
Abstract
Recent advancements in robot navigation, particularly with end-to-end learning approaches such as reinforcement learning (RL), have demonstrated remarkable efficiency and effectiveness. However, successful navigation still fundamentally depends on two key capabilities: mapping and planning, whether implemented explicitly or implicitly. Classical approaches rely on explicit mapping pipelines to transform and register egocentric observations into a coherent map for the planning module. In contrast, end-to-end learning often achieves this implicitly—through recurrent neural networks (RNNs) that fuse current and historical observations into a latent space for planning. While existing architectures, such as LSTM and GRU, can capture temporal dependencies, our findings reveal a critical limitation: their inability to effectively perform spatial memorization. This capability is essential for transforming and integrating sequential observations from varying perspectives to build spatial representations that support planning tasks. To address this, we propose spatially-enhanced recurrent units (SRUs)—a simple yet effective modification to existing RNNs—that enhance spatial memorization. To improve navigation performance, we introduce an attention-based network architecture integrated with SRUs, enabling long-range mapless navigation using a single forward-facing stereo camera. Additionally, we employ regularization techniques to facilitate robust end-to-end recurrent training via RL. Experimental results demonstrate that our approach improves long-range navigation performance by 23.5% overall compared to existing RNNs. Furthermore, when equipped with SRU memory, our method outperforms both RL baseline approaches—one relying on explicit mapping and the other on stacked historical observations—achieving overall improvements of 29.6% and 105.0%, respectively, in diverse environments that require long-horizon mapping and memorization capabilities. Finally, we address the sim-to-real gap by leveraging large-scale pretraining on synthetic depth data, enabling zero-shot transfer for deployment across diverse and complex real-world environments.
Introduction
End-to-end learning for robot navigation has recently gained significant attention with its potential to address two major challenges inherent in classical modular approaches: (a) system delays and (b) the difficulty of modeling complex kinodynamic environmental interactions. These challenges have traditionally hindered the development of high-speed platforms with intricate dynamics, such as legged-wheeled robots. However, end-to-end learning approaches face their own challenges, particularly in achieving efficient spatial mapping. Unlike classical mapping pipelines, which explicitly transform historical ego-centric observations into a coherent map frame for downstream planning, end-to-end learning relies on neural networks to implicitly learn this process. This requires the network to iteratively build and update an environmental representation of the surroundings and understand the spatial-temporal relationships between observations.
In autonomous driving, large-scale mapping modules (Mescheder et al., 2019; Mohajerin and Rohani, 2019; Wang et al., 2025; Wei et al., 2023) are trained on thousands of hours of data, enabling robust spatial mapping with specifically designed architectures, such as occupancy networks (Mescheder et al., 2019) or occupancy grid maps (Mohajerin and Rohani, 2019). However, such approaches are not easily deployable on smaller robotic platforms and often struggle to generalize to environments beyond structured road networks. In contrast, embedded robots often rely on end-to-end learning approaches, either by imitating behaviors from datasets (Cèsar-Tondreau et al., 2021; Karnan et al., 2022; Loquercio et al., 2021; Shah et al., 2023) or by optimizing policies through reinforcement learning (RL) (Surmann et al., 2020; Wijmans et al., 2020; Zhu et al., 2017). These methods typically employ specific network architectures, such as recurrent neural networks (RNNs), to implicitly learn spatial-temporal mappings (Wijmans et al., 2020, 2023). While these approaches have demonstrated success in structured indoor environments with discretized action and observation spaces, their performance often diminishes in more complex, real-world scenarios that involve continuous action spaces and dynamic motions.
Recently, for real-world deployments, researchers have started integrating explicit mapping pipelines (Miki et al., 2022b) to fuse ego-centric observations and provide environmental information to learning modules for tasks such as perceptive locomotion (Miki et al., 2022a) and navigation (Francis et al., 2020; Lee et al., 2024; Weerakoon et al., 2022). This raises an important question: can end-to-end learning networks with implicit memory mechanisms, such as RNNs, match or surpass the performance of approaches that rely on explicit mapping pipelines? Specifically, do RNNs have inherent limitations in learning spatial-temporal mappings?
While RNNs excel at capturing temporal dependencies, showcased by their success in various sequential tasks, such as natural language processing (Sutskever et al., 2014) and time-series prediction (Siami-Namini et al., 2019), their ability to learn spatial transformations and memorization remains a topic of research. RNNs are designed to process sequences of data by maintaining an internal state that captures temporal dependencies. However, it is not yet clear to what extent they can effectively learn spatial transformations and integrate observations from different perspectives. Classical approaches achieve spatial registration through homogeneous transformations in three-dimensional space, aligning observations into a consistent local or global frame. For RNNs to achieve effective spatial registration, they must not only memorize sequences but also learn to transform and integrate observations across time and space.
In this work, we examine the spatial-temporal memory capabilities of several recurrent architectures, including long short-term memory (LSTM) (Hochreiter and Schmidhuber, 1997), gated recurrent unit (GRU) (Cho et al., 2014), and recent state-space models (SSMs) such as S4 (Gu et al., 2022) and Mamba-SSM (Gu and Dao, 2023). We evaluate these models on two criteria: (i) their ability to memorize temporal sequences and (ii) their capacity to register and transform sequential observations across varying spatial perspectives. Our findings indicate that, while these models perform well in capturing temporal dependencies, they exhibit limitations in spatial registration, particularly under conditions of dynamic ego-motion and rapidly changing perspectives.
To address this limitation, we introduce spatially-enhanced recurrent units (SRUs), a simple yet effective modification to standard LSTM and GRU units that enhances their spatial registration capabilities when processing sequences of ego-centric observations. Unlike classical mapping pipelines that rely on explicit homogeneous transformations, our approach enables the recurrent units to implicitly learn the transformations from varying observation perspectives effectively. To further enhance the performance of long-range navigation tasks, we propose an attention-based network architecture integrated with SRUs, allowing the model to learn long-range mapless navigation policies using only ego-centric observations via end-to-end RL. Our experiments demonstrate improvements in spatial awareness compared to the baselines. With the SRU memory, the implicit recurrent approach via RL with sparse rewards promotes robust exploration in complex 3D and maze-like environments, outperforming the baseline that rely on explicit mapping and memory modules.
To prevent premature convergence to suboptimal strategies and fully exploit the capabilities of the proposed attention-based recurrent structure, we find that incorporating regularizations during end-to-end RL training is crucial. Furthermore, to address the sim-to-real gap caused by noisy depth images, we pretrain the image encoder on a large-scale synthetic dataset and augment the data using a fully parallelized depth-noise model, adapted from Handa et al. (2014), Barron and Malik (2013a), and Bohg et al. (2014a). In summary, our main contributions are as follows: • Addressing spatial mapping limitations with SRUs: We identify that standard RNNs, while effective in capturing temporal dependencies, can struggle with spatial registration of observations from different perspectives. To overcome this, we introduce spatially-enhanced recurrent units (SRUs) that enhance the ability to learn implicit spatial transformations from sequences of ego-centric observations. • End-to-end reinforcement learning with SRUs and attention-based policy: We integrate the SRU unit into a proposed attention-based network architecture, enabling improved end-to-end reinforcement learning for long-range mapless navigation tasks using only ego-centric observations. • Large-scale pretraining for zero-shot sim-to-real transfer in long-range mapless navigation: By leveraging large-scale synthetic pretraining and a parallelizable depth-noise model, our system bridges the sim-to-real gap, enabling zero-shot deployment on a legged-wheel platform in diverse real-world environments, using a single forward-facing stereo camera for long-range mapless navigation.
Related works
The navigation and planning problem has been studied extensively for decades. Early approaches relied on classic search-based methods, including Dijkstra’s algorithm and A* (Dijkstra, 1959; Hart et al., 1968) operating on pre-discretized grids, as well as on sample-based techniques such as the Rapidly-exploring Random Tree (RRT) family—including variants like RRT*, RRT-Connect (Karaman and Frazzoli, 2011; Kuffner and LaValle, 2000; LaValle et al., 2001), etc.—and probabilistic roadmap (PRM) methods, such as Lazy PRM and SPARS (Bohlin and Kavraki, 2000; Dobson and Bekris, 2014; Kavraki et al., 1996). While these techniques have achieved significant success in robotics and real-world applications (Wellhausen and Hutter, 2023), they depend on building or the existence of a predefined navigation or occupancy map. Consequently, they often struggle in unknown or dynamic environments (Yang et al., 2022a), particularly when planning under static world assumptions or when complex kinodynamic constraints are present (Ortiz-Haro et al., 2024; Webb and Berg Jvd, 2012). Moreover, these classical methods typically require an additional perception and mapping module, and the predetermined traversability or occupancy maps are usually based on heuristic designs rather than being optimized for a specific robotic platform.
To address these limitations, recent research has increasingly turned to learning-based approaches, especially for more complex robotic agents (e.g., quadrupeds or legged-wheel systems). For instance, recent works in imitation learning leverage large-scale video data or demonstrations (Bojarski et al., 2016; Loquercio et al., 2021; Pfeiffer et al., 2017; Shah et al., 2022, 2023) to directly map raw egocentric sensory inputs to navigation actions. Given the challenges of capturing dynamic, closed-loop interactions from purely offline data, researchers have also explored model-free reinforcement learning (RL) methods (Bhattacharya et al., 2025; Choi et al., 2019; Fu et al., 2022; Hoeller et al., 2021; Huang et al., 2023; Lee et al., 2024; Ruiz-Serra et al., 2022; Shi et al., 2019; Truong et al., 2021; Wijmans et al., 2020; Wu et al., 2021) that train navigation policies end-to-end by simulating the entire robot dynamics. By replacing the traditional perception, mapping, and planning pipeline with a tailored network—such as architectures based on recurrent networks (Choi et al., 2019; Hoeller et al., 2021; Wijmans et al., 2020; Wu et al., 2021) or Transformers with attention mechanisms (Bhattacharya et al., 2025; Huang et al., 2023; Ruiz-Serra et al., 2022; Zeng et al., 2024)—these approaches have achieved improvements in navigation tasks as well as in robotic locomotion (Kareer et al., 2023; Miki et al., 2022a; Yang et al., 2022b).
A key challenge with end-to-end approaches is learning a robust state representation from the partial observations provided by egocentric sensors. Recent studies have attempted to mitigate this challenge by incorporating explicit mapping and memory mechanisms (Cimurs et al., 2021; Fu et al., 2022; Lee et al., 2024; Savinov et al., 2018) or by employing specialized network architectures like RNNs (Choi et al., 2019; Hoeller et al., 2021; Wijmans et al., 2020). However, RNNs—originally designed to capture temporal sequences in language tasks (Cho et al., 2014)—are not inherently well-suited for spatial mapping, particularly when processing sequential egocentric observations from continuously changing perspectives. For instance, while prior studies in indoor navigation have shown that spatial cues can be decoded from RNN memories, this effect has been demonstrated only with binary contact sensing and does not extend to high-dimensional visual inputs (Wijmans et al., 2023). Moreover, recent findings suggest that variations in recurrent network architectures have minimal impact on the final task-level rewards achieved through reinforcement learning (Duarte et al., 2023). This indicates that, despite architectural differences, some fundamental limitations may persist across these RNN units.
In this paper, we explore a key limitation of existing RNN-based architectures in addressing partial observability—their spatial memorization capabilities—highlighting their shortcomings in learning spatial transformations and integrating observations from different perspectives. We then introduce spatially-enhanced recurrent units (SRUs) and demonstrate their effectiveness in improving long-range mapless navigation tasks with a specifically designed attention-based network structure via end-to-end reinforcement learning.
Problem statement
Consider a robot operating in a three-dimensional (3D) environment • • • • • • • γ ∈ [0, 1]: the discount factor that balances immediate reward and future payoffs.
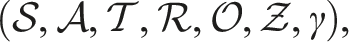
The action
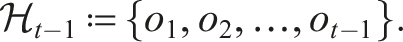
We define a function f that fuses current and historical observations into an estimate
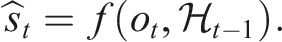
The policy π then maps the estimated state
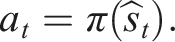
Due to the robot’s ego-motion, the current observation o
t
can be captured from a different perspective or observation frame compared to historical observations in
Methodology
Overview
To tackle the long-range navigation task, we first examine and demonstrate the limitations of existing recurrent architectures (e.g., LSTM, GRU, S4, and Mamba-SSM) in a spatial-temporal memory task. We then introduce the spatially-enhanced recurrent units (SRUs). Next, we integrate SRUs into an attention-based network architecture to learn long-range mapless navigation via end-to-end reinforcement learning. Furthermore, we discuss the importance of incorporating regularization techniques to prevent early overfitting, which we find to be crucial to enhance SRUs’ spatial memorization. Finally, we address the sim-to-real gap by pretraining the depth image encoder on large-scale synthetic depth data and incorporating a parallelizable depth-noise model, enabling zero-shot transfer to real-world environments.
Background: Recurrent neural networks
Recurrent neural networks (RNNs) are a class of neural networks designed to process sequential data by maintaining a hidden state that captures temporal dependencies. Given a sequence of inputs x≔(x1, x2, …, x
T
), an RNN computes a sequence of hidden states h≔(h1, h2, …, h
T
) using the following recursive formula:
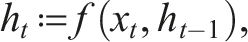
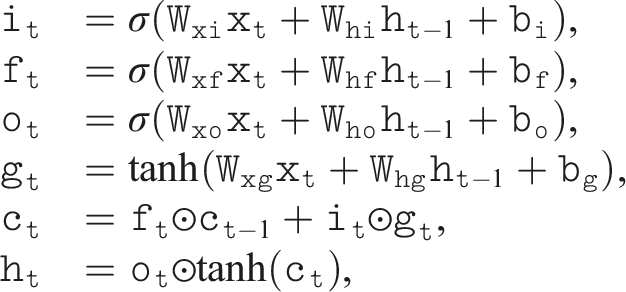
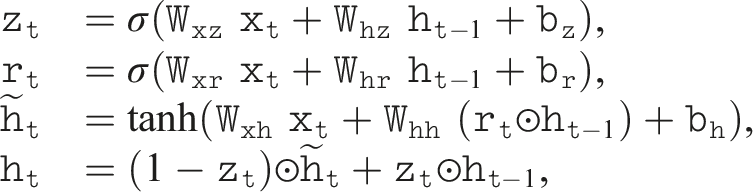
More recently, the State-Space Model (Gu et al., 2022) was introduced, which is inspired by the general form of state space models widely used in control theory. Such models take the following form in discrete time:
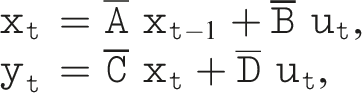
In Gu et al. (2020a), a so-called HiPPO matrix is proposed for
Spatial mapping limitations in RNNs
Achieving long-range mapless navigation from egocentric observations requires the robot to perform effective spatial mapping. In three-dimensional (3D) space, spatial mapping is commonly achieved using homogeneous transformations, which combine rotations and translations. A general representation of such a transformation is expressed as:
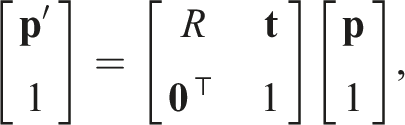
In this section, we assess the spatial and temporal mapping performance of existing recurrent structures—namely LSTM, GRU, and the recent S4 and Mamba-SSM—on two fronts: (i) temporal memorization and (ii) spatial transformation and memorization. Consider an abstract scenario relevant to the navigation task, in which a robot is initialized at a pose in SE(3) and moves randomly within the three-dimensional environment • Memorize and accurately predict the sequence of binary categorical labels associated with the observed landmarks, ensuring temporal association and order preservation (Temporal Task). • Transform and register the spatial coordinates of all observed landmarks into the final robot frame at t = T, achieving spatial alignment and memorization of their positions (Spatial Task).
The training details are provided in Appendix A. The results indicate that while LSTM, GRU, S4, and Mamba-SSM effectively encode temporal sequences and retain landmark categories, as shown in Figure 1(a), they face significant challenges in accurately memorizing and transforming landmark coordinates from sequential ego-centric observations. This limitation is reflected in the higher mean squared error (MSE) when recalling observed landmark positions during training, as depicted in Figure 1(b). Training for the spatial-temporal memorization: (a) Temporal memorization loss shows that standard RNN units (LSTM, GRU, S4, and Mamba-SSM) effectively recall sequential information. (b) Spatial memorization loss indicates that these units struggle with accurate spatial transformations and memorization under changing observation perspectives, resulting in misaligned landmark coordinates.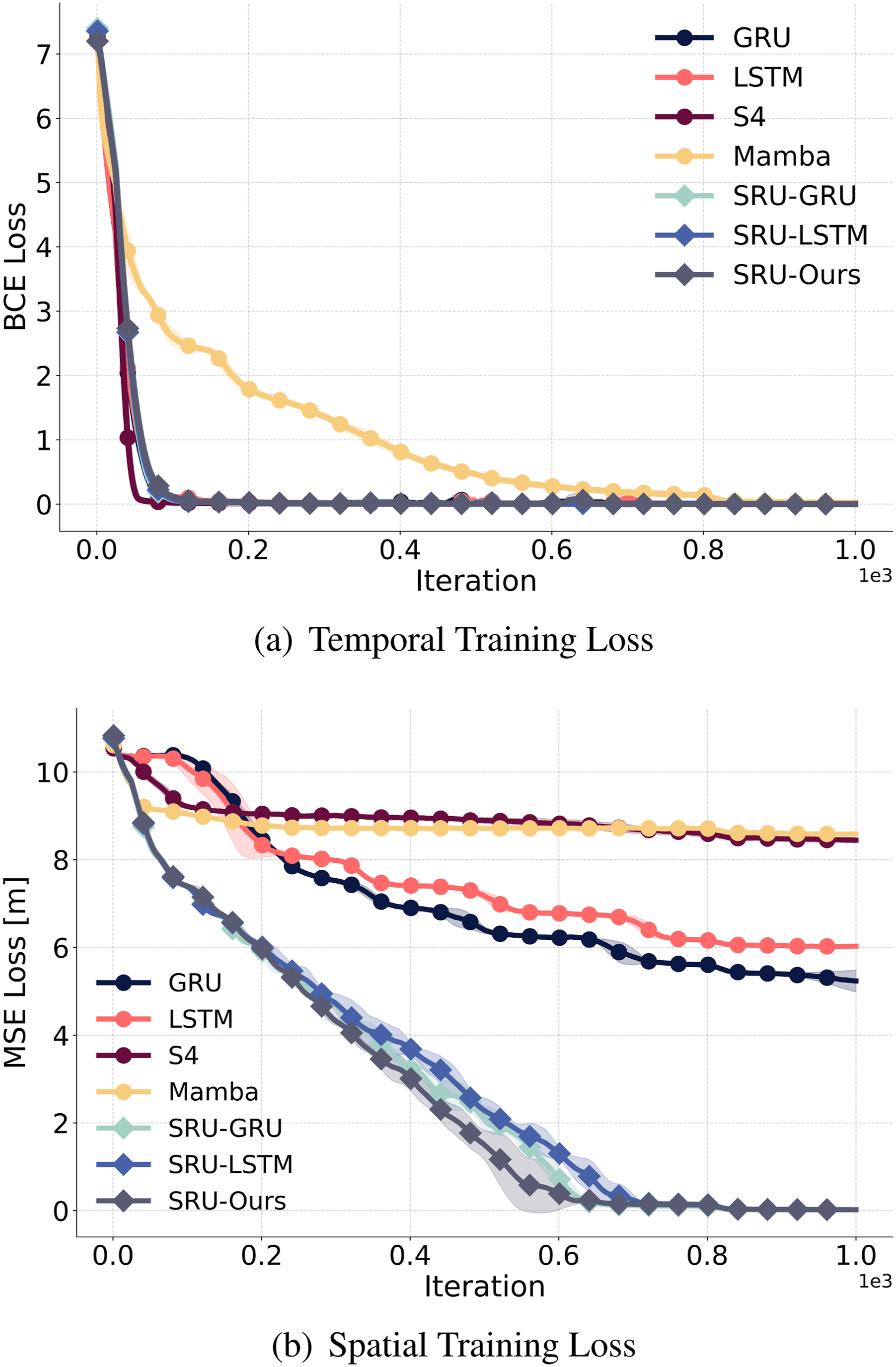
Spatially-enhanced recurrent unit
To address the limitations of spatial mapping of existing RNN units, we propose a modification to the standard LSTM and GRU architectures by introducing an additional spatial transformation operation. This enhancement results in a new class of units, termed spatially-enhanced recurrent units (SRUs). The added operation enables the network to implicitly learn spatial transformations, aligning and memorizing observations from varying perspectives while preserving robust temporal memorization capabilities.
The effectiveness of this approach is demonstrated by the training results of the spatial mapping task mentioned above and illustrated in Figure 1. With the SRU modification, the network effectively transforms and memorizes observed landmark coordinates from different perspectives, as indicated by the spatial loss curve in Figure 1(b), while preserving similar temporal memorization performance compared to standard LSTM and GRU units, as shown in Figure 1(a). The design of SRUs emerged through iterative experimentation and analysis of spatial mapping performance. The final formulation draws inspiration from the multiplicative form of homogeneous transformations and recent research on the use of the “star operation” (element-wise multiplication) to enhance the representational capacity of neural networks (Ma et al., 2024).
The following equations detail the modifications to incorporate spatial transformations into both LSTM and GRU units, ensuring a balance between spatial memorization and temporal dependency learning. In each case, we compute an additional spatial transformation term, denoted as
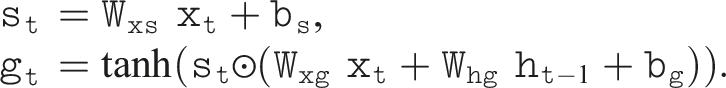
Similarly, for the modified GRU, referred to as SRU-GRU, the formulation is enhanced as follows:
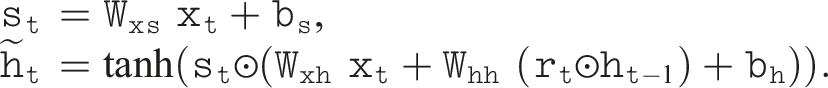
To further enhance spatial-temporal memorization, we extend the SRU-LSTM with a refined gating mechanism (Gu et al., 2020b), simply referred to as SRU-Ours in the following sections. This mechanism introduces an additional refining function to address gating saturation issues during recurrent training. The final modification, compared to the vanilla LSTM unit, is as follows:
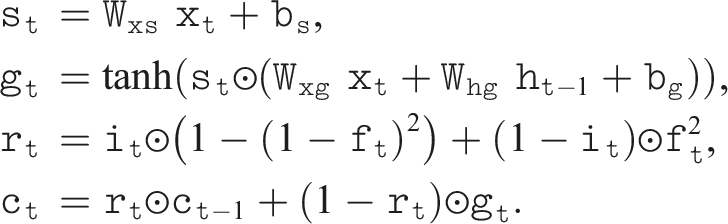
The effectiveness of SRU is further validated and compared to the standard LSTM unit in the designed spatial mapping task, as illustrated in Figure 2. In this task, the robot follows a spiral path, observing landmarks from varying perspectives along its trajectory. At the end of the path, the robot is tasked with memorizing and transforming the observed landmark coordinates into the final frame, as well as recalling the associated categories of the observed landmarks. Our experiments demonstrate that the SRU modification enables the network to effectively learn spatial transformations. In contrast, the baseline models struggle to align and memorize landmark coordinates observed in earlier steps, resulting in higher spatial errors, particularly for earlier observations, as depicted in Figure 2(c). However, both SRU and baseline models achieve 100% accuracy in recalling the categories of the observed landmarks. Since the temporal task results are identical across all models, they are not visualized specifically in Figure 2. Furthermore, the latest recurrent units, such as S4 and Mamba-SSM, which excel at long-term temporal memorization, exhibit even worse spatial memorization capabilities, as shown in both Figure 1(b) and Figure 2(c). The SRUs exhibit consistently low spatial errors across all observation steps, underscoring their superior spatial memorization capabilities. Spatial mapping comparison: (a) and (b) depict the spatial mapping performance of LSTM and SRU-LSTM units on synthetic data, respectively, as the robot follows a spiral path, observing landmarks from different perspectives. At the end of the path, the robot is tasked with memorizing and transforming the observed landmark coordinates into the final robot frame. Numbers indicate observation time steps. (c) illustrates the mean spatial memory errors (log scale) across observation step indices, ordered from the final (15) to the initial step (1), averaged over various randomly generated trajectories and observations.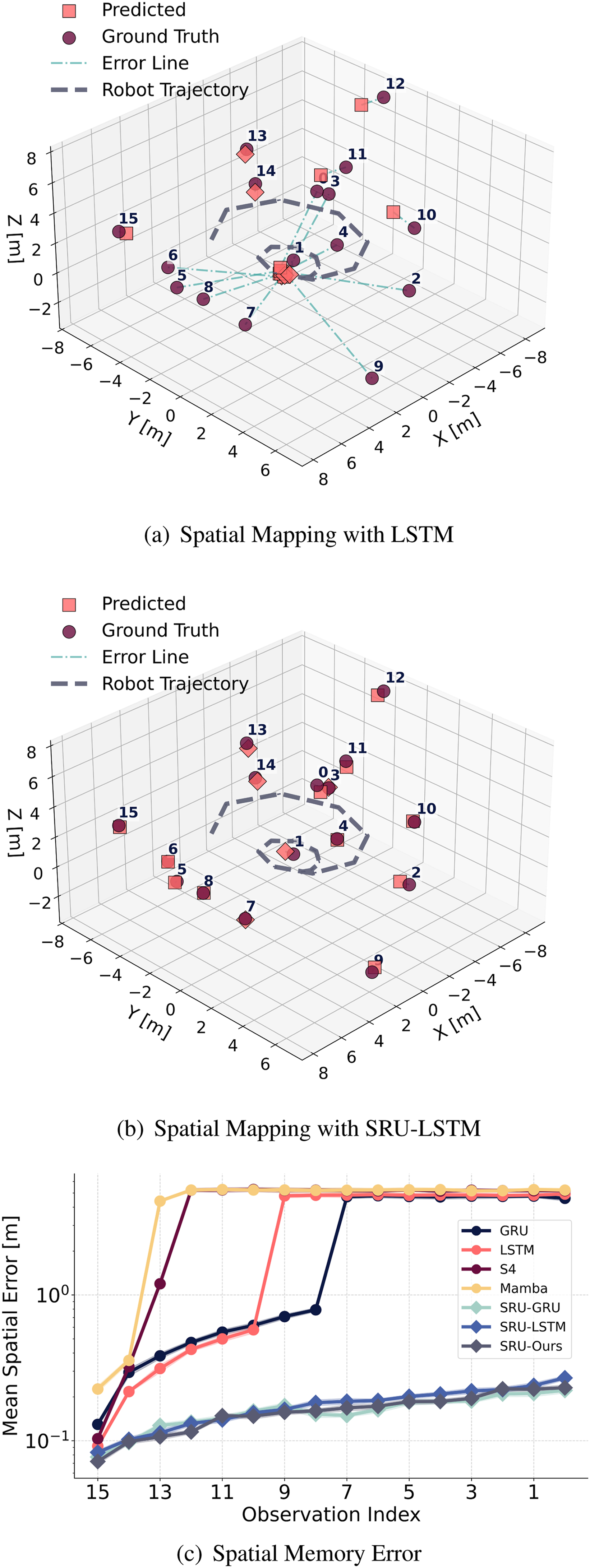
Attention-based recurrent network architecture for navigation
To leverage the SRUs in the navigation context, we propose an attention-based recurrent network architecture for long-range mapless navigation tasks using raw front-facing stereo depth input, as illustrated in Figure 3. The network consists of a pretrained depth image encoder, two spatial attention layers incorporating both self-attention and cross-attention mechanisms to enhance and compress the encoded visual features, and a recurrent unit (SRU) that learns a spatial-temporal representation of the state by fusing the current observation with historical observations. Finally, a multilayer perceptron (MLP) head computes the actions from the recurrent hidden state, outputting velocity commands for the robot’s locomotion controller. Attention-based recurrent network architecture for navigation: The network integrates a pretrained image encoder and an attention mechanism to compress and emphasize relevant features from encoded observations. These features, combined with proprioceptive inputs, are processed by the SRU unit, which learns spatial transformations and temporal dependencies and fuses them with historical observations to estimate the robot’s state. The state is then mapped to actions using an MLP-based head integrated with the temporally consistent (TC) dropout layer for improved robustness and generalization.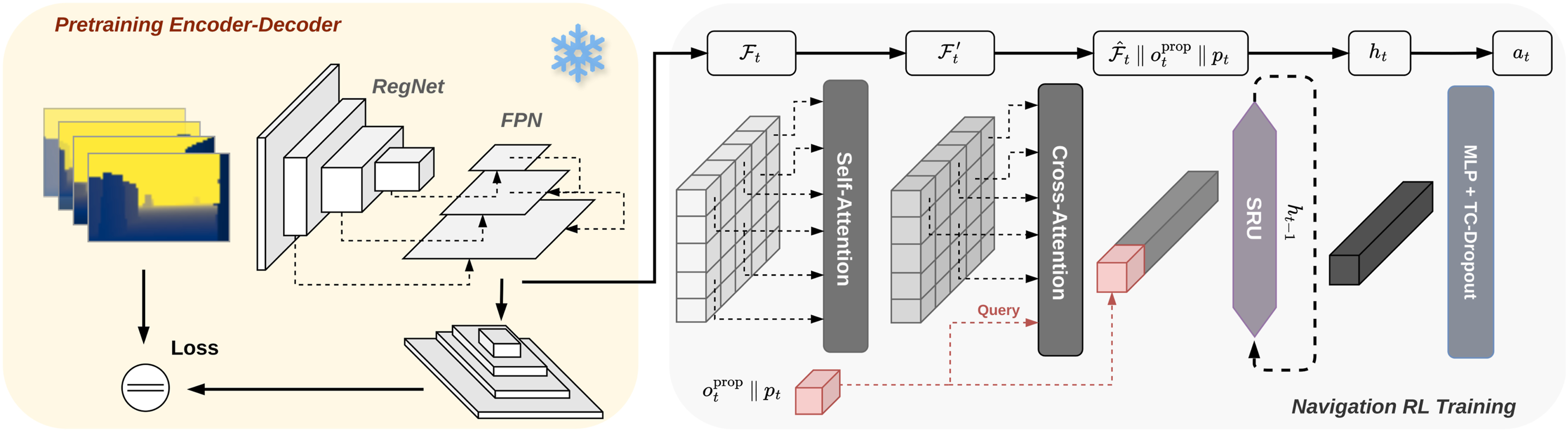
Depth encoder pretraining and simulated perception noise
For the depth encoder, we adopt a convolutional neural network (CNN) backbone based on RegNet (Radosavovic et al., 2020), chosen for its simplicity and efficiency. This is further enhanced with a feature pyramid network (FPN) (Lin et al., 2017) to capture spatial features across multiple scales. The encoder is pretrained for self-reconstruction on large-scale synthetic depth image data from TartanAir (Wang et al., 2020) using a variational autoencoder (VAE) framework. This pretraining enables the encoder to learn and extract robust and generalizable features from depth images, facilitating effective downstream navigation learning and deployment. However, depth images captured in simulation often differ from those obtained in real-world environments due to various sensor artifacts and noise. To address this sim-to-real gap, we integrate a parallelized depth-noise model, adapted from (Barron and Malik, 2013b; Bohg et al., 2014b; Handa et al., 2014), which introduces configurable noise to the depth images, such as: • Edge Noise: Distortions at sharp depth discontinuities due to abrupt changes in the scene. • Filling Noise: Blurring artifacts introduced during the interpolation of missing or unregistered pixels. • Rounding Noise: Quantization effects resulting from sensor resolution limitations, causing rounding errors.
Figure 4 illustrates an example of the simulated stereo depth noise. The depth-noise model is designed for efficient batch processing, enabling parallelized pretraining on large-scale datasets and during RL with simulated depth images. For implementation details, refer to Appendix B. Simulated stereo depth noise: (a) synthetic depth image from the TartanAir dataset (Wang et al., 2020) and (b) image with augmented artificial noise. The depth-noise model introduces edge, filling, and rounding noise to the depth images, simulating realistic sensor artifacts.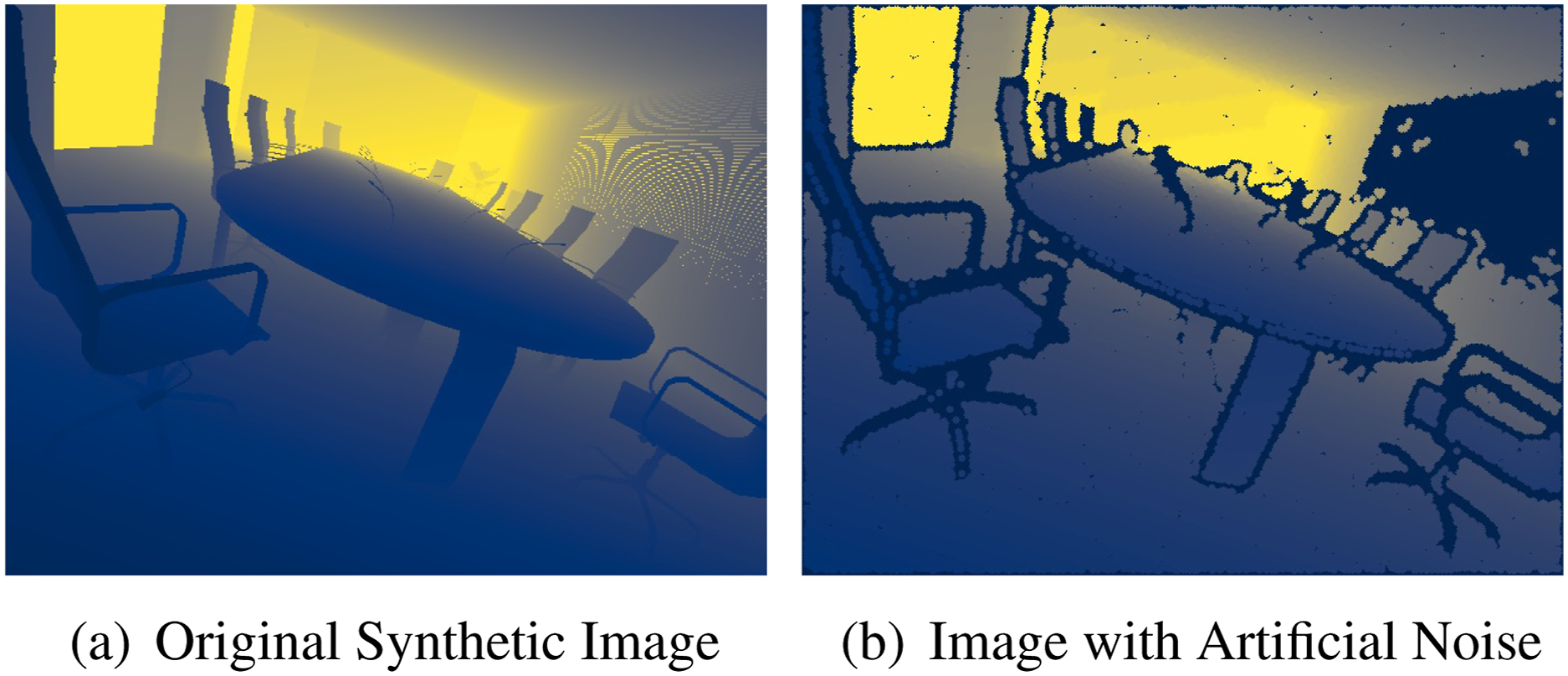
Attention layers for feature compression
During navigation, humans and animals tend to focus on the most relevant spatial cues rather than attempting to memorize all available information (Matthis et al., 2018). This selective attention enables more efficient and effective memory usage. To emulate this, we combine self-attention and cross-attention mechanisms in our architecture. These spatial attention layers process high-dimensional visual inputs, extracting the information most relevant to the robot’s current state. Specifically, given the feature map encoded by the pretrained depth encoder:
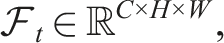
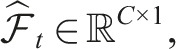
Figure 5 visualizes the output attention weights of the cross-attention layer across four distinct attention heads (depicted in different colors), overlaid on the depth input. It highlights how the attention mechanism focuses on depth features relevant to the robot’s current state. When the robot’s movement direction is manually altered, the output attention weights shift accordingly, emphasizing spatial regions and obstacles in the new direction. These behaviors emerge naturally during end-to-end learning, demonstrating the policy’s ability to effectively acquire critical spatial cues for navigation. Visualization of cross-attention weights corresponding to different robot states over raw real-world depth input: (a) when the robot turns left, the attention weights highlight the left region, focusing on the left pillar in the depth image; (b) when the robot moves straight, the attention weights emphasize the central region, capturing both pillars; (c) when the robot turns right, the attention weights focus on the right region, concentrating on the right pillar. Distinct colors in the attention weights visualizations represent different attention heads.
Spatially-enhanced recurrent unit
The spatially-enhanced recurrent unit (SRU), as described in Section 4.4, processes the compressed feature map
Learning navigation with sparse rewards and regularizations
The final attention-based network with the SRU is trained end-to-end using RL to achieve long-range mapless navigation, with the objective of maximizing the cumulative reward over the episode. The reward function for the navigation task is designed as a combination of task-level rewards rtask, regularization rreg, and penalty rpen terms, as follows:
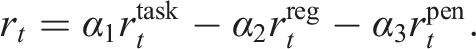
Here, α1, α2, and α3 are coefficients used to balance the contributions of the task-level reward, regularization, and penalty terms, respectively. The task-level reward
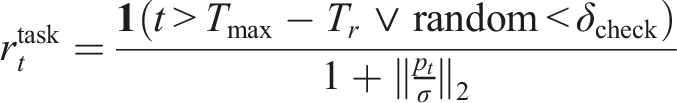
The regularization term
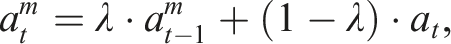
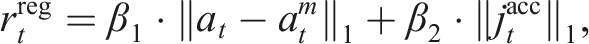
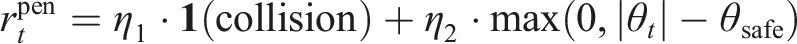
Training regularization
To mitigate overfitting and enhance robustness, we incorporate two additional regularization strategies during training. These strategies are crucial for training a robust spatial-temporal representation with SRUs, as explained below and demonstrated in the experimental results. The regularization techniques are as follows: • Deep mutual learning (DML): As described in Xie et al. (2025), DML involves training two policies simultaneously, enabling them to mutually distill knowledge from each other. This approach enhances generalization and mitigates the risk of convergence to suboptimal solutions. The mutual distillation is achieved by incorporating a Kullback–Leibler (KL) divergence loss between the two policies, both of which are trained using standard proximal policy optimization (PPO) (Schulman et al., 2017). • Temporally consistent dropout (TC-Dropout): Adapting from Hausknecht and Wagener (2022), we apply a consistent dropout mask across time steps during both rollout and training, ensuring stable memory learning within the recurrent structure.
As shown in Figure 1, SRUs exhibit a slower convergence rate for spatial memorization compared to learning temporal dependencies, highlighting the inherent complexity and slower pace of learning spatial transformations and forming spatial memory. This discrepancy can lead the network to favor easier-to-learn solutions early in training, relying on temporal features while neglecting the formation of good spatial memorization, resulting in suboptimal performance. To address this, it is crucial to incorporate regularization techniques that mitigate early overfitting and promote the exploration and development of more challenging spatial-temporal features during policy optimization. To tackle this challenge, we employ deep mutual learning (DML) strategies tailored for reinforcement learning (RL) (Xie et al., 2025). DML involves training multiple policies in parallel, allowing them to distill knowledge from one another. This mutual distillation process enhances the network’s generalization capabilities and fosters the learning of robust and essential features. By regularizing each other, the models are less likely to converge prematurely to suboptimal solutions that rely solely on easy-to-learn features, such as temporal dependencies. Instead, DML encourages the formation of spatial-temporal representations, leading to improved overall performance. This approach is critical for leveraging the full potential of the SRU network, as demonstrated in the experimental results.
Second, compared to standard dropout layers, consistent dropout addresses a critical issue in on-policy reinforcement learning, where standard dropout introduces inconsistent masks between the rollout and training stages (Hausknecht and Wagener, 2022). Building on this, we extend consistent dropout with temporal consistency for training the recurrent structure. Specifically, during the data rollout stage, we maintain the same dropout mask across all time steps, ensuring temporal consistency. During the training stage, the same dropout mask is applied to the policy network. This approach promotes stable memory learning through recurrent connections and enhances the robustness of the learned policy.
Experiments
To evaluate the effectiveness of the proposed spatially-enhanced recurrent unit (SRU) and the attention-based network architecture in enhancing long-horizon robot navigation, we conduct experiments in both simulated and real-world environments. We compare the SRU against standard LSTM and GRU units in long-range mapless navigation tasks, focusing on their performance in end-to-end reinforcement learning (RL) training and navigation success rates (SR). Additionally, we compare the SRU policy, integrated with our proposed network structure and trained using recurrent RL, against two current state-of-the-art (SOTA) baselines (Huang et al., 2023; Lee et al., 2024) for robot navigation with RL. Our evaluation highlights the advantages of the implicit recurrent memory provided by SRU in solving long-range mapless navigation tasks across diverse environments.
Furthermore, we ablate the role of our proposed spatial attention layers in compressing features from encoded observations to improve memorization and overall navigation performance. We compare our approach against the convolution and average pooling method used in Wijmans et al. (2020), as well as the attention mechanism introduced in Huang et al. (2023). We also investigate the impact of regularization techniques on training the SRU unit end-to-end in RL, evaluating their effectiveness in preventing early convergence to suboptimal solutions and enhancing navigation performance. Finally, we explain and validate the pretrained image encoder’s ability to bridge the sim-to-real gap by demonstrating zero-shot transfer across diverse and complex real-world environments.
Experimental setup
We conduct our experiments in simulated 3D environments using NVIDIA IsaacLab (Mittal et al., 2023), which provides a realistic physics engine and fast, parallelizable simulation capabilities. The environments are designed to challenge the robot’s navigation capabilities and include maze-like structures, randomly generated pillars, stairs, and environments with negative obstacles, such as holes and pits, as shown in Figure 6. The robot is equipped with front-facing depth sensors as the only exteroceptive input, capturing the surrounding environment from an egocentric perspective. Additionally, a state estimation and localization module provides the robot’s proprioceptive state Simulated environments used for training and testing RL-based navigation tasks: (A) maze, (B) random pillars, (C) stairs, and (D) pits. These environments are parameterizable and can be randomly generated during both training and testing using the NVIDIA IsaacLab (Mittal et al., 2023) simulation framework.
Comparsion with recurrent units
We evaluate the performance of the proposed spatially-enhanced recurrent units (SRUs) compared to standard LSTM and GRU units. Given the superior spatial memorization capability of SRUs, as demonstrated in Figure 1, we hypothesize that integrating SRUs will improve the performance of navigation policies in addressing long-range mapless navigation tasks. To test this hypothesis, we train, under same conditions, policy networks integrated with different recurrent units end-to-end using RL in the simulated 3D environments shown in Figure 6. All policies are equipped with the same components (attention, training regularization, and a pretrained encoder); only the recurrent network structure differs. We then evaluate their navigation performance.
As shown in Figure 7, the policy with the SRU memory unit is able to outperform those with standard LSTM and GRU units in terms of average return episode rewards during training, with results averaged across multiple random seeds. (Note: GRU training can exhibit instability, so only its successful runs are included in the analysis.) Table 1 provides a summary of the navigation performance for policies using different architectures. The best-performing model from each unit (determined by the highest average return rewards) is selected for comparison. The data is averaged over 4800 episodes across 120 randomly generated environments, which are different from the training set. The results are presented in terms of success rate (SR) for each environment. The SRU units consistently outperform the standard LSTM and GRU units, achieving an average 21.8% improvement in SR across all environments with the SRU modification alone. Furthermore, incorporating the refined gating mechanism in the SRU-Ours model further boosts the results, achieving an overall 23.5% increase in SR, demonstrating the effectiveness of these enhancements in improving navigation performance. Notably, in stair-like environments, where the 3D structure and significant occlusions pose challenges for navigation without precise spatial memorization and registration capabilities, the navigation policy with SRU units demonstrate over double the performance in success rate compared to standard LSTM and GRU units. Training curve comparison between policies integrated with different recurrent units: The average return from three random seeds during training. The architecture with SRU units achieves a higher return compared to the baseline LSTM and GRU units. Navigation success rate (SR) for policies integrated with different recurrent units across four environment types: Maze, random pillars, stairs, and pits. The table compares standard LSTM and GRU units with our proposed spatially enhanced counterparts: SRU-GRU, SRU-LSTM, and SRU-Ours. Bold values denote the highest performance within each column.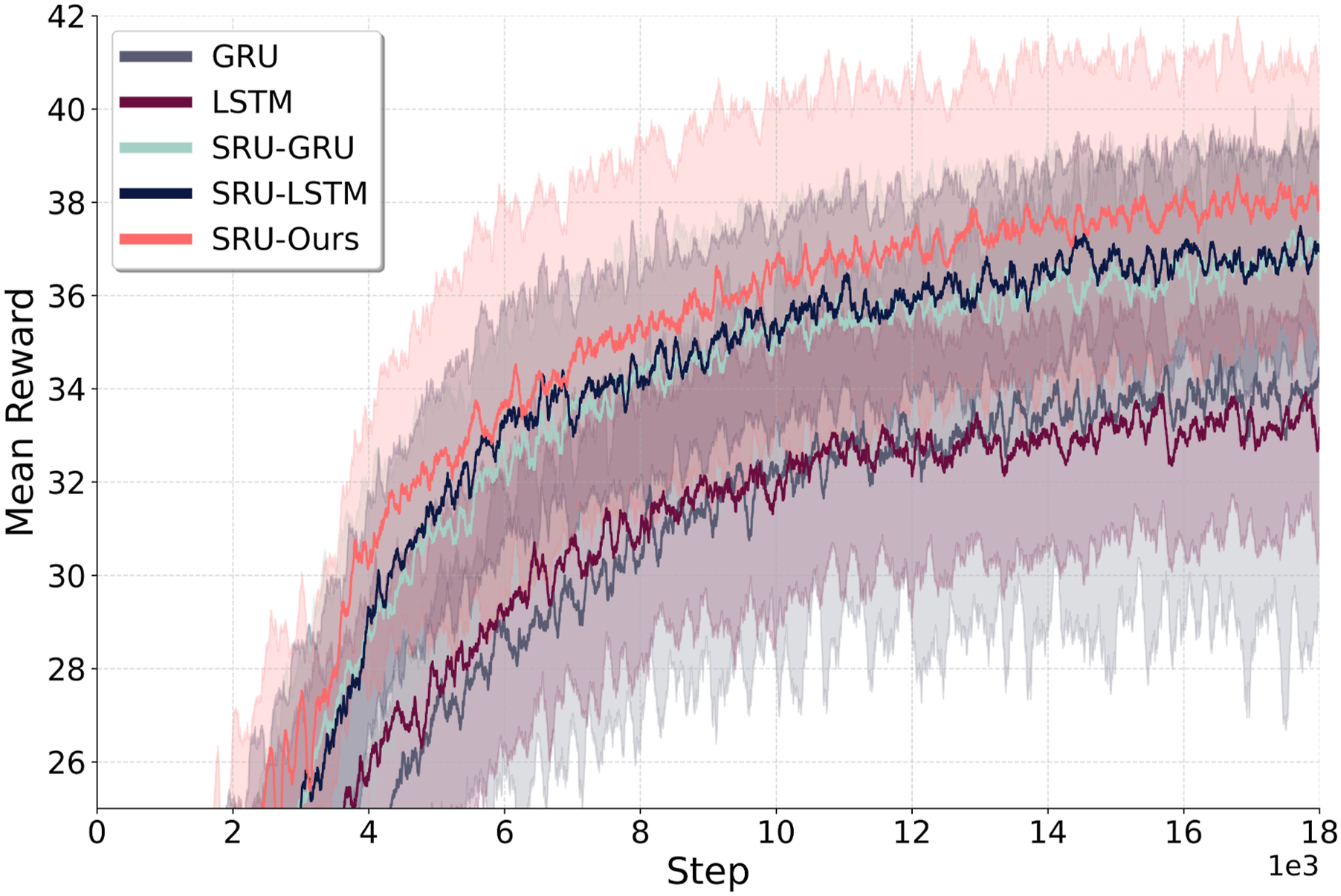
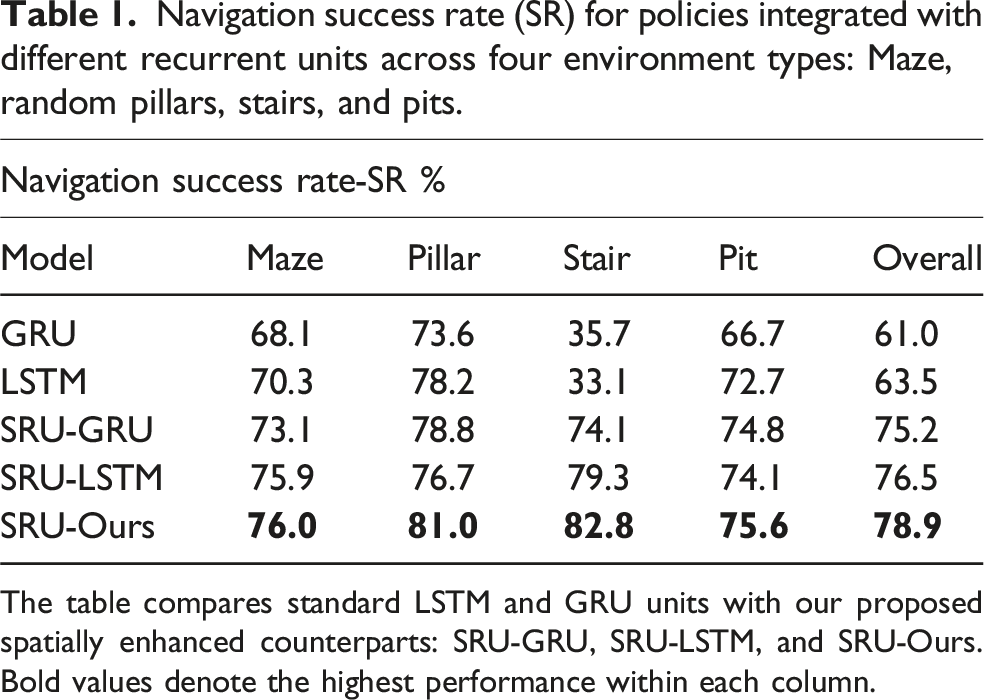
Figure 8 presents example traversed trajectories comparison between the SRU and standard LSTM policies. In maze environments, the LSTM policy gets trapped in a dead-end corridor, looping between points B and C, while the SRU policy successfully passes through the corridor, demonstrating better spatial memorization capability. In stair-like environments, although the LSTM eventually reaches the destination, it exhibits frequent back-and-forth movements (areas A and B), indicating less reliable spatial-temporal memorization and estimation of the current state compared to the policy with SRU. In pit environments, the LSTM policy fails to avoid the previously encountered pits that are no longer visible in the current depth observation, when turning at area A. In contrast, the SRU policy effectively recalls the locations of the pit and other previously observed obstacles, enabling it to avoid them during turns and backward motion. Comparison of navigation trajectories using (a) Navigation Policy with LSTM Unit and (b) Navigation Policy with SRU-Ours. The traversed trajectories are shown in yellow. In maze environments, the LSTM policy becomes trapped in a dead-end corridor, repeatedly looping between points B and C, while the SRU policy successfully navigates through the corridor, traverses region D, and reaches the goal. In stair-like environments, the LSTM policy exhibits frequent back-and-forth movements in areas A and B, indicating unreliable spatial-temporal mapping. In pit environments, the LSTM policy fails to avoid previously encountered pits during turns at area A, whereas the SRU policy effectively recalls their locations and avoids them, even during backward motion.
Comparsion against RL-based navigation baselines
Next, we compare our proposed network structure, trained using recurrent reinforcement learning with SRU, against two state-of-the-art RL baseline methods: the goal-guided transformer-based RL approach (GTRL) (Huang et al., 2023) and the RL approach with explicit mapping and historical path (EMHP) (Lee et al., 2024). GTRL employs a goal-guided transformer (GoT) architecture to extract task-relevant visual features from stacked historical observations, enabling mapless navigation using only egocentric input. EMHP employs an external mapping pipeline to integrate historical observations for local mapping (Miki et al., 2022b) and uses an explicit historical traversed path to address POMDP challenges in long-range mapless navigation. While explicit mapping (EMHP) can theoretically achieve high accuracy in spatial-temporal registration, it has two major drawbacks: (i) it introduces significant delays that hinder real-time performance, especially on high-speed, agile platforms (Lee et al., 2024), and (ii) it relies on heuristic rules (e.g., fixed context window lengths) to select information, limiting its ability to capture complex spatial-temporal dependencies and abstract information beyond the selected context window.
Figure 9(a) presents a comparison between the EMHP baseline and our SRU-based approach. The EMHP policy collects historical paths for approximately 20 m, which is insufficient to navigate the long corridor spanning around 30 m. In contrast, recurrent neural networks offer an unlimited context window and can learn intricate spatial-temporal dependencies optimized for the given task. This allows the SRU-based policy to adapt to long-horizon navigation challenges more effectively. Moreover, our end-to-end architecture processes raw depth sensor inputs, reducing latency and better supporting the agile and fast motion of legged-wheel platforms during deployment. For the GTRL baseline, temporal history is provided by stacking several past observation frames, which are then fused using the transformer-based architecture as described in Huang et al. (2023). Following the original approach in Huang et al. (2023), we use the 4-frame history in our experiments. However, the choice of the number of stacked frames remains heuristic: a short history may miss important context, while a longer history increases computational cost quadratically. For a fair comparison, we retrain the GTRL baseline, as described in Huang et al. (2023), within our environment. We replace the RGB input with depth images and utilize the same on-policy optimization method (PPO) for end-to-end RL training. To ensure consistency with the platform utilized in Lee et al. (2024), this comparison is conducted using the simulated wheeled ANYmal (Hutter et al., 2016) robot model, which differs from the robot model used in the other comparisons in this paper. All policies are trained under identical conditions and evaluated on an independent test environment set to ensure a fair comparison. Note that our policy and the GTRL baseline rely solely on a front-facing camera with a limited field of view, whereas the EMHP approach incorporates a local height scan with a similar range for environmental detection but benefits from a complete 360-degree field of view for mapping. Comparison of proposed mapless method with SRU recurrent memory against the EMHP baseline approach in a maze environment. The robot’s traversed trajectory is shown in yellow, with traversal order marked as A, B, C, and D. (a) The EMHP approach starts looping in the long corridor between points B and C, failing to navigate through the dead-end corridors. (b) Our approach, with SRU recurrent memory, successfully navigates from start to goal, rerouting through the dead-end corridors and reaching the goal through area D.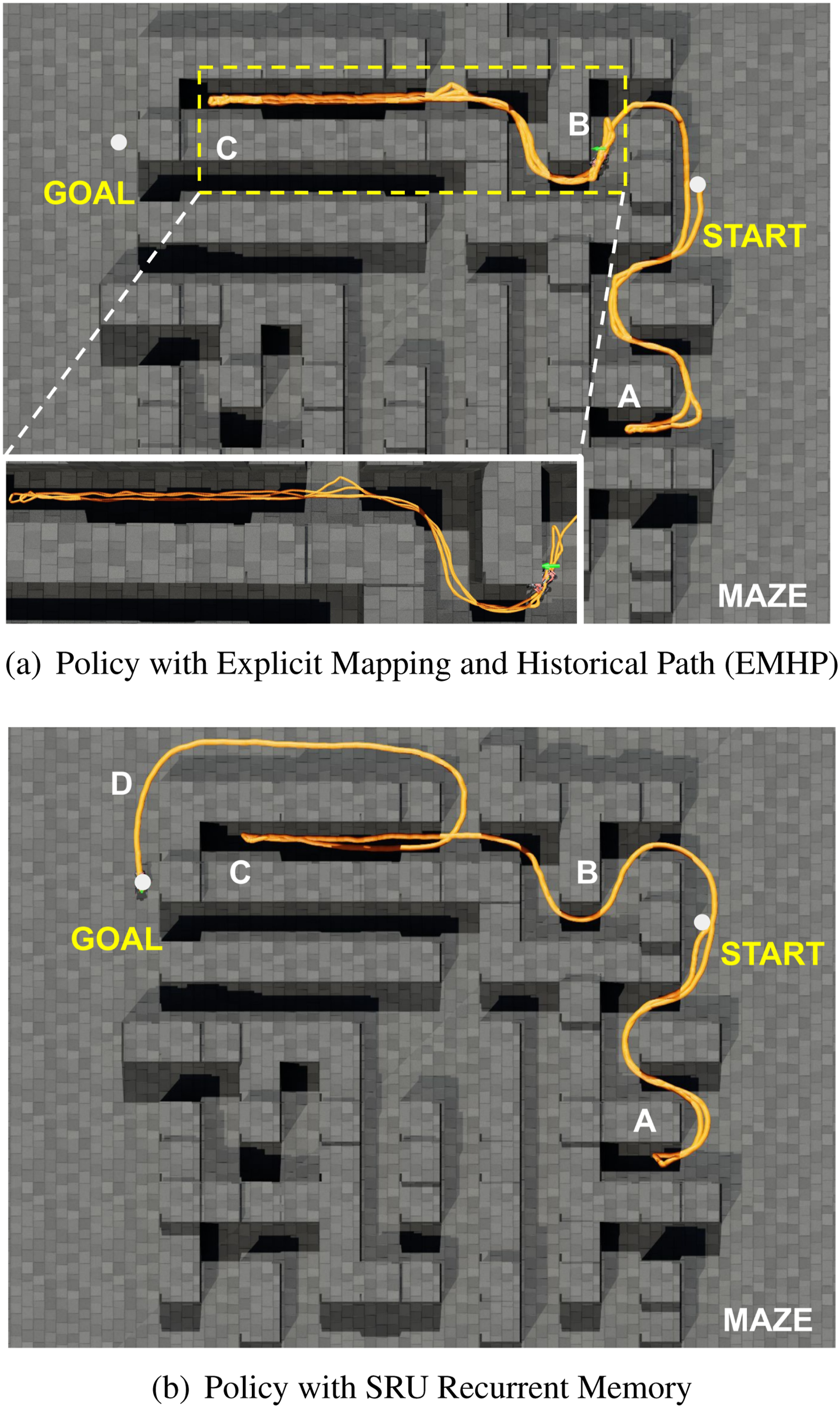
Overall navigation success rate (SR) comparison against baselines.

Policies with SRU implicit recurrent memory outperform: (i) GTRL (stacked historical observations) and (ii) EMHP (explicit mapping and historical path). GTRL* denotes our modified GTRL variant where stacked observations are replaced by SRU implicit memory, yielding a substantial gain over the original GTRL baseline. Bold values denote the highest performance.
Quantitatively, while the EMHP approach achieves comparable navigation performance, we also analyze the success rate (SR) as a function of travel distance to evaluate its long-range memorization and generalization capabilities. As shown in Figure 10, with a maximum episodic time of 60 s (consistent with training) and the robot’s maximum speed set to 1.5 m/s, the EMHP approach’s SR drops significantly when the travel distance exceeds 40 m. In contrast, our SRU-based approach maintains an SR of over 80% up to 50 m. When the maximum episode time is extended to 120 s, the EMHP’s SR still declines to below 60% at the same 40-m distance, constrained by its fixed context window. Conversely, our SRU-based approach sustains an SR of over 70% for distances up to 120 m, demonstrating the SRU’s superior ability to implicitly learn spatial-temporal mappings and generalize to distances beyond the training range. The baseline’s reliance on a fixed explicit memory window limits its capacity to capture long-range dependencies, hindering its generalization in extended long-distance navigation tasks. Success rate sorted by travel distance: comparison between the EMHP baseline approach, which uses explicit mapping and a fixed-length historical path, and our approach, which employs the implicit recurrent memory of SRU. Our method maintains a high success rate over longer distances and extends effectively with longer episodic times. In contrast, the baseline’s success rate drops significantly for longer travel distances, even when the maximum episodic time is doubled, due to its fixed context window limitation.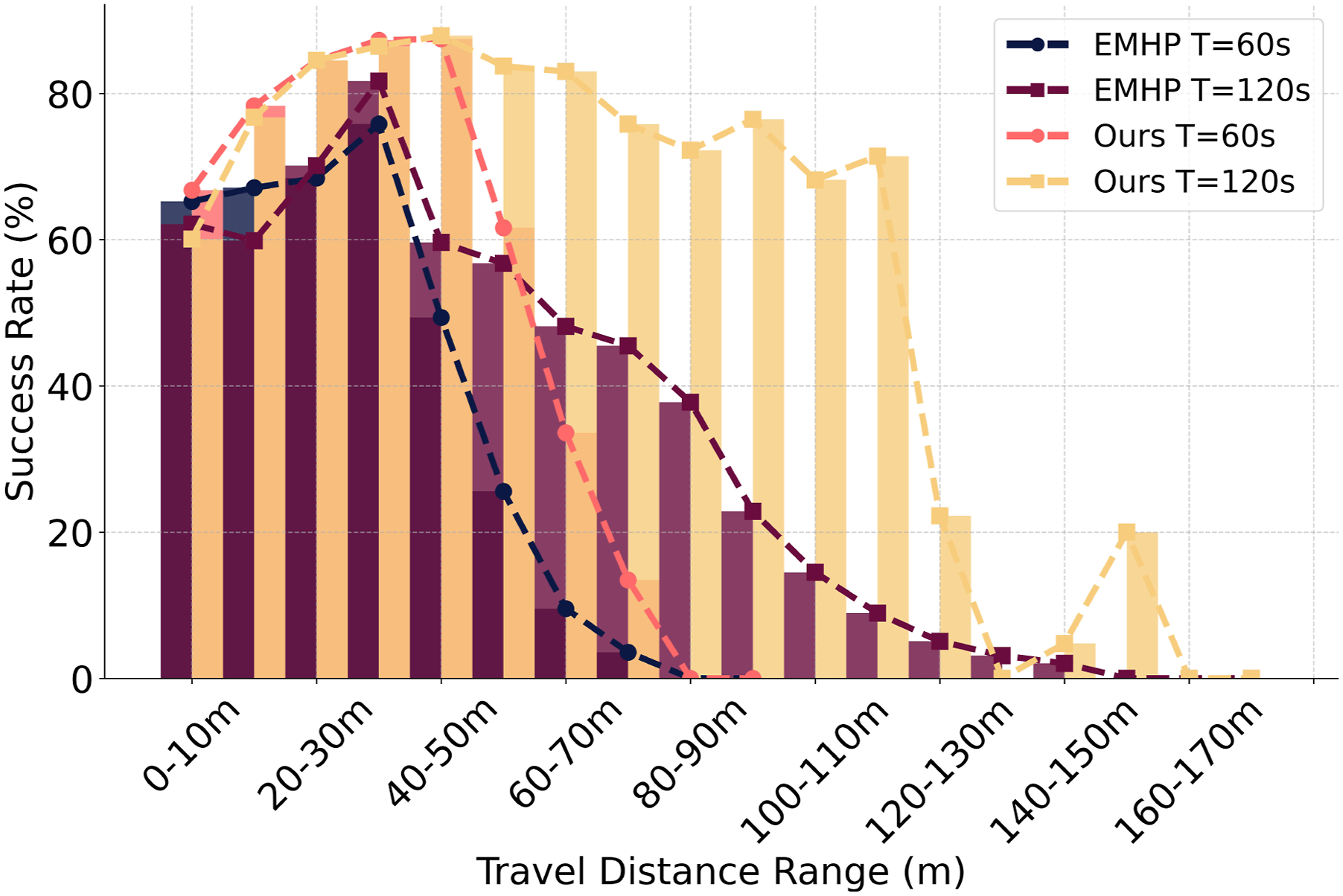
Furthermore, we observed that the EMHP policy struggles to effectively learn to climb staircases unless dense reward guidance is provided. We believe this limitation arises from the inherent difficulty explicit memory mechanisms face in capturing intricate spatial-temporal features, which are essential for the robot to develop the maneuvers required to overcome 3D obstacles effectively. Lastly, the end-to-end recurrent setup offers a simpler and more maintainable solution compared to baseline methods. In contrast, baselines rely on an external mapping pipeline and the storage of additional historical paths or observations for each robot, which can introduce complexity and overhead during both training and real-world deployment.
Importance of spatial attention layers
We now examine the role of the proposed spatial attention layers in the network architecture and evaluate their impact on navigation performance. These layers are designed to compress and emphasize relevant features from encoded observations, addressing a key challenge faced by recurrent structures: the difficulty of retaining long-term information due to the exponential decay of memory over time. By selectively focusing on the most salient features, the attention mechanism emphasizes the most relevant spatial cues for navigation based on the robot’s state and reduces the information density passed into the recurrent memory at each step. We hypothesize that this mechanism can improve the network’s memorization and navigation capabilities, enabling it to handle complex, long-range tasks more effectively.
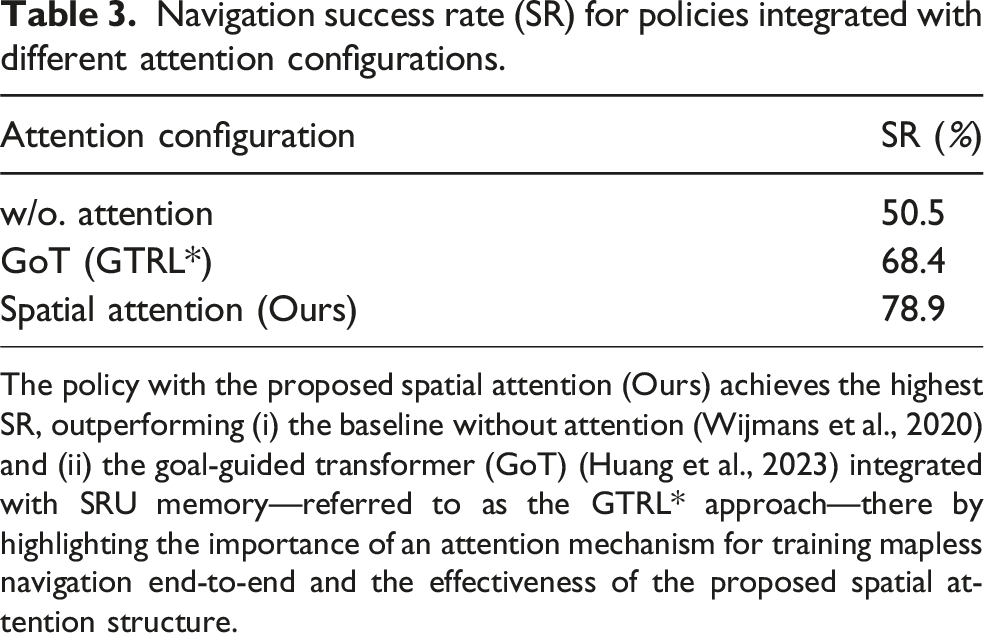
To test this, we conduct an ablation study by: (i) removing the attention layers from our network architecture and replacing them with convolution followed by average pooling for feature compression, as implemented in Wijmans et al. (2020), and (ii) comparing the performance of our proposed spatial attention layers against the goal-guided transformer (GoT) architecture proposed in Huang et al. (2023). The GoT architecture utilizes a modified vision transformer (ViT) that integrates the goal state as an additional token. It performs self-attention across both visual feature tokens and the goal token to extract goal-relevant features. In contrast, our approach first applies self-attention exclusively to visual tokens to enhance spatial features. Subsequently, the goal and proprioceptive state are used as queries in the cross-attention layer to compress and extract the most relevant features. For a fair comparison in the ablation experiments, we use identical training settings for all approaches, integrating the SRU memories and the pretrained encoder while varying only the attention layers used to process visual features during RL. The GoT integrated with SRU is the GTRL* approach, as described in Section 5.3. Figure 11 shows the average return rewards during training. The network without the attention layers exhibits significantly lower performance compared to the two policies utilizing attention mechanisms. Additionally, our proposed spatial attention layers outperform the GoT attention mechanism. Table 3 shows the SR performance of the three configurations: (i) without attention, (ii) with GoT attention, and (iii) with our proposed spatial attention (Ours). Our method achieves a 56.2% relative SR improvement over the no-attention baseline, highlighting the importance of selectively compressing and extracting spatial features for long-range mapless navigation when utilizing implicit recurrent memory. Furthermore, it achieves a 15.4% relative improvement (18.1% when trained with the ANYmal robot model, as shown in Table 2) over the policy utilizing GoT attention. This demonstrates that the proposed two-stage spatial attention mechanism more effectively extracts task-relevant cues, enhancing recurrent memorization and policy optimization. Average training return rewards for attention ablations (all using SRU recurrent memory): (1) without attention (w/o.) (Wijmans et al., 2020); (2) goal-guided transformer (GoT) attention (Huang et al., 2023); and (3) the proposed two-stage spatial attention (Ours). The proposed spatial attention achieves the highest returns, indicating more effective extraction of task-relevant spatial cues for improved recurrent memorization. Navigation success rate (SR) for policies integrated with different attention configurations. The policy with the proposed spatial attention (Ours) achieves the highest SR, outperforming (i) the baseline without attention (Wijmans et al., 2020) and (ii) the goal-guided transformer (GoT) (Huang et al., 2023) integrated with SRU memory—referred to as the GTRL* approach—there by highlighting the importance of an attention mechanism for training mapless navigation end-to-end and the effectiveness of the proposed spatial attention structure.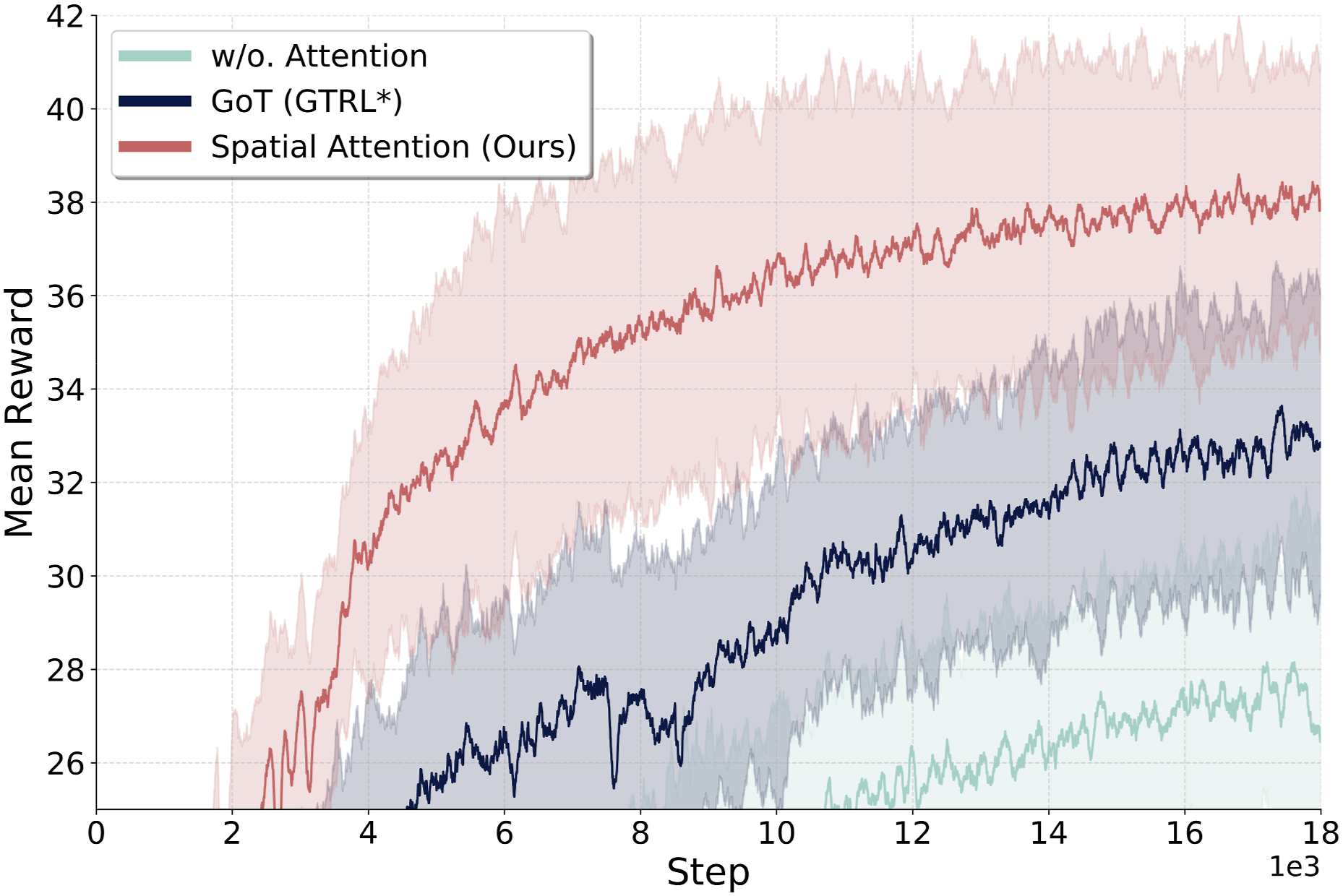
Notably, the attention effect emerges naturally during the end-to-end RL training without requiring additional supervision or auxiliary losses. Figure 12 illustrates the attention weights generated by the cross-attention layer over raw visual inputs in three distinct real-world deployment scenarios: an indoor office, an outdoor terrace, and a forest environment. The attention weights, with four attention heads (depicted in different colors), dynamically emphasize the most relevant spatial cues, such as obstacles and navigable free space, based on the robot’s state at the time the depth input was recorded. This highlights the effectiveness of training the spatial attention mechanism end-to-end and its ability to generalize across diverse and challenging environments. Visualization of attention weights for the cross-attention layer in three distinct real-world deployment scenarios over raw depth inputs: (a) office environment, (b) outdoor terrace environment, and (c) forest environment. The attention weights dynamically highlight relevant spatial cues for navigation based on the robot’s state. The RGB images in the top corners are included for visualization purposes only.
Training with regularizations
We evaluate the role of regularization techniques in the end-to-end training of the recurrent network using reinforcement learning. First, as shown in Figure 1 and discussed in Section 4.6, while the SRU unit effectively enhances the network’s ability to learn implicit spatial memorization from sequential observations, the learning curve indicates that spatial memory learning can converge significantly slower than temporal memorization. This discrepancy, combined with the inherent properties of standard policy optimization algorithms like PPO—which restrict deviations from previous optimization steps—and the complex structure of attention networks with RNNs prone to overfitting, suggests that without proper regularization, the network may converge to suboptimal strategies. Such strategies might overly rely on easier-to-learn temporal features to solve navigation tasks, thereby failing to establish robust spatial-temporal memorization. To test this hypothesis, we conduct an ablation study by removing the regularization techniques, specifically deep mutual learning (DML), from the standard PPO training setup and comparing the performance against the setup with DML regularization.
Figure 13 illustrates that the network without DML exhibits lower average return rewards during training. Notably, the performance difference between standard LSTM and SRU modifications becomes more pronounced when regularization techniques are applied. As shown in Table 4, the SR performance improves from 61.8% to 65.7% (a 6.3% increase) without DML and from 63.5% to 78.9% (a significant 24.3% increase) with DML. This finding underscores that, in certain RL tasks, the network’s architecture alone may not be the sole limiting factor. Instead, the optimization process plays a critical role in fully leveraging the network’s potential, highlighting the importance of effective training strategies. Training curve comparison between policies trained using PPO with deep mutual learning (DML) regularization and PPO: The network with DML regularization techniques achieves higher returns compared to the network trained with vanilla PPO. Comparison of the overall navigation success rate (SR) with and without DML regularization for policies using LSTM and SRU units. DML significantly enhances SR for SRU (over 20%) and provides a marginal improvement for LSTM (2.8%), showcasing DML’s effectiveness in unlocking SRU’s potential for long-range mapless navigation.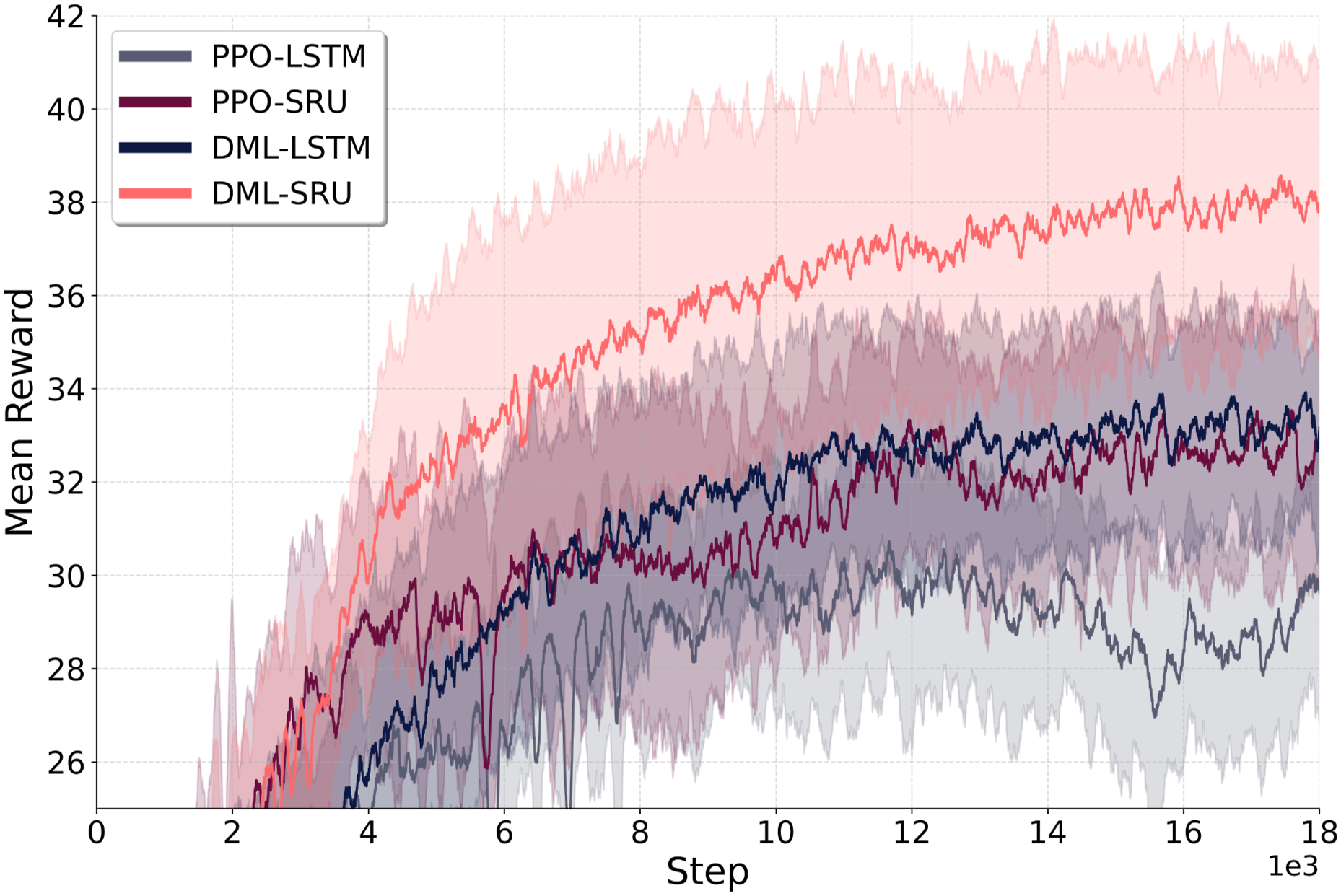

Evaluation of the overall navigation success rate (SR) with and without temporally consistent dropout (TC-D).

The network with TC-D is able to maintain a similar (or even higher) SR compared to the network without TC-D, while improving robustness and generalization.
Large-scale pretraining for sim-to-real transfer
In this section, we evaluate the pretrained image encoder, trained on a large-scale synthetic dataset, for its ability to bridge the sim-to-real gap in real-world perception. Additionally, we assess the effectiveness of the proposed depth noise model in reducing discrepancies between synthetic and real-world data. To this end, we conduct zero-shot transfer experiments on legged-wheel platforms across diverse real-world environments to demonstrate the generalization of our approach.
Pretrain and depth noise
Here, we analyze the latent space distribution of encoders trained under two distinct conditions: (i) an encoder trained exclusively on simulated depth images generated during RL navigation training (RL images), (ii) an encoder pretrained on large-scale synthetic data from Wang et al. (2020), augmented with the proposed parallelizable depth noise model (Figure 4). To evaluate these encoders, we compare the latent features extracted from their outputs using two data sources: (i) RL images and (ii) real-world stereo depth images captured by the ZEDX camera during deployment (real-world images). This analysis highlights their differences in latent space distributions depending on the pretraining data source used for the encoder.
Figure 14 illustrates a 2D principal components analysis (PCA) (Dunteman, 1989) projection of the latent features. The latent space distribution of RL-images shows a larger distribution range that encompasses the features extracted from real-world data when derived from the encoder pretrained on large-scale synthetic data (Figure 14(a)). This indicates that the encoder pretrained on large-scale synthetic data effectively captures a wide range of features, enabling it to generalize well to real-world scenarios. In contrast, the encoder trained solely on RL images (Figure 14(b)) exhibits a narrower latent space distribution, failing to cover many real-world features. This suggests that an encoder trained exclusively on simulated depth images collected during RL navigation training may struggle to generalize effectively to real-world data when deployed. Comparison of latent space distributions: (a) The feature distribution from the encoder pretrained on large-scale synthetic data effectively covers the distribution of real-world data, indicating better generalization. (b) The feature distribution from the encoder trained solely on simulated data collected during RL fails to cover the distribution of real-world depth images, posing challenges in generalizing to real-world data.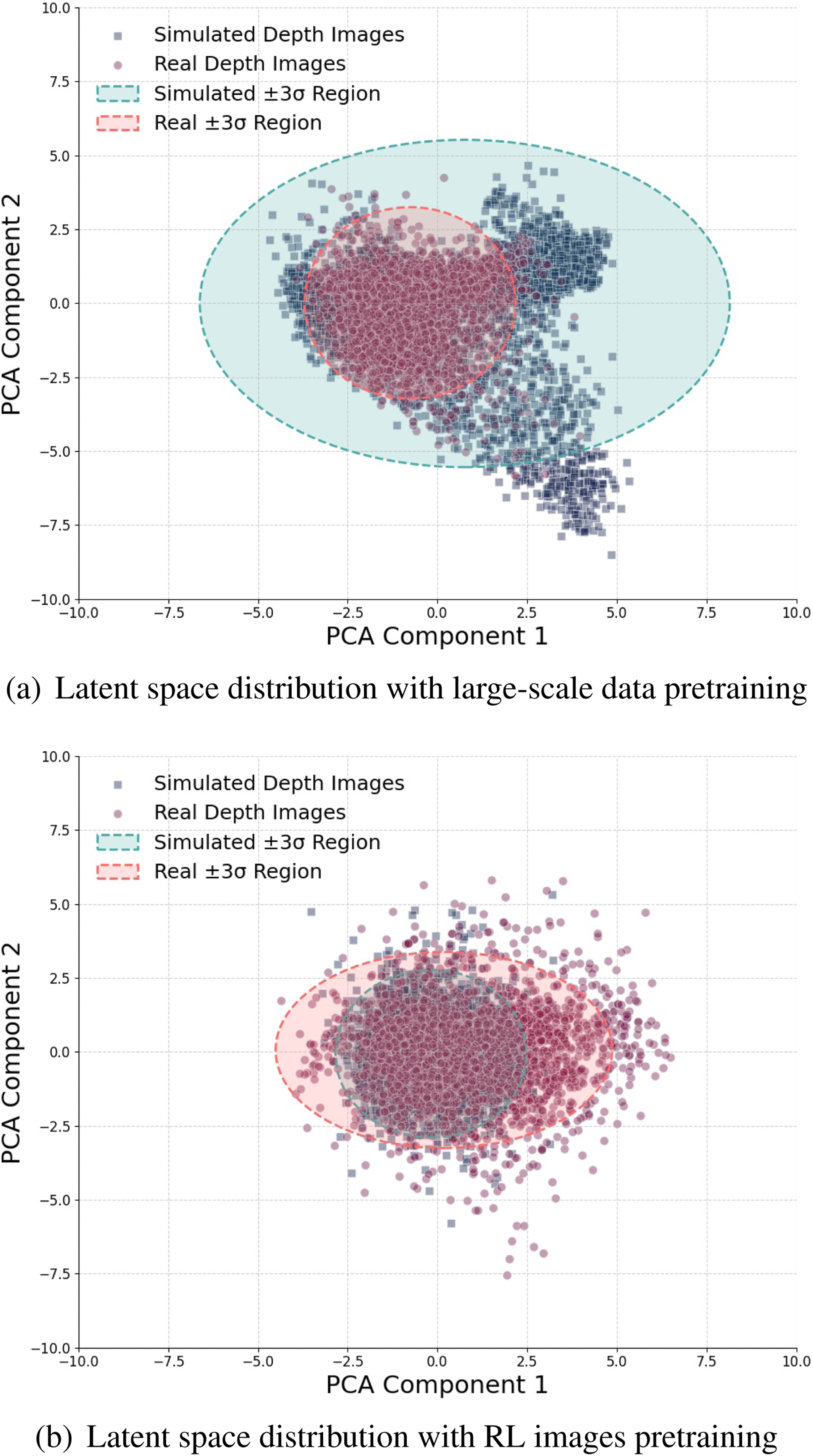
Additionally, Figure 15 provides a qualitative comparison of depth reconstruction using features extracted from the same two pretrained encoders. The comparison is based on a real-world stereo depth input captured during deployment. The encoder pretrained on large-scale data demonstrates effective reconstruction of the depth image, with only minor blurring effects (Figure 15(b)). In contrast, the encoder trained solely on RL images struggles to reconstruct the input depth image effectively, resulting in outputs with significant artifacts and noise (Figure 15(c)). Comparison of depth image reconstruction using features from encoders pretrained on different data sources. (a) Original input stereo depth image from real-world deployment, captured using the ZEDX camera. (b) Reconstructed depth image using features extracted from the encoder pretrained on large-scale synthetic data with noise augmentation. (c) Reconstructed depth image using features extracted from the encoder trained exclusively on simulated images collected during RL navigation training.
To quantitatively assess the distributional disparity of features from encoders trained on different sources, we adapt the method from Lee et al. (2018) to measure the Mahalanobis distance (MD) for the latent distributions derived from each encoder. In addition to the two pretraining sources mentioned earlier, we also analyze the latent distribution of the encoder pretrained on large-scale synthetic data without noise augmentation. This allows us to evaluate the effectiveness of the proposed depth noise model in further reducing the sim-to-real gap between synthetic depth images and real-world stereo depth. The MDs are computed between the latent features of real-world images and the latent feature distributions of RL images extracted from each encoder. As shown in Figure 16, pretraining on large-scale synthetic data effectively reduces the MD, lowering the median from 1.15 (RL images) to 0.82 (large-scale synthetic data without noise). This demonstrates the pretrained encoder’s effectiveness in covering the distribution of real-world perception inputs. Furthermore, incorporating the proposed depth noise model further reduces the MD to 0.69, underscoring its role in narrowing the differences between synthetic and real-world depth data. These results highlight that the encoder, pretrained on large-scale data and augmented with the proposed depth noise model, can effectively minimize the sim-to-real gap, enabling improved generalization to real-world environments. Comparison of Mahalanobis distances between the latent features of real-world images and the latent feature distributions of RL images, using encoders pretrained on different sources: (i) RL images, (ii) large-scale synthetic data without noise augmentation, and (iii) large-scale synthetic data with noise augmentation.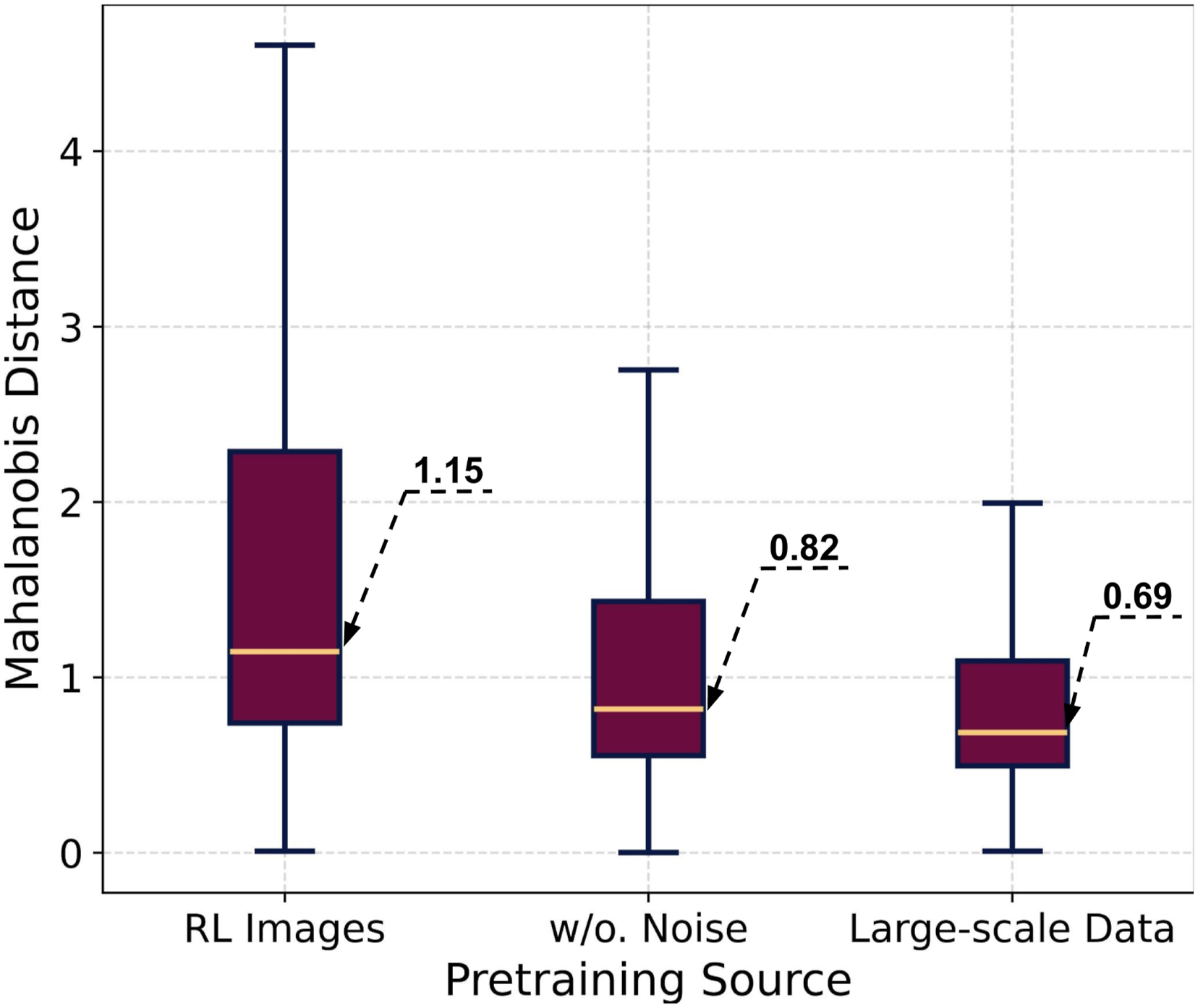
Real-world tests on legged-wheel robot
To evaluate the pretrained image encoder’s with the proposed attention-based recurrent network’s ability to generalize across in real-world environments, we conduct several zero-shot transfer experiments, on a Unitree B2W robot with a learning-based locomotion policy from RIVR. The robot is mounted with a ZEDX, front-facing stereo depth sensor, and NVIDIA Jetson AGX Orin for onboard compute for the policy. The pretrained encoder and network are directly deployed on the robot without any fine-tuning with real-world data. For all the test, the robot receives no prior information about the environment, and receives only the stereo depth images from the front-facing camera as the exteroceptive input. Additionally, a LiDAR-based state estimation and localization module (Chen et al., 2023) provide the robot’s proprioceptive state, including linear and angular velocities v t and ω t , projected gravity n t , and relative goal position p t with respect to the robot’s frame. The robot is controlled by a set of linear and angular velocities, referred to as action a t , which is the input to the locomotion policy.
First, we conduct an experiment in an office environment, as shown in Figure 17, to compare the navigation performance of our policy with the SRU memory module against a baseline model using a standard LSTM unit. In this experiment, the robot is tasked with navigating from one side of the office to the other while avoiding obstacles. To evaluate the long-term spatial-temporal memorization capabilities of the SRU module, several passageways are temporarily blocked, requiring the robot to backtrack and search for alternative routes to reach the goal. Additionally, dynamic changes are introduced by unblocking certain areas during navigation to further assess the robustness of the SRU-enhanced policy. The policy with SRU demonstrates the ability to explore dead ends, navigate around obstacles, and re-evaluate its path to adapt to dynamic changes in the environment (Figure 17(a)). The robot successfully reaches the goal, showcasing the effectiveness of utilizing the SRU memory module to learn robust spatial-temporal memorization from sequential observations. In contrast, the baseline model with a standard LSTM fails to reach the goal and repeatedly loops between dead-end areas, as shown in Figure 17(b). Comparison of navigation trajectories (orange) in an office environment. A, B, and C indicate areas that the robot traverses in sequence. (a) shows that the robot using the SRU memory module successfully navigates through two dead ends and reaches the goal while adapting to changes in the environment (the blocker located in area A was initially set and later removed). (b) illustrates that the baseline model with a standard LSTM fails to reach the goal and repeatedly loops between the dead-end areas C and B.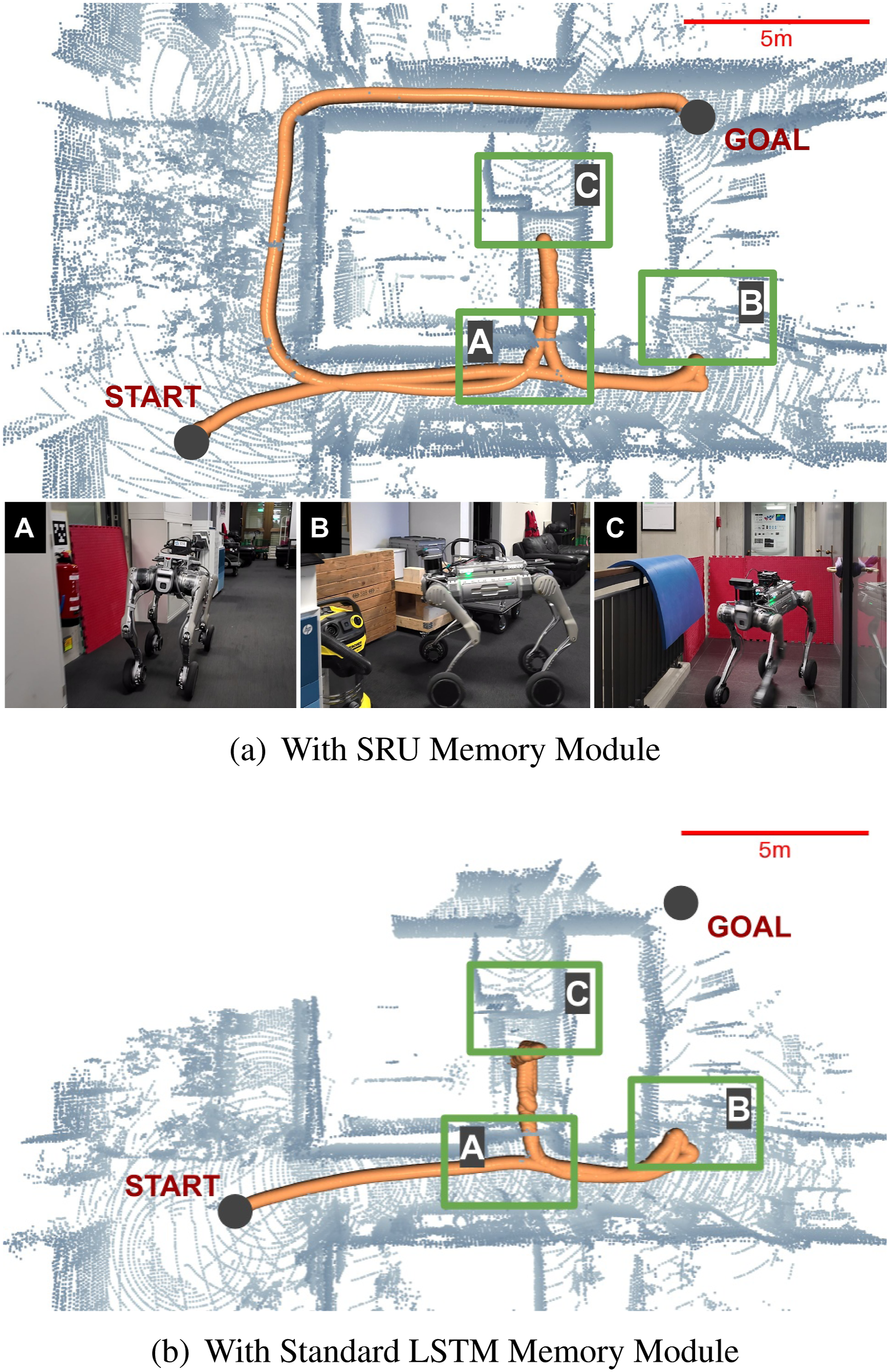
To further evaluate the generalization and performance of the proposed network architecture in long-horizon navigation tasks, we conduct experiments in a variety of real-world environments—including an indoor campus main hall, outdoor terrace areas, and forest environments—using the same pretrained encoder and navigation policy (see Figure 18). In these experiments, the robot is tasked with navigating to a designated goal and returning to its starting point. Note that the policy is designed to maintain episodic memory only between the start and the goal and is reset when a new goal is given. The results demonstrate that the policy generalizes effectively to unseen environments, handling diverse obstacles such as walls, stairs, vegetation, bushes, and trees, as well as navigating uneven terrains. Additionally, the policy adapts to larger-scale scenarios, including extended goal distances of more than 70 m and traversing over 100 m, as shown in Figure 18(c). Note that the maximum start-goal distance during RL training is 30 m. The figures show the trajectories of the robot successfully navigating through these environments, with point clouds generated from the state estimation module (Chen et al., 2023) provided solely for visualization. Note that, due to the absence of a dedicated mapping module or loop closure mechanism, the trajectories shown may exhibit some drift and errors. Evaluation of long-range mapless navigation in diverse real-world environments: (a) main hall of a university, (b) outdoor terrace, and (c) forest environment with natural obstacles. In each scenario, the robot is tasked with two separate navigation goals (memory reset between goals), resulting in two trajectory segments (orange and blue). Labels A, B, and C mark key areas traversed by the robot.
Limitations and future work
While the proposed SRUs in this paper demonstrate significant improvements in spatial-temporal learning capabilities, their recurrent nature remains subject to exponential memory decay, which can limit their ability to retain global context over extended sequences. As a result, the long-range navigation capabilities presented in this paper are centered on local, mapless navigation using egocentric sensing. In this context, “long-range” refers to planning horizons that extend well beyond the local perception radius (e.g., 10 m), enabling rerouting from local dead ends without reliance on an explicit global map. Extending this approach to global-scale navigation—spanning kilometers or hours—would likely require additional mechanisms or architectural enhancements, such as the integration or maintenance of a global map.
Furthermore, while SRUs enhance the network’s capacity for implicit spatial memorization and improve long-range navigation performance, the precise characteristics of the information retained and utilized during end-to-end navigation training remain unclear. This highlights a broader challenge in explainable artificial intelligence, where understanding the internal representations and decision-making processes of neural networks continues to be an active area of research (Mi et al., 2024). Future work could explore integrating SRUs with recent advancements in foundation pretraining, such as DINO (Caron et al., 2021), to combine their strengths in scene understanding with the efficiency of recurrent structures, further enhancing the policy’s performance in complex real-world environments. Investigating auxiliary losses or additional regularization techniques to further leverage the potential of spatial-temporal memorization in SRUs could also be beneficial. Additionally, extending the application of SRUs to other domains, such as robotic manipulation and 3D reconstruction, could unlock new possibilities and advancements in spatial-temporal learning. In summary, while SRUs are effective, they represent a simple yet practical solution—not necessarily unique or optimal—that proves successful in our end-to-end mapless navigation context. More importantly, this work aims to highlight the potential of implicit spatial memory mechanisms in addressing complex navigation challenges while identifying opportunities for further exploration and optimization in both methodology and application domains.
Conclusion
In this study, we identify and address a limitation of existing recurrent neural network architectures in the context of navigation: while RNNs excel at modeling temporal sequences, they are not inherently designed for spatial memorization or transforming observations from varying perspectives. This limitation makes them less effective in building the spatial representations required for mapless navigation using egocentric perception. To address this, we propose spatially-enhanced recurrent units (SRUs), which integrate an implicit spatial transformation operation into standard GRU and LSTM structures. These SRUs are incorporated into a novel attention-based architecture, trained end-to-end via reinforcement learning, achieving long-horizon navigation tasks with a single forward-facing depth camera. Our research further highlights the importance of regularization strategies in end-to-end reinforcement learning frameworks. Techniques such as temporally consistent dropout and deep mutual learning are crucial for fully leveraging SRUs’ potential and preventing early overfitting. Experiments demonstrate SRUs’ superior navigation performance compared to standard LSTM and GRU models. Moreover, we compare our implicit recurrent memory-based approach with a state-of-the-art baseline that utilizes explicit mapping and historical paths. Our findings illustrate the superior effectiveness of recurrent memory structures for long-range mapless navigation tasks. Additionally, through ablation studies, we demonstrate the role of specific design choices, particularly the spatial attention mechanism, in enhancing overall navigation performance. Lastly, we analyze and address the challenge of sim-to-real transfer for stereo depth perception by integrating large-scale pretraining. This approach enables successful zero-shot transfer and robust generalization across diverse real-world environments, including indoor, outdoor, and forest scenarios—as demonstrated in the supplemental video, underscoring the practical applicability and effectiveness of our proposed methodology.
Supplemental Material
Footnotes
Acknowledgments
The authors acknowledge Nikita Rudin, Takahiro Miki, Jonas Frey, Pascal Roth, and Chong Zhang for their valuable feedback and discussions. The authors also extend their gratitude to Marco Trentini for his assistance in conducting real-world experiments and testing the LiDAR-inertial state estimation module. Additionally, the authors recognize the RIVR team for their technical support with the legged-wheel robot platform utilized in this research.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The project is funded by the Swiss National Science Foundation (SNSF) under project No. 227617 and through the National Centre of Competence in Research (NCCR) Automation, as well as by the European Union’s Horizon Europe Framework Programme under grant agreements No. 101070596 and No. 101070405. Additional support was provided by Armasuisse Science and Technology and Mercedes-Benz AG.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.