
Abstract
Friends in early adolescence play a significant role in students’ lives, potentially influencing their academic performance. A multi-group stochastic actor-oriented model was employed to examine the effects of social selection and peer influence through friendship ties on Czech language grades and reading literacy among lower-secondary students, controlling for students' SES, gender, and network structure. The sample comprised 276 sixth-grade students across twelve classrooms, measured at two time points with an interval of seven months. No evidence of selection or influence in terms of grades and literacy was found. However, effects of gender and SES assortativity were observed. The findings are discussed in relation to potential publication bias in the existing literature, and implications for future research are outlined.
Keywords
Adolescents in schools tend to be friends with peers with similar characteristics, driven by two primary mechanisms: social selection and peer influence. Social selection, rooted in the theory of homophily, suggests that adolescents form relationships based on similar traits, as these similarities directly foster interpersonal attraction (Byrne, 1971; Turner et al., 1987). In contrast, peer influence, based on socialization theory, implies that adolescents may adopt behaviors or traits from their friends through shared social interactions (Homans, 1974). This is particularly pronounced with observable traits, which not only promote similarity but also enhance compatibility, critical elements in navigating adolescent peer cultures (Laursen & Veenstra, 2021). Together, these mechanisms illustrate how adolescents’ social networks are formed and transformed, emphasizing the key role that shared characteristics play in both the formation of friendships and the adaptation within peer groups.
Untangling social selection from peer influence is a central issue in educational research – especially when concerning the effects of peer relationships on academic performance. If the similarity in performance between friends results from peer influence as well as social selection, it lends support to the idea that educators, by mixing students into different classrooms, tracks, schools, and extracurricular activities, can influence students’ academic performance indirectly through shaping their relationships.
Over the last decade, substantial efforts using stochastic actor-oriented models (SAOMs Snijders et al., 2010) have been made to differentiate social selection and peer influence within educational contexts. SAOMs, essential for analyzing the co-evolution of relationships and actor covariates in longitudinal network studies, have consistently shown that peer influence shapes students’ academic performance, whereas social selection based on academic performance shapes peer relationships. The selection effect intensifies in environments where adolescents have known each other for a short time and can be moderated by the school type. Previous studies have operationalized academic performance as grade point average (GPA) (e.g., Gremmen et al., 2019), self-reported grades (e.g., Stark et al., 2017), and teacher-reported grades (e.g., Gremmen et al., 2018). Most SAOM-based studies dealing with friendships and peer influence have reported the presence of both social selection and peer influence (Flashman, 2012; Gremmen et al., 2019; Kretschmer et al., 2018; Laninga-Wijnen, 2019; Shen, 2022; Stark et al., 2017), while others found only peer influence (Gremmen et al., 2017; Gremmen et al., 2017; Palacios & Berger, 2022; Rambaran et al., 2017). Beyond GPA, Kiuru et al. (2013) reported friend influence on reading skills, with selection affecting only fluency. Broader aspects of these dynamics were explored by Kretschmer & Roth (2011), who found both selection and influence affected students’ educational expectations, Gremmen et al. (2018) observed influence on academic engagement, and both Rambaran et al. (2017) and Wang et al. (2018) found its impact on truancy.
Except for Kiuru et al. (2013), none of the studies employed validated measures for academic ability, relying instead on assessments that may vary across classrooms and schools. This reliance raises questions about whether the observed effects of peer influence reflect true changes in specific student abilities or changes in more easily observable traits, such as grades and effort. Disentangling influences based on actual academic ability from those based on proxy attributes is crucial for accurately understanding how peer dynamics affect genuine learning outcomes, rather than just influencing visible, but possibly less substantive indicators of student ability.
In this brief report, social selection and influence through friendship ties of lower-secondary students are investigated with longitudinal SAOM social network analysis focusing on two behaviors – Czech language grades and reading literacy. The grades represent a more visible trait that is frequently employed in educational assessments, and which was commonly used in the previous studies, while literacy offers a more direct measure of actual academic ability, with both grades and literacy revolving around the Czech language lessons. Employing state-of-the-art network modeling, this study accounts for the network structure of friendships and simultaneously examines both teacher-reported grades and a validated literacy test that remains independent of teacher assessments.
Methods
Participants
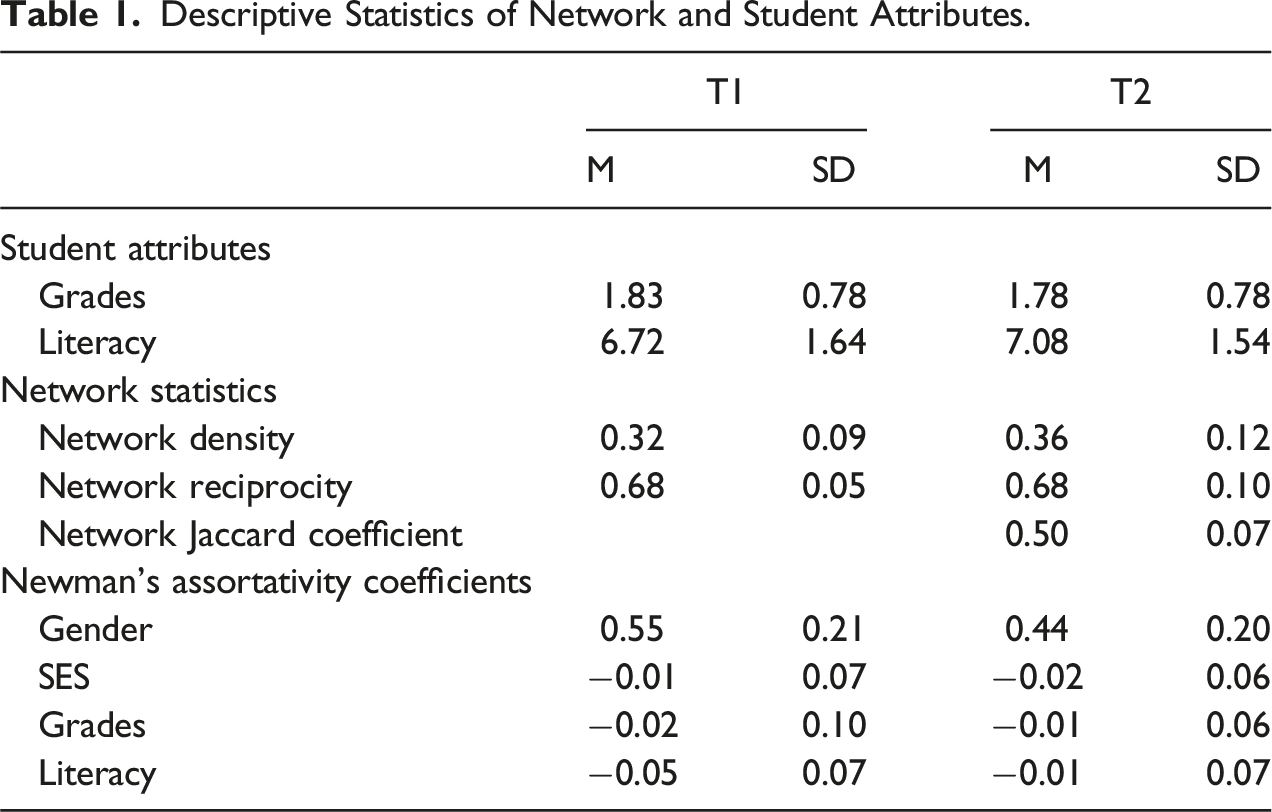
The sample comprised 276 early adolescents (48.55% girls, 51.45% boys) in Grade 6 (ages 11–12) in 12 comprehensive lower-secondary classrooms in the South Moravian Region of the Czech Republic. Grade 6 in the Czech Republic marks the beginning of the lower-secondary education, and classrooms are frequently completely reorganized. Hence, most students in our sample did not know each other before the beginning of the school year. The classrooms were gender balanced (Mgirls per classroom = 48.21%, SDgirls per classroom = 8.28%). Lintner et al. (2023) describe the context of this study as well as the details about the sample and missing data. 1
Procedure
At timepoint 1 (T1) – in the beginning of the 2021/2022 school year – network, grades, literacy, and demographic data were collected. At timepoint 2 (T2) – in the end of the 2021/2022 school year –the network, grades, and literacy data were collected again. Approximately 7 months elapsed between the two timepoints. Oral consent from school principals and teachers and written consent from teachers and parents of participating students was obtained. The students were able to withdraw from research at any time. As per the Czech Science Foundation’s requirements, ethical board approval for this project was not sought, as it was not required.
A single social network measure was acquired: friendship ties between individual students within the classroom. The information on friendship ties were collected with a pen-and-paper sociometric questionnaire consisting of a single nomination question (Del Vecchio, 2011; Poulin & Dishion, 2008) worded as ‘Write the names of the classmates you are friends with. You can write as many names as you want. The order of the names does not make any difference.’ Directed social networks for each classroom were created – while student A may have nominated student B, student B might not have reciprocated the nomination. The same procedure was applied for both timepoints.
The data on students’ gender and socioeconomic status (SES) were acquired as part of the computer-based questionnaire with first question asking students to write their gender and two questions worded as “What is the profession of your mother?” and “What is the profession of your father?” followed by a coding process based on International Socio-Economic Index of Occupational Status (ISEI) (Ganzeboom et al., 1992) aiming to identify student’s socioeconomic status based on their parents’ highest occupational status. The original SES range of 16–90 was changed to 0.16 to 0.90 to have the covariates on comparable scales to allow smoother convergence of models.
Students’ Czech language grades were given by their Czech language teachers on an ordinal 1–5 scale, where 1 represented the best and 5 the worst grade. The teachers gave grades by averaging results from a series of smaller assessments throughout the school year. The teachers did not use any standardized assessments when giving the grades.
Students’ level of reading literacy was measured with a standardized computer-based reading literacy test. The test contained items from the nationwide testing and was developed in such a way that, at both timepoints, the test difficulty remained the same, with none of the test items repeating. Each test contained 26 items covering five areas of literacy – distinguishing between opinions and judgements, distinguishing between subjective and objective statements, identifying manipulative communication in mass-media, using text as a study resource, and forming new text. The literacy test did not undergo item response theory (IRT) testing; however, it was made from the items from the nationwide testing which were formed on IRT, and the test underwent pilot testing. At each timepoint, students could score anywhere from −100 to 100 points – a student would get −100 points if they answered all items incorrectly, 0 points if they did not answer any item, and 100 if they answered all the items correctly. For the purposes of this analysis, the original values were transformed into an ordinal scale of 0 to 10 because RSiena in which the analysis was performed does not allow negative covariate values.
The Spearman’s correlation coefficients between Czech language grades and literacy test scores were calculated for T1 and T2. At T1, the correlation coefficient was −0.50, and at T2, it was −0.48, indicating a moderate relationship between the grades and literacy scores at both time points. The values are negative because of the reversed order of the grades with 1 representing the best grade. Although Czech language grades and literacy tests were supposed to assess related skills based on Czech language curriculum for Grade 6, the correlation coefficients suggest that they do not perfectly align.
Analytical Strategy
SAOM
SAOM (Snijders et al., 2010) in R (R Core Team, 2020) package RSiena (Ripley et al., 2011) was used to disentangle the effects of social selection and peer influence through friendship ties on students’ grades and level of literacy while controlling for gender, SES, and endogenous network structure effects. SAOMs are network models in which the dependent variable can be both a tie change and a change in behavior (in this case, literacy) conditioned on student characteristics and endogenous network effects. SAOMs are actor-oriented meaning that tie change between the students is assumed to be the result of students’ own choices about their outgoing ties. What changes students make is determined by the objective function, which contains the modelled effects capturing the hypothesized mechanisms, while how often they get to make these changes is determined by the rate function. Having two waves of data collection allowed assessment of the degree to which selection and influence processes contribute to friends’ similarity in grades and literacy as well as the direction of these processes (Steglich et al., 2010).
There are several approaches to estimating SAOMs for multiple networks, as outlined in Chapter 11 of RSiena manual (Ripley et al., 2011). In this study, the multi-group analysis approach (option two in the manual) was applied. This method consolidates the networks into a single multi-group dataset, estimates parameters in a unified step, and assumes uniformity across networks for all parameters, except for the basic rate parameters. This assumption is strong, and our model violated the assumption to some extent. The heterogeneity of parameter estimates was assessed using the score-type test (sienaTimeTest). sienaTimeTest is based on Schweinberger (2012) and it can test the heterogeneity assumption across both time periods and across multiple networks (Ripley et al., 2011). The test revealed significant differences in the effects that model network structure as described in the Model Specification section – outdegree, reciprocity, GWESP, indegree popularity, indegree activity, and outdegree activity – with p < .01. Conversely, other effects did not show significant variation across the networks. Thus, the estimates of structural effects warrant cautious interpretation due to their significant variability among the networks. Still, multi-group analysis was selected as it provided the most informative insights. Initially, a two-step meta-analysis (option three in the manual) was attempted; however, the individual networks were not informative enough to lead to well-converged estimates. Subsequently, a random-effect multi-level approach via sienaBayes (option four in the manual) was also considered, trying various combinations of random effects in the model, but the approach was ultimately not feasible due to its extensive computational demands, which precluded acquisition of reliable estimates in reasonable time. Therefore, despite the limitations, option two was adopted, enabling an exploration of selection and influence effects on both grades and literacy.
The parameter estimates and their standard errors were obtained using the Method of Moments estimation technique. The tie change was operationalized by the evaluation function meaning that the parameter estimates were calculated on the presence of ties regardless of whether they were newly created or maintained from T1 to T2. Since literacy is a continuous variable and a standard SAOM specification assumes the evolving behavior to be measured on an ordinal scale, the scale was discretized before estimating the parameters. The resulting parameter estimates are in log odds ratios. Their positive values indicate that when the network configurations embodied by the given parameter are attractive for the students, they are more likely to create or maintain ties embedded within them, whereas negative values indicate the opposite. Estimates with p < .05 were considered as significant.
The model used for analysis passed the convergence and goodness of fit (GoF) checks. The criteria in Ripley (2011) were used when assessing the convergence – the t-ratios for convergence for all model terms are recommended to be < 0.10, and the overall maximum convergence ratio is recommended to be < 0.25. GoF denotes the degree to which the model represents the observed real-world network. GoF was assessed by simulating a distribution of 1000 networks from the model and subsequently comparing this distribution to the observed data with respect to indegree and outdegree distributions, geodesic distances, and triad census. The model showed no misfits in terms of indegree and outdegree distributions, four networks showed signs of misfit in terms of geodesic distances, and two networks showed signs of misfit in terms of triad census. Supplemental Information 1 provides detailed GoF statistics.
Handling Missing Data
A small fraction of student covariates and network ties were missing because some students decided not to participate in our research or decided not to hand over the sociometric questionnaires. The variables were assumed to be missing at random and multiple imputation by chained equations with predictive mean matching imputation technique (Little, 1988) was applied to impute missing student covariates on SES and literacy. Incomplete variables were imputed under a fully conditional specification using the default settings of the mice package (van Buuren & Groothuis-Oudshoorn, 2011) in R. Since multiple imputation requires each model to be calculated multiple times, and the model required a significant amount of time for the estimation procedure, calculating many datasets for missing variable imputation was prohibitive. It was therefore decided to rely on the lower side of the recommended number of datasets for imputation (van Buuren, 2018) with five datasets made. The estimates were calculated in each imputed dataset separately and combined using Rubin’s rules (Rubin, 1987).
The missing ties were treated as non-informative and dealt with a method described in detail in Huisman & Steglich (2008) as method four. This method tries to minimize the impact of missing ties on the effect estimates. The models are based on simulations carried out over all variables as if they were complete, however, for the calculation of the target statistics the missing ties were not used. First, to allow full simulations, missing ties were imputed in a way that missing entries were treated as no-ties assuming sparse data. If there was a missing tie in T2 but a non-missing tie in T1, the tie from T1 was used for T2. Then, to ensure a minimal impact of missing data on the model results, the calculation of the target statistics used for estimation by the Method of Moments used only non-missing data.
Model Specification
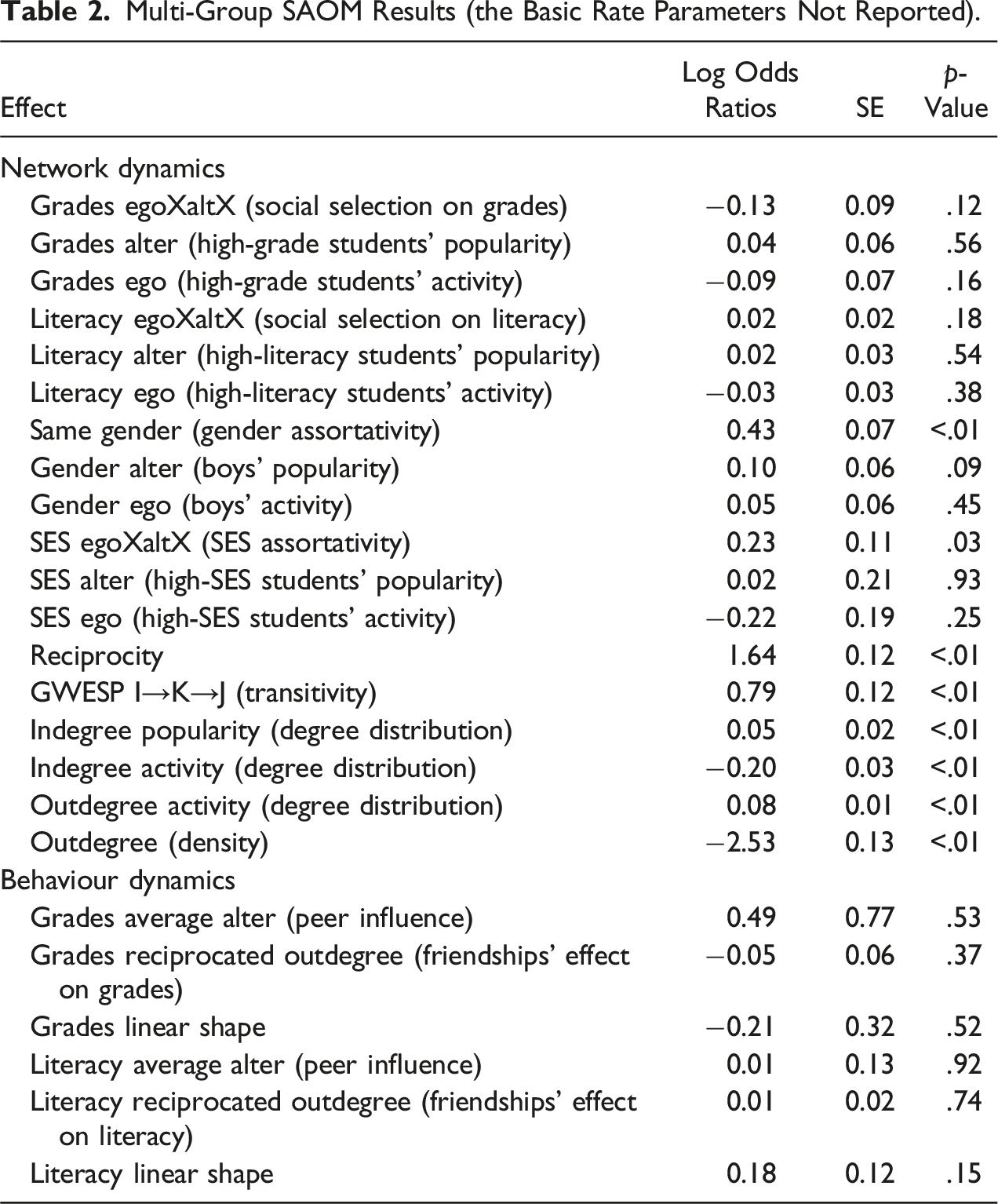
To capture social selection, grades egoXaltX and literacy egoXaltX effects were included, capturing the tendency of students to select friends with similar grades and similar level of literacy. To capture peer influence, grades average alter and literacy average alter effects were included, capturing the influence of student’s friends on their own grades and level of literacy. To control the influence of one’s grades and literacy on their number of friends, grades alter, grades ego, literacy alter, and literacy ego effects were included, capturing the tendency of students to give preference to friends with higher grades and higher level of literacy and the tendency of students with higher grades and higher level of literacy more likely to make friends. grades reciprocated outdegree and literacy reciprocated outdegree effects were also included, capturing the influence of having many reciprocated friendships on student’s grades and level of literacy, assuming that good relationships positively influence both grades and literacy.
Based on previous research on formation of peer relationships suggesting that students give preference to formation of assortative friendships in terms of both gender and SES (Campigotto et al., 2022; Lintner, 2022; Zwier & Geven, 2023) a series of student attribute effects were included as well: same gender effect capturing the tendency of students to select friends with same gender, gender alter and gender ego effects capturing the tendency of students to receive or send more friendship ties based on their gender, SES egoXaltX effect capturing the tendency of students to select friends with similar SES, and SES alter and SES ego effects capturing the tendency of students to give preference to friends with higher SES and the tendency of students with higher SES more likely to make friends.
Furthermore, the following effects modelling network structure were included: reciprocity capturing the tendency of students to reciprocate friendship nominations, GWESP I→K→J capturing the tendency of students to form transitive friendship ties in a way that if student I has a tie to student K and student K to student J, student I is more likely to form friendship with student J, indegree popularity and outdegree popularity capturing the tendency of students to send disproportional number of friendship ties to those students who already have many incoming and outgoing friendship ties, and indegree activity capturing the tendency of students to send disproportional number of friendship ties to others if they have disproportional number of incoming ties, with the last three effects capturing the degree distributions in networks.
Finally, several elementary effects were included: basic rate parameters denoting the average amount of opportunity a student had for changing their ties, outdegree serving as the intercept of the model denoting the baseline propensity of the students to form friendships regardless of any attributes, grades linear shape denoting the effect of linear increase in grades throughout the timepoints, and literacy linear shape denoting the effect of linear increase in literacy throughout the timepoints.
Results
Descriptive Statistics of Network and Student Attributes.
Multi-Group SAOM Results (the Basic Rate Parameters Not Reported).
Discussion
This study joins the array of developing research employing SAOMs to study the processes of social selection and peer influence on adolescents’ academic performance. A major asset of this study is the modelling of social selection and peer influence simultaneously for the Czech language grades and the reading literacy, with grades representing the more visible trait commonly used in the previous studies and literacy representing a more direct measure of an actual academic ability. The findings of this study do not support evidence of the effects of friendships on students’ grades or literacy, nor any evidence of the effects of students’ grades or literacy on their friendships. The findings of this study therefore do not support the previous research on social selection and peer influence among classmates (e.g., Stark et al., 2017).
The obvious question is why the results of this study do not support findings from the previous research. The discussion will now turn to potential reasons for the null findings observed in this study, which also highlight its limitations.
The relatively small sample comprising 276 students is perhaps the most obvious culprit for the unexpected results. It might have prevented getting enough statistical power to capture hard-to- track network mechanisms. Moreover, the analysis was based on a convenience non-representative sample of students, which might have resulted in selection bias. However, compared to Rambaran et al. (2017) and Palacios & Berger (2022) with 342 and 272 students respectively, the sample in this study does not seem extraordinarily small. Furthermore, none of the previous SAOM-based studies worked with a representative sample of students. The possibility of selection bias cannot be ruled out, however, there is also no assumption about why students included in this study would respond to social selection and peer influence differently than the general population of students in the Czech Republic. Similarly to the previous SAOM-based studies, the students were all from regular comprehensive schools and are therefore comparable to samples in previous studies.
Another limitation and a possible explanation for not capturing any of the main hypothesized mechanisms may be the relatively short interval between observed timepoints. Seven months might not be sufficient for the effects of peer influence to manifest, as evidence suggests that such influence only becomes apparent after students have known each other for at least a year (Gremmen et al., 2018; Laninga-Wijnen, 2019). Conversely, given the context of this study where students knew each other for only a short period, it could be expected that social selection would be evident (Gremmen et al., 2017); however, this was not the case.
Further limitations of this study include several methodological and contextual factors. While this study did not account for the nested structure of the data, the only nested structure present was at the school level, as different teachers taught and assessed each classroom. This variability in teaching approaches across classrooms minimizes the impact of the school-level nesting on the results, as there is no underlying assumption that sharing the same school would significantly influence social selection or peer influence within individual classrooms. Additionally, the results of the SAOM need to be interpreted with caution due to a non-ideal multi-group procedure that displayed heterogeneity in structural effects across networks, suggesting that the model may not have effectively captured variation among different classrooms. Furthermore, the study did not utilize the extension proposed by Niezink et al. (2019) for modeling behavioral variables as continuous variables, as it has not yet been implemented for multi-group SAOMs.
Publication bias might be another reason why the findings in this study differ from all previously published studies. It is established that in social science research, to various degrees, there is a tendency to have research published based on the strength of the study findings with studies with null or contradictory findings less likely to be published. Most often, publication bias occurs before the submission, authors tend not to even write papers with null results (Franco et al., 2014). The fact that none of the reviewed previous studies contained null or contradictory results might, at least to some degree, be influence by the unwillingness of authors to write papers on selection and influence with null results or the unwillingness of journals to publish them. It is important to note, however, that uncovering publication bias and assessing its impact on the current literature on selection and influence is beyond the scope of this paper.
This study has several implications for future research. First, it would be useful to use measurements of students’ abilities not dependent on teachers, or to distinguish between the selection and influence on ability using objective measurements of students’ ability and self- and teacher-reported measures of students’ ability. It is possible that, at least to some degree, selection and influence operate differently when inherent ability is considered compared to self-reports as self-reports might be influenced by students’ and teachers’ perceptions. Selection and influence may operate on students’ and teachers’ perceptions as mechanisms additional to the mechanisms of actual ability. Second, it might be useful to treat ability in SAOMs as a continuous measure and to compare the SAOM results based on whether ability is discretized or treated as continuous behavior. For this, it might be useful to implement the Niezink et al.’s (2019) extension for multi-group SAOMs. Lastly, it is possible that the effects of selection and influence are not as pronounced and widespread as the review of the previous research implied with publication bias operating behind the reporting practices. It is therefore essential that studies be published regardless of the effect sizes and directions found.
Supplemental Material
Supplemental Material - No Evidence for Social Selection and Peer Influence on Grades and Literacy Among Early Adolescents Through Friendship Ties
Supplemental Material for No Evidence for Social Selection and Peer Influence on Grades and Literacy Among Early Adolescents Through Friendship Ties by Tomáš Lintner in The Journal of Early Adolescence.
Footnotes
Declaration of Conflicting Interests
The author declares no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Grantová Agentura České Republiky (GA21-16021S).
Data Availability Statement
The dataset analyzed during the current study is available in Mendeley Data repository at https://doi.org/10.17632/9c3dth6cwp.3 with an accompanying data article at https://doi.org/10.1016/j.dib.2023.109641.
Supplemental Material
Supplemental material for this article is available online.
Note
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.