
Abstract
The question of how the mental lexicon of bilinguals is organized to incorporate more than a single language is of long-standing interest. Evidence regarding the structure of the bilingual system comes from word translation tasks, with a central issue whether translation speed, on the one hand, and semantic effects, on the other, are asymmetric dependent on direction of translation. We report a study in which unbalanced Chinese–English bilinguals translated words either in forward (first language to second language, i.e. L1 to L2) or backward (L2 to L1) direction. Words were presented in sets of semantically homogeneous or heterogeneous experimental blocks (‘semantic blocked naming/translation’). We found substantially faster forward than backward translation speed, as well as an inhibitory semantic effect which was larger in backward than in forward translation. We suggest that a word presented in L2 leads to a less stable/rich conceptual activation than one presented in L1, which in subsequent translation leads to slower translation times and larger semantic effects in backward than in forward translation. Results are informative with regard to the structure and organization of the bilingual lexicon.
I Introduction
Over the past few decades, an impressive number of empirical studies have endeavored to identify how bilinguals organize their multiple language systems (for comprehensive review, see Jiang, 2015). Earlier models of bilingual lexical organization sat at two extreme positions regarding the issue of how a word is represented in multiple languages and is translated from one language to another (Potter et al., 1984). The Word Association Model suggests that translation equivalent words are connected via direct links between the two lexicons, and translation involves accessing the word forms of the target language from their linked counterparts in the source language. In contrast, the Concept Mediation Model posits that translation equivalents are connected only via their shared conceptual representations, and hence word translation is always conceptually mediated. Kroll and Stewart (1994) proposed the Revised Hierarchical Model (RHM) according to which the strength of links between lexical and conceptual representations in bilingual memory varies as a function of language proficiency and relative language dominance. For less proficient learners of a second language (L2), newly acquired lexical representations in L2 have strong lexical links to their first language (L1) translation equivalents. Furthermore, L1 lexical representations have stronger links to their conceptual representations than L2 lexical representations, with the possibility that the L2-concept pathway is also asymmetric (strong links from L2 to concepts, but weaker links in reverse order; Kroll et al., 2010).
These assumptions have been the object of intense debate over the last few decades (e.g. Brysbaert and Duyck, 2010; Kroll et al., 2010) and, in our reading of the literature, the notion of direct associative links between translation equivalents has diminished in acceptance. For instance, the Sense Model advocated by Finkbeiner et al. (2004) assumes that separate L1 and L2 lexicons map onto a shared conceptual system, but with an important asymmetry regarding the number of senses that a word evokes in L1 vs. L2 (words presented in L1 typically evoke more senses than equivalent words in L2). The recently proposed Multilink computational model of bilingual word recognition and translation (Dijkstra et al., 2019) proposes integrated lexicons in bilinguals (i.e. activation of a word in one language induces cross-activation of orthographically and phonologically similar words in the other language) but (as in the Sense Model) the model implements no direct links between translation equivalents. Multilink proposes that orthographic input activates semantic representations which, in turn, activate phonological output, with a task/decision system restricting output to the input language when naming the word, and to the other language when translating the word. Proficiency in the non-native language is represented via modified resting levels of lexical representations, relative to words in the native language.
A large range of empirical tasks and methodologies has been used to explore the organization of the bilingual linguistic system (e.g. Schoonbaert et al., 2009). For instance, the question of the nature and extent of cross-language semantic priming has received a considerable amount of attention. Another method involves tasks in which a decision for a target word in one language is preceded by a – typically masked – prime word in another (‘translation priming’).
In the current article we focus on empirical tasks that require explicit word translation. Indeed, evidence that motivated the RHM came from a seminal translation study by Kroll and Stewart (1994). In their Experiment 3 words were presented in semantically categorized lists (where words in a list come from a single semantic category) or in semantically randomized lists (where words are drawn from various semantic categories). The experimental task was to orally translate words from L1 to L2 or vice versa. They found a pronounced asymmetry, with slower forward translation than backward translation, and forward but not backward translation subject to semantic effects (i.e. category interference). These findings were taken to suggest that there might be a differential reliance on lexical and conceptual routes dependent on the direction of translation: backward translation is mainly based on direct links from L2 to L1 and therefore shows little evidence of semantic effects, whereas forward translation is conceptually mediated and therefore should be slower and more prone to semantic effects. These findings and their interpretation make clear how evidence from translation tasks can be used to constrain assumptions about how the language system of bilinguals is organized. At the same time, it is likely to be more challenging than originally envisaged by Kroll and Stewart to draw inferences from empirical asymmetries in translation performance. To exemplify, Francis and Gallard (2005) asked trilinguals to translate words in all six possible directions. Performance (latencies and errors) reflected individuals’ relative proficiency in the three languages, but observed priming – due to repetition of a word/concept in input, output, or both – was in line with the assumption that, contrary to the RHM, translation was conceptually mediated in all cases.
Subsequent studies which involved explicit word translation used a similar approach to Kroll and Stewart (1994) to explore bilingual language organization, and virtually all of them also employed a semantic manipulation, such as the semantically blocked/randomized lists used by Kroll and Stewart described above. Areas of interest are therefore not only potential asymmetries in the translation speed dependent on direction (forward vs. backward translation), but also in the size of semantic effects. Individuals’ L2 proficiency is likely to be an important factor (e.g. Potter et al., 1984): balanced bilinguals’ translation speed should not depend on direction, and potential semantic effects should be symmetrical. But for bilinguals with a clear L1/L2 hierarchy, predictions are more complex. The RHM makes clear predictions of faster backward than forward translation (due to direct associative links for the former but not the latter) and larger semantic effects in forward than in backward translation (due to the former but not the latter being conceptually mediated). For models without links between translation equivalents, predictions are less straightforward. Translation involves conversion from written input to spoken output, and assuming weaker L2 than L1 representations (as, for instance, specified in the Multilink model) it is unclear whether the weaker system involving input (as in backward translation) or output (as in forward translation) should be relevant. Dijkstra et al. (2019: 670) reported results of a Multilink simulation that resulted in faster forward than backward translation, but it is not immediately clear why this asymmetry arose. Effects of semantic manipulations are also difficult to predict within the Multilink model, given that semantics is currently specified in terms of localist conceptual representations (one semantic node per word/concept). Because the model represents proficiency via resting levels of a given language, it is possible that for backward translation in which the weaker L2 system activates the semantic system, perhaps the latter is more susceptible to semantic effects than when – as in forward translation – the semantic system is activated by input in L1. This speculative hypothesis might predict larger semantic effects in backward than in forward translation, contrary to what the RHM predicts. The Sense Model stipulates that word translation only requires access to the sense shared across translation equivalents; in other words, the fact that L1 words may activate more senses than the L2 equivalents is probably not relevant for overall translation speed. But the sense asymmetry could affect semantic effects in translation: perhaps words presented in L1 (as in forward translation) evoke a richer set of semantic features/senses than words presented in L2 (as in backward translation), potentially evoking larger semantic effects in forward than in backward translation.
Below we review the existing evidence regarding overall translation speed and the presence of semantic effects in translation and, as will be shown, evidence regarding potential asymmetries is quite mixed. Table 1 presents an overview of the relevant studies from the last three decades of research on the topic. Most studies have employed translation of nouns; a few studies have involved the translation of number words, e.g. acht (‘eight’) → huit (Duyck and Brysbaert, 2004, 2008; Herrera, 2019). It is possible that number words develop stronger L2 → concept connections than non-number words, even at a relatively early stage of L2 acquisition (Duyck and Brysbaert, 2004) and, if so, this should result in semantic effects even in backward translation, as appears empirically to be the case. The assumptions embedded in competing models of bilingual lexical organization are most easily tested in empirical studies that involve explicit word translation and, hence, we restrict our review of this literature to these studies. However, in doing so we ignore a sizeable relevant literature of studies that do not involve translation. For instance, in so-called ‘translation priming’ studies a prime is briefly presented in one language, and is sandwiched between a forward mask (e.g. #####) and a target which is in the other language. Primes and targets are often translation equivalents but can also be related in other ways. The target is classified either as a word/nonword (lexical decision task; e.g. De Groot and Nas, 1991) or according to a semantic criterion (e.g. Finkbeiner et al., 2004). In this task, facilitation is observed from prime onto target but priming is often asymmetrical, with stable L1 → L2 effects but less stable L2 → L1 effects that may depend on participants’ proficiency level in L2 (e.g. Nakayama et al., 2016) but also on the task (Finkbeiner et al., 2004). For now we leave this literature aside because no explicit translation is required and, hence, forward and backward translation speed cannot be compared. We will attempt to relate the findings of our own study to the literature on translation priming in Section V.
Overview of studies on word translation, sorted by year of publication.
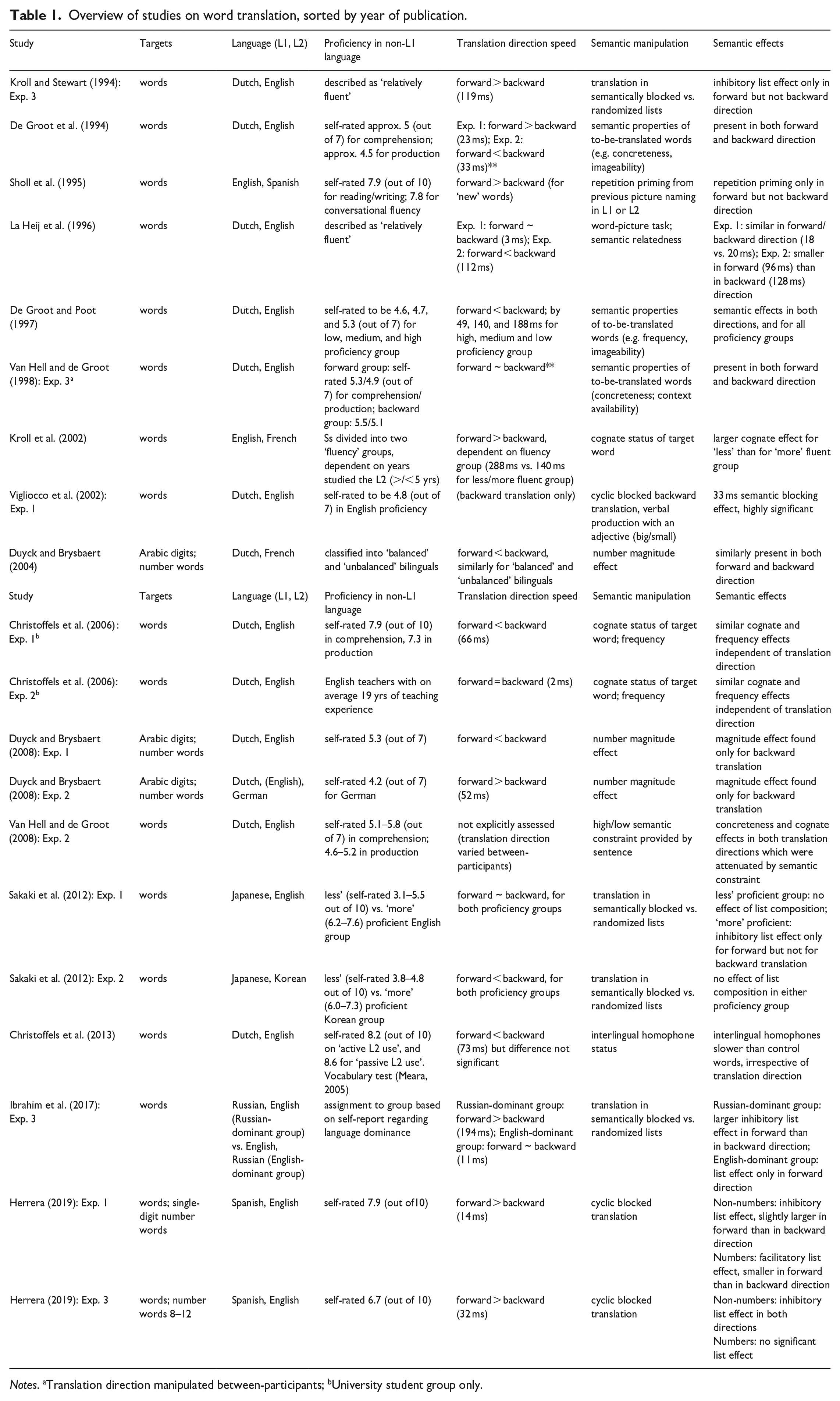
Notes. aTranslation direction manipulated between-participants; bUniversity student group only.
Further not included in Table 1 is an original approach that centers on ‘repetition priming’ between pictures named in the same or a different language, or between translation and picture naming episodes. Sholl et al. (1995) asked English–Spanish bilinguals to first name pictures (half in their L1 and half in their L2), followed by a block in which words were translated from L1 to L2 or vice versa. Repetition priming from previously named pictures on translation speed was found only for L1-to-L2 translations but not from L2-to-L1; this finding was interpreted as supporting the assumption that only the former but not the latter translation direction is conceptually mediated. However, subsequent work by Francis and colleagues cast doubt on that inference. Francis et al. (2003) disentangled picture identification from word retrieval in Spanish–English bilinguals. They found symmetric between-language priming in picture naming, but stronger within-language priming in the non-dominant than the dominant language. Furthermore, within-language priming for dominant and non-dominant language was symmetric in picture naming and translation, but priming was more pronounced in the non-dominant language. The authors concluded that translation is conceptually mediated independent of direction. A similar approach was taken by Francis and Saenz (2007) to explore the time course of repetition priming in picture naming and word translation across time intervals ranging from 10 minutes to one week. Francis et al. (2014) asked Spanish–English bilinguals to translate words in isolation or in sentence context which were later translated or their corresponding pictures named. Overall, and contrary to the claims originally made by Sholl et al. (1995), we read this literature to imply that translation is generally conceptually mediated (on translation in trilinguals mentioned earlier, see also the study by Francis and Gallard, 2005).
Overall, the findings appear inconsistent and challenging. Regarding overall translation speed in forward and backward direction, it is likely that highly proficient (nearly or fully balanced) bilinguals tend to generate symmetric translation times. Indeed, studies such as the one by De Groot and Poot (1997) suggest that the less balanced the participants, the more asymmetrical translation speed was; moreover, in Christoffels et al.’s (2006) Experiment 2 conducted with native Dutch English teachers with extensive experience in L2, speed of translation was nearly perfectly symmetric. On the other hand, the range of asymmetries reported in the literature varies dramatically, with asymmetry in some studies larger than 100 ms (e.g. Kroll et al., 2002) whereas in others the asymmetry is quite subtle (e.g. De Groot et al., 1994). More important is the direction of the asymmetry. Here a number of studies which reported the asymmetry predicted by the RHM (slower forward translation than backward translation; e.g. Herrera, 2019; Kroll and Stewart, 1998; Kroll et al., 2002; Sholl et al., 1995) contrast with others in which the asymmetry was in the opposite direction (e.g. Christoffels et al., 2006: Exp. 1; Christoffels et al., 2013; De Groot and Poot, 1997; La Heij et al., 1996: Exp. 2), and a few studies in which translation speed was largely symmetric even with clearly imbalanced bilinguals (e.g. La Heij et al., 1996: Exp. 1).
All summarized studies included a semantic manipulation in their design and, to recap, the observation in Kroll and Stewart’s (1994) seminar study was that semantic effects were more pronounced in forward translation than in backward translation. This pattern was found in some subsequent studies (e.g. Sakaki et al., 2012; Sholl et al., 1995) but others have found similar-sized semantic effects in both directions (e.g. De Groot and Poot, 1997; La Heij et al., 1996: Exp. 1) or even an asymmetry in the opposite direction (e.g. Herrera, 2019; La Heij et al., 1996: Exp. 2). Overall, the extant literature makes it difficult to adjudicate between competing models of word translation.
Most existing studies on word translation used combinations of Indo-European languages, which tend to share important linguistic characteristics (e.g. Dutch/English; English/French, etc.). Sakaki et al. (2012) introduced the notion that the linguistic similarity between language pairs could be an important factor. They compared translation between dissimilar language combinations (Exp. 1: Japanese/English) and similar language combinations (Exp. 2: Japanese/Korean). Participants who were classed as ‘less’ or ‘more’ fluent translated words that were either blocked by semantic category or randomized. Results suggested that for ‘more’ fluent Japanese/English bilinguals list composition exerted an inhibitory effect, but only in the forward direction (as was originally reported by Kroll and Stewart, 1994); for ‘less’ fluent Japanese/English speakers, list composition had no effect. For bilinguals with the more similar language pairs (Japanese/Korean) list composition was irrelevant independent of fluency. The authors suggested that ‘similarity of languages and second language proficiency do not act on the word recognition process independently. When one factor – language similarity – is high, it has the effect of weakening the typical effect of second language proficiency’ (p. 220). If so, then language proficiency should be particularly crucial when the language combinations are dissimilar. However, the lack of studies on dissimilar language pairs makes it difficult to verify this argument. The only other study that we are aware of that used a relatively dissimilar combination of (Indo-European) languages, namely Russian/English, was reported by Ibrahim et al. (2017). In their third experiment, bilinguals were either dominant in Russian or in English, and they translated words in either direction, either blocked by semantic category or randomized. For the Russian-dominant group they found slower forward than backward translation, and a larger inhibitory list effect in forward than in backward direction; for the English-dominant group, translation speed was very similar in both directions, and a list effect was present only in forward direction. Further research ought to explore the effects of word translation between dissimilar languages.
II The present study
In the study below we made a renewed attempt to tackle the issue of (a)symmetries in translation speed and the magnitude of semantic effects in unbalanced bilinguals. We used a task in which bilinguals translated small sets of words in forward and backward direction, with each response repeated multiple times. This task is normally used in a version in which pictures are named in speakers’ first (and often only) language, and it is referred to as ‘semantic blocking’ (e.g. Roelofs, 2018) or ‘cyclic blocking’ (Abdel Rahman and Melinger, 2019); in the current article we will use the former term. The central finding is an inhibitory effect of semantic context: latencies are substantially slower when pictures are named in blocks that consist of pictures of the same semantic category (‘homogeneous’), compared to when the same pictures are named, but now within blocks made up of various semantic categories (‘heterogeneous’; Damian et al., 2001).
In the study below we use a variant which uses word translation rather than picture naming. Vigliocco et al. (2002; see Table 1) conducted an experiment that involved backward translation from English (L2) to Dutch (L1) and reported a similar inhibitory effect than the one found in picture naming. More recently, Herrera (2019; see Table 1) reported a study that was mainly concerned with number word translation, but that also included translation of non-number words. Spanish/English bilinguals translated words in both directions; the results showed somewhat slower latencies, and slightly larger semantic effects, in forward than in backward translation.
A key distinction with other forms of semantic manipulations in tasks of this type is that in the ‘semantic blocking’ task many observations per cell can be collected because the same items are named/translated over and over again, with minimal error rates. Whereas in most other tasks each item is translated only once per participant and testing session, in the blocked naming task each response (a picture to be named, or a word to be translated) is generated repeatedly within each experimental block, and also across homogeneous and heterogeneous conditions, and each item constitutes its own control. This is particularly important in translation studies as the number of potential items that can be successfully translated is limited by participants’ proficiency in their L2.
An advantage of the semantic blocking task over alternative experimental procedures is that it critically relies on considerable repetition of just a few target items. The task therefore allows the accumulation of large numbers of data points per participant and condition. In the study that introduced the semantic blocked naming task in its most common form (with pictures as target), Damian et al. (2001: Exp. 1) used 10 speakers and 25 items (five pictures drawn from five semantic categories) and collected a total of 500 experimental trials per participant. They reported a semantic context effect of 29 ms, which was highly significant by participants and by items. In a subsequent magnetoencephalography (MEG) study using the same materials and design but increasing the number of experimental blocks, Maess, Friederici, Damian et al. (2002) accumulated a total of 1,200 trials per participant, and the effect remained highly significant and undiminished in size (26 ms). Hence the semantic context effect is extraordinarily stable across participants and items and is largely immune to practice effects. This renders it ideal for use in a translation study in which (due to L2 vocabulary constraints) the selection of L2 stimuli that are known to all participants is often challenging. 1 In the study reported below, each participant carried out 600 individual word translations, 300 in forward and 300 in backward direction. This number of trials allows for quite precise estimates of conditional response times, which would be very difficult to achieve with tasks in which each word is seen and translated only a single time.
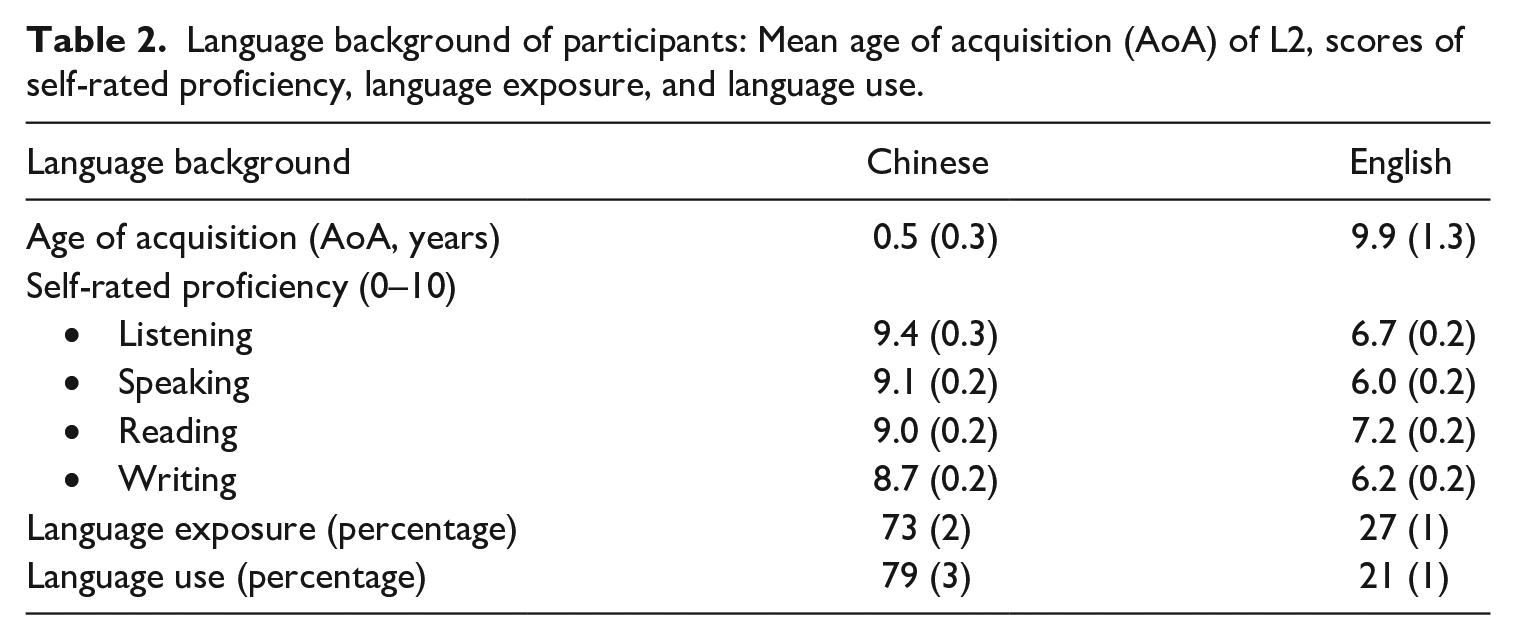
Our study used young Chinese–English bilinguals with self-rated ‘medium’ L2 proficiency (see Table 2). The Chinese/English language combination has to our knowledge not yet been explored in word translation studies that probe the structure of the lexico-semantic system. The two languages are so dissimilar that cognates are virtually non-existent, and this combination allows us to further assess the claim promoted by Sakaki et al. (2012) that similarity between languages might be an important variable in word translation.
Language background of participants: Mean age of acquisition (AoA) of L2, scores of self-rated proficiency, language exposure, and language use.
III Method
1 Participants
A total of 74 Chinese–English bilingual speakers participated in the study, with an average age of 19 (SD = 1.2) years. The age range of the participants was between 18 and 23 years, and 49 of them were female. All participants were right-handed, as determined by the Oldfield questionnaire (Oldfield, 1971), reported no language, hearing, or neurological impairments, and had normal or corrected-to-normal vision. Data from four participants were excluded from the analysis because two participants experienced technical issues with voice recording, and two further participants showed poor performance in the translation task, with one participant’s mean response times exceeding 2.5 standard deviations (SD) from the overall mean, and the other having an excessive error rate. As a result, the final sample for analysis consisted of 70 participants. The results below were analysed via linear mixed effect models; according to the guidelines by Brysbaert and Stevens (2017) a minimum of 1,600 observations per cell in repeated-measures designs is required to provide adequate statistical power. In our design, 50 data points per cell were collected, amounting to 3,500 observations per cell; hence, we considered the study to be adequately powered. The study was approved by the Ethics Review Board of Chongqing Medical University, China.
Table 2 presents information regarding the language background of participants. All participants were native Chinese speakers with Mandarin as their mother tongue (L1). They had started learning English as their second language (L2) between the ages of 7–12 years in primary education and had learned English for about 11–17 years by the time the experiment was conducted.
2 Materials and procedure
Fifty words (see Table 3) were chosen from English textbooks for the third-to-sixth Graders of primary school in China where English is learned as a foreign language. These words, all common concrete nouns, were specifically chosen for their high familiarity and ease of translation, ensuring that they were easily understandable and translatable by the participants. English words were of high frequency (mean value of 4.55, with a variability range of 3.63 to 5.44, as reported in the SUBTLEX-UK database by Van Heuven et al., 2014; Zipf values spanning from 1 to 3 denote low frequency, and those ranging from 4 to 7 signify high frequency). English words had a word length of 1–2 syllables with an average length of 1.2 ± 0.5 syllables, while their Chinese translation equivalents had a word length of 1–2 characters with an average length of 1.6 ± 0.5 characters. Words came from 10 semantic categories with five words each. Half of the 50 words belonged to five ‘non-living’ categories (transports, tableware, clothing, stationery, celestial phenomena) and the other half to five ‘living’ categories (fruits, livestock, body parts, plants, birds). A further nine concrete words were selected as practice materials and used as warm-up trials in the experiment.
Fifty target stimuli, with two 5 × 5 matrices arranging items into semantically ‘homogeneous’ and ‘heterogeneous’ blocks (rows and columns, respectively).
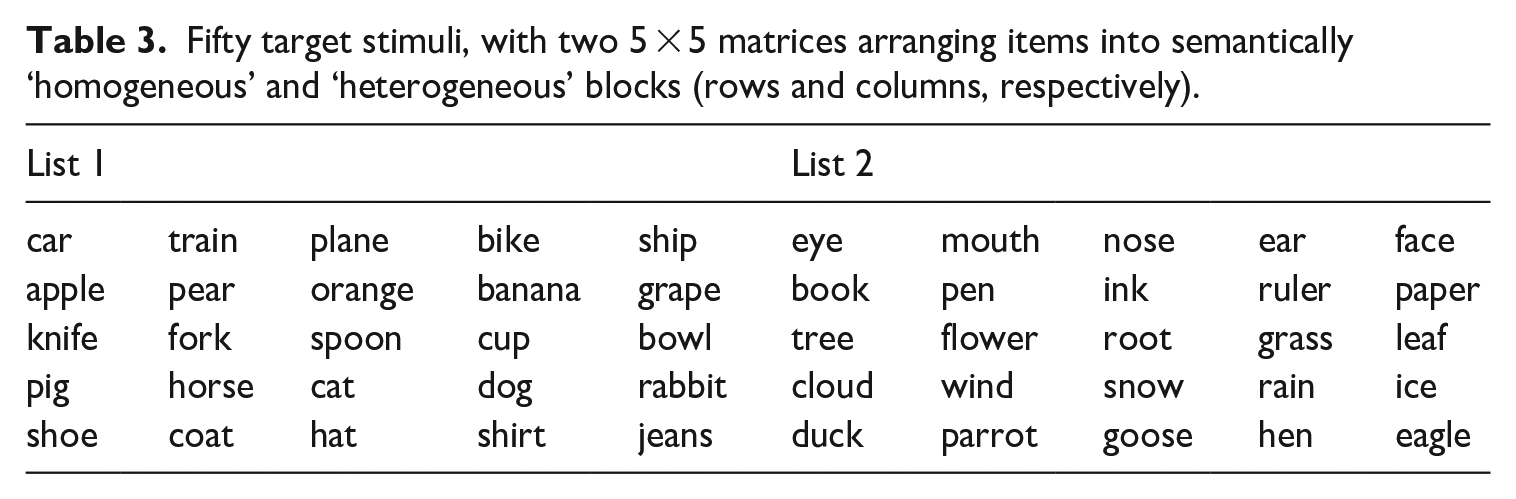
The 10 semantic categories were split into two lists (i.e. List 1 and List 2). In each list, 25 words were organized into a 5 × 5 matrix. Each row represented a category, thus creating five homogeneous (HOM) sequences of five words each. Each column represented five different sequences of the same size, but these sequences were mixed, thereby forming the heterogeneous (HET) condition (Damian et al., 2001). As such, in a list, the HOM block consisted of five semantically categorized sequences; whereas the HET block consisted of five semantically mixed sequences of the same size, with a constraint that words from the same category were separated by at least two semantically unrelated words.
Figure 1 shows the experimental pipeline. Participants conducted two sessions of translation tasks, one for Chinese-to-English and the other for English-to-Chinese, separated by 10–15 minutes. Each session consisted of three ‘cycles’. Within each cycle, the HOM and HET conditions were organized in four blocks that followed two different counterbalanced block orders (HOM–HET and HET–HOM), with each block having 25 words. More specifically, half of the 50 words from List 1 were arranged in a HOM block (Block 1) while the other half from List 2 were arranged in a HET block (Block 2). The words in the HOM block were then rearranged into a HET block (Block 3), while the words in the HET block were rearranged into a HOM block (Block 4). This arrangement was to ensure that each word was presented twice in a cycle, i.e. once in the HOM condition and once in the HET condition. 2
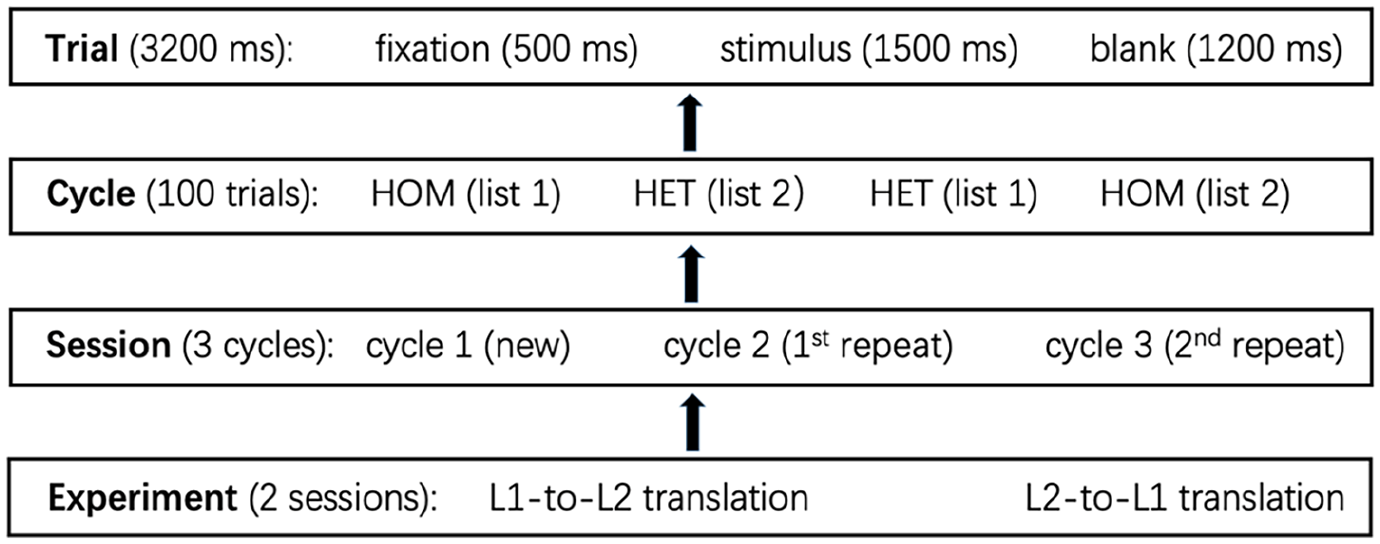
The experimental pipeline.
Therefore, the experiment followed a 2 × 3 × 2 design, with translation directionality (Chinese-to-English vs. English-to-Chinese), cycle (Cycle 1 vs. Cycle 2 vs. Cycle 3), and semantic context (HOM vs. HET) serving as within-participants variables. The HOM–HET or HET–HOM order remained identical across three cycles for each participant, but the order of semantic categories and the words within each category was pseudorandomized across cycles.
In total, the experiment included 600 trials, with 50 trials for each condition. Translation direction was counterbalanced across participants. In each trial, a fixation cross was displayed at the center of the screen for 500 ms. Subsequently, a word was presented for 1,500 ms or disappeared from the screen once the voice key was triggered. A blank screen then remained on the screen for 1,200 ms to serve as the inter-trial interval. The experiment was conducted in a sound-proof booth. E-Prime 3.0 software (Psychology Software Tools, Pittsburgh, PA) was utilized to display the trials on a DELL PC. The viewing distance from the screen was approximately 60 cm, with the screen having a refresh rate of 60 Hz and a resolution of 1024 × 768. Response times (RTs) were measured relative to stimulus onset by means of a Chronos microphone device (Psychology Software Tools, Pittsburgh, PA) and vocal responses were also recorded for offline check for erroneous responses. Meanwhile, outside the sound-proof booth, the experimenter coded errors on the spot via a wireless omnidirectional microphone system.
After signing informed consent forms, participants were seated in the dimly lit, sound-proof booth and tested individually. To familiarize participants with the task, 36 practice trials with nine practice words randomly repeated four times were conducted. The instruction and procedure in the practice session were identical to those in the experimental session: their task was to orally translate the word as quickly and accurately as possible (from Chinese into English or from English into Chinese, depending on the specific session). In the experiment, the first three trials within each block served as warm-up trials. At the end of the experiment participants were debriefed. Several days in advance of the testing sessions, participants were asked to fill out language background questionnaires, which served as a preliminary screening tool for participant selection.
IV Results
Trials were rated as incorrect (0.9% for forward and 0.8% for backward translation) if the participant made: (1) an incorrect translation; or (2) oral errors (a false start or an oral hesitation such as en, a). Response times (RTs) were analysed on valid trials only. Latencies from trials were also excluded from analyses if participants failed to respond within 2,000 ms (1.5% for forward, 2.9% for backward translation) or a response latency exceeded three standard deviations above or below the average (2.2% for forward, 1.2% for backward translation). 95.3% of trials remained in the response time analysis.
Response latencies were analysed with a linear mixed effects model which included translation direction, semantic context, and cycle. We used the R package afex (Singmann et al., 2024) with the Satterthwaite approximation, log-transformed latencies, and contrast-coded factors, and the package emmeans (Lenth, 2024) for follow-up comparisons. An initial model which specified a ‘maximal’ random effects structure (Barr et al., 2013) failed to converge; hence, we successively reduced model complexity by removing the correlations among the random terms, and further simplifying the structure of the random effects. The most complex model which successfully converged was log(RT) ~ translation_direction * semantic_context * cycle + (translation_direction + semantic_context || participant) + (translation_direction || stimulus).
Figure 2 shows estimated marginal mean conditional response latencies, separately for translation direction (Chinese-to-English vs. English-to-Chinese), semantic context (heterogeneous vs. homogeneous), and cycle (1–3). Results from the linear model showed that all three main effects were highly significant: a significant main effect of translation direction was found, F(1, 102.18) = 107.07, p < .001, with latencies 71 ms faster for forward (Chinese-to-English) than for backward (English-to-Chinese) translations (702 vs. 773 ms, respectively). A main effect of cycle was found, F(2, 39,713.57) = 1,021.81, p < .001, with progressively faster latencies across the three cycles (767, 729, and 714 ms, respectively). Holm-corrected comparisons showed that all three levels of the factor cycle differed significantly from one another, z ⩾ 12.63, ps < .001. A main effect of semantic context was found, F(1, 67.32) = 70.97, p < .001, with latencies 12 ms slower in the homogeneous than in the heterogeneous context (742 vs. 730 ms, respectively).
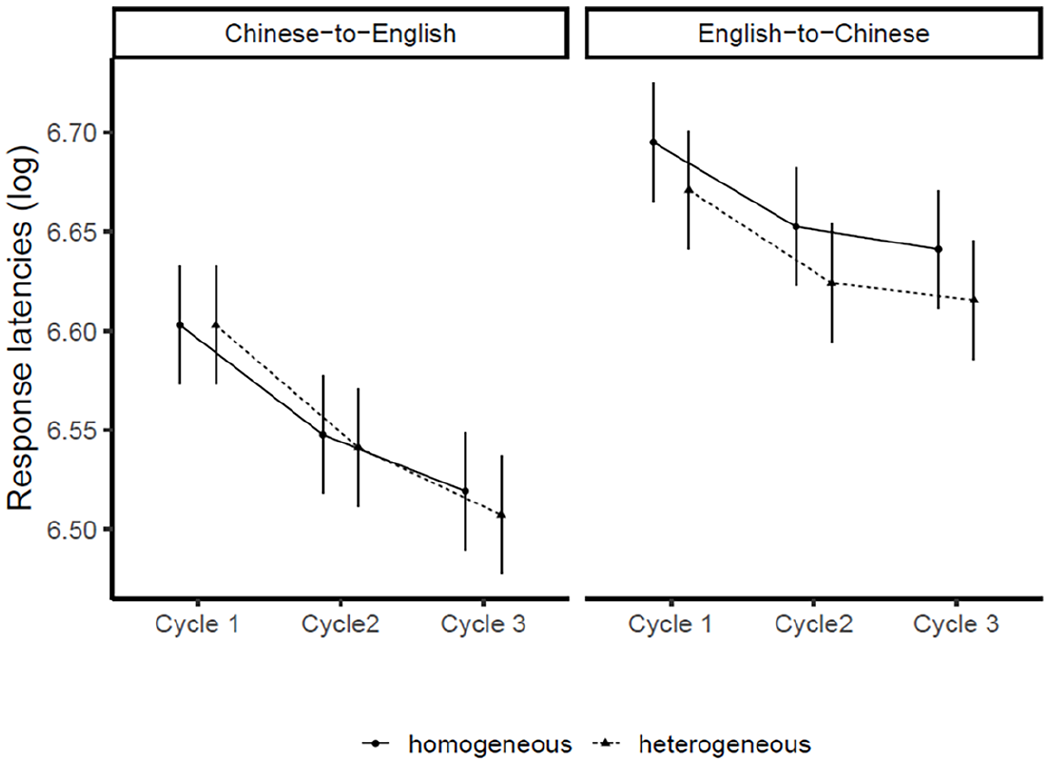
Estimated marginal means of response latencies (log-transformed) of word translation production as a function of translation direction (Chinese-to-English vs. English-to-Chinese), cycle (Cycle 1 vs. Cycle 2 vs. Cycle 3), and semantic context (homogeneous vs. heterogeneous.
Two significant interactions were obtained. An interaction between translation direction and semantic context was obtained, F(1, 39,722.30) = 55.36, p < .001, with the context effect much smaller in the Chinese-to-English (forward) direction (4 ms) than in the English-to-Chinese (backward) direction (20 ms). Follow-up analysis showed that the effect of context was significant for Chinese-to-English, z = 2.64, p = .008, and for English-to-Chinese, z = 11.12, p < .001. Furthermore, a significant interaction between translation direction and cycle was obtained, F(2, 39,715.75) = 57.93, p < .001, with the effect of cycle more pronounced in the Chinese-to-English (forward) translation direction than in the English-to-Chinese translation (backward) direction. Follow-up tests showed that for each translation direction separately, responses in all cycles differed significant from one another, z ⩾ 4.30, ps < .001. The interaction between semantic context and cycle was not significant, F = 2.32, p = .098, and neither was the three-way interaction, F = 1.43, p = .239.
Additionally, we conducted planned comparisons of the effect of semantic context, separately for each translation direction and cycle. Holm-corrected comparisons showed that for the Chinese-to-English direction, the effect at cycle 1 was not significant at cycle 1, ∆ = 0 ms, z = –0.01, p = .994, nor at cycle 2, ∆ = 5 ms, z = 1.85, p = .130, but it was at cycle 3, ∆ = 8 ms, z = 3.39, p = .002. For English-to-Chinese, the effects under all three cycles were highly significant, ∆ = 19, 22 and 19 ms, z ⩾ 6.70, ps < .001.
A parallel analysis was performed on errors, but with a binomial mixed effects model. The model with the most complex random effect structure which achieved convergence was error ~ translation_direction * semantic_context * cycle + (translation_direction || participant) + (translation_direction || stimulus). This model showed a significant effect of cycle, χ2(2) = 35.16, p < .001, with progressively lower error rates across the three cycles (1.2, 0.7 and 0.6%, respectively). Holm-corrected comparisons showed that error rates in cycle 1 were significantly higher than those in cycle 2 and cycle 3, z ⩾ 4.62, ps < .001, but error rates in cycle 2 and 3 did not differ significantly, z = 0.58, p = .564. Further, we found a significant effect of semantic context, χ2(1) = 14.98, p < .001, with error rates 0.3% higher in the homogeneous than in the heterogeneous context (1.0 vs. 0.7%). The main effect of translation direction was not significant, p = .135, and neither were any of the interactions, ps ⩾ .315.
V Discussion
The results of our study can be summarized as follows: (1) forward translation was substantially faster than backward translation (by 71 ms); (2) an overall significant inhibitory semantic context effect was found which interacted with the direction of translation: it was smaller in the forward (4 ms) than in the backward (20 ms) direction, with the effect in both directions statistically significant. An effect of ‘cycle’ was found, with latencies dropping across successive cycles. The effect of cycle was modulated by translation direction, with a more pronounced drop in the forward than in the backward direction.
In Section I, we summarized current thinking about how the mental lexicon of bilinguals is organized. We highlighted that the RHM featured direct associative links between translation equivalents, and an asymmetric structure resulting from stronger links from L2 to L1 than vice versa, and stronger links between L2 and concepts than vice versa. Our findings presented here are at odds with the predictions from this model. More recent models of bilingual organization have largely abandoned the notion of direct associative links and hence observed asymmetries in translation (and other) tasks must be accounted for via a different mechanism. What could account for our finding that forward translation was substantially faster than backward translation, and that the former exhibited smaller semantic effects than the latter? In unbalanced bilinguals, L2 representations are weaker than L1 ones, and so translation direction could in principle be asymmetric because the weaker system (L2) drives the receptive side in backward translation, but the productive side in forward translation. Hence in backward translation the difficulty is in the recognition of the to-be-translated word, whereas in forward translation it is in the production. Perhaps in our study forward translation was fast because Chinese words due to their L1 status gain quick and strong access to the conceptual system, and this strong conceptual activation drives efficient retrieval of the response word, even if that word resides in the relatively weaker L2 lexicon. By contrast, in backward translation the English words lead to relatively weaker and less stable conceptual activation which leads to a relatively slow retrieval of the appropriate response, even if this stems from the stronger L1 lexicon. The assumption of weaker / less stable conceptual activation in backward than in forward translation would also explain why semantic effects are more pronounced in backward than in forward translation: a less stable semantic system is plausibly more susceptible to semantic interference from related competitors than a stable one. Computational simulations are needed to evaluate whether these predictions bear out.
In our results, in the slower task (backward translation) semantic effects were larger than in the faster task (forward translation). Because slower responses are typically associated with larger experimental effects, perhaps some portion of the interaction which we found can be attributed just to the difference in overall response times. 3 This is a well-known problem when, for instance, investigating cognitive effects of ageing (older participants are typically slower than younger ones, and they also often show exaggerated experimental effects), and it is common to address this problem by analysing proportional, rather than absolute, experimental effects (via facilitation/interference ratios; e.g. Spieler et al., 1996). Descriptively, the semantic effect in our study corresponds to an effect of 2.6% in backward translation, but only 0.6% in forward translation; hence, the directional asymmetry is still present when overall response speed is taken into account. We additionally scrutinized the results from previous studies summarized in Table 1 in the same manner (is the slower translation direction associated with a larger semantic effect?) but were unable to identify a clear pattern.
As highlighted in Table 1, a wide variety of tasks and manipulations have been employed to test predictions of models of bilingual organization. To our knowledge, only two studies have adapted the ‘semantic blocked naming’ task to word translation. Vigliocco et al. (2002) used backward translation from English to Dutch in combination with semantic blocking, and reported a sizeable inhibitory semantic effect; however, forward translation was not included and so the results are difficult to interpret in the current context. The most directly relevant results were reported by Herrera (2019), although the main point of interest of that study was to explore the translation of number words. For non-number words which were also included in the semantic blocking task, Herrera reported slightly slower forward than backward translation speed, and slightly larger semantic effects in forward than in backward translation (i.e. effects opposite to ours). Compared to participants in our study, those in Herrera rated their L2 proficiency somewhat higher, which may explain why translation direction exerted only a very subtle effect. A further major difference is that Herrera’s study involved translation between (somewhat) similar languages (English/Spanish), whereas the latter involved two very different languages (English/Chinese). As outlined in Section I, Sakaki et al. (2012) postulated that the relationship between the two languages of a bilingual may play a major role in how their mental lexicon is organized and that the role of language proficiency is particularly crucial when the language combinations are dissimilar, whereas for more similar language pairs the asymmetry might be independent of proficiency. Language similarity and its interplay with L2 proficiency as a potential factor is currently poorly understood and more research is needed. A further – and related – difference between Herrera’s and our study is that the former used two languages with alphabetic orthography, whereas in our study one script was alphabetic (English) whereas the other one was logographic (Chinese). Could orthographic similarity play a role? Despite fundamental differences in how the orthographic system is organized, processing appears remarkably similar across different scripts. For instance, Zhang et al. (2023) compared word processing in Chinese (logographic) and Mongolian (alphabetic), and event-related potentials (ERPs) indicating early lexical processing showed a similar time course and topography in both languages. Participants in our study not only had weaker L2 representations, but also less exposure to an alphabetic orthographic system. Perhaps this aspect contributed to the asymmetry regarding overall translation speed: in backward translation, participants not only had to decode a word from the relatively weaker language, but also they had to deal with a less familiar orthographic system. Both aspects of this constellation (weaker L2 representations, but also less familiar orthography) could have potentially contributed to the weaker or less stable semantic activation which we hypothesized above, and which, in turn, would lead to stronger semantic effects in backward than in forward translation.
Application of the semantic blocked naming technique to the issue of word translation has been explored only in a few studies, but a variety of other techniques that are summarized in Table 1 have been previously used to investigate the issue. It is therefore important to interpret our findings in the wider context of these studies as well. As highlighted in Section I, the reported findings in the literature are remarkably inconsistent: some studies have reported the asymmetry originally reported by Kroll and Stewart (1994), i.e. faster backward than forward translation, but others have found the opposite pattern (e.g. De Groot and Poot, 1997) or similar translation speed in both directions (e.g. La Heij et al., 1996: Exp. 1). Likewise, with regard to the predicted asymmetry in semantic effects, some studies have found stronger effects in forward than in backward translation (e.g. Sakaki et al., 2012; Sholl et al., 1995) but others reported symmetrical effects (e.g. De Groot and Poot, 1997) or even a reverse asymmetry (e.g. Herrera, 2019). A number of studies have highlighted the role of L2 proficiency (e.g. Christoffels et al., 2006; De Groot and Poot, 1997) but it is difficult to operationalize this variable across studies and languages. Overall we conclude that, at present, a coherent account of the wide range of findings from word translation studies remains elusive.
The challenge is even more pronounced when additionally considering studies that have explored the structure of the bilingual lexicon with tasks that do not require explicit translation. For instance, a sizeable literature exists on ‘cross-language priming effects’ (e.g. Altarriba, 1992; De Groot and Nas, 1991). In studies of this type, a prime is presented in one language, often in masked form, and a target is presented and processed in the other language, with various types of relationships between prime and target. The extant literature presents with an extraordinarily complex picture, with prime/target relation (translation equivalents; semantically or form-related pairs), cognate status, orthographic similarity of language pairs, experimental task performed on the target (e.g. lexical decision, naming, semantic categorization), and temporal delay between prime and target all important variables. It is beyond the remit of the current article to summarize this literature (for a comprehensive overview, see Jiang, 2015). Having said that, ultimately computational models of bilingualism will have to account for results both from studies that require explicit word translation (such as the current one), and from studies that, although not requiring word translation, are nonetheless relevant for figuring out how the bilingual lexicon is organized.
As highlighted in Section I, the Multilink model recently introduced by Dijkstra et al. (2019) provides an integrated account of bilingual word recognition and translation. Notable is the absence of direct links between the two lexicons and, hence, translation must necessarily take place via conceptual mediation. The authors provided a simulation of the results reported by Christoffels et al. (2006), summarized in Table 1, who found faster forward than backward translations in Dutch–English bilinguals (as we did in our current study), and a larger effect for low proficiency bilinguals. Multilink approximated this pattern in its simulation results (it should be noted that the emphasis was on processing of cognate vs. non-cognate word pairs of high and low frequency, an issue which is not relevant in the present context). These results appear promising, despite the fact that Multilink in its current form is a model of alphabetic word processing (its input orthography layer consists of letter codes). Perhaps such a model could be expanded to incorporate non-alphabetic orthographic codes as well, such as those presumably used in our study when bilinguals translated words from Chinese into English.
A further interesting model of bilingual organization, briefly alluded to in Section I, is the Sense Model introduced by Finkbeiner et al. (2004). The central assumption is that most words have multiple usages/senses, and that words in L1 typically evoke a richer set of senses compared to L2 words. In the model, L1 and L2 lexicons map onto a shared conceptual system, which is represented in terms of distributed conceptual features (for earlier work, see De Groot, 1992). Via the notion that L1 words evoke a larger set of senses than L2 words do, this model elegantly accounts for asymmetry of semantic priming effects in lexical decision tasks, dependent on direction. Perhaps the suggested sense asymmetry could also explain the asymmetry of semantic effects in our results. In the experimental paradigm, the semantic effect arises as a consequence of very few words being grouped by semantic category (car–train–plane–bike–ship) or not (car–apple–knife–pig–shoe) and to be translated with their dominant noun sense. It is possible that, in the forward translation direction, an L1 word is presented and gives rise to a rich constellation of semantic features/senses that is largely immune to interference from semantically related set members in the semantically homogeneous condition. By contrast, a visually presented L2 word leads to a sparser semantic activation that is less stable and more susceptible to semantic interference. Computational modeling is needed to explore whether this speculative account bears out.
We take our results to argue against the possibility of direct inter-lexical links between translation equivalents (particularly in the L2-to-L1 direction, as originally hypothesized in the RHM). Our inference converges with conclusions drawn recently by Wu and Juffs (2019) based on an interesting methodological variation. These authors hypothesized that the null finding for semantic effects in backward translation originally reported by Kroll and Stewart (1994) may have come about due to a semantic facilitation effect residing in the L2-to-concepts pathway which cancelled out semantic interference and which is presumably present in both forward and backward translation in the concept-to-response pathway. They asked young Chinese–English bilinguals and English monolinguals to carry out a semantic judgement on word pairs presented in English (‘judge which word’s real-world referent is bigger in size’). A category facilitation effect based on presenting word pairs either in categorized or randomized lists was found not only for English native speakers who engaged in L1-to-concept processing, but also for the bilinguals who processed words in L2. The authors inferred that, in Kroll and Stewart’s experiment, speakers carrying out backward translation experienced facilitation (from L2-to-concepts) and interference (from concepts-to-L1 word production) simultaneously, which may have resulted in a net null effect. If so, the two opposing forces need not cancel each other out perfectly, which may help explain some of the diversity in findings reported in previous translation studies (see Table 1). However, in our own experiment, semantic effects were actually significantly larger in backward than in forward translation, a pattern that we find difficult to explain with the assumption of a complex interplay between semantic facilitation and interference.
In summary, our word translation study with Chinese–English bilinguals showed faster forward (L1 to L2) than backward (L2 to L1) translation speed, and more pronounced semantic context effects in forward than backward translation. Our results add to a complex literature that has explored the structure and organization of the bilingual lexicon via word translation and other techniques. Moreover, a comprehensive theoretical account that could explain the wide range of existing results remains elusive at present. Nonetheless, studies that require explicit word translation, as the current one, provide important constraints on current and future theoretical models of bilingualism.
Footnotes
Acknowledgements
For the purpose of open access, the authors have applied a Creative Commons Attribution (CC BY) license to any Author Accepted Manuscript version arising from this submission.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the National Social Science Foundation of China grant number 21XYY001.