
Abstract
In this paper, we present a neurosymbolic architecture for coupling language-guided visual reasoning with robot manipulation. A non-expert human user can prompt the robot using unconstrained natural language, providing a referring expression (REF), a question (VQA), or a grasp action instruction. The system tackles all cases in a task-agnostic fashion through the utilization of a shared library of primitive skills. Each primitive handles an independent sub-task, such as reasoning about visual attributes, spatial relation comprehension, logic and enumeration, as well as arm control. A language parser maps the input query to an executable program composed of such primitives, depending on the context. While some primitives are purely symbolic operations (e.g., counting), others are trainable neural functions (e.g., visual grounding), therefore marrying the interpretability and systematic generalization benefits of discrete symbolic approaches with the scalability and representational power of deep networks. We generate a 3D vision-and-language synthetic dataset of tabletop scenes in a simulation environment to train our approach and perform extensive evaluations in both synthetic and real-world scenes. Results showcase the benefits of our approach in terms of accuracy, sample-efficiency, and robustness to the user’s vocabulary, while being transferable to real-world scenes with few-shot visual fine-tuning. Finally, we integrate our method with a robot framework and demonstrate how it can serve as an interpretable solution for an interactive object-picking task, achieving an average success rate of 80.2%, both in simulation and with a real robot.
Introduction
As modern developments in robotics are beginning to move robots from purely industrial to human-centric environments, it becomes essential for them to be able to interact naturally with humans. This necessity poses two additional challenges to traditional autonomy, as the agent is expected to be interactive, that is, able to receive task-specific instructions from its human cohabitants, as well as interpretable, that is, complete the task in a manner that is fully explainable to non-expert users. The second feature is of particular interest, as it enables humans to diagnose and correct erroneous robot behaviors via online interaction, for example, through free-form natural language. Grounding perception and action in natural language has been a central theme in recent computer vision and robotics literature, from language-grounded 3D vision (Achlioptas et al., 2020; Azuma et al., 2021; Chen et al., 2020), to language-conditioned manipulation (Jang et al., 2022; Lynch and Sermanet, 2020; Stepputtis et al., 2020), to integrated language-based systems (Ahn et al., 2022; Huang et al., 2022b; Zeng et al., 2022a) for high-level reasoning and task planning. Across domains, language has shown to be a great inductive bias for effective robot learning, however, methods still struggle with grounding fine-grained concepts beyond object category (i.e., visual attributes and spatial relations) (Shridhar et al., 2021), as well as reasoning about them in an algorithmic fashion (e.g., counting). The end-to-end nature of most approaches leads to additional limitations, namely: (a) lack of interpretability, as the underlying reasoning process required to solve the task is captured implicitly in the network’s representations and thus cannot be retrieved from the output, (b) data-hungriness, that is, need of large vision-language datasets that sufficiently sample the space of all possible concept combinations, and (c) closed-endedness, as the end-to-end policy is trained for a fixed agent/environment and catalog of concepts and tasks.
We believe that these limitations stem from the holistic fashion in which most methods couple language with perception. In particular, they either rely on visual-text feature fusion in a joint space (Chen et al., 2021; Hatori et al., 2017; Shridhar et al., 2021; Shridhar and Hsu, 2018; Stepputtis et al., 2020), or FiLM-conditioning (Perez et al., 2017) the visual network with a sentence-wide embedding of the language input (Ahn et al., 2022; Jang et al., 2022). We argue that this methodology fails to exploit the compositional nature of language, instead relying on variance to learn one-to-one correspondences between task descriptions and robot behavior. For instance, consider a scenario like the one shown in Figure 1, where a human asks a question about the scene: (e.g., “How many sodas are in front of the white book?”). The task requires grounding multiple different concepts (i.e., visual—“book,” “white,” spatial—“front” and symbolic—“How many”) and reason about the intermediate results to reach a final answer. Our intuition is that, for a human, the logic behind solving this task is compositional (a hierarchy of primitive steps) and disentangled from perception, meaning that the reasoning steps illustrated in Figure 1 can be generalized to all similar questions regardless of the actual scene content. Example scenarios where a human user interacts with the robot in natural language. Understanding the input question/instruction often requires reasoning about properties or relations of appearing objects in a compositional manner. Neurosymbolic approaches parse the input question into the underlying reasoning program and execute it step-by-step in order to reach the final answer (top). Similarly, we propose a neurosymbolic model that represents grasp policies as programs in an interpretable formal language. End-to-end vision-language-grasping methods learn a policy directly from raw inputs and thus actions are generated regardless of the scene content. In the second example (bottom), there is no red soda for the robot to grasp, but only our approach is able to capture this and communicate it to the user.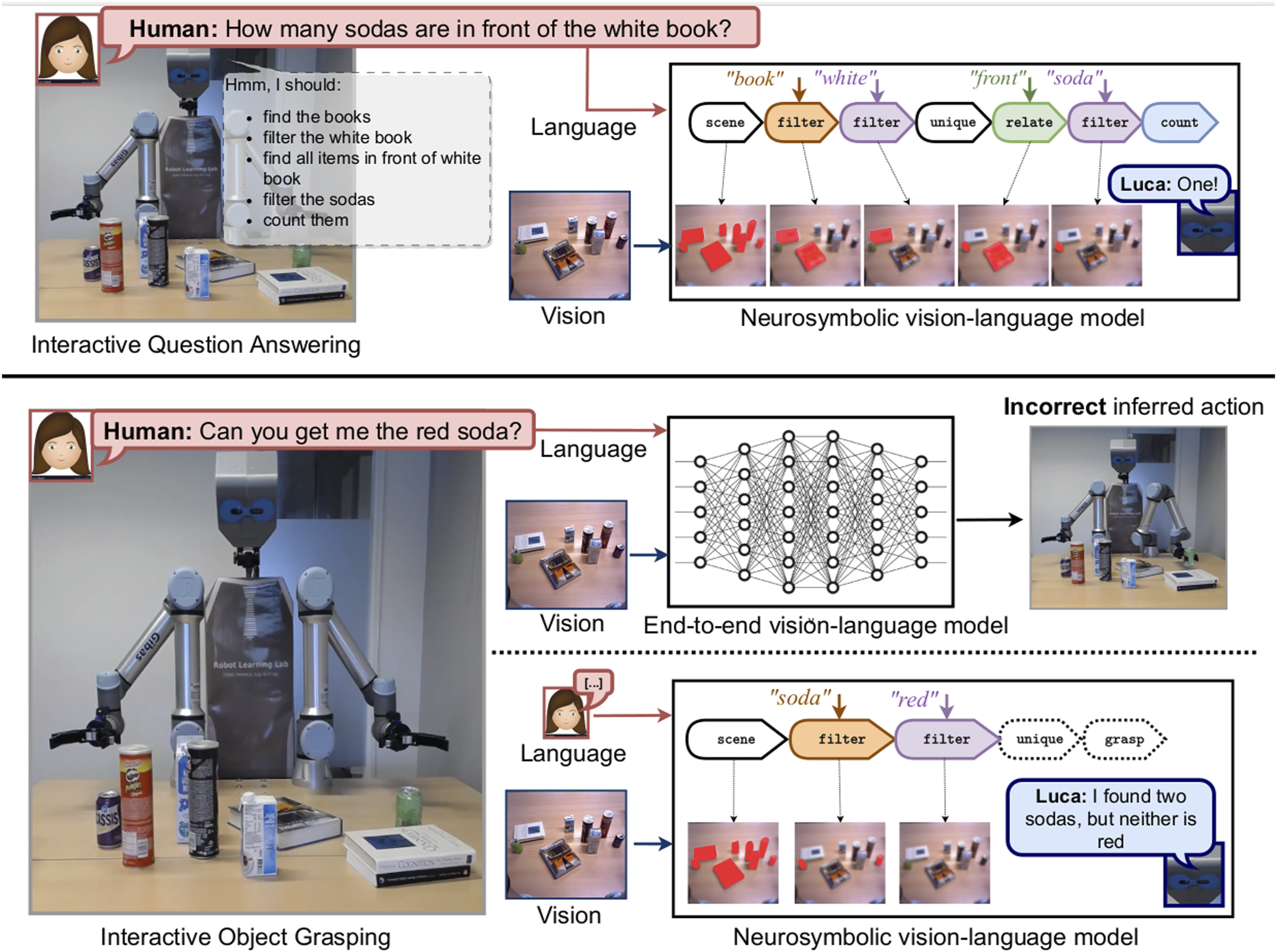
Such intuition is encapsulated within neurosymbolic frameworks (Johnson et al., 2016; Liu et al., 2019; Mao et al., 2019; Yi et al., 2018), that propose to further inject prior knowledge about language in the form of symbolic programs (Yi et al., 2018), which explicitly describe the underlying reasoning process. The overall task is decomposed into independent sub-tasks (primitives), and each one is implemented as a symbolic module in a Domain-Specific Language (DSL). The idea is to use deep neural nets as parsing tools—from images to structured object-based representations and from text queries to programs—and pair them with a symbolic engine for executing the parsed program in the scene representation to reach an answer. By disentangling perception and language understanding (neural) from reasoning (symbolic), neurosymbolic systems address several of the highlighted limitations, that is, other than a final answer, they output a formal interpretable representation of the underlying reasoning process (see Figure 1). Furthermore, utilizing programs as a prior for learning grants the system highly sample-efficient and aids in generalization to unseen concept-task combinations (Mao et al., 2019; Yi et al., 2018). However, prior arts are limited to REF/VQA tasks, and associated datasets (Johnson et al., 2016; Liu et al., 2019) model abstract synthetic domains with a poor variety of object and relation semantics. Proposed methods also fix their DSL to be aware of the domain vocabulary (i.e., primitives are coupled with concept arguments), limiting them to the concepts encountered at training time.
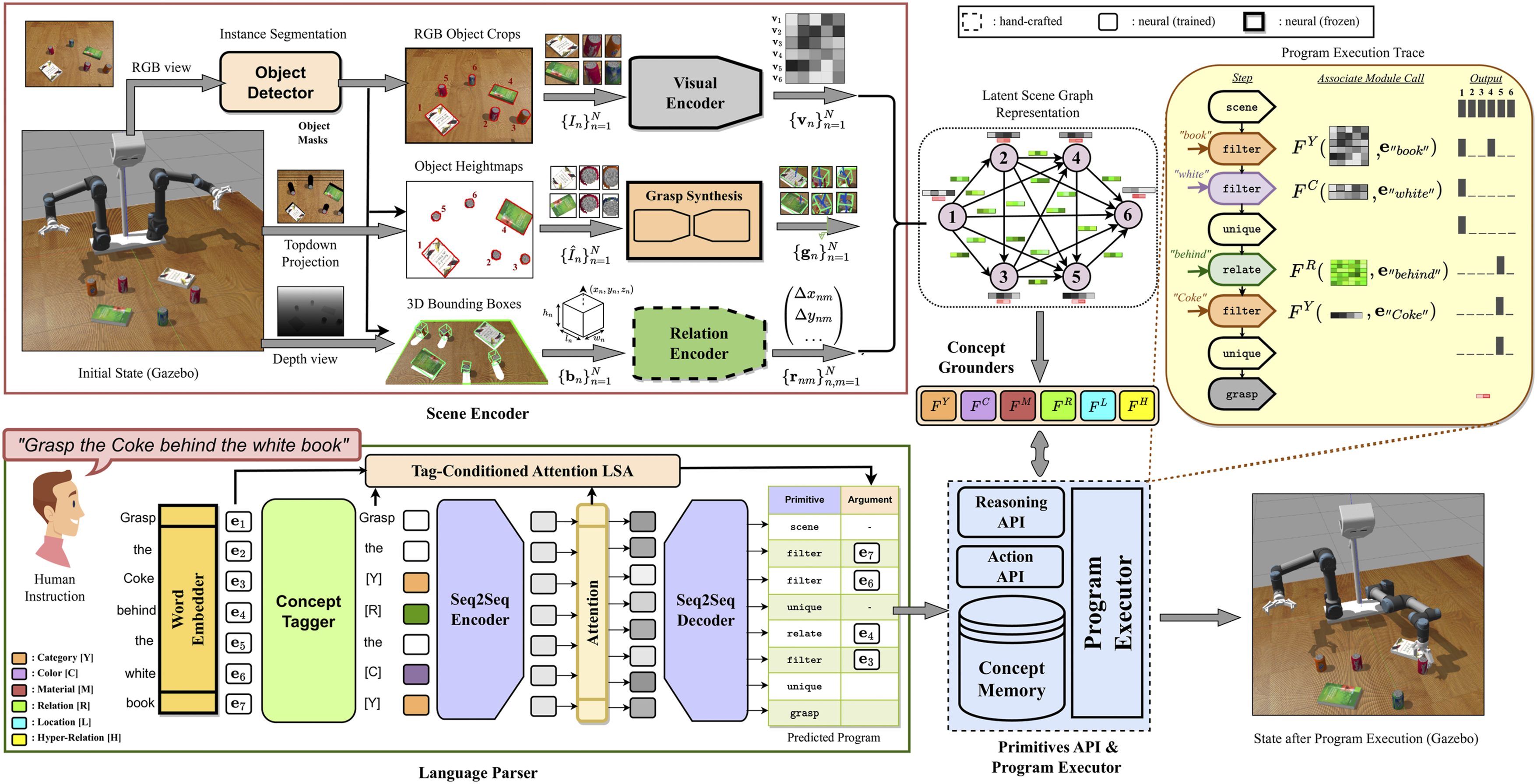
In this work, we wish to propagate neurosymbolic reasoning to the robotics field and utilize it as an auxiliary process for interpretable robot manipulation. To that end, we generate a synthetic 3D vision-and-language dataset with a broad collection of object categories, attribute, and relation concepts. We design a corresponding DSL and re-formulate components of previous neurosymbolic recipes in order to handle the open-vocabulary requirement (see schematic in Figure 2). In particular, we decompose the language-to-program module into two steps, first identifying concepts in the sentence to create an abstracted version of the query and then feeding it to a seq2seq network to generate the program, thus relieving the latter component from having to deal with the specific concept vocabulary of the training set. To ground (potentially unseen) concepts in the image, we use concept grounding networks that operate on latent object-relation features, serving as an alternative to classification. We compare our method with other holistic/neurosymbolic baselines in terms of accuracy and sample-efficiency and show that it can be transferred to real images via few-shot fine-tuning of the visual grounder network. We further integrate our model with a robot framework and test its performance in an interactive object grasping task, where we show that its highly interpretable nature allows us to study the distribution of failure modes across the different system components. We close our evaluation by showing that the method can be efficiently extended to more manipulation tasks with the cost of a few hundred relevant instruction-program annotations. In summary, the key contributions of this work are threefold: • We generate a synthetic dataset of household objects in tabletop scenes for REF/VQA/grasping tasks, equipped with program annotations for reasoning, and collect a small-scale real-scene counterpart for evaluation. We make both datasets publicly available. • We propose a neurosymbolic framework that integrates instance segmentation, visual/spatial grounding, semantic parsing and grasp synthesis in a vocabulary-agnostic formulation that supports application in unseen vocabulary, granting it transferable to novel concepts/tasks with minimal adaptation. • We perform extensive experiments to show the merits of our approach in terms of (i) interpretable, highly accurate, and sample-efficient reasoning, evaluated through a VQA task, (ii) robustness to users vocabulary, (iii) efficient adaption to natural scenes and more manipulation tasks, and (iv) applicability for interpretable interactive object grasping, tested both in simulation and with a real robot. A schematic of the proposed framework. First, objects are segmented and localized in 3D space (top left) and the scene is represented as a graph of extracted object-based features (visual, grasp pose) as nodes and spatial relation features as edges (top middle). A human user provides an instruction and a language parser generates an executable program (bottom left), built out of a primitives library (bottom middle). A program executor utilizes a set of concept grounding modules to ground words to different objects (center) and executes the predicted program step-by-step (top right), in order to identify the queried object and instructs the robot to grasp it (bottom right).
Related works
Grounding referring expressions
Grounding visual and spatial concepts expressed through language is a central challenge for an interactive robot. Deep learning literature poses this through the task of grounding referring expressions (REF) (Plummer et al., 2015; Yu et al., 2016a), that is, localizing an object in a scene from a natural language description. Methods usually employ a two-stage detect-then-rank approach, leveraging off-the-shell detectors to first propose objects and then rank their object-query matching scores through CNN-LSTM feature fusion (Mao et al., 2015; Rohrbach et al., 2015; Yu et al., 2016b) or attention mechanisms (Luo and Shakhnarovich, 2017). Alternatively, richer cross-modal contextualization between images and words is pursued through external syntactic parsers (Andreas et al., 2016; Cirik et al., 2018), graph attention networks (Wang et al., 2018; Yang et al., 2019a, 2019b), or Transformers (Chen et al., 2019; Li et al., 2019; Lu et al., 2019; Yu et al., 2020). Single-stage methods (Du et al., 2021; Sadhu et al., 2019; Yang et al., 2019c) attempt to alleviate the object proposal bottleneck by densely fusing textual with scene-level visual features to create joint multimodal representations. Transferring from large-scale vision-language pretraining (Li et al., 2021; Radford et al., 2021) aids in out-of-distribution generalization and can be used in zero-shot setups (Subramanian et al., 2022) or for open-vocabulary object detection (Gu et al., 2021). REF has been also extended to the 3D domain (Achlioptas et al., 2020; Chen et al., 2020), where similar to 2D, most methods employ detect-then-rank pipelines, fusing textual features with segmented point-clouds (Achlioptas et al., 2020; Zhao et al., 2021) or RGB-D views (Huang et al., 2022a; Liu et al., 2021). All the above approaches follow the holistic methodology, hence as argued in the previous section, suffer from data-hungriness and lack the desired interpretability property.
More closely to our work, modular approaches (Hu et al., 2016; Liu et al., 2018; Yu et al., 2018) decompose the grounding task in independent modules (e.g., entities, attributes, relations) and predict their composition based on the query’s structure with a language parser. Such methods use soft attention-based parsers that are trained end-to-end with the rest of the modules using weak supervision. In Tziafas and Kasaei (2022), the modules are trained separately using dense attribute- and relation-level supervision from synthetic data and are linked to words using a tagger network. However, module composition is handled by a linguistics-inspired heuristic, and hence, it is limited to referring expressions that follow a standard subject-relation-object syntax. Similarly, we use a tagger and dense synthetic supervision to train our modules but replace the heuristic with a seq2seq network, that can map arbitrary syntactic structure into a formal representation (program), expressed via a DSL. With this, we can extend the scope of the parser from grounding referring expressions to VQA and eventually robot action, by adding the associated modules in our DSL.
Neurosymbolic reasoning
Early works in modular networks for VQA (Andreas et al., 2015; Hu et al., 2017a, 2017b; Hudson and Manning, 2018; Johnson et al., 2017a, 2017b) demonstrate capacities for compositional vision-language reasoning, by integrating independent modules instead of end-to-end learners. More recently, a neurosymbolic model for VQA (NS-VQA) (Yi et al., 2018) in CLEVR (Johnson et al., 2016) and its extensions to natural images (Hu et al., 2019; Hudson and Manning, 2019; Wang et al., 2021) utilize a formal DSL and a symbolic program executor to run programs on parsed scene representations. Program generation and scene parsing (i.e., localization and attribute recognition) are trained separately and interface with the executor only at test-time. In such works, however, the scene is represented as a table of attribute labels (Yi et al., 2018) or features (Mao et al., 2019), without any relation information. Resolving spatial relations is then achieved by using concept-specific heuristics as primitives (e.g., relate left). Visual attribute concepts are either classified (Yi et al., 2018) and coupled with primitives or matched with concept representations learned jointly from a closed-set (Mao et al., 2019). This formulation makes the system fixed to the concept vocabulary encountered during training. In our work, we integrate relation concepts with object-based features in a latent scene graph representation and make our primitives vocabulary-agnostic, allowing extension to novel concepts without touching the DSL, via concept grounding networks. Like NS-CL (Mao et al., 2019), we enable open-vocabulary parsing by replacing lexical items in the input query with their corresponding concepts. Unlike NS-CL, which assumes access to ground truth tags, we learn the word-to-concept mapping through a tagging sub-module.
There are a few works that similar to our paper apply neurosymbolic reasoning in the robotics domain. ProgramPort (Wang et al., 2023) uses a CCG parser to construct programs, CLIP (Radford et al., 2021) for grounding attributes and learn a specialized pick-and-place module for selecting affordances on a top-down 2D image end-to-end. In Kalithasan et al. (2022), the authors use a similar neural scene encoder and semantic parser to our framework, but focus on learning transition models that can predict future states of objects for planning. Similarly, PDSketch (Mao et al., 2023) defines a DSL that allows human to draw program sketches for specific tasks, and learn elaborate transition models that include continuous parameters for actions. Our work differentiates itself by introducing the latent scene graph representation, which already contains action-related parameters (i.e., grasp poses) and focuses on generalizing semantic parsing and reasoning.
Language-guided manipulation
In the robotics field, language-conditioning has been an emergent theme in RL-based (Jiang et al., 2019; Luketina et al., 2019) and IL-based (Jang et al., 2022; Lynch and Sermanet, 2020; Stepputtis et al., 2020) manipulation. Such methods require prohibitive training resources or several hours of human teleoperation data, dedicated in fixed task settings. Shridhar et al. (CLIPort) (Shridhar et al., 2021) proposed to combine the pretraining visual-language alignment capabilities of CLIP (Radford et al., 2021) with spatial precision of TransporterNets (Zeng et al., 2020) to solve a range of language-conditioned manipulation tasks with efficient imitation learning. However, CLIPort struggles to ground expressions that require reasoning about arbitrary visual concepts and complex relationships between objects. Several other works propose disentangled pipelines for vision and action, with language primarily used to guide vision (Blukis et al., 2020; Chen et al., 2021; Hatori et al., 2017; Misra et al., 2014; Shridhar and Hsu, 2018). The guiding process is implemented via relevancy clustering of LSTM-generated image-text features (Shridhar and Hsu, 2018) or element-wise fusion of images with sentence-wide text embeddings (Chen et al., 2021; Hatori et al., 2017). Such holistic feature fusion approaches fall short to use richer object-word alignment, as motivated in the previous section. Instead, in our work, we employ a neurosymbolic framework that utilizes explicit semantics about words and phrases and their correspondence to referring expressions in language commands. In Misra et al. (2014), a parser is used to translate language instructions to formal programs operating on scene graphs, similar to our approach. However, programs and scene representations are built with a constituency parser and heuristics, respectively, thus being limited to the modeled vocabulary of concepts. In our work, we use deep neural nets to do parsing and scene representation, as well as object-concept grounding, therefore entertaining benefits from both explicit semantics and representational strength of deep networks.
A plethora of recent works use large language models (LLMs) as semantic parsers to map natural language into Python-based programs composed of primitives (S Huang et al., 2023; W Huang et al., 2023; Jin et al., 2023; Liang et al., 2022b; Zeng et al., 2022b), hence gaining open-vocabulary generalizability due to the Internet-scale pretraining of the language model. However, such works rely heavily on prompt engineering and incontext examples to steer the LLM generation, making the system brittle and unreliable. Further, they require closed APIs or intense computational resources as part of the overall architecture, thus hindering its real-time applicability, which is essential in robotics. Our works uses semantic parsing that is trained bottom-up from data, while maintaining open-vocabulary generalization by decoupling domain vocabulary from the DSL primitives.
Methodology
Our architecture is comprised of four components: (a) a scene encoder (hybrid), (b) a language parser (neural), (c) a dedicated language that implements a library of reasoning/action primitives, paired with a program executor (symbolic), and (d) a set of concept grounding modules (neural). Given a visual world state, the scene encoder constructs a scene graph representation that embeds object features as nodes and their spatial relations as edges. The language parser translates the input natural language query into the underlying program, expressed in our language, and the program executor executes it as a sequence of message passing steps in the extracted scene graph. The concept grounders are used to interface words from the query that represent concepts with their matching objects in the scene representation. The overall framework with a running example is illustrated in Figure 2.
Since our focus in this work is the application of the system in open-vocabulary fashion, we make two important modifications to previous works. First, we decompose the language parser into two sub-modules: a tagger network that replaces words in the query with their corresponding concept tags and a seq2seq network that translates the abstracted sequence to the final program. This setup enables us to parse potentially new vocabulary, as long as the tagger has recognized the corresponding concept correctly. Second, we replace hand-crafted relation primitives and attribute classification with object-concept grounding networks, opting to generalize to unseen concepts by leveraging the similarity semantics of pretrained word embeddings used to represent the concepts.
Scene encoder
Given an input RGB-D pair of images, we first apply an off-the-shelf object detector (He et al., 2017) in RGB for instance segmentation and crop the N detected object instances
Visual encoder
We pass the cropped RGB images I
n
to a pretrained network H:
Grasp synthesis
We utilize a pretrained vision-based grasp synthesis network G:
Relation encoder
We encode each pair-wise spatial relation between two objects (n,m) ∈
Formally, each edge representation in our scene graph is given by:
We find that the extra binary features are essential for successfully grounding concepts such as “behind,” as they contain more fine-grained relations about the object pair (e.g., overlap between objects in x-dimension). See Appendix B for more details.
Language parser
The language parser consists of two sub-modules, a tagger network that identifies concepts in the input query and a seq2seq network for generating the program. To deal with potentially unseen vocabulary, the seq2seq network generates only the primitive functions of the overall program, whose arguments are restored from the query via a tag-conditioned attention linear sum assignment (LSA) module.
Concept tagger
We treat concept tagging similar to named entity recognition task in NLP (Kim Sang and De Meulder, 2003), where we map each word in the input query
Seq2Seq encoder-decoder
We replace words that are mapped to concepts with the corresponding tag and feed the replaced sequence as input to a RNN-based seq2seq network, enhanced with an attention layer between the encoder and decoder (Bahdanau et al., 2014). A two-layer Bi-GRU (Chung et al., 2014) of hidden size D
π
encodes the input sequence into hidden states
Tag-conditioned attention LSA
For each generated primitive function π τ that receives concept arguments, only words tagged with the corresponding concept C τ should be selected (e.g., C τ = Color for π τ = filter_color). We filter word tokens that satisfy this constraint and consider their normalized attention scores ˆa tτ = {a tτ /∑ t a tτ |c t = C τ }. Intuitively, the word t whose hidden state was the most attended in order to generate the function π τ corresponds to the argument of the function. However, we experimentally find that when multiple instances of the same primitive appear in the program, not always the matching argument corresponds to the maximum attention score. We then want to select the configuration of unique function-arguments pairs (τ,t) that maximizes the attention scores across functions ∑ τ aˆ tτ , which is equivalent to the linear sum assignment problem, solved efficiently by the Hungarian matching algorithm (Kuhn, 1955). The cached embedding e t is used as the argument for primitive π τ for each selected pair.
Concept grounding
The purpose of concept grounders is dual: (a) to match scene objects n ∈ From left to right: (a) A visual grounder (VG) network is used to ground attribute concepts to object instances and vice versa. The program executor invokes VG to perform (b) filtering and (c) querying primitives by computing similarity scores for object-concept pairs. A concept memory (MC) provides concept values and their embeddings to enable the VG to query over all encountered concept values. (d) A spatial grounder (SG) network is used to ground relation concepts to object pairs. The program executor invokes SG to resolve: (e) relations, locations, and hyper-relations. The relation and location primitives can be implemented via the relation grounder, while hyper-relations are resolved via a dedicated hyper-relation grounder network.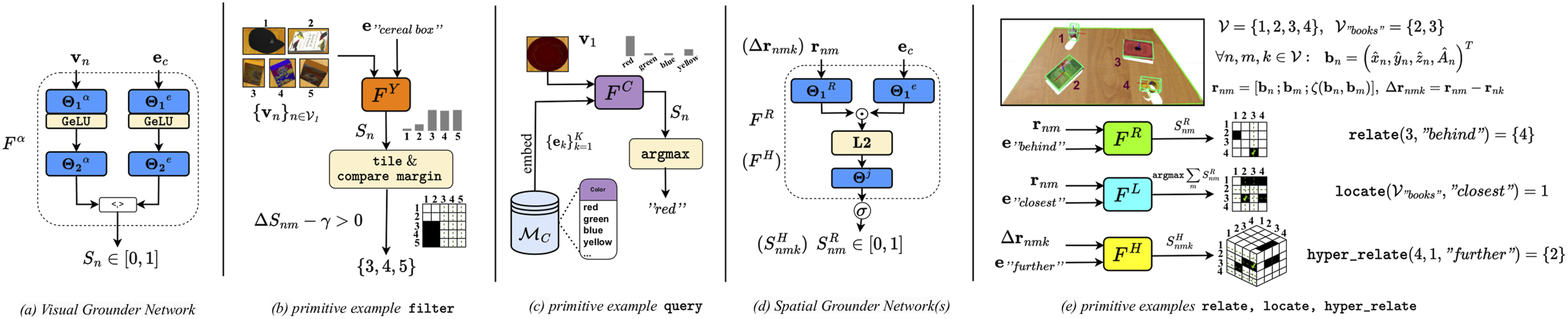
Visual grounders
We implement a module F
α
per attribute concept α ∈ {Color, Material, Category} that estimates a similarity score between a visual feature
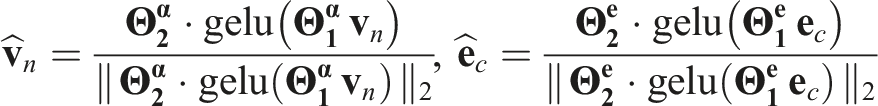
The library of reasoning primitives included in our language. For brevity we don’t enumerate all combinations of primitive and concept arguments, but illustrate the latter as a separate column. Visual modules interface with visual grounders and the scene’s visual features to reason about visual attributes. Spatial primitives interface with spatial grounders to resolve spatial relations, absolute relations (locations) and hyper-relations. Symbolic modules implement basic logic operations to incorporate integer and set semantics.


Spatial grounders
Resolving spatial relations comes in three flavors in our domain, namely: (a) binary relations (e.g., “left of”), that operate on pair-wise relation features
Formally: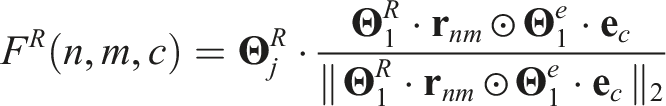
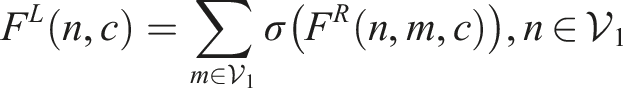
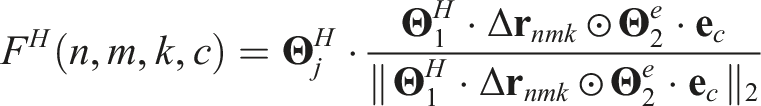
Primitives and program execution
Primitives library
We define our library of reasoning primitives Π similar to the CLEVR domain (Johnson et al., 2016), which we formally present in Table 1. The library includes two extra operational primitives, namely: (a) scene, which initializes an execution trace returning all objects
Program executor
Primitives are developed as functions in a Python API. Our type system supports basic variable types, as well as two special types for representing an object and an object set through their unique indices in the scene graph nodes V. All functions share the same type system and input/output interface and thus can be arbitrarily composed in any order and length. As in Yi et al. (2018), branching structures due to double argument primitives (e.g., and) are handled via the usage of a stack, allowing program execution as a chain of module calls, each receiving as input the output of the previous step and accessing the stack in case of double arguments. Whenever there is a type mismatch between expected and retrieved inputs/outputs, a suitable response is returned, enforcing interpretability by explaining to the user which reasoning step failed. To speed up computation, we first group all program steps that require concept grounding to do a single batched forward pass per grounder, and mask the network predictions during execution according to the previous steps.
Training paradigm
The training process entails two optimization objectives: (a) the correctness of the parsed program and (b) object-concept matching of the concept grounders. Following insights from prior works (Mao et al., 2019), we train using a curriculum learning approach. In particular, we first train the grounder modules to ground attribute concepts to objects (VG) and spatial concepts to object pairs (SG). To that end, we isolate input/output pairs from filtering, querying and relation-based operations from the execution traces of our dataset’s program annotations and express them as binary masks over the graphs nodes (VG)/edges (SG). We train the grounders on the checkpoint datasets and freeze their weights for the following steps. For language parsing, we first train the concept tagger on a small split of tagged queries and then the entire language parser objective following (Yi et al., 2018). First, we select a small diverse split of the training data, sampling uniformly from all different templates, and train using the ground truth programs with a cross-entropy loss. Finally, we combine the language parser with the grounders and the program executor and train the system end-to-end in the remaining scenes with REINFORCE (Williams, 1992), using only the correctness of the executed program as the reward signal.
Experiments
We structure our experimental evaluation as follows: First, we present the details of the synthetic dataset generation and the collected real-world dataset. In the two subsequent sections, we evaluate the visual reasoning capabilities of the proposed model through VQA, where we compare our approach with previous baselines in terms of accuracy, sample-efficiency and generalization to unseen vocabulary. In the next section, we study the transfer performance of our method in real scenes via few-shot fine-tuning of our visual grounder network. We further integrate our method with a robot framework and perform end-to-end experiments for an interactive object grasping scenario, where we examine the distribution of failure modes across system components in scene-instruction pairs with increasing complexity. Finally, we show that our method can be extended to more manipulation tasks via few-shot fine-tuning of the language parser.
Datasets
We present the synthetic and real versions of the dataset we release, termed: Household Objects placed in Tabletop Scenarios (HOTS). We refer the reader to Appendix A for more details on both versions.
SynHOTS
We collect from available resources a catalogue of 58 3D object models from five types (fruits (6), electronics (4), kitchenware (18), stationery (17) and edible products (13)), organized into 25 object categories, 10 color and 8 material concepts. As we strive for natural interaction, we also include instance-level object annotations according to their brand, variety or flavor (e.g., “Coca-Cola” vs “Pepsi,” “strawberry juice” vs “mango juice,” etc.) We render synthetic scenes in the Gazebo environment (Koenig and Howard, 2004) and generate around 8k training and 1.6k validation RGB-D pairs, additionally equipped with parsed semantic scene graphs, containing all location, grasp, attribute, and relation information for each object. For annotating our scene graphs with language data, we develop on top of the CLEVR generation engine (Johnson et al., 2016) and produce language-program-answer triplets from synthetic task templates by sampling concepts from the scene graphs. We extend the standard VQA templates of CLEVR to incorporate our designed DSL, as well as extra REF and grasping tasks, ending up with 11 distinct task families, spawning a total of 295 task templates, with rich variation in phrasing/syntax. For the VQA task (SynHOTS-VQA), we instantiate 66 templates for each scene (6 per task family) and generate around 500k training and 100k validation question-program-answer samples.
HOTS
In order to evaluate the performance of our model in natural scenes, we record a dataset of real RGB-D images captured from a robot’s camera. The real household objects used in this dataset, together with our dual-arm robot setup, are shown in Figure 4. The object catalogue is a subset of the synthetic one but includes a few novel attributes, for a total of 48 object instances with 25 category, 10 color, and 7 material concepts in 108 unique scene configurations. Twenty two scenes that provide a fair representation of all concepts are held out for potential fine-tuning experiments, and the 86 remaining scenes are used for testing. We extract scene graphs and repeat the language-program-answer data generation step as in simulation, ending up with 5676 scene-question pairs. A subset of the object catalogue included in the HOTS dataset (left) and an image of our real robot setup from the opposite perspective (right).
VQA evaluation in simulation
Setup
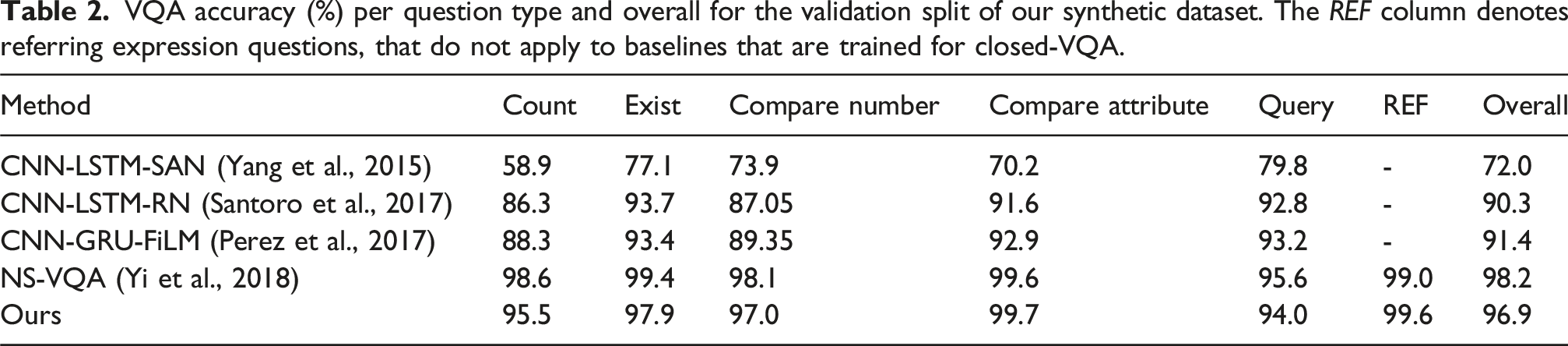
We compare our method with three holistic (Perez et al., 2017; Santoro et al., 2017; Yang et al., 2015) and the original NS-VQA (Yi et al., 2018) baseline. The holistic models are trained using the implementation and hyper-parameters from Perez et al. (2017) and NS-VQA is a replica of the original work, with the executor component adapted to incorporate our primitives library. We use a ResNet50 (He et al., 2015) backbone for visual feature extraction and sample 4000 images from our dataset to train the NS-VQA attribute classifiers and our grounders. NS-VQA and our method are pretrained with 300 programs sampled uniformly from all question families and fine-tuned with REINFORCE for the rest of the dataset. We note that our method additionally pretrains the tagger component of our parser with 500 question-tag pairs. We use Adam optimizer with batch size of 64 and train for 2k iterations in pretraining and 2M iterations in REINFORCE stage, using learning rates of 3 · 10−4 and 10−5, respectively. The reward is maximized over a constant baseline with a decay weight of 0.9.
Accuracy
VQA accuracy (%) per question type and overall for the validation split of our synthetic dataset. The REF column denotes referring expression questions, that do not apply to baselines that are trained for closed-VQA.
Sample-efficiency
We further analyze the sample-efficiency of our method compared to baselines in Figure 5, both in terms of pretraining and REINFORCE fine-tuning. Regarding tagger pretraining, we see that with a powerful pretrained model such as distilBERT (Sanh et al., 2019) we achieve 99.8% F1-score on the validation tags with only 500 samples. A GRU baseline with pretrained GloVe embeddings (Pennington et al., 2014) needs 2k samples to achieve the same performance. Regarding supervised pretraining, we see similar performance between NS-VQA and our method, with the latter being more efficient in weaker REINFORCE supervision (2k and 10k question-answer pairs). We believe this result is due to our two-step parser implementation, as, for example, for as little as 180 programs, the training examples most likely do not sufficiently cover the concept vocabulary of the domain for the NS-VQA parser, whereas in our method concept words are replaced by tags, which suffice in number. Finally, our method is the most sample-efficient in terms of required question-answer pairs, with a significant gap compared to holistic approaches, which comes at the cost of just a few hundred question-programs annotations for supervised pretraining. Sample-efficiency experiments on SynHOTS-VQA. From left to right: (left): F1-score of concept taggers versus number of tagged annotations used during pretraining, (middle): VQA accuracy versus number of pretraining programs; different curves indicate different amounts of data used at the REINFORCE stage, (right): VQA accuracy versus number of training question-answer pairs; NS-VQA and our method are pretrained with 500 programs.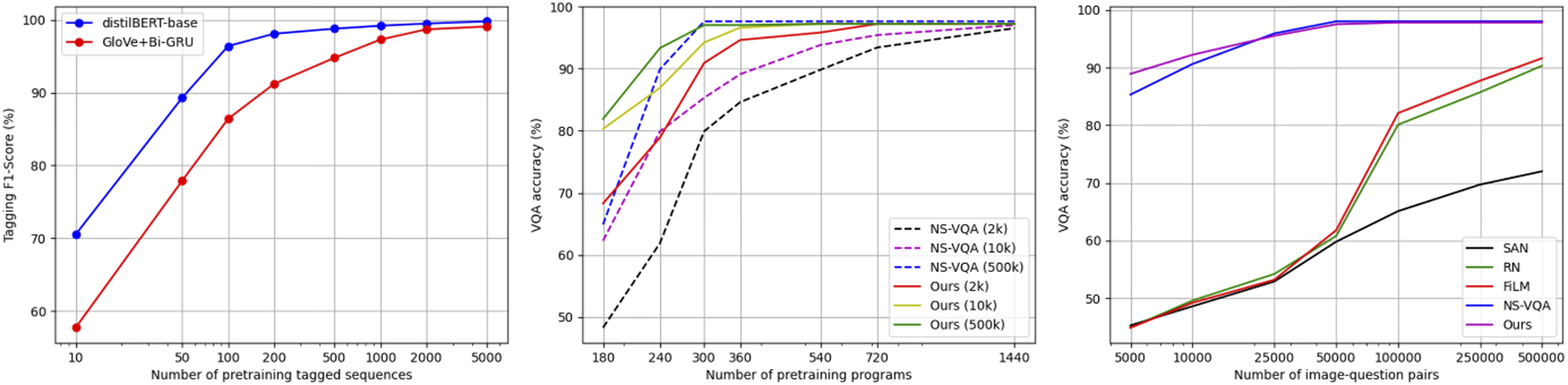
Generalization to unseen vocabulary
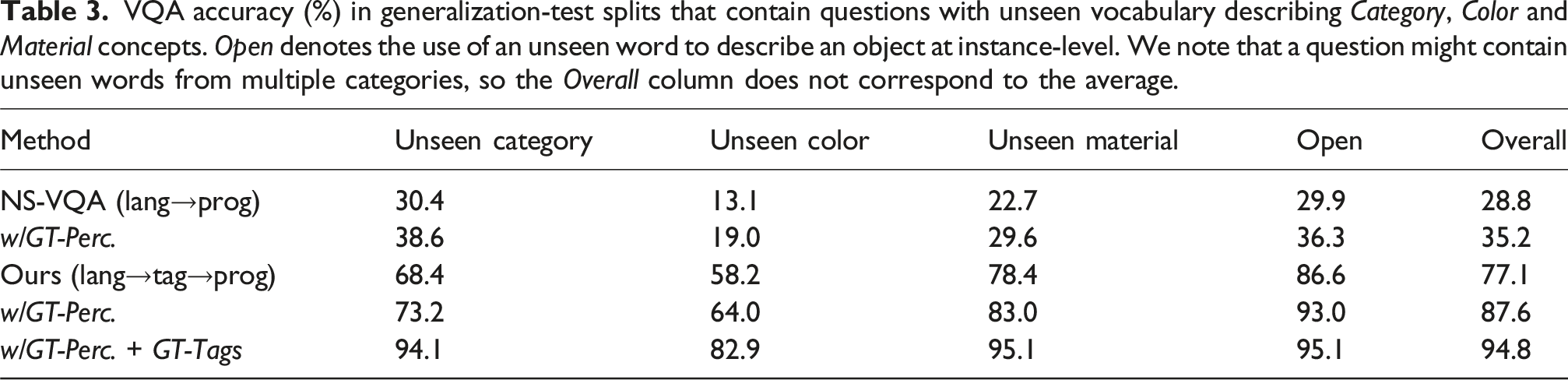
VQA accuracy (%) in generalization-test splits that contain questions with unseen vocabulary describing Category, Color and Material concepts. Open denotes the use of an unseen word to describe an object at instance-level. We note that a question might contain unseen words from multiple categories, so the Overall column does not correspond to the average.
Adapting to real scenes
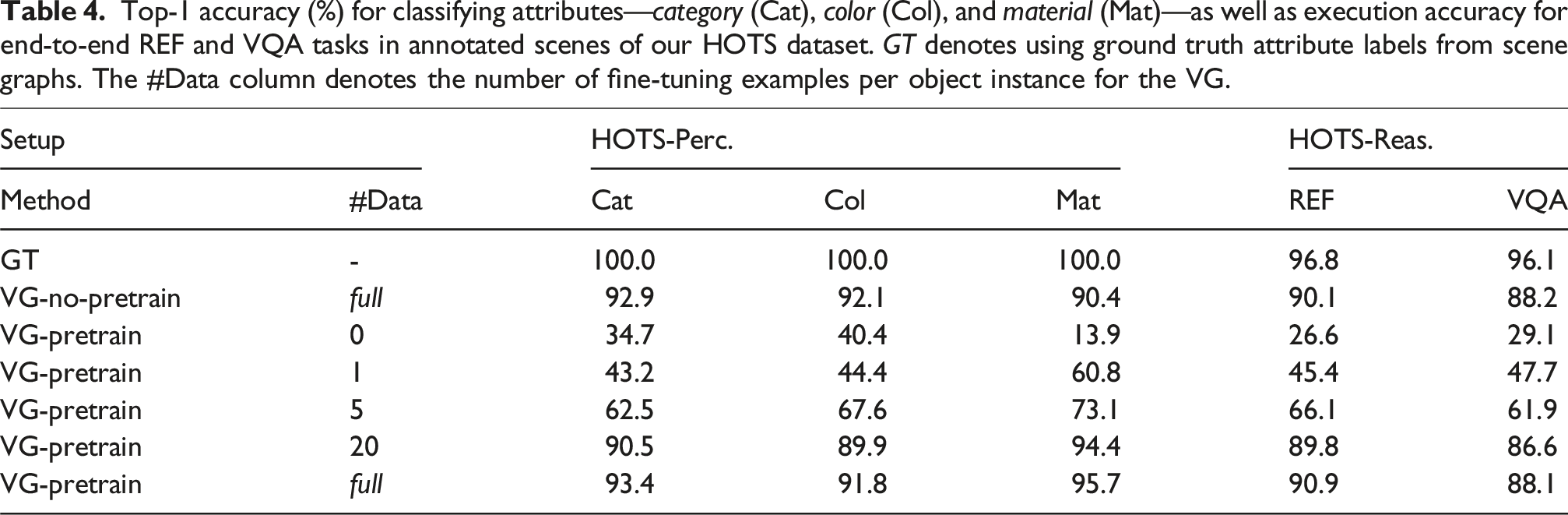
Top-1 accuracy (%) for classifying attributes—category (Cat), color (Col), and material (Mat)—as well as execution accuracy for end-to-end REF and VQA tasks in annotated scenes of our HOTS dataset. GT denotes using ground truth attribute labels from scene graphs. The #Data column denotes the number of fine-tuning examples per object instance for the VG.
Interpretable interactive object grasping
In this subsection, we integrate our method with the grasping pipeline of Oliveira et al. (2016) and evaluate its end-to-end behavior for an interactive object grasping task. An illustration of the setup and experiments is given in Figure 6. We conduct several trials, in which we randomly place objects on a table and instruct the robot to grasp an object in real time. The scenes always include distractor objects of a same attribute, requiring the user to use other attributes and/or spatial relations to uniquely refer to the goal object. We note that the instructor is not limited to the concept vocabulary of our domain and can use arbitrary phrasing, potentially outside the syntax of our scripted templates. The interpretable nature of our system allows us to examine the parsed program execution traces and diagnose the source of failures, including: (a) perception, where there is either a localization error or a grounder has given an incorrect match, (b) reasoning, where the parsed program is incorrect, or (c) grasping, where the grasping fails (e.g., due to collisions). A sequence of snapshots capturing the setup of our robot framework in Gazebo (top) and in a real-world environment (bottom). We generate a random scene and command the robot to grasp a specific item with a text instruction, referring to attributes/relations between objects (in pink). In the snapshots, we demonstrate the robot during the picking action (each-left) and the localization results in RViz (each-right), as well as the parsed program corresponding to the query (each-bottom).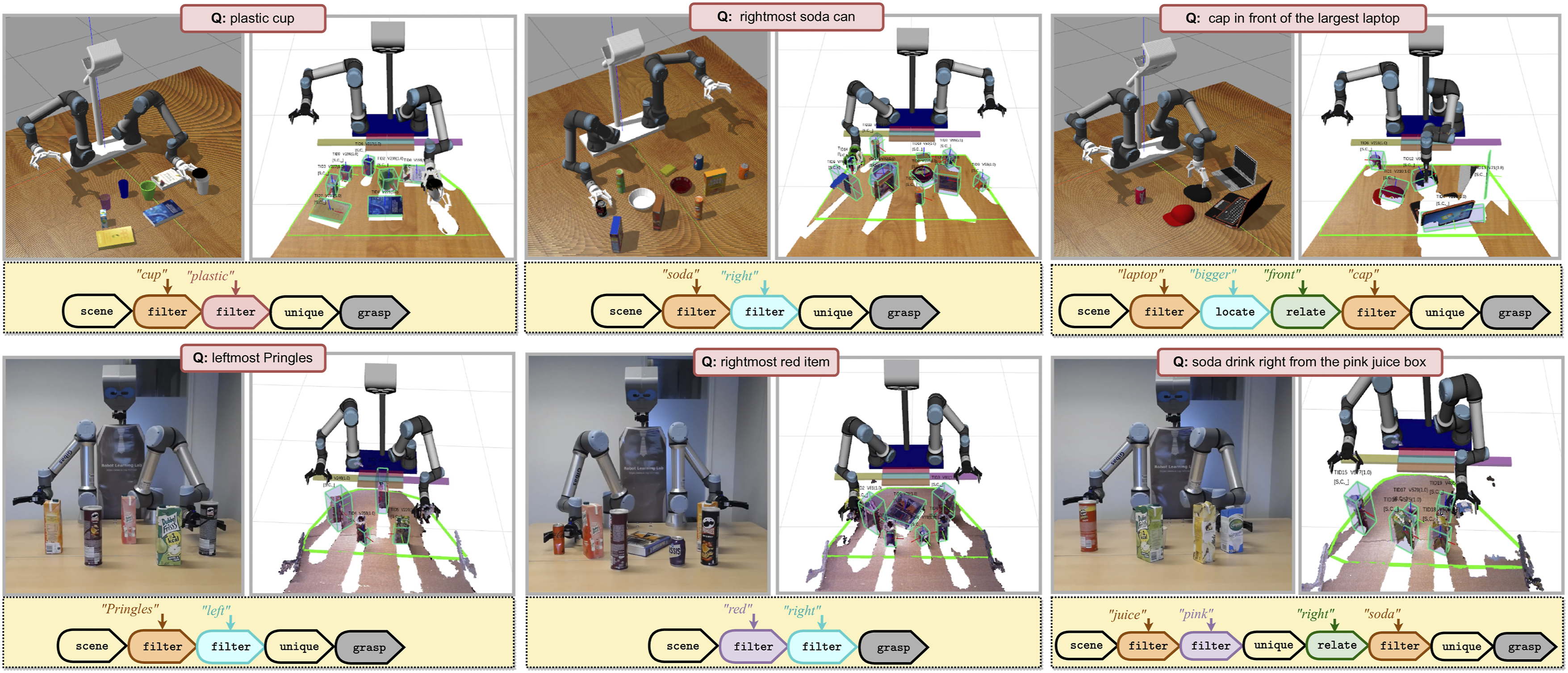
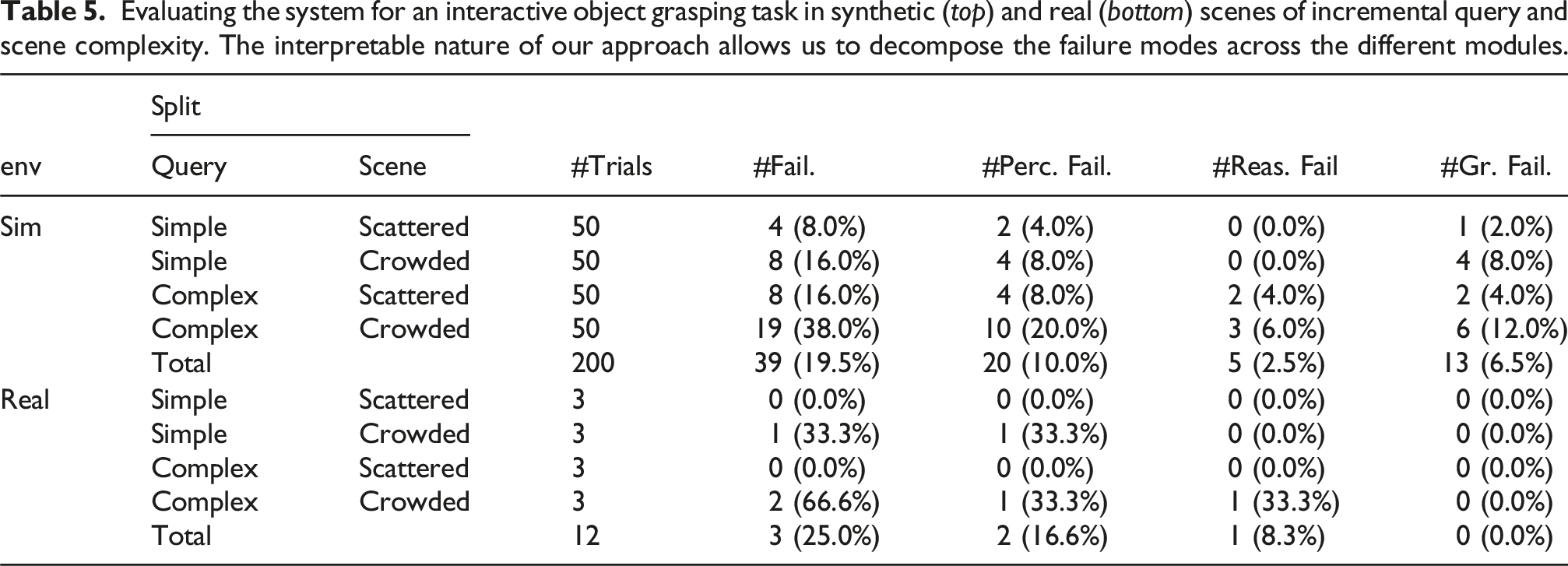
We report results in synthetic scenes separated in four splits, comprised of different levels of scene and query complexities (see Figure 7). We generate 10 scenes per split and conduct five trials for each, for a total of 200 scene-instruction pairs. For the real experiments, we conduct a total of 12 trials using objects from the HOTS dataset and the adapted visual pipeline of the previous section. Results are summarized in Table 5. We observe that in both setups the averaged error rate is similar (20%−25%), with the reasoning module being the most robust to grasping instructions across all trials. Exceptions are a few queries in cases of complex question splits. Such failures are mostly due to unique phrasing of the instruction by the human instructor, with one case of referring to an unknown spatial concept (e.g., “between”). Perception errors occur more frequently in the crowded scene setup, due to partial views of objects leading to occlusion. We include a video with robot demonstrations as supplemental material. The overall results showcase that the system can indeed serve as an accurate and interpretable interactive robotic grasper, while having relative robustness to free-form instructions. Example trials from the four splits used for simulated grasping experiments, namely: (a) Scattered scenes—simple queries, (b) crowded scenes—simple queries, (c) scattered scenes—complicated queries, and (d) crowded scenes—complicated queries. The green box denotes the target item, red denotes a distractor item of the same attribute and the dark box denotes all items involved in the reasoning process. Evaluating the system for an interactive object grasping task in synthetic (top) and real (bottom) scenes of incremental query and scene complexity. The interpretable nature of our approach allows us to decompose the failure modes across the different modules.
Extending to more manipulation tasks
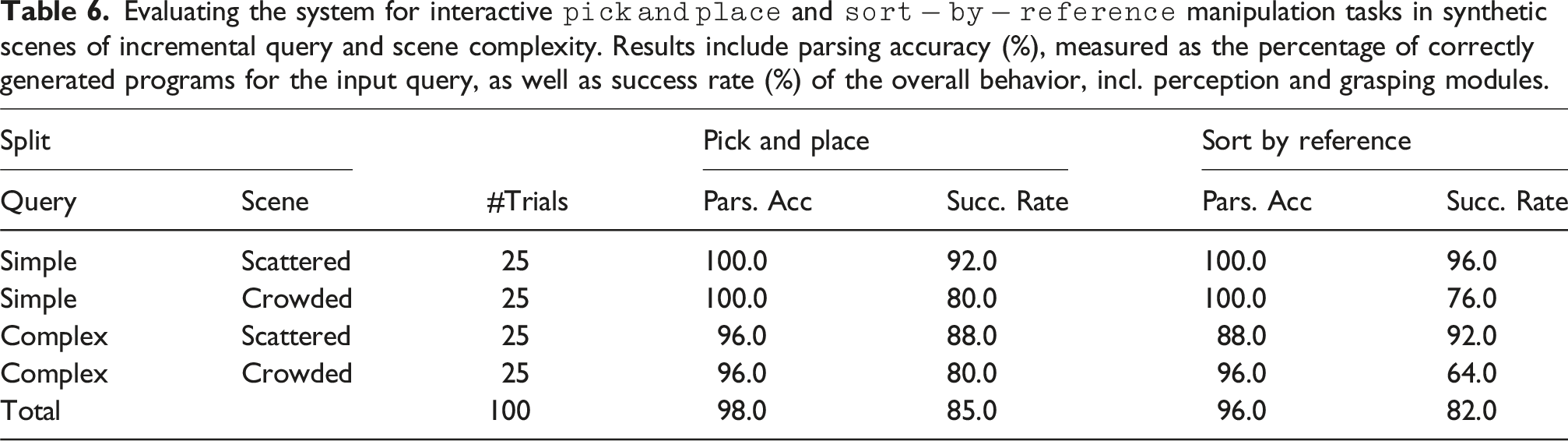
In this subsection, we explore how efficiently our model can adapt to more complex manipulation tasks beyond grasping. To that end, we implement two extra control primitives, which like grasp, act as terminal nodes in the parsed program, receiving unique indices of objects to manipulate and control the arm based on the grasp poses of the objects with an IK-solver. In particular, we implement: (a) pick and place, which receives two object inputs and a relation concept argument that map to what to pick, where to place, and how to place it, respectively, and (b) sort, which receives a set of objects to sort into a fixed container item (see Figure 8). We structure new templates for these tasks and generate 10 instruction-program pairs for 50 novel synthetic scenes with the same constraints as the grasping task, for a total of 500 pairs. We fine-tune our language parser in the new instructions (while keeping the rest of the system fixed) and report results in Table 6, using the same setup as the previous section for 100 trials per task in simulation. As with grasping, we observe that the reasoning module is robust in query complexity and task success is limited only by perception and grasping modules, in cases of crowded scenes. We further integrate policies obtained through behavioral cloning as control primitives and demonstrate more complex, long-horizon manipulation tasks in our supplemental material. Extending to more manipulation tasks: (top): pick an object and place it relative to another object, and (bottom): sort all objects in a pre-defined container according to a reference object. Evaluating the system for interactive 
Comparisons with foundation models
In this section we explore the comparative performance, as well as integration potential, of our neurosymbolic framework with approaches relying on modern foundation models (Tziafas et al., 2023; Tziafas and Kasaei, 2024), such as LLMs (OpenAI, 2023) and VLMs (Radford et al., 2021) for zero-shot semantic parsing and grounding. To that end, we perform three experiments studying relative performance in different parts of the pipeline, including parsing, grounding and end-to-end grasping from a language instruction. To strengthen our evaluation we also utilize the dataset OCID-VLG (Tziafas et al., 2023), which provides referring expression queries, accompanied with parsed program and ground-truth mask and grasp annotations for 1763 unique scenes from the OCID dataset (Suchi et al., 2019). To examine out-of-distribution generalization, we use the novel-classes split provided from the authors, which includes object category objects unseen during training. We note that NS-MAN is not equipped to deal with novel concept types, since it is trained only on those existing in the training data. However, we conduct evaluations in this split to explore trade-offs between foundation model-based and our neurosymbolic approach, as well as potential for integrating the two.
Semantic parsing
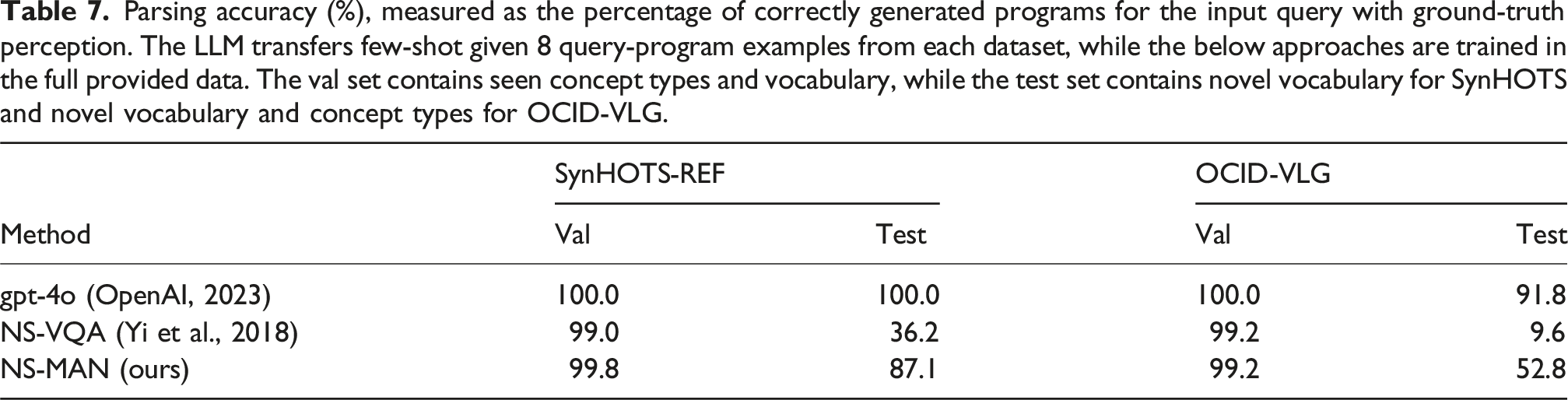
Parsing accuracy (%), measured as the percentage of correctly generated programs for the input query with ground-truth perception. The LLM transfers few-shot given 8 query-program examples from each dataset, while the below approaches are trained in the full provided data. The val set contains seen concept types and vocabulary, while the test set contains novel vocabulary for SynHOTS and novel vocabulary and concept types for OCID-VLG.
Visual grounding
Grounding accuracy (%), measured as the percentage of correctly grounded referring expressions, measured as final masks with IoU > 0.5 with the ground-truth mask. Combining VLM-based grounders with semantic parser improves the reasoning capability of the VLMs in cases of spatial reasoning queries.

Interactive object grasping
Jacquard metric J@1 (%), measured as the percentage of grasp predictions that have an IoU > 0.25 and a relative angle within 30° from ground-truth grasps. The val set contains seen query vocabulary, while the test set contains novel object queries.

Overall, we interpret the above results as a trade-off. LLM/VLM-based methods offer significant benefits when considering completely unseen concepts. NS-MAN achieves better/on-par results when in-distribution, or when considering unseen vocabulary of the same concept types, while doing so by being trained completely bottom-up from synthetic data. On the one hand, if generalization is required, foundation model approaches are a favorable choice, with the additional costs of latency, cost, privacy, and other factors.
On the other hand, if efficiency-cost is required, and we assume that we have generated synthetic training data for all concept types that will be ever observed by the robot, our proposed framework serves as an effective lightweight alternative. Further, as the results of this section suggest, LLMs for semantic parsing and/or VLMs for grounding can be drop-in replacements to corresponding modules of NS-MAN, thus boosting generalization to unseen concept types if in-the-wild scenarios are to be considered.
Discussion
In this section, we reflect on our results with regard to specific topics and discuss limitations and future work.
Adapting to novel content
One important benefit of the modular versus holistic design is the ability to adapt to novel content by only adapting the related module, instead of the entire pipeline (Tziafas and Kasaei, 2022). We believe that this translates to important benefits in terms of development cycles, as it alleviates the need for collecting large-scale multimodal data for training an end-to-end model. In summary, the steps required for the proposed method to extend to novel concepts/tasks are:
Handling failure via interactivity
With this work we wish to highlight the practical benefits of interpretability in the context of human–robot interaction applications. Beyond easiness of debugging and transparency of the model, this feature can augment models functionally by bringing humans in-the-loop. For example, by adding suitable responses when a module fails at execution time, we can employ the system in an online dialogue setup, enabling the user to give feedback on failures caused by either ill-formed queries or other ambiguities in the scene (see Figure 9). The unique primitive requires the input set to be unitary and therefore the execution will fail due to the presence of multiple matched objects. The system raises a relevant template response back to the user and integrates their feedback to correct the generated program. To achieve this, we process the feedback query to identify new present concepts from our concept memory. When new concepts are identified, the parsed program is re-structured appropriately and the system re-runs execution. By type-checking and adding failure wrappers in all of our primitive implementations, the system is able to identify sources of failure and return a suitable response to the user. In this example, the original query (first) is ill-posed as it refers to a soda object, while two sodas are present. This results in failure of the unique primitive, which will be prompted back to the user (second). The human responds with additional feedback (third) which results in a correct final gasping behavior (fourth). Such failure handling behaviors allow our model to interact naturally with human users in a dialogue setting.
Training time, real-time performance, and dynamic environments
Regarding training time, the entire curriculum training process discussed in Section 3.5 takes around 10 hours in a consumer GPU for the 500k scenes of SynHOTS-VQA. For inference, our end-to-end system (incl. the pretrained networks) can be used to produce a program at 4 fps in our hardware setup, 1 with the main bottleneck being Mask R-CNN for localization. In the future, we plan to integrate high-efficiency detectors to increase our throughput. Similarly to the previous subsection, failure handling in the implemented control primitives can be used to simulate closed-loop control, as in cases of dynamic environments the world state might change during execution. A failure wrapper around the grasp primitive verifies that the target object state is the same as when the execution trace started (i.e., scene primitive) and otherwise re-runs the program with the updated state.
Portability
Besides sample-inefficiency, holistic approaches are limited to the agents/environments that were used to generate training data. In contrary, our approach disentangles the actual policy (represented as a program) from the perceptual and motor components (represented as functions in the program), and hence can be transferred to new agents/environment with minimal effort. Similar to our experiments in Section 4.4, where we only adapt one module (VG) and transfer the overall system in a new visual domain, one could further replace the grasping module to use different arms or grippers and transfer to completely new robots and environments.
Conclusion
In this work, we bring together deep learning techniques for perception, grasp synthesis and NLP with symbolic program synthesis and execution in an end-to-end hybrid system, aimed for interactive robot manipulation applications. We design a dedicated language that implements visuospatial reasoning as primitive operations. We exploit linguistic cues in the input instruction to synthesize a program composed of such primitives. Programs interface with visual/spatial grounding and grasp modules to ground concepts and control the robot, respectively. We generate a synthetic tabletop dataset with rich scene graph and language-program annotations, paired with a real RGB-D scenes dataset, which we make publicly available. Extensive evaluation through a VQA task showcases that our method achieves near-perfect accuracy in-domain, while being fully interpretable and sample-efficient compared to baselines. Generalization experiments show that the vocabulary-agnostic formulation of our language and model enables better generalization to unseen concept words compared to previous works. Also, we show that with our modular design, the system can transfer to natural scenes with few-shot adaptation of the visual grounder, as well as transfer to more manipulation tasks with few-shot adaptation of the language parser module. We integrate our model with a robot framework and perform experiments for an interactive object picking task, both in simulation and with a real robot. Robot experiments demonstrate high success rate, and robustness to user instructions, with interpretability leveraged to actively detect reasoning failures and inform the user.
Footnotes
Acknowledgments
We gratefully acknowledge partial support from Google DeepMind through the Research Scholar Program for the project “Continual Robot Learning in Human-Centered Environments”.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.