
Abstract
Recent high-profile antitrust cases and policy proposals have put a spotlight on the relationship between firms’ access to big data and sustained competitive advantages in digital markets. In Europe, concerns about data-driven market power have led policymakers to propose far-reaching regulations of information technology (IT) in these markets. Despite the global policy relevance, the regulation of big data and its competitive effects has so far received little attention in information systems (IS) research. This article addresses this research gap by developing an overarching framework for future IS research on the role of IT for the regulation of data-driven market power. The proposed research framework builds upon a three-part analysis: First, we review the academic literature and show that there is extensive, although nuanced, empirical evidence for business value creation from big (user) data. Second, we draw on the resource-based view of the firm and recent policy reports to derive six facilitating factors that enable firms to establish market power based on sustained data-driven competitive advantages. Third, we characterize three regulatory approaches to govern market power and competition in data-driven digital markets: (i) empowering consumers, (ii) data openness, and (iii) limiting data scale. For each of these approaches, we highlight the key role of IT artifacts in mediating the effect of regulatory rules on actual practice.
Keywords
Introduction
Digital technology creates a wealth of data and has therefore given “rise to a new economy” (The Economist, 2017). Data itself is now recognized as a resource which creates value for businesses and societies (see, e.g., the “European strategy for data” by the European Commission, 2020a). At the same time, the digital economy has born a small number of “superstar firms” (Van Reenen and Patterson, 2017), whose success is frequently attributed to their superior access to data and capabilities to exploit this resource. However, whether the business value created by these firms yields long-term economic benefits for all stakeholders is currently controversially debated. High-profile antitrust cases against the most popular internet content and service providers (CSPs) have drawn scrutiny on whether these superstar firms have established significant market power based on their data resources, which could impede effective competition and innovation in digital markets.
Concerns about data-driven market power and anti-competitive conduct of data-rich firms have sparked a global policy debate about the need for ex-ante regulation of information technology (IT) in digital markets (Crémer et al., 2019; Furman et al., 2019; Scott Morton et al., 2019). Just recently, the European Union (EU) has agreed on landmark regulatory proposals for a “Digital Services Act” and a “Digital Markets Act,” which will implement far-reaching regulation to remedy the market power of data-rich superstar firms (European Commission, 2020b). Opponents of such regulatory proposals frequently cite a lack of empirical evidence that big data indeed constitutes a valuable and inimitable resource, which could establish market power (cf. Lambrecht and Tucker, 2017). They warn that data sharing regulation could endanger innovation in digital markets and that technical aspects and costs from regulation with respect to the underlying IT should be considered by regulators (see, e.g., Google, 2020).
Despite the global policy relevance and the significant impact of new regulatory rules, regulation of big data and its competitive effects have so far received only scant attention in information systems (IS) research (Clarke, 2022). This is exemplified by recent calls for research to investigate “how [firms] realize value from big data” (Günther et al., 2017: 200), “to identify universally valid success factors of [CSPs’] activities” in digital platform markets (Stummer et al., 2018: 173; De Reuver et al., 2018) and to assess the causal effects of policy proposals in forward-looking IS research (Hinz et al., 2019; Easley et al. 2018). Therefore, in this study, we develop a research framework that captures the major issues and dimensions of the regulation of data-driven market power to establish a conceptual basis for future research on the role of IT for regulation in digital markets (Gozman et al., 2020). 1 To this end, our study builds on and extends the following related streams of IS research: business value of data assets (Chen et al., 2015; Müller et al., 2018), IT-based competitive advantages (Bhatt and Grover 2005; Grover et al., 2018), governance of digital platform ecosystems (Jacobides et al. 2018; Tiwana et al. 2010), control points of digital infrastructures (Eaton et al., 2015; Tilson et al. 2010), and data access policies (Easley et al., 2018; Van Alstyne et al., 2021). We contribute to this literature by analyzing three main research questions on how technology and big data affect the need for and the implementation of regulation in the digital economy.
At first, we scrutinize the relationship between data as an input resource and its business value in digital markets. Although big data is hailed to deliver great economic benefits for businesses, systematic reviews based on comprehensive empirical evidence are scarce (cf. Günther et al., 2017). Therefore, our first research question asks what is the empirical evidence for business value creation from big (user) data? To this end, we review the academic literature and focus on (i) data-driven quality improvements and service personalization, (ii) personalized recommendations, and (iii) targeted advertising. Our findings demonstrate that the collection and use of big user data creates significant and manifold business value. However, the literature also identifies moderating factors and diverse categories of value creation that paint a nuanced picture of data-driven business value. By focusing on big data collected from users (cf. Aaltonen and Tempini, 2014), our findings complement extant research on value creation from non-personal data (e.g., Chen et al., 2015; Müller et al., 2018) and emphasize that regulation in digital markets should directly address consumers as the original data creators (cf. Jin and Wagman, 2021).
To eventually achieve a “sustained competitive advantage”, as understood by the resource-based view of the firm (Barney, 1991: 102), it is necessary that a firm’s data-driven value creation and the associated resources cannot be imitated by its competitors (Lambrecht and Tucker, 2017; Grover et al., 2018). Thus, our second research question asks which factors facilitate market power based on a sustained competitive advantage from data-driven business value creation and could thus warrant regulation? Building on a nascent literature stream of theoretical and empirical studies as well as recent policy reports, we propose a set of six facilitating factors that can prevent market entrants and competitors from imitating a firm’s data resources. In particular, we suggest that (i) exclusive access to data, (ii) exploitative access to data, (iii) economies of scale in data analytics, (iv) digital services ecosystems and economies of scope, (v) network effects and platform business models, and (vi) data-induced switching costs facilitate data-driven market power that can shield data-rich firms from competitive pressure. These findings complement extant studies on the value of big data for strategic decision-making (see, e.g., Constantiou and Kallinikos, 2015) and contribute to a better understanding of how data resources and capabilities can explain differences in firms’ performance (as, e.g., called for by De Reuver et al., 2018). Most importantly, our analysis adds to the current discourse on whether big data constitutes a valuable and inimitable resource (Grover et al., 2018) and can therefore be a source of market power. In contrast to previous studies (e.g., Lambrecht and Tucker, 2017), we conclude that regulatory intervention can be warranted due to the identified facilitating factors, albeit data being a non-rival economic good.
This leads us to our third research question about which regulatory approaches and rules are available to regulators to remedy data-driven market power and which role does IT play in the design and implementation of such regulation? Starting from the identified facilitating factors, we describe and categorize three regulatory approaches to mitigate negative effects of data-driven market power. First, empowering consumers aims to increase data mobility through improved transparency and more user control of personal data. Second, data openness aims to increase the availability of data resources, for example, through mandated data sharing. Third, limiting data scale aims to constrain data-rich firms in exploiting data-driven economies of scale and scope by means of data silos or structural separation. With regard to each of these approaches, we emphasize the key role of IT artifacts as institutions that mediate the effect of regulatory rules on actual practice as theorized by De Vaujany et al. (2018). In this vein, we provide a conceptual classification and a theoretical foundation for emerging research on specific data access policies (see, e.g., Van Alstyne et al., 2021). Moreover, we contribute to the literature on data neutrality (Easley et al., 2018) and show how this concept can be operationalized by regulatory approaches. More generally, we show how regulation can serve as a governance mechanism to address conflicts about control in platform ecosystems (cf. Parker & Van Alstyne, 2018).
Finally, based on these three main parts, we develop a research framework that integrates the previously analyzed concepts. In particular, the framework captures the manifold interdependencies between the design of IT artifacts and the effects of regulation, that ultimately shape regulatory outcomes. We propose that this framework can be operationalized to derive important and timely research questions. Taken together, they can build a holistic agenda for future IS research. In this vein, we encourage IS scholars to contribute their expertise to the regulation of data-driven digital markets and to change the status quo where “[r]egulation has not been a primary focus of research within the information systems discipline” (Clarke, 2022: 179). At last, this is highly relevant from a practical and social perspective (Clemons and Wilson, 2018) as value creation from big user data is becoming prevalent in ever more digital markets, and as new rules for governing data-driven market power will arguably be among the most consequential regulations to shape digital technologies and their social value in the coming decades.
Business value creation from big data use
The progress of IT combined with a shift of consumers’ activities to digital environments has led to a rapid growth of data being collected, stored, and analyzed (Acquisti et al., 2016). In the internet economy, CSPs collect data mainly in the form of transaction logs that record users’ behavior, giving rise to big user data (cf. De Fortuny et al., 2013; Martens et al., 2016). Big user data often contains information, which can—either directly or combined with additional data—be used to identify individuals (Bourreau et al., 2017). Therefore, big data is frequently also personal data (see, e.g., Art. 4(1) of the European GDPR). This data may be actively provided by users themselves (e.g., in the case of social networks) or may be collected by tracking users’ browsing, search, and purchasing behavior (Bujlow et al., 2017). Collected data may be further enriched by linking existing data sets (Stachl et al., 2020) or purchasing additional data from external sources (Federal Trade Commission, 2014).
Data-driven quality improvements and service personalization
Collection and use of big user data enables CSPs to continuously improve the quality of their offerings. In particular, the analysis of individual clickstream data can reveal users’ browsing behavior and provides opportunities to adapt user interfaces (UIs) to CSP’s business goals (Sismeiro and Bucklin, 2004). Additionally, CSPs can improve content presentation and navigation elements by running usability studies and experiments and simultaneously tracking changes in consumer behavior (Trusov et al., 2016). By continuously analyzing users’ actions, CSPs can also identify shifting demand patterns (Du and Kamakura, 2012). Moreover, by running experiments, CSPs can test the effects of incremental updates and identify new relevant offerings, thus increasing the rate of innovation through data collection and analysis (Manyika et al., 2011). In the context of online search, tracking user behavior enables search engine operators to refine their algorithms, thus improving search quality and the relevance of search results (Schaefer and Sapi, 2022; Yao and Mela, 2011).
Next to these general quality improvements, big user data is the basis for the personalization of content and services, which is defined as the delivery of “the right content to the right person at the right time to maximize immediate and future business opportunities” (Tam and Ho, 2006: 867). To this end, internal tracking data and external data are aggregated to create individual user profiles, approximating users’ interests and preferences (Trusov et al., 2016). Based on these profiles, websites, online retailers, and social networks can then tailor their content to users’ interests (Kalaignanam et al., 2018). For example, online retailers suggest delivery and payment options based on previous orders (Chellappa and Sin, 2005) and search engines use individuals’ search histories and locations to adjust the ranking of search results (Micarelli et al., 2007).
It is widely recognized that personalization can positively affect users’ satisfaction, retention, and cross-selling opportunities (Peppers et al., 1999). Moreover, personalization can foster customer loyalty and raise switching costs (see the section on Facilitating Factors of Data-Driven Competitive Advantages and Market Power) in online markets, where search and transaction costs are low and competition is thus often claimed to be “only a click away” (Kovacevich, 2009). In turn, this impedes customer poaching by competitors (Ansari and Mela, 2003). In a field experiment, Benlian (2015) demonstrates that personalization of website content and design can influence consumers’ willingness to stick with a website and their willingness to pay. Based on a sample of “brick-and-click” and online-only retailers, Thirumalai and Sinha (2013) show that personalizing transactions improves customer loyalty for most, but not for all retailers. In particular, they highlight that the business value of personalization hinges on characteristics such as product selection and variety. For personalized music playlists, Liebman et al. (2019) show that real-time personalization of services according to users’ preferences improves perceived user experience. However, personalization also affects the differentiation between CSPs and game theory analyses show that the impact of personalization can thus reduce profits of competing CSPs (Zhang, 2011). Moreover, it is well-known that collecting and using personal data to personalize content and services can elicit privacy concerns (Malhotra et al., 2004), which may negatively affect the likelihood of using personalized services. Chellappa and Sin (2005) show that CSPs can actively mitigate these negative consequences through trust-building measures. In particular, the reputation and perception of an online service has a significant impact on consumers’ willingness to accept or reject personalization.
Overview of empirical studies on the effectiveness of service personalization and recommender systems.
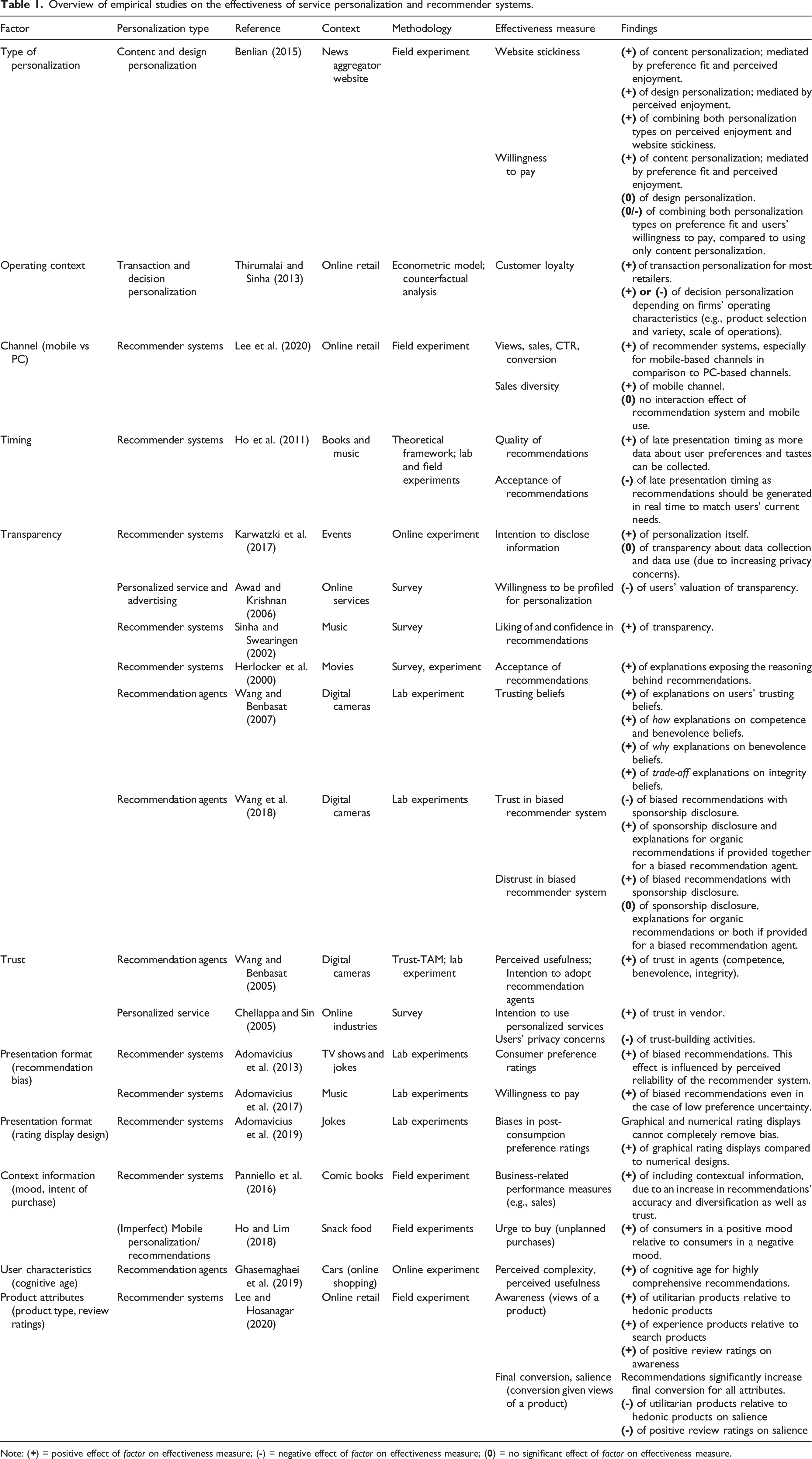
Note: (
Personalized recommendations
User profiling has fueled the growth of recommendation systems as a core value proposition of CSPs. Providing consumers with personalized recommendations—based on content, collaborative or hybrid approaches (Adomavicius and Tuzhilin, 2005)—simplifies users’ purchase or consumption choices by highlighting offers that match their interests and by reducing search costs (Ansari et al., 2000), especially for users of mobile devices (Lee et al., 2020). Personalized recommendations make it easier for consumers to discover niche products and to access previously unknown or new content and products (Brynjolfsson et al., 2006). By providing a greater product variety and more tailored offerings, a CSP can attract a larger customer base with diverse preferences (Brynjolfsson et al., 2010). Consequently, recommender systems significantly impact firms’ sales or the content consumed by their users, as summarized in the following.
Several studies discuss the impact of personalized recommendations on sales diversity (Brynjolfsson et al., 2010; Fleder and Hosanagar, 2009; Oestreicher-Singer and Sundararajan, 2012). On the one hand, the long-tail effect may increase demand for niche products. On the other hand, the superstar effect may promote sales concentration for popular blockbuster products. Moreover, recommendations are likely to increase demand due to cross-selling of complementary products that provide additional value to consumers (Pathak et al., 2010). Recommender systems may also increase consumption by attracting consumers without concrete purchase intention to make unplanned purchases and buy recommended products (Ho and Lim, 2018).
Experimental studies have investigated behavioral effects and demonstrate that recommendations and displayed ratings can change users’ preferences (Adomavicius et al., 2013; Adomavicius et al., 2019) and potentially increase their willingness to pay (Adomavicius et al., 2017). Thus, personalized recommendations can directly increase revenues and profitability or create indirect benefits, for example, when firms use recommendations to manage inventory.
The performance of recommender systems depends on the data which is fed into the system. Availability of data is a key prerequisite for the technical implementation of recommender systems and their success (Mican et al., 2020). Most systems base their recommendations on consumers’ past interaction with the service (Adomavicius and Tuzhilin, 2005) such that any firm must overcome the well-known cold start problem, that is, a critical mass of user data is required to elicit preferences and give useful recommendations (Schein et al., 2002). More generally, there is a positive relationship between training data and the accuracy of recommendations (De Fortuny et al., 2013). In particular, more comprehensive user profiles from larger data sets reduce profile fragmentation and decrease firms’ uncertainty about consumers’ preferences (Trusov et al., 2016). Data that reveals context information (such as time or users’ location) can further improve the accuracy of recommendations (Adomavicius and Tuzhilin, 2015; Panniello et al., 2016). To obtain accurate estimates of consumers’ preferences, their user profiles must be up-to-date (Pipino et al., 2002). Poor data quality can lead to ill-fitting recommendations, which lower customer satisfaction (cf. Amatriain et al., 2009).
Empirical research highlights additional factors that influence the effectiveness of personalized recommendations, such as the trade-off between timeliness and recommendation quality: Ideally, recommendations should be generated in real time before users make their own decisions. However, the longer the observation period, the more data about users’ preferences can be collected, which improves recommendation quality (Ho et al., 2011). Thus, online services have to weigh immediate sales against profiling (Johar et al., 2014). Furthermore, product attributes can have a moderating effect on the effectiveness of personalized recommendations: for example, Lee and Hosanagar (2020) find that the effectiveness of recommendations at different purchase stages depends on whether a product can be classified as a utilitarian, hedonic, experience, or search product. Ghasemaghaei et al. (2019) show that user characteristics, such as cognitive age, moderate the impact of recommendation comprehensiveness (e.g., the degree of detail) on users’ perceived complexity and usefulness. Finally, trust is found to play an important role for the effectiveness of recommendations as it improves perceived usefulness and consumers’ intention to adopt (Wang and Benbasat, 2005). Hence, firms can use transparency measures and explanations to positively influence users’ trusting beliefs (Wang and Benbasat, 2007). In contrast, trust may be eroded by biased recommendations, although sponsorship disclosures combined with further explanations may mitigate such detrimental effects (Wang et al., 2018). Moreover, transparency and explanations have been found to increase liking (Sinha and Swearingen, 2002) and acceptance of recommendations (Herlocker et al., 2000). However, Karwatzki et al. (2017) find no positive effect of more transparent data collection on users’ willingness to disclose data, due to an increase of their privacy concerns. Thus, personalized recommendations are likely to be more effective for less privacy-sensitive users (Awad and Krishnan, 2006).
Targeted advertising
Targeting, that is, the selection and tailoring of advertisements to consumers, is of particular importance to CSPs, as they frequently offer their services free of charge and rely on advertising revenues (Choi et al., 2020). The goal of targeting is to enhance advertising effectiveness by reaching those users who are likely to be interested in the promoted services or products. As a higher advertising effectiveness raises the net benefit for advertisers due to less wasted impressions and higher conversion rates, CSPs generally benefit from higher revenues. For users, advertising is possibly persuasive, but also informative, as it lowers consumers’ search costs (Bagwell, 2007).
In principle, three types of targeting can be distinguished: Context-based targeting displays advertisements that fit the content of a website (Goldfarb, 2014). Segment-based targeting categorizes consumers into groups based on demographic characteristics or observed attributes (Bleier and Eisenbeiss, 2015a) to customize advertisements according to group characteristics. Behavior-based targeting displays advertisements based on tracking data and user profiles that capture consumers’ online activity (Goldfarb, 2014). A popular form of behavior-based targeting in e-commerce is known as (dynamic) retargeting, which has been found to increase conversion rates (Lambrecht and Tucker, 2013; Sahni et al., 2019).
Recent studies provide robust empirical evidence for a general positive relationship between targeting and advertising effectiveness, whereby effectiveness has been measured with different performance indicators (Bleier and Eisenbeiss, 2015a), such as online sales (e.g., Lambrecht and Tucker, 2013), purchase intention of consumers (e.g., Goldfarb and Tucker, 2011a; Van Doorn and Hoekstra, 2013), website visits (e.g., Sahni et al., 2019), click-through rates (e.g., Tucker, 2014), and view-through rates (e.g., Bleier and Eisenbeiss, 2015a). In general, advertising effectiveness is affected by the timing and placement of targeted advertisements (e.g., Bleier and Eisenbeiss, 2015a; Goldfarb and Tucker, 2011a; Lambrecht and Tucker, 2013; Sahni et al., 2019). However, the use of big user data—which may be considered sensitive or inappropriate by consumers—also affects consumers’ perception and acceptance of targeted advertisements (Goldfarb, 2014). If consumers consider tracking of online activities and collection of personal data to be invasive, associated privacy concerns can lower the effectiveness of targeted advertising (Tucker, 2012). Hence, stricter privacy policies by firms, which limit the collection and use of personal data, can, in principle, mitigate consumers’ concerns and enhance the effectiveness of targeted advertising. At the same time, such constraints may impair targeting quality and generate less effective matches between ads and consumers, as shown by Goldfarb and Tucker (2011b) for the European Privacy and Electronic Communications Directive, which made it more difficult for advertisers to collect data for targeted advertising.
In order to alleviate consumers’ concerns and reactance, the empirical literature has identified transparency about data collection as an important moderating factor on consumers’ acceptance of targeted advertising. In particular, greater transparency is found to have a positive effect as non-transparent collection of personal data elicits a feeling of vulnerability (Aguirre et al., 2015). If consumers are informed about CSPs’ data collection practices, Aguirre et al. (2015) show that targeted advertisements increase click-through rates. Yet, the impact of transparency hinges critically on the type of information that is revealed: Kim et al. (2019) confirm that transparency promotes advertising effectiveness given that consumers trust the CSP and acceptable data collection practices are disclosed. In contrast, if transparency reveals data collection practices that are deemed unacceptable by consumers, advertising effectiveness decreases due to higher privacy concerns (Kim et al., 2019). Furthermore, consumers’ perceived control over their personal data has a significant effect on the effectiveness of targeted advertising: Tucker (2014) finds that clicks on personalized advertisements of a social network doubled after users were given more perceived control over their personal data, although advertisers’ ability to target ads was unaffected by this change. Similar to personalized recommendations, trust is recognized as an important factor to alleviate privacy concerns: Bleier and Eisenbeiss (2015b) demonstrate that more trusted online services can increase click-through rates by displaying advertisements which closely and exhaustively reflect consumers’ interest without evoking reactance and privacy concerns. Moreover, justification of ads can influence advertising effectiveness (White et al., 2008): Consumers’ acceptance of targeting and their willingness to disclose data increases if a CSP emphasizes that a service is free of charge (Schumann et al., 2014).
Overview of empirical studies on the effectiveness of targeted advertising.
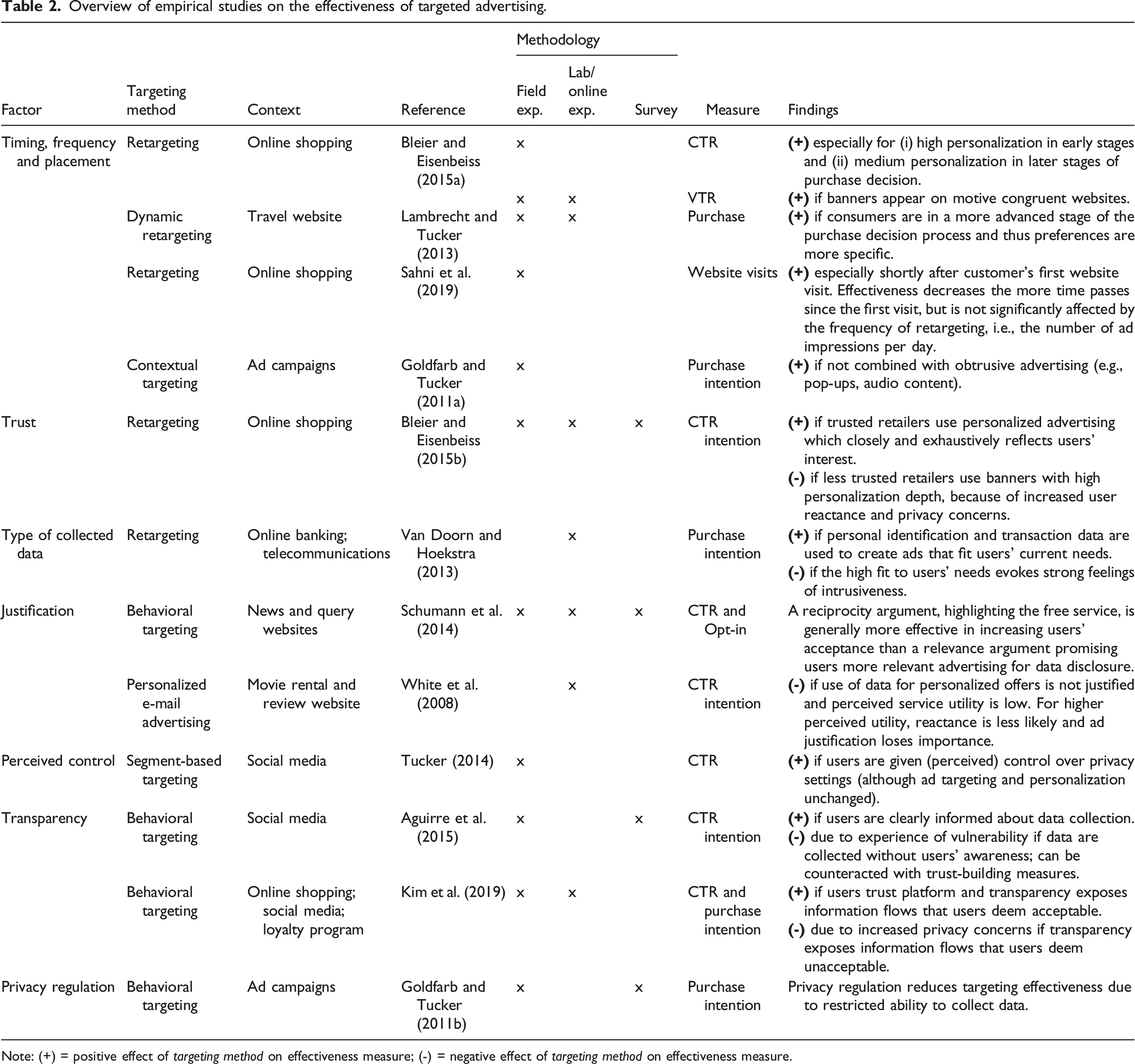
Note: (+) = positive effect of targeting method on effectiveness measure; (-) = negative effect of targeting method on effectiveness measure.
An overview of business value creation from big user data in digital markets
Altogether, big user data has been found to be a valuable input for business value based on quality improvements and service personalization, recommendations, and targeted advertising. Figure 1 illustrates our findings and highlights that business value is generated along different paths and in different forms. This integrated view allows us to distinguish three main categories of data-driven business value: (i) improved customer retention, (ii) increased revenue in the consumer market, and (iii) increased revenue on other market sides. Our review demonstrates that a CSP’s use of big user data may contribute to all of these value categories. Moreover, Figure 1 highlights relevant moderating factors that influence the effectiveness of service personalization, recommender systems, and targeted advertising in generating business value. Note that the illustrated sub-categories are not exhaustive with respect to big data applications in general. However, based on our literature review, we conclude that they capture the main benefits of big user data in the internet economy. Categories of business value creation from big user data in digital markets.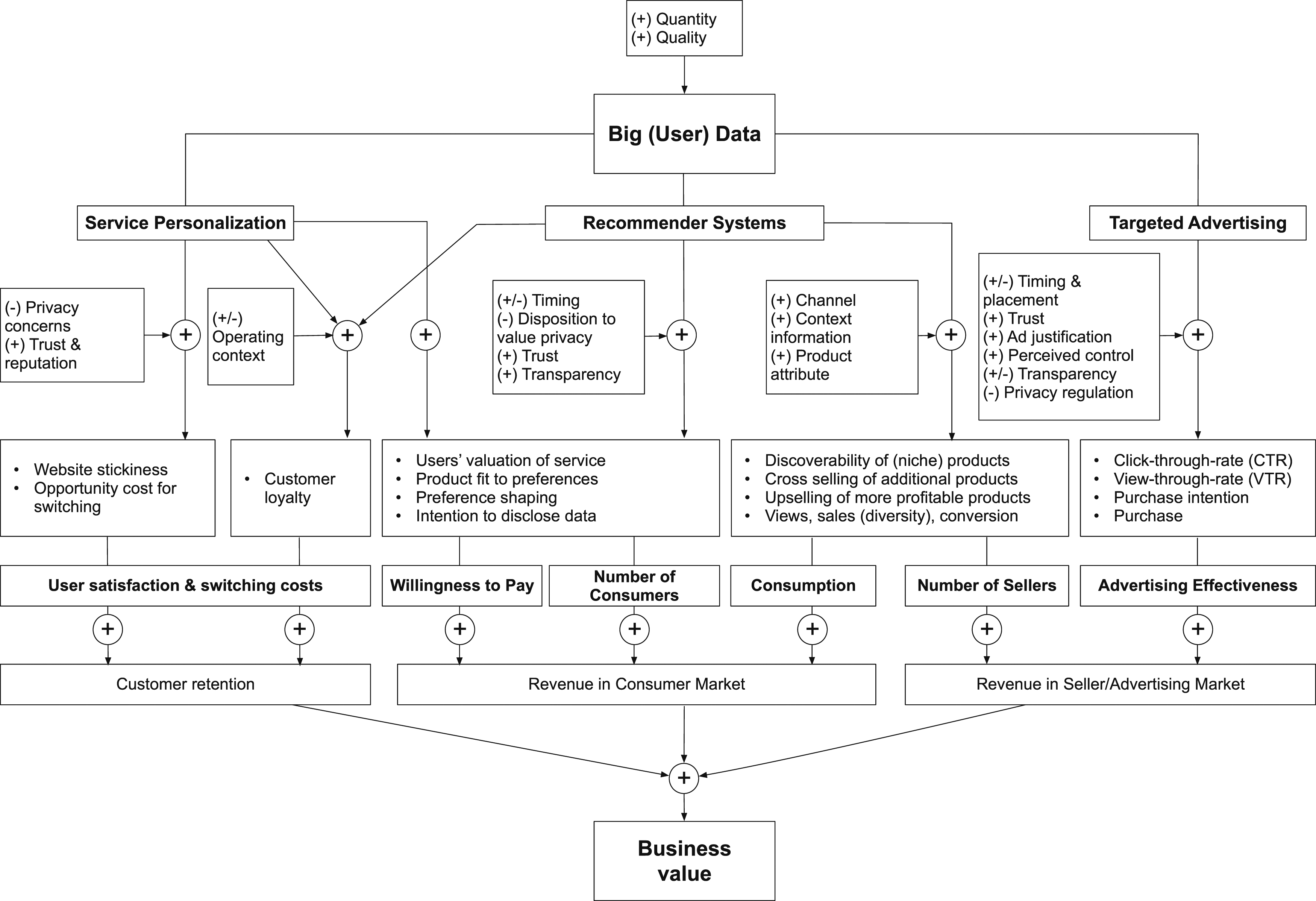
Facilitating factors of data-driven competitive advantages and market power
As highlighted in the previous section, big user data constitutes a valuable input for numerous business use cases in the digital economy. In principle, however, data-driven business value can be generated by any firm. To eventually achieve a “sustained competitive advantage” as understood by the resource-based view of the firm (Barney, 1991: 102), it is necessary that a firm’s data-driven value creation and the associated resources cannot be imitated by its competitors (cf. Lambrecht and Tucker, 2017; Nevo and Wade, 2010; Wade and Hulland, 2004). Only then, firms may establish data-driven market power and achieve a dominant position, which could warrant the regulation of data-rich firms. We therefore build on the nascent literature on data-driven competitive advantages and recent policy reports on digital markets (inter alia CMA, 2020a; Crémer et al., 2019; Furman et al., 2019; Scott Morton et al., 2019) to derive a set of facilitating factors that can render a firm’s data resources inimitable and promote a sustained competitive advantage based on big user data.
On the other hand, there are significant scale economies and incumbency advantages in the creation of user profiles. First, it is easier and less costly for firms with existing customer relations to collect first-party data. In particular, these firms are able to collect data as a by-product from interactions with their user base (CMA, 2020a). Second, firms may collect third-party data by tracking consumer behavior outside of their own services ecosystem. To this end, the creation of meaningful user profiles requires (i) extensive tracking across services, websites, and devices and (ii) the ability to link data to individual consumers or groups of consumers. However, empirical analyses show a long-tail distribution for third-party trackers with a high concentration at the top. In 2016, trackers of only four firms were present on more than 10% of websites, while the most widely encountered firm, Google, was active on more than 70% of websites (Englehardt and Narayanan, 2016). Third, digital platforms are in a special position as intermediaries to observe interactions and transactions carried out between affiliated parties over their platform (Mattioli, 2020). In this vein, platforms benefit from exclusive control over their digital infrastructures (Tilson et al., 2010) as they can monitor data flows between affiliated parties. At the same time, a platform can tighten its control by designing boundary resources (Eaton et al., 2015) and platform openness (Parker & Van Alstyne, 2018) to limit competitors’ and complementors’ data access.
Economies of scope with respect to data inputs have two main implications for firms’ expansion strategies in digital markets: On the one hand, there is an additional strategic incentive for firms to expand into other markets and to establish integrated services ecosystems, which is not captured by traditional theories of market power leveraging (Whinston, 1990). This is because integrated services ecosystems allow these firms to track users across a variety of services and obtain access to complementary user data (CMA, 2020b). Expansion into new markets may therefore be driven by the desire to gather even more comprehensive data sets on consumers. On the other hand, firms that already generate business value from data and have developed big data analytics capabilities (Wamba et al., 2017) are likely to have an advantage over independent firms when entering other existing or new markets. In this vein, data-driven network effects (Prüfer and Schottmüller, 2021), can enable a firm with more data to innovate at lower costs in “connected markets”, because, for example, cross-domain user data can be leveraged to personalize services and recommendations more accurately (e.g., Amatriain and Basilico, 2015). Hence, data-related economies of scope can facilitate data-rich firms’ entry into other markets and the expansion of their services ecosystems, thus making it even less likely that competitors can replicate their data resources.
With regard to multi-sided platform models (De Reuver et al., 2018; Parker and Van Alstyne, 2005), a firm’s superior access to data may likewise be protected by indirect network effects. In addition, platform intermediaries (Ghazawneh and Henfridsson, 2015) are able to collect additional data from interactions and transactions carried out on the platform as described above. If the platform is in competition with some of the affiliated parties in downstream markets, this puts the intermediary at a relative competitive advantage (Wen and Zhu, 2019; Zhu and Liu, 2018). The scale of data access is then difficult to replicate for competitors that must share their own data with the platform (Krämer et al., 2018).
Regulation of data-driven market power and the role of IT artifacts
The six facilitating factors demonstrate that deliberate strategies and special characteristics of digital markets can help data-rich firms to establish market power. Increasing market concentration is then likely to cause inefficient welfare outcomes that harm consumers (Furman et al., 2019) and endanger innovation (Prüfer and Schottmüller, 2021). In addition, the emergence of digital gatekeepers entails undesirable dynamics from a societal perspective (see, e.g., Guess et al., 2019 on political impacts). Consequently, there have been significant efforts by policymakers, especially in the EU, to draft new digital markets regulation.
So far, the debate on these new regulations (e.g., European Commission, 2020b) has centered around economic and legal arguments. However, for rules to take effect in commercial practice and to achieve intended policy goals, any regulation in this domain should consider IT artifacts as core building blocks of effective regulation. As highlighted by De Vaujany et al. (2018), successful regulation of IT requires a system-wide perspective that captures the interdependencies and mediating effects between rules, IT artifacts, and practices. In particular, technical constraints and IT artifact design introduce trade-offs that should be recognized in the policy process to avoid unintended adverse effects of regulation on stakeholders’ practices. This does not necessarily require that policies directly specify a particular IT design, but that the role of IT artifacts with respect to their effects on actual practices is considered. Moreover, explicit rules for the underlying IT systems may sometimes be desirable despite concerns that this could violate the principle of technology neutrality and stifle innovation (cf. Maxwell and Bourreau, 2015). For example, transparency rules may prove to be ineffective if abstract laws are undermined by dark patterns (Nouwens et al., 2020). In such cases, more specific rules for the underlying IT artifacts can render regulation more effective and reduce legal uncertainty.
Hence, IT artifacts play a crucial role in determining whether regulatory rules can indeed constrain or empower organizations in their data-driven business value creation. Especially the design of inter-organizational and user-facing interfaces of regulated firms’ IS will determine whether regulation of data-driven market power can ultimately be successful (see the subsequent sections on empowering consumers, data openness and limiting data scale).
In the following, we show that the facilitating factors derived in the section on Facilitating Factors of Data-Driven Competitive Advantages and Market Power can serve as a starting point for a regulatory framework that addresses concerns about data-driven market power in digital markets. In particular, as illustrated in Figure 2, the facilitating factors suggest three regulatory approaches: (i) empowering consumers, (ii) data openness, and (iii) limiting data scale. All three approaches share the ultimate goal to achieve a “level playing field” for competition in data-driven markets. However, the approaches differ with respect to the underlying key rationale to achieve this outcome and the focal stakeholder targeted by the respective regulation. Consequently, the approaches suggest different rules and require distinct IT artifacts to transform the abstract rules into material constraints (cf. Latour, 1992), which ultimately govern individuals’ and organizations’ data-related practices (cf. De Vaujany et al., 2018). Regulatory approaches and rules to address facilitating factors of data-driven market power.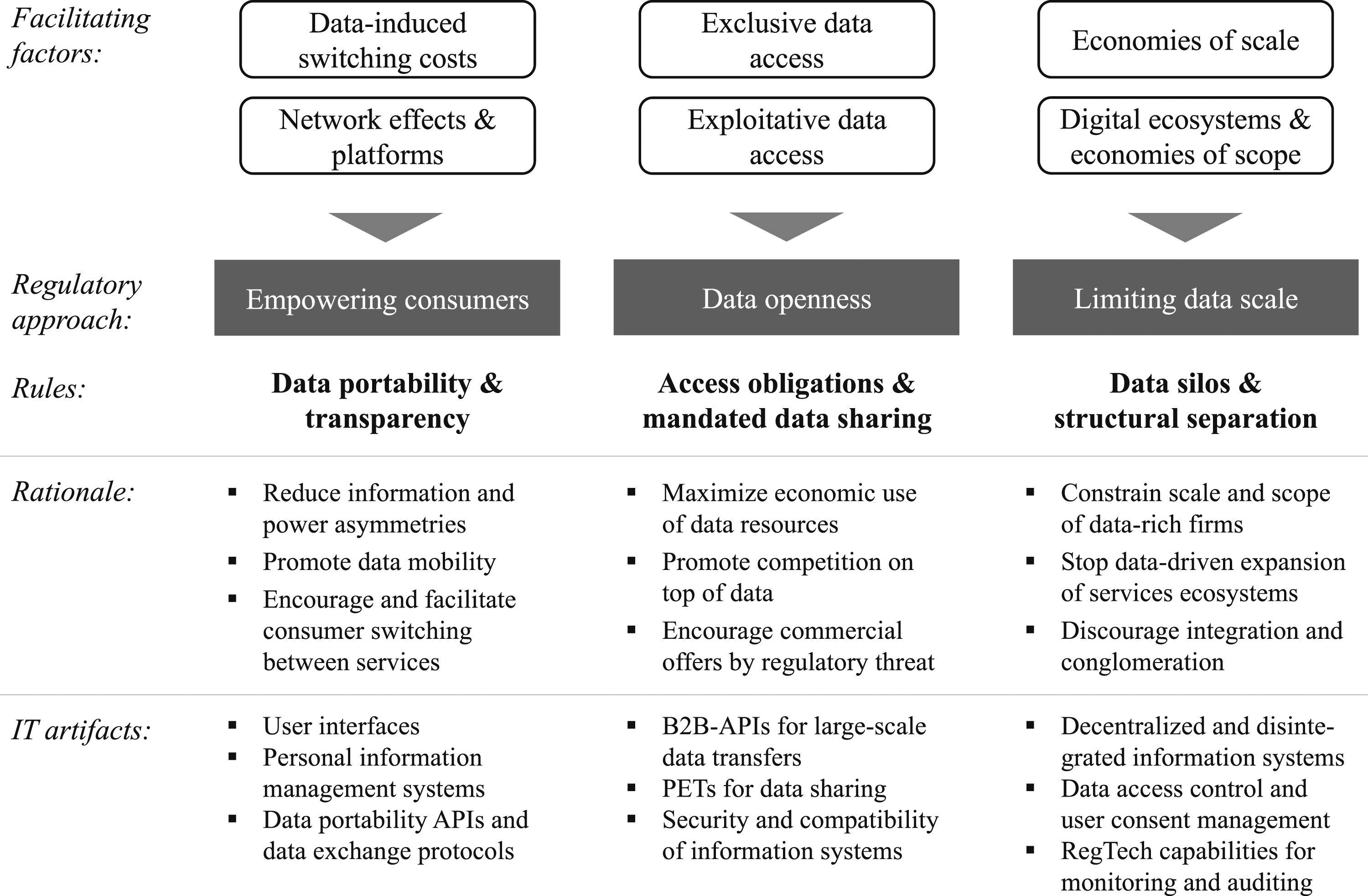
Empowering consumers through transparency obligations and data portability
The first approach focuses on consumers as the actual data providers and source of competition. Only if firms can entice customers of other firms, the competitive process can evolve. However, in the previous section, data-induced switching costs and network effects were identified as inhibiting factors for consumers’ switching between data-driven firms. Hence, this approach aims to strengthen consumers vis-à-vis the firms that collect their data.
IT artifacts for empowering consumers: User interfaces and personal information management systems
Rules aimed at improving transparency and augmenting user control relate to IT artifacts of firms whose design must comply with these obligations, but also to IT artifacts that allow consumers to exercise new control rights.
With respect to transparency about firms’ data collection and data use, it is well-known that the presentation of information and choices can alter individuals’ cognitive information processing and their privacy decisions. For example, additional visual cues can increase consumers’ tendency to buy from more privacy-friendly merchants (Tsai et al., 2011), while default framing of opt-out or opt-in choices affects users’ willingness to agree to data collection (Acquisti et al., 2017). More generally, (cognitive) biases in individual decision-making limit the effectiveness of transparency measures (Adjerid et al., 2013), especially when they are deliberately exploited by IS design.
On the consumer side, user-centric data management and data portability can only reach large-scale adoption if supporting IT artifacts and UIs are easy-to-use and if consumers trust that their data is secure. In this context, Personal Information Management Systems (PIMS, Abiteboul et al., 2015) are considered promising tools to automate data transfers and to facilitate user-controlled data management (EDPS, 2020). PIMS can further empower consumers to monetize their data and thus to directly benefit from the business value of data (Haberer et al., 2022). Democratizing data control may then allow more firms to use this data, thereby reducing exclusive data access. However, this requires that involved parties can rely on technical standards and application programming interfaces (APIs), which allow for data exchanges that preserve the data’s business value. This raises questions about design choices between open and proprietary standards, and whether such standards should evolve from voluntary cooperation or from mandatory regulation.
Privacy rules are regularly devised as symmetric regulation, that is, firms irrespective of size and market position have to adhere equally. Thus, the pro-competitive effects of such regulation should be weighed against compliance and implementation costs, for example, for IT infrastructures (Littrell and Thompson, 1997), as such costs can raise market entry barriers and entrench dominant market positions (see, e.g., Peukert et al., 2022 with respect to the GDPR). Hence, to avoid adverse effects, compatibility (Li and Chen, 2012), IT complexity (Widjaja and Gregory, 2020) and IT implementation costs (Zhuo et al., 2021) should be considered when specifying rules in the interest of consumers.
Data openness through access obligations and mandated data sharing
The second regulatory approach directly addresses exclusive and exploitative data access as facilitating factors of data-driven market power by opening up data sets of dominant firms and allowing other firms to use this data. In contrast to a consumer-centric approach, the focus here is on business-to-business data sharing, which allows regulators to directly define the scope and scale of competitors’ data access (Krämer et al., 2020). Therefore, this approach can facilitate large-scale data sharing, which is unlikely to be achieved by individual-level data portability regulation.
IT artifacts for data openness: B2B-interfaces and PETs for personal data exchange
Establishing IT systems to access and exchange big (user) data sets across organizational boundaries entails significant challenges. Ultimately, the IT infrastructure puts a limit on the availability, scale, and quality of data sets that can be retrieved by access seekers and thus determines the actual business opportunities and economic impact of these regulatory rules. For example, the implementation of APIs for data exchanges between firms (Arnaut et al., 2018), the design of data intermediaries (e.g., Balazinska et al., 2011), but also data integration on the recipient side (e.g., Kadadi et al., 2014) and the strategic management of electronic data interchanges (Galliers et al., 1995; Narayanan et al., 2009) represent important issues that have so far received scant attention in the regulatory discourse. Furthermore, technical design decisions do not only affect business opportunities of data recipients, but also regulatory burdens and implementation costs for data providers.
Beyond implementation and performance challenges, inter-organizational exchange of personal data requires secure and privacy-compliant IT (cf. Adjerid et al., 2016). In many cases, access regulation will limit the set of firms that can access data of a dominant firm or at least require a vetting procedure (Feasey and De Streel, 2020). Hence, authentication and authorization systems are necessary, and also data integrity must be ensured. Naturally, these security features will affect technical performance and require design deliberations (e.g., Prislan et al., 2020). With respect to sharing of personal data, privacy-enhancing technologies (PETs, Borking and Raab, 2001) and privacy by design (Oetzel and Spiekermann, 2014) can thus play an important role to reconcile conflicts between privacy protection and business value of data (e.g., Fung et al., 2010). This is especially relevant as traditional anonymization techniques fail when applied to big user data (De Montjoye et al., 2015).
Limiting data scale through data silos and structural separation
The third approach directly targets dominant firms by limiting data-driven economies of scale and scope, which were identified as facilitating factors of data-driven market power in the previous section. Limiting data scale can be achieved by a spectrum of rules that vary in how severely they interfere with a dominant firm’s business (Krämer et al., 2020). In any case, limiting scale and scope advantages necessarily implies that regulated firms become less efficient as they are forced to operate below optimal scale or must abstain from value-generating combination of data sources. Such losses in economic efficiency, in addition to regulatory costs (Littrell and Thompson, 1997), must be weighed against the benefits from limiting data scale.
IT artifacts for limiting data scale: Data firewalls, RegTech, and disintegration of IT architectures
Data silos require firms to redesign and reconfigure their data processing and storage facilities to erect digital “data firewalls”, that is, information barriers for different service divisions (Brewer and Nash, 1989). This can be achieved by duplicating data infrastructures, which, however, is very cost-inefficient. Instead, firms are more likely to implement an access control layer on top of a consolidated hardware infrastructure. To this end, firms must design data access management systems and organizational measures that ensure compliance with regulatory obligations.
Compliance monitoring and auditing requires regulators to build up their own technical capabilities. Large-scale data processing and analytics as well as automation of rule enforcement are necessary to deal with the high number of transactions and the complexity of processes in data regulation (Ryan et al., 2021). Hence, the development of regulatory technology (RegTech) is important for rules to effectively constrain the practices of a dominant firm and its employees (cf. Arner et al., 2016; Butler and O’Brien, 2019a; Gozman and Currie, 2014). By leveraging new technologies (see, e.g., Butler and O’Brien, 2019b on AI), RegTech can assist regulators to overcome information asymmetries vis-à-vis firms that run large and complex data processing systems.
Structural separation forces firms to revert the integration of business processes and the underlying IT infrastructure. Due to the complexity of today’s IT systems, this can resemble “unscrambling the scrambled egg”. Whereas there is by now an established body of knowledge on the integration of data (Goodhue et al., 1992) and IS (Wijnhoven et al., 2006), disintegration of IT infrastructure in consequence of regulatory obligations (Tanriverdi and Du, 2009) presents novel challenges for redesigning IT architectures and business processes as well as managing transition and change. Furthermore, if disintegrated services must remain interoperable after structural separation, ex-post IT systems must support an efficient and secure inter-organizational exchange of data.
An IS research agenda on the role of IT for regulation of data-driven market power
Building upon the three previous parts of this paper, we develop an overarching research framework (see Figure 3) that integrates the analyzed concepts and their relationships. New research questions can be derived from this framework by considering the characteristics and manifestations of the concepts (depicted as boxes) with respect to their effects along the proposed causal paths (depicted as arrows). Integrated framework for future IS research on the role of IT for regulation of data-driven market power.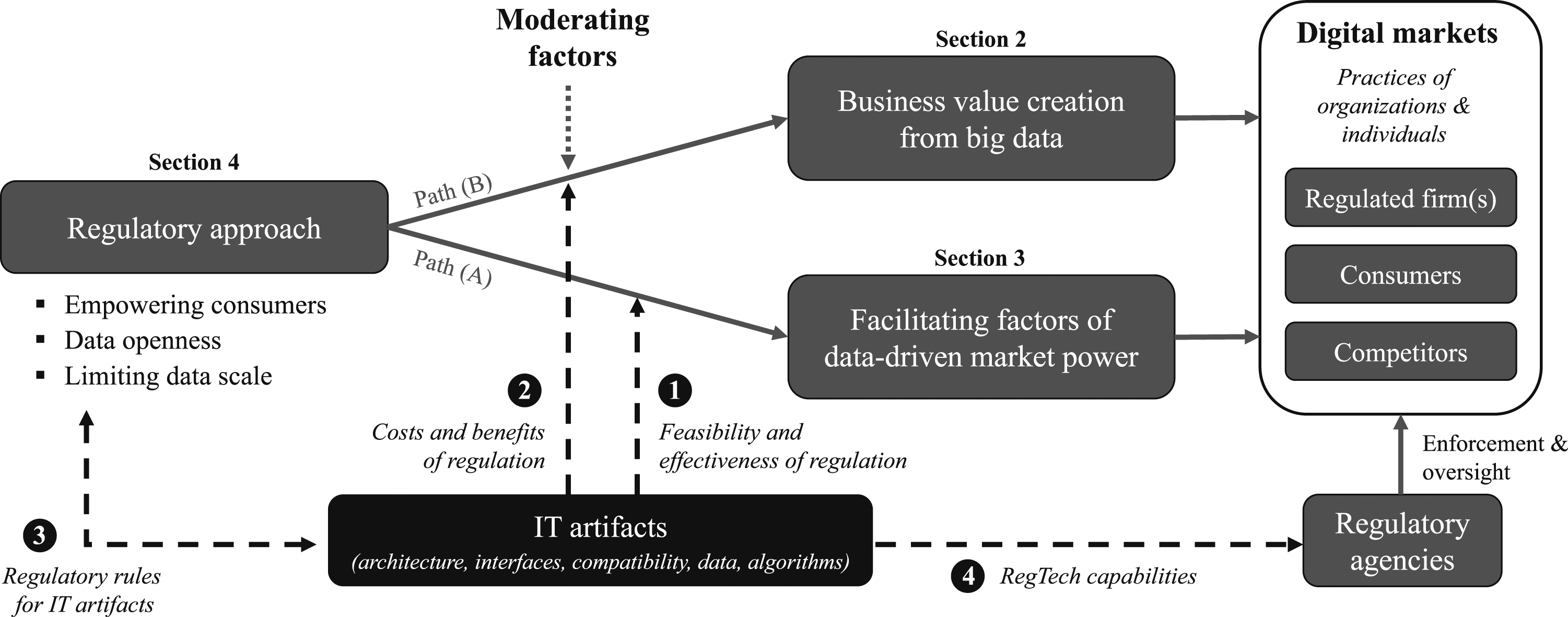
An integrated research framework
The gray-shaded components and solid arrows in Figure 3 highlight that the different regulatory approaches, as classified in the section on Regulation of Data-Driven Market Power and the Role of IT Artifacts, affect outcomes in digital markets along two main causal paths: (A) First, each regulatory approach aims to mitigate one or several facilitating factors of data-driven market power as identified in the section on Facilitating Factors of Data-Driven Competitive Advantages and Market Power. Hence, the impact of a regulatory approach hinges on its effectiveness in addressing the underlying causes for an inimitable competitive advantage of data-rich firms. (B) Second, regulatory intervention may affect market participants’ resources and capabilities to create business value from big user data contingent on moderating factors as summarized in the section on Business Value Creation from Big Data Use. That is, next to the intended effect on the causes of market power, regulation is likely to create costs and benefits for stakeholders that shape their incentives, capabilities, and practices.
Along these two paths, regulatory approaches affect the practices of regulated firm(s), competitors, and consumers. Taken together, these positive and negative effects on stakeholders’ practices will ultimately determine the net impact of regulation on outcomes in digital markets.
The black-shaded components and dashed arrows in Figure 3 illustrate the influence of IT artifacts on the effects of regulation and ensuing market outcomes: (1) As IT transforms regulatory rules into actual constraints, the design of the underlying technology determines whether a regulatory approach can address a specific facilitating factor and how effective regulation can remedy a cause of data-driven market power. (2) IT and its design set boundaries for the costs and benefits that regulatory approaches exert on business value creation from big user data. Along paths (1) and (2), IT artifacts directly shape the impact of regulation on practices of organizations and individuals, and thus the ultimate outcomes. (3) As posited by De Vaujany et al. (2018), there exists a direct interdependent relationship between regulatory rules and IT artifacts. In particular, the legal specification of rules offers policymakers many degrees of freedom on how regulation is actually implemented, for example, with respect to the specificity and level of technical detail or the prescribed enforcement procedures. The choice of a particular rule specification puts constraints or leaves flexibility on the design of corresponding IT artifacts. In reverse, available design options for IT artifacts may inform rule specification. (4) IT endows regulatory agencies with new capabilities to enforce regulation and monitor practices in digital markets (see the section on Limiting Data Scale through Data Silos and Structural Separation).
Altogether, the integrated framework highlights how IT can affect and shape the outcomes of regulation of data-driven market power. Hence, it sheds light on open research questions that have so far received scant attention. In this spirit, we propose that the presented framework can be operationalized to establish a research agenda for future IS research on the role of IT for regulation of data-driven market power.
Exemplary research questions on the role of IT for regulation of data-driven market power
Exemplary research questions derived from the integrated research framework as illustrated in Figure 3.

With respect to regulation aimed at
Regulation of
Finally, regulation aimed at
Conclusion
This article explores three key research questions on the regulation of data-driven market power in digital markets. In the first two parts, we have addressed the questions of whether and why data-driven value creation may require regulatory intervention in digital markets. Our review demonstrates that there is rich and nuanced empirical evidence on the business value that firms can generate from big user data. By focusing specifically on big user data, we complement previous studies on the business value of data assets (e.g., Chen et al., 2015; Müller et al., 2018). Furthermore, drawing on and extending the literature on IT-based competitive advantages (e.g., Bhatt and Grover, 2005; Grover et al., 2018), we have identified six facilitating factors which may impede competitors from imitating a firm’s data-driven business value creation and may thus give rise to market power. In the third part, we have addressed the question of how to regulate data-driven market power and classified three regulatory approaches to govern competition issues in the context of big user data. This analysis adds to existing IS research on control points and governance of digital platform ecosystems (Tilson et al. 2010; Tiwana et al. 2010) as well as on data access policies (e.g., Van Alstyne et al., 2021).
Building on this analysis, the article develops an integrated research framework on how technology and big data affect the need for and the implementation of regulation in the digital economy. Hence, this article contributes also to the growing literature on IT regulation (e.g., Clemons and Wilson, 2018; Currie et al., 2018; de Vaujany et al. 2018). In particular, the framework highlights the manifold interdependencies between regulation and IT artifact design that ultimately shape regulatory outcomes. We propose that this framework can be operationalized to derive important and timely research questions that together build a holistic agenda for future IS research.
Across the research issues that can be derived from the proposed research framework, a three-fold role of IT for competition regulation of big user data emerges: First, IT enables new regulatory approaches. Most notably, leveraging consumer-oriented IT artifacts allows for more consumer control and effective transparency in settings where transaction costs would otherwise overwhelm consumers. In addition, IT may render regulatory approaches feasible that would otherwise be too complex. In this vein, more research is needed on how design principles (e.g., for user-friendly privacy notices and controls) can find widespread adoption (Habib et al., 2021). Second, IT determines the costs of regulation. Compliance with regulatory rules, such as mandated data sharing or data siloing, requires fundamental changes to the IT systems of regulated firms. The (re-)design and implementation of rule-compliant IT systems will significantly determine the overall costs of regulation and constitute a benchmark that must be exceeded by the benefits of regulation to achieve a net welfare gain. Here, IS research can contribute by reinforcing early efforts (e.g., Tanriverdi and Du, 2009) to measure the impact of regulation on organizational costs and assess the IT risks of specific regulatory rules. Third, IT endows regulators with new RegTech capabilities. Given the scale, degree of automation, and complexity of data use in digital markets, RegTech capabilities are necessary to effectively execute, enforce and monitor regulatory rules. In this context, existing studies have pointed to the need for standardization (Butler, 2017), interoperability and automatization (Ryan et al., 2021), and availability of APIs (Nicholls, 2021) to reap the benefits of smart regulation.
Supplemental Material
Supplemental Material - Regulation of data-driven market power in the digital economy: Business value creation and competitive advantages from big data
Supplemental Material for Regulation of data-driven market power in the digital economy: Business value creation and competitive advantages from big data by Victoria Fast, Daniel Schnurr, and Michael Wohlfarth in Journal of Information Technology
Footnotes
Acknowledgments
We are grateful to the Special Issue Editors, especially Kalle Lyytinen for helpful guidance in the review process, and two anonymous referees for their valuable feedback and suggestions. We also thank participants at the ITS 2018 conference, the TPRC 2019 conference, the WI 2021 conference and the FSR Annual Conference 2022 as well as seminar audiences at the University of Passau and the Weizenbaum Institute for the Networked Society for helpful comments. The authors acknowledge generous funding by the Bavarian State Ministry of Science and the Arts (coordinated by the Bavarian Research Institute for Digital Transformation).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Bavarian State Ministry of Science and the Arts.
Supplemental Material
Supplemental material for this article is available online.
Note
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.