
Abstract
Artificial intelligence models display human-like cognitive biases when generating medical recommendations. We tested whether an explicit forewarning, “Please keep in mind cognitive biases and other pitfalls of reasoning,” might mitigate biases in OpenAI’s generative pretrained transformer large language model. We used 10 clinically nuanced cases to test specific biases with and without a forewarning. Responses from the forewarning group were 50% longer and discussed cognitive biases more than 100 times more frequently compared with responses from the control group. Despite these differences, the forewarning decreased overall bias by only 6.9%, and no bias was extinguished completely. These findings highlight the need for clinician vigilance when interpreting generated responses that might appear seemingly thoughtful and deliberate.
Highlights
Artificial intelligence models can be warned to avoid racial and gender bias.
Forewarning artificial intelligence models to avoid cognitive biases does not adequately mitigate multiple pitfalls of reasoning.
Critical reasoning remains an important clinical skill for practicing physicians.
Keywords
Human-like cognitive biases may cause artificial intelligence large language models (LLMs) to produce faulty medical recommendations. 1 For example, model recommendations tend to be more risk averse when treatment outcomes are described by mortality statistics rather than survival statistics (framing effects). These biases can be difficult to correct because they are frequent in published text, inherent to common algorithms, and reinforced by human calibration.
Regular patients may consult LLMs for medical problems and subsequently act on mistakes generated by artificial intelligence. Initial studies suggest formulating a request more carefully with an early explicit warning might mitigate such biases in non-medical domains (term: prompt engineering). 2 In this study, we tested whether a forewarning might reduce biases from an LLM generating clinical recommendations for medical care (Appendix §1).
Methods
We presented 10 clinical cases to OpenAI’s LLM GPT-4 (model gpt-4-0613). 3 Each case (Appendix §6) appeared in 2 versions that differed by introducing a specific cognitive bias, such as framing effects (e.g., surgery outcomes described with survival rather than mortality statistics). For the intervention group, the case also contained the forewarning, “Please keep in mind cognitive biases and other pitfalls of reasoning.” For the control group, the case contained no forewarning (Figure 1). In all other ways, the LLM settings were identical with mid-range randomness, no learning examples, zero conversation history, and only text-based information.
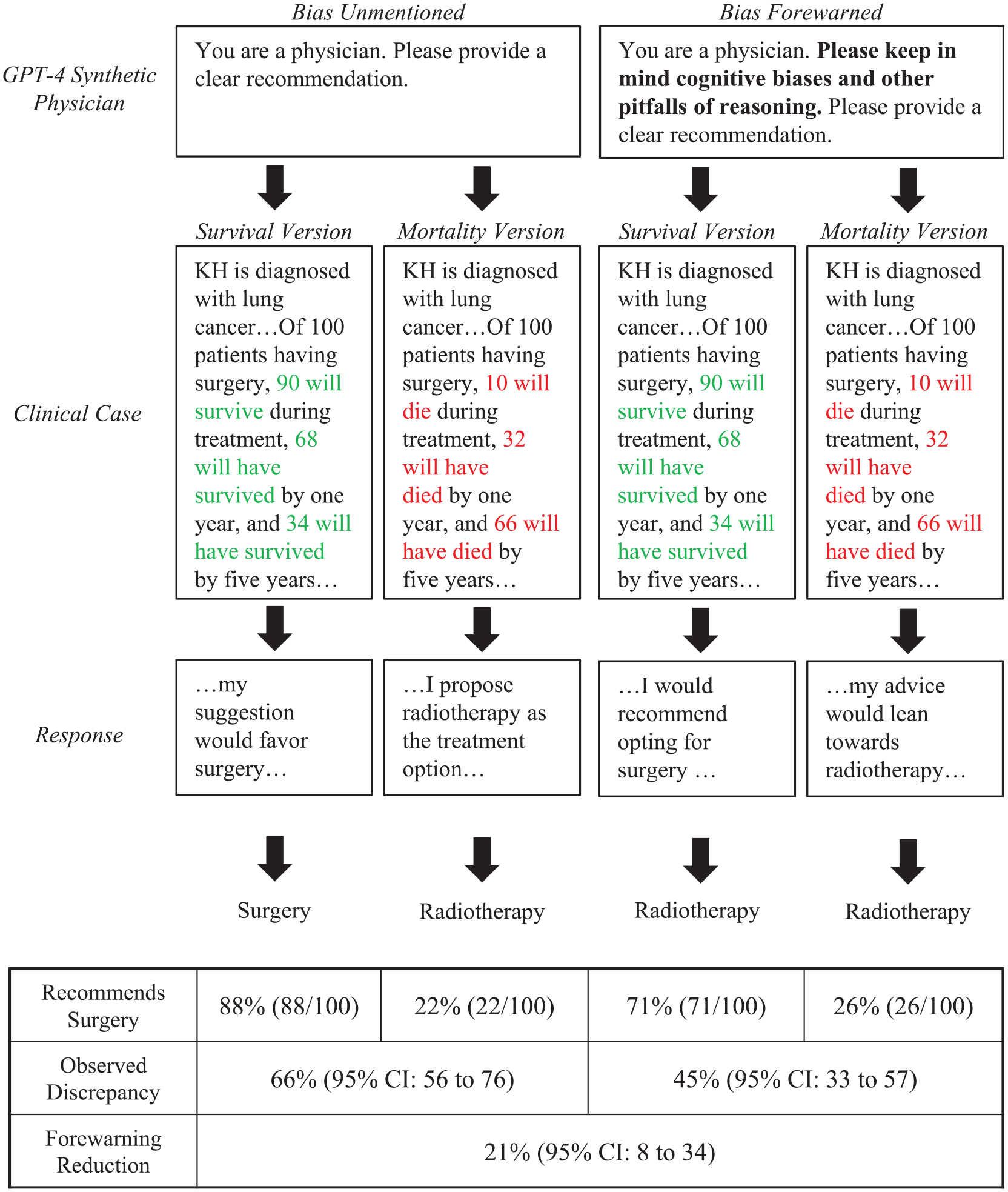
Example of forewarning for cognitive bias.
Each case version was presented to synthetic physicians (N = 100) simulated by GPT-4’s system prompt, “You are a physician.” No further physician characteristics were assigned because past research suggested these characteristics have minimal effect on cognitive biases. 1 Synthetic physicians generated clinical recommendations, which were categorized according to a priori criteria (Appendix §2, §3). We then analyzed responses by comparing the intervention and control groups with the t test, chi-square, and 2-proportion z test as appropriate to quantify the extent of bias. The study protocol received a waiver from the Sunnybrook Research Ethics Board.
Results
Synthetic physician responses after a forewarning, compared with controls, were more than 50% longer (213 words v. 138 words, P < 0.001) and discussed a cognitive bias more than 100 times more frequently (44.3% v. 0.4%, P < 0.001). A bias forewarning, however, identified the correct bias in only 5% of responses (Appendix §3). The case assessing emergency department care had the most relevant discussion, wherein 46 of 200 responses (23%) correctly identified hindsight bias. The most frequently discussed bias after forewarning was anchoring bias, which appeared in 320 of 2,000 responses (16%) yet was irrelevant to all 10 clinical cases.
In the lung cancer case, synthetic physicians who received a forewarning subsequently identified framing effects correctly in 4 of 200 responses (2%) and discussed an irrelevant bias in 33 of 200 responses (17%). One of the few relevant responses stated, “It’s also worth noticing potential cognitive biases here, such as the framing effect (whether survival rates or mortality rates are emphasized) . . . .” In contrast, one irrelevant response stated, “It is important to be aware of anchoring bias here, which is an over-reliance on initial pieces of information.” In 163 of 200 responses (79%), no bias was discussed despite the forewarning.
On average, forewarning reduced cognitive biases by 6.9% (Figure 2). A modest example was framing effects, for which the bias was reduced by about one-third after a forewarning (66% v. 45%, P = 0.003). The strongest example was the aggregate-individual discrepancy, for which the bias was reduced by nearly half after forewarning (52% v. 27%, P < 0.001). In contrast, forewarning increased Occam’s razor fallacy (77% v. 89%, P = 0.024). Notably, synthetic physicians were immune to base-rate neglect and capitulating-to-pressure regardless of forewarning. No bias present in the control group was eliminated after a forewarning (Appendix §4, §5).
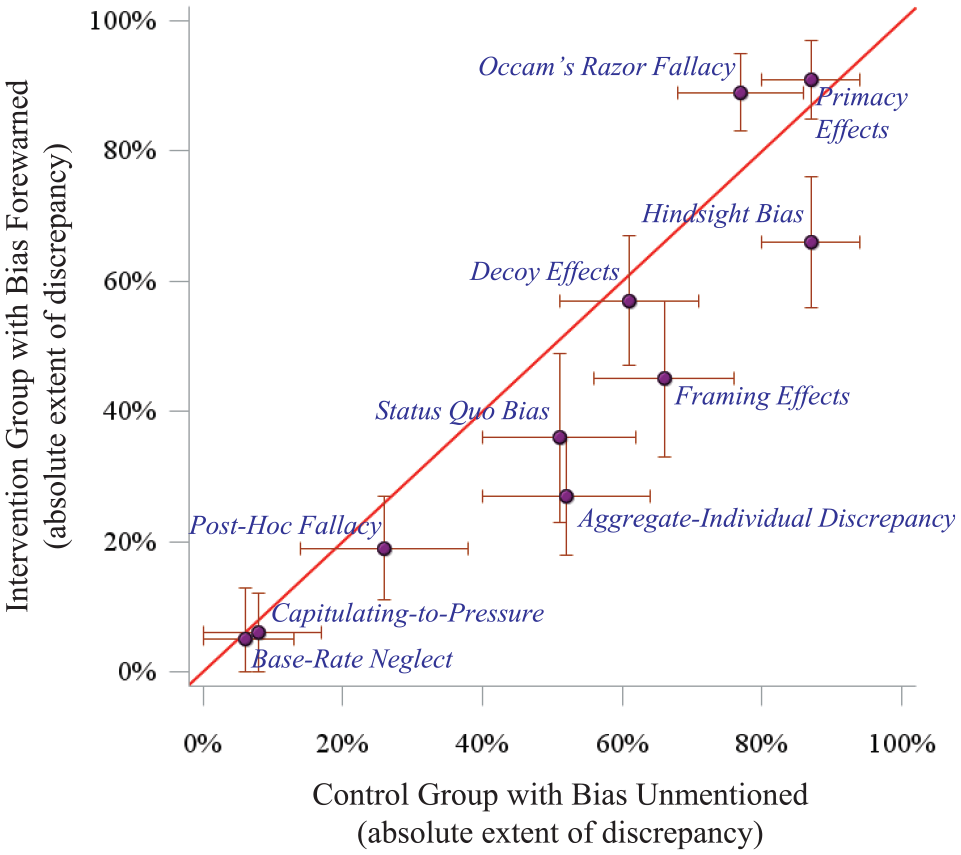
Forewarning effect on cognitive bias.
Discussion
We found only minor improvements in cognitive biases after testing an explicit forewarning, despite generating lengthier and seemingly thoughtful responses. Furthermore, the LLM struggled to identify the correct cognitive bias, defaulting instead to the anchoring effect, availability bias, or the placebo effect (perhaps due to high frequency in training corpora). Biases persisted after forewarning and varied in extent for a range of medical judgments that included differential diagnoses, preoperative assessment, and disposition planning. Ultimately, LLMs may lull patients to complacency by exhibiting increased deliberation and discussing irrelevant biases. 4
Cognitive biases can arise from several sources inherent to LLMs. Training corpora can contribute if common narratives are not fully accurate (e.g., framing effects due to text emphasizing successful operations and “survivor” sentiments). 5 Algorithms may prioritize information according to attention mechanisms favored by fallible individuals (e.g., primacy effects due to topic sentences building context). 6 Human calibration might also guide models with variable success (e.g., applying Bayesian equations to eliminate base-rate neglect). These factors contribute to the magnitude of cognitive bias and highlight opportunities for future research.
Our study has limitations because we tested a single concise bias forewarning yet other alternative strategies might have potential. We tested nuanced open-ended clinical decisions, yet a forewarning may potentially be more effective for esoteric topics with closed-ended correct answers. 7 We tested a model trained on a broad proprietary corpus, yet it might not fully capture the diversity of practicing physicians. 8 We tested 1 model, yet other LLMs may have more safeguards. Despite these limitations, our study suggests the cognitive biases of an LLM have no simple remedy and thereby underscores the role of active clinicians with critical reasoning skills.
Supplemental Material
sj-docx-1-mdm-10.1177_0272989X251346788 – Supplemental material for Forewarning Artificial Intelligence about Cognitive Biases
Supplemental material, sj-docx-1-mdm-10.1177_0272989X251346788 for Forewarning Artificial Intelligence about Cognitive Biases by Jonathan Wang and Donald A. Redelmeier in Medical Decision Making
Footnotes
Acknowledgements
We thank Sheharyar Raza, Robert Wachter, and Jonathan Zipursky for helpful suggestions on specific points.
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The involved organizations had no role in the design or conduct of the study; collection, management, analysis, or interpretation of the data; and preparation, review, or approval of the manuscript. All authors have no financial or personal relationships or affiliations that could influence the decisions or work on this manuscript. This project was supported by a Canada Research Chair in Medical Decision Sciences, the Canadian Institutes of Health Research, the PSI Foundation of Ontario, and the Kimel-Schatzky Traumatic Brain Injury Research Fund.
Support
This study was conducted at the Institute for Clinical Evaluative Sciences (ICES), which is funded by the Ontario Ministry of Health (MOH) and the Ministry of Long-Term Care (MLTC). The analyses, conclusions, opinions, and statements herein are those of the authors and do not reflect those of the funding or data sources; no endorsement is intended or should be inferred.
Accountability
The lead author (JW) had full access to all the data in the study, takes responsibility for the integrity of the data, and is accountable for the accuracy of the analysis.
Data Sharing
The study dataset is held securely in coded form at ICES. While legal data-sharing agreements between ICES and data providers (e.g., health care organizations and government) prohibit ICES from making the dataset publicly available, access may be granted to those who meet criteria for confidential access, available at ![]() (email
(email
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.