
Abstract
The current study proposes a new approach to weakness identification in diagnostic language assessment (DLA) for speaking skills. We also propose to design actionable and contextualised diagnostic feedback through the systematic integration of feedback and remedial learning activities. Focusing on lexical use in second language speaking, the current study developed and validated our DLA programme in terms of actual learning gains, using an experimental design. A total of 59 beginner-to-intermediate-level Japanese learners of English were randomly assigned to control or experimental groups. While both groups engaged in task repetition with a conversational artificial intelligence (AI) agent on six occasions, only the experimental group received the diagnostic feedback on lexical use including the paraphrased utterances of their original utterance. The results showed that the control group (task repetition only) demonstrated significant improvement during the task repetition sessions but failed to transfer and retain the learning gains. In contrast, despite the lack of practice effects, the experimental group (task repetition with diagnostic feedback) outperformed the control group at the posttest with a near-medium effect size. A qualitative investigation into learners’ perceptions further confirmed that the proposed contextualised diagnostic feedback succeeded in heightening their awareness of weaknesses.
Keywords
Introduction
Given the integral role of assessment in language learning and teaching, language testing research has explored various ways to conjoin different types of assessment with educational contexts. Among them, diagnostic language assessment (DLA) has attracted increasing attention from language testers. Diagnostic assessment is one type of assessment which aims at facilitating learners’ subsequent learning through the identification of their strengths and weaknesses (Alderson, 2005; Alderson et al., 2015). Strengths refer to what the learner has learned, whereas weaknesses are concerned with what the learner has not acquired with a particular focus on what hinders them from achieving successful performance. DLA research has tended to focus on weaknesses, which can offer useful information regarding learners’ states of target knowledge and thus can help learners and teachers to decide what to learn next and how (Harding et al., 2015). However, given the importance of learners’ psychological variables in learning outcomes (Jang et al., 2015; Xie & Andrews, 2013), both strengths and weaknesses should be assumed to facilitate their learning. For instance, feedback on strengths can foster the sense of achievement in their previous learning (i.e., self-efficacy; see Kormos & Wilby, 2019), subsequently contributing to their sustained motivation and offering insights into their self-regulatory strategies (Xie & Lei, 2021).
Alderson and colleagues (2015) have claimed that DLA tests should be specifically designed for a diagnostic purpose and that effective DLA may require consistency across different components of DLA, that is, diagnosis, feedback, and remedial learning (Lee, 2015). Moreover, possibly due to the challenges in weakness identification, DLA research has suffered from a lack of applications in speaking skills (for a rare exception, see Isbell, 2021), compared to those in receptive skills (Harding et al., 2015; Jang et al., 2015) and writing skills (Y.-H. Kim, 2011; Sawaki et al., 2013). In addition, Lee (2015) pointed out that to secure validity evidence for the effectiveness of DLA, the causal connection between certain components of DLA and the changes in learners’ subsequent learning should be made. Some recent studies longitudinally tracked learners’ development of target skills and gained useful insights into the potential of diagnostic assessments (e.g., Isbell, 2021). However, despite the persistent urge to collect this type of validity evidence of DLA (i.e., learning gains; Isbell, 2021; Lee, 2015), to the best of our knowledge, no studies have examined the effectiveness of DLA using an experimental design (e.g., random group assignment, comparison groups; Phakiti, 2015) to discuss the causal relationship between a target DLA programme and learning gains.
To address the aforementioned challenges in DLA research, the current study proposes a new approach to weakness identification in DLA for speaking skills with the assistance of artificial intelligence (AI) technologies, as well as the realisation of actionable and contextualised diagnostic feedback by systematically integrating the components of DLA (Lee, 2015). To this end, using an experimental design, the current study examined the effects of the DLA programme based on our proposed approach on the development of lexical use in speaking performance.
Background
Challenges in diagnostic assessment for second language speaking
Motivated by the potential of diagnostic assessment for second language (L2) learning, language testers have attempted to develop theories and principles to systematically design and evaluate DLA programmes. Lee (2015) proposes three major components of diagnostic assessment: diagnosis, feedback, and remedial learning. The primary goal of diagnosis is to identify both strengths and weaknesses that prevent learners from reaching the next level of learning or target skills. Feedback is concerned with the presentation of diagnostic results. The format of diagnostic feedback should be carefully designed so that learners and teachers can take appropriate action in response to their learning and teaching. The third component, remedial learning, refers to a set of pedagogical activities specifically designed to improve learners’ target skills by addressing the identified weaknesses. These activities should be in line with learners’ or teachers’ desired goal of L2 learning.
Another line of research is the identification of characteristics of effective diagnostic assessments and tests. Alderson and colleagues have established a list of distinctive features of diagnostic tests (Alderson et al., 2015; see also Alderson & Huhta, 2011). Alderson et al. (2015) claim that test items in DLA are “more likely to be discrete-point than integrative, or more focused on specific elements than on global abilities” and are “more likely to focus on ‘low-level’ language skills than higher-order skills which are more integrated” (p. 238). These statements highlight the transparent correspondence between test items and target constructs for diagnosis. A primary reason for this principle is the interpretability of test performance (Alderson, 2005). Speech production is realised through the orchestration of various cognitive and linguistic resources and processes, and thus it is not always straightforward to identify the cause of challenges at the level of underlying competence and knowledge (i.e., weaknesses) through spontaneous speaking performance (cf. S. Suzuki & Kormos, 2023). DLA practices that conform to the multi-componential nature of oral proficiency and speaking performance include the DIALANG project (Alderson, 2005) and a seminal study by Isbell (2021) on pronunciation, both of which commonly employ discrete-point elements for high interpretability of learners’ current states of target knowledge and skills. While this approach can help learners develop certain aspects of linguistic competence, care should be taken regarding the transferability of the attained knowledge to communicative situations. Drawing on the usefulness of learners’ global skills information for DLA (Alderson, 2005), a diagnostic assessment of speaking performance and skills might be expected to identify learners’ unsatisfactory approaches to language production through spontaneous speaking tasks (e.g., wrong word choice). However, this approach needs to consider the incremental and multi-faceted processes underlying spoken language production (Kormos, 2006), and thus some innovative method might be needed to identify weaknesses through actual language production.
To maximise the potential learning gains through diagnostic assessment, care should be taken regarding the consistency between the components of DLA. In light of feedback, Lee (2015) claims that diagnostic feedback should be actionable and contextualised. The ideal format of DLA feedback enhances its actionability—the probability that learners take remedial actions based on the diagnostic feedback (Lee, 2015)—by closely linking DLA feedback to subsequent learning activities. For instance, the feedback format can be designed with regard to how the content of feedback would be used in a specific remedial learning activity. Similarly, effective DLA feedback should also be contextualised to specific items and tasks, thereby drawing learners’ attention to their unsatisfactory responses. In the context of DLA for speaking, contextualised feedback targeting students’ inappropriate language use, for instance, can be realised by providing alternative expressions while maintaining the learner’s original intention and message. Such feedback can help them notice the gap between how they actually approached an item or task and how they should have approached it, raising their awareness of how to remedy their approach to a certain item or task (Isbell, 2021; Lee, 2015). Notably, these two criteria for diagnostic feedback cannot be achieved by feedback alone because the actionability and contextualization of feedback are determined when learners engage with subsequent remedial learning activities. Both criteria largely depend on the compatibility between assessment tasks in the diagnosis phase and remedial learning activities, as well as on the alignment between the feedback content and remedial learning activities (cf. Lee, 2015). In other words, these two important criteria of DLA feedback could be achieved through (a) establishing a close connection between DLA feedback content and remedial learning activities (i.e., actionability) and (b) contrasting learners’ responses with suggested corrections in relation to the actual communicative context of the test tasks (i.e., contextualization).
Integrating Instructed Second Language Acquisition (ISLA) research and cognitive psychology in diagnostic assessment
As mentioned earlier, learning gains through diagnostic assessment can be maximised by actionable and contextualised diagnostic feedback, which should be achieved through the systematic integration of feedback and remedial learning activities (Lee, 2015). Hence, the content of diagnostic feedback could arguably be optimised in accordance with the learning processes that the test designers intend to facilitate in the remedial learning activities. In this regard, Alderson and colleagues argued that a DLA programme could be “based on a specific theory of language development, preferably detailed rather than a global theory” (p. 238). To obtain insights into learning processes embedded in DLA, one may argue that theories and findings from the domain of ISLA and cognitive psychology can be useful. Drawing on ISLA research findings, both meaning-focused language use (e.g., spontaneous speech, conversation) and form-focused activities (e.g., grammar instruction, corrective feedback) are essential to developing L2 speaking skills (e.g., Rossiter et al., 2010; Sato & Lyster, 2012). Accordingly, spontaneous speaking activities as a remedial learning activity may play a central role in learning gains through diagnostic assessment, while the role of diagnostic feedback, which typically offers form-focused information about language use, should be indispensable. L2 learning is facilitated when such meaning-focused and form-focused activities are systematically aligned (e.g., Long, 2015), which supports the idea of realising contextualised diagnostic feedback by connecting the three DLA components: diagnosis, feedback, and remedial learning
To enhance the actionability of diagnostic feedback, a linkage between diagnostic assessment tasks and remedial learning tasks should be established. With regard to this principle, the pedagogical technique of task repetition (i.e., repeating the same or similar communicative task) might be particularly relevant. ISLA research has suggested that task repetition can facilitate the consolidation of linguistic knowledge (Kakitani & Kormos, 2024; Lambert et al., 2017; Y. Suzuki & Hanzawa, 2022). There are several variations of task repetition in terms of what to repeat: exact task repetition (same content, same procedure) and procedural task repetition (different content, same procedure). Exact task repetition generally yields greater learning gains (N. de Jong & Perfetti, 2011; Y. Kim & Tracy-Ventura, 2013). Furthermore, form-focused pedagogical activities and techniques, such as corrective feedback and consciousness-raising tasks, can be combined to direct learners’ attention to certain linguistic forms so that multiple aspects of speaking performance can be enhanced simultaneously (Tran & Saito, 2021; van de Guchte et al., 2016).
Recently, research on task repetition has been reconceptualised from the perspective of cognitive psychology, highlighting the importance of the schedule of task repetition (see Wiseheart et al., 2019). The implementation of task repetition can be viewed as retrieval practice, where learners attempt to retrieve newly acquired or partially consolidated knowledge (Ellis, 1995). Repeating such retrieval practice leads to the modification of learners’ memory system so that they can retain the target knowledge in their long-term memory. Key variables that can be manipulated to enhance learning gains through repetitive retrieval include the time interval between practice sessions (i.e., intersession interval [ISI]) and the interval between the final practice session and the testing session (i.e., retention interval [RI]). Although longer ISIs are preferable in general (i.e., spacing effects), the learning outcome tends to depend on the ratio of the ISI to the RI (i.e., ISI/RI ratio), which is ideally between 10% and 30% (Cepeda et al., 2008; Kakitani & Kormos, 2024; Rohrer & Pashler, 2007).
Another relevant issue affecting learning gains through retrieval practice is the complexity of target practice. According to the desirable difficulty framework (Bjork, 1994), optimal learning gains can be achieved when learners engage in effortful retrieval of target items, meaning that the difficulty level of activities and target forms should be matched with learners’ developmental readiness, that is, at a point where they can benefit from pedagogical activities based on their current L2 system (see Y. Suzuki et al., 2019). For the sake of achievable learning goals, it might thus be ideal to focus on linguistic features that are developmentally ready in the DLA context. Effective diagnostic feedback for lexical use in speaking, for instance, may incorporate usages characteristic of speakers at a slightly higher proficiency level than that of the target learner.
Potential of AI technologies in diagnostic assessment
In various speaking assessment contexts, language testers have admitted the potential of technologies such as AI to enhance the practicality and authenticity of assessment practices. Regarding speaking performance elicitation, the introduction of computer-based test format, such as that of the Test of English as a Foreign Language Internet-based Test (TOEFL iBT), has reduced the cost for the delivery of speaking tests. However, the mode of speaking has been limited to monologic speaking tasks, while dialogic speaking tasks have been, as yet, administered mostly by trained human examiners (e.g., Cambridge Assessment English exams). Recently, in response to the need for assessing interactional speaking skills, language testers have developed and validated the use of spoken dialog systems, which can orally ask questions to and generate responses to questions from test-takers, for eliciting test-takers’ interactive performance (Gokturk & Chukharev-Hudilainen, 2023; Ockey & Chukharev-Hudilainen, 2021). To further enhance the authenticity of assessment tasks, the potential of a multimodal spoken dialog system (hereafter, conversational AI agent), which is equipped with an avatar and thus can use non-verbal gestures, has also drawn increasing attention from language testers. Our precursor study confirmed that such a multimodal conversational AI agent can elicit ratable speech samples reflecting test taker’s upper limit of oral proficiency (e.g., linguistic breakdown) in an oral proficiency interview (OPI) format (Saeki et al., 2024).
The application of technologies to automated speech evaluation has also been advanced due to the development of neural network-based machine learning (ML) algorithms, which can recognise non-linear, dynamic patterns between speech characteristics and assigned scores. L2 research has conventionally employed rule-based feature extraction and a linear regression approach to score prediction for the sake of interpretability of predicted scores, targeting constructs such as fluency (S. Suzuki et al., 2021), comprehensibility (Saito, 2021) and, more holistically, oral proficiency (N. H. de Jong et al., 2012; Révész et al., 2016). However, one notable advantage of a neural network-based ML approach over traditional SLA feature extraction is that it can exhaustively capture various speech characteristics and even their interrelationships with outcome variables, typically in the form of feature vectors (e.g., transformer, attention mechanism; see Devlin et al., 2019; Vaswani et al., 2017). ML-based models have been reported to achieve high accuracy in predicting both holistic and analytic scores of L2 speaking performance (e.g., Chen et al., 2018; Ramanarayanan et al., 2017). In the context of an OPI task with a conversational AI agent, the automated scoring model, which incorporated neural network-based multimodal feature extractions and ML-based algorithm, achieved high consistency with trained human raters in predicting Common European Framework of Reference for Languages (CEFR) levels on the scales of Overall Oral Interaction, General Linguistic Range, Grammatical Accuracy, Overall Phonological Control, Fluency, and Coherence and Cohesion, as defined by the Council of Europe (2020) (Quadratic Weighted Kappa [QWK] = .934–.965; for details, see Takatsu et al., 2026). Despite the high prediction accuracy, an ML approach, however, has been criticised in various domains for the inherent “black box” nature, that is, the low interpretability of score prediction (for discussion in automated speaking assessment, see Khabbazbashi et al., 2021). Researchers have thus extended the framework of eXplainable Artificial Intelligence (XAI), which aims to offer insights into the decision-making processes of AI-based predictions, to avoid unwanted consequences of AI use, such as adopting unacceptable decisions, and to empower users in understanding the decisions made by AI-based systems (Saeed & Omlin, 2023).
Recently, with the assistance of ML and natural language processing (NLP) techniques, it has become possible to identify the usage that should be modified to make performance more successful in relation to a certain global skill or construct (e.g., Yoon et al., 2019), which provides insights into learners’ weaknesses at the level of linguistic knowledge. Several automated feedback systems for speaking performance have been developed and evaluated. In light of the diagnosis component, by using the SpeechRater engine, which is constructed to predict the scores of spoken responses in TOEFL iBT (Chen et al., 2018; Xi et al., 2006), Gu et al. (2021) designed the automated feedback based on six fine-grained features targeting the constructs of fluency, pronunciation and vocabulary. Focusing on the listening-to-speaking tasks in the TOEFL iBT test, Yoon et al. (2019) developed the diagnosis system on the content adequacy of spoken responses, by means of similarity scores between responses and source texts based on word-embeddings. In contrast, only a limited number of studies have developed feedback in relation to subsequent practices and have evaluated learning gains in target skills such as pronunciation (Cucchiarini et al., 2009) and syntactic knowledge (de Vries et al., 2015). 1 Finally, Isbell (2021) has developed the Korean Pronunciation Diagnostic with DLA principles (e.g., Alderson, 2005; Alderson et al., 2015), which provides the information of learners’ strengths and weaknesses in both perception and production at the phoneme level. Despite the lack of a control group, his in-depth qualitative investigation into the long-term impact of diagnostic feedback indicated that learning gains can vary according to individuals’ learning efforts after diagnosis.
Taken together, AI-powered technologies have enhanced the authenticity of speaking performance elicitation and the accuracy in predicting target skill scores. However, the black-box nature of ML-based diagnosis hinders a key criterion of DLA in the decision-making processes for subsequent learning activities—the interpretability of learner profiles. To maintain both the accuracy of ML-driven diagnosis and the interpretability of learners’ weaknesses, the framework of XAI may offer a promising solution for automated DLA systems. Provided the XAI framework aims to evade unwanted consequences of AI use and to assist users in better understanding the decisions made by AI-based systems, it could be considered compatible with the fundamental principle of language assessment, namely, the meaningful interpretation of assessment records (cf. Bachman & Palmer, 2010). In addition, in the context of speaking performance assessment, XAI might be used to demystify predicted performance assessment scores by identifying linguistic features that influence the AI model’s score prediction. One useful XAI technique is the Shapley Additive explanations (SHAP) framework (Lundberg & Lee, 2017), which is derived from cooperative game theory—Shapley values (Shapley, 1953). SHAP quantifies the relative contribution of individual features to the predicted value of outcome variables so that the relative importance of those features can be presented in an interpretable manner.
The current study
In response to the challenges of weakness identification in diagnostic assessment for speaking skills, the current study proposes a diagnostic approach that integrates skill-level assessment and discrete item-level linguistic features, orchestrating ML, NLP, and XAI techniques. To achieve actionable and contextualised diagnostic feedback, we also propose to closely align the design of diagnosis, feedback, and remedial learning with one another (see Lee, 2015). To this end, we incorporate one of the well-researched ISLA pedagogies—task repetition—into speaking tasks for diagnosis and remedial learning phases, using a conversational AI agent as an interlocutor. Moreover, the feedback contrasts learners’ unsatisfactory utterances identified as weaknesses with suggested corrections in relation to the actual questions from the AI agent.
Provided that L2 speaking performance is multidimensional (Kormos, 2006; Segalowitz, 2010) and that the quality of learning efforts during remedial learning activities can affect learning gains (Isbell, 2021), learners’ attention should arguably be regulated to relevant aspects of speech production when testing the effects of diagnostic feedback on a certain target skill. Given the lexically driven nature of speech production (Kormos, 2006), lexical use in speech is relatively less complex than other aspects of speech such as fluency (cf. S. Suzuki & Kormos, 2023). Therefore, we decided to test the effects of DLA based on the proposed approaches on changes in lexical use in this study. Specifically, the current study operationalised the intended lexical learning as the retention of new lexical items in spontaneous speech production. The holistic changes in the lexical use were measured on the CEFR General Linguistic Range scale (Council of Europe, 2020).
In response to the call for robust validity evidence of DLA in terms of learning gains (Lee, 2015; see also Isbell, 2021), the current study aims to examine the effects of the DLA programme on lexical use, using an experimental design. To capture the learning gains comprehensively, the current study followed recent L2 speaking task repetition research (Kakitani & Kormos, 2024; Y. Suzuki & Hanzawa, 2022), assessing the improvement (a) during the practice sessions, (b) after the sessions (i.e., retention) and (c) to a new task (i.e., transfer). The following research questions (RQs) were thus examined:
RQ1. What are the effects of contextualised diagnostic feedback on lexical use during the DLA programme?
RQ2. To what extent are the effects of contextualised diagnostic feedback on lexical use durable after 1 week?
RQ3. To what extent can contextualised diagnostic feedback improve lexical use in a new task?
Method
Overall design
The current study adopted an experimental design with a pretest, a posttest, and a delayed posttest to examine the effects of our DLA programme, which was conducted for six consecutive days (see Figure 1). In the control group, learners engaged in the exact task repetition of an OPI with a conversational AI agent. Prior to the task repetition session on each day, they received the estimated CEFR Overall level based on their performance on the previous day as minimum feedback. In the experimental condition, learners also engaged in the same task repetition programme as a remedial learning activity, whereas the results of diagnostic assessments were provided in addition to the estimated CEFR level. To ensure that the differences in learning gains between the groups could be attributed to the inclusion of contextualised diagnostic feedback, we controlled for learning opportunity during the remedial learning phase by offering the identical pedagogical activity (i.e., task repetition).
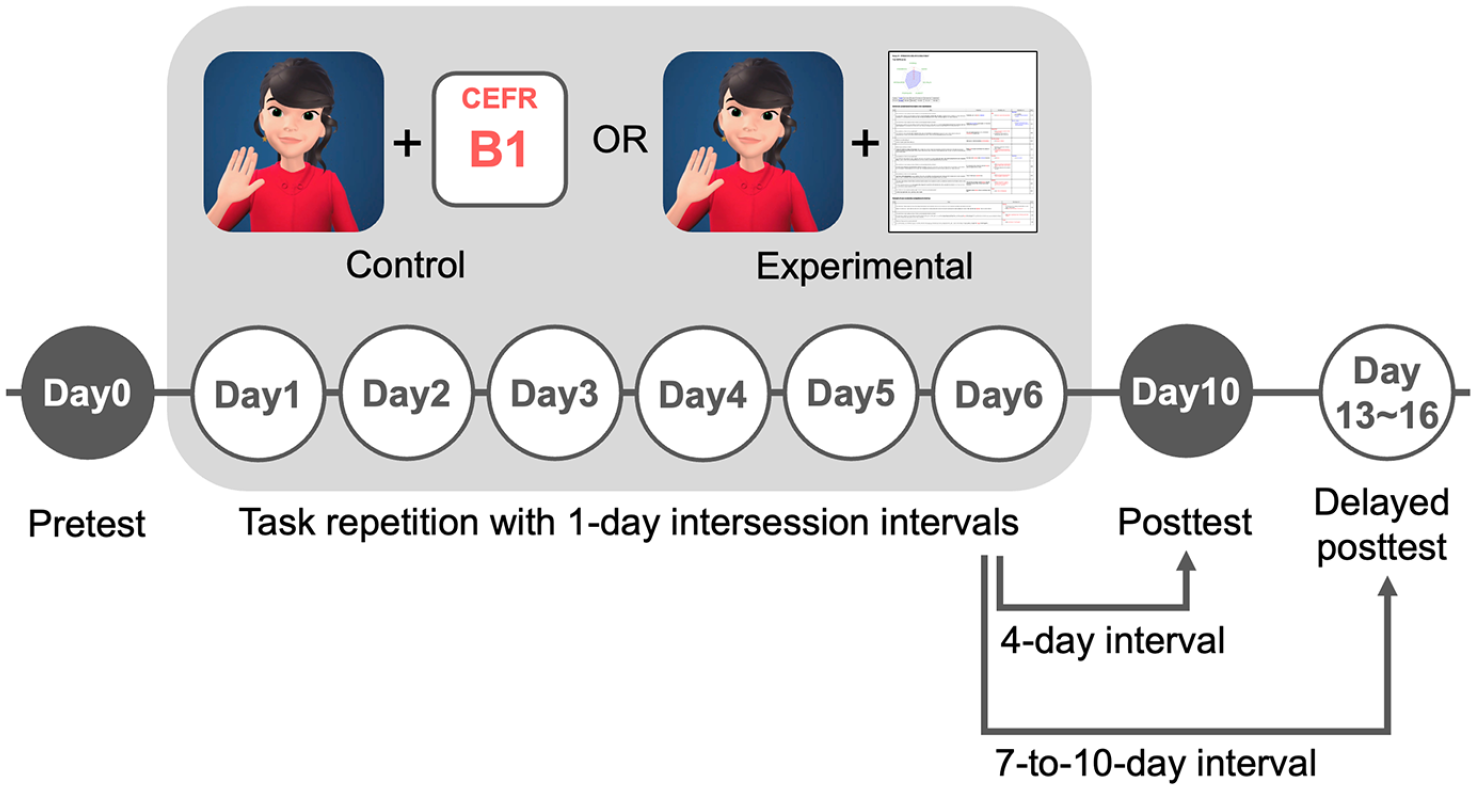
Overview of the experimental design for diagnostic language assessment. The study employed an experimental design with a pretest (Day 0), posttest (Day 10), and delayed posttest (Days 13–16) to examine the effects of contextualised diagnostic feedback. Both groups engaged in six consecutive days of task repetition with 1-day intersession intervals. Each session involved an oral proficiency interview (OPI) task with a conversational AI agent, covering three fixed interview topics. Pretest and posttest scenarios were counterbalanced across participants, while practice sessions and the delayed posttest used a separate fixed set. The control group (left) received only estimated CEFR levels as minimal feedback, whereas the experimental group (right) received diagnostic feedback.
In both groups, all sessions—including a pretest, practice sessions, a posttest, and a delayed posttest—were individually conducted outside the lab. To this end, three different sets of OPI questions were prepared, and two of these sets were adopted for a pretest and a posttest and were counterbalanced across participants. The remaining set was used for the remedial learning activity. To maximise the potential learning gains, the time periods between the final practice session and posttest (ISI/RI ratio = 25%) and between the final practice session and the delayed posttest session (ISI/RI ratio = 10–14%) were set within the optimal range proposed in previous studies.
Participants
We recruited a total of 80 Japanese learners of English at a private university in Japan via online advertisement. 2 To control for the effects of learners’ proficiency levels, we randomly assigned recruited participants into either a control or experimental group with a group matching technique based on their self-reported scores of proficiency tests. Although 12 students did not take the pretest, the remaining 68 students completed all the experimental sessions, adhering to the experimental schedule (e.g., 1-day ISI). However, after excluding participants whose recordings were not of sufficient quality, only the pretest, practice, posttest, and delayed posttest data from 59 students were included in the current study (see Procedure section). Before the treatment session, we delivered a fully automated speaking test with a conversational AI agent (Saeki et al., 2024) as the pretest, which assesses their overall oral proficiency on the CEFR scale of Overall Oral Interaction (hereafter, CEFR Overall; for the descriptors, see Council of Europe, 2020). 3 The resulting CEFR level was used to decide the difficulty level of interview topics in the treatment sessions. The distribution of their CEFR levels is summarised in Table 1.
Distribution of overall CEFR levels based on a pretest across groups.

DLA programme
Diagnosis through an OPI task
During the DLA programme, participants repeated an OPI task with a conversational AI agent (Saeki et al., 2024), and each session of task repetition served as both assessment tasks and remedial learning activities in our study. As illustrated in Figure 1, the whole DLA programme spanned six days, and the participants engaged in a practice session on a daily basis (i.e., 6 sessions in total). Each session consisted of three interview topics, covering familiar topics (e.g., breakfast, favourite season) to more abstract themes (e.g., community building, future trends) according to the target CEFR levels. Each topic comprised four to five questions. Building on the desirable difficulty framework (Bjork, 1994), the target difficulty level was determined as one level higher than the participants’ CEFR Overall pretest scores (e.g., B1-level topics for A2-level learners). Although the adaptive test format was adopted in the pretest and posttest (for details, see the “Pretest and posttest tasks” section), the order and content of topics were fixed throughout the practice sessions to maximise the opportunity to retrieve the same target expressions. Each task repetition session usually lasted approximately 10 minutes.
Estimation and feedback
Participants’ oral performance at each task repetition session was submitted to a ML-based automated scoring system (Takatsu et al., 2026), which returned their levels of proficiency on the CEFR scale of General Linguistic Range (hereafter, Range; Council of Europe, 2020). This scale primarily taps into the breadth and depth of lexical repertoires and grammatical structures while partially referring to the smoothness of lexical retrieval and search (see Appendix 1 for the scale). In our scoring system, the probabilities for the CEFR levels are estimated via neural networks from multimodal features and then are converted to a continuous value score
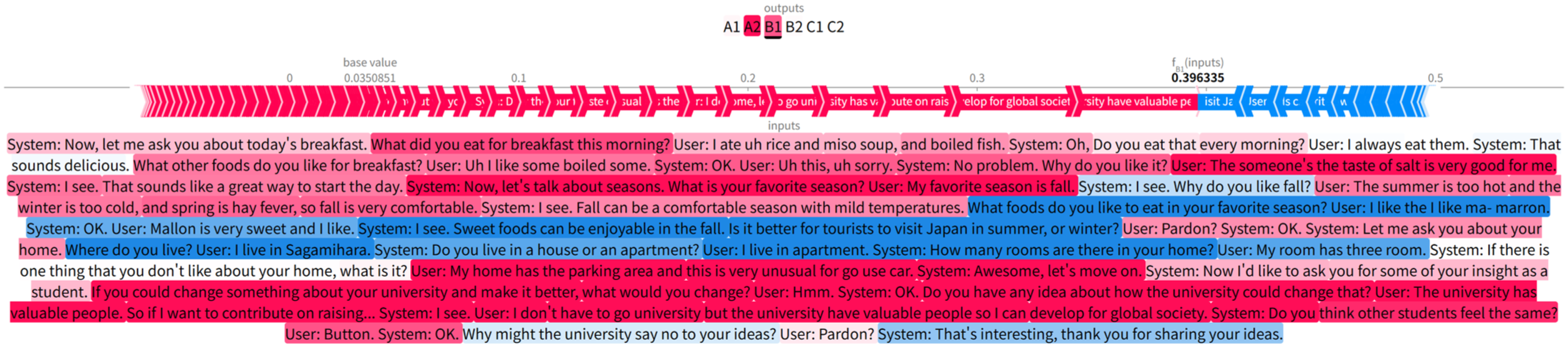
Example of visualisation of the contribution of each word of a transcribed dialogue to the B1 probability of a learner who is estimated as A2 level of Range.
The utterances labelled as weaknesses were then submitted to a large language model to generate a list of paraphrased sentences. In this study, we employed GPT-4 (OpenAI et al., 2023). To maintain the participant’s original intention as much as possible and to provide target lexical items in a contextualised manner, we generated a list of ten candidate sentences for each target utterance. The generated sentences were then filtered based on a set of criteria, including (a) semantic similarity to the student’s original utterance, by means of Word Rotator’s Distance (Yokoi et al., 2020), (b) appropriateness in spoken discourse, with assistance of Styleformer (Etinger & Black, 2019), and (c) the number of expressions at one level higher than the current CEFR level based on English Vocabulary Profile (Capel, 2010, 2012; http://vocabulary.englishprofile.org; for details, see Takatsu et al., forthcoming). The target expressions at one level higher (i.e., weaknesses) and those which are useful to maintain the current CEFR level (i.e., strengths) are highlighted by red and blue, respectively. A simplified example of diagnostic assessment record is available in Appendix 2. The complete version of the feedback sheet is available on the Open Science Framework (OSF; Suzuki, 2025).
Remedial learning
Our remedial learning activity consists of a score report activity and task repetition. The score report activity is designed to raise learners’ awareness of their learning through the subsequent task repetition and regulate their attention to expressions that they expect to manage to use by themselves (cf. Isbell, 2021). From a methodological perspective, this activity also helped researchers ensure that participants actively engaged with their diagnostic feedback, which could enhance the internal validity of the experimental condition. They were asked to review the diagnostic assessment record and then to evaluate each of the paraphrased sentences in terms of how likely they can use the suggested expressions by themselves using a 5-point scale (1 = I cannot use it at all, 5 = I can use it very well). This score report activity can encourage participants to pay attention to the expressions that are partially acquired rather than completely unfamiliar expressions. Immediately after completing the score report activity, they took an OPI with a conversational AI agent (Saeki et al., 2024) with the same procedure as the diagnosis phase described above.
Pretest and posttest tasks
Although both pretests and posttests were conducted in the same OPI format with the conversational AI agent as practice sessions, the difficulty level of topics was adaptively changed during the OPI based on the incremental automated assessment of the overall CEFR level to secure the opportunity for learners to demonstrate their upper limit of performance (for details, see Saeki et al., 2024). The pretests and posttests included three main topics in addition to a warm-up phase and a closing phase, following the ACTFL OPI (Salaberry, 2000). The format of the pretest and posttest was identical, while the pool of topics presented was counterbalanced so that we could test the transfer of learning effects on a new interview task. Only the recordings of responses to the main topics were submitted to the aforementioned automated scoring system.
Procedures
Pretest and posttest sessions
All the materials at the pretest and posttest sessions were delivered online. Participants were first asked to respond to a set of questionnaire items for individual difference factors using Qualtrics (www.qualtrics.com). However, they are beyond the scope of the current study and thus are not reported in this paper. After completing the questionnaire, they accessed another website specifically designed for this experiment to take the OPI with a conversational AI agent (see Figure 3). At the end of the posttest, participants also responded to a debriefing questionnaire about their opportunity to refer to our feedback sheet and use English outside the current DLA programme with a 6-point scale (1 = not at all, 2 = less than 15 minutes, 3 = 15–30 minutes, 4 = 30–60 minutes, 5 = 61–120 minutes, 6 = more than 120 minutes). To collect participants’ perceptions of the DLA programme, the debriefing questionnaire also included open-ended questions about strengths and challenges of our diagnostic assessment record.

Screenshot of the oral proficiency interview task with a conversational AI agent.
Practice sessions and a delayed posttest
The procedure of practice sessions was different between the first session (Day 1) and the remaining sessions (Days 2–6). On Day 1, students only completed the OPI with a conversational AI agent. On the subsequent days, they received feedback of their performance on the previous day from researchers via an email—only the overall CEFR level for the control group and diagnostic feedback for the experimental group. Participants in both groups completed the task repetition activity at the same time of day as much as possible so that the ISI approximated 24 hours. For the experimental group, to ensure that they process the diagnostic feedback, they were required to complete the score report activity using the Qualtrics software, prior to the task repetition activity. To ensure the internal validity of task repetition as retrieval practice, our participants were instructed not to view the feedback report during the task repetition activity. A delayed posttest was conducted using the same set of topics as the practice session. The time interval between the final practice session and the delayed posttest was initially set as 1 week (ISI/RI ratio = 14%). However, to reduce participants’ dropout due to the difficulties in adhering to the experimental schedule, we allowed the delayed posttest to be completed up to ten days after the final practice session. This adjustment kept the ISI/RI ratio (10%) within the ideal range suggested by previous studies (i.e., 10%–30%; see Kakitani & Kormos, 2024; Rohrer & Pashler, 2007).
Analysis
Due to the informal nature of the current practice activity, it is plausible to assume that some participants might not be engaged with the remedial learning activity. For the sake of internal validity of the current treatment, those participants should be excluded from the analyses. Following the literature of learner engagement (Hiver et al., 2021), we analysed their speech data in terms of the number of words produced and the mean length of turns in words as a proxy for behavioural engagement. With reference to those objective indices, we manually checked the video recordings of practice sessions. It was found that one student in the experimental group continuously provided irrelevant responses to the AI agent and that eight participants (four from the experimental group; four from the control group) failed to complete the interview task appropriately due to the problem of automatic speech recognition primarily caused by noise in the learners’ audio input. After excluding those cases, 59 participants’ data of speaking performance were submitted to the subsequent analyses.
To compare lexical performance within practice sessions (RQ1) and at the delayed posttest between groups (RQ2), we constructed a linear mixed-effect model. The automatically estimated numerical CEFR Range score was used as the outcome variable, and the fixed-effect predictor variables of Group (control vs. experimental) and Time were included as between-subject and within-subject variables, respectively. Regarding the predictor variable of Time, we narrowed down our scope to three crucial time points to minimise the rate of type II errors: Day 2 as learners’ first performance after they received their feedback, Day 6 as the final performance during the task repetition sessions, and delayed posttest. The difference between Day 2 and Day 6 reflects the potential learning gains within the DLA programme, whereas the comparison between Day 6 and delayed posttest gives insights into the durability of learning through the current DLA programme. The interaction term between Group and Time was included to detect the differential effects of treatment programmes (with vs. without diagnostic feedback) across time points. Following previous experimental studies on task repetition (Kakitani & Kormos, 2024; Y. Suzuki & Hanzawa, 2022), we also included participants’ CEFR Range score at Day 1 as the covariate to consider the potential baseline difference between the two groups. The model also included the random intercept of individual participants. To identify the location of statistically significant between-group and within-group differences, post-hoc comparisons were conducted with the Tukey adjustment method to account for multiple comparisons. To test the transfer of learning gains to a new context (RQ3), we built another linear mixed-effect model predicting the CEFR Range score from fixed-effect predictor variables of Group (control vs. experimental), Time (pretest vs. posttest) and their interaction term with the random intercepts of individual participants and interview scenarios. All these statistical analyses were conducted in R statistical software version 4.0.2 (R Core Team, 2020), using the packages of lme4 (Bates et al., 2015) and emmeans (Lenth, 2020). The R code and anonymized data set are available on OSF (https://osf.io/vtx3f/). Effect sizes were interpreted based on Plonsky and Oswald’s (2014) field-specific guidelines. For the post hoc comparisons, the effect sizes of Cohen’s d for intergroup (d = .40 as small; d = .70 as medium; d = 1.00 as large) and intragroup (d = .60 as small; d = 1.00 as medium; d = 1.40 as large) comparisons were computed based on the estimated marginal means.
In addition to statistical analyses, to capture participants’ perceptions of the current diagnostic assessment record, the responses from the experimental group to the open-ended questions about its strengths and challenges were coded using inductive content analysis (Selvi, 2019). The first author initially open-coded the responses to establish the coding scheme. The third author then blind-coded the entire responses, and the initial agreement rate was 65.4% and 95.0% for strength and challenges, respectively. All the disagreements were resolved through the discussion between them.
Results
Lexical changes within practice sessions and 1-week retention
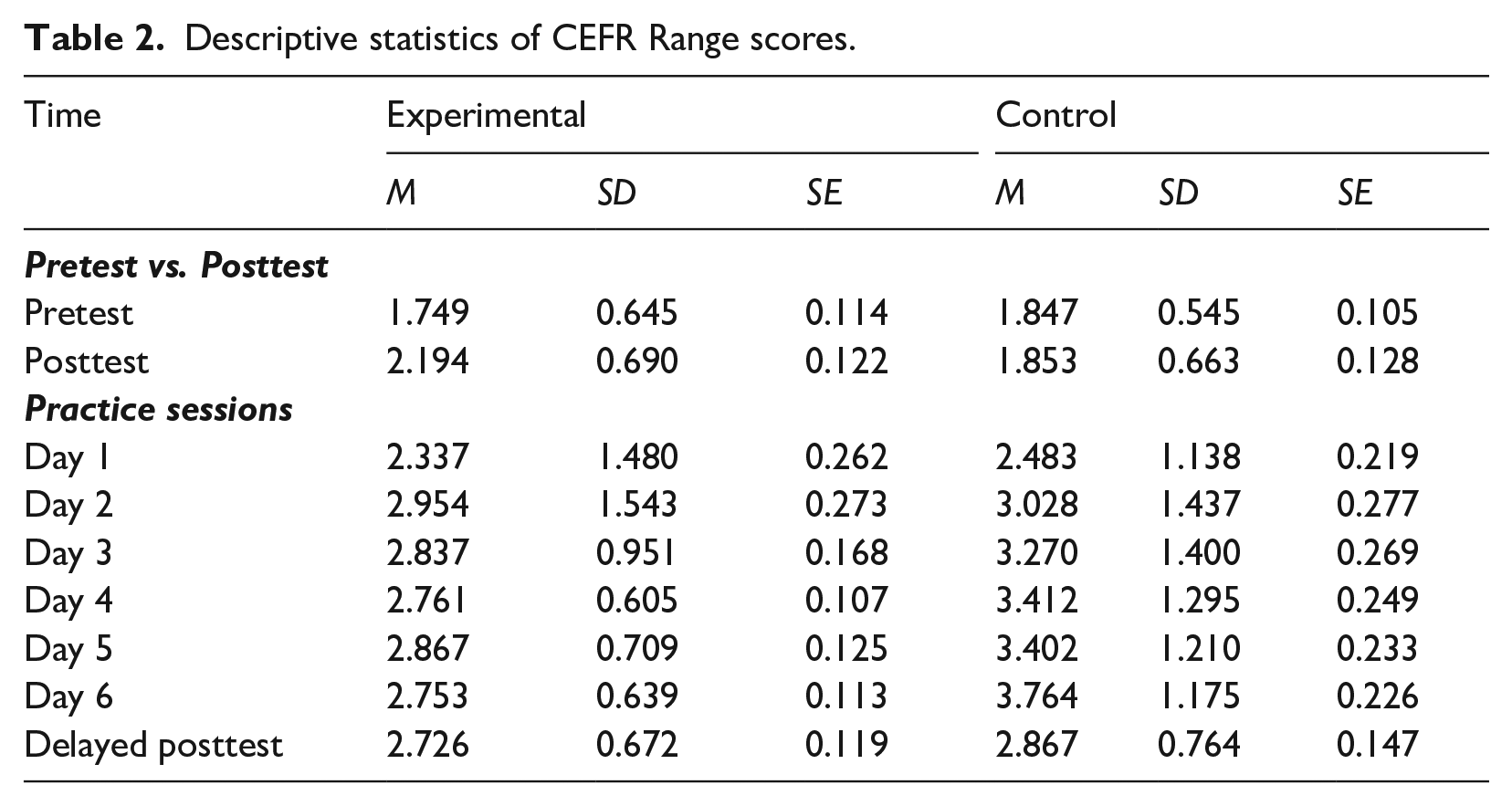
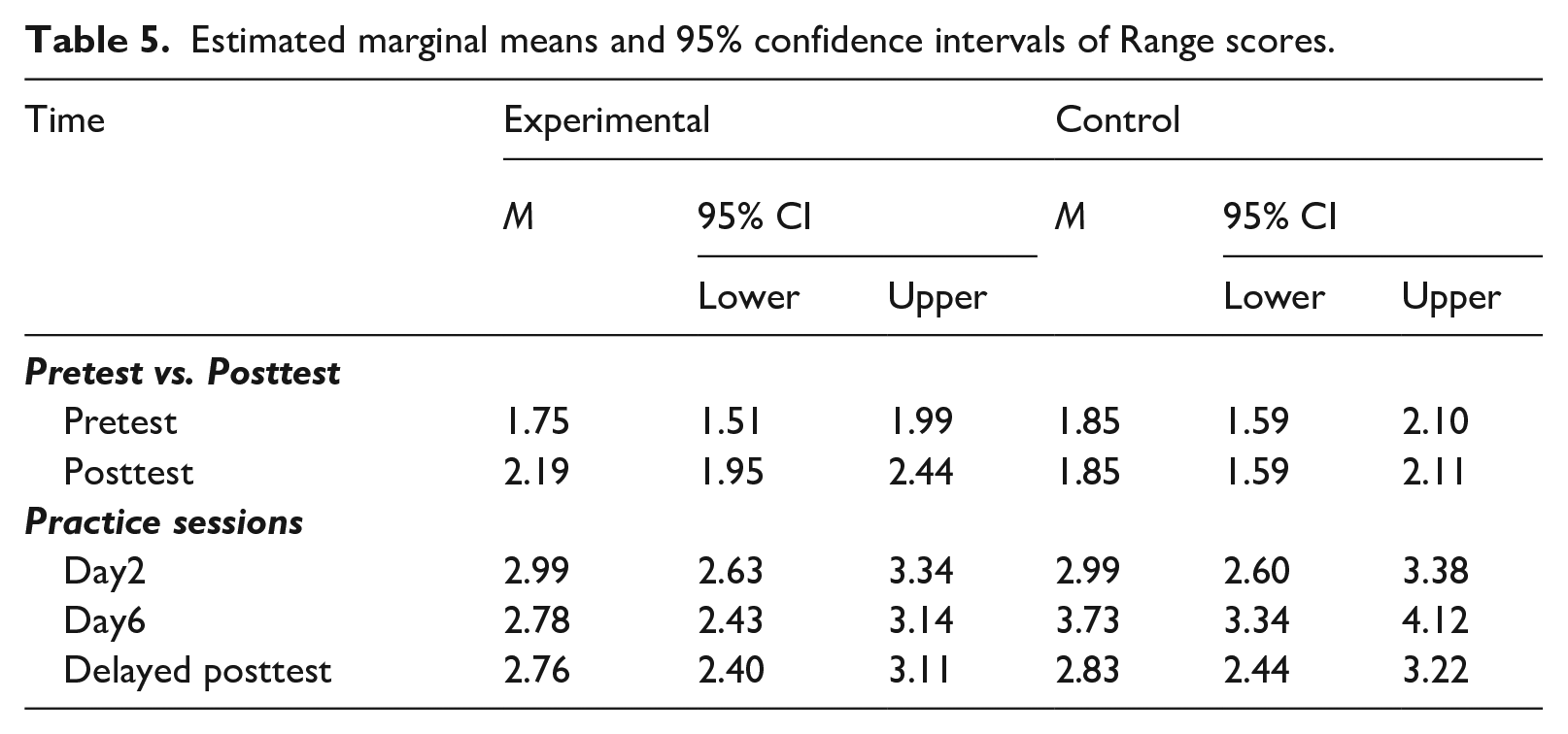
Figure 4 illustrates participants’ CEFR Range scores during the DLA programme and at the delayed posttest in both experimental and control groups (for descriptive statistics, see Table 2). To test the statistical differences in the pattern of lexical performance changes between the groups across three time points (Day 2, Day 6, Delayed posttest), we constructed a linear mixed-effect model predicting the CEFR Range scores from the fixed-effect predictor variables of Time, Group and the interaction term by these two variables, with their scores at Day 1 as the covariate (see Table 3). The results indicate a significant positive effect of participants’ Range score at Day 1, confirming the importance of considering the potential baseline score for performance changes. The regression model also showed a significant interaction effect between Time [Day 6] and Group (β = –0.938, p = .003), indicating that Range score changes between Day 2 and Day 6 can be differentiated by the experimental conditions. Accordingly, the post hoc comparisons were conducted with estimated marginal means across the time points and the conditions with the Kenward-Roger method. The results indicated that the control group significantly improved from Day 2 to Day 6 with a small effect size (β = –0.736, p = .019, d = –0.882) and also significantly decreased from Day 6 to the delayed posttest with a medium effect size (β = 0.897, p = .002, d = 1.074). There was no significant difference between Day 2 and the delayed posttest (β = 0.160, p = .981, d = 0.192). On the contrary, in the experimental group, there were no significant changes in any combination of three time points (see Table 4). It is notable that at the Day 6 session, the control group outperformed the experimental group with a large effect size (β = 0.942, p = .001, d = 1.128). However, there was no significant difference between the groups at the delayed posttest session (β = 0.072, p = 1.000, d = 0.086). The estimated marginal means and 95% confidence intervals are summarised in Table 5.
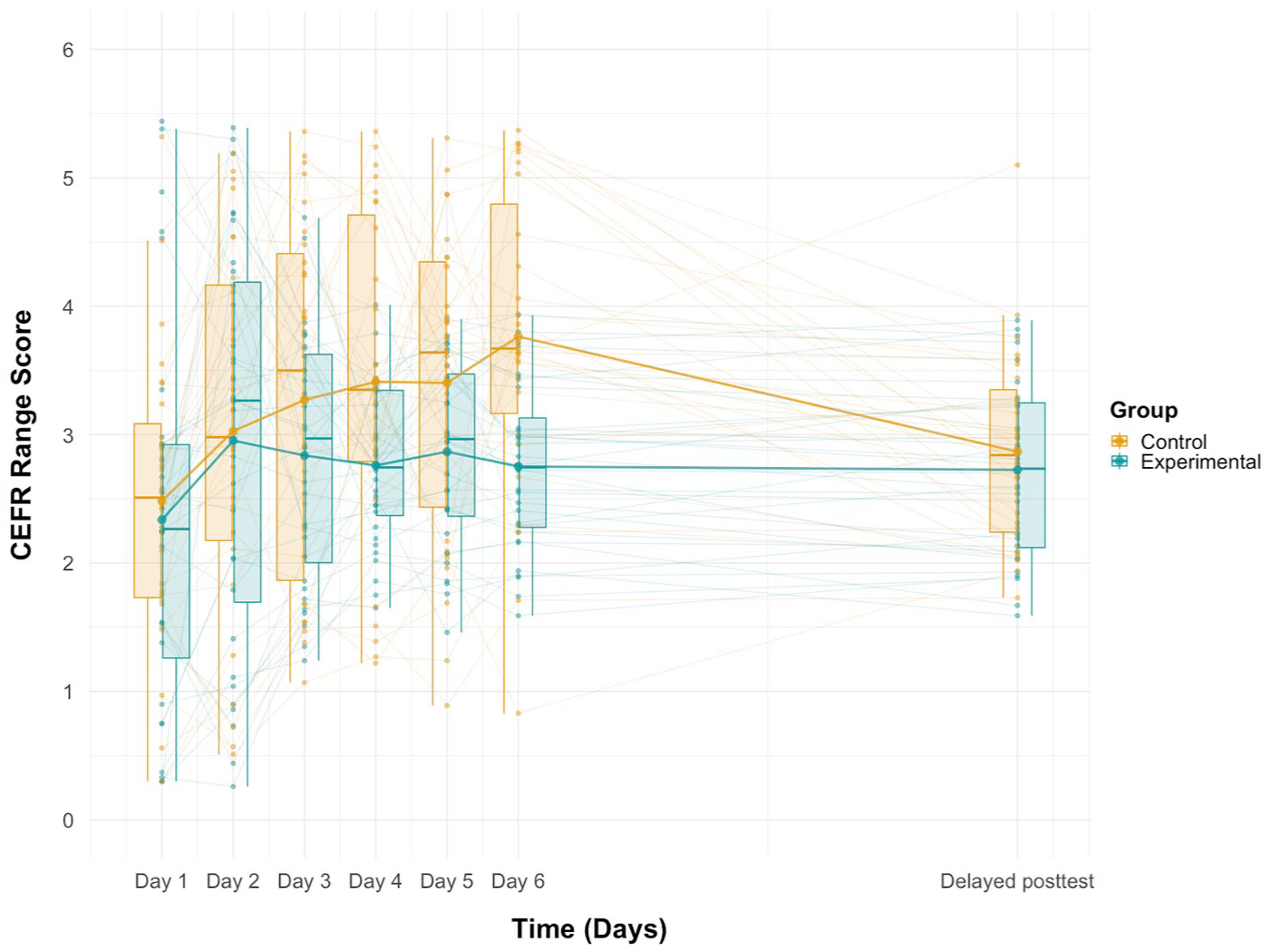
Range scores during practice sessions and at the delayed posttest.
Descriptive statistics of CEFR Range scores.
Model summary for practice data.
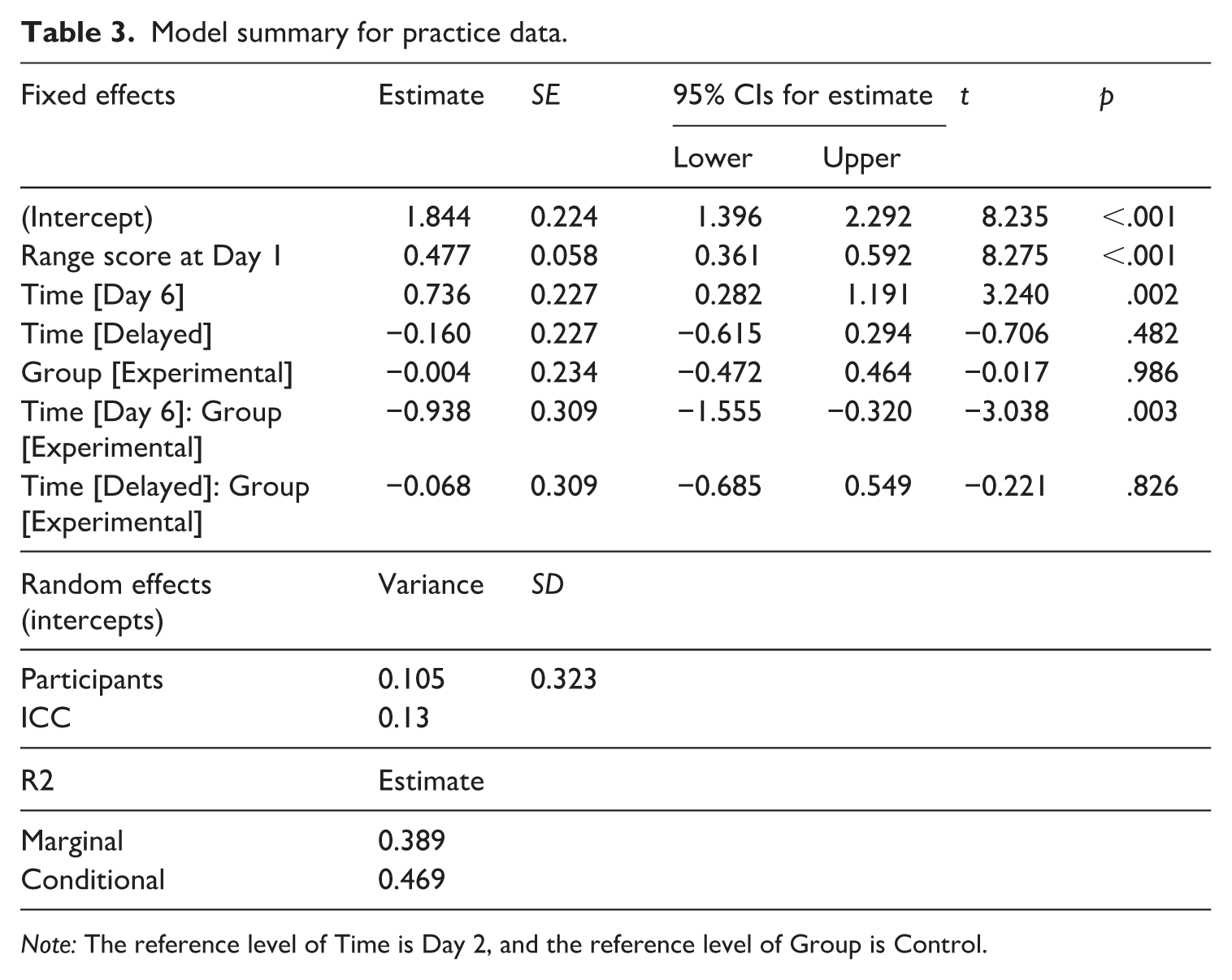
Note: The reference level of Time is Day 2, and the reference level of Group is Control.
Post-hoc comparisons for practice data.
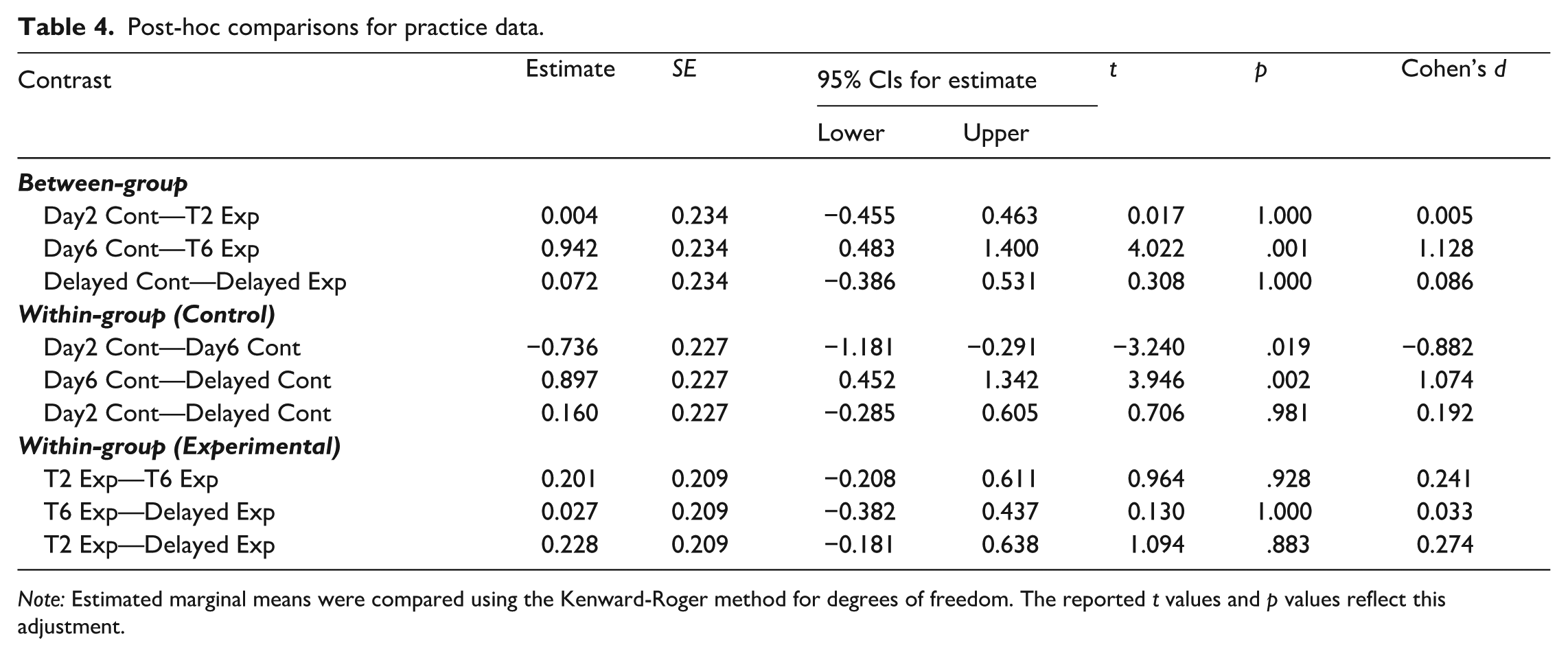
Note: Estimated marginal means were compared using the Kenward-Roger method for degrees of freedom. The reported t values and p values reflect this adjustment.
Estimated marginal means and 95% confidence intervals of Range scores.
Pretest–posttest changes
Figure 5 illustrates the Range scores at the pretest and posttest for both groups. To compare participants’ Range scores between the two groups at the posttest, we constructed another linear mixed-effect model predicting Range scores from the fixed-effect variables of Time (Pretest vs. Posttest) and Group (Control vs. Experimental) with random intercepts of individual participants and interview scenarios (see Table 6). The results indicated that an interaction effect between Time [Posttest] and Group was approaching statistical significance (β = –0.440, p = .052), suggesting that the Range scores might be differentiated by the conditions at the time of posttest. The post hoc comparisons based on the estimated marginal means with the Kenward-Roger method demonstrated that the experimental group might have outperformed the control group at the posttest with a near-medium effect size (β = –0.342, p = .044, d = –0.570; see Table 7).
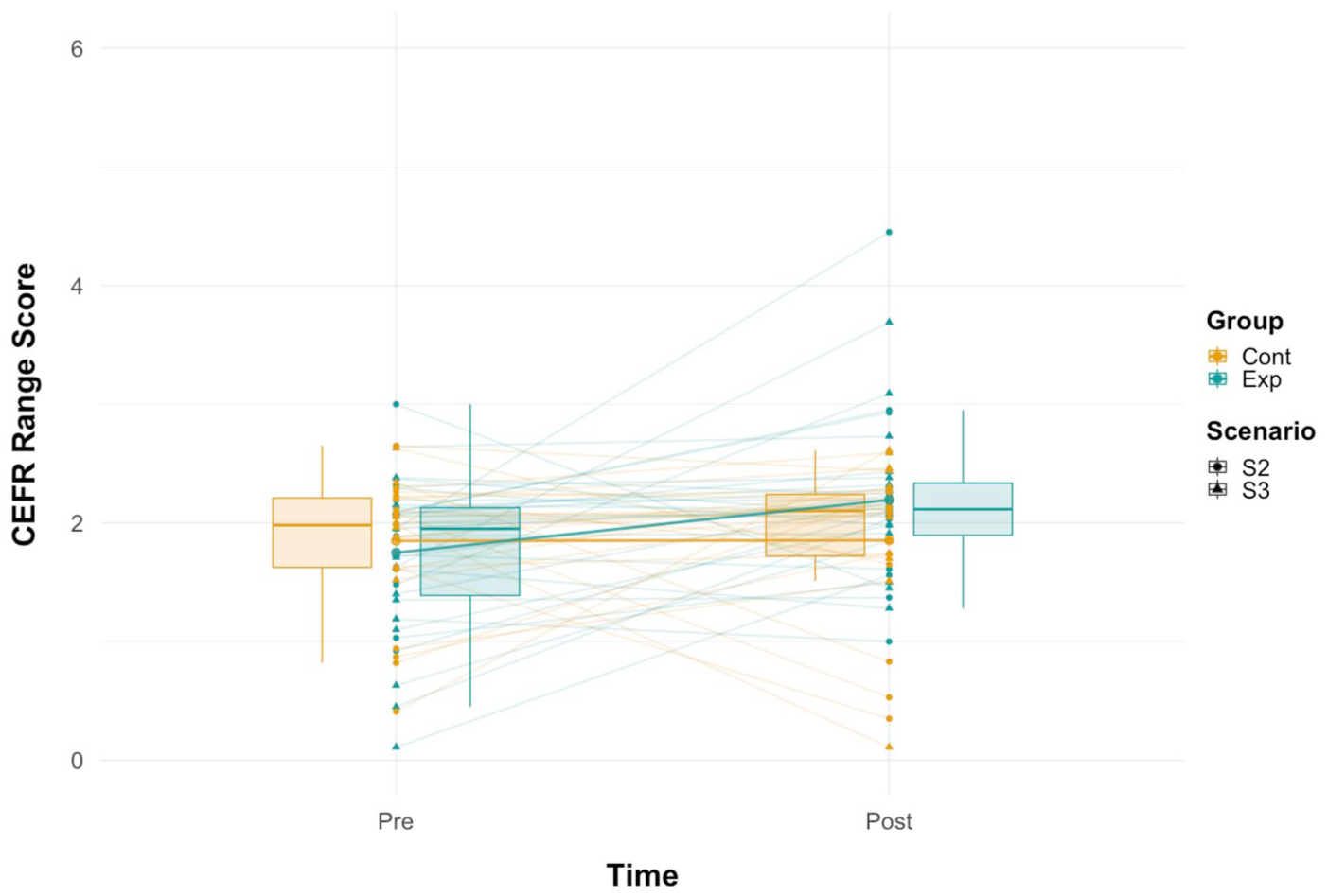
Range scores at a pretest and a posttest.
Model summary for pretest–posttest comparison.
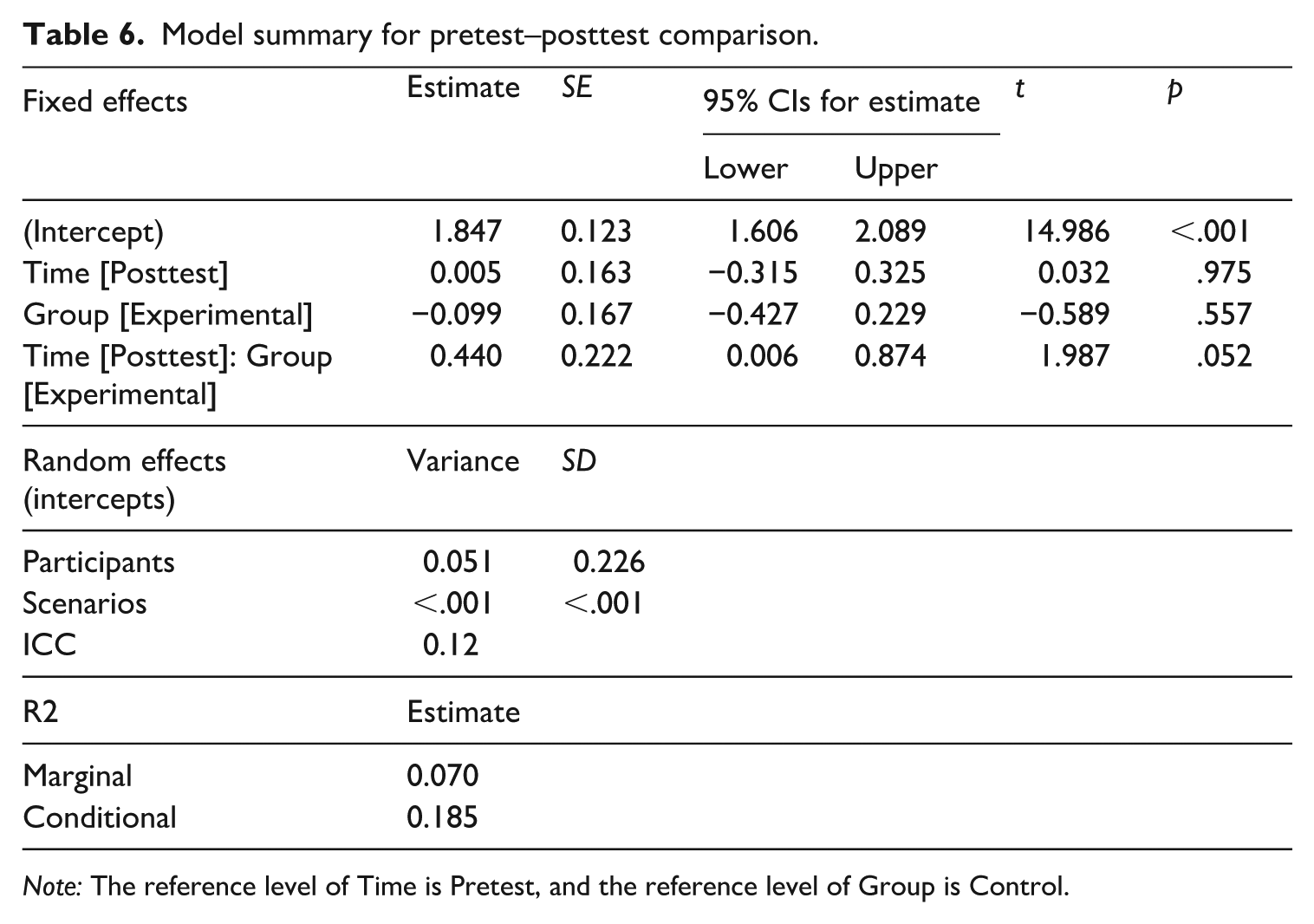
Note: The reference level of Time is Pretest, and the reference level of Group is Control.
Post-hoc comparisons for pretest and posttest data.
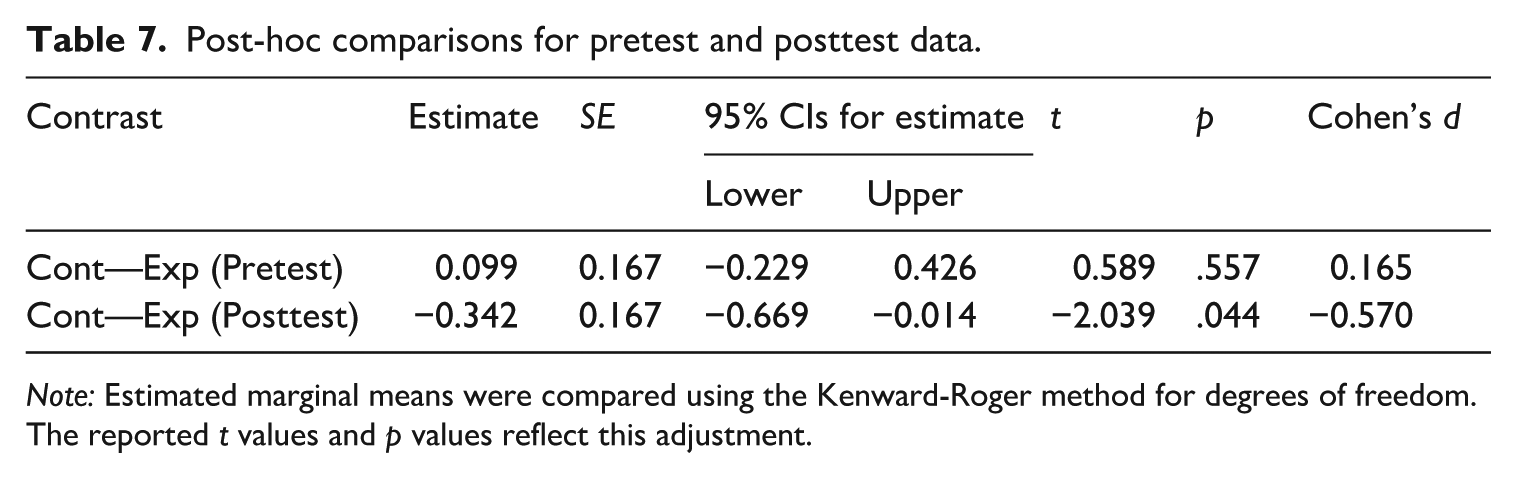
Note: Estimated marginal means were compared using the Kenward-Roger method for degrees of freedom. The reported t values and p values reflect this adjustment.
Learners’ perceptions of diagnostic feedback
To evaluate the current diagnostic feedback from the learners’ perspective, we summarised participants’ responses to two open-ended questions in the debriefing questionnaire, each of which addressed the strengths and challenges of our feedback, respectively (see Table 8). Regarding its strengths, seven participants pointed out the benefits of contextualised feedback in enhancing their awareness of alternative expressions, while four noted the high actionability of the feedback for their subsequent learning. As for the challenges of the diagnostic feedback, two participants stated that they expected multiple options of paraphrases so that they can choose their preferred expressions by themselves. Although this learning preference might not be predominant among the current participants, it suggests that diagnostic feedback should be designed to facilitate learner autonomy (cf. Isbell, 2021). Finally, technological challenges related to the quality of paraphrases were pointed out, such as automatic speech recognition accuracy (n = 4) and discrepancies between the paraphrase output by GPT-4 and their original intended message (n = 7).
Feedback categories relating to the diagnostic assessment feedback.
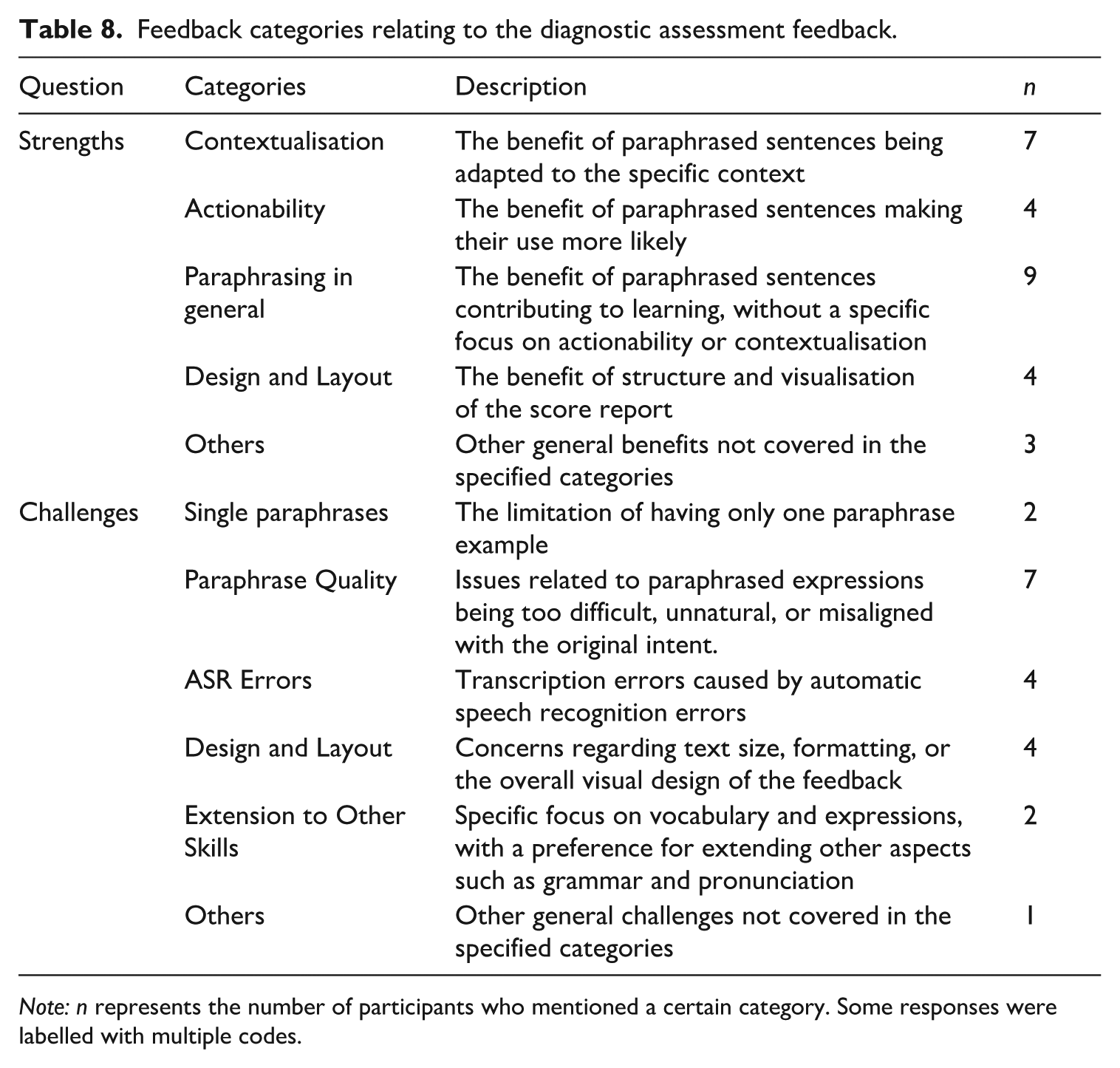
Note: n represents the number of participants who mentioned a certain category. Some responses were labelled with multiple codes.
Discussion
Learning gains during the practice sessions and their retention
To examine the learning gains in lexical performance within the current DLA programme (RQ1) and their retention (RQ2), we conducted linear mixed-effect modelling. The results indicated that participants in the control group who only engaged in the exact task repetition activity continually improved their lexical performance within the practice sessions, whereas the lexical improvement was not sustained for the 7- to 10-day RI. Given the current measure of lexical performance (i.e., CEFR Range score) is theoretically reflective of the breadth and depth of lexicogrammatical resources (Council of Europe, 2020), the score gains during the practice session might indicate the improvement of linguistic repertoires such as the use of advanced lexical items and complex sentence structures. However, given the failure to retain the improvement at the delayed posttest, it might be reasonable to regard the within-practice improvement as practice effects. From the perspective of speech production, one possible scenario is that the task repetition activities might have increased the resting activation level of relevant lemmas in learners’ mental lexicon, which could subsequently enhance the accessibility of other less accessible but advanced lemmas (Kormos, 2006). Yet the enhanced use of those linguistic items was likely temporary, as the higher resting activation level alone may not have been sufficient for their consolidation through six repetitions of identical communicative tasks.
In contrast, the experimental group who engaged with diagnostic feedback through the score report activity did not exhibit practice effects during the practice sessions nor the retention effects. Lack of practice effects may indicate that, despite the same interview topics, participants in the experimental group engaged with the interview task differently from session to session. Given that the only difference between the groups was the inclusion of diagnostic feedback, it is plausible that despite the lack of significant improvement in the target variable, the current diagnostic feedback at least differentiated their approach to the same OPI task. From the perspective of L2 development, such differentiation of approach to speech production may include the elaboration of new linguistic items and/or the modification of their lexical organisation in learners’ mental lexicon (Housen et al., 2012). These learning processes are theoretically assumed to be reflected in enhanced lexical complexity of their speaking performance (Housen et al., 2012). By contrast, the consolidation of these learning processes (i.e., automatization) can be observed as enhanced fluency in the later phase of development. Accordingly, the lack of practice effects in the experimental group might indicate that participants’ L2 systems were in the middle of elaboration and restructuring of their mental lexicon and did not reach sufficient consolidation of target linguistic items. This may also explain the lack of retention effects in the experimental group, despite the research-informed ISI-RI ratio of the current task repetition schedule. One possible reason for the emerging status of consolidation of target L2 items might be related to the way in which the current system selects target items across practice sessions. The DLA system identifies the utterances that lower the probability of being estimated as the level higher than the current CEFR level (i.e., weaknesses). The current DLA simply rans this system for each task repetition performance, which does not have a mechanism to maintain the same target items in the diagnostic feedback until learners are able to use them. Although the exact task repetition may have created an opportunity to use the expressions suggested at previous sessions, it is worth exploring the algorithm for selecting suggested expressions repetitively to optimise learning efficiency longitudinally (see Maie et al., 2025).
Effects of diagnostic assessment on lexical development
The third research question concerned the transfer effects of our DLA programme on lexical performance with novel speaking topics in terms of the pretest–posttest change. The results demonstrated that the experimental group outperformed the control group with a near-medium effect size at the posttest. Given the experimental design of the current study, it is plausible to regard this result as the positive evidence of the current DLA programme for vocabulary learning. In other words, the current approach to weakness identification through speaking performance by XAI techniques, as well as the contextualised diagnostic feedback, can be considered to meaningfully facilitate the restructuring of learners’ mental lexicon. In terms of effect sizes, the current findings are comparable with previous studies reporting the effects of task repetition combined with form-focused activities on item-based learning (Tran & Saito, 2021).
One may argue that the transfer effect in the experimental group appears to contradict the lack of meaningful improvements of lexical performance during the practice sessions and at the delayed posttest. One possible interpretation of those seemingly inconsistent findings is the complex interplay between the time interval between the final practice session and the posttest and the test format difference between the practice sessions and the posttest. From the perspective of cognitive psychology, it is common that longer spacing results in better learning gains than shorter spacing or a massed condition (Cepeda et al., 2008; Rohrer & Pashler, 2007; see also Kakitani & Kormos, 2024). Accordingly, it might have been possible that 1-day ISI during the practice sessions was not long enough to integrate the items retrieved in the previous sessions into learners’ long-term memory. By contrast, the 4-day interval between the final practice session and the posttest, which is the optimal ISI-RI ratio (25%), might have been long enough to assist them in utilising the expressions suggested by the current diagnostic feedback (for a similar discussion, see Y. Suzuki & Hanzawa, 2022). Additionally, it should be noted that the posttest followed the adaptive test format, as opposed to the fixed set of topics during the practice sessions and at the delayed posttest. In other words, the posttest might have been likely to elicit better performance and succeed in capturing the emerging developmental changes in their L2 systems, compared with the delayed posttest.
Limitations and directions for future research
The current study highlights the potential of weakness identification through speaking performance by means of ML, NLP, and XAI techniques, as well as the effectiveness of actionable and contextualised diagnostic feedback by closely integrating all three components of diagnostic assessment. To evaluate the learning gains through diagnostic assessment, the study adopted an experimental design in response to the call for robust validity evidence (Isbell, 2021; Lee, 2015). The results showed that the control group (task repetition only) demonstrated significant improvement during the remedial learning sessions but failed to transfer and retain the learning gains. In contrast, despite the lack of practice effects, the experimental group (task repetition with diagnostic feedback) outperformed the control group at the posttest with a near-medium effect size. However, we cautiously interpreted the current findings as positive evidence of our proposed approach to DLA for spontaneous speaking skills in light of methodological limitations of the current study.
First and foremost, the duration of the current DLA programme is shorter in than previous intervention studies on speaking skills, which typically detect a significant improvement after the time period of one academic semester (e.g., Saito et al., 2021) or even longer (e.g., Taguchi et al., 2022). To gain more insights into the short-term and long-term learning gains through the current DLA programme, more extended longitudinal studies with multiple time points and different ISIs are necessary.
Second, we adopted the score report activity to ensure that our participants process their diagnostic feedback for the sake of internal validity of our DLA programme. However, this could simultaneously caution that the current findings are limited to the inclusion of the activity, meaning that the effectiveness of our approach in other contexts may depend on the depth of processing diagnostic feedback. Future studies should explore the optimal design and format of feedback, such as the number of suggested expressions (cf. Maie et al., 2025).
Third, following previous studies on task repetition (Kakitani & Kormos, 2024; Y. Suzuki & Hanzawa, 2022), we adopted the same interview topics for the practice sessions and the delayed posttest to test the retention effects under comparable conditions. Accordingly, we decided not to include a delayed posttest with another new set of topics, because it could have made the research design unmanageably complex and also could have made it difficult to maintain the ISI-RI ratio within the optimal range. However, future research should examine how durable the transfer effects of DLA are, using a more longitudinal design.
Fourth, as the suggested expressions of the current feedback system are only based on learners’ actual utterances, it cannot provide feedback on what they cannot express or avoid using. Towards more sophisticated diagnostic feedback, a variety of AI-based technologies could be combined to detect learners’ linguistic breakdowns (including avoidance) and identify challenging lexical items based on the prediction of what they intend to express.
Finally, although the current study aims to test the improvement of lexical performance during the DLA programme, after the sessions (i.e., retention) and to a new task (i.e., transfer), further insights can be obtained through careful investigations of lexical items that learners actually used. For instance, combining the rate of using the suggested expressions with the learners’ responses to the score report activity, it might be possible to characterise actionable learning items. However, some methodological advances might be needed to distinguish items newly learnt through diagnostic assessment and those known by the learner beforehand.
Footnotes
Appendix 1
CEFR descriptor of general linguistic range.

| Level | Descriptor |
|---|---|
| C2 | - Can exploit a comprehensive and reliable mastery of a very wide range of language to formulate thoughts precisely, give emphasis, differentiate and eliminate ambiguity. No signs of having to restrict what they want to say. |
| C1 | - Can use a broad range of complex grammatical structures appropriately and with considerable flexibility. - Can select an appropriate formulation from a broad range of language to express themselves clearly, without having to restrict what they want to say. |
| B2 | - Can express themselves clearly without much sign of having to restrict what they want to say. |
| - Has a sufficient range of language to be able to give clear descriptions, express viewpoints and develop arguments without much conspicuous searching for words/signs, using some complex sentence forms to do so. | |
| B1 | - Has a sufficient range of language to describe unpredictable situations, explain the main points in an idea or problem with reasonable precision and express thoughts on abstract or cultural topics such as music and film. |
| - Has enough language to get by, with sufficient vocabulary to express themselves with some hesitation and circumlocutions on topics such as family, hobbies and interests, work, travel and current events, but lexical limitations cause repetition and even difficulty with formulation at times. | |
| A2 | - Has a repertoire of basic language which enables them to deal with everyday situations with predictable content, though they will generally have to compromise the message and search for words/signs. |
| - Can produce brief, everyday expressions in order to satisfy simple needs of a concrete type (e.g. personal details, daily routines, wants and needs, requests for information). - Can use basic sentence patterns and communicate with memorised phrases, groups of a few words/signs and formulae about themselves and other people, what they do, places, possessions, etc. - Has a limited repertoire of short, memorised phrases covering predictable survival situations; frequent breakdowns and misunderstandings occur in non-routine situations |
|
| A1 | - Has a very basic range of simple expressions about personal details and needs of a concrete type. Can use some basic structures in one-clause sentences with some omission or reduction of elements. |
Note: The original scale (Council of Europe, 2020) has the descriptor for Pre-A1 level, which was omitted when our precursor study developed an automated scoring system due to the limited number of training data in the target population of test-takers, that is, university students (Takatsu et al., 2026).
Appendix 2
A simplified example of the Diagnostic Assessment Feedback.
Sentences paraphrased into higher level expressions.
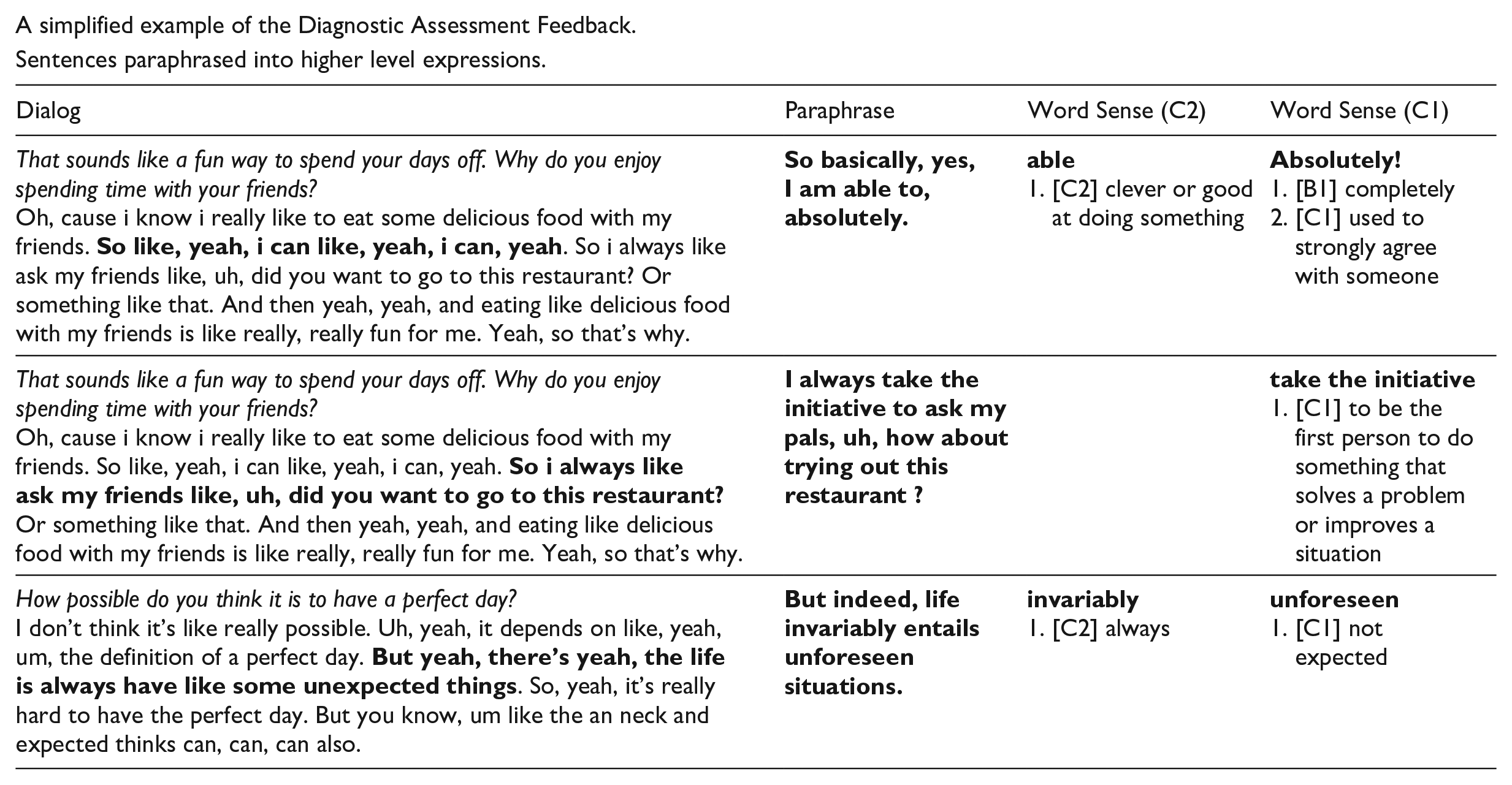
| Dialog | Paraphrase | Word Sense (C2) | Word Sense (C1) |
|---|---|---|---|
| That sounds like a fun way to spend your days off. Why do you enjoy spending time with your friends?
Oh, cause i know i really like to eat some delicious food with my friends. |
|
1. [C2] clever or good at doing something |
1. [B1] completely 2. [C1] used to strongly agree with someone |
| That sounds like a fun way to spend your days off. Why do you enjoy spending time with your friends?
Oh, cause i know i really like to eat some delicious food with my friends. So like, yeah, i can like, yeah, i can, yeah. |
|
||
| How possible do you think it is to have a perfect day?
|
|
Acknowledgements
We are grateful to Language Testing reviewers, the journal editor, Talia Isaacs, and the special issue editors, Eunice Jang and Yasuyo Sawaki, for their constructive feedback on earlier versions of the manuscript. The research presented in this study is based on results obtained from a project, JPNP20006 (“Online Language Learning AI Assistant that Grows with People”), subsidised by the New Energy and Industrial Technology Development Organization (NEDO).
Author contributions
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The conversational AI agent and the automated scoring system used in the present study were originally developed for research purposes as part of a research project at Waseda University, Japan. These systems were subsequently adapted and are currently maintained by Equmenopolis, Inc. for commercial use. The second, fifth, and sixth authors are affiliated with Equmenopolis, Inc.: Mao Saeki and Hiroaki Takatsu are employees, and Yoichi Matsuyama serves as CEO/CTO of the company. None of the other authors disclosed any conflicts of interest.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by JPNP20006 (“Online Language Learning AI Assistant that Grows with People”) from the New Energy and Industrial Technology Development Organization (NEDO).
Supplemental material
Supplemental material for this article is available on OSF (Suzuki, 2025) at the following link: ![]() .
.