
Abstract
The rating of proficiency tests that use the Inter-agency Roundtable (ILR) and American Council on the Teaching of Foreign Languages (ACTFL) guidelines claims that each major level is based on hierarchal linguistic functions that require mastery of multidimensional traits in such a way that each level subsumes the levels beneath it. These characteristics are part of what is commonly referred to as floor and ceiling scoring. In this binary approach to scoring that differentiates between sustained performance and linguistic breakdown, raters evaluate many features including vocabulary use, grammatical accuracy, pronunciation, and pragmatics, yet there has been very little empirical validation on the practice of floor/ceiling scoring. This study examined the relationship between temporal oral fluency, prompt type, and proficiency level based on a data set comprised of 147 Oral Proficiency Interview - computer (OPIc) exam responses whose ratings ranged from Intermediate Low to Advanced High [AH]. As speakers progressed in proficiency, they were more fluent. In terms of floor and ceiling scoring, the prompts that elicited speech a level above the sustained level generally resulted in speech that was slower and had more breakdown than the floor-level prompts, though the differences were slight and not significantly different. Thus, temporal fluency features alone are insufficient in floor/ceiling scoring but are likely a contributing feature.
Introduction
A common skill associated with spoken language proficiency is fluency, or the rate at which a speaker strings together linguistic sounds to communicate meaning in real-time sans intrusive pauses. The fundamental importance of fluency in achieving effective communication is reflected in the use of the adjectival form of the word—fluent—in common parlance to refer to overall oral ability (Chambers, 1997; Luoma, 2004). Lennon (1990) used the term broad in referring to fluency as an indicator of overall proficiency and narrow when referring specifically to temporal and repair fluency, which form part of an array of components that make up oral proficiency (e.g., accuracy and complexity). For researchers in applied linguistics, Lennon’s distinction between the broad and narrow use of the word fluency is key as many scholars in applied linguistics and language testing seek to uncover relationships between the two types of fluency by carefully measuring temporal and repair fluency (narrow interpretation) and their contribution to overall fluency (broad interpretation).
The primary focus of this study is to examine the role temporal utterance fluency plays in establishing a candidates’ sustained performance level, or floor, in an Oral Proficiency Interview - computer (OPIc) as well as the point of systematic breakdown, or ceiling, at the Intermediate and Advanced levels on the American Council on the Teaching of Foreign Languages (ACTFL) oral proficiency scale. To this end, we start out considering the construct of oral proficiency and its multi-componential nature. Following this discussion, we focus on the construct of fluency, its definition and measurement, its relationship with the overall speech production process, particularly task difficulty, and finally the nature of the OPIc oral assessment instrument. We conclude the article describing our own research using automated, quantitative measures of utterance fluency from 147 OPIc exams rated Intermediate and Advanced to explore the use of these temporal measures of fluency in identifying candidates’ performance floor and ceiling.
Oral proficiency as construct
Few scholars would disagree that second language oral proficiency is a complex, multi-dimensional construct that is extremely difficult to define and theoretically model. Luecht (2003) did not mince words in declaring that “strictly speaking, all models are wrong” (p. 528) but concedes the utility of some. According to Luecht, the purpose of a model of any type is primarily to represent a perception of reality and should be judged based on (1) how it fits that reality and (2) the practical uses and insights the model offers. He described three specific models related to language proficiency assessment, namely, a theoretical construct model, a test development model, and a psychometric model, and conducts an analysis of the Inter-agency Roundtable (ILR)/ACTFL proficiency scale through the lens of each model.
As a theoretical construct model, the inverted pyramid used to represent the ILR/ACTFL proficiency scales indicates visually that each level of the scale requires mastery of a larger number of abilities. Nevertheless, the “relationship among the old and new abilities changes” and does not presuppose “a fixed set of constructs that must apply to all levels of the scale in the same way” (Luecht, 2003, p. 529). In essence, the relationships among and contributions of discrete constructs, such as temporal fluency and grammatical accuracy, are dynamic across levels, influencing oral proficiency ratings in unique ways according to level.
Each major level is based on leveled language functions that require increasingly complex linguistic mastery to perform. Thus, the ACTFL advanced function of narrating an autobiographical story requires sufficient mastery of pronunciation and lexico-grammatical forms as well as temporal fluency so that someone not accustomed to interacting with language learners can understand the speakers easily. Hence, each major ACTFL level represents the convergence of a variety of linguistic aspects that are weighted differently across levels.
De Jong et al. (2012) gathered empirical data related to lexical and grammatical knowledge, pronunciation skills, and linguistic processing to examine the multi-componential nature of speaking proficiency and identified two distinct approaches to studying this complex construct: subjective-subjective and subjective-objective. The subjective-subjective approach compares evaluators’ global ratings of speaking performance with the ratings given to individual features of the learner’s speech, such as fluency and grammatical accuracy. The subjective-objective method of analysis relates overall scores of oral proficiency with objective measures of each linguistic feature of the speech sample such as lexical diversity, speech rate (SR), and number of grammatical errors. Not surprisingly, they found that regardless of the approach researchers adopted, significant relationships resulted between the scores given to the components comprising oral proficiency and global ratings. Moreover, the authors interpreted their findings as evidence that the weight of each component of speaking varies according to level.
Although De Jong et al. (2012) argued for the multi-componential nature of the speaking construct, they proposed that the subskills be categorized into two main groups that should be brought into relief in subsequent research about oral proficiency: linguistic knowledge and processing skills. This recommendation comes out of their empirical study whose results differed from Higgs and Clifford’s (1982) Relative Contribution Model, which predicts that each of five language skills (vocabulary, grammar, pronunciation, fluency, and sociolinguistic competence) contribute differentially to global proficiency depending on level, but in a fairly fixed pattern. By Level 5 on the Foreign Service Institute (FSI) scale, this model predicts that the five skills converge on 20% as the percentage that each contributes to the determination of global proficiency. In contrast, De Jong et al. found that for both the high group of L2 Dutch learners (top 40% of scores) and the low group (lower 40%) all but two measures (i.e., response latency, response duration) of nine total measures (i.e., vocabulary, grammar, speed of lexical retrieval, response latency, response duration, sentence building, speech sounds, word stress, intonation) proved to be significant predictors of oral proficiency among L2 Dutch speakers. Furthermore, De Jong et al.’s results indicated that, unlike the Relative Contribution Model, the weight for each predictor was always larger for the communicatively more successful group than for the less successful group. This means that a similar increase in linguistic knowledge or speed of processing predicts higher gain in speaking proficiency for the high group than for the low group. (p. 27)
In summary, De Jong et al.’s empirical exploration of Dutch L2 learners’ oral proficiency demonstrated that (1) the construct indeed appears to be multi-componential in nature with several latent variables contributing to overall oral proficiency and (2) the weight of predictor variables by level (high/low) does not conform to the detailed predictions of Higgs and Clifford’s Relative Contribution Model.
Fluency
As we have seen, given the complexity and multi-dimensionality of the speaking skill, it can be a difficult construct to unpack across proficiency levels. However, no less complex is the construct of fluency, and its deconstruction also presents challenges. Foremost among those challenges is the determination of what fluency is and which approach to its measurement best reflects the essence of the construct.
Before Lennon (1990) articulated the broad/narrow distinction, Fillmore (1979) had proposed four different types of L1 fluency: (1) lengthy discourse with a minimum number of pauses, (2) sentences packed with rich vocabulary and minimal use of semantically vacuous filler material, (3) language that adapts to the sociolinguistic demands of the context of speech, and (4) creative use of language in the form of metaphors, puns, witticisms, and so on. While Fillmore’s definition takes the perspective of the speaker, Lennon’s definition views fluency from the listener’s standpoint: “fluency is an impression on the listener’s part that the psycholinguistic process of speech planning and speech production are functioning easily and efficiently” (p. 391).
In his comprehensive volume of second language fluency, Segalowitz (2010) outlined three types of fluency related to L2 speech production: cognitive fluency, utterance fluency, and perceived fluency. Cognitive fluency has reference to the speaker’s deployment of cognitive resources for the rapid and efficient processing of speech. By the time an utterance has left a speaker’s vocal apparatus, it has passed through several stages including the coordination, mobilization, and integration of myriad underlying cognitive processes. As such, cognitive fluency pertains to the speaker and forms part of her language proficiency. In contrast, utterance fluency reflects measurable aspects of the utterance after it leaves the speaker’s mouth such as length and number of pauses, speech and articulation rate (AR) per word or syllable, repetitions, filler words, and false starts and other repair moves. These quantifiable properties of speech make up utterance fluency and do not reside with the speaker per se, but are best conceived of as physical, measurable characteristics of the speech separate from the utterer’s cognition. Finally, perceived fluency refers to the judgments hearers make about an individual’s language based on subjective impressions drawn from speech samples. Listeners use information taken from utterance fluency to draw conclusions regarding the speaker’s cognitive fluency, or the nature and efficiency of cognitive processes affecting speech production.
Given the concrete nature of utterance fluency and the relative ease with which it can be measured, it is not surprising that this particular fluency type is commonly subjected to quantitative analyses. Multiple types of analyses can be conducted on a speech sample, particularly with the advent of automated analyses facilitated by computer programs like PRAAT (Boersma & Weenink, 2021) that can count syllables, silent pauses, and SR with just a handful of settings configured by the user. De Jong (2018) included a long list of frequently used quantitative measures in fluency research. Despite the many measures available to researchers for the analysis of fluency, the lack of standardization across studies makes comparisons difficult to interpret (Lennon, 1990; Préfontaine & Kormos, 2015; Segalowitz, 2010) and pauses in particular can be difficult to interpret because of their multi-functional nature. Research has demonstrated clear trends in the use of pauses that are context dependent, affecting all speakers and not necessarily reflective of impaired processing due to insufficient proficiency. For example, filled pauses appear more in human–human interactions than in responding to a computer prompt and may serve discursive purposes like holding the floor. Pauses appear more frequently before low frequency words, syntactic boundaries, and when an alternative polysemous word is available, to name a few of the many findings related to the use of unfilled and filled pauses in L1 and L2 speech (De Jong, 2018).
According to De Jong, the most robust and accurate predictor of L2-specific fluency, as opposed to L1 personal speaking style, is AR—or its inverse—average syllable duration. In their work with L2 English speech of an in house oral English test, Ginther et al. (2010) examined 15 temporal fluency features and found three to have the strongest relationship with speaking scores on a test of English: SR, AR, and mean length of utterance (MLU). In addition, they recommended looking at silent pausing. Tavakoli et al. (2020) concluded that AR, SR, and MLU accurately differentiated oral performance at different levels and that lower proficient students’ speech contained longer and more frequent silent pauses than high-proficiency students.
Undergirding every spoken utterance, regardless of fluency, are myriad and complex cognitive processes. Levelt’s (1989, 1999) speech production model represents one of the most oft-cited frameworks for understanding the mechanisms required for human speech. De Bot’s (1992) adaptation and Levelt’s (1999) subsequent update to the model provide a detailed blueprint of how L2 speech comes about. Segalowitz (2010) identifies fluency vulnerability points for L2 speech production, which include every stage of the process from the macroplanning to the selection of the right L2 lemma from the mental lexicon during grammatical encoding to the increased attentional resources needed during self-monitoring after the utterance has been articulated. Skehan (2009) used Levelt’s model in discussing obstacles to fluent and accurate L2 speech. While Segalowitz’s offers a general analysis of fluency vulnerability points, Skehan identified facilitating and complicating influences presented by different task characteristics and task conditions and how they impact complexity, accuracy, and fluency within Levelt’s model. He concluded that the nature of the task and the circumstances in which it is completed can affect L2 speech at the following three major stages of speech production: Conceptualization, Formulation (Lemma Retrieval), and Formulation (Syntactic Encoding).
In the current study, task complexity and difficulty play a key role as the OPIc prompts are carefully constructed to elicit language reflective of the proficiency descriptions corresponding to the Intermediate, Advanced, and Superior levels of the ACTFL oral proficiency guidelines. Moreover, students’ final ratings are dependent upon their ability to avoid breakdown vis-a-vis the rating criteria while responding to prompts of one of the aforementioned major levels. The topic of task complexity and difficulty and their impact on learners’ oral production has been spearheaded by scholars such as Skehan (1998) and Robinson (2001). Although a thorough treatment of the topic and review of empirical literature extends beyond the scope of the current paper, a brief conceptual overview is in order. Robinson conceptualized task difficulty as a separate construct from task complexity, where the former relates to learners’ perceptions of task demands and their ability to meet them—perceptions that are mediated by affective factors such as motivation and confidence—and the latter a more objective indication of the linguistic and cognitive rigors of the task regardless of learner perceptions. Skehan’s model conceived of task difficulty as a broad construct that includes code complexity (i.e., linguistic demands), communicative stress, (i.e., situational factors) and cognitive complexity (i.e., level of familiarity) and type of cognitive processing required.
Bachman (2002) was keen to point out that the difficulty of a task is not uniform across speakers or inherent in the task characteristics and cannot be determined without considering the interaction between cognitive complexity, communicative context, individual learner ability, and other learner characteristics. Thus, task difficulty can best be considered a moving target rather than a fixed entity, with a variety of inputs contributing to how difficult a given task is for a particular learner. For example, for an L1 English speaker learning Spanish, a time-constrained, emotionally charged past-tense narration of a traumatic event to a police officer surely presents a formidable challenge given Spanish’s rich inflectional morphology used to encode aspect (i.e., preterit vs imperfect) and the absence of such verbal morphology in English.
In their innovative study using qualitative and quantitative data, Préfontaine and Kormos (2015) examined students’ perceptions of the difficulty of narrative tasks in L2 French as well as the relationship between those perceptions and automated measures of L2 French utterance fluency. Participants completed three speaking tasks eliciting (1) a coherent narrative based on six unrelated pictures (Task 1), (2) an oral retelling in French of a horse-riding accident taken from a short text in English (Task 2), and (3) a summary of an 11-frame cartoon strip presented in sequential order (Task 3). They then completed a 5-item questionnaire asking them to rate on a 6-point scale (i.e., very easy to very difficult) the difficulty of each task overall and the difficulty of four specific aspects of task completion: planning, lexical retrieval, grammar, fluency. The researchers also conducted a retrospective interview to qualitatively assess students’ subjective perceptions.
Préfontaine and Kormos’s (2015) analysis of the data led to several findings that apply to the current project. First, the results indicated significant differences in the difficulty students experienced in finding the words they wanted to say and speaking fluently when completing each of the three tasks. These same two task characteristics (lexical retrieval and fluency) were rated as the two most difficult for all three tasks with Task 3 resulting in the lowest level of perceived difficulty on both dimensions. The high correlations between lexical retrieval and fluency explained 48% (Task 1), 66% (Task 2), and 59% (Task 3), respectively, of the variance in students’ responses—setting them apart as quite robust variables associated with students’ perception of task difficulty. Second, planning and grammar difficulties did not result in significant differences between tasks. Third, of the four measures of utterance fluency included in the study (AR, phonation-time ratio, pause frequency, and average pause time), AR and average pause time resulted in statistically significant differences between tasks. Students’ AR was significantly higher on Task 3 than on Task 1 and Task 2, while Task 3 resulted in a higher average pause time than Task 1. The authors affirmed that their results “clearly indicate that the various speaking tasks show different relationships between perceptions of difficulty and measures of utterance fluency” (p. 109).
Hence, despite the challenges in defining the difficulty of a particular task for a specific learner in each context, task difficulty is a key construct with direct implications for the current study since the establishment of each candidate’s performance floor and ceiling is predicated upon the difficulty level of the prompts candidates receive. That is to say that all question prompts candidates receive during the OPIc have been categorized according to perceived levels of difficulty with Intermediate prompts presumably less difficult than Advanced prompts and Advanced prompts less difficult than Superior prompts insofar as the oral proficiency guidelines and rating criteria are concerned, which include fluency. Therefore, OPIc candidates should perform better and produce more fluent language on prompts below their level (i.e., less difficult tasks), than above it (i.e., more difficult tasks) if indeed fluency and global proficiency are associated one with another.
In her recent survey article on L2 fluency in language testing, De Jong (2018) drew this very conclusion, unequivocally stating that the research “clearly shows that objective measures of fluency are related to (gains in) proficiency, as well as to ratings of fluency and proficiency. In other words, temporal aspects of fluency can indeed be seen as indicators of proficiency” (p. 7). This is particularly true of certain measures of pauses and speech rate. Among her suggestions for future research, De Jong included the need to control for personal speaking style in the L1, to reduce the weight attributed to dysfluencies such as pauses at certain places in sentence creation such as syntactic boundaries, to identify the impact of task characteristics, to chart fluency gains within speakers longitudinally, and finally, to relate objective fluency measures to global measures of proficiency. It is this last recommendation that we take up in the present study.
ACTFL OPIc assessment protocol
The widely recognized ACTFL Oral Proficiency Interview (OPI) mirrors the Interlanguage Roundtable proficiency interview insofar as construct definition, proficiency scale, and floor/ceiling interview procedures are concerned (see Liskin-Gasparro [2003] for a detailed history of the ACTFL proficiency guidelines and OPI). As a result of the costly and logistically cumbersome nature of the traditional OPI with its requirement of a one-on-one, real-time encounter, ACTFL created the OPIc, an asynchronous interface that allows candidates to record their monologic responses to prepared aural prompts delivered by Ava the avatar (see Isbell and Winke [2019] for a detailed description and evaluation of the OPIc). The ACTFL OPIc uses the same proficiency guidelines and scale for rating candidate’s speech and does via the same basic four-part iterative exam structure: warm up, level checks, probes, and wind down. The asynchronous and non-interactive nature of the OPIc has facilitated its use in large-scale testing of language programs such as those represented in Isbell et al. (2019) and Winke et al. (2020).
To successfully rate a candidate’s speech sample collected using either modality, there must be evidence of the candidate’s floor and ceiling. The floor refers to the level at which the candidate’s speech demonstrates sustained performance that meets all the criteria for a particular major level. The performance ceiling is reached when the candidate’s production reflects consistent evidence of breakdown vis-a-vis the criteria for that level. Table 1 includes the various types of question prompts used in the OPIc and the level of language they are intended to elicit.
Question type by ACTFL major level.
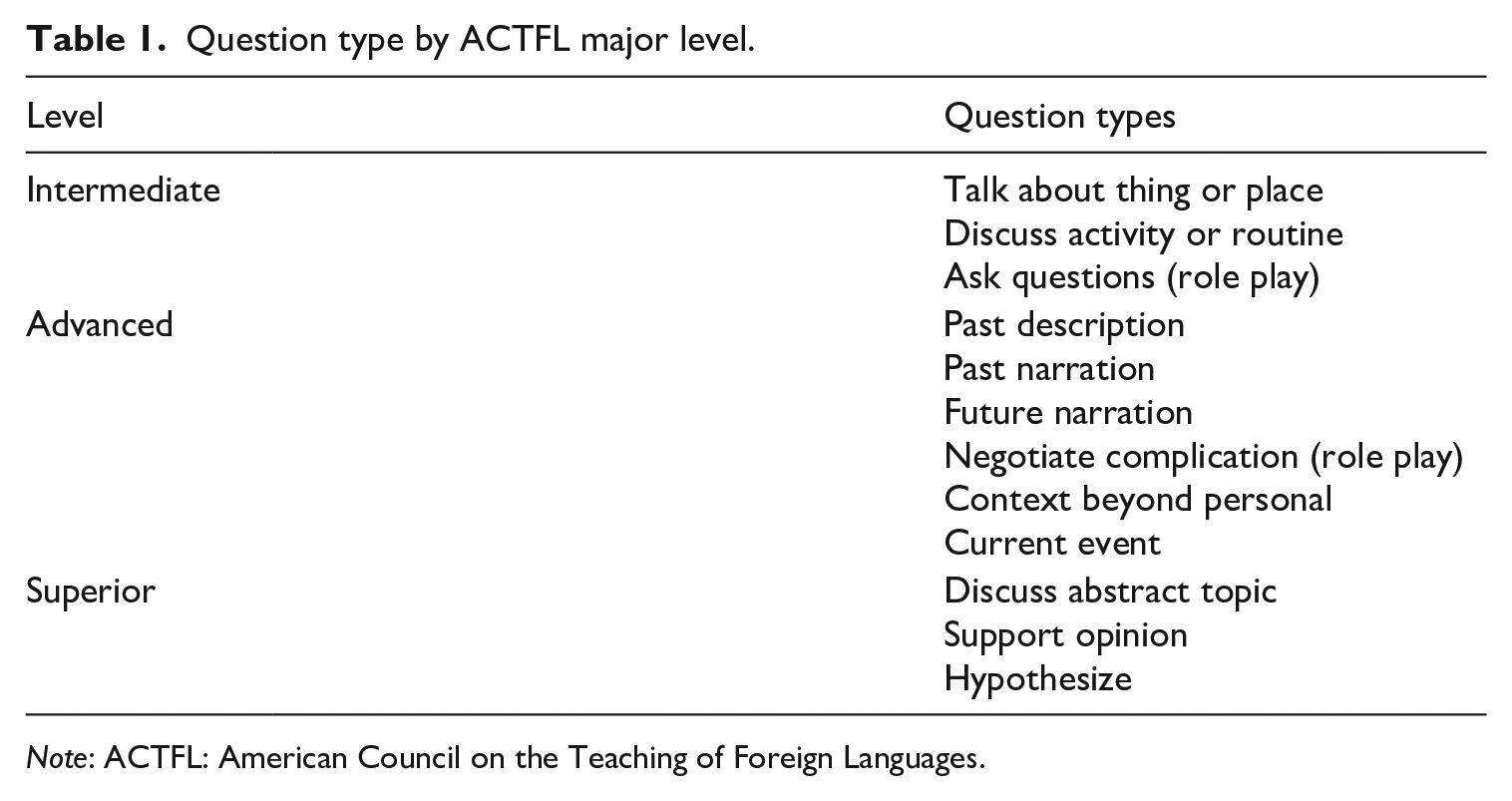
Note: ACTFL: American Council on the Teaching of Foreign Languages.
Based on the performance of floor and ceiling tasks, the tester can assign 1 of 10 ratings divided into four major levels: Novice (N), Intermediate (I), Advanced (A), and Superior (S). The sublevels of low (L), mid (M), and high (H) apply to the N, I, and A levels and reflect the examinees performance of both the floor and ceiling. The low sublevels (Novice Low [NL], Intermediate Low [IL], and Advanced Low [AL]) indicate the skeletal performance of the floor criteria, whereas the mid sublevels (Novice Mid [NM], Intermediate Mid [IM], and Advanced Mid [AM]) represent full and robust performance of the floor criteria. The high sublevels (Novice High [NH], Intermediate High [IH], and Advanced High [AH]) indicate performance at the next level most of the time, but not sustained performance. The descriptions of each level and sublevel are based on the four assessment criteria used to assign a rating: global tasks or functions, context and content, accuracy, and text type. Sublevels are used to differentiate more granular differences in performance on unique, major-level benchmarks. For example, within the global tasks or functions category, Advanced-level speakers can narrate in all major time frames, while Intermediate speakers can create with language but cannot effectively narrate across time frames. An AM speaker will provide more full and rich descriptions in narrations and be comfortable addressing a wider range of topics compared with an AL speaker, but both would demonstrate the ability to successfully narrate in the past. The narrations of an IH, however, would exhibit patterned breakdown that impedes the listener’s ability to understand the details of the story. Regarding text type, Advanced-level speech can be organized into paragraphs, while Intermediate speech includes discrete sentences that do not consistently create a cohesive discursive unit like a paragraph.
The ACTFL (2012b) training manual defined one aspect of linguistic breakdown as “Loss of fluency: frequent pauses are caused, not by the need to reflect on the substance of what is being communicated, but because of the lack of usable language” (p. 24). Within the four assessment criteria, ACTFL (2012b) has included fluency as part of accuracy/comprehensibility alongside vocabulary, grammar, pronunciation, pragmatic competence, and sociolinguistic competence. At times, the oral proficiency guidelines refer explicitly to fluency, such as when they describe AH speakers as showing “great fluency and ease of speech” (ACTFL, 2012a, p. 5). Other references to fluency are less explicit, but still quite evident as in the case of AM speech being “marked by substantial flow” (ACTFL, 2012a, p. 6). At the Intermediate level, the verbiage seems to identify specific causes for disfluency rather than referring in general terms to fluency. IL speech, for example, is characterized as being “filled with hesitancy” and “frequent pauses, ineffective formulations and self-corrections” (ACTFL, 2012a, p. 8).
Since the appearance of the OPIc, several studies have examined its reliability and validity (Brown et al., 2017; Cox, 2017; Cubbellotti, 2015; Gates et al., 2020; Surface et al., 2008; SWA Consulting Inc., 2009; Thompson et al., 2016; Tigchelaar, 2019) as well as how candidates’ fluency compared across the OPI and OPIc. In general, the OPI and OPIc provided similar ratings for candidates assessed by both with the OPIc resulting in slightly higher ratings for candidates falling within the Advanced sublevels (Thompson et al., 2016). Regarding fluency, Brown et al. (2017) found that when compared in aggregate, the examinees spoke faster during the OPI than during the OPIc, but their silent pauses were longer during the OPI. In a separate study, Gates et al. (2020) identified rehearsed segments from candidates’ responses on the OPIc and compared them with spontaneous segments by examining temporal fluency features and recurring linguistic patterns. Somewhat unsurprisingly, examinees’ AR was faster for segments tagged as rehearsed as compared with spontaneous and rehearsed segments that reflected a greater rate of off-topic responses and recycled material from previous responses.
Research questions
To evaluate the role temporal fluency plays with floor/ceiling scoring on the ACTFL OPIc, a two-step process will be followed. First, we need to establish if the average of the temporal fluency measures on all the intended item difficulty levels is related to the final rating of an OPIc. If so, then how do the temporal fluency features of responses to the floor and ceiling questions impact the sublevel ratings of examinees at the major level of Intermediate and Advanced? The following research questions have been formulated to determine the role temporal fluency plays in the floor/ceiling scoring of Spanish OPIc exams.
RQ1—How does the average temporal fluency on the whole test vary among examinees rated at different ACTFL sublevels on the OPIc when using the following measures?
• speed (AR and speech rate)
• breakdown (MLU and average number of silent pauses)
RQ2—With Intermediate-level speakers, how does the average temporal fluency of the Intermediate-level (floor) question responses compare with that of the Advanced-level (ceiling) question responses?
RQ3—With Advanced-level speakers, how does the average temporal fluency of the Advanced-level (floor) questions compare with that of the Superior-level (ceiling) questions?
Methodology
To determine how temporal fluency features varied, we drew on extant data from OPIc exams that had been previously administered and scored, and which formed part of a larger study. To answer the first research question, examinees were first grouped by ACTFL major level and sublevel before the temporal fluency features of speed and breakdown were analyzed using PRAAT (Boersma & Weenink, 2021). To answer the second research question, the oral prompts deployed in the OPIc were categorized by major level (Intermediate, Advanced, or Superior) according to the intended functions elicited. The temporal fluency of each examinee was then measured during their response to “floor” questions generated at their level, which should indicate sustained performance and also to “ceiling” questions—those questions which should elicit some type of breakdown in the candidate’s response. This approach allowed for inferences to be made regarding the relationship between breakdown, or temporal disfluency, question type and level, and candidates’ rated ACTFL level.
Participants
We recruited 147 candidates who were students in a large Spanish department (see Table 2) at a private university, 60 of whom were rated at a major level of Intermediate (IL, IM, or IH) and 87 at Advanced (AL, AM, or AH) on the OPIc, 81 of which took Test Forms 4 and 5. The participants self-assessed their proficiency and chose the test form that they felt best represented their language ability. The forms had between 13 and 17 prompts targeting different major levels. To be presented with prompts at the Superior level, examinees needed to choose either form 4 or 5. Of the 2321 prompts given candidates, 15 oral responses were missing from 11 different examinees, likely due to technical recording failures or the examinee simply not recording anything. In the end, there were 2306 oral responses collected from the 147 examinees.
OPIc examinees by ACTFL sublevel.
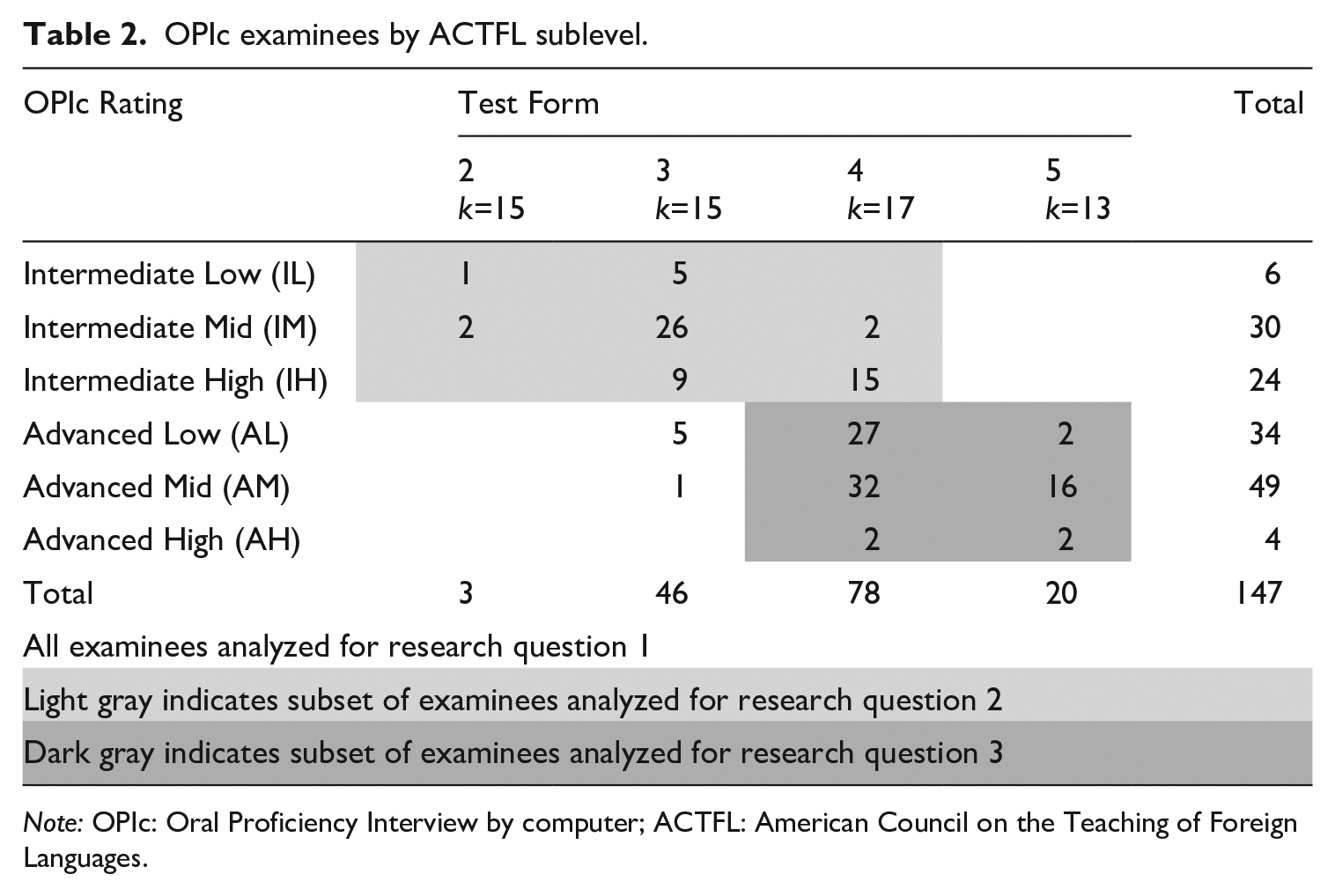
Note: OPIc: Oral Proficiency Interview by computer; ACTFL: American Council on the Teaching of Foreign Languages.
Procedures
The prompts given during the OPIc were analyzed using a PRAAT script (De Jong & Wempe, 2009) with the following settings: silence decibel threshold level = −25 dB (De Jong & Bosker, 2013), minimum dip between peaks = 2 dB, minimum pause duration = 0.3 seconds. Candidates’ responses to each prompt could be up to 2 minutes (120 seconds) in length, and to verify that examinees did not simply leave the recorder on without saying anything after finishing their response, a researcher checked every audio file 115 seconds or longer for silence. There were 36 files that had more than 3 seconds of silence immediately following the conclusion of the individual’s response. These files were inspected further and trimmed to remove any recorded silence after the candidate had completed her response. As the first prompt was a warm-up question asking candidates to introduce themselves, and is widely known among examinees, it is typically not rated. Therefore, we chose to exclude it from our analysis.
To measure speed, speech rate (number of syllables/total time) and AR (number of syllables/phonation time which is speaking time minus silent pausing time) were calculated. Since speech rate includes time spent pausing, it is considered a composite rather than a pure measure of speed (De Jong, 2016). To measure linguistic breakdown, we chose to follow the procedure in Ginther et al.’s (2010) study by examining the MLU (i.e., number of syllables/ number of pauses) and the silent pause ratio or average number of silent pauses (i.e., the number of silent pauses/total time).
Data analysis
To analyze these data, two procedures were followed. To answer the first question concerning differences among sublevels, four one-way analyses of variance (ANOVAs) were conducted with the dependent variables being speech rate, AR, MLU, and average number of silent pauses. The between-subjects variable was the OPIc rating sublevel of the ACTFL proficiency scale.
To answer the second and third questions on temporal fluency variance with items targeting different ACTFL levels, four repeated-measures ANOVAs were conducted for the Intermediate (Low, Mid, and High) and then Advanced (Low, Mid, and High) OPIc-rated examinees. The dependent variables were the same temporal fluency features used with the first research question. The within-subjects variables were the prompts for the floor- and the ceiling-level questions.
Results
RQ1a: Temporal fluency between sublevels—Speed
With the speed measures (AR and speech rate), moving from IL to AH, each sublevel was faster as examinees progressed up the scale. Table 3 demonstrates how the sublevels progress monotonically by mean. The x-axes represent the ACTFL sublevels ranging from IL to AH and the y-axes show the number of syllables per second. Thus, the mean and confidence intervals of the table can be mapped onto the figure.
Temporal Fluency Speed (Articulation and Speech Rate) by ACTFL Sublevel.
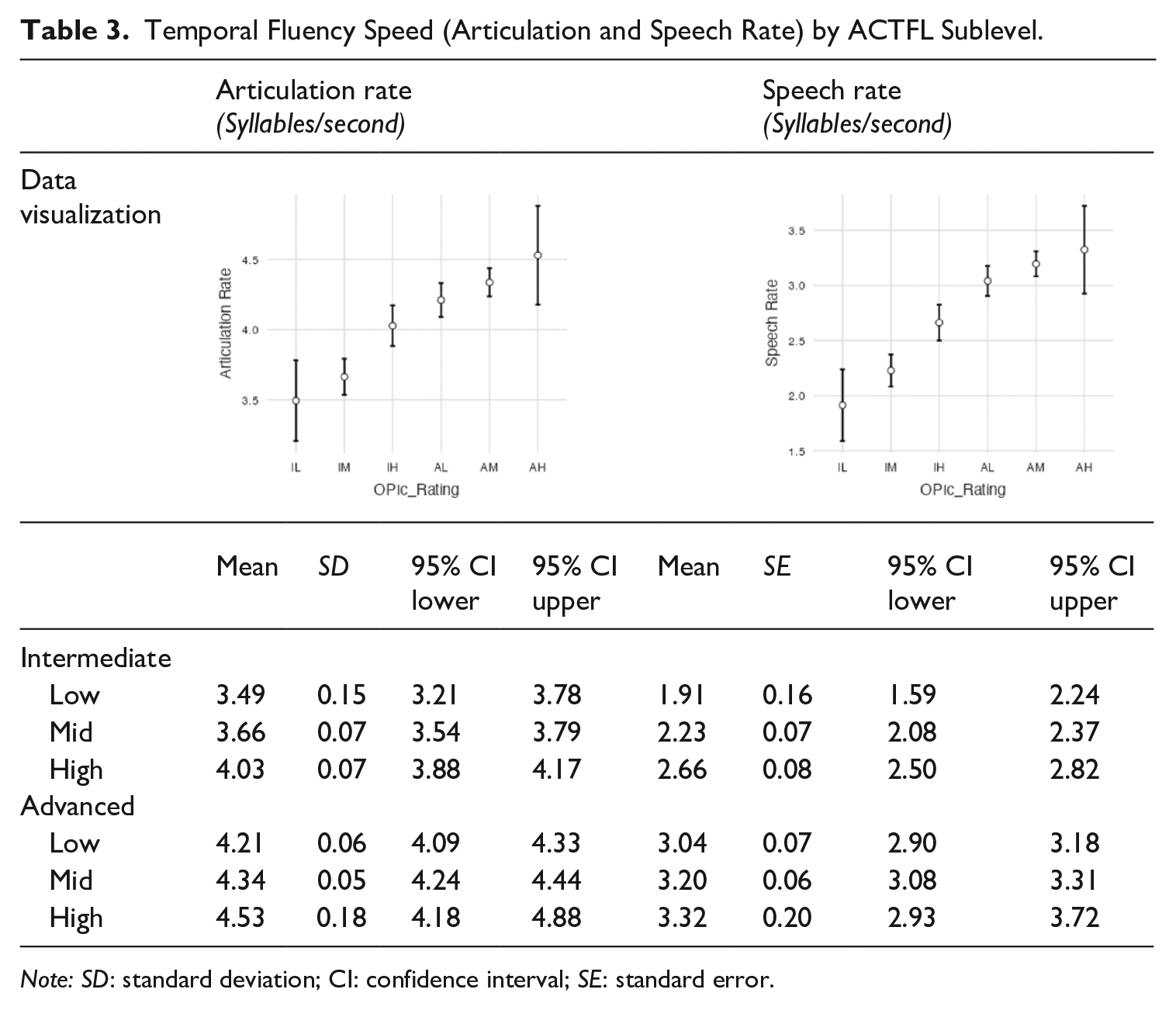
Note: SD: standard deviation; CI: confidence interval; SE: standard error.
With AR, a one-way ANOVA found a significant difference between the sublevels, F (5, 141) = 18.8, p < .001, with effect sizes for each sublevel (see Table 4) varying between no (<0.4), small (0.4 < 0.7), medium (0.7 < 1.0), and large (>1.0) (Plonsky & Oswald, 2014). Additionally, with speech rate, a one-way ANOVA found a significant difference between the sublevels, F(5, 141) = 31.6, p < .001, with no effect size (<0.4) between the Advanced sublevels, but medium effect sizes (0.7 < 1.0) between the others (see Table 4).
Effect Sizes of Temporal Fluency Speed by ACTFL Sublevel.
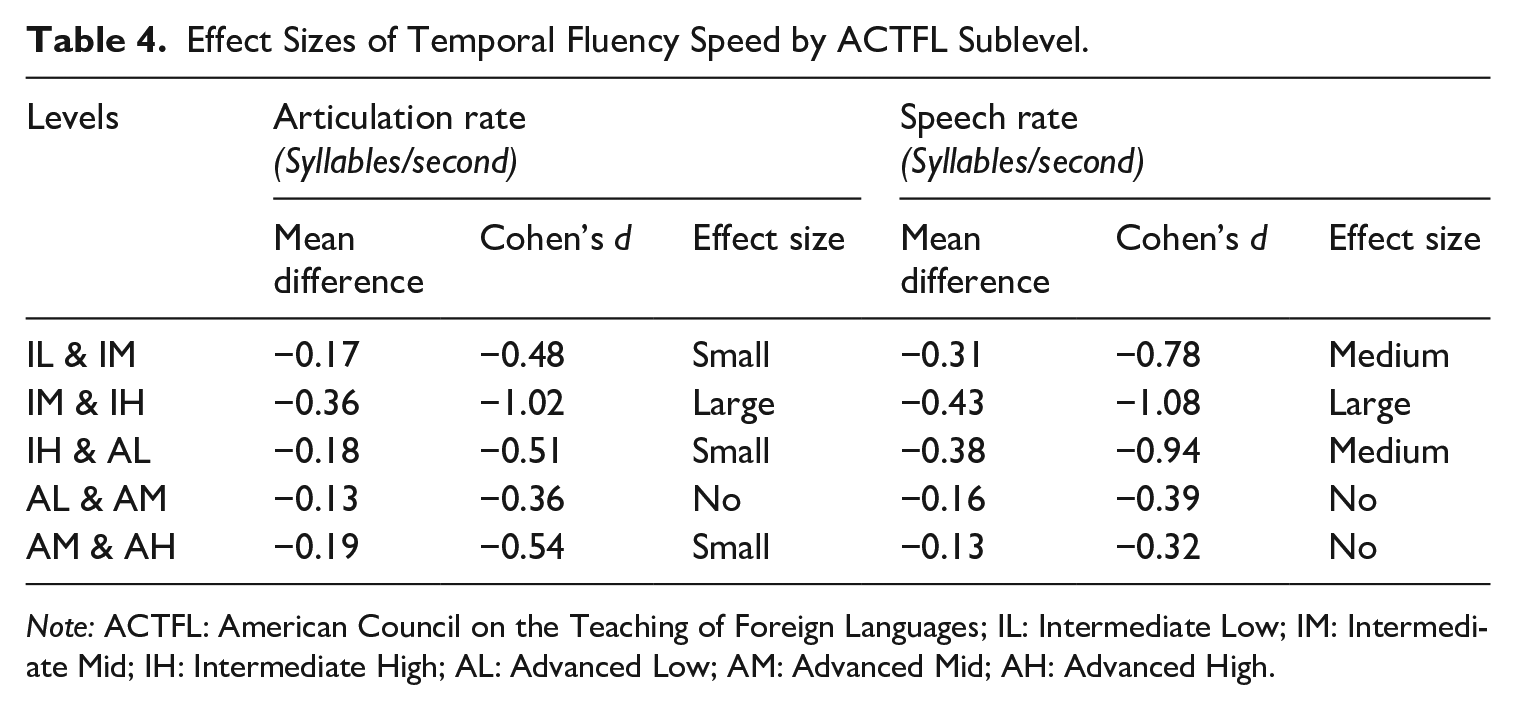
Note: ACTFL: American Council on the Teaching of Foreign Languages; IL: Intermediate Low; IM: Intermediate Mid; IH: Intermediate High; AL: Advanced Low; AM: Advanced Mid; AH: Advanced High.
RQ1b: Temporal fluency between sublevels—Temporal fluency breakdown
With the breakdown measures, moving from IM to AM, each sublevel exhibited less temporal fluency breakdown than the subsequent lower one; that is the utterances were both longer as measured by MLU and had fewer pauses as seen by the average number of silent pauses. Table 5 and its accompanying figures can be interpreted similarly to the description of Table 3 with the exceptions that the y-axes refer to (1) number of syllables and (2) seconds. The two exceptions to this monotonic pattern were that the MLU of the AH (n = 4) was slightly lower than the AM (n = 49) group and the average number of silent pauses of the IL (n = 6) was slightly lower than the IM (n = 30) group. Both the highest and lowest groups had fewer than seven examinees, and thus, this finding could be an artifact of the low numbers.
Temporal Fluency Breakdown by ACTFL Sublevel.
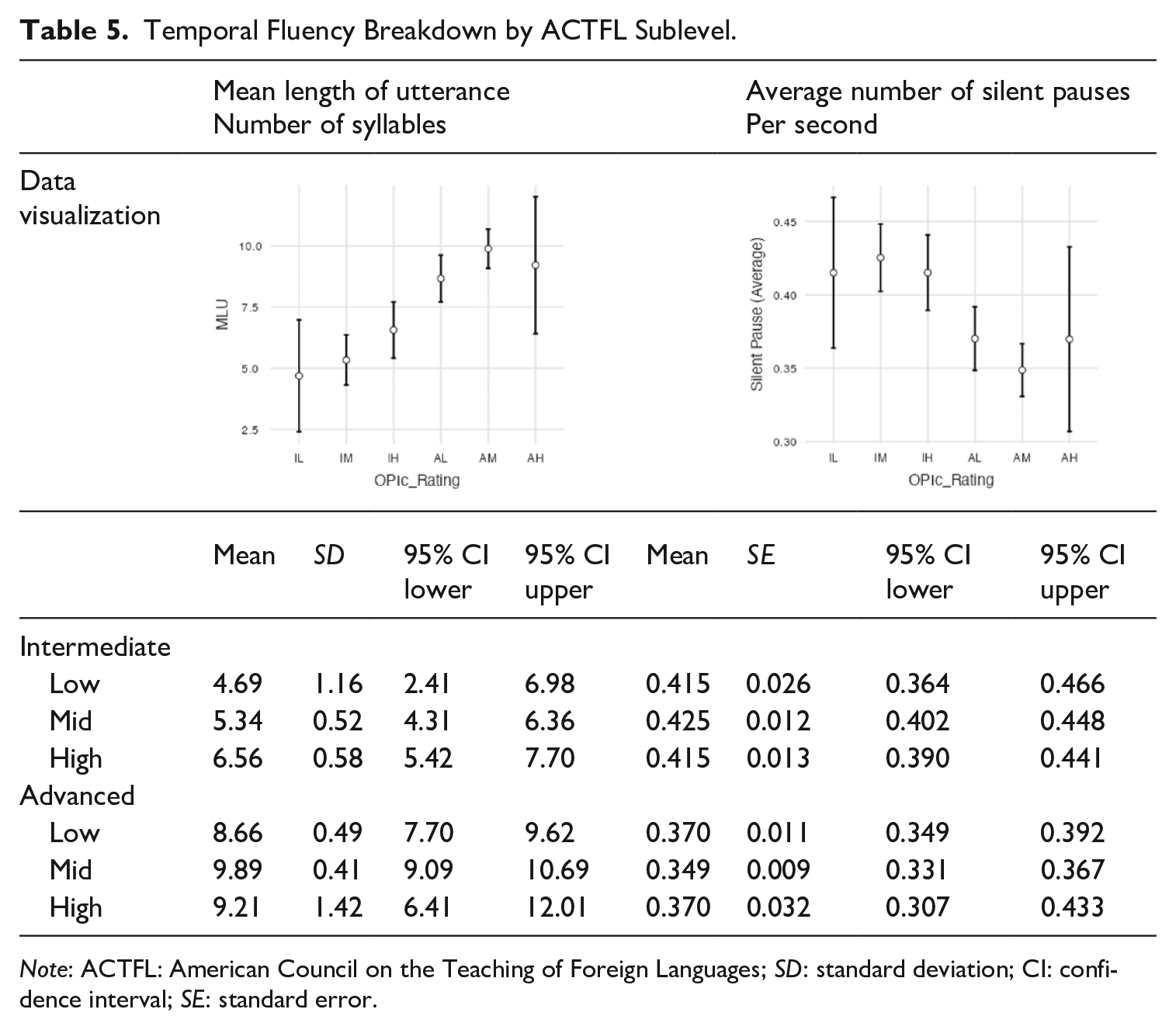
Note: ACTFL: American Council on the Teaching of Foreign Languages; SD: standard deviation; CI: confidence interval; SE: standard error.
With MLU, a one-way ANOVA found a significant difference between the sublevels, F(5, 141) = 13, p < .001, with a range of effect sizes from IM to AM (see Table 6). In addition, with the average number of silent pauses, a one-way ANOVA found a significant difference between the sublevels, F(5, 141) = 7.35, p < .001, with a range of effect sizes between the others. Note that MLU and average number of silent pauses were closely related to each other with a Pearson product correlation, r = .77, p < .001.
Effect Sizes of Temporal Fluency Breakdown by ACTFL Sublevel.
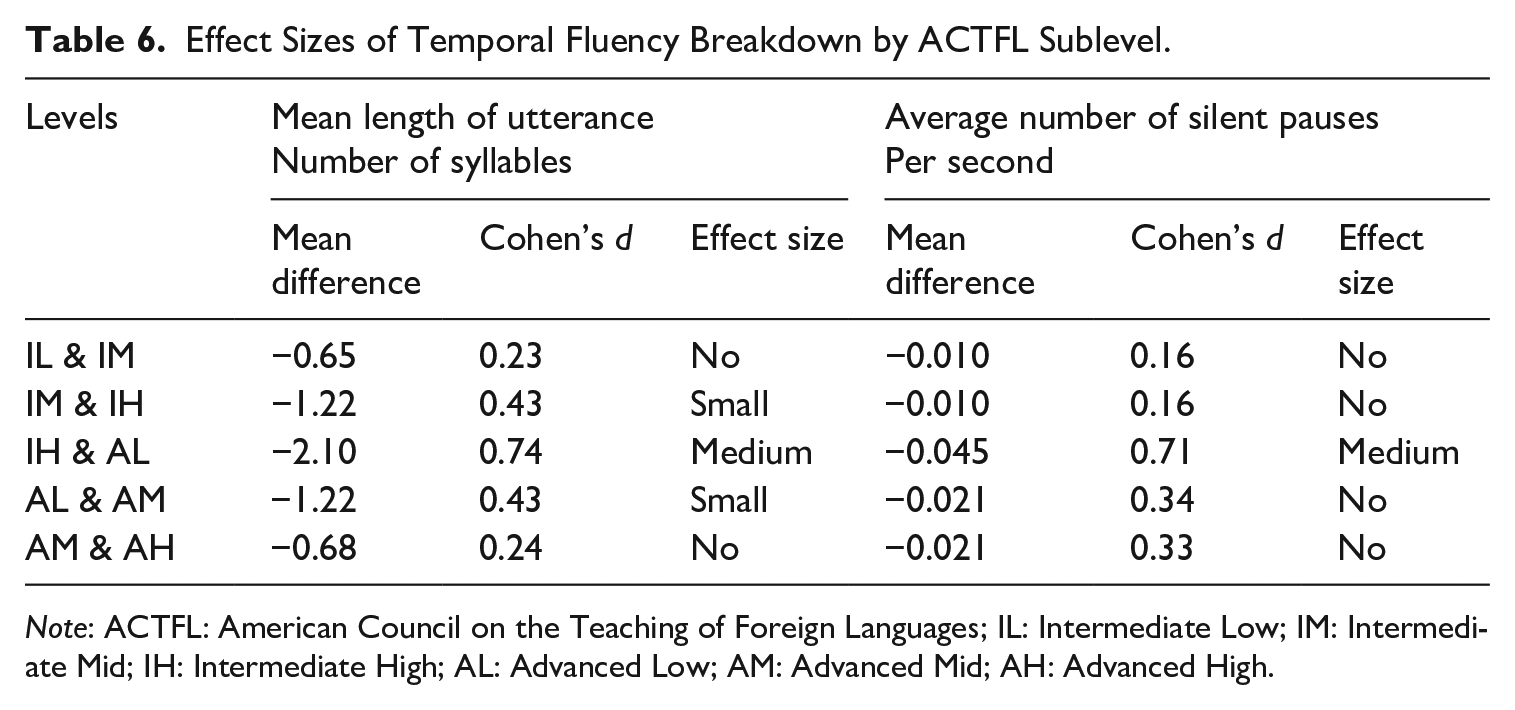
Note: ACTFL: American Council on the Teaching of Foreign Languages; IL: Intermediate Low; IM: Intermediate Mid; IH: Intermediate High; AL: Advanced Low; AM: Advanced Mid; AH: Advanced High.
RQ2: Intermediate speaker responses to intermediate (floor) and advanced (ceiling) prompts
There were 60 Intermediate Low (IL), Mid (IM), and High (IH) speakers whose temporal fluency features were compared between the two prompt levels. As might be expected from the results of the first research question, examinees with higher OPIc scores spoke more quickly. However, if exam prompts designed to target a candidate’s hypothesized floor and ceiling elicited responses with different temporal fluency features, it would provide evidence that the constructs at the major levels elicit different speech depending on examinee level.
With the speed measures of speech rate and AR, the results were as expected. Intermediate speakers had a faster speech rate when responding to Intermediate prompts than they had with the Advanced prompts. Note in Table 7 that the mean of all 60 Intermediate speakers was 2.38 syll/sec for the Intermediate items but slightly slower at 2.36 syll/sec for the Advanced items.
Speech Rate of Intermediate Speakers by Question Level and ACTFL Sublevel.
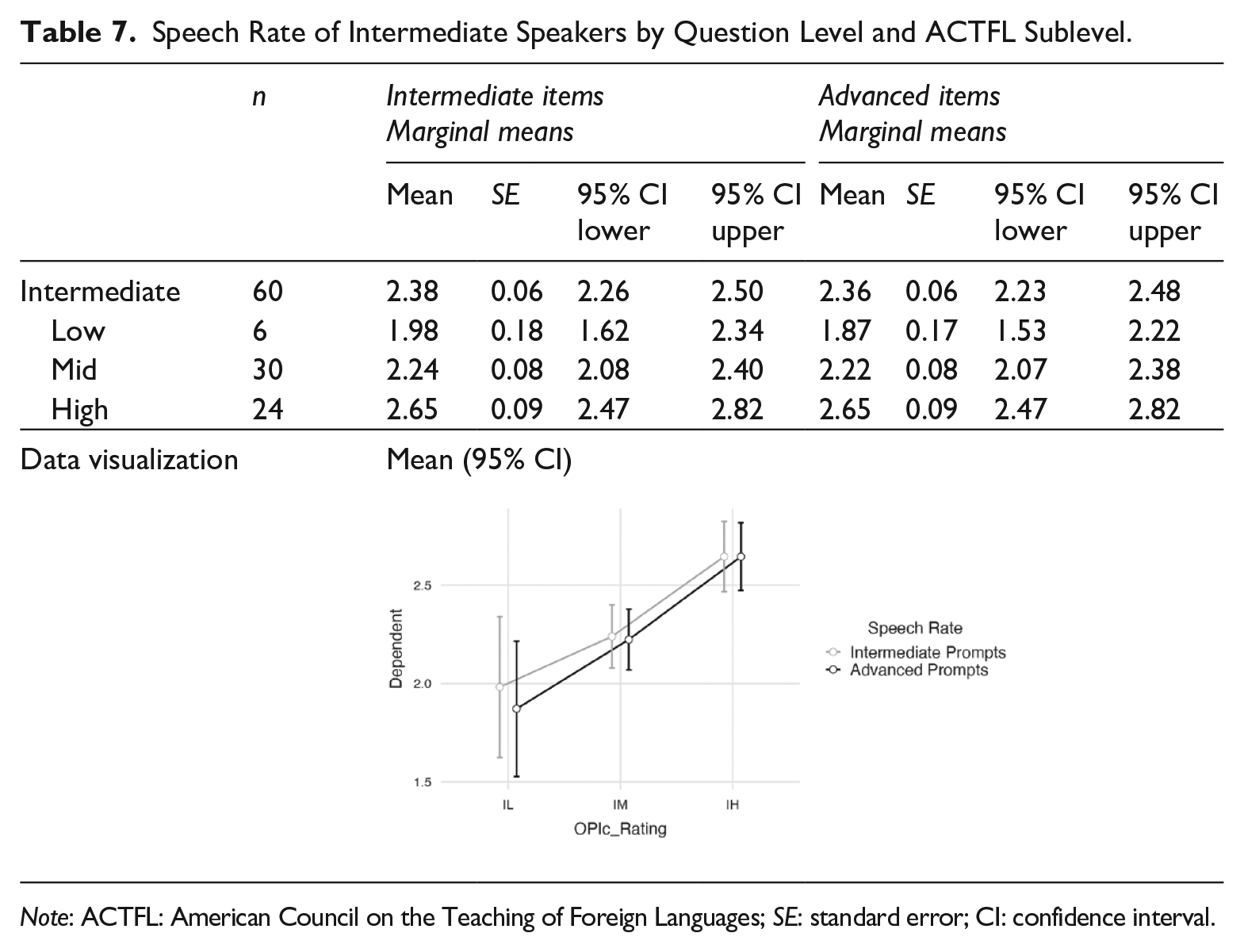
Note: ACTFL: American Council on the Teaching of Foreign Languages; SE: standard error; CI: confidence interval.
Similarly, Intermediate speakers had a faster AR with the Intermediate prompts than they did when responding to Advanced prompts. In Table 8, the AR mean of all 60 Intermediate speakers was 3.81 syll/sec for the Intermediate items and 3.77 syll/sec for the Advanced items.
Articulation Rate of Intermediate Speakers by Question Level and ACTFL Sublevel.
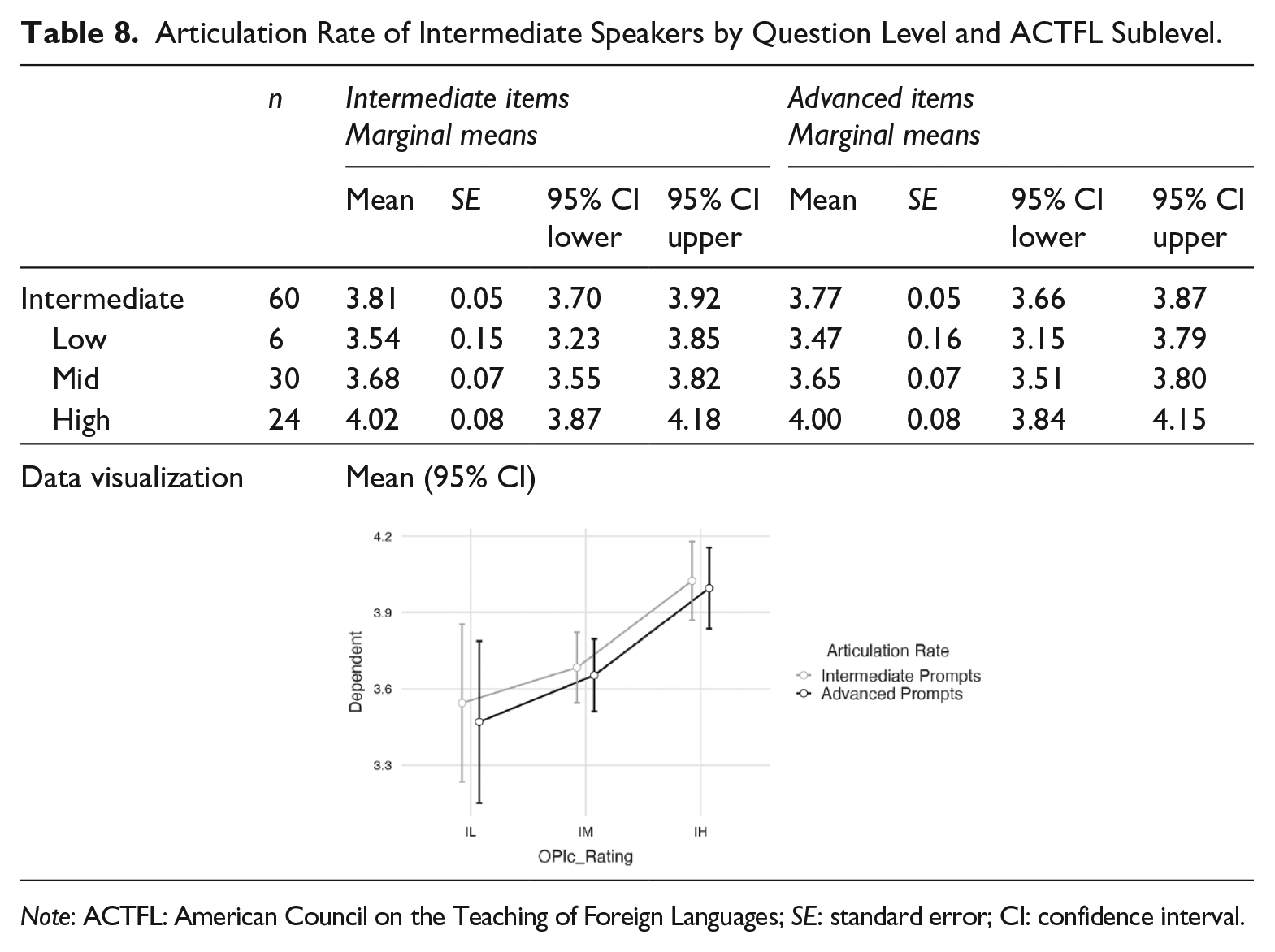
Note: ACTFL: American Council on the Teaching of Foreign Languages; SE: standard error; CI: confidence interval.
With the breakdown measures of MLU and average number of silent pauses, examinees with higher OPIc scores exhibited less breakdown. For MLU, Intermediate speakers had longer runs when responding to Intermediate prompts than when answering Advanced prompts. In Table 9, the mean run of all 60 Intermediate speakers was 5.97 syllables for the Intermediate prompts and 5.70 syllables for the Advanced ones.
MLU of Intermediate Speakers by Question Level and ACTFL Sublevel.
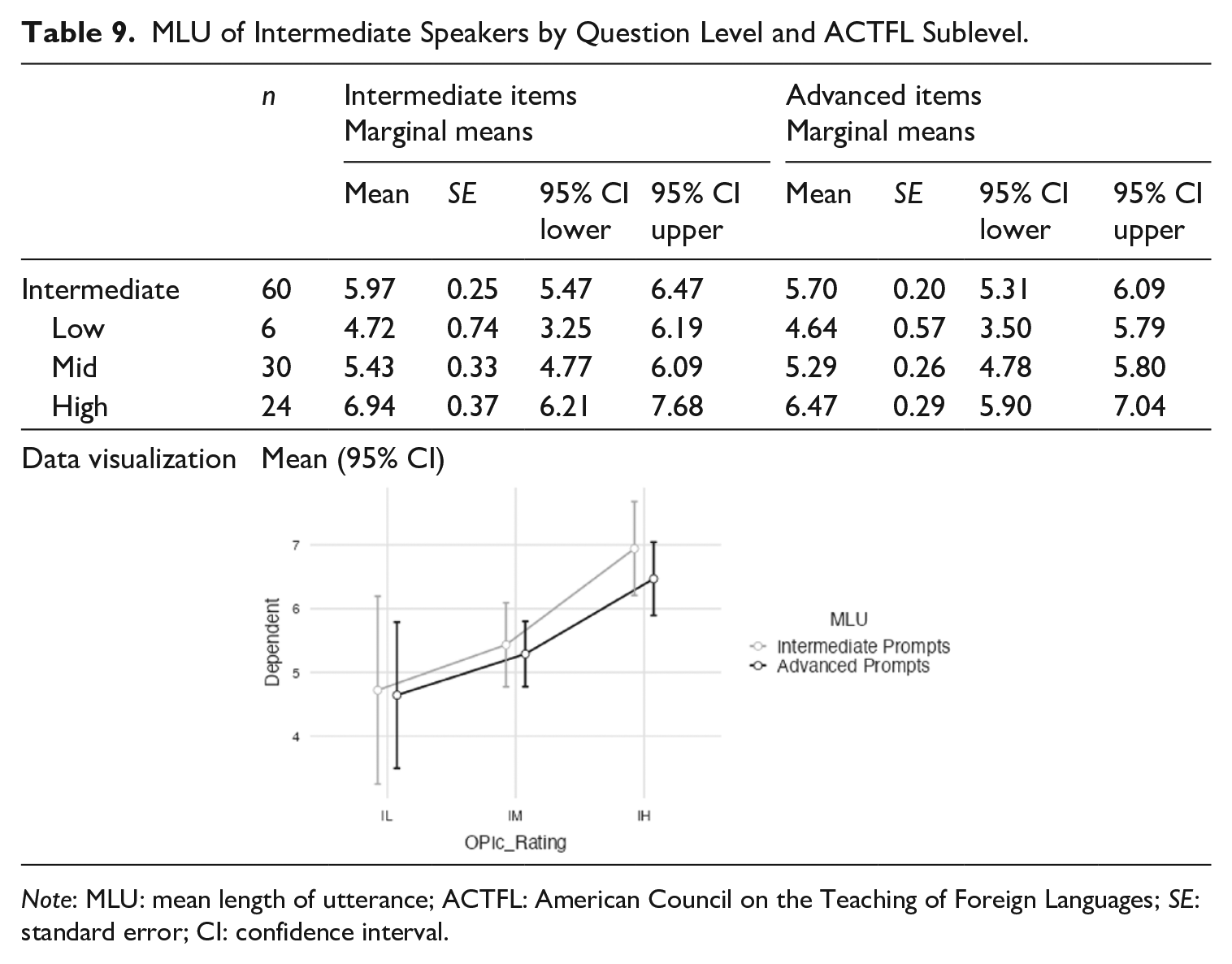
Note: MLU: mean length of utterance; ACTFL: American Council on the Teaching of Foreign Languages; SE: standard error; CI: confidence interval.
For average number of silent pauses, in general, the Intermediate speakers had fewer silent pauses when responding to Intermediate prompts than Advanced prompts. In Table 10, the mean average number of silent pauses of all 60 Intermediate speakers was 0.412 per second for the Intermediate items and 0.422 per second for the Advanced items. The only exception to this pattern was that the IL speakers (n = 6) had fewer pauses when responding to Advanced prompts than the Intermediate ones.
Average Number of Silent Pauses per Second of Intermediate speakers by Question Level and ACTFL Sublevel.
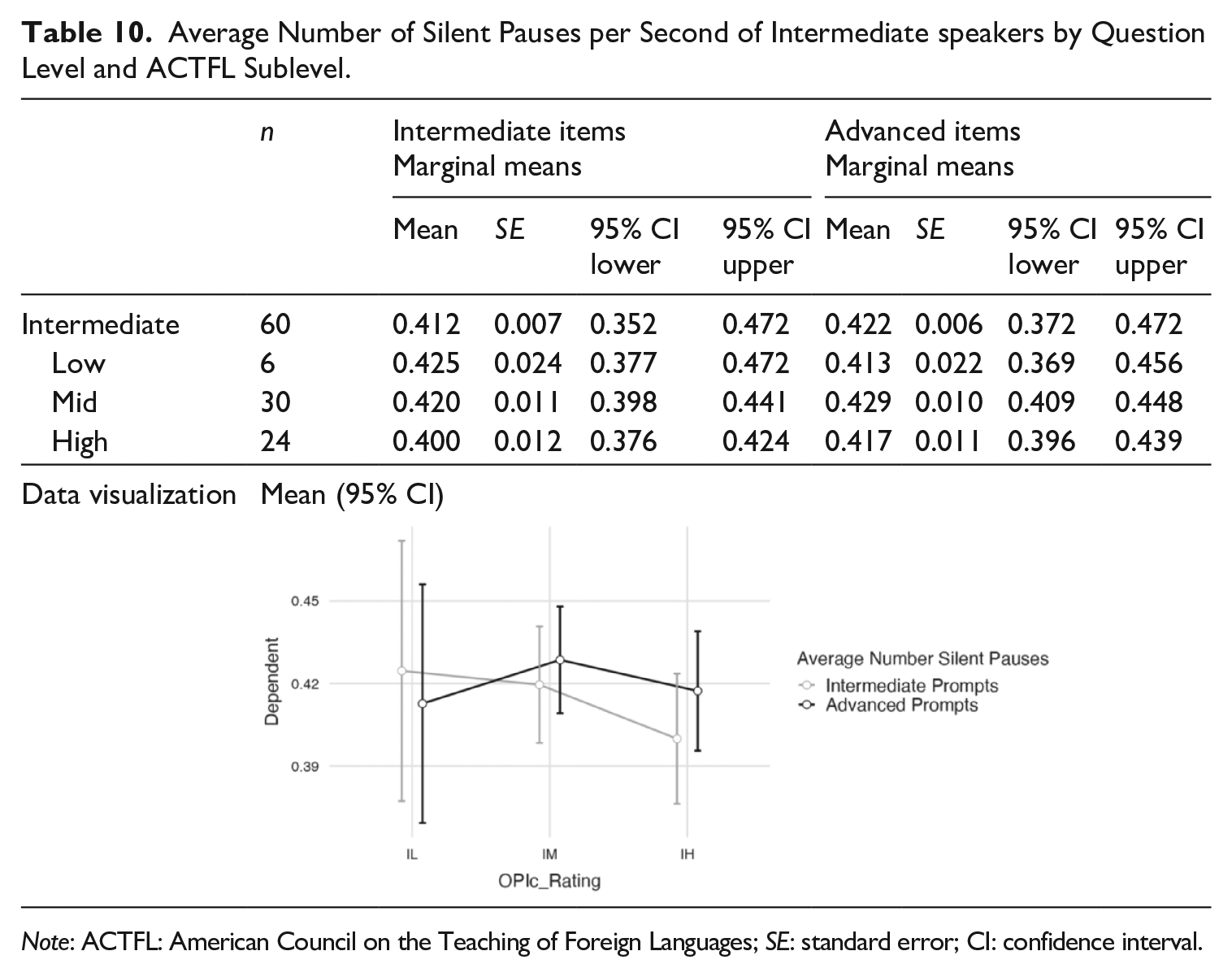
Note: ACTFL: American Council on the Teaching of Foreign Languages; SE: standard error; CI: confidence interval.
The 60 speakers rated as Intermediates (IL, IM, and IH) had faster responses with fewer breakdowns when answering floor questions (Intermediate) than they did to ceiling questions (Advanced). A repeated-measures ANOVA with four dependent variables measuring speed (AR and speech rate) and breakdown (MLU and average number of silent pauses) was conducted. The independent variables were prompt level (within subject) and OPIc rating (between subject). Table 11 shows that with prompt level, only AR was significantly different, F(1, 57) = 4.85, p = .03, between the floor and ceiling prompts; however, there was no real effect size. So even though the responses to the Intermediate, floor-level prompts were consistently faster, and exhibited fewer breakdowns than the Advanced, ceiling-level prompts, those differences were not statistically significant. The OPIc rating, however, was significantly different among the subset of these 60 examinees.
ANOVA on Differences between Intermediate and Advanced Prompts and Effect Sizes of Intermediate Speakers.
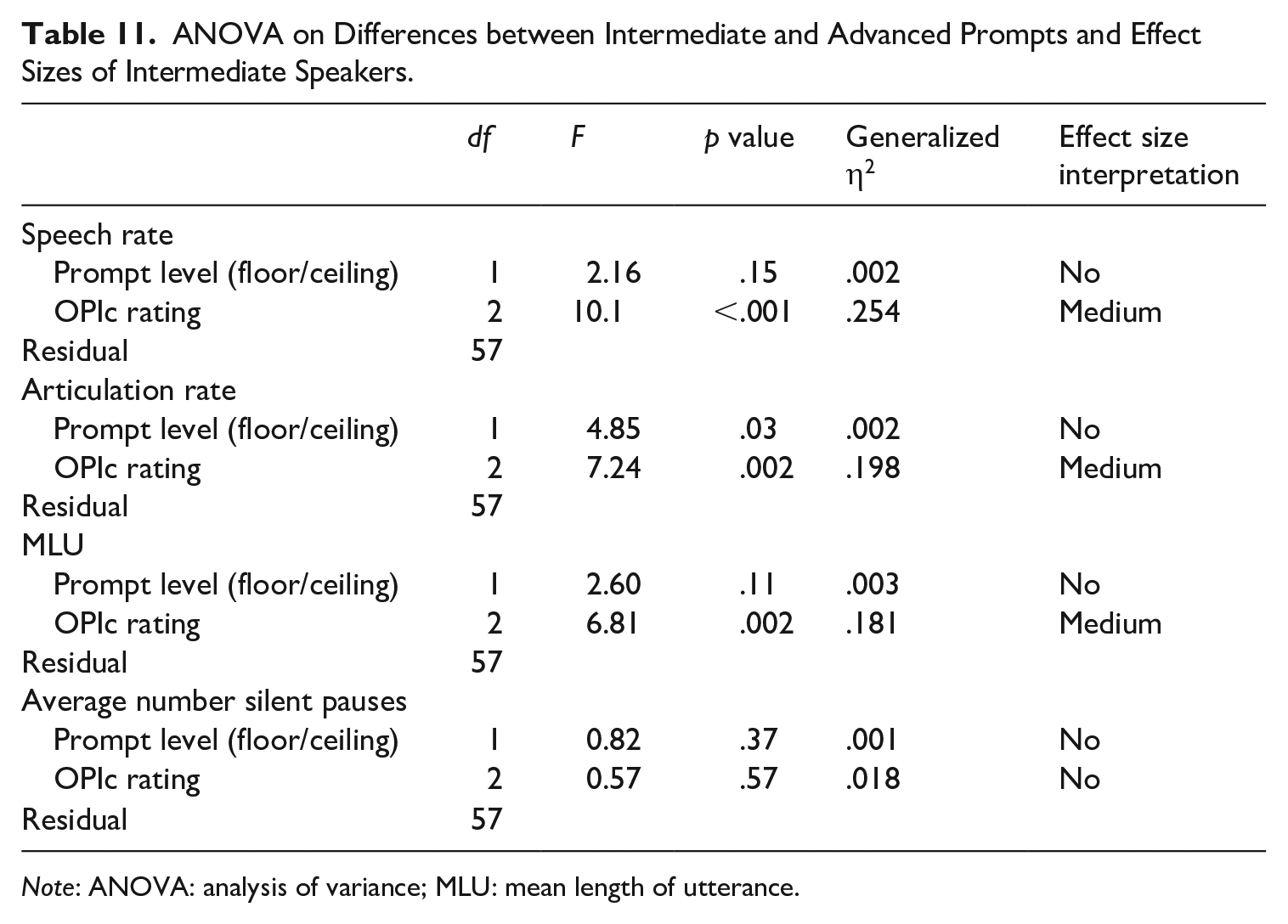
Note: ANOVA: analysis of variance; MLU: mean length of utterance.
RQ3: Advanced speaker responses to advanced (floor) and superior (ceiling) prompts
As might be expected from the results of the first research question, examinees with higher OPIc scores spoke more quickly. However, targeted question level (floor or ceiling) elicited responses with similar temporal fluency features and provided evidence that temporal fluency does not vary as much between Advanced and Superior.
With the speed measures of speech rate and AR, in some instances Advanced prompts were slightly faster but not significantly. With speech rate (see Table 12), the Advanced items (M = 3.17 syll/sec) were slightly faster than the Superior items (3.14 syll/sec).
Speech Rate of Advanced Speakers by Question Level and ACTFL Sublevel.
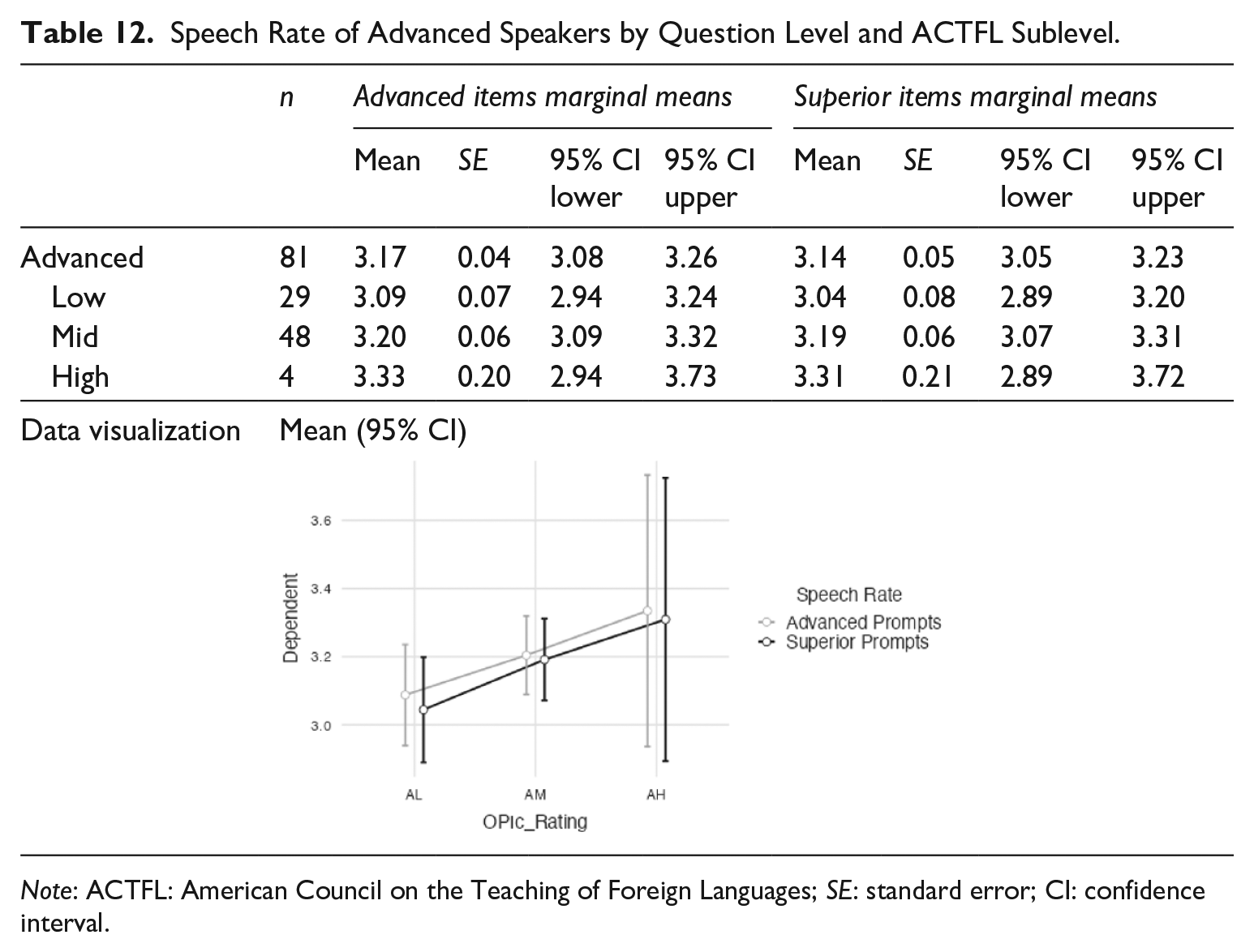
Note: ACTFL: American Council on the Teaching of Foreign Languages; SE: standard error; CI: confidence interval.
With AR (see Table 13), the Superior items (M = 4.33 syll/sec) were slightly faster than the Advanced items (4.29 syll/sec); however, it depended on the sublevel of the examinees; the AH were slightly slower when responding to the Superior prompts (4.52 syll/sec) than the Advanced ones (4.53 syll/sec).
Articulation Rate of Advanced Speakers by Question Level and ACTFL Sublevel.
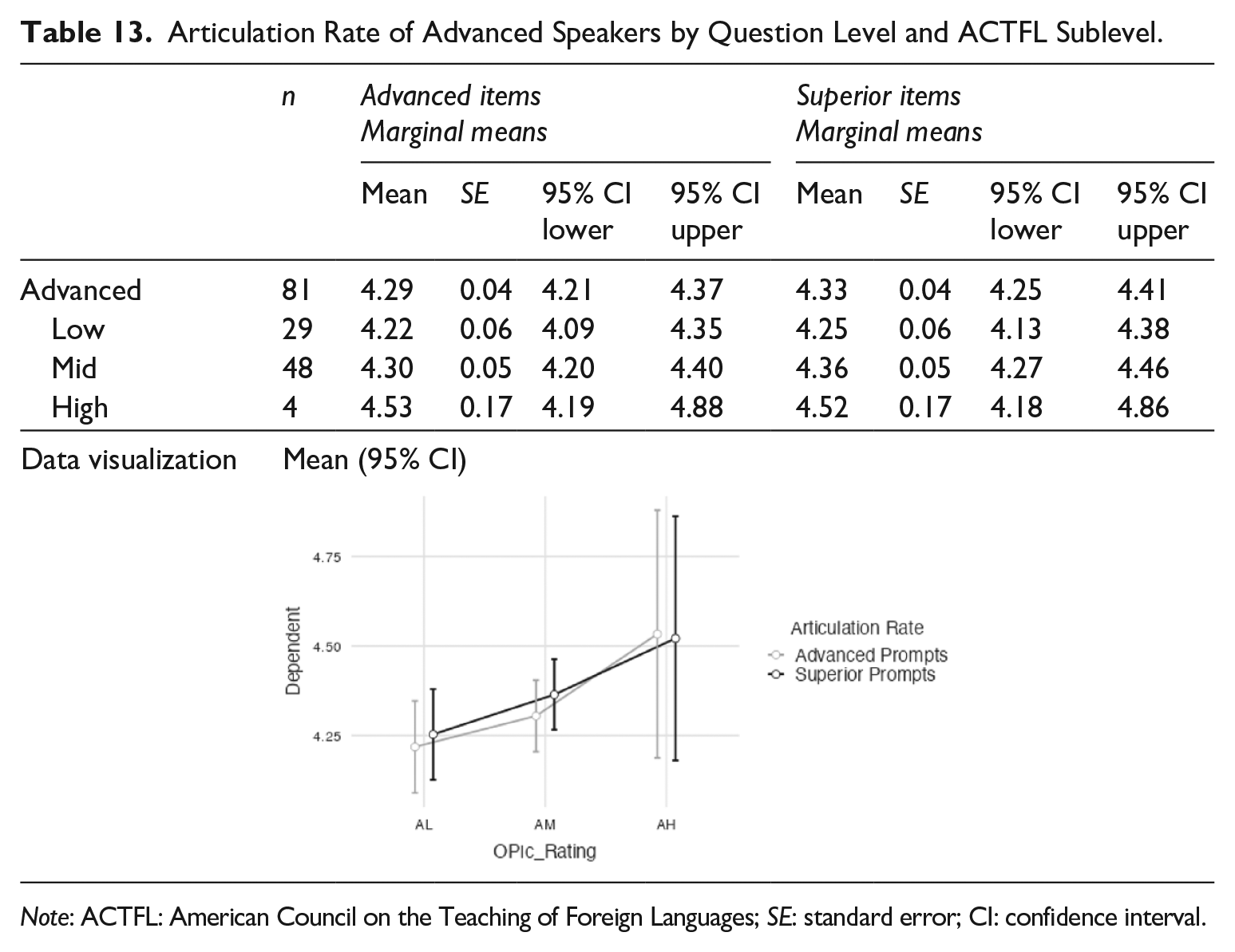
Note: ACTFL: American Council on the Teaching of Foreign Languages; SE: standard error; CI: confidence interval.
With the breakdown measures of MLU and average number of silent pauses, there was not much difference among the OPIc scores. For MLU, Advanced speakers had longer runs when responding to Advanced prompts than they did with the Superior prompts. In Table 14, the mean run length of all 81 Advanced speakers was 9.64 syllables for the Advanced prompts but only 9.32 syllables for the Superior ones. This difference was found across the three sublevels, though it did not progress monotonically from Low to High. The AM speakers had the longest MLU for prompts at both Advanced and Superior.
MLU of Advanced Speakers by Question Level and ACTFL Sublevel.
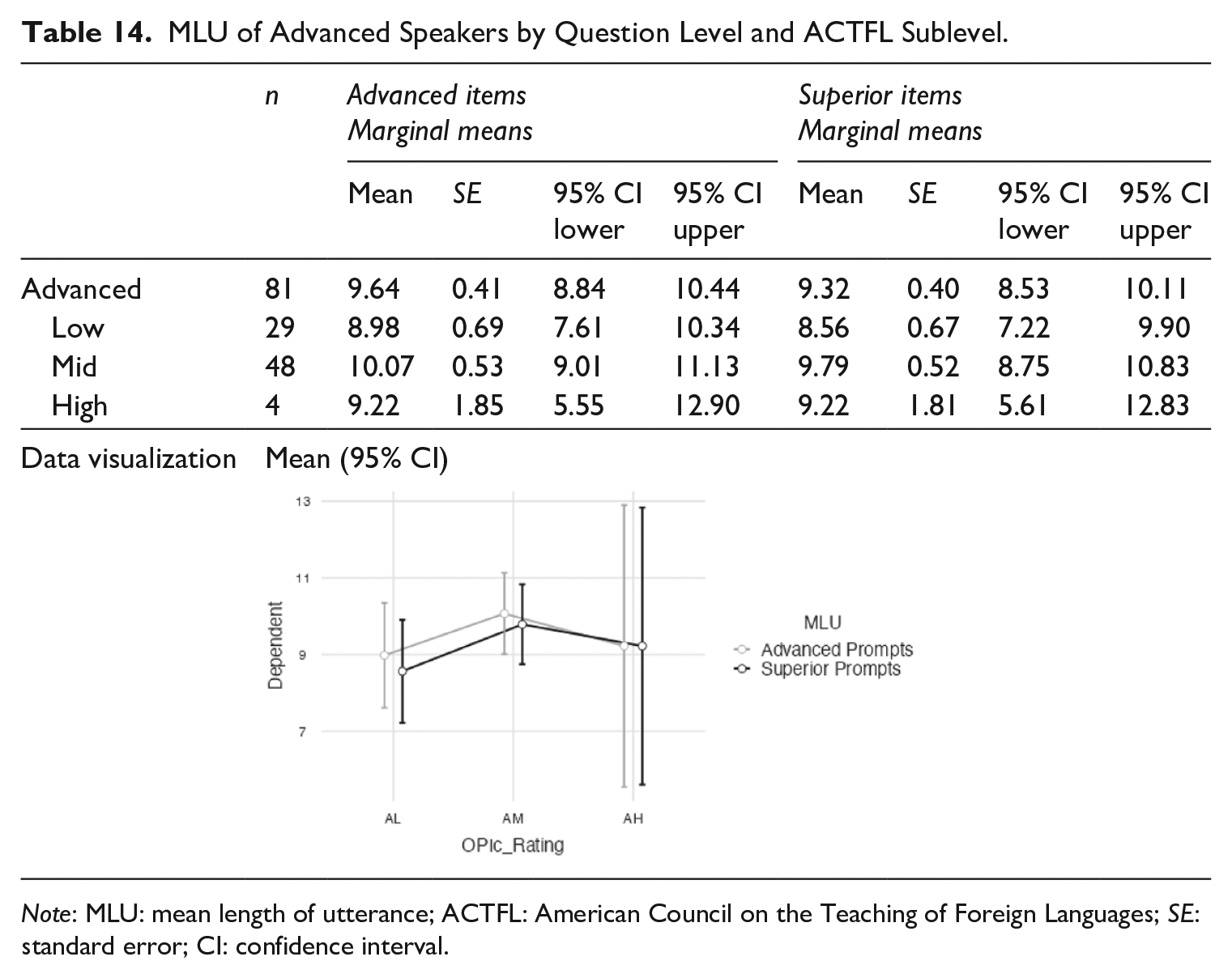
Note: MLU: mean length of utterance; ACTFL: American Council on the Teaching of Foreign Languages; SE: standard error; CI: confidence interval.
For average number of silent pauses, Advanced speakers had fewer silent pauses when responding to Advanced prompts than they did to the Superior prompts. In Table 15, the mean average number of silent pauses for all 81 Advanced speakers was 0.35 seconds for the Advanced items and was slightly more at 0.36 seconds for the Superior items. This difference was found across the three sublevels, though it did not progress monotonically from Low to High with the AM speakers having the shortest average number of silent pauses.
Average Number of Silent Pauses per Second of Advanced Speakers by Question Level and ACTFL Sublevel.
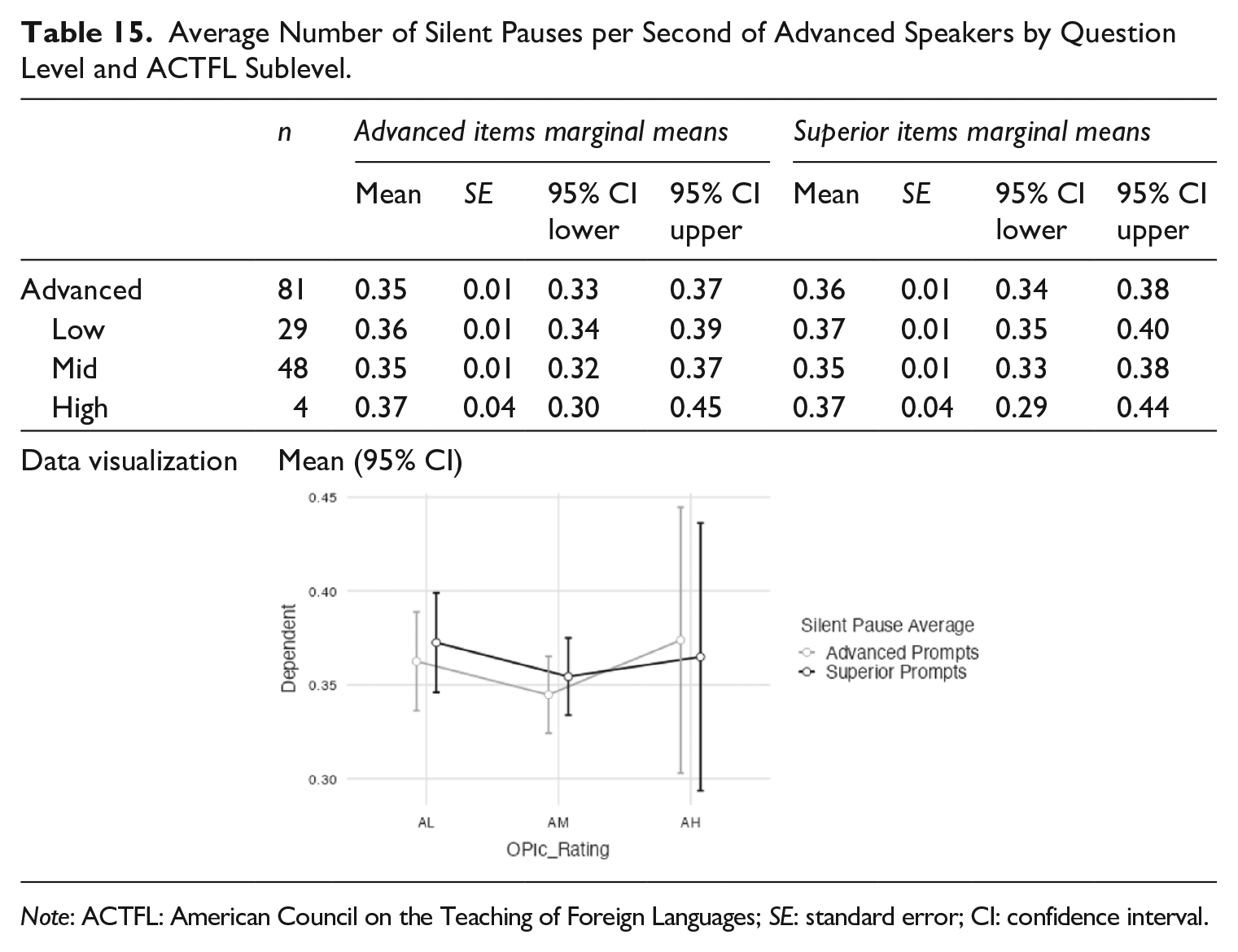
Note: ACTFL: American Council on the Teaching of Foreign Languages; SE: standard error; CI: confidence interval.
Advanced speakers had similar temporal fluency features when they responded to the “floor” questions (i.e., Intermediate level) compared with the “ceiling” questions (i.e., Advanced). There were 81 examinees whose temporal fluency features were compared between the two question levels. It was hypothesized that there would be more breakdown for Superior-level questions as compared with the Advanced questions. A repeated-measures ANOVA with four dependent variables measuring speed (AR and speech rate) and breakdown (MLU and average number of silent pauses) was conducted, and there were no significant differences nor were there any effect size differences (see Table 16).
ANOVA on Differences Between Advanced and Superior Prompts and Effect Sizes of Advanced Speakers.
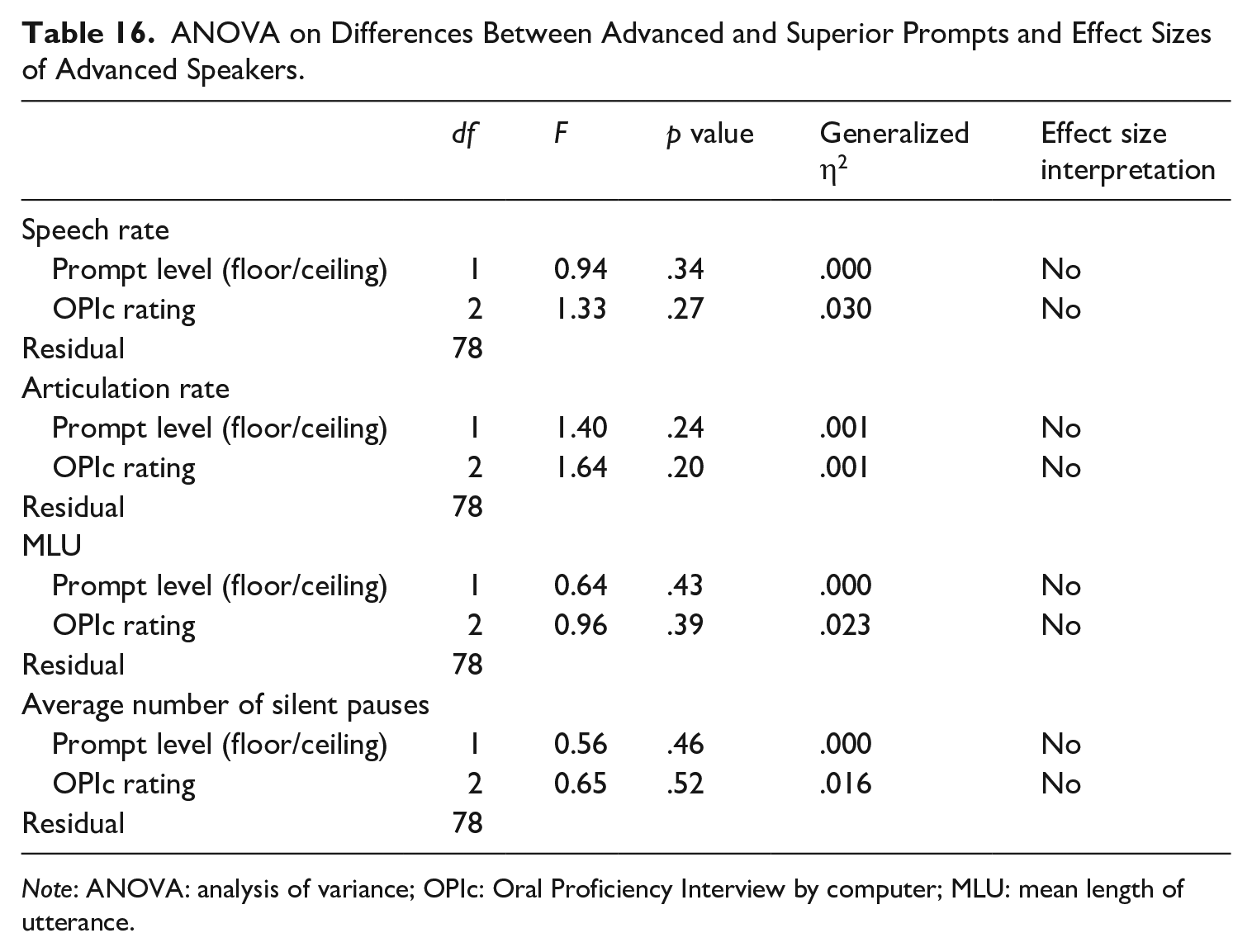
Note: ANOVA: analysis of variance; OPIc: Oral Proficiency Interview by computer; MLU: mean length of utterance.
From the analyses, it was found that the temporal fluency measures of examinees with higher ACTFL ratings was faster and had fewer linguistic breakdowns. Furthermore, the temporal fluency of prompts targeted at the major ACTFL levels (i.e., Intermediate and Advanced) varied with both speed and breakdown depending on whether speakers had been rated Intermediate or Advanced.
Discussion and conclusion
For the first research question, in terms of both speed and breakdown, the temporal fluency measures varied as described in the ACTFL guidelines. That is, as speakers progressed in proficiency, they were more fluent in the speed at which they produced discourse. The MLU increased and there were fewer silent pauses indicating either the use of more complex sentence structures or the ability to produce more robust discourse without pausing or hesitating. Breakdowns in temporal fluency often occur when searching for vocabulary or exerting cognitive resources to use grammatical forms that may have yet to be automatized. The only exception to this monotonic pattern in this study was (1) between MLU of the AM group and the AH group and (2) between the average number of silent pauses of the IL group and the IM group. While more research is needed to determine if there are some features of these groups that would cause this variation, it is believed that this is likely resultant from the small sample size (less than 7 for the IL and AH groups) of examinees who received those ratings. Future studies should consider larger numbers of participants for all sublevels under analysis to remove this possible design flaw.
The unidimensional progression, as shown in this study, lends credence to De Jong et al.’s (2012) assertion that traits vary by level, and supports Luecht’s (2003) assertion that each major ACTFL level is a constellation of unique trait mastery, and that temporal fluency contributes to the establishment of Intermediate and Advanced levels according to these characteristics. The fact that participants in this study progressed uniformly in their articulation and speech rate while showing a consistent increase in the MLU and a decrease in the number of silent pauses demonstrates how these characteristics not only are represented in different major levels but can also be used to better understand how learners exhibit their fluency in the OPIc. While the reduced sample size of Superior-level speakers in this study did not allow us to follow this progression past the Advanced level, future studies can compare a robust sample of Superior-level speakers and we would predict that the pattern would continue in this next major level.
Given the results from Préfontaine and Kormos (2015) regarding task difficulty and utterance fluency, we envisioned that as question difficulty increased, a subsequent decrease in temporal fluency would occur as answering the questions would require an increased cognitive load due to the need for additional lexical and grammatical resources (see also Skehan, 1998, 2009). Research questions 2 and 3 analyze examinee performance based on ACTFL level and anticipated prompt difficulty.
When considering the second research question, we did find slight systematic differences; however, they were not statistically significant. The Advanced questions elicited responses from Intermediate speakers that were slightly slower than the Intermediate questions. For temporal fluency breakdown, the MLU of the Intermediate questions was longer across all sublevels and the pause ratio was lower except for the IL sublevel.
Even though breakdown of Intermediate speech when attempting Advanced prompts was not significant, it could serve as one contributing part of the holistic constellation that defines major levels. That is, when IL, IM, and IH speakers respond to Intermediate-level prompts, the elicited speech has slight temporal differences compared with their performance on Advanced-level prompts. Thus, in conjunction with other features, there might be some support of Luecht’s (2003) hypothesis that different levels elicit separate constructs.
For the third research question regarding the performance of examinees on the Advanced (floor)- and Superior (ceiling)-level prompts, the hypothesis was that Advanced-level examinees would have more breakdown and shorter MLUs on the Superior-level prompts as well as a slower articulation and speech rate. We believed this would happen due to the complexity and cognitive demands of the Superior-level prompts. The results were not significantly different with either prompt level or OPIc rating.
This failure to find systematic temporal fluency differences with Advanced speakers based on OPIc ratings is likely attributable to the ACTFL definition of Advanced in which speakers can maintain oral, paragraph-length discourse. Failure at Superior prompts is more likely manifested through topic avoidance, as examinees switch from the abstract to the autobiographical to the personal rather than through linguistic breakdown in the form of diminished temporal fluency. Indeed, the difference between the Advanced and Superior speakers might be less “how fast you speak” and more “what you say” while maintaining a particular rate of speech. Content expressed through more sophisticated rhetorical structures differentiates the Superior speaker from the Advanced speaker more than a measure of temporal fluency might. Since this study did not include Superior speakers and did not examine the content or organization of the Intermediate and Advanced participants’ speech, this conclusion warrants empirical study.
We have identified several plausible explanations as to why we failed to find systematic temporal fluency differences between Advanced- and Superior-level responses, although more research is needed to determine the precise cause. First, it is likely that since these examinees were at the Advanced level, the Superior-level prompts were beyond their skill level that they simply responded to the questions with Advanced-level content and discourse. Although a Superior-level prompt might ask the examinee to hypothesize or state and logically defend an opinion about something, the individual might simply share a personal experience with narration in the past. This would be a good Advanced-level answer but fail to demonstrate the Superior level function the questions were intended to elicit. One other possible explanation for this difference is that the temporal fluency of the participants’ responses to the ceiling (Superior) questions may seem higher, but the quality of the responses is not. Examinees may be trying to maintain Superior-level discourse and speech while making a considerable number of grammatical or lexical errors that simply are not apparent in looking exclusively at temporal fluency. The difference between the responses may be more qualitative in nature and not quantitative as measured by temporal fluency. Future studies could look at comparing non-fluency aspects of candidates’ speech, such as the lexico-semantic, discursive, and grammatical features with temporal fluency. It may be that though Advanced speakers maintain a similar rate of speech as their Superior counterparts on Superior prompts, but that their levels of grammatical accuracy and discourse preclude them from reaching the Superior level. This would provide the qualitative data to support or refute the temporal fluency measures used in this study.
Finally, since there was not a human interviewer to push the examinees and elevate discourse to a Superior level, they may not have realized what Superior-level discourse was and simply dropped into a more comfortable speech range. Since most of the participants in this study were finishing their bachelor’s degree, it is likely that they would have the ability to speak at the Superior level in their L1. However, since they did not have an interviewer who could guide them and redirect examinees who started to narrate personal experiences, they may have felt that they were answering the Superior prompt even though they were using Advanced-level speech. Alas, one of the major weaknesses of the OPIc as compared with the OPI is the lack of personalization in the elicitation of speech. Many individuals do not converse on a regular basis at the Superior level with most daily conversations rooted in the Intermediate and Advanced range. Having static questions may have resulted in examinees not pushing themselves or understanding what a Superior response requires. Future studies could explore this phenomenon and see if there are individuals who receive an Advanced level on the OPIc, but a Superior level on the OPI to determine if a human interviewer helps students to maintain that higher level of speech.
One of the limitations of our study is that the participants received different test forms depending on their responses to the initial survey. Each form covered at least two major levels, but the number of floor and ceiling questions for each form varied. For example, for the three test forms used to analyze Advanced speakers, 3, 5, or 6 of the seven Advanced function question types were analyzed depending on the form selected. This was done because these were the question types that were common across the different forms making a comparison possible. Ideally, we would have liked to compare the same number of questions across all forms, but since we had extant data and were looking at resulting score and ACTFL level, we needed to use the forms and questions that each participant completed.
The results of this study bring into question claims that automated rating of speech can produce proficiency ratings, particularly if only one dimension, that is, temporal fluency, is examined. While automated speech rating has value as a blunt instrument to give a general idea of fluency, this study has shown that without careful regard to the prompts given to examinees and the lexical, semantic, and grammatical features of the candidate′s speech, automated rating that claims a floor/ceiling approach must be suspect.
In conclusion, determining an individual’s proficiency requires the assessment of myriad features and characteristics whose interaction and impact on ratings are still being understood. This study has provided further evidence as to the value of using temporal fluency measures as a guide to determine an individual’s proficiency. This is, however, conditioned by the type of prompts that are used and may very well not reflect qualitative differences at the Advanced and Superior levels. While automated analysis of speech characteristics, such as temporal fluency, has great value, and a growing body of research offers increasingly positive support for it, more research is needed to validly and reliably use such measures of speech to determine an individual’s proficiency.
Footnotes
Acknowledgements
The authors would like to thank ACTFL, the University of Kentucky, and Brigham Young University (in particular, the Center for Language Studies) for making this research possible.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.