Sampling units of optimal and PPSA allocations versus domain values.
5.1.3. Monte Carlo Simulation
Here, we compared the expected variances with the empirical variance achieved through a Monte Carlo simulation. We generated 1,000 samples from the fixed population illustrated in Subsection 5.1.1. While the population values remain fixed, the different Monte Carlo samples differ in the subset of elementary units selected in the sample. For each replication of a given sampling allocation , we calculated the domain EBLUP estimates . We compared the accuracy of the SAE estimates considering three different sampling designs:
the stratified simple random sampling design (from now on denoted as Stratified) where the sample sizes in strata are given by rounding up the opt solution;
the stratified balanced random sampling design (from now on denoted as Balanced) with the sample allocation equal to that of the stratified design, but where the sampling selection was carried out balancing the values at the domain level;
the SRSWOR design which represents the sampling design adopted when we do not consider the small areas in the design. We use this as the benchmarking sampling strategy.
The discussion of the results presented below is essentially based on two leading indicators, the Relative Root Mean Square Error (RRMSE) and Relative Bias (RB) defined as
5.1.4. Results
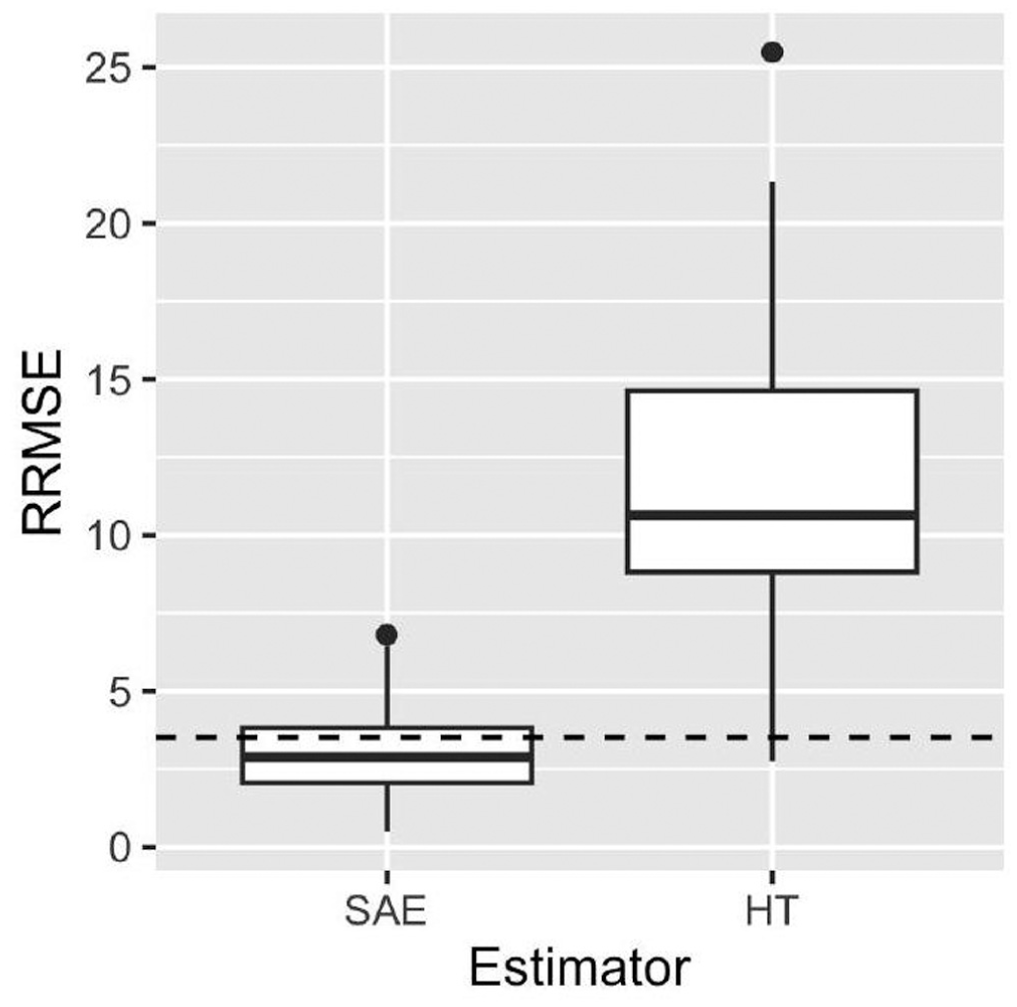
Figure 5 shows the Relative RRMSE of the eblup SAE and HT estimator using the Balanced sampling design. The SAE is the best choice in our experimental setting. The same results that were not presented in this paper arise using the stratified and SRSWOR sampling design.
RRMSE of the eblup SAE and Horvitz-Thompson estimator using the Balanced sampling design.
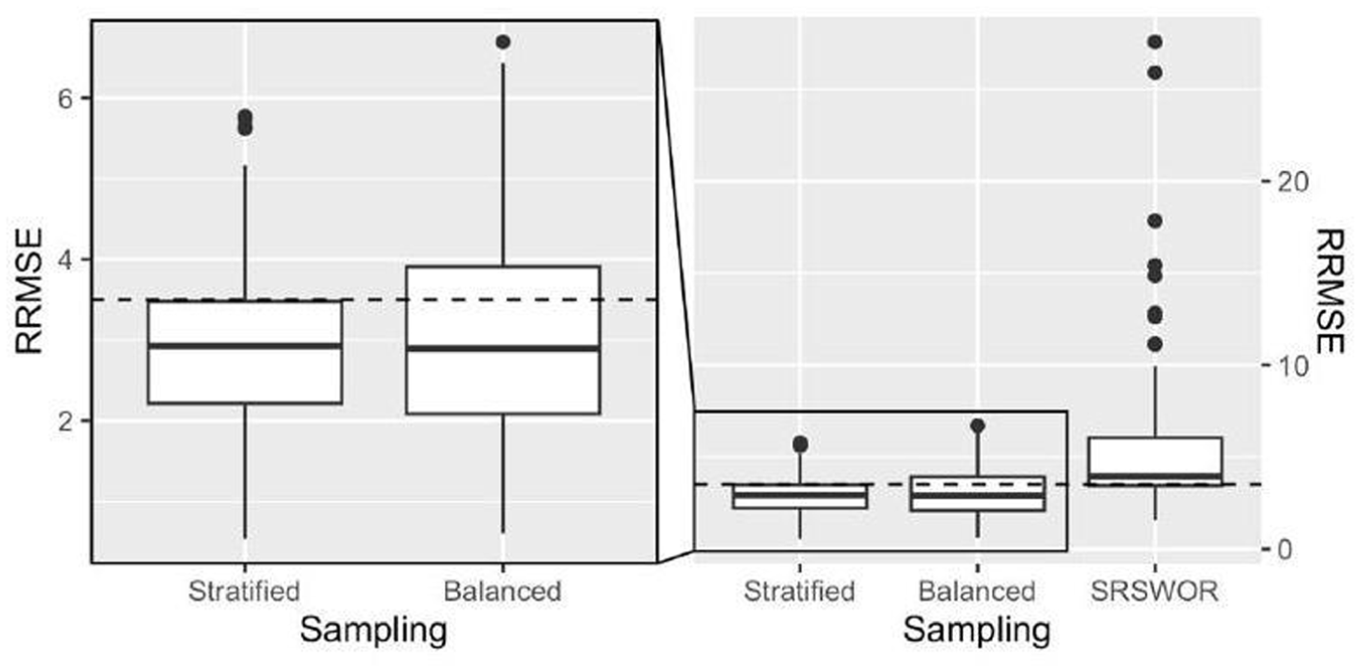
Focusing on the three different sampling designs and SAE, Figure 6 shows that the Stratified and Balanced design produced a smaller Monte Carlo RRMSE for the 100 domains compared to the SRSWOR design. The RRMSE is larger than expected in some Stratified and Balanced design domains. This evidence can be explained because the allocation method neglects the term. Furthermore, the EBLUP estimator is applied in the simulation, while the BLUP estimator is considered during the sampling allocation phase. This aspect can affect the observed empirical results. It is possible to observe empirical domain MSEs larger than the correspondent planned ones due to the relative impact of terms and for each domain and for each domain .
RRMSE of the eblup SAE estimator under different sampling designs.
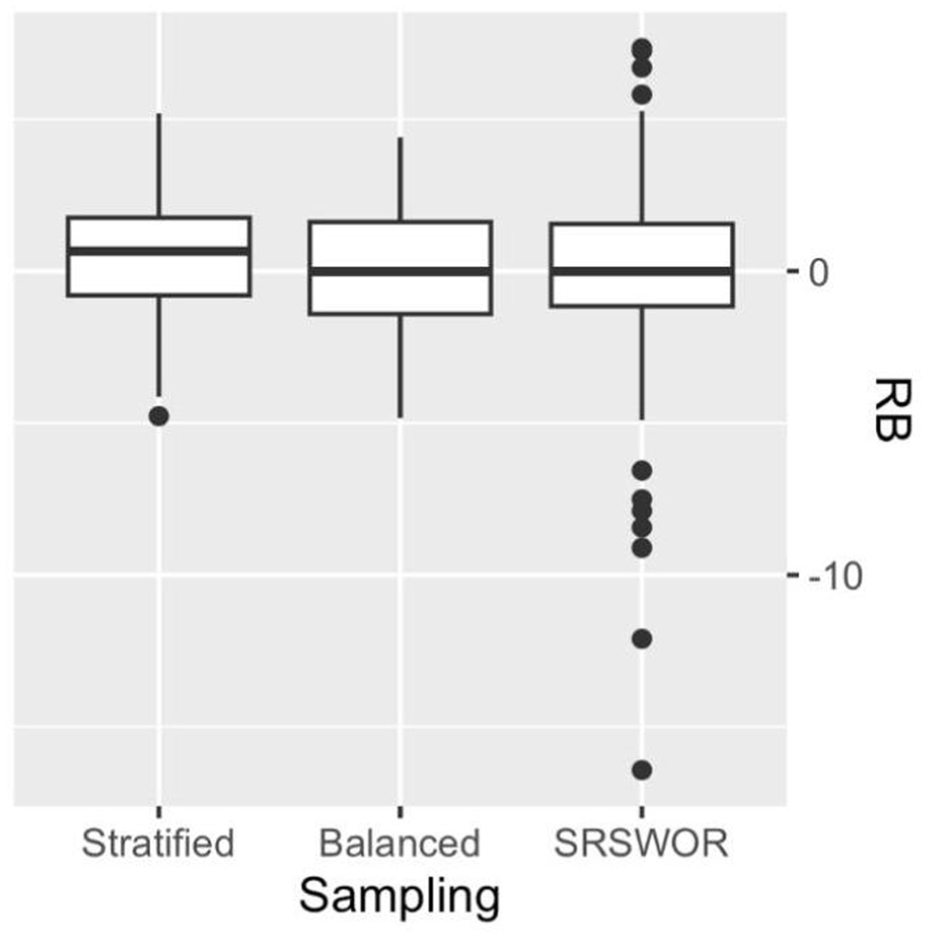
Finally, we compared the three sampling strategies based on their RB. The results for the 100 domains are presented in Figure 7. The Balanced strategy yielded estimates with smaller RB, making it the most effective. The expected RB value was negligible for both the Balanced and SRSWOR strategies, while it was slightly positive for the Stratified design. The SRSWOR strategy produced extremely large positive and negative RB values, making the Stratified or Balanced designs preferable alternatives.
RB of eblup SAE estimator under different sampling designs.
5.2. Real Data
5.2.1. Data Description
We tested the proposed approach on synthetic public data consisting of 10,000 individuals and 104 municipalities, available in the link provided in parenthesis (https://www.istat.it/microdati/rilevazione-sulle-forze-di-lavoro-dati-trasversali-trimestrali-file-per-la-ricerca/), derived from the Labor Force Sampling Survey by the Italian National Institute of Statistics. These data are provided to users to assist them in using the R package MIND (D’Alò et al. 2023) to implement multivariate models for small areas. After some data cleaning, we considered the target population as a subset of those data, consisting of 9,152 individuals and 92 municipalities. The small areas of our experiment are the 92 municipalities resulting after data cleaning. The variables for individual are: Sex by age class (14 categories), Educational level (six levels), Nationality (1 = Italian, 2 = otherwise), Municipality code (92 codes). We have two binary target variables describing the employment status where: if the person is seeking employment and , otherwise; if the person is employed and otherwise. Using these data, we applied model 2.5, obtaining the values of model variability shown in Table 1. Model 2.5 is highly predictive for employment but weaker for job seekers.
Model Variances of Real Data Used in the Experiment.
0.003
0.1943
0.002
0.1306
5.2.2. Sampling Allocation
We conducted the sampling allocation based on the computational simplification illustrated in Subsection 4.3.2. We partitioned the population in strata such that each small domain corresponds to a stratum . Moreover, we define a uniform inclusion probability and a uniform cost at the stratum level.
The allocation strategy was mainly focused on controlling the model error of the number of people seeking employment. This variable is considered the most challenging one for estimation, as it occurs less frequently, and the models used for estimation have lower predictive power. However, we also kept the error of SAE estimates relating to employed individuals under control.
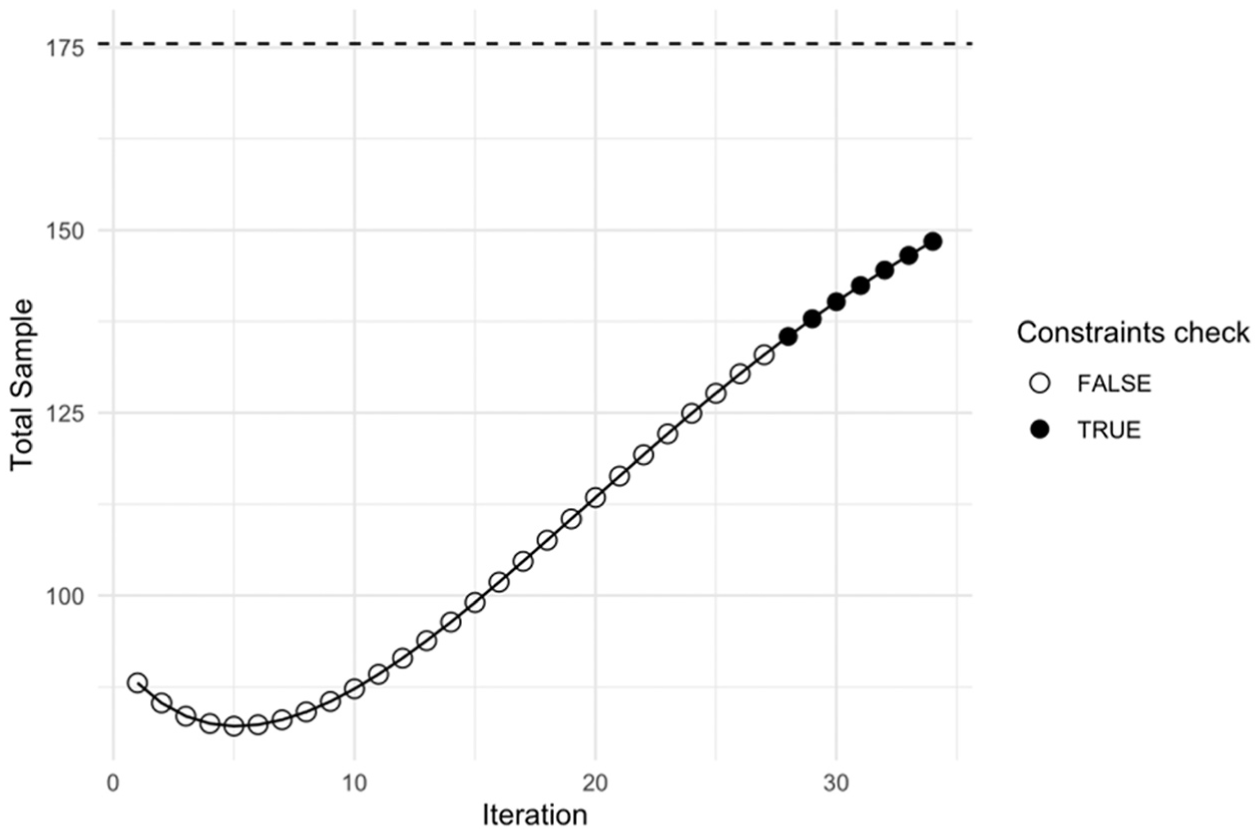
As in the case of simulated data, in this exercise we assumed a sufficient budget for around 150 interviews. To find a sampling solution compatible with this budget, we defined the OP benchmarks (expressed in relative error ) with values around 0.25 for people looking for work and 0.126 for employed people. Regarding the variable , it was not feasible to establish a single value for all domains, unlike in the simulated data. This was because, in certain domains, the average value was too low, resulting in a very small benchmark variance . This would have absorbed a disproportionately large sample in those domains, making it difficult to define an equal value across all domains. We ran the fixed-point algorithm and obtained a solution of approximately 136 units in total based on the given constraints. We denote this allocation as “opt.” The algorithm’s search path is displayed in Figure 8, where the dark circles represent the solutions that meet the constraints. As seen in the figure, the algorithm checks for local optima even after finding the optimal solution. The additional black points appearing after the optimal solution has been reached are due to an early stop mechanism in the algorithm. This mechanism halts the iterations after a certain number to prevent the risk of converging to a local minimum. The dashed line on the figure, around 175 units, represents the solution given by Powell’s algorithm, which converges faster but finds a less efficient solution (see Subsection 4.3.1).
The Search path of the optimal solution (opt) of the Fixed-point algorithm.
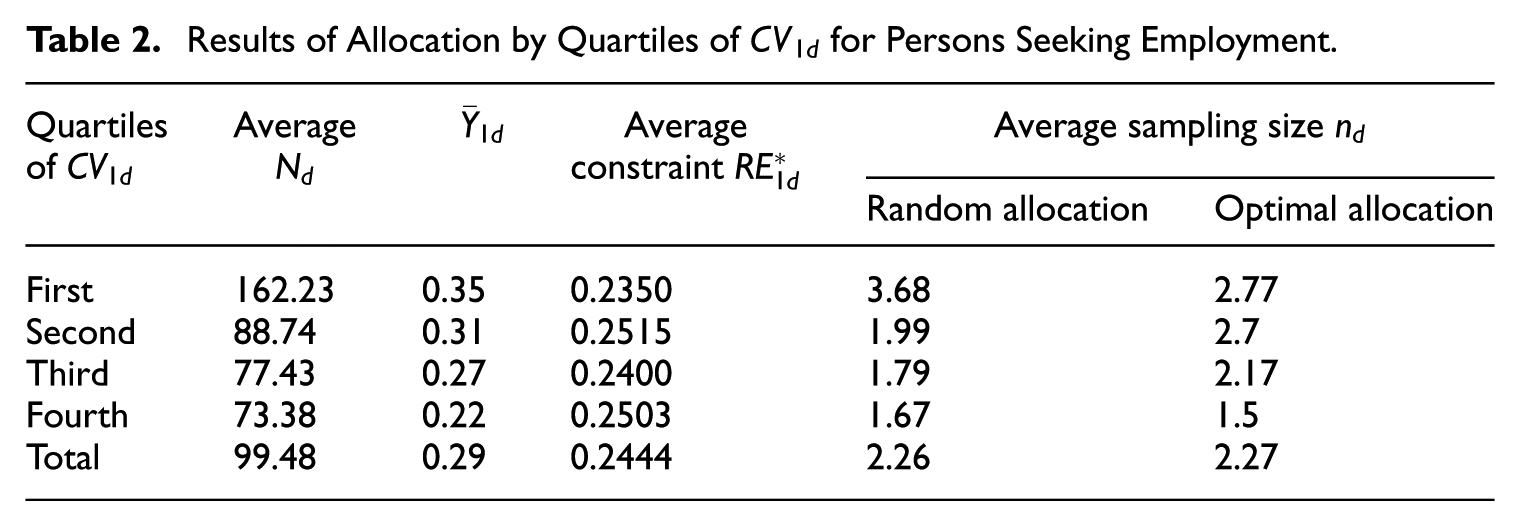
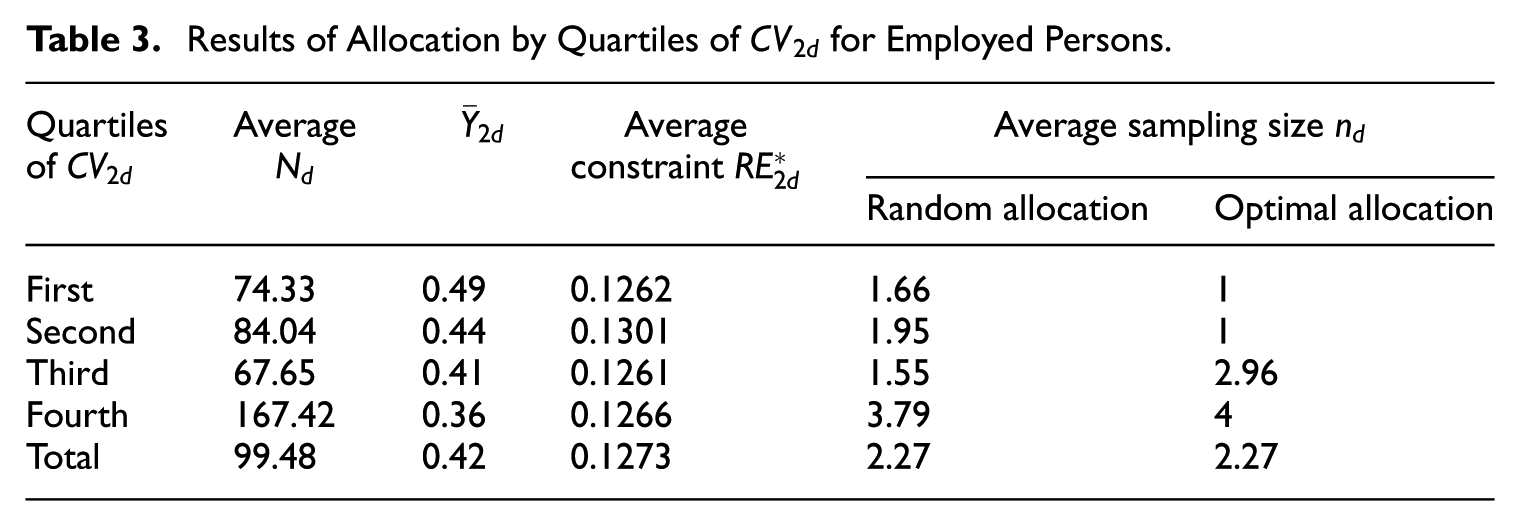
To explain the allocation process, we first calculate the coefficient of variation of the actual domain values, where , being . For each variable , we then classified the domains into quartiles based on their Tables 2 and 3 display the opt allocation results for job seekers and employed individuals, respectively, for each quartile. We compared these results with those of a random allocation, which, on average, allocates the sample into domains proportionally to their size in terms of units.
Results of Allocation by Quartiles of for Persons Seeking Employment.
Quartiles of
Average
Average constraint
Average sampling size
allocation
Optimal allocation
First
162.23
0.35
0.2350
3.68
2.77
Second
88.74
0.31
0.2515
1.99
2.7
Third
77.43
0.27
0.2400
1.79
2.17
Fourth
73.38
0.22
0.2503
1.67
1.5
Total
99.48
0.29
0.2444
2.26
2.27
Results of Allocation by Quartiles of for Employed Persons.
Quartiles of
Average
Average constraint
Average sampling size
allocation
Optimal allocation
First
74.33
0.49
0.1262
1.66
1
Second
84.04
0.44
0.1301
1.95
1
Third
67.65
0.41
0.1261
1.55
2.96
Fourth
167.42
0.36
0.1266
3.79
4
Total
99.48
0.42
0.1273
2.27
2.27
When it comes to the variable of individuals seeking employment, we observed that optimal allocation yields a more balanced distribution compared to random allocation. Random allocation tends to concentrate the sample in areas with higher population, whereas optimal allocation distributes the sample away from those regions and assigns it to areas that pose more difficulties. In the fourth quartile, however, the two allocations are approximately equivalent. This effect may be due to the need to ensure an error benchmark also for the estimate of employed people. Upon analyzing the employment estimate, we noticed that the third quartile of the distribution tends to be oversized. This could be due to the impact of other variables. The optimal allocation finds an efficient compromise between the requirements defined for the two variables.
The evidence from the last two columns of Tables 2 and 3 highlights that the planned accuracy ( = 0.25 for job seekers and 0.126 for employed individuals) can be attained with as little as one observation per domain.
5.2.3. Monte Carlo Simulation
From the population illustrated in Subsection 5.2.1, we selected 1,000 samples for each of the two allocations considered, and we constructed the EBLUP estimates. We also calculated the Horvitz-Thompson estimates for each sample selection of the random allocation. We then calculated the and indicators similarly to what was illustrated in Subsection 5.1.3. We present the results only for the variable “people seeking occupation” because there are no substantial differences between the two sample allocations for the other variable, which is undoubtedly due to the predictive goodness of the SAE model for this latter variable.
5.2.4. Results
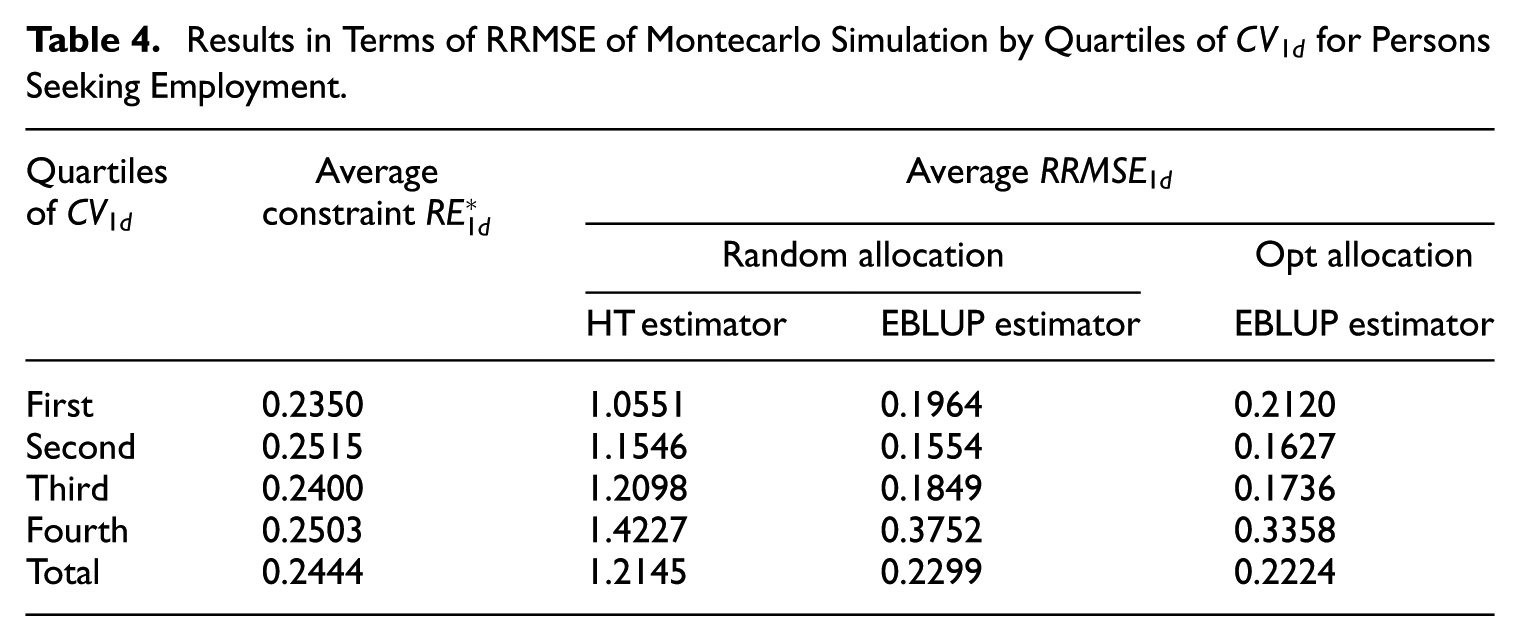
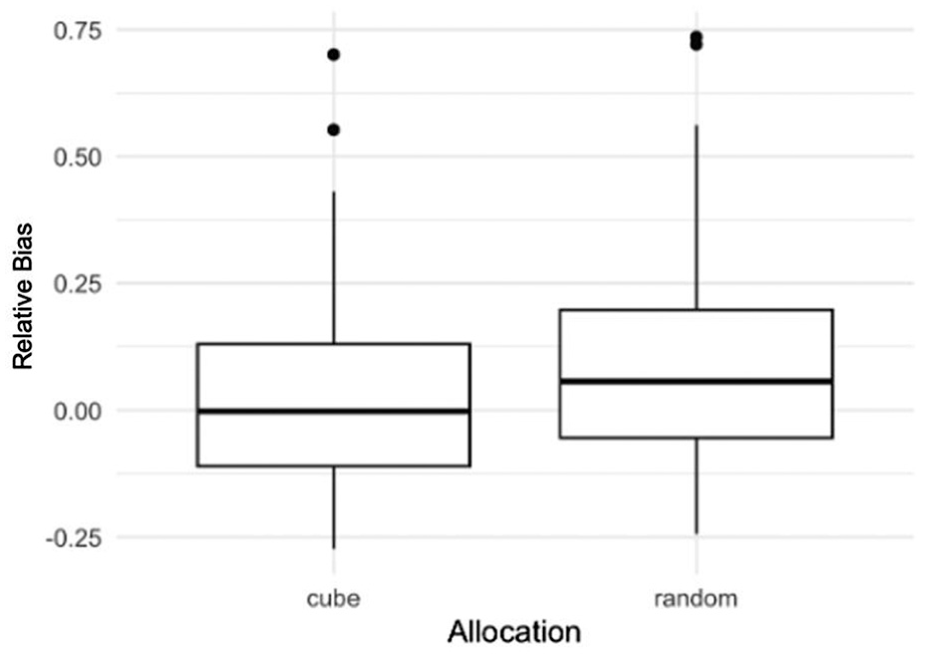
Table 4 illustrates the RRMSE results from Monte Carlo simulations by quartiles of for persons seeking employment. For domains above the median of the quartile distribution (i.e., those with higher difficulty), the EBLUP estimator under optimal allocation consistently achieves a lower RRMSE values compared to random allocation. This highlights the advantage of optimal allocation in reducing errors in problematic domains, which are characterized by higher variances and lower means. In contrast, for domains below the median of the quartile distribution (i.e., those with lower difficulty), the RRMSE values for both allocation strategies are approximately equivalent, with a slight preference for random allocation. However, these domains are not problematic, as they already provide accurate estimates regardless of the allocation method. In summary, we emphasize that our approach is a compromise. The key advantage of our proposed sampling method, in contrast to a standard one, is its ability to optimally allocate samples across various domains. This strategy helps us minimize excessively high errors in certain areas while only slightly increasing errors in domains where the SAE estimates are already accurate. This trade-off underscores the overall benefit of the optimal allocation strategy compared to random allocation. We further note that in the last quartile group, both methods fail to fully comply with the constraints. However, the RRMSE of the EBLUP estimate under optimal allocation is closer to the constraint. This non-compliance likely arises because the optimization assumes the absence of model estimation bias, which, in this case, is introduced by extreme values in the data (refer to Figure 9). Nevertheless, the scatter plots in Figure 9 indicate that the optimal allocation offers better protection against bias, further supporting its effectiveness in challenging scenarios.
Results in Terms of RRMSE of Montecarlo Simulation by Quartiles of for Persons Seeking Employment.
Quartiles of
Average constraint
Average
Random allocation
Opt allocation
HT estimator
EBLUP estimator
EBLUP estimator
First
0.2350
1.0551
0.1964
0.2120
Second
0.2515
1.1546
0.1554
0.1627
Third
0.2400
1.2098
0.1849
0.1736
Fourth
0.2503
1.4227
0.3752
0.3358
Total
0.2444
1.2145
0.2299
0.2224
The relative bias of EBLUP estimators for the two allocations.
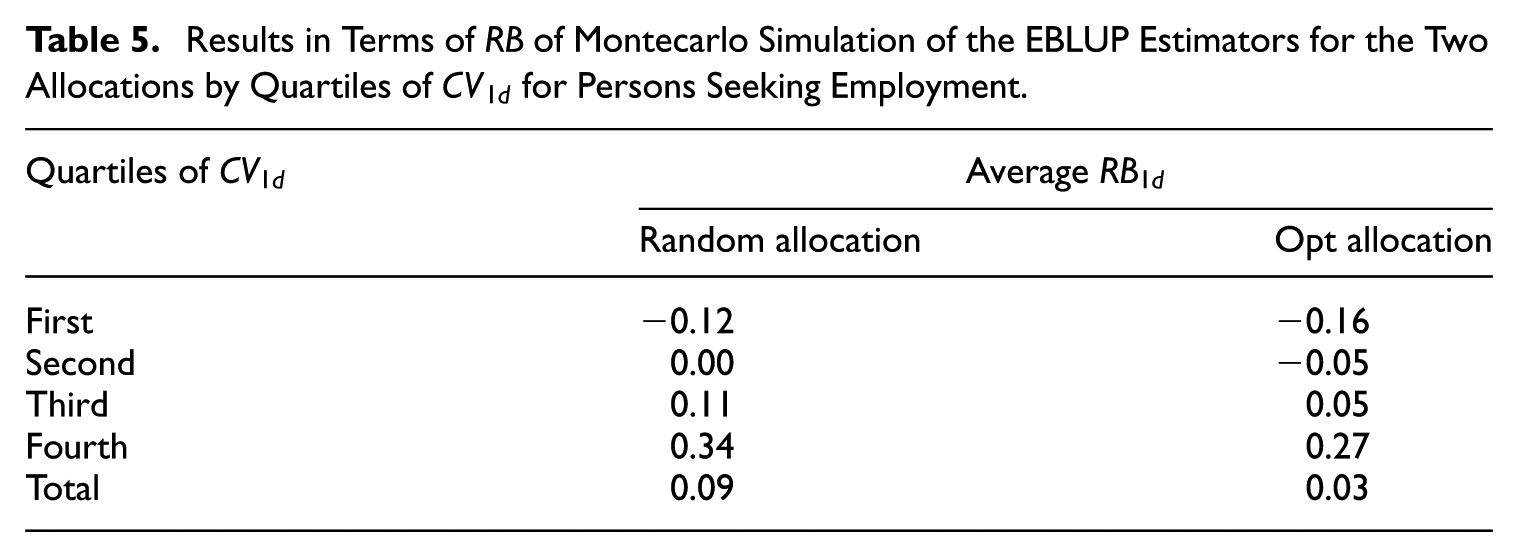
Finally, Table 5 illustrates the bias of EBLUP estimators for the two allocations. The relative bias of the opt allocation for the most problematic areas (i.e., those above the median) is lower.
Results in Terms of of Montecarlo Simulation of the EBLUP Estimators for the Two Allocations by Quartiles of for Persons Seeking Employment.
Quartiles of
Average
Random allocation
Opt allocation
First
−0.12
−0.16
Second
0.00
−0.05
Third
0.11
0.05
Fourth
0.34
0.27
Total
0.09
0.03
6. Conclusions
Developing an overall strategy to address the Small Area Estimation (SAE) problem remains an unsolved issue in the finite population inference. Usually, the SAE strategy focuses on the specific estimation techniques, moving the sampling design to the background. This paper has delved into how a carefully designed sampling design allows us to improve the accuracy of SAE estimates, at least in cases where small domains of interest can be identified at the sampling design stage.
The strategy we propose is based on three steps. First, we define a working SAE model for the small areas of interest. This model must be simple since sampled units have not yet been observed. Furthermore, the model must align with the overall available budget. Essentially, this means that the levels of the random factors defined in the model should not exceed the overall sample size permitted by the survey budget. In this way, we can select a sample where the various random components are predicted by direct observation and do not solely rely on the synthetic part of the estimator. The proposed working model must be a compromise between a complex model that accurately describes reality and a simplified model that nevertheless allows the fundamental random components to be kept under control.
Then, we defined a non-standard optimization method for defining the vector of inclusion probabilities in order to minimize the expected minimum cost sampling design, by ensuring that the model-based estimates respect the desired model-based accuracy. This optimization problem aims for an efficient allocation of the sample units in the estimation domains. We also studied the algorithmic solutions necessary to solve the optimization problem.
The third pillar of the strategy is based on sample selection. We suggest a balanced sample selection technique that allows to control the sample size for each of the random effects defined in the model and, if possible, to control the mean value of the auxiliary variables involved in the fixed part of the working model.
Experiments on a simulated data sets showed that controlling sampling sizes is crucial for small domains to protect against inaccurate model-based estimations and to ensure that the accuracy level never exceeds the established accuracy. In the experiments, strategies that neglect the sampling design exhibit highly heterogeneous sampling errors among the domains, with some domains receiving few or none sample units and others many more than needed.
It is worth noting that while our approach focuses on optimizing inclusion probabilities to guarantee cost-effective accuracy for small area estimation, the method of penalized balanced sampling proposed by Breidt and Chauvet (2012) enhances efficiency by modifying the cube method through penalization. The two strategies, therefore, differ in perspective: our solution ensures accuracy through planned allocation, whereas theirs emphasizes design-based efficiency via penalization, offering complementary but distinct pathways.
Future research on this topic will cover several aspects. In our view, the first point to be addressed is the one sketched in Appendix A3 for a simplified statistical setting, where an optimality condition is sought, considering that estimates for larger domains can be obtained with estimators (such as HT) that are unbiased concerning the sampling design. In contrast, those for smaller domains are obtained with model-based estimators. Other aspects that need to be addressed in more detail, both theoretically and in terms of application, are related to SAE models useful in situations where the overall survey budget only allows direct observation in some small areas. Such cases may represent considerable interest in many SAE real situations where the estimation domains are too small to control their sampling sizes in the design phase.
Footnotes
Appendix A1
Appendix A2
Appendix A3
Appendix A4
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
BurgardJ. P.MünnichR.ZimmermannT.2014. “The Impact of Sampling Designs on Small Area Estimates for Business Data.”Journal of Official Statistics30 (4): 749–71. DOI: https://doi.org/10.2478/jos-2014-0046.
4.
CadamuroE.2023. “A Sample Allocation on Small Area.” Master’s thesis. Available on request.
5.
ChambersR.ClarkR.2012. An Introduction to Model-Based Survey Sampling with Applications, Volume 37. Oxford Statistical Science Series. Oxford University Press.
6.
CochranW. G.1977. Sampling Techniques. New York: John Wiley & Sons.
7.
D’AlòM.FalorsiS.FasuloA.2023. “Mind, a Methodology for Multivariate Small Area Estimation with Multiple Random Effects.”METRON82 (1): 93–107. DOI: https://doi.org/10.1007/s40300-023-00258-z.
DevilleJ.-C.TilléY.2005. “Variance Approximation Under Balanced Sampling.”Journal of Statistical Planning and Inference128 (2): 569–91. DOI: https://doi.org/10.1016/j.jspi.2003.11.011.
10.
DorfmanA.ValliantR.2005. “Model-Based Prediction of Finite Population Total.” In Handbook of Statistics, Sample Surveys: Inference and Analysis, edited by RaoC. R., Volume 29B. Amsterdam: Elsevier. https://doi.org/10.1016/S0169-7161(09)00223-5.
11.
FalorsiP. D.FalorsiS.NardelliV.RighiP.2023. “Defining the Sample Designs for Small Area Estimation.”arXiv preprint arXiv:2303.08503. DOI: https://doi.org/10.48550/arXiv.2303.08503.
FriedrichU.MünnichR.RuppP.2018. “Multivariate Optimal Allocation with Box-Constraints.”Austrian Journal of Statistics47 (2): 33–52. DOI: https://doi.org/10.17713/ajs.v47i2.764.
15.
FuA.NarasimhanB.BoydS.2020. “CVXR: An R Package for Disciplined Convex Optimization.”Journal of Statistical Software94 (14): 1–34. DOI: https://doi.org/10.18637/jss.v094.i14.
16.
GablerS.GanningerS.MünnichR.2012. “Optimal Allocation of the Sample Size to Strata Under Box Constraints.”Metrika75: 151–61. DOI: https://doi.org/10.1007/s00184-010-03193.
17.
GrafströmA.LundströmN. L.2013. “Why Well Spread Probability Samples Are Balanced.”Open Journal of Statistics3 (1): 36–41. DOI: https://doi.org/10.4236/ojs.2013.31005.
HaslettS.JonesG.NobleA.BallasD.2010. “More for Less? Comparing Small Area Estimation, Spatial Microsimulation, and Mass Imputation.”Proceedings of the Section on Survey Research Methods-JSM.
KetoM.HakanenJ.PahkinenE.2018. “Register Data in Sample Allocations for Small-Area Estimation.”Mathematical Population Studies25 (4): 184–214. DOI: https://doi.org/10.1080/08898480.2018.1437318.
22.
KishL.1995. Survey Sampling. New York: Wiley.
23.
KordosJ.2014. “Development of Small Area Estimation in Official Statistics.”Statistics in Transition New Series and Survey Methodology17 (1): 105–32. Joint Issue: Small Area Estimation 2014. DOI: https://doi.org/10.59170/stattrans-2016-006.
LehtonenR.VeijanenA.2009. “Design-Based Methods of Estimation for Domains and Small Areas.” In Handbook of Statistics, Sample Surveys: Inference and Analysis, Volume 29B, edited by C. R.Rao. Elsevier. https://doi.org/10.1016/S0169-7161(09)00231-4.
PfeffermannD.Ben-HurD.2019. “Estimation of Randomisation Mean Square Error in Small Area Estimation.”International Statistical Review87: S31–S49. DOI: https://doi.org/10.1111/insr.12289.
RaoJ. N. K.MolinaI.2015. Small Area Estimation. Hoboken, NJ: Wiley.
32.
RoyleJ. A.DorazioR. M.2006. “Hierarchical Models of Animal Abundance and Occurrence.”Journal of Agricultural, Biological, and Environmental Statistics11 (3): 249–63. DOI: https://doi.org/10.1198/108571106X129153.
33.
SärndalC.SwenssonB.WretmanJ.1992. Model Assisted Survey Sampling. New York: Springer-Verlag.
TzavidisN.ZhangL.-C.Luna-HernandezA.SchmidT.Rojas-PerillaN.2018. “From Start to Finish: A Framework for the Production of Small Area Official Statistics.”Journal of the Royal Statistical Society Series A: Statistics in Society181 (4): 927–79. DOI: https://doi.org/10.1111/rssa.12364.
38.
UNECE. 2018. “Preliminary Experimental: Results on the Italian Population and Housing Census Estimation Methods.”Proceedings of the Twentieth Meeting of European Statisticians, Geneva, September 26–28. Item 2 of the agenda.
39.
ValliantR.DorfmanA. H.RoyallR. M.2000. Finite Population Sampling and Inference. New York: John Wiley & Sons.