
Abstract
Understanding and modeling mortality patterns, especially differences in mortality rates between populations, is vital for demographic analysis and public health planning. We compare three statistical models within the age-period framework to examine differences in death counts. The models are based on the double Poisson, bivariate Poisson, and Skellam distributions, each of which provides unique strengths in capturing underlying mortality trends. Focusing on mortality data from 1960 to 2015, we analyze the two leading causes of death in Italy, which exhibit significant temporal and age-related variations. Our results reveal that the Skellam distribution offers superior accuracy and simplicity in capturing mortality differentials. These findings highlight the potential of the Skellam distribution for analyzing mortality gaps effectively.
1. Introduction
Since the early nineteenth century, life expectancy in developed countries has shown consistent growth, particularly since the end of the Second World War (Oeppen and Vaupel 2002). Researchers, governments, and related organizations have often noted a faster-than-expected increase in longevity, posing financial challenges for life insurers, pension plans, and social security systems. A shift in longevity trends can substantially affect the number of elderly individuals and centenarians, thereby increasing demand for social services. Consequently, official forecasts that guide future pensions, healthcare, and other social needs can shape individual decisions on savings and retirement timing. In this context, methodological advancements in longevity studies have become increasingly important for anticipating future changes (see, e.g., Pascariu et al. 2018; Raftery et al. 2013; Torri and Vaupel 2012), aiming to reduce the gap between actual outcomes and projections.
Various approaches have been utilized to model the mortality surface, capturing how mortality rates evolve over time. Prior to the 1980s, mortality models were relatively simple and often depended on expert judgment (see Pollard 1987, for a detailed review). However, with the increased availability of mortality data and the advancement of statistical methods, more sophisticated and complex mortality models have since been developed.
According to Booth and Tickle (2008), three main paradigms in demographic modeling can be identified. The first paradigm, explanation, is based on structural or epidemiological models that focus on specific causes of death, such as a well-established link between lung cancer and tobacco smoking. The second paradigm, expectation, relies on expert opinions and may range from informal assessments to more formalized approaches. The third paradigm, extrapolation, utilizes regular patterns observed in age-specific mortality rates and temporal trends. This approach includes complex stochastic models, such as the Lee and Carter’s (1992) model and the generalized age-period-cohort model. Although the Lee–Carter model is regarded as one of the most influential in mortality modeling and forecasting, various extensions and modifications have gained considerable attention in actuarial and demographic literature (see, e.g., Brouhns et al. 2002; Cairns et al. 2006, 2009; Haberman and Renshaw 2011; Marino et al. 2023; Nigri et al. 2019; Shang and Haberman 2020; Shang et al. 2023).
Despite the widespread use of the Lee–Carter model and its variants, which serve as benchmarks for many new methodologies, these models have several limitations. Cairns et al. (2008) addressed the challenge of optimal mortality estimation by proposing criteria for a robust mortality model, emphasizing consistency with historical data and biologically plausible long-term dynamics. Apart from modeling age-specific mortality rates, research has shifted toward developing statistical frameworks that model the age-at-death distribution, allowing for parameter forecasting using econometric models (see, e.g., Aliverti et al. 2022; Basellini and Camarda 2019; Cardillo et al. 2023; Pascariu et al. 2019). However, researchers and practitioners have noted that separate forecasts for different populations or sub-populations can lead to unreliable scenarios, as backtesting often reveals diverging behaviors. Such inconsistencies in forecasts are implausible and may undermine decision-making processes.
Building on this discussion, we propose a novel approach for modeling and forecasting the gap in mortality counts between two populations. Specifically, we leverage recent developments in cause-of-death analysis (see, e.g., Arnold and Sherris 2015; Kjærgaard et al. 2019; Wilmoth 1995) by treating the two target populations as distinct causes of death within the same country. These two causes of death have implications for public health, particularly in identifying trends and temporal changes across different age groups. Understanding the trend associated with any specific cause of death enables policymakers to better allocate and target healthcare resources.
Our focus, therefore, is on the distribution of deaths, highlighting the disparities between two population counts, which represent the two leading causes of death, namely cancer and circulatory diseases, in the Italian population. These causes are major contributors to overall mortality. It is noteworthy that the two populations could also represent other categories, such as different genders, countries, or sub-populations within the same country. We aim to provide a more reliable and coherent forecast by addressing the inconsistencies often seen in separate forecasts for different populations or sub-populations. We develop a statistical toolkit for those working with mortality data, allowing for the joint modeling of mortality evolution between two populations while considering their differences. Alongside traditional alternatives like the double and bivariate Poisson distributions, we introduce the Skellam distribution, commonly used in fields involving count data, such as sport analysis.
Recently, Kung et al. (2021) introduced the Skellam distribution within the Lee-Carter framework to model the log-difference of mortality rates, focusing on age-dependent improvements in mortality and their implications for pricing longevity derivatives. While their work provides valuable insights into the dynamics of mortality improvement, our approach differs fundamentally in both scope and methodology. Specifically, we employ the Skellam distribution within the age-period framework to model differences in mortality counts across causes of death. In this context, it is standard practice to fix the age profile parameters, as the primary focus lies on capturing temporal (period) effects. This distinction highlights the originality of our contribution, which centers on analyzing mortality gaps with a straightforward and coherent structure tailored to demographic and public health applications.
Mortality data are commonly reported as count data within specific age-period domains for various populations. The simplest models for modeling mortality patterns use age and period as the only explanatory variables, since they capture all the necessary information intrinsic to the data. This approach serves as a foundational basis for exploring and understanding the complex dynamics of mortality across different populations.
The remainder of the paper is structured as follows: Section 2 introduces the motivating dataset and demographic measures. Sections 3 and 4 detail the methods used in our study. In Section 5, we present the implementation and evaluation of the distributions considered. Section 6 concludes the paper and offers some insights on potential extensions of the presented methodology.
2. Data and Measures
Let
We utilize period life tables by sex and single year of age (0–85+) from the Human Mortality Database (2024). We extract death counts by cause of death from the World Health Organization (2022) for the total population. This allows us to compute the proportion of deaths by cause, age group (in five-year intervals), and sex for each year from 1960 to 2015.
The data, in their original form, were classified using the seventh, eighth, ninth, and tenth revisions of the International Classification of Diseases (ICD). To analyze factors influencing Italian longevity, we group deaths into two major categories up to age 85+ (see Table 1): cancers and circulatory system diseases. These categories represent significant causes of death, capturing a substantial proportion of overall mortality. For details on ICD codes and the classification system, refer to Table 1.
ICD Codes and Our Classification into Two Major Groups.
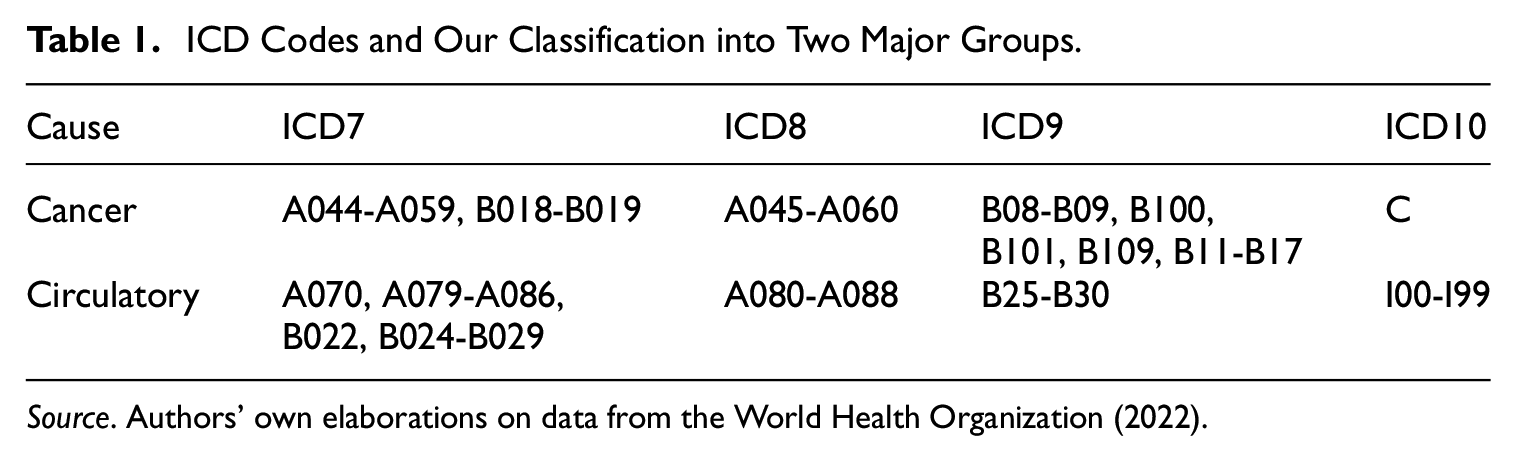
Source. Authors' own elaborations on data from the World Health Organization (2022).
We define the gap in deaths between two populations, in our case the two causes of death

Figure 1 provides a detailed depiction of the relationship between age and the temporal evolution of dynamics for a specific cause of death. It also illustrates the measure we are modeling: the difference in counts over time.
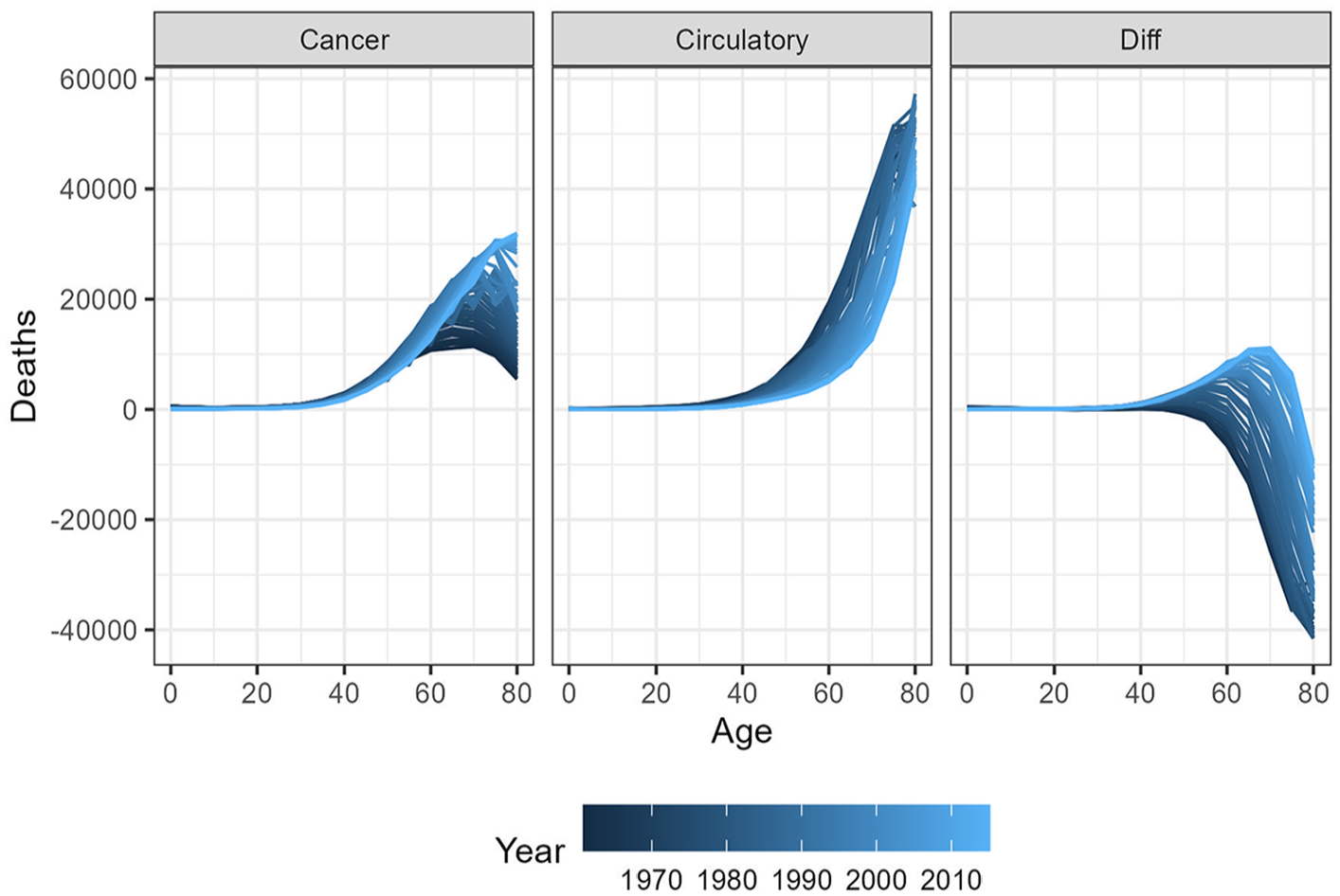
Trends in cancer and circulatory death counts, as well as their differences, by age and year in Italy (both sexes combined) from 1960 to 2018.
3. Models and Distributions
3.1. Age-Period Model
Statistical modeling in longevity analysis is essential for understanding its evolution and variability. The literature highlights three key components—age, period, and cohort effects—that provide valuable insights into non-observable causal mechanisms.
Age effect is associated with a specific population’s biological and social processes, linked to its age structure rather than the period. In contrast, the period effect results from external factors that impact all age groups equally at a particular calendar time. These effects may arise from various environmental, social, or economic factors; the Spanish flu, the First World War, and COVID-19 are prime examples. Lastly, cohort effect refers to variations that stem from a group of individuals’ unique experiences or exposures as they progress through time.
The model that integrates all these components is known as the age-period-cohort approach, which presents technical challenges that can complicate the interpretation and clarity of estimates, especially when working with causes of death (see, e.g., Mason et al. 1973, for more details).
The demographic literature centering on longevity risks has primarily proposed age-period models. Continuing this line of research, we focus on the age-period framework. A canonical regression model, based on the ordinary least squares method, is specified as follows:

where
Given the mortality data for two populations, A and B, specific to ages and years, our goal is to determine the average period trend and the age-specific profile of the differences in mortality. We leverage the fundamental assumption in mortality modeling that death counts for each population,
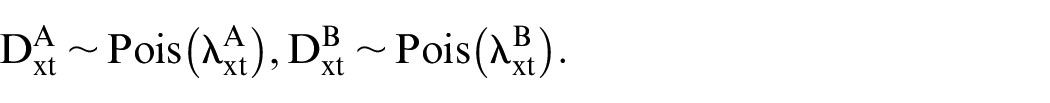
3.2. Poisson Distribution
3.2.1. Double Poisson
The simplest model employs two independent Poisson variables, where the parameters are constructed as the sum of age effects (
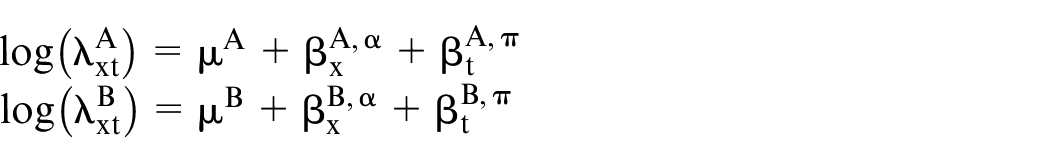
If the goal is to estimate the differences in deaths between the two populations by year and age, one can calculate:

where
The joint probability of the observations
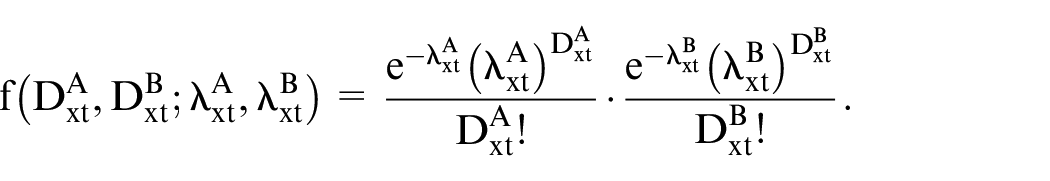
Given observations
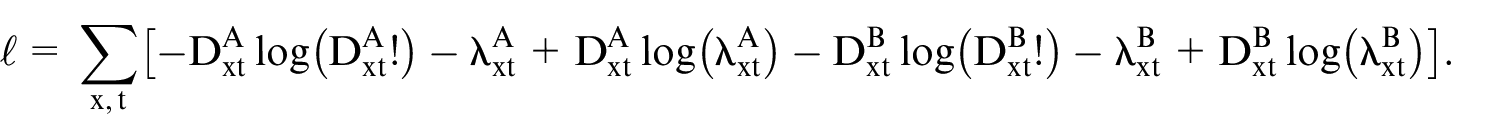
3.2.2. Bivariate Poisson
The double Poisson model, while straightforward, makes a somewhat unrealistic assumption by treating the processes as generated by two independent Poisson distributions. In cases where we consider two subpopulations within a single population (such as two sexes or two causes of death) or two populations experiencing similar environmental and external factors (such as neighboring countries), the correlation between deaths in the two groups can be quite high.
An alternative to the double Poisson model is the bivariate Poisson distribution, which accounts for the dependence between the two outcome variables. In this model, while the marginal distributions remain Poisson, the random variables are allowed to be dependent (Karlis and Ntzoufras 2005).
Consider random variables

Marginally, each random variable follows a Poisson distribution:
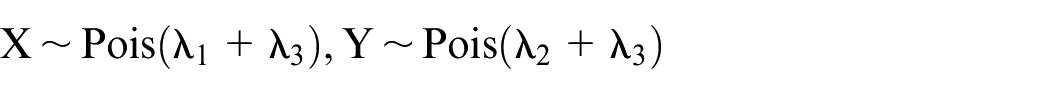
Moreover,
In the case of the death count of two populations, we have:
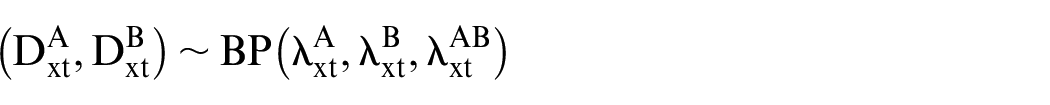
Therefore, the joint probability mass function is given by:
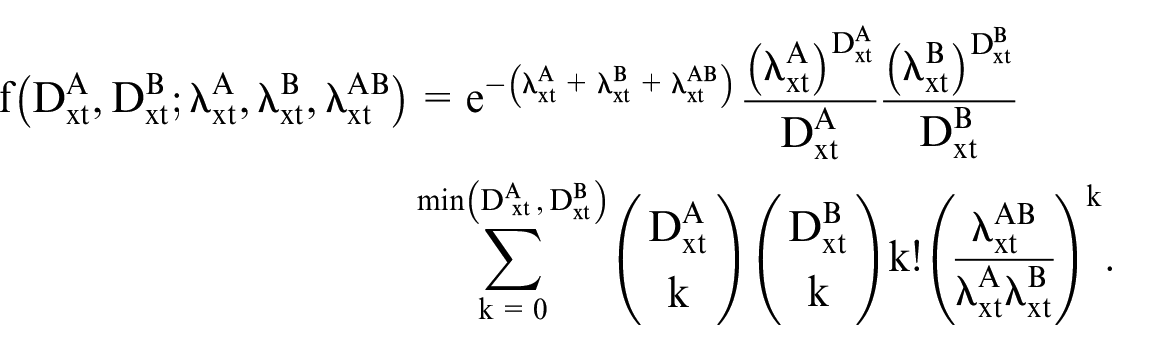
Given observations
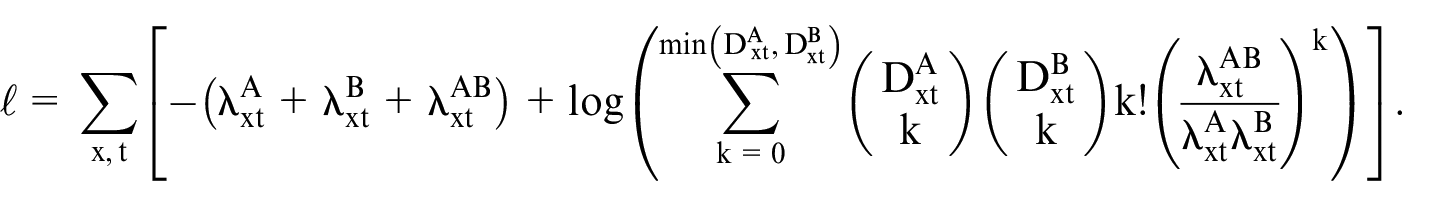
In our modeling using the bivariate Poisson distribution, we explore three distinct models, each concentrating on a different parameter.
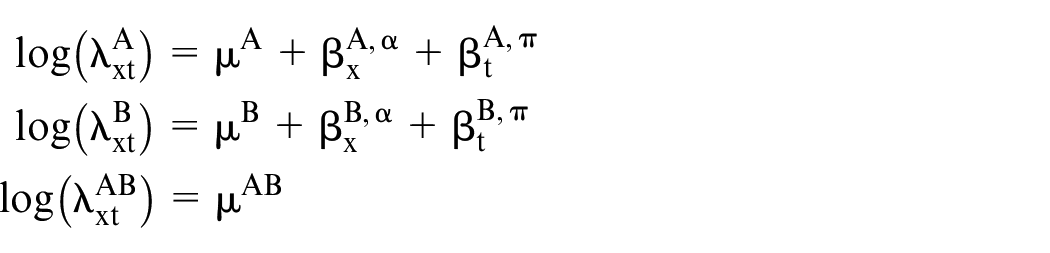
Following the work of Karlis and Ntzoufras (2005), we consider models with a constant
In the estimation of the mortality gap, we have simply:
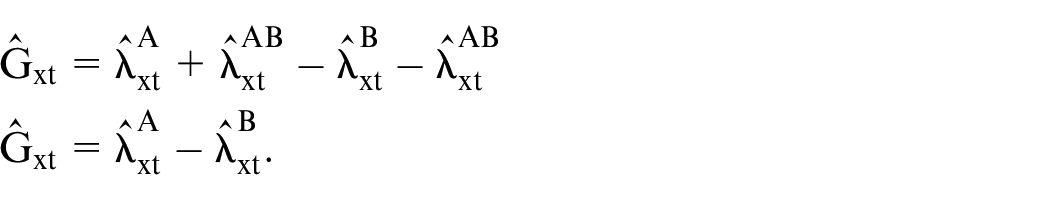
3.3. Skellam Distribution
By employing the bivariate Poisson distribution to estimate the gap between deaths, the correlation component is eliminated. We propose using the Skellam (or Poisson Difference) distribution to directly model the gap rather than jointly modeling the number of deaths for the two populations.
The Poisson Difference distribution, introduced by Skellam (1946), describes the difference
The probability mass function of
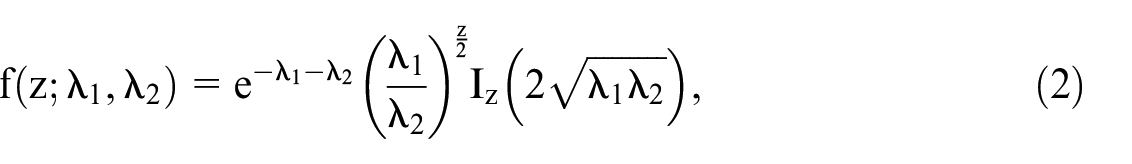
where
Therefore, we assume that
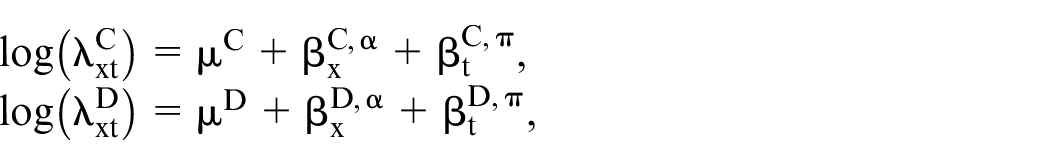
We use the superscripts
The fitted values from the regression directly provide estimates of the death gap:

The Skellam distribution requires only the series of differences in deaths between populations A and B, rather than the two death series individually.
We estimate the model parameters by maximizing the log-likelihood function of Skellam distribution, which is
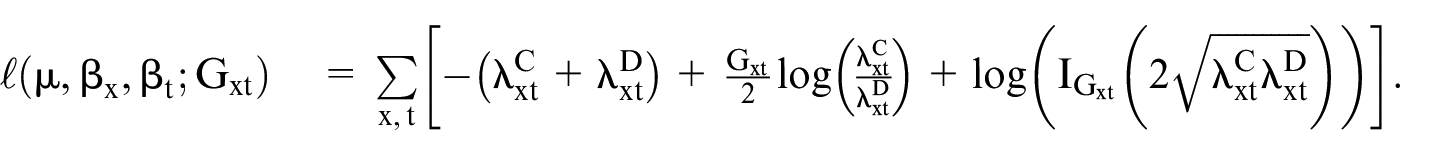
3.4. Estimation and Goodness of Fit
With regard to the estimation procedure, Ho and Singer (2001) proposes a generalized least squares method, whereas Kocherlakota and Kocherlakota (2001) outlines a Newton–Raphson approach for likelihood maximization in the context of bivariate Poisson regression models. In this application we leverage the approach by Karlis and Ntzoufras (2003) using the EM algorithm to obtain maximum likelihood estimates for both, double and bivariate Poisson. The EM algorithm proceeds by estimating the unobserved data via their conditional expectations at the E-step and then it maximizes the complete-data likelihood at the M-step (Karlis and Ntzoufras 2005).
The estimation of the parameters for the Skellam regression is performed by minimizing the negative log-likelihood using the Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm, using the optim function in  .
.
The parameter vector
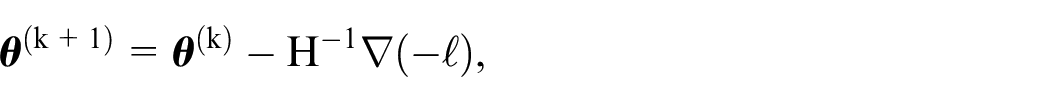
where
The optimization terminates when the norm of the gradient satisfies a convergence criterion, such as
In order to measure the goodness-of-fit in terms of the log-likelihood, Akaike information criterion (AIC), Akaike information criterion with small-sample correction (
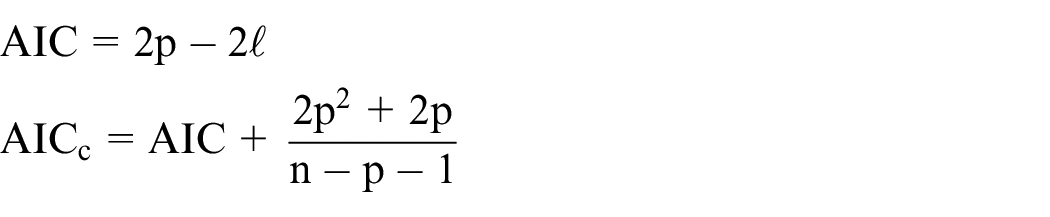
and

where p is the number of effective parameters, and n is the number of total observations. All the results are presented in Tables 2 and 3 of Section 5.
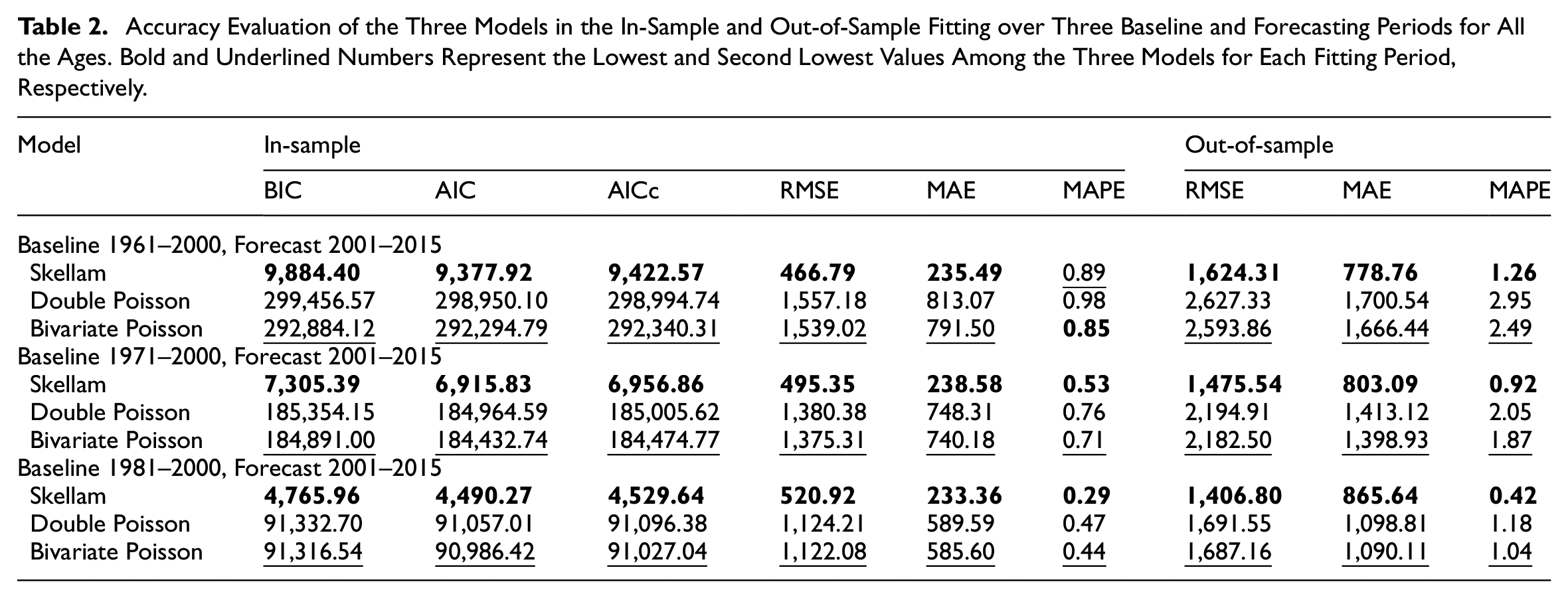
Accuracy Evaluation of the Three Models in the In-Sample and Out-of-Sample Fitting over Three Baseline and Forecasting Periods for All the Ages. Bold and Underlined Numbers Represent the Lowest and Second Lowest Values Among the Three Models for Each Fitting Period, Respectively.
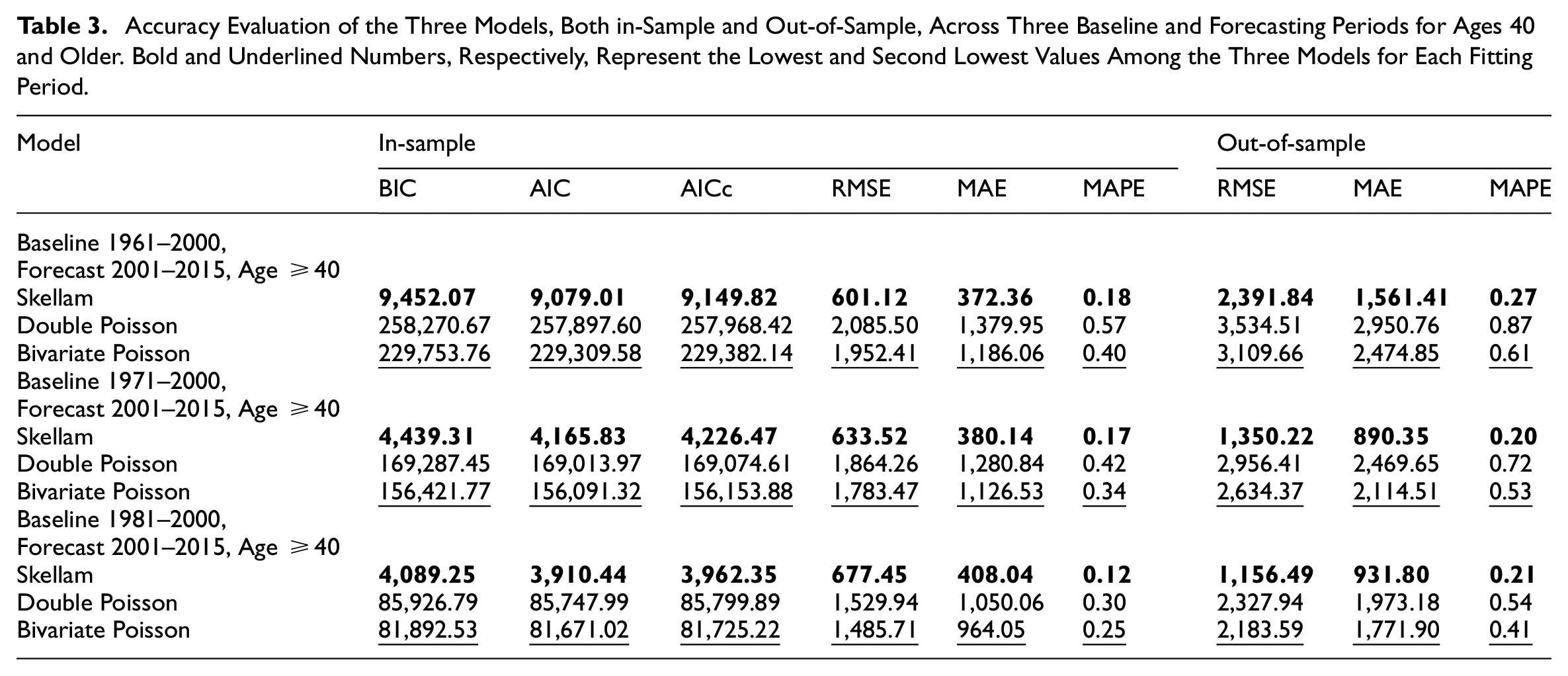
Accuracy Evaluation of the Three Models, Both in-Sample and Out-of-Sample, Across Three Baseline and Forecasting Periods for Ages 40 and Older. Bold and Underlined Numbers, Respectively, Represent the Lowest and Second Lowest Values Among the Three Models for Each Fitting Period.
4. Forecasting
Introducing a novel forecasting model for the differences in mortality between two distinct populations is crucial for several reasons. It allows for generating coherent forecasts for both populations, ensuring consistency in predictive analysis. By leveraging the Skellam distribution, which naturally models the difference between two Poisson-distributed variables, we can more accurately capture the inherent variability and interdependence between the causes of death. This approach enhances the reliability of forecasts and provides a deeper understanding of the underlying mortality dynamics, ultimately supporting more informed public health decisions and better resource allocation to address these gaps.
Given the age and period effects estimated during the baseline period using the regression models discussed in the previous subsections, the proposed forecasting method involves fixing the observed age profile
We aim to predict the differences in mortality between the two populations
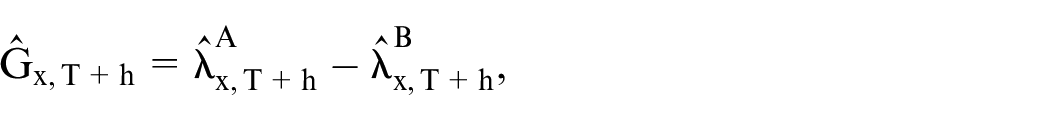
where
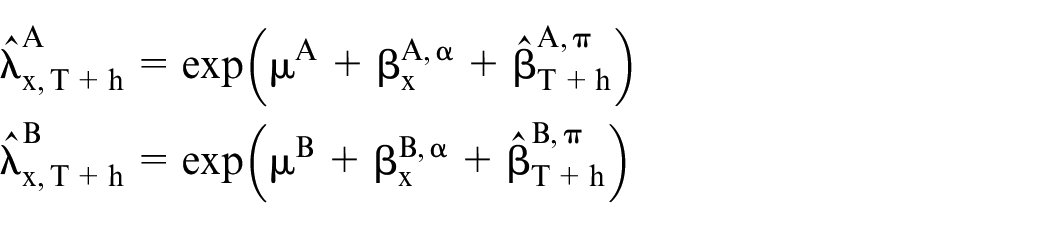
We propose using a multivariate random walk model to project the historical period effects for the two populations. This approach is selected because it effectively captures the joint dynamics and correlations between the two causes of death over time. The multivariate random walk model assumes that future values evolve as a stochastic process with a deterministic drift and random fluctuations. This framework offers both flexibility and robustness in modeling temporal dependencies and inherent randomness in mortality data, resulting in more accurate and realistic forecasts.
We denote
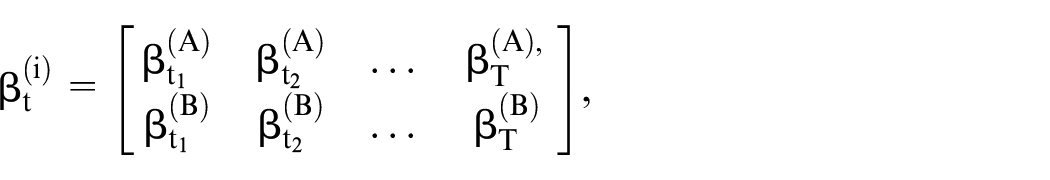
where the row indicates the specific population population and the column indicates the time.
Therefore,
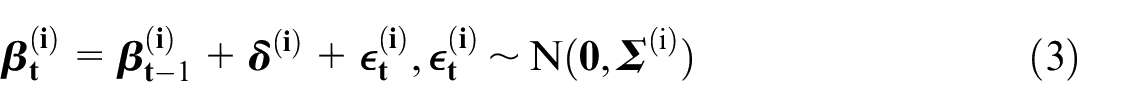
where
Using the in-sample data, we compute
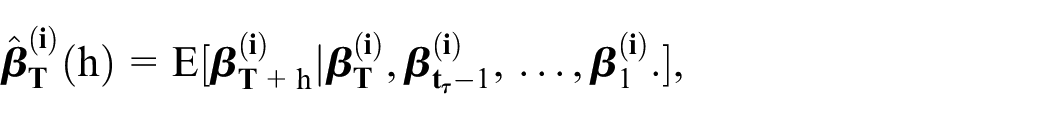
The

We evaluate the model’s performance using the mean absolute error (MAE), root mean square error (RMSE), and mean absolute percentage error (MAPE). Let
We calculate the MAE, RMSE, and MAPE for the differences in mortality between the two populations
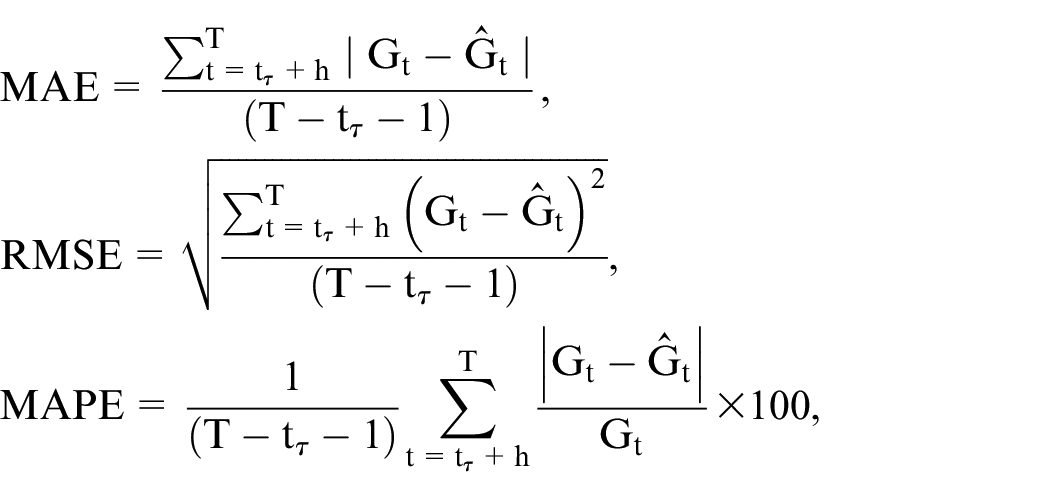
where
5. Application to Cancer and Circulatory Diseases
We applied the three models, treating age and years as categorical variables with the first category as the reference. This approach yielded two sets of age and period effects for each model, corresponding to the
We compare the accuracy of the three proposed models in estimating the differences in death counts (
Estimating and forecasting mortality is inherently challenging, particularly when introducing a novel approach. This complexity arises from the evolving nature of mortality dynamics, which has changed significantly over the past thirty to forty years due to both endogenous and exogenous factors, such as improvements in social and health conditions (Rau et al. 2008). Given this, each statistical model must be tested and calibrated to determine the period that best reflects the estimated parameters. In other words, it is crucial to identify the optimal period length and age range for feeding the model. These factors impact the estimation of model parameters and, consequently, the model’s reliability, as measured by backtesting errors.
This aspect is frequently underestimated in mortality studies. It is important to note that this issue is not limited to our model but is relevant to all mortality models, which should be subjected to a sensitivity analysis regarding period and age structure variations. To address this, we conduct a sensitivity analysis to evaluate how performance varies with different estimation period lengths and age ranges. For our analysis, we consider two distinct age ranges: (i) complete age range, from 0 to 80+ years; and (ii) a specific focus on the adult age range, from forty years onwards. For both age ranges, we examine three estimation periods: forty years (1961–2000), thirty years (1971–2000), and twenty years (1981–2000). All results are evaluated and compared over the same forecasting horizon, spanning the period 2001 to 2015, for consistency in the out-of-sample exercise.
The accuracy results, and the goodness-of-fit metrics related to the in-sample, are presented in Tables 2 and 3 for the full age range and ages 40+, respectively. The tables reveal several insights, the age-period model based on the Skellam distribution consistently provides superior in-sample estimates, demonstrating higher accuracy and superior goodness-of-fit across all periods and both age ranges.
In terms of out-of-sample estimation, the sensitivity analysis indicates that the model based on the Skellam distribution still outperforms the other two models. All the models have better performances on the more recent windows, which is not surprising because this is the period with the most regular longevity dynamics (Nigri et al. 2022).
To offer a more comprehensive analysis and enhance the understanding of the models’ behavior, we present a two-phase graphical investigation. In Figure 2, we provide heatmaps illustrating the out-of-sample RMSE across different age groups: young ages (0–24), adult ages (25–59), and elderly ages (60+). Additionally, scatterplots are presented to demonstrate the model fit, both in-sample and out-of-sample, over time for selected ages. The results for the period 1961 to 2000 are detailed below, with corresponding results for other periods available in Appendix.
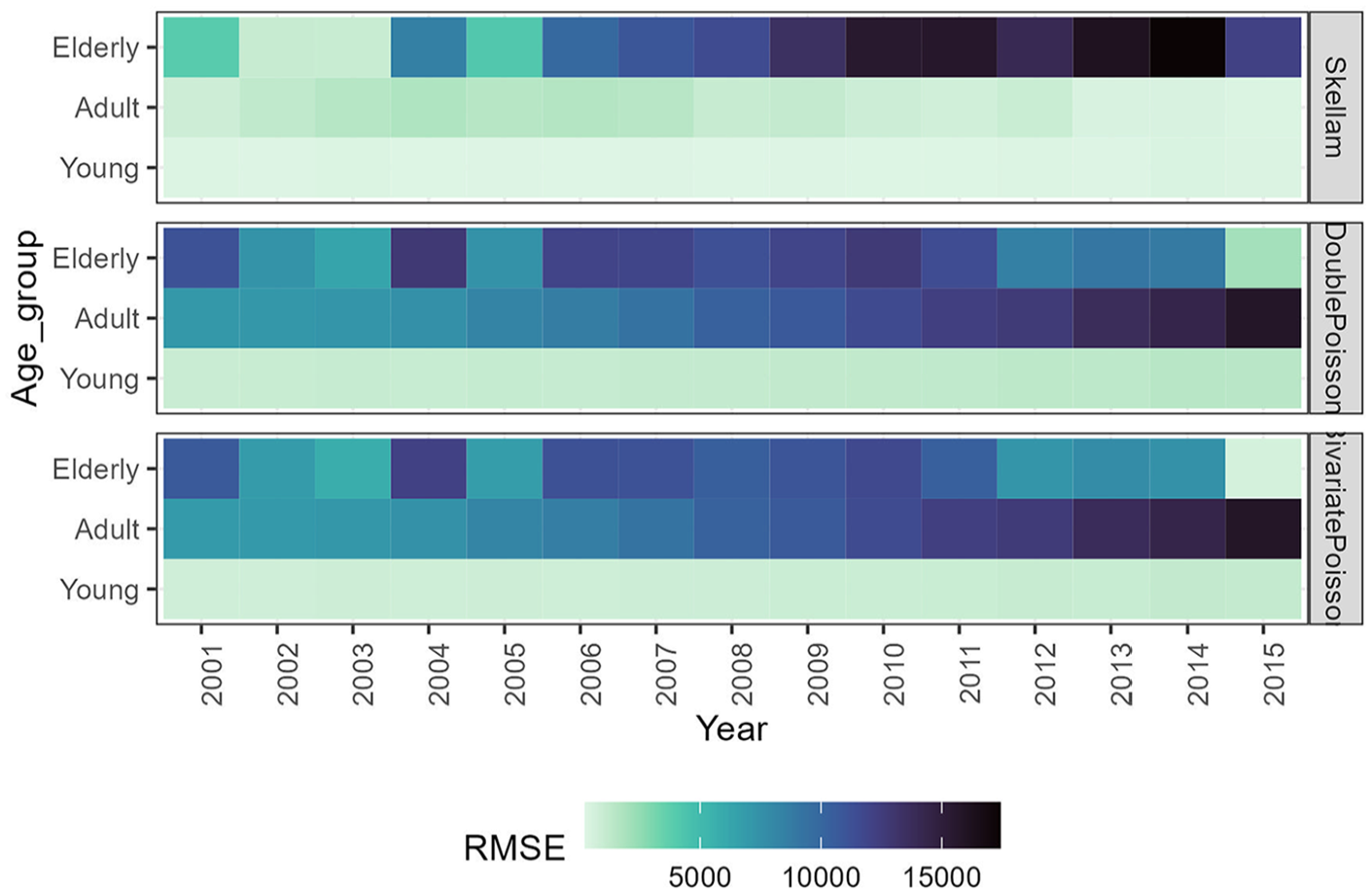
Root Mean Square Error (RMSE) of Forecasting Differences in Death Counts: Baseline 1961 to 2000; Ages 0 to 80+. Dark colors represent inferior forecasting accuracy.
Figure 2 shows that the models achieve better accuracy at younger ages, although even in this age group, the Skellam regression provides slightly more accurate forecasts. The accuracy advantage of the Skellam-based model becomes more pronounced at adult ages, as also confirmed in Figure 3. However, among older individuals, especially as the forecasting horizon approaches the last observations, the accuracy of the bivariate Poisson and double Poisson models surpasses that of the Skellam model. The two Poisson-based models exhibit fairly similar trends, though the bivariate Poisson model displays slightly lighter colors at adult and older ages.
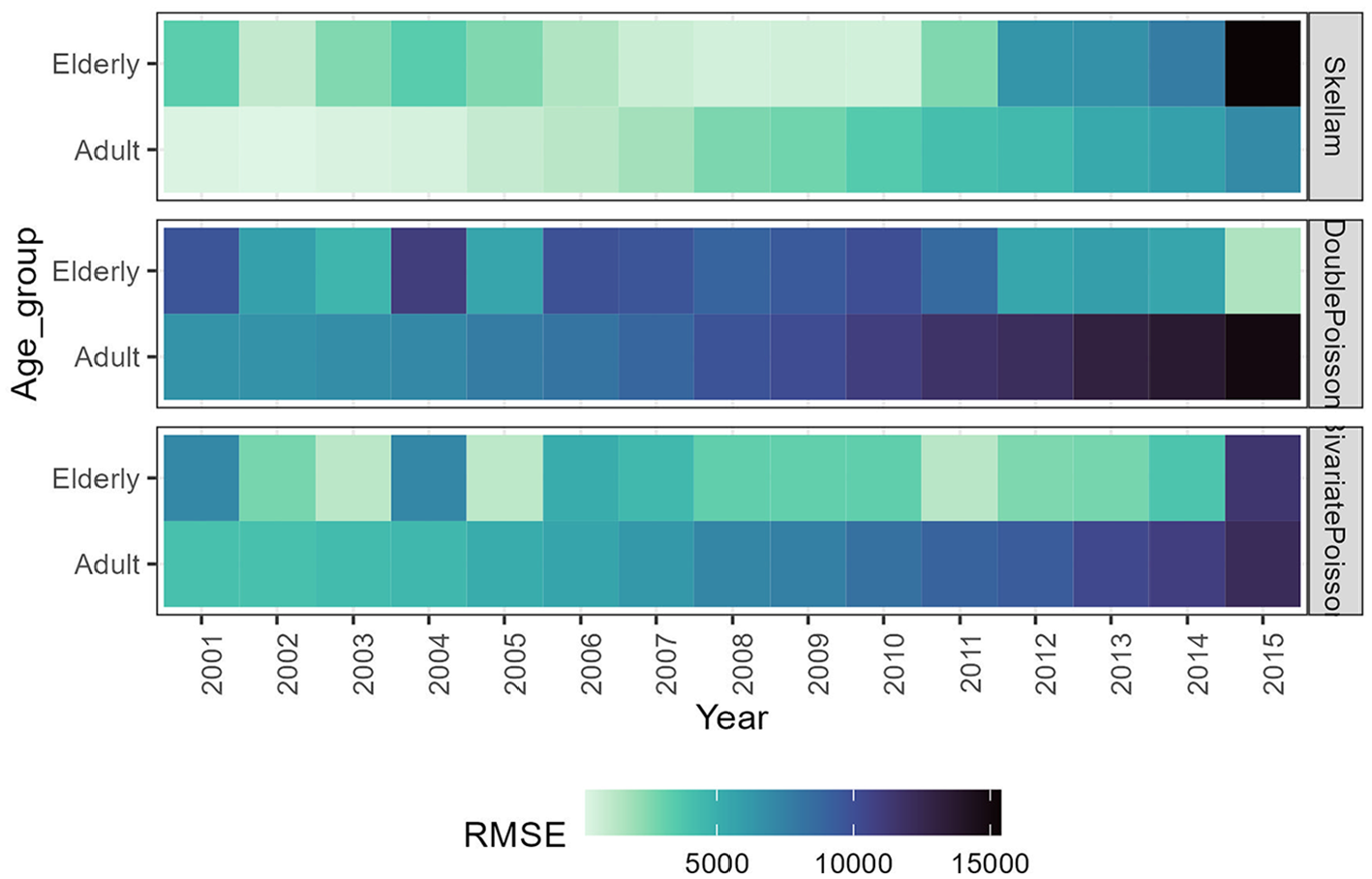
Root Mean Square Error of forecasting estimation for differences in death counts. Estimations are based on the baseline period 1961 to 2000 for ages 40 to 80+. Dark colors represent inferior forecasting accuracy.
Furthermore, we can observe from Figures 4 and 5, both in-sample and out-of-sample results demonstrate that the Skellam-based model provides an exceptional fit to the data compared to the other models, and importantly, it maintains this consistency over time. When the model is trained on a shorter baseline period (see Appendix), the accuracy decreases but remains outstanding for some ages, mainly in the in-sample fitting.
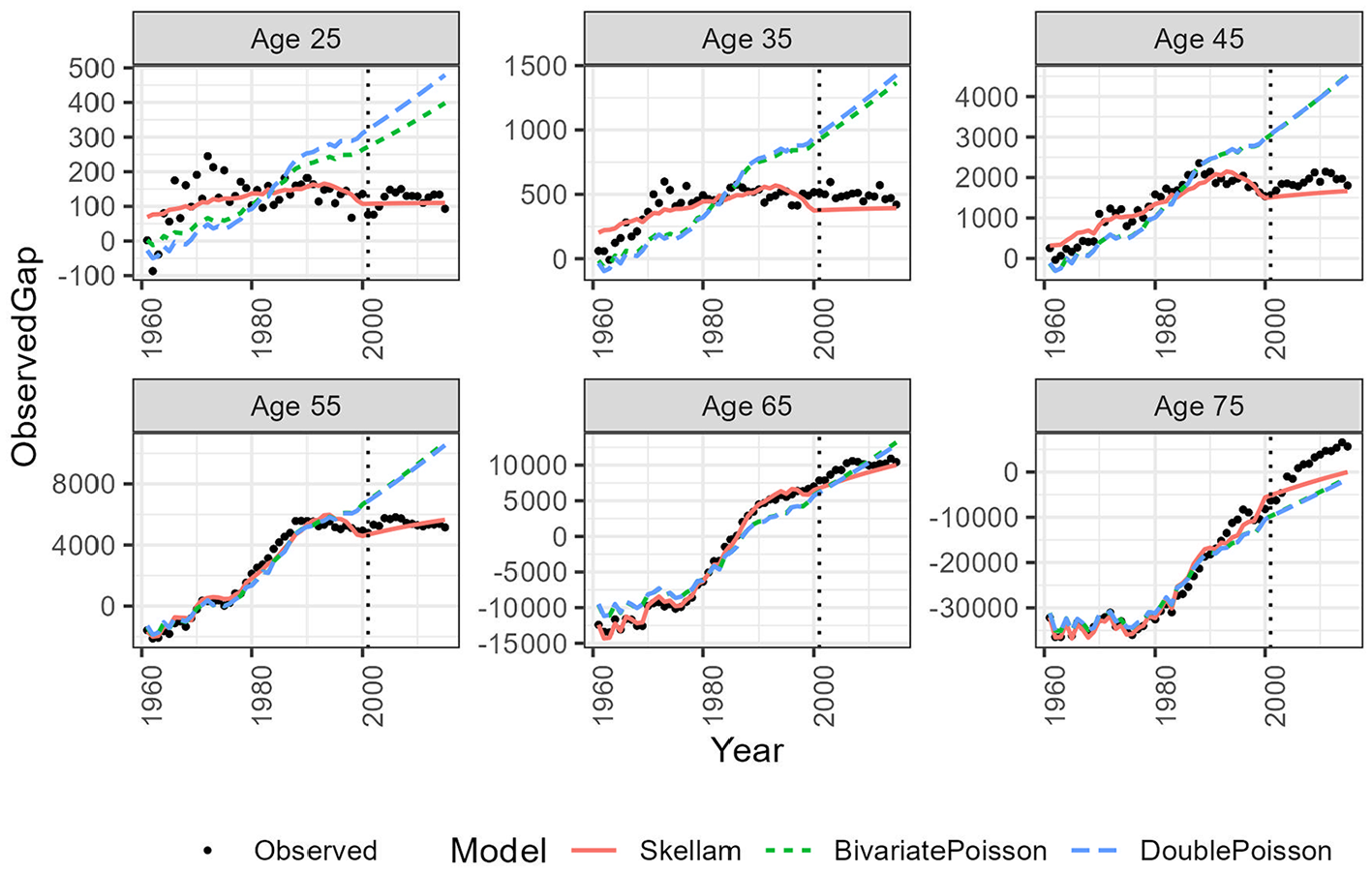
In-sample and out-of-sample analysis for specific ages, with estimations based on the baseline period 1961 to 2000; ages 0 to 80+.
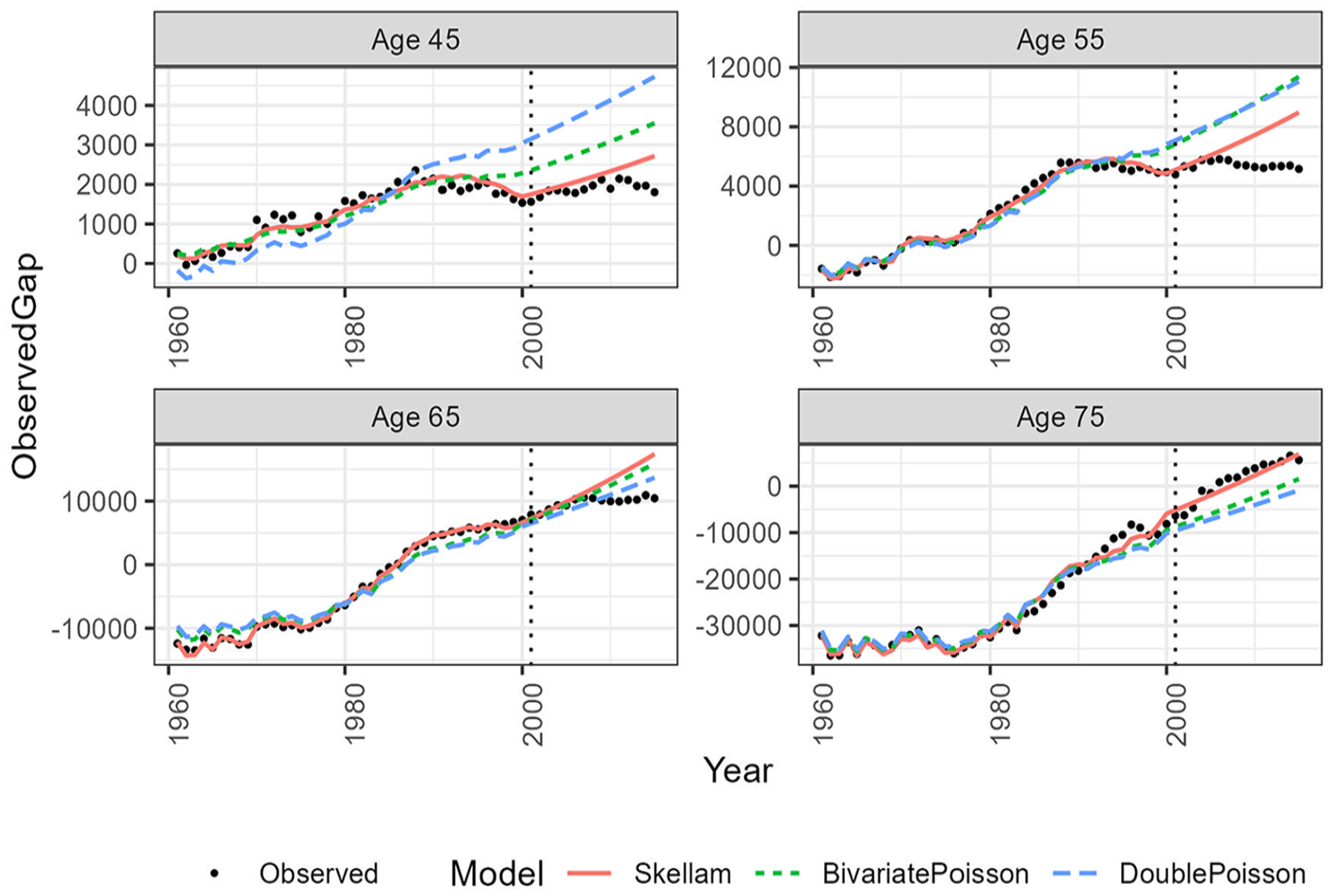
In-sample and out-of-sample exercise for specific ages. Estimations based on the baseline period 1961 to 2000; ages 40 to 80+.
5.1. Diebold-Mariano (DM) Test
To compare the predictive accuracy of competing forecasts, we employ the DM test (Diebold and Mariano 1995). In essence, the forecast error

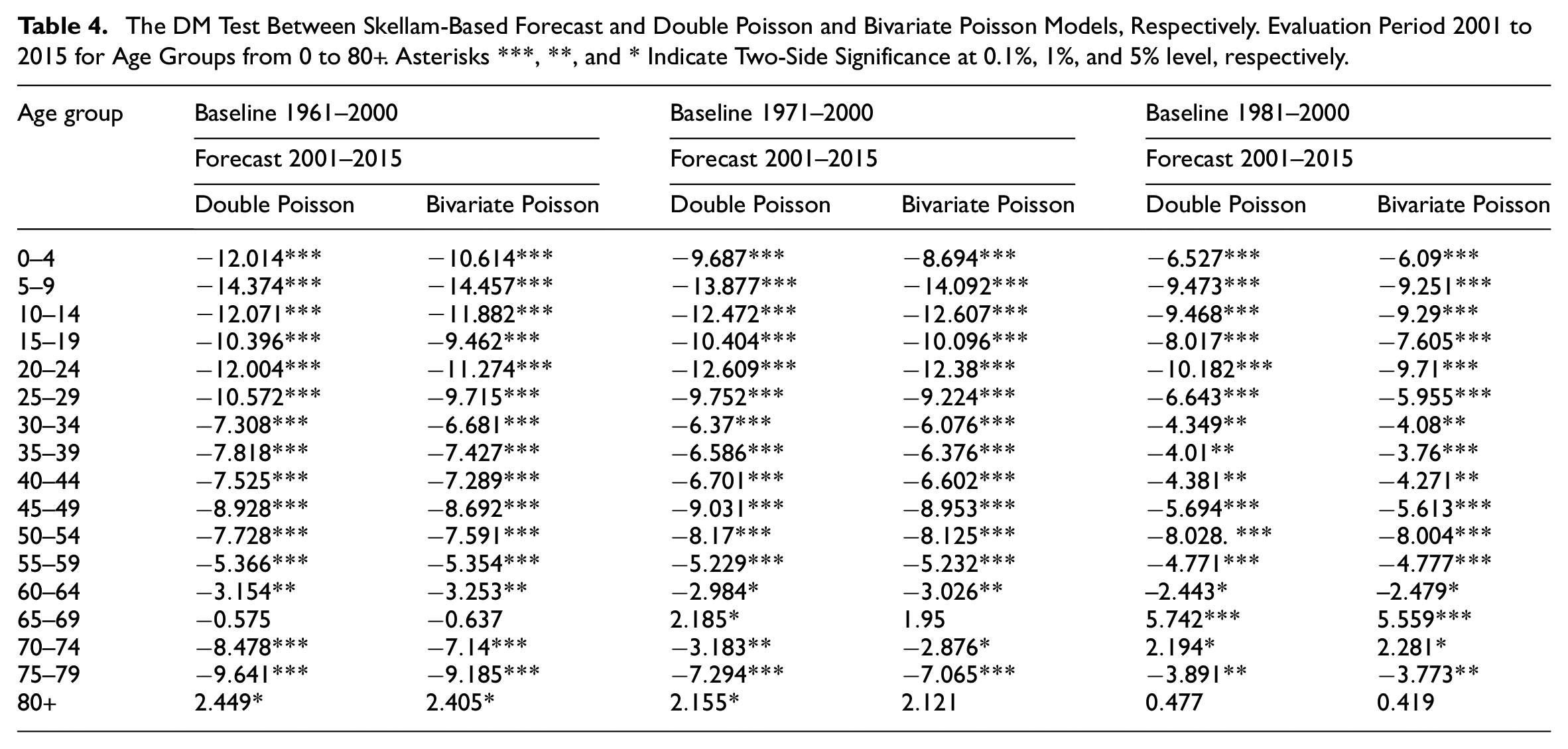
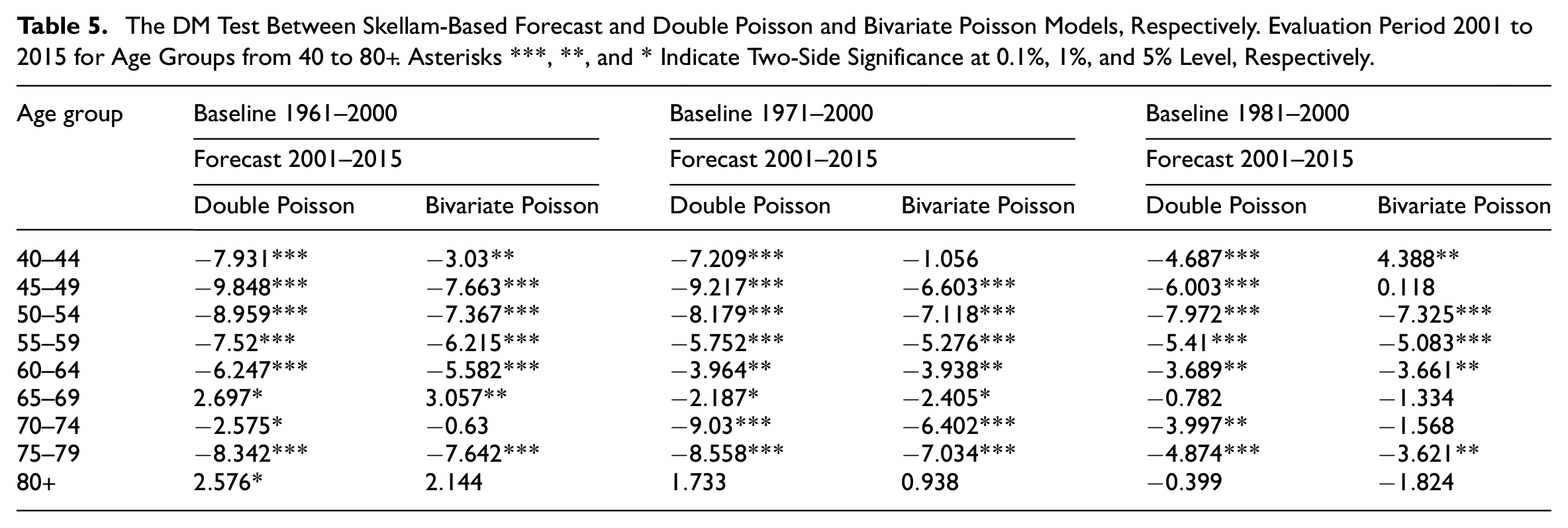
where
We apply the DM test to compare the forecast accuracy of the Skellam Model against the double Poisson and bivariate Poisson models. The results of the DM test are reported in Tables 4 and 5. When the null hypothesis is rejected at a certain level of significance, it indicates that the differences between the two models are statistically significant, and the forecasting accuracy of the first model (Skellam, in our study) is superior to that of the second model. From Tables, we observe that the forecasts produced by the Skellam approach consistently exhibit higher accuracy compared to those from the other two models.
The DM Test Between Skellam-Based Forecast and Double Poisson and Bivariate Poisson Models, Respectively. Evaluation Period 2001 to 2015 for Age Groups from 0 to 80+. Asterisks ***, **, and * Indicate Two-Side Significance at 0.1%, 1%, and 5% level, respectively.
The DM Test Between Skellam-Based Forecast and Double Poisson and Bivariate Poisson Models, Respectively. Evaluation Period 2001 to 2015 for Age Groups from 40 to 80+. Asterisks ***, **, and * Indicate Two-Side Significance at 0.1%, 1%, and 5% Level, Respectively.
6. Conclusion
We propose three distinct modeling approaches to analyze death counts and their differences, each grounded in the fundamental assumption that deaths at each age and year follow a Poisson distribution. Our approaches include three age-period models: the classic double Poisson, the more advanced bivariate Poisson, and the novel Skellam distribution. These models represent a progression from traditional methods to more sophisticated and innovative techniques in studying mortality gaps.
We applied the three modeling approaches to analyze differences in death counts for two major causes of death in Italy: cancer and diseases of the circulatory system. By focusing on causes of death, we bypass the need to account for risk exposures, as the exposure populations are consistent for both causes, allowing us to directly compare mortality rates and death counts.
Our comparison of the three models reveals that the Skellam distribution model, an innovative approach in this context, provides the best fit to the data and requires the least amount of input information.
Given the complexity of mortality, which is influenced by numerous factors, no single statistical model can fully capture its dynamics. To address this, our study includes a sensitivity analysis to evaluate how performance varies with different estimation periods and age ranges.
Leveraging model selection criteria such as AICc and BIC in the in-sample study, and also exploiting both metric errors and hypothesis tests (DM test) for the out-of-sample exercise, we found that the Skellam distribution is valuable for jointly and consistently modeling mortality differences. Its versatility also allows for generalization to other contexts, such as comparing deaths between different sexes, countries, or economic conditions. Utilizing the Skellam distribution enables the development of coherent forecasting models for these scenarios.
All codes, data, and supplementary results are available on the online Repository in GitHub.
There are at least two ways in which our work can be further extended, and we briefly outline two: (1) Leveraging the Skellam-based framework to improve the forecasting of the death count of one of the two populations, such as one of the two causes. Combining forecasts for one of the two causes using Poisson methods with gap forecasts made using the more accurate Skellam method can also enhance the forecasting accuracy for the other cause of death. (2) Including other covariates in the models to account for the geospatial dimension in the difference in the death counts of the two populations.
Footnotes
Appendix
Acknowledgements
The authors thank the reviewers for the comments that led to a much improved manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Financial support from the Italian MUR (PRIN 2022 n° 2022CENE9F, “The pre-Covid19 stall in life expectancy in Italy: looking for explanations”) is gratefully acknowledged.
Received: September 18, 2024
Accepted: May 27, 2025