
Abstract
This article introduces the CELI corpus, a new learner corpus of written Italian consisting of ca. 600,000 tokens, evenly distributed among CEFR (Common European Framework of Reference for Languages) proficiency levels B1, B2, C1 and C2. The collected texts derive from the language certification exams administered by the University for Foreigners of Perugia all around the world. The corpus contains rich metadata pertaining to text-related and learner-related variables. It expands the domain of learner corpora by being, among other things, both freely available online to the research community, and by focusing on a target language other than English. The article also presents and evaluates the POS-tagging procedure, thus contributing to best practices in learner corpus annotation.
I Introduction
In learner corpus research (LCR), critical reflection on design criteria is crucial in structuring the rich reservoir of empirical data that is typical of corpora in line with the needs of research in second language acquisition (SLA; Gilquin, 2015; Tono, 2003). As language learning is, by definition, a developmental process taking place over time, empirical data collected and organized longitudinally or pseudo-longitudinally are of considerable interest (Gilquin, 2015; Myles, 2005). Furthermore, in the case of pseudo-longitudinal designs, text attribution to proficiency level is critical in order to ensure comparability among different studies (Carlsen, 2012). Additionally, the presence of balanced subcorpora within a corpus can allow systematic comparisons among the different parts that make up the corpus (e.g. among different proficiency levels) (Tracy-Ventura and Paquot, 2021). Finally, target languages other than English are needed in order to gain a broader view of second language acquisition processes and dynamics (Lozano, 2022; Vyatkina, 2016).
However, an inspection of the learner corpora listed in the Learner corpora around the world 1 list reveals that most corpora developed so far lack one or more of these features. Most of them, in fact, are characterized by a cross-sectional design, while very few have a longitudinal or pseudo-longitudinal design, covering a significant timeframe or including balanced sets of proficiency levels (Meunier, 2015). Furthermore, the vast majority of learner corpora built so far refer to English as the target language, despite a few notable exceptions (e.g. Lozano, 2022; Vyatkina, 2016). Another issue related to corpus design concerns the ways in which a learner text is attributed to a certain proficiency level. This is an issue that has seldom been at the centre of learner corpus research discussion, despite proficiency level being arguably a ‘fuzzy variable’ in the design of learner corpora (Carlsen, 2012).
In this paper, we seek to address some of the gaps that still characterize learner corpus research, by introducing the CELI corpus (https://apps.unistrapg.it/cqpweb/; https://lt.eurac.edu/cqpweb/), a new corpus of second language (L2) Italian writing. Our goal is to highlight the contribution that this corpus could make in the field of LCR and SLA at large, with special reference to the domain of Italian L2 studies, which is still under-resourced as far as corpora are concerned. More particularly, the aim of this article is twofold: (1) to present the CELI corpus, by illustrating its general architecture, the text- and learner-related variables it includes, the methods adopted in compiling it, and its contents; (2) to discuss the quality of the annotation procedures conducted on the corpus, by reporting on a study that measured and evaluated the performance of the part-of-speech tagger (POS-tagger), in light of the features that most typically characterize learner language. The next section reviews existing online learner corpora of Italian, with respect to size, design, proficiency levels, criteria for text attribution to CEFR (Common European Framework of Reference for Languages; Council of Europe, 2001) proficiency levels, balancing criteria. A description of the CELI corpus, along with an evaluation of the reliability of the tagging procedures that were applied to it, will follow.
II Online learner corpora of Italian
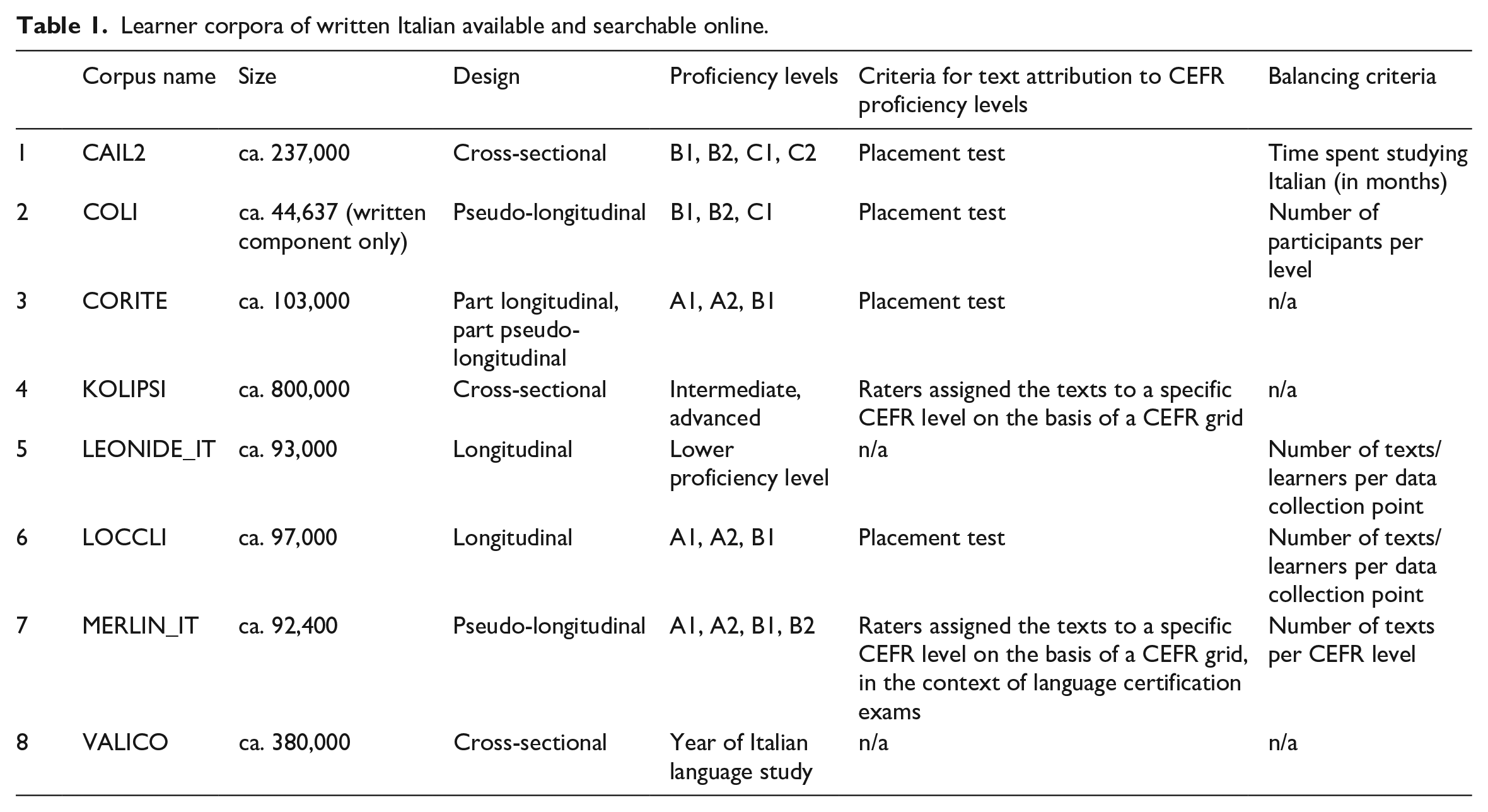
In this section, we review the learner corpora of written Italian currently available and searchable online. Although oral corpora of learner Italian are also available, we focus our review on written corpora only so as to reflect the specific domain in which the CELI corpus is situated. A total of eight corpora emerge from our search, which are listed in Table 1 in alphabetical order and in relation to size, design, 2 proficiency levels, criteria adopted for text attribution to CEFR proficiency levels, and criteria adopted to create balanced subcorpora within the corpus. With specific reference to the last two aspects, we see that in order to attribute a text to a certain proficiency level, placements tests were used in half of the cases, that is in the corpora CAIL2 (Bratankova, 2015), COLI (Spina, forthcoming), CORITE (Bailini and Frigerio, 2018), and LOCCLI (Spina and Siyanova-Chanturia, 2018). Particularly in the context of Italian L2 language testing and assessment, placement tests, however, often lack the breadth and solidity of CEFR-based certification exams, and this hinders the reliability of text attribution to proficiency level. In the case of KOLIPSI (Glaznieks et al., in preparation), the texts were attributed to proficiency levels by professional CEFR raters, while in the case of MERLIN_IT (Boyd et al., 2014) they derived from language certification exams. In the cases of VALICO (Corino et al., 2017) and LEONIDE_IT (Glaznieks et al., 2022), no explicit proficiency levels are recorded. As for the balancing criteria, we can see that these are either non-existent (CORITE, KOLIPSI, VALICO), or alternatively refer to time spent studying Italian (CAIL2), number of learners per level (COLI), number of texts/learners per data collection point (LEONIDE_IT, LOCCLI), and number of texts per CEFR level (MERLIN_IT).
Learner corpora of written Italian available and searchable online.
III The CELI corpus: Description
1 Design
The CELI corpus is a pseudo-longitudinal corpus of Italian L2; its main goal is to be representative of written Italian produced by learners belonging to the intermediate and advanced levels of proficiency according to the CEFR.
As Gilquin (2015) argues, a learner corpus should be designed by adopting specific criteria, ‘given the highly heterogeneous nature of interlanguage, which can be affected by many variables related to the environment, the task and the learner him-/herself’ (p. 16). Furthermore, Tracy-Ventura et al. (2021) make several recommendations when designing a learner corpus: to consider L2s other than English; to build more multilingual corpora to promote cross-linguistic comparisons; to document all the stages of learning development including not only intermediate and advanced learners but also beginner learners; to include learners with different ages and with different first languages (L1s) and from different contexts of learning; to reconsider what a ‘control’ corpus is and how it can be used in comparing data; to collect metadata systematically and document them accurately including more learner and task variables; to document transcription and annotation stages; to include spoken data; and to collect longitudinal data. Moreover, they recommend making the learner corpus freely available (Tracy-Ventura et al., 2021).
Among these recommendations, we adopted the following four: (1) to consider L2s other than English; (2) to include learners at different levels of proficiency, from different age groups and with varied L1s; (3) to collect metadata systematically and document them accurately; and (4) to make the learner corpus freely available. Further, another criterion was followed in designing the CELI corpus: to balance subcorpora in terms of tokens and make them comparable.
The above adopted criteria make the CELI corpus a reliable tool in the investigation of L2 Italian. First, it is representative of an L2 different from English (i.e. Italian), which is still an under-represented L2 in the LCR context. Second, it includes learners from different ages and from different levels of proficiency providing varied objective measures of proficiency. Third, metadata were systematically collected and are fully documented (as will be shown in Sections III.2 and III.3, the CELI corpus presents different variables for both texts and learners). Fourth, its subcorpora are designed according to the same criteria and balanced in terms of tokens in order to make them comparable. Finally, the CELI corpus is a freely available and searchable corpus. Searchability is another crucial factor to consider in designing a learner corpus allowing different kinds of queries. To this end, the CELI corpus is searchable from a CQPweb interface (Hardie, 2012), on the basis of a range of metadata including CEFR level, learners’ sex, learners’ age, learners’ nationality, exam centre location, task assignment ID, text genre and text type.
2 Text variables
Written texts produced by Italian L2 learners were collected from the written examinations for the language certificates of Italian as a foreign language (CELI – Certificati di Lingua Italiana) developed by the Center for Language Evaluation and Certification (CVCL – Centro per la Valutazione e le Certificazioni Linguistiche) at the University for Foreigners of Perugia (Italy). For the purpose of the present project, the written texts were collected from CELI 2, CELI 3, CELI 4 and CELI 5, which certify Italian language knowledge with respect to proficiency levels B1, B2, C1, and C2 respectively. The CELI exams consist of an oral part and a written part.
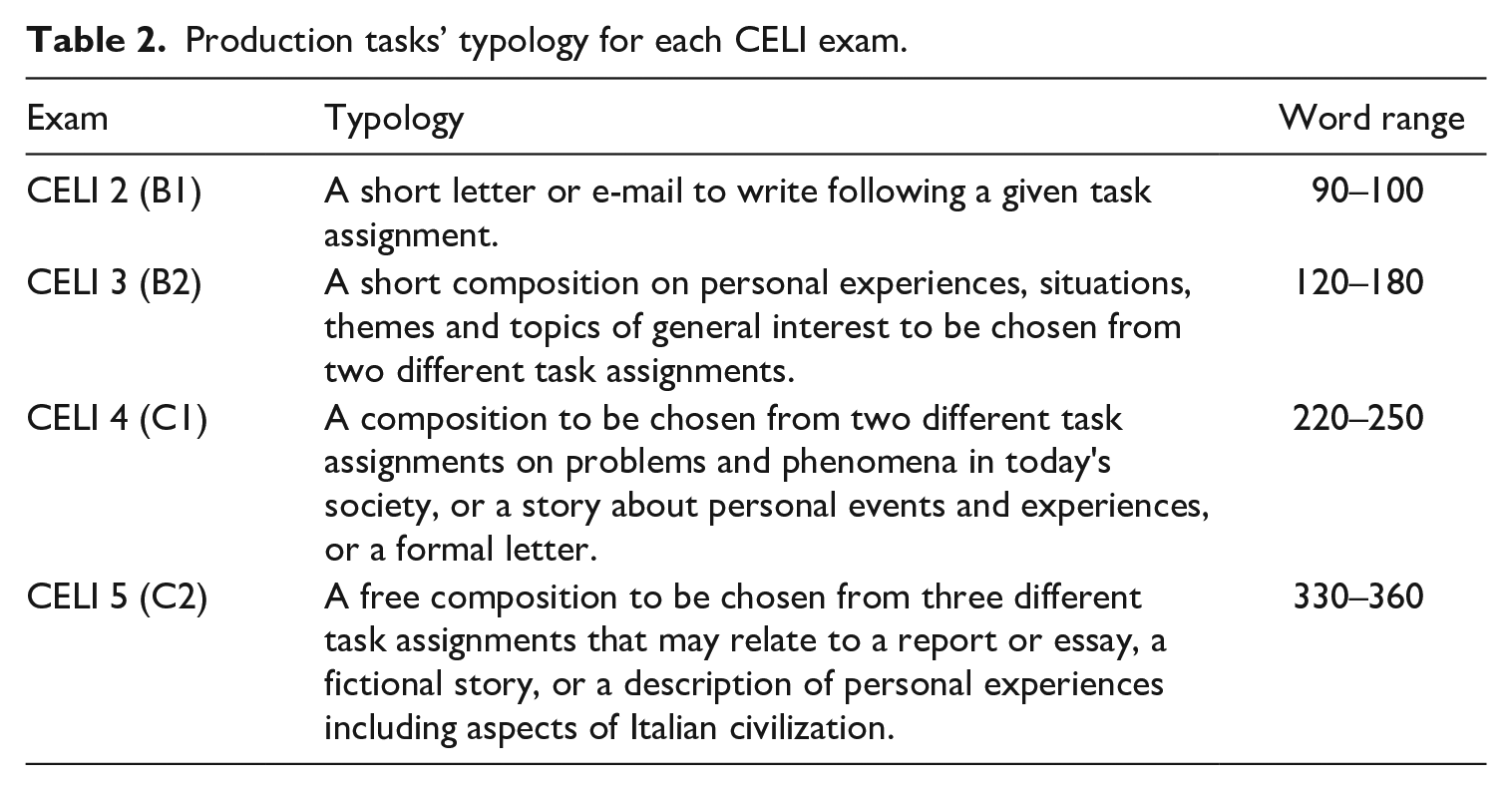
The written part is articulated in different components: (1) reading comprehension; (2) written production; (3) language competence; and (4) listening comprehension (Grego Bolli, 2004). The written production includes a series of production tasks. The texts contained in the CELI corpus were collected from one specific production task, for each CELI exam (Spina et al., 2022). Details of the production tasks for each CELI exam are shown in Table 2.
Production tasks’ typology for each CELI exam.
Several metadata are recorded for each text:
the identification number of the text;
the identification number of the exam centre where the candidates took the exam;
the task assignment to which the text is associated;
the CEFR level for which the candidate took and passed the certification exam (B1; B2; C1; C2);
the total score assigned to the whole exam;
the score band of the score on the whole exam (A; B; C);
the total score assigned to the written part of the exam;
the total score assigned to the production task;
scores related to four assessment criteria (vocabulary control; grammar accuracy; sociolinguistic appropriateness; and coherence and cohesion).
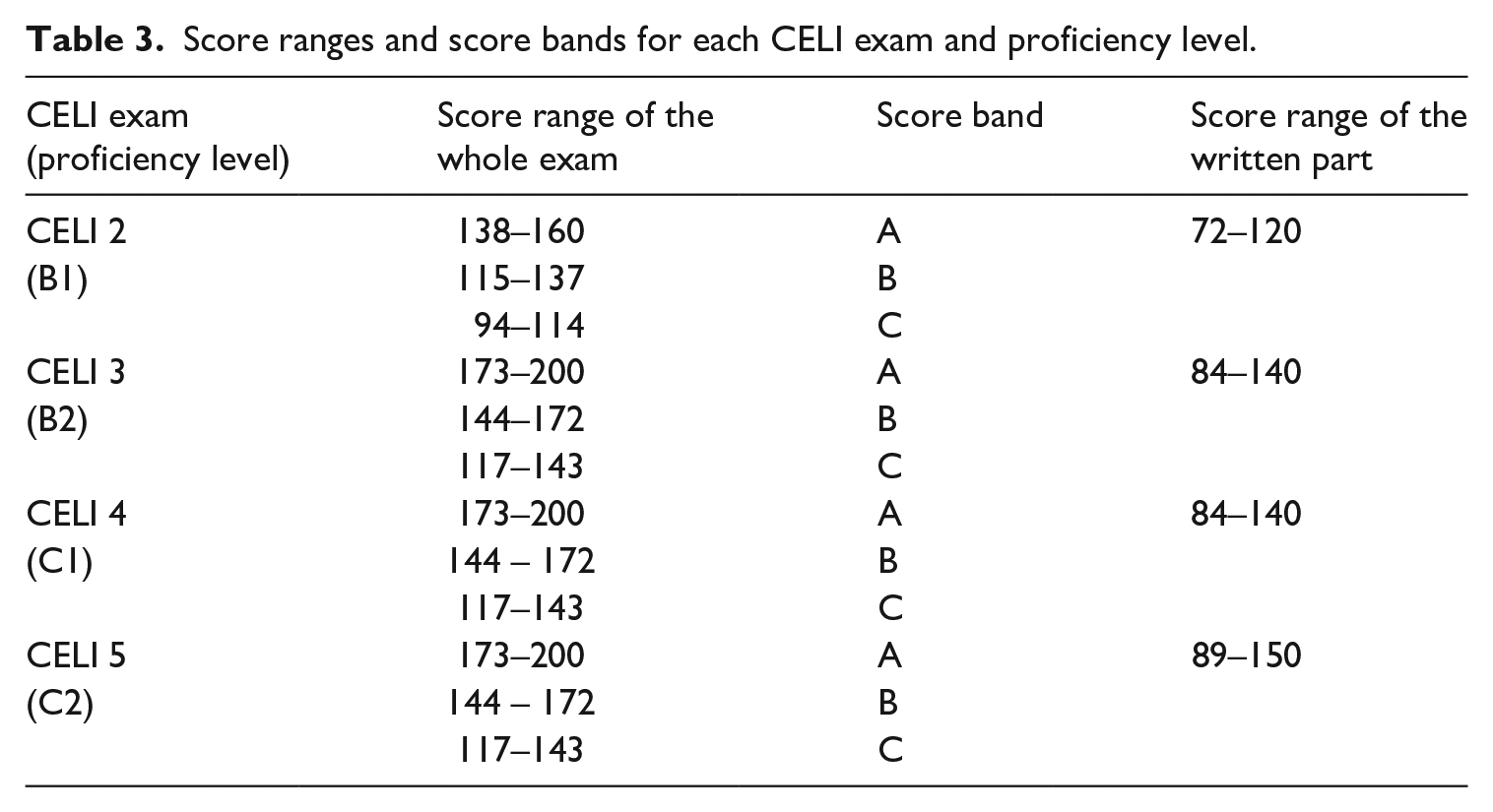
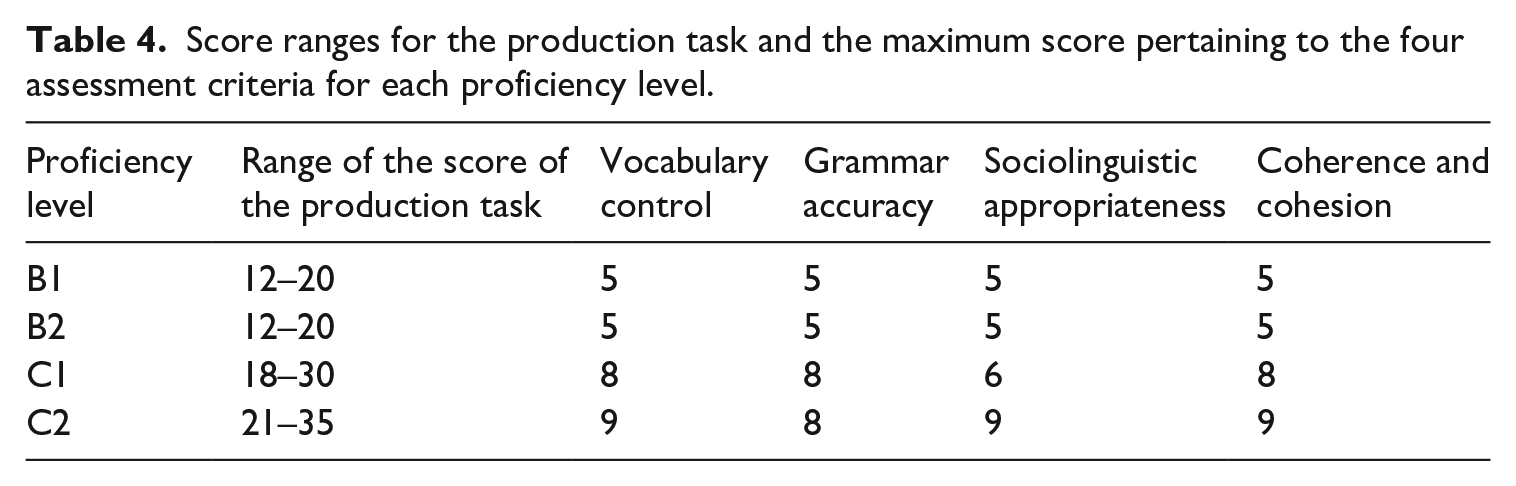
The total score assigned to the whole exam derives from the sum of the score assigned to the written part and the score assigned to the oral part, and it is associated with a score band (A = excellent; B = good; C = passing grade). The score assigned to the production task is derived from the sum of the scores related to the aforementioned four assessment criteria. Table 3 shows, for each proficiency level, the score ranges with their associated score bands for the whole exam, and the score ranges related to the written part of the exam. The score ranges of the production task for each proficiency level, and the maximum scores related to the four assessment criteria, are shown in Table 4. 3
Score ranges and score bands for each CELI exam and proficiency level.
Score ranges for the production task and the maximum score pertaining to the four assessment criteria for each proficiency level.
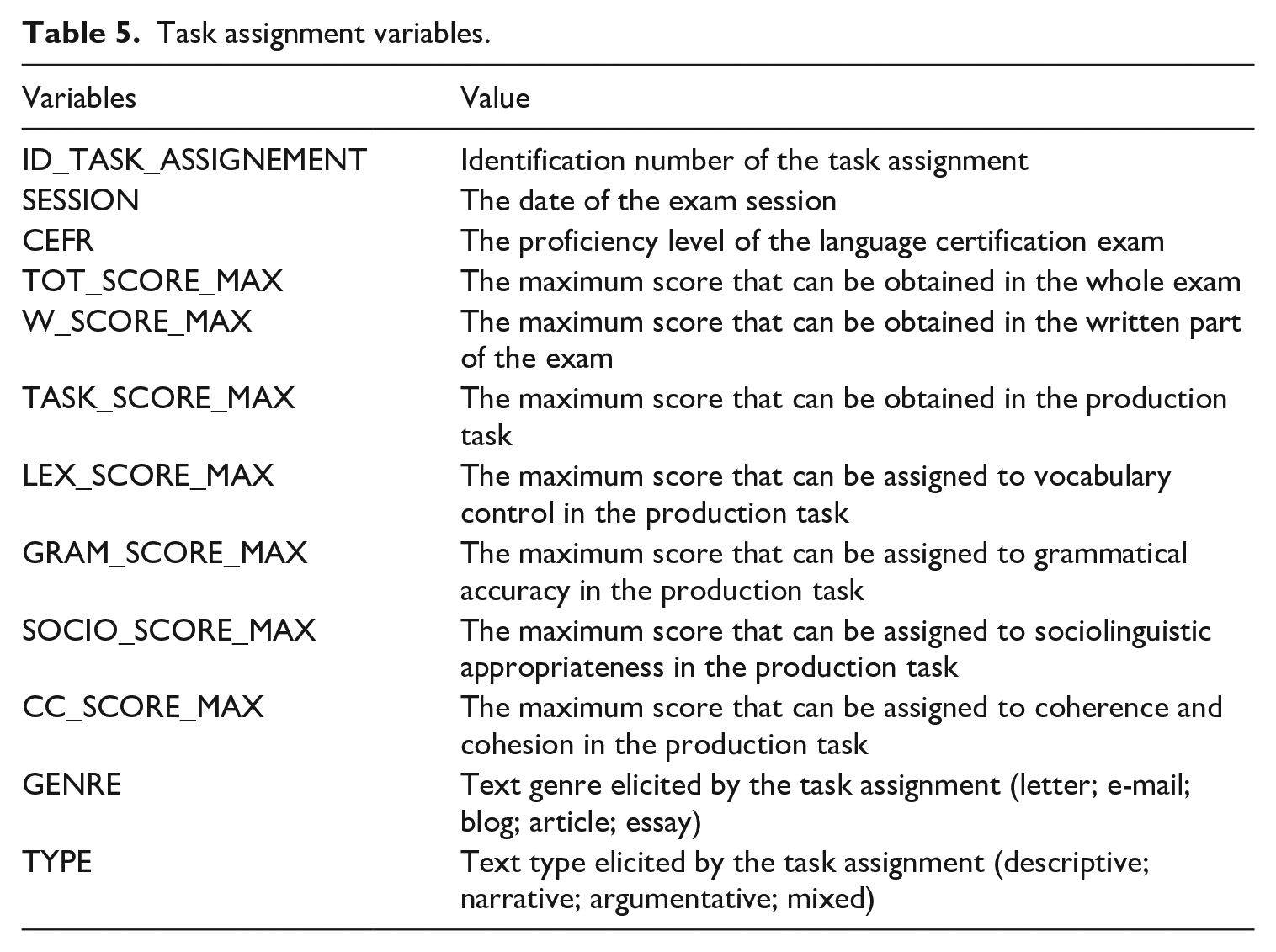
Each text is associated with its task assignment. Each writing prompt is reported in the corpus with an identification number which allows the information about the exam session (when the candidate has performed the exam) to be derived. Further, the task assignment is associated with the other metadata indicated in Table 5.
Task assignment variables.
3 Learner variables
For each learner, the metadata about sex (female/male), age and student registration number are reported. Further, candidates performed the language test in different exam centres located not only in Italy, but also elsewhere in Europe and in other countries worldwide. Another variable that should be considered in the design of a learner corpus is the learners’ L1 (Tracy-Ventura et al., 2021). This information cannot be derived from the CELI certification, as candidates are asked to report only their nationality, which does not always reflect the learners’ mother tongue (Spina et al., 2022), as in the case of the EFCAMDAT corpus (Murakami and Ellis, 2022). In any case, learners’ nationalities were kept as balanced as possible by collecting the same nationalities for each subcorpora and the same number of candidates of a specific nationality for each subcorpora.
In the CELI corpus information about learners’ proficiency is provided through different objective indexes: (1) the CEFR level of the CELI certificate; (2) the score obtained in the whole exam; (3) the score band; (4) the score obtained in the written part of the exam; and (5) the score assigned to the production task. Texts were included in the corpus if learners obtained at least the passing grade in the production task. Furthermore, we included in the corpus only learners that passed the whole exam within a single exam session. Learners that did not obtain the passing grade at the oral part as well as at the written part were excluded from the data collection.
4 Data collection and transcription criteria
The handwritten exam texts were manually typed and digitized (Spina et al., 2022). Data collection started in February 2020 and ended in February 2021. Texts were reproduced as faithfully as possible. However, learners’ errors could complicate the POS-tagging procedure (see next section). Thus, a manual error correction was carried out according to the target hypothesis (TH), which is the assumed ‘correct’ form. As Vyatkina (2016) points out, several types of THs are possible, so it should be specified which criteria are adopted. We used the minimal TH or TH1 layer (Reznicek et al., 2013), which usually corrects only spelling and morpho-syntactic mistakes. Specifically, we normalized only learners’ spelling errors, such as the unnecessary doubling of letters – (1) and (2) – or the absence of graphic accents (2), as exemplified below:
(1) [. . .] il nostro *svillupo è stato sorprendente. *Abiamo scoperto un modo di [. . .].
*svillupo (‘progression’, ‘development’) > svi
‘Our progression was amazing. We discovered a way to [. . .]’
(2) Ti chiedo *scussa che non sono fatta viva *pero sono stata molto occupata.
*scussa (‘sorry’, ‘pardon’) > scu
‘I am sorry that I did not get in touch with you but I have been very busy.’
Further, we normalized word forms with spelling errors when the POS was ambiguous, and the correct POS could be disambiguated taking into account the context. For example, learners frequently produced the verb ‘to have’ without the grapheme for the unvoiced fricative; see (3). Given that these forms can be easily confused with conjunctions during automatic tagging procedures, they were corrected (e.g. è ‘is’ vs. e ‘and’; ho ‘to have’ vs. o ‘or’).
(3) *
Finally, we normalized phonographematic errors, 4 as shown in the following examples:
(4) *
(5) *ce
By contrast, errors ascribable to a possible L1 influence, lexical mistakes, and mismatches in the morpho-syntactic agreements, were left unmodified. All these cases are illustrated in examples (6)–(8):
(6) Una
(Possible L1 influence)
‘An ancient legend [. . .] about the soul of Portugal.’
(7) Non si può *
‘We cannot blame social media.’
(8) Butto nella plastica
‘I throw the packet of yogurt into the plastic.’
In (6) learner produced a lexical mistake in the Italian collocation dare la colpa (‘to blame’) by substituting the typical verb dare (‘to give’) with fare (‘to do’). Further, (7) shows an agreement mismatch between the article la (singular) and the noun confezioni (plural). Finally, in (8) the forms lenda antiqua and alma have not been normalized as they are probably produced through a transfer from the learner’s L1.
5 Composition of the corpus and its subcorpora
The CELI corpus contains 3,041 texts amounting to 608,614 tokens and 24,698 types. Its subcorpora, one for each proficiency level (B1; B2; C1; C2), present the same design and are balanced with respect to number of tokens (see Table 6). As the four subcorpora are equally designed and balanced in terms of tokens, they can be easily compared in terms of number of learners that have taken the exam in Italy or elsewhere outside Italy, and scores obtained in the different tasks (Table 7).
Composition of CELI corpus and its subcorpora.
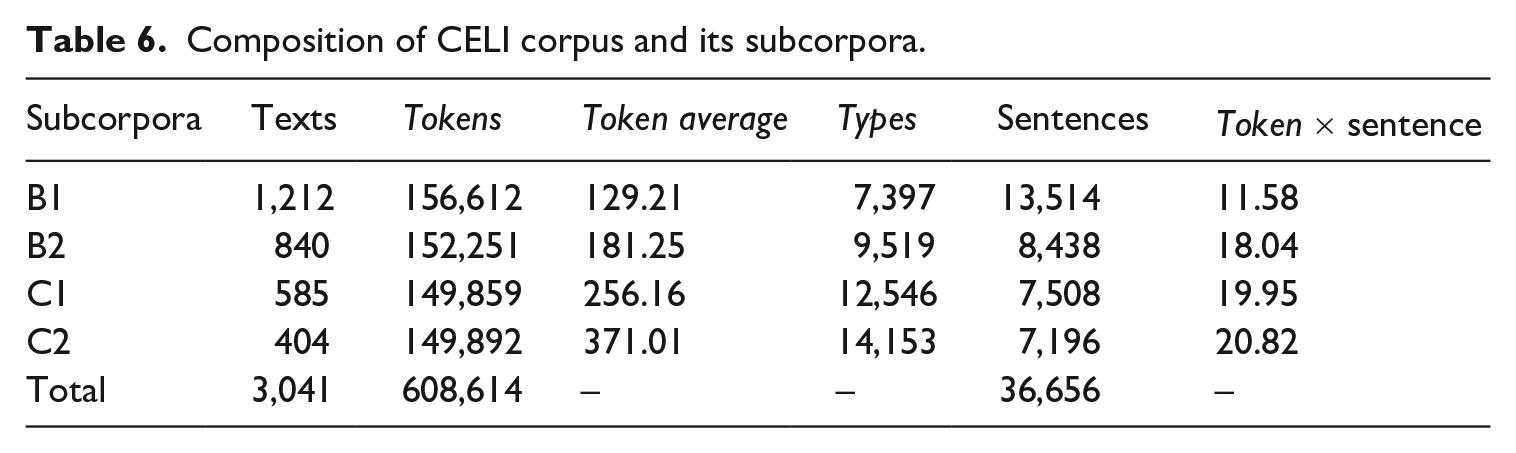
The four subcorpora compared by scores.
IV POS-tagging of the CELI corpus: Procedure and evaluation
Most of the annotation work on learner corpora has traditionally been focused on error tagging (Lüdeling and Hirschmann, 2015; Van Rooy, 2015). In recent decades, the focus has shifted from error tagging to a more ‘purely linguistic annotation, irrespectively of errors’ (Valverde Ibañez, 2011: 214), therefore relying even more extensively on automated annotation tools, such as, among others, part-of-speech tagging.
However, POS-tagging of learner corpora has received limited attention in the literature (Picoral et al., 2021), with a prominent focus on ICLE (De Haan, 2000; Meunier and De Mönnink, 2001; Van Rooy and Schäfer, 2002, 2003), and on other corpora of L2 English (the MACLE: Malaysian corpus of learner English or Spanish; Aziz and Don, 2019), on corpora of L2 Spanish (the CORANE corpus: Corpus para el análisis de errores de aprendices de E/LE; Valverde Ibañez, 2011), of L2 German (the KANDEL corpus: Kansas developmental learner corpus; Vyatkina, 2016), and of L2 French (the FLLOC corpus: French learner language oral corpora; Marsden et al., 2002). In most of these cases, learner data were processed using taggers, tagsets and training procedures that are commonly used to process corpora of native data (Campillos Llanos, 2016).
Accurate POS-tagging allows more sophisticated corpus queries, in order to investigate more thoroughly learners' interlanguage, and can be followed by other language processing tasks, such as parsing.
1 Annotation procedure
The POS-tagging of the CELI corpus involved three distinct stages: (1) an automatic tagging procedure; (2) a semi-automatic post-editing step, aimed at correcting recurrent tagger errors; (3) a final manual resolution of all the lemmas that were unknown to the tagger.
The 3,041 learner texts included in the CELI corpus were first automatically tokenized, lemmatized, and annotated for POS using TreeTagger (Schmid, 1994). In line with what is considered common practice, we opted for a domain transfer solution, consisting in the use of a version of the tagger that was pre-trained on native Italian texts, which had already been used to tag native Italian corpora (Spina, 2014). According to previous studies (De Haan, 2000; Van Rooy and Schäfer, 2002, 2003; Vyatkina, 2016), taggers trained on error-free native texts can be used on non-native texts with fairly good results in terms of accuracy. For the benefit of accuracy, the texts included in the CELI corpus underwent a limited normalization process prior to POS-tagging, which particularly concerned spelling errors such as double consonants instead of single consonants (and vice versa), and few very frequent word pairs that are orthographically similar in Italian and are often confused by learners (see Section III.4). Abundant evidence (De Haan, 2000; Valverde Ibañez, 2011) indicates that the learner errors mostly affecting the accuracy of the tagger are spelling errors, especially when they involve non-standard forms that correspond to existing words in the target language, as in the examples provided in Section III.4. Similar evidence on the relevance of spelling errors was provided for dependency parsing of learner data (Huang et al., 2018).
The second stage of the POS-tagging process was a semi-automatic editing procedure, which was carried out on specific POS tags with the aim of correcting recurrent tagger errors, revealed by previous analyses on Italian native corpora (Spina, 2014). These post-editing operations involved frequent and grammatically ambiguous forms, such as come, dove, che (‘like’, ‘where’, ‘that’) or verbal forms with incorporated clitic pronouns that are not included in the lexicon, 5 and therefore are not recognized by the tagger (e.g. spronarsi ‘to push oneself’; raccontartene ‘to tell you about it’). Through the use of a set of regular expressions searches, this post-editing process allowed us to correct almost 2,800 tagging errors.
In the final stage, we proceeded with a manual resolution of all the lemmas tagged as ‘unknown’ by the tagger. Many of these were non-standard forms produced by learners, which had not been normalized during the data transcription, such as *devano for devono (lemma dovere ‘must’) in (9). In this case, we simply replaced the ‘unknown’ label applied by the tagger with the lemma dovere (9).
(9) Penso che i giovani
‘I think that young people should browse social networks very carefully.’
devano VER:fin → unknown > devano VER:fin
2 Measuring and evaluating tagger performance
This evaluation process relied on the use of a tagger pre-trained on native Italian data to annotate texts produced by learners. It addressed three specific objectives: (1) measuring the performance of TreeTagger on L2 Italian texts; (2) analysing the most frequent tagger errors; (3) investigating to what extent and how tagger errors are related to learner errors.
To address these objectives, we randomly selected 24 texts included in the CELI corpus, so that they would meet the following balancing criteria: we extracted one text for each of the six most represented countries (Greece, Spain, Romania, Switzerland, Albania and Germany), for each of the four proficiency levels. The total length of the 24 selected texts was approximately 8,000 tokens, that were manually annotated by two pairs of linguists (the four authors of this article), so that each pair of annotators would tag 12 texts. According to a well-established practice (e.g. Vyatkina, 2016), the two annotators, working separately on the same texts, discussed the cases where there was disagreement in the chosen tags until they reached a shared consensus. Once consensus was reached for the total POS tags, the manually POS-tagged texts were identified as the gold standard, that is the human-produced labels used for comparison against the labels produced by a software (Picoral et al., 2021). To measure the performance of TreeTagger and evaluate its accuracy on learner data, this gold standard was used in two distinct evaluations: in the first one, the gold standard was compared to the raw product of the POS-tagging of the same sample of 24 texts, carried out with TreeTagger; a second evaluation compared the gold standard to the product of the following, semi-automatic post-editing stage (the second stage of our POS-tagging procedure, as described in Section IV.1), performed on the same sample of 24 texts. In both raw and post-edited tagger output evaluations, we identified correct POS tags as the tags where the tagger annotation matched the gold standard, and the incorrect ones as those where this match was not found.
Three measures were used to quantify different aspects of the tagger performance (Picoral et al., 2021): the most basic measure of accuracy, calculated by dividing the number of correct tags by the total number of tags; precision, calculated by dividing the number of tokens correctly assigned to a POS ‘×’ by the total number of tokens tagged as ‘×’; and recall, calculated by dividing the number of tokens correctly assigned to a POS ‘×’ by the total number of ‘×’ in the data.
Table 8 shows the values of overall accuracy for both the raw and the post-edited annotation. These two accuracy values are compared to the accuracy values obtained from the evaluation of the TreeTagger performance on Italian native data (Spina, 2014), which adopted the same procedure. As the native Italian corpus was much larger, this evaluation was carried out on a larger sample of approximately 22,000 tokens. The two datasets were, however, symmetrical to those used for the CELI corpus: the first one included the original raw data, unmodified with respect to the direct product of automatic POS-tagging, and the second one contained the data corrected through the same semi-automatic post-editing procedure used for the CELI corpus.
The overall accuracy of both the raw and the post-edited annotation (percentages).

The data on accuracy reveals two different results. First, the tagger performs in a similar way with native and learner data. The peculiarities of learners' interlanguage, whether errors or other non-standard forms, do not seem to affect the correct automatic identification of grammatical categories. This is true mostly for the raw sample, where accuracy values are almost identical, while for the post-edited sample there is a slight difference, which may suggest a somewhat higher effectiveness of post-editing on native data. This result is in line with previous studies on POS-tagging accuracy on learner data (De Haan, 2000; Meunier and De Mönnink, 2001; Valverde Ibañez, 2011; Van Rooy and Schäfer, 2002), which consistently demonstrated that the learner errors that have the greatest negative impact on tagger performance are spelling errors. Second, a series of post-editing operations, aimed at correcting a core of recurrent errors identified by previous studies (Spina, 2014), is effective for both native and learner data. Our analysis of tagger performance then focused on the POS tags that resulted as the most challenging for the tagger. Table 9 shows the eight POS tags with the lowest precision values in the two evaluations.
The eight part-of-speech (POS) tags with lowest precision values in both raw and post-edited samples, with their respective recall values (percentages).
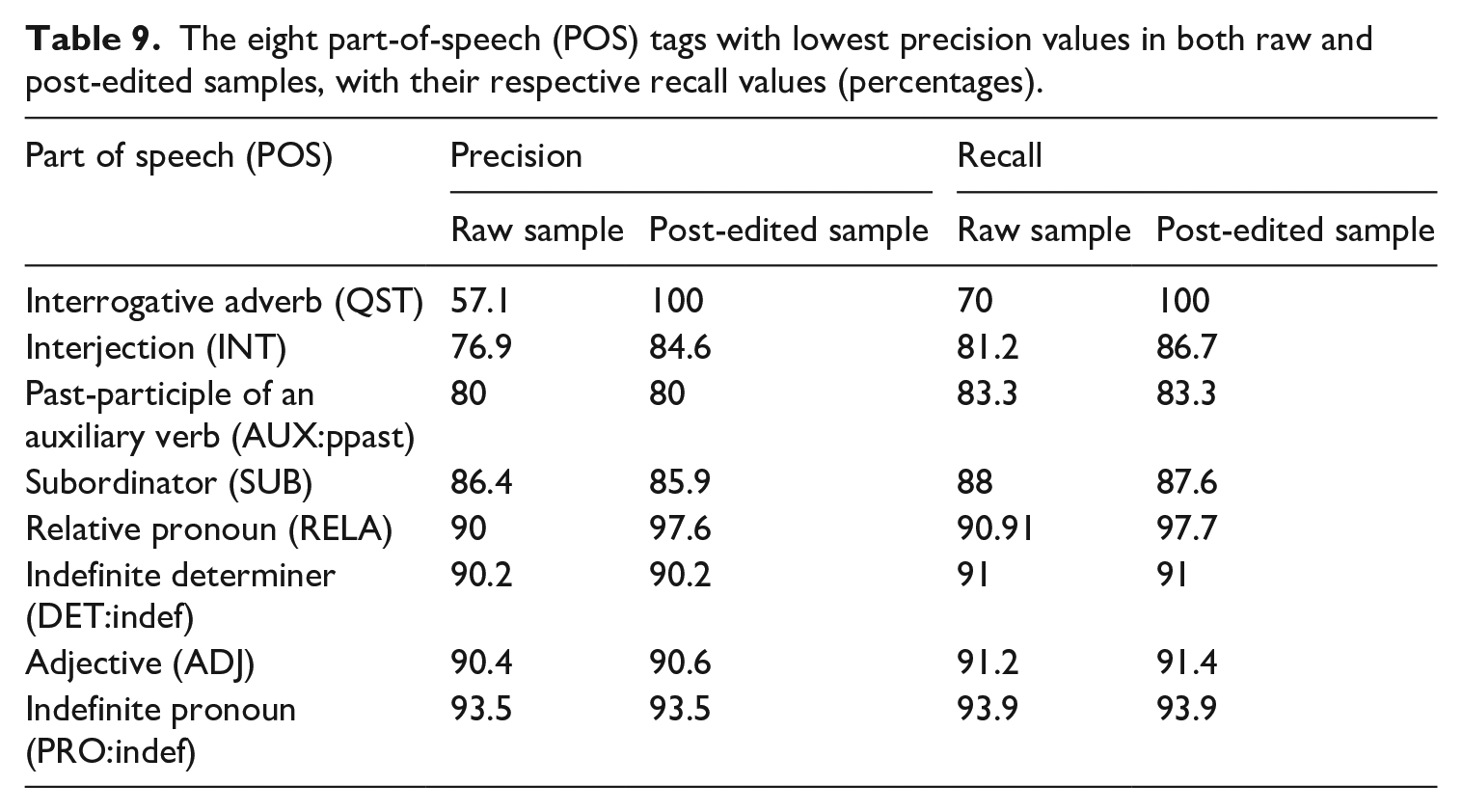
The POS tag assigned by the tagger which returned the highest number of errors is that of the interrogative adverb (QST), which has a precision value of 57% in the raw sample. This tag is also problematic in data produced by native Italians (Spina, 2014), as it mostly involves grammatically ambiguous forms (quanto ‘how much’; quando ‘when’; dove ‘where’; quale ‘which’), which can function as interrogative adverbs, or pronouns, subordinators or relative pronouns. Example (10) is an example of wrong attribution of the POS QST to a subordinator (quante ‘how many’). In this case, moreover, the semi-automatic post-editing operations were able to correct all the errors made by the tagger in the raw sample, reaching accuracy and recall values of 100% in the sample.
(10) Non esistono statistiche per sapere
→ *
‘There are no statistics showing how many people change jobs completely.’
A similar case is the opposite, the wrong attribution of the tag SUB (subordinator) to an interrogative adverb (QST), as in (11):
(11) Ciao Marco,
→
‘Hi Marco, how are you?’
These tagger errors are therefore more due to the inherent ambiguity of the forms, rather than to learners' interlanguage errors.
Interjections also had a relatively low precision value in the raw sample (76.9%), which reached 84.6% after the post-editing operations. Again, tagger errors do not appear to be due to learner errors, but to ambiguities in the forms that the tagger fails to resolve, as in the case of (12), where grazie (‘thank you’) is labelled as an interjection, while it is a noun, because it forms a construction with the preposition it is followed by grazie + ai (‘thanks to’):
(12) Però
→ *
‘But thanks to my friends I managed to get through all this tragedy.’
The other POS tags that were most often wrongly attributed (past participles of auxiliary verbs, subordinators, relative and indefinite pronouns, adjective and indefinite determiners; see Table 8) range from 80% to 93.5% of precision. With regard to the effectiveness of the post-editing operations performed after POS-tagging, the comparison of respective precision and recall values highlights three possible scenarios. In most cases, post-editing increased – sometimes in a highly significant manner, as in the case of interrogative adverbs (11) and interjections (12) – the accuracy of POS-tagging, by removing many of the tagger errors.
In a few cases, post-editing had no effect on accuracy, as precision and recall values remained unchanged. This happened for example with indefinite pronouns (13):
(13) Conosco
→
‘I know so many words and I can find a thousand meanings for you [. . .]’
In order to analyse more closely the most common types of tagger errors in the annotation of learner data, Table 10 shows in a reduced form the complete matrix of the number of errors per POS. The POSs involved in the most frequent tagger errors are seven (adjective, adverb, noun, finite mood verb, finite mood auxiliary verb, preposition, past participle). The errors that occur more frequently are the tagging of an adjective as a past participle (frequency in the raw sample = 22) (14), with its opposite (a past participle as an adjective: frequency = 4) (15), and a noun as an adjective (frequency = 16) (16), with its opposite (an adjective as a noun: frequency = 6) (17).
(14) Ma i suoi genitori non erano
→
‘Yet her/his parents were not certain about her/his choice.’
(15) Mezz’ora dopo essermi
→
‘Half an hour after I had been lying down [. . .].’
(16) Parenti, amici,
→
‘Relatives, friends, neighbours, we all have at least an acquaintance that [. . .].’
(17) E se ci si sente soli, non è perché siamo
→
‘And if you feel alone, it is not because you are alone, but [. . .].’
The number of the most frequent tagger errors in the raw sample (in parentheses, the number of errors in the post-edited sample, where there are differences).
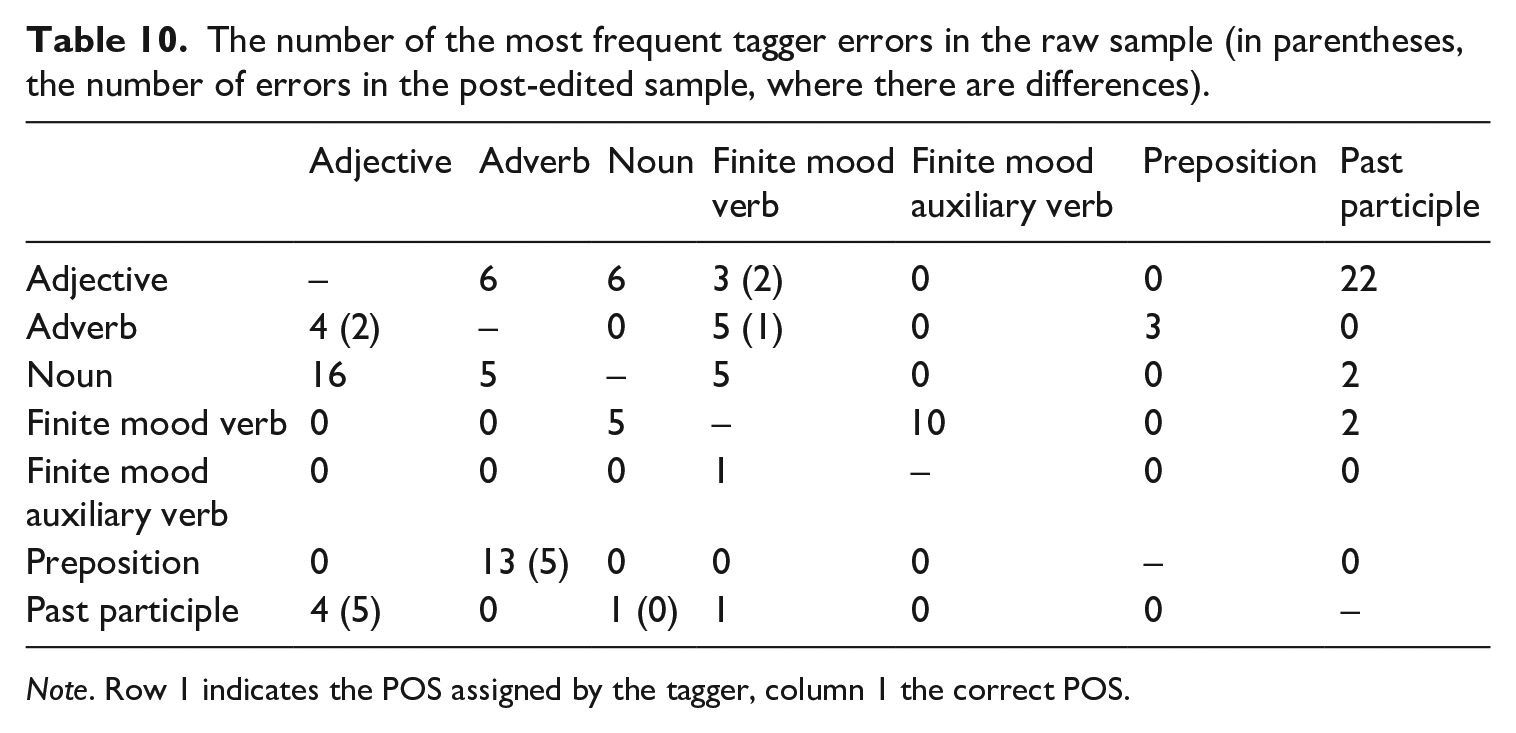
Note. Row 1 indicates the POS assigned by the tagger, column 1 the correct POS.
Errors between noun/adjective and adjective/past participle are also very common in the POS-tagging of texts produced by native Italian speakers (Spina, 2014): the contexts in which the two pairs of grammatical categories occur are, in fact, very similar, and this makes the tagger's task more complex. Another error that occurs frequently is the tagging of prepositions as adverbs (frequency = 13) (18).
(18) [. . .] nessuno ci pensa due volte
→
‘[. . .] nobody thinks twice before writing [. . .].’
Again, the similarity of the contexts in which the two POSs occur also apply in this case. However, given that the two POSs are either closed categories (prepositions) or categories including a limited number of forms (adverbs), the post-editing phase was effective and led to a reduction of errors by 61%.
This data confirms what has already been shown in the previous paragraphs: there are no substantial differences in the tagger accuracy with data from native Italians and learners, and a post-editing phase aimed at specific recurrent POS errors is able to improve the tagger performance.
3 The impact of learner language on POS-tagging performance
By performing a more thorough analysis of the POS errors, we were able to verify that only a limited number of tagging errors actually coincide with learner errors. In particular, incorrect tagging usually occurs when learners’ erroneous forms turn out to be homographs with other common Italian words.
One of the most common learner errors types which affected the automatic POS tagging can be identified as typographic. For example, in (19), giungo, which is the first person singular of the present tense of the verb giungere (‘to arrive’), was employed by the learner instead of the noun giugno (‘June’), probably due to confusion caused by the closeness in their spelling. In this particular case, TreeTagger assigned to this instance of non-standard language a *VER:fin tag (giungo) instead of a NOUN tag (giugno), leading to a tagging non-compliant with the target hypothesis, if compared with the manual gold standard annotation of the sample:
(19) Durante la cerimonia, organizzata il 2
→ *
‘During the ceremony, which was organized on the 2nd of June at the Faculty of [. . .].’
Another type of learner error leading to POS tagging non-compliant with the target hypothesis is represented by morphological errors, as shown in (20). Here, interesso, which is the first person of the present tense of the verb interessare (‘to interest’), was used in place of the noun interesse (‘interest’), 6 thus resulting in a *VER:fin tag (interesso) in place of a NOUN tag (interesse).
Similarly, in (21) the feminine plural adjective deserte (‘desolate’, ‘deserted’) was employed instead of the masculine plural noun deserti (‘deserts’), causing an *ADJ (deserte) in place of NOUN (deserti) tagging not compliant with the target hypothesis:
(20) Penso che questo articolo è di importanza vitale per l’
→ *
‘I think that this article is vital for your readers’ interests.’
(21) [. . .] una splendida natura: mari (oceani), laghi, boschi, montagne,
→ *
‘[. . .] wonderful nature: seas (oceans), lakes, woods, mountains, deserts [. . .].’
Furthermore, we could also observe some lexical errors, such as in (22), where conosciuto (‘known’), which is the past participle of the verb conoscere (‘to know’), was used inappropriately instead of the noun conoscente (‘acquaintance’), producing a *VER:ppast (conosciuto) in lieu of NOUN (conoscente) non-compliant tagging.
Similarly, in (23), the feminine indefinite pronoun qualcuna (‘somebody’) was used instead of the determiner qualche (‘some’), returning a *PRO:indef (qualcuna) instead of a DET:indef (qualche) non-compliant tagging.
(22) [. . .] che ci fanno vedere chi è un vero amico e chi è solo un
→ *
‘[. . .] that make us see who is a real friend and who is just an acquaintance.’
(23) [. . .]oppure sussurrare mentre sta passando
→ *
‘[. . .] or whispering while some girls are passing by.’
Nevertheless, there are learner errors which do not affect the POS-tagging process. These learner errors ‘have effective information that helps determine the POSs’ (Mizumoto and Nagata, 2017: 55). For instance, in our sample we found the sentence in (24), where the misspelt word *divettando (correct diventando ‘becoming’), while producing an unknown lemma, was correctly tagged as VER:ger, as it presents the typical characteristics of the gerund form of first-conjugation verbs, i.e. the ending in -ando.
In (25), spero, which is the first person singular of the present tense of sperare (‘to hope’) was used inappropriately instead of the verb aspettare or attendere (‘to wait for’), probably due to L1 influence (compare Spanish esperar, ‘to wait for’/‘to hope’), producing anyhow the correct POS tag, VER:fin.
(24) Da piccola, mi popolavano i sogni gli eroi dei libri,
→
‘When I was a child, my dreams were filled up with heroes from books, who ended up becoming my personal heroes too.’
(25)
→
‘I’m looking forward to your reply.’
Although our sample is very small, we found that learner errors which did affect the automatic POS-tagging represent 6% of the total POS tag errors in the raw sample and 5% in the post-edited sample. 7 Furthermore, we were also able to spot differences in terms of learners’ rate of errors affecting the tagger accuracy at different proficiency levels. As expected – even though we need to take these findings cautiously with such a limited sample size – a computation of errors on a 1,000 token basis shows that the learner errors actually affecting the POS-tagging are 2.3 for the B1 texts, 1.8 for the B2, 1.4 for the C1, and 0.7 for the C2 texts in our sample. As we hypothesized above, these are learner errors that led to actual tagging errors, which were not detected even in the further post-tagging phase, mainly because they often involve forms belonging to open grammatical categories, such as verbs, nouns and adjectives, for which a semi-automatic correction of tagger errors cannot be envisaged.
V Conclusions
Design and annotation criteria are key issues in learner corpus design. As for the former, while still not receiving the attention it deserves, rigorous proficiency level attribution in learner corpora allows reliable comparability between different learner corpora so as to inform a sound discussion of empirical findings within the broader domain of second language acquisition research. A corpus such as the CELI corpus goes in this direction with a design including balanced subcorpora of written texts produced in a language certification context, and with reference to a language other than English, i.e. Italian.
The CELI corpus also contributes to learner corpus design from the perspective of the annotation criteria adopted. The annotation procedure involved an automatic POS-tagging, followed by a semi-automatic post-editing step to correct frequent tagger errors on grammatically ambiguous forms, and a final manual resolution of the lemmas which the tagger did not recognize. The effort produced to make the POS-tagging as effective as possible seems to have been worthwhile: an evaluation of the tagger's performance revealed that its accuracy on learner data is comparable to that on data produced by native Italian speakers. Data on accuracy also suggested that the post-editing procedure resulted in a further improvement in annotation accuracy, by removing a small number of recurrent tagger errors.
All in all, the CELI corpus introduces new ways to analyse the acquisition of Italian L2 from an empirical perspective, with the advantages deriving from a pseudo-longitudinal design, while relying on solid annotation procedures. It is hoped that many studies can stem from it, thus helping us expand our knowledge of Italian L2 acquisition dynamics and, more generally, of the multiple affordances that learner corpora entail in the different domains of second language teaching and learning.
Footnotes
Author Contributions
The present article is a joint effort by the co-authors. LF wrote the following sections: Introduction, Online learner corpora of Italian, and Conclusions. IF wrote the CELI corpus description and design. SS wrote the POS-tagging of the CELI corpus and Annotation procedure sections. Both SS and FZ contributed to the Measuring and evaluating tagger performance section. FZ wrote The impact of learner language on POS-tagging performance section. All authors contributed to the final manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The publication of this article was financially supported by the Italian Ministery of “PHRAME – Phraseological Complexity Measures in learner Italian. Integrating eye tracking, computational and learner corpus methods to develop second language pedagogical resources”.