
Abstract
The current study examined the extent to which first language (L1) utterance fluency measures can predict second language (L2) fluency and how L2 proficiency moderates the relationship between L1 and L2 fluency. A total of 104 Japanese-speaking learners of English completed different argumentative speech tasks in their L1 and L2. Their speaking performance was analysed using measures of speed, breakdown, and repair fluency. L2 proficiency was operationalised as cognitive fluency. Two factor scores of cognitive fluency—linguistic resources and processing speed—were computed based on performance in a set of linguistic knowledge tests capturing vocabulary knowledge, morphosyntactic processing, and articulatory skills. A series of generalised linear mixed-effects models revealed small-to-moderate effect sizes for the predictive power of L1 utterance fluency measures on their L2 counterparts. Moderator effects of L2 proficiency were found only in speed fluency measures. The relationship between L1 and L2 speed fluency was weaker for L2 learners with wider L2 linguistic resources. Conversely, for those with faster L2 processing speed, the L1-L2 link tended to be stronger. These findings indicate that the L1-L2 fluency link is subject to the complex interplay of phonological differences between learners’ L1 and L2 and their L2 proficiency, offering implications for diagnostic speaking assessment.
Introduction
In the context of second language (L2) assessment, both human- and machine-scored high-stakes speaking tests, such as the Test of English as a Foreign Language (TOEFL) and the International English Language Testing System (IELTS), assess fluency as a key construct in speaking tests. This is in line with research findings that demonstrate that L2 fluency is a robust indicator of L2 oral proficiency (Tavakoli et al., 2020). In addition, recent advances in acoustic analyses and natural language processing have contributed significantly to increasing the potential for automated scoring of L2 speaking performance (De Jong, 2018; Ginther et al., 2010). In this line of research, objective measures of fluency, such as speech rate and mean number of silent pauses, have been found to play a vital role in the estimation of test-takers’ speaking scores. It is thus essential to understand and continuously monitor the validity of measurements of oral fluency.
L2 researchers have attempted to identify a set of valid objective measures of fluency in light of the underlying linguistic knowledge and competence (De Jong et al., 2013; Kahng, 2020). Following Segalowitz’s (2010) framework, the former is commonly termed utterance fluency (UF), and the latter cognitive fluency (CF). However, the validity of UF measures should be discussed in terms of not only their association with CF but also their relative independence from first language (L1) fluency (De Jong, 2018). Individual speakers’ idiosyncratic characteristics, such as general cognitive skills and speaking style, might contribute to L2 UF and thus cause construct-irrelevant variance in assessment (see Segalowitz, 2010). These idiosyncratic factors have been found to play a similar role in L1 and L2 speech production (see Peltonen, 2018; Williams & Korko, 2019). Previous studies have operationalised these idiosyncratic factors as the covariance between L1 and L2 UF measures and examined the association between L1 and L2 UF (e.g., Bradlow et al., 2017; De Jong et al., 2015; De Jong & Mora, 2019; Peltonen, 2018). Accordingly, the understanding of the association between L1 and L2 UF measures may provide insight into the selection of valid L2 UF measures for both research and assessment purposes.
Although prior research has shown that the L1-L2 UF link is cross-linguistically robust (Bradlow et al., 2017), previous studies have been largely limited to closed tasks (see Pallotti, 2009), such as picture and personal narrative tasks, as well as to the L1-L2 combination of stressed-timed or syllable-timed languages (e.g., Dutch, English, French, Spanish). In addition, albeit only with a few studies available to date, previous studies have suggested that the strength of the association between L1 and L2 fluency can be moderated by L2 proficiency (Derwing et al., 2009). Therefore, to further explore the generalisability of previous research findings, the current study examines the L1-L2 UF link in the context of open-ended speech produced by L1 Japanese (mora-timed language) learners of English (stress-timed language), as well as the moderator effects of L2 proficiency on the L1-L2 UF link.
Background
L1-L2 utterance fluency link
From the perspective of speech production mechanisms, both L1 and L2 speech production commonly proceed in the following order: conceptualisation, formulation, and articulation (Kormos, 2006; Levelt, 1989). Conceptualisation involves planning the speech content and organising it for subsequent linguistic processing (i.e., formulation) and articulation. Among these speech production processes, language-general processing is primarily limited to conceptualisation, while formulation and articulation are considered to be language-specific (Kormos, 2006; Suzuki & Révész, 2023). Accordingly, it can be argued that the processes and resources for conceptualisation are shared between L1 and L2 speech production. Furthermore, even L1-specific linguistic knowledge can be transferred to L2 speech production when the mechanisms for L2-specific processing (e.g., syntactic encoding, phonological encoding) are not yet fully developed (Kormos, 2006). Therefore, the L1-L2 UF link can reflect the speaker’s efficiency in language-general processes and the transfer of L1 knowledge to L2 speech production. The former could presumably be independent of the speaker’s L1 and L2 background and L2 proficiency, while the latter might be contingent upon their L2 proficiency.
The L1-L2 UF association has been found to be cross-linguistically robust in speaking rate measures 1 (Bradlow et al., 2017). Nonetheless, as summarised in Table 1, the effect sizes in previous studies have not always been consistent, possibly because of the three distinctive dimensions of UF—speed (speed of delivery), breakdown (pausing behaviours), and repair aspects (disfluency features) of fluency (Suzuki & Kormos, 2023; Tavakoli & Skehan, 2005). First, the strength of association between L1 and L2 speed fluency measures has been found to be either moderate (De Jong et al., 2015; Huensch & Tracy-Ventura, 2017) or strong (De Jong & Mora, 2019; Peltonen, 2018; Peltonen & Lintunen, 2022). Although most studies employed picture narrative tasks to elicit learners’ speech and commonly reported moderate-to-strong correlations, a strong correlation was also found in role-play tasks (r = .70; De Jong & Mora, 2019). The relatively stronger association in role-play tasks might be due to the open-ended nature of the task. Role-play tasks allow for a somewhat more flexible speech content and, hence, learners’ speaking style might be better reflected in performance. In other words, one might assume that learners’ speaking styles manifest more strongly in open tasks, such as argumentative speaking tasks, than in closed ones (cf. Gao & Sun, 2024).
Summary of 10 key studies on L1-L2 utterance fluency link.

Note: Some studies included proficiency variables without formal analyses of moderator effects of L2 proficiency due to the focus of the studies.
Regarding breakdown fluency, both pause frequency and pause duration measures tend to show moderate to strong correlations between L1 and L2 speech (De Jong et al., 2015; Peltonen, 2018). However, the effects of pause type (silent vs. filled pauses) on the predictive power of L1 measures in the corresponding L2 measures have varied across studies. The correlation coefficients between L1 and L2 silent pause frequency tend to be moderate to strong, whereas the strengths of the L1-L2 association of filled pause frequency vary considerably across studies. Given that previous studies commonly involved participants with a combination of stress-timed and syllable-timed L1 background and target L2, the varied strength of association between L1 and L2 filled pause frequency may not be attributed to cross-linguistic differences (e.g., rhythm, tempo). An alternative possible reason for the variation in the strength of association between L1-L2 filled pause frequency is cultural differences, because even phonologically similar languages can have different norms for temporal features (Tian et al., 2017). Similarly, the correlation coefficients between L1 and L2 pause duration measures tend to be moderate to strong (De Jong et al., 2015; De Jong & Mora, 2019; Huensch & Tracy-Ventura, 2017; Peltonen, 2018). As regards pause location, L1 and L2 end-clause pause duration are more strongly associated than are L1 and L2 mid-clause pause duration (De Jong et al., 2015; Huensch & Tracy-Ventura, 2017; Peltonen, 2018). End-clause pauses are reflective of conceptualisation processes, which are shared across different language systems within individuals (De Jong, 2016). Accordingly, the covariance of end-clause pause duration between L1 and L2 may derive from the language-general processes underlying end-clause pauses.
The effect sizes of the L1-L2 UF link in repair fluency measures can vary considerably. One plausible reason for such varying effect sizes is the incompatibility of the focus of repair fluency measures across studies. Some studies count different kinds of disfluency phenomena altogether for the sake of the validity of classification (Duran-Karaoz & Tavakoli, 2020; see also Suzuki et al., 2021), while other studies have targeted certain disfluency features and have employed fine-grained measures, such as self-repetition frequency and self-correction frequency (De Jong et al., 2015; Huensch & Tracy-Ventura, 2017). However, even for the same target repair features, different effect sizes for the L1-L2 association have been observed. For instance, in the case of self-repetition frequency, a strong effect size was reported in De Jong et al.’s (2015) study, while a non-significant correlation was found in Peltonen’s (2018) research. These inconsistent findings may indicate the association between L1 and L2 UF measures might be affected by moderator variables. Two of these important moderators between the L1-L2 UF link might be cross-linguistic differences between L1 and L2, and learners’ L2 proficiency (Huensch & Tracy-Ventura, 2017).
Cross-linguistic variability
Cross-linguistic similarities and differences are assumed to moderate the strength of the L1-L2 UF association. Bradlow et al.’s (2017) cross-linguistic study confirmed that in speaking rate measures (speech rate and articulation rate), the predictive power of L1 UF on L2 UF was robust across different L1 backgrounds, while the strengths of the L1-L2 association tended to vary according to speakers’ L1. There are theoretically relevant linguistic features to temporal aspects of speech: rhythmic patterns (e.g., stress-timed vs. syllable-timed language) and syllable complexity (Pellegrino et al., 2011). Based on previous studies examining the L1-L2 UF link, one can argue that while the most researched target L2 is English, participants’ L1s were mainly either stress-timed languages, such as Slavic languages (Derwing et al., 2009), or syllable-timed languages, such as Finnish (Peltonen, 2018), Mandarin (Derwing et al., 2009), Spanish (De Jong & Mora, 2019), and Turkish (Duran-Karaoz & Tavakoli, 2020). However, to the best of our knowledge, no studies have examined the L1-L2 UF link in the context of learners of L2 English with mora-timed L1 language backgrounds. One representative mora-timed language is Japanese (Vance, 2008). According to Pellegrino et al. (2011), the Japanese language has relatively low syllable complexity (indexed by the mean number of constituents per syllable; 2.65 in Japanese vs. 3.70 in English and 3.87 in Mandarin) and information density (indexed by the average semantic information per syllable; 0.49 in Japanese vs. 0.91 in English and 0.94 in Mandarin). Therefore, to better understand the cross-linguistic effects on the L1-L2 UF link, the association between L1 and L2 UF behaviours should be examined with Japanese-speaking learners of English.
Moderating role of L2 proficiency
In examining the L1-L2 UF link, previous studies have operationalised L2 proficiency in different ways, such as through examining longitudinal changes (Derwing et al., 2009; Huensch & Tracy-Ventura, 2017), using standardised test scores (Duran-Karaoz & Tavakoli, 2020; Gao & Sun, 2024) and through obtaining vocabulary size estimates (De Jong et al., 2015; De Jong & Mora, 2019; Peltonen, 2018). Among these different operationalisations, the potential moderator effects of L2 proficiency on the L1-L2 UF link can be observed based on the longitudinal changes in correlation coefficients between L1 and L2 fluency measures. Derwing et al.’s (2009) study tracked the relationship between L1 and L2 fluency longitudinally in a cross-linguistically different L1-L2 group (Mandarin learners of English) and a cross-linguistically similar L1-L2 group (Slavic learners of English) in Canada where English is both an official and the dominant language. They found that L1-L2 correlations of speech rate and silent pause frequency decreased as a function of time in the former group, while in the latter group, the correlation coefficients were relatively stable across three time points with moderate-to-strong effect sizes. Similarly, Huensch and Tracy-Ventura’s (2017) longitudinal study included two groups of English-speaking students who had learned either French or Spanish as L2 and had resided in an L2-speaking environment. Their study found that in both groups, L1-L2 correlations in some fluency measures, such as articulation rate and silent pause duration (especially within the analysis of speech units; cf. Foster et al., 2000), increased after 5 months’ residence in the L2-speaking environment. However, for English-speaking learners of French, the non-significant L1-L2 correlation of self-repetition frequency before residence abroad (r = .12) became moderate to strong (r = .55) after 5-month residence in the L2-speaking environment. In contrast, the same pattern was not found in the group of English-speaking learners of Spanish. Taken together, these findings suggest that the L1-L2 UF association may reflect the complex interplay between cross-linguistic effects and learners’ L2 proficiency (for a review, see Huensch & Tracy-Ventura, 2017).
The aforementioned studies claimed that changes in the L1-L2 relationship can be derived from gains in L2 proficiency. However, longitudinal residence in the L2-speaking environment may not entail only a gain in underlying linguistic competence, but also changes in affective status (e.g., willingness to communicate; Lee, 2018), which can also contribute to fluency in L2 speech production (Segalowitz, 2010). Meanwhile, Gao and Sun’s (2024) study directly examined the moderator effects of L2 proficiency on the L1-L2 fluency link specifically in breakdown fluency measures. Notably, their participants are school-age Chinese students rather than adult learners as in the abovementioned studies. They adopted the picture narrative task of the sample test of TOEFL Junior speaking test, and the speech samples were assessed by their trained raters based on the scoring criteria of the TOEFL Speaking test. Their results showed that there was no significant interaction effect between TOEFL Junior speaking test scores, as the measure of L2 proficiency, and L1 breakdown fluency measures. Although they concluded the L1-L2 UF link is independent of L2 proficiency, their L2 proficiency scores and L2 fluency measures were obtained from the same speech samples of the TOEFL Junior speaking test. The lack of independence of the observations of these two variables might have obscured the moderator effects of L2 proficiency on L1-L2 UF link.
From a methodological perspective, to better understand the mechanisms of the L1-L2 fluency link, a fine-grained measurement of L2 proficiency is needed that can specifically tap into L2-specific competence or fluency-related processing skills (Huensch & Tracy-Ventura, 2017; Pérez Castillejo & Urzua-Parra, 2023). In the domain of L2 fluency research, such competence is conceptualised as L2-specific cognitive fluency, which refers to the efficiency of the speaker’s L2-specific cognitive and linguistic processes that underlie L2 utterance fluency (Segalowitz, 2016). More specifically, cognitive fluency is assumed to have two interrelated dimensions: linguistic resource (i.e., breadth and depth of linguistic knowledge) and processing speed (i.e., automaticity in accessing and manipulating linguistic knowledge; Suzuki & Kormos, 2023). Previous studies have also demonstrated strong predictive power of cognitive fluency to UF performance (De Jong et al., 2013; Kahng, 2020; Suzuki & Kormos, 2023). Therefore, the current study operationalised L2 proficiency as L2-specific cognitive fluency.
The current study
To explore the generalisability of the L1-L2 UF link, the current study examines the L1-L2 UF link in the context of argumentative speech produced by L1 Japanese (mora-timed language) learners of English (stress-timed language). In addition, a synthesis of previous studies suggests that the strength of the association between L1 and L2 fluency can vary as a function of L2 proficiency. To examine the moderator effects of L2 proficiency on the L1-L2 UF link, our study used factor scores based on the latent variables of CF as a proxy for L2 proficiency from the results of our precursor study (Suzuki & Kormos, 2023). The following research questions (RQs) were formulated:
RQ1. To what extent are L2 English utterance fluency measures predicted by the corresponding L1 Japanese measures in an argumentative task?
RQ2. To what extent is the relationships between L1 and L2 utterance fluency measures moderated by cognitive fluency scores?
Our precursor study (Suzuki & Kormos, 2023) examined what linguistic knowledge (i.e., CF) contributes to three dimensions of UF (i.e., speed, breakdown, and repair fluency) using L2 speech samples elicited via four different speaking tasks including one argumentative speech task, which was also part of the current study. In contrast, the study reported in this paper examines the extent to which L2 UF measures are explained by their L1 counterparts. To this end, participants’ L1 speech data are exclusively used in the current study, and the sample of this research includes only the participants who completed two argumentative speaking tasks in L2 English and another argumentative task in L1 Japanese (for more details, see Supplementary Appendix A; Suzuki & Kormos, 2024).
Method
Participants
As part of a larger project, the current study included 104 Japanese learners of English (female = 61, male = 43; Mage = 20.03, SDage = 1.52), all of whom were recruited at a private university in Japan and voluntarily participated in the project. Their self-reported university’s in-house placement English test scores 2 suggested that most of them could be placed on the B1–B2 levels of the Common European Framework of Reference for Languages (CEFR) scale with some students at the C1 level at the time of data collection (see Figure 1).
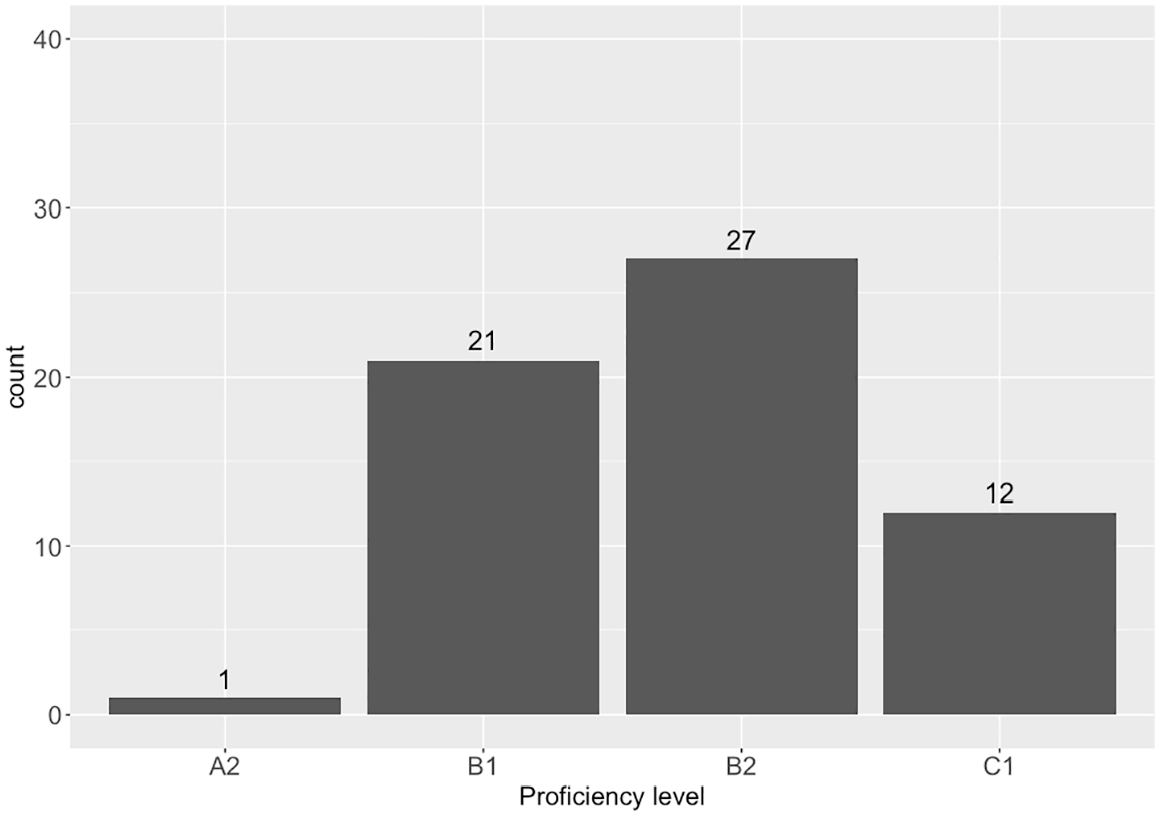
Histogram of 61 out of 104 students’ self-reported English scores on in-house university placement tests, equated to CEFR level equivalents based on the test provider’s concordance tables.
Materials
Speaking tasks
As discussed earlier, the association between L1 and L2 speech production may be stronger in open-ended speaking tasks than in closed ones. In open-ended tasks, speakers have considerable flexibility in adjusting their message to their own L2 linguistic resources. The effect of personal speaking style might thus be apparent in their L2 performance in this type of task. Accordingly, the current study elicited L1 and L2 monologue speech samples, using different argumentative speech tasks with an identical task format and procedure. All prompts are available on the Open Science Framework (OSF; Suzuki & Kormos, 2024). In the L1 argumentative speech task, participants were provided with a statement—Japan should stop its lifetime employment system—and then were instructed to argue the extent to which they agree with the statement. For L2 speech elicitation, for the sake of the robustness of findings, two separate L2 argumentative tasks were employed. The following two statements were provided, and in each L2 argumentative task, the students were asked to discuss the extent to which they agree with them:
With the development of technology and the Internet, libraries will be unnecessary and will disappear.
The Tokyo Olympics in 2020 will bring economic growth to Japan. 3
Cognitive fluency scores
To operationalise L2 proficiency in a way that it is relevant for oral fluency, the current study adopted the L2-based measurements of CF and computed two separate factor scores, that is, linguistic resource (LR) and processing speed (PS), using confirmatory factor analysis (CFA). LR refers to the breadth and depth of linguistic knowledge for speech production, whereas PS is concerned with the automaticity of information processing related to speech production (Suzuki & Kormos, 2023). Building on the theoretical assumptions and empirical studies of CF (De Jong et al., 2013; Segalowitz, 2010), the factor score of LR was constructed based on the measurements of productive vocabulary size (Productive Vocabulary Levels Test; Laufer & Nation, 1999), syntactic encoding accuracy (Maze task; Suzuki & Sunada, 2018), and the accuracy of grammaticality judgement (timed grammaticality judgement test; Godfroid et al., 2015). Meanwhile, the factor score of PS was estimated with the measurements of lexical retrieval speed (picture naming task; De Jong et al., 2013), syntactic encoding speed (Maze task; Suzuki & Sunada, 2018), the speed of grammaticality judgement (timed grammaticality judgement test; Godfroid et al., 2015), and articulatory speed (controlled speech production; Weinberger, 2011). For details of score estimation procedures, see Suzuki and Kormos (2023).
L2 utterance fluency measures
Following prior research into L2 UF, the current study targeted three major aspects of UF—speed fluency, breakdown fluency, and repair fluency (Tavakoli & Skehan, 2005). As for speed fluency, there is one measure that solely taps into the construct of speed fluency, that is, articulation rate, or its inversed measure, mean duration of syllables (Tavakoli et al., 2020). Regarding breakdown fluency, previous studies have used a fine-grained set of pause-related measures in response to the multidimensional nature of pausing behaviour, that is, type (silent vs. filled pauses) and location (mid- vs. end-clause pauses) (De Jong, 2016; Suzuki & Kormos, 2020). As regards repair fluency, previous studies have shown that distinct cognitive processing might underlie different disfluency phenomena, such as self-corrections (Kormos, 1999), self-repetitions (Dörnyei & Kormos, 1998), and false starts (Williams & Korko, 2019). For the sake of comparability with previous studies, we also included two common composite measures: speech rate and mean length of run. The selected UF measures, which were adopted from Suzuki and Kormos (2023, pp. 44–45), are listed below:
Speed fluency
1. Articulation rate (AR). The total number of syllables produced per second, divided by speech duration excluding pauses (i.e., phonation time).
Breakdown fluency
2. Mid-clause pause ratio (MCPR). The total number of silent pauses within clauses, divided by the total number of syllables produced.
3. End-clause pause ratio (ECPR). The total number of silent pauses between clauses, divided by the total number of syllables produced.
4. Filled pause ratio (FPR). The total number of filled pauses, divided by the total number of syllables produced.
5. Mid-clause pause duration (MCPD). Mean duration of pauses within clauses.
6. End-clause pause duration (ECPD). Mean duration of pauses between clauses.
Repair fluency
7. Self-correction ratio (SCR). The total number of self-corrections, divided by the total number of syllables produced.
8. False start ratio (FSR). The total number of false starts/reformulations, divided by the total number of syllables produced.
9. Self-repetition ratio (SRR). The total number of self-repetitions, divided by the total number of syllables produced.
Composite measures
10. Speech rate (SR). The total number of syllables produced per second, divided by total speech duration time, including pauses.
11. Mean length of run (MLR). The average number of syllables produced in utterances between pauses.
The speech data were transcribed and then annotated for the boundaries of clauses. The measures of breakdown and repair fluency were standardised by the number of syllables produced in pruned transcripts (i.e., excluding disfluency words) rather than by speech duration to reduce the possible collinearity with other UF measures (see Bosker et al., 2013; Suzuki & Révész, 2023). For the measure of speed fluency and the composite measures, the number of syllables produced in pruned transcripts was used in the calculation. To annotate temporal features, Praat speech analysis software was applied (Boersma & Weenink, 2012). Following prior research (e.g., Bosker et al., 2013), the threshold for silent pauses was defined as 250 ms (see also Suzuki et al., 2021). With the assistance of automated detection of silence, clause boundaries and locations of pauses (i.e., mid- vs. end-clause pauses) were manually annotated on the TextGrid files of the Praat. Subsequently, for accurate pause identification, the locations of automatically annotated silence intervals were manually modified by the researcher.
L1 utterance fluency measures
This study calculated the same set of L1 UF measures as the L2 measures listed in the previous section. Considering the syllable structure and phonological properties of the Japanese language, we employed a mora as the standardised unit for the calculation of L1 Japanese UF measures. Note that a mora is fundamentally shorter than English syllables because the basic structure of morae allows only one consonant at the position of onset of the syllable (Vance, 2008), which should be carefully considered when comparing UF measures between different languages.
Procedures
All the CF tasks were administered in one session except for the controlled speaking task for measuring articulatory speed. Approximately 1 week later, all participants performed a total of five spontaneous speaking tasks, including the current argumentative tasks and the controlled speaking task in L2 English. They then completed the L1 argumentative speaking task in another session. The order of the two L2 argumentative tasks was counterbalanced across participants. In both L1 and L2 argumentative tasks, 3 minutes were provided for pre-task planning. During the planning time, note-taking was not allowed for any of the tasks (for details, see Suzuki & Kormos, 2023).
Statistical analysis
As a preliminary analysis, descriptive statistics and correlational analyses were performed to examine the distributions of all the variables and the interrelationships among them (for all statistics, see Supplementary Appendix B; Suzuki & Kormos, 2024). The descriptive statistics and Shapiro–Wilk tests suggested that most of the UF measures were not normally distributed, whereas the density plots indicated that articulation rate can be regarded as being normally distributed. In the subsequent generalised linear mixed-effects models (GLMMs), the Gaussian distribution (i.e., normal distribution) was thus applied to the models of articulation rate, whereas the gamma distribution—one of the continuous probability distributions where a possible range of values is from zero to +∞ (Coupé, 2018)—was applied to the models of the other UF measures with the log link function.
Correlational analyses were also conducted between L1 UF measures and L2 counterparts in the two prompts. Considering the non-normal distributions of most of the UF measures, we employed Spearman’s rank-order correlation coefficients. The correlational pattern between L1 and L2 UF performance did not substantially differ between the two topics of the L2 argumentative tasks (see Supplementary Appendix B; Suzuki & Kormos, 2024). The subsequent GLMMs predicting L2 UF measures from the corresponding L1 UF measures, therefore, included both of the L2 argumentative tasks and handled the topics as the random-effects variable to control for the variability of the L1-L2 UF link across topics.
For GLMMs with the gamma distribution, non-positive values (basically zero values in the current dataset) may prevent the estimation of statistical models. The zero values were thus replaced with the −3 SD values of the theoretical distributions of the variables, estimated by maximum likelihood (ML) estimation. All GLMMs reported in the study were estimated through the glmer function in the lme4 package (Bates et al., 2015), using R statistical software 4.0.2 (R Core Team, 2020). The R code and anonymised dataset are available on OSF (Suzuki & Kormos, 2024).
To examine the overall associations between L1 and L2 UF measures (RQ1), GLMMs were constructed to predict L2 UF measures from their L1 counterparts with random intercepts of individual participants and topics of the L2 argumentative tasks. To investigate the moderator effects of L2 proficiency on the L1-L2 UF link (RQ2), two interaction terms by L1 UF and each of the CF factor scores (LR and PS) were added to the GLMMs constructed for RQ1. To control for the simple effects of the predictor variables (i.e., L1, LR, and PS) on L2 UF, the GLMMs for RQ2 included these predictors as well. From a statistical perspective, RQ2 addresses whether those two interaction terms (i.e., by L1 and LR factor score; and by L1 and PS factor score) are significant in a confirmatory manner. Accordingly, to avoid overly complex models with many predictor variables, the GLMMs for RQ2 did not include the two-way interaction between LR and PS and the random-slopes of the individual participants and topics for the target interaction effects (for details of model building procedures, see Supplementary Appendix B; Suzuki & Kormos, 2024). The planned models for RQ1 and RQ2 are as follows.
RQ1
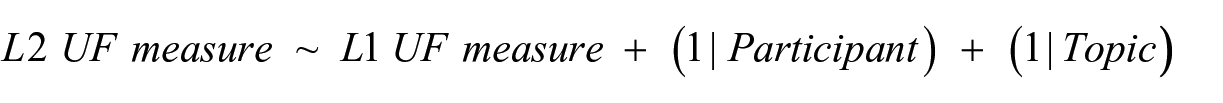
RQ2
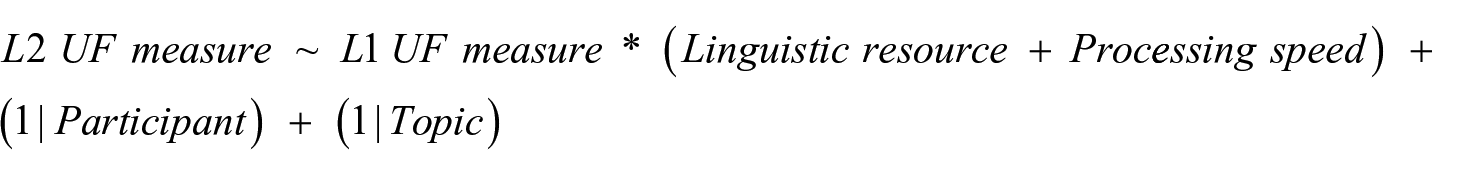
Results
Predictive power of L1 utterance fluency in L2 utterance fluency
To examine the predictive power of L1 UF performance in L2 counterparts (RQ1), a set of GLMMs was constructed. For all GLMMs, the outcome variable was L2 UF measures, and the fixed-effects predictor variable was the L1 counterparts, with the random intercepts of Participants and Topics of the L2 argumentative tasks. As summarised in Table 2, the GLMMs suggest that all L2 UF measures were significantly predicted from the corresponding L1 UF measures. However, the amount of variance of the L2 UF measures explained by the corresponding L1 UF measures varied considerably across the UF measures. The marginal R2 values refer to the variance explained by the fixed-effects variables (the corresponding L1 UF measures, here), whereas the conditional R2 values refer to the variance explained by both random- and fixed-effects predictors altogether. For instance, in the case of the GLMM of mean length of run, the variance explained by the corresponding L1 UF measures was 19.6%. According to Plonsky and Ghanbar’s (2018) guideline (R2 = .10–.18 as small; R2 = .18–.51 as medium; R2 = .51–.70 as strong), these variances explained by the fixed-effects predictor (marginal R2 = 5.2–24.7%) suggest the small-to-medium effect size of the overall predictive power of L1 UF in most L2 UF measures, while a medium-to-large amount of variance of L2 UF measures was explained by the random-effects predictors (R2 = 36.4%–66.2%; individual participants and topics, here). Closely looking at the marginal R2 values, the predictive power of L1 UF was negligible in articulation rate, self-correction ratio, and false start ratio (R2 = 5.2%–7.1%). Meanwhile, the relatively strong predictive power of L1 UF was indicated by mean length of run, filled pause ratio, and self-repetition ratio (i.e., small-to-moderate effect sizes; R2 = 17.1%–24.7%).
Summary of the effects of L1 utterance fluency measures on the corresponding L2 utterance fluency measures.
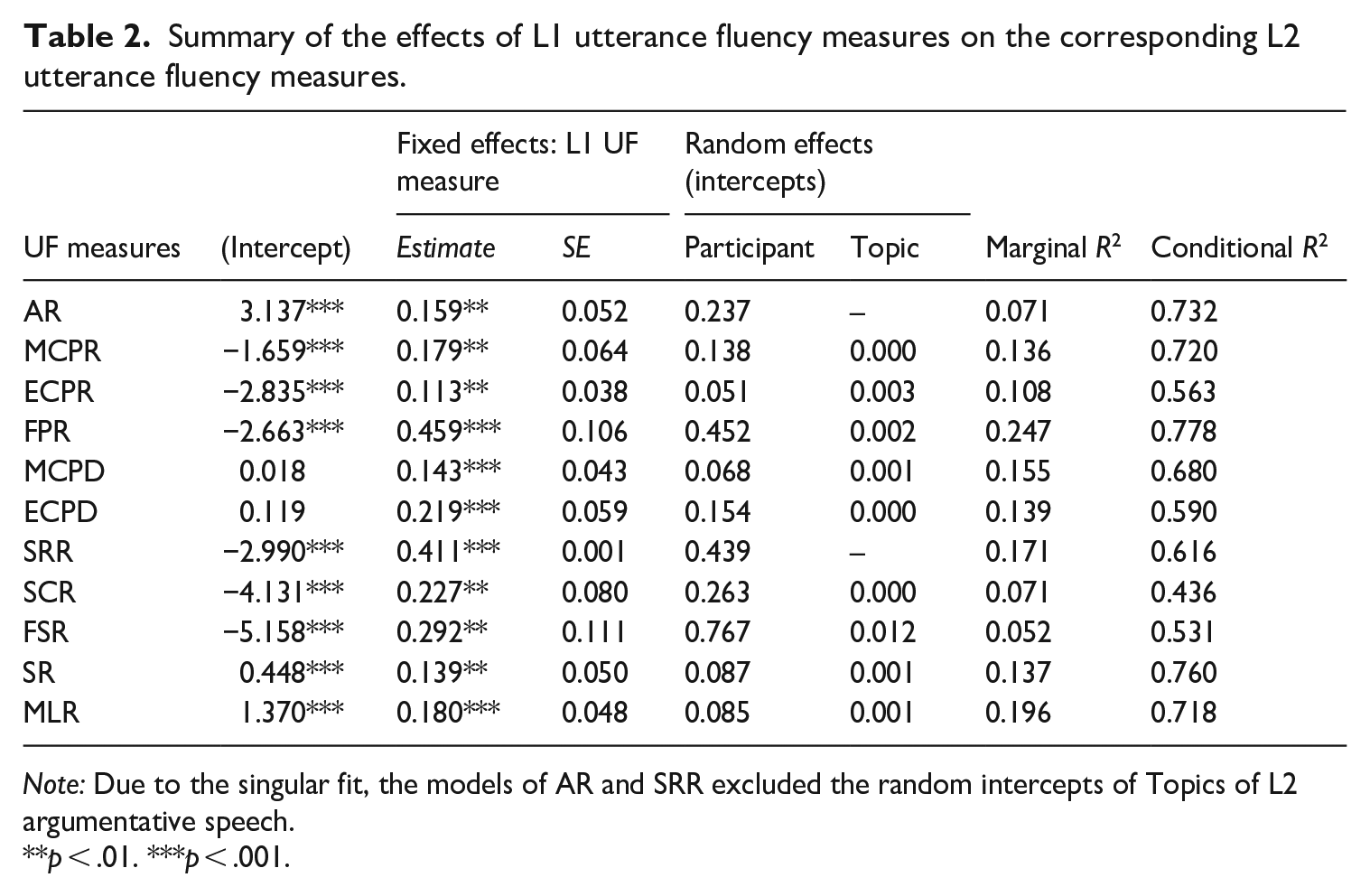
Note: Due to the singular fit, the models of AR and SRR excluded the random intercepts of Topics of L2 argumentative speech.
p < .01. ***p < .001.
Moderator effects of L2 proficiency on L1-L2 utterance fluency link
RQ2 addresses whether the predictive power of L1 UF for L2 UF is moderated by the speaker’s L2 proficiency. To operationalise L2 proficiency in the context of L2 fluency research, the factor scores of CF were estimated based on a series of CF measurements. Two interaction terms by L1 UF and each of the CF factor scores (LR and PS) were then added to the GLMMs constructed for RQ1. For all GLMMs for RQ2, the structure of random-effects variables was identical to the one constructed for RQ1. As summarised in Table 3, the significant moderator effects of L2 CF on the L1-L2 UF link were found only in speed fluency and composite measures—articulation rate, speech rate, and mean length of run (for full statistical estimates, see Supplementary Appendix B; Suzuki & Kormos, 2024). More specifically, the L1-L2 association in articulation rate was weakened by the score of LR and was also enhanced by the score of PS. In other words, for those who acquired a wider range of L2 LRs, L2 articulation rate tended to be relatively independent of L1 articulation rate (see Figure 2). In contrast, the L1-L2 association in articulation rate, speech rate, and mean length of run was stronger for those who have faster L2 processing skills (see Figures 3–5). This consistent pattern in speed fluency measures suggests that the more efficiently learners can process L2 knowledge, the closer to L1 their L2 speed fluency is.
Summary of the interaction effects by L1 utterance fluency measures and linguistic resource and processing speed on the corresponding L2 utterance fluency measures.
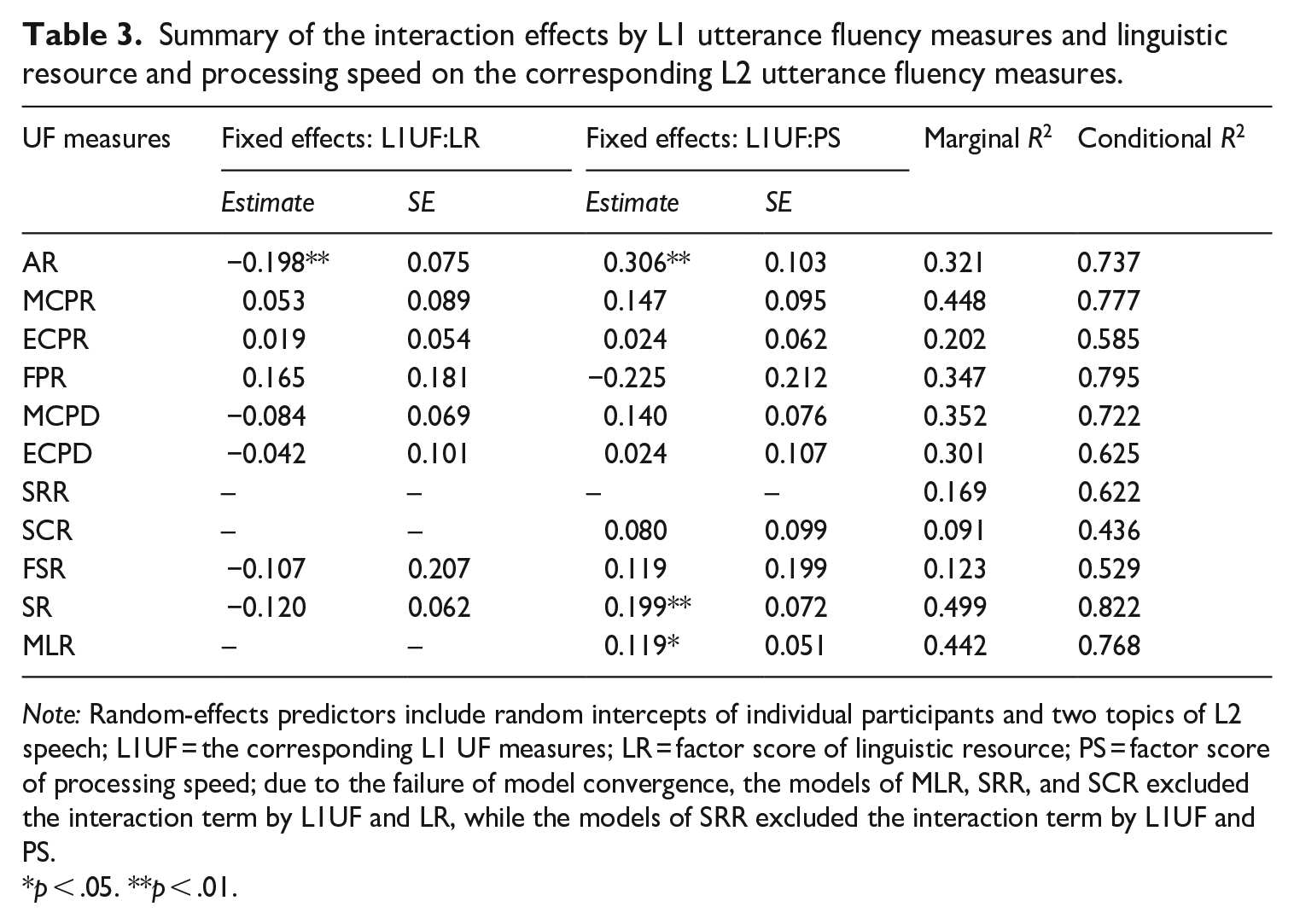
Note: Random-effects predictors include random intercepts of individual participants and two topics of L2 speech; L1UF = the corresponding L1 UF measures; LR = factor score of linguistic resource; PS = factor score of processing speed; due to the failure of model convergence, the models of MLR, SRR, and SCR excluded the interaction term by L1UF and LR, while the models of SRR excluded the interaction term by L1UF and PS.
p < .05. **p < .01.
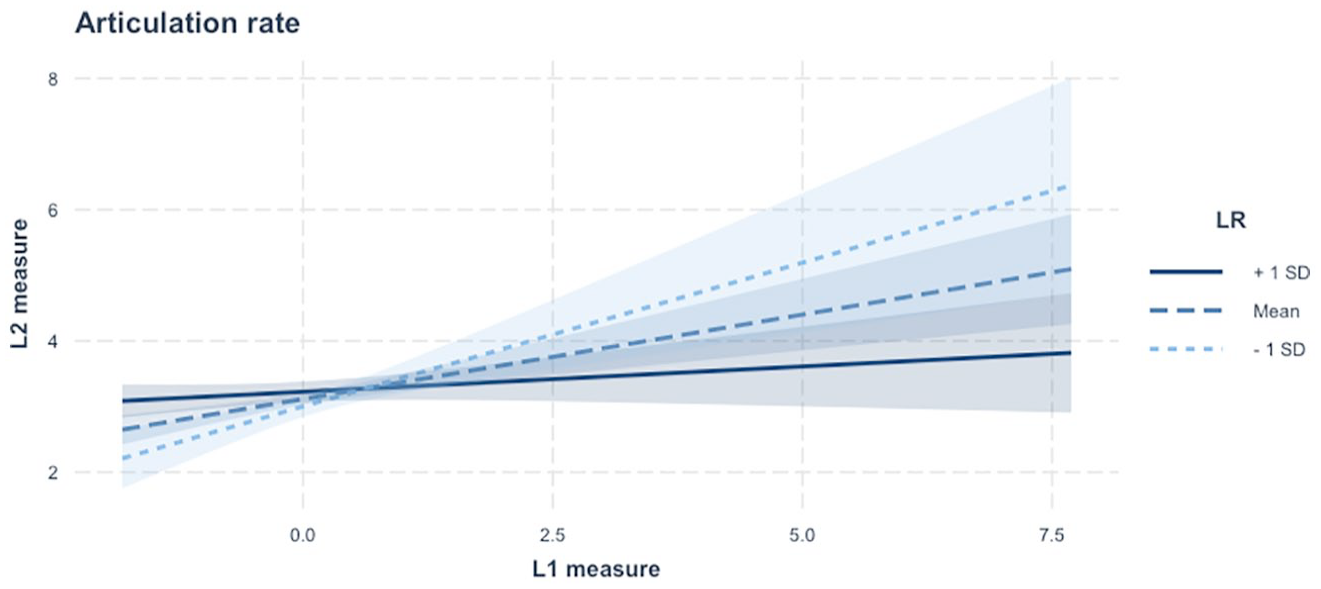
Interaction plot of the relationship between L1 and L2 articulation rate measures, separated by L2 linguistic resource scores.
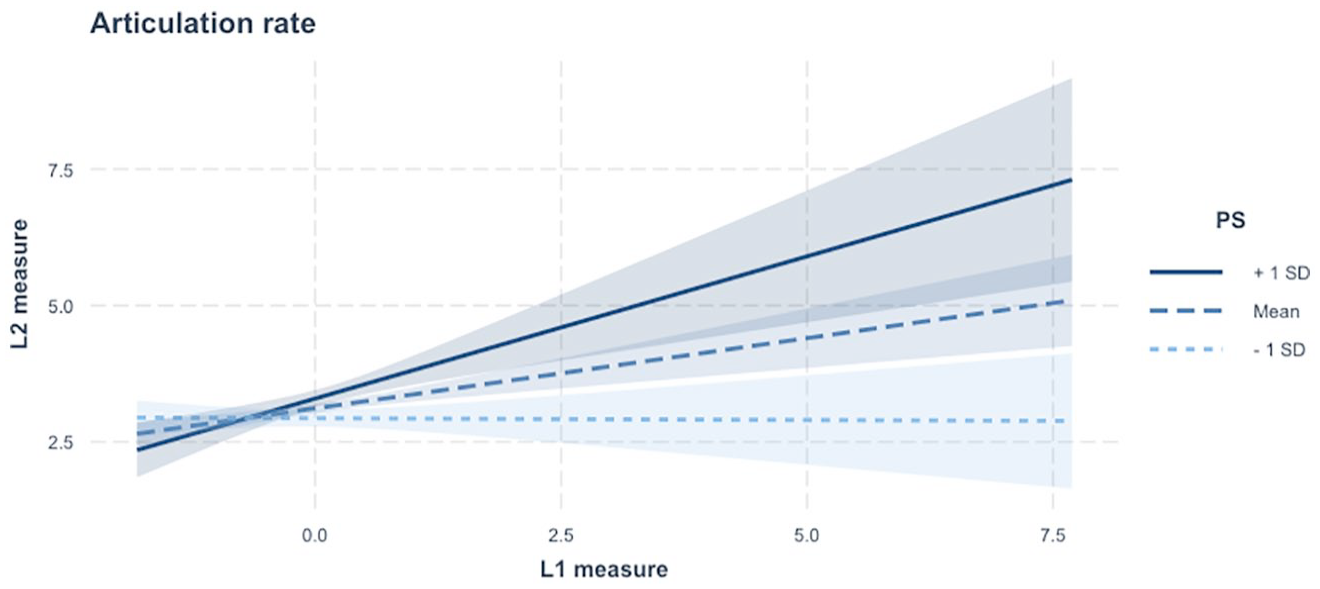
Interaction plot of the relationship between L1 and L2 articulation rate measures, separated by L2 processing speed scores.
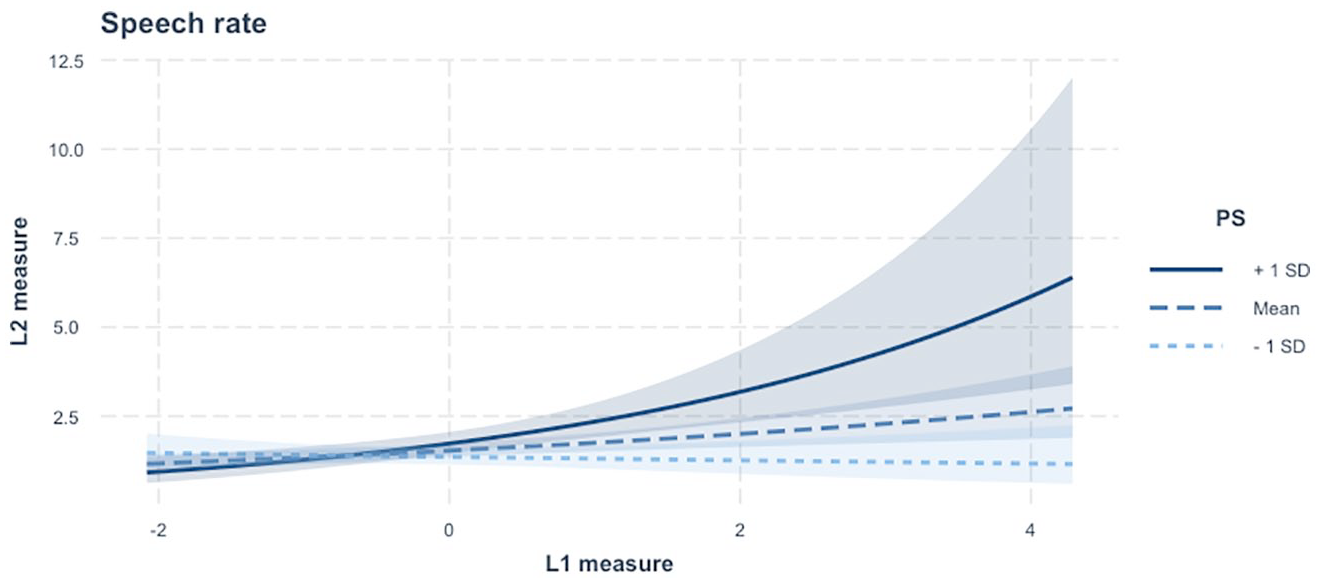
Interaction plot of the relationship between L1 and L2 speech rate measures, separated by L2 processing speed scores.
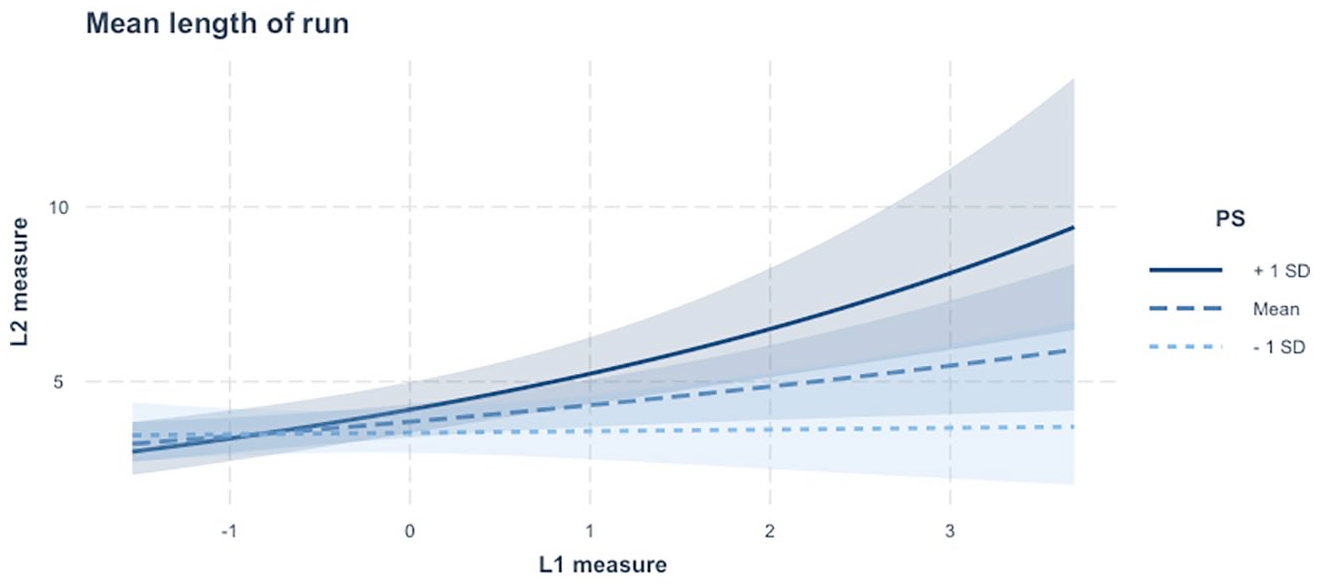
Interaction plot of the relationship between L1 and L2 mean length of run measures, separated by L2 processing speed scores.
Discussion
Motivated by the lack of studies on the L1-L2 UF link in the pair of mora-timed and stress-timed languages as well as those using open-ended speaking tasks, the current study investigated the extent to which L2 UF measures can be predicted from the corresponding L1 measures (RQ1), using L1 and L2 argumentative speech data produced by Japanese-speaking learners of English. Using the factor scores of CF as the measures of L2 proficiency, the study also examined whether L2 CF significantly moderate the predictive power of L1 UF measures in L2 UF measures (RQ2).
Predicting L2 utterance fluency from L1 utterance fluency
Our analysis detected significant associations between L1 and L2 UF for all of the investigated UF variables. In addition, the results showed small-to-medium effect sizes for the overall predictive power of L1 UF measures in their L2 counterparts while negligible effect sizes were found in several measures (marginal R2 = .052–.247). The effect sizes found in our study were lower than those in previous studies, which reported moderate-to-strong effect sizes of correlation coefficients especially in speed and breakdown fluency (e.g., De Jong et al., 2015; Huensch & Tracy-Ventura, 2017; Peltonen, 2018). The coefficients of determination based on the correlation coefficients also suggested a similar range of explained variance of L2 UF measures (R2 = .013–.228 for the topic of Library; R2 = .059–.251 for the topic of the Tokyo Olympics). Accordingly, the relatively smaller effect sizes in the current study may not have been caused by differences in the statistical analyses (e.g., gamma distributions, mixed-effects modelling). Therefore, we can hypothesise that the L1-L2 fluency link is relatively weak in our research context. As we discussed earlier, the L1-L2 UF link has mostly been examined with L2 learners of English (stress-timed language) whose L1 was a syllable- or stress-timed language. In terms of syllable complexity and information density, the phonological difference between Japanese and English might be larger than that between English and other stress- and syllable-timed languages particularly in terms of syllable complexity and information density (cf. Pellegrino et al., 2011). It can thus be assumed that due to such cross-linguistic divergences between English and Japanese, the participants in the study may have been relatively unlikely to transfer temporal aspects of L1 Japanese to L2 English speech. Furthermore, it is worth noting that in the current GLMMs, the random-effect predictors (participants, topics) explained a medium-to-large amount of variance of L2 UF measures, meaning that there might be other meaningful predictor variables related to individual differences and speaking task design features.
Small-to-medium effect sizes of the L1-L2 UF association were found for mean length of run, filled pause ratio, and self-repetition ratio. As regards mean length of run, each run is segmented by pauses. Previous studies have shown that L1 speakers produce pauses at clause boundaries more frequently than in the middle of utterances (De Jong, 2016), which suggests that breakdowns in L1 speech production are mainly caused by content-related processing that end-clause pauses are supposed to reflect. Therefore, especially for those who have attained highly automatised linguistic knowledge (e.g., L1 speakers and advanced L2 learners), the length of run might be reflective of the unit of conceptual planning (Kormos, 2006; Levelt, 1989). Considering the language-general nature of conceptualisation processes, the L1-L2 link in mean length of run may indicate the extent to which the speakers’ capacity and efficiency in content planning are shared across L1 and L2 speech.
Previous studies have commonly reported moderate-to-strong effect sizes of the L1-L2 UF link in filled pause frequency (De Jong et al., 2015; Duran-Karaoz & Tavakoli, 2020; Peltonen, 2018) and self-repetition frequency (De Jong et al., 2015; Huensch & Tracy-Ventura, 2017). The current results also confirmed the small-to-medium effect sizes for these measures, despite the cross-linguistically divergent pair of L1 and L2 (i.e., Japanese-speaking learners of English). It may thus be argued that these disfluency features are reflective of individual speaking style in a relatively robust manner. This argument may also be supported by the relatively large amount of variance explained by the random-intercepts of individual participants (see Table 2). In addition, filled pauses can be associated with the demands on content planning (Fraundorf & Watson, 2014). Provided that the L1-L2 UF link can reflect speakers’ language-general processing or idiosyncratic factors, the current finding may strengthen the evidence that speakers tend to elaborate speech content similarly in L1 and L2 speech production.
The current study also found a small effect size of the L1-L2 link in the measures of silent pause frequency and duration, regardless of pause location. Our findings were surprising because conceptualisation-related processes, which end-clause pauses are supposed to reflect (De Jong, 2016), are theoretically assumed to be shared across L1 and L2 speech production. Therefore, one would have anticipated that end-clause pause measures would show a strong relationship in L1 and L2 production. The relatively small effect sizes of end-clause pause measures in the current study might be explained by participants’ proficiency range, including variability in the effective use of planning before starting to speak (i.e., scope of planning; Gilbert et al., 2020). As pauses at clausal boundaries can be regarded as the starting point of planning for the subsequent unit of ideas (cf. Foster et al., 2000), end-clause pauses may be reflective of the scope of planning. A variety of individual difference factors associated with L2 proficiency (e.g., self-perceived proficiency, cumulative exposure to L2) were found to affect how far ahead L2 learners plan their utterances before speaking (see Gilbert et al., 2020). Some students may have prepared not only for content planning but also for some linguistic planning (e.g., vocabulary and pronunciation) at clausal boundaries. Consequently, such individual variability in L2-specific speech planning at clausal boundaries might have reduced the covariance of end-clause pause measures between L1 and L2 speech in the current study.
In contrast, the L1-L2 link in mid-clause pauses was expected to have a small or even negligible effect size because of their association with language-specific linguistic processing (for a similar argument, see Peltonen, 2018). However, the current results showed that mid-clause pause frequency and duration in L1 speech were weakly but significantly associated with their counterparts in L2 speech. This is possibly due to the relatively difficult and abstract topics of the argumentative tasks for both L1 and L2 speech production. Even in the L1 argumentative task, infrequent and sophisticated vocabulary items may have been needed to complete the task. It can thus be assumed that such high demands on lexical retrieval in L1 speech might have contributed to the similarity between L1 and L2 speech production, that is, the covariance between L1 and L2 mid-clause pause measures.
Furthermore, the current results revealed that there were no meaningful L1-L2 UF associations in articulation rate, self-correction ratio, and false start ratio. Regarding articulation rate, previous studies commonly reported moderate-to-strong effect sizes of correlation coefficients between the measures in L1 and L2 speech (De Jong et al., 2015; De Jong & Mora, 2019; Huensch & Tracy-Ventura, 2017) as well as their cross-linguistic robustness (Bradlow et al., 2017). However, the current study found negligible predictive power of L1 articulation rate for its L2 counterpart. One possible reason for this may lie in the cross-linguistic difference between the mora-timed L1 (Japanese) and stress-timed target L2 (English) of the participants. The maintenance of isochronous rhythm in Japanese is achieved by every single mora rather than stressed syllables, as opposed to the stress-timed feature of English. The cross-linguistic differences in rhythmic aspects are thus relatively divergent between Japanese and English (e.g., vowel reduction ratio, varying syllable length; cf. (Pellegrino et al., 2011; Vance, 2008), compared with the pair of syllable-based languages in previous studies. It can thus be assumed that Japanese-speaking learners of English may have a limited range of rhythmic features that can be transferred from L1 Japanese to L2 English speech.
Although the L1-L2 UF link in false starts has rarely been examined, previous studies have reported a significant predictive power of L1 self-correction behaviour on its L2 counterpart (De Jong et al., 2015; Huensch & Tracy-Ventura, 2017). Albeit speculative, one possible explanation for the inconsistent results between previous studies and the current study may lie in the cross-linguistic and/or cross-cultural differences in the norms for self-repairs in spontaneous speech (see Tavakoli & Wright, 2020). The descriptive statistics of self-correction ratio and false start ratio indicated that the participants in the current study produced a limited number of self-corrections and false starts, compared with previous studies (see De Jong et al., 2015; Huensch & Tracy-Ventura, 2017). It can thus be hypothesised that L1 Japanese speakers may aim to avoid self-repair in monologues regardless of the language for production (for the descriptive statistics of the current data, see Supplementary Appendix B; Suzuki & Kormos, 2024). However, only a few studies have investigated the cross-linguistic and cross-cultural differences in the norm of temporal features in speech (e.g., Tian et al., 2017, for filled pauses). Therefore, future studies are needed to examine the cross-linguistic and cross-cultural influences on the L1-L2 UF link, especially in repair fluency features.
The moderating role of L2 cognitive fluency in L1-L2 fluency link
In addition to cross-linguistic effects, L2 proficiency has been regarded as another important characteristic that can influence the relationship between L1 and L2 UF. Given the high predictive power to UF performance (De Jong et al., 2013; Kahng, 2020; Suzuki & Kormos, 2023), the current study adopted two factor scores of CF—LR and PS—as a proxy for L2 proficiency. A set of GLMMs predicting L2 UF from the L1 counterparts, these two CF scores, and their interactions with L1 UF measures suggested that the L1-L2 UF link was moderated by the CF scores only in articulation rate, speech rate, and mean length of run. More specifically, the L1-L2 link in articulation rate was weaker as the score of LR increased. In other words, for those who acquired a wider range of L2 knowledge, L2 articulation rate tended to be relatively independent of L1 articulation rate. Note that despite the marginally significant level, the score of LR positively contributed to articulation rate (β = .122, p = .099; see Supplementary Appendix B; Suzuki & Kormos, 2024). The GLMM of articulation rate indicates that the wider L2 resources the speaker has, the more fluent their L2 speech tends to be. Accordingly, as a function of L2 resources, students’ L2 articulation rate was enhanced and also was simultaneously dissociated from L1 articulation rate. This finding may be explained by the interplay between the nature of the articulation rate measure and L2 proficiency. First of all, articulation rate is assumed to capture the overall efficiency of speech production (cf. Kormos, 2006; Segalowitz, 2010). The dissociative pattern of the L1-L2 UF link in articulation rate as a function of linguistic resourcess indicates that among learners with limited L2 knowledge, relatively larger variance of L2 articulation rate is explained by its L1 counterpart. In other words, language-general processes and/or idiosyncratic factors may contribute to the overall efficiency of L2 speech production to a larger extent for learners with limited L2 resources than for those with extensive L2 resources. It could thus be hypothesised that the increase in L2 linguistic resources may not only speed up the overall speech production process but may also modify the underlying speech processing mechanisms. Due to the holistic nature of articulation rate, one can only speculate what speech production components contribute to these potential modifications in speech processing. However, such potential changes in speech processing may include the changes in the structure of the mental lexicon (e.g., Revised hierarchical model; Pavlenko, 2009) and even the specifications of preverbal message (cf. thinking for speaking; Slobin, 1996).
In contrast, the L1-L2 link in articulation rate, speech rate, and mean length of run was enhanced as a function of L2 PS scores. Note that both speech rate and mean length of run tap into the aspects of speed fluency to a large extent. This consistent pattern in these measures thus suggests that the more efficiently learners can process L2 knowledge, the closer their L2 speed fluency is to that of their L1. This finding is in line with Huensch and Tracy-Ventura’s (2017) and Peltonen’s (2018) results. In the current study, students’ speech was more fluent in L1 than in L2 (for the results of statistical testing, see Supplementary Appendix B; Suzuki & Kormos, 2024). The results suggest that efficient L2 processing skills may help learners to reduce the gap between their L1 and L2 fluency. Note that the direction of moderator effects of L2 proficiency scores on the L1-L2 UF link was opposite between the scores of LR and PS. These opposite patterns of the moderating role of L2 proficiency may expand the understanding of the interplay between cross-linguistic differences and L2 proficiency in the L1-L2 UF link (Derwing et al., 2009; Huensch & Tracy-Ventura, 2017).
In contrast to the measures related to speed fluency, the GLMM did not show significant moderator effects of L2 CF on the L1-L2 UF link in any of the breakdown and repair fluency measures. Hence, the current results indicate that L2 breakdown and repair fluency measures are associated with their L1 counterparts, and those associations tend to be independent of L2 speech-specific competence (cf. Gao & Sun, 2024). This finding regarding the L1-L2 UF link may support the use of L1-corrected L2 UF measures of breakdown and repair fluency for a more valid assessment of L2 oral proficiency (De Jong et al., 2015). However, it is worth emphasising that different weights of correction might be needed for speed fluency measures and composite measures across proficiency levels, as suggested by the interaction effects by L1 UF measures and L2 proficiency scores (for a detailed discussion, see De Jong, 2018).
Conclusion
Motivated by the scarcity of studies on the L1-L2 UF link in the pair of mora-timed and stress-timed languages as well as the predominant use of closed speaking tasks, the current study examined the association between L1 and L2 UF performance, using L1 and L2 argumentative speech data elicited from Japanese-speaking learners of English. The study also aimed to shed light on the moderating role of L2 proficiency in the L1-L2 UF link. The GLMMs revealed that all L2 UF measures were predicted by their L1 counterparts, generally with small-to-medium effect sizes in terms of the variance explained (Marginal R2 = 5.2%–24.7%). These effect sizes were relatively small compared with previous studies, suggesting that the L1-L2 UF link tends to be weak in learners with cross-linguistically divergent L1 and L2 backgrounds in terms of phonological features (i.e., Japanese-speaking learners of English). The revised GLMMs with the interaction terms between L1 UF and two factor scores of CF—linguistic resource and processing speed—showed that L2 proficiency only moderated the L1-L2 UF association in the dimension of speed fluency. Specifically, the strength of the L1-L2 UF association in articulation rate was dissociated with an increase in L2 linguistic resources. This finding confirmed that in the case of learners with a phonologically divergent pair of L1 and L2, the cross-linguistic influence of L1 speech production mechanisms on L2 speech production may decrease as a function of L2 proficiency (Derwing et al., 2009). In contrast, the L1-L2 association in articulation rate, speech rate, and mean length of run was enhanced as a function of L2 processing speed. The results indicated that increase in L2 processing speed (i.e., automatisation of L2 knowledge) can allow L2 users to speak in L2 with a similar level of fluency as they do in their L1. These opposite directions of the effect of L2 CF in the L1-L2 UF link in speed fluency suggest that particularly in the case of learners with a phonologically divergent L1–L2 pair, the relationship between the L1-L2 UF link and L2 proficiency can vary depending on how the construct of L2 proficiency is operationalised.
Although the current study aimed to provide a better understanding of the construct of fluency, which is a key component of high-stakes L2 speaking assessment, the results also have implications for diagnostic and formative assessment of speaking skills. In most assessment contexts, the contributions of L1 speaking style to L2 fluency can be regarded as construct irrelevant variance (De Jong, 2018). To achieve the effective diagnosis of learners’ challenges regarding L2 fluency, for instance, classroom teachers may consider students’ L1 oral performance as another resource for individualised feedback. To offer more practical suggestions for the summative assessment of L2 speaking performance, follow-up studies could collect listener-based judgements of fluency (i.e., perceived fluency; Segalowitz, 2010) and examine the extent to which and how raters detect and might be influenced by temporal features that are primarily related to L1 fluency. If such rater biases are observed, sensitivity to features of L1 fluency can be included in rater training.
Several methodological limitations of the current study need to be acknowledged. Although the current study statistically controlled for the effects of the topic of L2 argumentative tasks on the prediction of L2 UF measures from the L1 counterparts, the results are limited to one single task type, an argumentative task. Similarly, the topic of the argumentative tasks was not counterbalanced between L1 and L2 speech. Accordingly, the differences in UF performance between L1 and L2, at least to some extent, might have been subsumed under the topic effects. In addition, following previous studies (De Jong et al., 2015; Duran-Karaoz & Tavakoli, 2020; Peltonen, 2018) and L2 speech production models (de Bot, 1992; Kormos, 2006; Segalowitz, 2010), the current study assumed that the covariance between L1 and L2 UF measures reflects language-general processes and idiosyncratic factors shared across L1 and L2 speech production. For a better understanding of the L1-L2 UF link, however, this assumption should also be further validated to clarify what underlies the covariance between L1 and L2 UF measures, by correlating it with language-general individual difference factors, such as working memory capacity and personality-related variables (e.g., Gagné et al., 2022).
Footnotes
Acknowledgements
This study is based on part of the first author’s PhD thesis at Lancaster University, supervised by the second author. Both authors are grateful to Language Testing reviewers, as well as the journal editor, Talia Isaacs, for their constructive feedback on an earlier version of the manuscript.
Author contributions
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by Grant-in-Aid for Early-Career Scientists from Japan Society for the Promotion of Science (22K13181) to the first author.