
Abstract
While it is known that heritage speakers diverge from the homeland baseline, there is still no consensus on the mechanisms triggering this divergence. We investigate the impact of two potential factors shaping adult heritage language (HL) grammars: (1) cross-linguistic influence (CLI), originally proposed for second language acquisition (SLA), and (2) background factors associated with input. To assess the role of CLI and input we compared two groups of adult heritage speakers of Russian (n = 66) with two typologically distinct societal languages (SLs), Hebrew and American English. Their production was evaluated for three morphosyntactic phenomena: adjective–noun agreement, accusative case morphology, and numerical phrases. Using self-rating and baseline vocabulary tasks as proficiency measures, we conducted controlled experiments to assess mastery of the target phenomena. Our results show that, while CLI is the main mechanism behind HL grammar maintenance, increased input and proficiency can modulate performance in the absence of grammatical similarities between the HL and SL. An analysis of non-target responses revealed systematic patterns, including reliance on default, or unmarked, forms in both groups, in line with previous research. These findings contribute to the literature on the mechanisms of HL grammar formation and maintenance.
I Introduction
1 Heritage language grammars
Heritage speakers are individuals who are exposed, to varying degrees, to a language at home that is different from the dominant societal language (SL) (Benmamoun et al., 2013; Montrul, 2016; Polinsky, 2018a; Rothman, 2009). Such speakers exhibit a high level of variance in proficiency levels, with some achieving near-native fluency in their heritage language (HL) and others retaining just minimal control of it, to the point that they understand it to some degree but cannot produce it at all (Montrul, 2016; Montrul and Polinsky, 2022; Polinsky, 2018b).
Experimental investigation of HLs is still in its early stages, and a number of empirical gaps are yet to be filled. Largely lacking are comparative studies of the same HL in the context of different SLs. The present study attempts to fill this research gap by comparing morphosyntactic mastery of adult heritage Russian speakers dominant in Hebrew and American English. Furthermore, ours is among the first studies comparing two groups of heritage speakers to each other, rather than to a monolingual control group. This comparison can shed light on the ways in which heritage speakers’ internal and external linguistic contexts affect their grammars.
In our production study, we investigate the relative contribution of cross-linguistic influence (CLI) and input in the shaping of HL morphosyntax. In particular, we are interested in the extent to which HL morphosyntax is influenced by one or both of these factors, if at all. To evaluate the role of CLI and input, we first collected subjective and objective proficiency measures from participants (using self-reports and a baseline vocabulary task), as well as measures of HL input and use across the lifespan, and then used experimental tasks to assess mastery of adjective–noun agreement, accusative case morphology, and numerical phrases in Russian spoken by Hebrew- and English-dominant speakers.
While heritage Russian in contact with English, and to a lesser but still notable extent in contact with other SLs, has been studied, few comparisons exist of heritage Russian across different SLs. Turning to Hebrew-dominant Russian speakers, experimental studies of heritage Russian in Israel have focused on children, rather than adults (Armon-Lotem et al., 2011; Gagarina et al., 2007; Gupol et al., 2012; Janssen and Meir, 2018; Meir and Polinsky, 2021; Schwartz et al., 2015). Thus, our work will provide novel contributions to address both these gaps, assessing the language skills of adult heritage speakers of Russian and comparing the same in contact with two typologically different SLs, allowing us to evaluate the effect of cross-linguistic influence from the SL and the effects of exposure characteristics.
2 Mechanisms shaping HL grammars
While researchers agree that HL grammars diverge from the baseline, the reasons for this divergence are hotly debated. The factors that drive this divergence include CLI, or transfer from the dominant SL, and diminished input, or a decrease in the quantity and quality of HL input over time, often as a result of increasing SL input. Both factors can lead to language-internal restructuring, or a rearrangement of properties present in the baseline (Benmamoun et al., 2013; Flores et al., 2017; Kupisch and Rothman, 2018; Ortega, 2020; Pires and Rothman, 2009; Polinsky, 2018a; Polinsky and Scontras, 2020a, 2020b; Rinke and Flores, 2014; Rothman, 2007; Tsimpli, 2014). The effects of CLI and diminished input might not be mutually exclusive (Daskalaki et al., 2019, 2020; Meir and Janssen, 2021; Van Dijk et al., 2022), as has been demonstrated for child bilinguals. Furthermore, the effects of CLI and diminished input are often difficult to distinguish, which serves as a strong motivation for considering the same HL in contact with different SLs; for instance, if we find recurring properties in the same HL across different SLs, that could constitute an argument against CLI.
a Restructuring due to cross-linguistic influence
CLI, or transfer, is one of the potential mechanisms triggering divergence in heritage grammars. The traditional understanding of CLI concerns the imposition of L1 structures, rules, or features onto the L2 learned later in life. We distinguish between surface and abstract transfer. Surface transfer applies to visible cues from the dominant language, while abstract transfer encompasses the application of particular operations (e.g. verb raising) and the internal structuring or (re-)assembly of features or categories. With respect to HLs, features of the dominant language (which often counts as an early L2 for sequential bilinguals) are imposed onto the native but weaker language over time (Benmamoun et al., 2013). Thus, traces of the dominant SL can be observed in HL grammars (Aalberse et al., 2019; Muysken, 2013).
There are a number of ways to model CLI formally. In particular, similarities and differences between the L1 and L2 can be caused by feature mappings (Lardiere, 2007, 2008, 2009; Lee and Lardiere, 2019). Following this account, originally proposed for second language acquisition (SLA), the realization of functional categories in the dominant language will influence the way they are put together in the weaker language. Feature acquisition depends not only on whether a certain feature is present or absent in the two languages, which will determine the presence of abstract transfer, but also on how that particular feature is configured in them. Lardiere (2007: 236) contends that ‘the acquisition of functional categories then, consists in appropriately re-configuring or re-assembling formal and/or semantic feature bundles in the L2 grammar, and determining the specific conditions under which their properties may or must be morphophonologically expressed.’ For instance, the acquisition of plural markers in L2-English by L1-Korean and L1-Chinese participants is linked to the way in which the feature of plurality is configured in these languages (Lardiere, 2009). Although the three languages all have the feature [plural], which should trigger abstract transfer, the languages differ in the co-occurrence of this feature with definiteness, specificity, and animacy, as well as its lexical realization. This lexical realization is associated with surface transfer, introducing [plural] in structurally different ways. Languages with similar feature realization will exhibit a facilitative CLI effect, giving rise to surface transfer, while those with more prominent differences will show an impeding effect. This hypothesis is now being extended to questions of HL development and maintenance (Cuza and Pérez-Tattam, 2016; Meir and Janssen, 2021; Putnam et al., 2019) and has motivated our focus on HL Russian in contact with typologically distinct SLs. Additionally, a recent meta-analysis on child HL development showed a robust effect of CLI in the domain of morphosyntax (van Dijk et al., 2022). The authors found that the effect of the SL on the HL was more robust than the effect of the HL on the SL. Meanwhile, findings for adult heritage speakers conflict.
b Restructuring due to diminished input
Another potential explanation for the distinction between HL grammar and monolingual baseline grammar is diminished input (Montrul, 2016; Polinsky, 2018a, 2018b), which refers to reduced quantity and quality of HL input over time, often as a function of increased exposure to the SL. There are different indices used in the literature to capture diminished input, such as the age of SL onset (AoO), cumulative input over different stages of life, and current relative input (e.g. HL use in different settings; for more information, see Armon-Lotem and Meir, 2019; Unsworth, 2016). Following this hypothesis, speakers with less input in the home language will show more profound restructuring in the HL grammar and in the HL lexicon (indexed through noun-naming proficiency), as compared to speakers with more HL input. Furthermore, restructuring under diminished input will be guided by language-internal factors (such as the frequency, transparency and/or regularity of the marking of a given morphosyntactic phenomenon), rather than pressure from the SL.
AoO, the first of the aforementioned indices of diminished input, is the age at which a speaker is first exposed to the SL. Among heritage speakers, there is great variability in the age at which the SL is acquired, with some being exposed to it from birth (in parallel to the HL), and others learning it only years later. AoO is considered a classic measure of input, due to the assumption that the start of exposure to the SL marks a clear shift in HL input quality and quantity, as the number of topics and conversation partners in the HL become constricted compared to those in the SL. It has also been suggested that individuals with later AoO of the SL are more proficient in the HL (Bylund, 2009; Flores, 2010; Montrul, 2008; Rodina et al., 2020), particularly in morphosyntax (Armon-Lotem et al., 2021). Regardless of AoO, grammatical structures which are acquired in later stages of childhood by a monolingual speaker of the HL will not be acquired or solidified by a heritage speaker in the HL before the SL sets in (Meir and Polinsky, 2021) and, in that regard, AoO connects with the timing of acquisition; lexical items, structures, or registers of one’s HL that are acquired later in life tend to present challenges to heritage speakers (Montrul, 2016).
Next, the quantity of input as indexed by cumulative and/or current input measures is an important predictor of successful HL acquisition and later use (De Houwer, 2017; Gathercole and Thomas, 2009). It is reasonable to expect that individuals whose families encouraged the use of the HL at home at all times would be more advanced than those who were allowed to communicate freely in the SL. It has been found that childhood use of the HL in the home is a strong predictor of performance on grammatical tasks, specifically adjective–noun agreement (Rodina et al., 2020). Furthermore, individuals who commonly interact with the HL outside the home are expected to be more proficient than those whose language use is limited in quantity and quality and contextualized to one space alone (He, 2014, 2016). If one’s HL is used exclusively at home, the breadth of the speaker’s vocabulary would also be constricted, as terms beyond the speaker’s domestic context would be irrelevant.
From the above example, we can see that input can directly translate into vocabulary knowledge, or lexical proficiency. However, this relationship is not so clear-cut, as proficiency may also be influenced by non-input-based factors, such as linguistic aptitude and cognitive abilities. Furthermore, there is no consensus regarding which input factors influence lexical proficiency, and in what ways, as different factors have been found to affect heritage speakers’ vocabulary knowledge to different extents (Gharibi and Boers, 2017). Lexical proficiency, in turn, has been found to be highly correlated with grammatical knowledge (Polinsky and Kagan, 2007). Therefore, when considering effects of input on HL grammars, lexical proficiency should be considered as both a potential byproduct as well as a potential covariant of input factors.
In testing production accuracy on adjective–noun agreement among heritage Russian speakers (SLs: English, German, Hebrew, Norwegian, Latvian), Rodina et al. (2020) found that input influenced performance, while CLI did not. Janssen and Meir (2018)’s study of Russian accusative-case production in L1-Russian/L2-Hebrew and L1-Russian/L2-Dutch children found input, as indexed by AoO of the SL, to be the strongest predictor of accuracy. AoO was similarly found to be a strong predictor of accuracy on numerical-phrase tasks in bilingual adults (Meir and Polinsky, 2021). In contrast, a recent study on grammatical gender in HL-Spanish/SL-English-speaking children did not confirm the link between accuracy in HL gender production and input (Martinez-Nieto and Restrepo, 2023), as measured by current hours of HL use. Further studies additionally found that factors such as family type (one vs. two HL-speaking parents) and mixed vs. consistent parental input play a significant role in production (Rodina and Westergaard, 2015). As can be seen from this short overview, studies show inconsistent results regarding the weight of individual factors.
To explore the relative contribution of CLI and input, we compare three grammatical phenomena of Russian (adjective–noun agreement, accusative case morphology, and numerical phrases) as spoken by HSs in Israel and the US. In the next section, we provide an overview of the communities and the phenomena in question. We also discuss the relevant language-internal properties that might be implicated in the acquisition of each of the three phenomena.
II Russian speakers and target grammatical phenomena
1 Russian as a heritage language in Israel and in the United States
Russian speakers are a visible presence in Israel and in the US, and both immigrant groups have received a great deal of coverage in the sociological, linguistic, and sociolinguistic literature (Brehmer, 2021; Isurin, 2011; Ivanova-Sullivan, 2019). In this article, we only focus on those aspects of the respective Russian-speaking communities that are relevant for our discussion of HL maintenance.
Following the fall of the Soviet Union, a large number of expatriates from the former USSR began immigrating to Israel and the United States. In Israel, the number of Russian-speaking immigrants continues to make up a highly significant portion of the total population (around 15%, over 1 million people) and accounts for over half of all immigrants to the country (Konstantinov, 2017). These numbers make Russian the most widely spoken language in Israel after Hebrew and Arabic (Spolsky and Shohamy, 1999). Today, there are television and radio channels that broadcast exclusively in Russian. Russian-language community shops and cultural centers service predominantly Russian-speaking areas, and the language is ubiquitous in all arenas of Israeli public life. Israelis without Russian origins continue to perceive ‘Russians’ as a distinct segment of Israeli society, which in turn propagates a sense of ‘otherness’ among the Russian speakers (Altman et al., 2021; Kopeliovich, 2011).
With over 800,000 speakers residing in the country, Russian is one of the top 10 languages spoken in the United States, but given the size of the country, this number is relatively modest compared to the Israeli Russian-speaking community. Nearly a third of US Russian speakers reside in New York, but small Russian-speaking communities can be found in virtually every large American city (Laleko, 2013). New York aside, most Russian speakers in the US do not reside in ethnically delineated enclaves. Furthermore, while Russian after-school programs (sometimes called complementary schools, Sunday schools, language schools, community schools, etc.) do exist, they are found almost exclusively in major metropolitan areas. Because of demographic spread and resource limitations, opportunities for Russian language exposure outside the home are quite restricted (Laleko, 2013). It is therefore reasonable to expect that the community distinctions between Russian speakers in Israel and the US might play a role in their overall input and HL maintenance.
2 Morphosyntactic phenomena and their acquisition
We consider three morphosyntactic phenomena which demonstrate interesting differences across Russian, Hebrew, and English: adjective–noun agreement, accusative case morphology, and the structure of numerical phrases.
a Adjective–noun agreement
The two language-internal factors relevant for this task are gender and transparency. Russian has a three-way gender system (masculine, feminine, and neuter), and Hebrew has a two-way gender system, while English has no grammatical gender at all. Thus, agreement in gender offers a promising test bed for comparing Russian in Israel and Russian in the USA. In what follows, we discuss only the singular form, as gender distinctions are neutralized in the Russian plural.
Masculine nouns in Russian constitute about 46% of all nouns; feminine nouns, 41%, and neuter nouns, 13% (Corbett, 1991). Roughly speaking, gender is assigned to a noun based on its declension; in that assignment, the ending of the unmarked case (nominative) and stress are only partially predictive, and the genitive form is more telling (Corbett, 1991; Zaliznjak, 1967). A large number of masculine nouns end in a non-palatalized consonant (e.g. dom ‘house.M’), while many feminine nouns end in -a (e.g. koljaska ‘stroller.F’). Nouns which follow these patterns are transparent, as their gender assignment is predictable from the nominative (Taraban and Kempe, 1999). The gender of end-stressed neuter nouns (e.g. oknO ‘window.N’) is transparent. 1 Given the variable stress of Russian, the unstressed -a ending is realized as a schwa, and the same schwa is found in the ending of stem-stressed neuter nouns, for example, JAbloko ‘apple.N’. Such stem-stressed neuter nouns can on occasion be mistaken for feminine nouns, which makes them opaque with respect to gender assignment (Taraban and Kempe, 1999). Similarly, nouns that end in a palatalized consonant may be either masculine (e.g. gus′ ‘goose.M’) or feminine (e.g. kost′ ‘bone.F’); thus, they are also opaque with respect to gender assignment. 2
By age 2;6 (2 years and 6 months), monolingual Russian-speaking children acquire transparent feminine and masculine gender assignment: they produce correct adjectival agreement in phrases with feminine nouns ending in -a and masculine nouns ending in non-palatalized consonants (Voeikova, 2017). The gender assignment of neuter nouns ending in a stressed vowel is acquired by monolingual children by age 3–4 years, while the gender of stem-stressed neuter nouns is acquired by age 6 (Cejtlin, 2009). Since neuter nouns are less frequent, they tend to be assigned feminine in early acquisition, by analogy with stem-stressed feminines. Gender assignment on opaque nouns ending in a palatalized consonant remains problematic up to the age of 7;0 in monolingual acquisition, tending towards overgeneralization of the masculine (Cejtlin, 2009; Gvozdev, 1961).
In Hebrew, many feminine nouns in the singular end in -a (e.g. agala ‘stroller.F’) or -et/-it/-at (e.g. rakevet ‘train’), and the masculine can be viewed as default (Ravid and Schiff, 2015; Schwarzwald, 1982). As in Russian, there are also opaque feminine nouns. These nouns may appear to be masculine and end in a consonant other than t, but are in fact feminine, as becomes clear in adjective–noun agreement (e.g. xatser ‘yard’). Similarly, there are masculine nouns (e.g. aba ‘father.M’, mivta ‘accent.M’) that have the characteristic feminine ending -a. Nouns can also switch gender cues between singular and plural; however, we only consider the singular here. Gollan and Frost (2001) provide the following distribution of grammatical genders in Hebrew: masculine 56.5%, feminine 43.5%. Transparent masculine and feminine forms constitute the majority of nouns: 89% of masculine and 99% of feminine forms.
In both Russian and Hebrew, a modifying adjective agrees with the head noun in gender and number, as shown in Table 1. In addition to gender and number, Russian adjectives also show case concord (e.g. bol′š-oj dom ‘big-M.NOM house.M.NOM’; bol′šo-go dom-a ‘big-M.GEN house.M.GEN’).
Adjective–noun agreement in Russian and Hebrew.

Since Hebrew and Russian both have gender agreement on adjectives, that similarity between the two languages should have a facilitative effect on adjectival agreement in the HL. This is in line with the gender production study by Schwartz et al. (2015), who compared bilingual heritage Russian-speaking children with different SLs (English, German, Hebrew, and Finnish) and found that participants whose SLs exhibited grammatical gender performed better on adjective–noun agreement tasks in their HL than those whose SLs did not. However, a study by Rodina et al. (2020) did not confirm CLI effects for HL Russian acquisition in bilingual children speaking SLs with different grammatical gender properties: English (no grammatical gender), Latvian, Hebrew, and Norwegian (all two-way gender systems), and German (a three-gender system). Rather than CLI, the results showed robust effects of input (as indexed by family type, age, and current HL exposure).
b Accusative case morphology
The expression of the Russian accusative case is determined by the noun’s declension class and animacy. Russian nouns fall into several declension classes (Zaliznjak, 1967, 2002). Simplifying things somewhat, feminine and masculine nouns ending in -a (e.g. devočk
Neuter and inanimate masculine nouns in the accusative case have a form that coincides with the nominative case. The accusative case of class-II animate nouns is homophonous with the genitive. Class-I nouns have a dedicated form of the accusative regardless of animacy, which is distinct from the nominative or genitive forms. These data are summarized in Table 2. We will be referring to nouns whose accusative and nominative cases are homophonous as ‘invisible’; nouns with a distinct accusative form and overt case marking are ‘visible’. In the discussion below, we will address the effects of this language-internal property of visibility on the maintenance of the accusative case in heritage speakers.
Russian nominative and accusative case forms.
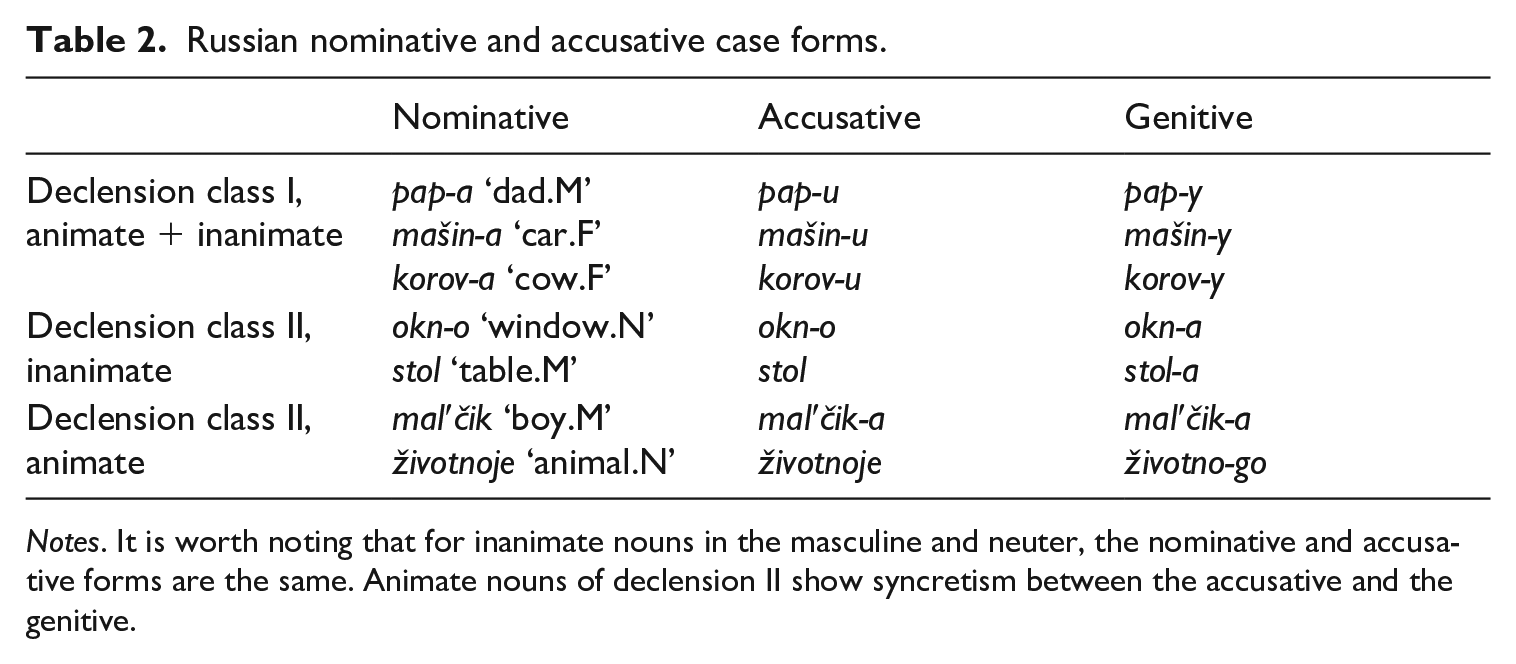
Notes. It is worth noting that for inanimate nouns in the masculine and neuter, the nominative and accusative forms are the same. Animate nouns of declension II show syncretism between the accusative and the genitive.
The nominative singular form dominates at the onset of monolingual acquisition (Voeikova and Gagarina, 2002); this is due to its frequency (for example, in naming entities in the world) and its morphologically unmarked status. The earliest use of marked cases occurs around 1;9 (Voeikova and Gagarina, 2002). By age 3 years, monolingual Russian-speaking children show error-free case production (Hržica et al., 2015; Gagarina and Voeikova, 2009; Protassova, 1997; Protassova and Voeikova, 2007).
In Hebrew, the accusative case is only marked by the preposition et on definite nouns (Danon, 2001). Thus, case marking intersects with definiteness, not animacy or gender. Finally, in English, overt case marking is only observed with pronouns, with nominative–accusative distinction.
A recent study on the production of Russian accusative-case morphology (Meir et al., 2021) found that adult and child heritage Russian speakers in Israel diverged significantly from the monolingual baseline (despite great between-group variability). Based on that result, it is not only the presence/absence of a feature in the HL and the SL, but also the way that feature is represented and mapped in each language, that play a role.
In sum, an explicit marker of the accusative case for nouns is present in both Russian and Hebrew. However, while in Russian the accusative case is expressed by nominal inflection, in Hebrew it appears as a separate particle. Additionally, the case feature is bundled differently in the two languages: in Russian with gender, number, and animacy, and in Hebrew, with definiteness.
c Numerical phrases and count forms
A count form is the form of a noun that appears in numerical expressions, in combination with a numeral. Count forms are expressed differently in the three languages discussed here.
In Russian, the form of a noun in a numerical expression differs depending on the case of the numerical expression; we will only discuss numerical expressions that appear in the nominative (see Table 3). The numeral odin ‘one’ behaves as an adjective and agrees with the noun in gender and number. Paucal numerals (1½, 2, 3, 4) combine with the paucal noun form, which, for most nouns, coincides with the genitive singular (Franks, 1995; Ionin and Matushansky, 2018; Rappaport, 2002; Zaliznjak, 1967, 2002). Numerals 5 and above co-occur with the noun in the genitive plural form. Thus, the two relevant language-internal properties which might potentially affect the acquisition of numerical phrases are the count form (paucal and genitive plural) and the declension of the noun, which is in turn related to the noun’s gender.
Russian numerical phrases.

Based on a combination of acquisitional observations (Babyonyshev, 1993; Cejtlin, 2009; Gagarina and Voeikova, 2009; Gvozdev, 1961; Mitrofanova et al., 2021), adjective–noun agreement and accusative-case morphology are almost target-like from the onset of production, while numerical phrases exhibit a long acquisition process in Russian, in line with a protracted acquisition of numerosity in general (Lipton and Spelke, 2005). For example, the numeral 2 appears at around age 2, the numeral 3 appears after the age of 2;6, and numerals 4 and 5 appear around age 4. By age 5, Russian-speaking monolingual children learn the appropriate count forms.
In Hebrew, the number system reflects gender distinctions, as shown in Table 4. Hebrew also has dual forms (i.e. mixnas-ayim ‘pants’, yom-aim ‘2 days’) which show additional complications. We do not consider them here, as they cannot be applied to all nouns. In English, nouns are obligatorily marked for plural when used with numerals ‘two’ and higher. For nearly all nouns, the plural marking is in the form of the suffix -s.
Hebrew singular and plural nouns.

Numerical phrases are present in all three languages. In all three, a suffix is mapped onto the end of the noun, and this suffix differs based on whether the noun is singular or plural. In Hebrew, this feature is additionally bundled with gender for singular and plural, and in Russian it is bundled with gender and declension class for singular, genitive plural, and paucal.
A study that compared the comprehension of adjective–noun phrases and numerical phrases in Russian showed that Hebrew-dominant heritage Russian speakers performed better on the former on a grammaticality judgment task (Meir and Polinsky, 2021). This might imply a facilitative effect of SL-Hebrew on the maintenance of adjective–noun agreement but not on numerical phrases. However, the authors did not rule out potential effects of input and timing of acquisition, as numerical phrases are acquired later than adjective–noun agreement.
III Research questions and hypotheses
The current study seeks to understand the contribution of potential factors shaping morphosyntactic paradigms in HLs. Using data from heritage Russian, we ask the following general questions:
To what extent do CLI and input characteristics affect adult HL mastery?
Does only one of these factors play a role or do they both contribute?
To test for possible inter-participant differences when considering the effects of CLI and input characteristics, we additionally consider noun-naming proficiency.
These research questions led to the following hypotheses. According to the null hypothesis, for all tasks in this study there should be no effect of CLI (that is, no significant difference in performance between the SL-Hebrew and SL-English groups) and no contribution of HL input characteristics.
If, however, CLI is the primary mechanism contributing to HL mastery, we make the following predictions. For all three phenomena, we can expect to observe abstract transfer, as described in detail below. However, we expect to observe surface transfer only for the adjective–noun agreement task, with the SL-Hebrew group outperforming the SL-English group.
On the adjective–noun agreement task, the SL-Hebrew group will outperform the SL-English group (due to the similarities between Hebrew and Russian morphophonological gender cues). This would be an example of both abstract transfer, as Russian and Hebrew both exhibit gender agreement while English does not, and importantly also of surface transfer, as the visible cues for gender agreement are similar in the two languages.
On the accusative-case task, there are two possibilities. One option is that SL-Hebrew speakers will outperform SL-English speakers on the visible form of the accusative case, since Hebrew has its own accusative marker. This would evidence abstract transfer. However, such a facilitative effect from Hebrew is not a foregone conclusion, because the accusative in Hebrew and in Russian bundles with different grammatical categories (inflections in Russian and the particle et in Hebrew). Here, we might expect to see abstract transfer (if any), as the two languages use similar rules but distinct cues for realizing these rules. Due to these distinct cues, we do not expect to find evidence of surface transfer. In the event that there is no transfer, it is possible that the SL-Hebrew and SL-English groups will perform equally on this task.
On the numerical-phrase task, we foresee two possibilities. First, we may expect no difference between the two HL groups, as the Russian system is quite different from that of both Hebrew and English. Noun forms in Russian are determined by numerals (paucal or plural), whereas such numeral divisions do not exist in English or Hebrew. Alternatively, we expect the SL-Hebrew group to have an advantage due to Hebrew’s overall rich nominal morphology compared to that of English, as well as the division of numerals into dual and plural, which would be an indication of possible abstract transfer.
If diminished input is the main factor in shaping HL grammars, then we expect individual background factors, such as AoO, Cumulative Input, Russian Use at Home, and Russian Use at Work to serve as an indicator of better performance. In particular, the effects of input are expected to be more robust on the numerical-phrase task, as these constructions are acquired later in childhood than adjective–noun constructions and case (see Section II.2.c). Thus, we expect that speakers with later SL AoO and/or with more extensive use of Russian throughout childhood and adolescence would do relatively well on the numerical-phrase task.
We additionally entertained the idea that CLI and diminished input conspire in shaping HL grammars. In this scenario, we would expect to see interactions between the variables. This would lead to an expectation of differential input effects depending on the properties of the SL. It is plausible that, if the SL and HL show considerable overlap, less input would be required to consolidate the acquisition process of a given phenomenon.
Finally, we consider the role of lexical noun-naming proficiency in performance on the three grammatical tasks. Due to demonstrated correlations between lexical knowledge and grammar (Polinsky and Kagan, 2007), we expect to find that participants with higher noun-naming accuracy likewise perform better on the grammatical tasks. We may additionally find that proficiency correlates with input as a set of predictors, due to the close connection between the two factors; alternately, we may find that once proficiency is entered into the model, effects of input disappear, such that they do not, in fact, work in tandem.
IV Experiment
1 Participants and procedure
Participants were recruited online through social media and personal contact and interviewed via Zoom. Prior to the interview, they signed a consent form in their SL and filled out a background questionnaire (see Appendix A). Participants were then given a series of elicitation tasks. The sessions were audio-recorded for off-line transcription and coding. This study was approved by the Institutional Review Board of Bar Ilan University, Israel.
Data were collected from 66 participants divided into two groups: 30 HL Russian speakers in Israel (SL-Hebrew) and 36 HL Russian speakers in the United States (SL-English). Each group was controlled for gender and age such that there was an even gender distribution in both groups, and the age range and mean were matched. The participants were either born in their country of residence or immigrated from countries of the former Soviet Union before age 5.
2 Materials
The current study was part of a larger project investigating properties of HL Russian in contact with Hebrew and English. In addition to the background questionnaire and the baseline and experimental tasks, participants were also given a free speech task, narrative elicitation task, and nonce word adjective-agreement task. The data from these tasks will not be reported in the current study.
a Background questionnaire
In a background questionnaire (Meir and Polinsky, 2021), participants were asked to indicate their gender, age, country of birth, and age of immigration, if relevant. They were then asked to subjectively rate their HL reading and writing proficiency, as well as overall proficiency in both Russian and their SL on a scale of 1–5, 5 being the highest. They were also asked about their primary language use during different stages of their lives, and about the frequency of their HL use at home and at work. The background questionnaire was used to obtain measures of individual differences in language use, as a complement to the status of Russian in their respective countries. Because some heritage speakers have limited literacy skills in their HL, participants filled out the questionnaire in their SL.
The participants’ background information is presented in Table 5. The groups showed a significant distinction in Russian Use at Work, where the SL-Hebrew group used Russian at work much more frequently than the SL-English group. Participants also noted the languages used over four periods of their life (ages 0–5, 6–12, 13–17, and 18+ years), which we coded as:
0: other languages and/or only SL;
1: Both SL and HL; and
2: Only HL.
Participant information.
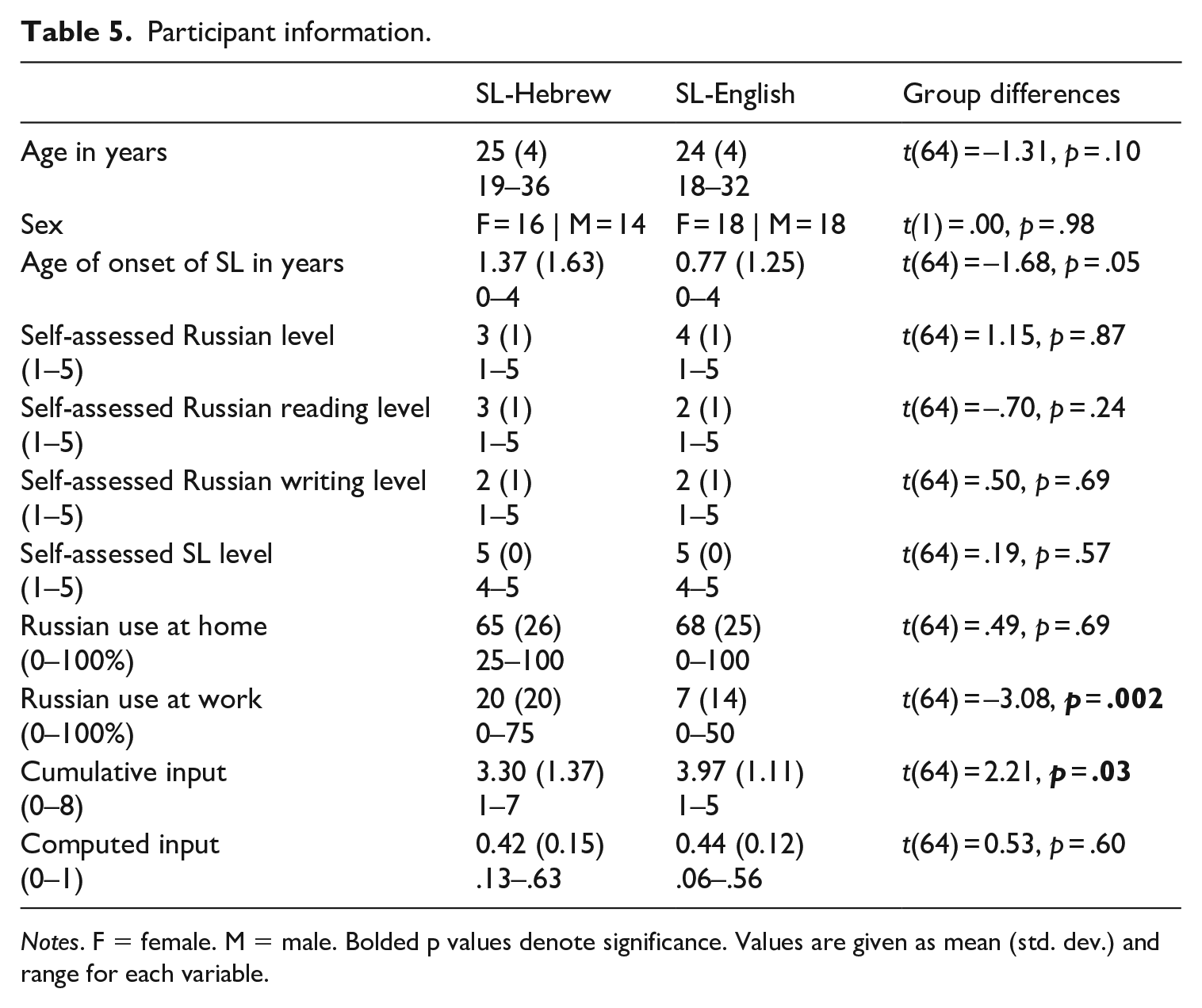
Notes. F = female. M = male. Bolded p values denote significance. Values are given as mean (std. dev.) and range for each variable.
These ratings were summed to create a cumulative input measure (with a maximum score of 8). On this measure, the SL-English group reported significantly higher cumulative input than the SL-Hebrew group. Finally, we computed a single input variable which averaged current input (Russian Use at Home and Russian Use at Work) with the cumulative input measure described above. Thus, someone who has used (and continues to use) exclusively Russian since birth would have a score of 100. No group differences were observed on this overall input measure.
b Baseline tasks
In the baseline vocabulary task, participants were shown a series of 51 images and asked to name what they saw in each image (see Appendix B1). The task was designed using the stimuli from the ‘Noun and Object: Stimuli Database’ (Akinina et al., 2015). The purpose of this task was to estimate the range of the participants’ lexical knowledge and determine whether the SL-Hebrew and SL-English groups differed in lexical knowledge, as well as to obtain an objective measure of HL proficiency. At the group level, there was no significant difference in performance on the objective noun-naming task (SL-Hebrew: M = 30.23, SD = 8.0; SL-English: M = 29.94, SD = 8.78; [t(64) = −1.58, p = .06]), with neither group reaching the ceiling level of 51.
c Experimental tasks
In the adjective–noun agreement task, participants were shown 30 pairs of objects in two different colors (for the task, see Appendix B2 and Rodina et al., 2020; Mitrofanova et al., 2018). Then, one of the members of the pair disappeared, and the participants had to name the disappearing object; since it differed from the remaining one in color, they had to use the relevant color term. To denote the colors of the missing objects, we invariably used end-stressed adjectives (zolotOJ ‘gold’ or golubOJ ‘light blue’), which made gender marking unambiguous. Examples are given in Table 6.
Adjective–noun agreement task.
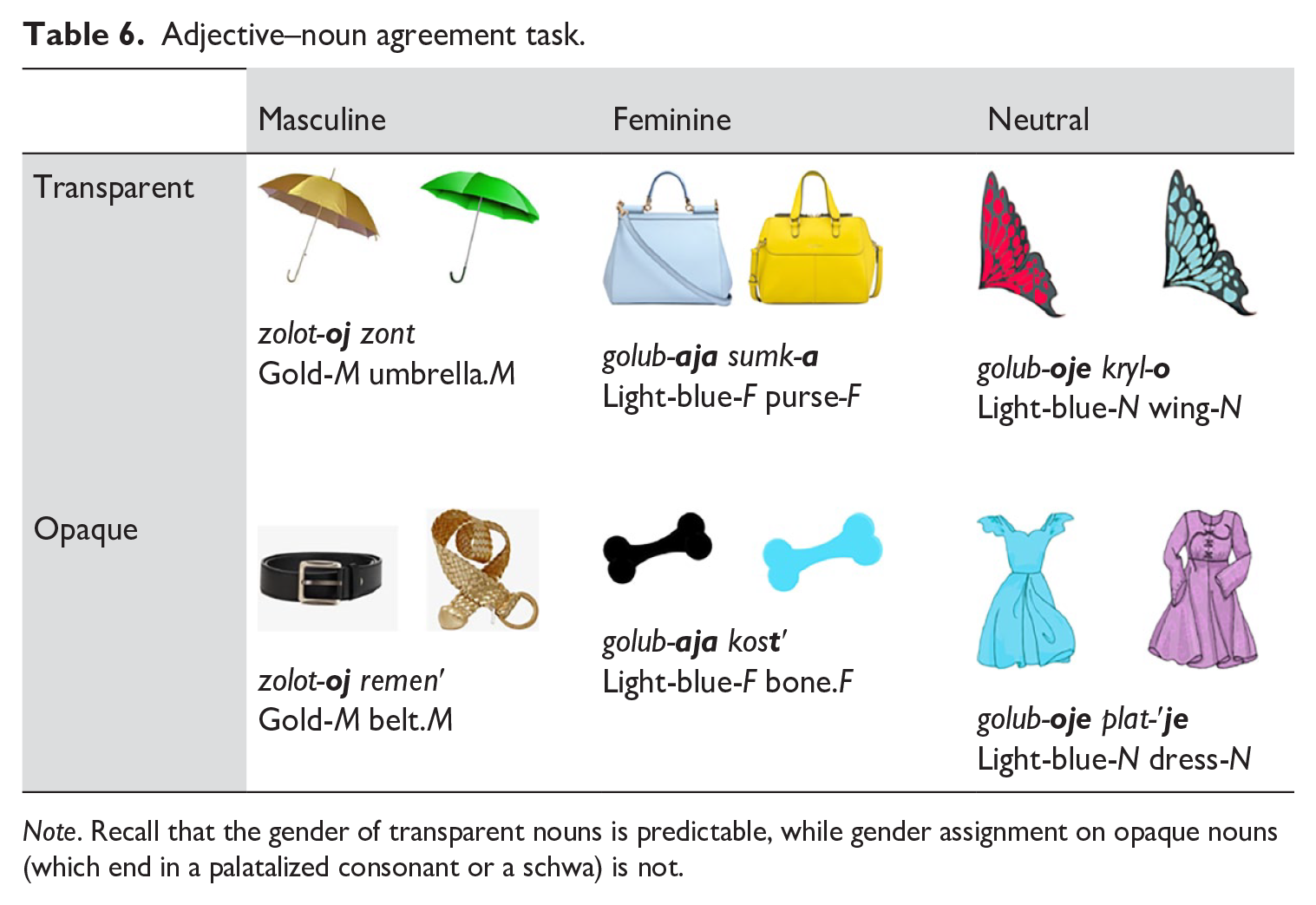
Note. Recall that the gender of transparent nouns is predictable, while gender assignment on opaque nouns (which end in a palatalized consonant or a schwa) is not.
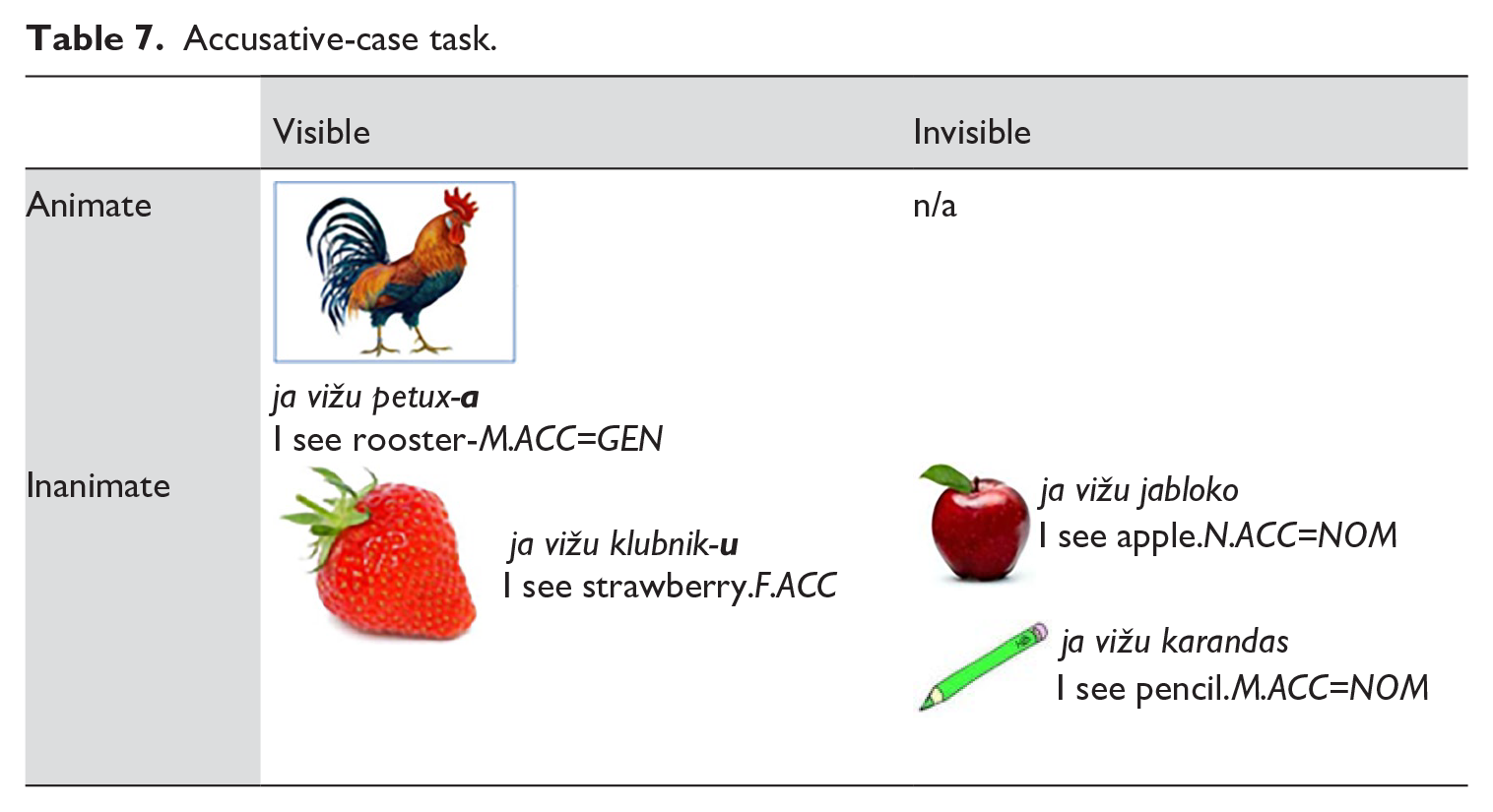
In the accusative-case task (Janssen, 2016; Janssen and Meir, 2018; Meir and Janssen, 2021; Meir et al., 2021) participants saw 36 images (for some examples, see Table 7; for a full list, see Appendix B3). In order to elicit the accusative form, they had to say ‘I see . . .’ followed by the name of the object. Recall that visible nouns refer to ones whose accusative form is different from the unmarked nominative form.
Accusative-case task.
In the numerical-phrase task, participants were asked to count the number of objects (and to name the objects) in each of 24 images. This task (see Table 8) manipulated gender (masculine, feminine) and number (paucal, plural). 3 Note that the paucal forms of feminine nouns are homophonous with nominative plural forms, while paucal masculine forms are predominantly homophonous with the singular genitive. The nouns selected for this task were taken from the Russian version of the CDI (Vershinina et al., 2011). For a list of the target responses in this task, see Appendix B4.
Numerical-phrase task.
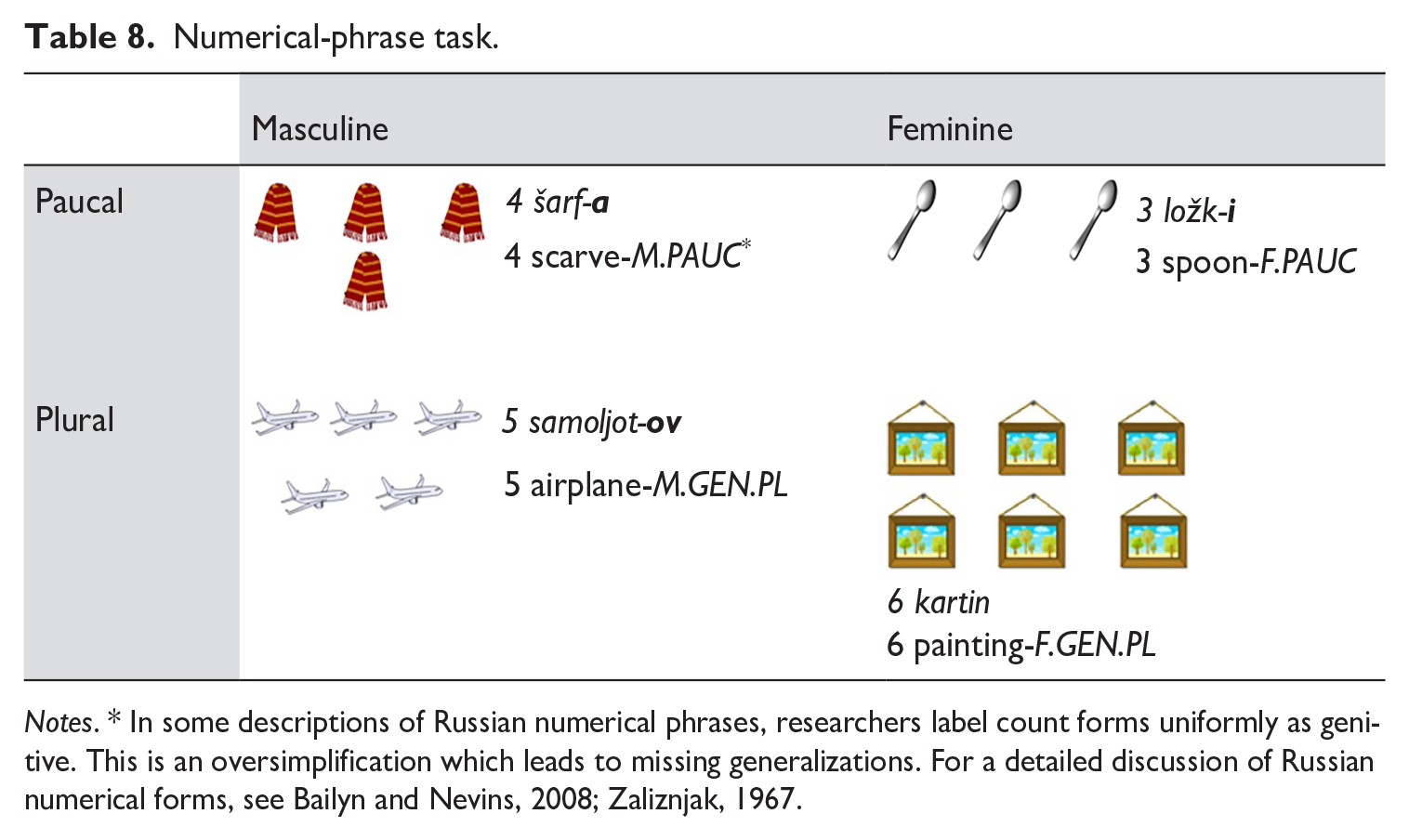
Notes. * In some descriptions of Russian numerical phrases, researchers label count forms uniformly as genitive. This is an oversimplification which leads to missing generalizations. For a detailed discussion of Russian numerical forms, see Bailyn and Nevins, 2008; Zaliznjak, 1967.
3 Coding
Responses were first binarily coded as target (1) or non-target (0). Next, participants’ response patterns were recorded, allowing for several layers of analysis. Responses using a non-target noun of a different gender (e.g. stul ‘chair.M’ for kreslo ‘armchair.N’) were not counted in the total scores for each participant, even if the corresponding adjective, inflection, or numerical phrase was correct, to control for the number of target nouns of each gender. A total of 1.6% of responses across the three tasks were excluded in this way. Next, a detailed analysis of non-target responses was carried out, in which we investigated not only response accuracy but also response content and patterns therewithin. In the adjective–noun agreement task, we considered the non-target use of masculine and feminine. In the accusative-case task we looked at the non-target use of an inflection (e.g. -u inflection: *ja vižu žirafu; zero inflection: *ja vižu slon). Finally, we noted non-target responses in the numerical-phrase task, such as the use of genitive plural with paucal numbers, e.g. *tri šarfov ‘three scarves’, or the use of the paucal form with numbers 5+, e.g. *pjat′ samoljota ‘five planes’.
4 Statistical analysis
The analysis was conducted using R (RStudio Team, 2020). First, we ran a correlation analysis to test for multicollinearity between input and proficiency, as well as to evaluate the links between performance on different morphosyntactic phenomena. We then fitted binomial mixed-effects logistic regression models for each task separately. The models were built by adding random and fixed variables in a step-by-step procedure, starting with an intercept-only model as a baseline. The null models included both by-subject random intercepts and by-stimulus random intercepts. We started with language-internal factors: For the adjective–noun agreement task, the fixed variables were Gender (M, F, N) and Transparency (Transparent, Opaque). For the accusative-case task, the fixed variable was Visibility. For the numerical-phrase task, the fixed variable was Condition (M-PAUC, F-PAUC, M-GEN-PL, F-GEN-PL). We then added Group (SL-English, SL-Hebrew), input factors (AoO and Input, the aggregate score explained in Section IV.2.a). Next, we added proficiency (Noun Naming) to test whether group and input effects disappear with its inclusion. Three-way interactions between language-internal factors, Group, and Input and between language-internal factors, Group, and proficiency were also added to test our interaction hypothesis, which predicted that these factors might modulate each other. The variables and variable interactions were kept only if they significantly improved the fit of the model and resulted in a reduced AIC-value. In Section V, we report the minimal adequate models that performed significantly better than the intercept-only baseline model. We report results from the highest-level model that converged (Barr et al., 2013). We also present results from pairwise post-hoc comparisons with Tukey adjusted significance levels.
V Results
1 Background factor and task correlations
Figure 1 presents correlations between age, input factors (AoO and Input), proficiency (Noun Naming) and the three experimental tasks. The three tasks are most highly correlated, which suggests that the grammatical features under discussion are part of a highly-interconnected system. This system is structured in such a way that high performance on one task likely entails high performance on another. The three tasks are also strongly correlated with noun-naming proficiency.
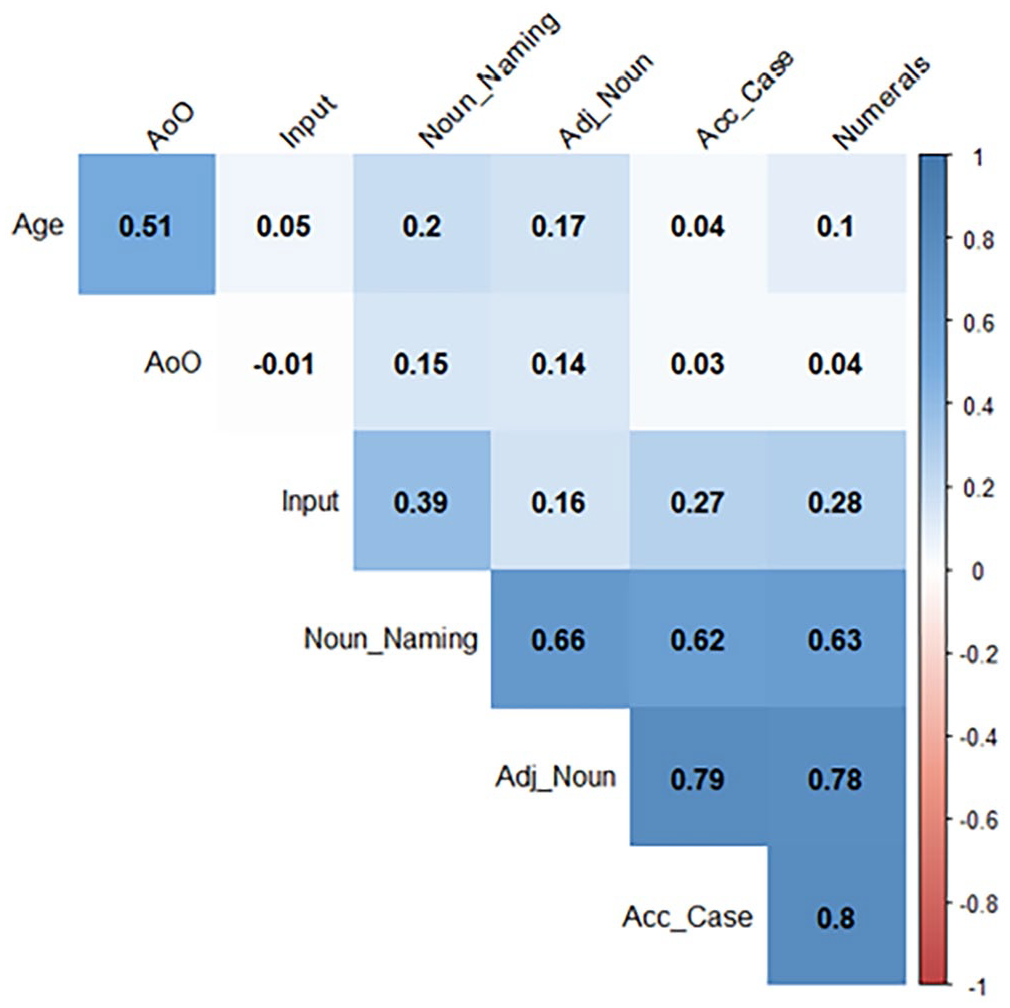
Correlational analysis.
2 General results
Performance in both groups showed a high level of heterogeneity. The SL-English group had the greatest variance on all three tasks (see Figure 2). In the following subsections, we present the results of each task in detail, considering effects of Group, Input, and Proficiency across different morphosyntactic paradigms.
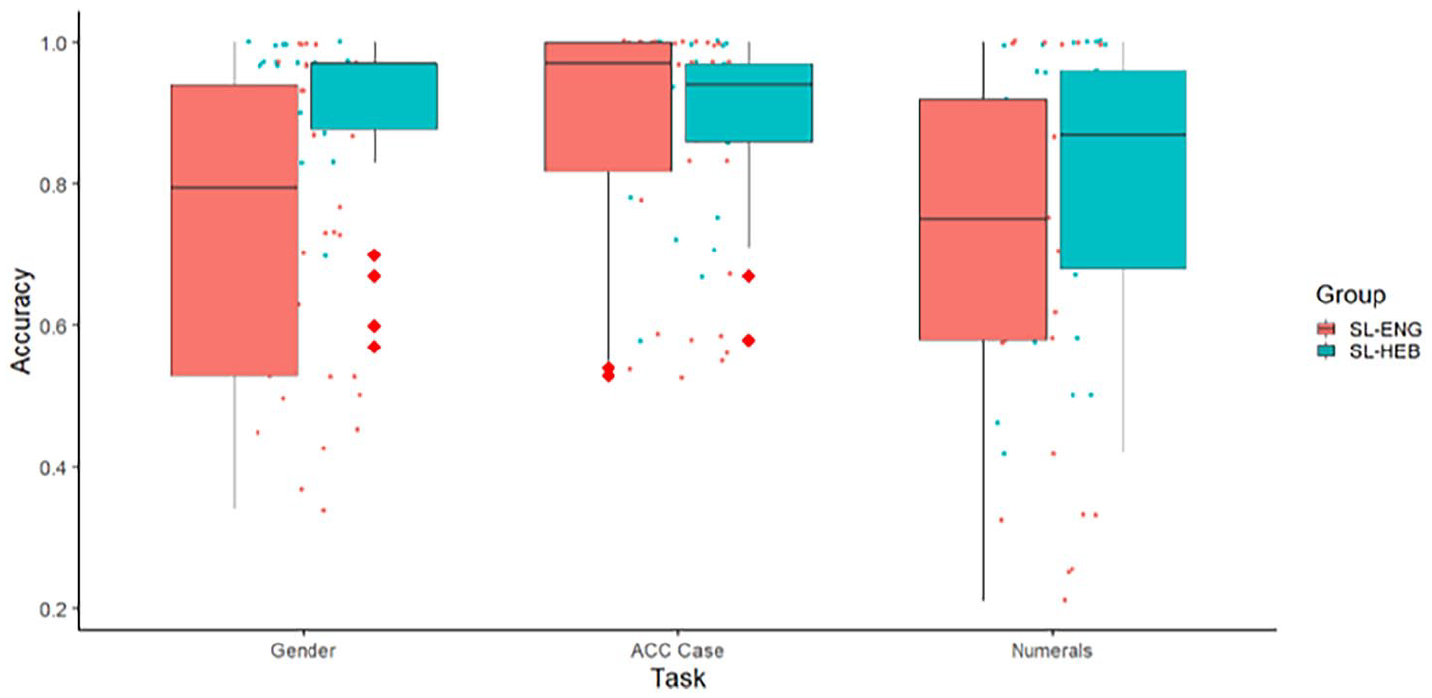
Overall task comparison at group level.
3 Adjective–noun agreement
Figure 3 presents target and non-target responses of both groups on adjective–noun agreement by grammatical gender and noun transparency. The final analysis of production accuracy on this task, coded in a binary manner (1 = Target, 0 = Non-Target), is presented in Table 9; it was generated by the following formula:
ADJ.Final <- glmer(Accuracy ~ (1 | CODE) + (1 | Stimuli) + Gender +Transparency + Group + Noun_Naming, family = binomial, data = ACC,control=glmerControl(optimizer=“bobyqa”))
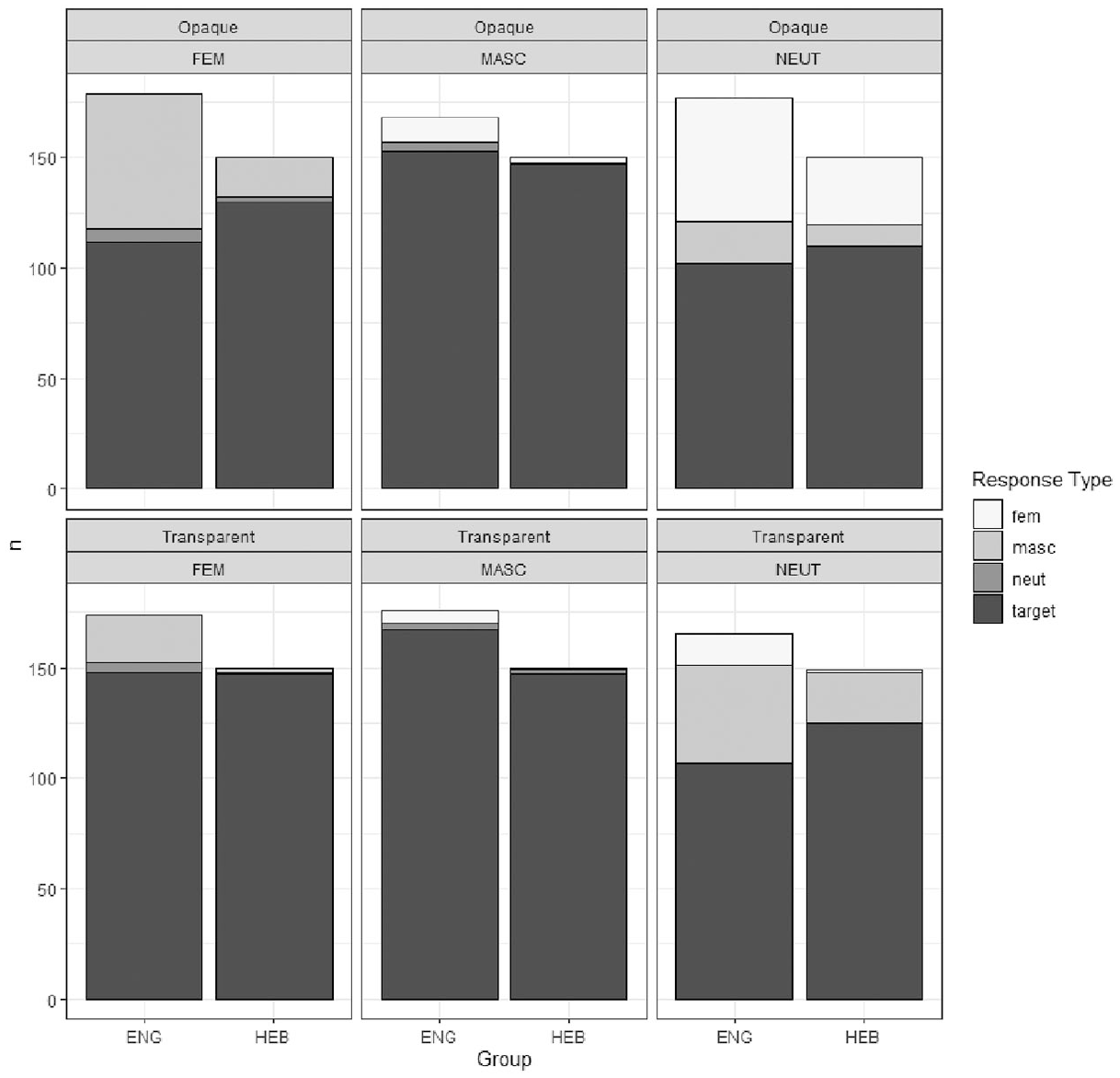
Performance on the adjective–noun agreement task by group, gender, and transparency.
Predictors of performance on the adjective–noun agreement task.
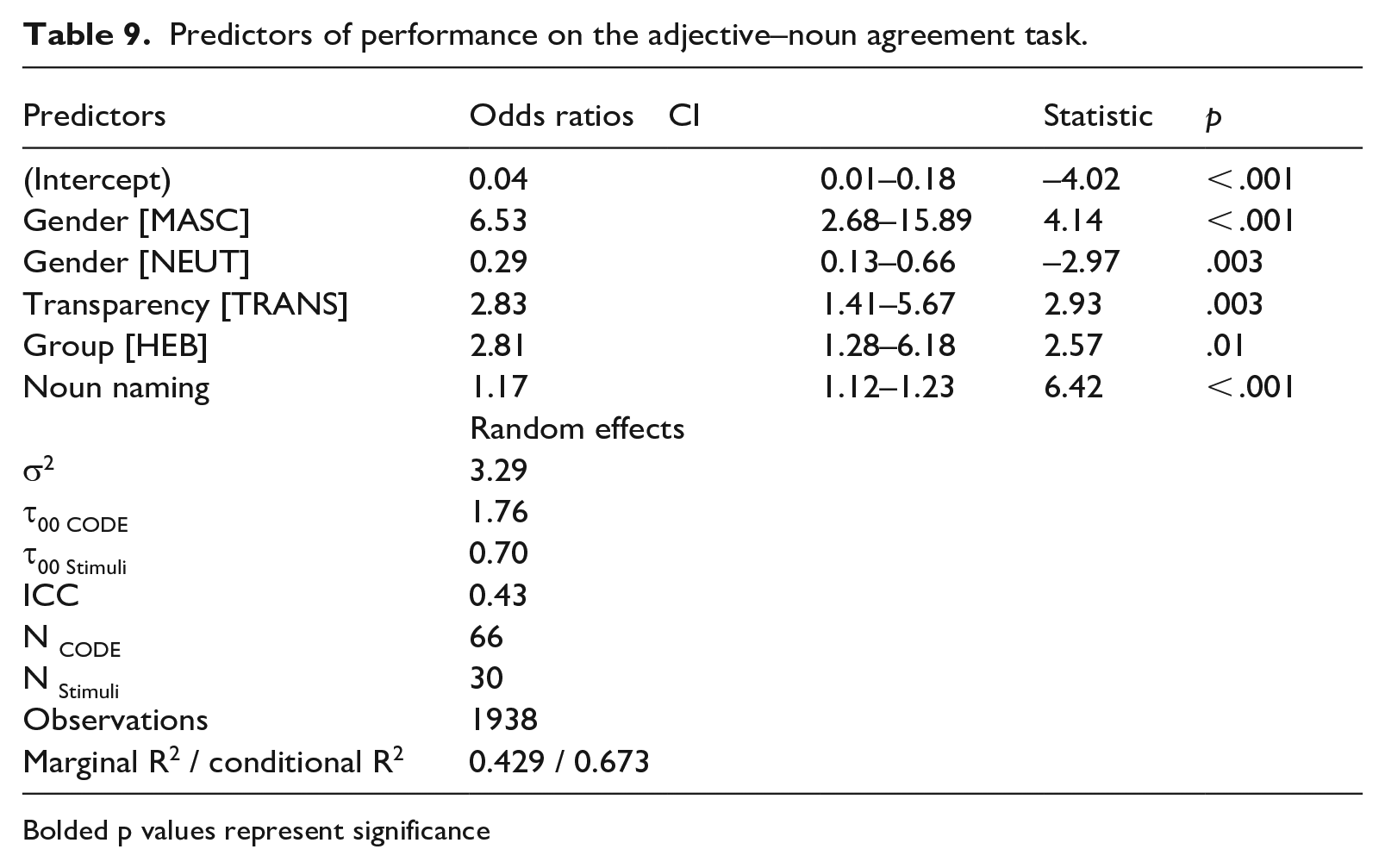
Bolded p values represent significance
Transparency predicted performance accuracy, with both groups performing better on transparent nouns than on opaque ones. Likewise, noun-naming proficiency and group significantly predicted performance, while the inclusion of input did not significantly alter the fit of the model. Similarly, the inclusion of three-way interactions did not improve the fit of the model, and, with the inclusion of the four-way interaction, the model did not converge.
In considering non-target responses on opaque feminine nouns, we find that both groups primarily defaulted to the masculine, (e.g. *golubOJ noč′ ‘blue.M night’). On opaque neuter nouns, both groups erred primarily toward the feminine (e.g. *zolotAja sItə ‘gold.F sieve’), followed by the masculine. Similarly, on transparent neuter nouns, both groups tended toward the masculine (e.g. *golubOJ oknO ‘blue.M window’). Here, diverging from patterns of the SL-Hebrew group, the SL-English group additionally erred toward the feminine (e.g. *golubAja oknO ‘blue.F window), and on transparent feminine nouns toward the masculine (e.g. *zolotOJ klubnIka ‘gold.M strawberry’).
The key takeaways from the results of the adjective–noun agreement task were that language-internal features (gender and transparency), group, and noun-naming proficiency significantly predicted performance, while input did not. Non-target response patterns between the groups were fairly similar.
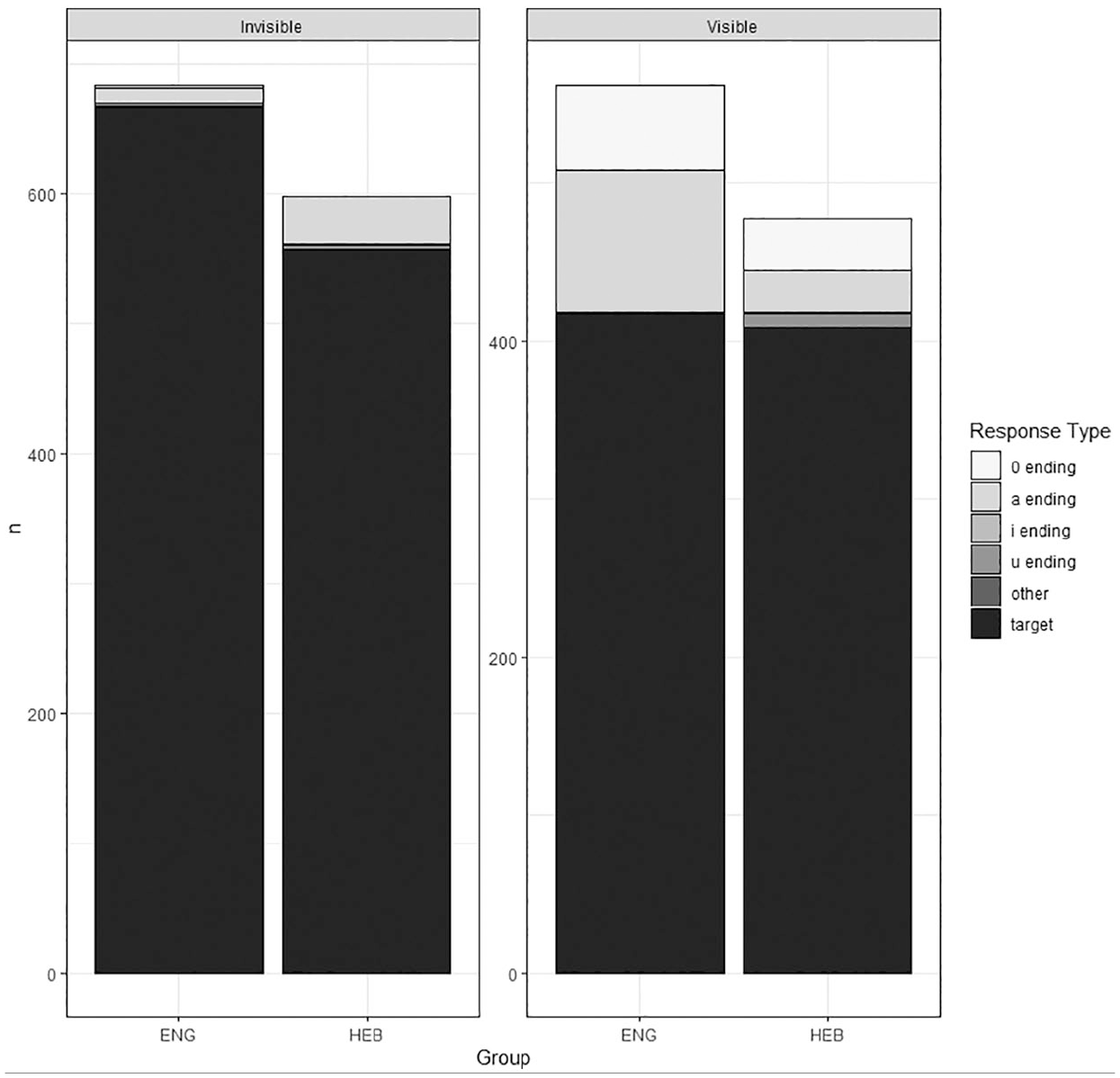
4 The morphology of the accusative case
Figure 4 presents target and non-target responses for the accusative-case production task by group and visibility. Table 10 shows the results for the final binomial logistic regression fitted for the accusative-case task, coded in a binary manner (1 = Target; 0 = Non-target). It was modeled using the following formula:
ACC.Final <- glmer(Accuracy ~ (1 | CODE) + (1 | Stimuli) + Visibility + Input + Noun_Naming, family = binomial, data = ACC, control=glmerControl(optimizer=“bobyqa”))
Performance on the accusative-case task by group and visibility.
Predictors of performance on the accusative-case task.
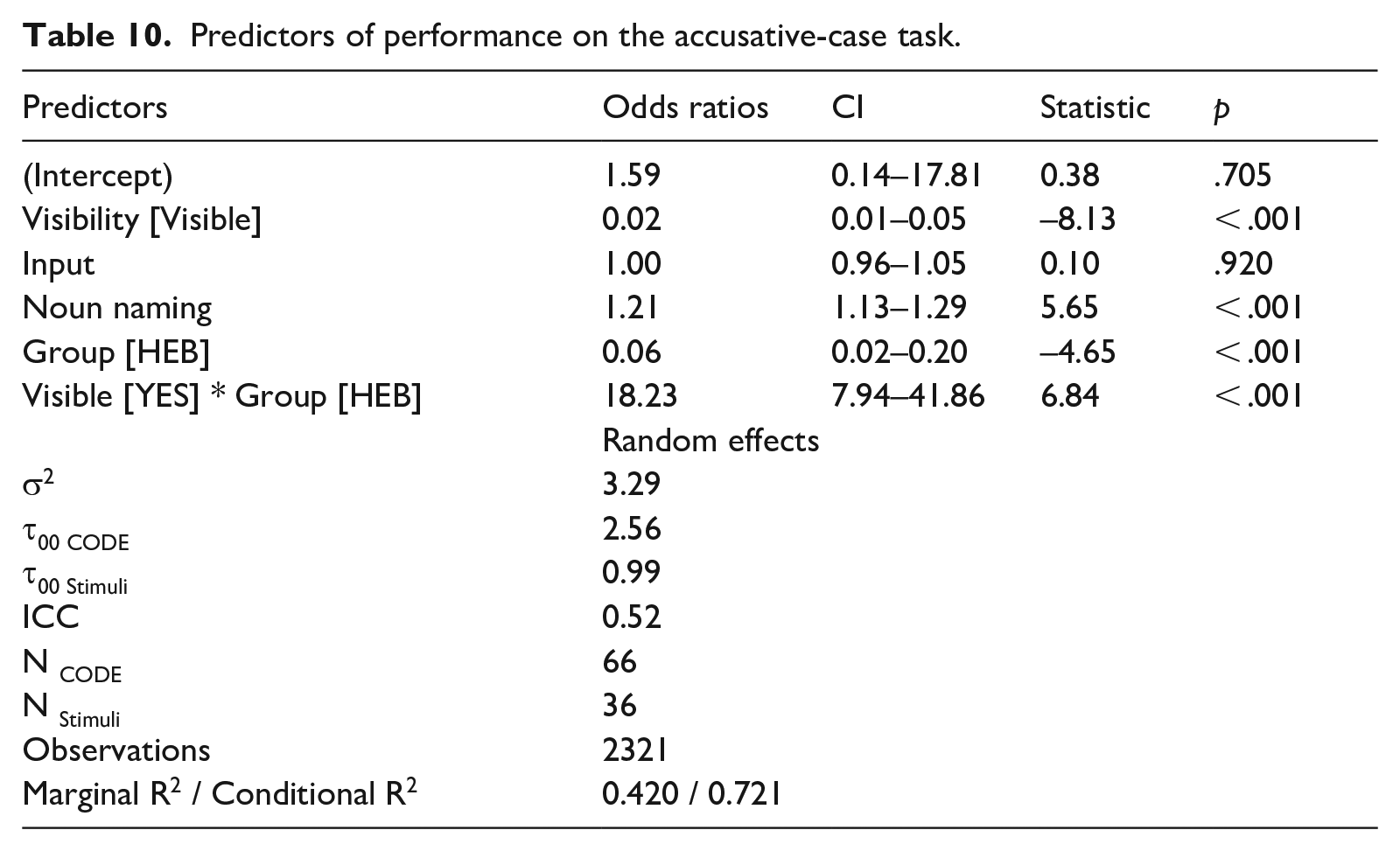
On this task, performance was significantly predicted by language-internal factors (Visibility) and noun-naming proficiency, as well as a two-way Group*Visibility interaction, while Group and Input did not improve the fit of the model. With the inclusion of three-way interactions, the model did not converge.
The follow-up on the two-way interaction showed that the SL-English group significantly outperformed the SL-Hebrew on nouns with invisible accusative-case morphology (p < .001), whereas nouns with a visible accusative case marker did not evoke significant differences between the groups (p = .80).
Among non-target responses, the most common one in both groups was the use of the unmarked (nominative) form, noted in Figure 4 as having a 0-ending (e.g. *ja vižu krokodil ‘I see crocodile.M.NOM’) and the nominative inflection -a (e.g. *ja vižu kukla ‘I see doll.F.NOM’). This latter pattern was considerably more common in the SL-English group than the SL-Hebrew group. Additionally, some speakers in the SL-Hebrew group overextended the -a ending on masculine nouns to inanimates (e.g. *ja vižu stol-a ‘I see a table-ACC’), as shown for invisible nouns in Figure 4. One participant in the SL-English group used a non-existent -e ending on a neuter noun, marked in Figure 4 as ‘other’.
The key takeaways from the accusative-case task were that there were no group differences on visible nouns, which require the use of a dedicated accusative inflection. Proficiency predicted performance on this task, while once again input did not contribute to the fit of the model. While non-target response patterns varied, both groups leaned heavily towards overuse of the unmarked default nominative form (zero inflection for masculine and -a ending for feminine).
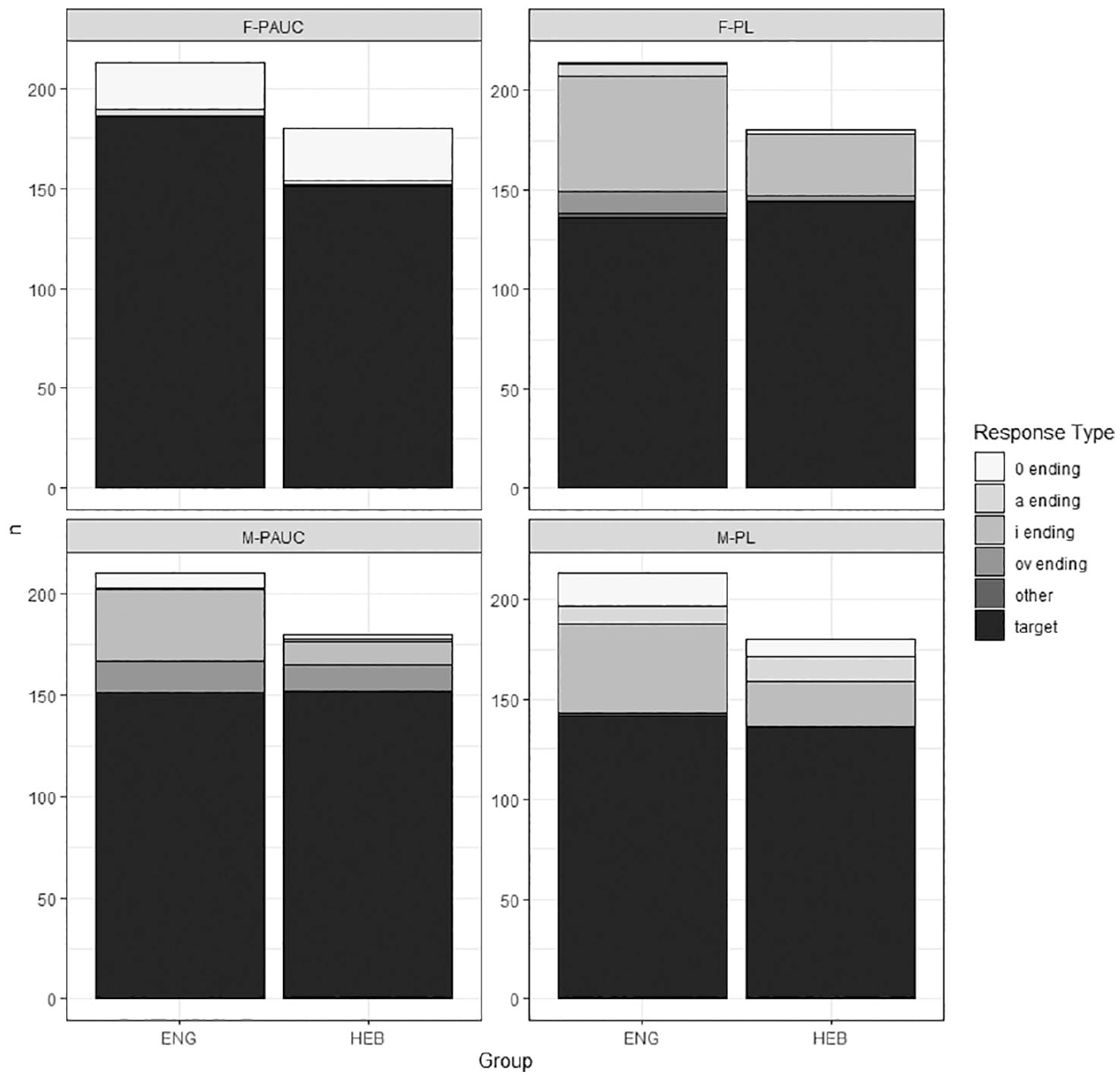
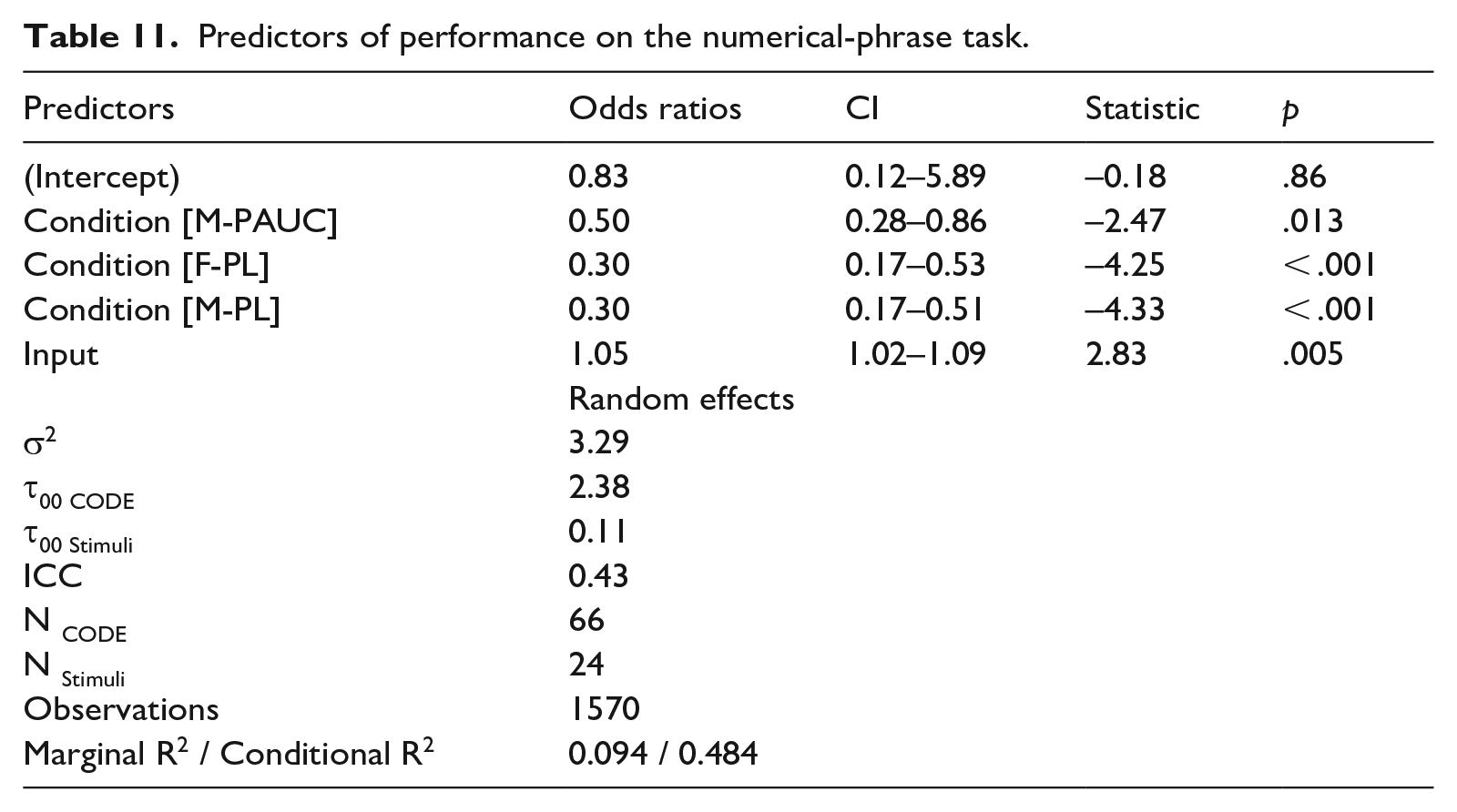
5 Numerical phrases
Figure 5 presents the performance of both groups on feminine and masculine paucal and plural nouns. A binomial logistic regression analysis was run on the results from the numerical-phrase production task. The final model was generated using the following formula:
ACC.Final <- glmer(Accuracy ~ (Accuracy ~ (1 | CODE) + (1 | Stimuli) + Condition + Input, family = binomial, data = ACC, control=glmerControl(optimizer=“bobyqa”))
Performance on numerical phrases by group and condition.
The results indicated that there was an effect of Condition and of Input, whereas the effects of Group and noun-naming proficiency were not significant. With the inclusion of proficiency as well as two-way and three-way interactions, the model failed to converge. The final and most parsimonious model is presented in Table 11. A follow-up on the effect of Condition indicated that there were significant differences between all the conditions (at p < .001) with performance on F-PAUC being the highest.
Predictors of performance on the numerical-phrase task.
The most common non-target response type from both groups on the paucal masculine and both plural forms was the -i/-y ending (e.g. *dva stoly ‘two table.NOM.PL’; *šest′ knigi ‘six book.NOM.PL’; *šest′ stoly ‘six table.NOM.PL’), which is the nominative plural or the feminine paucal form (due to syncretism among homophonous count forms in Russian, we cannot know for certain which of these two systems participants were drawing from). The second most common non-target response type, present in both groups on the paucal masculine form, and among the SL-English group on the plural feminine form, was the -ov ending (e.g. *dva stolov ‘two table.GEN.PL’; *šest′ knigov ‘six book.M.GEN.PL’). While participants were most accurate overall on the paucal feminine form, the most common non-target response type from both groups was the zero-ending (e.g. *dve knig ‘two book.GEN.PL’). Thus, we see that the most common non-target response type across the board is the default nominative plural, followed by intermixing between genders and numerical forms. Additionally, there were three cases of ‘other’ non-target responses, including the -u ending (e.g. *pjat′ mašinu ‘five car.ACC.SG’), which is the singular accusative case, and the -ax ending (e.g. *pjat′ malchikax ‘five boy.PREP.PL.), which is the plural prepositional case.
The key takeaways from the results of the numerical-phrase task were that language-internal factors (Condition) and Input predicted performance, while Group and noun-naming proficiency did not. Non-target response patterns were similar in both groups, with both groups tending toward the default nominative plural form.
VI Discussion
Among the first to compare adult heritage speakers with different dominant languages, this study set out to investigate the role of CLI and input in the morphosyntactic production of heritage Russian speakers dominant in Hebrew (SL-Hebrew) and American English (SL-English).
We collected responses from 66 participants in the two groups and analysed their performance for quantitative accuracy and detailed response patterns at the group level. In line with previous studies, participants showed considerable variability in their performance across the tasks, with some performing poorly and others achieving near-ceiling accuracy.
Let us start with reiterating the quantitative results for accuracy. For the adjective–noun agreement task, we showed that language-internal features (gender and transparency), group, and noun-naming proficiency significantly predicted performance, while input did not. On the accusative-case task, there were no group differences on visible nouns, which require the use of a dedicated accusative inflection, while for invisible nouns (whose accusative and nominative forms are homophonous), the SL-English groups outperformed the SL-Hebrew group. Proficiency also predicted performance on the task, while input did not. Finally, for numerical phrases, language-internal factors (Condition: Paucal-Feminine, Paucal-Masculine, Plural-Feminine, Plural-Masculine) and input predicted performance, while group and noun-naming proficiency did not. Below, we expand on these results in the context of our primary hypotheses, and then explore insights from non-target response patterns on each task.
1 Effects of cross-linguistic influence on HL morphosyntactic mastery
By hypothesis, if CLI is the primary mechanism at play in the morphosyntactic mastery of adult heritage speakers, the SL-Hebrew group would outperform the SL-English group on the adjective–noun agreement task due to the impact of abstract and surface transfer, since gender assignment cues largely overlap in Russian and Hebrew. As for the accusative-case task, two scenarios were proposed:
Under abstract transfer, the SL-Hebrew group would show an advantage; and
Under surface transfer, there would be no advantage.
Similar predictions were formulated for the numerical-phrase task.
In line with our prediction, the SL-Hebrew group significantly outperformed the SL-English group on the adjective–noun agreement task. It is worth noting that CLI from Hebrew to Russian works in multiple ways; first, Hebrew marks grammatical gender (while English does not), and, second, the surface cues for gender assignment in Hebrew are similar to those in Russian (the final -a for feminine; a final consonant for masculine).
Recall that we entertained two predictions for accusative-case performance with respect to the effect of CLI. One was the expectation that the SL-Hebrew group would have an advantage over the SL-English group in the production accuracy of the visible form of the accusative case, because Hebrew also marks the accusative. However, the Hebrew accusative is marked by a prenominal particle and is contingent on definiteness. Because of these differences in the mapping and feature association of the accusative in Russian and Hebrew, we formulated an alternative prediction: no significant differences between SL-Hebrew and SL-English groups in the production of the visible form of the accusative case. Let us underscore that good performance on the invisible form of the accusative case does not indicate mastery of Russian grammar or a facilitative effect of CLI, because this form corresponds to the default unmarked nominative form. When speakers use it, they simply resort to the absence of marking. This is why only performance on the visible forms can be taken as indication of mastery of the Russian accusative. Our results show no significant group difference on the production of the visible form of the accusative case. Neither group has case-marking advantage because the accusative is mapped differently, if at all, in the relevant languages. Indeed, the SL-English group significantly outperformed the SL-Hebrew group on invisible nouns. To reiterate, we attribute this advantage to the use of an unmarked form; the usage happens to correspond to the target form, but it is a side effect of case syncretism, and not necessarily a reflection of grammatical knowledge.
Finally, our CLI hypothesis held that there would be no group differences on the numerical-phrase task, due to the unique handling of this phenomenon in the HL and both SLs, and thus to the lack of surface transfer. Alternately, we entertained the idea that the SL-Hebrew group might have an advantage caused by abstract transfer from Hebrew, as Hebrew exhibits rich nominal morphology and the division of some nouns into dual and plural forms. Our findings showed no group differences. Thus, as with the accusative-case task, no abstract transfer occurred on the numerical-phrase task.
In sum, our CLI hypothesis was upheld as expected. We did not observe abstract transfer, where the presence of a feature in one language would facilitate its acquisition and maintenance in another. We found evidence only for surface transfer, where acquisition and maintenance is facilitated by the feature’s specific cues and realization in both languages, not just the feature’s presence. However, in addition to finding support for the CLI hypothesis, we found additional task-dependent effects of input and noun-naming proficiency, which are discussed below.
2 Effects of input and proficiency
We hypothesized that, if diminished input across the lifespan is the primary mechanism that affects adult HL grammar, we would find effects of individual background characteristics (AoO and Input, as averaged from current and cumulative Russian use) rather than an effect of group. We also predicted that the effects of CLI and input might not be mutually exclusive and that they might form an interactive relationship. In our study we did not find evidence of interactions between CLI and input.
In Section VI.1, we showed that the effect of group was present in the adjective–noun agreement task, but not in the other two tasks. We found no effect of AoO on any of the experimental tasks, likely due to the variable’s small range (0–4). 4 We found a significant effect of input only on the numerical-phrase task. One should bear in mind that numerical phrases are acquired later compared to the other two phenomena (on the acquisition of numerical phrases, see Gagarina and Voeikova, 2009; Gvozdev, 1961; on the acquisition of adjectival agreement, see Voeikova, 2017; on the acquisition of accusative-case morphology, see Gagarina and Voeikova, 2009; Hržica et al., 2015; Protassova, 1997; Protassova and Voeikova, 2007).
On the accusative-case task, the addition of input improved the fit of the model, but this effect disappeared once proficiency was brought into the picture, suggesting that it is proficiency, rather than increased input per se, that improved the performance. While input predicted performance only on the numerical-phrase task, noun-naming predicted performance only on adjective–noun agreement and the accusative case, with more proficiency predicting better performance in both groups. Following the proposal by Tsimpli (2014), the input factor in accuracy on numerical phrases makes sense considering the fact that numerical phrases are acquired later as compared to adjective–noun agreement and the accusative case. Thus, more input would be needed to improve performance on the former task, while proficiency would not significantly improve performance beyond this. Input does not have as clear a role in the earlier-acquired phenomena, while having a more extensive vocabulary is likely correlated to greater familiarity with these grammatical structures, leading to improved performance. While inevitably linked, proficiency and its measures cannot be wholly categorized under input, as they may also be related to individual cognitive abilities, learning aptitude, motivation, and other factors. We therefore consider these variables separately, while acknowledging that they likely work in tandem.
Based on our findings, when the two languages of a bilingual build a particular grammatical structure in a similar way, as is the case for Russian and Hebrew adjective–noun agreement, the properties of the dominant language might facilitate the maintenance of that structure in the weaker language. That happens regardless of individual aptitude characteristics. However, when properties or structures are configured differently in the two languages, increased input and/or higher proficiency might help overcome production difficulties.
3 Non-target performance and its reflection of HL grammar
On the adjective–noun agreement task, our results showed that both groups performed best on masculine nouns. This supports prior findings that heritage Russian speakers rely on masculine as the default (Polinsky, 2008; Rodina and Westergaard, 2017). On transparent neuter nouns and all feminine nouns, both groups defaulted to the masculine (although the SL-English group produced a notable number of feminine adjectives, as well). A similar default strategy was also found in a study on Norwegian heritage Russian speakers (Rodina and Westergaard, 2017). On opaque neuter nouns, most participants in both groups erred toward the feminine, which lends indirect support to the conception that heritage Russian speakers may develop a two-gender system, with masculine and feminine, but no neuter (Polinsky, 2008; Rodina et al., 2020). The overall poor performance on neuter nouns could also reflect the smaller size of the neuter class in Russian, as compared to masculine and feminine (see Section II.2.a).
Turning to the accusative-case task, participants in the SL-English group tended to respond with the unmarked case (e.g. the correct ja vižu stol ‘I see table’, and the analogous *ja vižu kukla ‘I see doll’). By contrast, SL-Hebrew participants, who in principle know that some nouns should inflect for case but may be unsure of which ones in particular, erred toward overmarking. As a result, they tended to extend the overt accusative marking to all masculine nouns, regardless of animacy. They also treated some neuter nouns as feminine, which again resulted in the use of a dedicated accusative, e.g. *ja vižu kreslu ‘I see armchair’ (instead of the neuter kreslo). Similar patterns are also found in young monolingual children (Cejtlin, 2009; Gvozdev, 1961). Thus, we observe the use of the default unmarked form in both groups, and a considerable degree of overmarking in the SL-Hebrew group, in which neuter nouns were re-analysed as feminine nouns. This pattern from the SL-Hebrew group is likely due to the fact that the Hebrew grammatical gender system has a feminine form, on the one hand, and overall richer morphological paradigms of Hebrew compared to English, on the other hand.
As for numerical phrases, all groups performed best on the paucal feminine condition, likely due to the homophony of the paucal feminine form with the nominative plural. As further support for this explanation, the -i/-y ending (which coincides with the feminine paucal/nominative plural form) was the top non-target response for each of the remaining three conditions.
While many of the non-target responses can be attributed to the use of the unmarked plural form (nominative), Russian case syncretism also leaves open the possibility of alternative explanations. In particular, declension I nouns use the same surface form as the genitive singular, paucal, and nominative plural (e.g. kniga–knigi ‘book.NOM.SG’–‘book.GEN.SG/PAUC/NOM.PL’). For some nouns of this declension class, stress can be used to differentiate between the forms (e.g. ovcY ‘sheep.GEN.SG/PAUC’ – Ovcy ‘sheep.NOM.PL’), but no such nouns were present in our stimuli. Based on these observations, we conclude that participants in both groups, but especially those in the SL-English group, tend to produce the unmarked (default) form as a non-target response.
4 Limitations of the present study and future directions
The novelty of this study consists of comparing speakers of the same HL with two different SLs, but this comparison is not without limitations. To measure input, we had to approximate by estimating HL use during different age ranges, its current use at home, and its use at work. Since previous research has demonstrated that input cannot be fully ruled out as a contributing factor, future adaptations should attempt to investigate input using more fine-grained measures. Along these lines, the background questionnaire could be expanded to probe participants’ motivations (if any) for maintaining their HL, and the importance of the HL to their identity. It would be reasonable to assume that those for whom the HL is important and plays a key role in their identity would work harder to maintain it. It follows that those who are less attached to the HL would be less driven to keep up their skills, which might then be reflected in their performance.
It would be desirable to extend this study to a wider range of grammatical structures; that would allow us to determine the generalizability of our results across morphosyntactic phenomena. Specifically, one should target those structures or grammatical features that exhibit more overlap between the languages in a particular bilingual dyad and avoid or limit the speakers’ reliance on default forms.
VII Conclusions
This study considered production accuracy on three morphosyntactic tasks among heritage Russian speakers in Israel and in the US. The participants were dominant in Hebrew and American English, respectively. The tasks included adjective–noun agreement, accusative-case morphology, and numerical phrases. We investigated cross-linguistic influence, diminished input, and noun-naming proficiency as potential key factors in HL production by adult speakers.
We found that the SL-Hebrew group significantly outperformed the SL-English group only on the adjective–noun agreement task, while no effect of group was found on the other two tasks. We explain this by referring to CLI; Hebrew grammatical-gender agreement provides speakers with an advantage in preserving Russian agreement, due to surface transfer, while English-dominant speakers have no such crutch. Input predicted performance only on the numerical-phrase task, while noun-naming proficiency predicted accurate production of adjective–noun agreement and accusative case morphology. Thus, our study shows that, while CLI is a crucial factor behind HL grammar maintenance, increased input and proficiency can modulate performance, especially in the absence of grammatical similarities between the HL and the SL. We also found that heritage speakers tend to resort to default/unmarked forms, a trend found in both SL groups.
Ours is among the first studies comparing two groups of adult heritage speakers with typologically-distinct SLs to each other, rather than to a monolingual baseline group. Determining the strength of CLI effects for different types of HL-SL pairs (morphosyntactically similar/dissimilar) and for different grammatical structures can further reveal which external and internal factors might affect HL maintenance. The results can then feed into adult language pedagogy, serving as the basis for best practices in the (re-)learning of an HL and in minimizing L2 interference in SLA.
Footnotes
Appendix A: Background questionnaire
This is a link to the questionnaire sent to each of the SL-English participants. The SL-Hebrew group saw a Hebrew translation of the same content.
Appendix B: Task targets
Acknowledgements
The authors would like to thank all the participants of the study for their cooperation. We also thank Tatiana Verkhovtceva for her help with data collection.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Israel Science Foundation (ISF), grant number 552/21 ‘Towards understanding heritage language development: The case of child and adult heritage Russian in Israel and the USA’ granted to Dr Natalia Meir.
1.
Here and below we indicate stress by capitalizing the stressed vowel.
2.
3.
The status of paucal in Russian is not fully settled, with some researchers associating it with case and others with number (for discussion, see Bailyn and Nevins, 2008; Xiang et al., 2011). The issue is orthogonal to the points made here, and we leave it open for future investigation.
4.
However, previous research showed a robust effect of AoO for HL acquisition in adult bilinguals with a wider AoO range (0–12 years) (Meir and Polinsky, 2021).