
Abstract
The cognitive entrenchment of frequent sequences comes as ‘chunking’ (holistic storage) and as ‘procedure strengthening’ (predicting elements in a sequence). A growing body of research shows effects of entrenchment of multi-word sequences in the native language, which is learned and shaped continuously and intuitively. But how do they affect second language (L2) speakers, whose language acquisition is more analytic but who nonetheless also learn through usage? The present study tests advanced English learners’ receptive processing of multi-word sequences with a word-monitoring experiment. Recognition of to in the construction V to Vinf was tested for full and reduced forms ([tʊ] vs. [ɾə]), conditioned by the general frequency of the V-to sequence and the transitional probability (TP) of to given the verb (V > to). The results are compared with those previously obtained from native speakers. Results show that recognition profits from surface frequency, but not from TP. Reduced forms delay recognition, but this is mitigated in high-frequency sequences. Unlike native speakers, advanced learners do not exhibit a chunking effect of high-frequency reduced forms, and no facilitating effect of TP. We attribute these findings to learners’ lesser experience with spontaneous speech and phonetic reduction. They recognize reduced forms less easily, show weaker entrenchment of holistic representations, and do not draw on the full range of probabilistic cues available to native speakers.
Keywords
I Introduction
According to usage-based models of language, speakers’ grammatical competence develops through experience with linguistic forms and structures (Bybee, 2010; Diessel, 2019; Ellis, 2013, 2019; Goldberg, 2006; Tomasello, 2000, 2005). Language learning is ‘a predominantly inductive and experience-driven process’ (Wolter and Gyllstad, 2013: 452), in which the frequency of linguistic items and their combinations play a central role. From this perspective, any language acquisition results from ‘an accumulation of statistical probabilities and abstraction of regularities out of previous construction encounters’ (Supasiraprapa, 2019: 988). Thus, the mind builds up its knowledge of linguistic structures by forming dynamic associations between signs or constructions. These can achieve different degrees of cognitive entrenchment (Blumenthal-Dramé, 2012, 2018; Langacker, 1987). A high degree of entrenchment increases the probability that a particular linguistic item will be (re)used in the future, as well as reinforcing the associations in which that linguistic item takes part (see Balog, 2023; Diessel, 2019; Schmid, 2015, 2020).
Support for the usage-based perspective comes from studies demonstrating that language users are sensitive to frequency effects across different levels of the system: pronunciation variants (Brand and Ernestus, 2018; Bürki et al., 2011; Connine and Pinnow, 2006), syllables, morphemes, words (Alvarez et al., 2001; Reichle and Perfetti, 2003), phrasal and clausal structures (Arnon and Snider, 2010; Bannard and Matthews, 2008; Jurafsky et al., 2001; McConnell and Blumenthal-Dramé, 2021; Reali and Christiansen, 2007). At the phrasal level, for instance, Bannard and Matthews (2008) and Arnon and Snider (2010) show that children and adult first language (L1) speakers, respectively, process frequent multiword sequences faster than low-frequency ones.
A number of studies have suggested a similar role for frequency and intuitive statistics in the learning of a second language (Diependaele et al., 2013; Ellis, 2019; Ellis et al., 2016; Hernández et al., 2016; Ortega, 2013; Sonbul, 2015; Supasiraprapa, 2018, 2019; Wolter and Gyllstad, 2013). On the other hand, it has been argued that frequency information is not as central, or that it might be processed differently, in L2 learning because of nonnative speakers’ more analytical/non-formulaic approach to the target language (Wray, 2002), or because of the meddling of automatized routines shaped in the L1 (Ellis, 2006: 164). Yet, proficient learners have shown a notable degree of reliance on frequency information in language perception (see Durrant and Schmitt, 2010; Siyanova-Chanturia et al., 2011; Supasiraprapa, 2019; Wolter and Gyllstad, 2013; Yamashita and Jiang, 2010).
The present study re-examines these issues with regard to the entrenchment of multi-word sequences and processing of reduced forms. While multi-word frequency effects have been found in second language use and perception (see Section I.1), the possible routes of entrenchment (as either ‘procedure strengthening’ / sequential knowledge or ‘chunking’ / holistic access; see Section I.2) have rarely been discussed explicitly. Therefore, we address the following questions:
To what extent do second language learners form holistic units from frequent compositional sequences?
Do they rely on probabilistic information in receptive processing?
How do frequency-based expectations affect their recognition of reduced forms, given that reduction generally poses a problem even to advanced learners (Ernestus et al., 2017)?
We investigate the interplay of frequency information and reduction in the perception of English verb + to-infinitive sequences (V to Vinf, e.g. want to Vinf, pretend to Vinf) with advanced L2 learners (L1 Spanish). The experiment design – a word-monitoring task – is adapted from a previous L1 study (Lorenz and Tizón-Couto, 2019). The results can therefore be directly compared to those from native speakers.
The remainder of this introduction provides a review of entrenchment of multi-word sequences. Section II presents the experiment materials and design, including a list of variables considered and the data analysis procedure. The results are shown in Section III. We discuss the findings and compare them to those from native speakers in Section IV. Section V summarizes the main findings, suggesting that proficient L2 listeners draw on frequency information, but do not avail themselves of the full range of it.
1 Entrenchment of multi-word sequences in L2 learning
Entrenchment as an effect of frequency is known to pertain not only to single items but also to sequences. A deeply entrenched multi-word sequence may be produced or understood without the need to process every element incrementally (see Balog, 2023: 214–218; Blumenthal-Dramé, 2018; Siyanova-Chanturia, 2015), and ‘phrases that are of sufficient frequency can attain independent representation as a way of making processing more efficient’ (Arnon and Snider, 2010: 69). Although the nature of this independent mental representation is complex (and deserves further explanation; see Section I.2); existing research attests to the effects of frequency and entrenchment of multi-word sequences in the native language, which speakers learn and shape continuously and intuitively (see Arnon and Snider, 2010; Blumenthal-Dramé, 2018; Kapatsinski and Radicke, 2009; Reali and Christiansen, 2007; Siyanova-Chanturia et al., 2011; Sosa and MacFarlane, 2002; Tremblay et al., 2011).
Even though the acquisition process of a second language usually differs from that of the native language, there is good evidence that (proficient) L2 learners can also use frequency information to process language beyond the single-word level, as in formulaic sequences and collocations. For instance, a number of studies have confirmed the more efficient processing of formulaic sequences (e.g. take the bull by the horns) by L2 learners: they are processed faster and more accurately than nonformulaic sequences (Conklin and Schmitt, 2008; Jiang and Nekrasova, 2007; Underwood et al., 2004; Yamashita and Jiang, 2010). Similar findings have been reported with (non-formulaic) collocations and multi-word sequences. Durrant and Schmitt (2010) show that proficient learners can memorize lexical items better from collocations (
However, other studies have reported that collocations and multi-word expressions pose a challenge to non-native speakers, and that other factors may impede learners’ sensitivity to frequency. González-Fernández and Schmitt (2015) find only a modest frequency effect for the knowledge of two-word collocations by Spanish learners and highlight the role of language exposure (similarly, Smith, 2021). Fioravanti et al. (2021) suggest that (non-)compositionality plays a greater role than frequency, such that chunking might be limited to non-compositional idioms in L2 learners. In von Stutterheim et al.’s (2021) study on expressions of motion events, the typical event construal in the L1 appears to determine proficient non-native speakers’ choice of constructions, overriding the effect of frequency in the L2.
Overall, there is strong evidence that gradual, frequency-driven entrenchment of multi-word sequences plays a role in L2 learning, especially at higher levels of proficiency. The jury is still out on whether or how this differs from processes in the L1. More specifically, an open question regards entrenchment as ‘chunking’ versus sequential knowledge, as discussed in the next section.
2 Entrenchment of sequences and chunking
Entrenchment of a frequent sequence can be apprehended in two different, though not mutually exclusive, ways. First, what is strengthened in memory may be the string as a whole, i.e. a complete, largely invariant phrase or bigram, such as I don’t know or want to. This view corresponds to the notion of chunking, which leads to a memory representation as a single unit in which internal elements and boundaries are no longer salient or perceptually relevant (see Bybee, 2006; Diessel, 2007; Ellis, 2002a, 2002b; Ellis et al., 2008). Second, a sequence can be entrenched by ‘procedure strengthening’ (Divjak and Caldwell-Harris, 2015: 66–67; Hartsuiker and Moors, 2018). The individual elements are not backgrounded, but rather predictable from each other, due to a tacit knowledge of their frequent co-occurrence.
In both perspectives, entrenchment provides a general processing advantage for the respective sequence: a holistic unit is more easily recognized than an assembled string of items, as is a predictable sequence.
It has been suggested that procedure strengthening and chunking are on a continuum: A frequent sequence is entrenched as a procedure, and this entrenchment eventually leads to an increasingly holistic perception and storage, i.e. chunking (see Blumenthal-Dramé, 2012: 68–69; Langacker, 1987: 59–60). This has been supported by word-monitoring studies which find chunking effects only at very high collocation frequencies (Kapatsinski and Radicke, 2009; Sosa and MacFarlane, 2002). However, given that mental representations are gradient and can be redundant (see Elman, 2009), a stored ‘chunk’ does not preclude recognition of the sequence, and a phrase might even be acquired as a whole before its composition from the parts (see Arnon and Christiansen, 2017: 632; Siyanova-Chanturia, 2015). That the components of frequent sequences remain relevant is shown by Arnon and Cohen Priva (2014), where both n-gram frequency and individual word frequency showed effects on word durations in speech production (see also Konopka and Bock, 2009; Molinaro et al., 2013; Snider and Arnon, 2012). Moreover, individuals differ in their tendency to focus on the elements or the whole (McConnell, 2023; see also Balog, 2023).
The status of a ‘chunk’ need not be strictly a matter of ‘stored vs. computed’ (Caldwell-Harris et al., 2012: 4). It can be defined by ‘global precedence’, by which ‘the configuration as a whole is cognitively more prominent than its individual component parts’ (Blumenthal-Dramé, 2018: 138). A holistic and a compositional access can be activated at the same time, at varying levels. This also shows in our earlier findings (Lorenz and Tizón-Couto, 2019), where a chunking effect depends not just on frequency but also on form (reduction). Phonetic reduction is known to result from entrenchment generally. Yet, its role in L2 processing is still under-researched.
As this summary shows, it is important to ‘directly [consider] the relationship between the parts and the whole’ (Siyanova-Chanturia, 2015: 291), as well as the forms they take. The present study addresses this by means of a word-monitoring experiment with advanced L2 learners of English.
II Method
Our study focuses on the V + to-infinitive (V to Vinf) construction in English. High-frequency types of this construction (e.g. have to Vinf, want to Vinf) are often regarded as chunks and frequently reduced in spontaneous speech (see Krug, 2000; Lorenz and Tizón-Couto, 2024a; Tizón-Couto and Lorenz, 2018). We might assume that the rate and degree of reduction is directly linked to the item’s general frequency (Bybee, 2001: 165–166, 2006; Ellis, 2002b: 331) and to its predictability in context (see Flach, 2020; Levshina and Lorenz, 2022). However, usage of a reduced variant is also contingent on register and style (Berglund, 2000; Levshina and Lorenz, 2022; Lorenz, 2020), as well as morpho-phonological properties and semantic transparency (Lorenz and Tizón-Couto, 2020). Some reduced forms have acquired degrees of conventionality, even to the point of divergence and ‘emancipation’ from the source form (e.g. gonna vs. going to; Lorenz, 2013; Mahler, 2022).
We investigate how chunking and procedure strengthening apply to V to Vinf constructions by testing the recognition of the element to. If the element is predictable due to the frequency of the sequence or its likelihood given the preceding verb, this should result in faster recognition. If, on the other hand, the V-to item is initially perceived as a chunk, recognition of the element will be slowed down. Importantly, we include full and reduced realizations, to see how probabilistic expectation might help non-native listeners cope with reduction.
1 Experiment design and task
The experiment is a replication of the word-monitoring task reported in Lorenz and Tizón-Couto (2019), except with advanced learners of English instead of native speakers. The task consists in listening to recorded sentences and responding to the word to (or noting its absence) as quickly as possible.
The participants were 44 Spanish learners of English living in the region of Galicia (all right-handed and of normal hearing). All had a certified C1–C2 level of proficiency according to the Common European Framework of Reference (CEFR, 2001).
The input material was recorded by a female speaker with a General American accent. The experiment comprises 126 sentences, of which 42 each are target, control and distractor items (for a list of the items, see Appendix 1 in supplemental material). Target items contain a V to Vinf construction – examples (1a) and (1b) – control items contain to in a different context (2), and distractors include no to at all (3). The control items contain the same verbs as the target items, but with a different complement (e.g. prefer and agreed in example (2); compare (1a)–(2a) and (1b)–(2b)), so that participants could not expect a V to Vinf pattern whenever the verb might trigger it.
(1) a. When the monkeys have their party I prefer to leave the house. b. The elephants all agreed to have their tusks painted. (2) a. At dinner parties I prefer penguins to monkeys. b. We all agreed that it was a bad idea to paint the elephants’ tusks. (3) There is just no point in teaching the crocodiles manners.
Target items come in one of two forms: A full form in which to is fully articulated [tʊ], or a reduced form with to pronounced with an alveolar flap and a schwa [ɾə]. Each participant was assigned to one of two versions of the presentation list, so that they would hear half of the items in the full form and the other half reduced. While one version contained, for example, prefer [tʊ] and remember [ɾə], the other version had prefer [ɾə] and remember [tʊ]. Apart from this, the items were the same.
The experiment was carried out on a laptop computer with OpenSesame (version 3.2.6; Mathôt et al., 2012) with the ‘Expyriment’ backend (Krause and Lindemann, 2014). Participants heard the stimuli on studio over-ear headphones and were asked to hit a marked button on the keyboard as soon as they heard the word to; another button was to be pressed if to was absent from the sentence. The response and reaction time (from onset of to) were recorded. The actual task was preceded by a practice round of four items; stimuli in the main task were presented in random order. To ascertain participants’ continuing attention, short questions about the content of individual sentences were strewn in at varying intervals.
2 Variables
The variables and analysis are built on our previous experiment (Lorenz and Tizón-Couto, 2019: 757–760), with the addition of control variables which particularly relate to L2 acquisition. Our main analysis concerns response times (RTs) on correctly identified items, as a measure of processing effort. RTs were measured from the onset of to, i.e. from the release burst of the plosive. For the analysis, we transformed them to logarithmic values, so as to not overestimate the differences between longer response times (see Baayen, 2008: 30).
We also tested for the following set of control variables.
a Frequency of to-Vinf and backward transitional probability
Phonetic reduction of an item can be conditioned by its collocational frequency with the following word (see Barth and Kapatsinski, 2017; Bell et al., 2009; Gradoville, 2017; Kilbourn-Ceron et al., 2020). A word that often occurs after to might aid the hearer to more quickly detect the element to. This is controlled for by considering both the surface frequencies of to-Vinf sequences and the probability of to given the following word (backward TP), as derived from the spoken section of COCA.
b Verb duration, syllable count and verb form
The duration of the verb in each V-to item was measured, ranging from 182 ms to 590 ms (mean = 350 ms). Since many verbs are monosyllabic, an additional factor considers whether the verb has one syllable or more. The inflectional forms of the Vs reflect the form with the highest surface frequency in the corpus (e.g. trying for the lemma
c Merged plosive cluster
In verbs ending in alveolar stops (/d/ or /t/ in need to or forgot to), this sound merges with the initial /t/-sound in to, regardless of its variant (full or reduced). The separation between the verb and to is less marked in these cases (19 out of 42) and might delay recognition.
d Preceding sound
Lenited /t/-sounds are typically disfavored after fricatives in speech production (see Lorenz and Tizón-Couto, 2024a). Because some of our experimental items include this context (10/42), the sound segment preceding /t/ was coded for two levels: fricative (e.g. deserve to) or vowel/nasal (e.g. continue to, began to).
e Control before target and item count
This variable checks whether the control item with a given verb was heard before the target item with the same verb, as this situation might have led to a priming effect.
To control for learning or fatigue effects, the item count during the experiment was considered, both as a control variable and as a by-participant random slope in the statistical model (see Section II.3).
f Gender and age
Participants were asked to provide their details as they were introduced to the experiment. Twenty-seven reported ‘female’, 15 ‘male’ and one ‘other’. Age was taken up by year of birth and ranges from 17 to 54 years (mean = 30; median = 27).
g Proficiency level of participants (certificate and test score)
So as to cross-check the proficiency levels certified by the participants (C1 or C2 in CEFR) before the experiment, they completed a brief comprehension test consisting of two listening tasks. They listened twice to two original recordings of American English extracted from a lecture and a radio programme, and then had to fill gaps of one to four words in 18 sentences (9 per task) about the content of the recordings. The two tasks were designed on the basis of the guidelines for standardized tests for the C1 level, in particular those implemented at Escuela Oficial de Idiomas (Specialized Official Foreign Language Education) within the Spanish educational system. The proficiency level of participants was coded on the basis of both their overall certification and the score they achieved in the listening comprehension test. The latter measures listening proficiency directly, which is especially relevant for the experiment.
h Years of learning English and time abroad
Participants were asked to provide the number of years learning English at school, high school, university or elsewhere. They also listed previous stays in English speaking countries which were longer than one month. This variable was coded as ‘none’, ‘UK’, or ‘America’ (where ‘America’ means any stay in the U.S.A. or Canada).
i Congruency
The native languages of the participants are Spanish and Galician. 1 These two languages might feature either a particle (que, a, de, etc.) between the V and the Vinf in instances corresponding to the English ‘V to Vinf’ construction (e.g. tengo/teño que ver, comenzar/comezar a sentir, tratar de explicar) or an empty slot (zero in quiero/quero comer, necesita parar, etc.). On the basis of the distinction proposed in Yamashita and Jiang (2010) or Wolter and Gyllstad (2013) for two-word collocations, we coded this variable as ‘congruent’ (the corresponding Spanish/Galician sequence includes a particle) or ‘incongruent’ (the Spanish/Galician equivalent does not include a particle).
3 Data analysis
The experiment yielded 3,612 responses in total (1,806 each of target and control items). We define a correct response to a target item as identifying to within 100–3,000 ms of its onset. Earlier or later responses, even if correct, are arguably due to either false recognition or later-stage re-processing after hearing the complete sentence. The resulting accuracy rate on target items, i.e. the rate of correct responses, is 78% (1,412/1,806). 2
The analysis of response times concerns only correct responses to target items. After removing individual outliers (by-subject z-score > 2.5; see Baayen and Milin, 2010: 16), the final data set comprises 1,372 data points. We modeled the results by way of a mixed-effects generalized additive model (GAM; Wood, 2017) on the logarithmized response times.
3
A GAM can represent correlations without enforcing a linear correspondence between variables. We applied exactly the same modeling procedure as in the native-speaker study, where it is laid out in fuller detail (Lorenz and Tizón-Couto, 2019: 760–761). We employ
The resulting model includes the control variables logrt ~ s(logfreq, bs = ‘cr’, by = condition) + s(TP, bs = ‘cr’, by = condition) + s(subject.fac, bs = ‘re’) + s(verb, bs = ‘re’) + s(count_exp_items, subject.fac, bs = ‘re’) + s(condition, verb, bs = ‘re’) + condition + backward_TP + log(verb_duration) + condition * plosive_cluster + condition * prec.sound + condition * test_score
III Results
We first report briefly on accuracy, as incorrect responses are a coarse indicator of recognition problems – more detail and the statistical model for accuracy can be found in Appendix B in supplemental material. Between conditions, the accuracy rate is significantly lower for reduced forms (67%) than full forms (89%). Moreover, accuracy on reduced forms is lower with low-frequency items (see Appendix B in supplemental material). This confirms the expectation that reduced forms are more difficult to recognize, especially in less common, less familiar bigrams.
The core of the study design is the response times (RT) when to was correctly recognized. Overall, reduced items come with greater response latencies, compared to both full and control items (see Figure 1). These differences match those produced by native speakers, although native speakers showed a higher overall accuracy (86%; Lorenz and Tizón-Couto, 2019: 761).
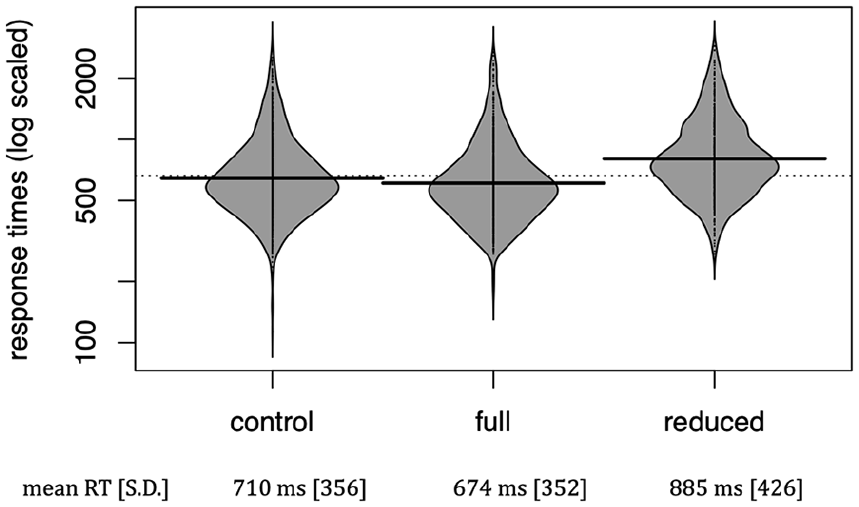
Beanplot:* Response times to control, full and reduced items (correct responses only).
How are these response latencies affected by bigram frequency, transitional probability, or other variables? The main results – for the test variables
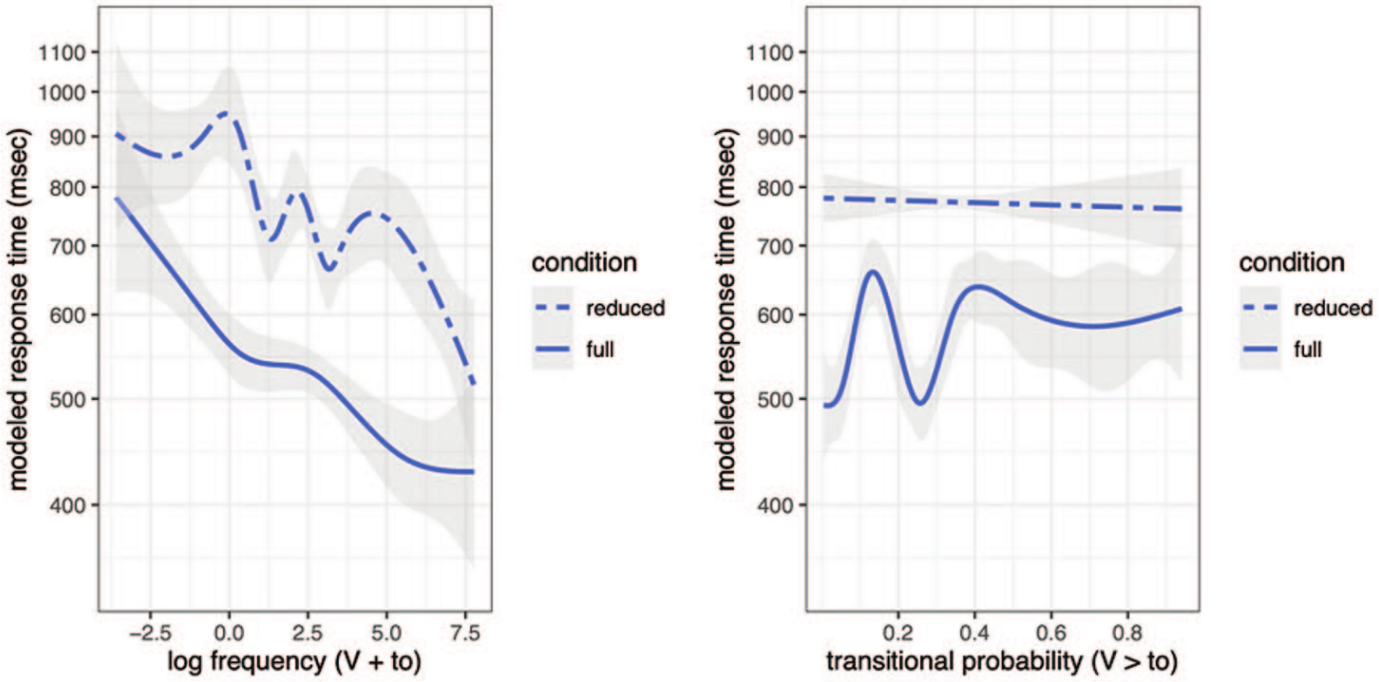
Response times to full and reduced items by
In both graphs, recognition of reduced items is consistently slower than that of full forms, as expected. Surface frequency (Figure 2, left panel) shows a continuous facilitating effect on full forms, with only slight bends in the curve (left panel, blue line). The effect of frequency with reduced items is more erratic, but also generally such that higher frequency aids recognition, with the strongest effect at the high end of the frequency scale (the steep downward slope between log frequency 5.0 and 7.5). It is in these high-frequency sequences that we might expect delayed responses due to chunking, as was observed with native speakers. Advanced learners show no indication of such a chunking effect, though they clearly are responsive to bigram frequency in terms of procedure strengthening.
The transitional probability of to given the preceding verb has no evident effect on its recognition (Figure 2, right panel). The fluctuation in the curve for full forms shows that there is some variance between items, but the result is inconclusive at best. Generally, reduction delays recognition evenly across the TP range. This is different from the finding with native speakers, where reduced item recognition profited immensely from high TP. Thus, advanced learners seem to lack the sensitivity to this conditional frequency measure that native speakers have.
Five additional variables turned out to affect response times (see Figure 3). Three of these concern acoustic/phonetic properties of the main verb:
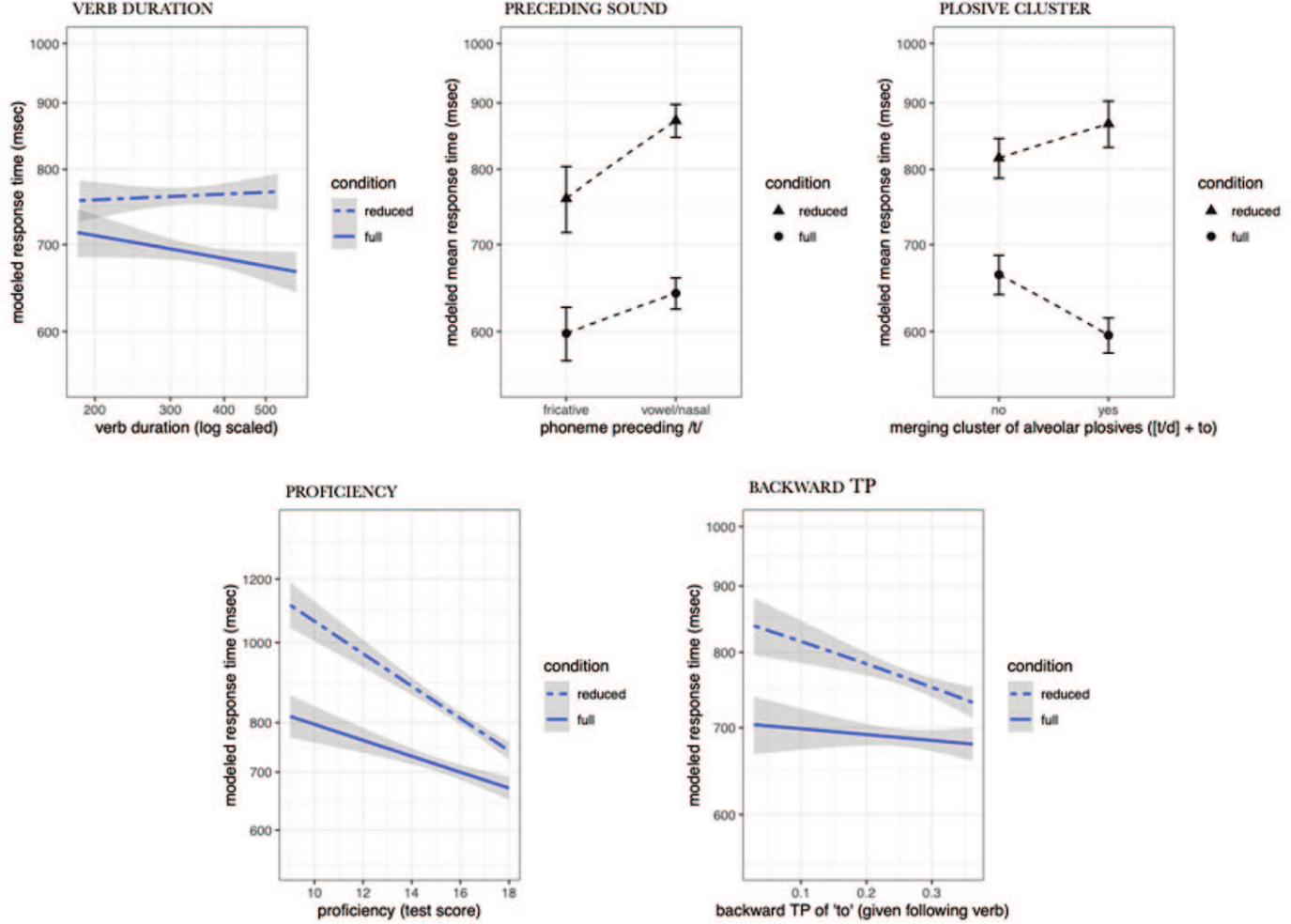
Response times to full and reduced items by control variables.
Participants with higher test scores respond faster in both conditions, though the effect is stronger with reduced items (Figure 3, lower left panel). Apparently there are large differences even between advanced learners in how effectively they process spoken input and how well they can cope with reduction. However, we do not find any effect of
A merged
An additional – and surprising – relevant variable is
IV Discussion
We first discuss the results of the word-monitoring study with advanced learners of English in comparison to those gained from native speakers with the same study design (Lorenz and Tizón-Couto, 2019). Then we will relate the findings to what is known about second language processing and comprehension.
First, it is no surprise that learners show a lower accuracy rate and longer response times overall. Processing a spoken input in a foreign language clearly is more difficult than in the native language (see Arnon and Christiansen, 2017; and, for an overview, see Ernestus et al., 2017: 3–4). However, the relative delay and lower accuracy in response to reduced forms is very similar between the cohorts. Reduction generally makes for a less clear acoustic signal, which puts the burden of reconstructing the item on the hearer (see Ernestus, 2014; Ernestus et al., 2002; Lindblom, 1990). This has been shown even for frequently reduced items (Pitt, 2009; Pitt et al., 2011; Ranbom and Connine, 2007), and it holds in our results for advanced learners (this study) as well as native speakers (Lorenz and Tizón-Couto, 2019).
How do advanced learners make use of frequency information, compared to native speakers? To what extent do they form sequential expectations or holistic units from compositional sequences? In Lorenz and Tizón-Couto (2019) we have adopted a view that high-frequency combinations can be entrenched first as sequential information (‘procedure strengthening’) and, second, as holistic storage (‘chunking’); see Section I.2 above, and Divjak and Caldwell-Harris (2015), Siyanova-Chanturia (2015), and Blumenthal-Dramé (2018). We argued that these are not mutually exclusive; reduced forms can make the individual parts less discernible and give prominence to the whole, while full forms make it easier to recognize the items in sequence. Moreover, native speakers identify reduced items more quickly when they are predictable from the immediate context (as measured by transitional probability). This implies a tacit knowledge of conditional probabilities and the ability of ‘predictive processing’, of intuitively forming and updating expectations of what comes next (see Divjak, 2019, chapter 8; Kuperberg and Jaeger, 2016; Pickering and Garrod, 2007). With native speakers, these expectations come to bear when facing a reduced input, that is, as a ‘helping hand’ when the acoustic signal is weakened (Huettig and Mani, 2016; for a recent discussion, see McConnell and Blumenthal-Dramé, 2021). In our present findings, advanced learners are sensitive to frequency information, too, and can reach for its ‘helping hand’. They clearly profit from higher bigram frequencies, which we interpret as an entrenchment effect in terms of procedure strengthening. However, this is limited to surface frequency: the more complex cue from transitional probability seems to require more experience to enable reliable predictions (see also Grüter and Rohde, 2021).
We also do not observe a chunking effect with high-frequency bigrams. This might be explained in two ways: first, if chunking only sets in at very high frequencies, most learners may simply not have had the necessary amount of exposure, especially to reduced forms; second, learners might be trained to parse structures in the target language in a more analytical, word-by-word fashion (see Wray, 2002: 205–206). Moreover, the task of the present experiment rather discourages holistic processing, so the effect of chunking will only show when it indeed overrides sequential prediction. Other studies that show collocation frequency effects in learners have evoked chunking as an explanation but do not distinguish it from procedure strengthening (e.g. Durrant and Schmitt, 2010; Sonbul, 2015).
Given that transitional probability has no interpretable effect in either condition, we could conclude that learners base their expectations solely on surface frequency and do not draw on any more complex probabilistic information. However, higher backward transitional probability does facilitate recognition. This indicates that learners are not really insensitive to conditional probabilities, though they differ from native speakers. A native-speaker production study by Bell et al. (2009) suggests that reduction of high-frequency function words (such as to) is contingent on the previous word, especially when reduction affects the onset (as in the reduced variant [ɾə] that we used). This was matched in the effect of (forward) TP in the word-monitoring study with native speakers (Lorenz and Tizón-Couto, 2019: 772). The learners’ responses seem to rather correspond to mid-frequency function words, which are affected by their predictability given the following word (Bell et al., 2009: 102). Thus, the difference could be explained by learners’ generally lower exposure to the language. It is probably reinforced by their longer response times: their reaction extends past the following word, which consequently has a greater influence than with faster reactions. An additional factor might be that in English teaching, verbs are often presented with their to-infinitive, so that to V becomes an overtly learned pattern, while V to is much less so.
Another difference from native speaker responses is the delayed recognition of reduced to when it follows a vowel or nasal. These are typical environments for /t/-reduction, though both production and perception of reduced forms vary with lexical frequency (Patterson and Connine, 2001; Pinnow et al., 2017; Pitt et al., 2011). The observed effect may then also be interpreted as a result of learners’ lower frequency of exposure, especially to casual speech. They will be less familiar with the reduced form and therefore less likely to expect it even in its typical environments; but it is these environments where it is less clearly marked off from the preceding phone. In this respect, it is also noteworthy that proficiency in listening comprehension makes a strong difference especially on the recognition of reduced forms, even though all participants had a very high level of English overall. This confirms that coping with reduction is a particularly demanding aspect of speech perception, and is not easily acquired. It remains an open question to what extent this depends on reduction patterns in the L1; for example, vowel reduction to schwa is relatively rare in Spanish/Galician (our participants’ L1). Speakers of languages in which it is more common (e.g. Portuguese, French, German) might be able to profit from this in the L2.
Our findings dovetail with usage-based accounts of second language acquisition, which take input frequencies as a crucial element of developing the L2 inventory (e.g. Ellis, 2002a, 2015; Ellis and Wulff, 2020; Eskildsen, 2009; Wulff, 2019). Second language learners do not only learn by the book but also, like native speakers, keep tally of commonly occurring items and combinations of items. Then, how do frequency-based expectations come to bear in coping with reduction? In our results, the clearest and strongest effects are those of V + to bigram frequency. This shows especially at the high end of the frequency range, where the slope is at its steepest (see Figure 2, left panel, above). At the highest frequency, reduced items are recognized almost as quickly as full forms and much faster than mid-frequency reduced items. It is known that learners often rely on constructional prototypes, fixed sequences that serve as templates around which constructional patterns are construed (Eskildsen and Cadierno, 2007; Myles, 2004). While this has usually been reported from less advanced learners’ L2 production, it is plausible that it still affects highly proficient learners’ perception. High-frequency V-to items like going to, want to, have to (with log frequencies around 7 in our data) may well be such formulaic prototypes in a learner’s English inventory, and therefore be much more deeply entrenched than the runners-up in terms of frequency, such as need to and used to (with log frequencies around 5). Still, there seems to be no interference from holistically stored reduced variants (in contrast to the chunking effect found with native speakers). While the frequency effects that we find are better attributed to procedure strengthening than chunking, they do not disprove the idea that L2 learners can also draw on chunks based on frequency and form: at least, the effects of phonological environment (preceding sound and plosive cluster merging) show that they are sensitive to the phonological embedding of reduction. Substantial effects of memorized chunks might depend on a very high level of exposure, particularly to spontaneous spoken language.
V Conclusions
In sum, our word-monitoring experiment adds to the evidence of frequency effects in advanced learners’ speech perception. A high surface frequency of a bigram clearly facilitates recognition and also aids the recovery of a reduced form. We do not, however, observe a chunking effect of high-frequency sequences, where a holistic perception would take precedence over the compositional one. Moreover, learners seem to make little use of predictability from transitional probability in the given task.
This differs from earlier findings with native speakers, where a wider range of frequency effects was observed (facilitation with increasing surface frequency, chunking effect with reduced forms, faster recovery of reductions with high transitional probability). In comparison with other second language studies, our results confirm that learners are sensitive to collocation frequencies (see Conklin and Schmitt, 2008; Siyanova-Chanturia et al., 2011; Wolter and Gyllstad, 2013), and support the notion that learners rely primarily on surface frequency and less on sequential probabilities (see Arnon and Christiansen, 2017; Diependaele et al., 2013; Ellis et al., 2008). Thus, advanced L2 learners profit from frequency information, but do not avail themselves of the full range of it. The ‘helping hand’ of probabilistic knowledge is there, but L2 learners only reach for its little finger.
In our understanding, much of this can be explained by learners’ generally lower exposure to the target language, even at an advanced level of proficiency. Probabilistic information is relatively complex, as it involves not only the frequency of a given sequence but also of potential competitors. For hearers to be able to draw on this kind of information for effective speech perception may require a large amount of experience and a diverse input of spoken language. The way in which second language learners acquire the finer skills of processing that optimize speech perception may be similar or identical to that of native speakers: intuitive, through experience, by a gradient entrenchment of structures and patterns. It is the amount and kind of experience that is different.
Supplemental Material
sj-docx-1-slr-10.1177_02676583241246147 – Supplemental material for Learning to predict: Second language perception of reduced multi-word sequences
Supplemental material, sj-docx-1-slr-10.1177_02676583241246147 for Learning to predict: Second language perception of reduced multi-word sequences by David Tizón-Couto and David Lorenz in Second Language Research
Supplemental Material
sj-docx-2-slr-10.1177_02676583241246147 – Supplemental material for Learning to predict: Second language perception of reduced multi-word sequences
Supplemental material, sj-docx-2-slr-10.1177_02676583241246147 for Learning to predict: Second language perception of reduced multi-word sequences by David Tizón-Couto and David Lorenz in Second Language Research
Footnotes
Acknowledgements
We would like to thank the editorial board of Second Language Research for their scrutiny and valuable suggestions; and three anonymous reviewers for their constructive criticism and insightful comments. We would also like to acknowledge the useful feedback we received from various colleagues at the Fifth Variation and Language Processing Conference (VALP5) in Copenhagen (2021), the Ninth International Conference of the German Cognitive Linguistics Association (DGKL/GCLA-9) in Erfurt (2022), and the Fourteenth International Conference of Experimental Linguistics (ExLing 2023) in Athens. All of these have immensely improved this article; any remaining obscurities are entirely our own responsibility.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported in this article was funded by grant PID2020-118143GA-I00, awarded by MCIN/AEI/10.13039/501100011033/, and Xunta de Galicia (grant ED431C2021/52); support is gratefully acknowledged.
Open Badges Statement
The datasets and R-scripts used in the present study are published as Lorenz and Tizón-Couto (2024b) in the Tromsø Repository of Language and Linguistics (TROLLing), available at ![]() .
.
Supplemental material
Supplemental material for this article is available online; it includes the list of stimulus sentences (Appendix 1) and the statistical model summaries (Appendix 2).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.