
Abstract
Real-world object manipulation has been commonly challenged by physical uncertainties and perception limitations. Being an effective strategy, while caging configuration-based manipulation frameworks have successfully provided robust solutions, they are not broadly applicable due to their strict requirements on the availability of multiple robots, widely distributed contacts, or specific geometries of robots or objects. Building upon previous sensorless manipulation ideas and uncertainty handling approaches, this work proposes a novel framework termed Caging in Time to allow caging configurations to be formed even with one robot engaged in a task. This concept leverages the insight that while caging requires constraining the object’s motion, only part of the cage actively contacts the object at any moment. As such, by strategically switching the end-effector configuration and collapsing it in time, we form a cage with its necessary portion active whenever needed. We instantiate our approach on challenging quasi-static and dynamic manipulation tasks, showing that Caging in Time can be achieved in general cage formulations including geometry-based and energy-based cages. With extensive experiments, we show robust and accurate manipulation, in an open-loop manner, without requiring detailed knowledge of the object geometry or physical properties, or real-time accurate feedback on the manipulation states. In addition to being an effective and robust open-loop manipulation solution, Caging in Time can be a supplementary strategy to other manipulation systems affected by uncertain or limited robot perception.
Keywords
1. Introduction
Object manipulation is a fundamental ability for robots to engage themselves in tasks where physical interactions are expected (Billard and Kragic, 2019). While research in this field has seen significant advancements with data-driven frameworks and sensing-enhanced systems (Kaelbling, 2020; Lee et al., 2019; Yuan et al., 2017), we still do not see many robot systems working robustly around us. Among others, two major reasons are typically observed for this challenge: 1) real-world physical uncertainties are significantly more complex than any lab environment, often rendering certain modeling assumptions invalid (Rodriguez, 2021) and 2) perception or sensing is almost never good enough for real-world robot deployments. Gaps between modeling assumptions and reality, domain variations, and random occlusions often worsen the perception performance, or even cause a perception system to completely lose track of target objects (Bohg et al., 2017). As such, approaches fully relying on closed-loop control for robot manipulation have been constantly challenged in real-world applications.
Unlike approaches that focus on contacts, caging configuration-based manipulation has provided a novel paradigm to significantly reduce perception requirements. More importantly, although it does not aim at accurate control, caging configurations can robustly work by fully ignoring the effect of physical uncertainties, such as seen in grasping, in-hand manipulation, and multi-robot coordination tasks (Bircher et al., 2021; Rodriguez et al., 2012; Song et al., 2021). Concretely, a caging configuration aims at completely constraining all possible configurations of the target object within a known region (cage). The target object is manipulated as the cage moves or deforms, while the configuration of the target object is guaranteed to follow the cage to complete the task (Wang et al., 2005). However, it has been a challenge to apply this idea to general manipulation tasks, since forming a caging configuration has very strict requirements on the hardware, such as multi-agent coordination, widely distributed contacts, or specific geometries of the robot or the object to construct such configurations (Makita and Wan, 2018).
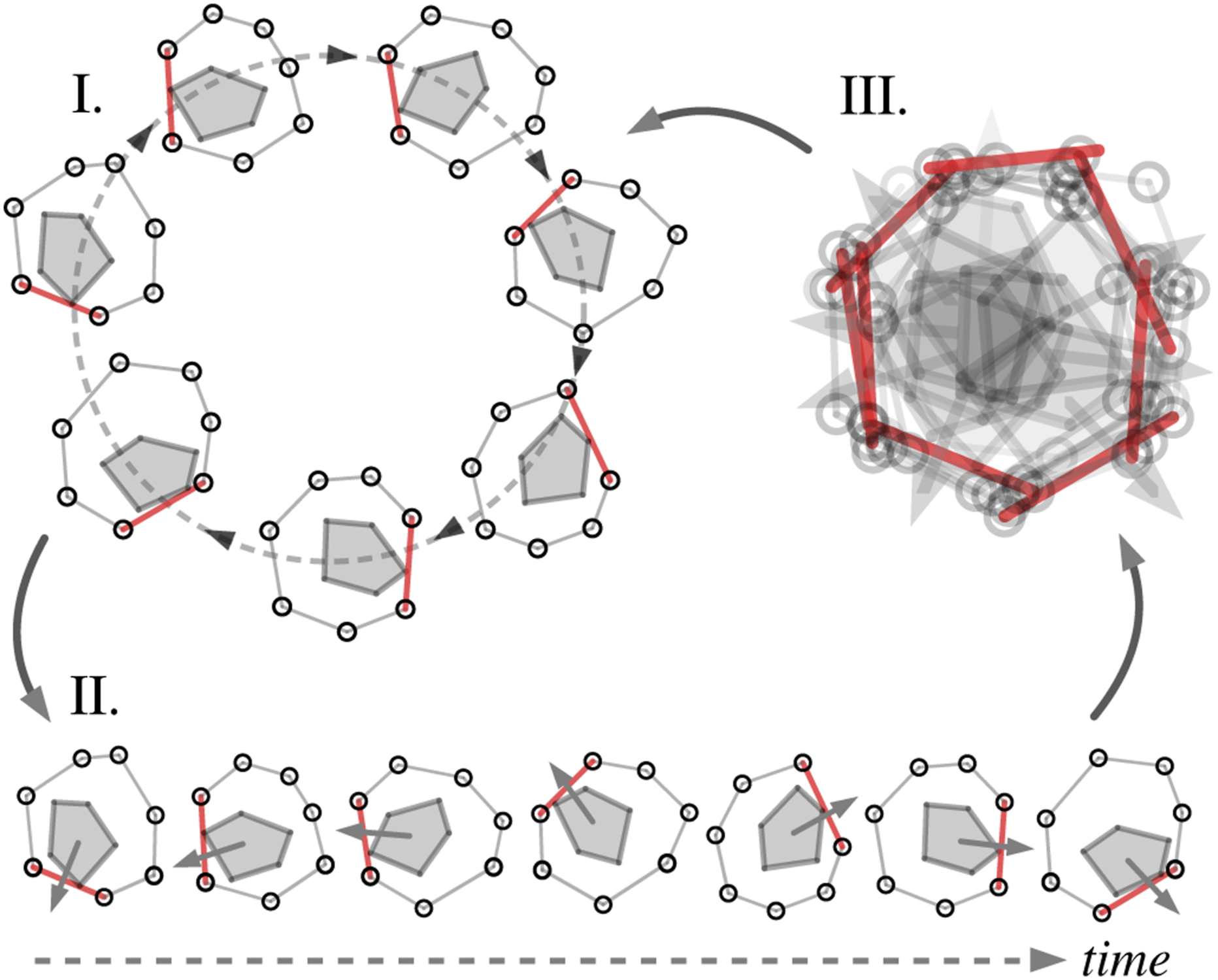
This work proposes a novel concept, termed Caging in Time, to extend caging configuration-based manipulation to more general problems without hardware-specific assumptions. Example applications are shown in Figure 1. The high-level idea of this framework can be explained as follows. In an extreme situation, let us assume we have an object to manipulate and a robot is able to make an infinite number of contacts everywhere on the object. As such, the object is fully caged, and arbitrary manipulation can be achieved by moving all contacts simultaneously. In another extreme situation, let us assume a robot can make one contact with the object at a time, but it is able to switch the contact to other locations infinitely fast so that virtually there are contacts everywhere on the object. Equivalently to the former case, arbitrary manipulation can also be achieved with this virtual cage. Our idea of Caging in Time exploits the possibilities between these two extremes: We assume a robot can make one or a few contacts at a time, and it can switch to other contacts fast enough as needed so that, in time, it makes a cage. This idea is visualized in Figure 2 via a planar pushing task, where an object is pushed by a virtual cage (gray) with multiple bars through a circular trajectory. Note that, physically and in time, only one bar (red) is effectively needed at a time to complete the task. Furthermore, by collapsing the configurations of the effective bars through time, a cage is formed and can be unrolled in time to complete the task as if a complete cage has always been there. Example object manipulation tasks via Caging in Time. Top: Object planar pushing to trace “RICE.” Without sensing feedback, unknown objects were randomly replaced during the manipulation process. The recordings were taken at different times and concatenated to show all objects. Bottom: Ball catching on a flat end-effector without any sensing feedback. The theory of Caging in Time visualized through an example planar pushing task. 
We instantiated the Caging in Time theory on both quasi-static and dynamic manipulation tasks with a real robot. It is worthwhile to note that, the example instantiations showed that Caging in Time can be applied on general cage formulations, including geometry-based and energy-based cages. Without any sensing feedback, Caging in Time showed guaranteed task success on all experimented tasks, even when the manipulation is physically affected by in-task perturbations and unknown object shape variations. In comparison with a baseline closed-loop control approach, we show that our framework is similarly accurate, while being significantly more robust against perception uncertainties, as enabled by zero reliance on precise sensing feedback.
Contributions: The proposed Caging in Time concept makes three contributions: 1) providing a planning paradigm for robust robot manipulation that can significantly mitigate the effect of perception uncertainties; 2) broadening the traditional caging configuration-based manipulation to a more general manipulation framework as enabled by strategic sequential robot motions; and 3) offering an option for manipulation without relying on sensing feedback to support robust manipulation in various real-world tasks, especially in scenarios where perception is not reliable.
Limitations: The work reported in this paper is the first step towards general applications of the Caging in Time concept. With an emphasis on the derivation of the foundations of the theory, this work does not develop algorithms for addressing general manipulation problems via Caging in Time skills. Specifically, we identify the following major limitations of the current scope of this work and state them before the details of the proposed theory: 1) as example instantiations of the proposed theory, the reported manipulation algorithms were designed for implementing Caging in Time on specific tasks only; 2) manipulation physics or dynamics models are analytically derived for the purpose of explicitly verifying the theory, although simulation or learning-based models can be more efficient; and 3) this work mainly handles perception uncertainties while uncertainties in action execution and certain environmental interactions are not considered. Nevertheless, we underscore that the proposed Caging in Time framework is a complete theory for general manipulation problems as discussed in Section 4 and Section 8.
2. Related works
2.1. Perception assumptions in manipulation
Contact properties, geometric and physical properties of objects, and perfect perception are commonly presumed when modeling manipulation systems (Bütepage et al., 2019; Suomalainen et al., 2022). Alternatively, recent learning-based approaches instead assume training data adequately covers all relevant task variation domains, with perception systems matching those in training environments, for example, similar camera poses (Andrychowicz et al., 2020; Kaelbling, 2020; Kroemer et al., 2021; Lee et al., 2019). Meanwhile, interactive perception has significantly reduced the requirements for certain prior knowledge and direct perception (Bohg et al., 2017; Hang et al., 2021), while still assuming reliable perception through some channels for iterative state estimation. Despite demonstrating great performance in the lab, the robustness of many manipulation approaches typically faces significant challenges from unreliable perception in the real world, such as tracking noise, signal latency, and occlusions.
In early works, uncertainty was discussed in object pushing through analytical modeling (Akella and Mason, 1992; Lynch, 1999; Lynch and Mason, 1995, 1996), enabling robust planar pushing despite uncertainties. While these approaches handled some uncertainties in object–surface interactions, they still required precise object geometry and sensor feedback. Meanwhile, sensorless manipulation (Akella et al., 1997; Erdmann and Mason, 1988; Goldberg, 1993) provided inspiration for addressing manipulation without any feedback, with applications in orienting planar parts without sensors (Akella and Mason, 1998; Bohringer et al., 2000). However, these approaches were specifically limited to parts orienting, rather than general manipulation tasks. Later works on motion cones (Chavan-Dafle et al., 2020) and in-hand manipulation (Bhatt et al., 2021; Holladay et al., 2015) extended these concepts beyond pushing.
Notably, a recent work in robust pushing shares a similar idea with our work through variance-constrained optimization based on belief dynamics, generating stable pushing trajectories also in open-loop (Jankowski et al., 2025). While theoretically rigorous, this approach remains confined to quasi-static pushing scenarios, without addressing its potential applications in broader manipulation contexts.
Therefore, a comprehensive framework that can robustly handle uncertainty even without requiring feedback and apply across diverse manipulation tasks is valuable. Different from most existing works, Caging in Time aims to use caging configurations along the time dimension to eliminate the reliance on, hence the negative effect of, unreliable perception. Importantly, our work is not intended to replace existing planning or control methods, but rather to complement them as a supplementary approach to enhance manipulation robustness under unreliable perception.
2.2. Caging configuration-based manipulation
Caging configuration initially emerged as a concept for multi-robot systems in SE(2) to constrain the motion of a target object, enabling robust object transportation (Pereira et al., 2004; Sudsang and Ponce, 2000; Wang et al., 2005), or even herding mobile agents (Song et al., 2021). This concept was subsequently extended to planar grasping, with the objective of restricting the pose of a target object within a confined region (Rimon and Blake, 1999; Rodriguez et al., 2012; Stork et al., 2013a; Varava et al., 2016), sometimes even with partially observable object geometries (Zarubin et al., 2013), as well as hooking and latching techniques developed through topological analysis (Stork et al., 2013b). Recently, in-hand manipulation has been enhanced through caging configurations where objects are manipulated via controlled states within deformable cages (Bircher et al., 2021; Komiyama and Maeda, 2021). Besides algorithmic advances, the caging concept has also inspired specialized end-effector designs that enhance manipulation through physical embodiment (Dong et al., 2025; Xu et al., 2024). However, the most fundamental limitation of traditional caging is that multiple robots (ZhiDong Wang and Kumar, 2002), widely distributed contacts (Rodriguez et al., 2012), or specific geometries of the robots or objects (Varava et al., 2016) are required, making caging a concept not applicable to more general setups.
Beyond complete geometric caging, extended formulations have been proposed including energy-bounded caging to incorporate external forces like gravity (Mahler et al., 2016, 2018), and partial caging to relax full enclosure requirements (Varava et al., 2016, 2019)—both demonstrating that complete caging becomes unnecessary with environmental force assistance, broadening the application range for caging. These advancements necessitated practical metrics for escape probability evaluation (Stork et al., 2013a; Varava et al., 2019), with sampling-based algorithms enabling quality assessment through escape path clearance analysis (Varava et al., 2020a, 2020b). Such quantification methods have evolved beyond traditional caging to evaluate diverse manipulation tasks including pushing, soft object interaction, and multi-object handling (Dong et al., 2023, 2024; Dong and Pokorny, 2024). Despite effectively extending traditional formulations, energy-based partial caging still demands specific robot-object geometry knowledge and maintains complete constraints at each discrete time point, preserving specific end-effector geometry requirements. While robustness prediction metrics have advanced for more general tasks, the fundamental challenges of autonomous caging-based planning and control remain largely unresolved.
Building upon unified geometric and energy-based caging principles, Caging in Time departs from the conventional understanding that a cage must be complete at every moment. Instead, we establish a paradigm where a cage can be considered complete when it achieves completeness across the space-time continuum, thus significantly relaxing hardware requirements and expanding the practical applications of caging-based manipulation. Additionally, traditional methods require very complex algorithms to verify caging configurations (Varava et al., 2021), which can be even harder for partial cages (Makita and Nagata, 2015). As will be seen with Caging in Time, since we can, in theory, virtually have our robots or contacts everywhere as needed, caging verification is generally simpler as we only need to make sure that the object does not penetrate the predefined cage boundaries.
2.3. Theories for uncertainty handling
Our approach draws inspiration from foundational theoretical frameworks that address uncertainties through diverse mathematical formulations across control theory, motion planning, and decision-making. Belief space planning transforms state estimation into probability distributions for decision-making under uncertainty (Kurniawati et al., 2008; Platt et al., 2010). POMDPs formalize partial observability by optimizing over belief states (Kaelbling et al., 1998; Silver and Veness, 2010). Contraction theory provides stability guarantees through analysis of convergence properties (Lohmiller and Slotine, 1998; Manchester and Slotine, 2017), while reachability analysis enables formal safety verification by computing attainable states (Althoff, 2010; Mitchell et al., 2005). LQR trees combine optimal control with sampling-based planning for stabilizing controllers (Majumdar and Tedrake, 2017; Tedrake et al., 2010), and set-based control ensures invariance properties for worst-case scenarios (Rakovic et al., 2005).
While all these approaches can effectively address uncertainties in different ways, they still rely on the assumption that perception feedback or certain prior geometric knowledge of the tasks is always, or at least partly, available. Inspired by these prior works and with an aim to address their limitations in contact-rich manipulation tasks, our proposed Caging in Time synthesizes their insights, including those in state representations and uncertainty-aware planning, from these fundamental theories into a framework that focuses on large perception uncertainties, in order to enable robust manipulation skills with practical real-world implementations.
3. Preliminaries
In this section, we first introduce notations in Section 3.1 for traditional caging definitions, and then in Section 3.2 extend the notations to more general task spaces to enable the derivation of our proposed Caging in Time framework.
3.1. Traditional caging as object closure
In the scenario of an object caged by multiple robots, we denote the configuration space (C-space) of an object by An illustration of the workspace 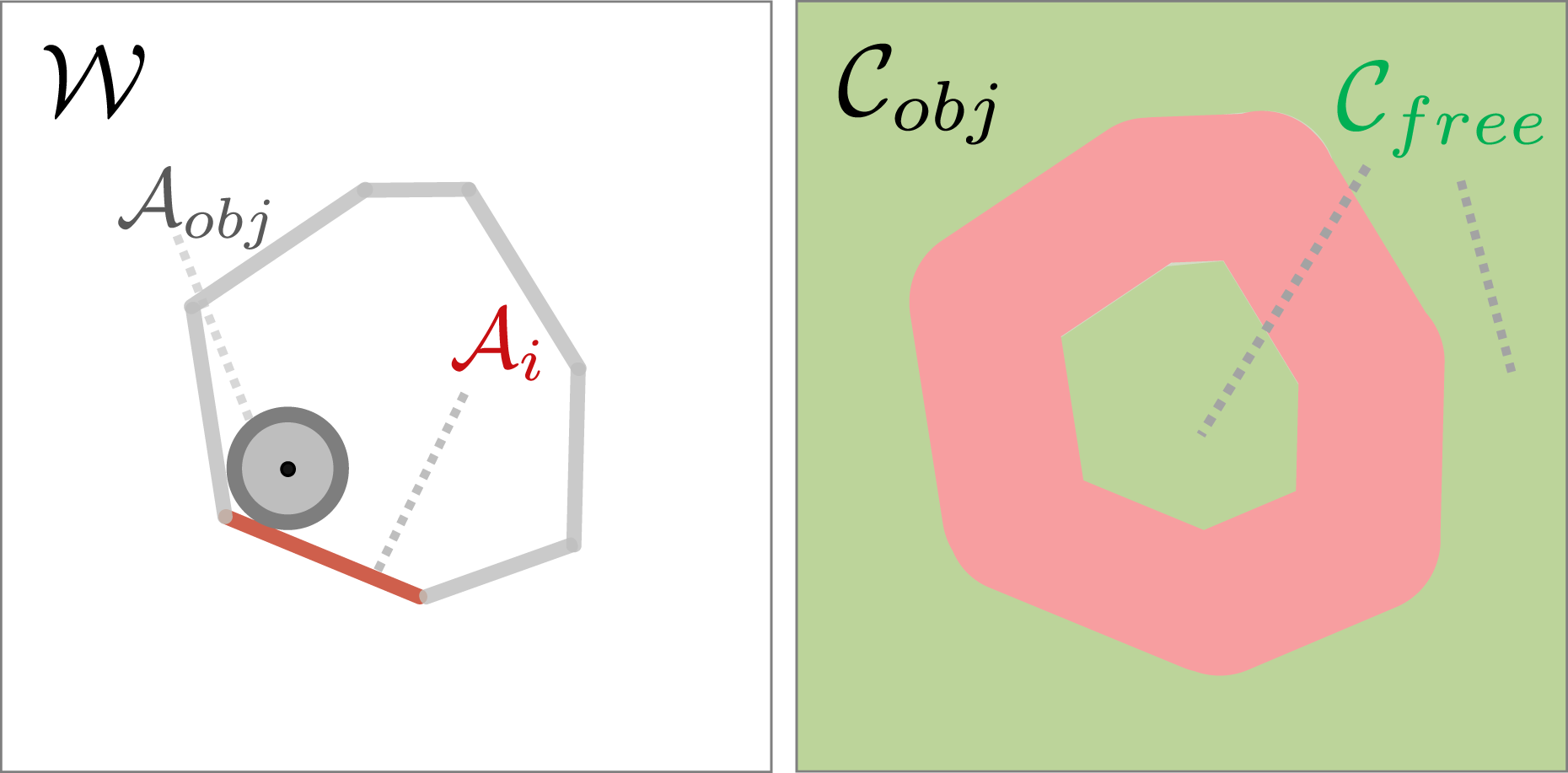
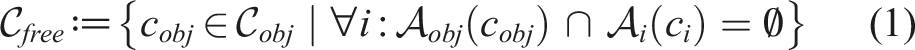
The traditional definition of caging, initially termed object closure, was first introduced by ZhiDong Wang and Kumar (2002) as a condition for an object to be trapped by robots. In other words, the caging condition is met when there is no viable path for the object to move from its current configuration to a configuration infinitely far away.
As depicted in Figure 4, given a point infinitely far away from the current c
obj
in the C-space An illustration of the traditional caging condition. Left: The green region and the red region represent 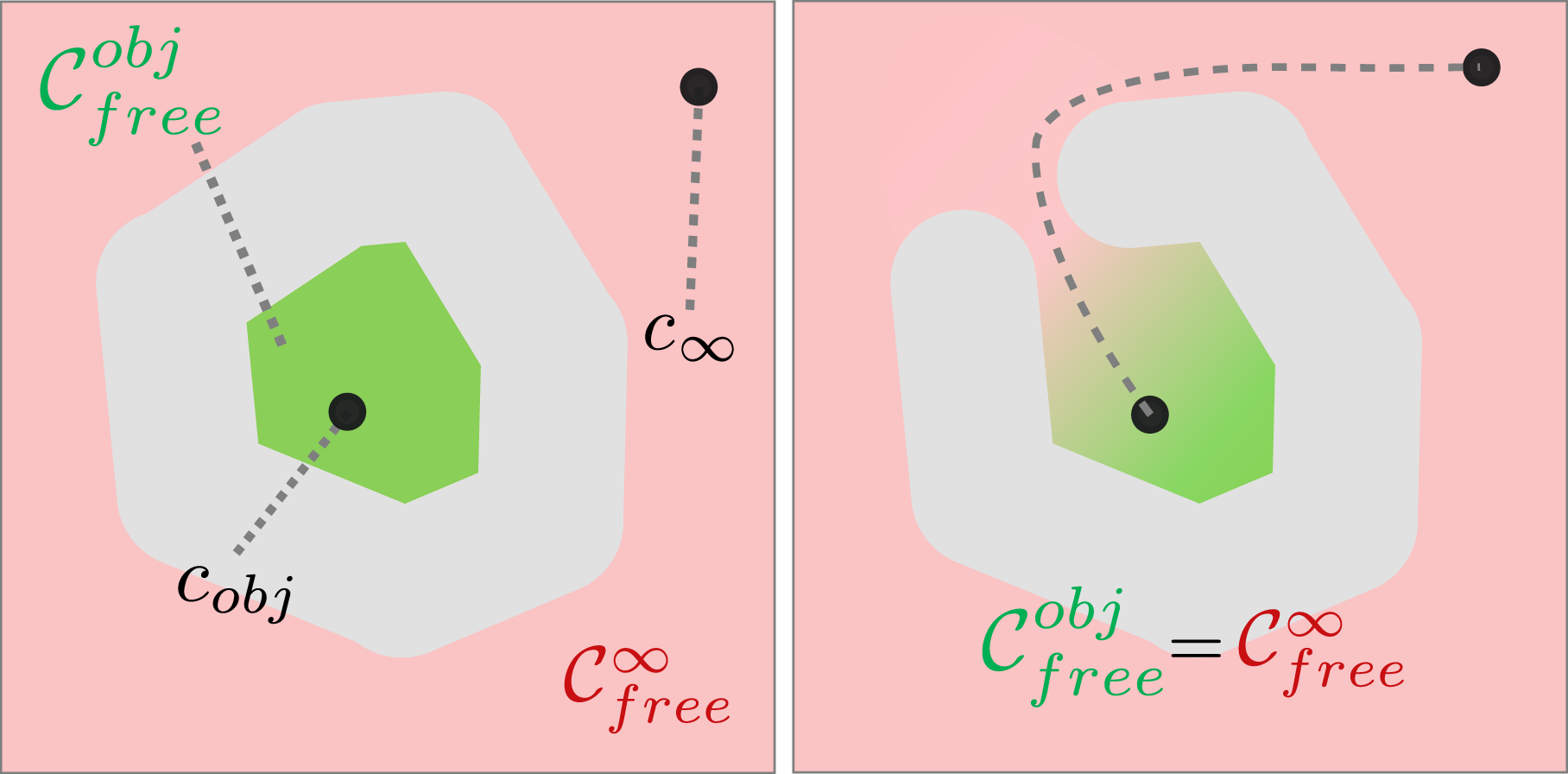
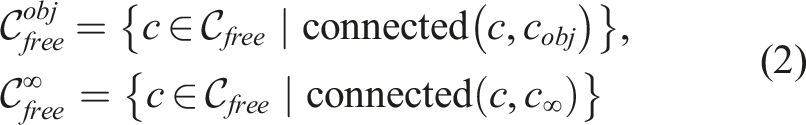

3.2. Generalized representations
To enable the derivation of the Caging in Time theory, we now generalize the representations and notations from configuration spaces to state spaces. This allows for more comprehensive descriptions of manipulation tasks and accommodates various dynamic scenarios and uncertainties, as opposed to the traditional quasi-static configuration-based caging definitions.
We denote the state space of an object by
Furthermore, often in real-world systems, the state of the object at time t is not exactly known due to perception uncertainties or modeling simplifications. To account for such uncertainties, we define the
4. Caging in Time
In this section, we will formally introduce the definition of our proposed Caging in Time theory. With as few as only a single robot interacting with the object, Caging in Time verifies that the object’s state remains caged while being manipulated, thereby enabling open-loop manipulation and guaranteeing the desired movement of the object. As an essential component of our theory, we need to predict the bounded motions of the object, which involves propagating the PSS over time, as will be introduced in Section 4.1. Then, we will formally define Caging in Time in Section 4.2.
For more intuitive illustrations of the proposed concepts, figures in this section are sketched in 2D spaces. However, it is important to emphasize that
4.1. Propagation of PSS
At time t, for each specific state of the object in the PSS
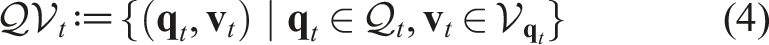
However, the above propagation function only predicts a single state for the next time step. In our Caging in Time framework, we need to know all the possible states propagated from the previous step, that is, the PSS An illustration of the PSS propagation. Left: The propagation for a single state 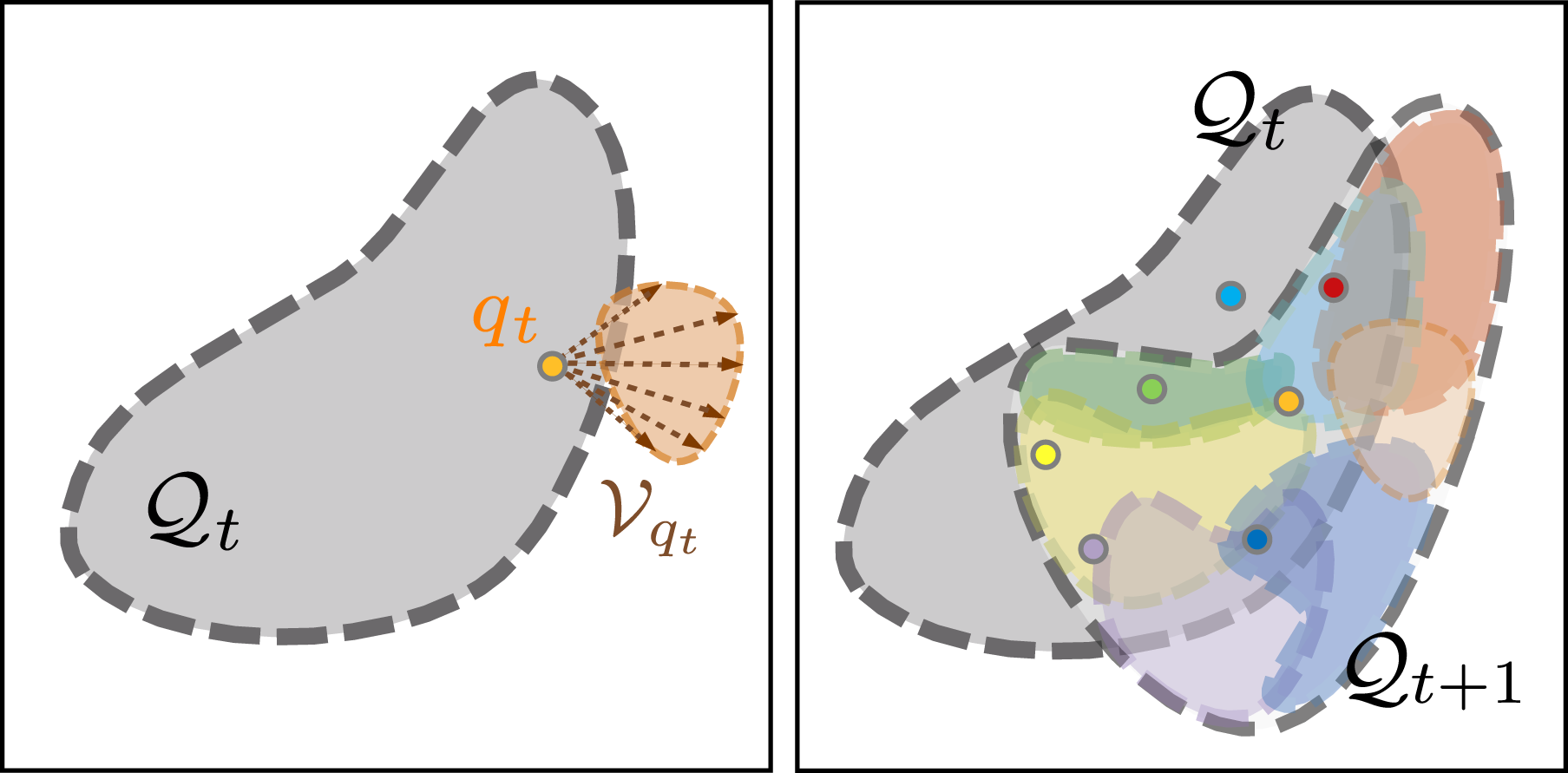
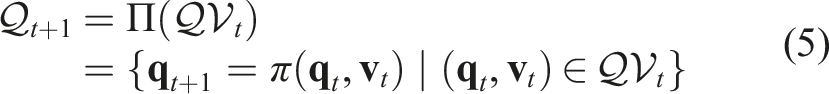
4.2. Caging in Time
Unlike the traditional caging introduced in Section 3.1, our Caging in Time framework only requires one robot to manipulate the object. The cage is formed over time by switching the single robot to a different configuration and interacting with the object differently at each time step. Figure 6 shows an example where a robot pusher can push an object from various possible initial locations relative to the object (marked by the gray bars on the right). At each time step, by predicting the object’s possible motion via the propagation function Π defined in Section 4.1, the robot needs to figure out which candidate push to select (e.g., the green bar in the right figure of Figure 6), to prevent the object from escaping. As such, the object can always be confined to a bounded region as the robot pusher switches to different positions over time and pushes the object in different directions. A 2D pushing example showing how the PSS propagation is influenced by a robot action. Left: A scenario where 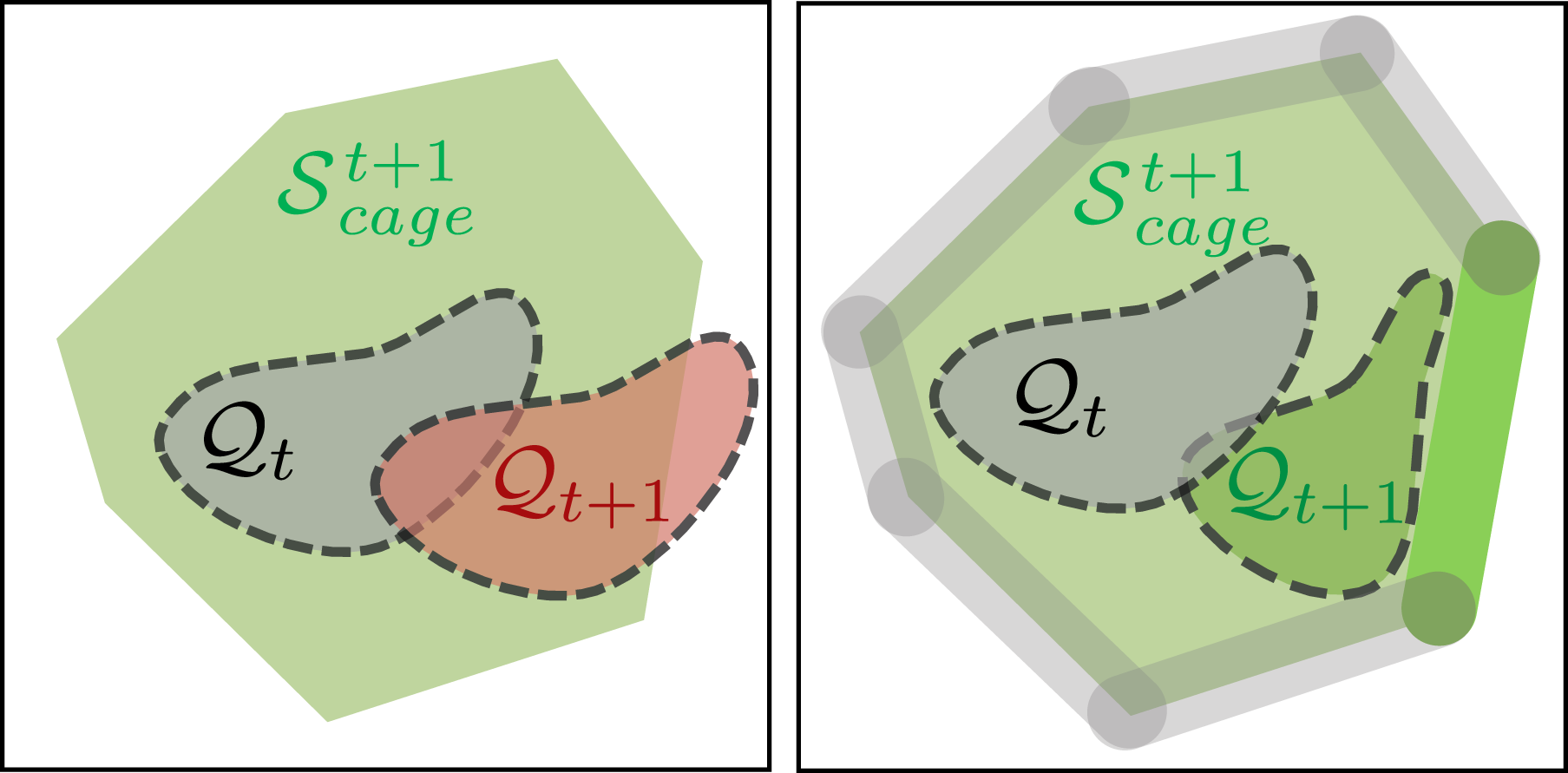
Specifically, for every time step t, we want to confine the object’s state to be always inside a region
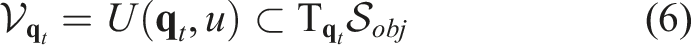
Applying a robot action u may cause the object to move in a direction towards the outside of the cage region
For a time-varying cage
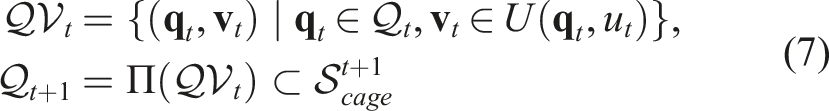
It is worth noting that Caging in Time does not guarantee the existence of such robot actions
The process of determining whether Caging in Time is achieved is detailed in Algorithm 1. When the Caging in Time condition is met, the object is guaranteed to be caged inside a cage region


5. Quasi-static tasks
In this section, we instantiate the Caging in Time theory on a quasi-static planar pushing problem. To facilitate the instantiation, we also develop relevant tools for propagating the PSS of the object in a 2D space and generating open-loop robot pushing actions to cage the object. With the Caging in Time framework applied to the planar pushing problem, we can enable a single robot to push an object of unknown shape to follow certain trajectories in an open-loop manner, without requiring sensory feedback, exact geometric information, or any other physical properties of the object. This is an instantiation of Caging in Time with a geometry-based cage.
5.1. Problem statement
The robot is tasked to push an object on a 2D plane. To generalize over different shapes of the object without requiring exact geometric modeling, we represent the object’s geometry by a simplified bounding circle with radius r, that is,
While the configuration space of a quasi-static 2D object is SE(2), requiring both the position and orientation of the object, our use of a bounding circle allows us to simplify the object’s state space to its position only: 
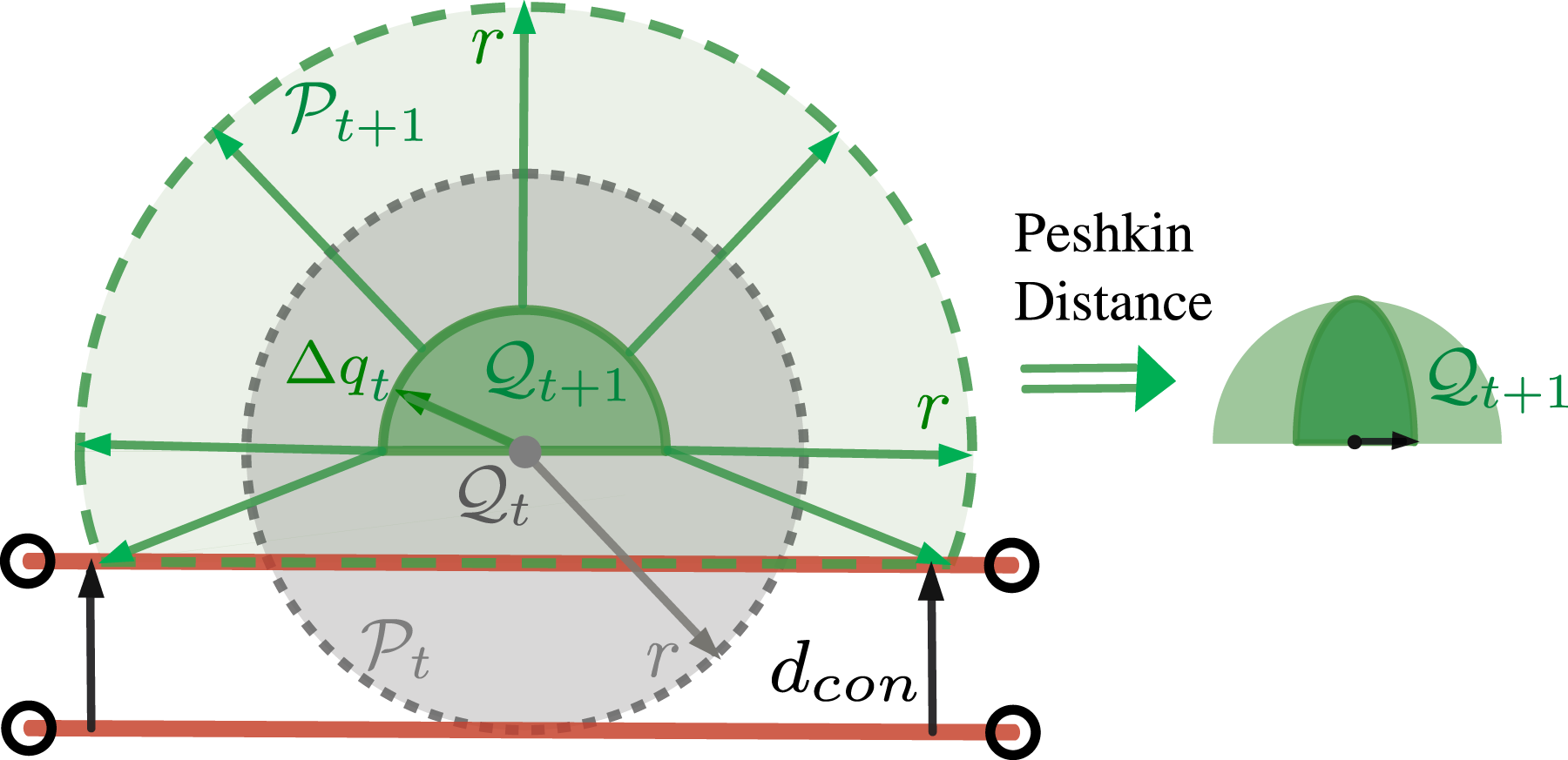
The “cage region”
The robot action is characterized by a scalar angle θ, as shown on the left of Figure 7. The robot will first place the center of the line pusher in a starting position determined by θ, which is always at the boundary of the circle Representation of robot actions and heuristic evaluation for planar pushing. Left: The green dashed circle is 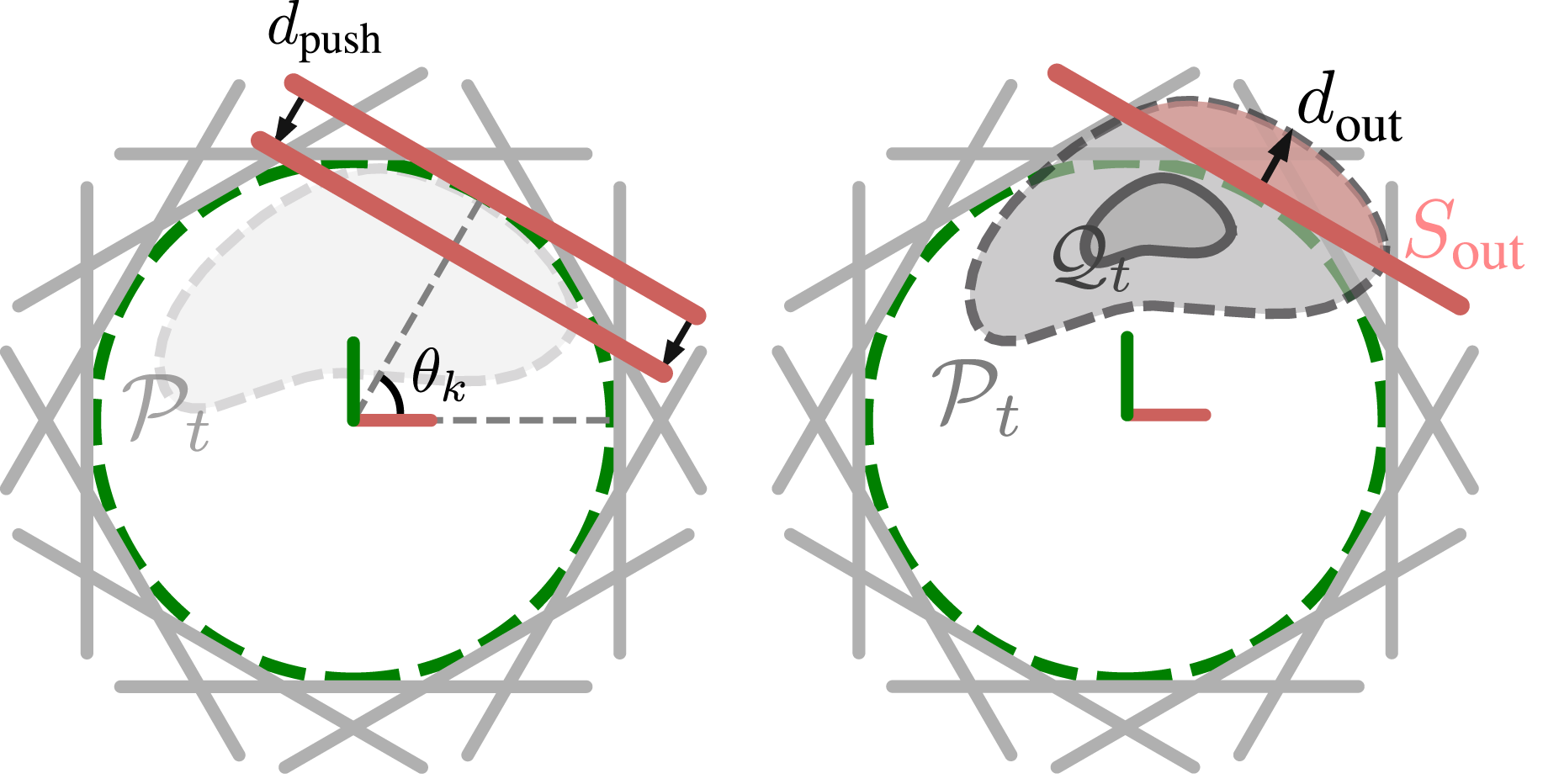


Next, we develop an algorithm for solving the planar pushing problem based on the proposed Caging in Time theory. A high-level description of the developed algorithm is detailed in Algorithm 2. At each time step t, an open-loop robot action
5.2. Unknown object shape and its motion
For planar pushing, we represent the motion of the object by the displacement of the position of the object between adjacent time steps, denoted as
For a specific object’s configuration The illustration of the bounds for the object’s displacement. The maximum displacement of the object equals d
con
. Therefore, 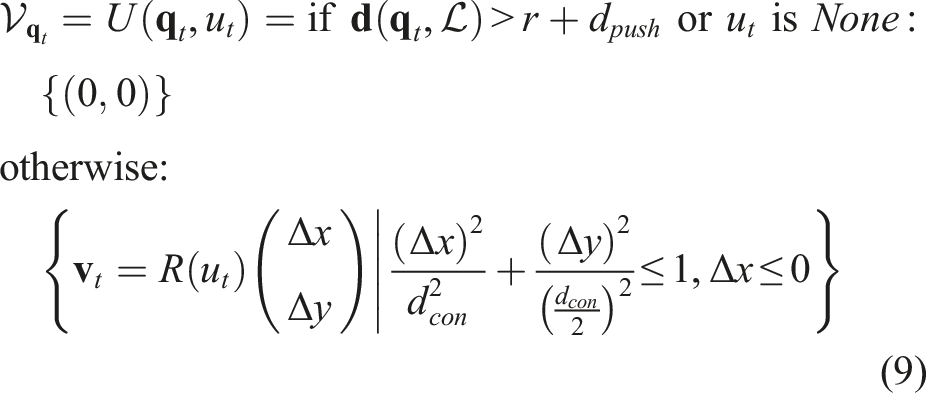
The PSS An example showing how the PSS (white region) and the POA (green region) evolve in the discretized space relative to a moving cage. The moving direction of the cage is shown by the yellow arrows. Left: Without robot intervention, the PSS and the POA remain unchanged. However, they will translate to the left since the cage is moving towards the right. Right: If the POA is predicted to be moving outside of 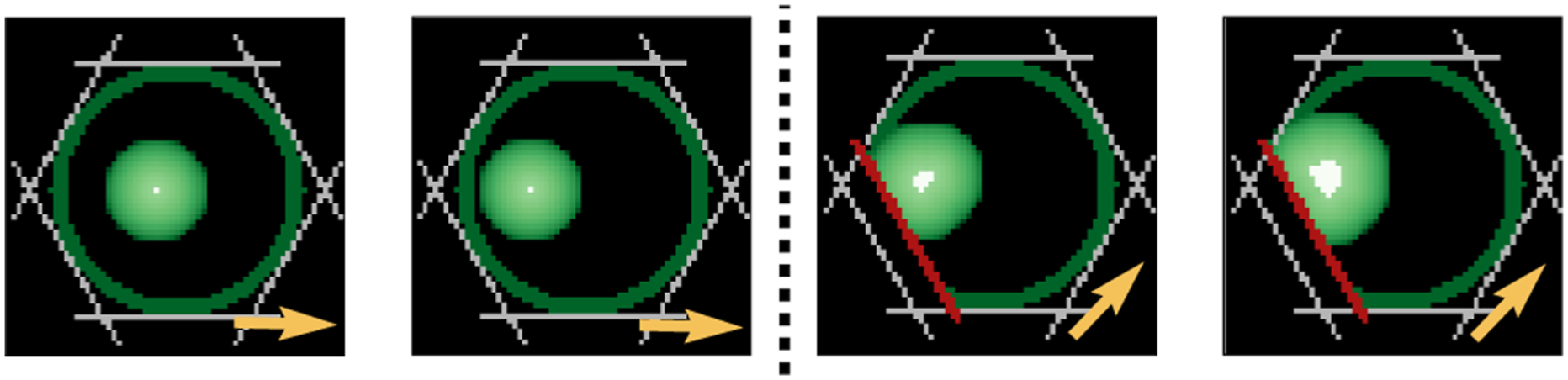


5.3. Cage the push in time


As the cage moves from
Recall that in Section 5.1, each candidate action in
The top five candidate actions with the highest heuristic scores, which compose a set The propagation of PSS (white region) and POA (green region) when the cage is following a circular path. Each image is centered at the center of the cage. The yellow arrow in each image represents the motion direction of the cage. In this example, K = 32 candidate actions are used, represented by the gray bars. With a different pushing action selected (red bar) for each step, the object is always caged in time, and the POA always stays inside 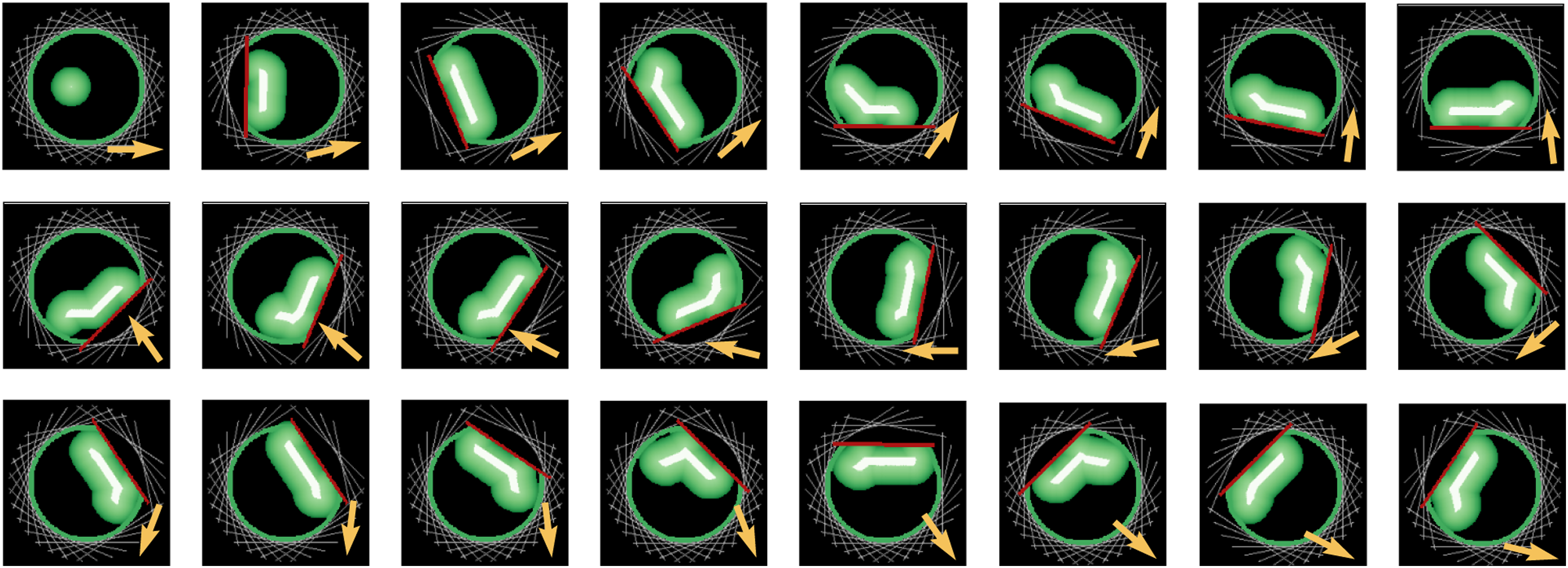
6. Dynamic tasks
In this section, we extend our Caging in Time theory from quasi-static tasks to dynamic scenarios where we instantiate the same framework on a challenging dynamic ball balancing problem. Tools are developed for propagating the ball’s PSS of its position and velocity, as well as for generating open-loop robot actions to keep the ball balanced while the robot end-effector follows different trajectories without requiring any sensory feedback. This is an instantiation of Caging in Time with an energy-based cage.
6.1. Problem statement
The robot is tasked with balancing a rolling object on a tilting plate (end-effector) while the plate follows different trajectories in the workspace. The plate is an n-dimensional flat surface in a workspace of dimension n + 1, where n = 1 or 2. Each dimension of the plate has a size ranging from −l to l. The object has mass m, radius r
b
, an estimated rolling friction coefficient μ
r
, and an estimated moment of inertia I
b
. We assume that the object only rolls on the plate without slipping. Figure 11 illustrates example setups where n = 1 and 2. The position of the plate is denoted as Illustration of the dynamic ball balancing system for plate dimension n = 1 and n = 2. Left: Physical setup when n = 1. 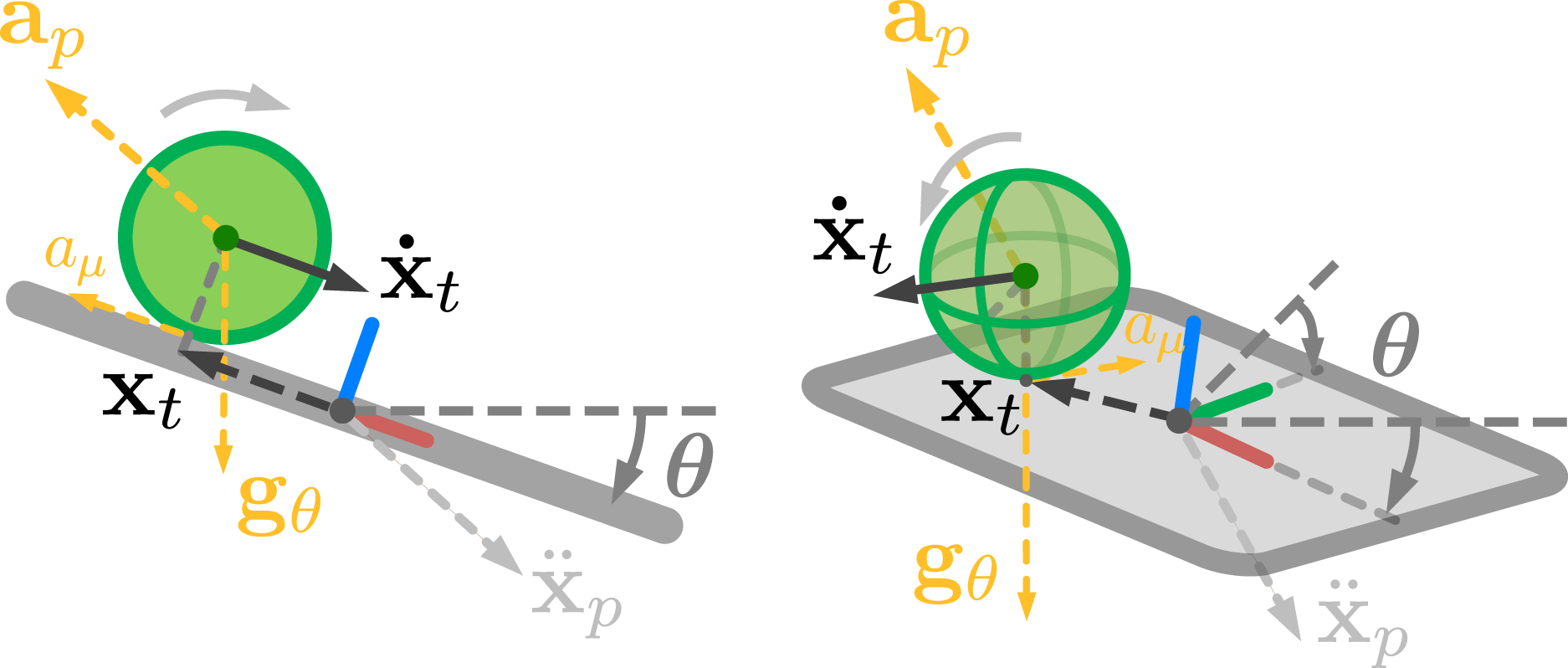
Although our framework employs a pure rolling assumption, this approach leverages a physical insight: rolling friction coefficients are typically smaller than sliding, introducing a higher dynamic uncertainty. Our Caging in Time, specifically designed based on PSS, capitalizes on this property by effectively handling the more uncertain rolling dynamics, inherently encompassing all possible motion states, including sliding behaviors and transitional contact modes, without requiring explicit modeling of each interaction type.
The state of the object at time t is defined as
To represent the distribution of states in a continuous way, we define the probability density of the object in state 
After defining PSS, a “cage region” is needed to constrain these states. Unlike quasi-static tasks where the cage is defined geometrically (Section 5.1), dynamic systems require a different approach because their state space encompasses both configuration and velocity. For such systems, energy provides a powerful and intuitive framework for representing and constraining motion-inclusive states. Here, we define the cage region in the state space based on system energy:
The total energy of the system E(
To establish an upper limit on the allowable energy that ensures that the object cannot “escape” from the plate, we consider an extreme scenario where the object is statically positioned at the edge of the plate as viewed from the plate frame. This maximum allowable energy, Emax, is defined as: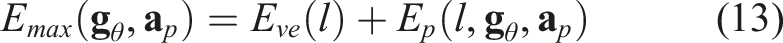
If the total energy of the object exceeds Emax at any time step, it would have enough energy to move beyond the plate’s boundaries, even if its current position is within the plate. By maintaining the energy of the object under the condition E(
This energy-based definition of the cage region can capture both position and velocity constraints and establish boundaries that prevent the object from leaving the plate to effectively cage it in the state space and enable robust dynamic object manipulation.
The control action of the robot is defined by adjusting the tilt angle vector
Next, we develop an algorithm for solving the dynamic ball balancing problem based on the proposed Caging in Time theory. At each time step t, we compute the maximum allowable energy, calculate the weighted average energy of the current PSS, and solve an optimization problem to find the optimal control input
6.2. Ball dynamics and PSS propagation
As mention above, the system state at time t is denoted as 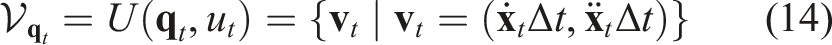
The propagation function π that propagate from 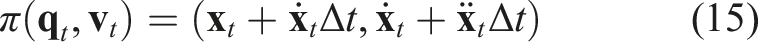
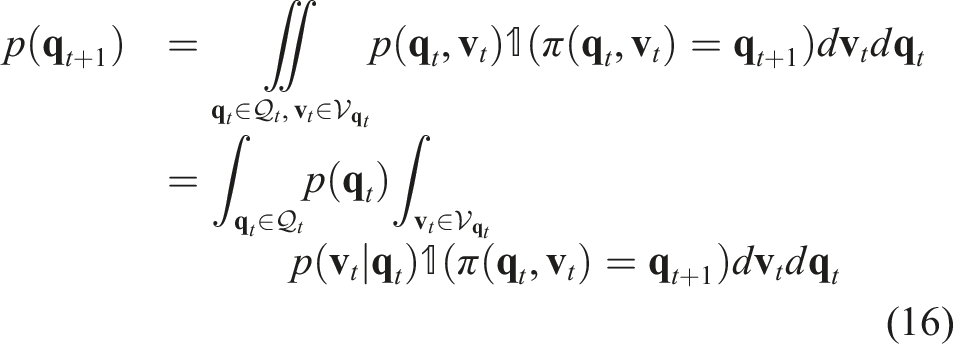
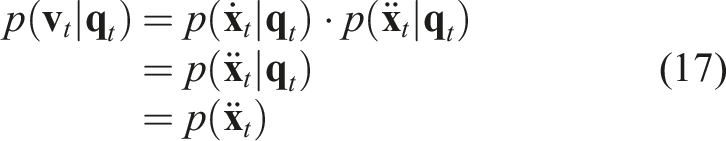
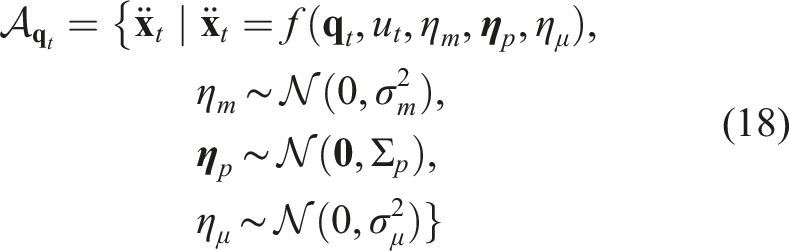
Leveraging the closure property of Gaussian distributions under linear operations, we can conclude that the acceleration 
Given this Gaussian distribution of
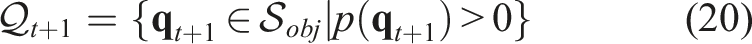


To numerically implement the PSS propagation described by equations (20) and (16), we employ a discretized representation of the state space, similar to the approach used in the quasi-static case (Section 5.2). However, instead of binary values, we use continuous values to represent the probability distribution of the PSS in the state space.
We construct a 2n-dimensional array Discretized representation of the state space 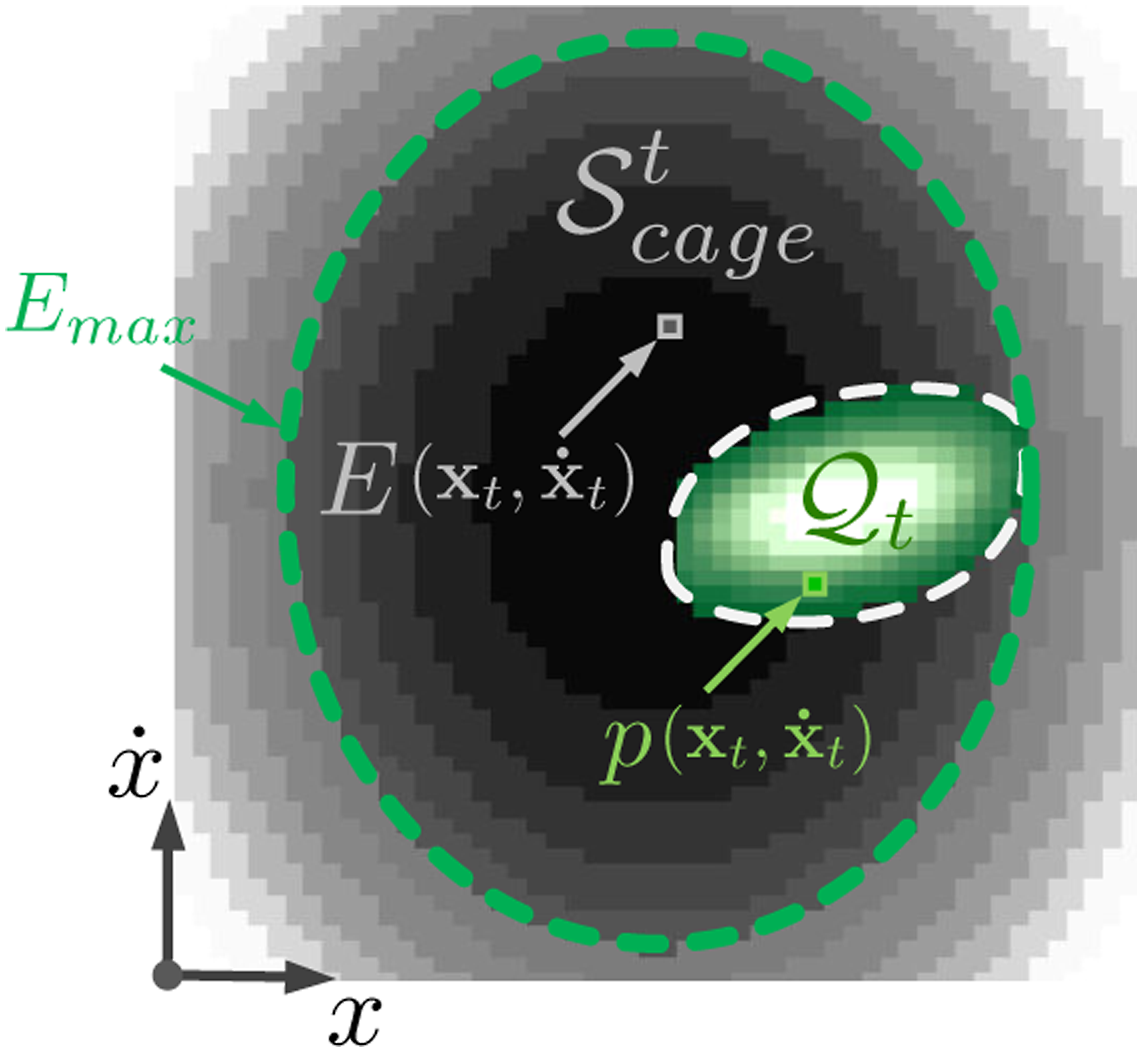
The PSS propagation is implemented in Algorithm 5, which discretizes the continuous integrals in equation (16). For each 
This pixel-based approach provides a computationally efficient representation of the PSS in state space, avoiding the exponential increase in computational cost associated with the sampling methods used in previous caging work in long-horizon tasks (Makapunyo et al., 2012; Welle et al., 2021).
Figure 13 illustrates the propagation and caging of the PSS in the state space during the tracking of an ∞-shaped trajectory for a one-dimensional plate (n = 1). The PSS initially manifests as a compact Gaussian distribution, subsequently expanding before converging to a stable size caged by the energy boundary. Sequence of the ball’s PSS evolution during dynamic balancing where the plate dimension n = 1. Top rows: State space representation of the PSS 
6.3. Cage the ball in time
To achieve Caging in Time for the dynamic ball balancing, we employ a control optimization strategy that combines Control Barrier Function (Ames et al., 2019) and Control Lyapunov Function (Anand et al., 2021) to keep the ball on the plate while following the desired trajectory.
In our case, Control Barrier Function (CBF) is utilized to implement the concept of “caging” in a dynamic setting. As a physical cage constraining an object within a defined space, the CBF establishes an energy-based cage that can be characterized by the margin between the maximum energy attainable within the PSS and the preset energy boundary:
This creates an energy barrier and acts as the mathematical representation of our cage. By ensuring that
To further ensure that our control actions maintain this energy barrier, we enforce a CBF condition. This provides a forward-looking constraint that considers not only the current state but also the future behavior of the system, rather than simply enforcing 
In this condition,
Control Lyapunov Functions (CLFs), on the other hand, are used to optimize the control performance by driving the system towards a desired state. In our context, we use a CLF to encourage the ball to stay near the center of the plate and maintain a well-distributed probability state, with both the system’s energy and entropy considered:
This CLF balances two objectives: minimizing the expected energy of the system, which tends to keep the ball near the center of the plate, and maximizing the entropy of the probability distribution, which maintains a well-distributed probability state, ensuring both stability and robustness in the face of uncertainties. By minimizing this CLF, we drive the system towards a state where the ball is likely to be near the center of the plate, but with some uncertainty to handle unexpected disturbances.
Similar to CBF condition, we enforce the CLF condition to ensure the CLF decreases over time: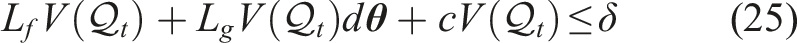
By combining the CBF and CLF conditions, we formulate a Quadratic Program (QP) that not only keeps the ball on the plate but also tries to keep it centered and stable.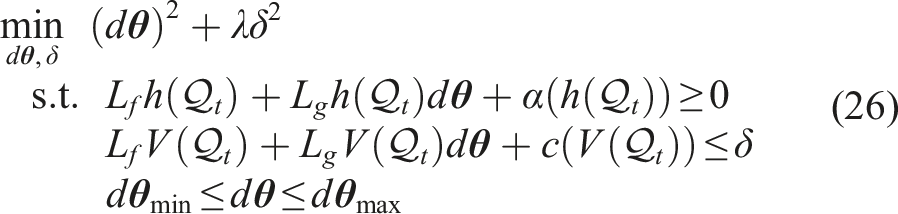
By solving this QP at each time step, we obtain the optimal control input that maintains the ball within the energy-based cage while following the desired trajectory. The detailed implementation is presented in the Appendix 9.2.2.
This approach allows us to cage the ball in time under dynamic conditions on a tilting plate, accounting for the ball’s dynamics, uncertainties, and energy constraints. By solving the QP at each time step, we generate a sequence of actions that keeps the ball within the energy-based cage region with the plate following the desired trajectory.
7. Experiments
We conducted extensive experiments to evaluate our Caging in Time framework using a Franka Emika Panda robot arm for both quasi-static pushing tasks and dynamic ball balancing tasks with different end-effectors shown in Figure 14. All algorithms were implemented in Python and executed on a single thread of a 3.4 GHz AMD Ryzen 9 5950X CPU. Experiment setup. Left: Robot and camera setup. The robot performs the experiment on a transparent surface (blue) with a pre-installed line pusher (green). We used cameras 2 and 3 below the surface to record (not to track) the trajectories of the objects through April-Tag. Camera 1 was used to record the experiment from an upper view. Top Right: The 3D-printed objects used in the experiments. 1. Square with two trimmed tips, 2. Pentagon, 3. Triangle with trimmed tips, 4. Octagon, 5. Square, 6. Heart, 7. Hexagon, 8. Ellipse, 9. Circle, and letter-shaped objects: R, I, C, E. Bottom Right: 3D printed plates, tennis ball and plastic fruits for dynamic tasks. The square plate is for ball balancing when dimension n = 2, and the thinner one is for ball balancing and catching when dimension n = 1, which has a guide rail to constrain the motion of the ball only on the required dimension. The plastic fruits are strawberry (YCB #12), plum (YCB #18), pear (YCB #16), and lemon (YCB #14).
Our experimental setup utilized multiple cameras for recording: the cameras shown on the left of Figure 14 for quasi-static tasks, with an additional camera for dynamic tasks. For quasi-static experiments, object tracking was achieved using AprilTags (Olson, 2011), while in dynamic scenarios OpenCV was employed to track the ball’s motion. It is important to note that object tracking served only for trajectory visualization and accuracy evaluation, and all experiments were conducted in an open-loop manner.
To quantify manipulation precision, we adopted the Mean Absolute Error (MAE) as our primary metric, calculated by averaging the absolute distances between the actual and reference trajectories throughout the manipulation process.
As in this initial exposition of our framework, we deliberately selected two representative manipulation paradigms, one quasi-static and one dynamic, to evaluate fundamental capabilities while facilitating clear visualization of PSS propagation. Through these experiments, we aimed to thoroughly assess the performance, robustness, and versatility of our Caging in Time framework, establishing a foundation for future extensions to more scenarios.
7.1. Quasi-static tasks
Through quasi-static experiments, we aimed to investigate the performance of our framework from three aspects: 1) Without any sensing feedback besides the size and initial position of the bounding circle, can robust planar manipulation be achieved by the proposed Caging in Time? 2) If so, what precision can be achieved and how is the robustness affected by different settings of the framework and outer disturbances? 3) Under imperfect perceptions like positional noise and network lag, can Caging in Time surpass closed-loop methods?
As shown in Figure 14, the robot in this task used a 100 mm line pusher, and objects of various shapes were 3D printed in a similar size, fitting within a bounding circle of radius r = 25 mm. The pushing distance for each action was set as d push = 20 mm. The computation time for each step in action selection and PSS propagation was 26.2 ± 8.5 ms.
7.1.1. Evaluation of cage settings
The task of this experiment is to push the object through a predefined circular trajectory. This experiment focused on evaluating the precision of our framework by varying two key parameters: R − r, the cage size, and K, the number of candidate actions. We selected values for R − r and K from the sets R − r = {10, 20, 30, 40} mm and K = {16, 32, 64, 128}. For each combination of R − r and K, five trials were conducted using five different objects (Object 1–5; see Figure 14). We generated only one robot action sequence per (R − r, K) setting, following Algorithm 2 and applied it to different objects in an open-loop manner. The MAE across these trials was averaged and presented in Figure 15, which also includes the actual trajectories recorded from all experiments with different settings and different objects. Evaluation results in terms of the cage size (R − r) and number of candidate actions. Top: All trajectories (nine trajectories of different objects are overlaid in the plot per circle) Bottom: Mean Absolute Error of the shown trajectories under different cage settings. “CA” stands for candidate action.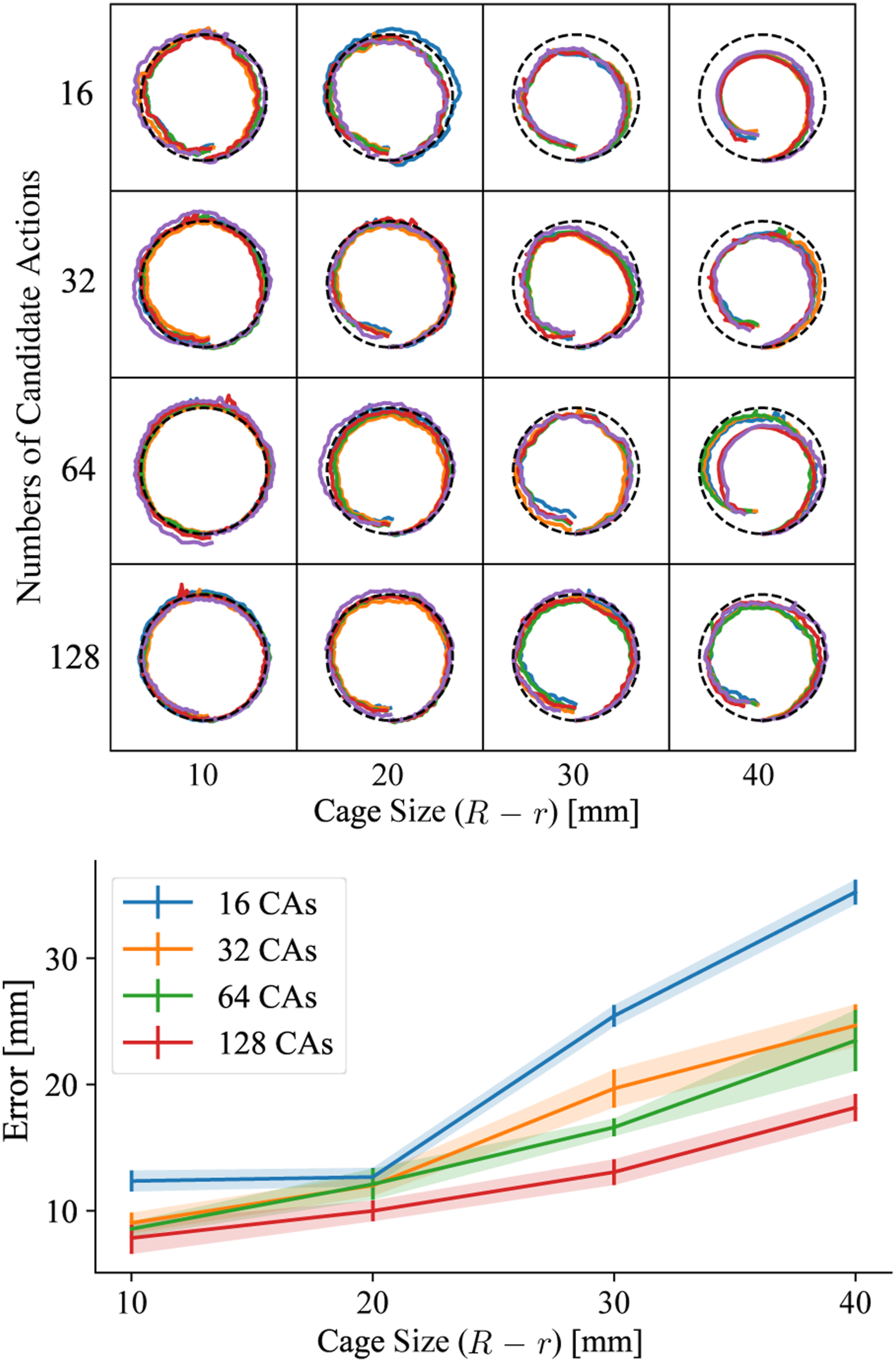
From the results, we can see that the performance follows two major trends. One is that a larger cage radius tends to increase the average error. The other trend is that an increase in the number of candidate actions generally leads to a decrease in error. As shown in Figure 16, with larger cage sizes, the POA will grow larger, therefore, increasing the range the object could possibly deviate from the reference trajectory. Also, with more candidate actions, it increases the possibility of finding the optimal action in Algorithm 4. Visualization of POAs (the white boundaries) in real pushing experiment recordings under various cage sizes.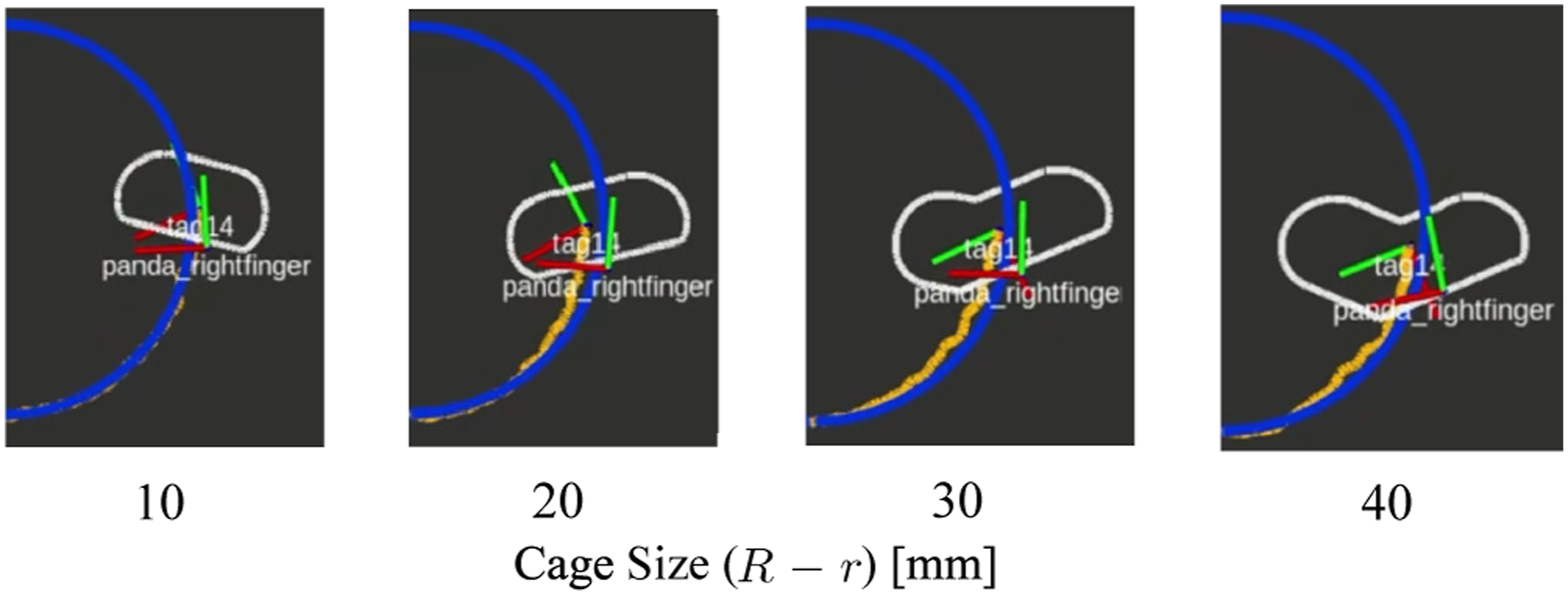
Examining the trajectories in Figure 15, we observed that all the paths remained within their respective cage regions. In particular, trajectories generated by the same action sequence showed similar patterns across different objects. For example, trajectories with 16 candidate actions and a cage size of 40 mm (R − r) mostly moved to the left of the reference path, indicating that the action sequence plays a more dominant role in the performance than the shape of the object.
7.1.2. Why caging in time
Although the line pusher might be perceived as a stable method for pushing an object in an open-loop way, this stability is often compromised by the unpredictability of the object’s physical properties and shape, which necessitates the implementation of Caging in Time.
To validate the necessity and robustness of our approach, an object was tasked to navigate a ∞-shaped trajectory repeatedly for 10 cycles. A comparative analysis was performed against a naïve pushing strategy, where the pusher simply followed the target trajectory with its orientation parallel to the direction of the trajectory. As shown in Figure 17, in contrast to the naïve method, where the pusher lost control of the object after a few steps, our approach successfully maintained control over the object after 10 rounds with an average error of 10.09 mm. Robustness validation with a ∞-shaped trajectory. This experiment was conducted with the heart-shaped object (9), recorded by camera 2. Top: Ten loops conducted by Caging in Time. Bottom: A failed attempt by a naïve pushing strategy.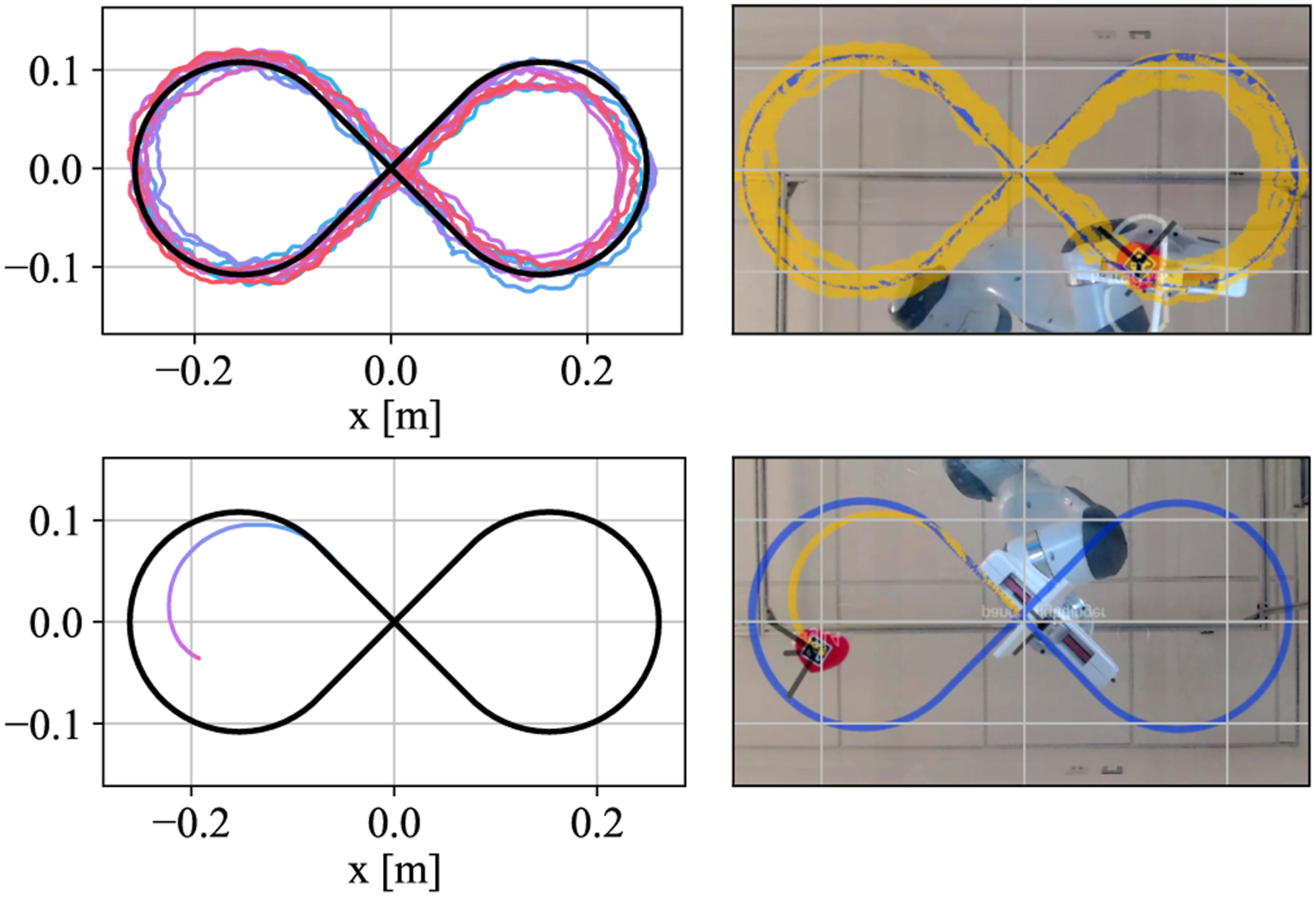
7.1.3. Comparison with a closed-loop method
To further validate the effectiveness of our framework, we conducted a comparative study against a closed-loop pushing method: a proportional controller (P-controller) implemented under the quasi-static assumption. The P-controller works by calculating an error vector from the object’s current position to the nearest waypoint on the reference trajectory. This error vector is then scaled by the P-gain (set to 0.5) to determine the direction and magnitude of the pushing action. Specifically, the pushing direction is aligned with the scaled error vector, while the pushing distance is capped at 20 mm for each action, consistent with the d push used in our Caging in Time experiments.
We introduced two types of disturbances to simulate real-world scenarios with imperfect perception and communication delays. First, positional noise was added as Gaussian noise with a standard deviation of the noise level in both x and y directions, simulating the imperfect perception, such as that of an RGBD camera under dim lighting conditions. Second, to emulate potential packet loss during data transmission or sudden obstruction of the object from the camera, we introduced a network lag that for each execution step, there was a 50% possibility that the controller would receive the object’s position from 0.5 or 1 second ago.
The experimental results, as shown in Figures 18 and 19, demonstrate that our Caging in Time approach achieves accuracy comparable to that of the P-controller with perfect perception. Moreover, the accuracy of the P-controller deteriorates significantly under the influence of perception noise or network lag. As shown in Figure 18, when the Gaussian noise is large, the resultant trajectory tends to exhibit random motion patterns, whereas network lag induces classic sinusoidal fluctuations in the trajectory. Trajectory comparison between Caging in Time with 20 mm cage size and 128 candidate actions and the P-controller under varying positional noise levels and network lags. Odd rows: Representative recordings of a single object. Even rows: Overall trajectories from all nine test objects. Evaluation results of the P-controller in terms of the noise level (blue) and network lag (red) compared to the Caging in Time framework (yellow) under 20 mm cage size and 128 candidate actions.
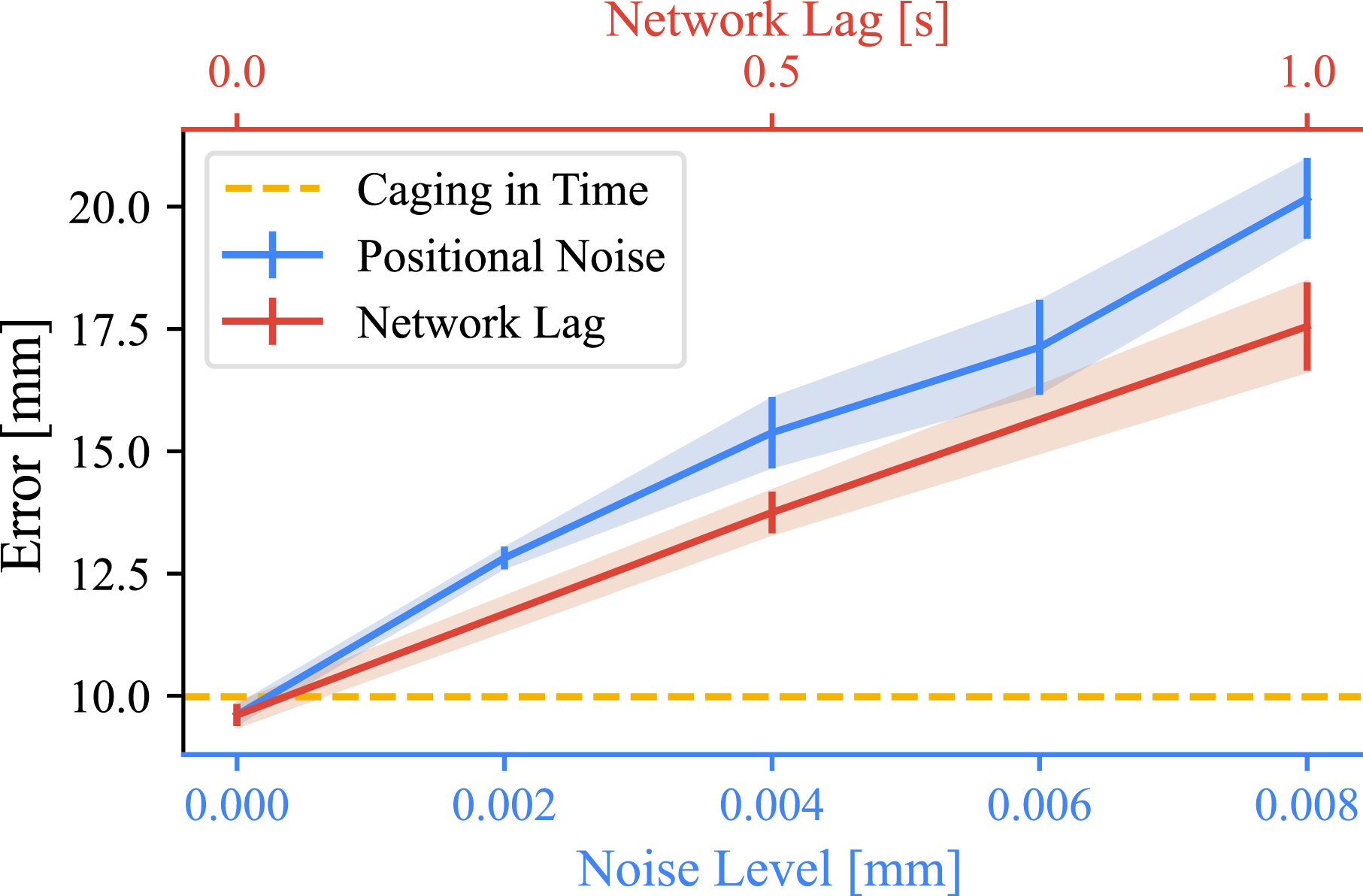
These findings underscore the robustness of our Caging in Time framework, particularly in real-world scenarios where perception and communication are often imperfect. The open-loop nature of our approach eliminates the need for continuous feedback, making it inherently resilient to perception noise and network delays that can significantly impair the performance of closed-loop methods.
7.1.4. In-task perturbations
The robustness of Caging in Time was further tested by maneuvering objects along specially designed trajectories shaped by the letters “RICE,” as shown in Figure 20. Trajectory following with in-task perturbation using six different objects (4, 7, 9, R, C, E) for tracing “RICE.” The manipulated objects are shown at the start point of each segment after the switch, with the color of the objects matched with their trajectories. The real recording is shown in Figure 1.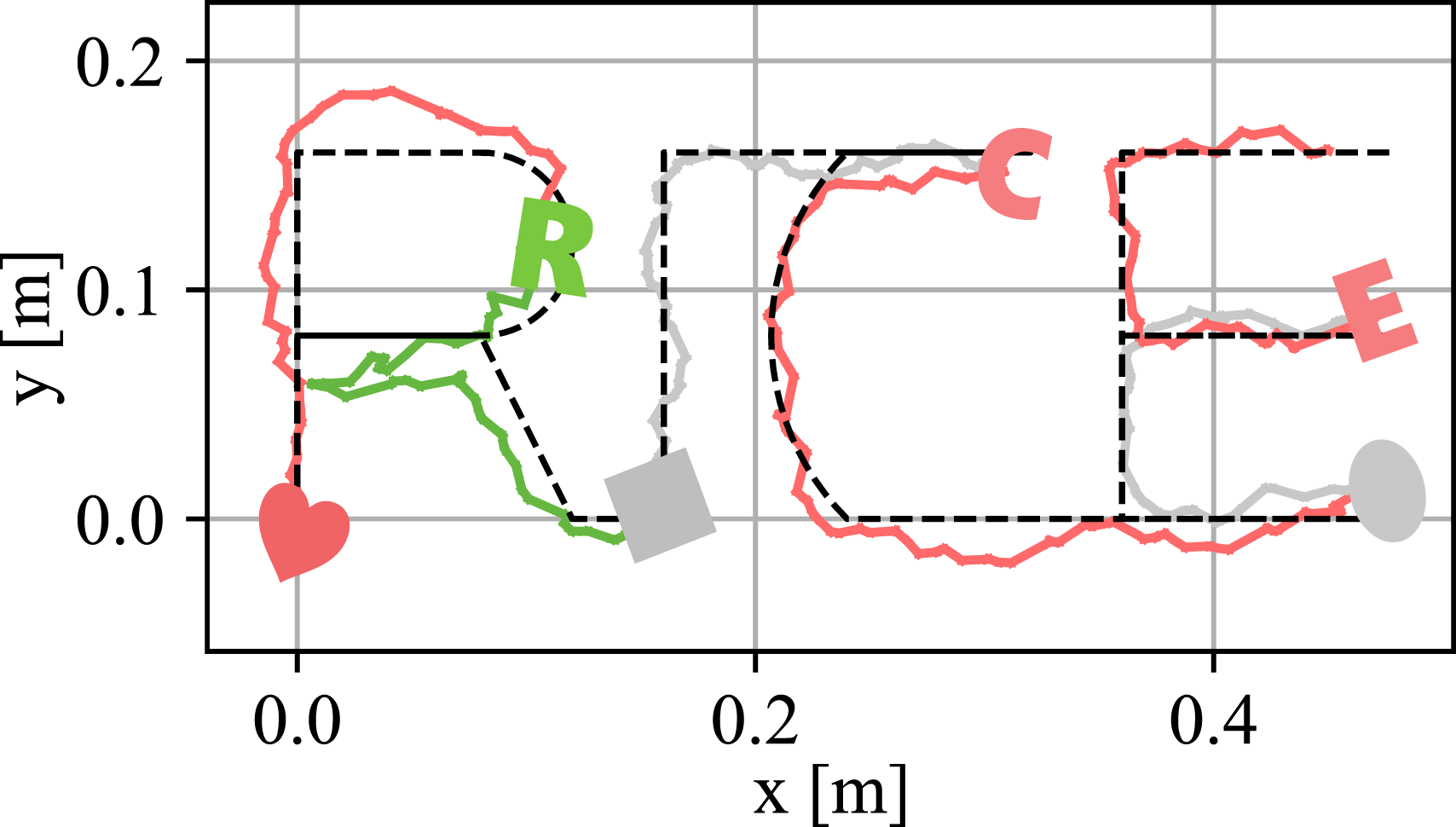
Notably, during this task, objects were intermittently randomly replaced by a human operator to test the system’s ability to adapt to new shapes and position perturbations while maintaining trajectory precision in one single task. The results have further shown the robustness of our proposed Caging in Time framework: as long as the new object was positioned within the current PSS
7.2. Dynamic tasks
To evaluate the capabilities and limitations of Caging in Time in handling various dynamic tasks, we conducted a series of experiments using a tennis ball of diameter 6.6 cm with end-effector plates in different sizes, as shown in Figure 14.
Like quasi-static tasks, dynamic experiments also focused on three key aspects: 1) Can Caging in Time achieve robust ball balancing on a moving plate along different trajectories without real-time sensing feedback? 2) How well does the framework perform in more extreme dynamic scenarios, such as catching a ball in an open-loop manner? 3) How robust is Caging in Time when handling uncertainties higher-dimensional state spaces?
In the following experiments, the plate followed a predefined translational trajectory
7.2.1. Dynamic sensitivity analysis
Before proceeding with experiments, we conducted a dynamic sensitivity analysis to examine how Caging in Time performance in the ball catching tasks responds to initial state distribution and hardware limitations, as previously mentioned in Algorithm 1 and equation (26). Figure 21 illustrates the success rates for finding feasible action sequences in Algorithm 1 for a ball catching task across varying initial velocity uncertainties Ball catching success rate evaluation of finding feasible action sequences in PSS propagation over initial velocity uncertainty range 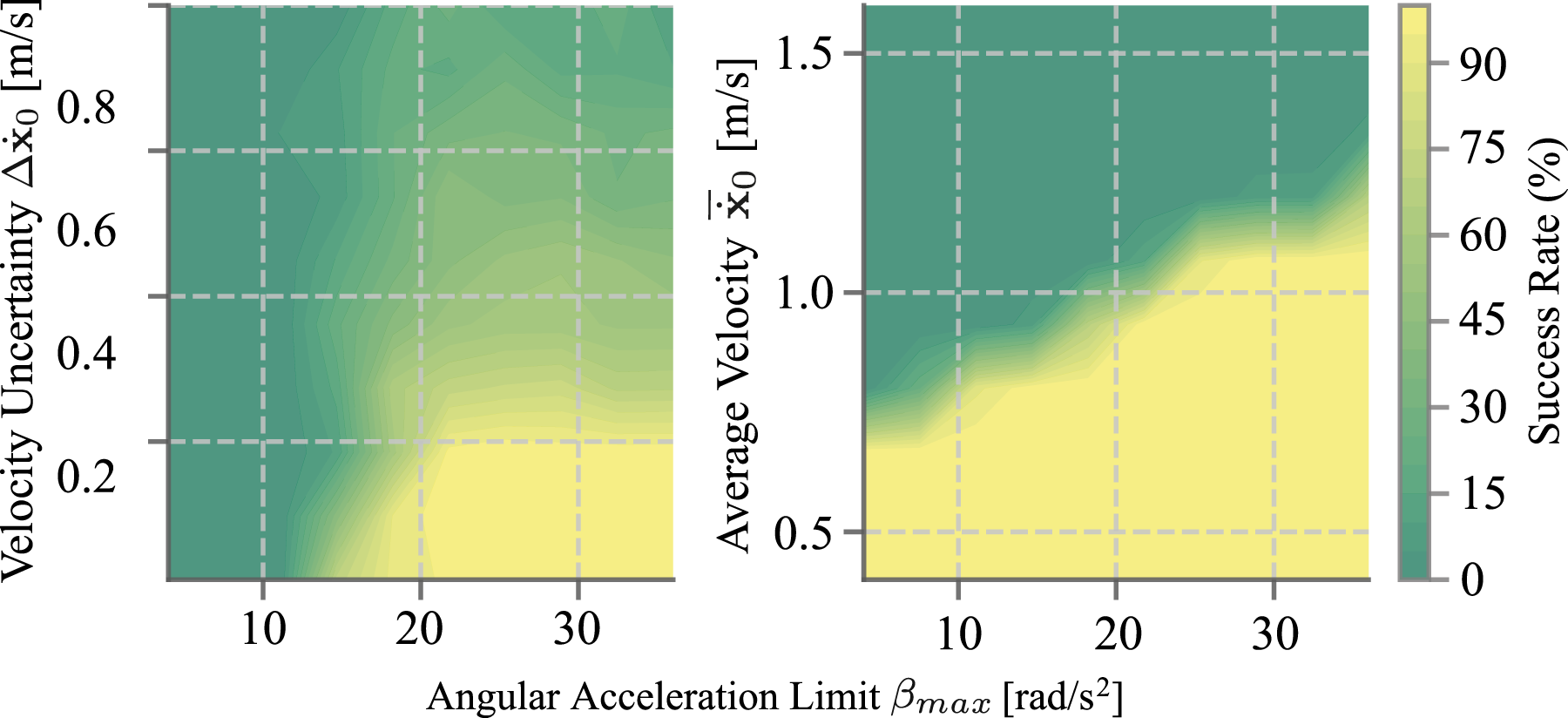
As shown in Figure 21, with a fixed
7.2.2. Ball balancing
We first tested ball balancing with dimension n = 1 on two different trajectories, as shown in Figure 22. The plate used in this task is 16 cm long and has a guide rail to constrain the ball’s rolling to the x-axis only, as shown in the bottom right of Figure 14. The “RICE” trajectory, featuring sharp turns, resulted in an average error of 20.12 ± 5.66 mm. The ∞-shaped trajectory, repeated four times to test smooth recurring curves, yielded an average error of 26.59 ± 7.54 mm. Both experiments were repeated 20 times, with the ball consistently remaining on the plate, demonstrating the robustness and stability of Caging in Time for long-horizon dynamic tasks. Experimental validation of Caging in Time for dynamic manipulation tasks using a tennis ball and a support surface where dimension n = 1 (see Figure 14). Top row: Representative frames from video recordings, with overlaid transparent balls showing the ball’s position at different time points. Bottom row: Trajectory plots of 10 repeated trials for each task. Left: Ball balancing while tracing “RICE.” Middle: Ball balancing along an ∞-shaped trajectory. Right: Ball catching with the balls rolling down from the same height on a slope to achieve consistent initial tossing velocity.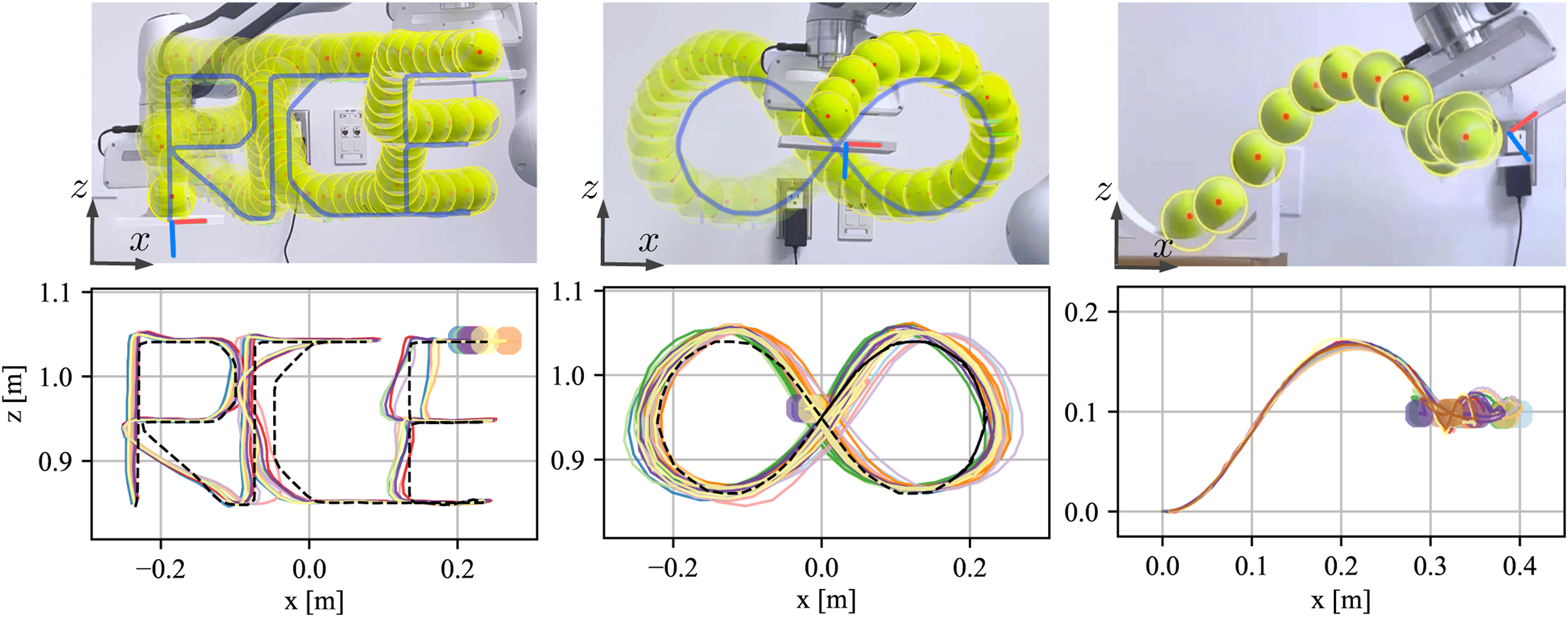
We observed that sharp turns in the trajectory of the plate caused sudden changes in
7.2.3. Ball catching
To further challenge the capability of Caging in Time to handle complex dynamic tasks, we implemented an open-loop ball catching experiment using the same plate with a 1D track constraint where dimension n = 1. In actual implementation, to ensure appropriate timing for initiating the action sequence, we utilized OpenCV to detect when the ball entered the camera frame. The open-loop action was activated upon detection with a manually tuned fixed time offset. Within the Caging in Time framework, we considered the task to start when the ball made contact with the plate, ignoring bouncing effects. In addition, we incorporated a hard-coded translational retreat motion to minimize ball rebounds on the plate.
We conducted two sets of experiments. In the first experiment, balls were released from a fixed height on an inclined slope, ensuring a consistent initial position and approximately the same velocity of the ball upon leaving the slope. Out of 20 trials, the system successfully caught the ball in all 20 attempts, as shown in Figure 22 (right). This demonstrates the reliability of Caging in Time under well-defined initial conditions.
In the second experiment, we introduced greater uncertainty by having a human manually toss the ball onto the plate, as illustrated in Figures 1 and 23. Due to the inherent difficulty in controlling the landing position of hand-tossed balls, we only recorded trials where the ball successfully landed on the plate. Out of 20 such successful tosses, the system was able to catch and stabilize the ball in 13 trials. This partial success rate demonstrates the framework’s robustness to velocity uncertainties within a certain range, as well as the limitations of the Caging in Time framework’s pre-configured error tolerance. This tolerance is constrained to ensure feasible actions within the robot’s hardware torque limits, and some human tosses evidently introduced velocity variations beyond this tolerance range.
To quantitatively evaluate task completion rates under varying uncertainty conditions, we analyzed success rates in ball catching across different initial velocity distributions. Our data shows that slope dropping with velocities of 0.84 ± 0.12 m/s achieved a 100% success rate, while human tossing with greater variability beyond the tolerance range (0.93 ± 0.28 m/s) yielded a 65% success rate. This real-world evaluation further validates our dynamic sensitivity analysis in Figure 21 and demonstrates the framework’s performance boundaries under different uncertainty magnitudes.
7.2.4. Caging with uncertainty
To test the robustness of the framework to shape uncertainty, we balanced various fruits in the YCB dataset shown in Figure 14 along the “RICE” trajectory with dimension n = 1, as shown in Figure 24. Although the shape uncertainty brought higher uncertainties to the system dynamics, the framework could still make sure that the object motion stays in the caged PSS. In 10 trials, all objects remained on the plate, demonstrating the adaptability of Caging in Time to shape variations. Demonstration of object-agnostic robustness in Caging in Time. Balancing of diversely shaped YCB fruits from Figure 14 where dimension n = 1 using the same open-loop action sequence for the tennis ball. Each figure shows multiple instances of the same fruit, representing its position at different time points during the balancing task.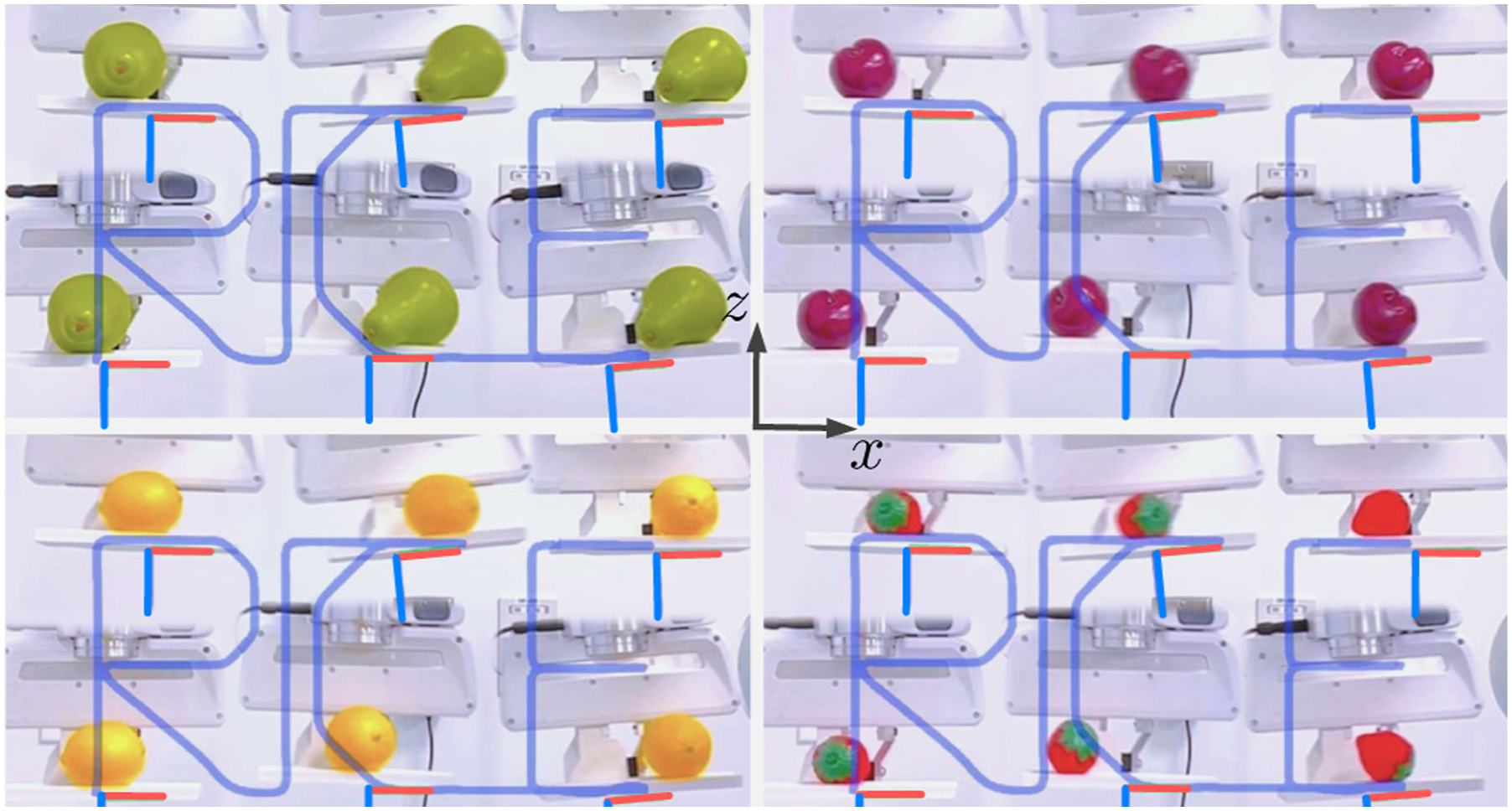
To note that, the success of these tasks can be partially attributed to the nature of irregular shapes, which are less likely to roll freely due to their inherent energy traps created by their non-uniform geometries. This characteristic actually aids in maintaining stability, as the objects tend to settle into local energy minima, complementing the caging strategy of our framework.
7.2.5. Caging in higher dimensions
Lastly, we extended our experiments to higher-dimensional spaces using a 16 cm×16 cm plate, where the absence of the guide rail allows the ball to move freely in both the X and Y directions, significantly increasing the complexity of the balancing task. As shown in Figure 25, we performed ball balancing with dimension n = 2, where the ball’s state is represented in a 4D state space Ball balancing using Caging in Time with the dimension n = 2 while tracing “RICE.” Left: Representative frames from recordings. The overlaid transparent balls show the ball’s position at different time points during the task. Right: Qualitative trajectory plots of 10 repeated trials for each task.
In 10 trials, the ball consistently remained on the plate, showcasing Caging in Time’s applicability to higher-dimensional scenarios. The trajectories shown in Figure 25 are for illustrative purposes due to non-orthogonal camera placement and may not represent exact quantitative performance, where we can visibly tell that the trajectories exhibit larger deviations compared to the previous balancing experiments. This increased error is attributed to the unrestricted rolling direction in this setup, which introduces greater uncertainties and control challenges.
8. Applications in practice
Applications for Caging in Time could potentially extend beyond previous experiments to broader manipulation domains. This section explores the possibilities and practical considerations for implementing Caging in Time in various scenarios.
8.1. Example applications
In Caging in Time, according to Section 3.2, object states are represented through PSS
8.1.1. In-hand manipulation
For in-hand manipulation, our framework enables instantaneously incomplete cages to dynamically form complete cages over time, guiding objects toward target states with containment guarantees, significantly relaxing the requirement for in-hand caging (Bircher et al., 2021) in both quasi-static and dynamic cases.
In quasi-static cases, the state space is
In dynamic cases, the state
Maintaining this time-varying cage requires coordinated finger actions including sliding for continuous contact adjustment, rolling for smooth surface transitions, and gaiting for discrete contact reestablishment. These motion primitives and underlying finger reconfigurations strategically evolve both geometric constraints and energy barriers over time, known as Caging in Time.
8.1.2. Extrinsic dexterity
Extrinsic dexterity leverages environmental features as complementary cage elements, extending manipulation capabilities beyond what is possible with end-effectors alone.
As aforementioned, in quasi-static setup, the state space
In dynamic scenarios, the state space also expands to
The cage is maintained through strategic management of object-environment and object-robot contacts relative to environmental features, and multi-modal motion primitives like pushing, flipping, and grasping. Unlike traditional extrinsic dexterity approaches (Yang et al., 2023), Caging in Time explicitly plans transitions between contact states without requiring continuous feedback, extensive training, or specific object geometry limits, ensuring continuous caging in time despite uncertainties.
8.1.3. Deformable object manipulation
For deformable objects, each state
The cage is formed through strategically distributed contacts that constrain the PSS while transforming the object shape. Using an estimated deformation model that can cover general PSS motion similarly to equation (9) in planar pushing, we can create spatial barriers that limit possible deformations from exceeding the cage, enabling shape control without requiring precise physical models of complex deformation or large amounts of data.
Unlike object pushing, the action space for deformable object manipulation encompasses material-specific motion primitives such as pushing, pinching, folding, and rolling. By sequencing these primitives strategically, Caging in Time creates virtual cages whose deformation directly controls object transformation, maintaining reliable manipulation even under occlusion or complex deformation scenarios.
8.2. Implementation guidelines
Adapting Caging in Time to new manipulation applications requires systematic consideration of several key elements:
State space formulation: Define 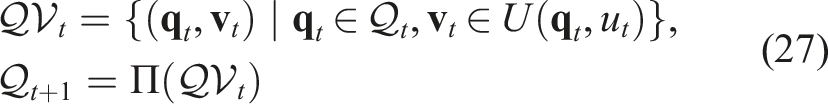
Action space design: Define the action space
Cage region: Design the cage in time
Action selection: Determining optimal actions
Computational efficiency: Current action selection and PSS propagation require 26.2 ± 8.5 ms (pushing) and 67.3 ± 12.6 ms (ball balancing) on a single CPU thread, with potential for optimization through GPU acceleration. Though currently offline-computed, these timings show feasibility for integrating Caging in Time into the online planning for more diverse and dynamic scenarios.
9. Conclusion
In this work, we proposed and evaluated Caging in Time, a novel theory for robust object manipulation. Our framework demonstrated robust performance in both quasi-static and dynamic tasks without requiring detailed object information or real-time feedback. Rigorous evaluations highlighted the framework’s resilience and adaptability to various objects and dynamic scenarios. The Caging in Time approach proved effective in handling new objects, positional perturbations, and challenging dynamic tasks, showcasing its potential for reliable manipulation in uncertain environments.
While the current Caging in Time framework shows promising results, it is important to acknowledge its limitations. Currently, the framework requires manual definition of task-specific parameters and the PSS propagation function. This reliance on human expertise may limit its generalizability to a wider range of manipulation tasks. Additionally, the current approach may not fully capture the complexity of certain real-world scenarios where object interactions and environmental factors are highly unpredictable.
Looking forward, we aim to address these limitations and expand the horizons of Caging in Time. A key direction for future research is the integration of learning techniques, LLMs, and diffusion models to autonomously construct and learn Caging in Time tasks. This approach could enable the framework to automatically derive appropriate propagation functions and strategies, reducing the need for manual parameter tuning. We also plan to explore its applications as mentioned in Section 8, while potentially leveraging reinforcement learning to handle increased task complexity and environmental variability.
Supplemental Material
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science Foundation under grant FRR-2240040.
Supplemental Material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.