
Abstract

1. Introduction
I have been asked to present some thoughts on the future challenges and research needs of statistical data editing. While the scope of this short note is necessarily limited and my choice of topics is without a doubt subjective, I still hope it will be of interest to some readers.
Statistical data editing is connected to imputation and the two are often grouped together as “E&I” (GSDEM 2019). Here, I will focus on the editing part. Granquist (1997) identified three purposes of data editing for the production of official statistics based on surveys:
1. “Identify and collect data on problem areas, and error causes in data collection and processing, producing the basics for the (future) improvement of the survey vehicle.”
2. “Provide information about the quality of the data.”
3. “Identify and handle concrete important errors and outliers in individual data.”
To this, EDIMBUS (2007) added a fourth goal:
4. “When needed, provide complete and consistent (coherent) individual data.”
The rest of this note is structured as follows. Sections 2 and 3 discuss the topics of selective editing and automatic editing, respectively. Section 4 briefly discusses approaches that could be used as alternatives or supplements to editing. Some final remarks follow in Section 5.
2. Selective Editing
In general, statistical output is affected by many sources of potential inaccuracy (see, e.g., Bethlehem 2009), of which only a subset can be addressed by data editing. It is therefore not necessary—and in fact could be counterproductive—to try to edit the data until all individual errors have been removed. This idea can be traced back to Nordbotten (1955; and possibly further) but it only started to become accepted widely in official statistics during the 1980s and 1990s, thanks to studies such as Granquist (1984, 1995) and Granquist and Kovar (1997).
For business surveys in particular, which tend to contain mostly variables with right-skewed distributions, it has been found that manually editing a limited number of highly influential errors is usually sufficient. The residual effects of measurement errors on statistical output have then become negligible compared to other sources of inaccuracy, such as sampling error or coverage error. Continuing to edit the data after this point would be inefficient and amounts to “over-editing” (Granquist 1997). To guide the manual editing process, the challenge now becomes to identify beforehand which observations contain influential errors. Methods developed for this purpose are known as selective editing or significance editing (De Waal et al. 2011, Chapter 6).
The main technique developed for selective editing is the score function. Key references include Hidiroglou and Berthelot (1986), Latouche and Berthelot (1992), Lawrence and McKenzie (2000), Hedlin (2003), and Norberg (2016). Most score functions combine a measure of the suspicion that an observation contains an error with a measure of the potential impact on statistical output of editing that observation if it is found to contain an error. Each so-called local score function is related to a specific (combination of) variable(s) and a specific statistic at some level of aggregation. For the purpose of prioritizing units for selective editing, different local scores can be aggregated to a single global score (Hedlin 2008). Finally, a threshold can be chosen such that only units with a global score above the threshold are selected for manual editing.
Selective editing is now widespread in national statistical institutes (NSIs), at least for business surveys, and has contributed to establishing production processes that are more efficient and rational. For the most part, the techniques have been developed in a heuristic way. This has often led to systems that are either easy to use but specific to one particular application, or generic and flexible enough to handle many applications but at the cost of having many parameters to be set by a user. The SELEKT framework, developed by Statistics Sweden (Norberg 2016), is perhaps the most advanced generic system of this type so far. More recently, two approaches to selective editing have been proposed that are grounded in statistical theory: the SeleMix framework (Di Zio and Guarnera 2013), based on a contamination model for the observed data, and the SelEdit framework (Arbués et al. 2013; Salgado et al. 2018), based on a mathematical optimization problem in combination with an observation-prediction model.
De Waal (2013) identified as “the most important research question for the near future” regarding selective editing: how to support the practical application of selective editing frameworks? Over ten years on, this remains an important topic. Most score functions rely on a predicted or anticipated value and the efficiency of a selective editing procedure depends strongly on the quality of these predictions. Traditionally, historical data have often been used for predicted values. Developing a good selective editing procedure in practice remains challenging for variables that are inherently difficult to predict (e.g., investments). Semi-continuous variables that are non-zero intermittently over time are a case in point. For instance in the case of foreign trade statistics, certain expensive goods are traded occasionally, so the next value in a time series could be either zero or (much) larger than zero and the score function should account for both options (Van de Pol 1998).
The rise of artificial intelligence, including machine learning, may provide opportunities for improved selective editing (Dumpert 2020); see Forteza and García-Uribe (2025) for a recent application. Barragán and Salgado (2022) used machine learning for selective editing in two different ways: (i) obtaining predicted values for a traditional score function and (ii) letting the algorithm classify directly whether an observation requires manual editing. During a discussion at the 2022 UNECE Expert Meeting on Statistical Data Editing, David Salgado noted that these could be seen as two extreme cases of a general approach, in which an algorithm is trained to prioritize observations for manual editing and the user imposes more or less structure on the way the algorithm operates. Exploring intermediate cases of this approach and optimizing the degree of imposed structure may be interesting topics for future research.
Finally, selective editing of categorical data appears to be a neglected topic. Of course, in a purely categorical context all observations are equally influential and selective editing is not particularly useful. Suppose, however, that the parameters of interest are domain totals of the form
For an application to statistics on energy use (
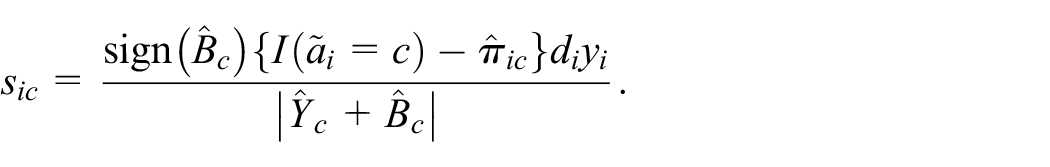
For each
3. Automatic Editing
Automatic editing is an umbrella term for methods that try to correct errors in microdata without human intervention. This can involve both deductive (often rule-based) correction of systematic errors (i.e., errors with a known cause) and error localization of random errors (i.e., all other errors); see, for example, Pannekoek et al. (2013) for more details. Deductive correction occurs in some form or other for most surveys, for instance to correct unit of measurement errors such as the “thousand error” (De Waal et al. 2011, Chapter 2). Error localization has so far been applied less widely, but it is an important process step for some surveys, in particular to ensure that the microdata are fully consistent with all edit rules.
Current applications of error localization are usually based on the seminal work of Fellegi and Holt (1976). Given a set of edit rules that should be satisfied by the data and a positive reliability weight
The Fellegi-Holt paradigm can be generalized. Scholtus (2013, 2015) proposed an extension that can accommodate soft edit rules (i.e., edit rules that may be failed by error-free data). Scholtus (2016) and Daalmans and Scholtus (2018) proposed a generalized error localization problem which minimizes the sum of reliability weights of so-called edit operations specified by the user. Each edit operation is supposed to correct one error by changing one or more variables in a prescribed way, which may involve zero, one or more free parameters. In particular, this allows for errors that affect multiple variables at the same time, such as interchanged values. The original Fellegi-Holt paradigm occurs as a special case, for a particular choice of edit operations.
Early implementations of automatic editing required a large investment to develop dedicated tools. Nowadays, it is possible to implement an entire automatic editing production system using open source R packages (Van der Loo and De Jonge 2018).
It is unlikely that automatic editing will ever completely remove the need for selective manual editing. Nonetheless, it could probably be used more than is done in current practice (Pannekoek et al. 2013). Rather than theoretical limitations of the methods themselves, the main obstacle in practice seems to be a lack of subject-matter information that can readily be incorporated in these systems, in the form of edit rules and reliability weights. What happens during manual editing is often not well-documented and relies on subject-matter knowledge that may be implicit and unstructured (and in some cases subjective). Implementing an automatic editing system that adequately mimics the decisions made by human editors can therefore be a long process of trial and error, requiring iterative feedback from subject-matter experts (Di Zio et al. 2005; Rhodes et al. 2024). From a purely theoretical point of view, the error localization problem—especially in its generalized form—is quite flexible. In principle, one could tailor the reliability weights, edit operations, and even the edit rules to each unit separately. However, in practice this is seldom done, due to a lack of suitable unit-specific information.
Again, artificial intelligence may be of use here (Dumpert 2020). One option is to use machine learning to search for suggested new edit rules or deductive correction rules based on historical edited data, although this may lead to relatively complicated rules without a clear substantive meaning (see, e.g., Petrakos et al. 2004). For error localization, a way forward might be as follows:
Use a model or algorithm to predict the above-mentioned probabilities
For a given unit, immediately apply all edit operations for which
If at least one edit rule remains failed after the previous step, then solve the error localization problem with the remaining edit operations, using
Here, Fellegi-Holt-based error localization is used as a final step to ensure that all edit rules can be satisfied, which is difficult to achieve for complex systems of rules using machine learning alone. In practice, a limiting factor may be the availability of sufficient training data (Dumpert 2020).
On a practical level, techniques such as web scraping and text mining could be of interest to make unstructured information which is already used by analysts during manual editing also available as auxiliary data for automatic editing. This includes, for instance, financial statements published by businesses. Potentially, this could be very useful to increase the quality of automatic editing.
A possible criticism of the above discussion is that I am showing a lack of imagination, by staying quite close to existing methodology. For a more radical vision of the future, in which generative artificial intelligence becomes an important tool to enhance data quality, see Azeroual (2024).
Finally on this topic, it should be noted that as an alternative to the Fellegi-Holt-based approach some innovative Bayesian methods have been developed for combined editing and imputation; see Kim et al. (2015) and Aßmann et al. (2024). Similar in spirit to multiple imputation (Rubin 1987), these methods allow the uncertainty due to automatic editing in resulting statistical output to be taken into account, which has traditionally often been ignored. Currently, this approach still has important practical limitations; it is, for instance, challenging to take complex systems of edit rules into account. Moreover, this approach is quite far removed from current practice at most NSIs. But both of these things might change in the future. An alternative, general approach for measuring the total variance of an estimation process, including the uncertainty due to automatic editing and imputation, is provided by the bootstrap (Efron and Tibshirani 1994; Van der Loo et al. 2017).
4. Beyond Editing?
Data editing is currently the main approach to handle measurement errors at NSIs. Outside of official statistics, although some basic form of editing may still occur, it is more common to rely on other approaches that account for measurement error at the estimation or analysis stage. This includes robust estimation methods (Beaumont et al. 2013; Huber 1981) and statistical models that include an explicit measurement error component, such as latent variable models (Biemer 2011; Bollen 1989). It is interesting to consider whether such approaches could also be used more for official statistics, enabling a further reduction in selective manual editing.
In a similar spirit, but closer to current practice at NSIs, is the suggestion of Ilves and Laitila (2009) to draw a probability sample of units for manual editing, including units with scores below the usual selection threshold. This would allow the quality of statistical output after the regular selective editing process to be estimated in a design-based way. This is in line with the proposal of Zhang (2023) to use audit sampling as a framework for design-based quality evaluation of statistical output; here, an audit sample is a sample that is drawn not to estimate the target parameter itself, but rather to assess the quality of an existing estimator of the target parameter.
Zhang’s paper specifically discusses multisource statistics, that is, statistical output based on several data sources, which may include traditional surveys, registers, web scraped data, etc. On one hand, having multiple data sources provides an opportunity for improved editing because more information is available, but on the other hand, the challenges of selective and automatic editing become even larger in this context due to the size and complexity of data and edit rules.
The current methods for selective and automatic editing have been developed mostly in the context of traditional sample surveys. With the trend of using more different data sources and in particular non-survey data sources for the production of official statistics, approaches that go beyond editing may become more relevant in the coming years. For handling measurement errors in large administrative datasets, let alone “big data,” existing editing techniques may not be suitable. For instance, a selection of only the influential suspicious cases from an administrative dataset may still be too large to edit manually. Moreover, many analysts might not have the required administrative knowledge to perform suitable edits on those data. For a discussion of statistical data editing for “big data,” see De Waal et al. (2014).
5. Concluding Remarks
I conclude with two points that did not fit into the previous sections. First, statistical data editing is traditionally done in so-called stovepipes, where each editing process runs mostly in isolation. As a result, large inconsistencies between statistics can go unnoticed for a long time, until they are finally found during the production of national accounts. A somewhat recent development is that some NSIs have introduced so-called Large Cases Units that perform integrated editing across statistics for the largest and most complicated businesses (Vennix 2012). Recently at Statistics Netherlands, work has been done to apply editing across statistics as well to the rest of the business population. For selective editing, this has been tested successfully in a few places (Vaasen-Otten et al. 2022) and is now being implemented. Research on automatic editing across statistics is ongoing (Scholtus et al. 2024).
Finally, looking back at the four goals of editing mentioned in the introduction, it should be noted that Granquist considered these goals ranked by priority, from most to least important. However, in practice attention is often still focused mainly on the last two goals, while the first two goals have been more elusive (De Waal 2013). Thus, an important challenge remains for the future.
Footnotes
Acknowledgements
The views expressed in this article are those of the author and do not necessarily reflect the policies of Statistics Netherlands. I would like to thank Jeroen Pannekoek and an anonymous reviewer for several helpful comments.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Received: January 11, 2025
Accepted: March 22, 2025