
Abstract
Recent investigations have highlighted that the linguistic characteristics of the contexts in which bilinguals are immersed might account for processing differences both at the lexical and cognitive levels. The present study examined the extent to which verbal and non-verbal cognitive performance in bilinguals varied as a function of two different contexts of language use: separate or integrated. The separate context was characterized by participants’ use of Spanish and English in specific situations and with different interlocutors, whereas the integrated context was characterized by the frequent use of both languages in the same situations and with the same interlocutors. Participants were two groups of young Mexican-born sequential Spanish-L1–English-L2 bilinguals (n = 50, 34 females), who reported either the separate or integrated use of both languages. We found a positive correlation between overall linguistic exposure and the number of words produced in English in a Category Fluency task for bilinguals in the integrated context. Our results also showed that more frequent code-switching positively correlated with the magnitude of the interference effect as measured with a Flanker task, but only for participants in the separate context. These results suggest that the separate or more integrated use of the more dominant language (L1) and the less dominant one (L2) can impact bilinguals’ performance differently in verbal and non-verbal cognitive tasks.
I Introduction
Bilingualism, or the use of two languages, is thought to result in two mental representations that compete for selection during language comprehension and production (Bialystok et al., 2012). Empirical evidence related to bilingual processing has shown that both languages are jointly activated to some degree even when a bilingual is immersed in a monolingual context that only requires the use of the L1 or more dominant language, or the L2 or less dominant one (e.g. Blumenfeld and Marian, 2007; Colomé, 2001; Dijkstra and Van Heuven, 2002; Macizo et al., 2010). Thus, the bilingual speaker selects the language that is appropriate to the interlocutor, the demands of the situation, and/or the context, while avoiding the intrusion of the other language. The co-activation of a bilingual’s two languages has been reported at lexical, syntactic, and phonological processing levels (e.g. Carrasco-Ortiz et al., 2012; Costa, 2005; Kroll et al., 2006, 2012).
The parallel activation of the L1 and the L2 appears to result in the competition between lexical items from both languages or cross-linguistic competition (e.g. Marian and Spivey, 2003). To solve such competition, the individual is believed to recruit domain-general cognitive control mechanisms. In other words, some of the executive control mechanisms that underlie the alternation between languages appear to be present when changing between different types of information, beyond the linguistic domain (Timmer et al., 2019). This assumption has been supported by neuroimaging studies that show some overlap in the neural networks that serve language selection and the selection of non-linguistic criteria (Bialystok and Craik, 2022).
When assessing lexical production, for instance, monolinguals tend to outperform their bilingual pairs (De Baene et al., 2015; Luk et al., 2011) who have been reported to be slower in picture naming paradigms (Gollan et al., 2005; Kaushanskaya and Marian, 2007), show reduced fluency when naming exemplars within a given category (Gollan et al., 2002; Rosselli et al., 2000), exhibit poorer performance in word identification through noise (Rogers et al., 2006), and who are more prone to tip-of-the-tongue experiences (Gollan and Acenas, 2004).
In non-verbal cognitive tasks that involve executive control mechanisms, bilingual participants tend to exhibit advantages. For example, they generally yield higher indexes of accuracy and faster reaction times, particularly in tasks involving conflict resolution – like in the frequently used Simon, Stroop, and Flanker tasks (e.g. Bialystok et al., 2004; Colzato et al., 2008; Prior and MacWhinney, 2010; Treccani et al., 2009).
Research centered on the possible impact that using two or more languages might have on the engagement of cognitive control mechanisms has yielded mixed outcomes. Some studies have supported positive results (Grundy and Timmer, 2017; van den Noort et al., 2019), whereas others have reported null ones (Donnelly et al., 2019; Lehtonen et al., 2018). There are authors who suggest that evidence in favor of an advantage in the performance of bilingual participants might be due to confounding variables (ethnicity and socio-economic status; Morton and Harper, 2007), the characteristics of the task being used (Paap et al., 2015), and/or inadequately matched samples (Antoniou, 2019). The lack of consensus and the complex nature of both bilingualism and executive control have resulted in researchers using measures like the language entropy measure (Gullifer and Titone, 2020) to quantify the linguistic variability within the contexts in which bilinguals are immersed. Notwithstanding, the implications of the potential effect of bilingualism on cognitive control merit further investigation (Bialystok and Craik, 2022).
Different models have attempted to explain the possible relation between bilingualism and non-linguistic outcomes, as well as the mechanisms of executive control involved. One of the most widely recognized models is the Inhibitory Control model (IC model; Green, 1998), which proposes that inhibitory control mechanisms allow the speaker to select the intended language while inhibiting the non-intended one, resolving the conflict that arises from the simultaneous activation of the lexical competitors from both languages (e.g. perro and dog). The model describes a supervisory attentional system or SAS in charge of controlling the activation of competing schemas. The SAS, initially proposed by Norman and Shallice (1986), guides and interacts with various cognitive mechanisms and is involved in the construction and/or modification of existing schemas and the monitoring of the execution required to achieve the objectives of different tasks. In other words, Green’s IC model conceptualizes inhibitory control as both selective attention and inhibition (Bialystok and Craik, 2022), and, therefore, it could help explain how the habitual use of two languages may potentially impact the cognitive processes underlying domain-general areas.
Additionally, Green and Abutalebi (2013) proposed the Adaptive Control Hypothesis (ACH), an expanded version of the IC model (Green, 1998), in which they point out that the characteristics of the contexts of language use might account for processing differences between different bilingual groups (Hartanto and Yang, 2016; Yang et al., 2016). Those characteristics encompass conversational partners, situations, and frequency of code-switching, among others. Therefore, linguistic contexts that foster either the separate or the more integrated use of the L1 and the L2 could have different effects on the cognitive demands that some executive functions pose for the bilingual speaker. Green and Abutalebi (2013) propose three types of interactional contexts: single-language, dual-language, and dense code-switching contexts. In the single-language context, bilinguals tend to use each language in different situations and with different interlocutors while in the dual-language context, both languages coexist in the same settings but usually with different partners. In the dense code-switching context, speakers generally use both languages and code-switch during a conversation and even within a sentence.
Code-switching frequency has been proven to enhance mechanisms of inhibitory control. For instance, findings have revealed that bilinguals who live in contexts dense in code-switching tend to exhibit more efficient performance in tasks that involve conflict resolution, particularly if the task demands high levels of monitoring (e.g. Costa et al., 2009; Hofweber et al., 2016). Timmer et al. (2019) found that a short training in language switching led to an improvement in a non-linguistic switching task. They interpreted this as a transfer from the linguistic to the non-linguistic domain for switch cost, which would indicate some overlap between sub-mechanisms across domains. Verreyt et al. (2016) compared bilinguals who reported either more frequent or less frequent code-switching and found that a higher frequency of switching between languages had a positive impact on interference inhibition mechanisms, particularly in proficient bilinguals. Hence, the frequency of bilinguals’ code-switching appears to be a relevant factor in their performance in non-linguistic tasks that involve executive control mechanisms (Barbu et al., 2018; Hartanto and Yang, 2016; Prior and Gollan, 2011).
Hofweber et al. (2016) compared the interplay between monitoring and inhibitory control observed in a Flanker task with the same mechanisms used during code-switching and found that these mechanisms seemed to be responsible, to a certain extent, for the control of the co-activated languages (Bialystok et al., 2012; Costa et al., 2009). The Flanker task has generally been used as a measure of inhibitory control by computing the interference effect, or the difference between reaction times (RT) in incongruent and congruent trials (Hilchey and Klein, 2011). However, Costa et al. (2009) concluded that the bilingual advantage reported in studies using this type of task was usually found when participants were required to switch between trial types within the same block. The results led the authors to propose that the advantages found in bilinguals stem not only from inhibitory control but also from monitoring.
The present study set out to investigate the extent to which certain context characteristics associated with use and exposure to two or more languages would modulate both verbal and non-verbal cognitive performance in bilingual young adults. These bilinguals are immersed in their L1 Spanish; however, because of their geographical location, the separate group exhibits a more compartmentalized use of their L1 and L2 than the integrated group. Thus, the first objective of our study was to evaluate bilinguals’ lexical production in each of their languages using a Category Fluency task. This task is thought to reflect individuals’ regular use of the L1 and the L2 (Shao et al., 2014) and their control of cross-language competition (Sandoval et al., 2010). We hypothesized that the differences in the relative exposure and use of the L1 and L2 that characterize the separate and the integrated contexts would likely be reflected in the number of words generated by participants from each context in the L2, English. Our second objective was to assess monitoring and inhibitory control with a high-monitoring version of the Flanker task (Costa et al., 2009). Unlike bilinguals who use and are exposed to more than one language within the same context, bilinguals who use their languages separately are not usually required to monitor the context to adjust to linguistic changes. Therefore, we expected bilinguals in the integrated context to demonstrate enhanced attentional and inhibitory performance in the Flanker task when compared to bilinguals in the separate context. We also hypothesized that code-switching frequency would modulate participants’ performance in the task (Hofweber et al., 2016) and, specifically, that a higher frequency of code-switching would relate to a smaller magnitude of the interference effect. To our knowledge, this is a pioneer study on the association of bilingualism and cognitive control in young Mexican sequential Spanish–English bilinguals who are immersed in the L1 but live in two different regions of Mexico, one of which affords more opportunities for Spanish and English to coexist.
II Current study
The general aim of this investigation was to explore the verbal and cognitive performance of bilingual participants immersed in two different contexts: one where each language is generally used in specific settings/situations and with different interlocutors, and another one where both languages are often used in a more integrative manner, sometimes in the same situations and with the same conversational partners. The present study recruited bilingual young adults, most of whom acquired English after the age of 5 years (sequential, late bilinguals), in a school context, and whose proficiency level varied between low and high-intermediate. All the participants were immersed in the L1, Spanish, and reported alternating between Spanish and English.
Exposure to diverse linguistic experiences in bilinguals may result in differences in their lexical production and engagement of executive control mechanisms when performing a non-verbal cognitive task. Because previous studies have shown variability regarding the effect of language use and exposure on lexical production and executive control in bilinguals, particularly with populations of young adults, the goal of the present study was to further address this question with bilinguals who live in Mexico and who are immersed in contexts characterized by subtle differences in the patterns of exposure and use of Spanish and English.
More specifically, this study was designed to provide answers to the following research questions:
• Research question 1: To what extent is lexical production affected by the experiences that characterize the separate and integrated contexts of language use and exposure?
• Research question 2: How does the separate or more integrated use of Spanish and English and, particularly, the frequency of code-switching impact participants’ engagement of cognitive control mechanisms?
We hypothesized that while both groups would produce a higher number of words in Spanish than in English, bilinguals from the integrated context would produce more words in English than their counterparts from the separate context. We also expected that the frequency of code-switching would modulate the cognitive control mechanisms in both bilingual groups, as reported in previous studies (e.g. Hartanto and Yang, 2016; Hofweber et al., 2016, 2020; Jylkkä et al., 2017; Yang et al., 2016).
To answer the first question, participants were asked to complete a Category Fluency task aimed at assessing their lexical production in Spanish and English. The variables of interest were the average number of words in Spanish and English across categories. To address the second question, bilinguals were presented with a Flanker task, intended to evaluate their attentional and inhibitory skills. We computed indexes of accuracy and RT in congruent and incongruent trials, as well as the interference effect or the difference between RT in congruent minus incongruent trials.
III Method
The entire procedure described in this study was carried out in accordance with the Norma Oficial Mexicana (‘Official Mexican Standards’) and both experiments were approved by the Comité de Ética de la Facultad de Psicología de la Universidad Nacional Autónoma de México (‘Ethics Committee of the School of Psychology at the National Autonomous University of Mexico’), approval number EP/PMDPSIC/0219/2021.
1 Participants
The sample consisted of 50 participants between the ages of 19 and 34 years (M = 24.6, SD = 4.51), with a mean age of acquisition of 7.59 years (SD = 4.48) who were recruited through non-random sampling by convenience, by sharing posts through social media. They were placed in one of two groups: separate context or integrated context.
Twenty-five participants had been born and lived in Mexico City and surrounding areas (19 in Mexico City, 4 in Estado de Mexico, and 2 in Queretaro). They reported using Spanish and English in different situations and with different interlocutors and, therefore, were included in the separate group. The other 25 participants had been born and lived in the north of Mexico, close to the border with the United States (10 in Baja California, 5 in Chihuahua, 2 in Coahuila, 2 in Sonora, and 6 in Nuevo León). They reported using Spanish and English in many of the same contexts and with the same interlocutors and were thus included in the integrated group.
When participants reported knowledge of a third language (L3), they were included only if they did not exceed the pre-intermediate level in that language and/or if it was a language that they did not practice at the time of recruitment. This criterion aimed to confirm that English was indeed the participants’ L2. The list of languages included: French (13), German (8), Japanese (3), Italian (7), Chinese (2), and Portuguese (1). Additionally, to be accepted into the study participants had to report normal hearing, normal or corrected-to-normal vision, no history of neurological disorders, and a minimum proficiency of low intermediate in both English and Spanish. Lastly, participants were recruited only if they confirmed that they alternated between Spanish and English (code-switching). Participants who completed the study were either invited to participate in a raffle of Amazon gift cards of MXN $250.00 (USD 12.50 approximately) each or were paid MXN $150.00 (USD 7.50 approximately).
Participants were sent a link to a digital Google format that started with an informed consent. Once they agreed to be part of the study, which took place entirely online, participants were able to automatically access the questionnaires and tests described in the following paragraphs.
Participants first completed an adaptation of the Language Experience and Proficiency Questionnaire (LEAP-Q; Marian et al., 2007) in Spanish. This language history questionnaire includes information on participants’ age, gender, and L2 age of acquisition, as well as self-rated general measures of language proficiency, relative use of and exposure to Spanish and English, whether participants were ever immersed in a country where the L2 was the dominant language and for how long, and the contribution of several factors to the acquisition of and exposure to the L1 and the L2, among others.
Once bilinguals completed the LEAP-Q, they answered the Bilingual Switching Questionnaire (BLSQ; Rodriguez-Fornells et al., 2012), also in Spanish. This questionnaire consists of 12 questions each of which can be answered on a 5-point Likert scale, from 1 (‘never’) to 5 (‘always’). Questions are related to four code-switching aspects:
• L1 switch: the tendency to switch to the L1 (e.g. ‘When I cannot recall a word in English, I tend to immediately produce it in Spanish’);
• L2 switch: the tendency to switch to the L2 (e.g. ‘When I cannot recall a word in Spanish, I tend to immediately produce it in English’);
• Contextual switch: the frequency of switching that is triggered by particular situations, topics, or settings (e.g. ‘There are situations in which I always switch between the two languages’); and
• Unintended switch: the frequency of switching that is involuntary (e.g. ‘Without intending to, I sometimes produce the Spanish word faster when I am speaking in English’).
There are three questions for each of the four constructs measured, and the scores for each set of three questions are averaged. The average per switch type may range from 1 to 5, and larger values indicate more frequent switching. Thus, the questionnaire yields one score for each switch type (L1-switch, L2-switch, contextual switch, and unintended switch), and a total of four scores per participant.
The Google format also included the LexTALE – Lexical test for advanced learners of English (Lemhöfer and Broersma, 2012), a standardized vocabulary test designed for English L2 students. It is a non-timed, visual lexical decision task in which bilinguals are presented with 60 words and/or pseudowords and must respond with ‘yes’ or ‘no’ depending on whether the word exists in English or not. The Spanish version, which has 90 words and/or pseudowords, of the same test was also administered (LexTALE-Esp – Lexical test for advanced learners of Spanish; Izura et al., 2014). These tests were used to confirm participants’ proficiency levels in the L1 and L2.
Table 1 shows descriptive data for participants’ age, years of formal education, and proficiency scores in Spanish and English per context. Other variables of interest that were collected in the first part of the study were English age of acquisition, percentages of relative exposure to Spanish and English, and length of immersion experiences in a country where English was spoken, as seen in Table 2.
Mean and standard deviations for participants’ age, years of formal education, and proficiency scores in Spanish and English, per context of language use (standard deviations in parentheses).
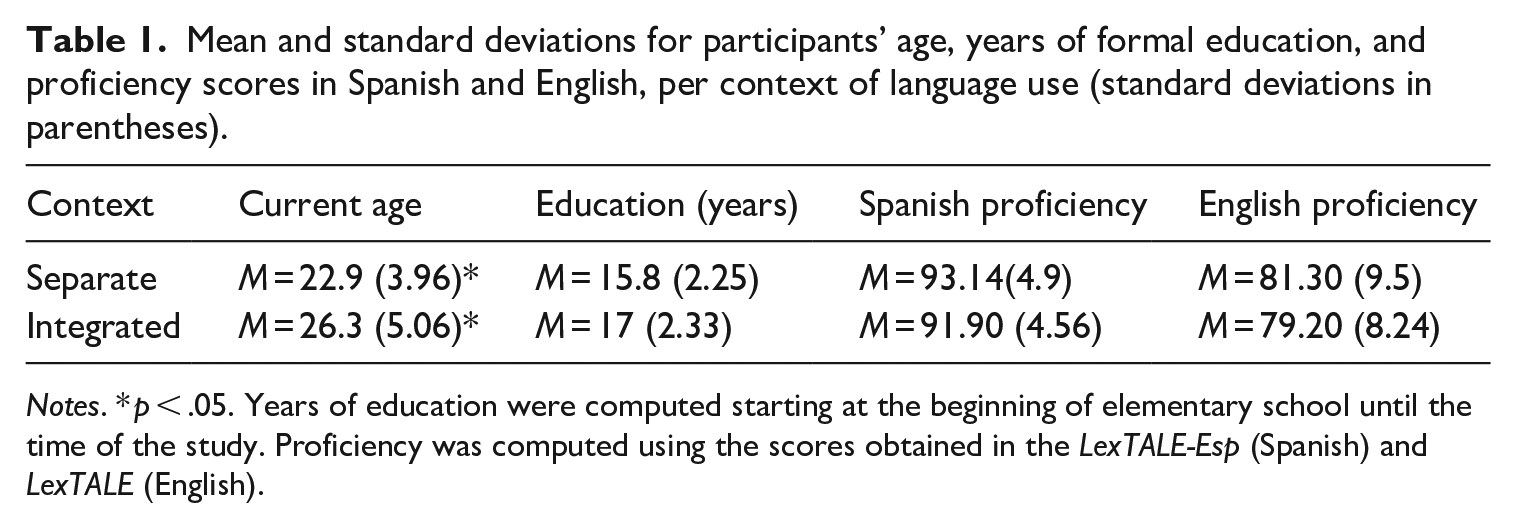
Notes. * p < .05. Years of education were computed starting at the beginning of elementary school until the time of the study. Proficiency was computed using the scores obtained in the LexTALE-Esp (Spanish) and LexTALE (English).
Mean and standard deviations for participants’ English age of acquisition, percentage of exposure in Spanish and English, and length of immersion experiences in a country where English was spoken, per context of language use (standard deviations in parentheses).
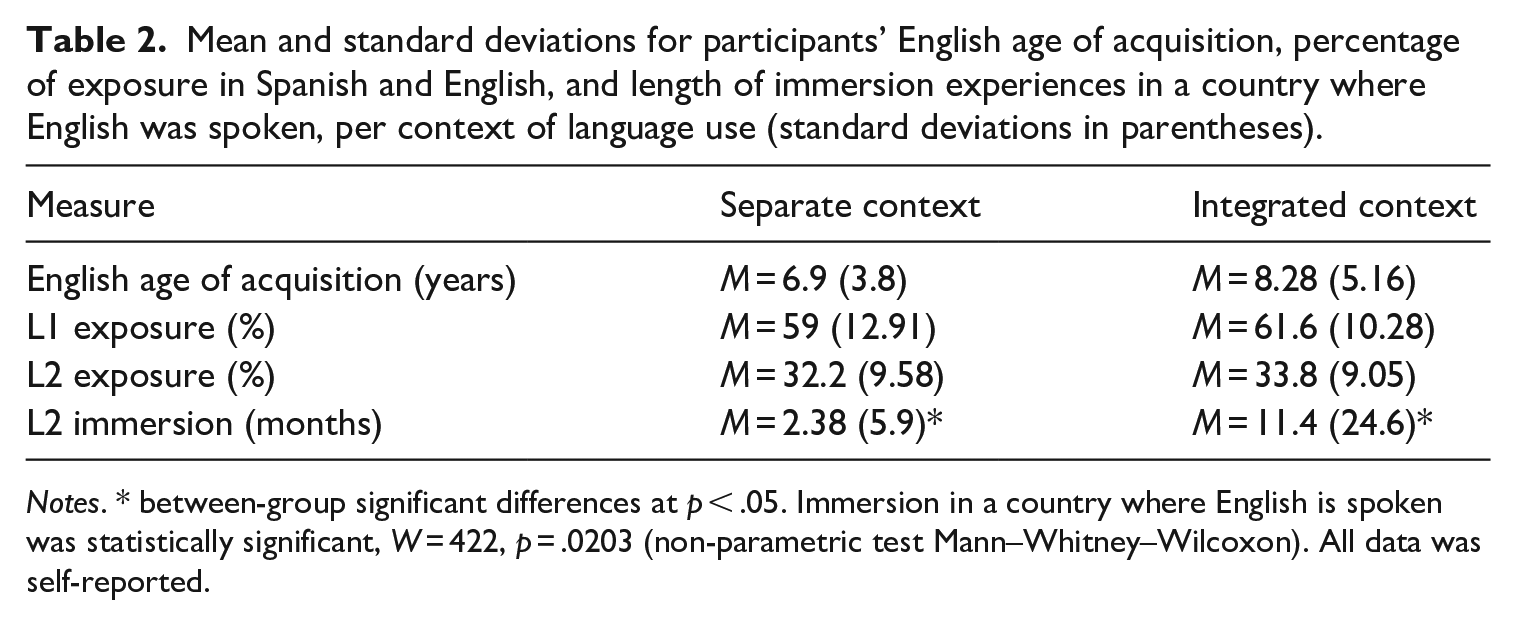
Notes. * between-group significant differences at p < .05. Immersion in a country where English is spoken was statistically significant, W = 422, p = .0203 (non-parametric test Mann–Whitney–Wilcoxon). All data was self-reported.
Participants from the separate context were overall younger when they started to acquire English, but the statistical difference between groups was non-significant (t(48) = 1.089, p = .281), and exposure to each language was very similar for both contexts. When comparing the length of immersion experiences in the L2 reported by the participants from each group, bilinguals from the integrated context appeared to have spent significantly longer periods in countries where English was spoken compared to bilinguals from the separate context. Immersion experience in the L2 was highly variable for bilinguals from the integrated context. Some participants reported spending up to one year or more in English-speaking countries, while others reported only a few days or no immersion experience at all. The comparison between both contexts was carried out using the non-parametric test Mann–Whitney–Wilcoxon (W = 422, p = .02).
Overall, the only significant differences between the two groups in relation to the measures collected through the Language Experience and Proficiency Questionnaire (LEAP-Q; Marian et al., 2007) and the vocabulary tests, were the participants’ age at the time of the study and length of immersion in an English-speaking country, both of which were higher for the integrated context.
The answers obtained from the Bilingual Switching Questionnaire (BSWQ; Rodriguez-Fornells et al., 2012) showed that participants in the integrated context reported a higher overall percentage of switches than participants from the separate context, and that, in general, contextual and L2-switches were more frequent than the other two types of switches, as shown in Table 3.
Mean and standard deviations for participants’ scores in the Bilingual Switching Questionnaire Subscales (Rodriguez-Fornells et al., 2012), per context and overall (standard deviations in parentheses).
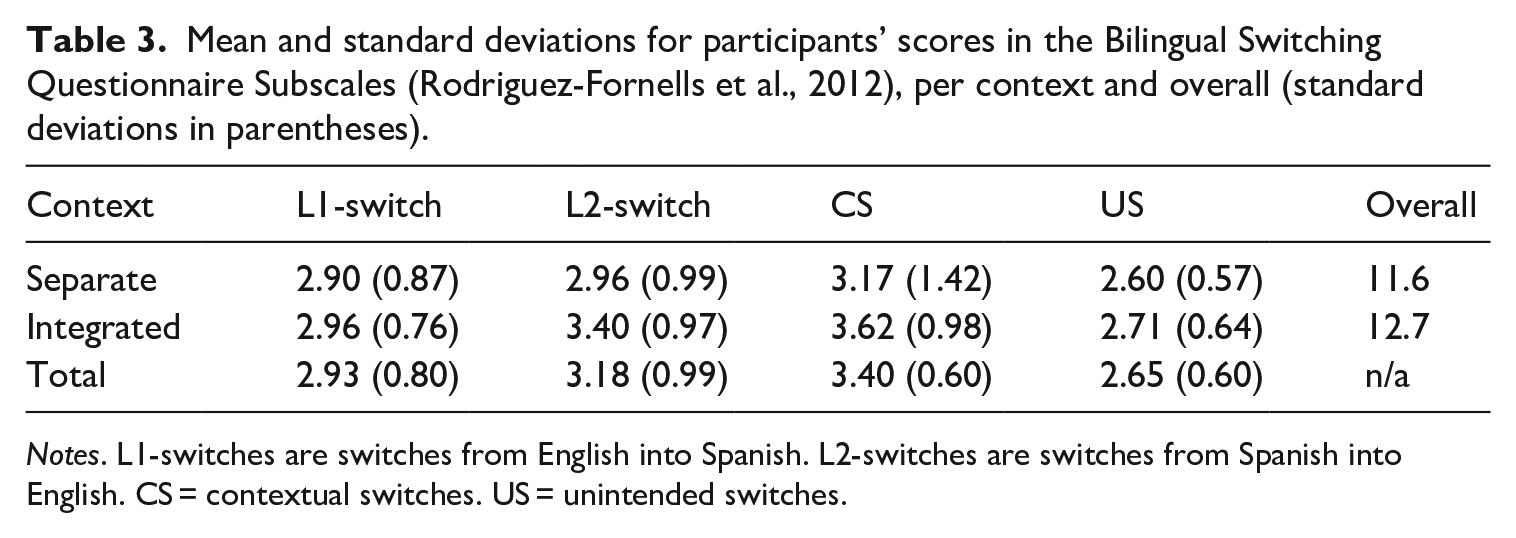
Notes. L1-switches are switches from English into Spanish. L2-switches are switches from Spanish into English. CS = contextual switches. US = unintended switches.
To analyse whether there were significant between-group differences in the percentages of the four different types of switches, a 2 × 4 ANOVA was performed with Context as the between-participants factor (Separate vs. Integrated) and Switch Type as the within-participants factor (L1-switch, L2-switch, contextual switches, unintended switches). Main effects for Context (F(1) = 4.12, p = .04) and Switch Type (F(3) = 5.98, p = .0006) were found; however, their interaction was not significant (F(3) = 0.54, p = .58).
In sum, participants from both groups reported a greater percentage of contextual switches than the other three types of switches (L1-switch, L2-switch, and unintended switches), and participants from the integrated context reported a greater percentage of switches in general in comparison to bilinguals from the separate context.
2 Experimental procedure
Participants who completed the two questionnaires and the two vocabulary tests described in the previous section were sent a link to the behavioral experimental platform Gorilla Experiment Builder (Anwyl-Irvine et al., 2019). Once they consented to participate, they were given access to the two experimental tasks included in the study: the Category Fluency task and the Flanker task.
In the Category Fluency task participants were instructed to name as many words as possible from a semantic category that appeared on the screen for 30 seconds. There were eight categories: Animals, Musical instruments, Clothing, Colors, Fruits, Furniture, Vegetables, and Body parts (same categories used in Baus et al., 2013; Beatty-Martinez et al., 2019; Linck et al., 2009). These categories were previously validated with a group of four Spanish native speakers and four English native speakers to match them according to their level of difficulty, determined by the average number of exemplars provided by participants in each category for 30 seconds. In Spanish, the easiest and the most difficult categories were Body parts, M = 15.7, SD = 5.16 and Vegetables, M = 9.1, SD = 1.97, respectively; in English, the easiest and the most difficult categories were Animals, M = 13.4, SD = 3.31 and Musical instruments, M = 10.3, SD = 3.59, respectively.
The Flanker task (Eriksen and Eriksen, 1974) was adapted from Costa et al. (2009) whose high-monitoring version included an equal number of congruent and incongruent trials to increase the attentional demands of the task because participants were young adults, an age group that frequently reaches ceiling effects. The experiment started with 6 practice trials for participants to familiarize themselves with the task, followed by three blocks of 96 trials each. Each trial began with a 400-ms fixation cross in the center of the screen followed by a display with five arrows that was presented until the participant pressed the key indicating the direction the central arrow was facing (‘J’ for right, ‘F’ for left) or until 1,700 ms had elapsed.
IV Analyses and results
Analyses were performed using ANOVAs, correlations, and generalized mixed-effects models, with the lme4 package (Bates et al., 2015), R programming environment (R Core Team, 2012, version 4.0.5). Mixed-effects models were used in this study because they allow the estimation of trial-level and subject-level data in the same analysis (Baayen et al., 2008; Judd et al., 2017), and because they are recommended when there is non-independence in the data.
To facilitate comprehension, the following subsections present each research question with its corresponding task and the proposed analytical model.
1 Lexical production: Category fluency task
To understand the extent to which participants’ language production was affected by the experiences that characterize the separate and integrated contexts of language use and exposure, participants were assessed with a Category Fluency task.
Half of the categories appeared in the English block and the other half in the Spanish block, and they were counterbalanced by language. Participants were asked to avoid repetitions and proper names, and answers were digitally recorded for their analysis. The dependent measures were the average number of words produced across categories in each language. A response was classified as incorrect in the event of word repetition, microphone miss-triggering (due to the participant’s coughing, hesitation, or self-correction midway through an answer), or when an incorrect exemplar (not appropriate for the category or language) was provided, resulting in the elimination of 0.02% of the collected data. Results showed that all participants produced more exemplars in Spanish than in English (Table 4).
Mean and standard deviations for number of words in Spanish and English produced by participants in each context of language use (standard deviations in parentheses).
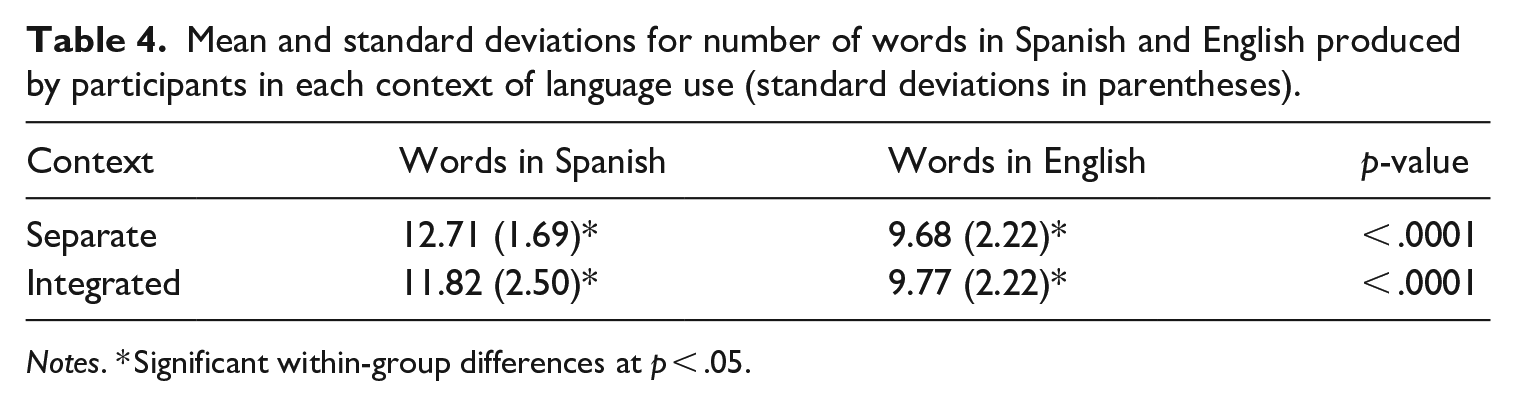
Notes. * Significant within-group differences at p < .05.
A 2 × 2 ANOVA was performed with Context as the between-participants factor (Separate vs. Integrated) and Language Block as the within-participants factor (Spanish vs. English). A main effect of Language Block was found with a significantly higher number of exemplars in Spanish than in English (p < 0.01), but no significant interaction between Context and Language was observed.
We used the entropy measure to quantify the linguistic variability in the separate and the integrated contexts and its association with the results from the Category Fluency task, specifically, the average number of words generated in L2 English across categories. Entropy scores ranged from 0 to 1.00 for participants who reported the use of two languages and from 0 to 1.56 for participants who reported the use of an L3 (third language). A score close to 0 indicates that the speaker most likely uses only one language and, as the score moves away from 0, the likelihood of using more than 1 language increases. Lower scores, therefore, are an index of a more separate or compartmentalized use of two or more languages, whereas higher scores are an indicator of a more integrated use of the languages (Wagner et al., 2023).
Based on Gullifer and Titone (2020), we extracted measures of interest from the self-reported data collected in the LEAP-Q for the L1, L2, and L3 when appropriate (34 of the 50 participants reported knowing an L3) and converted them into entropy scores. Of particular importance for the objectives of our study were: home context, social context, speaking, and overall exposure to languages. We expected to find more variability in language use and exposure in social contexts than in family-related contexts where participants were more likely to use Spanish, their L1. Similarly, we hypothesized that participants from the integrated context would be more likely to use and be exposed to English than participants from the separate context. The home and social data was elicited using Likert scales from 1 (‘never’) to 5 (‘always’) (e.g. ‘Please rate to what extent you are currently exposed to English in the following contexts’). Also following Gullifer and Titone (2020), the scores were baselined by subtracting 1 from each score such that 0 represented ‘never’ and 4 represented ‘always’. The speaking and the overall exposure data were elicited using percentages. For speaking, the question was ‘When choosing a language to speak with a person who is equally fluent in all your languages, what percentage of time would you choose to speak each language?’ For overall exposure, participants read the following instruction: ‘Please list what percentage of the time you are currently and on average exposed to each language.’ Percentages added up to 100. All answers were converted into proportions and, subsequently, into entropy scores using the languageEntropy package in R (Gullifer and Titone, 2018).
We performed a correlational matrix between the entropy scores for home, social, speaking, and overall exposure and the average number of words that participants had produced in the English block of the Category Fluency task. We found a significant positive correlation between overall exposure and the average number of words in English for bilinguals in the integrated context (r = 0.47, p = .01). Results indicated that for participants in the integrated context, greater linguistic variability was associated with more words being produced in English, the L2. No correlation was found between overall exposure and the number of words in English for participants in the separate context (r = −0.23, p = .26), or between overall exposure and the number of words produced in Spanish neither in the integrated nor in the separate context.
2 Non-verbal cognitive control: Flanker task
The Flanker task was included in the present study as a measure of attentional and inhibitory control. The purpose of the task was to answer whether the demands posed by each context of language use – a separate or more integrated everyday use of L1 and L2 – impact cognitive control mechanisms, in particular monitoring and inhibitory control. This task was also used to determine if participants’ code-switching frequency influences the magnitude of the interference effect, as suggested by previous studies (Hofweber et al., 2016, 2020).
Both accuracy rates and RT were computed. However, due to the age range of the participants, accuracy rates were expected to reach ceiling effects. Incorrect responses and omissions were excluded from the computation of RT, as well as RT under 200 ms and over 1,200 ms (Costa et al., 2009), which resulted in the removal of 0.4% of the data.
Table 5 shows the average accuracy rates and RT in congruent and incongruent trials per context, as well as the interference effect, or the difference between the mean RT in incongruent minus congruent trials. A 2 × 2 ANOVA with Context as the between-participant factor and Trial Type as the within-participant factor was performed and revealed a main effect of Trial Type (p = .0209), that is, participants in general made fewer mistakes in congruent trials than in non-congruent trials. A visual inspection of RT showed that participants from the integrated context were overall faster in both congruent and incongruent trials (Table 5). A 2 × 2 ANOVA was performed with Context as the between-participants factor (Separate vs. Integrated) and Trial Type as the within-participants factor (Congruent vs. Incongruent) and showed a moderate effect of Context (p = .0505) but no effect of Trial Type or the interaction between the two (F < 1).
Mean and standard deviations for accuracy indexes, reaction times (RT), and the interference effect in congruent and incongruent trials per context of language use (standard deviations in parentheses).
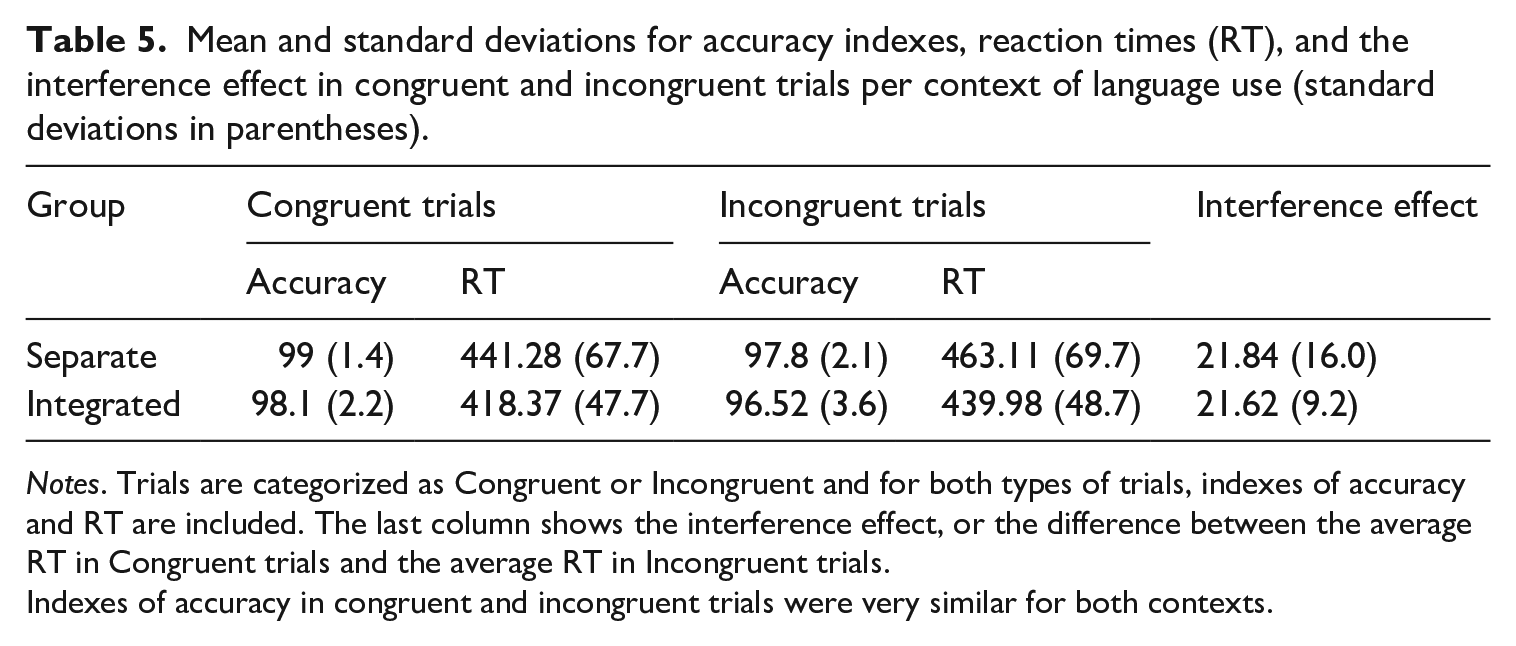
Notes. Trials are categorized as Congruent or Incongruent and for both types of trials, indexes of accuracy and RT are included. The last column shows the interference effect, or the difference between the average RT in Congruent trials and the average RT in Incongruent trials.
Indexes of accuracy in congruent and incongruent trials were very similar for both contexts.
To answer whether more frequent code-switching would result in a smaller magnitude of the interference effect, linear mixed-effects models were performed. The fixed effects were the frequency of code-switching and the context of language use (0 for separated, 1 for integrated), as well as the interaction between the two. The frequency of code-switching was z-scored to facilitate the interpretation of the model. Random effects included intercepts and slopes by participant and item in order to account for between- and within-group variability. Model comparison was performed using a chi-squared log-likelihood ratio test with maximum likelihood to specify the random effects’ structure. The model including by-participant and by-item random intercepts and Code-switching frequency and Context as fixed effects was significantly better than the model that did not include Context (X2(2, n = 50) = 3,177.5, p < .0001). When comparing the model with random by-participant and by-item intercepts with the one with random by-participant intercept only, no significant differences were found except for the AIC (Akaike Information Criteria). The model with the lowest AIC was the one with by-participant intercept only (−52,972) in contrast with the model including by-participant and by-item intercept (−52,970). Fixed effects of Context and Code-switching Frequency were significant at p < .001, as well as their interaction (Table 6). The syntax of the final model was Interference Effect ~ Code-switching Frequency × Context + (1|Participant).
Estimated coefficients from the mixed model on interference effect as f function of code-switching frequency and context.
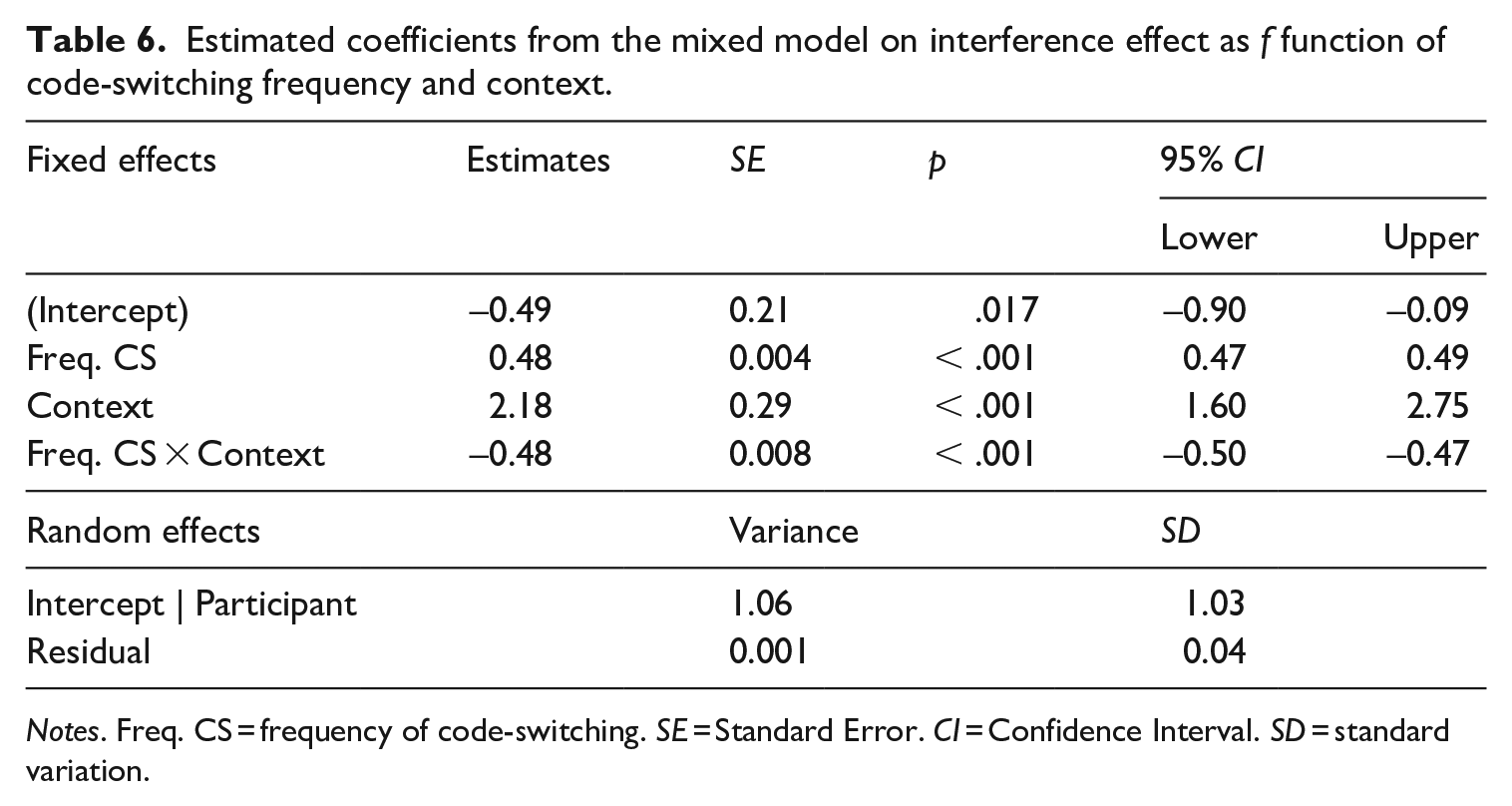
Notes. Freq. CS = frequency of code-switching. SE = Standard Error. CI = Confidence Interval. SD = standard variation.
The model predicted that as frequency of code-switching increases one unit, the interference effect increases 48 ms for bilinguals in the separate context. The interaction between code-switching frequency and the context of language use indicates that when the frequency of code-switching increases, the interference effect is larger, as seen in Figure 1. Lastly, we found no significant correlations between the entropy scores for home, social, speaking, and overall exposure, and the interference effect as computed through the Flanker task.

Model estimates of the magnitude of the interference effect where zero (0) is the centered mean.
V Discussion and conclusions
The general objective of the present investigation was to compare two groups of Mexican young adults, Spanish–English bilinguals, who live in two different contexts of language use. In the first context, the separate context, bilinguals are exposed to and use English in specific situations and with different interlocutors, while in the second one, the integrated context, bilinguals frequently alternate between Spanish and English in the same situations and, oftentimes, with the same interlocutors. Assuming that the separate or more integrated use and exposure to Spanish and English might impact participants’ performance in lexical production and in non-verbal cognitive tasks that involve attentional and inhibitory control mechanisms, differences between groups were expected to arise when performing a Category Fluency task and a Flanker task.
In line with our hypothesis, bilinguals from both groups generated more words in Spanish than English since Spanish is their L1 and the language they were immersed in (Linck et al., 2009).
We extracted the self-reported linguistic measures for home context, social context, speaking, and overall exposure from the LEAP-Q (Marian et al., 2007) and converted them into entropy scores (Gullifer and Titone, 2020; van den Berg et al., 2022; Wagner et al., 2023). These measures were selected because we expected to find between-group differences in the use and exposure to the L1 Spanish and the L2 English. Overall exposure positively correlated with the number of words that participants produced across the four categories included in the English block of the Category Fluency task, but only for the integrated context. Since we anticipated that higher entropy would be associated with greater linguistic variability, it made sense that participants who reported higher overall exposure would probably have more opportunities to use English and would therefore produce more words in that language. The fact that no correlation was found between overall exposure and lexical production in English for bilinguals in the separate context seems to indicate that a more separate or more integrated exposure and use of the L1 and the L2 may differentially influence bilinguals’ lexical production.
The Flanker task was included to assess how the separate or more integrated use of Spanish and English would impact participants’ engagement of attentional and inhibitory control mechanisms. Descriptive analyses were carried out comparing accuracy rates and RT. Both groups achieved high accuracy rates for congruent and incongruent trials and although bilinguals from the integrated context appeared to be faster overall, differences did not reach statistical significance. We then examined whether the frequency of code-switching reported by participants would modulate the interference effect. The results showed that code-switching frequency and context were significant predictors of the magnitude of the interference effect and that the context of language use modulated the impact of code-switching. We expected participants who code-switched more frequently to suffer a smaller interference effect, as reported in previous studies (e.g. Hartanto and Yang, 2016; Hofweber et al., 2016; Yang et al., 2016). We found, however, a positive correlation between code-switching frequency and the magnitude of the interference effect, but only for the bilinguals in the separate context, indicating that those bilinguals who are exposed to and use English only in specific situations experienced a larger interference effect as code-switching frequency increases. These findings are partially supported by previous studies like the one from Jylkkä et al. (2017) who reported that higher rates of contextual code-switching predicted larger RT in switching costs in a number-letter task.
Differences between the two contexts of use and exposure to the L1 and the L2 can explain participants’ performance in the Flanker task. Bilinguals in the integrated context tend to alternate between languages opportunistically, which means that they use the language that is ‘at hand’ to achieve their linguistic goals (Green and Abutalebi, 2013). This is especially the case when they meet with other young adults in social, academic, and work-related situations. Thus, the practice they acquire through these exchanges might enhance the cognitive mechanisms involved in conflict monitoring and inhibition, resulting in a smaller difference between RT in congruent vs. incongruent trials of the Flanker task (Hofweber et al., 2016, 2020; Verreyt et al., 2016). In contrast, bilinguals from the separate context use English in their language classes, to read articles related to their majors, and to listen to music and/or watch movies. They are usually able to anticipate when they will use the L2, for what purposes, and with whom. Most importantly, when they interact with other young adults, outside their English classes, it is usually in Spanish. Thus, bilinguals in the separate context use the L2 only for specific purposes, and when the demands of code-switching increase, they appear to be more likely to show an interference effect. Whether languages are frequently used separately or in a more cooperative manner has been found to influence cognitive control differentially (Han et al., 2023).
In addition, we expected that bilinguals’ language experiences would also result in differences in code-switching frequency and direction, a critical factor in our study. Contrary to our expectations, the frequency and direction of code-switching reported by participants from each group were not statistically significant. We need to consider the possibility that participants might have experienced difficulties when calculating the frequency and direction of the code-switching they engage in, an issue that has been addressed in previous studies (e.g. Jylkkä et al., 2017). However, despite the similar language switching direction and frequency reported by our participants, code-switching modulated cognitive performance only for the separate context, thus pointing to processing differences between groups. As suggested by Ooi et al. (2018), even when the type of interactional context is related to the frequency of code-switching, they are discrete concepts.
The Adaptive Control Hypothesis (Green and Abutalebi, 2013) proposes three distinct contexts of interaction, single-language, dual-language, and dense code-switching, that vary in terms of the cognitive demands they pose for speakers. In our study, the separate context is predominantly a single-language context, and the integrated context is more similar to a dual-language/dense code-switching context. Bilinguals from the latter context are exposed to situations in which Spanish and English coexist, and they often interact with other bilinguals who also code-switch. Therefore, their frequent code-switching is likely to enhance mechanisms of monitoring and inhibition. This assumption is supported by studies like the one by Ooi et al. (2018) who reported that bilinguals from dual-language or dense code-switching contexts exhibited more efficient performance on a Flanker task than participants who came from single-language contexts. Hartanto and Yang (2016) also found that bilinguals immersed in a dual-language context suffered smaller switching costs in a color-shape switching task when compared with participants from a single-language context. In contrast, bilinguals from the separate context use the L1 most of the time and the L2 in very specific situations. Thus, we can assume that these bilinguals do not train their monitoring and inhibitory mechanisms as much. For the integrated context group, code-switching might be easier than keeping their languages separate (Rodriguez-Fornells et al., 2012). Conversely, for the separate context group, code-switching may involve greater cognitive control and, thus, changing from one language to the other might be more effortful, reflecting in a larger interference effect in the Flanker task.
In addition to the relevance of the interactional context, recent studies have focused on the extent to which code-switching and cultural variables may covariate when investigating cognitive control (Tran et al., 2019; Treffers-Daller et al., 2020). Ye et al. (2016: 848) concluded that a bicultural context might enhance the cognitive performance of proficient bilinguals. This view has also been supported by West et al. (2017: 975), who suggested that it might be more viable to find cognitive advantages in bilinguals who are also bicultural. From a cultural perspective, therefore, we could assume that the bilinguals in the integrated context who live close to the US–Mexico border, are more likely to be exposed to both cultures from an early age and in a variety of situations. As a result, these bilinguals might identify themselves as bicultural, whereas bilinguals from Mexico City (the separate context) might not be as immersed in the culture of the L2. As suggested by Muysken (2000, 2013), code-switching can be prompted by sociolinguistic factors such as depth of language contact. To put it briefly, both the interactional context and the cultural identity of the participants in each context, separate and integrated, might help explain the differences found in the way that our participants engaged cognitive mechanisms when performing the Flanker task.
In sum, the results from the current study provide evidence of the impact that the linguistic characteristics of the context, in particular the separate or more integrated use and exposure to the L1 and the L2 and the experience of code-switching, may have on bilinguals’ performance in verbal and in non-verbal cognitive tasks.
A limitation to this study is that we did not administer an instrument to gather information on the specific type of code-switching that our participants engaged in; for example, whether it was insertion, alternation, or dense code-switching (Green and Wei, 2014; Hofweber et al., 2016). In the future, it might be advisable to use complementary methods, like code-switching frequency tasks, to collect such data (e.g. Treffers-Daller et al., 2020).
A second limitation might be that this study was carried out online due to the Covid-19 pandemic. Participants completed the experiments from their homes where testing conditions may not have been as controlled as in a laboratory setting. Nevertheless, all participants were tested under the same conditions. Another consequence of the lockdown was that our participants probably had limited face-to-face interactions, although most of them were taking classes online and many of them were doing home office, which would account for other types of oral exchanges.
Footnotes
Acknowledgements
The authors would like to express their gratitude to the participants of the study and the members of the Psycholinguistics Lab (Laboratorio de Psicolingüística) at the Universidad Nacional Autónoma de México for their support and feedback. The authors would also like to thank the anonymous reviewer who suggested the use of the entropy measure.
Data availability statement
The authors confirm that the data supporting the findings of this study are available within the article and/or upon reasonable request from the corresponding author.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the CONACYT (Consejo Nacional de Ciencia y Tecnología de México) National grant 2018 awarded to Alejandra Raisman-Carlovich (grant number 726489, CVU 178455).