
Abstract
In the present study, 48 native speakers of Swedish and 46 Finnish-speaking learners of Swedish read sentence preambles with or without grammatical gender cues to an upcoming picture/noun, and named the picture in Swedish as fast as possible. The study investigated whether facilitation from the gender cues, in terms of faster naming latencies to the nouns, was modulated by markedness and the number of gender cues. In both groups, facilitation only emerged for nouns of the marked gender (neuters) and only after preambles with two gender cues, suggesting that both groups showed similar sensitivity to markedness and to the number of gender cues. This was the case, despite the learners’ first language (L1) Finnish lacking grammatical gender. These results appear more in line with proposals which assume that anticipatory mechanisms are similar and are modulated by similar factors in the L1 and the second language (L2).
Keywords
I Introduction
Research in second language (L2) processing is concerned with whether adult L2 learners use similar processing mechanisms as native (L1) speakers while parsing the L2 input (e.g. Clahsen and Felser, 2006, 2018; Hopp, 2022; Kaan, 2014). For example, L1 speakers rely to some extent on prediction, which broadly refers to a process by which the available context facilitates the processing of upcoming information ahead of the bottom-up input (for reviews, see Kuperberg and Jaeger, 2016; Pickering and Gambi, 2018). In the L2 literature, evidence has been provided that L2 processing, too, is sometimes predictive, although L2 learners are more variable than L1 speakers in their recruitment of anticipatory strategies (for reviews, see Kaan, 2014; Kaan and Grüter, 2021; Schlenter, 2022). To account for this variability, Grüter and colleagues have proposed that the ability to predict or the utility of prediction is reduced in the L2 (e.g. Grüter and Rohde, 2021; Grüter et al., 2012; Kaan and Grüter, 2021). They argue that predictive cues have lower reliability in the L2, compared to the L1, due to cross-linguistic differences and differences between L1 and L2 acquisition. For example, when the predictive cue is absent or realized differently in the L1, L2 learners might weigh its predictive strength differently from L1 speakers. Alternatively, Kaan (2014) has proposed that predictive processing is similar and is impacted by similar factors in the L1 and the L2, such as the accuracy and quality of lexical representations, individual differences in cognitive factors (for a detailed account, see Kaan, 2014), and factors that are unique to the L2 (e.g. cross-linguistic differences, proficiency). In their state-of-the-art review, Kaan and Grüter (2021) called for more research aimed at identifying sources of variability in L1 and L2 predictive processing. This is one of the goals of the present study, which investigates the extent to which L1 speakers of Swedish and advanced L2 learners of Swedish with Finnish as their L1 use grammatical gender cues to speed up lexical access. Specifically, our study examines the extent to which the facilitative use of gender is modulated by factors related to the L2 grammar and input, such as morphological markedness and the number of gender cues.
1 The acquisition and processing of gender
The acquisition and processing of grammatical gender has been extensively examined in the L2 literature (e.g. Franceschina, 2005; White et al., 2004). Much of this research aimed to adjudicate between representational and computational accounts of variability. The former argue that L2 learners cannot create native-like representations of L2 features that are absent in the L1 due to maturation (e.g. Hawkins, 2009; Hawkins and Chan, 1997; Tsimpli and Dimitrakopoulou, 2007), while the latter posit that learners can come to represent gender like native speakers regardless of the properties of their L1, but have difficulty accessing those representations in real-time due to computational pressure, for example in online production (e.g. Montrul et al., 2008; Prévost and White, 2000; White, 2011) or online comprehension (e.g. Grüter et al., 2012; Hopp, 2010). Although this debate is not settled, the evidence suggests that, in offline tasks, advanced L2 learners can reach native-like levels of accuracy in syntactic gender agreement (i.e. the operation by which a noun’s gender is marked in words such as articles and adjectives), even when their L1 is [–gender] (e.g. Grüter et al., 2012; López-Prego and Gabriele, 2014; White et al., 2004). In production, however, learners continue to show variability at the upper levels of proficiency, although their errors mainly reveal difficulty with lexical gender assignment (i.e. the assignment of nouns to their gender classes), especially with nouns that lack distributional cues to gender (e.g. Grüter et al., 2012; McCarthy, 2008; Montrul et al., 2008). Previous studies have also observed that learners’ errors often reflect the markedness asymmetries inherent to the L2 gender system (e.g. McCarthy, 2008; White et al., 2004). In these studies, markedness is defined in terms of hierarchical feature geometries. Under this approach, the different values of a feature are asymmetrically represented (Harley and Ritter, 2002). For example, in Spanish, masculine is the underspecified or default gender, as it only entails the presence of gender. In contrast, feminine is specified or marked, as it entails the presence of both gender and the value ‘feminine’. This explains why masculine inflection is sometimes compatible with feminine nouns, but the reverse is not true, as in el valle y la pradera son hermosos/*hermosas (‘the valley-MASC and the prairie-FEM are beautiful-MASC.PL/*-FEM.PL’). 1 In a study investigating morphological variability, McCarthy (2008) found that intermediate and advanced L1-English learners of Spanish overextended masculine to feminine contexts, but rarely did the reverse, suggesting that learners have difficulty acquiring the full specification of features. Finally, some studies have shown that intermediate and advanced learners display native-like processing for gender violations online, even when their L1 is [–gender] (e.g. Alemán Bañón et al., 2014, 2017, 2018; Foucart and Frenck-Mestre, 2011; Gillon-Dowens et al., 2010) and even in non-local domains (e.g. Alemán Bañón et al., 2014, 2017, 2018), although this depends on the transparency of the gender system (e.g. Alemán Bañón et al., 2018).
2 The facilitative use of gender in the L2
Another line of research has investigated how L2 learners exploit gender cues in comprehension and production. In some of these studies, gender cues make the upcoming noun’s gender predictable, which then facilitates the noun’s retrieval from the lexicon (e.g. Guillelmon and Grosjean, 2001; López-Prego, 2015; Montrul et al., 2014). In others, the gender cues allow the parser to select a specific noun from a reduced set of pictures (e.g. Dussias et al., 2013; Fowler and Jackson, 2017; Grüter et al., 2012; Hopp, 2013; Hopp and Lemmerth, 2018; Johannessen et al., 2024). In both cases, gender cues carry predictive value, although the activated representation (i.e. what is predicted) might differ.
In a study using a word repetition task, Guillelmon and Grosjean (2001) found that both L1-French speakers and early English–French bilinguals repeated nouns faster following a gender-informative article, compared to a gender-uninformative pronoun (e.g. le/leur joli bateau ‘the-MASC/their beautiful ship-MASC’), suggesting that gender cues facilitated lexical retrieval. In contrast, a group of proficient late L2 learners showed no facilitation from gender-marked articles, which the authors attributed to their late age of acquisition (see also Montrul et al., 2014).
In a related study using the Visual World Paradigm (VWP), Grüter et al. (2012) found that high-proficiency English-speaking learners of Spanish made gender assignment errors in production and did not use gender-marked articles to predict familiar nouns in online comprehension, despite the fact that their accuracy with gender agreement offline was native-like. The authors proposed that L2 learners establish weaker links between abstract gender nodes and nouns due to differences between L1 and L2 acquisition. As a result, learners have difficulty retrieving lexical gender online and are less likely to use gender predictively. A subsequent VWP study by Hopp (2013) provided evidence in line with Grüter et al.’s (2012) proposal, which he dubbed the Lexical Gender Learning hypothesis. In Hopp’s study, L1-English learners of German with near-perfect gender assignment in production used gender-marked articles predictively to the same extent as L1-German speakers. In contrast, learners with variable gender assignment did not, suggesting that the ability to use gender predictively is linked to the robustness of the L2 learner’s lexical gender representations. Finally, while all of the above studies tested learners whose L1 is English, a [–gender] language, other studies have directly investigated how L1–L2 similarity modulates the predictive use of gender. These studies found that L2 learners are more likely to use gender predictively when the L1 is [+gender] (e.g. Dussias et al., 2013; Johannessen et al., 2024). When both the L1 and the L2 instantiate gender, learners are more likely to use gender predictively if the cue is realized in a syntactic context where both languages mark gender, especially for nouns with the same gender value in the L1 and the L2 (e.g. Hopp and Lemmerth, 2018; but see Johannessen et al., 2024), although this depends on the learners’ proficiency (e.g. Dussias et al., 2013; Hopp and Lemmerth, 2018).
3 Markedness and the number of cues
Only a few studies have explored how the facilitative use of gender is modulated by factors inherent to the L2 grammar and input, such as markedness (López-Prego, 2015) and the amount of gender cues (Fowler and Jackson, 2017; Garrido-Pozú, 2022), which are the focus of the present study. With respect to markedness, it has been argued that marked/specified features are more informative to the parser and are thus maintained longer in the focus of attention (Wagers and McElree, 2022). In turn, this may confer marked features greater predictive strength (Alemán Bañón and Rothman, 2019; Nevins et al., 2007; Wagers et al., 2009). The idea is that, upon encountering the marked gender, the feature becomes activated and the parser can use it predictively. Underspecified features, however, are less visible to the parser, as they do not activate a feature. This proposal aligns well with current claims that predictive cues vary in their reliability and, therefore, in their utility (Kuperberg and Jaeger, 2016), although these two literatures have developed independently. For example, in Spanish, cues of the underspecified/masculine gender do not always reliably predict that only masculine nouns will follow. In coordination structures such as Quedaron destrozados tanto el coche como la casa (‘were destroyed-MASC.PL both the car-MASC and the house-FEM’), the masculine adjective destrozados can be followed by nouns of both genders. In contrast, the specified/feminine counterpart Quedaron destrozadas tanto . . . reliably predicts that only feminine nouns are upcoming.
To our knowledge, only the self-paced reading study by López-Prego (2015) has examined this question among late L2 learners. López-Prego (2015) had L1-Spanish speakers and advanced L1-English–L2-Spanish learners read grammatical sentences that involved long-distance adjective–noun gender agreement for comprehension. In the relevant conditions, shown in (1), the adjective was either overtly inflected for feminine (i.e. marked) or invariant for gender.
(1) a. Como es As it is new-FEM I have decided that I’ll wear the-FEM blouse-FEM that I bought in Paris. b. Como es As it is green I have decided that I’ll wear the-FEM blouse-FEM that I bought in Paris.
López-Prego’s results revealed that both the L1-Spanish speakers and the L1-English learners read the complementizer following the target noun (blusa) faster when the preceding adjective carried overt feminine inflection (nuev
Brouwer et al. (2017) also found facilitation for nouns of the marked gender among children learning L1 Dutch, a language with a common/neuter gender distinction, neuter being the marked gender. In a VWP experiment, children with consistent gender assignment in a production task used gender-marked articles predictively, while children with inconsistent gender assignment did not. Nevertheless, both groups of children processed neuter nouns faster in contexts with informative neuter cues, suggesting that they made use of marked cues facilitatively.
Finally, it remains unclear whether additional gender cues modulate the facilitative use of gender. Outside of the domain of gender, there is evidence that both L1 speakers and advanced L2 learners generate morphosyntactic predictions faster and more accurately when redundant cues from different linguistic domains (e.g. case and prosody) are available (e.g. Henry et al., 2017, 2022). It is, therefore, possible that redundant gender cues will be beneficial, since they reinforce an interpretation that a noun of a given gender is upcoming. This is important, since learners otherwise tend to allocate less weight to morphosyntactic than semantic cues, especially when morphosyntactic cues are absent in the L1 (e.g. Grüter et al., 2020; Hopp, 2015). In addition, additional gender cues have been found to help learners with gender assignment (Fowler and Jackson, 2017) and agreement (Garrido-Pozú, 2022). For example, using a picture naming task embedded in sentences, Fowler and Jackson (2017) found that L1-English learners of L2 German named primed nouns faster in gender-informative vs. gender-uninformative trials when the primes included two gender cues (e.g.
In sum, previous research suggests that gender cues facilitate lexical retrieval among L2 learners, contingent on the robustness of the learners’ gender assignment accuracy (e.g. Hopp, 2013), L1–L2 similarity, and proficiency (Dussias et al., 2013; Hopp and Lemmerth, 2018; Johannessen et al., 2024). The extent to which markedness and the number of gender cues facilitate lexical retrieval remains an open question, although evidence has been provided that (1) marked gender cues facilitate the checking of gender features (López-Prego, 2015) and (2) learners assign nouns to their gender classes more efficiently when two cues are available, compared to just one (Fowler and Jackson, 2017). We contribute to this line of research with a study investigating the extent to which gender cues facilitate lexical retrieval among L1 speakers of Swedish and advanced Finnish-speaking learners of Swedish. Specifically, our study examines how markedness and the number of gender cues facilitate lexical retrieval. Similar to previous L2 studies, we define markedness theoretically, in terms of feature hierarchies (e.g. López-Prego, 2015; McCarthy, 2008). Two aspects of the specific L1–L2 combination examined here are particularly relevant relative to the previous literature. First, the learners’ L1, Finnish, lacks gender but it is an inflectionally rich language that expresses most grammatical relations via suffixation, which is how Swedish marks gender. This is important, since native experience with an inflectionally rich language has been argued to facilitate gender-based predictions, at least among balanced early bilinguals (Molinaro et al., 2017).
2
In addition, the learners’ L2, Swedish, provides orthographic evidence for the link between gender nodes and nouns, since definite articles in Swedish are sometimes suffixed to the noun (en bok ‘a-COM book-COM’, bok-en, ‘book-DEF.COM’, ‘the book’;
II The Swedish gender system
Swedish nouns are classified as common or neuter. Some semantic regularities exist (e.g. most animate nouns are of common gender), but there are numerous exceptions (e.g. vittne ‘witness-NEU’). Additionally, most nouns are phonologically opaque for gender (Andersson, 1992). This makes the acquisition of Swedish gender particularly challenging for L2 learners.
Swedish nouns trigger gender agreement on a number of syntactic categories, including articles and adjectives, as shown in (2). Adjectives agreeing with common singular nouns are uninflected (with only a few exceptions), whereas neuter adjectives are inflected with -t/-tt (compare 2a to 2b).
(2) a. En gul bil a-COM yellow-COM car-COM ‘A yellow car’ b. Ett gult hus a-NEU yellow-NEU house-NEU ‘A yellow house’
Common is the default or underspecified gender, while neuter is marked/specified (Josefsson, 2006). Evidence for this comes from agreement with personal pronouns. For example, the sentences in (3) show that right-dislocated NPs agree in gender with the preceding pronoun and adjective: (3) a. it-COM is late-COM, bus-DEF.COM ‘It is late, the bus’ b. it-NEU
is late-NEU, train-DEF.NEU ‘It is late, the train’
In contrast, personal pronouns such as han/hon ‘he/she’ are compatible with right-dislocated nouns of both genders, as shown in (4), suggesting that they lack a grammatical gender feature. Importantly, those same personal pronouns trigger common inflection on agreeing adjectives (sen ‘late’), as expected if common is underspecified for gender.
3
(4) a. he/she was late-COM the-DEF.COM stupid donkey-DEF.COM ‘He/she was late, the stupid donkey.’ b. he/she was late-COM the-DEF.NEU stupid cow-DEF.NEU ‘He/she was late, the stupid cow.’
The markedness asymmetry is also reflected in the fact that neuter forms are built on common forms (e.g. gul/gul-t ‘yellow-COM/-NEU’) and in the fact that neuter nouns account for only 20%–25% of the lexicon (Andersson, 1992). This is important for the purposes of the present study, since it suggests that, in comprehension, cues of the marked gender (i.e. neuter) are orthographically and phonologically more salient (Battistella, 1990) and allow the parser to delimit the lexical search to a larger extent.
Some adjectives are invariable for gender, as shown in (5). In addition, adjectives in definite phrases, such as genitive phrases, are inflected for definiteness with the suffix -a (or -e), but not for gender. The examples in (6) show a genitive phrase headed by the referential possessive pronoun hans ‘his’, which also lacks grammatical gender. The fact that different adjectives and syntactic configurations vary in informativeness with respect to a given noun’s gender allows us to compare lexical retrieval in contexts that provide no gender cues (as in 6) to contexts that provide one or two gender cues (as in 5 and 2, respectively).
(5) En annorlunda bil och ett annorlunda hus a-COM different car-COM and a-NEU different house-NEU ‘A different car and a different house’ (6) a. Hans gula bil His yellow-DEF car-COM b. Hans gula hus His yellow-DEF house-NEU
III The present study
The present study uses a Picture Naming Task to investigate the extent to which grammatical gender cues facilitate lexical retrieval among L1-Swedish speakers and advanced Finnish-speaking learners of Swedish. Participants read grammatical sentences ending in a picture, and named the picture as fast as possible. We examined whether gender cues shortened naming latencies to the noun, by using preambles with or without cues to the gender of the upcoming noun. We used both common and neuter nouns in order to explore the role of markedness. Furthermore, the number of informative cues was manipulated in two separate experiments. Importantly, our learners’ L1 lacks grammatical gender and articles altogether. Since articles are considered to be the morphological exponence of abstract gender nodes (Grüter et al., 2012), this might cause difficulties for the L2 learners (Hopp and Lemmerth, 2018; Ionin et al., 2008). Simultaneously, however, Finnish inflection is rich and informative about various grammatical relations, such as case and number (Stolt et al., 2009), which might make L1-Finnish learners more attuned to gender inflection in Swedish. Below are our research questions and predictions.
Research question 1: Do gender cues facilitate naming times for native speakers and L2 learners of Swedish?
If so, L1-Swedish speakers should show faster naming times for nouns after informative vs. uninformative preambles (e.g. Guillelmon and Grosjean, 2001; Jacobsen, 1999; Wicha et al., 2005). If the L1-Finnish learners show a similar effect (even if Finnish is genderless), facilitation might be modulated by their overall lexical gender accuracy (i.e. their accuracy assigning all experimental nouns to their genders) (e.g. Grüter et al., 2012; Hopp, 2013). Alternatively, if learners weigh gender cues differently than L1-Swedish speakers because those cues are absent in their L1, they might show no or reduced facilitation from gender cues (e.g. Grüter and Rohde, 2021; Kaan and Grüter, 2021).
Research question 2: If facilitation emerges, to what extent is it modulated by markedness?
If marked/specified features carry more predictive strength than unmarked/underspecified ones due to feature activation, L1 speakers should show larger facilitation in contexts with neuter cues (Alemán Bañón and Rothman, 2019; Nevins et al., 2007; Wagers and McElree, 2022). As for the L2 learners, existing proposals about the role of prediction in the L2 have not focused on markedness. One possibility is that the L2 learners, too, will experience greater facilitation from neuter cues if prediction is modulated by similar linguistic factors in the L1 and the L2, as argued by Kaan (2014) (see also López-Prego, 2015). Alternatively, since learners can have difficulty acquiring the full specification of gender features, especially when their L1 is genderless (McCarthy, 2008), they might not show sensitivity to markedness.
Research question 3: To what extent is facilitation modulated by the number of gender cues?
It is possible that both L1 and L2 speakers will benefit from redundant gender cues, since they reinforce the expectation about the upcoming noun’s gender (Fowler and Jackson, 2017), thereby facilitating lexical access. Thus, facilitation is more likely to surface in trials containing two as opposed to one gender cue.
IV Methods
1 Participants
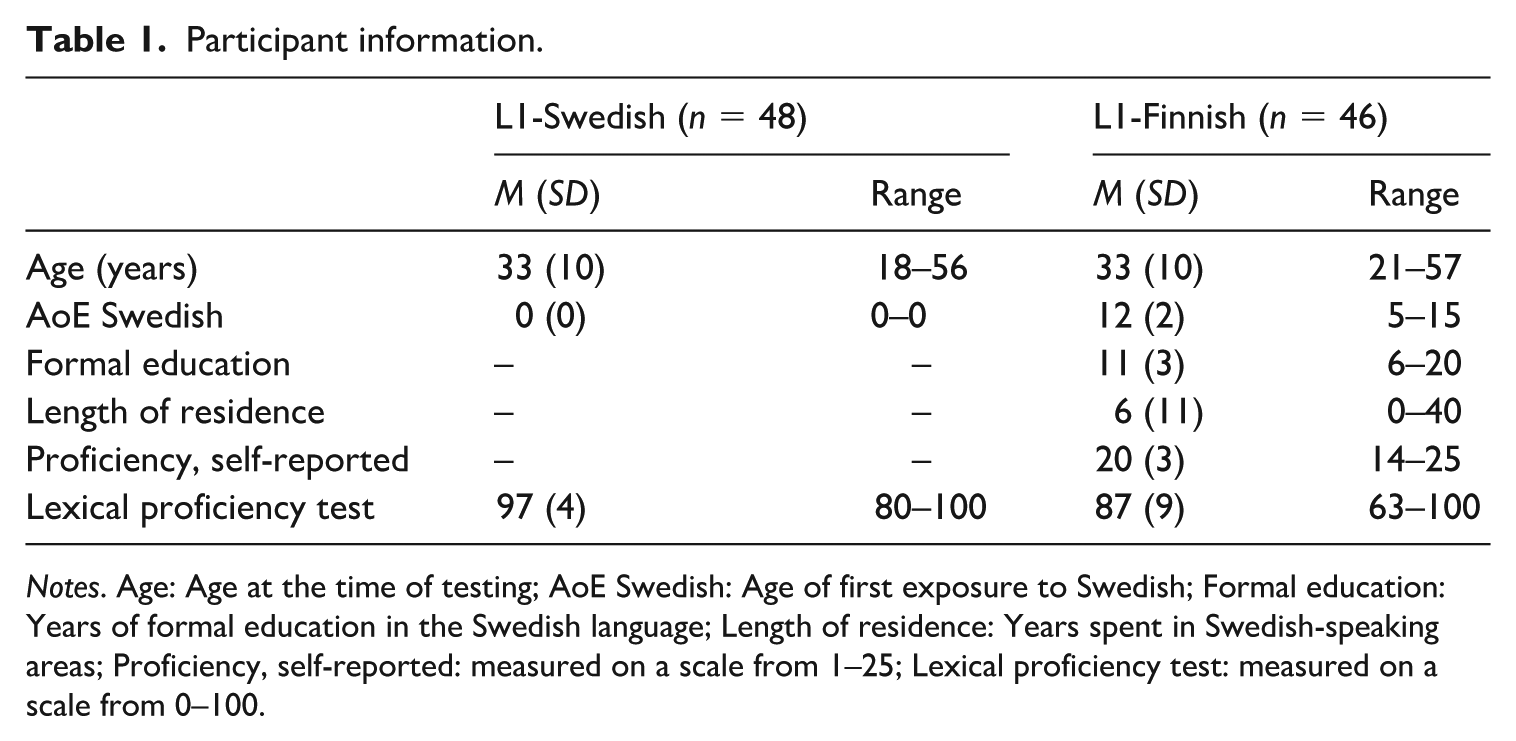
Forty-nine L1 speakers of Swedish (29 female) and 47 L1-Finnish–L2-Swedish learners (40 female) provided their informed written consent to participate in the study. Data from one participant from each group were lost due to technical failure during the recording. Table 1 outlines the biographical information of the participants included in the final analysis. All participants reported growing up in monolingual households without any early exposure to other languages. Based on the learners’ self-report and on the results of a Lexical Proficiency Test modeled after the LexTALE (Lemhöfer and Broersma, 2012; see Covey et al., 2018), the L2 learners’ proficiency in Swedish was considered to be advanced, although the sample includes intermediate proficiency learners. Five L1-Finnish learners were first exposed to Swedish around age 5 years, but none of these learners considered themselves native speakers of Swedish (see Peters et al., 2018). The rest started acquiring Swedish between the ages of 9–15 years. Although some learners were exposed to Swedish relatively early, it is still significantly later than the age by which Swedish children acquire gender, at around age 2 years (e.g. Andersson, 1992; Bohnacker, 2003). All learners started acquiring Swedish in a formal setting. Fourteen of the Finnish-speaking learners had never lived in a Swedish-speaking area. Participants were compensated for their time.
Participant information.
Notes. Age: Age at the time of testing; AoE Swedish: Age of first exposure to Swedish; Formal education: Years of formal education in the Swedish language; Length of residence: Years spent in Swedish-speaking areas; Proficiency, self-reported: measured on a scale from 1–25; Lexical proficiency test: measured on a scale from 0–100.
2 Picture naming task
Figure 1 provides a schematic of the picture naming task. We start by describing the properties of the pictures/nouns and we then describe the properties of the preambles, which represents the order in which we built the materials.
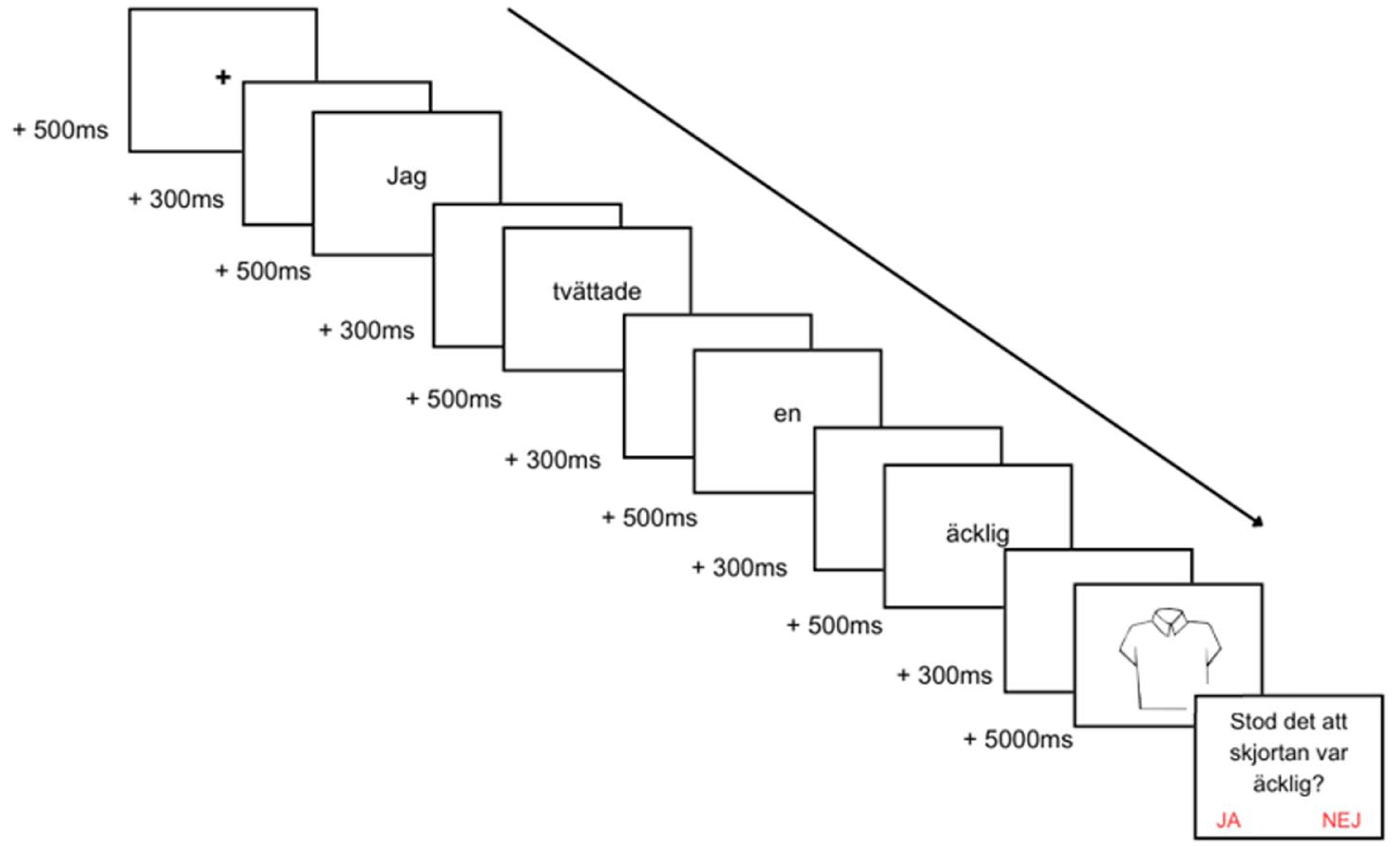
Stimulus presentation.
a Target pictures/nouns and Picture Norming Study
One hundred and twenty images depicting concrete objects/entities were chosen for the study (60 common nouns, 60 neuters) based on a separate Picture Norming Study conducted offline with a different group of 30 L1-Swedish speakers (Mage = 31; SD = 9). Only pictures for which > 75% of participants provided the intended noun were chosen for the experimental materials. As Table 2 shows, mean name agreement was very high (i.e. > 94%) for both common and neuter nouns. We prioritized high-frequency nouns that would be familiar to the L2 speakers and we excluded compounds, since Swedish compounds can provide conflicting cues for gender (e.g. blåbär ‘blueberry’ includes the neuter noun bär ‘berry’ and the adjective blå ‘blue’ in the default/common form).
Lexical properties of the nouns.
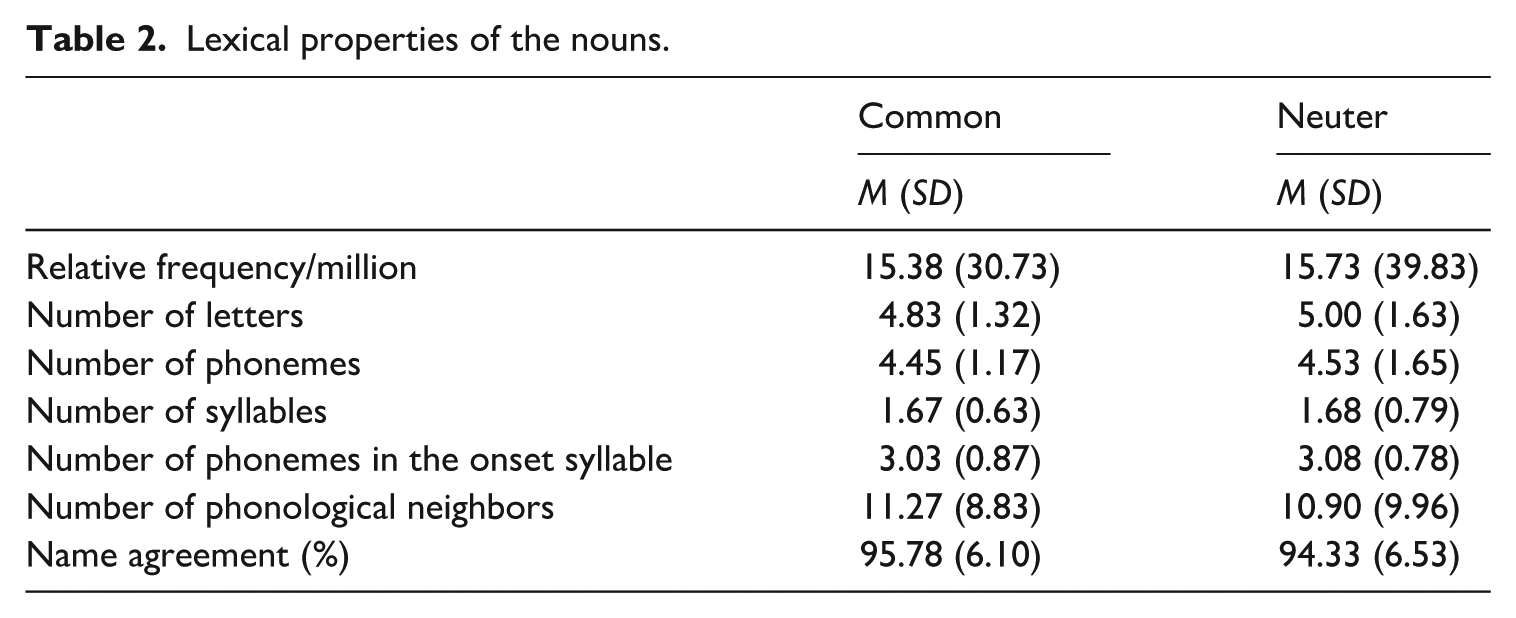
The common and neuter nouns were matched for lexical frequency, according to the Korp corpus (Borin et al., 2012). We also used the Swedish Word Metrics website (Witte and Köbler, 2019) to match the nouns with respect to number of letters, phonemes, syllables, and phonological neighbors. The common and neuter nouns were also matched with respect to the number of phonemes in the onset syllable.
b Sentence preambles
We created the preambles based on the selection of the pictures/nouns. Crucially, the preambles were always grammatical and they were manipulated for informativeness (informative vs. uninformative) and number of informative cues (one vs. two). Table 3 shows the resulting eight experimental conditions.
Experimental condition samples.
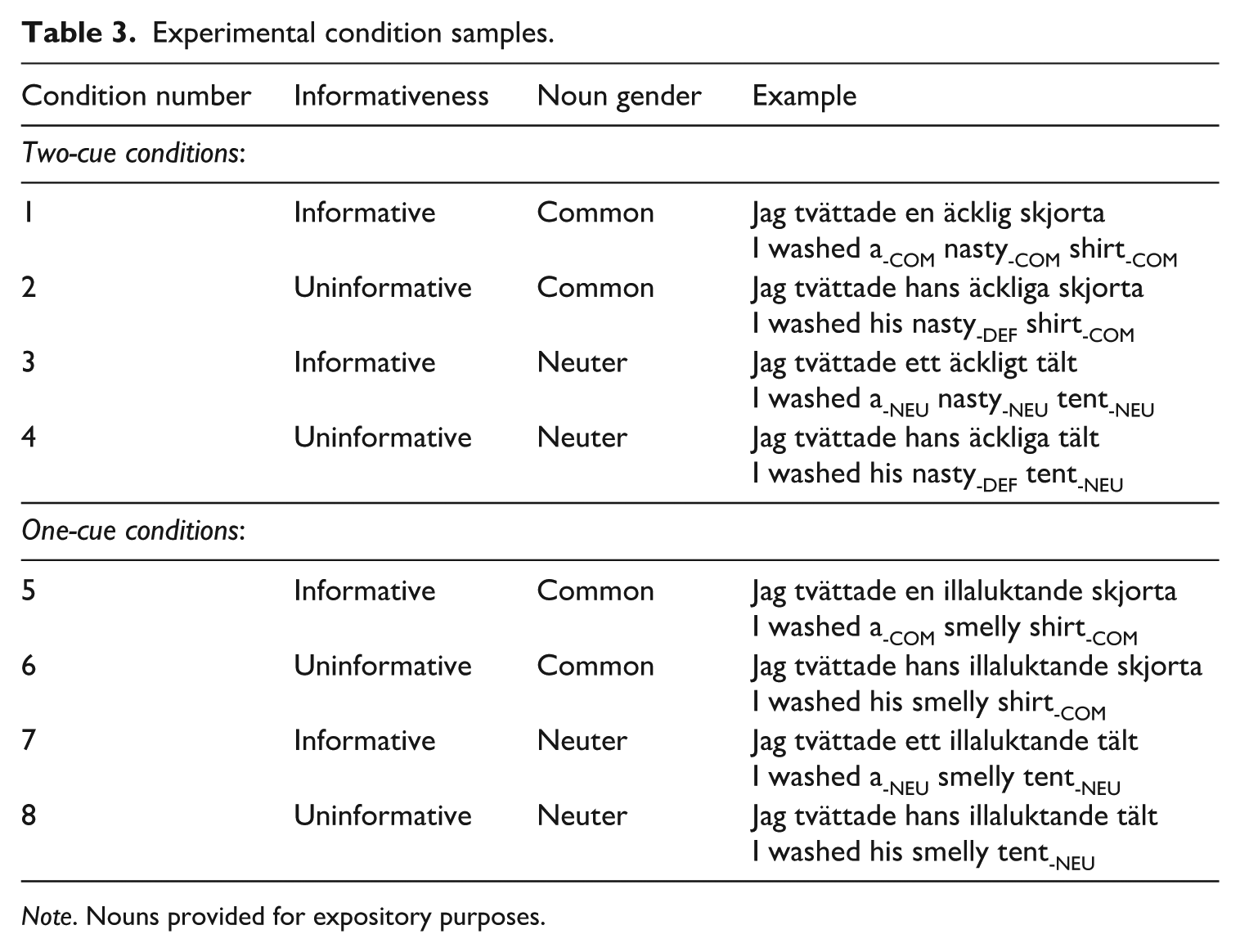
Note. Nouns provided for expository purposes.
Conditions 1–4 examine facilitation for common and neuter nouns in preambles including two gender cues. In conditions 1 and 3, there are two gender cues, one on the indefinite article (en vs. ett) and one on the adjective (äcklig vs. äcklig
Each noun appeared in four different preambles (see conditions 1–2 and 5–6; conditions 3–4 and 7–8), which resulted in 120 quadruplets of items. Items were rotated across four different lists using a Latin-square design, so that each list only included one version of each quadruplet. Across participants, all nouns appeared in all four conditions of its corresponding gender. Each list contained 15 items per condition, and 60 fillers (described below).
c Cloze probability rating
All sentence preambles were rated for cloze probability, to ensure that the target nouns were not predictable based on cloze probability alone. Forty L1-Swedish speakers who did not participate in the Picture Naming Task (10/list; Mage = 34, SD = 8) read the preambles and provided the first noun that came to mind that they thought best completed the sentence. Mean cloze probability of the nouns was low across all eight conditions (M ⩽ 4%, range: 1% to 4 %), suggesting that the target nouns were not predictable. Crucially, after informative frames, the probability of participants providing a noun of the target gender was 100%, meaning that the gender of the upcoming noun was predictable based on the gender cues. After uninformative frames, the proportion of responses with common and neuter nouns mirrored the distribution of the two genders in the Swedish lexicon: 75% of answers involved common nouns and the remaining 25% neuters.
d Comprehension questions
Each item was followed by a comprehension yes/no question in order to keep participants on task. The questions targeted the truth values of the sentences, as shown in (7–8), which show the questions for the sample items in Table 3. This required that participants pay attention to the adjectives (7) or the possessives (8) in the sentences, even though no explicit information was provided to them about these categories or about the gender cues. The same comprehension question was used for each of the quadruplets (see Table 3) and the number of yes and no answers was equal in all four lists.
(7) Stod det att skjortan var äcklig? ‘Was the shirt nasty?’ (8) Stod det att tältet tillhörde Peter? ‘Did the tent belong to Peter?’
e Fillers
Sixty filler items (30 with common nouns, 30 with neuters) were added following the same format as the experimental materials. Some of the fillers included the first-person singular possessive pronoun (min-COM, mitt-NEU). The number of gender cues for common and neuter was balanced. None of the filler nouns were used in the experimental materials. In addition, the comprehension questions for the fillers sometimes targeted different parts of the sentence than those for the experimental trials (e.g. the first-person possessives, the nouns).
f Trial structure
Participants first saw a fixation cross for 500 ms. Then, the sentence was visually presented word by word (500 ms/word) with 300 ms blank screens in between (see Figure 1). Participants were instructed to read the preambles silently and name the picture aloud as quickly and accurately as possible. The image stayed on the screen for 5,000 ms and naming latencies were recorded. Participants then read and answered the comprehension question without a time constraint.
3 Gender assignment task (GAT)
We measured the participants’ knowledge of the target nouns’ gender with a GAT. Participants were presented with the 120 target nouns from the Picture Naming Task (60 neuters) in written form, and they selected the corresponding indefinite article (en/ett) with a mouse click. Presentation order was randomized and the task was untimed.
4 Procedure
Participants were tested individually in a quiet room. First, they filled out the consent form and a background questionnaire. They then completed the Picture Naming Task, which included eight practice rounds with feedback and eight without feedback. The whole task contained 180 trials, divided into six blocks with short breaks in between. The order of presentation was randomized for each participant. The Picture Naming Task was followed by the GAT. Then, participants completed the Lexical Proficiency Test. Finally, they took the GAT for a second time, with the same items.
5 Analysis
Sound files from the Picture Naming Task were transcribed and scored for accuracy. For all items named with the intended noun, naming latencies were obtained by analysing the spectrograms on Praat (Boersma and Weenink, 2022). Naming latencies were trimmed by participant by first removing all values below 500 ms (Levelt, 1999) or above 4,000 ms. This is considerably longer than, for example, the 1,300 ms cutoff point used by Fowler and Jackson (2017). However, we did not show the pictures to the participants beforehand. Thus, we allowed a longer time window that was still shorter than in previous picture-naming studies (Gollan et al., 2008). All values 2.5 SD over or below each participant’s mean were subsequently removed. This resulted in the removal of around 2.65% of the data. 4 Only nouns for which a participant had correctly assigned the target gender across both iterations of the GAT were included in the naming latencies analysis (for a comparable approach, see Hopp, 2013), which resulted in a loss of an additional 8.23 % of data. Thus, these analyses examine whether gender cues facilitate lexical retrieval when the cues are both objectively and subjectively informative for the L2 learners.
The analyses were conducted separately for the two-cue and one-cue conditions, as invariant adjectives, like those used in the one-cue conditions, have been found to cause processing difficulties for both L1 and L2 speakers, even more so than gender-mismatching adjectives in the case of L2 learners (López-Prego, 2015). For all analyses, we used mixed-effects models (Baayen et al., 2008) to analyse the naming latencies in R v.4.2.1 via the lme4 package (Bates et al., 2015). We obtained p-values via the lmerTest package (Kuznetsova et al., 2017), and ran multiple comparisons with the emmeans package (Lenth, 2022). For clarity of presentation, we describe the structure of the models before immediately reporting their results.
V Results
1 Gender assignment task (GAT)
Responses were considered accurate if they consistently followed objective gender assignment across both iterations of the GAT. Accuracy scores are presented in Table 4. L1-Swedish speakers scored at ceiling, while the L2 learners showed a wide range of accuracy scores, which includes 100% accuracy for all three measures. In addition, the L2 learners were significantly less accurate with neuter than common nouns, as determined by a two-tailed paired-samples t-test (t(45) = 5.90, p < .001, d = 0.87). A previous study by Johannessen et al. (2024) looking at a variety of L2 Norwegian with a common/neuter gender distinction also found that learners were significantly less accurate with neuters.
Experimental group results (accuracy) in the gender assignment task (GAT).
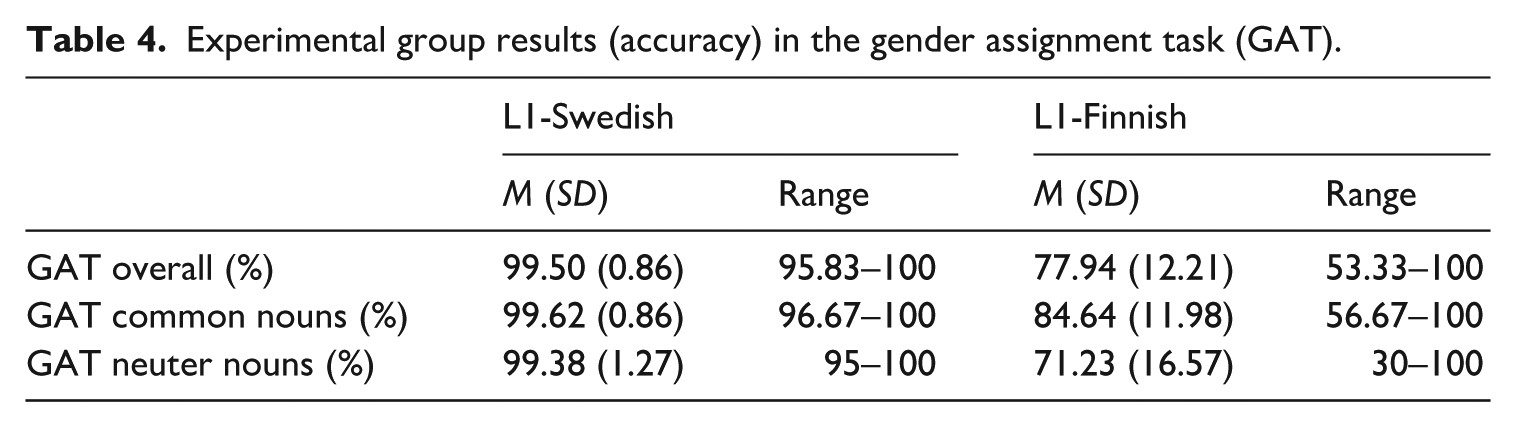
Participants completed both GATs after the Picture Naming Task, which did not include any gender violations. To rule out the possibility that the informative conditions in the Picture Naming Task boosted the learners’ accuracy in the GAT, a two-tailed paired-samples t-test was conducted to compare accuracy in the GAT with nouns encountered in informative vs. uninformative frames, but the difference was not significant, t(45) = −0.33, p = .743.
2 Picture naming task
Mean accuracy on the comprehension questions was high for both groups, suggesting that participants paid attention to the sentence preambles. The L1-Swedish speakers had a mean accuracy of 92% across the eight conditions (range of condition means = 90% to 95%). The L2 speakers displayed a mean accuracy of 89% (range of condition means = 88% to 93%).
a Two-cue conditions
Naming Latencies (ms) were log-transformed and entered as the dependent variable. Gender (−0.5 = Common; 0.5 = Neuter), Informativeness (−0.5 = Uninformative; 0.5 = Informative), and Group (−0.5 = Swedish; 0.5 = Finnish) were entered into the model as contrast-coded fixed effects, with a three-way interaction. The maximal random effects structure included random intercepts for subjects and items, by-subject random slopes for Gender and by-item random slopes for Group. The results are shown in Table 5.
Results from the two-cue conditions.
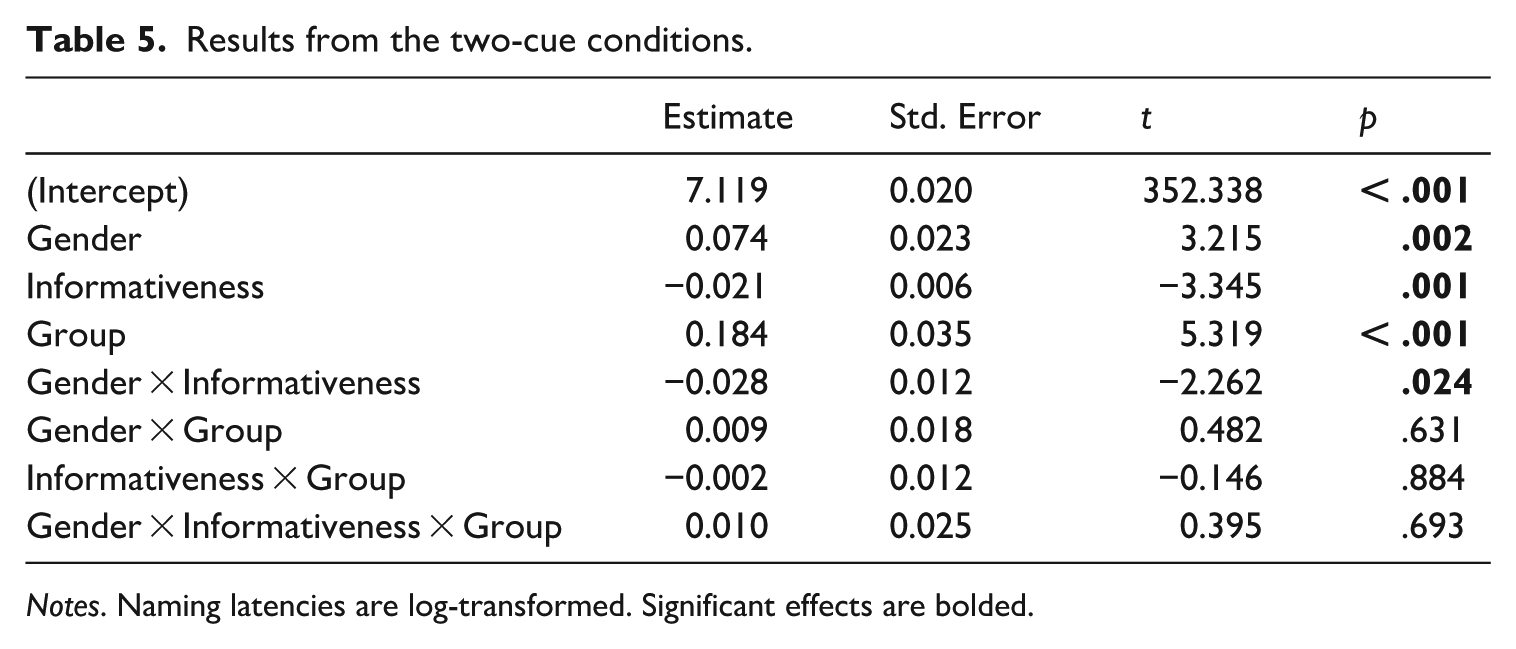
Notes. Naming latencies are log-transformed. Significant effects are bolded.
The results revealed a significant main effect of Gender, with common nouns being named faster than neuters (Common, M = 1,195 ms; SD = 393 ms; Neuter, M = 1,253 ms; SD = 384 ms, ηp2 = 0.291). 5 The main effect of Informativeness was significant, such that nouns in Informative frames were named faster than the same nouns in Uninformative frames (Informative, M = 1,210 ms; SD = 384 ms; Uninformative, M = 1,232 ms; SD = 396 ms, ηp2 = 0.063). The main effect of Group was significant, with L1-Swedish speakers naming nouns faster than L1-Finnish learners (L1-Swedish, M = 1,137 ms; SD = 294 ms; L1-Finnish, M = 1,345 ms; SD = 473 ms, ηp2 = 0.220). These effects are visible in Figure 2.
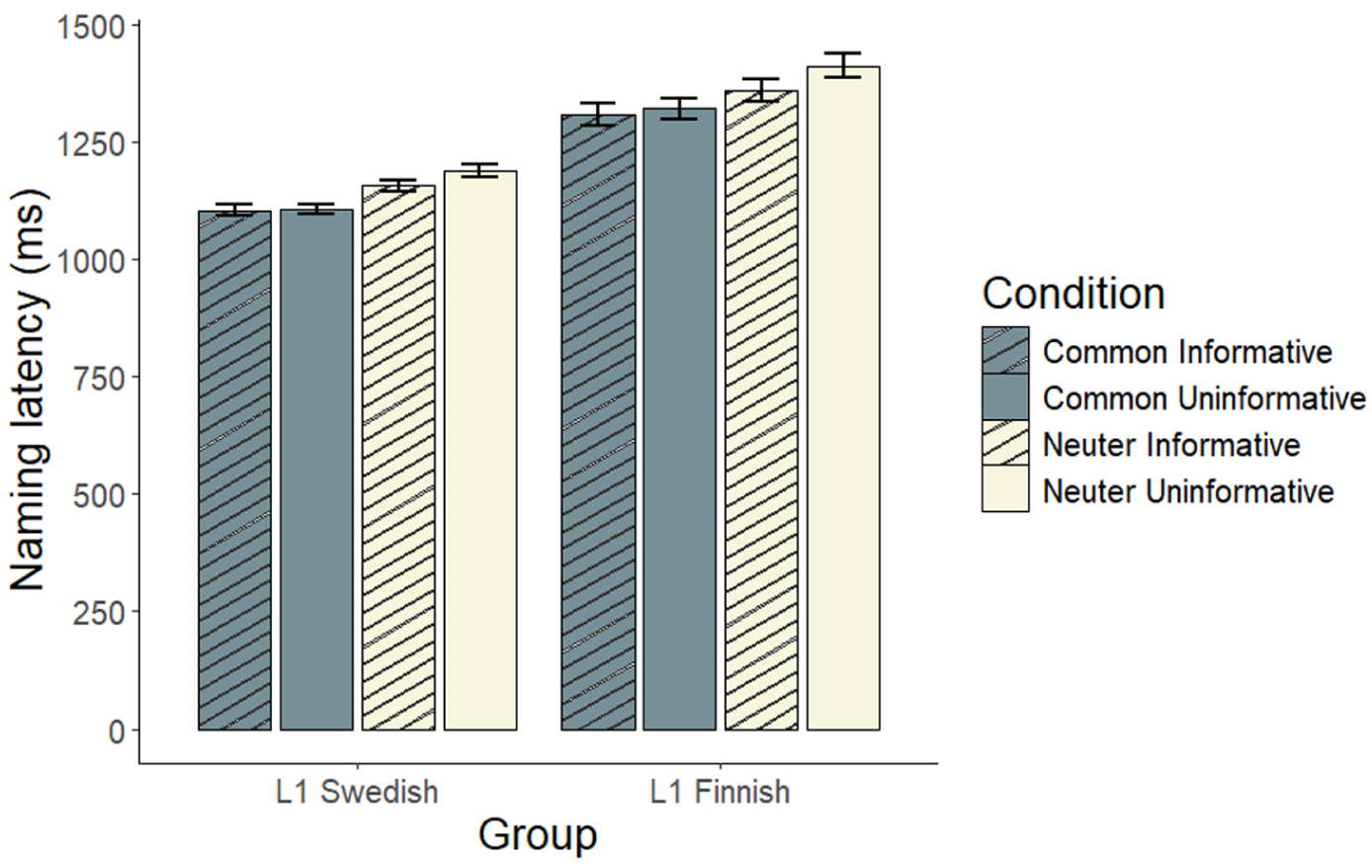
Naming latencies (ms) by Gender, Informativeness, and Group in the two-cue conditions.
Crucially, the Gender by Informativeness interaction was significant. We followed up on this interaction by examining the main effect of Informativeness separately for common and neuter nouns, across both groups. Bonferroni-corrected multiple comparisons revealed that the main effect of Informativeness was significant for neuters (Estimate = 0.035, SE = 0.009, p < .001, ηp2 = 0.042), with nouns being named faster in Informative (M = 1,233 ms; SD = 363 ms) than Uninformative frames (M = 1,275 ms; SD = 405 ms), but not for common nouns (Estimate = 0.007, SE = 0.008, p = .826). The relatively large standard deviations indicate considerable variability in naming times, most likely resulting from learners displaying higher variance. 6
b One-cue conditions
Log-transformed Naming Latencies were modeled as a function of Gender (−0.5 = Common; 0.5 = Neuter), Informativeness (−0.5 = Uninformative; 0.5 = Informative), Group (−0.5 = L1 Swedish; 0.5 = L1 Finnish), and their interaction. The model also included by-subject and by-item random intercepts, by-subject random slopes for Gender, and by-item random slopes for Group. These results are listed in Table 6.
Results from one-cue conditions.
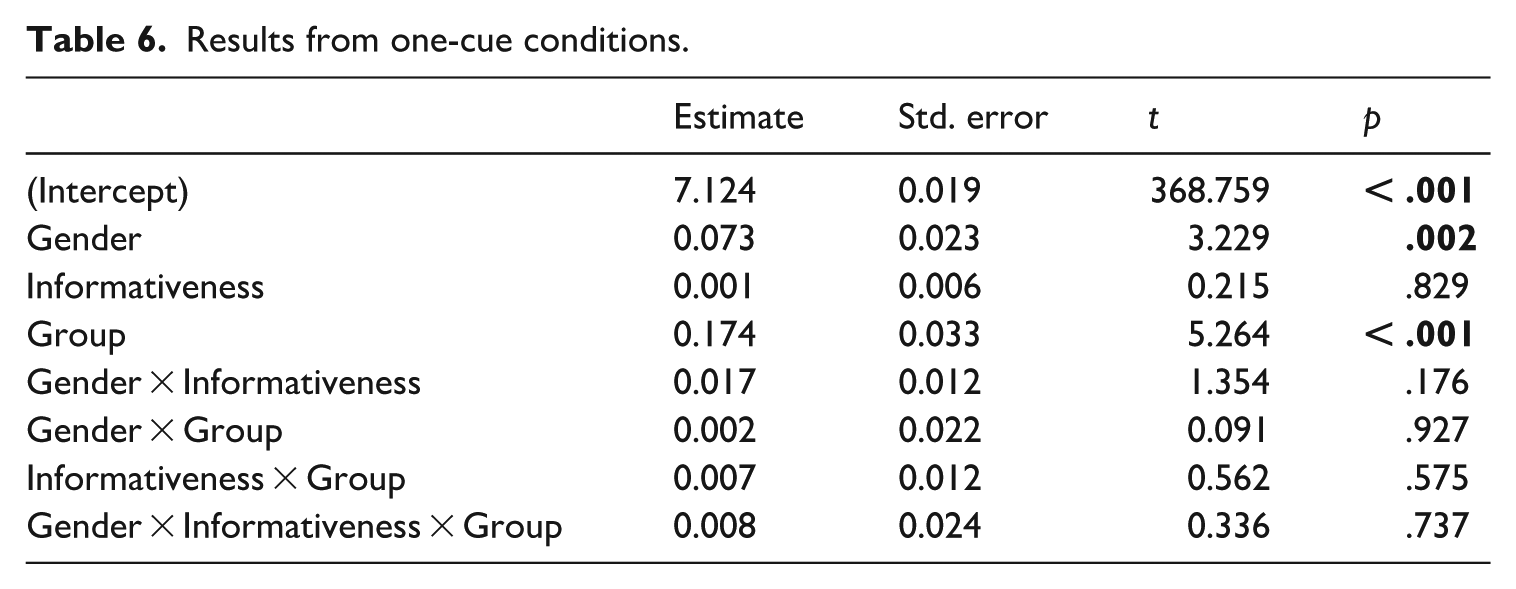
As in the two-cue conditions, the main effect of Gender was significant, with common nouns being named faster than neuters (Common M = 1197; SD = 368; Neuter, M = 1268; SD = 382, ηp2 = 0.172). The main effect of Group was also significant, with L1-Swedish speakers naming nouns faster than the L1-Finnish learners (L1-Swedish, M = 1150; SD = 294; L1-Finnish M = 1344; SD = 446, ηp2 = 0.211). These effects are illustrated in Figure 3. Unlike the two-cue conditions, the main effect of Informativeness was not significant, and neither were any of the interactions.
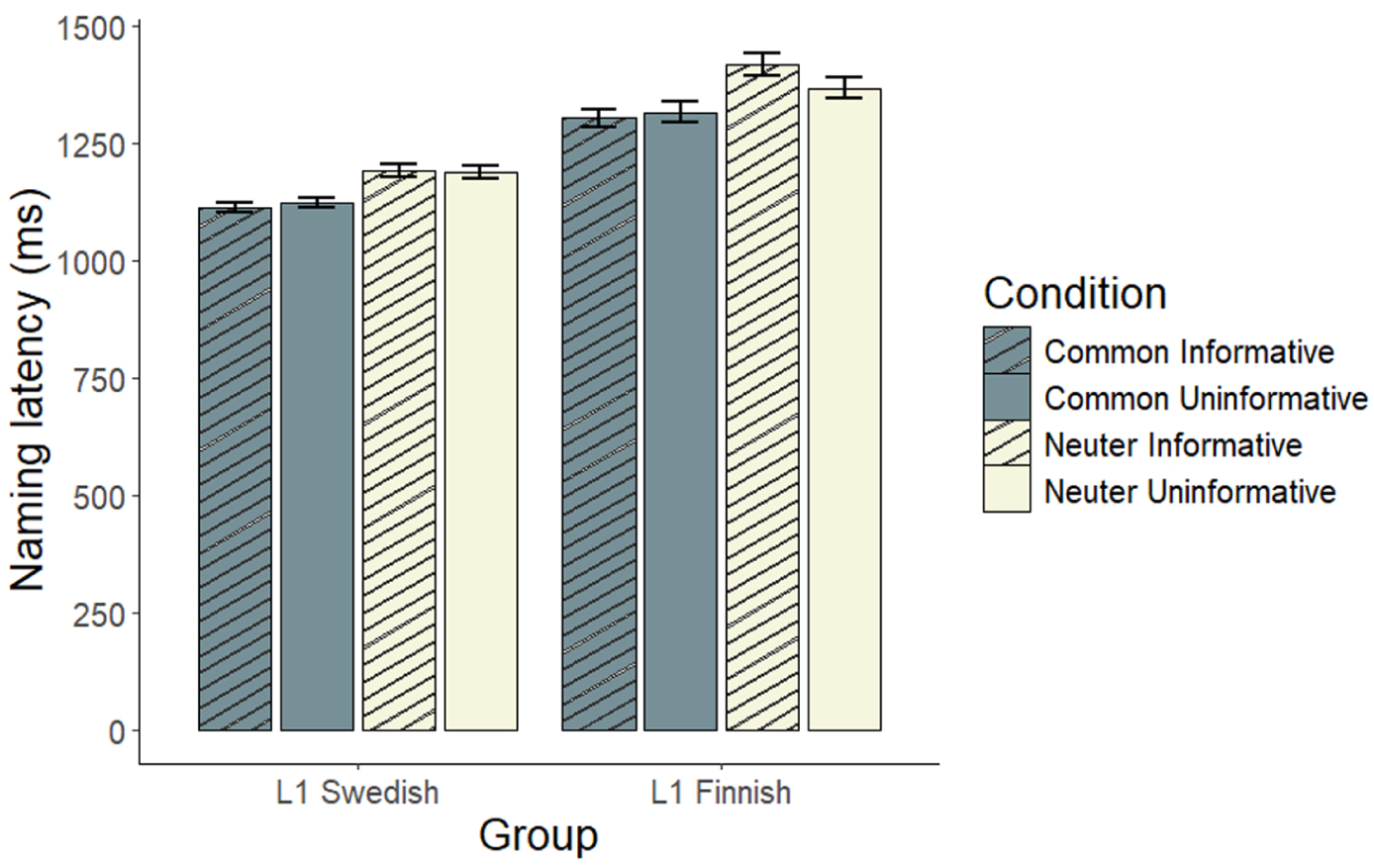
Naming latencies (ms) by Gender, Informativeness, and Group in the one-cue conditions.
3 Additional analyses
a Gender assignment task accuracy as a predictor
We ran additional analyses including only the learners, to explore whether overall lexical gender accuracy, operationalized as overall accuracy in the GAT (i.e. the first row in Table 4), modulated the facilitative use of gender, separately for the two- and one-cue conditions. In both models, Naming Latencies were modeled as a function of Gender (−0.5 = Common; 0.5 = Neuter), Informativeness (−0.5 = Uninformative; 0.5 = Informative), a centered continuous predictor measuring overall GAT accuracy, and their interaction. The models also included by-subject and by-item random intercepts. The model for the two-cue conditions converged with by-subject random slopes for Gender, and by-item random slopes for Informativeness, while the model for the one-cue conditions only converged with by-item random slopes for Informativeness. These results are summarized in Table 7. In neither of the models did GAT interact with any of the other fixed effects. In the two-cue conditions, the main effect of GAT was marginal such that higher accuracy with gender assignment reduced naming latencies overall.
Results from the analysis on the L2 data including gender assignment task accuracy as a predictor. The results from the two-cue conditions are presented first.
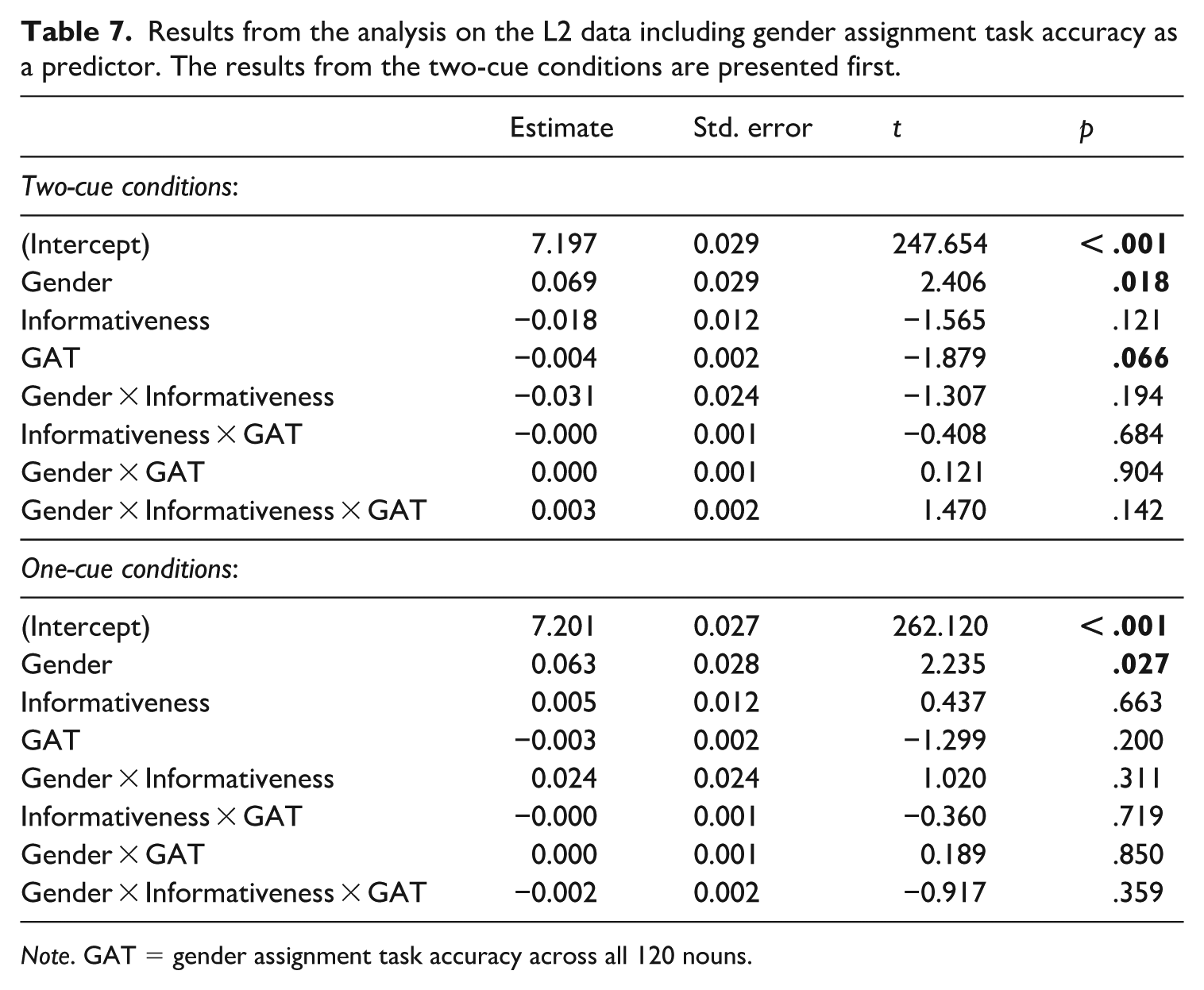
Note. GAT = gender assignment task accuracy across all 120 nouns.
b The effect of number of cues on neuter nouns
Since our results only revealed facilitation when the preambles contained two neuter cues, we ran an exploratory analysis to directly compare Naming Latencies in the one- and two-cue conditions for neuter nouns only. Here, Naming Latencies were modeled as a function of Informativeness (−0.5 = Uninformative; 0.5 = Informative), Group (−0.5 = L1 Swedish; 0.5 = L1 Finnish), and Experiment (−0.5 = One-cue conditions; 0.5 = Two-cue conditions), and their interaction. The models also included by-subject and by-item random intercepts, by-subject random slopes for Informativeness and by-item random slopes for Group. The model revealed a main effect of Group (Estimate = 0.177, SE = 0.034, p < .001) and Informativeness (Estimate = −0.013, SE = 0.006, p = .048). The main effect of Experiment was not significant (Estimate = −0.004, SE = 0.006, p = .543) but it interacted significantly with Informativeness (Estimate = −0.047, SE = 0.013, p < .001), such that after Informative preambles, nouns were named significantly faster in the two-cue than the one-cue conditions.
VI Discussion
The present study set out to examine whether gender cues facilitate lexical retrieval for L1-Swedish speakers and advanced L1-Finnish learners of L2 Swedish, and the extent to which markedness and the number of gender cues modulate this process. The study employed a Picture Naming Task in which participants read grammatical sentence preambles and named the picture at the end. Crucially, the preambles were manipulated for informativeness, whether the cues were for the marked or default gender, and the number of gender cues.
Beginning with the informativeness and markedness manipulations, we predicted that native speakers would name nouns faster when images were preceded by gender cues (e.g. Jacobsen, 1999; Wicha et al., 2005), and that this facilitation might be greater from neuter (marked) than common cues, based on proposals arguing that marked features have more predictive strength (Nevins et al., 2007; Wagers and McElree, 2022). We predicted that the L2 learners might also experience facilitation from gender cues, which might be modulated by their overall lexical gender accuracy, in line with proposals which identify lexical aspects of gender as the locus of L2 variability with gender (e.g. Grüter et al., 2012; Hopp, 2013; Prévost and White, 2000). We hypothesized that learners might also benefit more from neuter cues, based on Kaan’s (2014) proposal that similar factors impact anticipatory processing in the L1 and the L2, as well as previous findings (e.g. López-Prego, 2015). Alternatively, since our learners lack gender in their L1, they might not weigh gender cues similarly to native speakers, even though they otherwise possess native experience extracting relevant grammatical information from inflection via their L1, Finnish. Thus, if gender cues have reduced utility for them, they might show no or reduced facilitation (e.g. Grüter and Rohde, 2021; Kaan and Grüter, 2021). Below, we evaluate our results in light of research question 1 and research question 2.
Our results revealed that both the L1-Swedish speakers and the L2 learners named neuter nouns faster after preambles with two neuter cues, relative to the same nouns following preambles without gender cues. We observed no facilitation for common nouns, or for nouns of either gender with only one gender cue. These results are mostly in line with our predictions that native speakers and L2 learners use gender cues to facilitate lexical access, and that marked cues lead to greater facilitation. Interestingly, the learners’ global gender assignment accuracy, as determined by their overall score in the GAT, did not modulate the facilitative use of gender. This was true despite the fact that we only analysed nouns which learners had assigned to their correct gender (twice) in the GAT. These results contrast with those by Fowler and Jackson (2017, Experiment 1), who found that the predictive use of gender among L1-English–L2-German learners in a Picture Naming Task marginally increased as a function of their global lexical gender accuracy. Whether our results are inconsistent with the Lexical Gender Learning hypothesis (Grüter et al., 2012; Hopp, 2013) is less obvious, since that hypothesis posits a categorical rather than linear relationship between gender assignment accuracy and predictive behavior. For example, Hopp (2013) found that only L1-English learners of German with near-perfect gender assignment used gender-marked articles predictively in a VWP task. We evaluated this prediction in an additional analysis comparing learners whose overall accuracy in the GAT was either ⩾ 85% or < 85% (17 and 29 learners, respectively), but the facilitative use of gender did not differ between the two groups, either in the one-cue or in the two-cue conditions (available in the project’s OSF repository). 7
It is possible that facilitation was not modulated by global gender assignment accuracy in our study because we captured a different type of facilitation from the studies by Hopp (2013) and Fowler and Jackson (2017). In those studies, gender-marked articles made it possible to anticipate the upcoming noun ahead of the input, from a reduced set of two/four already activated candidates. In our experimental paradigm, however, gender-marked articles only made it possible to anticipate the upcoming noun’s gender, but not the noun itself. Thus, facilitation from gender cues in terms of faster lexical retrieval was only captured once the nouns/pictures became available in the input. With respect to the mechanisms underlying this process, we propose that our participants preactivated an abstract component of the lemma of a lexical entry, namely a gender node including the neuter feature, which in turn facilitated the retrieval of the noun from the mental lexicon for production. This is still consistent with Kuperberg and Jaeger’s (2016: 30) broad definition of prediction, according to which the information provided by the preceding context facilitates the processing of new input, but it might be different from the type of anticipatory processing probed in the studies by Grüter et al. (2012) or Hopp (2013). It is unclear why the robustness of lexical gender representations would not be predictive of the type of facilitation captured in the present study. Our results are, however, similar to those by Brouwer et al. (2017), who found that L1 Dutch children processed neuter nouns faster in contexts with gender-informative articles (in a VWP study), regardless of whether their lexical gender accuracy in production was target-like (⩾ 75%) or not (< 62.5%).
Our results are also in line with previous studies probing a similar type of gender-based facilitation, such as Guillelmon and Grosjean (2001), who found that L1-French speakers and early English–French bilinguals, but not late L2 learners, repeated nouns faster after gender-informative articles relative to gender-uninformative possessives. In our study, however, this effect also emerged for L2 learners. Montrul et al. (2014) also found that gender cues facilitated word repetition among L1-Spanish speakers and English-speaking learners of Spanish. However, this effect did not emerge when comparing informative vs. uninformative frames. It only emerged when comparing grammatical and ungrammatical frames, and only for nouns with transparent endings. With noncanonical nouns (comparable to the Swedish nouns we tested), the learners behaved differently from the L1 speakers. In the present study, we did not include any gender violations, since they might reduce the reliability of the gender cues and, thus, their utility within the experiment (Grüter and Rohde, 2021; Hopp, 2016; Kuperberg and Jaeger, 2016). Summing up, the preliminary answer to research question 1 ‘Do gender cues facilitate naming times for native speakers and L2 learners of Swedish?’ is ‘yes’. However, this process is modulated by markedness similarly for both L1 and L2 speakers, and facilitation emerged only with two cues.
Before moving on to research question 2, we address two potential concerns about our results. The first one is that the observed effect might not reflect facilitation from the gender cues but rather a cost in the uninformative condition. Since -a marks both definiteness (regardless of number) and plural on adjectives, it could be argued that learners named images more slowly in the uninformative condition because they were expecting the image to depict more than one item (hans äckliga . . . ‘his disgusting-PL . . .’), which was never the case. However, if so, similar effects should have emerged in all comparisons that involved conditions with definite adjectives vs. conditions with gender-inflected adjectives, which was not the case. In addition, participants were explicitly told that all images/nouns would be singular, which was reinforced during the practice.
The second one is that the relatively high proportion of informative trials in the experiment might have prompted participants to look for gender cues. To evaluate this possibility, we examined whether facilitation effects changed over the course of the experiment as participants accumulated exposure to gender-informative trials (i.e. whether there was adaptation). In this analysis (available in the project’s OSF repository), adaptation did not account for the Informativeness by Gender interaction in the two-cue conditions, suggesting that facilitation was not driven by strategic adaptation. Future studies could manipulate the proportion of informative trials (e.g. across blocks) to examine the impact of proportion on the facilitative use of gender cues (e.g. Alemán Bañón and Martin, 2024).
With respect to research question 2 ‘If facilitation emerges, to what extent is it modulated by markedness?’, we hypothesized that neuter cues might carry greater predictive strength, since common is underspecified for gender in Swedish (Josefsson, 2006). This prediction is informed by claims that marked feature values (like neuter in Swedish) are more visible to the parser, since they activate a feature, unlike underspecified values (e.g. Wagers and McElree, 2022). This proposal originated in the psycholinguistic literature on agreement (e.g. Nevins et al., 2007; Wagers and McElree, 2022), where it has been found that marked features are more likely to impact agreement operations. For example, there is abundant evidence that plural, which is marked for number, is more likely to cause agreement attraction than the underspecified singular (e.g. Wagers et al., 2009). Likewise, Alemán Bañón and Rothman (2019) found that L1-Spanish speakers were more sensitive to person agreement violations in Spanish when the subject was marked for person (i.e. first person), compared to when the subject was underspecified (i.e. third person). In the present study, we only obtained facilitation for neuter nouns across both L1 and L2 speakers, which is consistent with this proposal. Our results are in line with those by López-Prego (2015), who found that feminine gender cues (marked for gender in Spanish) facilitated feature checking to a larger extent than masculine cues for both L1 and L2 speakers. Our results are also similar to those by Brouwer et al. (2017) for L1-Dutch children, although those authors did not interpret the markedness effect in their results.
Other dimensions of markedness might have contributed to this effect, although our study cannot tease them apart. For example, since neuters only make up 25% of the lexicon, neuter cues might be more informative, since they delimit the lexical search to a larger extent than common cues. Thus, upon encountering neuter cues, participants might have preactivated a smaller set of candidates for production than they would have with common cues, which in turn might have facilitated lexical access. In fact, our Cloze probability rating revealed that, after uninformative preambles, around 75% of responses consisted of common nouns. Therefore, the benefit from common cues relative to the possessive hans might be negligible when it comes to lexical retrieval. In contrast, neuter cues provide a sizeable advantage over hans for predicting neuter nouns. In addition, as is typical of markedness asymmetries, neuter cues might be more salient than common cues, as they are orthographically and/or phonologically longer (en-COM konstig-COM vs. ett-NEU konstigt-NEU, ‘a strange . . .’). This might have made it easier for our participants to detect the neuter cues. Recall, however, that we measured naming latencies for the nouns, which were matched for several lexical properties, including lexical frequency and length (see Table 2).
The finding that gender-based facilitation, in terms of faster lexical retrieval, emerged across both groups aligns with claims that anticipatory mechanisms are similar in the L1 and the L2, such as Kaan (2014). The fact that this facilitation was modulated by markedness in both groups further supports Kaan’s (2014) proposal that similar factors modulate the recruitment of such mechanisms in the L1 and the L2. If marked cues carry greater utility than unmarked ones, these results are also consistent with current accounts highlighting the role of cue utility in predictive processing (Kaan and Grüter, 2021; Kuperberg and Jaeger, 2016). Whether our L2 learners showed the same facilitation as native speakers based on their native experience with an inflectionally rich language cannot be answered on the basis of these results alone, since we only tested one L2 group. We are currently testing learners of Swedish who are native speakers of English, a language that is similar to Finnish in that it lacks gender, but different in that it also lacks rich inflectional morphology.
Finally, research question 3 examined whether redundant gender cues modulate the facilitative use of gender. We hypothesized that facilitation would be more likely to emerge in the conditions containing two gender cues, for both groups. Previous research has demonstrated that both L1 and advanced L2 speakers benefit from redundant cues, even when the cues come from different linguistic domains (Henry et al., 2017, 2022). Moreover, since learners tend to assign less weight to morphosyntactic than to semantic cues (Grüter et al., 2021; Hopp, 2015), we reasoned that redundant gender cues might support lexical retrieval by reinforcing the expectation that a noun of a given gender will follow. In addition, previous studies have shown that providing learners with redundant gender cues improves gender assignment (e.g. Fowler and Jackson, 2017).
Our results revealed that both the L1 and the L2 speakers only displayed facilitation in the two-cue conditions, and only for neuter nouns. This was supported by a post-hoc analysis including only the neuter nouns, which revealed an interaction between informativeness and number of cues. Nevertheless, as Figure 3 clearly shows, the interaction is partly driven by the fact that the learners unexpectedly named neuter nouns more slowly after informative compared to uninformative preambles in the one-cue conditions, although this effect was not significant. It is possible that the learners treated the invariant adjectives in informative sentences as missing inflection, which could have yielded incongruity effects that spilled over to the noun. Since those adjectives form a reduced set, our learners might not have an accurate representation of which adjectives belong to this set. Simultaneously, as most of those adjectives end in -a or -e, they would not have caused difficulty in the uninformative condition if learners were expecting definite inflection on the adjective following hans, since definite inflection is realized with the suffixes -a or -e. For common nouns, we did not find the same pattern, as they do not trigger overt inflection on adjectives. Interestingly, López-Prego (2015) also found that invariant adjectives caused a significant slowdown in self-paced reading relative to informative adjectives for both L1 and L2 speakers of Spanish, and even relative to gender-incongruent adjectives for the learners. Future L2 research on agreement might explore the source of difficulty behind these invariant adjectives.
Other factors might explain why facilitation only emerged in the two-cue conditions, although they cannot readily explain why learners would name neuters more slowly in informative frames in the one-cue conditions. For example, the gendered adjective and the noun were adjacent in the two cue-conditions (e.g.
An interesting follow-up could examine whether reading the preambles aloud, rather than silently, enhances the use of gender cues. For example, Lelonkiewicz et al. (2021) had English native speakers name pictures following either high- or low-constraint preambles, which they read either silently or aloud. Their results revealed faster naming latencies in high- compared to low-constraint frames, an effect that was enhanced when participants read the preambles aloud, lending support to proposals that anticipatory mechanisms are supported, at least partly, by the production system (e.g. Pickering and Gambi, 2018). With such a set-up, gender-based facilitation might even obtain from the common cues or with only one cue. This might also shed light on whether similar mechanisms support this type of gender-based facilitation.
VII Conclusions
The present study is among the first to examine how markedness modulates the facilitative use of gender among L1 and L2 speakers. Our results suggest that cues of the marked gender are more likely to facilitate lexical retrieval for both groups, lending support to psycholinguistic proposals that marked values are more informative to the parser and carry more predictive strength (Nevins et al., 2007; Wagers and McElree, 2022) and, potentially, to views of prediction which capitalize on the utility of predictive cues (Kaan and Grüter, 2021; Kuperberg and Jaeger, 2016).
Footnotes
Acknowledgements
The authors thank Scarlett Mannish and Susan Sayehli for their help with the first draft, Victor Norrman for his help with data processing, Maryann Tan for her help with the R code, and all participants for their time. We also thank the editor and three anonymous reviewers for their valuable feedback during the review process.
CRediT author statement
Rebecca Borg: conceptualization, methodology; formal analysis; investigation; writing – original draft preparation; writing – review & editing. José Alemán Bañón: conceptualization; formal analysis; supervision; funding acquisition; methodology; writing – original draft preparation, writing – review & editing.
Data availability statement
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a Riksbankens Jubileumsfond grant to José Alemán Bañón (grant number P18-0756:1). The authors acknowledge support from the Centre for Research on Bilingualism.
Ethical considerations
All experimental procedures were discussed with a research ethics expert at Stockholm University and were deemed not to require official ethical vetting under Swedish law. All participants provided their informed written consent to participate in the study, and the project followed all guidelines typically required by ethical committees.
Consent to participate
All participants provided their informed written consent to participate in the study.