
Abstract
While much research has examined second language (L2) phonetic acquisition, less research has examined first language (L1) attrition in terms of the voice onset time (VOT) of voiceless stops. The current study examined L2 acquisition and L1 attrition in the VOT of word-initial voiceless stops among late English–Arabic and Arabic–English bilinguals in order to explore the role of phonetic similarity in L2 acquisition and L1 attrition of speech. The study included 60 participants: 15 monolingual Arabic speakers, 15 monolingual English speakers, 15 English–Arabic bilinguals and 15 Arabic–English bilinguals. The bilinguals had been living in their L2 environment for more than 15 years. The participants narrated two cartoons in Arabic and/or three in English. The monolingual groups’ results revealed clear cross-language differences in the VOT of voiceless plosives between the two languages. Phonetic similarity affected L2 acquisition in that those L2 sounds that were close in phonetic space to L1 sounds (i.e. /t/ and /k/) were more difficult to acquire than those that were dissimilar to L1 sounds (i.e. /p/). However, L1 attrition showed an asymmetric pattern, occurring only in the English–Arabic bilinguals’ productions of the English /k/. We suggest that markedness might contribute to explaining this asymmetry.
Keywords
I Introduction
Adults speaking a second language (L2) are generally influenced by the phonetic or phonological properties of their first language (L1), which can lead to a perceived foreign accent in the L2 (Brennan et al., 1975; Flege, 1980; Flege and Port, 1981; Piske et al., 2001; Scovel, 1969). A growing body of research has shown that the reverse is also possible: namely, that L2 learning can lead to changes in speakers’ L1 pronunciation (Bergmann et al., 2016; de Leeuw, 2009; de Leeuw et al., 2018a; Dmitrieva et al., 2010; Hopp and Schmid, 2013; Major, 1992; Mayr et al., 2012; Stoehr et al., 2017). This change in an individual’s L1 linguistic system in a healthy individual immersed in an environment where the L2 is dominant is commonly referred to as L1 attrition and can affect any linguistic level (Lambert and Freed, 1982; Köpke, 2004; Köpke and Schmid, 2004; Schmid, 2007; Seliger and Vago, 1991). When L1 attrition affects pronunciation, L1 speakers may exhibit changes to their native accent to the extent that they may be perceived as sounding non-native (Bergmann et al., 2016; de Leeuw et al., 2010; Hopp and Schmid, 2013; Kornder and Mennen, 2021a). 1
While it is now widely accepted that the L1 is susceptible to pronunciation changes, it has also become clear that such changes do not occur in all individuals (de Leeuw et al., 2018a; Major, 1992; Mennen, 2004), nor in all phonetic aspects (Hazan and Boulakia, 1993; Mayr et al., 2012; Stoehr et al., 2017). There has so far been little attempt to establish which factors drive L1 attrition of speech (but see Hopp and Schmid, 2013), i.e. which variables can predict the relative difficulty that individuals will have in maintaining particular phonetic aspects. In L2 speech learning, the notion of phonetic similarity of L2 and L1 segments is invoked to predict the relative difficulty that L2 learners will experience with particular L2 sounds. This notion has been adopted by theoretical models, such as the (revised) Speech Learning Model (SLM, Flege, 1995; SLM-r, Flege and Bohn, 2021) and the Perceptual Assimilation Model (PAM, Best, 1995). While these models assume that the capacity to form new phonetic categories remains accessible to L2 learners throughout the lifespan, new categories will nevertheless not be formed for all L2 sounds that differ phonetically from L1 sounds. The likelihood of a new category to be formed crucially depends on the degree of perceived (dis)similarity of an L2 sound to the closest L1 sound in the phonetic space. If an L2 sound is perceived to differ sufficiently from the closest L1 sound, it is likely that a new phonetic category will be formed. New phonetic categories will, however, be blocked for L2 sounds that are perceived ‘as being too similar phonetically to the closest L1 sound’ (Flege and Bohn, 2021: 41). In such cases, the phonetic properties of the L2 sound and the closest L1 sound will merge, which in turn ‘may cause the L1 sound to shift toward (assimilate to) the L2 sound in phonetic space’ (Flege and Bohn, 2021: 42). According to the SLM, L1 and L2 sounds are perceptually linked through a mechanism known as ‘interlingual identification’. The mapping of L2 to L1 sounds is based on perceived rather than acoustic differences between the sounds (Flege and Bohn, 2021). To give an example, Spanish contrasts prevoiced ‘voiced’ and short-lag ‘voiceless’ plosives, whereas English contrasts short-lag ‘voiced’ and aspirated ‘voiceless’ plosives. Thus, the short-lag plosives are classified as voiceless in Spanish but voiced in English. If interlingual identification were based on acoustic similarity, native English listeners would identify short-lag Spanish /t/ tokens as instances of /d/, whereas Spanish listeners would identify short-lag English /d/ tokens as /t/. However, Bohn and Flege (1993) found that when asked to choose between ‘d’ or ‘t’, English listeners identified the short-lag Spanish /t/ tokens as ‘t’ well above chance. Similarly, Spanish listeners identified the short-lag English /d/ tokens as ‘d’ even though these tokens were acoustically similar to what is classified as /t/ in Spanish (Bohn and Flege, 1993). Furthermore, the Spanish listeners consistently identified the long-lag English /t/ tokens as ‘t’, despite their voice onset time (VOT) values being far removed from what would be appropriate for /t/ in Spanish.
Even when new L2 categories are formed, they may still diverge from those of monolingual speakers, as they ‘may shift away from (i.e. dissimilate from) neighbouring L1 categories to maintain phonetic contrast between certain pairs of L1 and L2 sounds’ (Flege and Bohn, 2021: 42). The SLM posits that these assimilation and dissimilation effects arise because bilinguals’ L1 and L2 phonetic categories share a common phonetic space, which remains, to some degree, flexible over the lifespan. This implies that L1 categories can change due to L2 acquisition, possibly leading to L1 attrition and potentially creating a foreign accent in the L1. 2 The SLM has therefore been adopted to interpret phonetic L1 attrition in a number of previous research studies (Bergmann et al., 2016; de Leeuw, 2018a; de Leeuw et al., 2018a; Mayr et al., 2012, 2020) and, if attrition is found in the present study, the SLM may also provide a useful framework for explaining L1 attrition in the current context. 3
The current article aims to contribute to the issues of phonetic similarity by investigating the L1 and L2 productions of similar and dissimilar sounds by two groups of late, highly fluent bilinguals differing in learning direction (L1-Arabic–L2-English and L1-English–L2-Arabic) to consider possible bidirectional L1–L2 influences in their phonetic systems. In order to understand how bilinguals organize phonetic categories, it is important that the phonetic properties of both L1 and L2 speech are investigated (as in Chang, 2012; de Leeuw et al., 2013; Flege and Eefting, 1987a, 1987b; Mayr et al., 2012; Mennen, 2004). Moreover, to observe possible L2 effects on the L1, this article investigates very experienced and highly fluent bilingual speakers, immersed in an L2-speaking environment, as these speakers have previously been shown to experience more profound changes in their L1 phonetic system (e.g. Mayr et al., 2012; Stoehr et al., 2017) compared to less experienced, non-immersed speakers who are more likely to exhibit rather subtle and mostly reversible L2-induced modifications in their L1 pronunciation system (e.g. Chang, 2012, 2019). Our main objective is to further broaden our understanding of potential L1 attrition phenomena and their interplay with L2 acquisition in the context of bilingual speech production. Based on this, the current article considers the following two research questions:
Research question 1: To what extent are L1 Arabic and L1 English advanced learners of L2 English and L2 Arabic, respectively, able to produce L2 plosives with native-like VOT?
Research question 2: Do the advanced L2 learners show attrition of L1 VOT?
While most studies focusing on phonetic/phonological L1–L2 interactions in bilingual speakers assess bilingual productions solely with reference to monolingual data (see, for example, among many others, Bergmann et al., 2016; Flege and Hillenbrand, 1984; Flege, Munro, and MacKay, 1996; Major, 1992), the present investigation examined the VOT productions of two bilingual speaker groups, differing in learning direction, comparing the VOTs of each bilingual group to each other and also to monolingual Arabic and monolingual English speakers, respectively. The decision to juxtapose two bilingual groups is in line with previous propositions that comparing and contrasting different bilingual populations – for instance differing in the direction of learning, as in the present study – offers a promising path to explore processes of cross-linguistic interactions operating in bilingual speakers (see, for example, Hopp and Schmid, 2013).
1 Arabic and English voice onset time systems
This article focuses on L2 acquisition and L1 attrition in the production of voice onset times (VOTs), particularly the voiceless plosives /p/, /t/ and /k/, in late consecutive Arabic–English and English–Arabic bilingual adults. Lisker and Abramson (1964: 422) define VOT as ‘the time interval between the burst that marks the release [of the stop closure] and the onset of periodicity that reflects laryngeal vibration’. They observed that values for VOT from a number of languages appeared to fall into three clusters: (1) voicing lead or pre-voicing, which comprises negative VOT values, where the vocal folds start vibrating before the burst of the stop; (2) short-lag VOT with small positive VOT values ranging from 0 to about 25 ms; and (3) long-lag VOT or aspirated with large positive VOT values of roughly 60–100 ms (see Lisker and Abramson, 1964). Languages differ in how they implement these clusters to distinguish phonologically voiced and voiceless plosives. In addition, the separation of aspirated and unaspirated stops is sometimes argued to be arbitrary and more continuous in nature than suggested by these clusters (e.g. Cho and Ladefoged, 1999; Cho et al., 2019). Languages with a two-way stop distinction 4 are typically divided into ‘true voicing’ languages (e.g. Dutch, French, Russian, and some Arabic dialects) that generally contrast pre-voiced stops with voiceless short-lag VOT, and ‘aspirating’ languages (e.g. English, German, and Mandarin) that contrast short-lag unaspirated stops with voiceless aspirated ones (see Lisker and Abramson, 1964). Assessing VOT in voiceless stops is the focus of this study because in prior investigations, divergences in VOT have been found to contribute to foreign accents in L2 speakers and those experiencing L1 attrition (Flege and Hillenbrand, 1984; Flege and Eefting, 1987b; Major, 1987; Sancier and Fowler, 1997; Schoonmaker-Gates, 2015; Stoehr et al., 2017; Tobin et al., 2017). Specifically, the current study measures VOTs of voiceless plosives and examines the role of perceived phonetic similarity in L1 attrition and L2 acquisition in highly fluent, late consecutive Arabic–English and English–Arabic bilinguals compared to monolingual, native speakers of both languages.
Arabic and English both have a two-way distinction for laryngeal contrast between stops, which phonologically classifies them into voiced and voiceless. As stated by Olson and Hayes-Harb (2019: 30), in both English and Arabic ‘voice onset time [. . .] provides a robust acoustic cue to stop voicing contrast in initial position, with longer VOTs associated with voiceless stop consonants and shorter VOTs associated with voiced stop consonants.’ We focus here on Standard Southern British English (SSBE) and Modern Standard Arabic (MSA), the standard, or formal, varieties of the UK and Arab countries, respectively, given that both the bilingual and monolingual participants selected for the present investigation were speakers of the standard-oriented varieties of the respective languages (for further details, see Section II.1). SSBE is an aspirating language, discriminated by the feature [spread glottis] (see Beckman et al., 2013), and has the phonologically voiced short-lag plosives /b/, /d/ and /ɡ/ and the voiceless long-lag aspirated plosives /p/, /t/ and /k/ (Docherty, 1992; Keating et al., 1983; Klatt, 1975; Lisker and Abramson, 1964; Port and Rotunno, 1979; Weismer, 1979). Previous studies measuring VOTs in adult speakers of SSBE report VOT durations in the range of 22 ms to 117 ms (M = 62 ms) for English /p/, 48 ms to 105 ms (M = 73 ms) for /t/, and 65 ms to 145 ms (M = 86 ms) for /k/ (Chao and Chen, 2008; see also Docherty, 1992).
Unlike English, the Arabic consonant inventory does not contain the bilabial plosive /p/ (e.g. Al-Ani, 1970). Traditionally, Arabic has been described as a ‘true voicing’ language which distinguishes between fully voiced (pre-voiced) /b /d/ and /ɡ/ and voiceless unaspirated (short-lag) /t/ and /k/ (for an overview, see Al-Tamimi and Khattab, 2018). Research suggests, however, that this is the case only for some dialects of Arabic, including for instance Lebanese (e.g. Al-Tamimi and Khattab, 2018; Yeni-Komshian et al., 1977) and Palestinian Arabic (e.g. Tamim and Hamann, 2021). By contrast, other Arabic dialects, such as Najdi and Qatari Arabic, do not display a voicing lead vs. short-lag plosive contrast, but exhibit a distinction between prevoiced and aspirated (long-lag) plosives (e.g. for Najdi, see Al-Gamdi et al., 2019; for Qatari, see Kulikov, 2020). Saudi speakers of MSA – as the speakers in the present investigation – have been observed to produce phonologically voiced plosives with short positive (short-lag) VOTs which are contrasted with moderately aspirated (long-lag) voiceless plosives. For both MSA /t/ and /k/ occurring in word-initial or syllable-initial position, previous investigations report a mean VOT duration of around 53 ms (AlDahri, 2012a, 2012b, 2013; Alotaibi and AlDahri, 2011), suggesting that MSA voiceless plosives fall in the long-lag VOT range, similar to English voiceless targets. English and MSA voiceless stops do, however, differ in their degree of aspiration as manifested in overall longer VOT durations in word-initial English /t/ and /k/ (mean VOT of 73 ms and 86 ms, respectively) compared to MSA /t/ and /k/ (mean VOT of 53 ms for both). Hence, despite both MSA and SSBE plosives falling in the traditional long-lag VOT category, as suggested by Lisker and Abramson (1964), they exhibit differences within this category relating to the degree of aspiration. As argued by Cho and Ladefoged (1999), the three VOT categories introduced by Lisker and Abramson (1964) to classify stops in different languages (i.e. pre-voiced, short-lag, and long-lag) may be too general and do not properly reflect potential differences in the degree of aspiration found within and between languages. Therefore, they propose four plosive aspiration categories, namely unaspirated (mean VOT of 30 ms), slightly aspirated (mean VOT of 50 ms), aspirated (mean VOT of 90 ms), and highly aspirated (mean VOT longer than 90 ms). According to this categorization, MSA voiceless stops fall in the ‘slightly aspirated’ category while SSBE stops can be classified as ‘aspirated’ or ‘highly aspirated’. Thus, Arabic–English and English–Arabic bilinguals have to acquire an L2 aspiration category which differs from their respective L1 category while at the same time maintain native-like aspiration in their L1.
2 Perceived phonetic similarity of Arabic and English voiceless stops
While a considerable amount of research has considered the L2 adult acquisition of VOT in English (Cho et al., 2019; Flege, 1987b, 1991; Flege and Eefting, 1987a, 1987b; Kim et al., 2018; Schmid and Hopp, 2014; Simon, 2009; Simon and Leuschner, 2010; Stoehr et al., 2017), relatively few studies have examined VOT in L2 English productions by adult Arabic speakers. For instance, Flege (1980), Flege and Port (1981) and Port and Mitleb (1983) found that adult learners, particularly those with little experience with the L2, ‘carry over’ the phonetic features of their Arabic plosive VOT contrast onto their plosive production in English. Alanazi (2018) examined advanced adult Saudi learners of English and found that the participants produced voiceless stops in L2 English with VOT values between the monolingual English and monolingual Arabic norms. Additionally, to the best of our knowledge, no previous study has examined VOT in L2 Arabic productions by English–Arabic bilingual adults (though see Khattab, 2002, for Arabic VOT data from English–Arabic bilingual children).
Much the same holds true for studies on L1 attrition of VOT. Changes to L1 pronunciation have been evidenced for vowels (Bergmann et al., 2016; Guion, 2003; Mayr et al., 2012), laterals (de Leeuw, 2019; de Leeuw et al., 2013), rhotics (de Leeuw et al., 2018b; Ulbrich and Ordin, 2014), intonation (de Leeuw et al., 2012; Mennen, 2004), as well as VOT in stop consonant productions (Flege, 1987b; Major, 1992; Mayr et al., 2012; Sancier and Fowler, 1997; Stoehr et al., 2017) of highly proficient L2 speakers. However, similar to the lack of research focusing on English–Arabic speakers’ acquisition of L2 VOT, no studies have investigated phonetic attrition of L1 VOT in highly-fluent Arabic–English or English–Arabic speakers.
Most studies on both L2 acquisition and L1 attrition of VOT have examined bilingual speakers of ‘voicing’ languages (e.g. Dutch, French, Russian) who acquired an ‘aspirating’ language (e.g. English, German, Mandarin) as their L2 and vice versa (Alanazi, 2018; Bohn and Flege, 1993; Flege, 1980, 1987b; Flege and Eefting, 1987a; Flege and Port, 1981; MacKay et al., 2001; Port and Mitleb, 1983). These studies show that bilinguals are likely to perceptually link L1 and L2 plosives to one another due to their perceived similarity. The present study, as outlined above, compares two languages differing in the degree of aspiration in voiceless plosives, with MSA /t/ and /k/ being less aspirated compared to English /t/ and /k/. In addition, the MSA phoneme inventory lacks the bilabial plosive /p/. Given the interlingual identification of similar L1 and L2 sounds reported in previous investigations, it is likely that Arabic–English and English–Arabic bilinguals will merge similar L1 and L2 plosives, i.e. /k/ and /t/ which are shared by both English and Arabic, resulting in VOT values that are intermediate between native L1 and L2 values. That is, we would expect experienced Arabic–English and English–Arabic learners to ‘only partially approximate the phonetic norms of L2’ in their productions of L2 sounds that are perceptually linked to L1 sounds (Flege, 1987a: 28). By contrast, according to the SLM and SLM-r, the likelihood that a new category will be formed increases the more dissimilar an L2 sound is perceived to be from the closest L1 sound at a position-sensitive allophonic level (Flege, 1995; Flege and Bohn, 2021). As MSA does not have a /p/ in its phonetic inventory, the L2 English /p/ will be a ‘new’ sound to Arabic learners of English and should be perceived as phonetically dissimilar from any other L1 sound. Hence, category formation should be possible while, as previously mentioned, category formation for L2 /t/ and /k/ is likely to be inhibited by assimilatory effects.
As stated above, such assimilation effects (where bilinguals’ productions are between the two languages’ monolingual norms) have been reported for the L2 acquisition of voiceless plosives by learners from voicing languages who acquired aspiration in L2 long-lag plosives (e.g. Flege, 1987b, 1991; Flege and Eefting, 1987a; Stoehr et al., 2017) and in L1 speakers of an aspirating language acquiring a voicing language as their L2 (e.g. Flege, 1987b; Flege and Hillenbrand, 1984). Flege (1987b), for example, observed assimilation effects for French learners of English who produced VOT values for L2 English /t/ that were intermediate between monolingual English long-lag and monolingual French short-lag VOT, showing that the L2 phonetic norms were only partially acquired. Similarly, Flege (1991) and Flege and Eefting (1987a) found that Spanish–English bilinguals’ VOT productions in L2 English were longer (i.e. more native-like) than their Spanish VOTs, but nevertheless shorter than those of monolingual English speakers and thus intermediate between the L1 and L2 (see Simon and Leuschner, 2010), again showing partial acquisition. Similar intermediate VOT values were found for Dutch learners of German (Stoehr et al., 2017), who were observed to produce L2 German voiceless plosives with VOT values which were too long for Dutch but still not falling in the long-lag native range of German. Such intermediate values were also found for English learners of French, who produced L2 French /t/ with values that were longer than those produced by monolingual French speakers but shorter than those produced by monolingual English speakers (Flege, 1987b). The few studies that have investigated Arabic learners of English also found intermediate values for L2 voiceless plosives between the native monolingual norms of each language, with VOT values that are closer to the Arabic than the English norm (Alanazi, 2018; Flege, 1980; Flege and Port, 1981; Port and Mitleb, 1983).
While there is abundant evidence for assimilation of VOT values in bilinguals, dissimilation effects in L2 speech acquisition might also occur, that is, a bilingual’s L2 sound category might be shifted away from both L1 and L2 native norms in an attempt to enhance contrast between the L1 and the L2 target (see, for example, Flege and Eefting, 1988). Dissimilatory effects have been most frequently observed in the segmental productions of early sequential bilinguals 5 (see, for example, Flege and Eefting, 1988; Guion, 2003; Mack, 1990; Oh et al., 2011). Mack (1990), for example, examined the production of /p/, /t/ and /k/ by an early French–English bilingual and found that the bilingual produced the target sounds in both languages with VOT values considerably exceeding the monolingual norms of French and English, respectively. This suggests that despite not being able to produce the plosives in a native-like fashion, the speaker was able to maintain contrast between the respective L1 and L2 sounds. Given that the formation of new sound categories – instead of producing merged L1–L2 categories – resulting from category dissimilation is most likely to occur among early bilinguals, we do not expect dissimilation effects in the current study, which examines late consecutive bilinguals.
Since the SLM assumes a bidirectional interaction between bilinguals’ L1 and L2 systems, it is also possible to make predictions concerning the English–Arabic and Arabic–English bilinguals’ productions of plosives in their respective L1s. According to the SLM, the merging of phonetic properties of perceptually linked L1 and L2 sounds may cause the L1 sound to assimilate to (i.e. ‘shift toward’) the L2 sound (Flege and Bohn, 2021: 39), and this L2-on-L1 influence is expected to be strongest in L2 speakers with high levels of proficiency (Flege, 1995) and in those whose L2 has become the dominant language (Schmid and Köpke, 2007). The few studies that have investigated L2-on-L1 influences on the production of VOT in voiceless plosives have found evidence for assimilation in late consecutive bilinguals. For instance, Major (1992) examined the VOT of English /p/, /t/ and /k/ in the speech of late English–Portuguese bilinguals and found that all participants demonstrated attrition in their native English to differing degrees, with higher L2 proficiency related to more L1 attrition, as manifested in a merging of L1 and L2 VOT values (for similar results, see Flege, 1987b). Similarly, Mayr et al. (2012) found evidence for L1 attrition of VOT in voiceless plosives in a highly proficient Dutch–English bilingual, with Dutch values falling between the native Dutch and native English norms. Similar observations were, for instance, made for Dutch–German bilinguals who produced Dutch voiceless plosives with VOT values that were intermediate between the values for native Dutch and native German controls (Stoehr et al., 2017). Evidence for dissimilation was reported in only one study examining Dutch–English bilinguals’ productions of the Dutch /t/ with VOT values that were even shorter than the Dutch norm, which were in turn shorter than the English norm (Flege and Eefting, 1987a). This shift not towards the English norm, but away from it, was particularly prevalent in highly proficient learners of English, and this shift may serve the purpose of maintaining phonetic contrast between the Dutch and the English /t/ phonemes.
Despite the few studies that have been conducted to examine L2-influences on L1 VOT outlined above, some predictions can be made as to the likelihood that Arabic–English and English–Arabic bilinguals will maintain native-like productions of voiceless plosives in their L1. As the /p/ is not present in the MSA phonetic inventory and hence not part of the Arabic–English bilinguals’ L1, it cannot attrite. As for English–Arabic bilinguals, we also do not expect to find any L1 attrition, given that there is no close counterpart to the English /p/ in Arabic, and thus there is no close L2 sound to interact with. While the SLM makes predictions for individual sounds, an alternative prediction is that L1 attrition may occur at a system-wide level (as suggested in Chang, 2010, 2011; Guion, 2003; Mayr et al., 2012). If this was the case, the English–Arabic speakers may, under the influence of their L2 Arabic, associate all voiceless stops with generally shorter VOTs than their monolingual counterparts. As a result, they may produce /p/ in their L1 English with shorter VOTs than English monolinguals, thus showing L1 attrition for a sound that has no close counterpart in the L2.
While English /p/ has no direct counterpart in MSA, the voiceless plosives /t/ and /k/ are shared by both inventories. Hence, English and Arabic /t/ and /k/ are likely to be perceptually linked to one another through the mechanism of interlingual identification, both for the Arabic–English and for the English–Arabic learners. Given this perceptual linking, it is unlikely that a new phonetic category will be formed for the L2 plosives, and – based on previous literature suggesting that assimilation is more frequently observed among late bilinguals than dissimilation (e.g., Mack, 1990) – the phonetic properties of these L1 and L2 sounds are expected to merge. This merging can affect L1 production of VOT, which is likely to shift toward the L2. Hence, for Arabic–English bilinguals we would expect longer VOT values and thus a higher degree of aspiration than those produced by monolingual speakers of Arabic. In a similar vein, we would expect English–Arabic bilinguals to produce shorter VOT values and thus a lower degree of aspiration than those produced by monolingual English speakers. In both cases, we would expect VOT values to be intermediate between the monolingual norms for each language, although it is possible that the bilinguals will be able to differentiate VOT between their two languages, as for instance observed in Flege’s (1987b) study on VOT patterns in French learners of English.
II Methods
1 Participants
The study consisted of 60 participants divided into four groups (for a summary of participant characteristics, see Table 1). Fifteen participants (four males and 11 females, mean age = 36.07 years; SD = 7.20) were monolingual native Arabic speakers from different regions in Saudi Arabia: Jeddah, Makkah, Riyadh and Abha. Another 15 of the participants (two males and 13 females, mean age = 39.87 years; SD = 9.06) were monolingual native English speakers from different regions of the UK: Sheffield, Chester and London.
Summary of participant characteristics.
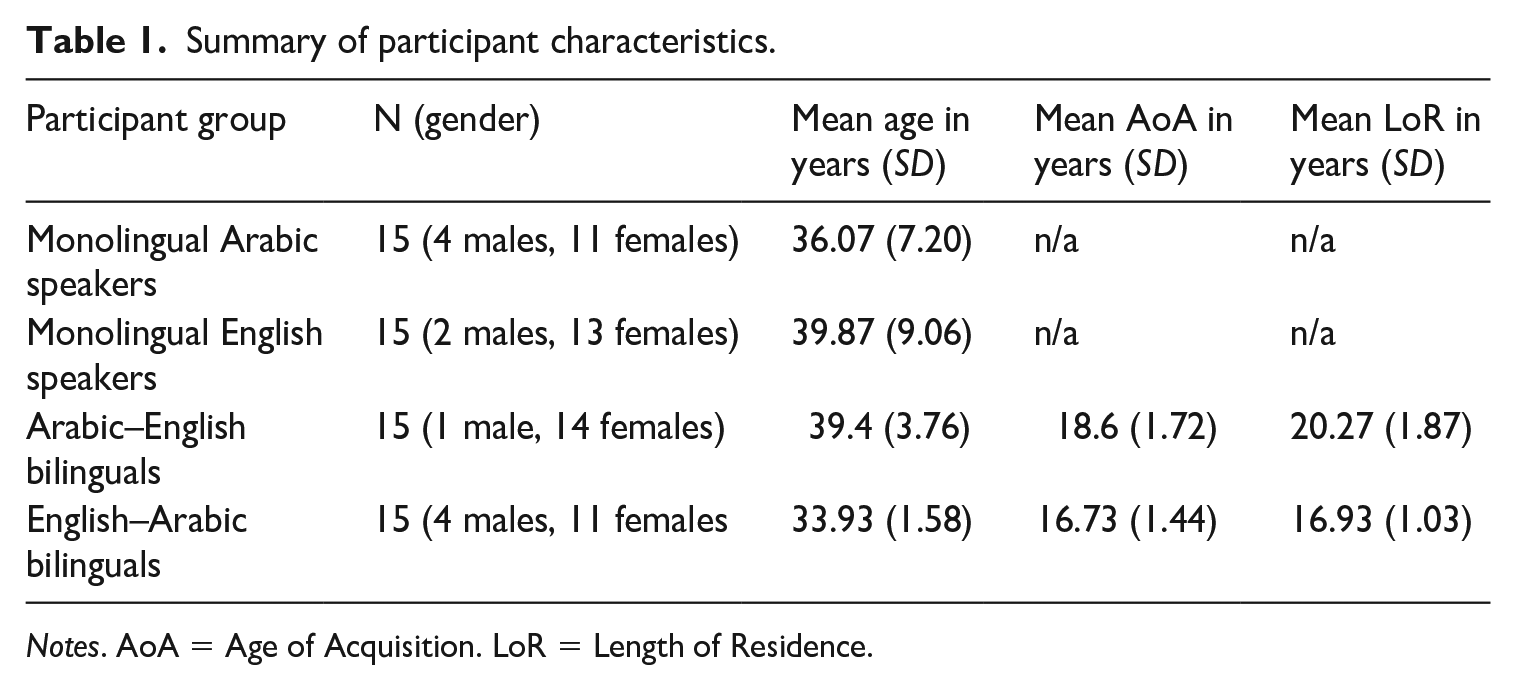
Notes. AoA = Age of Acquisition. LoR = Length of Residence.
The two monolingual groups were matched with the bilingual groups in terms of regional dialect as closely as possible. The Arabic–English bilingual group included 15 participants (one male and 14 females, mean age = 39.4 years; SD = 3.76) who were MSA speakers from Saudi Arabia (Jeddah, Makkah or Riyadh) or from eastern Yamani, but who had lived most of their childhood in Makkah and Jeddah. Both Saudi and Yamani Arabic are close to each other and to MSA. The speakers from Riyadh spoke both MSA and the Najdi dialect of Arabic (Al-Gamdi et al., 2019). They regularly used MSA at work and completed the tasks eliciting Arabic materials for this study in MSA. In addition, the principal investigator running the speech elicitation task is a speaker of MSA (and SSBE) who was able to judge if the speakers did actually rely on MSA in the speech production task. The Arabic–English bilinguals were highly proficient in their L2 English as shown by the grammar and listening comprehension parts of a practice version of the Test of English as a Foreign Language (ETS, 2021) (mean = 42.1; SD = 1.8; range = 39–45, with a possible maximum of 45), having acquired and predominantly speaking SSBE. 6 They completed the English tasks in the present study in SSBE. To be included in the study, Arabic–English bilingual participants had to have fully acquired their L1 in their home country, moved to the UK after the onset of puberty (mean Age of Acquisition [AoA] = 18.6 years; SD = 1.72) and had to have lived in the UK (Sheffield, Chester and London) for 15 years or longer at the time of the study (mean Length of Residence [LoR] = 20.27 years; SD = 1.87).
The English–Arabic bilingual group included 15 native English speakers of SSBE (four males and 11 females, mean age = 33.93 years; SD = 1.58). The grammar and listening comprehension parts of an Arabic Proficiency Test that is used as a placement test for students wishing to study Arabic Language Teaching at Umm Al-Qura University showed that all participants had a high proficiency in MSA (mean = 43.6; SD = 1.5; range = 42–46, with a possible maximum of 46). Again, to be included in the study, the English–Arabic bilinguals had to have fully acquired their L1 (English) in their home country, in this case in Sheffield or London; to have moved to the Kingdom of Saudi Arabia (KSA) (Makkah and Jeddah) or Yemen after the onset of puberty (mean AoA = 16.73 years; SD = 1.44); and to have lived in KSA or Yemen for 15 years or longer at the time of the study (mean LoR = 16.93 years; SD = 1.03).
Participants in the two bilingual groups did not differ significantly in their phonetic aptitude across three tests (p-values for all Welch two-sample t-tests > 0.1). The three aptitude tests were adapted from online samples of the Modern Language Aptitude Test (Carroll and Sapon, 1959) and the Pimsleur Language Aptitude Battery (Pimsleur, 1966) and tested sound-symbol associations, memory for novel words, and discrimination of pitch, orality and nasality (for more information, see Alharbi, 2019). In terms of language use in the family, questionnaire results showed that, overall, both bilingual groups used more English than Arabic, suggesting that the L1 English group used their L1 more frequently than their L2 Arabic while the L1 Arabic group used their L2 more often than their L1 Arabic in a family context. In addition, when comparing the use of English in the family in the two bilingual groups, it was shown that the English–Arabic bilinguals tended to use relatively more English (and relatively less Arabic) than the Arabic–English bilinguals. With regard to language use in a work environment, both Arabic–English and English–Arabic bilinguals used their respective L2 more frequently than their L1. By contrast, both bilingual speaker groups used mostly Arabic when interacting with friends.
2 Materials
We collected spontaneous speech production data for Arabic and English voiceless plosives from the participants. We used spontaneous speech because it ‘reflects overall abilities the best, allowing especially representative impressions of fluency, speaking rate, choice of words, choice of prosodic patterns and segmental realizations’ (Jilka et al., 2008: 228). Bilingual and monolingual participants narrated short cartoons, each chosen to elicit a particular target word (Larson, 1992, 1984; Watterson, 1995). All target words were animals – cow, tiger and penguin for English, and /kalb/ (dog) and /tem-saːħ/ (crocodile) for Arabic – and each cartoon pictured its target animal to ensure that participants would produce the target word.
The vowel following the initial plosive in the target words was matched across languages as much as possible. Specifically, /k/ was followed by /aʊ/ in English and /a/ in Arabic, and /t/ was followed by /aɪ/ in English and /e/ in Arabic. Previous research on the effects of a following vowel on VOT has been inconclusive. While Lisker and Abramson (1967) found no effect of a following vowel on VOT, Klatt (1975), Weismer (1979), and Port and Rotunno (1979) found that the VOT of plosives were longer when followed by tense high vowels than for all other vowels. Therefore, none of the plosives in the target words preceded tense high vowels.
3 Procedure
Data collection occurred over six months in KSA and the UK. After receiving participants’ consent via email, the bilinguals attended three sessions and the monolinguals two sessions on separate days spanning up to one week. The first session assessed bilingual participants’ proficiency in the L2, followed by the three phonetic aptitude tests (see Section II.1). For the bilinguals, the second and third sessions consisted of three different production tasks eliciting wh-question prosody, vowels and plosives, respectively, with L2 productions being recorded in the first session and L1 productions in the other. The Arabic and English recordings occurred across separate sessions to ensure that participants were in a monolingual language mode for each session (Grosjean, 2001). Each monolingual participant engaged in the production tasks only in their native language. Thus, their participation involved only one production session. The current article focuses on productions from the task eliciting plosives: The bilingual participants narrated five different cartoons – three in English eliciting /t/, /k/ and /p/ on one day, and two in Arabic eliciting /k/ and /t/ on the other day. The monolingual English participants narrated three different cartoons in English eliciting /t/, /k/ and /p/, and the monolingual Arabic participants narrated two different cartoons in Arabic eliciting /k/ and /t/. All participants were recorded with a handheld Sony tape recorder (SONY ICD PX333 Digital Voice Recorder) in a quiet environment. Recordings were in WAV format with a sampling rate of 44.1 kHz.
4 Data analysis
We conducted analyses of the VOT values for word-initial voiceless plosives in the participants’ first productions of each target word. The VOT values were measured using Praat (Boersma and Weenink, 2016) as the duration of the interval between the plosive release and the onset of voicing, using a combination of both wideband spectrogram and oscillogram displays. 7 The first token for each participant (60 tokens for each plosive) was selected because most of the participants replaced the target nouns with pronouns after the first mention. None of the tokens had to be excluded due to dysfluencies or other irregularities. We analysed the VOT values for each of the plosives (/k, /t/, and /p/) using linear mixed effects models. For all analyses, the Arabic and English monolinguals together formed the monolingual group and were compared with both the Arabic–English and English–Arabic bilingual groups. The analyses were performed in R (R Core Team, 2019) using the lme4 (Bates et al., 2015) and lmerTest (Kuznetsova et al., 2017; with p-values calculated via the Satterthwaite’s degrees of freedom method) packages and the emmeans (Lenth, 2019) package for post-hoc comparisons (with Kenward Roger degrees of freedom approximation and Tukey-adjusted p-values when comparing three levels). We also calculated the marginal and conditional R2GLMM values to estimate effect sizes (Johnson, 2014; Nakagawa and Schielzeth, 2013; Nakagawa et al., 2017). The marginal R2GLMM captures variance explained by a model’s fixed factors and the conditional R2GLMM captures variance explained by a model’s fixed and random factors. An alpha-level of 0.05 was adopted throughout. The anonymized data and analysis scripts are available on the Open Science Framework at https://osf.io/xh46r.
III Results
1 The velar voiceless plosive /k/
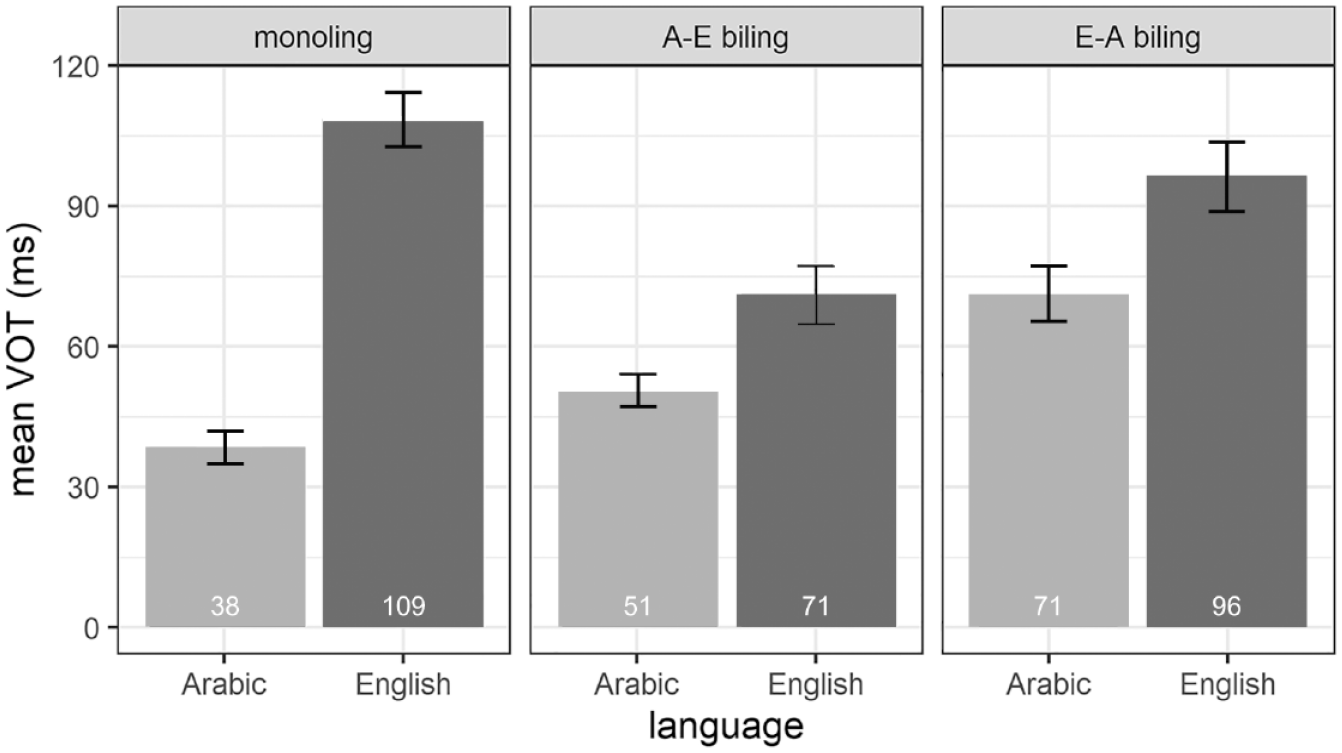
We begin by analysing the VOT values for the velar voiceless plosive /k/. Figure 1 shows mean VOT values for /k/ in Arabic and English as produced by the Arabic and English monolinguals (monoling), Arabic–English bilinguals (A–E biling; L1 Arabic) and English–Arabic bilinguals (E–A biling; L1 English). First, considering the bilinguals’ L2 productions of /k/, the figure reveals that the Arabic–English bilingual speakers produce L2 English /k/ with a shorter mean VOT duration (81 ms) than both the monolingual English (111 ms) and the L1 English (92 ms) speakers. The English–Arabic bilinguals, on the other hand, produce L2 Arabic /k/ with a mean VOT duration of 71 ms, which is longer than both monolingual Arabic (48 ms) and L1 Arabic (56 ms). In terms of the bilinguals’ L1 productions, Figure 1 shows that the Arabic–English speaker group realizes L1 Arabic /k/ with VOT values which are on average slightly longer (56 ms) than the mean VOT duration measured for monolingual Arabic /k/ (48 ms). By contrast, the English–Arabic bilingual group produces L1 English /k/ with a mean VOT duration of 92 ms, which is shorter than the monolinguals’ production of the target plosive.
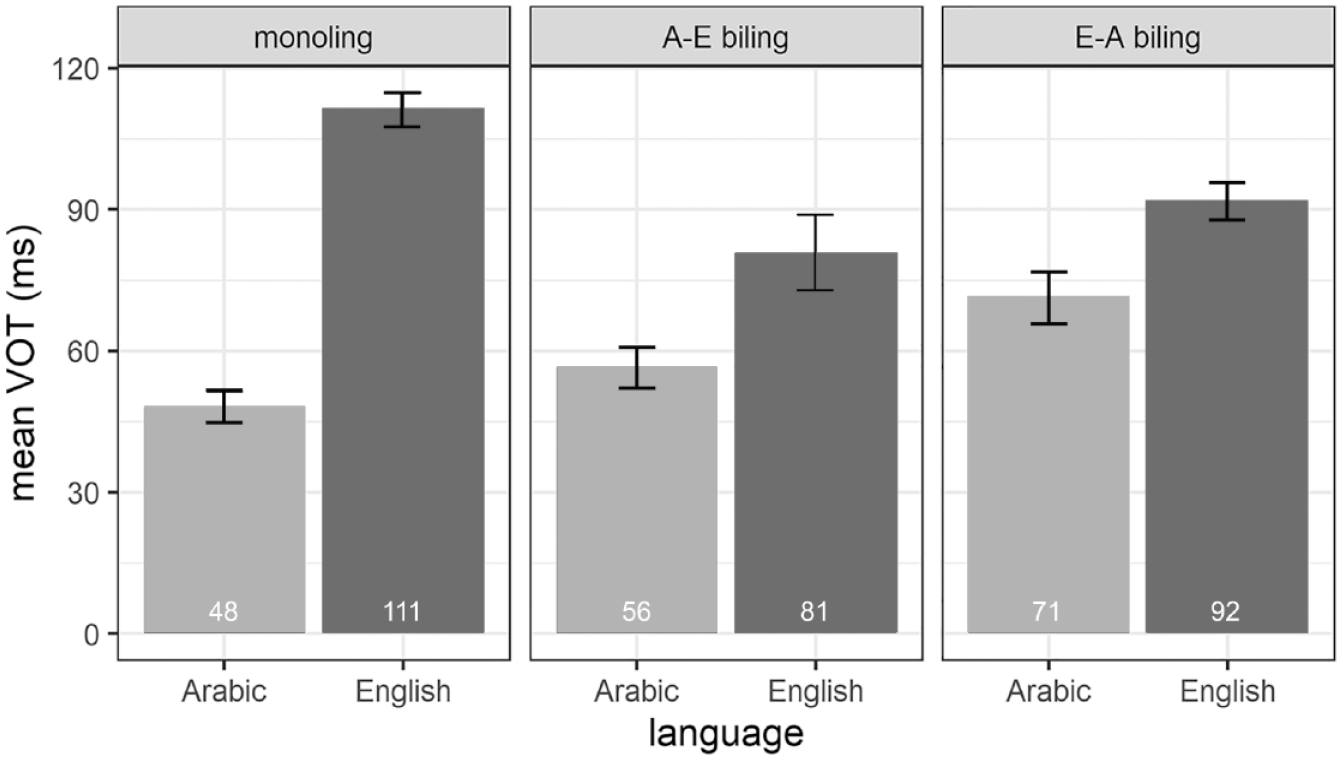
Mean VOT values (in ms) of the Arabic (A) and English (E) /k/ as produced by the two monoling groups, the A–E biling and the E–A biling groups.
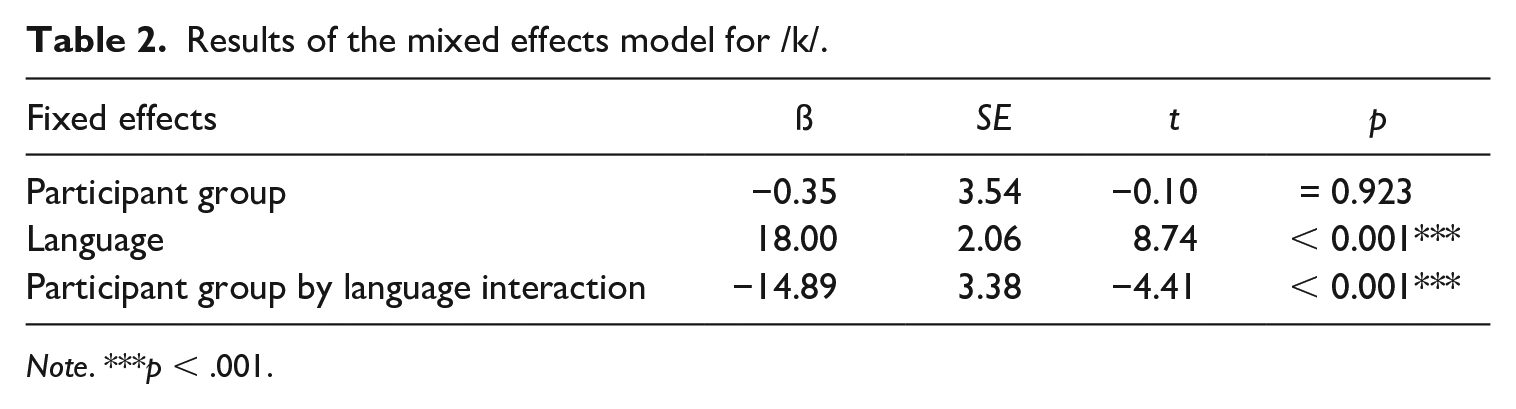
A mixed effects model determined whether participant group (monoling, A–E biling, E–A biling) and language (English vs. Arabic) affected VOT values for /k/. The model included VOT (in ms) as the response variable, participant group, language and the participant group by language interaction as fixed effects, and random intercepts for participants. Fixed effects were centred to avoid collinearity, and sum-coding was used for ANOVA-style main effects and interactions. The results of the analysis in Table 2 show a statistically significant effect of language on VOT values, confirming that English VOTs are significantly longer than the Arabic VOTs. The participant group by language interaction is also significant. The model’s marginal and conditional R2GLMM values are 0.49 and 0.54, respectively. This suggests that 49% of the variance in VOT values can be explained through the fixed effects language and participant group, with only slightly more of the variance additionally explained by the random effect, i.e. by individual differences across participants.
Results of the mixed effects model for /k/.
Notes. ***p < .001 .
To explore the participant group by language interaction, we ran post-hoc comparisons using simple contrasts for both participant group and language. The results from the post-hoc tests are shown in Tables 3 through 5 and reveal different patterns for the two languages. For the Arabic /k/, Table 3 shows that there is no significant difference in VOTs between the Arabic monolinguals and the Arabic–English bilinguals. We thus find no evidence for L1 attrition for Arabic /k/ in the Arabic–English speaker group. In contrast, significant differences were observed between the English–Arabic bilinguals’ and the Arabic monolinguals’ productions of Arabic /k/, which confirms, as shown in Figure 1, that the L2 Arabic speakers produce longer VOTs for Arabic /k/ than the monolinguals. This suggests that the L2 Arabic bilingual group produces Arabic /k/ with non-native VOT. Furthermore, there is no significant difference between the two bilingual groups for the Arabic /k/. For the English /k/, significant differences were observed for both bilingual speaker groups when being compared to monolingual English /k/, as manifested in shorter (and hence more Arabic-like) VOT values in the bilingual groups than in the monolingual English group (see Figure 1). This suggests that the English /k/ is both subject to attrition in the L1 English bilinguals and is produced in a non-native manner by the L2 English bilinguals. There is no significant difference between the two bilingual groups for the English /k/. In line with the main effect of language, Table 5 shows that there is a significant difference in VOT duration between Arabic /k/ and English /k/ for all three participant groups, confirming that – overall – Arabic /k/ is produced with shorter VOT values than English /k/ (Figure 1).
Simple contrasts for the Arabic /k/.
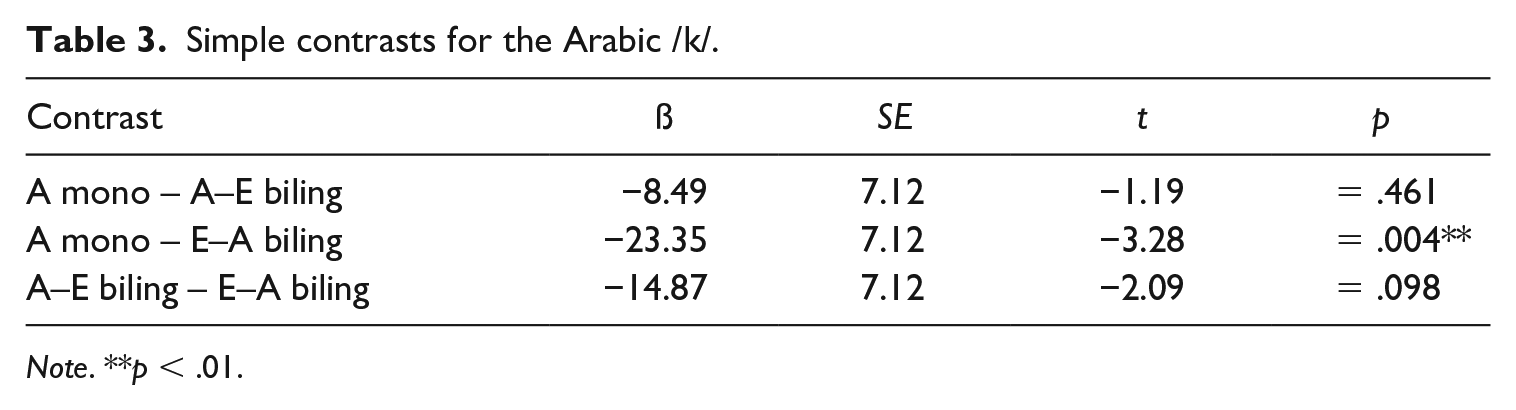
Notes. **p < .01.
Simple contrasts for the English /k/.
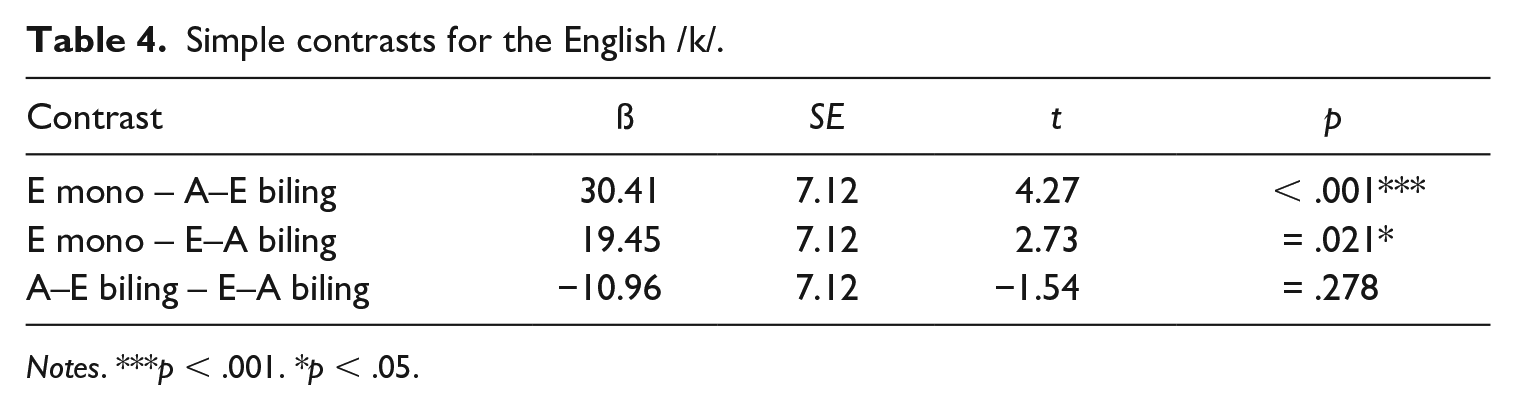
Notes. ***p < .001. *p < .05.
Simple contrasts for each participant group, comparing the Arabic /k/ with the English /k/.
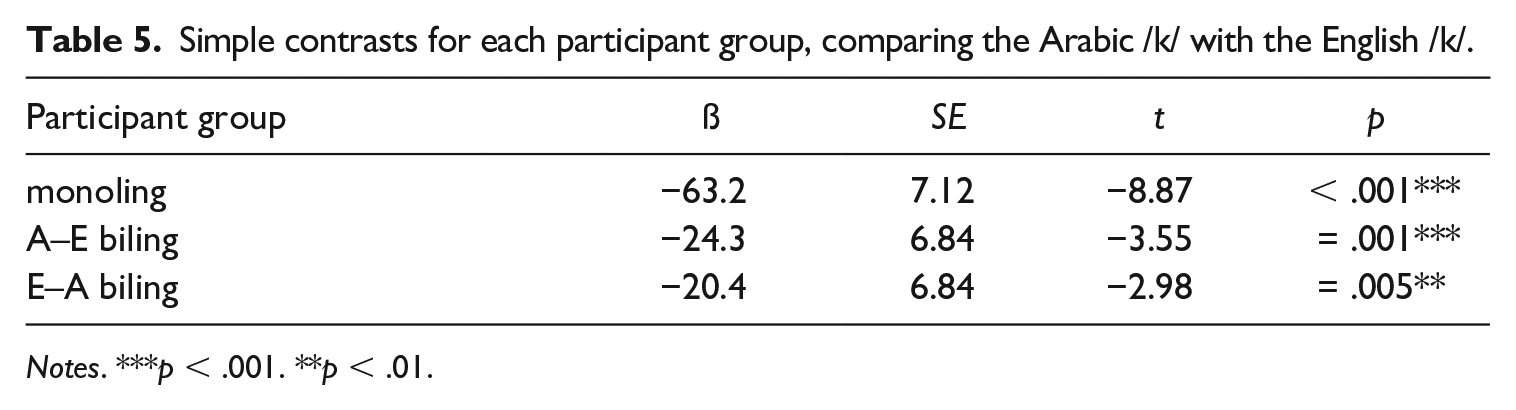
Notes. ***p < .001. **p < .01.
2 The alveolar voiceless plosive /t/
We continue with the VOT values for the alveolar voiceless plosive /t/. Figure 2 shows mean VOT values for /t/ in Arabic and English as produced by the Arabic and English monolinguals (monoling), Arabic–English bilinguals (A–E biling) and English–Arabic bilinguals (E–A biling). In terms of the bilinguals’ productions of L2 /t/, Figure 2 shows that the Arabic–English speakers produce L2 English /t/ with a mean VOT duration of 71 ms, which is shorter than the mean VOT found in both the monolingual English (109 ms) and the L1 English (96 ms) group. The English–Arabic bilinguals, as can be seen in Figure 2, produce L2 Arabic /t/ with a mean VOT duration which is longer (71 ms) than the mean VOT measured for monolingual Arabic /t/ (38 ms) and for L1 Arabic /t/ (51 ms). Considering the bilinguals’ productions of /t/ in their L1, Figure 2 reveals that the Arabic–English group produces L1 Arabic /t/ with slightly longer VOT (51 ms) compared to the monolingual Arabic group (38 ms). The English–Arabic group was observed to produce L1 English /t/ with a mean VOT of 96 ms, which is slightly shorter than the mean VOT duration measured in the monolingual English group (109 ms).
Mean VOT values (in ms) of the Arabic (A) and English (E) /t/ as produced by the two monoling groups, the A–E biling and the E–A biling groups.
A mixed effects model determined whether participant group (monoling, A–E biling, E–A biling) and language (English vs. Arabic) affected VOT values for /t/. As before, the model included VOT (in ms) as the response variable, participant group, language and the participant group by language interaction as (centred and sum-coded) fixed effects, and random intercepts for participants. The results in Table 6 show a statistically significant effect of language on VOT values, confirming that English VOTs are significantly longer than the Arabic VOTs. The participant group by language interaction is also significant. The model’s marginal and conditional R2GLMM values are 0.45 and 0.52, respectively. This suggests that 45% of the variance in VOT values can be explained through the fixed effects language and participant group, with only slightly more of the variance additionally explained by the random effect, i.e. by individual differences across participants.
Results of the mixed effects model for /t/.
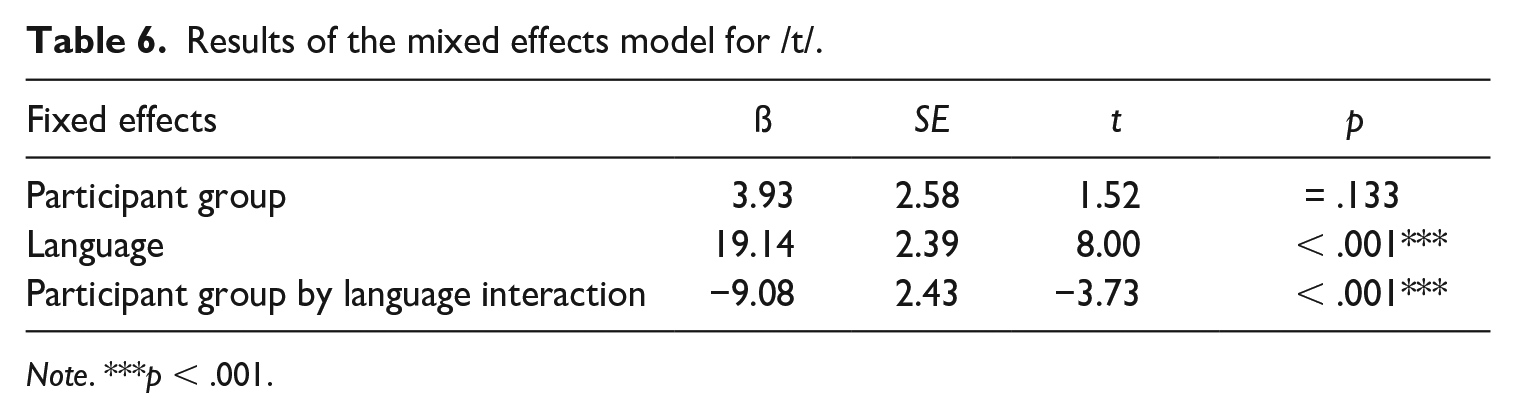
Notes. ***p < .001.
To explore the participant group by language interaction, we again ran post-hoc comparisons using simple contrasts for both participant group and language. Tables 7 through 9 show the results from the post-hoc tests, and again reveal differences between the three speaker groups in terms of VOT productions. For the Arabic /t/, Table 7 shows that there is no significant difference in VOTs between the Arabic monolinguals and the Arabic–English bilinguals. We thus find no evidence for L1 attrition for the Arabic /t/ in the Arabic–English bilingual speaker group. In contrast, the comparison between the English–Arabic bilinguals and the Arabic monolinguals revealed significant differences between the two groups in terms of VOT durations for Arabic /t/, confirming that the bilinguals’ VOTs are considerably longer than the monolinguals’ VOTs (see Figure 2). This suggests that the English–Arabic speaker group does not produce L2 Arabic /t/ with native-like VOT values. Furthermore, there is a significant difference between the two bilingual groups for the Arabic /t/, that is, as shown in Figure 2, the English–Arabic speakers produce L2 /t/ with considerably longer VOT values compared to the Arabic–English group. For the English /t/, Table 8 shows that the Arabic–English bilinguals’ VOT values are significantly different from both the English monolinguals’ and English–Arabic bilinguals’ VOTs, as manifested in shorter VOT durations measured for the Arabic–English group compared to the English–Arabic and the monolingual group, respectively (see Figure 2). By contrast, no significant differences were detected between the English–Arabic speaker group and the monolingual English group in terms of English /t/, which suggests that the bilingual group produces the English target sound with VOT values similar to those of monolingual English speakers. Overall, this means that we found no evidence for L1 attrition for the English /t/ in the English–Arabic bilinguals, but non-native-like L2 productions of the English /t/ for the group of Arabic–English bilinguals. In line with the main effect of language, Table 9 shows that there is a significant difference in VOT duration between Arabic /t/ and English /t/ for all three participant groups, confirming that Arabic /t/ is produced with overall shorter VOT values than English /t/ (Figure 2).
Simple contrasts for the Arabic /t/.
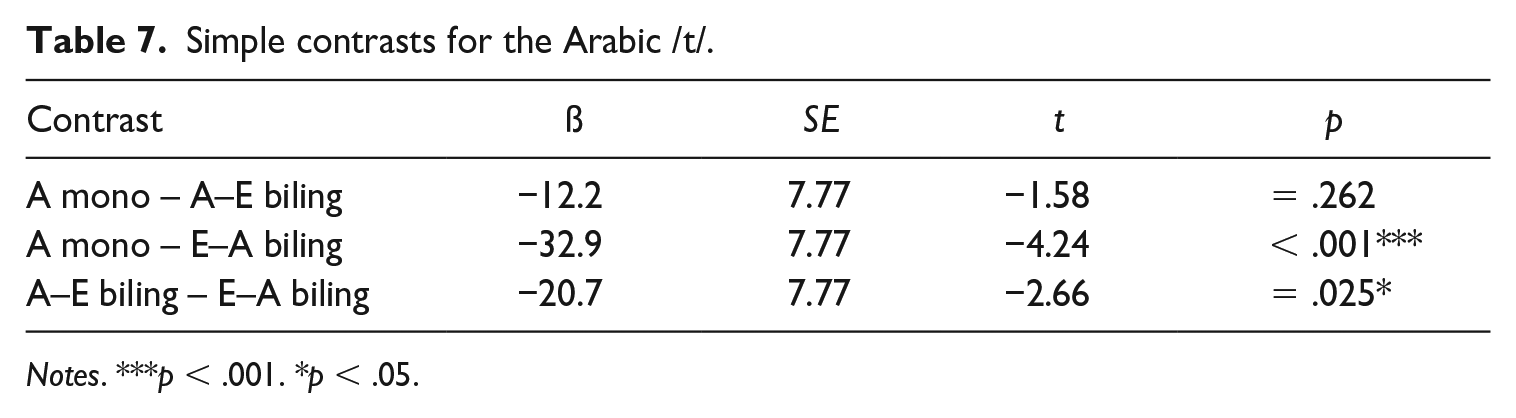
Notes. ***p < .001. *p < .05.
Simple contrasts for the English /t/.
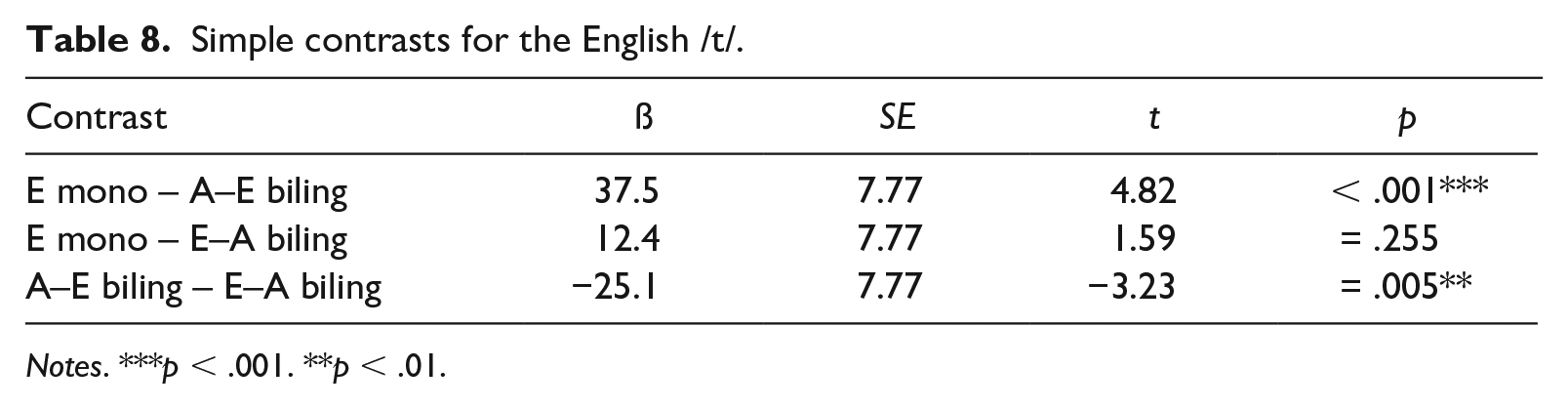
Notes. ***p < .001. **p < .01.
Simple contrasts for each participant group, comparing the Arabic /t/ with the English /t/.
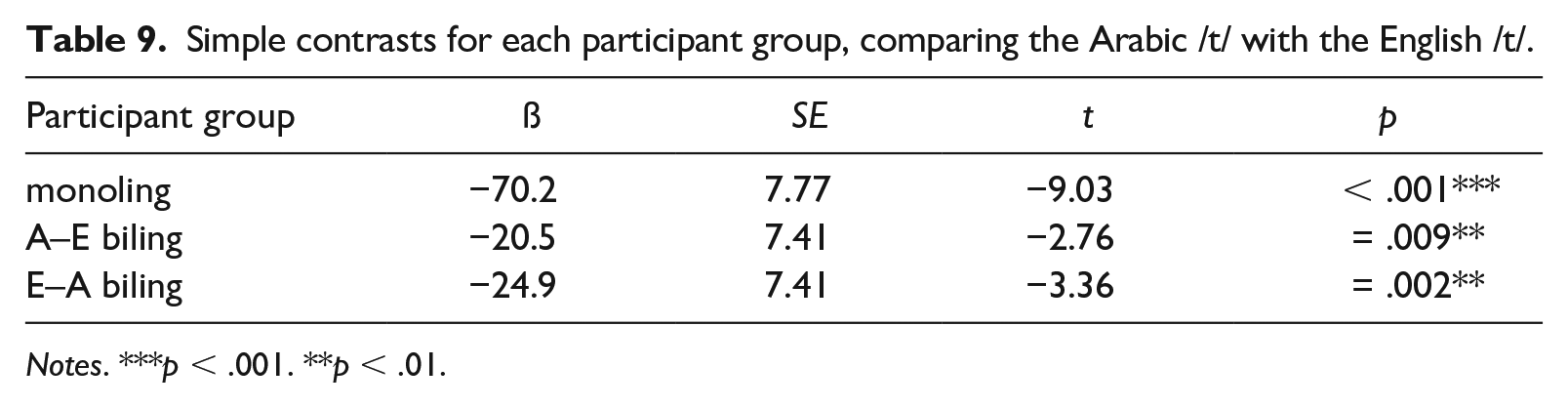
Notes. ***p < .001. **p < .01.
3 The bilabial voiceless plosive /p/
We continue with the VOT values for the bilabial voiceless plosive /p/. Since MSA does not have the phoneme /p/, we present only English data. Figure 3 shows the mean VOT values for the English /p/ as produced by the English monolinguals (E mono), Arabic–English bilinguals (A–E biling) and English–Arabic bilinguals (E–A biling). The figure reveals that the English /p/ is in the long-lag range for all three participant groups, with slightly shorter mean VOT duration measured in the Arabic–English group (69 ms) compared to both the English–Arabic bilinguals (81 ms) and the monolingual speakers (83 ms).
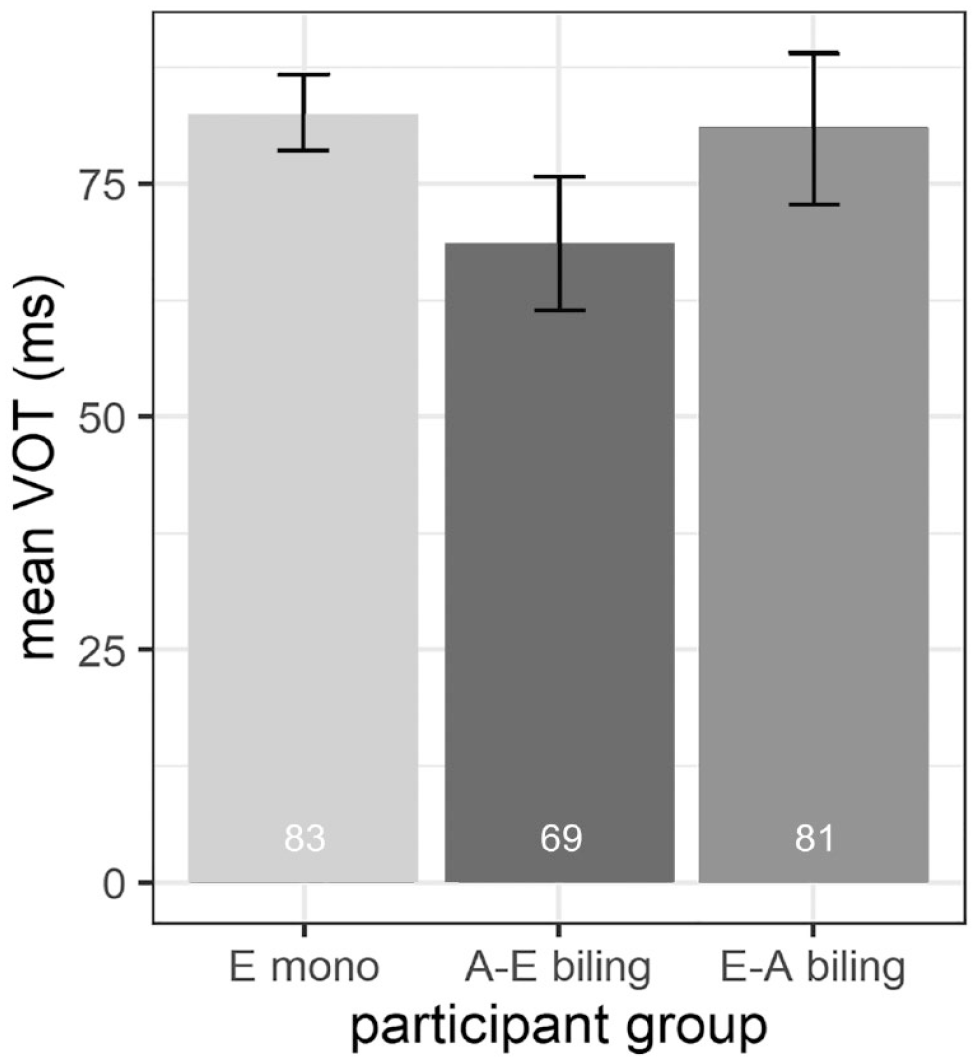
Mean VOT values (in ms) of the English (E) /p/ as produced by the E mono, A–E biling and E–A biling groups.
A mixed effects model determined whether participant group (E mono, A–E biling, E–A biling) affected VOT values for /p/. The model included VOT (in ms) as response variable, participant group (centred and sum-coded) as fixed effect, and random intercepts for participants. The results of the analysis revealed no significant effect of participant group (β = −0.68; SE = 3.97; t = −0.17; p = .864). We thus find no evidence for L1 attrition in the pronunciation of the English /p/ for the English–Arabic bilingual group. Furthermore, the Arabic–English bilingual group produced the English /p/ in a native-like manner.
IV Discussion
The current study examined the VOT values of voiceless plosives in L2 acquisition and L1 attrition for speakers of two typologically different languages, specifically, late English–Arabic and Arabic–English bilinguals. We will first briefly discuss our findings concerning the monolingual speakers’ VOT productions in Arabic and English and then more closely focus on the L2 acquisition and L1 attrition results obtained in our study.
Our findings confirm results from the previous literature that the VOTs of the voiceless stops /k/, /t/ and /p/ in SSBE clearly fall in the traditional long-lag VOT range (Lisker and Abramson, 1964) and are strongly aspirated (see Cho and Ladefoged, 1999). When it comes to the monolingual MSA speakers’ productions of /t/ and /k/, we observed that Arabic /k/ was produced with a mean VOT duration of 48 ms, suggesting moderate aspiration (see Cho and Ladefoged, 1999), while the speakers produced MSA /t/ with a mean VOT duration of 38 ms, that is, on average 10 ms shorter than the VOTs obtained for their productions of /k/ and also shorter than the mean VOT duration of roughly 53 ms previously reported for MSA /t/ (e.g. AlDahri, 2012a, 2012b). Our results thus confirm the common finding that voiceless velar stops typically have longer VOT durations than voiceless alveolar stops, i.e. VOT increases from a bilabial to a velar place of articulation (e.g. Cho and Ladefoged, 1999; Theodore et al., 2009; Volaitis and Miller, 1992). However, the values found for monolingual MSA /t/ in the present investigation are still slightly below the moderately aspirated category previously reported for MSA (AlDahri, 2012a, 2012b, 2013; Alotaibi and AlDahri, 2011). This might be related to differences in the speech elicitation tasks used in the present (cartoon narration task) and in previous studies (single-word reading task in AlDahri, 2013), considering that plosive tokens produced in sentences tend to have overall shorter VOT durations compared to tokens produced in isolation (e.g. Braun, 1996; Lisker and Abramson, 1967). This might explain why the monolingual MSA speakers in our study exhibited shorter VOT durations compared to what has been previously reported for MSA. Given, however, that a rather limited number of studies has been conducted so far to examine VOT in MSA speakers (see AlDahri, 2012a, 2012b, 2013; Alotaibi and AlDahri, 2011), additional investigations will be necessary in order to further establish which VOT categories MSA speakers use for their voiceless plosives.
The L2 acquisition data showed that both bilingual groups produce the voiceless /k/ and /t/ in their respective L2s with VOT values that were, on average, intermediate between the values found for the monolingual speakers of English and Arabic, suggesting that both bilingual groups did not acquire L2 /k/ and /t/ in a native-like manner, if measured against the monolingual norms of the respective language. Similarly, when comparing the bilingual groups to each other (i.e. L2 Arabic to L1 Arabic, and L2 English to L1 English), we found that L2 Arabic speakers produced Arabic /t/ with considerably longer (and thus more English-like) VOT values compared to L1 Arabic speakers, and L2 English bilinguals produced English /t/ with significantly shorter (and thus more Arabic-like) VOT values than L1 English speakers, which confirms that the bilinguals’ L2 productions of /t/ do not fall within a native VOT range. We also found that L2 Arabic speakers produced Arabic /k/ with overall longer VOT compared to L1 Arabic bilinguals, and L2 English speakers produced English /k/ overall shorter VOT compared to L1 English bilinguals. However, this difference was not statistically significant, which indicates that while the bilinguals may not have met the monolingual target in their L2 productions of /k/, as outlined above, their productions of L2 /k/ do not significantly differ from that of the respective L1 bilingual group. Furthermore, we observed that Arabic–English bilinguals produced L2 English /p/ similarly to both monolingual English and L1 English speakers (possibly because they perceive it as a new sound), suggesting native-like production of English /p/.
When considering the bilinguals’ L1 productions, it was shown that the English–Arabic group produced L1 English /k/ with significantly shorter – and hence more L2 Arabic-like – VOT values compared to the monolingual English control group, suggesting L2-induced modifications of the speakers’ L1 productions. Since attrition effects have only been observed in one bilingual speaker group, namely the English–Arabic group, and since only one phoneme was affected (i.e. English /k/ but not /t/), we refer to these L2-induced modifications as ‘asymmetric’ L1 attrition. We will discuss the L2 acquisition patterns and the asymmetry of the L1 attrition results in detail in the following sections, considering different explanatory frameworks to interpret our findings.
1 Phonetic similarity
In the present study, we identified two acquisition patterns, i.e. native-like VOT productions of L2 English /p/ by the Arabic–English speakers and nonnative-like productions (i.e. merged/intermediate VOT values) of both L2 English and L2 Arabic /t/ and /k/, respectively. Both acquisition patterns are compatible with the SLM’s notion of phonetic similarity between the two languages (Flege, 1995). Specifically, the SLM predicts that bilinguals establish new categories for L2 sounds that differ substantially from the nearest L1 sound, and produce such L2 sounds potentially in a native-like manner. This is indeed what we found for the acquisition of /p/, a sound which does not exist in MSA and is thus not shared across the two languages, with the Arabic–English bilinguals showing native-like production of the English long-lag aspirated /p/ and no attrition in the VOT production of /p/ in the English–Arabic bilinguals. We further expected the voiceless stops /t/ and /k/ to be produced with merged values, which typically lie between the two native norms. This was indeed confirmed by our results, which showed that while the L2 productions of the voiceless stops /k/ and /t/ differed significantly from both languages’ native norms, the VOT values were intermediate between the monolingual norms for the two languages, showing non-native-like L2 production. However, with the exception of the Arabic–English bilinguals’ English /t/, both groups of bilinguals produced L2 VOT values that were numerically closer to the target L2 values than to their own L1 norms, suggesting that the bilinguals may be approaching the L2 target norms.
In addition to the different L2 acquisition patterns discussed above, our findings show evidence for L1 attrition and thus confirm previous observations that, even in adulthood, L1 phonetic categories remain flexible and malleable (e.g. Bergmann et al., 2016; Kornder and Mennen, 2021b; Mayr et al., 2012; Stoehr et al., 2017). In line with the SLM, the phonetic properties of the similar L1 and L2 plosives /t/ and /k/ are likely to merge, which may result in L1 VOT productions shifting closer toward the L2. We therefore expected L1 Arabic /t/ and /k/ to have longer (more English-like) VOT values than monolingual Arabic /t/ and /k/, and we expected L1 English /t/ and /k/ to have shorter (more Arabic-like) VOT values than monolingual English /t/ and /k/. However, the pattern we found was asymmetrical, with L1 attrition identified only in the English–Arabic bilinguals’ productions of /k/, but not /t/. Specifically, the English–Arabic bilinguals produced English /k/ with shorter VOTs than monolingual English speakers, indicating a shift of the speakers’ VOT for L1 /k/ closer toward their L2. No signs of L1 attrition of VOT were found in the productions of /t/ and /k/ by the Arabic–English bilinguals. While previous studies examining attrition phenomena do show that attrition effects are selective and do not necessarily affect a bilingual’s entire L1 pronunciation system (e.g. Kornder and Mennen, 2021b; Mayr et al., 2012), an asymmetric pattern as identified in our study has – to the best of our knowledge – not been reported so far. 8
By and large then, phonetic similarity appears to be a useful notion to predict the relative difficulties that L2 learners will experience with particular L2 sounds, and may be able to explain at least to some extent which sounds are affected by L1 attrition, that is, the English–Arabic speakers produced L1 English /k/ – which has a direct counterpart in their L2 Arabic – with shorter and thus less English-like VOT values compared to monolingual English speakers. However, phonetic similarity and the SLM cannot explain the asymmetrical attrition present in our data, nor why some similar sounds (English /k/) were affected while others were maintained (English /t/, Arabic /t/ and /k/).
2 Asymmetries in L1 attrition
In this section we explore the possible reasons for the asymmetric results that we found for L1 attrition of VOT in voiceless stops, i.e. that we only found L1 attrition in the English–Arabic bilinguals’ productions of English /k/. Specifically, we propose that markedness may affect L1 attrition. The Markedness Differential Hypothesis (Eckman, 2008; Eckman et al., 2003) predicts that those L2 sounds that are marked are more difficult to acquire than those that are unmarked. Whether a sound (or any other linguistic structure for that matter) is considered marked or unmarked depends on its complexity and distribution both within and across languages; that is, marked forms are more complex and have a narrower linguistic distribution than unmarked forms. Whereas markedness as a factor of successful L2 speech acquisition has been studied extensively (for an overview, see Eckman, 2008), few studies have investigated whether markedness plays a role in L1 attrition of speech (e.g. Chang, 2014). Research in areas other than pronunciation, however, suggests that markedness should be considered as an influencing factor in L1 attrition, showing that marked linguistic features in the L1 system are more susceptible to attrition compared to unmarked features (e.g. Andersen, 1982; Gürel, 2004; Hansen and Chen, 2001; Yılmaz, 2011). In other words, more marked L2 items are more difficult to acquire, i.e. enter the representation less straightforwardly. At the same time, they are less stable in the attriters’ representation, such that in both cases the representations of the marked items are more vulnerable or less deeply entrenched (see Bardovi-Harlig and Stringer, 2010). A survey of more than 400 languages showed that aspirated plosives, as can be found in both SSBE and MSA, are less common than unaspirated plosives, and can therefore be considered marked (Maddieson, 1984). In the present investigation, we are comparing voiceless plosives with possibly moderate aspiration (MSA) to voiceless plosives with strong aspiration (SSBE). To the best of our knowledge, no work has explored whether moderately or strongly aspirated plosives should be considered to be more marked, and it is therefore not clear how markedness may or may not relate to L1 attrition in this particular context. However, we can derive a further prediction based on the notion of markedness. Within the voiceless plosives, the velar plosive /k/ has a narrower distribution than the bilabial and alveolar plosives /p/ and /t/, which are distributed equally in the world’s languages (Maddieson, 1984; Stefanuto and Vallée, 1999). Specifically, languages with plosives in only two places of articulation typically have bilabial and alveolar stops, such that alveolars and bilabials are more widely distributed across languages than velar stops. Thus, the velar plosive /k/ is more marked than the bilabial and alveolar plosive /p/ and /t/. We therefore argue that markedness can explain why we found L1 attrition in the English–Arabic bilinguals’ English /k/, but not in their English /t/ or /p/. Overall, we suggest that the notion of markedness might be a useful explanatory framework to explain asymmetries in attrition data.
In the following, we consider two proposals that have previously been invoked to explain selective attrition effects, but which we argue cannot explain the particular asymmetric results of the current study. Thus, our attrition results do not support these explanatory approaches. A factor which has previously been shown to influence L1 attrition – at least to some extent – is language use (for an overview of factors affecting L1 attrition, see de Leeuw, 2018b). Stoehr et al. (2017), for example, found an asymmetric pattern for the attrition of L1 VOT in German–Dutch and Dutch–German bilinguals living in the Netherlands, which could be related to language use: While the German–Dutch bilinguals in the study used their L2 Dutch both in and outside of the home, the Dutch–German bilinguals used their L2 German only in the home. In line with this, Stoehr et al. (2017) found L1 attrition of VOT in voiceless plosives in the German–Dutch bilinguals, but not in the Dutch–German bilinguals, suggesting that increased L2 use might contribute to L1 attrition. However, language use is unlikely to explain the results of the present study. Specifically, if increased L2 use contributes to L1 attrition, we would expect for the English–Arabic bilinguals to use their L2 (i.e. Arabic) more than the Arabic–English bilinguals use their L2 (i.e. English) as we found L1 attrition only in the English–Arabic, but not in the Arabic–English group. In other words, if both participant groups used Arabic more than English overall (that is, at work, with friends and in the family), this would suggest that the English–Arabic bilinguals used their L2 Arabic more than the Arabic–English bilinguals used their L2 English, which would in turn be compatible with the idea that increased L2 use might contribute to L1 attrition. However, we found such a language use pattern only for interactions with friends (i.e. both bilingual groups used more Arabic when interacting with friends), but not for interactions in the family, where participants overall used more English than Arabic, or at work, where both participant groups used their L2 more than their L1. We argue that if increased L2 language use had contributed to our asymmetric results in a similar way as in Stoehr et al. (2017), we should have found a clearer pattern, with higher Arabic than English use across the board (or at least in two of the three domains for which we have information), not just when interacting with friends.
Another possible explanatory framework which could account for L1 attrition phenomena in previous studies (e.g. Keijzer, 2004, 2010) is the regression hypothesis – first formulated by Jakobson (1941) in the context of linguistic theory – which states that what is learned earlier is less prone to attrition than what is learned later (also referred to as ‘first in, last out’; Bardovi-Harlig and Stringer, 2010; Jakobson, 1941; Montrul, 2008). McLeod and Crowe’s (2018) review of 64 studies of consonant acquisition involving over 25,000 children acquiring 27 languages suggests that /p/ and /t/ are generally acquired earlier than /k/. In the case of English, however, the review shows that /p/ is acquired first, followed simultaneously by /k/ and /t/ (McLeod and Crowe, 2018, Figure 2). Similarly, /k/ and /t/ seem to be acquired at the same time in Arabic (Alquattan, 2015; Amayreh and Dyson, 1998; Ayyad et al., 2016). The regression hypothesis would then suggest that we should be more likely to find L1 attrition in the English–Arabic bilinguals’ English /t/ and /k/ compared to their /p/ given that the latter is acquired earlier than /t/ and /k/, respectively. Our results are indeed compatible with this prediction, that is, /p/ was not observed to be affected by L1 attrition, but since English /p/ does not have a direct counterpart in MSA, the SLM would make the same prediction. Given that English /t/ and /k/, based on what has been previously reported (see McLeod and Crowe, 2018), seem to be acquired at the same time, we would not expect English /k/ to be affected by attrition while English /t/ remains unaffected, as the present findings reveal. Hence, despite the fact that the ‘first in, last out’ hypothesis has been confirmed in previous investigations on L1 attrition phenomena (see, for example, Keijzer, 2004, 2010), it cannot convincingly account for the asymmetry in L1 attrition observed in the present investigation.
V Conclusions
The present study examined the role of phonetic similarity in the VOT production of voiceless plosives by highly fluent Arabic–English and English–Arabic late consecutive bilinguals. In addition, two control groups were included in the study, one for monolingual speakers of Arabic and one for monolingual speakers of English. The results of VOT productions for the two monolingual groups confirmed previous accounts that there are clear cross-language differences between Arabic and English voiceless plosives, that is, English voiceless targets are typically produced with a higher degree of aspiration compared to MSA plosives, as manifested in overall longer VOT durations observed for English than for MSA. The results revealed that while a native-like category was established for the ‘new’ sound /p/ by the Arabic–English bilinguals, i.e. they produced English /p/ with native VOT values, the ‘similar’ sounds /t/ and /k/ were produced with VOT values that were intermediate between the L1 and L2. This was the case in both groups of bilinguals in their L2. Finally, we found evidence for L1 attrition in the data, but only in the English–Arabic bilinguals’ English /k/. While both the concepts of phonetic similarity and markedness could explain some of our L1 attrition findings, neither concept was able to fully explain these findings. In particular, phonetic similarity could predict that the English /p/, which does not occur in Arabic, would not attrite and markedness might explain why L1 English /k/ but not /t/ was affected by attrition. We therefore conclude that using both phonetic similarity and markedness in tandem to predict L1 speech maintenance might be a useful avenue.
As such, the present investigation contributes to previous findings concerning cross-linguistic influences on bilinguals’ first and second language pronunciation, showing that neither the L2 nor the L1 are stable and impermeable linguistic systems. In particular, the investigation of Arabic–English and English–Arabic VOT production suggests that L1 attrition is a selective phenomenon which may affect only some speakers – in this case English–Arabic bilinguals – and only some speech sounds, which has been identified as an asymmetry in L1 attrition in our study. Although previous investigations confirm the observation that L1 attrition operates selectively (e.g. Bergmann et al., 2016; Kornder and Mennen, 2021b; Mayr et al., 2012), it has not been reliably established so far which pronunciation features are more susceptible to L2-induced changes than others, why this seems to be the case, and if it is possible to identify universal patterns across different bilingual populations. Therefore, we need further in-depth investigations looking into various segmental and prosodic features in speakers of different languages and language combinations in an attempt to more closely characterize the underlying mechanisms of L1 attrition and their relation to processes of L2 acquisition in late consecutive bilinguals. Also, given that speech production and speech perception are closely related and since the present study examined the production of voiceless plosives, a future perception study on L1 attrition and L2 acquisition would be valuable to assess whether perception experiments would confirm the current results.
Furthermore, as stated in Section I, previous research suggests that both successful L2 acquisition of speech and L1 maintenance of pronunciation are likely to be affected by individual variation, even among speaker groups which have been carefully screened for a variety of factors, including language background, age of acquisition, and language proficiency (e.g. Bergmann et al., 2016; Face and Menke, 2020; Major, 1992; Mennen, 2004). In the context of the present investigation, it was not possible to closely examine if and to what extent inter-speaker variability could account for VOT differences observed in the bilingual speaker groups due to the fact that a limited number of plosive tokens was collected for each speaker (i.e. one repetition per plosive per speaker). In order to further assess individual variation in VOT and to find out if some speakers are more likely than others to show an L2-influence on L1 pronunciation and vice versa, future studies will need to elicit a larger pool of test tokens representing individual VOT productions in both the L1 and the L2.
Footnotes
Acknowledgements
We would like to thank the participants who took part in this study.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The first author received a scholarship from Umm Al-Qura University to complete this work. The authors furthermore acknowledge the financial support by the University of Graz.