
Abstract
This work addresses the problem of online exploration and visual sensor coverage of unknown environments. We introduce a novel perception roadmap we refer to as the Active Perception Network (APN) that serves as a hierarchical topological graph describing how to traverse and perceive an incrementally built spatial map of the environment. The APN state is incrementally updated to expand a connected configuration space that extends throughout as much of the known space as possible, using efficient difference-awareness techniques that track the discrete changes of the spatial map to inform the updates. A frontier-guided approach is presented for efficient evaluation of information gain and covisible information, which guides view sampling and refinement to ensure maximum coverage of the unmapped space is maintained within the APN. The updated roadmap is hierarchically decomposed into subgraph regions which we use to facilitate a non-myopic global view sequence planner. A comparative analysis to several state-of-the-art approaches was conducted, showing significant performance improvements in terms of total exploration time and surface coverage, and demonstrating high computational efficiency that is scalable to large and complex environments.
Keywords
1. Introduction
The general problem of online exploration and visual surface coverage of a priori unknown structure or environment can be referred to as online sensor-based coverage planning (OSCP). For this, a robot such as a Micro Aerial Vehicle (MAV) must efficiently discover the spatial and geometric structure of an initially unknown environment using an onboard depth sensor. The robot must traverse the environment to perceive the unknown space from different perspectives, accumulating the acquired sensor knowledge in a spatial map. OSCP is a prerequisite problem for a wide range of applications involving operation in an unknown environment, such as structural modeling and inspection, surveying, search and rescue, and many others (Quattrini Li, 2020).
The global coverage problem of OSCP is to achieve maximum coverage of the target surfaces as efficiently as possible. Naturally, this cannot be solved directly due to the lack of a priori knowledge, and can only be solved online in an incremental fashion. This leads to the incremental exploration problem which represents an iterative action selection problem: given the current incomplete knowledge, determine the optimal action to increase the current knowledge. As each action is executed, the incremental objective is recursively solved using feedback from the added environment knowledge until the global coverage objective has been achieved.
1.1. Related work
The purpose of online exploration and coverage can vary between different applications and tasks. For example, some applications seek knowledge of the traversable space within an unknown environment for subsequent navigation tasks, while others may seek detailed coverage of the surfaces for 3D modeling or inspection purposes. It is important to recognize such differences in the intended application, as this can greatly influence how the problem is approached and how its performance is evaluated.
1.1.1. Frontier-based exploration
Autonomous exploration was pioneered by Yamauchi (1997) by introducing the now well-known concept of spatial frontiers. Frontiers represent boundaries within a partially built map between unknown space the robot seeks to observe, and the free space the robot can use to make the observations. The original frontier exploration algorithm, referred to as classical frontier exploration, was implemented for a mobile ground robot building a 2D occupancy grid map. The algorithm selects the closest frontier as the goal, and navigates toward the goal while using reactive collision-avoidance. Upon arrival, a new sensor scan is acquired of the region and added to the map, repeating the process until no unvisited and reachable frontiers remain.
Many extensions have been proposed to the initial frontier-based approach, including more efficient frontier detection methods (Keidar and Kaminka, 2014; Topiwala et al., 2018) and extensions for 3D maps (Zhu et al., 2015). However, a significant drawback of classical frontier exploration is that frontiers indicate only the existence of adjacent unknown space, but not the quantity or quality. Using a frontier location directly as the navigation goal ignores sensor’s measurement range, thus causing inefficient and wasteful motions. Furthermore, a frontier location near surfaces generally do not represent a feasible goal for a robot due to collision with the surface obstacle, making their direct use in this way ineffective for surface coverage tasks.
1.1.2. Next-best-view (NBV) sampling
Exploration can be effectively modeled as an extension of the Next-Best-View (NBV) problem introduced by Connolly (1985), which can overcome several of the drawbacks associated with classical frontier-based approaches. Here, a view refers to a hypothetical pose of the sensor apparatus used to predict and analyze the spatial information expected to be visible if the real sensor were to be placed at this pose. The expected visible information is then said to be covered by the view.
The classical NBV problem assumed full prior knowledge of the target object is given to facilitate the search and evaluation of NBVs, where the objective was to find a minimum set of views that maximizes coverage of the known surfaces of the object model. This premise can be adapted for online exploration tasks by instead evaluating views according to currently unknown parts of the environment model, rather than the known parts.
Next-best-view (NBV)-based exploration methods typically utilize a generate-and-test paradigm which apply sampling techniques necessary to discretize the continuous configuration space into a finite set of candidate views for analysis (Scott et al., 2003). The quality of a view is evaluated according to some measure of its information gain (IG), which quantifies the new spatial information potentially observable from the view (Heng et al., 2015; Kaufman et al., 2016; Song and Jo, 2018; Stachniss et al., 2005). A cost metric is additionally used to evaluate the expected effort for the robot to visit the view (e.g., time or energy). Most critical differences between existing NBV approaches occur within the sampling strategy for generating view candidates, and the formulation of metrics for analyzing and comparing candidates for goal selection.
Information gain is commonly computed volumetrically by finding the expected amount of unknown space visible from a view (Dang et al., 2019; Kompis et al., 2021; Okada and Miura, 2015). This necessarily involves checking for occlusions within the known space using techniques like raycasting, which incurs high computational complexity that can rapidly increase with various factors like map resolution, sensor field of view, and sensing range. This limits the number of distinct views that can be practically evaluated within a given time period. The high complexity also makes it difficult to analyze overlapping or mutual information between views, such that most approaches treat the gain as an independent value that prevents an understanding of the unique gain contributions of each view within a group.
1.1.3. Tree-based planning
Tree-based methods organize sampled views as vertices in a geometric tree where directed edges between vertices represent feasible paths between views. The RH-NBVP approach of Bircher et al. (2016b, 2018) applies rapidly-exploring random tree (RRT) to grow a tree rooted at the robots current position. Each node in the tree is weighted according to their predicted information gain based on how much unknown space lies within the view. Cost weights are aggregated along each branch, and the leaf node with the highest value is used to identify the best branch to explore, iteratively repeating the process in a receding horizon fashion. This has become a well-known approach and is often used as a baseline for comparative analysis (Cieslewski et al., 2017; Dai et al., 2020; Selin et al., 2019).
A hybrid approach that combines both frontier-based and NBV-based techniques was introduced by Selin et al. (2019), referred to as AEP. It combines the RH-NBVP strategy for local planning, while switching to frontier-based planning for global search when local planning fails to find informative views. FFI (Dai et al., 2020) is also a hybrid approach that uses an efficient frontier clustering strategy to guide view sampling.
A significant drawback of tree-based planning is the difficulty in preserving the previously computed tree structure as the robot navigates to each goal. The RH-NBVP approach builds a new tree each iteration, discarding the previously built structure that may still contain useful knowledge. Other approaches attempt to transfer as much of the previous tree structure as possible by rewiring its edges to initialize the construction of a new tree. Since tree-based methods are rooted at the robots position, they tend to become increasingly inefficient over larger distances, making it difficult to handle dead-end or backtracking cases.
1.1.4. Graph-based planning
Various approaches have utilized graph structures that can overcome some of the limitations and drawbacks of trees. The approach of Witting et al. (2018) builds a history graph that stores previously visited positions and their edge connections. These are used as potential seed points for RRT, which allows a tree to be grown from different positions across the map, rather than just from the robot position. An approach using Rapidly-Exploring Random Graphs (RRG) was presented in Dang et al. (2019) for exploration of subterranean environments. A Probabilistic Roadmap (PRM) strategy was used by Xu et al. (2021) to build a graph of feasible configurations and paths over the map as it is explored.
1.1.5. Topological maps
Topological maps have been applied by recent works which aim to reduce the planning complexity through the compact representation provided by a topological map. Topological maps can be considered as an extension to graph-based methods, where vertices represent some volumetric sub-map, or place, and edges represent the adjacency or reachability between places. This coarse and abstracted representation is more efficient for handling large-scale environments, which can become intractable to explore online using alternative approaches. However, they usually lack sufficient metric knowledge for direct use in navigation.
A topological map was used by Silver et al. (2006) for exploration of underground mines by a ground robot. The regions of intersection between passageways were represented as nodes, and exploration was planned along the edges between nodes.
Other approaches have applied spatial partitioning of the known free space to identify a topological map structure. A contour-based segmentation approach was presented by Fermin-Leon et al. (2017) to decompose a 2D occupancy grid into polygonal regions corresponding to meaningful regions like corridors or rooms of a building. Yang et al. (2021) used convex polyhedra to decompose a 3D map into distinctive exploration regions for subterranean exploration. A uniform decomposition method was proposed by Cao et al. (2021) which partitions space into even cuboid subspaces.
1.1.6. Myopic greedy planning
The majority of existing methods compute navigation goals using myopic planning strategies that greedily optimize the cost of the next single planning decision (Dai et al., 2020; Palazzolo and Stachniss, 2018), or within a limited planning horizon (Bircher et al., 2016b; Selin et al., 2019). Some works allow planning to search for goals using the full map, but still consider only the local costs and independent rewards of each goal and apply greedy search strategies. These are sometimes referred to as global planning methods, but we clarify they are still considered myopic.
Myopic strategies bias exploration toward regions with high information gain, while ignoring small gains even if they are closer. This bias can frequently create regions of incomplete coverage when a high-gain goal leads the exploration away from the current region before it is fully mapped. This can also result in frequent back-and-forth oscillation between goals, or require re-visitation of these regions after the robot has traveled a significant distance, backtracking over potentially large distances. This greatly reduces efficiency, and can result in sparse coverage gaps or failure to fully explore an environment within an allowed time limit, especially over large-scales.
1.1.7. Non-myopic planning
Non-myopic planning has been referred to using several names, such as view path planning or informative path planning (IPP). It can be effectively formulated using variations of the Traveling Salesman Problem (TSP) or shortest Hamiltonian path problem which seek an ordered exploration path that optimally explores the remaining unknown parts of the map. In this way, planning can account for the conditional information gain of each path point, dependent on the information and costs along the previous parts of the path. Offline approaches using such formulations have been developed (Bircher et al., 2016a; Shang et al., 2020) when a prior map is available, but are infeasible for online applications which require iterative replanning as the map evolves.
Online global and non-myopic planning has only been considered by a relatively small number of recent papers.
A sector decomposition approach was presented by Song et al. (2020), which partitions the map into a set of convex sectors used to compute a TSP sequence. However, the sector decomposition method is computationally expensive, especially for finer map resolutions, which can greatly decrease the update rate of the map and planning. Additionally, sectors form an exact partitioning of the space, which can make the geometric properties of the resulting sectors difficult to control, and can result in a large number of sectors that cannot be handled over large-scale and complex environments.
Zhou et al. (2021) developed a hierarchical planning approach based on a novel frontier information structure. Frontiers are globally clustered and used to estimate a global exploration route, planning a more detailed view sequence within a local horizon.
A hierarchical planning approach presented by Cao et al. (2021) partitions the map into even cuboid subspaces to build a topological map. Global planning operates by finding the sequence to visit each subspace, using A* to search for minimum-cost paths connecting subspaces. Local planning then operates at higher resolution within the current subspace about the robot to find an ordered sequence of views to maximize coverage of the local subspace.
However, a drawback of these forms of top–down decomposition is that they can arbitrarily divide regions of the map without considering the underlying reachability within the environment; the information content of each subspace and its candidate views are secondarily evaluated. When a global plan is computed, the executed traversal cost may differ greatly from the estimated cost between the regions. For example, a region A may contain information only visible from a view in an adjacent region B. This will only be discovered once region A is visited, and thus it fails to accurately anticipate the future action costs. Also under some conditions, such as highly complex geometries of the environment, certain subspaces can be way more complex than some other subspaces, which can lead to inefficient coverage paths. For several of the cited works, the underlying metric space may not be explicitly represented (e.g., using a graph or roadmap). Path searches thus operate directly on the map, and may need to be recomputed from scratch in each update. This can become too expensive at large scales or fine resolutions, potentially restricting their applicability.
1.1.8. Environment and task-specific constraints
Simplifying or restrictive assumptions are sometimes made on the operational environment. This can include indoor operation, or reliance on certain regular geometric features, for example, room structures used for segmentation. Some applications are intended to operate in relatively obstacle-free environments, such as outdoors or underwater (Ellefsen et al., 2017), which contain an abundance of free-space that greatly simplifies collision checking and other sub-tasks. Others assume the environment can be explored along a relatively planar path, which helps reduce the dimensionality, but may become infeasible for applications that extend throughout all spatial dimensions. Assumptions can significantly restrict the practicality of many approaches for general use, or require fine tuning of parameters between different environments to achieve their rated performance.
1.1.9. Limitations of existing approaches
Limitations of existing approaches are summarized as follows: • Greedy and myopic planning strategies that focus on the incremental exploration objective, but fail to consider the global one, • Non-generalized approaches that are limited to small-scale environments, or specialized for specific environments or conditions (e.g., subterranean or building-like structures), • Most approaches succumb to high computational costs: – They do not scale well with respect to environment size or map resolution, – The ability to quickly replan on added knowledge diminishes, where a suboptimal plan is fully executed before replanning, – Reduced velocities are often required to compensate for low planning rates, – Frequent stop-and-go motions can occur.
There is currently a lack of modular and generalizable software to sufficiently overcome the aforementioned limitations. Online exploration involves many interacting subsystems and maintenance of large amounts of dynamically changing data structures, often with dependencies between different forms of dynamic data. Fully designing such a system is a large-scale and time-consuming development task, often requiring high levels of programming expertise that not all researchers may possess. To compensate, most researchers tend to reduce the development burden by ignoring software aspects like reusability, maintainability, and extensibility, where the resulting software becomes highly coupled to the formulations and specifications of their specific approach (Kortenkamp et al., 2016). This is known as technical debt (Suryanarayana et al., 2014). In consequence, the software has low reusability to other researchers with different specifications, and thus they can use the same development approach that repeats this cycle. In practice, software challenges can create an entry barrier leading to a bottleneck to the rate of research progress for online exploration and similar problems, and they also make benchmark analysis very difficult.
1.2. Contributions
This work is motivated to alleviate some of the limitations of the existing approaches in handling the OSCP problem. We focus first on how to dynamically compute and maintain the accurate global knowledge necessary to a non-myopic planning algorithm, since this represents a significant bottleneck in terms of computational complexity and exploration quality in the existing work. Our key contributions are as follows: • A novel dynamic multi-layer topological graph designated as the Active Perception Network (APN). The APN serves as a global hierarchical roadmap over the spatial map that accumulates the incrementally computed knowledge of the exploration space. It is defined and organized around adaptive nodes to best represent the perceptual and actionable environment knowledge discovered to minimize the complexity, which allows it to be efficiently accessed and searched for planning purposes. • A dynamic update procedure referred to as Differential Regulation (DFR) to incrementally build and refine the APN as environment knowledge is increased. This procedure addresses the complexity of updating the APN as its size and the map scale increase, while ensuring sufficient global knowledge is maintained for effective planning. • A non-myopic planning approach denoted as APN-Planner (APN-P) that demonstrates how the APN can be leveraged to compute and adaptively refine a globally informed exploration sequence. • A detailed performance analysis and comparison to existing approaches among the state-of-the-art. • An open-source release of our Active Perception for Exploration and Mapping (APEXMAP) software framework, which was used to implement the APN, DFR, and APN-P. This framework is designed to address exploration and active perception in a generalized and reusable fashion. It factorizes the general aspects of the problem domain into modular components that enable rapid development of a wide range of approaches. This contribution is intended to reduce the existing entry-barriers for online exploration and active perception research.
2. Problem formulation
We assume exploration is performed using an MAV equipped with an onboard depth sensor (e.g., stereo-visual, RGB-D, or LiDAR) to perceive 3D space, noting that other systems such as mobile ground robots could also be utilized without loss of generality. We define the following terms and symbols to facilitate the description of our approach.
2.1. Environment and map model
Let
The intersection boundaries between occupied and free-space define the surface manifolds,
A spatial map
Each voxel stores the occupancy probability of its volume, which is updated from sensor measurements depending on whether occupied or free-space was observed. The probability value is discretized by an occupancy state
Spatial frontiers,
2.2. Robot model
The robot agent is modeled by a rigid body with pose configuration
2.3. Sensor model
The robot’s depth sensor is modeled by the parameter vector
The sensor parameters can be combined with a pose
2.4. Reachable configuration space
Given the robot’s initial position
2.5. Goal space
The surfaces that can possibly be covered at any point during exploration are inherently restricted to a subset
2.6. Exploration state space
The exploration state space, Ω, refers to the collectively available knowledge necessary to solve the incremental exploration problem. This mainly consists of the robot pose
2.7. Myopicity
A planning strategy operates on the exploration state space to search for the optimal goal
In contrast, a non-myopic strategy searches over a long horizon that spans most or all of the available map. It additionally considers how the particular selection of a goal and its associated action may alter the future exploration state space. This involves search and evaluation over ordered sequences of actions, rather than each action individually. This results in solutions that are more optimal with respect to the long-term global coverage objective.
3. Methodology
We will start with an overview of our approach and then describe each important component of the approach in turn.
3.1. Approach overview
In this work, we address how to build a reusable exploration state space Ω that is adaptively maintained over the full spatial map as it is built concurrently. The iteratively built exploration space is then used to facilitate efficient non-myopic planning. We seek an approach that generalizes well to different environments with varying complexities and geometric characteristics, and efficiently scales to large-sized environments that cannot be effectively solved by myopic approaches.
To achieve this goal, we introduce a novel graph-theoretic information structure named the Active Perception Network (APN) to model the exploration state space data, detailed in Section 3.2. A key feature of the APN is a hierarchical decomposition that allows the underlying graph structure to be simultaneously represented by a reduced-size topological map.
In contrast to the top–down decomposition methods used in other works, the APN uses a bottom–up approach where the high resolution reachability, visibility, and other information is built and maintained globally, and the high-level topological subspaces are then computed from the low-level structure. This allows the formation of topological regions to be guided by the actual traversability and costs of the underlying space. Thus, the visible information of each subspace is implicitly captured in terms of the actual configurations and the associated traversal costs to observe it. Furthermore, subspaces do not form a dense space partition, instead they can be focused around only the data of interest, reusing the underlying edge structures to perform traversal between subspaces.
Another focus of the APN is the storage, organization, and analysis of the contained data, such that dynamic changes can be efficiently made to any of its contents as its size increases, while also maximizing the low-level efficiency for search and query operations. These aspects relate to optimization of the running time computation efficiency, which is related to software, data structures, and other implementation aspects. However, these technical implementation details are largely beyond the scope of this work; instead, the APN will primarily be described from a modeling perspective, with some additional implementation details provided in the Appendix.
We additionally introduce the process of Differential Regulation (DFR) in Section 3.3, which operates on the APN to modulate its state with respect to the increasing map knowledge. DFR consists of sampling-based methods for increasing knowledge of the goal space and reachable space. A novel approach for information gain analysis is utilized that enables the individual and mutual information gain of the APN to be efficiently computed, which is leveraged to accelerate informative view sampling, pruning, and refinement.
Differential Regulation (DFR) exploits the incremental nature of map building where each sequential map update induces changes that occur only within a relatively small local region of bounded volume, independent of the total map size. With this insight, these incremental changes are tracked and cached using difference-awareness and memorization strategies to greatly reduce the computational overhead necessary to update the APN. This allows more discrete updates to be performed in a given time period, increasing the completeness and accuracy of each update. The ability to quickly perform each update is also critical to ensure the size of the map changes remain small, since the complexity of each update scales with the size of the changes.
An anytime exploration planner is presented in Section 3.4, which demonstrates the use of the APN to efficiently compute non-myopic global exploration sequences. The hierarchical representation of the APN is leveraged to first compute a global topological exploration plan over the full map. The beginning of the global plan is then locally optimized at a higher-resolution. Similar to the difference-aware approach used by DFR, sequential changes to the APN typically occur within locally bounded regions which are leveraged to initialize new planning instances from previous results. This allows optimizations to achieve faster convergence despite the increasing size of the map and APN.
The iterative exploration pipeline is illustrated in Figure 1, which consists primarily of two asynchronous processing loops. The first loop is dedicated for spatial mapping to allow continuous integration of the sensor measurement data, Mapping, frontier detection, and Differential Regulation process pipelines used to update the APN.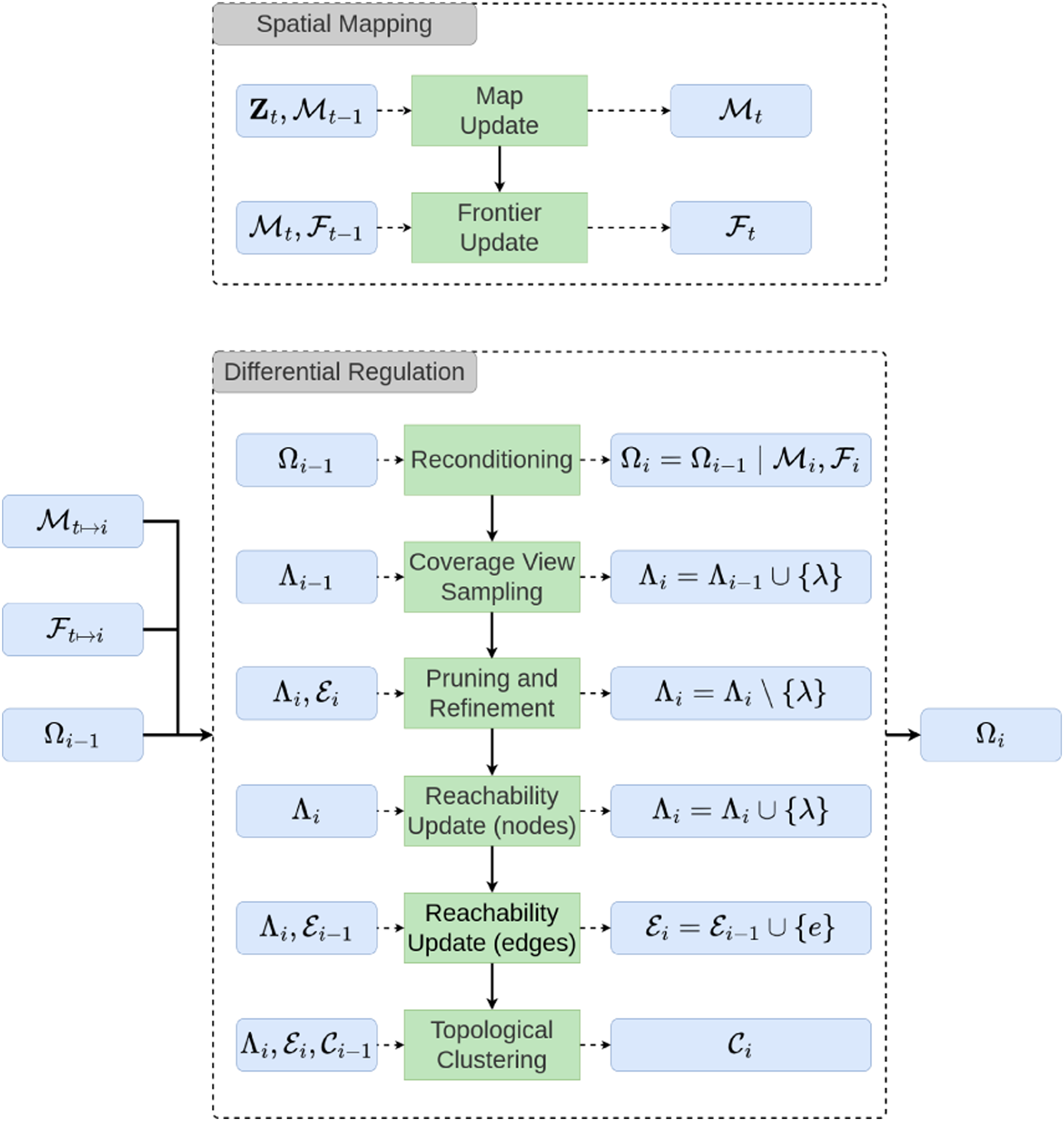
3.2. Active perception network (APN)
The Active Perception Network (APN) serves as a topological roadmap that stores the unified knowledge of the dynamically exploration state space. Its fundamental structure is represented by a hypergraph


Several important classifications are defined over • A unique node • The previously traversed path of the robot is represented by a path-connected set of keyframe nodes, • Unvisited nodes with positive information gain are classified as NBV candidate nodes, represented by the set • The remaining traversal nodes,
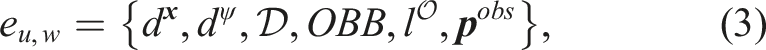
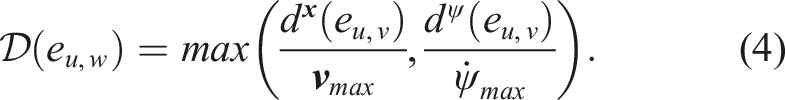
Each edge also stores the Oriented Bounding Box (OBB) enclosing the endpoints, and the collision state of the space contained in the OBB is stored by
3.2.1. Hyperedge clusters
A set of hyperedges
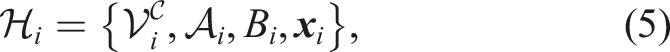
Induced edges of a cluster
3.3. Differential regulation
The APN is incrementally built by the process of Differential Regulation (DFR), which manages how information is added, removed, or modified in the APN with respect to the concurrently built spatial map. DFR evaluates the APN according to a set of objectives and constraints conditioned on the current map and executes a set of modifying procedures on the APN as needed to ensure they remain satisfied as the map evolves.
The broad purpose of the DFR procedures is to (a) re-evaluate map-dependent analytical measures to ensure their accuracy (e.g., information gain of existing nodes), (b) add node and edge elements to increase the completeness of the network while pruning redundant or overcomplete elements, and (c) recompute the topological clustering of the updated graph state. A diagram of these procedures is shown in Figure 1, and detailed in the following subsections.
3.3.1. Reconditioning
Each DFR cycle i begins at a time t with the latest spatial map
Each regulation cycle then begins by updating the pose of the agent node v
agent
and its local edges. The length of the local path is then checked and compared against a keyframe threshold distance. If the threshold is exceeded, a new keyframe view v
kf
is created from v
agent
and added to the keyframe set
3.3.2. View analysis and coverage sampling
View analysis and coverage sampling
A sampling-based approach is used to incrementally build
3.3.2.1. Information gain analysis
A common approach in the literature to evaluate the expected information gain of a viewpose is by tracing the voxels along a dense set of raycasts within view’s FoV, projected from its origin. This has a high computational cost that can become prohibitive when evaluating many views and as the map resolution increases. Additionally, it is difficult to efficiently determine the visible information overlap between different views, such that information gain is usually treated as an independent measure between views. This prevents an understanding of the unique or redundant coverage within a set of views, or how efficiently they cover the given map.
To mitigate these drawbacks, we directly use the frontier voxels within a view’s FoV to constrain the evaluation of information gain. Given a voxel along a ray is only considered visible if no occupied voxels precede it, it can be inferred that the first unknown voxel traversed by a ray must be preceded by a free voxel to satisfy the visibility conditions. This transition from a free to an unknown voxel natural represents a frontier boundary, allowing a precondition to be defined that any raycast capable of containing information gain must at some point cross a frontier boundary. This allows the subset of raycasts that may contain some gain to be quickly identified based on the visible frontiers, which can greatly reduce the number of discrete raycast operations considered per view.
A visibility map
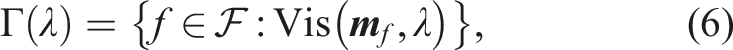
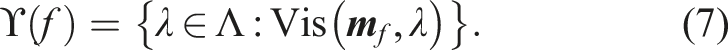
The individual gain,

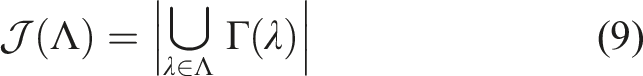
The exclusive gain,
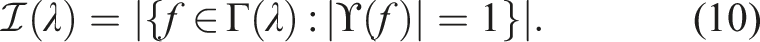
3.3.2.2. Coverage view sampling
An iterative objective of DFR is to ensure maximum coverage of the current unknown space is maintained. ϒ supports evaluation of the coverage completeness of the unknown map space by the current views Λ. Let
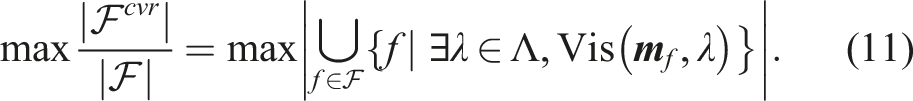
A frontier-guided sampling strategy is presented to perform the maximization of (11) by iteratively sampling viewposes to observe the non-covered frontiers. This effort is concentrated within ΔB which contains the most recent changes to the frontier distribution. Given the high complexity potentially involved in the sampling procedure, a performance tuning parameter
A second parameter
The sampling procedure is given in Alg. 1, which begins by calling
Next, a frontier queue
Upon finding a valid sample, it is used to add a new node to the network, and all of its visible frontiers are computed to update the visibility map. If any of these frontiers are contained in

3.3.3. Pruning and refinement
The growth rate of the network is reduced by pruning unnecessary views that no longer provide any individual gain contribution, and redundant views with little or no exclusive information gain. These conditions naturally occur as the robot progresses its exploration of the map and observes the previously unknown space within each view. They also occur as a result when new view samples are added to the network which overlap with the pre-existing views, decreasing their exclusive gain. The goal is to identify the views that can be removed from the network without loss of the overall joint gain.
Given the initial views Λ and their joint gain
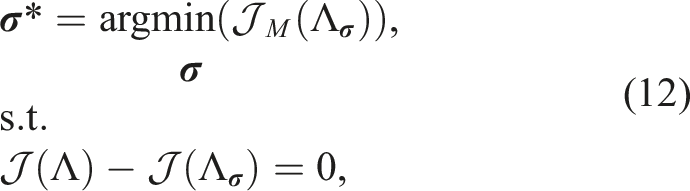
To solve Equation (12), a set of pruning candidates is found by searching for views that have negligible individual or exclusive information gain. Given the local difference neighborhood ΔB, the search is restricted to the views located within visible range
Once the pruning stage is complete, the coverage views of
3.3.4. Reachability update
The reachability knowledge represented by

The pseudocode for the reachability update procedure is shown in Alg. 2, which contains two primary stages. The first stage samples traversal nodes to increase the distribution density within the graph, and the second stage increases the total edge density.
In the first stage, collision-free positions are uniformly sampled from
The second stage begins by extracting the local set of candidate edge pairs
Each edge is evaluated by
3.3.5. Topological clustering
The graph nodes are decomposed into a set of subgraph regions represented by the hyperedges Depictions of the APN composition.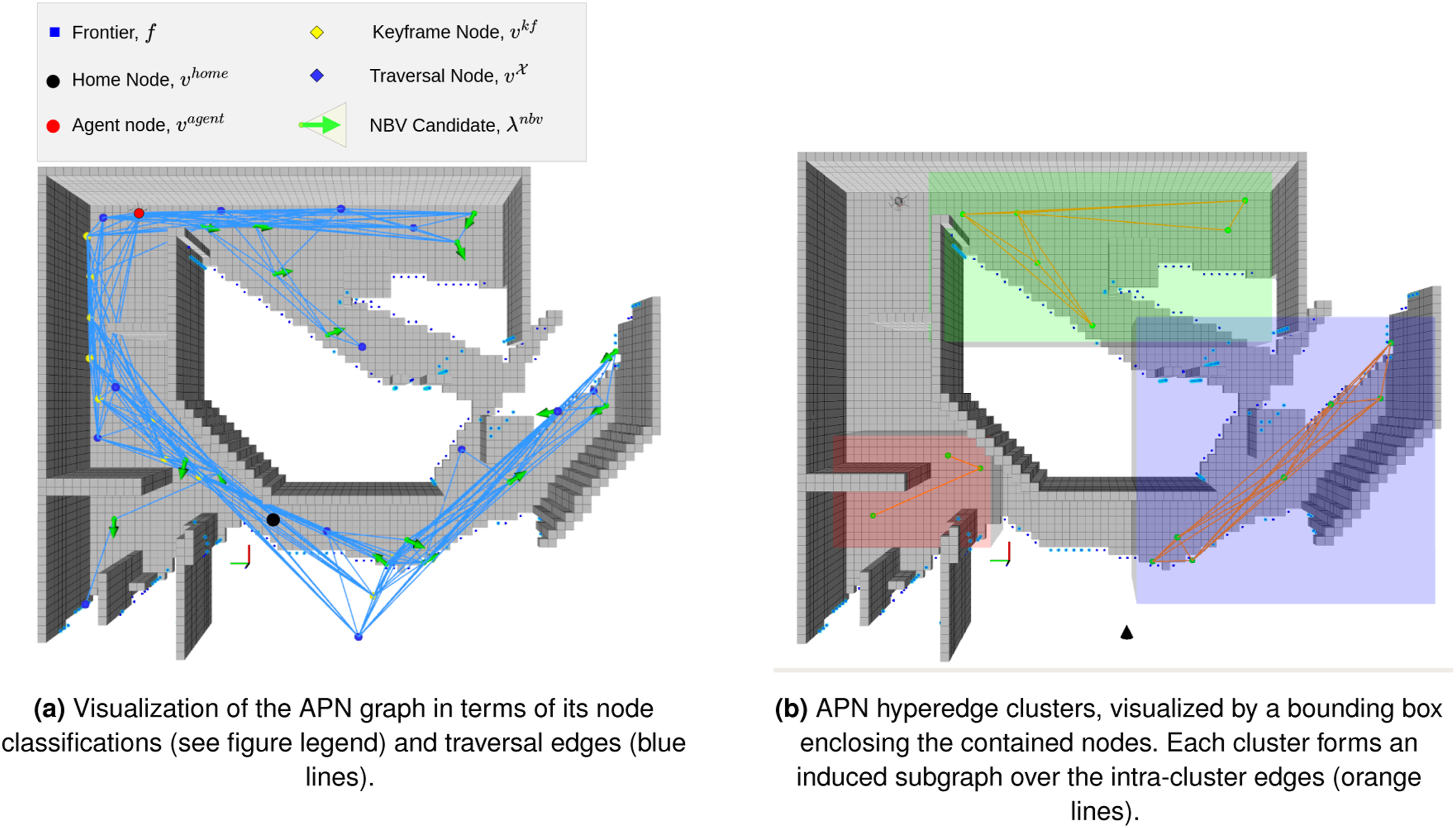
To compute the hyperedges, we use a density-based clustering approach based on Ankerst et al. (1999) and Ester et al. (1996), extended to leverage both the geometric and reachability knowledge already present in the APN. The algorithm uses two parameters, D c and ρ c , where D c defines neighborhood distance threshold, and ρ c defines a density threshold for the neighborhood.
Let a node v p be defined as a core node if it has at least ρ c edge-connected neighbors within distance D c . A node v q is then defined as a reachable node from v p only if there exists an edge connection between v p and v q , and v q is within distance D c from v p . Given a core node v p , a cluster is formed by all nodes reachable from v p . Any remaining nodes that are neither core nodes nor reachable from a core node are assigned as singleton clusters.
This approach allows clusters to form more naturally by additionally considering the edge connectivity between points. They are also not required to be geometrically convex as with other clustering approaches. This enables fewer clusters to be formed, since they can be better fit to the nodes over arbitrarily shaped space. Explicit constraints on the maximum number of clusters or their size are also not necessary, such that clusters can conform to the map with variable size and density, which can effectively handle environments where different regions may have different geometric characteristics and complexities.
3.4. Hierarchical evolutionary view planning
The iteratively updated APN provides a generalized representation of the exploration state space, which can be utilized by any graph-based planning strategy for global and local planning. In this section, we present an anytime planning approach referred to as the APN Planner (APN-P), which leverages the hierarchical decomposition of the APN to plan a global sequence over the topological subgraph regions. A second planning stage then optimizes the low-level view path for the first subgraph of the topological sequence. Each stage is formulated as a Fixed-Ended Open Traveling Salesman Problem (FEOTSP), solved using an evolutionary optimization approach to determine the optimal sequence orders. A visualization of this procedure is displayed in Figure 3. Visual depiction of the hierarchical planning strategy. The first stage computes the global path (dark red arrows) over the node clusters, with the start fixed to the robot location and the end fixed to the home location. The second stage optimizes the NBV sequence (depicted using tan arrows) within the first cluster of the global sequence (green bounding box).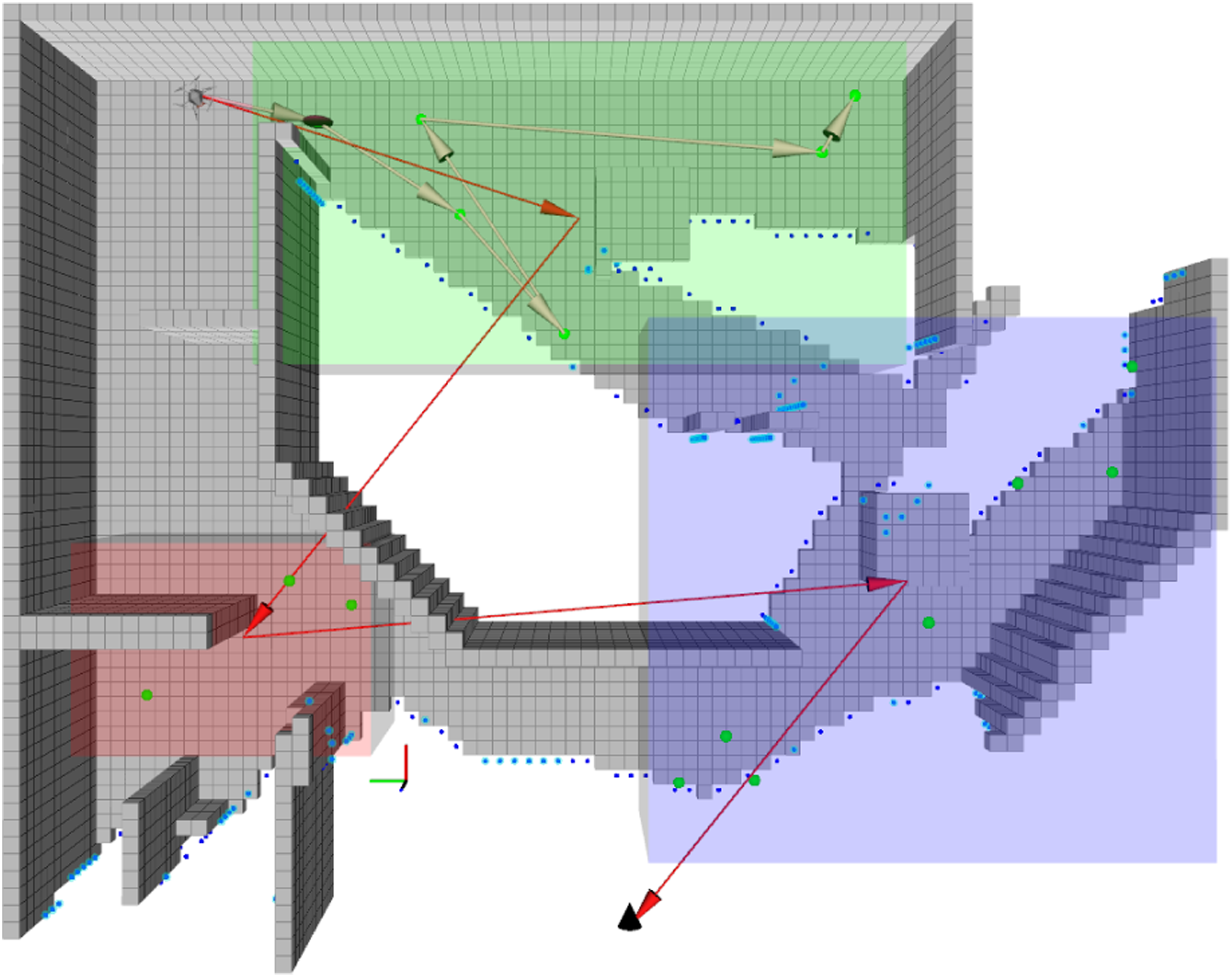
Let
Given first cluster
The optimized sequences are preserved in a data cache allowing them to be used to re-initialize subsequent planning cycles. Given a planning cycle i and target cluster
Sequence optimization is executed using a mimetic evolutionary algorithm (Deb et al., 2002). Given the reference index set,
Once the exploration plan optimization is complete, the first view of the local sequence represents the updated navigation goal, λ g . If the robot is not currently navigating towards a goal, or if the previous goal has already been reached, a trajectory is computed to reach λ g by RRT* (Sucan et al., 2012), using the APN to find a feasible path to initialize the trajectory planner. Similarly, if the reward of current goal falls to zero and is pruned by the latest DFR update, the new λ g is automatically set as the current target.
For cases where the robot is still navigating towards a previous goal λg,prev ≠ λ g that has not yet been reached, the planner decides whether to reject λ g until λg,prev ≠ λ g is reached, or to immediately accept and begin navigation towards λ g . This is decided by comparing the cost and rewards of their respective sequences, adding a penalty for changes to the direction of motion. In this way, the robot does not commit to a given goal until it is reached, but constantly evaluates if a better goal has been discovered. This is in contrast to many existing approaches, which often fully execute each goal before replanning.
3.5. Computational complexity
Occupancy queries require
The local change neighborhood ΔB is used to guide each DFR stage. Define
For the Pruning stage, evaluating pruning conditions for each view can be done in constant time, and each view contained by ΔB is checked to yield a complexity
The complexity of planning depends primarily on the construction of the cost matrix, and the sequence optimization. Edge costs can be retrieved from the APN in constant time for adjacent nodes, but otherwise require path search using A* (or similar algorithms), which takes
Summary of Computational Complexity Terms.

A significant component of the planning complexity is the construction of the cost matrix, which scales polynomial with the number of sequence elements (i.e., clusters and NBVs). Additionally, if elements are not directly adjacent, their cost must be computed by finding the shortest path through the graph. As the map is explored, the separation distance between many NBVs can continually increase, requiring larger search efforts through the graph. The cluster hypergraph helps reduce both the number of occurrences and cost of these long-distance path searches. Since each NBV polynomially increases the planning problem size, the Pruning Stage further helps to reduce the planning costs by ensuring only the minimal set of NBVs are included.
Finally, the running time is an important aspect that is generally hidden from the Big O notation, but is a critical factor for online algorithms. For example, an increase by a constant factor to the running time would not change its order of complexity, but the increased computation time would impact the online feasibility. The running time can have a direct impact on the overall exploration quality, since the optimality of a previously computed goal may decrease with new information. Faster update cycles help to minimize the time spent following inefficient paths as better ones become feasible. Our use of change detection and caching techniques helps to minimize the scale of each update and reduce wasteful or redundant computations, maximizing the rate of DFR and APN-P updates. The APEXMAP software framework additionally provides efficient data structures and design patterns for efficient management of dynamically changing data structures and other general runtime optimizations.
4. Evaluation
The APN and APN-P were evaluated through ROS-based simulations using Gazebo (Koenig and Howard, 2004) and the RotorS MAV simulation framework (Furrer et al., 2016). The AscTec Firefly MAV model provided by RotorS was used to simulate the robot dynamics and control systems, and was equipped with a stereo depth sensor for visual perception. The simulations and all algorithms were executed using a single laptop computer with Intel Core i7 2.6 GHz processor and 16 GB RAM. The test results were used to analyze the computational performance and planning efficiency of the proposed approach.
Exploration was tested using several different 3D structure models with various scales as displayed in Figure 4, with a visual comparison of their relative scales shown in Figure 4(e). In addition to varying sizes, each environment provides different characteristics for evaluation, such as obstacle density, narrow spaces opposed to open space, dead-ends, and overall geometric complexity. Visualization of each evaluated world scenario. The relative scale of each scenario is depicted in 4e according to their bounding box dimensions, where red represents the Apartment (slightly offset from the origin for visual clarity), blue represents the Maze, grey represents the Industrial Plant, and green represents the Warehouse.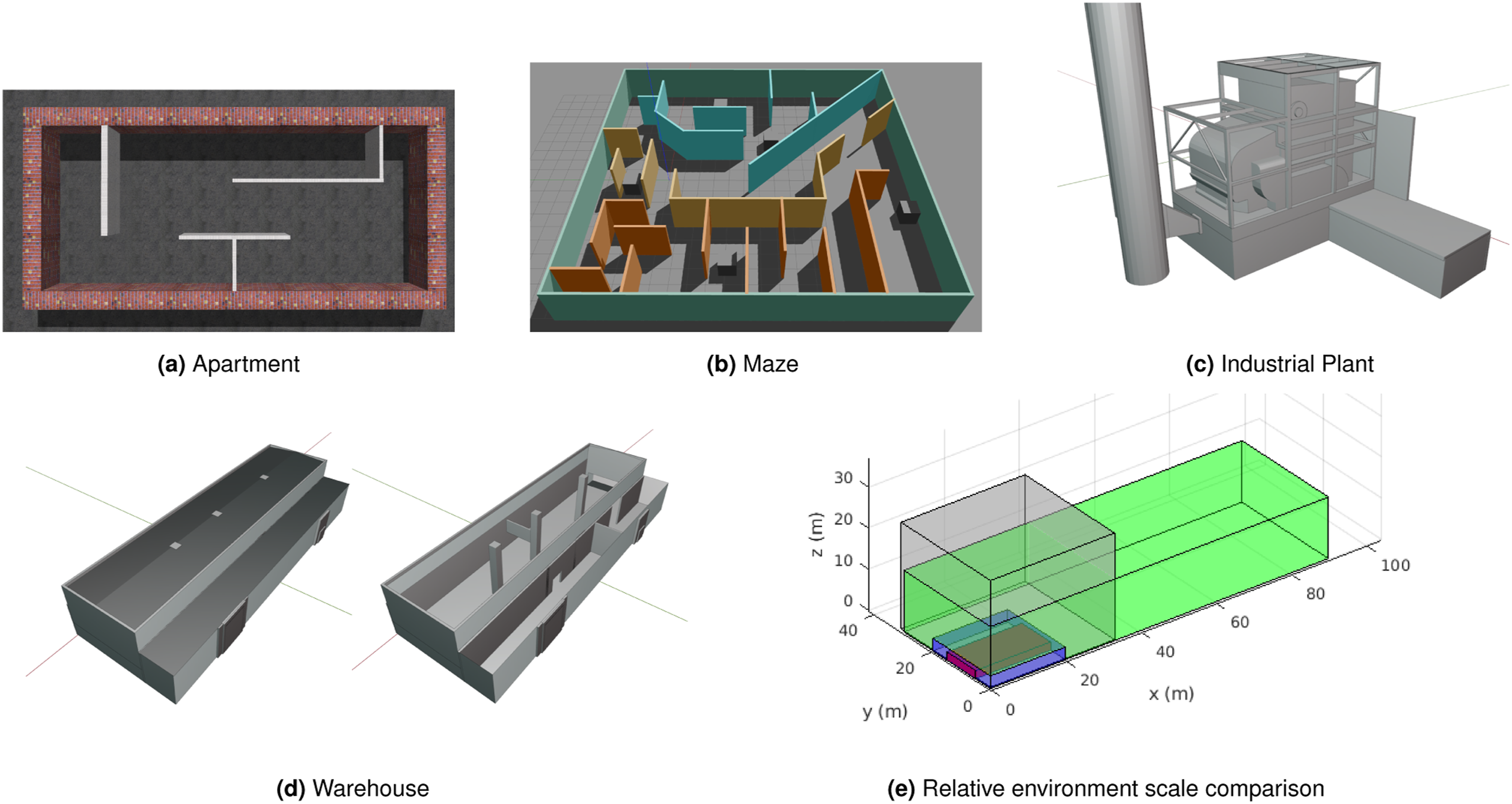
A video presentation demonstrating the operation and performance of the APN-P is included with this work. The simulation environment is used to visualize the concepts of operation as they are executed. The Apartment scenario is used in the video presentation to demonstrate the real-time operation of the full exploration procedure while visualizing the APN’s dynamically changing structure.
Summary of Performance Analysis Metrics.

The total map coverage is given as the ratio
The APN is evaluated according to its average node density
The following baseline approaches were used for comparative analysis with the APN-P: • RH-NBVP (Bircher et al., 2018): A receding horizon method that finds informative view paths using RRT-based expansion within a local region of the robot. • AEP (Selin et al., 2019): An approach that extends the strategy of RH-NBVP, using RH-NBVP for local planning and frontier-based planning for global search when local planning fails to find informative views. • FFI (Dai et al., 2020): A hybrid frontier-based and sampling-based approach that uses an efficient frontier clustering strategy to guide the sampling of views. • Rapid (Cieslewski et al., 2017): An extension of frontier-based planning designed to maintain the fastest allowable velocity by guiding towards frontiers within the sensors current field of view, and using classical frontier planning when no visible frontiers are available.
Summary of Common Configuration Parameters.
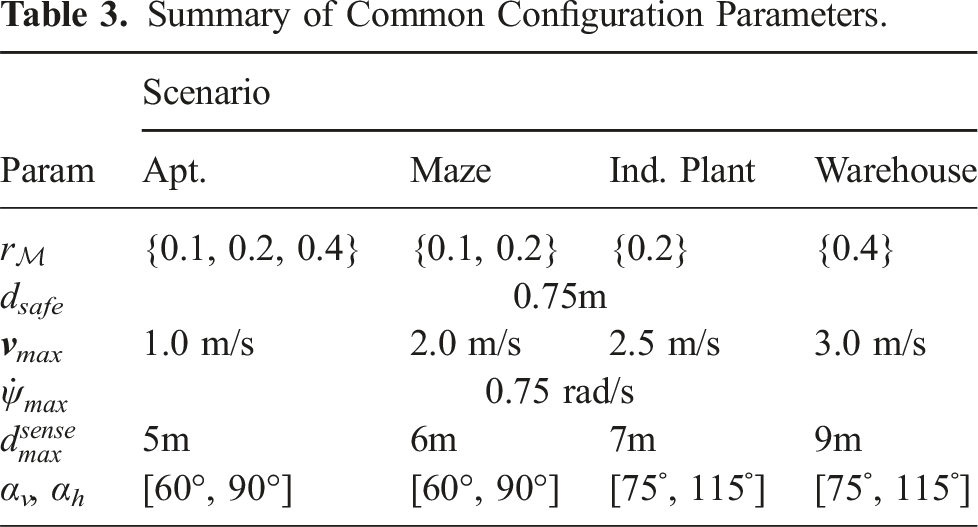
Coverage view sampling parameters related to Alg. 1 were set as
4.1. Apartment scenario
The apartment scenario in Figure 4(a) is a relatively small scale interior space with the dimensions 20 × 10 × 3(m3), used as a baseline for comparing the larger and more complex scenarios. An example map reconstruction by APN-P is shown in Figure 5(a) with the traced exploration path, and the APN roadmap is shown in Figure 5(b). The average distance traveled was 76.5 m, and a surface coverage completeness of Exploration results for the Maze Scenario. (a): The explored path is plotted in red, with intermediate keyframe configurations represented by yellow points. (b): The APN nodes and edges overlayed in blue.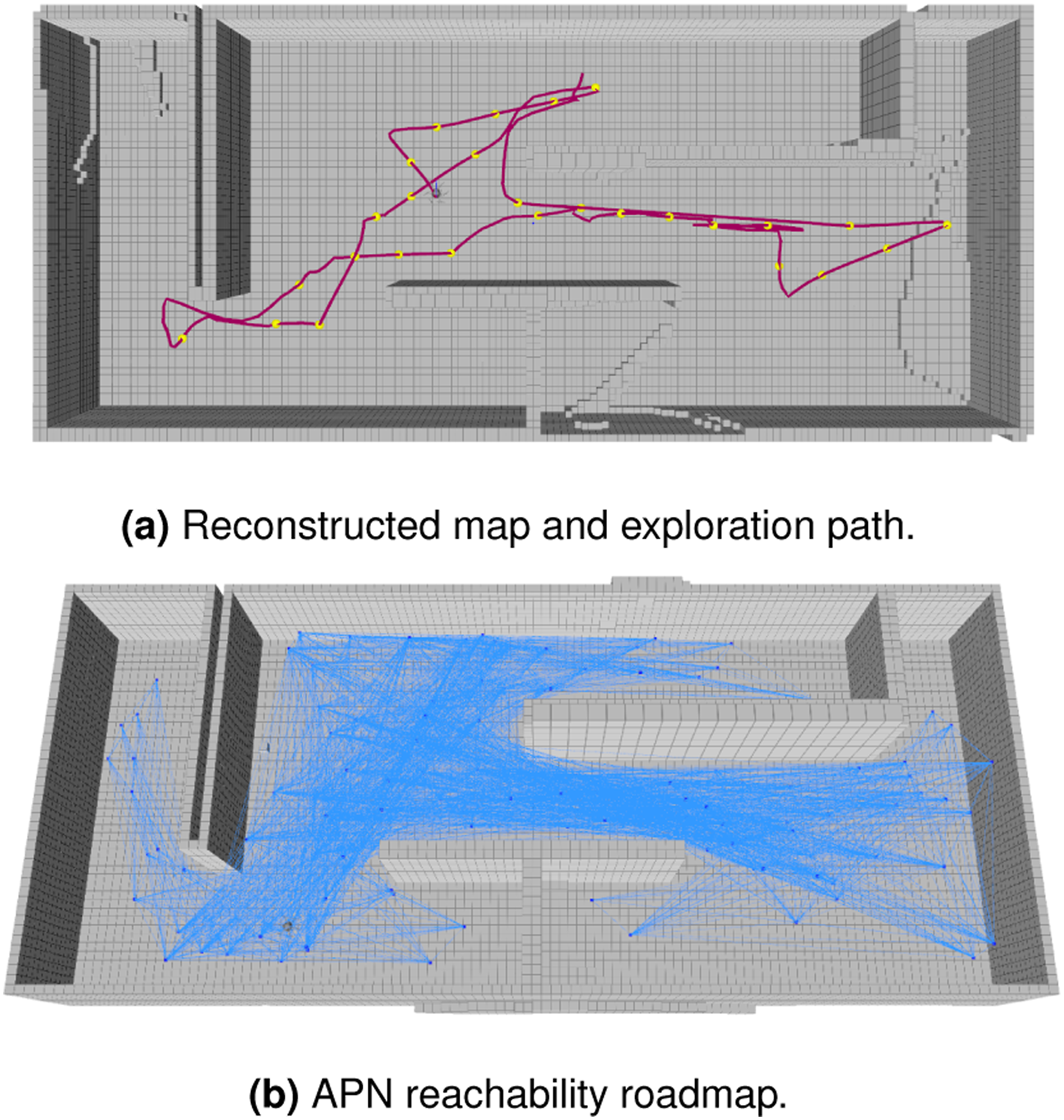
Figure 6(a) shows an example of the explored map volume over time using resolution 0.2 m for reference. The surface coverage rate Representative results of the exploration progress over time. (a) - (d): explored map in terms of total voxels and their volume. (e) - (h): corresponding APN size in terms of its nodes (red) and edges (blue), with the respective node density 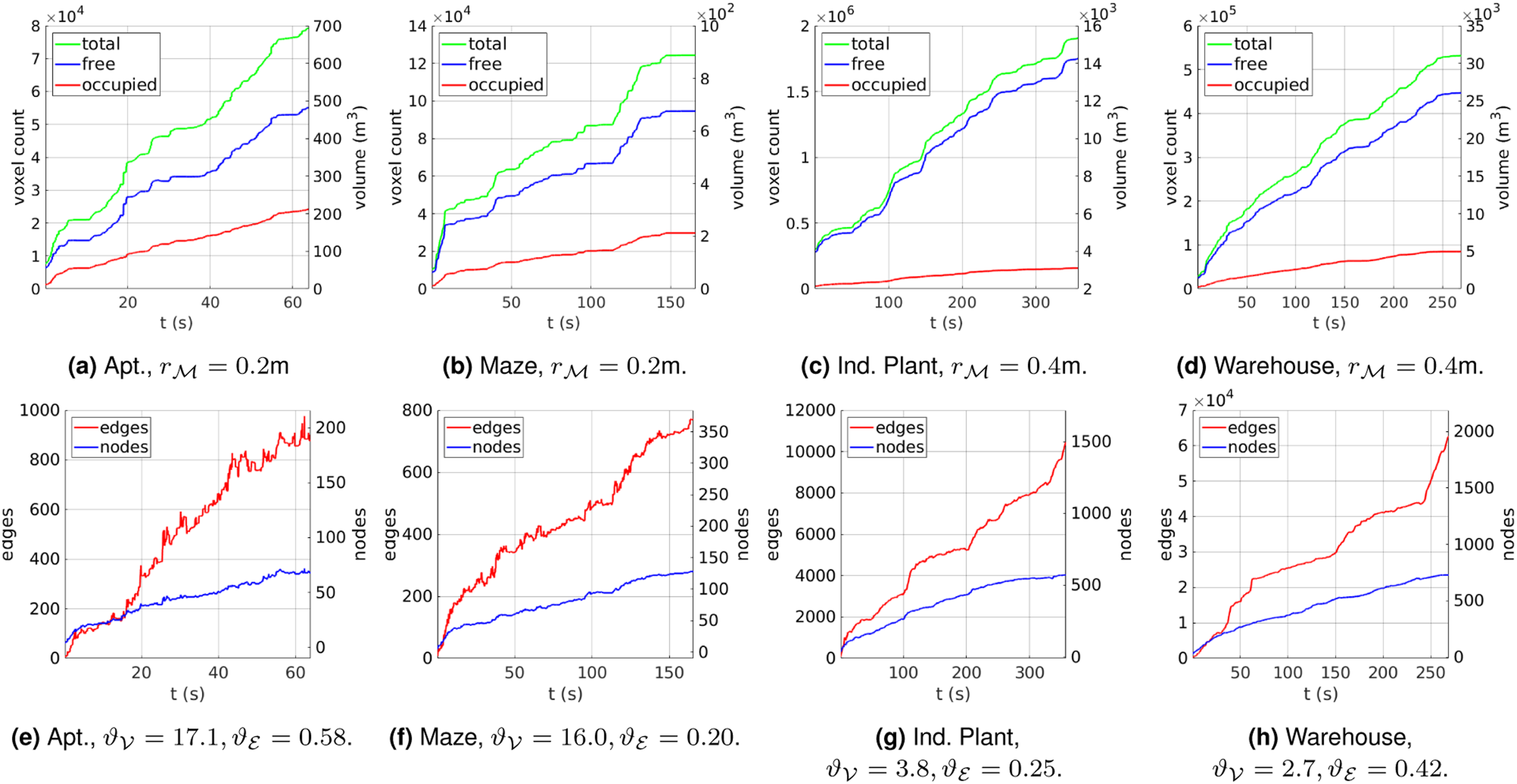
The size growth of the APN over time is shown in Figure 6(e). Compared to the map scale in Figure 6(a), the APN is significantly smaller and its growth over time is non-monotonic due to iterative pruning and refinements. The final state of the APN roadmap is shown in Figure 5(b), which can be seen to expand throughout the reachable free-space at a sufficient density for planning and navigation.
Figure 7(a) shows representative results of the computation times per cycle, using map resolution 0.2 m as reference. The time taken for DFR remains fairly consistent over time despite the increasing map size. This demonstrates the effectiveness of the difference-aware update procedures at constraining the complexity as the map grows. A statistical boxplot of the respective procedures executed per cycle is shown in Figure 7(e). The majority of computation time per cycle was spent on view planning, which had a median value of 13.6 ms. The time spent on global cluster planning was negligible due to the relatively small size and complexity of this environment. The APN contained an average of only 1.2 clusters, resulting in a trivial instance of cluster sequence optimization. The computation times for all differential regulation procedures were minimal compared to planning, given the relatively simple environment. Timing performance for each exploration scenario. (a)–(d): depict the processing time taken per cycle. (e)–(h): display the median statistical boxplot of the DFR and planning computation times per cycle.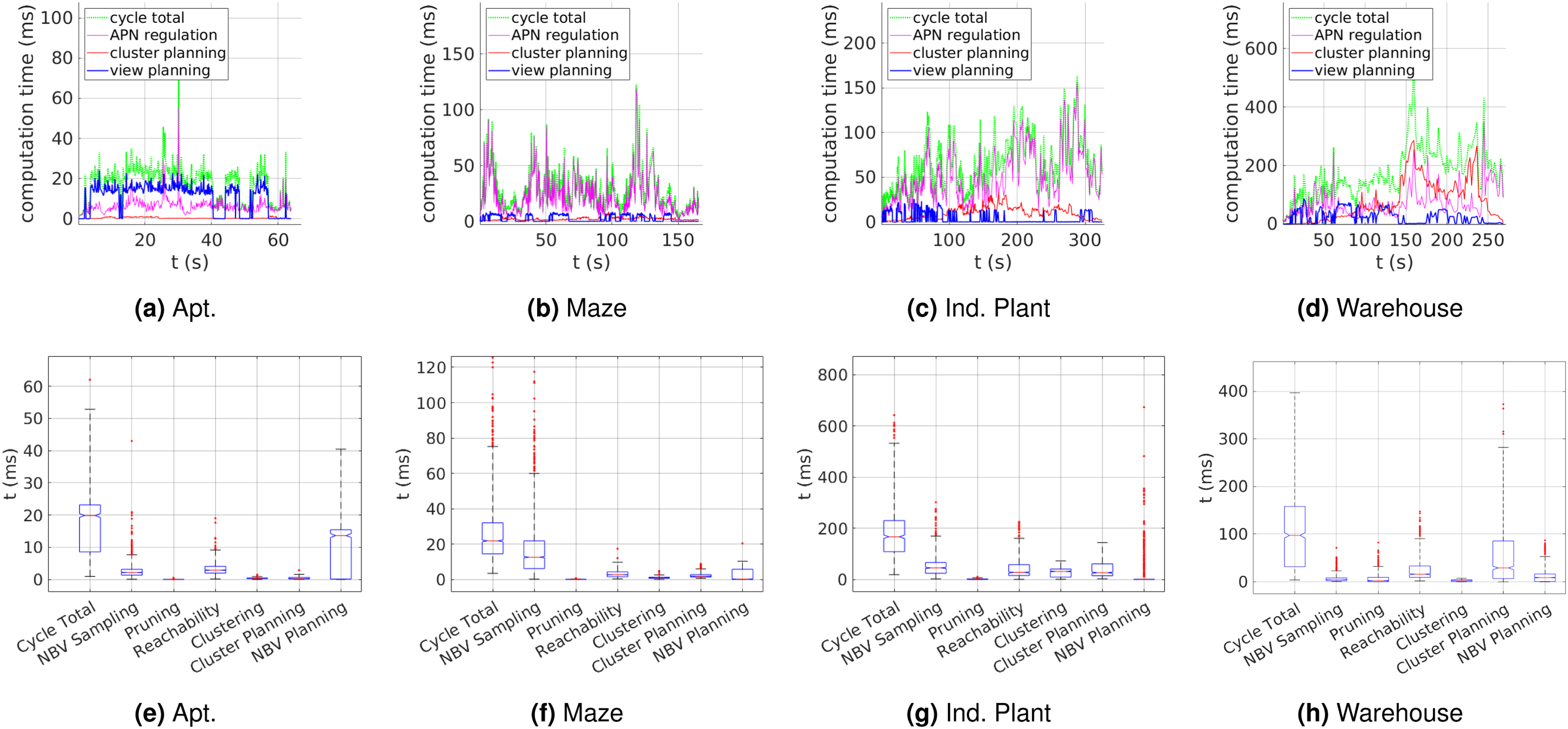
Time Performance Comparison in Terms of Total Exploration Completion Time
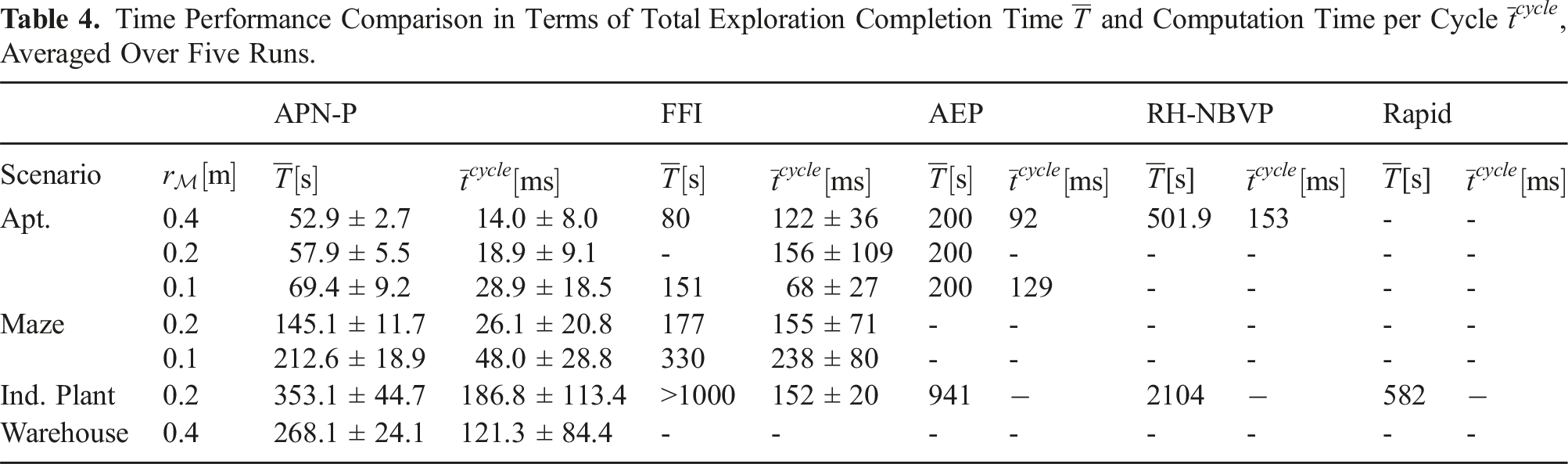
The RH-NBV approach required the highest total exploration time of 501.9s, with an average computation time per iteration of 153 ms. For AEP, the total exploration time for each resolution was reported to take approximately 200s on average (exact quantities were not specified), with an average computation time per iteration of 98 ms. FFI reported the fastest exploration time of the compared methods, with a total time of 80s and 151s for the respective map resolutions 0.4 m and 0.1 m. It should be noted that this approach was terminated once 95% exploration was reached, rather than full coverage.
The APN-P performance demonstrated a significant improvement over the compared state-of-the-art implementations in terms of both total exploration time and per-iteration computation times. Compared to FFI, APN-P achieved complete coverage while the exploration time was reduced by 34% using resolution 0.4 m, and 54% using resolution 0.1 m. Additionally, the percent improvement between resolutions indicates better scalability to higher resolution mapping.
4.2. Maze-like scenario
A maze-like environment is presented in Figure 4(b) with the dimensions of 20 × 20 × 2.5(m3). This scenario was tested using map resolutions of 0.1 m and 0.2 m; higher resolutions were not evaluated since there are narrow passageways that require lower resolutions to admit collision-free paths, as also noted in (Dai et al., 2020). This scenario was primarily compared against FFI, as this scenario was not evaluated in the original works of the other approaches.
A representative example of the mapped environment after exploration is shown in Figure 8(a) with the executed exploration path overlayed in red. The path shows that very few redundant motions were executed and progresses smoothly throughout the maze passages, with an average total path length of 208.9 m. Exploration results for the Maze Scenario. (a): The explored path is plotted in red, with intermediate keyframe configurations represented by yellow points. (b): The APN nodes and edges overlayed in blue.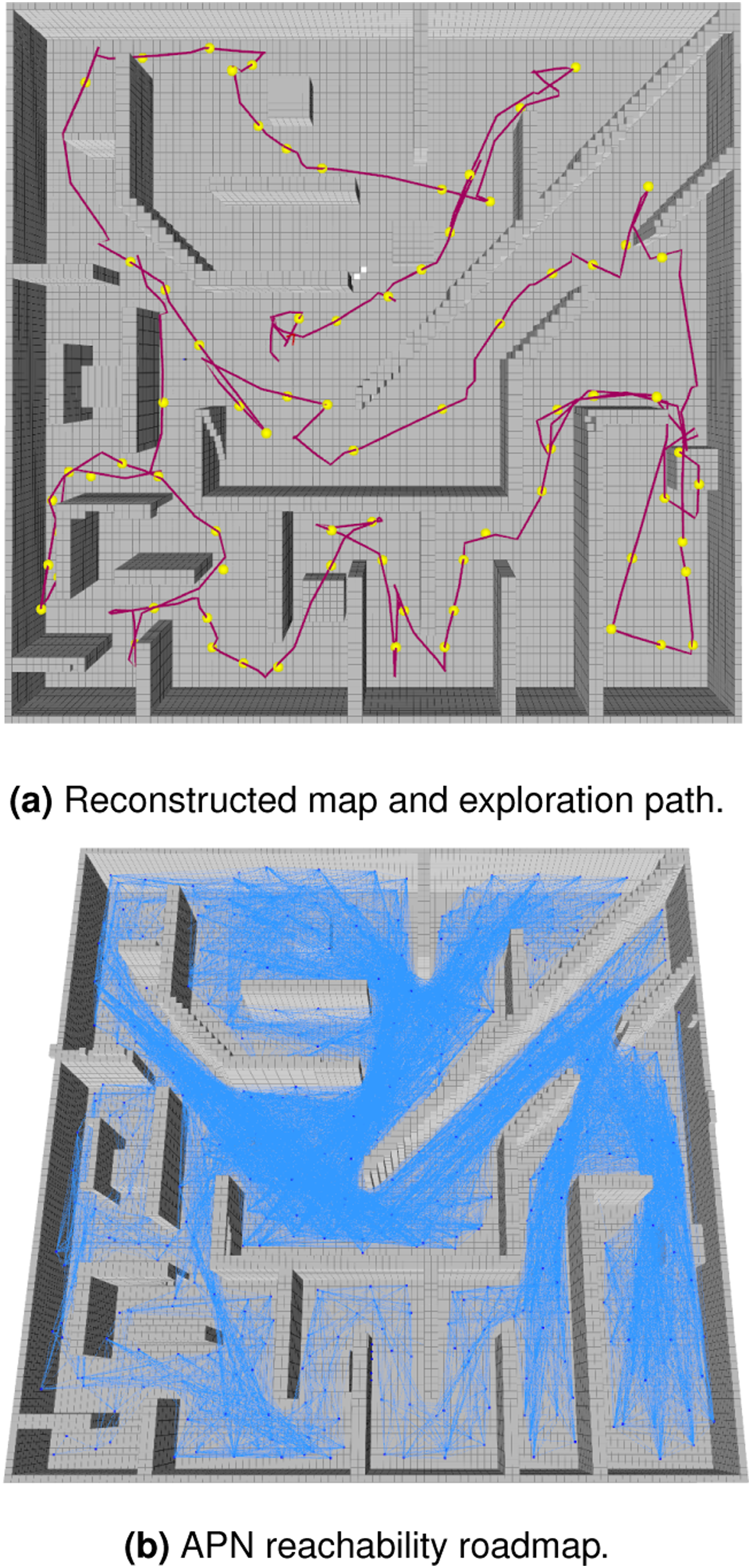
Figure 6(b) shows the map construction over time. An average coverage value of
The computation times per cycle are plotted in Figure 7(b) with a statistical analysis of the computation time taken per procedure shown in Figure 7(f). For this scenario, most of the computation time went towards APN regulation, with coverage view sampling requiring the most time of 15.8 ms due to the prevalence of obstacles and occlusions. Despite the high obstacle density, the computation times for reachability updates remained relatively small, while still maintaining sufficient node and edge densities to facilitate planning. This demonstrates the effectiveness of the local difference-awareness and efficient data caching strategies that minimize wasteful or redundant processing.
Table 4 summarizes the exploration efficiency of the compared approaches with respect to total exploration time and computation time per cycle. Note that as previously mentioned, exploration time for FFI was reported when 95% coverage was achieved, rather than 100%. The APN-P completed the exploration with 100% coverage in an average time of 145.1s and 212.6s for map resolutions 0.2 m and 0.1 m, respectively. These are significant improvements over the results of FFI, while the processing time per cycle was also reduced by around 80% and had much less variability. Additionally, the total exploration time for FFI increased by 86% between the two map resolutions, while the respective increase for the APN-P was 45%. This further demonstrates the performance scalability for higher mapping resolutions using larger and more complex environments.
4.3. Industrial plant scenario
The Industrial Plant scenario shown in Figure 4(c) is an outdoor environment based on the Gazebo Powerplant model, truncated to the approximate dimensions of 33 × 31 × 26(m3). It represents both a large-scale and complex exploration task due to intricate structural geometries with many auto-occlusions. It was tested using a map resolution of 0.2 m and maximum velocity of 2.5 m/s, consistent with the compared approaches.
An example of the explored map is shown in Figure 9(a), with the explored volume over time plotted in Figure 6(c). A high surface coverage rate of Exploration results of the Industrial Plant scenario.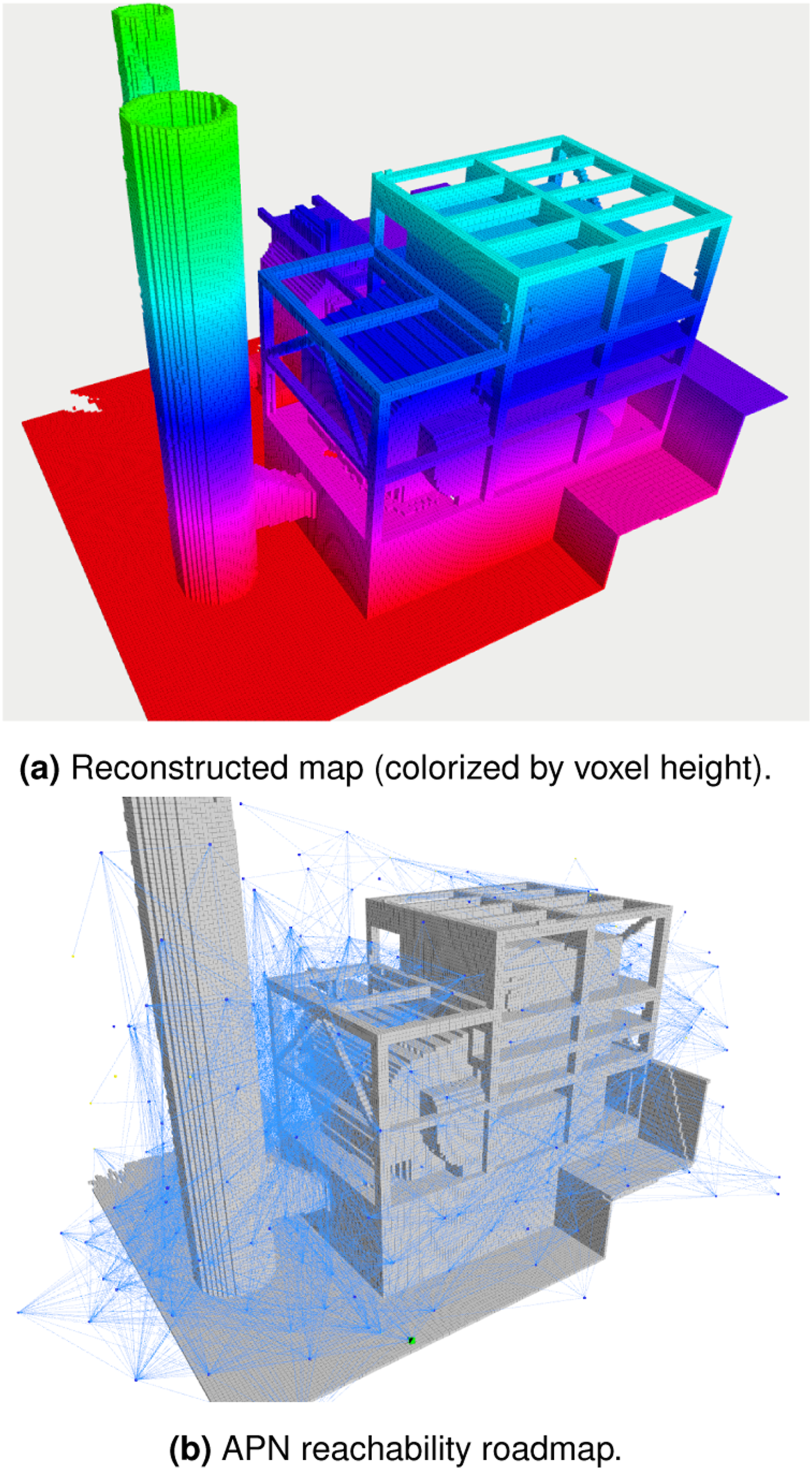
The APN size over time is plotted in Figure 6(g), with the final roadmap structure visualized in Figure 9(b). The average node and edge density were
The processing time per cycle is displayed in Figure 7(c), with a statistical boxplot of the time taken by each subroutine shown in Figure 7(g). Traversal edge maximization required the most computation time during differential regulation with an average of 67.2 ms due to the large scale and the amount of empty-space surrounding the structures which is initially unknown. Unknown edges are repeatedly checked for collision checks until they can be determined as either completely free, or having an occupied collision after which they are suppressed. The processing time spent on planning was well-balanced between the hierarchical layers.
A comparison of the timing results to the baseline approaches is shown in Table 4. We note that this environment was not originally tested by the authors of RH-NBVP; instead, the corresponding value of 2104s was obtained from the comparative analysis performed by Cieslewski et al. (2017).
Rapid performed with the fastest total exploration time among the compared methods, taking 582s with an average total distance of 728m. This was also the only approach able to finish exploration within the rated time limit Tmax of 840s. This could be explained because this approach takes advantage of the large amount of free space to maintain high velocity, which helps to offset the diminished efficiency from greedy planning. However, this also has the effect of frequently leaving regions that have only been partially mapped. Coverage gaps can frequently occur that require large redundant paths to revisit, or otherwise reduce the completeness of the final map depending on the specific termination criteria.
Additionally, the authors of Rapid note that their implementation can spend a significant amount of time computing paths over large distances (up to 10 seconds) using Dijkstras algorithm over the map. These computation times were omitted from the reported total exploration time to focus evaluation only on the quality of their flight behavior. Even without this consideration, the APN-P was still able to reach complete exploration around 65% faster on average with a decrease in distance traveled of around 10%. This also highlights the importance of the APN efficiency to prevent such high computation times from occurring in practice.
APN-P exhibited significantly better performance than all compared methods, requiring an average total exploration time of only 353.1s, with each cycle requiring an average of 186.8 ms. The average total distance traveled was 406.3 m, with mean velocity of 1.9 m/s. The MAV was able to maintain higher velocities due to the fast cycle times, which enabled the system to quickly react to the changing spatial map and re-plan its exploration path. Often the information gain of the current NBV goal gets fully observed as the MAV gets closer which can be quickly reflected within the network, allowing it to maintain its momentum by not needing to completely stop at each goal.
To evaluate how the larger size of this scenario correlates to the processing time per cycle, the Ind. Plant was additionally evaluated against the Maze scenario. To enable more consistent comparison, the map resolution was kept at 0.2 m, and the maximum velocity and sensor parameters were assigned the values used for the Maze as indicated in Table 3. The resulting cycle processing time for the Ind. Plant decreased by around 58%, with each cycle taking an average of
The effects of map resolution were analyzed by a testing the timing performance using map resolution of 0.4 m. This resulted in a significant decrease in the cycle processing time, which was reduced to
4.4. Warehouse Scenario
The Warehouse scenario is a large-scale indoor environment with the approximate dimensions 90 × 30 × 15 (m3), shown in Figure 4(d) with its exterior shown on the left, and the interior structures shown on the right. The models exterior structure was derived from the Powerplant model available from the Gazebo model library, while the interior was modified by adding a various geometric features and structures to create a more intricate environment for exploration. Since this was a custom built model, the APN-P was evaluated independently as comparative results were unavailable.
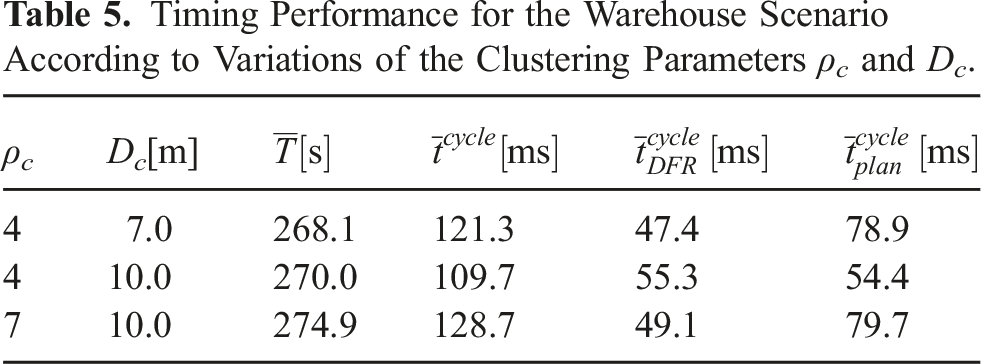
Timing Performance for the Warehouse Scenario According to Variations of the Clustering Parameters ρ c and D c .
A representative example of the reconstructed map results shown in Figure 10 and the explored map volume over time is shown in Figure 6(d). A minimum coverage ratio of The reconstructed map of the Warehouse scenario colorized by voxel height. The maximum height of displayed voxels is truncated for visual clarity.
The computation time per cycle is plotted in Figure 7(d) and summarized in Table 4. Similar to the Ind. Plant scenario, the time spent on APN regulation remains within a bounded range despite the increasing size of the map and APN. The exploration time performance results are summarized in Table 4, requiring an average exploration time of
Different clustering parameter variations were applied and the resulting time performance is summarized in Table 5. The average exploration time did not significantly change between parameter variations, indicating the low sensitivity of these parameters. The primary effect of the variations was on the per-cycle computation time, though the differences were relatively minor. Using the values ρ
c
= 4 and D
c
= 10.0, the cycle time was nearly evenly distributed between differential regulation,
4.5. Ablation studies
Ablation studies were devised to discover insights into the performance and behavior of our methodology. These primarily focus on the performance effects of pruning and hierarchical planning, and are divided into two test cases as follows: • Case 1: pruning disabled; • Case 2: pruning and hierarchical planning disabled.
For Case 1, the pruning stage described in Section 3.3.3 was disabled from the system while keeping all other operations intact. In Case 2, the use of hierarchical planning was also disabled, where planning instead operates on all candidate NBVs within the APN to find the non-myopic global exploration sequence without being informed by the topological cluster regions. Case 1 and Case 2 were evaluated using the Maze Scenario with map resolution 0.2 m, and Case 2 was further evaluated using the Warehouse Scenario with map resolution 0.4 m to observe the effects at large-scales. The baseline of each case corresponds to the previous parameters and results without ablations for each scenario, as described in the previous subsections. Each case was performed 5 times to compute the statistical averages.
Summary of Ablation Case Performance in Terms of Percent Difference from Baseline.
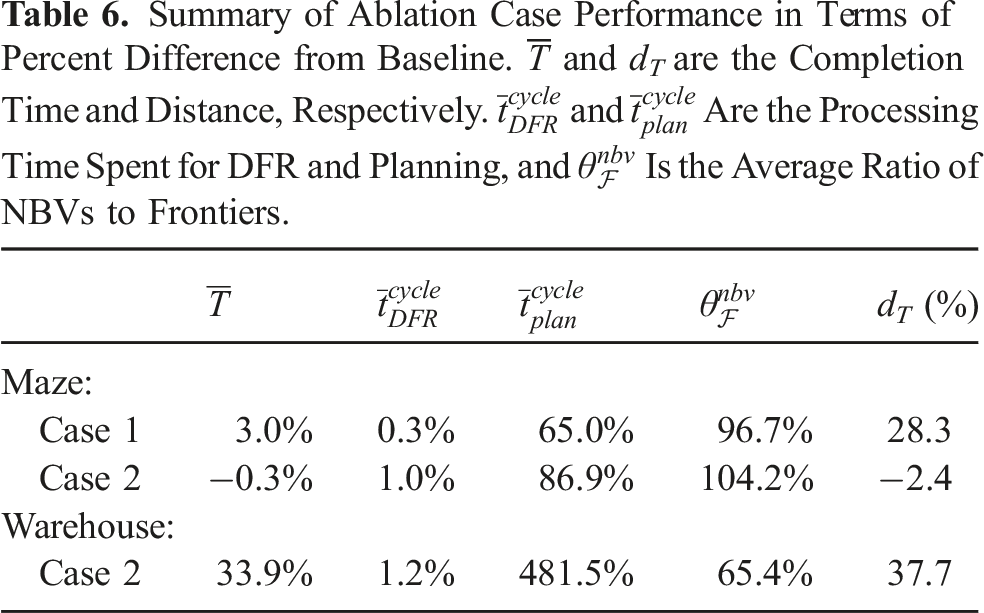
For the Maze Scenario, removing the pruning stage (i.e., Case 1) prevented the analysis and removal of redundant NBVs that covered no exclusive information, increasing the average NBV to frontier ratio
Using Case 2 for the Maze Scenario, the results show a significant increase in average planning time per cycle by 86.9%, while the total completion time did not significantly change. This can be explained intuitively, as the use of hierarchical planning serves as an approximation of the underlying view sequence, decreasing the problem size but also introducing resolution losses. Planning over the full set of NBVs allowed finer optimization resolution, but at the cost of longer computations. Still, given the smaller scale of the Maze scenario, the increased computations were not large enough to greatly impact its overall performance.
For Case 2 applied to the Warehouse Scenario, as also summarized in Table 6, the increased planning complexity when pruning and hierarchical planning are disabled becomes very apparent. An increase of 481.5% to the planning time per cycle was experienced, with the maximum planning time taking over 4.5s compared to the maximum of 374 ms for the baseline case. For the baseline case, planning was performed over an average of 21.2 clusters, and 13.7 NBVs. Comparatively, Case 2 planned over an average of 57.1 NBVs while omitting the cluster planning stage.
Furthermore, the total completion time
4.6. Discussions
The experimental results show that our approach has the ability to iteratively update the APN and replan the exploration path at an average rate of at least 20 Hz for the two smaller scale scenarios (Apt. and Maze), and at least 5 Hz for the larger scales (Industrial Plant and Warehouse). However, the difference between these cycle rates is not primarily due to the larger environment sizes. Instead, the larger sensor view volume and higher maximum velocities are the more significant factors, which result in a larger amount of map data for processing per cycle, but these factors are not directly related to the environment size. This helps to explain the scalability of our approach for larger environments.
For the smaller environments, most of the planning time is spent on local view planning (see Figures 7(e) and 7(f)), This is due to the relatively few clusters needed to partition the nodes, resulting in trivial cluster planning instances. However, planning directly over all NBVs can quickly become intractable as the map size increases, either resulting in unacceptably large processing times, or would otherwise require premature search termination that degrades the planning quality.
The hierarchical planning strategy of APN-P helps to mitigate the complexity by keeping the problem size manageable. Furthermore, planning convergence is further accelerated by initializing each planning cycle from the partially optimized solution of the previous cycle. This reduces the need to introduce further problem simplifications or approximations that would decrease the planning quality. These effects are demonstrated by the results shown in Figures 7(d) and 7(h). The distributed planning time remains relatively low and does not exhibit continually increasing growth, despite the increasing size of the map and APN as shown in Figures 6(h) and 6(d).
The frontier-guided information gain and sampling strategy of DFR provides an effective way to avoid the prohibitively high computation costs for analyzing information gain by the existing (compared) approaches and to balance processing time per cycle and update rates. This enables maximized coverage of the unknown map regions to be maintained at high update rates, providing the necessary knowledge needed for non-myopic planning.
4.7. Further comparative study
We focus here on a comparative study between our APN-P system and the TARE system (Cao et al., 2021), as both use hierarchical planning. The TARE system uses a top-down approach to divide a map into even cuboid subspaces and conduct two-level planning: global planning to find a sequence to visit each subspace and local planning within each subspace. In contrast, our APN-P system uses a bottom–up approach which computes the reachable configurations first, then analyzes their structure on the fly to determine the topological structure.
To compare the performance between APN-P and TARE, each system was evaluated within the Corridors Scenario shown in Figure 11(a), which has the maximum dimensions of 130 × 100 × 4 (m3). The open-source software of TARE was used for its implementation which also includes a test application and configuration parameters tuned specifically for the Corridors Scenario. Though TARE is capable of being adapted for use with either ground or aerial vehicles, we note that the open-source software only supports ground-based exploration. For this reason, TARE was tested using an unmanned ground vehicle (UGV) equipped with a Velodyne Puck LiDAR scanner with a horizontal FoV of 360◦ and vertical FoV of 30◦, and the APN-P was tested using the Firefly MAV modified to use the Velodyne LiDAR instead of the stereo camera sensor from the previous scenarios. Each system used a map resolution of 0.5 m for occupied surface representation. The Corridors Scenario with the maximum dimensions of 130 × 100 × 4 (m3).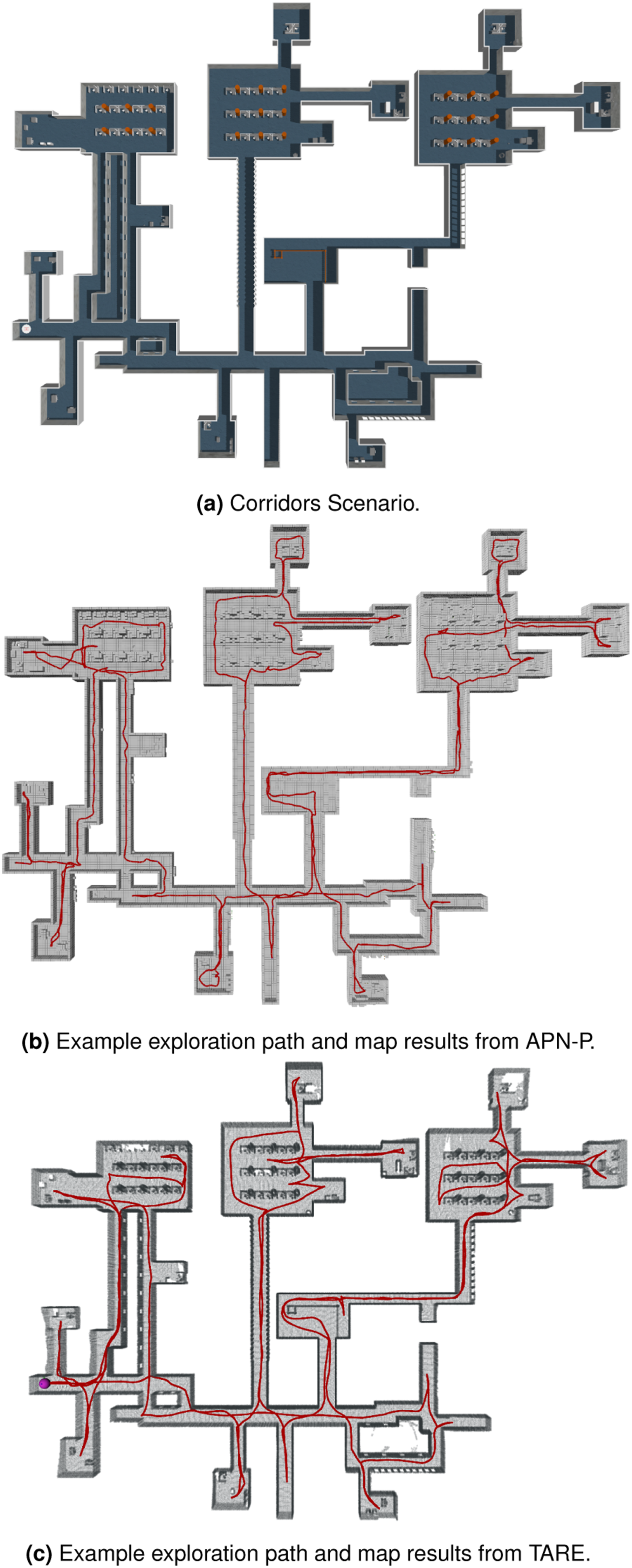
Given the different robots used to evaluate each system, additional steps were taken to ensure fair comparison between the approaches. To equalize the robot workspaces, modifications were made to our approach to restrict all robot configuration of the APN to fixed plane equal in altitude to the height of the sensor on the UGV. The altitude restriction was enforced by restricting the vertical dimension of all sampling and motion planning procedures according to the fixed altitude. This ensures all APN nodes and their edges will lie on the same traversal plane as the UGV sensor, along with any trajectories planned between APN nodes. Additionally, collision detection was updated to check for obstacles along the ground plane, such that configurations are treated as a collision if the space directly underneath is not traversable. This ensures any valid configuration will be valid for both vehicles, and that the MAV does not traverse any path that could not be traversed by the UGV. Further, each vehicle was limited by a common maximum velocity of 2 m/s.
Key Performance Metric Result Comparison Between APN-P and TARE Using the Corridors Scenario.
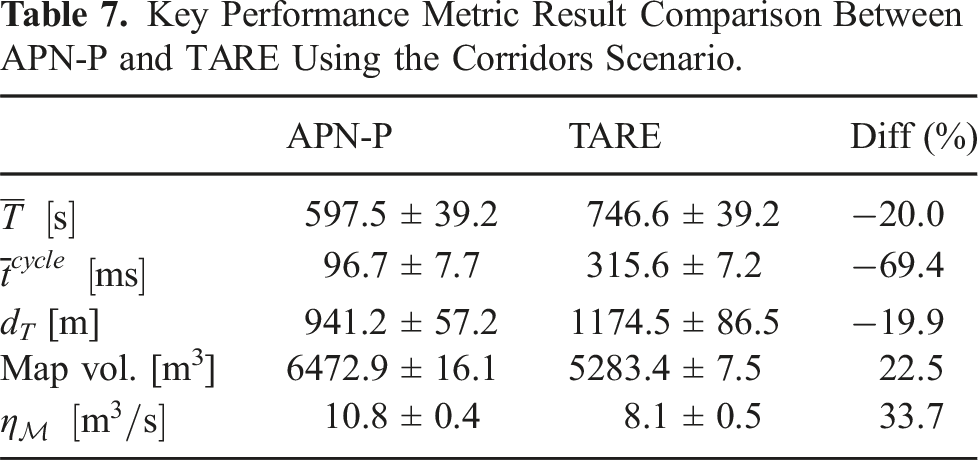
Both systems were able to consistently explore the full environment, with example exploration paths and map coverage results for each system shown in Figures 11b and 11(c). TARE took an average total time of 746.6s for exploration and APN-P took an average of 597.5s, an improvement of around 20%. Though both methods were able to explore all traversable regions, APNP-P also achieved higher environment coverage with a 22.5% increase in the explored map volume, which can be seen from comparing the mapping results in Figure 11. Additionally, the average cycle processing time for TARE was 315.6 ms, while APN-P was more than three times as fast at 96.7 ms. From these comparisons, APN-P demonstrates faster exploration with higher coverage completeness while still using less processing time per cycle.
Further results of APN-P are shown in Figure 12 regarding the map exploration progress over time compared to TARE (Figure 12(a)), with cycle processing times plotted in Figure 12(b) and statistical breakdown of subprocess times shown in Figure 12(c). Figure 12(a) shows the APN-P explores the map at a faster rate throughout execution, where TARE has longer periods of low gain (indicated by flat peaks in the plot). This effect is most prominent for TARE toward the end of the run in Figure 12(a), where significant backtracking is needed to reach distant regions where coverage was not completed before moving to other regions. Representative performance results for the Corridors Scenario from APN-P.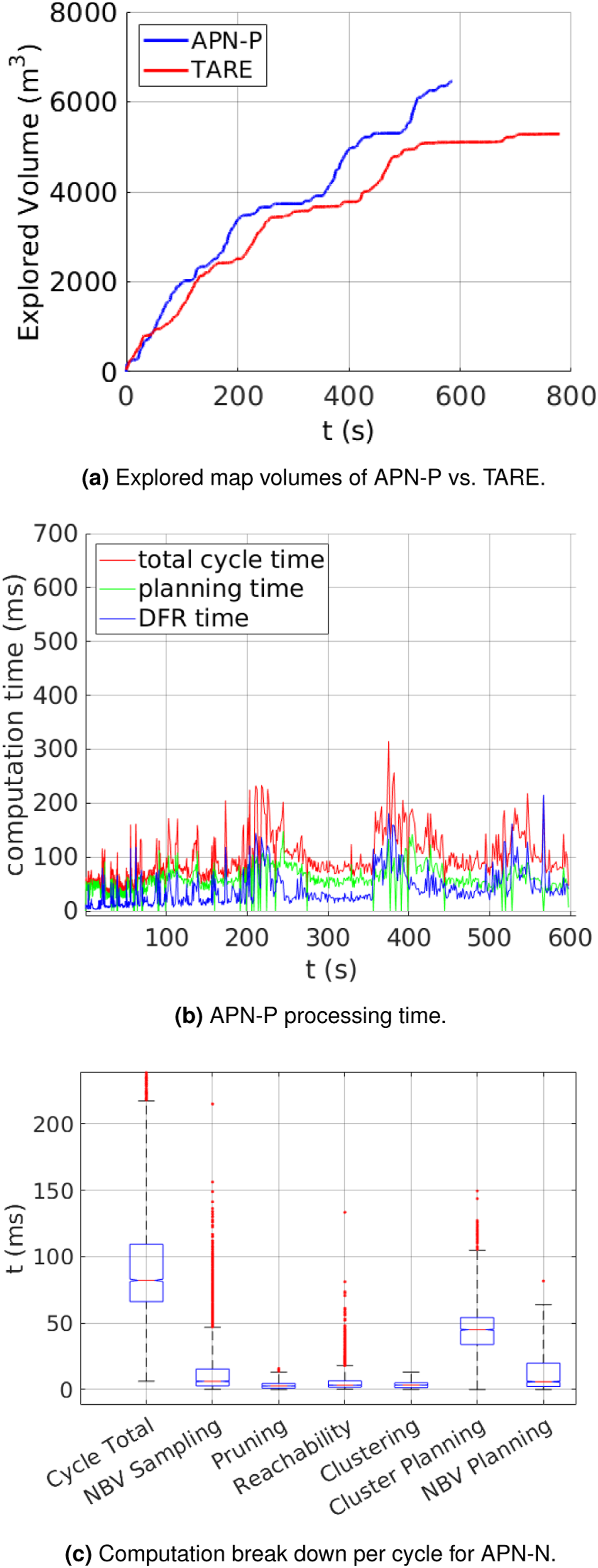
The average time APN-P spent on DFR was 32.7 ms, and planning took an average of 10.85 ms for global cluster planning, and 38.35 ms for local NBV planning. For each planning instance, the global plan was optimized over an average of about 7.4 clusters, with the local plan optimized over an average of five NBVs. In comparison, TARE used an average of 283.5 ms spent to update its environment representation, over eight times longer than APN-P, and used an average of 27.1 ms for global planning and 5.1 ms for local planning. While the planning times for TARE are slightly shorter than the APN-P’s, they do not appear to be as high quality as those planned by the APN-P, as indicated by the faster exploration times in Table 7. This may be explained by the way TARE uses simplified subspace representations with regular size and spacing and do not consider the underlying reachability given their top–down approach. This approach can reduce the computation times, but can cause lower quality paths to be planned such as when adjacent clusters or views are not directly reachable from each other, as the method initially assumes.
5. Conclusions and future work
This paper has presented the Active Perception Network (APN), serving as a topological roadmap of the dynamically changing exploration state space, the differential regulation (DFR) update procedure that incrementally adapts the APN to the changing environment knowledge, and an exploration planner APN-P, which leverages the APN to find non-myopic exploration sequences through the APN.
The results demonstrate the efficiency of DFR in performing each cyclic update and its scalability with increasing map sizes. In comparison to several state-of-the-art approaches, the APN-P consistently demonstrated improved performance in terms of total exploration time and coverage completeness. The improved performance was achieved over a variety of different environments, both indoor and outdoor, with only minor parameter adjustments between them. We expect to make all implementations of the presented work available as open-source, including the full development framework it was built upon (briefly introduced in the Appendix).
Several areas of future work have been identified. The testing and analysis of this work assumed ideal localization without noise or uncertainty to facilitate analysis of the theoretical performance separately. In practice, noise and uncertainty cannot be ignored. However, our methodology is well-suited to be extended for handling noise and uncertainty in terms of the approach and through the extensibility of our software framework.
Handling uncertainties and noise would involve the incorporation of Active SLAM strategies, which often make use of graph structures. The APN and DFR models can be adapted, for example, to consider additional features like localization landmarks for visibility analysis, and additional cost and reward functions can be associated to nodes or edges of the APN related to uncertainty analysis. DFR can then be modified to include additional stages to update the additional information aspects, while keeping the existing stages intact for computing the reachability space. The evolutionary planning approach can then be readily extended to perform multi-objective optimization that considers minimization of localization uncertainty. The high computational efficiency currently achieved provides much latitude for handling the increased computational costs. Further ablation studies and analysis of parameter sensitivity will help understand how to best tune their values to guide future developments that are generalizable to a wider range of environment scenarios and that reduce or eliminate the need for more parameter tuning.
Supplemental Material
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) were partially supported by the University of North Carolina at Charlotte and Worcester Polytechnic Institute for the research, authorship, and publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.