Abstract
Neuromorphic computing mimics computational principles of the brain in silico and motivates research into event-based vision and spiking neural networks (SNNs). Event cameras (ECs) exclusively capture local intensity changes and offer superior power consumption, response latencies, and dynamic ranges. SNNs replicate biological neuronal dynamics and have demonstrated potential as alternatives to conventional artificial neural networks (ANNs), such as in reducing energy expenditure and inference time in visual classification. Nevertheless, these novel paradigms remain scarcely explored outside the domain of aerial robots. To investigate the utility of brain-inspired sensing and data processing, we developed a neuromorphic approach to obstacle avoidance on a camera-equipped manipulator. Our approach adapts high-level trajectory plans with reactive maneuvers by processing emulated event data in a convolutional SNN, decoding neural activations into avoidance motions, and adjusting plans using a dynamic motion primitive. We conducted experiments with a Kinova Gen3 arm performing simple reaching tasks that involve obstacles in sets of distinct task scenarios and in comparison to a non-adaptive baseline. Our neuromorphic approach facilitated reliable avoidance of imminent collisions in simulated and real-world experiments, where the baseline consistently failed. Trajectory adaptations had low impacts on safety and predictability criteria. Among the notable SNN properties were the correlation of computations with the magnitude of perceived motions and a robustness to different event emulation methods. Tests with a DAVIS346 EC showed similar performance, validating our experimental event emulation. Our results motivate incorporating SNN learning, utilizing neuromorphic processors, and further exploring the potential of neuromorphic methods.
1. Introduction
Modern autonomous systems excel at specific tasks, but lack capabilities that the average human exemplifies, including rapidly learning for and accomplishing various unstructured tasks. A potential reason is the fundamental differences in human and artificial intelligence (AI) due to their respective physical substrates (biological vs silicon-based) (Korteling et al., 2021). AI systems can have superior information propagation speeds, communication bandwidths, and raw computational power. Though this may imply a greater capacity for multi-sensory processing, robotic agents embodying AI still struggle with everyday tasks that our brains facilitate with relative ease. This poses the question of whether the information propagation mechanisms and computational architectures present in our brains could be key factors in the advancement of reliable autonomy.
The human brain maintains multiple, complex cognitive processes while being more energy-efficient than contemporary computers. It simultaneously regulates essential processes and controls numerous high-level functions while consuming ∼20W of power (Drubach, 2000). Comparable and less-capable computers require power inputs that are many orders of magnitudes higher. This is evident when simulating cortical neural networks on conventional computers; at the scale of a mouse, such a simulation could run at 40,000 more power and 9000 times less speed, while projections from the Human Brain Project underscore the colossal power requirement for simulating a human brain (Thakur et al., 2018). Such neuroscientific studies indicate the vastly superior performance-to-efficiency ratio of the brain and motivate the consideration of biologically-inspired circuitry, sensors, and algorithms in intelligent robot design, which is the aim of this work.
Biological inspiration has frequently driven practical innovations, such as IR detectors and gyroscopes (Wicaksono, 2008), learning paradigms such as evolutionary algorithms and reinforcement learning (RL) (Sutton et al., 1998), and locomotion control using elementary neural circuits (Ijspeert, 2008). Artificial neural networks (ANNs) are based on their biological counterparts: the earliest models consist of interconnected layers of simple computational units with adjustable synaptic connections, while later convolutional neural networks (CNNs) aim to mimic connectivity patterns observed in animal visual cortices.
CNNs have been largely successful in some visual processing tasks (see Goodfellow et al., 2016) and are commonly deployed on robots. Nevertheless, these models are crude approximations at best. Biological neurons asynchronously aggregate inputs over time and propagate discrete, sparse spikes (action potentials), whose precise timings are thought to encode useful information. Conversely, ANN neurons synchronously propagate real-valued signals, abandoning an additional temporal dimension afforded by relative spike timings. These discrepancies have become relevant following observations that deep neural networks (DNNs), despite their notable successes, still suffer from ever-growing numbers of parameters, correspondingly sizable data requirements, poor generalization to unobserved yet similar inputs, and catastrophic failures in response to minor perturbations (Serre, 2019). Our brains seem better-equipped to handle an extraordinary range of problems while exhibiting superior generalization and robustness than present AI models.
1.1. Neuromorphic computing
Neuromorphic engineering/computing reproduces characteristics of the brain in hardware. The field was established in the 1980s by Carver Mead, who suggested analogies between neuronal dynamics and the physics of sub-threshold regions of transistor operation (Mead, 1990). This has given rise to various models of spiking neural networks, neuromorphic processors, and neuromorphic sensors. This research is motivated by the pursuit of brain-like computation to improve efficiency, parallelization, and energy consumption (Thakur et al., 2018) through a fundamental paradigm shift, which could benefit various applications including autonomous vehicles, wearable devices, and IoT 1 sensors (Rajendran et al., 2019). Naturally, it holds promise for robotic systems as well.
Various studies provide empirical evidence of the advantages of neuromorphic computing: 10 and 1000 factor increases in speed and energy-efficiency when learning on a neuro-processor compared to a conventional processor (Wunderlich et al., 2019), a four-fold increase in the energy-efficiency of a spiking network versus a DNN for speech recognition (Blouw and Eliasmith, 2020), better energy-per-classification ratios in deep learning problems when comparing to a Tesla P100 GPU (Göltz et al., 2021), and speed and efficiency gains in various classical problems (Davies et al., 2021). These results have coincided with, or perhaps fostered, an ongoing interest in the field, typified by the recent establishment of the “Neuromorphic Computing and Engineering” journal (Indiveri, 2021).
1.2. Event cameras
Event cameras (ECs) are neuromorphic sensors that are modelled after biological retinas. ECs exclusively record per-pixel events at which the change in intensity crosses a threshold, mimicking retinal photoreceptor cells (Posch et al., 2014). Consequently, they only capture significant intensity changes, often due to motion (Figure 1), in contrast to frame-based cameras, whose pixels synchronously and continuously transmit absolute values, much of which is often redundant information. Images captured with a DAVIS346 EC. 1a shows an RGB image of a fast-moving object and 1b visualizes the captured events 1c and 1d show events superimposed on images captured while moving the camera.
ECs offer lower power consumption, lower transmission latencies, higher dynamic ranges, and more robustness to motion blur than traditional cameras (Gallego et al., 2022; Chen et al., 2020a), which have been experimentally validated (Sun et al., 2021). These properties can address limitations of frame-based vision in power consumption and bandwidth due to transmitting larger amounts of data (Dubeau et al., 2020). External clock-driven data acquisition naturally leads to redundant image information and the potential loss of inter-frame information (Risi et al., 2020). Instead, ECs selectively acquire data based on scene dynamics. ECs have most often been deployed in applications requiring rapid reaction speeds, such as drone flight, due to characteristically high temporal resolutions.
Event-based data necessitates correspondingly novel methods and algorithms; the artificial analogs of visual cortical cells, spiking neurons, are prime candidates.
1.3. Spiking neural networks
Spiking neural networks (SNNs) are a neuromorphic alternative to ANNs in which computational units propagate sparse sequences of spikes (Figure 2). Input spikes contribute to a neuron’s decaying internal aggregate of past inputs: its membrane potential. When a threshold is exceeded, the neuron emits a spike (or action potential) which resets its potential. Spiking neurons operate asynchronously, such that information flows through the network through trains of distinctly-timed spikes. These neuronal dynamics match those observed in biology (particularly in the primary visual cortex; Chen et al., 2020a), but raise challenges concerning the encoding/decoding and processing of spiking data as well as learning methods, which remain open areas of research. Neuronal dynamics in conventional ANNs (left) and SNNs (right). Gray/black borders signify inactivity/activity; only the bottom SNN neuron is active here, since it had just spiked.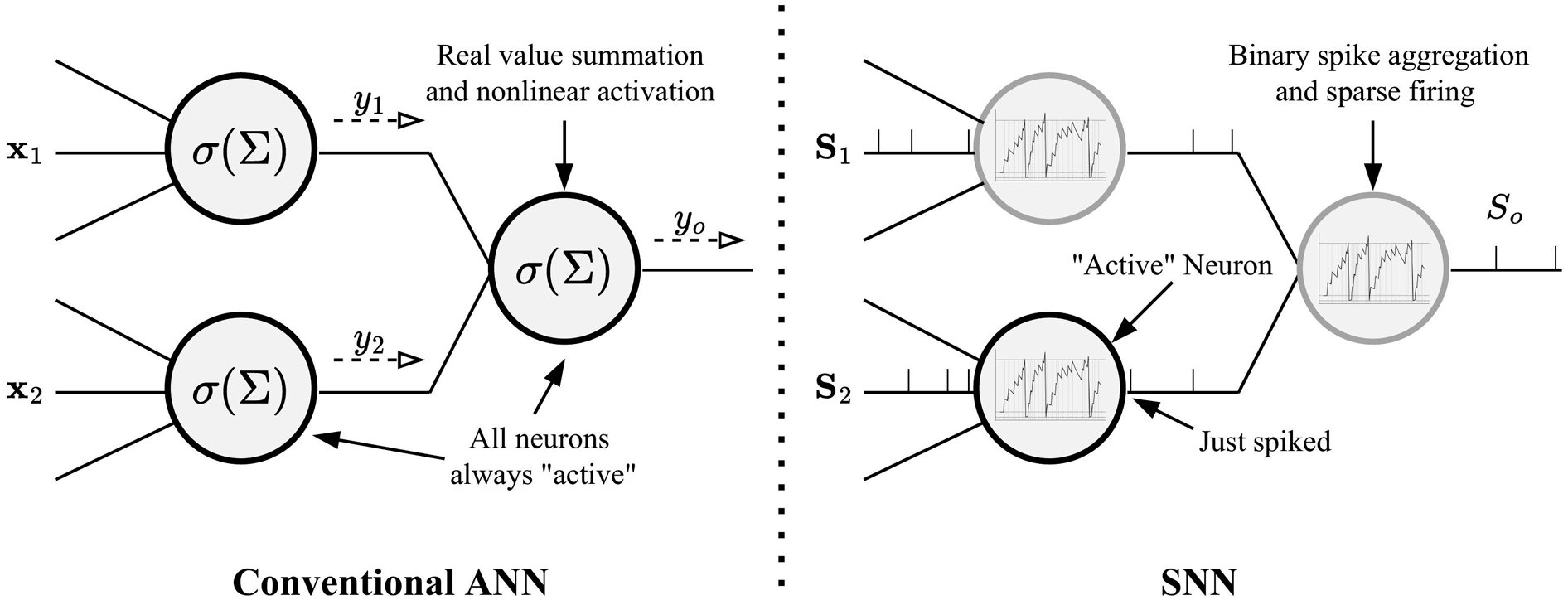
Similar to the event/frame-based camera dichotomy, SNNs have stimulated interest due to their potential advantages over ANNs. SNNs can be as, or potentially more, expressive than ANNs (Maass, 1997), and successful applications in common visual tasks have shown that they can consume less power and exhibit faster classification inferences (Neil et al., 2016), as well as outperform ANNs in energy-delay-product 2 (Davies et al., 2021). This energy-efficiency is due to neurons emitting outputs only when significantly stimulated, as opposed to constant computations, though this advantage is fully realized with dedicated neuromorphic hardware. This is also reflected in response latencies; in classification problems, SNNs could produce a correct inference before a frame-based approach could fully process all input pixels (Neil et al., 2016).
Although often associated with embodied agents, SNNs have been applied in other areas of research, such as for detecting Covid-19 from CT scans (Garain et al., 2021).
1.4. Contribution
In this paper, we investigate the viability and utility of neurologically-inspired sensors and algorithms in the context of robotics by implementing and experimentally evaluating a neuromorphic approach to a common problem. We specifically address real-time, online obstacle avoidance on a camera-equipped manipulator by designing a neuromorphic pipeline that enables end-to-end processing of visual data into motion trajectory adaptations, and which relies on event-based vision and an SNN.
In our pipeline, an EC emulator transforms RGB data into event data, which is in turn processed by a convolutional SNN. The SNN output is then decoded into avoidance velocities by a dedicated component that employs a potential fields (PF) method. The result is used to adapt a pre-planned end-effector trajectory using a dynamic motion primitive (DMP) formulation in a motion control component. These components, collectively referred to as an SNN-based obstacle avoidance module, operate in a closed-loop, online procedure for transforming a trajectory into an adapted version that avoids obstacles through SNN feedback.
ECs excel at capturing rapid motions, while SNNs are best-suited to process event data, thus motivating their utilization for deriving corrective avoidance motions. A significant amount of research on obstacle avoidance deals with UAVs and mobile robots, while relatively few works address manipulation and take a similar neuromorphic approach. This work is unique in addressing manipulator obstacle avoidance by utilizing event data from an onboard camera, SNN processing, and an adaptive trajectory representation. Most solutions rely on external cameras and classical methods for filtering images, removing backgrounds, object segmentation, etc. (refer to Section 3.4 for examples of classical approaches). Our approach may show that event data and SNN processing could eliminate the necessity of manual operations that preclude generalization over environments, lighting conditions, and platforms.
Due to the scarcity of comparable works, proposed evaluation methodologies, and performance metrics, we formalize a set of quantitative metrics and qualitative criteria with which we evaluate our implementation. We conduct experiments first in simulations and then on a real Kinova Gen3 arm. These experiments constitute repeated executions in a range of obstacle scenarios drawn from a task distribution. During simulation tests, we use different task scenarios to tune, validate, and finally test candidate sets of parameter values. The results demonstrate consistent success in avoiding obstacles, which a non-adaptive baseline is incapable of. We also analyze statistical performance across many trials, showing that the adapted trajectories do not drastically increase execution times, trajectory lengths, and velocities. Moreover, we assess how reliable, predictable, and safe the trajectories are in our qualitative evaluation, and find at least moderately positive results in each.
In further analyses, we additionally explore certain properties of the neuromorphic elements. We implement and compare different event emulation strategies, based on their event outputs, SNN responses, and ultimate task performances; this yields the insight that the SNN exhibits robustness to variations in event data. To validate its utility, we test the exclusion of the SNN and the derivation of obstacle avoidance accelerations directly from raw events, which we show adversely affects the success of obstacle avoidance. We also investigate the effect of varying SNN weights, showing a slight variance in performance. Finally, we show the successful integration of a real EC: a DAVIS346, and present results of preliminary experiments. Most notably, we find that the resultant performance is fairly similar, validating our experimental emulation method and the compatibility of the pipeline with a real camera.
The paper is structured as follows. Section 2 provides additional background information on event-based vision, SNNs, and DMPs. Section 3 contains a review of related work on the relevant areas of research. In Section 4, we present our proposed approach, elaborating on the design principles and the pipeline components. Section 5 is dedicated for a detailed description of our evaluation methodology, including evaluation tasks, metrics and criteria, and experiment design and procedures for both the simulation and real experiments. Section 6 discusses the results of these experiments. Section 7 presents the analyses concerning the event emulation and SNN components, as well as the real EC tests. We conclude in Section 8.
2. Preliminaries
2.1. Event-based vision
Silicon retinas were developed to imitate the neural architectures of biological retinas in analog VLSI circuits, giving rise to neuromorphic computing (Mahowald, 1994). Contemporary models are known as neuromorphic retinas, dynamic vision sensors (DVS), or event cameras (ECs). EC pixels mimic retinal ganglion cells by asynchronously emitting a binary signal, i.e. an event, only when the incident light intensity significantly changes. Using an address event representation (AER), the pixel arrays provide streams of spatio-temporally-registered events which encode typically interesting information, such as motion.
An event can be represented as a tuple of pixel position, emission timestamp, and polarity: e
k
= (
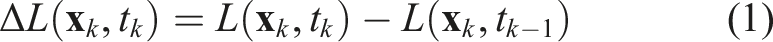
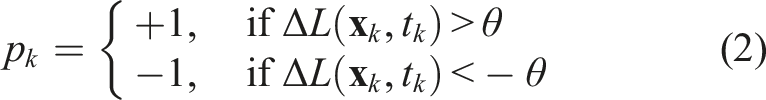
It follows that event data can be emulated from conventional camera data, a method often used due to the scarce availability of or relative expense of acquiring ECs (García et al., 2016; Hu et al., 2021; Rebecq et al., 2018).
2.2. Spiking neural networks
Spiking neural networks (SNNs) are more biologically-plausible models in which neurons communicate via asynchronous spikes to replicate the complex neuronal dynamics observed in the brain. Figure 3 illustrates these spiking dynamics. An illustration of spiking neuron dynamics.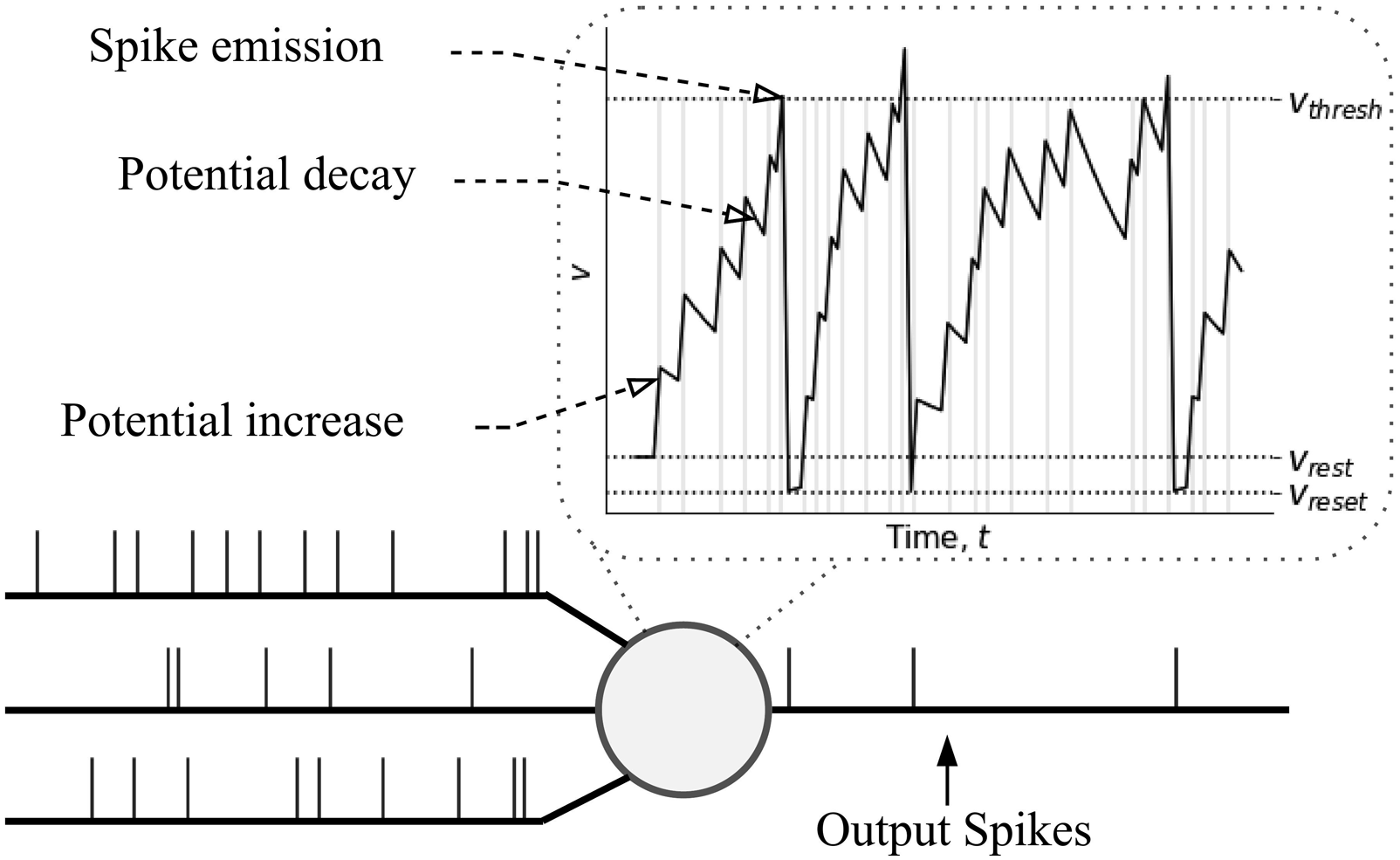
Neurons propagate sequences of sparse, binary spike trains, across their synapses. Each pre-synaptic spike contributes to the post-synaptic potential (PSP) or membrane potential, v, of a post-synaptic neuron: an internal analog representation of neuronal activation that decays over time, and an approximation of ionic concentrations across a nerve cell’s membrane. A neuron whose potential exceeds v thresh emits a spike and enters a short refractory period in which it is inhibited from spiking (not depicted). Following a spike, the potential is reset to a baseline value, v reset . Individual neurons therefore fire or are active only in response to a significant aggregate of recent inputs. Information can be contained in average spiking rates and/or the relative timings of spikes, a concept drawn from neuroscientific evidence (Fairhall et al., 2001). The time-varying potential signal inherent to every neuron and the independent spiking latencies create an additional temporal dimension in SNNs.
Various mathematical approximations and abstractions of neuronal dynamics have been employed in SNN research to produce a variety of neuron models, including the Hodgkin-and-Huxley model (Hodgkin and Huxley, 1952), Spike Response Model (SRM) (Gerstner, 1995), Izhikevich model (Izhikevich, 2003), and various probabilistic models (Jang et al., 2019). The most commonly used model is the leaky integrate-and-fire (LIF) model (Rajendran et al., 2019; Lee et al., 2020; Dupeyroux et al., 2021).
A LIF neuron represents a leaky integrator modeled as an RC circuit with an equation describing membrane voltage:
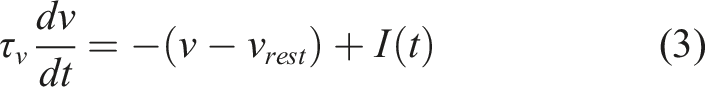
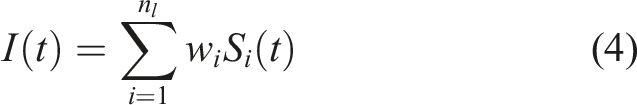
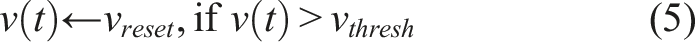
2.3. Dynamic motion primitives (DMP)
Dynamic motion primitives capture and reproduce discrete or rhythmic motions using a set of differential equations that produce stable global attractor dynamics (Ijspeert et al., 2013). For discrete motions, DMPs model the evolution of a position variable,
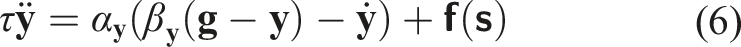

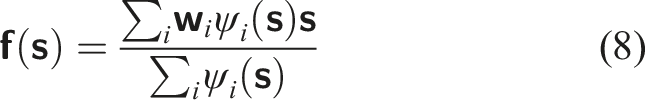
3. Related work
3.1. Event-based vision
Event cameras (ECs) are inspired by biological retinas’ superior efficiency compared to conventional, frame-based cameras. The silicon retina (Mahowald, 1994) paved the way for modern ECs including the DVS (Lichtsteiner et al., 2008), ATiS (Posch et al., 2010), and DAVIS (Brandli et al., 2014) 3 . Refer to Gallego et al. (2022) for an extensive survey of event-based vision.
Recent publications highlight applications of event-based vision in various domains. A survey of bio-inspired sensing for autonomous driving, presented in Chen et al. (2020a), provides a review of EC signal processing techniques and successful implementations for segmentation, recognition, optical flow (OF) estimation, image reconstruction, visual odometry, and drowsiness detection. In a more resource-constrained scenario, event-based vision has been employed in a gesture recognition smartphone application in Maro et al. (2020). In Dubeau et al. (2020), a combination of RGB-D and EC data for DNN-based 6-DOF object tracking is shown to outperform an RGB-D-only DNN.
In the context of robotics, ECs have most often been utilized on aerial robots, such as for high-speed obstacle avoidance (Falanga et al., 2020) powerline tracking (Dietsche et al., 2021), and fault-tolerant control (Sun et al., 2021). UAVs particularly benefit from the advantages of ECs on account of frequent high-speed motions and motion blur, energy consumption constraints, and rapid changes in illumination. We focus here on applications that do not involve flight, where ECs may similarly provide opportunities for improving robot capabilities.
Bečanović et al. used precursory optical analog VLSI (aVLSI) sensors in soccer robots, harnessing the faster reactivity properties to improve ball control and goalkeeping (Bečanović et al., 2002a, 2002b). Simultaneous localization and mapping (SLAM) has been addressed with stereo visual odometry using DAVIS346 ECs in Zhou et al. (2021b), facilitating scene mapping and ego-motion estimation and matching the performance of mature frame-based approaches on benchmark datasets, while demonstrating robustness in difficult lighting conditions. In Arakawa and Shiba (2020), EC data was used for visual RL of tracking and avoidance policies. The authors train in simulations using emulated data and deploy the model on a robot equipped with a DAVIS240. In Chen et al. (2019), event data was used to train DNNs for Atari gameplay and action recognition, outperforming RGB image-based networks. While these works adapt DNNs to process event frames, our approach utilizes SNNs, which are naturally suited to processing the spike-like event data.
For this work, we implemented a software component that emulates event data from a stream of conventional images in a live camera feed or a ROS topic (see Section 4.2). pydvs is a python-based DVS emulator that can similarly convert image intensity differences to rate- or time-encoded spikes/events (García et al., 2016), but does not natively support ROS. The prominent ESIM simulator provides a framework for simulating 3D scenes (in OpenGL and the Unreal rendering engines) and user-defined camera motions as well as event outputs (Rebecq et al., 2018). Microsoft’s AirSim offers an EC emulation component which is similarly coupled to its rendering engine. Naturally, such a coupling limits applicability to the associated simulation. The v2e toolbox (Hu et al., 2021) was designed to address assumptions of the ESIM simulator that deviate from real cameras, but is limited to video files. In Joubert et al. (2021), the ICNS emulator for video files and Blender scenes was qualitatively compared to ESIM, v2e, and a real DVS. Despite some limitations (coupling to rendering engines and the absence of out-of-the-box support for live feeds and ROS data), all reviewed emulators are publicly available and provide useful tools for research and development in event-based vision.
3.2. Spiking neural networks
Research into SNNs is motivated by attempts to approach the computational capability coupled with energy efficiency of the brain (as expressed by the most works reviewed in this section), compared to the more specialized yet drastically less efficient computer systems of today (Roy et al., 2019).
The so-called third generation of neural networks can be potentially more expressive than first and second-generation NNs in addition to requiring significantly less neurons to represent some functions (Maass, 1997). The authors of Neil et al. (2016) converted ANNs pre-trained for MNIST digit recognition into SNNs and analyzed the comparative performance. The SNNs achieved comparable accuracy using significantly less computational operations (42-58% less) and in less time. These and similar results demonstrate that SNNs could be as expressive/accurate as ANNs, while consuming less power and exhibiting faster inference.
The prevalence of deep learning with ANNs has ignited research into the same in the spiking domain, not least because of prospective improvements in energy efficiency. Pfeiffer and Pfeil (2018) and Tavanaei et al. (2019) provide extensive overviews of SNNs and focus on methods for training deep SNNs, reviewing spiking analogs of CNNs, RNNs, LSTMs 4 , and echo state networks. The authors of Bouvier et al. (2019) reviewed hardware implementations that leverage SNN characteristics and associated challenges. Jang et al. (2019) presents a probabilistic view of SNNs, the main advantage of which is to facilitate gradient-based learning and other well-known statistical methods.
SNN implementations have been demonstrated for solving common AI problems, particularly involving vision. Diehl et al. trained two-layer SNNs with STDP 5 for MNIST digit recognition and achieved state-of-the-art classification accuracy among unsupervised methods (95%) (Diehl and Cook, 2015). In Mirsadeghi et al. (2021), a supervised learning algorithm, STiDi-BP, is shown to achieve an accuracy of 99.2% on MNIST. Spike-YOLO was created by converting a pre-trained Tiny-YOLO model to an SNN, achieving comparable results on the PASCAL and COCO datasets, while being 2000 times more energy efficient (Kim et al., 2020). Similarly, the supervised STBP-tdBN algorithm achieved state-of-the-art results on the CIFAR and ImageNet datasets and was among the few to successfully train relatively deep SNNs (of 50+ layers) (Zheng et al., 2020). Zhou et al. presented object recognition in datasets of DVS (N-MNIST, DVS-CIFAR10, etc.) and LIDAR (KiTTi) data, demonstrating the applicability of SNNs to different data modalities (Zhou et al., 2021a).
Various works have successfully applied SNNs in robotics. An extensive survey of SNNs for robot control is presented in Bing et al. (2018b), underscoring significant potential for improving speeds, energy efficiency, and computational capabilities. In Bing et al. (2018a), SNNs were trained using R-STDP on DVS event data for lane-keeping on a mobile robot, outperforming a conventional Braitenberg controller. Zahra et al. utilized shallow SNNs to learn a differential sensorimotor mapping for a UR3 robot that supports reliable Cartesian control (Zahra et al., 2021). In a fully-embedded applications of SNNs (on an Intel Loihi neuro-processor), Dupeyroux et al. designed a neuromorphic vertical thrust controller for landing a quadrotor (Dupeyroux et al., 2021). The input is a spike representation of OF divergence that is estimated using data from an onboard CMOS camera. The SNN was trained (with an evolutionary algorithm) and evaluated on a neural simulator, PySNN, achieving consistent landing behaviour. A limitation on the generality of this approach is the controller’s dependence on a pre-set visual pattern for OF estimation. In the present work, we similarly utilize a neural simulation tool.
An event-driven, SNN-based PD thrust controller was designed to achieve high-speed orientation adjustment on a dual copter in Vitale et al. (2021). The authors demonstrated superior control speeds and reductions in latencies, particularly when running on a neuro-processor (vs a CPU). In Risi et al. (2020), reliable stereo matching of event data from two DAVIS sensors was achieved using an SNN architecture designed with neuronal populations implementing coincidence and disparity detectors, and running on a DYNAP neuro-processor. This approach was particularly favoured for the temporal dimension of the asynchronous event and SNN spike data, which enable exploiting temporal coincidences and thus improve stereo matching. Similar to our approach, no learning is involved; the SNN architecture’s inherent properties are shown to be beneficial in realizing the desired behaviour.
Most publications in robotics address relatively constrained navigation and flight tasks (e.g. lane-keeping and 1D thrust control). Our work demonstrates a less common application in obstacle avoidance for manipulation.
3.3. Neuromorphic computing
Neuromorphic computing/engineering mimics the fundamental neural architectures and dynamics of the brain in silico, aiming to replicate its superior energy efficiency, compute, and robust learning capabilities in computer architectures and engineered systems. Common approaches incorporate asynchronous event-driven communication, spike-based neural processing, analog neuronal dynamics, and local synaptic adjustments. This research serves a dual purpose: enhancing AI systems with lessons from neuroscientific research, and advancing our understanding of the brain by experimenting with neurologically-inspired platforms. Among the most prominent results are ECs and neuro-processors designed to run SNN architectures. A review of neuromorphic hardware and applications can be found in Rajendran et al. (2019), which highlights the role of neuro-processors in realizing the full potential of SNNs for exploiting event-based sensing, learning and inference.
Neuro-processors model membrane potential evolution using voltages across capacitors or transistor sub-/supra-threshold dynamics, and transfer spikes via an AER. Furber (2016) provides a survey of pioneering neuro-processors, namely IBM’s TrueNorth, Stanford’s Neurogrid, BrainScaleS and SpiNNaker, and compares their performances. Other notable surveys provide similar statistical comparisons of these processors, in addition to the more recent Intel Loihi, DYNAP, PARCA, Braindrop, ODIN, and Deepsouth (Bouvier et al., 2019; Thakur et al., 2018; Rajendran et al., 2019). The Loihi and its applications have been extensively discussed in Davies et al. (2021). The variety of domains the Loihi was shown to be successfully implemented in demonstrates the general applicability of SNNs, while the quantified gains in energy efficiency validate the benefits of the neuro-processor. In addition, the authors find that conventional DNNs exhibit little to no benefits when run on the Loihi, but SNNs achieve orders of magnitude less energy consumption and latency in some applications.
Several publications investigated the effects of neuro-processors on speed and energy efficiency. SNNs trained with R-STDP on a BrainScaleS2 processor to control an agent in playing the game of Pong and achieved one and three orders of magnitude improvements in speed and energy efficiency when compared to a CPU simulation (Wunderlich et al., 2019). The authors of Ceolini et al. (2020) achieved hand-gesture recognition with a neuromorphic sensor fusion approach, where DVS streams and EMG signals (converted to spikes/events) were used to train SNNs running on a Loihi or ODIN. With respect to a GPU-based implementation, this was at least 30 times more energy-efficient, though inference was 20% slower. Taunyazov et al. (2020) presented a visual-tactile SNN (VT-SNN) which fuses data from an EC and a spike-based tactile sensor to accomplish robot manipulation tasks requiring object classification and slip detection. The SNN classifiers running on a Loihi performed similar to state-of-the-art DNNs run on GPUs while consuming 1900 times less power and exhibiting lower latency. In Göltz et al. (2021), backpropagation was used to train SNNs for MNIST classification on a BrainScaleS and then compared to the performance of a conventional CNN running on an NVidia Tesla P100 GPU. The authors show that the neuromorphic implementation is (approx. 100 times) more energy-efficient, at the cost of a slight drop in accuracy and the number of classifications per second (since the GPU implementation utilizes parallelization, while individual images must be processed sequentially on the SNN).
The related field of neurorobotics studies the design of computational structures that are inspired by the human and animal nervous systems in robots (Van Der Smagt et al., 2016) and has led to various interesting applications (Dumesnil et al. (2016); Lobov et al. (2020); Falotico et al., 2017). A review in Chen et al. (2020b) demonstrated the utility of neurorobotics for explaining how neural activity gives rise to intelligence, as a form of computational neuroethology. Robotics could thus similarly benefit from ongoing research and development efforts aimed at drawing inspiration from the brain.
In the present work, we do not run SNNs on neuromorphic hardware, instead aiming to investigate the utility of an event-based SNN approach on conventional hardware. Nevertheless, the reviewed research motivates exploiting the potential gains in energy efficiency and latency in a subsequent study. On a broader scale, this may additionally inspire the pursuit of neuroethology-based robot designs that advance further into the realm of biological realism.
3.4. Obstacle/collision avoidance
Obstacle avoidance is a critical feature for planning robot motions in evolving, dynamic environments, where obstacles may appear during task execution and invalidate motion plans. We discuss seminal works in this domain, focussing on relevant approaches and especially those that address manipulation problems and employ camera sensors.
Research on the rudimentary issue of reactively computing collision-free paths has led to established methods such as vector field histograms (VFH) (Borenstein and Koren, 1991), the Dynamic Window Approach (DWA) (Fox et al., 1997), and the elastic strips framework (Brock and Khatib, 2002). The artificial potential fields (PF) method represents task criteria in the form of attractive and repulsive forces acting on an agent moving within a virtual force field (Khatib, 1986). PF techniques have been extensively applied and improved upon, and are utilized in the present work. A helpful review of classical methods is provided in Minguez et al. (2016).
Optical flow (OF) estimation, a bio-inspired computer vision technique that is applicable to obstacle avoidance, shares similarities to the methods proposed here. OF quantifies the motion of light intensity patterns observed on a sensor as it moves relative to observable objects, and is used by organisms, such as honeybees, for navigation (Van Der Smagt et al., 2016). This can provide estimates of ego- or object motion, which facilitate tracking and collision avoidance. In Schaub et al. (2016), OF is computed from an autonomous car’s monocular camera data and used to optimize maneuvers to avoid obstacles. OF estimation approaches are split into two categories. In estimating object motion, dense OF tracks changes to every pixel between consecutive frames and sparse OF relies on tracking identified features. The former imposes high computational and memory costs, while the latter depends on the reliability of feature matching algorithms and may not generalize if object models have to be specified a priori (Lee et al., 2021). In comparison, our approach is designed to eliminate unnecessary computations, by virtue of the event-based processing, and be independent of specific obstacle features.
Compared to 3D sensors, IMUs, and laser sensors, cameras are less frequently used for obstacle avoidance. Lee et al. (2021) demonstrated DNN-based obstacle recognition and avoidance on a UAV navigating a plantation, where trees are recognized, distances are estimated, and free regions are determined for simple heading adjustments. Limitations include a restriction to obstacles that the DNN is trained to recognize and the entailed computational costs. In Hua et al. (2019), semantic segmentation DNNs recognize roads and obstacles that a mobile robot encounters, which are incorporated in PF-based local path planning. More rudimentary approaches involve classical methods such as detecting contours for obstacle detection (Martins et al., 2018) or using feature extractors like SURF to recognize known obstacles (Aguilar et al., 2017), followed by searching for free regions and applying corrective motions. These approaches may be susceptible to changes in lighting conditions, where ECs are expected to perform better. In addition, purely reactive approaches require rectifying velocity commands that return the agent to its original path. In our work, we propose using DMPs for adaptive path plans that obviate the need for extra corrective computations.
For robot manipulation, obstacle detection and avoidance could be crucial in safety-critical human-robot collaboration settings. The authors of Chiriatti et al. (2021) designed a control law for a UR5 manipulator that incorporates collision cylinders instantiated from estimates of obstacle geometries, positions and velocities, demonstrating constrained avoidance behaviours. The method was tested in simulation with prior obstacle information; extending this to real environments requires dedicated sensors and algorithms to estimate the pose of every person/object. In Safeea et al. (2019), collision bounds on a person are incorporated in a PF approach to controlling a KUKA LBR iiwa. These are obtained using IMUs placed on persons in an industrial workspace. Another approach relies on proximity sensors placed on the manipulator, which provide time-of-flight, IMU, and gyroscope readings (Escobedo et al., 2021). While reliable behaviours are achievable by deploying arrays of sensors, this may limit generalization to different scenarios, especially when a robot is not confined to a controlled workspace or when arbitrary sensor placement is not possible. In contrast, our approach relies on a single onboard camera.
Other notable implementations integrate vision-based sensing, leveraging RGB-D cameras in particular. Mronga et al. used pointcloud data to extract convex hulls of obstacles that are incorporated as constraints in an optimization problem whose solution leads to avoidance motions on a dual-arm system (Mronga et al., 2020). The optimizer leads to task-compliant avoidance, but depends on cameras covering the workspace and several pointcloud processing steps. A similar strategy is applied in Song et al. (2019), where obstacles in a bin-picking task are avoided by detecting moving objects in a pointcloud and accordingly adjusting motions through a PF algorithm. These implementations benefit from depth perception that monocular RGB or event cameras do not provide. However, event-based processing could impose a significantly lower computational overhead than pointcloud processing, which may be a concern in applications that require rapid reactivity.
A few publications are particularly relevant for their similar approaches and thus merit mentions in the remainder of this section. In Park et al. (2008), a DMP obstacle avoidance term was first introduced and used within a PF formulation. We similarly utilize DMPs and draw insights from the authors’ mathematical integration of obstacle avoidance information for the method presented in Section 4. Scoccia et al. presented offline planning of trajectories along with online adjustments using a formulation of PFs that operates on the Jacobian matrices for null space control (Scoccia et al., 2021).
Another implementation of manipulator obstacle avoidance combined PFs and elastic bands for adaptive trajectory planning (Tulbure and Khatib, 2020). Here, an RGB-D camera capturing the workspace provided pointcloud data which is processed to estimate obstacle positions that affect the PF. The authors augment a PF algorithm with an elastic bands planner, which enables adjusting a global plan with minimum deviations, thus addressing the susceptibility of PFs to local minima. This resembles our application of PFs for local velocity corrections, while our DMP maintains a high-level plan. Again, pointcloud processing introduces a computational expense and a dependence on the camera position and/or robot platform, thus placing theoretical limits on generality and applicability to different environments.
The utility of event-based vision for obstacle avoidance has been demonstrated in the past. Milde et al. (2015) presents event-based collision avoidance on a mobile robot by computing OF from DVS data and deriving velocity commands. Here, the usage of ECs is motivated by the redundancy in data and wastage of computations associated with processing conventional camera images, particularly when the robot is stationary. Furthermore, the authors suggest extending their work with a “neuromorphic circuit” and SNNs to address limitations, including the significant amount of data required by their PCA-based method for computing OF. In Sanket et al. (2020), dynamic avoidance on a quadrotor was achieved by training CNNs on event data to estimate the OF of moving objects, while placing priors on obstacle shape (sphere) for tractability. Our work differs in addressing tasks where the robot must avoid obstacles whilst actively moving towards a goal and employing SNNs. In a navigation scenario, Yasin et al. utilized a DVS for car obstacle avoidance in low-light settings, demonstrating superior reaction times when compared to standard cameras (Yasin et al., 2020). Objects in the event image are obtained through denoising, corner detection, segmentation, and filtering procedures, and used to recompute plans. While these efforts present viable applications of event data, much of the requisite pre-processing may be obviated by utilizing SNNs: the natural complement to event-based vision.
This usage of SNNs has nevertheless also been shown in recent years. Salvatore et al. (2020) demonstrated neuro-inspired UAV collision avoidance by running event data on an SNN that was converted from a trained deep Q-Learning (DQN) ANN. Successful behaviours were achieved in AirSim simulations after training the DQN agent on emulated event data, transferring weights to an equivalent SNN, and further training the SNN with data from successful trials. Of greatest similarity to our work is the feasibility study of a neuromorphic approach to obstacle avoidance presented in Milde et al. (2017). Their method involves processing event data from a DVS mounted on a mobile robot in SNNs that are implemented on a ROLLS neuro-processor, whose output is decoded into avoidance and target-following behaviours by aggregating responses of neuron populations. As in our approach, SNN connections are non-plastic (i.e. not adjusted through learning); the inherent properties of the SNN architecture are shown to facilitate viable navigation behaviours. The present work proposes a similar approach in the context of manipulation, which presents a different set of challenges.
4. Proposed approach
We present a neuromorphic approach that incorporates event-based vision and SNNs for adaptive motion execution.
In this approach, we use DMPs to generate trajectory plans for reaching tasks. The DMP formulation supports additive acceleration terms which we utilize to inject obstacle avoidance information and therefore adapt to guide the robot’s motion away from perceived obstacles. This information is obtained by continuously processing visual, event-based data within an SNN, then decoding neural activation maps into avoidance accelerations. The latter procedure involves a potential fields (PF) method for computing the most favourable avoidance direction. By utilizing events induced by relative motion and the spatio-temporal filtering properties of SNNs, we can extract reactive motions that modify high-level motion plans to account for obstacles while maintaining progress towards the task goal, thus achieving real-time, online trajectory adaptation.
A core aspect of our approach is the synergy between global planning and local corrections that enables goal-directed, obstacle avoidance. The common alternative: completely re-planning whenever obstacles are encountered, can impose higher computational expenses and latencies (D’Silva and Miikkulainen, 2009; Feng et al., 2020), which are particularly undesirable in dynamic environments. Instead, we utilize the DMP as an adaptive planner, where perceived obstacles are handled by appropriately adjusting the next waypoint during execution and the global attractor dynamics ensure a graceful return to the original path.
The choice of SNNs is justified by their natural compatibility with and direct applicability to event-based vision, unlike conventional computer vision algorithms, such as CNNs (Chen et al., 2020a; Vitale et al., 2021). SNNs are designed to process discrete, asynchronous signals and may be key in achieving compelling real-world applications of ECs. The combination of events and spiking neurons particularly holds potential for capturing temporal information relating to obstacle avoidance, such as through the decaying influence (neural activation) of an obstacle that has just been observed. Furthermore, the analog SNN dynamics can inherently induce temporal filtering properties that negate effects of insignificant events (see Section 4.3).
4.1. Overview
We designed a modular pipeline of specialized components that enable end-to-end processing of visual data into motion trajectory adaptations: 1. 2. 3. 4.
These components form an SNN-based obstacle avoidance module which is designed to easily integrate within an existing robot software stack.
Figure 4 depicts the processing stages and the data flow (top arrows) within the pipeline, which we describe in the following sub-sections. The main components and processing stages of our neuromorphic pipeline. The plot on the right shows a pre-planned trajectory (grey) and a resultant trajectory (green) adapted to avoid an obstacle (blue).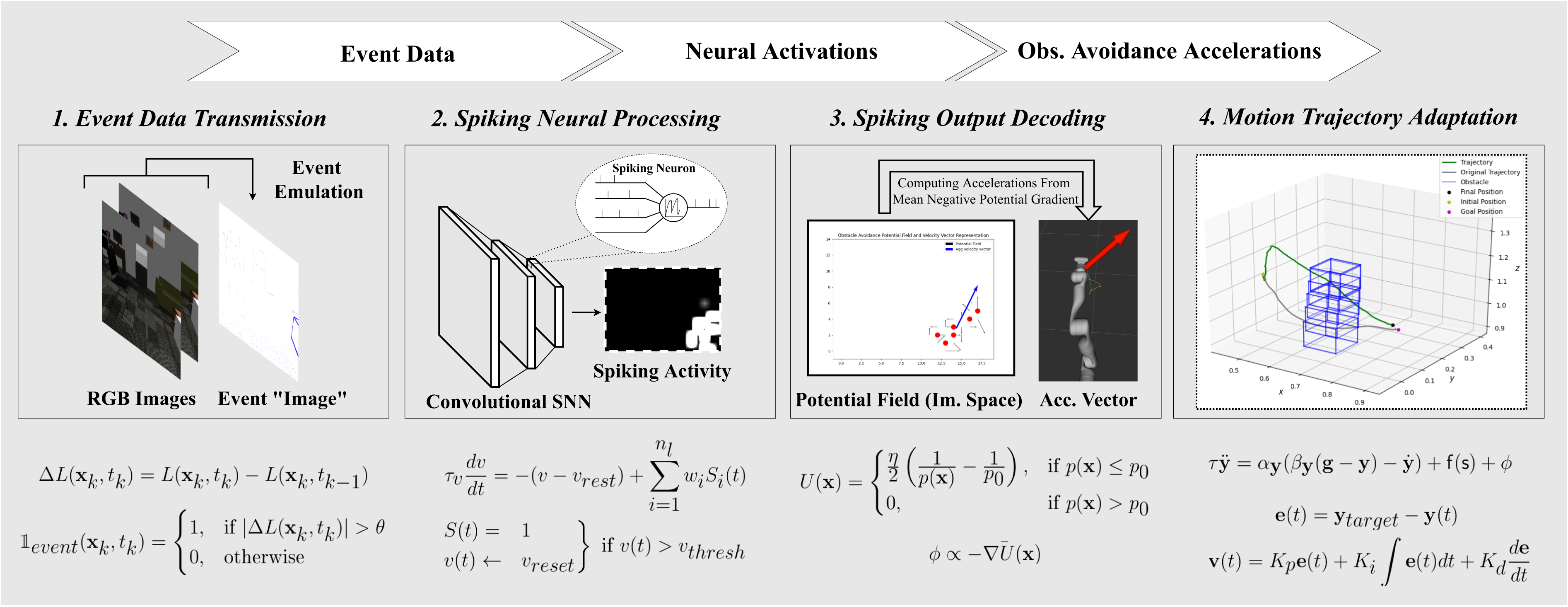
4.2. Event camera/emulator
The sensory input is event data that is derived from RGB camera data through an emulator. Following the fundamental EC operating principles, events can be generated from the thresholded intensity difference at every pixel between consecutive timesteps. Section 3.1 contains a review of existing emulators and their deficits, which motivate developing our
An event e
k
= (
We form an event image representation by placing p
k
of every event at the respective pixel location. The resulting event image, I
e
, is a single-channel analog of the source RGB images that contains values, i
k
∈ { + 1, 0, − 1}. An event image derived from two consecutive RGB images is shown in Figure 5. The distinction of event polarity is often of little importance and OFF (−1) events are either ignored or treated the same as ON (+1) events, as we do here (and similar to Dubeau et al., 2020 and Maro et al., 2020). Emulated events due to object motion on the right. Here, any event (ON or OFF) is indicated by a blue pixel on the event image. This was captured as the camera moved forward, inducing some events on the edges of distant objects. (a) RGB Image 1. (b) RGB Image 2. (c) Event “Image”.
4.2.1. Limitations of emulation
Note that deriving events from differences in RGB frames places an upper bound on the event generation rate: the camera frame rate. This effectively negates the advantages of event asynchrony and the theoretically higher transmission rates in comparison to conventional camera pixels. Nevertheless, it provides a reasonable approximation for demonstrating and presenting elementary arguments for our approach. We verify this by comparing the output and consequent task performance of our emulator to those of a real EC in Section 7.4.
4.2.2. Filtering event noise: binary erosion
We have found that applying a binary erosion filter produces cleaner event images in cases where certain textures or surfaces (e.g. rough carpets) induce too many insignificant background events that may lead to over-reactive responses. The filter effectively removes events at which the local region does not contain sufficiently many other events.
4.3. Convolutional spiking neural network
The resulting event data is processed by a C-SNN.
4.3.1. Input data encoding
We utilize a Poisson process spike generation model to induce spikes in the input layer from incoming event images. A Poisson process presents a plausible stochastic approximation of biological neuron firing activity, in which the generation of each spike is assumed to depend on some firing rate, r, and be independent of all other spikes (Heeger, 2000).
Given a w × h event image I
e
, we assign rate values according to:
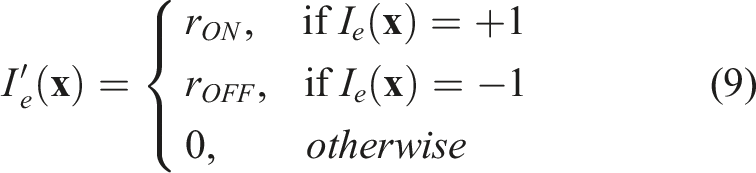
Subsequently, the spike train entering each input neuron across T is drawn from a Poisson process, resulting in sequences of spikes that follow an average firing rate but exhibit random spike timings. Figure 6 illustrates an example of a 3 × 3 event image patch and the spike trains generated at every pixel/input neuron. The result is a w × h × T binary matrix S, where each element Poisson spike trains generated from events at 9 input neurons. Positive and negative events are shown in blue and red. Note the lower spiking frequency at negative events.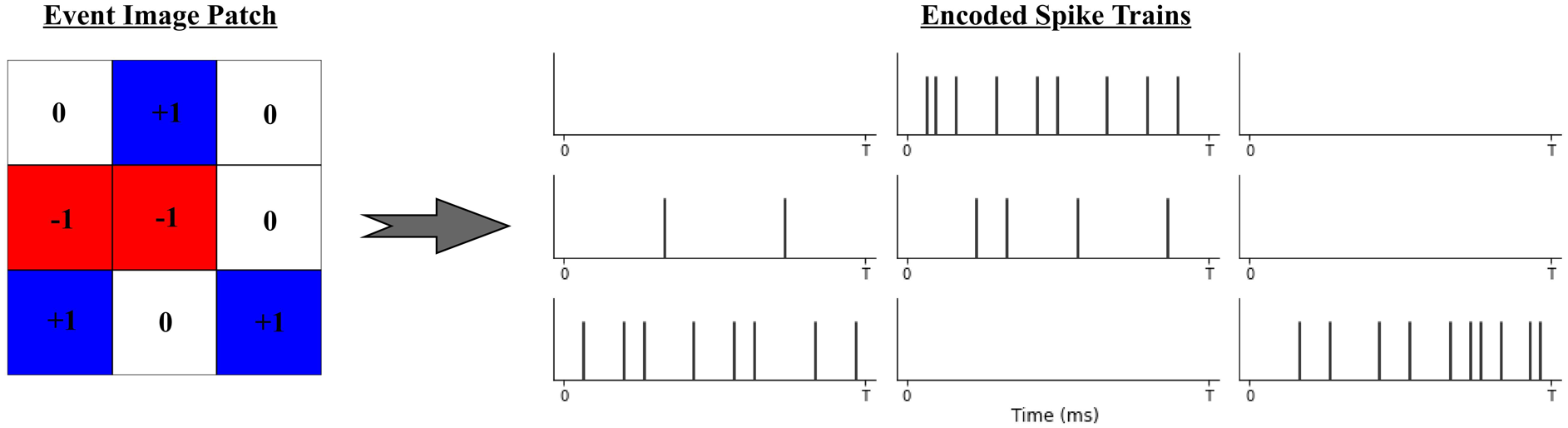
4.3.2. Convolutional network topology
The C-SNN resembles a CNN in architecture and weight sharing principles; neurons are arranged in two-dimensional layers and information is propagated through convolution operations. Here, the input to each neuron is a pre-activation computed by convolving the spiking output of neurons in the previous layer that occupy the target neuron’s receptive field and a kernel matrix of shared, real-valued weight parameters, K. This is encapsulated in the following adaptation of the convolution equation provided in Goodfellow et al. (2016), where the pre-activation of neuron (i, j) in layer k + 1, at time-step t, is computed by convolving a kernel with spike trains arriving from the preceding layer, k: An illustration of convolving a 2 × 2 kernel with a 3 × 3 layer (k) of spiking neurons, whose output spike trains are depicted within each cell. Assuming a stride of 1 × 1, the result is the pre-activations of neurons in layer k + 1 (see equation (11). The summation resulting in 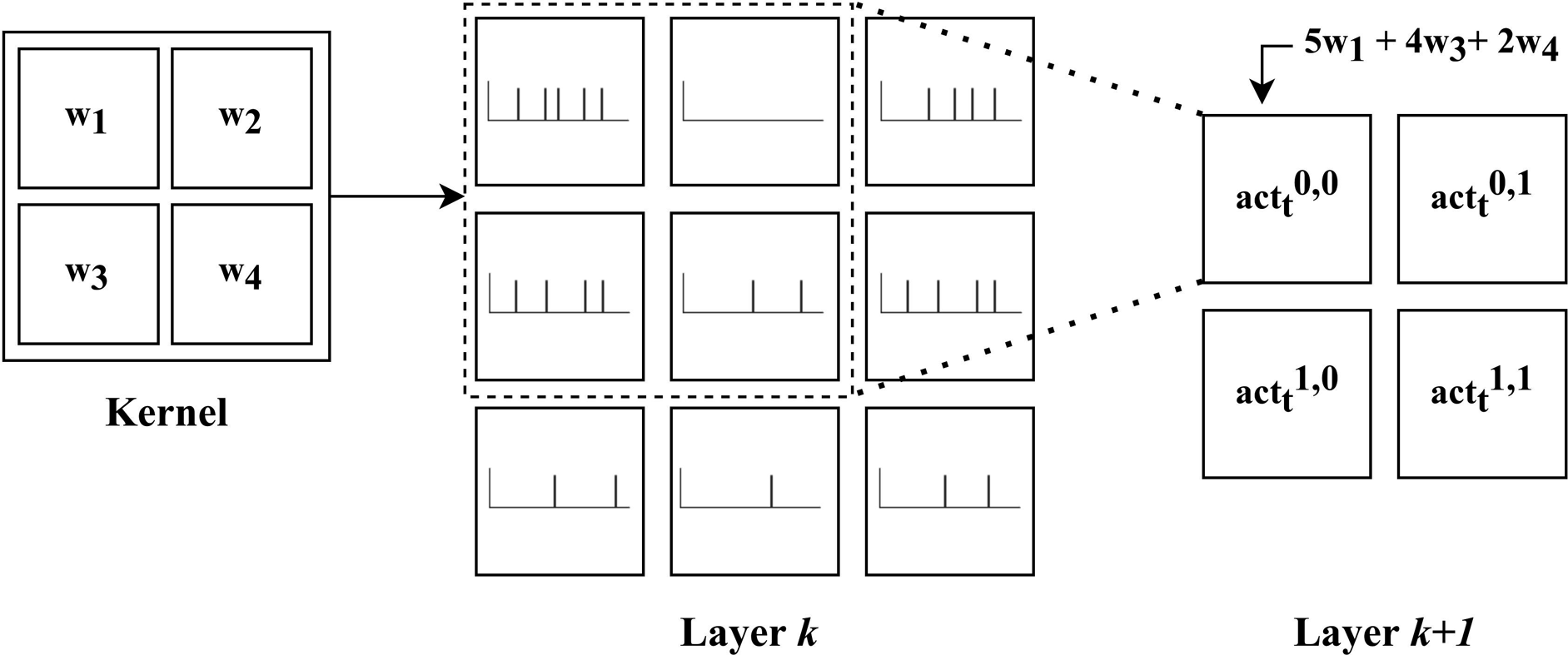

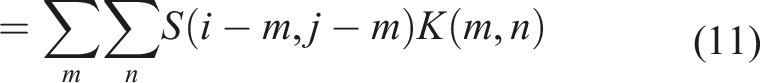
Spatio-temporal distributions of spikes within an SNN lead to novel dynamics from which interesting properties may arise. The convolutional operator and the analog dynamics of the neurons create a form of spatio-temporal filter, where signals that are particularly persistent in space and time are selectively propagated. Moreover, spiking neurons possess a form of memory in the decaying potential, which reflects recent levels of stimulation. The spike trains emitted at the output neurons are used to derive obstacle avoidance in the next component of the pipeline.
We set the synaptic weights to fixed, random values. Non-plastic SNN connections have often been employed in SNN applications, such as in Risi et al. (2020) (see Section 3.2) and Milde et al. (2017) (see Section 3.4), which demonstrated the achievement of desired behaviours solely due to the properties of spiking dynamics. Similarly, we presently involve no learning, and instead investigate how robust task performance is to different random, but fixed, “features” that manifest through the randomly sampled weights. Future extensions will incorporate weight adjustment strategies through, for example, STDP and supervised variants or RL. The weight values are initialized by sampling from a standard uniform distribution, scaled by a weight factor, w
c
:

4.4. Obstacle avoidance component
The obstacle avoidance component decodes the SNN’s output into meaningful avoidance signals. This step involves extracting indications of obstacle presence or motion from the spiking activity and deriving velocities/accelerations that can adapt the planned motion trajectory. To that end, we utilize a first-spike-time representation of spiking activity and a PF method.
4.4.1. SNN output representation
Spike trains can be represented in various temporal and rate coding schemes. We use first-spike-time (FST) temporal coding to interpret the output spiking activity (Tuckwell and Wan, 2005; Göltz et al., 2021; Liu et al., 2021). Within this scheme, the time until a neuron’s first spike after stimulus presentation fully determines the magnitude of stimulation: the earlier a neuron first spikes, the more stimulated it is. When applied to the output spike trains, the FST code provides a neural activation map, as illustrated in Figure 8. Significantly intense neural activation at a given neuron is expected to indicate the persistent presence and (relative) motion of a perceived object in regions of the input image for which that neuron is in the effective receptive field. This provides indications of avoidance directions. A depiction of the FST code applied to 25 output neurons. On the right, cell brightness corresponds to each neuron’s FST and thus activation magnitude. Note: the top-right neuron has a higher activation due to an early first spike, although the neuron just under exhibits a higher spike count.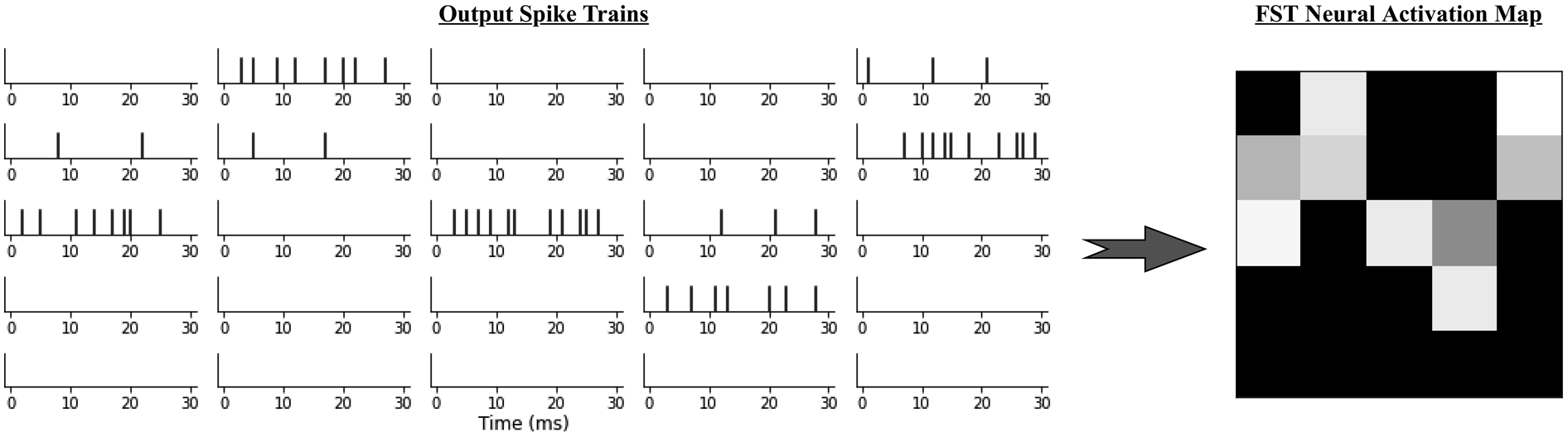
Other common codes include the absolute or average number of spikes. Like either, the time to the first spike can indicate a neuron’s level of stimulation; however, FST necessitates flagging only the first spike, as opposed to waiting until all spikes in a given time window are accumulated. Consequently the FST code could reduce time-to-solution or energy-to-solution and thus be more efficient (Göltz et al., 2021). Note that the FSTs are calculated with respect to the time point at which the last event image was presented.
4.4.2. Computing obstacle avoidance direction using potential fields
The neural activation map can be interpreted as a downscaled version of the input event image, filtered in the space and time dimensions to indicate approximate locations of persistent obstacles (while removing potential noise). Therefore, we regard high activation regions as obstacle points in this space. In order to derive an avoidance motion vector, we utilize a method that can aggregate the obstacle points’ spatial influences and compute a direction that maximizes movement away from these points.
Artificial potential fields (PFs) are fields of attractive and repulsive forces overlaid on a robot’s environment to drive goal reaching and avoidance behaviours, respectively. We compute a PF from the neural activation map, with obstacle points set to exert repulsive forces, using the formulation presented in Park et al. (2008). For an arbitrary point on the field, The PF computed from an SNN’s output neural activation map, visualized in 2D (9a) and 3D (9b), the latter showing the slope that determines the motion vector (blue). (a) Neural activation map to potential field. (b) 3D potential field.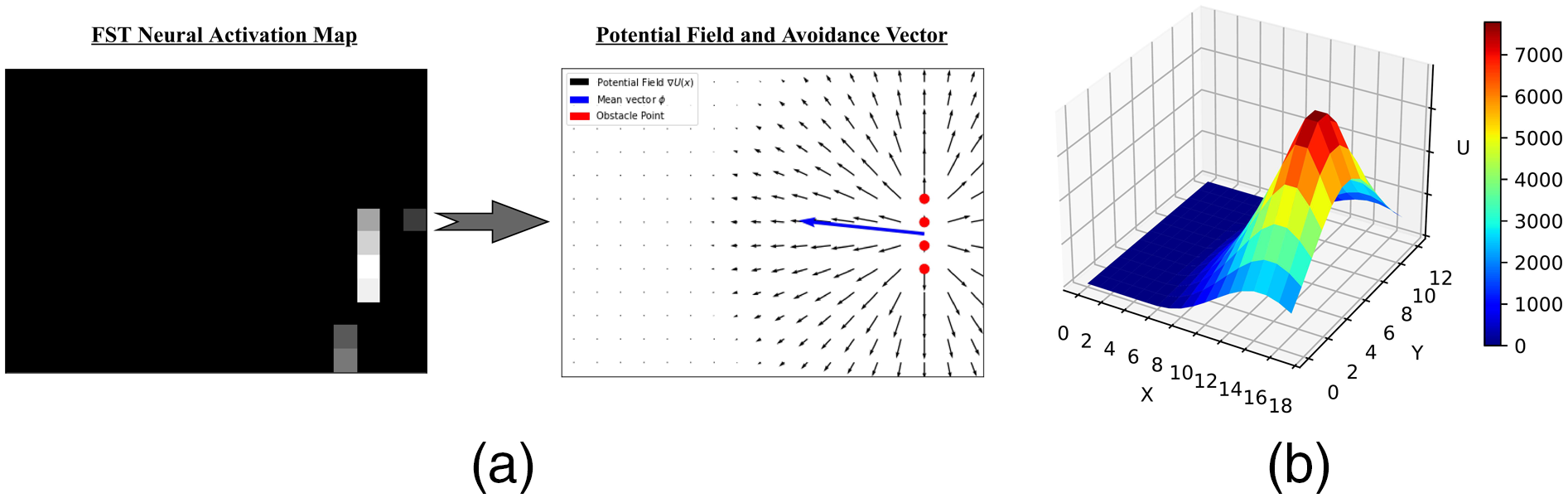
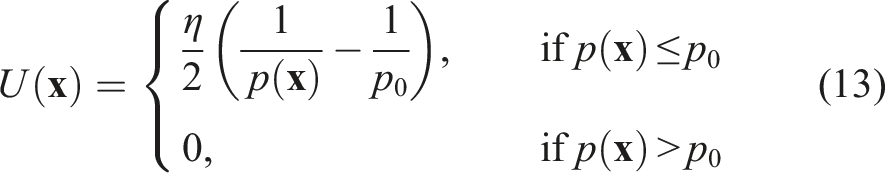
The SNN output is thus decoded into motion vector
4.5. Motion planning and control
The aforementioned components operate alongside the planning and control component, which generates and executes trajectories. It also utilizes feedback from the obstacle avoidance component to adapt motion plans online by deviating to avoid obstacles while maintaining progress towards the goal; this is accomplished through a DMP. The robot follows the positions specified by the DMP planner through velocity commands generated by a PID controller.
4.5.1. Dynamic motion primitive (DMP)
Dynamic motion primitives (DMPs) can model the evolution of a point’s position over time in a set of differential equations that produce stable global attractor dynamics (see Section 2.3). A particularly useful property is the extensibility of the transformation system equations with task-related acceleration terms.
A secondary objective can be accomplished by adding appropriate acceleration values to equation (6) during the evolution of variable
Here, the DMP controls the end-effector’s position,
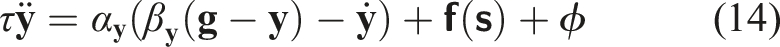

Note that
The resulting obstacle-avoiding trajectory is finally executed by following positions integrated from equation (14).
4.5.2. PID controller
We use a PID controller to compute velocity commands that move the robot’s end-effector between DMP positions during task execution. Given current and target positions, A block diagram depicting the PID controller.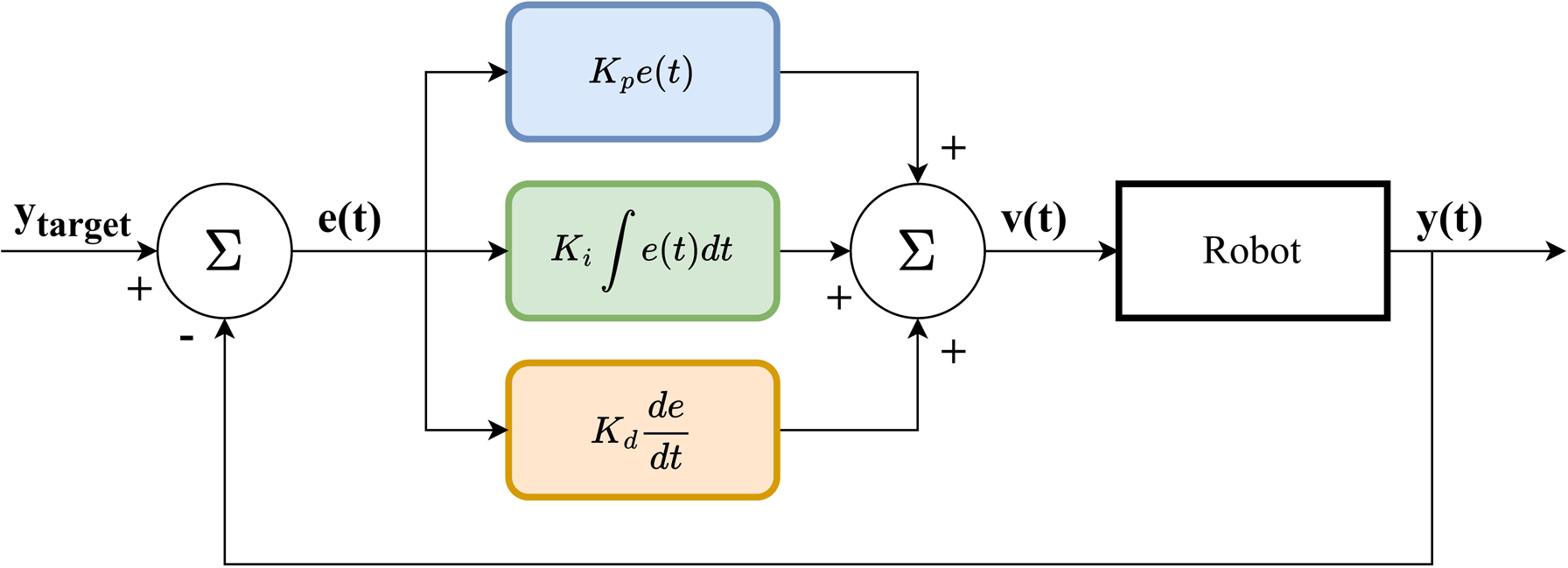
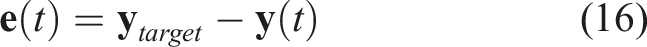
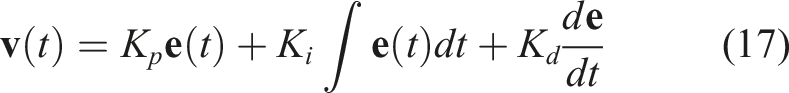
By tuning the respective gains, we can optimize for properties such as the smoothness and stability of motions. In addition, the tight integration between motion and sensor-based obstacle avoidance corrections requires motions to be responsive and reliable or risk not adequately utilizing the feedback provided by the obstacle avoidance component.
The neuromorphic pipeline described in this section was implemented using the ROS framework. Refer to Appendix D for implementation details.
5. Evaluation methodology
Our implementation was evaluated in experiments of simple reaching tasks on a Kinova Gen3 arm (shown in Figure 11) that involve static and dynamic obstacles. These were designed to compare outcomes of task executions with and without the presented SNN-based obstacle avoidance module and thus verify the merits of our neuromorphic approach. We initially tune and evaluate performance in simulations before running experiments on the robot for a final validation of the module and how well it transfers to the real world. In the following, we describe these experiments, including the formalized task scenarios, metrics, and performance criteria. The Kinova Gen3 arm configuration used in the experiments. (a) In simulation. (b) The robot platform.
5.1. Simulation experiments
We use an adapted version of the Gen3 Gazebo simulation provided in the 1. 2. 3.
5.1.1. Evaluation tasks
We formulated four goal-directed tasks for evaluating obstacle avoidance capabilities. In each task, a regular course of action leads to an imminent collision, unless a deliberate avoidance action is taken. Therefore, we address situations in which naïve motion planning is certain to fail and investigate how well our obstacle-aware manipulation trajectories solve the problem.
The set of tasks in our simulation experiments consists of: • • • •
Refer to Figures 23–26 in Appendix A for visual illustrations of the tasks.
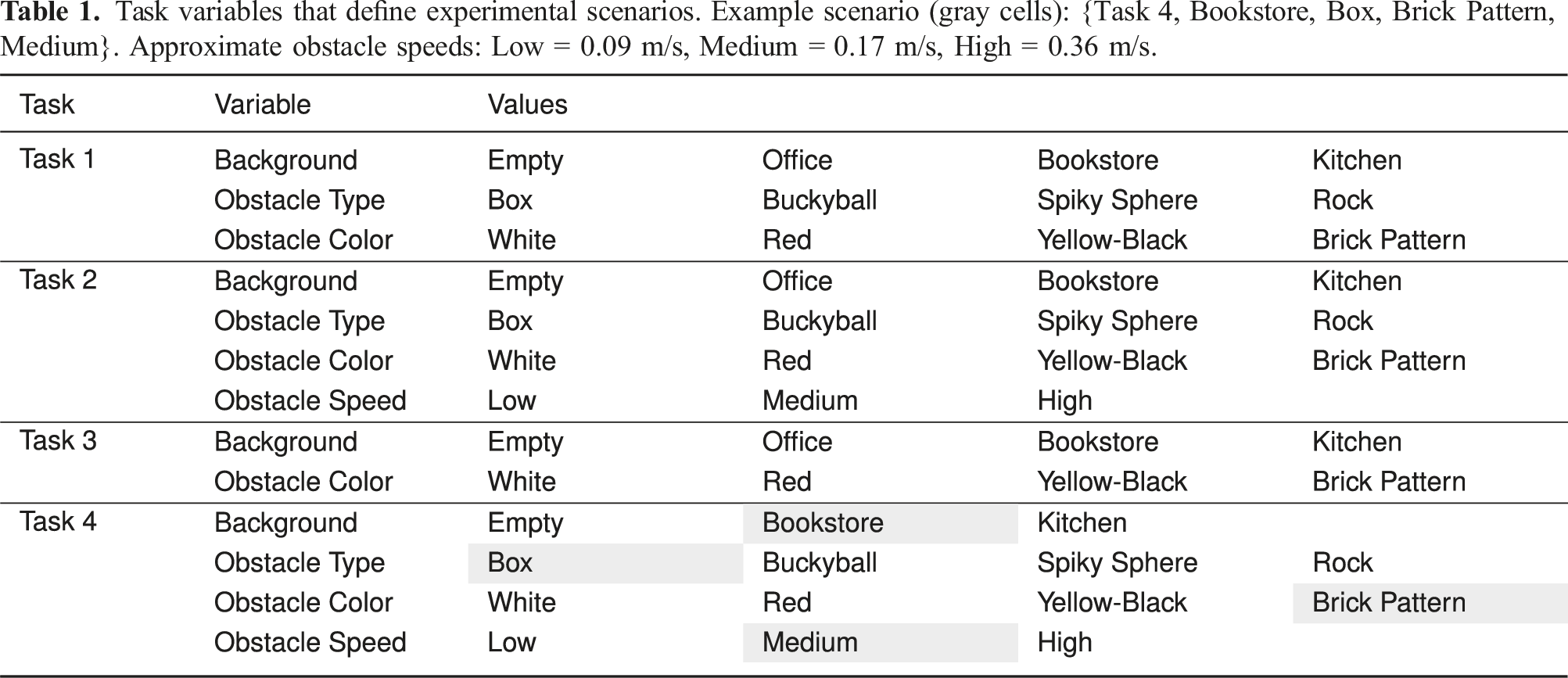
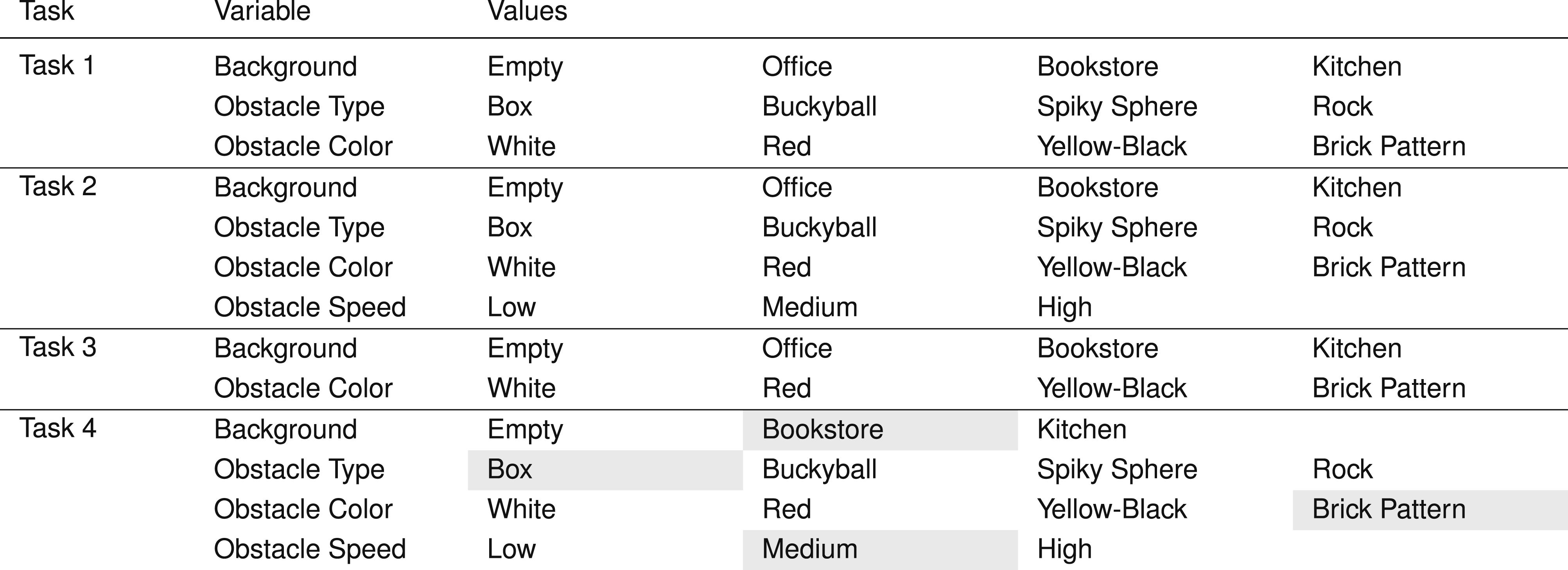
Task variables that define experimental scenarios. Example scenario (gray cells): {Task 4, Bookstore, Box, Brick Pattern, Medium}. Approximate obstacle speeds: Low = 0.09 m/s, Medium = 0.17 m/s, High = 0.36 m/s.
5.1.2. Tuning, validation and testing
The task variables form a distribution of 416 task scenarios which we utilize for parameter tuning in addition to the final evaluation. Inspired by a common methodology in machine learning (ML) research, we draw disjoint sets of scenarios that we use to initially optimize and ultimately evaluate through a tuning, validation, and testing strategy. The tuning set is used to tune sets of parameter values to achieve adequate performance, while the validation set is used to evaluate the degree to which a given set (or “model”) generalizes to unseen conditions and to select a candidate set. Our experiments involve testing with the selected values on the testing set and comparing to executions that do not utilize the avoidance module. This eliminates biases that could result from optimizing and evaluating on the same data and ensures that we do not “overfit” to specific environmental conditions.
The tunable parameters that we consider govern the behaviour of each pipeline component outlined in Section 4 and are listed in Table 10 of Appendix E.
From the scenario distribution, we allocated 3 in the tuning set, 8 in the validation set, and 20 in the testing set. The first two were manually selected to guarantee some variation in scenario properties (with the validation set containing more variations, some unobserved during tuning) and to ensure that at least one task and one background are never observed in either phase. Testing scenarios were sampled randomly from the remaining pool, with the only restriction being at least N s = 5 scenarios per task, resulting in a set that includes a novel task and a background/environment. In this case, these were Task 2 and the Kitchen environment (which is characterized by dim ambient lighting).
Table 7 in Appendix B lists the scenarios of each set. Note the inclusion of an additional scenario at the top (Task 1, Empty, Cracker Box), which was used to establish baseline parameter values in initial tests, termed a pre-tuning phase.
5.1.3. Evaluation metrics and criteria
The relevant literature presents scarce results of obstacle avoidance performance and limited consensus on the appropriate quantitative metrics thereof. We address this deficit by establishing a set of quantitative metrics and qualitative criteria for our evaluation.
The quantitative metrics we use to analyze the performances of parameter sets and to ultimately evaluate our approach are: • Task execution time, T • Trajectory length, l
• Number of collisions, N
collisions
• Final distance to goal, d
G
• Success (reaching the goal and never colliding), S • End-effector velocities and accelerations,
Refer to Appendix C for detailed descriptions of each. These metrics facilitate a holistic evaluation of the SNN-based obstacle avoidance module and comparisons to baseline task executions on the basis of task success and along other dimensions that describe trajectory properties.
Qualitative performance criteria.

5.1.4. Experiment procedure
Our experiments involve running N
trials
executions in all testing scenarios in each of two cases: 1. Baseline executions that do not involve the obstacle avoidance module. 2. Executions that incorporate the obstacle avoidance module, using the selected parameter set.
We then analyse and compare performance using the described metrics and criteria.
5.2. Real experiments
The real experiments are conducted on a Kinova Gen3 arm attached to a mobile platform (see Figure 11(b)), to determine how well the tuned parameters transfer to the real world and for a more concrete validation of our approach. These experiments contain fewer variations of scenarios from a subset of the tasks defined in Section 5.1.1 but share the same evaluation metrics/criteria and experimental procedure.
5.2.1. Evaluation tasks
We consider two of the tasks defined in Section 5.1.1: • • Real experiment Task 1 setup. A baseline end-effector trajectory is illustrated in green. (a) Start; (b) end. Real experiment Task 2 setup. The obstacle’s trajectory and a baseline trajectory are illustrated in red and green. (a) Start. (b) End.
The task setups are shown in Figures 12 and 13.

These tasks are equivalent to the simulated versions with a few exceptions. Firstly, the object in Task 1 was suspended but is now placed on a surface. For Task 2, the simulation offers accurate control of the obstacle’s trajectory and thus a high degree of consistency across trials. On the other hand, the object’s trajectory is controlled manually in the real experiments, which may introduce inter-trial inconsistencies, although preventative steps such as guiding markers on surfaces and periodic measurements to verify the object’s initial position were taken. While the simulated experiments were designed to gather statistical evidence from highly repeatable trials, which rarely occur in the real world, the primary objective here is to transition into real-life conditions and investigate how well the implementation adapts. Furthermore, for reasonably small variations in conditions, results from multiple trials can eliminate any variance due to these imprecisions.
The real experiment task scenarios are varied exclusively along the “Background” and “Obstacle Type” variables. “Lab Background 1” is situated in an area near a window providing a natural but dim light (see Figure 12) while “Lab Background 2” has a much brighter artificial lighting and contains a large table and other objects (see Figure 13). The obstacles are a wooden block, a metal bar, and a person’s hand. The latter is a particularly relevant case for human-robot collaborative scenarios 10 . Table 8 in Appendix B lists the four scenarios we conduct our real robot experiments in.
5.2.2. Evaluation metrics and criteria
The performance is evaluated using the same metrics and criteria of the simulation experiments. However, the N collisions metric was excluded since it was only possible to evaluate in simulations by disabling collision dynamics and counting the number of instances in which the end-effector intersects an obstacle model. Instead, collisions are only reflected in the execution success, as before, which is true only if the end-effector never collides and also reaches its goal.
6. Results and discussion
6.1. Simulation experiments
Parameter tuning, validation, and testing in the simulation experiments was preceded by a pre-tuning phase, where an initial set of values was established. Next, we tuned several variants of this set on the tuning scenarios, validated their performance on the validation scenarios, and finally selected the best-performing set to run on the testing scenarios.
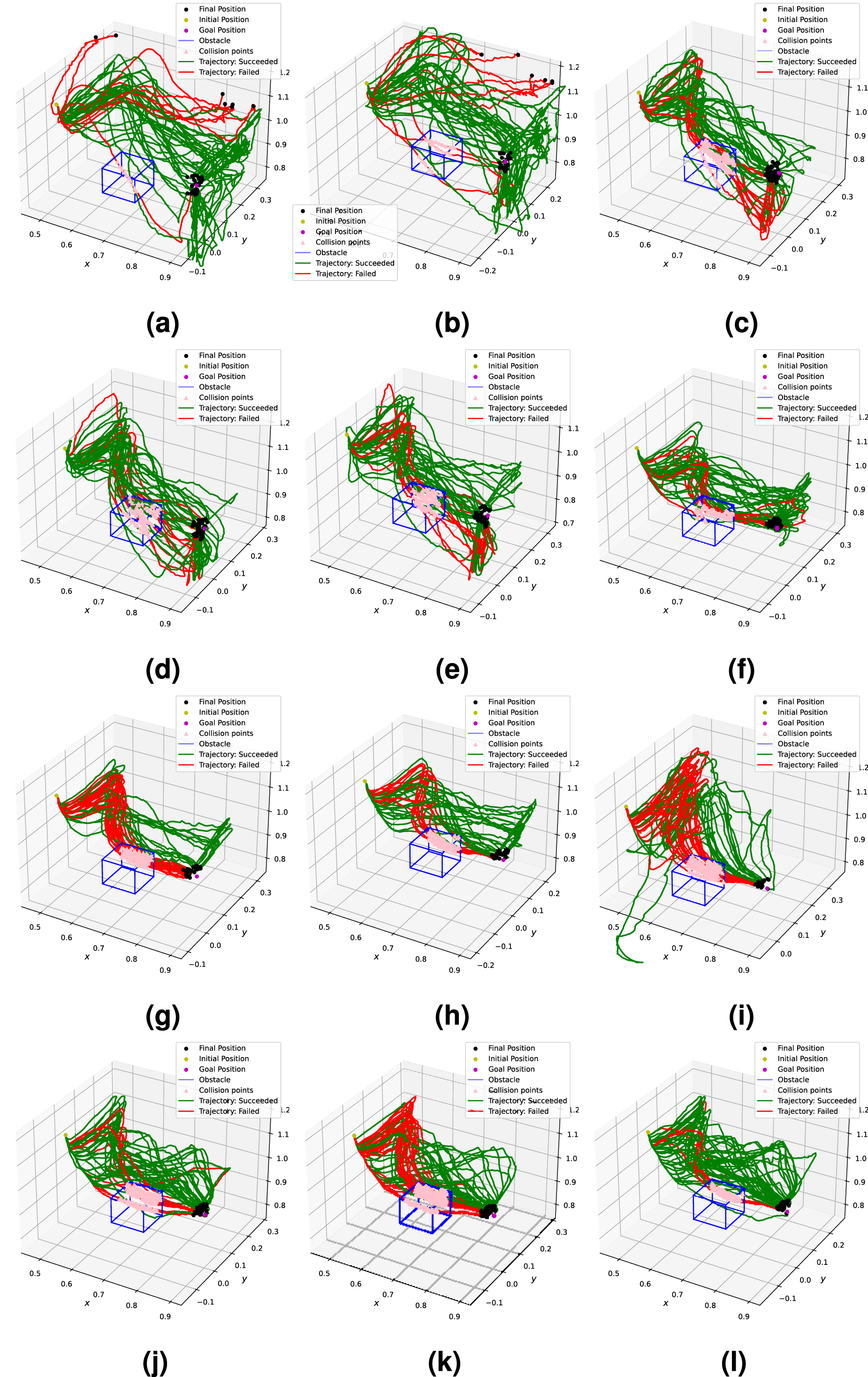
Figure 14 illustrates the evolution of executed trajectories during this process in a Task 1 scenario. Trajectories executed during pre-tuning and tuning trials. (a) Without SNN feedback. (b) With pre-tuning parameter set. (c) With post-tuning parameter set (12).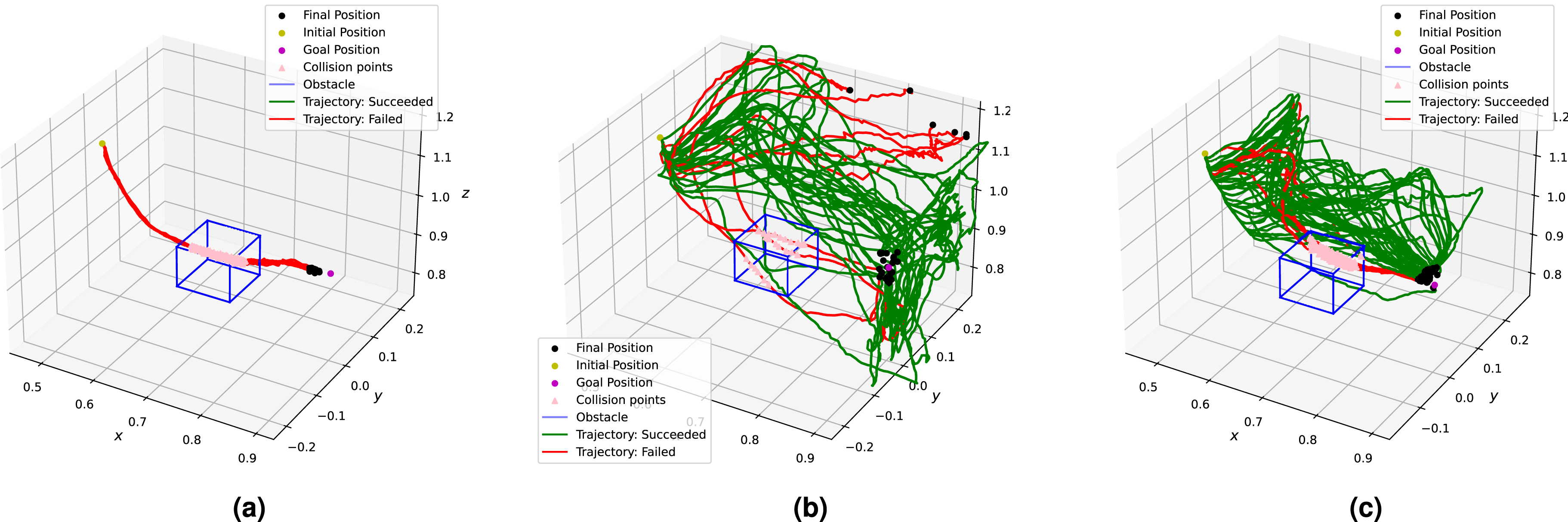
6.1.1. Initial parameterization (pre-tuning phase)
This phase consisted of iterative testing to search for a region in the parameter space that leads to acceptable performance. The main targets of this optimization were motion control parameters, such as the PID gains, distance tolerances, and motion loop frequency; PF parameters; SNN parameters, including the architecture, weight initialization, and SNN dynamics variables; and event emulation variables, such as RGB versus grayscale inputs and the event emission threshold (θ). These tests were conducted in a pre-tuning scenario: a variant of Task 1 containing a “Cracker Box” object that is excluded from the task distribution defined in Table 1.
The SNN architecture that was selected during the pre-tuning phase.

The pre-tuning parameters were evaluated by running N trials = 30 trials in both testing cases. As expected, the trajectories executed in the baseline case all fail by colliding with the obstacle (see Figure 14(a)). On the other hand, utilizing the module leads to trajectories that are adapted to avoid the obstacle while moving towards the goal (Figure 14(b)), which were 80% successful in these trials.
The obstacle avoiding trajectories tended to have higher execution times, T, and trajectory lengths, l
6.1.2. Tuning results
Using the tuning scenarios, we derived and iteratively optimized 12 parameter sets that were expected to improve results. Furthermore, we extended our implementation and parameters to address some failures that we had observed in pre-tuning and initial tuning trials.
In order to address the problem of reaching singular arm configurations, which could lead to failures and potentially unsafe executions, we implemented a safety strategy that discourages excessive motions away from the pre-planned trajectory by reducing velocities and accelerations that move the end-effector further beyond a definite safety boundary. This method is described in the box below. Note that for Task 4, the safety strategy penalizes motions that deviate a certain distance from the initial position.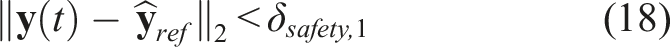
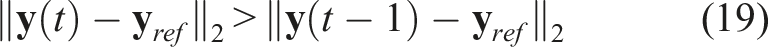

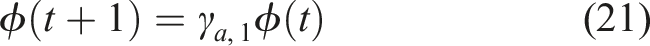
We also added optional workspace boundaries: positional limits beyond which a planned DMP position is rectified by clipping its value: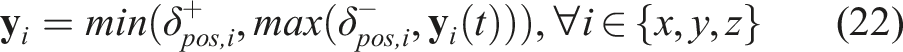
We ran batches of trials without SNN feedback (baseline) and with SNN feedback, the latter with each of the parameter sets, on each of the three tuning scenarios (1, 2, and 3). The baseline batches consisted of N trials = 30 trials, while the rest consisted of N trials = 40 each for a total of 1530 trials.
The trajectories executed in scenario 1 are shown in Appendix H in Figure 34.
Scenario 1 trials confirmed that the safety strategy reduced instances of terminal arm configurations. Some parameter sets (particularly 6-9) exhibited less reactive motions due to stronger event erosion filter parameterizations, which lead to more collisions. Similar failures were observed in scenario 2 trials for the first nine parameter sets, which were also attributed to a weak response due to parameters that control sensitivity to inputs, including the event emission and filter thresholds, neuronal spiking thresholds, and ϕ acceleration parameters. Sets 10-12 were tuned to address this limitation and were successful in improving results. Scenario 3 trials revealed that earlier parameter sets suffered from the opposite: a higher reactivity lead to unstable motions. These observations point to a trade-off: increasing sensitivity to inputs at the perceptual, motion, or intermediate levels in the pipeline may lead to excessive, dangerous or oscillatory motions, while decreasing sensitivity may risk not reacting fast enough to avoid collisions.
6.1.3. Validation results
Next, we selected a subset of the parameter sets on the basis of best average performance and trajectory properties: 5, 8, 10, and 12.
Due to initial observations and unsatisfactory performance in a challenging, high-speed validation scenario (8), we instantiated two additional sets: 13 and 14. These were aimed at exploring quicker responses and faster real-time performance, mainly by testing a single-layer SNN and tuning motion loop frequency parameters.
We ran N trials = 30 baseline trials and N trials = 40 trials with the avoidance module parameterized by each of the six parameter sets. All trials were repeated in each of the eight validation set scenarios (4-11): a total of 2160 trials.
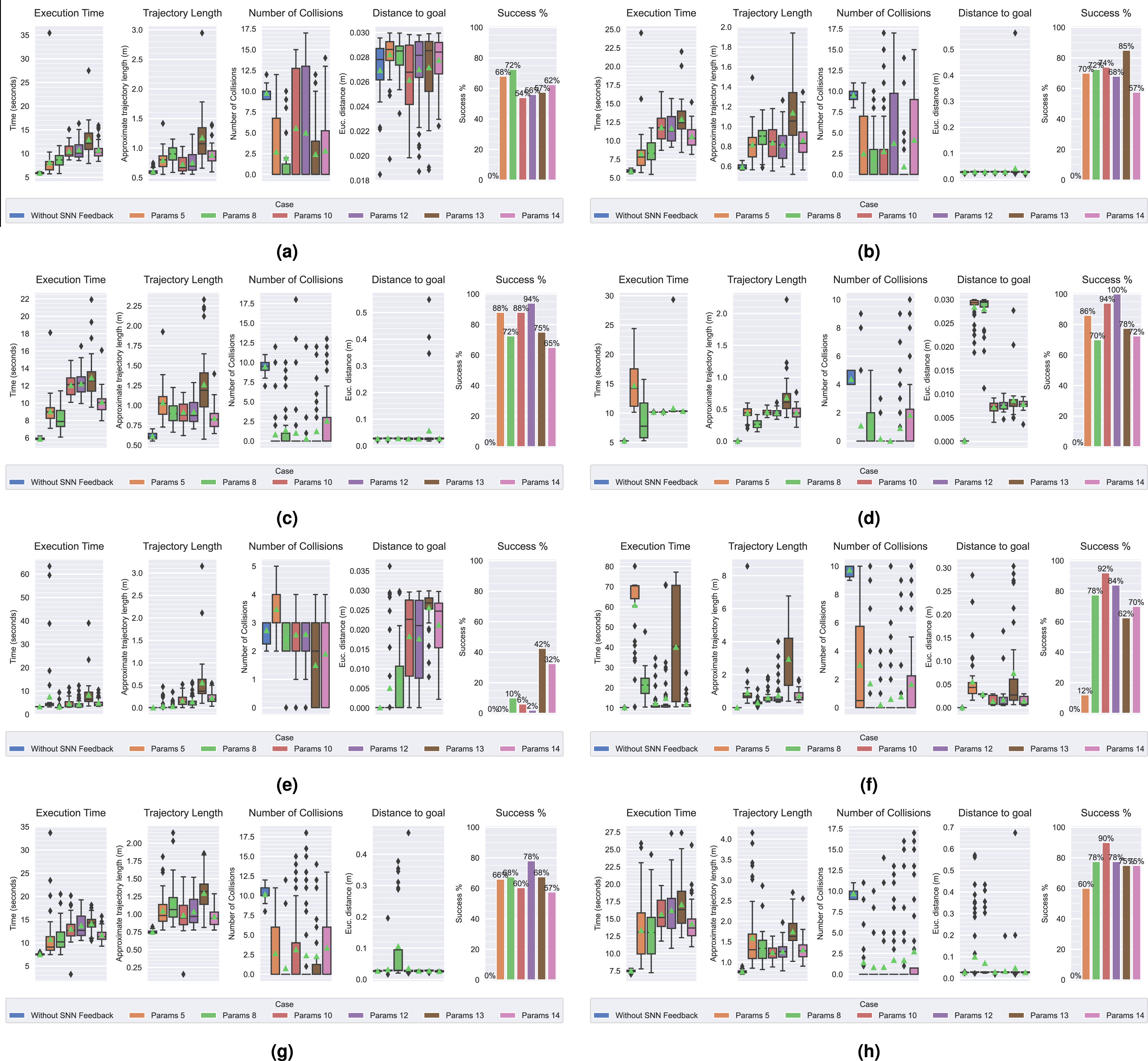
Figure 36 in Appendix H contains the metrics plots summarizing the quantitative performance in all scenarios.
Results from Task 1 scenarios (4-6) indicated that the module performed worse in the “Office” environment (scenario 4) than in “Store” or “Empty”. A likely cause is the relatively lower illumination, which decreases contrasts between the background and the obstacle, thus leading to less events being generated and in turn more latency in or lower magnitudes of avoidance velocities. Another potential reason is the relative background clutter which, despite event filtering, may produce more background events that saturate the overall response of the SNN.
Results from Task 4 scenarios (7-9) varied significantly. Most sets performed well with medium-speed obstacles (scenario 7) but considerably worse in response to the high-speed obstacle of scenario 8 (traveling about twice as fast). While the module would react to the obstacle, which was visible for a shorter amount of time, the eventual response would not be sufficiently effective. This was a product of fewer events, a resulting lower SNN activation, and the limited speed of the arm. Sets 13 and 14 yielded more positive results through stronger responses, leading to less predictable and potentially unsafe trajectories. In addition, these improvements did not extend to the low-speed case.
All selected parameter sets performed at least better than the baseline and reasonably well in most scenarios. However, the last findings indicate a limit on how fast we can command the arm to move before approaching dangerous speeds. While sets 13 and 14 improved performance, they exhibited significantly higher accelerations that enable the necessary sudden reactions. This is characteristic of unsafe trajectories and presents an undesirable compromise. Instead, it is reasonable to acknowledge an inability to reliably react to and avoid obstacles whose speeds exceed a certain threshold.
6.1.4. Testing results
Quantitative results of the testing phase runs, averaged over the N trials trials of each scenario.
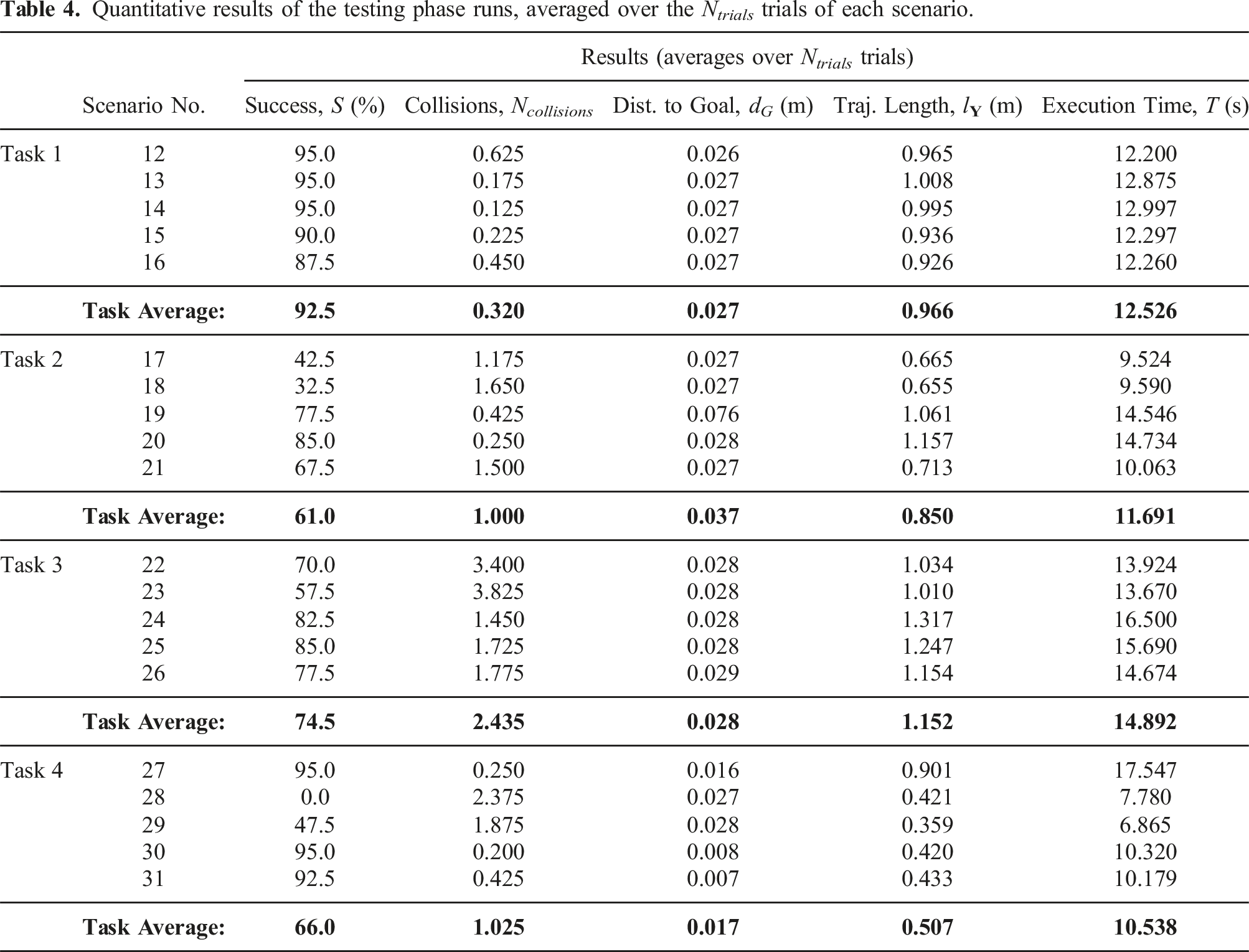
The avoidance module succeeded in 92.5% of all Task 1 trials. The success rate, distance-to-goal, trajectory length, and execution time exhibited low variances, indicating a high level of consistency over the five environments, including the novel, low-light setting of scenario 14.
Performance was less consistent in the novel Task 2, where success rate had an average and standard deviation of 61% and 22.6%, respectively. Most failures were observed in the “Office” scenarios 17 and 18, where the relatively low mean trajectory length and execution time indicated less movement, possibly due to lower neural activations. The avoidance behaviour succeeded more often in the remaining scenarios and was not affected by obstacle speed.
Success in Task 3 scenarios averaged at 74.5% and had a standard deviation of 11%. While the end-effector always reached the goal, N collisions varied significantly across trials of a given scenario and we observed no correlations between the different task variable values and the frequency of failures. Occasionally, initial trajectory adaptations moved the end-effector to a region closer to the obstacle from which subsequent corrections were unlikely to effectively steer it away. These occurrences indicate some uncertainty in the resultant trajectory which may be attributed to the cascade of non-linear operations performed within the pipeline.
The reported mean success rate in Task 4 (66%) is skewed due to failures in the high-speed obstacle scenario 28 (the median is 92.5%). This reinforces the validation phase findings concerning very fast obstacles.
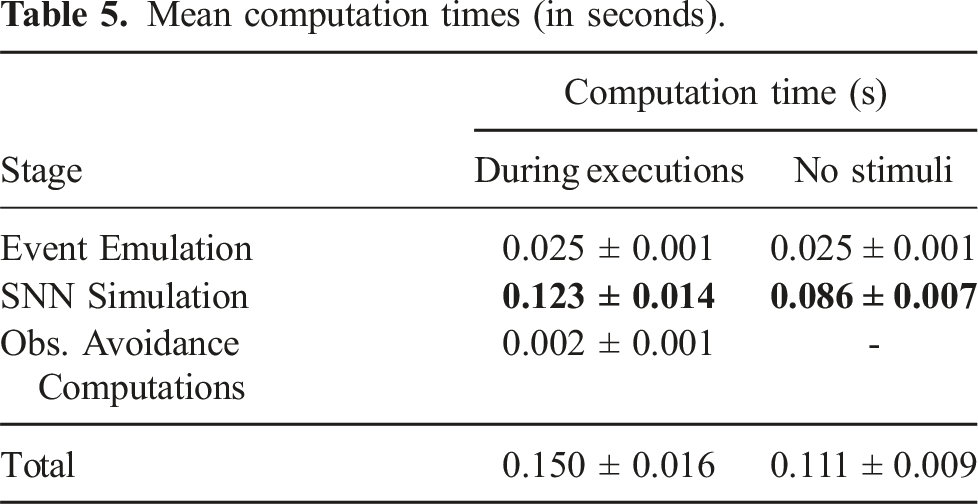
Mean computation times (in seconds).
Finally, we evaluated executions based on our qualitative criteria (refer to Appendix C for descriptions of each).
We correlate reliability with the consistency of positive results (i.e. success rates) in consistent task conditions. Each row in Table 4 represents the success rate in a given set of controlled conditions, the average of which is 74%, including the scenario 28 outlier. The median, which is less influenced by the outlier, is 84%, and success rates were higher in half of the scenarios. Overall, this indicated the moderate reliability of the implementation and chosen parameter values.
We observed a high level of predictability in motions by analyzing the magnitudes of directional changes. The estimated values of heading angular velocities,
For evaluating the safety of obstacle-avoiding trajectories, we measured the overall end-effector speeds, which averaged at
6.2. Real experiments
The pipeline implementation and tuned parameter values (12) were directly transferred to a real Kinova Gen3. Preliminary tests showed acceptable performance except for a slight degradation in motion smoothness, which necessitated minor adjustments of 5 of the 26 parameters: • K
p
: 5.0 → 2.0; K
d
: 10.0 → 5.0; K
i
: 0.0 → 5.0 • δ
• θ : 28 → 45
The controller gains were a primary cause, which verifies expected discrepancies between the simulated and real-world dynamics (mainly in the actuators). Transitions between trajectory positions were less abrupt after slightly increasing the position reaching tolerance, δ
We ran N trials = 30 trials in each scenario, which are listed in Table 8 in Appendix B, with and without the module.
Figure 15 contains the quantitative results of these experiments from each scenario (R1-R4) in addition to a single batch of baseline trials
12
. Table 6 contains the mean values of each metric and the averages for each task. Quantitative metric results without versus with SNN feedback: real experiment scenarios R1-R4. Quantitative results of the real experiment runs, averaged over the N
trials
trials of each scenario.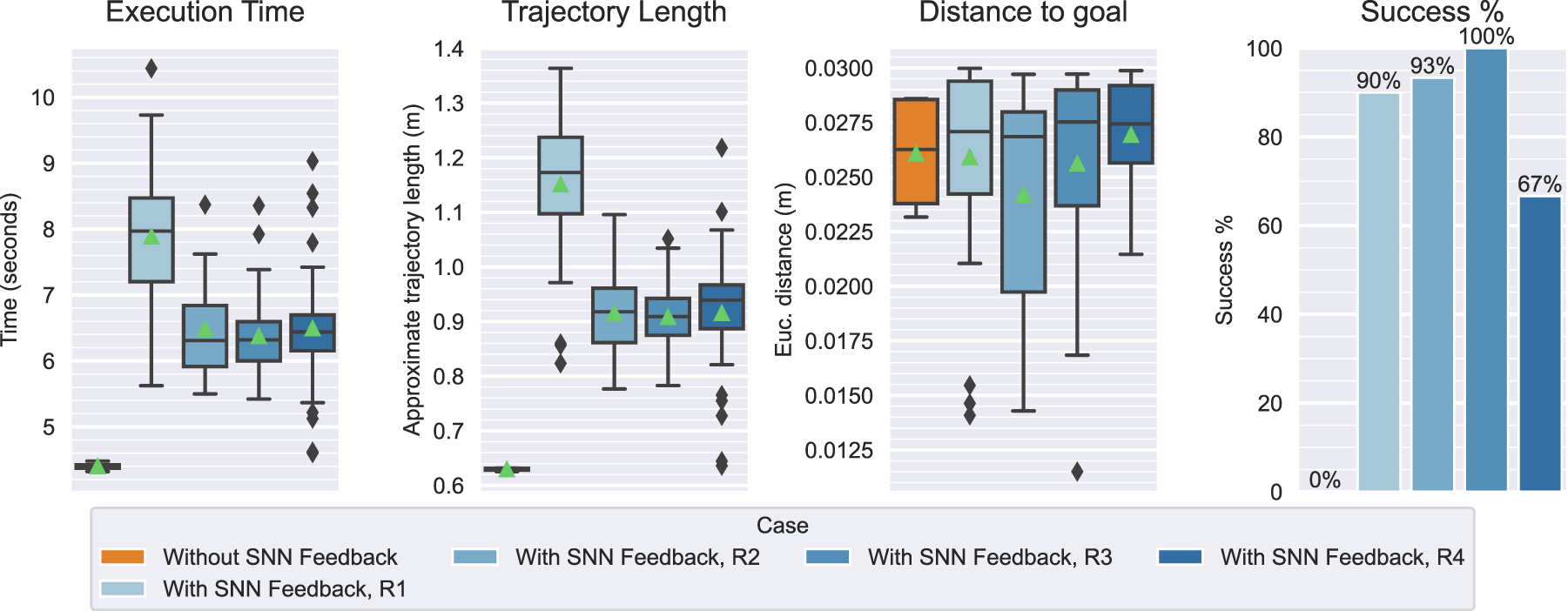
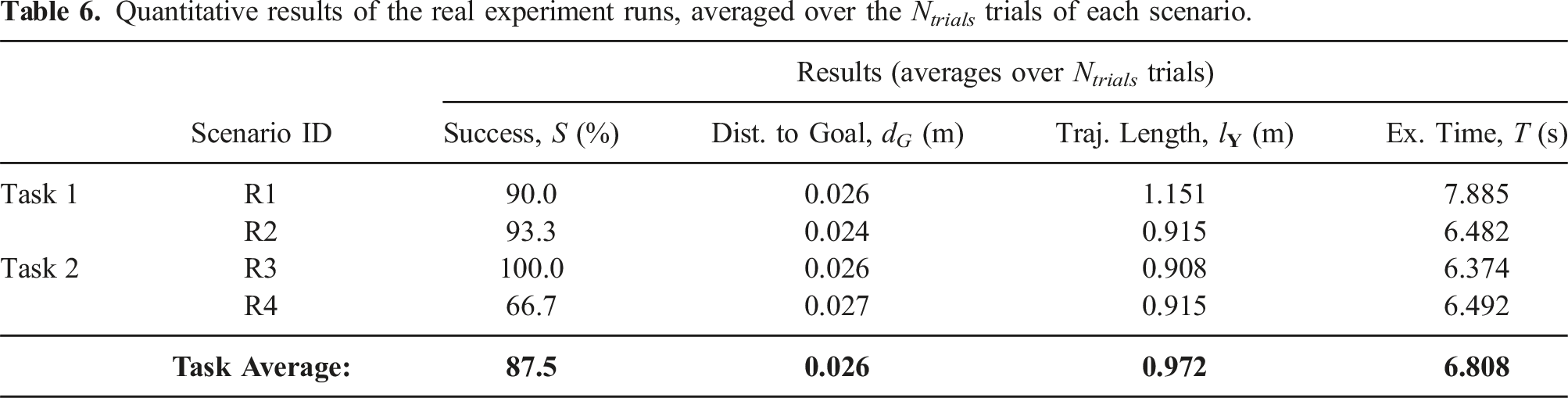
The avoidance module succeeded in 87.5% of all 120 trials. In the Task 1 scenario, the arm was 90% successful in avoiding the wooden block. In Task 2, the arm was most successful with the metal bar obstacle (R3), as it never failed the task, followed by the hand (R2) with a success rate of 93% and the wooden block (R4) with 67%. Since the goal was always reached, all failures were due to collisions.
The higher failure rate in R4 was due to the visual properties of the wooden block, which blended with the background (see Figure 16(a)). As the obstacle comes into view, it generates less events and less neural activation than the more contrasting objects, causing trajectory adaptations to occasionally be too weak or late to effectively avoid the obstacle. The perfect success in R3 could be explained by the significantly higher color contrast (see Figure 16(b)). Therefore, similar colors induce lower intensity differences that lead to a less effective response for less visible objects. Images captured by the onboard camera during an execution of scenarios R4 and R3 (Task 2). (a) Scenario R4. (b) Scenario R3.
When comparing the baseline and adaptive cases, we observed similar distributions of accelerations and velocities, which are shown in Figure 17. However, magnitudes in y were marginally higher in the second case. This indicates a preference for side-ways motions, that is, in the y direction (left-right axis, relative to the camera), which is expected due to the avoidance velocity vectors being computed from the camera’s image space, ruling out motions in x (front-back axis), as expressed in Section 4.5.1. Accelerations and velocities in x tended to be lower with the avoidance module, indicating that the trajectory adaptations naturally slow down forward motion when avoiding perceived obstacles, which is a desirable effect when aiming to safely clear an obstacle while continuing progress towards a goal. Distributions of instantaneous velocities and accelerations in each spatial dimension, measured during real robot experiments. The figure contains data from nominal executions (without SNN Feedback) and scenarios R1-R4. (a) Velocities. (b) Accelerations.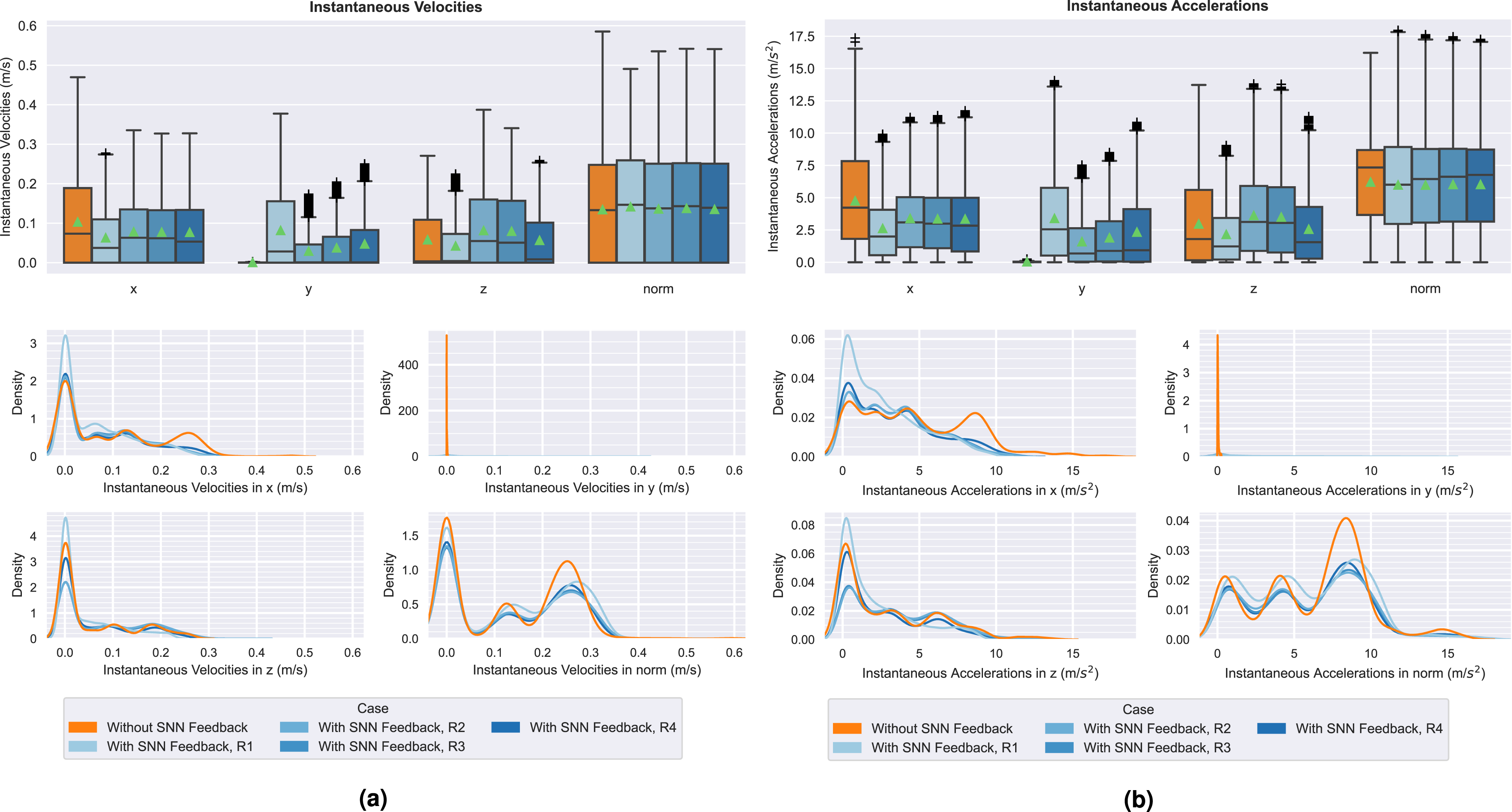
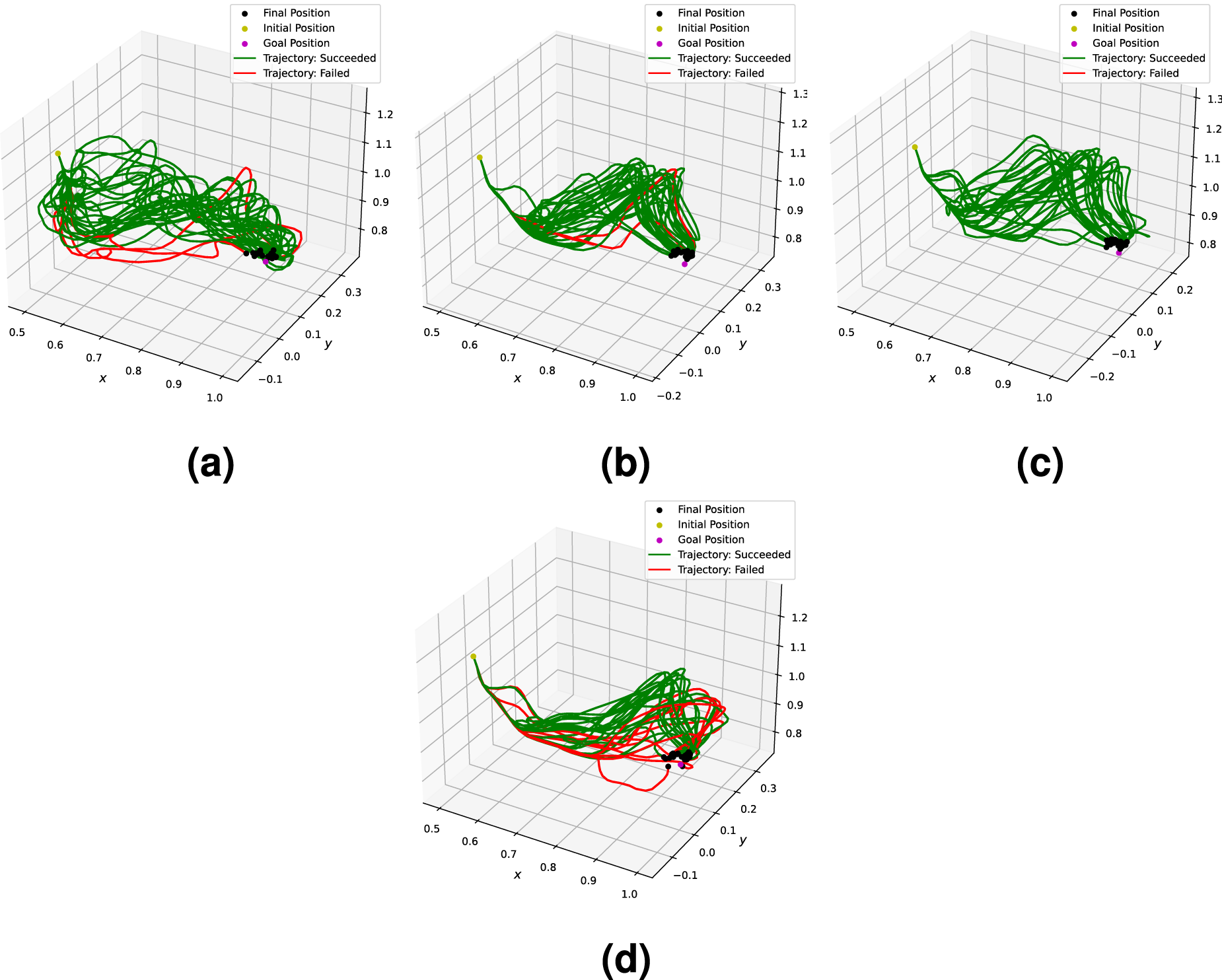
The trajectories executed in these experiments (plotted in Figure 35 in Appendix H) were qualitatively similar to the simulation counterparts and lead to similar conclusions from the qualitative evaluation.
The average success rate was 87.5% (the median was 91.7%), indicating a moderately high level of reliability.
The distribution of
The same safety comparison to the reference velocity threshold (0.25 m/s) indicated that trajectories were fairly safe, albeit to a less degree than in the simulation. While the overall end-effector velocity averaged at 0.13 m/s, the Task 1 and Task 2 maximums approached 0.5 m/s and 0.55 m/s. However, these values lay beyond the third quartile of the distribution (upper plot in Figure 17(a)). We can assume that this is not an effect of the avoidance maneuvers themselves, but rather the controller parameterization (since similar values are observed in the Without SNN Feedback case).
Overall, the SNN-based obstacle avoidance module demonstrated 84% and 92% median success rates in simulated and real experiments. Execution times, trajectory lengths, and velocity and acceleration magnitudes indicated that the adaptive trajectories were quantitatively similar to baseline executions, but with the added capability of consistent obstacle avoidance. The qualitative assessment suggested that these trajectories were adequately reliable, predictable, and safe, although they were directly optimized only for obstacle avoidance. Finally, we demonstrated comparable performance in the real domain.
7. Further analyses
We additionally explored properties of our neuromorphic components through further experimentation. We first compared different event emulation methods in terms of output events, spiking responses, and effects on performance. To validate the SNN’s utility, we excluded the component from the pipeline and tested the decoding of avoidance behaviour from raw events. Furthermore, we investigated the effects of random SNN weight values on performance by repeating scenario trials with different initializations. Finally, we substituted our event emulator with a real EC and repeated experiments on the robot.
7.1. Comparing event emulation methods
For this analysis, we compared five emulation strategies: • • • • •
Our default strategy, M1, involves computing the differences in absolute intensities at every pixel, Δ
For the second method (M2), we blur the source images before computing Δ
M3 emits events according to differences in log intensities: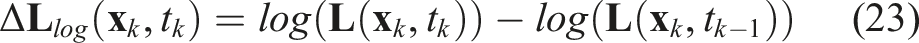
The fourth method (M4) is based on a strategy employed in Salvatore et al. (2020), where the log of a sum of weighted channel intensities is used to compute the difference: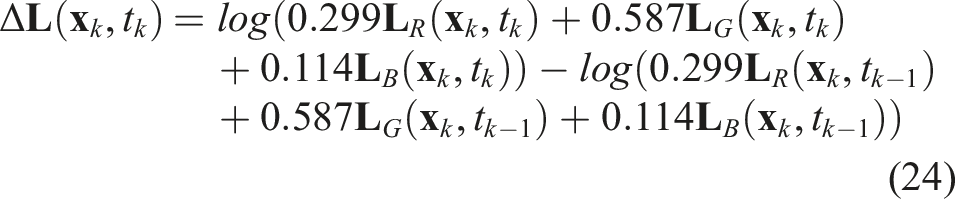
Finally, M5 mimics the pyDVS emulator (García et al., 2016), which encodes pixel intensities using Gamma functions, instead of absolute or log values.
While all methods could be run interchangeably, it was necessary to adjust some θ thresholds.
Firstly, we visually compared events and SNN responses. Three pairs of consecutive images that were captured during a scenario R3 trial were used to generate event images using each method. These were then input to the SNN, from which we recorded the spike trains output in a period of T sim = 40 ms. Appendix F contains the event images (Figure 30) and plots that depict the resulting spike trains and output neuron spike counts across T sim (Figure 31).
We observed subtle variations in the emulated event data. The blurring applied in M2 leads to similar images but additionally eliminates seemingly spurious events. The event distributions appear notably different in M3; for instance, darker regions produce significantly more events than brighter regions. This is likely due to the higher sensitivity of the log-based measure to darker (lower intensity) colors. The other log-based method, M4, showed less dark/bright differences and its event data was denser in the most relevant regions (containing obstacle motion). Results from M5 measure look fairly similar to M2’s, except for a slight reduction in apparent noise. Similar to the first two methods, M5 reacts strongly to reflective surfaces, such as one near the center of the frame, which produce high and unstable intensities.
The SNN responses largely matched the input events. For example, M1-M4 caused significant spike counts for the first sample in the first few neurons (by index); these neurons correspond to upper regions of the image, which contained strong event activity. Although the blurring in M2 produced less noisy events than M1, both resulted in very similar spike distributions. A likely reason is that the SNN’s dynamics filter out spurious inputs anyway, which indicates that the SNN could obviate the need for such a denoising operation. Generally, the SNN’s responses were similar across methods (except for M5), showing a degree of robustness to variations in events (see in Figure 31, for example, the spike trains concentrated in the top and bottom regions of the plots for sample 3 across methods). The ultimate obstacle avoidance response would also be similar due to our FST decoding strategy: we consider neurons that fire before t act (depicted as a yellow line in the plots) active and indicative of obstacle points, and neurons that spike first are generally around similar positions across methods.
We repeated N
trials
= 40 trials in scenario 30 for each method to compare the resultant obstacle avoidance performance through our quantitative metrics, which are plotted in Figure 18. The results were not significantly affected by the emulation method; M5’s success rate of 85% deviated most notably from the mean (94%). This verifies that the resultant behaviours are fairly similar, as we would expect from the similarity in SNN responses. Quantitative metric results for testing scenario 30: without SNN feedback and four batches, each with a different event emulation method: M1 (default) to M5.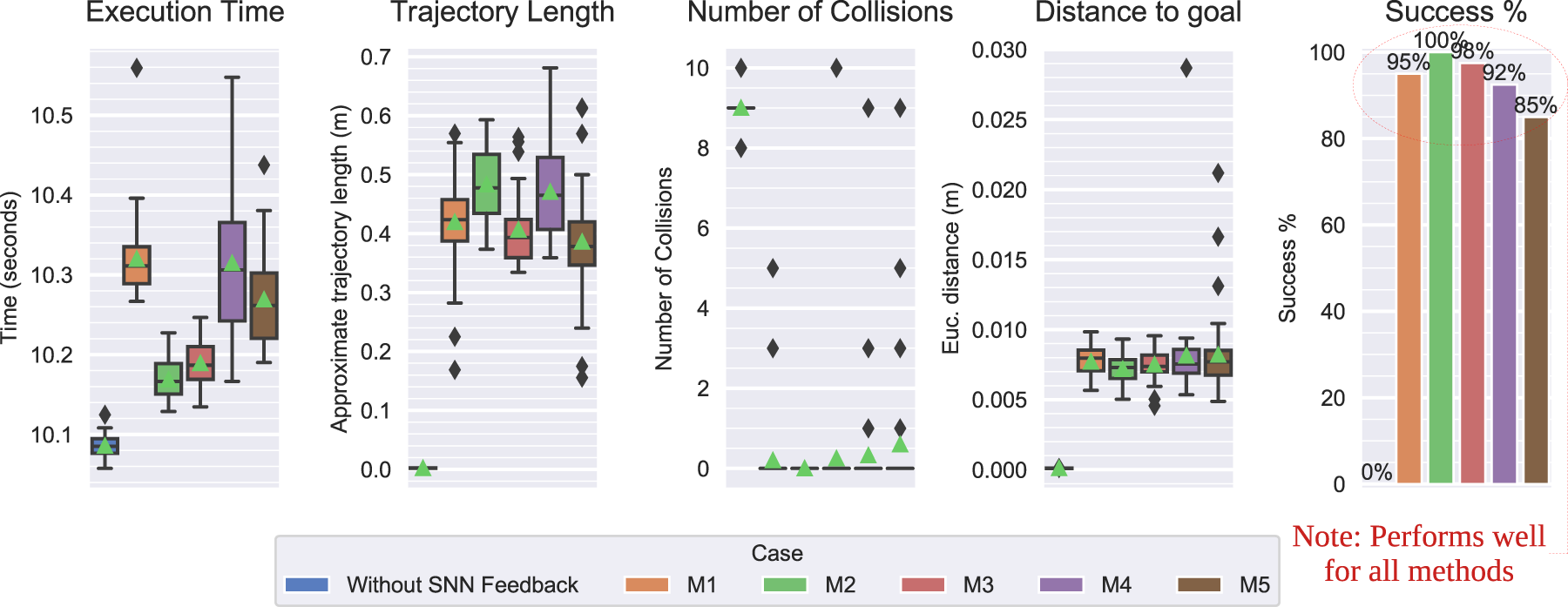
The spiking responses and task performance we observed indicate that our SNN is robust to differences in the emulated event data, since they are inherently tolerant to some noise or variance. A different SNN output decoding strategy that, for example, considers more than neurons’ first spike times may result in more nuanced and varied responses and behaviours between the EC emulation methods and is thus worth exploring in future work.
7.2. Decoding avoidance behaviour from raw event data
We experimented with decoding trajectory adaptations directly from raw events, instead of spikes output by the SNN in response to events. Additionally, we tested decoding random events, in order to verify that the presented results are indeed due to the information contained in the event data and the subsequent SNN processing.
In our approach, the output first-spike-times define the neural activation map which contains the obstacle points in the output feature space. To decode raw events directly, we resized the event images to match the SNN’s output feature space (using bilinear interpolation) and designated events as the obstacle points. The PF-based decoding procedure that follows is otherwise identical, resulting in the ϕ accelerations that in turn dictate trajectory adaptations.
To quantitatively evaluate effects on task performance, we repeated N trials = 40 trials in scenario 25, while (i) decoding from raw events and (ii) decoding from random events.
In both cases, the robot failed in all trials and would often oscillate due to the accelerations induced by the raw events and never reach the goal, despite subsequent efforts to re-tune parameters. We illustrate the metric results in Figure 19. Quantitative metric results for testing scenario 25: without SNN feedback, with SNN Feedback, and decoding obstacle avoidance behaviour from raw or random events.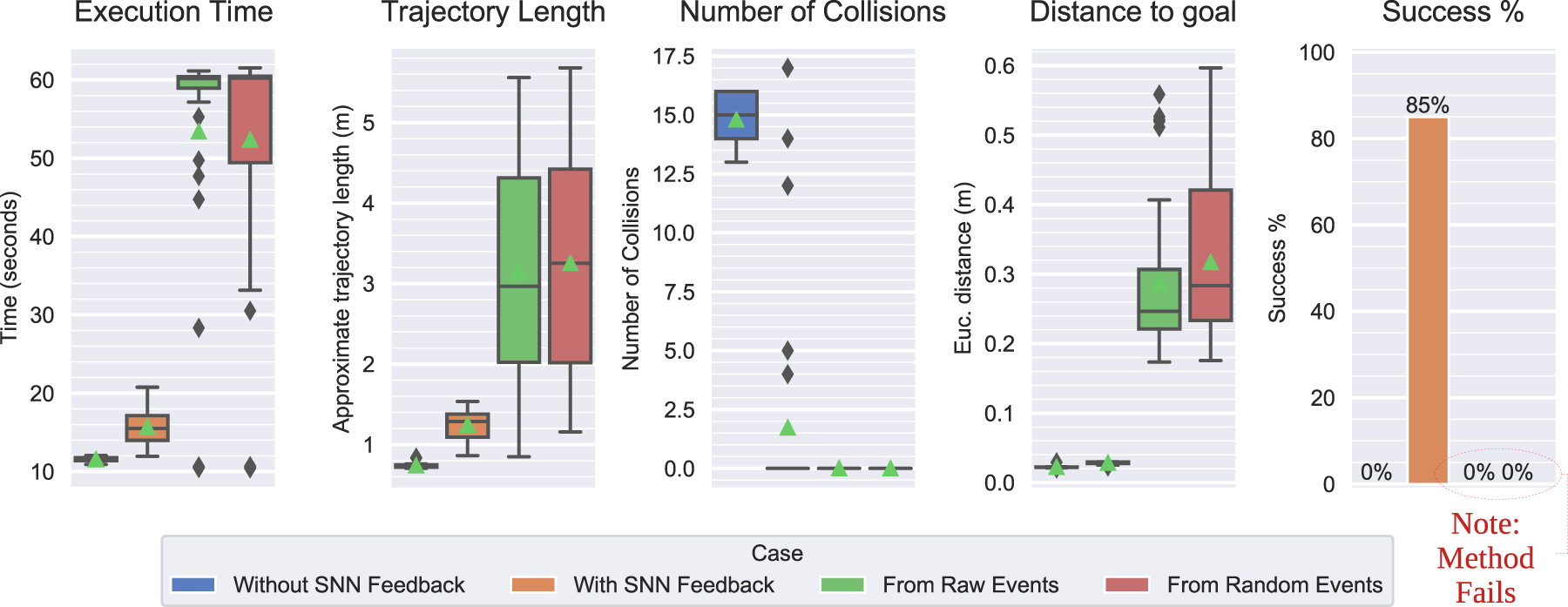
The inadequacy of raw event data indicates that the neural dynamics of the SNN are integral for processing that data to achieve successful trajectory adaptations. The similarly negative results obtained from either random events or the raw events further confirm the insufficiency of the event data in our approach and the importance of the SNN.
7.3. Testing effects of SNN weight initializations
In all experiments, we constrained the SNN weights to a set of random values to eliminate the variance in results. To investigate their influences, we analyzed performance with different random weight initializations.
We ran eight batches of N trials = 60 trials in scenario 31, initializing the SNN with a different set of weights in each.
Figure 20 shows the metrics plot (note that “Seed 1” refers to the batch from the original experiments). The success rate varied around 90.5% with a standard deviation of 3.5%, indicating that the weight values have a non-negligible, but not excessive, effect on performance. Except for occasional outliers, the other metrics’ distributions were similar across weight initializations. No differences between the resultant trajectories were perceptible from visual observations. Quantitative metric results for testing scenario 31, repeated with eight random SNN weight initializations.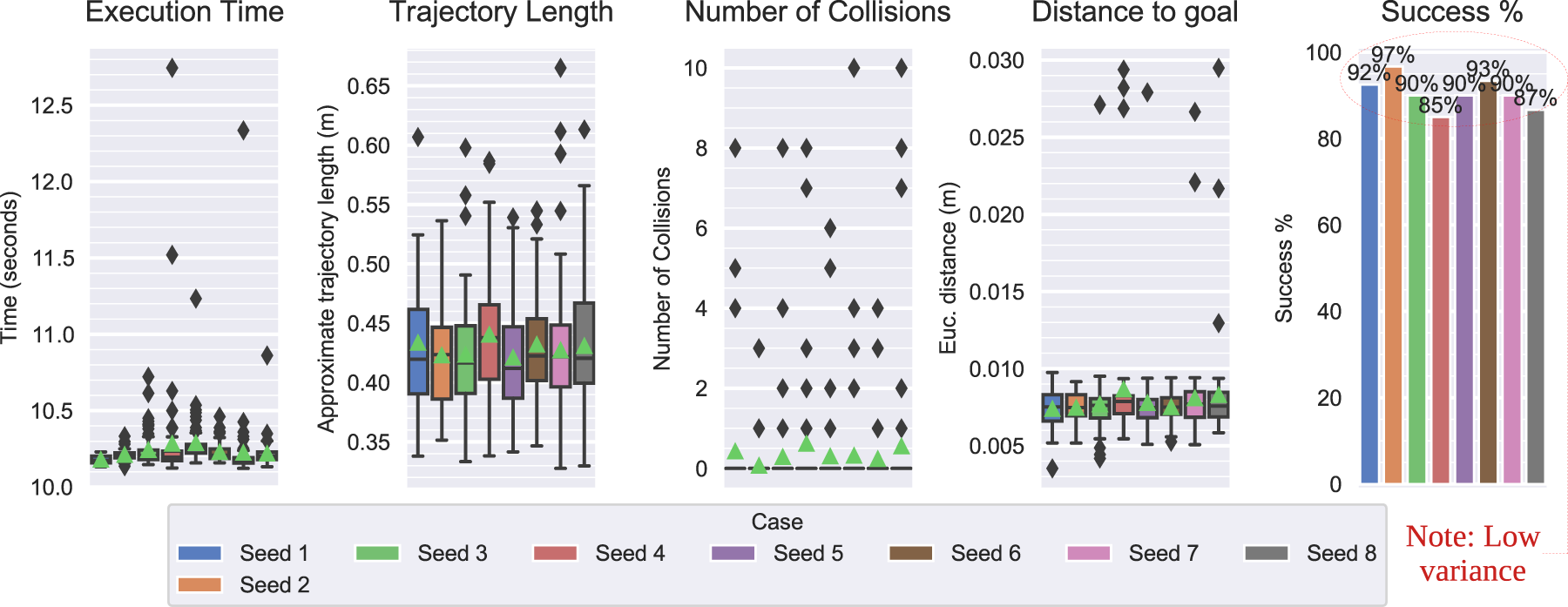
The limited variation in the results was not significant enough to invalidate previously established conclusions and, in fact, has positive implications for applications of learning. In particular, the observed relevance of the weights motivates searching for values that could improve performance, for example, through optimization and learning algorithms to tune SNN weights; an interesting avenue for future work.
7.4. Testing real event camera data
We had utilized event emulation within our pipeline with the hypothesis that our conclusions can be extended to a system equipped with a real EC. As an initial validation step, we integrated and conducted preliminary tests with an EC.
We used a DAVIS346 EC, which contains a dynamic vision sensor (DVS) and active pixel sensor (APS) that enable capturing event and RGB data, respectively. The DAVIS346 has a relatively large pixel size of 18.5 μm2 and a resolution of 346 × 260. By comparison, the Omnivision OV5640 sensor mounted on the Kinova Gen3 has a pixel size of 1.4 μm2 and a resolution that ranges from 320 × 240 to 2592 × 1944. However, the DAVIS has a significantly higher dynamic range (120 dB vs 68 dB). In addition, the OV5640 consumes
Figure 21 depicts the events generated for four frames of a simple hand motion by the emulator and the DAVIS. Evidently, the events are spatio-temporally similar, but the DAVIS is more sensitive to minute motions and produces significantly more salient events. On the other hand, its output is notably noisier, but may be alleviated with careful tuning of the camera’s parameters. A comparison of events generated by our emulator and the DAVIS346. Note: RGB images captured by the DAVIS346 were used to generate the emulated event images.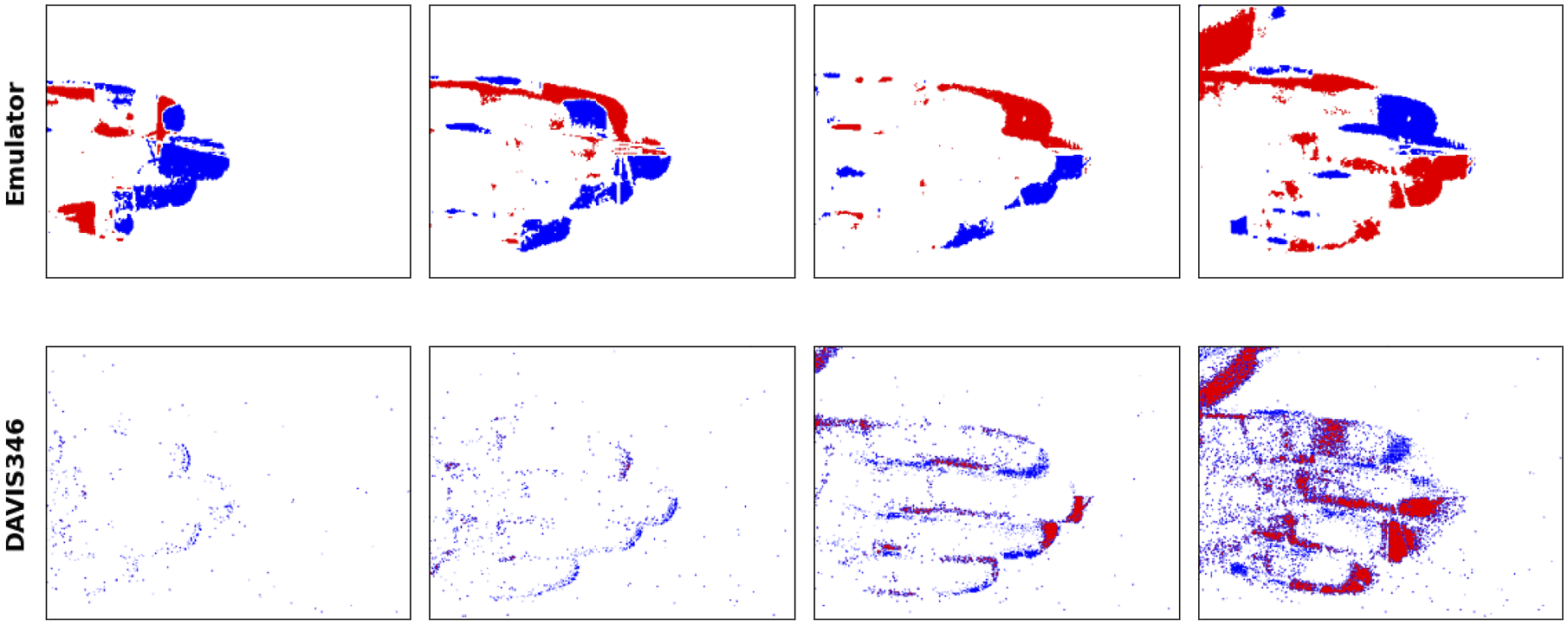
For evaluating the DAVIS’s performance, we repeated executions of scenario R3 trials. The camera parameters, particularly the emission thresholds, were moderately adjusted to induce SNN responses of similar magnitudes to those induced by the emulator. However, the DAVIS produced denser and noisier event data on average, which necessitated diminishing sensitivity to the event data elsewhere in the pipeline. To that end, we modified the values of (i) the limit on instantaneous avoidance accelerations, ϕ max and (ii) the binary erosion filter size, s BE . N trials = 30 trials were executed and compared to the previous trials.
Figure 22 illustrates the quantitative results with event emulation and with the DAVIS346. Most significantly, we observed a similarly high success rate with the EC, despite three observed failures, two of which were light touches of the obstacles. Ultimately, the minimal tuning of the DAVIS’s parameters led to similar results and trajectory shapes. Quantitative metric results for scenario R3 with results when using the event emulation (obtained during the experiments discussed in Section 6.2) and the real EC.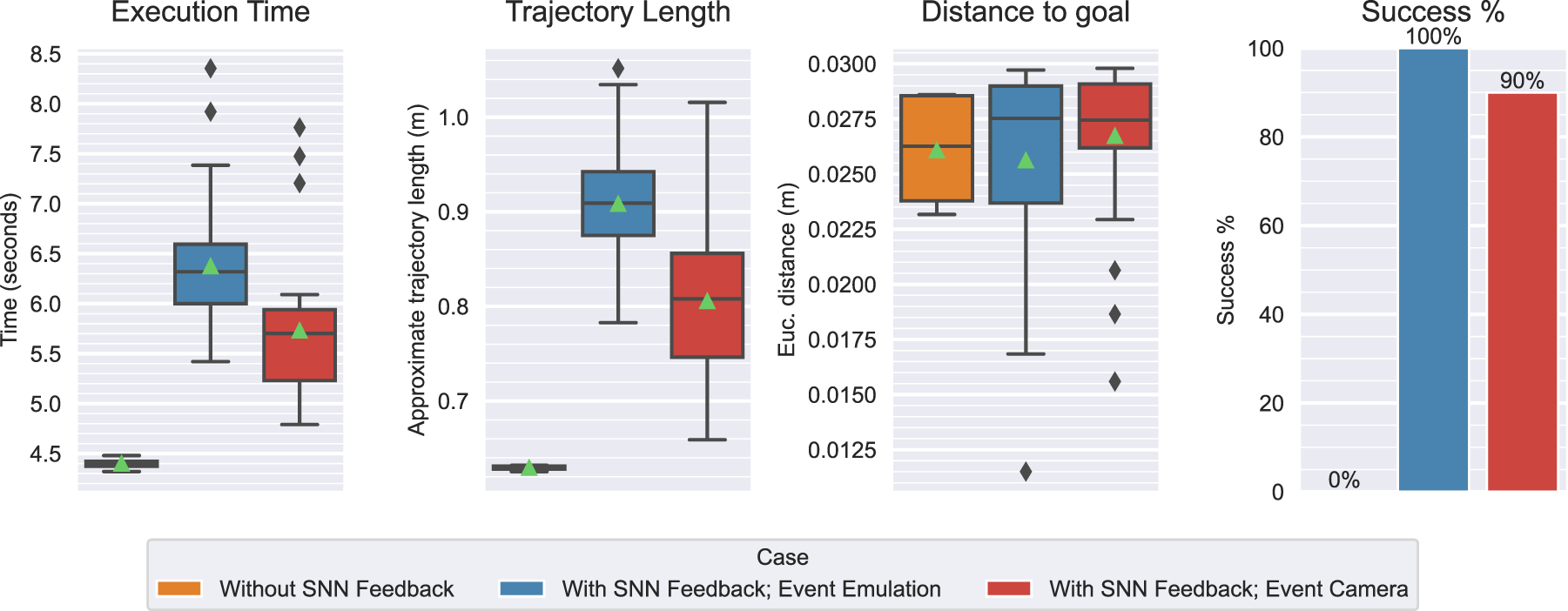
These tests show the seamless substitution of the emulator with an EC. The similarity in task performance indicates that our experiment conclusions could be extended to a system incorporating a real EC, and provides some validation for using emulation as a substitute in research. Nevertheless, testing in more scenarios may yield more insights, especially since the relatively large number of camera parameters have not been fully explored. The small decrease in task success may be due to a sub-optimal tuning of the DAVIS parameters, in contrast to the emulator’s parameters, which underwent a more rigorous refinement process during our tuning phase.
8. Conclusion
We presented and evaluated a neuromorphic approach to obstacle avoidance on a manipulator with a single onboard camera. Our pipeline transforms visual inputs into corrective obstacle avoidance maneuvers, combining high-level trajectory planning and low-level reactive adjustments using DMPs. We utilized event-based vision and spiking neural networks for neuromorphic sensing and processing capabilities. Simulated and real experiments have demonstrated its success in achieving real-time, online obstacle avoidance across various task scenarios, proving its utility over a non-adaptive baseline. The adaptive trajectories minimally deviated from the baseline and were often predictable, safe, and reasonably smooth.
Further analyses highlighted useful properties of the SNN, such as robustness to variations/noise in event data. The proportionality of computations to input magnitudes, as evidenced by the time analysis, validates two suppositions: the SNN’s tendency to exclusively process relevant information, which can save energy and time, and the homogeneity of EC data and SNNs. Since the relevant information for the problem we address is relative input change, events efficiently distill this information and the SNN selectively performs computations only on those portions of the visual inputs. Additionally, the SNN weight analysis motivated future applications of learning-based optimization. Finally, we verified the compatibility of our implementation with a real EC.
8.1. Limitations
We noted a limited capability of avoiding high-speed obstacle collisions, which could be addressed by increasing sensitivity but at the cost of compromising safety. Therefore, we presently acknowledge a fundamental limitation in reliably reacting to fast obstacles due to physical constraints. Additionally, two factors that seemed to occasionally cause failures were dimmer lighting, which lead to less contrasts between foreground and background, and clutter, which could contribute to more background events that saturate the SNN response, possibly overwhelming localized responses at obstacle positions.
We presented a set of well-formulated qualitative evaluation criteria, for which we selected specific quantitative measures to evaluate each. However, since concepts like predictability can be interpreted in different ways, a better approach could aggregate multiple measures, including from user data, to evaluate each criterion.
The method discussed in this paper does not provide a mechanism for distinguishing obstacles from objects that the robot must interact with, since it is intended to solely enable fast, reactive obstacle avoidance (which could be considered a low-level behaviour). The ability to recognize goal-relevant objects could be delegated to a higher-level planning component that adapts the behaviour of the avoidance module according to task-specific knowledge, such as an object to be grasped. In this case, a simple adaptation could be to dampen or cancel the effects of the avoidance module when the input data corresponds to the location of the task object. Therefore, we currently assume that this method is augmented by such planning components.
As mentioned in Section 4.5.1, our obstacle avoidance is currently restricted to motions in two dimensions that align with the camera’s image plane. While this is sufficient for the targeted type of tasks, other situations may require more general motions. Although it is outside the scope of this work, it is worth noting that this could be addressed through a novel method for recovering depth information from distributions and magnitudes of local events in event images or using stereo vision (such as in Zhou et al., 2021b, and Risi et al., 2020), which is often applied in conventional camera systems to achieve some depth perception and is biologically plausible in principle.
While this work focuses on the design, implementation, and systematic evaluation of the novel neuromorphic pipeline itself, with obstacle avoidance being a representative application, we do not experimentally compare to conventional obstacle avoidance methods, which could be useful in validating our method. Such a comparison to existing, non-neuromorphic methods can be challenging due to the drastically different sensor configurations (refer to Section 3.4 for discussions of examples) and approaches to collision avoidance that they apply. In particular, most reviewed methods employ multiple sensors on and around the robot, most commonly RGB-D cameras, compared to our single, biologically-inspired, onboard event camera, which presents a novel paradigm.
8.2. Future work
An interesting extension is to incorporate learning for adjusting the SNN weights and optimizing the hyperparameters of the pipeline. Given the results of our random weights analysis, we expect synaptic weight tuning to have a positive impact on avoidance behaviour. The best method to train an SNN remains an open question, but we could consider STDP or surrogate gradient methods. Other approaches include liquid-state machines (Ponghiran et al., 2019) and applying a simple rule such as linear regression on a representation of output spiking activity (Michaelis et al., 2020).
Although our manual hyperparameter tuning procedure leads to interpretable results, it could limit applicability to different tasks and situations. This could be substituted by a learning or optimization algorithm, such as RL or evolutionary optimization, with a formalized objective function, thereby avoiding the tedium of manual tuning and potentially yielding better parameter values. In addition, these optimization algorithms could be deployed online to adapt and adjust parameters to different tasks and situations.
Given preliminary results with the DAVIS346, a next step is to further explore and utilize the capabilities of the event camera.
We presented additional analyses of particular components in Section 7, which could be extended further with ablation studies. These studies could involve conducting experiments that enable studying and evaluating the neuromorphic components more intensively and potentially drawing more interesting connections to their biological counterparts.
Our qualitative evaluation can be improved by conducting user studies in which executions are evaluated by naïve subjects through questionnaires designed to elucidate the general perception of the robot’s behaviour.
We noted some uncertainty in trajectory outcomes in one of the simulation tasks (3). The slight variations in results are due to the complex interactions and data flow within the pipeline stages. In order to better understand these interactions, we could formulate experiments designed to quantify the effects of input variations, the results of which may explain the observed differences in trajectories.
We have only considered collisions of the end-effector throughout this work, but we could augment our trajectory adaptation approach to incorporate avoidance of collisions with the rest of the robot’s body. For example, one could incorporate information on the robot morphology in the replanning of motion trajectories, which could be achieved more easily in the case of DMPs by representing trajectories in joint space (not end-effector space) or using other motion planners and feeding back obstacle information to ultimately ensure that all parts of the robot body maintain distance from perceived obstacles. In addition, higher-level planning behaviours can be implemented to maintain a memory of perceived objects around the workspace and to execute motions whose purpose is to perceive and “remember” object locations even when they are no longer within the field of view (similar to mapping the environment), particularly since EC data relies on relative motion.
The full extent to which the SNN provides processing speed, power consumption, and other improvements can be studied only when the networks are run on neuromorphic hardware. Naturally, a potential extension is thus to explore the integration of a neuromorphic processor as a step towards a more fully neuromorphic processing approach.
Finally, we have demonstrated our approach in the domain of robot manipulation. In future work, we can apply our implementation to a navigation scenario, for example. The results of experiments in a different domain can provide further validation of the neuromorphic concept we have developed and evaluated in this paper.
Footnotes
Acknowledgements
We gratefully acknowledge the support by the b-it International Center for Information Technology.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Appendix A. Experimental scenario variables
This appendix contains visualizations of the tasks and variables (backgrounds, obstacle types, and obstacle colors) that define the scenarios of the simulation experiments.
Appendix B. List of Experiment scenarios
This appendix contains the lists of task scenarios that were used in the simulated and real experiments in Tables 7 and 8. List of tuning, validation, and testing scenarios. List of real robot experiment task scenarios.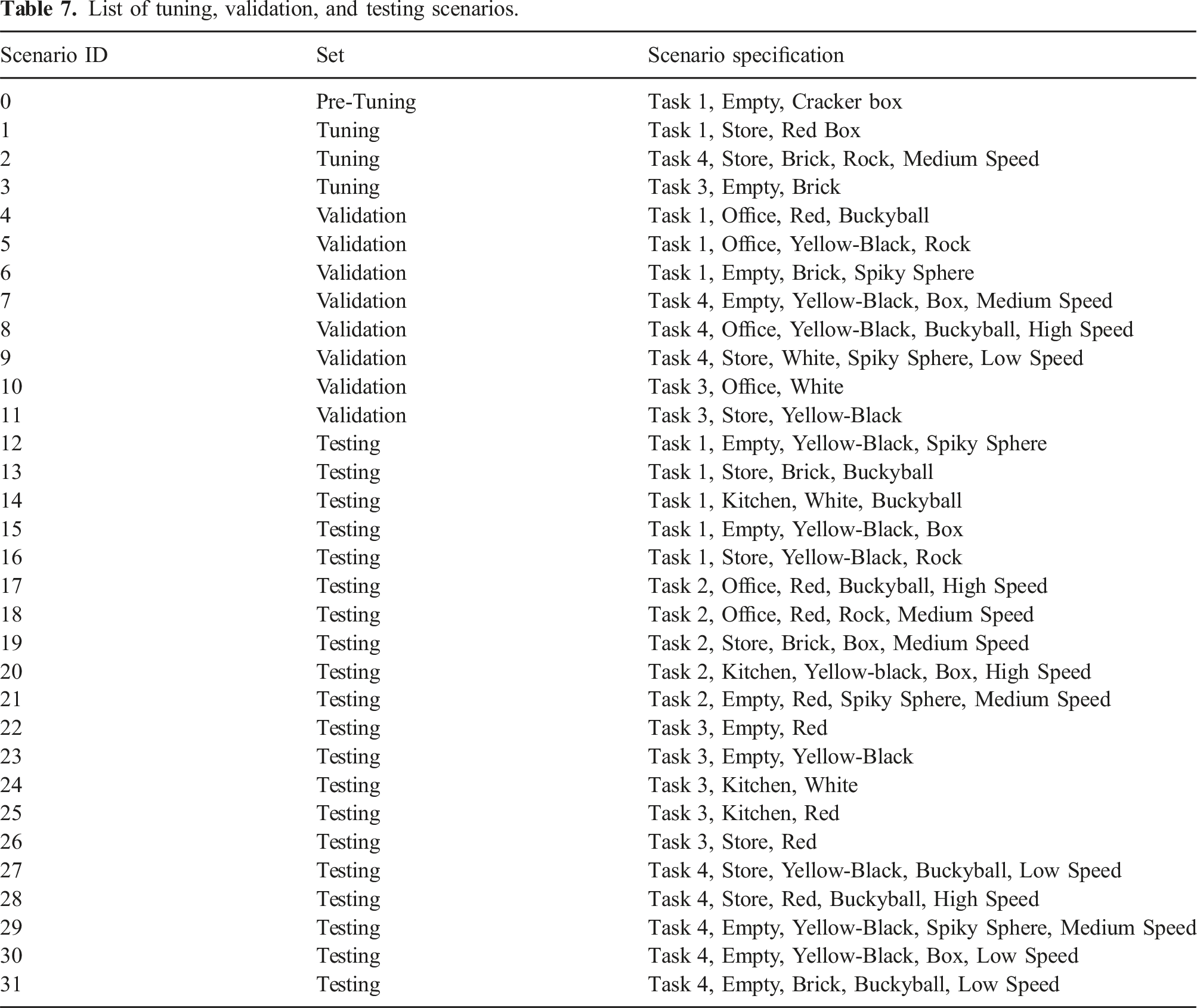
Scenario ID
Set
Scenario specification
0
Pre-Tuning
Task 1, Empty, Cracker box
1
Tuning
Task 1, Store, Red Box
2
Tuning
Task 4, Store, Brick, Rock, Medium Speed
3
Tuning
Task 3, Empty, Brick
4
Validation
Task 1, Office, Red, Buckyball
5
Validation
Task 1, Office, Yellow-Black, Rock
6
Validation
Task 1, Empty, Brick, Spiky Sphere
7
Validation
Task 4, Empty, Yellow-Black, Box, Medium Speed
8
Validation
Task 4, Office, Yellow-Black, Buckyball, High Speed
9
Validation
Task 4, Store, White, Spiky Sphere, Low Speed
10
Validation
Task 3, Office, White
11
Validation
Task 3, Store, Yellow-Black
12
Testing
Task 1, Empty, Yellow-Black, Spiky Sphere
13
Testing
Task 1, Store, Brick, Buckyball
14
Testing
Task 1, Kitchen, White, Buckyball
15
Testing
Task 1, Empty, Yellow-Black, Box
16
Testing
Task 1, Store, Yellow-Black, Rock
17
Testing
Task 2, Office, Red, Buckyball, High Speed
18
Testing
Task 2, Office, Red, Rock, Medium Speed
19
Testing
Task 2, Store, Brick, Box, Medium Speed
20
Testing
Task 2, Kitchen, Yellow-black, Box, High Speed
21
Testing
Task 2, Empty, Red, Spiky Sphere, Medium Speed
22
Testing
Task 3, Empty, Red
23
Testing
Task 3, Empty, Yellow-Black
24
Testing
Task 3, Kitchen, White
25
Testing
Task 3, Kitchen, Red
26
Testing
Task 3, Store, Red
27
Testing
Task 4, Store, Yellow-Black, Buckyball, Low Speed
28
Testing
Task 4, Store, Red, Buckyball, High Speed
29
Testing
Task 4, Empty, Yellow-Black, Spiky Sphere, Medium Speed
30
Testing
Task 4, Empty, Yellow-Black, Box, Low Speed
31
Testing
Task 4, Empty, Brick, Buckyball, Low Speed

Scenario ID
Set
Scenario specification
R1
Testing (Real)
Task 1, Lab Background 1, Wooden Block
R2
Testing (Real)
Task 2, Lab Background 2, Hand
R3
Testing (Real)
Task 2, Lab Background 2, Metal Bar
R4
Testing (Real)
Task 2, Lab Background 2, Wooden Block
Appendix C. Evaluation metrics and criteria details
This appendix contains more detailed descriptions of the quantitative metrics and qualitative evaluation criteria presented in Section 5.1.3.
Appendix D. Implementation details
The components described in Section 4 were implemented as ROS nodes, using the ROS Noetic Ninjemys distribution and Python 3.8 for development. This section summarizes details of our the ROS stack and the augmented Gazebo simulation of the Kinova Gen3.
Appendix E. Pipeline component Parameters
Table 10 lists and describes the main parameters of our neuromorphic pipeline, divided by component. The parameters of each pipeline component. The (*) indicates a parameter which was not tuned in our experiments.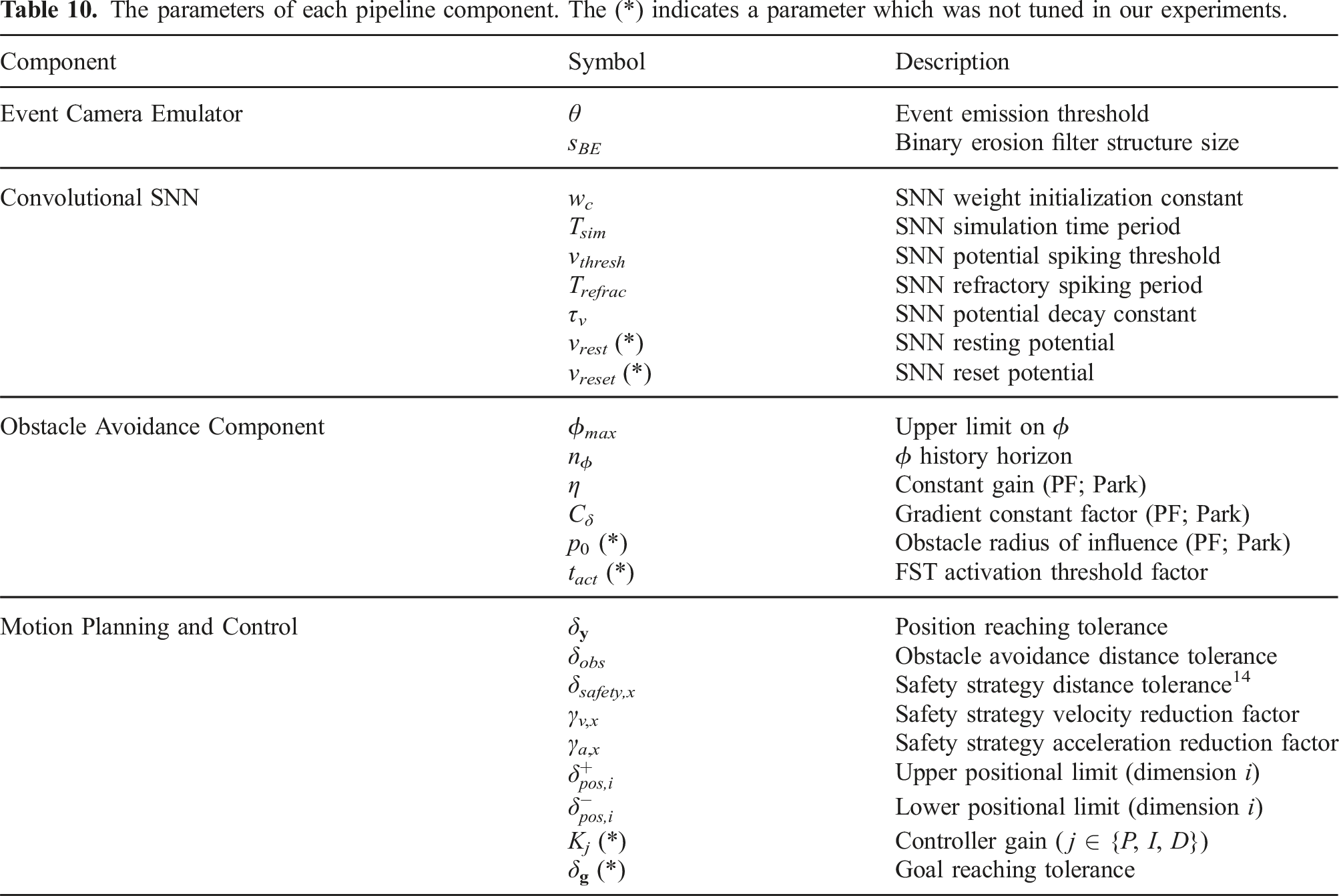
Component
Symbol
Description
Event Camera Emulator
θ
Event emission threshold
s
BE
Binary erosion filter structure size
Convolutional SNN
w
c
SNN weight initialization constant
T
sim
SNN simulation time period
v
thresh
SNN potential spiking threshold
T
refrac
SNN refractory spiking period
τ
v
SNN potential decay constant
v
rest
(*)
SNN resting potential
v
reset
(*)
SNN reset potential
Obstacle Avoidance Component
ϕ
max
Upper limit on ϕ
n
ϕ
ϕ history horizon
η
Constant gain (PF; Park)
C
δ
Gradient constant factor (PF; Park)
p0 (*)
Obstacle radius of influence (PF; Park)
t
act
(*)
FST activation threshold factor
Motion Planning and Control
δ
Position reaching tolerance
δ
obs
Obstacle avoidance distance tolerance
δ
safety,x
Safety strategy distance tolerance14
γ
v,x
Safety strategy velocity reduction factor
γ
a,x
Safety strategy acceleration reduction factor
Upper positional limit (dimension i)
Lower positional limit (dimension i)
K
j
(*)
Controller gain (j ∈ {P, I, D})
δ
Goal reaching tolerance
Appendix F. Event emulation comparison visualizations
This appendix contains figures that supplement the event emulation strategy comparison presented in Section 7.1. The event images produced by all five methods for the three sample RGB inputs and the resulting SNN responses are shown in Figures 30 and 31, respectively. In the latter, each sub-plot depicts the recorded spike trains (left) and the total count of spikes (right) across T
sim
at each output neuron. Note that the shared y-axes are indexed by a row-major re-ordering of the neuron indices, which are originally arranged in a two-dimensional grid, where the first and last indices are in the top-left and right-bottom positions, respectively. Event images produced by each emulation strategy described in Section 7.1. Although the event distributions are fairly similar, a few notable differences include M2 (with blurring) producing less noisy events than M1, the log-based methods M3 and M4 producing more events in darker regions, and M1, M2, and M4 reacting more strongly to reflective surfaces. SNN responses to input events from each emulation strategy described in Section 7.1 for each sample. The plots show the spike trains (left) and spike counts (right) for each output neuron. The responses largely match the input events shown in Figure 30 (e.g. more spikes in the first few neurons for M1-M4, which correspond to the top regions of the event images). Despite some differences in the input event data, the SNN responses are similar (except for M5), indicating an inherent robustness to variations in events.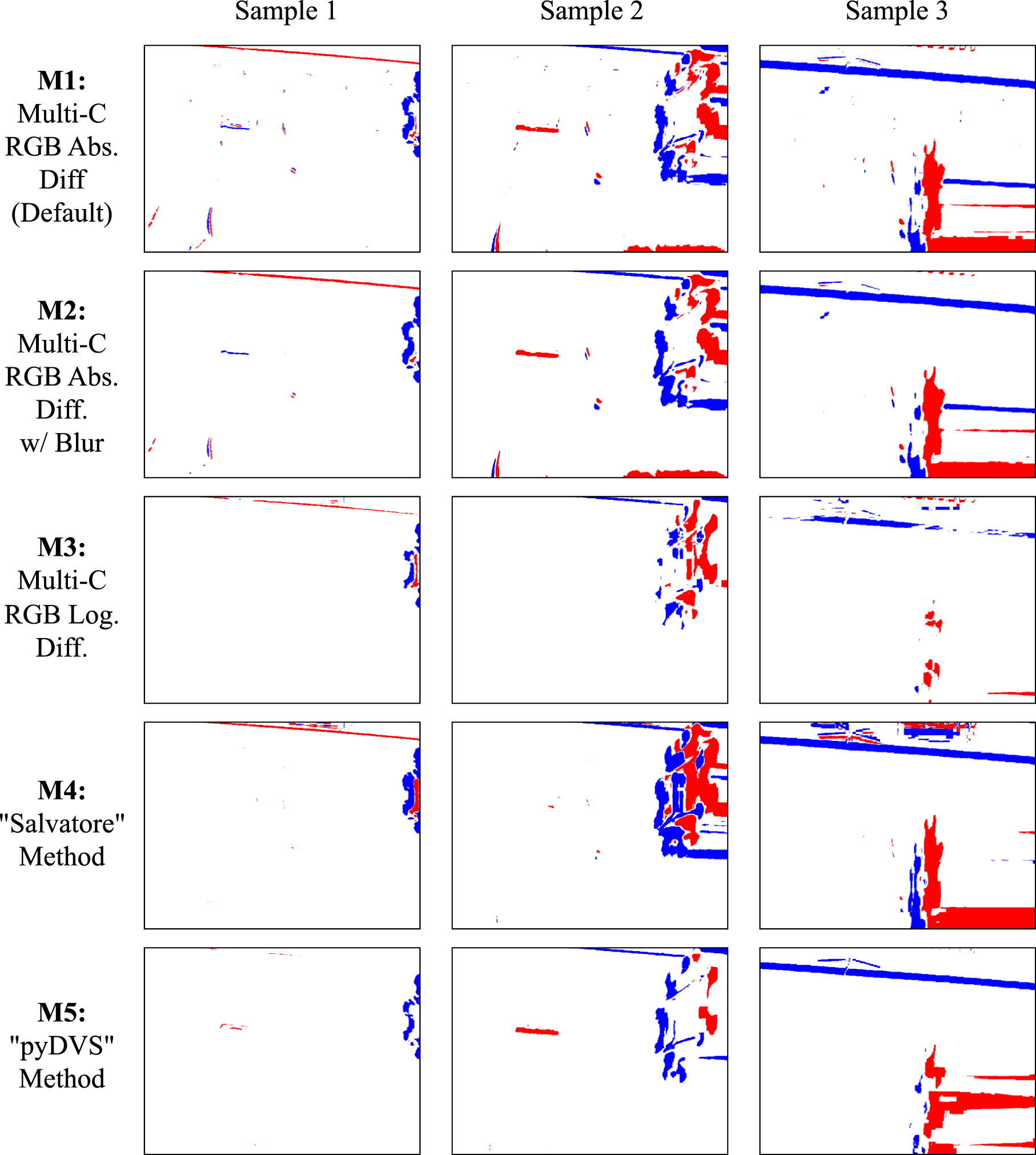
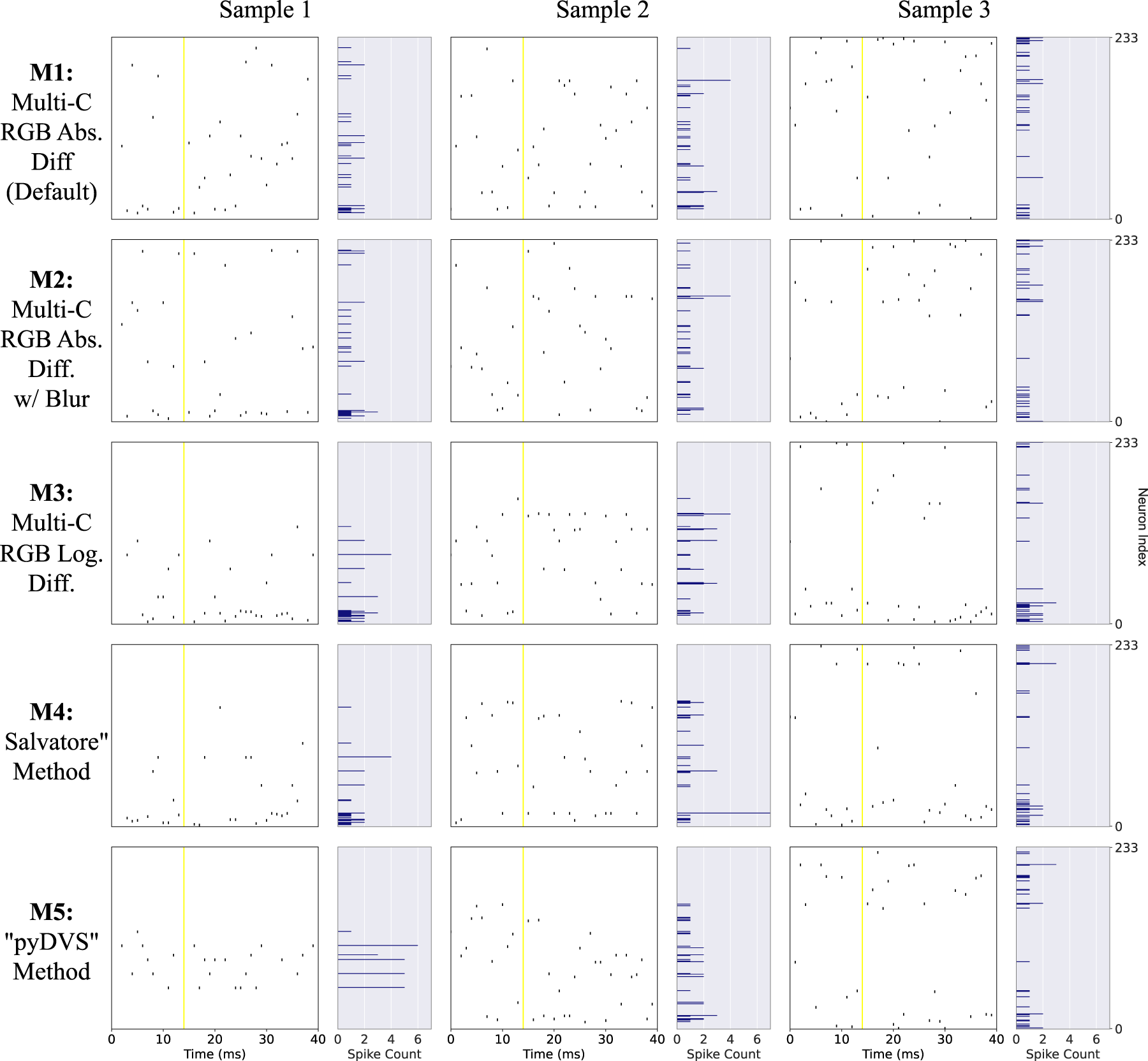
Appendix G. Qualitative evaluation visualizations
This appendix contains supplementary figures for the predictability qualitative evaluations.
Appendix H. Results metrics and trajectory plots
This appendix contains quantitative metric results and trajectory plots that are referred to in discussions of the tuning, validation, and testing phases of the simulation experiments in Sections 6.1.2, 6.1.3, and 6.1.4: • Tuning phase trajectories executed in scenario 1 (parameter sets 1-12): Figure 34 • Real experiment trajectories executed in scenarios R1-R4: Figure 35 • Validation phase metrics in scenarios 4-11 (selected parameter sets): Figure 36 • Testing phase metrics in scenarios 12-31 (selected parameter set): Figure 37 Trajectories executed in tuning scenario 1: parameter sets 1-12 (discussed in Section 6.1.2). (a) Parameter Set 1. (b) Parameter Set 2. (c) Parameter Set 3. (d) Parameter Set 4. (e) Parameter Set 5. (f) Parameter Set 6. (g) Parameter Set 7. (h) Parameter Set 8. (i) Parameter Set 9. (j) Parameter Set 10. (k) Parameter Set 11. (l) Parameter Set 12. Trajectories executed in real robot experiments with SNN feedback in scenarios R1-R4 (discussed in Section 6.2). (a) Scenario R1. (b) Scenario R2. (c) Scenario R3. (d) Scenario R4. Quantitative metric results for validation scenarios 4-11: without SNN feedback and with selected parameter sets. (a) Scenario 4. (b) Scenario 5. (c) Scenario 6. (d) Scenario 7. (e) Scenario 8. (f) Scenario 9. (g) Scenario 10. (h) Scenario 11. Quantitative metric results without versus with SNN feedback (best parameter set): testing scenarios 12-31. (a) Scenario 12: {T1, Empty, Yellow, Spiky Sphere}. (b) Scenario 13: {T1, Store, Brick, Buckyball}. (c) Scenario 14: {T1, Kitchen, White, Buckyball}. (d) Scenario 15: {T1, Empty, Yellow-Black, Box}. (e) Scenario 16: {T1, Store, Y-B, Rock}. (f) Scenario 17: {T2, Office, Red, Buckyball, High}. (g) Scenario 18: {T2, Office, Red, Rock, Med.}. (h) Scenario 19: {T2, Store, Brick, Box, Med.}. (i) Scenario 20: {T2, Kitchen, Y-B, Box, High}. (j) Scenario 21: {T2, Empty, Red, Spiky Sphere, Med.}. (k) Scenario 22: {T3, Empty, Red}. (l) Scenario 23: {T3, Empty, Y-B}. (m) Scenario 24: {T3, Kitchen, White}. (n) Scenario 25: {T3, Kitchen, Red}. (o) Scenario 26: {T3, Store, Red}. (p) Scenario 27: {T4, Store, Y-B, Buckyball, Low}. (q) Scenario 28: {T4, Store, Red, Buckyball, High}. (r) Scenario 29: {T4, Empty, Y-B, Spiky Sphere, Med.}. (s) Scenario 30: {T4, Empty, Y-B, Box, Low}. (t) Scenario 31: {T4, Empty, Brick, Buckyball, Low}.