
Abstract
Shared perception between robotic systems significantly enhances their ability to understand and interact with their environment, leading to improved performance and efficiency in various applications. In this work, we present a novel full-fledged framework for robotic systems to interactively share their visuo-tactile perception for the robust pose estimation of novel objects in dense clutter. This is demonstrated with a two-robot team sharing their visuo-tactile scene representation which then declutters the scene using interactive perception and precisely estimates the 6 Degrees-of-Freedom (DoF) pose and 3 DoF scale of a target unknown object. This is achieved with the Stochastic Translation-Invariant Quaternion Filter (S-TIQF), a novel Bayesian filtering method with robust stochastic optimization for estimating the globally optimal pose of a target object. S-TIQF is also deployed to perform in situ visuo-tactile hand-eye calibration, since shared perception requires accurate extrinsic calibration between the two different sensing modalities, tactile and visual. Finally, we develop a novel active shared visuo-tactile representation and object reconstruction method employing a joint information gain criterion to improve the sample efficiency of the robot actions. To validate the effectiveness of our approach, we perform extensive experiments across standard datasets for pose estimation, as well as real-robot experiments with opaque, transparent and specular objects in randomised clutter settings and comprehensive comparison with other state-of-the-art approaches. Our experiments indicate that our approach outperforms state-of-the-art methods in terms of pose estimation accuracy for dense visual and sparse tactile point clouds.
Keywords
1. Introduction
Humans are capable of seamlessly integrating perceptual information from vision and touch (haptic) to maintain a high-level of cognitive understanding of the environment (Ernst and Banks, 2002; Hatwell, 1987). Robots should also be able to achieve a similar level of scene understanding given that they are similarly equipped, for example, with visual and tactile sensing. The shared perception among complementary sensing modalities offers a comprehensive and accurate scene representation as well as addressing the weaknesses inherent in individual sensor systems. This should make perception robust against sensor failure, as the robot could then rely on the other modality to retain the same level of functionality (Murali et al., 2022d). As with humans, robots have also the option to enhance their perceptual information through purposeful manipulative actions, a technique known as interactive perception which forges a symbiotic relationship between action and perception (Bohg et al., 2017). Thus, by leveraging shared and interactive perception, robots can potentially increase their autonomy and efficacy in real-world scenarios.
However, sharing multi-modal visuo-tactile perceptual information is challenging due to the weakly paired and complementary nature of the sensing modalities. Visual perception provides dense and global information of the scene, whereas tactile perception provides sparse and local contact information. Temporal misalignment also affects shared perception as visual data can be captured in one shot while tactile data acquisition requires sequential contact interactions with objects (Li et al., 2020). Previous research in the realm of multi-robot and multi-sensor shared perception frequently relies on employing identical sensing modalities, typically using multiple cameras. This simplification streamlines the representation of the shared scene (Lauri et al., 2020). Active perception techniques, characterized by the proactive selection of sensor positions to enhance information gathering, are often utilized in the context of single sensor setups or setups with multiple sensors of the same modality (Connolly, 1985; Delmerico et al., 2018). Nevertheless, the extension of active perception methods to multi-sensor configurations comprising different modalities, such as visual and tactile sensing, poses a non-trivial challenge. Similarly, there are recent works tackling the problem of category-level object pose estimation wherein the exact CAD models of object of interest are unknown but prior knowledge of objects belonging to the same category are available. These works typically regress a shared canonical representation of all possible object instances within a category and use the measured depth information to lift from 2D to 3D space to perform object pose estimation (Deng et al., 2022; Lee et al., 2021; Wang et al., 2019).
In summary, the state-of-the-art methods have several limitations: (a) Category-level pose estimation techniques are predominantly tailored to visual sensing information (RGB and depth data), rendering them unsuitable for direct adaptation to other sensory modalities, such as tactile sensing; (b) these methods are also not evaluated for photometrically challenging objects such as transparent objects (Wang et al., 2022); (c) active perception methods that are designed for mono-modal settings cannot be directly extended to multi-modal settings; (d) misalignment between multi-modal visual and tactile data often arises due to calibration errors that affects the shared perceptual information. Addressing the misalignment requires specific calibration procedures, which are often laborious and time consuming.
In our previous work (Murali et al., 2021), we presented a recursive Bayesian filtering approach for object pose estimation through point cloud registration termed translation-invariant quaternion filter (TIQF). However, we assumed a priori knowledge of the CAD model of the target object and TIQF is prone to get stuck in local minima if incorrectly initialized. Furthermore, in our recent work (Murali et al., 2023) we demonstrated a data-driven approach to reconstructing novel transparent objects belonging to known categories through tactile sensing alone. In this work, we solve the limitations of our previous works (Murali et al., 2021, 2023) and present several new contributions as follows: I. We propose a novel shared visuo-tactile perception method for scene representation and object reconstruction through a data-efficient joint information-theoretic approach for active perception (vision or tactile). II. We present Stochastic Translation-Invariant Quaternion Filter (S-TIQF) which is a recursive Bayesian filtering method with robust stochastic optimization for globally optimal pose estimation. S-TIQF estimates the 6 DoF pose and 3 DoF scale of unknown instances of categorical objects and relaxes the need for prior known model of the object. III. A necessary condition for shared perception is the accurate calibration between the sensing modalities. We present a novel approach for in situ visuo-tactile-based hand-eye calibration using arbitrary objects which removes the constraint of specific hand-eye calibration targets and time-consuming calibration procedures. IV. We integrate our developed methods into a full-fledged framework that enables multi-robot teams to share their perceptual information with the objective to declutter a complex scene, reconstruct and robustly estimate the pose of objects.
We conducted extensive experiments to validate our framework against state-of-the-art approaches, using various benchmark datasets and real-world robotic experiments (Figure 1). To the best of our knowledge, this is the first work tackling the problem of shared visuo-tactile interactive perception for robust object pose estimation. Experimental setup: A universal robots UR5 sensorised with tactile sensor arrays on the Robotiq Gripper, a Franka Emika Panda robot equipped with an Azure Kinect RGB-D camera and clutter objects containing the novel target object. The objective is to collaboratively declutter the scene, share the visuo-tactile perceptual information and find the pose of the target object.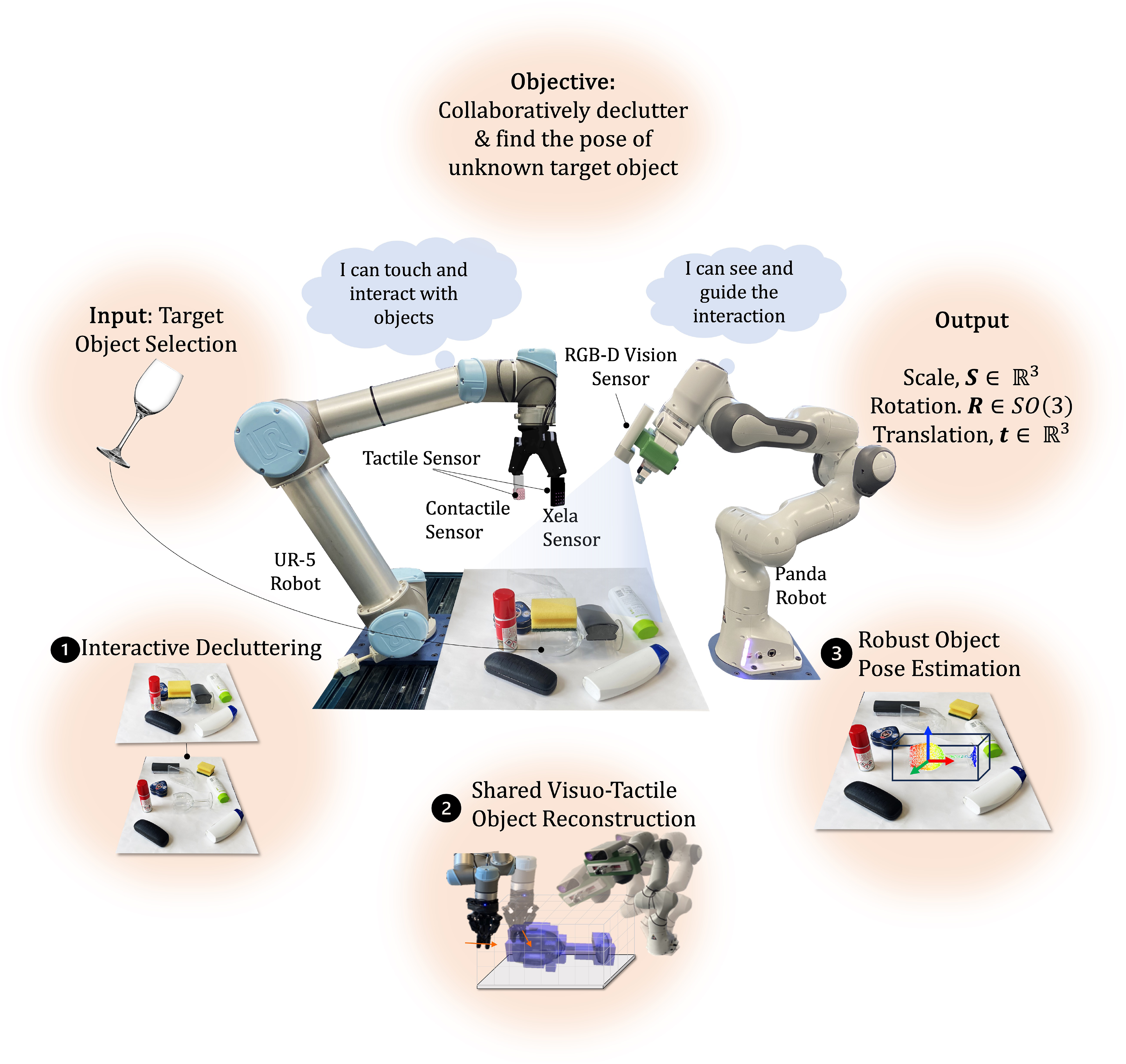
This paper is organized as follows: Section 2 summarizes the state-of-the-art in interactive perception, object reconstruction and pose estimation and highlights our contributions in the context of current and related research. Our framework and methodology are presented in Section 3. The experimental results are reported in Section 4 and finally concluded in Section 5.
2. Related work
We review the state-of-the-art methods for interactive perception, shared perception for object reconstruction and object pose estimation and their relation to our work in this section.
2.1. Interactive perception
Interactive perception or perceptive manipulation is any kind of purposeful manipulation actions performed to simplify or enhance the perception of the environment (Bohg et al., 2017). Interactive perception techniques rely upon effective scene understanding in order to plan and execute manipulative actions. The scene understanding iteratively improves upon performing manipulation actions. In unstructured cluttered scenarios, the target object may have multiple other objects overlapping on it in random configurations. A typical choice for scene understanding in computer vision is scene graph which is a data structure that describes objects in a scene and the relationships between these objects (Johnson et al., 2015). Support graphs, a type of scene graph, have been introduced to describe the support relations between objects in the scene through geometric reasoning (Kartmann et al., 2018; Mojtahedzadeh et al., 2015; Schwarz et al., 2018). Sui et al. (2017) presented an axiomatic scene estimation method to describe the relationship between objects and object poses as a scene graph for manipulation. Mitash et al. (2019) developed a Monte Carlo Tree Search-based technique for scene understanding leveraging physics-priors of objects in clutter for pose estimation. Zhang et al. (2021) tackled the issue of inferring object relationships through a neural network performing classification task on all possible pairwise permutations between the objects in the scene.
Scene understanding is followed by planning manipulation actions in clutter which is a challenging task and has received immense research interest. Typically, research works on grasping in clutter falls into model-based approaches or data-driven methods. Analytical or model-based approaches have been deeply studied in Bicchi and Kumar (2000). Berenson and Srinivasa (2008) devised an optimisation method for generating the gripper pose in clutter given the knowledge of the object shape to ensure force closure. Some works such as Moll et al. (2017) and Dogar et al. (2012) rely upon physics simulators to model the robot-object and object-object interactions while performing manipulation actions in clutter. More recent studies involving data-driven grasping have leveraged deep neural networks (DNNs) to achieve significant results as detailed in Bohg et al. (2013). Several works leveraging data-driven methods have focused towards grasping a priori known objects (Detry et al., 2011; Goldfeder et al., 2007; Miller et al., 2003; Przybylski et al., 2011) or familiar objects with known object class by matching with a known database of grasping information or ranking based on prior grasping experience (Detry et al., 2012; Mahler et al., 2016; Patten et al., 2020). For grasping of unknown objects, prior works rely upon global shape or features from sensory data and a set of heuristics (Bohg et al., 2013; Morrison et al., 2020; Schaub and Schöttl, 2020; Schmidt et al., 2018). For instance, Morrison et al. (2020) developed an object-independent grasp synthesis method from depth images using their generative grasping convolutional neural network (GG-CNN). Tactile sensors have also been used for manipulation of deformable objects (Kaboli et al., 2016). However, most of the prior works focused on singulated objects (single objects in the scene) or structured clutter wherein there are multiple objects in the scene but they are spread apart with minimal contact between them. However, in dense unstructured clutter there are multiple objects which are densely packed over one another in randomised configurations. In such scenarios, relying upon only grasping actions can severely handicap the robot as some objects may be very hard to grasp due to the surrounding clutter. Some recent works have leveraged both prehensile manipulation such as grasping and non-prehensile manipulation such as pushing actions (Danielczuk et al., 2019; Dutta et al., 2023; Murali et al., 2022b; Zeng et al., 2018). If the objective is to grasp and retrieve an object, then pushing is often used to singulate the object away from clutter aiding subsequent grasp action (Grimm et al., 2021). However in mechanical search the goal is to retrieve a target object, both grasp and pushing actions are used in conjunction in order to declutter the workspace around the target object (Danielczuk et al., 2019; Murali et al., 2022b). The work by Danielczuk et al. (2019) focused on retrieving a target object from clutter and they used a heuristic that removes the largest object first. Furthermore, the target object in their work is known a priori. Their framework is based on deep reinforcement learning to learn the synergy between grasping and pushing and is more data-hungry and compute-intensive.
In comparison with the prior work reviewed above, we focus on estimation of the pose of an unknown target object in dense unstructured clutter. We present a declutter scene graph-based approach that directly encodes the relationship between objects in the scene as well as the type of action to perform (grasp/push) to declutter the objects. Our formulation ensures that only necessary minimal actions are performed such that the target object is not occluded for pose estimation. The actions are also chosen automatically based on the grasp affordance of the object.
2.2. Object reconstruction
Object reconstruction follows the process of capturing the shape and appearance of a 3D object by moving a suitable sensor around the object. Typically, object reconstruction approaches can be classified into statistical model-based and deep learning-based generative models (Phang et al., 2021). Some statistical methods involve capturing point clouds from various viewpoints and aggregating into a common coordinate frame using point cloud registration (Delmerico et al., 2018). Xie et al. (2021) designed a generative model based on PointNet (Qi et al., 2017) capable of performing reconstruction and interpolation. We focus on active object reconstruction techniques wherein the sensing locations are chosen autonomously by robots to improve performance efficiency and avoid an exhaustive search. In this regard, Delmerico et al. (2018) compared various next-best-view (NBV) strategies for an object in an uncluttered scene in simulation demonstrating the usability of information-theoretic criteria for efficient reconstruction. Similarly, Bissmarck et al. (2015) devised an efficient volumetric NBV algorithm exploiting frontier voxels and spatial hierarchy. While these works are limited to one camera, more recently, multiple cameras have been used for reconstruction by exploiting the joint uncertainty in the modelling (Lauri et al., 2020). Along similar lines, Cui et al. (2019) devised a multi-sensor strategy for next best view calculation with a laser range sensor and RGB-D camera based on occupied voxel metrics.
Typical vision sensors, in particular depth sensors are sensitive to transparent and specular objects producing erroneous or missing regions in the measurements. To overcome this limitation, recent works have leveraged transfer learning techniques from the RGB modality which are comparatively less sensitive to transparency/specularity into the depth modality and utilized off-the-shelf depth-based grasping methods for manipulating such objects (Weng et al., 2020). Similarly, Sajjan et al. (2020) developed a technique to reconstruct transparent objects wherein convolutional neural networks are used to infer the normals, contours and semantic segmentation from RGB images which are used to refine the depth estimate in order to recover the shape of transparent objects. Along similar lines, Zhang et al. (2022) developed a transformer-based architecture for depth completion when provided with instance-based segmentation and RGB images for reconstruction of transparent objects. A detailed review on robotic perception for transparent objects is found in Jiang et al. (2023). As majority of the vision-based techniques for reconstruction of transparent objects depend on the availability of high fidelity RGB image priors, it cannot be always ensured in unstructured environments wherein the environmental lighting conditions can vary. Low and bright lighting conditions cause erroneous results with transparent objects (Sajjan et al., 2020). Moreover, such transparent and specular objects when present in cluttered environments are also challenging for vision-based sensing due to shadows and occlusions.
On the contrary, tactile sensors are more robust to the ambient lighting conditions, and are relatively more robust to the transparency or specularity of the objects compared to visual sensors. Thus, tactile sensors have been used independently or in conjunction with vision sensors for robotic object perception (Dutta et al., 2024; Kaboli et al., 2015, 2018; Murali et al., 2022c). Gaussian processes implicit surfaces (GPIS) have been used for shape reconstruction from both vision and tactile inputs (Rustler et al., 2022; Suresh et al., 2022). However, GPIS approaches are known to be computationally expensive (Schulz et al., 2018). Similarly, Wang et al. (2018) designed a framework for generating 3D shape of objects from a single visual image using learnt shape priors which is refined using tactile sensing. They also performed uncertainty based next-best-touch (NBT) computation while keeping the camera static.
Previous works used touch to refine the shape estimated prior by vision in a two-step process. In comparison, in this work we present a novel approach for shared active object reconstruction using a joint information gain metric for sensor selection criteria and next-best-view (NBV) or next-best-touch (NBT) execution. The robots equipped with vision and tactile sensors coordinate autonomously to reconstruct the object with minimal actions for the objective of object pose estimation and avoid overlapping regions of data collection.
2.3. Object pose estimation
Object pose estimation is a broad field of research in computer vision and robotics with approaches broadly categorised depending on using 2D data (RGB images) or 3D data (RGB-D images or point clouds) as input (He et al., 2020). Here, we review point cloud based approaches for object pose estimation as they are relevant to our work. Typically, with point cloud-based approaches, a point cloud that corresponds to the object CAD model is registered or matched with the sensor acquired point cloud from the scene and the output of the registration process yields the 6 DoF pose of the object. Iterative closest point (ICP) and its variants are popular point-cloud based approaches for pose estimation (Pomerleau et al., 2013). They fall into the category of simultaneous correspondence estimation and pose estimation methods wherein there is an iterative alternation between estimation of the closest point in the target point set and minimisation of the distance between the corresponding points (Besl and McKay, 1992). However, such methods are local approaches and require good initialisation as they tend to converge to local minima. In contrast, other approaches rely upon finding dense point-to-point corresponding using feature extraction and then optimise for 6D pose (Gentner et al., 2023; Huang et al., 2021b; Rusu et al., 2009; Yang et al., 2020). Choukroun et al. (2006) devised a Bayesian filtering approach for only the rotation estimation (so-called Wahba’s problem) between two coordinate systems. Whereas in this work, we tackle the problem of full SE (3) pose and scale estimation by converting the non-linear problem of pose estimation into decoupled rotation and translation estimation by exploiting the geometry of the measured point clouds. Recently, deep learning based approaches have been used to learn robust features for generating correspondences followed by an optimization such as RANSAC (Deng et al., 2018; Zeng et al., 2017). Deep learning approaches have also been used to regress the pose directly using an end-to-end approach. This is done by learning to regress the pose parameters directly from the features of the input point clouds (Huang et al., 2021a; Pais et al., 2020; Yang et al., 2019).
Contrary to instance-based methods, recent works have addressed the pose estimation of unknown objects from known object categories without any prior instance-specific CAD models available which is known as category-level object pose estimation. Wang et al. (2019) introduced the problem of category-level pose estimation and presented the Normalised Object Coordinate Space (NOCS) that produces a shared canonical representation for all object instances in each category. The predicted NOCS map is used to extract the pose and shape of objects with the observed depth map. Lee et al. (2021) extended the NOCS map with a CNN-based category level pose estimation with RGB images with little or no depth information. Similarly, other works have used variational auto-encoders (VAE) for generating the canonical 3D point clouds and the pose is regressed using another deep neural network (Chen et al., 2020). Some works explicitly model the intra-class shape variations using deformation from pre-learned shape priors (Tian et al., 2020). In addition to pose estimation, Deng et al. (2022) combined their category-level auto-encoder with a particle filter framework for tracking of unknown objects in an iterative manner. The method relies upon accurate depth estimation and semantic segmentation as input. Similarly, Wen and Bekris (2021) performed 6D pose tracking for unknown objects using learnt networks for segmentation and keypoint extraction and pose graph optimisation for pose tracking. As the accuracy of category-level estimation is far from satisfactory in comparison to instance-level methods, some works perform iterative point cloud pose refinement after finding the categorical shape prior (Liu et al., 2022b).
2.3.1. Visuo-tactile-based pose estimation
Prior works used accurate depth or RGB images for category-level pose estimation, however in case of photometrically challenging objects (transparent, shiny, reflective), input visual depth data are unreliable. However, such transparent and shiny objects like wine glasses, metallic cutlery are ubiquitous in unstructured environments wherein the robust operation of robots are necessary as evidenced by rise in datasets such as PhoCal Dataset (Wang et al., 2022). Prior works on object pose estimation for robots have leveraged high fidelity tactile sensing embedded on the end-effector or body surface to improve the visual pose estimate (Kaboli and Cheng, 2018; Kaboli et al., 2017; Murali et al., 2021, 2022a). Although tactile sensing can provide accurate grounded information regarding the objects, it has complementary characteristics to that of vision sensing. Visual sensing provides dense information of the global scene whereas current commercial tactile sensors generally provide sparse and local information about the object in contact. While vision sensors capture the entire scene information in one shot, tactile sensors acquire information sequentially and require memory of previous acquisitions to iteratively build the scene information (Dahiya et al., 2019; Li et al., 2020; Liu et al., 2022a; Liu and Sun, 2018). Contrasting to vision sensing, tactile data are action-conditioned, such that the kind of data acquired depends on the type of action performed (Kaboli et al., 2019). Point clouds are preferred for array-based tactile sensors expressing the visual and tactile data in the same domain for pose estimation. In case of known objects, point cloud registration provides the accurate 6 DoF pose of the target object in the scene (Pomerleau et al., 2015). However, state-of-the-art techniques as well as standard methods such as ICP and variants perform poorly on sparse tactile data (Pomerleau et al., 2013). Hence, due to the sparsity and sequential nature of tactile data, prior works have used sequential filter-based methods for pose estimation (Murali et al., 2021; Petrovskaya and Khatib, 2011; Vezzani et al., 2017). Some works have also developed novel tactile descriptors regardless of the type of tactile sensor or method of tactile data extraction (Kaboli and Cheng, 2018). Another method has been proposed to extract local geometric features using PCA and estimate the pose by matching the covariance between the extracted tactile data and object model (Bimbo et al. (2016)). On the other hand, methods based on vision-based tactile sensors express the tactile data as RGB images or pressure heatmaps and use feature extraction and pose estimation techniques that are typical in the computer vision literature (Bauza et al., 2019; Kuppuswamy et al., 2019; Li et al., 2014; Suresh et al., 2021). Recently, rising number of works have used visuo-tactile sensing for accurate object pose estimation. Vision has been used to provide an initial estimate of the object pose that is finely refined by tactile localisation using local or global optimization techniques (Hebert et al., 2011). Bhattacharjee et al. (2015) stated that visually similar surfaces need to have similar haptic properties as well. Based on this fact, they create a dense haptic map efficiently across visible surfaces with sparse haptic labels which allow a humanoid to perform a reaching task in cluttered foliage. De Gregorio et al. (2018) leveraged vision and tactile sensing to accurately estimate the pose of a deformable wire in an insertion task. While manipulating objects in-hand, the objects are typically occluded from the line-of-sight of the camera. Prior works have fused vision and tactile sensing data to accurately measure and track the pose of in-hand objects using Bayesian filtering techniques and deep learning methods (Álvarez et al., 2019; Dikhale et al., 2022; Pfanne et al., 2018). Recent works used deep learning based approaches along with pose-graph optimization to track and recover the shape of novel objects during in-hand manipulation by combining visual and tactile sensing (Qi et al., 2023; Suresh et al., 2023).
3. Methodology
3.1. Problem formulation and framework
The objective is to accurately identify the rotation Our proposed framework for shared interactive visuo-tactile perception for active object reconstruction and robust pose estimation in dense clutter including a novel approach for in situ visuo-tactile based hand-eye calibration. (a) Visuo-tactile based interactive scene decluttering. (b) Shared visuo-tactile based active object reconstruction. (c) Visuo-tactile based robust pose estimation List of Notations.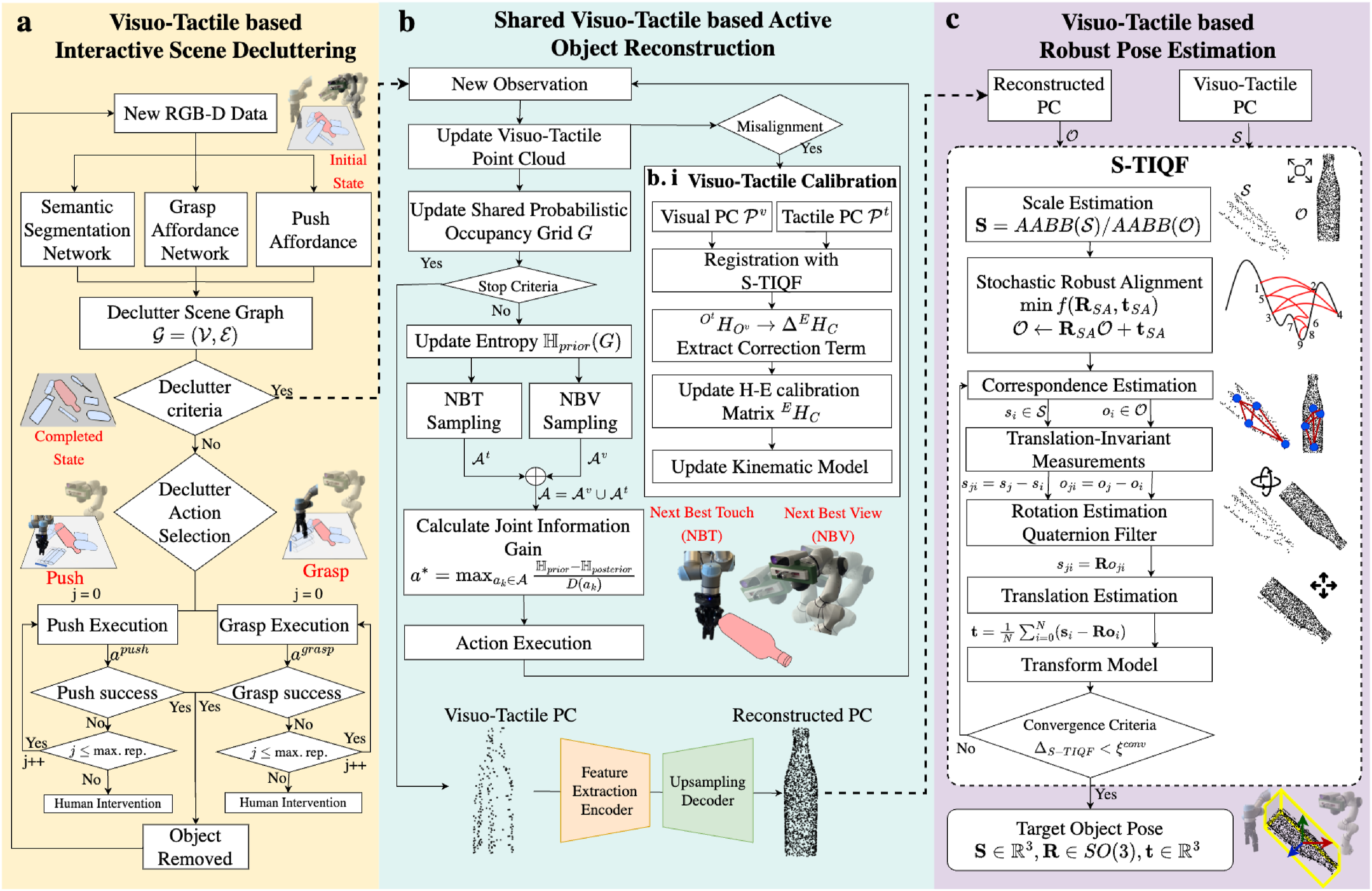

3.2. Visuo-tactile-based interactive scene decluttering
Before being able to estimate the pose of individual objects using our proposed novel S-TIQF algorithm, we may need to declutter a possibly cluttered scene. As objects may be present in random configurations in the scene, a method and formalism are necessary to encode the spatial and support relationships between the objects. We encode such relationships in the form of a scene graph termed declutter graph and has been presented in our previous work (Murali et al., 2022b). We briefly describe it in this section for the sake of completeness and readability. The decluttering process is shown in Figure 2(a).
The declutter graph is a directed graph
Overlap Metric: Two objects representing the vertices of the graph v
i
, v
j
constitute an edge
Proximity Metric: Two objects representing vertices of the graph v
i
, v
j
constitute an edge Thus, an edge Each edge 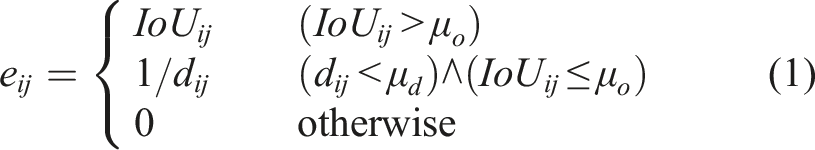
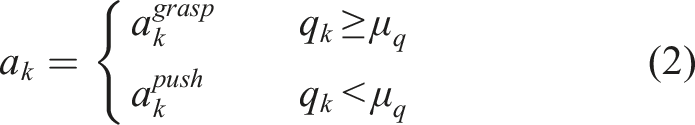
3.3. Shared visuo-tactile-based active object reconstruction
As the shape of the target object is unknown, reconstruction of the object is necessary for pose estimation and other possible downstream tasks such as precise manipulation. Our framework autonomously chooses (a) which sensor to use, (b) where to perform sensing and (c) how much of the object information is necessary for the chosen objective of pose estimation. In a single sensor scenario, the next best action selection problem seeks to find the optimal next sensory action to perform based on current knowledge of the environment in order to maximise the information gain that is calculated through an objective function. In a multi-agent and multi-sensor scenario, there is additionally the sensor selection problem which seeks to find the optimal sensor to employ given the current knowledge of the environment and incentivises the coordination between the agents as well as reducing the redundant data collection. In our case, the two robots equipped with a visual RGB-D sensor and tactile sensor array, respectively, as shown in Figure 1 are tasked to reconstruct the object in a coordinated and time-efficient manner.
3.3.1. Vision and tactile action sampling
For the Next-Best-View (NBV) and Next-Best-Touch (NBT) selection, we perform Monte-Carlo sampling of the visual and tactile actions, respectively, around the target object. The centroid o centroid of the target object is extracted from the semantic segmentation mask.
For NBV sampling, N
nbv
viewpoints are sampled on the hemisphere space centred on o
centroid
of the target object. The radius of the hemisphere is determined empirically considering the maximum reach of the robot and any possible vertical offset between o
centroid
and the robot base frame. The Panda robot has a maximum kinematic reach of 855 mm and we set the radius to a nominal value of 550 mm to avoid singularities at the kinematic extremity. A viewpoint 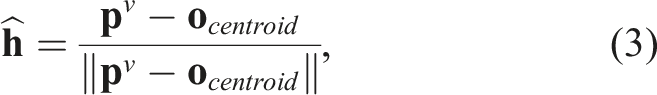
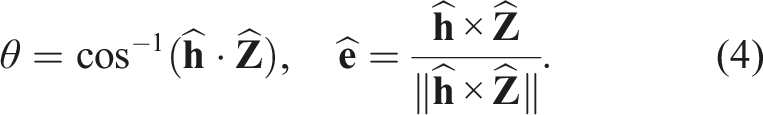
For the NBT sampling, we define the tactile action as Next best view (NBV) and next best touch (NBT) action selection.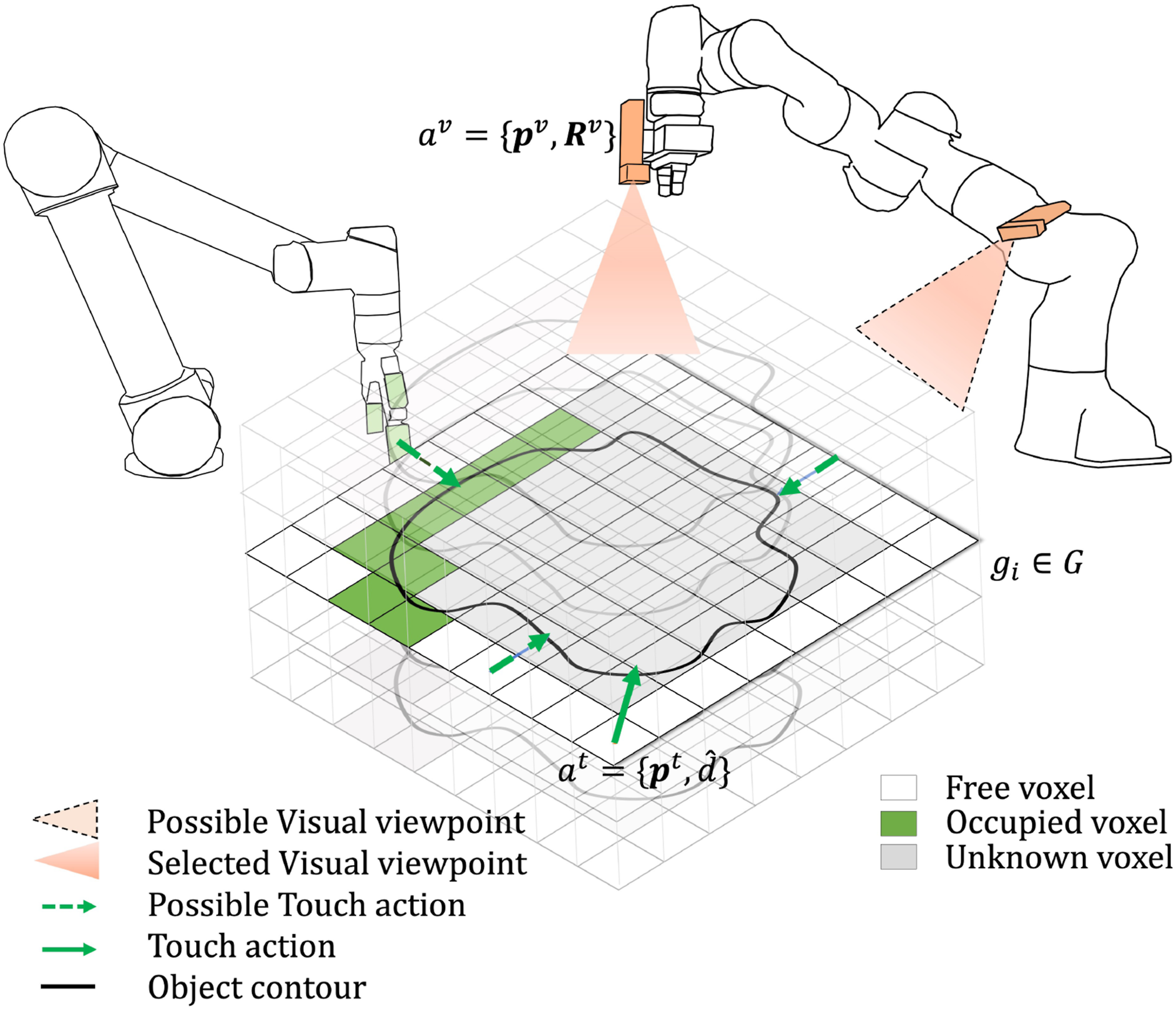
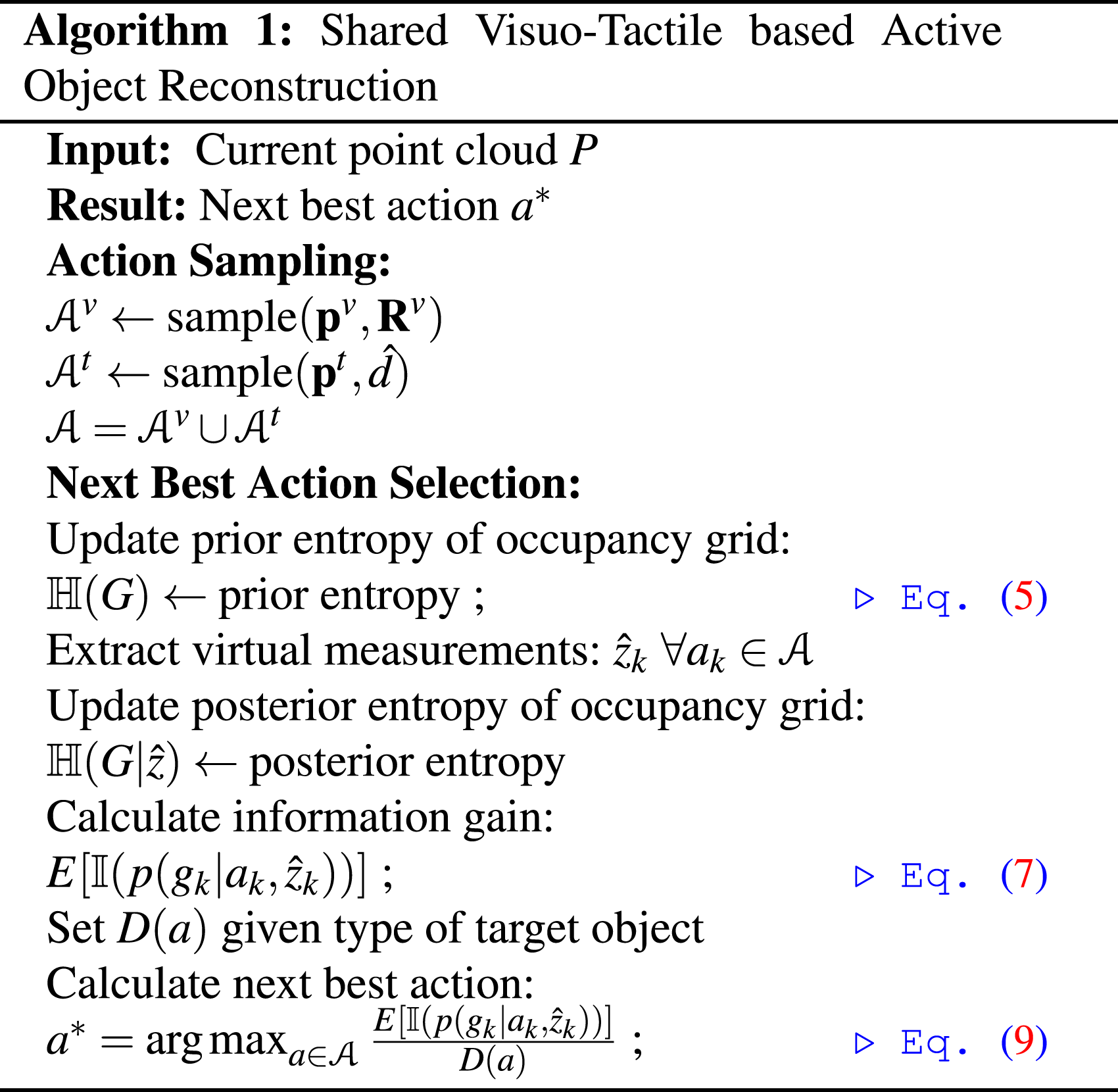
3.3.2. Active sensor selection and next best action selection
At each iteration, the next best action a* is selected from the set 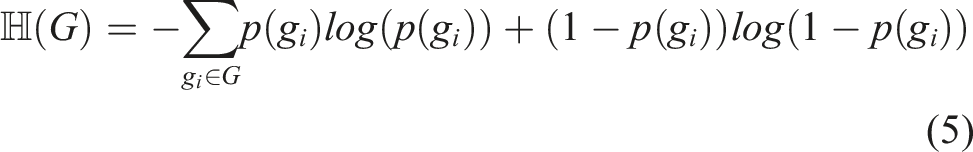
Given a point cloud captured by the camera or tactile sensor, the occupancy grid is updated with probabilities using the respective sensor models (Hornung et al., 2013). We define a virtual sensor measurement model for visual and tactile sensors respectively for the NBV and NBT calculations. The visual sensor generates the point cloud using a time-of-flight (ToF) sensor. The virtual vision sensor model is defined by a set of beam measurements 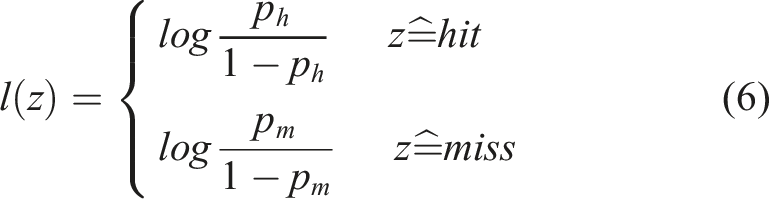
For a single sensor case, the expected information gain by taking an action 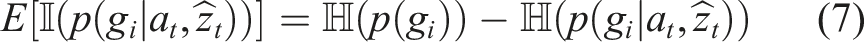
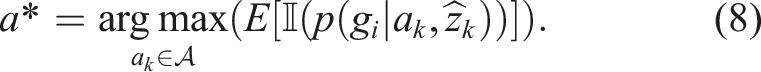
A näive way of extending to multiple sensors is to compute eq. (8) for each sensor. However, this would result in collection of redundant data due to sensor data overlap. Furthermore, there would be no incentive for coordination between the robots as well as leveraging the vision and tactile sensors with complementary properties. Hence, we present a joint sensor selection and action selection method for vision and tactile sensors. We can utilise the same occupancy grid formulation for integrating the sensor information from vision and tactile sensors. For each cell of the occupancy grid, the probabilistic evidence from each sensor needs to be updated. We can define an energy cost D (a
t
) that encodes the time taken to perform the robot action. In general, performing visual actions is faster than performing tactile actions with the robot. Hence, we set 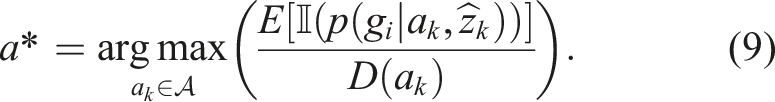
3.3.3. Detection of transparent objects
Detecting transparent objects is a challenging task for off-the-shelf visual cameras with RGB and depth sensing. Many prior works are available for detection of transparent objects with the usage of specialized sensors or specific calibration setups, and with analytical or data-driven methods (Ihrke et al., 2010). We design a simple heuristic approach to detect object transparency in order to set the energy cost D(a
t
) during object exploration. We extract the RGB image and point cloud of the target object from a perpendicular top-down view. We extract the bounding box Bounding box segmentation and IoU calculation using (a) RGB image and (b) point cloud for detecting transparent objects.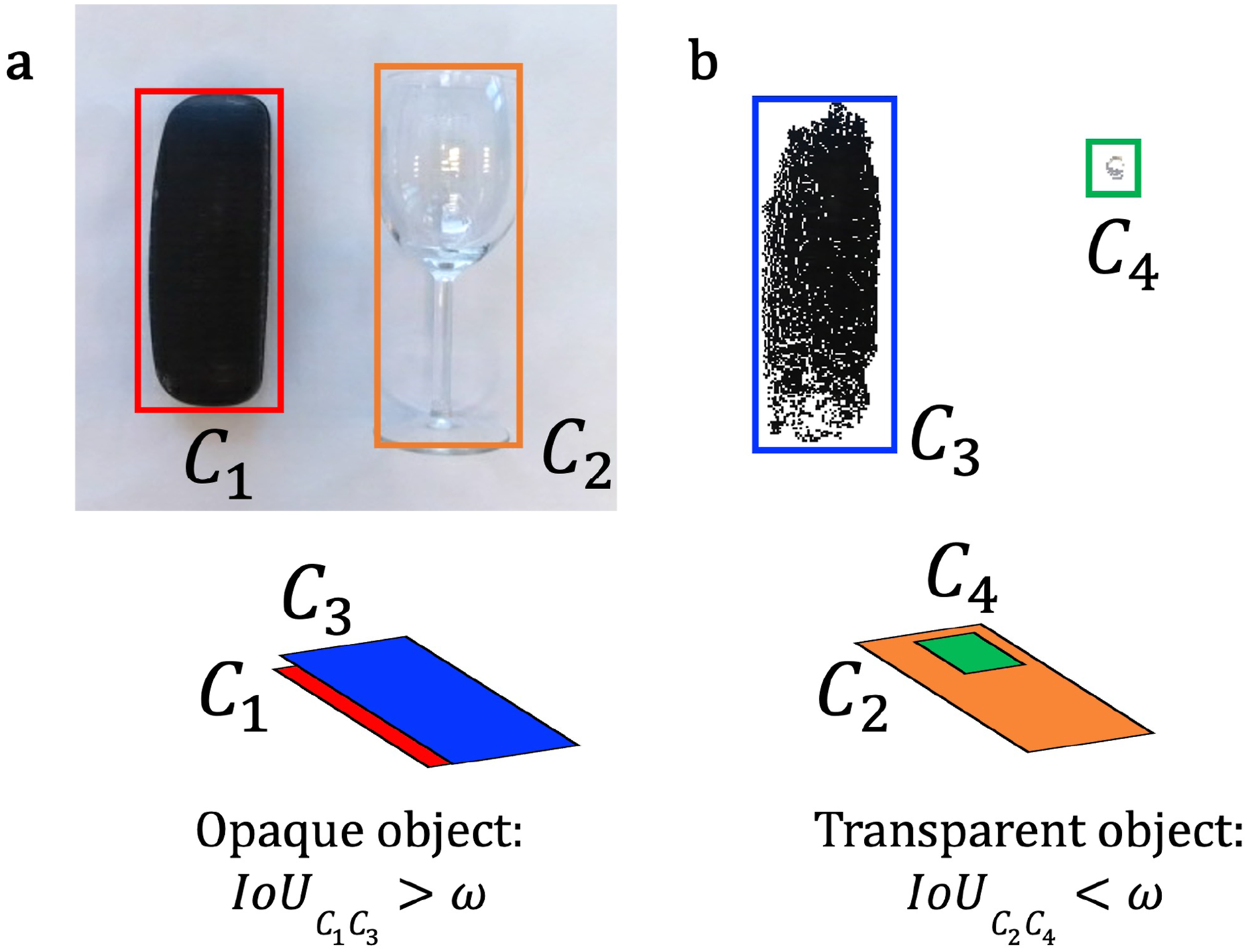
The sensor acquired point cloud is used to reconstruct the object model as described in Section 3.3.4.
3.3.4. Category-level object shape reconstruction
In order to recognize the shape of category-level objects, we present a self-supervised learning approach with an auto-encoder network that aims to reconstruct the original point cloud when provided a subsampled point cloud. The network is trained on only synthetic object models belonging to the same category but not identical as the real-world objects. We generate a dataset Architecture for the reconstruction network.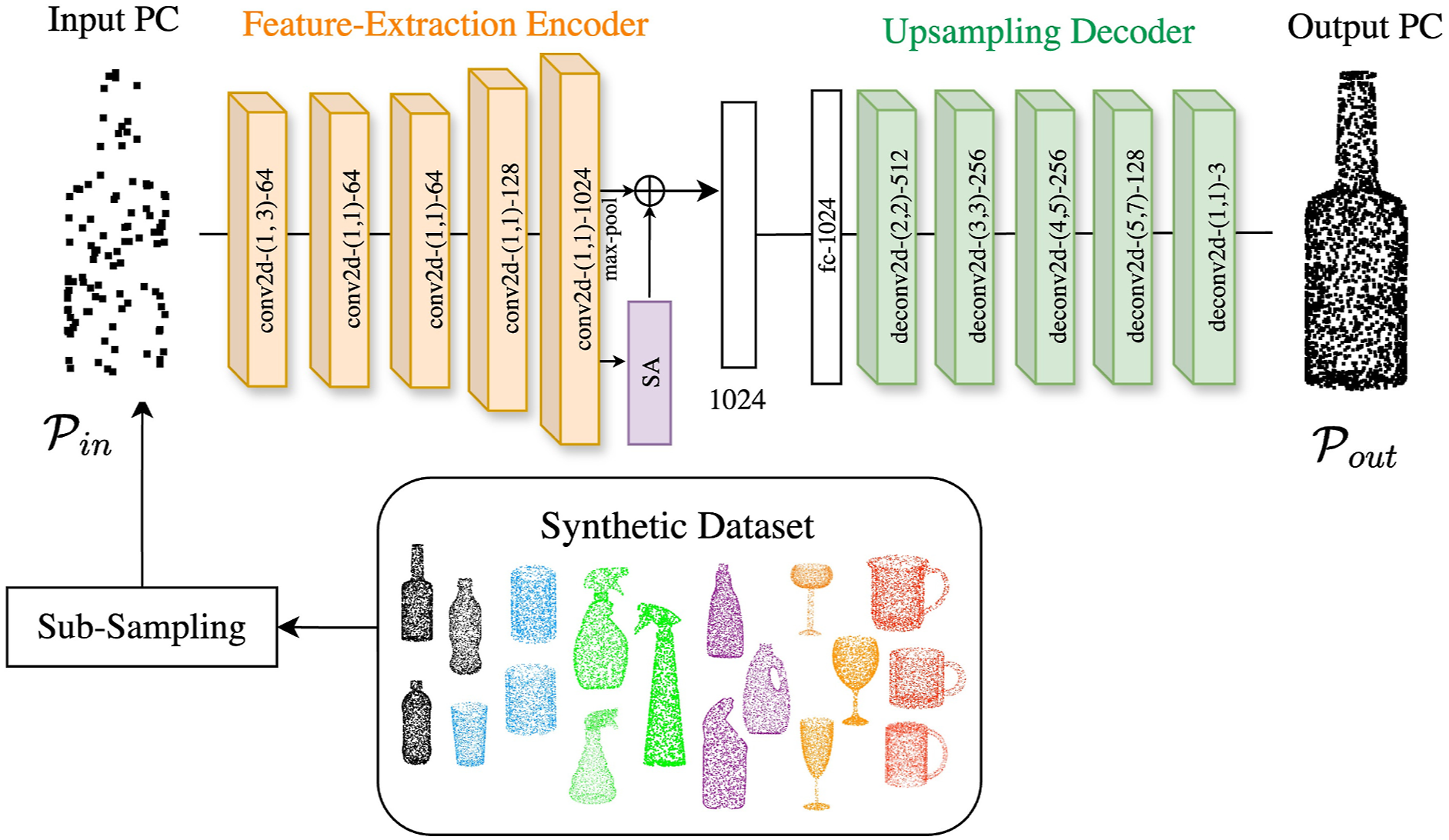
3.3.4.1. Feature-extraction encoder architecture
The encoder creates a high dimensional feature vector from a possibly sub-sampled point cloud as its input. This feature vector encodes the input point cloud’s overall geometric shape data. For the encoder, we employ a modified PointNet architecture (Qi et al., 2017). The encoder network produces a feature vector of 1024 dimension by selecting the informative and distinctive parts of the point cloud. The encoder consists of [1 × 1] convolutions with output channels size (64, 64, 128, 1024) with the first convolutional layer with kernel size [1 × 3] to encode the input point cloud of N × 3 dimension. The convolution layers are aggregated by a max-pooling layer. Furthermore, we add a self-attention layer (Zhang et al., 2019) whose outputs are aggregated with the max-pooled features to provide the global feature vector. The self-attention mechanism allows the model to weigh the importance of each point with respect to the other points in the input point cloud.
3.3.4.2. Upsampling decoder architecture
The upsampling decoder enlarges the feature vector input to generate a more detailed output point cloud
3.3.4.3. Loss function
We utilize the Chamfer distance (Borgefors, 1986) as the loss function which ensures the reconstructed point cloud follows the 3D shape of the ground truth point cloud. Given the input point cloud to our network prior to subsampling 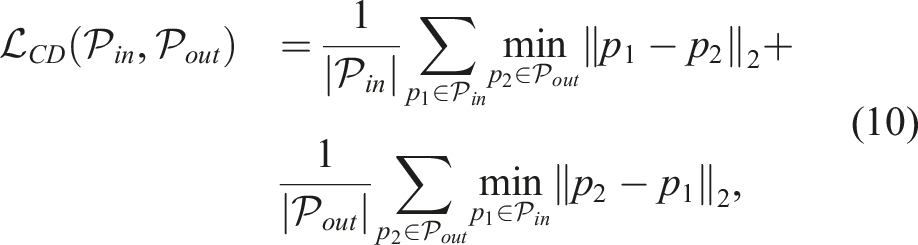
3.4. Visuo-tactile-based robust pose estimation
3.4.1. Stochastic translation-invariant quaternion filter (S-TIQF)
Upon reconstructing the object point cloud, we are able to perform pose estimation which is to compute the unknown scale 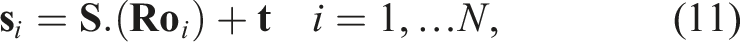
3.4.1.1. Scale estimation
The reconstructed object point cloud 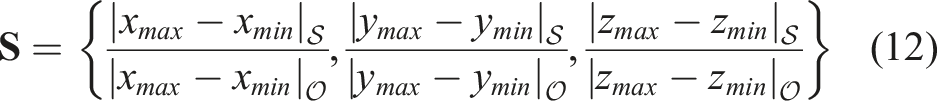
Subsequently, we can scale the object point cloud
3.4.1.2. Stochastic initial alignment
We presented our Translation-Invariant Quaternion Filter (TIQF) in our prior work (Murali et al., 2021) which is a Bayesian filtering approach for point cloud registration applicable for dense visual and sparse tactile point clouds. However, TIQF is sensitive to initialisation conditions. Figure 6 shows an example error surface for point cloud registration with TIQF using the Stanford Bunny dataset (Levoy et al., 2005). It is obtained by varying the initial position about one axis in the range of [−5.0, 5.0] and initial orientation about one axis in the range of [−π, π]. The error is calculated as the root mean squared error of the distance metric between corresponding points. We note from Figure 6 that the error surface contains multiple local minima in which the optimization can be trapped depending upon the initial conditions. We solve this problem with a stochastic initialization method for TIQF that is robust against local optima termed StochasTIQF (S-TIQF). Error surface calculated as the distance between corresponding points of two clouds upon performing TIQF with initialisation parameters (translation and rotation) varied (best viewed on-screen and in colour).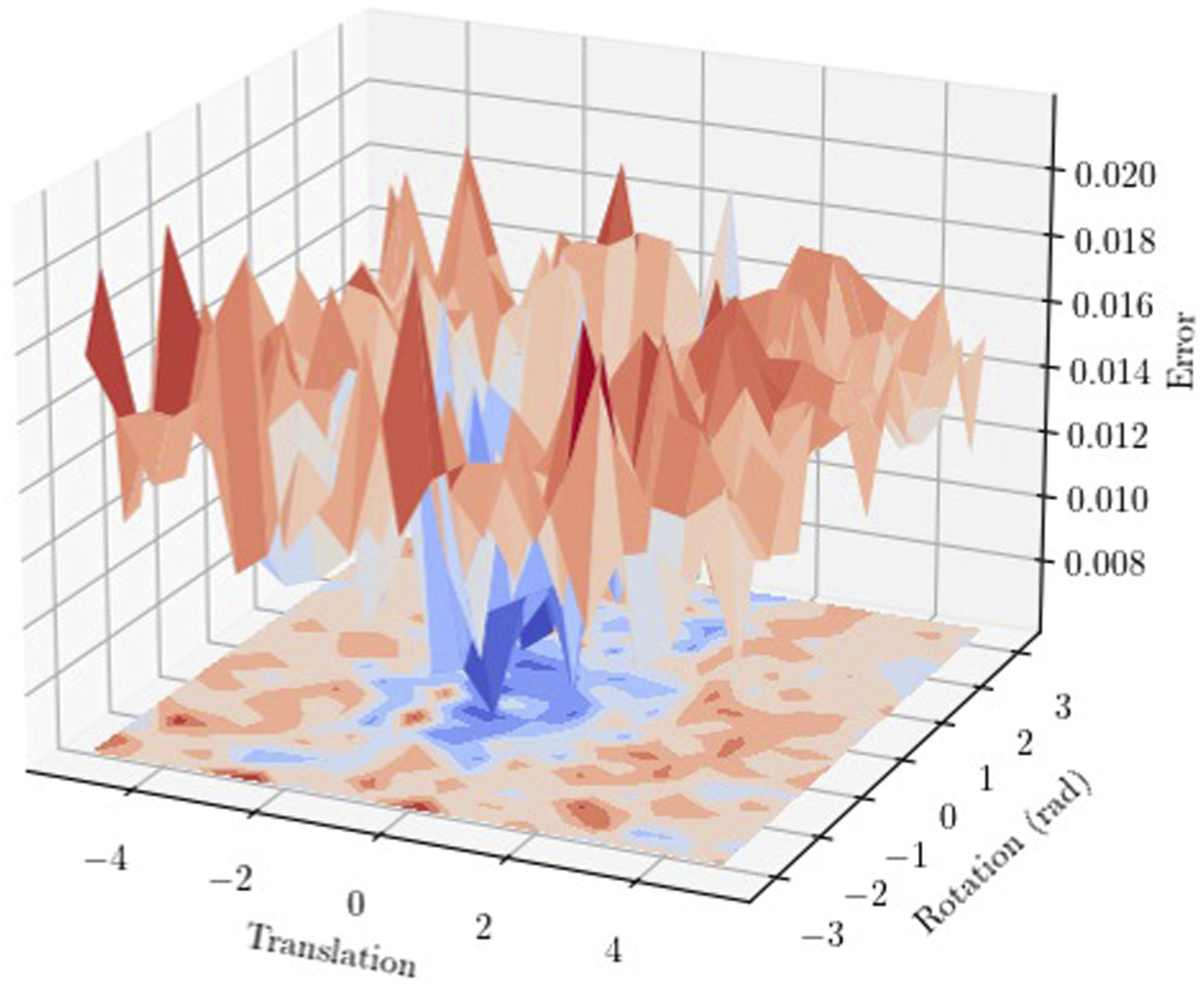
The stochastic initial alignment is performed through Simulated Annealing (Bertsimas and Tsitsiklis, 1993). Simulated Annealing (SA) is a well-known stochastic probabilistic method for approximating the global optima for a given function f (b). In SA, a temperature variable is used to guide the exploration. An initial temperature t = t0 is chosen and the temperature is reduced in each iteration according to the geometric cooling rate, that is, t′ = tζ where ζ is the cooling rate. This is termed as the annealing schedule. At t = t0, an initial state b = b0 is chosen at random and the cost is computed using the cost function c0 ← f (b0). At every iteration, a random state in the neighbourhood of the current state is chosen and the difference in cost Δc is calculated. The probability of accepting the new state is provided by the following condition: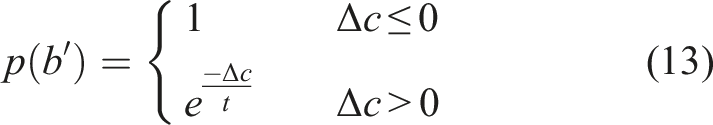
The new state b′ is accepted if p(b′) > random (0, 1). The process is repeated until a pre-defined temperature threshold is reached t < t
min
or for a fixed number of iterations. Random restarts are also used wherein t is set to t0 when t ≤ t
min
. In our experiments, random restarts are performed 10 times. In order to use simulated annealing with TIQF, a cost function for SA needs to be designed that upon finding the solution provides a good initialization for TIQF to extract the rotation and translation estimates. The cost is defined as the root mean squared error of the nearest neighbour point-to-point distances for each state b = {R, t}. The nearest neighbourhood correspondence assignment allows fast computation of the costs and thereby allowing larger iterations of SA. The state with minimal cost naturally minimizes the distance between the two point clouds. Hence for two point sets 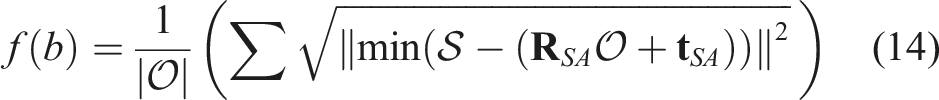
The temperature variable allows exploration in the initial phase thereby escaping the local minima and gradually converges to an optimal solution. The estimated rotation
3.4.1.3. Correspondence estimation
A crucial factor in point cloud registration from eq. (11) is the knowledge of point correspondences in the two point sets. In realistic scenarios, the point correspondences are not known a priori. On the one hand, simultaneous pose and correspondence estimation methods such as ICP and its variants rely upon nearest neighbour search for extracting point correspondences while iteratively improving the pose in successive steps (Besl and McKay, 1992). On the other hand, correspondence based methods extract point correspondences through feature matching and may employ rejection techniques to remove outlier correspondences prior to performing registration. In the case of visual and tactile point clouds, there are further challenges: (a) the point density difference between visual and tactile point clouds and (b) visual point clouds can be captured in one shot whereas tactile point cloud is aggregated through sequential tactile actions. Due to the point sparsity, typical feature-based correspondence matching algorithms are not accurate as they depend on local surface information. Similarly, nearest neighbour search as used in ICP is not robust to outliers and can get stuck in local minima.
We use the mutual nearest neighbours or Best-Buddies Pairs (BBP) (Oron et al., 2017) to estimate the point correspondences. It has been shown in Oron et al. (2017) that the BBP measure is robust to outliers and differences in point density but in the context of template matching in the image domain. The point 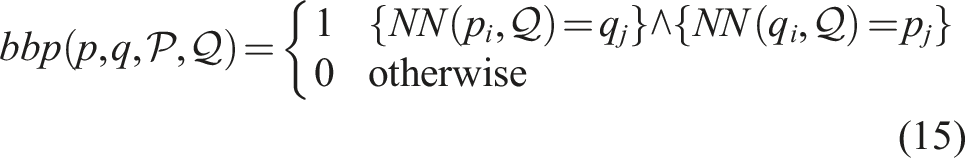
3.4.1.4. Rotation estimation
The estimation of rotation and translation is decoupled and performed in consecutive steps. The decoupling is done by computing the relative vectors between pairs of corresponding points as 

Eq. (17) is independent of translation 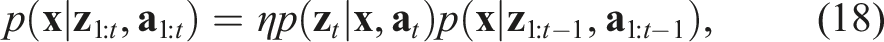
We estimate the current belief p(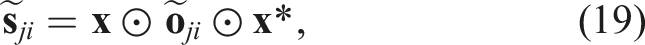
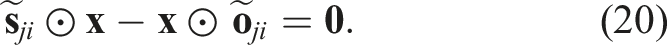
The quaternion multiplication can be reformulated in matrix form as: Hence, we can reformulate eq. (20) as: Eq. (24) is of the form The pseudo-measurement matrix Eq. (24) can be reformulated as a pseudo-measurement model as: Using eq. (26), we can reformulate eq. (27) as follows: Eq. (29) represents a linear equation in the state Hence, we can define the Kalman filter equations as follows: We must note that the Kalman filter does not preserve the constraints on the state-variables such as the unit-norm property of the quaternion. Hence, a common technique is to normalise the state and the associated covariance matrix after each update: The rotation estimate 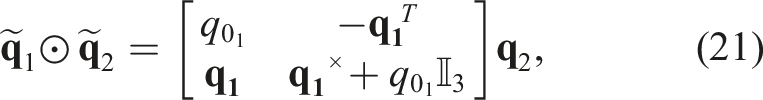
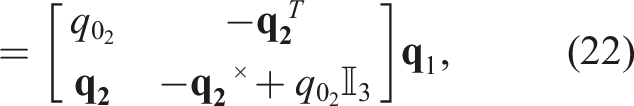
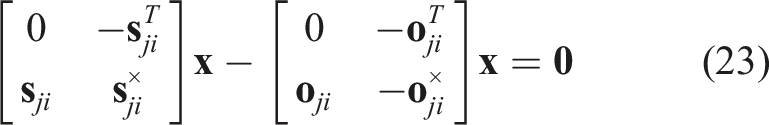
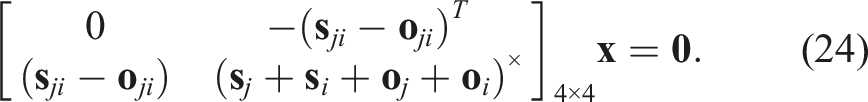
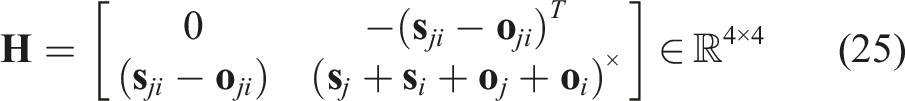




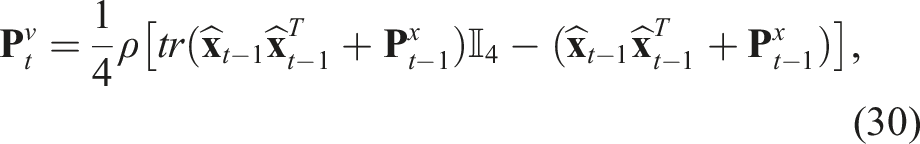
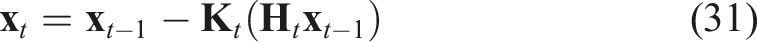

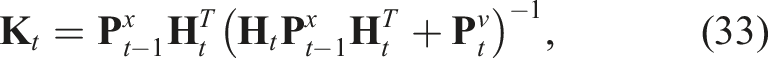
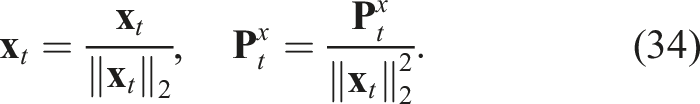
3.4.1.5. Translation estimation
Once the rotation estimate 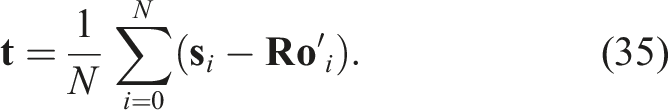
Thus, with each iteration of the S-TIQF we obtain a new rotation and translation estimate that is used to transform the model. The transformed model is used to recompute correspondences and repeat the TIQF update steps. We calculate the change in homogeneous transformation between iterations ΔS−TIQF < ξ conv , that is, if the difference in the output pose is less than a specified threshold which in our experiments is 0.1 mm and 0.1°, respectively, and/or maximum number of iterations in order to check for convergence (max_itS−TIQF = 100). The pseudo-code of the S-TIQF algorithm is shown in Algorithm 2.

3.5. Visuo-tactile hand-eye calibration
As described in our framework in Figure 2bi, if there is a discrepancy between visual and tactile point clouds for a static object, it is typically due to incorrect hand-eye calibration (c.f., Figure 18(a)). Conventionally, the hand-eye calibration is performed using a specialized target such as a calibration grid as shown in Figure 7(a). However, this process is time-consuming as it adds additional overhead such as specialized targets and calibration procedures. Furthermore, the grid-based calibration technique may contain residual errors as it is dependent on the chosen robot end-effector poses, lighting conditions, and sensor noise. Recent works have introduced deep-learning based markerless hand-eye calibration methods using segmentation and differentiable rendering techniques to regress the camera-to-robot pose based on input images of the robot and associated joint kinematics (Labbé et al., 2021; Lu et al., 2023). While the disadvantages of solely relying upon visual images such as occlusions, challenging backgrounds for segmentation, and lighting conditions still apply, there is an additional overhead of training requirement for various types and kinematic configurations of the robots. These methods are typically used to compute the camera-to-robot (eye-to-hand) transform and they need to be extended for eye-in-hand cases wherein the camera is attached to the end-effector of the robot as in our scenario. In this work, we relax the need for a specific calibration artifact or target and demonstrate how to perform hand-eye calibration using any known object present in the workspace of the robot, hence termed as in situ calibration. Furthermore, by combining visual and tactile perception, we effectively provide grounding to the estimation and correct the visual estimate with sparse tactile data for improving hand-eye calibration. (a) Classical grid-based hand-eye calibration method and (b) our in situ visuo-tactile hand-eye calibration method.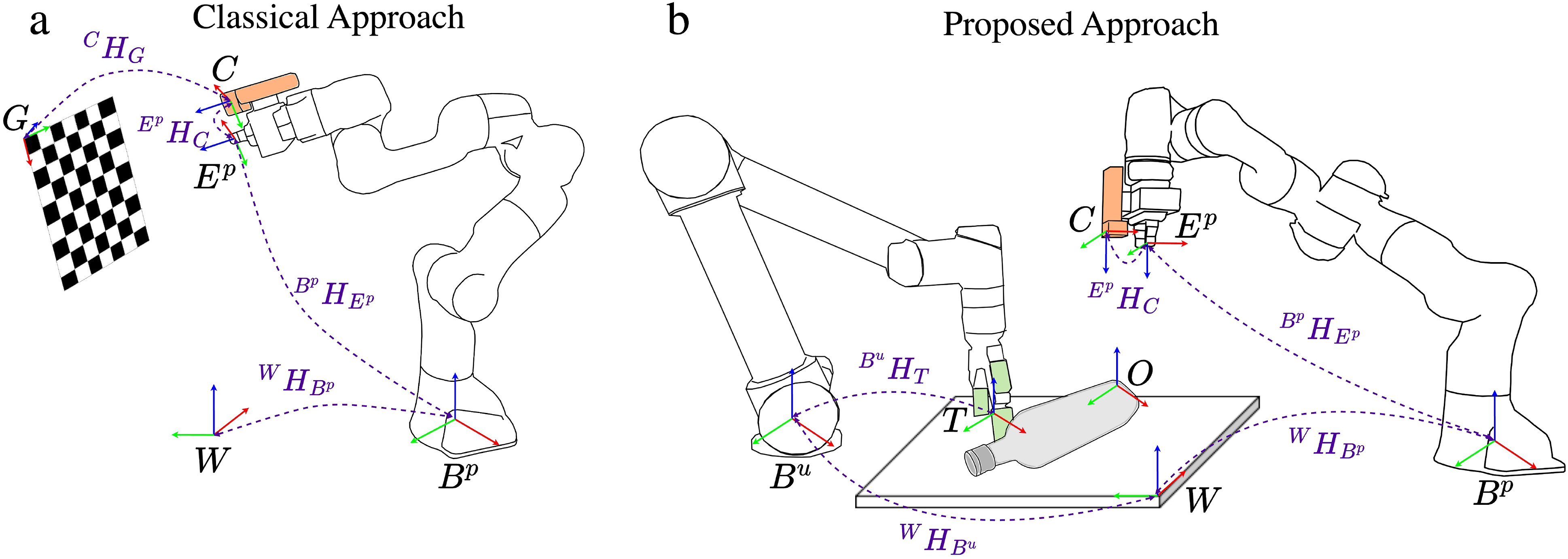
Consider the two-manipulator system shown in Figure 7(b). We cast the hand-eye calibration problem of finding 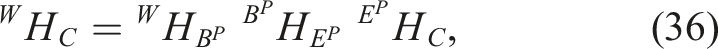
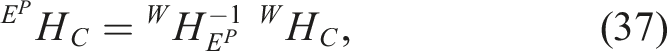
Let’s denote 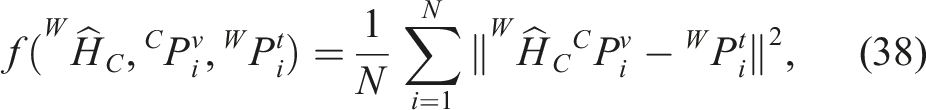
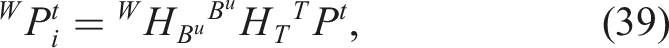
As the tactile data is high fidelity, we aim to register the dense visual point cloud
C
P
v
to the sparse tactile point cloud
W
P
t
using our S-TIQF algorithm as detailed in Section 3.4.1. Note that any point cloud registration method can be used but as we demonstrate in Section 4, state-of-the-art point cloud registration methods perform poorly in dense-sparse registration whereas our S-TIQF approach shows high accuracy even with low number of points. The S-TIQF algorithm produces the homogeneous transform
4. Experiments
4.1. Experimental setup
The experimental setup shown in Figure 1 consists of a Universal Robots UR5 robot with a tactile sensorised Robotiq 2F140 Gripper and Franka Emika Panda robot with the standard Panda Gripper. The tactile sensor array of the two-finger gripper is acquired from XELA robotics© and Contactile©. The Contactile sensors embedded on one finger on the outer and inner-side comprises of 3 × 3 tactile array. The XELA sensors embedded on the other finger comprises of 6 × 4 array on the outer side and 4 × 4 array on the inner side of the finger. The fingertip of the finger sensorised with the XELA sensors also has 6 × 1 array to touch objects from the top. Each taxel of both types of sensor arrays provides three-axis force measurements. This configuration allows the robot to acquire tactile data while touching with the outer side and from the fingertip. We intentionally used two different types of tactile sensors that are based on different operating principles in order to show that our framework is agnostic to tactile sensing technology. The normalised force values of the tactile sensors are measured and contact is established when the force exceeds the baseline threshold f
ts
≥ τ
f
where τ
f
= 1.1. The contact points
4.1.1. Object list
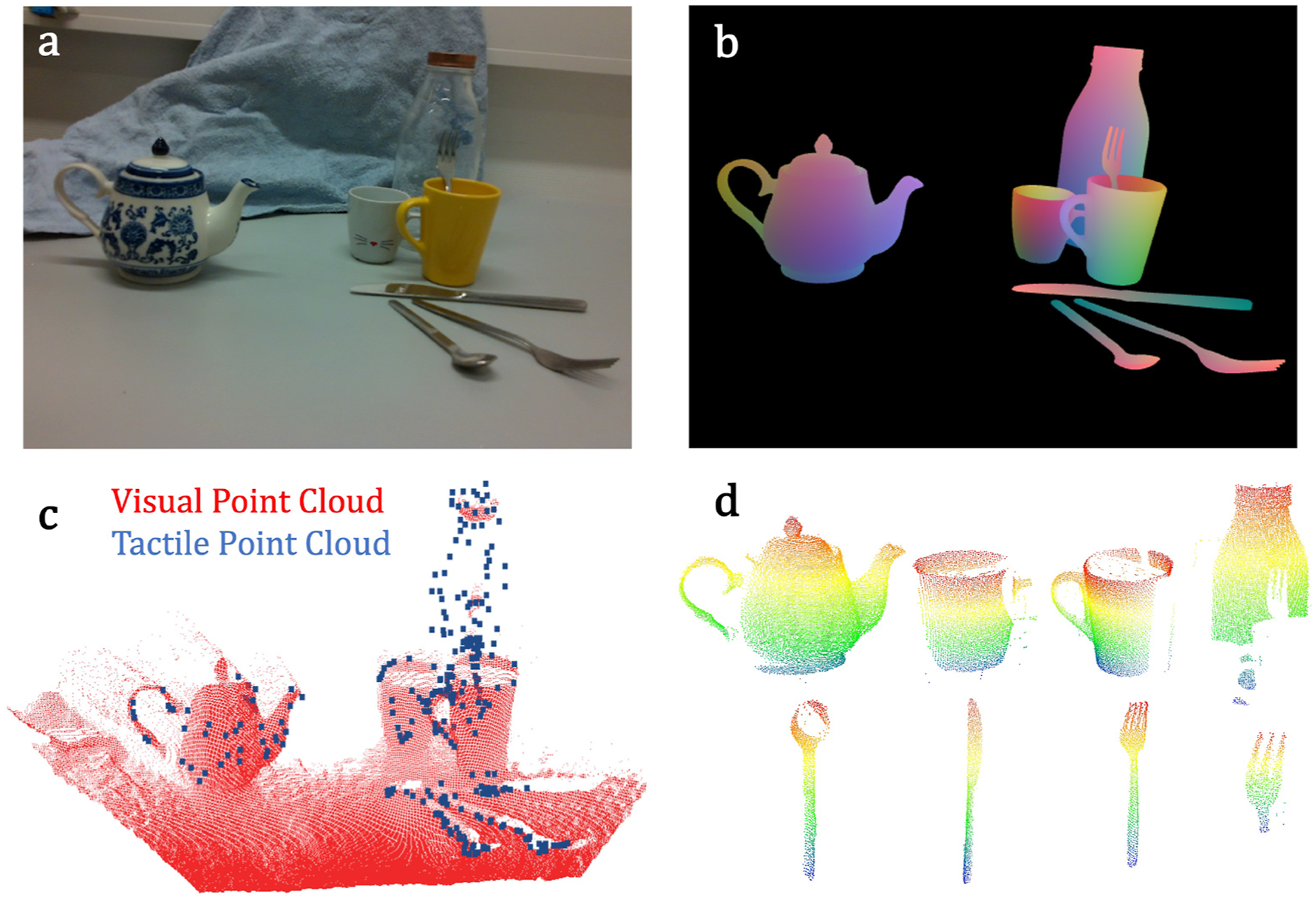
In order to be easily reproducible, widely available daily objects are used for experimentation from the following categories: (a) bottle, (b) cup, (c) mug, (d) spray, (e) detergent, and (f) wineglass. The objects in each category are shown in Figure 8(a). These objects are unknown and their models are reconstructed, and pose estimation is performed. Furthermore, a set of other objects shown in Figure 8(b) are used to clutter the workspace and the target object. Each scene is composed of one target object from any category and a subset of clutter objects placed around the target object in randomised dense clutter scenarios. (a) Target unknown objects. The properties evaluated by human experts: T: transparency/specularity, C: shape complexity, S: symmetry, +: medium, ++: high. (b) Objects used to clutter the workspace. (c) Visuo-tactile point cloud of an exemplary object demonstrating the need for tactile exploration in reflective regions where vision data is absent. (d) Visuo-tactile point cloud of a transparent object wherein visual data is completely missing and object is reconstructed and localised with tactile data.
4.2. Active visuo-tactile-based target object reconstruction
As the target objects list contains both transparent and opaque objects, our framework automatically prefers tactile exploration for transparent objects and visuo-tactile exploration for opaque objects using the joint criteria defined in eq. (9). An exemplary case that demonstrates the benefit of our method is shown in Figure 8(c). The ketchup bottle has parts of opaque and reflective regions. The vision point cloud shown in red captures the overall shape but contains some missing points in the reflective region (highlighted in the green box). Due to our information gain method for object exploration, tactile acquisitions are performed only in the regions where the visual points are missing or there is uncertainty due to noisy data (around the edges). Similarly for transparent object shown in Figure 8(d), the visual data is completely missing (shown in red points) and the tactile data captures the overall shape of the object (shown in blue points).
For reconstruction evaluation, we use the Chamfer distance (CD) metric defined in eq. (10) with the ground truth point clouds shown in Figure 10. The chamfer distance (CD) is defined as the sum of the average nearest-neighbour distance between one point cloud and the other and vice versa. Lower CD value denotes higher reconstruction precision. For the ideal case where the reconstructed point cloud exactly matches the ground truth, CD ≈ 0.0 m. Qualitatively, through empirical analysis, we found that CD < 0.01 m denotes accurate reconstruction, 0.01 m < CD < 0.1 m denotes good reconstruction while CD > 0.2 m implies poor reconstruction of the point cloud. The qualitative results for the reconstruction with vision and tactile data with our network are shown in Figure 9. Our method, with the help of the learned model over the category-level synthetic objects, is able to reconstruct the object even with sparse input point clouds. We performed five repeated experimental trials for each target object and with each exploration strategy: active, random and uniform, resulting in 210 total trails (14 objects, 3 strategies, 5 repetitions). We note that for opaque objects, the shared visual and tactile data result in a higher accuracy of reconstruction (CD < 2 cm) as seen in Figure 10(a). The visual point clouds for opaque objects capture all the sides of the objects due to the active visual exploration. On average, combining with tactile data improves visual reconstruction accuracy by 17%. For opaque objects, the tactile reconstruction accuracy is relatively worse due to the fact that incomplete tactile point clouds are collected as the robot only explores regions unseen by the camera. Visuo-tactile point clouds and the respective reconstructed point cloud using our reconstruction network. Quantitative reconstruction results showing the chamfer distance (CD) metric of the reconstructed point cloud compared with the ground-truth point cloud for (a) opaque objects and (b) transparent objects. The bar graph represents the average values and the error bars represent the standard deviation.
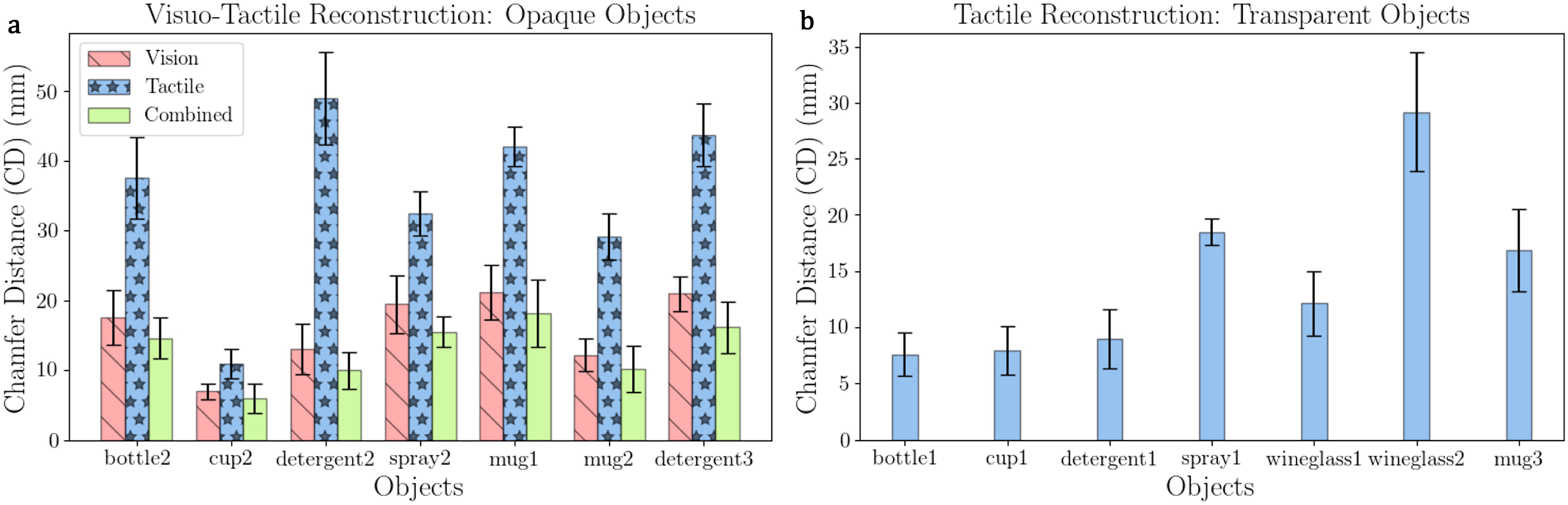
For transparent objects, even a sparse input point cloud provides acceptable reconstruction accuracies as seen in Figure 10(b). In this case, since no visual point cloud is available, the robot explores the object with only tactile sensing in an information-gain seeking strategy. All objects are accurately reconstructed (CD < 2 cm) by the network except the
Furthermore, we performed a comparison study of our active exploration strategy with baseline random and uniform strategies for both vision and tactile modality. The baseline strategies for tactile exploration are defined as follows: the bounding box on the target object is discretised into a 3D grid with each grid cell of size 3 cm × 3 cm which corresponds to the size of the sensor patch. The robot is moved to touch the grid cell closest to its base frame and sequentially touches each cell in a uniform manner. In contrast, the random strategy involves choosing the next possible grid cell in a randomised manner. In a similar manner, we define random and uniform exploration strategies for the vision modality: viewpoints on the hemisphere sphere are sampled uniformly in the same way as described in Section 3.3 and the robot starts from one extreme possible position and sequentially moves to the next viewpoint in a uniform manner. The random strategy chooses one among the possible sampled viewpoints at random. As we want to compare the sample efficiency of the actions and to have an unbiased comparison with each strategy, we limit to 20 actions for tactile-only actions for transparent objects and to 3 visual actions and 5 tactile actions for the remaining opaque objects. The results for reconstruction of opaque objects with visuo-tactile sensing is shown in Figure 11(a) and transparent objects with tactile sensing in Figure 11(b). As the exploration is performed for the objective of object reconstruction, CD is used as a metric for comparison. For both transparent and opaque objects, increasing the number of exploratory actions reduces the CD value. For transparent objects that rely upon only the sense of touch, active exploration converges to an accuracy of CD ≈ 2 cm within 20 touches. Random exploration converges to CD ≈ 5 cm in 20 touches, but with higher variance due to the stochasticity of exploratory actions. Uniform exploration has the least accuracy due to the fixed nature of exploration, which often collects redundant data, leading to long data collection times. In contrast for opaque objects, random and active strategies perform similarly on average (CD ≈ 1.5 cm) and subsequently active tactile strategy slightly improves the reconstruction accuracy (CD ≈ 1.1 cm). Negligible reduction in CD value is reported with random and uniform tactile actions following visual perception for opaque objects. (a) Active visuo-tactile reconstruction accuracy for opaque objects and (b) active tactile-only reconstruction accuracy for transparent objects compared with random and uniform strategies. The error bars in (a) and shaded regions in (b) represent the standard deviation.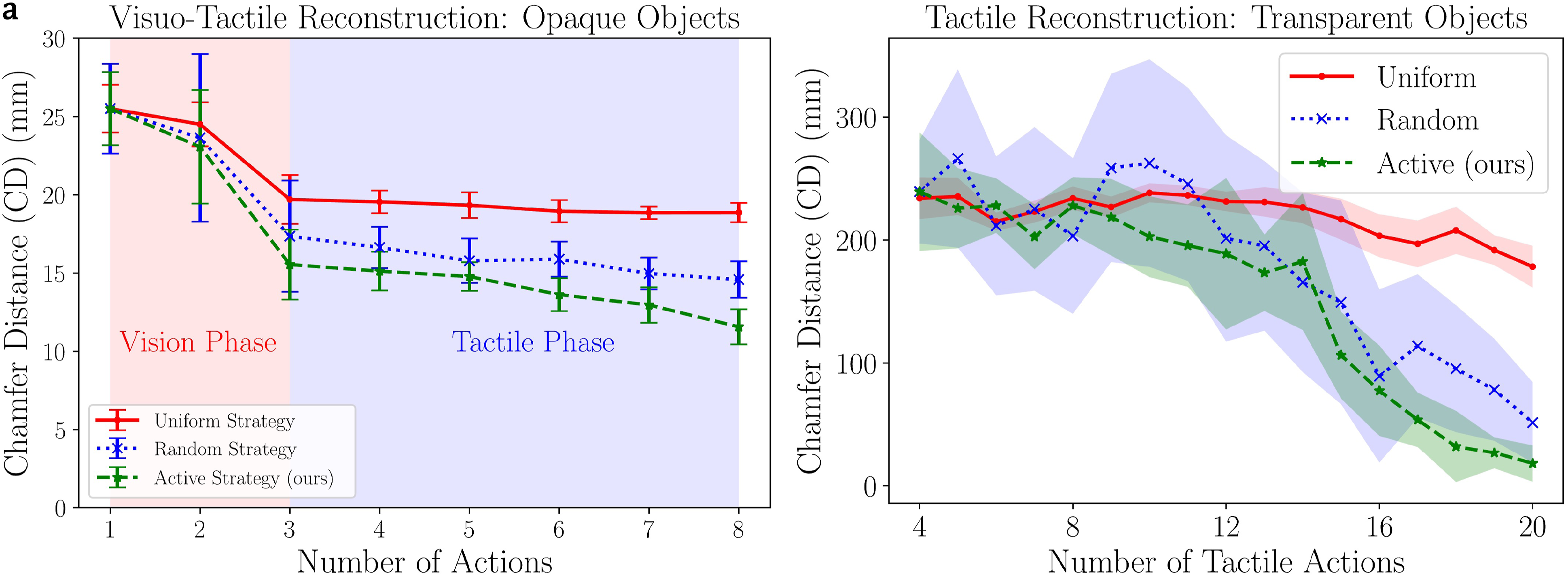
4.3. Category-level visuo-tactile-based pose estimation
In order to benchmark our stochastic TIQF (S-TIQF) and previously proposed TIQF methods, firstly we perform instance-level pose estimation where the object model point cloud is obtained from the ground truth mesh on the Stanford Scanning Repository benchmark. The following state-of-the-art methods are used for comparison: Iterative Closest Point (ICP) (Besl and McKay, 1992), Sparse iterative closest point (S-ICP) (Bouaziz et al., 2013), Random sample consensus (RANSAC) (Fischler and Bolles, 1981), Truncated least squares Estimation And SEmidefinite Relaxation (TEASER++) (Yang et al., 2020) and PREDATOR (Huang et al., 2021a). We compare with both local registration methods such as ICP and S-ICP, global optimization methods such as RANSAC and TEASER++ and learning methods such as PREDATOR. We chose these popular baselines are they are often used in the literature for the point cloud registration task. Furthermore, some of these baselines such as ICP and RANSAC are also used to perform the final registration task with learning-based methods where the features are learnt using a neural network. We also compare with the learning-based method termed PREDATOR (Huang et al., 2021a) which learns to predict the registration of point clouds with low overlap between each other as is the case with visuo-tactile point clouds. We used the pretrained model of PREDATOR (available with their open-source implementation
1
) and set the hyper-parameters as suggested in the paper with the exception of
4.3.1. Benchmark experiments
4.3.1.1. Stanford scanning repository benchmark
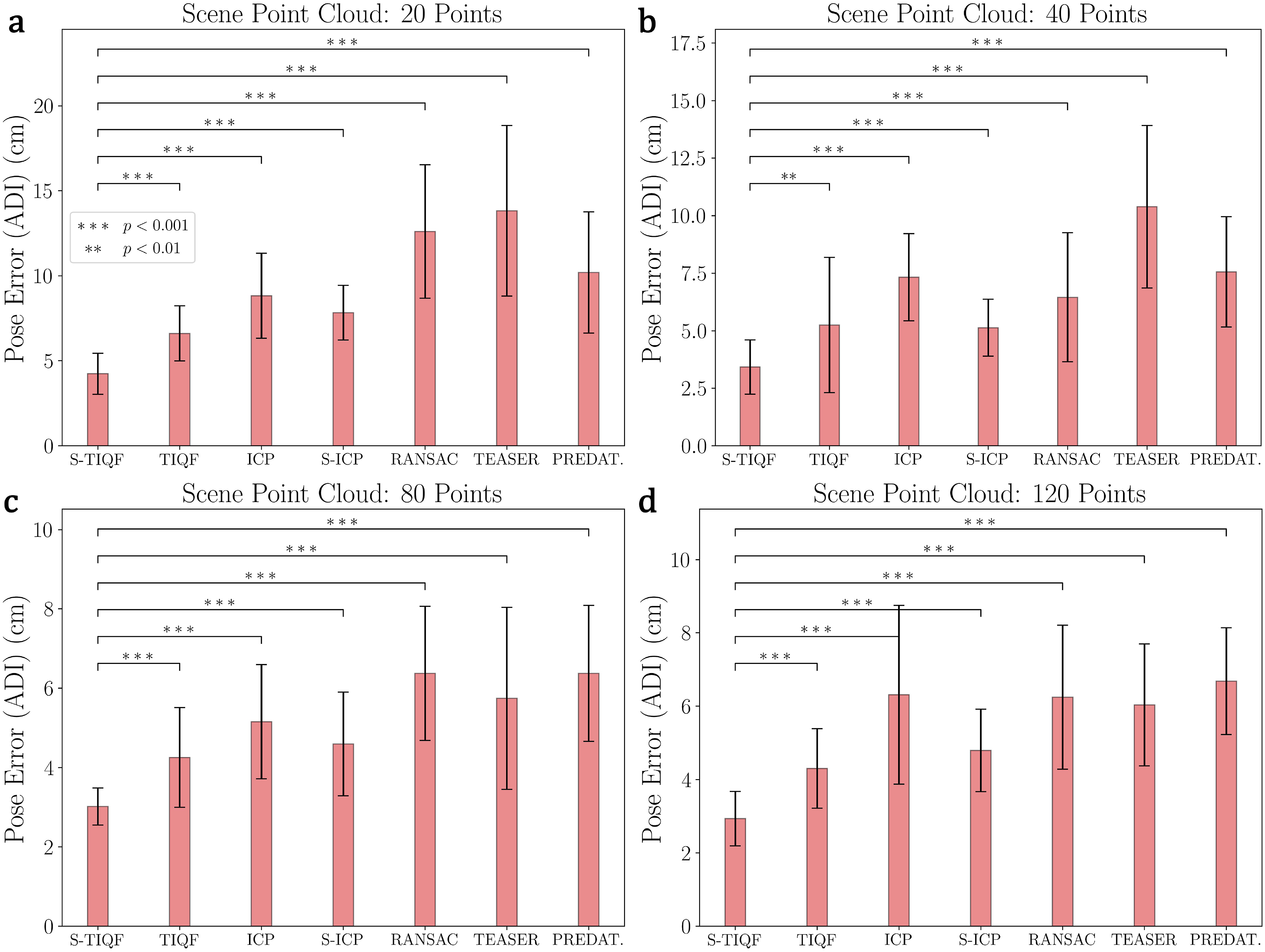
In order to benchmark our methods against the state-of-the-art, we use the standard point cloud registration benchmark from the Stanford Scanning repository (Levoy et al., 2005). We used six CAD models from the dataset namely bunny, dragon, happy Buddha, Lucy, statue and armadillo (Levoy et al., 2005). In order to have an unbiased comparison of pose estimation, we used the model point cloud derived from the CAD mesh in the dataset. This is done because errors in shape reconstruction can propagate and influence pose estimation. Each model point cloud is sampled uniformly from the CAD mesh to have 1024 points. The scene point cloud is sampled randomly from the CAD mesh and the point numbers are set to 20, 40, 80 and 120 points. The varying degree of sparsity can test the robustness of our approach against state-of-the-art methods. The model and scene point clouds are normalized and scaled to lie within a [−1, 1]3 m cube. In order to evaluate the sensitivity of our method against local optima, the initial pose for the model point cloud is randomly chosen from a position range of [−5.0, 5.0] m and rotation from [−180°, 180°] for each experimental trial. The correspondence estimation for ICP and S-ICP is based on nearest neighbourhood search whereas RANSAC and TEASER++ are based of Fast Point Feature Histograms (FPFH) descriptors (Rusu et al., 2009). For each selected model from the Stanford scanning repository, the experiment is repeated five times with the initial pose randomly varied for each trial. The errors are measured as using the Average Distance of model points with Indistinguishable views metric (ADI) which is insensitive to object symmetries (Hinterstoisser et al., 2013). The ADI metric is measured as: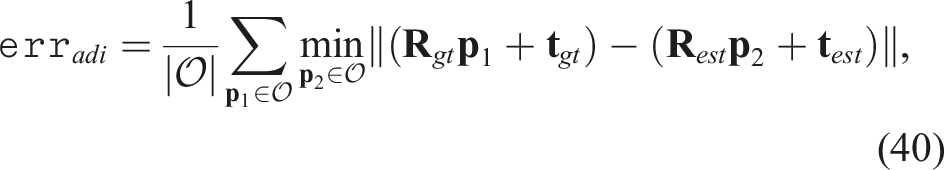
Qualitative results with the Stanford Bunny model are shown in Figure 12. Quantitative results evaluated with all the models selected from the Stanford scanning repository are provided in Figure 13. It can be seen that for all levels of point sparsity (20–120 points), our S-TIQF outperforms baselines (p < .001 for Welch’s t-test in all cases except for scene cloud with 40 points with TIQF where p < .01). Interestingly, S-TIQF also outperforms TIQF method and this is due to the stochastic initial alignment used in S-TIQF. For instance, in the case of the scene point cloud with 20 points, S-TIQF outperforms the closest baseline S-ICP by 45% on average and 38% for scene point cloud with 120 points. The results corroborate the known weaknesses of correspondence-based techniques such as RANSAC and TEASER++ as they rely upon features for estimation correspondences. These correspondences remain fixed throughout the pose estimation process. Due to point sparsity, feature extraction methods such as FPFH fail to generate valid correspondences. Similarly, our S-TIQF and TIQF outperforms the learning-based method PREDATOR by more than 50% on average for all levels of point sparsity (20–120). The point sparsity and absence of neighbourhood points is challenging for the graph neural network in PREDATOR to extract good features for the overlapping regions. Furthermore, simultaneous pose and correspondence methods such as ICP and TIQF perform relatively well on sparse data but rely on good initialization. Our S-TIQF approach removes the need for good initialization through the stochastic search for initial alignment. Furthermore, to demonstrate that the effectiveness of our approach, we performed an ablation study shown in the Appendix A.3 where we provide the output from the stochastic alignment (SA) module to the baseline methods ICP and S-ICP. We show that S-TIQF still outperforms the modified baseline algorithms SA + ICP and SA + S-ICP by at least 20% in terms of ADI error (cf., Table 3). Qualitative results on the Stanford bunny dataset: The grey mesh represents the model at ground truth for reference, the blue sparse point cloud represents the scene point cloud and the red dense point cloud represents the transformed model point cloud after performing point cloud registration. Pose error calculated as ADI error for models from the Stanford scanning repository. The object point cloud consisting of 1024 points is sampled from the models while the scene point cloud is randomly sampled from the model and consists of (a) 20, (b) 40, (c) 80 and (d) 120 points, respectively. p values calculated by Welch’s t-test shown as ∗. The bar plot represents the average and the error bars represents the standard deviation.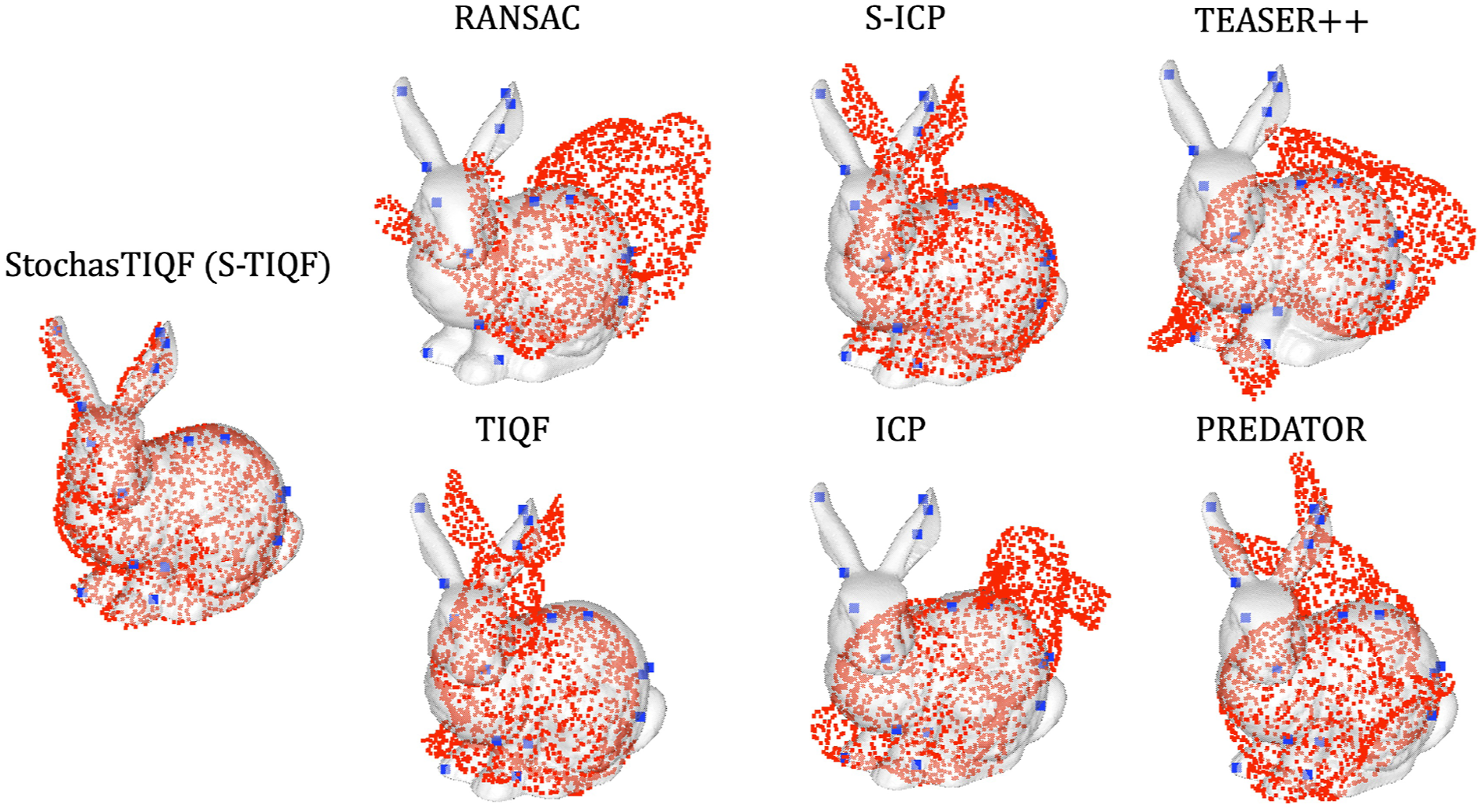
4.3.1.2. PhoCal dataset benchmark
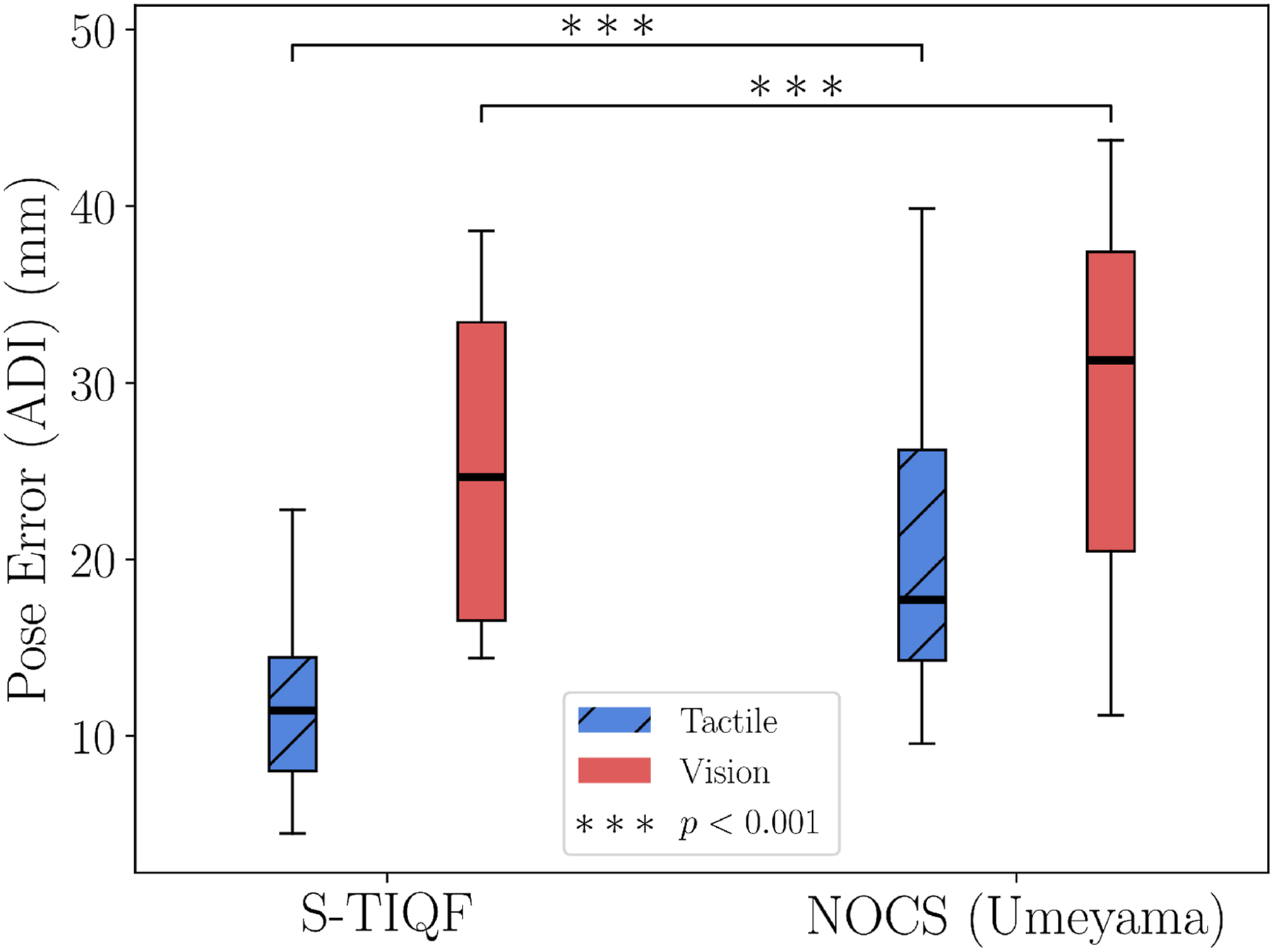
We conducted a feasibility study with the PhoCal dataset (Wang et al., 2022) to demonstrate category-level pose estimation with our method. In contrast to our reconstruction network which is trained on point clouds of synthetic objects belonging to the same category as the real-world objects, the Normalized Object Coordinate Space (NOCS)-based framework (Wang et al., 2019) can also be used to generate the point cloud of the objects. Given RGB inputs, the NOCS network learns a NOCS map which is a shared canonical space of objects within a category. The NOCS map can be combined with the depth map to lift from 2D image to 3D point cloud space. This is used as the object point cloud and the point cloud from the depth map is considered as the scene point cloud for point cloud registration. Furthermore, point cloud registration methods such as Umeyama algorithm (Umeyama, 1991) are used to perform pose estimation with the NOCS-based framework (Wang et al., 2019). The PhoCal dataset (Wang et al., 2022) contains the RGB, depth and learnt NOCS maps of real world objects belonging to different categories particularly for photometrically challenging objects. In order to perform accurate 6D pose annotation, the authors of the PhoCal dataset (Wang et al., 2022) used a tool-tip on a robotic manipulator to manually touch the object at various locations that are sparsely distributed on the object. We use these touch points as the tactile point cloud. The learnt NOCS maps are used to generate the object model point cloud and the depth map provides the visual point cloud. We compare our approach with methodology introduced in Wang et al. (2019) for pose estimation. Figure 14 shows an example from the PhoCal dataset demonstrating the rendered NOCS map (Figure 14(b)) and the reconstructed models (Figure 14(d)). We note that the reconstructed point clouds are partial (see bottle and fork in Figure 14(d)) as only the visible portions of the scene are used to generate the NOCS map and provides further challenges for pose estimation. Figure 15 shows the comparison results of S-TIQF method against the Umeyama approach (Umeyama, 1991) used in (Wang et al., 2019). We demonstrate that our approach outperforms the baseline method for tactile point clouds by approximately 35% median ADI error and about 20% ADI error when applied to dense visual point clouds (p < .001). We also evaluated the scale estimation approach we use for visual and tactile sensing based point clouds. The scale error is calculated as: Qualitative results using the PhoCal dataset: (a) RGB input, (b) rendered NOCS map, (c) visual and tactile point cloud, and (d) reconstructed model point clouds from NOCS maps in (b). Comparison of our method against the NOCS (Umeyama method) (Wang et al., 2019) performed as a feasibility study with the PhoCal dataset. p values calculated by Welch’s t-test shown as ∗.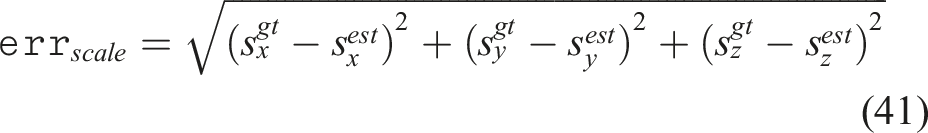
4.3.2. Robotic experiments
In order to validate our method in real world settings, we carried out extensive experiments using the robotic setup shown in Figure 1 and everyday objects shown in Figure 8. Similar to the benchmark experiments, our S-TIQF and TIQF methods are compared against the same baseline methods. The model point cloud is derived from the reconstructed point cloud from the reconstruction network. The scene point cloud comprises of vision and/or tactile data. For each target object, the experiment is repeated five times by randomising the cluttered scene for each iteration. Similar to the previous experiments, the initial pose is sampled randomly from [−5.0, 5.0] m and [−180°, 180°] for each trial and the same initial pose is provided to all comparison methods. The quantitative results for transparent objects are shown in Figure 16(a) and opaque objects in Figure 16(b). The results with transparent objects are similar to the benchmark experiments due to the nature of sparse tactile point clouds and S-TIQF outperforms the baseline approaches. For instance, S-TIQF outperforms the next best baseline method S-ICP by nearly 40% on average for sparse tactile point clouds (p < .001). In comparison, it can be seen from Figure 16(b) that for dense visual point clouds, nearly all the methods perform equally well and our S-TIQF method compares favourably with the state-of-the-art (p < .001). Our method achieves an average ADI error of 2.1 cm whereas TEASER++ achieves an error of 2.5 cm for dense visuo-tactile point clouds (p = .04034). The learning-based approach PREDATOR also performs on-par with other baselines for the dense visuo-tactile point clouds with average ADI error of 3.1 cm. However, the performance of PREDATOR with sparse tactile point clouds for transparent objects is much worse, with the average accuracy of S-TIQF nearly 65% better than PREDATOR. The PREDATOR method assumes sufficiently dense local point features even if there is minimal overlap for the overlap attention module which is not the case for sparse tactile point clouds and results in lower performance. In fact, it can be seen that the combined visuo-tactile point clouds results in better accuracy than visual or tactile point clouds alone, demonstrating the importance of shared perception. For instance, the accuracy improves by Average pose error for real-world objects for (a) opaque objects with visuo-tactile perception and (b) transparent objects with tactile perception. p values calculated by Welch’s t-test shown as ∗. Object-wise pose estimation results with S-TIQF. The figure shows a standard box-and-whisker plot with the box extended between the upper and lower quartile and line showing the median. The whiskers show the range of the data.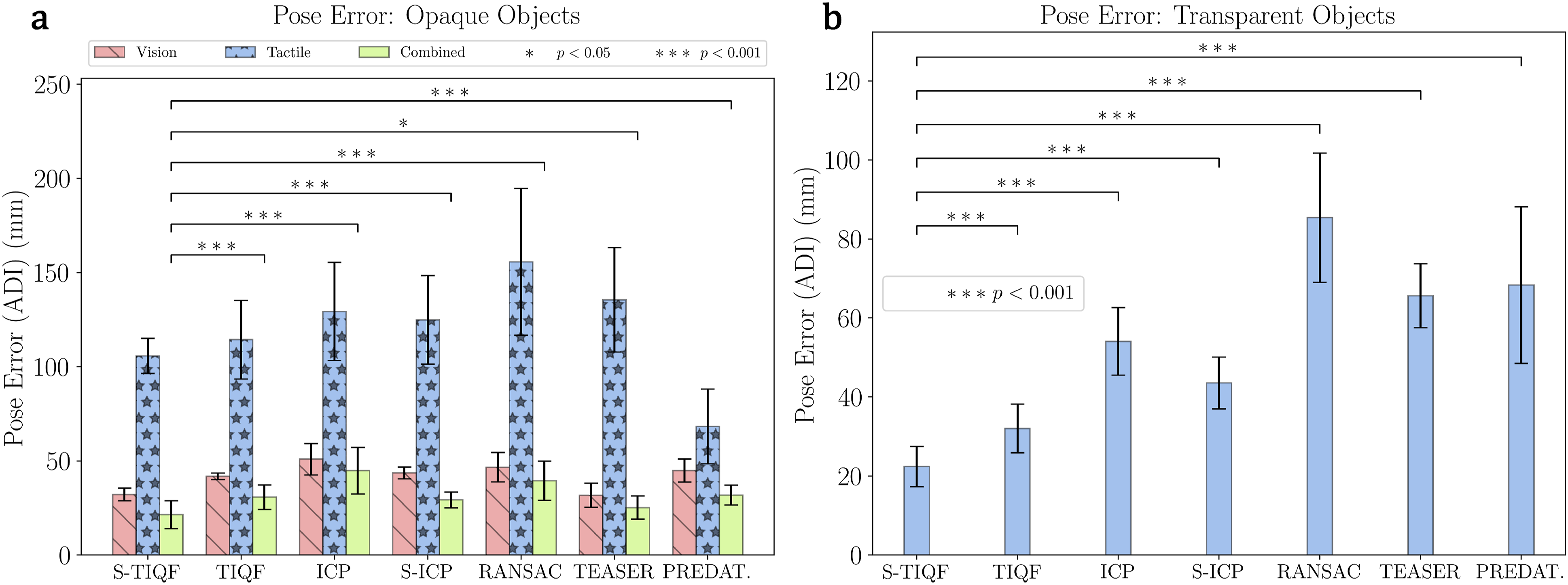
4.4. Visuo-tactile hand-eye calibration
This section provides comparative studies performed for hand-eye calibration of our in situ approach and standard methods using calibration grid with the algorithm originally presented by Tsai (Tsai and Lenz, 1989). For the calibration grid method, the grid was fixed at a suitable distance from the camera such that it is clearly within the field of view of the camera. Ten different viewpoints were chosen manually ensuring that the different end-effector rotations were incorporated. The experiment was repeated five times. Our in situ visuo-tactile calibration approach does not require a specialized grid. Any object in the workspace of the robot can be used as long as an accurate point cloud corresponding to the object is available. The object must be immobilised and multiple visual pointclouds are captured from different viewpoints. With an incorrect hand-eye calibration, the point clouds from different views would not overlap accurately and result in the scenario shown in Figure 18(a). Furthermore, when tactile data are collected from the same object, resulting in the tactile point cloud, an incorrect hand-eye calibration can be described in the scenario shown in Figure 18(b). The tactile sensors are rigidly attached to the end-effector and the robot kinematics are accurate enough to provide a grounding of the object pose. Using the calibration grid method, an acceptable accuracy can be achieved, but residual errors would still be present. The qualitative results are shown in Figure 18(c). Using our in situ approach with the S-TIQF method, a highly accurate solution can be obtained (Figure 18(d)). Quantitative results are shown in Figure 18(e). Our approach achieves Qualitative results of hand-eye calibration: Effects of incorrect calibration when point clouds are acquired from different viewpoints (a) and (b). The different colours for the point clouds in (a) highlight the effect of incorrect calibration when overlapped with each other. The accuracy of calibration using grid-based method (c) and our method (d). Quantitative analysis of the error in hand-eye calibration (position and rotation) (e). p values calculated by Welch’s t-test shown as ∗.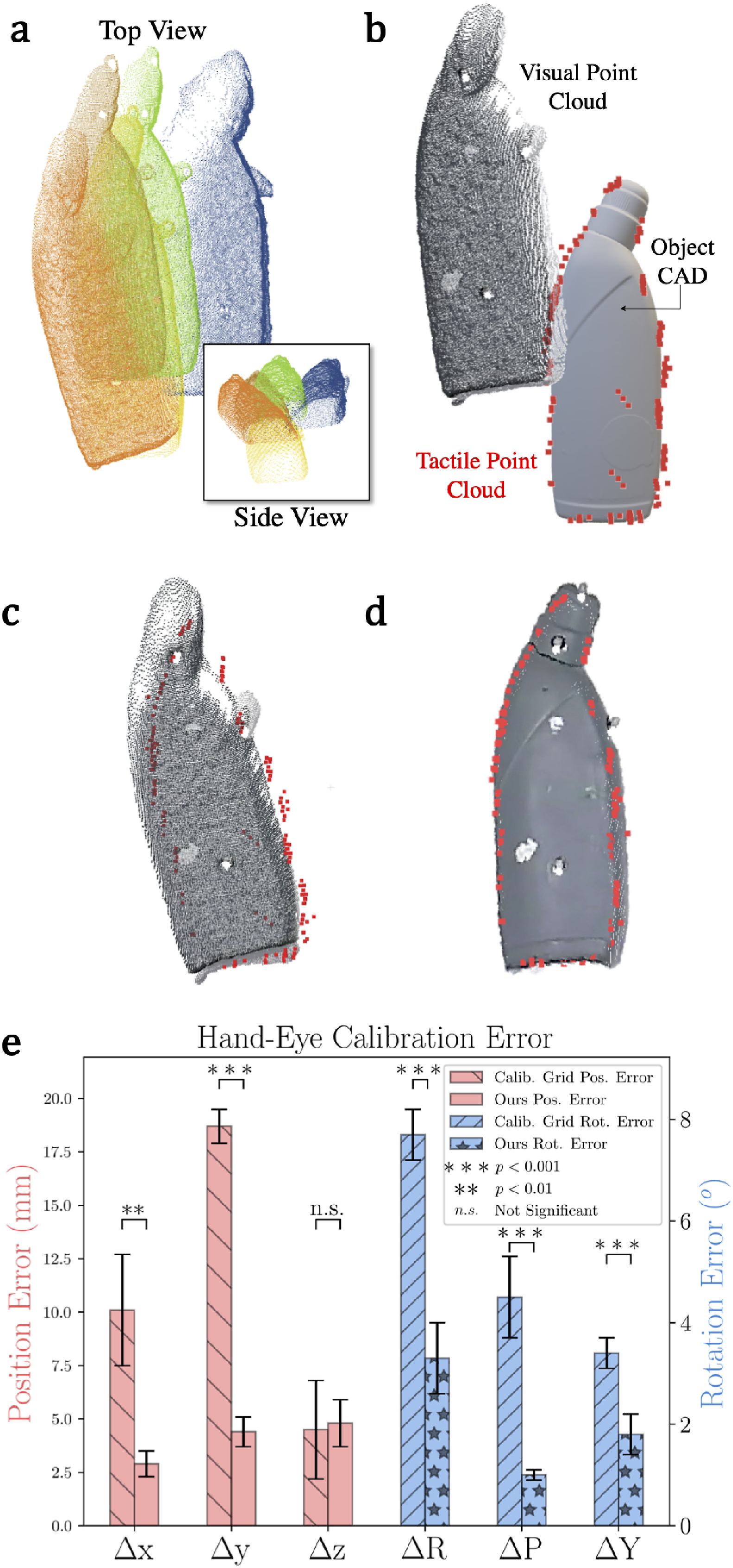
4.4.1. Robot kinematic accuracy benchmark for calibration
Our in situ visuo-tactile-based hand-eye calibration method depends on the accuracy of the kinematic calibration (especially for the robot with tactile sensing). Although this assumption is commonly used in the case of hand-eye calibration (Sun and Hollerbach, 2008), we benchmarked the kinematic accuracy of both robots using an external sensor system to evaluate the effect on hand-eye calibration. We used the OptiTrack motion capture system (NaturalPoint, Inc.) to track a specially designed coordinate marker frame with embedded markers that is attached to the gripper fingers, as shown in Figure 19(a). The motion capture system has an average accuracy of 0.1 mm. The UR5 robot, which is sensorized with tactile sensors, has a pose repeatability of 0.1 mm and is kinematically calibrated by the manufacturer.
2
The Franka Emika robot which is sensorised with the camera also has a pose repeatability of 0.1 mm obtained from the datasheet of the manufacturer. Both robot’s end effector were moved in arbitrary trajectories covering all 6 DoF by the human user with manual hand guiding and the pose of the end-effector was extracted from the kinematic model and using the motion capture system, respectively. The static offset which arises due to pose difference between the robot’s end-effector frame and the designed marker frame which is attached to the end-effector that needs to be compensated. The end-effector poses expressed in the world-coordinate frame are extracted from the robot kinematic model and the poses of the marker frame expressed in the world coordinate frame extracted from the Optitrack system are used while the robot is stationary and the static offset is measured as the averaged RMSE of the two poses. We compare the accuracy between these poses in Figure 19(b) and (c) where the plots of the end-effector trajectory are shown with the kinematic pose calculation in blue and the motion capture calculated pose in red. The numerical results are shown in Table 2. We recognize the intrinsic uncertainties inherent in our comparative analysis: sporadically, the human operator might occlude the markers from the field of view of certain OptiTrack cameras during manual guidance, despite the strategic deployment of six OptiTrack cameras surrounding the workspace. Hence, we measure the median error and median absolute deviation to disregard spurious outlier points. We note that the kinematic accuracy of the UR5 robot with our benchmarking 0.303 ± 1.82 mm, which is crucial for the calculation of the tactile point clouds. We note that this accuracy for the tactile measurements is within the tolerance bounds. The kinematic discrepancies observed in the Panda robot are more pronounced (±4 mm median absolute deviation); however, their impact on the hand-eye calibration process remains minimal, as the tactile point cloud serves as the reference for the registration of the corresponding visual point cloud. Our method works identically for the case where the camera is kept static and visual point cloud of the object is registered to the tactile point cloud. (a) Benchmarking the robot kinematics with high-precision marker-based motion capture system (OptiTrack) for (b) UR5 robot and (c) Franka Panda robot. The robot poses are shown in blue and the pose calculated by the motion capture system in red. Numerical results from kinematic calibration benchmark showing the median error and median absolute deviation.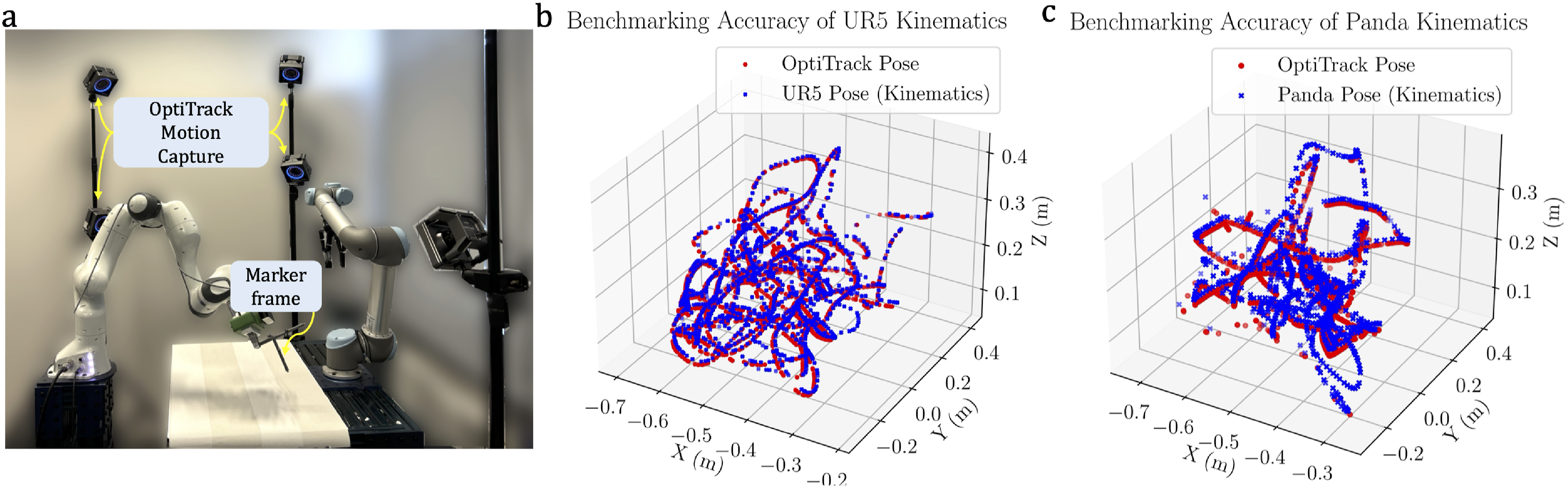

4.5. Discussion
4.5.1. Individual sub-system evaluation
We presented a novel interactive shared visuo-tactile perception approach for unknown target object reconstruction and robust pose estimation. To retrieve the target object, the robots coordinate together to declutter the scene. We used target objects of varying shape complexity and transparency to extensively evaluate our reconstruction and pose estimation pipeline. Our approach is able to accurately reconstruct both transparent and opaque novel objects efficiently in an active information-gain seeking manner. We note from Figure 11(a) for transparent objects, the uniform strategy requires a large number of tactile actions for accurate reconstruction of the objects leading to increased data collection time. Random exploration strategy has high standard deviation (CD ≈ 3 cm after 20 actions) that stems from the stochastic nature of the exploration. Our active strategy has lower variance and higher accuracy (CD < 2 cm) within 20 actions, outperforming both random and uniform strategies. For vision based object reconstruction, due to the workspace limitations, wide field of view of the camera and limited size of the objects, on average three viewpoints are sufficient to completely explore the objects. However, as seen from Figure 11(b), uniform strategy is less accurate than random and active strategy for visual reconstruction. Furthermore, the subsequent tactile actions after visual perception improve the reconstruction accuracy by 17% with our active strategy whereas the improvement is marginal with random and uniform strategies. The acquired tactile data with random and uniform strategies are redundant with the visual point cloud data whereas with active strategy, the regions unexplored by the visual modality are explored with the tactile modality. Shared visuo-tactile perception proves more advantageous than sole reliance on mono-modal visual or tactile perception, and the proficient sharing of perceptual attributes between modalities demonstrates efficacy across various object types, including both transparent and opaque entities. Furthermore, active perception is required for effective shared perception to avoid redundant data collection and overlap between sensing data.
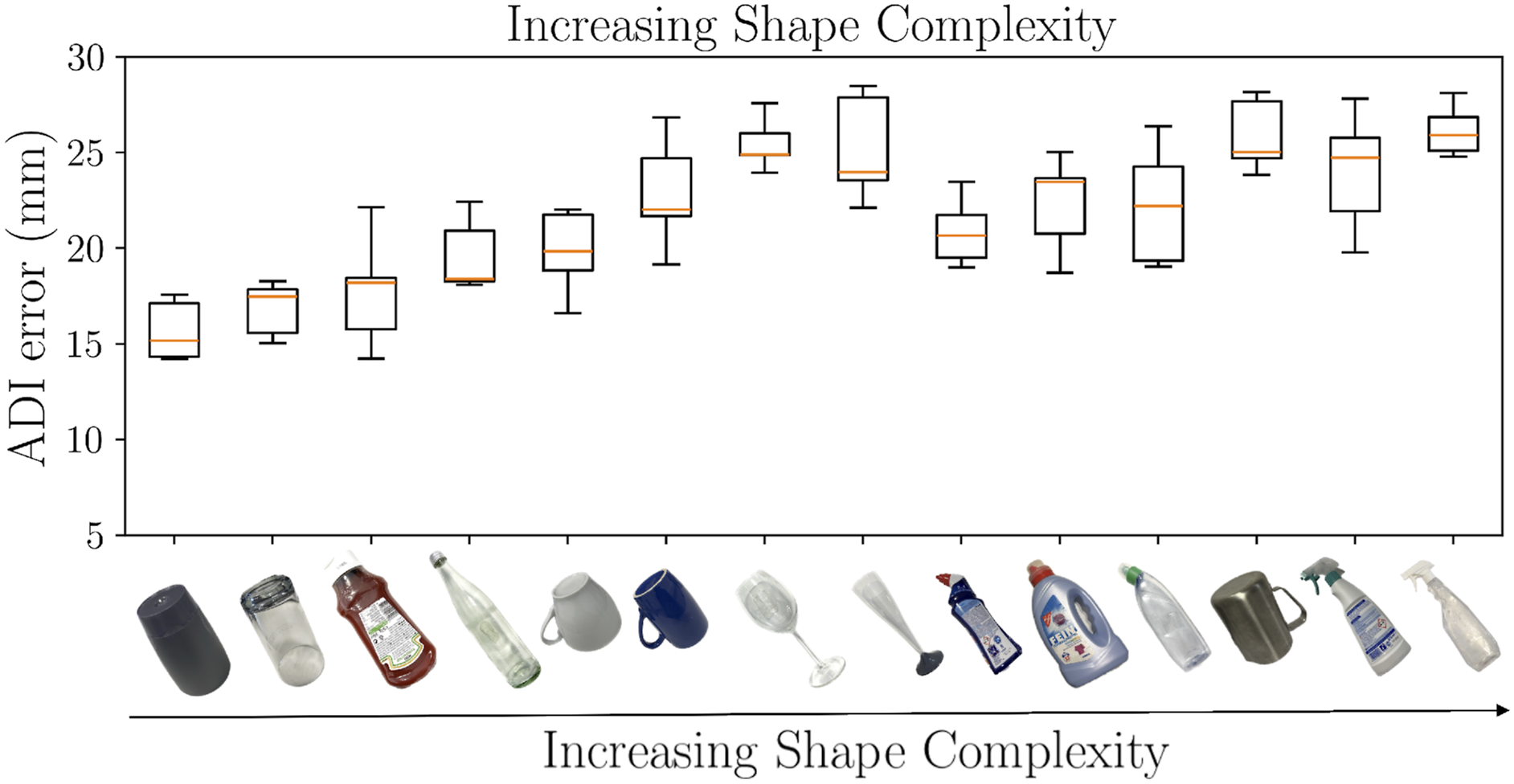
Similarly, for category-level pose estimation with the reconstructed point clouds of real-world objects, our S-TIQF method outperforms all the baseline strategies for tactile based pose estimation due to sparsity of tactile point clouds with an average ADI error around 2 cm as seen from Figure 16(a) (p < .001). Whereas for opaque objects, our method compares favourably to state-of-the-art methods for dense visual and visuo-tactile point clouds (p < .05). We have compared with geometry-based point cloud registration methods such as ICP (Besl and McKay, 1992), S-ICP (Bouaziz et al., 2013), RANSAC (Fischler and Bolles, 1981) and TEASER++ (Yang et al., 2020) which does not require any neural network learning component as well as with PREDATOR (Huang et al., 2021a) which is a learning-based registration method. Furthermore, some of these popular baselines such as ICP and RANSAC are also used as a “backend” to perform the final registration task with learning-based methods where the features are learnt using a neural network. In fact, even the PREDATOR method (Huang et al., 2021a) learns the feature points where there is maximal overlap between the point clouds and RANSAC is used to extract the final pose estimate using the correspondences found. Our S-TIQF approach allows for incorporating sparse as well as dense measurements for pose estimation. S-TIQF also outperforms TIQF by 35% for tactile and visuo-tactile-based pose estimation. Our stochastic initialization strategy proves effective for escaping local minima. We note from Figure 17 showing the object-wise pose estimation results, that increasing shape complexity results in marginal reduction in pose accuracy as to be expected. Transparent objects show higher average errors compared to opaque objects as they rely solely upon tactile perception resulting in sparse data. However, the worst-case error (for instance
Furthermore, we evaluated our approach on various point cloud registration datasets and real world objects with different sensors. The S-TIQF method can be applied to various sensing modalities, including LIDAR or RADAR sensors, capable of supplying point cloud data. This versatility extends its utility to applications like mapping, localization, and sparse-to-dense registration when integrated with depth cameras. Given that S-TIQF relies directly on raw point clouds containing only positional information (i.e. x, y, z coordinates) and potentially normals data when available, with minimal parameter tuning, it stands as an effective choice for diverse applications requiring precise point cloud registration.
4.5.2. Overall system evaluation
To evaluate the performance of the entire pipeline as shown in Figure 1, we choose the criterion such that if
4.5.3. Future work
We aim to extend our pose estimation approach to non-rigid objects such as articulated and deformable objects as part of future work. Extending our shared perception formulation to other sensors apart from visual and tactile sensing is also worth investigating, due to the generalized formulation that depends only on 3D position data. As noted in Section 4.4.1, there is an uncertainty about tactile measurements that arises due to the inherent uncertainty of robot kinematics. Another avenue for future research involves the integration of uncertainty quantification within the registration process, which has the potential to further mitigate calibration errors. While the shared perception in this work focused on the shape information, further object properties may also be shared through multi-modal perception allowing for robust manipulation strategies.
5. Conclusions
In this work, we proposed a novel full-fledged framework for interactive shared visuo-tactile object reconstruction and pose estimation of unknown target objects in dense clutter. In our scenario, two robots equipped with vision and tactile sensors coordinate to declutter the workspace using our proposed declutter scene graph approach. Visual and tactile sensing are efficiently shared to explore the unknown target object using the joint information gain criteria. This ensures non-redundant actions performed in a greedy-information gain manner improving the sample efficiency of actions. Tactile perception is prioritised for transparent objects that are challenging for visual perception. The extracted point cloud data is used for inferring the reconstructed model of the object using our reconstruction network. Finally, our novel S-TIQF method is performed for robust pose estimation that is accurate for both sparse and dense point cloud data. It provides globally optimal pose that is robust against local minima. Our method has been extensively validated using benchmark datasets and with real-robot experiments and it outperforms state-of-the-art techniques. Furthermore, we demonstrate how our S-TIQF method can also be used for hand-eye calibration using any arbitrary objects through visual-tactile data which is critical for shared multi-modal perception.
Supplemental Material
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Funded in part by the BMW Group and EU Horizon Project PHASTRAC under Grant ID 101092096.
Supplemental Material
Supplemental material for this article is available online.
Notes
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.