
Abstract
With a rapidly ageing population, innovative social care solutions are essential. This paper introduces an adaptive planning framework for assistive-care robotic missions, particularly focusing on mobile robots that interact with humans in home environments and provide support with everyday tasks. Our framework employs a modified version of Dijkstra’s algorithm and probabilistic model checking to ensure both efficient robot navigation for task support and human safety. Key contributions include the integration of formal verification techniques and adaptive path-finding methods, ensuring robust operation, even under the uncertainty that arises from runtime changes in the environment. Evaluation through simulation and real-world experiments with a mobile robotic platform PAL Robotics TIAGo demonstrates the effectiveness of the framework and the feasibility of our proposed approach, which contributes to the promotion of independent living for people with mild motor or cognitive impairments.
Keywords
Introduction
With a rapidly ageing population, the world is facing a social care crisis (Gordon and Dhesi, 2023; Woo, 2018). Without a step change in the provision of social care, especially for the elderly, the increase in the budgets and resources allocated to social care will soon become unsustainable. Ambient assisted living (Calvaresi et al., 2017; Monteriù et al., 2024), that is, the provision of support with daily tasks in the environment of a person by robotic and autonomous systems (RAS), artificial intelligence (AI), and other technologies, is widely envisaged as a key enabler of such a step change (Lee and Riek, 2018; Napoli et al., 2023).
Given this vision, the development of assisted-living RAS and AI solutions has been the focus of intense research and industrial effort in recent years (Abdi et al., 2018; Trainum et al., 2023). Designed for use at home and in care homes, these solutions aim to support people with motor or cognitive impairments in a wide range of tasks, increasing their ability to carry out daily living activities independently. Examples of such tasks (Figure 1) include guiding users around a care home (Takanokura et al., 2023), monitoring the elderly in their home environment (Mireles et al., 2023), and performing kitchen activities such as unloading a dishwasher (Wong et al., 2021). Other RAS and AI assistive-care applications involve the use of care robots to prevent falls, detect emergencies, bring objects, and offer reminders to users (Bajones et al., 2018, 2019); and the use of AI agents to provide step-by-step voice commands, enabling dementia sufferers to complete their daily activities (Green et al., 2024; Morris et al., 2024). RAS assistive care solutions utilizing a TIAGo robot (PAL Robotics, 2024). From left to right: Interacting with an older person in a care home; using fall-detection mechanisms to monitor the health of a patient; helping with household tasks such as unloading a dishwasher.
These advances have provided RAS solutions capable of assisting elderly and disabled users in both monitoring and advisory roles, as well as with physical tasks. However, integrating the two types of assistance into a combined assistive-care RAS solution that can be used safely over a long period of time still poses significant challenges. Although RAS solutions have been embedded in social and health care environments (Andriella et al., 2023; Aymerich-Franch and Ferrer, 2023; Silvera-Tawil, 2024), they have been largely limited to simple applications, such as support for social and physical activities and room monitoring, often without considering potential interactions with humans. To expand the range of these applications, the human user and the robot need to interact in order to perform tasks together (Calinescu et al., 2019). This interaction, which has recently been the focus of recent work in the social care domain (Lestingi et al., 2023, 2024), should be prioritised with an emphasis on human safety (Calinescu, 2013; Gleirscher et al., 2022).
The RAS adaptive planning framework proposed in our paper, after consultations with our partner ACE Alzheimer Center Barcelona – a major Spanish care provider supporting sufferers of Alzheimer’s disease and other dementias – addresses these challenges through: (1) The integration of safe household-item manipulation and advisory human–robot interaction capabilities into a holistic assistive-care robotic platform; (2) The use of formal verification to support the assurance of long-term deployments of an assistive-care robot in a home environment; (3) The adoption of adaptation methods to enable assistive-care robots to cope with the uncertainty and disruptions, which are unavoidable in a home environment.
Our framework enables the development of assistive-care RAS applications that support such interaction and ensures their safety by: (i) modelling the environment as a graph whose nodes represent locations where the robot can perform tasks; and (ii) using graph traversal algorithms and probabilistic model checking to plan the execution of RAS missions comprising combinations of such tasks. The main contributions of our paper are: (1) A generalised approach for modelling environments as graphs in which edges are annotated with levels of risk; (2) An extension of Dijkstra’s path-finding algorithm that enables risk reduction in uncertain environments; (3) A simple predictive behaviour model that forecasts human actions and dynamically updates risk levels associated with graph edges; (4) A framework that combines modelling methods, adaptive path-finding techniques and runtime probabilistic model generation for safety verification into an end-to-end solution for autonomous robotic mission planning; (5) A combination of simulations and real-world experiments with a PAL Robotics TIAGo mobile robotic platform that show the effectiveness of our framework.
These contributions extend our preliminary exploration of adaptive planning for assistive-care robots (Hamilton et al., 2022) significantly, first by providing a full description of the theory underpinning our approach, and second by evaluating our extended approach for the first time, both in simulation and in a real-world environment.
The remainder of the paper is organised as follows. The ‘Motivating example' section presents the example used to illustrate the stages and application of our approach. The ‘Related work' section compares our research with the state-of-the-art. The ‘Preliminaries' section introduces key terminology, concepts, and techniques employed by our approach. The ‘Adaptive planning framework' section presents our framework and the ‘Implementation and evaluation' section details its implementation and evaluation. Finally, the ‘Conclusion and future work' section summarises our contributions and outlines directions for future research.
Motivating example
As a motivating example for our research, we consider an autonomous assistive-care robot supporting an elderly person with mild cognitive or motor impairments in activities associated with preparing a simple pasta meal. We assume that the robot is deployed in a home environment, as illustrated in Figure 2. This motivating example is informed by both prior empirical research (Korchut et al., 2017) and our own analysis described in ‘Requirements elicitation' section. These efforts involved elderly people, caregivers and medical professionals, and helped identify and prioritise relevant assistance needs through structured surveys and focus-group discussions. Illustration of a PAL Robotics TIAGo (PAL Robotics, 2024) assistive care robot deployed in a multi-room home environment, tasked with carrying out meal preparation and environment monitoring operations.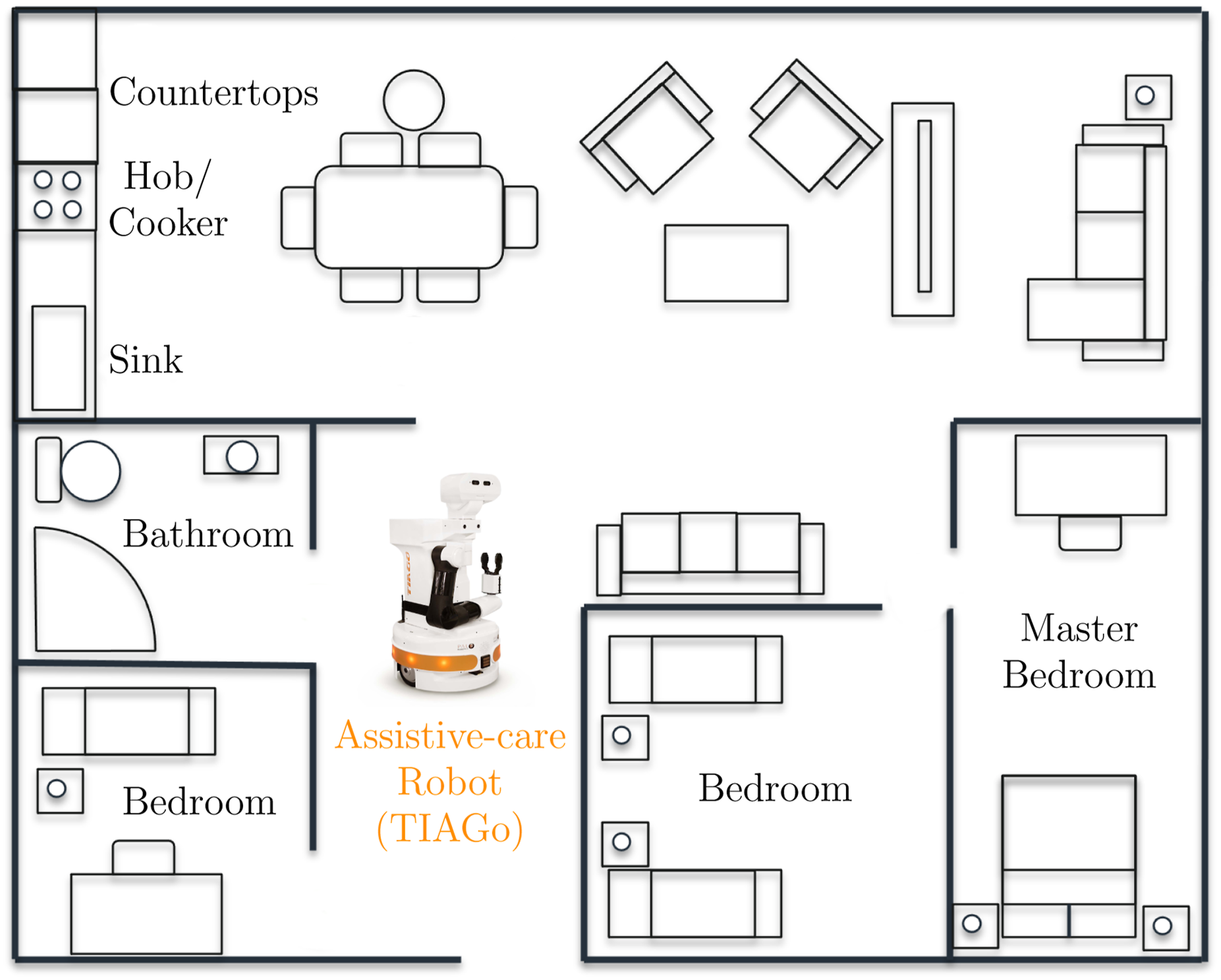
The robot is required to perform the following tasks individually or in collaboration with the person. First, the robot should detect the person in the environment, inform them when it is time to prepare food, and seek the person’s approval to begin the meal preparation process. Depending on the person’s answer (‘YES’ or ‘NO’), different robot actions will be triggered. Assuming that the answer is ‘YES’, the robot (a) informs the person about all the required ingredients and utensils; (b) confirms that it will take care of bringing the tomato sauce and the spaghetti to the location where cooking will take place, with the person being instructed to bring the utensils. The robot then proceeds to check if the necessary ingredients are available, collects them, and reports the status (i.e., proceed with the meal preparation or insufficient ingredients – meal postponed) to the person. While performing the designated tasks, the robot provides step by step instructions, and waits for the person’s confirmation (e.g., by saying ‘OK’ or a similar phrase) before proceeding to each next task.
We additionally assume that throughout the execution of this mission, the robot is required to avoid obstacles (i.e., the human or objects in the environment) and follow alternative routes to its destination, if needed, in order to preserve the human’s safety. Although minimising the risk of collision is the most critical factor for the robot, performance should also be considered by traversing the environment through the shortest and safest path to reach the task locations. If a safe path cannot be identified or the human is blocking the robot’s path, the robot ultimately must wait for the user, making the human aware of the situation via voice prompts suggesting appropriate actions (e.g., redirect requests – ‘please move to the left’ or ‘please wait on the right at a safe distance’). Finally, if an emergency situation is detected (e.g., the human lying unconscious on the floor), the robot should call another person for help, if available, or call an emergency contact.
This form of interaction is inspired by common caregiving practices (National Institute on Aging, 2025). In elderly care and other assistive-care contexts, human caregivers routinely ask individuals to reposition themselves to enable safe or efficient care delivery, such as moving to prevent accidents or to facilitate assistance. This approach is both socially acceptable and practically effective in real-life settings. It is also consistent with the ethical principles that guide socially assistive robotics (SAR). As noted in Tapus et al. (2007), SAR systems are designed to avoid physical contact, instead relying on verbal or gestural interaction. The principles of beneficence and nonmaleficence for caregivers (i.e. promoting the user’s well-being while avoiding harm) justify the use of these low-risk socially grounded behaviours. In this context, issuing a redirection request aims to preserve both user safety and robot functionality in constrained environments. Furthermore, as emphasised by Broekens et al. (2009), assistive robots should uphold user autonomy and comfort, particularly for elderly individuals, by issuing polite, non-intrusive requests rather than enforcing physical action.
Related work
Autonomous planning in dynamic environments
When planning mobile robot missions in dynamic environments, navigation paths that are optimal against some cost function (e.g., time or safety) must be produced for the robot. In the event that knowledge of the environment changes, the optimality of the path may change and require re-computation to achieve new mission optimality. To that end, robot-mission planning approaches such as Brumitt and Stentz (1996), DeCastro et al. (2018), and Kalluraya et al. (2023) perform multi-robot mission planning in dynamic environments. In particular, DeCastro et al. (2018) and Kalluraya et al. (2023) achieve this by utilising linear temporal logic (LTL) to specify and manage high-level tasks for multi-robot systems in dynamic environments.
Kalluraya et al. (2023) address the problem of multi-robot mission planning in environments with mobile and uncertain semantic targets. These targets have uncertain current and future positions and semantic labels, influenced by stochastic dynamics and external disturbances. The robots are tasked with collaborative semantic missions expressed in LTL. A sampling-based approach is proposed to design optimal paths that are adjusted online based on perceptual feedback. The method showcases the ability to handle semantic tasks under uncertainty. DeCastro et al. (2018) present an approach for synthesising controllers for multi-robot teams operating in dynamic environments. The method combines reactive mission planning using LTL and local motion planning with convex optimization to ensure collision-free navigation. The high-level planner generates a correct-by-construction controller based on a given mission specification, while the local planner manages dynamic constraints and avoids collisions in real-time. The approach guarantees task completion even in the presence of potential deadlocks, offering minimal human-readable assumptions for deadlock conditions.
Unlike the previous two approaches, which leverage LTL for high-level task specifications and guarantee collision-free navigation through formal methods, Brumitt and Stentz (1996) focus on continuous adaptation and reassignment of tasks based on real-time environmental feedback, providing a more flexible but less formally guaranteed solution compared to the LTL-based methods. Using a dynamic planner, the system dynamically reassigns robots to goals as new information is acquired, aiming to minimise mission completion time. The dynamic planning approach contrasts with static planners by continuously optimising robot motion in response to real-time environmental changes. The system’s efficacy is demonstrated through simulations where three robots achieve six goals, showing a 25% improvement in mission performance over static planning. The paper also outlines a preliminary design for extending the system to more complex scenarios, emphasising the importance of real-time updates and reassignments to handle uncertainties and optimise mission outcomes effectively.
This class of approaches differs from ours as it does not consider collaboration between the deployed robots and humans, and aims to enhance the efficiency and effectiveness of multi-robot systems in dynamic and uncertain environments, without considering the safety of humans in the environment. The focus is on improving how robots collaborate to complete complex tasks by ensuring adaptability to changing conditions, avoiding collisions, and optimising mission performance.
Numerous approaches model uncertainties within the environment probabilistically, for example, Lu and Kamgarpour (2020) and Tihanyi et al. (2021). In the approach proposed by Lu and Kamgarpour (2020), paths are generated in a grid-world environment, maximising safety while producing computationally tractable solutions. This was achieved by decoupling the environment and its uncertainties from the robot’s trajectory, as well as designing a Monte Carlo approximation for the environment’s uncertainty. The above work was expanded upon in Tihanyi et al. (2021) by incorporating multi-robot task allocation, in which three robots have a series of targets to accomplish before reaching the goal. The environment contains walls and hazards, where paths are produced for each robot based on maximising the probability of all robots reaching the goal state successfully. Two variants of a greedy algorithm enable efficient distribution of tasks between the robots for maximising safe mission completion. However, this method has very high computational overheads even for small missions, with computation times ranging from 7 minutes (forward greedy) to almost 5 hours (brute force) for allocation of five tasks between three robots operating in a 17-by-13 grid space.
Markov decision process models have been used, for example, in Lacerda et al. (2017, 2019), to represent a social robot operating in an uncertain environment, with formal guarantees of performance through probabilistic verification techniques. During robotic missions, the robot was assigned a series of tasks, with the optimal policy generated based on maximising the probability of completing a task. Using a task progression function, in the event that a task could not be guaranteed completion, the robot would maximise progression, with the expected time and cost minimised. Similarly to our approach, the above-mentioned work utilises probabilistic model checking to verify the synthesised polices. However, unlike our work, it does not consider the collaborative aspect of the social robot within the environment.
Cámara et al. (2020) propose a planning approach that assesses the impact of mutual dependencies between software architecture and task planning on the satisfaction of mission goals. Similarly to our approach, the authors employ Dijkstra’s algorithm to compute and rank paths in ascending distance to reduce the computational cost compared to considering the full solution space in a single model checking run. This work differs from ours because it focuses on architecture reconfiguration and does not consider potential interactions with humans. The self-adaptation of autonomous robots is also the subject in Jamshidi et al. (2019). The difference between this work and our approach is that Jamshidi et al. (2019) uses machine learning to find Pareto-optimal configurations without having to explore every configuration and restrict the search space to such configurations to make planning tractable, but again without considering any potential interactions with humans like our approach.
Devising methods for synthesising Pareto-optimal safety controllers to ensure human operator safety in collaborative robot tasks is the focus of both Gleirscher et al. (2022a) and Stefanakos et al. (2022). Gleirscher et al. (2022a) present a tool-supported approach for the synthesis, verification, and testing of safety control software designed for human–robot collaboration in manufacturing processes. The focus is on developing software-based safety controllers that can improve operational safety by handling critical events, such as triggering shutdown mechanisms to prevent accidents. The approach uses probabilistic model checking and the stochastic model synthesis tool EvoChecker (Gerasimou et al., 2015) to handle complex controller requirements and ensure high levels of safety and utility. Its effectiveness is demonstrated through a case study involving a manufacturing work cell equipped with a collaborative robot, showing the controller’s ability to detect hazards, mitigate risks, and resume normal operations after hazard mitigation. Similarly, Stefanakos et al. (2022) describe a case study focusing on the creation of a safety controller for a mobile collaborative robot (cobot) operating alongside a human operator. This study employs probabilistic model checking to ensure that the cobot performs its tasks safely without posing risks to human operators in the shared workspace. The approach involves modelling the manufacturing process, identifying potential hazards, and implementing mitigation strategies based on probabilistic data. This approach is tested and validated within a digital twin environment, simulating real-world conditions to ensure the cobot’s safe interaction with human operators while maintaining optimal performance in the manufacturing process. Both of these approaches work under the assumption that the operator is a trained user and uncertainty arising due to unpredictable human behaviour is not a critical factor, contrary to our work.
The enhancement of human–robot interaction is a central theme in both Hoffman and Breazeal (2004) and Karami et al. (2010). Hoffman and Breazeal (2004) enable intuitive and natural communication with a human. The robot and human are cooperating as partners in a collaborative mission. The robot does not perform mission management in the traditional sense, but maintains a repertoire of tasks represented as a hierarchical structure of actions and sub-tasks, arranged into an action tuple data structure. This work focuses on task dialogue and social communication in the theoretical framework of joint intention theory rather than on the safety aspects resulting from human–robot collaboration. Finally, Karami et al. (2010) presents human–robot collaboration towards completing a common mission, where the robot builds a belief of the human’s intentions by observing their actions, supported by the use of partially observable Markov decision processes. However, the demonstrations are conducted in highly controlled situations with the human and robot located in a small and clutter-free environment. Both approaches differ from ours as they do not fully address the dynamic and safety-critical aspects of human–robot collaboration in more complex and unpredictable environments.
Autonomous navigation in domestic environments
Domestic environments pose unique challenges for autonomous navigation, significantly different from those found in structured industrial settings. Irregular layouts, limited manoeuvring space, frequent occlusions, and the presence of untrained human occupants with unpredictable behaviour make safe and socially acceptable navigation essential (Bogue, 2017). These environments are also shaped by informal routines and users who may struggle to articulate their needs, especially in assistive contexts involving older adults, making requirement elicitation particularly difficult (Veling and Villing, 2024). Many expectations are implicit, variable, or context-dependent, requiring robots not only to avoid physical harm but also to behave in a minimally intrusive and socially appropriate manner. To address these challenges, we conducted a requirement elicitation study (see ‘Requirements elicitation' section) involving practitioners and end users to inform design decisions on appropriate robot behaviours when interacting with individuals with mild cognitive or motor impairments.
A number of studies highlight the critical role of adaptability and system-level integration in domestic service robotics, emphasising not only isolated components but also overall software architecture, implementation strategies, and realistic evaluation to enable autonomous operation in unstructured home environments (Breuer et al., 2012; De La Puente et al., 2019; Holz et al., 2009). In line with this, competitions such as RoboCup@Home 1 have been instrumental in promoting dynamic benchmarking of fully integrated systems, encouraging greater robustness and versatility. Nevertheless, a substantial gap remains between performance in controlled, home-like testbeds and true deployment in real-world domestic settings (Iocchi et al., 2012). Unlike industrial environments, real homes present increased levels of unpredictability and complexity, which are difficult to manage reliably (Soroka et al., 2012). As a result, most long-term studies conducted in actual user residences have been limited to either static robotic platforms or semi-autonomous systems (De Graaf et al., 2016).
Researchers have explored specialised strategies such as human-aware navigation, which incorporates human action patterns into planning and decision-making. These approaches aim to reduce the risk of route conflicts by predicting and accommodating likely human movements. For example, Kostavelis et al. (2016) proposed a human-aware navigation approach that integrates common user standing positions and predicted movement paths into the robot’s global planning strategy. By encoding proxemic preferences using Gaussian kernels and applying Dijkstra’s algorithm, their approach enables socially compliant path generation in domestic settings. Teja Singamaneni et al. (2021) presented a highly adaptable human-aware navigation planner that leverages multiple planning modes to handle a variety of interaction contexts, ranging from narrow corridors to open crowds. Their planner emphasises proactive planning, predictive modelling of human paths, and dynamic mode-switching to ensure both safety and social acceptability. Unlike this work, our framework explicitly addresses real-time collaboration and negotiation in environments where fixed goals may be interrupted by unpredictable human movement. In contrast to prior approaches that rely solely on predictive models or predefined zones, our framework dynamically integrates risk-aware planning and redirection strategies, allowing the robot to respond adaptively, even when no immediate safe path is available. Moreover, we demonstrate our solution in both simulated and real-world settings, validating its effectiveness in scenarios that include human unpredictability and evolving task requirements.
Wen et al. (2025) introduce a socially-aware navigation framework that integrates deep reinforcement learning with large language models to facilitate rich bidirectional communication with humans during navigation. This approach enables the robot to interpret human intentions and engage in natural language dialogue to negotiate shared space. Although effective in contexts requiring fluid interaction, such an approach may not be suitable in assistive-care scenarios involving older adults with mild cognitive or motor impairments. In our framework, we intentionally minimise interaction complexity, avoiding reliance on extended conversations. Instead, the robot communicates essential information through brief and polite notifications, such as task reminders or simple spatial requests, thereby reducing cognitive load while still ensuring safety and social acceptability.
Preliminaries
This section introduces core concepts relevant to our approach. In the section titled ‘The travelling salesman problem', we summarise the travelling salesman problem, a widely used combinatorial optimisation problem. The ‘Probabilistic model checking' section presents probabilistic model checking (PMC), a formal verification technique for systems exhibiting stochastic behaviour. We outline the fundamentals of Markov decision processes (MDPs) and introduce probabilistic computation tree logic (PCTL), which is used to formalise properties of MDPs analysed through PMC.
The travelling salesman problem
The travelling salesman problem (TSP) is a fundamental combinatorial optimisation problem that involves finding the shortest route that a salesman can take to visit a set of cities and return to the initial location (Applegate et al., 2007; Hoffman and Padberg, 2001). TSP is a challenging problem even for small instances of the problem, as the number of possible routes that the salesman can take grows exponentially with the number of cities.
Let
The length of a path can be obtained by adding the distances associated with its edges.
Given an edge-weighted directed graph
The TSP is formally defined as follows.
Given an edge-weighted, directed graph
TSP relates to the problem we address in this paper as it provides a framework for identifying the shortest path a robot can take to traverse an environment by visiting a series of points and returning to the start. When integrated with safety considerations, TSP can be adapted not only to find the minimum travel distance but also to incorporate safety constraints into the path selection process. Using edge weights that reflect both distance and risk levels, our enhanced TSP allows the synthesis of routes that optimise both travel efficiency and safety.
Probabilistic model checking
Probabilistic model checking is a formal verification method for the analysis of quantitative properties of systems exhibiting stochastic behaviour (Kwiatkowska et al., 2010), where this behaviour is formalised using Markov models. PMC operates with a wide range of Markov models (Katoen, 2016), each of which enables the analysis of a different class of system behaviour and/or properties.
Markov decision processes
In this section, we provide a brief introduction to MDPs, the type of probabilistic models used within our framework.
A Markov decision process over a set of atomic propositions AP is a tuple • S is a finite set of states; • s0 ∈ S is the initial state; • A ≠ ∅ is a finite set of actions; •
• L: S → 2
AP
is a state labelling function that maps each state s ∈ S to the set of atomic propositions L(s) ⊆ AP that hold in state s; •
Note that, in the general formulation of MDPs, the reward function R may include negative values. In this work, however, we restrict R to non-negative values, as it models physical distances traversed by the robot in the environment. This modelling choice reflects our robotics application, where rewards are used to encode traversal effort or progress, and are therefore inherently non-negative.
For each state s ∈ S, the set of actions a ∈ A for which
A (deterministic memoryless) policy of an MDP is a function σ: S → A that maps each state s ∈ S to an action from A(s).
Probabilistic computation tree logic
The properties of MDPs analysed through PMC are formally expressed in PCTL (Hansson and Jonsson, 1994), a branching-time temporal logic with the following syntax.
PCTL state formulae Φ and path formulae ϕ over an atomic proposition set AP are defined by the grammar:
where a ∈ AP, ϕ is a path formula, ⋈ ∈ {<, ≤, ≥, >} is a relational operator, p ∈ [0, 1] is a probability bound,
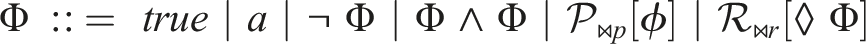
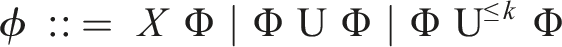
The PCTL semantics is defined using a satisfaction relation ⊨. Given an MDP
Adaptive planning framework
Our adaptive planning framework (depicted in Figure 3) receives as input a map of the environment (described in ‘Environment modelling' section), and a mission specification. This specification defines the process to be carried out together by the robot (or ‘agent’) and the human user, organised into a sequence of phases, each comprising a number of tasks associated with locations within the environment (‘Mission modelling' section). The Mission planner at the core of the framework is responsible for orchestrating the synthesis of a mission plan from these inputs by using the other modules of the framework. These modules include: a Task scheduler, which receives as input the tasks for each of the mission’s phases, and returns a specification of the optimal order of performing these tasks; the Human predictive modelling module, which receives a list of the tasks to be performed by the human user and returns the predicted path of the user within the environment; and, finally, the Path planner module, which utilises Dijkstra’s algorithm to return two solutions for the agent, based on the path of least distance and the highest probability of success when traversing the environment, respectively (‘Path-finding' section). PMC is then used to formally assess the suitability of the two solutions. The framework’s output is the optimal plan for the agent to traverse the environment and perform its tasks within the mission while maximising the safety of the user. Adaptive mission planning framework.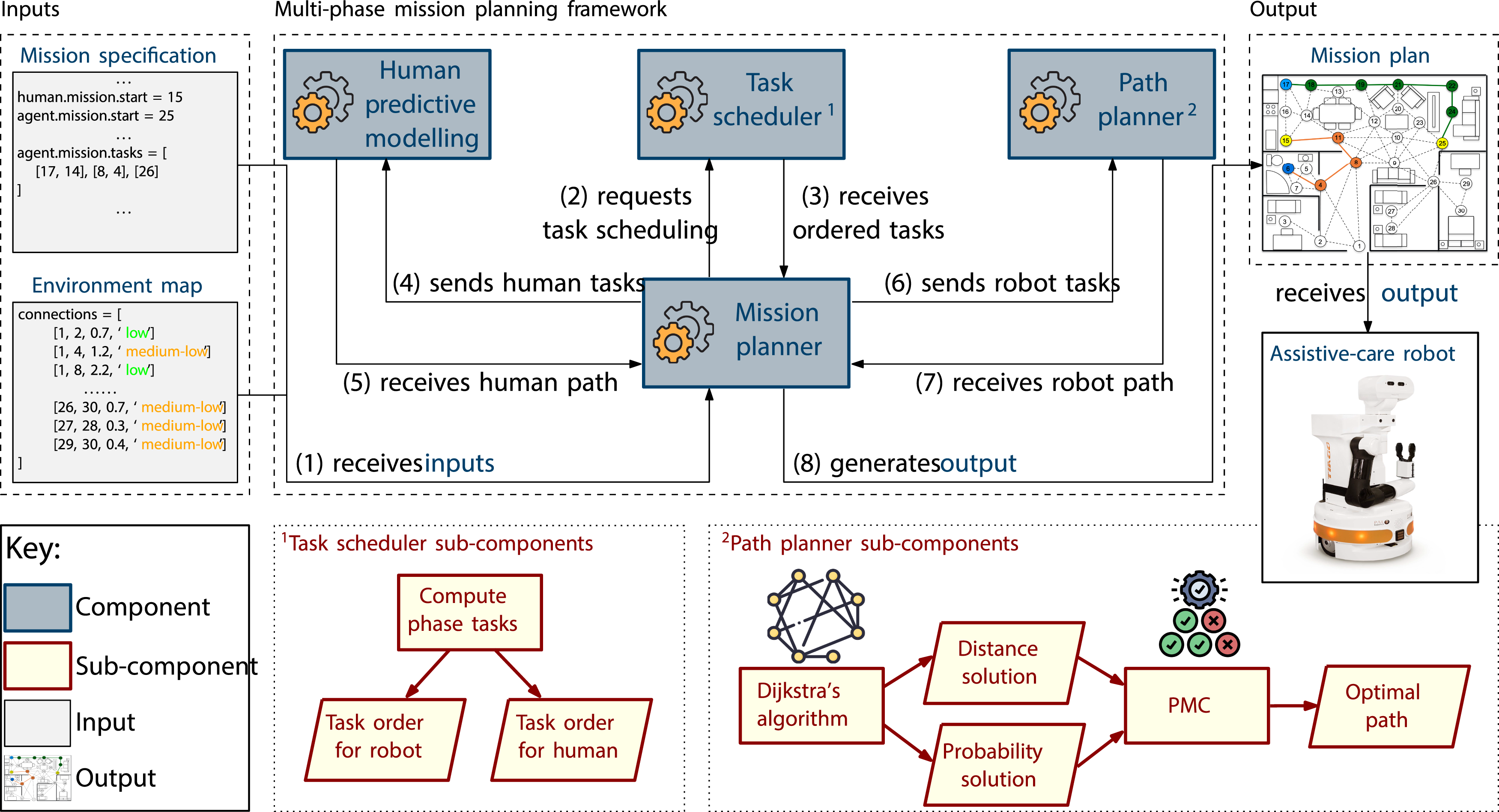
Environment modelling
When modelling the environment, we initially consider the layout of the room(s) in which the robot will be deployed, as seen in Figure 4(a). In this example, the depicted environment has a multi-room layout consisting of an open-plan living, kitchen, and dining area, as well as a master bedroom, two secondary bedrooms, and a bathroom. Key locations within the kitchen area are also labelled (i.e. the counter tops, the hob/cooker, and the sink) as an indication of possible human–robot collaborative tasks that can be performed at these locations. Example model of a multi-room environment. Starting from left to right, we have a plain representation of the modelled environment, containing annotations about both rooms and key locations. The possible connections between the defined location nodes are shown next, and finally, a depiction of risk severity using colour-coded edge connections.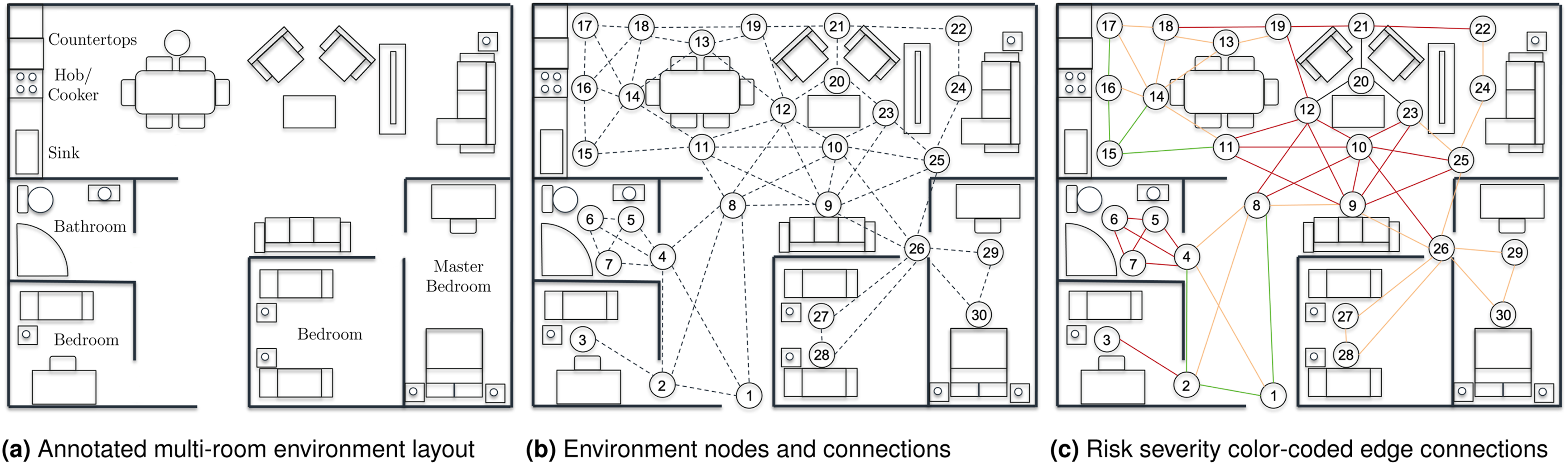
We then proceed with the modelling of the environment as a graph
To describe any connection between two nodes within the environment, we use a risk metric (as seen in Listing 1) consisting of three main categories and nine intermediate sub-categories of risk (i.e. in ascending order of risk: low, medium-low, medium, medium-high, high-low, high-medium, high, high-high, very high). In practice, these risk levels correspond to numerical risk values that describe the probability of successfully traversing the edge (P
s
) at any time. Node and connection initialisation example.
Consider the first connection from Listing 1. Its first two values indicate the connecting nodes (i.e. node 1 is connected to node 2), the third value corresponds to the distance between the two nodes (i.e. 0.70), and the fourth value represents the associated risk (i.e. ‘low’) when traversing from one node to another. The risk values were selected to correspond to success probabilities ranging from 0.95 or higher for low risk to 0.40 or lower for very high risk. Factors that impact the level of risk for an edge include the extent of clutter within the vicinity of the edge, whether the edge intersects one or more other edges, and whether the edge is likely to be in an area predicted to be busy
2
. Figure 4(c) shows the environment map with the applied risk metric, where the colour of each edge corresponds to a primary risk category (low = green, medium = orange, high = red, very high = black).
Mission modelling
A mission is defined as a series of phases, with each phase comprising a number of tasks, represented by nodes in the environment. A task is defined as an action or a series of actions performed by the robot accounted for by the inner-loop control system embedded on the robot. Such local tasks include the identification of objects and the manipulation of objects during an object retrieval mission. When considering a mission where a robot patrols an assistive care environment navigating between specific waypoint targets and performing checks at each location, the order the robot paths between each location may not be important to the outcome of the mission and can therefore be performed in the most efficient order, or the order which maximises safety of the overall mission, provided all tasks are completed.
To illustrate this point, Listing 2 depicts the definition of a mission profile as a list of waypoint targets, creating a repertoire of locations within the environment where the robot must perform a specific task. In this example mission, node 22 is assigned to both start and end locations (lines 1 and 3, respectively) for the robot. Together with a list of defined tasks (line 2) they constitute the profile of the mission (line 6). Example mission comprised of start location, series of unordered tasks, end location and heading references.
Definition of task headers.

When the mission planning framework receives a mission as an input (along with the modelled environment), the headers variable is used to identify regions of ordered, unordered, and human-allocated tasks before determining the optimal order of the tasks. The first step involves the creation of a secondary map of the environment where the nodes correspond only to the locations identified within the mission (Figure 5(a)). Since the agent can move between any location in the mission environment, each node is fully connected to all other nodes, creating a complex web of edges with unknown distance and probability parameters (Figure 5(b)). Visual representation of mission modelling based on Listing 2. (a) and (b) depict the secondary map generated by the mission planning framework and the graph connections based on mission tasks, respectively. (c) and (d) (colour-coded for clarity) depict the map fully connected resulting from the processing taking place in the Path planner module, starting from node 22 and visiting all nodes comprising the mission graph. Finally, (e) and (f) are the resulting least distance and highest probability path solutions, respectively, obtained via permutation analysis on the secondary map of the environment.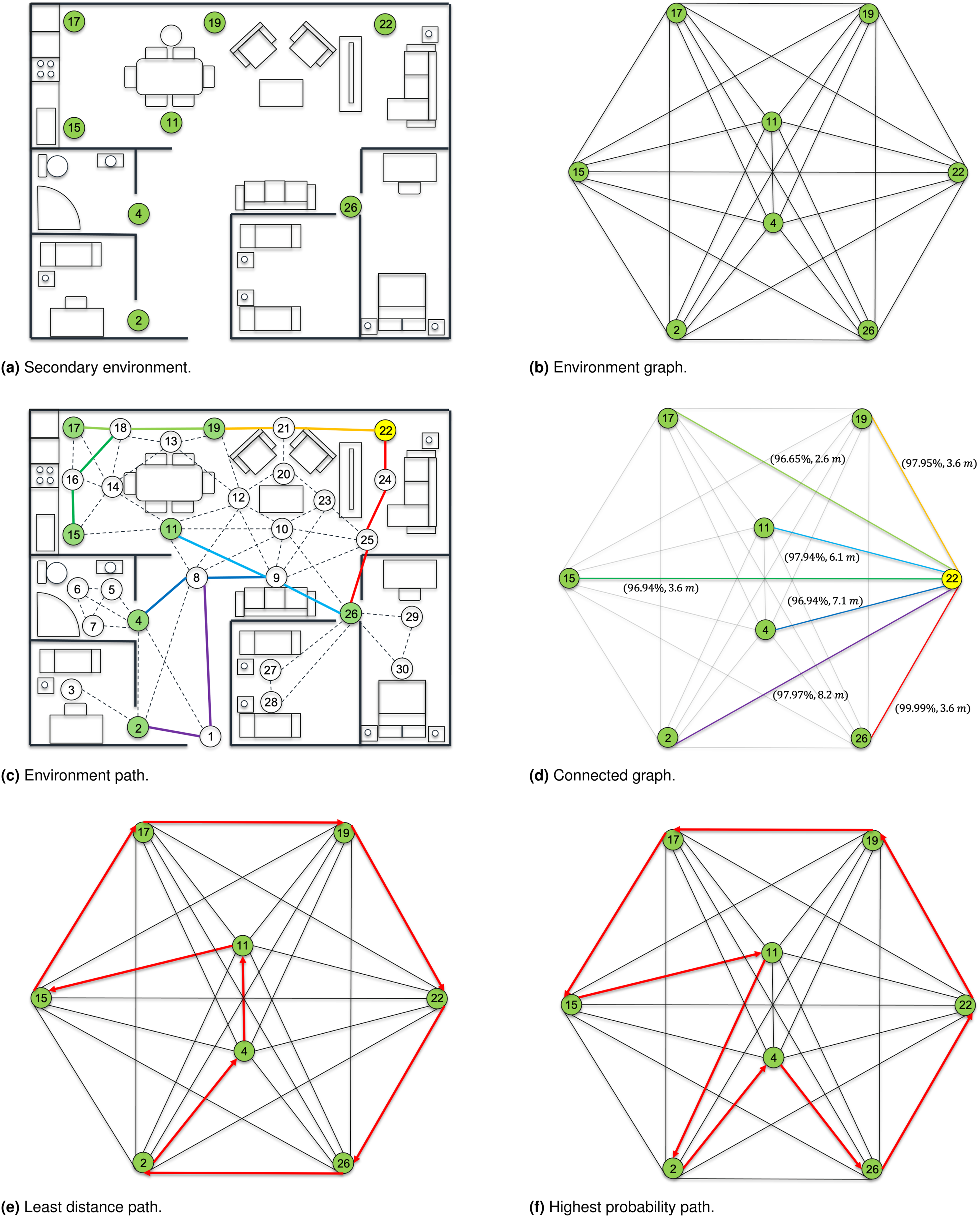
Each unknown edge has its distance and the probability of successfully traversing the edge determined by performing path-finding on the primary environment (Figure 4) using Dijkstra’s algorithm discussed in more detail later in section ‘Path-finding'. This creates two local solutions corresponding to the path of least distance and path with the highest probability of success when navigating the graph-based environment model. An example of this process can be seen in Figure 5(c) where starting from node 22, paths are found through the primary environment based on the highest probability of success to all node locations within the mission map. Each local solution computes the length of the path and probability of successfully navigating along the path, which are applied as edge metrics for the fully connected mission graph, as depicted in Figure 5(c). This exhaustive process of path-finding is performed for navigation between every connected node located in the mission graph (Figure 5(d)), enabling the optimal route through the environment to be solved as a travelling salesman solution, evaluating all permutations of unordered tasks, creating the overall mission from start to finish.
Taking again into account the example from Listing 2, the agent starts at node 22 with the headers describing seven unordered tasks that must be performed at seven different locations creating the local mission map depicted in Figure 5(a). All edges of the mission map have been computed using the same procedure discussed above and depicted in Figure 5(c). Initially, the agent can travel to any node within the mission graph before moving to any additional unordered task nodes. Once all unordered tasks are completed, the agent travels to the location of the next ordered task, which in this mission is the end location defined at node 22 with the heading value O, signalling the end of the mission.
Given a total of seven unordered tasks defined in this example, there exist 5,040 possible permutations for the mission outlined in Listing 2. Once all 5,040 possibilities are evaluated, two mission profiles are returned: one that minimises the distance travelled (Figure 5(e)), and one that maximises the probability of success (Figure 5(f)).
The mission presented here consists of only a single phase, where the agent starts in one location (node 22) and performs a series of unordered tasks before finishing at an ordered location (again node 22). This is a relatively simple mission structure, where the mission profile was determined by creating a single mission map and solving the unordered permutations for a single phase. However, missions may contain more than one phase (multi-phase), where each phase must be performed in sequential order while the phase’s task(s) remain unordered. The presented framework (Figure 3) supports the definition of multiple phases within a mission using the same headers structure as per previous example.
For any multi-phase mission, each phase is identified based on the presence of ordered tasks, since an ordered task implies that all previous tasks must be completed before reaching this stage. Listing 3 provides an example of such a mission. Looking at the headers structure of the mission it becomes apparent that the first phase starts from node 22 and has two unordered tasks to be performed at nodes 30 and 28, before finishing at node 10. Since node 10 is identified as an ordered task, this translates to all previous tasks must be completed before the agent reaches node 10, thus indicating the end of the first phase and the start of the second phase. The unordered tasks of the second phase (i.e. 15, 14, and 17) will be performed in the closest-to-optimal order before the agent returns to node 22 to end the mission. The mission graph created by the framework can be seen in Figure 6, where the two phases of the mission are connected through the end location of the first phase and the start location of the subsequent phase. Example multi-phase mission comprised of start location, series of unordered tasks, an ordered task, end location, and heading references. Multi-phase mission graph derived from Listing 3. Yellow nodes represent the starting location for each phase (22 for phase 1 and 10 for phase 2), blue nodes represent the ending location for each phase (10 for phase 1 and 22 for phase 2), and green nodes represent unordered tasks within each phase (phase 1: [28, 30], phase 2: [14, 15, 17]).
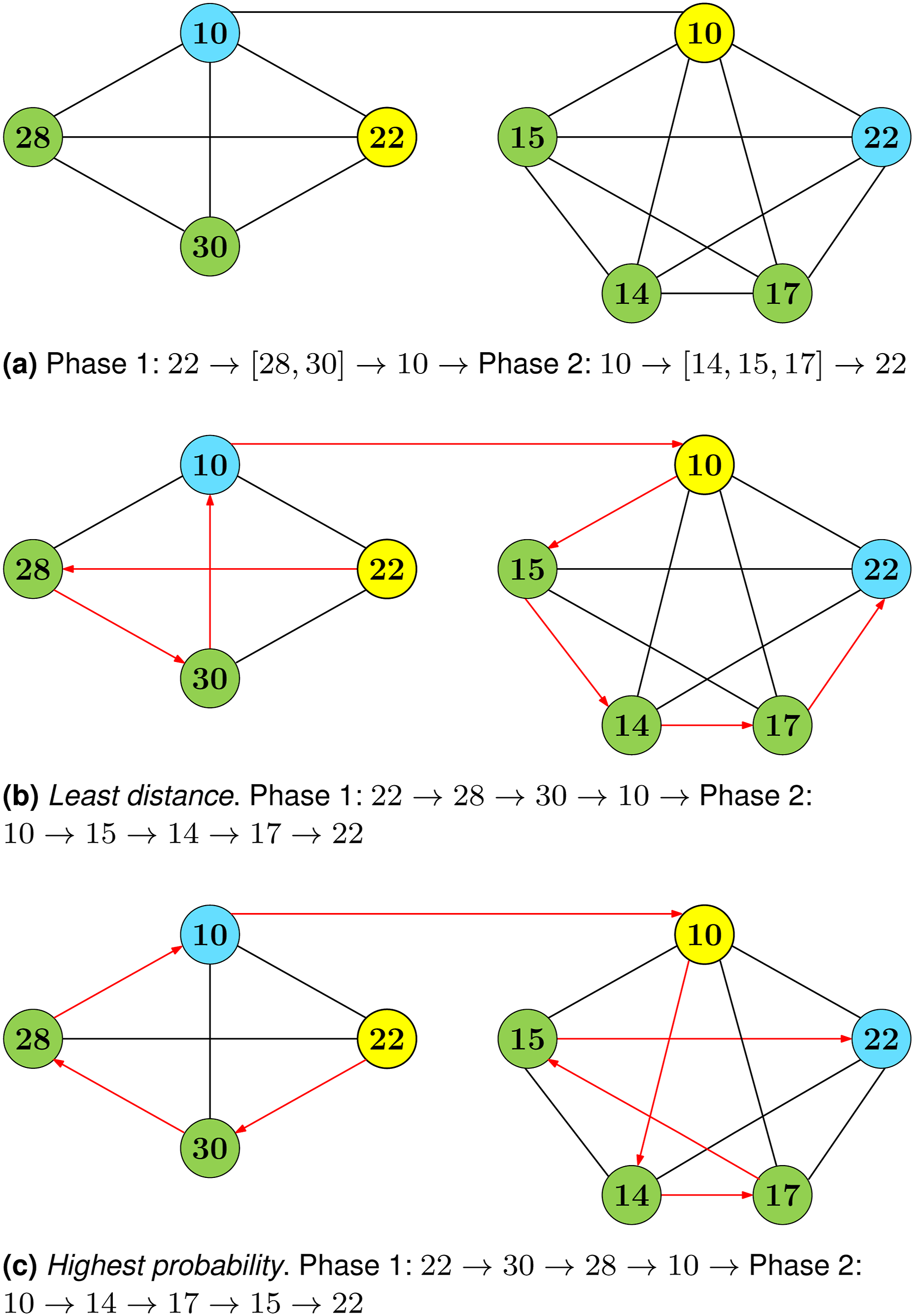
Creating and populating the edges of the multi-phase mission map is performed under same methodology as the previous single-phase mission example (Listing 2), where exhaustive path-finding is performed on the main environment between all of the connected nodes within the mission’s map. Obtaining the solution for each phase of the mission as a TSP is performed iteratively, with each stage evaluated independently of the other and two solutions produced for each phase of the mission. The first solution, as seen in Figure 6(b), focuses on distributing the tasks in a way that minimises the distance travelled by the agent during each phase of the mission. Although it has already been discussed that minimising the distance travelled is not as important as maximising safety, when pathing locally between tasks, the selected path is also the safest route locally through the environment. The second solution, shown in Figure 6(c), focuses on task allocation to maximise the probability of successfully completing the mission. As in the least-distance solution, pathing between each task location at a local level still maintains the path of the highest probability of success.
Path-finding
Producing a framework that allows for online path planning in a dynamically changing environment at runtime is a complex problem. First, the representation of the environment needs to be updated at a high frequency to ensure that it remains accurate. Second, performing safe navigation is essential, particularly in applications where a robot is operating in the presence of a human, and/or they are collaborating together to achieve a common goal. For these reasons, having a path-finding algorithm that systematically quantifies the safety of paths is highly desirable, as this enables a cohesive plan to be integrated where safety and resilience of the RAS are the primary objectives. However, methods to achieve this, such as probabilistic model checking (Katoen, 2016) and controller synthesis (Baier et al., 2004) can incur large computational overheads, so systematically analysing a large number of paths at each instance in time becomes intractable. Therefore, in this methodology, we use a graph-based path-finding algorithm, such as Dijkstra, to solve the path-planning problem based on two parameters: least distance and highest probability of success. The validation of both solutions is performed at runtime using the probabilistic model checker PRISM (Kwiatkowska et al., 2011).
Dijkstra’s algorithm is widely recognised for its robustness and efficiency in finding the shortest path in a network. In ‘Environment modelling' section, we discuss how connections between nodes are established, including the assignment of linear distance values (see Listing 1). These linear distance values serve as input for Dijkstra’s algorithm to determine the shortest path through the environment. While distance is generally a useful metric for most applications, in this particular context, where improving safety is paramount, it is crucial to know the shortest path both for algorithmic validation and for comparison with what is perceived to be the safest path.
Although the simplest and most common use case of Dijkstra’s algorithm is for determining the path of least distance, different solutions can be obtained by changing the weighting values and adjusting the algorithm to either minimise or maximise the cost function. This is demonstrated in Figure 7, where the same graph structure is shown with two different sets of edge values. In Figure 7(a), the edge values represent the distance between two nodes, while in Figure 7(b), the edge values represent the probability of successfully reaching a neighbouring node. By adjusting Dijkstra’s algorithm to maximise the cost function instead of minimising it, vastly different solutions are obtained. The path of least distance is 1 → 3 → 5 (i.e. 2.8 m and 10% success chance), while the path with the highest probability of success is 1 → 2 → 4 → 5 (i.e. 3 m and 44% success chance). Example of Dijkstra’s algorithm minimizing path distance (a) and maximising probability of success (b).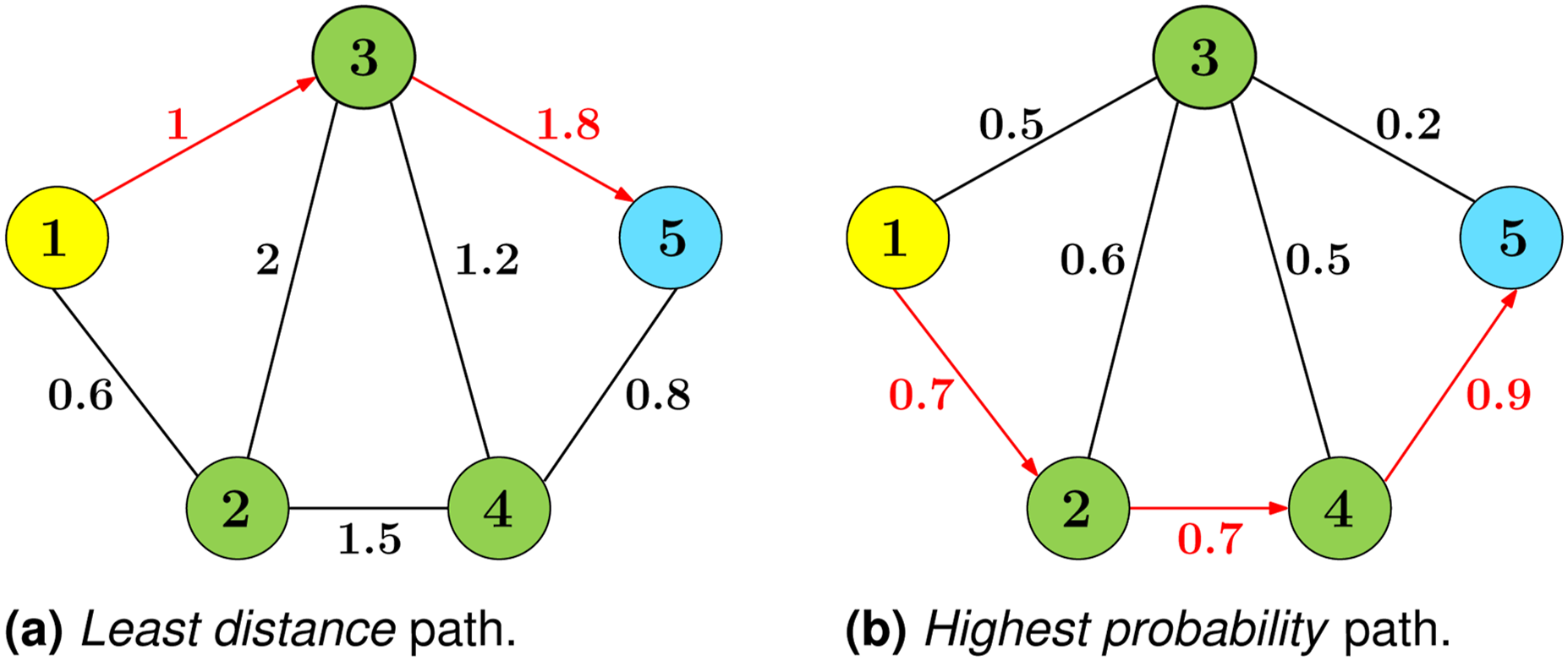
For simplicity, the safest route through the environment is defined as the path with the highest probability of success, as this reduces the probability that the system will reach a failure state. Edge values represent the level of risk when moving between connected nodes, specifically the probability of the agent successfully traversing the edge, denoted P success . The remaining probability is divided between two other outcomes: P fail and P return . However, when using Dijkstra’s algorithm to maximise safety, these two parameters (P fail and P return ) are challenging to interpret because of their semantics.
First, if Dijkstra’s algorithm were to minimise the cost associated with P fail , it would select the path with the lowest probability of failure. However, this approach lacks incentive to move toward the goal, as successive multiplication of probabilities less than one would continue to reduce the overall path probability, potentially extending the path length toward infinity. It is important to note that while distance is additive in traditional graphs, the overall probability of success in a probability-annotated graph is obtained through multiplication.
Second, P return represents the probability that, if the agent attempts to traverse an edge and fails, it returns to its original location. Although the probability of this scenario might be low, it can lead to situations where the agent becomes trapped in an infinite loop of states P return , unable to progress. Dijkstra’s algorithm cannot account for this, as it simply selects the optimal edge at each step and moves to that location without considering potential return loops. This systematic evaluation, coupled with the possibility of return states, underscores the importance of validation through probabilistic model checking within this framework. Therefore, the P success metric was used as the edge weight for Dijkstra’s algorithm, with the cost function maximised over the environment.
Maximising the cost function not only enhances path safety, but also reduces the number of nodes considered, preventing the path from expanding indefinitely. This occurs because the algorithm prioritises paths with higher success probabilities, effectively avoiding paths that would extend unnecessarily or loop infinitely. However, it is important to note that the output from Dijkstra’s algorithm does not directly represent the overall probability of successfully reaching the end state. Instead, it reflects the cumulative probability of success at each step along the path, meaning that the probability of success is considered separately for each transition between nodes.
To accurately determine the overall probability of successfully navigating the paths identified by Dijkstra’s algorithm, an MDP model is created based on the environment and the navigation along each path. The PCTL formula Pmax = ?
Our framework employs two variants of Dijkstra’s algorithm for path-finding, as outlined in Algorithm 1. First, the conventional Dijkstra’s algorithm is used to identify the shortest distance path between the start and final task locations of the robot. Second, our own modified version of Dijkstra’s algorithm is applied to find the optimal path based on a cost function that maximises the probability of successfully reaching the end state. The implementation details of this modified algorithm are provided in Algorithm 3.
The function P

The algorithm computes two paths: the shortest distance path,
Algorithm 2 extracts an MDP (cf. Definition 4) that encodes the behaviour of the robot moving in a scenario from a graph

The process outlined in Algorithm 3 is largely similar to the conventional Dijkstra’s algorithm. The primary modification lies in how new values are interpreted and accumulated within the connection values during the path-finding process. This adjustment allows the algorithm to accommodate different cost functions or risk assessments, as needed for the specific application.
In the conventional Dijkstra algorithm, initial values for each connection are typically set to zero or infinity to represent the start of the algorithm, where no nodes have been explored. This approach works well when minimising distance or cost, as the initial value of zero correctly signifies the shortest path from the starting node to itself. However, when adapting Dijkstra’s algorithm to maximise probability, using an initial value of zero can cause issues because probabilities are accumulated multiplicatively. If the initial probability is zero, any subsequent multiplication will result in zero, incorrectly indicating that there is no viable path.
To address this, the modified Dijkstra algorithm, namely P
As the algorithm iterates through the priority queue (line 8), it pops the node with the highest current probability (line 10 – we assume that the function first returns the first element in a sequence). The tuple (curr_ prob, curr_node) is extracted from the queue, where curr_ prob is the accumulated probability of reaching curr_node. The algorithm then examines all neighbouring nodes connected to curr_node (line 11). Note that for convenience, we define a function
After handling zero probabilities, the algorithm calculates new_ prob to reach the neighbour. Initially, when curr_ prob is zero, indicating that curr_node is the start node, the algorithm directly sets new_ prob to the edge probability. This ensures that the first step from the start node is calculated correctly without being influenced by the initial zero state. For subsequent nodes, where curr_ prob has been updated, new_ prob is calculated as the product of curr_ prob and edge (line 13). This multiplication accumulates the probability of successfully reaching the neighbour via curr_node, ensuring that the overall probability of the path is updated correctly.
The algorithm then compares new_ prob with the current recorded probability of the neighbour (line 14). If new_ prob is greater, indicating that a more probable path has been found, it updates nodes [c.p j ] to new_ prob and records curr_node as its predecessor in the history dictionary (lines 15–16). The updated (new_ prob, c.p j ) tuple is then pushed onto the priority queue for further exploration (line 17 – We note that operator ‘ ⌢’ designates sequence concatenation).
Once all nodes have been processed and the priority queue is empty, the algorithm reconstructs the optimal path by backtracking from the end node to the start node using the history dictionary (lines 21–26). This backtracking involves tracing the most probable sequence of nodes from the start to the end, after which the path is reversed to present it in the correct order (line 27).
These modifications are crucial for adapting Dijkstra’s algorithm to maximise the probability of success in navigating through a graph. By initialising the start node with a probability of one and carefully managing edge cases where the probability of success is zero, the algorithm effectively identifies the most probable path through the environment. This approach ensures that even paths with low but non-zero probabilities are considered, allowing for a more robust exploration of possible routes.
Consider the single-phase solo mission depicted in Figure 8. The agent is required to navigate from its current location (node 25) and inspect the working surface at node 17. The agent is operating inside the environment with no human presence, that is, the produced paths by the algorithm are determined solely by the default environment map created during the initialisation period. It is evident that the least distance path (Figure 8(b) navigates the agent through the centre of the environment and into a region that is expected to be cluttered with a higher risk level (see Figure 4(c)). In contrast, the path that maximises the probability of success (Figure 8(c)) avoids clutter unless entirely necessary, with the agent navigating around the perimeter of the living/dining area. This demonstrates how Dijkstra’s algorithm can be configured to produce two different paths through the environment based on minimising or maximising two different metrics.
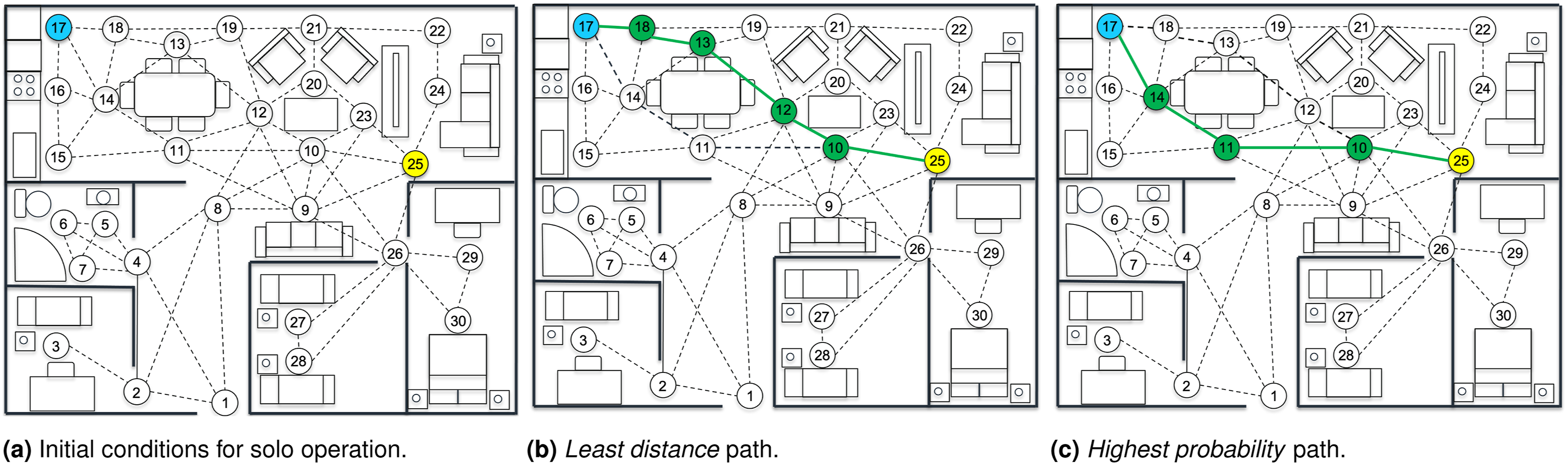
Example of a single-phase solo mission. (a) depicts the start (node 25) and end (node 17) mission locations. (b) and (c) depict the obtain solutions after the application of the path-finding algorithm following the paths of least distance, and highest probability of success, respectively.
When comparing the overall lengths of both solutions from Example 2, the path found using the least distance configuration of Dijkstra’s produced a path of length of 2.9 m. This is a reduction of approximately 27% compared to the path produced by Dijkstra’s configured to maximise the probability of success, with a path length of 4 m. Given that the overall difference in path distance is relatively small between the two solutions and that the primary focus of this framework is to maximise safety when operating in the presence of a human, it is expected that selecting the solution that maximises the probability of success should be the more appropriate solution. To validate both solutions systematically, an MDP model is created, with its action set derived from the sequence of actions along the proposed path. The model is evaluated using the previously defined PCTL property to assess the likelihood of successful task completion. From this validation, the probability of successfully navigating the environment and reach the end state using the path of least distance was approximately 93.6%, while this value increased to 97.4% when using the path with the highest probability of success. Although this does not represent a drastic change in the success of the system, any increase in safety, particularly when operating in the presence of a human, is deemed a benefit to the overall process.
During the first demonstration of the path-finding algorithm, the agent was operating alone in the environment. When introducing the presence of a human, the location and the human intentions require high level of attention, yet cannot necessarily be accurately modelled without assumptions being made. Example 3 extends the previously presented scenario in Example 2 with a human traversing the environment. The agent follows the same mission objective as before and operates under the assumption that the location and intentions of the human (i.e. the intended target location of the human and how the human intends to path through the environment) are known. The agent also assumes that the human navigates through the environment using the path of least distance, as depicted in Figure 9(a). Example of a single-phase co-op mission. (a) illustrates the predicted least-distance human path, starting at node 15 and ending at node 6 with intermediate locations nodes 11, 8, and 4. (b) depicts the conflicted agent and human paths, with the highest probability of success path for the agent (introduced in Figure 8(c)) no longer holding true. Thus, recalculating the agent’s path with the aim of maximising the probability of success is necessary to ensure the safety of the human traversing the environment. The updated highest probability of success path for the agent, taking into account the human’s intentions, can be seen in (c).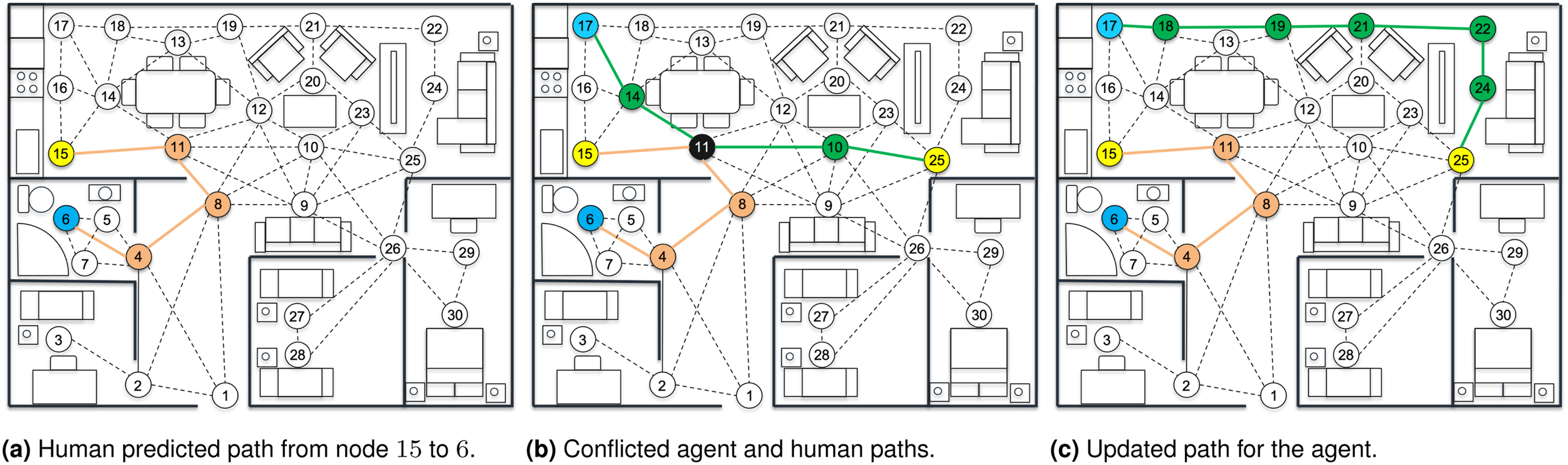
Expanding on Example 2, the agent has the same initial and final conditions, but now a human has been placed in the environment at node 15. The agent infers or predicts the human’s intention to move to the bathroom (node 6) based on its observations of the human. Using Dijkstra’s algorithm, the predicted path for the human is shown in Figure 9(a). Since the agent maintains the same mission profile, the solutions obtained from Dijkstra’s algorithm are initially the same. However, the predicted path taken by the human causes a spatial conflict with the highest probability path taken by the agent, where both entities will be located at node 11 at some point in time (Figure 9(b)). This affects safety because the agent may be aligned on a trajectory in close proximity to the human or cause distress by blocking their path. However, using the proposed framework (Figure 3), the predicted path of the human is interpreted by the agent’s representation of the environment in the form of a risk-augmented map. Path-finding is then performed again for the agent based on this updated interpretation of the environment.
Since the predicted path for the human was spatially conflicted with the original highest probability of success path for the agent (Figure 9(b)), the obtained success probability no longer holds due to the increased risk from the presence of the human (97% to 40% drop). Therefore, when path-finding for the agent is performed using the updated environment representation, a different solution is returned corresponding to the highest probability of success. This can be seen in Figure 9(c) where an updated path of highest probability guides the agent in avoiding the cluttered central area taken by the path of least distance, with an approximately 96% probability of success.
Human–robot interaction and adaptation
Since ensuring human safety is the most critical aspect of this research, the robot should adapt its plan during the mission to account for the human’s location and movement. For example, if a human is present in a specific area of the environment, the robot should avoid navigating through that area and instead find an alternative route to reach its destination. If no alternative route is available because the human is blocking the robot’s path, the robot should not attempt to move. Instead, it should either wait until the human clears the area or, when appropriate, issue a redirection request asking the human to move in a socially acceptable manner.
Similarly, if the human’s position is in the location where the robot needs to perform a task or if the human is blocking the robot’s path with no alternative route available, the robot should recompute the mission plan. The robot should then perform another task if possible, returning to the current task only when it is safe to do so. However, if the blocked task must be performed next due to an ordered sequence, the robot may wait until the path is clear. Lastly, if the human is approaching the robot and the human’s intentions are unclear, the robot should pause its mission progress and wait until the human safely passes by.
Our framework assumes that the robot can engage in basic, socially appropriate interactions with the human, including two distinct forms of communication: (1) task-related reminders issued during collaborative missions (e.g. prompting the person to retrieve an item required to carry out a collaborative task), and (2) safety-preserving spatial requests in general navigation (e.g. asking the person to momentarily move aside or wait). These interactions are designed to support cooperation and ensure safe operation in shared environments. Based on the findings of our requirements elicitation study (see ‘Requirements elicitation' section), a human will generally be happy to comply with such requests, particularly when they are clearly and politely framed. When the human complies, the robot predicts the human’s movement during this phase of the mission, assuming that the person will choose the shortest path. This prediction is then used to reduce potential spatial conflicts by adjusting risk costs in the robot’s own path planning.
The human predicted path is determined using the Dijkstra algorithm outlined in ‘Path-finding' section, but with a modified cost function that minimises the distance travelled instead of reducing risk. This predicted path is then incorporated into the robot’s path planning by applying a linear risk scaling factor to edges where a positional conflict between the human and the robot could occur.
Additionally, it is acknowledged that the human may not always follow the predicted path. To account for the uncertainty typically associated with human behaviour (Calinescu et al., 2020; Hezavehi et al., 2021), a variable is introduced that represents the likelihood of unpredictable actions. Consequently, a secondary evaluation of the edges connected to the human’s current position is conducted to identify possible next moves in case the human deviates from the predicted path.
Implementation and evaluation
This section describes the technical aspects and specification of the robotic system introduced in the ‘Motivating example' section, as well as the process to identify suitable use cases. We demonstrate the applicability of our approach in both simulated and real-world scenarios derived from the aforementioned use cases.
Robot implementation
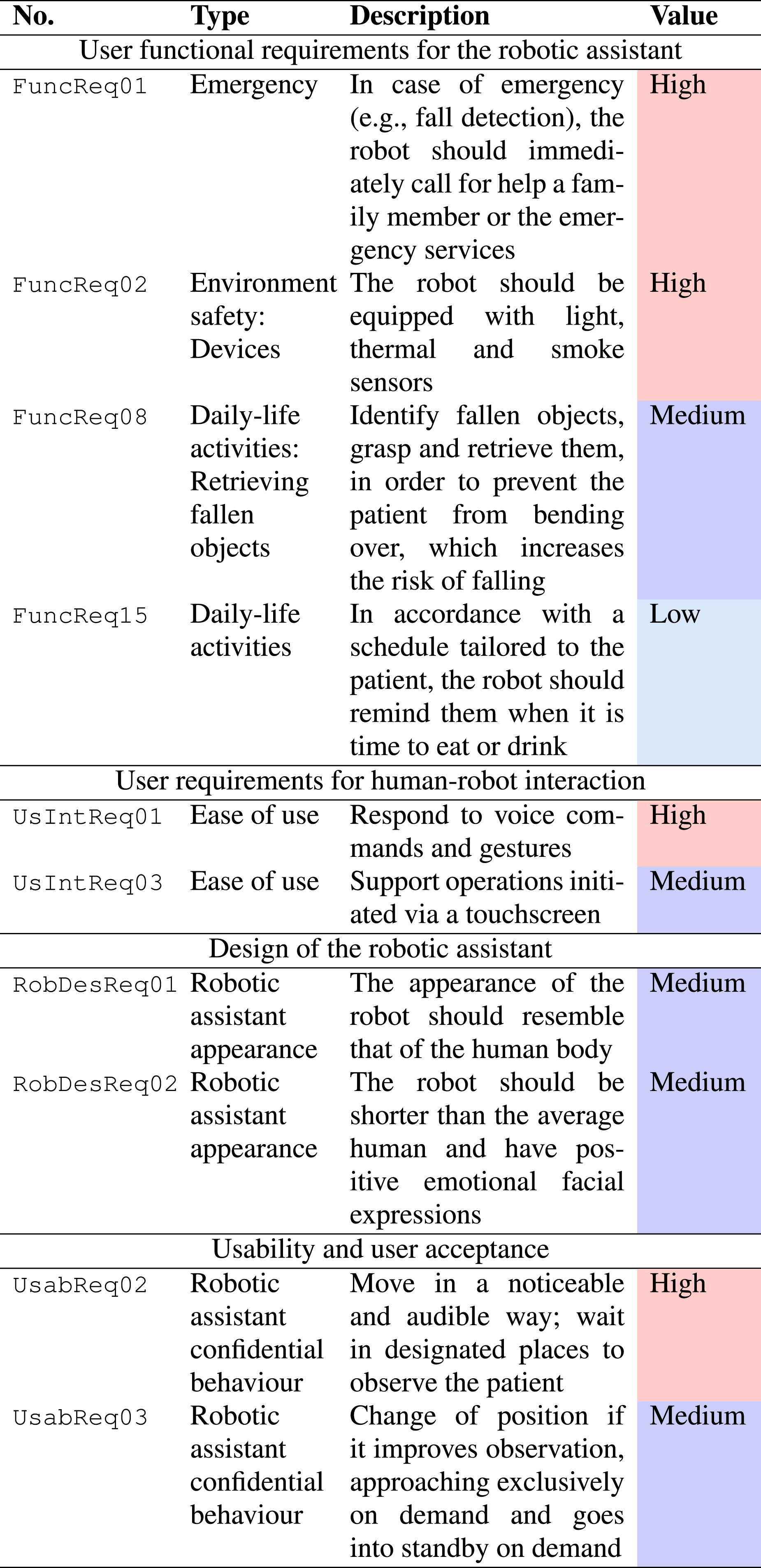
Sample user requirements for robotic assistant.
Robot architecture
The hardware architecture of the customised TIAGo robot is done with a Linux-based on-board computer that manages the real-time part of the control software due to the modified kernel developed by PAL Robotics. Communication interfaces are performed using CAN, Ethernet, and USB technology. There are also some distributed boards and microcontrollers over the robot that are in charge of providing power and communication to all sensors and motors.
The software architecture of the onboard computer of TIAGo has been designed in order to accommodate (a) third-party operating systems (OS), middlewares, and software packages; (b) PAL proprietary software and ROS packages; and (c) developer software and ROS packages. In this work, TIAGo uses Ubuntu LTS 64-bit and real-time control software (RT-Preempt), together with ROS Melodic and PAL Robotics packages.
TIAGo is also customised to be safer, robust, and compliant following the standards 13482:2014 and 10218−1. For this purpose, additional torque sensors are being used at each joint to perceive and counteract the external forces applied at any link of the robot, as well as to be adaptable to a changing environment. The objective is to have a compliant arm in all joints and links and, thus, to be safe to work close to the robot.
Mapping, localisation, and autonomous navigation
TIAGo utilises a customised ROS navigation stack that enables the use of its sensors to map the operating environment through the Karto ROS package 3 . Once a map is built, it navigates autonomously using particle-filter–based localisation and motion planning that considers dynamic obstacles detected by the sensors and depth camera. This is particularly useful in our scenarios to avoid obstacles and people in the surrounding area.
TIAGo’s map editor interface allows users to send the robot to a specific point of interest (PoI), that is, a point in the map identified by a logic name. Based on our motivating example, this could be a set of positions next to the cupboards from which TIAGo can manipulate objects more easily. Alternatively, users could send the robot to a sequence of waypoints or PoI to pre-define a trajectory where the robot can go to look for a person and give a reminder. This interface also allows retrieving a zone of interest in which the robot is located, enabling the definition of areas where the robot can move. Finally, there is also the option of adding virtual obstacles in areas where the robot cannot or is not supposed to enter, for instance, if there are parts in the kitchen or surrounding area that are hazardous for the robot or the users do not want it go (e.g. WC).
Other capabilities
We also make use of TIAGo’s speech-based user interaction capabilities through its integrated ACAPELA text-to-speech system 4 which is compatible with Google’s speech recognition system. The text-to-speech voices used are based on real voices that make them more user-friendly. In this work, these modules are used to send reminders to the user during collaborative tasks.
TIAGo has object and person detection capabilities through its RGB-D 3D camera mounted on the robot’s head. Specifically, it supports the integration of available open-source ROS packages such as find_object_2d. For person detection and recognition, we used a wrapper offered by PAL Robotics that enables the integration of Verilook’s facial identification technology 5 , that is, facial attributes and emotions. A dedicated endoscopic camera was also added on the end-effector of the robot for object localisation and to better visualise the objects being grasped. For improved object detection, an NVIDIA Jetson was added to the robot, enabling it to recognise different objects.
Requirements elicitation
The identification and selection of relevant case studies to demonstrate the applicability and usefulness of our methodology was carried out through a detailed analysis of user requirements based on previously published data (Korchut et al., 2017), and following the sequence of activities shown in Figure 10. The approach consisted of surveys through questionnaires that were administered to (a) medical personnel, (b) caregivers, and (c) potential end users. User surveys, originating from social science research, involve administering a set of written questions to a sample population of stakeholders and are usually aimed at obtaining statistically relevant results. Questionnaires are widely used in human–robot interaction, especially in the early design phases, and should be carefully designed to achieve the set objectives in the gathering of user requirements (Oppenheim, 2000). Activity sequence of the requirements elicitation approach.
In total, there were 18 participants included in moderated discussions, of which 10 were from Fundació ACE; and 264 participants completed questionnaires, of which 154 were from Fundació ACE. The analysis of the questionnaires completed during the surveys, along with the analysis of the outcomes of the focus group discussions, led us to define a prioritised list of user requirements for the TIAGo robot. Finally, we defined a set of use cases based on the prioritised list of user requirements.
User requirements and prioritisation
Following the results of the user surveys as described above, the next step of the approach focused on the definition of the prioritised list of user requirements of the TIAGo robot and their importance-based ranking. The assessed user requirements are organised into four distinct categories: (a) functional characteristics of the TIAGo robot; (b) human–robot interaction; (c) design of the robotic assistant; and (d) usability and user acceptance.
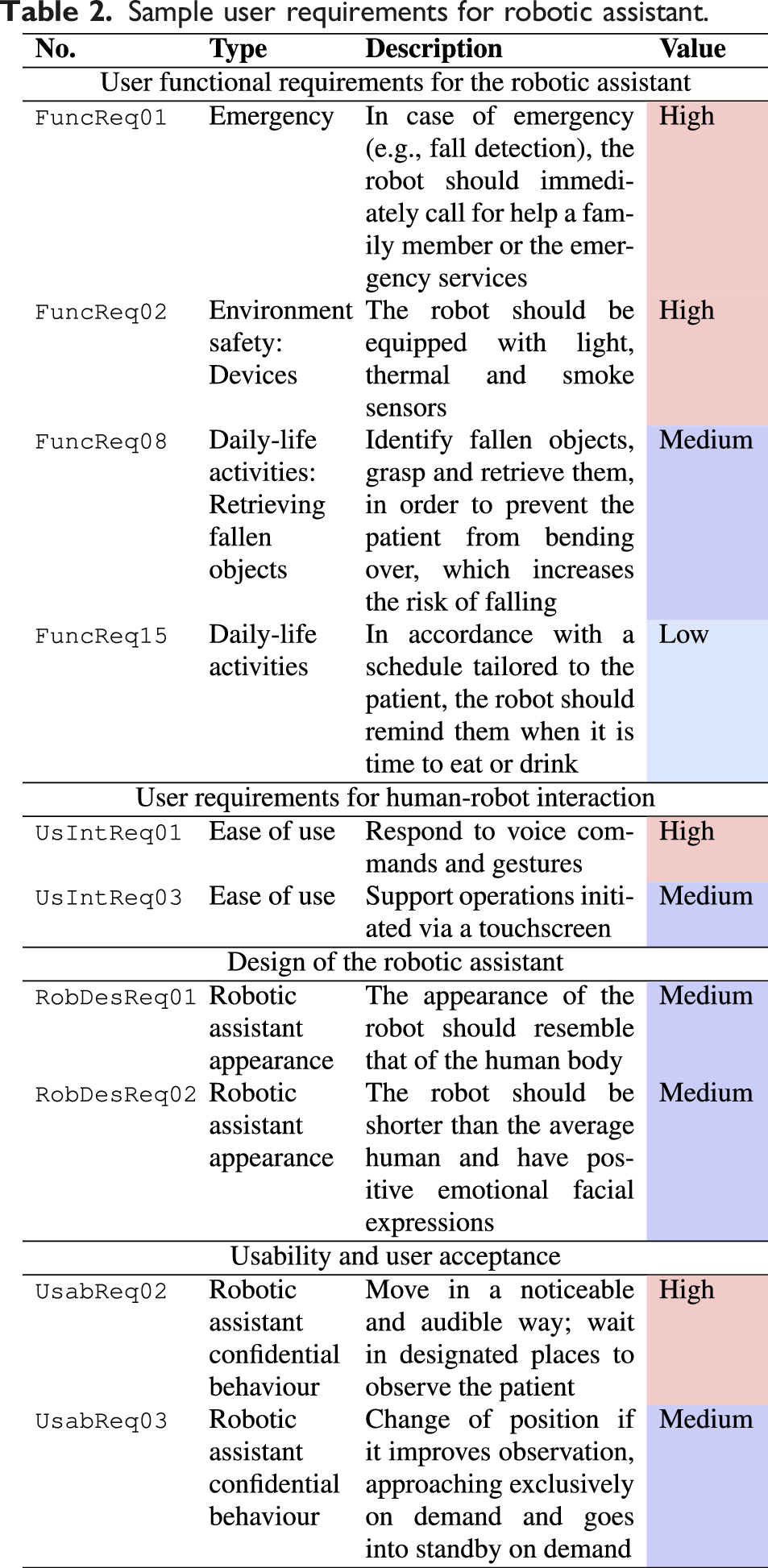
For each category, a requirements elicitation and prioritisation analysis was performed, in order to define the importance value of the requirements that would then drive the definition of the prioritised use cases for TIAGo. In addition, we followed the rationale that user requirements can generally be structured in three prioritisation categories (high, medium, low), grounded on the importance and frequency of occurrence of each requirement (Korchut et al., 2017). Table 2 presents a portion of the results obtained through the requirements elicitation and prioritisation analysis.
Use cases
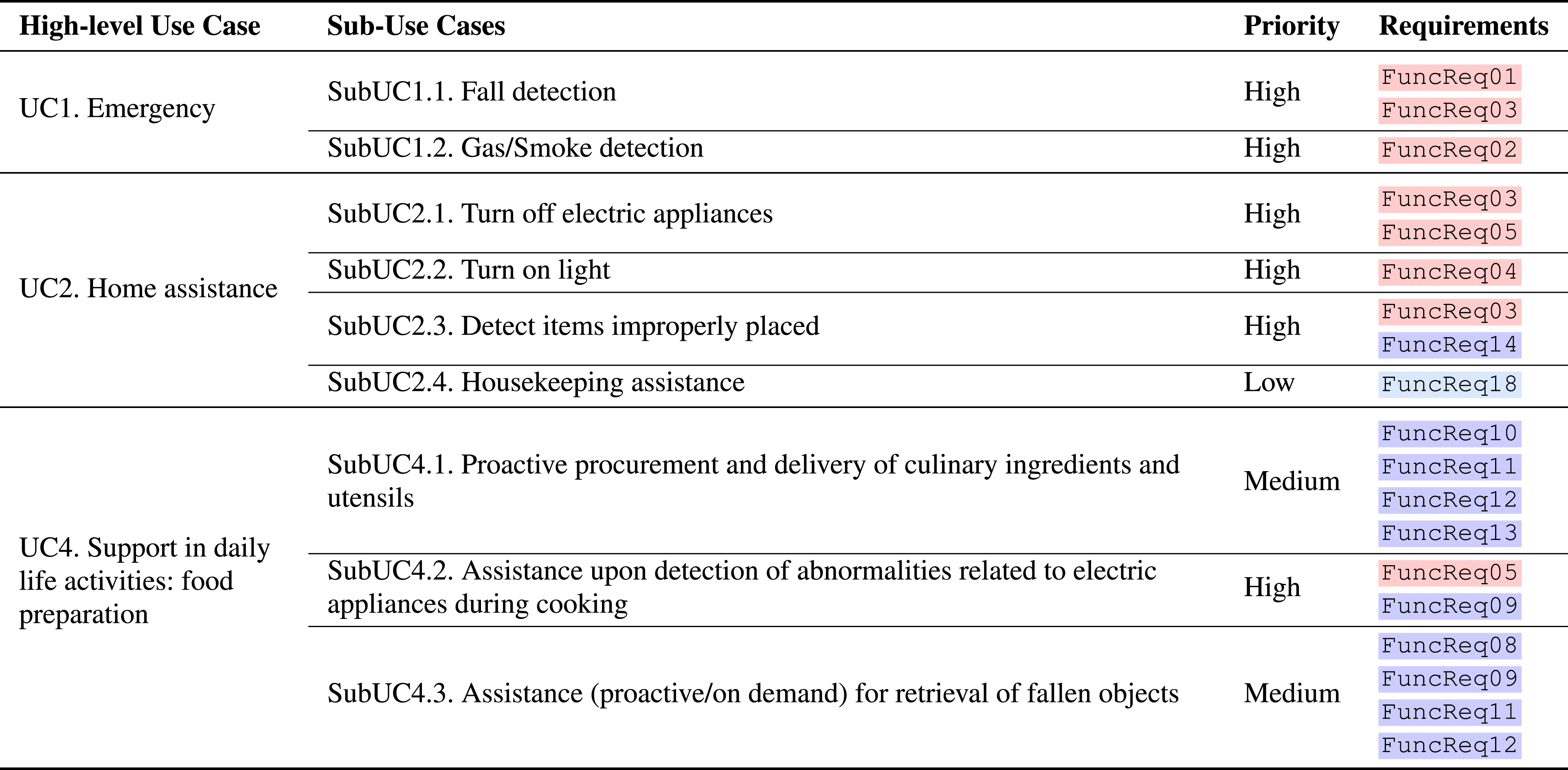
Summary of the high-level use cases (UCs).

Decision-making on the definitions of UCs and SubUCs was informed by the value of the importance of user requirements and the availability of technical opportunities. A preliminary technical feasibility assessment was performed to implement the associated UCs while weighting the potential technical risks associated with their implementation. In addition, every use case was scrutinised for its advantages and anticipated outcomes. Specifically, the definition process for the target SubUCs of TIAGo involved: (1) User Feedback: We gathered requirements, needs, beliefs, and expectations from potential users, caregivers, and medical personnel through surveys. The information was then prioritised to obtain clear insight into specific user requirements, technical prerequisites, and associated risks. (2) Technical Capability: This entails both hardware and software capabilities and limitations. A feasibility analysis for the UCs was conducted, particularly focusing on the functional requirements of the TIAGo robot. This analysis is integral to the functional review of the expected robotic system. (3) Effort Estimation: We assessed the amount of work and effort necessary for system integration. (4) Implementation Possibilities: We examined the potential and organisational constraints for integrating new assistive technologies.
Subsequently, the final ranking of specific SubUCs was influenced by the survey results. The most significant factor was the feedback from potential users on the importance of needs related to each use case. Caregiver feedback was also considered. In instances where there was a divergence between end users and caregivers, we prioritised the perspective of the target end users. This prioritisation process underscored our user-centric approach in analysing user requirements and breaking down use cases. The end result ensured that the target use cases highlighted the end user’s viewpoint. We classified the use cases into three priority levels: • HIGH PRIORITY SubUCs • MEDIUM PRIORITY SubUCs • LOW PRIORITY SubUCs
Summary of the high-level sub-use cases (SubUCs).

We demonstrate the applicability of our proposed framework in a simulated digital-twin environment, developed on the Gazebo simulator
6
, as well as in a real-world setting using the TIAGo robot and the PAL Robotics facilities. For this purpose, we focused on two different use cases, derived from the above analysis, including both solo and collaborative scenarios performed by the agent and the human: • UC1 (support in daily activities): The main goal of this use case is to support the user in activities of everyday life such as food preparation, for example, by bringing ingredients proactively and/or on demand. This use case is divided into two different scenarios, Scenario A and Scenario B, involving a static and an active human presence, respectively. • UC2 (emergency): The main goal of this use case is the robot’s appropriate response to health and emergency situations, for example, to call for help in the event of fall detection or lack of contact/activities.
Scenario-based evaluation
The first step towards evaluating our proposed solution is in a simulated digital-twin environment in which we recreated Scenario A and Scenario B of UC1. Figure 11 shows the map representing the kitchen environment at PAL Robotics, consisting of nodes (i.e. locations) and edges connecting these nodes, which are further classified according to the severity of risk as a colour code. For example, traversing from node 2 to node 4 imposes a low risk (green solid line) due to the open space in that area. However, moving from node 17 to node 19 imposes a high risk (red dashed line) due to cluttered furniture in the area. The benefit of choosing this environment is twofold. First, it is expected that social robots will be deployed and operate in such environments, and second, we took the opportunity to utilise the TIAGo robot as discussed later in ‘Real-world deployment' section. Risk severity colour-coded edge connections between locations in the depicted environment. This environment is a representation of the PAL Robotics kitchen where the real-world experiments took place.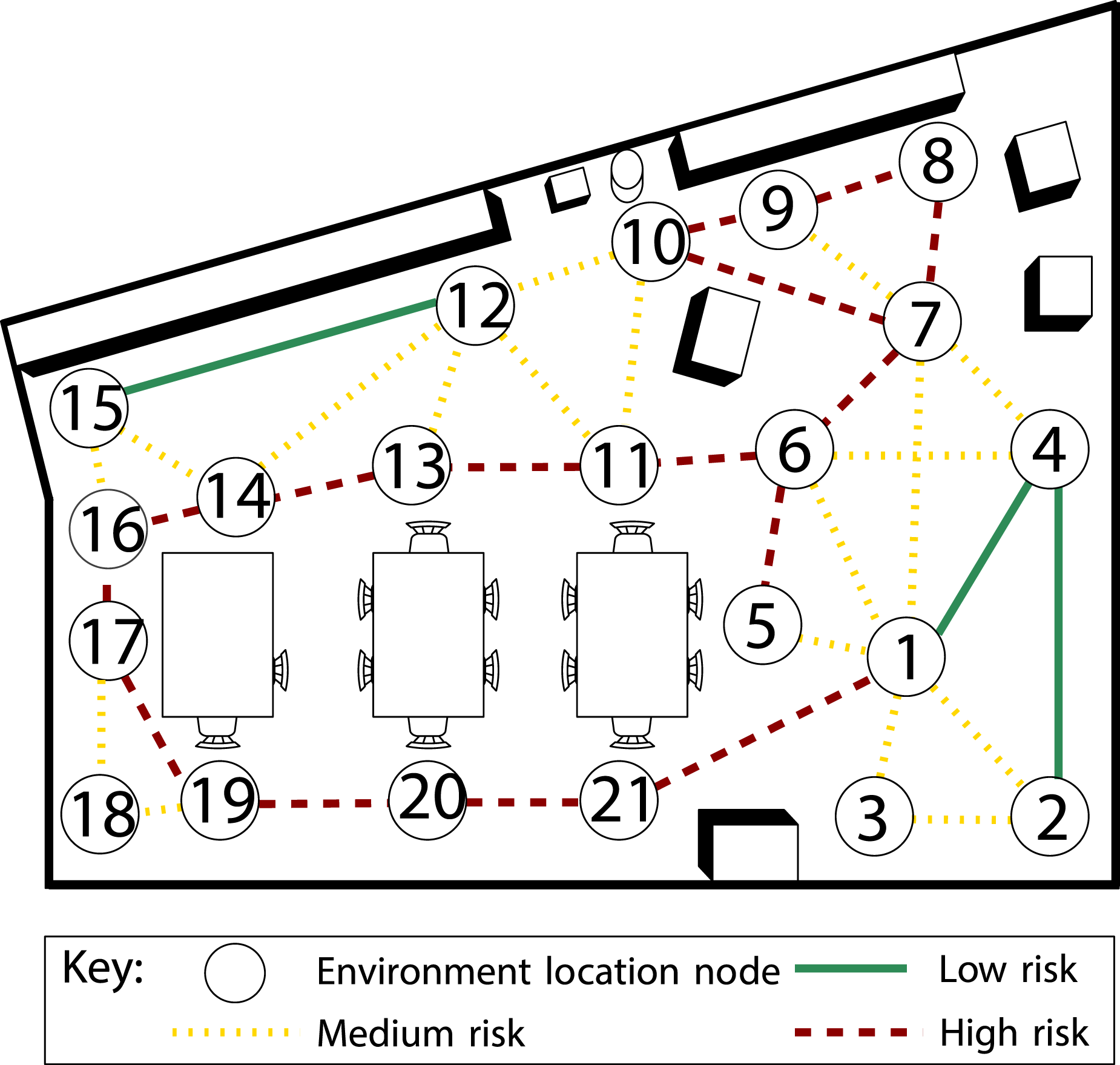
Listing 4 outlines the mission details for both scenarios in UC1. These missions are multi-phased, consisting of ordered sets of tasks. In the given examples, each phase contains only one task, meaning that the mission outcome is to execute these tasks in a specific sequence. The key difference between the two scenarios, as shown in the listing–lines 2 and 11 versus lines 3 and 12–is that, in the latter (lines 3 and 12), the human is not initially in the correct position to begin the mission. As a result, the human needs to move to the specified location, indicated by the header ‘H’ in the listing, before the collaborative mission (i.e. food preparation) can proceed. Multi-phase mission specifications for scenarios A and B of UC1.
Figure 12 illustrates the timeline of the two multi-phase mission scenarios in the simulated environment from Figure 11. Specifically, Figure 12(a) shows the path of the agent and its task locations during Scenario A. In this scenario, the human is in a static position (node 17) and does not move from it during any phase of the mission. The agent, starting at node 1, moves toward node 16 to ask the human permission to initiate meal preparation actions, following the path 1 → 6 → 11 → 12 → 15 → 16, with an elapsed time of Timeline graphs illustrating the evolution of physical/simulated routes taken by both human and agent over time during Scenario A and Scenario B of UC1. (a) shows the movement of the agent in the environment (green colour nodes) during Scenario A in order to perform the assigned tasks at the designated nodes (yellow colour). The location of the human is indicated by the blue coloured node. Scenario B ((b)) contains the same task locations for the agent, but this time the human traverses the environment at the beginning of the mission, starting at node 8. The result of the agent’s path adaptation compared to the previous scenario is an alternative route (traversing from node 11 to node 13 instead of 12) to avoid the human coming from node 10. However, the agent switched back to the original path as the human would then be located at node 14, blocking the agent’s way.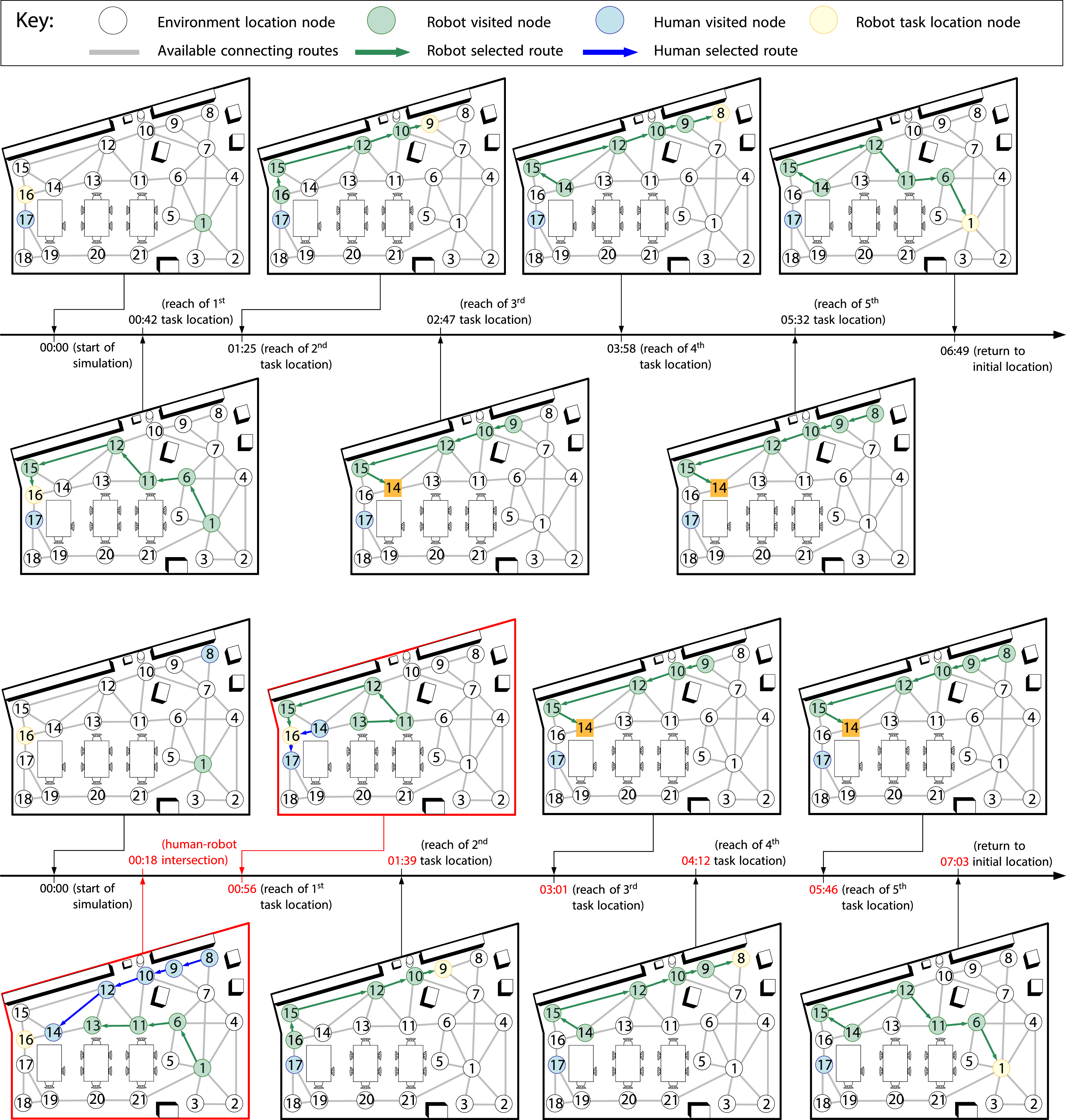
Scenario B, illustrated in Figure 12(b), involves the same tasks as the previous scenario, but this time the human’s starting location is at node 8. Thus, resulting in the human moving from node 8 to node 17 at the beginning of the mission, following the path 8 → 9 → 10 → 12 → 14 → 16 → 17. The reason behind this additional scenario is to showcase the capability of our mission planning algorithm in adapting the path of the agent based on human intentions. The main difference from Scenario A is shown during the initial stages of the second simulated run, during which both the human and the agent travel towards the same area as shown in the graph pointing to the
Detailed videos showcasing UC1 scenarios A and B, captured from the simulated Gazebo environment, are available in our Zenodo repository (Stefanakos et al., 2024).
Real-world deployment
The mission planning framework applied during the simulation was also launched on the real robot with some adjustments to account for human detection functionality, speech recognition, and fall detection. These features, supplied by the OpenDR toolkit 7 , were necessary to evaluate our proposed solution in an emergency situation as described in UC2. Although the speech and person detection functionalities were active in the real robot, they were not supported in the simulated environment. Thus, UC2 was conducted solely in the real-world setting created within the main PAL Robotics facility in Barcelona, Spain.
Figure 13 provides a visualisation of the real-world deployment using the TIAGo robot and the above mentioned toolkits. Specifically, in Figure 13(a) the TIAGo robot can be seen performing an object pickup task as part of UC1. Figures 13(b) and (c) are associated with UC2 and show the person detection and fallen person detection capabilities utilising the inbuilt cameras of TIAGo. During UC2, a single-phase mission with multiple task locations was generated randomly. The robot was required to traverse key locations in the environment in no specific order to check on the well-being of the human. We also refer the reader to the project’s demonstration video (PAL Robotics, 2023), which shows the overall approach, and particularly the scenarios presented in this section replicated in the real-world. TIAGo’s functionalities in our real world demonstrator. (a) depicts TIAGo during an object pickup task performed in both Scenario A and B of UC1. (b) and (c) showcase the person and fall detection performed by the TIAGo robot.
Algorithm efficiency evaluation
The focus of this section is to assess the efficiency of the path-planning framework, which aims at maximising the agent reaching the end state (mission’s final location), while increasing the uncertainty value of the human during a single-phase mission. The uncertainty of the human is a measure of how predictable human movements are, where uncertainty ∈ [0, 1]. As uncertainty tends towards zero, the human movements become predictable, and as it tends towards one, they become unpredictable.
A single-phase mission is comprised by multiple un-ordered tasks (‘U’) with only a single ordered task (‘O’), the end state. This means that it is up to the mission planning framework to determine the optimal mission plan. To test the uncertainty value of the human, the tasks within the mission remained constant throughout the duration of the test, with the mission tasks designed to replicate a surveillance mission whereby the robot navigates the entirety of the multi-room environment introduced in ‘Motivating example' section and depicted in Figure 14. All experiments were conducted on a 64-bit Ubuntu 20.04.6 LTS (Focal Fossa) computer with an Intel Core i9-10980XE @ 3.00 GHz × 36 CPU and 64 GB of RAM. The elapsed time for each experiment ranged from 7 to 8 hours, with the planning of individual robot paths requiring a mean time of 2.4 seconds with a standard deviation of 1.34 s. Each experiment used a single CPU, so multiple experiments were run concurrently on our 36 CPU server. Illustration of the surveillance mission within the environment described in the ‘Motivating example' section.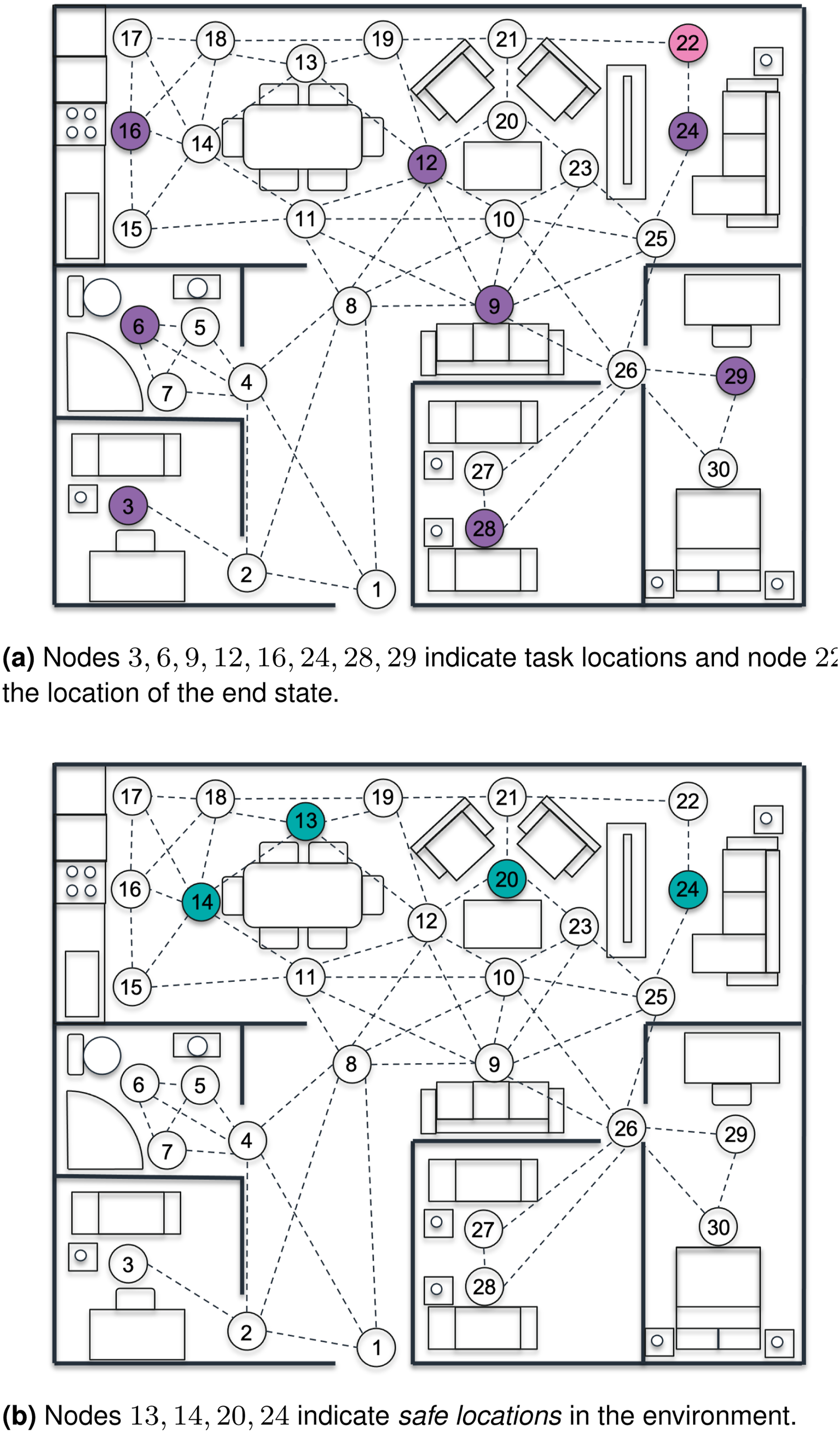
The overview of the mission can be seen in Listing 5, where the start location for the agent during each episode is randomly computed amongst all nodes. During this mission, human participation in performing tasks is not requested. However, as previously mentioned, the human is present in the environment, with the initial location of the human randomly computed at the start of the simulation. This means that at the start of the simulation run, the human and robot can be located at the exact same node, with the framework having to adapt to ensure the robot detects the situation and selects the appropriate action to maximise safety. Surveillance mission overview.
The tasks for this mission are 3, 6, 9, 12, 16, 24, 28, 29 with 22 being the end location of the robot as seen in Figure 14(a). The human is also present in the environment. As mentioned above, the robot can ask the human to move if the robot’s path is blocked or if there is too much uncertainty for the robot to move safely. This redirect request is performed by asking the human to move to a predefined safe location. In such safe locations, the human can rest without blocking the path of the robot. In our case study, safe locations are 13, 14, 20, 24 (cf. Figure 14(b)).
When the robot requests a redirect to minimise disturbance to the human, it only directs them to a safe location if that location will not create a conflict in the near future. This means that if a safe location is scheduled for a future task within the mission, the robot will avoid instructing the human to move there to prevent new conflicts and the need for additional redirects. This logic does not guarantee that a conflict-free safe zone will always be available; if all safe locations potentially lead to future conflicts, the robot will opt for a less than optimal node within the environment as a final measure to maximise mission progress.
For the purpose of this evaluation, we modified the way the environment is initialised, as detailed in ‘Environment modelling' section. A risk matrix is used to determine the probability of successfully completing a transition between two nodes (P s ). Based on P s , two additional parameters, P r and P f , are determined such that P s + P r + P f = 1. The values P r and P f are generated randomly when the environment is created, where P r > P f and P f → 0. These parameters are crucial for creating probabilistic models that are used in both verification and simulation to predict the outcome of the robot’s actions. Although P f → 0 and is therefore very small, over a duration of thousands of episodes, this failure state will be triggered, causing the simulation to end as a product of probability as opposed to an error in the framework or through the induced nature of uncertainty. Since this evaluation focused on assessing the impact of increasing the uncertainty value on effectiveness, failures due to probabilistic uncertainties within the environment would have created false negatives, therefore, the state P f was set to zero.
The final modification to the framework occurred in the action selection process, in which the agent selects the path with the highest probability of success and begins to transition along the nodes within that path. However, a high probability of success does not guarantee safety. Therefore, we implemented a threshold value that ensured that the robot would not attempt to move along a node if P s < 0.9. Instead, it will engage a hold state or request that the human performs a redirect. This adjustment increases operational safety by reducing uncertainty.
To better contextualise the role of redirection within our evaluation framework, we emphasise that redirection is employed when no safe feasible trajectory is available. In such cases, the robot issues a verbal request politely asking the human to momentarily move aside or wait. This form of social negotiation acts as a critical fallback mechanism that allows the robot to proceed safely in otherwise blocked or constrained environments. From a behavioural standpoint, redirection events are closely aligned with near-encounter situations, reflecting spatial conflicts that the robot cannot resolve autonomously.
The redirection metric thus serves a dual role in our evaluation. On the one hand, it quantifies the frequency of critical human–robot interactions required to maintain progress. On the other hand, it functions as an indirect measure of mission success dependency on human cooperation. Successful redirection enables the robot to complete its task safely; however, repeated failure to resolve a conflict through redirection results in termination of the mission. In this sense, the metric reflects how the framework balances autonomy and collaboration to achieve its goals in environments shared with humans.
The uncertainty was evaluated in the range of [0, 1] in increments of 0.1, with each increment evaluated over 25,000 episodes. Each assessed episode was given a pass or fail using the following criteria: (1) If the agent reaches the end of the mission, the episode was a success. (2) If the agent engages in a hold state for 10 consecutive steps, the mission ends with a failure. (3) If the agent fails due to an uncertain probabilistic action, the mission ends with a failure.
Success, failure, and redirects under varying uncertainty.
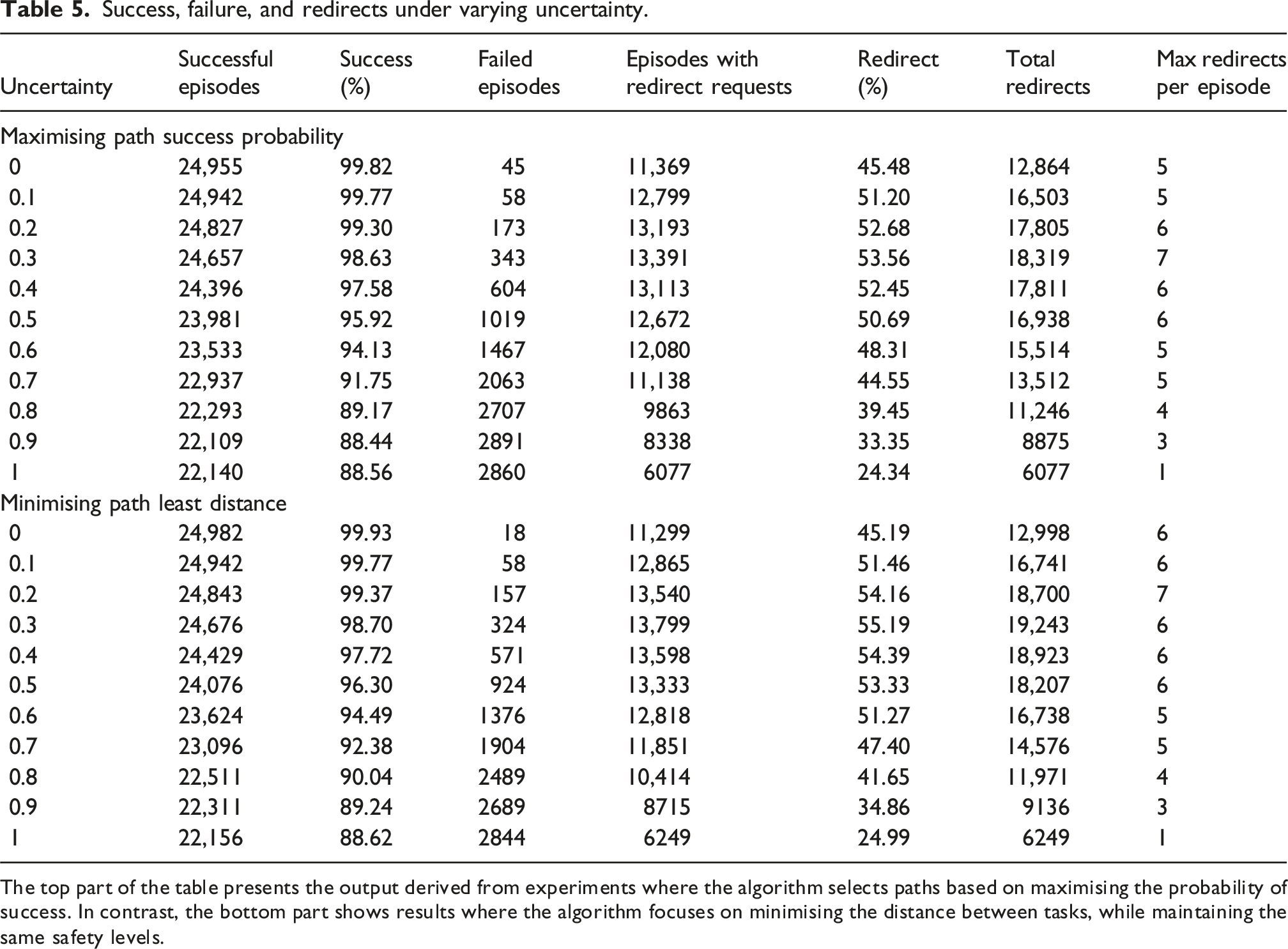
The top part of the table presents the output derived from experiments where the algorithm selects paths based on maximising the probability of success. In contrast, the bottom part shows results where the algorithm focuses on minimising the distance between tasks, while maintaining the same safety levels.
If the robot is initialised at node 1 and the human is initialised at node 8, there is initially no conflict. However, when the robot successfully completes tasks 3 and 6, and attempts to navigate towards the main living area, the human is blocking its path and a redirect request is required in order to complete the remaining missions tasks.
The number of successful (left) and unsuccessful (right) episodes by redirect requests, measured under varying uncertainty for both solutions: maximising success probability and minimising distance between tasks.
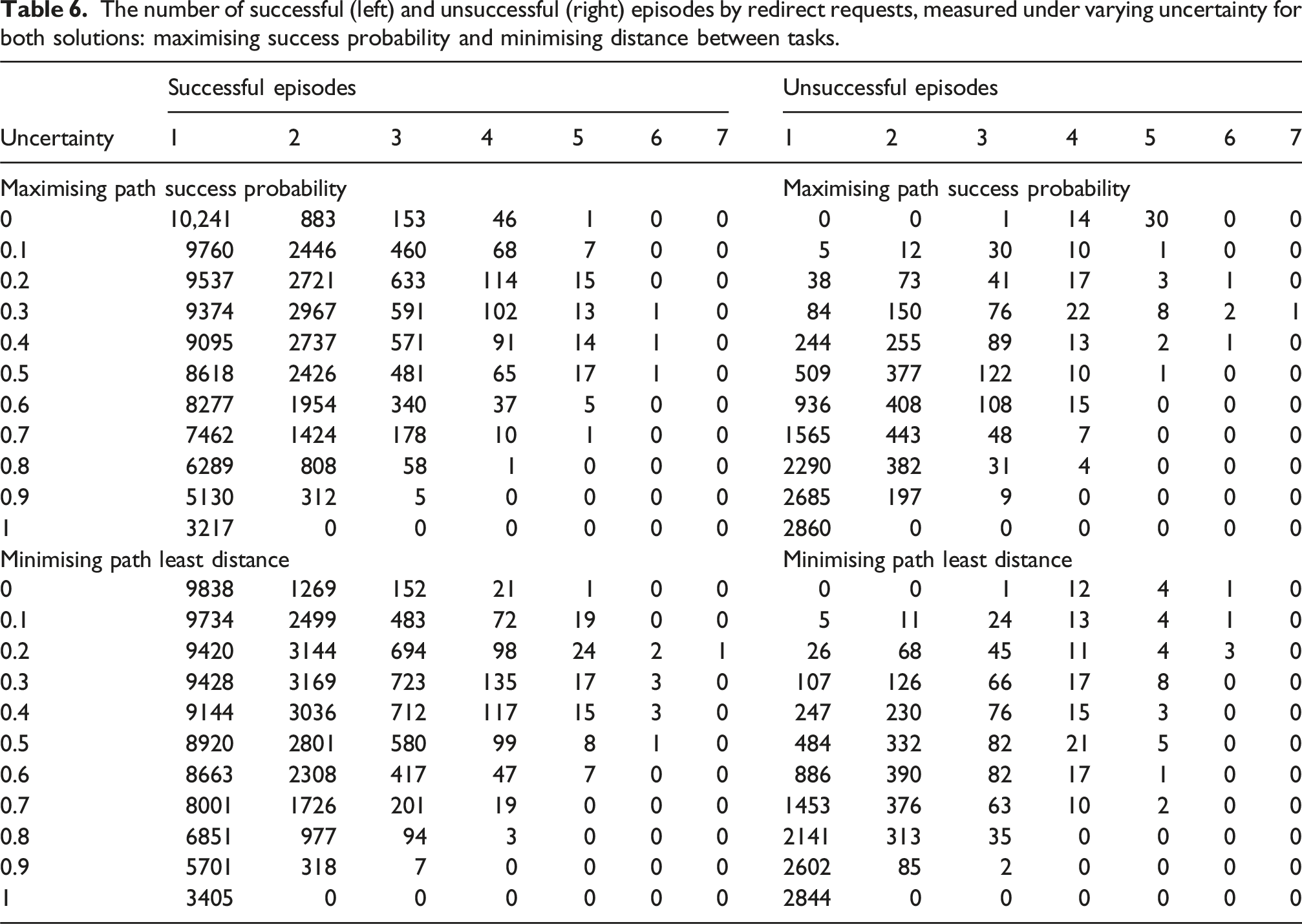
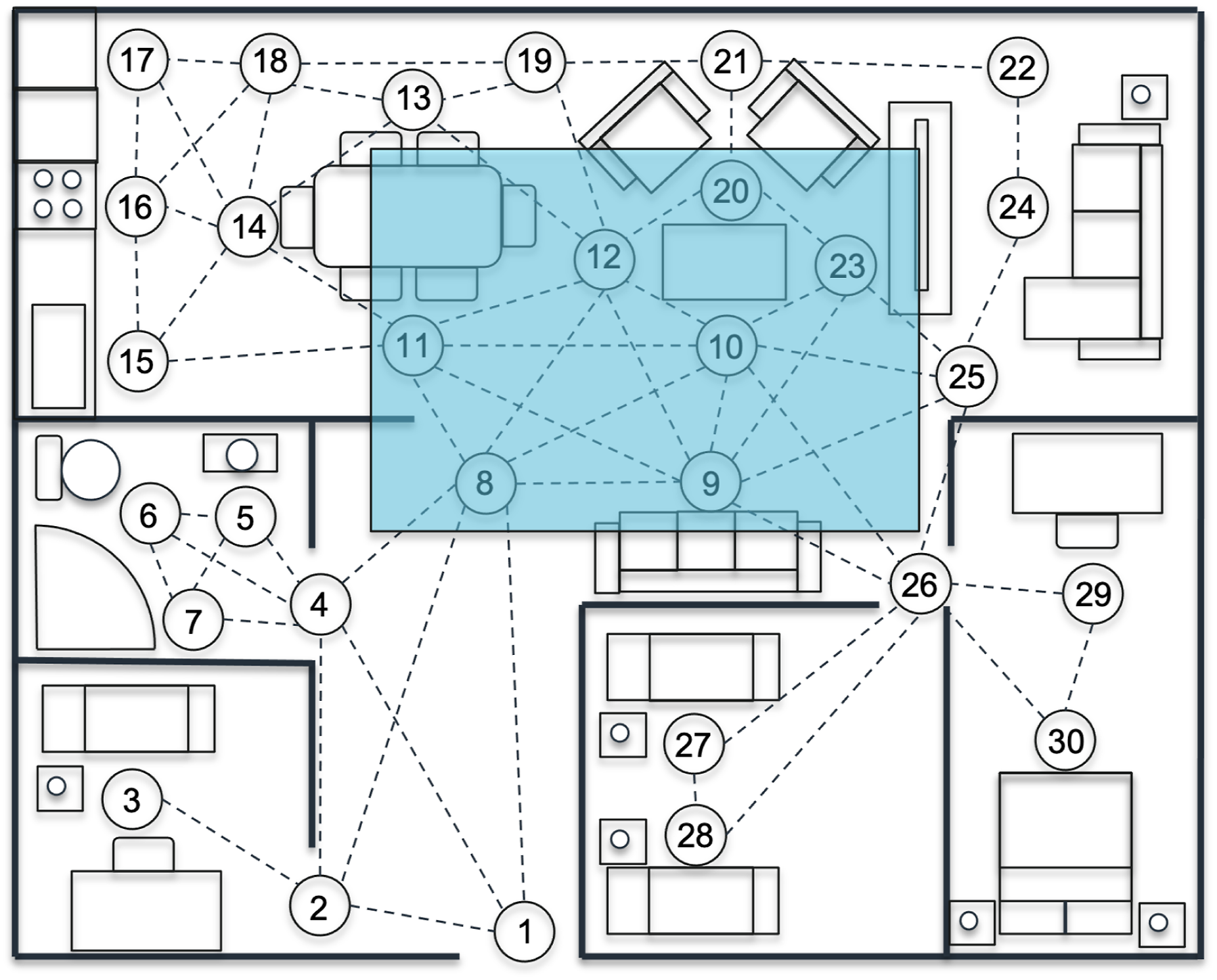
Conflicting zone in the analysed environment.
As the uncertainty value increased, the human was more likely to move away from the central region. For values 0.3 and 0.4, the likelihood that a mission would succeed with a high number of requests increased substantially (e.g. episodes with five requests for 0.3 uncertainty had 83% success rate, compared to the 3% success rate for 0 uncertainty). When the uncertainty exceeded 0.4, the human became more unpredictable, reducing the probability of a human–robot encounter along a path and requesting a redirect. Despite the erratic behaviour of the human, missions continued to reduce the maximum number of requests made as the human would directly encounter the robot less frequently, with only 24% of episodes having at most one redirect as the uncertainty approached 1. Despite a lower number of requests overall and per episode, the robot success rate continued to decline proportionally to uncertainty, as human behaviour led the threshold value to drop below 0.9 which was required for the robot to move to the next node.
It is evident that there is a fine balance between what is deemed acceptable with regard to human uncertainty. A high success rate (over 98%) is achieved when the human moves only on request. However, when operating in a heavily connected region, the movement of the robot can stagnate due to a high threshold value (0.9) to select a movement. As the uncertainty of the human started to increase, the likelihood that the human would remain within this heavily connected region reduced, increasing the probability that an episode which had numerous requests would still remain successful. Despite this, the number of successfully completed missions continued to decline, as the unpredictable human movement reduced the probability of successfully traversing an edge due to increased uncertainty. It is expected that lowering the threshold value for the robot would allow the robot to select less risk-averse actions, but would also increase the probability of reaching a failure state.
When comparing the two strategies – maximising the path success probability versus minimising the path distance between tasks – it becomes clear that both approaches respond differently to increasing uncertainty. The path success probability approach results in slightly fewer successful episodes overall, but requires fewer redirects, particularly as uncertainty increases (see Figure 16). For example, at 0.5 uncertainty, the path success probability approach has a mission success rate of 95.92%, while the path distance-minimising approach reaches 96.30%. However, the number of redirects is noticeably higher for the path distance-minimising approach at the same uncertainty level, indicating that, while this method may slightly improve task completion rates, it comes at the cost of more frequent path adjustments. This suggests that the path-success probability method is more resilient to uncertainty, producing stable results with fewer disruptions. The mission completion percentage (solid red line) and the number of redirect requests (dashed blue line) are plotted against varying levels of uncertainty for two approaches: one maximising path success probability and the other minimizing path distance between tasks. (a) depicts a slightly lower mission success rate compared to (b), but at the advantage of requiring fewer redirects during the mission. Both approaches must adhere to a 0.9 success threshold when selecting a path. This requirement allows the path-distance-minimisation approach more flexibility, leading to a slightly higher success rate, though at the expense of requiring more redirects. Nonetheless, both approaches comply with the specified safety constraints.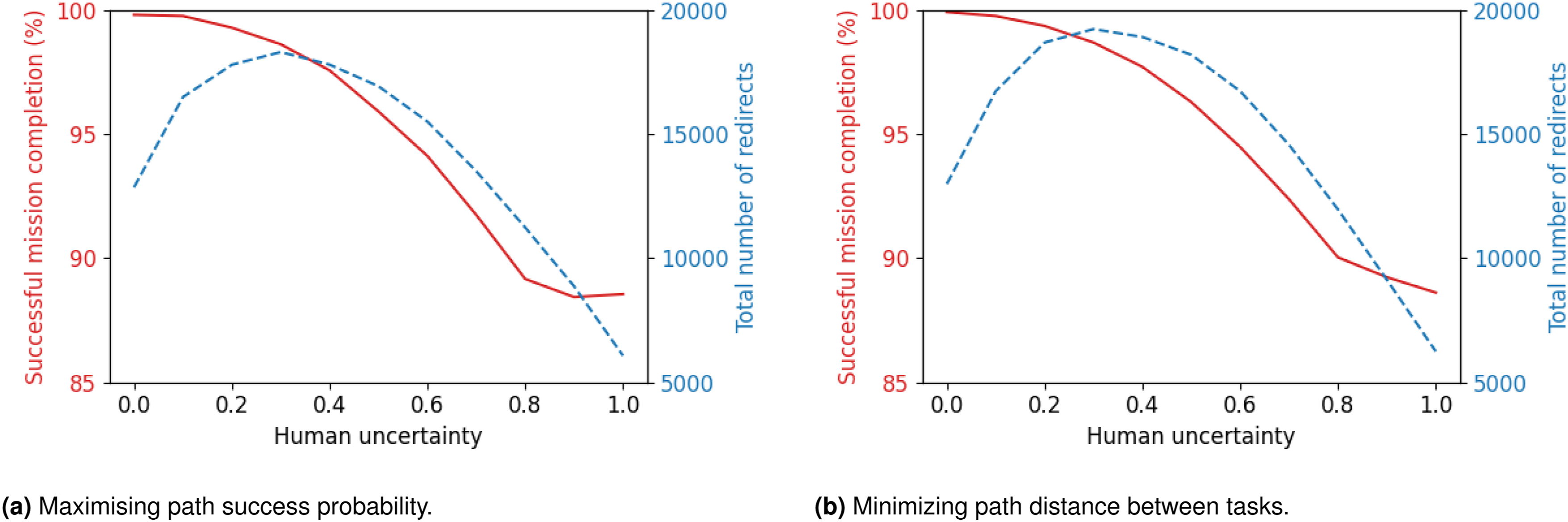
However, the path-distance minimising strategy consistently leads to a marginally higher mission success rate across all levels of uncertainty, especially when uncertainty is low. However, this benefit is counterbalanced by the increase in the number of redirects and episodes requiring path adjustments, as seen, for instance, in the 0.5 uncertainty where the total redirects are 18,207 compared to 16,938 for the path success probability approach. This indicates that minimising the distance between tasks can lead to more complex navigation and require more intervention, particularly in uncertain environments, but it offers a slight edge in terms of completing tasks successfully.
The implementation of our path-finding framework is available on our GitHub repository https://github.com/is742/ALMI. The framework is highly customisable and can be adapted to various scenarios and needs. Detailed instructions are provided to replicate the experiments presented in this section or to define new missions, environments, and objectives.
Discussion
Having applied our approach for safe navigation in a case study with different use cases and scenarios, both in simulation and real-world, and evaluated its effectiveness, we can now provide insights regarding the use of assistive care robots in shared environments with humans. First, the use of the TIAGo robot has proven instrumental in navigating and interacting within complex environments. The robot’s ability to perform tasks in dynamic settings, adapting to changes and obstacles, has been a great asset in demonstrating the applicability of our solution. The evaluations conducted of our approach in both simulated and real-world environments have shown how it can guide the robot effectively to handle unexpected human movements and maintain operational safety, even under increased uncertainty levels.
A critical aspect of our discussion centres on the adaptation methods employed. These methods allow the robot to preplan its path in response to changes in the human intentions, ensuring minimal disruption to the human activities, and maintaining a high mission success rate in task completion. The robot assesses the probability of success before proceeding and improves safety by mitigating risks associated with unpredictable human behaviour.
However, our study also acknowledges potential limitations. The assumptions made regarding human movement patterns may not always hold true in every scenario, particularly with elderly or cognitively impaired individuals who may exhibit less predictable behaviours. Additionally, the complexity of real-world environments poses ongoing challenges in terms of sensor accuracy and algorithm efficiency, highlighting areas for further refinement and development. We provide a detailed description of how we aimed to minimise these threats to the validity of our approach in ‘Threats to validity' section.
Our results reaffirm the significant potential of adaptive robotic systems in assistive-care settings and highlight the need for future research directions to address challenges during human–robot interaction, with the goal of enhancing both the safety and efficiency of these systems in real-world applications.
Threats to validity
In this section, we outline the potential threats to the validity of our study, focusing on construct, internal, and external validity to address the concerns associated with the assumptions and methodologies used in our approach.
Construct validity threats may arise from assumptions about the assistive-care robot, humans, and their interactions within a shared environment. Specifically, in reasoning about the selection of optimal paths for the robot to safely navigate the environment shared with humans, we assumed that humans move based on the path of least distance towards their desired destination. This assumption was made to preserve optimal robot performance, as increased uncertainty regarding human intentions would limit the paths available from the planning algorithm. However, this assumption does not compromise human safety, as the robot is equipped with sensors to detect if a human diverges from the estimated path and moves in close proximity to the robot. A comprehensive survey conducted in Rudenko et al. (2020) on human motion trajectory prediction shows that the optimal performance of planning-based approaches depends on (a) the explicit definition of the goals that agents aim to achieve and (b) the availability of a map of the environment. Our proposed path-planning approach satisfies both of these requirements.
Internal validity threats may stem from the inefficiency of our path-planning algorithm in scenarios where human behaviour is highly unpredictable. Our algorithm can make predictions based on both the path of least distance and the path with the highest success probability, which may not be reliable due to the high uncertainty. To alleviate this threat, we evaluated the efficiency of our approach in scenarios involving variations in human behaviour, ranging from completely predictable to extremely unpredictable. The results of this analysis can be found in ‘Algorithm efficiency evaluation' section, along with a follow-up discussion in ‘Discussion' section.
External validity threats could affect the applicability of the path-planning framework to additional case studies and in real-world deployments. To mitigate this threat, we assessed our approach in various use cases and scenarios, involving both solo and collaborative missions between the human and the agent. These use cases and scenarios were carefully selected by rigorously evaluating the requirements, as detailed in ‘Requirements elicitation' section. The demonstration took place in both the real-world and in simulation, showcasing the applicability of the approach and its adoption from the motivating example, first introduced in ‘Motivating example' section, to a real-world case study with multiple use cases and scenarios in ‘Implementation and evaluation' section.
While the evaluation in this study primarily focuses on performance metrics such as trajectory success and task completion, these alone do not capture how users, particularly elderly individuals or their caregivers, perceive the robot’s behaviour in terms of comfort, safety, and social appropriateness. This represents a potential threat to the validity of the findings. To mitigate this, the design of the use cases and requirements was informed by prior stakeholder engagement, including input from medical personnel, caregivers and end users (‘Requirements elicitation' section).
Furthermore, a complementary research effort has been initiated to formally assess whether the robot’s behaviour aligns with normative expectations and human values. Preliminary findings from this study are available in an online repository of use cases 8 and are presented in a separate research paper (Feng et al., 2024). These steps aim to ensure that the robot’s interactive behaviours are not only functionally effective but also socially acceptable within real-world domestic environments.
Conclusion and future work
In this paper, we have presented an adaptive path-planning framework for ensuring safety during assistive-care robotic missions, which may be carried out in collaboration with a human. Our approach not only focuses on the safety of the human in the environment shared with a robot, but also ensures efficient robot navigation within complex spaces. The integration of a modified Dijkstra’s algorithm, coupled with probabilistic modelling and analysis, provides a robust mechanism to adapt robot operations in response to human movements, significantly reducing the risk of collisions while maintaining high mission success rates.
Having applied our framework for safe navigation in a case study with different use cases and scenarios, both in simulation and in a real-world controlled environment, we evaluated its effectiveness and provided insights regarding the use of assistive-care robots in environments shared with humans. Guided by our framework, the TIAGo robot demonstrated its ability to navigate and interact in complex and dynamic settings, effectively adapting to changes and obstacles. The capability of the framework to handle unexpected human movements and maintain operational safety, even under uncertainty, underscores its practical applicability. The adaptation methods employed enable preplanning of paths in response to human intentions, minimising disruptions to human activities while maintaining high task completion rates. However, the study also highlights limitations in modelling human movement patterns, particularly in elderly or cognitively impaired individuals, and challenges associated with sensor accuracy and algorithm efficiency in real-world environments. These insights pose open challenges that need to be addressed in the future to design safer and more effective systems for human–robot interaction.
In addition to the positive results demonstrated in our study, the versatility of the proposed framework suggests broader applications beyond assistive-care settings. For example, similar adaptive path-planning approaches could be employed in industrial environments where robots collaborate closely with human workers, or in service-based roles in public spaces where safe interaction with humans is essential.
Future work will broaden the scope of testing through a wider range of case studies and extend the framework to accommodate multiple robots and humans in shared environments. This expansion will offer deeper insights into the framework’s versatility and scalability, allowing for a more comprehensive evaluation of its performance under diverse operational conditions and ensuring its applicability across a variety of human–robot interaction scenarios.
Another key area of exploration will be the integration of machine learning techniques to enhance the framework’s adaptability and predictive capabilities. Reinforcement learning (RL) can be leveraged to enable robots to learn optimal navigation strategies through continuous interaction with dynamic environments, addressing uncertainties, and improving decision-making. To mitigate RL’s challenges, such as safety during exploration and data inefficiency, a hybrid approach can be adopted, where RL handles dynamic and uncertain aspects while the current framework ensures baseline safety and efficiency. Deep learning models could further improve the framework’s ability to predict human movements and intentions with greater precision, even in highly uncertain and complex scenarios. Additionally, incorporating transfer learning techniques will allow the system to generalise across diverse environments and tasks, minimising the need for extensive retraining when deployed in new settings.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Lloyd’s Register Foundation Assuring Autonomy International Programme, the University of York’s Centre for Assuring Autonomy (CfAA), and the EPSRC project EP/V026747/1 ‘UKRI Trustworthy Autonomous Systems Node in Resilience’.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.