
Abstract
Simultaneous Localization and Mapping (SLAM) refers to the common requirement for autonomous platforms to estimate their pose and map their surroundings. There are many robust and real-time methods available for solving the SLAM problem. Most are divided into a front-end, which performs incremental pose estimation, and a back-end, which smooths and corrects the results. A low-drift front-end odometry solution is needed for robust and accurate back-end performance. Front-end methods employ various techniques, such as point cloud-to-point cloud (PC2PC) registration, key feature extraction and matching, and deep learning-based approaches. The front-end algorithms have become increasingly complex in the search for low-drift solutions and many now have large configuration parameter sets. It is desirable that the front-end algorithm should be inherently robust so that it does not need to be tuned by several, perhaps many, configuration parameters to achieve low drift in various environments. To address this issue, we propose Simple Mapping and Localization Estimation (SiMpLE), a front-end LiDAR-only odometry method that requires five low-sensitivity configurable parameters. SiMpLE is a scan-to-map point cloud registration algorithm that is straightforward to understand, configure, and implement. We evaluate SiMpLE using the KITTI, MulRan, UrbanNav, and a dataset created at the University of Queensland. SiMpLE performs among the top-ranked algorithms in the KITTI dataset and outperformed all prominent open-source approaches in the MulRan dataset whilst having the smallest configuration set. The UQ dataset also demonstrated accurate odometry with low-density point clouds using Velodyne VLP-16 and Livox Horizon LiDARs. SiMpLE is a front-end odometry solution that can be integrated with other sensing modalities and pose graph-based back-end methods for increased accuracy and long-term mapping. The lightweight and portable code for SiMpLE is available at: https://github.com/vb44/SiMpLE.
Keywords
1. Introduction
Simultaneous Localization and Mapping (SLAM) is the problem of localizing a mobile platform while constructing a map of its environment. Early work on the problem in robotics goes back to Leonard and Durrant-Whyte (1991). Durrant-Whyte and Bailey (2006) identified solving the SLAM problem as an essential step towards fully autonomous robots to estimate their position and orientation, or pose, within an environment. SLAM is a difficult problem as localization requires a map of the environment, and a pose estimate is required to construct the map. Pomerleau et al. (2015) recognized the accelerated interest in this problem since the introduction of laser scanners in the early 1990s. SLAM has become a prominent and expanding research field with applications in autonomous platform positioning (Cao et al., 2021; Lategahn et al., 2011), search and rescue robots (Chen et al., 2017a; Kleiner et al., 2006; Wang et al., 2018), indoor and outdoor mapping (Filipenko and Afanasyev 2018; Zheyuan and Uchimura., 2009), and has future applications in interplanetary exploration (Chen et al., 2017b).
SLAM is commonly divided into sub-problems, both of which have received significant attention. The first is a front-end, responsible for providing real-time odometry from incoming sensor information. This is also commonly referred to as recursive pose estimation as the registration result at time k is dependent on the result at time k − 1 and is therefore prone to accumulate drift over extended periods due to sensor measurement error and numerical errors introduced in pose estimation calculations. A real-time or post-processing back-end is usually employed to reduce the accumulated drift and correct the pose estimates. This is generally modelled as a batch or incremental optimization problem. The performance of the back-end solution depends on the accuracy of the front-end algorithm as large drift may cause errors in loop closure identification methods. The goal is to achieve accurate and real-time localization of the mobile platform within an unknown or known environment. For this paper, we focus on providing a front-end Light Detection and Ranging (LiDAR) odometry method that does not require significant configuration or tuning to achieve low-drift performance.
The localization and mapping problem continues to attract the interest of researchers as new sensors and methods are developed in the pursuit of more precise and robust solutions. The authors of this paper observe an increasing complexity of algorithms with larger configuration parameter sets. Increasing the size of the configuration parameter set tailors to the use case they are developed for. We eschew this and seek general applicability without tailored configuration.
This paper presents an efficient and accurate LiDAR odometry algorithm that provides a minimal configuration front-end only LiDAR odometry method. This algorithm performs among and better than most top-ranked LiDAR odometry methods benchmarked on the publicly available KITTI dataset by Geiger et al. (2012) and outperforms all methods in the MulRan dataset by Kim et al. (2020) and the UrbanNav dataset by Hsu et al. (2021). The solution is simple to understand, simple to implement, and simple to configure. Hence, we name the algorithm Simple Mapping and Localization Estimation or SiMpLE. Figure 1 illustrates the performance of leading LiDAR odometry methods, evaluated through benchmarking on the KITTI and MulRan datasets. The figure also displays the associated number of reported configuration parameters for each method. SiMpLE demonstrates superior performance compared to numerous open-source methods, all while boasting the smallest configuration set. This solution serves as a solid basis for seamless integration with other sensing modalities, such as IMUs or cameras, and can be effectively combined with a back-end to create a full SLAM solution. The state-of-the-art LiDAR odometry methods have similar performance but with a significant difference in the number of configuration parameters. Our solution, SiMpLE, has only five configurable parameters and performs among the top-ranked algorithms. The translational error for the KITTI sequences 00-10 (left) is as published by the respective methods. The translational error for the MulRan sequences (right) is as reported by Vizzo et al. (2023).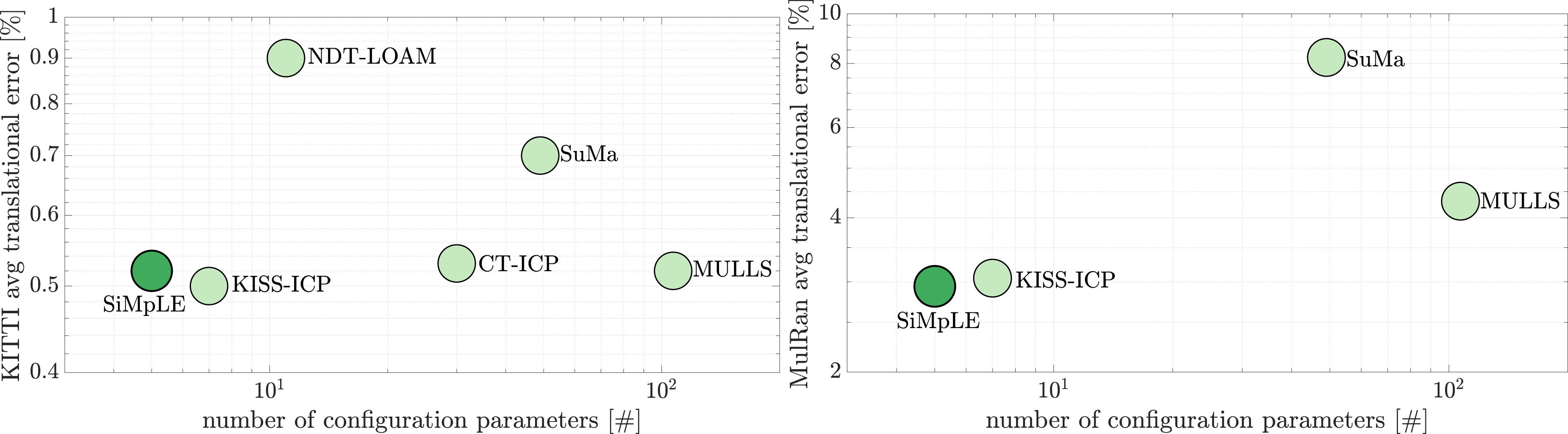
Unlike many published methods, we do not modify or tweak existing solutions or require complex pre-processing steps such as outlier removal or noise rejection. The formulation for SiMpLE is designed to use raw point cloud data. This continues previous work by using reward-based metrics to solve pose estimation problems as introduced in Phillips et al. (2021); Bhandari et al. (2023). The paper’s contributions are first to introduce a straightforward, and possibly the simplest, LiDAR odometry solution, showcasing state-of-the-art performance across different scenarios. Second, the paper offers an open-source, lightweight, portable, and readily accessible code implementing the method, available at https://github.com/vb44/SiMpLE.
This paper is organized as follows. Section 2 discusses the challenges of providing an accurate and real-time LiDAR odometry solution. Section 3 provides an overview of classical and modern SLAM algorithms. Section 4 formulates the SiMpLE algorithm. Section 5 benchmarks the performance of SiMpLE across publicly available datasets and a dataset recorded at the University of Queensland. Future work is detailed in Section 6 and concluding remarks are made in Section 7.
2. The challenges of providing accurate and real-time LiDAR odometry
SLAM methods employ a variety of sensing modalities to construct an understanding of the surrounding environment. LiDARs are commonly used as the prominent sensing modality due to their high accuracy, fast data acquisition rates, and increasing availability. Pomerleau et al. (2015) identified PC2PC registration, or scan matching, as the foundation of many front-end odometry algorithms. PC2PC registration aims to find the 6-DOF homogeneous transform consisting of the (roll-pitch-yaw) rotations and (x-y-z) translations that best align consecutive static point clouds in a timely manner. In an otherwise static environment, the relative transformation between the point clouds corresponds to the movement of the sensor and, consequently, the platform to which the sensor is rigidly mounted, for example, a car. When applied to successive point clouds obtained from a moving platform, this method enables the localization of the platform and the construction of a map of the environment using the relative transformation between each point cloud.
LiDARs provide a point cloud that represents the surrounding environment with a set of 3D Cartesian points and corresponding intensity values. New technologies such as Aeva’s FMCW LiDAR also provide per-point relative radial velocity (Aeva, 2022). However, these measurements contain no interpretable semantic information or association with the environment they represent. The ability to draw reliable and timely references from the raw data is limited, and the understanding of the point cloud is open to interpretation. Algorithms must be robust, safe, and reliable as they affect the quality of subsequent planning and control stages. There are several challenges associated with point cloud interpretation that inhibit the ability to provide accurate and real-time recursive pose estimates.
The accuracy of the result(s) interpreted from point cloud data is subject to various sources of uncertainty. The sensor itself will have a documented range measurement uncertainty. Per-beam intrinsic calibration parameters are only known to a level of certainty and must be correct for high-quality point clouds as considered by Sheehan et al. (2012) and Bergelt et al. (2017). The sensor’s installation involves assumptions about its position, leading to uncertainty in its extrinsic registration to the platform. Phillips et al. (2015) and D’Adamo et al. (2018) emphasize the importance of accurate registration for providing a correct interpretation of the point cloud. These uncertainties combine and propagate to provide an erroneous representation of the environment.
The environment itself may provide various challenges. It is difficult to detect motion in a featureless environment using LiDAR points only. PC2PC registration algorithms require unique features in the environment to estimate the transformation between successive point clouds. This is a well-known problem of LiDAR odometry, often referred to as the corridor mapping problem explored by many researchers including Diosi et al. (2005), Zang et al. (2006), and Yu and Zhang (2018).
Moreover, algorithms relying on feature matching often assume a static environment. Static environments are well captured by point cloud data as the range measurements provide a true representation of the environment. While point cloud data can accurately represent static environments due to the precise range measurements, many real-world settings encompass dynamic elements. These dynamic elements introduce complexity in understanding moving objects within the scene, making the interpretation of the environment a challenging task. When assuming a static environment with dynamic objects, incorrect feature matching occurs, leading to inherent errors in the pose estimates. This highlights the importance of accounting for dynamic elements in the environment to achieve more accurate and reliable odometry results.
Reliable estimates should be provided under adverse environmental conditions. The quality of the point cloud measurements is dependent on weather conditions. Heinzler et al. (2019) and Kutila et al. (2016) report degraded sensor performance in the presence of rain and fog. Phillips et al. (2017) detail similar findings in the presence of dust. LiDAR sensors commonly struggle to distinguish spurious data points, resulting in a misrepresentation of the environment that necessitates additional processing. These errors can compromise derived point cloud geometric properties, including surface normals.
A LiDAR odometry method should be agnostic to the sensor used to generate the point clouds. Many 3D LiDAR products are commercially available and provide unique scan patterns, point cloud density, fields of view, and resolution. The scan pattern demands further consideration since point cloud measurements become sparser at longer ranges and significantly denser close to the sensor. This often affects the ability to extract features for matching scans. Mechanical rotating LiDARs have a scan pattern that does not move linearly with the platform. The ring pattern from rotating LiDARs causes incorrect correspondence between scans, leading to pose estimation errors.
A requirement for autonomous systems is to interpret sensor data in real-time at rates faster than the planning and control decisions. More time occupied by the perception stage decreases the available time for making critical decisions or introduces lag where decisions are made from outdated beliefs. The accuracy is often decreased to increase processing times, introducing the risk of making non-optimal decisions in subsequent stages. This is made challenging with modern 3D LiDARs providing millions of points per second at frame rates between 10 and 20 Hz. The hardware on many platforms is limited, reducing the computational resources available for interpreting the data.
In common applications of PC2PC registration, addressing a combination of these challenges is necessary to achieve robust, accurate, and reliable pose estimates. Nonetheless, we argue that simpler solutions are feasible and will prove more effective, efficient, and robust.
3. An overview of localization algorithms
The following provides a review of LiDAR odometry algorithms and approaches to overcoming the challenges previously identified. Attention is drawn to the increasing complexity of algorithms, and potential gaps are identified and addressed in the SiMpLE formulation in the next section.
3.1. Classical approaches
The Iterative Closest Point (ICP) algorithm, introduced by Besl and McKay (1992), is the most common method for solving the PC2PC registration problem. The algorithm iteratively searches for the homogeneous transformation that minimizes the distance error between the source and target point cloud. The method assumes data association and a static environment. ICP is simple to implement and provides accurate results using noise-free point clouds in static environments. However, these conditions are not typically observed in real-world operating environments. In its raw form, the algorithm also possesses flaws; it requires a good initial transformation guess, incurs high computational costs, and is susceptible to local extrema. Other limitations stem from its utilization of an error-based metric and dependence on assigning correspondences between point clouds, see Phillips et al. (2021).
Researchers have introduced numerous variants of ICP to overcome these limitations, see Rusinkiewicz and Levoy (2001). KISS-ICP by Vizzo et al. (2023) uses an adaptive threshold for data association and outlier rejection for highly accurate alignment of the point clouds. Donoso et al. (2017) compared 20,736 distinct ICP variants resulting from permutations and combinations of pipeline steps applied to three different scenes (data sets). The findings indicate, among other things, that no single variant stands out as the best, highlighting that performance is closely linked to both the data and the algorithms used. The validity of using ICP for PC2PC registration is brought into question by these findings. Nevertheless, it persists and continues to be utilized in new approaches, as seen in Clotet and Palacín (2023).
The introduction of the Normal Distributions Transform (NDT) by Biber and Straßer (2003) overcomes some shortcomings of the ICP algorithm. NDT does not assume correspondence between scans and uses a probabilistic reward-based framework instead of the error-based metric in ICP. The point cloud is divided into voxels of a grid size selected by the user, and the mean and covariance of each grid are calculated and used to assign a reward value when matching a consecutive scan. Using reward instead of error and making no assumption about the correspondence allows for robustness in dynamic environments. However, Magnusson et al. (2007) note the optimal size and distribution of cells depend on the shape of the input data and on the application. NDT is fast, but Ulaş and Temeltaş (2013) identify discontinuities in the surface representation due to discretization.
To reduce the effect of discretization, Biber and Straßer mention the use of multiple grids at the cost of compromising the algorithm’s speed. The grid size selection is also a sensitive parameter, as discussed by Kaminade et al. (2008). Hong and Lee (2017) reduce the effect of the grid size parameter by introducing a probabilistic Normal Distributions Transform representation that uses the probabilities of point samples instead of only building distributions for the divided grids, allowing for all points to contribute towards the reward evaluation. Even though the minimum point requirement to form distributions is removed, the presence of the cell size remains. Other attempts such as by Ulaş and Temeltaş (2013) use multi-resolution grid sizes to overcome this issue.
3.2. Modern approaches
PC2PC methods, like ICP and NDT, rely solely on the raw point cloud data. However, many modern techniques extract additional geometric properties from the point cloud to complement and enhance the accuracy and convergence time of ICP or NDT scan matching. Nonetheless, this often introduces more parameters and increased complexity. Feature-based methods, for example, extract lines, planes, and landmarks from the point cloud to improve scan matching. They are commonly used as a coarse registration method, providing a good initial estimate for fine registration methods like NDT and ICP (Cheng et al., 2018; Huang et al., 2021). LOAM, introduced by Zhang and Singh (2014), is a popular method utilizing feature extraction. It extracts edge and planar points to achieve accurate scan alignment, ranking among the top LiDAR odometry methods. Similarly, F-LOAM developed by Wang et al. (2021), constructs a local edge and plane map to facilitate feature-based registration.
Many methods provide a full SLAM solution. MULLS is a state-of-the-art method proposed by Pan et al. (2021). At its core, the method uses a feature extraction-based front-end with a multi-metric linear least square ICP algorithm. Feature extraction involves classifying various feature points such as the ground, façade, pillars, and beams. The back-end uses hierarchical pose graph optimization composed of sub-maps registered using TEASER++ by Yang et al. (2020) for constructing global maps. The complete algorithm is composed of many stages with 107 identified configurable parameters. While the performance is promising and provides real-time results, the algorithm is complex and requires appropriate parameter selection for ideal performance depending on the environment.
Similar approaches are taken by other methods such as Efficient LiDAR odometry by Zheng and Zhu (2021). It is a front-end method only, using a multi-stage pipeline consisting of spherical projection, ground segmentation, range-adaptive normal estimation, bird-eye-view projection, and ICP at its core for point cloud registration. As before, many configurable parameters are involved for each stage.
Alternative representations are often used to overcome the challenge of constructing large maps. A common approach is to use surfel-based maps and is implemented by robust approaches such as SuMa by Behley and Stachniss (2018) and Wildcat by Ramezani et al. (2022).
In an effort to reduce the configuration effort of handcrafted algorithms, Yin et al. (2020) use a deep learning foundation for feature extraction and keyframe selection to aid in point cloud matching. Deep learning methods also extend geometric feature extraction to recently published semantic-based approaches such as SuMa++ by Chen et al. (2019), and PSF-LO by Chen et al. (2021), allowing for dynamic object detection and accurate mapping in featureless environments. However, the complexity is increased with the design of the deep learning model architecture and providing sufficient training data for high-accuracy performance. Examining errors also becomes difficult as the output needs to be back-traced through many layers, which is not always possible using deep learning methods. Considerable research has been conducted into deep learning frameworks by Wang et al. (2017), Li et al. (2019), Li and Wang (2020), and Zheng et al. (2020).
3.3. The increasing complexity of SLAM methods
There is a noticeable trend in SLAM research towards increasingly complex algorithms that achieve similar performance to existing methods. However, very few approaches offer manageable and meaningful parameter sets along with straightforward and implementable methodologies, particularly when it comes to examining LiDAR odometry algorithms. Even widely used solutions such as Google Cartographer acknowledge the challenges of parameter tuning, stating ‘Tuning Cartographer is unfortunately very difficult. The system has many parameters many of which affect each other’ (Cartographer, 2022). Such complexity is far from ideal, often leading to post-processing and iterative tuning to achieve an optimal solution or tailoring algorithms to work with specific use cases. Our approach aligns with the philosophy of KISS-ICP (Vizzo et al., 2023), which advocates for a return to fundamental techniques to decrease complexity. This strategy enables easier identification of failure modes and ensures the algorithm remains user-friendly across a wide range of sensor types and environments.
4. The SiMpLE algorithm
SiMpLE is a scan-to-map registration algorithm inspired by our previous work in applying reward-based metrics for pose estimation problems using point cloud data in Phillips et al. (2021) and Bhandari et al. (2023). The algorithm rewards trajectories that locate new point cloud measurements in proximity to previously mapped point cloud measurements. We use scan-to-map instead of scan-to-scan registration to maximize the overlap between previous and new point clouds as the spatial resolution of LiDARs is known to reduce with distance, decreasing the overlap between consecutive scans (Mendes et al., 2016). The map keeps a temporal history of previous scans that is used to register against new point clouds, as detailed further below. The following three subsections detail the three steps of the SiMpLE algorithm.
4.1. Step 1: Input scan spatial subsampling
The first step is to spatially subsample the new scan,
4.2. Step 2: Point cloud-to-map registration
The second step is to register the subsampled new scan,
The scan-to-map registration step comprises two components: (i) an objective function used to score a pose estimate hypothesis and (ii) a search algorithm used to explore the pose hypothesis space for the highest-scoring pose estimate.
The SiMpLE objective function is predicated on the belief that the most likely pose estimate,
Figure 2 depicts the objective function as it is applied to the j-th pose estimate, The subsampled new scan, 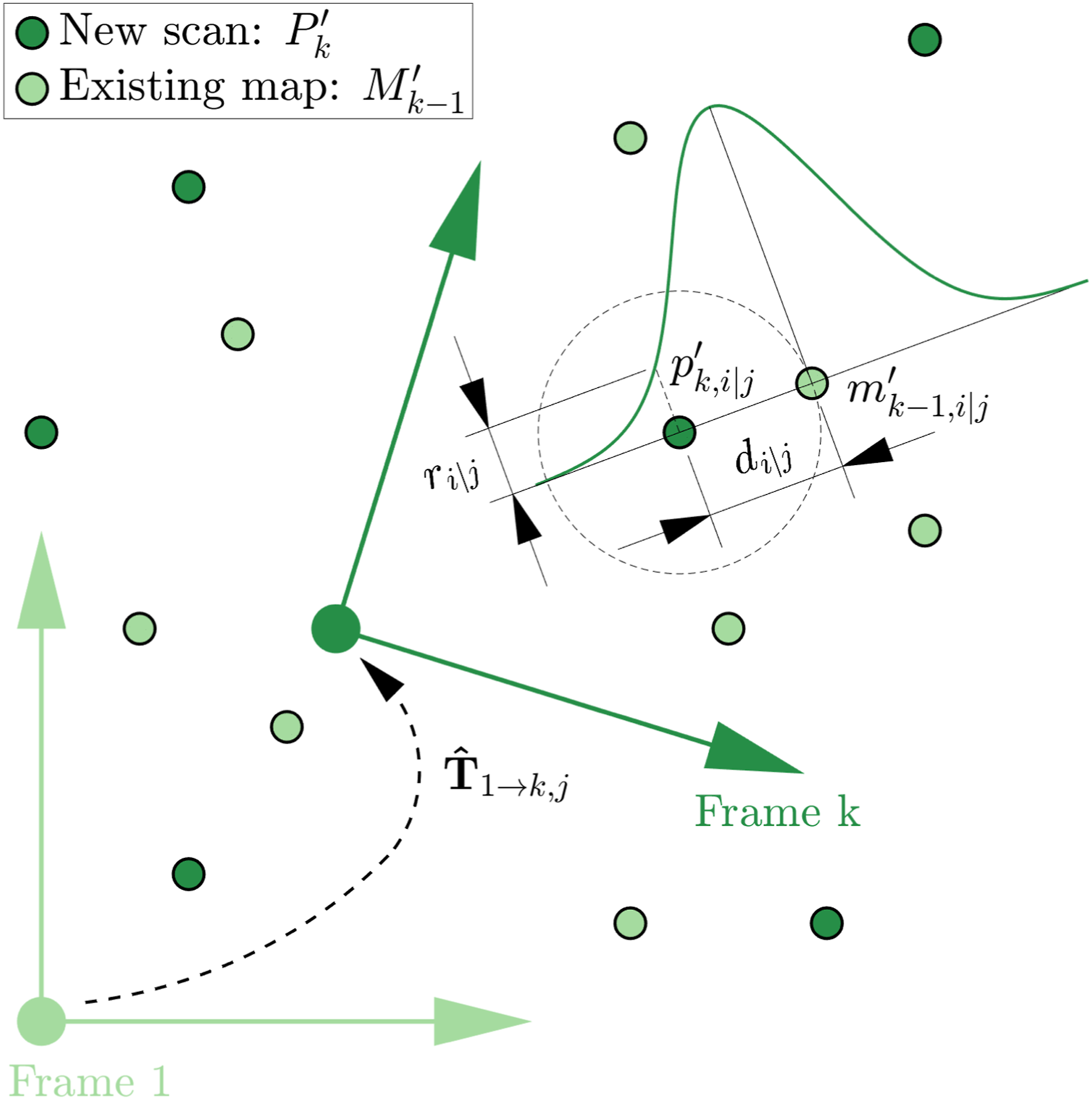
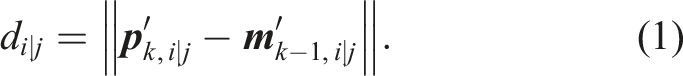
A reward Gaussian is overlaid which illustrates the reward, ri|j, decreasing as the distance between points, di|j, increases. The SiMpLE objective function seeks to find the transformation that maximizes the sum of ri|j over all
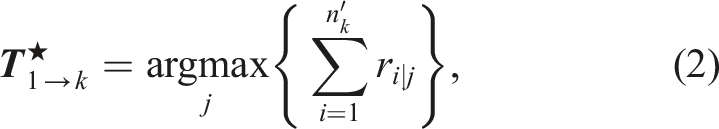

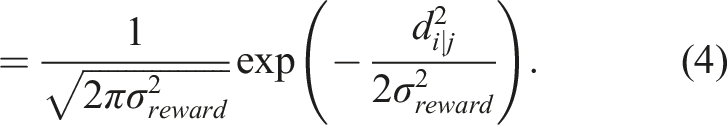
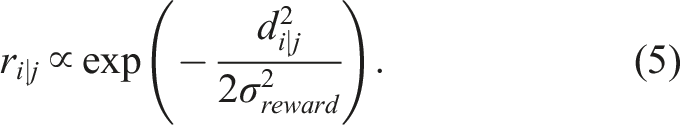
The method described in this step is summarized in the appendix in Algorithm 3 and is closely related to the formulation of ICP, whereby the closest point is used. However, instead of directly minimizing the error between the point cloud measurements, here, points are rewarded for being close to other points. This single difference eliminates the need for point cloud pre-processing steps such as random sample consensus used for ground plane fitting by Pan et al. (2021), classification, clustering, segmentation, and all associated configurable parameters.
A search algorithm is required to find the highest-scoring pose estimate. The SiMpLE objective function does not require a specific search algorithm, and various algorithms are suited to this task, including gradient, simplex, and particle filter-based methods. While gradient-based solvers are susceptible to finding local extrema, we have found they are suitable because the transformation between successive scans is small for high-frame rate LiDAR scanners.
The implementation presented in this paper uses the Broyden–Fletcher–Goldfarb–Shanno (BFGS) Quasi-Newton optimization solver to search for the 6-DOF pose that best aligns the point cloud to the local map. The BFGS Quasi-Newton implementation performs an unconstrained optimization of the objective function using approximate derivatives starting at a provided seed described further below. The search termination condition is a user-defined parameter, ɛ tol , which is a threshold for the minimum change in the registration reward between successive estimates before stopping the search. Dlib’s open-source implementation of BFGS Quasi-Newton by King (2009) is integrated with the described objective function.
Pose search algorithms rely on having a good initial guess, or seed, to avoid finding local extrema. A constant velocity model is used in SiMpLE’s implementation to provide an initial guess for the pose search algorithm. Given the initial pose,

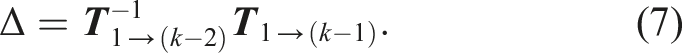
Alternative approaches include using an IMU to approximate the current pose given the previous estimate.
The parameter σ
reward
influences the optimization solver’s solution. It effectively acts as a bandwidth parameter, similar to that used in a kernel density estimator, trading off between variance and bias in the surface of the reward function (Botev et al., 2010; Turlach, 1993). Section 5.5 demonstrates the insensitivity of σ
reward
to small changes. The plots for two different values of σ
reward
are displayed in Figure 3. The effect of changing the σ
reward
configuration parameter. σ
reward
is similar to the bandwidth parameter used in kernel density estimation in that it trades off between bias and variance. A small value for σ
reward
(left) has the potential to under reward good hypotheses, whereas, a larger value of σ
reward
can over reward weaker hypotheses. A sensitivity analysis is provided in Section 5.5 which shows that similar registration results are obtained over a wide range of σ
reward
values.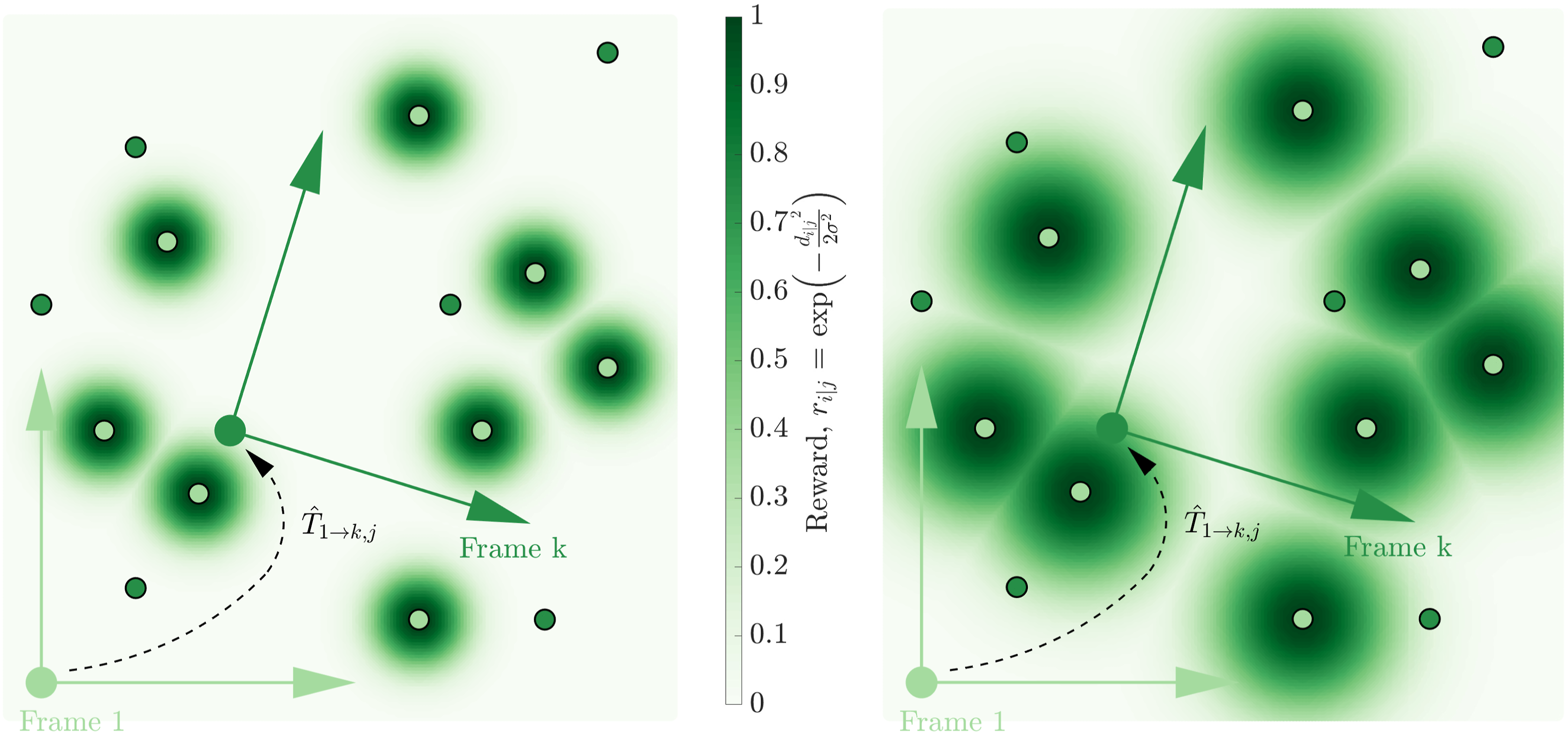
4.3. Step 3: Map update
Once the registration result has converged within ɛ
tol
, the map is updated. The current subsampled scan,
Scan-to-map registration is used to reduce the effects of the LiDAR’s scan pattern and maximize the overlap between the map and the new scan for improved point cloud registration. This method is chosen in preference to scan-to-scan matching, which is biased towards locating the scan pattern’s concentric rings on top of each other between successive scans.
4.4. Algorithm summary
Listing of algorithm configuration parameters.

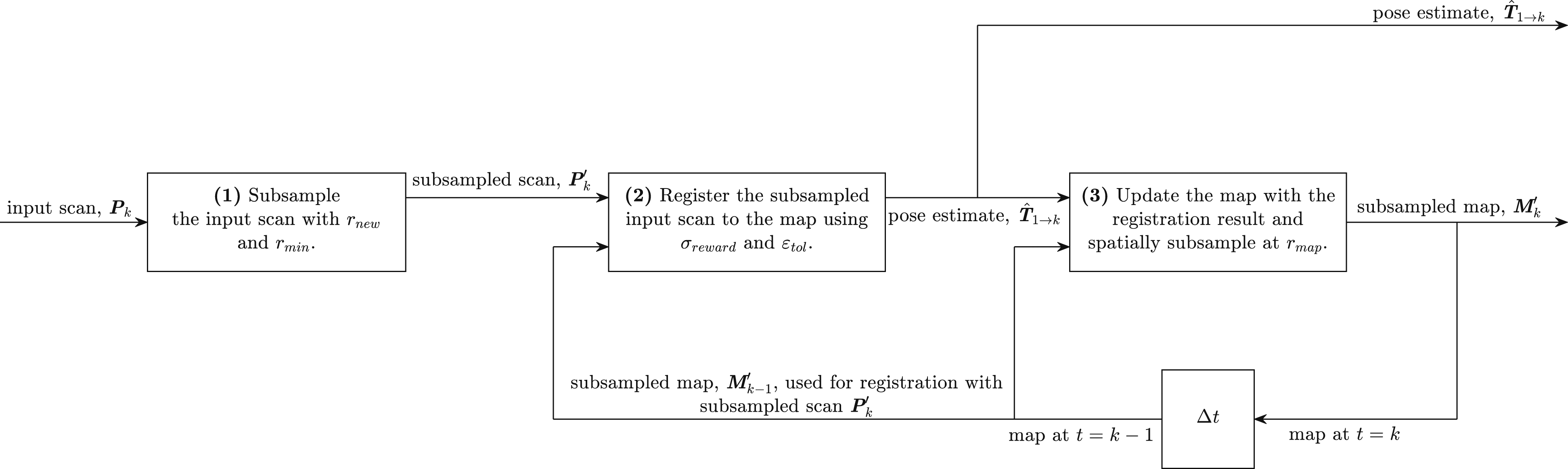
The SiMpLE algorithm consists of three steps and five configuration parameters. A new scan is first spatially subsampled before being registered against the incrementally generated map. The result provides the current pose estimate, which is directly used to update the map for the next registration result.

The SiMpLE algorithm contributes to providing a minimal configuration objective function. It is important to make a distinction between algorithm parameters that are configured upon general use (as displayed in Table 1), and those for which we use default values which are introduced by using open-source libraries. The five algorithm configuration parameters listed in Table 1 stem from the design of the SiMpLE algorithm.
There are also other parameters introduced in the implementation from the nanoflann library (Blanco and Rai, 2014) used for nearest neighbour searches, and the Dlib optimization library (King, 2009) used for searching for the highest-scoring scan-to-map registration result. We use default values for parameters present in these libraries and leave them unchanged. For example, we use the recommended KD-tree leaf size of 10 as it allows for fast nearest point queries and do not change this throughout the evaluation. Similarly, the optimization solver has fixed search-specific parameters for the BFGS Quasi-Newton implementation described by Nocedal and Wright (1999). These parameters have nominal values and are hardcoded in the Dlib library. As the open-source library parameters are not configured upon using SiMpLE, we do not account for them in the algorithm’s configuration parameter count. This allows for a direct comparison of configuration parameters with existing approaches as well.
Default parameters introduced by using open-source libraries.

5. Results
The results demonstrate the performance of the SiMpLE algorithm in comparison to other state-of-the-art LiDAR odometry methods using various case studies. The results demonstrate accurate localization with significantly less configuration than other methods. The KITTI, MulRan, UrbanNav, and a dataset recorded at the University of Queensland (UQ) are used to evaluate SiMpLE’s performance. Each dataset is recorded using a different sensor in dynamically changing environments. Figure 5 displays example scans from the datasets. Example scans from the evaluation datasets have varying densities and fields of view. The examples include a Velodyne HDL-64 scan from the KITTI dataset (top left), an Ouster OS1-64 scan from the MulRan dataset (top right), a Velodyne VLP-16 scan from the self-recorded dataset (bottom left), and a Livox Horizon scan (bottom right) from the self-recorded dataset. The axes display the origin of the sensor.
The KITTI dataset uses a Velodyne HDL-64E, providing dense point clouds with more than 100,000 points per scan on average. The Ouster OS1-64 in the MulRan dataset outputs 65,536 measurements per scan and has a 70-degree blind spot due to the placement of the sensor in front of a radar. The UQ dataset consists of a Velodyne VLP-16 providing low-density point clouds with 30,000 points per scan, and a Livox Horizon providing 48,000 points per scan at 10 Hz with a limited field of view.
Case study 1 (KITTI) uses the provided deskewed scans from the dataset for direct comparison with other methods. All other case studies use the raw point clouds to estimate the trajectory. The point clouds can be deskewed using a timestamped IMU or a constant velocity model as a pre-processing step and require knowledge about the sensor characteristics such as the timestamped beam firing sequence. The result can be used directly with SiMpLE.
The results presented below use a BFGS Quasi-Newton optimization solver, implemented using the open-source Dlib library by King (2009). The initial condition or seed for each optimization problem is estimated using the constant velocity model and the previous pose estimate as detailed in Section 4.2. The closest point search is computed using a KD-tree implementation from the open-source nanoflann library by Blanco and Rai (2014). All testing is performed using an Intel i7 CPU @ 3.80 GHz with 62.5 GiB memory running Ubuntu 20.04.5 LTS, and the results are computed using CPU threading only, implemented using Intel’s open-source Thread Building Blocks API (Intel, 2023). KITTI’s evaluation metric is used for reporting translational and rotational errors for the KITTI and MulRan datasets for direct comparison with other published methods. The evaluation metric is detailed in Geiger et al. (2012). All tests use (r new , r map , ɛ tol ) = (0.5, 2, 10−3). Hardware configures rmax while σ reward depends on point cloud density. All results are reproducible using the provided code.
5.1. Case study 1: KITTI dataset
The KITTI training dataset is a benchmark for algorithm performance and consists of 11 sequences of urban, highway, and country environments with varying difficulty concerning path length, vehicle speed, and localization features. SiMpLE uses only the Velodyne HDL-64E scans to generate a trajectory estimate. A calibration factor is applied to the KITTI scans to account for intrinsic errors identified by Deschaud (2018).
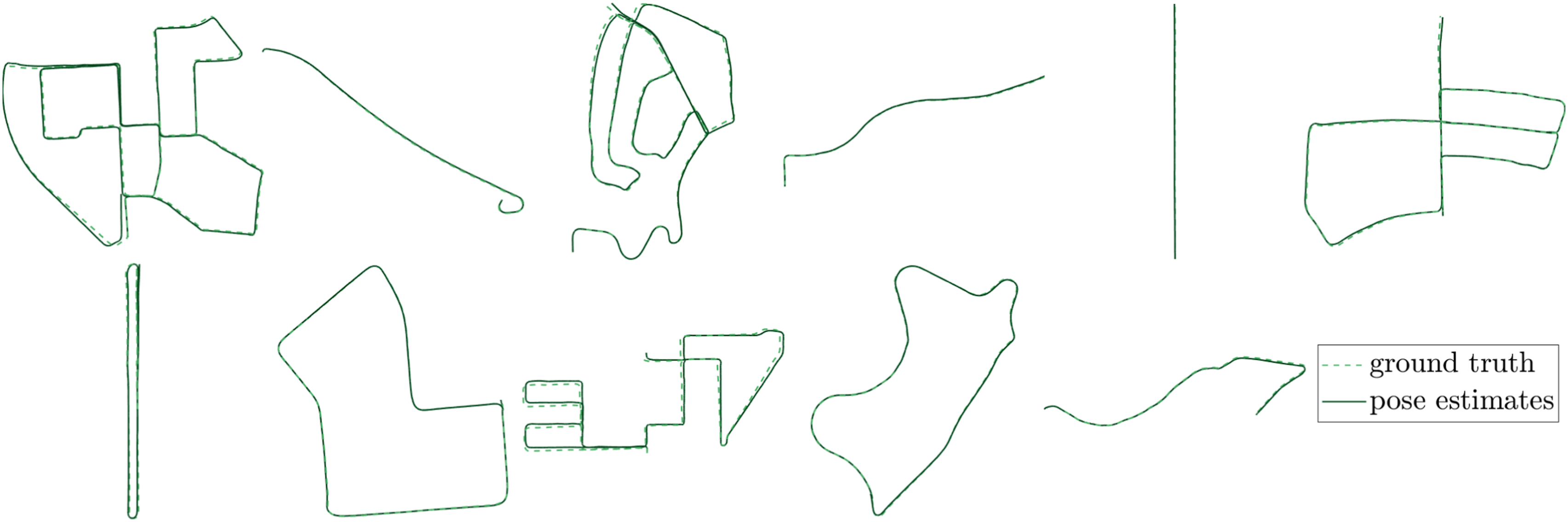
The performance of SiMpLE in comparison to other published methods is displayed in Figure 6, with the average translational error for each sequence listed in Table 3, evaluated using the KITTI metric for each sequence. Similar performance is achieved in comparison to state-of-the-art LiDAR odometry and loop closure methods at a significantly lower configuration burden. We outperform many sophisticated loop closure methods such as S4-SLAM by Zhou et al. (2021), and deep learning-based methods such as LoDoNet by Zheng et al. (2020) and LO-Net by Li et al. (2019). These methods are of higher fidelity and require training sets in some instances. Improved performance is achieved compared to state-of-the-art LiDAR odometry methods such as LOAM by Zhang and Singh (2014) and F-LOAM by Wang et al. (2021). Figure 7 displays a comparison between the ground truth and pose estimates for sequences 00-10. We achieve a mean translational and rotational error of 0.52% and 0.0013 deg/m offline and 0.57% and 0.0023 deg/m in real-time for the training dataset evaluated using KITTI’s metric. All tests use σ
reward
= 0.3 m for the high point cloud density. An extensive comparison between LiDAR odometry methods utilizing a variety of techniques including point cloud registration, pose graph, feature extraction, semantic understanding, and deep learning. SiMpLE performs among the top-ranked LiDAR odometry methods (left). We use only front-end point cloud registration and perform similarly to the majority of the LiDAR odometry methods, with an average translational error of 0.52% offline and 0.57% in real-time, evaluated using KITTI’s provided metric. The results for the other methods are taken as published in Pan et al. (2021), Vizzo et al. (2023), and Kovalenko et al. (2019). SiMpLE outperforms state-of-the-art LiDAR odometry methods in the MulRan dataset’s four scenarios (right). Each scenario consists of three sequences, whose results have been averaged and presented. The results for the other methods are obtained from Vizzo et al. (2023). KITTI benchmark sequences 00-10 dataset results summary. The results are reported using the KITTI error metric. SiMpLE’s pose estimation results for KITTI sequences 00-10, consisting of 23,201 scans over 22.17 km. All sequences exhibit low drift using front-end LiDAR odometry only.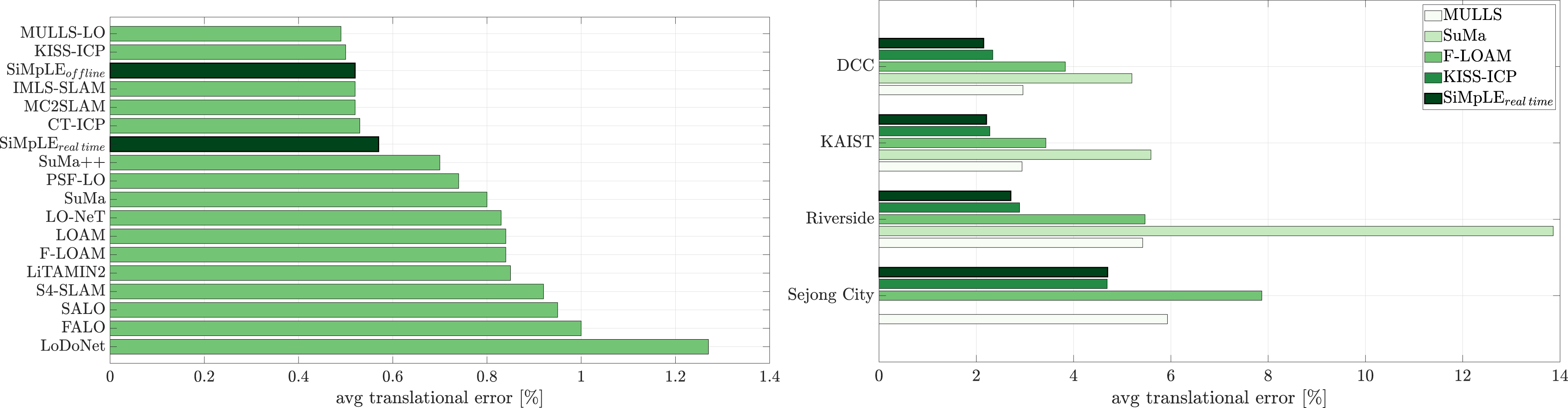

5.2. Case study 2: MulRan dataset
The recently introduced MulRan dataset by Kim et al. (2020) provides 12 challenging sequences in urban environments with corresponding ground truths. The sequences are considerably larger than KITTI in length and provide a greater structural and temporal diversity by being recorded at different locations and times of the year. Point clouds are obtained from a 64-beam Ouster OS1 LiDAR and are provided in the same format as the KITTI dataset. A challenging aspect of the dataset is the 70-degree blind spot in the LiDAR’s field of view due to the location of the radar. LiDAR odometry methods relying on point cloud registration suffer from incomplete scans.
MulRan benchmark results summary. The sequence number corresponds to the DCC (

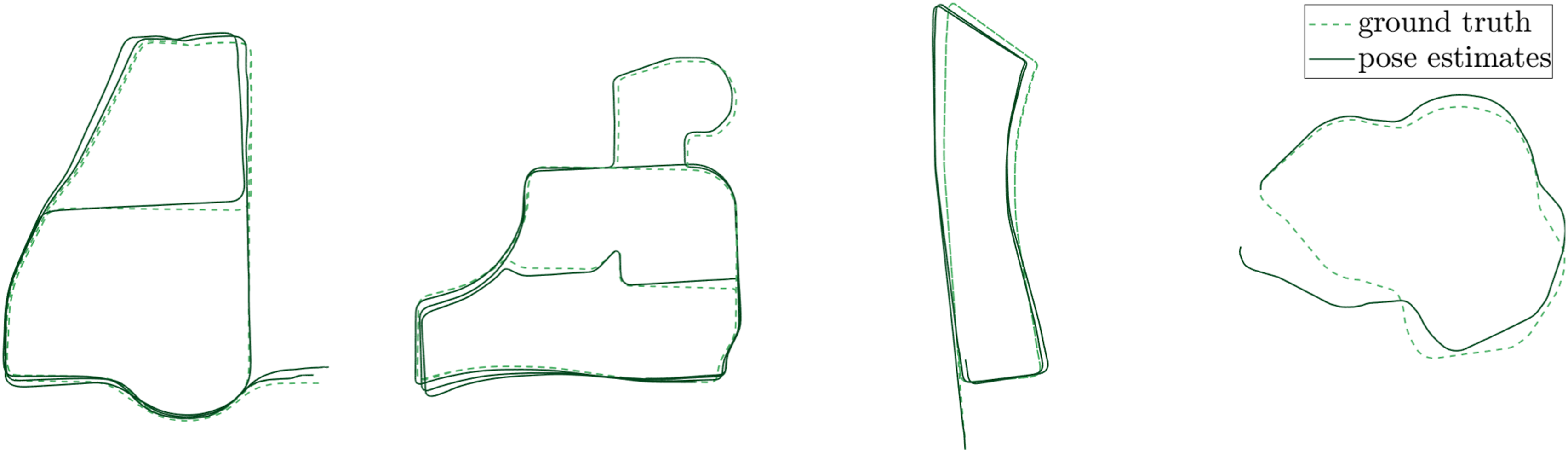
Example of pose estimation results from the MulRan dataset using SiMpLE for sequences (left to right) DCC (4.9 km), KAIST (6.1 km), Riverside (6.8 km), and Sejong (23.4 km). The complete 12 sequences consist of 154,035 scans over an approximate distance of 123.6 km, hence the increasing drift over longer distances using front-end LiDAR odometry only.
5.3. Case study 3: UrbanNav Dataset
SiMpLE UrbanNav results for Data1 and Data2.
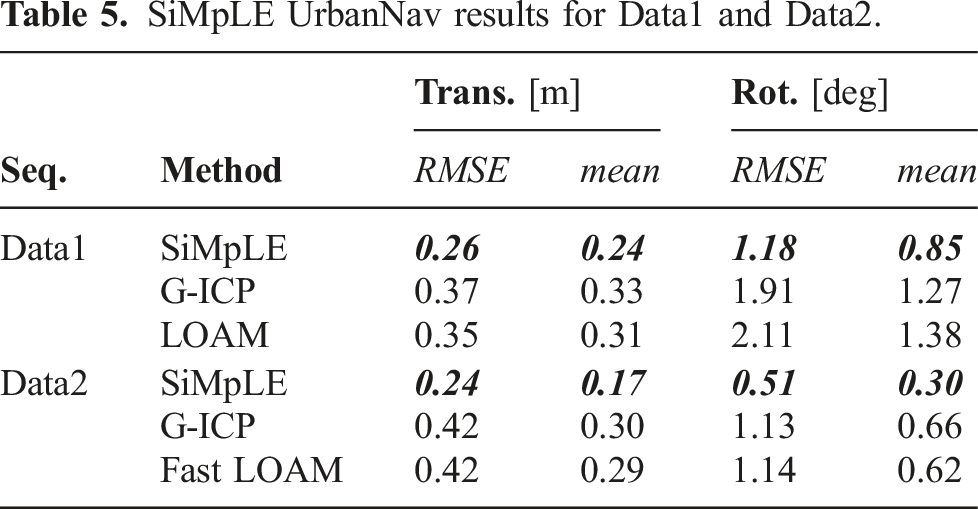
UrbanNav trajectory estimates for Data1 (left) and Data2 (right). SiMpLE experiences low drift in highly dynamic urban canyons. Loop closure methods can be employed with SiMpLE for better localization accuracy at the expense of increasing the configuration set.
5.4. Case study 4: The University of Queensland (UQ) St Lucia Campus
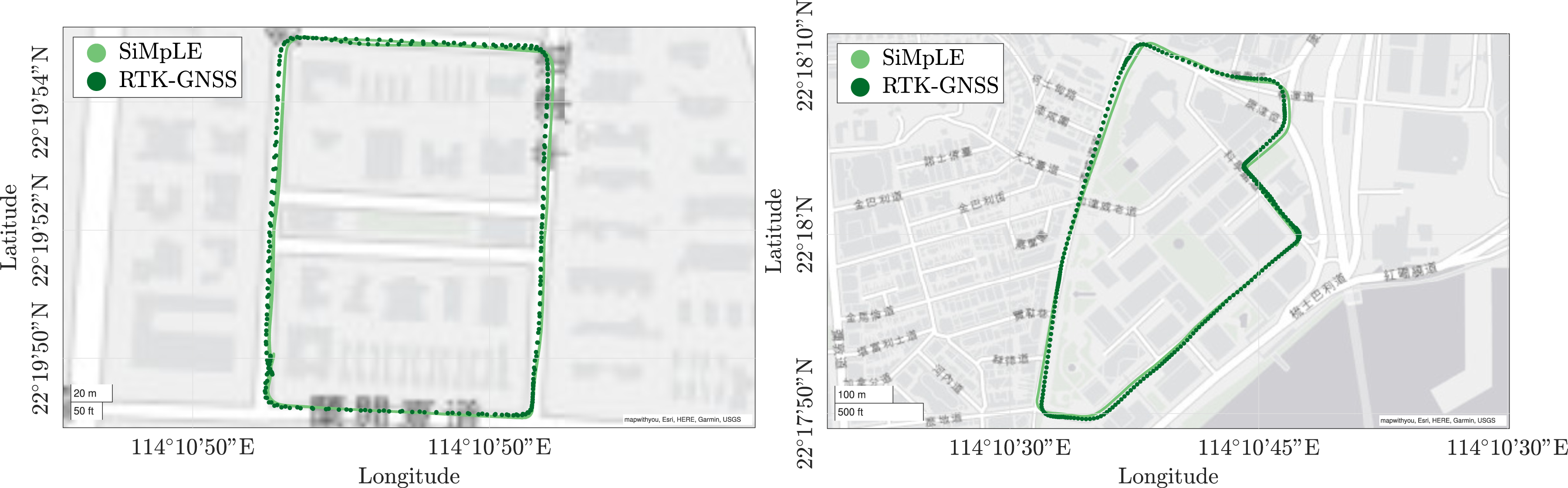
The KITTI, MulRan, and UrbanNav datasets provide high-density point clouds. To test SiMpLE’s performance with a different field of view and low-density point clouds, a vehicle was mounted with a Livox Horizon (Livox, 2019), a KAARTA Stencil 2 (KAARTA, 2021) using a Velodyne VLP-16, and a NovAtel navigation solution as displayed in Figure 10. The designed testing platform consists of a Livox Horizon, KAARTA Stencil 2, Velodyne VLP-16 LiDAR, and a NovAtel navigation solution.
Self-recorded sequences.

Figure 11 displays the results for a large dynamic sequence of 12,000 VLP-16 scans at 10 Hz recorded in the presence of other vehicles and pedestrians. The environment is mostly static with substantial vegetation alongside the road. Multiple closed loops are provided to aid the KAARTA SLAM solution. Using the raw VLP-16 scans only, SiMpLE adequately tracks the vehicle position and accumulates low drift over the entire sequence. The KAARTA solution with and without loop closure accumulates more drift and is unable to provide a reasonable trajectory. The large error in the KAARTA closed-loop trajectory may exist due to incorrect loop closure identification, offsetting the entire trajectory. SiMpLE only has five parameters, whereas the performance of the KAARTA solution is affected by up to 73 parameters (KAARTA, 2020). Further tuning the KAARTA parameters may result in a better trajectory. Figure 12 displays the pose estimation results for two sequences consisting of 2600 and 2300 scans each recorded using the Livox Horizon LiDAR. This dataset is included to show SiMpLE’s performance with a LiDAR with a different field of view and scan pattern. Low drift is accumulated along the entire sequence. Trajectory estimate results around the University of Queensland St Lucia campus generated from 12,000 Velodyne VLP-16 scans at 10 Hz. SiMpLE (left) accumulates low drift over the entire sequence using front-end odometry only. Decreasing the subsampling from r
new
= 0.5 m to r
new
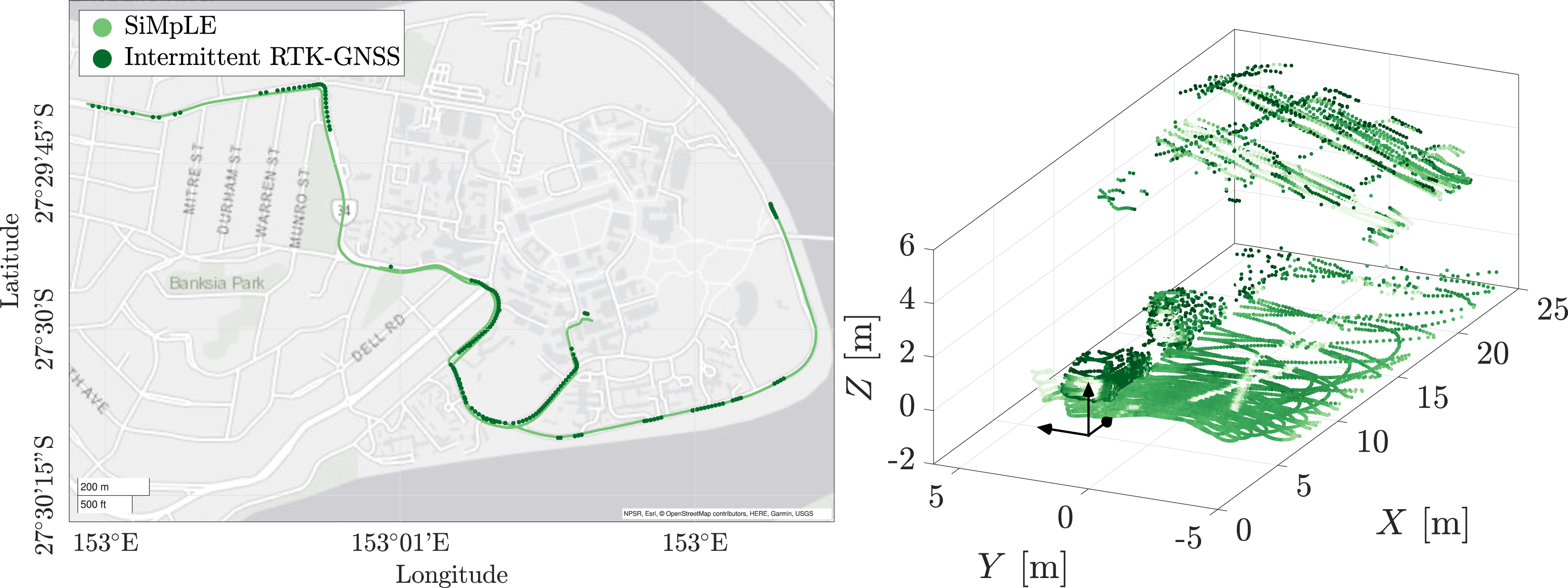
= 0.25 m allows for highly accurate localization. The KAARTA front-end odometry (middle) and KAARTA SLAM (right) solutions drift significantly over time and may be corrected by tuning the configuration parameters. The GNSS solution drops out on multiple occasions due to loss of signal in paths with significant vegetation cover. The SiMpLE odometry results (left) for two sequences recorded using a Livox Horizon mounted at the front of the vehicle. SiMpLE accurately tracks the vehicle position with low accumulated drift. A sample scan from the Livox LiDAR is shown on the right (the full scan is not shown due to the sparsity at long range). The field of view and scan pattern is different compared to a mechanical rotating LiDAR such as the Velodyne VLP-16. The scan shows parked vehicles, the road, and an overhead bridge, with the point colour indicating the return intensity.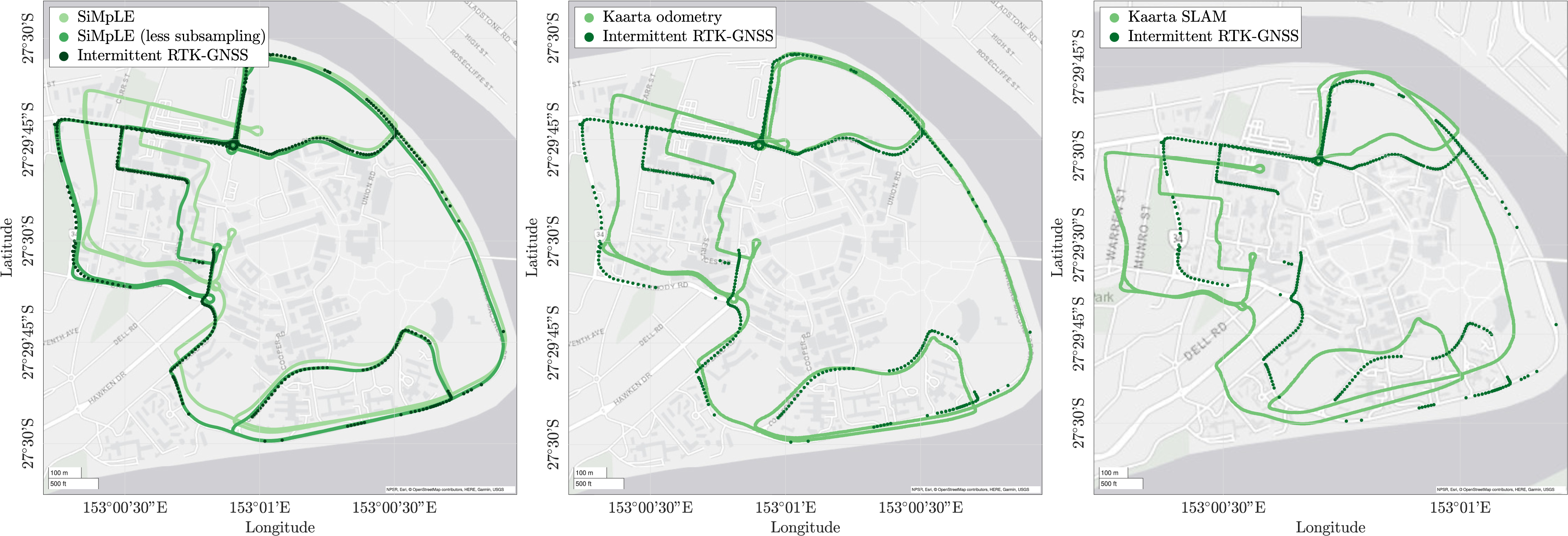
5.5. Parameter sensitivity
SiMpLE has five configuration parameters. Along with limiting the possible permutation of configuration parameters, the parameters should be insensitive to small deviations for applicability in different environments and point cloud characteristics such as the scan pattern and point cloud density. Many methods rely on fine-tuning the configuration parameters for optimal performance. Figure 13 displays the average translational error for KITTI sequences 00-10 across 27 permutations of the input parameters; r
new
, r
map
, and σ
reward
. Similar results are obtained regardless of the configuration, with a low standard deviation of 0.07% translational error. Real-time pose estimation demands a generic set of parameters that do not require post-processing tuning. For optimal performance, the input scan subsampling, r
new
, should be as small as possible to provide an accurate representation of the environment. This is limited by the computational resources, as each point in the input scan is rewarded when evaluating the objective function. The algorithm needs to provide pose estimates commensurate with the required rate of control decisions. The size of the map depends on the subsampling radius, r
map
, and is generally set to be larger than r
new
to overcome the effect of the sensor’s scan pattern. The registration reward, σ
reward
, is shown to be insensitive above, and is generally set to a value similar to the input scan subsampling, r
new
. SiMpLE’s configuration parameters are insensitive to small changes. The heatmaps demonstrate minimal changes in the translational error results for the KITTI training dataset over 27 permutations of the configuration parameters, r
new
, r
map
, and σ
reward
. The best result is indicated with a star. Only having three main configuration parameters allows for visualization of the configuration space. This is not possible for the majority of LiDAR odometry methods.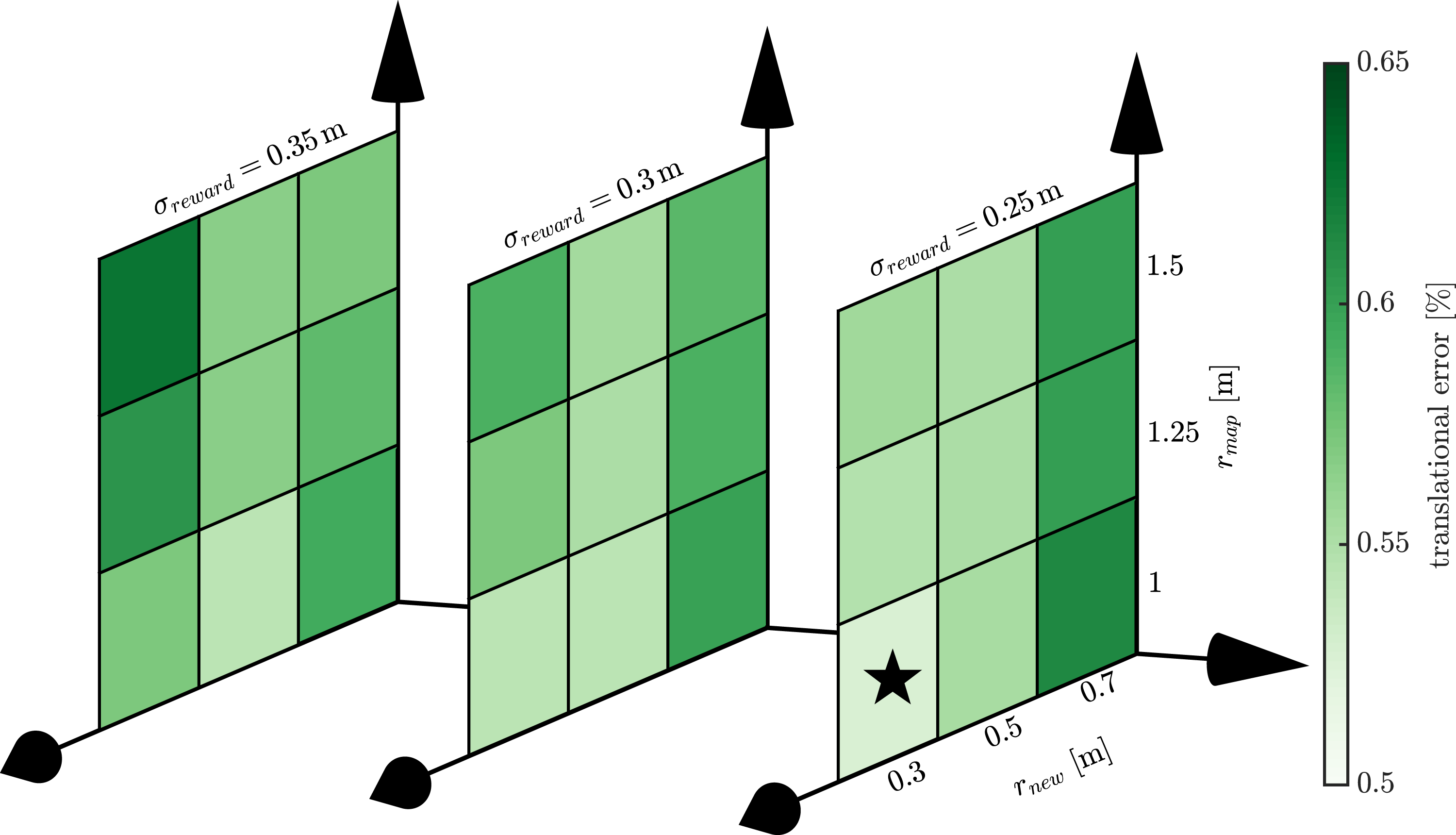
5.6. Real-time performance
Effect of Ɛ tol on the translational and rotational error, and the average execution time for KITTI sequences 00-10.
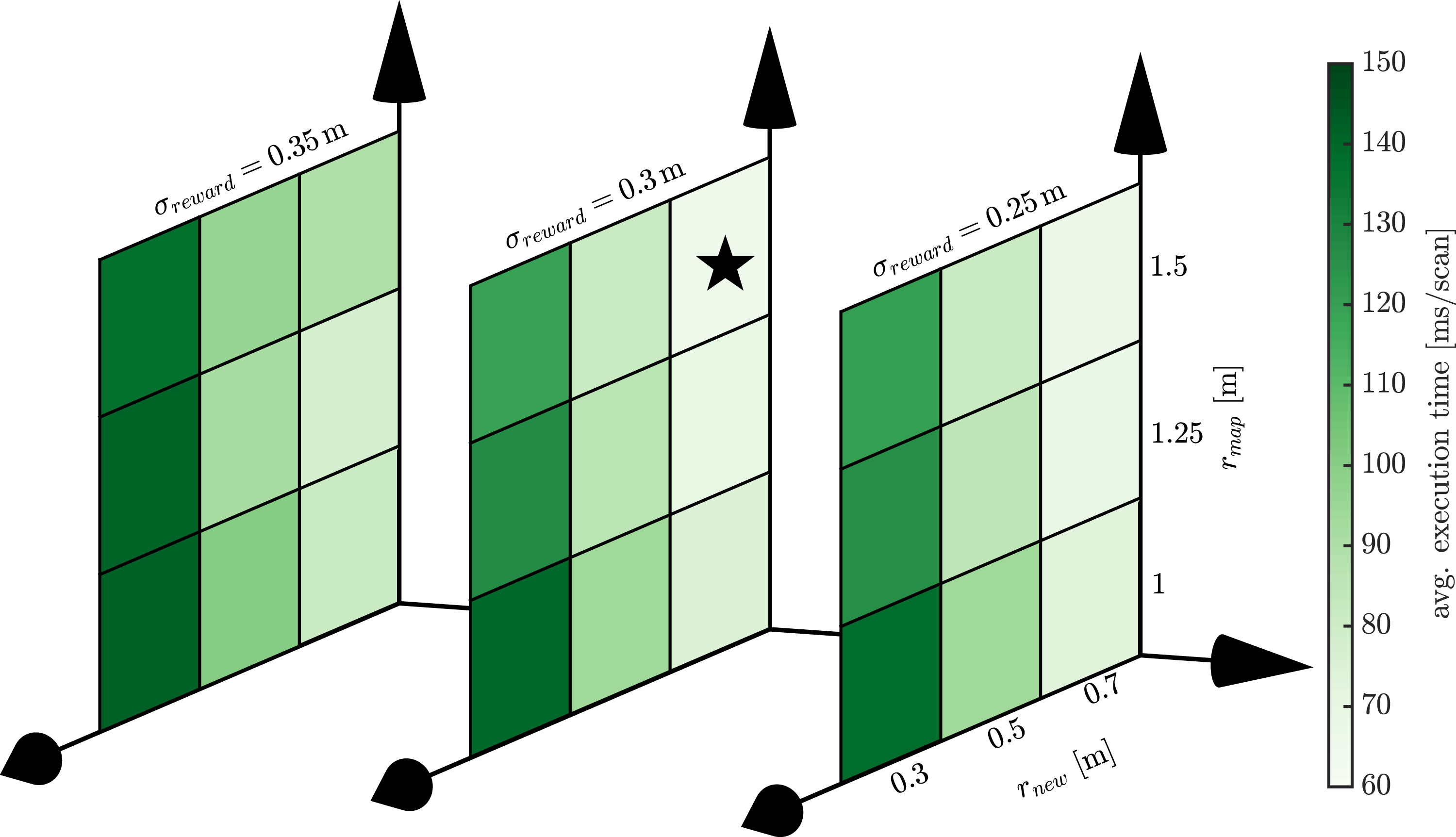
The average execution time per scan is proportional to the size of the point cloud being scored in the objective function. A smaller subsampling radius preserves the geometrical features of the point cloud and results in higher accuracy as illustrated in Figure 13, but results in a greater execution time as illustrated here. This is severely impacted by the size of the original point cloud. For example, the KITTI point clouds are double in size compared to the MulRan dataset. The results are demonstrated using the KITTI training dataset with the star indicating the fastest average evaluation time.
Average SiMpLE processing times.

An optional parameter, r
min
, may be used to reduce the number of points per scan and allow for real-time applicability when using a small subsampling radius. Scan points with a range of less than r
min
are discarded. Figure 15 displays the effect of applying r
min
to a scan, and Table 9 displays the effect of r
min
on the algorithm performance. We emphasize this is optional and for computational benefit only. The r
min
parameter can be disregarded given adequate computational resources. The MulRan and self-recorded dataset provides real-time pose estimates using the default value of r
min
= 0 m. The original scan with 124,668 points using the default r
min
= 0 m (left). The same scan with 62,304 points using r
min
= 10 m. The scan properties and features are preserved with only the inner rings removed. This reduces the point cloud size by approximately 50%, allowing for faster objective function evaluations. Effect of r
min
on the translational and rotational error, and the average execution time for KITTI sequences 00-10.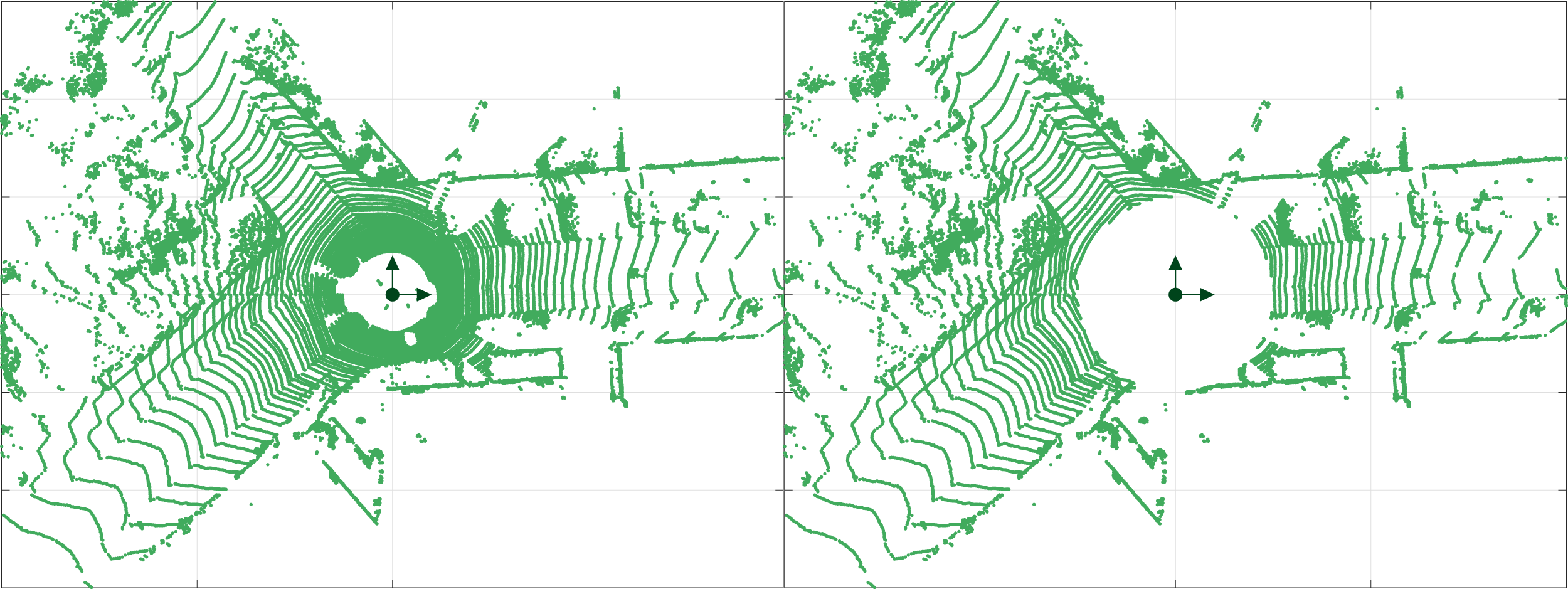

The real-time performance depends strongly on the ability to perform CPU threading. The objective function benefits immensely from the parallel computation of the independent per-point reward calculation. Common open-source threading APIs such as Intel’s Thread Building Blocks (TBBs) (Intel 2023) and OpenMP (OpenMP, 2023) allow for easy parallelization. We have tested with TBB on Intel and macOS ARM processors, and OpenMP is documented to support Intel, AMD, and ARM processors. TBB is used for our open-source implementation as our testing has demonstrated superior performance to OpenMP with automatic thread allocation.
1
The dependence on threading for real-time performance is depicted in Figure 16, along with a comparison of TBB vs OpenMP for our specific task. We use TBB as it performs automatic thread allocation and provides a greater than three times faster evaluation of the objective function. SiMpLE’s real-time performance relies on the ability to thread the objective function evaluation. The plot shows the effect of increasing the number of threads on the average execution time, with the real-time results indicated in a darker colour. The threads are set manually using OpenMP, with TBB having automatic thread allocation. Threading allows for the average execution time to decrease from approximately 250 ms to 75 ms, a greater than three times speed benefit. The error bars show the standard deviation of the timing results, with the execution time varying with the density of the point cloud. All results presented in this paper are executed in real-time using TBB.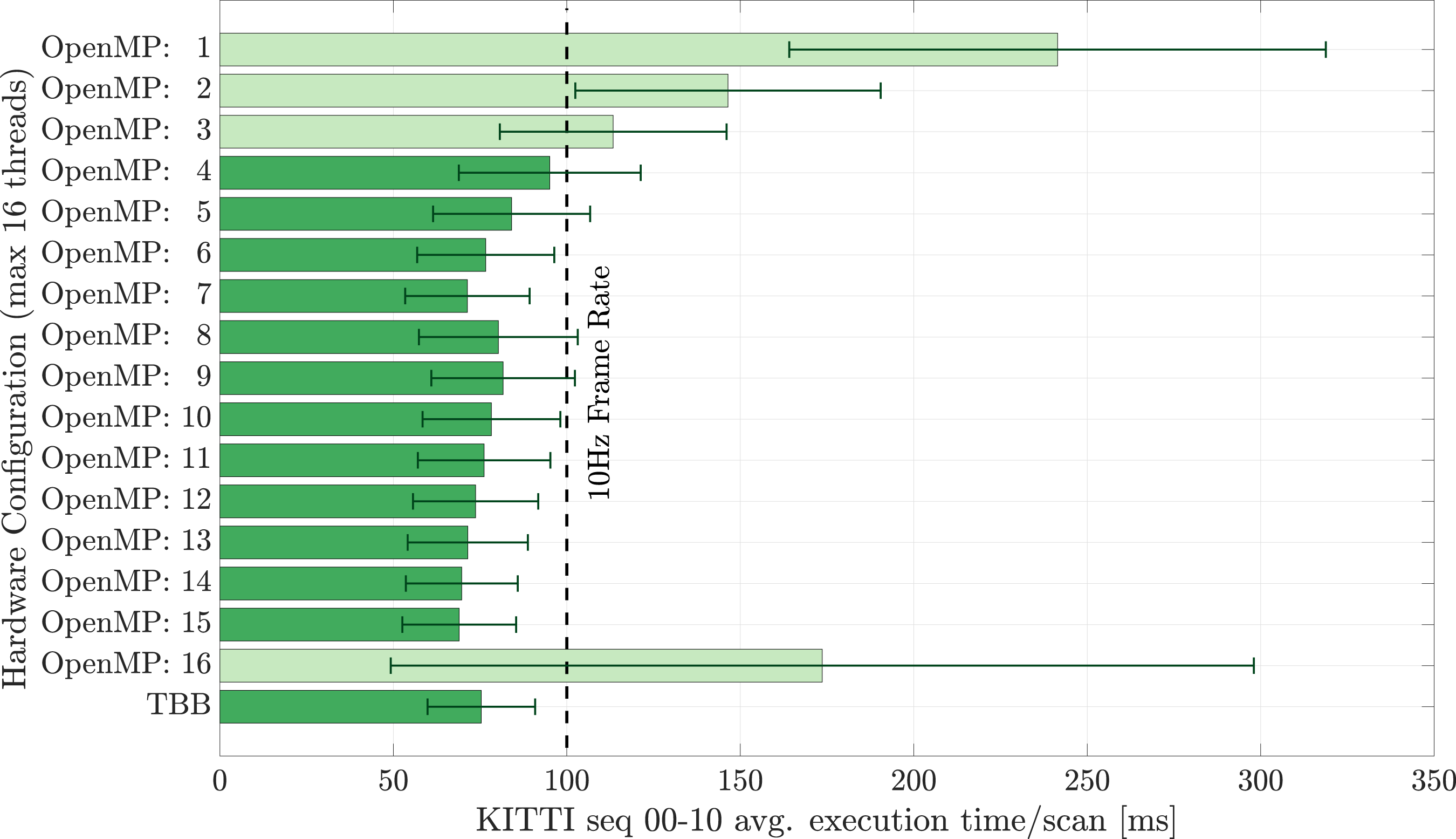
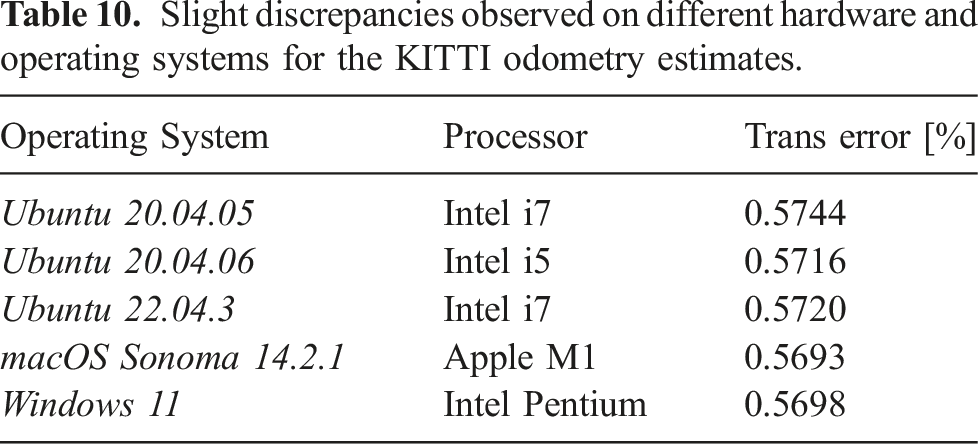
Slight discrepancies observed on different hardware and operating systems for the KITTI odometry estimates.
6. Future work
We propose SiMpLE as a fundamental work that provides a significant opportunity for development to achieve improved registration accuracy, speed, and robustness of localization methods. However, many of these occur at the cost of increasing the configuration set, detracting from the simplicity of SiMpLE. A few of the extensions are discussed below.
SiMpLE is a recursive pose estimator. The result at time k is dependent on the registration result at time k − 1. A single large registration error has the potential to offset the entire trajectory and a lack of back-end processing results in future estimates propagating the error. The integration of a constant velocity or constant acceleration process model with common filter-based state estimators such as a Kalman filter is expected to reduce the effect of erroneous registrations. The current implementation is agnostic to the dynamics of the mobile platform, but this prior information could be used to increase the accuracy of the results. However, this comes at the expense of adding configuration parameters in implementing the filter. A measure of uncertainty for the PC2PC registration process also needs to be derived as an input to the filter.
The filter can also be used to integrate information from other sensing modalities, such as GNSS, IMU, and vision-based approaches for increased robustness and redundancy. D’Adamo et al. (2022) formulated an Extended Kalman Filter to fuse information from a GNSS, IMU, and LiDAR to increase pose estimation accuracy and allow for 6-DOF pose estimation using two GNSS receivers only. An IMU can also be used directly in the SiMpLE algorithm as an alternative to the constant velocity model used to estimate the seed for the optimization solver. This is expected to allow for faster convergence to the optimal solution. LiDAR-inertial odometry has been vastly explored, with Wildcat by Ramezani et al. (2022) being a prominent example.
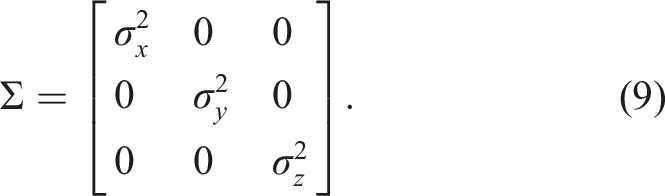
SiMpLE’s objective function uses a single configuration parameter, σ
reward
. In this paper, σ
reward
is selected arbitrarily and shown to be insensitive over a range of values. Currently, the scalar distance between two points is used in the Gaussian function as displayed in equation (1) and equation (5). This rewards distance errors in each axis, x, y, and z, equally. However, this may not be accurate when examining the shape of the point cloud, where there is different movement in each axis for a given mobile platform. For example, a car moves significantly more in the forward axis of a mobile vehicle than in other directions. Similar to NDT, σ
reward
can be expanded to a 3 × 3 matrix to allow for scoring each axis separately and hence extending the equation (5) to a matrix operation.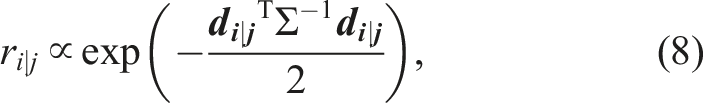
As mentioned previously, SiMpLE provides a front-end solution only. Back-end methods have been extensively explored as they have the potential to reduce accumulated drift. Due to the high portability of SiMpLE, it can be integrated directly with existing back-end solutions such as GTSAM by Dellaert and Kaess (2017) or g2o by Kümmerle et al. (2011). The results demonstrate that SiMpLE accumulates low drift over long sequences, aiding the pose graph methods.
SiMpLE uses CPU threading to accelerate the evaluation of the objective function. It is apparent that lower subsampling radii better preserve the structure of the scan and map; however, this leads to increased computation time and provides offline results. A GPU-based implementation can be explored to accelerate the execution with minimal subsampling.
7. Conclusion
The significant contribution of this paper is providing and demonstrating that a simple solution to the localization problem exhibits similar, if not better, results than most LiDAR odometry solutions available. The simple process of using scan-to-map registration with a reward-based metric provides robust pose estimation results. With the applications and use of SLAM in modern robotics growing exponentially, proposed solutions are increasing complexity to adapt to new challenges and consequently growing configuration parameters. While tuning guides are often prescribed, a user-friendly algorithm should limit the configuration permutations and the sensitivity of the parameters.
This paper derives a LiDAR odometry method from raw point cloud data, demonstrating real-time and highly accurate registration in a variety of scenarios with a minimal and low-sensitivity configuration set. SiMpLE has five configuration parameters; namely r new and r map for the subsampling of the input scan and map respectively, r min for computational benefit, σ reward for the scan-to-map registration, and ɛ tol for the optimization search termination condition. All parameters are shown to be insensitive to small changes, providing similar results with various permutations.
SiMpLE is benchmarked using the 11 KITTI training sequences consisting of 23,201 Velodyne HDL-64E scans, 12 MulRan sequences consisting of 154,035 Ouster OS1–64 scans, and the UrbanNav dataset. SiMpLE outperforms top-ranked LiDAR odometry methods on all datasets. To test the proposed algorithm with low-density point clouds, a dataset was recorded at the University of Queensland using a Velodyne VLP-16 and Livox Horizon LiDAR and evaluated using a NovAtel ground truth. The SiMpLE solution outperforms the out-of-the-box KAARTA solution with and without loop closure.
SiMpLE is an easy-to-configure and use solution to the LiDAR odometry problem. The open-source code provided is extremely lightweight and written to match the layout of the paper. It easily integrates into existing projects with minimal dependencies. As explored in the previous section, SiMpLE provides a significant opportunity for improvement by augmenting the method with state estimators, other sensing modalities, and loop closure methods, all at the cost of expanding the configuration set. Using only five configuration parameters, the algorithm performs among top-ranked LiDAR odometry methods including MULLS, KISS-ICP, F-LOAM, and SuMa. This paper addresses the foundation of the LiDAR odometry problem only using scan-to-map registration.
Footnotes
Acknowledgements
The authors would like to thank the reviewers and editors for their constructive feedback.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The first named author has been funded by the Research Training Program (RTP) provided by the Australian Commonwealth and administered by the University of Queensland.
Note
Appendix
The algorithms for the spatial subsampling and objective function are summarized below.