
Abstract
We present NeuSE, a novel Neural SE(3)-Equivariant Embedding for objects, and illustrate how it supports object-based Simultaneous Localization and Mapping (SLAM) for consistent spatial understanding with long-term scene changes. NeuSE is a set of latent object embeddings created from partial object observations. It serves as a compact point cloud surrogate for complete object models, encoding the full shape, scale, and transform information about an object. In addition, the inferred latent code is both SE(3) and scale equivariant, enabling strong generalization to objects of both unseen sizes and different SE(3) poses. This makes NeuSE particularly effective in real-world scenarios where objects may vary in size or spatial configuration. With NeuSE, relative frame transforms can be directly derived from inferred latent codes. Our proposed SLAM paradigm, using NeuSE for object shape, size, and pose characterization, can operate independently or in conjunction with typical SLAM systems. It directly infers SE(3) camera pose constraints that are compatible with general SLAM pose graph optimization, while maintaining a lightweight, object-centric map that adapts to real-world changes. Our evaluation is conducted on synthetic and real-world sequences with changes in both controlled and uncontrolled settings, featuring multi-category objects of various shapes and sizes. Our approach demonstrates improved localization capability and change-aware mapping consistency when working either independently or as a complement to common SLAM pipelines.
Keywords
1. Introduction
The ability to conduct consistent object-level reasoning is crucial for many high-level robotic tasks, especially those involving repetitive traversal in the same environment, such as household cleaning and object retrieval. In a constantly evolving world, robots are expected to accurately locate themselves and their target while keeping an updated map of the environment, ensuring that a specific “blue coffee mug” can always be retrieved regardless of its location since its last use.
Traditional Simultaneous Localization and Mapping (SLAM) approaches (Campos et al., 2021; Engel et al., 2014; Klein and Murray, 2009) see the world through a static set of low-level geometric primitives extracted from observations, making them less amenable to human-like reasoning about the world. In the absence of semantic information, these unordered collections of points, lines, or planes are not completely compatible with object-level interpretation, making them susceptible to false correspondence matches when faced with scene changes over time.
As the world changes and operates under the minimal unit of objects, objects serve as an intuitive source for assisting localization and an object-centric map can act as a lightweight and flexible reflection of the latest environment layout. To facilitate the communication between objects and typical SLAM systems, previous works have experimented with various object representations to guide back-end optimization, ranging from pre-defined object model libraries (Salas-Moreno et al., 2013; Tateno et al., 2016), semantic segmentation masks (McCormac et al., 2017; Mccormac et al., 2018; Runz et al., 2018; Xu et al., 2019), to parameterized geometry (Hosseinzadeh et al., 2019; Nicholson et al., 2019; Wang et al., 2024; Yang and Scherer, 2019). However, they are confined to either a limited number of objects, or a loss of geometric details due to partial reconstruction or simplification of object shapes.
Recently, neural implicit representations have been introduced (Rosinol et al., 2023; Sucar et al., 2020, 2021; Wang et al., 2021; Zhu et al., 2022b) to SLAM as object or scene representations, working with probabilistic rendering loss to help constrain camera localization. However, since both object and scene representations are not directly interpretable, an expensive rendering procedure is necessary to convert representations to explicit reconstructions, which can then be iteratively optimized to reflect SE(3) camera pose constraints embedded within observations. This incurs extra training and computation overhead and these camera constraints are sensitive to starting pose initializations.
To more effectively leverage the shape description power of neural representations and bypass the undesirable iterative refinement, we depart from the dominant “render-optimize” convention in previous works by directly embedding geometric constraints into object representations. We introduce NeuSE, a novel category-level
By constructing this latent representation of an object, we can directly distinguish between objects by their latent shapes, scales, and relative spatial relations. Simultaneously, the SE(3) equivariance of this latent representation allows relative frame transformations to be directly computed from the corresponding latent codes of an object when it is observed in different frames. To account for the pose ambiguity arising from symmetrical geometry, we further train NeuSE’s latent point cloud to conform to the object’s geometric ambiguity. In this way, working with NeuSE’s latent canonical point cloud of an object is akin to working with the full object model, only with operations applied to a compact latent point cloud surrogate with known correspondences, which can be directly inferred from partial observations. Furthermore, the learned SE(3) and scale equivariance in NeuSE allows inferred latent codes to generalize effectively to objects with distinct poses, shapes, and sizes beyond those seen during training, which helps promote NeuSE’s generalization and adaptability for robust spatial understanding.
In this paper, we present NeuSE and further demonstrate how it supports object SLAM targeting spatial understanding with long-term scene inconsistency (see Figure 1). By using NeuSE for object shape, scale, and pose characterization, we unify the representations of major SLAM modules, for example, data association and pose constraint derivation, around one versatile latent code. Our proposed approach can either work as a standalone system or complement common SLAM systems by directly inferring SE(3) camera pose constraints compatible with general SLAM pose graph optimization and maintaining a lightweight, object-centric map with change-aware mapping ability. Schematic of consistent spatial understanding with NeuSE. An object-centric map of multiple object categories constructed from real-world data is shown for illustration. (a) NeuSE acts as a compact point cloud surrogate for objects, encoding full object shapes and sizes and transforming SE(3)-equivariantly with the object in the physical world. Latent codes of bottles and mugs from different frames can be effectively associated (dashed line) for direct computation of inter-frame transforms, which are then added to constrain camera pose (T
i
) optimization both locally (T
Li
) and globally (T
Gi
). (b) The system performs change-aware object-level mapping, where changed objects (highlighted in orange) are updated alongside unchanged ones with full shape reconstructions in the object-centric map. (c) With SE(3) and scale equivariance, NeuSE effectively handles multiple instances of identically shaped objects (dark bottles d1 and d2), as well as objects with diverse shapes (bottles, mugs, and cans) and sizes (big white bottle w1 and small white bottle w2).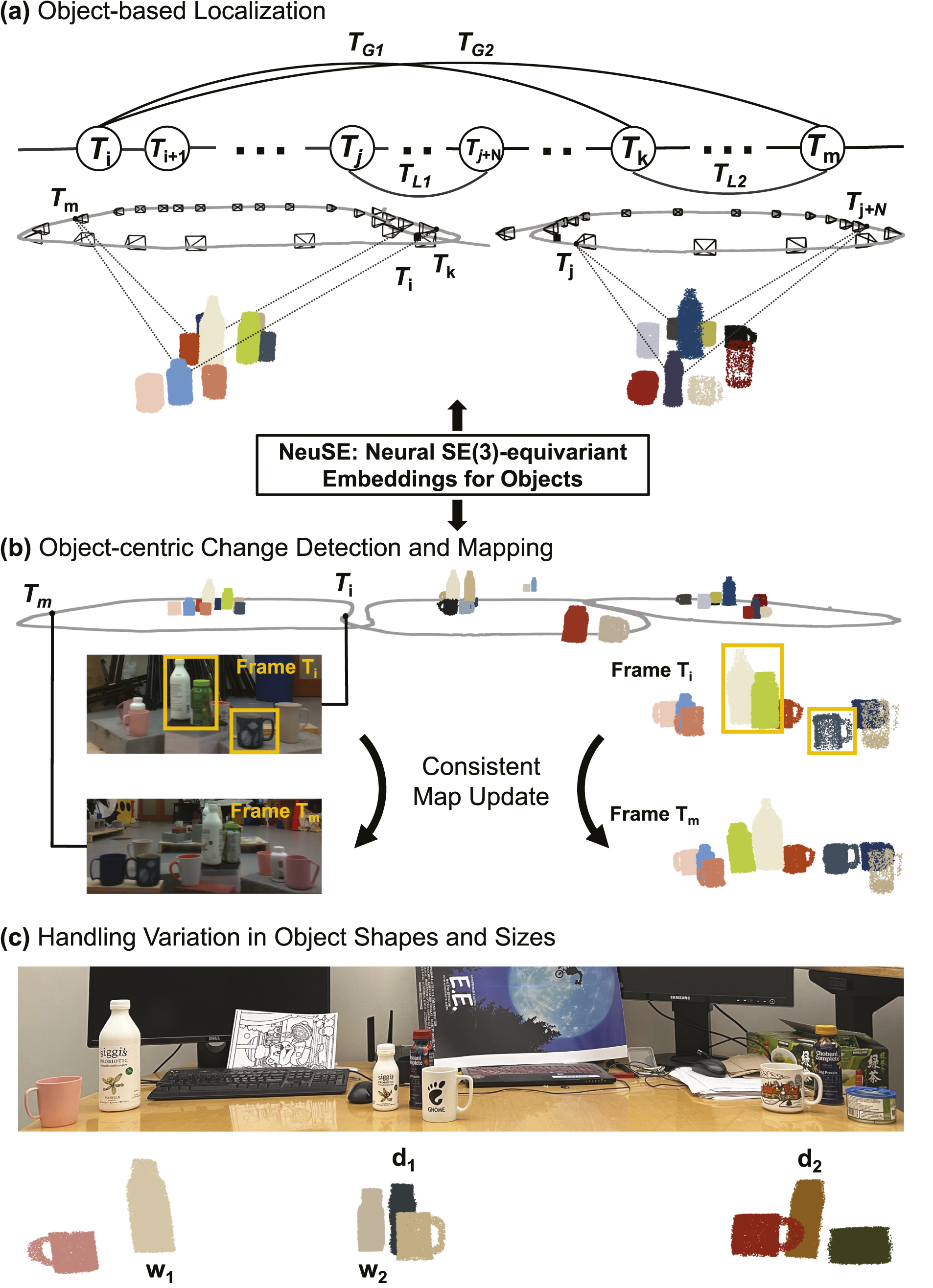
We provide a system overview of the proposed NeuSE-based object SLAM pipeline in Figure 2, which consists of six functional modules and a database for storing object and frame information. The system takes as input both depth images and segmentation masks of objects of interest, where the masks are obtained by segmenting the corresponding RGB images. These inputs generate partial point clouds of the observed objects, serving as the sole data source for the system. The six modules perform three main functions: NeuSE extraction, NeuSE odometry generation and pose graph update, and change detection. These modules operate in sequence, continuously interacting with and updating the object and frame information in the database. The system’s output, which can be retrieved from the database, includes the estimated camera poses for the current image stream and the most up-to-date object-centric map, consisting of full shape reconstructions of the objects of interest in the environment. System overview. The input to the system is a depth image and segmentation masks of objects of interest, generated from the corresponding RGB images, which together create partial object point clouds. The system’s six modules then process these partial point clouds to interact with and update object and frame information in the database. The output of the system can be retrieved from the database as camera pose estimates for input frame sequences and the latest object-centric map of the environment, consisting of full shape reconstructions of the objects of interest.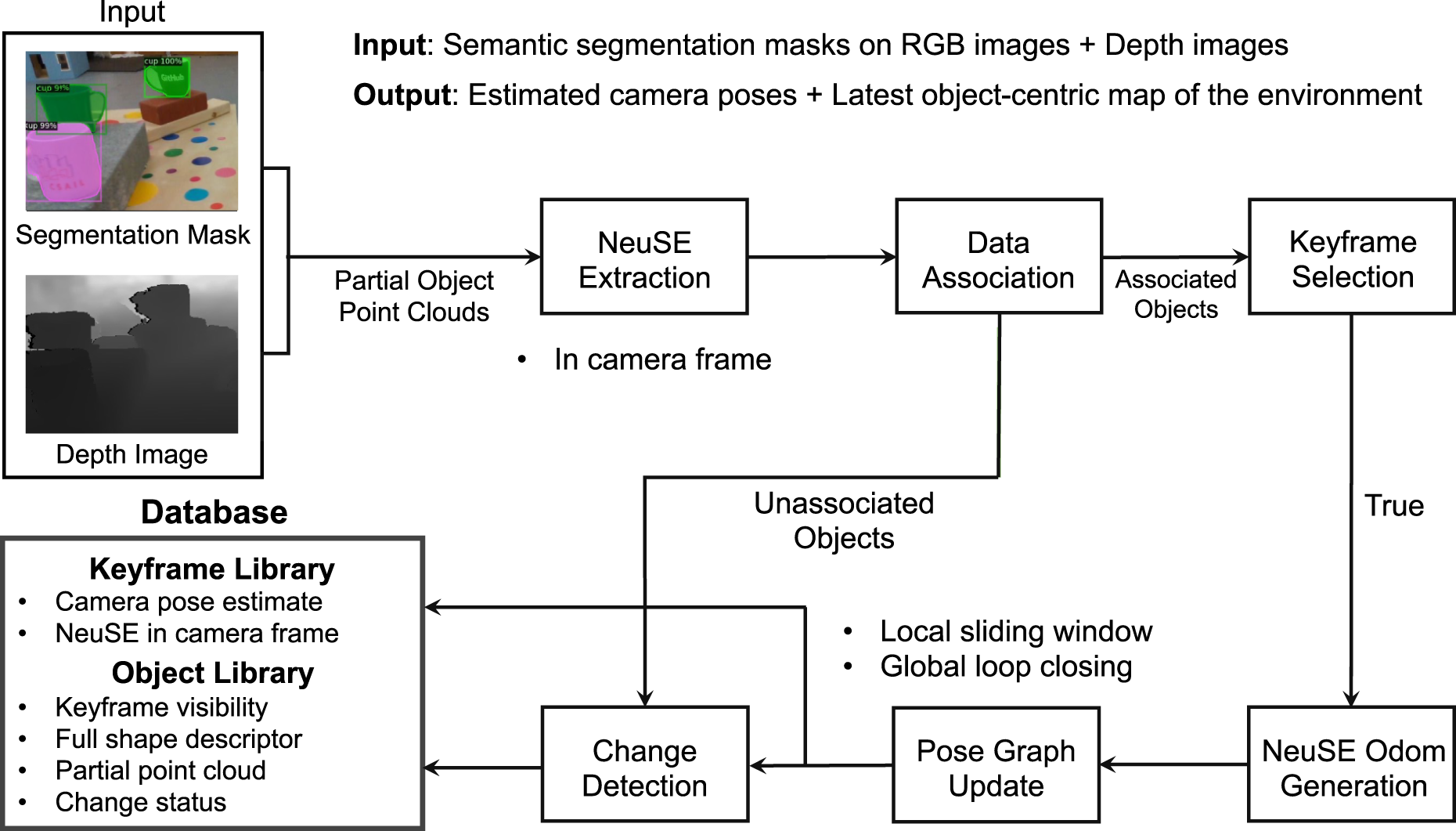
Our main contributions are as follows: (1) We introduce NeuSE, a canonical latent point cloud representation that encodes the full object shape, scale, and transformation, transforming and scaling equivariantly with the physical object. (2) We propose a NeuSE-based object SLAM paradigm targeting long-term scene inconsistency, enabling NeuSE-predicted object-level localization and change-aware mapping. (3) We evaluate our approach on synthetic and real-world sequences, in both controlled and uncontrolled settings with objects of varying shapes and sizes, demonstrating improved localization performance and adaptable mapping capability when working as a standalone system or jointly with common SLAM pipelines.
2. Related work
2.1. Object-based SLAM
SLAM++ (Salas-Moreno et al., 2013) introduced object-based SLAM by incorporating camera-object constraints with objects from a predefined model database. Attempts (McCormac et al., 2017; Mccormac et al., 2018; Runz et al., 2018; Xu et al., 2019) were made to leverage semantic segmentation for instance-level dense reconstructions. Furthermore, simple parameterized geometry, for example, ellipsoids adopted by Nicholson et al. (2019) and Hosseinzadeh et al. (2019) and cuboids by Yang and Scherer (2019), were explored to guide the joint optimization of the object shape parameters and camera poses. For environments with moving objects, Strecke and Stueckler (2019) proposed an object-level SLAM approach that utilized local Signed Distance Function (SDF) object volumes for tracking moving objects and performing camera localization. A recent work, VOOM by Wang et al. (2024), described landmarks in a hierarchical manner that combined high-level objects, represented as dual quadrics, with low-level feature points to create a visual object odometry and mapping framework. The proposed pipeline enabled efficient object optimization and association, leading to improved localization accuracy and demonstrating a certain level of robustness in dynamic scenes. Efforts have also been made to integrate neural shape priors into the object SLAM pipeline. NodeSLAM (Sucar et al., 2020) adopted a class-level optimizable object shape descriptor and used RGB-D images for joint estimation of object shapes, poses, and camera trajectory through iterative probabilistic rendering optimization. DSP-SLAM (Wang et al., 2021), on the other hand, used DeepSDF (Park et al., 2019) for object representation and optimized the object code, camera poses, and sparse landmark points altogether through a similar rendering loss in RGB, stereo, or stereo+LiDAR modalities. As the rendering process is parameterized as a neural network with no interpretable meaning, both methods require iterative optimization with a proper initialization to obtain the SE(3) transform constraint that aligns with the real-world observation. This results in added training and computational expenses, making the adoption of neural representations a complex process.
2.2. Neural implicit representations for robotics
Neural implicit representations have emerged as a promising tool to encode the underlying 3D geometry of objects and scenes (Mescheder et al., 2019; Ortiz et al., 2022; Park et al., 2019). Different works have explored how neural implicit representations can be used in various fields, including change detection (Fu et al., 2022), localization (Adamkiewicz et al., 2022; Moreau et al., 2022), SLAM (Chung et al., 2023; Rosinol et al., 2023; Sucar et al., 2021; Zhi et al., 2019; Zhu et al., 2022b), and manipulation (Chun et al., 2023; Driess et al., 2023; Kerr et al., 2023; Khargonkar et al., 2023; Li et al., 2022; Lin et al., 2023b; Ryu et al., 2023; Shen et al., 2022; Simeonov et al., 2023).
Notably, some works extended the original representation by integrating SO(3) or SE(3) equivariance for tasks such as reconstruction (Deng et al., 2021), point cloud registration (Lin et al., 2023a; Zhu et al., 2022a), and manipulation (Simeonov et al., 2022) as well as scale equivariance (Lei et al., 2023; Yang et al., 2024). Zhu et al. (2022a) learned SO(3)-equivariant features to perform correspondence-free point cloud registration, while Lin et al. (2023a) used SE(3)-equivariant representations to obtain and refine the registration result globally and locally. Simeonov et al. (2022) learned SE(3)-equivariant object representations for manipulation and estimated relative transforms through optimization. These methods target point clouds known to be associated with the same object, which can suffer from performance degradation for partially overlapped point clouds (Lin et al., 2023a; Zhu et al., 2022a) or require iterative refinement to recover the desired relative transform (Simeonov et al., 2022).
In the context of SLAM, most works, other than the object-based methods listed in the previous section, utilized scene-level neural implicit representations to be jointly optimized with camera poses. iMap (Sucar et al., 2021) showed that a multilayer perceptron (MLP) could serve as the scene representation for real-time RGB-D SLAM. NICE-SLAM (Zhu et al., 2022b), built on top of iMap, further introduced a hierarchical grid-based neural encoding, enabling RGB-D SLAM on a larger scale. In terms of monocular SLAM, Nerf-SLAM (Rosinol et al., 2023) relied on an indirect loss for pose estimation and produced higher-quality reconstructions by supervising the radiance field with depth information. These methods, like their object-based counterparts, still require undesirable iterative optimization with photometric or depth loss for localization, while being hard to adapt to changes with the scene represented as one single code.
Our NeuSE-based SLAM paradigm differs from prior SLAM works with neural representations by further explicitly imposing SE(3) and scale equivariance onto the vanilla neural object representations. To handle unknown data associations, in contrast to previous works on point cloud registration or manipulation with equivariant representations, we can directly use the implicit shapes and scales captured by latent representations. This allows partial point clouds to be robustly associated regardless of viewing angle differences. With additional regularization for objects with pose ambiguity, we ultimately achieve direct inference of SE(3) camera pose constraints from partial object representations. This eliminates the need for the computationally expensive “render-optimize” process and offers a lightweight yet flexible solution to object SLAM problems with long-term changes.
3. Category-level neural SE(3)-equivariant embedding (NeuSE) for objects
3.1. SE(3) and scale equivariance
We propose to represent each object in a scene by using a corresponding SE(3)-equivariant latent embedding with scale equivariance. Precisely, given a point cloud

Simultaneously, given a uniform scaling factor s:

In Figure 3, we present two examples explaining both types of equivariance, that is, how latent representations transform and scale within the latent space, corresponding to the physical transformations of objects in the real world. Although these latent embeddings do not visually resemble the actual objects, they maintain consistent behaviors in latent space, following the objects’ transformations in the physical world. This consistency offers the following three benefits: Illustration of SE(3) and scale equivariance. Equivariance means that the latent representation, though not visually resembling the physical object, transforms in the latent space in the same way as the object does in the real world. (a) With SE(3) equivariance, the latent code undergoes the same SE(3) transform 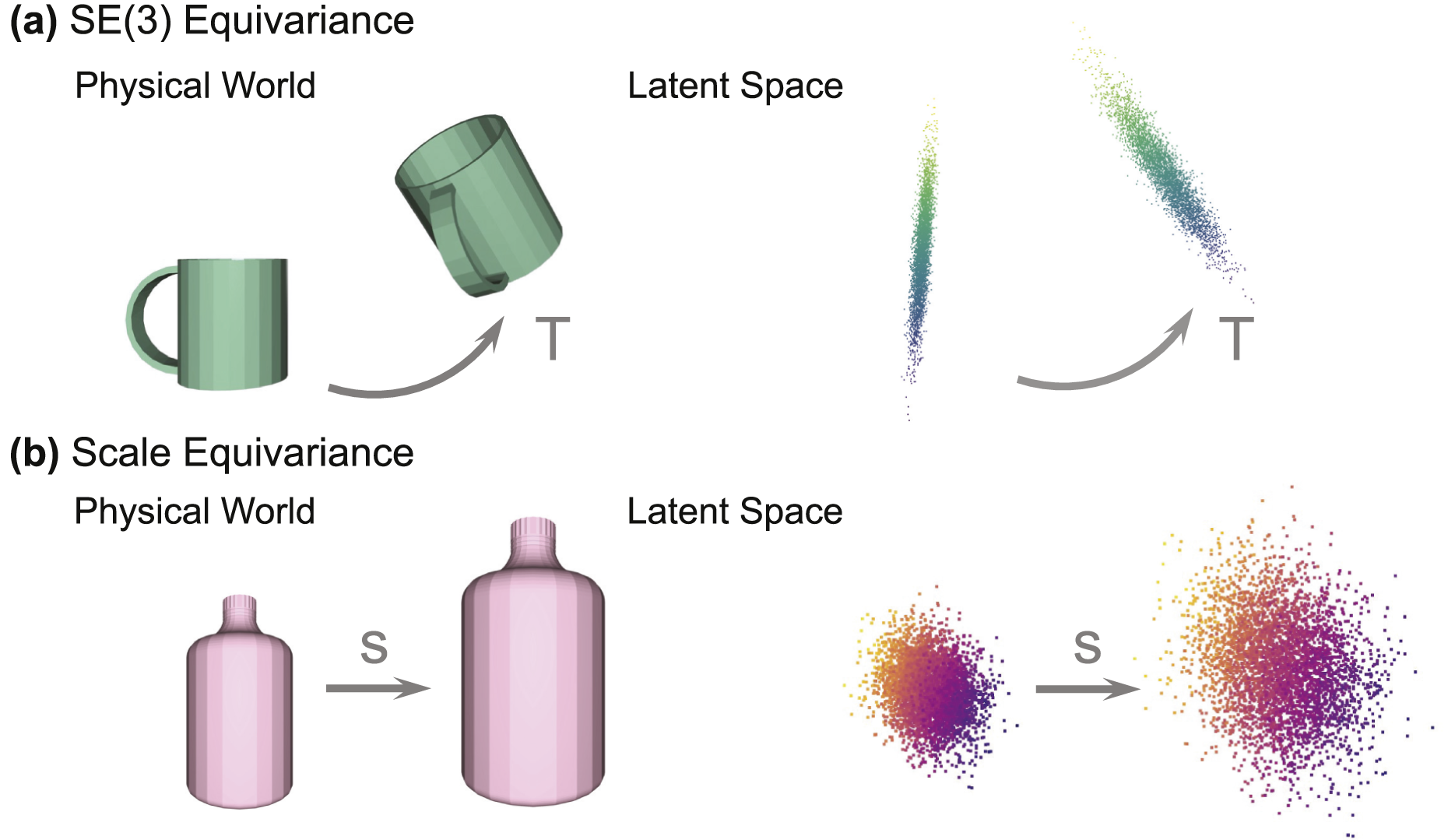
3.1.1. Latent pose constraints
The underlying latent embedding space operates under the same SE(3) action as the point cloud. Thus, we may express pose constraints between matched objects directly in the latent space as opposed to the full point cloud space of objects. As the latent space is both low-dimensional and canonical, pose constraints may be more efficiently computed using the closed-form solution developed by Horn (1987).
3.1.2. Implicit pose representation
The object latent code implicitly captures the underlying SE(3) transform of an object. This circumvents the need to explicitly specify 6-DOF poses of objects when computing pose constraints, which may not always be accessible and can be ill-defined for objects with symmetrical ambiguity.
3.1.3. Implicit shape representation
The object latent code richly encodes the underlying shape, size, and features of an object, which enables robust data association across viewing angle disparity.
3.2. Constructing equivariance
To infer SE(3)-equivariant latent codes with scale equivariance, NeuSE uses a SO(3)-equivariant encoder function (Deng et al., 2021) f
θ
(
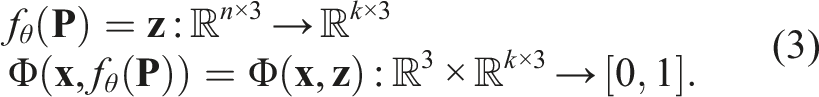
We modify the encoder function from Deng et al. (2021) to achieve scale equivariance by normalizing the cross-product encoding of the point cloud using the point cloud’s norm. The subsequent vector neuron layers are then scale equivariant by construction.
By feeding Φ(⋅, ⋅) with a query point cloud
3.3. Learning SE(3) equivariance across viewing angles
While equation (1) holds for identical but transformed point clouds, capturing the same object point cloud as the robot moves is nearly impossible due to constantly changing camera views and occlusion patterns, resulting in varying partial observations of the same object. To maintain consistent equivariant behaviors between the latent representation and the associated physical object, SE(3) equivariance must hold not only for one single partial point cloud from a specific view but also across the varying partial point clouds observed of the object.
To achieve this, we construct SE(3) equivariance from partial point cloud
For rotation equivariance, as our encoder is rotation equivariant, when a point cloud is rotated by
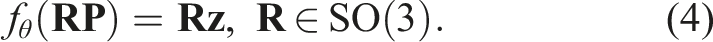
Since
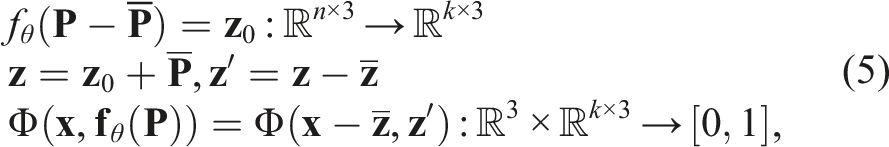
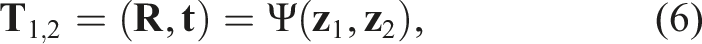
3.4. Dealing with pose ambiguity
SE(3) equivariance is desirable for revealing the relative transform between the two frames where the same object is observed. However, shape symmetry can result in ambiguity in the inferred transform, causing our latent codes to be fallible when the transform selected is one of many possible candidates rather than the correct one.
To make our representations applicable to a broader range of objects, we therefore propose separate training objectives for object shapes with and without ambiguity w.r.t. the camera viewing frustum.
3.4.1. Unambiguous objects
For objects without pose ambiguity (e.g., mugs with a handle), the transform (
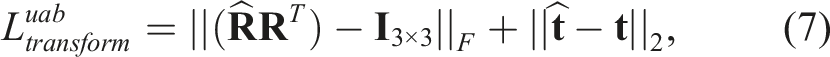
3.4.2. Ambiguous objects
We limit “ambiguous objects” to objects with pose ambiguity from their shapes (e.g., upright wine bottles), but not the ones that may appear ambiguous due to occlusion (e.g., mugs with their handles obscured).
Since ambiguous objects have multiple or infinitely many valid transforms that can meet the current observation, the exact single correct transform can never be learned. We instead wish that the derived transform will always lead to similar object shapes when transforming the object’s point cloud from one frame to another. In a nutshell, we require the latent code
Hence, given the full object point clouds in two frame coordinates,
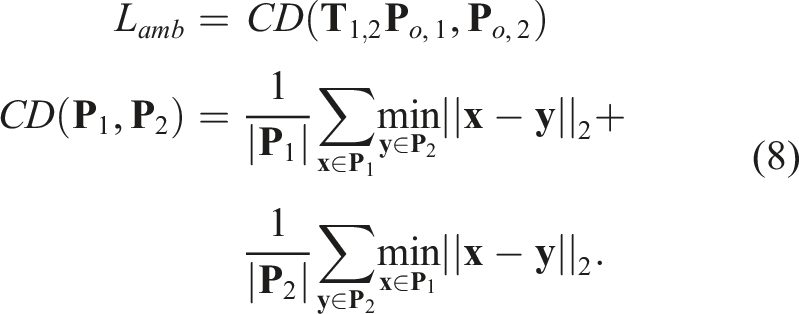
We can recover the exact transform that simultaneously justifies all current object observations by intersecting the distributions of possible transforms for multiple ambiguous objects (see Figure 4(a) for the reasoning of the base two-object case involving two bottles), or further refine the predicted one when working together with unambiguous objects. Note here we do not account for the rare degenerate case of colinear axes of symmetry for all visible objects. (a) Breaking pose ambiguity with covisible ambiguous objects. Motions around a bottle’s axis of symmetry result in seemingly identical observations, making it impossible to determine inter-frame transforms. However, with two covisible bottles, the intersection (green) of their camera pose distributions (yellow and blue) for the current observation reveals the true camera pose, where inter-frame transforms can then be determined without ambiguity. (b) Latent symmetry. The canonicalized latent embedding should be invariant to camera motion (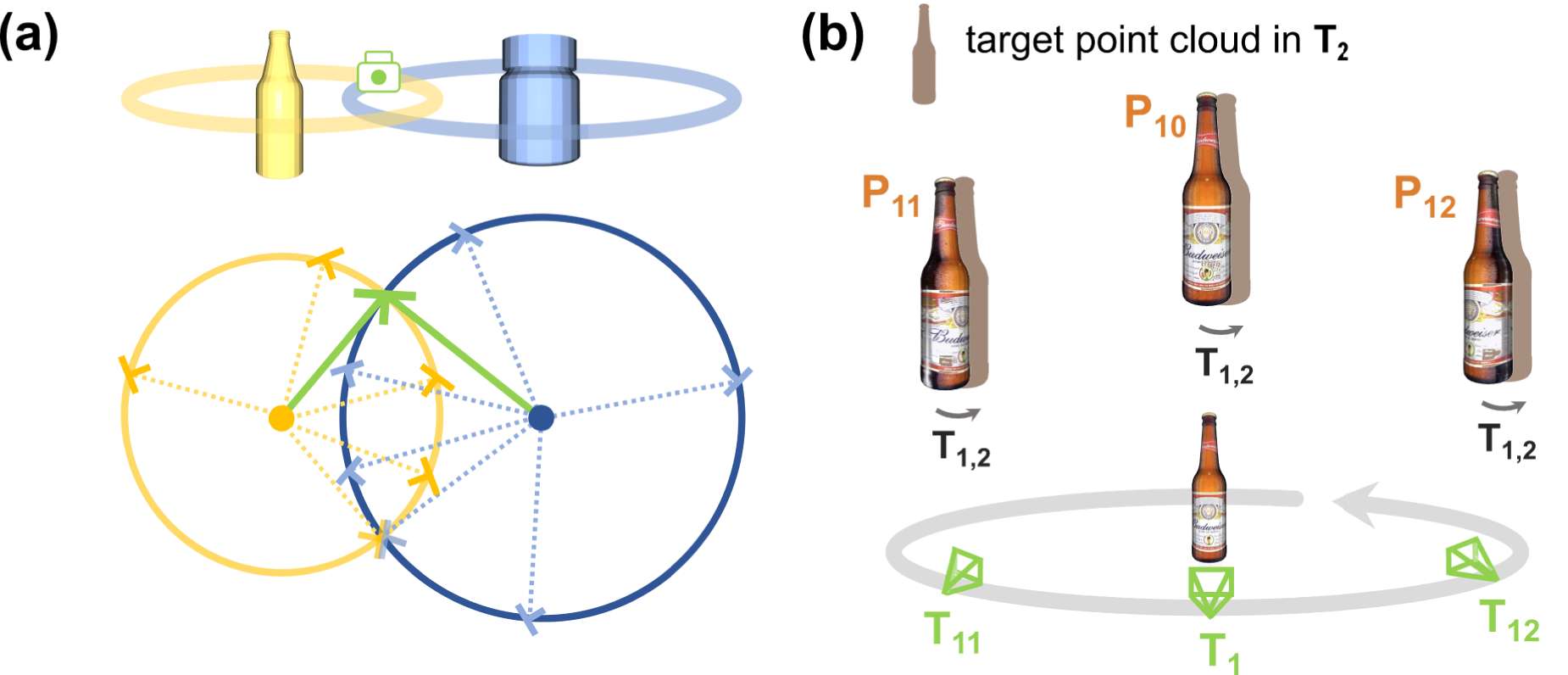
Furthermore, to facilitate the learning of the underlying distribution, we further augment the original (
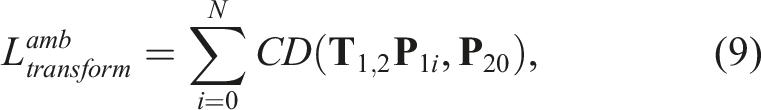
Finally, the target inter-frame transform can be similarly obtained using equation (6), with the two latent codes
3.5. Shape consistency across viewing angles
Since
As
Following Fu et al. (2022), we adopt the batch-hard shape similarity loss Lb_shape, enforcing
Lb_shape takes the form of the triplet loss as [anchor, positives, negatives]. To allow for a variety of viewing angle combinations during training, we populate each training batch B with M partial observations for each of the N randomly drawn objects. Samples of the same object instance serve as mutual anchors and positives, (
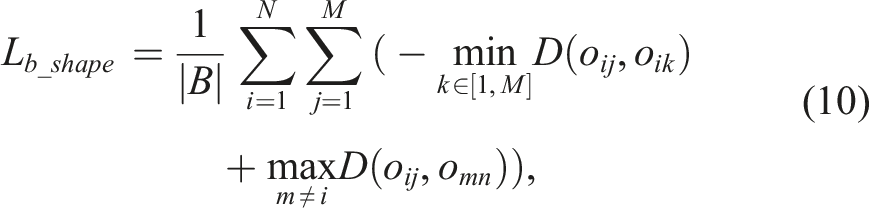
3.6. Capturing relative scale
As
However, given two point clouds
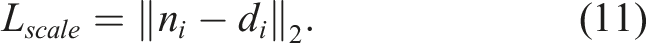
This ensures that the norm of the inferred latent code accurately captures scale information in the object shape.
3.7. Training in simulation
3.7.1. Training objective
NeuSE is trained with partial object point clouds and corresponding 3D occupancy voxel grids of objects’ complete geometry. The full model [f
θ
, Φ] predicts the complete 3D occupancy values at query object locations, which is then evaluated by the standard cross-entropy classification loss
The ambiguous and unambiguous object categories are trained separately, with respective L
transform
and shared L
occ
, L
shape
, and L
scale
. The final training objective is then defined as:
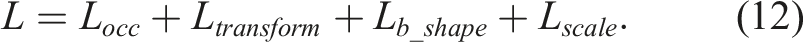
The training samples are organized following Lb_shape’s formulation, where L occ and L scale are evaluated for each sample in B and L transform for any two observations of the same object. With this composition of the training data, the model is expected to see various pairs of viewing angles and learn to predict the relative transform between two frames within a certain range of separation.
3.7.2. Data generation
NeuSE is trained fully in simulation with RGB-D images rendered with Pybullet (Coumans and Bai, 2016–2021). We place a randomly posed principal object on the table, along with 2–4 (for unambiguous objects) and 1–2 (for ambiguous objects) objects arbitrarily selected from the trained categories to simulate a typical cluttered environment. To ensure a variety of viewing angles, for each multi-category object layout, we uniformly sample a fixed number of camera locations over the hollow cubical space centered around the table. The cubical space is set to be [d n , d f ] away from the table within the table plane and [d l , d h ] away from the table in the vertical direction, thus accounting for observations from near, far, low, and high viewpoints.
4. NeuSE-based object SLAM with long-term scene inconsistency
NeuSE enables robust data association across viewing angles and further serves as a lightweight, alternative “sensor” for providing cross-frame camera pose constraints. We propose a NeuSE-based localization strategy in tandem with a change-aware object-centric mapping procedure to enable robust robotic operation in scenes with long-term changes.
4.1. System formulation and update
Our object-based SLAM problem is formulated as a pose graph consisting of only keyframe camera pose vertices, where an edge exists to constrain the two vertices if there are inter-frame transform measurements available from NeuSE or any other sources. The measurement error between vertices i and j for each edge is defined as
The system maintains a library of keyframes with the latest camera pose estimates obtained via pose graph updates, as well as NeuSE latent codes of the observed objects in the frame coordinate. The camera pose of the current frame is recovered as the smoothed estimate of pose constraints from associated objects and external sources between the frame itself and the nearest keyframe.
The objects in the system are recorded by their per-keyframe visibility, change status, a partial point cloud from their last keyframe observation (for query point generation during rendering), and the latest shape descriptor from initialization or mapping updates.
For localization, the system works only with latent codes in the local camera frame, while their world-frame counterparts are used for mapping operations. When an object is first observed, its world-frame latent code is initialized and then updated as needed by averaging the back-projected latent codes of the same object using the latest camera pose estimates recorded in the keyframe library.
4.2. Data association
NeuSE-predicted inter-frame transforms are only valid when computed from latent codes belonging to the same object. Our data association scheme first leverages semantic labels to select candidates within the query observation’s category, and then progressively uses scale, shape similarity, and spatial proximity to ensure that pose constraints are generated only between latent codes with reliable object associations (see Figure 5). Data association. With NeuSE as the object representation, we utilize semantic labels, scale, shape, and spatial proximity for effective data association. After associating the unambiguous mug observation with the correct purple mug in the database, the bottle observation undergoes four steps to eliminate incorrect candidates in the dashed gray box and identify the correct green bottle: (a) Semantic matching selects the bottle-labeled instances from the object library; (b) scale comparison rules out the smaller orange bottle; (c) shape comparison eliminates the yellow bottle with a different shape; and (d) spatial proximity comparison identifies the correct green bottle, as the transform derived from the combination of the purple mug and green bottle results in minimal center difference for their partial point clouds.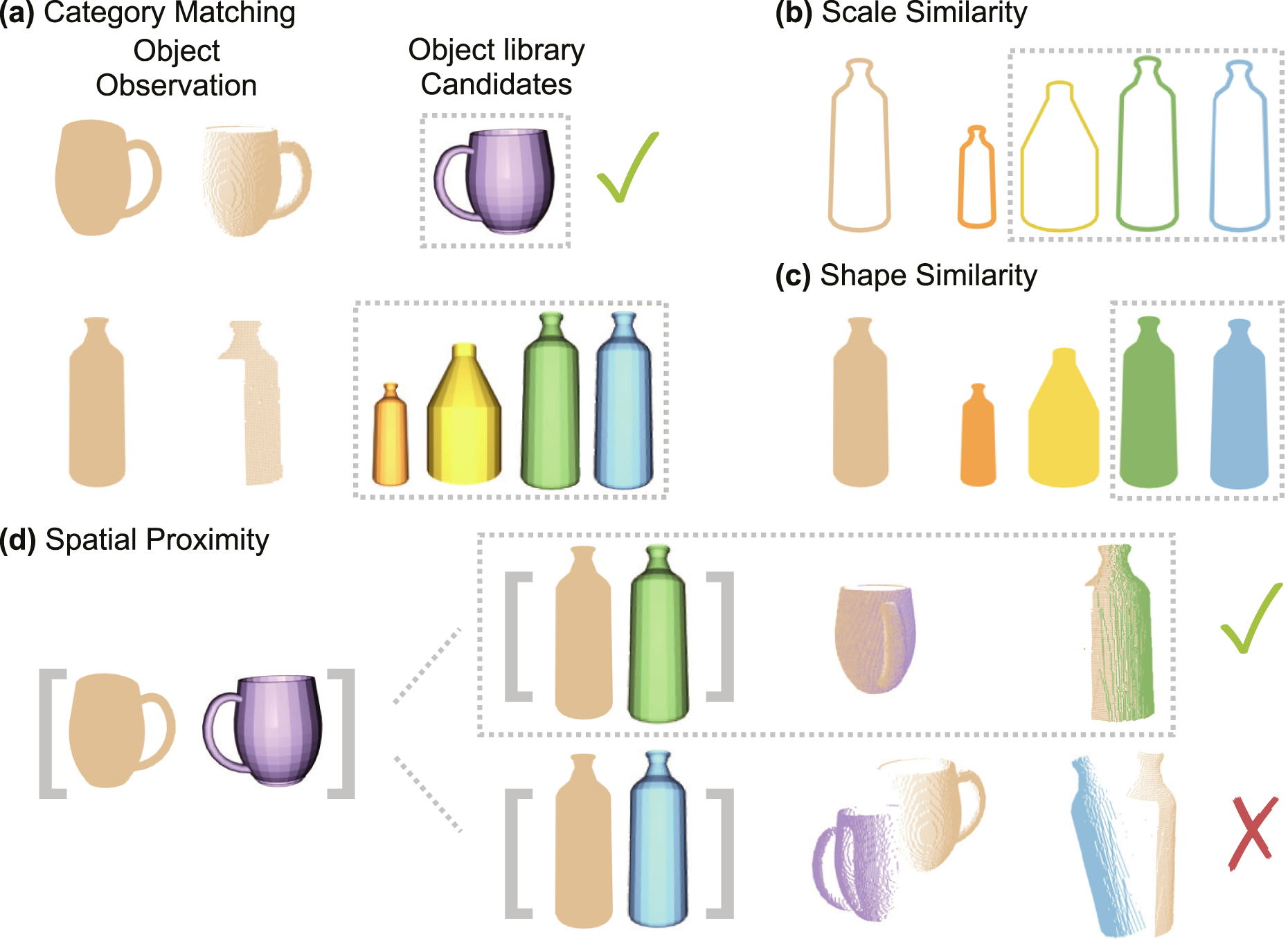
4.2.1. Semantic category matching
To improve the efficiency of object matching, we first use semantic labels to eliminate candidates from other categories, focusing only on potential matches within the same category, as illustrated in Figure 5(a).
4.2.2. Scale similarity
Leveraging NeuSE’s scale equivariance, we filter data association candidates based on object sizes. We compute the norm of the latent code for the current observation and search for objects in the library within a |δ size | scale difference. This reduces the candidates to those of similar sizes to the object represented by the query partial point cloud, thereby reducing the computational load in subsequent steps, as shown in Figure 5(b).
4.2.3. Shape similarity
As described in Figure 5(c), when multiple candidates are of similar sizes to the current object, we then extract the shape descriptor from the latent code and calculate its cosine shape similarity (as adopted in equation (10)) with all object candidates. Objects with a shape similarity score greater than δ
shape
are considered potential data association candidates
4.2.4. Spatial proximity
Spatial proximity involves examining the Euclidean distance between the partial point cloud centers of the current object and its candidates in
The procedure is first performed on unambiguous objects, followed by ambiguous objects. For unambiguous objects, we compute the transform directly from the concatenated latent codes using Horn’s method, selecting the candidate combination that minimizes the partial center distances of all observed unambiguous objects in the frame. For ambiguous objects, we utilize the transform from associated unambiguous objects if available. If not, we perform an exhaustive search of all paired combinations of covisible object candidates in previous keyframes, similar to the process for unambiguous objects. We compute the inter-frame transform from the concatenated latent codes, selecting the combination that results in the smallest partial center distance for all object observations in the current frame.
Hence, we divide all covisible objects
4.3. Pose graph optimization
With objects successfully associated across frames, we compute NeuSE-predicted transforms among frames to constrain the pose graph both locally and globally (see Figure 6). Pose graph optimization. With objects observed in periods of consecutive frames, we derive from corresponding latent codes (1) short-range odometry constraints (gray) within a local K-frame sliding window, and (2) global loop closure constraints (black) between the current (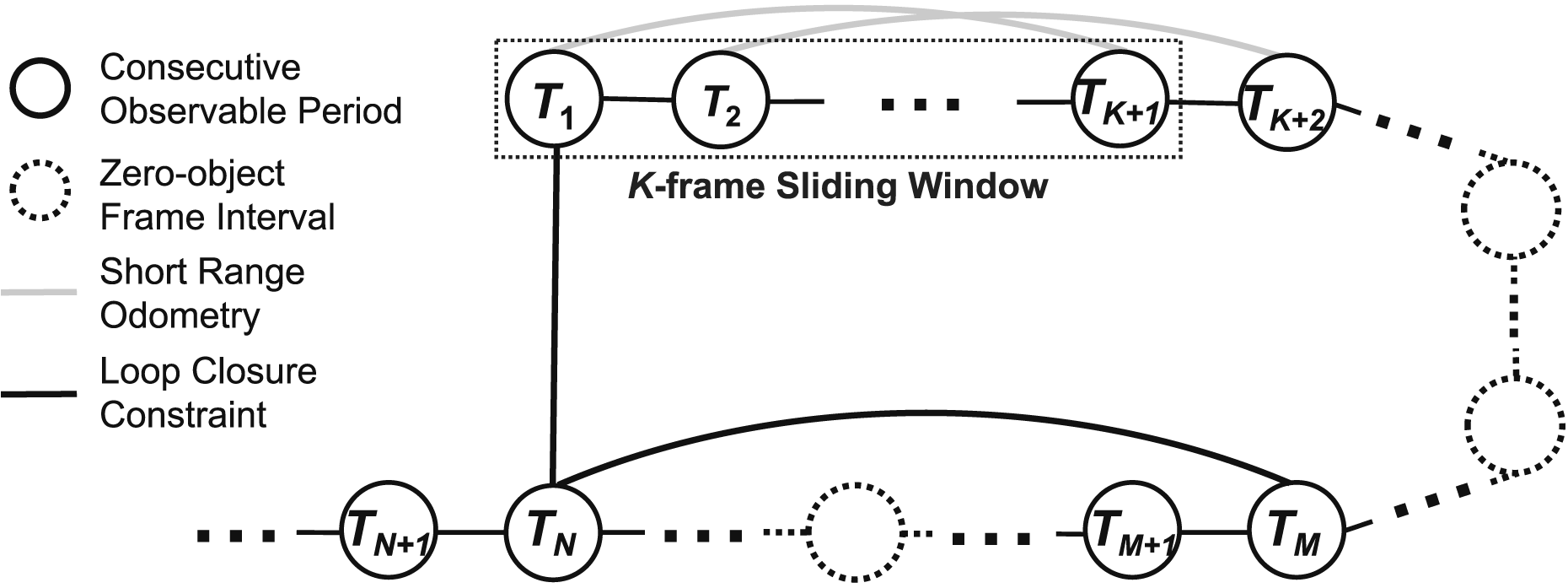
4.3.1. Keyframe selection
Keyframes are selected based on the presence of new objects and proximity to previous keyframes. New objects trigger the selection of a frame as a keyframe, and frames located at least 0.04 m away from the previous keyframe based on accumulated odometry are also chosen. Additional keyframes may be added after change detection for frames with changes.
4.3.2. Short-range odometry
To reduce local drift in frames with persistently observed objects, short-range NeuSE-predicted pose constraints are applied to a sliding window optimization of K keyframes. For each newly added keyframe, we search its preceding
4.3.3. Long-range loop closing
Global loop closing is activated when an object is detected again in a frame after its last consecutive observable period. The common objects between the current frame and the initial frames of all its previous observation periods are identified, and relative transform constraints are derived from the concatenated NeuSE latent codes. These constraints are then added to the pose graph, which initiates a global optimization process using the latest pose estimates from the local sliding-window optimization as the starting point.
4.4. Change-aware object-centric mapping
Change detection is performed frame by frame on objects in O unmatched that match in shape but are identified as spatially apart based on latent codes, providing a foundation for consistent long-term mapping.
Since changes are often gradual and occupy only a small portion of the object clutter in long-term scenes, here change detection is performed by comparing the relative layout of the query unmatched object
We represent the local layout with a directed object graph G constructed with
We build the local and reference object graphs, G and G′, respectively, for Object layout comparison through graph matching. Object graphs are constructed for the current frame (G) and the library (G′). For object a and b, which are similar in shape to the blue mug and pink bottle in the library, respectively, the inter-object distances between them and the anchor objects in the four corners are computed and compared. (a) All corresponding edges (dashed and solid lines) with anchor objects have similar oriented lengths, indicating that the mug is unchanged but was seen with an occluded handle, leading to a false ambiguous transform by the latent code. (b) There are no similar edges, indicating a different layout with the bottle moved.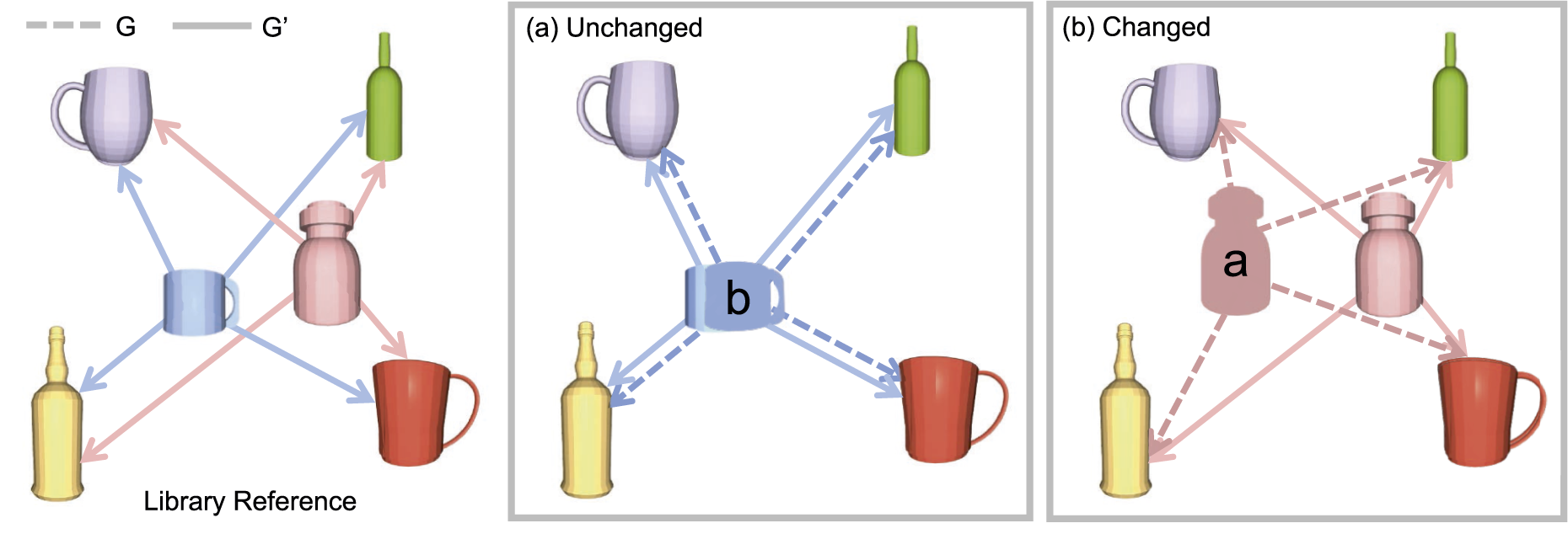
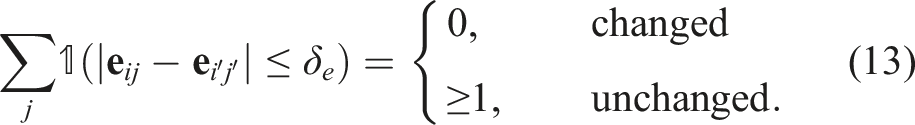
An object o i is marked as unchanged if at least one pair of edges is found to be closer than a threshold δ e . This indicates that its inter-spatial relationship with at least one of the anchor objects is consistent. If no edges are found to be close, the object is marked as changed and its change status and partial point cloud are updated in the object library. Here, we define an object to be “removed” from the scene if it has never been shape-matched during frame periods with global loop closure.
Therefore, we are able to maintain a lightweight, object-centric map that accurately reflects full object reconstructions from NeuSE predictions. By using objects as the basic building blocks of the map, we can update changes seamlessly by replacing the old latent code with the new one during the decoding stage, avoiding cumbersome and artifact-prone point- or voxel-wise modifications commonly used in traditional low-level geometric maps.
5. Experiment setup
In our experiments for evaluation, we first assess NeuSE’s efficacy in characterizing object shapes and poses from partial object observations. We then investigate how NeuSE can be utilized for robust spatial understanding across scenes.
Specifically, we aim to answer three questions: (1) Can NeuSE provide an effective object representation with SE(3) and scale equivariance, enabling accurate shape and pose descriptions even under challenging conditions such as varying viewpoints and occlusions? (2) Can NeuSE-based object SLAM perform reliable localization independently or enhance existing results when integrated with other SLAM measurements, particularly in the presence of temporal scene inconsistency? (3) Can the proposed approach build a consistent object-centric environment map with timely updates to reflect scene changes?
We therefore trained NeuSE fully in simulation and evaluated the proposed algorithm directly on both synthetic and real-world sequences, featuring unseen objects from the trained categories with greater size variation than the training data. We first verified the proposed SE(3)- and scale-equivariant object characterization of NeuSE using controlled synthetic sequences and further demonstrated its applicability to long-term object-based SLAM on both synthetic and real-world traversals, where multi-category objects of diverse sizes were added, removed, or switched places.
Given the limited availability of object model collections for training and the scarcity of public datasets featuring appropriate object-level scene changes, we generated our own synthetic and real-world testing sequences. These sequences included multiple categories of daily objects with gradual layout changes in both controlled experimental settings and less structured lab-office environments.
We selected objects from five categories: mugs, bottles, bowls, cans, and trash bins, to capture a diverse range of shapes, sizes, and spatial ambiguities, such as cylindrical or rectangular shapes. This diversity allows for a comprehensive evaluation of the effectiveness and generality of our latent code design.
5.1. Implementation details
To train NeuSE’s occupancy network, for each object category, we generated training samples using the corresponding models from ShapeNet (Chang et al., 2015) rendered in Pybullet, each containing 60,000 RGB-D partial observations with segmentation masks. We followed the sample generation strategy proposed in Section 3.7.2: 2,000 object layouts were created in Pybullet with the target object category mixing with all categories of interest, from each of which 30 views were uniformly sampled with [d n , d f ] = [0.3, 4] (m) and [d l , d h ] = [−0.4, 0.4] (m). We trained our model on two NVIDIA RTX 3090 GPUs using a learning rate of 5 × 10−4 with the Adam optimizer. The latent code size was k = 512 and the occupancy threshold for reconstruction was v0 = 0.5. The training batch was populated with eight object shapes, each with 15 partial observations, by setting M = 15 and N = 8.
For the object SLAM system, we used Mask R-CNN (He et al., 2017) to generate segmentation masks of interest. For data association and change detection, we used (δ size , δ shape ) = (0.01, 0.95), (δ prox , δ e ) = (0.03, 0.02) (m) for the synthetic sequences, (δ size , δ shape ) = (0.02, 0.90), (δ prox , δ e ) = (0.03, 0.02) (m) for the controlled environment and (δ size , δ shape ) = (0.02, 0.90), (δ prox , δ e ) = (0.03, 0.03) (m) for the hand-held sequences. We set the sliding window size to K = 10 and adopted the factor graph representation for SLAM pose graph optimization. The local sliding-window optimization was solved with a Levenberg-Marquardt fixed-lag smoother, and the global pose graph was solved with iSAM2 (Kaess et al., 2011), both using implementations from GTSAM (Dellaert and Contributors, 2022).
6. SE(3) and scale equivariance of object representations
We first assess the SE(3) and scale equivariance of object representations in NeuSE, which are crucial for its effective application in robotic spatial understanding tasks. In principle, NeuSE is SE(3)- and scale-equivariant by construction when given the same transformed object point cloud. However, in real-world robotic executions, partial point clouds of an object vary across viewing angles, making it important to demonstrate that NeuSE’s equivariance is learned to still hold across different observations of the same object.
To test the robustness of NeuSE’s SE(3) and scale equivariance under partial observations, we conducted controlled experiments in simulation. In these experiments, we applied SO(3) rotations, three-dimensional translations, and scaling to objects, observing them from the same view before and after each transformation
The testing data were generated in PyBullet using object instances from ShapeNet, covering all five chosen categories. For each equivariance experiment, that is, rotation, translation, and scaling, we created 100 samples per category, for a total of 500 samples. In each sample, an object was randomly selected from a category, and a randomly generated transformation was applied to obtain object observations before and after the change from the same camera view.
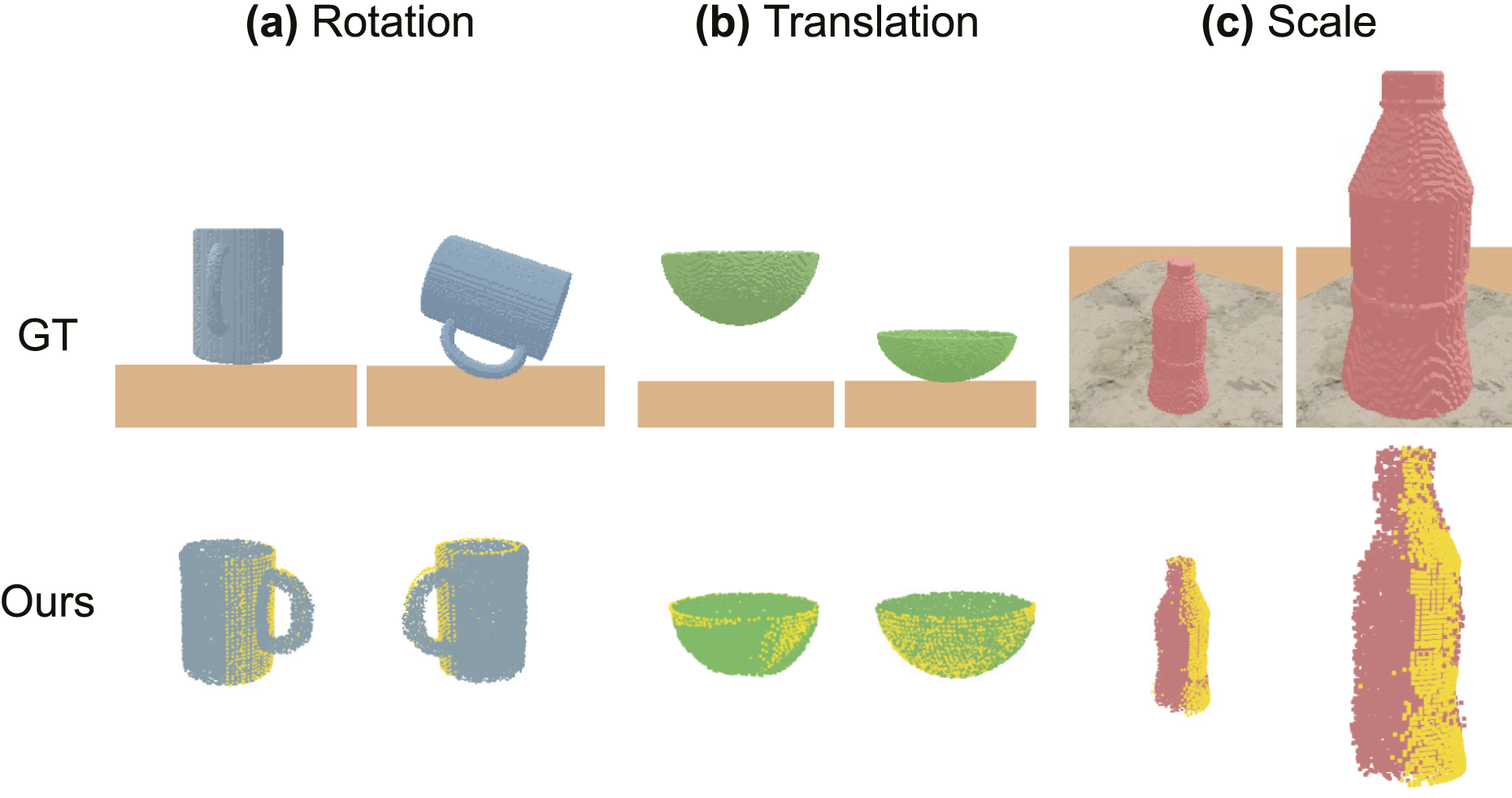
We quantitatively present the distribution, along with the mean and standard deviation of the errors of the NeuSE-inferred distribution, in Figure 8, and provide qualitative examples of NeuSE’s reconstructions of different object instances before and after transformation in Figure 9. Equivariance error distribution. Scatter plots showing the error distributions from the testing data across five object categories in three equivariance experiments. (a) Most normalized RMSE values across the full rotation range (0°, 180°) are bounded within a range close to zero, indicating small differences between the latent codes of the original and rotated objects, thus demonstrating strong SO(3)-equivariance. (b) The RMSE values between predicted and ground truth translations are concentrated below 0.01 m, reflecting NeuSE’s high translation encoding accuracy. (c) For scale changes ranging from one to nearly seven times the original size, the errors between the estimated and ground truth scale ratios average around 0.011, with most error values ranging between −0.01 and 0.03, suggesting NeuSE’s scale equivariance across object sizes. Robust reconstruction with equivariance. Examples of robust object reconstructions (Ours) compared to the ground truth (GT). Yellow points represent partial point cloud observations, and the colored reconstructions are shown from viewing angles that emphasize the occluded parts completed by NeuSE. Across the three transformations applied to the example objects: (a) SO(3) rotation on the mug, (b) 3D translation on the bowl, and (c) scaling on the bottle, NeuSE effectively encodes and reconstructs the full object shape, consistently aligning with partial observations from both the original and transformed states.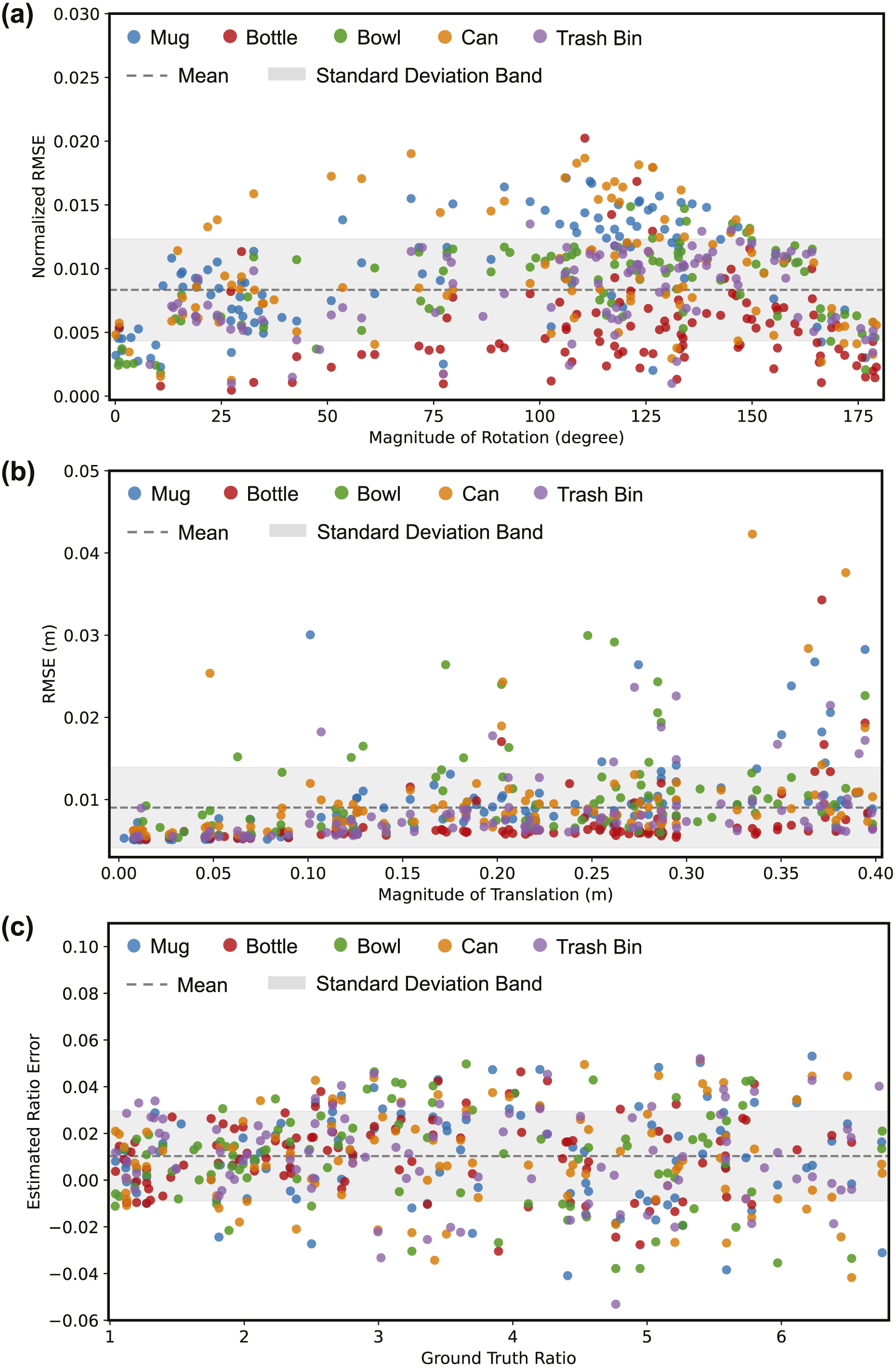
6.1. Rotation equivariance
Following the definition of rotation equivariance in equation (4), Figure 8(a) illustrates the distribution of the Normalized Root Mean Squared Error (RMSE) between the latent codes
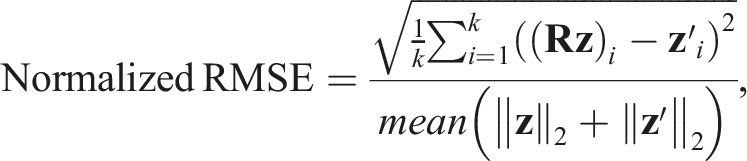
As shown in Figure 8(a), with the magnitudes of sampled rotations covering nearly the entire (0°, 180°) range and a mean normalized RMSE of 0.83%, we observe a consistent trend of low normalized RMSE values across different rotation angles for all object categories, indicating NeuSE’s equivariance with physical-world rotations. Notably, the variation in normalized RMSE remains within an acceptable range of (0.4%, 1.2%), further demonstrating NeuSE’s consistency in encoding the intrinsic geometric structure of objects in the latent space after various degrees of rotation. This is further supported by Figure 9(a), which presents an example of a full mug reconstruction before and after applying the rotation. Despite the significant change in the visible portion caused by the rotation (the yellow point region), the full mug reconstruction still aligns well with the visible part and accurately recovers the complete mug shape with the correct orientation.
6.2. Translation equivariance
The other component of SE(3) equivariance is translation equivariance. Given an applied translation
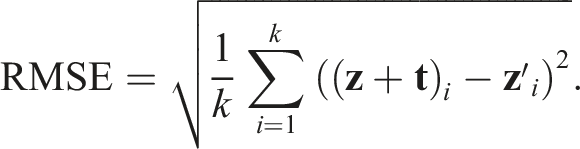
In Figure 8(b), we plot the RMSE against the translation magnitude, where the translation is controlled to be within 0.4 m. This limit is based on the maximum potential distance we set between two keyframes within the sliding window of the pose graph. Most of the points, well within the standard deviation band, are concentrated below 0.01 m, regardless of the object category or translation magnitude. This demonstrates NeuSE’s ability to robustly encode the complete object shape, effectively inferring the offset between the observed partial object center and the true object center, despite variations in the observable parts caused by translation. This finding is further supported by Figure 9(b). Whether the bowl is initially observed in a closer, upper position with only the bowl body visible (left), or later seen in a more distant, lower position with the rim also visible (right), NeuSE consistently reconstructs the complete bowl shape, which aligns reliably with the yellow observable portion.
6.3. Scale equivariance
To evaluate scale equivariance, we apply a scaling transformation to change the object size (scaling the bounding box diagonal length, as adopted in equation (11)), by a factor s within the range of [1.03, 6.75]. This results in overall object sizes ranging from 0.05 m to 0.75 m, which is similar to the size range of daily objects used in our real-world experiments. To quantify the change in NeuSE’s representation before and after scaling, we compute the difference between the NeuSE-inferred scaling ratio and the ground truth ratio s as:

As shown in Figure 8(c), NeuSE effectively generalizes across different object categories and size variations, maintaining a small and consistent estimated ratio error even with scaling up to 6.75 times the original size. For smaller scaling factors (e.g., below 1.5), the inferred ratios closely match the ground truth, remaining well within the standard deviation band and close to zero. This demonstrates NeuSE’s accuracy in encoding object sizes. Even with larger scaling transformations that introduce significant changes to partial observations, NeuSE kept the prediction error mostly below 0.05, even for size increases ranging from 3 to 6.75 times the original size. Figure 9(c) further illustrates NeuSE’s ability to generalize across scales with an example of the bottle category. Despite the object being scaled to approximately three times its original size, NeuSE reliably reconstructs both the small and bigger bottles, demonstrating its robustness in capturing object shapes across varying scales.
7. Spatial understanding with NeuSE: localization with temporal scene inconsistency
Having demonstrated the equivariant properties of object representations in NeuSE, we proceed to assess whether these properties enable NeuSE to support robust spatial understanding for robots. Specifically, we explore how NeuSE, by leveraging its inherent equivariance, can facilitate reliable localization in environments with long-term scene inconsistency and achieve change-aware object-centric mapping.
Building on NeuSE’s desirable equivariance properties, in this section, we first demonstrate its application to enhance robot localization in environments with long-term changes. To evaluate the effectiveness of the proposed NeuSE-based object SLAM paradigm, we collected testing sequences in both simulation and real-world environments involving the five selected object categories. These sequences featured multiple instances of objects with varying shapes and sizes, with camera motion ranging from steady movement with a robot-mounted camera in a controlled environment to more dynamic, less constrained movement using a hand-held camera in larger, less structured lab-office spaces. In this way, we included various scenarios with varying levels of scene complexity in the testing sequences.
We report the performance of our approach and baselines on localization with temporal scene inconsistency in both simulated and real scenes. All results were obtained on a laptop with an Intel Core i7-9750H CPU and an Nvidia GeForce RTX 2070 GPU. NeuSE network inference takes 6 ms per object, with inter-frame pose constraint calculation taking 1 ms. One-time rendering for object-centric map construction costs 30 ms per object with 20,000 query points. With data association included, the speed is approximately 20 fps for generating object-level inter-frame pose constraints with our NeuSE-based front end, making it possible for NeuSE to be integrated as an external “constraint sensor” with real-time operating speed. The final overall localization speed of our change-aware SLAM system is around 4 fps in the current, more crowded controlled experiment setting, with sequential processing of observed objects, no software optimization, or major tuning of the back-end iSAM2 solver.
7.1. Synthetic sequences
The ability to easily render observation trajectories in simulation allows us to extensively evaluate NeuSE’s capabilities for conducting change-aware localization and mapping and study their sensitivity to various factors in simulation. In addition, in the multi-category setting in simulation, all object categories, except mugs, possess some cylindrical or rectangular ambiguity, enabling the validation of our design on employing covisible ambiguous objects to support localization.
7.1.1. Data preparation
The environment was rendered in PyBullet with objects placed on multiple tabletops across a 10 m × 15 m area. To thoroughly evaluate NeuSE’s SE(3) and scale equivariance, and its capability to handle covisible ambiguous objects, two object sets of increasing complexity were used, varying in instance density, shape, size, and occlusion patterns: (1) 50 unseen mug and bottle instances distributed across 10 tables (Figure 10(a)) adopted in Fu et al. (2023), and (2) approximately 75 unseen multi-category instances, including mugs, bottles, bowls, cans, and trash bins, placed on 12 tables (Figure 10(b)). To further assess NeuSE’s SE(3) equivariance, two different object layouts were generated: (1) a roughly planar layout with all objects standing upright, and (2) a non-planar, “hilly” layout, with nearly half of the objects laid down and arbitrarily oriented on tabletops. The camera followed a preset closed-loop trajectory, recording RGB-D images and segmentation masks for both layouts. This resulted in two sequences featuring uninterrupted object observations for each of the two object sets, where most objects were revisited from approximately opposite views with low overlap. For each sequence, objects were added, removed, or relocated, resulting in 9 to 10 changes along the trajectory. Synthetic data overview. Table layouts with object changes and the ground truth camera trajectories of (a) the mug-bottle, 10-table setting, and (b) the multi-category, 12-table setting.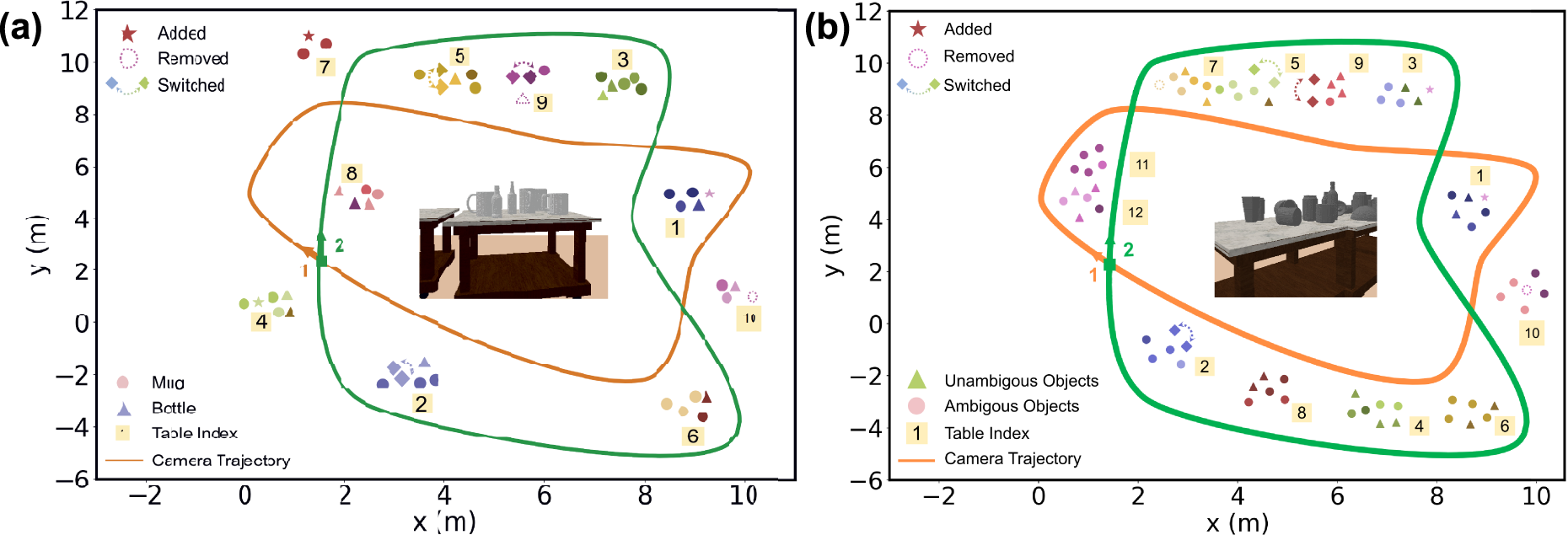
7.1.2. Localization with scene changes and object variation
To assess NeuSE’s capability to handle occlusion and viewing angle variation, and to validate our approach of including ambiguous objects to improve localization accuracy, we compare three data variants for both planar and non-planar object configurations: (1) localizing using only mugs in the mug-bottle sequences (Mug-only), (2) localizing using all objects in the mug and bottle sequences (All-object), and (3) localizing using all objects in the multi-category sequences (Multi).
Furthermore, since the objects in the multi-category sequences have a wider size range (0.05 − 0.75 m) compared to those in the training data (0.3 − 0.6 m), we also report the performance of the SE(3)-only variant of NeuSE without scale equivariance (Multi(SE(3)-only)) from Fu et al. (2023) for the planar and non-planar multi-category sequences. This provides a clearer examination of the benefits of scale equivariance in enhancing NeuSE’s object characterization ability, particularly in dense object layouts.
In this way, building upon the SE(3)-only results from Fu et al. (2023) on the mug-bottle sequences for configurations (1) and (2), we further explore the impact of both object ambiguity and scale equivariance on the accuracy of camera pose constraint generation.
For the few frames with no objects for data association or pose generation, we maintained system operation with odometry measurements corrupted from ground truth by a zero-mean Gaussian noise with σ = 0.003 rad for rotation and σ = 0.05 m for translation. The RMSE of the translational Relative Pose Error (RPE) and Absolute Trajectory Error (ATE) are used as evaluation metrics.
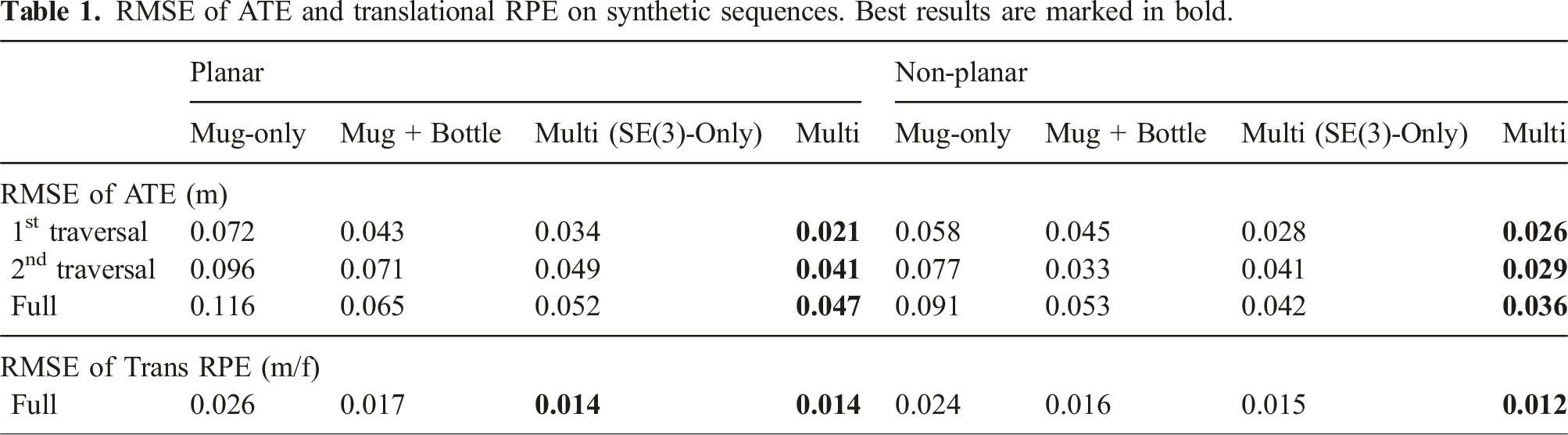
RMSE of ATE and translational RPE on synthetic sequences. Best results are marked in bold.
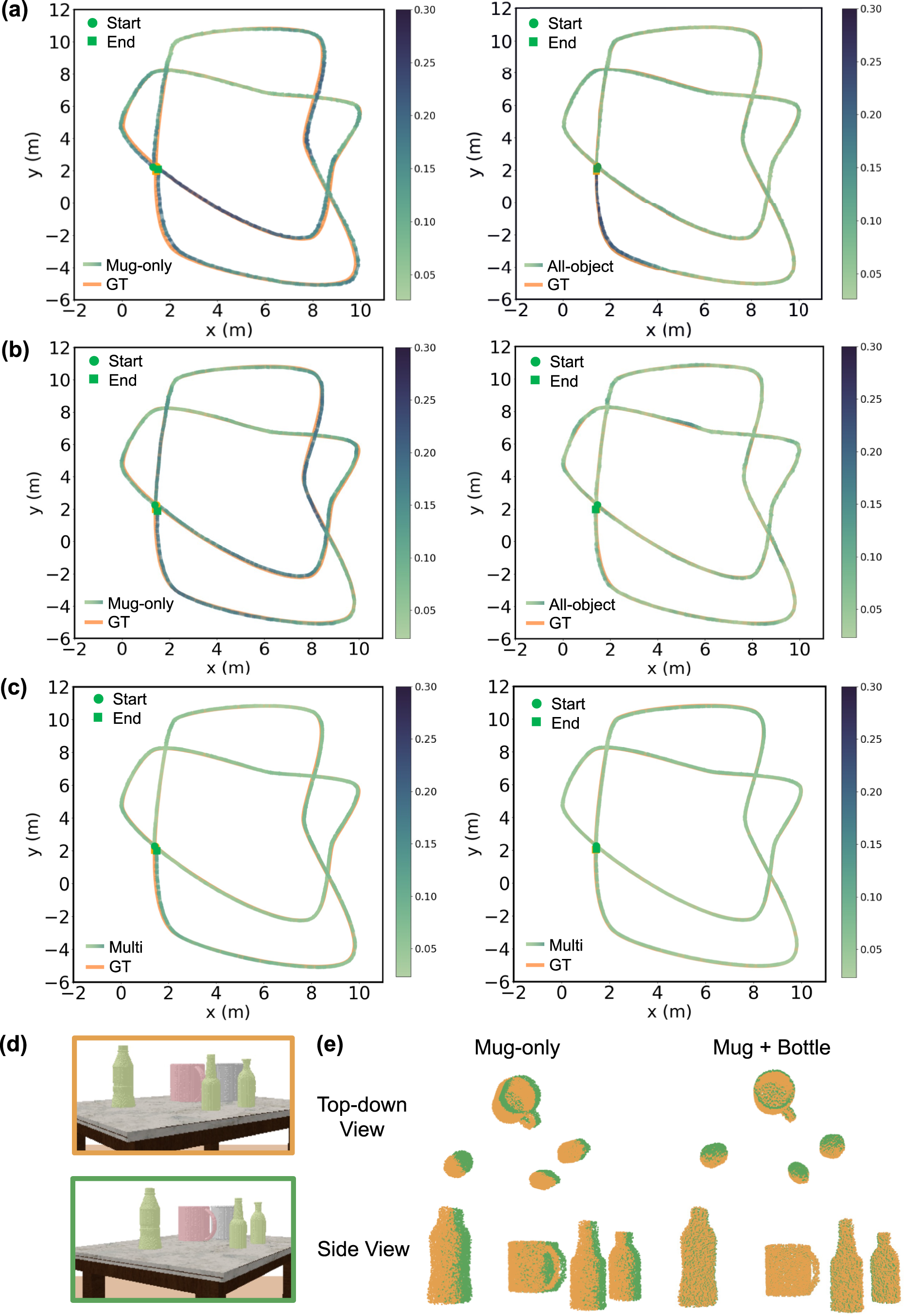
(a)–(c): Comparison of estimated and ground truth (GT) trajectories on synthetic sequences. (a) Mug + Bottle planar sequences. (b) Mug + Bottle non-planar sequences. (c) Multi-category planar (left) and non-planar (right) sequences. Trajectory color variation indicates ATE distribution. The decreasing ATE values, shown by lighter trajectory colors from (a) to (c), demonstrate the efficacy of NeuSE’s SE(3)-equivariance in handling randomly oriented objects from (a) to (b) and highlight the benefit of including ambiguous objects for improved inter-frame transform prediction. (d) and (e): Ambiguous objects for inter-frame transform prediction. In (d), object point clouds are transformed from the orange frame to the green frame using transforms derived from the pink mugs alone, or together with green bottles. The improved point cloud alignment in (e), using all the objects (Mug + Bottle) compared to Mug-only, demonstrates the effectiveness of using covisible ambiguous objects to enhance transform prediction accuracy.
The RPE and ATE values in Table 1 show that (1) NeuSE is a reliable “constraint sensor” for producing consistent short- and long-range camera pose constraints, and (2) our system is capable of producing a globally consistent trajectory, despite various object sizes, occlusion patterns, viewing angle disparities, and object changes along the traversal.
Specifically, we observe from Table 1 that the proposed object SLAM approach performs better on the non-planar object layout, fully showing the efficacy of our SE(3)-equivariant representations in handling randomly oriented objects. This can be attributed to our training data generation strategy, which includes various views and occlusion patterns to learn robust geometric features of object shapes across viewing angles. Further, the lying-down mugs in the sequence help reduce shape ambiguity by providing more valid observations for generating camera pose constraints, as their handles are more frequently visible when pointing upwards than in the usual sideways direction. With the SE(3)-equivariant property of NeuSE, our approach can learn from upright observations to benefit the processing of laid down objects, thus enabling generalization to new scenarios with various object orientations.
Validation of using ambiguous objects for pose constraint generation is confirmed by the decreasing RPE and ATE RMSE values in Table 1 with increasing object number and orientation complexity from the mug-only to multi-category and planar to non-planar scenarios. In addition, in Figure 11(d) and (e), with object point clouds in (d) transformed from the upper (orange) to the lower (green) frame using transforms derived from only the pink mug and together with green bottles, the improved point cloud alignment in (e) for Mug + Bottle compared to Mug-only demonstrates the viability of leveraging covisible ambiguous objects for improving transform estimation accuracy.
Furthermore, from Table 1 we can also conclude that the incorporation of scale equivariance greatly enhances NeuSE’s ability to generalize across objects of different sizes, as indicated by NeuSE’s lower ATE and RPE RMSE values compared to its SE(3)-only counterpart. Scale equivariance facilitates the effective transfer of learned geometric knowledge to objects with similar shapes but varying sizes, thereby allowing NeuSE to accurately infer previously unseen object sizes with comparable precision and contributing to its broader generalization capability.
7.1.3. NeuSE for robust data association
In the last section, we demonstrate NeuSE’s effectiveness as a standalone “constraint sensor” for generating consistent camera pose constraints, due to its successful data association throughout the trajectory with continuous object observations. However, real-world SLAM systems do not always have uninterrupted object observations and often have external odometry measurements that are prone to noise and drift.
In this section, we test the ability of NeuSE for robust data association when dealing with such noisy odometry measurements. We generated noisy odometry data from the ground truth camera trajectories for both the multi-category planar and non-planar sequences (shown as the gray dashed trajectories in Figure 12). With ground truth data association available in the synthetic data, we apply our NeuSE-based object SLAM pipeline to these noisy odometry measurements and compare the data association accuracy (of partially observed object point cloud observations) and camera pose estimation results with those obtained using the commonly adopted point cloud overlap data association scheme. Our goal is to assess whether the proposed NeuSE-based SLAM framework will have robust data association and localization performance under noisy odometry, in addition to the robustness to viewing angle variations and occlusions already shown in the previous section. Comparison of estimated trajectories on synthetic sequences with point cloud-based (PC-based) and NeuSE-based (Ours) data association. (a) Results on planar multi-category sequence. (b) Results on non-planar multi-category sequence. Trajectory color variation indicates ATE distribution. Our approach with NeuSE-based data association consistently improves external noisy odometry by encoding full object shapes to handle partial observations, outperforming the point cloud-based method in both sequences. The point cloud-based approach struggles more on the non-planar sequence due to the more complex occlusion patterns and the reduced observation overlap from a mix of upright and laid-down objects.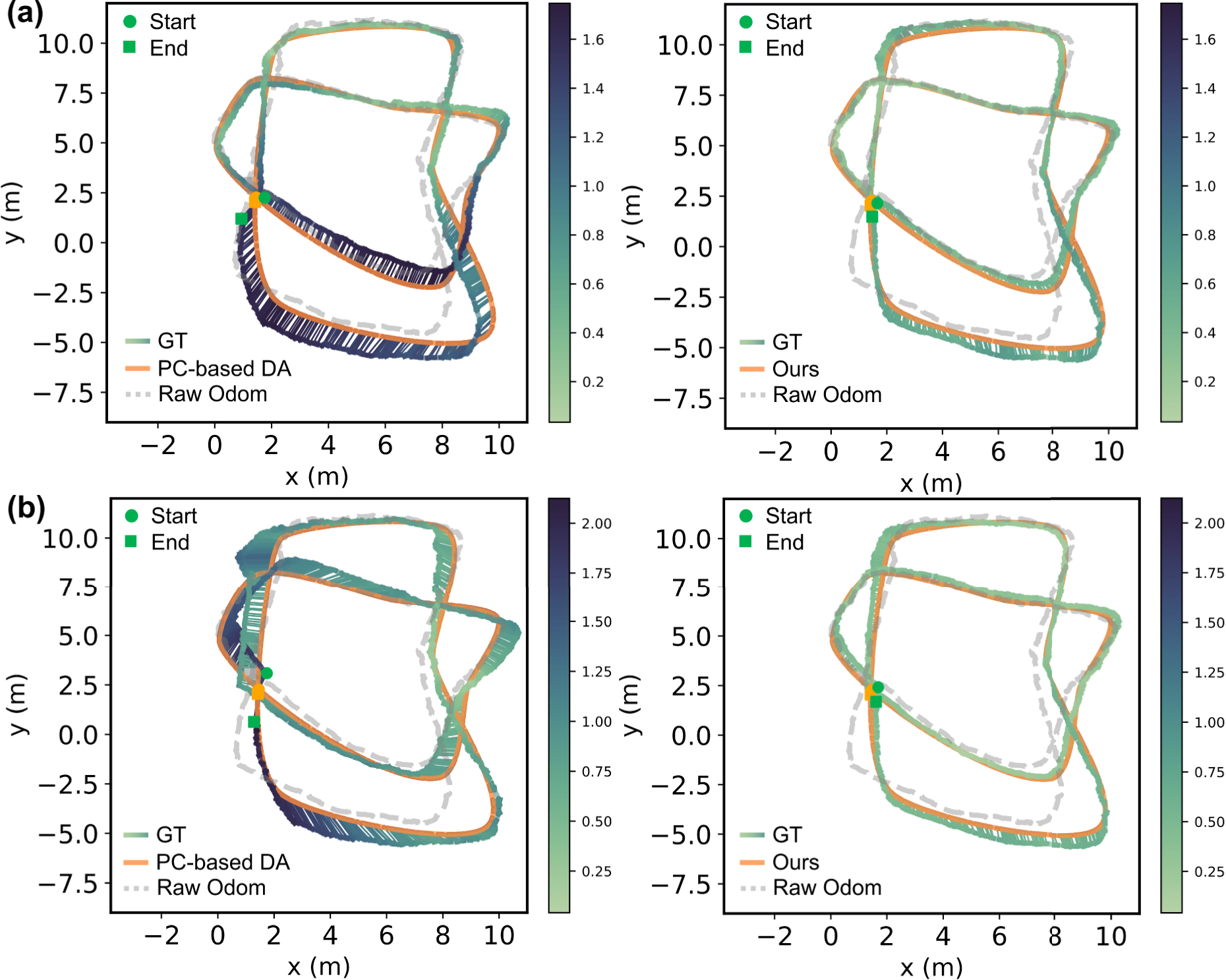
For the point cloud overlap baseline, we modify the proposed NeuSE-based object SLAM pipeline by replacing NeuSE’s data association step with a method that finds the associated object, 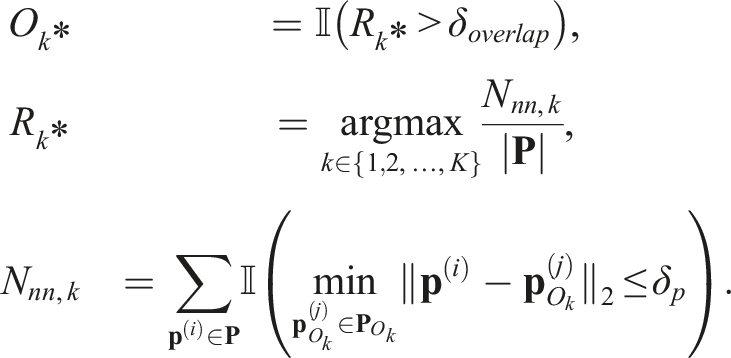
Here, δ
p
= 0.01 m is the threshold to determine whether a point in the partial point cloud has a nearest neighbor in the reference one. We compute the nearest neighbor overlap ratio R
k
relative to the size of the observation point cloud for each of the K object point clouds in the library and find the maximum overlap ratio
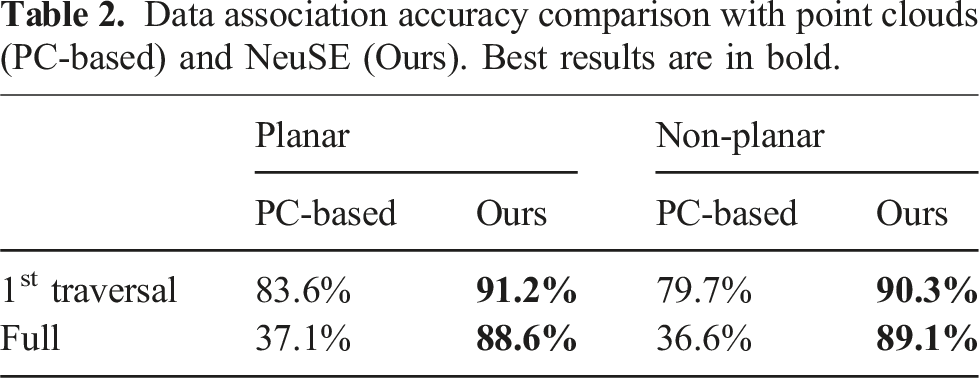
Data association accuracy comparison with point clouds (PC-based) and NeuSE (Ours). Best results are in bold.
RMSE of ATE and translational RPE of camera trajectory estimates with point cloud-based and NeuSE-based data association. Best results are marked in bold.
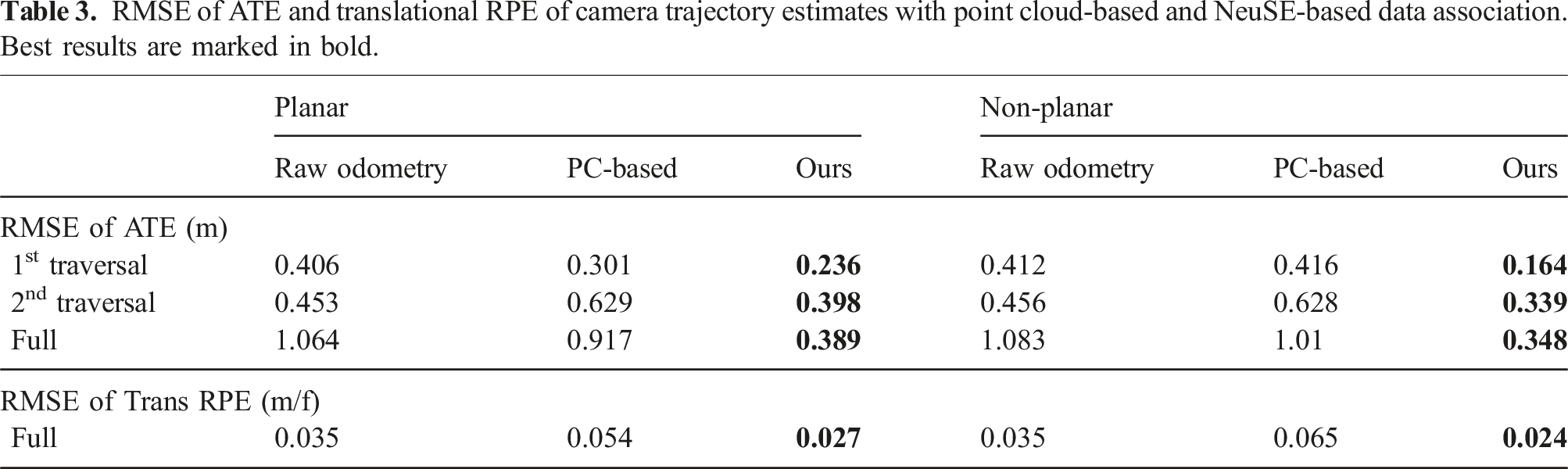
As shown in Table 2, the NeuSE-based data association maintains consistently high accuracy throughout the trajectory, from the first traversal before object changes to the end after changes occur. In contrast, the point cloud-based method experiences a significant drop in accuracy, from slightly above 80% to around 37% after the second traversal. This decline is partly due to the low object observation overlap between the first and second traversals, as many objects are observed from nearly opposite views (e.g., objects on the second through ninth tables in Figure 10(b)). Additionally, the point cloud-based approach is highly sensitive to external odometry noise, as inaccurate odometry can project partial point clouds to incorrect locations, leading to false associations through overlap comparison. In contrast, NeuSE achieves accurate data association with no reliance on external odometry and robustness to low observation overlap, leveraging SE(3) equivariance for potential projection transformations while embedding full shape and scale information within a fixed-size latent code.
As a result, NeuSE also leads to a more lightweight data association process. After two rounds of candidate filtering based on latent code scale and shape similarity, most observations are narrowed down to 1–2 potential candidates. A final spatial proximity comparison between the projected partial point cloud centers, requiring little computation, allows NeuSE to complete data association and camera constraint generation at the reported speed of 20 Hz. On the other hand, the point cloud-based method accumulates a growing number of increasingly large object point clouds over time, incurring higher memory usage and longer computation time, particularly due to the expensive nearest neighbor search for overlap computation. By the end of the second traversal, when revisiting 75 objects, each object observation can take up to 0.07 seconds for nearest neighbor comparison with objects in the library, with each library object’s voxel-downsampled point cloud containing about 2,500 points. This creates a significant speed bottleneck, reducing data association performance to 1–3 Hz in our current setting.
The benefit of NeuSE-based data association is further reflected in camera pose estimation. As shown in Table 3, NeuSE significantly outperforms the point cloud-based method, yielding much lower ATE and RPE values. Moreover, the point cloud-based method performs worse on the non-planar sequence than the planar one, due to the more complex occlusion patterns and the reduced observation overlap from a mix of upright and laid-down objects. This indicates the advantage of NeuSE’s full-shape encoding ability in handling partial observations. The second column of Figure 12 further emphasizes this, showing how NeuSE corrects heavily drifted odometry in the lower half of the trajectory (around tables 2, 4, 6, and 8 in Figure 10(b)), resulting in a 65% improvement in ATE RMSE values and better alignment with the ground truth. This demonstrates NeuSE’s ability to perform robust data association and the potential to enhance camera localization with noisy external odometry.
7.1.4. Robustness to occlusion and depth noise
In mobile robotic tasks, partial object observations arise not only from changes in viewing angles but also from occlusions by nearby objects. Since NeuSE relies on partial point clouds for object inference, and hence for data association and camera pose constraint generation (as discussed above), the occlusion level and the quality of depth measurements are crucial. To assess the impact of occlusion and depth noise, we conduct ablation studies by systematically varying their levels and observing how NeuSE’s equivariance responds in localization and shape reconstruction performance.
In line with this goal, we simulated a tabletop scene in PyBullet with a central mug surrounded by six bottles of increasing size. A camera circled around the setup, generating a trajectory that started near the purple bottle and ended around the yellow one, while consistently keeping the mug’s handle in view (see Figure 13(a)). The decreasing size of the bottles along the way results in varying degrees of occlusion, leading to changes in mug visibility ratio throughout the sequence. We plot the visibility ratio of the mug across the camera trajectory in Figure 13(b.2), where we use nearest-neighbor occupancy calculation between the mug observation and the mug model points to compute the visibility ratio. The trajectory starts near the biggest purple bottle with a low visibility ratio of around 16% and ends around the smallest yellow bottle. Throughout the trajectory, as the camera moves, the mug visibility ratio first increases and then decreases due to changes in bottle size and viewing angle, covering various visibility levels ranging from 12% to 41%. (a) Ground truth scene setup: A mug is centered with six bottles of increasing size around it. The camera orbits from the largest purple bottle to the smallest yellow bottle, creating varying mug visibility along the trajectory. (b) Translational RPE curves (b.1) against mug visibility ratio (b.2), plotted with a shared x-axis of frame index. NeuSE exhibits robustness to occlusion at lower noise levels, while a higher 8 mm noise level produces a U-shaped RPE curve, indicating increased sensitivity to occlusion under noisier depth data.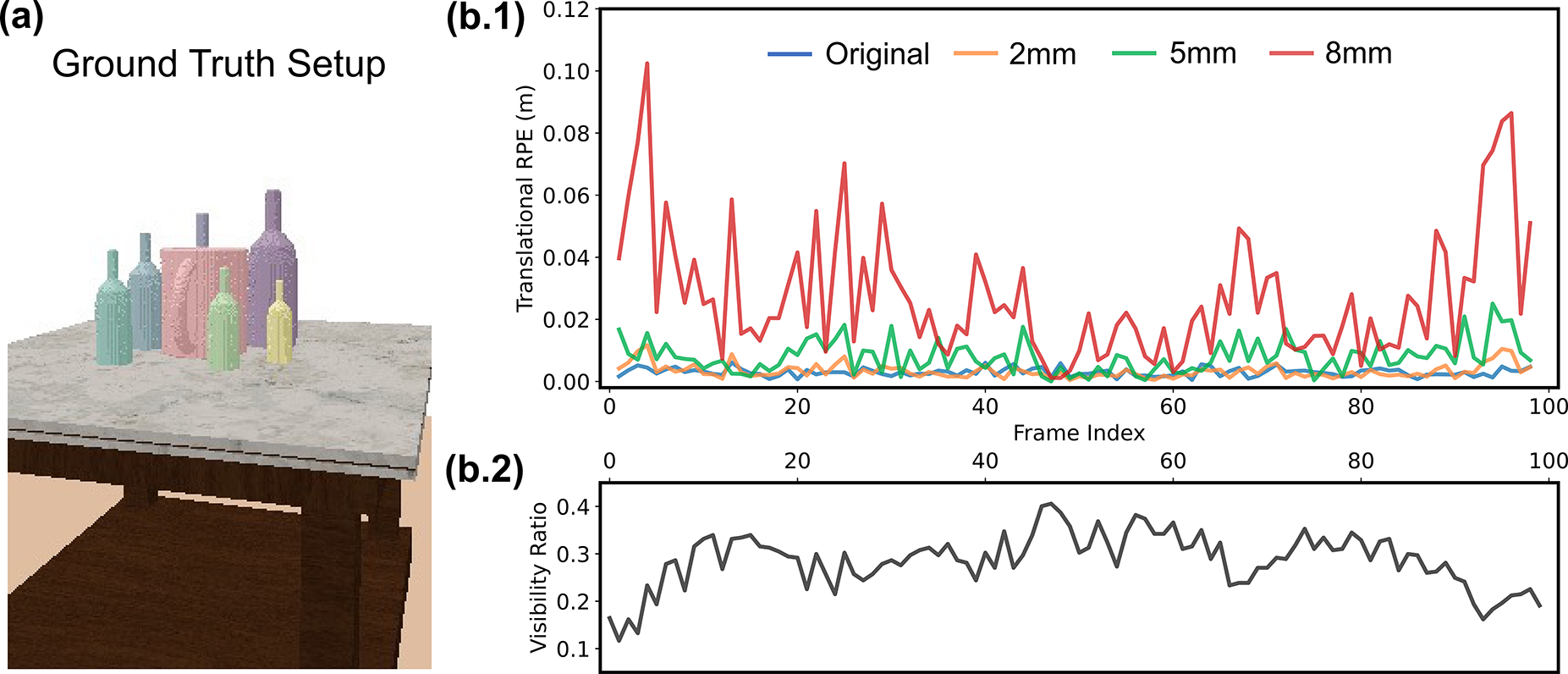
To examine the effects of depth noise on NeuSE’s performance, we simulate noise values according to the distance-dependent noise characteristics of commercial depth sensors, such as Azure Kinect and RealSense cameras (Servi et al., 2021; Tolgyessy et al., 2021). We vary the sensors’ maximum depth noise value, σmax, at different levels and employ a simple distance-dependent Gaussian noise model to generate noisy depth measurements, dnoisy, as follows: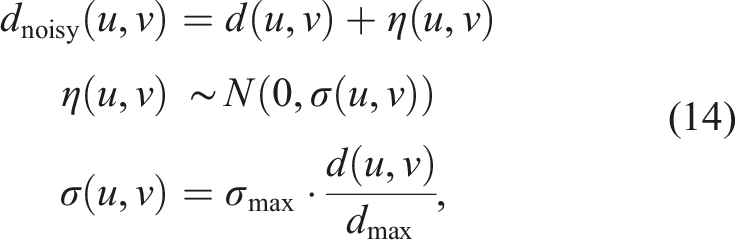
Since depth measurement noise increases proportionally with distance, we corrupted the data based on noise levels across depth sensing ranges, following the σmax values of commercial depth sensors for close (within 3 m), medium (3–5 m), and far (beyond 5 m) ranges. In particular, we applied noise levels of σmax as follows: 2 mm and 5 mm to represent depth noise for close-range measurements, 8 mm for mid-range measurements, and 1 cm for far-range measurements. In our testing data, dmax typically fell within the close-range depth measurements with distances of around 2 m, making the 2 mm and 5 mm noise levels the most meaningful.
Below, we report the performance of our approach under both object occlusion and depth noise.
7.1.4.1. Occlusion
Taking the visibility ratio curve in Figure 13(b.2) as the reference, in Figure 13(b.1), we observe that the RPE values remain relatively stable throughout the trajectory at low to medium noise levels, even as visibility fluctuates, which corresponds to the closely aligned camera trajectory estimates in Figure 14(a)–(c). Higher RPE peaks occur primarily at the start and end of the trajectory, where the visibility ratios are the lowest. In the middle of the trajectory, where the camera moves through areas with smaller and more spaced-out bottles, visibility ratio increases, resulting in smaller and smoother RPE fluctuations. The mug reconstructions shown in Figure 15 further illustrate NeuSE’s ability to recover the full mug shape despite varying levels of occlusion under close to medium range noise levels. This robustness can be attributed to NeuSE’s training data design, which incorporates diverse occlusion patterns, enabling it to handle partial observations effectively. Visualization of estimated trajectories against ground truth (GT) for the original and corrupted data at varying noise levels. Trajectory color variation indicates ATE distribution. (a) also shows object reconstructions, illustrating the camera’s approximately circular path around the object setup. From (a) to (d), NeuSE remains robust at lower noise levels (2 mm and 5 mm), recovering camera trajectories that closely align with the ground truth. At the higher noise level (8 mm), the estimated trajectory becomes jagged, especially near the start and end where mug visibility is low, indicating NeuSE’s sensitivity to occlusion under high depth noise. Multi-view mug reconstruction with varying visibility and noise levels. Ground truth views are arranged along the camera path, including frames with maximum, minimum, and intermediate mug visibility to highlight the visibility variation along the way. Yellow points represent the observed partial point clouds. NeuSE demonstrates strong robustness at lower noise levels (2 mm and 5 mm), accurately reconstructing the full mug shape in alignment with partial observations, regardless of visibility changes. At the 8 mm noise level, NeuSE’s sensitivity to occlusion increases, resulting in artifacts like a falsely shaped square handle and residual points around the mug body in low-visibility frames (first and last columns). At the 1 cm level, where NeuSE fails to recover the camera trajectory, reconstructions degrade further, producing entirely incorrect mug shapes, as the impact of noise dominates over that of occlusion.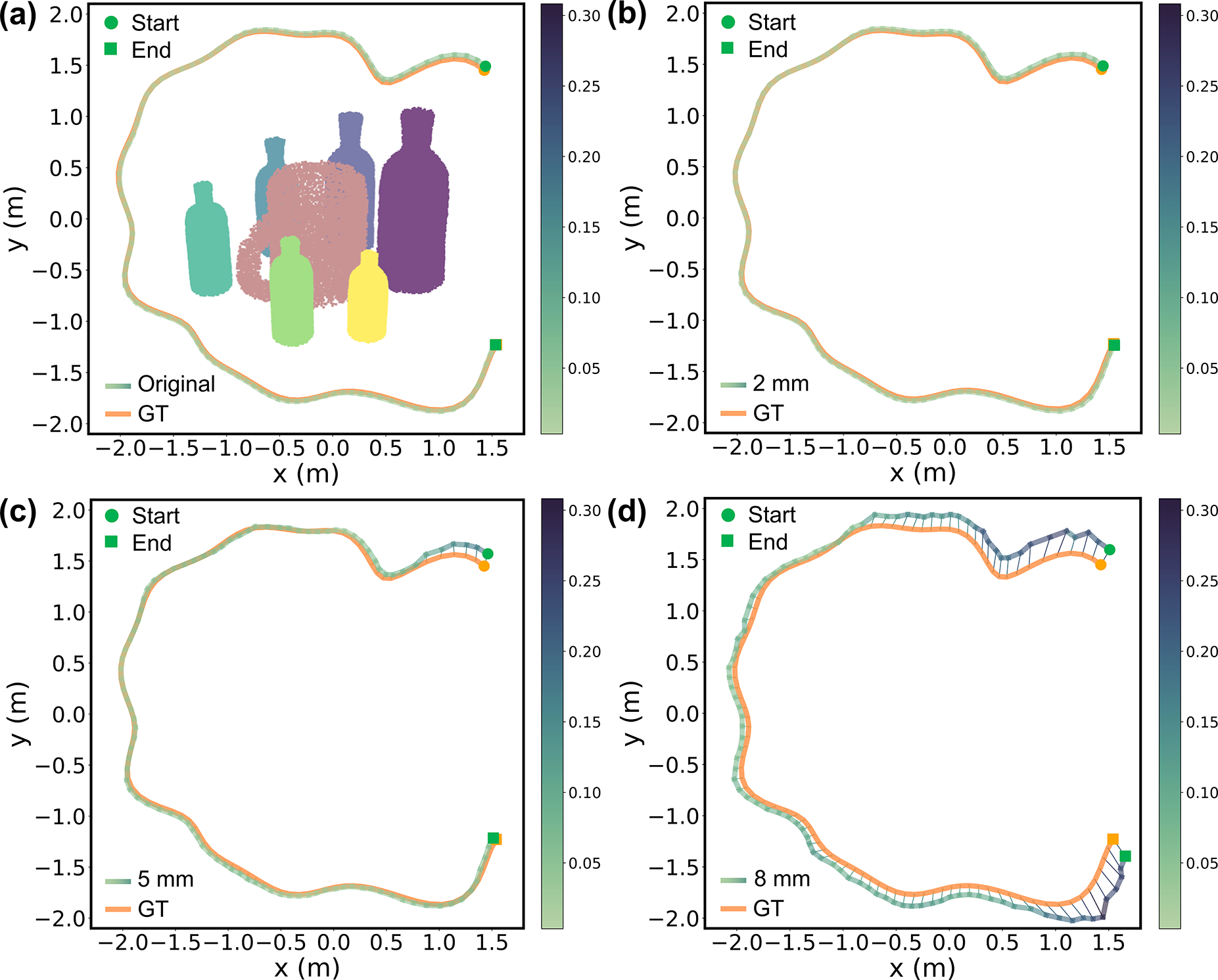
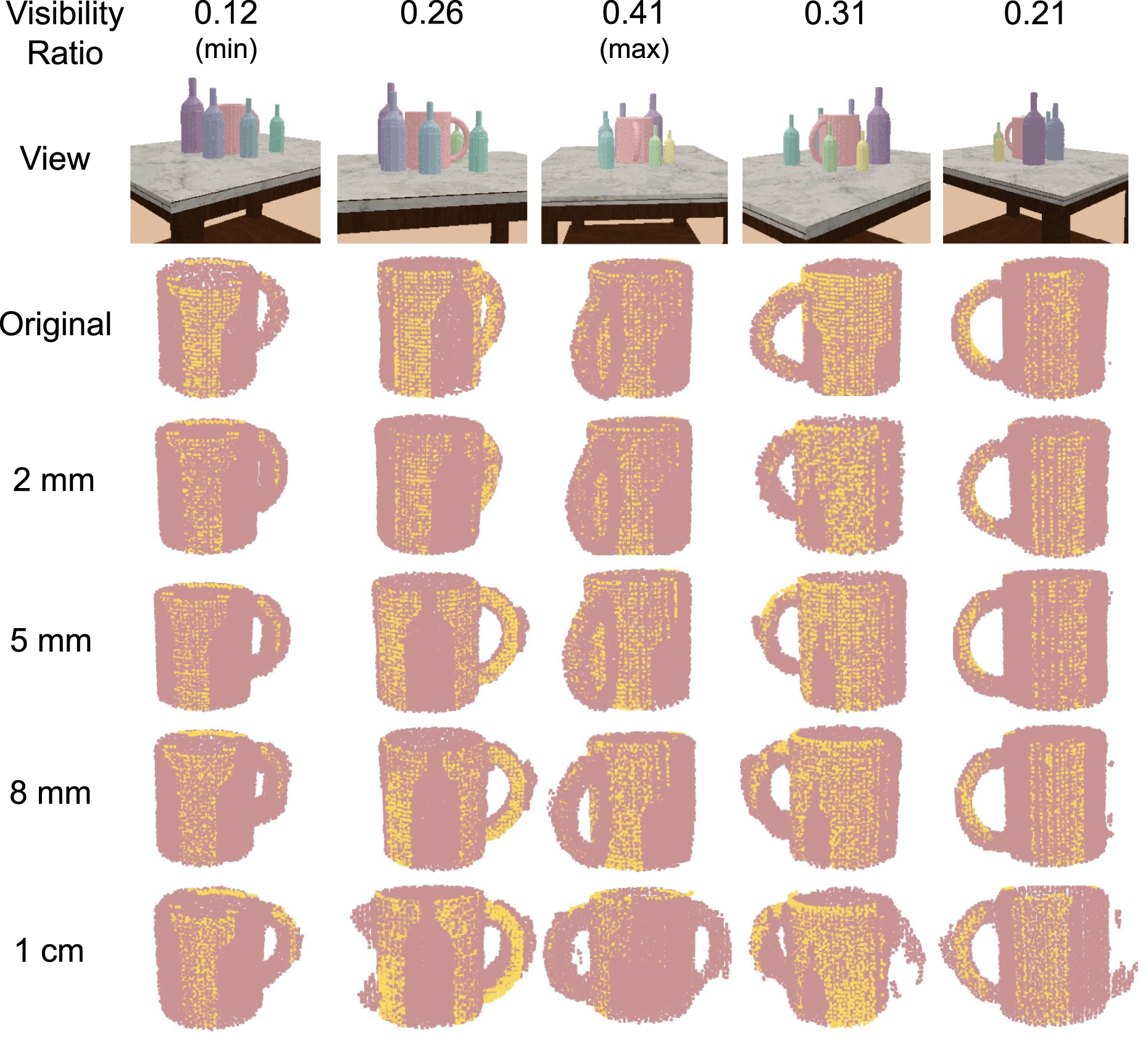
7.1.4.2. Depth noise
RMSE of ATE and translational RPE on synthetic sequences of different depth noise levels.
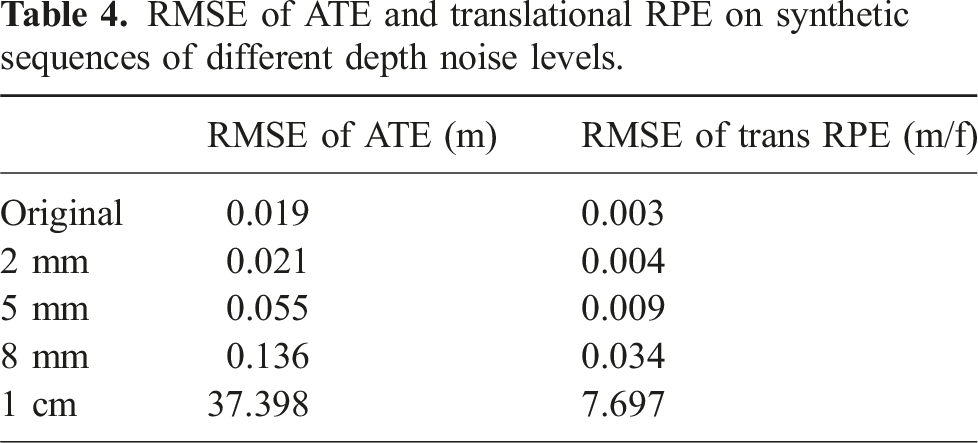
As the noise level increases to 5 mm, representing the higher end of close-range depth sensing noise, NeuSE continues to perform well across most of the trajectory. However, it becomes affected in regions with low visibility, such as at the beginning of the trajectory around the least visible part, as shown in Figure 14(c). At higher noise levels, such as 8 mm and 1 cm, NeuSE struggles to handle the noisy measurements. The once smooth camera pose estimates seen at lower noise levels become inconsistent, and NeuSE becomes more sensitive to occlusion, as reflected in the more erratic RPE curve in red (Figure 13(b.1)). This degradation is also evident in the jagged and drifted trajectory in Figure 14(d) for the 8 mm noise level, while for the 1 cm noise level, NeuSE fails to recover a valid trajectory.
NeuSE’s robustness to close-range noise is also demonstrated by the mug reconstructions, which remain complete and accurate at noise levels up to 5 mm, as shown in the first three rows of Figure 15. However, as noise levels increase, NeuSE’s sensitivity to occlusion becomes more apparent. For instance, at the 8 mm noise level, the handle shape of the mug is reconstructed incorrectly, and at 1 cm, the entire mug shape is falsely recovered, further showcasing the challenges posed by higher depth noise.
7.2. Real-world sequences
Having studied the properties of NeuSE in simulation, we now extend our evaluation to real-world robot motion, where diverse object occlusion patterns and varying camera angles are common. As the robot moves, objects of interest may intermittently go out of sight. Building on our previous results showing NeuSE’s ability to handle noisy external odometry, this section further demonstrates its practical application in long-term, real-world scenarios. We emphasize its ability to complement other SLAM systems in both controlled and uncontrolled settings, showcasing its smooth transition from simulation training to real-world deployment. NeuSE consistently produces globally accurate trajectory estimates, even in the presence of challenges such as temporal scene inconsistency, densely placed objects with varying shapes and sizes, freeform camera motion, and potential drift due to tracking loss.
7.2.1. Data preparation and choice of baselines
The real-world data were collected in two different settings with object instances from five categories: mug, bottle, bowl, can, and trash bin. The settings were as follows: (1) a controlled environment containing 49 object instances densely arranged on five tables within a 7 m × 5 m space (Figure 16(a)), and (2) a less constrained lab-office environment consisting of two interconnected areas, a smaller indoor space and an open lab space connected by a corridor. In this setting, 45 object instances were distributed on the floor and across 16 tables of varying heights (Figure 16(b)). Real-world data overview. (a) Object layout and the ground truth camera trajectory of the controlled environment. Object changes occur at each junction of the colored trajectory segments. (b) Camera setup and open lab (second row) and indoor office (third row) environments for the hand-held sequences.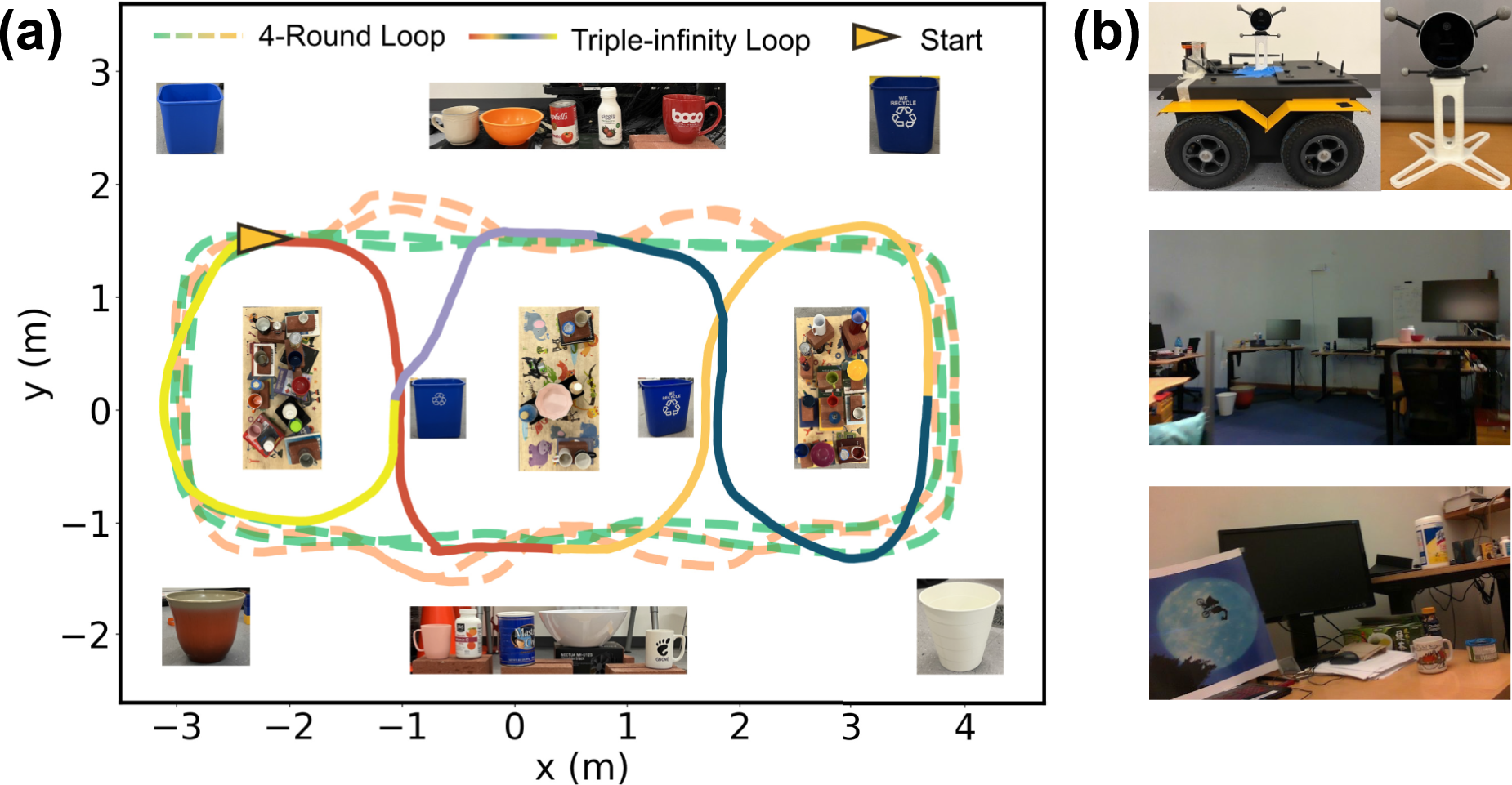
In the first controlled setting, 14 to 16 objects were added, removed, or relocated to create two distinct object arrangements. An RGB-D dataset was recorded using a RealSense D515 camera mounted on a Clearpath Jackal robot, following two preset closed trajectories: (1) a four-round peripheral loop around three central tables, with the former two rounds recorded under one object arrangement and the latter two under the other arrangement, and (2) a more challenging triple-infinity loop traversing two central and two side tables, with seven object changes made along the way. Ground truth camera trajectories were obtained using a Vicon motion capture system.
In the second uncontrolled setting, 8 to 9 objects were added, removed, or relocated to create two distinct object layouts. The same RealSense D515 camera, mounted on a tripod, was carried by hand to record RGB-D data along the tables in the scene before and after object changes (please refer to the supplementary video for further details). Two trajectories were collected: (1) a two-round scan along eight indoor tables against the office walls, using top-down and near-far viewing angles, with each round corresponding to one object layout; and (2) a two-round “freeform” traversal among 16 tables spanning both indoor office and open lab spaces. The trajectory began indoors, passed through a corridor into the open lab space, and returned back to the office after object changes in both the indoor office and outside lab areas. Motion capture data were available for the indoor office portion, covering 24% of the trajectory. No motion capture was available in the open lab space, and a “blackout” period occurred in the corridor where no objects of interest were visible.
To evaluate the global consistency of camera localization, we adopt ATE as the evaluation metric and compare our approach against the popular state-of-the-art ORB-SLAM3 (Campos et al., 2021) pipeline and three directly deployable object-based SLAM systems: CubeSLAM (Yang and Scherer, 2019), EM-Fusion (Strecke and Stueckler, 2019), and VOOM (Wang et al., 2024). Both CubeSLAM and VOOM are built on top of ORB-SLAM2 (Mur-Artal and Tardós, 2017) to conduct joint optimization of object representations and camera poses. CubeSLAM uses cuboids for object representation, while VOOM represents objects with dual quadrics in a hierarchical manner in combination with map points. CubeSLAM assumes a static operating environment (or objects with known motion models, which do not apply in our case), while VOOM is reported to have a certain level of robustness to scene dynamics. EM-Fusion, on the other hand, uses local Signed Distance Function (SDF) object volumes for tracking moving objects and performing camera localization, making it capable of handling dynamic scenes. These approaches serve as baselines to evaluate object SLAM performance and the potential impacts of object changes in the scene. For CubeSLAM, we used the implementation integrated with ORB-SLAM.
7.2.2. Controlled environments: 4-Round and Triple-Infinity loops
The two sequences in controlled settings were captured with objects densely arranged on tabletops and positioned around distant corners. This led to a series of observations featuring variations in both near and far viewing angles, as well as rich occlusion patterns.
As ORB-SLAM3 does not address temporal scene inconsistency, to further explore the effect of object changes on localization performance, we generated two sets of ORB-SLAM3 odometry measurements from its camera trajectory estimates as starting points by running it: (1) non-stop (ORB3-NS) for the whole trajectory, and (2) piecewise (ORB3-PW) for each trajectory segment with consistent object layout (as shown in Figure 16(a)).
Before showcasing NeuSE’s ability to complement external SLAM systems, we first need to verify NeuSE’s ability to transfer from simulation to the real world. We follow the object-only experiments for synthetic data and run Mug-only and All-object on these two real-world sequences. Raw Odometry, generated from RGBD images using Open3D (Zhou et al., 2018) based on photometric and geometric loss (Park et al., 2017), is adopted to sustain system operation when no objects are in sight or associated for generating pose constraints.
Building on the synthetic sequence experiments, we further investigate whether the advantage of scale equivariance in generalizing to objects of different sizes extends to real-world data. To this end, we also evaluate NeuSE’s SE(3)-only variant (SE(3)-only) across all previously generated odometry sets.
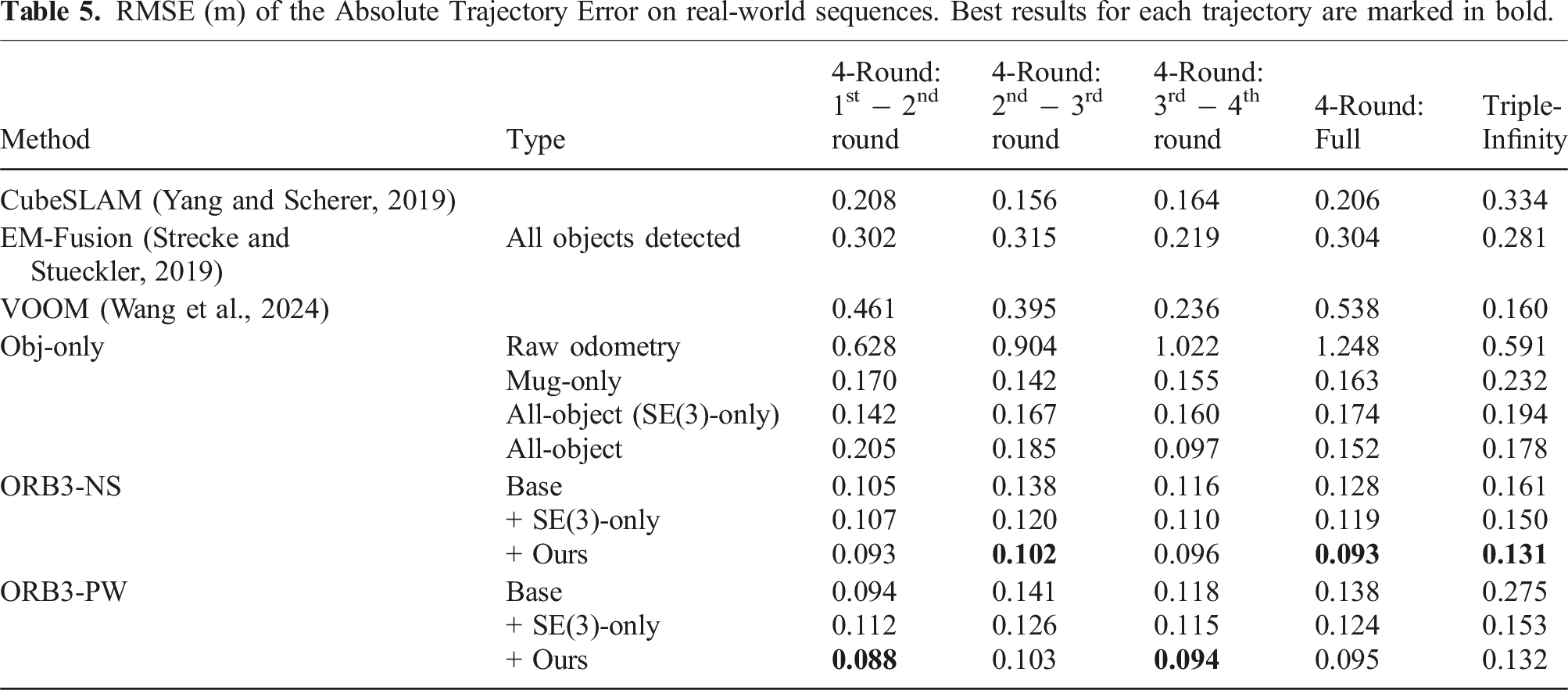
RMSE (m) of the Absolute Trajectory Error on real-world sequences. Best results for each trajectory are marked in bold.

Baseline trajectory estimation results against ground truth (GT) on the 4-Round (left) and Triple-Infinity loops (right). (a) EM-Fusion; (b) CubeSLAM; (c) VOOM. All chosen baselines suffer from either localization drift in the 4-Round trajectory or failure to close the loop in the Triple-Infinity trajectory.
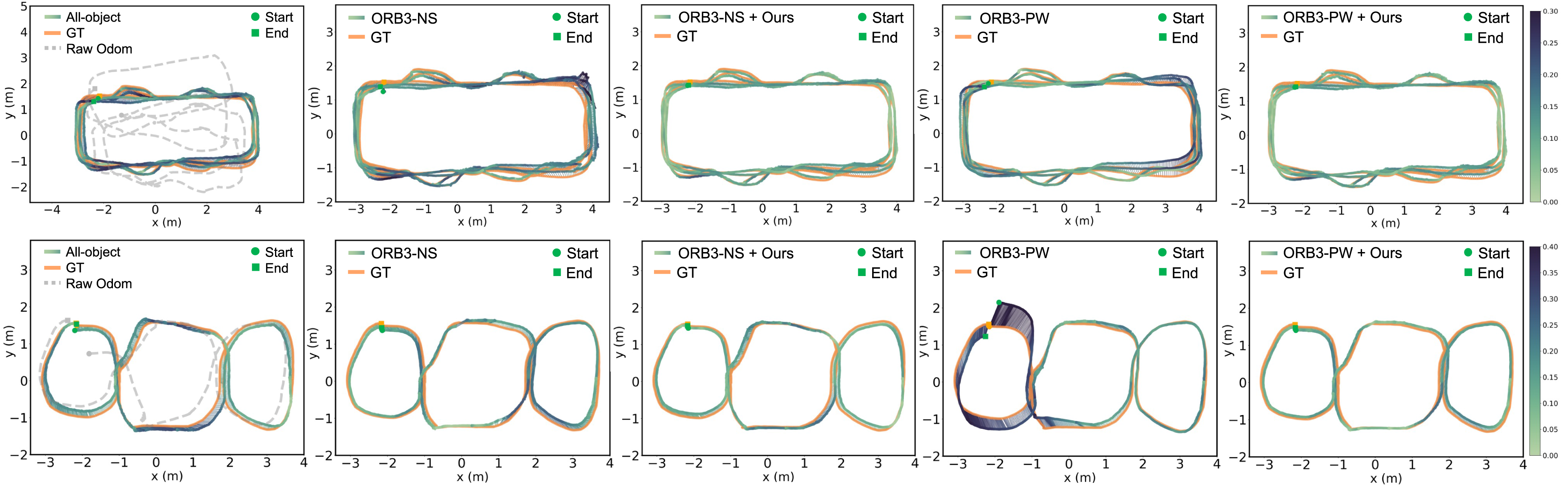
Visualization of estimated trajectories against ground truth (GT) on controlled sequences. Trajectory color variation indicates ATE distribution (color bar on the right). Top: Estimated trajectories of the 4-Round loop. The integration of our strategy (columns 3 and 5) helps smooth unstable trajectory estimates and improves general estimation accuracy, as showcased by the absence of small spikes (upper right) seen in column 2 and the consistently lighter colors of lower ATE values along the way. Bottom: Estimated trajectories of the Triple-Infinity loop. Our strategy (column 5) successfully corrects the accumulated start and end point drift for ORB3-PW (column 4), leading to an improved and consistent trajectory estimate when revisiting the leftmost table.
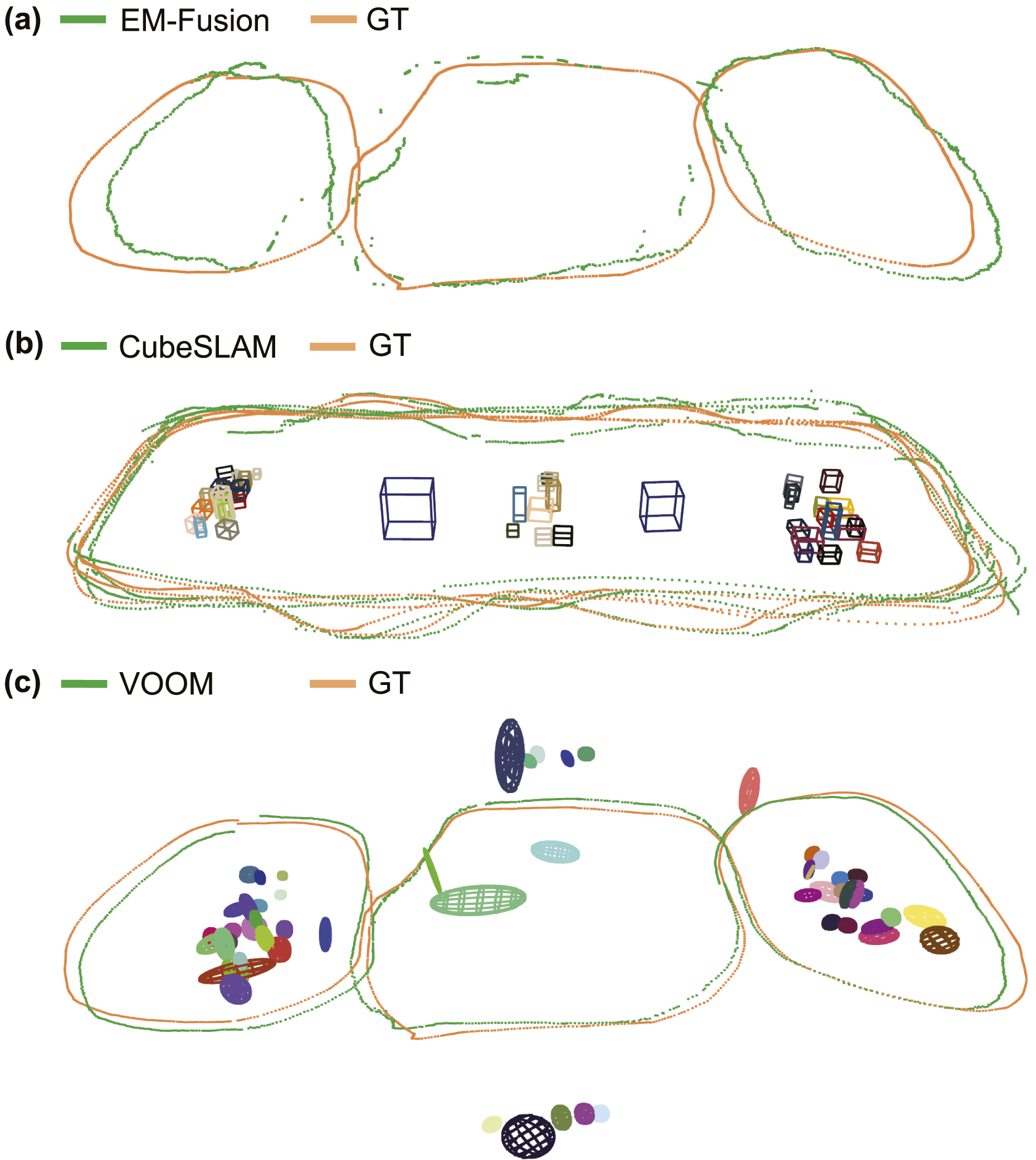
Trajectory estimation and object mapping artifacts in selected baselines. (a) EM-Fusion undergoes heavy out-of-plane drift and intermittent loss of tracking in the Triple-Infinity loop due to the rapid rotations around corners. (b) CubeSLAM fails to handle object changes effectively, resulting in data association errors, missed detections, drift, and overlapping cuboids, which affect the joint optimization of cuboid and camera trajectory estimates. (c) VOOM produces an object map with incorrect object count, scale, and pose estimates, including a green object falsely intersecting with the camera trajectory. Its use of dual quadrics as the object representation struggles to capture the full size of objects from partially occluded point clouds, particularly in cluttered scenes.
Although relying on noisy Raw Odometry when objects are unavailable, NeuSE successfully transfers from simulation to the real world, generating accurate camera pose constraints that offset and correct accumulated drift from Raw Odometry, resulting in overall lower ATE RMSE values, as shown in the results of “Obj-only” method in Table 5 and the first column of Figure 18. This confirms NeuSE’s full functionality when applied to real data. Furthermore, the results of “Obj-only” in Table 5 indicates that the All-object approach outperforms the Mug-only approach in both sequences, verifying the effectiveness of our strategy in extracting useful camera pose constraints from covisible ambiguous objects.
We compare our approach to three selected object SLAM baselines that use all detected objects in the scene, as shown in Table 5. Our approach, All-object, using only NeuSE-based camera pose constraints supported by noisy Raw Odometry, achieves performance nearly on par with VOOM on the Triple-Infinity loop and outperforms the rest of the baselines on both sequences, even though the baselines directly use existing powerful SLAM systems such as ORB-SLAM2. This demonstrates NeuSE’s advantage in facilitating lightweight and robust localization in real-world sequences with scene inconsistency.
Notably, CubeSLAM fails to close the loop in Figure 17(b) after returning to the leftmost table with object changes in the Triple-Infinity loop. In terms of object estimates, it also produces multiple missed, drifted, or falsely overlapped cuboid estimates shown in Figure 19(b). This could be attributed in part to the difficulty of accurate cuboid detection with diverse occlusion patterns. Moreover, assuming a static environment, CubeSLAM struggles to address object changes within the two sequences, leading to errors in cuboid association and estimation between old and new objects in neighboring areas. This results in false camera-cuboid geometric constraints and ultimately affects the joint optimization of object cuboids and camera trajectory.
Meanwhile, EM-Fusion, as shown in Figure 17(a) and Figure 19(a), gives subpar, bumpy, and drifted trajectory estimates. While it can handle scene layout changes at sequence segment intersections, EM-Fusion suffers from lower tracking accuracy due to the accumulated drift from limited object overlap. In addition, since EM-Fusion was initially tested on tabletop scenes, it requires a coarser SDF background volume resolution to prevent memory exhaustion in our larger multi-table scenario, which further reduces the accuracy of its camera tracking.
VOOM performs best on the Triple-Infinity loop, with the smallest start-to-end drift among the three baselines, but struggles significantly on the 4-Round loop, as shown in Figure 17(c). The drift worsens with each round, especially after object changes, such as the removal of large objects (e.g., trash bins) between the central tables, which introduces confusion in object odometry and mapping due to the lack of mechanisms to handle such changes. VOOM’s use of dual quadrics for object representation makes it difficult to accurately capture full object sizes from partially occluded point clouds, particularly when objects are densely placed on the tables. This results in inaccurate object initialization and odometry, which further hinders the mapping process. An example of this is the green object in Figure 19(c), which falsely intersects with the camera trajectory.
We next illustrate how NeuSE can be directly combined with other SLAM systems for additional improvements. First, in the last column of Table 5, NeuSE helps improve both ORB3-NS and ORB3-PW, with our combined object SLAM system outperforming all methods including the VOOM baseline on the Triple-Infinity loop. We then compare the “Base” and “+ Ours” variants of ORB3-NS and ORB3-PW methods. We observe consistent improvement in terms of the RMSE of ATE values along two sequences when integrating our proposed strategy using all objects of interest (“Ours”) with the vanilla ORB-SLAM3 measurements (“Base”), as also supported by the lighter colors in columns 3 and 5 of Figure 18 compared to columns 2 and 4. Furthermore, NeuSE enables robust data association and manages to prevent the occurrence of unstable tracking, for example, the small spikes in column 2 of Figure 18 for the 4-Round trajectory.
The greatest RMSE improvement in Table 5 is observed from ORB3-PW + Ours on the Triple-Infinity trajectory. Our proposed strategy helps decrease the RMSE by 52% from 0.275 m to 0.132 m while aligning the start and end points with better trajectory accuracy when revisiting the leftmost table. In this way, with abundant objects visible for deriving camera pose constraints, ORB3-PW + Ours outperforms ORB3-NS and is almost on par with ORB3-NS + Ours, despite receiving less global loop closing constraints from ORB3-PW than ORB3-NS. Considering the little scene overlap within each of the four trajectory segments, this notable improvement highlights the critical role of our strategy in constraining camera pose estimates in short and longer ranges, especially when insufficient loop closing (e.g., throughout ORB3-PW) is performed by the external SLAM system.
Our strategy also demonstrates robustness in handling scene changes, despite the less significant improvement in the 4-Round loop due to the numerous loop closure opportunities offered by ORB-SLAM3. Columns 3–6 of Table 5 present the RMSE values of ORB3-NS at different stages of the 4-Round loop, as the sequence proceeds with object layout transition. Note that ORB3-PW does not run between the second and third rounds, with the corresponding values included for comparison only. When object changes happen at the intersection of the second and third rounds, ORB3-NS is clearly affected and shows an RMSE of ATE value jump from 0.105 m to 0.138 m. On the contrary, our effective data association based on full object scale and shape similarity as well as spatial proximity allows ORB3-NS + Ours to maintain a relatively steady and lower RMSE of ATE around 0.10 m, reducing the overall RMSE of ATE by 27.3% from 0.128 m to 0.093 m.
We further compare our approach with its SE(3)-only variant. We observe that while it still leads to more accurate camera trajectory estimates when used alongside other SLAM measurements, its improvements are less significant compared to the full SE(3)- and scale-equivariant version. This is indicated by the modest reduction in the RMSE of ATE values in Table 5 across various types of trajectories. This degraded performance can be attributed to its limited ability to handle objects whose sizes fall outside the distribution of the training data, leading to less accurate camera pose constraints. This limitation is further illustrated in Figure 20, which shows greater deviations from the ground truth in both the 4-Round and Triple-Infinity loops, particularly in regions involving larger objects, such as trash bins, as highlighted by the two cyan blocks. This again demonstrates the advantage of incorporating scale equivariance, which enhances NeuSE’s generalization ability to better transfer category-level geometric knowledge to instances that are smaller or larger than those encountered during training. Trajectory estimation against ground truth (GT) of NeuSE’s SE(3)-only variant on controlled sequences. The SE(3)-only variant has difficulty handling objects with sizes outside the training data distribution, leading to less accurate camera pose constraints, such as in regions with the larger trash bins. This limitation is highlighted by the cyan blocks in (a) for the 4-Round loop and (b) for the Triple-Infinity loop.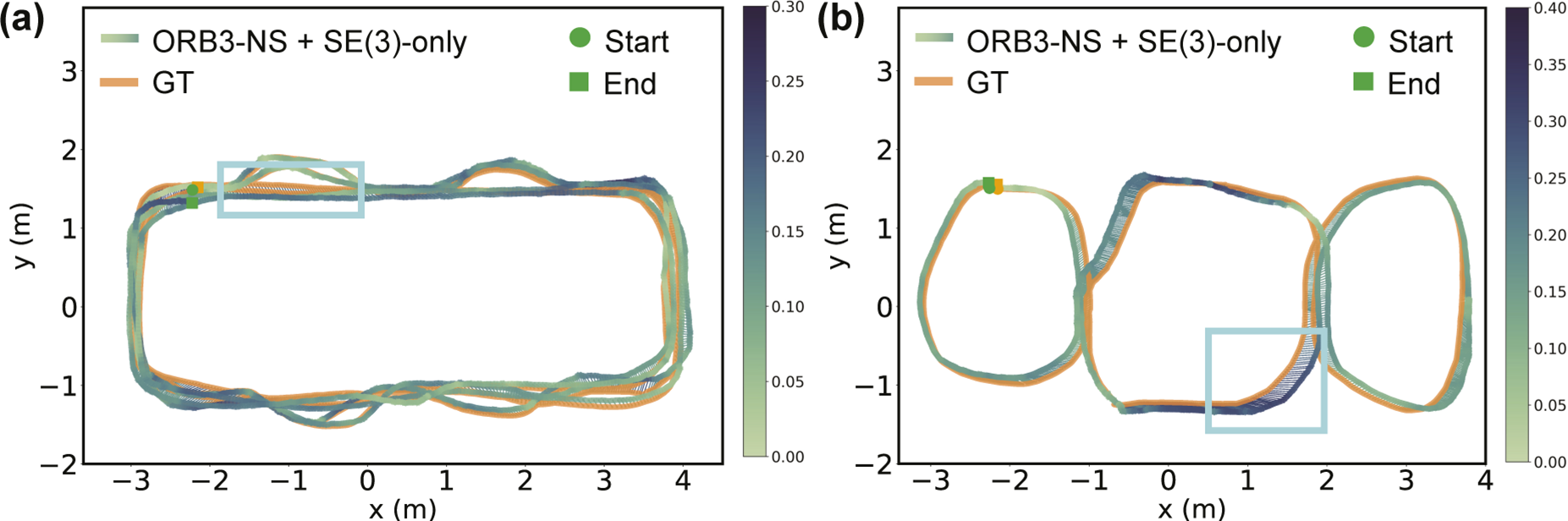
7.2.3. Uncontrolled environments: Indoor and Freeform loops
RMSE (m) of the Absolute Trajectory Error on hand-held sequences. Best results for each trajectory are marked in bold.
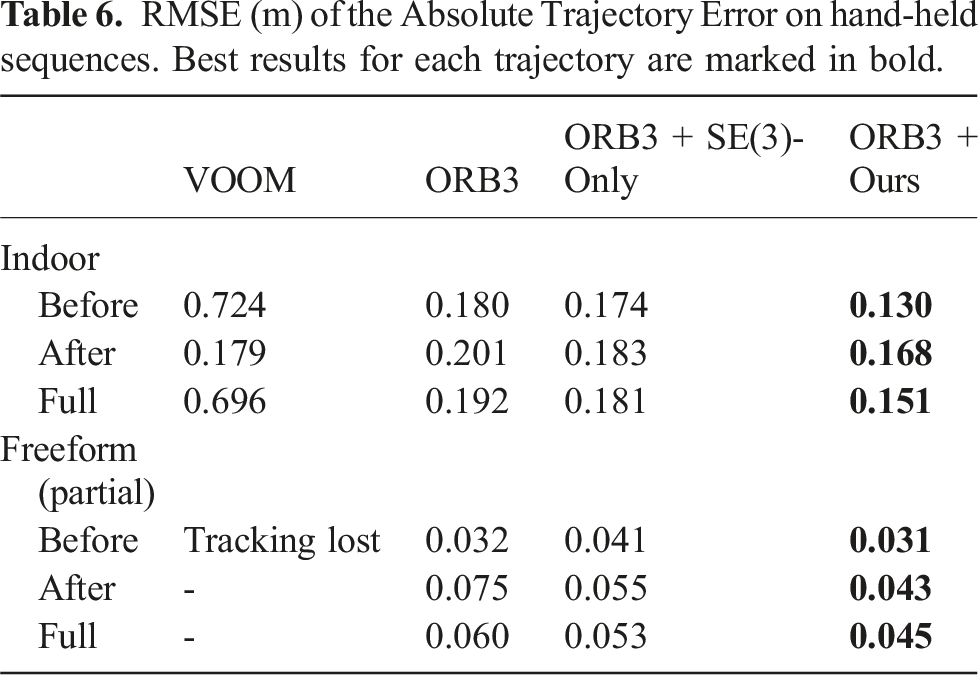
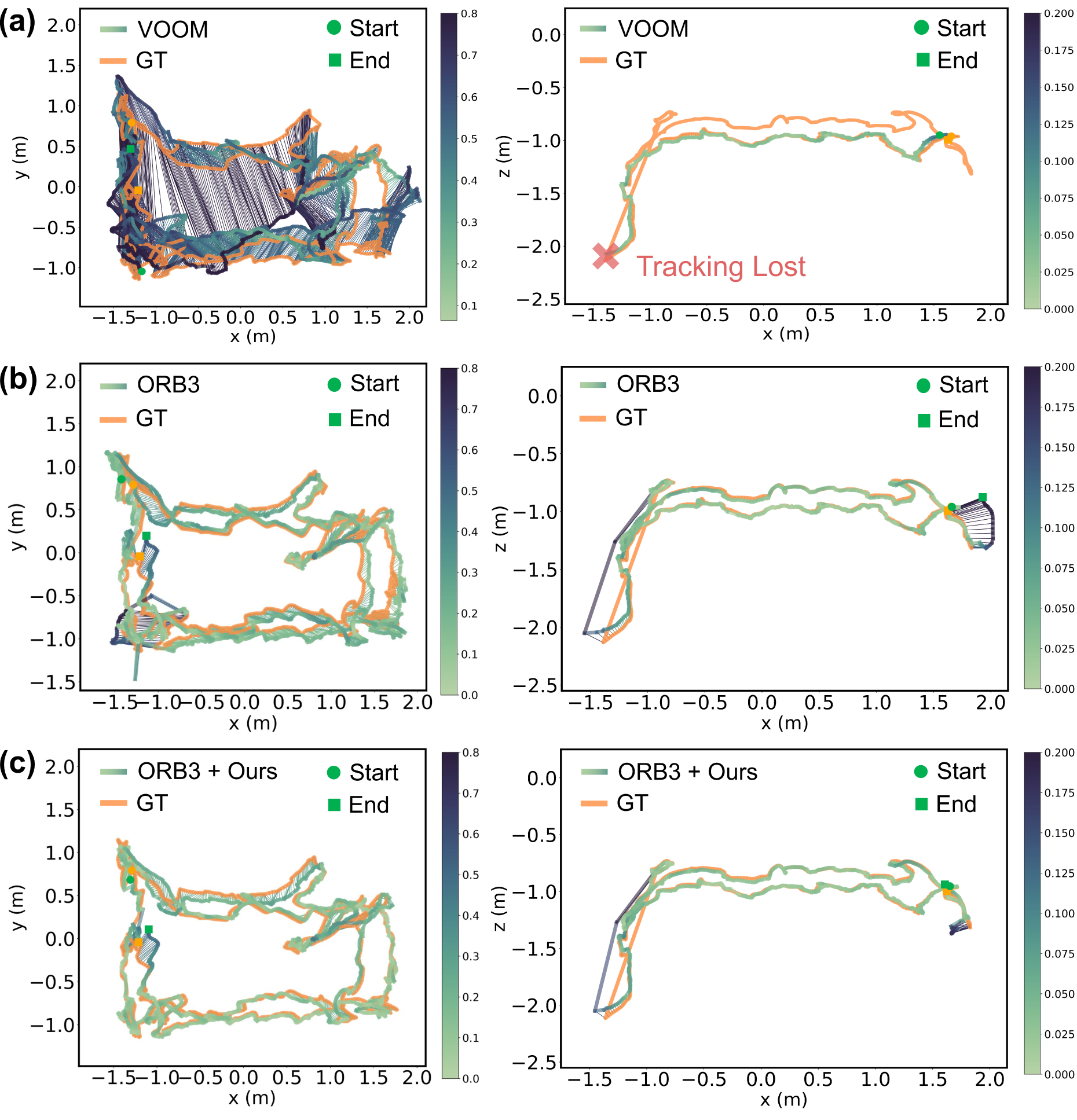
Comparison of estimated trajectories against ground truth on hand-held sequences. Column 1: Top-down views of the full Indoor sequence. Column 2: Side views of the start and end segments of the Freeform sequence, where ground truth camera poses are available. (a) VOOM completes the Indoor loop but suffers from significant drift and loses tracking early in the Freeform loop, indicating its limited ability to handle more drastic variations in viewing angles. (b)–(c) NeuSE-derived camera pose constraints consistently enhance ORB-SLAM3’s localization performance across both sequences, despite the more complex hand-held motion and varied viewing angles. The stronger alignment between ORB3 + Ours and the ground truth, particularly in the Freeform loop in (c), highlights our method’s effectiveness in facilitating relocalization after tracking loss, such as when the camera re-enters the office space following the corridor “blackout.”
For the Indoor loop, we observe that ORB3 + Ours successfully prevents the tracking failure (the spike in the lower-left corner of Figure 21(b)) that originally occurs during the independent execution of ORB-SLAM3. Additionally, the improved alignment of the trajectory with the ground truth from ORB3 + Ours demonstrates our approach’s ability to facilitate localization in a confined space with full SE(3) motion.
In the Freeform loop, as illustrated in the second column of Figure 21, we observe improved alignment and reduced trajectory drift from ORB3 + Ours compared to the ground truth. This improvement is particularly evident at the sequence’s left and right ends, specifically when (1) navigating through the door after the corridor blackout, where camera tracking is lost, and (2) approaching the starting point with a sharp turn. NeuSE’s effectiveness in robust relocalization, particularly in data association across diverse viewing angles, and our purely geometric approach, which does not rely on pixel information susceptible to motion blur, together contribute to this improvement. Hence, our strategy effectively aids localization in a larger motion space and supports reliable relocalization during potential blackout periods.
For both loops, the SE(3)-only variant improves the original ORB-SLAM3 results, but only slightly in terms of final trajectory accuracy, as indicated by the lower RMSE of ATE values. Notably, in the Freeform loop, the performance of the SE(3)-only variant actually worsens during the first loop, prior to any object changes, as reflected by the RMSE of ATE values. This degradation stems from its inability to effectively process the newly added white square jar, which is significantly smaller than the typical trash bin sizes seen during training. The failure to handle this object introduces a lingering effect on the localization performance, adversely impacting the quality of camera pose constraints generated jointly from the jar and other objects in the frame. This results in a more remarkable drift in the trajectory estimate wherever the jar appears, as highlighted by the two cyan blocks in Figure 22. In contrast, no significant drift is observed in these regions when using NeuSE with full scale equivariance (Figure 21(c)), further demonstrating the capability of scale equivariance to generalize to objects of varying sizes. Trajectory estimation against ground truth (GT) for NeuSE’s SE(3)-only variant on handheld sequences. The SE(3)-only variant offers less noticeable improvements in camera pose estimation accuracy compared to the full SE(3)- and scale-equivariant version. Specifically, unlike NeuSE, this variant fails to process observations of the white square jar, an instance intentionally included under the trash bin category with a similar shape but significantly smaller. The jar is used to test the approach’s ability to handle objects of varying sizes. This failure to correctly handle objects of out-of-distribution sizes results in persistent drift in areas where the jar is observed, as highlighted by the cyan blocks in (a) for the Indoor loop and (b) for the Freeform loop.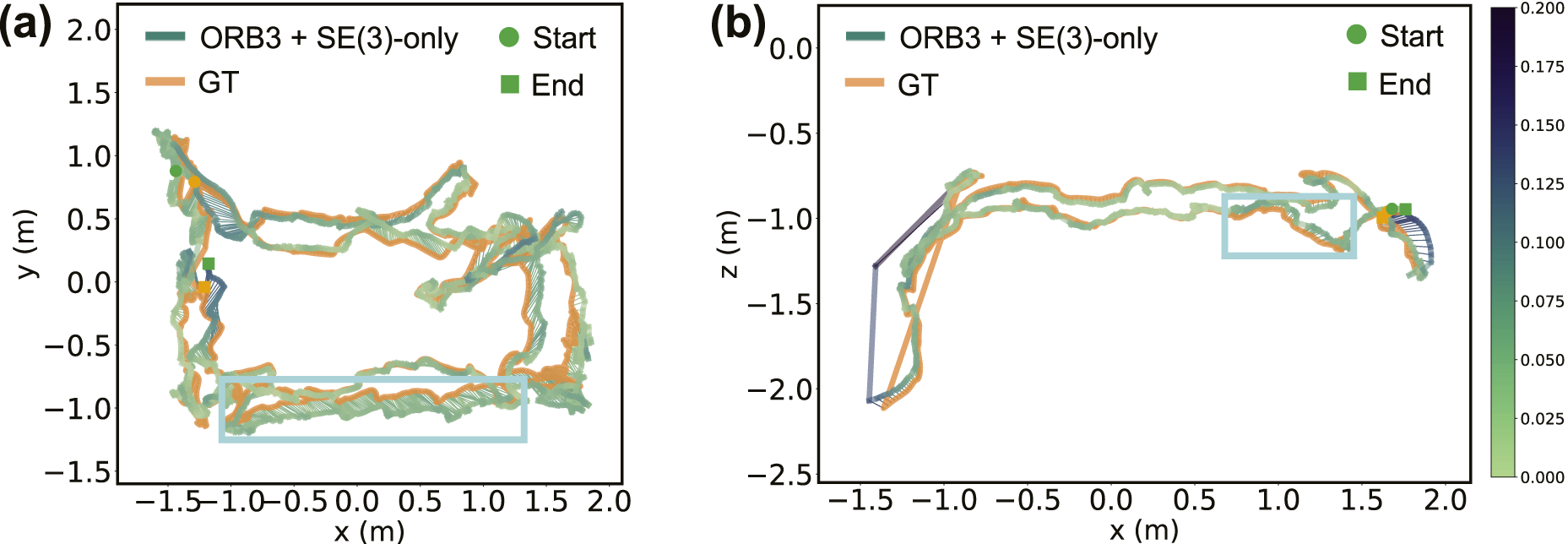
8. Spatial understanding with NeuSE: Change-aware object-centric mapping
In this section, we demonstrate how our approach constructs and maintains object-centric maps by utilizing equation (5) to generate consistent object reconstructions from each latent embedding. We further show how these maps can be updated to reflect changes in object layouts.
8.1. Multi-view multi-scale object mapping
Here, we showcase the robustness of NeuSE-based object mapping under varying viewing angles, object sizes, and shapes across categories.
In Figure 23, we present the multi-view reconstruction of the leftmost table (referred to as table 1 in Figure 26(a.1) and (d)) from the controlled environment, along with the blue trash bin placed just behind it (see “Side View 1” in Figure 23). This table is selected as a representative example because it contains objects from all the five categories and is one of the tables with the highest object density across all four real-world sequences, thereby introducing more occlusion patterns. Despite the cluttered layout, the reconstructions demonstrate decent consistency with the ground truth from both side views. NeuSE successfully recovers the full shape of each object and accurately estimates their locations, yielding a spatial layout that closely aligns with the actual physical arrangement. Consistent multi-view object reconstruction. We present our reconstruction (Ours) of the table with the highest object density across the four real-world testing sequences, including the trash bin visible in the first side view. Across all the five object categories present, the reconstruction maintains shape and spatial consistency, closely aligning with the ground truth (GT), as confirmed by the two side views.
In terms of NeuSE’s ability to generalize across object scales, Figure 24 displays the reconstructions of the largest and smallest objects from each of the five categories, mug, bottle, bowl, can, and trash bin in our real-world sequences. The reconstructions are rendered to approximate their actual size ratios within each object pair. For object pairs in Figure 24(a), where no reference objects are present in the ground truth images for relative scale comparison, we provide the approximate volume details: beer mug (600 mL) and espresso cup (60 mL), trash bin (26.5 L) and small bin (0.3 L), yellow plastic can (494 mL) and tuna can (188 mL). Despite the considerable scale variations listed here, NeuSE effectively handles significant differences in object shapes and sizes, consistently demonstrating reliable reconstruction performance across these multi-category, multi-scale objects in real-world sequences. Object reconstruction across scales. We present NeuSE’s reconstructions of the largest and smallest objects from real-world sequences across each of the five categories: mug, bottle, bowl, can, and trash bin. Reconstructions are visualized to preserve the approximate relative size ratios of the objects within each pair. (a) For object pairs without reference for relative scale ratio in ground truth images, the rough volumes from left to right are: beer mug (600 mL) and espresso cup (60 mL); trash bin (26.5 L) and small jar (0.3 L); yellow can (494 mL) and blue can (188 mL). From (a) through (b), despite the considerable intra-category scale variation, NeuSE maintains consistent reconstruction performance across both categories and object sizes.
8.2. Object-centric mapping with changes
Since there are no suitable object-based SLAM pipelines for direct comparison of mapping with temporal scene changes, we use the object-level mapping method with online change detection, panoptic multi-TSDFs (PMT) by Schmid et al. (2022), as our baseline. We feed PMT with our trajectory estimates that have the lowest RMSE of ATE values and compare the change detection results for synthetic and real-world sequences.
Change detection results on the synthetic and real-world sequences. Best results are marked in bold.
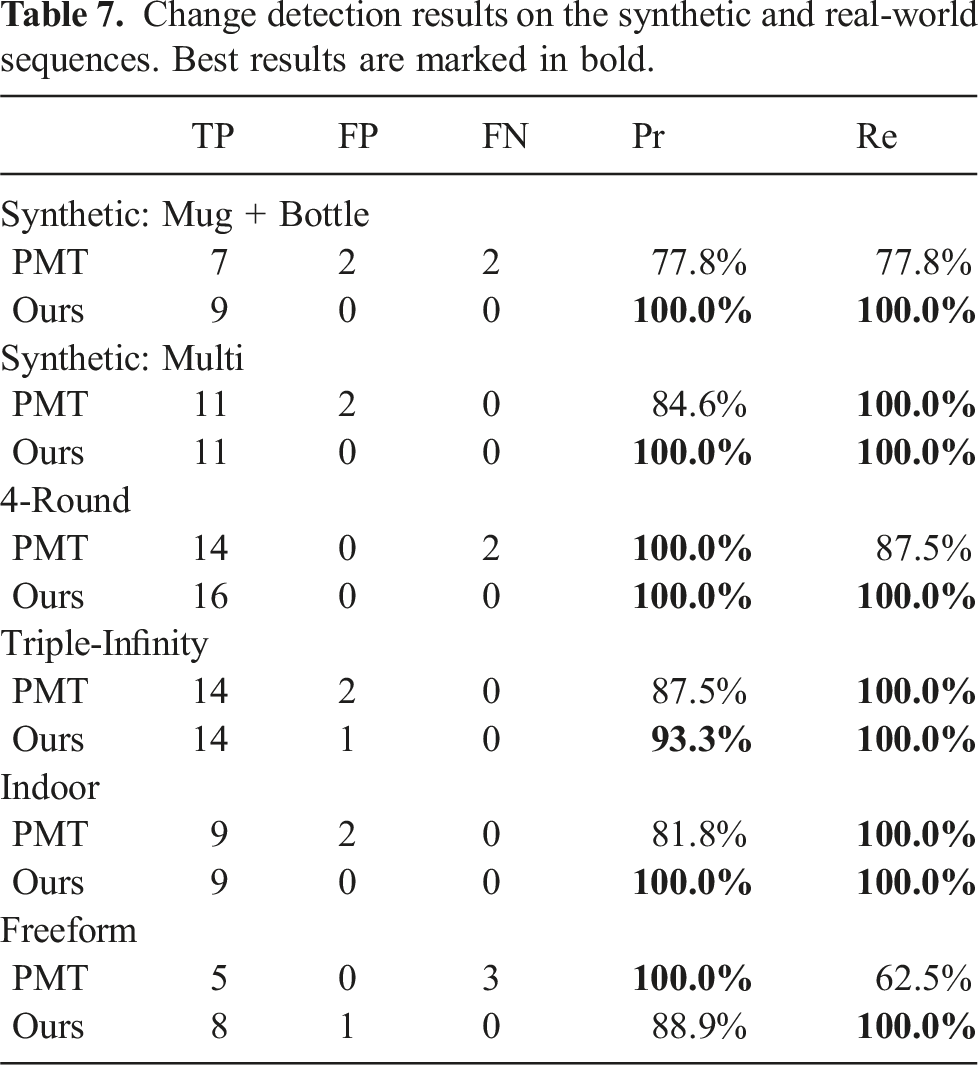
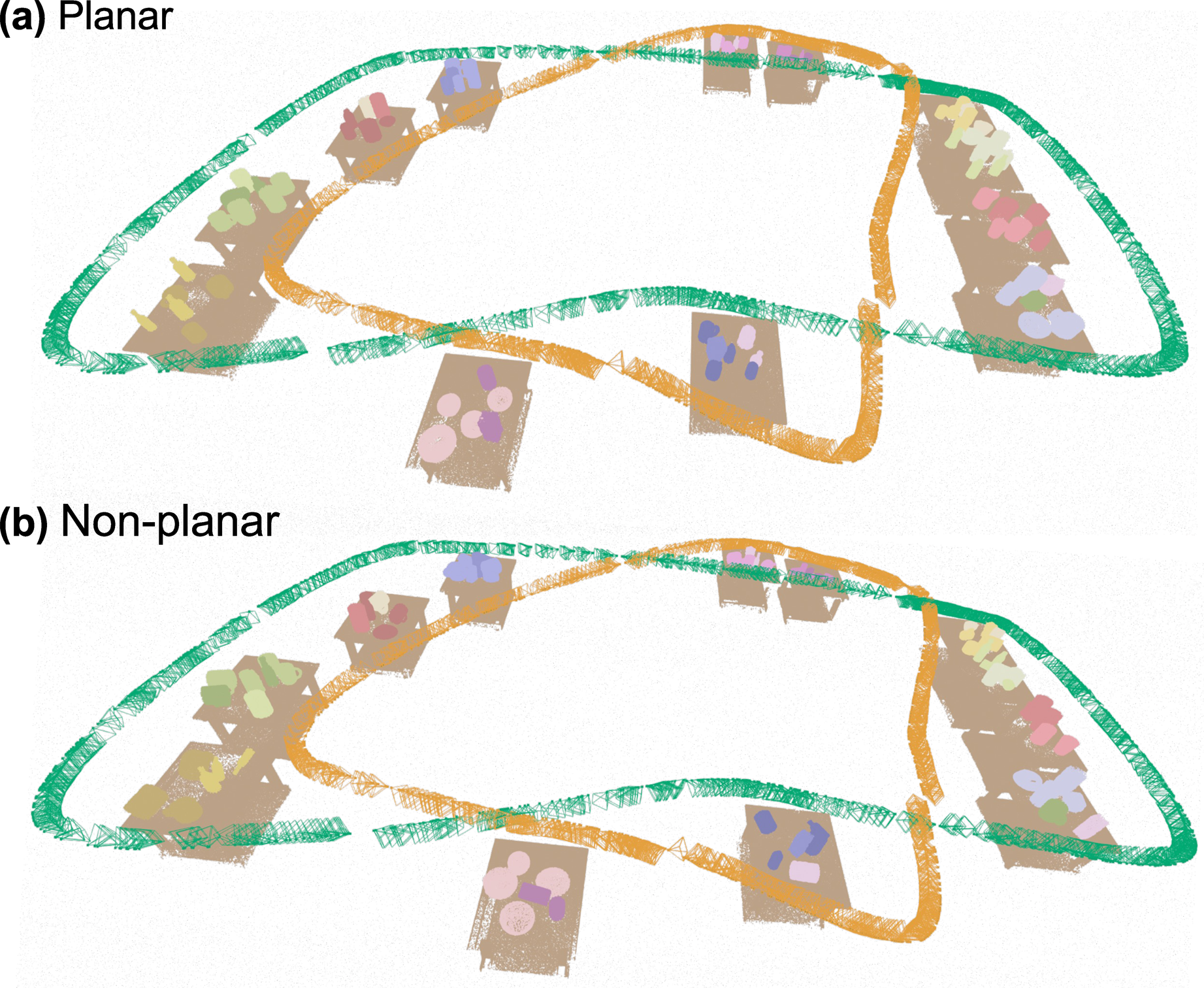
Complete object reconstructions of the synthetic multi-category sequences with planar and non-planar object layouts. (a) Planar layout. (b) Non-planar layout. Tables are rendered for visual clarity, with points back-projected to the world using camera pose estimates from NeuSE-predicted constraints, demonstrating the effectiveness of our localization strategy.
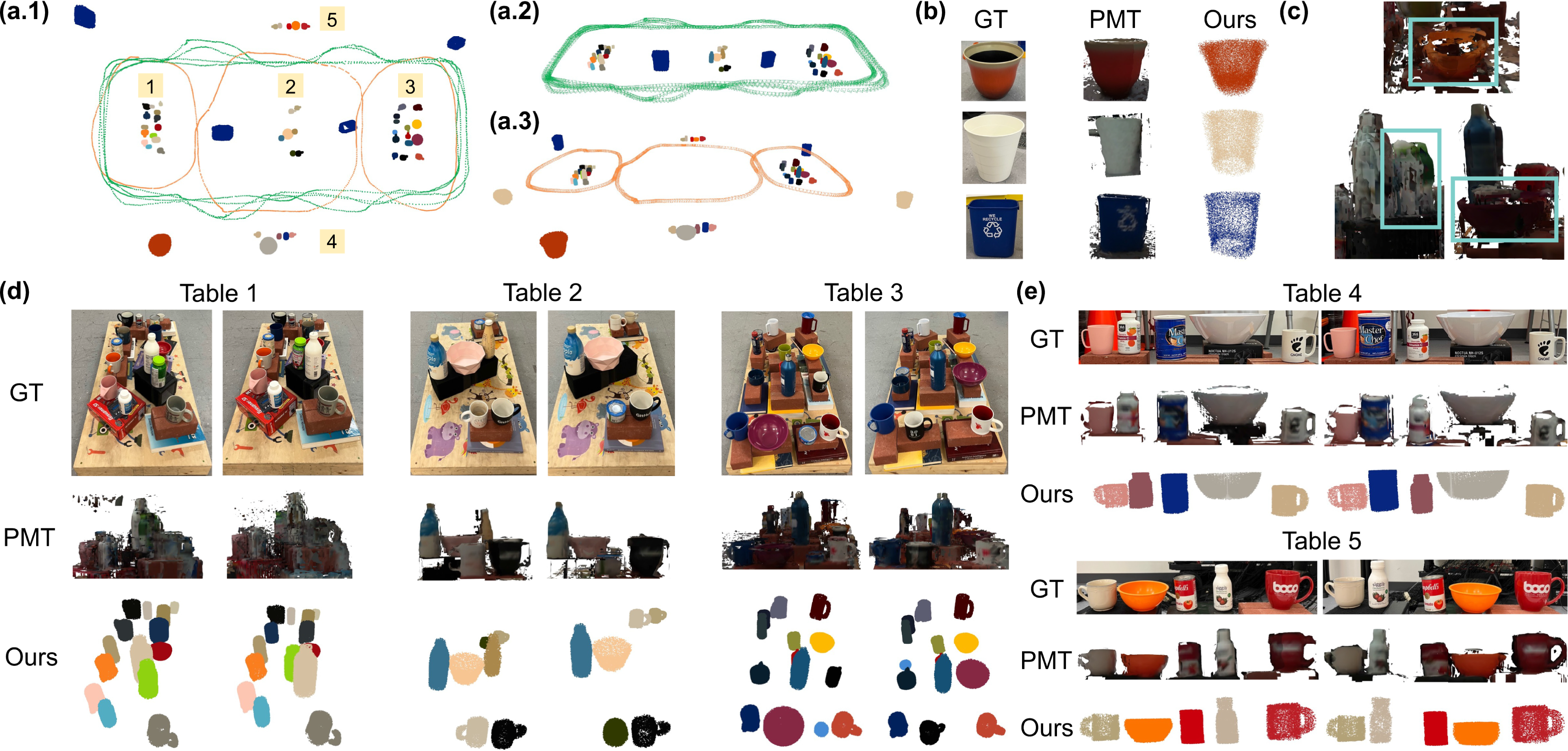
Results of change-aware mapping for real-world controlled sequences. (a) (a.1) presents the reconstructed object-centric map with camera trajectory estimates, illustrating the spatial consistency between object reconstructions and actual camera motion. (a.2) and (a.3) display full object reconstructions and estimated trajectories for the 4-Round and Triple-Infinity sequences. (b) Comparison of non-tabletop object reconstructions, i.e., various trash bins on the floor, across ground truth scenes (GT), from Panoptic Multi-TSDF Mapping (PMT), and from our object-centric maps (Ours). (d)–(e) Reconstructed objects and layouts of all the five tables in the controlled environment, shown before (left) and after (right) changes, comparing GT, PMT, and Ours. Our approach provides a lightweight, object-centric map that better captures object changes and outperforms PMT in both reconstruction quality and change detection accuracy. (c) Failures in PMT’s change detection and reconstruction are highlighted in cyan blocks. Top: The orange bowl on table 3 is falsely labeled as changed by PMT during the Triple-Infinity loop due to the little overlap between the nearly opposite camera views when the bowl is visible. Bottom: PMT fails to correctly detect the objects that switch locations, resulting in overlapping reconstructions of the white and green bottles (left) and the black mug in the red bowl(right).
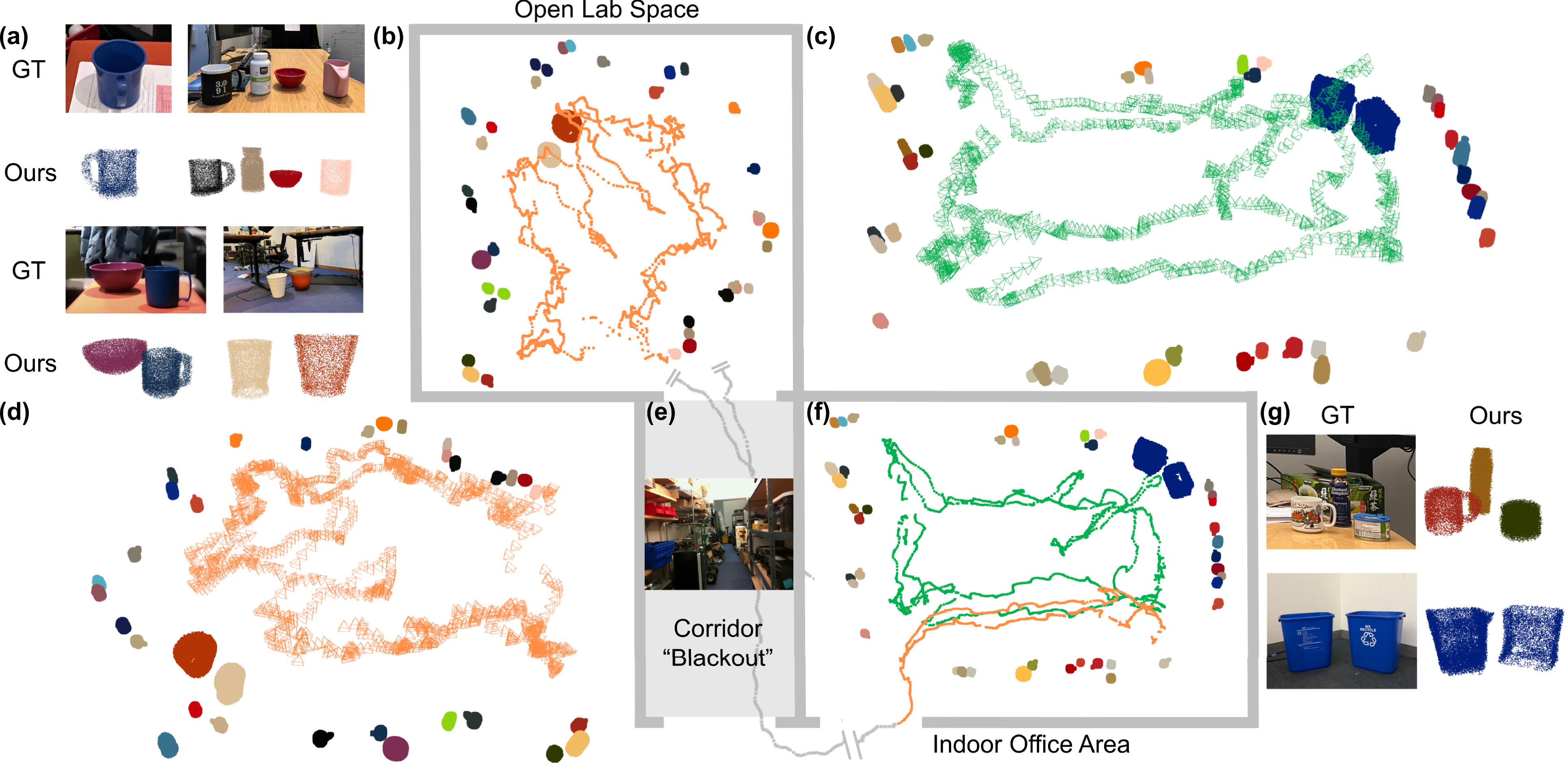
Overview of the reconstructed object-centric map and camera trajectory in the uncontrolled environment. The reconstruction and the camera trajectory estimates cover two regions, the indoor office area and the open lab space, connected by a blackout corridor, and demonstrate spatial consistency both within each region and across them, well aligned with the overall floor plan. (b)–(e)–(f) show the reconstructed object layout and camera trajectory estimates for the Indoor and Freeform loops, with a gray segment in the corridor to be the “blackout” part of the Freeform loop, where no objects of interest are available and ORB-SLAM3 tracking fails to recover the accurate trajectory. (a) shows the reconstructions for the unchanged objects while (d) presents the full estimated camera trajectory with the object layout in the open lab space. For the indoor office area, (c) outlines the Indoor trajectory estimate with the reconstructed object-centric map, and (g) exhibits the unchanged objects in the indoor office room.

Object reconstruction and change detection in the indoor office area. The map progression of the five tables is shown before and after the object changes (the left figure is the original state of the table, and the right figure is the new state of the table). Our approach maintains a clean and up-to-date object-centric map with all changes correctly detected. While for PMT, as its TSDF-based mapping method is limited by the parts of objects it has observed and the quality of camera trajectory estimates, the reconstructions can be incomplete and noisy, for example, the map for table 1 before changes. Moreover, as highlighted by the cyan blocks, PMT fails to remove the orange bowl on table 3 (right figure) after it is moved to the right side of the table. PMT also leaves a residual volume of the large blue bottle on table 5 at its previous location, and makes it overlap with the blue can after it is moved to the right side of the windowsill.

Object reconstruction and change detection in the open lab space. The map transition of the five tables is shown before and after the object changes (the left figure is the original state of the table, and the right figure is the new state of the table). Our method accurately captures object changes and recovers complete object shapes across categories. In contrast, as highlighted by the cyan blocks, PMT produces incomplete reconstructions, such as the missing blue can on table 3, and fails to remove the dark bottle from table 1 after it is moved.
8.2.1. Controlled environments: 4-Round and Triple-Infinity loops
In Figure 26, we present the full reconstructions of all the objects in the sequences of the controlled environment. Our approach generates a lightweight, object-centric map that precisely captures changes (see Figure 26(d) and (e) for the object-centric maps constructed for each table before and after changes). In contrast, PMT, being a traditional TSDF-based mapping technique, fails to perform accurate change detection and produces reconstructions with various defects. PMT is sensitive to limited viewing angle overlap, especially when coupled with localization errors, which can easily lead to false positive changes. This occurs when there is little overlap between the two partial object volumes due to localization drift, such as the orange bowl in the first row of Figure 26(c), which is falsely marked as changed. In addition, PMT struggles to distinguish between objects that switch places due to its inability to perform full object shape comparison as NeuSE does. This is shown by the overlapping reconstructions of the white and green bottles, as well as the black mug in the red bowl, in the bottom row of Figure 26(c).
8.2.2. Uncontrolled environments: Indoor and Freeform loops
In Figure 27, we present the reconstructed object layouts and full trajectory estimates for the Indoor and Freeform sequences. The strong spatial consistency between the camera trajectory estimates and the object layouts, shown in the Indoor (Figure 27(c), (f), and (g)) and Freeform (Figure 27(a), (b), and (d)–(f)) loops, demonstrates our approach’s ability to handle 3D motion and generate globally consistent trajectory estimates from surrounding object observations.
We also illustrate the spatial relationship between the open lab space (Figure 27(b)) and indoor office area (Figure 27(f)), connected by the blackout corridor (Figure 27(e)), in a floor plan style. Despite the tracking loss in the corridor, NeuSE-based relocalization allows the Freeform trajectory to align with the indoor space, achieving cross-region spatial consistency. This is proven by the alignment of the Freeform indoor trajectory (orange) with the indoor trajectory (green) in Figure 27(f), especially after the camera passes through the blackout period in the corridor and re-enters the office.
For object change detection in the Indoor (Figure 28) and Freeform (Figure 29) loops, we present the development of object maps before and after object changes for all the tables in both sequences. Along with the reconstructed objects, we also observe smooth and consistent TSDF reconstructions of several tabletop surfaces from PMT when using NeuSE-based camera pose estimates as the input for localization. Notably, accurate tabletop reconstructions are achieved for tables in both the indoor office area and the outer open lab space, which further validates the accuracy of our camera pose estimates.
We also highlight instances, marked in cyan blocks in Figures 28 and 29, where PMT struggles with change detection and reconstruction due to TSDF’s inherent limitations in shape reasoning and PMT’s sensitivity to localization errors. These artifacts include the residual orange bowl remaining in its original position after being moved to the right side of the table in table 3, as well as the duplicate volume of the large blue bottle in the middle after it is moved to the right of the windowsill in table 5 of Figure 28. Furthermore, in Figure 29, the blue can on table 3 is missing from the reconstruction, and there is a false negative detection of the dark yogurt bottle on table 1, which is not properly removed from the map.
9. Limitations and future work
Our evaluation on both synthetic and real-world sequences demonstrates NeuSE’s effectiveness in object-based SLAM. With its SE(3) and scale equivariance, NeuSE facilitates spatial understanding across objects of varying shapes and sizes, effectively handling occlusion and varying viewing angles to achieve robust long-term scene consistency. However, there are a few limitations worth addressing.
First, NeuSE operates as a category-level representation, requiring category-specific training for each type of object before being applied to a scene. This limitation reduces its flexibility and poses challenges when scaling to larger environments, especially in “open-set” spatial understanding, where no prior knowledge of object categories is available. In future work, we aim to overcome this by moving beyond category-level features and incorporating representations based on canonical geometric shapes, such as spheres, cylinders, and cuboids. In this spirit, we hope to make NeuSE interpolable in the latent space, allowing it to approximate actual object shapes more effectively with combinations of canonical shapes, thereby enhancing NeuSE’s capability to handle diverse object shapes in real-world scenarios.
Second, NeuSE performs best with high-quality partial object point clouds, which depend on reliable depth measurements and clean RGB segmentation masks. Few straightforward approaches to address this are to further train NeuSE with additional depth noise building on its demonstrated robustness and to leverage advances in the image segmentation community for higher-quality segmentation masks. Beyond this, we plan to extend NeuSE’s SE(3) and scale equivariance to handle not only individual objects but also small clusters of objects, enhancing its ability to manage smaller objects where current segmentation methods may struggle.
Finally, NeuSE relies on prior information, such as ambiguity patterns (e.g., unambiguous, cylindrical, or cubical) and accurate semantic labels for effective object association. Preparing training data with these ambiguity labels requires additional annotation effort. Moreover, NeuSE’s SE(3) equivariance is effective only when the latent codes belong to the same category, making it sensitive to semantic labeling errors. Introducing thresholding based on confidence scores for semantic labels could provide a simple yet effective solution to mitigate the impact of labeling inaccuracy. In future work, transforming NeuSE from a category-level into a shape-based representation, as mentioned earlier, could be another promising direction. Beyond learning the latent interpolation of different canonical shapes to approximate the shape of the query object, we also aim to reveal ambiguity patterns through latent interpolation from these canonical shapes. This approach could significantly reduce the effort required for labeling ambiguity patterns from labeling different shape instances to only a few canonical shapes, while also decreasing our dependence on semantic labels for object association.
Overall, our results demonstrate that NeuSE is a compact and effective object representation for object-based SLAM. NeuSE-based object SLAM provides a fundamental step in spatial understanding by localizing and constructing an object-centric map. A promising direction for future work is to explore how NeuSE, along with SLAM results, can be directly integrated into downstream tasks such as navigation and mobile manipulation. Compared to explicit spatial representations like point clouds or voxel grids, NeuSE offers a more semantically meaningful description of a scene based on its objects and their relationships, and can be efficiently queried to support navigation tasks, which favors holistic descriptions of the objects in the scene. Furthermore, NeuSE’s ability to construct a lightweight change-aware object-centric map can be crucial in scenarios involving changes caused by external agents or the robot’s interactions with its surroundings, such as for initializing and updating the scene representation each time the robot acts on an object during mobile manipulation tasks.
10. Conclusion
In this paper, we present NeuSE, a category-level neural latent embedding for objects, and demonstrate its ability to support object-based SLAM for consistent spatial understanding, even in the presence of long-term scene changes. NeuSE distinguishes itself from previous neural representations used in SLAM by allowing key SLAM components to be operating with a unified set of inferred latent embeddings. Camera pose constraints between objects can be derived directly from the corresponding latent representations, which are associated through scale, shape, and spatial information embedded in the representations. Furthermore, with its SE(3) and scale equivariance, NeuSE is able to handle a broader range of object shapes and sizes during inference compared to those seen during training, while also constructing flexible object-centric maps that can easily accommodate long-term scene changes. Our evaluation on synthetic and real-world data, in both controlled and uncontrolled settings, demonstrates the feasibility of our approach for change-aware localization and object-centric mapping, whether functioning independently or as a complement to traditional SLAM pipelines.
Supplemental Material
Footnotes
Acknowledgments
The authors thank Shichao Yang for discussions and guidance in setting up CubeSLAM for the real-world testing sequences, as well as Tim Magoun and Gabriel Margolis for help with data collection.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by ONR MURI grant N00014-19-1-2571 and ONR grant N00014-18-1-2832.
Supplemental Material
Supplemental material for this article is available online.
Appendix
Here, we provide additional details on our experiment setup and mapping procedures.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.