
Abstract
The application of supervised Machine Learning (ML) in material science, especially towards the design of structural Multi-Principal Element Alloys (MPEAs) has rapidly accelerated over the past five years. However, several factors are limiting the impact that these ML methodologies can have, chief amongst them being the availability and fidelity of data. This review analyses how ML has been utilised to accelerate the design of novel structural MPEAs, outlining the standard procedures followed, and highlighting the successes and common pitfalls identified in current studies. The need for experimental validation and incorporation into closed loop ML pipelines is also discussed, including the influence and integration of manufacturing methodologies into the ML decision making process.
Keywords
Introduction
High Entropy Alloys (HEAs), first introduced to the scientific community in 2004 by Yeh et al. 1 and Cantor et al. 2 respectively, are conventionally defined as a class of alloys containing five or more elements in either equiatomic elemental concentrations, or elemental concentrations in the range of 5 to 35 at.%. 1 This concept leads to HEAs occupying a vast uncharted compositional space 3 and sparking a wealth of studies and debates in the literature, not least on appropriate naming conventions. Consequently, several different terms have been proposed and are used to encompass different classes of materials such as, multi-component alloys, compositionally complex alloys, complex concentrated alloys or indeed the broader term, Multi-Principal Element Alloys (MPEAs). Concurrently, the term HEA has evolved to more routinely describe single phase MPEAs.4,5 For consistency in this review, MPEA will be used to refer to all subclasses listed above. Recent review articles and critical assessments of the MPEA field are available for readers unfamiliar with the background and application of these materials.4–8
Machine Learning (ML) is a methodology whereby computer systems can learn to perform specific data-based tasks without any explicit programming. Broadly speaking, ML can be split into three different categories, supervised, unsupervised and reinforcement learning. 9 This review will focus on the application of supervised learning, where ML models are fit on data containing known target outputs. Hence, the model can be trained to recognise patterns and trends in the available input data to predict the output. 10 Supervised learning can be further subdivided into classification and regression tasks. Classification is used to categorise the discrete values of a variable and separate the predictions into different categories. In contrast, regression is used to predict continuous numerical values. 9
With microstructural simplicity being a founding principle of the field, efforts have been made to develop rules to enable the prediction of the formation of solid-solution phases. These rules commonly take the form of two-dimensional phase stability plots and are based on the Hume-Rothery, Gibbs free energy and valence electron criteria.11–18 Furthermore, a significant number of experimental studies have been conducted to determine the microstructural and mechanical properties of different MPEA compositions, fabricated through a variety of manufacturing techniques as well as evaluating the impact of post processing methods.19–24 The generation of rules describing the phase stability of MPEAs, continuous experimental data collection, and vast compositional space, results in a natural relationship forming between ML and the MPEA field. As ML tools and materials data have become more accessible, especially since 2014, the application of ML in the field of material science has been growing exponentially. 25 ML is rapidly becoming an accepted tool to automate materials discovery,26,27 expediting searches of the compositional space in an unconstrained manner, 28 whilst minimising the need for expensive trial and error experiments. 29 ML can guide these experimental investigations by reviewing large amounts of data to discover patterns and trends in higher dimensions than possible for humans. Subsequently enabling downselection of compositions with desirable mechanical and microstructural properties for the intended applications.26,29 These predictions can be performed quickly and produce informative results while being reproducible with the capability for future scaling. 9 Furthermore, newly available data can be directly incorporated into future iterations to improve the prediction capabilities. 28
However, despite these advantages there are several drawbacks to the application of ML to the MPEA field. Firstly, the success and development of ML within the MPEA field is intrinsically linked to the experimental exploration of the compositional space. 26 Diverse and expansive databases are required to train supervised ML algorithms, but MPEA databases typically only contain a few hundred to a few thousand data points.29,30 ML calculations are also susceptible to overfitting, where an ML model too closely matches the training data and may be unable to make more generalised predictions on unseen data. 27 Furthermore, ML models are typically seen as “black boxes”, with limited interpretability into the internal mechanisms that map the input features to the target outputs 9 and a lack of materials science insights. Interpretability refers to the transparency of the model's decision making process and how easy the methodology of decisions is understood. 31
Therefore, it is the aim of this review to investigate the implementation of supervised ML for the design of MPEAs through physical property predictions and the challenges associated with utilising this methodology. The order of this review follows the key steps of a typical ML study, Figure 1. Firstly, the availability of MPEA data suitable for ML is discussed. Secondly, the different input features and ML algorithms utilised in recent studies on ML for structural MPEA design are assessed. Finally, experimental validation of ML predictions and the impact of manufacturing on the application of ML within the MPEA field is examined and areas of further work identified and discussed.
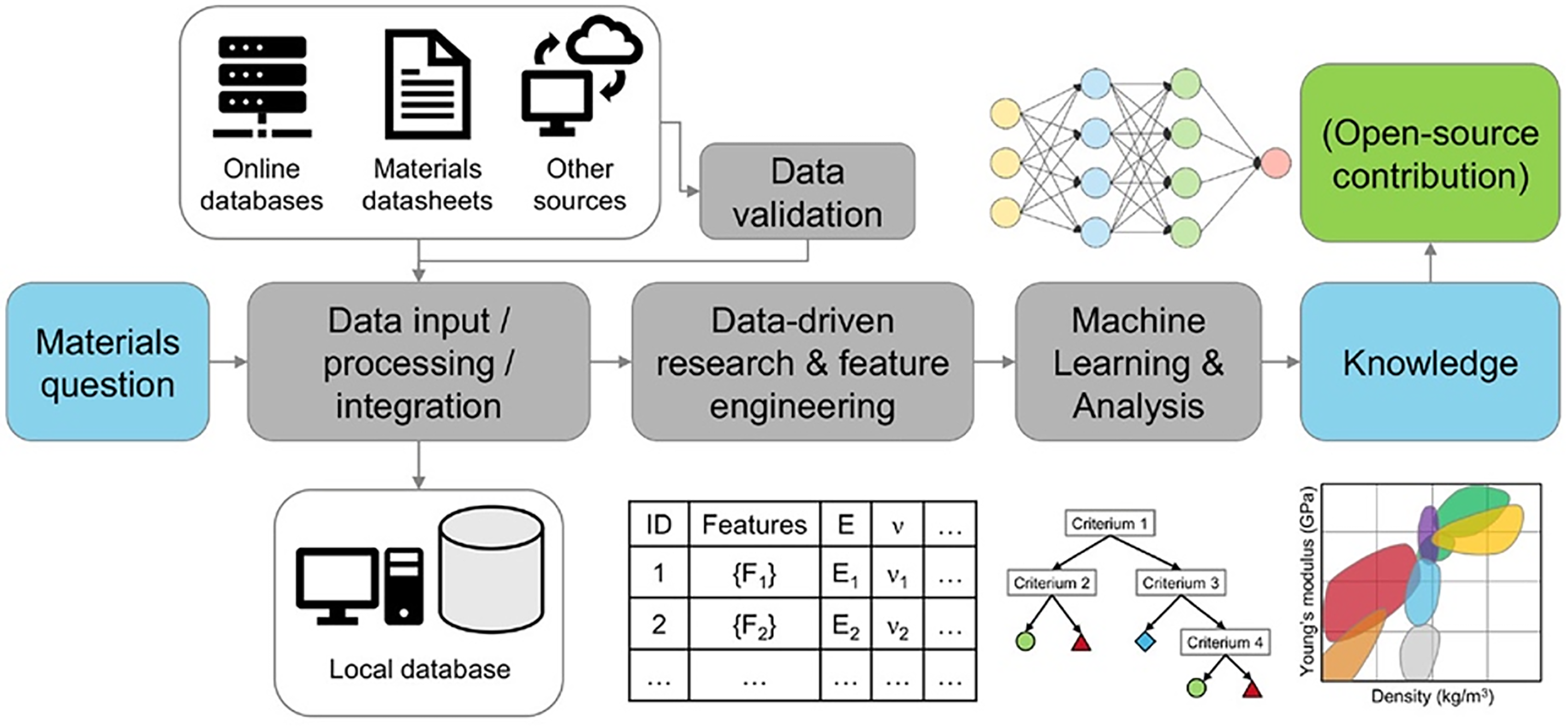
Example of a typical ML study workflow or pipeline within materials science. Reprinted with permission from. 30 ©2024 American Chemical Society
Multi-principal element alloy experimental data
In any supervised ML task, the first step is collecting the appropriate data with which to train and test the models, 31 as shown in Figure 1. ML performs best when the data and its interrelations are too complex for humans to rationalise and often fails to produce meaningful relationships from small amounts of data. 30 Hence, to maximise the ML models’ performance and predictive power, large volumes of high-quality data are required.26,32–34 Furthermore, the size of the available data is critical in determining the optimal ML algorithm for the task. For small datasets, classical and statistical models such as regression, clustering and tree based methods perform best. 30 Significantly more complex algorithms, such as neural networks, require large amounts of data, thus, are only suitable when thousands of unique datapoints are available.30,35
Despite significant research and publications in the field of MPEAs since 2004, the available MPEA data for ML tasks is still sparse.33,36,37 Many ML studies within the MPEA field report that this paucity of data is the main limiting factor in the performance of ML models.27,32,36,38–45 In addition, MPEA data is highly imbalanced because of the initial emphasis towards the discovery of single-phase solid solution microstructures and tendancy to not report negative results in peer-reviewed literature.3,5,10,25,35 When dealing with real world data, duplicated, poorly formatted, and irrelevant and incomplete data is an unavoidable problem. Therefore, to prepare the raw data for analysis, data cleaning and pre-processing is a critical, yet often undocumented step within MPEA ML studies.30,31,33,46
Table 1 summarises a series of experimental MPEA databases available in the published literature, combinations of which are often used as the foundational training data for many published ML studies. 47 Table 1 highlights that significantly more work is needed in making well populated MPEA data open access in standardised formats, to prevent data siloing and facilitate data sharing.25,26,48 All reported results and data from MPEA focussed ML studies should be provided, but this is very often not the case. 30 In addition to these experimental databases, there are many databases constructed from modelling simulations. One example of this is the Materials Project, providing structural and property information on over 150,000 inorganic materials, including MPEAs, from Density Functional Theory (DFT) calculations. 49
Experimentally calculated MPEA databases published in peer-reviewed literature.

*Corrigendum
Because of the relative lack of availability of MPEA data, ML models are often constructed using sparse datasets. For example, to the authors’ knowledge, the largest experimental training dataset was used by Pei et al. 59 and consisted of 1252 datapoints. Conversely, a significant number of studies constructed models from databases containing 200 or fewer datapoints.36,40,42,60,61
To combat the insufficient data within the MPEA field, many data supplementation techniques have been utilised. The CALculation of PHAse Diagrams (CALPHAD) method has been utilised to both generate databases and supplement existing experimental data. Vazquez et al. 35 performed single-point equilibrium calculations to generate an MPEA database of 229,156 compositions. Similarly to CALPHAD, DFT calculations have also been applied to generate MPEA databases for ML training. Zhang et al. 37 generated a dataset of 3579 quaternary MPEAs while Kaufmann et al. 43 supplemented 134 experimental compositions with 1664 DFT compositions. This use of CALPHAD and DFT to generate data for ML training raises the question, if it is possible to generate data in this way to train ML models, why use ML? There are multiple reasons for this. Firstly, CALPHAD is calculated based on energy minimisation of experimental data, which for most alloys, often requires extrapolation from binary and ternary systems that comprise the thermodynamic databases. Secondly, ML is significantly faster and incurs lower computational costs 38 than both CALPHAD and DFT calculations. Vazquez et al. 35 reported that their neural network is 436 times faster than the CALPHAD method, and Kaufmann et al. 28 stated that DFT can take 100s of hours of computation per composition.
As illustrated in Table 1, MPEA data on properties such as phase, collected under a variety of experimental conditions, are published in small datasets across a range of literature. Therefore, it would seem logical to aggregate these data sources to enhance the quantity of MPEA data for ML model training. However, Ottomano et al. 62 argue that expanding datasets in this way may affect the organicity and overall quality of the available data. To demonstrate this, model performance of a range of algorithms was compared before and after aggregation using a variety of collation techniques. In all cases, classical ML algorithms such as random forest and logistic regression demonstrated a reduction in performance. In contrast, deep learning models showed greater robustness, but no significant change in performance. Therefore, when collating data to increase data quantity, it is critical to consider the type of ML algorithm being utilised and the difference in origin of the individual data.
Other methods to combat insufficient data can be as simple as employing an empirical relationship. For example, Equation 1 was used by Huang et al.
27
to convert reported yield strength data σy, to the target variable hardness HV. However, such practices come at the risk of introducing low quality data into the training dataset. Equation 1 for example, has been found to be accurate for BCC MPEAs, but less so for FCC MPEAs.
27
Thus, such practices are generally not recommended for MPEA studies, unless sufficient evidence is present to ensure the fidelity of generated data. Alternatively to physics based or empirical modelling approaches towards data generation, ML can also be used to generate data for ancillary ML algorithms. Lee et al.
63
produced a Conditional Generative Adversarial Network (CGAN) to generate additional training data, and demonstrated that employing a CGAN in conjunction with a neural network can improve phase prediction performance for MPEAs. However, the number and diversity of the generated samples depends on the original dataset. Hence, on smaller datasets, CGAN augmentation has limited impact on model performance.
32
Finally, Pilania et al.
10
discusses the potential shift in focus towards utilising natural language processing as a technique to strip materials knowledge and data from published literature. This could efficiently compile existing materials knowledge to produce substantial databases for MPEA based ML studies.64,65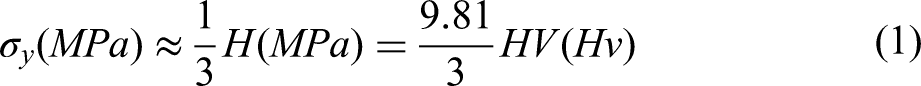
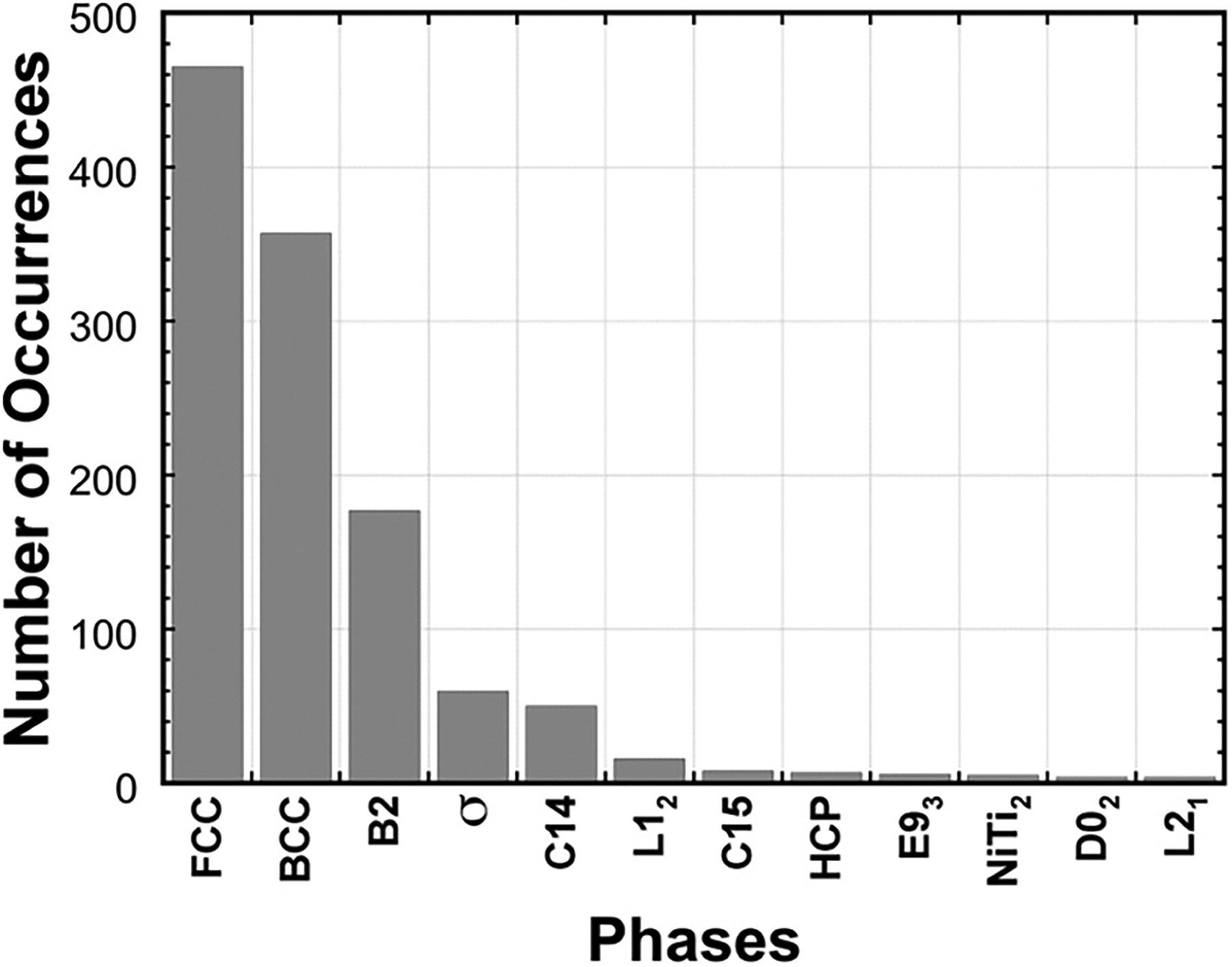
Data imbalance and domination of FCC and BCC phases across 648 published reports of microstructure within MPEA studies. Phases appearing less than 4 times are not shown. 6 ©2024 reused with permission from Elsevier
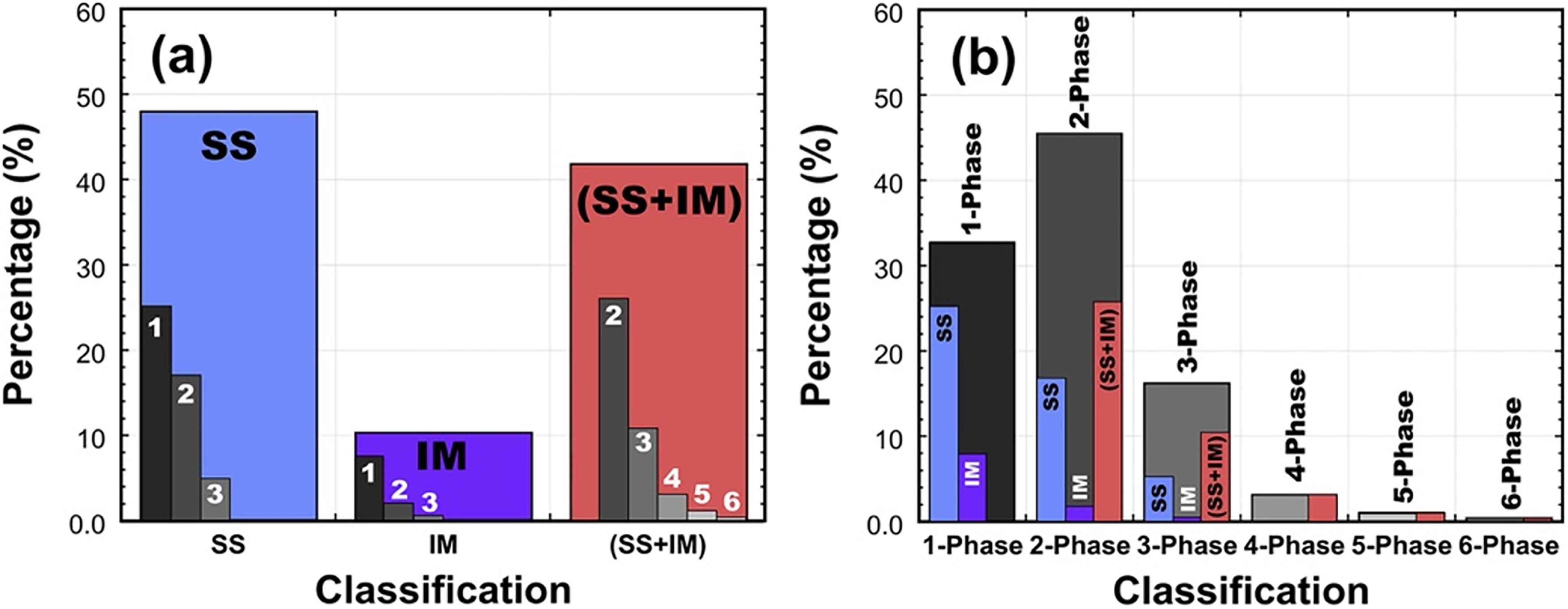
Classification of solid solution and intermetallic phases within MPEA data. (a) Microstructure classification by phase type with sub-classification by number of phases, (b) Number of phases classification with sub-classification by type of phase. 6 ©2024 reused with permission from Elsevier
The most common methods to tackle the issue of imbalanced data are random oversampling and undersampling. 31 Oversampling supplements the available training data with clones of the minority classes in order to balance them with the majority class. 66 Risal et al. 66 applied random oversampling and found it to be effective for phase prediction based on the available dataset. Ren et al. 33 also utilised random oversampling to change the distribution of their datasets and although the authors did not directly comment on the impact of the data augmentation, they successfully produced two models to predict high hardness MPEAs. In contrast, undersampling modifies the class distribution by reducing the data of every class to match the minority class. 66 This technique is significantly less popular in the MPEA field as it means the removal of precious data from already small datasets. Hence, oversampling is generally preferred. Another technique to combat data imbalance is Synthetic Minority Oversampling Technique (SMOTE). 67 SMOTE generates synthetic samples based upon the minority classes of the input dataset, using k-nearest neighbours to sample the feature space of the class, such that the distribution of data across all the classes is balanced. Crucially, this method increases the number of datapoints while maintaining the original trend.39,68 Bansal et al. 68 reported an improvement in model prediction by increasing the quantity of datapoints using synthetic data. However, Singh et al. 69 argue that implementing augmented data to combat data imbalance is not reliable. The authors claim that accuracy alone is not the most robust measure for assessing performance from ML models constructed from imbalanced data and, that it cannot be guaranteed the generated samples are MPEAs. To investigate this, multiple “vanilla” ML classifier models were compared with SMOTE-Tomek augmented models of the same algorithms. The best performing classifier was found to be a random forest model and despite the claims that augmenting data is not the optimal approach the augmented models showed better performance scores in all cases than the vanilla models. Hareharen et al. 70 also find that SMOTE improves the ML model's ability to differentiate between the various classes.
Multi-principal element alloy feature selection
Supervised ML tasks aim to construct models to predict a target variable from a set of input features. 9 In the case of MPEAs, the target is often phase formation47,71 as a proxy for microstructure, which dictates structural and mechanical properties. Thus, the input features are most commonly empirical relations based on the atomic properties of the alloys’ constituent elements describing electronic, thermodynamic, physical and chemical characteristics.32,72 Table 2 summarises several examples of features frequently utilised in MPEA ML models.
Examples of features commonly used in ML models in the MPEA field

Quantities denoted with a bar indicate that it is the average value, while quantities with an i indicate the i’th element. c represents the atomic fraction of the element, r denotes the atomic radii and E represents the Youngs modulus. R is the molar gas constant. For
Features, such as those summarised in Table 2, often originate from the Hume-Rothery rules on solid-solution formation for binary systems. For example, the need for small atomic size differences, comparable valency and similar electronegativities. 80 These features have been shown to display clear trends with MPEA microstructural and mechanical properties, thus, successfully translating to MPEA ML studies. Guo et al. 13 determined Valence Electron Concentration (VEC) to be the physical parameter controlling formation of FCC (VEC ≥ 8) or BCC (VEC < 6.87) solid solutions. This observed phase formation has a strong impact on mechanical properties with BCC phases typically observed to display a higher hardness, 81 but a lower ductility compared to their FCC counterparts.8,82,83 Similarly, Wang et al. 18 developed a new parameter, γ to describe atomic packing as an improvement to the commonly accepted atomic size difference, δ, where γ < 1.175 results in solid-solution formation. Indeed, these trends have also been observed when applied to ML studies, with VEC and δ being reported as two of the most important features by many authors investigating both microstructural and mechanical properties,27,33,41,42,84 demonstrated in Figure 4. This importance is defined and measured according to how much impact the feature has on the models decision making process.
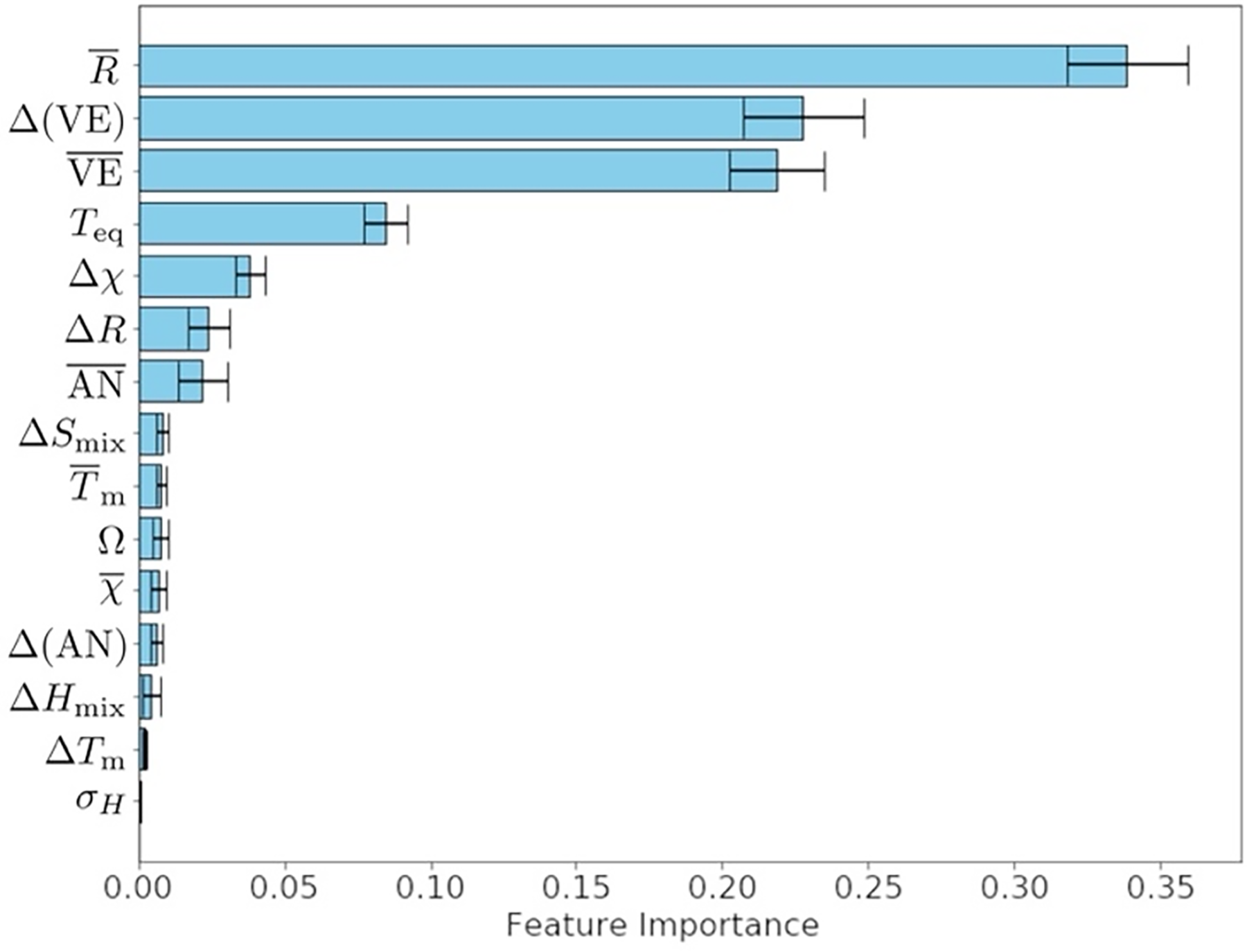
Feature importance scores of 15 features within an XGBoost model used for phase classification. In this case R denotes atomic radius and VE represents valence electron count. 85 ©2024 adapted with permission from Elsevier
An important decision when selecting features for MPEA ML studies is whether to include the chemical composition of the alloy as an input feature. Bakr et al. 45 demonstrated that it is possible to train an artificial neural network for phase and hardness prediction of MPEAs using only the chemical composition as the input feature. Similarly, Jain et al. 46 included the elemental compositions as features for phase predictions and used them as the only feature for hardness predictions. However, Wen et al. 86 argue that utilising the elemental composition, in conjunction with the elemental property features discussed above, significantly out-performs just training ML models on the elemental composition. Furthermore, Morgan et al. 25 state that utilising composition as an input feature means that the model cannot be used to extrapolate to systems including elements outside of the training data. Hence, they argue that it is better to represent each element with elemental properties to enable feature generation by taking compositionally averaged combinations of the constituent elements, as in Table 2. If utilising ML to optimise the composition of an already defined MPEA system, then including composition may be useful. For example, Chen et al. 41 include the molar fraction of the six constituent elements of their MPEA system as features for the model, but only hardness optimisation of a single alloy system was investigated. Alternatively, if the goal of ML application is materials discovery, then evidence suggests prioritising elemental property features.
Subsequent to data collection, feature engineering is the next step in model construction and consists of feature generation and selection. Firstly, the features chosen for any ML model must be both machine readable and relevant to the target variable.
25
Following the discussion of the need for high quantities of data to train ML models, it could be assumed that the more features available to make predictions of the target, the better a model will perform. However, this is not the case and many MPEA ML studies demonstrate that as the number of features increases, prediction accuracy plateaus,33,86–88 as illustrated in Figure 5
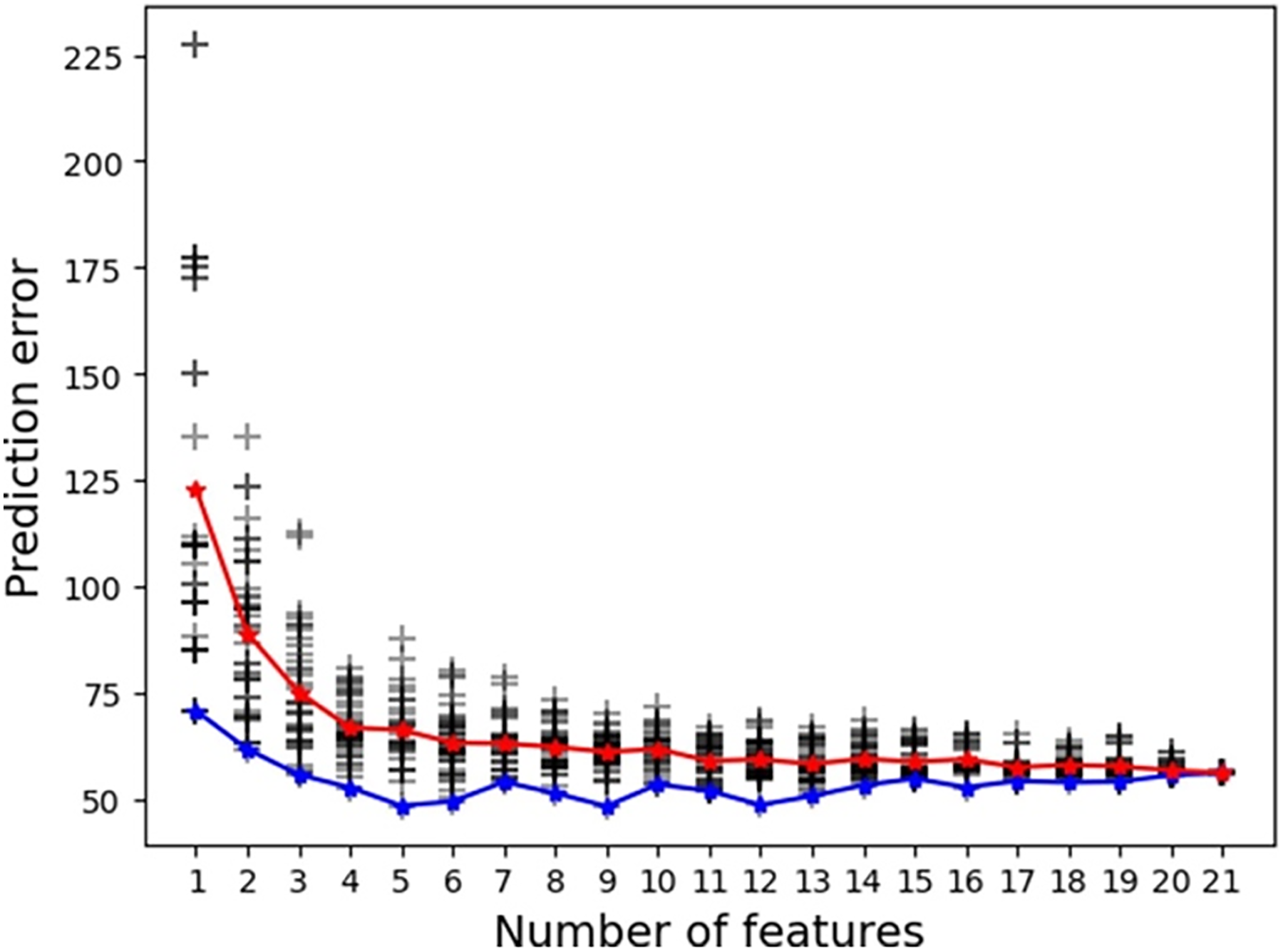
Model performance plateaus as the number of features is increased, in this case for a support vector machine model. The red and blue lines represent the average and lowest prediction error for that number of features respectively. 88 ©2024 reused with permission from Elsevier
Collinearity of features is detrimental to model performance,
33
computational efficiency and, crucially, interpretability, Further, it restricts the ability to ascertain the individual contribution of each feature to the model.
90
Hence, for features that are correlated, the least important feature is typically omitted.40,44 To detect collinearity, the most popular method is to measure the correlation of individual features using the Pearson Correlation Coefficient (PCC),34,91 given by Equation 2.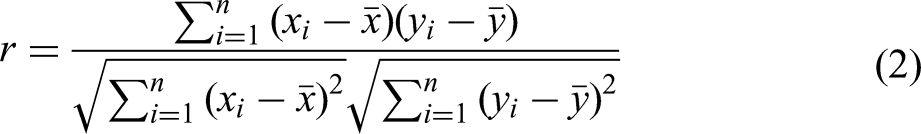
Data, features, and models are extensively interlinked and so the optimal feature combinations for the available data must be found for each model tested. However, it can be computationally prohibitive to test every possible permutation. 25 Several techniques and approaches have been developed to enable feature engineering. The first and simplest method of feature selection is human context. Nonsensical features and those with no relation to the target variable should be removed. 25 Sequential feature selection iteratively adds or subtracts features from the dataset in order to maximise model performance.25,33,87 Li et al. 88 utilised a genetic algorithm to find the optimal combination of features. The genetic algorithm mimics the mechanism of natural selection to arrive at the global optimum performance without testing every possible combination. This saves on computational efficiency over the exhaustive sequential feature selection methods, especially for large feature spaces. MPEA ML studies mostly agree that fewer features (4 or 5) are optimal for predicting phase formation33,86–88 and mechanical properties. 29 However, although Huang et al. 40 agrees that the optimal number of features for phase selection is small (5), they find that the optimal number of features for hardness prediction is much larger (13), in contrast to the majority of MPEA studies.
Machine learning algorithms for multi-principal element alloy design
An exhaustive discussion on how each individual supervised ML algorithm functions is beyond the scope of this review. See Hastie et al. 71 and James et al. 90 for an overview. No supervised ML algorithm is by default superior to any other and the choice of optimal algorithm depends strongly on the available data and target output.30,87 Choosing a suitable algorithm is critical for improving model performance and efficiency. 33 Therefore, many ML studies trial a handful of potential ML algorithm candidates to determine which performs the best, for example,34,40,87 shown in Figure 6. Alternatively, some ML MPEA studies already have a specific algorithm in mind because of the benefits of that particular methodology. For example, Bhandari et al. 44 and Choudhury et al. 94 select a random forest algorithm for its simplicity and interpretability.
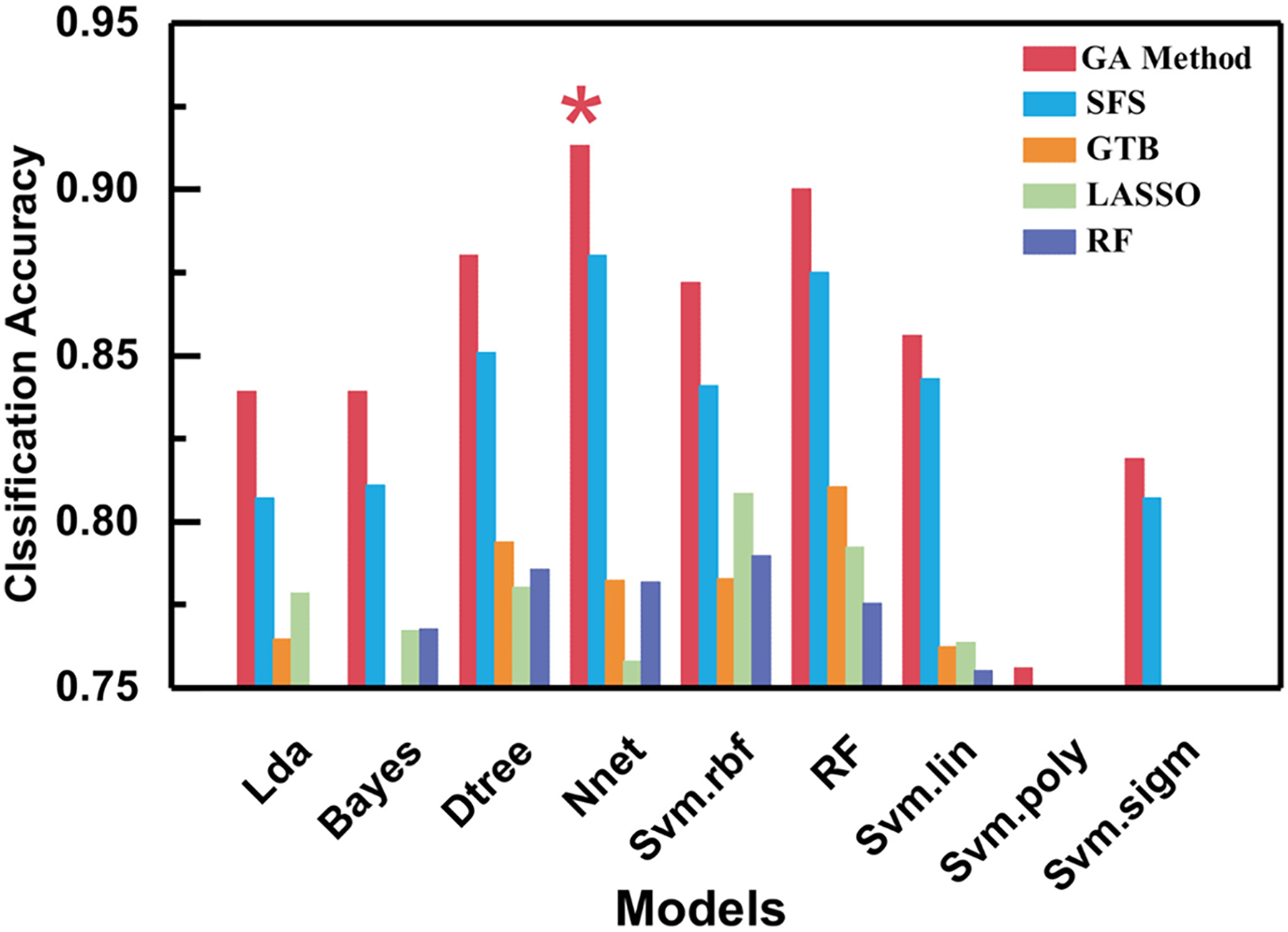
Comparison of model performance across the same experimental database. Each column represents a different feature subset selected by application of the models indicated in the legend. 87 ©2024 adapted with permission from Elsevier
Simple linear regression models are much easier to interpret but lack in predictive power and performance. 30 Clustering algorithms, such as k-nearest neighbours, often suffer from low accuracy and when the data is imbalanced, the more frequent classes significantly dominate predictions, becoming more noticeable as the number of neighbours considered increases.27,34 Tree based algorithms have very high interpretability and training speed but are susceptible to overfitting. However, ensemble tree based models such as random forest have anti-overfitting properties.10,34 In contrast, support vector machines and neural networks can provide a boost in predictive performance at the cost of model interpretability and the need to scale input data. Lastly, neural networks require significantly more computational power and training time for small gains in performance.10,30,31 Figure 7 provides an illustration of this transparency to performance trade-off.
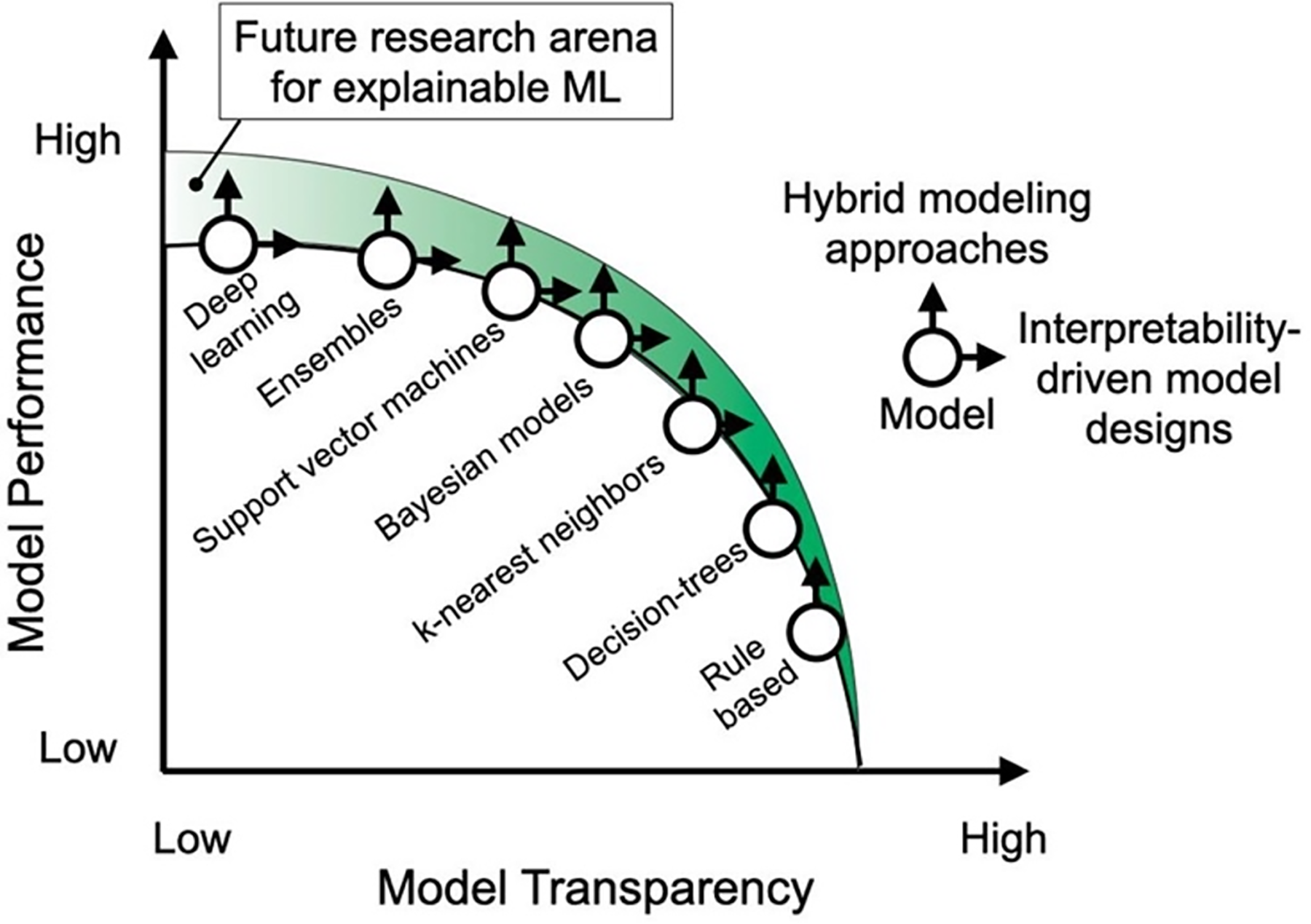
Trade-off between model transparency and model predictive performance. 10 ©2024 reused with permission from Elsevier
To assess the predictive performance of supervised ML models a range of metrics are available, split between the classification and regression tasks, that assess the difference between the model's predicted outputs and the true outputs from the validation data set.
25
For classification tasks, accuracy, precision, recall, and F1-score are the most common performance metrics in MPEA ML studies, provided in Equation 3.39,45,47,94 A complete description of these can be found in Dalianis.
95
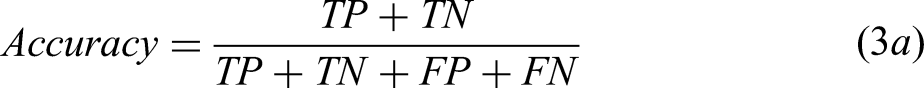


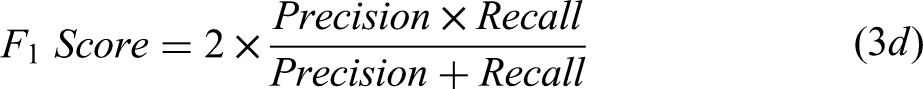
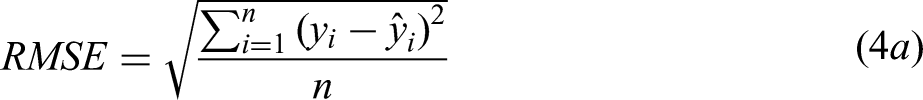


There are two common ways to split the data to train an ML model and assess its performance. The first is Train-Test-Split where the database is simply split into fixed fractions (e.g., 80% – 10% – 10%). However, this can cause poor generalisability in the data across the fractions if the data distribution is imbalanced. 33 Bakr et al. 45 reported a significant difference between the RMSE of the training and testing data due to a different distribution of data across the two sets. The second approach is k-fold cross-validation, Figure 8. In this method the dataset is divided into k equal fractions, with each fraction used once as validation data while the other k-1 fractions are used for training. After k iterations, the model will have been trained and validated k times on the same database, eliminating the effect of sampling. This enables the average performance metrics to be calculated, providing a more appropriate assessment of model performance, and is particularly useful for small datasets, such as those in the MPEA field.27,33,45 However, while the majority of MPEA ML studies detail the methodology they have used to assess the performance of the model on the available data, very few discuss retraining the final model using the whole database. This is a key step to maximise the amount of training data. As it is not often discussed in the published literature, it is unclear if this step is performed in MPEA ML studies, with the notable exception of Liu et al. 36
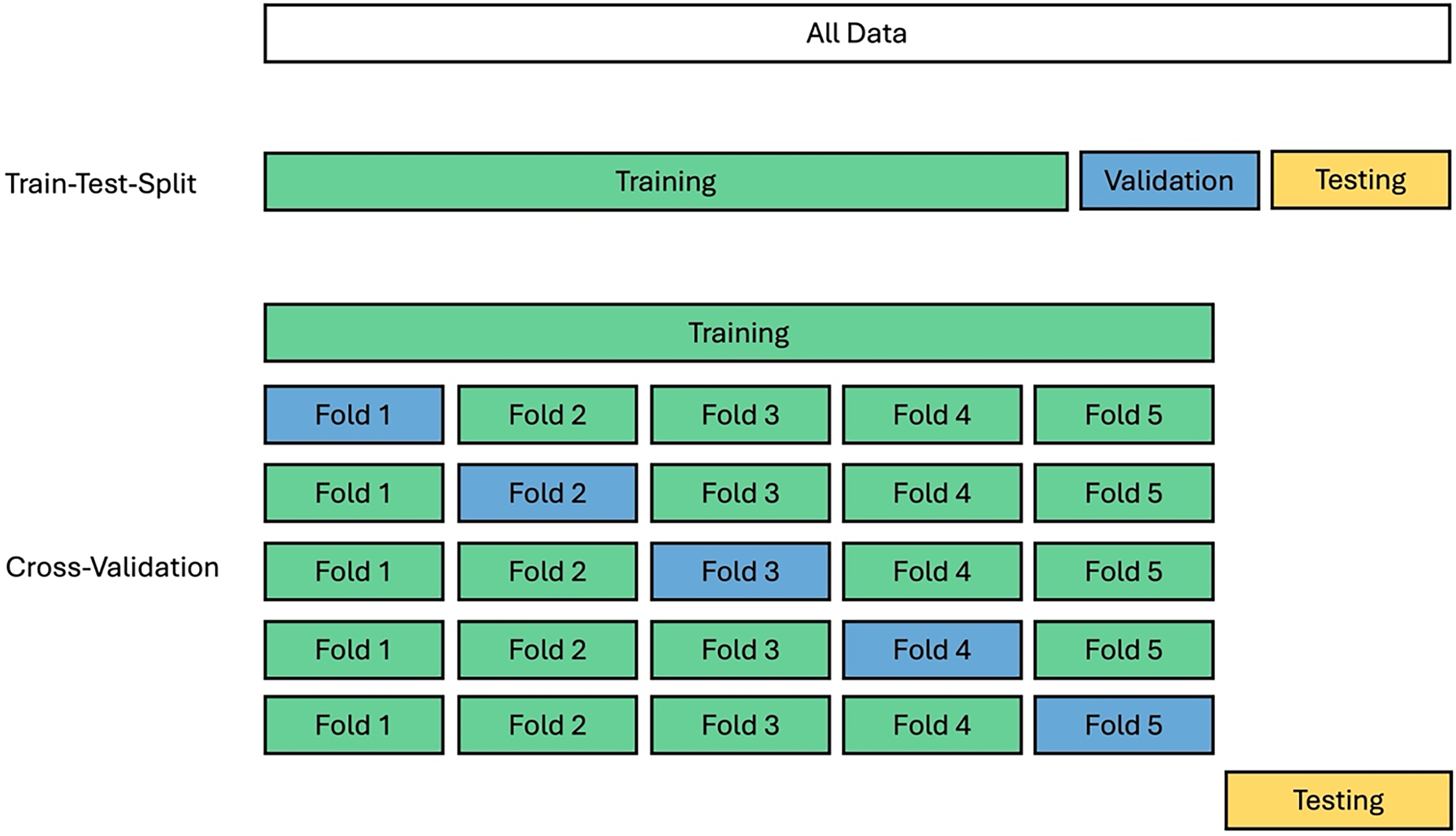
Comparison of the train-test-split and cross-validation model performance assessment methodologies. Highlights how cross-validation allows the model to be trained and validated multiple times before final testing.
Hyperparameter optimisation is a key step in the development of ML models and features in the vast majority of MPEA ML studies. Hyperparameters are guidelines for the ML model construction that control the learning process. 30 For example, they could be controlling the maximum number of trees and branches in a random forest or the number of nodes and layers in a neural network. 72 It is important to optimise the hyperparameters of an ML model to maximise the model performance and speed.33,96 The two most common methods of hyperparameter optimisation within MPEA ML studies are grid search and Bayesian optimisation. For grid search, a range for each hyperparameter is specified and each possible combination of these parameters is tested against a baseline to find the optimal combination. This can also be performed randomly rather than exhaustively to save on computation time. In contrast, Bayesian optimisation minimises the loss on an error function to find the optimal hyperparameters for a model. Neither method is by definition better than the other, but both have been used successfully in MPEA ML studies.39,84 Hyperparameter optimisation is also coupled with cross-validation to provide a more accurate assessment of the impact of hyperparameter changes on performance.33,43
Table 3 summarises many recent studies where ML has been utilised to predict MPEA microstructural and mechanical properties, demonstrating the rapid adoption of ML in the field, in contrast to the lack of development in data availability, Table 2. As illustrated in Table 3 it is clear that the majority of ML models target alloy phase formation, because of the strong dependence of mechanical properties on microstructure. Of the alloy mechanical properties, hardness is the most commonly investigated in ML based MPEA studies, likely due to the ease of experimental measurement to validate model predictions and generate data. 3
List of current publications on utilising supervised ML for MPEA design. In studies that compared multiple models, the best performing model or the one used to make predictions on unseen data is quoted in the table. Training data is experimentally determined unless otherwise stated. Data availability is the measure of how readily available the data for the published work is.
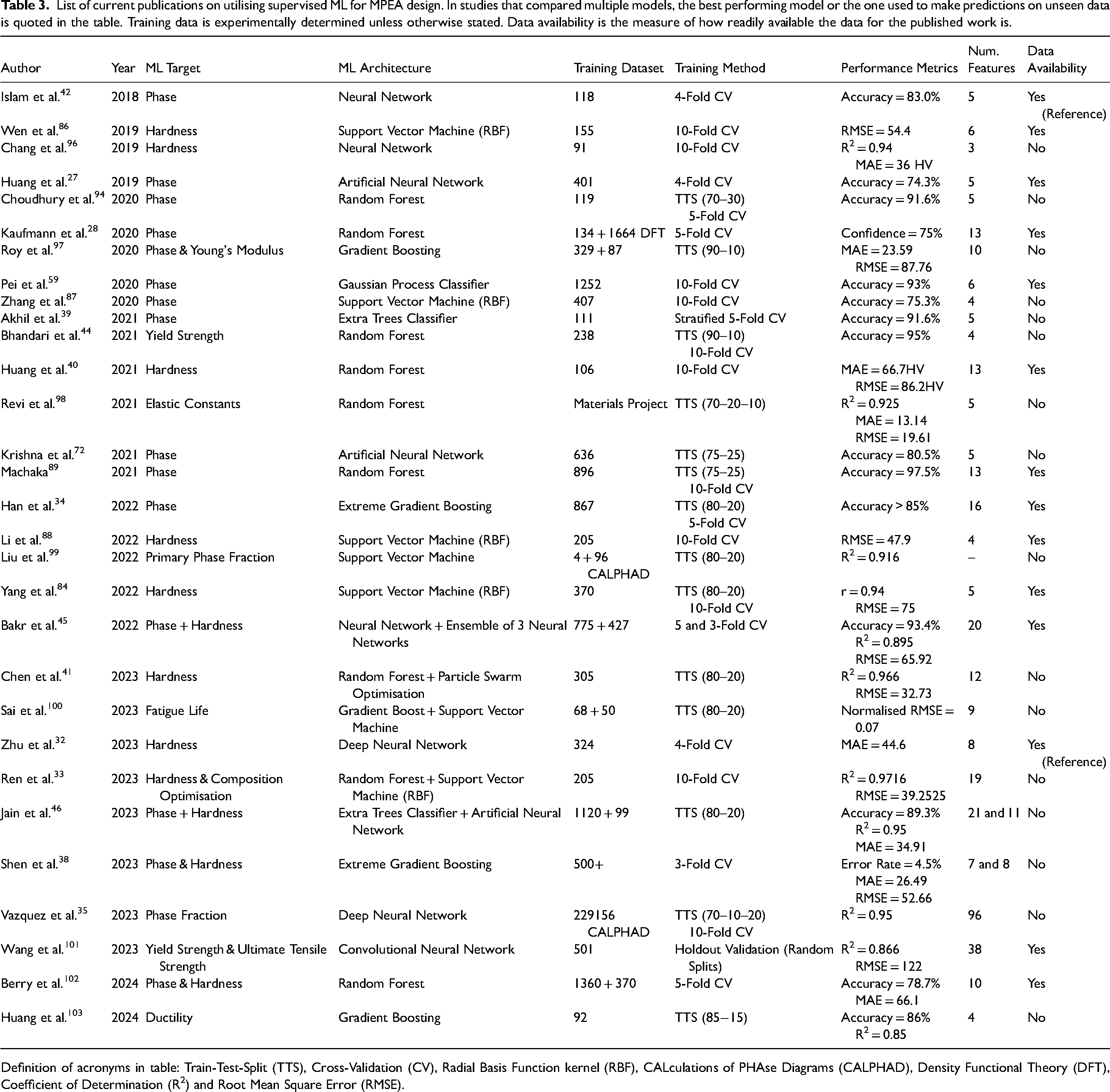
Definition of acronyms in table: Train-Test-Split (TTS), Cross-Validation (CV), Radial Basis Function kernel (RBF), CALculations of PHAse Diagrams (CALPHAD), Density Functional Theory (DFT), Coefficient of Determination (R2) and Root Mean Square Error (RMSE).
Phase formation prediction is a complex classification task with many possible phases that can form within MPEAs. Hence, many MPEA ML studies drastically condense the phase space in order to simplify the ML task and improve performance. For example, the MPEA database produced by Machaka et al. 56 contains 35 distinct labels for the phases of different compositions, which is simplified to 7 distinct labels. Furthermore, many MPEA ML studies reduce the classification problems down to binary and tertiary cases where the model is predicting whether or not solid solution formation occurs, or some form of solid solution, intermetallic or amorphous phase respectively.27,34,42,72,94 This reduction in the number of classes is helpful to obtain meaningful results from the ML, but can be exaggerated in the aim of maximising performance.
The studies in Table 3 mostly utilise standard ML algorithms with a small number of input features based on the intrinsic properties of the constituent elements. Furthermore, these studies typically utilise small databases, often with insufficient data to effectively train the more complex models, such as neural networks. In some cases these studies are lacking experimental validation of the model outputs, availability of data to enable future iterations, and sufficient consideration of the impact of manufacturing on MPEA design.
From machine learning to multi-principal element alloy design
Once the models have been successfully constructed, trained and their performance assessed, the next step is to use the model to predict on unseen data. To do this most MPEA studies generate a virtual candidate search space. This involves selecting the desired elements and considering every possible combination in equimolar ratios, in a system of chosen size. For instance, Zhang et al. 87 considered 30 different elements in MPEA systems containing 4–6 elements in equimolar ratios. This produced a total of 763,686 unexplored alloy compositions for the ML to make predictions on the phase formation. This search space can be expanded to cover non-equimolar compositions, with each element typically being varied between 5 and 35 at.% with a compositional granularity of 1 at.%.84,86 In some MPEA studies, constraints are placed on the search space to further narrow it down. For example, in the study by Akhil et al., 39 the search space was reduced by first applying the constraints, δ < 6.6% and −15 < Hmix < 5 kJ/mol to aid in the search for HCP forming MPEAs. However, this is an unnecessary step as ML is a very fast process and if this constraint was suitable for mapping HCP formation, then it would be expected to be predicted accordingly by the ML model if trained correctly.
Alternatively, an inverse design methodology can be utilised. 104 In this case the final output property criteria is first specified as an input. The trained ML model then predicts feature configurations and hence, alloy compositions, that could satisfy the chosen property criteria.101,105 Yang et al. 84 utilised an inverse design methodology by projecting samples in the optimal property zone of the performance space and then deducing the features yielding this performance by inverse projection. Finally, the MPEA composition closest to the performance projection point by Euclidean distance was selected as the alloy composition to yield the high-performance property and was experimentally fabricated. From this inverse projection three MPEA compositions were downselected, synthesised and characterised. The best performing of these compositions exhibited a hardness 24.8% higher than the highest composition in the original dataset. Guo et al. 106 also apply inverse projection, but to optimise the composition of a preselected MPEA system, AlCrFeNiTi, to maximise hardness. From this inverse projection, four of the optimised composition alloys were experimentally synthesised. The highest hardness of these demonstrated a hardness 21.5% higher than any composition in the original dataset.
Debnath et al. 107 performed a comparative study of forward and inverse design methodologies with a case study on the ultimate tensile strength of refractory MPEAs. The authors observed that the inverse design methodology could identify a composition with the same constraints as the forward scheme, but produced a higher target property prediction. Additionally, the authors state that for the inverse design case the addition of new conditions and generation of new candidates is incredibly fast compared to the forward case, which needs to be regenerated with each iteration. However, inverse design is not without its disadvantages. Often numerous feasible solutions are presented by the inverse ML due to a greater number of variables than constraints and, minor variations in the desired property can produce significant changes in alloy composition prediction. 108
Experimental validation
As previously discussed, the success and development of ML within the MPEA field is intrinsically linked to the experimental exploration of the compositional space. However, a significant number of MPEA ML studies do not contain any form of experimental validation.28,39,44,45 The most common approach to experimental validation is to fabricate a small number of downselected samples, typically between 5 and 10, via vacuum arc or induction melting, or through powder metallurgy routes. 109
Once the samples have been fabricated, the standard approach is to investigate the microstructure and mechanical properties to validate the results of the ML predictions and discover new compositions with exceptional properties. The vast majority of MPEA ML studies perform this investigation via the application of scanning electron microscopy, in conjunction with energy dispersive x-ray spectroscopy, to determine the microstructure, compare the nominal to actual composition, and observe any elemental segregation. X-ray diffraction is also used to further crystallographically analyse the phase formation within the alloy. Mechanical property assessments, most commonly hardness, are performed using Vickers microhardness indentation.33,38,40,86,96 Examples of this experimental assessment are provided in Figure 9. Additional analysis techniques such as electron backscattered diffraction, 34 transmission electron microscopy and selected area diffraction 99 can enable greater insight into the crystallographic phase formation of the fabricated MPEAs, but this is typically above the resolution needed for ML model validation. However, there is a clear absence of extensive mechanical testing and post processing of the alloys, with Wang et al. 101 being one of the few to measure tensile properties of MPEAs following different post processing regimes predicted through ML.
Experimental analysis performed on a series of 5 different compositions within the FeNiCuCo alloy system, downselected using a random forest model. a) Hardness. b) X-ray diffraction. c) Back scattered electron images. d) Energy dispersive x-ray spectroscopy maps of elemental distributions. 40 ©2024 reused with permission from Elsevier
The manufacturing methodology used to synthesise MPEAs significantly impacts alloy microstructure and phase formation, which governs the materials mechanical properties and overall performance.36,45,110,111 Post processing heat treatments can also further alter alloy microstructure and improve alloy mechanical performance. 112 For example, Otto et al. 113 demonstrated that even the most exemplar single-phase solid solution MPEA system, CrMnFeCoNi, is not always single phase. After annealing at intermediate temperatures (<700°C), it will decay to form several secondary precipitates. Hence, incorporating the manufacturing and processing history into the ML task would assist the models to make accurate predictions irrespective of synthesis methodology.
For small scale trials of new MPEA compositions, arc melting is the dominant method for MPEA manufacture, 114 especially for refractory MPEAs due to the high arc temperature. 110 However, the formation of defects such as cold shuts, 115 cracking and elemental segregation are common in arc-melted ingots.110,114 Thus, the microstructure and mechanical properties can vary significantly throughout the ingot in the as-cast state. 114 Additive manufacturing processes offer faster cooling rates than conventional casting, resulting in a much finer grain structure, potentially enhancing mechanical properties. 112 However, the microstructures are more complex due to the different temperature histories and heating of subsequent layers. 112 In both cases, subsequent heat treatments can initiate phase transformations and improve mechanical properties. Homogenisation of MPEAs typically leads to higher strength than their as-cast counterparts 111 as well as mitigating or eliminating defects. 112
Despite this, the majority of MPEA literature presents microstructure and mechanical properties in the as-cast condition,69,114 which is not indicative of industrial applications. Furthermore, the majority of MPEA ML studies don’t appropriately account for processing conditions,45,116 select only as-cast data or omit any samples not in the as-cast state and manufactured via arc melting.33,40,84,86,87 The first barrier to the implementation of processing to MPEA ML studies is the lack of information available in publications, as it is not consistently reported within the literature.40,45 In addition, Machaka 89 reported that post processing heat-treatment features performed poorly in classification of phase formation tasks.
To incorporate the effect of manufacturing into the ML process Zhu et al. 32 inserted the fabrication method into the input layer of a deep neural network for prediction of hardness by one-hot encoding. This is a process where categorical variables are mapped to integers so that they can be interpreted by the ML model. However, heat treated and laser remelted values of hardness were removed from the database in the initial data cleaning stage to eliminate the influence of process treatments. Two deep learning models were produced and the one incorporating manufacturing was found to perform better, highlighting the need to consider manufacturing conditions. Wang et al. 101 employed a similar approach, but instead utilised processing conditions, such as annealing time and temperature, as input features due to their influence on mechanical properties. Bakr et al. 45 trained a series of neural networks, using nominal MPEA composition, manufacturing route and heat treatment temperature as the direct input features in the hardness model.
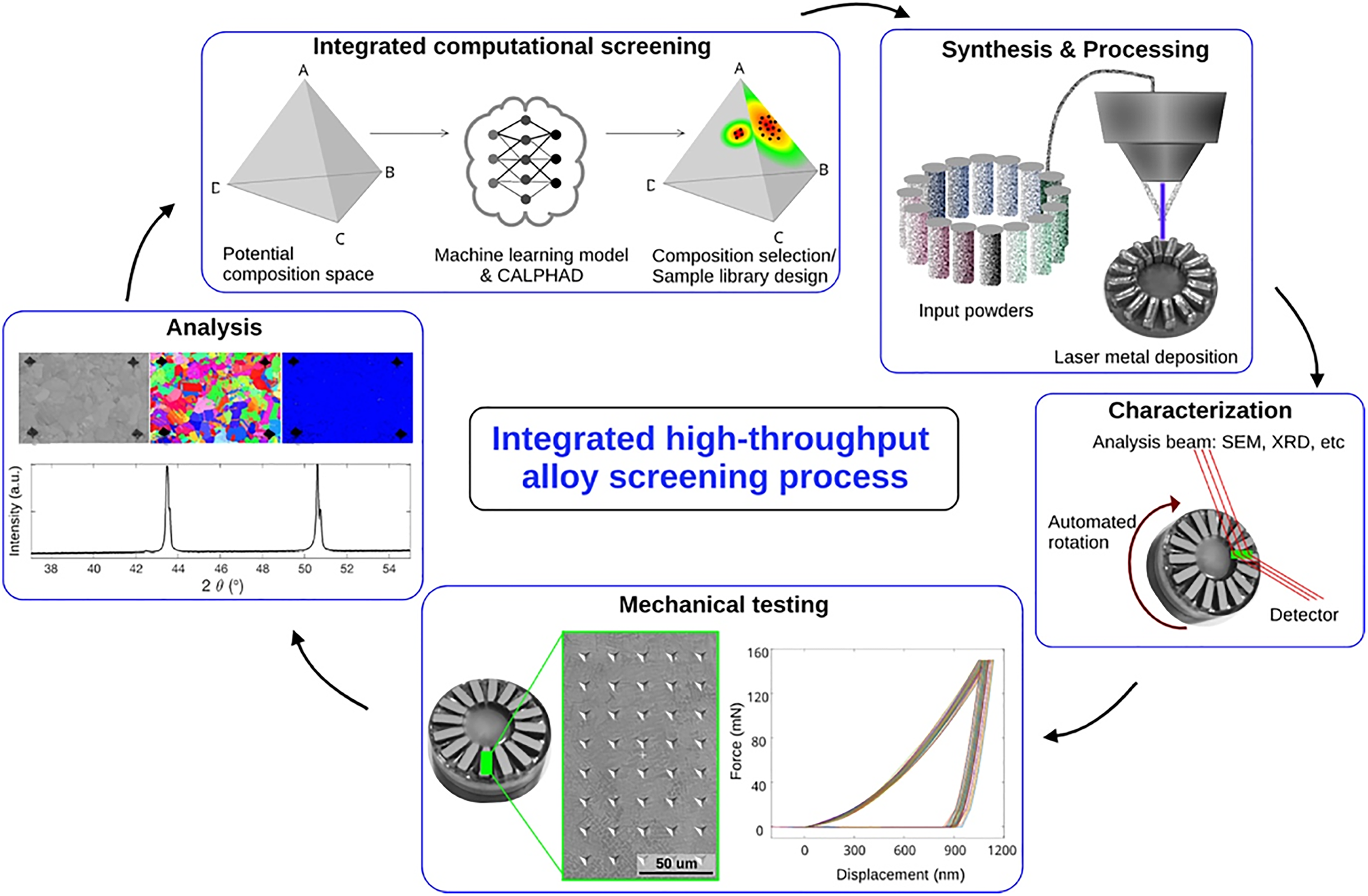
High-throughput experimental workflow from computation ML model predictions through alloy fabrication, characterisation, testing and analysis in an automated high-throughput manner, before closing the loop. 119 ©2024 reused with permission from Elsevier
As discussed, when MPEA ML studies experimentally validate the ML model predictions they fabricate a small sample of compositions. 36 However, the combination of large MPEA compositional space and capability of ML to rapidly make predictions across this unexplored space makes the connection of ML to High-Throughput Experiments (HTE) a logical advancement. HTE enable rapid synthesis and characterisations of MPEAs to validate ML predictions with enhanced efficiency. 110 Thus, the application of HTE approaches to ML has the potential to further accelerate and reduce cost of MPEA design. 117 Furthermore, the rapid generation of experimental data by implementation of HTEs can aid in constructing substantial MPEA databases for the development of future ML models. 36 Moorehead et al. 118 utilised additive manufacturing in the form of directed energy deposition to construct arrays of different MPEA compositions onto a single build plate. 50 individual MPEA compositions are printed onto a single plate and x-ray diffraction, scanning electron microscopy and energy dispersive x-ray spectroscopy are all performed without removing the parts from the build plate. Moorehead et al. 118 also produced an arc-melted button, indicative of those typically produced by MPEA ML studies for validation and found that additive manufacturing enabled a time saving of an order of magnitude compared to conventional casting. Vecchio et al. 119 validated computational predictions of phase formation using CALPHAD, and hardness using an ML model with HTEs. MPEA samples were printed using directed energy deposition with a special hopper system allowing 16 different alloy compositions to be printed per build cycle. The MPEAs are built specifically to allow characterisation of microstructural and mechanical properties to also be performed in a high-throughput manner, Figure 10. In contrast, Liu et al. 36 applied HTE prior to ML to fabricate 138 MPEA compositions of the chosen alloy system through powder metallurgy. These compositions were then used to train an ML model to reveal the complete composition-hardness relationships across the compositional range of the chosen system. In addition, future expansion of HTE methodologies to include the implementation of autonomous or self-driving laboratories could further accelerate the discovery and optimisation of materials,120–122 with MPEAs representing a suitable materials candidate.
Conclusions
Supervised ML has the potential to accelerate materials design and discovery within the MPEA space. The current direction of travel in the application of ML to the MPEA field is towards the complete automation of the materials design process. ML can be used to make large numbers of predictions on MPEA compositions to identify those with potentially advantageous mechanical and structural properties. These identified compositions can then be fabricated in a high-throughput manner within automated laboratories to enable model validation and assess their suitability to meet the design criteria. Regardless of the level of automation, domain knowledge of materials science is still integral to ensure the application of ML within the field is logical and incorporates the established understandings of decades of research. Additionally, there are many gaps identified within the field that need to be addressed in the interest of standardising and enhancing the use of supervised ML for MPEA design.
First and most critical, is the availability of MPEA data. Lack of available data is the most commonly cited reason for performance issues encountered in MPEA based ML studies. Hence, experimental MPEA data needs to be published and made open access to be utilised effectively in future work within the field. This must include the method of fabrication and testing to improve the reliability of the data and enable it to be incorporated into ML models. The CALPHAD and DFT based data used in some studies to train models should also be made available to save on computationally expensive and time-consuming calculations. Furthermore, a wider, more general issue within the MPEA field is the need for a standardised naming convention for MPEAs to be established, making pre-existing data on alloy compositions easier to discern.
The relationship between supervised ML based alloy design methodologies and traditional alloy design methodologies needs to be considered. As discussed and shown in Table 3 of this report, a majority of ML MPEA studies focus on the optimisation of a single alloy property, either within a preselected system or across the whole MPEA space. In contrast, conventional alloy design processes look to balance many properties to achieve high performance while minimising cost and maintaining manufacturability. Hence, there is a clear need to move to multi output models.
Finally, the success and development of ML within the MPEA field is intrinsically linked to the experimental exploration of the compositional space. Many ML MPEA studies contain a workflow that portray data looping, where the experimental results of the study are fed back into the available data. However, the studies themselves end at the experimental assessments and publication. Thus, it is imperative that this data is not lost and is indeed recycled back into openly available databases to fuel further ML studies.
Footnotes
Acknowledgements
This work was supported by Oerlikon AM Europe GmbH (website: https://www.oerlikon.com/am/en/), Engineering and Physical Sciences Research Council UK [EP/S022635/1] (website: ![]() ).
).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Engineering and Physical Sciences Research Council, Oerlikon AM Europe GmbH, (grant number EP/S022635/1).