
Abstract
This study reports syllable position effects on second language (L2) Portuguese speech perception, revealing that L2 segmental learning may be prone to an influence from the suprasegmental level. The results show that first language (L1) Mandarin learners had diminished performance on the discrimination between the target Portuguese liquids (/l/ and /ɾ/) and their position-dependent deviant productions, suggesting that the cause of their perceptual confusability differs across syllable positions. Another syllabic position effect was attested in the acquisition order (/l/onset > /l/coda, /ɾ/coda > /ɾ/onset), demonstrating that an L2 sound is not mastered equally in all positions. Furthermore, we also observed that an increase in L2 experience affected only the perceptual identification accuracy of [l], but not of [ɾ]. This seems to suggest that L2 experience may exert different degrees of impact, depending on the L2 segments. Both theoretical and methodological implications of these results are discussed.
Keywords
I Introduction
Prior research has shown that, when acquiring the European Portuguese (henceforth, Portuguese) /l/ and /ɾ/, first language (L1) Mandarin-speaking learners do not master the target liquids in all positions equally (Liu, 2018; Zhou, 2017; Zhou and Hamann, 2020). Some intriguing non-native patterns may emerge, depending on the syllabic position, namely, the lateral /l/ is always produced accurately in syllable onset, but very often vocalized as [w] in coda. In the case of the tap /ɾ/, more target-like productions are found in coda than in onset; when failing to realize it, native Mandarin learners replace /ɾ/ only with [l] in onset, while employing various segmental (e.g. [l], [t/d/th] and [ɻ]) and structural repairs (e.g. epenthesis and deletion) in coda.
In light of major second language (L2) speech models, wherein a tight link between L2 perception and production is assumed (Best and Tyler, 2007; Escudero and Boersma, 2004; Flege, 1995), previous studies have argued that the aforementioned syllable position effects can be ascribed to the cross-linguistic influence on L2 speech perception (Zhou, 2017; Zhou and Hamann, 2020). In particular, due to acoustic/perceptual similarity, it is very likely that Mandarin speakers perceptually assimilate L2 Portuguese liquids to their closest L1 Mandarin categories. These L1 categories, which are similar but still different from the Portuguese liquids, are thus associated to L2 phonological representations, giving rise to the deviant production of these L2 sounds. Although the perception-based account is theoretically well grounded, the empirical data of these L2 syllable position effects were collected only through production experiments (Liu, 2018; Zhou, 2017; Zhou and Hamann, 2020). The lack of direct perceptual evidence makes it impossible to confirm a perception-based account, since there is an increasing number of studies showing that L2 learners’ production may not mirror their perceptual performance (e.g. Baese-Berk, 2019; de Leeuw et al., 2021; Sakai, 2016), and that the relationship between two speech modalities may change over time in L2 speech learning (Jia et al., 2006; Nagle and Baese-Berk, 2021; Rallo Fabra and Romero, 2012)
This study thus aims to fill this gap in empirical research by assessing the observed syllable position effects on the L2 acquisition of the Portuguese /l/ and /ɾ/ by L1-Mandarin learners from a perceptual perspective. We believe that adding perceptual data not only leads to a better understanding of the syllable position effects that emerged in Chinese-accented Portuguese, but also contributes to the long-standing debate on the relationship between speech perception and production in L2 speech learning.
1 Background
Both Portuguese and Mandarin have a contrast between an apical lateral and a rhotic, while the two languages differ with respect to the distribution and phonetic realization of these liquids.
The Portuguese /l/ is traditionally described as exhibiting two allophonic variants, namely an alveolar lateral [l] in onset and a velarized [ɫ] in coda (Mateus and Andrade 2000). Cross-linguistically, it has been observed that the velarized variant [ɫ] differs from [l] by involving a secondary velar articulation (i.e. raising of the back of the tongue towards the velum; Browman and Goldstein, 1995), which is instantiated acoustically by the relatively low second formant (F2) values (Lehiste, 1964). Some previous phonetic studies on Portuguese laterals has raised questions about the existence of such allophonic alternation by demonstrating that the Portuguese /l/ manifests low F2 values irrespective of syllable position (Andrade, 1999; Oliveira et al., 2011). A recent acoustic study by Rodrigues and colleagues (2019) further confirmed that the lateral velarization occurs consistently in Portuguese (low F2 values across syllable positions); however, their data revealed that the Portuguese /l/-velarization takes place in a gradual manner, since the third formant (F3) of /l/, another acoustic correlate of degree of velarization, is higher in coda than in onset position. This corroborates the findings on two Catalan dialects reported in Recasens and Espinosa (2005).
Regarding distribution, the Portuguese /ɾ/ 1 can occur in all prosodic contexts, except word-initially (Mateus et al., 2005). It is canonically realized as a tap, though other phonetic variants may also surface, depending on the adjacent segment and position. In particular, when followed by a stop (e.g. largo ‘square’), /ɾ/ is most often produced as a tap plus an epenthetic vowel, while a fricative realization is more prevalent, when /ɾ/ precedes a fricative consonant (e.g. curso ‘course’; Silva, 2014). Moreover, in word-final position, /ɾ/ very often occurs phonetically as a voiceless fricative (Jesus and Shadle, 2005), and can even be omitted, especially when the following word starts with a consonant (Mateus and Rodrigues, 2003; Rodrigues, 2003).
Compared to Portuguese, Mandarin displays a more reduced syllable inventory, i.e. no branching onset is allowed (Duanmu, 2007; Lin, 2007). The distribution of the Mandarin /l/, on the one hand, resembles that of the Portuguese lateral, since, in both languages, /l/ may occupy the non-branching syllable onset; on the other hand, Mandarin differs from Portuguese in not licensing /l/ in coda position. The Mandarin rhotic /ɻ/, which may occur both in syllable onset and coda, is an underlying approximant (Duanmu, 2005; Lin, 2007). 2 In syllable onset, the phonetic realization of /ɻ/ may vary between an approximant and a fricative (Chen and Mok, 2019; Zhu 2007), whereas, in coda, /ɻ/ is always an approximant and largely resembles the rhotic in English (Chen and Mok, 2019; Jiang et al., 2019). Articulatory and acoustic evidence furthermore reveal that the Mandarin rhotic appears in syllable nucleus, after the dental and retroflex sibilants (Lee-Kim, 2014).
In the following part of this section, we will review the syllable position effects attested in Chinese-accented Portuguese speech, outlining the possible explanations for their emergence. These syllable position effects reported in previous production studies are summarized in Table 1.
Syllable position effects in the acquisition of Portuguese /l/ and /ɾ/ by L1-Mandarin speakers 3 .
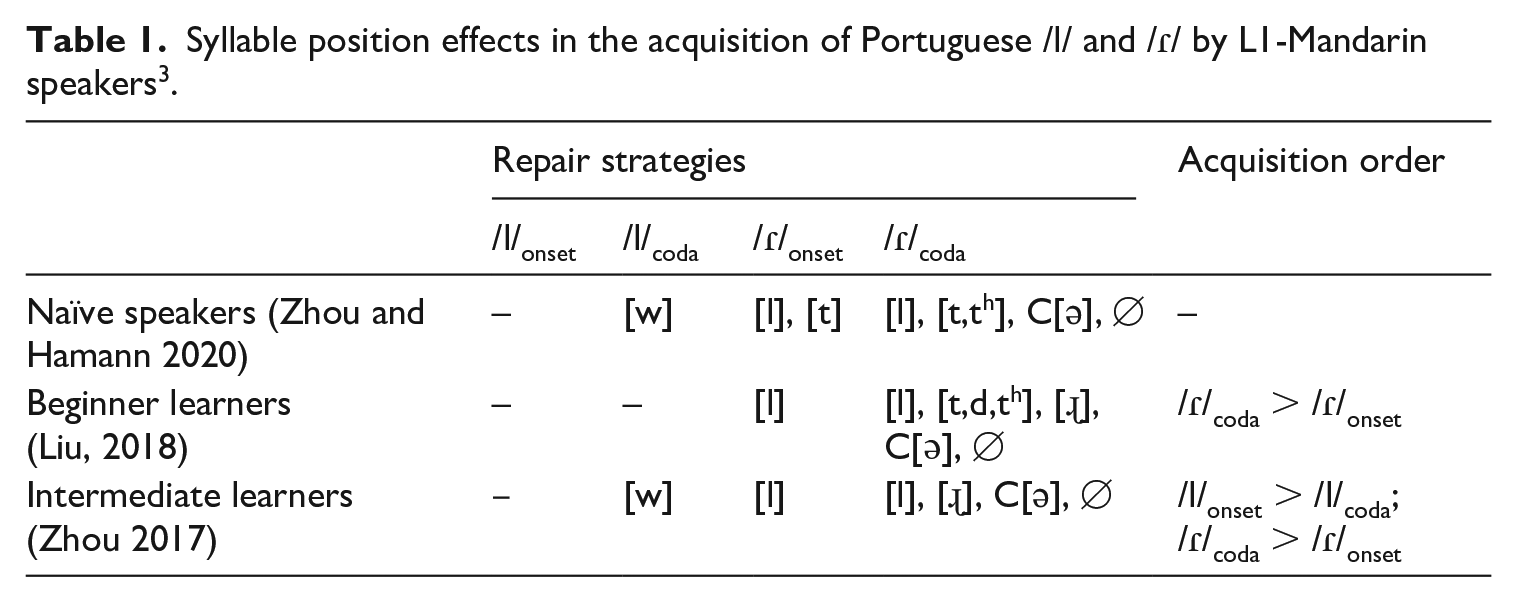
When acquiring the Portuguese /l/, learners master this segment in syllable onset 4 before coda. This acquisition order (/l/onset > /l/coda) is not surprising, since the alveolar lateral is licensed in syllable onset both in Mandarin (L1) and in Portuguese (L2). That is to say, a positive transfer of the Mandarin [l] will lead to high accuracy in L2 speech. The learning of /l/ is hindered in coda, presumably due to its higher degree of velarization in that position (Rodrigues et al., 2019). It has been speculated that L1-Mandarin learners might perceptually miscategorize [ɫ] as /w/, because of acoustic similarity (both [ɫ] and [w] display low F2 values). If this were true, Portuguese words with /l/coda (e.g. pape[ɫ] ‘paper’) would be stored with a diphthong (pape/w/) in the L2 lexicon and be produced differently from the target. This line of reasoning is in accordance with mainstream L2 speech theories, namely, the Speech Learning Model (SLM; Flege, 1995; Flege and Bohn, 2021), the Perceptual Assimilation Model-L2 (PAM-L2; Best and Tyler, 2007), and the Second Language Linguistic Perception model (L2LP; Escudero, 2005; Escudero and Boersma, 2004). These models converge on the idea that the creation of a novel sound category hinges on how this sound is perceptually categorized by learners, under the influence of their L1 phonology (cross-linguistic influence). For instance, if an L2 sound is different from any existing segment in the learners’ L1 system, yet similar enough to be considered a good token of its closet L1 counterpart (the ‘similar’ scenario in the SLM; the ‘single-category assimilation’ pattern in the PAM-L2; and the ‘new’ scenario in the L2LP), the formation of a novel sound category is expected to be hindered; instead, an L1-like phonological representation will be stored in the learners’ lexicon and retrieved in L2 production. This perception–production loop in L2 speech has been evidenced by a large number of studies in the literature (e.g. Bion et al., 2006; Brunner et al., 2011; Rauber et al., 2010; for an overview, see Bohn, 2017).
Although many L2 deviant productions are rooted in misperception due to cross-linguistic influence, some non-target-like forms can also stem from motor control issues (Honikman, 1964; Zimmer and Alves, 2012), without echoing perceptual distortion. For instance, in the acquisition of the Portuguese /l/, the articulation of its coda allophone [ɫ] may be challenging for Mandarin speakers, because it involves an entirely novel coordination between the coronal and the dorsal gestures. In such case, when producing [ɫ], learners might prioritize the realization of the dorsal gesture, which is more salient and precedes the coronal gesture (Sproat and Fujimura, 1993), resulting in [w]. The fact that articulatory difficulty predicts L1-Mandarin learners’ productions is further supported by the evidence that the articulatory factor alone is sufficient to trigger /l/-vocalization (Recasens and Espinosa, 2010). In other words, regardless of whether L1-Mandarin learners are able to perceptually identify [ɫ] and [w] as two categories, they might vocalize [ɫ] in L2 speech production due to articulatory imprecision.
In the case of the Portuguese tap (/ɾ/), its early acquisition in coda, compared to onset, is a developmental pattern rarely reported in L2 speech learning literature. The syllable onset position has been argued to be universally salient in terms of accessibility and learnability (Carlisle, 2001; Ohala, 1996), which may explain why syllable onset is usually targeted before coda both by children acquiring their L1 (e.g. Fikkert 1994; Freitas, 1997) and by adults learning a foreign language (e.g. Bent et al., 2007; Colantoni and Steele, 2008; Rogers and Dalby, 2005; Waltmunson, 2005). The unusual acquisition order (/ɾ/coda > /ɾ/onset) attested in L2 Portuguese production has been attributed to the Mandarin phonotactic restriction (Zhou 2017; Zhou and Hamann 2020): The Portuguese /ɾ/ is challenging for L1-Mandarin speakers, because they perceptually confuse this L2 sound with the L1 lateral [l] (Cao, 2018; Vale, 2020). This L1 interference (perceptually-driven L2-to-L1 category assimilation) is assumed to be more moderate in coda than in syllable onset, because the output of misperception, i.e. /l/, is only legitimate in onset, but not in coda, according to the Mandarin phonology (i.e. only nasals and /ɻ/ are allowed in coda; Duanmu, 2005; Lin, 2007). Mandarin phonotactics may thus help learners mitigate the segmental confusability between [ɾ] and [l] in coda position.
No current L2 speech theories put forward predictions on which speech modality the intervention from L1 phonotactics may occur. Empirical studies, on the other hand, have provided conflicting evidence. The documentation of the L1 phonotactic constraint on L2 speech perception can be dated back to Polivanov (1931): native Japanese speakers perceive different epenthetic vowels to accommodate an illegal consonant cluster, /o/ after a coronal stop (/d/) and /u/ (the default epenthetic vowel) elsewhere, due to the fact that the sequence /du/ is not allowed by the Japanese phonotactics. However, in the perceptual study by Monahan and colleagues (2009), the Japanese participants only epenthesized an illusorily [u], but not [o]. This led Monahan and colleagues to speculate that some phonotactic restrictions, such as */du/ in Japanese, may be only active in speech production, but not in perception.
Apart from the acquisition order /ɾ/coda > /ɾ/onset, the Mandarin phonotactic restriction has also been argued to be responsible for the structural modifications attested in coda position, namely the deletion of /ɾ/ and the insertion of a schwa /ɾə/ (e.g. (ca[ɾ]ta ‘letter’ produced as ca[ɾə]ta or ca[∅]ta; Zhou, 2017; Zhou and Hamann, 2020). The Mandarin phonology, which does not license any consonantal clusters, could act as a perceptual sieve (much like how it underlies L2-to-L1 category assimilation), accommodating an illicit L2 structure in accordance with the Mandarin phonotactic well-formedness. Such L1 structural influence on L2 speech perception has been well attested in the literature, giving rise to either an ‘illusory vowel’ (e.g. [ebzo] perceived as /ebuzo/ in Dupoux et al., 1999; also see Cardoso, 2011; Kabak and Idsardi, 2007) or perceptual deletion (e.g. [tmafa] as /mafa/ in Davidson and Shaw, 2012; also see Mah et al., 2016; Melnik and Peperkamp, 2019; Steele, 2009). If the Portuguese words with /ɾ/coda (e.g. ca[ɾ]ta ‘letter’) were indeed perceptually reconstructed conforming to the Mandarin phonotactics (e.g. ca[ɾə]ta 5 or ca[∅]ta), according to the perception–production loop assumed by L2 speech models, the corresponding deviant forms would be stored in the L2 lexicon and consequently retrieved in L2 production.
Another line of research (e.g. Davidson, 2006; Funatsu and Fujimoto, 2012), nevertheless, has pointed out the possibility that the structural modification may be an instantiation of articulatory difficulty. To produce a target-like Portuguese tap, L1-Mandarin learners need to learn an articulatory gesture that is not used in their L1: a ballistic movement of the tongue toward the dental/alveolar region (Mateus et al., 2005). The non-mastery or unsuccessful implementation of this gesture might trigger the omission of /ɾ/, regardless of the quality of the phonological representation of this L2 rhotic. In addition to deletion, gestural mis-timing between the coda tap and the following consonant can likewise trigger epenthesis (Davidson, 2006; Funatsu and Fujimoto, 2012). By acoustically measuring the transitional vowels inserted in illegal consonant clusters by English-speaking participants, Davidson (2006) demonstrated that the epenthetic vowels were substantially distinct from the lexical schwa, both in terms of duration and formant values. This acoustic disparity suggests that vowel insertion occurs after phonological computation, in support of the idea that certain epenthesis is driven by gestural mis-timing. Davidson’s postulation was borne out in Funatsu and Fujimoto (2012), who provided direct evidence for the articulation-induced epenthesis, using electromagnetic articulography: the insertion of a vocalic element to break the illegal consonant clusters by both Japanese and German speakers is driven by the non-target-like timing between the articulatory movement and vocal fold vibration.
To summarize, in light of mainstream L2 speech acquisition theories (Best and Tyler, 2007; Escudero and Boersma, 2004; Flege, 1995), the syllable position effects (position-dependent repair strategies and order of acquisition), observed in L2 Portuguese spoken by L1-Mandarin learners, can be ascribed to the cross-linguistic influence on L2 perception (Zhou, 2017; Zhou and Hamann, 2020); nevertheless, the lack of direct perceptual evidence does not allow one to refute an alternative articulation-based account, as discussed in this section.
2 Overview of the study
The goal of this study is to fill the gap in the literature by studying the syllabic position effects in L1 Mandarin speakers’ acquisition of L2 Portuguese via a perceptual testing protocol. Specifically, we intend to explore the following research questions:
• Research question 1: Can L1-Mandarin learners perceptually detect the difference between the target Portuguese liquids (/l/ and /ɾ/) and their repair forms across syllable positions as reported in previous production studies?
• Research question 2: Is the L2 acquisition order observed in perception the same as that reported for production?
• Research question 3: Does L1-Mandarin learners’ perceptual accuracy on Portuguese /l/ and /ɾ/ improve with the increase of L2 experience?
To answer these questions, we designed two perceptual tasks, which will be introduced in detail in the next section. Following major L2 speech learning models (SLM, PAM-L2 and L2LP), in which a tight link between two speech modalities is assumed, we hypothesize that the syllable position effects attested in L2 production will be mirrored in L2 perception. More specifically, L1-Mandarin learners will have difficulty in reliably discriminating between the target Portuguese consonants and their repair forms across syllable positions and the acquisition order will resemble that attested in production (i.e. /l/onset > /l/coda and /ɾ/coda > /ɾ/onset). Furthermore, given that L2 experience estimated on the basis of length of received formal instruction and length of residence in the target country is shown to play a positive role in L2 phonological category learning (e.g. Flege et al., 1997; Trofimovich and Baker, 2006), we predict that learners with more L2 experience will outperform less experienced L2 learners.
II Methods
1 Participants
Sixty-one L1-Mandarin learners of Portuguese (female = 50; mean age = 22.3 years, SD = 2.5) and 10 native Portuguese listeners (female = 7; mean age = 29 years, SD = 1.5) completed the perceptual tasks. All participants were recruited in Lisbon. The L1-Mandarin participants were born and raised in different areas in mainland China. The inclusion criteria for Chinese participants were as follows: (1) to be native speakers of Mandarin (considered Mandarin as their dominant language regardless of the Chinese region where they were raised); (2) to have no fluency in or regular use of another language other than English.
According to the background questionnaire, all Chinese participants spoke English as an L2, aside from Portuguese, but none was ever immersed in an English-speaking environment for more than six months. Regarding L2 experience, 31 L1-Mandarin learners had a relatively homogeneous experience with Portuguese (studying Portuguese for two years in a formal setting in China, and being immersed in a Portuguese language course in Lisbon for 2 months; in total 2.17 years), while the other 30 participants reported more experience with Portuguese both in terms of formal education (all had completed a 4-year bachelor degree in Portuguese from a Chinese university) and immersion (all had spent at least a year studying or working in Portugal; in total 5.5 years). On the basis of self-reported L2 experience, the former group was considered to have an intermediate proficiency level in Portuguese and the latter group was classified as advanced learners.
Ten Portuguese controls, who were all born and educated in Portugal, also participated. These native listeners were either master or PhD students at the University of Lisbon. All participants completed a language background questionnaire which ensured that they met the inclusion criteria. No participants reported any hearing, speech or any other language impairment. They all gave informed consent at the beginning of the study. This project was approved by the Ethics Committee of the School of Arts and Humanities of the University of Lisbon (15_CEI2019).
2 Materials and recordings
Stimuli for the AXB discrimination task were pairs of trisyllabic pseudo-words. The target segment was always in a stressed syllable, and vowels /a/ and /i/ were used in adjacent vocalic contexts (with the purpose of reducing the homogeneity of the stimuli) and counterbalanced across stimuli. In the test word pairs, the target Portuguese liquid alternated with its corresponding repair form(s) (i.e. [ɫ]coda – [w], [ɾ]onset – [l], [ɾ]coda – [l], [ɾ]coda – [ɾə] and [ɾ]coda – [∅]). To give an example, for the contrast [ɫ]coda – [w], the test items were triplets of pseudo-words, such as pa[ɫ]fa – pa[ɫ]fa – pa[w]fa. Fillers were word pairs containing easily discriminable contrasts (/l–k/, /t–s/, /t–k/) for Mandarin listeners. There were 120 trials in total, consisting of 80 test trials: four trials per contrast × four counterbalancing orders (AAB, ABB, BBA, BAA) × five contrasts. In addition, there were 40 fillers: 4 contrasts × 10 repetitions.
The 12 test items created for the identification task were trisyllabic pseudo-words, comprising the target segments /l/ and /ɾ/ in stressed intervocalic onset position. The adjacent vowels were either /a/ or /i/ and counterbalanced across stimuli. Fillers contained voiceless stops, which are present in both the Mandarin and the Portuguese inventories. There were 24 test tokens in total: six words per segment × two segments (/l/ and /ɾ/) × two repetitions and 12 fillers. The stimuli used for the AXB discrimination task and identification task are listed in Appendix 1.
A male native Portuguese phonetician was recorded reading all stimuli in a sound-proof booth with a Zoom H4n pro recorder, and a Shure SM58 microphone. The recordings were digitized at an audio sampling rate of 44.1 kHz. All recorded sound files were adjusted to the average intensity of 70 dB in Praat 6.1.05 (Boersma and Weenink, 2019). For the AXB discrimination task, two renditions were obtained for each pseudo-word, so that the audio stimulus for A, for example in a triplet AAB, was actually instantiated by two acoustically different tokens. All test items were naturally produced.
Regarding the test items with an epenthetic vowel, it is worth mentioning that the duration and spectral properties of the inserted vowel (e.g. ta[ɾ
3 Experimental tasks
Two perception tasks were designed: an AXB discrimination task and a forced-choice identification task. In the AXB task, the participants were presented with a sequence of three auditory stimuli and were required to indicate whether the second (X) was more similar to the first (A) or to the third (B) by pressing the corresponding buttons on a keyboard. Stimulus presentation was counterbalanced across trials. Within each trial, the inter-stimulus interval (ISI) was set to 1,200 ms in order to encourage judgment at the phonological level, rather than trigger acoustic comparison (Escudero et al., 2009). After a short practice (4 trials), the task ran with 4 blocks, each containing 20 test trials and 10 filler trials. The test trails were balanced across blocks so that every block contained all stimulus types. Participants were given self-paced breaks between blocks to avoid fatigue.
As a complement to the discrimination task, a forced-choice identification task was employed. Production data in the literature showed that L1-Mandarin learners only replace target onset /ɾ/ with [l], but never inversely (*/l/ →[ɾ]), and thus it will be interesting to see whether the same asymmetry is mirrored in L2 perception. A discrimination task only informs us on whether learners can perceptually discern the difference between the two sounds ([l] and [ɾ]), while an identification task will reveal the directionality of the confusability. During the identification task, the participants were presented with a single auditory stimulus each time and were required to assign a label to the stimulus by choosing one of four orthographically represented alternatives, which were composed of target segments (/l/ and /ɾ/ in onset) and two distractors containing either /k/ or /t/. For instance, after hearing the auditory form [fɐˈlapɐ], learners were asked to choose the correct response from <falapa>, <farapa>, <facapa> or <fatapa>. If there is an asymmetry, as attested in production, [l] will be labelled as <l> (indicating /l/), [ɾ] as <l> and <ɾ> (indicating /l/ and /ɾ/).
All participants were tested in a quiet room. The experiment was set up and run in OpenSesame 3.2.8 (Mathôt et al., 2012), with auditory stimuli presented through noise-cancelling Sony headphones WH1000XM3. After answering a background questionnaire and signing the consent form, the participants first completed the AXB discrimination task and then the identification task. Screenshot examples of the two tasks are shown in Figure 1. Both tasks were self-paced and the two perceptual tasks together took about 20 minutes to complete.

Screenshot examples of the AXB discrimination task (left) and forced-choice identification task (right).
4 Data analysis
The data from the native control and L2 learner groups were analysed separately, because the two groups differed with respect to sample size (for a similar procedure, see Ortín and Simonet, 2021). During data exploration, we first analysed the task performance of the native Portuguese controls, and then explored the perceptual behaviour of the 61 L1-Mandarin learners as a single group. This allowed us to conceptually compare the control and learner data, making sense of the overall patterns found in the two groups. Finally, considering that the 61 Mandarin-speaking participants had different amounts of experience with Portuguese, we performed statistical analysis to assess whether L2 perception of Portuguese /l/ and /ɾ/ across syllable positions improved with the increase of L2 experience.
The data set pertaining to native controls’ responses in the AXB task consisted of 800 observations (4 trials per contrast × 4 counterbalancing orders × 5 contrasts × 10 participants), and the data set of the L2 learners’ responses in the discrimination task included 4,880 observations (4 trials per contrast × 4 counterbalancing orders × 5 contrasts × 61 participants). The responses in the forced-choice identification task also resulted in two data sets, one with 240 observations (6 words per segment × 2 segments × 2 repetitions × 10 participants) and one with 1,464 observations (6 words per segment × 2 segments × 2 repetitions × 61 participants), for the control and learner groups, respectively.
Data processing was conducted in R (R Core Team 2021), with the tidyverse package (tidyverse.org), and data visualization was performed using the ggplot2 package (Wickham, 2016). For the analysis of the binary accuracy data (1 or 0), we built several mixed logistic regression models, using the lme4 package (Bates et al., 2015).
III Results
1 Portuguese control group
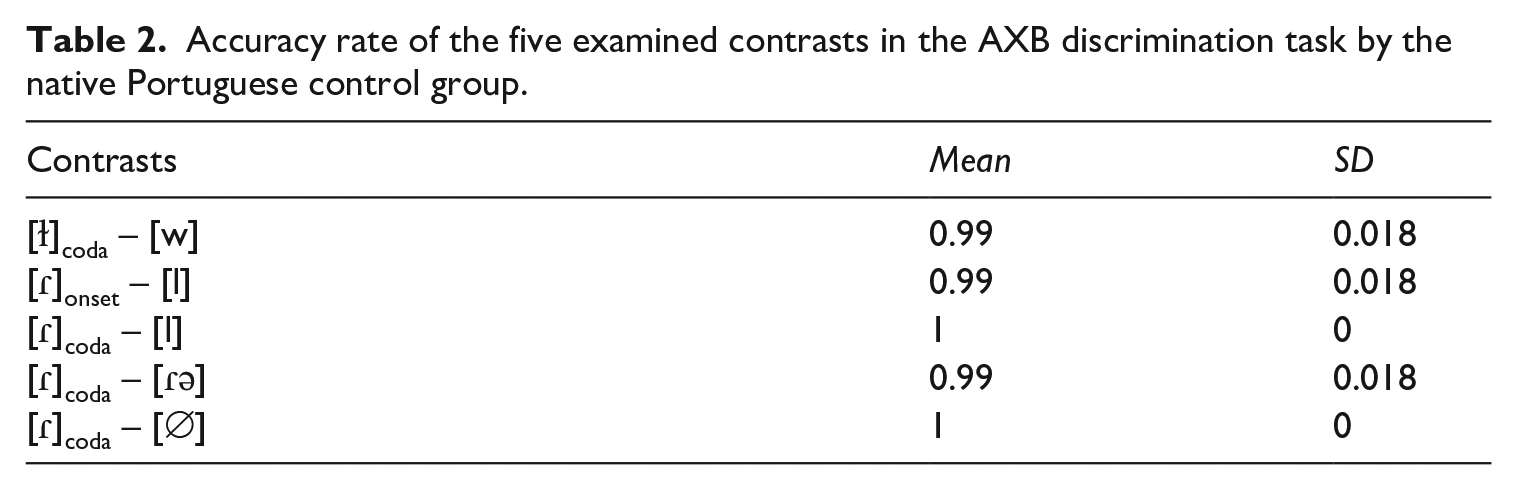
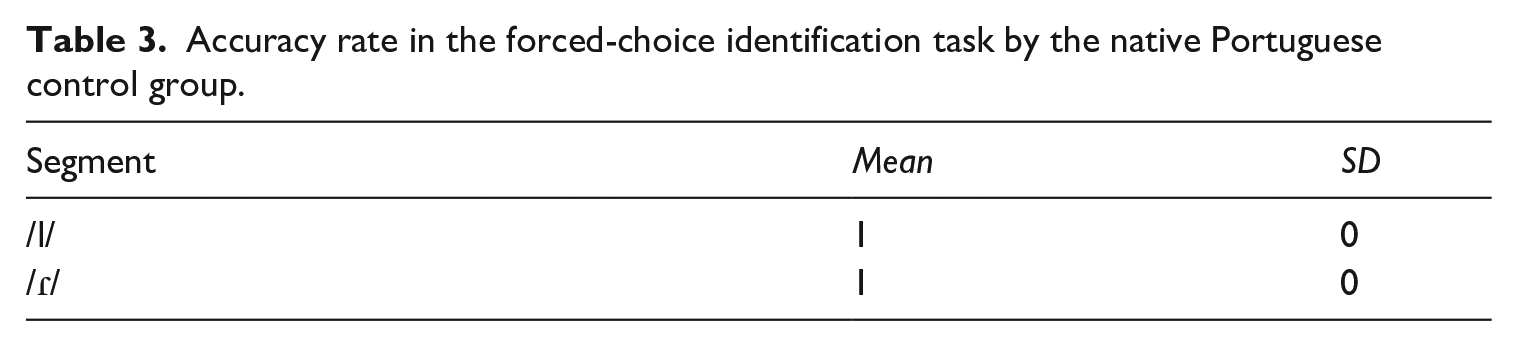
The inclusion of a group of native Portuguese speakers allowed us to validate the two perceptual experiments. The native control group scored at ceiling for both perceptual tasks, as shown in Tables 2 and 3. They performed as predicted given that the auditory stimuli in both tasks represent sound contrasts that are difficult for L1-Mandarin learners, but not for native speakers of Portuguese.
Accuracy rate of the five examined contrasts in the AXB discrimination task by the native Portuguese control group.
Accuracy rate in the forced-choice identification task by the native Portuguese control group.
2 Learner group
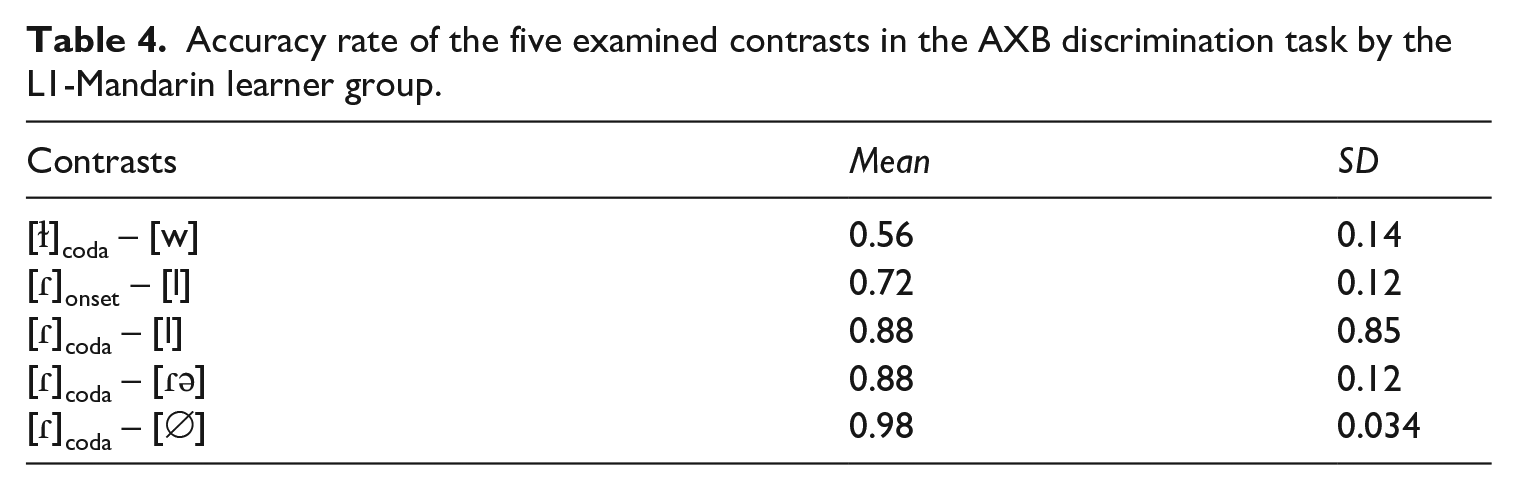
The L2 learner group’s accuracy rates in the AXB discrimination task are reported in Table 4 and visualized in Figure 2. (The contrast [ɾ]coda – [l] is coded as l–r-coda, [ɾ]onset – [l] as l–r-onset, [ɫ]coda – [w] as l–w-coda, [ɾ]coda – [∅]as r-0-coda and [ɾ]coda – [ɾə] as r–e-coda.) Except for the contrast where the test items with a syllable-final tap (e.g. pa[ɾ]fa) is compared against their counterparts without coda (e.g. pa[∅]fa), the learner group had diminished performance on the discrimination between the target Portuguese liquid and its deviant form. The contrast between a velarized lateral in coda and a semivowel [w] posed the greatest challenge for the Mandarin learners of Portuguese, followed by the contrast [l]–[ɾ] in syllable onset. For the target Portuguese tap in coda position, the segmental repair [l] and the structural repair [ɾə] seem to cause a similar degree of perceptual difficulty. These results partially confirmed our prediction in research question 1 that L1-Mandarin learners would have difficulty in reliably discriminating between the target Portuguese liquid and its repair forms in different syllable positions. This holds true for most of the contrasts examined in the current study, but the omission of the coda tap in L2 production cannot be ascribed to perceptual deletion.
Accuracy rate of the five examined contrasts in the AXB discrimination task by the L1-Mandarin learner group.
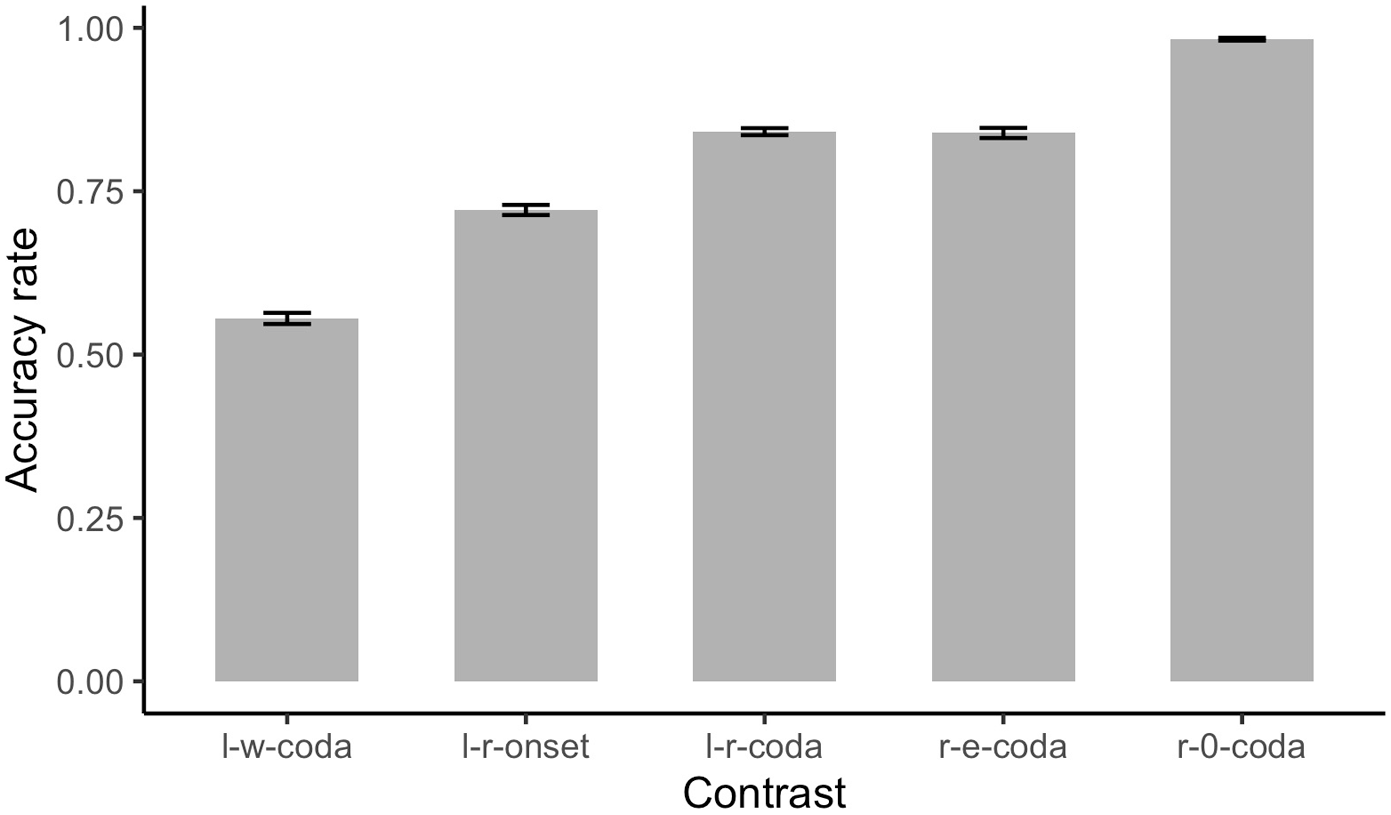
Accuracy rates for different contrasts by 61 L1-Mandarin learners of Portuguese in the AXB discrimination task.
Turning to the developmental path (research question 2), we predicted that, if L1-Mandarin learners of Portuguese perceptually distinguish the target Portuguese liquid from its confusable deviant form more accurately in syllable position A than position B, they will master the Portuguese sound in position A before B. For the Portuguese lateral, which is better produced in syllable onset than in coda (Zhou, 2017), this reasoning entailed that learners would perform better with the contrast l–r-onset (target [l] vs. repair [ɾ]) than with l–w-coda (target [ɫ] vs. repair [w]). Regarding the Portuguese tap, which is acquired in reverse order (Liu, 2018; Zhou, 2017), L1-Mandarin learners are expected to perform better in rejecting the deviant forms in coda position (target [ɾ] vs. repair [l] and [ɾə]) than in onset (target [ɾ] vs. repair [l]). Note that the deletion of the coda tap was not considered to influence the acquisition order in L2 perception, as it is not perceptually driven.
A mixed-effects logistic regression model was built as in (1). The responses on the contrasts l–r-coda and r–e-coda are aggregated in the model (recoded as r–l/e-coda), representing learners performance in discrimination between the target Portuguese tap and its repair forms in coda ([l] and [ɾə]). This model had the accuracy results by the learner group as the outcome (binary: 1 for correct; 0 for incorrect), Contrast (three levels, l–w-coda, l–r-onset, r–l/e-coda) as predictor. The predictor was dummy coded with l–r-onset, underlined in (1), as the reference level. The model also included random intercepts for Participant and Trial, and random slopes for Contrast by Participant. Model 1’s results are summarized in Table 5.
(1) Accuracy ~ Position + (1 + Position | Participant) + (1 | Trial) Position = (
Summary of model (1) for the acquisition order.

Results of Model (1) indicate that L1-Mandarin participants were more accurate in discriminating between the target /l/ and its repair form in syllable onset than in coda, while they performed better in rejecting the deviant form for the target tap in coda than in onset. Therefore, our prediction regarding the acquisition order of the Portuguese liquids (i.e. /l/onset > /l/coda and /ɾ/coda > /ɾ/onset) in L2 speech perception was confirmed.
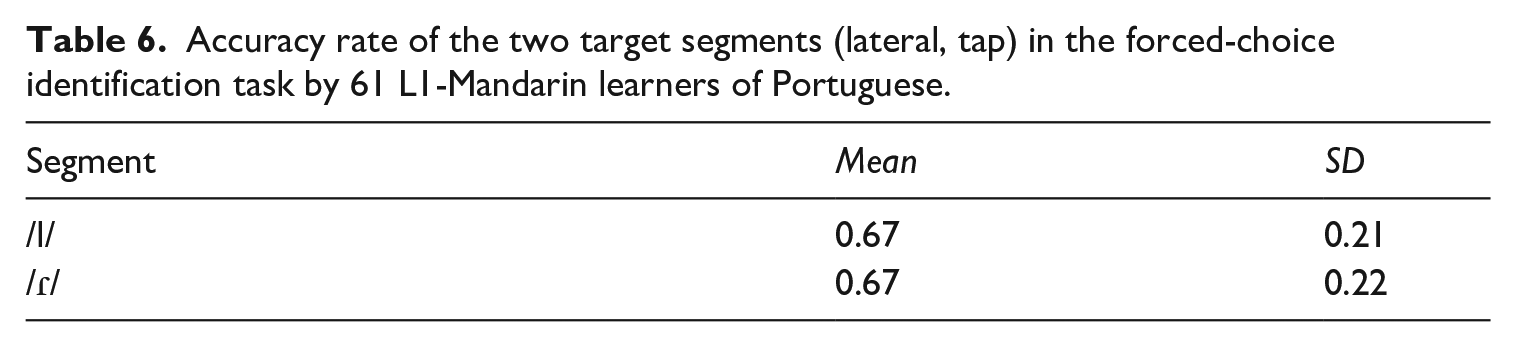
Table 6 presents the identification accuracy rates on /l/ and /ɾ/ by the learner group in the forced-choice identification task. Results of the identification task revealed that L1-Mandarin learners very often misperceived [l] as /ɾ/ and [ɾ] as /l/, which may be unexpected not only with respect to the native controls, but also to previous production results (/ɾ/ is sometimes produced as [l] by L1-Mandarin learners, but never inversely */l/ → [ɾ]; Zhou, 2017; Zhou and Hamann, 2020).
Accuracy rate of the two target segments (lateral, tap) in the forced-choice identification task by 61 L1-Mandarin learners of Portuguese.
3 Effect of experience with Portuguese
Given the fact that the L1-Mandarin participants reported different prior experience with Portuguese, we ran some additional analyses to explore whether different amounts of experience with Portuguese have an impact on their perceptual performance in both the discrimination and the identification tasks.
The accuracy rates of the five examined contrasts in the AXB discrimination task as a function of learner group are plotted in Figure 3.
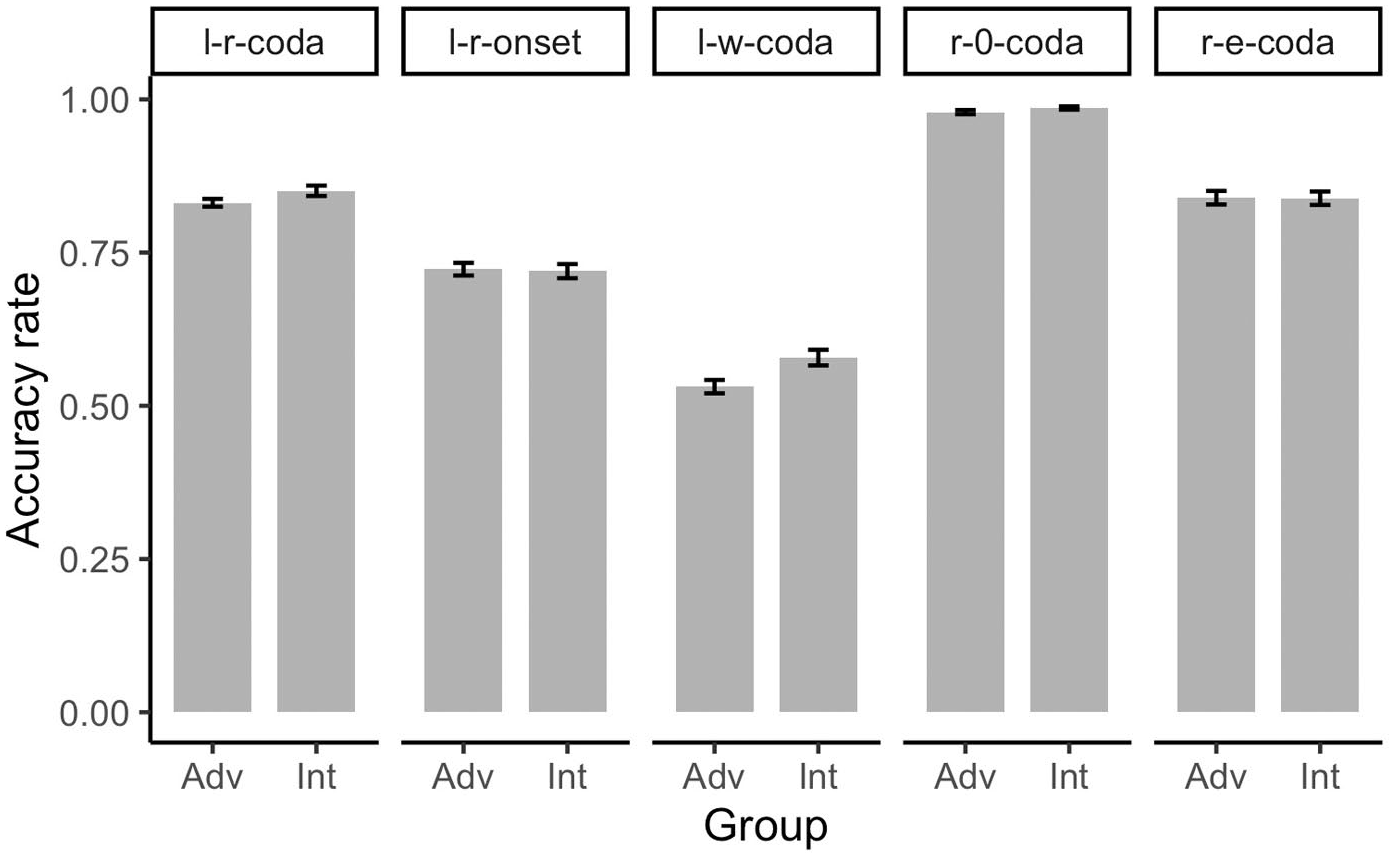
Accuracy rates for different contrasts by advanced (Adv) and intermediate (Int) second language (L2) learners in the AXB discrimination task.
In contrast to our prediction that advanced learners would perform better than intermediate learners, the visual inspection suggests that there is no accuracy difference between the two learner groups. In order to confirm this observation, we ran four mixed logistic regression models on the accuracy results of four contrasts, 6 namely [ɫ]coda – [w], [ɾ]onset – [l], [ɾ]coda – [l], [ɾ]cod – [ɾə]. These models had L2 Experience (two levels, intermediate and advanced; reference level, advanced) as predictor. Random intercepts for Participant and Trial, and Random slopes for L2 Experience by Trial were also included, as shown in (2).
(2) Discrimination accuracy ~ L2_Experience + (1 | Participant) + (1 + L2_Experience | Trial) L2_Experience = (
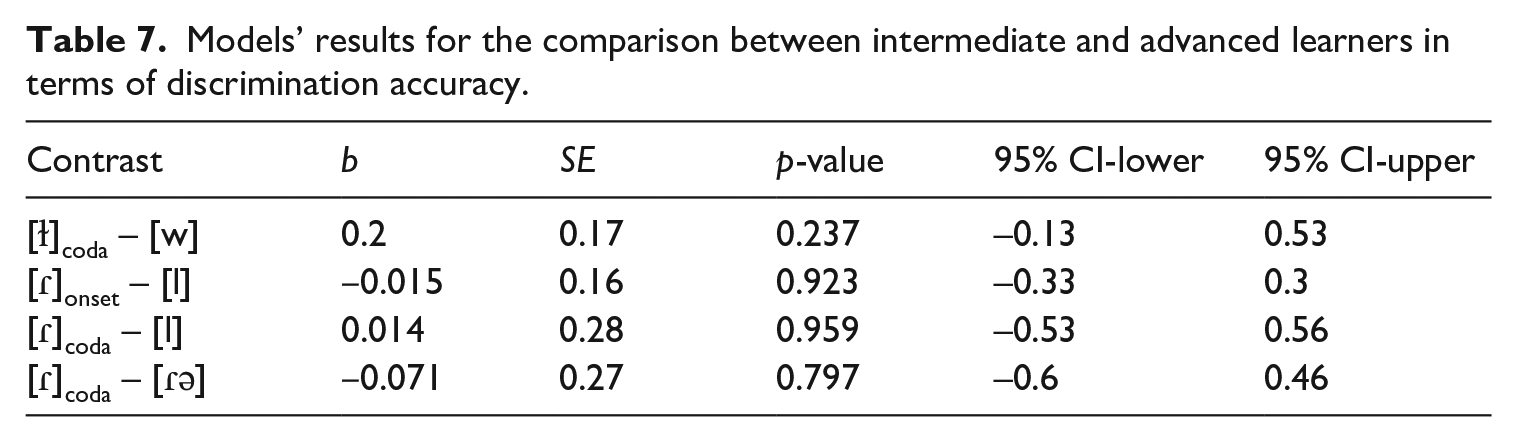
As shown in Table 7, in which the models’ results are summarized, no significant effect of L2 Experience was found in any of the models. In other words, we did not find evidence that more experience with Portuguese predicts L1-Mandarin learners’ better performance in discriminating between the Portuguese liquids (/l/ and /ɾ/) and the corresponding deviant form(s).
Models’ results for the comparison between intermediate and advanced learners in terms of discrimination accuracy.
Contrary to what was observed in the AXB discrimination task, there seemed to be an effect of experience on L1-Mandarin learners’ performance in the identification task, namely in the responses to the Portuguese [l], as illustrated in Figure 4.
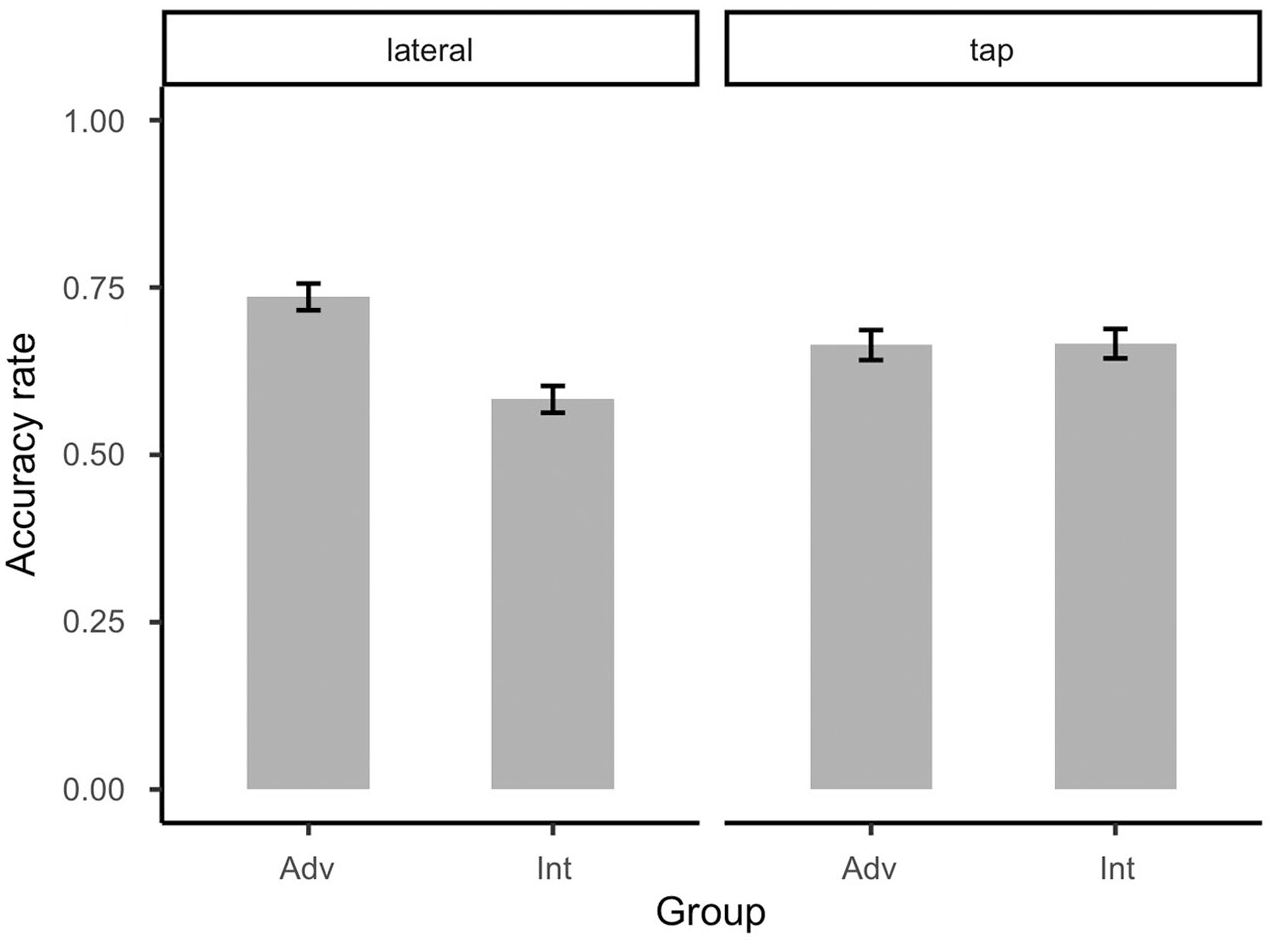
Accuracy rates for the Portuguese lateral and tap by advanced (Adv) and intermediate (Int) second language (L2) learners in the forced-choice identification task.
Other two mixed logistic regression models, as in (3), were built for the accuracy data from the identification task, one for the responses to the Portuguese lateral, and the other for the responses to the tap. Both models had L2 Experience (two levels, Intermediate and Advanced; reference level, Advanced) as predictor. The models also included random intercepts for Participant and Trial, and random slopes for L2 Experience by Trial. The two models’ results are summarized in Table 8.
(3) Identification accuracy ~ L2_Experience + (1 | Participant) + (1 + L2_Experience | Trial) L2_Experience = (
Models’ results for the comparison between intermediate and advanced learners in terms of identification accuracy.
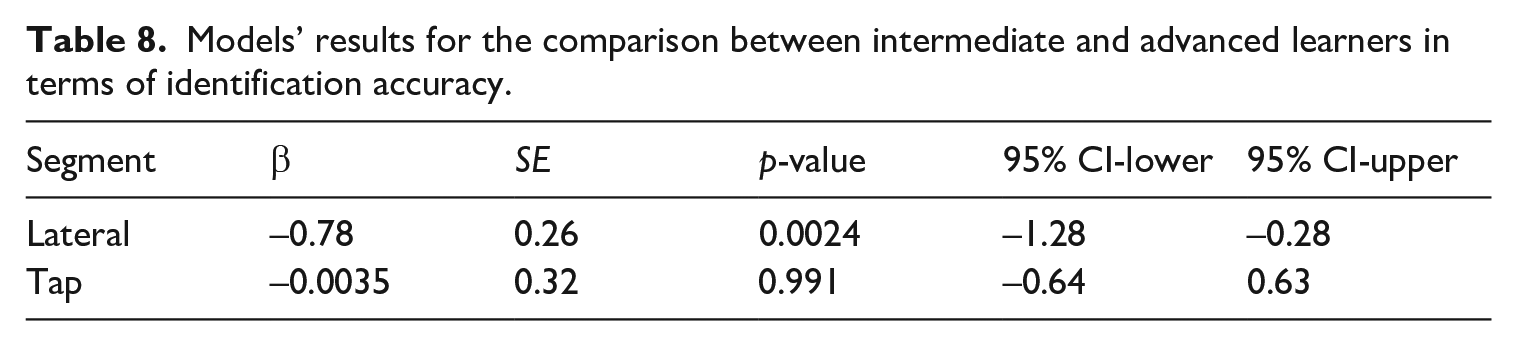
As shown in Table 8, an effect of L2 experience was only found in the responses to [l], but not to [ɾ], confirming what was observed in Figure 4. This indicates that the categorization of the Portuguese [l] by L1-Mandarin learners improved with the increase of L2 experience, while no evidence on such improvement was observed for the perception of [ɾ].
IV Discussion
1 General discussion
The main purpose of this study was to investigate whether L1 Mandarin learners’ perception of Portuguese /l/ and /ɾ/ is subject to the syllable position effects reported previously in studies on L2 production (Liu, 2018; Zhou, 2017; Zhou and Hamann, 2020). Specifically, we explored whether the position-dependent repair strategies reported in L2 production of the Portuguese /l/ and /ɾ/ are rooted in misperception and whether the acquisition order in L2 perception is the same as attested in L2 production studies. Following major L2 speech learning models’ premises (SLM, PAM-L2 and L2LP), which assume a link between L2 speech perception and production, we predicted that (1) L1-Mandarin learners would have difficulty in reliably discriminating between the target Portuguese segments and their repair forms across syllable positions and (2) the acquisition order in L2 perception would mirror that attested in L2 production (i.e. /l/onset > /l/coda, /ɾ/coda > /ɾ/onset). Two perceptual tasks (an AXB discrimination and a forced-choice identification) were first validated by 10 native Portuguese listeners and then administrated to 61 L1-Mandarin learners of Portuguese.
Regarding research question 1 on the position-dependent repair strategies, our prediction was largely borne out. In contrast to the native Portuguese listeners, who always performed at ceiling level, the L1-Mandarin participants indeed very often perceptually confused the target Portuguese liquids (/l/ and /ɾ/) with the deviant forms that they may employ in production. Namely, most segmental ([w] for /l/coda, [l] for /ɾ/) and structural repairs ([ɾə] for /ɾ/) previously attested in L2 production were indeed correlated with misperception. These results not only corroborate the prediction of major L2 speech models that cross-linguistic influence shapes L2 speech perception as a function of L2-to-L1 sound category assimilation, but also echo many empirical studies showing that perceptual cross-linguistic influence operates beyond the segmental level (Cardoso, 2011; Dupoux et al., 1999; Kabak and Idsardi, 2007). It is noteworthy that L1-Mandarin learners do not have difficulty in perceptually detecting the omission of the coda tap, a repair strategy applied in L2 production (Liu, 2018; Zhou, 2017). This implies that it cannot be attributed to perceptual deletion. We will return to this point in Section IV.3.
Pertaining to the order of acquisition (research question 2), perceptual data obtained in this study confirmed our prediction that the developmental path in L2 perception (/l/onset > /l/coda, /ɾ/coda > /ɾ/onset) is the same as attested previously in L2 production. For L1-Mandarin learners, the Portuguese lateral is perceptually confusable with the tap in syllable onset, while with the semivowel [w] in coda position. This can be ascribed to different degrees of velarization of the Portuguese lateral across syllable positions (Rodrigues et al., 2019). We speculate that it would be easier for native Mandarin speakers to detect and eventually learn the perceptual difference between [l] and [ɾ] than that between [ɫ] and [w]. The Portuguese [l] and [ɾ] can be distinguished on the basis of multiple cues, such as F1, F2, F3, F4 formants, F2 transition and duration (Rodrigues, 2015). The durational cue ([l]: 92 ms; [ɾ]: 33 ms) could be particularly helpful, as it has been argued to serve as a universal source for phonological distinction that L2 learners can rely on, when the learners’ L1 has insufficient spectral distinctions to separate two L2 categories (Desensitization Hypothesis; Bohn, 1995). However, for discriminating between [ɫ] and [w], learners might have to rely on spectral cues (F3 transition; Colantoni et al., 2015).
With respect to the acquisition order of the Portuguese tap in L2 speech perception, following previous research (Zhou, 2017; Zhou and Hamann, 2020), we reckon that it can be attributed to the influence of L1 Mandarin phonotactic restrictions. The target tap is mainly confusable with [l] and this holds true for both syllable onset and coda positions. However, the confusable L1 sound [l] is only phonotactically legitimate in onset position, but not in coda. This indicates that the perceptual confusability between [ɾ] and [l] can be mitigated by the Mandarin phonotactic constraint in coda position, because categorizing the target coda tap as [l] violates the Mandarin phonotactic restriction. This unusual L2 acquisition order for the Portuguese tap (coda > onset), attested in both perception (this study) and production evidence (Liu, 2018; Zhou, 2017), provides a new insight into the interaction between L2 segmental learning and phonotactic restrictions. Namely, apart from triggering structural repairs (e.g. perceptually epenthesis or deletion), L1 phonotactics may even help alleviate the confusability between two categories in L2 speech learning.
2 Effect of L2 experience
In the literature, L2 experience is often estimated on the basis of the learners’ self-reported amount of L2 use, length of residence in the target country, or learning time which was spent either in a naturalistic or classroom-based setting. The 61 L1-Mandarin learners that participated in the current study were divided into two groups, according to the amount of received formal instruction and the length of their immersion experience in Portugal. Results of two perceptual experiments indicated that the advanced learner group outperformed their intermediate-level peers only in accurately identifying the Portuguese /l/, but not /ɾ/. If we assume that these two learner groups differed mainly in terms of the amount of L2 input that they have received, whether from formal instruction or from immersion in Portugal, the observed asymmetry between the perceptual identification of /l/ and /ɾ/ might be explained by how L2 input triggers the development of L2 sound categories.
It has been well acknowledged that sound category learning benefits from both ‘bottom-up’ and ‘top-down’ processes (e.g. Boersma et al., 2003; Nixon, 2020): the former refers to the ability of tracking statistical distribution of auditory tokens in the input, known as Distributional Learning (Maye et al., 2002), while the latter stands for feedback on auditory categorization (e.g. Ganong, 1980). The top-down influence (lexical feedback) has been conceptualized as a trigger for L2 phonological development 7 (Escudero and Boersma, 2004). Namely, each time a learner detects an error in their speech, perhaps due to the semantic violation denoted by sentential context (e.g. a perceived pu/l/o, which means ‘jump’, is not the intended adjective in the sentence: O ar aqui é mais pu|ɾ|o ‘The air here is cleaner’), they will adjust the sound category boundary in order to accommodate the auditory input more accurately in the future (also known as error-driven or lexicon-driven learning; Boersma and Hayes, 2001). A considerable number of studies have demonstrated, however, that an L2 lexical representation is very often fuzzy (Cook et al., 2016; Darcy et al., 2013). A fuzzy lexical representation can be understood as phonologically underspecified, 8 compatible with both the target form and its confusable counterpart. In this case, a mismatch between the perceived form (either target or not) and the lexical form would barely occur, providing little lexical feedback for the improvement of that L2 phonological representation. As speculated above, the L2 lateral representation may well be a copy of the L1 lateral (fully specified), while the novel phonological representation of the tap is compatible with both [l] and [ɾ] (underspecified). Consequently, lexicon-driven learning would be expected to only occur to /l/, but not /ɾ/, prompting the asymmetrical effect of L2 experience.
3 Implications for the link between L2 speech perception and production
The findings of this study confirm that L1-Mandarin learners’ perception of L2 Portuguese /l/ and /ɾ/ is prone to the syllable position effects (i.e. order of acquisition and position-dependent repair strategies) reported in prior production studies (Liu, 2018; Zhou, 2017; Zhou and Hamann, 2020). In our view, this constitutes a further piece of evidence that there is a link between speech perception and production in L2 phonological development. Previous studies mostly infer the relationship between the two speech modalities L2 speech from correlating the accuracy scores from a perceptual task with those obtained in a production experiment or from examining whether laboratory training on one modality can lead to improvement in the other one (for review, see Sakai and Moorman, 2017; Thomson, 2022). Despite having yielded compelling evidence, these two approaches focus only on production accuracy and pay little attention to how a difficult L2 phonological representation is reconstructed by learners. Repair strategies, however, have been considered an important resource for revealing how speech sounds are mentally represented (e.g. Goldrick and Daland, 2009) and how these mental representations are developed over time (e.g. Fikkert, 1994; Freitas, 1997).
Although the results of this study imply a correlation between the two speech modalities in L2 speech, some of our findings challenge the view that L2 speech perception and production are always intertwined (see also Baese-Berk, 2019; de Leeuw et al., 2021; Nagle and Baese-Berk, 2021; Sakai, 2016). For instance, the L1-Mandarin participants were as accurate as their native peers in detecting the absence of the syllable-final tap, indicating that the omission of [ɾ] in the L2 Portuguese production cannot be attributed to perceptual simplification. Instead, we deem that the segmental deletion may stem from articulatory difficulty. The Portuguese [ɾ] stipulates gestural movement and coordination (a ballistic movement of the tongue tip and a constriction towards the pharynx; Barberena et al., 2014; Berti, 2010) that are entirely novel to the native Mandarin speakers. It is thus not surprising that these learners may sometimes fail to articulate such complex gestures, especially in word-internal coda position, where consonant-to-consonant co-articulation may further increase articulatory difficulty (Theodore et al., 2011). Apart from the modality-specific repair strategy, another mismatch between L2 perception and production was revealed by the identification results. In contrast with L2 Portuguese production, where /l/ is never misproduced (Zhou, 2017; Zhou and Hamann, 2020), the confusability between /l/ and /ɾ/ is bidirectional in speech perception. In other words, the distinction between /l/ and /ɾ/ is somehow preserved in L2 production but not in perception, suggesting that production may precede perception in L2 speech learning (e.g. Darcy and Kruger, 2012; Sheldon and Strange, 1982). There is no doubt that a better understanding of this mismatch can only be achieved by testing L2 perception and production by the same group of learners. We speculate that this between-modality difference may stem from the fact that experimental tasks used for studying L2 speech perception and those employed for investigating L2 speech production may target different paralinguistic processes (Boersma, 2006).
The perceptual experiments employed to assess the L2 perception of Portuguese /l/ and /ɾ/ (an AXB discrimination and an identification task) evaluated how auditory inputs are mapped onto the learners’ phonological categories. Comparable to many L2 perception studies in the literature, only pseudo-words were used as test items, with the purpose of avoiding top-down lexical interference (Ganong, 1980). On the contrary, the production experiment in Zhou (2017) is a picture-naming task, in which lexical retrieval was demanded. We speculate that it is the lexical level – absent in the perception experiments but present in the naming task – that gives rise to the divergence between perceptual and production data. It has been shown in many psycholinguistic studies that a distinction between two L2 categories that are indistinguishable in perception can be established at the lexical level (Cutler et al., 2006; Darcy et al., 2013; Weber and Cutler, 2004). This kind of lexical distinction may be achieved with the help of orthography, if the confusable sounds are represented by different graphemes (Cutler, 2015; Escudero et al., 2008). Such orthographic cue is available in Portuguese (for /l/ and for /ɾ/), which in principle can guide L1-Mandarin learners to establish different representations for /l/ and /ɾ/ in the L2 lexicon: /l/ is a copy of the L1 lateral, while the tap is underspecified, compatible with both [l] and [ɾ]. As a result, even though learners fail to perceptually discriminate between [l] and [ɾ], they are still able to produce /l/ accurately, relying on the lexical information. Future studies directly tapping into the learners’ L2 lexicon without requiring explicit production (e.g. a lexical-decision task) are needed to confirm our speculation.
V Conclusions
In this study, we attested that the L2 perception of Portuguese /l/ and /ɾ/ by the L1-Mandarin learners is subject to the syllable position effects reported in previous production studies, thus supporting the view that L2 speech perception and production are correlated. Moreover, our results obtained through two perceptual experiments also demonstrate that some modality-specific phenomena may occur, such as the production repairs induced by articulatory difficulty and the direction of L2 segmental confusability in speech perception and production.
Taken together, the experimental findings of this study have some theoretical and methodological implications that are worth the attention of L2 researchers. First, both phonotactic restrictions and articulatory difficulty need to be integrated into a model that intends to fully account for L2 speech phenomena. Second, future studies exploring the relationship between L2 speech perception and production should assure that their perceptual and production experiments target the mappings between the same representational levels. The experimental tasks to be employed in L2 perception studies may evaluate a linguistic process (from auditory events to sub-lexical phonological categories) that is essentially different from the one activated in L2 production (from phonological categories stored in the learners’ lexicon to articulatory gestures).
Footnotes
Appendix 1
Stimuli used in the identification task.
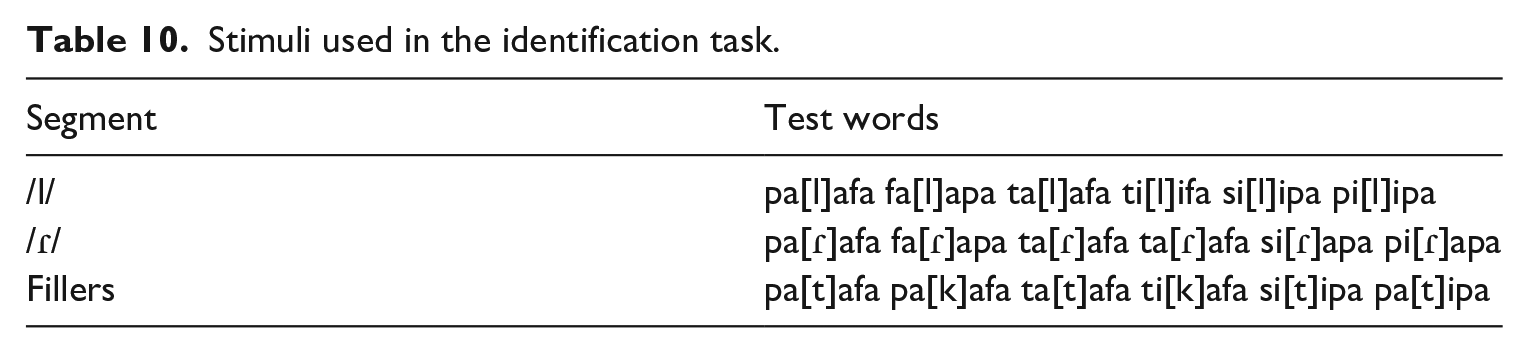
| Segment | Test words |
|---|---|
| /l/ | pa[l]afa fa[l]apa ta[l]afa ti[l]ifa si[l]ipa pi[l]ipa |
| /ɾ/ | pa[ɾ]afa fa[ɾ]apa ta[ɾ]afa ta[ɾ]afa si[ɾ]apa pi[ɾ]apa |
| Fillers | pa[t]afa pa[k]afa ta[t]afa ti[k]afa si[t]ipa pa[t]ipa |
Acknowledgements
We would like to thank Maria João Freitas and Paula Fikkert for their comments and suggestions on earlier versions of this article. Thanks also to the Associate Editor Esther de Leeuw and three anonymous reviewers for their insightful feedback which helped us to improve the article greatly.
Declaration of Conflicting Interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Doctoral Degree Scholarship Program 2017, Language Sciences by University of Lisbon, and also by grant UIDB/00214/2020 from the Portuguese Foundation of Science and Technology (FCT).