
Abstract
Research has revealed substantial individual differences in how language is processed during reading by both first-language (L1) and second-language (L2) speakers, with morphosyntax in particular being identified as a ‘bottleneck’ area in L2 acquisition. While some predictors of reading performance are well studied (e.g. working memory, individual word knowledge), recent research has suggested a role for multiword unit chunking ability in L1 sentence processing. However, the role of chunking ability in L2 processing has received less attention. This study explores chunking as a particularly relevant mechanism for the processing of L2 Spanish gender agreement, during which nouns and gender-marking cues in determiners and adjectives must be chunked together. We examined whether chunking ability and working memory predict syntactic processing involving gender agreement in Spanish during a self-paced reading task. We created a Spanish version of a multiword chunk sensitivity task and used it to obtain measures of chunking ability from English learners of Spanish in both languages. Results revealed no significant effect of working memory, while L1 chunking ability predicted L2 processing: only higher-chunking-ability learners showed sensitivity to gender agreement during processing, even after controlling for proficiency; lower-chunking-ability readers showed a lack of sensitivity to agreement during online processing.
I Introduction
One critical question in research on second language (L2) processing is what factors may predict variability among individuals, with morphosyntax being identified as a ‘bottleneck’ area in L2 acquisition (e.g. Hopp, 2022; Slabakova, 2009). Within L2 research on Spanish and other romance languages, the acquisition of grammatical gender has emerged as a case in point, in which even advanced learners show substantial variability.
In the last two decades or so research on L2 Spanish has investigated whether difficulties in the acquisition of grammatical gender are due to representation or performance issues. Contrary to earlier proposals that learners could not acquire new L2-specific features (e.g. Failed Functional Features Hypothesis, Hawkins and Chan, 1997; Representational Deficit Hypothesis, Tsimpli and Dimitrakopoulou, 2007), subsequent studies indicated that L2 learners can successfully develop representations of L2 gender (e.g. Alemán Bañón et al., 2014, 2018; Tokowicz and MacWhinney, 2005). Indeed, studies have consistently found that accuracy rates for gender assignment and agreement are quite high when measured off-line, typically ranging between 80% and 90% accuracy (e.g. Grüter et al., 2012; White et al., 2004). Although models such as the Shallow Structure Hypothesis (Clahsen and Felser, 2006) proposed that morphosyntactic difficulties have to do with underusing syntactic representations, data in recent years supports the idea that such difficulties may instead stem from slower or less automatic integration of morphosyntactic cues during real-time language processing, rather than a fundamental deficit in syntactic knowledge. Indeed, evidence from online processing studies (e.g. Steinhauer et al., 2009) indicates that L2 users engage syntactic representations whose temporal dynamics are critically modulated by proficiency.
Therefore, recent accounts have suggested that variable performance on L2 gender processing does not stem from a lack of representations, but rather from delays or difficulties in retrieving morphosyntactic information in real time (e.g. Grüter et al., 2012; Hopp, 2013, 2016; Prévost and White, 2000). While some accounts emphasize production-based difficulties (e.g. Missing Surface Inflection Hypothesis, Prévost and White, 2000; Haznedar and Schwartz, 1997), approaches that also consider processing-related difficulties are particularly relevant to the present work (e.g. Grüter et al., 2012; Hopp, 2016). For example, previous work on the processing of Spanish gender agreement has revealed that L2 speakers have difficulty exploiting their knowledge of gender agreement in real time (Grüter et al., 2012; although, for evidence from more proficient L2 speakers, see Dussias et al., 2013).
Building on such findings, the Lexical Bottleneck hypothesis (Hopp, 2018) proposes that lexical factors may be responsible for non-native performance in the production and processing of gender agreement (see also Hopp, 2013, 2016). In support of this hypothesis, Hopp (2013, 2016) showed that difficulties in L2 lexical retrieval can account for delays and errors in the processing of morphosyntactic cues during online sentence reading. As a consequence, L2 processing and, in particular, lexical retrieval, have been proposed to exert greater demands on working memory (WM), with negative consequences for sentence processing. The prediction that individual differences in WM might account for variation in online sentence processing also aligns with major models of reading, and has received support from a number of L2 studies showing that higher-WM readers perform at a level comparable to first language (L1) speakers (e.g. Dussias and Piñar, 2010; Hopp, 2014). But despite the preeminent role of WM in the sentence processing literature, its theoretical and explanatory scope is mostly concerned with information that has already been activated (i.e. standard WM accounts focus on limitations on maintaining and using information in short-term memory). It does not, however, account for comprehenders’ ability to activate target representations by mapping the input to long-term memory representations derived from prior experience. 1
In the present study, we take a novel approach by considering L2 users’ ability to identify and exploit existing associations between the elements in a sentence based on their ability to map the input to existing representations (e.g. experience with gender cues attached to nouns or adjectives). To do so, we investigate learners’ ability to detect patterns of co-occurrence present in the input – an ability best captured by measures of ‘chunking ability’ (for discussions of chunking in L1 and L2, see Arnon and Christiansen, 2017; Contreras Kallens and Christiansen, 2022; Wang and Christiansen, 2024).
1 Acquiring morphological gender cues: The role of chunking
The tracking of distributional regularities among co-occurring elements has been identified as a central element in the acquisition of grammatical gender. In Spanish, gender is expressed via morphophonological cues (word endings) as well as morphosyntactic cues (via agreeing determiners and adjectives surrounding the noun or pronoun). Importantly, previous research has underscored that morphophonological cues (i.e. Spanish gender suffixes such as -o for masculine and -a for feminine) are less reliable cues, as some nouns have non-transparent or inconsistent endings (see examples in Figure 1; Kirova and Camacho, 2021; Markovits Rojas, 2022). In contrast, as noted by Grüter et al. (2012), morphosyntactic cues (e.g. prenominal determiners such as el-masc and la-fem) are ‘the only consistent and fully reliable cue to a noun’s gender class’ (p. 193). That is, distributional, co-occurrence relations are consistently instantiated in transparently gender-marked modifiers such as determiners and adjectives, but not necessarily in the noun, as illustrated in (1).
(1) El-masc árbol roj-o-masc The-masc tree red-masc ‘The red tree’

Sample multiword units as the building blocks for the development of gender agreement.
Therefore, the ability to bind or ‘chunk’ the gender-marking determiner with the noun as a unit may play a central role in the acquisition of grammatical gender. Initial support for this suggestion comes from an artificial language learning study showing that only when participants were first exposed to determiner–noun combinations – instead of the target nouns on their own – were they able to master the grammatical gender (Arnon and Ramscar, 2012).
At its simplest, ‘chunking’ can be understood as an essential pattern-based memory skill that facilitates the grouping together (or compression) of incoming input based on prior experience with co-occurring elements stored in long-term memory (e.g. syllables, words, multiword units and morphosyntactic patterns). As such, chunking provides a measure of an individual’s ability to group elements (e.g. words) in the input so that they can be treated as a single unit (Gobet et al., 2016); each unit (or ‘chunk’) is then passed on for further processing (a process termed ‘Chunk-and-Pass’; Christiansen and Chater, 2016). By grouping multiple elements into a unit, chunking is thought to also reduce the number of elements that need to be held in short-term memory, alleviating pressures on WM (Ericsson and Kintsch, 1995). In cases in which speakers must hold multiple cues in WM during sentence processing, efficiency in how speakers initially segment or ‘chunk’ the input may be a determining factor shaping real-time processing.
Unlike some of the previous proposals discussed above, we argue that difficulties in processing morphological cues arise not only because multiple sources of information must be maintained in memory simultaneously, but also because individual L2 users differ in their capacity for chunking. We propose that this variation in chunking ability serves as a critical predictor of learners’ efficiency in processing morphological cues in real time. In the context of the present study, we suggest that successful processing of gender agreement requires L2 users to track the co-occurrence of multiple linguistic elements and to bind them simultaneously; that is, to ‘chunk’ nouns together with their determiners and adjectives.
A small number of previous studies has now specifically explored the role of chunking ability as a predictor of efficiency during L1 sentence processing (McCauley et al., 2015, 2017; Pulido and López-Beltrán, 2023). However, to the best of the authors’ knowledge, only one previous study examined the role of chunking during processing of L2 multiword units (Pulido, 2021), and there is currently a gap in that no previous studies have examined how chunking influences L2 morphosyntactic processing. The present study builds on previous work to examine whether memory for chunks (i.e. ‘chunk sensitivity’) predicts online L2 gender processing, independently from any potential contribution of WM. To do so, in the experiment reported below, we examine the processing of Spanish grammatical gender agreement in L1-English–L2-Spanish speakers.
In the remainder of the introduction, we first briefly review the literature on limited-capacity models that propose processing ‘bottlenecks’ to account for variability in online sentence processing, often in connection with WM capacity. We then review evidence for the role of chunking as a recently identified relevant mechanism in online sentence processing.
2 Processing bottlenecks and individual differences in L2 sentence reading
Previous L2 work has attempted to explain why the processing of core grammatical features that are experienced with high frequency – such as gender or number agreement – remain difficult for advanced L2 users. For example, even when L2 speakers know the gender of lexical items, online processing of L2 gender agreement is not without its difficulties. Although local agreement is less problematic (determiner–noun; Foucart and Frenck-Mestre, 2012; Tokowicz and MacWhinney, 2005), processing of non-local L2 agreement (e.g. between noun and adjective) remains variable and more challenging even for highly advanced L2 speakers (Foucart and Frenck-Mestre, 2012; Gillon Dowens et al., 2010). One potential explanation is that this is due to the inherent cognitive demands that reading an L2 poses on the processing system. In this vein, McDonald (2006) proposed that the difficulties experienced by L2 English speakers, relative to L1 speakers, stem from limited working memory (WM) capacity during L2 processing, as well as from inefficient decoding and inadequate L2 processing speed. McDonald (2006) found that taxing English native speakers’ WM led them to perform much like L2 speakers do under similar cognitive constraints.
In more recent research that examined both the production and predictive processing of L2 gender, Hopp (2013) found that the speed of lexical access influenced L2 users’ ability to process grammatical gender in real time, suggesting that lexical access acted as a bottleneck impairing the processing of L2 morphosyntax (for data from object cleft sentences, see Hopp, 2016). Based on such findings, the Lexical Bottleneck Hypothesis proposes that processing of L2 morphosyntax is significantly constrained due to ‘slower retrieval from the bilingual mental lexicon’ (Hopp, 2022). Other proposals have suggested similar constraints due to limited capacity in processing (for difficulties at the interfaces, see Sorace, 2011; for difficulties in prediction, Grüter et al., 2017; Kaan, 2014).
Limited-capacity proposals such McDonald’s (2006) or the Lexical Bottleneck Hypothesis make an interesting and straightforward prediction for a strong role of WM limitations. Due to less efficient retrieval, L2 processing is seen as being inherently more effortful and as posing greater demands on WM than L1 processing. This entails that readers measured to have lower WM capacity should experience greater difficulty during processing of morphosyntactic cues. This prediction appears to be supported particularly in what concerns the processing of non-canonical or less frequent syntactic constructions (e.g. object-extraction structures; Hopp, 2014; Dussias and Piñar, 2010). However, limited-capacity models do not provide a straightforward account for difficulties when the input presents morphosyntactic features that are highly frequent (e.g. gender agreement), and processing occurs in the absence of overly taxing conditions that burden WM. Perhaps more importantly, there is no clear association between WM and the ability of learners to establish strong lexical connections between gender-marking morphosyntactic cues (e.g. determiners) and nouns. In fact, L2 studies have typically found WM to be an unreliable predictor of online processing of gender agreement. For example, using the self-paced reading paradigm, Foote (2011) investigated the association between WM and the processing of number and gender agreement in L1 and L2 Spanish speakers. At the group level, L1 and L2 speakers showed sensitivity to gender agreement. However, contrary to Foote’s predictions, no association was found between WM and sensitivity in online response times (RTs) recorded during self-paced reading. In another self-paced reading study, Sagarra and Herschensohn (2010) found no effect of WM on the processing of number agreement violations, nor of gender, in beginner learners but found an association only in intermediate learners (for further evidence of the same pattern in L2 Spanish gender, see Durand-López, 2024).
In summary, while work in recent years has provided data pointing to performance limitations in L2 processing, there is less clear support for the role of WM in the processing of highly frequent morphosyntactic features (such as gender agreement). In the following sections, we review work on chunking ability as a potential alternative predictor of L2 processing.
3 Chunking and the Now-or-Never bottleneck
Recent developments in the literature on sentence reading have come from a renewed interest in chunking as a cognitive mechanism underlying language processing. The relevance of chunking to the language processing mechanism was highlighted in a proposal by Christiansen and Chater (2016). Based on a number of well-known limitations on short-term memory, Christiansen and Chater proposed that language users face what they referred to as the ‘Now-or-Never Bottleneck’. To illustrate, while the average speech rate of an English speaker is 10–15 phonemes per second, humans’ ability to process discrete non-speech sounds is limited to about only 10 sounds per second (Studdert-Kennedy, 1986). Further, our memory for sequences of input is limited to approximately 4 to 7 elements (i.e. single units of information, whether a single name, a sequence of numbers retrieved as a unit, a sequence of chess positions, or some other independent chunk; Cowan, 2000; Miller, 1956). Given these perceptual and cognitive limitations, input must be processed rapidly or else it will be interfered with by new incoming signals. Importantly, where constraints exist in the processing of the L1, one should expect such limitations to be exacerbated during the processing of an L2 that is less automatized.
To address the apparent paradox that normal processing skills exceed memory limitations, Christiansen and Chater proposed that each unit in the linguistic signal (from syllables, to morphemes, to words, to multiword units) must be rapidly ‘chunked’ and integrated with other elements based on previous memory representations (note that this differs from previous bottleneck proposals that focus just on, e.g. single lexical items). In this sense, input encoding first proceeds based on the ability to map the incoming input to long-term memory representations at multiple levels of abstraction. 2 That is, through experience, speakers become attuned to the patterns that exist in the input. The segmentation of the input based on familiar chunks constitutes in itself an ‘input-reduction’ mechanism that compresses the linguistic signal based on familiar representations (‘Chunk-and-Pass’).
Even though Chunk-and-Pass processing is proposed to affect every level of abstraction, it provides a particularly appealing account for the acquisition of Spanish gender. As discussed above, learners must learn to chunk nouns with determiners and adjectives, which provide consistent gender cues through morphosyntactic agreement (the only reliable cues for nouns with opaque gender endings). In Spanish, recent evidence shows that gender acquisition is more fully developed only when L2 speakers automatize the association between nouns and determiners, but not when they rely on the morphophonology of noun endings (Kirova and Camacho, 2021; Markovits Rojas, 2022; for support for chunking in gender acquisition, see also Arnon and Ramscar, 2012; Siegelman and Arnon, 2015). Indeed, within usage-based approaches to L1 and L2 (Ellis and Ferreira-Junior, 2009; Lieven, 2014; Tomasello, 2001), the ability to chunk multiword sequences in the input has been proposed to be an essential mechanism scaffolding the development of more complex linguistic constructions, as well as the acquisition of non-adjacent linguistic dependencies (e.g. Isbilen et al., 2022a). Before speakers can form abstract representations of constructions, they must first acquire concrete representations for specific lower-level instances of usage they encounter in the input (Arnon and Christiansen, 2017; Goldberg, 2003, 2005), forming the basis of syntactic agreement relationships, such as gender (see Figure 1). Accordingly, multiword units have been proposed to provide the building blocks on which speakers, including adult learners of an L2, are partly able to develop more schematic patterns, whether implicitly or explicitly (Ellis and Ferreira-Junior, 2009; Lesonen et al., 2020, 2022; Myles, 2004; Pulido, 2024; for a review, see Wang and Christiansen, 2024).
A hypothesis explored in this line of work is that speakers with better chunking ability are more efficient language processors and learners. In the following section, we review recent findings that point at the promise of chunking ability as a predictor of L2 online sentence processing.
4 Chunking ability as a predictor of sentence processing
Direct evidence of the role of chunking ability in processing comes from recent work with L1 speakers. Initial studies examined whether individual variability in chunking ability might account for variability in speakers’ online sentence processing (McCauley and Christiansen, 2015; McCauley et al., 2017). To investigate the role of chunking in processing, McCauley et al. devised a ‘chunk sensitivity’ task, as an index of an individual’s ability to bind elements (e.g. words) in the input into a single unit (Gobet et al., 2016). In baseline items, participants are tasked with the remarkable challenge of recalling a string of 12 unrelated elements, such as individual words (e.g. years got don’t to game have she mean to them far is). In comparison, target trials that are formed by 12-word strings can be chunked into recognizable trigrams, even in the absence of prosodic cues; these are corpus-derived multiword trigrams of high frequency (e.g. have to eat | good to know | don’t like them | is really nice). Based on an individual’s ability to recognize usage-based word co-occurrences, experimental trials can be chunked into four discrete elements (rather than as 12 unrelated elements; thus, chunking words into trigrams reduces the demands imposed on short-term memory). An individual chunk sensitivity score is calculated based on the difference in recall accuracy between the target strings and the (typically lower) recall for unrelated controls. The chunking ability task provides an index of an individual’s sensitivity to patterns in the language as a result of extended experience with co-occurrence probabilities in linguistic input (Isbilen et al., 2022b). 3
A number of recent studies have supported the notion that chunking mediates sentence processing. Results from L1 self-paced reading found that higher chunking ability correlated with faster processing of object relative clauses (McCauley and Christiansen, 2015), and with more efficient processing of locally distracting number information (McCauley et al., 2017). In addition, recent evidence has also highlighted that chunking ability is associated with sensitivity to statistical regularities, which may result in faster RTs, but in some cases also lead to increased processing costs. In a self-paced reading study with L1 speakers of Spanish, Pulido and López-Beltrán (2023) examined the association between chunking ability and processing of gender agreement in relative clauses. In their study – which used the same manipulation as the present experiment – Pulido and López-Beltrán employed syntactically ambiguous relative clauses preceded by complex noun phrases (NPs) headed by the preposition ‘with’, capitalizing on the well-documented preference for low-attachment (i.e. a local interpretation). To illustrate, in examples (2) and (3) the NP2 is typically interpreted by Spanish and English speakers alike as the subject of the relative clause. However, the presence of gender agreement in Spanish allows an alternative (dis-preferred) interpretation (4), in which NP1 must be attached to the predicate in the relative clause.
(2) There comes the flight attendant-np1 [with (3) NP2-attachment: Ahí viene la azafata-np1-fem
(4) NP1-attachment: Ahí viene Gloss: ‘Here comes the flight attendant with the pilot who is nice.’
The logic was that if readers use grammatical gender information encoded in the adjective (e.g. simpatico-masc/‘nice’) to guide their interpretation of the input in real time, a cost was expected for processing of (dis-preferred) NP1-attachment items. The data from Pulido and López Beltrán (2023) showed that readers experienced processing costs for NP1 items, and that these were mediated by chunking ability. Interestingly, readers with higher chunking ability exhibited slower RTs, revealing increased sensitivity to gender agreement when processing the dis-preferred NP1 trials as chunking ability increased (i.e. greater costs as revealed by slower RTs; although for a facilitatory effect of chunking ability in other constructions, see, for example, McCauley and Christiansen, 2015). In a gradient effect of chunking ability, medium-chunking ability readers showed the expected costs for NP1 attachment although to a lesser extent, whereas low-chunking ability showed no sensitivity to gender agreement in online processing. The results revealed important variability among L1 speakers when processing a core feature of their language, and that this variability was predicted by individual chunking ability.
But despite the promise of the limited data available, the L2 research conducted to date has not examined the effect of chunking ability on the processing of L2 morphosyntactic patterns (though for processing of multiword units, see Pulido, 2021; and for utterance-level processing, Culbertson et al., 2020). In particular, examining the processing of gender agreement is an important goal because the variation observed to date in L2 processing research might be, in part, modulated by individual differences in chunking abilities. This is the goal of the present experiment.
II The present study
In the current study, we investigate whether, and how, the reading performance of adult L1-English–L2-Spanish learners is predicted by individual chunking ability measured in their L1 and L2, in conjunction with other linguistic and cognitive measures. As our dependent L2 measure, we tested participants’ sentence processing skills using a syntactically ambiguous relative clause that has been extensively examined in prior L2 processing studies (Carreiras and Clifton, 1993; Felser et al., 2003; Gilboy et al., 1995; Kasparian and Steinhauer, 2017; Papadopoulou and Clahsen, 2003). The present study employs the same manipulation described above in Pulido and López-Beltrán’s (2023) study with L1 speakers (further details below).
As noted above, previous research has shown that, in ambiguous relative clauses containing the preposition with, disambiguation towards the second noun phrase (NP2) is cross-linguistically preferred over first noun phrase (NP1) disambiguation (Felser et al., 2003; Papadopoulou and Clahsen, 2003). This cross-linguistic preference holds even for languages that typically favor high attachment (i.e. NP1 disambiguation), such as Spanish. In example (2), the thematic preposition with creates a strong preference to chunk the adjective (e.g. simpático) along with NP2, which acts as the subject of the relative clause.
We capitalized on this property to ask whether L2 speakers would show a processing cost modulated by attachment bias violations, based on a gender agreement manipulation. Spanish has a two-gender noun system in which all definite nouns carry feminine gender (e.g. la cuchara ‘the-fem spoon-fem’) or a masculine gender (el tenedor ‘the-masc fork-masc’); importantly, determiners and adjectives must also agree in gender. Thus, we exploit the fact that gender agreement is a cue available in Spanish that can also guide how relative clauses should be interpreted.
We manipulated gender agreement to create sentences that respected the preference of with-relative clauses for NP2-attachment (example 3 above) and others that did not (example 4). We hypothesized that sentences such as (3) should be read with relative ease, while those similar to (4) would incur processing costs (i.e. higher RTs), given that computing agreement correctly (el piloto . . . simpático ‘the-masc pilot-masc . . . nice-masc’) would entail going against the NP2 attachment preference and require revising the initial bias.
Importantly, disambiguation during online processing requires exploiting the cue of gender agreement in real time. Based on this manipulation, a specific connection between chunking ability and gender processing is expected. Given the previously documented preference for NP2 attachment in with-relative clauses, example (3') below illustrates the expected input structure, whose chunking pattern is indicated through bracketing; in contrast, example (4') requires a strongly dis-preferred and more difficult discontinuous ‘chunking process’. Thus, with-headed relative clauses provide a particularly suitable testing ground for the examination of gender agreement cues. This manipulation will allow us to test the influence of chunking ability in processing a costlier long-distance dependency between the NP1 and the gender-agreeing adjective, rather than the preferred local NP2-adjective association.
(3') NP2-attachment: . . . [la azafata-np1-fem [
(4') NP1-attachment: . . . [
How will individual chunking ability influence online processing of L2 morphosyntactic gender cues? Based on results from L1 speakers exposed to the same experimental manipulation employed here (Pulido and López-Beltrán, 2023), higher chunking ability should predict increased sensitivity. This increased sensitivity would result in increased efficiency during processing of the preferred NP2-attachment items, but in increased difficulty processing L2 gender agreement in the dis-preferred high-attachment condition. Alternatively, and in addition, it is possible that due to the strong cross-linguistic bias for the pattern in (3'), some readers will fail to process agreement information and mis-process items that require chunking the elements in the sentence through NP1 attachment as in (4'). That is, some L2 speakers are expected to show a lack of sensitivity to the gender-based manipulation, in line with lower chunking-ability L1 speakers who revealed no sensitivity to the online processing of gender agreement (Pulido and López-Beltrán, 2023).
Because, as mentioned, the role of chunking as a mechanism in L2 processing is still unexplored, we simultaneously consider the potential independent role of WM (e.g. Keating, 2005), to test for the former while controlling for the influence of the latter.
III Research questions and predictions
In the present study, we investigated the following research questions and predictions:
Research question 1: Do advanced L2 learners show online sensitivity to attachment bias violations, guided by morphosyntactic (gender) cues? ○ If L2 speakers successfully compute agreement, then NP1-attachment should be more difficult than NP2-attachment, leading to lower RTs in the latter as shown in L1 speakers. That is, the difficulty in the resolution for NP1-attachment (contrary to the preference for NP2-attachment) should induce a processing cost during reading of the critical adjective region, due to the need to revise the initial bias for NP2 and re-interpret the input (and re-chunk) in NP1 items (for details on the disambiguating region, see Section IV.6). However, such relative facilitation (NP2) and costs (NP1) may be modulated by chunking ability, with sensitivity increasing with higher chunking ability (Pulido and López-Beltrán, 2023). ○ On the other hand, given previous findings from online L2 processing (and even L1 processing, Pulido and López-Beltrán, 2023), it is expected that learners will vary in their sensitivity to gender cues, and that the effect might be absent or mixed in L2 speakers, especially for those with relatively lower levels of proficiency. Should L2 speakers not process gender agreement online, it can be assumed that the ‘default’ NP2 interpretation will be unaffected (in either condition), with no differences in RTs. Only if readers detect the mismatching gender in the NP2 condition online, do we expect differences between the two conditions.
Research question 2: How do chunking ability measures (in the L1 and/or the L2) modulate online processing of gender agreement?
Based on the available data from L1 speakers exposed to the same experimental manipulation employed here (Pulido and López-Beltrán, 2023), it would be expected that higher chunking ability will be associated with increased sensitivity (i.e. slower RTs) to L2 gender agreement in the dis-preferred high-attachment condition. A first, straightforward, assumption may be that L2 chunking ability should be a good predictor of L2 gender processing (Culbertson et al., 2020), in the same way that L1 chunking is a good predictor of L1 processing. Alternatively, it may be that chunking ability as measured in the L1 – because it is unaffected by L2 proficiency – is a better index of overall chunking ability and therefore a more reliable predictor of L2 sentence processing. Importantly, in our analysis, we also explicitly consider the contribution of WM to control for any potential confounds.
IV Method
1 Participants
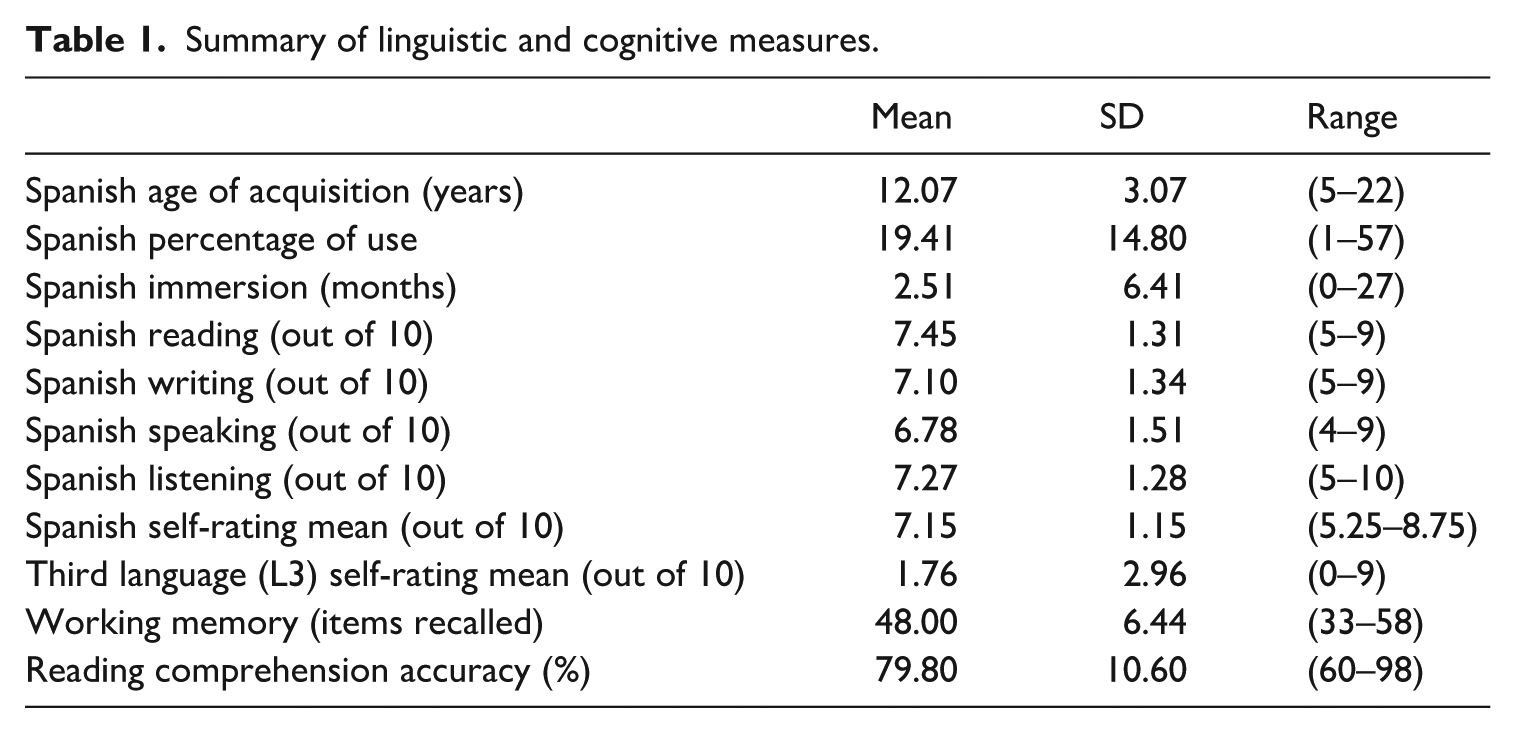
Forty-two L1-English–L2-Spanish learners participated in this study. One participant was excluded due to experiment failure during the main self-paced reading task, leaving 41 valid participants (29 female, 12 male; mean age: 21.37 years, SD: 1.97). Participants were recruited from advanced undergraduate Spanish courses at The Pennsylvania State University; all learned the L2 in a formal learning context and were tested in the US (L1 environment). These groups were selected because, before reaching these levels, learners have already completed extensive testing demonstrating knowledge and use of gender agreement. Participants completed three main tasks: two multi-word chunk sensitivity tasks and a word-by-word self-paced reading task. They also completed a battery of behavioral tasks that assessed language background and proficiency, and individual differences in WM. Reading accuracy rates were derived from the comprehension questions to experimental trials included in the self-paced reading task. Additionally, individual proficiency means were derived by averaging self-reported ratings for speaking, writing, reading, and listening. Two participants reported knowledge of another language with higher proficiency than for Spanish; removing these two participants did not alter the pattern of results, and the analysis conducted on the full dataset is reported below for completeness. We detail all the measures below and report the results in Table 1.
Summary of linguistic and cognitive measures.
2 Multiword chunk sensitivity tasks
Two chunking tasks (one in English and one in Spanish) measured participants’ individual ability to chunk strings of words based on conventional multiword units. Participants were tasked with recalling strings of 12 individual words, with each string consisting of four trigrams. Because previous work on chunking determined that short-term memory is limited to about 5–9 units of information (whether sounds, words, phrases; Cowan, 2000; Miller, 1956), a string of 12 separate words cannot be easily recalled because it would exceed this limit; however, if the same 12 words are chunked into four trigrams, this would fall comfortably within that memory range. While control trials contained trigrams of unrelated words with no statistical association, target trials were made up of frequent trigrams that could be recognized and chunked as a unit. The materials for the English version of the task were the same as those used in McCauley et al. (2017), consisting of multiword trigrams extracted from the American National Corpus (Reppen et al., 2005) and the Fisher corpus (Cieri et al., 2004) which, combined, contain about 39 million words of American English. The materials for the Spanish version were created specifically for the present study using a subsection of the Corpus del español (Davies, 2016), which has over 30.7 million words. Auditory stimuli were recorded for the Spanish version of the task by a female L1 speaker of Spanish. For English, the original auditory stimuli from McCauley et al. (2017), created with a male voice synthesizer, were used. The Spanish chunk sensitivity task materials developed for this study are available to download from the IRIS Repository (Marsden et al., 2016) at https://www.iris-database.org/details/QEdsC-8YeqK.
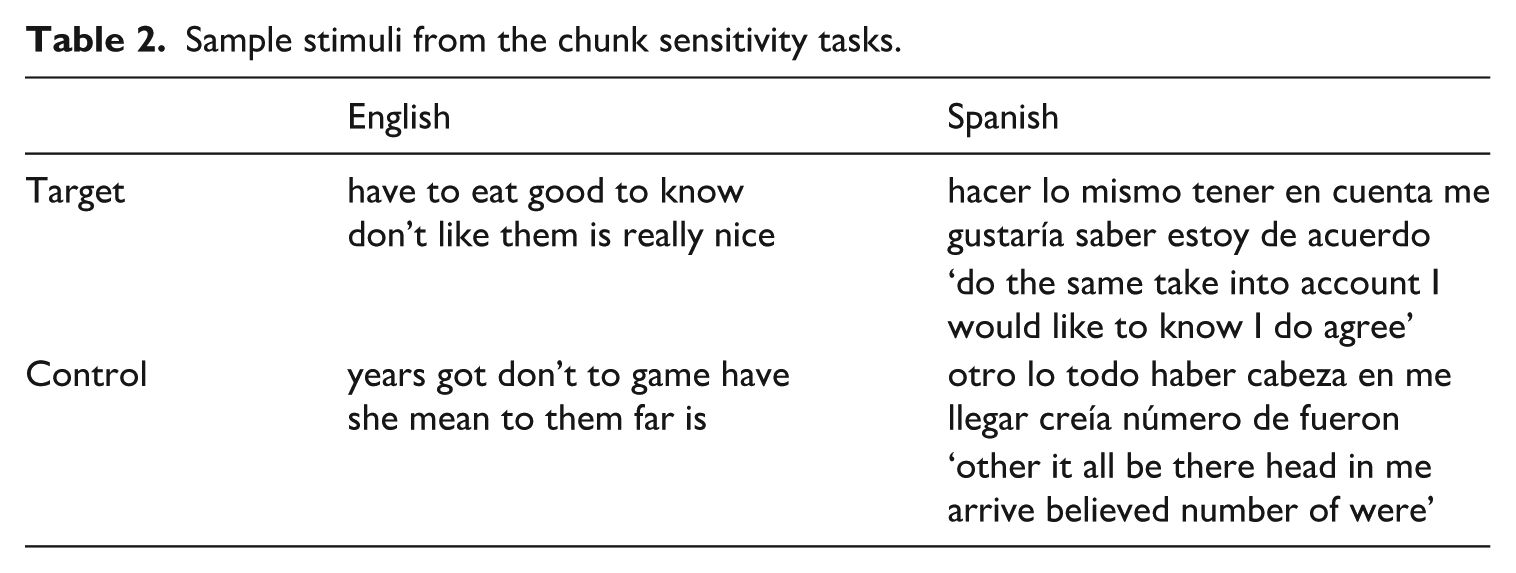
Target trigram frequencies for English ranged from 0.08 to 40 occurrences per million, averaging 0.73; target trigram frequencies for Spanish ranged from 0.55 to 39.2, averaging 10.97. 4 To avoid any potential effects of supra-segmental cues, audio files were generated individually for each word and combined into trigrams later. To provide a non-chunk-based control trigram condition, target trigrams were matched to controls in the frequency of individual words; the content words of targets were not re-used in the control items to avoid potential priming. The final item set for each task consisted of 20 sequences (10 experimental, 10 control). An example of a matched set of sequences is shown in Table 2.
Sample stimuli from the chunk sensitivity tasks.
To calculate the chunk sensitivity score, the accuracy of participants’ responses was coded according to their content and order accuracy (as in previous studies on L1 chunking ability; for a detailed methods description and coding, see the supplemental materials in Isbilen et al., 2022b). The difference in accuracy between conditions (i.e. target vs. control) was then calculated for each participant. We refer to the resulting measures as the English chunking score and Spanish chunking score, respectively, and use them as predictors of sentence processing in our analyses.
3 Self-paced reading task
A word-by-word self-paced reading (SPR) task in Spanish was designed to examine participants’ online processing of gender-based dependencies in relative clauses. The target sentences contained ambiguous relative clauses – headed by the thematic preposition with – whose interpretation was contingent on gender agreement expressed in the adjective within the relative clause. Thus, we designed our sentences so that Condition 1 favored the earlier mentioned NP2 bias of the preposition, based on the gender of the adjective within the relative clause (i.e. mentiroso-masc ‘liar’; see Table 3). Condition 2 violated this bias because the grammatical gender of the adjective within the relative clause favored NP1 attachment (Table 3).
Self-paced reading task stimuli.

A total of 80 experimental sentences were created: 40 with NP2 attachment and 40 with NP1 attachment. Each item in the NP2 attachment condition had its NP1 counterpart, and therefore participants only saw half of the items in each list to avoid repetition. A total of 80 nouns were used in the experimental sentences; 40 were in the NP1 position (mean lexical frequency: 59.44; mean length: 8.20) and 40 in the NP2 position (mean lexical frequency: 42.10; mean length: 7.82). All NPs consisted of animate (human) referents. In addition, 40 adjectives were used (mean lexical frequency: 18.41; mean length: 7.75), half marked in each gender. All experimental nouns and adjectives were matched for orthographic length and lexical frequency across conditions; both measures were extracted from the Corpus del español (Davies, 2016). We report lexical frequency per million and orthographic length in number of characters. In addition, 6 practice items and 40 filler sentences were also created, which contained manipulations including superlatives, and did not repeat experimental nouns or adjectives.
The set of 80 experimental items was counterbalanced into two lists to avoid repetition of nouns and adjectives (for an example, see Table 3). Each list contained 40 experimental items (20 per condition) as well as the fillers, and practice sentences displayed at the beginning. Comprehension questions were also included for all items to check the accuracy of reading comprehension. Participants were asked to judge each question as true or false. The questions required that the full sentence (including the relative clause) be read and understood, without repeating the adjectives or asking explicitly about them. Items were presented in a pseudo-randomized fashion.
4 Proficiency and cognitive measures
a Language background questionnaire and reading proficiency
Participants answered a language history questionnaire (LHQ) in which they self-rated their linguistic ability in both languages, as well as in additional languages (L3) beyond Spanish and English. While there are known issues with self-ratings (particularly when comparing different populations, which is not the case in this study; Tomoschuk et al., 2019), self-ratings provided an additional measure that is completely independent from the main experiment. Additionally, to obtain an objective measure of reading proficiency, we computed the accuracy of the responses to the comprehension questions corresponding to the experimental items in the main SPR task.
As might be expected, a correlational analysis showed that self-ratings were significantly correlated with individual performance in reading comprehension questions during the task (r = 0.45, p = .002).
b Operation span
Participants were administered the operation span (O-Span) task as a measure of WM ability. This task was selected because it is a primarily non-linguistic WM task that has been found to account for variance in comprehension at a similar level as tasks that rely on language processing (reading/listening span; e.g. Daneman and Merikle, 1996). Participants were presented with simple arithmetic problems alongside a potential solution and were instructed to respond yes/no to indicate whether the solution was correct or incorrect. After each problem, an English word appeared on the screen; participants were told to memorize these words for later recall. Individual scores were calculated as the total number of correctly recalled words.
5 Procedure
All participants completed the tasks in the same order in a single two-hour session: Spanish SPR, Spanish chunking, O-Span, English chunking and LHQ. The questionnaire was presented using Qualtrics (Qualtrics, Provo, UT), while the other tasks were administered through E-Prime 3.0 (Psychology Software Tools, Pittsburgh, PA).
a Self-paced reading task procedure
The trials of the SPR task were presented in pseudo-randomized order using a self-paced word-by-word display, similarly to previous studies reviewed above. At the beginning of each trial, the first word of each sentence appeared automatically in the center of the screen. After that, participants pressed a button on a Chronos box (Psychological Software Tools, Inc.) to advance to each of the subsequent screens. Words were displayed in Consolas 25; participants sat at approximately 60 cm from a 24 inch (60 cm) monitor. Reaction times were recorded for each button press. Following each sentence, participants answered a yes/no comprehension question using buttons marked ‘Y’ and ‘N’, respectively.
b Multiword chunk sensitivity tasks procedure
Each trial consisted of a 12-word sequence presented auditorily. The words in each sequence were separated by a 250 ms pause, avoiding any acoustic or prosodic cues in the input that might bias chunking patterns. Upon completion of the string, the participant was prompted to verbally recall as much of the sequence as possible in the same order as presented. Responses were digitally recorded and transcribed later.
6 Data cleaning
Following previous studies, the critical region was defined as the critical word (i.e. the disambiguating gender-marked adjective) plus a spillover region consisting of the two following words. Spillover regions are assumed to reflect later phases of comprehension and can be indicators of processing difficulty that is persistent or delayed (Christianson, 2002; Jegerski, 2014; Nicenboim et al., 2014). In our materials, all the adjectives in experimental trials were followed by two words that were identical across conditions (a preposition followed by a determiner or an indefinite adjective) as illustrated in (5).
(5) Ahí viene la vendedora con el cliente que es ‘There comes the salesperson with the client who is a liar to everyone.’
Data cleaning and outlier removal procedures were performed on the critical region (consisting, as described above, of the adjective and the spillover region) prior to the analysis; RTs on the critical region were the dependent variable of the analysis. The first step in cleaning the data was to remove RTs that were above 3,000 ms and below 100 ms (Jegerski, 2014; Roberts and Felser, 2011), which eliminated 0.79% of the data. Values were normalized with the normalize function in the Rling package (v. 1, Levshina, 2015; MAD method). Next, all trials with inaccurate comprehension responses were removed (9% of the data). The median absolute deviation method (MAD; Leys et al., 2013; Rling package v. 1.0, Levshina, 2015) was used to detect and remove outliers on normalized RTs on a by-participant basis. Based on these values, a cut-off of 3 deviations below or above the median was established to remove outliers. This resulted in the removal of 4.59% of the data.
7 Statistical analysis
Linear mixed-effects models were fit using the buildmer function in the buildmer package (v. 1.3, Voeten, 2019) in the statistical software R (v. 4.4.0, R Core Team, 2024). This function uses lmer from the lme4 package (v 1.1.35.3, Bates et al., 2024) but allows for a systematic and replicable way of simplifying random effects structures and testing fixed effects. The function starts by attempting to fit a maximal model. If the model fails to converge, the function then simplifies the fixed and random effects structure by only including the most information-rich effects that make a significant contribution (Bates et al., 2015). Once the maximally converging model has been identified, it is simplified via backwards stepwise elimination based on their importance as measured by the likelihood-ratio test statistic. In addition, the function calculates p-values for all remaining fixed effects based on Satterthwaite denominator degrees of freedom using the lmerTest package (v. 3.1-3, Kuznetsova et al., 2020).
Separate analyses were performed on each individual word RTs (adjective, adjective+1, adjective+2; see below for a combined analysis, following Pulido and López-Beltrán, 2023, with the same pattern of results). The first fully specified model created included Condition, English chunking, Spanish chunking, O-Span, Orthographic length, Spanish immersion time (months), weekly percentage use of Spanish, and the two proficiency measures (mean accuracy in reading comprehension, L2 self-reported ratings); as well as all resulting two- and three-way interactions of Condition with O-Span, the Chunking ability and proficiency measures. Random effects were specified by participant, and by item, including random slopes for the fixed factors of Chunking and O-Span mentioned above.
V Results
The results for both chunking tasks are reported in Table 4. A score of 0 indicates no advantage in recall of trigrams relative to the baseline of unrelated words; higher scores indicate greater chunk sensitivity. A reliability analysis performed on the new Spanish measure of chunking ability and the original English version (psych R package, v.2.2.5; Revelle, 2022) indicated very good internal consistency (Spanish Cronbach’s alpha: 0.91; English Cronbach’s alpha: 0.89). In what follows, we first report the results of the linear mixed effects model to address our research questions. Data and script for all analyses reported below are available in the Supplementary Materials at https://osf.io/vx5g8/?view_only=017dc9ce63244a0fb2bf08b796f31d9e.
Summary of results of chunking tasks.
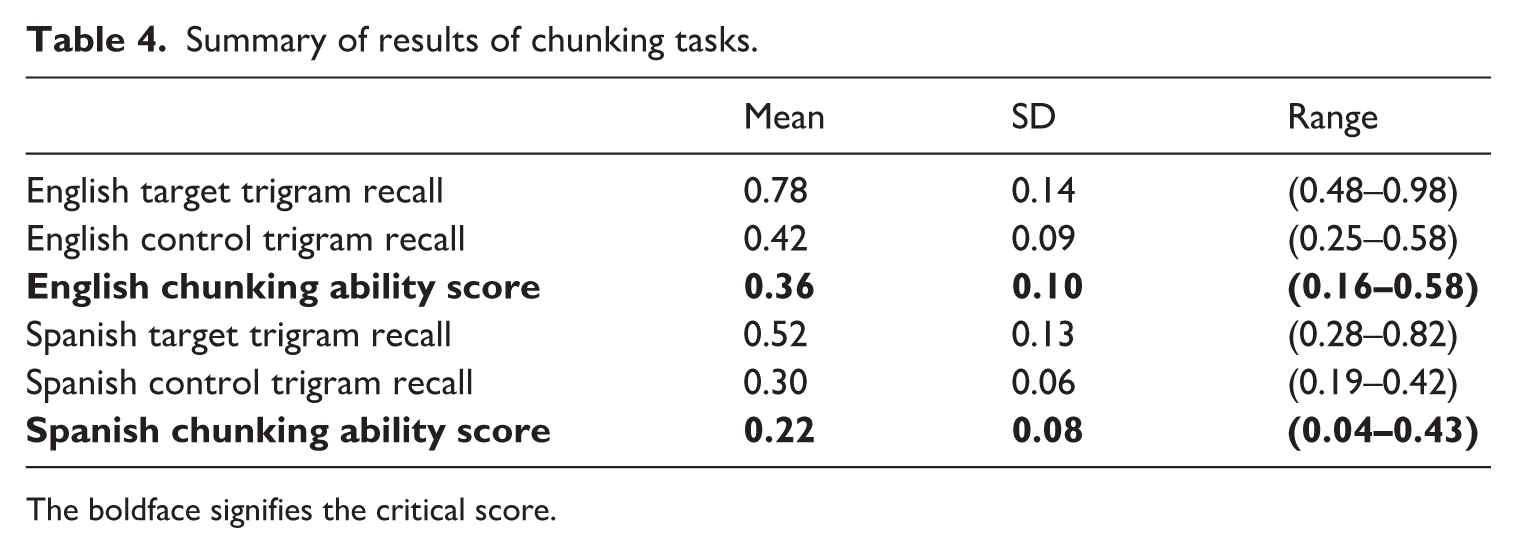
The boldface signifies the critical score.
1 Chunking and Self-paced reading
We were primarily interested in the extent to which differences in RTs between conditions were present in L2 readers (research question 1), and whether any differences could be predicted by the chunking ability measures collected (research question 2), as well as the contribution of the additional variables (and particularly, WM). For descriptive statistics, see Table 5.
Mean (SD) self-paced reading times by region (in ms).

a Adjective region
For the critical adjective region, the results of the selected mixed-effects model (Table 6) revealed a significant effect of Orthographic length, with longer words resulting in longer RTs. Higher proficiency (self-rated scores) significantly reduced RTs; L2 immersion was selected but had no significant effect on RTs.
Output of the final mixed effects models for self-paced reading times by region.
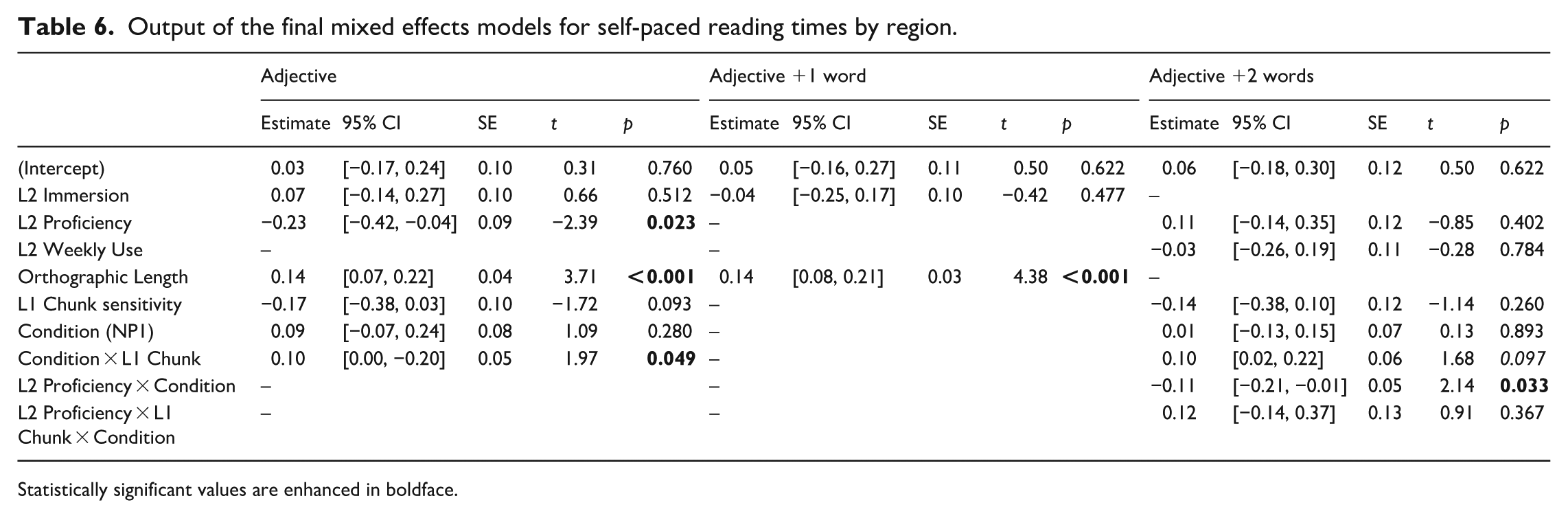
Statistically significant values are enhanced in boldface.
Marginally significant main individual effects of Condition (research question 1) and English Chunking ability were revealed. Critically, there was a significant interaction between Condition and English (L1) chunk sensitivity (research question 2). 5 This interaction suggested that the effect of experimental conditions varied across subjects and were present for only a subset of our participants (see also Pulido, 2021). As illustrated in Figure 2, the difference in RTs by condition was modulated by participants’ English chunking sensitivity score, such that only participants with higher scores showed the predicted effect; namely, that NP1 attachment should be more costly than NP2. 6 This indicates that only participants who were better chunkers successfully processed gender agreement for disambiguation purposes, by detecting the mismatch in agreement between NP2 and adjective, and possibly chunking the non-adjacent adjective together with NP1 (e.g. el cliente-masc-np1 . . . que es mentiroso-masc chunking; for additional considerations, see Section VI).
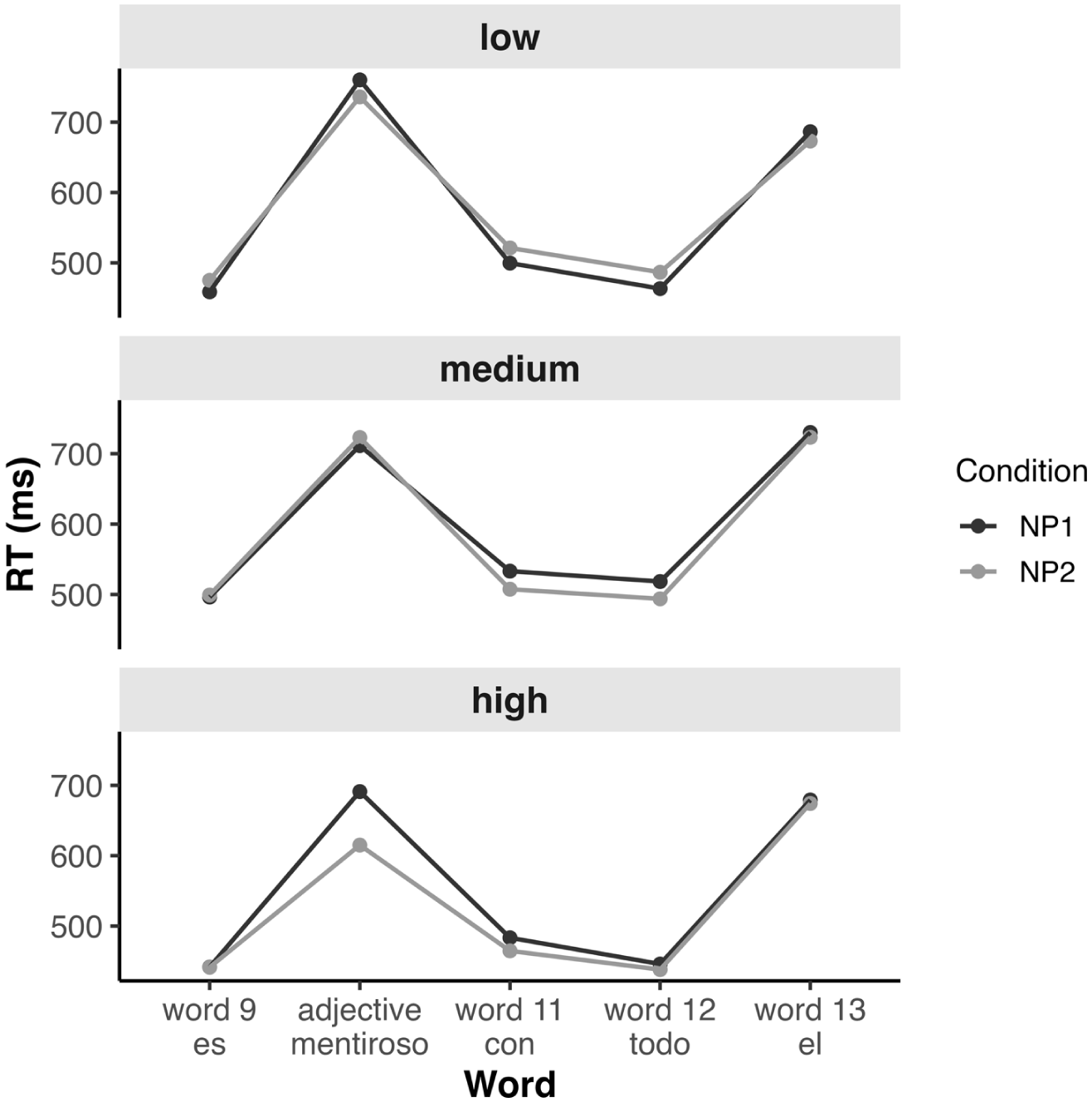
The interaction based on the lower, medium and higher terciles of the English chunk sensitivity scores.
We also note that, importantly, WM was not selected; an alternative analysis that forced the inclusion of WM showed the same pattern of results, with no significant contribution of WM. Additionally, models in which WM replaced Chunking ability were run to control for any potential confounds: removing WM from such models had no significant effect on the model fit (indicating a lack of significant contribution of WM, unlike the selected models that included Chunking ability; code available in the supplemental material). 7
b Spillover regions (adjective +1 and +2 words)
The spillover regions consisting of the two following words were also examined, given that experimental effects in self-paced reading sometimes emerge after the critical region, particularly in L2 data (Jegerski, 2014). However, for the adjective + 1 spillover region, no significant effects were revealed, except for the effect of orthographic length (see Table 6). In contrast, for the second word in the spillover region, the interaction of L1 Chunking ability by Condition reached marginal significance (p = .097), resembling the effect detected at the critical adjective region, and proficiency interacted with Condition, with higher proficiency reducing reading times in NP1. 8
The interaction of Condition and L1 Chunking ability, and its effect on reading times, are further illustrated in Figure 3. The figure shows that high-chunking ability participants were significantly slowed down by the dis-preferred NP1 items, revealing the expected sensitivity to the experimental stimuli.
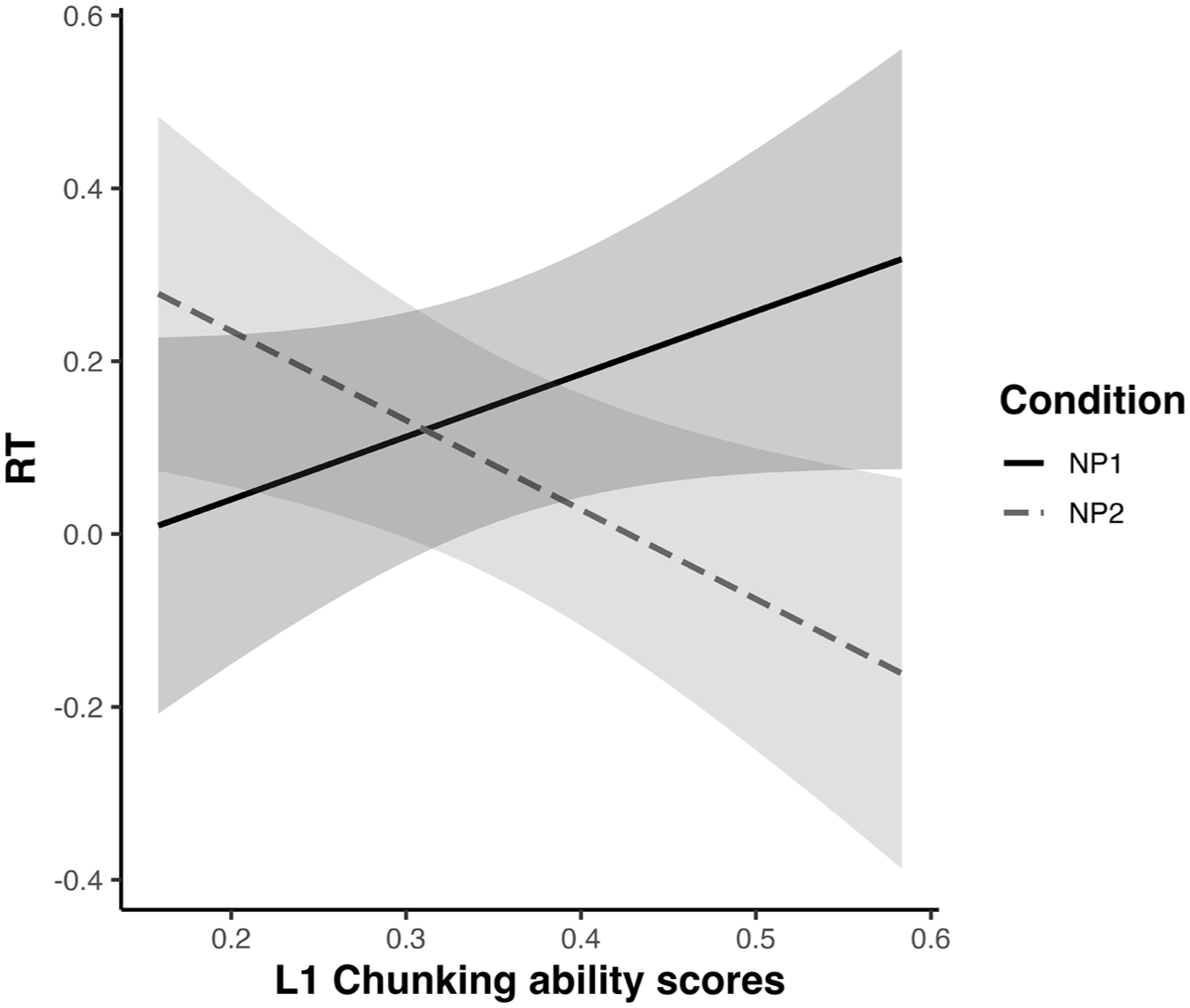
Model interaction between first language (L1) Chunk sensitivity and Condition.
2 Gender transparency
Although our materials contained only human NPs whose gender tends to be marked transparently, some of our items did not conform to this pattern. Indeed, we note that L2 speakers often rely on morphology to assign gender, e.g. -a is associated with feminine in cases like lingüista, regardless of the fact that ending is not reliable here (el lingüista is the correct masculine form).
One possibility is that L2 speakers might have relied on morphophonological cues in noun endings (e.g. -a for feminine, -o for masculine), even if morphosyntactic cues in determiners are the more reliable cues (as noted in Section I).
To consider this possibility, we re-ran the analysis including only items that would provide a valid morphophonological cue (e.g. la lingüista ‘the linguist’, in which both the -a morpheme and the determiner cue the feminine gender). We preserved only cases in which both morphosyntactic and morphophonological cues consisted of congruent morphology (e.g. la-fem lingüist-a-fem); and we removed ambiguous items in which cues conflicted (
3 The association of L2 chunking with other measures
Overall, participants performed significantly better in the L1 English than in the L2 Spanish chunk sensitivity task (t(77.98) = 6.53, p < .0001; for detailed scores, see Table 4). Although chunking is a domain-general mechanism, it is mediated by expertise (proficiency) in a given domain (Ericsson and Kintsch, 1995), an aspect that we aimed to control for by considering various L2 proficiency and experience measures in our analysis. To further investigate the lack of effect of L2 chunking ability in the main analysis, and its association with the other variables, we conducted a follow-up exploratory simple linear regression analysis. The regression included L2 chunking ability as the dependent variable, and L1 chunking ability, WM, L2 proficiency measures (comprehension accuracy and self-ratings) and L2 immersion experience as predictors. There was a significant association between Spanish and English chunk sensitivity, indicating that some individuals were overall better ‘chunkers’ across both languages. As could be expected, higher L2 chunking ability was significantly associated with higher L2 self-ratings and with higher L2-immersion experience (consistent with the idea that chunking is mediated by expertise in a given domain, e.g. L2). In line with the main analysis above, WM was non-significant (Table 7). No collinearity was found (all VIF values between 1.1 and 1.5; for a detailed correlation matrix, see the supplemental material).
Output of linear regression model for Spanish Chunking ability predictors.
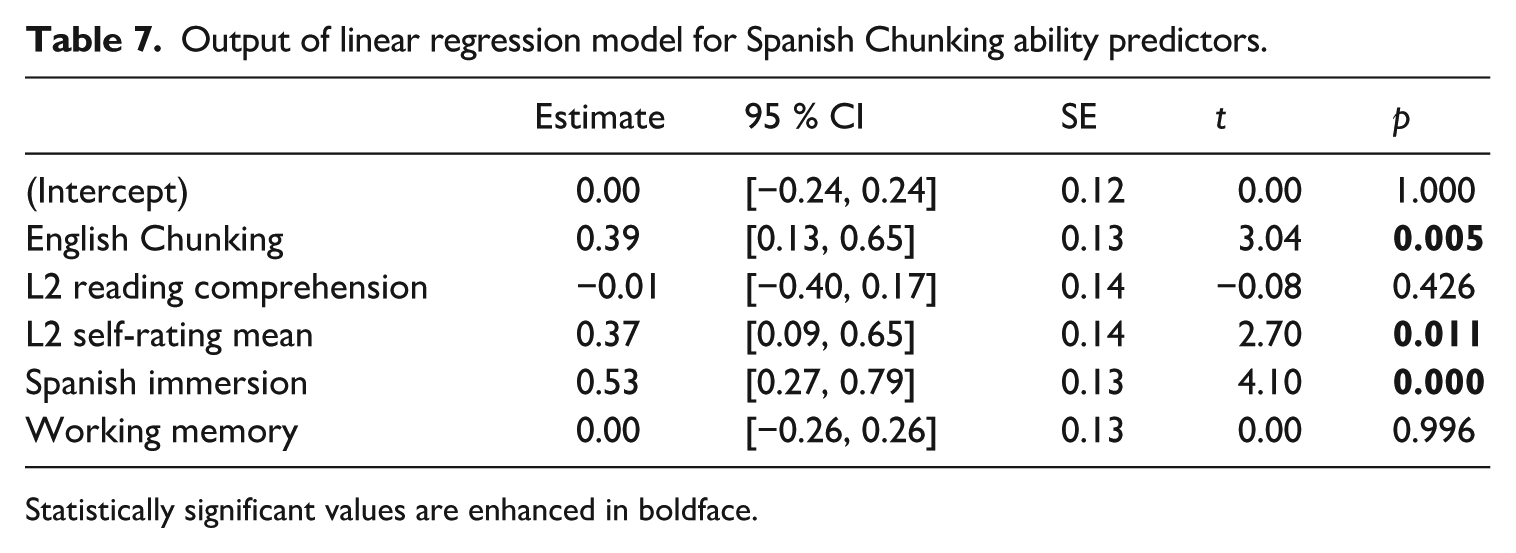
Statistically significant values are enhanced in boldface.
VI Discussion
The current study builds on previous models that propose that L2 speakers’ processing is affected by cognitive limitations (e.g. WM) that result in bottlenecks during processing of morphosyntax (e.g. Hopp, 2013, 2022). However, the present experiment specifically focused on the processing of L2 Spanish gender agreement, whose acquisition has been proposed to rely on learners’ ability to chunk nouns with surrounding gender markers (e.g. determiners, adjectives; Arnon and Ramscar, 2012; Christiansen and Arnon, 2017). Here we build on recent research that found chunking ability to be a significant modulator in L1 speaker processing of syntactic dependencies. Using a newly developed Spanish version of the multiword chunking ability task (McCauley et al., 2017), we tested the effect of L1 and L2 chunk sensitivity as predictors of L2 Spanish gender processing during a self-paced reading task. The experimental manipulation capitalized on two linguistic features: (1) The use of relative clauses headed by the preposition with, whose associated NP is cross-linguistically favored as the subject of an upcoming relative clause; and (2) gender agreement (a property specific to participants’ L2) to either favor a cross-linguistically preferred interpretation, or to force the disfavored interpretation.
Our research questions asked (1) whether L2 speakers would show a processing cost modulated by attachment bias violations, based on the gender agreement manipulation; and (2) whether and how chunking ability (as measured in the L1 and/or the L2) modulated the presence and magnitude of costs. In line with previous evidence showing a preference for NP2 attachment in with relative clauses (Felser et al., 2003; Papadopoulou and Clahsen, 2003), we predicted that L2 speakers would be strongly biased towards NP2-attachment. The experimental manipulation to force NP1-attachment based on gender agreement was expected to induce a cost when processing sentences with the dis-preferred NP1 interpretation (due to the need to revise the initial interpretation), instantiated in slower RTs. Importantly, we expected the differences between conditions to be modulated by individual chunking ability, in the L1 English and/or the L2 Spanish version of the task. Based on previous evidence of variability in processing of L1 Spanish gender (Pulido and López-Beltrán, 2023), it was expected that chunking ability should predict online sensitivity to gender agreement among some L2 speakers. In particular, as individual chunking ability increased, greater facilitation would be expected for trials with low-attachment (NP2) agreement in with-relative clauses, and higher costs for the items forcing the dis-preferred high-attachment (NP1) interpretation. In contrast, a lack of online sensitivity to online agreement might be expected for readers at lower levels of chunking ability.
1 Gender sensitivity and chunking sensitivity in the L2
The results presented three main findings in connection with our research questions.
At the group level, as expected, the Spanish learners in our sample revealed high variability in their online sensitivity to the gender-based experimental manipulation, which was unexplained by their L2 proficiency or L2 immersion. Consistent with this variability in sensitivity to gender, the analysis revealed no main effect of Condition in the L2 readers at the grand-average level (research question 1).
Critically, the interaction of English chunking ability (L1) and Condition revealed that processing was not equal for all the participants in our sample, and that L2 learners with high L1 chunking ability did, in fact, show the expected costs for the NP1 condition (research question 2). This finding was in line with data from the same manipulation in L1 speakers (Pulido and López-Beltrán, 2023). The significant contribution of L1 chunking ability was independent of the effect of WM, as indicated by a lack of significance of WM in the analyses.
The first finding revealed the expected variability in sensitivity to the experimental manipulation at the group level. While the preference for NP2 disambiguation in with relative clauses has been well attested in both English and Spanish (i.e. participants’ L1 and L2), recent data from Pulido and López-Beltrán (2023) revealed variability in L1 readers that was predicted by chunking ability, with some readers showing insensitivity to gender during online processing. Similarly to the above-mentioned L1 data, the absence of generalized slower rates in the NP1-attachment condition in L2 readers is due to wide variability, which was accounted for by our chunking ability measure. The lack of costs in the dis-preferred NP1 condition is more adequately interpreted as a lack of morphological processing online, i.e. it seems to indicate a failure by some participants to detect the gender cue that requires revising the default interpretation of NP2-attachment.
Given that theoretical knowledge of gender agreement is a basic feature of Spanish introduced at the beginner level (Collazos and Hurtado, 2017), the advanced-level L2 participants recruited were certainly not unfamiliar with gender agreement. Computing gender agreement correctly requires, of course, access to the grammatical gender of words. This aspect was carefully controlled in our stimuli, with all nouns being preceded by explicit gender-marking determiners (el/la) and with adjectives that contained transparent gender morphology.
Nonetheless, automatization and efficiency in the use of gender agreement is known to be a notoriously difficult feature to master (Franceschina, 2001; Sabourin et al., 2006; Unsworth, 2008). This is partly because gender agreement must be computed incrementally online alongside other aspects of the input (see, for example, Hopp, 2013), and is thus subject to the ‘Now-or-Never Bottleneck’ constraint. As discussed in the literature review, the measures of chunk sensitivity collected should provide indices of an individual’s ability to chunk elements together during real-time processing.
In connection with the second research question, the interaction of English chunk sensitivity (L1) and Condition revealed that some L2 learners showed the expected costs for the NP1 condition. More specifically, individuals with higher English chunk sensitivity showed longer RTs for sentences with Spanish NP1 attachment, revealing that they had indeed developed target-like representations online. 10 Readers with lower English Chunking Sensitivity scores, however, did not show significant differences based on the experimental manipulation. 11
2 Chunking ability in the L2
As reviewed in Section I, chunking is considered a domain-general mechanism allowing to group elements in the input based on prior patterns stored in long-term memory (Ericsson and Kintsch, 1995). As such, chunking is modulated by knowledge of specific patterns, with differences in chunking ability being mediated by expertise/experience in a given domain (in the present case, knowledge of lexical co-occurrences). Thus, one question was whether L2 processing would be best accounted for by a chunk sensitivity measure collected in speakers’ L1 (reflecting more stable language knowledge, and the domain-general nature of chunking) or whether a measure in the L2 would have higher predictive power (reflecting the mediating experience in a specific language).
Against this backdrop, a revealing outcome of our analysis was the lack of a main effect of Spanish (L2) chunk sensitivity on RTs. We suggest that, at least, three potential explanations may account for this: (a) the correlation between L2 chunk sensitivity and L2 proficiency; (b) the association between L1 and L2 chunk sensitivity; and (c) a potential floor effect due to the difficulty of the Spanish chunk sensitivity task. We discuss these in turn.
As reported, an exploratory follow-up analysis was conducted to investigate the association of the L2 chunking ability tasks with other measures, including language proficiency. The results revealed that L2 proficiency measures were a predictor of Spanish chunking ability. As expected, a significant correlation between Spanish chunk sensitivity and Spanish proficiency suggested that both measures are not entirely independent, with chunk sensitivity being mediated by L2 proficiency or vice versa (this is congruent with the idea that a domain-general mechanism, such as chunking, is mediated by level of expertise in a given domain; Cooke et al., 1993).
A second related point is that the association of L2 proficiency with L2 chunking ability might also indicate that it is necessary to reach a certain level of proficiency in language processing before L2 chunking becomes a facilitating factor. That is, the validity of L2 chunk sensitivity as a predictor of processing may increase as proficiency increases (cf. Culbertson et al., 2020).
Finally, and relatedly, we note that the ranges of the L1 and L2 versions of the chunking ability task were largely overlapping (in this regard, it is worth noting that the frequency of trigrams in our Spanish version was relatively higher than in the English measure, a difference that would have facilitated chunking for L2 Spanish learners). Even in this case, however, and as would be expected, the mean L2 scores were significantly lower than the L1 scores (as reported in Section V.2). This suggests that the L2 task was at an appropriate level of difficulty (i.e. with no floor effect); by way of comparison, the L2 Spanish chunking ability scores were also lower but within an overlapping range of performance relative to L1 Spanish speakers (Pulido and López-Beltrán, 2023, reported M = 0.39, SD = 0.11, range = 0.16–0.63). Nonetheless, we cannot exclude the possibility that the overall lower L2 Spanish chunking scores might have contributed to the lack of a significant correlation with the sensitivity to online gender agreement.
3 Chunking ability as a novel and independent predictor of L2 sentence processing
This study makes several novel contributions to our understanding of L2 sentence processing as influenced by chunking ability. The findings provide empirical support to the Now-or-Never Bottleneck hypothesis (Christiansen and Chater, 2016), which proposes that processing efficiency hinges on the encoding and chunking of the input (‘Chunk-and-Pass’), as guided by familiar patterns previously stored in long-term memory. The results suggest that chunking ability may account for individual differences in the processing of agreement dependencies that hinge on speakers’ sensitivity to co-occurrence patterns (e.g. determiners+nouns).
More broadly, this proposal complements limited-capacity models that have highlighted the role of short-term memory constraints when processing conditions are cognitively taxing (e.g. when processing low frequency vocabulary), but which have had less success accounting for online processing of grammatical gender.
VII Conclusions
The primary goal of this study was to examine individual differences in chunking ability as a modulator of L2 processing. The data reported here suggest that chunking ability influences how L2 morphosyntax is processed in real time. The results indicate that L2 readers’ ability to process grammatical agreement online is predicted by a measure of L1 chunking ability. In addition, our results provide support for a contribution of chunk sensitivity measures to our understanding of individual differences in L2 processing, independent of other factors, such as measures of WM. In all, the results of this study highlight the potential of chunking ability in L2 research and open new avenues for future research in this area.
Footnotes
Acknowledgements
The authors are grateful to the editors and to three anonymous reviewers for the helpful comments.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly supported by NSF grant OISE-1545900 to Paola E. Dussias; and by a Penn State’s Liberal Arts College Endowed Fellowship to Manuel F. Pulido.
Open Badges Statement
Data and script for analyses are available, as well as materials, at the Open Science Framework repository (https://osf.io/vx5g8/?view_only=017dc9ce63244a0fb2bf08b796f31d9e). The linguistic materials of the Spanish chunking task are also available at the IRIS database (![]() ).
).
Supplemental material
Supplemental material for this article is available online.