
Abstract
This paper introduces a neural nonlinear model predictive control (NMPC) framework for mapless, collision-free navigation in unknown environments with Aerial Robots, using onboard range sensing. We leverage deep neural networks to encode a single range image, capturing all the available information about the environment, into a signed distance function (SDF). The proposed neural architecture consists of two cascaded networks: a convolutional encoder that compresses the input image into a low-dimensional latent vector, and a Multi-Layer Perceptron that approximates the corresponding spatial SDF. This latter network parametrizes an explicit position constraint used for collision avoidance, which is embedded in a velocity-tracking NMPC that outputs thrust and attitude commands to the robot. First, a theoretical analysis of the contributed NMPC is conducted, verifying recursive feasibility and stability properties under fixed observations. Subsequently, we evaluate the open-loop performance of the learning-based components as well as the closed-loop performance of the controller in simulations and experiments. The simulation study includes an ablation study, comparisons with two state-of-the-art local navigation methods, and an assessment of the resilience to drifting odometry. The real-world experiments are conducted in forest environments, demonstrating that the neural NMPC effectively performs collision avoidance in cluttered settings against an adversarial reference velocity input and drifting position estimates.
Introduction
Recent advances in autonomous navigation and aerial robotics have enabled the large-scale deployment of robots in several challenging applications, such as subterranean or forest exploration and ship inspection (Fang et al., 2017; Tian et al., 2020; Tranzatto et al., 2022). However, navigation in unknown and unstructured environments while relying only on onboard sensing remains a strenuous challenge. This is particularly true in perceptually-degraded environments and conditions, where mapping systems are failure-prone (Ebadi et al., 2024).
Conventional state-of-the-art navigation stacks often involve the construction of a reliable volumetric map of the scene, followed by a planning step (Sucan et al., 2012; Tranzatto et al., 2022). Although this approach has proven effective in many cases, errors at the mapping level (such as a sudden localization drift) propagate downstream, adversely affecting planning and control. Furthermore, the sequential update of dense maps before motion planning induces latency, which limits the responsiveness to unforeseen events. Enhanced resilience w.r.t. collisions can be achieved by integrating map-based methodologies with local reactive strategies that rely on instantaneous exteroceptive observations.
Accordingly, the robotics community has investigated a set of approaches for the so-called mapless navigation problem, that is, the problem of achieving collision-free navigation without relying on explicit mapping. Beyond early heuristic approaches to reactive collision avoidance (Siegwart et al., 2011), more advanced strategies have emerged in recent years. While initial efforts focused on model-based methods (Florence et al., 2018; Gao et al., 2019; Florence et al., 2020; Yadav and Tanner, 2020; Zhou et al., 2021a), deep learning-based techniques have taken the field by storm, primarily due to their scalability to high-dimensional exteroceptive inputs such as depth images. Relevant learning strategies include imitation learning (IL) (Loquercio et al., 2021; Lu et al., 2023), and reinforcement learning (RL) (Hoeller et al., 2021; Ugu et al., 2022; Kulkarni and Alexis, 2024). In addition to these end-to-end methods, recent research has investigated the use of deep learning for implicit environment representations, combined with principled control strategies (Harms et al., 2024; Jacquet and Alexis, 2024).
This work falls into this latter category, and its main contribution is threefold. First, we introduce a neural architecture for encoding a single range observation as an signed distance function (SDF) (Park et al., 2019; Sitzmann et al., 2020). Unlike prior work on (neural or non-neural) scene-scale implicit SDF encoding—which primarily targets mapping and planning applications (Ortiz et al., 2022; Wu et al., 2023)—we explicitly avoid aggregating multiple observations. Second, we integrate this representation into a neural nonlinear model predictive control (NMPC) for achieving collision-free, mapless navigation in unknown environments. We verify that the NMPC satisfies recursive feasibility (under fixed observations) and stability conditions. An overview block diagram of the contributed method, referred to as SDF-NMPC, is shown in Figure 1. Third, we conduct a detailed, component-wise evaluation, including a quantitative assessment of the neural environment encoding, ablation studies, comparisons with existing methods, and real-world experiments involving drifting odometry and adversarial reference inputs. An overview of the proposed SDF-NMPC method. The left side depicts the neural architecture used to approximate the mapping between the input depth images and the corresponding SDF, through sampling-based training in the 3D sensor frustum. The Convolutional encoder-decoder and MLP networks are trained sequentially. The right side presents the proposed control scheme, highlighting the contributed neural-constrained NMPC for velocity tracking, and the color-coded learning-based components.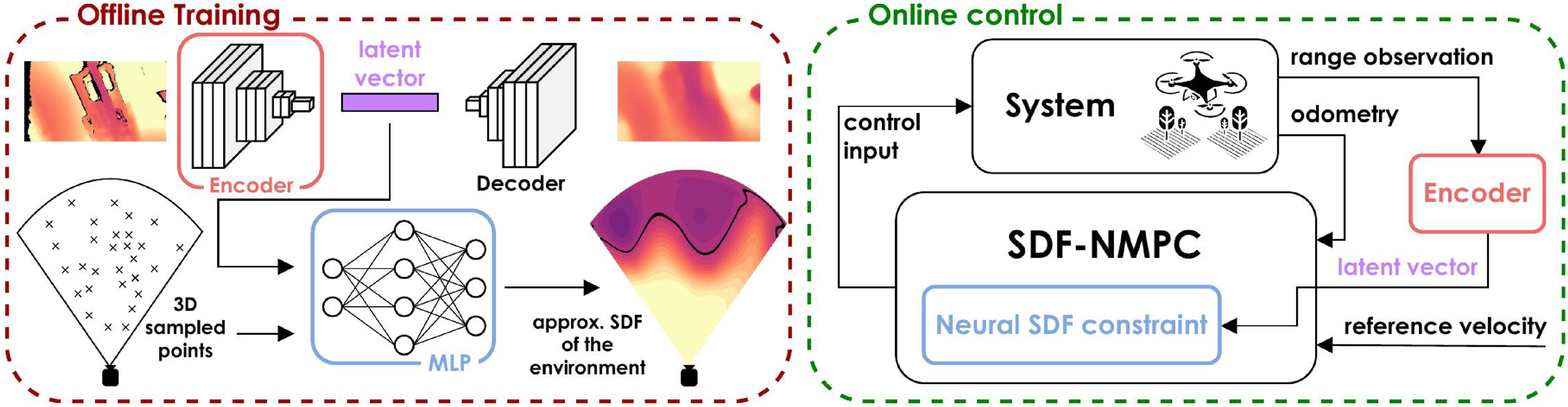
The proposed NMPC relies solely on instantaneous range measurements from an onboard sensor and on odometry, which may suffer from position drift. The neural SDF encoding of the current range observation parametrizes a position constraint for the controller. To address the limited sensor field of view (FoV), the predicted motion is also constrained to remain within the visible frustum. The controller generates thrust and attitude commands that satisfy both collision and FoV constraints, and is integrated in a velocity-tracking framework for real-time control of an aerial robot (AR). The implementation of the contributed NMPC and the associated neural networks is released open-source. 1
Accordingly, this work departs from several limitations of our previous contribution in Jacquet and Alexis (2024). First, the proposed control scheme generalizes to the nonlinear dynamics of the multirotor, moving beyond the previously considered unicycle-like motions. Second, we make use of a richer 3D representation. Indeed, the SDF is well-suited for collision avoidance, being a continuous, almost everywhere differentiable 3D field that encodes both the distance and direction to the nearest obstacle. Defined purely at the position level, it can be constructed directly from sensor measurements, whereas defining safe sets for derivative states (e.g., velocity or acceleration) is often challenging for nonlinear, higher-order systems (Harms et al., 2024). Moreover, the neural encoding provides a closed-form differentiable expression, enabling straightforward integration with gradient-based NMPC. The SDF formalism also facilitates the definition of a forward-invariant safe set for the receding-horizon problem, allowing us to establish recursive feasibility of the control law without introducing excessively restrictive terminal constraints. Lastly, the evaluation is substantially more comprehensive, including the explicit evaluation of the resilience of the 0-memory approach against drifting odometry.
The remainder of this article is structured as follows. First, we provide an overview of the related literature, followed by the problem statement. Then, the proposed method is presented, covering the neural environment encoding and the collision-avoidance NMPC framework. Finally, we present a comprehensive evaluation of the method, before discussions and final remarks.
Related work
This section presents related work and especially (a) recent advances in neural NMPC, (b) methodologies for mapless navigation, and (c) neural distance fields and their applications in robotics.
Neural MPC
Nonlinear model predictive control (MPC) has become a widely adopted control strategy for constrained systems, showing strong performance for ARs (Sun et al., 2022).
With advances in onboard computing and machine learning, learning-based MPC emerged as a successful alternative to robust or stochastic MPC, offering online adaptability to model mismatches and external disturbances (Hewing et al., 2020). Gaussian Processes, for instance, have been used to model residual dynamics in Kabzan et al. (2019) and Torrente et al. (2021). Neural networks (NNs), capable of capturing complex data patterns, have also been used to model complex dynamics, such as aerodynamic effects for quadrotor flight (Bauersfeld et al., 2021). Following a similar approach, neural NMPC has been proposed, embedding small-scale NNs to learn unmodeled dynamics (Williams et al., 2017; Chee et al., 2022; Gao et al., 2024). Going further, Syntakas and Vlachos (2024) introduce an ensemble approach based on the Monte-Carlo dropout technique, addressing the epistemic uncertainty in the neural models. RL has also been used to optimize the NMPC model, cost, and constraints to enhance closed-loop performance (Gros and Zanon, 2020), further extended by including a neural model for unknown dynamics (Adhau et al., 2024).
An open-source toolbox for integrating large NNs into NMPC is proposed in Salzmann et al. (2023), enabling tasks like navigation in turbulent flow (Salzmann et al., 2024). This paved the way for exploiting complex neural representations in NMPC. In Alhaddad et al. (2024), a transformer-based NN has been used to represent obstacle fields as repulsive cost, while Jacquet and Alexis (2024) embed depth camera observations into a differentiable occupancy map, explicitly used as a position constraint. This work builds upon this architecture.
Other recent architectures reframe NMPC as a parameterized controller learned via policy search for agile flight (Song and Scaramuzza, 2022), or integrate differentiable MPC into RL agents for tighter coupling between short- and long-term control (Romero et al., 2024). RL-based warm-starting strategies have been proposed to initialize the NMPC with actor-critic rollouts (Reiter et al., 2024), or approximate terminal costs using neural networks (Alsmeier et al., 2024). Additionally, Celestini et al. (2024) leverage a Transformer to generate trajectory candidates for warm-starting the solver.
A set of novel architectures for neural MPC has been explored. In Song and Scaramuzza (2022), the NMPC is formulated as a parametrized controller learned via policy search for agile flight. Another avenue relies on NN to approximate the infinite horizon cost. In Romero et al. (2024), a differentiable MPC implementation (East et al., 2020) is integrated in the RL agent, such that the MPC drives the short-term actions while the critic network manages the long-term ones. RL-based warm-starting strategies have been proposed in Reiter et al. (2024) to initialize the NMPC via policy roll-out. In Alsmeier et al. (2024), the long-horizon cost of the MPC is approximated by the NN, and used as the terminal cost of a short-horizon problem, for computational efficiency. Additionally, in Celestini et al. (2024), a Transformer is used to generate candidate trajectories for warm-starting MPC solver.
Mapless navigation
Mapless navigation has gained attention in recent years. A first class of approaches constructs local volumetric representations from recent observations using structures like k-d trees (Florence et al., 2018; Gao et al., 2019), enabling fast collision checking. Ray-casting (Yadav and Tanner, 2020) or depth map back-projection (Matthies et al., 2014) can also be used for fast collision checks. Leveraging such efficient checks, motion primitives have been used for planning (Lopez and How, 2017; Bucki et al., 2020). In Zhou et al. (2021a), a spline-based planner using differentiable repulsive forces from visible obstacles is introduced. Contrary to these works, which rely on a single depth measurement to perform checks, Florence et al. (2018) introduce a data representation for querying points in a sliding window of consecutive observations, explicitly accounting for the transform uncertainty induced by the uncertain state estimation. In Zhang et al. (2025), a NMPC is proposed leveraging a k-d tree to query the N closest obstacles for each shooting node along a pre-sampled path, that are in turn used as 1D position constraints for this shooting node. The approach struggles in cluttered settings where the path must significantly diverge from the straight-line reference.
Deep learning offers an alternative to collision checking, and exhibits good results for mapless navigation. Nguyen et al. (2022, 2024) propose a neural architecture to correlate depth images to near-future collisions for a given action. This method was extended with a variational auto-encoder (VAE) to allow more control over the latent representation, enabling semantic augmentation for task-specific navigation (Kulkarni et al., 2023). A similar approach is proposed in Lu et al. (2023) where a Q-value-inspired model predicts action values using expert policy rollouts. In Liang et al. (2024), a generative NN is used to generate candidate trajectories that satisfy traversability and coverage learned from A*-generated data.
Imitation learning (IL) has also been employed to learn how to generate sensor-based trajectories by imitating a map-informed export policy, such as an NMPC (Tolani et al., 2021), a sampling-based expert (Loquercio et al., 2021), or a privileged RL agent (Song et al., 2023). However, IL often lacks generalization of the learned policy. Thus, numerous works tackled this problem with RL (Kahn et al., 2021a, b). For instance, Ugu et al. (2022) train a policy from depth data but neglect AR dynamics during training, while Kulkarni and Alexis (2024) incorporate dynamics and achieve real-world deployment. Some RL-based approaches also learn implicit representations of time-consistent environments and robot state (Hoeller et al., 2021).
A hybrid strategy leverages NNs to encode a compressed, interpretable environment representation. Several works use neural networks to learn control barrier functions (CBFs) for a given system, which describes safety w.r.t. to the obstacles as described in range measurements. A relevant instance is provided by Dawson et al. (2022), where an observation-based CBF is learned for a first-order system. The method relies on approximating the LiDAR observation dynamics, which is difficult for higher-order systems and error-prone in complex environments, because the true observation dynamics are, in general, discontinuous. More accurate prediction of the next observation can be achieved with a NeRF (Tong et al., 2023) and used in the CBF, but is still limited to linear (first or second order) dynamics and struggles to extend to nonlinear motions.
Instead of approximating the observation dynamics, Harms et al. (2024) propose treating observations as parameters of safe sets in a switching approach, relying on the principle that a state safe under one observation remains safe over time, and provides a constructive approach of the LiDAR-based CBF (for an input-constrained second-order linear system). Other works approximate a CBF from obstacle-centered SDFs (Long et al., 2021) or via a GP (Keyumarsi et al., 2024), though both are restricted to first-order dynamics.
In general, these techniques struggle to faithfully encode observation-based safe sets for systems with complex (i.e., nonlinear or high-order) dynamics. Our previous work (Jacquet and Alexis, 2024) proposes an alternative that consists of using the NN to encode a simpler, position-only representation in the form of an occupancy map, while the dynamics are handled by an NMPC. However, the occupancy map gradient is nearly zero everywhere except at obstacle boundaries, limiting expressivity our proposed method overcomes this by encoding observations as an SDF.
Implicit distance fields
In computer vision, NNs are commonly used for implicit representation of surfaces or volumes, that is, as the 0-levelset of a scalar field. Indeed, coordinate-based networks (Tancik et al., 2020) take spatial coordinates as input and output the corresponding Boolean occupancy (Chen and Zhang, 2019; Mescheder et al., 2019) or SDF values (Park et al., 2019), offering continuous, compact representations encoded in network weights or latent spaces. These methods have been applied to shape rendering (Wang et al., 2021; Azinović et al., 2022; Wang et al., 2022) and completion (Dai et al., 2017; Stutz and Geiger, 2018).
In robotics, SDFs are often organized as Euclidean signed distance functions (ESDFs), assigning voxel-wise distances to the nearest obstacle. However, obtaining an SDF from sensor data, online, can be a challenging task. Classical approaches (Newcombe et al., 2011; Oleynikova et al., 2017) often construct these incrementally from truncated signed distance functions (TSDFs), which store truncated distances along sensor rays. In Han et al. (2019), an efficient alternative using occupancy grids with fast indexing is proposed.
Consequently, neural SDFs have gained traction for mapping and localization. Neural SLAM frameworks have been introduced in Sucar et al. (2021), Zhu et al. (2022), and Wang et al. (2023), where an SDF is encoded in a multi-layer perceptron (MLP) and learned online from RGBD images. Other approaches build SDFs online using TSDFs-inspired schemes (Yan et al., 2021; Ortiz et al., 2022), with extensions for object structure (Jang et al., 2024) and hierarchical representation (Vasilopoulos et al., 2024). A comprehensive mapping framework with global consistency is proposed in Pan et al. (2024). Separately, a relevant, non-neural framework uses GP-based SDF for non-neural mapping, odometry, and planning (Wu et al., 2023).
Aside from mapping and navigation, implicit SDFs are also employed for manipulation, for example, as observations to an RL agent for grasping in Mosbach and Behnke (2022). Differently, in Lee and Liu (2024), a network is trained to predict SDF of the swept volume of a manipulator arm, to ensure operator safety. A non-neural example is provided in Marić et al. (2024), where the SDF is approximated using piecewise polynomial SDFs with enforced
Problem statement
We consider the problem of collision-free navigation in an unknown, static environment by exploiting the immediate high-resolution exteroceptive range observations. We assume a reference velocity to be available, which is followed when possible while remaining collision-free. The AR is assumed to be a rigid body, whose state vector is denoted by
The system state evolves according to

We specifically tailor the scope of this work to 0-memory navigation, that is, at a given time t, the set
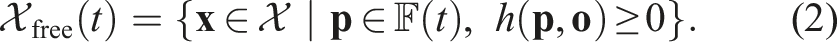
This mapping h defines the position constraint that must be satisfied to ensure collision avoidance. However, the time derivative of h cannot be obtained, as ξ is unknown and in general discontinuous. Instead, we resort to a switching update approach, as in Harms et al. (2024), that avoids an explicit approximation of the observation dynamics. At each step k, the discrete
Our proposed method for tackling this problem is presented hereafter. In Section 4, we present an approach for approximating h
Learning the environment representation
Given the most recent observation
The core of the proposed approach is to leverage deep learning to encode the sensor observation into a single volumetric constraint, using a neural implicit SDF constructed from a single depth image.
SDF from observations
We define the distance field as the spatial distance function to the surface of visible obstacles. Specifically, it must have negative values for non-visible space, and positive values for visible space, as shown in Figure 2. Such a function is called a distance transform (Maurer et al., 2003). As commonly done for neural SDFs (Park et al., 2019), with inherently limited representation capabilities, the SDF is truncated beyond some user-defined distance, denoted TSDF. For precise surface encoding, TSDF is typically a few centimeters. For navigation, however, the obstacles are represented at a larger scale and we set TSDF = 1 m. A 2D visualization of the distance transform (left) with two visible obstacles (gray). The blue line marks the 0-level set of the SDF, and its dashed part illustrates its heuristic extension beyond the FoV 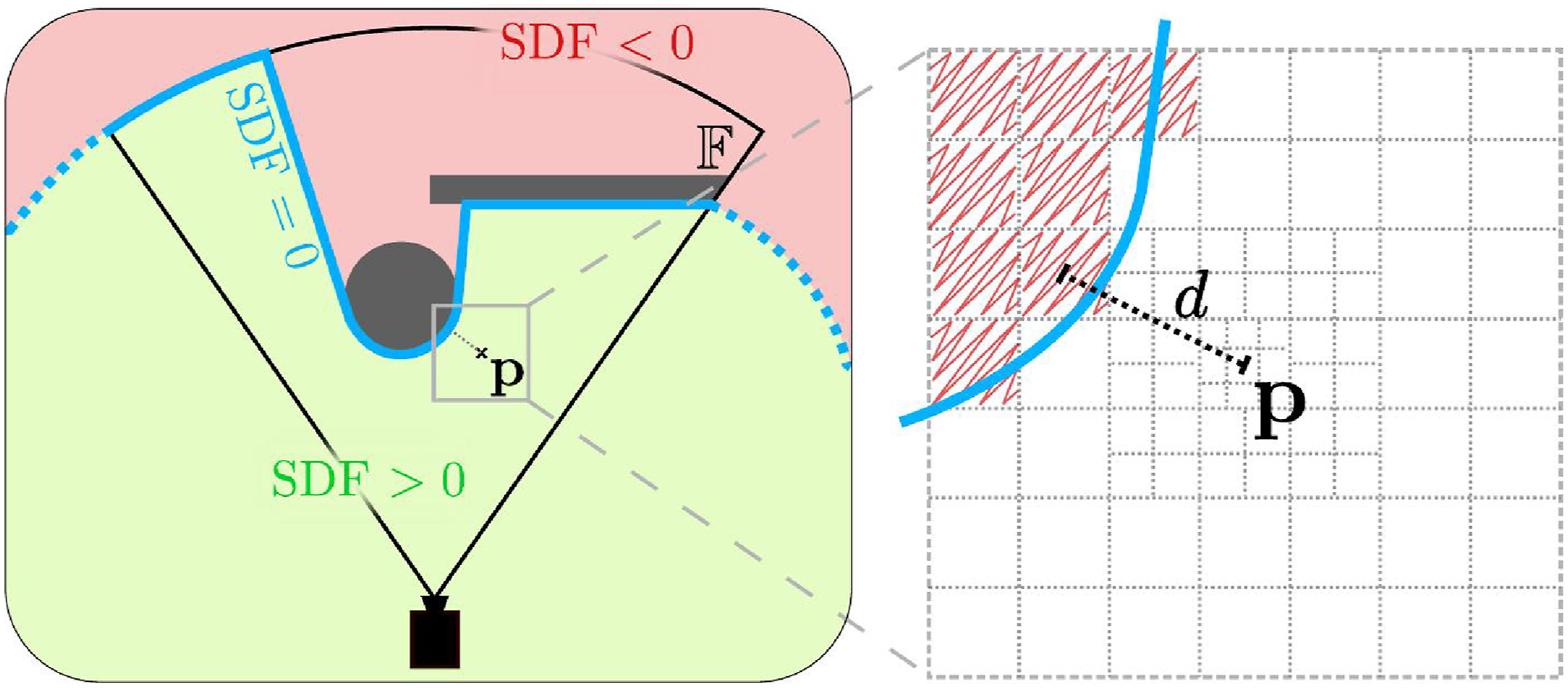
However, this distance transform is defined on Architecture of the neural networks. Convolution and deconvolution layers are pictured in orange, linear layers in green, activations in purple, and pooling layers in blue. The encoder computes a Gaussian latent representation of the image, parametrized by its mean and std. The latent is sampled and decoded to reconstruct the input image. The decoder (blue rectangle) is used for training the VAE but is disabled for inference. The Residual block for a given size N is pictured in the gray rectangle and instantiated in the network structure. Residual Deconvolution blocks follow the exact same structure.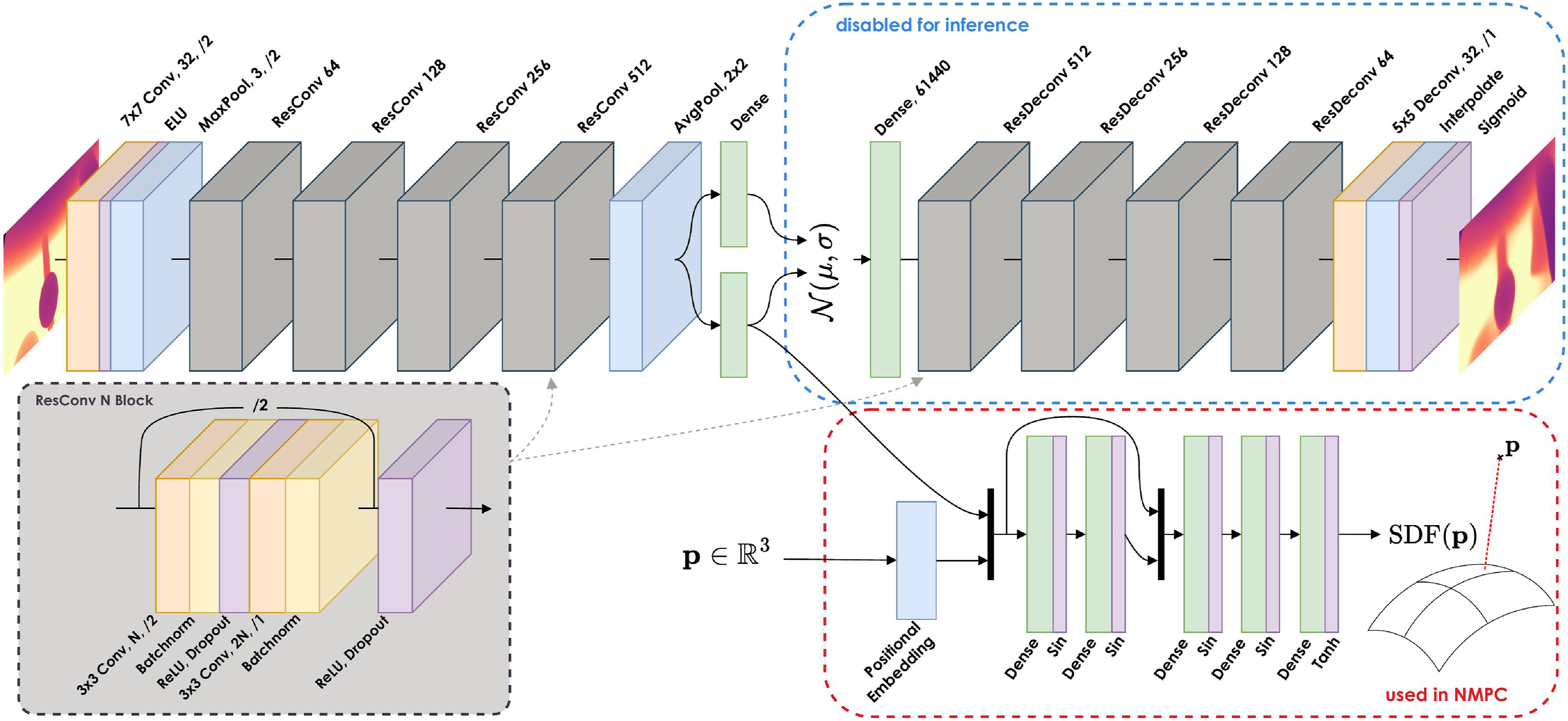
Although there exist efficient parallelized algorithms for computing such a transform (Criminisi et al., 2008; Cao et al., 2010), those are tailored for computing the full distance transform over a given grid. This is typically not well suited for sampling-based training. Instead, we utilize an approximation algorithm to generate the target values SDF(

We note that the precision of the approximation algorithm is therefore lower bounded by the thinnest resolution of the grid. This algorithm can be tensorized for online training data generation. It relies on a routine for evaluating the occupancy of arbitrary points given the input image, which can be efficiently implemented on GPU kernels via backprojection onto the pixel grid, for example, using Warp (Macklin, 2022).
NN architecture
We use a two-step process to handle observations (Figure 3). First, a convolutional neural network (CNN) encodes the observation into a compact representation. This latent vector is then passed through a MLP for further processing, exploiting the spatial correlation properties of convolutions.
The two-step approach allows for (a) avoid redundant computation when evaluating the SDF at multiple points given the same observation, (b) leverage spatial patterns in the input via the CNN, while keeping the MLP (which parametrizes the collision constraint) lightweight, and finally (c) improve robustness to the noise and systematic errors in the observations (Kulkarni et al., 2023) (e.g., stereo shadow and invalid LiDAR rays).
We use a β-VAE (Higgins et al., 2017) architecture with a ResNet-10 network as the encoder. It incorporates ReLU activations, batch normalizations, and dropout regularization for improved generalizability. The final convolution volume is passed through an average pooling, before flattening and processing through a fully connected (FC) layer for computing the mean (
The latent encoding
Similar to Ortiz et al. (2022), positional embedding is first applied to the 3D point
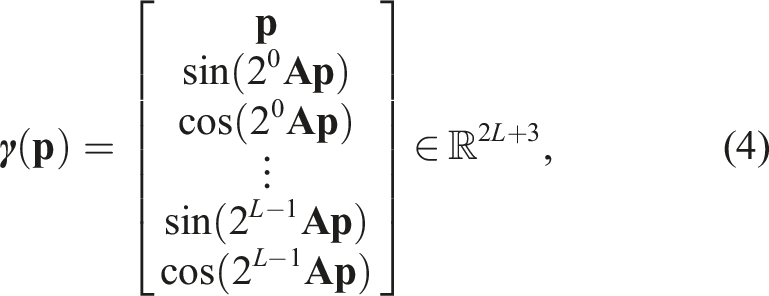
This embedding is concatenated to
We note that the VAE operates directly on pixels, and is therefore agnostic of the sensor FoV. However, because of the convolution operations, the network is trained for a specific input image ratio, which tends to differ between depth cameras (e.g., 16:9) and LiDAR range images (e.g., 4:1).
The SDF MLP operates on spatial data and implicitly encodes the intrinsic projection matrix, and is therefore trained for a specific sensor.
Training procedure
The VAE and MLP are trained sequentially.
VAE training
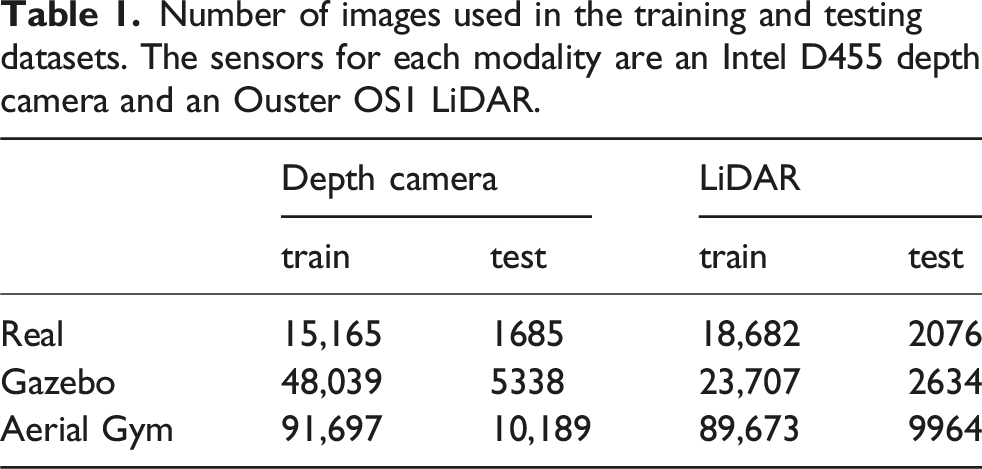
Number of images used in the training and testing datasets. The sensors for each modality are an Intel D455 depth camera and an Ouster OS1 LiDAR.
We follow the training procedure in Kulkarni et al. (2023), that is, no reconstruction loss is computed for the invalid pixels caused by stereo shadow or obstructions.
Because the encoder is used to prevent collisions, all obstacles must be reconstructed despite the high compression rate, in particular those close to the robot. We therefore propose to bias the VAE to reconstruct close obstacles with higher accuracy. This is achieved by scaling the loss function according to the distance value of the target pixel. The scaling factor is computed such that it equals 1 for 0-valued pixels, and
The pixel-wise MSE reconstruction loss function of the VAE for an observation 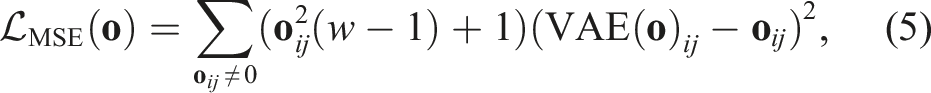
Additionally, a β-scaled Kullback-Leibler divergence (KLD) metric 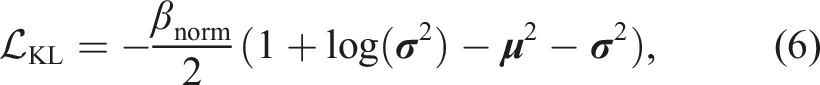
SDF training
Then, the weights of the encoder are frozen, and the MLP is trained to approximate the SDF. The training is also fully supervised, using regression of the target SDF value and gradient at sampled 3D points. Target values for sampled points are computed following the procedure described in Section 4.1. The training is performed using the same dataset as the VAE. However, because the SDF ground truth approximation relies on backprojection onto the image plane, the image must contain only valid pixels. The images from the real sensors are therefore not used for training the MLP. The sampling process is such that points are sampled (a) within
The loss function is defined as the weighted sum of two MSE losses, for both the target SDF value and its gradient.
We note that the MSE loss on the unit norm gradient includes the satisfaction of the eikonal property (3). We report, in Appendix A, the training losses and metrics for both the VAE and SDF networks, which are used in the remainder of the paper.
Neural NMPC
Mathematical notations and coordinate frames
We denote a coordinate frame • as
Lastly, we consider the inertial frames Planar representation of the relevant 3D frames used in the paper, including the inertial frames at time t0 where the sensor observation is captured (left), and the sensor frustum 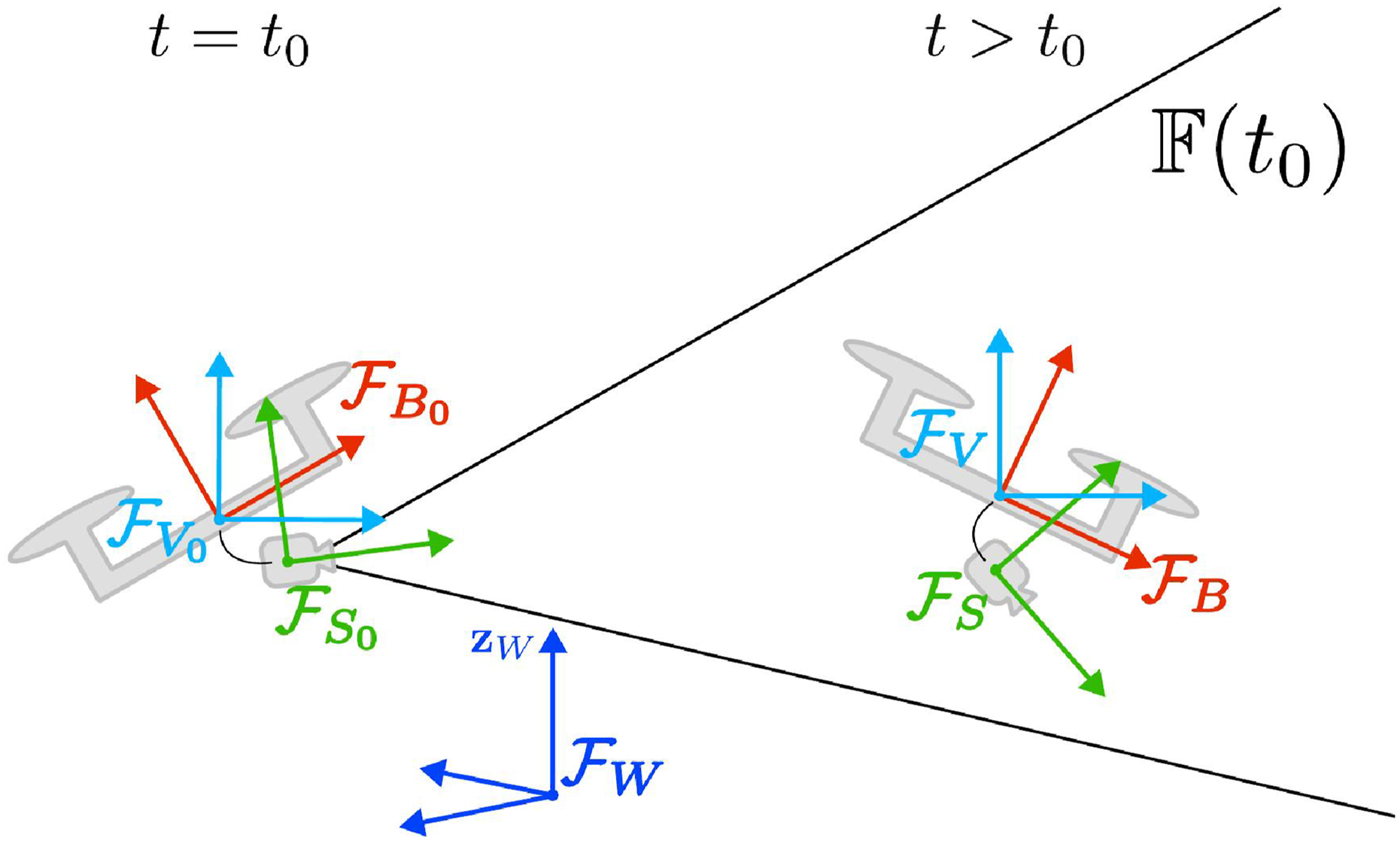
The relative position of
Lower and upper bounds on any variable are, respectively, denoted with
System modeling
The AR considered hereafter is a standard co-planar multirotor. It is modeled as a rigid body of mass m centered in O B , and actuated by four or more co-planar propellers. We assume that the robot is fully enclosed in a sphere of radius r.
We denote t0 as the time at which the most recent observation is acquired. We chose to represent the system position and orientation w.r.t. the inertial, switching frame
Therefore, the system state is described, dropping the subscript •
B
for legibility, by the vector***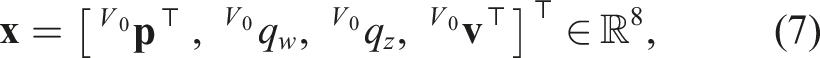
Accordingly, we select the system input variables in order to control the 3D thrust (magnitude and orientation through roll and pitch) and yaw rate, as typically done for co-planar multirotors (Furrer et al., 2016). The system input vector is therefore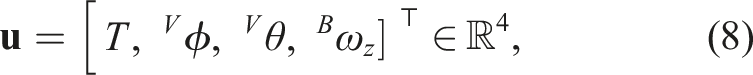
The system dynamics (1) considered in the problem formulation are therefore instantiated as
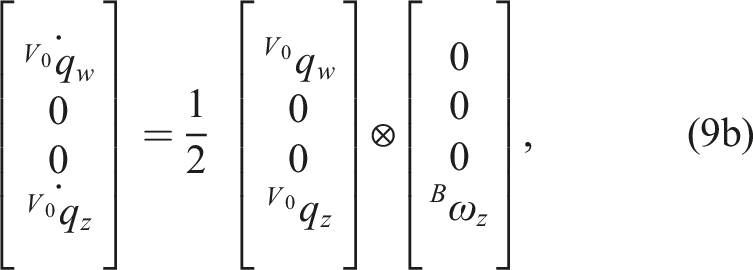
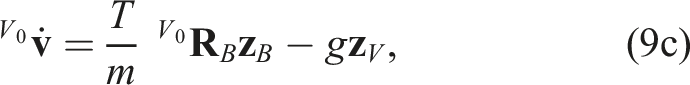
where
We further motivate this choice of dynamics representation in Appendix B.
The onboard range sensor, whose principal axis is
Local navigation neural MPC
Obstacle avoidance constraint
We assume that the observation 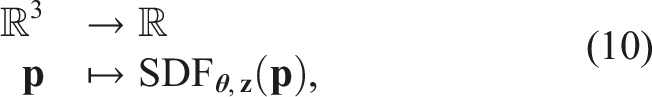
which is parametrized by 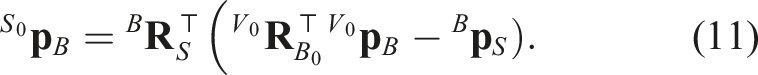
Then, we impose on the NMPC the constraint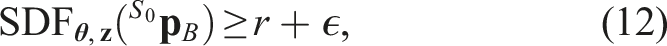
Field of view constraints
Because the collision-free set is defined in the sensor frustum
We denote the transformations from Euclidean coordinates to the azimuth and elevation angles as 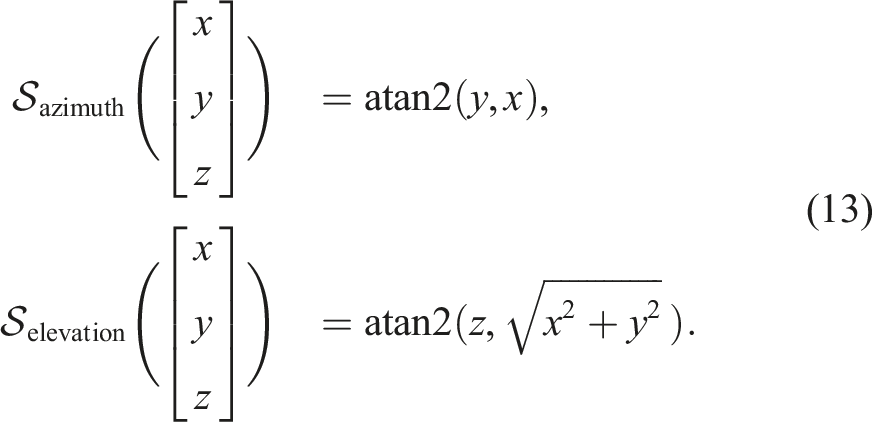
The resulting constraints are then written as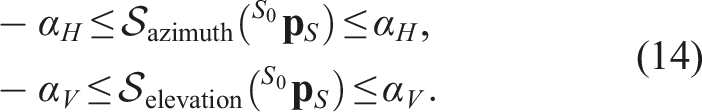
We note that an additional maximum range constraint would be redundant, as it is already encoded in (12) that every position past dmax is unsafe.
Objective function for velocity tracking
We assume that a reference velocity and a reference heading, both expressed w.r.t.
Following Brescianini and D’Andrea (2020), we express the heading errors in quaternions. Let
V
0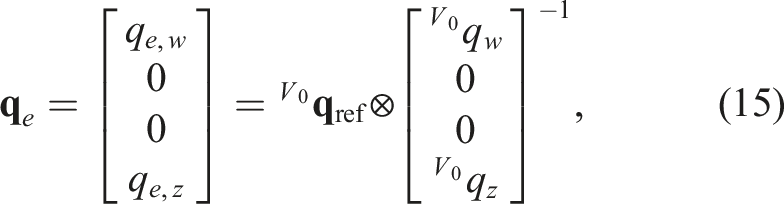
and minimizing the heading error is therefore equivalent to minimizing qe,z.
Additionally, a control input objective penalizes the magnitude of the roll, pitch, and yaw rate, as well as the deviation from mg of the vertical projection of the thrust
The stage cost ℓ(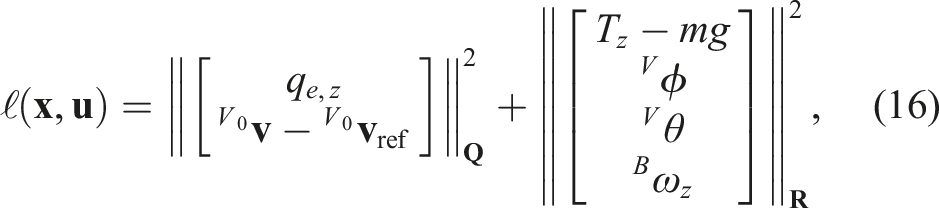

Theoretical analysis
In this study, we construct a terminal constraint to ensure recursive feasibility of the control law. Specifically, we enforce the terminal state to be such that there exists a sub-optimal terminal control policy that is recursively feasible under all constraints.
We then derive sufficient conditions on an appropriate terminal cost to ensure that the optimal cost becomes a non-increasing Lyapunov function under the sub-optimal terminal control policy. This step is then used to quantify a region of local stability that scales with the choice of the free parameters in the terminal cost.
For the remainder of the analysis, we consider the evolution of the system dynamics under a fixed observation. This means that we effectively neglect inaccuracies of the SDF approximation and the observation-dependent nature of
The yaw dynamics are disregarded since they are decoupled from position dynamics for the considered AR.
Recursive feasibility
For all terminal states 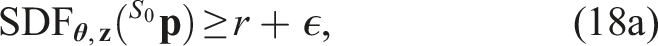

The maximum braking policy, denoted πb(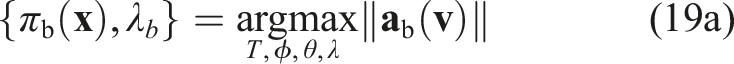
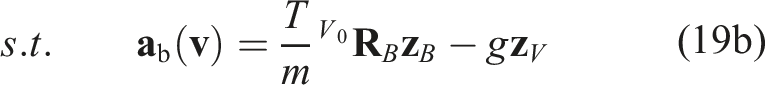






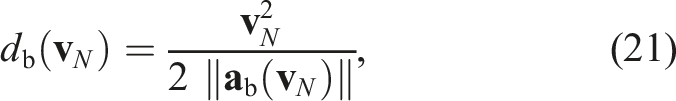
The condition (18a) is thus enforced by the terminal constraint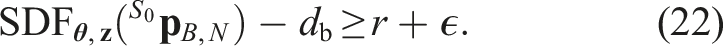
Because 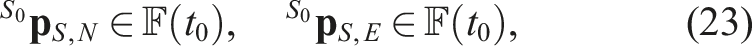

Stability
The current problem setting does not allow the establishment of asymptotic stability under arbitrary reference velocities due to the conflicting objectives in the stage cost (reference velocity tracking) and terminal cost and policy (coming to a stop). Further, the collision constraint may prevent the AR from converging to the desired reference velocity. An intuitive example of this is when a forward reference velocity is given while a wall is blocking the way; in this case, the constraint brings the system to a full stop. As a result, asymptotic stability (to a zero-cost equilibrium) cannot be established in general.
We instead derive sufficient conditions such that the optimal cost of the controller remains non-increasing. This is achieved by selecting an appropriate terminal cost V(
We emphasize that while stability is established under certain assumptions on the reference velocity
The Lyapunov stability condition on J* is written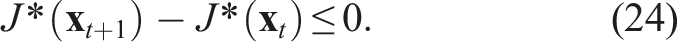
Expanding the two terms, this condition can be equivalently written as a condition on the terminal cost V(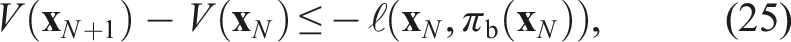
We define the terminal cost as
Nonlinear programming
The discrete-time nonlinear programming (NLP) over the receding horizon T, sampled in N shooting points, at a given instant t, given a range image captured at t0 ≤ t and compressed into a latent vector 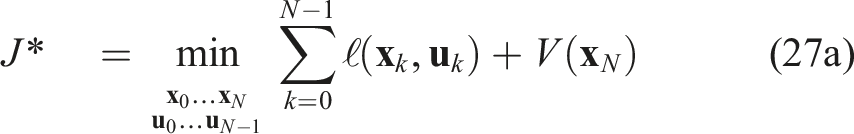

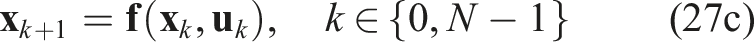
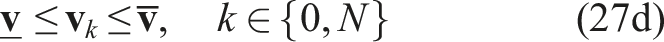
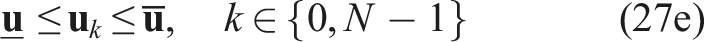
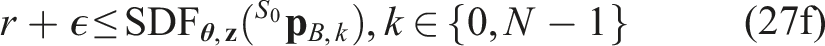
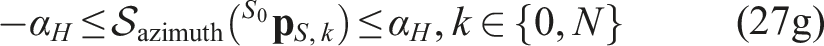
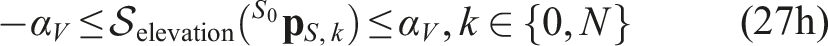
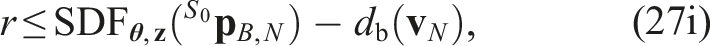
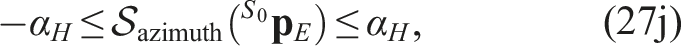
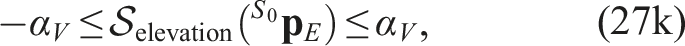
Implementation details
The above NLP is implemented in Python using Acados (Verschueren et al., 2021) and Casadi (Andersson et al., 2019). The neural network is implemented with PyTorch, and it is interfaced with the NMPC using L4Casadi (Salzmann et al., 2023). The NLP is transformed into a Sequential QP solved with Interior Point Method (Frison and Diehl, 2020) with a real-time iteration (RTI) scheme.
We use Levenberg–Marquardt (LM) regularization to improve the stability of computing sensitivities. We remark that this has a strong impact on the stability of the SQP solution under switching observations, and thus switching constraints. This is a consequence of both using a neural constraint parametrized with a large number of neurons, and of using the RTI suboptimal solving strategy, which relies on a reliable warm start from the previous solution. We empirically set the LM regularization factor to 10.
The FoV and neural constraints (27f), (27g), and (27h) are implemented as slackened constraints. This allows both to retain feasibility w.r.t. noisy feedback on the initial state
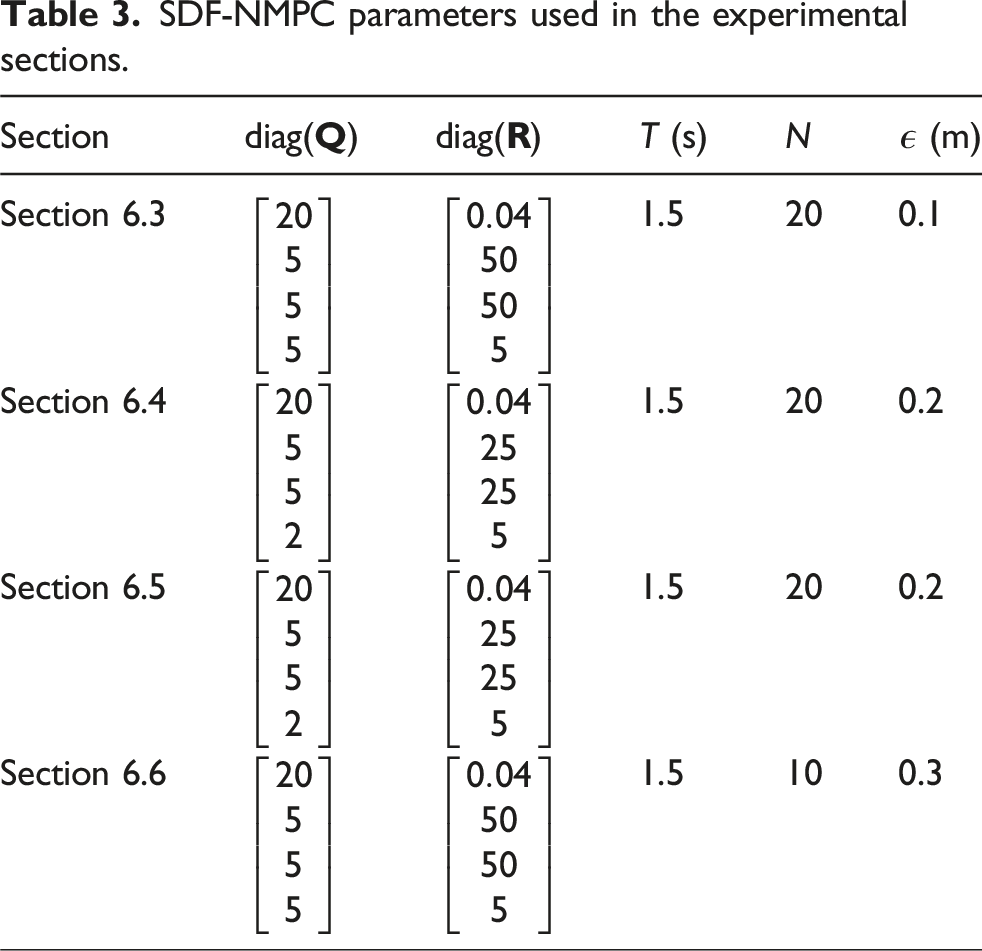
SDF-NMPC parameters used in the experimental sections.
Validation
In this section, we evaluate the components of the proposed method. First, the encoding capabilities of the VAE and SDF networks are evaluated. Then, the neural controller is evaluated through randomized simulations to assess its sensitivity to the various parameters. The proposed method is then compared against two state-of-the-art mapless navigation methods. We perform an ablation study to quantify the resilience to odometry drift. Finally, the controller is integrated into a real system and validated in hardware experiments.
In order to properly study the properties of the proposed NMPC method, we avoid relying on a map-informed high-level planner generating the velocity reference provided to the NMPC. Instead, we consider a worst-case setting and implement a naive, obstacle-agnostic goal-seeking planner. It provides a reference
V
0
VAE evaluation
This subsection presents a qualitative and quantitative evaluation of the VAE reconstruction. We chose a latent space dimension of 128, which offers a good trade-off between quality and compression for the same input image size (480 × 270 pixels) (Kulkarni et al., 2023). We compare the proposed distance-weighted (biased) VAE, introduced in Section 4.3, with a standard (unbiased) VAE. The tuning parameter is fixed at w = 0.01. We also include a baseline compression method based on the fast Fourier transform (FFT), which retains the 64 complex frequencies (i.e., 128 real values) with the largest magnitudes.
Pixel-wise RMSE [m] using a FFT, a standard VAE, and the proposed biased VAE, on the LiDAR and Depth Camera datasets, both on the full image and on the non-background pixels. Bold values indicate the best result per row.

The biased VAE tends to reconstruct pixels closer to the camera. This is illustrated in selected instances in Figure 5. This results in a conservative approximation of the obstacles, in particular w.r.t. thin or small obstacles. This (even partial) reconstruction of an obstacle indicates that it is encoded in the latent representation, and therefore can be captured by the SDF network. Reconstruction error using the proposed biased VAE and a vanilla VAE. The blue pixels correspond to reconstructions “closer” than the actual pixel value. The green circles highlight instances of thin obstacles whose reconstructions are improved.
To assess generalization, we compute the reconstruction error on depth images from the TartanAir dataset (Wang et al., 2020). A total of 30,000 randomly sampled images are evaluated. These are cropped at dmax = 5 m, and images with little to no nearby content (within dmax) are excluded to ensure a representative sample.
The resulting pixel-wise RMSE is 0.225 m, which is consistent with the error magnitudes reported in Table 4 for our testing depth images. Specifically, this value is slightly lower as the TartanAir environments typically feature lower spatial frequency than the randomized training scenes.
The average inference time of the VAE encoder, respectively, on CPU (Intel Core i7-12800H) and GPU (NVIDIA GeForce RTX 3080 Ti Laptop), is 84.03 ms and 1.27 ms. This highlights the importance of GPU acceleration for real-time deployment.
SDF reconstruction
We now evaluate the SDF-approximating MLP.
Neural network size
We assess how the reconstruction errors vary with the number of neurons. Network size is indeed a critical parameter, as it directly affects both the solving time of the NMPC, and the quality of the obstacle avoidance (through the accuracy of the environment encoding).
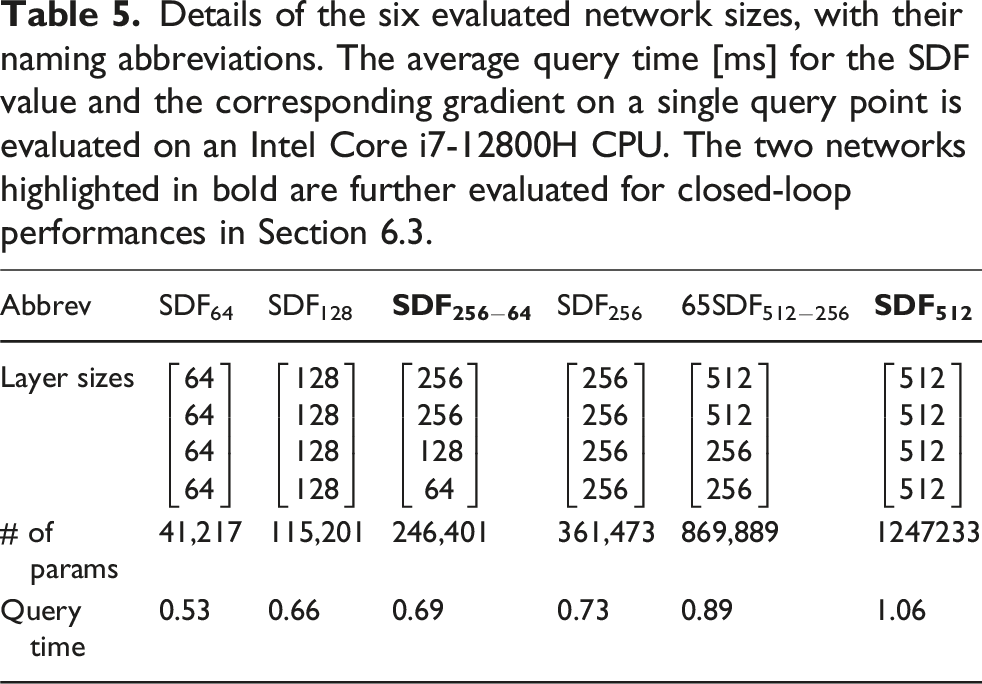
Specifically, we evaluate six sets of layer sizes, and report the corresponding SDF reconstruction errors (and gradient direction errors) in Figure 6. The evaluated network sizes, detailed in Table 5, are named after the following convention: SDF
N
denotes a network where all four layers have N neurons, and SDFN−M denotes a network with decreasing layer sizes from N in the first layer to M in the last. We chose as the smallest architecture SDF64 the one used in Jacquet and Alexis (2024), which has been shown successful in encoding an occupancy map, that is, a different (simpler) spatial representation. The network size SDF256 is similar to the one used in Ortiz et al. (2022) for online learning of a weight-encoded SDF. Metrics are computed on a 3D grid with a resolution of 10 cm within the sensor frustum. The evaluation is performed solely on simulated data, as the ground truth cannot be obtained for images that contain invalid pixels. It can be observed that the RMSE is higher in the LiDAR case, which is consistent with the VAE results in Table 4. RMSE of the SDF estimation (blue) and of its gradient orientation (orange), for the depth (circles) and LiDAR (triangles) images, as a function of the neural network size. Details of the six evaluated network sizes, with their naming abbreviations. The average query time [ms] for the SDF value and the corresponding gradient on a single query point is evaluated on an Intel Core i7-12800H CPU. The two networks highlighted in bold are further evaluated for closed-loop performances in Section 6.3.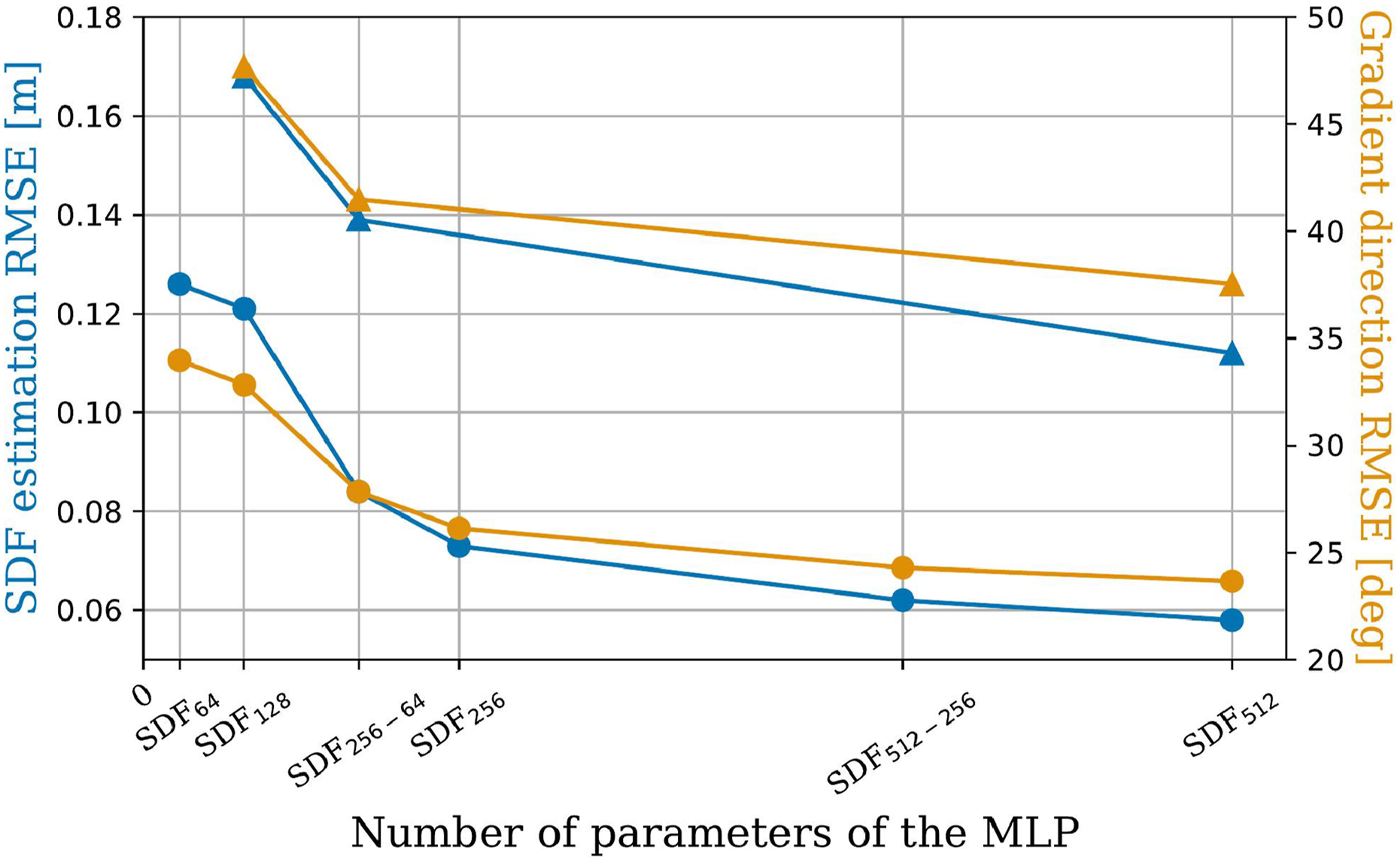
In order to provide visual insights on the neural 3D field, some instances of 2D SDF reconstruction are depicted in Figure 7 for the slices z
B
= 0. It illustrates the convergence of the network-predicted SDF (r + ϵ)-level set (blue) toward the ground truth (cyan) as network size increases. Notably, the SDF128 architecture exhibits significant penetration into obstacle, rendering it unsuitable for navigation tasks. Indeed, Figure 6 shows a strong error decrease between SDF128 and SDF256−64. We select SDF256−64 as the default architecture for the remainder of the paper, as it provides a practical trade-off between computational efficiency and reconstruction accuracy. For comparison, we also evaluate SDF512 to explore how further accuracy improvements translate to closed-loop navigation performance. 2D slice of the estimated SDF at z = 0 (shown as the green line). The green cones depict the FoV. The color gradient shows the neural SDF, and the white curve marks the visible obstacle surface. The blue and cyan curves are the neural (r + ϵ)-level sets, used as constraint, and its ground truth, respectively.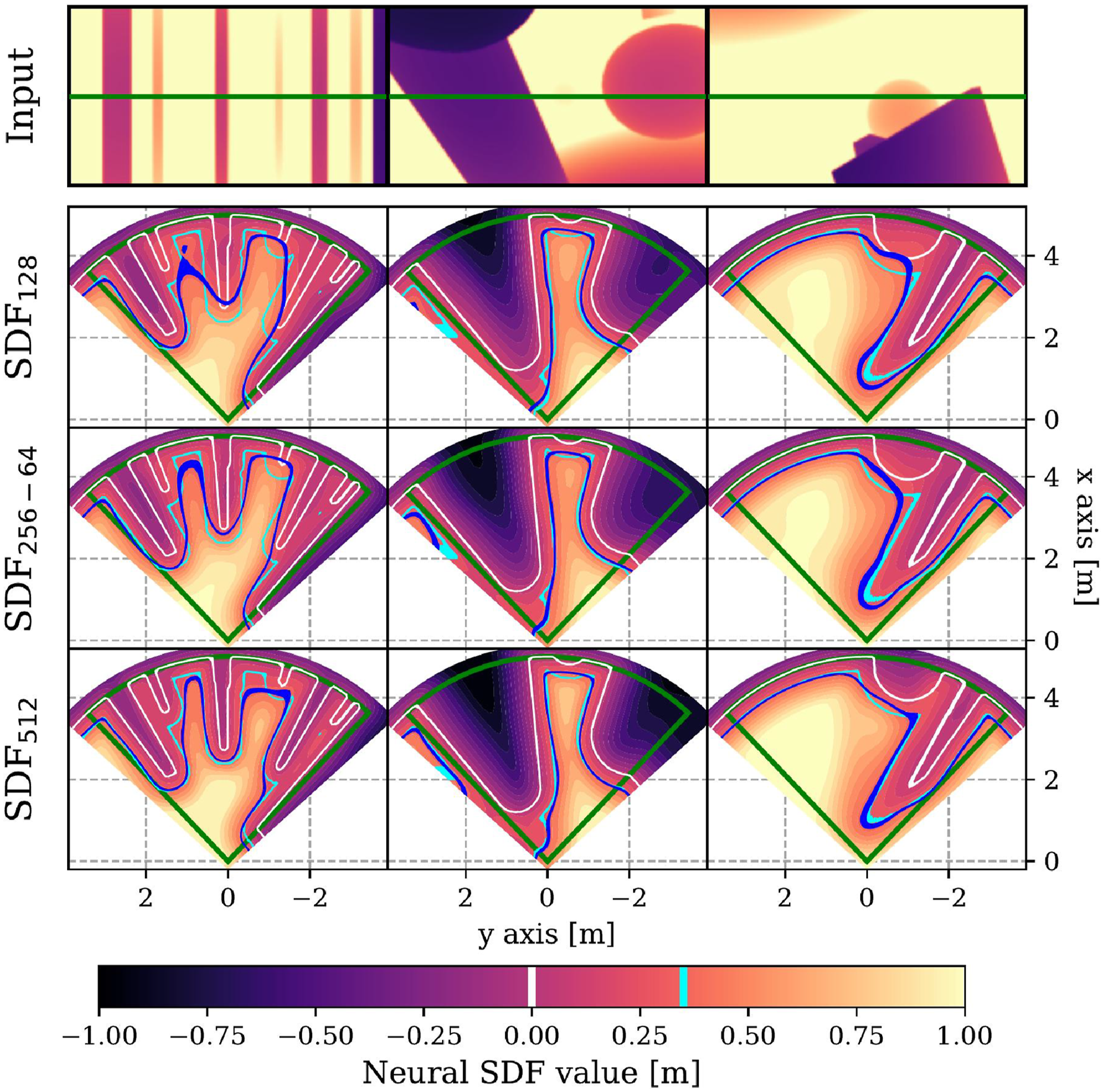
Comparison with other SDF approximations
Computation times [ms] for the construction and query (of the value and gradient) for different SDF approximation methods applied to depth images, with varying input dimensions.
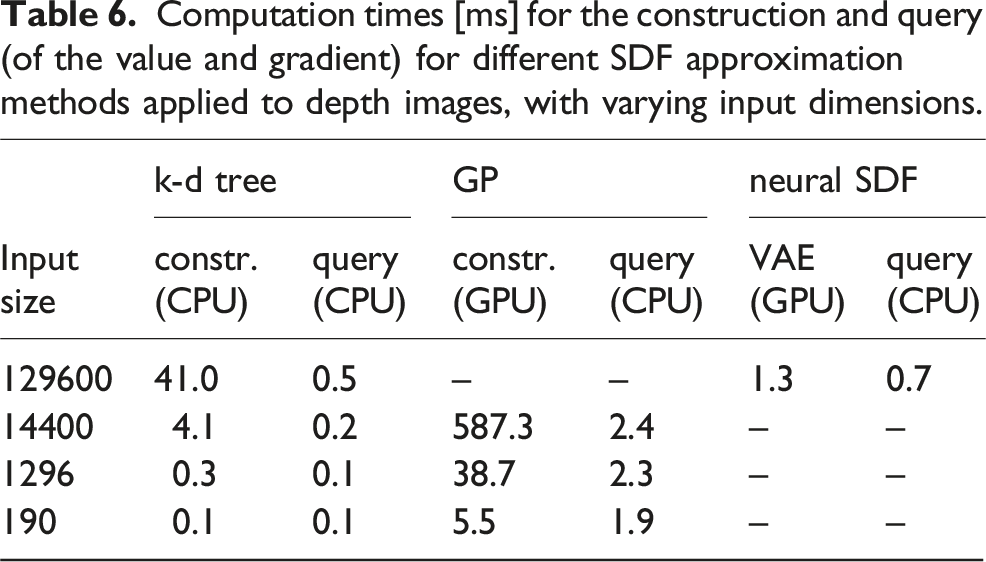
While these methods compute a different SDF representation, preventing a direct one-to-one comparison, we include the reconstruction errors reported in Wu et al. (2023) and Ortiz et al. (2022) for reference alongside the values reported in Figure 7. The former reports an instance of scene RMSE of 7.7 cm, and the latter reports errors between 3 and 7 cm across different scenes. These values are comparable in scale to the RMSE obtained with our neural SDF (albeit generally lower). The gradient error reported in Ortiz et al. (2022) is also comparable, lying between 25° and 30°.
Generalizability
We further evaluate the SDF reconstruction error on depth images from the TartanAir dataset Wang et al. (2020). Using the same 30,000 images as in Section 6.1, we compute the reconstruction error with the SDF256-64 network, on a 3D grid with a resolution of 10 cm. The recorded RMSE is 9.1 cm (+8%) for the SDF estimation, and the gradient direction errors is 31°(+10%), both remaining within the same range as those reported in Figure 6 and in related works.
Ablation study
In this section, we evaluate the sensitivity of performances w.r.t. the various hyperparameters. Although NMPC is typically paired with a low-level feedback controller for added robustness against model mismatches, we isolate our analysis by modifying the NMPC to output body wrench commands directly. We perform the simulations in the Aerial Gym simulator (Kulkarni et al., 2025), which supports customizable physics stepping frequencies, randomized obstacle generation, and parallel rollouts. Control is executed at 50 Hz, while the physics engine runs at 500 Hz.
The simulated AR weights 1.25 kg and has a radius r = 25 cm. We fix the safety margin ϵ = 10 cm. Each rollout samples a new obstacle configuration within a 10 × 10× 5 m environment, as well as the start and goal locations on opposite sides. Rollouts terminate colliding with an obstacle, or timing out after 30 s, if the goal is not reached, indicating that the robot is stuck in a dead-end. This behavior is expected in highly cluttered scenarios, as the planner only has access to local information.
Performance metrics include success, failure, and timeout rates, as well as other metrics indicating the navigation performance: average speed, average minimum neural SDF evaluation during the rollout, the true SDF values based on range observations. The robot consistently reaches its target speed for a significant portion of time; specifically, we verify that the average 90-th percentile speed remains above 0.95vref.
We consider two classes of environments, pictured in Figure 8. First, the obstacles are vertical pillars of circular or square sections, with diameters (or diagonals) ranging from 0.2 to 0.4 m. These are sampled using Poisson discs, with a tunable minimum inter-obstacle distance dmin. This setup creates an effectively 2D navigation problem, enabling easier qualitative interpretation. Second, we use 3D randomly sampled cuboids, spheres, pillars, and rods, with smallest dimensions as low as 0.2 m. We also assess the impact of thinner obstacles (with smallest dimensions < 0.05 m), such as small cuboids and rods. Instances of the two classes of environments used in the ablation study.
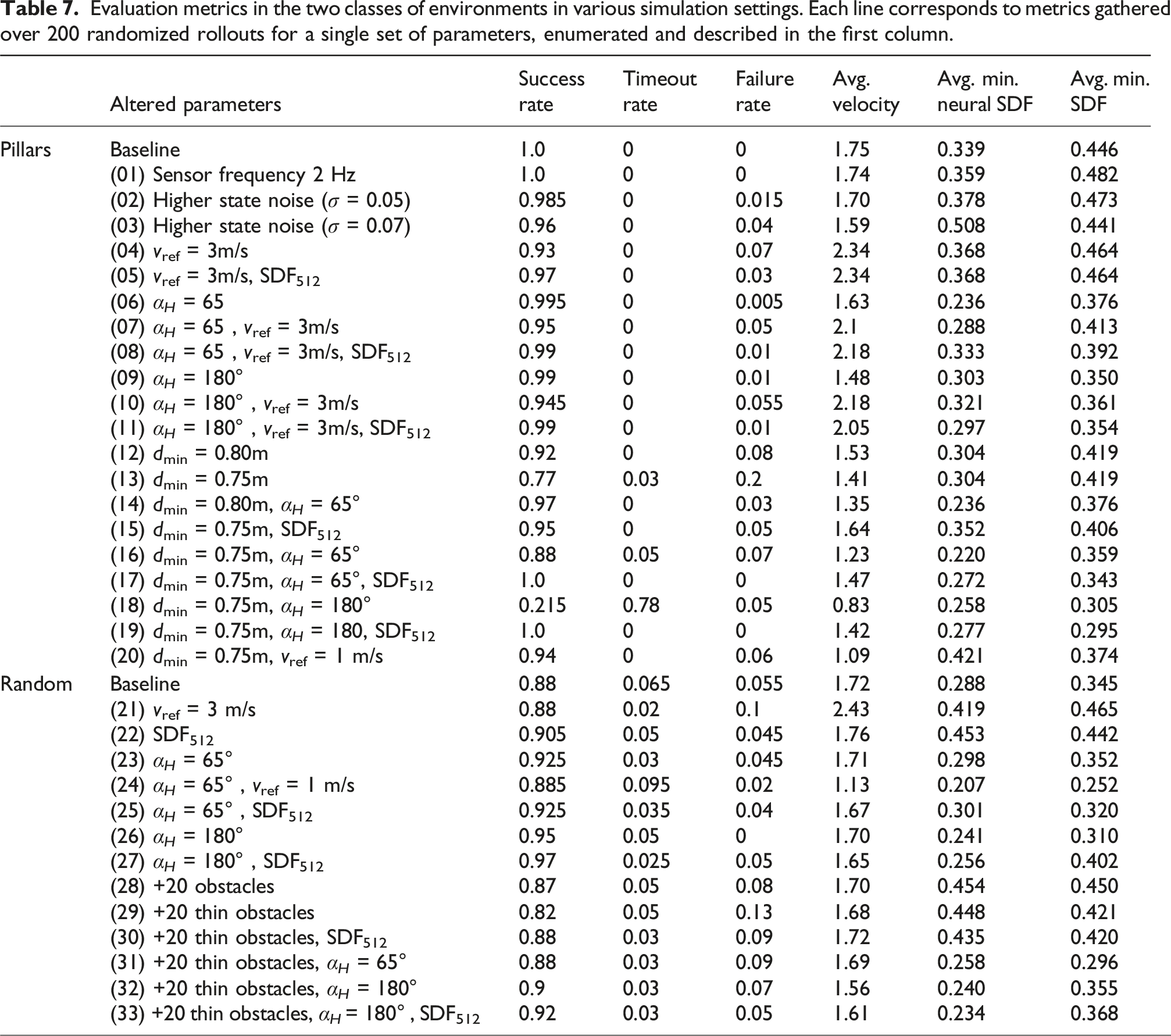
Evaluation metrics in the two classes of environments in various simulation settings. Each line corresponds to metrics gathered over 200 randomized rollouts for a single set of parameters, enumerated and described in the first column.
Pillar environments
First, we observe (lines 1–3) that the framework exhibits resilience to reduced sensor frequency and moderate state noise—maintaining failure rates under 4% even with noisy feedback. The parameters that critically affect the success metrics are the reference velocity, the obstacle density, and the SDF network size. At higher velocities (lines 4–5, 7–8, and 10–11), reduced reaction times increase sensitivity to SDF approximation errors. This is mitigated by using the SDF512 network, which enables sharper reconstructions (see Figure 7). In the simple baseline environment (lines 1–11), the FoV only marginally impacts the performance. However, increasing the obstacle density (lines 12–20) causes a drop in success (down to 20% failure rate, line 13). This is attributed to the slackened constraint (27g) which allows slight lateral drift and results in collisions in denser layouts. A larger FoV mitigates this issue. It can be noted that the baseline SDF network struggles to reconstruct properly the narrow gaps in dense environments, especially for large FoV (line 18). This leads the neural constraint to prevents motion entirely, causing timeouts despite no actual dead-ends being present (since we ensure dmin > 2(r + ϵ) = 0.7 m).
3D random clutter
Simulations in 3D environments show similar trends, though baseline failure rates are non-zero (5.5%), reflecting the known difficulty of mapless methods in cluttered settings with limited FoV. Slack FoV constraints also contribute to lateral collisions in dense areas. In such unstructured environments, increasing the FoV dramatically improves the success rate (lines 23–27), approaching 100% success rate in the 360° FoV case (lines 26–27). The framework also scales favorably with increasing obstacle density (lines 28), but performance degrades in the presence of thin obstacles (lines 29–33) (from 8% to 13% failure rate). Thin obstacles are challenging to encode and reconstruct, especially with the smaller SDF256−64 network. The larger SDF512 improves results (line 33), reducing the failure rate to 5%.
Across all simulations, the final columns of Table 7 indicate that the SDF network is generally conservative in its distance estimates. This suggests that most SDF constraint violations stem from discontinuities in the observations and poor estimations in the SDF network.
The average NMPC solving time on an Intel Core i7-12800H CPU is 8.51 ms using SDF256−64, and 15.18 ms using SDF512.
Comparison with existing methods
In this section, the proposed SDF-NMPC method is evaluated against three state-of-the-art collision avoidance approaches based on local depth observations, both neural and non-neural: • Spline-based EGO-Planner from Zhou et al. (2021a) (and more specifically, the improved implementation EGO-Swarm(Zhou et al., 2021b; 2022)) • Neural, motion-primitive-based collision predictor ORACLE from Nguyen et al. (2024) • k-d tree-based NMPC from Zhang et al. (2025).
A key distinction of our method is its formal consideration of safety as an explicit constraint in the optimization, rather than the heuristic collision score in ORACLE or the optimization co-objective in EGO and KDtree-NMPC.
The comparison is conducted using the Flightmare simulator (Song et al., 2021) and benchmarking metrics from Yu et al. (2023): (1) Path optimality, that is, the ratio of excess traveled distance relative to an A* baseline (2) Average speed, normalized by the optimal path length (3) Energy efficiency (i.e., the integral of the jerk).
All methods are evaluated in the same 32 randomly sampled environments, both indoor and outdoor (Yu et al., 2023). The obstacles are sampled through Poisson disc distributions with radii chosen to cover a large range of traversability ( ≈ 4 to 16). The target navigation speed is 2 m/s.
Baseline parameters are drawn from publicly available implementations, and fine-tuned for performance in the evaluation environments. Simulations are performed on a workstation equipped with an NVIDIA GeForce RTX 3090 GPU and an AMD Ryzen Threadripper 3970X CPU. A visualization of the simulations is included in Extension 1, and results are reported in Figure 9. Comparative metrics for the four evaluated methods. The boxplots are overlayed with the individual samples for each of the successful rollouts, colored by traversability, as defined in Yu et al. (2023).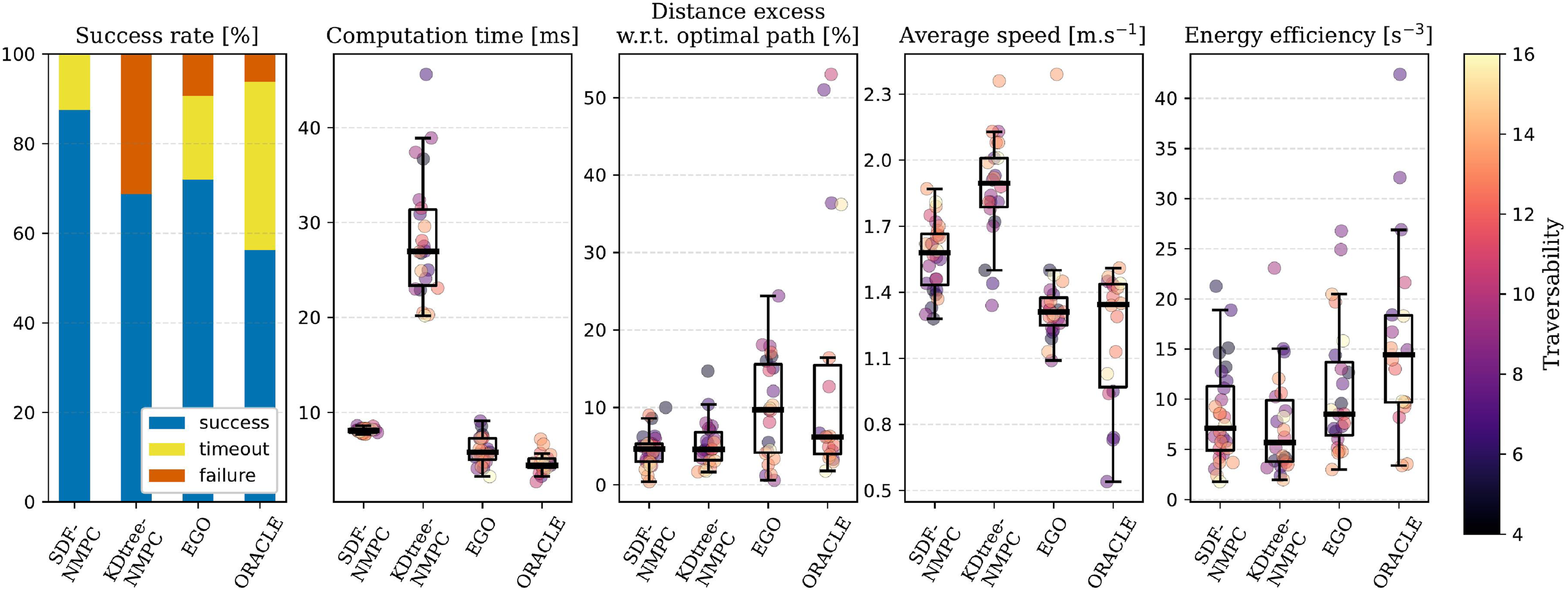
The proposed NMPC method (using SDF256−64) outperforms the other methods in terms of success rate, achieving zero collisions. While being more computationally demanding than EGO and ORACLE, it maintains a control frequency above 100 Hz and is more efficient than the KDtree-NMPC. Notably, its computation time is more consistent around the average, whereas the baselines show increased computational load as traversability decreases.
In terms of path optimality, both our NMPC and KDtree-NMPC outperform EGO and ORACLE, benefiting from objectives of minimizing deviation from a straight path. Although KDtree-NMPC achieves higher speeds, our method still surpasses EGO and ORACLE in this regard, demonstrating strong tracking performance without compromising safety.
Finally, energy efficiency is comparable across most methods, except for ORACLE, whose switching acceleration and yawing rate outputs do not account for dynamic feasibility and smoothness.
Resilience to drifting odometry
Because the collision avoidance is formulated in the local frame, our framework is resilient to drifting odometry, which would hinder the construction of a reliable map. In this section, we present an ablation study evaluating the method’s resilience to increasing odometry drift and decreasing sensor frequency. The latter is relevant since, without new measurements, the method relies on the forward-propagated last received measurement; thus, a lower frequency implies a higher sensitivity to drift.
In this study, we perform simulations in Gazebo, and deteriorate the state feedback provided to the NMPC. Specifically, velocity and yaw rate are perturbed using Gaussian noise and a random-walk bias. Position and heading are then obtained through integration. The tilt angles are not altered, as those are non-drifting quantities directly observable using an IMU.
The parameters of these noises are empirically selected to achieve the desired relative position error (RPE) (Geiger et al., 2012) (computed for a delta of 10 m). This metric computes the position RMSE per delta of traveled distance. It offers a more meaningful measure of drift than absolute position error. For reference, the visual-inertial odometry (VIO) methods ROVIO (Bloesch et al., 2017) and VINS-Mono (Qin et al., 2018) both report RPE of 1 to 2% for the same delta.
We perform these simulations in random, cluttered environments where spheres of 1 m radius are sampled using 3D Poisson Discs with a radius of 1.5 m. The environment is 50 m long, enclosed by walls, and the robot must reach a waypoint on the opposite end (with a reference speed of 2 m/s). This setup is intentionally challenging due to high clutter and a constrained FoV, making it a rigorous test of the method’s resilience to drift. An illustrative, 2D example of such an environment is provided in Figure 10. We evaluate the success rate of the NMPC by performing rollouts in each scenario. Top-view of a 2D trajectory where the NMPC receives drifting odometry (red). Despite the drift, the real system (green trajectory) avoids collisions, as the controller operates in a local observation frame independent of map-based positioning. The orange circle depicts the robot size.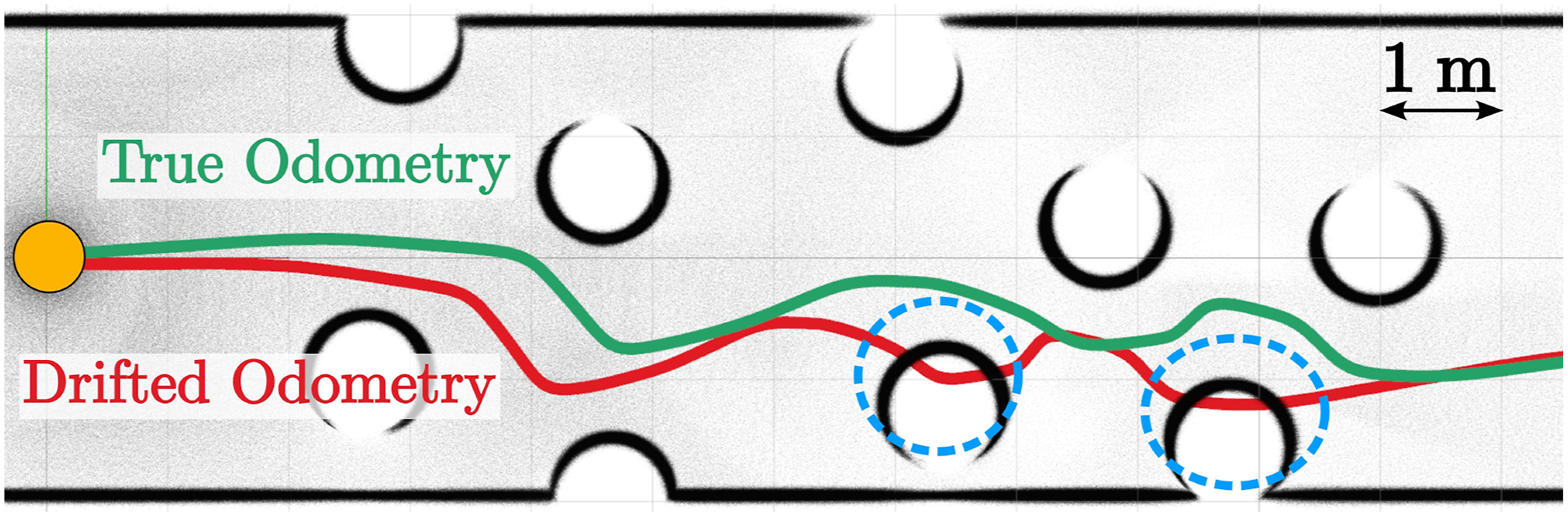
Number of successes out of 10 rollouts with increasing RPE and decreasing sensor frequency. The reference velocity is 2 m/s.

These results highlight the local aspect of the method, which achieves collision avoidance while relying on short-term, local consistency of the state estimate in the weakest sense without explicitly considering robust formulations (i.e., allows forward propagation in between two successive range measurements).
Real world experiments
System setup
We finally present hardware experiments for both the depth camera and 360° LiDAR cases. Experiments are conducted with a custom-built RMF-class quadrotor (De Petris et al., 2022), with dimensions 0.52 × 0.52×0.3 m and mass 2.58 kg. The AR integrates PX4-based autopilot avionics for low-level control, together with an NVIDIA Orin NX Single-Board Computer (SBC) running ROS Noetic. The exteroceptive sensor used for navigation is either an Ouster OS0-64 LiDAR or a Luxonis OAK-D Pro Wide depth camera (whose halved horizontal FoV α
H
is 63°). The sensor frequencies are set to 20 Hz. Further, the system employs a Texas Instruments IWR6843AOP FMCW radar sensor. Odometry is obtained by fusing a VectorNav VN-100 IMU with the LiDAR observations using CompSLAM (Khattak et al., 2020), or with the radar measurements (Nissov et al., 2024) in the drifting case. A block diagram of the system is depicted in Figure 11. Block diagram on the SDF-NMPC framework. The contributed controller, which integrates the neural SDF network as a constraint, is highlighted in purple.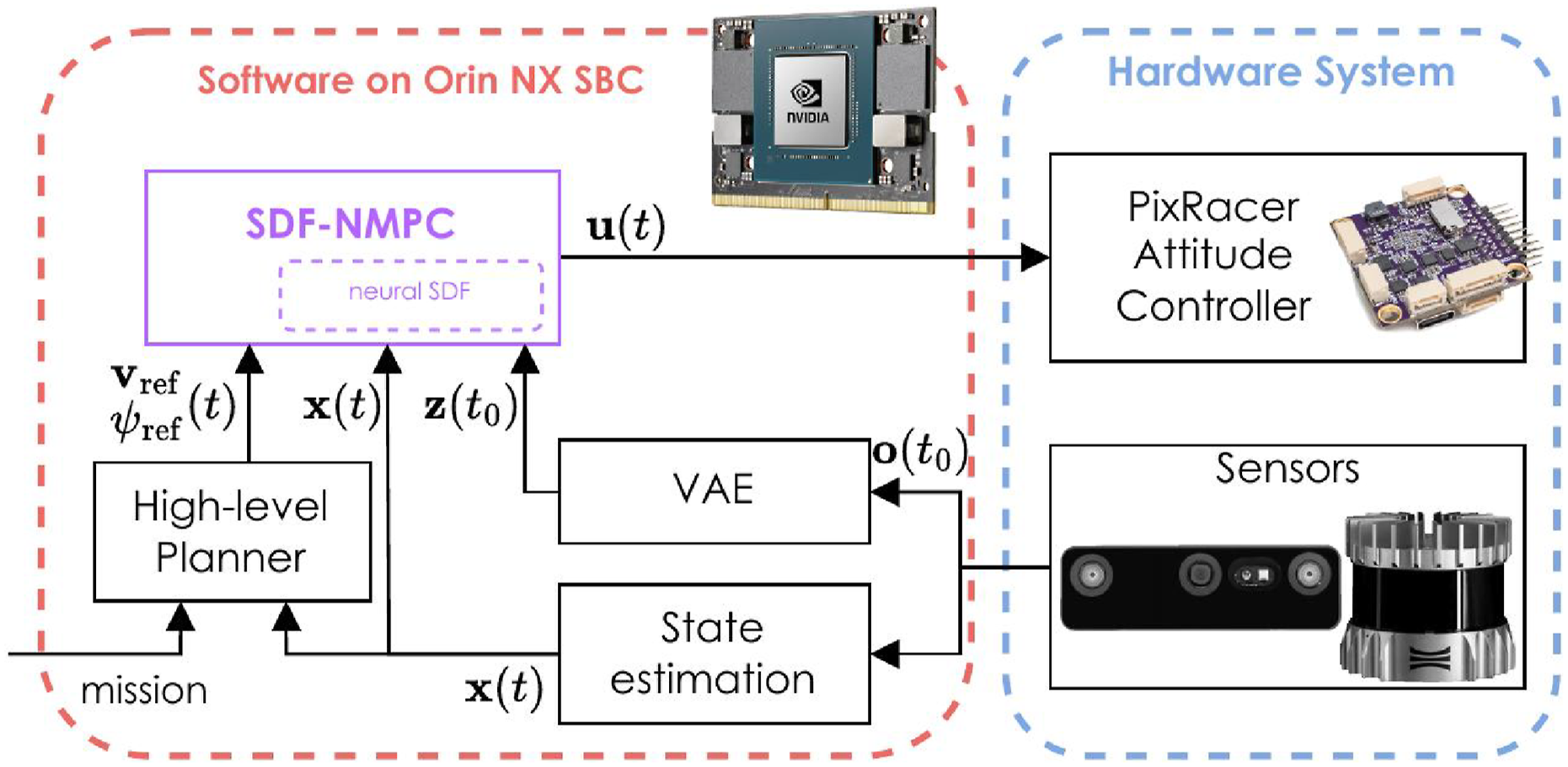
The VAE encoding is executed on the Orin NX GPU, with an average inference time of 12.4 ms. The neural NMPC solver (using SDF256−64) runs on the CPU, with an average solving time of 15.4 ms. The resulting control frequency, including the reference velocity reference generation and the overhead induced by the Python implementation, is ≈ 40 Hz.
Recordings of each of the three following experiments are presented, respectively, in Extension 2, Extension 3, and Extension 4, along with relevant visualizations to appreciate the action of the NMPC.
Experiment with depth camera
This first experiment is conducted using the depth camera for navigation, with LIDAR-inertial odometry. Figure 12 presents an overview of the experiment. The AR is tasked with reaching a waypoint 15 m ahead, through a 12 m-long tree-filled section. The reference speed is set to vref = 1.5 m/s, and the observed 90th percentile velocity is 1.25 m/s. The resulting motion properly avoids the trees, despite the naive environment-agnostic reference velocity. The systematic noise in the input image (black pixels) is handled by the VAE. The encoded SDF shows a decrease toward the obstacles, and the constraint embedded in the NMPC (pictured as the blue line) becomes active, deflecting the trajectory to the side. Third-person view of a trajectory (white path) among trees, showing the aggregated pointclouds from the depth camera. On the left is the input depth image at a given time instant, along with its VAE reconstruction, and a top-view of the z
B
= 0 slice of the neural SDF, its 0- and (r + ϵ)-levelsets (respectively, white and blue), the reference velocity (black arrow), and the predicted trajectory (green line).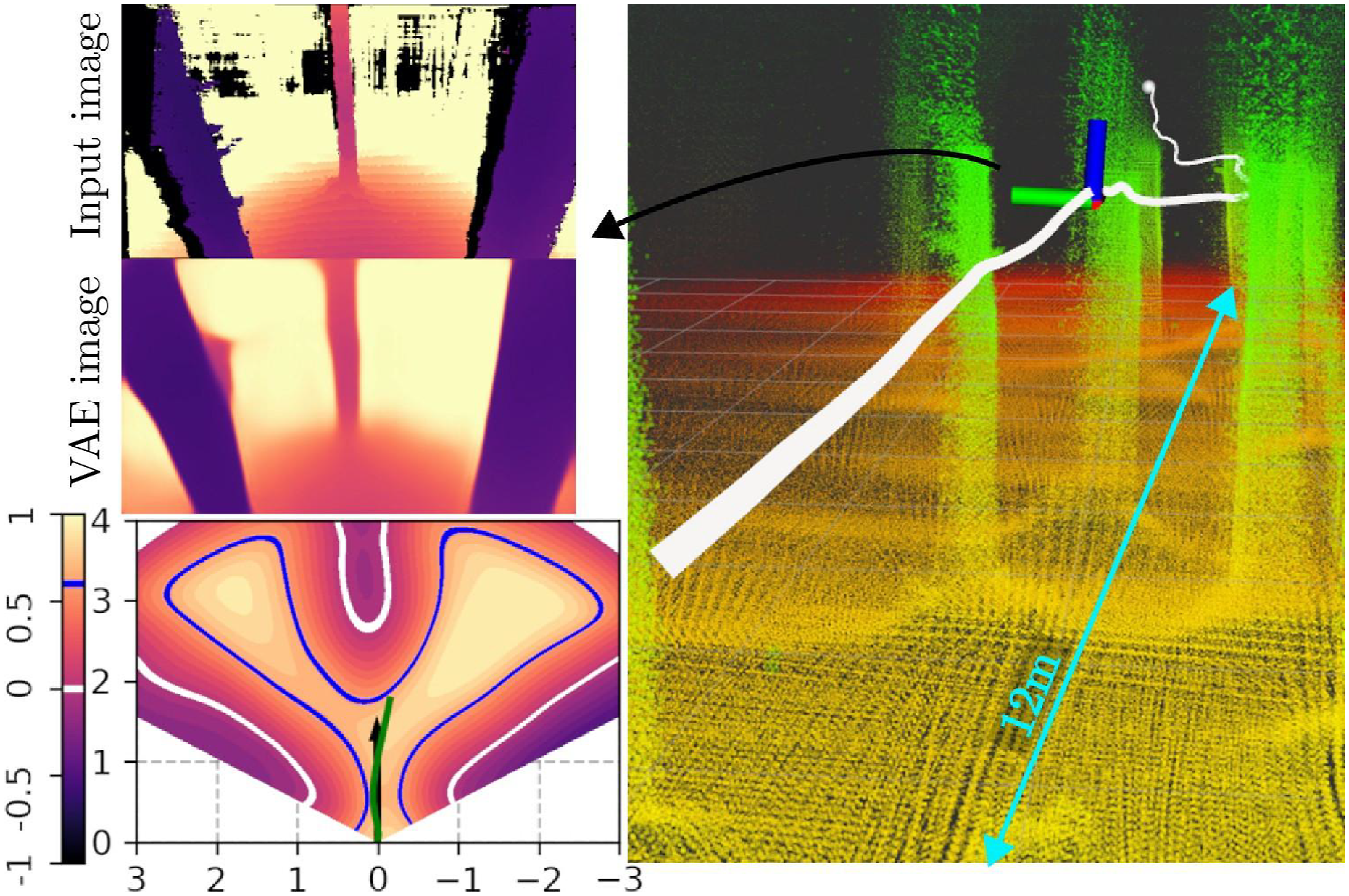
Experiment with LiDAR with adversarial reference velocity
This second experiment is conducted using the LiDAR for navigation and LiDAR-inertial odometry. Unlike the previous setup, the reference policy is not provided by the goal-seeking planner. Instead, an adversarial velocity input is provided by a human operator through a remote joystick, actively trying to collide the AR with the trees. Figure 13 pictures three time instances along the experiments which highlight that the NMPC effectively prevents collision by either deflecting the trajectory through some free space (instances B and C), or by bringing the robot to a full stop (instance A) when the trees form a wall-like obstacle, blocking the half-space where the velocity projection would yield a cost decrease. Additionally, Figure 13 also illustrates that the VAE is capable of successfully reconstructing the range image despite the significant amount of invalid pixels in the input image (both in the long-range regions and within four vertical clusters obscured by the propellers and the outer cage of the AR). Bird’s eye visualization of a LiDAR-based experiment among trees. The top-most row depicts three zoomed-in time instances A, B, and C, along with the z
B
= 0 slice of the neural SDF, following the same nomenclature as Figure 12. The next two rows show the corresponding LiDAR input range image and its VAE reconstruction.
Experiment with drifting odometry
This last experiment implements the drifting odometry case discussed in Section 6.5. The experimental settings are similar to the previous one, that is, the LiDAR range image is used for maintaining collision avoidance in the presence of adversarial velocity reference. However, instead of relying on the accurate LiDAR-based odometry, we implement a frequency modulated continuous wave (FMCW) radar-based velocity estimator which provides, through integration, a drifting position and heading odometry. Indeed, while the LiDAR-based position estimate is accurate in well-structured environments (including forests), the radar measurements have several orders of magnitude fewer points with generally greater noise, thus resulting in scan-to-scan matching approaches being impractical. However, the availability of Doppler measurements enable reliable velocity estimation, though without position corrections, inevitably leading to drift over time.
Specifically, we implement the radar-inertial part of the factor-graph estimator presented in Nissov et al. (2024), whose details are reported in Appendix D. The odometry has an RPE of 3% and a heading RPE of 2° against the LiDAR odometry from Khattak et al. (2020), which we use as ground truth.
Figure 14 shows a bird’s eye view of the trajectory. Both odometries (red for radar, green for ground truth) are reported, showing the progressive drift between the two. This experiment further verifies the associated results on drifting odometry previously presented in simulation within Section 6.5. Bird’s eye view of the trajectory with both odometries (drifted in red, ground truth in green). The white pointcloud depicts a single observation given to the NMPC. The controller is agnostic of the map, and operates in the local frame, and therefore maintains collision avoidance despite the drift.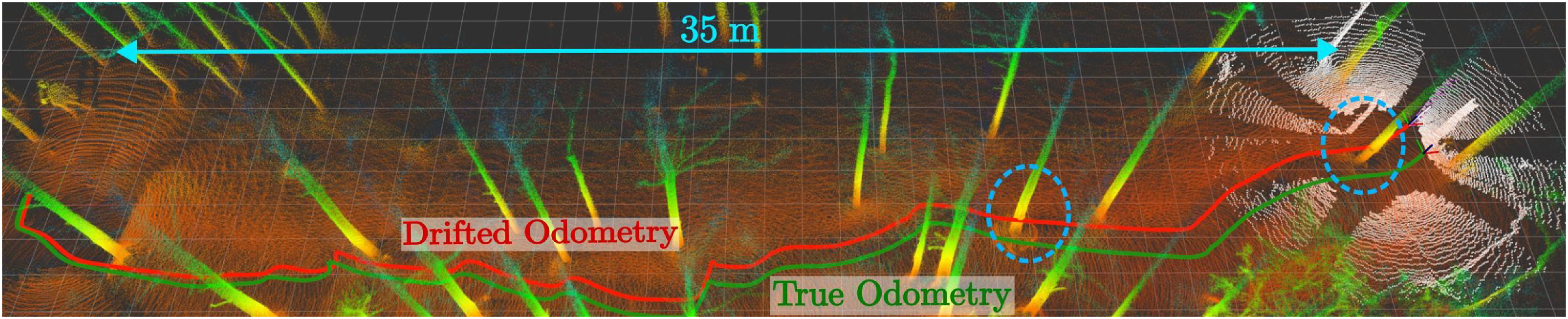
Conclusion
This work contributes an NMPC framework for collision avoidance using a neural SDF as a differentiable, volumetric approximation of exteroceptive data. This representation enables the optimal controller to enforce position constraints, thus enforcing collision avoidance. The neural architecture is divided into two parts, trained sequentially: a VAE which encodes the image in a low-dimensional latent space, and a four-layer coordinate-based MLP which approximates the corresponding SDF. We further perform a theoretical analysis of the recursive feasibility and stability properties of the proposed NMPC, and derive corresponding terminal conditions. The neural SDF encoding is first evaluated, then the NMPC controller is evaluated through several ablation studies and comparisons. Furthermore, it is validated through outdoor experiments at 1.5 m/s, demonstrating the avoidance of trees against adversarial inputs and drifting odometry.
This method results in a tightly integrated control and collision-avoidance policy that achieves competitive navigation performance with low computational cost. Additionally, the approach exhibits strong resilience—within identified thresholds—in scenarios where odometry estimation drifts. This addresses the primary motivation for adopting mapless navigation policies. Finally, our results demonstrate the effectiveness of neural SDF encoding as a foundation for mapless navigation. Future work includes seven key directions. First, improving the framework’s implementation allows for reduced sensing-to-action delay. This could be achieved by optimizing neural network architecture and weights, and improving CPU-GPU memory transfer. Second, investigating energy-based approaches to ensure that the NMPC retains a dissipative behavior when the active collision constraints prevent matching the reference velocity. Third, extending the neural representation to consider the orientation would relax the spherical robot assumption and enhance maneuverability. Fourth, incorporating visual sensing alongside or instead of range data could mitigate sensor degradation and better capture fine features, with a bimodal VAE fusing sensor inputs. Fifth, relaxing the 0-memory assumption through temporal observation windows, key-frame selection, and uncertainty-aware filtering. Another avenue for this task is the use of neural world models, encoding a temporal sequence of image data into a latent representation. Sixth, relaxing the static world assumption by predicting obstacle motion over time would further benefit from world modeling. Finally, future work could focus on the uncertainty awareness, w.r.t. both the noisy state information and the coarsely approximated SDF from the (also noisy) observations, for example, by extending the proposed method to an uncertainty-informed stochastic MPC, or using a robust formulation that incorporates error bounds.
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Footnotes
Acknowledgments
We thank Morten Nissov for his help in the setup of the radar and the corresponding estimation software.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the European Commission Horizon projects DIGIFOREST (EC 101070405) and SPEAR (EC 101119774).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Note
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.