
Abstract
Contextual information can shape the aesthetic judgements of music compositions. Recently, a study proposed the existence of an AI composer bias; namely, listeners tend to like music less when they think (or are told) that it was composed by an AI. In this online study (N = 120), we used a cross-over experimental design to verify whether such bias extends to audiovisual music performance. The participants rated three videos of classic piano music performances in two versions with identical audio: one with a professional pianist who pretended to play, and one with the piano playing automatically, allegedly thanks to an AI. As hypothesised, the participants rated the performances as more likeable, engaging, higher in emotional valence, and of higher quality when the pieces were “performed” by the pianist. Notably, these effects were insensitive to the participants’ musical expertise but moderated by their attitudes toward AI. Interestingly, when asked what differences they had found between the two renditions, the participants confabulated about differences in rhythm, tempo variations, dynamics, and dissonances, pointing to underlying psychological processes, such as expectations and beliefs about humanness. Implications for Aesthetics and the Psychology of Art are discussed.
Introduction
Artificial intelligence (AI), a key element in modern technology, such as smart devices and social media platforms, elicits varying opinions regarding its potential benefits, risks, and overall perception among individuals (Stein et al., 2024). Indeed, research on social acceptance of AI, i.e., technologies that can perform tasks which normally require human intelligence, shows both fears and concerns as well as fascination and curiosity (Bergdahl et al., 2023). The (dis-)liking of AI technology is influenced by a variety of factors including demographic and sociocultural variables, personality traits, anxiety, and trust (e.g., Kaya et al., 2022).
Recently, research has begun to explore the use and effects of AI in art and culture (Latikka et al., 2023). In general, people show less positive attitudes toward AI in the art and culture realm in comparison with other fields, such as medicine (Latikka et al., 2023; Longoni et al., 2019). Despite possibly higher innovation in artworks by AI, the (perceived) lack of human emotionality may remove a fundamental ‘humanness’ that carries significant cultural value for people (Tubadji et al., 2021). However, somewhat surprisingly, findings from empirical studies indicate that people may not always be able to discern AI-produced art from human-produced art (e.g., Gangadharbatla, 2022) but tend to favour art made by humans over AI alternatives (e.g., Chamberlain et al., 2018). This anti-AI bias in art judgements can be found among different art forms, including visual arts (Nam et al., 2022), creative writing (Raj et al., 2023), poetry (Hitsuwari et al., 2023; Köbis & Mossink, 2021), dance (Darda & Cross, 2023), and music (Shank et al., 2023). In literature aiming to explain the negative assessment of AI-generated art (probably an instance of the more general algorithm aversion, for which see Jussupow et al., 2020, 2024 or Turel & Kalhan, 2023), one recurring theme is the significant impact of source or attribution knowledge, that is, information about who created the content (Gangadharbatla, 2022). Evaluation processes and attitudes may thus be more influenced by perceived authorship than by the art creation itself. The label “AI” tends to exhibit negative connotations, possibly because people tend to view art as a mirror of a unique human-specific experience (Bellaiche et al., 2023). Similarly, by giving the algorithm a more human-like artistic process, the anti-AI bias can be reduced (Chamberlain et al., 2018), hinting at the influence of perceived effort and time on the evaluation processes of art. Further, it has been suggested that people dislike machine-generated art because of outdated schema and stereotypes regarding the quality of computer-produced art (Samo & Highhouse, 2023). Correspondingly, people also experience more positive emotions with human-generated art (Samo & Highhouse, 2023). Manipulating source or attribution knowledge about the origin of art may therefore significantly impact how individuals perceive and evaluate the artwork.
Especially in the music industry, AI technology is increasingly used to create or assist in the production of musical pieces, developing tools that can emulate the music of famous composers (e.g., Hadjeres et al., 2017). In the aesthetic judgement of music, major theories highlight the essential role of contextual and extramusical information 1 (e.g., Brattico et al., 2013; Chatterjee & Vartanian, 2014). For instance, one key contextual feature influencing how we judge music is knowing the composer. One study found that listeners preferred music purportedly attributed to Mozart over the one attributed to an unfamiliar composer (Fischinger et al., 2018). The composer's psychological traits seem to matter as well: individuals show greater appreciation for music by artists with personalities similar to their own (Greenberg et al., 2021). Regarding AI technology and music, a recent study, from which we took inspiration, found that people tend to like human-sounding classical music excerpts less when they think (or are told) that these are composed by an AI (Shank et al., 2023). The authors suggest that the aversion towards AI-created music may be partially due to a strong emotional identification with music and its central role in a sense of self. However, these studies focused on musical composition, which may inherently involve algorithmic aspects in the process (e.g., order and recombination of ideas) and thus might require less human emotional involvement. Correspondingly, several algorithmic composition methods of both classical and rock and jazz music have been successfully developed (e.g., Hadjeres et al., 2017; Wiriyachaiporn et al., 2018).
In contrast to music composition, the act of performing music before the AI era seemed to be closer to a solely human endeavour, probably harder to imitate credibly by non-human entities. The two main functions music performance serves are to convey musical structure and to convey emotions (Huang & Krumhansl, 2011). Musicians manipulate performative expressive cues such as bodily and head movements and gestures (Castellano et al., 2008), tempo, timing, dynamics, intonation, timbre, tone onsets and offsets, and vibrato in order to express specific emotions (Gabrielsson, 1999). Interestingly, such use of expressive cues is not exclusive to musicians but extends to non-expert individuals with lower levels of formal music training (Kragness & Trainor, 2019).
However, things have rapidly changed in more recent times, and music performance is no longer considered as a solely human enterprise. Although some embryonal attempts to create an AI-based Interactive Computer Performer date back to the early nineties (Baird et al., 1993), due to the progress in robotics and Artificial Intelligence, it has become increasingly less rare to witness audiovisual performances (broadly meant) by AI agents. For example, virtual influencers and actors (e.g., magazineluiza, lilmiquela, guggimon, liam_nikuro, Aitana Lopez) are gaining significant popularity on social media. In Japan, AI-based robots are employed in nursing homes, offices, and schools. In South Korea, an AI-powered virtual news anchor resembling a real-life female presenter has appeared on the MBN TV channel (Kyodo News, 2020).
In the musical domain, AI performers are now documented. As we write, the AI DJ Aimee May (Aimee May: Embracing the Future with Aimee May: AI Model and AI Influencer, 2023) has just released her latest club single and music video Cosmic Love (Music Crown, 2024). In 2007, the Japanese company Crypton Future Media developed Hatsune Miku (Japanese: 初音ミク), a personification of a vocaloid software voicebank that has performed at live virtual concerts in the form of an animated holographic projection. According to the website of the company, such a virtual performer featured in over 100,000 songs worldwide, not to mention its sold-out 3D concerts in Los Angeles, Taipei, Hong Kong, Singapore, and Tokyo (Crypton Future Media, INC, 2024). Later on, the same company launched Kagamine Rin & Len (Japanese: 鏡音リン・レン), a duo of twin 14-year-old virtual singers, and Megurine Luka, a 20-year-old virtual singer, with similar results.
In addition, there is also MAVE:, a fully virtual K-pop girl group formed in 2023 by Metaverse Entertainment. MAVE: consists of four AI-generated members (i.e., Siu, Zena, Tyra, and Marty) who are brought to life through machine learning, deepfake, and 3D animation technologies. Notably, their music and performances are shaped by AI-driven voice synthesis and choreography (Reuters, 2023). Such virtual performers mark a new frontier in AI integration within popular music, which surely deserves further investigation.
When it comes to classical music, despite the complexity of music performance, similar to music composition studies, previous research on computer algorithms trying to mimic human performance (e.g., Schubert et al., 2017) found that listeners, including expert classical musicians, cannot differentiate between the performance of a human expert and an algorithmic realisation, provided the algorithm incorporates expressive nuances and the music doesn’t sound mechanical. Furthermore, contextual information, such as the performer's identity, might also play a significant role in human perception of the music. For instance, in another study, the human-attributed performance of a Chopin prelude was rated higher in quality than the computer-attributed one despite no discernible differences in their expression of emotions (Ziv & Moran, 2006). However, these studies used only auditory stimuli (audio excerpts) without any visual components, although seeing the performer can influence performance evaluations (e.g., Huang & Krumhansl, 2011).
The present study aims to expand past research to investigate the question: Does a bias against AI also exist in the domain of audiovisual music performance? Based on the reviewed evidence, in particular the findings by Shank et al. (2023), we hypothesise that such an AI performer bias exists. We further aim to explore potential factors that might influence the AI performer bias, including general attitudes towards AI, musical expertise, and familiarity with the music.
To test this hypothesis, an online experiment was carried out which investigated the extent to which the aesthetic judgements and emotional impact of a musical performance are affected by the presence of a human being as opposed to an allegedly AI-based performance. In this experiment, we manipulated the participants’ beliefs about the performer's nature; namely, the participants rated three videos of classical music performances in two different versions, i.e., human and “AI”: in the human version, a professional pianist sat on the piano, pretending to play. In the AI version, the pianist was absent, and the participants saw the piano playing autonomously, allegedly thanks to an AI trained at interpreting classical scores. Notably, the audio was identical in both versions; indeed, the piano was playing automatically in all videos.
Method
Procedure
An online experiment with a cross-over design was built and administered through Qualtrics.com; the experiment was accessible via laptops, tablets, and smartphones. The participants watched three videos from one experimental condition (i.e., Pianist vs “AI”) and rated the performances right after each video. The questions were presented simultaneously (i.e., on a single screen) in a fixed order. After that, they watched and rated the videos from the other experimental condition. The order of the experimental conditions was randomised. The presentation order of the pieces was randomised for each participant but kept consistent between the experimental conditions. Before each piece, the piece's name and composer were shown to the participant.
After the two listening sessions, the participants replied to some questions about their listening experience (see the Dependent variables section) and the differences between the two renditions of the pieces (i.e., Pianist vs “AI”). We called this phase “Reality check”. Lastly, the questions about their musical expertise and attitudes towards AI were administered [Figure 1]. The median duration of the procedure was 18.68 minutes (SD = 11.31). In greater detail, 90% of the participants took between 9.07 and 37.10 min to complete the task, based on the 5th and 95th percentiles of the data. The listening times for all listening sessions were tested to ensure they were not significantly shorter than the video lengths, confirming that participants likely watched the videos in full 2 .
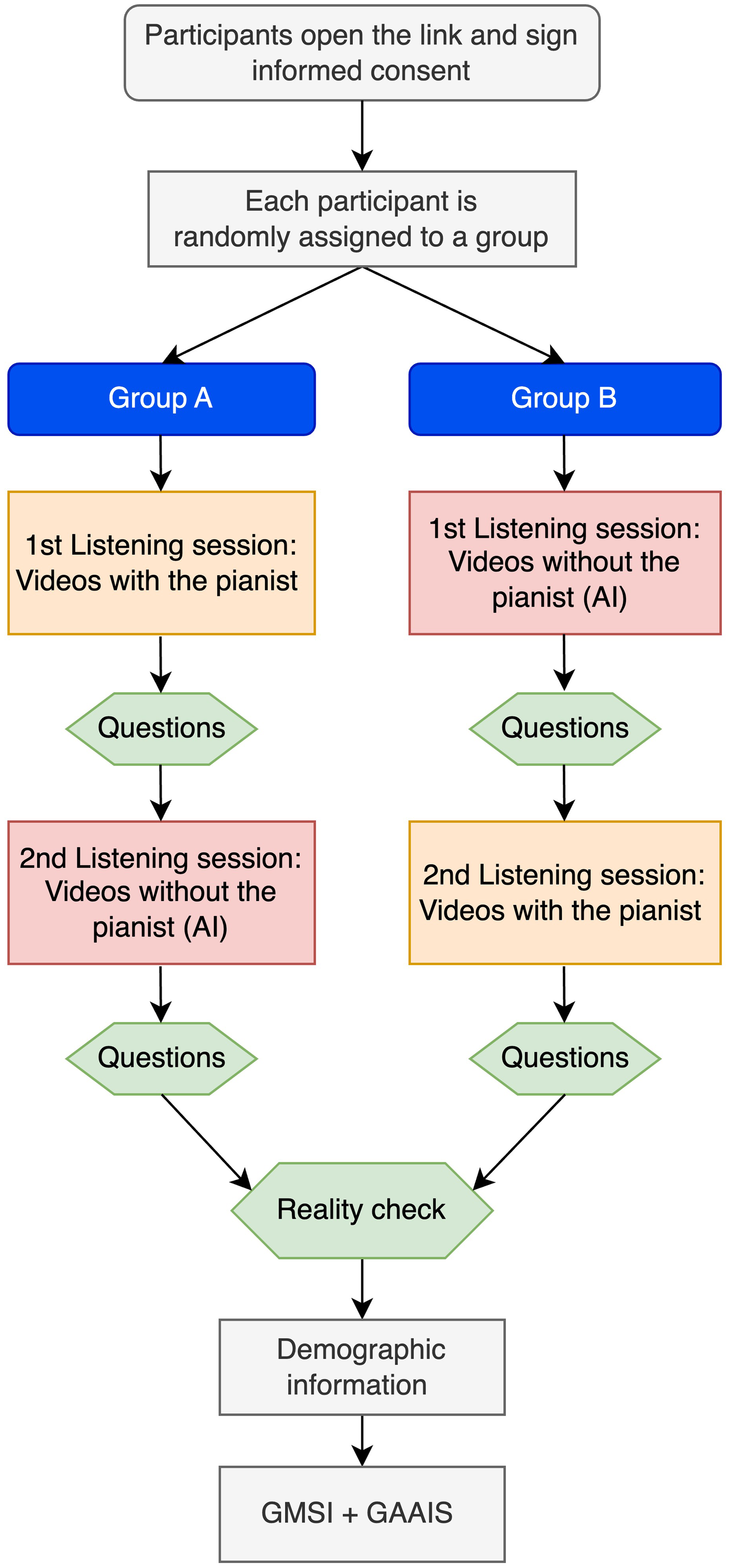
Experimental design.
The experimental procedure is described in Figure 1; the experimental prompts can be found in the Supplemental Materials.
Materials
Musical Pieces and Video Recordings
We resorted to two experts to select the pieces: a professional music composer and a professional piano player who “performed” the pieces in the videos. After analysing 20 pieces, the chosen ones were:
● Ludwig Van Beethoven: Sonata No. 8, 2nd Movement - Adagio cantabile (length: ∼ 1:05) ● Fryderyk Chopin: Étude Op. 10 No. 3 (length: ∼ 1:15) ● Modest Mussorgsky: Pictures at an Exhibition, Promenade (length: ∼ 1:28)
The pieces were chosen to include different composers, from Classicism to Romanticism. Furthermore, the experts ensured that, in the opening bars of the pieces - the ones used in the videos - the note range was not too wide; more specifically, they made sure there were no fast passages with a wide note range. This would have required quick and broader arm movements, potentially compromising the credibility of the experimental manipulation (i.e., it would have been easier for the participants to uncover the pianist’ acting). For the same reason, the experts selected pieces with a limited dynamic range.
A human-performed MIDI score was found for each musical piece, and all these MIDI scores were positively evaluated by our experts. The chosen MIDI files were played by a “player piano” with a built-in mechanism (i.e., Disklavier Mark IV Media Centre DMC-100) that allowed the instrument to reproduce the performances by playing back the MIDI data, making the keys and pedals move as if being played by an invisible pianist. The model of the piano was a Yamaha C7. The MIDI signal was sent to the Disklavier through a Focusrite Scarlett 2i2 MIDI-audio interface.
For the purposes of the study, all three scores played by the grand piano were videographed twice. One version always had a human professional pianist mimicking the playing of the piece, and the other version was without the human player. The videos were recorded from two angles: a wide shot from behind the piano, and a close-up of the keyboard from its right side [Figure 2]. The video editing was performed so that the viewers couldn’t detect that the pianist was acting instead of actually playing the piece.

Screenshots of the stimuli.
Dependent Variables
After each video, five questions were shown to the participants. The first four were drawn from Shank et al. (2023); however, we slightly modified the wording to focus on performance rather than composition. We added a question about engagement for two main reasons: first, it is considered a key construct in music fruition (Chin & Rickard, 2012) and concerts (Garrido & Macritchie, 2020; Swarbrick et al., 2019; Wimmer, 2021); secondly, differently from the other constructs involved, being engaged in a music performance entails an interactive aspect connecting the audience with the performer. In our case, being the performer an AI performer, we expect a significant lack of engagement.
Each question was associated with a 100-point Visual Analogue Scale (VAS). Here are the questions’ formulations:
● Liking: How much did you like what you just heard? (100-point VAS from “dislike a great deal” to “like a great deal”) ● Quality: How well do you think the pianist/AI performed the piece? (100-point VAS from “not well at all” to “very well”) ● Valence: The emotions evoked by this performance are (100-point VAS from “very negative” to “very positive”, the middle point being “no emotions”). ● Arousal: Did you find this performance more relaxing or more stimulating? (100-point VAS from “very relaxing” to “very stimulating”) ● Engagement: How engaging did you find it? (100-point VAS from “not engaging at all” to “very engaging”)
Furthermore, after the first occurrence of each piece, the participants were asked to state whether they knew the piece before the experiment.
After the listening sessions, the participants entered the “Reality check” section where they were asked to tell:
● Whether they noticed any differences between the pianist's performance and that of the Artificial Intelligence (Yes/No question) ● How much the two performances (Pianist and AI) were different from each other (100-point VAS ranging from “Completely indistinguishable” to “Very different”) ● In what ways, in their opinion, they were different (open question)
Trait Variables
We also collected the participants’ musical expertise and attitudes toward AI to verify whether these had a moderating role in the anti-AI bias.
Participants
Data collection was mainly performed via university mailing lists. Moreover, several announcements containing a QR code with the experiment link were hung on the notice boards of the involved universities. The participants did not receive any form of compensation. 128 participants were recruited, and 8 were excluded due to incomplete participation. The final sample consisted of 120 valid participants (Mage = 33.26, SD = 13.79). The sample was composed of 73 females (60.9%), 45 males (37.5%), 1 non-binary (0.8%), and 1 individual who did not disclose their gender (0.8%). The sample was diversified in terms of music expertise: 14.7% were non-musicians, 28.7% described themselves as music-loving non-musician, 16.3% were amateur musicians, 23.7% were serious amateur musicians, 9.0% identified as semi-professional musicians, and 5.7% were professional musicians. 2 participants did not disclose their musical expertise. The mean value of the G-MSI was 3.73 (SD = 1.73) out of 7.
As for the participants’ attitudes toward Artificial Intelligence, the mean value of the GAAIS was 3.01 (SD = 0.81) out of 5, thus indicating average values.
Statistical Analyses
A Linear Mixed Modelling (LMM) approach was implemented in R via the lme4 package (Bates et al., 2015). Consistent with Shank et al. (2023), a LMM was run for each dependent variable (i.e., Liking, Quality, Valence, Arousal, and Engagement). To take into account the variability among participants and musical pieces, the participants and musical stimuli were modelled as random intercepts (Judd et al., 2012). Moreover, the condition was modelled as a random slope within participants, thus allowing for its effect (i.e., Pianist vs. “AI”) to vary across participants.
The formula was:
DV = condition*condition position + condition*G-MSI + condition*GAAIS + condition*familiarity + (1 + condition | ID) + (1 | musical stimulus) 3 .
In the results section, the reader will find the unstandardised beta coefficients 4 for all the significant effects, their significance level, and, for the condition's effect, the effect size in terms of Cohen's d (Sullivan & Feinn, 2012) obtained through R's emmeans package (Lenth, 2024). Power analysis and more details can be found in the Supplemental Materials.
Results
Liking
A significant effect of the condition was found, b = 21.11, SE = 7.94, p = .008, d = 0.68, 95%CI [0.44, 0.92]. GAAIS has a significant positive effect on the liking, b = 6.47, SE = 2.12, p = .002 [Figure 3]. An interaction was found between the condition and GAAIS, b = −4.82, SE = 2.17, p = .028. A simple effect analysis showed that the anti-AI bias was stronger for people with poorer attitudes toward AI (i.e., GAAIS score: mean − 1SD), b = 14.60, SE = 2.49, p < .001 and weaker for people with better attitudes toward AI (i.e., GAAIS score: mean + 1SD), b = 6.77, SE = 2.46, p = .006. Lastly, the familiarity with the piece interacted with the condition, b = 6.33, SE = 2.89, p = .029, d = 0.46. More specifically, the anti-AI bias was significantly stronger when the pieces were known by the listener (b = 13.79, SE = 2.34, p < .001), compared to when they were not known (b = 7.46, SE = 2.19, p < .001).
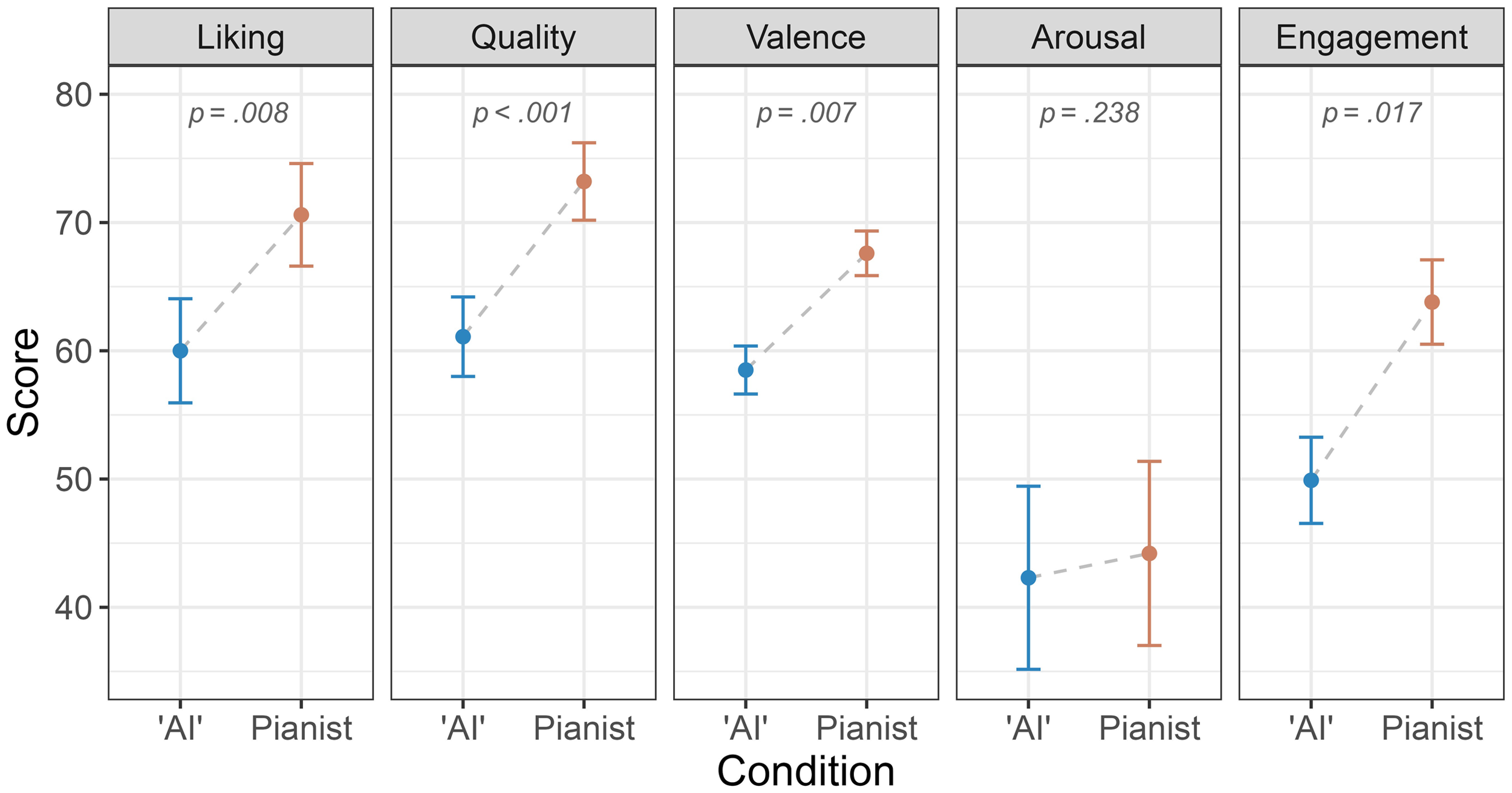
Results.
Quality
A significant effect of the condition was found, b = 31.74, SE = 9.09, p < .001, d = 0.81, 95%CI [0.52, 1.10]. GAAIS had a significant positive effect on musical quality, b = 5.95, SE = 2.32, p = .011 [Figure 3]. Moreover, GAAIS significantly interacted with the experimental condition, b = −6.51, SE = 2.50, p = .010. As in the case of liking, the attitudes toward AI moderate the anti-AI bias so that it appears stronger for those with poorer attitudes, b = 17.40, SE = 2.87, p < .001, and weaker for those with better attitudes, b = 6.89, SE = 2.84, p = .016.
In this model, we also observed an effect of the position, b = 11.39, SE = 3.73, p = .003, d = 0.59, 95%CI [0.31, 0.87]. However, the validity of the cross-over design was confirmed by the non-significant interaction with the condition.
Valence
A significant effect of the condition was found, b = 20.02, SE = 7.32, p = .007, d = 0.59, 95%CI [0.37, 0.82] [Figure 3]. Moreover, GAAIS had a significant positive effect on valence, b = 4.99, SE = 1.82, p = .007. Condition significantly interacted with GAAIS, b = −4.29, SE = 2.04, p = .037 so that the effect of the experimental condition was increasingly stronger with lower GAAIS values. In greater detail, the estimates oscillated between b = 5.65, SE = 2.31, p = .015 for high GAAIS values (i.e., mean + 1SD) to b = 12.60, SE = 2.34, p < .001 for low GAAIS values (i.e., mean − 1SD).
Arousal
No significant effect of the condition was found, b = 9.26, SE = 7.89, p = .238, d = 0.09, 95%CI [0.07, 0.26] nor any other interactions [Figure 3].
Engagement
A significant effect of the condition was found, b = 22.25, SE = 9.21, p = .017, d = 0.78, 95%CI [0.53, 1.03] [Figure 3]. GAAIS had a significant positive effect on engagement, b = 5.56, SE = 2.31, p = .017 and a significant interaction with the condition, b = −5.42, SE = 2.55, p = .035. As in the previous models, the effect of the condition was stronger for lower values of GAAIS, ranging from b = 9.57, SE = 2.88, p = .001 for high values of GAAIS (i.e., mean + 1SD) to b = 18.03, SE = 2.93, p < .001 for low values of GAAIS (i.e., mean − 1SD).
Reality Check
95 participants out of 120 (79%) reported to have noticed differences between the two renditions. A logistic regression was run to check whether the Musical Expertise could predict such a variable, but it did not reach significance, OR = 1.00, 95%CI [0.78, 1.29], p = .952. The average score of the noticed differences (i.e., the response to the question “How much were the two performances (AI and Pianist) different from each other?”) was 49.04 (SD = 26.39), namely, equally distant from somewhat different (i.e., 33) and very different (i.e., 66), with a distribution approaching normality (Skewness = 0.22; Kurtosis = −0.73).
No correlations were found between such a score and Age (r = .03, p = .724), G-MSI (r = −.08, p = .345), or GAAIS (r = −.11, p = .223).
Open Question
A total of 84 participants provided an answer to the open question (i.e., “In what ways, in your opinion, were the two performances different?”). A quanti-qualitative analysis was conducted and three dichotomous variables were created depending on whether the response mentioned musical features (e.g., tempo, rhythm, melody, harmony), emotional terms (e.g., emotion, facial expressions, soul, coldness, engagement), or something different which did not fit in any of the previous categories (e.g., the beginning was different, AI playing was flat). 50 participants (59.52%) mentioned different musical features, 33 (39.28%) mentioned emotion-related terms, and 11 (13.09%) mentioned both. A logistic regression model indicated that the likelihood of mentioning musical terms increased with musical expertise, although the model just grazed statistical significance, OR = 1.24, 95%CI [0.96, 1.60], p = .091. The attitudes toward AI did not predict the likelihood of mentioning musical or emotional terms.
The most common terms (> 5 occurrences) were emotion (N = 18), expression (N = 8), emotions (N = 8), dynamics (N = 7), engagement (N = 6), rhythm (N = 5), and tempo (N = 5).
Notably, the majority of the answers, especially by participants with higher musical expertise, entailed very specific details about the “differences” between the two conditions, e.g., “AI was too “robotic” when it comes to subtle tempo variations the performer can make. Also, AI was too literal when it came to interpreting dynamics added to the score. AI was either robotic or the changes were too sudden when it comes to dynamics.” (Male, 33 yrs, serious amateur musician); “Pianist's versions were more “airy”, light and felt more dynamic in the sense of movement and dynamics. AI's versions felt kind of dull, even soulless at times, robotic. […]” (Female, 31 yrs, semi-professional musician); “microtimings, inappropriate pedal blurring in the AI performance, inner voices popping out too much in AI performance” (Female, 23 yrs, professional musician); “The timing of the AI is in some places “too precise” so as to sound unnatural or unmusical. […]” (Female, 32 yrs, serious amateur musician).
In some cases, the aesthetic judgement was pretty harsh: “The first two pieces played by AI were sounding like a beginner musician playing in front of his parents and friends at the music school first year ending concert.” (Male, 54 yrs, serious amateur musician).
Other answers were more focused on emotional and expressive aspects: “emotion, soul, and musical fluidity” (Male, 38 yrs, professional musician); “It may seem strange, but in the pianist's performances, I felt that my emotional side was more stimulated, as if he could better convey meaning. It felt like the music was played not only with his hands but also with his heart” (Female, 20 yrs, music-loving non-musician).
Discussion
Building on previous research demonstrating an anti-AI bias in the general art and culture realm (e.g., Bellaiche et al., 2023) as well as music specifically (Shank et al., 2023), the present study aimed to expand this finding from music composition to music performance. To mimic the experience of a real performance, audiovisual stimuli in the form of video recordings were presented to the participants in an online experiment. Overall, our findings document the existence of a strong AI performer bias. First, although the audio was identical in both conditions, the vast majority of the participants (79%) reported having noticed differences between the two renditions; in some cases, with a high level of confidence, as suggested by the answers to the open question. For instance, one participant stated that “the difference that immediately strikes the ear is that in the musician's performance, the timing is very swinging and less rigid, whereas the AI performs everything in a more squared-off, more ‘robotic’ manner”. This connotation of AI music performance being more mechanical and the human performance being livelier might hint at potential underlying processes, such as beliefs about humanness and cultural values (Tubadji et al., 2021). Even social psychological phenomena (i.e., in-group favouritism and out-group discrimination; Abbink & Harris, 2019) might play a role here, which could be further explored in future research. The perceived differences in AI- vs. human-attributed music in our study correspond to previous studies showing that people often struggle with correctly identifying and classifying human- and machine-generated art (e.g., Chamberlain et al., 2018). Furthermore, they corroborate similar findings on music performance of a human expert versus an algorithmic realisation (e.g., Schubert et al., 2017).
Second, the findings of the present study showed that, compared to the “AI” condition, the participants’ aesthetic and emotional judgements systematically improved in the videos with the pianist, regardless of whether they were presented in the first or second position. Notably, all effect sizes were larger than average: the strongest effect was found for quality (d = 0.81), followed by engagement (d = 0.78), liking (d = 0.68), and valence (d = 0.59).
Based on research on music composition (Greenberg et al., 2021), which indicates a preference among people for music composed by artists with similar personalities to theirs, it could be inferred that people might also favour music performed by humans due to their greater similarity to themselves compared to AI. Further, musical preferences and tastes are highly unique and often form an integral part of an individual's identity (Lamont & Loveday, 2020), which might make an anti-AI bias regarding music performance particularly personal and significant to protect one's own sense of self and humanness. Indeed, the higher ratings of a human-attributed music performance in our study substantiate previous work showing a general preference for human-attributed artwork (e.g., Bellaiche et al., 2023; Chamberlain et al., 2018; Hitsuwari et al., 2023; Köbis & Mossink, 2021).
Regarding the different effect sizes, while the ratings of engagement, liking, and valence may represent more subjective and emotional states, it seems that there is particular importance for people to distinguish AI from humans regarding an “objective” criterion, such as quality. This might reflect either a strategy to address the perceived uncertainty and risks of AI technology or a general belief of AI not being able to reach the competence of a human performer. Indeed, theoretical frameworks and models on aesthetic judgements of arts (Chatterjee & Vartanian, 2014) and music specifically (Brattico et al., 2013) highlight the essential role of expectations and attitudes in evaluating artwork. In line with previous work suggesting outdated schemas and stereotypes regarding computer-generated art (Samo & Highhouse, 2023), our findings also indicate that people might have pre-existing (biased) ideas and opinions on how an AI music performance would look and sound like influencing their judgements.
Interestingly, we did not find a main effect on arousal. Since the item indicated a continuum from relaxing to stimulating, both of which might not be an inherently positive or negative experience, arousal may not be a significant criterion for people to distinguish human from AI performance. In other terms, a favoritism of the human performance might not be captured in the direction of the arousal states. Future research might employ physiological measures, such as heart rate variability or skin conductance, to examine possibly unconscious arousal patterns in the evaluation of AI versus human artwork.
The large effect on engagement can be interpreted as a sign of the lack of a proper communicative interaction with the performer. Namely, the absence of a human performer has cut the strings that tie the performer to the audience, thus undermining (if not annulling) one of the most vital aspects of music: its social function (Schäfer et al., 2013). We will return to this point in greater detail later.
In the present study, we also aimed to gain insight into factors that influence an AI performer bias. Concerning musical expertise, the lack of significant interactions in the models strongly suggests that such a bias exists regardless of the viewers’ musical background. Moreover, somewhat surprisingly, higher musical expertise did not decrease the likelihood of noticing differences between the Pianist and AI performances. Expanding previous research on auditory-only stimuli (Schubert et al., 2017), our findings thus indicate that musicians and non-musicians are equally likely to be deceived by appearances even based on audiovisual cues. As discussed above, this points to more general psychological processes at play than the musical background.
For instance, the preference for a real pianist over an AI-driven rendition could be attributed to the halo effect, where positive attributes typically associated with humans (e.g., emotional expressiveness, authenticity, empathy, and the ability to convey personal interpretations), are extended to their musical performances. This cognitive bias could lead participants to perceive human performances as more emotional, engaging and of higher technical quality regardless of the objective quality of the execution. Similarly, previous work shows that the narrativity (story) and perceived effort behind artwork moderate the labelling effect of human- vs. AI-created (Bellaiche et al., 2023), possibly contributing to the perception of a more human-like artistic process. Indeed, it has been suggested that anthropomorphising machine-generated art might decrease negative judgement (Chamberlain et al., 2018).
Furthermore, in our analyses, the attitudes towards AI moderated the anti-AI bias so that it was stronger for those participants with scarcer attitudes toward AI in all models. This finding highlights the importance of further exploring the role of what Scherer and Coutinho (2013) defined as listener features in the research about Music & AI. More in general, it underscores the importance of considering individual differences in future research examining anti-AI bias regarding music and arts (Bellaiche et al., 2023), such as trust in technology or personal experience with AI as well as personality traits or cognitive flexibility.
Limitations and Future Directions
Our findings should be considered in light of several limitations. First, our choice of stimuli was limited regarding the musical genre, musical pieces, and the performer in the videos. In particular, the pianist clearly exhibited Asian facial features; this could have had some impact on the results, although it is fairly hard to foresee in which direction. Indeed, two opposite stereotypes exist connecting Asian musicians and classical music: they are often seen as highly skilled musicians, but up to the point of being less warm and expressive in their playing (Case et al., 2021; Fiske, 2018; Yang, 2007). Future research should replicate our findings regarding other musical genres (e.g., popular or jazz music) and different performers (e.g., gender, age, ethnicity). Second, although we selected the rating criteria (i.e., dependent variables) based on previous work (Shank et al., 2023), other relevant criteria for evaluating the music performance might have been overlooked. While the present study provides initial evidence for the existence of an AI performer bias, more research is necessary to elucidate why people favour human music performances, for instance, by including ratings of perceived effort, emotionality, or meaningfulness (Bellaiche et al., 2023).
Furthermore, it is paramount to emphasise once more that the current work does not directly compare real and AI-driven musical performances; instead, it simply aims to analyse the impact of leading an audience to believe that a performance is AI-driven. Future research should explore full factorial designs wherein AI-played and human-played musical stimuli are coupled with both AI and human performers.
Lastly, although attention checks are commonly used in online experimental procedures to ensure data quality (Abbey & Meloy, 2017), they were not included in the present study. This decision was made for several reasons. First, unlike regular online surveys that entail repetitive tasks, the procedure at hand was inherently more interactive and engaging. Second, attention checks could have disrupted the natural flow of the task, especially since the comparison between two versions of the same pieces was the core part of the study. Third, participants did not receive any compensation, reducing the likelihood of careless or insufficient effort responding (C/IER) (Muszyński, 2023). While more direct attention checks or item-level response time analyses could have further improved data reliability, alternative measures were used to ensure data quality, such as monitoring overall and listening session completion times (see Procedure). Importantly, the significant and coherent results suggest that the absence of attention checks did not introduce substantial noise into the data.
Implications for Aesthetics and the Psychology of Art
This study corroborates, within the field of audiovisual performance, the already large evidence with respect to the impact that contextual information exerts on aesthetic judgements. On the psychological level, the mere human presence in the performance seems to be powerful enough to decept perception so profoundly that not only did the participants judge the human performances better, but they also justified their more positive judgements based on confabulated opinions. Such confabulations around the judgements of artworks are the aesthetic equivalent of what happens in the moral psychology domain under the name of moral dumbfounding (Haidt, 2001); namely, the impossibility for the subject to explain why a certain action is morally wrong while still clearly perceiving it as morally unacceptable. Indeed, Nichols (2023) defined such a phenomeon under the name of aesthetic dumbfounding.
On the philosophical level, these findings raise serious doubts about the intrinsic validity of aesthetic judgements in the age of AI. A long-standing tradition in philosophy, starting with Immanuel Kant's Critique of Judgement (1790/2000), has sought to defend the rationality of aesthetic judgements and the notion that there is a common ground on which all individuals can agree. In this view, despite being based on personal experiences, aesthetic judgements carry an implicit universality. When we call something beautiful, we expect others to agree, reflecting a shared understanding and rational discourse that aspires to a unique form of objectivity in the aesthetic realm.
However, if aesthetic judgements are susceptible to manipulation, vulnerable to bias and deception, or even entirely shaped by knowledge (or misinformation) about a work of art, what remains of their intersubjective validity?
These questions also carry practical implications, particularly for the concepts of expertise in art and music, as well as the role of critics. Art critics, by definition, are tasked with formulating aesthetic judgements about artworks or performances, balancing objective criteria with subjective impressions. Their judgements are generally considered more reliable than those of non-experts, as they are believed to rest on a refined capacity to detect nuances that others may overlook (Elkins, 2003). However, if, as these results suggest, both expert and non-expert judgements are equally shaped by biases and preconceptions, the very foundation of expert judgement is called into question. Without an objective basis to guide these evaluations, why should a critic's assessment carry more weight than that of any other listener? And if aesthetic evaluations are, as the findings imply, little more than post-hoc rationalisations, why should we believe that studying art and music confers any special ability to make more reliable judgements?
Fortunately, this kind of investigation doesn’t only lead to negative prospects. If we want to look at the bright side of such a research, we might claim that it permits us to see, in backlight, what our relationship with art is truly about. Indeed, studying the judgement motivations in cases where a human work of art (in a broad sense) is judged better than an AI one can be revealing of what is missing in AI-composed or AI-performed art, which will eventually lead to a better understanding of what we really look for in art. Why do we enjoy it? What in it is our hook for appreciation? Why do we like it less when we perceive it as “robotic”, “rigid”, or not emotional? To put it briefly, what is missing in the poorly judged AI art is ultimately a window into our (presumed) necessities as art spectators. One possible explanation suggested by this and other studies is that art appreciation extends beyond the final product to encompass the creative process behind it. Philosopher Denis Dutton (1979, 1983, 2003, 2009) argues that people evaluate all types of artworks – whether paintings, sculptures, or musical performances – as end-products of human activity. In this sense, art inherently incorporates the notion of performance, embodying human creativity, effort, and accomplishment. Indeed, psychological evidence by Chamberlain et al. (2018) converges on this idea, in that, in their study, the anti-AI bias in the evaluation of artworks was attenuated when participants witnessed robots in the process of making art.
Therefore, when assessing a piano performance, we may focus on technical elements such as dynamics, phrasing, tempo, and accuracy, but our deeper appreciation arises from recognising the human achievement behind (or above) the sounds.
This understanding may clarify the strong bias against AI performances. Our experience of music, like other forms of art, is never solely about perceiving sound; it also involves appreciating the human effort and accomplishment that underlies the creation. We perceive music as something created by a specific individual, shaped by the technical and conventional challenges they face. This sense of overcoming limitations is central to our expectations when evaluating a piece of music, making human achievement a key element of the aesthetic experience (Dutton, 1979, p. 304). However, AI performances lack the elements of human struggle, creativity, and decision-making; not to mention they lack the possibility of making mistakes. The absence of such a human dimension could account for the reluctance to attribute equal worth to these performances, even when the final result is indistinguishable from that produced by a human artist.
As we write, this hypothesis is receiving further empirical validation in several artistic domains. When it comes to our appreciation of music, it's ever more apparent that sound is merely a small part of what makes it resonate with us.
Conclusions
When judgeing audiovisual musical performances with identical audio, the mere presence of a human pianist, compared to an automated piano, fosters improved aesthetic judgements (i.e., liking and quality) and a stronger emotional impact (i.e., emotional valence and engagement) in the audience. Such an anti-AI bias holds regardless of the audience's musical expertise, but it's moderated by the listeners’ attitudes toward AI. These findings further emphasise the role of contextual or extramusical information in aesthetic judgements. On the one hand, the very foundation of aesthetic judgements is put under scrutiny. On the other, scrutinising what lacks in AI-performed music constitutes a privileged point of view from which to closely observe the indispensable elements of our appreciation of music.
Supplemental Material
sj-docx-1-art-10.1177_02762374241308807 - Supplemental material for AI Performer Bias: Listeners Like Music Less When They Think it was Performed by an AI
Supplemental material, sj-docx-1-art-10.1177_02762374241308807 for AI Performer Bias: Listeners Like Music Less When They Think it was Performed by an AI by Alessandro Ansani, Friederike Koehler, Lisa Giombini, Matias Hämäläinen, Chen Meng, Marco Marini and Suvi Saarikallio in Empirical Studies of the Arts
Footnotes
Acknowledgements
We would like to express our gratitude to Davide Umbrello for his consultancy in selecting the musical stimuli. We also thank Dr. Nicola Di Stefano for his suggestions on the first draft of the manuscript.
Authors’ Contributions (CRediT)
Alessandro Ansani: Conceptualisation, Methodology, Formal analysis, Investigation, Resources, Data curation, Writing - Original Draft, Writing - Review & Editing, Visualisation, Project administration;
Friederike Koehler: Writing - Original Draft, Writing - Review & Editing;
Lisa Giombini: Conceptualisation, Writing - Original Draft, Writing - Review & Editing, Project administration, Supervision;
Matias Hämäläinen: Software, Investigation, Resources;
Chen Meng: Resources;
Marco Marini: Visualisation, Writing - Review & Editing;
Suvi Saarikallio: Funding Acquisition, Supervision, Writing - Review & Editing
Consent to Participate
Informed consent was obtained from all individual participants included in the study.
Data Availability
All data, midi scores, and audiovisual stimuli are available at the following Open Science Framework (OSF) repository: https://osf.io/6k289/. Data were analysed using RStudio, version 2024.04.2 Build 764 and the packages listed in the Method paragraph.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Considerations
The study was approved by the Research Ethics and Integrity Committee of the National Research Council of Italy (n. 0323801/2024). The procedures used in this study adhere to the tenets of the Declaration of Helsinki.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Research Council of Finland (grant number 346210).
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.