
Abstract
This article explores the role of Universal Grammar (UG) in second language (L2) acquisition. Drawing on the weak conformity hypothesis (WCH), which posits that developing interlanguage grammars may temporarily deviate from UG but ultimately conform to it, the article proposes that UG functions as a linguistic dissonance resolution device (LDRD). In this framework, UG becomes active when learners adopt UG-incompatible rules or ‘wild grammars’ in their interlanguage, working to revise these inconsistencies so that they align with UG constraints. In contrast to standard assumptions, I argue that L2 learners do not necessarily explore only within UG bounds. Rather, UG plays a monitoring role: It detects UG-inconsistent rules and triggers revision. Such revisions can occur when feature selection or feature reassembly is required, as long as wild grammars are present in the learner’s interlanguage grammar. As addressed in this article, this account makes novel predictions about which features are acquirable or reconfigurable and which are not. Thus, the UG-as-LDRD proposal not only offers a potential solution to the poverty-of-the-stimulus problem in L2 acquisition, but also provides a broader explanatory scope that may surpass that of existing generative L2 hypotheses.
Keywords
I Introduction
Research on second language acquisition (L2A) within the generative framework has provided evidence that Universal Grammar (UG) plays a role in L2A (Dekydtspotter et al., 1997, 1998; Flynn, 1984; Kanno, 1996, 1997; Martohardjono, 1993; White, 1989). However, specific proposals regarding the mechanisms by which UG operates in L2A remain limited (Gregg, 1996; for exceptions, see Kimura, 2022a, to appear; Kimura and Wakabayashi, 2024; Truscott and Sharwood Smith, 2004). The acquisition of abstract linguistic properties (e.g. syntactic operations and grammatical features), which learners cannot infer inductively from the input or their first language (L1), supports the argument that the genetic endowment or UG plays a major role in L2A (Hawkins, 2001; Schwartz, 1998; White, 2003). Decades have passed since this poverty-of-the-stimulus problem was identified, and it is now necessary to reconsider the role of UG, extending it beyond traditional assumptions.
In this context, this article revisits the role of UG in L2A. In first language acquisition (L1A), UG is assumed to function as a language acquisition device (LAD), which takes the totality of the primary linguistic data available to the learner (PTotal) as input and yields an individual grammar (G) as its output (Chomsky, 1986a: 3, 52): (1) UG as a language acquisition device (LAD) LAD(PTotal) = G
Thus, UG is a prerequisite for L1A. Furthermore, since L1 acquirers explore grammatical options within the boundaries defined by UG, their developing grammars are constrained by UG at all stages (Crain and Thornton, 1998, 2012).
In line with this view, generative L2 research has posited that interlanguage grammars remain UG-constrained throughout development (see, amongst others, Adjemian, 1976; White, 1985, 2003; Liceras, 1986; Schwartz and Sprouse, 1994, 1996; Lardiere, 2008, 2009). This position is stated in (2):
1
(2) Strong conformity hypothesis (SCH) All developing interlanguage grammars conform to UG.
Despite various counterarguments (see, for example, Clahsen and Hong, 1995; Clahsen and Muysken, 1986; Klein, 1993, 1995; Meisel, 1991, 1997), this hypothesis has long served as the standard position within generative L2 research.
To preview the discussion, this article reconsiders the SCH and introduces an alternative account. In brief, I argue for a weaker position, namely, the weak conformity hypothesis (WCH; see Sharwood-Smith, 1988): (3) Weak conformity hypothesis (WCH) Developing interlanguage grammars can deviate from UG, though they eventually conform to it.
In essence, the WCH permits the existence of so-called ‘wild grammars’ in interlanguage representations (Klein, 1993, 1995). However, I do not intend to endorse impairment hypotheses such as those proposed by Clahsen and Muysken (1986), Clahsen and Hong (1995), or Meisel (1991, 1997). Rather, building upon the WCH, I propose that UG functions in L2A as a linguistic dissonance resolution device (LDRD), which addresses poverty-of-the-stimulus problems in L2A.
2
Formally, the LDRD takes a wild grammar (wg) and yields a UG-compatible grammar (g):
3
(4) UG as a linguistic dissonance resolution device (LDRD) LDRD(wg) = g
Unlike L1 acquirers, adult L2 learners make use of a variety of resources (e.g. their L1, explicit knowledge, etc.). Given this, it is conceivable that L2 learners may construct ‘wild’ grammatical rules that deviate from UG constraints (see Klein, 1993, 1995). However, if UG indeed functions in L2A, then, analogous to the body generating antibodies against viruses, UG may act to eliminate UG-incompatible grammatical ‘viruses’ or resolve linguistic dissonance and reshape them into UG-compliant forms (see Sobin, 1997). In this article, I explore this possibility through empirical analysis.
The structure of the article is as follows: Section II outlines generative assumptions underlying UG with respect to grammatical organization and acquisition. Section III introduces the notion of UG as an LDRD, focusing particularly on abstract grammatical features that cannot be acquired through inductive learning. It will be argued that this proposal not only clarifies UG’s role in L2A – particularly in processes of feature selection and reassembly (see Hawkins and Hattori, 2006; Hawkins and Liszka, 2003; Lardiere, 2008, 2009; Tsimpli and Dimitrakopoulou, 2007) – but also accounts for why some features are acquirable and others are not. Finally, Section IV presents the conclusions.
II Generative assumptions
1 UG
UG is a theory that defines the constraints on the possible forms of language (Chomsky, 1981, 1986a). It encompasses the basic elements that underlie all human languages, regardless of whether a particular I-language employs them. Specifically, UG provides a set of invariant principles, which allow only a limited number of options among numerous logical possibilities, and parameterized properties, which account for cross-linguistic variations (Chomsky, 1981, 1995; Chomsky et al., 2019). The following overview of UG will serve as theoretical background in the subsequent sections.
First, UG includes grammatical primitives such as features, which are integrated into syntactic structures via core syntactic operations provided by UG, such as Merge and Agree, to form complex syntactic objects.
Merge is an operation that takes α and β as inputs and forms an unordered set {α, β} (Chomsky, 1995, 2000; Collins, 2017). Additionally, these derived structures must be legible at the interfaces with sound and meaning (Chomsky, 1995; Chomsky et al., 2019). This requirement is formalized as the Principle of Full Interpretation (PFI; Chomsky, 1995). Structures may include uninterpretable features (uFs), which are unvalued in the lexicon (e.g. [unumber:__]), and interpretable features (iFs), which are assigned specific values (e.g. [inumber: plural]) (Chomsky, 1995, 2001). Since uFs are unvalued, they are uninterpretable at the interfaces and thus violate the PFI. The Agree operation solves this problem by assigning values to these features. In the configuration below, the [uF:__] on head X acts as a probe and searches for a goal with a matching interpretable feature [iF: val] in its c-command domain (5a), resulting in feature valuation. As shown in (5b), [uF:__] is successfully valued, allowing for legible interpretation at the interfaces (Chomsky, 2000, 2001).
(5) a. X[uF:__] . . . Y[iF: val] (. . . indicates c-command relations) b. X[uF:
In contrast, Move occurs in configurations where the structural relationship between X and Y is reversed compared to (5) (Bošković, 2007). In (6a), the uF on X cannot locate the corresponding interpretable feature on Y by probing downward. This results in a valuation failure and crash at the interfaces. To resolve this, X must move above Y, as in (6b), allowing the uF on X to successfully reach and be valued by Y’s iF via Agree (6c), thereby satisfying the PFI.
(6) a. Y[iF: val] . . . X[uF:__] b. X[uF:__] . . . Y[iF: val] . . . tX c. X[uF:
Furthermore, there also exists ‘optional movement’, a representative example of which is scrambling in Japanese. In Japanese, NPs can relatively freely undergo preposing.
(7) a. Taro-wa hon-o yon-da. Taro-TOP book-ACC read-PAST ‘Taro read a book.’ b. Hon-o Taro-wa___yonda.
The optionality of scrambling is attributed to the fact that it is not uF-driven (see Fukui, 1993; Saito, 1985, 1992, 2003). In fact, scrambling is immune to the locality conditions that constrain uF-driven movement (see Aoun and Li, 1993; Cable, 2010; Hagstrom, 1998).
In summary, UG provides the foundational elements of human language by offering a constrained set of hypotheses that shape the possible form of human languages. It includes basic syntactic operations (e.g. Merge, Agree, Move), a restricted inventory of syntactic atoms (e.g. uF/iF), and core principles (e.g. PFI) that govern syntactic structure-building.
The discussion to follow will focus on the acquisition of abstract syntactic properties such as uFs and the associated operations. Importantly, such properties are typically too abstract to be acquired through inference or statistical learning from input alone. For most L2 learners, who receive limited L2 input and lack formal syntactic training, it is extremely unlikely that such abstract operations or features could be deduced from surface evidence alone. This underscores the necessity of positing an innate mechanism such as UG to account for their acquisition. 4
2 UG in (L2) acquisition
Based on the above background, this section briefly considers the role of UG in language acquisition. In L1A, UG functions as an LAD, as mentioned above. Under this conception, language acquirers explore the options within the hypothesis space provided by UG, selecting those options that best align with primary linguistic data (see, for example, Crain and Thornton, 1998, 2012). Since children acquiring their L1 lack prior knowledge of specific languages and typically have minimal explicit grammatical knowledge, UG can operate with little external interference to facilitate efficient acquisition.
By contrast, L2 learners encounter markedly different conditions. From the early stages of learning, they already possess knowledge of their L1 as well as substantial explicit grammatical knowledge, both of which are highly likely to yield non-target-like representations. These factors play a significant role in shaping interlanguage development. Thus, even if UG remains operative in L2A, it is logically possible that the resulting L2 grammatical representations may deviate from UG constraints.
Nevertheless, generative L2 research has long adhered to the hypothesis that maintains that all developing L2 grammars fall within the bounds of UG and do not permit UG violations, in accordance with the SCH (e.g. Adjemian, 1976; Epstein et al., 1996; Schwartz and Sprouse, 1994, 1996; White, 1985, 2003). This approach (sometimes implicitly) assumes that, like L1 acquirers, L2 learners reconstruct their interlanguage by navigating the hypothesis space provided by UG (Schwartz and Sprouse, 1996; White, 2003). Accordingly, UG-incompatible rules are not expected to emerge, leaving no theoretical room for L2 grammars to diverge from UG.
However, the validity of this assumption is not guaranteed. While the assumption holds for L1-acquiring children, who have limited access to non-UG resources, it becomes questionable in L2 contexts. There are several compelling reasons to challenge the SCH.
First, L2 learners can draw upon a wide range of resources beyond UG. Research has shown that interlanguage grammar construction is often influenced by surface-level syntactic characteristics not grounded in UG, including linear sequences (see, for example, Kimura, 2022a; Meisel, 1997; Miyamoto and Iijima, 2003; Oshita, 2001; see also Al-Kasey and Pérez-Leroux, 1998; Ard and Gass, 1987; Yuan, 1999). Similarly, even native speakers sometimes construct antihierarchical or nonconfigurational (i.e. non-UG-based) rules, for social or stylistic reasons (e.g. ‘Mary is richer than I (me)’ / ‘There are (is) a book a cat and a dog in the garden’), which Sobin (1994, 1997) refers to as grammatical viruses. 5
Further insights come from semi-artificial language acquisition studies, which can simulate initial stages of L2A. Semi-artificial languages are constructed by combining the learner’s L1 vocabulary with the grammar of a natural language and, hence, the syntactic system remains natural (i.e. governed by UG). This design provides an ideal experimental setting in which participants face no lexical challenges, allowing researchers to examine how learners process entirely novel syntactic rules at the initial stage of L1+n acquisition (see, for example, Williams and Kuribara, 2008). The studies suggest that learners often form syntactic rules independent of UG when acquiring new language data sets (Williams and Kuribara, 2008). Such findings imply that reliance on non-UG sources of knowledge is common in the initial stages of L2A, making the construction of UG-deviant rules plausible.
Importantly, the emergence of UG-incompatible rules has been interpreted as evidence that UG is not accessible in L2A (see Clahsen and Hong, 1995; Clahsen and Muysken, 1986; Klein, 1993, 1995; Meisel, 1991, 1997). However, this conclusion may be misplaced. As noted earlier, the standard ‘Full-Access-to-UG’ hypothesis is often conflated with the SCH, which assumes that L2 learners only explore UG-sanctioned hypotheses. Thus, when UG-incompatible rules are observed, it is not necessarily evidence against UG access per se, but rather against the SCH. That is, even if learners construct interlanguage grammars that temporarily deviate from UG, it remains possible that UG is fully accessible in another form: a possibility that will be further discussed in the following section.
III Revisiting the role of UG
1 Proposals
In light of previous findings, L2 learners – particularly during the early stages of interlanguage development – may construct grammatical rules that deviate from UG. (Further empirical evidence will be presented later.) Based on this observation, I argue for the weak conformity hypothesis (WCH; see Sharwood-Smith, 1988), defined above. However, I do not assume, as Clahsen and Muysken (1986), Meisel (1997), Schachter (1989), or Bley-Vroman (1989), among others, have, that L2A is guided by general cognitive mechanisms. Rather, if UG plays a role in L2A, it should not allow such wild grammatical rules to persist unchecked. Instead, UG may function as a mechanism of revision, ensuring that interlanguage grammars ultimately conform to UG by eliminating UG-incompatible rules.
To formalize this proposed role of UG in L2A, I introduce the concept of a linguistic dissonance resolution device (LDRD):
6
(8) UG as an LDRD LDRD(wg) = g
The idea is that UG, functioning as an LDRD, takes a deviant grammar and returns a revised grammar that is compatible with UG. 7
L2 learners construct interlanguage grammars using various resources, including L1 knowledge, UG, statistical learning, and explicit instruction. 8 Once we set aside the assumption that L2 learners operate solely within the bounds of UG, nothing prevents them from formulating rules that violate UG constraints, namely, ‘wild grammars’. To name a couple of potential examples of wild grammars (as will be discussed in detail below), learners might apply an optional movement rule in an obligatory manner to mimic surface target-like sequences (e.g. Kimura, 2022a; Miyamoto and Iijima, 2003), or they might assign a syntactic structure based on linear word order that conflicts with UG constraints (e.g. Oshita, 1997, 2001).
The emergence of such wild grammars creates a form of linguistic dissonance: UG prohibits the inclusion of a wild rule, but the learner’s interlanguage grammar erroneously includes it. According to the UG-as-LDRD model, it is at this point that UG intervenes by functioning as a filter or revision mechanism. It resolves this dissonance by reshaping wild rules into UG-compatible alternatives.
Here, let us consider the similarities and differences between this proposal and earlier views, particularly the SCH. 9 Proponents of the SCH argue that UG is accessed whenever an interlanguage grammar is restructured in response to input (Schwartz and Sprouse, 1994, 1996; Lardiere, 2008, 2009). Similarly, the LDRD proposal assumes that UG offers an inventory of grammatical features and options in L2A. 10 Without this inventory, no viable grammatical alternatives would exist to replace wild rules. In this respect, the UG-as-LDRD approach aligns with previous generative accounts. However, unlike the standard one, the present approach is grounded in the WCH. It allows L2 learners to consider grammars not sanctioned by UG and to revise wild rules at later stages. Crucially, this model explains why learners do not require observable evidence to acquire the abstract grammatical features or operations, which provides a key advantage when addressing poverty-of-the-stimulus situations. Under the UG-as-LDRD model, the linguistic dissonance or UG-violation is expected to occur but are also predicted to be only temporary. These violations trigger UG to revise the grammar and guide it back into conformity.
In passing, it is worth noting that both the WCH and the UG-as-LDRD hypotheses are falsifiable, despite Klein’s (1995) incorrect claim of a falsifiability problem with this type of hypothesis. To disprove them, one would need to identify persistent UG violations in learners’ grammars even at ultimate attainment. Moreover, since the LDRD mechanism is assumed to activate only when a rule violates UG, a UG-compatible misanalysis should not trigger revision (see Section III.3.b). 11
2 Empirical considerations
Here, I examine empirical data to evaluate the role of UG as proposed in the preceding section.
a Wh-movement
As previously discussed, forced movement is driven by a uF. English wh-movement exemplifies such a case. In English, wh-phrases bear an uninterpretable Op(erator) feature ([uOp:__]), while the C-head bears a corresponding interpretable [iOp:value] feature (Cable, 2010; Cheng, 1991; Chomsky, 2001; Tsai, 1999), as illustrated in (9a). To ensure compliance with the PFI, the wh-phrase moves to Spec-CP above the C-head, where the [uOp:__] is valued (9b): (9) a. [C’ C[iOp:value] [. . . Bill bought [QP what[uOp: ]]]] b. [CP what[uOp:
Wh-movement in English is constrained by islands. Movement out of strong islands (10a, b) results in more severe violations, while weak islands (10c, d) induce somewhat milder effects (Chomsky, 1986b; Cinque, 1990; see also Ross, 1967): (10) a. ?? What do you believe [NOUN-COMPLEMENT the claim that Alice saw___ ]? b. ?? What did you ask [EMBEDDED-QUESTION whether Edward bought___]? c. * What did Kate find the woman [RELATIVE-CLAUSE who fixed___]? d. * What did you wake up [ADJUNCT-CLAUSE after Erika cooked___]?
In contrast, in a language like Japanese, interrogative force is marked not by wh-movement but by a quantificational particle (Q-particle) such as ka, and wh-phrases (e.g. nani ‘what’) typically remain in situ: (11) Anata-wa Bill-ga you-TOP Bill-NOM ‘What do you think that Bill bought?’
This is because Japanese wh-phrases lack inherent quantificational force; instead, Q-particles provide this force (see, for example, Hagstrom, 1998; Kuroda, 1965; Nishigauchi, 1986, 1999; Shimoyama, 2006): (12) a. nani-ka (what-existential/‘something’) b. nani-mo (what-universal/‘everything’)
According to Hagstrom (1998) and Cable (2010), Q-head ka bears [uOp:__] and is generated adjacent to the wh-phrase (13a). The Q-particle then moves into the C-domain, where the C-head has [iOp: value], thus establishing the Agree relation (13b). The wh-phrase itself remains in situ, as it does not participate in Agree: (13) a. [QP nani ka[uOp:__]] b. [CP [C’ . . .[QP nani tka] C[iOp: value] Q
Thus, the difference between English and Japanese wh-syntax does not lie in the presence or absence of relevant features, but rather in how these features are assembled.
Because Japanese lacks wh-movement, Japanese wh-questions are insensitive to island constraints. Moreover, although embedded-question islands are considered weak islands in English, they yield strong-island effects in Japanese (Nishigauchi, 1986; Shimoyama, 2006; Watanabe, 1992): (14) * Taro-wa [EMBEDDED-QUESTION Hanako-ga Taro-TOP Hanako-NOM what-ACC bought whether Jiro-ni tazune mashita Jiro-DAT askedHONORIFIC Q ‘What did Taro ask Jiro whether Hanako bought?’
This is attributed to movement of a Q-particle (ka) across another intervening Q (ka-douka), violating (featural) Relativized Minimality (Rizzi, 2001, 2017):
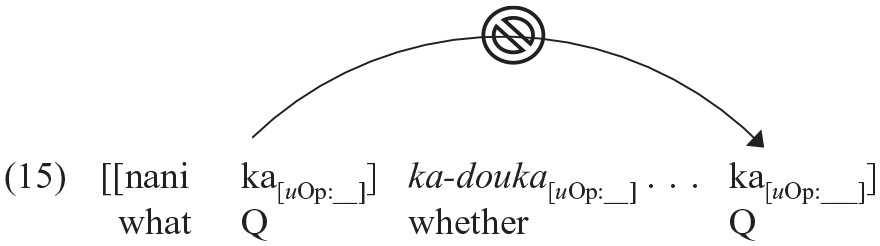
Another important aspect of Japanese wh-syntax is that non-feature-driven scrambling can optionally move wh-phrases to the clause edge: (16) [Nani-o [anata-wa Bill-ga____ katta to omoimasu] ka]? what-ACC you-TOP Bill-NOM bought COMP think Q literally: What (do) you think Bill bought?
These cross-linguistic differences have notable implications for L2A. If Japanese-speaking learners of English (JLEs) transfer the syntax of their L1, they may form English wh-questions by either (1) moving only the Q-feature and leaving the wh-phrase in situ, or (2) applying scrambling as a substitute for wh-movement.
Numerous studies have investigated the acquisition of English wh-syntax by JLEs. Kimura (2022a), through an acceptability judgment task, found that lower-intermediate JLEs treat embedded-question islands as strong islands, as in Japanese. This suggests that learners were applying a Q-feature-movement derivation, rather than wh-movement. Additionally, their responses showed consistency with scrambling-based derivations for other types of islands. Thus, Kimura concluded that these learners misanalyse English wh-questions by moving only the Q-feature to CP, while the wh-phrase itself moves independently via scrambling.
Further supporting this claim, Kimura’s elicited production task revealed frequent errors in wh-phrase positioning, such as ‘(What) do you think who . . .?’ 12 In English, the wh-phrase bears [uOp:__], which must be placed and valued in the matrix Spec-CP to mark scope. Misplacing the wh-phrase in medial positions suggests that learners’ interlanguage grammar fails to associate the wh-phrase with the [uOp:__] feature, consistent with scrambling-based derivations. Notably, no wh-in-situ errors were observed; all wh-phrases were fronted, implying that scrambling had been incorrectly reanalysed as obligatory.
If this analysis is correct, then intermediate JLEs apply a forced scrambling operation, an operation not permitted under UG constraints (see also Miyamoto and Iijima, 2003). However, more advanced JLEs show target-like behaviors in both acceptability and production tasks (see also Umeda, 2006; Yusa, 1999). This developmental pattern suggests that UG-conforming wh-movement is eventually acquired. These findings support the WCH and UG-as-LDRD proposal: learners initially construct UG-incompatible rules, such as forced scrambling, but these are subsequently revised to conform to UG. Then, a question arises: What exactly is revised?
In the relevant observable English input, wh-phrases are consistently fronted (see, for example, Nguyen and Legendre, 2021). If learners employ scrambling to mimic this consistent fronting of wh-phrases, they may overgeneralize by applying scrambling obligatorily. Consequently, learners’ internal syntactic knowledge and input analyses give rise to the interlanguage rule of forced scrambling for the obligatory wh-fronting phenomenon. 13 Since scrambling is optional under UG, and obligatory movement must be uF-driven, the learner must revise the trigger for movement. Thus, the optimal solution under UG is to reanalyse the movement as driven by a [uOp:__] feature. 14
In this way, UG-as-LDRD explains why and how learners can acquire abstract features like [uOp:__], even in the absence of explicit input cues. Such feature acquisition, otherwise puzzling under poverty-of-the-stimulus conditions, becomes comprehensible within this framework. 15
b Unaccusative trap
Oshita’s (1997, 2001) unaccusative trap hypothesis also finds a straightforward explanation within the UG-as-LDRD proposal. Unergative verbs have an underlying structure as shown in (17a), while unaccusative verbs have the structure in (17b).
(17) a. [NPAGENT V] b. [V NPTHEME]
According to Oshita, the acquisition of unaccusative verbs progresses through several developmental stages. Initially, L2 learners erroneously analyse unaccusatives as having the unergative structure (i.e. *[NPTHEME V]). At the next stage, the Uniformity of Theta-role Assignment Hypothesis (UTAH) (Baker, 1988), a UG principle, begins to guide learners toward the correct structure. This results in errors that were previously absent. For example, decreased acceptability of canonical unaccusative word order in experimental settings (Hirakawa, 1995, 2000; Oshita, 1997; Yip, 1995), or the production of unaccusative passive errors (e.g. *The train
In this developmental trajectory, the initial misanalysis violates the UG-principle, namely, UTAH, by placing NPTHEME in Spec-VP, a position that, according to the UTAH, is reserved for NPAGENT. This representation results in a linguistic dissonance with UG, which is consistent with the WCH. The UG-as-LDRD hypothesis predicts that this type of deviation should be corrected over time. Indeed, learners revise the wild grammar *[
c Cases where revision does not occur
Let us now consider situations where UG-as-LDRD is not expected to be triggered, namely, when the learner’s misanalysis is compatible with UG.
Let us first consider quantifier scope, which is known to be extremely challenging to acquire in L2A. In English, sentences with multiple quantifiers show ambiguity with respect to scope (Beghelli and Stowell, 1997; Szabolcsi, 2010): (18) A boy loves every girl. a. a>every: There is a boy who loves every girl. b. every>a: For every girl x, there is a boy who loves x.
This ambiguity arises because every undergoes covert movement to a position where it can check its [uOp:__] feature against [iOp: distributive] on a DistP head (19; Beghelli and Stowell, 1997; Szabolcsi, 2010):
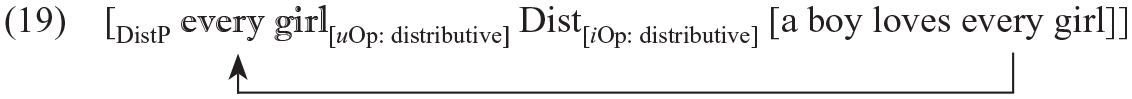
This movement allows every to take scope over a boy, achieving scope reversal despite surface word order.
In contrast, East Asian languages (e.g. Japanese, Chinese) exhibit scope-rigidity, aligning interpretation strictly with the surface word order (Hoji, 1985; Kuroda, 1970): (20) Aru syonen-ga dono-syozyo-mo aisiteiru. (a>every, *every>a) a boy-NOM which-girl-every love ‘A boy loves every girl.’
Previous studies have shown that learners from scope-rigid L1 backgrounds struggle to acquire English inverse scope, even at advanced levels (Chu et al., 2014; Kimura, 2022b; Wu and Ionin, 2022; for a review, see Marsden, 2024). For instance, Chu et al. (2014) found that advanced Chinese-speaking learners of English overwhelmingly preferred surface scope (98%) and almost never accepted inverse scope (5%). Similarly, Kimura (2022b) confirmed that JLEs face significant difficulty in accepting inverse scope readings but found that they could interpret every as distributive (and non-collective) to some extent.
This suggests that such learners may misrepresent every as bearing [iOp: distributive], thereby allowing for distributive interpretations while resisting scope reversal because of the lack of movement. Although this syntactic analysis is non-target-like, it does not conflict with UG, as it remains within its permissible hypothesis space. Therefore, UG-as-LDRD is not activated, and the misanalysis may persist.
A similar pattern emerges in the domain of aspectual auxiliaries. According to Rouveret (2012), perfective -en carries [uAsp:__], which is valued by the auxiliary have ([iAsp: perfective]). In contrast, -ing carries the progressive meaning on its own and bears [iAsp: progressive]. Indeed, isolating -en results in a passive meaning (21a), but not a perfect meaning (21b; Collins, 2005). When combined with have as in (21b), -en acquires perfectivity, indicating that -en carries [uAsp:__].
(21) a. Written in only three days, this book sold millions of copies. b. * (Having) written her dissertation in only three days, Sue took a break. (Collins, 2005: 92, slightly modified)
A recoverability constraint is posed on ellipsis. Rouveret (2012: 900) states that elided elements must not contain unrecoverable iFs. Consider the contrast:

In (22a), -en with [uAsp:__] is elided, but it does not hinder recoverability. In (22b), however, the sentence sounds awkward because the elided portion includes [iAsp: progressive] unrecoverable from the antecedent, violating the principle of recoverability.
Based on this theoretical background, Hawkins (2012) investigated learners’ knowledge of VP-ellipsis involving auxiliaries through a judgment task administered to intermediate and advanced Mandarin Chinese- and Arabic-speaking learners of English. The study found that learners correctly rejected sentences with illicitly elided V-ing[iAsp: progressive], but they incorrectly rejected V-en[uAsp:__] ellipsis, suggesting they might erroneously assume [iAsp: perfective] for V-en. This observation implies that learners do not successfully posit [uAsp:__] on V-en. Again, this misanalysis, while non-native, does not violate UG, and hence does not trigger activation of the UG-as-LDRD mechanism. Thus, the findings align with LDRD’s selective application to UG-incompatible constructions.
One might argue that the difficulty in acquiring these grammatical phenomena stems from the absence of observable positive evidence in the input (see, for example, Lardiere, 2009; Schwartz and Sprouse, 1994, 1996; Wu and Ionin, 2022). However, this explanation incorrectly predicts that the acquisition of (almost) all uFs and/or abstract syntactic operations would be impossible, an outcome contradicted by empirical evidence, since, as previously discussed, such properties rarely yield detectable positive evidence. If our argument is correct, the UG-as-LDRD proposal accounts for both the acquisition of certain features despite the poverty-of-the-stimulus condition and the non-acquisition of others due to the absence of a trigger that would activate the revision mechanism.
IV Concluding remarks
In this article, building on the WCH, I proposed a novel role for UG in L2A: UG as a linguistic dissonance resolution device (LDRD). This proposal claims that UG functions not only as a provider of a restricted hypothesis space, but also as a corrective mechanism that identifies and eliminates interlanguage rules that deviate from UG (i.e. linguistic dissonance), thereby guiding learners back toward UG-conforming grammars. As such, UG-as-LDRD offers a potential solution to the poverty-of-the-stimulus problem in L2A.
Notably, recent hypotheses have largely left unaddressed fundamental questions such as why uFs that are not selected or are differently assembled in learners’ L1 can still be acquired in L2A, and how UG functions under such conditions. In contrast, the UG-as-LDRD proposal directly tackles these questions by offering a theoretical framework that explains how and when UG is activated during the acquisition process. Since the proposal applies not only to feature selection, but also to feature reassembly and other tasks, it holds promise for broad empirical coverage.
Furthermore, the proposal generates various testable predictions regarding which features are likely to be successfully acquired (i.e. selected or reassembled) and which are not. Some of these predictions may diverge from those made by existing hypotheses such as the Feature Reassembly Hypothesis (Lardiere, 2008, 2009), the Representational Deficit Hypothesis (e.g. Hawkins and Hattori, 2006), or the Interpretability Hypothesis (Tsimpli, 2003; Tsimpli and Dimitrakopoulou, 2007). Continued empirical investigation will help refine our understanding of the precise role that UG plays in L2 development.
Footnotes
Acknowledgements
I would like to thank the three anonymous Second Language Research reviewers and the editor for their insightful comments and suggestions, which greatly improved the quality of this manuscript. I am also grateful to the audiences at GASLA 16 and L3 Workshop (Symposium on L n Acquisition Studies Based on Linguistics and their Implications for L3 Research), where earlier versions of this study were presented. Special thanks go to Shigenori Wakabayashi for his valuable feedback and discussions. All remaining errors are, of course, my own.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by KAKENHI (grant number JP24K16042).