
Abstract
How to optimize ordering the parts of a language test (e.g., items, tasks, and sections) is often overlooked or assumed to be self-evident. However, ordering choices are an essential component of test design as they may impact test takers’ objective performance, perceived performance, or affective states. In this paper, we report on a systematic review of test component ordering research, focusing on 88 studies from 1933 to 2023. We provide a narrative synthesis, describing typical outcome variables (e.g., test-taker performance), independent variables (e.g., order of difficulty), and mediating variables (e.g., language proficiency). Key findings, mostly from higher educational contexts, indicate that easy-to-hard ordering may lead to better performance, though these effects are mediated by various test-taker characteristics, especially anxiety and proficiency. While section ordering by language skills is common practice in language testing, there is scant empirical support for this approach, or for organizing tests by content or format. We discuss the implications of these findings for language test developers and suggest avenues for future research, particularly the need for more studies on ordering effects in language assessment contexts.
Test design has many elements relating to both task specifications and the structural characteristics of the test. Collectively, these constitute the “blueprint” of the test (Bachman & Palmer, 2010). In this systematic review, the blueprint element of interest is the sequence of parts (i.e., components) of the test. We conceptualize these components at varying levels of granularity, following definitions in Davies et al. (1999). The smallest are items—individual units of measurement such as a single multiple-choice question (MCQ) or a blank in a cloze passage. Larger tasks may comprise multiple items (e.g., a reading passage with several comprehension questions, also called an item set) or involve more complex performance of speaking or writing (e.g., describing an image). The largest components are often referred to as (test) sections (also called subtests or testlets, for example, a reading section), commonly grouping multiple tasks or items by language skill or content area. While terminology can vary or overlap, in this review, we primarily use items, tasks, and sections to refer to these distinct levels. To describe the intentional sequencing of test parts of all sizes, we use the term ordering, for example, ordering items or tasks from easier to harder or ordering sections according to language skill.
In Bachman and Palmer’s (1996) framework of task characteristics, sequence of parts is specified as an aspect of test organization within structure (i.e., how test parts are assembled and presented), and it also relates to the input facet (i.e., how information is presented to test takers). Likewise, “the ordering of items and sections” is part of test specifications discussed in the Standards for Educational and Psychological Testing (American Educational Research Association [AERA] et al., 2014). The explicit inclusion of ordering in these texts indicates that test component ordering is a non-trivial design choice that can influence key aspects of test usefulness, particularly construct validity and impact (cf. Bachman & Palmer, 2010). For instance, the sequence of test parts can affect the accurate measurement of communicative competence by introducing construct-irrelevant variance through factors such as induced anxiety, fatigue, or cognitive load. Furthermore, ordering directly shapes test-taker experience (Burstein et al., 2022), potentially influencing test takers’ affective states (e.g., motivation and confidence) and perceptions of the test’s difficulty and fairness. Understanding these effects is therefore necessary for developing assessments that are both psychometrically sound and equitable for all test takers.
These considerations are particularly salient in language testing, given the aim of assessing the multifaceted construct of communicative language ability. An interactionalist perspective (e.g., Chapelle, 1998; Messick, 1989; Young, 2011) posits that test performance arises from an interaction between test takers’ underlying traits (language skills, competencies, and strategies) and the context of the assessment, including task characteristics. Test component ordering is a critical feature of this context. For instance, task sequencing might influence how effectively different aspects of communicative competence are elicited and interact (e.g., organizational and pragmatic language competences; Bachman & Palmer, 1996, 2010). Through the lens of Canale and Swain’s (1980) Communication Competence Model, task order could impact the deployment of strategic competence, influencing how test takers manage task demands, compensate for difficulties, or plan responses based on prior or anticipated test components. The ordering of tasks, especially those involving complex production, may thus affect an assessment’s ability to reflect how these competences are deployed in authentic, sequenced communicative activities. Accordingly, ordering choices may alter which subconstructs are elicited, the cognitive demands placed on test takers, and the resulting inferences about communicative competence.
Despite the theoretical imperative to carefully consider ordering, it is often overlooked or assumed to be self-evident (Fulcher, 2010), and explicit, evidence-based justification is generally absent from test development guidelines and specifications. The consequences of this oversight are stark and could lead to random error, thereby threatening test reliability (Pettijohn & Sacco, 2007). Such construct-irrelevant variance, if it differentially impacts test-taker subgroups, would constitute bias.
Additionally, the ongoing trend of computer-based, remote language testing obviates the constraints on ordering imposed by group administrations, presenting an unprecedented opportunity to rethink test component ordering, including in computer-adaptive tests (CATs). However, despite this opportunity and the distinct characteristics of language assessment, from its multidimensional nature to its focus on evaluating communicative competence, empirical research examining ordering effects in language testing contexts is scarce. Therefore, in this paper, we systematically review extant ordering research in cognitive ability testing in the broader educational assessment literature.
Previous Secondary Test Ordering Research
To our knowledge, four previous papers have synthesized primary test component ordering research: three non-systematic literature reviews (Hauck et al., 2017; Leary & Dorans, 1985; Stout & Dellva, 1990) and one meta-analysis (Aamodt & McShane, 1992). A search of the International Database of Education Systematic Reviews (IDESR, n.d.) did not return any relevant results. The earliest of the four papers, Leary and Dorans (1985), reviewed literature on altering item context in aptitude and educational testing, including item-difficulty ordering, conceptual grouping, and section arrangement effects. The authors concluded that while some context effects were evident, they were not substantial enough to invalidate test theory or practice that relies on item parameter invariance. Stout and Dellva (1990) reviewed research on potential sources of test bias in business education contexts, examining item-difficulty ordering, topic ordering, and section placement effects. The authors highlighted mixed findings across studies, especially for item-difficulty and topic-ordering effects, and limited evidence of section placement effects. Most recently, Hauck et al. (2017) reviewed relationships between item ordering (by difficulty and content) and performance on multiple-choice exams in psychology courses, finding little consistent impact on exam scores. Finally, and most germane to our study, Aamodt and McShane (1992) conducted a meta-analysis on item characteristics effects (item-difficulty and content ordering) on test scores and completion times. They found small positive effects on test scores of easy-to-hard (E–H) ordering compared to random or hard-to-easy (H–E) ordering. They also found a very small but statistically significant effect favoring exams ordered by content. They concluded that item-difficulty ordering only had a significant impact on state anxiety when comparing E–H and H–E conditions. Importantly, their analysis was limited to a limited set of studies with available effect sizes.
The scope of these evidence syntheses is substantially different from the present review in terms of domain and/or time period. Yet, they unanimously emphasized the need for further research, whether on how ordering may differentially affect test-taker subgroups (Aamodt & McShane, 1992; Leary & Dorans, 1985), perceived difficulty (Hauck et al., 2017), or domain-specific ordering effects (Stout & Dellva, 1990). As such, an updated review of this topic is needed through the lens of relevance to language testing. While these studies did not meet the inclusion criteria for our analysis as they are non-experimental secondary research, we make reference to them to provide additional perspective.
In this review, we address the following overarching research question:
In educational and particularly language proficiency assessment, what impact does the ordering of test parts have on test-taker performance (both objective and subjective) and test-taker experience/affect?
Methods
We conducted the review following the PRISMA-S checklist (Page et al., 2021), which can be accessed on the project’s Open Science Framework (OSF) page (Naismith & Cardwell, 2025): https://osf.io/c6zf2/.
Eligibility Criteria
We included studies that met all of the following criteria:
Investigated assessments of knowledge and cognitive skills, including educational testing.
Presented original empirical research.
Compared two or more purposive ordering conditions.
We excluded studies that:
Investigated solely the order in which response options are presented within items.
Investigated solely the effect of item location on test forms.
Investigated solely rating order effects.
Were not peer-reviewed.
We applied these criteria first to titles and abstracts, then to full texts. No restrictions on publication language were applied, although searches were conducted in English only. The final database searches were conducted on 15 January 2025.
Information Sources and Search Strategy
To identify relevant research, we systematically searched a selection of databases, journals, test developer research repositories, and conference programs. Two large, multidisciplinary databases were searched: (a) ERIC (Education Resources Information Center), due to its comprehensive coverage of educational research, and (b) PsycInfo to cast a broader net from behavioral and social sciences, areas that often inform educational testing practices (AERA et al., 2014). To ensure thorough coverage of language testing research, we also conducted targeted searches of two premier journals in language assessment: Language Assessment Quarterly (LAQ) and Language Testing (LT). Additionally, we searched the research repositories of the following organizations that develop or research language tests to identify relevant research not otherwise published in peer-reviewed outlets, that is, reputable gray literature: Educational Testing Service, College Board, Cambridge Assessment, Pearson, and Center for Applied Linguistics. However, only research or technical reports that explicitly employ a peer-review process were included. Lastly, we searched all Language Testing Research Colloquium (LTRC) conference programs available on the International Language Testing Association (ILTA) website (years 1979–2019; 2021–2024). Due to the lack of advanced search capabilities on test organizations’ websites and LTRC programs, we were unable to fully apply the systematic search procedure and instead assessed records for inclusion using the keywords shown in the search strategy in Figure 1. Where the search engine allowed, we searched for variants of test, exam, and assessment, combined with variants of order, sequence, and arrangement. Variants of higher order were excluded, as this term relates to thinking skills and statistical modeling rather than test ordering. We used Zotero to manage bibliographic information, notes, and article PDFs.

Systematic review search term.
To supplement these searches, we undertook two additional steps. First, citation searching was carried out by compiling relevant citations from publications identified through the initial search. Second, as the initial search of relevant databases, journals, and testing organization repositories yielded few ordering studies in language assessment, we conducted a subsequent search on Google Scholar. Google Scholar was incorporated at this stage due to its extensive multidisciplinary indexing, which often includes a broader range of publication types and sources (e.g., articles in press, institutional repositories, and smaller journals) than many curated databases.
Study Selection
We reviewed all unique publications identified through the database search (n = 223), reading each title and abstract, and where necessary the full papers, to determine suitability (Figure 2). Following recommended practice (McDonagh et al., 2013), 20% of identified studies were randomly sampled and independently double reviewed (n = 45). Inter-coder reliability was almost perfect with only one disagreement (agreement = 97.8%, κ = 0.92), indicating that a single review of the remaining publications and targeted search results was acceptable. Any discrepancies were resolved through discussion.
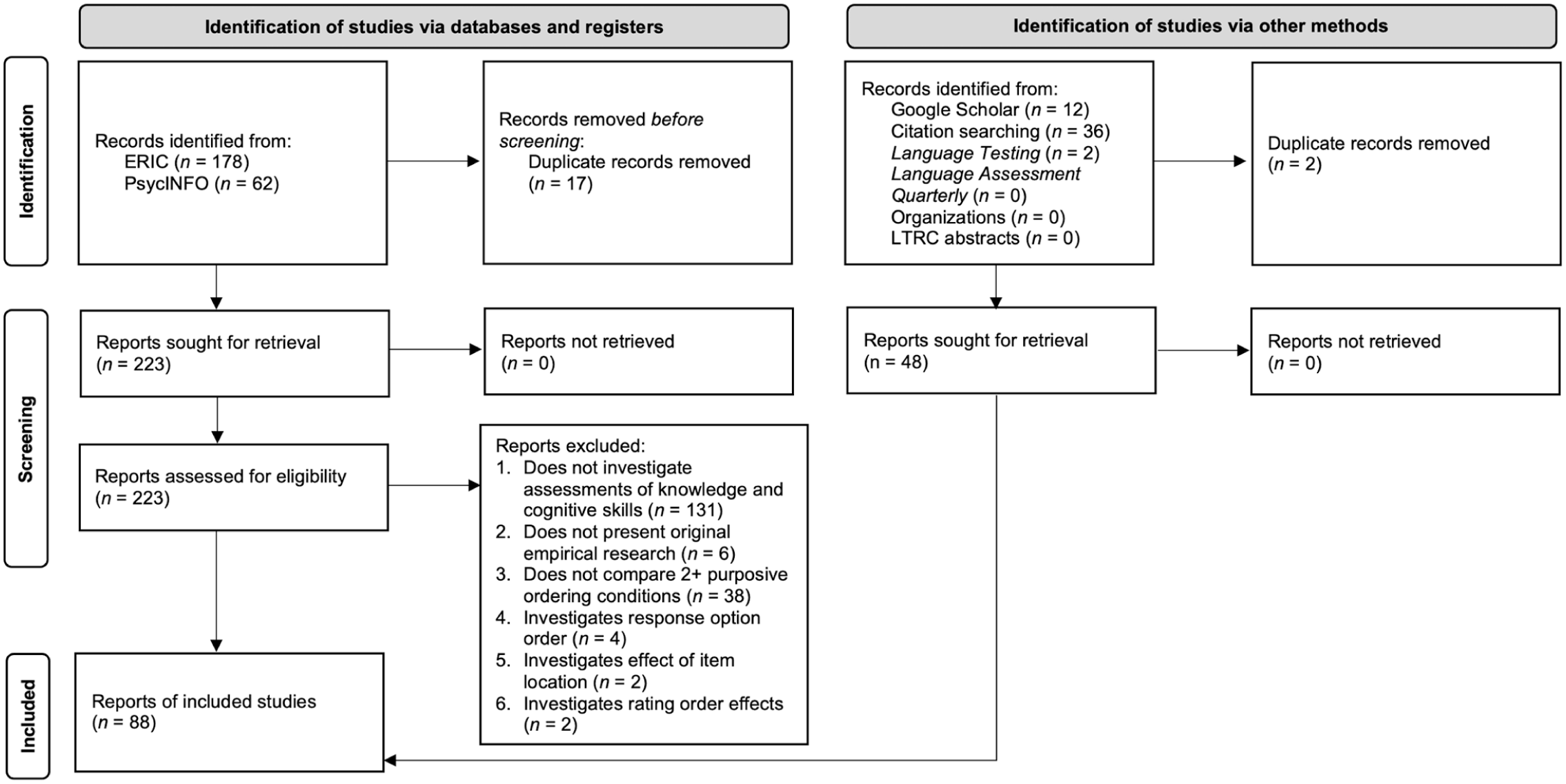
Systematic review process.
Deduplication of results yielded 40 publications from the databases and 36 from citation searching. No eligible studies were found on testing organization research websites, nor in LTRC programs. The Google Scholar search produced a further 12 articles that met the inclusion criteria, bringing the total to 88 studies. Of the 12 articles discovered through Google Scholar, nine were published in journals indexed by PsycInfo and/or ERIC, but their titles did not meet the keyword criteria used in the systematic search. This issue demonstrates the challenge of searching for research on test component ordering, as we found no term or set of terms that can identify relevant studies with both high precision and high recall.
The final pool of literature consists primarily of relevant research on educational tests in subfields of social science (33/88), STEM (22/88), and business (15/88), and language tests (3/88) to a much lesser extent. These studies are fairly homogeneous in terms of the participants and settings (mostly US-based undergraduates) and the types of tasks (mostly MCQs). In addition, these tests are mostly fixed-form tests rather than CATs (c.f. Ling et al., 2017). The publication dates of included studies spanned 1933–2023, with consistent research on the topic beginning in the 1960s, primarily conducted on university exams (Figure 3).
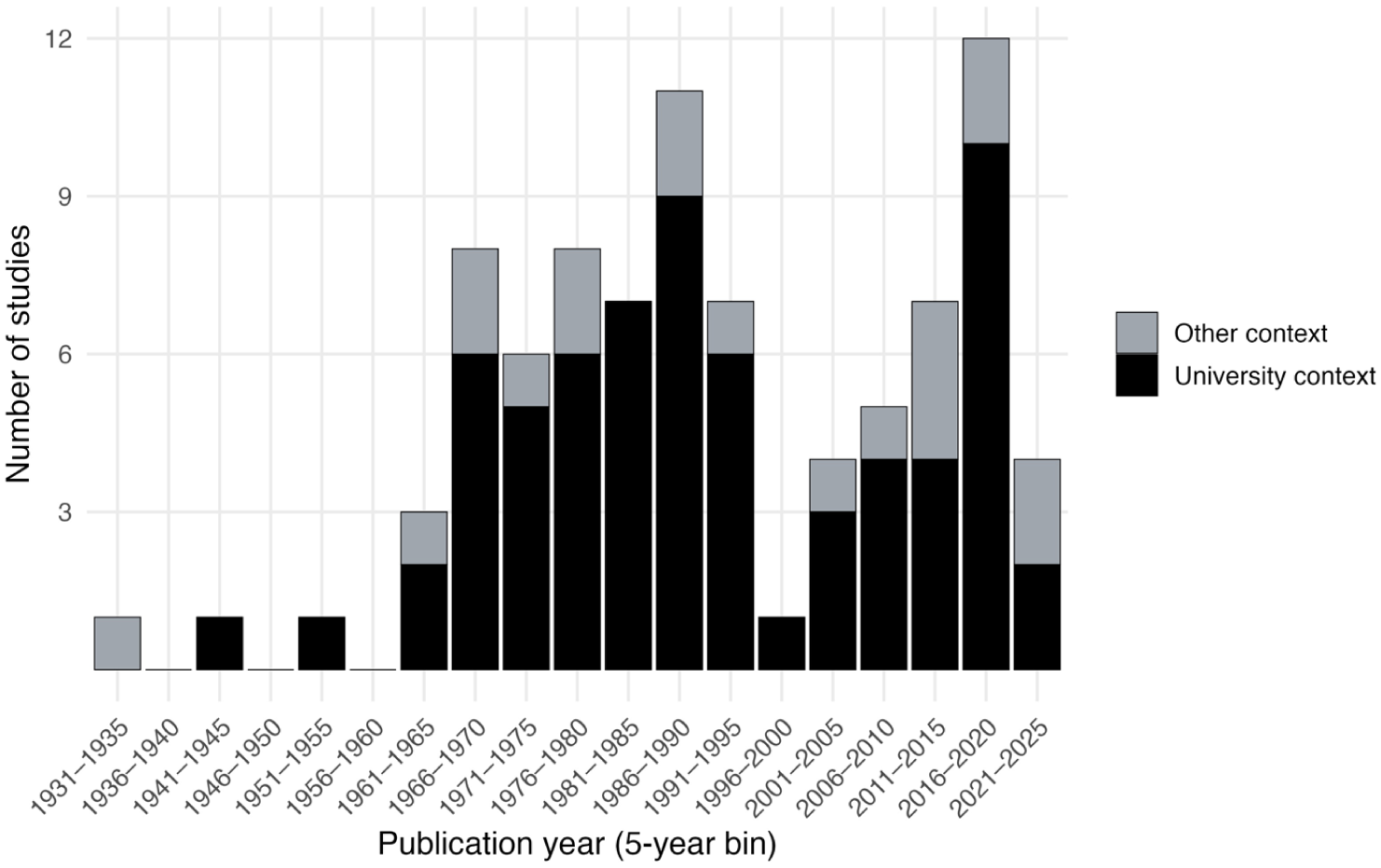
Temporal trends in publications, stratified by context.
Reviewing the studies chronologically shows shifting emphases in outcome, independent, and mediating variables. Early work through the mid-1960s used simple designs, chiefly testing effects of item-difficulty or content order on scores, sometimes adding quantitative outcomes such as items attempted (Sax & Carr, 1962) or reliability (Brenner, 1964). The two earliest studies invoked general intelligence as a mediator (Capron, 1933; Newburger, 1942), but most investigations were one-off and yielded inconsistent results.
From the late 1960s, research volume increased and coherent research programs emerged (e.g., Munz & Smouse, 1968; Sax & Carr, 1962; Sax & Cromack, 1966; Smouse & Munz, 1968). Anxiety became a central mediator at this time, persisting through the early 1980s, including in Plake’s research program (Plake & Ansorge, 1984; Plake et al., 1981, 1982). The 1970s also introduced studies outside university psychology courses (e.g., geography and mathematics) and briefly examined test-taker perceptions of difficulty and fairness, a thread that faded for two decades.
The 1980s–1990s focused on university classroom testing in more disciplines and introduced the first language testing ordering study (Coniam, 1993). Since 2000, work has broadened beyond classrooms. Studies on SAT essay placement examined section ordering and expanded beyond selected-response tasks (J. Liu et al., 2004; Oh & Walker, 2006), with few subsequent language-related studies (Ahmadi et al., 2012; Soureshjani, 2011). More recently, research has shifted to non-classroom general knowledge tests (e.g., Weinstein & Roediger, 2010) and to richer outcome measures—including engagement (Ling et al., 2017), confidence (Cathey et al., 2018), persistence (Miller & Andrade, 2020), and emotions (Bieleke et al., 2023)—to probe the cognitive–emotional mechanisms underlying item-difficulty ordering effects.
Data Collection
We coded for Year, Context (geographic location, online/offline, low-stakes/high-stakes, university/high school, etc.), Subject area, Sample size, Outcome variable(s), Independent variable(s), Mediating variable(s), Ordering conditions, and Significant ordering effects using a data extraction form. An effect for the latter variable was coded as significant if the authors reported it as statistically significant for an ordering condition. Most studies followed the conventional significance level of p = .05, while some studies (e.g., Weinstein & Roediger, 2012) adjusted the significance level for multiple comparisons. This approach relied on the authors’ determination of significance, rather than re-calculation of effects or application of a uniform effect size threshold. We acknowledge that heterogeneous alpha levels and multiple-comparison adjustments can bias tallies of “significant” versus “non-significant” findings, which is one reason meta-analysis and subgroup tables were not pursued. All data were extracted directly from the published articles, and no attempts were made to contact study authors for additional information. See the project’s OSF page (Naismith & Cardwell, 2025) for an overview table of all 88 articles, with relevant contextual information, variables investigated, ordering conditions, significant findings, and methodological quality appraisals.
Data coding to identify variables in the publications was conducted independently by the two authors. One author annotated 100% of the publications and the second author coded 20%. For these double-rated items, agreement for the key categorical variables for this study (outcome variables, independent variables, mediating variables) was calculated using exact agreement and Krippendorff’s Alpha (2019), suitable for unordered categorical coding of this nature. After standardizing the variable names, the exact agreement was 83.5% and Krippendorff’s Alpha was 0.86, indicating reliable ratings and a satisfactory level of agreement. Subsequently, any discrepant or uncertain items were discussed jointly.
Quality Assessment
To assess the methodological quality of included studies, we used an adapted version of Gorard’s sieve (Gorard, 2014). This tool is designed for judging the trustworthiness of research findings and has been employed in various systematic reviews in educational research (e.g., See et al., 2020). While other common instruments are available for assessing methodological rigor, they were deemed a poor fit for the highly heterogeneous and often observational designs in our pool. For example, the Eight Big Tent criteria are designed for qualitative research, while the Cochrane tools (e.g., RoB2 and ROBINS-I) are specific to randomized trials and non-randomized intervention studies, respectively.
The original Gorard’s sieve is essentially an analytic rubric with six categories and a rating scale from 0 to 4, which results in a numeric, judgment-based appraisal of research trustworthiness. In our adapted version of this tool (see Appendix 1), we edited the wording to (a) increase applicability to test ordering studies, which typically did not have interventions, (b) removed the “Fidelity” category, which primarily pertains to the implementation of interventions, and (c) modified the “Outcomes” category to “Measures” to better reflect the nature of variables commonly used in observational research. As a result, each study could receive a total score of 0–20. These adaptations were intended to preserve the sieve’s core function of providing a judgment-based appraisal of research trustworthiness while tailoring its criteria to the specific research designs of included studies (though see the “Limitations” section).
To apply the sieve, two coders collaboratively rated one publication for standardization. Thereafter, one coder rated all publications and the second independently rated 20%. For these double-rated items, Quadratic Weighted Kappa (QWK) was calculated, appropriate for interval data, yielding agreement of .89 QWK for the total scores. For all publications, the mean total rating was 18.22, indicating high quality (M = 3.6 per category), and no publications received scores below a pre-determined threshold that we established of 10 (average of 2/category); the lowest overall rating was 14. Therefore, all studies were retained.
Synthesis Methods
A narrative synthesis approach was adopted due to the heterogeneity of study designs, contexts, and measures in the studies, which spanned > 90 years. The synthesis was structured according to three analytic categories:
Outcome variables: Through this analysis, three main themes emerged: objective performance (e.g., test scores), perceived performance (e.g., ratings of perception of difficulty), and test-taker affect (e.g., state anxiety measures).
Independent variables: This analysis revealed three primary approaches to test ordering: item difficulty-based ordering, context switching, and skills-based ordering.
Mediating variables: We examined the most frequently occurring or discussed mediating variables across the studies, focusing on gender/sex, proficiency level, trait anxiety, and speededness.
Because only three studies directly investigated second-language proficiency tests, our discussion focuses on the extrapolation of findings from the broader pool of studies. This approach allowed us to identify both established patterns in general educational testing relevant to language test developers and potential gaps in language assessment research. In addition, we used the quality assessment reported above to prioritize studies for citation and discussion in the synthesis, promoting the citation of higher-rated studies and weaving the 19 studies that received the maximum quality score into the narrative.
Results and Discussion
Of the 88 included studies that directly investigated the manipulation of test component order, the focus is overwhelmingly on item ordering, with 79 studies examining ordering conditions at this granular level. A smaller but distinct group of seven studies investigated the sequencing of major test sections. Although tasks could be considered a conceptually distinct intermediate size of test component (see Introduction), research manipulating task order was lacking, with only three examples in the included studies (Carter & Prevost, 2018; Monk & Stallings, 1970; Newburger, 1942). Given this limited number, findings related to these task-ordering studies are integrated into relevant thematic discussions and are explicitly noted as pertaining to task-level manipulations.
Outcome Variables of Interest
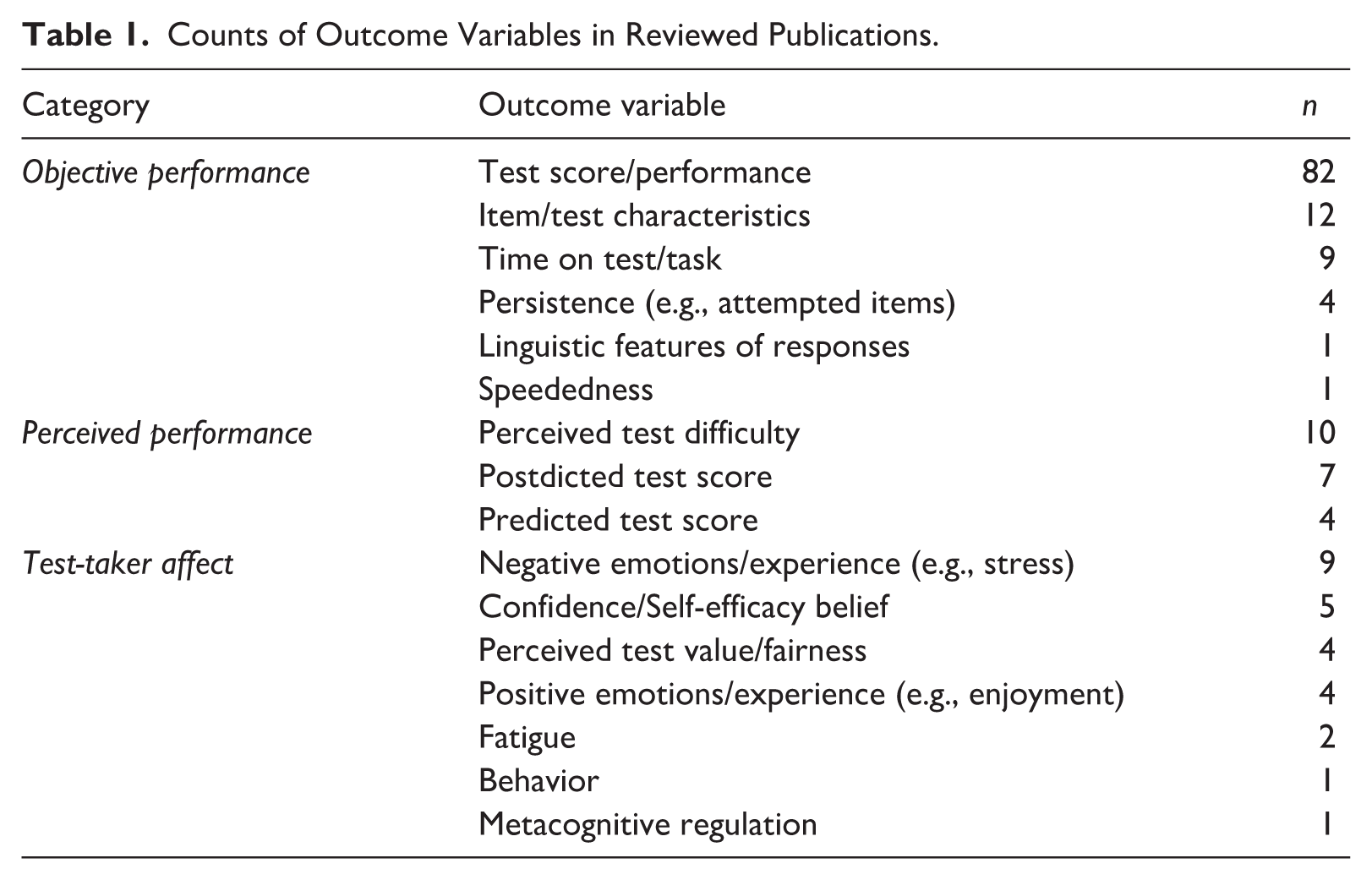
Table 1 lists the outcome variables coded in the reviewed publications. These variables can be mostly grouped into three categories: objective performance, perceived performance, and test-taker affect.
Counts of Outcome Variables in Reviewed Publications.
Objective Performance
Objective performance, particularly test scores, is by far the most researched dependent variable category concerning test component arrangement. The vast majority of studies analyzed some form of test scores (82/88), sometimes as one of several dependent variables. The total score was almost always a number correct/sum score, that is, not scored with item response theory (IRT), which takes item difficulty into account when computing scores. It is important to keep this limitation in mind when considering the conclusions about how, and to what degree, test ordering impacts scores.
Some studies (27/88) have also investigated other measures related to objective performance, such as item/test characteristics (e.g., Carlson & Ostrosky, 1992) or time on test/task (e.g., Ling et al., 2017). How test component ordering impacts objective performance is perhaps of greatest importance to high-stakes assessments, as any impact could change score distributions, score interpretations, and reliability estimates, with potentially serious consequences for test takers.
Perceived Performance
Some studies (21/88) examined test-taker perceptions of their performance and/or test difficulty (e.g., Barcikowski & Olsen, 1975; Laffitte, 1984), which can be unrelated to quantitative measures of performance/difficulty. Perceived performance can be operationalized as predictions of test/item scores on upcoming parts of the test, predicted scores after completing the test (also called postdictions), or qualitative descriptions of performance (e.g., “well” and “good”). Perceived difficulty can be measured immediately following the test and/or at time points during the test. Perceived performance is important to test developers because perceptions of success or failure during task engagement are known to influence effort and persistence, which in turn can affect performance outcomes (Bandura, 1997). For instance, we might expect test takers who perceive they are doing poorly during the test to exert less effort. Beyond any potential impact on objective performance, perceived performance might plausibly impact factors such as face validity and repeat testing behavior.
Test-taker Affect
We use test-taker affect to refer to temporary, context-dependent psychological states that test takers experience during and immediately following the testing experience, such as self-efficacy (e.g., Habbert & Schroeder, 2020) or emotions (e.g., Bieleke et al., 2023). Of the 26 studies to report such variables, nine measured negative emotions/experience, including stress and test anxiety, defined as anxiety due to anticipation of failure and associated negative cognitive and physiological responses (Chen, 2012). Chen posits two competing views of how anxiety impacts test performance: the monotonic view (more anxiety leads to worse performance) and the non-linear view (moderate anxiety leads to optimal performance).
For language tests specifically, test anxiety is part of the broader construct of language anxiety. As first described in Horwitz et al. (1986), language anxiety consists of three components: communication apprehension, fear of negative evaluation, and test anxiety. In numerous studies, language (including test) anxiety has been shown to produce negative academic effects (e.g., lower grades), cognitive effects (e.g., slower language processing), and social effects (e.g., reduced linguistic self-confidence; MacIntyre, 2017).
Like perceived difficulty/performance, affect is a test taker’s subjective perception of something that is not captured by their responses to test items. Research in this area thus usually involves presenting test takers with additional, non-test items to measure affect (e.g., Ahmadi et al., 2012; Plake et al., 1981) before, during, and/or after the testing experience. The difference from perceived difficulty/performance is that the focus is on the test taker’s emotional/affective state. Test-taker affect is important for test developers to consider because it can impact performance and/or sentiment about the assessment. Of particular concern is the possibility of differential impact on affect (e.g., by proficiency level), leading to sources of unfairness.
Independent Variables
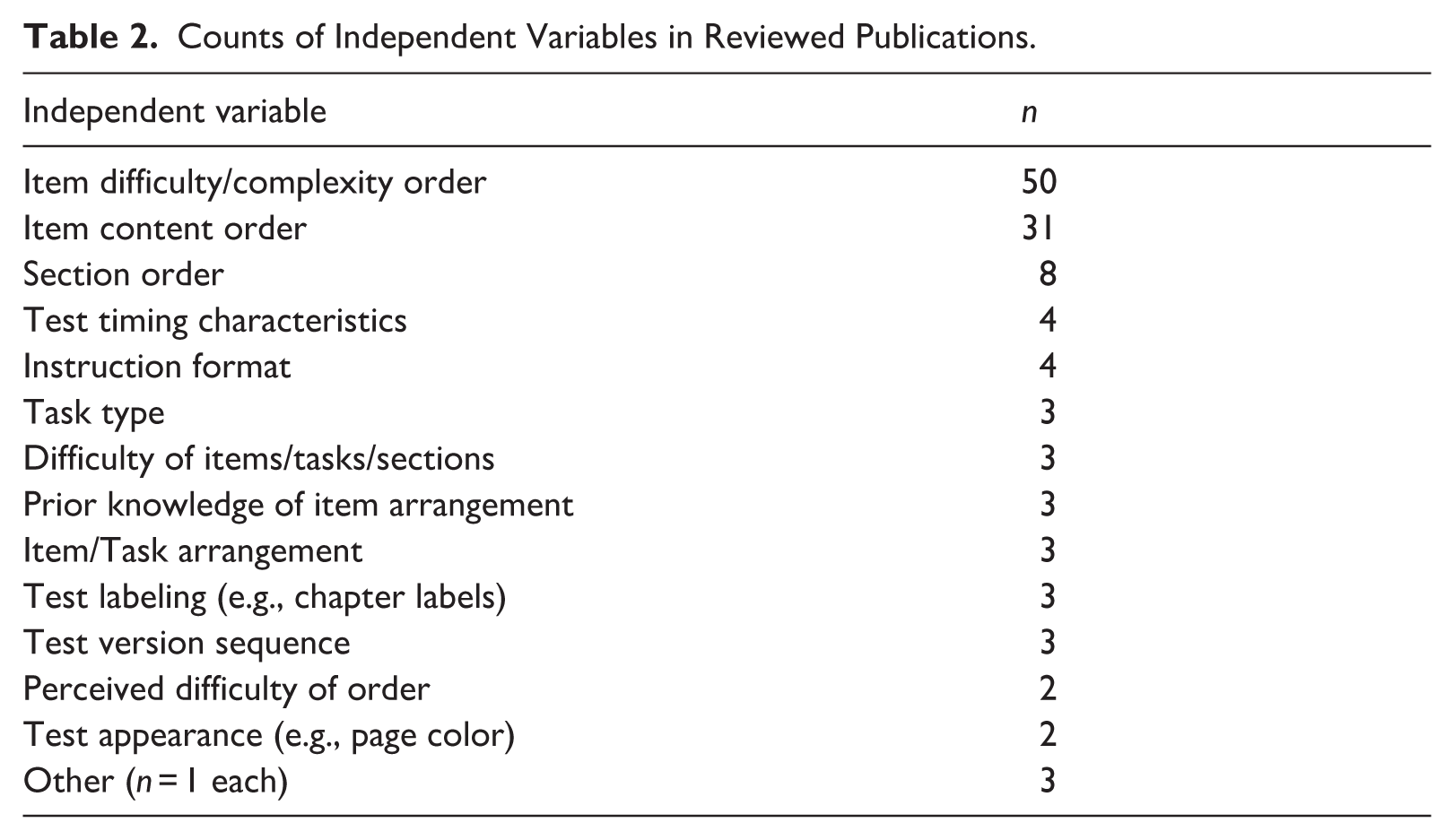
We now consider commonly investigated independent variables and their impact on outcome variables. Many studies’ independent variables can be grouped, in order of how much they have been researched, into item difficulty-based ordering and context switching (Table 2). For the latter, we focus on section ordering, especially in relation to skills, given its importance in language test design.
Counts of Independent Variables in Reviewed Publications.
Difficulty-Based Ordering
It is unclear from the public documentation of most high-stakes language proficiency tests whether items are intentionally and systematically ordered by difficulty. For CATs, item-difficulty ordering is dictated by test-taker responses, but for fixed-form tests, it may be that E–H ordering is implicitly assumed to be best (a tendency noted over 90 years ago by Capron, 1933). Item-difficulty ordering is by far the most researched topic within the literature on test ordering (50/88), 1 with E–H ordering the most researched item arrangement (48/88).
Of the studies comparing E–H ordering to alternative orderings in terms of impact on test scores, most (29/38) found no consistent, overall significant difference (e.g., Marso, 1970; Perlini et al., 1998; Plake & Ansorge, 1984; Şad, 2020), while a few (9/38) found a consistent benefit of E–H ordering (e.g., Anaya et al., 2022; Hodson, 1984b; Holliday & Partridge, 1979; Sax & Carr, 1962). For instance, Hodson (1984b) reported significantly higher mean scores on an A-level chemistry test with E–H versus H–E sequencing, and Sax and Carr (1962) found that an aptitude test with different item types intermixed and in E–H order yielded significantly higher scores and more items attempted than when items were grouped into subtests by content. Of note, the studies finding significant score differences in favor of E–H ordering typically considered speeded tests (6/9). In a study of untimed math exams, Gruss and Clemons (2023) found that the difficulty of the first two items did not significantly predict the overall score, noting that lack of a time limit may offset any effect of initial item difficulty. In studies by Plake and colleagues (1981, 1982), prior knowledge of the ordering arrangement did not affect scores.
Aamodt and McShane (1992) found only a small effect size of E–H versus random order (d = .11, studies n = 26, participants n = 13,428) and a larger but still modest effect size of E–H versus H–E (d = .22, studies n = 11, participants n = 1564). However, one of the studies in the meta-analysis found a significant interaction of item order and anxiety types, despite no main effect of item order (Munz & Smouse, 1968); facilitators (people who benefit from test anxiety) performed significantly higher in the E–H and random order conditions, but there were no significant group differences in the H–E condition. Chen (2012; n = 250) also found an interaction between item order and anxiety levels; however, all anxiety-level groups performed significantly better on a CAT version of the test than a H–E fixed version. 2
The potential benefit of beginning with easy items is conceptually related to the common practice in language pedagogy of starting lessons with a warm-up activity. In our pool, only two studies empirically examined difficulty ordering effects for language tests. In Soureshjani (2011), intermediate EFL learners in Iran (n = 70) completed two forms of a 40-item multiple-choice English grammar test (covering tenses, modals, gerunds/infinitives). They first completed the E–H form and 2 weeks later the H–E form, with item difficulties based on pilot data. Scores on the E–H form were significantly higher (no effect size reported). This finding of the positive impact of E–H ordering is noteworthy, given that the fixed administration order (E–H then H–E) meant any practice effects would have presumably benefited the H–E form, potentially masking the full extent of the E–H advantage. Soureshjani (2011) acknowledged this potential for practice effect, though he pointed to the potentially mitigating 2-week interval between administrations. He proposed that the benefit of the E–H ordering might stem from reduced student anxiety and improved student confidence.
In Coniam (1993), 342 intermediate-level secondary-school EFL students in Hong Kong completed an MCQ listening comprehension test and an MCQ cloze test in either E–H (n = 163) or H–E (n = 179) item ordering conditions based on pilot data. A post-test questionnaire then assessed motivation through students’ perceived test difficulty, effort expended, confidence, and enjoyment. Unlike Soureshjani (2011), Coniam found no significant difference between groups in scores for either task type or for any aspect of motivation. He suggested that for global, integrative language tasks that require sustained comprehension, the ordering of individual items by difficulty might be less impactful than for discrete-point tests.
Research has also investigated how item ordering affects perceptions of test difficulty, with mixed results. Barcikowski and Olsen (1975) and Olsen and Barickowski (1976) found that students perceived items as easier in the hard-medium-easy condition, but that these perceptions did not typically correspond to differences in test scores. Bieleke et al. (2023) also found that students (n = 208) who started a math test with a section of easy items perceived the test as more challenging than students who started with a section of difficult items. Perlini et al. (1998) noticed that students (n = 140) perceived they had performed better on a H–E psychology exam than when ordered randomly, despite no significant difference in scores. Munz and Jacobs (1971) also sequenced items on the basis of student-perceived difficulty and found that although there was no effect on test scores or on situational test-taking anxiety, the E–H sequence was regarded by examinees as easier and fairer than the random and H–E test forms. Conversely, Aamodt and McShane (1992) did not find E–H and random orders to significantly impact perceived exam difficulty. Thus, there seems to be some, but not unanimous, evidence of an item-difficulty order effect when comparing E–H and H–E.
More recent studies have explored the mechanism of the item-difficulty order effect. Weinstein and Roediger (2010, 2012) found that participants in the E–H condition postdicted higher scores, and participants in the H–E condition perceived the test as more difficult, despite no significant group difference in scores. The authors concluded that the results supported the anchoring explanation (i.e., the earliest questions anchor test-taker perception of the entire test). This position aligns with earlier work suggesting that initial perception of low difficulty is better (Carlson & Ostrosky, 1992). Further supporting the anchoring hypothesis, Bard and Weinstein (2017) found that participants’ (n = 55) optimism about their performance on a general knowledge test did not change when they took the test in opposite difficulty orders; participants who took the E–H version first were still more optimistic about their performance than those who took the E–H version after already seeing the same items on the H–E version. Additional support comes from Habbert and Schroeder (2020), who observed that participants in a series of experiments tended to perform better under H–E ordering, even though a majority of participants expressed an a priori preference for the E–H order; these findings suggest that people over-emphasize the earliest tasks when imagining a series of tasks, and thus prefer delaying more difficult tasks.
Multiple studies (10/88) have also investigated the impact of item-difficulty ordering on test-taker affect, primarily state anxiety (i.e., the temporary experience of anxiety due to a particular context or stimulus). Based on five studies (total n = 378) comparing E–H to random order, Aamodt and McShane (1992) concluded that there was no significant difference in test-taker anxiety levels. For example, Smouse and Munz (1968) found no difference in state anxiety between E–H, H–E, and random orders, possibly due to high baseline test anxiety masking item order effects. However, three other studies (total n = 189) comparing E–H and H–E orders supported a significant moderate effect on anxiety (mean d = -.3), with E–H causing less anxiety. Recently, Bieleke et al. (2023) demonstrated that ending a math test on the most difficult items caused more negative emotions (e.g., boredom and anger) among the 8th-grade participants, concluding that it is best to avoid clear monotonic patterns in item-difficulty arrangements.
A few studies have investigated test-taker affect indirectly by analyzing completion rate (4/88) or time on test/task (9/88) as an outcome variable. Ling et al. (2017) found that middle-school students spent longer on an easy CAT (i.e., target probability of correct response > 50%) than on a regular CAT. Miller and Andrade (2020) found that alternating between easy and difficult items led to greater persistence on “impossible” items at the end of the test. And Anaya et al. (2022) found that participants in the H–E condition of a low-stakes online math test were 50% more likely to abandon the test than those in the E–H condition. Thus, while the studies cannot conclusively explain the affective mechanism at play, there is more recent evidence that alternating item difficulty can help maintain intrinsically motivated persistence, which may be less evident in high-stakes testing contexts with highly motivated test takers. One scenario where the link between difficulty and persistence may be especially relevant is in wide-range language assessments taken by lower-proficiency test takers. For example, productive skills tasks with linguistically complex prompts could conceivably function as an initial “hard” or “impossible” item; encountering such items earlier in the test could increase the chance of task abandonment, not due to productive skills, but because of a failure to comprehend the instructions, combined with lower persistence due to the H–E order.
These studies in this section provide empirical support that E–H item ordering slightly increases scores and decreases anxiety, although impacts may be mediated by trait anxiety and/or proficiency. However, these findings are by no means definitive; Hauck et al. (2017) identified 18 studies comparing scores under E–H, H–E and/or random order conditions. Across these studies, the most common finding was no significant difference, with only two consistently showing higher scores for E–H > H–E, one for H–E > E–H, and two for E–H > Random. Item ordering may also be moderated by test time limit and scoring mechanism (i.e., number correct vs. IRT).
On the contrary, ending a test with the most difficult items can decrease motivation/persistence and leave test takers in a more negative emotional state. Collective evidence suggests a potential benefit of starting with easy items and alternating between difficult and easy items over the course of the test, avoiding a monotonic increase in difficulty. However, this particular item arrangement has not been widely investigated. Notably, item-difficulty ordering studies have not looked specifically at language tests, presenting an opportunity for novel research. For example, we might hypothesize that the effect of variables could be exacerbated in a language testing context due to test takers’ foreign language anxiety.
Context Switching
The studies reviewed in this section involve manipulations at various levels of test structure. These include the ordering of items based on their content, and of task formats or characteristics. Broader context switching of test sections is then discussed in the subsequent section on Section/Skills-based Ordering.
On tests measuring multiple subskills or comprising multiple task types (i.e., most language tests), some context switching is inevitable. There are three primary ways in which test takers switch contexts: content, format, and skill/modality. Content-related context switching occurs when adjacent tasks use stimuli on different topics (e.g., two clozes on different topics). Format-related context switching occurs when adjacent tasks or items are of different formats (e.g., an MCQ item followed by a matching item). Skill/modality-related context switching occurs when adjacent tasks assess different skills (e.g., a listening task followed by a reading task). Skill/modality-related context switching is particularly relevant to language proficiency tests and will be addressed in more detail in the following section.
Two contradictory hypotheses exist about context switching’s effect on test performance. The debilitative hypothesis supposes that context switching will hurt test performance due to the additional time and mental effort required to adjust to new task requirements and/or activate different mental resources. The facilitative hypothesis supposes that context switching has a net positive effect by avoiding monotony and fatigue of specific mental processes. However, little research has directly addressed this issue, and thus, there is no clear consensus on whether tasks or items should be grouped by format and/or content. This topic is conceptually related to the notion of schemata, as applied in the field of language pedagogy, which suggests learners are better able to perform tasks for which their schemata have been activated (Carrell, 1987).
Studies investigating item grouping by content (31/88) are more numerous than those on grouping by format or skill/modality (15/88). The earliest and most direct study is Newburger (1942), investigating task-level characteristics in the context of homogeneity and potential fatigue. In this study, participants responded to spatial reasoning MCQs in easy or hard and homogeneous or heterogeneous item sets. The author concluded that sustained engagement with highly similar tasks can reduce performance due to fatigue from repeatedly activating the same cognitive processes (Newburger). This finding illustrates how the homogeneity of a sequence of cognitive demands at the task or item-block level, rather than just individual item characteristics, can impact performance.
Numerous subsequent studies (17/88) have found no significant group differences in mean scores due to syllabus/coursebook/topic-based ordering (e.g., Davis, 2017; Marso, 1970; Pettijohn & Sacco, 2007). For example, Marso (1970) investigated item ordering on a university-level psychology final exam (n1 = 122, n2 = 156), comparing random, chronological (by course coverage), and reverse chronological ordering, finding no significant impact on scores or test completion time. Similarly, in a series of three experiments, Neely et al. (1994) found no consistent evidence that sequential (by topic) item ordering in psychology exams resulted in better student performance compared to random ordering. Likewise, Cathey et al. (2018) reported no significant effects of sequential chapter-based versus random item ordering on psychology students’ exam performance, test anxiety, or confidence, even when chapter labels were used to make the sequential organization explicit. Klosner and Gellman (1973) simultaneously investigated both difficulty ordering and content ordering for an educational measurement exam (n = 54), arranging items either by subject matter, E–H, or E–H within subject matter. Overall interaction of ordering condition and performance was not significant, but poor-performing students (based on midterm grades) performed best when difficulty increased within subject matter areas, pointing to the importance of considering mediating variables.
In contrast, a number of studies (14/88) observed improved scores for sequential ordering, either forward sequencing (e.g., Balch, 1989; Togo, 2002) or reverse sequencing (e.g., Baldwin & Howard, 1983; Gruber, 1987). Conversely, Norman (1954) found a negative effect of reverse chronological ordering, but only on MCQs. Aamodt and McShane (1992) found a minuscule effect size (d = .04) of content-based item organization across 16 studies, and Hauck et al. (2017) likewise noted conceptual item ordering’s lack of impact. Of note, Carlson and Ostrosky (1992), in a study comparing multiple forms of a microeconomics exam, manipulated both difficulty ordering and content ordering of items. Although they found no difficulty ordering effect, they reported marginal significance (p = .06) that items ordered sequentially by chapter content led to higher performance than items scrambled by content.
As noted, less research has explored format-based context switching, for example comparing grouping/ordering of item or task formats. Monk and Stallings (1970) investigated this area by ordering geography exams in different configurations, with blocks of items grouped by format (e.g., MCQs, True/False, and matching). Under their primarily unspeeded conditions, they generally found no significant impact of these rearrangements on overall test scores, individual item difficulties, or test reliabilities; however, items were always grouped by format, so this study did not address grouping by format versus alternating item formats. In research on fatigue effects of the SAT, J. Liu et al. (2004) assert that other studies have indicated that more frequent switching between tasks could alleviate the necessity for breaks.
Further contributing to the understanding of format-related context switching at the task level, Carter and Prevost (2018) examined the ordering of two distinct constructed-response tasks, one requiring students to define a physiological principle and another requiring them to provide an example of it. Their findings revealed a conceptual priming effect: students generally produced better quality responses on whichever task was positioned second in the sequence. Specifically, definitions improved when they followed the example-generation task, and examples were better when they followed the definition task. These findings suggest that the sequence of tasks with differing cognitive demands or formats can meaningfully impact student performance through mechanisms like priming.
Overall, research on context switching in assessments is scant and does not focus on language testing. Based on the existing research, one takeaway for language test developers is that there is currently no solid empirical foundation for organizing tests by content or item/task format. However, there is weak evidence and speculation that monotonous task sets increase mental fatigue, which would support alternating task types during test administration if validated. Given the lack of evidence, it may be advisable for psychometric and item-bank considerations to carry more weight in determining item order.
Section/Skills-Based Ordering
This subsection centers on research that has manipulated the order of major test sections. As indicated above, a smaller but distinct group of seven studies investigated ordering effects at this macro-level, often focusing on sequences based on language skills.
At a minimum, context switching occurs between test sections. Traditionally, most language tests comprise speaking, writing, listening, and reading (SWRL) sections. This configuration intuitively aligns with common conceptualizations of language skills and is expedient for administering pen-and-paper tests (e.g., playing listening stimuli for all test takers simultaneously), as well as some group-administered computer-based testing (e.g., to avoid test takers speaking at different times). However, there is little empirical basis for this configuration, including both the grouping of test content into skills-based sections and the ordering of these sections. Furthermore, as tests are increasingly being designed (or retrofitted) for remote administration, practical considerations relevant to pen-and-paper tests are often moot, and the lines between test sections may be blurred or nonexistent.
Research regarding the impact of test section configurations is sparse (see Stout & Dellva, 1990). Smeding et al. (2013) showed that middle-school girls (n1 = 1127, n2 = 498) performed significantly worse on a standardized math test when it was administered before a verbal test, whereas this effect was not observed in boys. The authors attributed the results to stereotype threat, demonstrating how test component ordering can interact with test-taker characteristics to introduce construct-irrelevant score variance. More relevant to language testing, J. Liu et al. (2004) examined the effects on performance and test-taker affect when the SAT’s essay section was placed at either the start or end of the test. Essay placement did not affect performance, though starting with the essay was preferred by the participants and reportedly reduced anxiety. As a follow-up, Oh and Walker (2006) examined additional test variables in a larger sample (n = 5982). Unlike J. Liu et al. (2004), a difference in essay performance was found, with the “essay-first” group scoring significantly higher, though essay placement only accounted for 2% of essay score variance. It is noteworthy that in these studies examining essay placement on the SAT, an entire “section” effectively consisted of a single, substantial task (the essay). Consequently, while the manipulation occurs at the macro-level of test structure (section placement), the findings also offer insights into the sequencing of a longer productive skills task relative to other sections. These findings are relevant to language assessment decisions of where to place open-ended productive skills tasks, which are often perceived as inducing high anxiety.
Ahmadi et al. (2012) is the only study to explicitly examine skills-based language test section order (Reading, Listening, and Writing). Students in IELTS preparation classes (n = 60) were surveyed about their preferred section order, with the two most popular being Listening–Reading–Writing and Reading–Listening–Writing. Reasons given focused on the relative difficulty of different modules and the anxiety/confidence they induce. Practice tests arranged in these two orders were then administered to test takers (n = 120). For intermediate and advanced learners, ordering did not significantly affect performance. However, beginners performed better overall when listening came first. These results illustrate the potential interaction of proficiency and section order on performance. The preference for Listening first among these Iranian IELTS test takers, and the performance benefit for beginners when Listening was placed in initial position, may be partly understood in the context of national IELTS performance patterns. IELTS (2025) Academic test-taker performance data from 2023–2024 shows that Iranian candidates (and candidates in most reported countries) tend to score higher in Listening (M = 6.6) than in Writing (M = 6.0). However, such national performance trends, and thus perceived or actual relative skill difficulty, vary by country (e.g., in Oman, Listening M = 5.3 and Writing M = 5.4). These score trends suggest that the preferred or optimal skill sequencing may differ by first language or educational contexts.
In this section, we have seen that research into section ordering is limited, and sections may be ordered for historical or practical reasons. However, different language skills may be (or may be perceived) as more challenging for test takers. As such, further research into the effects of section ordering is needed. Table 3 presents a sample of high-stakes language tests and their section orders, as inferred from public documentation. This brief survey shows consistency amongst high-stakes language proficiency tests: typically, sections are clearly defined according to traditional SWRL language skills; receptive skills (reading and listening) are followed by productive skills (speaking and writing); and objective tasks are followed by subjective tasks.
Examples of language Test Section Ordering.
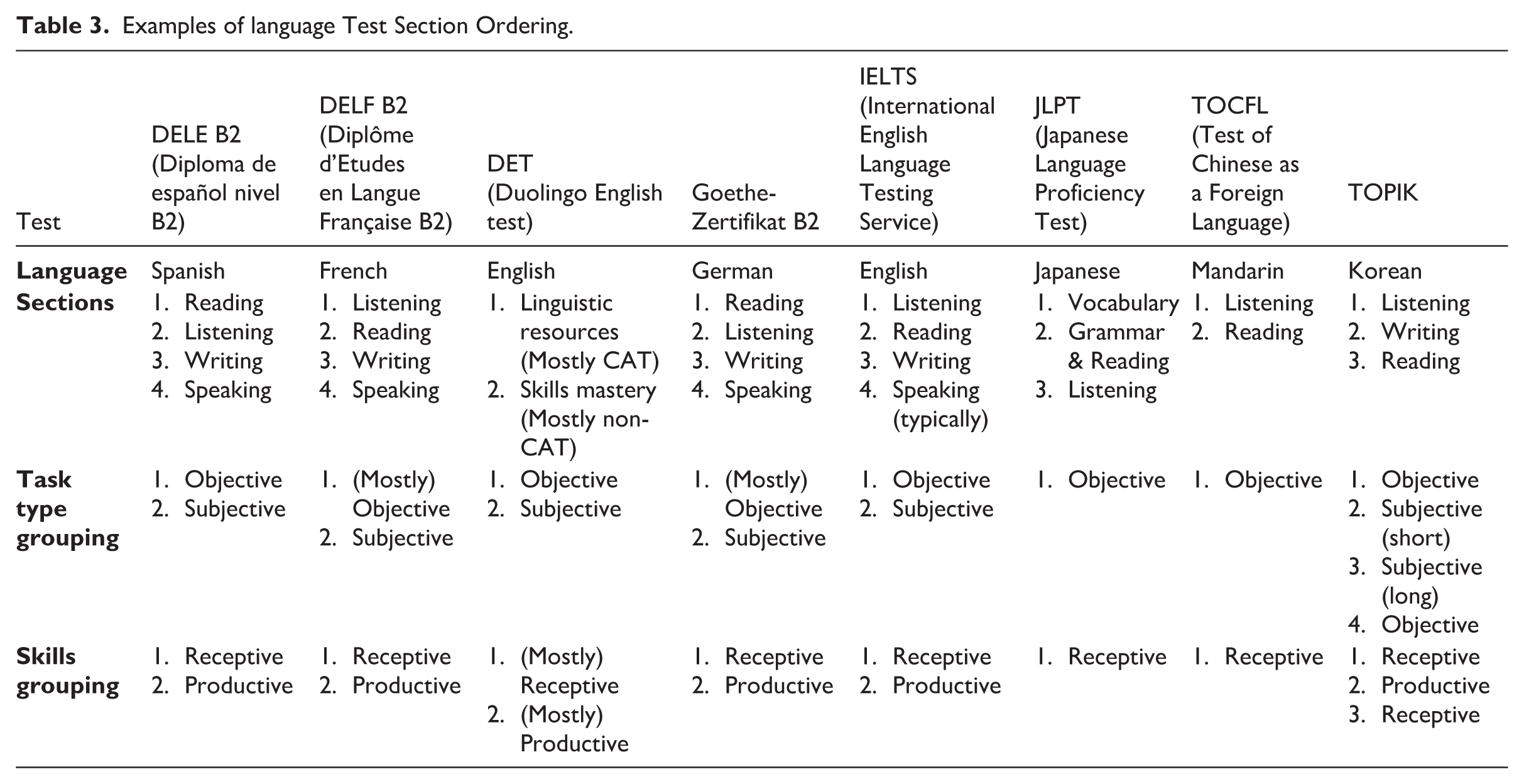
If minimal context switching is preferable, then tasks should continue to be clustered into test sections based on skills grouping, though the implications for computer-adaptive administration must be considered. For example, tasks could follow the traditional SWRL grouping (e.g., IELTS and TOEFL); broader receptive or productive skill groups (e.g., DET and PTE Academic); or integrated skill groups mirroring the categories in the updated Common European Framework of Reference for Languages (CEFR; Council of Europe, 2020): Reception, Production, Interaction, and Mediation.
Mediating Variables
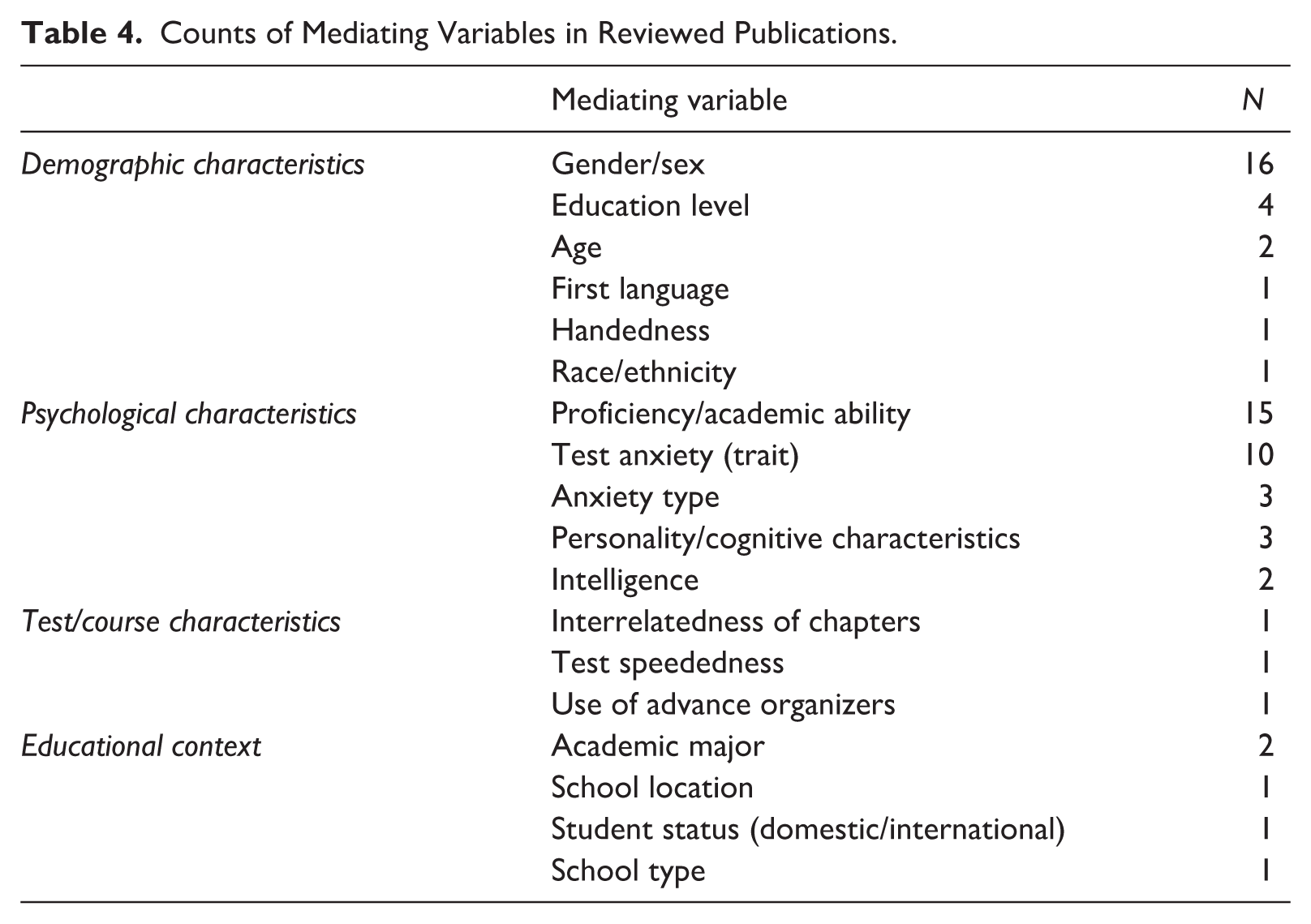
To better understand the mixed findings related to ordering effects, another factor to consider is the presence of mediating variables. Mediating variables interact with ordering conditions to affect test-taker subgroups predictably. We consider four frequently investigated or considered mediating variables—gender/sex, proficiency/academic ability, trait anxiety, and speededness—which provide a more nuanced picture of ordering effects (Table 4). The first three variables were selected for discussion based on their frequency in the reviewed studies. Speededness was only investigated experimentally as a mediating variable in one study (Becker et al., 2022) but is discussed because it is widely acknowledged as a potentially relevant factor, mentioned in 30/88 included studies (e.g., Plake et al., 1982; Undersander et al., 2017).
Counts of Mediating Variables in Reviewed Publications.
Gender/Sex
Gender/sex, the most commonly included demographic variable (16/88), has an unclear mediating impact with mixed findings. In half of the studies including this variable (8/16), across many contexts, gender/sex was not found to have a significant mediating effect (e.g., Anaya et al., 2022; Capron, 1933; Gruss & Clemons, 2023; Oh & Walker, 2006).
However, half of the studies did find gender/sex to significantly mediate ordering effects. For example, Plake et al. (1982, 1988) found a significant interaction between item order and gender, with males scoring higher in the E–H condition on statistics exams, and Plake and Ansorge (1984) found a significant sex by item order interaction on students’ anticipated performance (but not actual scores) on an educational psychology exam. Conversely, Kennedy and Butler (2013) observed that females outperformed males in the H–E condition. Likewise, in Harrington et al. (2019), H–E item ordering in computer science exams, despite little overall impact, significantly boosted female students’ confidence and performance, while males showed higher confidence and better performance with E–H ordering. Gender/sex has also been found to show complex relationships with item ordering and item content (e.g., Ryan & Chiu, 2001), as well as test section ordering and performance (e.g., Smeding et al., 2013, discussed previously). Ryan and Chiu (2001) found that, in mathematics placement exams, altering item order (random vs. E–H within content) generally did not change the overall patterns of differential item functioning (DIF), though E–H ordering of algebra items modestly improved performance for both genders.
Proficiency/Academic Ability
The interaction of language proficiency or domain-specific academic ability and ordering conditions is relevant to language test developers. Lower-proficiency test takers could be especially sensitive to ordering differences, which could provoke additional anxiety or require them to deploy more cognitive resources. However, because most ordering studies are not on language tests, such hypotheses cannot be confirmed.
One exception is Ahmadi et al. (2012), in which participants were split into three broad proficiency categories of beginner, intermediate, and advanced. An ordering effect was uncovered for beginners, who performed better when the listening section was first. Likewise, Kobayashi (2002) found that, in a reading comprehension test of Japanese university students (n = 754), the lower-proficiency group performed better with controlled task types such as cloze tests and reading passages that were more descriptive as opposed to densely informational. Although Kobayashi is not strictly related to ordering, the work of this nature points to the manner in which test specifications interact with language proficiency. In contrast to Ahmadi et al. (2012), Hodson (1984a), in a non-language assessment context (O-level chemistry), found that E–H item ordering significantly improved scores only for high-ability students, with no significant E–H effect on the overall group’s performance.
Şad (2020) also conducted an ordering study which included proficiency (referring to level of academic achievement) as a mediating variable. Turkish students in a teacher training program (n = 554) completed an MCQ test about measurement and assessment with E–H and H–E item orders. The author found no mediating effect for the proficiency group, regardless of difficulty order. As described previously, Baldwin and Howard (1983) found that GPA mediated the effects of course-sequenced versus scrambled item ordering for a financial accounting exam (n = 167). However, subsequently Baldwin et al. (1989) did not see this effect for a managerial accounting exam (n = 282).
These findings suggest that language proficiency cannot be easily grouped together with other proficiency types when considering ordering effects, that subject matter is also a mediating variable, and that the interaction of proficiency and difficulty ordering remains inconclusive.
Trait Anxiety
Previously, we described studies where state anxiety was an outcome variable, that is, where anxiety was affected by item-difficulty ordering. However, there are also a small number of studies (10/88, mostly from the 1960s and 1970s) that investigated test takers’ baseline anxiousness (i.e., trait anxiety) as a mediating variable. The studies from the 1950s and 1960s uncovered a relationship between trait anxiety and test performance under different conditions. For example, Munz and Smouse (1968) investigated the test performance of undergraduate psychology students (n = 120), finding only a significant interaction of item-difficulty ordering and test anxiety subtype. Specifically, participants classified as facilitators (meaning their anxiety leads to the optimal level of arousal) based on the Achievement Anxiety Test (AAT) scored higher with the E–H order. They therefore recommend using the H–E order, which was not shown to significantly interact with anxiety types.
Later studies using the AAT to operationalize trait test anxiety failed to find significant interactions between ordering and trait anxiety. Hambleton and Traub (1974) examined item-difficulty order and stress levels for high school students (n = 140) completing a math test. The inferential analysis, using baseline pulse as a covariate, did not find evidence to support the hypothesis that item-difficulty ordering differentially affected test takers of different anxiety levels. Similarly, other studies (e.g., Marso, 1970; Plake et al., 1981) examined the impact of item-difficulty ordering and test-taker anxiety levels on MCQ test performance of undergraduate students. Overall, there was no consistent significant main effect or interaction of trait anxiety in any such study.
More recently, Chen (2012) asked English-major Chinese university students (n = 250) to complete an MCQ cultural knowledge test. Participants also completed the Test Anxiety Inventory and were grouped into low-, mid-, and high-anxiety groups. The author found an interaction between item order and anxiety levels, with the performance of low-anxiety participants not significantly affected by fixed item orders. As in Munz and Smouse (1968), the E–H order leads to less anxiety for some but not all test takers, in this case, those with moderate to high test anxiety. Together, the findings from some of these studies support the position that ordering effects are moderated by test takers’ initial anxiety level in various ways, with stronger effects for more anxious students.
Several methodological and contextual factors likely contribute to the inconsistent evidence that anxiety mediates ordering effects. First, the operationalization of trait anxiety varied, including by instrument(s) used to measure anxiety (e.g., AAT alone vs. combined with the State-Trait Anxiety Inventory), AAT subscales used (e.g., debilitating scale alone vs. combined with facilitating scale), and the nature of the anxiety variable used in analyses (e.g., categorical vs. integer). Second, the studies took place in a variety of contexts, including both high school and university, as well as both authentic classroom exams and contrived laboratory experiments. Perhaps most importantly, the studies generally had modest sample sizes, ranging from 41–352 participants, meaning some analyses may have been underpowered. Collectively, the heterogeneity of study designs, contexts, and sample sizes makes it less likely that a uniform pattern of results would emerge.
In summary, findings are mixed concerning how ordering is mediated by commonly considered variables. However, there is some evidence that more anxious and lower‑proficiency test takers are impacted more by ordering and that E–H ordering may negate these unwanted effects. Mixed results for anxiety likely reflect differences in operationalization, study design, and contextual moderators.
Speededness
Speededness refers to “the extent to which test takers’ scores depend on the rate at which work is performed as well as on the correctness of the responses” (AERA et al., 2014, p. 223; see also Jurich, 2020). Prototypical speeded tests comprise items of similar difficulty levels and differentiate test-taker proficiency levels by the number of items completed within a strict time limit. Prototypical power tests, on the other hand, include items of varying difficulty and are designed to allow test takers enough time to attempt all items. Most high-stakes tests are not explicitly designed to be speeded tests, in that test takers are expected to attempt all tasks (Kane, 2020); however, high-stakes tests still have an element of speededness (Powers & Fowles, 1996). For speeded assessments, test ordering naturally affects performance as test takers may not reach later items on the test (Becker et al., 2022; Leary & Dorans, 1985; Sax & Cromack, 1966). Becker et al.’s (2022) simulation study demonstrated how different item orders can result in large score differences on a speeded test, corroborating the conclusion from earlier research on the impact of speededness (e.g., Kleinke, 1980). To mitigate this issue, Becker et al. (2022) suggest using a single fixed item order at the end of the test across forms and placing time-intensive items at the end of the test.
Many high-stakes language tests, such as IELTS, TOEFL, and TOPIK, aim to assess a wide range of language proficiency levels in a single fixed form and therefore include items of different difficulty levels, resembling power tests in their construction. However, low-proficiency test takers may not have enough time to thoroughly attempt all items, leading to differential speededness. In situations where test takers have no control over the speed of the stimulus presentation (e.g., listening tests), low-proficiency test takers may need to rush responses to items. Therefore, for language tests with a single form comprising items of widely varying difficulty and insufficient time limits for the lowest-proficiency test takers to attempt all items, E–H item ordering is arguably advisable to minimize unfairness based on proficiency. This recommendation does not apply to CATs and testing programs with multiple forms targeting specific ability levels, such as separate tests for each CEFR level. Further research is needed to determine the effects of different item orders in these cases.
Conclusions
This systematic review examines studies on how test component ordering impacts test-taker performance, perceptions, and affect. Despite mixed findings, some general tendencies emerged that are relevant to language test researchers and practitioners:
E–H ordering by items may lead to better performance, especially under time pressure and for lower-proficiency or more anxious test takers. However, while E–H item ordering appears to provide performance benefits in certain contexts, some studies found no significant differences, emphasizing the need to consider potential moderating factors such as test speededness, scoring method, task type, proficiency level, and test modality.
Grouping items by task type or language skill could reduce the need for context switching. The effects of this change could be positive (faster processing) or negative (greater fatigue). Nevertheless, findings on context switching remain mixed, with outcomes likely influenced by factors such as task complexity, cognitive load, and test length.
Ordering sections by language skills is commonplace but has rarely been empirically tested to optimize measurement quality or test-taker experience. In line with difficulty ordering studies, it appears that the first language skill/task type may hold particular importance.
The findings of this review, while mixed, can be tied to Bachman and Palmer’s (1996, 2010) framework of test usefulness and its six usefulness qualities (Reliability, Construct validity, Authenticity, Interactiveness, Impact, and Practicality). In Bachman and Palmer’s (2010) conceptualization of a test blueprint, the sequence of parts is a core design decision, so ordering is not a neutral choice; it must be justified and evaluated, particularly vis-à-vis construct validity and impact, so as not to introduce construct-irrelevant variance. Furthermore, our findings underscore the importance of interactiveness, that is, the engagement of test-taker characteristics with the task (Bachman & Palmer, 1996). Variables that repeatedly emerged in our review as mediators, proficiency and anxiety, align with the characteristics of language ability and affective schemata in Bachman and Palmer.
Limitations
This systematic review is subject to several limitations. First, there is a dearth of studies conducted in language testing contexts specifically and, hence, included in this review. Caution should be exercised in extrapolating findings from other domains to the language assessment field. Second, all included studies were published in English. The searched databases (ERIC, PsycInfo, and Google Scholar) index materials in other languages, often with titles and abstracts in English. Thus, the absence of non-English publications in our dataset likely reflects the broader dominance of English in academic research rather than a true lacuna (see W. Liu, 2017). Nevertheless, relevant non-English publications may be missing from the review.
In addition to these conceptual gaps, we acknowledge four methodological limitations. First, while a systematic approach was followed in identifying and coding studies, we did not prospectively register our protocol. Second, the sample in this review did not naturally lend itself to analyzing effect sizes due to the heterogeneity of studies across a wide time period. This factor, along with inconsistencies in the reporting of subgroup information, also made it infeasible to conduct subgroup analyses to systematically disentangle ordering effects across potentially relevant variables. Third, publication bias is a common concern in secondary research where studies reporting favorable or statistically significant results may be preferentially published (Rothstein et al., 2005). Nonetheless, our review identified a substantial number of studies reporting null ordering effects. Fourth, for our quality appraisal, Gorard’s (2014) sieve was adapted to better suit the characteristics of the test ordering studies reviewed. While these modifications aimed to tailor the instrument, this adapted version of the tool has not undergone separate validation. However, together with other recent evidence syntheses in language testing (e.g., Han et al., 2025), our study models how methodological rigor and research reporting standards can be enhanced by tailoring an existing tool to evaluate the methodological quality of included studies (Plonsky et al., 2025).
Future Research Directions
Based on the findings and limitations of this study, several important questions remain unanswered on the topic of test component ordering, especially concerning language assessments. At present, common ordering practices in language testing, such as sequencing from receptive to productive skills, appear to be based more on convention and practical considerations than empirical evidence. This gap between practice and research is especially notable given the field of language assessment’s general emphasis on rigorous validation of test design choices. Future research should systematically investigate whether test ordering choices affect test-taker performance, perceptions, or fairness. For one, the generalizability and strength of item-difficulty ordering effects in language testing contexts deserve investigation, and future research could examine how test format and timing constraints interact with ordering effects. After all, speededness is a critical factor to consider, since ordering effects may be magnified in time-constrained assessments.
The findings from this review, though largely derived from research on fixed-form tests spanning a wide time period, nevertheless offer insights for modern language assessments of all formats. Crucially, non-adaptive computer-based tests (CBTs) remain widely used and provide the opportunity for significant ordering flexibility beyond paper-based formats. For instance, these platforms permit test developers to set individual item time limits or to alternate task types/skill areas, even if this results in, for example, some test takers completing listening tasks while others are completing writing tasks. Therefore, principles from this review regarding, for example, E–H item ordering, context-switching effects, and affective impacts of sequence, directly inform principled design of such CBTs. Further research should continue to explore how specific CBT affordances for ordering can be best leveraged to enhance measurement quality and test-taker experience.
Furthermore, these insights are also applicable to designing CATs and scenario-based assessments, as tests of any kind must inevitably present tasks in some sequence, whether that sequence is fixed or personalized. For example, ordering principles can guide the structuring of initial routing items or fixed modules in multi-stage tests (MSTs; see Yan et al., 2025) to optimize test-taker experience. Even within CATs, sequencing diverse task types or content essential for the multidimensional construct of language proficiency necessitates ordering decisions beyond item-difficulty adaptation.
As such, and given the increasing prevalence of CATs, we strongly advocate for research focusing on dynamic ordering in computer-adaptive language tests (CALTs; see Cardwell et al., 2024, for a recent overview). While current CALTs primarily adapt to test-taker proficiency by choosing selected-response items, tasks, or sections of appropriate difficulty, future research should leverage advances in computational linguistics and artificial intelligence to explore more sophisticated sequencing. Options include investigating how real-time natural language processing of constructed responses could inform sequences that better target individual learner profiles, manage cognitive load by adjusting task complexity, or assess complex interactive constructs more authentically (e.g., Runge et al., 2025). Such an agenda must address significant challenges, notably ensuring adequate construct coverage for the multidimensional language construct within adaptive algorithms that often assume unidimensionality (Min & Aryadoust, 2021), and advancing real-time automated scoring for productive skills to effectively inform these dynamic sequences (Cardwell et al., 2024). Successfully developing dynamic ordering of this nature could offer more personalized, and potentially more fair and valid, assessment pathways. This idea could be viewed as an example of personalized ensemble testing (von Davier, 2024), a recently introduced concept that proposes to extend personalization beyond CATs to include the administration of different task types and test sections depending on test-taker background and testing purpose.
In fact, we argue that there remain entirely unexplored possibilities for radically different approaches to test administration enabled by technological developments, but only if test developers take a more critical look at status-quo constraints on test component sequencing imposed by traditional test administration practices. Naturally, in conjunction with such experimentation, we advocate for research to determine whether ordering effects manifest differently across such varying formats. We also encourage language assessment researchers to consider ordering experiments beyond item difficulty, investigating other variables that may impact test-taker performance and experience. Context-switching experiments would be particularly informative, for example, grouping by task type versus alternating task types. Likewise, language test section ordering experiments are needed, for example, ordering tasks in different configurations based on individual or integrated skills. For all these suggestions, we recommend considering mediating traits in the experiment, particularly anxiety and proficiency.
Overall, the paucity of language test ordering studies, combined with the new possibilities afforded by advances in test administration technologies, should serve as a rallying call for language testing researchers to give attention to this sorely under-researched topic. We hope research of this nature will allow language test developers to make decisions about test component order based on empirical evidence rather than intuition or tradition alone.
Footnotes
Appendix 1
Acknowledgements
We thank the editors and reviewers for their comments and suggestions and Shawn Suyong Yi Jones for his assistance in collecting, compiling, and annotating the papers for review.
Author Contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Open Practices
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The authors are employed by Duolingo, Inc. and work on the Duolingo English Test (DET). As part of their remuneration packages, the authors receive equity-based compensation. The views expressed are those of the authors and do not necessarily represent the views of Duolingo, Inc. The authors have a professional interest in test component ordering, particularly for computer-adaptive four-skill language tests, given the relevance of this topic to optimizing test-taker experience and mitigating potential bias.