
Abstract
Autonomous navigation and information gathering in challenging environments are demanding since the robot’s sensors may be susceptible to non-negligible noise, its localization and mapping may be subject to significant uncertainty and drift, and performing collision-checking or evaluating utility functions using a map often requires high computational costs. We propose a learning-based method to efficiently tackle this problem without relying on a map of the environment or the robot’s position. Our method utilizes a Collision Prediction Network (CPN) for predicting the collision scores of a set of action sequences, and an Information gain Prediction Network (IPN) for estimating their associated information gain. Both networks assume access to a) the depth image (CPN) or the depth image and the detection mask from any visual method (IPN), b) the robot’s partial state (including its linear velocities, z-axis angular velocity, and roll/pitch angles), and c) a library of action sequences. Specifically, the CPN accounts for the estimation uncertainty of the robot’s partial state and the neural network’s epistemic uncertainty by using the Unscented Transform and an ensemble of neural networks. The outputs of the networks are combined with a goal vector to identify the next-best-action sequence. Simulation studies demonstrate the method’s robustness against noisy robot velocity estimates and depth images, alongside its advantages compared to state-of-the-art methods and baselines in (visually-attentive) navigation tasks. Lastly, multiple real-world experiments are presented, including safe flights at 2.5 m/s in a cluttered corridor, and missions inside a dense forest alongside visually-attentive navigation in industrial and university buildings.
Keywords
1. Introduction
Recent breakthroughs in the field of aerial robotics have enabled their widespread adoption in various applications including in subterranean exploration, construction, agriculture and forestry Tranzatto et al. (2022); Loquercio et al. (2021); Petracek et al. (2021); Zhou and Gheisari (2018); Kulbacki et al. (2018). Extremely agile navigation of quadrotors has been demonstrated recently in the context of drone-racing competitions Foehn et al. (2022); Wagter et al. (2021) or in broader field tests Loquercio et al. (2021); Kaufmann et al. (2020). However, the task of autonomous 3D navigation and efficient information gathering in challenging, geometrically complex, perceptually-degraded environments remains demanding since a) the robot’s sensors may be susceptible to non-negligible noise, b) the onboard localization and mapping may be subject to significant uncertainty and drift Ebadi et al. (2022); Cadena et al. (2016), and c) performing collision-checking or evaluating utility functions for high-quality information sampling using a map often results in high computational cost Schmid et al. (2020).
While map-based methods require building a consistent map of the environment, for example via octrees Hornung et al. (2013), TSDFs Oleynikova et al. (2017); Han et al. (2019), or VDB structures Museth (2013), map-less methods follow another approach by only relying on a single observation or a (spatio)-temporal window of recent observations possibly combined with high-level commands from the operator or path planners. Traditional map-less approaches utilize various data structures such as kd-trees Florence et al. (2018); Gao et al. (2019), 3D circular buffers Usenko et al. (2017), rectangular pyramids Bucki et al. (2020) or directly use disparity images Matthies et al. (2014) for fast collision checking. Recent work on data-driven learning offers another promising pathway towards low-latency navigation by exploiting both the parallel computing capabilities of GPUs Kew et al. (2021); Kahn et al. (2021a) and the universal approximation power of deep neural networks Tabuada and Gharesifard (2022) to directly map raw sensor observations to control actions, thus bypassing the need for separate perception, mapping, and planning modules Loquercio et al. (2021); Kaufmann et al. (2020).
Our work falls into this latter category of approaches as we aim to develop an efficient collision-free and information-gathering navigation method that does not rely on the global map or position information of the robot. Learning-based methods can offer low computation costs, however, only a few works discuss the effects of different uncertainties on the robot’s navigation capabilities. In turn, modern deep neural networks are notoriously famous for giving unjustifiably overconfident predictions Guo et al. (2017); Abdar et al. (2021). Hence, it is essential to handle uncertainty in neural network prediction properly in safety-critical applications.
Simultaneously, we further aim to address the challenge of combining such map-less safe navigation with efficient sampling of information about interesting areas in the environment. Relevant works in the literature of informative path planning have been various Hollinger and Sukhatme (2014); Forssen et al. (2008); Dang et al. (2018); Popovic et al. (2018), but usually require building maps of the environments and tend to be computationally expensive, which hinders their deployability or the quality of the achieved solution given the limited computing resources onboard most aerial robots.
Responding to the combined problem of map-less collision-free and visually-attentive navigation, we propose a duo of new methods, called “Attentive ORACLE” (A-ORACLE) and “ORACLE.” Attentive ORACLE trains two deep neural networks: a Collision Prediction Network for predicting uncertainty-aware collision costs and an Information gain Prediction Network for estimating information gain values of a set of action sequences in a Motion Primitives Library. While the Collision Prediction Network utilizes only depth data—alongside a partial robot state that does not involve its position—and is built and expanded upon our earlier work Nguyen et al. (2022), the new Information gain Prediction Network utilizes both depth images and visual detection results and is trained with the information gain labels provided by an offline expert that relies on a volumetric mapping representation of the environments. Given the predictions from the two networks, in addition to a unit goal vector given by any high-level planner, the method derives the safe (collision-free) motion primitive having the highest information gain and leading towards a desired direction. This is then commanded and executed in a receding horizon fashion. It is noted that when the Information gain Prediction Network is not engaged, the method reduces to 3D ORACLE which ensures safe uncertainty-aware map-less navigation.
Compared to our previous work on ORACLE Nguyen et al. (2022), this manuscript represents a major extension and claims a set of contributions as outlined below.
First, it is about introducing visual attention-aware navigation into the framework through the Information gain Prediction Network which in turn allows to combine safe navigation with implicit information sampling (contribution 1). Second, we present a significant upgrade of Nguyen et al. (2022) as the new method a) extends the previous one from 2D to 3D navigation enabling safe flight in complex and cluttered scenes without the need for a map or position estimates (contribution 2) and further b) utilizes a deep ensembles method, called Deep Ensembles Lakshminarayanan et al. (2017), instead of Monte Carlo dropout Gal and Ghahramani (2016) for the neural network’s epistemic uncertainty estimation thus offering performance robustness against sources of noise (contribution 3).
To realize these goals, ORACLE and A-ORACLE employ a novel supervised learning paradigm for collision prediction and assessment of the informativeness of candidate motion primitives where both the epistemic and aleatoric uncertainty are accounted for collision prediction through the Deep Ensembles and the Unscented Transform over the robot’s partial state covariance (contribution 4). Finally, a new set of simulations and real-world experiments are conducted to verify the proposed uncertainty-aware and visually-attentive framework. The method is thus extensively evaluated including successful sim-to-real transfer, an ablation study, and comparative analysis against other methods of the state-of-the-art highlighting its advantages (performance claim).
Specifically, more thorough simulation studies are conducted to demonstrate the performance of our method against noisy inputs including the robot’s velocity estimate and the depth image (linked to contributions 2–4). An ablation study regarding the role of the Deep Ensembles is also conducted in simulation (linked to contribution 3), alongside a comparative analysis of ORACLE with the work in Loquercio et al. (2021) (linked to contributions 2–4). Moreover, simulation results with different sources of visual attention are performed to illustrate the advantages of our visually-attentive navigation method compared to other baselines and an appropriately modified version of the informative planning work in Schmid et al. (2020) (linked to contribution 1). Finally, real-world experiments, a subset of which is depicted in Figure 1, including safe flights with a reference forward speed of 2.5 m/s in a cluttered environment (linked to contributions 2–4), autonomous missions in a highly cluttered forest (linked to contributions 2–4), and visual attention-aware navigation in industrial and campus buildings (linked to contribution 1) are also presented. As demonstrated and analyzed, the method not only utilizes partial state information and transfers well to the real system but also presents robustness to state uncertainty and exteroceptive sensor noise that is unseen during training (contributions 2–4). For the remainder of this manuscript, the 3D ORACLE method which ensures safe uncertainty-aware map-less navigation is simply called ORACLE. Instances of real-world experiments demonstrating the proposed methods, including safe flights with a reference forward speed of 2.5 m/s in a cluttered corridor (1a), under canopy flights inside a dense forest (2a) and visual attention-aware navigation in an industrial silo tank (3a) and a university’s hall (4a). The bottom row (b) illustrates prediction results from the method where the spherical markers correspond to the estimated trajectory endpoints of a set of action sequences, while among them green markers illustrate the subset of safe action sequences (with orange being unsafe), and the blue marker with an arrow corresponds to the selected action sequence.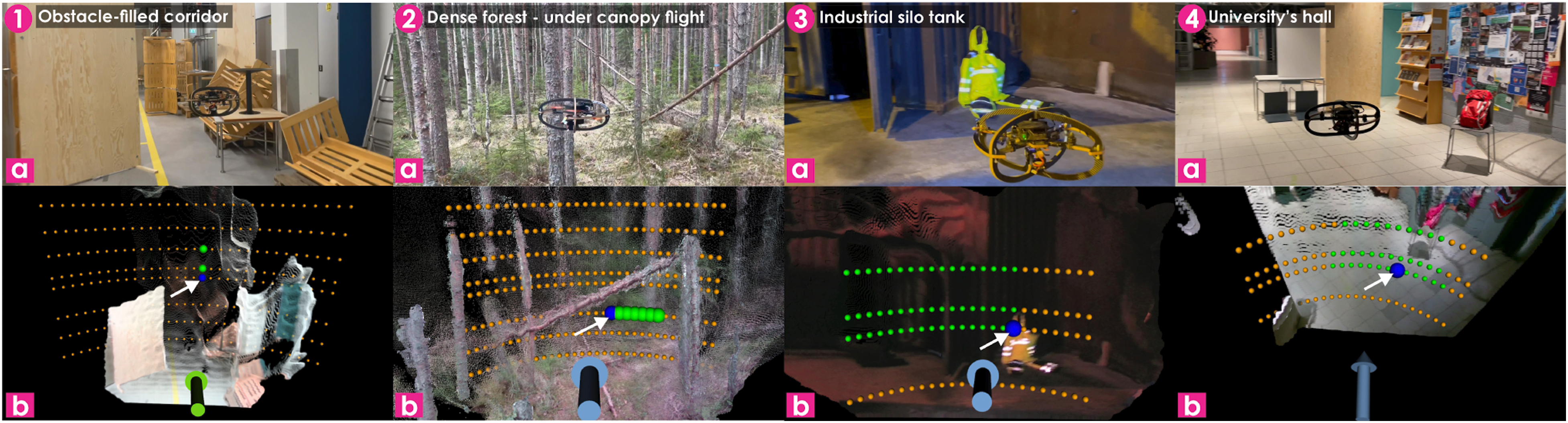
The remainder of this paper is organized as follows: Section 2 presents related work, followed by the problem statement in Section 3. The proposed method is presented in Section 4 while evaluation studies are detailed in Section 5, followed by conclusions in Section 6.
2. Related work
A set of contributions in a) learning-based navigation, b) uncertainty-aware navigation and modeling uncertainty in deep neural networks, and c) visually-attentive navigation relate to this work.
2.1. Learning-based navigation
In recent years, a large amount of work has been devoted to harnessing the power of deep learning in various ways to solve the problem of autonomous navigation. A group of work focuses on solving the global path planning problem efficiently in which a top-down image or point cloud of the whole environment is provided a priori Ichter and Pavone (2019); Srinivas et al. (2018); Qureshi et al. (2021). However, in this work, we focus on the setting where the global map of the environment is not available and the robot needs to navigate in a collision-free manner given only local onboard observations. Several works utilize neural networks to solve the local navigation problem. The authors in Loquercio et al. (2021) and Tolani et al. (2021) use imitation learning to generate collision-free smooth trajectories which are then tracked by model-based controllers. Nevertheless, position information may not be reliable in many perceptually-degraded environments. On the other hand, other low-level commands (velocity/steering angle, acceleration, or angular velocity/thrust commands) can be inferred by deep navigation policies which can be trained by various schemes including reinforcement learning Francis et al. (2020), supervised learning where ground-truth commands are readily available in a driving dataset Loquercio et al. (2018), provided by human operators Shah and Levine (2022) or demonstrated by an expert Kaufmann et al. (2020), and self-supervised learning Gandhi et al. (2017); Kahn et al. (2021a); Kahn et al. (2021b). In this work, we choose to use velocity/steering angle commands to allow the robot to not rely on reliable position estimation.
A body of work utilizes deep learning to derive interpretable maps, which are then used by classical planners to plan collision-free paths Wang et al. (2021); Frey et al. (2022); Castro et al. (2023); Zeng et al. (2019). Instead of learning classical map representations from raw observation data, many works present methods to encode raw sensor data into an implicit latent vector Hoeller et al. (2021); Dugas et al. (2021); Ichter and Pavone (2019); Srinivas et al. (2018); Qureshi et al. (2021). Control actions can then be inferred through these latent representations thus offering the benefit of low-latency navigation Loquercio et al. (2021), utilizing the computing capability of modern GPU for efficient deep neural network’s inference. The latent vectors in our work are learned to implicitly encode information about the environments as well as the robot’s partial state to predict collision events and information gains at future time steps.
Like other works that apply deep learning to score each motion primitive in a discrete set (Veer and Majumdar, 2020); Kahn et al., 2021a); Kahn et al., 2021b), our work also falls into this category. However, we explicitly consider the effects of uncertainties when scoring each motion primitive.
2.2. Modeling uncertainty in deep neural networks and uncertainty-aware learning-based navigation
When using deep neural networks for making predictions, there are two kinds of uncertainty that need to be considered: a) aleatoric uncertainty which captures inherent and irreducible data noise and b) epistemic uncertainty which accounts for model uncertainty and cannot be negligible for out-of-distribution inputs Kendall and Gal (2017). Two main methods for estimating epistemic uncertainty that can be applied to large neural networks and large datasets are a) approximate Bayesian inference and b) ensembling (Gustafsson et al., 2020); Abdar et al., 2021). Monte Carlo (MC) dropout (Gal and Ghahramani, 2016) is an approximate Bayesian inference method that is widely used in deep learning due to its simplicity and efficiency. On the other hand, ensembling methods use an ensemble of neural networks to derive the output uncertainty. Empirically, studies in Gustafsson et al. (2020); Ovadia et al. (2019) conclude that Deep Ensembles (Lakshminarayanan et al., 2017), an ensemble method that assembles different neural networks trained with different initialization weights and shuffling of the same dataset, can provide more reliable and useful uncertainty estimates than MC dropout.
Additionally, methods for propagating aleatoric uncertainty from the input to the output of the neural network can be classified into two main groups: layer-wise and entire-network uncertainty propagation (Abdelaziz et al., 2015). Though layer-wise uncertainty propagation methods (Ghosh et al., 2016); Hernández-Lobato and Adams, 2015); Gast and Roth, 2018); Wang et al., 2016); Astudillo and Neto, 2011) can offer the distributions of hidden layers, they often require modification to the original network during the training or inference phases. Moreover, Abdelaziz et al. (2015); Chua et al. (2018) demonstrate that entire-network uncertainty propagation through particle-based propagation methods such as the Unscented Transform Julier and Uhlmann (1997) can be competitive in terms of accuracy and computation.
As demonstrated in traditional belief space planning methods (Bry and Roy, 2011); Agha-mohammadi et al., 2018); Sun et al., 2021), modeling uncertainty is vital to achieving safe navigation in challenging environments where the state of the robot or the map of the environment can be highly uncertain. Most existing works applying deep neural networks for autonomous navigation account for epistemic uncertainty only, for instance, by using autoencoders Richter and Roy (2017), dropout and bootstrap Kahn et al. (2017); Georgakis et al. (2022); Lütjens et al. (2019), 2D spatial dropout Amini et al. (2017), evidential fusion Liu et al. (2021). One of the exceptions is Loquercio et al. (2020) which accounts for both uncertainties in the image data using Assumed Density Filtering Ghosh et al. (2016) and epistemic uncertainty using MC dropout. Chua et al. (2018) propose to use particle propagation to estimate the aleatoric uncertainty and Deep Ensembles to derive the epistemic uncertainty. However, this work focuses on the different problem of control of robot dynamics as opposed to the task of safe and attentive flight exploiting exteroceptive sensor data, employs reinforcement learning instead of supervised learning, is not verified onboard a robot for autonomous navigation and thus does not address the sim-to-real challenge, especially with high-dimensional data. Moreover, in Chua et al. (2018), to predict future plausible state trajectories, all the state particles are initially created from the same current state since the aleatoric uncertainty considered is the inherent stochasticities of the dynamics model (e.g., process noise). Our work considers the aleatoric uncertainty of the system as the prediction uncertainty due to the noisy robot’s partial state estimates. Thus, our particles are chosen as the sigma points around the current robot’s partial state estimate, given by the Unscented Transform.
2.3. Visually-attentive navigation
Our problem is also closely related to the informative path planning (IPP) problem where the robots need to find trajectories to maximize information gathered along the trajectory, given a constrained budget of time, fuel, or energy (Hollinger and Sukhatme, 2014). Traditionally, the IPP problem can be tackled by performing coverage path planning and viewpoint selection on the pre-built map of the environment (Hollinger and Sukhatme, 2014; Forssen et al., 2008) or adapting the paths online based on the latest map to focus on the areas of interest (Dang et al., 2018; Popovic et al., 2018; Schmid et al., 2020). Learning-based methods have been applied to solve the IPP problem efficiently. While Choudhury et al. (2017) present an imitation learning approach where an agent imitates an “information-gathering” planner with full information about the world map, other works in Niroui et al. (2019); Chen et al. (2020); Zhu et al. (2018) train reinforcement learning agents to output the next frontiers to visit for autonomous exploration. Furthermore, the works in Tao et al. (2023); Georgakis et al. (2022) use neural networks to predict the occupancy maps and calculate the informative trajectories to reduce the uncertainties of the map.
The step of evaluating the information gains for all the trajectories, however, can be time-consuming Schmid et al. (2020). Accordingly, several works have proposed methods to reduce the computational time of the information gain calculation step, either by subsampling ray casting (Selin et al., 2019; Oleynikova et al., 2018; Zhou et al., 2021), avoiding redundant voxel checks (Zhou et al., 2021; Millane et al., 2018; Schmid et al., 2020), or calculating an analytical formula for a specific metric (Zhang et al., 2020). Rckin et al. (2022) combined tree search with offline-learned neural network predicting informative sensing actions. The method, however, requires the robot’s position and a cost feature map input to the network which relies on the assumption that the robot’s underlying localization and mapping are accurate.
Our work proposes to efficiently approximate an information gain formula tailored to obtaining high-quality observations of interesting areas with a neural network. The prediction is then combined with an uncertainty-aware Collision Prediction Network, exploiting the Unscented Transform and Deep Ensembles, alongside input from a high-level planner to achieve efficient uncertainty-aware visually-attentive navigation without relying on a map of the environment or the robot’s position information.
3. Problem formulation and notations
The problem considered in this work is that of autonomous uncertainty-aware and visually-attentive aerial robot navigation. The method explicitly assumes no access to the map of the environment (neither offline nor online) and no information for the robot position but only a partial state estimate of the robot combined with the real-time depth data and a 2D detection mask representing the interestingness of every region within an angle- and range-constrained sensor frustum. We assume that there is a global planner providing the 3D unit goal vector
In the following sections, we will denote
4. Proposed approach
To satisfy the two objectives of collision-free navigation and information sampling, we design two deep neural networks to efficiently estimate the ground-truth collision score c
col
and the information gain g for each action sequence, namely, the “Collision Prediction Network (CPN)” and “Information gain Prediction Network (IPN),” respectively. Both networks assume access to a) either the depth image (CPN) or the stacked matrix of the current depth image and the detection mask (IPN), alongside b) the estimates of the robot’s linear velocities, z-axis angular velocity, and roll/pitch angles, as well as c) candidate action sequences from a Motion Primitives Library (MPL). The choice of using the MPL instead of regressing the action (Francis et al., 2020) or trajectory (Tolani et al., 2021) directly from the input is based on the observations that MPL is a multi-modal output by construction, which is vital for the collision-avoidance task (Loquercio et al., 2021). Attentive ORACLE identifies the next-best-sequence of actions, specifically 3D velocity-steering commands over certain time periods, that ensure that the system is navigating towards where the unit goal vector is pointing, while not only avoiding the obstacles but also gathering information about interesting areas in the environment. The first action of this sequence is executed by the robot, while the process continues iteratively in a receding horizon manner. Importantly, the “global” goal vector may be provided by any global planner thus allowing Attentive ORACLE to be combined with any high-level planning framework Dang et al. (2020); Galceran and Carreras (2013); Kim and Ostrowski (2003); Achtelik et al. (2014). Figure 2 provides an overview of the architecture of the method. It is noted that the CPN accounts both for a) the estimation uncertainty of the robot’s partial state and b) the neural network’s epistemic uncertainty, and thus considers sigma points given the partial state estimate and its covariance, while simultaneously using an ensemble of neural networks to evaluate the collision scores. IPN is not concerned with the uncertainty of the partial state estimate and the epistemic uncertainty for computational reasons. Overview of the algorithmic architecture of Attentive ORACLE (A-ORACLE). We design two deep neural networks to efficiently estimate the uncertainty-aware collision score and the information gains for multiple action sequences, namely the “Collision Prediction Network (CPN)” and “Information gain Prediction Network (IPN)”, respectively. Both networks assume access to (a) either the depth image (CPN) or the stacked matrix of the current depth image and the detection mask (IPN), alongside, (b) the estimates of the robot’s linear velocities, z-axis angular velocity, and roll/pitch angles, and (c) candidate action sequences in a Motion Primitives Library (MPL). Notably, CPN utilizes 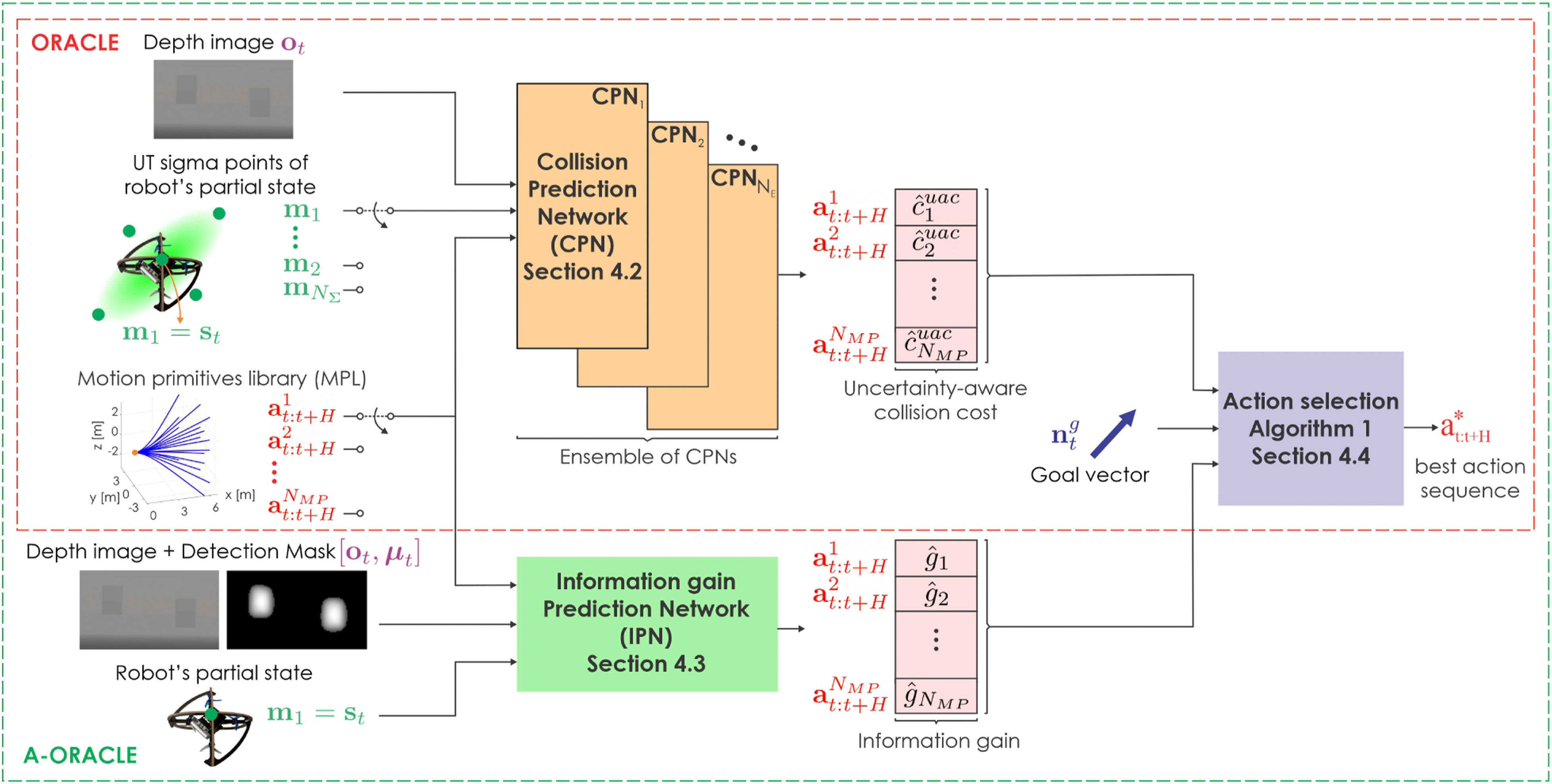
4.1. Velocity-steering angle motion primitives library
For each candidate action sequence in the MPL, the commands at each time step have the same velocity in the corresponding
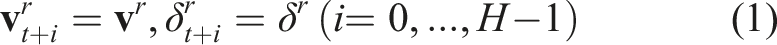



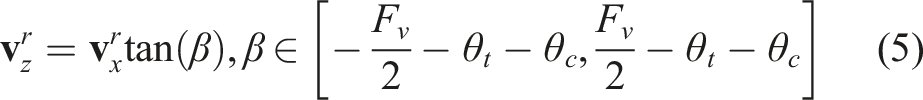
We denote (a) Estimated trajectories from an indicative MPL having 16 action sequences and 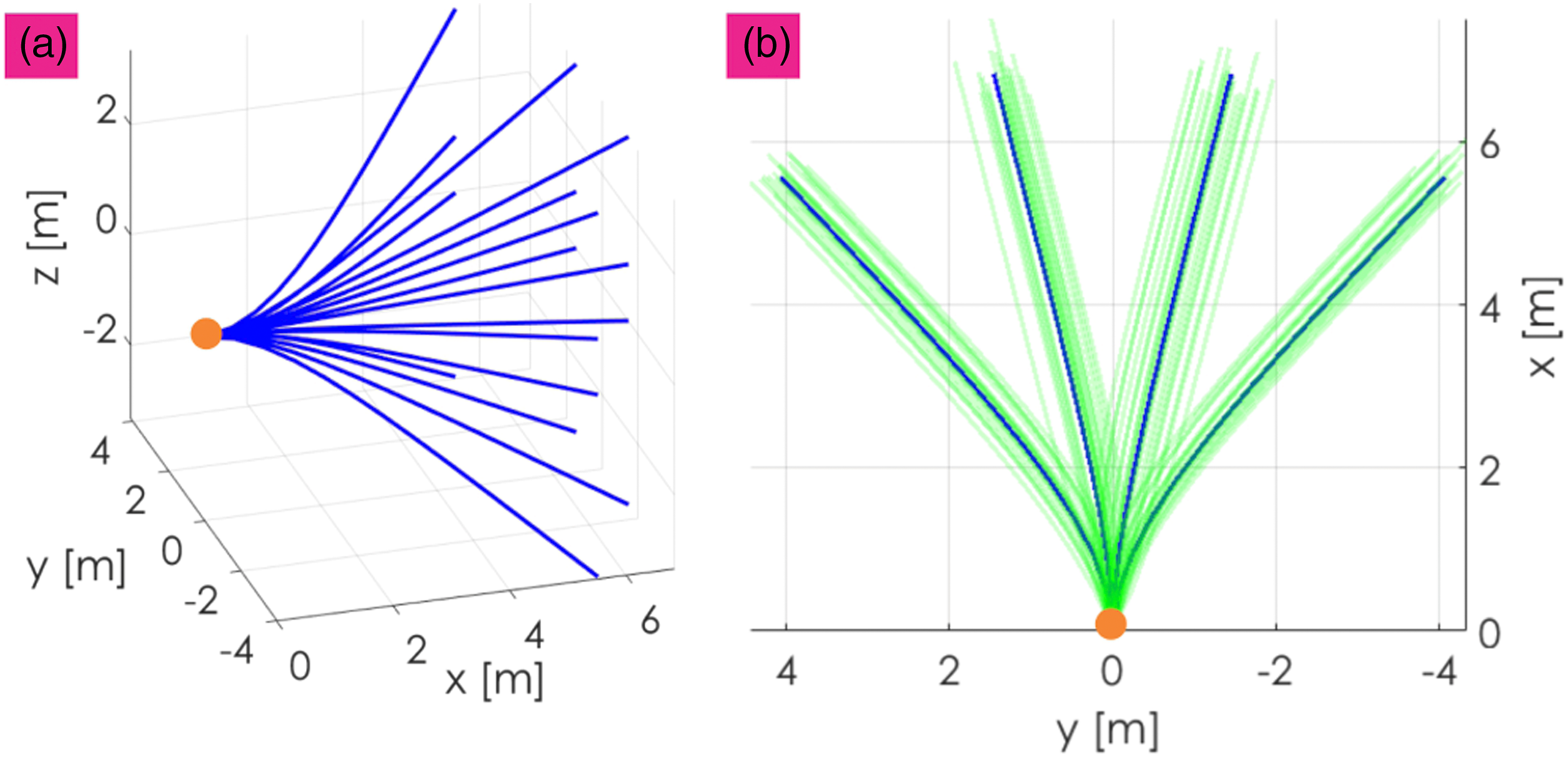
4.2. Uncertainty-aware collision-free navigation
At the core of the collision-free navigation task is the CPN which processes a) the input depth image
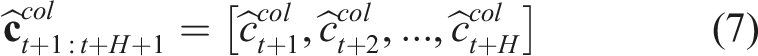
By entirely using collision data in simulation. Thus, ORACLE avoids the need for hand-engineered collision checking algorithms such as in Bucki et al. (2020); Gao et al. (2019) or access to a reconstructed map of the environment Funk et al. (2021); Tabib et al. (2022). The collision costs for every action sequence in the MPL of velocity-steering commands can then be evaluated in parallel as per Kew et al. (2021), exploiting modern GPU architectures and thus enable high update rate compute. Notably, when evaluating the collision costs, ORACLE does not only consider the mean estimate of the robot’s partial state but also its estimated uncertainty (exploiting the Unscented Transform) as calculated by any onboard localization system, as well as the epistemic uncertainty in the neural network model, as detailed in Section 4.2.3.
4.2.1. Neural network architecture
To predict a sequence of collision labels
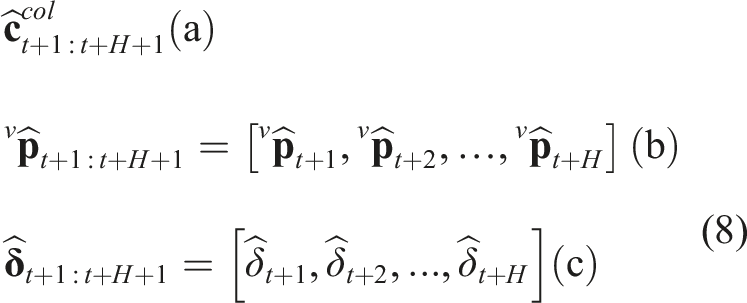
Instead of regressing the robot’s low-level commands directly from the network inputs, our CPN learns to perform collision checking implicitly for each action sequence. This is shown to generalize well to different simulated and real-world environments, as demonstrated in section 5. Intuitively, the method opts to rely on a priori set of motion primitives as candidate action sequences and then solves the simpler problem of collision checking on them instead of regressing directly the control action which would represent a more complex and thus potentially harder to generalize formulation. It is noted that the position and relative yaw angle prediction output heads are only executed in the training phase to provide additional back-propagated gradients to train the CPN and are not evaluated in the inference mode. The prediction network architecture, as shown in Figure 4, is inspired by the network in Kahn et al. (2021b). However, we replace the MobileNetV2 part with the ResNet-8 network as in Loquercio et al. (2018) for faster onboard inference speed. Architecture of the Collision Prediction Network (CPN). The convolutional hyperparameters are represented in the format (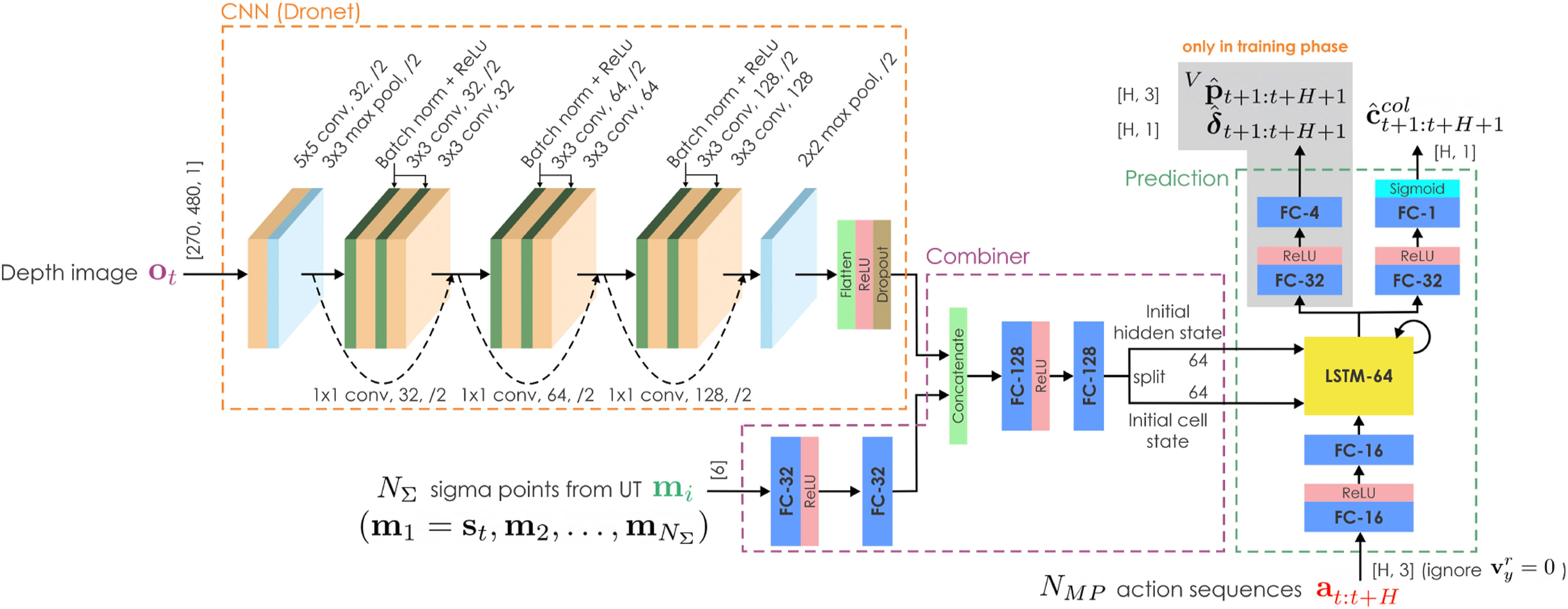
4.2.2. Data collection and augmentation
The RotorS simulator (Furrer et al., 2016) is used to collect data for training the CPN. To ensure successful sim-to-real transfer, the dynamics of the simulated model should be matched with the intended real system, in this case, the custom quadrotor described in Section 4.5.2. Relevant methods for dynamic system identification of MAVs are presented in Sa et al. (2017). To collect data for predicting collision scores at the future time steps, an action sequence with random
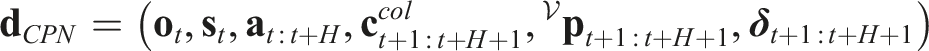
1) The depth camera follows the pinhole camera model. 2) The xOz-plane of 3) The low-level closed-loop dynamics of the robot can be approximated by the system of equation (6).
If the above assumptions are satisfied, the augmented data point
In order to collect a comprehensive dataset for training the collision predictor, we randomized the initial position and orientation of the robot, as well as the obstacles’ poses, categories, dimensions, and densities in order to collect around 1.5 million data points, including augmented ones, in total. The entire data collection process in the Gazebo simulator requires approximately 6 days on a laptop with AMD Ryzen 9 4900HS CPU with 32 GB of RAM. Figure 5 illustrates one indicative training environment which has a size of 40 × 40 × 10 m and includes obstacles having primitive shapes such as spheres, pyramids, cylinders, T-shape and U-shape blocks, as well as common real-world obstacles such as trees, tables, chairs, walls, or fences. The derived dataset was then split into a training and validation subset with an 80%: 20% ratio. The network is trained end-to-end with the Adam optimizer Kingma and Ba (2015) and the loss function as the weighted sum of the binary cross-entropy (BCE) loss for collision prediction (binary classification task) and the mean-squared error (MSE) loss for position and relative yaw angle predictions (regression tasks): An indicative simulation environment for collecting training data.
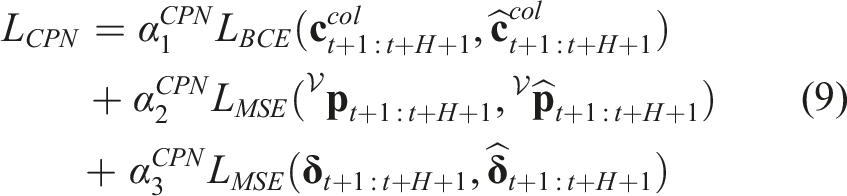
4.2.3. Uncertainty-aware prediction
As mentioned, the method further considers the uncertainty of the robot’s partial state and the epistemic uncertainty of the collision prediction network. First, we calculate the combined collision cost for each action sequence in the MPL as the weighted sum of the collision scores at future time steps. Specifically, the sooner the collision event is predicted to happen, the higher its contribution to the final collision cost:
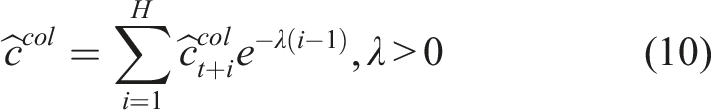


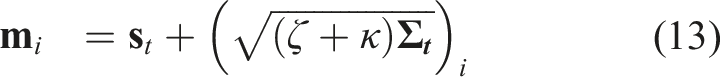
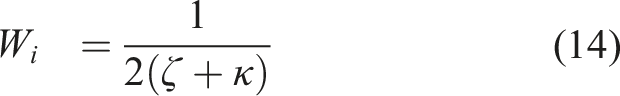
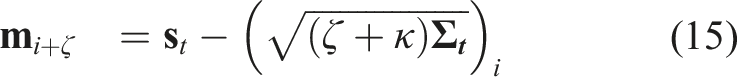
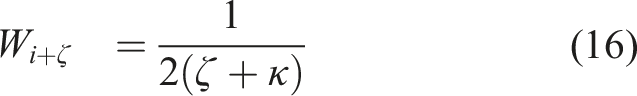
Additionally, the epistemic uncertainty—which can be significant for novel input data—can be captured by the variance between the outputs of different models in an ensemble of neural networks as in Lakshminarayanan et al. (2017). Specifically, we train the CPN with different initial weights and shuffling of the dataset to obtain multiple final weights for it. This is shown empirically to explore more diverse modes in function space compared to MC dropout Fort et al. (2019); Pop and Fulop (2018). For efficient neural network forward pass and uncertainty estimation, we split the neural network shown in Figure 4 into 3 parts, namely, the CNN, Combiner, and Prediction networks. Let a)
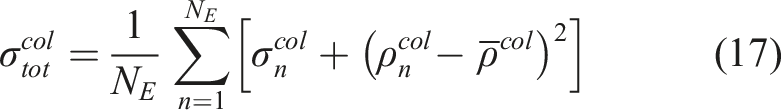
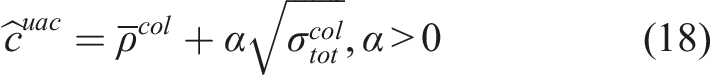
Specifically, we denote (a) The ensemble of CPNs takes as inputs the current depth image, the set of sigma points calculated from the Unscented Transform based on the mean value 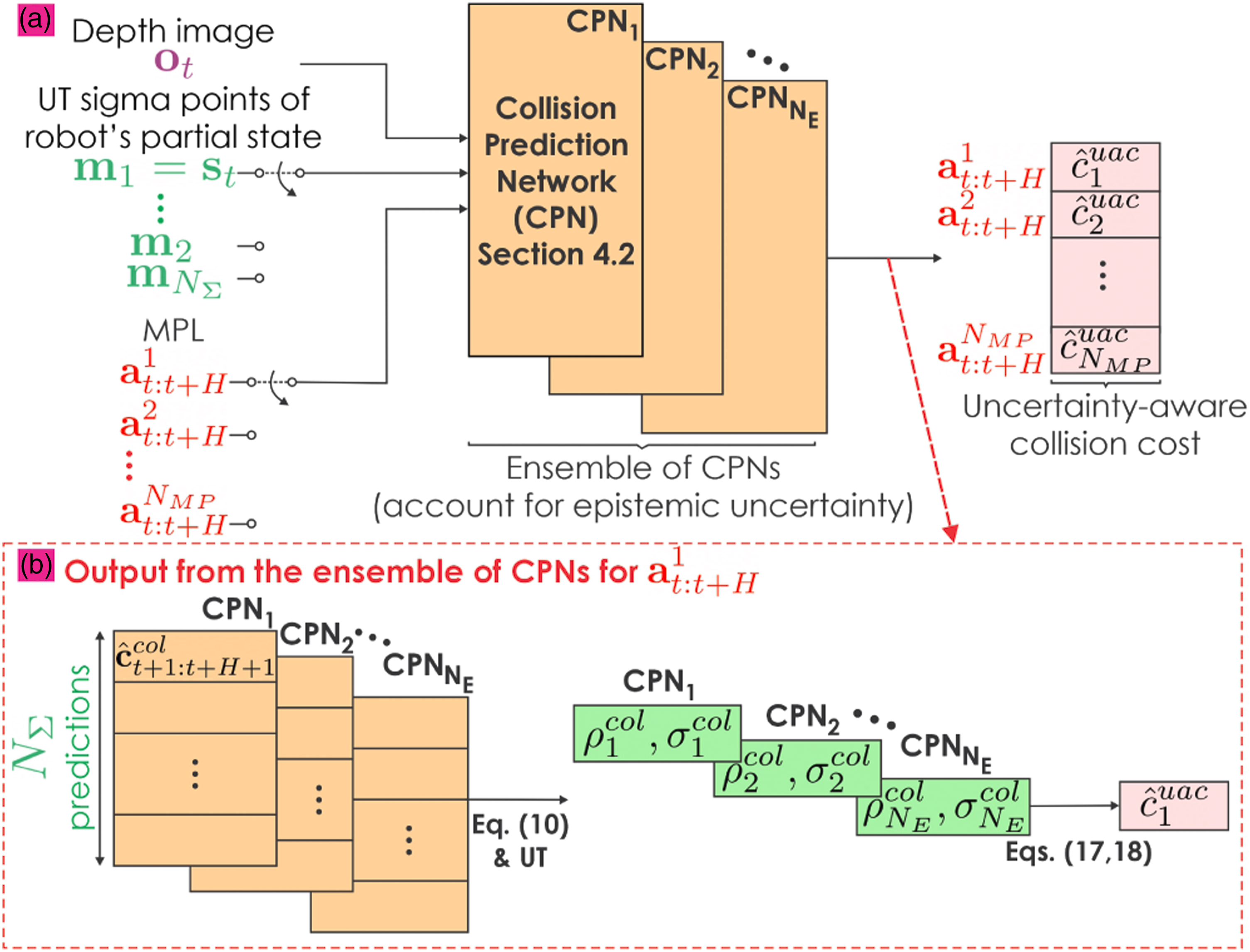
4.3. Visually-attentive navigation
Solutions to the information-gathering problem usually involve the evaluation of utility functions Fox et al. (1998); Popovic et al. (2018), which is one of the main computational bottlenecks in informative path planning Schmid et al. (2020); Rckin et al. (2022). In this work, we aim to allow efficient information gathering based on the latest sensor observations by designing an IPN to approximately estimate the information gains of multiple action sequences. Specifically, the IPN considered in this work is a neural network that takes as input a) the depth image and a 2D detection/interestingness mask stacked together
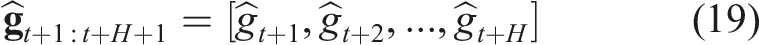
4.3.1. Neural network architecture
Figure 7 describes the architecture of the IPN. To predict a sequence of information gain labels at future time steps Architecture of the Information gain Prediction Network (IPN). The convolutional hyperparameters are represented in the format (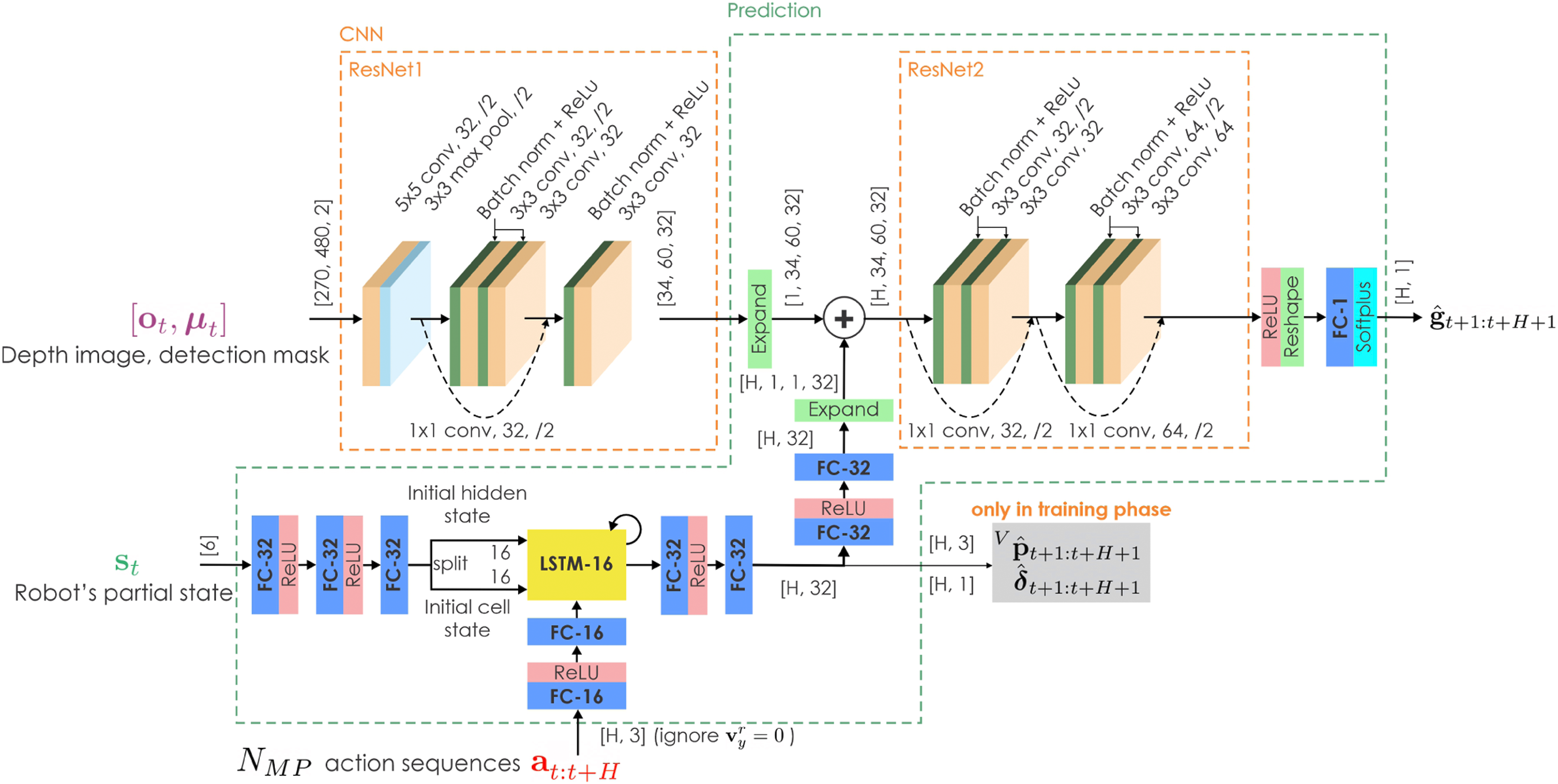
We also tested the same architecture as the CPN, described in Figure 4, for the information prediction task. However, the output feature map from the CNN part of the CPN does not have enough spatial resolution to enable the information gain prediction task. Moreover, we tried to replace the ResNet2 (Figure 7) with a 2D Convolutional LSTM Shi et al. (2015) while using the output feature map from ResNet1 as the 2D LSTM’s initial state, and the output sequence from the 1D LSTM as the 2D LSTM’s input sequence. However, the resulting network was slow to train and perform inference. The choice of using the network architecture presented in Figure 7 (using a 1D LSTM for position and relative yaw angle predictions and using the ResNet2 with shared weights for information gain prediction at every future time step) balances the accuracy of the prediction and the speed of training and inference.
For efficient neural network forward pass, we split the neural network shown in Figure 7 into 2 parts, namely, the CNN and Prediction networks. We can then perform inference on the CNN and Prediction networks with different input batch sizes of 1 and N MP , respectively, avoiding the need to use the same input batch size of N MP for the whole IPN. Intuitively, given that the IPN can closely approximate the information gain then the ability to run it efficiently allows high planning rates which benefits online performance.
4.3.2. Ground-truth information gain label
The ground-truth information gain label for training the IPN is calculated using Voxblox’s volumetric map (Oleynikova et al., 2017) augmented with an additional interestingness field for each voxel. Specifically, we denote Outline of how the information gain label 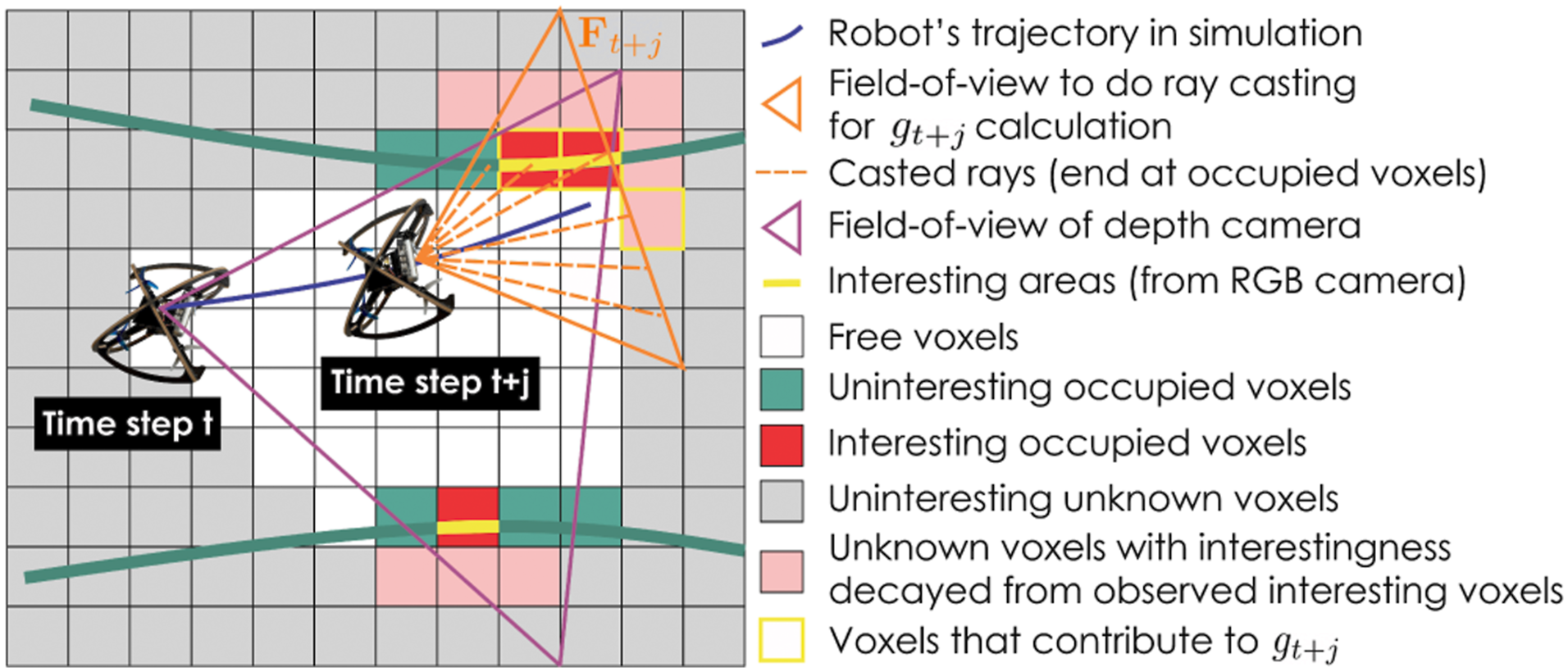
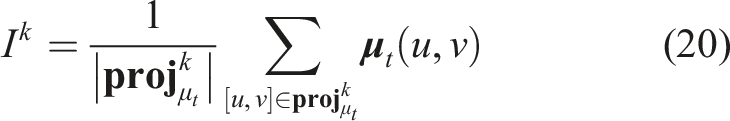
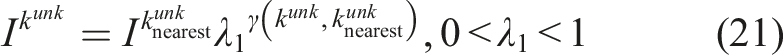
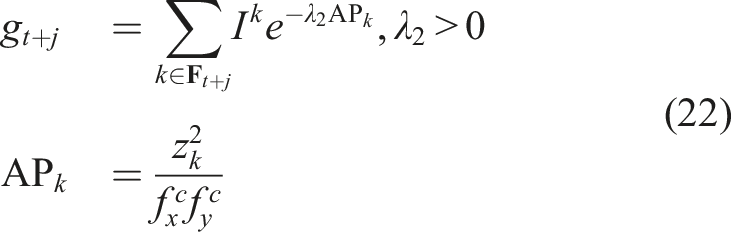
4.3.3. Data generation and augmentation
To create a diverse dataset for training the IPN, we utilize the same dataset collected for training the CPN and create synthetic detection masks, Steps to create synthetic detection masks to train the IPN. From left to right: (1) Multiple ellipses are created with random positions and dimensions for training purposes. (2) A Gaussian filter with random kernel size is further applied. (3a) The depth image is loaded. (3b) The final detection mask is generated by combining all valid pixels (having values within the range limits) of the depth image with the mask created by filtering randomly generated ellipses.
A data point d
IPN
can then be created with the format:
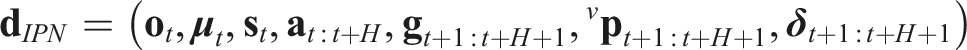
4.3.4. Network training and inference
A weighted-MSE loss is calculated for the regression tasks of the three output prediction heads depicted in Figure 7 and the Adam optimizer Kingma and Ba (2015) is utilized to train the IPN. The loss function has the form:
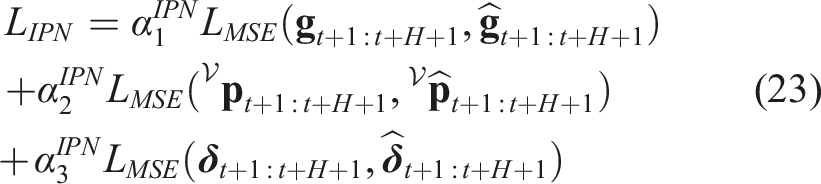

Additionally, to reduce the computational time of the IPN in inference mode, we can estimate the information-gain for one in every
4.4. Uncertainty-aware visually-attentive collision-free navigation

Algorithm 1 outlines Attentive-ORACLE’s key steps. After calculating the uncertainty-aware predicted collision cost for each action sequence in the MPL, as described in section 4.2.3 (line 6–19), the minimum collision cost
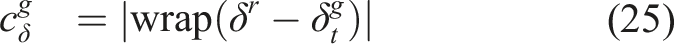
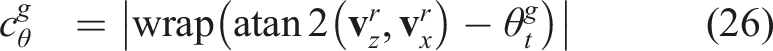

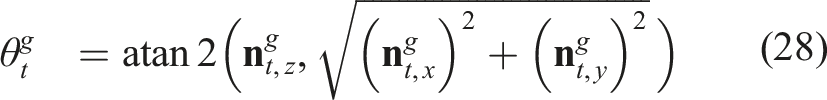
4.5. Implementation details
4.5.1. Hyper-parameters for training CPN and IPN
Both CPN and IPN are trained with the learning rate set to
4.5.2. System overview
We design a quadrotor, dubbed Learning-based Micro Flyer (LMF), which inherited the collision-tolerant design of the Resilient Micro Flyer De Petris et al. (2020), yet with an increased diameter of 0.43 m and a mass of 1.2 kg. It integrates a Realsense D455 to obtain depth and RGB data at a 480 × 270 resolution with FOV of [F
h
, F
v
] = [87, 58]° and a frequency of 15 FPS, a PixRacer Ardupilot-based autopilot delivering velocity and yaw-rate control, and a Realsense T265 fused with the IMU of the autopilot allowing it to estimate the velocity, orientation and angular rates of the robot. Notably, the position estimates of the T265 are not required by ORACLE or A-ORACLE except for calculating the unit goal vector Main hardware components onboard LMF.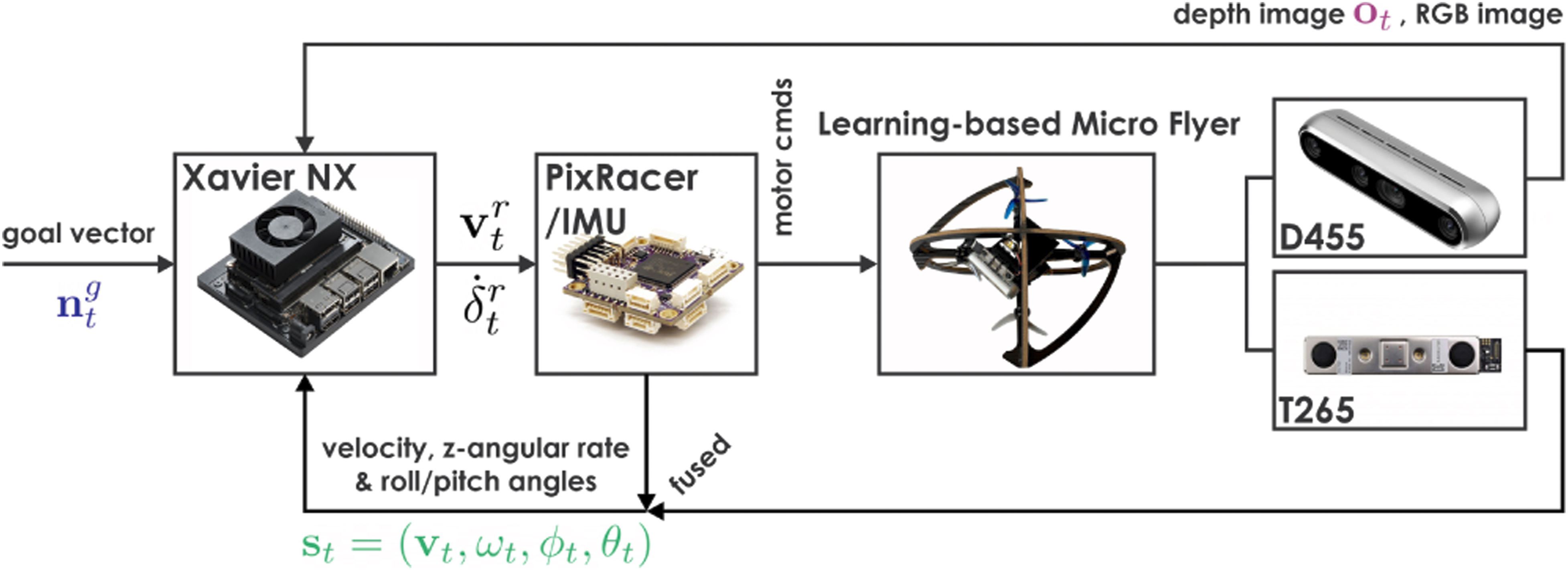
4.5.3. Image pre-processing step
Since real-life depth images are often subject to several shortcomings compared to simulated data, including a) missing information, b) loss of detail, and c) depth noise Hoeller et al. (2021), we perform an additional pre-processing step using the IP-Basic algorithm Ku et al. (2018) to refine the depth frame and thus reduce the mismatch between the real and simulated depth images. Specifically, this pre-processing step applies a series of morphological transformations and blurring operation to fill in empty pixels in the depth images. Figure 11 illustrates the effect of the depth image pre-processing step. Depth-image preprocessing results. (a) RGB images from the Realsense D455 camera. (b) Raw depth images returned by the Realsense D455. Areas marked in blue boxes contain empty depth pixels due to textureless features caused by a light (1a) or reflective surface (2a). “Stereo shadow” regions can also be seen around the left object in 1b and the left part of (2b). (c) Depth images after the empty pixels are filled in.
5. Evaluation studies
A set of evaluation studies were then conducted to verify the proposed learning-based attentive navigation method.
5.1. Simulation studies
5.1.1. Uncertainty-aware navigation
To evaluate ORACLE’s ability to navigate cluttered environments in combination with degraded state estimates and noisy depth image inputs, we conducted simulation studies and compared ORACLE with 2 baselines. Specifically, the proposed approach was compared with a) the “Naive” method which utilizes the CPN directly to calculate the collision cost without considering the uncertainty of the partial state estimate An indicative simulation environment for simulation studies evaluating ORACLE (a) and enlarged view of a specific section in the environment (b). The ceiling is removed for visualization purpose.
The robot is modeled as a sphere of radius 0.22 m. We randomly generated 10 different environments, and both ORACLE and the 2 baselines are deployed in each environment 10 times with the same start point and end goal, which is 110 m ahead of the start point in the x-axis, but with different noise inputs at each run. Specifically, we deteriorated the partial state estimate with additive Gaussian noise on the x, y, and z-velocity components simultaneously, leading to
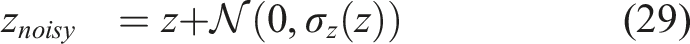

It is noted that the negligible first- and zeroth-order terms are ignored in this formula. The Intel Realsense RGB-D camera D435 is found to have d
z
≈ 0.004 in Ahn et al. (2019) while we use the later version of this sensor, Intel Realsense D455, in this work. We chose to simulate the depth image noise up to d
z
= 0.005. For all simulations, the robot reaches the goal when it is within a radius of 5 m from the goal or if it crosses the line x = 110 m, additionally a timeout period of 100 s is also applied. The depth camera is simulated with a maximum range of
It is noted that the reference forward speed of 2.5 m/s is higher than the reference speed of 1.5 m/s used in Bartolomei et al. (2023), where no velocity or image noise is simulated and the density of the simulation environments is δ1 = 2.23 m. While our reference speed is lower than the flying speed of 10 m/s in Loquercio et al. (2021), where the maximum density of the simulated environments is δ1 = 5 m and the diameter of the obstacles is about 0.6 m, our maximum simulated velocity noise (σ v = 0.6 m/s) is around 3 times the standard deviation of the velocity noise in the y-axis, the main reactive axis of the robot, simulated in Loquercio et al. (2021). Additionally, an empirical image noise model is applied in our simulation evaluation study. It is aimed to systematically evaluate the performance of our method when exposed to novel noisy depth images that are unseen during the training process. The average and 1-σ boundaries of the success (non-collision) rate of each simulation study are reported below.
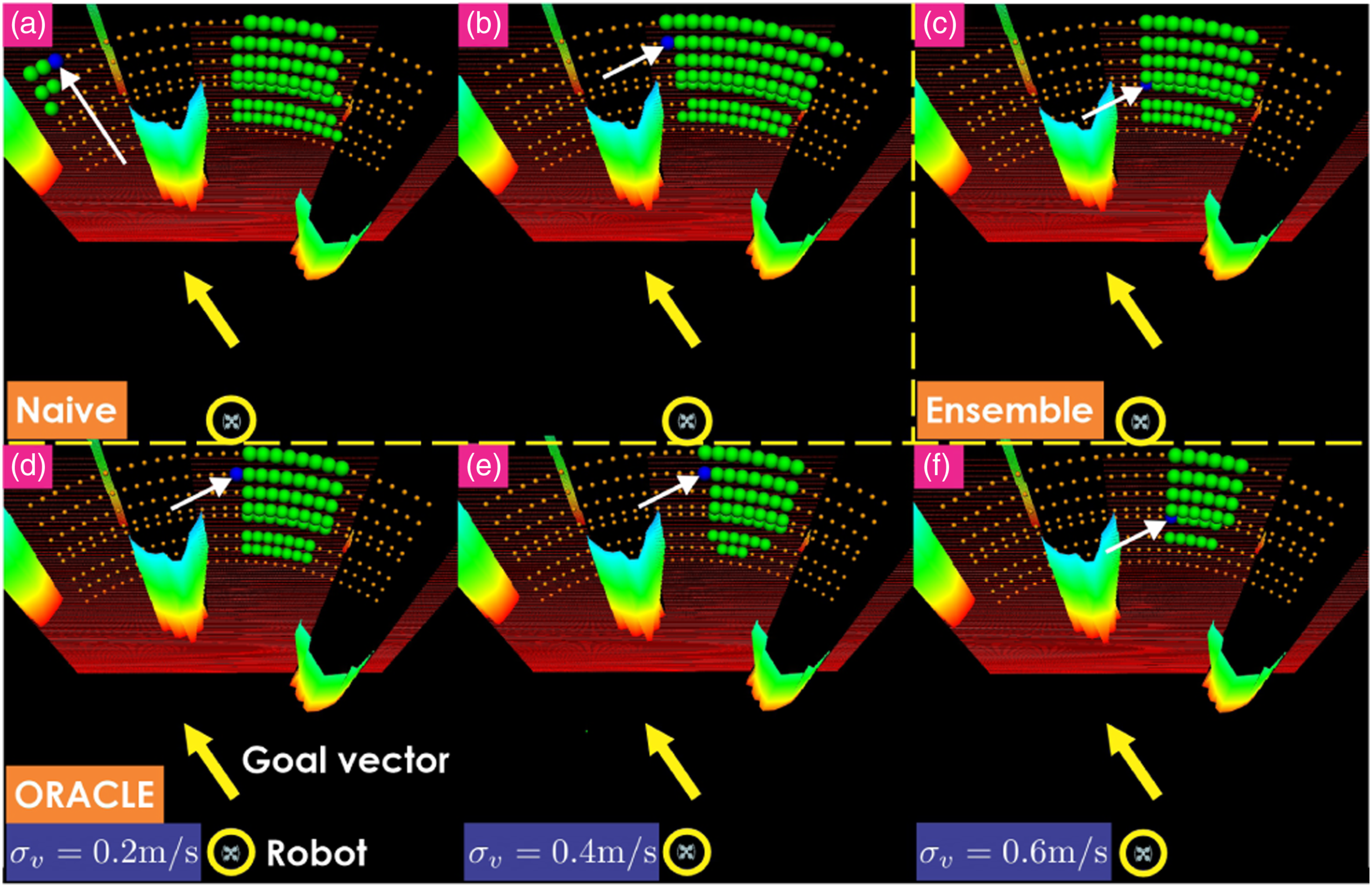
Figure 13 demonstrates the success rate when the velocity estimation deteriorates. As shown, the Naive method exhibits more significant drops in the performance when the velocity noise in all axes is increased (drops by 28% at 0.2 m/s- but 50% at 0.4 m/s- and 60% at 0.6 m/s-noise level). On the other hand, the Ensemble method shows smaller drops in the performance at all levels of noise (drops by 12% at 0.2 m/s-, 28% at 0.4 m/s- and 32% at 0.6 m/s-noise level). Lastly, ORACLE is the least sensitive to velocity noise. Its success rate drops marginally at 0.2 m/s, while it drops by only 6% at 0.4 m/s- and 14% at 0.6 m/s-noise level. The predictions from 2 CPNs in the Ensemble are illustrated in Figure 14(a) and (b). The Ensemble baseline utilizes prediction from multiple CPNs, resulting in a more conservative set of safe action sequences, as presented in Figure 14(c). Lastly, when ORACLE is deployed and σ
v
utilized in the UT is increased from 0.2 to 0.6 m/s (Figure 14(d)–(f)), the safe set of action sequences is further reduced, leading to a safer action sequence chosen finally when the velocity estimate is subjected to noise. However, a more conservative set of safe action sequences can lead to a larger deviation from the goal vector. Sensitivity analysis of noise in velocity estimation (100 runs were performed). The x-axis shows the standard deviation of velocity noise applied simultaneously in all axes. The presented results relate to contributions 2–4. Collision-score predictions from Naive baseline with 2 different CPN’s weights (a), (b), Ensemble baseline (c) and ORACLE with different σ
v
utilized in UT (d, e, f). Green markers: estimated trajectory endpoints of safe action sequences, blue marker with an arrow: estimated trajectory endpoint of chosen action sequence. The presented results relate to contributions 2-4.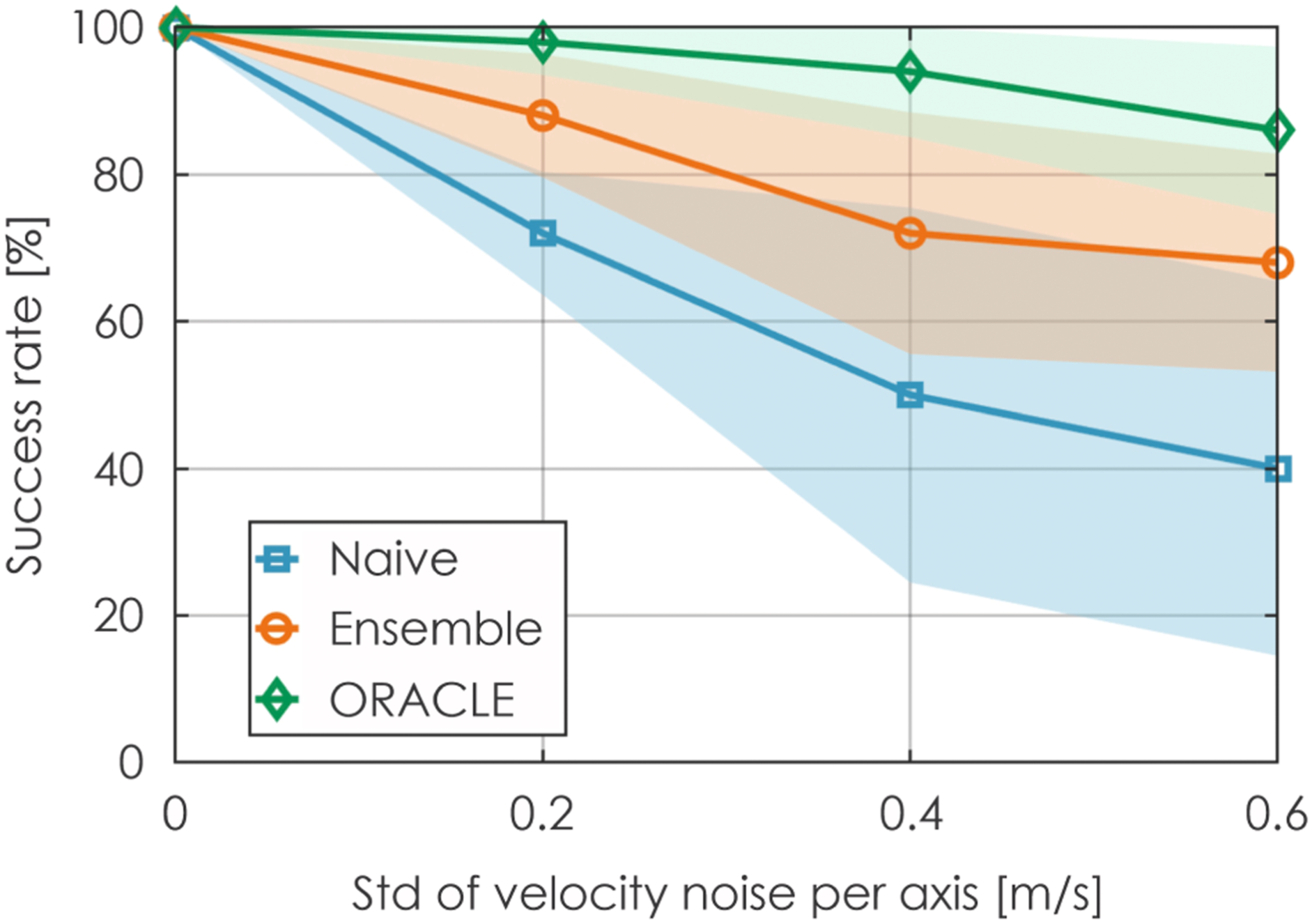
We also verified the performance of ORACLE when the velocity noise is wrongly estimated. Figure 15 shows the success rates of ORACLE when a fixed standard deviation σ
v
= 0.2 m/s is used while the actual standard deviation of the velocity noise in all axes varies between 0 and 0.6 m/s. It can be concluded that the higher the true noise level is compared to the estimated noise level, the lower the success rate. However, the performance drops gracefully when the actual noise level is close to the estimated one (drops by only 2% at 0.4 m/s-noise level compared to using ORACLE with the actual σ
v
) and the performance is still higher than the Ensemble baseline which does not use the UT. Sensitivity analysis of noise in velocity estimation when wrong σ
v
is utilized in the UT (100 runs were performed). The x-axis shows the standard deviation of velocity noise applied simultaneously in all axes. The presented results relate to contributions 2-4.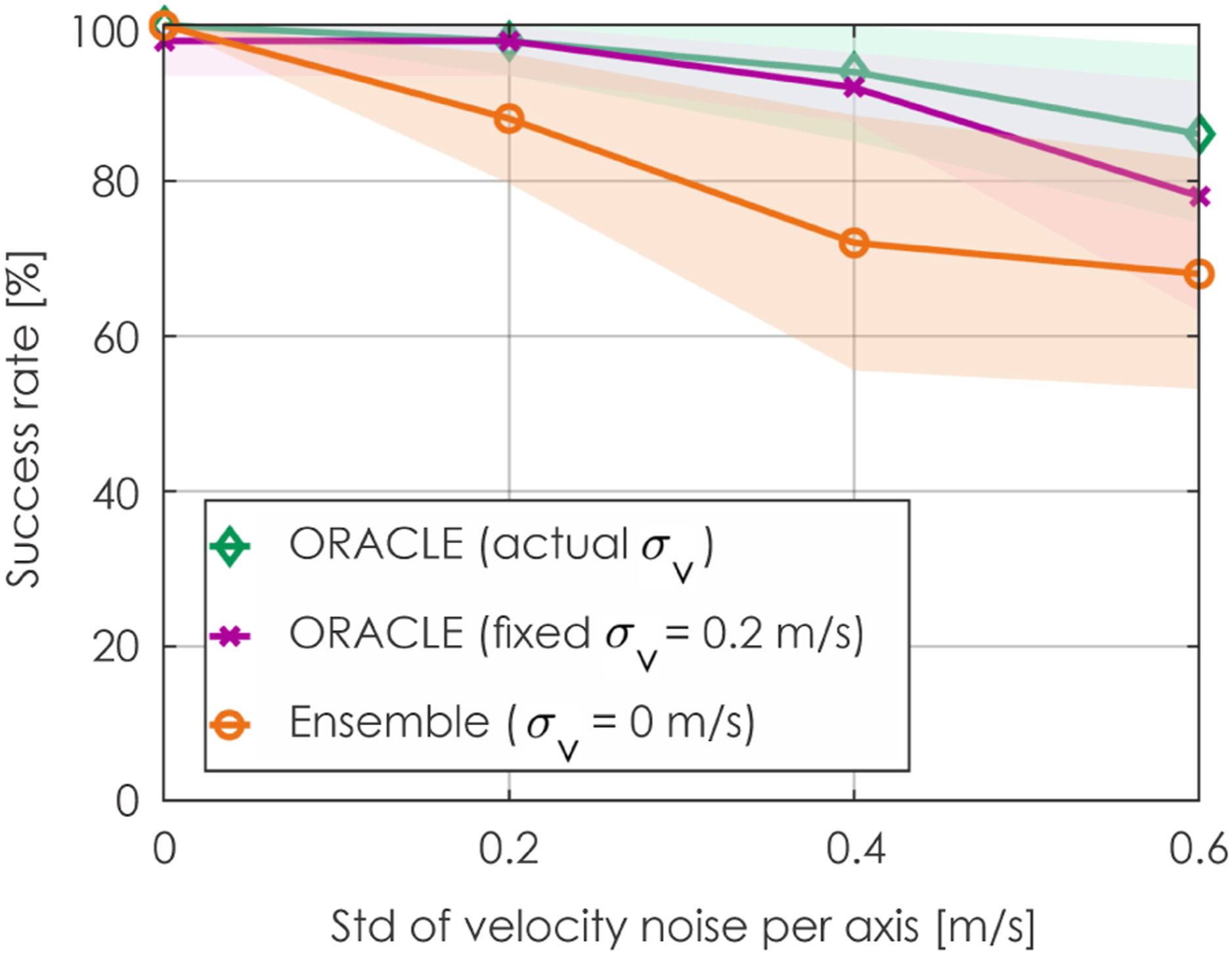
The performance of the Naive baseline and Ensemble baseline, which is similar to ORACLE in this case, with different levels of depth image noise is given in Figure 16. As shown, the performance of the Naive method is greatly affected by the image noise (drops to 0%-success rate at the highest level of depth image noise). On the contrary, the use of the ensemble of CPNs renders the Ensemble method much less sensitive to depth image noise, only exhibiting a drop of around 20% at the highest noise level. Sensitivity analysis of noise in depth image (100 runs were performed). The presented results relate to contributions 2-4.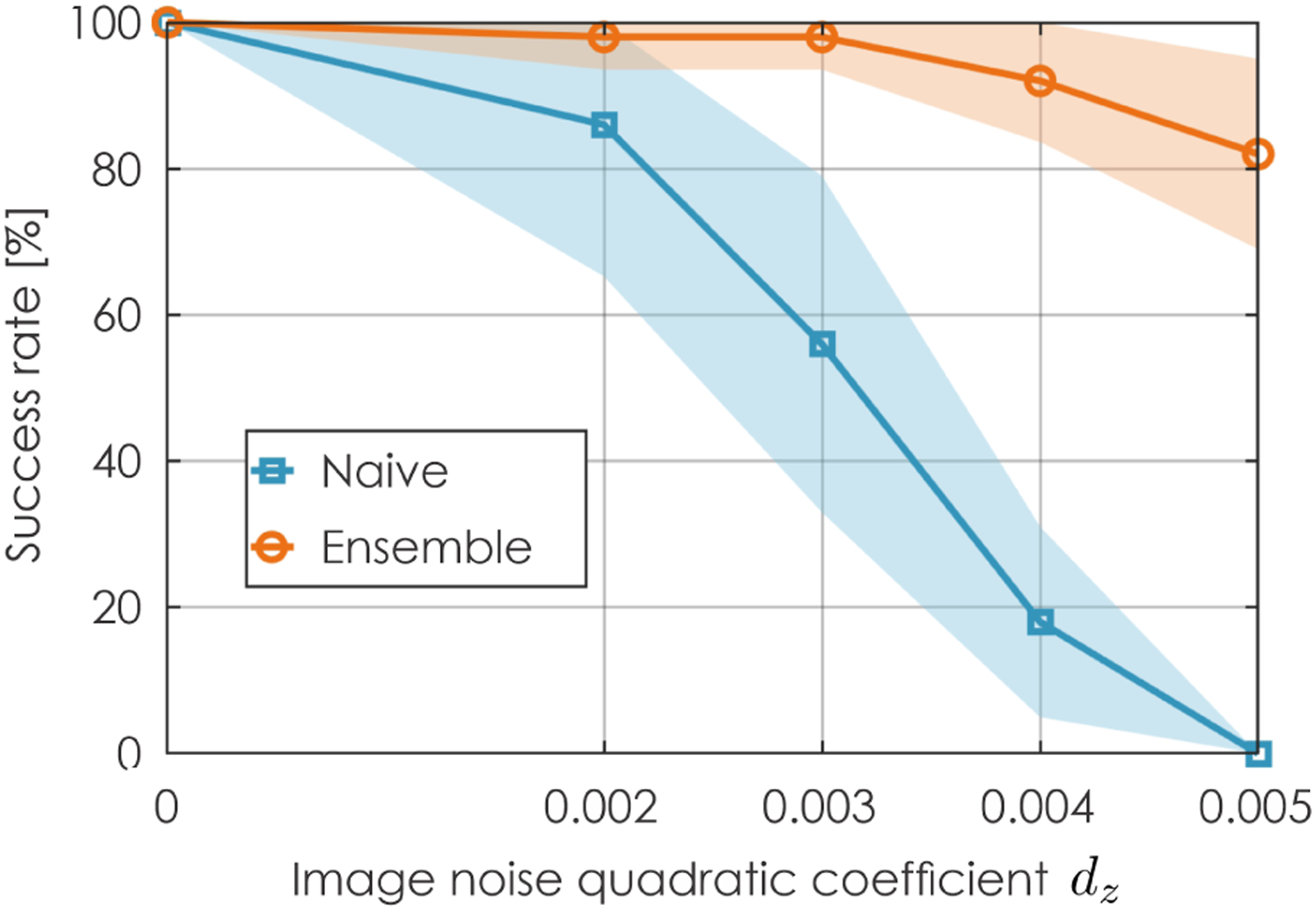
Lastly, we also compared ORACLE with the two baselines when both the velocity noise of 0.5 m/s std in all axes and the depth image noise are applied. As depicted in Figure 17, the performance of the Naive method drops drastically when the noise level is increased, reaching less than 10% at the highest noise level. On the other hand, the Ensemble method shows smaller degradation in the performance but still drops to around 56%-success rate at the highest noise level. On the other hand, ORACLE is the least sensitive to both velocity and depth image noise. Its success rate is around 74% when the noise level is the most significant. Sensitivity analysis of noise in both velocity estimation and depth image (100 runs were performed). The presented results relate to contributions 2-4.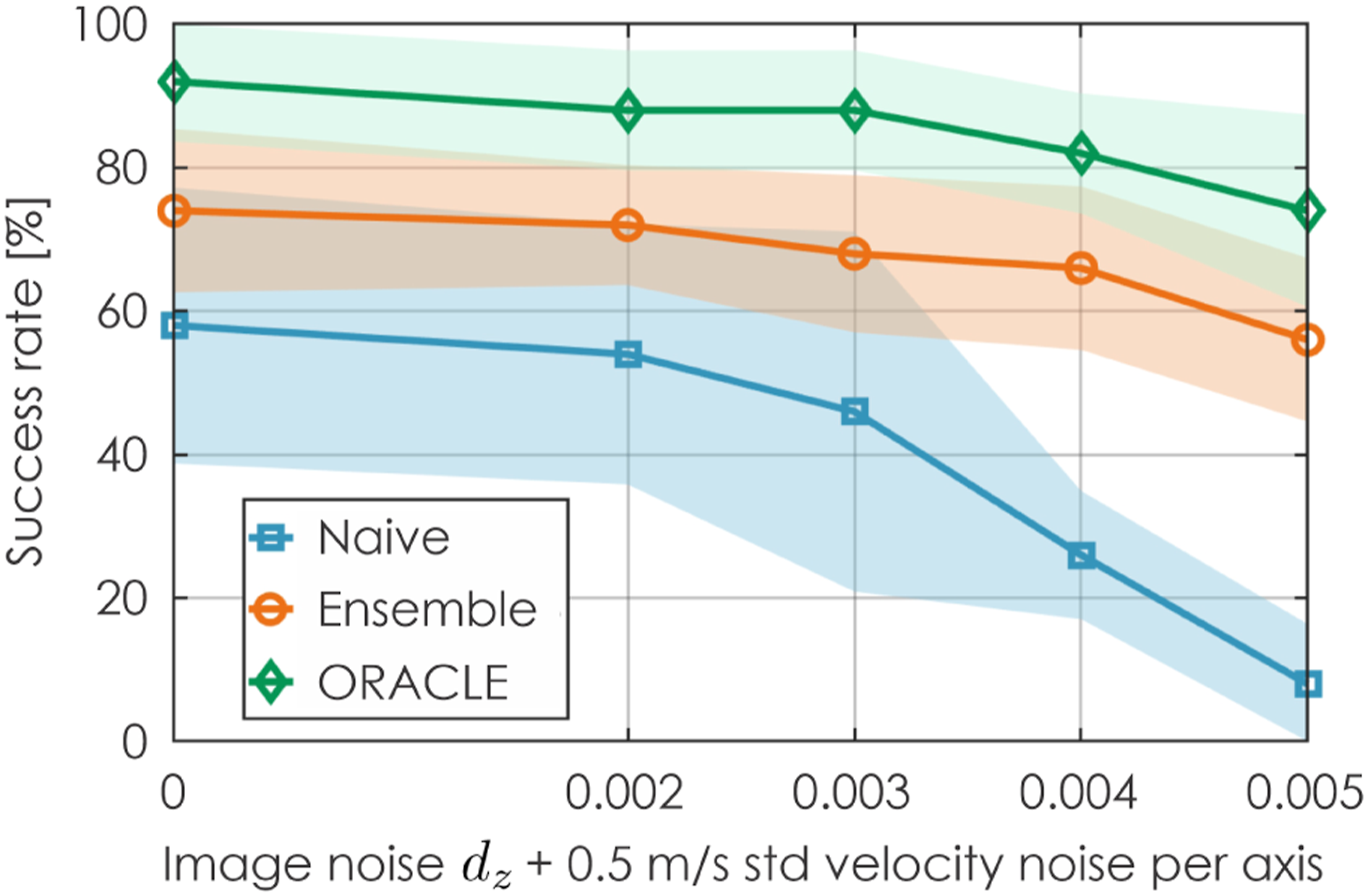
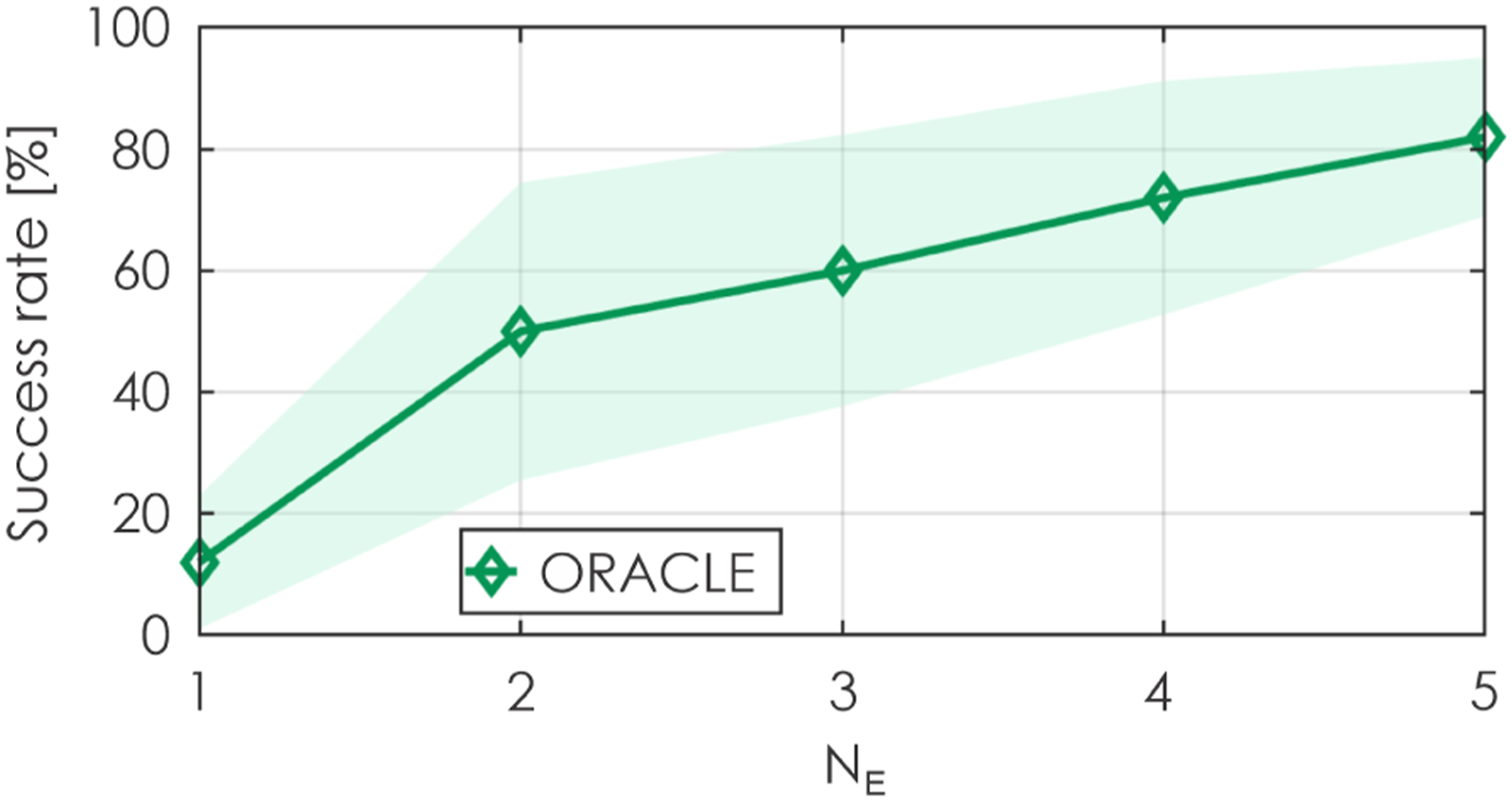
An ablation study is also conducted to study the effect that the number of neural networks in the Deep Ensembles, N
E
, has on the planning performance of ORACLE. Specifically, the highest noise levels in Figures 13, 16, and 17 are injected into the robot, and the success rates of ORACLE with different N
E
parametrizations are reported in Figures 18–20 (N
E
= 1, …, 5). As shown, the planning performance generally increases when the ensemble utilizes a larger number of neural networks, albeit at the expense of increased running time. Onboard running time with different numbers of neural networks in the ensemble is analyzed in section 5.3. This analysis reveals the important role of the Deep Ensembles. Planning performance when different N
E
is utilized in ORACLE and velocity noise with σ
v
= 0.6 m/s is applied on all x, y, z axes simultaneously (100 runs were performed). The presented results relate especially to contribution 3. Planning performance when different N
E
is utilized in ORACLE and image noise with d
z
= 0.005 is applied (100 runs were performed). The presented results relate especially to contribution 3. Planning performance when different N
E
is utilized in ORACLE and both image noise with d
z
= 0.005 and velocity noise (σ
v
= 0.5 m/s on all x, y, z axes simultaneously) are applied (100 runs were performed). The presented results relate especially to contribution 3.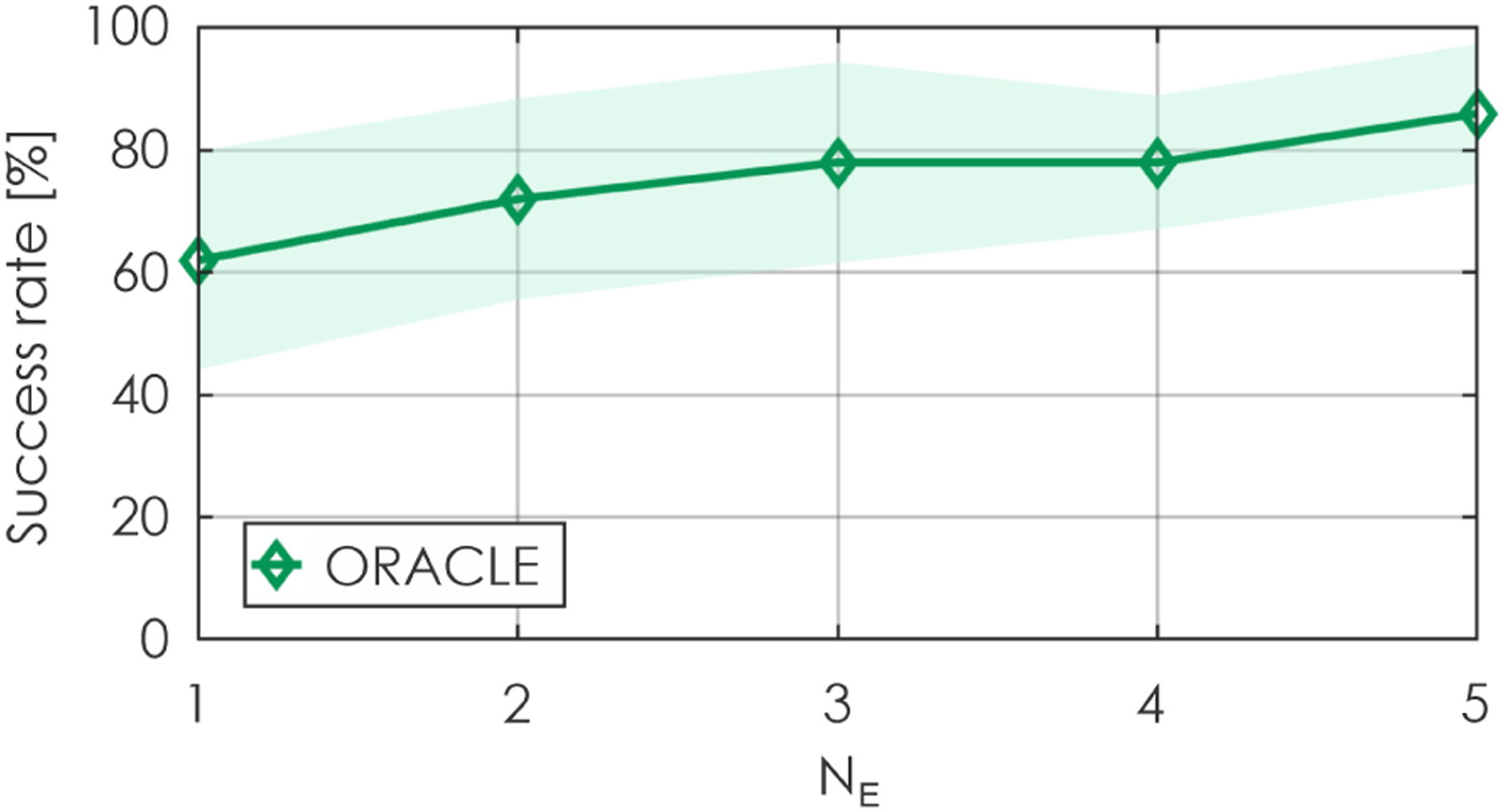
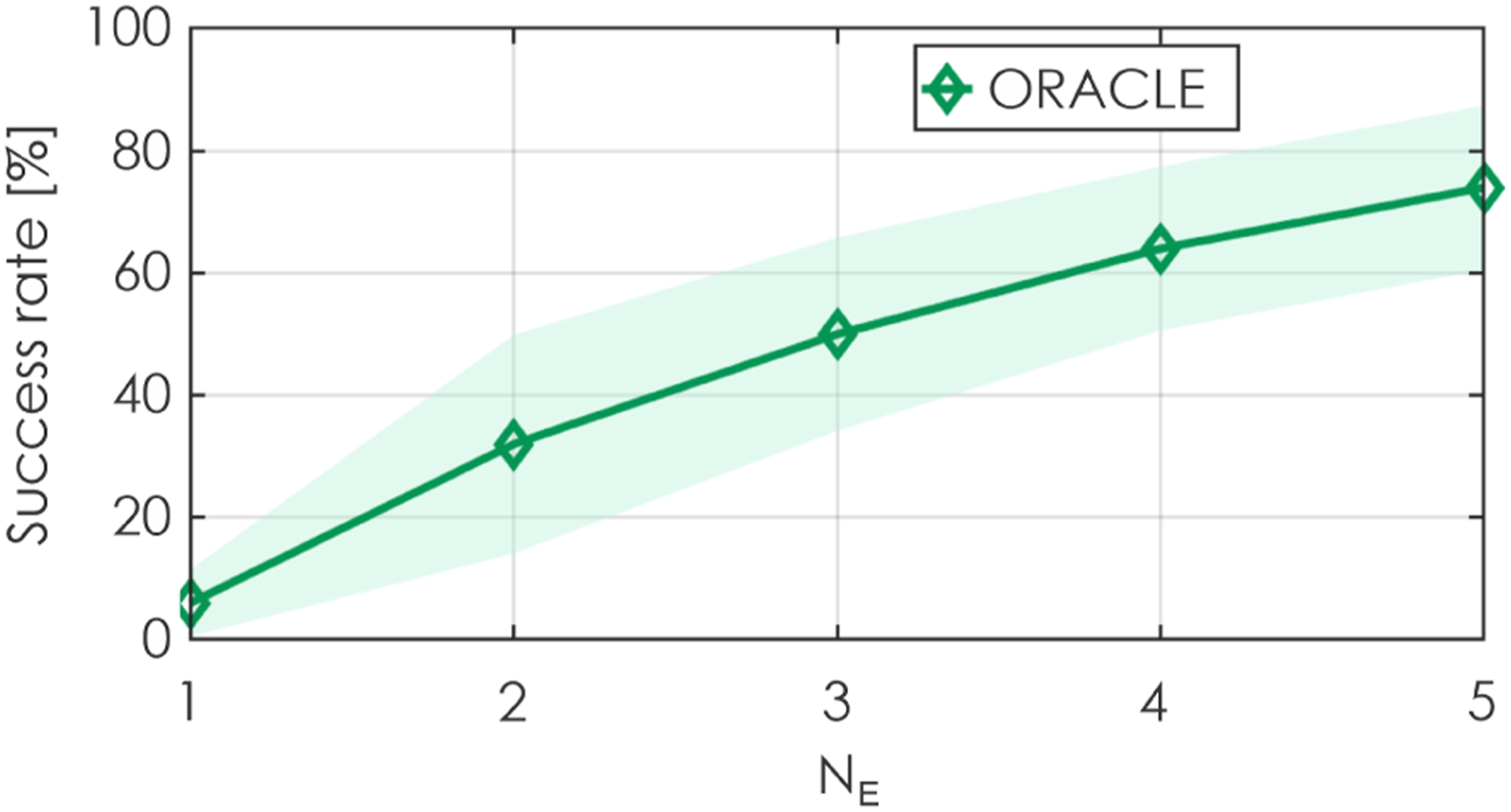
While most state-of-the-art learning-based navigation methods do not explicitly account for the uncertainty in the robot’s partial state estimate and noisy exteroceptive data that is unseen during the training process (Loquercio et al., 2021; Kaufmann et al., 2020), we demonstrate that using the Unscented Transform and Deep Ensembles (Lakshminarayanan et al., 2017) make our method more resilient against a) noise in the robot’s partial state estimate and b) novel noisy depth image inputs, while not relying on consistent position estimate.
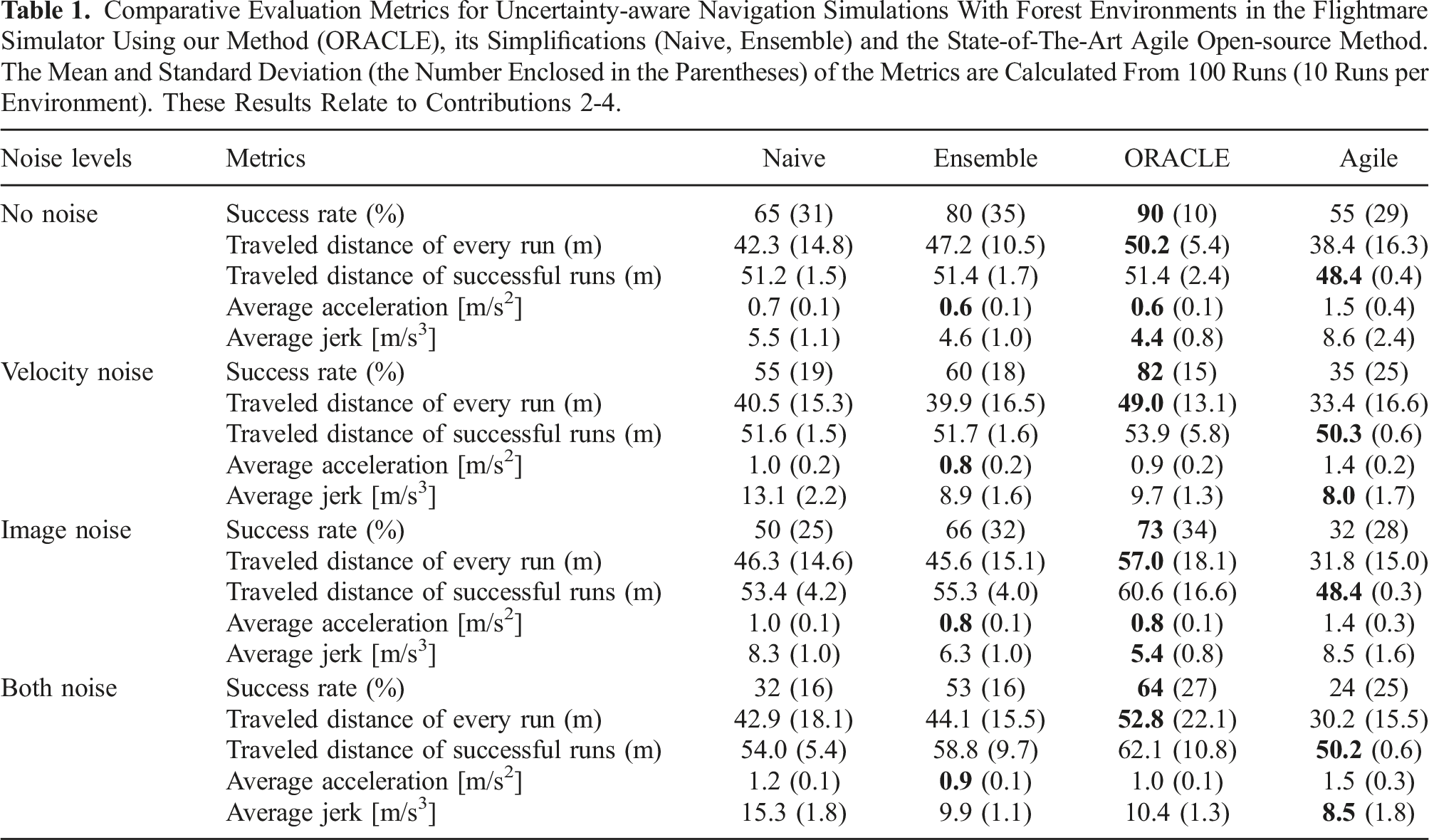
Moreover, to verify the performance of our methods in context with the literature, we modified our code to work with the Flightmare simulator Song et al. (2020) and compared our method (ORACLE) alongside its two simplifications (Naive, Ensemble) against a state-of-the-art learning-based navigation method for drones, namely, the work in Loquercio et al. (2021) called “Agile.”
Specifically, forest environments provided by Flightmare where the trees follow a Poisson disc sampling with a density of δ = 4.5 m are chosen to benchmark the methods. The final waypoint is 50 m in front of the robot and the commanded velocity is 2.5 m/s for all the methods. Additionally, a timeout period of 100 s is applied. Notably, ORACLE and its simplifications have not been trained or fine-tuned explicitly for this type of environment, while it is clarified that we have used the pre-trained weights for Agile as provided by its authors in order to facilitate fairness. Whereas Agile employs a default camera model with a resolution of 640 × 480, FOV of [91, 75]°, and max range of
Comparative Evaluation Metrics for Uncertainty-aware Navigation Simulations With Forest Environments in the Flightmare Simulator Using our Method (ORACLE), its Simplifications (Naive, Ensemble) and the State-of-The-Art Agile Open-source Method. The Mean and Standard Deviation (the Number Enclosed in the Parentheses) of the Metrics are Calculated From 100 Runs (10 Runs per Environment). These Results Relate to Contributions 2-4.
The robots’ trajectories in indicative environments using Flightmare where (i) ORACLE succeeds and Agile fails and (ii) both ORACLE and Agile succeed. The onboard RGB-D images from ORACLE’s sensor model are visualized in 1-4a,b (the ground-truth depth images from Flightmare are illustrated here, whereas they are saturated to
The above examples demonstrate the performance and robustness characteristics of ORACLE against a state-of-the-art method. As can be seen, ORACLE presents high performance with good generalization in collision-free navigation across simulated forest environments, this is driven by a) it being robust against depth image noise-induced uncertainty through the Deep Ensembles, alongside b) accounting for partial state uncertainty in all cases. As shown in Table 1, the Naive method has generally similar performance with Agile but when the Deep Ensembles and the consideration of state uncertainty are factored in, ORACLE significantly outperforms Agile across simulated forest environments and noise conditions. Consideration of depth image noise through the Deep Ensembles supports safe navigation through added conservativeness. The introduced conservativeness promotes the selection of safer paths—even if potentially slightly longer than necessary—which is essential especially in cluttered environments and when operating subject to noisy depth images. Likewise, accounting for partial state uncertainty has similar positive effects. Interestingly, the two remain beneficial even in the “No noise” case as they still offer enhanced conservativeness (e.g., a fixed state uncertainty is considered by ORACLE in any case even when such noise is not presented in the simulated data), as explained in Figure 14. Despite its superior performance when it comes to success ratio, when only successful paths are considered for both methods, ORACLE on average employs longer paths compared to Agile, as illustrated in Figure 21.
5.1.2. Visually-attentive navigation
We conducted a set of simulation studies to evaluate the proposed visually-attentive navigation method (A-ORACLE) with two different sources of visual interestingness detection: visual saliency detection Frintrop et al. (2015) and object detection using YOLO Redmon and Farhadi (2018).
For the case of using saliency as a method to derive detection masks to guide the robot’s attention, we use art gallery environments with varying densities (sparse, average, and dense) of salient objects (paintings and furniture) as in Dang et al. (2018) to evaluate A-ORACLE and the baselines. The detection mask (1) Art gallery environments for visually-attentive navigation simulation with the detection masks derived from the saliency maps, the salient objects are the paintings and furniture (visualized in the orange boxes). (2) and (3) show specific planning instances with the point clouds annotated with saliency values from the detector and the network predictions (a), images from the onboard RGB camera (b), and saliency detection mask (c). Green markers: estimated trajectory endpoints of safe action sequences, blue marker with an arrow: estimated trajectory endpoint of chosen action sequence. (4) Illustration of a saliency mask (b) obtained from an onboard RGB image (a) when the robot is spawned in front of a painting. The presented results relate to contribution 1. Evaluation metrics for visually-attentive navigation simulations with saliency detection inputs in art gallery environments. The metrics displayed in the table include 1) the number of valid interesting voxels (valid interesting voxels), 2) the volume of valid interesting voxels (volume), 3) the total traveled distance, and 4) the processing time. The average and standard deviation (the number enclosed in the parentheses) of processing time is calculated from 500 planning iterations on a laptop with AMD Ryzen 9 4900HS CPU and RTX 2060 GPU. These results relate to contribution 1.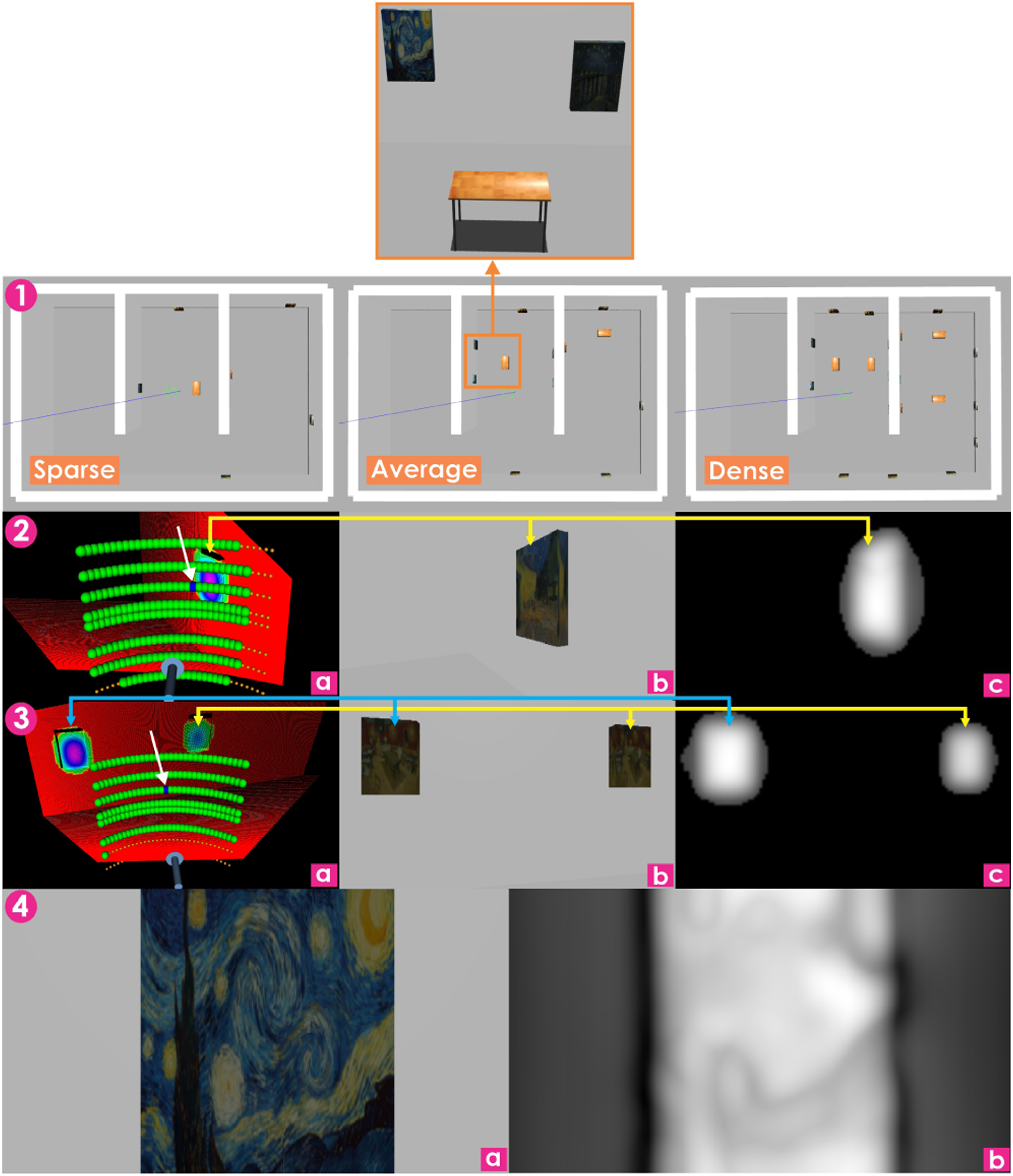
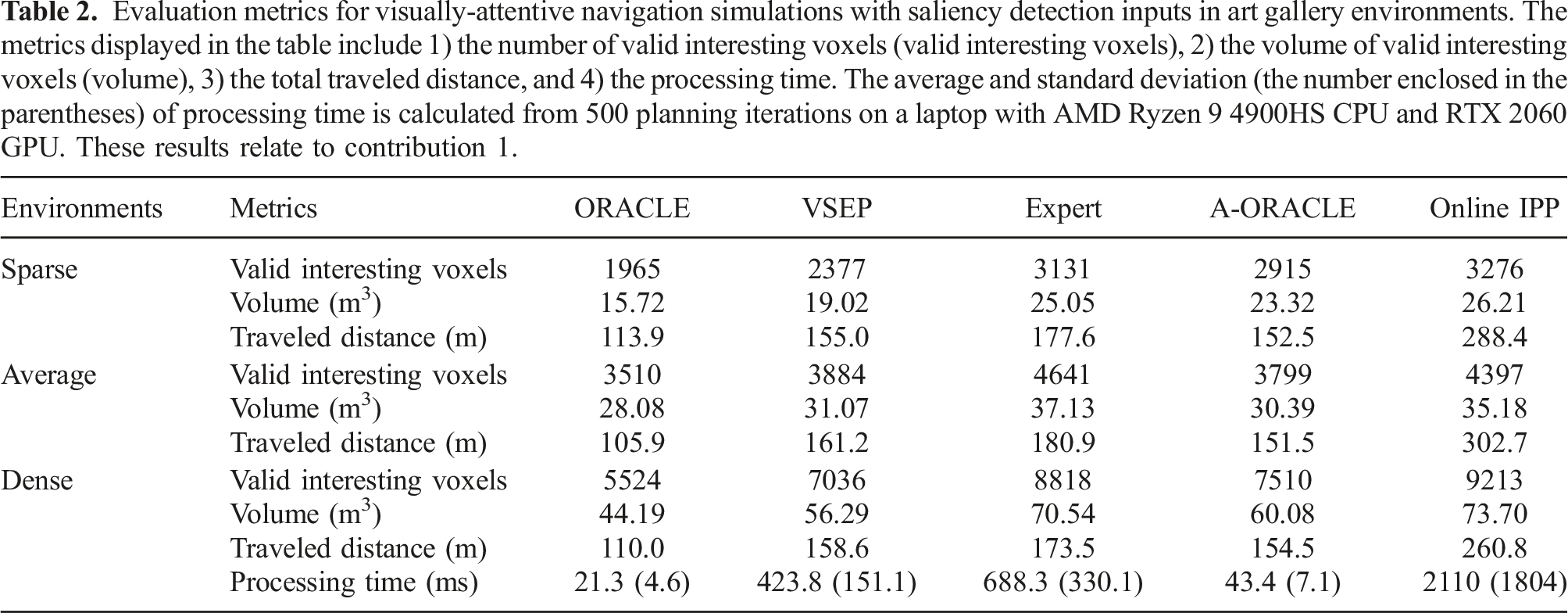
To compare the five methods, we run the Voxblox mapping framework and annotate each voxel based on the saliency mask using equation (20). A valid interesting voxel k is defined as a voxel being observed in at least N
th
camera frames and having interestingness I
k
> I
th
. For each valid interesting voxel, we also logged its minimum viewing distance from all observed camera frames. Figure 23 shows the percentage of valid interesting voxels, calculated based on the total number of valid interesting voxels seen by the Expert, plotted against their minimum viewing distances for each method. It can be seen that Attentive ORACLE views more valid interesting voxels from closer distances than ORACLE and VSEP, leading to a higher quality of observations of the objects. Table 2 presents the average metrics of 10 runs/environment for each method. As depicted, the number of valid interesting voxels observed by A-ORACLE is 1.08 − 1.48 times that of those observed by ORACLE, 0.98 − 1.23 times that seen by VSEP, 0.82 − 0.93 times that observed by the Expert, and 0.82 − 0.89 times that of those viewed by the Online IPP, while having average travel distances that are very similar to those of VSEP and the Expert, and only 0.5 − 0.6 times that of those covered by the Online IPP. It is stressed that the Online IPP can plan the viewpoints outside the current FOV of the robot’s depth camera, as opposed to the MPL utilized in ORACLE, A-ORACLE, and the Expert. Notably, the average inference time of A-ORACLE is just 6.3% of that of the Expert, 10.2% of that of VSEP, and 2.1% of that of Online IPP, while managing to achieve comparable or better performance than VSEP and comparable performance with the Expert. Figure 22.2-3 illustrates specific instances with the point clouds annotated with saliency values and the network predictions (left column), the onboard RGB image (middle column), and the detection mask (right column) where the brighter the color, the higher the saliency value. Simulation results for visually-attentive navigation with saliency detection inputs in art gallery environments. Top row: The x-axis shows the minimum viewing distances for the valid interesting voxels and the y-axis shows the percentage of seen valid interesting voxels (average value and 1 − σ boundaries of 10 runs/environment), with respect to the Expert, having minimum viewing distances less than x. Bottom row: the mean and 1 − σ error bar of the total traveled distance of each method. The presented results relate to contribution 1.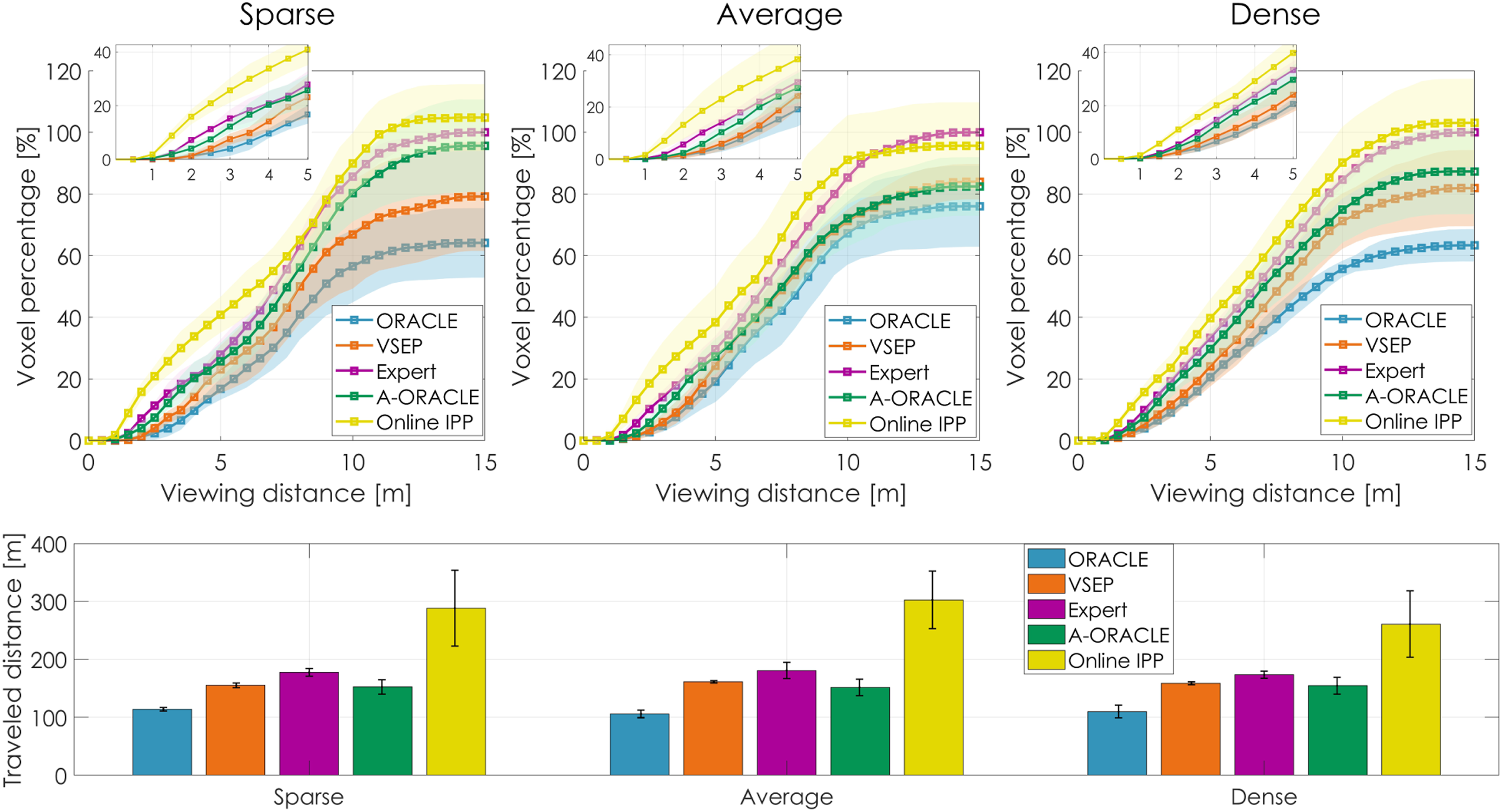
To demonstrate that our method can work with multiple visual detection input sources, we also verified A-ORACLE using the output of the YOLO object detector Redmon and Farhadi (2018), as trained for the DARPA Subterranean Challenge by Team CERBERUS Tranzatto et al. (2022), as a cue for interestingness. Specifically, the detection mask (a) Subway station environments for visually-attentive navigation simulation with YOLO detections as attention input. The red backpacks visualized in the image are the objects of interest in this case. (b) The robot’s trajectory when A-ORACLE is deployed and the waypoints marked with the numbers representing the visiting order. The presented results relate to contribution 1.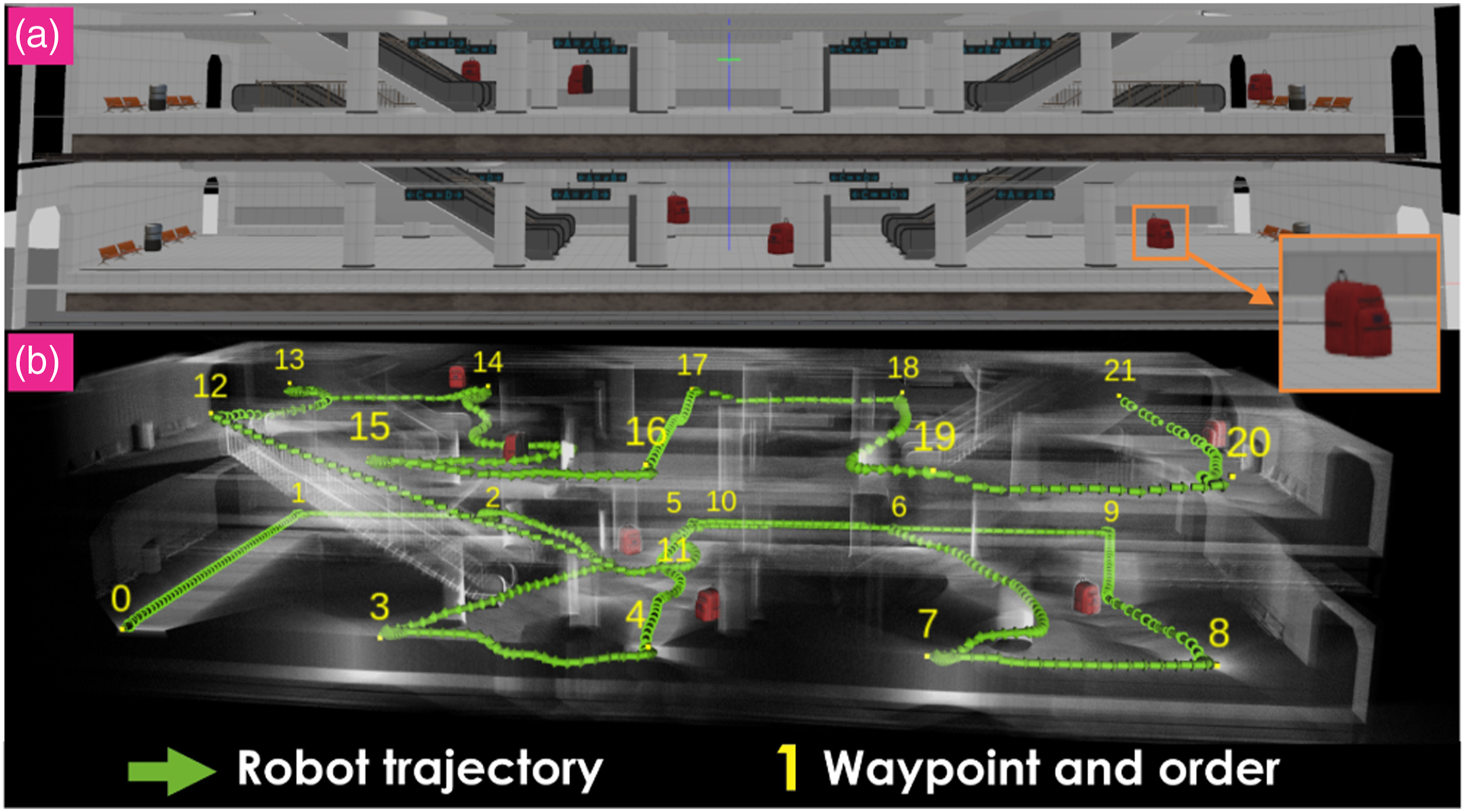
Figure 25 shows the percentage of valid interesting voxels, calculated based on the total number of valid interesting voxels seen by the Expert, plotted against their minimum viewing distances for each method. It can be seen that A-ORACLE views more valid interesting voxels from closer distances than ORACLE, leading to a higher quality of observations of the objects. Table 3 presents the average metrics of 10 environments for each method. As depicted, the number of valid interesting voxels observed by A-ORACLE is 15% more than that of those observed by ORACLE, and 9% less than that observed by the Expert-baseline, while having an average travel distance that is only 9.5% longer than that of ORACLE (and 7.1% less than that of the Expert). Figure 24(b) shows the robot’s trajectory when A-ORACLE is deployed in a specific environment where the red backpacks visualized are the objects of interest. Simulation results for visually-attentive navigation based on YOLO detection inputs in subway station environments. The x-axis shows the minimum viewing distances for the valid interesting voxels and the y-axis shows the percentage of seen valid interesting voxels (average value and 1 − σ boundaries of 10 runs), with respect to the Expert, having minimum viewing distances less than x. The presented results relate to contribution 1. Evaluation Metrics for Visually-Attentive Navigation Simulations Based on YOLO Detection Inputs in subway Station Environments. All Distances are in Meters, and all Volumes are in Cubic Meters. These Results Relate to Contribution 1.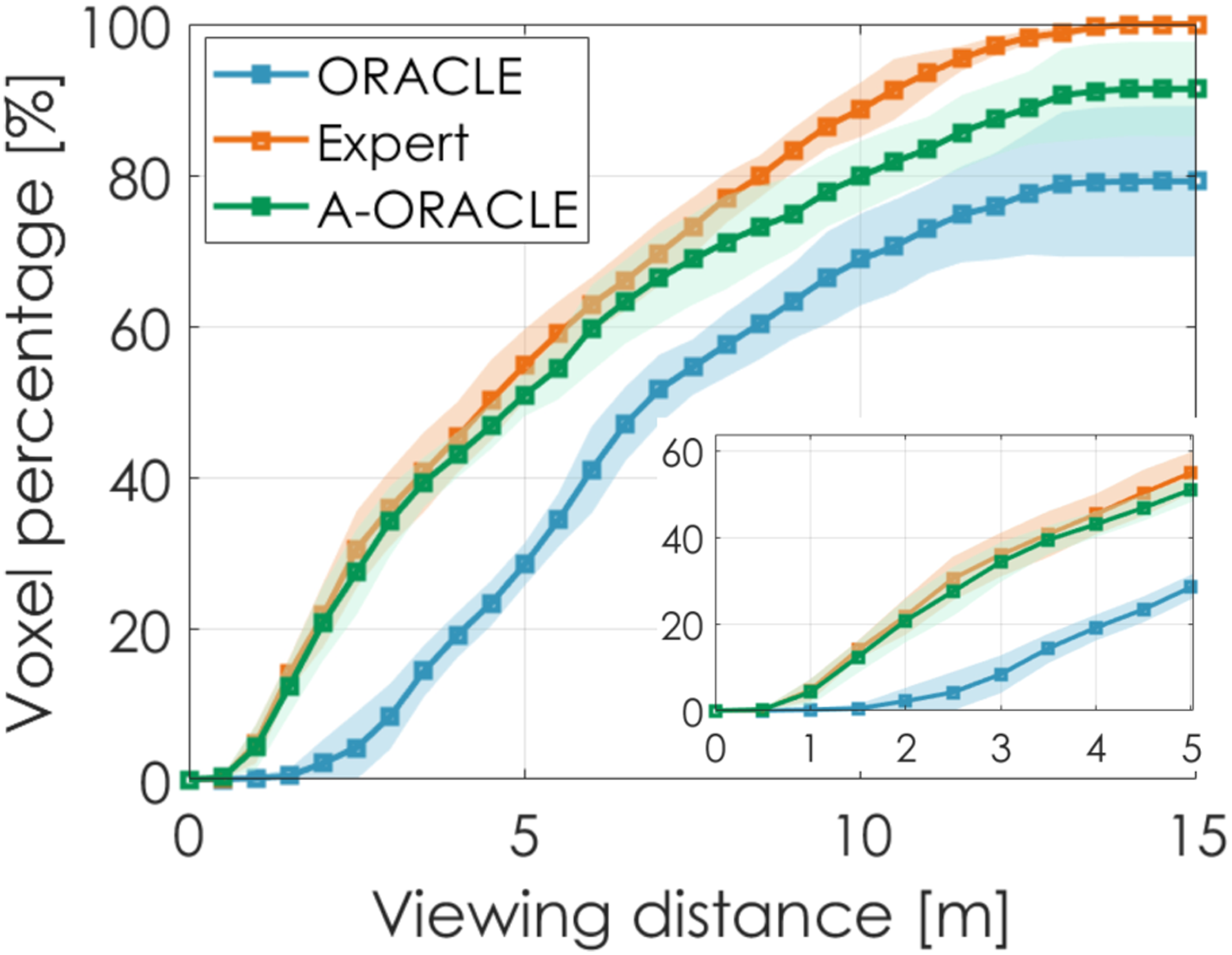

5.2. Experimental studies
Experiment parameters.
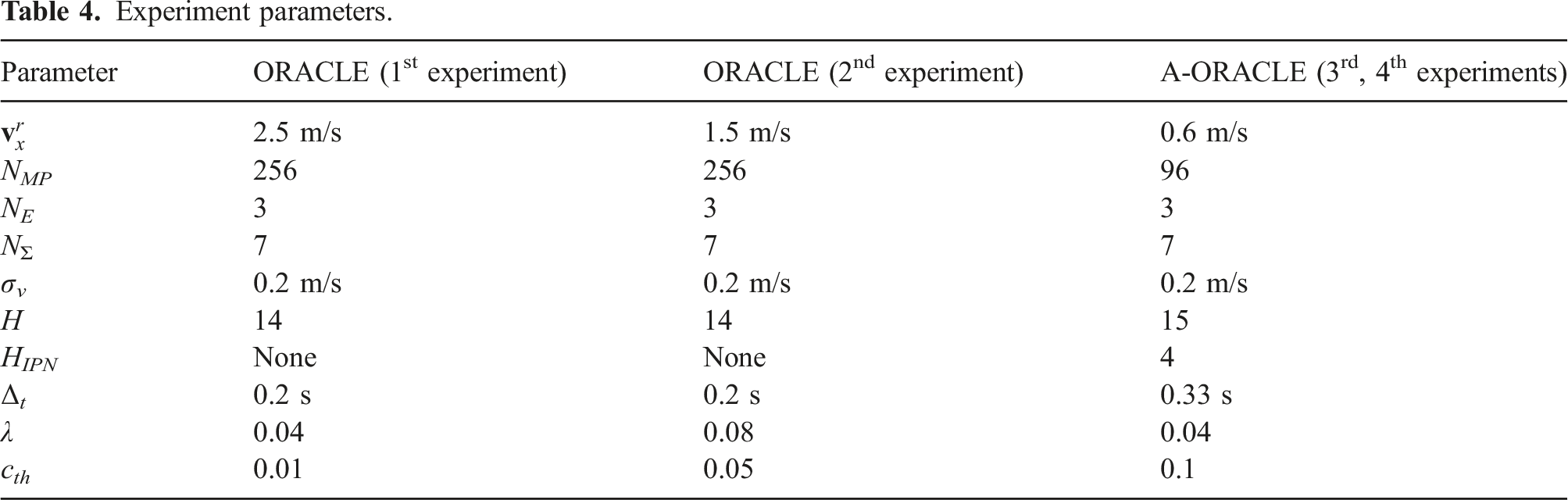
Since the Intel Realsense T265 estimation output does not contain covariance information, we used a fixed standard deviation of σ
v
= 0.2 m/s for the velocity noise. It is also noted that compared to the simulated parameters in Section 5.1, we used an ensemble of N
E
= 3 neural networks in all real-world experiments and used N
MP
= 96 with A-ORACLE to reduce the inference time of the CPN and the IPN onboard the robot. The running times of different components of ORACLE and A-ORACLE are provided in Section 5.3. Additionally, we used a lower threshold c
th
for the first and second experiments compared to the other experiments to allow safer navigation when the robot was tasked to fly faster in more cluttered environments. We also chose λ = 0.08 in the second experiment in which the environment is the most cluttered, as shown in Figure 27, to prioritize the predictions at smaller time steps. Experiment 1: experiment with ORACLE in a corridor filled with obstacles. The map of the environment, reconstructed from the Realsense T265’s odometry and the Realsense D455’s pointclouds, is given in the top row while some instances of the experiment are shown in 1-3 where the predictions from the CPN are illustrated in 1-3a (green markers: estimated trajectory endpoints of safe action sequences, blue marker with an arrow: estimated trajectory endpoint of chosen action sequence), the third-person views are displayed in 1-3b, and the onboard RGB-D images are visualized in 1-3c,d, respectively. The robot was commanded to fly toward a waypoint in front of it with the reference forward velocity of 2.5 m/s, as shown in the velocity profile plot. The presented results relate to contributions 2-4. Experiment 2: experiment with ORACLE in a dense forest during under canopy flight. The maps of the environment and the odometry estimates of the robot, derived by RTAB Labbé and Michaud (2019), are given in the top row while some instances of the experiment are shown in 1-3 where the predictions from the CPN are illustrated in 1-3a (green markers: estimated trajectory endpoints of safe action sequences, blue marker with an arrow: estimated trajectory endpoint of chosen action sequence), the third-person views are displayed in 1-3b, and the onboard RGB-D images are visualized in 1-3c,d, respectively. The robot was commanded to fly towards a waypoint in front of it with the reference forward velocity of 1.5 m/s. Each square in the figure has dimensions equal to 5 m × 5 m. Note that the position estimates are not provided to the robot during the mission and the results of RTAB-based map are only derived in post-processing given the relative drift experienced by the onboard T265 odometry. The presented results relate to contributions 2-4.

In the first experiment, illustrated in Figure 26 and Extension 1, the robot was tasked to reach a waypoint that is in front of it with the reference forward speed of
The second experiment related to a forest during under canopy flight and took place near Evo, Finland, and was presented in Extension 2. The robot was commanded to navigate safely towards a waypoint that is in front of it with reference forward speed of
In the third experiment, we performed flight tests with A-ORACLE and ORACLE in an industrial silo tank at the RelyOn training facility in Trondheim, Norway, as presented in Figure 28 and Extension 3. The robot was tasked to navigate safely in the environment following a pre-defined set of waypoints, while it was allowed to deviate from the intended waypoints to gather higher quality observations of objects of interest (a backpack and a protective suit simulating a human in this case). YOLO Redmon and Farhadi (2018), as trained for the DARPA Subterranean Challenge by Team CERBERUS Tranzatto et al. (2022), was utilized as the object detection algorithm, and its output detection masks are depicted in Figure 28.1-2(d). While moving from waypoint 1 to 2 and 5 to 1 (marked with the white ellipses in Figure 28), the robot deviated from the straight-line connection between the waypoints in order to look at the objects of interest from closer distances, as illustrated in Figure 28.1-2(b). For comparison, ORACLE was also deployed with the same set of waypoints and the trajectory of the robot is visualized in the bottom left of Figure 28. As can be seen, since ORACLE does not consider the quality of observations of interesting objects, straight-line connections between the waypoints were usually chosen (except when moving from waypoint 3 to 4). It is noted that the straight-line connection between waypoints 3 and 4 is not collision-free. Notably, when the robot traversed closer to the survivor when A-ORACLE was engaged, it detected a dead end, depicted in Figure 28.3, and performed a yaw-in-spot action until it found a free direction, as presented in line 21 of Algorithm 1. Figure 28.4 shows the CPN’s prediction around waypoint 3, demonstrating the capability of our methods to provide a multi-modal navigation solution where the robot can choose to turn left or right to avoid the front obstacle. Experiment 3: experiments with both A-ORACLE and ORACLE in an industrial silo tank. The map of the environment (reconstructed from the Realsense T265’s odometry and the Realsense D455’s pointclouds), the given waypoints, and the trajectories taken by the robot when ORACLE and A-ORACLE are deployed are shown on the left. As shown in the white ellipses, the robot traversed closer to the interesting objects, which are marked with yellow boxes and visualized in 1-2c, when A-ORACLE was engaged compared to ORACLE. Some instances of the experiment with A-ORACLE are shown in 1-4. The predictions from the CPN are illustrated in 1-4a where the green markers correspond to the estimated trajectory endpoints of safe action sequences, and the blue marker with an arrow corresponds to the estimated trajectory endpoint of chosen action sequence (determined using both the prediction results from the CPN and the IPN). The third-person views are displayed in 1-2c, and 3-4b, while the onboard RGB images and detection masks from YOLO are visualized in 1-2b, and d, respectively. The presented results relate to contributions 1-4.
The fourth experiment, as seen in Extension 4, was conducted in a hall inside a building on the campus of NTNU. The robot was given a waypoint that is in front of it and the straight-line connection between the start and end points is not collision-free. Three backpacks were placed along the hall to represent the objects of interest and YOLO Redmon and Farhadi (2018) was again utilized to detect the objects. Similar to the second experiment, when A-ORACLE was deployed, the robot traversed closer to the objects of interest to view them from smaller distances. Notably, in this environment, the position estimates from the Realsense T265 drifted significantly, possibly due to the darkness in some parts of the environment, as can be seen from the onboard RGB image in Figure 29.c. The ground-truth reconstructed maps and odometry estimates of the robot, visualized in the top row (A-ORACLE) and the left column in the second row of Figure 29 (ORACLE), are estimated offline using the method presented in Labbé and Michaud (2019). The drifted map with wrong dimensions (25 m versus 40 m) and odometry estimates from Realsense T265 are visualized in the right column in the second row of Figure 29. A-ORACLE and ORACLE could still avoid obstacles and additionally, A-ORACLE could pay attention to interesting objects in this case despite the significant drift of the position estimates. Experiment 4: experiments with both A-ORACLE and ORACLE in a hall inside a building on the campus of NTNU. The maps of the environment and the odometry estimates of the robot, derived by RTAB Labbé and Michaud (2019), are shown in the first row (A-ORACLE) and the left plot in the second row (ORACLE). On the other hand, the drifted map of the environment, reconstructed from the Realsense T265’s odometry, and the Realsense T265’s odometry solution are shown in the right plot in the second row. Some instances of the experiment with A-ORACLE are shown in 1-3. The predictions from the CPN are illustrated in 1-3a where the green markers correspond to the estimated trajectory endpoints of safe action sequences, and the blue marker with an arrow corresponds to the estimated trajectory endpoint of chosen action sequence (determined using both the prediction results from the CPN and the IPN). The third-person views are displayed in 1-3b, while the onboard RGB images and detection results from YOLO are visualized in 1-3c, and d, respectively. Owing to its design, A-ORACLE and ORACLE can still avoid obstacles and additionally, A-ORACLE can pay attention to interesting objects, marked with yellow boxes, despite the significant drift of the position estimation of Realsense T265. The presented results relate to contributions 1-4.
5.3. Onboard running time
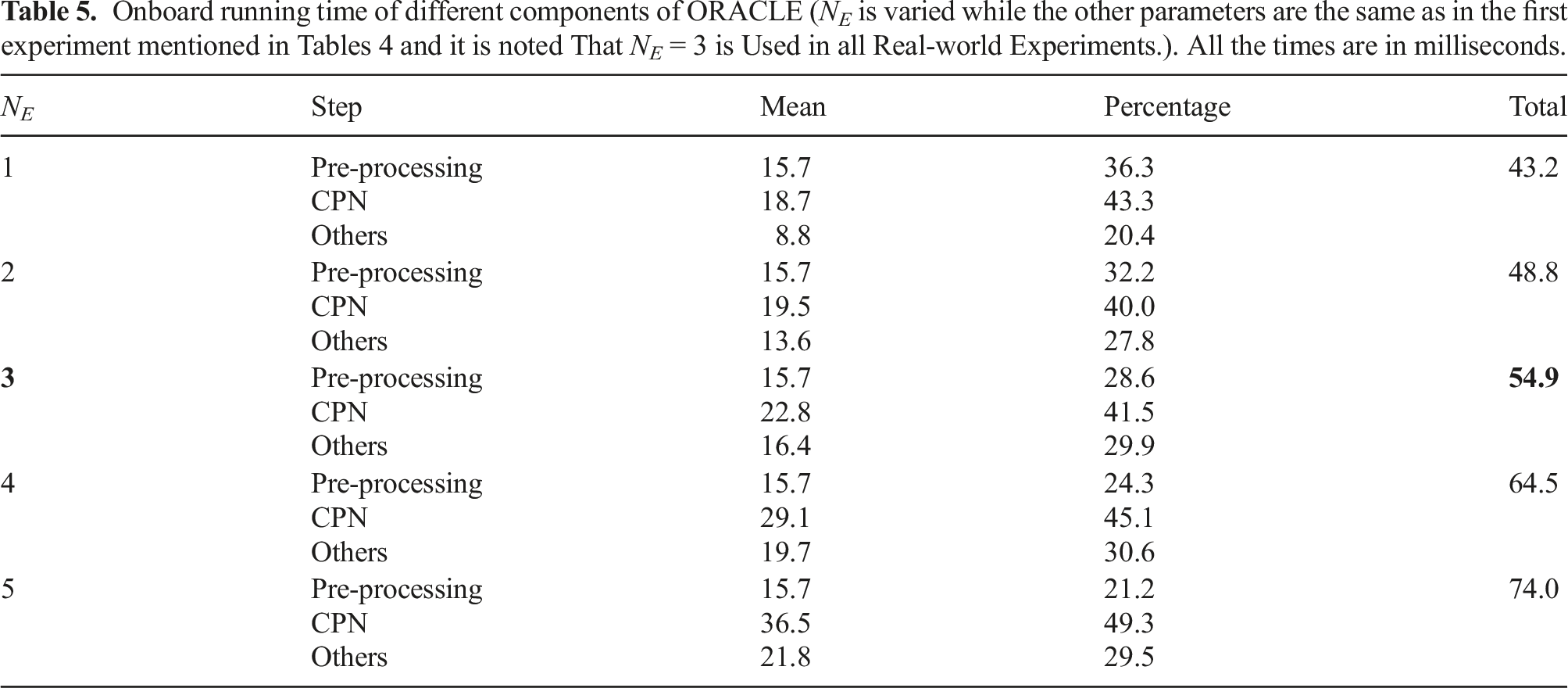
Onboard running time of different components of ORACLE (N E is varied while the other parameters are the same as in the first experiment mentioned in Tables 4 and it is noted That N E = 3 is Used in all Real-world Experiments.). All the times are in milliseconds.
Onboard running time of different components of A-ORACLE in the third and fourth experiments. All the times are in milliseconds.

6. Conclusions
This paper presented a learning-based method to efficiently tackle the problem of visually-attentive uncertainty-aware 3D navigation without relying on a map of the environment or the position estimate of the robot. Two neural networks are designed in this work: a Collision Prediction Network for predicting the uncertainty-aware collision costs for action sequences in a Motion Primitives Library (utilizing the Unscented Transform and an ensemble of neural networks) and an Information gain Prediction Network for estimating their associated information gain. The networks’ outputs are used in addition to a unit goal vector, given by any high-level global planner, to determine the best action sequence to be executed in a receding horizon fashion. We conducted a set of simulations and real-world experiments to verify the proposed method. Extensive simulation studies involving navigation with noisy inputs including the robot’s velocity estimate and the depth image demonstrate the robustness of our methods (ORACLE and A-ORACLE). Moreover, visual attention-aware navigation with different sources of visual detection input is performed to show the benefits of A-ORACLE compared to other baselines. Finally, several real-world experiments including collision-free flights with the reference forward speed of 2.5 m/s in a cluttered corridor, and visually-attentive navigation in industrial and university environments are also described, demonstrating that the method can transfer well to real systems and complex environments. The code and training datasets will be publicly released at https://github.com/ntnu-arl/ORACLE upon acceptance.
Regarding future work, five important directions are identified. First, this relates to extending the exteroceptive sensor inputs of the method to enable multi-modal fusion, especially of depth and visual data. Visual data can deliver the resolution and acuity typically lacking in depth images, while co-fusing depth data allows to benefit from the more direct collision information they offer and their ability to be simulated with higher fidelity which supports successful sim-to-real transfer. This direction of future work is especially motivated by our experience from field testing within dense forests including hard-to-detect thin branches (e.g., with a cross section less than 1 cm) where the depth camera faced limitations in its ability to correctly provide range information. Second, we aim to investigate the potential of offering safety certificates in order to not only have high performance in statistical terms but guarantee the system’s safety. A plausible direction is that of developing a safety filter through control barrier functions. This is a critical domain of research that aims to address core limitations of neural network-based methods within critical tasks such as robot control and navigation. Third, also related with the previous direction, we aim to investigate the online detection of situations where the robot is exposed to inferring from data significantly different from those experienced during training. The latter could be used to trigger another fallback system to safeguard the robot or its environment. Fourth, the method can be extended to use a sequence of depth images with the goal of handling dynamic obstacles. Finally, future work may focus on alleviating the limitation of hand-tuning certain parameters in the loss equations used to train the CPN and the IPN by automatically learning such weights at training time.
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Footnotes
Acknowledgments
We appreciate the help of the employees at RelyOn Nutec Trondheim, who provided us access to their facilities for conducting experiments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the This material was a) supported by Research Council of Norway under project SENTIENT (grant number 321435) and also b) based upon work supported by the Air Force Office of Scientific Research under award number FA8655-21-1-7033.
Supplemental Material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.