
Abstract
Two acoustic studies of voice onset time (VOT) in sibilant–stop (ST) consonant clusters, produced by first language (L1) speakers of Polish, are presented. In the first, a baseline study of L1 Polish comparing ST clusters with initial singleton stops, a small degree of VOT shortening after /s/ was found for /p/, but not /t/. The second study compared ST productions by L1 Polish speakers of second language (L2) English across two levels of proficiency, speaking in both L1 and L2. Rather than shortening post-/s/ VOT, as is common in L1 English, speakers from both proficiency groups exhibited longer VOT in their L2 than in their L1. These results are consistent with the claim that Polish learners of English mistakenly apply the long VOT of L2 English singleton fortis stops in the post-/s/ position. A phonological interpretation of the results within the Onset Prominence framework is provided.
Keywords
I Introduction
In the field of second language (L2) phonological acquisition, the phonetic realization of voicing contrasts in L2 English has been widely studied (for reviews, see Broselow and Kang, 2013; Chang, 2019; Zampini, 2008). Many scholars, starting with Flege (1987), have investigated the degree to which bilingual speakers and L2 learners produce aspiration in English voiceless (fortis) stops in word-initial position, with a particular focus on the role of learner-oriented factors on the success of acquisition. These factors have typically included first language (L1) background, age of onset of L2 learning, age of arrival in the L2-speaking country, prevalence and frequency of use of both L1 and L2, explicit or formal training in pronunciation, and learner motivation (Flege, 1995; Moyer, 1999; Piske et al., 2001). Interestingly, the majority of these studies examine only aspirated English stops, without examining the realization of voiced (lenis) consonants, which also show cross-language differences. Another widely studied aspect of voicing in L2 English is the contrast in word-final position. Many languages, such as Russian, German, Czech and Polish, have a process of final devoicing, which is traditionally described as neutralizing the L1 contrast in favor of the voiceless variant. Since in English, the laryngeal contrast is maintained word-finally, many scholars (e.g. Gonet and Pietroń, 2004; Schwartz, 2012; Skarnitzl and Šturm, 2016; Smith et al., 2009) have investigated the question of whether L1 speakers of languages with final devoicing acquire the L2 contrast, to what extent the failure to do so contributes to the perception of a foreign accent, and the role of linguistic experience as a contributing factor.
The present article takes up a phonetic aspect of English laryngeal contrasts that has received only minimal attention in the L2 speech literature: the realization of English fortis stops after the fricative /s/ (ST-type consonant clusters). 1 The post-/s/ context is of course familiar as a position in which aspiration in English does not occur, and the stops in ST clusters in English are characterized by short voice onset time (VOT; Lisker and Abramson, 1964). The short-lag VOT of English /p t k/ after word-initial /s/ indeed resembles that of /b d g/ in the language (Cho et al., 2014). It is therefore said that English lacks a voicing contrast after initial /s/, and some phonological proposals (see, for example, Szigetvari, 2020) have claimed that /p t k/ following /s/ are better analysed as lenis. From the point of view of L2 acquisition, successful learning of English ST clusters entails the production of short-lag, lenis-like VOT.
If aspiration is a product of fortisness in the production of English /p t k/, then the realization that is observed after /s/ may be thought of as the result of a weakening process. By contrast in Polish, the L1 that is examined in this article, no weakening or neutralization is said to exist in this position. Both /b d g/ and /p t k/ may appear after fricatives, and it is the stop, via regressive assimilation, that determines the voicing profile of the cluster. Phonetically, there is no connection in Polish between post-/s/ /p t k/ and /b d g/, the latter of which are fully voiced. Finally, standard descriptions (e.g. Dukiewicz and Sawicka, 1995) do not report significant phonetic differences between initial and post-/s/ voiceless stops. This state of affairs raises the research questions that are investigated in the present article. These questions are stated below.
Research question 1: In L1 Polish, are there differences in the VOT in ST clusters as opposed to initial singleton stops?
Research question 2: Do Polish learners of English show VOT shortening in their L2 English productions of ST clusters relative to L1?
Research question 3: Does proficiency level affect the degree to which Polish learners produce VOT shortening in ST clusters in L2 English?
Research question 1 will be addressed in an acoustic study of monolingual L1 Polish speakers (Section III), which serves as a baseline experiment establishing Polish norms for ST clusters. Research question 2 and research question 3 will be addressed in a cross-proficiency-level acoustic study of L1 Polish learners of English producing ST clusters in both L1 and L2 (Section IV).
The results of the studies described in this article have wider implications for L2 speech research. Post-/s/ stops in English form an apparent mismatch between their underlying phonological specification as fortis stops, and their phonetic realization with short-lag, lenis-like VOT. ST clusters across languages therefore provide a useful testing ground for examining the predictions of theoretical models of L2 speech acquisition, particularly with regard to the relative contribution of phonological and phonetic differences in determining patterns of cross-language interaction. Different theories of L2 speech place different weight on phonetic as opposed to phonological considerations. For example, Flege’s Speech Learning Model (SLM; Flege, 1995) deals with phonetic categories compared at the allophonic level, as reflected in the acoustic signal. Best and Tyler’s Perceptual Assimilation Model (PAM-L2; Best and Tyler, 2007) focuses on L2 contrasts, placing a larger burden on phonology in governing cross-language relationships, which in their model are encoded in articulatory gestures. The data presented here present a challenge to both of these approaches, suggesting the need to revise some of our assumptions about the relationship between phonetics and phonology, and the implications of this relationship for L2 speech.
An interpretation of the results of our study will be presented in the Onset Prominence representational framework (OP; Schwartz, 2016, 2018), in which ST clusters may take on different structural configurations that may or may not be conducive to weakening of the stop. Crucially, the OP model proposes a non-mainstream approach to the phonetics-phonology relationship, which can enrich theories of L2 speech by providing a new perspective on cross-language similarity and differences. Since phonetic or phonological similarity is crucial to both the SLM and PAM-L2, it is important to establish clear criteria by which it may be defined. This is one of the primary goals of the OP research program (see Schwartz, 2020). We shall see that with a refined view of the relationship between phonological ‘segments’ and larger prosodic units such as the ‘syllable’, OP allows us to envision the notions of both similarity and ‘common phonological space’ (Flege, 1995) that underlie cross-language phonetic interaction.
The rest of this article is organized as follows. Section II will present background on the phonology and phonetics of ST clusters. Section III will describe a baseline acoustic study of ST clusters in L1 Polish, comparing cluster-internal voiceless stops with singleton stops word-initially. Section IV describes a cross-language acoustic study, in which L1 Polish learners of English at two levels of proficiency produce ST clusters both in L1 and L2. Section V concludes the article with an interpretation of the data within the OP representational framework.
II Background: ST clusters in English and Polish
This section will describe the phonological and phonetic properties of word-initial ST clusters in English and Polish. In this connection, we note that relative to singleton plosives, ST clusters in English are associated with acoustically weaker stops and shortened VOT. One thing that has not been documented is whether VOT shortening is observed in Polish ST clusters. In addition, there are clear phonological differences between the two languages. In English, ST clusters constitute the primary exception to phonotactic rules governing word-initial consonant sequences. In Polish, the clustering possibilities are much more liberal, so ST clusters are not exceptional. In Section V, following the empirical studies, we will return to the question of how the phonological representation of ST clusters may differ in the two languages.
1 ST and syllable structure
Sibilant–stop clusters have an unusual place in phonology. This is due to implications of ST consonant sequences for cross-language generalizations about the relationship between consonant type and syllable structure. In English, as in many other languages, it is said that segments in a syllable are arranged in order of their ‘sonority’ (Jespersen, 1904; Parker, 2002; Vennemann, 1972), a scalar grouping of sounds that is traditionally assumed to represent a combination of articulatory openness and acoustic amplitude. A textbook example of a sonority scale, from least to most sonorous, is given in (1).
(1) stops → fricatives → nasals → approximants → vowels
The relevant generalization for our purposes is that sonority is said to increase toward the peak of a syllable, which is typically a vowel. According to this generalization, at the beginning of a word or syllable, the second consonant in a CCV sequence is higher in sonority than the first. For the most part, word-initial consonant clusters in English, and in a large number of other languages, obey this generalization, as we can see in the following selection of words: twin, flash, snack, swing, cry, pure, shred, grow. In each of these words, C2 is more sonorous than C1 according to the scale in (1). ST clusters constitute the only type of exception to this generalization in English. 2 Fricatives are higher on the sonority scale than stops, so words such as spit, score, and stick all show a word-initial sonority decrease. Nevertheless, despite their status as sonority violations, ST clusters are extremely common in English.
Additionally, it worth noting that sonority violations in English onset clusters are more constrained than the sonority scale in (1) would have us believe. It is not the case that English words can begin with any fricative–stop cluster (*ft, *zd). Rather, the fricative has to be the voiceless alveolar sibilant /s/, and the stop has to be fortis /p/, /t/, or /k/. No other combinations are possible.
Because of these restrictions, there is a trend among works in theoretical phonology (e.g. Goad, 2012; Kaye, 1992) to treat ST clusters not as single syllable ‘onsets’, as descriptive tradition would have us expect. Rather, the fricative /s/ is assumed to have unusual phonetic and phonological properties by which it is not joined in a single constituent with the following stop. 3 Theorists have garnered a body of phonological evidence from a number of languages, including Italian, Ancient Greek, Portuguese, and English (see Goad, 2012; Kaye, 1992), in support of this claim. For example, in Italian the form of the masculine definite article before both rising sonority clusters and singleton consonants is il (il treno, il sale ‘the train’, ‘the salt’). If ST clusters constituted a single onset in Italian, we would expect forms like *il studente ‘the student’, but the article in fact has a different variant (lo) before ST-initial words: ‘the student’ is lo studente. An additional case is found in varieties of English that preserve post-consonantal /j/ before /u:/, as in words like lure, lute. This /j/ is dropped after rising sonority clusters (glue, blew), but preserved after ST (stupid, skewer). These cases strongly suggest that the stop in the ST cluster constitutes a singleton onset after which /j/ is allowed. The issue of how ST clusters should be encoded in phonological systems will be revisited in Section V.
In Polish, ST is just one of a large number of violators of the rising sonority generalization. The language features many other initial clusters with sonority decreases (e.g. lwa /lva/ ‘lion (gen.)’, lnu ‘linen (gen.)’), and sonority plateaus (e.g. kto, gdy ‘who, when’), as well as larger clusters (pstrąg, krtań ‘trout, larynx’). As a result of words like these, the status of sonority sequencing in Polish has been the subject of a large number of theoretical investigations (Cyran and Gussmann, 1999; Kuryłowicz, 1952; Orzechowska, 2019; Rochoń, 2000; Rubach and Booij, 1985). Although these works have offered competing explanations for the unusual nature of Polish cluster phonotactics, one generalization is uncontroversial. Unlike in English, there is no reason to claim that ST clusters in Polish constitute an exceptional configuration.
2 ST and the phonetics of the stop
Two additional generalizations may be made about word-initial ST clusters in English (see, for example, Collins and Mees, 2009; Cruttenden, 2001). First of all, as is well known, aspiration of fortis stops does not occur after /s/. Second, in this context there appears to be no contrast between fortis and lenis stops: after /s/ we always find phonemic /p t k/, but never /b d g/. These generalizations raise both phonetic and phonological questions about the status of post-/s/ stops in English. It is fair to ask if the stop in English ST clusters is indeed fortis.
Acoustic studies of English (e.g. Cho et al., 2014) have shown that /p t k/ after /s/ closely resemble /b d g/ in initial position. This may be attributable to the short VOT of post-/s/ voiceless stops, which is in the 15 ms range in Cho et al.’s study, analogous to initial singleton voiced stops, and in stark contrast to the familiar long-lag values of singleton voiceless stops. This relationship is illustrated in Figure 1, which shows a spectrogram of bill (left) and spill with the /s/ silenced (right), produced by a male L1 speaker of North American English. Both items have VOT of less than 15 ms, and both sound impressionistically like bill. 4 At the same time, the impressionistic VOT-based link between unvoiced lenis and post-/s/ stops in English does not necessary mean that they are acoustically identical. Hanson (2009) showed that f0 (pitch) is raised after ST clusters relative to initial lenis stops, suggesting that the supposed phonological neutralization of the laryngeal contrast is not complete. This difference is in fact visible in the pitch tracks in Figure 1. At the beginning of the vowel, we can see a raised f0 in the token of spill with a silenced /s/.
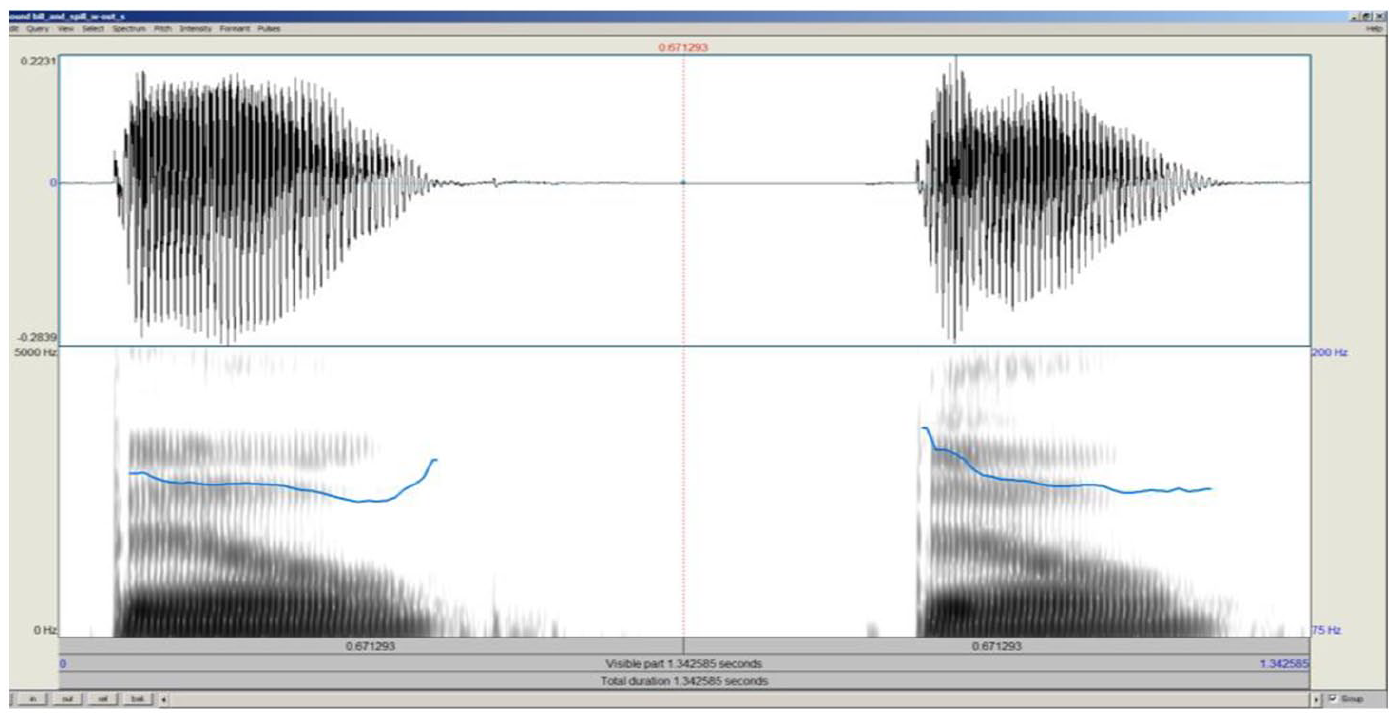
Waveform and spectrogram of English bill (left) and spill, with the /s/ silenced in spill.
A possible explanation for the acoustic patterns of ST clusters in English is offered by studies examining the temporal coordination of glottal opening with supra-laryngeal articulation. For example, Tsuchida et al. (2000) found that in /s/-stop clusters in English there is a single glottal opening gesture that is timed with the fricative. As a result, by the point of stop release, adduction of the vocal folds has already taken place, so voicing is not delayed, and VOT measures are short (for similar data from German, see Hoole and Bombien, 2014).
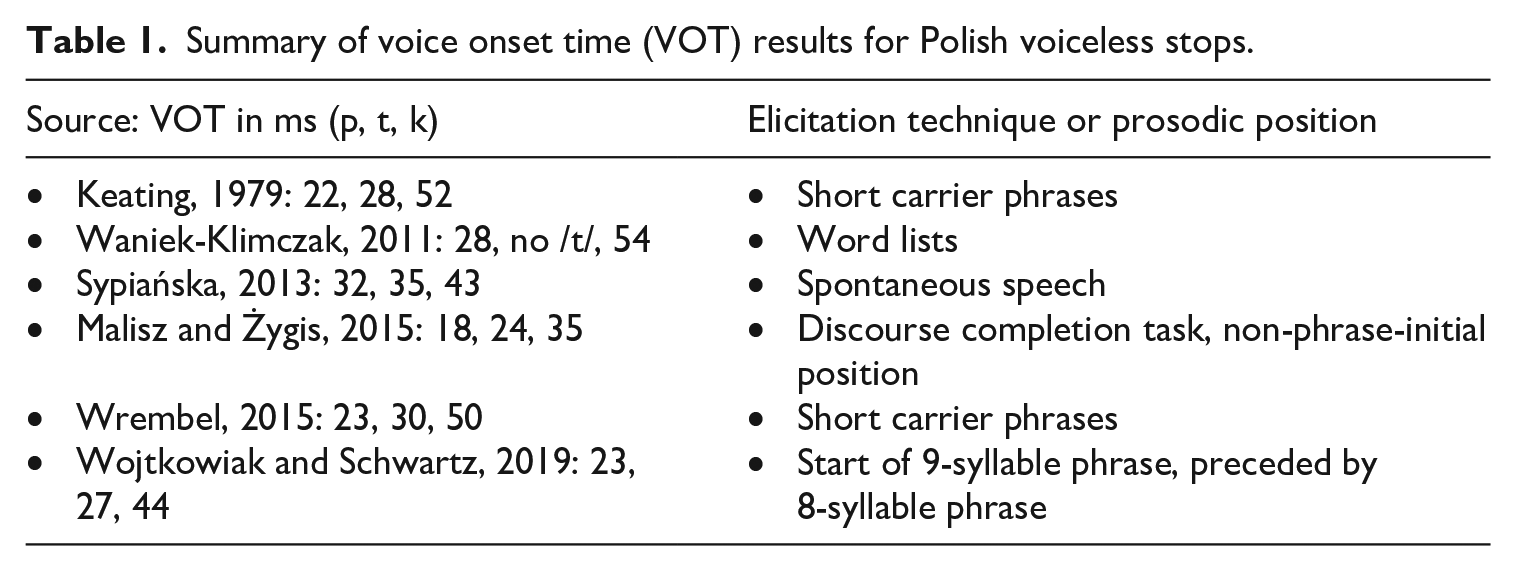
In Polish, there is a lack of studies on VOT in ST clusters, but many works have described the VOT of singleton voiceless stops (e.g. Keating, 1979; Malisz and Żygis, 2015; Sypiańska, 2013; Waniek-Klimczak, 2011; Wojtkowiak and Schwartz, 2019). The general consensus of these studies is that Polish voiceless stops have short-lag VOT, 5 analogous to lenis plosives in English. At the same time there is evidence that the short VOT in Polish stops plosives is longer than what we find in English lenis plosives and English fortis plosives after /s/, which both show VOTs in the 10–25 ms range (Cho et al., 2014; Docherty, 1992; Kim et al., 2018; Lisker and Abramson, 1964). By contrast, typical VOT values for Polish /p t k/ range between approximately 20 and 50 ms. A survey of VOT results for Polish voiceless stops is provided in Table 1.
Summary of voice onset time (VOT) results for Polish voiceless stops.
The phonological inventory of onset clusters in Polish also suggests that ST clusters constitute different phonological structures in Polish and English. Notably, after fricatives both voiceless and voiced stops can occur, and it is the stop that determines the voicing profile of the cluster. Thus, both voiced and voiceless fricative–stop clusters are both found, and they are subject to regressive voicing or devoicing, which produces cluster-internal agreement in voicing specification. As an example, consider the verbal prefix /z/ ‘down, off’ (e.g. zdjąć /z+djɔ̃t͡ɕ/ ‘take off’; zbić /z+bit͡ɕ/ ‘knock down’), which is realized as /s/ before voiceless stops, as in spaść /s+paɕt͡ɕ/ ‘fall down’. Thus, in Polish, the stop affects the realization of the fricative in fricative–stop clusters, unlike in English, where the /s/ is responsible for the lack of aspiration in the stop. From the perspective of speech production, the phonological facts would have us expect a glottal opening gesture in Polish ST clusters timed with the stop closure, in a similar fashion to singleton voiceless stops. If this is the case, we should expect minimal VOT differences in Polish between singleton /p t k/ and /p t k/ appearing in ST clusters (see research question 1).
III Experiment 1: Is VOT shortened in ST clusters in L1 Polish?
This section describes an acoustic study that seeks to establish baseline norms of the VOT of stops in ST clusters in L1 Polish. The working hypothesis, based on the phonological considerations discussed above, is that VOT of voiceless stops in ST clusters should be equivalent to that of singleton voiceless stops. In other words, unlike in English, we should expect minimal VOT shortening in clusters, if any, relative to singleton voiceless stops.
1 Participants
This study is based on recordings of 38 L1 speakers of Polish, with minimal knowledge of other languages. The speakers were all between the ages of 19 and 27 years (Median = 24, Mean = 23.75, SD = 2.48). Twenty-six of the speakers were female and 12 were male. None reported any hearing or speech impairments.
2 Materials and procedure
The data to be presented are based on recordings of six pairs of Polish words taken from 12 utterances, contrasting initial voiceless stops with stops in initial ST clusters. The 12 utterances were part of a set of 48 utterances elicited in a larger project related to the effects of prosodic position on segmental phonetics in Polish. In each case, the target stop /p/ or /t/6 precedes the first vowel in a two-syllable word, and within each pair the place of articulation of the first consonant of the second syllable is the same. The quality of the first vowel (/a ɔ ɨ/) was counterbalanced for height, since higher vowels are known to affect VOT (Maddieson, 1997). The list of target words is given in Table 2, while the utterances they were embedded in are given in Appendix 1.
List of Polish items used in baseline study.

Recordings were carried out in a sound-attenuated booth at a Polish university. Speakers familiarized themselves with the utterances before the recording session. The utterances were presented in a pseudo-randomized order. During the session, the utterances were elicited using PowerPoint slides on a monitor housed inside the recording booth. The booth was equipped with a Shure SM35-XRL head-mounted microphone, which was connected to a Roland UA-25 USB audio interface that allowed for recordings made directly on to a computer (44 kHz sampling rate). Speakers read two repetitions of each utterance, yielding a total of 912 items (12 words * 38 speakers * 2 repetitions).
Prosody was controlled for in the following way. The target words were placed in phrase-initial, yet utterance-medial position. An example of a pair of elicitation materials is given in (2) and (3), while the entire set is provided in Appendix 1. The target words are bolded (they were not in the elicitation slides). Note that the target word was always a two-syllable word, preceded and followed by the same number of syllables (8) in the utterance, and the final syllable before the target word always ended in /ɨ/ (<y> in Polish orthography). The phrase-initial position in the recordings was confirmed on the basis of a pitch rise before the target word at the end of the previous phrase. Utterance-initial items, also elicited in the recording session, were preceded by a pause, as well as a pitch fall at the end of the previous utterance.
(2) W miarę jak je rozruszamy, ‘As we move them our (3) Zanim ją polerujemy, ‘Before we coat it, we must clean the
3 Acoustic and statistical analysis
Acoustic annotation of the recordings was done manually in Praat (Boersma and Weenink, 2017). Voice onset time (VOT), defined as the time window from the release of the stop to the onset of periodicity in the waveform, was marked by hand into Praat text grids. The duration of the target word was also labeled during annotation. From the text grids, a script automatically extracted the VOT and word duration measures. After data extraction, measures of 100 randomly selected items were double-checked to ensure that the script worked properly. The VOT measure was standardized by dividing VOT by the duration of the entire word.
The data (912 items in total) were analysed using the SPSS statistical software (IBM Corporation, 2017). Linear mixed models were fitted, with standardized VOT as the dependent variable. 7 Predictors included Position (initial or post-/s/), Consonant Place (/p/ or /t/), and quality of the following vowel. Model selection proceeded in a step-up manner, and was based on the Akaike Information Criterion (AIC), as well as visual inspection of residual plots. The best fitting model according to the AIC had an interaction term of Position (initial or post-/s/) * Consonant place (/p/ or /t) * Vowel Quality (/a/–/ɔ/–/ɨ/) as a fixed effect. This interaction term allows for determination of whether effects of Position upon VOT hold across different stop places of articulation (we expect longer VOT for /t/ than /p/; Maddieson, 1997), and different qualities of the following vowel (we expect longer VOT before higher vowels; Maddieson, 1997). Since both speaker-specific and item-specific variation in VOT may be expected, by-speaker and by-item random intercepts were included. Additionally, a by-speaker random slope for Position was included to quantify variation in the extent to which Position affects VOT for different speakers.
4 Results
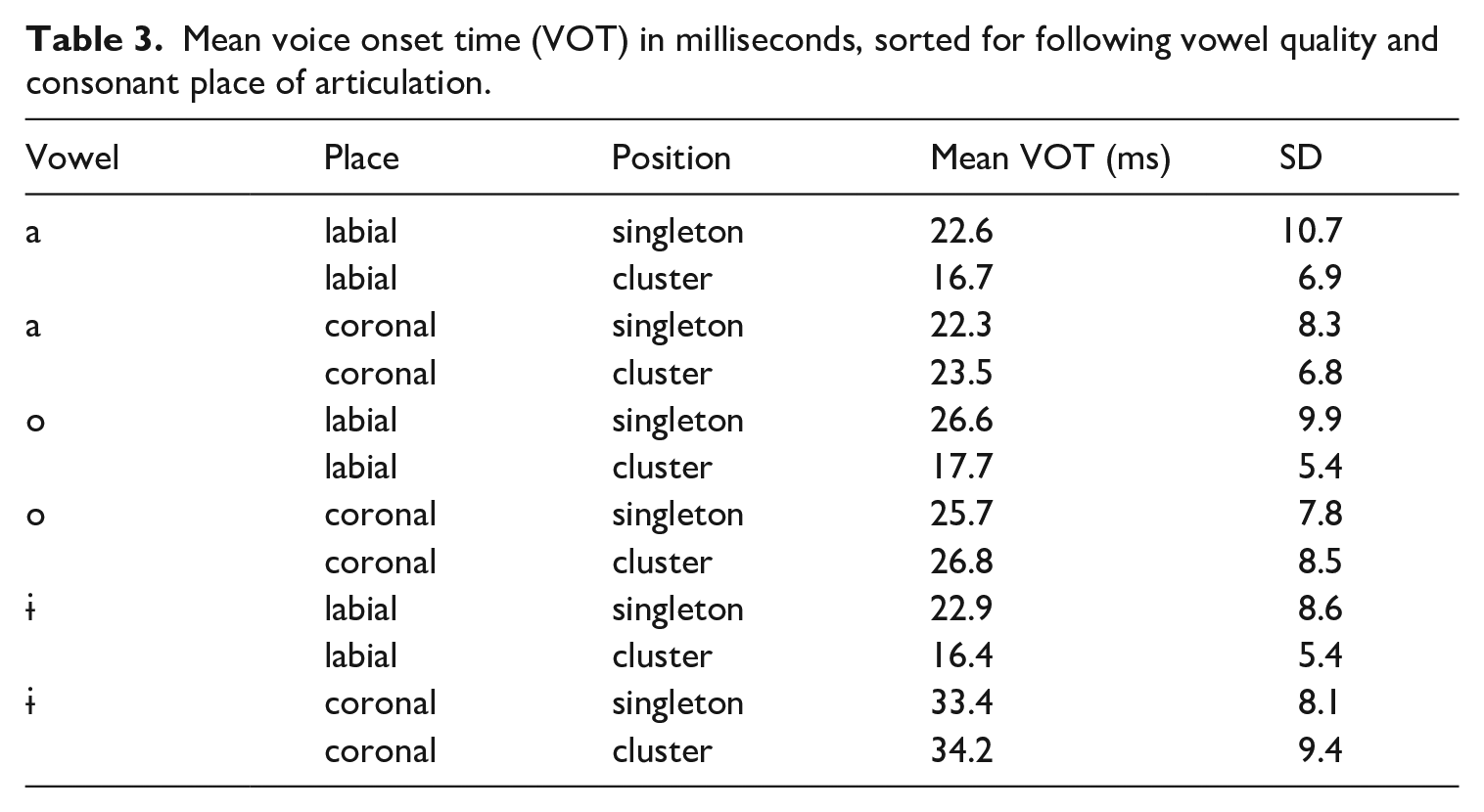
The mean raw VOT measures, collapsed across vowel quality and consonant place were 25.5 ms (SD = 9.7) for singleton stops, and 22.5 ms (SD = 9.8) for post-/s/ stops. Table 3 breaks down these measures according to consonant and the following vowel.
Mean voice onset time (VOT) in milliseconds, sorted for following vowel quality and consonant place of articulation.
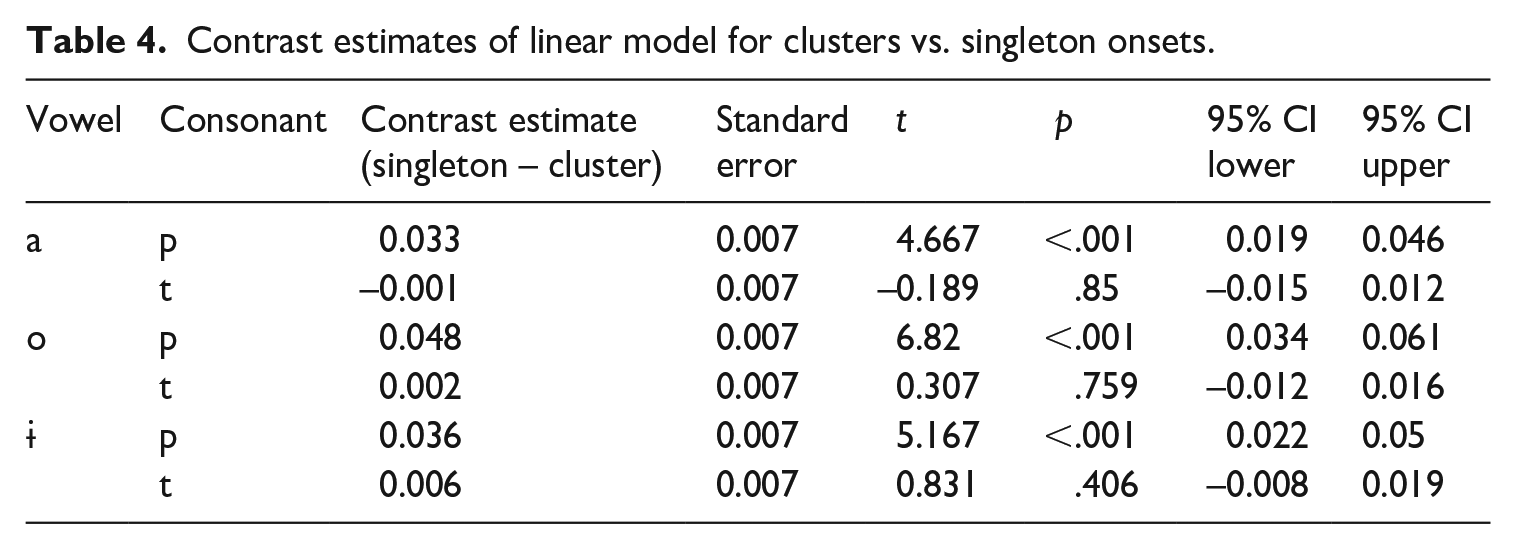
Contrast estimates for the linear model, based on the standardized VOT measure, are provided in Table 4, while the full coefficient table is provided in Table 5. The results of the analysis reveal that across vowel qualities, VOT of /p/ was shorter in clusters for singleton onsets, but VOT of /t/ was not.
Contrast estimates of linear model for clusters vs. singleton onsets.
Coefficient table for first language (L1) baseline study.
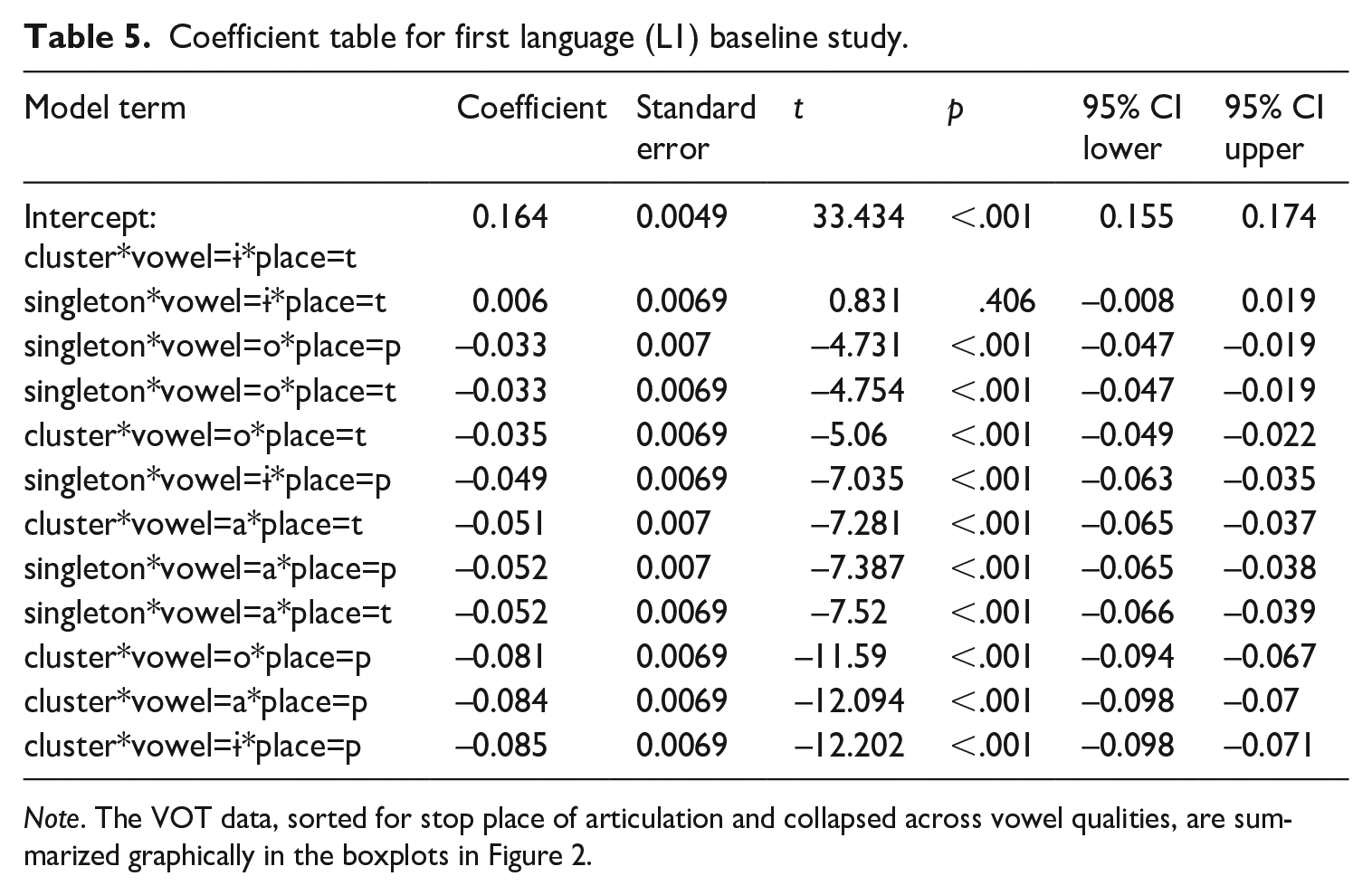
Note. The VOT data, sorted for stop place of articulation and collapsed across vowel qualities, are summarized graphically in the boxplots in Figure 2.
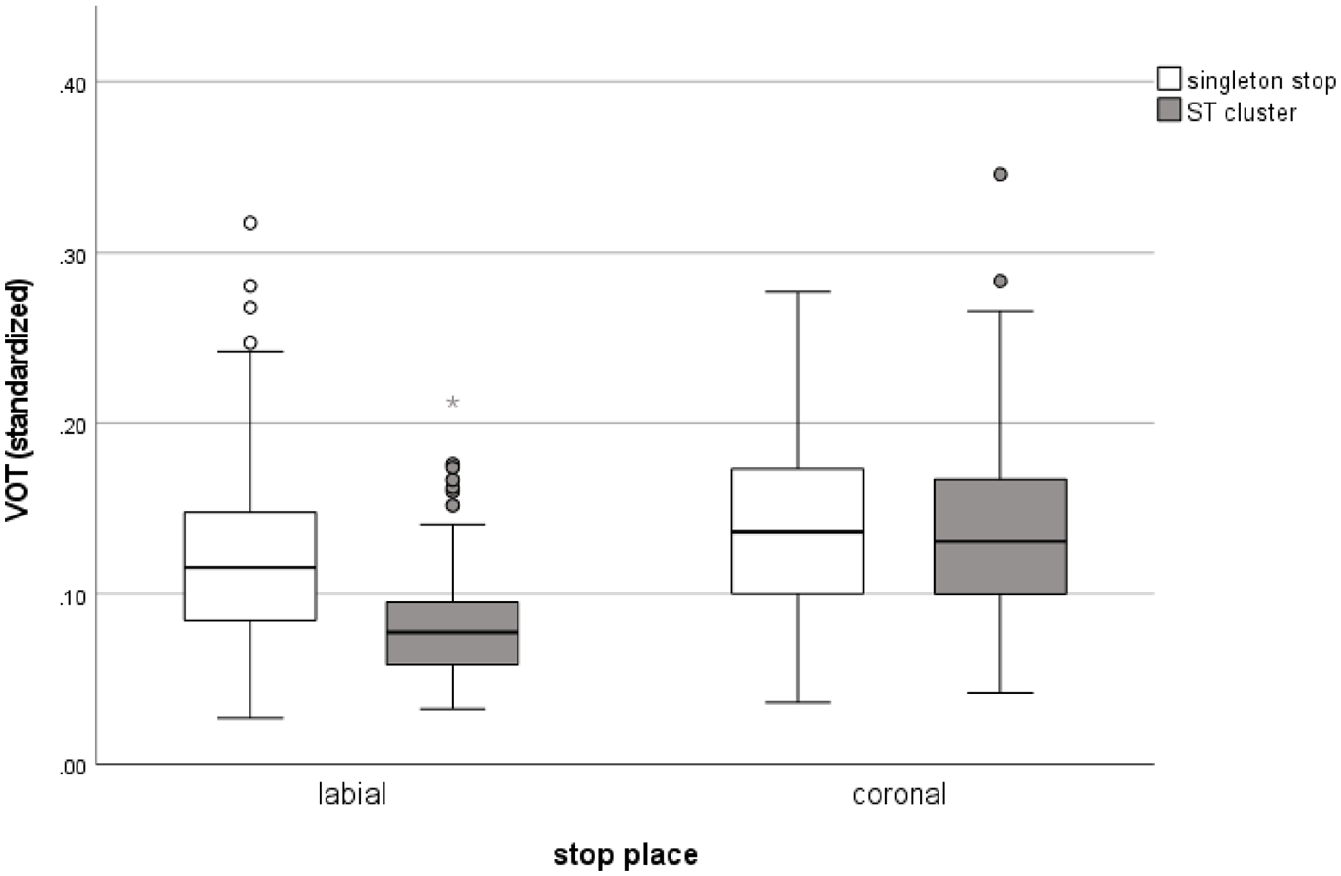
Boxplots of standardized voice onset time (VOT) results in L1 Polish as a function of consonant, sorted for position.
Figure 3 presents VOT measures as a function of individual speaker, grouped for position, with separate panels for the labial and coronal stops. In Figure 3 the circles represent singleton stops, while the crosses represent post-/s/ stops. The x-axis is organized on the basis of increasing within-speaker mean VOT. While the figure shows inter-speaker VOT variability, we can see the effect by which longer VOTs for singleton stops are found for /p/, but not /t/. In the labial panel at the top, we consistently see that the highest value is a singleton for all but two speakers. In the coronal panel, no such pattern is visible.
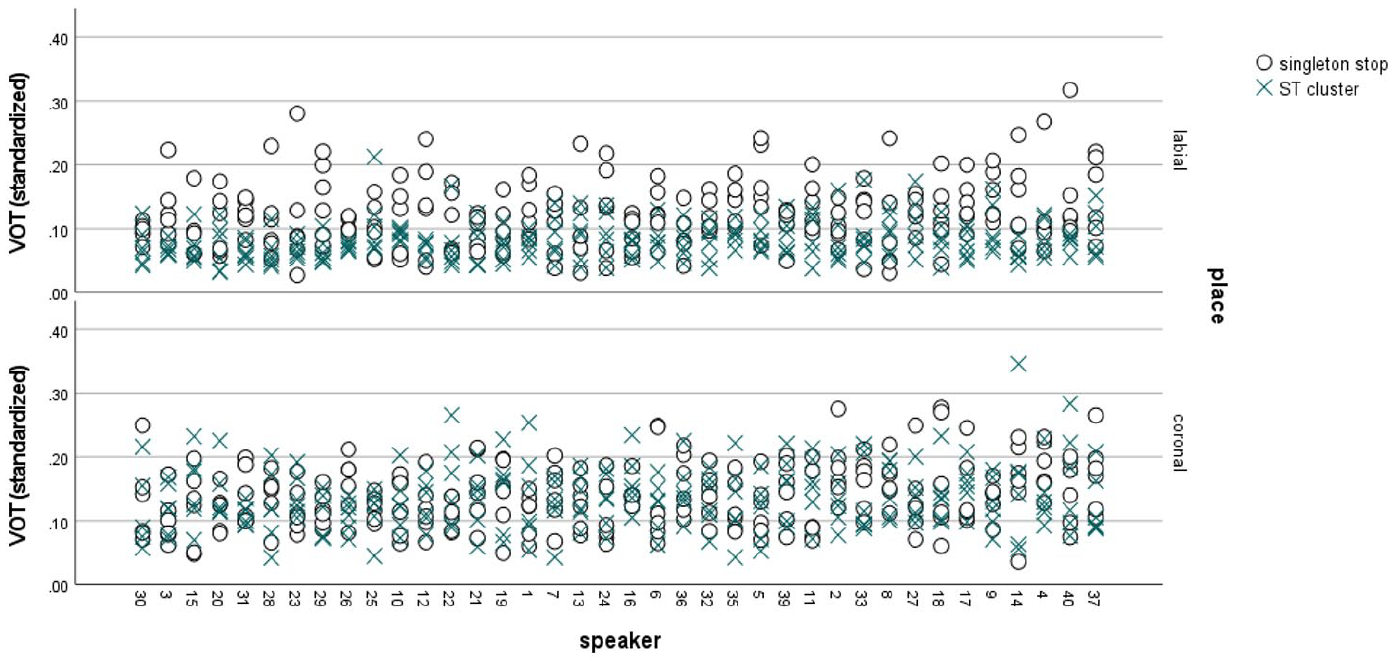
Individual voice onset time (VOT) measures of /p/ and /t/ in L1 Polish sorted for position.
5 Discussion
The results of this study showed VOT shortening in ST clusters in Polish in the case of the bilabial /p/, but not the coronal /t/. This difference in behavior between /p/ and /t/ may be attributable to the labial place of articulation of the former. Research on speech articulation (Pastätter and Pouplier, 2017) has shown that labial consonants are among the least resistant to coarticulation with neighboring sounds. It is therefore possible that the /p/ in the /sp/ clusters showed a greater degree of coarticulation with the preceding /s/ than the /t/ in /st/ clusters. This in turn may have led to a slightly earlier glottal opening gesture during the cluster, which may have induced the slight VOT shortening relative to the singleton stop. Another possible interpretation is that in some cases speakers lengthened the VOT of singleton bilabial stops. In accordance with phonetic universals (e.g. Stevens, 1997), bilabials typically have both the lowest amplitude bursts and the shortest VOTs among labial, coronal, and dorsal places of articulation. It is therefore possible that speakers lengthened their initial /p/ as compensation for these patterns – that is, to enhance the perceptibility of the stop.
Regardless of which explanation is more accurate, it is apparent that the shorter VOT of /p/ in the clusters relative to singletons was not due to any sort of systemic VOT shortening of the type observed in English ST clusters. A true phonological effect would have been observable in the VOT of /t/ as well. Thus, from the results of this baseline study of L1 Polish it becomes clear that the acquisition of native-like ST clusters in L2 English should require L1 Polish learners to master a consonantal configuration that is new from the point of view of their L1. Post-/s/ stops in Polish are, from the perspective of VOT, phonetically rather similar to initial singleton stops. The situation in English, as is well known, is quite different, with VOT shortening in ST clusters.
IV Experiment 2: ST clusters in the speech of Polish learners of English
This section will describe an experiment in which L1 Polish speakers of L2 English produce ST clusters in both L1 and L2. On the basis of the background in Section II and the results of the baseline study in Section III, our working hypotheses are that VOT should be shortened in L2 English relative to L1 Polish (see research question 2 in Section I) and that more proficient L2 users should show greater VOT shortening (research question 3).
1 Participants
Two groups of L1 Polish speakers of English took part in the experiment. The first group (Students) comprised 20 first year students (15 female, 5 male; ages 19–24 years, Median = 21, Mean = 21.7, SD = 1.89), majoring in English at a Polish university. Their English proficiency level was B1 according to the Common European Frame of Reference for Languages (CEFR; Council of Europe, 2011). This is the level that is required for entry into the university program, and none of the Students had spent more than two months in an English speaking country. The Students’ group was receiving intensive training in English pronunciation as part of their specialization in English studies. The second group (Teachers) was made up of 14 members of the teaching staff (8 female, 6 male; ages 24–60 years, Median = 33, Mean = 36.3, SD = 10.2) employed in the same English department that the students were attending. The Teachers’ group had C2 proficiency in English according to the CEFR, and impressionistically, their English speech exhibited no immediately apparent features of a Polish accent (e.g. final devoicing, lack of vowel reduction, voicing assimilation, missing vowel contrasts; see Gonet and Pietroń, 2004). The Teachers are all graduates of the same program that the Students were enrolled in, and had completed two years of phonetic training.
2 Materials and procedure
Recordings were carried out in a sound treated booth at a Polish university. Speech materials were based on citation form productions of 12 pairs of phonologically ‘similar’ words (e.g. ENG still vs. PL styl /stɨl/ ‘style’; see Appendix 2) in English and Polish, each of them beginning with an ST cluster. The pairs were counterbalanced for stop place of articulation, including 6 /sp/ and 6 /st/ clusters. These words were embedded in larger word-lists used in separate experiments, and arranged in a pseudo-randomized order, obscuring the goal of the experiment. Items were elicited using PowerPoint slides projected onto a monitor in the recording booth. Each slide contained a single item to prevent possible list-reading prosodic effects. Two separate recording sessions were carried out with a minimum of one week between them, one entirely in Polish, the other entirely in English. This was done in order to avoid possible language mixing effects (Grosjean, 1998).
Single-item elicitation, as opposed to the meaningful L1 sentences used in the baseline experiment, was employed to control for prosodic structure in a cross-language situation. Since we cannot assume that the prosodic hierarchy is constructed the same way in two different languages (see Schiering et al., 2010), the most reliable way of controlling for prosodic position in a cross-language comparison to elicit items in isolation. In the case of Polish and English, basic differences in prosodic structure are apparent in the different types of sandhi processes that are observed (Schwartz, 2016; see also Wojtkowiak and Schwartz, 2022). For example, English allows for resyllabification at word boundaries (e.g. Giegerich, 1992), but Polish does not (Rubach and Booij, 1990). For this reason, it that may be assumed that elicitation of larger utterances would have resulted in undesirable prosody-induced differences in segmental phonetics in the two languages, and that single-item comparison was the best strategy for obtaining data bearing on research question 2 and research question 3.
3 Acoustic and statistical analysis
Acoustic annotation of the recordings was done manually as in the baseline study. Linear mixed models were fitted with VOT and standardized VOT as the dependent variables. Predictors included Language (English v. Polish), Group (Students v. Teachers), Consonant (/p/ vs. /t/), and the interactions among them. Vowel Height (high–mid–low), and Vowel Length (yes–no; i.e. whether the English member of the pair had a phonologically long vowel) were entered as control variables, included in the model to quantify variation they may have induced. Random effects included by-speaker and by-item random intercepts, a by-speaker random slope for Language, and a by-item random slope for Group. As with the previous experiment, model selection proceeded in a step-up manner, based on the Akaike Information Criterion, as well as visual inspection of residual plots. The best fitting model included a Language*Group*Consonant interaction term, with Vowel Height as an additional fixed effect.
4 Results
As with the first experiment, the standardized VOT measures correlated closely with the raw measures (Figure 10 in Appendix 3). The mean raw VOT measures, sorted for place of articulation of the stop appearing in the ST clusters, are summarized in Table 6. Across both groups, and both consonants, the mean VOT of the stop was longer in English than in Polish.
Summary of voice onset time (VOT) results in L1–L2 study.
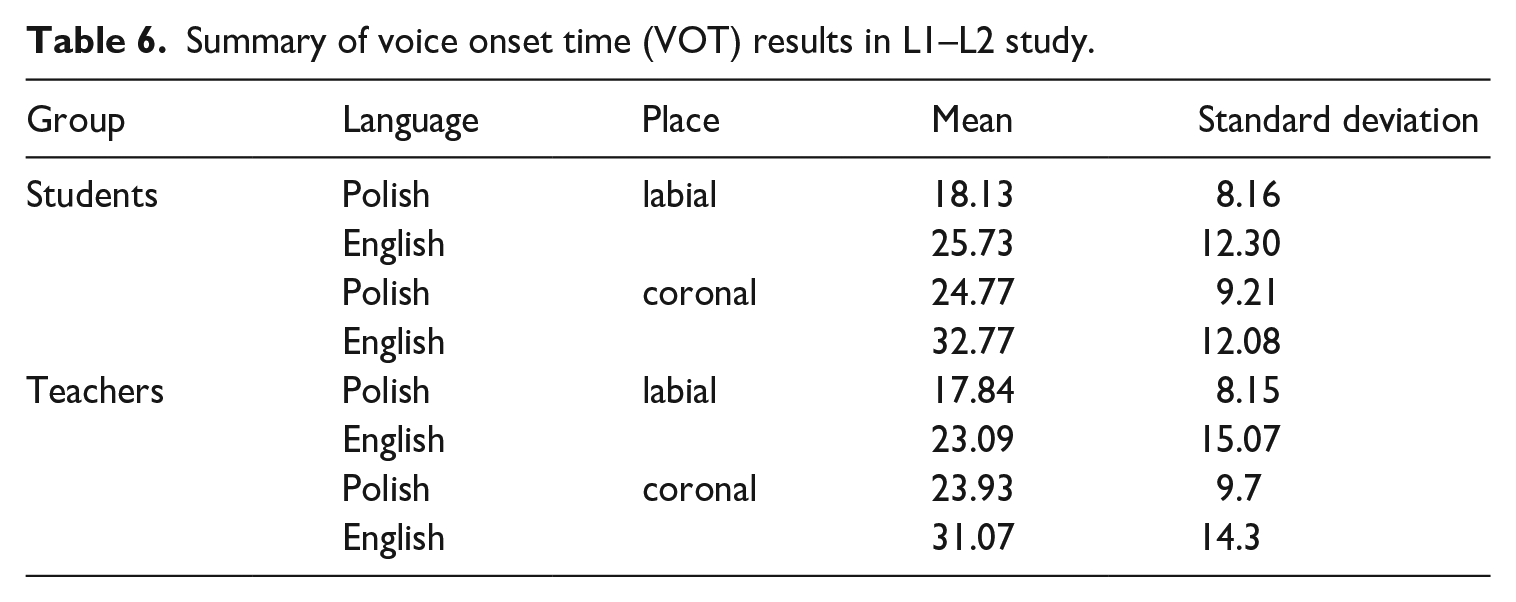
The contrast estimates for Language of the linear model VOT are given Table 7. The negative coefficients indicate longer VOT in English, an effect which was significant for all Group-Place combinations except for labial stops in the Teachers’ productions. The results are summarized graphically in the boxplots in Figure 4. The full coefficient table for the linear model is provided in Table 8.
Contrast estimates of linear model of L1–L2 study.
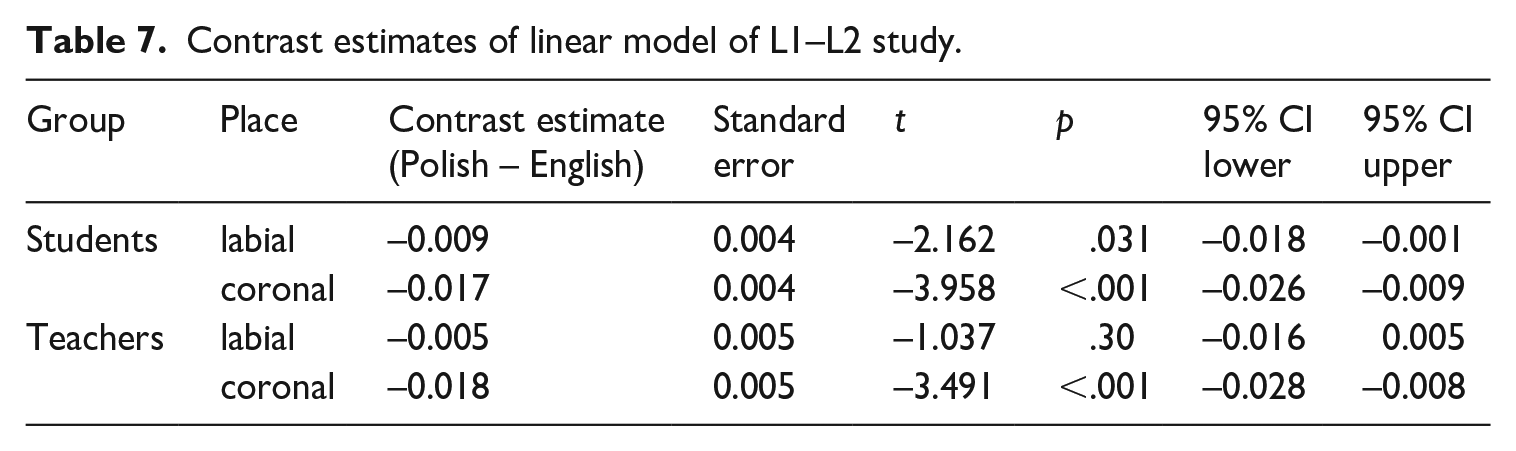
Box plots of voice onset time (VOT) results as function of Group sorted for Language.
Coefficient table for L1–L2 study.
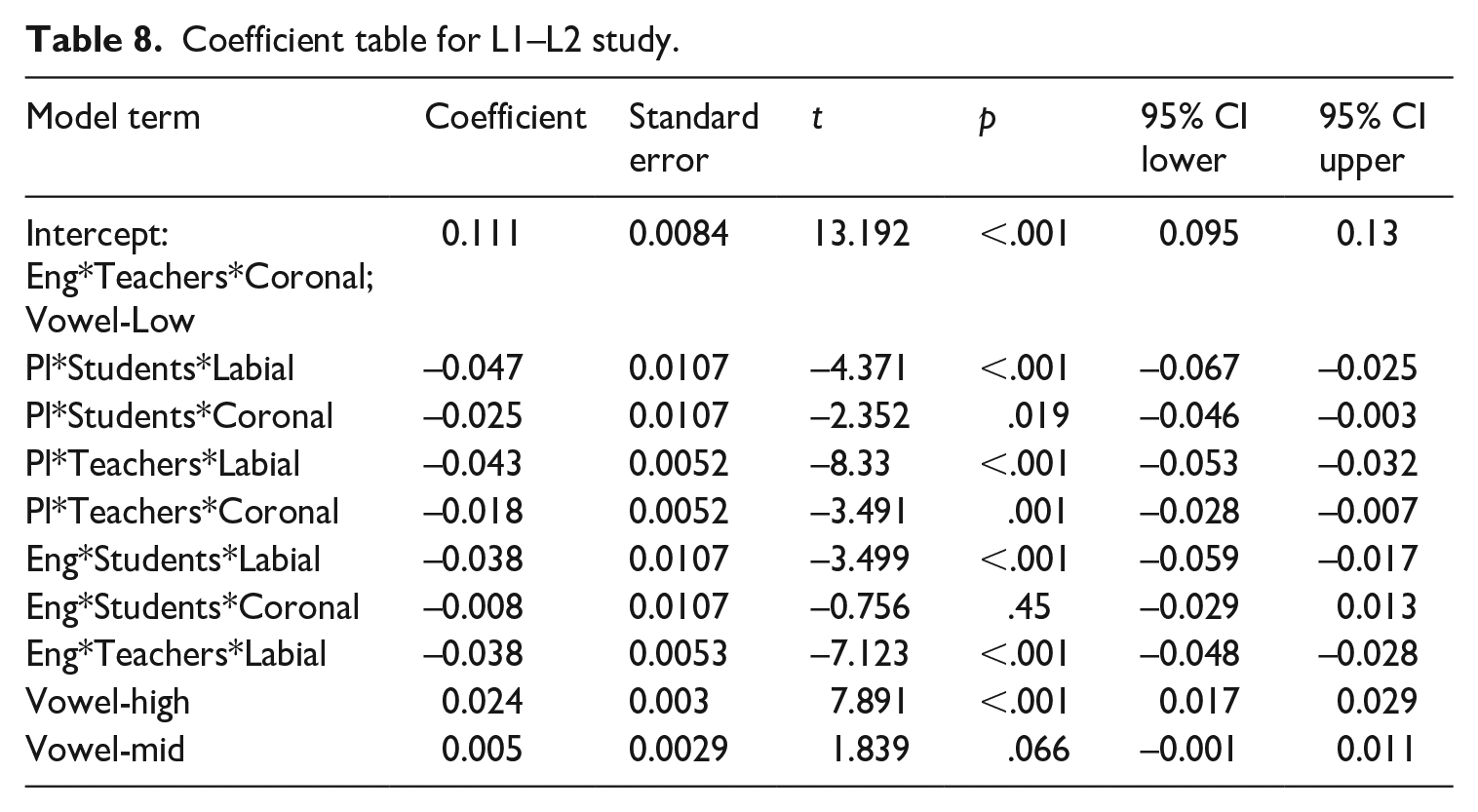
Figure 5 presents mean individual VOT differences (L1 minus L2) between the paired items in the two languages. Error bars represent 95% confidence intervals. Speaker numbers preceded by T indicate the Teachers’ group, while those from the Students group are preceded by S. Negative values indicate a longer mean VOT in L2 English. Individual speakers are arranged on the x-axis in descending order as a function of their mean VOT differences between languages. In the figure, there appears to be no consistency as a function of group – the x-axis is relatively evenly interspersed with speakers from both the Students and Teachers’ groups. It is also apparent that a majority of individual speakers produced longer VOT in L2 English, as is evidenced by the negative VOT differences.
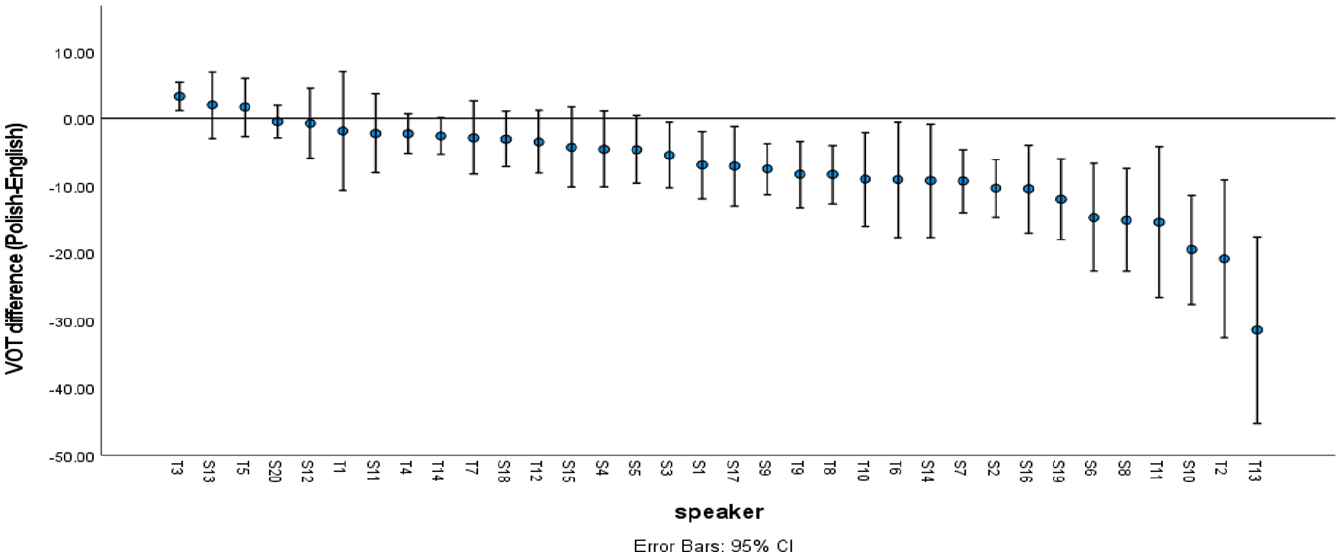
Mean voice onset time (VOT) differences (Polish minus English) as a function of speaker.
5 Discussion
The main aims of the cross-language study were to determine whether Polish learners of English produce shorter VOT in L2 English ST clusters (research question 2), and to check whether L2 proficiency had an effect on VOT in the L2 clusters (research question 3). Our working hypotheses were that VOT should be shorter in L2 English, and that the shortening effect should be greater in the speech of the more proficient L2 users (the Teachers). It is clear that these hypotheses were not confirmed. Neither group of L1 Polish speakers produced L2 English ST clusters with native-like shortened VOT. This was apparent both in the group data (Figure 4), as well as the individual results (Figure 5), with the exception of one speaker (T3 in Figure 5). Speakers from both groups produced longer VOT in L2 English ST clusters than in L1 Polish ST clusters. The only proficiency-based difference was found in /p/, for which the Teachers’ VOTs did not differ significantly in the two languages.
The present results therefore suggest that the accurate production of English ST clusters presents difficulties for L1 Polish speakers. These difficulties have also been documented in perception. Rojczyk (2019) studied the Polish learners’ perception of VOT differences between word-internal ST clusters and those spanning word-boundaries (e.g. Lou spills vs. loose pills; for similar studies with other L1 groups, see Altenberg, 2005; Shoemaker, 2014). He found only slightly better than chance performance in a two-alternative forced-choice experiment across two proficiency levels.
The present findings from ST clusters differ sharply from results obtained in studies examining the acquisition of aspiration and long VOT in L2 English singleton fortis stops. Many studies with groups of L1 Polish learners that are comparable to the groups analysed here (Schwartz, 2022; Schwartz et al., 2020; Waniek-Klimczak, 2005; Wojtkowiak, 2022; Zając, 2015) have documented success in the acquisition of aspiration in L2 English. Indeed, the Schwartz (2022) study was carried out with the same speakers as those examined here. Both groups from the present cross-language study produced initial singleton /p t k/ in English with VOT in the range between 50 and 80 ms. Thus, the question that needs answering is why L2 English fortis stops are acquired successfully when they are singletons, but not when they appear in ST clusters.
In addressing this question, we consider the perspective of Flege’s (1995) Speech Learning Model (SLM; see also Flege and Bohn, 2021). According to Hypothesis 5 of the SLM (Flege, 1995: 239), successful acquisition of an L2 sound may be hindered by ‘equivalence classification’ (e.g. Flege, 1987). Equivalence classification is said to occur when an L1 and L2 sound are similar to each other at an allophonic level, rather than an abstract phonemic level (Hypothesis 1; Flege, 1995: 239). In accordance with the SLM, allophonic similarity leads L2 learners to perceive certain corresponding L1 and L2 sounds as the same, which in turn reduces perceptual sensitivity to phonetic differences between them. By contrast, when listeners attend to phonetic differences between L1 and L2 sounds, a new L2 category is formed and acquisition is more successful. It appears that L1 Polish learners attend to the VOT differences in singleton stops, and aspiration is acquired successfully (Schwartz, 2022; Schwartz et al., 2020; Waniek-Klimczak, 2005; Wojtkowiak, 2022; Zając, 2015), according to the SLM’s predictions. What is less clear is what predictions may be made for ST clusters, and how those predictions may relate to the L1–L2 results from this article.
At first glance, two possibilities present themselves. Due to the VOT resemblance between English post-/s/ stops and English /b d g/, we might expect Polish listeners to perceptually link both English post-/s/ stops and English /b d g/ with Polish voiced stops. The linkage between short-lag and pre-voiced stops has been observed between the languages for /b d g/, and in many other language pairings (for discussion, see Schwartz, 2022). Clearly, however, Polish speakers do not hear English ST clusters as SD (D = voiced stop), a context which would induce regressive voicing assimilation in Polish. While equivalence classification in the SLM is claimed to operate at the allophonic level, the VOT link between English ST clusters and English /b d g/, which is assumed to be allophonic, leads to incorrect predictions about cross-language equivalence between Polish and English ST clusters.
Alternatively, the data from the L1–L2 experiment described in this article may be claimed to suggest interference between abstract phonemes /p t k/ across the two languages, irrespective of their VOT. In other words, the cross-linguistic link may be posited to exist at an abstract phonological level, rather than at an allophonic phonetic level (see, for example, Chang, 2015). However, under a phonemic approach it would be difficult to explain the different degrees of success by Polish learners in acquiring singleton as opposed to post-/s/ fortis stops. At an abstract phonological level, all fortis stops are equivalent, so we should expect comparable success in L2 acquisition across the two positions. Also, a purely phonological approach would have no way of explaining the L2 VOT lengthening observed in the cross-language study described in this article.
A way out of this conundrum may be found in another of the SLM’s postulates, Postulate 4, which states that L1 and L2 categories exist in a ‘common phonological space’ (Flege, 1995: 239). In accordance with this postulate, it may be suggested that L1 Polish learners of English perceptually link post-/s/ fortis stops in English with English initial fortis stops. Under this view, the source of interference is not L1 voiceless stops with short VOT, but rather L2 English voiceless stops with long VOT that have been acquired in initial position. That is, our results point to a kind of hypercorrection, by which L2 learners mistakenly insert ‘initial’ L2 fortis stops into a non-initial context. Assuming this interpretation is correct, a deeper understanding of this common phonological space requires us to reconsider the phonological representation of ST clusters in the two languages.
V General discussion: Cross-language differences in the representation of ST clusters
This section will provide a phonological interpretation of ST clusters within the Onset Prominence representational framework (OP; Schwartz, 2010, 2013, 2016, 2017, 2022). It will be shown that OP can capture the two major generalizations that emerge from the cross-language data on ST clusters described in this article. 8 First, ST clusters have different structural properties in Polish and English, despite the fact that they are equivalent with regard to segmental transcription. This is clear from the results of the L1 Polish study (Section III) showing the lack of systematic VOT shortening of the type observed in English. It is also clear from the different phonological behavior of ST clusters in the two languages (Section II). Second, L1 Polish learners of English do not shorten the VOT of ST clusters in their L2. Rather, they lengthen them, as was shown in the cross-language study in Section IV.
The key aspect of the OP model is that both ‘segments’ and prosodic constituents such as ‘syllables’ are built from a single representational building block: a hierarchy of phonetic events associated with a stop–vowel CV sequence. The OP hierarchy is shown in Figure 6. Each level of the hierarchy is associated with a particular phase in the articulation of the stop–vowel sequence, reflected in the labels of the nodes: Closure, Noise, Vocalic Onset (VO), Vocalic Target (VT). For thorough discussion, see Schwartz. 2016. In OP, the CV sequence is not a linear string of consonant and vowel segments. Rather, it is a single unit from which individual consonants and vowels are extracted. Notably, the hierarchy encodes rising sonority in onsets, since sonority increases at lower levels. This postulate is shown in Figure 6 as the labels on the terminal nodes. Stops and nasals are at the top, 9 then fricatives, then approximants, then vowels. OP represents manner of articulation in terms of the structural nodes present in a given ‘segmental’ tree. For more thorough discussion, see Schwartz, 2016.
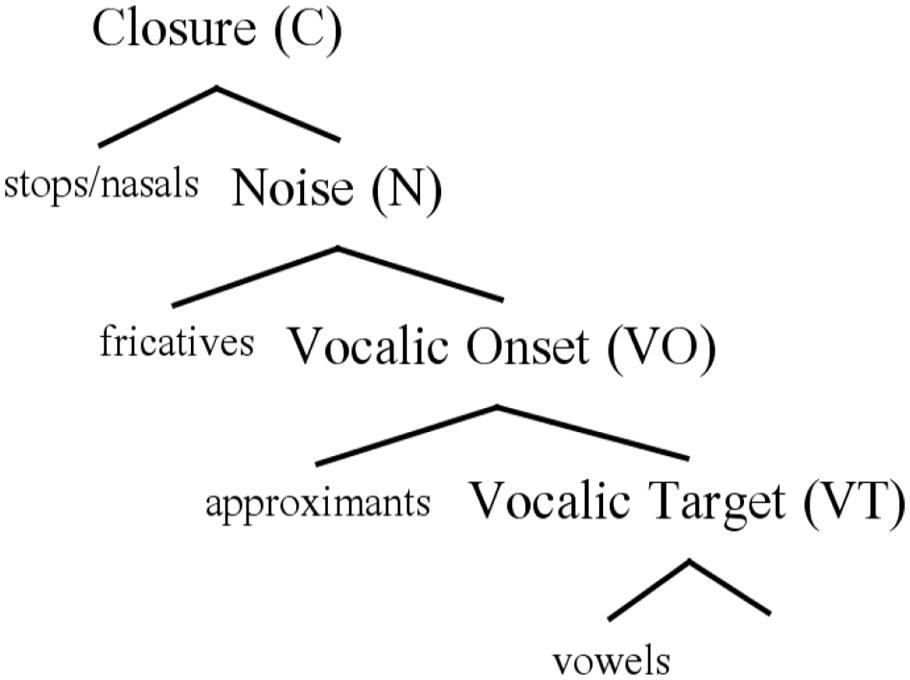
The Onset Prominence representational hierarchy.
Before discussing ST clusters, let us briefly examine the representations for singleton voiceless stops in English and Polish. The difference between short-lag /p t k/ in Polish and aspirated /p t k/ in English depends on the level in the OP hierarchy at which a feature [fortis] is assigned. 10 Closure-level [fortis] assignment yields aspiration, while VO-level [fortis] assignment yields unaspirated voiceless stops. This is illustrated in Figure 7. For more discussion of OP laryngeal phonology, including discussion of the representation of voiced stops, see Schwartz, 2017, 2022.
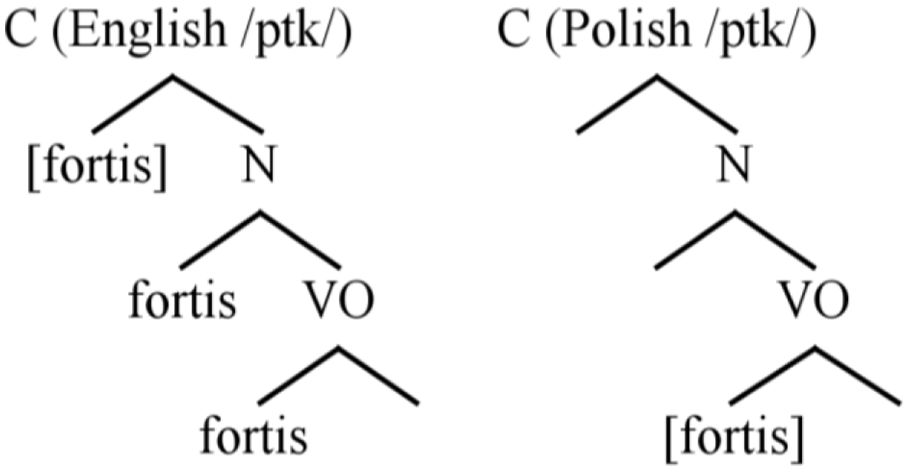
Aspirated English and unaspirated Polish singleton stops.
From the perspective of L2 acquisition, a crucial aspect of Figure 7 is that fortis stops are represented differently in the two languages, so equivalence classification is not expected, and Polish learners of English should be successful in acquiring aspiration in L2 English. This prediction has been borne out in previous studies of L1 Polish learners (Schwartz, 2022; Schwartz et al., 2020; Waniek-Klimczak, 2005; Zając, 2015), as well as studies of other L1 speakers of voicing languages (for discussion, see Schwartz, 2022).
Now we turn to the representation of consonant clusters. Since the basic building block in OP is a CV unit, consonant clusters (and coda consonants) are by definition derivative entities, and we need to describe how they may form. Rising sonority onset clusters can be expressed in a single iteration of the tree structure in Figure 6 (for details, see Schwartz, 2016). However, the formation of non-rising-sonority clusters, including ST sequences, requires additional mechanisms that combine OP trees. ST clusters may emerge from two such mechanisms – submersion and adjunction – whose results are shown in Figure 8. The submersion mechanism is found in English, while the adjunction mechanism occurs in Polish. These mechanisms have independent motivation in the OP model that are related to restrictions on prosodic minimality (see Schwartz, 2016).
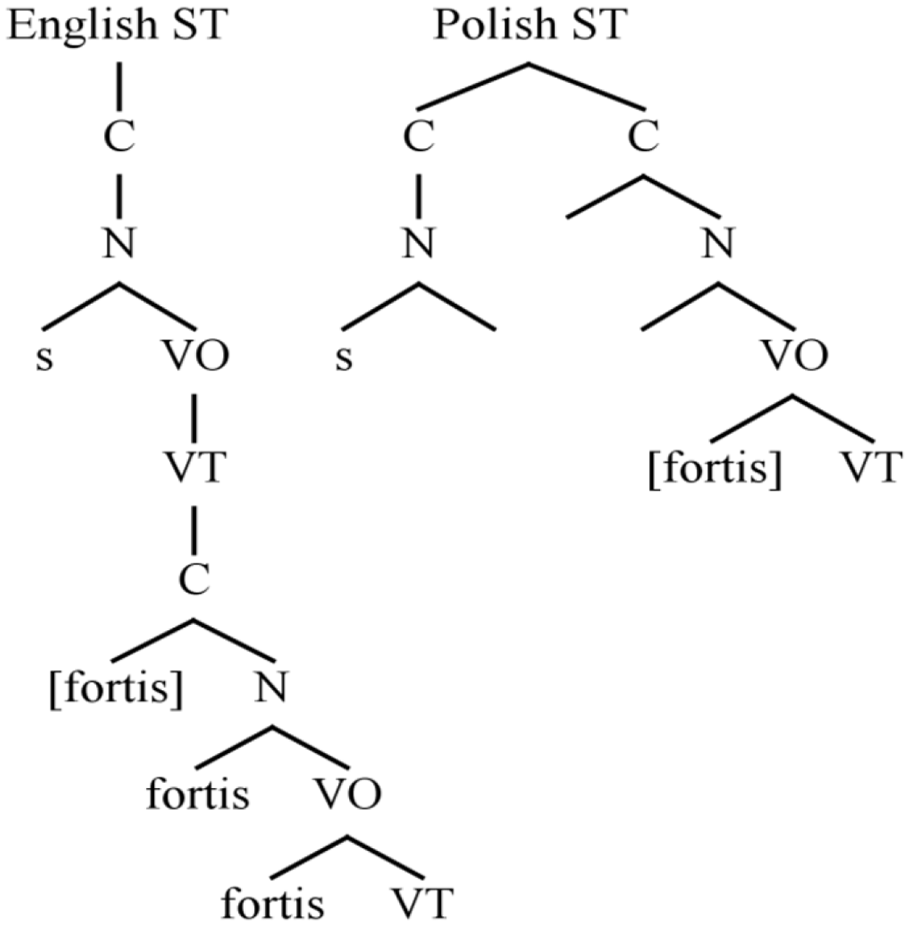
Onset Prominence (OP) configurations for submerged sibilant–stop (ST) clusters in English (left) and adjoined Polish ST clusters.
In the submerged ST cluster shown on the left in Figure 8, both consonants are contained in a single tree, but the stop is housed underneath the /s/. The submerged configuration facilitates weakening and VOT shortening of the stop, as we typically observe in English, since the stop is lower in the hierarchy than the fricative. The adjunction mechanism yields a configuration in which the two consonants are contained in separate trees that are linked at a higher level of structure. In the adjoined configuration, the fricative and stop are at the same hierarchical level and no weakening is expected. The results from the L1 study in Section III are compatible with the adjoined configuration posited for Polish. Crucially, there are a number of arguments, independent of cluster phonotactics, in favor of positing submerged structures in English as opposed to adjoined structures in Polish (for discussion, see Schwartz, 2016).
Before revisiting the results of our experiment against the background of the representations in Figure 8, let us briefly compare OP with traditional segment-based approaches to ST clusters. The basic insight of many phonological approaches, as discussed in 2.1, is that ST clusters do not behave as single syllable ‘onsets’. This insight is clearly expressed in the representations in Figure 8. In neither of those configurations would ST be considered a single onset, since both the submerged and adjoined structures require two iterations of the OP hierarchy from Figure 6. As a result, OP has no problem capturing the phonological patterns discussed in 2.1.
At the same time, traditional approaches appear to make undesirable and infelicitous claims about the representation of ST clusters. In segment-based models, the weakening of post-/s/ stops in English might be thought of as the loss of a contrastive laryngeal feature ([fortis]/[spread glottis]/[-voice]). Two objections to this approach may be raised. First, assuming the phonological arguments about syllable structure described in 2.1 are correct, post-/s/ stops should be thought of as singleton onsets, so in English such an approach would force us to posit the loss of a contrastive phonological specification in ‘onset’ position. This would be quite an unusual process typologically. The onset position is one where contrastive features are observed most consistently – neutralization is generally associated with ‘codas’. In the OP approach, ‘onset’ and ‘coda’ are epiphenomena that are not formally encoded, so no such controversial claims about onset neutralization are made.
Another objection to the traditional approach is that the neutralization of the contrast after /s/ appears to be incomplete, as mentioned in Section II.2. Although the short VOT contributes to the percept of a lenis stop when the recording is taken out of context, another acoustic correlate of voiceless stops, a slightly raised pitch on the following vowel, is still present (Hanson, 2009; see also Figure 1 in this article). Unaspirated fortis stops taken out of context may be perceptually indistinguishable from lenis stops, but they are not acoustically identical to them. Thus, it is not entirely accurate to express weakening in terms of a phonological rule that neutralizes the laryngeal contrast. The OP approach does not suffer from this problem – the stop in English ST clusters is weaker because it is lower in the representational hierarchy, but it is not lenis.
This was clearly the case for the L1 Polish learners of English described in the cross-language experiment (Experiment 2). For these speakers, post-/s/ stops in English are undoubtedly fortis, as was evidenced by the VOT lengthening that was observed. This result suggests that the speakers in the cross-language experiment have not acquired the submerged structure from Figure 8, in which the stop is phonologically weaker after /s/. Rather, the lengthening of VOT in English points to Polish adjoined structure, but with English fortis stops, characterized by Closure-level laryngeal specification. This structure is shown in Figure 9, alongside the English and Polish ST configurations from Figure 8. In the rightmost tree, an English-style fortis stop is placed into a Polish-style adjoined cluster, resulting in longer VOT in L2 English than in Polish.
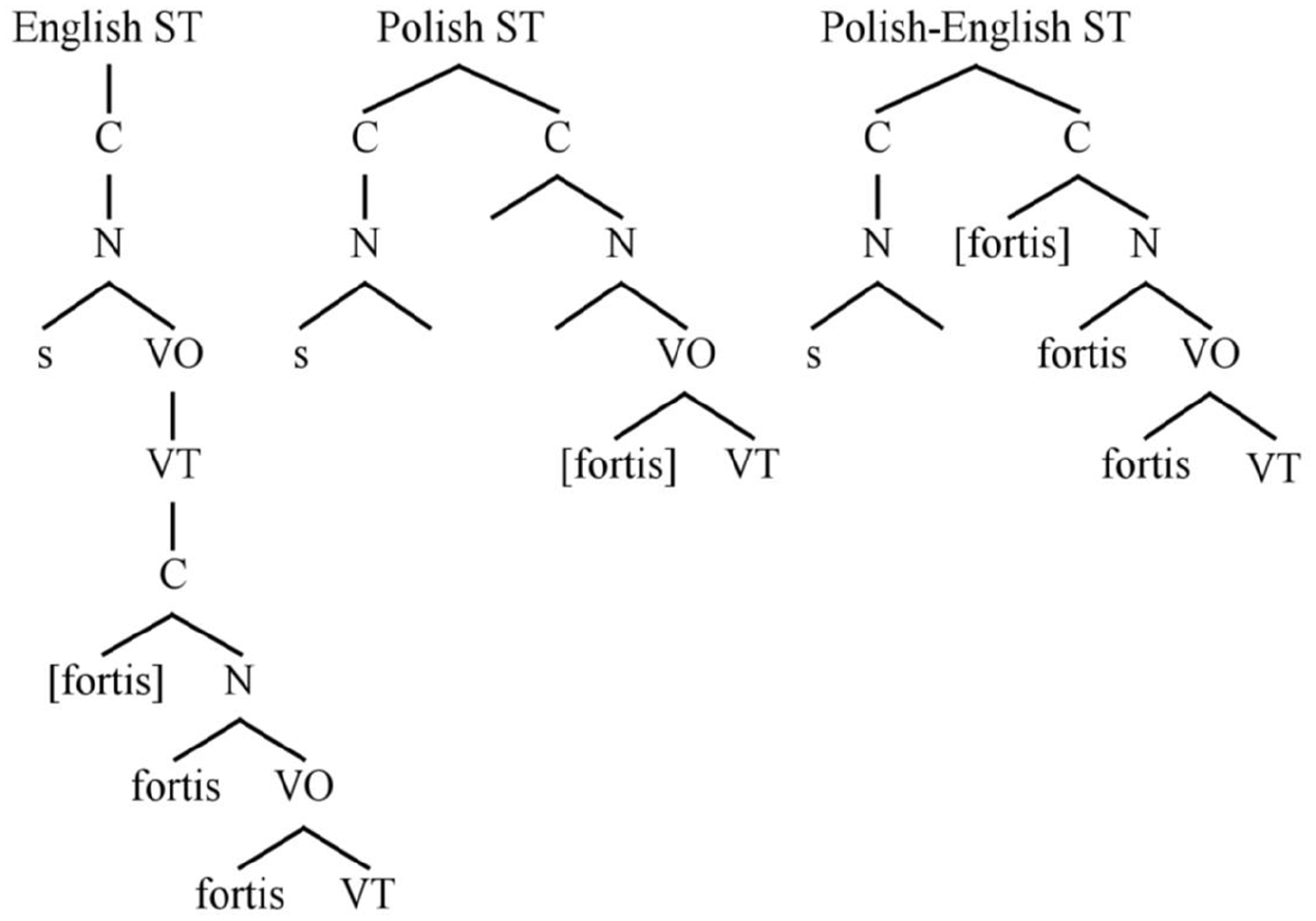
Onset Prominence (OP) configurations for English (left), Polish, and Polish–English sibilant–stop (ST) clusters.
The generalization that emerges in Figure 9, and reflected in the data described here, is that the higher in the structure the [fortis] specification is found, the longer the VOT. Assuming the representations in Figure 9 are correct, it appears that L1 Polish speakers of English place L2 fortis stops, which by all accounts they acquire successfully as singletons in initial position (Schwartz, 2022; Schwartz et al., 2020; Waniek-Klimczak, 2005; Zając, 2015), into a structural configuration found in L1. Thus, Figure 9 allows us to visualize a truly ‘common phonological space’, as posited by the SLM, in which L1 and L2 may interact.
This article has presented cross-language VOT data on ST clusters in the speech of Polish learners of English. The results of the study suggest that L1 Polish speakers mistakenly substitute not an L1 sound, but rather L2 aspirated fortis stops, which had already been acquired. At the same time, the correct structural configuration containing this L2 sound has not been acquired. The contribution of the OP model is that it allows us to visualize and explain the results of the data described here, adding to an increasing number of L2 speech phenomena (Schwartz, 2020) on which OP has provided an insightful perspective.
Footnotes
Appendix 1
Appendix 2
Appendix 3
Appendix 4
Acknowledgements
Thanks go to Ewelina Wojtkowiak, Zuzanna Cal, Joanna Maciąg, Kamil Kaźmierski, Adam Olender, the Second Language Research editorial team, and three anonymous reviewers. Any remaining errors are my own responsibility.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by a grant from the Polish National Science Centre (Narodowe Centrum Nauki), project number UMO-2018/29/B/HS2/00088.