
Abstract
Photorealistic synthetic data and novel rendering techniques significantly advanced computer vision research. However, datasets focused on computer vision applications cannot be easily applied to robotics because they typically lack physics-related information. This, combined with the difficulties of realistically simulating dynamic worlds and the insufficient photorealism, flexibility, and control options of common robotics simulation frameworks, hinders progress in (visual-)perception research for autonomous robotics. For instance, most Visual Simultaneous Localization and Mapping methods are passive, developed under a (semi-)static environment assumption, and evaluated on just a limited number of pre-recorded datasets. To address these challenges, we present a highly customizable framework built upon NVIDIA Isaac Sim for Generating Realistic and Dynamic Environments—GRADE. GRADE leverages Isaac’s rendering capabilities, physics engine, and low-level APIs to populate and manage realistic simulations, generate synthetic data, and evaluate online and offline robotics approaches, including Active SLAM and heterogeneous multi-robot scenarios. Within GRADE, we introduce a novel experiment repetition approach that allows environmental and scenario variations of previous simulations within physics-enabled environments, enabling flexible and continuous testing, development, and data generation. We then use GRADE to collect a high-fidelity and richly annotated synthetic video dataset of indoor dynamic environments. With that, we train detection and segmentation models for humans and successfully address the syn-to-real gap. We then benchmark state-of-the-art dynamic V-SLAM algorithms, revealing their limitations in tracking times and generalization capabilities, and evidencing that top-performing deep learning models do not necessarily lead to the best SLAM performance. Code and data are provided as open-source at https://grade.is.tue.mpg.de.
Keywords
1. Introduction
Directly conducting robotic experiments in the real world to test and validate new approaches can pose safety risks. Unforeseen failures of methods and sensors, corner cases, or loss of control of the autonomous robot platform may easily lead to damage or injuries. This problem is further exacerbated when the robot relies on exteroceptive sensors: noise, domain shifts, and the lack of formal performance guarantees or uncertainty quantification in most deep learning (DL) models can make behaviors unpredictable. Surely, pre-recorded datasets have been widely used to develop and evaluate new approaches. Those designed for computer vision research, such as Lin et al. (2014); Saini et al. (2022); Varol et al. (2017), are visually appealing due to the use of real-world images or advanced rendering engines like Blender 1 and Unreal Engine (UE 2 ). However, the absence of basic sensor readings (e.g., IMU, LiDAR), sensor states (e.g., position, orientation, velocity), and (in general) temporal information restricts their applicability in robotics contexts, where physics- and time-related information is necessary.
At the same time, gathering ground-truth data for robotics poses significant challenges. In addition to the safety risks, accurately measuring physical quantities can be intricate, time-intensive, and impractical. Even when feasible, it demands costly specialized sensors requiring rigorous calibration and synchronization, both among themselves and with other hardware like cameras, making the process particularly difficult. For example, despite the centrality of the problem to higher-level tasks, there exist only a handful of real-world SLAM benchmark datasets with ground-truth information, especially for dynamic environments (Bujanca et al., 2021; Burri et al., 2016; Geiger et al., 2013; Sturm et al., 2012). Furthermore, relying solely on already available datasets for real-world robotic applications is not straightforward due to differences in robot form factors (e.g., sensor placement), sensor configurations (e.g., camera focal length, sensor publishing frequency), and different noise models. This requires researchers to rely on their own data or a limited selection of datasets, which can overfit specific scenarios and hinder reproducibility, robustness, and broader deployment. Finally, datasets are “fixed” in time, as one cannot introduce new sensors or modify recorded environmental conditions (e.g., removing dynamic elements or changing lighting conditions) after data collection. This limitation further restricts their usage, making them inadequate for evaluating methods that require real-time dynamic decision-making, such as obstacle avoidance, environment interaction, or Active SLAM.
Therefore, to overcome the static nature of pre-recorded datasets and facilitate the safe development and evaluation of robotics methods, simulation engines such as Gazebo (Koenig and Howard, 2004) and WeBots (Michel, 2004) are widely used. However, with those, it is often challenging to (i) obtain and finely control realistic animated rigid and non-rigid assets, (ii) simulate dynamic environments, (iii) customize and control the simulation engines, and thus (iv) bridge the gap between simulations and the real world. Moreover, the low visual fidelity of many robotics simulators exacerbates the sim-to-real transfer gap. As a result, most robotics research is conducted in highly controlled scenarios with several simplifying assumptions. Indeed, although (non-)rigid moving objects are common in real life and significantly affect vision-based localization or navigation methods, many current approaches still assume a (semi-)static world (Abaspur Kazerouni et al., 2022; Bujanca et al., 2021; Saputra et al., 2018) or use simplified dynamic environments composed of basic 3D shapes (Shao et al., 2024; Wu et al., 2024). Overall, this is detrimental to the development and evaluation of robotic systems which depend heavily on visual perception to operate reliably in dynamic environments. Thus, it is imperative to have a simulation framework that incorporates at least the following key characteristics: (i) physical realism—to correctly simulate dynamics, (ii) photorealism—to reduce the perception gap, (iii) low-level access—to allow full control, and (iv) the capability to simulate dynamic entities—to enable widespread deployment. Integration with ROS, although optional, would further encourage wider adoption of such a framework, given its common use in developing higher-level software that functions simultaneously in both simulation and real robots. In short, an easily controllable simulation that closely resembles the real world with a minimal sim-to-real gap is essential to enable quick and reliable real-world deployment of robotic methods.
To address these issues, we present a solution for Generating Realistic And Dynamic Environments—GRADE. GRADE is a flexible, controllable, customizable, photorealistic, ROS-integrated pipeline that can produce visually realistic data in physically enabled environments. GRADE is built directly upon NVIDIA Isaac Sim,
3
leveraging its rendering and PhysX engines. In contrast to existing methods, our work is not merely a new benchmarking approach or an application-specific platform; instead, it provides an open system that can be easily expanded towards different research goals. We make available a set of functions, tools, and case studies that serve as an entry point with low-level access to Isaac Sim’s capabilities. This enables researchers to easily customize simulations to meet their needs and further bridge the gap between simulation and real-world scenarios. A sample image generated with GRADE, displaying diverse subjects, environments, and overlaid robots, is shown in Figure 1. Example scenes generated by GRADE with overlaid drones. This figure shows two different scenarios simulated with GRADE. [Left] An outdoor savanna environment with manually placed animated zebras (the same scene is also present in Figure 4e). The savanna world and the animated zebras are freely available assets we obtained from the Unreal Engine and SketchFab marketplaces. This scene is used only to evaluate the generalization of the method to different environments and assets. [Right] An indoor environment with animated humans (also present in Figures 4b-4d Figures 6 Figures 8). The UAVs and the UGV (in the right image only) are captured in the scene itself from an external point of view and then manually overlaid to highlight their movement in the environment (similar to Figure 9a and 9b). The 3D-Front indoor environment (on the right), populated with animated SMPL humans from the Cloth3D dataset, resembles a scene that we used to generate the data used for training our syn-to-real detection and segmentation models in Section 6.2 and to evaluate Dynamic V-SLAM approaches in Section 6.3. This indoor scene has been automatically created using our data generation procedure, including the placement of the dynamic assets. 
This work presents different case studies highlighting GRADE’s versatility, including visual data collection (Section 4.1), Active V-SLAM, and heterogeneous multi-robot simulations (Section 4.2). Among those, we also introduce a novel experiment repetition procedure (Section 4.3) that enables the exact reproduction of simulation trials under varying environmental conditions and adjustments to the robot’s settings and equipment, all within a physically controlled environment. We then use GRADE to automatically generate a novel extensive dataset, which we release publicly, collected in indoor dynamic environments (Section 5). We employ this dataset, consisting of more than 615K frames, to assess the visual realism of the simulation through extensive experiments on human detection and segmentation with YOLOv5 (Jocher et al., 2022) and Mask R-CNN (He et al., 2017), demonstrating strong sim-to-real performance (Section 6.2). Indeed, our results highlight that pre-training with GRADE-generated data enables models to outperform the baseline on the COCO (Lin et al., 2014) dataset. Moreover, training with synthetic images alone achieves results comparable to the baseline, even without any fine-tuning, on the TUM RGB-D (Sturm et al., 2012) dynamic sequences. Using GRADE, we also extensively benchmark state-of-the-art indoor Dynamic V-SLAM algorithms (Section 6.3). Our evaluations provide evidence of their limited generalization capabilities, as they fail to either accurately or completely track trajectories. Additionally, contrary to common belief, we show that using the best-performing deep learning model does not always yield the best results in Dynamic V-SLAM scenarios. All our source code and generated data are made freely available to the community, thanks to our choice of using only freely available assets as the foundational components of our work.
The rest of this paper is organized as follows: in Section 2, we review the related work about (i) robotics simulators, (ii) indoor environments datasets, and (iii) simulated animated humans. In Section 3, we introduce and detail the main components of the proposed framework, GRADE, in four main aspects: (i) asset preparation, (ii) robot creation and control, (iii) simulation management, and (iv) post-processing tools. Section 4 is then dedicated to exemplifying four different case studies implemented with GRADE. In there, we also introduce our novel experiment repetition approach. Following that, in Section 5 we provide details of the data generation procedure and the datasets released with this work. The description and analysis of our experiments and results are reported in Section 6. These include syn-to-real learning performance using the generated data and our evaluations of state-of-the-art Dynamic V-SLAM methods using both synthetic and real data. Finally, we report our conclusions and final remarks in Section 7.
2. Related works
Here, we present the state-of-the-art of robotics simulators (Section 2.1) and of the main components of our data generation procedure, namely, indoor environments datasets (Section 2.2) and simulated animated humans (Section 2.3).
2.1. Robotics simulators
Gazebo (Farley et al., 2022; Santos Pessoa De Melo et al., 2019) is one of the go-to choices thanks to its simplicity, reliable physics engine, and ROS (Quigley et al., 2009) integration. However, it lacks photorealism and full simulation control, supports only a limited range of assets and worlds, and struggles to deliver real-time performance, even for single robots in simple worlds with minimal rendering necessities (Abbyasov et al., 2020; Noori et al., 2017; Platt and Ricks, 2022). For example, Gazebo has been used in the context of bridging the perception gap between real and simulated environments by Bayraktar et al. (2018). They introduced ADORESet, a hybrid image dataset. The combination of real and synthetic images in ADORESet aims to improve the robustness of computer vision systems by leveraging the strengths of both data types. However, contrary to what we will show in our results (Section 6.2), their data does not generalize to the real world as shown in Table 6 of their paper. This is likely due to the low realism of Gazebo. Alternatives such as BenchBot (Talbot et al., 2020), AirSim (Shah et al., 2017), Ai2Thor (Kolve et al., 2017), iGibson (Shen et al., 2021), AI-Habitat (Savva et al., 2019), and Sim4CV (Müller et al., 2018) all lack essential features such as low-level simulation controllability, ROS integration, or realistic physics and visual fidelity. Additionally, some simulators model only rigid objects (Koenig and Howard, 2004; Manolis Savva* et al., 2019) or do not include dynamic assets, as this would introduce challenges for their correct placement, management, or generation. Finally, computer-vision-focused simulators like Sim4CV or Kubric (Greff et al., 2022) are difficult to adapt for robot simulations, as they lack many robotics-specific sensors, accurate physics simulations, and support for robotics platforms and ROS.
Among robotic simulators, AirSim seeks to bridge the visual realism gap by building on top of Unreal Engine. However, it provides limited APIs, lacks support for custom or multiple heterogeneous robots, and does not enable direct joint control. Its native integration with ROS is also loose and incomplete. 4 – 6 Ai2Thor, designed primarily for AI and visual tasks, is not customizable for general robotics purposes, as it lacks essential sensor interfaces, such as IMUs and LiDARs, 7 , 8 and does not offer native ROS support. 9 Similarly, AI-Habitat is mainly focused on navigation tasks. Although a community plug-in exists for ROS integration (Chen et al., 2022), it is an external package with limited support rather than a core feature, for example, currently it does not support ROS2 or Habitat2.0. 10
Notably, Habitat3.0 (Puig et al., 2023), which was released recently and concurrently with this work, allows the integration of
Recent simulation platforms have also introduced novel approaches to robotic learning and environment modeling. Genesis, 12 a newly proposed physics engine, aims to support general-purpose robotics, embodied AI, and physical AI applications. While details remain unpublished, it appears to offer diverse material simulation, a lightweight robotics environment, and high-fidelity rendering. If integrated with ROS, it could rival Isaac Sim and GRADE. Similarly, RoboGen (Wang et al., 2024b) employs foundation and generative models in a propose-generate-learn cycle for autonomous skill acquisition but lacks ROS support and focuses on RL and manipulation tasks. Therefore, a more direct comparison for RoboGen would be Isaac Lab. 13 (formerly Isaac Gym 14 ) which is specifically designed for training RL and robotic tasks.
Finally, BenchBot (Talbot et al., 2020) and its extension BEAR (Hall et al., 2022) are two solutions aimed at introducing a procedural way to benchmark (active) SLAM methods using Isaac Sim. However, they do not include any dynamic assets natively and, as a benchmark suite, are a closed system by nature. They also employ fixed control policies that could be unrealistic for most robots (e.g., 1 cm and 1°goal position accuracies). Then, due to their limited scope and the additional APIs layers between the user and the simulator itself, they lack the desirable customization possibilities, while being quite limited in their scope. For example, it is hard to integrate already-developed methods to control robots, or adapt the system to different platforms or tasks, as they only provide a limited set of predefined actions (i.e.,
In contrast to previous approaches, GRADE supports multiple robots, Software-In-the-Loop (SIL), and ROS packages, and offers a customizable system where tools, settings, and simulation runs can be personalized to meet the specific needs of the researcher at the same time. By leveraging Isaac Sim, GRADE provides a highly flexible simulation system where various components can be adjusted, modified, or redefined. Its core strength lies in a modular architecture allowing researchers to customize the simulation pipeline to fit their specific needs. Unlike simulators focused on benchmarking particular approaches like Active SLAM, GRADE supports diverse experiments, including those that bypass the physics engine for efficient photorealistic data generation. It also introduces an independent automatic procedural asset placement system that can be replaced as needed and is not restricted to specific robots or perception systems. By exposing low-level functionalities, GRADE enables a degree of customization that is difficult to achieve in many existing frameworks. This ensures that researchers can modify and personalize their pipeline—from scene generation to control execution—making it a powerful tool for robotics and computer vision research.
2.2. Indoor environments datasets
There are two main ways in which we can represent indoor scenes within a simulation environment (Roldão et al., 2022): scans of real-world environments or posed meshed objects. Using scans of the real-world, for example, HM3D (Ramakrishnan et al., 2021), Matterport3D (Chang et al., 2017), Gibson Env (Xia et al., 2018), SceneNN (Hua et al., 2016), Replica (Straub et al., 2019), or Structured3D (Zheng et al., 2020), poses several issues. First, those are non-interactive environments in which all the objects are non-movable. Second, any
Using worlds based on meshed 3D assets addresses these problems while also allowing randomization (e.g., on textures, and object placement) and, eventually, interaction. However, datasets based on those, like ML-Hypersim (Roberts et al., 2021) and InteriorNet (Li et al., 2018), usually rely on non-freely available elements and only release rendered images, making them unusable for our purposes. These factors limit their adoption, reproduction, and expansion. Furthermore, the InteriorNet simulator has not been made available, while HyperSim’s engine is not physics-based and its sequences relate only to very short trajectories (just 100 frames). ProcThor (Deitke et al., 2022) is a recently developed framework to procedurally generate environments. However, it is limited in the quality of the assets and usable only within the Ai2THOR suite, which is focused on visual AI rather than robotics and offers no ROS support. OpenRooms (Li et al., 2021b) has not yet released any assets or CAD models publicly. 3D-Front (Fu et al., 2021a, 2021b) is a large publicly available dataset with meshed, professionally designed, and semantically annotated room layouts. This is, by far, the largest dataset available nowadays based on meshes that can be adopted. However, the annotations are not perfect and objects sometimes co-penetrate each other (Khanna et al., 2024). Finally, HSSD (Khanna et al., 2024) is a synthetic Matterport-like dataset of indoor scenes. While this is a viable alternative to 3D-Front, it is still much smaller and does not provide light sources. The five environments released with BEAR (Hall et al., 2022) in five variations each are only slight modifications of worlds commercially available from Evermotion. Finally, we must mention that recently a mesh-based generation strategy for indoor environments, Infinigen Indoor (Raistrick et al., 2024), has been released. As it is already usable with Omniverse, it can be easily integrated into GRADE, allowing it to scale the automatic testing and data generation considerably by removing the necessity of limited mesh-based datasets.
Commercial solutions such as ArchVizPRO 15 and Evermotion 16 offer high-quality assets but are not freely available. In GRADE, we adopt 3D-Front for our simulations due to its accessibility, large variability, and mesh-based nature, which eliminates lighting inconsistencies. As discussed in Section 3.1.1, beyond seamlessly integrating them with Isaac Sim in our data generation procedure and in our custom automatic 3D-based asset placement strategy (Section 3.1.4), we further enhance these environments with randomized textures and lighting conditions and partially refine the semantic mapping during conversion.
2.3. Simulated animated humans
Most dynamic content in indoor scenes comes from human movement. In V-SLAM and autonomous robotics, handling dynamic elements is crucial, as they disrupt key processes (Bescos et al., 2018; Liu et al., 2022; Xu et al., 2025) (e.g., loop closures, visual odometry) or necessitate the implementation of additional techniques (Wang et al., 2023) (e.g., dynamic obstacle avoidance). These challenges are often addressed using DL methods for detection, segmentation, and motion prediction (Bescos et al., 2018; Wang et al., 2020, 2023), which require large-scale ground-truth datasets.
Collecting real-world GT human motion data is limited to controlled setups like Vicon Halls or motion capture (MoCap) systems (Mahmood et al., 2019), which use multi-camera marker-based tracking for high-precision joint estimation. The humans can then be represented virtually as parametric 3D human models that can be used for different tasks like 3D human reconstruction (Saito et al., 2019; Xiu et al., 2023) and pose estimation (Li et al., 2021a; Saini et al., 2022), even from single images. Those models can also provide fine control over pose, shape, and motion. Commonly used human body models include SCAPE (Anguelov et al., 2005), GHUM (Xu et al., 2020), and the SMPL series (Loper et al., 2015; Pavlakos et al., 2019; Romero et al., 2017). SMPL is arguably the most widely adopted thanks to its flexibility, capability to model hands and facial expressions, and compatibility with various simulation engines.
Unfortunately, MoCap and Vicon systems support only a narrow range of subjects, clothing, and scenarios. To overcome these constraints, synthetic data has become increasingly popular, leveraging parametric 3D human models rendered in engines like Blender and Unreal Engine (Black et al., 2023; Saini et al., 2022). However, most of them have significant limitations. Many are generated by compositing human figures onto static backgrounds (Black et al., 2023; Ebadi et al., 2022) or capturing single-frame images rather than full video sequences (Saini et al., 2022; Yang et al., 2023), often leading to artifacts such as floating humans and incoherent placements (Ebadi et al., 2022; Pumarola et al., 2019). Clothing representation is another challenge, as most SMPL-based datasets lack 3D clothing (Varol et al., 2017) or rely on explicit point-cloud-based models (Heming et al., 2020; Su et al., 2023; Wang et al., 2024a), which are difficult to edit and integrate into simulations. This is partly due to their use in rendering engines without physics simulation and the predominant research focus on human shape over clothing dynamics. Commercial solutions like RenderPeople 23 or CLO 24 offer realistic clothed human models, but freely available datasets with animated clothed SMPL humans remain rare. Notable exceptions include Cloth3D (Bertiche et al., 2020) and BEDLAM (Black et al., 2023).
As discussed in Section 1, existing datasets are often inadequate for robotics. They lack key information needed for autonomous systems, such as camera states, IMU readings, scene depth, and point-cloud data. Additionally, they are non-interactive, limiting their applicability in developing autonomous systems that must respond to human movement in real-time. Advancing robotics research in dynamic environments requires integrating animated human assets into realistic, robot-focused simulations, particularly for tasks like obstacle avoidance and Active V-SLAM.
In GRADE, we use Cloth3D and AMASS as primary sources of animated human models for indoor dynamic environments. Cloth3D provides diverse, physically plausible clothing deformations, while AMASS offers a large corpus of high-quality human motion sequences. To integrate them into Isaac Sim, we developed a custom SMPL converter, detailed in Section 3.1.3. Note that Isaac Sim also supports realistic physics-based clothing simulation, but we do not use this capability in this work.
3. Materials and methods
Following the logical structure depicted in Figure 2, we outline here the key components of GRADE: asset preparation and placement (Section 3.1), robot creation and control (Section 3.2), simulation management (Section 3.3), and post-processing tools (Section 3.4). Recap of the main components of the GRADE framework. With a blue background, we highlight the software developed within this work’s scope and reference the specific repository in the footnotes.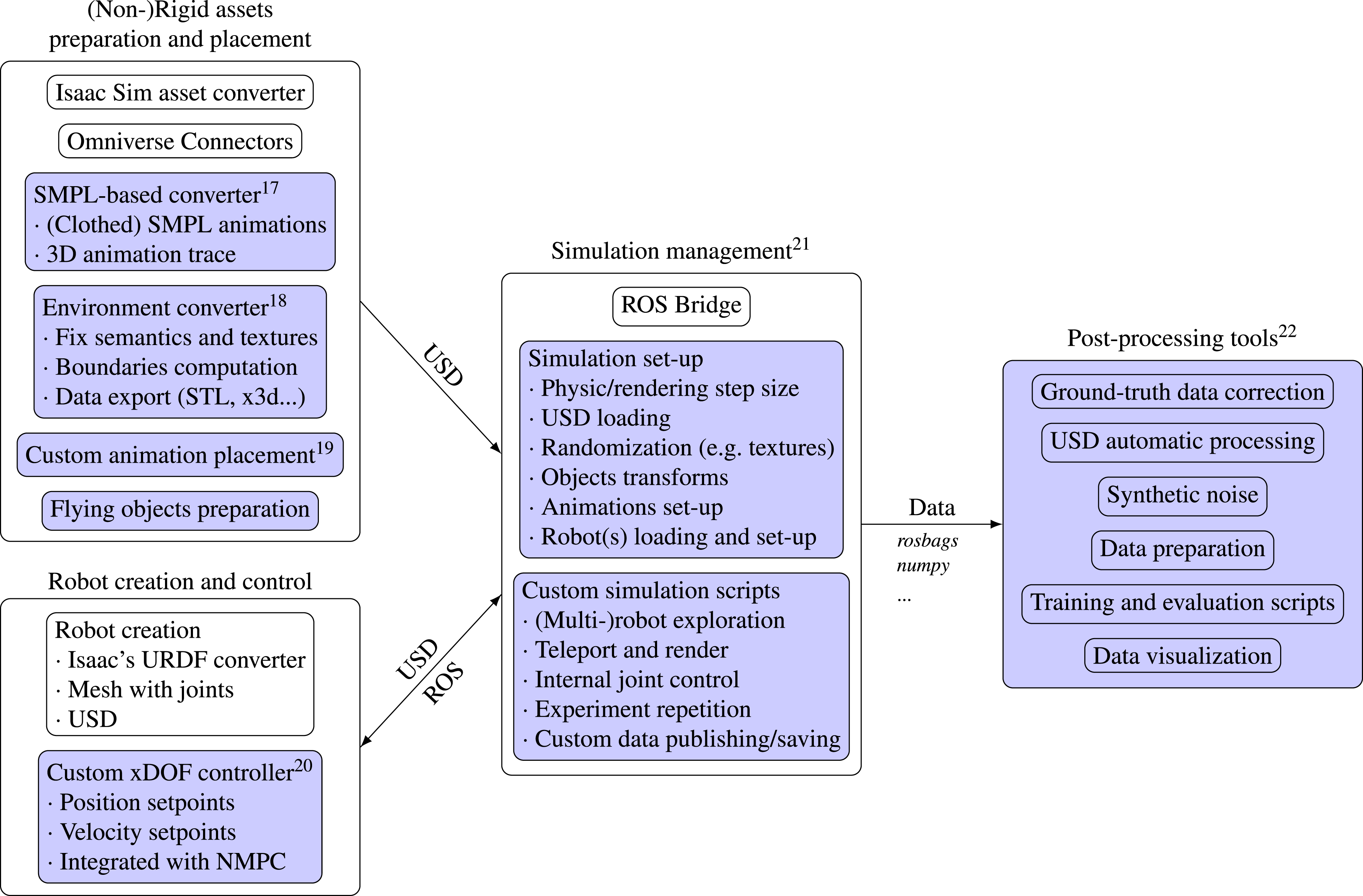
3.1. (Non-)Rigid assets preparation and placement
Isaac Sim relies on the Universal Scene Description (USD) format, thus requiring the conversion of assets into USD files before their integration into the simulations. This process poses several challenges, as many objects or complex animated models cannot be easily or directly converted. Nonetheless, adopting the USD format significantly enhances the overall flexibility of the system, enabling the inclusion of assets from various sources, including UE, Blender, AutoCAD, Maya, and more, through Omniverse Connectors 25 and custom software—a common limitation for other simulation tools, such as Gazebo or Habitat.
3.1.1. Environments
First, we prepare the assets that will be the robot’s working environments within our simulation. Although Isaac Sim provides a converter for common OBJ and FBX files to the USD format, this process often fails with complex models and hierarchies. Moreover, additional processing, like incorporating semantic classes, exporting supplementary data, or adjusting the scale of the environments, is generally desirable. Therefore, we customize BlenderProc (Denninger et al., 2023) to enable a reliable conversion and preparation of our environments to the USD format. Specifically, we modify its 3D-Front processor by fixing the texture generation, scaling of the assets, merging geometries, and refining the semantic mapping procedure adopted specifically for the 3D-Front dataset (Fu et al., 2021a) (our main source of environments) to partially correct its wrong mappings. 26 We then export the environment in USD, STL, and x3d formats. The USD file is loaded into Isaac Sim during our simulations, while the x3d file can be easily converted into an octomap (Hornung et al., 2013) for subsequent evaluations. Additionally, we also compute the enclosing rectangle and an approximated non-convex polygon that, along with the STL file, are used during the assets placement procedure (see Section 3.1.4).
3.1.2. Objects
In addition to the environment itself, we aim to have the ability to include additional objects within the simulation to increase its diversity and complexity. To achieve this, we adapt the standard converter to be able to dynamically download and load various objects at runtime from datasets such as Google Scanned Objects (Downs et al., 2022) (GSO) and ShapeNet (Chang et al., 2015). These objects can then be placed randomly or at predefined locations, or animated as flying entities through random, non-physics-enabled transformations.
3.1.3. Pre-animated assets
The Omniverse connector that converts assets from Blender to the USD format works well for simple animated assets. However, similar to the challenges faced with environment conversion, it fails when handling complex objects like SMPL-based animations. As mentioned in Section 2.3, SMPL fittings are one of the most widespread models used to represent and control human pose and shape in simulations. Therefore, to incorporate animated humans into our experiments with GRADE, we introduce a new software tool based on Blender to automatically convert (clothed) SMPL animated sequences to USD format, for example, from the Cloth3D dataset (Bertiche et al., 2020). This tool allows us to correctly process and load various pre-animated human assets into GRADE, performing different pre-recorded motions as non-rigid entities, either through deformable meshes or subsequent skeletal transformations. Additionally, we generate the STL of the 3D trace of the animation. The STL files store the evolution of the 3D surface geometry occupied by the animated humans and their clothing throughout their entire animated sequences. By combining these with the STL representation of the environment (exported in the previous step), we construct a unified geometric representation that enables precise collision detection. This is thus fundamental to our automatic placement procedure, described in the next section, as it allows us to efficiently evaluate candidate positions and orientations of the animated assets.
3.1.4. Asset placement
Given an environment and a set of (animated) assets, we should avoid physical overlap among them. To this end, different strategies can be employed, such as hardcoding or manually setting their locations in advance (see Section 4.1). Still, to achieve randomized data generation and seamless testing across diversified scenarios, the placement procedure must be automated. However, simple 2D occupancy projections are not a good approach in our case. As we use clothing animations and diversified actions (e.g., jumping, dancing) the projected footprints, usually approximated with rectangles, can be significantly larger than the human model itself. However, their overlap with the footprints of the objects in the environment would not necessarily indicate a real collision. For instance, an animation where the arm passes over a table would indicate a collision when using a 2D occupancy map of the world, even though they are not actually colliding with each other.
Therefore, with GRADE, we introduce a custom placement strategy specifically tailored for (clothed) animated humans, which we use in our data generation procedure (see Section 5). The pseudocode of our approach is provided in Algorithm 1.
First, we load the STL files containing the 3D trace information of human and clothing animations along with the environment. The placement procedure is attempted up to 10 times per asset; if a valid position is not found, the asset is discarded (Algorithm 1, line 8). Each trial begins by selecting a candidate position and orientation for the asset origin. To ensure broad coverage and variation across experiments, the position is chosen randomly, uniformly distributed over the floorplan or enclosing rectangle (Algorithm 1, lines 9−13). The yaw orientation is instead uniformly chosen between 0 and 360°. We then check for intersections between the candidate asset, the environment, and any previously placed assets using the information we saved in the STL files. To balance realism and feasibility, we use an empirically determined collision threshold of 200 intersection points between the asset we are trying to place and any other mesh in the environment (Algorithm 1, line 15). Assets with fewer intersections remain in the scene to prevent unnecessary rejection of minor overlaps, such as slight penetrations with plant leaves or clothing. If the number of intersections exceeds this threshold, the placement attempt fails, and the loop repeats. Otherwise, after a successful placement, the environment updates dynamically to account for newly added assets. We implement this through a custom MoveIt interface, leveraging its integration with the Flexible Collision Library (FCL) for checking collisions between meshes. Notably, GRADE’s modular and flexible design enables seamless integration of alternative placement strategies when desired.

3.2. Robot creation and control
3.2.1. Creation
Theoretically, custom robots can be loaded into Isaac Sim through the integrated URDF format converter. However, this does not work correctly for our robots—a three-wheeled omnidirectional robot and a flying drone—due to incorrect scaling factors, missing parts and joints, and improperly placed or absent sensors. To address these limitations, we construct our robot platforms directly within Isaac Sim by adding revolute and translational joints to mesh objects and saving them as single USD files. Joint configurations (e.g., limits, maximum speed) and sensor specifications (e.g., type, settings) can be predefined in the USD model, similarly to URDF files, or loaded and modified dynamically during the simulation. In GRADE, we implement the latter approach, enabling greater flexibility compared to URDF definitions or USD pre-configurations. We load and configure our robots
3.2.2. Control
Isaac Sim provides only a few default approaches to control assets and robot movements. However, using teleportation or rigid and non-physics-based transformations is inadequate for simulating realistic robot motions and collecting useful sensor data. Nonetheless, these methods can be viable when physics information is unnecessary, such as when collecting only visual data (see Section 4.1). Additionally, Isaac Sim allows direct joint control through low-level APIs via position or velocity setpoints, as applied in our experiment repetition procedure (see Section 4.3). However, this requires pre-configured waypoints and does not support pre-developed Software-In-the-Loop (SIL) control frameworks commonly integrated through ROS and Gazebo. Alternatively, Isaac Sim includes built-in motion and control models for a few specific platforms—an ineffective approach when working with custom robots that are not natively supported. For example, BenchBot (Talbot et al., 2020) relies on this feature to simulate ground robots, while also offering only a narrow set of predefined commands, further constraining its flexibility and generality. Moreover, Isaac Sim lacks support for fluid-dynamic physics, which is necessary for simulating UAVs and, similarly to Gazebo, it does not model frictionless perpendicular translation movements required for omnidirectional wheels (Bonetto et al., 2022). The recent PegasusSimulator (Jacinto et al., 2023) addresses PX4 UAV control by directly applying force to the drone mesh, thus still without simulating actual fluid dynamics.
Our approach differs as we seek to allow for custom robot simulation and control by employing a PID-based joint-level controller to manage robot movements. We leverage the ROS communication system and joint definitions, receiving position or velocity setpoints from other software, such as (N)MPC or Active SLAM frameworks, and convert them into low-level commands. The simulation software then processes those and translates them into robot movements. The ROS communication system is crucial for seamless integration with the Isaac Sim framework, allowing us to assign velocity and position setpoints to each joint independently while remaining agnostic to the underlying robot architecture. As a result, GRADE can support multiple platforms, from UAVs to robotic arms, and is not limited to individual robots or simple camera setups, unlike other simulators or frameworks.
3.3. Simulation management
The main simulation cycle, which uses Isaac Sim APIs along with custom utilities, primarily manages: (i) starting and configuring the simulation environment, (ii) loading, placing, and configuring assets and robots, (iii) executing several randomization procedures, (iv) launching complementary ROS nodes when necessary, and (v) managing simulation steps (both physics and rendering) and data saving. Through this framework, we can control various options, such as the number of dynamic assets, the initial location of the robot, and the size of the physics and rendering steps. It also allows programmatic and dynamic modification of environmental conditions, physics and rendering settings, light colors and intensity, material reflection parameters, asset textures, and the time of day, among others, thereby increasing the variability of simulations. This variability, along with the ability to independently enable or disable physics and ROS, allows us to support a wide range of simulation scenarios, thus enabling broader applicability.
In our work, we have explicitly implemented several illustrative simulations demonstrating different desirable applications, including Active-SLAM-based exploration, ROS-free data collection in a savanna environment with animated zebras, or experiment repetition, as described in Section 4. While Isaac Sim provides randomization and ground-truth data-saving methodologies, we found these functionalities limited. With GRADE, we expose and integrate the underlying methods directly into our simulation management approach for a customized experience. In particular, the default data-saving tool is restricted to camera-related information and executed each time a rendering call is made. However, as multiple rendering calls are required to generate an accurate image of complex environments due to path-tracing computations, this results in neither accurate nor comprehensive data. To address these limitations, we modify the saving process to gain finer control, fix various issues (e.g., segmentation ID overflow), and collect additional information, such as the camera’s vertical field of view and IMU measurements at each timestep. Moreover, our finer control allows us to customize sensor and ROS message rates independently of rendering and to access and modify the information before publishing, for instance, to add noise or implement custom drop rates.
3.4. Post-processing tools
Real-world sensor data is inherently noisy, exhibiting issues like measurement drift in IMUs, motion blur in images, and depth inaccuracies from sensors that follow exponential noise models. Therefore, ground-truth data generated by the engine must be processed to closely replicate real-world conditions, which is essential for training robust DL systems and evaluating methods such as Dynamic V-SLAM. Noise could also be introduced at runtime by modifying the data from the simulator before it is saved or published by ROS nodes. However, post-processing the saved ground-truth data offers greater flexibility by allowing, for example, multiple experiments with different noise levels.
Therefore, within GRADE, we develop a tool to introduce noise into the saved ground-truth data, building upon and extending methods from RotorS (Furrer et al., 2016) and Zhang et al. (Zhang et al., 2020). Specifically, our approach incorporates: (i) IMU noise and bias, (ii) RGB motion blur and rolling shutter noise, and (iii) depth filtering and noise. The noise augmentation tool is structured to allow seamless extension to additional sensor modalities. The framework processes raw data sequences or rosbags by applying user-defined perturbations to different data streams. Its structured pipeline separates data modalities (e.g., RGB, IMU), allowing different integrations with minimal modifications. We use this tool in experiments to prepare data for Dynamic V-SLAM and network training, adding noise to depth and RGB for one dataset while also augmenting segmentation masks for motion blur in another(see Sections 6.2 and 6.3). Beyond the noise augmentation, we also automate Dynamic V-SLAM evaluation and address errors in the generated ground-truth data caused by known issues in Isaac Sim, such as inaccurate 3D bounding boxes, 27 incorrect poses of some animated assets, 28 , 29 and timing discrepancies in rosbags. 30
4. GRADE case studies
We use GRADE to address three sample case studies that cover the different ways we can apply the framework. These are (i) a ROS-free simulation and curated data collection in a savanna environment (Section 4.1), (ii) online testing of Active SLAM approaches in a (multi-)robot scenario (Section 4.2), and (iii) our newly introduced experiment repetition setup (Section 4.3). Throughout this work, we use (i) a UAV Firefly model from RotorS (Furrer et al., 2016), and (ii) a three-wheeled omnidirectional robot from iRotate (Bonetto et al., 2022). As mentioned in Section 3.2, each robot is equipped with a single joint for every degree of freedom (six for the UAV and three for the omnidirectional ground robot), and their sensors (camera, IMU) are loaded dynamically at runtime.
4.1. ROS-free simulation in a savanna environment
In this example, we deploy a UAV in a savanna environment
31
with several simulated animated zebras. The focus is on creating a custom simulation without using either ROS or any additional SIL method to control the robot. A schematic of this setup is provided in Figure 3. While the primary focus of this paper is on indoor dynamic environments, we include this experiment to demonstrate the adaptability of GRADE beyond human-centric indoor scenes. By evaluating GRADE in a completely different setting—an outdoor savanna with dynamic, non-human agents—we validate its ability to incorporate diverse environment sources, such as those available in Unreal Engine, and diverse animation sources, beyond SMPL-based humans, and extend its applicability to other domains where dynamic elements play a key role. The zebra and their animations are sourced from a free SketchFab
32
asset. Using Blender, we export four animation sequences, namely, walking, eating, trotting, and jumping, create three different transition sets between these animations, and manually place the zebras within the main environment (Figure 4e, left side of Figure 1). Waypoints are provided to the Isaac engine directly from the main simulation loop as predefined position/orientation goals. We use either (i) a scripted sequence of waypoints for each of the six joints using the physics engine, or (ii) a physics-less mode where the drone acts as a floating object that “slides” smoothly between waypoints. The drone dynamics are governed by its mass and joint characteristics (e.g., damping coefficient) in the physics-enabled mode. Otherwise, the UAV follows an interpolated trajectory between goal locations. Flow diagram of the ROS-free system used in the savanna simulation presented in Section 4.1. In blue, we highlight our customizations. Here, we take a savanna environment from UE and an animated zebra model from Sketchfab. We combine them manually in a single USD environment. This USD is then loaded with the UAV robot model in Isaac Sim. The robot is controlled by the main simulation script directly, whether with or without the physics engine, which also manages the rendering and the data-saving steps. Few examples of environments that can be simulated with GRADE. The RGB images are shown in the top row, with the associated instance segmentations (randomly colored) below. For the multi-robot UAV images (Section 4.2), we highlight the other robots in the field of view with a red box. An external view of the UAV observing the city and the apartment environments can be observed in Figure 9. The images are best viewed in color.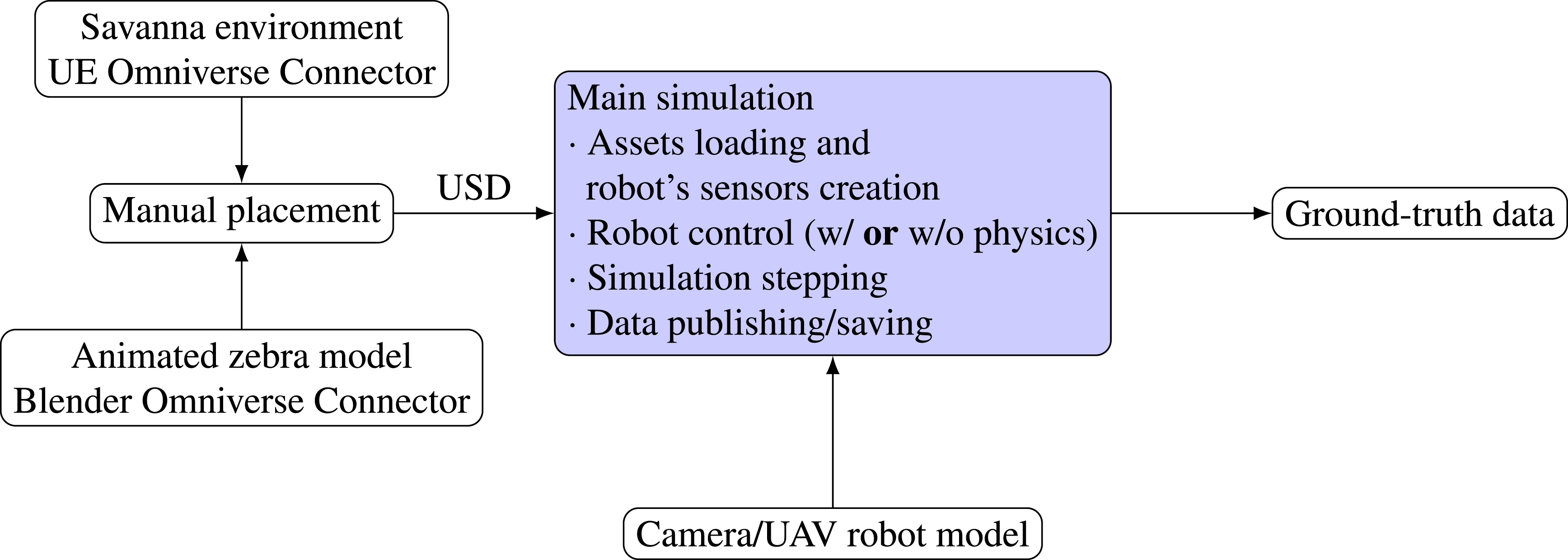
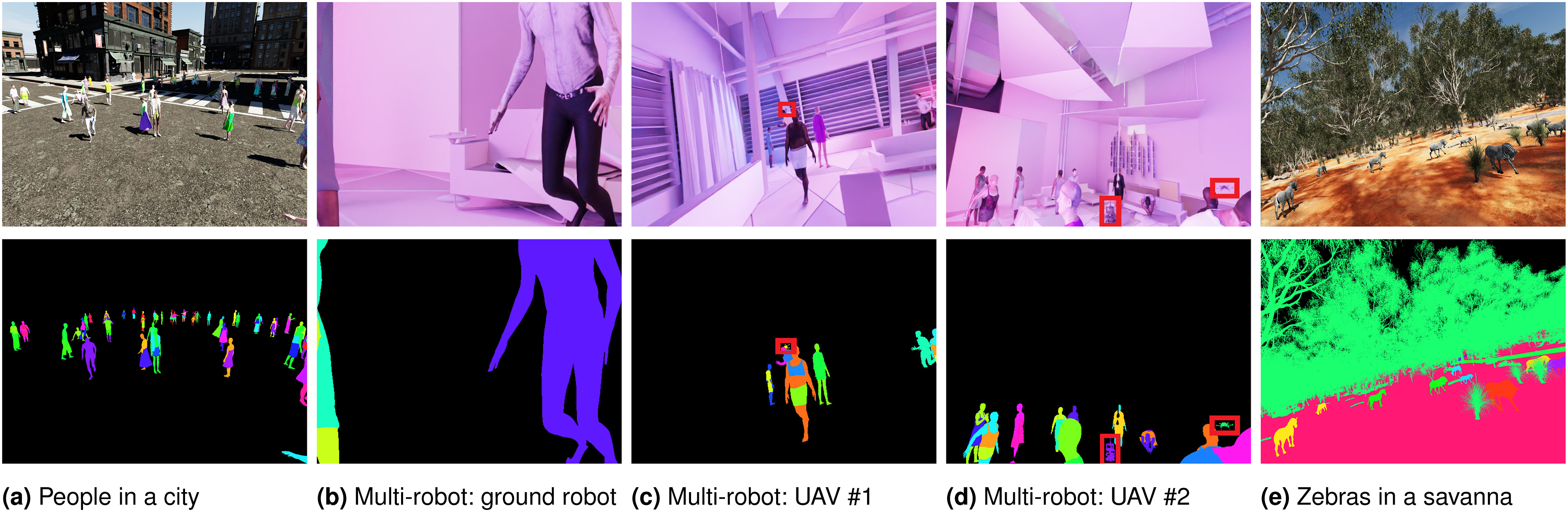
4.2. (Multi-)Robots and active SLAM
This scenario uses GRADE in conjunction with previously developed ROS approaches. Specifically, we aim to use Active SLAM methods to explore indoor environments (from 3D-Front) with both UAVs and UGVs. The scheme of this workflow is depicted in Figure 5. We adapt and interface the FUEL (Zhou et al., 2021) Active SLAM framework with Isaac Sim to compute exploration goals for the UAV. FUEL uses online RGB-D and odometry data from the simulation to actively compute exploration goals. However, the original FUEL implementation leverages an integrated custom and simplified simulation to control the drone movements. Therefore, to bridge this gap and interface ourselves with Isaac Sim and GRADE, we supply the exploration goals to an additional NMPC (Kamel et al., 2017) to predict a realistic trajectory for the UAV. The final predicted state of this trajectory is then sent to our custom controller which then provides commands to the simulation itself. The omnidirectional robot is instead managed by the iRotate (Bonetto et al., 2022) framework in conjunction with our custom controller without any additional layer, as it natively provides NMPC velocity setpoints for the base and the independently rotating camera (Bonetto et al., 2021). In this scenario, we also create simulations that simultaneously manage multiple and heterogeneous robots. The challenge here is that we have to load specific sensor suites and set different ROS topics for each one of the robots created dynamically. We do so by allowing dynamic reconfiguration and loading of parameters within the same simulation script. An example of the multi-robot simulation is shown in Figure 4b-d. In those, two robots are UAVs, each running a different instance of FUEL, and one is the three-wheeled ground omnidirectional robot. A flow diagram of the main dataset generation pipeline presented in Sections 4.2 and 5.1. In blue, we highlight our customizations. First, we take environments from 3D-Front, flying objects (when desired) from ShapeNet and GSO, and animated humans from Cloth3D. We process both the environment and the animated humans using our custom converters, preparing the data for the simulation and the asset placement procedure. A single procedure then takes care of running the simulation, from the asset loading and placement to the data publishing and saving. The main simulation is in the loop with an Active SLAM method and a customized 6DOF controller that communicate with each other using ROS. The ground-truth data is then processed by our tools that apply fixes when needed (as described in the main paper), noise, and use it to train detection and segmentation approaches and evaluate Dynamic V-SLAM methods.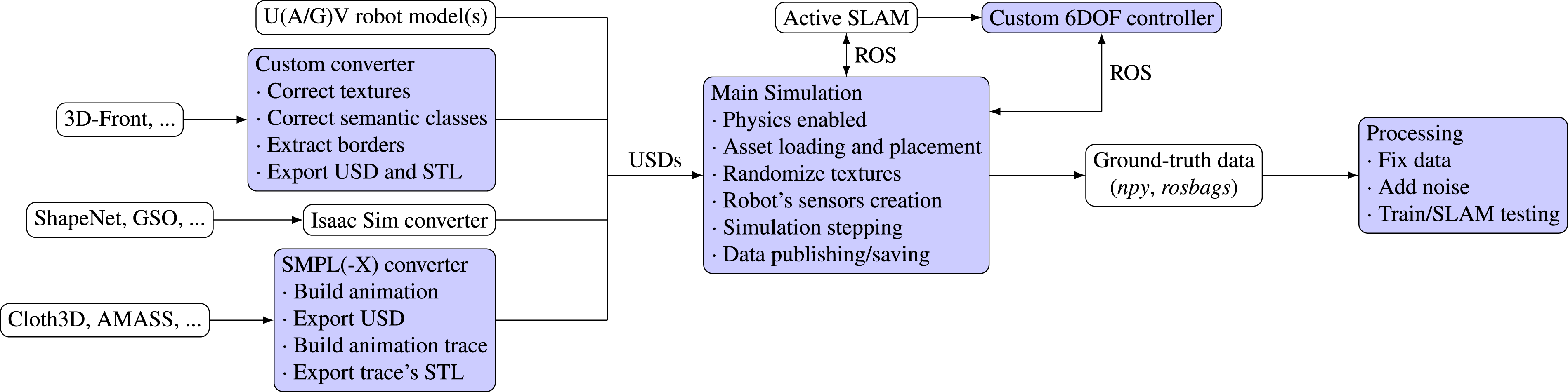
4.3. Experiment repetition and enhancement
GRADE provides a way to replay any previously recorded experiment precisely. This can be done either by keeping them as-is or by modifying them by selectively altering any number of conditions. These include, for example, attaching new sensors (e.g., cameras, LiDARs) to the original robot itself, changes in light conditions, or the inclusion of new robots, humans, animals, or other objects in the surrounding environment. This is while keeping the physics simulation enabled. Therefore, with GRADE, we introduce a new method that allows studying the robustness of different approaches by changing the robot’s surrounding conditions and/or expanding previously collected datasets under the exact same settings, for example, by collecting new data. To this end, we provide two possible solutions under the requirements that both (i) all of the robot poses throughout the experiment and (ii) the initial simulation conditions were logged. We either teleport the robot to the exact logged location and re-render the scene and the new sensors as-is, or use the previously logged joint velocities and target positions at every time step as targets of the Isaac Sim internal joint controller. While more flexible, this second approach could generate some minor deviation due to the unknown acceleration between two timesteps. However, combining the two strategies can easily mitigate this effect. Moreover, we can further interpolate the missing poses when necessary, for example, if a newly added sensor has a different rate than the one with which the pose was saved. Notably, repeating experiments with this approach removes any variability that the developed method might have—for example, when testing Active SLAM approaches. At the same time, it ensures that the remainder of the simulation is conducted under controlled and physically realistic conditions. Note that, differently from replaying rosbags, using fixed seed numbers when the simulation is prepared, or deterministic Gazebo runs, our approach allows changing the underlying state of the simulation. This would happen, for example, following modifications like adding new sensors to the robot (with mass), different scene content that is impacted by physics, additional robots in the scene, or fully disabling the physics to re-render a scene without dynamic elements, as we do in our experiments (Section 6.3.1). All of this can be controlled programmatically through the means of a simple Python script with which we can selectively choose both what to alter and then how to control the simulation itself.
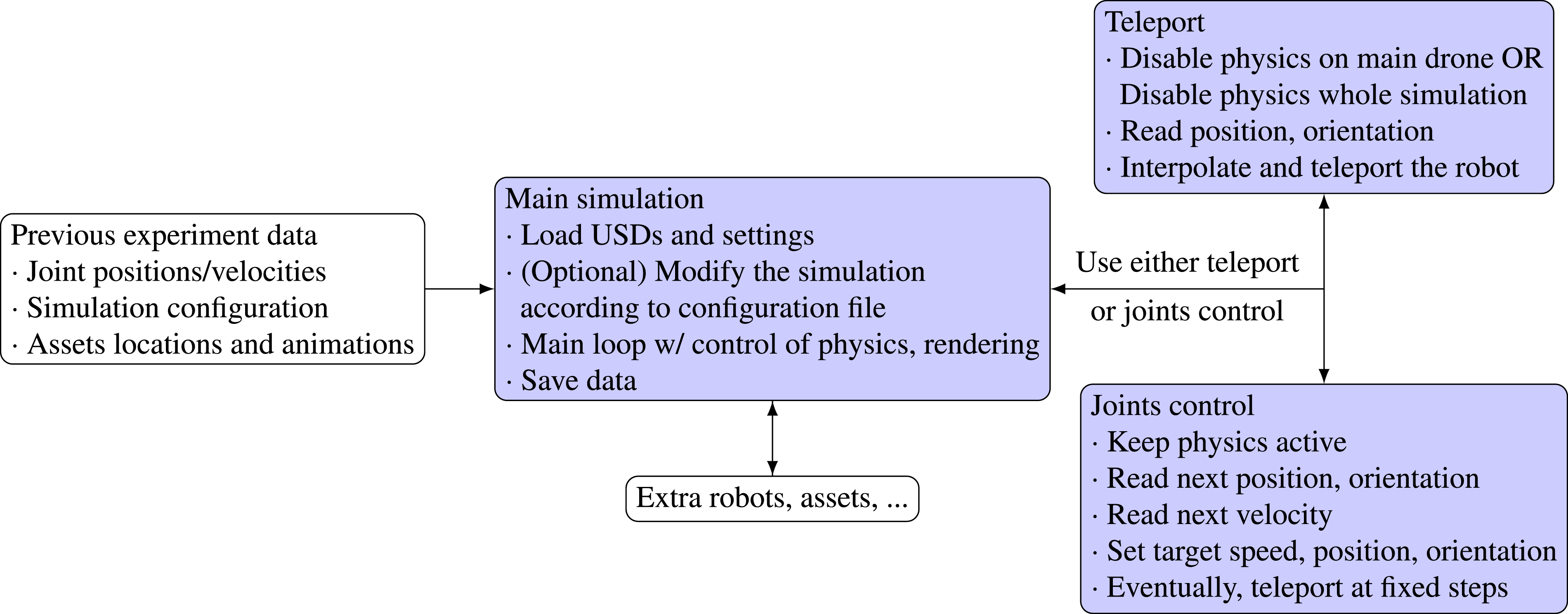
Examples of the re-rendered images and depth maps during an experiment repetition run are provided in Figure 6, while the workflow can be found in Figure 7. In Figure 6 we also show an example of changes in the original simulation run by changing the scene contents and lighting conditions and observing the scene from a new perspective. We will evaluate the deviation w.r.t. the logged poses and the rendering differences in Section 6.1. Examples of RGB and depth maps generated using the experiment repetition functionality of GRADE. In the first column, we show the original RGB and depth frames. The second column depicts the re-generated sensor readings captured at the same location. In column c we show the difference between the two corresponding frames in the RGB and depth domains, that is, the difference between columns a and b. Columns d and e show the same scene with a different lighting condition, where column d uses the same viewpoint but hiding all the dynamic objects and column e changes the camera viewpoint to a different orientation. In column e the depth map is inverted for clarity. The images are best viewed in color. Flow diagram of the experiment repetition pipeline presented in Section 4.3. In blue, we highlight our customizations. Given the previously recorded experiment data, consisting of the simulation configuration, logged joint positions and velocities, and assets locations and animation sequences, we can exactly repeat the experiment while allowing a wide range of modifications. The main simulation tool loads the assets, optionally modifies the simulation content (e.g., removes objects, changes lighting conditions, adds sensors to the robot), repeats the experiment, and saves the data. Additional robots, assets, or SIL can be configured to interact with the repeated experiment by integrating them into the script that manages the simulation. The main robot can be controlled either by using teleporting or the joint control system. Both receive the logged information from the main simulation tool.
5. Data generation
We use GRADE to generate the data for our experiments in indoor dynamic environments through the aforementioned Active V-SLAM modality. Following what we described in the previous sections we use (i) the custom environment converter, to prepare the world and extract its STL and boundaries; (ii) the SMPL animation converter, to prepare the animated assets and extract the STL representing their trajectories; (iii) the custom placement procedure; (iv) GSO and ShapeNet as flying objects; and (v) our custom controller to manage the robot(s). An example of the richly annotated data generated can be seen in Figure 8 and the summary of the data we release with this work is presented in Section 5.1. An example of the data generated using our simulation framework GRADE. Top row, left to right: rendered RGB image, corresponding depth map, optical flow, and surface normals. Bottom row, left to right: 2D bounding boxes, semantic instances, semantic segmentation, and SMPL shapes. The images are best viewed in color.
Our main source of environments is the 3D-Front (Fu et al., 2021a) dataset, that is, one of the largest collections of mesh-based indoor environments. We enhance them with random textures from ambientCG
33
and varying lighting conditions. We also collect data in one outdoor city environment from the Unreal Engine marketplace
34
(Figures 4a Figures 9a), and once in an indoor
35
world from SketchFab (Figures 4b-d Figures 9b), both used also to further validate GRADE and Isaac Sim’s flexibility across different sources. The dynamic components in the scenes are animated humans and, in some experiments, random flying objects. The humans are taken from the Cloth3D (Bertiche et al., 2020) and AMASS (Mahmood et al., 2019) datasets. While Cloth3D provides clothed assets, AMASS CMU sequences consist of only unclothed SMPL fittings. While doing so, we randomize the appearance of the assets by using Surreal’s SMPL textures (Varol et al., 2017), that is, freely available low-resolution textures, as shown, for example, in Figure 8. The flying objects belong to various categories (e.g., toys, balls, tables, etc.) and serve multiple purposes: they generate occlusions between the camera and the other elements in the environment, increase the variability of the scene, and introduce dynamic elements that can challenge Dynamic V-SLAM methods. For example, they negatively impact feature rejection methods such as segmentation and detection models or optical flow approaches since they create occlusions, do not belong to common dynamic classes, and have unpredictable motions. Additionally, their presence reduces the likelihood of loop closures, as they can randomly cover the scene, further testing the robustness of the evaluated V-SLAM systems. Moreover, introducing them will allow us to automatically create images with partially covered humans, thus increasing the variability of their appearance on the images we will use to train detection and segmentation models. These objects, belonging to the GSO and ShapeNet datasets, are loaded dynamically at runtime. We rigidly “animate” them through random time-keyed transformations in scale, orientation, and position using multiple goals set within the environment limits. By design, this is done without considering any possible collision with the environment or other assets. While precise collision-avoidance strategies can be implemented, like pre-computing safe trajectories, this allows a higher variability of their motion patterns. Overall, this diverse data generation approach, enabled by GRADE, allows us to systematically analyze the impact of dynamic elements on perception and localization tasks. We show here an external view of the UAV (similar to Figure 1) in a city environment and an apartment, which are the same used in Figure 4a and 4b–9d, respectively. In (b) it is also possible to observe the UGV.
We Report the Joint Limits Used for the UAV in Our Data Generation Procedure, as Described in Section 5.1.

Summary of our generated data, including the number of sequences released for each configuration. nThe number of humans is randomly selected between 7 and 40 before placement. However, the final number of humans in the scene may be lower due to space constraints that prevented their successful placement, as explained in Section 3.1.4. The number of flying objects taken from the GSO and ShapeNet datasets is fixed. A tick in the horizontal column indicates whether the uav is free to move or constrained to a horizontal orientation (i.e., can only rotate in yaw).

After loading and setting up the simulation experiment, we bootstrap the first 1 second for every experiment to randomize the initial conditions of the robot. When the bootstrap sequence ends, we publish a single message to signal the start of the experiment and record data for 60 seconds. In the main simulation loop, we (i) advance the physics one step at a time, (ii) automatically control the animation timeline and the rendering steps, (iii) publish the ROS information at the desired rates (using the physics step as a reference), and (iv) write data to the disk. The control of the animation timeline and the rendering steps is necessary because, as mentioned previously, multiple calls to the path-tracing function are necessary to render complex scenes correctly. Each one of these calls, however, will “advance” the animations in the scene (by advancing the time on the timeline). Therefore, in GRADE, we implement a procedure to ensure a correct alignment of the physics, rendering, and animations towards a precise data generation procedure.
For each sensor (first row), we report the frequency in Hz used during our data generation procedure (Section 5.1).

5.1. Summary of released data and code
We release 342 sequences of 1800 frames each that, at 30 fps, correspond to 342 minutes of video, that is, 615K frames. Those are summarized in Table 2. For each of these 342 experiments, we release depth data, instance segmentation (including clothing segmentation), 2D tight and loose bounding boxes, 37 3D bounding boxes, and the corresponding camera information and poses. Additionally, we release the processed animated human data with 3D per-vertex locations and skeletal information. All of the aforementioned data is saved via numpy arrays. For each sequence, we also release the recorded rosbags with IMU readings, TF tree, joint states, low-resolution RGBD images, and the robot’s state. For convenience, IMU readings, camera pose, and robot pose, which we originally stored in the rosbags, are also provided independently from them as numpy arrays. For each experiment, we provide the initial configuration of each asset, the state of the random number generator used, the USD file of the simulation, and other accompanying information necessary to replay the experiment. Other data, such as normal vectors and optical flow, can be generated using the experiment repetition tool.
Legend of the nomenclature used in the training and evaluation of the syn-to-real testing of the humans’ detection and segmentation models introduced in Section 6.2. In the first column, we indicate the abbreviation used throughout this work. In the second column, we report its brief description. When needed, the last two columns contain the number of samples in the training and validation sets, respectively.

6. Results
In this section, we first analyze the experiment repetition module in Section 6.1 to verify that the re-generated poses, images, and depth maps correspond to the ones of the original experiment. We then evaluate how well the generated data can address the syn-to-real gap in Section 6.2. Finally, we benchmark Dynamic Visual SLAM methods in Section 6.3 to verify the usability of the simulated data to evaluate such approaches. There, we will study their limitations and the relation between their performance and the underlying deep detection and segmentation models.
6.1. Experiment repetition evaluation
Evaluation of the precision of the robot poses obtained using the experiment repetition tool. For each component, we report the mean and the standard deviation of the difference between the repeated and the original values computed over 3601 instances. Position errors are expressed in meters while angle errors in radians.

6.2. Syn-to-real transfer learning
Our objective is to demonstrate that synthetic data generated with GRADE successfully captures real-world features and enables the training of models that generalize well over real images. To this end, we evaluate GRADE’s syn-to-real transfer capabilities using two popular neural networks: YOLOv5 (Jocher et al., 2022) and Mask R-CNN (He et al., 2017). Our objective is the detection and segmentation of humans. We train the networks in three modalities: (1) from scratch with both synthetic and real data, (2) fine-tuning with real-world images the networks pre-trained on synthetic data, and (3) using datasets of mixed synthetic and real-world data, indicated with a “+” sign between the datasets’ acronyms.
To train YOLO and Mask R-CNN, we use both (i) a subset of the generated dataset, which we will refer to as
The real data is obtained from the COCO dataset and the fr3/walking sequences of TUM RGB-D (Sturm et al., 2012). From COCO, we utilize only the subset of data containing humans in the frame and will call this dataset
6.2.1. Human detection with YOLOv5
YOLOv5s bounding box evaluation results. We report the mAP50 and mAP over the specified validation set. We put in
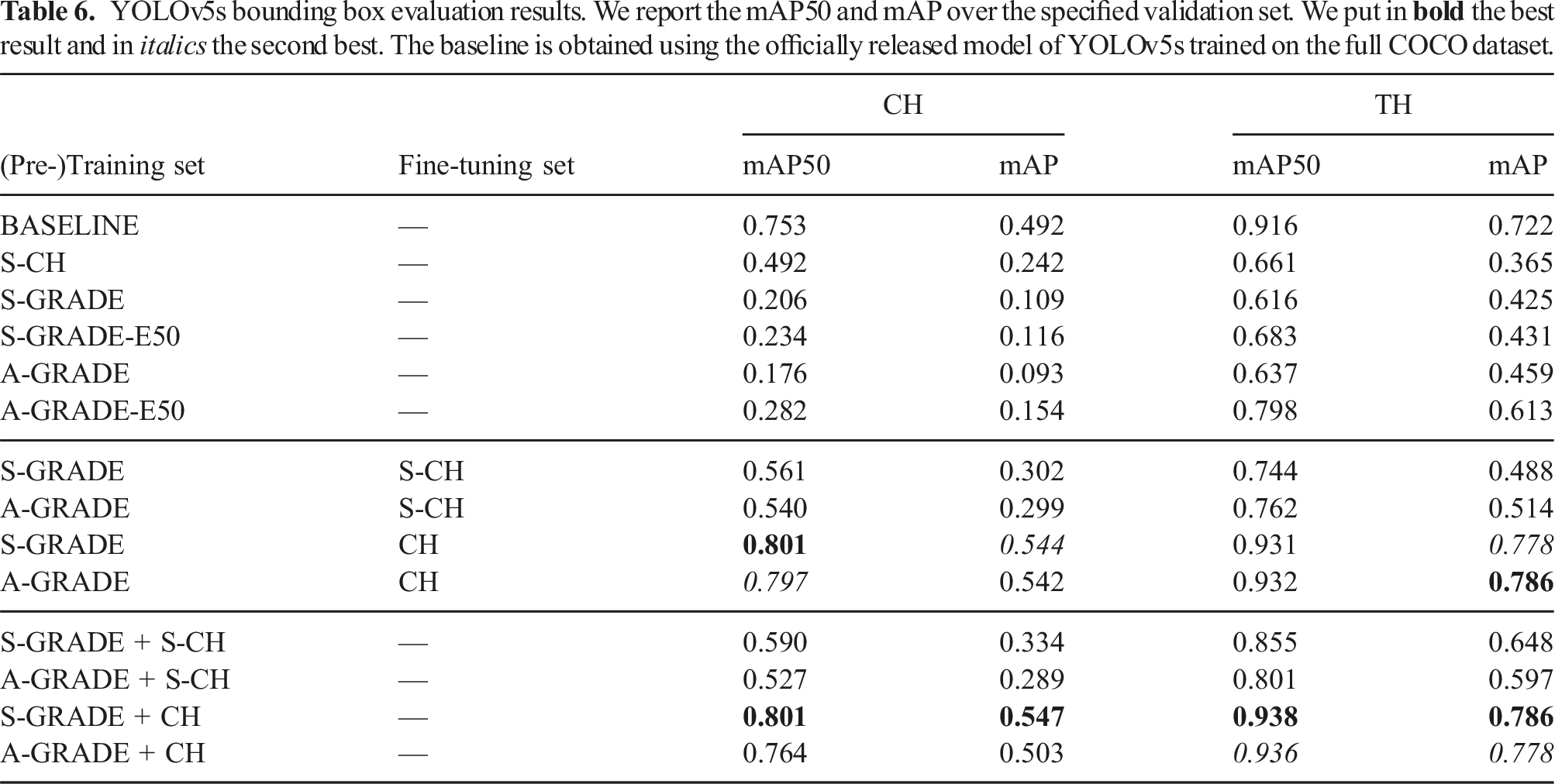
We first analyze the models trained only on single datasets. When evaluated on CH validation data, the model trained from scratch with the S-GRADE dataset exhibits lower precision than the one trained solely with S-CH. However, on TH data, these models show comparable performance, with the network trained solely on S-GRADE achieving approximately
Training using mixed synthetic and real datasets generally outperforms the corresponding pre-training and fine-tuning strategy using the same datasets. For example, the results on the TH dataset increased by up to
Overall, the best-performing model we obtained is S-GRADE+CH with an improvement over the baseline of
6.2.2. Human detection and segmentation with mask R-CNN
We use the detectron2 (Wu et al., 2019) implementation of Mask R-CNN, using a 3x training schedule 39 and a ResNet50 backbone. We use the default steps (210 K and 250 K) and maximum iterations (270 K) parameters with four images per batch when training A-GRADE and CH. We reduced those to 60 K, 80 K, and 90 K when training S-GRADE and to 80 K, 108 K, and 120 K and two images per batch for S-CH due to their relatively small size. We evaluate the models every 2 K iterations and save the best one by comparing the mAP50 metric on each of the two tasks, detection and segmentation. Due to the size of the A-GRADE dataset, we evaluate the model trained from scratch on this data every 3 K iterations. We save the best model separately for each task and evaluate its accuracy using 0.05 and 0.70 confidence thresholds. Since the training and evaluation schedules greatly impact the performance of this network 40 we also train from scratch the same network with the CH data using our configuration.
Mask R-CNN detection and segmentation results using both thresholds, i.e., 0.7 and 0.05. For both tasks, we report the mAP50 and mAP over the specified validation set. We put in
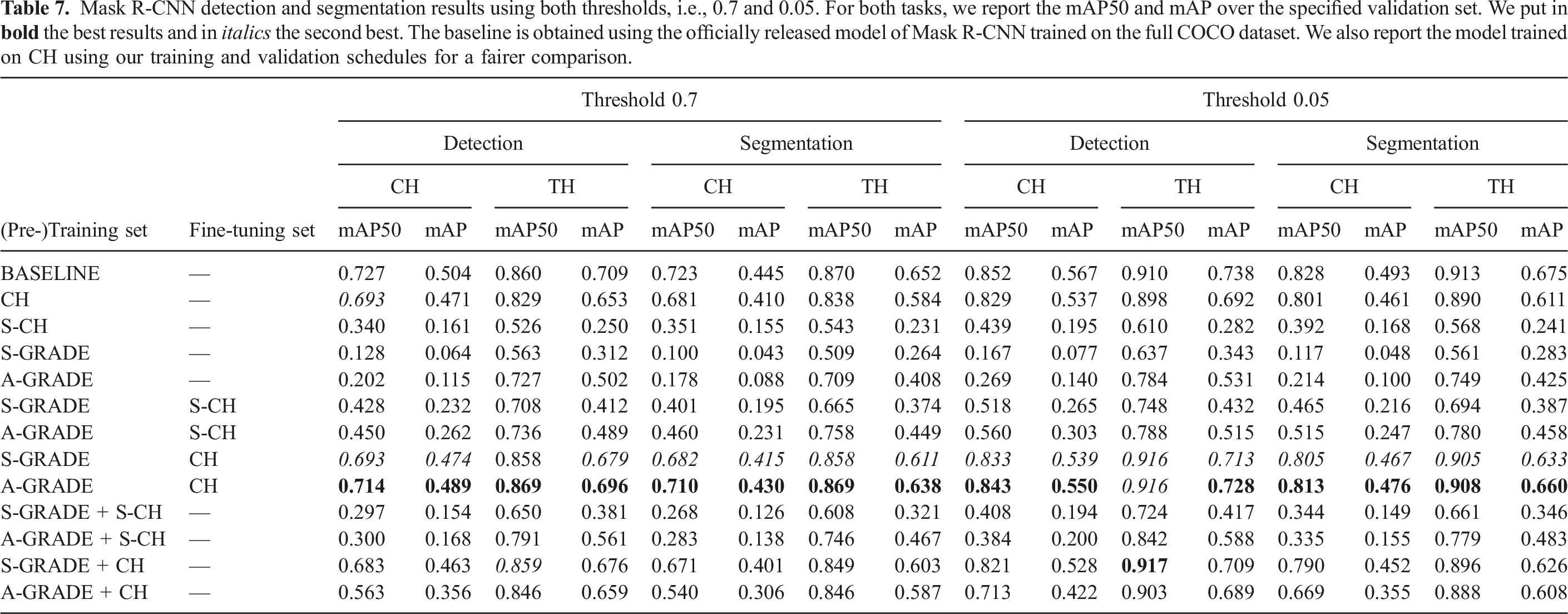
These tests also show that, when using the A-GRADE dataset, we can consistently outperform the corresponding model that uses S-GRADE in both datasets and tasks. At the same time, the model trained only with A-GRADE synthetic data performs worse than the one trained only with S-CH real data when evaluated on CH. Still, the result is reversed on the models validated on the TH dataset, with one trained only with A-GRADE outperforming the one trained only with S-CH data of up to
Overall, the best model is obtained by pre-training on A-GRADE and fine-tuning on CH. This training strategy yields an improvement of
Notably, unlike prior work such as Bayraktar et al. (2018), our approach achieves strong (although not perfect) generalization to real-world images using only synthetic data, even without incorporating real data in the validation set. Similar to their findings, mixing datasets leads to improved performance over the baseline. However, an equally crucial factor is the visual realism of the simulation itself, as one aims to avoid retraining perception models for every new task or system verification. Moreover, for better generalization, a system trained solely on synthetic data can be applied to out-of-distribution tasks where annotated datasets or large volumes of real images are unavailable (Black et al., 2023; Bonetto and Ahmad, 2023, 2024; Saini et al., 2022; Zuffi et al., 2017). Our results highlight the effectiveness of our approach in leveraging synthetic data for robust generalization. This reinforces the potential of our method for applications where real annotated data is scarce or unavailable.
6.3. Dynamic Visual SLAM
With these evaluations, we pursue the following objectives. First, we must verify that the synthetic data generated with GRADE can be successfully used to evaluate V-SLAM approaches in static environments. Then, we benchmark current state-of-the-art methods using simulated runs in dynamic indoor environments. We do so in Section 6.3.1. Finally, we will study in Section 6.3.2 the impact that the performance of the underlying detection and segmentation models have on two different Dynamic V-SLAM methods using both synthetic and real-world sequences.
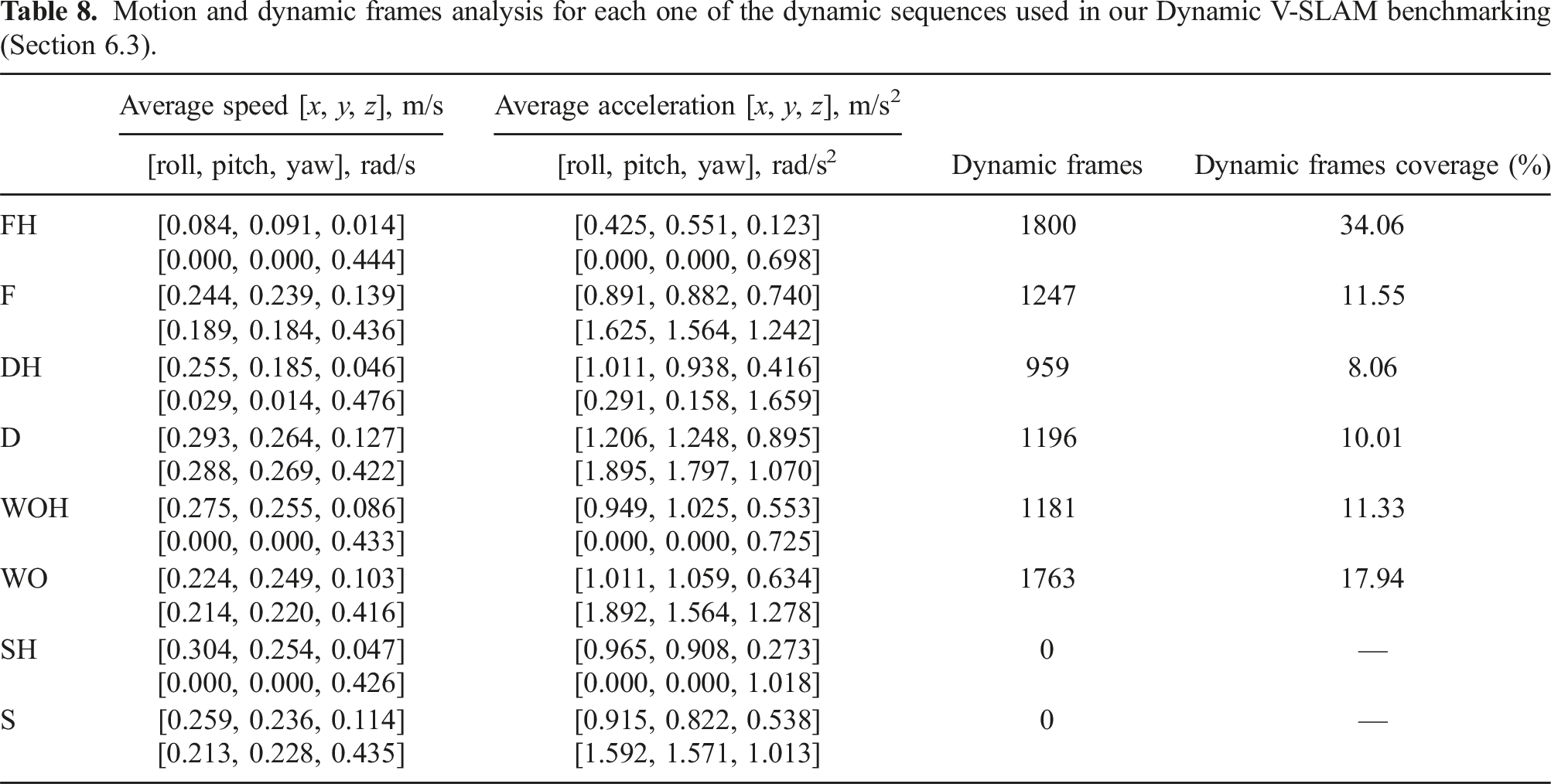
Motion and dynamic frames analysis for each one of the dynamic sequences used in our Dynamic V-SLAM benchmarking (Section 6.3).
The ground-truth data generated by the simulator is processed before the evaluations to make it closer to real-world conditions. Depth data is first limited to 3.5 m—a reasonable value when using, for example, a RealSense D435i. Then we limit it to 5 m, to study the effect of the depth range on the SLAM methods. We evaluate the SLAM frameworks using the same data but enhanced with additional noise. The noise applied to the depth values is based on the RealSense noise model. 41 We apply random rolling shutter noise (μ = 0.015, σ = 0.006) and blur (following Zhang et al. (2020)) to the RGB data. The IMU drift and noise parameters are taken from Furrer et al. (2016).
We will evaluate two static V-SLAM methods and four Dynamic V-SLAM approaches. Those are: (i) RTABMap (Labbé and Michaud, 2019) and (ii) ORB-SLAM2 (Mur-Artal and Tardós, 2017), which do not explicitly address dynamic entities; (iii) DynaSLAM (Bescos et al., 2018), which uses Mask R-CNN to segment dynamic content; iii-iv) DynamicVINS (Liu et al., 2022) (in both its VO and VIO variations, abbreviated to DynaVINS here), which uses YOLO to detect it; (v) StaticFusion (Scona et al., 2018), a non-learning method that performs RGB-D based clustering; and (vi) TartanVO (Wang et al., 2020), that is, a learned visual odometry system developed specifically for challenging scenarios. For fairness, we choose to not modify the parameters of any of the SLAM approaches we benchmark. Despite that, we had to increase the number of extracted features to 3000 in both DynaSLAM and ORB-SLAM2 to allow for an easier and repeatable initialization in some sequences, and edit DynaVINS, taking inspiration from VINSFusion (Qin et al., 2019), to keep the system running in case of a tracking failure.
We report the absolute trajectory error (ATE) (Bujanca et al., 2021) and the total time a considered V-SLAM framework can successfully track the trajectory. The latter, expressed as tracking rate (TR), is a critical quantity to be considered. It helps the reader put ATE values in perspective whenever the tested method fails due to some featureless frames or occlusions, as the ATE alone cannot completely quantify the robustness (Bujanca et al., 2021). The ATE has been computed using the standard TUM RGB-D evaluation tool. We perform 10 different trials and report the mean and standard deviation of both metrics for each test.
6.3.1. Visual SLAM performance
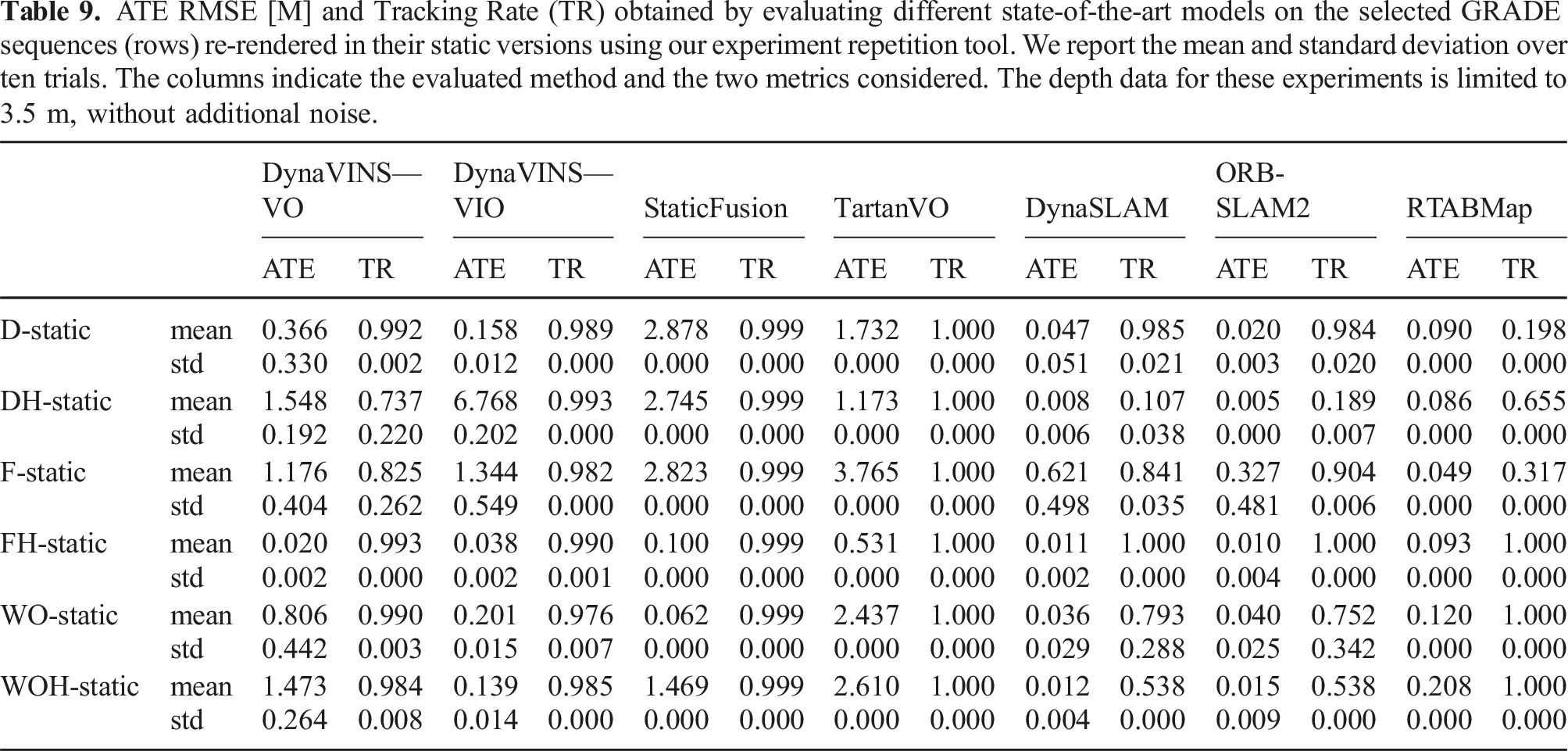
ATE RMSE [M] and Tracking Rate (TR) obtained by evaluating different state-of-the-art models on the selected GRADE sequences (rows) re-rendered in their static versions using our experiment repetition tool. We report the mean and standard deviation over ten trials. The columns indicate the evaluated method and the two metrics considered. The depth data for these experiments is limited to 3.5 m, without additional noise.
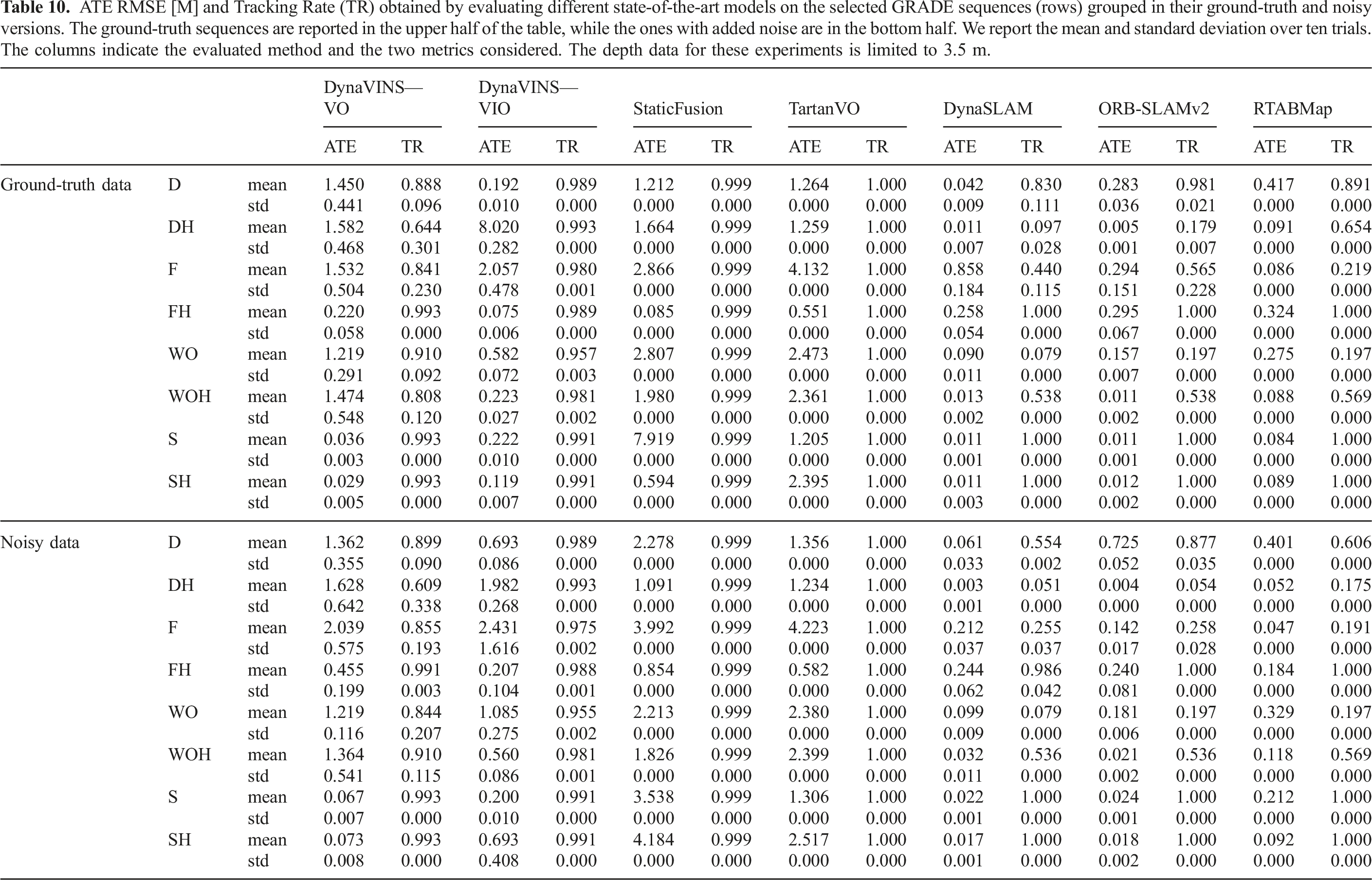
ATE RMSE [M] and Tracking Rate (TR) obtained by evaluating different state-of-the-art models on the selected GRADE sequences (rows) grouped in their ground-truth and noisy versions. The ground-truth sequences are reported in the upper half of the table, while the ones with added noise are in the bottom half. We report the mean and standard deviation over ten trials. The columns indicate the evaluated method and the two metrics considered. The depth data for these experiments is limited to 3.5 m.
ATE RMSE [M] and Tracking Rate (TR) obtained by evaluating different state-of-the-art models on the selected GRADE sequences (rows) grouped in their ground-truth and noisy versions. The ground-truth sequences are reported in the upper half of the table, while the ones with added noise are in the bottom half. We report the mean and standard deviation over ten trials. The columns indicate the evaluated method and the two metrics considered. The depth data for these experiments is limited to 5 m.
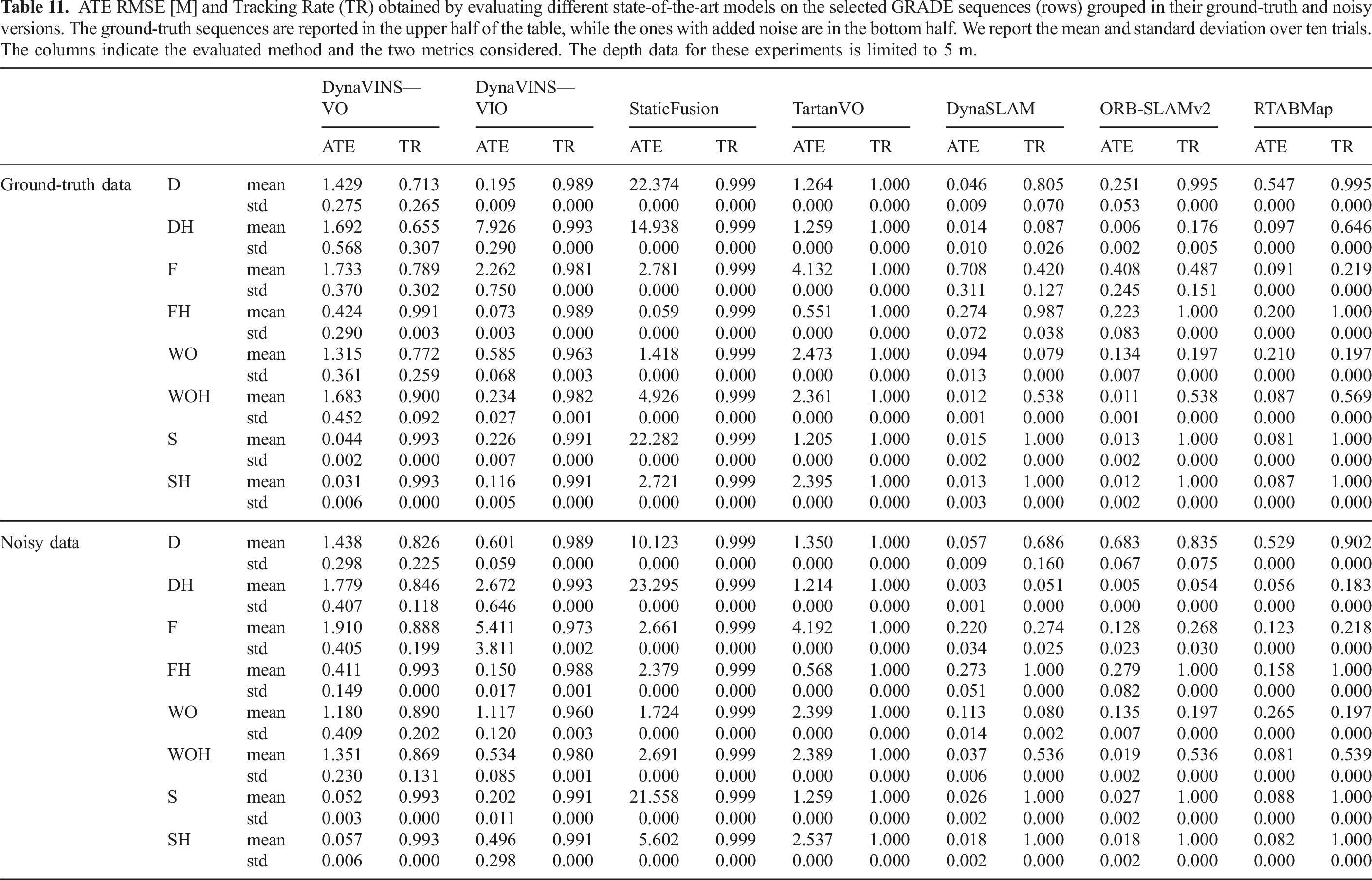
The results of testing the selected methods on the re-rendered static sequences are presented in Table 9. In Table 10 and Table 11 instead we report the experiments on S and SH. We can observe how, generally, all methods perform well in SH and S, with low ATE and high tracking rates. Meanwhile, in the other sequences, the results vary a lot, though at least one method consistently achieves good performance. These results show that the data generated by GRADE can be used effectively to perform visual odometry and demonstrate, at the same time, the low adaptation capabilities of some of these algorithms. The low tracking rates of RTABMap on D-static, DH-static, and F-static are to be associated with events in which the system loses track of the odometry and resets, without recovering. Notably, while both ATE and TR vary across methods, the standard deviations are generally low.
For dynamic sequences, the good ATE results of certain methods can be misleading. For example, in four out of eight sequences without added noise where the depth data is limited to 3.5 m (Table 10) DynaSLAM loses track of the trajectory for at least
6.3.2. Dynamic V-SLAM and deep learning relation
ATE RMSE [M] and Tracking Rate (TR) obtained by evaluating DynaVINS and DynaSLAM while varying the model checkpoint used by the underlying YOLO and Mask R-CNN networks (columns). The evaluations are performed using both the TUM RGB-D (top half of the table) and selected GRADE sequences (bottom half of the table). We report the mean and standard deviation over ten trials. GRADE’s data has no additional noise. The depth data for these experiments is limited to 3.5 m.
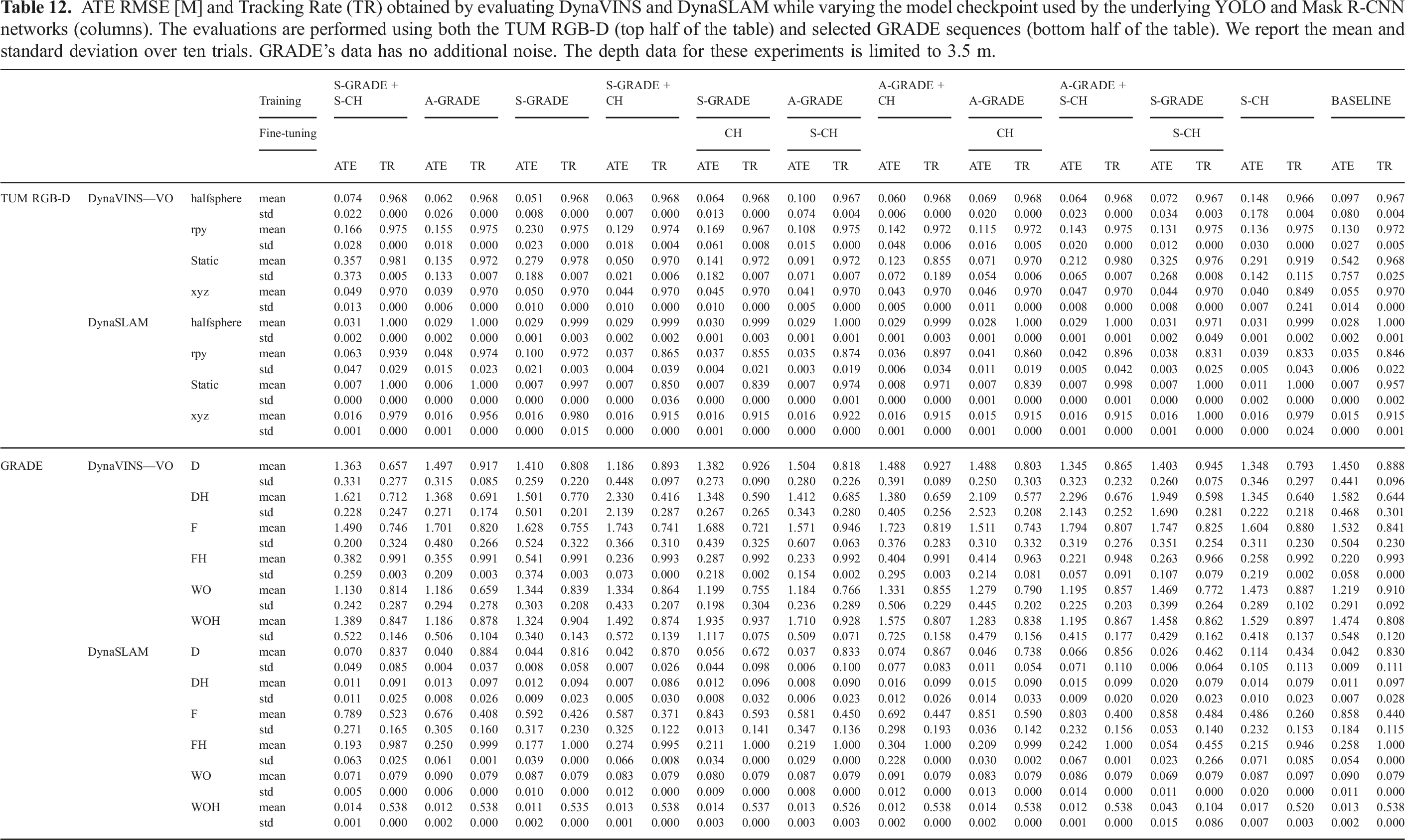
Results on the TUM dataset indicate that changing the model for DynaVINS has no impact on TR. In contrast, DynaSLAM is highly influenced by the segmentation step, with many trials achieving TR on par with or better than the baseline. Surprisingly, this happens even when using lower-performing segmentation models. For example, with the model pre-trained on S-GRADE and fine-tuned on S-CH we can observe a tracking time 8.5% higher on the xyz sequence. For both SLAM frameworks, the ATE varies based on the model used. However, the best-performing networks are often not associated with the best ATE and TR couple. For example, using the model trained only with S-GRADE yields already compelling results. When using it with DynaVINS we can obtain the best performance on halfsphere sequence, with half of the ATE w.r.t. to the baseline. The results obtained using DynaSLAM with Mask R-CNN trained on S-GRADE show ATEs comparable to the baseline results but with higher tracking times, thus with better overall performance. At the same time, DynaSLAM on the rpy sequence with the model pre-trained on A-GRADE and fine-tuned on CH, that is, the best performing one according to the results shown in Table 7, significantly degrades the tracking rate of approximately 5%. Finally, when we evaluate the same SLAM methods using the different trained models on the different GRADE sequences, we find that it influences both the TR and ATE. However, as with the TUM RGB-D sequences, these results show no clear advantage in using the models with the highest performance as, unintuitively, even the ones performing poorly in the detection and segmentation tasks can attain higher TR and ATE w.r.t. the other ones. Notably, we can see from these results that even while using the baseline network both methods suffer from imperfect tracking rates which can go as low as 84.6% for DynaSLAM on the rpy sequence.
7. Conclusions
GRADE is a novel flexible solution for simulating robots in photorealistic dynamic environments enabling efficient research, development, and benchmarking of autonomous robotic systems. GRADE addresses the limitations of previous robotics and vision-focused simulation frameworks by providing a streamlined system for simulation setup and management, ground-truth data generation, offline and online robot testing, as well as benchmarking of robotics and visual-based (learning) methods in physical and photorealistic environments. This is achieved through the exploitation, integration, and expansion of Isaac Sim’s capabilities via customizable (animated) assets preparation and placement, data saving and processing procedures, and robot preparation, setup, and control.
We demonstrate GRADE flexibility by employing it in different case studies, ranging from simple visual data generation in physics-less simulations to heterogeneous multi-robot experiments managed by Active SLAM frameworks. Unlike previous systems that leveraged Isaac Sim, GRADE is not focused only on providing a closed framework for specific robots or applications, for example, benchmarking V-SLAM systems. Instead, it is built as close as possible to the low-level APIs of Isaac Sim, allowing for finer control and customization over the experiments. All the code and the data generated through GRADE for our experiments are provided as open-source for the benefit of the community.
With GRADE we provide the first method allowing for precise programmatic experiment repetition with adaptable surroundings in physics-enabled simulations. Data can now be modified or expanded in simple and effective ways after the simulation happens by, for example, changing surroundings conditions (e.g., removing or adding dynamic objects) or adding new sensors (e.g., a stereo camera). Unlike previous systems, our approach is not limited by fixing seed numbers or rigid simulation conditions. Instead, it extends beyond simple changes (e.g., lighting adjustments), enabling substantial modifications to the simulation environment. This is an important step towards flexible testing, higher robustness, and thus better generalization, helping reduce the sim-to-real gap.
The strong syn-to-real performance of the learned human detection and segmentation tasks demonstrates the effectiveness of our simulation and its visual realism. Notably, even without incorporating highly detailed human models with features like hair, shoes, or high-resolution textures, the generated data proves sufficiently realistic to significantly enhance network performance when combined with real-world images. Furthermore, training exclusively on GRADE synthetic data achieves results that closely match the baseline in indoor environments, greatly reducing the need for extensive data collection and manual annotation and clearly addressing the sim-to-real gap. While commercial synthetic clothed human models, such as RenderPeople or CLO, could further enhance realism and potentially improve training outcomes, we deliberately avoid their use to ensure the reproducibility and open redistribution of our generated data, which is essential for open research. Moreover, we want to emphasize the fact that we obtain these results without introducing or leveraging any domain-adaptation technique, as opposed to previous approaches. Using GRADE we can address the syn-to-real gap by generating a high amount of realistic and diverse data.
Then, our thorough testing on several state-of-the-art Dynamic V-SLAM methods using synthetic sequences obtained with GRADE shows how most methods fail to track sequences that are out of distribution compared to common datasets. They also highlight the necessity of reporting the average sequence tracking rate to correctly evaluate overall SLAM performance, as the ATE alone may mislead evaluations—especially in dynamic environments. Our results show how state-of-the-art methods fail either in correctly (i.e., high ATE) or completely (i.e., low ATE but low tracking rate) estimating the trajectories, despite their good performance when tested on common datasets. Moreover, our evaluations performed on TUM RGB-D and synthetic sequences using our trained detection and segmentation models exemplify the demand for thorough evaluations and studies in Dynamic V-SLAM. Indeed, using the best-performing trained networks does not always yield the best result, suggesting that more reliable feature rejection procedures and robust methods are needed. Notably, the enhanced realism and flexibility of GRADE have enabled rigorous and diverse testing of SLAM approaches in simulation. By closely mirroring real-world conditions, our framework allows for widespread and stress testing of state-of-the-art methods, exposing them to a broader range of scenarios and edge cases. As a result, even without explicitly introducing dedicated sim-to-real adaptation techniques, the improved evaluation process can inherently facilitate the smooth and effective transfer of these methods to real-world conditions by allowing researchers to evaluate adaptability and robustness beforehand.
Footnotes
Acknowledgments
The authors thank the International Max Planck Research School, Germany for Intelligent Systems (IMPRS-IS) for supporting Elia Bonetto.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Cyber Valley Research Fund Project “WildCap” (CyVy-RF-2020-13).