
Abstract
Comparative Judgement (CJ) is an evaluation method, typically conducted online, whereby a rank order is constructed, and scores calculated, from judges’ pairwise comparisons of performances. CJ has been researched in various educational contexts, though only rarely in English as a Foreign Language (EFL) writing settings, and is generally agreed to be a reliable method of evaluating performances. This study extends the CJ research base to young learner EFL writing contexts and innovates CJ procedures with a novel dimension-based approach. Twenty-seven Austrian EFL educators evaluated 300 young learners’ EFL scripts (addressing two task types) from a national examination, using three scoring methods: standard CJ (holistic), CJ by dimensions (our new criteria-based method), and the exam’s conventional analytic rating. It was found that both holistic CJ and our dimension-based CJ were reliable methods of evaluating young learners’ EFL scripts. Experienced EFL teachers who also have experience with using marking schemes proved to be reliable CJ judges. Moreover, despite the preference of some for the more familiar analytic rating method, teachers displayed higher reliability and shorter decision-making times when using CJ. Benefits of dimension-based CJ for reliable and economical scoring of large-scale young learner EFL writing scripts, and the potential for positive washback, are discussed.
Keywords
Introduction
Human rating using holistic or analytic scales is a common method of script evaluation for written English as a Foreign Language (EFL) tests. Often-cited disadvantages concern training and rating costs, and time required. An increasingly prevailing alternative (or complementary approach) involves the use of automated scoring systems, especially in large-scale testing contexts (e.g., PTE Academic, TOEFL). While these systems allow for fast scoring, they are associated with considerable development costs, carry the risk that test-takers learn how to game the system (Blood, 2011), and often capture a narrow(er) construct, with these last two features potentially impacting negatively upon teaching and learning practices (Xi, 2010). Recently, researchers have started exploring another evaluation approach, namely Comparative Judgement (CJ). Proponents of this method claim that it offers some of the benefits of automated scoring such as speed, more moderate ongoing financial commitment, and increased reliability, without losing the human aspect of rating (Pollitt, 2012a, 2012b) and without what has been termed the “reductionism” of automated scoring (Fulcher, 2015, p. 35). While CJ has been employed and studied quite widely in areas ranging from consumer research and product design (e.g., Franceschini & Maisano, 2015; Viswanathan & Childers, 1995) to general educational assessment and subject areas such as maths and L1 (e.g., Jones & Inglis, 2015; McGrane et al., 2018), explorations of its potential and suitability for evaluating L2 work are limited to date and have focussed on adult language learning.
Comparative Judgement
CJ as an evaluation method evolved from Thurstone’s 1927 Law of Comparative Judgement (Thurstone, 1994), which is based on the principle that when people see something, they ascribe a value to it and can then judge other items to be better or worse than the original (Pollitt, 2012a). In practice, in CJ as it is typically used in educational settings, a judge is presented with two performances side by side and asked to evaluate the pair guided by a question such as “Which response is better?” (see, e.g., Şahin, 2021; Sims et al., 2020). CJ is usually conducted online and involves a group of judges, with each judge working individually and often remotely on a pool of performances. Computer algorithms manage the allocation of a selection of performances to individual judges to avoid the unrealistic workload of all judges comparing all performances. Once a judge has clicked on the performance that they deem to be “better” than the other, the next pair appears onscreen. This continues until each judge has completed their allocated number of judgements and, therefore, the CJ session. Early in the CJ session, scripts are typically randomly assigned to make pairs. Non-adaptive CJ systems continue with such random pairings for the entire CJ session. In contrast, adaptive CJ systems (another type of system) use the information added to the system via the early judgement decisions to determine subsequent pairing combinations. By using such information, the computer algorithms can enable reliable scoring decisions to be reached more efficiently with fewer judgements required from each judge. In both types of system, as judging progresses, statistical modelling enables the performances to be assigned scaled scores; Thurstone’s law presupposes that, when pairs of items are compared a sufficient number of times, a rank order can be formed by placing items on a measurement scale (Cheng et al., 2013; Pollitt, 2012b; Verhavert et al., 2018). The scaled score awarded to a performance, therefore, is the score formed from the pairwise judgement decisions made by all the judges.
Research into CJ has expanded rapidly over the past decade (Bartholomew & Jones, 2022), and various reasons for using it over other evaluation methods have been given (Jones & Davies, 2023). Generally, CJ has been seen as a cost-efficient evaluation method because it requires minimal training of the judges (e.g., Paquot et al., 2022; Şahin, 2021) and is a faster method of evaluation (Pollitt, 2012a, 2012b). However, while many studies indeed found CJ to be a quick evaluation method (e.g., Sims et al., 2020), not all did (e.g., Holmes et al., 2017), and the CJ judges in some studies reported concerns regarding time needed (Coertjens et al., 2021; Marshall et al., 2020).
Another often-cited strength of CJ is that it has been shown to be a reliable method of evaluation (Buckley et al., 2022; Kimbell, 2021). While concerns were expressed initially, for example around the impact on reliability of algorithms that assign pairings based on judges’ previous decisions (Bramley, 2015), these have been broadly resolved (Kimbell, 2021; Rangel-Smith & Lynch, 2018). Furthermore, CJ has been shown to be reliable without prior training of judges, even when these were crowdsourced and had little or no relevant experience (Paquot et al., 2022). At the same time, variation between judges is valued in CJ (van Daal et al., 2019), and it has been argued that this variety in decision-making is a key part of CJ validity, where varying views on text quality are combined (Lesterhuis et al., 2022) and where rater effects, such as leniency/severity, are minimised or negated entirely (Pollitt, 2012b). However, outlying decisions by judges can have a negative impact upon CJ scoring; therefore, individual judges’ performance can be evaluated by averaging the reliability coefficients of all their judgements, with the resulting statistic being compared to the consensus of the other judges (Pollitt, 2012b). Further advantages cited in the literature on CJ comprise its ability to score more open performances, and its precision—as each performance is awarded a score from a broad scale (Jones & Davies, 2023).
Challenges of CJ, on the contrary, are that it typically requires a large number of judges and that it assumes a shared understanding of the construct that is being measured whilst also expecting judges to use their subjective judgements of the performances (Pollitt, 2012a, 2012b; van Daal et al., 2019; Wheadon et al., 2020). There is, however, limited insight into the features that judges consider while evaluating, and whether these are construct-relevant and encompass the entirety of the construct (Chambers & Cunningham, 2022; Lesterhuis et al., 2018). Furthermore, CJ’s holistic approach (Pollitt, 2012a, 2012b) and lack of transparency in the grading process (Chambers & Cunningham, 2022) mean that the method does not generate detailed feedback for test-takers and other stakeholders (Pollitt, 2012b; Walland, 2022). This might hinder public acceptance of results in high-stakes testing situations (Walland, 2022) and limit CJ’s usability for diagnosis in educational settings.
CJ by dimensions
To consider CJ as an evaluation method to score multi-dimensional scripts and provide stakeholder feedback equivalent to feedback generated using traditional (analytic) rating approaches, the evaluation of these scripts by different aspects of the performance (dimensions) may be necessary. To date, to our knowledge, CJ’s potential in this area has been researched only once, by McGrane et al. (2018), in an L1 context with two criteria where pairwise comparisons were used to rank exemplar scripts required for later script evaluation. McGrane et al.’s study broadened the traditional use of CJ to incorporate a two-staged process, using CJ to generate calibrated exemplars followed by matching of exemplars to performances. The study focused on evaluating performances across two different tasks—narrative and persuasive writing—and comprised performances from two calendar years of administration. Judgements were made along two different criteria/dimensions, i.e. writing conventions and authorial choices. Overall, McGrane et al.’s findings supported the use of such a method; however, a need for simplification was indicated particularly in the second part of the study where CJ was not used for pairwise comparison. Instead, assessors needed to become familiar with 36 exemplars of extended writing for matching purposes, which was found to be “more cognitively challenging” (McGrane et al., 2018, p. 308). In addition, in a large study that looked into judges’ decision-making when using two CJ methods (pairwise comparisons and rank ordering) to evaluate GCSE English Language essays (UK secondary school exams) for the purposes of standard maintaining, Curcin et al. (2019) found that judges were able to accommodate tasks with different weightings. These studies suggest that judges can consider different aspects of performances when using CJ. In further support of using CJ to judge a performance by different aspects of that performance, one of the first proponents of CJ in education, Pollitt (2012b), noted that “if it is considered important to judge scripts analytically as well as or rather than holistically, ACJ [Adaptive Comparative Judgement] can still be used for each component, and may still prove more reliable than marking” (p. 292).
CJ for L2 writing assessment
Only until very recently have researchers started exploring the potential of CJ for evaluating L2 writing. For example, Sims et al. (2020) investigated the use of CJ for English as a Second Language (ESL) placement essays in an intensive English programme in the USA. The scores using CJ from novice and experienced raters (eight undergraduates on a programme in Teaching English to Speakers of Other Languages [TESOL] and eight trained raters with two to seven years’ experience) were compared to the scores obtained using the traditional rating scale. CJ was found to be a reliable, practical approach for more and less experienced raters.
Şahin (2021) used CJ for the evaluation of paragraphs (approximately 150 words) written by university-level English language learners in Türkiye. The study showed that experienced educators (n = 10) could reliably use this evaluation method and that they generally preferred it to more traditional marking methods. Students also took part in the study as peer assessors (n = 112), and those who had written good-quality paragraphs themselves were recognised as capable of evaluating the work of others using CJ, possibly after some instruction. Paquot et al. (2022) used crowdsourced judges (n = 43)—most of whom were degree-level educated and proficient in English, with varying levels of experience assessing L2 learner texts—to evaluate TOEFL essays using CJ (n = 50). No significant differences in judge reliability were found for judges’ language background or experience in assessing learner texts, although previously formally trained judges seemed to differ in their decisions from untrained judges.
The present study: Context and rationale
This study expands the currently scarce research base on the usefulness (or otherwise) of CJ for evaluating L2 writing. Motivated by the study’s context (see below), this investigation extends CJ research to the contexts of young learner assessment, compulsory schooling, and educational system attainment of national L2 learning standards. As indicated above, CJ L2 writing research has so far focused on adult, university/academic assessment contexts. In addition, and importantly, while CJ is generally used as a holistic evaluation approach (with one overall judgement normally being made on a pair of performances), consequently offering little by way of diagnostic or detailed insights into ability, this study set out to explore the potential of a novel, adapted CJ approach to evaluate L2 writing by constituent dimensions (cf. sub-constructs, criteria). Such a dimension-based approach also encourages construct-relevant considerations by directing judges to explicitly consider different aspects (dimensions/criteria)—as defined by the test developers—of the script, like analytic rating approaches aim to do. If shown to be useful (cf. Bachman and Palmer’s [1996] conceptualisation of test usefulness), CJ might broaden the range of evaluation methods language testers, teachers and policy makers consider for assessing L2 writing.
The present study relates to a national, standardised testing programme for monitoring standards in mainstream education in Austria, which is otherwise primarily characterised by an assessment paradigm involving teacher-based decisions on pupil progression. Our research focus was on the tests used for standards monitoring of the core EFL subject at the lower-secondary school level (Year 8). The tests were administered in 2013 and 2019, and included a writing section (among other language skills). To evaluate the resulting EFL scripts, a selection of English teachers across Austria were trained to rate performances using a standardised, specially designed, analytic rating scale. An analytic approach, offering more detailed insights and feedback, had been chosen “to trigger a process of innovation and change in the teaching, learning and assessment of foreign languages” (Mewald, 2018, p. 445), including “[to] impact on the way writing is taught and assessed in Austrian schools” (Gassner et al., 2011, p. 3). Post-2019, the EFL testing programme shifted online and was restricted to the testing of reading and listening. While the reasons for dropping the writing section (and moving the testing online) were not made public, presumably the demand on human and financial resources of rating writing on a large scale, and the long gap between testing and outcome reporting, played a role. However, at the time of writing this article, plans were announced to re-introduce the testing of EFL writing in the national programme, in three-year cycles from the school year of 2024-25 (IQS, 2023).
In light of the above, this study aimed to investigate whether CJ could be a practical alternative to analytic rating for future national evaluations of EFL writing. For this purpose, “practical” was operationalised as:
(a) Offering a comparable level of scoring and scoring reliability to the previous evaluation method, i.e. to analytic rating by trained EFL educators, typically classroom teachers. In what follows, we term this conventional approach R-Analytic.
(b) Being compatible with previous reporting procedures, i.e. CJ results would need to address each of the four separate dimensions used in analytic rating in 2013 and 2019: Task Achievement, Coherence & Cohesion, Grammar, and Vocabulary. As the typical use of CJ–which we term CJ-Holistic–evaluates the entirety of writing features of one script against the entirety of writing features of a second script, a different CJ approach was needed. We therefore adapted the CJ method to elicit distinct judgements on each of the four writing dimensions (see Methods for more detail). We term this new application of CJ in an educational context CJ-Dimensions.
(c) Being acceptable and doable for evaluators, i.e. EFL classroom teachers would need to be amenable to using CJ and the time demands would need to be proportionate (without affecting reliability).
Research questions
Based on the research gaps on CJ and on the Austrian context described above, the following research questions (RQs) were formulated:
For the Austrian Year 8 exam for EFL,
RQ1. Can classroom teachers reliably score young learners’ EFL written performances using CJ: (a) holistically, and (b) by dimension?
RQ2. To what extent do classroom teachers’ CJ-Dimensions scores correlate with: (a) their CJ-Holistic scores, and (b) expert ratings using the conventional analytic rating scale (R-Analytic)?
RQ3. What are classroom teachers’ perceptions of CJ-Holistic, CJ-Dimensions, and R-Analytic?
The research reported in this article was part of a larger study (Sickinger, 2023), which additionally looked into the scoring validity of CJ, judge cognition, and the impact of judge characteristics. Due to article-scope limitations, this article is restricted to reliability and judge perception investigations; for the investigation of CJ validity aspects, readers are directed to Sickinger (2023).
Method
L2 writing scripts
For the purposes of this study, the Austrian administrative body (IQS—Institut des Bundes für Qualitätssicherung im österreichischen Schulwesen, a subordinate department of the Ministry of Education, Science and Research) responsible for the national testing system selected 300 EFL writing scripts from approximately 160,000 scripts of the 2013 administration of the Year 8 EFL exam (2019 scripts were not yet available for research at the time of conducting the study). The selection comprised performances responding to the same writing prompts and representing all eight scoring bands (0–7) of the analytic rating scale, taking the scripts’ official 2013 ratings.
The EFL writing test which had elicited the performances consisted of two tasks: one shorter writing task intended to generate an A2-level response from pupils and one somewhat longer writing task targeting a B1-level response (Gassner et al., 2011; Siller et al., 2019). The writing prompts for the scripts in this study are presented in Figure 1. All prompts in the testing system were designed to be age-appropriate (Year 8, 14-year-olds) and reflect the construct operationalised in the writing competencies of the Austrian National Education Standards and the topics stipulated in the Austrian curriculum (Kulmhofer & Siller, 2018; Siller et al., 2019). Of the 300 scripts used in the current study, 150 were from the short task (hereafter, short scripts) and 150 from the longer task (long scripts).

Short and long writing tasks.
Participants
Twenty-seven participants (74% female; Mage = 44.07, SDage = 11.95) evaluated the scripts for the purposes of this study. They were recruited across a range of Austrian EFL teaching contexts—including rater training courses, in-service and pre-service EFL teacher training, and secondary schools—to reflect the range of EFL educators normally (expected to be) involved in the Year 8 writing test evaluations. As described in Table 1, these participants can be characterised according to their teaching and rating experience.
Participants’ profile according to teaching and rating experience.

Only three participants had no prior experience at all with the analytic rating scale of the Austrian Year 8 EFL writing test. Two of these were trainee teachers (inexperienced); the third reported lacking experience using any formal marking scheme despite being an experienced (t-experienced) teacher (> 15 years).
Script evaluation procedures
Participants evaluated the scripts using three different methods:
a. CJ-Dimensions: all participants made 78 random 1 pairwise comparisons from the 150 short scripts using CJ-Dimensions for each of the four dimensions; and a further 78 random 1 pairwise comparisons from the 150 long scripts using CJ-Dimensions for each of the four dimensions (see Table 2).
b. CJ-Holistic: all participants made 78 random 1 pairwise comparisons from the 150 short scripts using CJ-Holistic; and a further 78 random 1 pairwise comparisons from the 150 long scripts using CJ-Holistic (see Table 2).
c. Analytic rating: all participants rated 30 scripts (randomly allocated to each participant from the 300 scripts) using the analytic rating scheme (R-Analytic).
For methods a and b, scripts were randomly allocated by the CJ platform; for method c, by the researcher. Methods a and b together constituted 10 different CJ sessions (see Table 2).
CJ sessions.
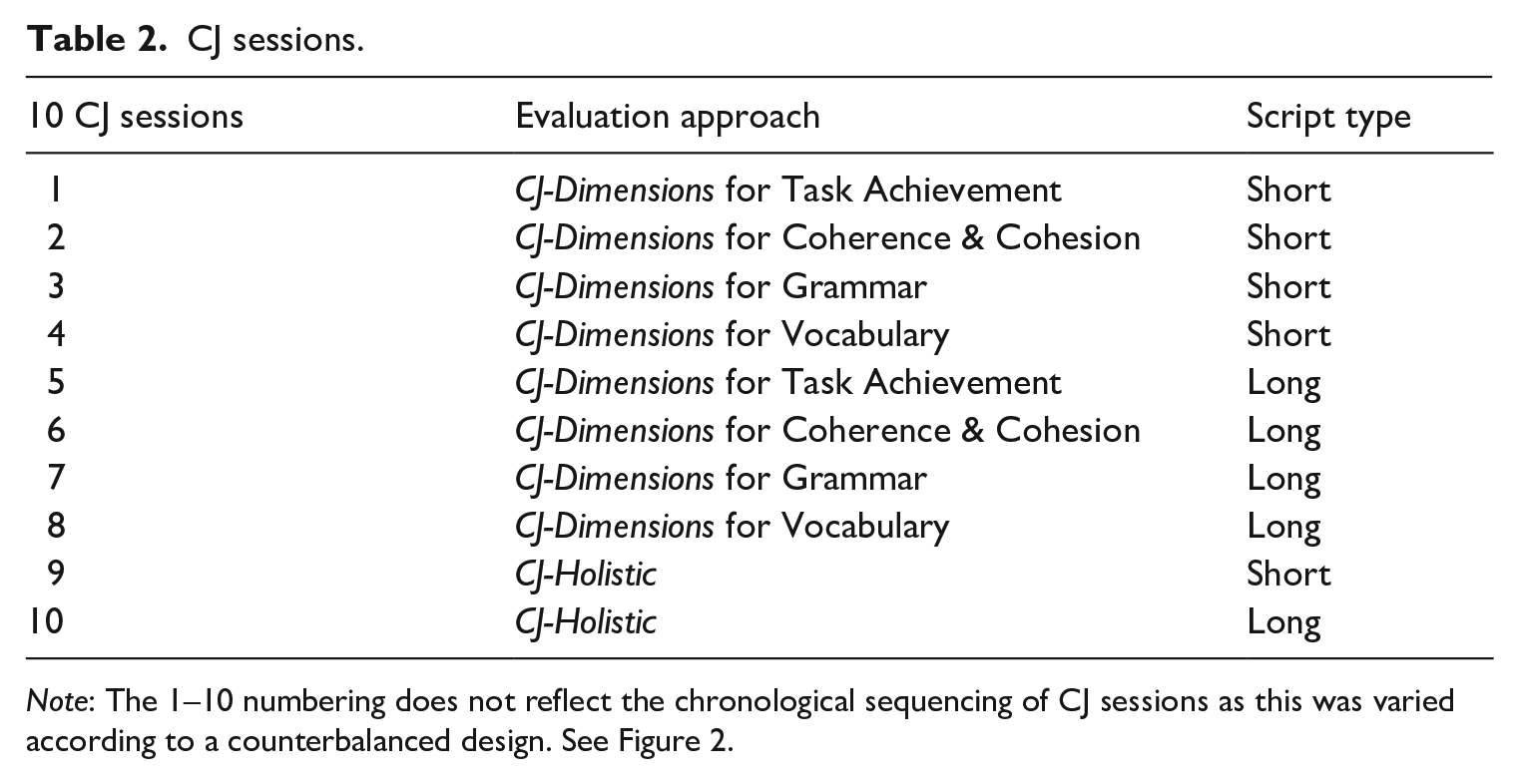
Note: The 1–10 numbering does not reflect the chronological sequencing of CJ sessions as this was varied according to a counterbalanced design. See Figure 2.
Research design.
Comparative judgements Platform
To conduct the comparative judgements, the scripts were uploaded to the CJ platform No More Marking (https://www.nomoremarking.com; from a commercial online CJ provider, but complimentary for researchers). This platform was chosen because it is freely available for researchers, conforms to Austrian confidentiality stipulations, and is what could be termed a low/medium adaptive system, as it selects pairings based on the number of previous comparisons and not on previous judges’ decisions. 1 It has also been used in previous L2 research employing CJ (Han, 2022; Şahin, 2021; Sims et al., 2020). In the current study, the default ascending scale of 0–100 for CJ scores was used.
Instructions
To direct the judges’ decisions, the CJ-Holistic sessions instructed: “Choose the better response.” The CJ-Dimensions sessions, with four separate sessions, one for each of the four dimensions, asked: “Which text best fulfils the criteria for [Task Achievement / Coherence & Cohesion]? Which text demonstrates the best range and accuracy of [Grammar / Vocabulary]?” The first two questions were intended to direct the judges’ attention to CJ supporting information (see below), while the latter two aimed to reflect the stated Austrian language-teaching philosophy of prioritising range over accuracy in marking (Siller et al., 2019). For both CJ-Holistic and CJ-Dimensions, the participants were explicitly instructed to use the supporting materials (see below) to guide their evaluation.
Supporting Materials
Previous studies found that CJ can proceed without supporting materials (e.g., Paquot et al., 2022; Şahin, 2021; Sims et al., 2020) or with only brief information (e.g., Gijsen et al., 2021; van Daal et al., 2019) to support the quality question (i.e. instructions). This study have experienced and inexperienced teachers, trained and untrained in rating, evaluated the scripts—necessitated supporting information for CJ evaluation.
Two crib sheets (see Supplementary Materials 1) were designed to support judges in their decision-making—the only difference between them being the instructions at the top of the sheet. For CJ-Holistic, judges were reminded that their decision between two scripts should relate to the script overall. For CJ-Dimensions, they were asked to consider only the dimension currently being evaluated. The crib sheets retained the criteria from the EFL writing test’s analytic rating scale: Task Achievement, Coherence & Cohesion, Grammar, and Vocabulary. Concisely worded bullet points listed aspects of writing that were expected for each dimension (designed to support less complex decisions between two rather different scripts) and an adjacent list of pointers advising judges of criteria they should consider for each dimension (designed to support more complex decisions between two rather similar scripts).
Judgements. The number of judgements per performance required to reliably score performances using CJ remains undetermined (Kelly et al., 2022; Verhavert et al., 2019); nevertheless, multiple-marking is a fundamental feature of CJ (Pollitt, 2012a). Rangel-Smith and Lynch (2018) explicitly link the number of judgements with the level of adaptivity, noting that highly adaptive CJ systems may need at least 25 rounds (first round: initial pairings of all scripts; second round: second pairings of all scripts, etc.) to reach sufficient accuracy (within 5%), and medium adaptive systems 12–15 rounds. Since a low/medium adaptivity algorithm was used in this study, 1 14 rounds were conducted and each script was judged approximately 28 times in total in each of the 10 separate CJ sessions.
Analytic rating
Each participant also rated a set of 30 scripts (15 short and 15 long scripts) using the test’s conventional analytic rating scale (freely accessible on p. 23 of Siller et al., 2019). Random allocation of the 300 scripts to participants’ sets of 30 scripts, resulted in 45 short and 45 long scripts being double-rated and 105 short and 105 long scripts triple-rated. Each script was rated on an ascending scale of 0–7 for each of the four dimensions (criteria): Task Achievement, Coherence & Cohesion, Grammar, and Vocabulary. Participants who were trained raters were asked to follow the advice they had been given during their training (others did not receive additional training). Everyone was provided with publicly available support material—a Technical Report on the test (Siller et al., 2019) together with the prompts and rating scale.
Perception questionnaires
After applying each individual evaluation method, participants completed a short online post-evaluation questionnaire (containing 0–10 sliding scales, 5-point Likert scales and open-ended questions), asking, for example, about ease of using the method, usefulness of the crib sheets, and how prepared they had felt. A final, post-study questionnaire (containing 0–10 sliding scales, rank-order and open-ended questions) asked for opinions on the three evaluation methods together (CJ-Holistic, CJ-Dimensions, R-Analytic), including their ease of use and participants’ preferred method. Questionnaire content and responses were in English. A copy of the questionnaires can be found in Supplementary Materials 2.
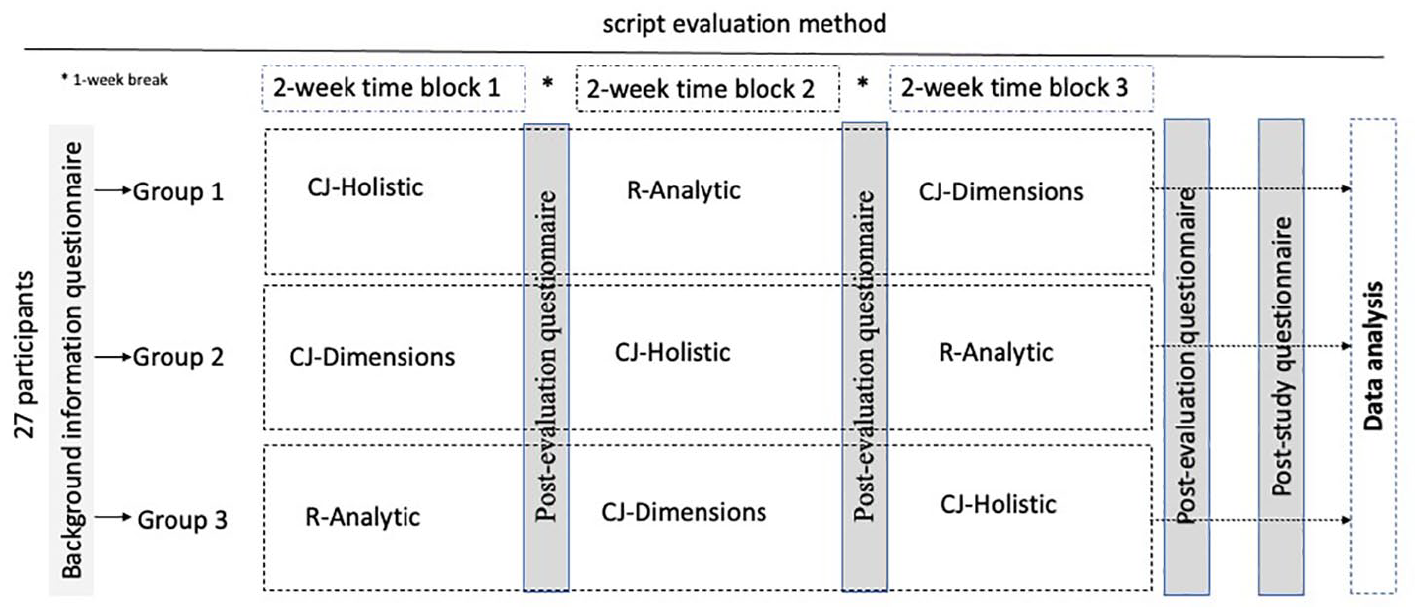
Research design
A counterbalanced design was used to compensate for potential order effects of evaluation methods. Therefore, the participants were divided into three groups balanced for members’ teaching and rating characteristics. Each group conducted the three evaluation methods in a different order (see Figure 2).
Analyses
To indicate the overall reliability of the CJ sessions (RQ1), the reliability figure used in CJ was scrutinised, i.e. the Scale Separation Reliability (SSR; Verhavert et al., 2019) which shows values between 0 and 1. This measure is derived in a similar manner as the person separation index in Rasch (Andrich, 1978) and comparable to Cronbach’s alpha (Jones et al., 2019; Pollitt, 2012b). SSR gives “a sense of the ‘separatedness’ of scores and the size of their standard errors. The more separated the scores and the smaller the standard errors, the greater SSR” (Jones & Davies, 2023, p. 6). Bramley (2015, p. 5) defines SSR as:
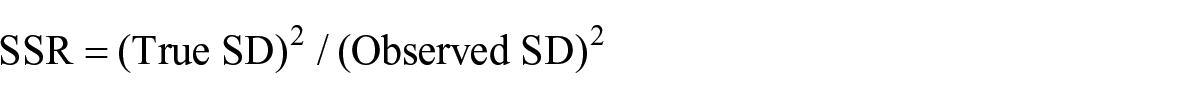
where
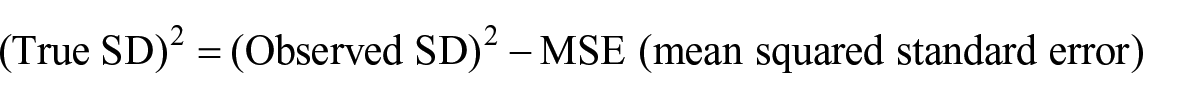
An individual judge’s performance can be measured by averaging the SSRs of all their judgements and observing how their resulting statistic differs from the consensus of the other judges (Pollitt, 2012b). The resulting infit value indicates how closely each judge’s overall decision-making conformed to the consensus made by all judges in the CJ session. The infit value > 1.5 limit, which is frequently used to illustrate a lack of internal consistency of raters when rating (Green, 2013) and also used for CJ (see, e.g., Chambers & Cunningham, 2022; Steedle & Ferrara, 2016), was employed in this study. Judges’ CJ infit values as provided by the CJ platform were compared to the > 1.5 limit to address RQ1 on judge reliability.
To ascertain that the order of script evaluation method (order effects; see Figure 2, Groups 1, 2 and 3) did not impact on reliability (as shown by judge infit values), Kruskal-Wallis H-tests were run.
The participants’ analytic ratings were analysed using Facets (v3.84; Linacre, 2022), which converts qualitative observations to linear measures and accounts for rater variability (Eckes, 2015; Linacre, 2022). Facets provides several reliability statistics including the infit mean square (MNSQ) calculated from the differences between the observed rating (what the rater awarded) and the expected rating (what the many-facet Rasch model expected to be awarded) (Eckes, 2015). These values, ranging from 0 to infinity, with an expected value of 1, show the rater’s internal consistency: intra-rater reliability (Eckes, 2015; Green, 2013). Generally, higher values (> 1.5) indicate unexpected variation in ratings (underfit/misfit). Conversely, lower values (< 0.5) indicate ratings that are too predictable (overfit; Green, 2013).
To address RQ2a, a Spearman’s rank-order correlation was calculated to assess the relationship between each short script’s CJ-Holistic scaled score and its CJ-Dimensions scaled score (one for each of the four dimensions). The same analyses were conducted for the equivalent scores for the long scripts.
As participants proved to be less reliable when rating the scripts using the analytic rating scale than when using CJ (see Results), the analytic scores provided by those four participants who were considered expert raters (prompt developers and rater trainers for the EFL writing test) were extracted from the dataset for correlation with CJ scores (the scaled scores allocated to each script based on the judgements of all judges in each CJ session). In total, these four expert raters rated 60 short and 60 long scripts (15 short and 15 long scripts each). To address RQ2b, their raw rating scores (four scores, one each for Task Achievement, Coherence & Cohesion, Grammar, and Vocabulary, for each script) were correlated (Spearman’s rank-order correlation) with the equivalent CJ-Dimensions scores for the same 60 short and 60 long scripts compiled from the judgements of all participants. In addition, their composite raw rating scores (an average of the four scores, one each for Task Achievement, Coherence & Cohesion, Grammar, and Vocabulary, for each script) were correlated (Spearman’s rank-order correlation) with the equivalent CJ-Holistic scores for the same 60 short and 60 long scripts compiled from the judgements of all participants.
To address RQ3, judges’ open comments on the perception questionnaires were noted verbatim; a selection of these is quoted in the Results section. The responses on the sliding scales and rank-order items were tabulated. CJ median judgement times generated by the CJ platform were also recorded as were participants’ self-reported mean times for R-Analytic rating. Furthermore, to investigate whether the time taken by judges affected their reliability, the median time taken for each CJ session was correlated with the respective judge’s infit values (Kendall’s tau_b correlation).
Results
With respect to RQ1, all CJ sessions showed high reliability (from 0–1 with figures closer to 1 showing higher reliability), for both the short and long scripts, and for all dimensions (Table 3). All sessions were at, above, or only just below, .9—the level recommended for high-stakes examinations (Verhavert et al., 2019).
CJ sessions’ Scale Separation Reliability (SSR).
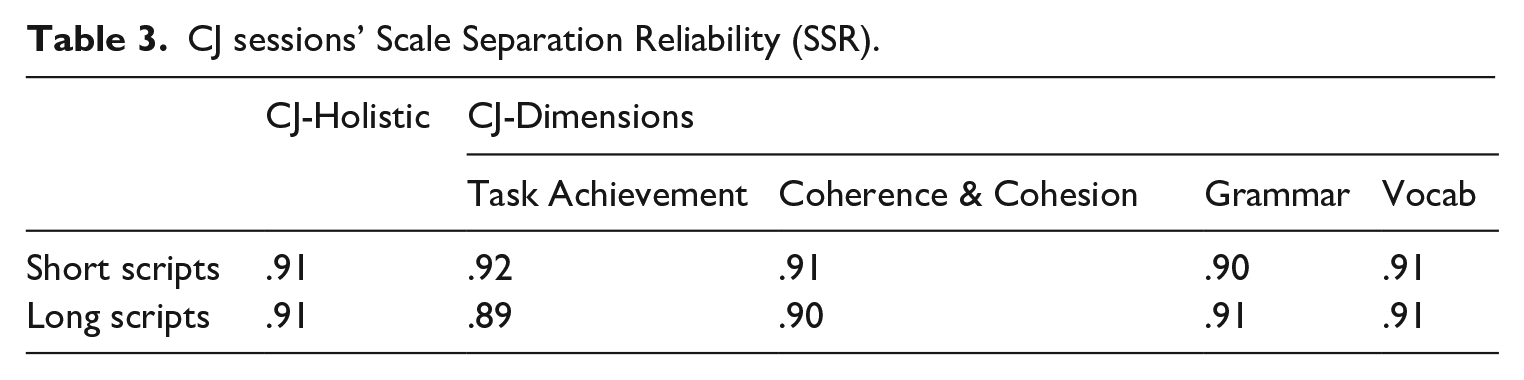
Participant reliability
Comparative Judgement
The majority of participants showed good fit, indicating adequate reliability. As shown in Table 4, only two judges showed misfit (Infit MNSQ > 1.5) when using CJ to judge the short scripts: one experienced teacher for CJ-Holistic and one inexperienced teacher for CJ-Dimensions Task Achievement. Three judges showed misfit when judging the long scripts (i.e., Infit MNSQ > 1.5): the same experienced teacher in three sessions and two inexperienced teachers for CJ-Dimensions Grammar. Notably, the experienced teacher (P5 [Participant 5]) who showed more misfit than any other participant had reported a lack of experience with marking schemes for the evaluation of student writing. All other experienced teachers (who did have experience using marking schemes in their professional practice) were found to be reliable CJ judges, regardless of whether they had been specifically trained for rating the Austrian Year 8 test.
Participants with inconsistent judgements by CJ session (Infit MNSQ > 1.5).

Note: P = participant.
Further analysis was conducted to determine whether the order of script evaluation method (CJ-Holistic, CJ-Dimensions, R-Analytic) had impacted judge reliability (as shown by judge infit values). Kruskal-Wallis H-tests showed no statistically significant differences in infit values between the three order groups. See Figure 2, Groups 1, 2, and 3, in all 10 comparisons, H(2) < 3.1 and p > .05.
Analytic rating
For rating, misfit is considered more problematic than overfit, as the latter may be offset by the resolution of misfit occurrences (Eckes, 2015). Participants in this study included inexperienced and experienced EFL teachers, with some of the latter having been trained for analytic rating of the Year 8 test and others not. It is therefore unsurprising that several participants showed misfit when rating, with the possible consequence that some well-trained raters showed overfit. Consequently, the focus in this study is on misfit rather than overfit data. Table 5 details infit MNSQ values for those participants showing misfit when they were rating the scripts. All inexperienced participants showed some misfit during their rating while, reassuringly, none of the expert raters did. Three of the five t-experienced participants showed some misfit, with one participant (who had indicated a lack of experience in the use of formal rating schemes) showing significant misfit in all four dimensions for both the short and long scripts. Half of the previously trained rater participants (7 from 14) showed some misfit during their rating. Misfit occurrences were fairly evenly spread across the four dimensions; however, raters were slightly more reliable when rating Grammar and slightly less when rating Coherence & Cohesion.
Participants with infit MNSQ > 1.5.

Note: P = participant.
Facets bias interaction analysis (Eckes, 2015; Smith & Wind, 2018) showed no statistically significant differences for short or long scripts relating to whether participants had received rater training, their teaching experience, or the sequence of evaluation methods. Table 6 lists the 27 participants showing one or more misfitting values (i.e., Infit MNSQ > 1.5) for the different evaluation methods. This indicates that CJ generated more consistent scoring than analytic rating from all teacher groups with the exception of one inexperienced teacher who was the only participant to show more scoring consistency when rating using the analytic mark scheme than when using CJ-Dimensions. The fact that half (two of four) of the inexperienced participants and the one experienced teacher who lacked formal marking scheme experience (P5) showed some inconsistent scoring when using CJ, suggests that such experience, in the classroom or examinations, is necessary for CJ judge reliability.
Evaluation method CJ infit/R-Analytic infit MNSQ > 1.5.

Note: P = participant, TA = Task Achievement, CC = Coherence & Cohesion, G = Grammar, V = Vocabulary.
Correlation of scores
With regard to RQ2a, Strong (Dancey & Reidy, 2017) positive correlations were found between CJ-Holistic and CJ-Dimensions scores for both the short and long scripts (Table 7). This suggests that the scores for CJ-Holistic did reflect all dimensions.
Correlation of CJ-Holistic and CJ-Dimensions (Spearman’s rho).

Correlation is significant at the 0.01 level (two-tailed).
Regarding RQ2b, there was a statistically significant and strong (Dancey & Reidy, 2017) positive correlation between the 60 short CJ-Holistic scores (all participants including expert raters) and the expert raters’ averaged 2 short script R-Analytic scores [rs(58) = .825, p < .001]. This was also the case for the long scripts [rs(58) = .771, p < .001].
Table 8 shows the expert raters’ R-Analytic scores by dimension were compared to the equivalent CJ-Dimensions scores (all participants). The strong (Task Achievement, Coherence & Cohesion, Grammar) and moderate (Vocabulary) correlations between short scripts’ CJ-Dimensions and expert raters’ R-Analytic scores, and the strong (Coherence & Cohesion, Grammar) and moderate (Task Achievement, Vocabulary) correlations between long scripts’ CJ-Dimensions and expert raters’ R-Analytic scores indicate that scores from the CJ process reflect the evaluations of the same scripts by the expert raters using an analytic rating scale.
Correlation of CJ-Dimensions and expert raters’ R-Analytic scores by dimension.

Correlation is significant at the 0.01 level (two-tailed).
Participants’ views on the evaluation methods
In relation to RQ3, perception questionnaires at the end of the study asked participants through a slider scale from 0 (very difficult) to 10 (very easy) how easy it was to judge using CJ-Dimensions and to rate using the analytic rating scale. They indicated finding R-Analytic generally easier than CJ-Dimensions (Figure 3) despite their CJ-Dimensions scoring being more reliable (Table 6). CJ-Holistic was generally considered easier than CJ-Dimensions; this might reflect the fact that CJ-Dimensions required eight separate CJ sessions (one for each dimension for the short and long scripts; see Table 2).
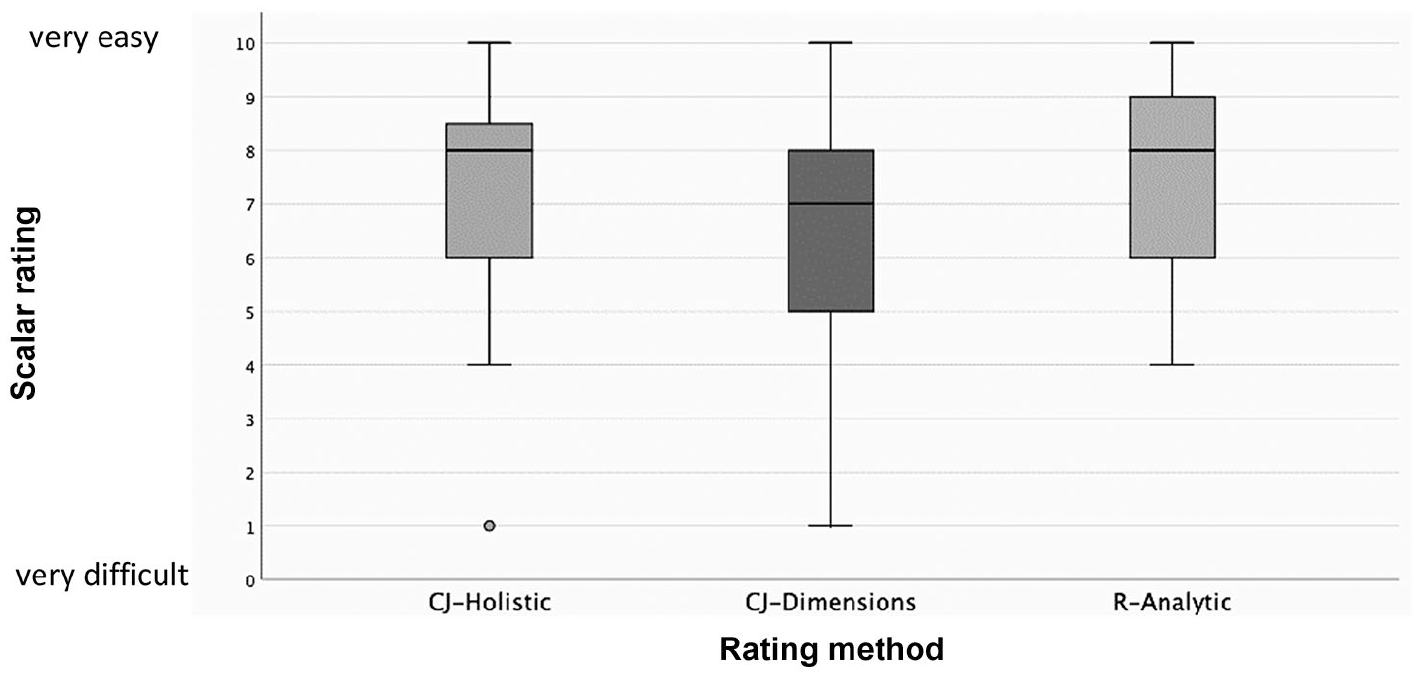
Participants’ views on ease of use of each method.
These observations—CJ-Holistic and R-Analytic perceived easier than CJ-Dimensions—mainly reflected the views of the experienced educators (Figure 4). The inexperienced teachers, in contrast, found CJ-Dimensions easier than CJ-Holistic. In addition, they found R-Analytic the easiest, so, overall, the inexperienced teachers seemed to appreciate more detailed guidance with criteria. The t-experienced and expert raters found the more usual holistic version of CJ (CJ-Holistic) easiest out of all three; raters held rather similar views on the ease of CJ-Holistic and R-Analytic, and also found CJ-Dimensions easier than any of the other groups had.
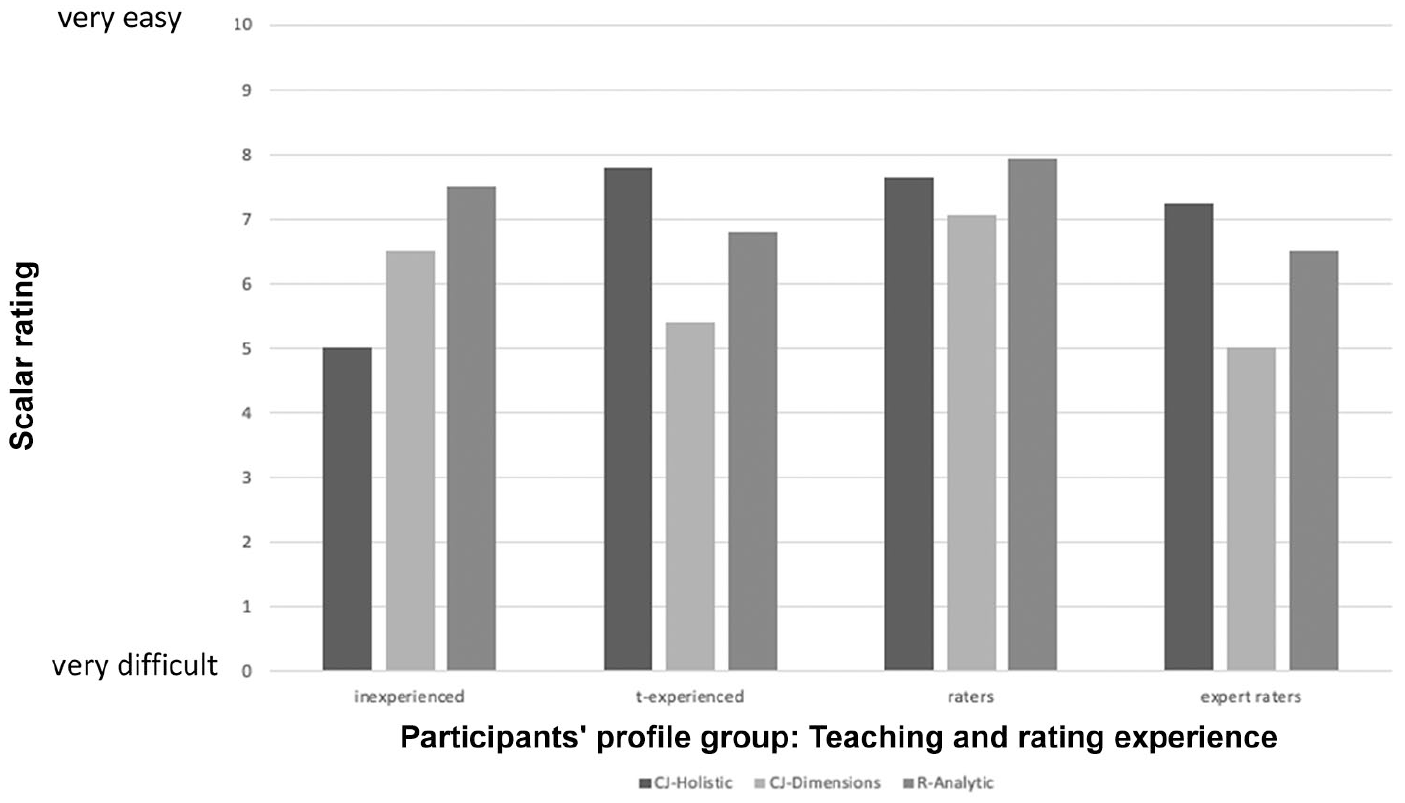
Participants’ views on ease of use of each method by participant characteristics (mean averages given for each group).
More insights into judges’ views on CJ were gauged from their open-ended comments. Note that, while we report the quoted raters’ profile below for reasons of completeness, these instances should not be interpreted as representing their profile group; systematic connections between profile and open-ended comments were not observed and it should be kept in mind that not all participants offered open-ended comments.
Regarding CJ-Holistic, five judges reported that it was quick and easy. One stated it was “a really fast method” (P21 expert rater) although another noted that some judgements were very quick but others, when the quality was similar, took longer. This reflects the findings of previous studies (e.g., Gijsen et al., 2021; van Daal et al., 2017). Several judges worried that they might have missed aspects of the scripts they were considering as the fluency of the text seemed to override other considerations. One judge found it “stressful” (P11 expert rater) while conversely, another said it was “uncomplicated” (P3 rater). One judge noted that “creativity” (P23 inexperienced) could be accommodated along with other factors that might not be listed on a traditional analytic scale, indicating an appreciation of the open nature of CJ.
For CJ-Dimensions, as with CJ-Holistic, comments were made concerning the challenge of having to make a decision between two performances. Several judges stated having to read the same scripts multiple times due to the different dimensions: “this is very tedious and exhausting as you read texts over and over again” (P11 expert rater). Another judge stated: “frustrating” (P22 rater). On the contrary, other judges did not mind repeated CJ judgements: “I think that comparing the texts is useful” (P23 inexperienced). Notably, in the larger study (Sickinger, 2023), a subset of judges, who did not read scripts in detail, displayed a fast, efficient decision-making approach, whereas other judges seemed to use other decision-making processes, including those associated with analytic rating, such as full detailed reading of scripts. This suggests it might be beneficial to offer training to all judges on a CJ-specific, faster decision-making approach, which would alleviate the need for extensive reading. A benefit of CJ is that it relies on multiple pairwise comparisons, some of which, particularly when performances are significantly different in quality, are “cognitively much simpler” and intended to be quicker than traditional rating (Benton & Gallacher, 2018, p. 22).
Some judges also noted that CJ-Dimensions was similar to analytic rating, with each dimension being considered in turn as the 18 raters and expert raters had been previously trained to do (experienced and inexperienced participants were also provided with the official Technical Report from the 2013 test [Gassner et al., 2011] as a guide). Some liked this: “it was easier to concentrate only on one dimension” (P18 rater), and some did not: “it is very hard to focus only on one aspect when making a decision. Using CJ for holistic rating does make more sense to me” (P11 expert rater). One judge found that CJ-Dimensions “eased my indecisiveness a bit because I only had to focus on one category at a time” (P14 inexperienced).
Several participants explicitly commented on the time requirements of the different evaluation methods. For CJ-Dimensions decisions, views ranged from “rather fast” (P21 expert rater), “quicker” (P9 rater) to “took a lot longer than the holistic method and longer than I had anticipated” (P12 expert rater). This variation was confirmed by the timings recorded by the CJ platform (Table 9). In addition, time requirements between evaluation methods differed, based on the CJ platform’s median time (in seconds) taken by judges to compare a pair of scripts and on judges’ self-reported mean time for R-Analytic rating per script (Table 9). However, CJ-Holistic and CJ-Dimensions proved to be considerably faster for individual judges than R-Analytic. It needs to be kept in mind, though, that CJ requires multiple judgements and the overall time taken depends on the number of performances, judges, and judgements required. In addition, timings for R-Analytic were self-reported and, therefore, probably less accurate than the automatic timings made by the CJ platform.
Average timings (in seconds) taken for each evaluation method.

Note: CJ median times = for a pair of scripts (data provided by the No More Marking platform). R-Analytic times = mean times self-reported approximate timings by participants for one short or one long script (two participants did not provide times).
Associations between judges’ reliability (CJ infit MNSQ values) and their median time taken for pairwise comparisons were explored using Kendall’s tau_b (Table 10). For CJ-Dimensions Task Achievement, which requires time to check that four content points for the short prompt and six content points for the long prompt (Figure 1) are addressed, a small statistically significant correlation was found between time taken and judge reliability. Small associations were also found for CJ-Holistic long scripts, where the six bullet points would need to be checked, and for CJ-Dimensions Coherence & Cohesion for long scripts. Again, although total timings for evaluation using CJ would depend on the number of judgements (dimensions) required, CJ is clearly a more time-efficient method of evaluation particularly when the additional training time required for rating is considered. Furthermore, overall, the data indicate participants could judge both fast and reliably.
Correlation of CJ judge infit values and median judging time by CJ session (Kendall’s tau_b).

Correlation is significant at the 0.01 level (two-tailed); *Correlation is significant at the 0.05 level (two-tailed).
When asked to rank the evaluation methods by preference, different participant groups expressed different preferences (Figure 5). Reflecting their ease of use views, R-Analytic was placed as first choice by most of the inexperienced participants whereas none of the expert raters opted for this; most expert raters preferred CJ-Holistic. For the raters, R-Analytic was the preferred method while for t-experienced, CJ-Holistic and R-Analytic were the first choice for an equal number of participants. Opinions regarding CJ-Dimensions were mixed but only a minority of participants chose it as their preferred method of evaluation with majorities in most groups selecting it as their least preferred preferences. For t-experienced, CJ-Holistic was the most commonly selected third choice of evaluation method, although it was the method they reported as being the easiest to use. It should be kept in mind, of course, that the separate groups (apart from raters) comprise small numbers of participants and views might not scale up.

Participants’ preference rankings of the evaluation methods by participant characteristics (shown as percentages).
Overall, for all participants together, the more familiar method R-Analytic was generally preferred (first choice), with CJ-Dimensions being comparatively least preferred (third choice) (Figure 6). The result that participants generally find it hard to adjust to a new evaluation method and tend to apply strategies from their established method reflects findings from previous studies (Leech & Chambers, 2022; Marshall et al., 2020; Rodeiro & Chambers, 2022). Possibly, training and familiarity would allow judges experienced in rating to become comfortable with the CJ method and inexperienced judges to gain the knowledge needed to evaluate reliably.

Participants’ preference rankings of the evaluation methods.
Discussion
In the current study, participants scored scripts using: CJ-Holistic (when the entirety of one script was compared to the entirety of a second script); CJ-Dimensions (when features of writing for one dimension from one script were compared to the features of writing for the same dimension of a second script); and R-Analytic (the conventional analytic rating method). Results showed that generally participants were most reliable when scoring using CJ and least reliable when scoring using R-Analytic. However, most participants reported finding the more familiar rating method easier than the CJ method. CJ-Dimensions was the least preferred option. It is unclear whether this was due to the far greater workload of CJ-Dimensions, where all participants judged scripts in all dimensions for both short and long scripts. In practice, the time demands could be reduced significantly, though, by assigning each judge to only one dimension in a live testing situation, for example one judge to Task Achievement and another judge to Grammar. Judge allocations could thereby be rotated between dimensions in different administrations of the test. Alternatively, significantly more judges could be recruited, each judging fewer scripts. The latter two suggestions would maintain judges’ exposure to the full test construct, which is likely to be beneficial for classroom washback. Involving a larger number of teachers as judges could also enable a broader range of views on the written performances to be included, thus encompassing the multi-dimensional nature of writing and possibly minimising construct underrepresentation (Lesterhuis et al., 2022).
Our findings also showed that classroom teachers with experience of using marking schemes to evaluate young learners’ EFL written performances were able to reliably evaluate such performances using CJ-Holistic and CJ-Dimensions. One experienced teacher (> 15 years’ teaching experience) and two inexperienced teachers with little or no experience of using an analytic marking scheme were not able to reliably evaluate scripts using CJ (or when rating). This suggests that some experience using an analytic mark scheme might be beneficial for reliable use of CJ to evaluate scripts.
We also found that most experienced educators with classroom and marking scheme experience were more able to score scripts reliably when using CJ than when rating. This finding, combined with the fact that all experienced teachers with marking scheme experience (expert raters, raters, and t-experienced with the exception of P5 who lacked marking scheme experience) demonstrated reliable CJ scoring, suggests that young learners’ EFL written performances could be reliably judged using CJ by experienced EFL classroom teachers with minimal (or no) prior training. Such evaluation could thus be more cost-efficient. In addition, the direct involvement in the national testing process of large numbers of teachers for CJ may also promote washback to the teaching and learning of EFL writing in the classroom—an original aim of the Austrian Year 8 test (Gassner et al., 2011; Mewald, 2018; Siller et al., 2019). Furthermore, when using CJ-Dimensions, cut-score decisions might be simpler as the performances have already been rank ordered so an ultimate decision need only be made between two adjacent performances (criteria-referenced). In addition, within the Austrian educational system (and in several other contexts), norm-referenced reporting of candidates’ results within the school population is regular practice (often also expected by stakeholders); the use of CJ still allows for this easily (perhaps making it even easier). Moreover, CJ accommodates the insertion of pre-rated “anchor” scripts to a pool of scripts (Pollitt et al., 2004). Such anchor scripts, possibly from earlier tests or pilots, can be chosen to mark grade boundaries as well as allowing for comparability with previous test iterations and for the measurement of judge reliability (Marshall et al., 2020; Steedle & Ferrara, 2016).
There is a tension in CJ, however, between its conceit as an open method of evaluation where judges are free to use their expert, inherent, subjective knowledge, and the potential requirement of stakeholders for transparent assessment criteria. If CJ is to be a valid evaluation method with the backing of various stakeholders, then supporting materials that describe judgement criteria might be necessary. These materials could for example take the form of crib sheets, as successfully trialled in this study. Furthermore, if the test aims to provide some level of diagnostic feedback (as the Austrian Year 8 test does), scores should be linked to common criteria that teachers can clearly understand and use to improve classroom teaching. The innovative method of CJ-Dimensions supports this by allowing more detailed feedback than CJ-Holistic; however, the CJ-Dimensions method requires additional CJ sessions to accommodate the requirement for each script to be judged separately for each dimension. Despite this, the current study has shown that CJ-Dimensions can produce reliable scores in a time-efficient manner. The potential should be recognised of CJ-Dimensions to conduct reliable and speedy script evaluation for large-scale tests where large numbers of judges can be employed, possibly with no or minimal training when experienced in using marking schemes.
Conclusion
With this study, we contribute a new, dimension-based approach to using CJ for scoring EFL writing. In addition, we extend the presently scarce literature on CJ from adult to young learner EFL writing contexts. Our study showed that CJ, both in its holistic and dimension-based formats, is a reliable method for evaluating young learners’ EFL scripts (especially when judges are supported by crib sheets that remind them of the target construct), and that experienced EFL teachers who have experience with marking schemes are reliable CJ judges. Furthermore, while several participants preferred the more familiar analytic rating, they displayed higher reliability and shorter decision-making times when using CJ.
CJ can also meet calls for democratic evaluation approaches, with the sizeable number of judges potentially involved. It is furthermore practical to implement, requiring only minimal training, thus being more cost-effective and enabling wider stakeholder representation (e.g., teachers from more and different [types of] schools and regions). Greater involvement of teachers in national exam processes might improve washback to the classroom and standardisation of writing development practices across schools. Our innovative dimension-based CJ method seems particularly worthwhile considering for use in the Austrian national Year 8 EFL exam, and in other large-scale second/foreign language writing assessments, as it allows more detailed feedback than the more common holistic form of CJ. Involvement in CJ could also be a form of professional development (Rotaru, 2022); classroom teachers might gain exposure to a wider range and levels of written performances which could benefit their classroom teaching of EFL writing.
It should be emphasised, however, that our findings regarding the reliability of CJ applied to judges who were experienced teachers and also had experience with using marking schemes; lack of teaching or marking scheme experience negatively affected CJ reliability. Although the number of participants in the latter category in this study was small, this observation seems to underline the importance of general professional development of (aspiring) teachers, including before involving them in CJ. We also want to highlight that, although CJ frequently proceeds without training, some of our experienced participants felt that some training would nevertheless be useful. As mentioned, the larger project the present study was part of (Sickinger, 2023) identified a fast and efficient decision-making approach employed by some highly reliable participants. This might be further explored as a potential focus for training. Similarly, training might help raise teachers’ awareness of their adequate scoring reliability even while being new to CJ-Dimensions and despite preferences for familiar rating methods. Finally, if considering adoption of CJ, in the Austrian young learner EFL writing examination or other contexts, engagement with a wide variety of stakeholders and conducting research into their views is indicated.
We acknowledge limitations to the research reported in this article. While it proposes and sheds empirical light on a new form of CJ (CJ-Dimensions), the findings are based on a study situated within a specific context (Austrian lower-secondary EFL writing standardised testing for educational system monitoring). Also, participant sub-group analyses and questionnaire open comments were based on smaller numbers of participants and might thus not be fully representative or generalisable. Further large-scale research in other contexts is thus called for. In addition, our focus here was on the investigation of reliability of CJ, complemented with some insights into practicality. While these are key dimensions of test usefulness, which have been most documented in the CJ research base to date, other principles equally necessitate consideration, not the least investigations of validity. For research and findings on the validity of CJ, as employed in this study, we refer readers to Sickinger (2023).
Supplemental Material
sj-pdf-1-ltj-10.1177_02655322241288847 – Supplemental material for Comparative Judgement for evaluating young learners’ EFL writing performances: Reliability and teacher perceptions of holistic and dimension-based judgements
Supplemental material, sj-pdf-1-ltj-10.1177_02655322241288847 for Comparative Judgement for evaluating young learners’ EFL writing performances: Reliability and teacher perceptions of holistic and dimension-based judgements by Rebecca Sickinger, Tineke Brunfaut and John Pill in Language Testing
Supplemental Material
sj-pdf-2-ltj-10.1177_02655322241288847 – Supplemental material for Comparative Judgement for evaluating young learners’ EFL writing performances: Reliability and teacher perceptions of holistic and dimension-based judgements
Supplemental material, sj-pdf-2-ltj-10.1177_02655322241288847 for Comparative Judgement for evaluating young learners’ EFL writing performances: Reliability and teacher perceptions of holistic and dimension-based judgements by Rebecca Sickinger, Tineke Brunfaut and John Pill in Language Testing
Footnotes
Acknowledgements
The authors thank the participants who took part in this study, and the Institut des Bundes für Qualitätssicherung im österreichischen Schulwesen (IQS) for providing them with Year 8 EFL writing exam scripts and the exam’s analytic rating scale. They are also grateful for Aaron O. Batty’s statistical advice.
Author contribution(s)
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Rebecca Sickinger conducted consultancy work for IQS between 2015 and 2023, including on the Year 8 EFL reading, writing, and speaking exams and was a rater for the 2013 Year 8 EFL writing test. Tineke Brunfaut conducted consultancy work for IQS between 2015 and 2023, including on the Year 8 EFL reading and listening exams (not the writing exam). In 2022, John Pill conducted consultancy work for IQS on a lower-secondary school EFL reading exam.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.