
Abstract
The purpose of this paper is to (a) establish whether meaning recall and meaning recognition item formats test psychometrically distinct constructs of vocabulary knowledge which measure separate skills, and, if so, (b) determine whether each construct possesses unique properties predictive of L2 reading proficiency. Factor analyses and hierarchical regression were conducted on results derived from the two vocabulary item formats in order to test this hypothesis. The results indicated that although the two-factor model had better fit and meaning recall and meaning recognition can be considered distinct psychometrically, discriminant validity between the two factors is questionable. In hierarchical regression models, meaning recognition knowledge did not make a statistically significant contribution to explaining reading proficiency over meaning recall knowledge. However, when the roles were reversed, meaning recall did make a significant contribution to the model beyond the variance explained by meaning recognition alone. The results suggest that meaning recognition does not tap into unique aspects of vocabulary knowledge and provide empirical support for meaning recall as a superior predictor of reading proficiency for research purposes.
A continuing debate in L2 vocabulary research relates to which modality of vocabulary knowledge displays the strongest correlation with reading proficiency, with some researchers favoring tests of meaning recall knowledge (McLean et al., 2020), and others arguing that meaning recognition tests are the superior predictor (Laufer & Aviad-Levitzky, 2017). While a recent meta-analysis indicated that, on average, meaning recall measures have superior predictive power to meaning recognition (S. Zhang & Zhang, 2020), other researchers argued that these modalities should be treated as multiple imperfect measures that could be used in unison as manifest variables under a latent variable approach (Cromheecke & Brysbaert, 2022). There is a theoretical basis for this latter approach in vocabulary research. For instance, Laufer and Aviad-Levitzky (2017) argued that by presenting answer options, meaning recognition items trigger recall of meaning in a manner that could be of relevance to reading. Even if meaning recognition correlates to reading are lower, the format could still tap unique aspects of reading proficiency that could aid in predictive power.
The goal of this study is to (a) study meaning recall and recognition modalities under a latent variable approach using confirmatory factor analyses in order to determine whether the two modalities can be considered psychometrically distinct measures of different forms of vocabulary knowledge and (b) determine whether one modality has unique predictive power of reading ability over the other using hierarchical regression.
Literature review
The past two decades have witnessed a surge of research related to L2 vocabulary learning. An analysis of vocabulary-related research articles published between 1916 and 2010 illustrated a considerable increase since a low-water mark in the 1970s (Meara, 2014). In a study of second language acquisition (SLA) research articles published in 16 prominent international applied linguistics journals between 1997 and 2018, X. Zhang (2020) observed a marked increase in citations of vocabulary research for the 2008–2018 period. Many of these studies target vocabulary either as a type of knowledge in its own right or its relation to other language skills. In terms of the latter, one topic that has been increasingly investigated is the relationship between vocabulary knowledge and reading proficiency.
Claiming that vocabulary plays a key role in reading ability is uncontroversial, and seminal work on reading puts the knowledge of words center stage. Grabe (2009) postulated that word retrieval cognition is widely accepted in the research community as one of the most important processes contributing to reading comprehension. He also highlighted how average native speaker readers are extremely apt at word recognition, capable of orthographic identification in well under 100 milliseconds. Similarly, Alderson (2000) stressed the importance of vocabulary knowledge, pointing to its routinely reported high correlations with measures of reading skills, emphasizing that it is the single best predictor of text comprehension.
Researchers have repeatedly observed strong correlations between an individual’s vocabulary knowledge and their reading abilities, both in L1 and L2 (for L1: Carver, 2000, 2003; Stanovich, 1986; Thorndike, 1973; and for L2: Laufer & Ravenhorst-Kalovski, 2010; M. Li & Kirby, 2015; Nguyen & Nation, 2011; Verhoeven, 2000; though see Schmitt et al., 2011, for slightly weaker relationships). Interestingly, Stanovich (2000) argued for a reciprocal causal relation between reading and word knowledge, in that better word knowledge leads to better reading proficiency, and conversely that reading helps boost word knowledge. The close relation between the two is frequently cited as a justification for why it is important to be able to assess L2 learners’ vocabulary knowledge accurately (Gyllstad et al., 2015; Nation, 2006; Nation & Beglar, 2007).
However, as it is widely agreed that vocabulary knowledge is an inherently complex construct, for pedagogical and assessment purposes general terms like “vocabulary knowledge” are too vague for operationalization. The overall construct has to be defined more precisely. In this regard, it is common to depict vocabulary as encompassing what researchers more or less interchangeably refer to as dimensions, aspects, constructs, and/or components. Some of these conceptualizations address a more superordinate level, with a number of assumed dimensions. However, there is a good deal of variation and overlap between researchers’ construct definitions. For example, Meara (2005) argued for a division into size, organization, and accessibility, whereas Daller et al. (2007) suggested breadth, depth, and fluency. Read (2004) provided critical discussion on the depth construct, and Schmitt (2014) reported on the conceptual and empirical inter-relation between size and depth. Other researchers home in on a more detailed subordinate level, with Nation’s word knowledge framework (Nation, 2013) as the most prominent. Nation’s analytical framework postulated an initial division into form, meaning, and use, which in turn all have subcomponents, such as written form, spoken form, and word parts for the form component. Schmitt (2019) noted that although useful and influential, the framework has nothing to say about the order in which the different subcomponents are learned, and that this limits its pedagogical value.
A further level of vocabulary knowledge analysis, and one that is more germane to the present article, regards abilities related to the nature and ease with which a learner can access and draw on cognitive representations of word knowledge. In relation to L2 vocabulary knowledge, the “form-meaning link” has become established as its foundational aspect, with knowledge of L2 vocabulary’s L1 meaning most important for receptive skills and knowledge of vocabulary’s L2 form more important for productive skills. However, how these aspects of knowledge are demonstrated varies depending on test item format, to the point different measures of L2 form and meaning may alter which construct is being measured. In addition to form and meaning, a distinction can be made between recognition, in which a learner is subjected to a L2 word form and is expected to activate its meaning(s), and recall, in which the learner is subjected to some kind of stimulus through which the L2 word form is activated from memory (Read, 2000). These four concepts were combined by Laufer and Goldstein (2004) into active recall, active recognition, passive recall, and passive recognition. A modification of these terms can be seen in Schmitt’s (2010) suggested terminology, with form recognition, form recall, meaning recognition, and meaning recall. In this article, we will henceforth use Schmitt’s terminology. Empirically testing learners’ knowledge along these four types, Laufer and Goldstein found a hierarchy of difficulty from easiest to hardest among L2 learners as follows: meaning recognition < form recognition < meaning recall < form recall. Interestingly, González-Fernández and Schmitt (2019) observed that four tested knowledge components from Nation’s (2013) framework differed on the level of the distinction between recognition and recall, with all four components known on a recognition level first and on a recall level later. This led Schmitt (2019) to suggest that the key descriptor of vocabulary knowledge may not be the word knowledge components themselves, but instead recognition versus recall mastery of those components.
The distinction between recognition and recall may have important implications for word mastery. Although recognizing words as legal structures in a language is a prerequisite for subsequent understanding of the sentences and paragraphs of a read text, it does not in itself necessarily and automatically imply a high level of comprehension of said text. A high level of recognition allows for greater fluency when reading, but as argued by Perfetti (2007), it is the nature of the actual retrieval of mental lexical representations that provide the meanings that a reader needs in a given context. Thus, it is the quality of word knowledge, essentially form-meaning mappings, that ultimately determines the outcome. Perfetti refers to this as “lexical quality” (p. 359) and stated that this component has to be both precise and flexible to allow for a distinction between the meanings of homonyms and homophones, and for the ability to realize, for example, that a concept can be described in a dense short structure and paraphrased in a longer, more verbose paraphrase.
Many recent and influential vocabulary tests that have been used to investigate the relation between reading proficiency and specific types of word knowledge are receptive multiple-choice tests, for example, the Vocabulary Levels Test (VLT; Nation, 2013; Schmitt et al., 2001) and the Vocabulary Size Test (VST; Nation & Beglar, 2007). When these tests are administered, test takers are not required to produce any language, but, rather, to select L2 synonyms or translational equivalents from a list, which means that they tap into meaning recognition knowledge. This raises the question as to whether such tests are suitable representations of the reading process, which arguably is more akin to meaning recall knowledge, where learners must recall word meanings when encountering written words in a text (Gyllstad et al., 2015; Kremmel & Schmitt, 2016), and where no possible meaning definitions of words from which they can choose are provided. Thus, the kind of item format employed in tests like the VLT and VST do not directly target the relevant construct and on these grounds must therefore be questioned in terms of adequacy and validity.
This position, however, has been disputed by Laufer and Aviad-Levitzky (2017), who argued for the use of meaning recognition test formats to predict reading ability. Based on data from 116 university undergraduate students in Israel, the learners’ scores on a meaning recognition test and a meaning recall test yielded strong but very similar significant correlations to reading proficiency. Laufer and Aviad-Levitzky proposed that the meaning recognition construct was still a superior predictor of reading proficiency. Specifically, the conclusion was based on an analysis whereby the participants in the study were divided into three reading proficiency groups and associated with estimates of the size of their vocabularies based on Nation (2006). Readers with knowledge of fewer than 3000 words were labeled “Non-readers,” readers with knowledge of 3000–6000 words were called “Assisted readers,” and readers with knowledge of 6000–9000 words were considered “Independent readers.” The authors’ analysis considered which of the two vocabulary tests deviated less from the corpus predictions, concluding that the meaning recognition test underestimated fewer learners’ reading ability than did the meaning recall for the “Assisted Readers.” In Laufer and Aviad-Levitzky’s (2017) view, the findings therefore suggested that meaning recognition is the superior predictor of reading ability.
Other studies have arrived at different results than Laufer and Aviad-Levitzky (2017). Reporting on a meta-analysis carried out on a total of 59 studies appearing between 1979 and 2011, Jeon and Yamashita (2014) observed stronger correlations between L2 reading comprehension and meaning recall modalities, compared to meaning recognition modalities. However, the difference was not statistically significant, likely due to the small sample size for the meaning recall measure, n = 6. In another meta-analysis based on more than 100 studies, S. Zhang and Zhang (2020) found that the strongest correlation between L2 reading and vocabulary knowledge was for the meaning recall mode followed by form recall and meaning recognition. The authors concluded that the type of form–meaning knowledge that is the most critical for L2 reading comprehension is meaning recall.
Leaving the results reported in meta-analyses, Cheng and Matthews (2018) observed higher correlations between form recall measures and reading comprehension than those between meaning recognition and reading. An exploratory factor analysis (EFA) indicated that the two vocabulary measures loaded onto the same latent variable. However, the authors also conducted a hierarchical multiple regression analysis, which revealed that only the form recall measure contributed uniquely as a predictor of the reading scores of L1 Chinese learners of L2 English. This is in contrast to Laufer and Aviad-Levitzky (2017), who posited that partial knowledge and cued recall supplement written sight vocabulary to contribute to reading comprehension. Finally, McLean et al. (2020) demonstrated that although correlations to reading proficiency can differ between test forms due to random error, meaning recall had on average a higher correlation to reading proficiency than meaning recognition. However, although McLean et al. (2020) demonstrated that meaning recognition had a lower average correlation to reading proficiency, their study did not address the question of whether it remains a unique predictor of some skills related to reading proficiency, over and above what can be predicted by meaning recall.
Despite conflicting evidence, it remains possible that by measuring partial knowledge and cued recall in addition to sight vocabulary, meaning recognition could still explain unique variance when predicting reading proficiency relative to meaning recall. If so, this would imply that tests of the two constructs should be considered distinct predictors of vocabulary knowledge. Although the research reviewed above appears to establish that meaning recall has a stronger correlation to reading proficiency than meaning recognition, it is possible that the two measures represent unique skills capable of contributing to reading proficiency predictions in different ways. For example, it could be the case that although meaning recall is a more accurate measure of vocabulary knowledge, meaning recognition format tests measure important inferential skills or a distinct form of “cued recognition,” meaning that it could be advantageous to measure learners on both constructs concurrently. Laufer and Aviad-Levitzky (2017) argued that unlike meaning recall, meaning recognition “triggered meaning” (p. 738), thus potentially tapping a unique cognitive skill. Furthermore, in accordance with Perfetti and Hart’s (2002) lexical quality hypothesis (LQH), the higher scores observed for meaning recognition tests could be interpreted as a reflection of partial word knowledge, whereby orthographic knowledge of a word can be accrued without semantic knowledge. For instance, Perfetti and Hart presented the word incarcerate as an example and described a reader with limited experience who is capable of (a) recognizing the orthographic form, (b) pronouncing it with accuracy, and (c) understanding that the word has negative connotations, all without understanding what the word means nor being able to produce the word when required. In this example, said reader would perhaps correctly respond to incarcerate on a meaning recognition test, but not a meaning recall one. Were this the case, meaning recall and meaning recognition vocabulary knowledge could possibly be considered separate measures that uniquely contribute to predicting reading ability and could in fact be deployed in tandem as part of multicomponential models of reading ability. Rather than attempting to identify a single best test, the two modalities might better be treated as two imperfect vocabulary measures that are better utilized as manifest variables under a latent variable approach to vocabulary knowledge modeling (Cromheecke & Brysbaert, 2022).
Research questions
As a contribution to research into this topic, the present study’s aim is to report empirical psychometric support regarding the nature of the meaning recall and meaning recognition constructs by addressing the following three research questions (RQs):
1. Are meaning recall and meaning recognition distinct constructs of vocabulary knowledge?
2.1. Does meaning recognition make a contribution to the prediction of reading proficiency that is unique over and beyond the contribution of meaning recall?
2.2. Does meaning recall make a contribution to the prediction of reading proficiency that is unique over and beyond the contribution of meaning recognition?
An answer to RQ1 is of importance to the field because unless the two constructs are empirically distinct, the value of further discussion of their differences based on theory becomes questionable. This RQ will be answered by using confirmatory factor analyses and by confirmation of the resultant factors’ discriminant validity.
Answers to RQ2.1 and RQ2.2 are of value to the field because even if the two constructs can be shown to be psychometrically distinct, the properties that make these constructs unique to one another may not necessarily be related to reading proficiency. The question will be addressed by correlating test scores targeting the two constructs with a measure of reading proficiency. More specifically, hierarchical multiple regression analyses will be conducted to determine whether meaning recognition explains unique variance in reading proficiency that is not explained by meaning recall knowledge alone, and vice versa.
Method
Participants
The analysis was conducted with data from McLean et al. (2020), in which 103 Japanese university students took meaning recall and meaning recognition tests of the 2001–3000 most common words in the New General Service List (NGSL; Browne et al., 2013). The participants were aged between 18 and 32 and displayed a wide range of English proficiency, with a mean Test of English for International Communication (TOEIC) Listening and Reading Test score of 531.75 (SD = 194.42). Table 1 shows that the participants’ mean TOEIC Reading score, M = 226.50, SD = 101.87, was comparable to the mean score for test takers in Japan, M = 229, SD = 97 (Educational Testing Service [ETS], 2021), indicating that the sample was closely representative of the Japanese TOEIC test-taking population. Total scores ranged from 190 to 920, which, according to the publisher, corresponds to Common European Framework of Reference for Languages (CEFR) levels ranging from A1 to B2 (ETS Global, 2021). The correlation between TOEIC Reading and meaning recall score, r = .79 [.70, .85], and meaning recognition score, r = .72 [.61, .80], was large when interpreted according to Plonsky and Oswald’s (2014) thresholds.
Descriptive statistics for 103 participants’ TOEIC reading scores.
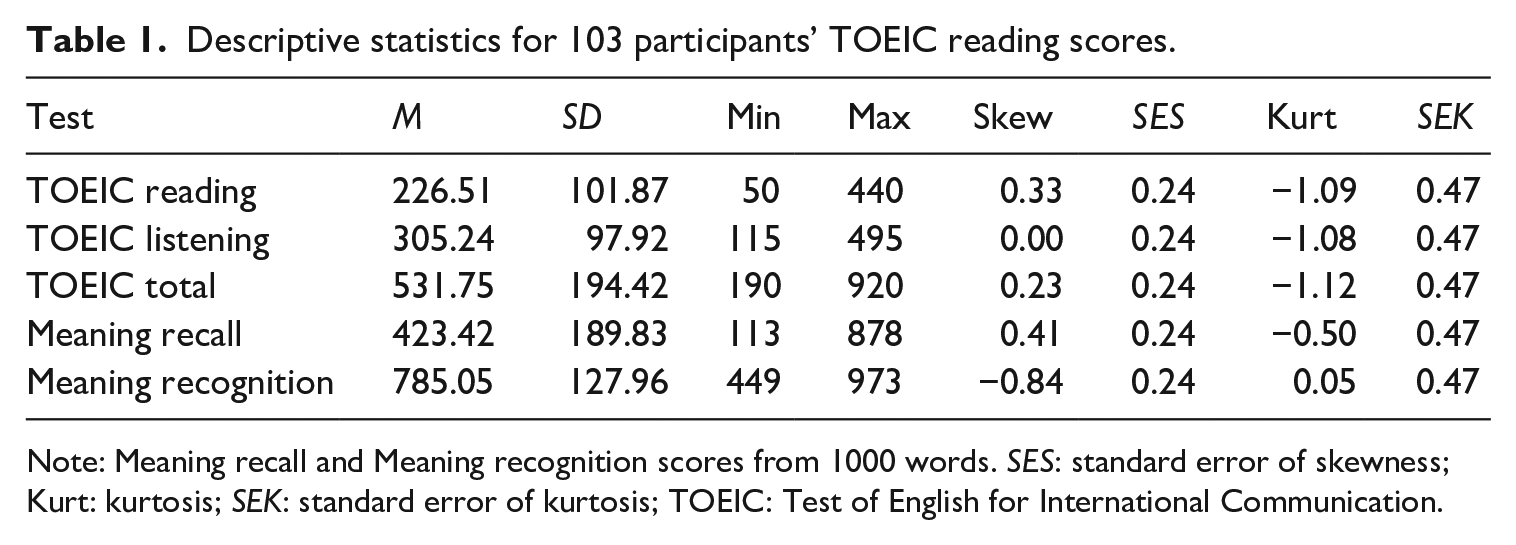
Note: Meaning recall and Meaning recognition scores from 1000 words. SES: standard error of skewness; Kurt: kurtosis; SEK: standard error of kurtosis; TOEIC: Test of English for International Communication.
Ninety-six participants (all female) were university undergraduates studying International and English Interdisciplinary Studies. Four participants (two males and two females) were Japanese third-year non-English majors who had studied or lived abroad. Three participants (two females and one male) were Japanese applied linguistics master’s students. All participants were paid volunteers, were informed of the nature of the research, and signed informed consent forms in accordance with the guidelines of the institutions at which the participants were students.
Instruments
Vocabulary tests
The participants completed two different vocabulary tests measuring their knowledge of the same 1000 words in two different modalities: meaning recall and meaning recognition. All tests were administered via the Survey Monkey web platform (https://www.surveymonkey.com) with no time limit. The words were selected from the 31,242-word NGSL corpus (Browne et al., 2013) and comprised the third 1000 most frequent flemmas in the corpus as sorted by the words’ Standard Frequency Indices (SFIs). A detailed description of the two item modalities and how they were marked is provided in Supplementary Materials A.
TOEIC reading section subtest
All participants completed the TOEIC following the most recent changes to TOEIC in Japan in April 2017. The TOEIC Reading section consists of 30 incomplete sentence questions, 16 text completion questions, and 54 reading comprehension questions, 29 of which are over a single passage and 25 of which require the test-taker to compare two or three related passages (ETS, 2019). Descriptive statistics for the participants’ TOEIC Reading scores are displayed in Table 1.
Procedures
Participants first completed the meaning recall before the meaning recognition test, and all 1000 words were tested under both item formats. In accordance with Laufer and Aviad-Levitzky’s (2017) experiment, the meaning recall test was given first to ensure that answer options from the meaning recognition test did not give away answers to the meaning recall test. Difficulty of the modalities is typically understood to build from meaning recognition, through meaning recall, and finally to form recall (Laufer & Goldstein, 2004). By moving down the theoretical hierarchy of difficulty, the danger of exposure to the words in earlier tests affecting the scores on later tests was mitigated (Laufer & Goldstein, 2004; Nation, 2013; Nation & Webb, 2011; Schmitt, 2010). Random shuffling of the item orders, in addition to the very large number of items (n = 1000), also contributed to making it difficult for one version of the test to inform a successive version. For a more detailed description of the process and item formats, please see Supplementary Materials A.
It should be noted that in most circumstances, learners rarely take 1000-item tests. An advantage of this methodological design was that the large number of items ensured that items could be subdivided into relatively large item parcels, ensuring continuous variables for factor analyses. Although commonly overlooked, an assumption of factor analysis is that variables are continuous (Y. Li, 2014). By ensuring continuous variables, we make a best effort to avoid Type II error and falsely conclude there is not a statistically significant difference between a two-factor model and a one-factor model (for more information on item parceling in factor analysis and assumption checks, please refer to Supplementary Materials B). If a difference between constructs cannot be proven even with such a large number of items, it is unlikely it could be proven based on analyses using shorter tests. In the event of a significant difference, exploration of the practical meaning of the difference for shorter test forms was planned via analyses of convergent and divergent validity, and finally hierarchical regression to determine whether each test has unique predictive power of reading proficiency. If this is the case, there may be benefits for educators and researchers to measure both skills. For more information on instruments, scoring, and data collection methods, please refer to Supplementary Materials A.
Analysis
Confirmatory factor analysis
Confirmatory factor analysis (CFA) was conducted to address RQ1, which related to the psychometric distinctiveness of meaning recall and recognition knowledge. Factor analysis is the collective name of a set of statistical processes for investigating the correlational structure intrinsic to a collection of variables (Loewen & Gonulal, 2015). CFA was conducted to investigate whether the two vocabulary knowledge constructs can be considered distinct. The aim of the analysis was to determine which model provided a better fit: a one-factor model with meaning recall and recognition loading onto a single factor (see Figure 1(a)), or a two-factor model with the two vocabulary knowledge types loading onto separate factors (see Figure 1(b)). CFA was preferred over EFA because the analysis was conducted with a clear idea of how many factors were expected and which factors each item parcel would load onto. To determine which model provided better fit, chi-square (χ2) goodness-of-fit tests, Tucker–Lewis index (TLI), root mean square error of approximation (RMSEA), Akaike information criterion (AIC), and Bayesian information criterion (BIC) were compared. All analyses were conducted with JASP (JASP Team, 2022), and the output files and Supplementary Materials are available on the Open Science Framework (OSF; Nicklin et al., 2023).
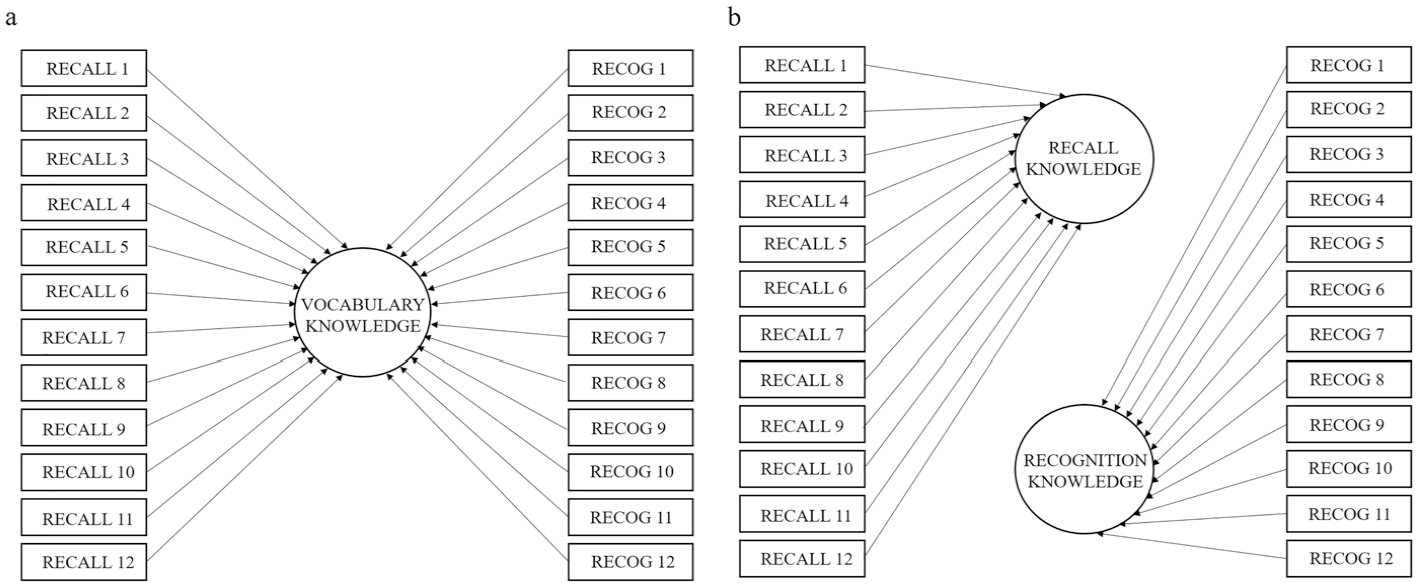
Plots of the (a) one-factor model and (b) two-factor model.
A concern regarding the use of factor analysis is attaining an adequate sample size. Although the literature abounds with recommendations for adequate sample sizes, estimates can differ greatly, and are often without empirical basis. According to Mundfrom et al. (2005), factor communality, the number of factors, and the ratio of variables per factor determine necessary minimum sample sizes, with more variables per factor lowering the necessary minimum rather than raising it. Their findings showed that for a simple two-factor model with 11–12 indicator variables per factor, a sample size as small as 60 could suffice for the worst-case scenario of a factor solution with low communality, and that this minimum would relax further for solutions with higher communality. It was therefore determined that the 103 learners comprising this sample would be sufficient for the current analysis, provided an adequate number of indicator variables were used for each of the two constructs.
For this reason, 12 indicator variables were constructed for each factor by creating 12 sets of 20-item parcels (or “mini-tests”) from the dataset of 1000 item responses per construct. The items were randomized prior to the parcel creation, and different word test scores were used for each construct. The sampling for the parcels was therefore done without replacement, so that no single item appeared twice in any of the analyses. This design ensured that any similarities found between the factors were due to more broadly generalizable similarities in the constructs, rather than construct-irrelevant variance (e.g., factors correlating very highly due to learners simply knowing identical sets of words tested twice using both item formats). The descriptive statistics for the parcels are reported in Table 2. The lack of 95% confidence interval (CI) overlap between the scores derived from the meaning recall and recognition versions of each parcel was in accordance with Laufer and Goldstein’s (2004) difficulty hierarchy, whereby meaning recall items were more challenging than recognition items regardless of the parcels’ item composition. Furthermore, the significant difference between the scores, also found by Laufer and Goldstein (2004), could be construed as initial evidence that the two item types measure psychometrically distinct constructs.
Descriptive statistics for the 12 parcels constructed to address RQ1.
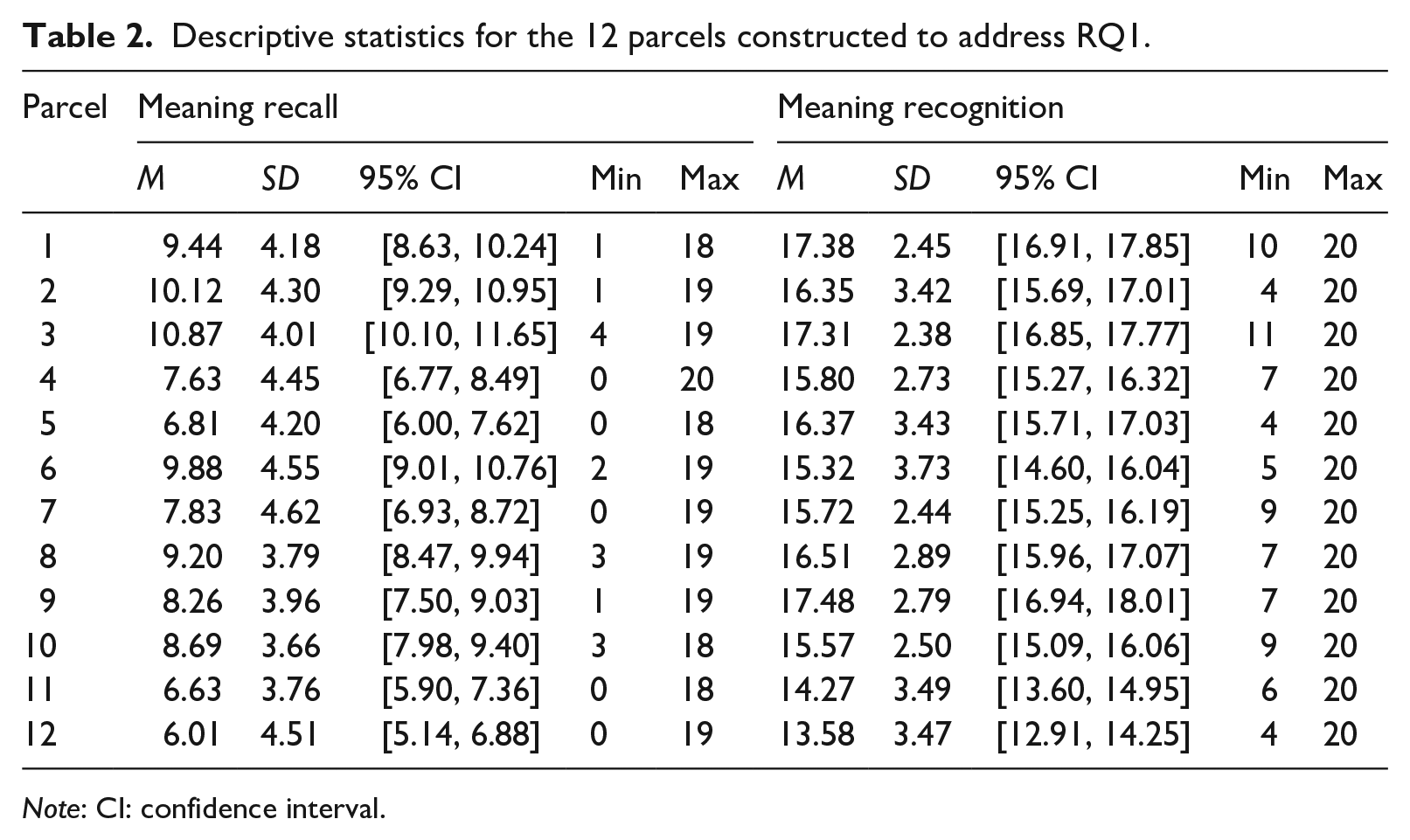
Note: CI: confidence interval.
Hierarchical regression
Hierarchical regression models were constructed to address RQ2.1 and RQ2.2, which asked whether the two vocabulary knowledge types under investigation contributed unique variance to reading proficiency. To answer RQ2.1, an initial model comprising all 103 participants’ TOEIC reading scores was regressed on the meaning recall scores, and then meaning recognition scores were added to the model and the increase in explained variance, R2, was observed. To address RQ2.2, TOEIC reading scores were first regressed on meaning recognition scores and then meaning recall scores were added to the model. The results from these models were assessed for evidence of the two vocabulary knowledge types behaving as distinct psychometric constructs. The regression model assumptions were met for both models, as reported in Supplementary Materials C. As with the CFAs, all regression analyses were conducted with JASP and the output files are available on the OSF. The regression models were conducted on 12 more sets of 20-item meaning recall and meaning recognition parcels, which were all constructed from the data that remained after the initial set of parcels were removed. This second batch of parcels was also subjected to CFA to ensure that the factor structure observed for the initial batch of parcels constructed for RQ1 was also true of this second batch. The descriptive statistics for this second batch of parcels are reported in Table 3.
Descriptive statistics for the 12 parcels constructed to address RQ2.1 and RQ2.2.
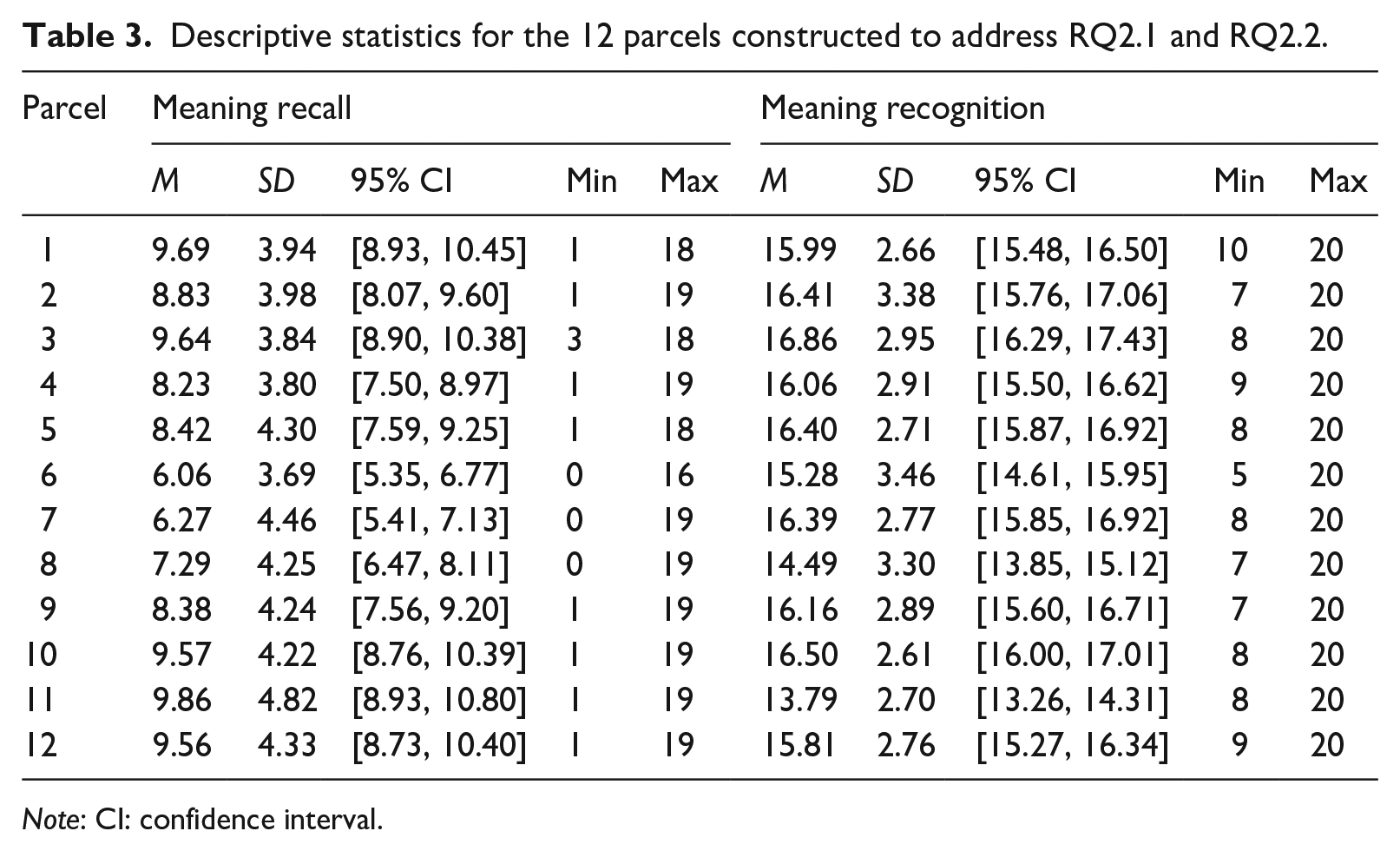
Note: CI: confidence interval.
Results
To address RQ1, which was posed to investigate whether meaning recall and meaning recognition are psychometrically distinct constructs of vocabulary knowledge that represent unique skills, CFAs were conducted for one- and two-factor solutions using a maximum likelihood estimator. The aim was to determine whether the variables would load onto two distinct factors without a priori specification, as was hypothesized. The chi-square goodness-of-fit tests for both the one-factor CFA model, χ2(252) = 701.80, p < .001, and the two-factor model, χ2(251) = 334.25, p < .001, suggested that the null hypothesis could be rejected. The two-factor CFA solution had demonstrably better fit than the one-factor model, as can be seen by the larger comparative fit index (CFI) and TLIs, and smaller RMSEA, AIC, and BIC values in Table 4.
Fit indices and information criteria for 1 and 2 factor CFAs attending to RQ1 and RQ2.
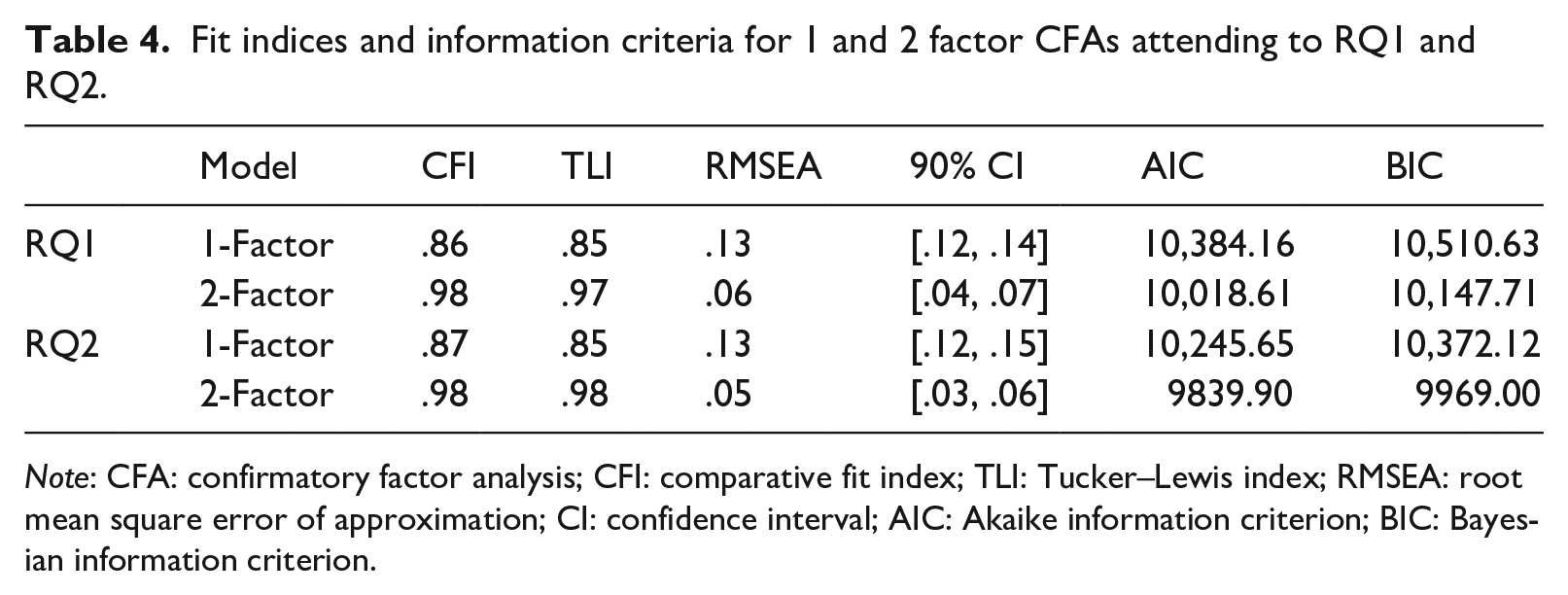
Note: CFA: confirmatory factor analysis; CFI: comparative fit index; TLI: Tucker–Lewis index; RMSEA: root mean square error of approximation; CI: confidence interval; AIC: Akaike information criterion; BIC: Bayesian information criterion.
To address RQ2.1, CFA was conducted on a second batch of 12 meaning recall and recognition parcels constructed from different data, and the results followed the same pattern as the first batch. For both the one-factor model, χ2 (252) = 716.12, p < .001, and the two-factor model, χ2 (251) = 308.37, p = .008, the chi-square goodness-of-fit tests indicated that the null hypothesis could be rejected. Table 4 shows that the fit for the two-factor CFA solution was once again better than the single-factor model. This was also supported by the smaller AIC and BIC values for the two-factor model.
By some estimates, even a factor correlation of .70 indicates a high degree of overlap between measures and a risk that two constructs measure the same thing (Hodson, 2021). Although statistically distinct, the factors had a correlation of .85, raising questions about their discriminant validity. If correlations between two latent constructs are high, they may be redundant, as a learner’s score on one may be highly predictive of the other. If this is the case, it may not be justifiable to consider meaning recall and recognition as distinct components of vocabulary knowledge despite the good fit of the two-factor solution.
In previous research, criteria such as average variance explained (AVE) and the Fornell–Larcker (1981) criterion have been used to demonstrate discriminant validity. However, recent research suggests that these approaches may not reliably detect a lack of discriminant validity in some common research contexts (Ab Hamid et al., 2017; Henseler et al., 2015). Therefore, we employed Henseler et al.’s more stringent heterotrait-monotrait (HTMT) ratio of correlations method to determine discriminant validity. The authors suggest an HTMT value of .90 as a “liberal” criterion for discriminant validity, and a value of .85 as a “strict” criterion. The two factors exhibited an HTMT ratio of .86, indicating that the constructs’ discriminant validity is loosely acceptable (Henseler et al., 2015), but would be rejected under a strict criterion.
Hierarchical regression
Ultimately, the potential value of treating any single theorized form of vocabulary knowledge as a distinct construct of vocabulary knowledge lies in any unique contribution the construct can make to a form of language proficiency, and most importantly in regard to written receptive vocabulary knowledge, L2 reading proficiency. Using hierarchical regression, it is possible to determine whether meaning recognition vocabulary knowledge explains a greater amount of variance in reading proficiency after accounting for meaning recall knowledge, and vice versa. To address RQ2.1, which asked whether meaning recognition made a contribution to the prediction of reading proficiency beyond the contribution of meaning recall, an initial model was constructed by regressing the 103 learners’ TOEIC reading scores on the results from the 1000-word meaning recall test, F(102) = 167.11, p < .001. The effect of adding the results from the 1000-word meaning recognition test as an additional predictor was then observed. Table 5 shows that meaning recognition proved to be a nonsignificant predictor of reading scores when added to the initial model, which already included meaning recall, F(102) = 85.31, p < .001. The models’ effect sizes indicated that meaning recognition contributed approximately 1% to the explained variance above meaning recall, ΔR2 = .01, and less than 1% to the model’s adjusted R2, as can be seen in Table 5.
Hierarchical regression models.
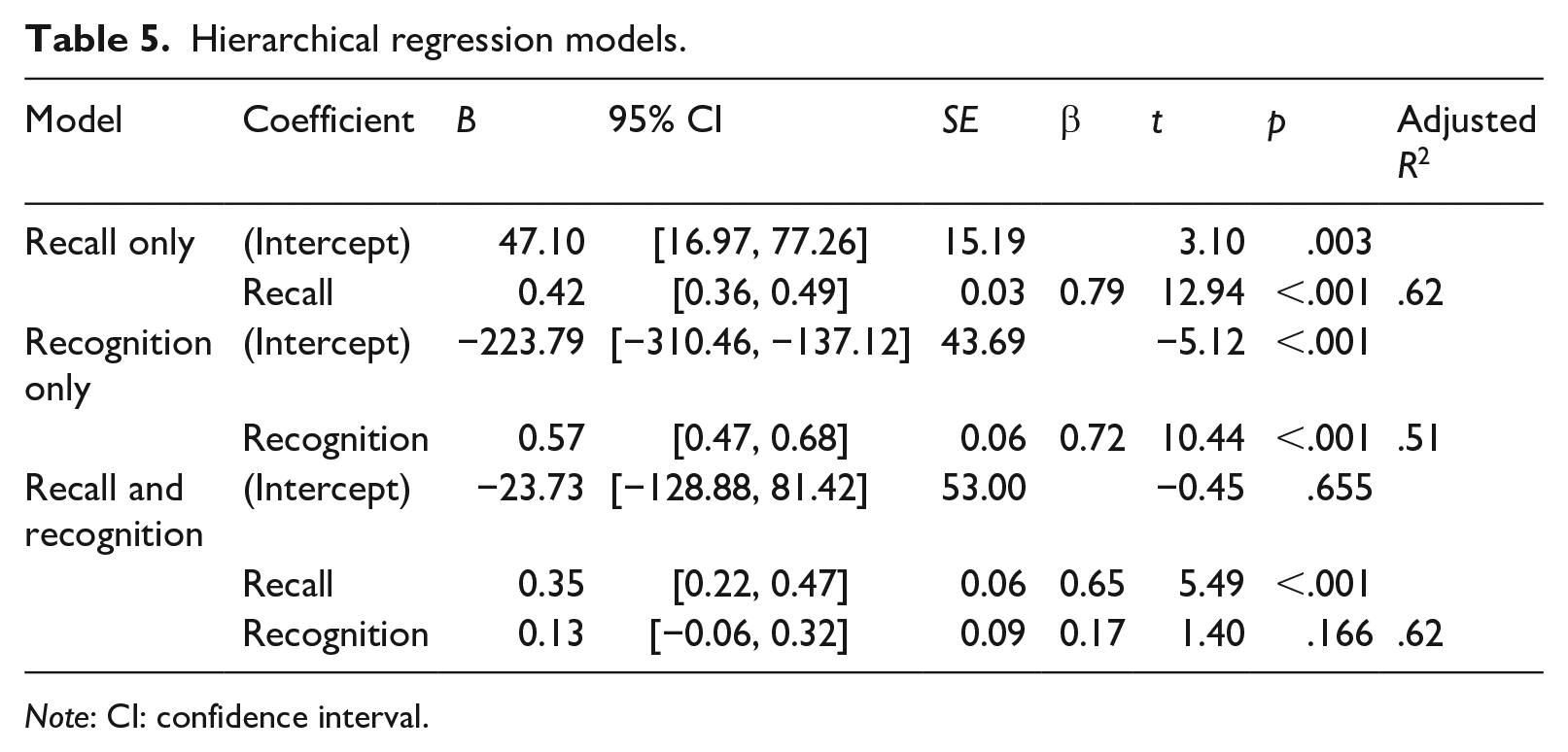
Note: CI: confidence interval.
Although the above analysis demonstrates that meaning recognition does not explain more variance than meaning recall to a statistically significant degree, it does not prove the opposite, that meaning recall explains variance over and above meaning recognition. Therefore, it was necessary to determine whether a regression model built in two steps with meaning recall added in the second step could explain a greater amount of variance in reading proficiency above and beyond a model that involved meaning recognition knowledge only. Thus, RQ2.2 was posed to test this possibility. In this instance, the initial model, F(102) = 85.31, p < .001, comprised the meaning recognition scores regressed on the TOEIC reading scores, with meaning recall scores added afterward. Table 5 shows that meaning recognition scores were a significant predictor of TOEIC reading scores in the initial model, but not once the meaning recall scores were added. The adjusted R2 effect sizes show that the explained variance increased from approximately 51% in the recognition only model, R2 = .51, to approximately 62% in the recall and recognition model, R2 = .62, indicating an 11% increase in explained variance once meaning recall was added to model, ΔR2 = .11. These results imply that meaning recall scores are a significantly stronger predictor of TOEIC reading scores than meaning recognition scores and demonstrate that meaning recall scores explained additional variance to that explained by meaning recognition scores while the reverse was not true. Overall, meaning recognition was not revealed to be a psychometrically distinct construct to meaning recall in relation to reading proficiency. Rather, meaning recall was shown to account for the variance explained by meaning recognition and also explain more. Given these results, it does not appear that there is added benefit for researchers in choosing meaning recognition as a predictor of reading proficiency over meaning recall, nor in using both concurrently.
Discussion
The aims of this study were to determine whether (a) meaning recall and meaning recognition can be considered empirically distinct psychometric constructs that represent unique skills and (b) either of the two constructs have unique predictive power of L2 reading proficiency in comparison to one another. Based on both CFAs, our results indicate that although meaning recall and meaning recognition can be considered distinct latent traits, the discriminant validity between the two factors was somewhat marginal and fails a strict criterion. Furthermore, under hierarchical regression, meaning recognition did not make a statistically significant contribution to explaining reading proficiency over and above meaning recall, further weakening the hypothesis that meaning recognition is a distinct construct of vocabulary knowledge. On the whole, these results provide support to previous findings from meta-analyses (Jeon & Yamashita, 2014; S. Zhang & Zhang, 2020). Conversely, the findings contrast with those reported in Laufer and Aviad-Levitzky (2017). In this section, these findings are discussed, and the study’s implications are addressed in terms of vocabulary acquisition theory and testing.
While learner responses to meaning recognition test items may differ somewhat from responses to meaning recall items psychometrically, these differences do not appear to be related to unique components of reading proficiency. It is possible that differences between constructs could be due to, for example, learner skill in educated guessing behaviors when encountering multiple-choice options on tests. These educated guesses could hypothetically differ from random guesses, which merely contribute to error. However, as data from commonly used meaning recognition vocabulary tests are frequently in practice utilized to indicate the ability to employ lexical knowledge when reading (Kremmel & Schmitt, 2016; Stoeckel et al., 2020), any components added to data by recognition tests which are not unique components of reading proficiency per se reduce the construct validity of the test data and ultimately the value of the recognition tests.
The performance on meaning recognition test formats and meaning recall test formats can be interpreted in light of Perfetti’s LQH (Perfetti, 2007; Perfetti & Hart, 2002). The LQH predicts that it is the variation in the quality of various facets of word representations in readers’ mental lexicons that governs outcomes for reading skills, including comprehension. A high lexical quality implies nuanced and partly redundant representations of form knowledge for both orthography and phonology, and also meaning representations that are flexible enough to be conducive to very fast and reliable semantic activation. In contrast, a lower level of lexical quality implies mental representations that are less specific and less flexible, leading to word-related problems in comprehension. Arguably, an assumed difference in lexical quality across readers or learners may not overtly show if a meaning recognition format is used, since any deficit in form and meaning representation is downplayed by the provision of alternatives to choose from. However, if tested on a meaning recall format, we would expect to see a difference, and in turn observe a difference in performance as to reading comprehension.
These findings have implications for theory of vocabulary acquisition. Meaning recall vocabulary tests have been shown to be more difficult for learners than meaning recognition tests (Laufer & Goldstein, 2004). These differences have been seen as an indication that meaning recognition vocabulary develops more quickly than meaning recall knowledge (see results in González-Fernández & Schmitt, 2019) and that it may be more appropriate to test lower level learners with meaning recognition tests of words that are not known under meaning recall, as knowledge of this “weaker” construct may indicate an earlier stage of learner development of vocabulary knowledge (Laufer et al., 2004). Operationalizing this hypothesis, tests such as the computer adaptive test of size and strength (CATSS; Aviad-Levitzky et al., 2019) test both constructs simultaneously in an attempt to capture vocabulary knowledge at varying levels of acquisition along a hypothesized continuum of learner strength of vocabulary knowledge (Laufer et al., 2004). However, although a laudable endeavor in itself, this practice seems more questionable if the findings of the current study hold in future studies, and it becomes clear that these highly correlated constructs’ differences are unrelated to vocabulary knowledge or L2 reading proficiency. As McLean et al. (2020) argue, even if a given meaning recognition test yields data in which learners are well separated, and perhaps even better than a given meaning recall test, it does not necessarily mean that the meaning recognition test ultimately has better construct validity or that it predicts the target construct better (see also Stoeckel et al., 2020).
Although the present study’s CFAs imply that a two-factor model better fits the data than a one-factor model, it is possible for substantively trivial factors to emerge from factor analysis due to item format similarities that are not of theoretical interest to researchers (Reise et al., 2007). In relation to the findings of the hierarchical regression used to answer RQ2.1 and RQ2.2, rather than being symptomatic of a “weaker” form of vocabulary knowledge (Laufer et al., 2004), meaning recognition tests may simply be relatively poorer tests of vocabulary’s form-meaning link, with lower internal reliability when compared to open-ended formats (McLean et al., 2020), weaker correlations to reading proficiency (Jeon & Yamashita, 2014; McLean et al., 2020; S. Zhang & Zhang, 2020), and inflated estimates of learner vocabulary size or vocabulary mastery level (Gyllstad et al., 2015, 2021; Stewart, 2014; Stoeckel et al., 2020).
A general question that emerges from our study is whether there is a place for vocabulary meaning recognition tests as valid predictors of reading skills. Recently, Schmitt et al. (2020) championed the use of more rigorous and systematic validation procedures in the area of vocabulary test development. Specifically, they called for more self-policing inside the community. This plea is easy to sympathize with, and besides the results reported in Laufer and Aviad-Levitzky (2017), studies and meta-analyses investigating the extent to which meaning recognition or meaning recall is the better gauge and predictor of reading comprehension skills point toward the latter being the most appropriate (S. Zhang & Zhang, 2020). This raises the question as to whether the vocabulary research community should refrain from using meaning recognition tests in research on L2 reading ability whenever possible.
Schmitt et al. (2020) proposed that researchers “self-police” with respect to validating vocabulary test results. However, such acts must be preceded by a critical yet respectful and balanced scholarly discussion, informed by empirical results rather than a reflexive defense of tradition or current practices (as argued by Kremmel, 2018; Schmitt et al., 2020). Instead, consideration of the purpose of the test and construct validity must be the guiding principle. Research disciplines like SLA or Language Testing and Assessment (LTA) are by nature slow when it comes to change. For instance, despite the almost 10 years of methodological reform in SLA prompted by Plonsky (2013), recent systematic reviews of vocabulary research have indicated little improvement in terms of sample size and other areas of research design (e.g., Vitta et al., 2022). Even if there are occasional examples of what are sometimes called bandwagon effects (Meara, 2009), this slowness to enact methodological changes can be seen as a counterbalance to such bandwagon trends. However, in order for self-policing to work, with a more self-critical approach to test development, at least in higher-stakes situations the community should to a greater extent refrain from using tests that either overestimate or underestimate learners’ “true” knowledge and avoid using tests solely because they are quick and easy to use and to mark. Multiple-choice tests became popular in vocabulary testing in no small part because the simplicity with which they can be scored makes them attractive to researchers and test makers; expediting marking was, for example, listed as a reason for the use of the multiple-choice format in the VST (Beglar, 2010), and they may remain in use for this reason. However, the widespread availability of computer technology has made the use of meaning recall item formats much more feasible. As an example, tools and features available in VocabLevelTest.org (McLean & Raine, 2018) can greatly expedite the marking process in cases where learners share a single or limited number of L1s. It might be that meaning recognition tests are appropriate for low stakes, day-to-day classroom assessment, but for more serious, higher-stakes endeavors, such as language research and program-level placement testing, meaning recall tests are arguably preferable.
Conclusions and limitations
In this study, CFAs were conducted to determine whether meaning recall and meaning recognition of L2 vocabulary can be considered a single skill, or unique skills which should be measured separately. In addition, hierarchical regression models were employed to assess if one of the two constructs makes a unique contribution to predicting L2 reading proficiency over the other. The results indicated that it is possible to distinguish the two constructs psychometrically. However, the discriminant validity between the two factors is questionable, and meaning recognition did not make a statistically significant contribution to explaining reading proficiency over and above meaning recall, while meaning recall did make a significant contribution over and above meaning recognition.
Despite our best efforts, this study has two limitations regarding the sample and the conditions in which the test was administered. First, the sample size is relatively small, with all the tested learners coming from a single L1 background. Furthermore, the sizable majority of the sample were female, which could further affect the representativeness of the sample. Second, it is also possible that the student motivation was affected by the length of the tests, or by the fact that the tests were low stakes and unattached to grades. Finally, in regard to suggestions for future research, it would be of benefit to replicate this analysis with other data sets and operationalizations of the meaning recognition and meaning recall constructs. However, in the meanwhile, the findings in the present study give tentative support for the possibility that L2 vocabulary meaning recall tests may be preferable for tapping into the construct of L2 reading comprehension. Overall, we hope these findings stimulate more research on this topic, in order to better align theories of modalities of vocabulary knowledge with empirical evidence.
Supplemental Material
sj-docx-1-ltj-10.1177_02655322231162853 – Supplemental material for Establishing meaning recall and meaning recognition vocabulary knowledge as distinct psychometric constructs in relation to reading proficiency
Supplemental material, sj-docx-1-ltj-10.1177_02655322231162853 for Establishing meaning recall and meaning recognition vocabulary knowledge as distinct psychometric constructs in relation to reading proficiency by Jeffrey Stewart, Henrik Gyllstad, Christopher Nicklin and Stuart McLean in Language Testing
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.