
Abstract
Grounding language to a navigating agent’s observations can leverage pretrained multimodal foundation models to match perceptions to object or event descriptions. However, previous approaches remain disconnected from environment mapping, lack the spatial precision of geometric maps, or neglect additional modality information beyond vision. To address this, we propose multimodal spatial language maps as a spatial map representation that fuses pretrained multimodal features with a 3D reconstruction of the environment. We build these maps autonomously using standard exploration. We present two instances of our maps, which are visual-language maps (VLMaps) and their extension to audio-visual-language maps (AVLMaps) obtained by adding audio information. When combined with large language models (LLMs), VLMaps can translate natural language commands into open-vocabulary spatial goals (e.g., “in between the sofa and TV”) directly localized in the map, and be shared across different robot embodiments to generate tailored obstacle maps on demand. Building upon the capabilities above, AVLMaps extend VLMaps by introducing a unified 3D spatial representation integrating audio, visual, and language cues through the fusion of features from pretrained multimodal foundation models. This enables robots to ground multimodal goal queries (e.g., text, images, or audio snippets) to spatial locations for navigation. Additionally, the incorporation of diverse sensory inputs significantly enhances goal disambiguation in ambiguous environments. Experiments in simulation and real-world settings demonstrate that our multimodal spatial language maps enable zero-shot spatial and multimodal goal navigation and improve recall by 50% in ambiguous scenarios. These capabilities extend to mobile robots and tabletop manipulators, supporting navigation and interaction guided by visual, audio, and spatial cues. Code and videos are available at https://mslmaps.github.io.
1. Introduction
People are excellent navigators of the physical world due in part to their remarkable ability to build cognitive maps (McNamara et al., 1989) that form the basis of spatial memory (Chun and Jiang, 1998; Newman et al., 2007) to (i) localize landmarks at varying ontological levels, such as a book; on the shelf; in the living room, or to (ii) determine whether the layout permits navigation between two points. Meanwhile, humans exhibit a remarkable ability to integrate and leverage multiple sensing modalities to efficiently move around in the physical world. Our actions are driven by a myriad of sensory cues: the sound of glass breaking might signal a dangerous situation, the microwave might buzz to indicate it is done, or a dog might bark to draw our attention. Acoustic signals particularly represent a valuable complementary form of information, also evident by the utility that they provide for the visually impaired, who may rely on them for navigation. Research in cognitive science also suggests that children understand and integrate information from different sensing modalities into spatial cognitive maps (Körding et al., 2007).
Classic methods for robot navigation (Endres et al., 2012; Thrun et al., 1998) build geometric maps for path planning. Although some previous extensions parse goals from templated natural language commands (MacMahon et al., 2006; Tellex et al., 2011), they struggle to generalize to unseen instructions. Learning methods directly optimize for navigation policies grounded in language end-to-end (commands to actions) (Anderson et al., 2018b, 2021) but require copious amounts of data. Recent works demonstrate that multimodal foundation models (Li et al., 2021; Radford et al., 2021) pretrained on Internet-scale data (e.g., images and their captions) can be used out-of-the-box to ground language to the visual observations of a navigating agent, without additional data collection or model fine-tuning. These models enable mobile robots to handle new instructions that specify unseen object goals and can be combined with exploration algorithms to search for the first instance of any object (CoW) (Gadre et al., 2023) or traverse object-centric landmarks in graphs (LM-Nav) (Shah et al., 2023). While promising, these methods predominantly use vision language models (VLMs) as critics to match image observations to object goal descriptions, but remain disjoint from the mapping of the environment, lacking the fine-grained spatial precision of classic geometric maps. Furthermore, they neglect the great potential of information in other sensing modalities such as audio. Therefore, these methods struggle to (i) localize spatial goals, for example, “in between the sofa and the TV,” to (ii) build persistent representations that can be shared across different embodiments, for example, mobile robots, drones, or to (iii) localize multimodal goals, for example, “the sound of the baby crying,” or an image of a refrigerator. How to best spatially anchor various sensing modalities, including visual and audio signals, in ways that enable effective data-efficient cross-modal reasoning for downstream robotics tasks, remains a relatively open question.
In this work, we address that question by introducing Multimodal Spatial Language Maps, a general mapping framework that is (i) spatial, (ii) multimodal, (iii) reusable across different robot embodiments, and (iv) readily extensible to additional sensing modalities in the future. At the heart of our approach are two concrete map instances: Visual-Language Maps (VLMaps) and their multimodal extension, Audio-Visual-Language Maps (AVLMaps). We begin by evaluating VLMaps, which fuse pretrained visual-language features from image observations with a 3D reconstruction of the environment. This fusion makes VLMaps both spatial-preserving, enabling localizing queries like “in between the sofa and the TV” in the map, and reusable across embodiments, since the same voxelized map can generate tailored obstacle grids for different robots by defining different sets of obstacle categories. VLMaps can be built from a robot’s video stream using standard exploration strategies. When coupled with a large language model (LLMs) in a Socratic fashion (Zeng et al., 2023), they translate long-horizon natural-language commands into sequences of open-vocabulary, spatially grounded goals.
Subsequently, we extend VLMaps to Audio-Visual-Language Maps, AVLMaps, a unified 3D spatial map representation for storing cross-sensing information from audio, visual, and language modalities. By introducing a new modality, audio, we extrapolate the capabilities of our framework to the multimodal setting, showing its extensibility to additional sensing modalities. AVLMaps can be built from image and audio observations captured during reconstruction, by computing dense pre-trained features from open-vocabulary multimodal foundation models trained on Internet-scale data (Ghiasi et al., 2022; Guzhov et al., 2022; Li et al., 2022) and fusing them into a shared 3D voxel grid representation. Beyond VLMaps, AVLMaps: • allow for landmarks (or areas and regions of interest) indexing in the environment via open-vocabulary multimodal queries (e.g., abstract textual descriptions, images, or audio snippets), enabling downstream applications including multimodal goal-driven navigation, without domain-specific model finetuning. • include audio information, which allows robots to more often correctly disambiguate goal locations using sound (e.g., “go to the table where you heard coughing” in environments where there are multiple tables, etc.). • extend the spatial characteristic of VLMaps to the multimodal domain, enabling zero-shot multimodal spatial goal localization, for example, “Go in between the {image of a refrigerator} and the sound of breaking glass” as in Figure 1. AVLMaps provide an open-vocabulary 3D map representation for storing cross-modal information from audio, visual, and language cues. When combined with large language models, AVLMaps consumes multimodal prompts from audio, vision, and language to solve zero-shot spatial goal navigation by effectively leveraging complementary information sources to disambiguate goals.
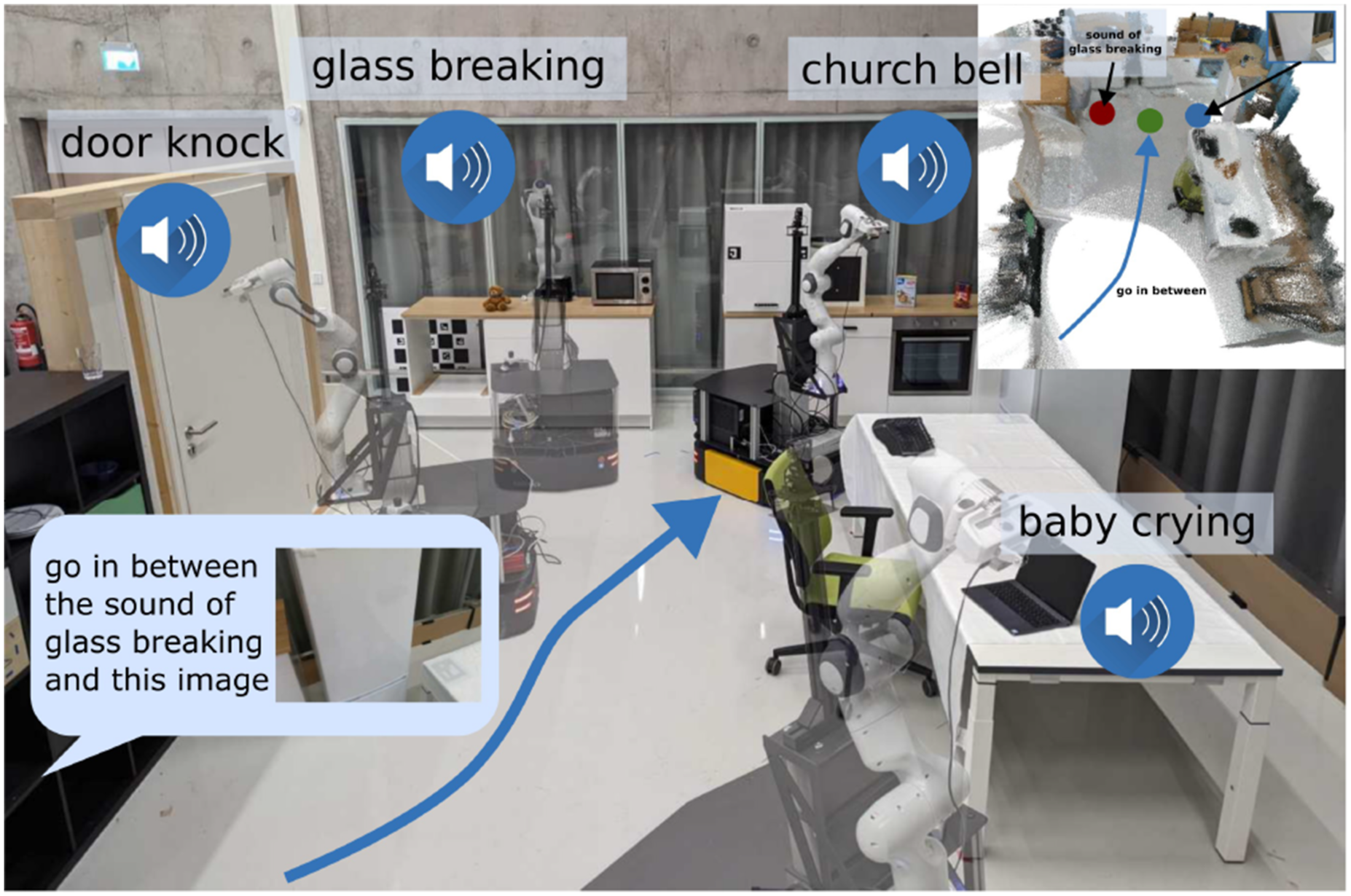
Extensive experiments in both simulated and real-world settings demonstrate that our VLMaps enable more effective long-horizon language-conditioned spatial goal navigation than baseline alternatives, such as CoW (Gadre et al., 2023) and LM-Nav (Shah et al., 2023). They can be shared across different robot embodiments to generate tailored obstacle maps for efficient, embodiment-specific path planning. Building on this, AVLMaps further extend these capabilities to navigating to goal locations specified by, for example, natural language descriptions of sounds or visual landmarks—and notably, can disambiguate multiple possible goal locations using multimodal information, (using object semantics to pinpoint one of the multiple possible sound goals, or using vision to pinpoint one of the multiple possible locations where similar objects were found) quantitatively better than unimodal baseline alternatives by up to 50% in top-1 recall in ambiguous scenarios. This article expands our previous work (Huang et al., 2023b, 2023a) by expanding our evaluation to demonstrate that AVLMaps’ capabilities continue to naturally improve with better-performing pre-trained audio-language foundation models such as AudioCLIP (Guzhov et al., 2022) and CLAP (Elizalde et al., 2023) and that the achieved multimodal disambiguation capabilities also translate to challenging robot manipulation tasks. AVLMaps are simple and effective in leveraging multiple multimodal foundation models together in tandem to reach broader language-driven robot navigation capabilities, but are also not without limitations—we discuss these and avenues for future work. The code is available at https://mslmaps.github.io/.
2. Related work
2.1. Semantic mapping
In recent years, the synergy of the traditional SLAM techniques and the advancements in vision-based semantic understanding has led to augmenting 3D maps with semantic information (McCormac et al., 2017; Salas-Moreno et al., 2013). Stemming from the intuition of augmenting 3D points in the map with 2D segmentation results, previous works focus on either abstracting the map at object-level with a pose graph (McCormac et al., 2018) or an octree (Xu et al., 2019) or modeling the dynamics of objects in the map (Runz et al., 2018). Despite lifting the 3D reconstruction to a semantic level, these methods are restricted to a predefined set of semantic classes. Recent works like LM-Nav (Shah et al., 2023), CoW (Gadre et al., 2023), VLMaps (Huang et al., 2023b), NLMap-SayCan (Chen et al., 2023a), OpenScene (Peng et al., 2023), or CLIP-Fields (Shafiullah et al., 2023) have shown that integrating visual-language features, generated by either pre-trained or fine-tuned models, into a topological graph or an occupancy map enables open-vocabulary object indexing with natural language, freeing the maps from fixed-size semantic categories. Recent approaches also investigate other open-vocabulary map representations such as NeRF (Engelmann et al., 2024; Kerr et al., 2023; Kim et al., 2024), Gaussian Splattings (Qin et al., 2024; Zuo et al., 2024), and Scene Graphs (Gu et al., 2024; Werby et al., 2024). However, these works focus on visual perception to map and move through an environment, overlooking complementary sources of information such as acoustic signals. In contrast, AVLMaps integrate audio, visual, and language cues into a 3D map, equipping the agent with the ability to navigate to multiple types of multimodal goals and effectively disambiguate goals.
2.2. Vision and language navigation
Recently, also Vision-and-Language Navigation (VLN) has received increased attention (Anderson et al., 2018b; Krantz et al., 2020). Further work has focused on learning end-to-end policies that can follow route-based instructions on topological graphs of simulated environments (Anderson et al., 2018b; Fried et al., 2018; Guhur et al., 2021). However, agents trained in this setting do not have low-level planning capabilities and rely heavily on the topological graph, limiting their real-world applicability (Anderson et al., 2021). Moreover, despite extensions to continuous state spaces (Hong et al., 2022; Krantz et al., 2020, 2021), most of these learning-based methods are data-intensive. The recent success of large pretrained vision and language models (Brown et al., 2020; Radford et al., 2021) has spurred a flurry of interest in applying their zero-shot capabilities to open-vocabulary object navigation (Gadre et al., 2023; Shah et al., 2023). LM-Nav (Shah et al., 2023) combines three pre-trained models to navigate via a topological graph in the real world. CoW (Gadre et al., 2023) performs zero-shot language-based object navigation by combining CLIP-based (Radford et al., 2021) saliency maps and traditional exploration methods. However, both methods are limited to navigating to object landmarks and are less capable of understanding finer-grained queries, such as “to the left of the chair” and “in between the TV and the sofa.” In contrast, our method, VLMaps, enables spatial language indexing beyond object-centric goals and can generate open-vocabulary obstacle maps. Our extension, AVLMaps, further enables multimodal spatial concept indexing such as “between the image of a refrigerator and the sound of breaking glass.”
2.3. Multimodal navigation
Recent advances in simulation applications (Chen et al., 2020; Gan et al., 2020a; Kolve et al., 2017; Savva et al., 2019) have boosted research on multimodal navigation in two distinct directions: (i) vision-and-language navigation (VLN) (Anderson et al., 2018b; Krantz et al., 2020) where an agent needs to follow a natural language instruction toward the goal with visual input, and (ii) audio-visual navigation (AVN) (Chen et al., 2020) in which an agent should navigate to the sound source based on information from a binaural sensor and vision. Despite different degrees of success in both directions (Chen et al., 2021a; Fried et al., 2018; Gan et al., 2020b, 2022; Guhur et al., 2021; Younes et al., 2023), less attention has been paid to solving the navigation problem involving vision, language, and audio at the same time. The most relevant concept to our knowledge is from AVLEN (Paul et al., 2022), which extends the AVN with a further query step, introducing a language instruction that helps with navigating to the sound source. In addition, most of the existing methods on AVN focus on approaching the sound without understanding its semantics. In our work, we propose a method to integrate both visual and sound semantics into the same map, enabling a robot to navigate to multimodal goals specified with either goal image or natural language like “go to the sound of baby crying,” “go to the table” or multimodal prompts such as “go to the {image of a table} where the sound of the microwave was heard.”
2.4. Pre-trained zero-shot models in robotics
Recent trends have shown that pre-trained foundation models (Brown et al., 2020; Liang et al., 2023a; Radford et al., 2021) serve as powerful tools for robotic tasks. Most works exploit the inherent perception and reasoning abilities of Vision Language Models (VLMs) or Large Language Models (LLMs) trained with cloud-sourced data to boost the performance of robot tasks including object detection and segmentation (Gu et al., 2021; Kamath et al., 2021; Li et al., 2021), robot manipulation (Chen et al., 2024a; Liang et al., 2023b; Mees et al., 2022a, 2022b, 2023; Rosete-Beas et al., 2022; Shridhar et al., 2022; Zawalski et al., 2024; Zhou et al., 2024), and navigation (Chen et al., 2023b; Gadre et al., 2023; Gu et al., 2024; Hirose et al., 2024; Huang et al., 2023b; Shah et al., 2023; Werby et al., 2024). With access to a growing volume of robot control data annotated with semantic language labels, recent approaches have advanced the training of a Vision-Language-Action (VLA) model, bridging the gap between visual-language comprehension and low-level robot control within a unified foundational model (Brohan et al., 2023; Doshi et al., 2024; Kim et al., 2025; Octo Model Team et al., 2024; O’Neill et al., 2024; Zitkovich et al., 2023). Despite promising results from previous methods, little effort has been made to exploit the audio-language pre-trained models (ALMs) (Elizalde et al., 2023; Guzhov et al., 2022) in robotic tasks. In this work, we leverage the foundation models focusing on different modalities, for example, audio, language, and vision, to create a mapping pipeline to understand multimodal information in the scene and achieve robot navigation given language, image, or audio description queries. Concurrent work ConceptFusion (Jatavallabhula et al., 2023) demonstrates that audio can be used as queries to index locations in a visual-language map. However, it doesn’t support integrating audio information from the observation data into the representation of the scene as we do in this work.
3. Method
Our goals are two-fold: (i) build a visual language map representation that synergizes the open-vocabulary capability of vision-language models and the spatial characteristic of geometric maps, and (ii) extend such a map to a multimodal spatial language map representation, in which object landmarks (“sofa”), areas (“kitchen”), audio semantics (“the sound of a baby crying”), or visual goals can be directly localized using natural language or a target image. To achieve the first goal, we propose VLMaps, which can be constructed with pre-trained visual-language models by consuming RGB-D streaming data and camera odometry. Such a map allows for spatial goal indexing like “to the left of the sofa,” and can dynamically adapt to different embodiments, enabling users to freely define obstacle categories for the robot to generate a customized occupancy map for path planning. For the second goal, we propose a more general representation, AVLMaps, which takes VLMaps as one sub-module and extends it to consume multimodal data during mapping and support multimodal concept indexing, such as audio, images, and language. We also propose a cross-modal reasoning method to disambiguate locations referring to targets from different modalities (“the sound of brushing teeth near the sink,” or “the table near this image: {image}”). In the following subsections, we first start with (i) how to build a VLMap by integrating visual-language features into spatial map location (Section 3.1), (ii) how to use this map to localize open-vocabulary landmarks (Section 3.2), (iii) how we can build open-vocabulary obstacle maps from a list of obstacle categories for different robot embodiments (Section 3.3), and (iv) how we can use this map for spatial goal navigation with the help of an LLM (Section 3.4). Later, we consider VLMaps in a broader context, and demonstrate (v) how to extend it to a multimodal map that integrates audio, language, and visual information in the map and use it for localizing different targets (Section 3.5), (vi) how to disambiguate goal locations with multimodal information (Section 3.6), and (vii) how such a multimodal map can be used with large language models (LLMs) for multimodal goal navigation, without additional data collection or model fine-tuning (Section 3.7). We show the pipeline of building a VLMap in Figure 2, and later show the system pipeline of our multimodal map representation in Figure 7. The creation and language-conditioned indexing of a VLMap. A VLMap is created by fusing pretrained visual-language features into the reconstruction of the environment to enable visual-spatial-language-based reasoning. By providing a list of open-vocabulary labels, we retrieve segmentation masks for semantic classes required by downstream applications.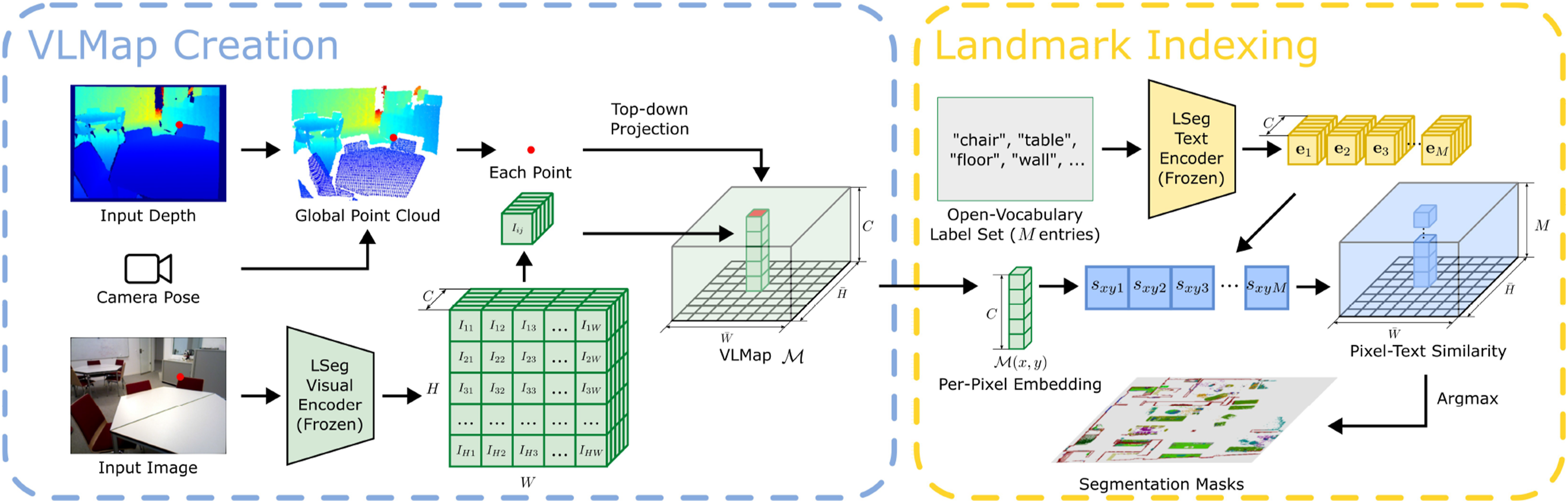
3.1. Building a visual-language map
The key idea behind VLMaps is to fuse pretrained visual-language features with a 3D reconstruction. We achieve this by computing dense pixel-level embeddings from an existing visual-language model (over the video feed of the robot) and by back-projecting them onto the 3D surface of the environment (captured from depth data used for reconstruction with visual odometry). The overview of VLMaps creation is shown on the left of Figure 2.
In our work, we utilize LSeg (Li et al., 2021) as the visual-language model, a language-driven semantic segmentation model that segments the RGB images based on a set of free-form language categories. The LSeg visual encoder maps an image such that the embedding of each pixel lies in the CLIP feature space. In our approach, we fuse the LSeg pixel embeddings with their corresponding 3D map locations. In this way, without explicit manual segmentation labels, we incorporate a powerful language-driven semantic prior that inherits the generalization capabilities of VLMs. The only assumption we make is access to odometry, which is readily available from RGB-D SLAM systems and enables us to build a map from sequences of RGB-D images.
Formally, we define VLMap as
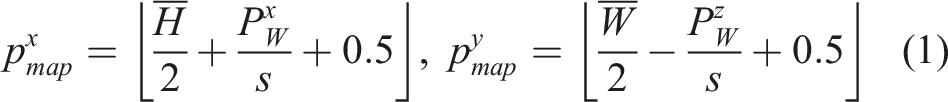
Once we build the grid map, we apply LSeg’s visual encoder
3.2. Localizing open-vocabulary landmarks
We now describe how to localize landmarks in VLMaps with free-form natural language. The overview of the indexing process is shown on the right of Figure 2. Formally, we define the input language list as
3.3. Generating open-vocabulary obstacle maps
Building a VLMap enables us to generate obstacle maps that inherit the open-vocabulary nature of the VLMs used (LSeg and CLIP). Specifically, given a list of obstacle categories described with natural language, we can localize those obstacles at runtime to generate a binary map for collision avoidance and/or shortest path planning, as is shown in Figure 3. A prominent use case for this is sharing a VLMap of the same environment between different robots with different embodiments (i.e., cross-embodiment problem (Ganapathi et al., 2022; Zakka et al., 2022)), which may be useful for multi-agent coordination (Wu et al., 2021). For example, a large mobile robot may need to navigate around a table (or other large furniture), while a drone can directly fly over it. By simply providing two different lists of obstacle categories—one for the large mobile robot (that contains “table”), and another for the drone (that does not), we can generate two distinct obstacles maps for the two robots to use, respectively, sourced on-the-fly from the same VLMap. The overview of building customized obstacle maps for different robot embodiments. By specifying different obstacle categories in natural language for different embodiments, different obstacle maps can be built to ensure the most efficient path planning for different embodiments.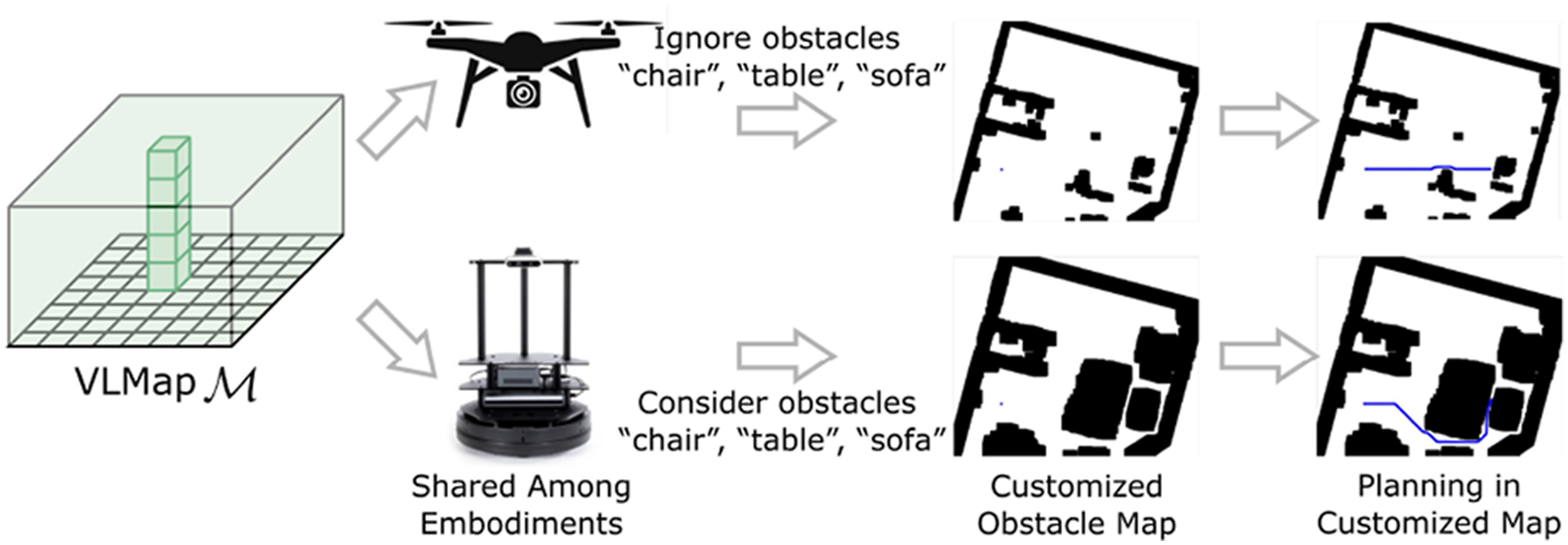
To do so, we first extract an obstacle map
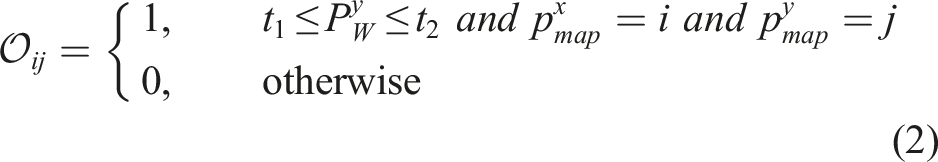
3.4. Zero-shot spatial goal navigation from language
In this section, we describe our approach to long-horizon (spatial) goal navigation, given a set of landmark descriptions specified by natural language instructions such as
Notably different from prior work (Gadre et al., 2023; Shah et al., 2023), VLMaps allow us to reference precise spatial goals such as: “in between the sofa at the TV” or “three meters to the east of the chair.” Specifically, we use a large language model (LLM) to interpret the input natural language commands and break them down into subgoals (Ahn et al., 2022; Shah et al., 2023; Zeng et al., 2023). In contrast to prior work, which may reference these subgoals with language and map to low-level policies with semantic translation (Huang et al., 2022a) or affordances (Ahn et al., 2022; Huang et al., 2022b; Zeng, 2019), we leverage the code-writing capabilities of LLMs to generate executable Python robot code (Brown et al., 2020; Chen et al., 2021b; Liang et al., 2023b; Mees et al., 2023) that can (i) make precise calls to parameterized navigation primitives, and (ii) perform arithmetic when needed. The generated code can directly be executed on the robot with the built-in Python
Navigation API library for spatial goal navigation in VLMaps.


The full context prompt (prompt in gray) VLMap used for achieving spatial goal navigation tasks in the experiments.
Spatial goals are defined as positions around the reference object based on spatial descriptions, for example, “in the middle of the counter and the fridge” or “to the left of the sofa”. Traditional object goal navigation methods either directly retrieve the target object’s location on the map and plan to it (Gadre et al., 2023; Shah et al., 2023) or are trained to approach objects as a reactive system (Chaplot et al., 2020). These methods fall short in reaching spatial goals since these goal locations are free space rather than retrievable locations on semantic maps. However, when we know the reference position, those spatial locations can be computed with simple offsets. The navigation primitive functions (APIs) being called by the language model (e.g., VLMaps enable a robot to perform complex zero-shot spatial goal navigation tasks given natural language commands, without additional data collection or model finetuning.
At test time, the LLM is prompted with context examples (in gray) in Figure 4 as well as commands (in green) in Figure 6. It can autonomously re-compose API calls to generate new robot code that not only references the new landmarks mentioned in the language commands (as comments), but also can chain together new sequences of API calls to follow unseen instructions accordingly. The inference process is shown in Figure 6, and generated outputs are highlighted. The query and the generated results from the LLM for spatial goal navigation tasks. During the query, the context prompt in Figure 4 and the input task commands are prompted to the LLM together. The input task commands are in green and generated outputs are highlighted.
3.5. Building an audio visual language map
VLMaps provide an intuitive interface for humans to issue natural language commands to robots, enabling open-vocabulary spatial goal navigation. However, interacting with the world is inherently a multimodal experience. Since VLMaps primarily rely on visual information for map construction, it is important to consider other complementary sources of information that can enhance navigation. Motivated by this, we broaden the scope of VLMaps and propose a more general framework, AVLMaps, which enables robots to integrate and interpret multimodal information, including audio, images, and language, within a unified representation (as illustrated in Figure 7). In this paper, we present the extension to audio and image modalities as a case study, showcasing the modularity and extensibility of our multimodal spatial language maps. The AVLMaps framework is flexible and designed to accommodate future integration of additional sensing modalities, such as temperature, tactile feedback, or magnetic fields. The key idea behind AVLMaps is to combine visual localization features, pre-trained visual-language features, and audio-language features with a 3D reconstruction. Given an RGB-D video stream with an audio track and odometry information, we utilize four modules to build a multimodal features database. Given a specific query, each module returns predicted spatial locations on the map in the form of 3D voxel heatmaps. A heatmap can be denoted as System overview. AVLMaps are constructed from RGB-D, audio, and odometry inputs, converting raw data into visual localization features, visual-language features, and audio-language features. During inference time, each module’s output is unified with cross-modal reasoning, allowing users to query spatial location with multimodal information.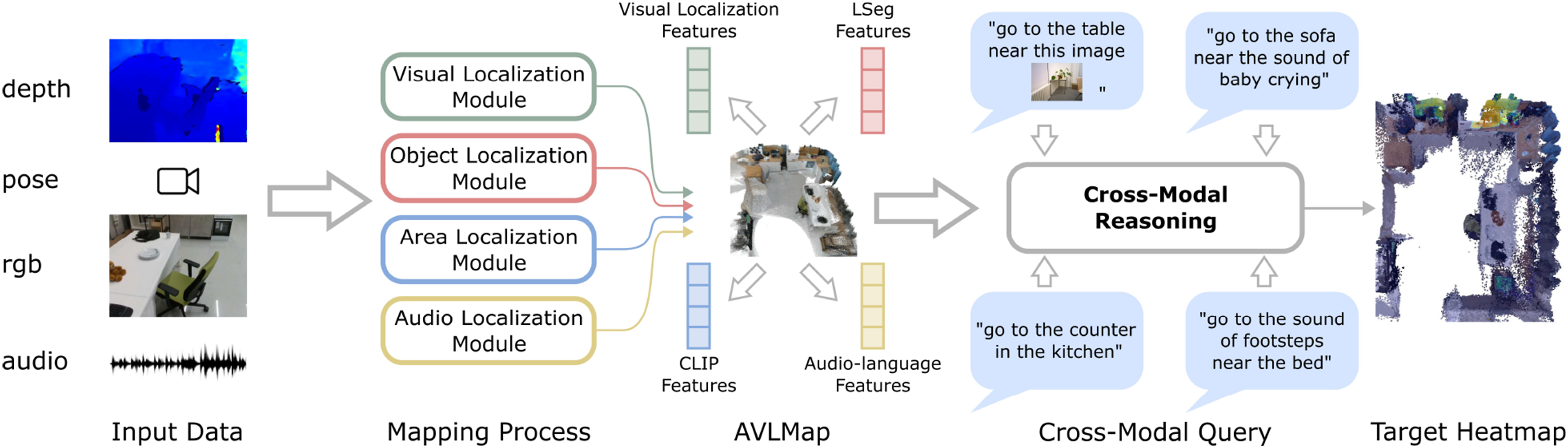
3.5.1. Visual localization module
The overview of the module is shown in Figure 8. The main purpose of this module is to localize a query image in our map. To achieve this goal, we follow a hierarchical localization scheme (Sarlin et al., 2019, 2020). We first compute the NetVLAD (Arandjelovic et al., 2016) global descriptors and SuperPoint (DeTone et al., 2018) local descriptors for all images from the RGB stream during exploration and store them with the corresponding depth and odometry as a reference database. During inference, we compute the global and local descriptors for the query image in the same manner. By searching the nearest neighbor of the query NetVLAD features in the reference database, we can find a reference image as our candidate. Next, we use SuperGLUE (Sarlin et al., 2020) to establish key point correspondences between the query image and the reference image we retrieve with NetVLAD from the database with their local SuperPoint features. With registered depth, we back-project the reference image’s key points into the 3D space and obtain the 3D–2D correspondences for the query key points. In the end, we can apply the Perspective-n-Point method (Fischler and Bolles, 1981) to estimate the query camera pose relative to the reference camera, and thus obtain the global camera pose with the odometry of the reference camera. The overview of the visual localization module. We follow the hierarchical localization scheme by using NetVLAD and SuperGLUE to localize the query image’s location before generating a heatmap as the indexing result.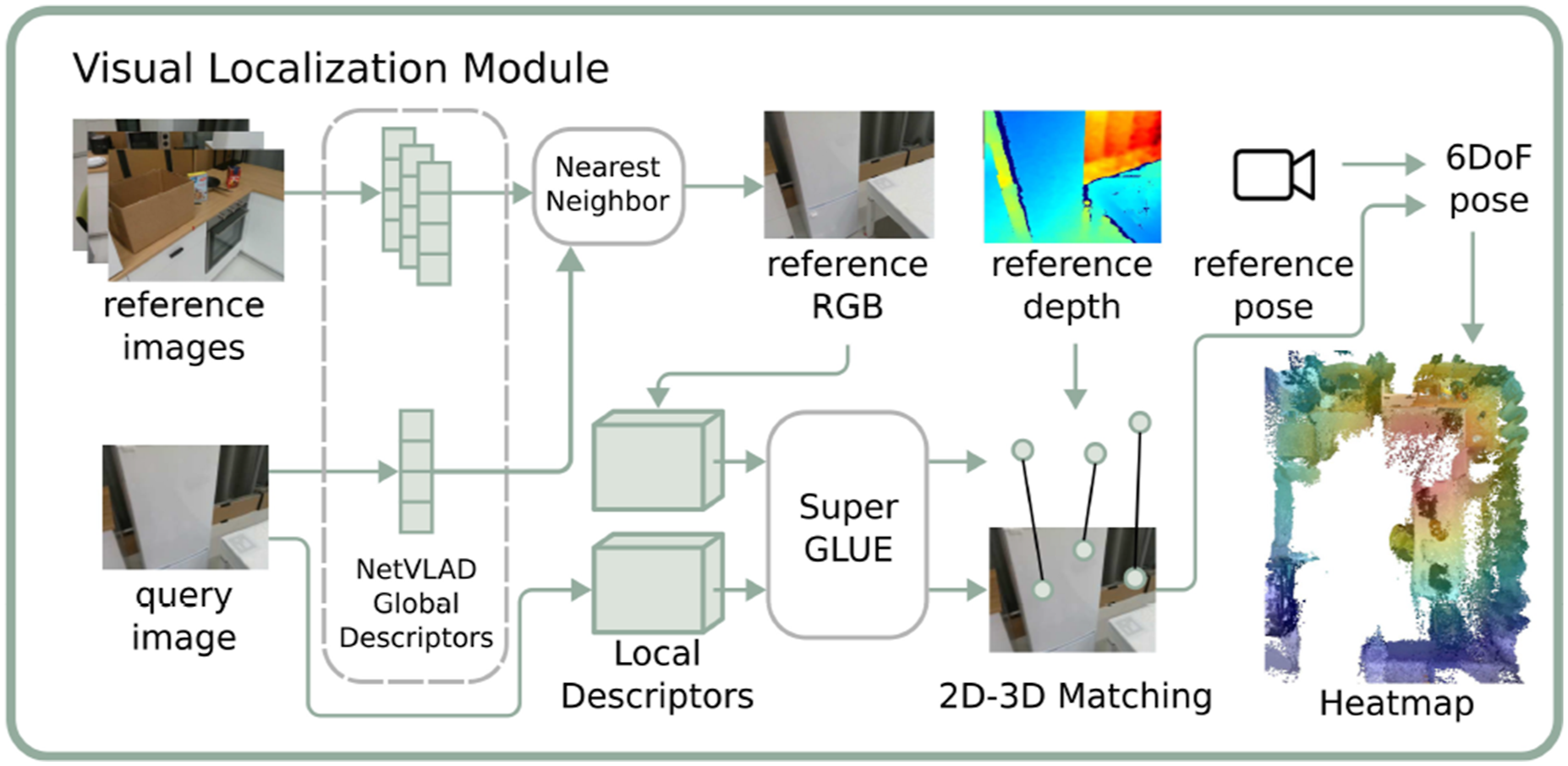
In the visual localization module, the predicted global camera location is denoted as 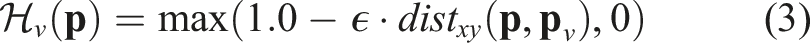
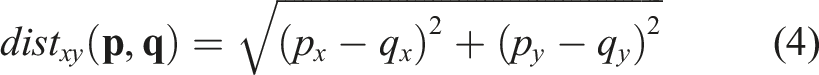
3.5.2. Object localization module
The overview of the object localization module is shown in Figure 9. This module is abstracted from the VLMaps we introduced in Section 3.1, Section 3.2, and Section 3.3 with some minor changes. The key idea is to exploit an open-vocabulary segmentation method (e.g., LSeg (Li et al., 2022) or OpenSeg (Ghiasi et al., 2022)) for pixel-level feature generation from the RGB image and to associate these features with the back-projected depth pixels in the 3D reconstruction. Different from Section 3.1, we don’t project the 3D points into the top-down plane to create a 2D grid map but maintain a 3D voxel map where each voxel is associated with a visual-language feature. When there are multiple points projected into the same voxel, we store their mean features at the voxel. The inference process is similar to Section 3.2. We define a list of categories in natural language and encode them with the language encoder. We compute the cosine similarity scores between all voxel-wise features and language features and use an argmax operator to select the top-scoring voxels for a certain category in the map. Depending on the application, the top-scoring 3D voxel points for a certain category can be used as the target point cloud for manipulation tasks or can be projected onto a top-down map for navigation purposes. The overview of the object localization module. Similar to Section 3.1, during mapping, the RGB images in the exploration video are input to a vision-language model, LSeg (Li et al., 2021), to generate pixel-level features. Corresponding pixels are back-projected with depth images and transformed to locations in the global coordinate frame, where the features are associated with. During inference, the query text is encoded by LSeg’s text encoder, and a dot product with the point-level embeddings generates a score for each point. A heatmap is then created based on point scores and distances.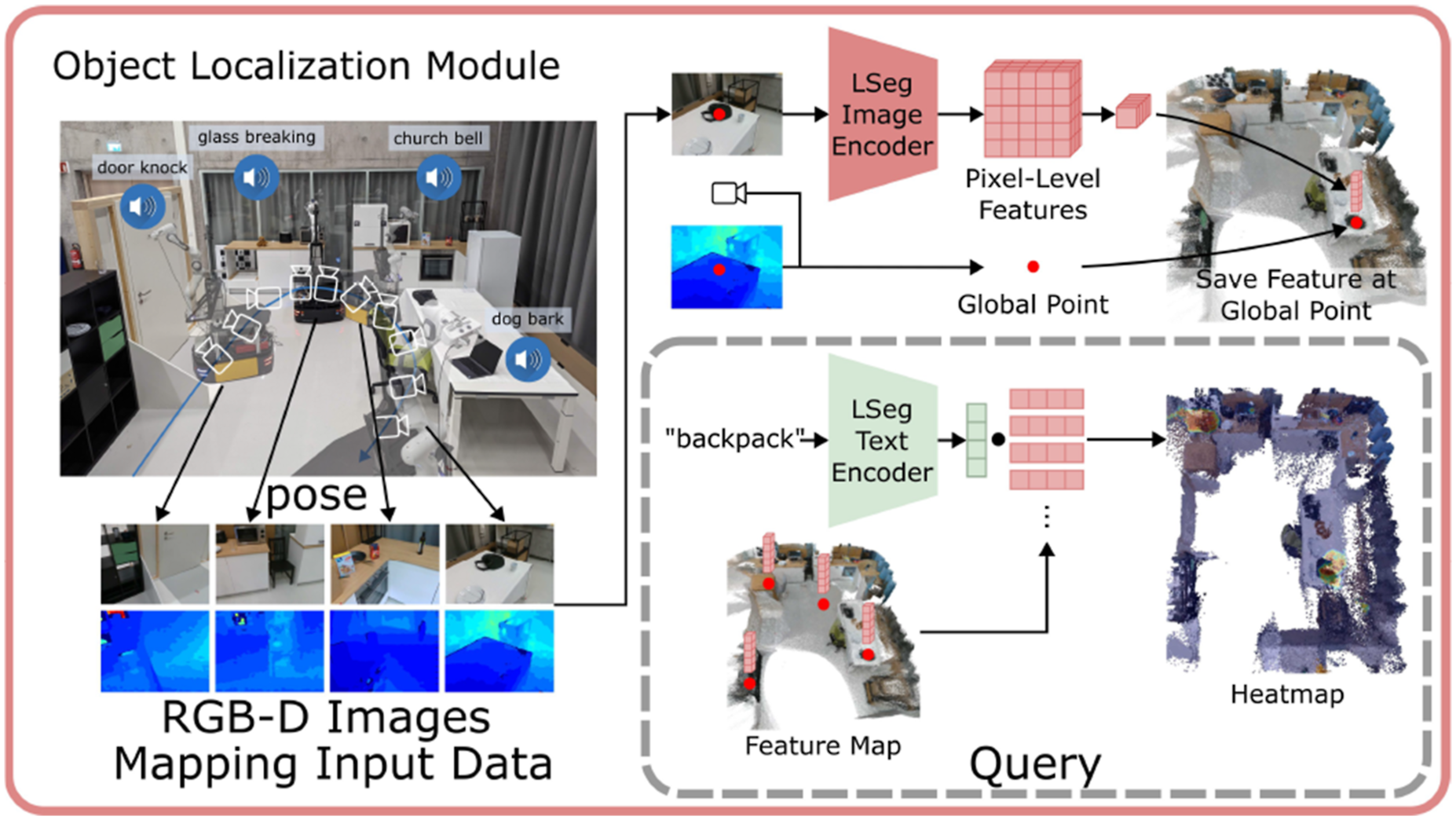
The object localization results are a list of points, denoted as {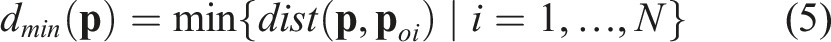
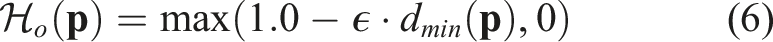
In AVLMaps, the object localization module is also used to generate a 2D obstacle grid map for path planning, as is shown in Section 3.3. Different from the 2D feature grid map of a VLMap, the visual language map is now in the form of a 3D voxel grid where each occupied voxel is associated with a feature. We prompt the map with a list of free area concepts (e.g., “floor”) and obstacle concepts (e.g., “chair,” “table,” “counter,” and “other”) for a specific embodiment, assigning a score to each concept for every voxel. Each voxel is then labeled with the concept that achieves the highest score, resulting in a 3D semantic voxel map. We merge the voxels labeled with obstacle concepts into a combined obstacle map, and then perform a top-down projection to produce a 2D obstacle grid map. In this grid, all pixel locations corresponding to projected obstacle voxels are marked as occupied, while all others are marked as free and navigable. It is worth noting that beyond object categories, AVLMaps also support the definition of audio or images as obstacles. For example, we can define “the sound of glass breaking,” or a list of images as obstacles, generate their corresponding heatmaps, and treat locations with heat above a certain threshold as obstacles. This capability is useful when the forbidden regions are hard to describe with only object descriptions, like a glass-breaking scene without surrounding objects, or a region specified with a cell phone video.
3.5.3. Area localization module
While the object localization module is good at extracting object segments on the map, it falls short of localizing coarser goals such as regions (e.g., “the area of the kitchen”). This is because the visual encoder for generating pixel-aligned features is obtained by fine-tuning a pre-trained model on a segmentation dataset, leading to the notorious catastrophic forgetting effect. Therefore, the visual encoder is better at segmenting common objects while worse at recognizing general visual concepts (Jatavallabhula et al., 2023). To take advantage of both pre-trained and fine-tuned methods, we propose to build an extra sparse topological CLIP features map similar to (Shah et al., 2023). The idea is to compute the CLIP visual features (Radford et al., 2021) for all images from the RGB stream and associate the features with corresponding poses. During inference, given the language concept like “the area of a bedroom,” we compute the language features with the CLIP language encoder and the image-to-language cosine similarity scores. These similarity scores indicate how likely these images match the language description. The odometry together with the score of each image indicates the predicted location with a confidence value.
The area localization results are a list of position-confidence pairs, denoted as {(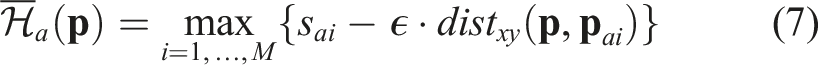
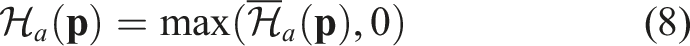
3.5.4. Audio localization module
The overview of the module is shown in Figure 10. In this module, we utilize the audio information from the input stream. The key idea is to compute the audio-lingual features with audio-language pre-trained models such as wav2clip (Wu et al., 2022), AudioCLIP (Guzhov et al., 2022) or CLAP (Elizalde et al., 2023). We first segment the whole audio clip into several segments with silence detection. Whenever the volume is above a threshold, we mark this time step as the starting point of a segment. Whenever the volume of the sound is not larger than this threshold for a certain duration, we end the segment. In the next step, we compute the audio features for each segment with pre-trained audio-language models and associate the features with the odometry at the specific segment. During inference, given a language description of the sound, like “the sound of door knocks,” we encode the language into language features and compute the matching scores between the language and all audio segments in the same way as in the object localization module. The odometry associated with the top-scoring segment is the predicted location. The overview of the audio localization module. During mapping, the exploration video’s audio is segmented by silence and encoded using AudioCLIP’s audio encoder. The resulting embeddings are linked to poses based on their timestamps. During inference, the query text is encoded by AudioCLIP’s text encoder, and a dot product with the pose embeddings generates a score for each pose. A heatmap is then created based on pose scores and distances.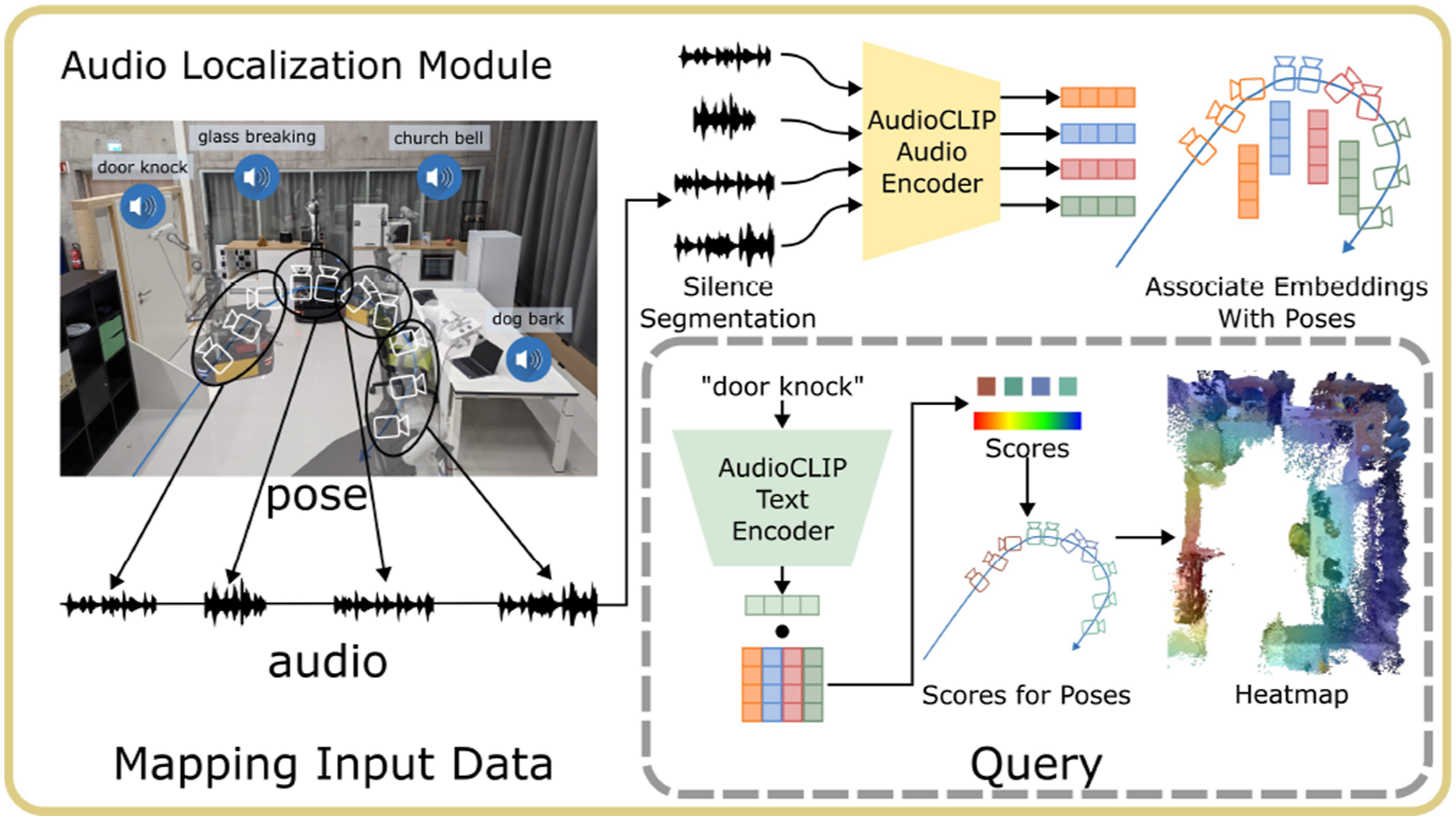
The audio localization results are similar to those of the area localization module. The position-score pairs are denoted as {(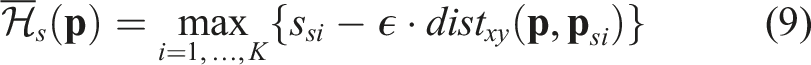
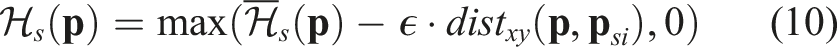
3.6. Cross-modality reasoning
A key advantage of our method is its capability to disambiguate goals with additional information, even from different modalities. The goal of the cross-modality reasoning method is to output a target location of a specific concept (e.g., “the sofa”) given the information of other nearby concepts (e.g., “near the sound of glass breaking”). In the last section, we introduced how we generate heatmaps for concepts of different modalities. Given these heatmaps, we want to further narrow down the target location.
3.6.1. Cross-modal reasoning
The main idea of our cross-modal reasoning method is shown in Figure 11. We treat the predictions from four modules as four modalities. When there are several queries referring to different modalities, we compute the respective heatmaps first and then perform element-wise multiplication among all heatmaps: The key idea of cross-modal reasoning is converting the prediction from different modalities into heatmaps, and then fusing them with element-wise multiplication, effectively using complementary multimodal information to resolve ambiguous prompts.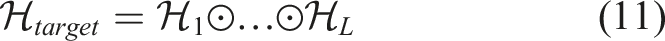
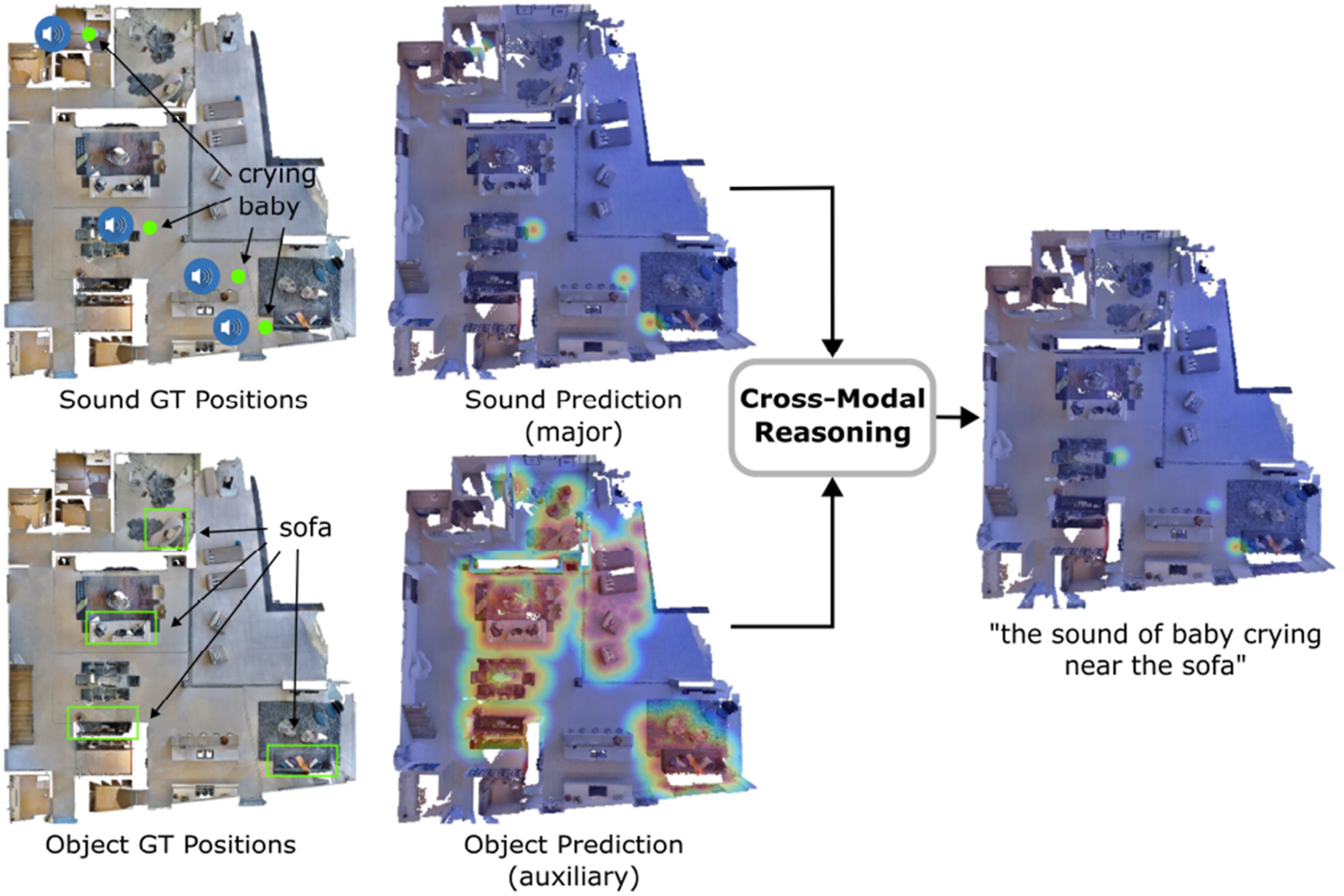
When we compute the heatmaps, there is always a primary heatmap while others are auxiliary ones. For example, in Figure 11, in the query “the sound of baby crying near the sofa,” the heatmap for “the sound of baby crying” is the primary heatmap, while the heatmap for “the sofa” is the auxiliary. We set the decay rate for the primary heatmap higher (e.g., 0.1 in this work for voxel map with 0.05 m voxel size) since we want to know the exact location of the target while tuning the decay rate for the auxiliary heatmap lower (e.g., 0.01) as having a broader effect area to narrow down major targets is desirable. More specifically, a higher decay rate indicates that the relevancy to the concept decreases faster when the location is farther away from the concept locations (heat value decreases 0.1 for every 0.05 m). When there are multiple concepts or modalities mentioned in the target specification, the map with a high decay rate refers to the target concept we want the robot to get closer to. Those maps with low decay rates serve as constraints to select targets in the main map. From another perspective, the decay rates of multiple maps represent the importance weights we assign to their corresponding concepts. The higher the decay rate is, the more important that concept is, and we want the robot to get closer to that concept. When the decay rates of two concepts are the same, the two concepts are equally important, and the fusion of the two concepts’ heatmaps will peak at the middle points between those concepts.
It is worth noting that our cross-modal reasoning method is relatively simple and has the underlying assumption that the heatmaps from different modalities are conditionally independent. Despite this simplification, our method proves to be effective across our experiments. Nonetheless, exploring more advanced cross-modal fusion techniques remains an exciting direction for future work.
3.7. Multimodal goal navigation from language
In the setting of multimodal goal navigation from language, the agent is given language descriptions referring to targets from different modalities (e.g., sounds, images and objects), and is required to plan paths to them. While most of the previous navigation methods focus mainly on a specific type of goal, we unify these tasks with the help of large language models (LLMs). Following a similar spirit to Section 3.4, we use an LLM to interpret the natural language commands and synthesize API calls combined with simple logic structures in the form of executable python code. In the following, we will detail the code generation process for multimodal goal navigation, including (i) the introduction of the API library as a tool set for the LLM to use during code generation, (ii) the mechanism of spatial goal reasoning, (iii) the way we generate multimodal maps with code, (iv) the method to achieve cross-modal reasoning with code, and (v) the conversion of code to navigation commands that robots receive. At the end, we provide the prompt and an example of inference for our method.
3.7.1. Navigation API library
Navigation API library for multimodal goal navigation in AVLMaps.

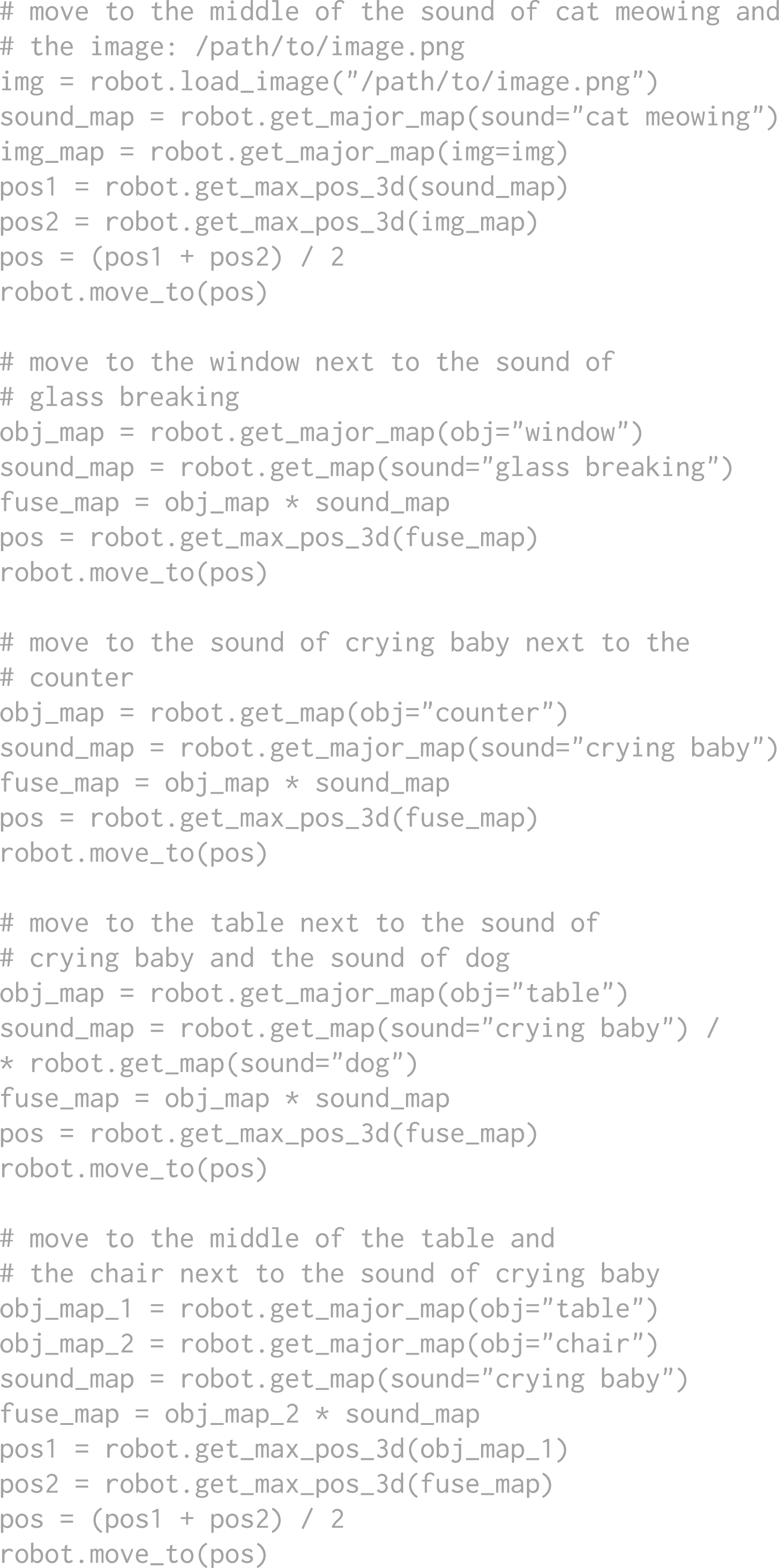
The full context prompt (prompt in gray) AVLMaps used for achieving all navigation tasks in the experiments.
3.7.2. Spatial goal reasoning
We follow the intuition in Section 3.4 that spatial locations can be computed with simple math during code generation. For example, the location of “in between the counter and the fridge” can be obtained by getting the positions of the counter and the fridge, respectively, and apply an average to the two locations. In the multimodal goal navigation prompt, we reduce the spatial goal API calling examples to lay the focus more on multimodal targets and cross-modal reasoning. In principle, more diverse spatial concept reasoning examples could be integrated into the prompt, as is shown in Section 3.4.
3.7.3. Multimodal heatmap generation with code
For heatmap generation, we implement interfaces
3.7.4. Cross-modal reasoning with code
As is introduced before, the logic of the cross-modal reasoning is relatively simple, which is just an element-wise multiplication of all relevant heatmaps. In the code, it can be performed with one line of code
3.7.5. Navigation commands from code
The API
3.7.6. Prompt and an inference example
Since large language models are great few-shot learners (Brown et al., 2020), they are able to learn and imitate internal patterns when several simple examples are provided as context in addition to the direct query. To enable the LLM to understand how to use our APIs, we need to provide a few examples of how to use these APIs to tackle tasks described with language instructions. During the inference, we prompt the full context prompts (in gray) in Figure 12 together with task command (in green) in Figure 13 and an example of the generated outputs is highlighted. In our work, we use OpenAI’s The query and the generated results from the LLM. During the query, the context prompt in Figure 12 and the input task commands are prompted to the LLM together. The input task commands are in green and generated outputs are highlighted.
4. Experiments
In this section, we aim to evaluate our multimodal spatial map representations in a variety of tasks. More specifically, we address nine key questions: (i) how is VLMaps’ spatial language goals navigation performance compared to recent open-vocabulary navigation baselines (Section 4.1), (ii) whether VLMaps with their capacity to specify open-vocabulary obstacle maps can provide utility in improving the navigation efficiency of different robot embodiments (Section 4.2), (iii) how AVLMaps enable a robot to navigate to multimodal goals, including sound, image, and object queries (Section 4.4), (iv) how our cross-modality reasoning approach helps a robot to disambiguate goals with multimodal information (Section 4.5), (v) how the performance of AVLMaps scales with recent advanced foundation models specialized in different modalities (Section 4.7), and (vi) how AVLMaps’ multimodal indexing and reasoning capabilities translate to real-world environments, empowering robots with diverse embodiments to perform tasks that demand comprehensive multimodal understanding, such as mobile navigation (Section 4.8) and table-top manipulation with multimodal prompts (Section 4.9).
4.1. Zero-shot spatial goal navigation from language
4.1.1. Experimental setup
We use the Habitat simulator (Savva et al., 2019) with the Matterport3D dataset (Chang et al., 2017) for the evaluation of multi-object and spatial goal navigation tasks. The dataset contains a large set of realistic indoor scenes that help evaluate the generalization capabilities of navigating agents. To evaluate the creation of open-vocabulary multi-embodiment obstacle maps, we adopt the AI2THOR simulator due to its support of multiple agent types, such as LoCoBot and drone. In these two environments, the robot is required to navigate in a continuous environment with actions:
4.1.2. Baselines
We evaluate VLMaps against three baseline methods, all of which utilize visual-language models and are capable of zero-shot language-based navigation: • LM-Nav (Shah et al., 2023) creates a graph where image observations of an environment are stored as nodes while the proximity between images is represented as edges. By combining GPT-3 and CLIP, it parses language instructions into a list of landmarks and plans on the graph toward corresponding nodes. • CLIP on Wheels (CoW) (Gadre et al., 2023) achieves language-based object navigation by building a saliency map for the target category with CLIP and GradCAM (Selvaraju et al., 2020). By thresholding the saliency values, it retrieves a segmentation mask for the target object category and then plans the path on the map. • CLIP-features-based map (CLIP Map) is an ablative baseline that generates a feature map for the environment in a similar way as ours. Instead of using LSeg visual features, it projects the CLIP visual features onto the map averaged across views. Object category masks are generated by thresholding the similarity between map features and the object category features.
For additional context and analysis, we also report results from a system that has access to a ground truth semantic map for navigation (GT Map), to provide a systems-level upper bound on performance.
4.1.3. Tasks collection
The success rate (%) of zero-shot spatial goal navigation with language.
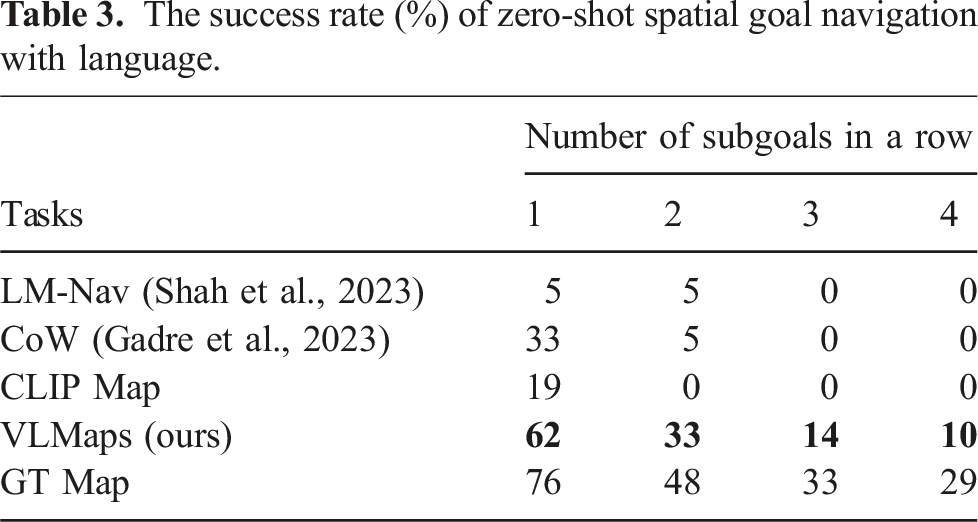
Table 3 summarizes the zero-shot spatial goal navigation success rates. Our method outperforms other baselines in this task. Different from object navigation tasks where agents only need to approach a certain object type within a range, disregarding the relative spatial shift to the object, the language-based spatial goal navigation tasks require the robot to accurately arrive at the described location in reference to the object. This poses a bigger challenge to the landmark localization ability of the method. The low localization ability of CoW and CLIP Map leads to their high failure rates in this task.
4.2. Cross-embodiment navigation
4.2.1. Experimental setup
We collect 1,826 RGB-D frames across 10 rooms in AI2THOR (Kolve et al., 2017) and build the VLMaps for these scenes. We study the ability of VLMaps to improve navigation efficiency by retrieving different obstacle maps for different embodiments (given the same VLMap) in navigation tasks. We evaluate more than 100 sequences of object subgoals in the AI2THOR simulator. We evaluate VLMaps on both a LoCoBot and a drone to test its capability of generating obstacle maps at runtime for multi-embodiment navigation.
4.2.2. Obstacle maps generation
We apply the open-vocabulary obstacle map generation method in Section 3.3 to create an obstacle map for the drone (drone map) and one for the LoCoBot (ground map) by defining obstacles for them differently. For the LoCoBot (ground robot), we first define a potential obstacle list as [
4.2.3. Baselines
We test the navigation ability of these embodiments with three setups: a LoCoBot with a ground map, a drone with a ground map, and a drone with a drone map.
4.2.4. Metrics
We evaluate the Success Rate (SR) and the Success rate weighted by the (normalized inverse) Path Length (SPL) (Anderson et al., 2018a) defined as:
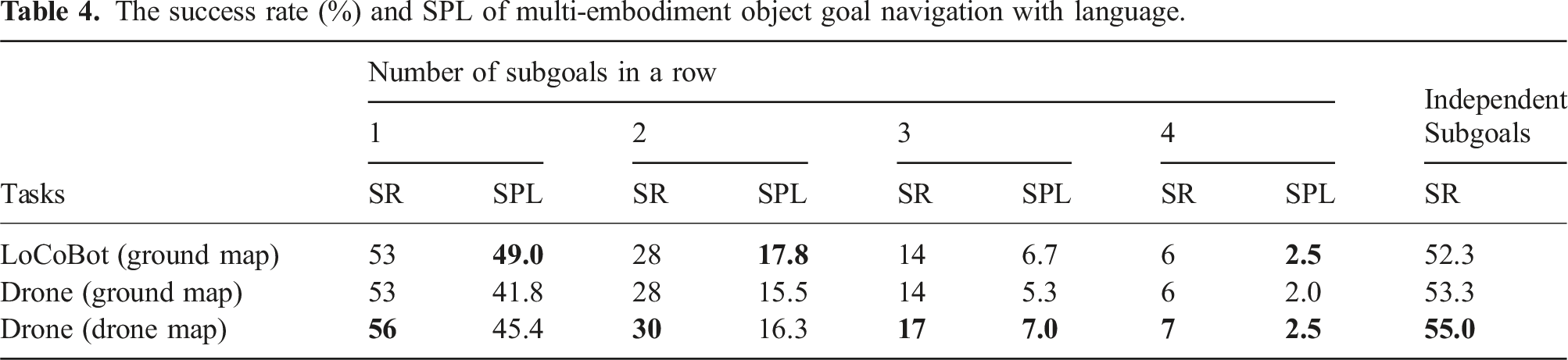
The success rate (%) and SPL of multi-embodiment object goal navigation with language.

VLMaps enable different embodiments to define their own obstacle maps for navigation. The left image shows the top-down view of an environment. The middle columns show the observations of agents during navigation. The images on the right demonstrate the obstacles maps generated for different embodiments and the corresponding navigation paths.
4.3. Multimodal navigation simulation setup
4.3.1. Experimental setup
We use the Habitat simulator (Savva et al., 2019; Szot et al., 2021) with the Matterport3D dataset (Chang et al., 2017) for the evaluation of multimodal navigation tasks. For mapping purposes, we manually collect RGB-D video streams in the simulator across 10 different scenes and add random audio tracks to the videos to simulate the audio sensing modality. All audio comes from the validation fold (Fold-1) of the ESC-50 dataset (Piczak, 2015), which contains 50 categories of common sounds. In navigation tasks, the robot has four actions to take:
4.3.2. Tasks collection
In multimodal goal navigation tasks in Section 4.4, we consider three kinds of goals: image goals, object goals, and sound goals. For image goals, we randomly sample positions and orientations on the top-down map and render images as targets. For object goals, we access the metadata (e.g., bounding boxes and semantics) from the Matterport3D dataset and sample a list of categories in each scene as queries. For sound goals, we randomly sample sound classes of audio merged with the mapping videos as targets, treating the video frame positions as the ground truth.
In cross-modal goal indexing tasks in Section 4.5, we collect three types of datasets: • • •
In cross-modal goal navigation in Section 4.6, we randomly sample starting pose in 10 scenes and treat the visual-object and object-sound cross-modal goals in Section 4.5 as navigation goals. For all cross-modal navigation and indexing tasks, we use the prompt introduced in Section 3.7 to generate navigation commands.
4.4. Multimodal goal navigation
4.4.1. Sound goal navigation
The success rate (%) of sound goal navigation with AVLMaps.

4.4.2. Visual and object goals navigation
The success rate (%) of multimodal goal navigation with AVLMaps. The agent is required to navigate to one visual goal and two object goals in sequence.

4.5. Cross-modal goal indexing
When we refer to a goal with language, it is likely that the goal can be found in more than one place in the environment. A major strength of our method is that it can disambiguate goals with multimodal information. In this experiment, we will show the cross-modal goal reasoning capability of AVLMaps.
4.5.1. Area-object goal indexing
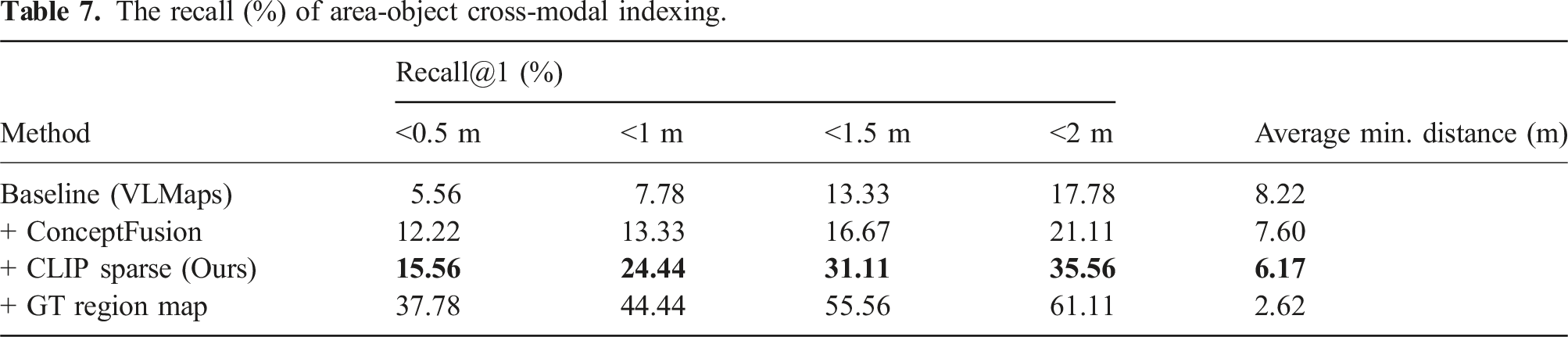
The recall (%) of area-object cross-modal indexing.
4.5.2. Object-sound goal indexing
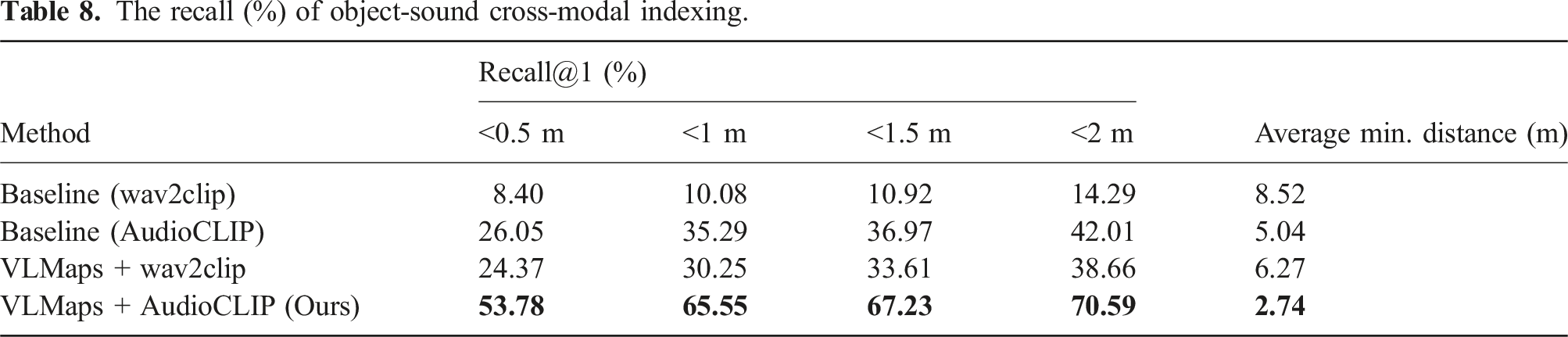
The recall (%) of object-sound cross-modal indexing.
4.5.3. Visual-object goal indexing
The recall (%) of visual-object cross-modal indexing.

4.6. Multimodal ambiguous goal navigation
The success rate (%) of multimodal ambiguous goal navigation with AVLMaps. The agent is required to navigate to one ambiguous sound goal and one ambiguous object goal sequentially.
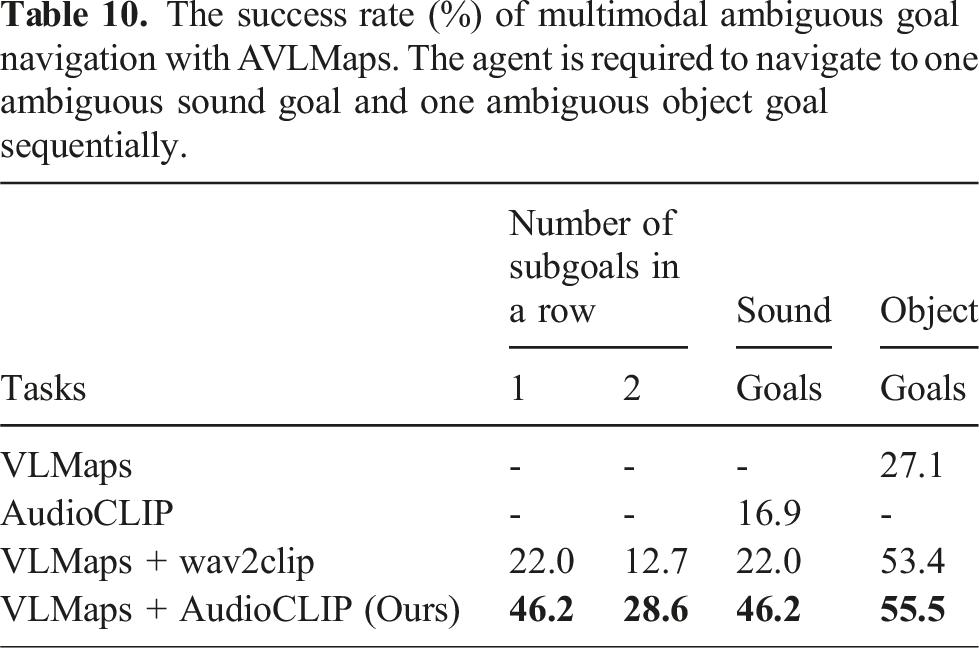
4.7. Scaling experiment
Since AVLMaps is highly modular, each module can be upgraded with advanced foundation models that generate similar audio-language features or visual-language features. In this section, we explore whether AVLMaps can evolve with the advancement in foundation model research. We follow similar settings of multimodal goal navigation as in Section 4.4 to test the AVLMaps modules supported by different foundation models. In this experiment, the robot needs to navigate to a sound goal, a visual goal, and two object goals in a sequence and we report the in-a-row navigation success rate as well as the success rate for each type of goal. In this experiment, we mainly focus on analyzing how the performance scales with improved Audio Language Models and Vision Language Models. We fixed the visual localization module as NetVLAD and SuperGLUE.
4.7.1. Audio language models
We compare the downstream performance of using AudioCLIP (Guzhov et al., 2022) with respect to a more recent CLAP (Elizalde et al., 2023) model.
4.7.2. Vision language models
In order to leverage pretrained Vision Language Models, we require the encoder to generate pixel-wise features in CLIP embedding space. We compared LSeg (Li et al., 2021), the VLM used in VLMaps (Huang et al., 2023b), with OVSeg (Liang et al., 2023a) and a method that uses SAM (Kirillov et al., 2023) and CLIP (Radford et al., 2021) introduced in HOV-SG (Werby et al., 2024). The method in HOV-SG first leverage SAM (Kirillov et al., 2023) to generate class-agnostic masks. Each region cropped with a mask and its zero-background version are encoded with a CLIP image encoder and their embeddings are summed with weights. The resulting embedding is assigned to all pixels in the masked region.
4.7.3. Results
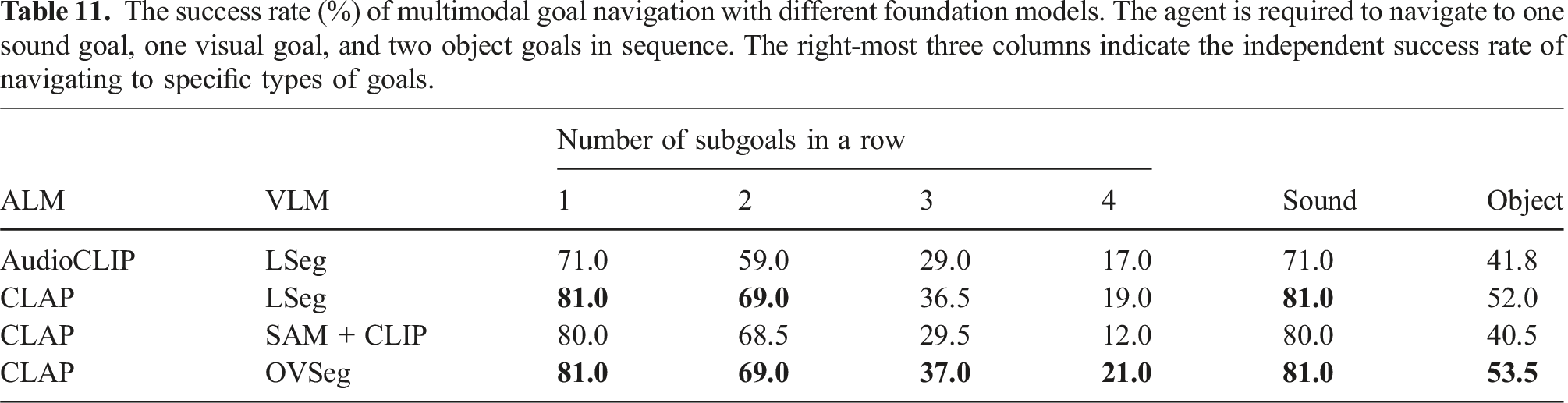
The success rate (%) of multimodal goal navigation with different foundation models. The agent is required to navigate to one sound goal, one visual goal, and two object goals in sequence. The right-most three columns indicate the independent success rate of navigating to specific types of goals.
4.8. Real world experiment for mobile robot
To answer the question of how AVLMaps applies to real-world environments and benefits multimodal navigation, we designed a mobile navigation experiment in which the robot must locate sound, image, and object-based goals within an environment containing duplicate objects from certain categories such as chairs, backpacks, shelves and so on. This setup demonstrates how AVLMaps enables the robot to retrieve multimodal concepts and disambiguate goals by leveraging information from additional modalities.
4.8.1. Robot setup
In the real-world experiment setting, we use a mobile robot equipped with a Ridgeback omnidirectional platform from Clearpath Robotics as the mobile base, and a Panda manipulator from Franka Emika. We mount a RealSense D435 RGB-D camera at the gripper of the Panda manipulator. During the mapping, we run a LiDAR localizer to provide the odometry for the robot base and derive the camera pose through the forward kinematics of the robot arm.
4.8.2. Environment setup
We choose a room with multiple ambiguous goals such as tables, chairs, paper boxes, counters, and backpacks, which are shown on the left in Figure 15. We control the robot in this environment and record RGB-D video. Then we artificially add sounds to the RGB-D video when the robot moves to certain locations. The sound locations are shown on the right in Figure 15. Real-world navigation experiments are conducted in a room with multiple ambiguous goals such as tables, chairs, backpacks, and paper boxes (left). The robot setup is also shown in the left image. We leverage dense SLAM techniques to build a 3D reconstruction of the scene from RGB-D camera data into which we anchor features from multiple foundation models (right). We artificially insert sounds with different semantics at locations shown in the image. Different sounds are played when the robot moves to these locations during mapping. Sounds are sampled from the ESC-50 dataset.
4.8.3. Audio recording and denoising
To make the experiment more realistic, instead of simply adding clean audio to the video, we recorded environmental noise using a microphone during the robot’s exploration. We then overlaid semantic soundtracks from ESC-50 onto the recorded environmental noise at specific locations. This approach provides an approximation of real-world audio conditions with background noise. We also experimented with playing sounds through a speaker in the environment and recording both the environmental noise and semantic audio simultaneously. However, the mobile robot produced significant vibration noise while moving, which masked the played sounds and rendered them largely inaudible. As a result, we approximated the noisy semantic audio by mixing the semantic soundtracks with the recorded environmental noise.
Since current audio language models are sensitive to noise in input audio, we apply a noise filtering algorithm as a pre-processing step to the audio before sending them to the audio localization module. In our case, we use a noise gate, as shown in Figure 16. A noise gate applies thresholding with smooth fade-in and fade-out transitions. Instead of simply zeroing out values below the threshold, it includes three phases: attack, hold, and release. When the input audio level exceeds the threshold, the output ramps up linearly from zero to the input level over a period defined by the attack time. Once the input drops below the threshold, the output stays at the input level for the duration of the hold time. If the input remains below the threshold after the hold period, the output level decreases linearly to zero over the release time. This approach effectively reduces environmental noise. We then apply silence segmentation to further extract meaningful audio clips. In our setup, the noise gate threshold is set to −10 dB (dB = 20 ∗ log 10 (amplitude)), with an attack time of 250 ms, hold time of 1000 ms, and release time of 170 ms. The silence segmentation threshold is set to 0.1. As noise cancellation is not the primary focus of this work, these parameters were selected based on empirical experience. In the future, a more robust approach would involve adding random real-world noise during audio language model pretraining to improve noise tolerance. Audio denoising for real-world experiment. We pre-process the audio by applying a noise gate. Simply applying a threshold for filtering out low-level noise might lead to frequent fluctuation of the audio level, leading to fragmentation of the target audio (see the left). A noise gate contains “attack,” “hold,” and “release” phases, which introduce smooth transitions and prevent cutting off short audio signals (see the right).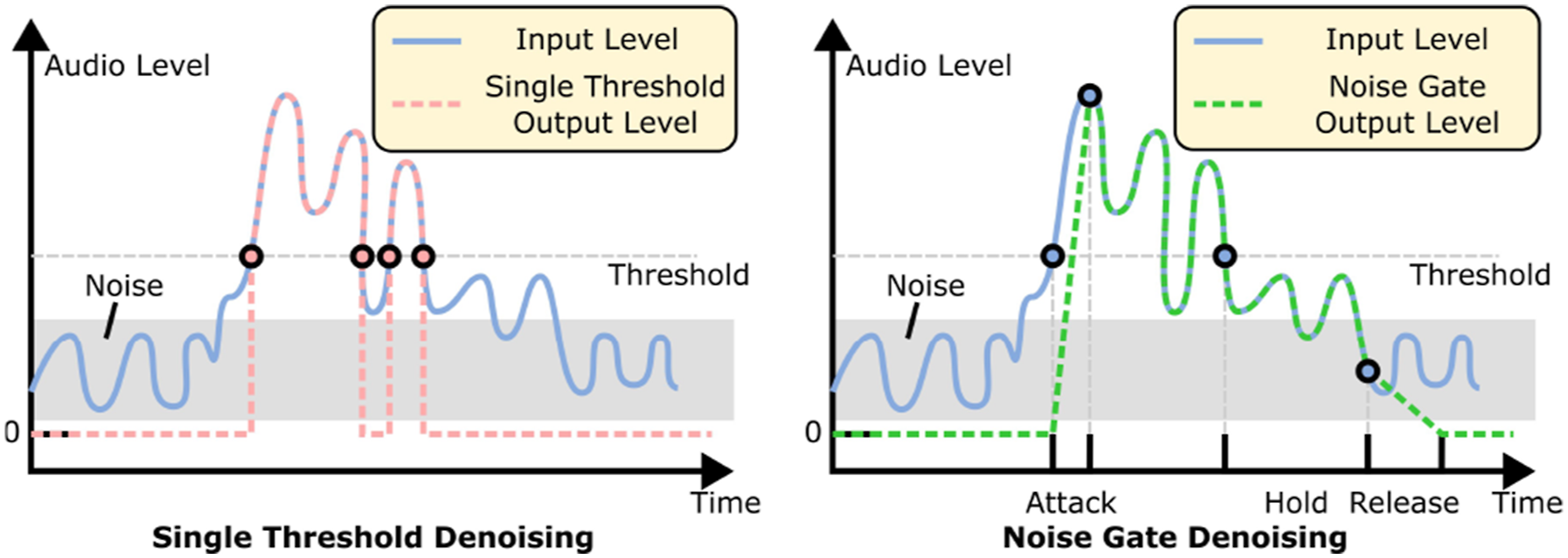
4.8.4. Map building and navigation
After collecting the data, we run the AVLMaps mapping offline. For navigation tasks, we provide the AVLMaps and the language instruction as input. The robot parses the instruction (Section 3.7) and executes the generated Python code for goal indexing and planning. We use the ROS navigation package (Quigley, 2009) for global and local planning. We pre-process sound inputs with background noise subtraction to avoid including noise from the robot operation.
4.8.5. Multimodal spatial goal reasoning and navigation with natural language
We design 20 language-based multimodal navigation tasks, asking the robot to navigate to sounds, images, and objects. We report an overall success rate of 50%. We also design an evaluation consisting of 10 multimodal spatial goals. The agent needs to reason across object, sound, image and spatial concepts. An example is “navigate in between the backpack near the sound of glass breaking and {the image of a fridge}.” In the end, six out of 10 tasks were successfully finished. We show in Figure 17 the process of resolving ambiguities in the scene. There are different ambiguous objects in the scenes including paper boxes, backpacks, shelves, tables, chairs, and plates. The first and the second columns in Figure 17 show the ground truth positions of the target objects and sounds. The third and fourth columns show that AVLMaps can accurately localize objects, sounds, and visual goals in the form of 3D heatmaps. The final column shows that our method can correctly narrow down targets in spite of object ambiguities. We can observe from the figure that AVLMaps can accurately localize ambiguous concept with language, audio and image. We observe that the failures come from the composition of the imperfection of different modules. For example, the object localization module (e.g., VLMaps) fails to recognize rare objects like various toys. It also mistakes some shelves for chairs. Similar failures happen in audio localization module. In the second row and the fourth column in Figure 17, the church bell sound should be at the top-right corner but the module also gives high score for the sound heard at bottom-left. Visualization of example heatmaps in AVLMaps for multimodal goal reasoning for ambiguous object goals. The first column shows the positions of ambiguous objects (green bounding boxes) and the location of a sound (the icon of a speaker) or an image (the icon of a camera), while the second column shows the close-up view of ambiguous objects in the scene. The third column shows the predicted 3D heatmap for the object. The fourth column shows the heatmap for the extra modality, and the fifth column shows the fused heatmap after cross-modal reasoning. Sounds are artificially inserted into the scene for benchmarking and evaluation. The locations of sounds are not sound-source locations but the places where the sounds were heard. The heatmap is shown in the JET color scheme (red means the highest score and blue means the lowest score).
4.9. Real world experiment for table-top goal reaching
In the previous section, we demonstrated how AVLMaps empower a robot to interpret multimodal goals in room-scale mobile navigation tasks. Here, we extend our investigation to assess how AVLMaps benefit a fixed-based manipulator in real-world table-top tasks, which require a more detailed semantic understanding of the scene. In this setup, the robot manipulator must approach multimodal goals with a stricter tolerance for error (within 10 cm). Additionally, we explore AVLMaps’ potential for application across robots with varied embodiments.
4.9.1. Robot setup
We set up a Panda robot arm from Franka Emika on a table and mount a FRAMOS D345e industrial RGB-D camera at the gripper of the manipulator. Before the experiment, we calibrate the extrinsic matrix from the end effector coordinate frame to the camera frame. We use an HTC Vive VR controller to teleoperate the robot end effector to collect observation data.
4.9.2. Experiment setup
We set up two tabletop scenes where different objects are lying on the table at random locations. In one scene, we deliberately place duplicate objects on the table to simulate the ambiguity of objects. Subsequently, we teleoperate the robot end effector with a VR controller and collect observations including the RGB, the depth, and the robot end effector poses relative to the robot base coordinate frame. The recording frequency is 30 Hz. Later, we derive the camera poses relative to the base coordinate frame using the end effector pose and the extrinsic matrix obtained during the calibration. For each scene, we first collect a sequence of data for generating maps with the object localization module and the visual localization module. We then control the robot to different areas on the table and collect an episode of data in each region, to which we later insert a random segment of audio sampled from ESC-50 dataset in a similar way as the mobile robot experiment setting. These observation data augmented with audio are used to generate the audio map with the audio localization module. Thanks to the insights we obtained from the scaling experiments in Section 4.7, we use CLAP (Elizalde et al., 2023) and OVSeg (Liang et al., 2023a) as our foundation models for the audio localization module and the object localization module. For the visual localization module, we still use the NetVLAD (Arandjelovic et al., 2016) and SuperGLUE (Sarlin et al., 2020) scheme as in Section 3.5.
4.9.3. Tabletop manipulator goal reaching
We randomly moved the robot arm and collected a sequence of RGB images as the visual goals used for querying the AVLMaps created earlier. During inference, we prompted the robot with randomly selected visual goals (sampled from the collected images), sound categories (matching the inserted audio types), and object categories (language descriptions of objects on the table), instructing it to approach the target region. If the final position of the robot’s end effector was within 10 cm of the ground truth, the trial was considered successful. We tested 20 visual goals, 12 sound goals, and 13 object goals. The robot successfully reached 100% of the visual and sound goals, and nine out of 13 object goals. Additionally, we tested 10 ambiguous goals, such as “the light near the sound of clock alarm” or “the apple near the image {path/to/image}” and the robot successfully approached 9 out of 10. In summary, AVLMaps demonstrated excellent performance in a tabletop setting, successfully navigating to multimodal goals, including ambiguous ones. The results are shown in Figure 18. Visualization of tabletop goal-reaching experiments. We set up two tabletop scenes and inserted sounds to different locations in the observation data (left). We show the indexing heatmap results of sound goals, visual goals, object goals, and ambiguous goal reaching results on the right. In addition, for visual goals, object goals, and ambiguous goals, we show the ground truth target locations (green cubes or green boxes) as well as the reached positions (red cubes). The heatmap is shown in the JET color scheme (red means the highest score and blue means the lowest score).
5. Limitations and discussions
While our multimodal spatial language maps approach is versatile in terms of navigating to various spatially grounded concepts and is effective in the disambiguation of duplicate goals with extra information, it does have certain limitations. In this section, we thoroughly discuss the major drawbacks of our method, along with potential directions for extension and improvement. Through this analysis, we aim to offer insights to the community and inspire future research.
5.1. Transient sound reaction
One of the main challenges with our AVLMaps is that sound is inherently transient, while the map relies on pre-exploration and offline mapping to embed the information for navigation tasks. Even if sounds are associated with specific locations during the exploration phase, those sounds might disappear or shift to new locations by the time of the inference and navigation. Therefore, AVLMaps struggles to support reactive navigation toward transient sound goals. Previous work on vision and audio navigation (Chen et al., 2020; Gan et al., 2020b; Younes et al., 2023) has focused on enabling robots to respond to transient sounds using biaural and visual observations. However, these methods are limited to transient goals and have been tested only in simulated environments. We argue that both transient sounds and previously heard sounds are essential for intelligent navigation. Transient sounds serve as important cues for immediate action, while past sounds provide valuable references for narrowing down possible targets based on prior experiences. For example, when instructed to go to “the café where you heard the song,” we can recall the specific café and adjust our navigation accordingly. A robot must be able to understand and navigate toward both kinds of sound goals to achieve human-level intelligence in sound-based navigation. However, no current system integrates these dual capabilities. We believe this gap presents an exciting opportunity for future research.
5.2. Sound localization
While AVLMaps manages to comprehend the semantic meaning of sounds, it struggles to localize the sound sources. In this paper, the audio localization module assumes monaural audio input, lacking in the ability to utilize binaural audio to localize sound sources with triangulation like humans. More specifically, a sound can be heard in all locations inside a room, but we only associate its features with the robot’s current location. Encouragingly, several concurrent works are actively addressing the sounds source localization, including efforts to learn the real-world acoustic sound field (Chen et al., 2024b), reconstruct the acoustic properties of environments (Wang et al., 2024), and develop more acoustically realistic simulation environments (Chen et al., 2022).
5.3. Dynamic scenes
Another challenge faced by our multimodal spatial language maps (both VLMaps and AVLMaps) is their inability to handle dynamic scenes. One form of dynamics involves in-view dynamics, such as walking humans and moving articulated objects during exploration. These dynamic entities easily corrupt the object map, leaving behind point artifacts that trace their movement trajectories. The semantic features of the moving objects may be erroneously associated with these artifact points, leading to inaccurate representations of their true locations. Another form of dynamics involves long-term dynamics, such as object relocations between the exploration and inference phases. These relocations can invalidate the pre-built map, necessitating an updating mechanism to ensure accurate navigation. Currently, our multimodal spatial language maps lack mechanisms to address both types of dynamics. To explore potential solutions, we investigated approaches to mitigating the impact of dynamics. Prior works have addressed in-view dynamics by removing or tracking certain classes of semantic masks during mapping (Runz et al., 2018; Xu et al., 2019). For long-term dynamics, recent research has proposed learning-based object association methods to update the locations of relocated objects in the map (Huang et al., 2025; Yan et al., 2025). These solutions could be integrated into our mapping pipeline to enhance its robustness.
5.4. Extension to more modalities
In this paper, we have demonstrated the feasibility of integrating information from multiple modalities into a unified map representation. More broadly, our method provides a framework that can be extended to additional modalities, such as odor, temperature, magnetic fields, infrared imagery, and point clouds. In our implementation, we selected audio, language, and vision because they closely mirror human perceptual capabilities. Viewed from a broader perspective, AVLMaps can be regarded as a case study in building a multimodal spatial memory system, with inherent flexibility to incorporate more modalities. Extending the system to a new modality X involves three steps: (i) implementing the “X localization module” which includes mapping (embedding and storing the data into a representation) and retrieval (generating a heatmap based on the query data and the map) functions for the new modality, (ii) implementing the
6. Conclusion
In this paper, we introduced multimodal spatial language maps, a unified mapping framework that is spatial, multimodal, reusable, and extensible. We first introduced a visual language map representation, VLMaps, that enables robots to navigate to long-horizon spatial goals in a zero-shot manner. By defining the categories where the robot can and cannot traverse, our map representation can adaptively generate obstacle maps for different embodiments, allowing for efficient path planning. Subsequently, we further extend our visual-language maps to a multimodal version, AVLMaps, which is a unified 3D spatial map representation for storing cross-modal information from audio, visual, and language cues. AVLMaps retain the spatial and reusable properties of VLMaps while enabling robots to reason over multimodal cues to disambiguate goals using large language models. Experiments in both simulated and real-world environments with different robotic embodiments demonstrate that our multimodal spatial language maps enable zero-shot spatial and multimodal goal navigation, significantly outperforming baselines in navigation success rate and landmark indexing accuracy, especially in scenarios with ambiguous goals. Moreover, extensive experimentation reveals that the performance of multimodal navigation and manipulation tasks scales with the capabilities of the underlying foundation models. At the end of the paper, we also present an in-depth discussion of the limitations and potential directions for future work, to inspire further research in multimodal spatial reasoning for robotics.
Supplemental Material
Footnotes
Acknowledgements
This work was partially supported by the BrainLinks-BrainTools center of the University of Freiburg by providing infrastructure, and by Toyota Motor Europe by providing an HSR robot.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.