
Abstract
Automated speaking assessment (ASA) of second language proficiency benefits both learners and educators. However, developing these systems for less commonly taught languages like Finnish and Finland Swedish is hindered by the need for large datasets with equal representation of all proficiency levels. Traditional machine learning algorithms used in ASA are data-driven and consequently struggle to generalize to underrepresented proficiency levels. This study leverages large language models (LLMs) to enhance scoring performance in underrepresented proficiency levels through two approaches: augmenting the learner’s corpus with LLM-generated transcripts (simulating data) and applying LLMs to score the transcripts of learners’ responses directly. Our findings show that both solutions are comparable to or better than a traditional machine learning model trained on the original data for proficiency levels with fewer examples. Additionally, we found that providing LLMs with examples of human grading at various proficiency levels significantly enhances their performance as graders, especially when compared to using a single demonstration or none at all. Finally, our study confirms that using automatic speech recognition transcripts instead of human transcripts does not compromise assessment quality, enabling the development of LLM-based systems that can generate proficiency ratings directly from audio input.
Introduction
Automated assessment of second language (L2) speech, a form of artificial intelligence (AI) based language assessment technique, can offer significant benefits for students and teachers, potentially reducing educators’ workload and supporting learner self-assessment (Evanini & Zechner, 2020). In recent years, language teachers are increasingly using generative AI tools, for example, ChatGPT, to translate texts or produce materials such as word lists, pictures, and texts that target a particular topic or a certain learner proficiency level. In response to this trend, universities have published policy statements for the use of AI in teaching and learning (Voss et al., 2023). When the use of AI is welcomed and supported in language classrooms, teachers must verify that the material created is appropriate for the intended use and level. Nevertheless, the utilization of AI in language assessment is viewed with caution, perhaps due to the potential consequences of assessment. Restrictions and concerns (validity, bias, privacy, and copyright) also complicate its adoption (Voss et al., 2023). Still, there are promising examples of using AI-based tools for speaking assessment (Chapelle & Chung, 2010; Evanini & Zechner, 2020). These tools may be especially valuable in languages with fewer learners, or less commonly taught languages, where instructional and assessment resources are limited (see e.g., Dhahbi et al., 2025; Yan et al., 2020).
Training an automatic assessment system for such low-resource languages presents significant challenges, primarily due to data scarcity and imbalance. The limited availability of data stems from the logistical complexities of designing speech tasks and corpora, and collecting and annotating speech data from a relatively small learner population, especially compared to more commonly spoken and widely studied languages like English. After the data are collected, the balanced representation of proficiency levels is not guaranteed. As Al-Ghezi, Voskoboinik et al. (2023b) found, the challenge of data scarcity was further intensified by the class imbalance within the data. In machine learning (ML), these target categories are called classes, so in this case, each proficiency level is a class. Thus, class imbalance means that some proficiency levels are less represented in the data, with very few samples. This issue hinders the effectiveness of traditional approaches to Automatic Speaking Assessment (ASA), which typically require abundant and balanced datasets. While ASA has evolved (from hand-crafted features to utilizing advanced pretrained neural networks), these advanced methods still require training with significant parameter updates and extensive data, limiting their effectiveness for scarce and imbalanced settings.
That said, it has recently been shown that large language models (LLMs) can complete new tasks in a zero-shot fashion when given only a textual instruction (Radford et al., 2019). LLMs are neural networks with large numbers of parameters, trained on vast text corpora. Zero-shot means that the model receives only one instruction on how to solve the problem. That is, the model (unlike traditional ML models) does not require retraining with parameter updates for a specific task to be able to solve it The ability of LLMs to solve tasks can be further improved when the model receives demonstrations of expected behavior, referred to as in-context learning (ICL) (Brown et al., 2020). The addition of one demonstration to the given instruction is referred to as one-shot learning. As such, the model can be further enhanced when it receives more than one demonstration (i.e., few-shot learning). In addition, ICL performance can improve further when LLMs are fine-tuned with follow-up instructions (Mishra et al., 2022; Wei, Bosma, et al., 2022), especially when they are aligned with human intent (Ouyang et al., 2022).
Traditional ML models learn from patterns in labeled data such as proficiency scores in language assessment. These models often struggle with underrepresented classes, which is a common issue in L2 datasets. LLMs, by contrast, can generalize from task instructions and a handful of demonstrations, and can also generate synthetic data to augment limited datasets. However, as text-based models, they cannot process audio directly and instead rely on transcripts, which both underrepresent the full construct of speaking proficiency and differ from the written language based on which LLMs are typically trained. In this study, we examine whether LLMs, although not tailored for speech data, can still achieve reliable scoring in low-resource L2 contexts, particularly for underrepresented proficiency levels, through synthetic transcript generation and direct grading. We focus on Finnish and Finland Swedish, testing LLM performance on human- and ASR-produced transcripts and comparing them to traditional ML models trained on the same input.
Related work
Speaking is a key component of language proficiency and, thus, is essential for its assessment (e.g., Isaacs, 2016). However, scoring speaking performances is markedly more cost- and time-intensive, as it relies on multiple trained human raters to achieve reliable scores. Consequently, some large-scale L2 proficiency tests have excluded the assessment of speaking. Finland’s Matriculation Examination, taken at the end of upper secondary education, assesses listening, reading, grammar, and writing but omits speaking due to limited resources.
ASA offers a scalable alternative to manual scoring, especially in under-resourced contexts, by reducing costs and speeding up scoring (Isaacs, 2018). It also helps mitigate rater effects, such as rater fatigue (Ling et al., 2014), rating and training experience (Davis, 2016), or accent familiarity (Kang et al., 2019), by consistently assigning the same score to the same response. From the learner's perspective, ASA supports formative assessment by providing more reliable scores and immediate feedback, which may reduce speaking anxiety and promote self-regulated learning (Qiao & Zhao, 2023; Zhai & Wibowo, 2023).
An ASA system processes an audio recording of a learner performing a speaking task and outputs a proficiency score that ideally reflects the judgment of a well-trained, unbiased human rater. To learn this behavior, the system is trained on previously scored responses, using ML to map human scores to features capturing relevant aspects of language ability (Evanini & Zechner, 2020). Scores can be holistic, reflecting overall ability, or analytic, targeting specific aspects like delivery, language use, topic development, or interactive competence. What can be evaluated depends on the task: constrained formats like read-aloud support only delivery scoring, while open-ended tasks allow broader construct coverage. Features must align with the construct: delivery can rely on acoustic properties, while topic development typically requires transcripts produced by automatic speech recognition (ASR), which must itself be trained to handle learner speech.
ASA systems learn to map features to scores by adjusting parameters to minimize the difference between predicted and human-assigned scores (Bishop, 2006; LeCun et al., 2015). Models are evaluated on their ability to generalize to unseen response–label pairs. When training data is limited, especially for certain proficiency levels or accents, the mappings may not generalize reliably (He & Garcia, 2009) and the model’s predictions can may diverge from human judgment. Moreover, if the training data contains biased or inconsistent ratings, the model may replicate those biases. Over time, a range of strategies has been developed to support this learning process, from hand-crafted linguistic features to deep neural networks that jointly learn feature representations and scoring functions.
ASA approaches
Originally, proficiency scoring of L2 speech involved extracting predefined, linguistically informed hand-crafted features. These were aligned with scoring rubrics and provided interpretable measures of language ability, such as fluency and pronunciation (Zechner et al., 2009), language use (Chen & Zechner, 2011), and content appropriateness (Xie et al., 2012). The features were combined using either linear or non-linear models to produce a final score. Over time, hand-crafted features were replaced by representations learned directly from data by neural networks (Qian et al., 2019), which demonstrated better performance at the cost of interpretability.
With the introduction of Transformer-based models (Vaswani et al., 2017), the field of natural language processing (NLP) has undergone considerable advances. These models, initially designed for text, are trained via self-supervised learning on extensive, unlabelled corpora. In self-supervision, the model generates its own labels from the data’s inherent structure. For instance, in text, the model might mask certain words and learn to predict them from the surrounding context. By carrying out such tasks, the model acquires general language representations that can be directly employed as features or further fine-tuned for specific applications, reducing the need for labeled data. The efficacy of these pretrained models for ASA was demonstrated in Wang et al. (2021), where fine-tuning Bidirectional Encoder Representations from Transformers (BERT; Devlin et al., 2019) and XLNet (Yang et al., 2019) on ASR-transcribed speech surpassed human levels of agreement. However, the performance of these models relies heavily on accurate ASR output, as they extract features only from text.
Recent studies have shown that self-supervised audio models, such as wav2vec 2.0 (Baevski et al., 2020), are well suited for both ASR and ASA of L2 speech, including applications not only in English (Bannò & Matassoni, 2023) but in Finnish and Finland Swedish as well (Al-Ghezi et al., 2021; Al-Ghezi, Getman 2023a). Like their text-based counterparts, these audio models are trained in a self-supervised manner and can then be further adapted for tasks like audio classification. It means these models can surpass the ASR bottleneck, as they do not rely on transcribing the data and can directly produce representations from audio for both the content and delivery aspects of the recording. Both text and audio models can be mono- or multi-lingual, depending on the data they were trained on. Meaningful representations are available only for languages they were trained with. Although pretrained models mitigate data scarcity issues, they remain susceptible to data imbalance challenges, especially when scarcity and imbalance co-occur. Moreover, these models still require task-specific examples for fine-tuning, and updating their parameters complicates deployment.
Handling scarcity and imbalance in ML
Approaches to handling data imbalance are well researched and there are different ways to address theproblem. In general, the problem could either be addressed on the data level or the algorithmic side. Over- and under-sampling (Weiss et al., 2007) are two options for the former, while class weighting (Xu et al., 2020) is a classic example of the latter. The common factor of all solutions is the emphasis on the rare class samples to ensure higher performance on rare data without sacrificing too much accuracy for the over-represented categories: oversampling replicates smaller class examples, undersampling removes larger class examples, and class weighting assigns higher importance to rare classes during training.
While previous techniques address imbalanced data, they do not solve imbalance when data are scarce. Data augmentation (Mumuni & Mumuni, 2022) offers a solution for both problems by generating more training samples from existing ones. Each field has developed many augmentation methods, and initial efforts used noise injection to enhance the variability of existing datasets and create additional training samples (Xie et al., 2020). In speech processing, speed perturbation (i.e., slowing down or speeding up the audio) and frequency masks removing the speech signal energies in random frequency intervals were popular (Park et al., 2019). For NLP, back-translation technique that simply translates the text into another language and back has been used (Edunov et al., 2018). Later, new techniques appeared that started using other AI models to create realistic samples, most notably generative adversarial networks (GANs; Goodfellow et al., 2014). While these methods of alleviating imbalance and scarcity remain useful, LLMs offer an alternative path. They can be used both to generate new training data, and to solve tasks directly through instructions, without the need for additional parameter updates.
LLMs for data challenges
What is an LLM?
LLMs are a specialized type of language model (LM), namely, a neural language model (NLM; Mikolov et al., 2010). The exact architecture of a neural network used in NLMs varies, often involving either recurrent neural networks (RNNs) (Mikolov et al., 2010), or transformers (Vaswani et al., 2017). NLMs solve the task of language modeling as follows: given a sequence of words, they estimate the probability of all words in the vocabulary to be the next word of this sequence. This is achieved by first representing the sequence of words as a feature vector in a d-dimensional space, where “dimension” refers to an axis or feature used to encode information about the input. The number of dimensions (d) is an arbitrary value that can range from hundreds to thousands in modern models. This vector is then transformed into a v-dimensional vector, where v equals to the vocabulary size of the model. Each dimension in this vector acts as a score (known as a logit) for a potential next word. These logits are converted into probabilities using a softmax function. To predict the most probable next word, the model selects the word corresponding to the highest logit or probability.
Predicting the most probable next word is referred to as greedy sampling. The model’s token selection process described above is shown in Figure 1. To enhance the diversity of next token predictions, a technique known as nucleus sampling can be used, where only the top, for instance, 10% of the probability mass is considered for randomly selecting the next word. Additionally, logits can be scaled with a temperature parameter in the softmax function to smoothen the probability distribution. With a temperature of 0, the model is forced to use greedy sampling. Higher temperatures facilitate greater “creativity” in model outputs by broadening the word pool for nucleus sampling.
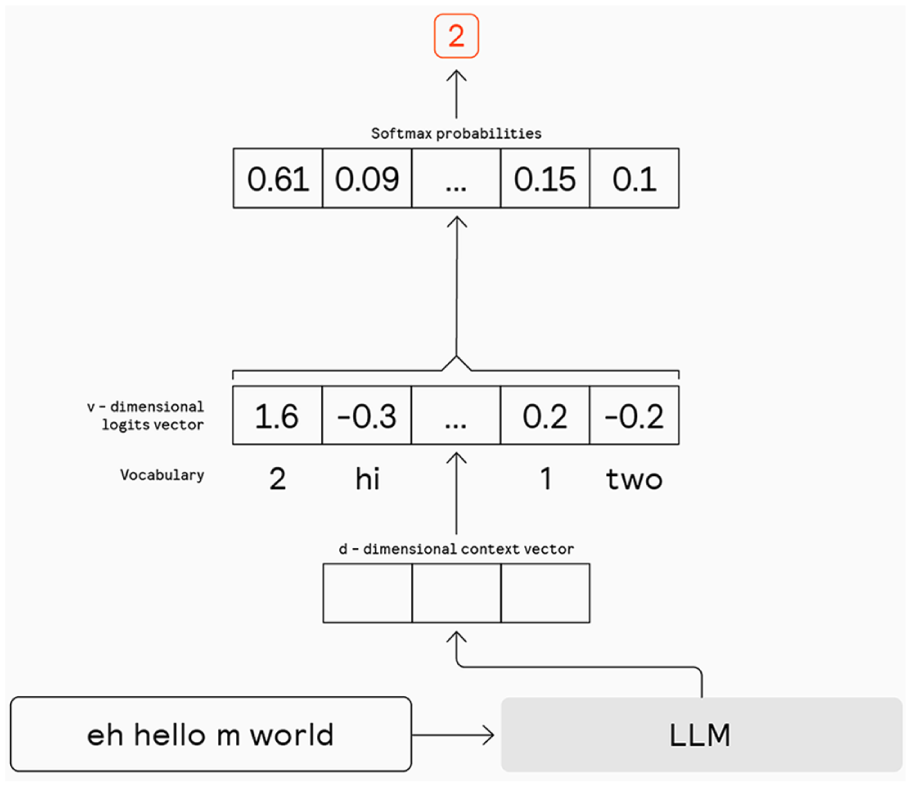
LLM greedy next token prediction.
Typically, LLMs are NLMs that utilize transformer architecture. The term “Large” refers to the substantial number of trainable parameters these models possess. Research suggests that model performance improves with increased size (Brown et al., 2020) and emergent capabilities begin to appear (Wei, Tay et al., 2022). Currently, the developers or marketers for prominent models such as GPT-3 (Brown et al., 2020) and PaLM (Chowdhery et al., 2023) report having over 100 billion parameters.
What is prompting?
In discussions of LLMs “solving” tasks, it is crucial to understand that their fundamental operation involves predicting the next word rather than having a specific modle as was done in traditional ML. The input text, commonly referred to as a “prompt,” guides the model by delineating the task or providing specific instructions. This capability of LLMs to solve tasks solely with prompts was first demonstrated by GPT-2 (Radford et al., 2019). Furthermore, when LLMs are described as being instruction-tuned or aligned to human intent, this means that the models have been trained to generate tokens that adhere closely to provided instructions and effectively respond to user intent. One of the primary applications of LLMs is engaging in conversations with users. In such models, special tokens are injected to delineate different roles within the text, such as system, user, and assistant. These roles organize the prompt as a simulated dialogue. For more details on prompt formatting and its use in ICL, please refer to Supplementary Appendix 1.
LLMs for data generation
With the rapid advancements in generative AI, a new direction has become available. LLMs are shown to produce synthetic data that is almost indistinguishable from the real one. In Yoo et al. (2021), GPT-3 is used to generate realistic text samples from a mixture of real samples, and Dai et al. (2023) demonstrate how ChatGPT can rephrase sentences to expand corpora. Synthetic data can also improve the very model that produced it. For instance, an LLM can enhance its instruction-following by training on its own outputs (Wang et al., 2023). Notably, LLM-generated data boosts reasoning abilities across various languages, including those with limited training resources (Whitehouse et al., 2023). In addressing data imbalance, it was found that generated data enhances text classification performance (Cai et al., 2023), and similar benefits were reported in Cloutier and Japkowicz (2023), particularly for non-binary classification tasks.
LLMs for scoring
There is also work on evaluating the scoring ability of LLMs (Zheng et al., 2024), and their results have shown that LLMs are capable of assessment to the same level as human experts. Furthermore, research demonstrates that LLMs can be effective tools for automated writing evaluation, including assessing discourse coherence in L2 texts (Naismith et al., 2023), assigning proficiency levels to L2 essays (Yancey et al., 2023), and evaluating L2 Chinese writing (Jiang et al., 2023).
ICL strategies
When applying LLMs to tasks, it is crucial to proceed with caution due to the potential instability of prompts. The factors that contribute to successful ICL remain unclear. For example, the order in which examples are presented in a few-shot prompt can dramatically impact performance, leading to outcomes ranging from state-of-the-art results to random guessing (Lu et al., 2022). Furthermore, when exploring what examples to use as demonstrations, it was suggested that the balance of labels might not be the most important, but covering all possible labels gives the best result (Zhang et al., 2022). At the same time, it might not be the label but the text that guides the model. It was shown that demonstrations with random labels are better than no demonstrations (Min et al., 2022).
Research gap and research questions
While most of this work on LLMs addressing data scarcity, imbalance, and reasoning focuses on English, we are optimistic that similar approaches can be applied to other languages, such as Finnish and Finland Swedish. Additionally, while LLM-based evaluations of L2 proficiency have focused primarily on written text, our work takes a distinct path by applying LLMs to score speech transcripts (produced by both human and ASR), where the characteristics of speech differ from those of written text. We aim to examine whether LLMs be effective in addressing both the challenges of data scarcity, and the unique demands of L2 speech proficiency assessment.
Below we present our research questions (RQs):
RQ1. To what extent does training traditional ML models on transcripts generated by LLMs affect the scoring of Finnish and Finland Swedish speech, particularly at proficiency bands with limited examples?
RQ2. How effectively can LLMs grade Finnish and Finland Swedish speech transcripts, particularly at proficiency levels with limited examples?
RQ3. How well do LLMs maintain scoring performance when ASR transcripts were used to replace human transcripts in real-world assessment scenarios?
RQ4. What is the impact of LLM size in a low-resource setting, specifically the transcript-based assessment of speech proficiency in Finnish and Finland Swedish learners?
Methods
This study consists of four experiments, each designed to address one of the RQs . In this section, we first describe the participants and datasets, and then the evaluation metrics, followed by the methodology used in each experiment.
Dataset and Participants
This study uses data from the DigiTala dataset, available through The Language Bank of Finland (FIN-CLARIN) (Kielipankki, 2024). The dataset contains L2 speech from learners of Finnish and Finland Swedish. We focus on a subset collected through low-stakes online speaking tests conducted as part of a research pilot (Al-Ghezi, Voskoboinik, et al., 2023b). These tests targeted four learner groups: upper secondary school and university students studying either Finnish or Finland Swedish.
The dataset used in this study included some student participant background information, which, however, was not available for Swedish school participants. Finnish school participants were all under 22 years, predominantly female, with Finnish, Swedish, and Russian as the main L1s. Finnish university participants were mostly 22–26 years, predominantly male, with English, Russian, German, and Vietnamese as the main L1s. Swedish university participants were mostly over 26, predominantly female, with Vietnamese, Russian, and English as the main L1s. For more details about participants’ characteristics, refer to Kurimo et al. (2023).
Speaking Tasks
For Finland Swedish, we selected two tasks (A and B) completed by high school students (Karhila et al., 2016) and one task (C) from a university test (von Zansen, 2022b). In Task A, students were asked to thank someone for throwing a party within a 10-second response time. Task B required a longer response, where students were shown a picture of a moose crossing a road and were prompted to simulate a call to the police, with an expected answer length of about 30 seconds. Finally, in Task C, students were asked to talk for a minute about their typical day. For the Finnish dataset, we selected two tasks (D and E) from upper secondary school tests and one task (F) designed for university students. Task D asked students to speak for one minute about a place that is important to them. In Task E, students were asked to describe the picture of the university library in one minute. Finally, Task F requested students to describe their typical day, similar to Task C in the Finland Swedish dataset. The tasks for both groups are presented in Supplementary Appendix 2.
The test tasks for the school students were designed for the B1-B2 levels on the Common European Framework of Reference for Languages (CEFR), while the tests for the university students targeted A1-A2. Each test included a mix of read-aloud and free response tasks (semi-structured and open-ended), except for the Swedish school test, which included only free response tasks. All student responses were recorded and manually annotated with transcripts and proficiency scores. For ASR training, we used all available responses across all tasks. For ASA experiments, we focused on a subset of six free response tasks (three per language). From these tasks (tasks A–F hereafter), we used transcript–score pairs for training and evaluation, and the corresponding task instructions were used as inputs in LLM-based experiments. The remainder of this subsection describes the annotation procedures for transcripts and scores and explains the criteria for selecting the six tasks used in ASA.
Label construction: Transcriptions
Six university students, recruited and briefed by the research team, created transcriptions. Specifically, two transcribed Finnish recordings, two transcribed Finland Swedish university recordings, and two transcribed Finland Swedish school recordings. They were instructed to capture the audio as accurately as possible, including any hesitations and mispronunciations, to reflect both content and pronunciation. Additionally, the transcriptions contained meta-annotations, such as <garbage> for unintelligible speech and <bgnoise> for background noise. Agreement between transcribers was measured on 200 recordings from the Swedish university dataset, revealing that 14% of words differed between the two transcriptions. Verbatim transcription using alphabetic characters is especially challenging, as some learner-produced sounds do not clearly map onto the phonological system of the target language. For other recordings, agreement could not be assessed, as no other recordings were transcribed by multiple transcribers.
Label construction: Human ratings
Proficiency scores were assigned by experienced language teachers and teacher trainers familiar with the CEFR, using rubrics created for the purpose of this research. All raters received training prior to scoring, to become familiar with the task types and assessment procedures. The Finnish raters spoke either Finnish or Russian as their L1s, whereas the Swedish raters spoke Finnish or Swedish as their L1s (for details, see von Zansen et al., 2022). The raters worked independently after training. There were 18 raters grading Finland Swedish school recordings and 14 raters rating Finland Swedish university responses. Finnish school recordings were graded by 25 raters, whereas Finnish university recordings received ratings from 24 raters. The rubrics used for grading both Finnish and Finland Swedish were in Finnish, drafted based on the Finnish National Core Curriculum (NCC) for general upper secondary education (Finnish National Agency for Education, 2003). The rubrics were drafted for research purposes mostly targeting low-stakes assessment contexts such as supporting self-regulated learning. The holistic and analytic rating scales were presented on separate scales to avoid possible halo effects.
Free response task speech productions were rated in terms of holistic proficiency, along with multiple sub-dimensions: pronunciation, fluency, accuracy, range, and task completion (Al-Ghezi, Voskoboinik et al., 2023b). This study focuses on the holistic scores, with raters selecting a score from 1 to 7, roughly corresponding to CEFR levels from below A1 to C2 (for scale validation of the NCC scale, see Hildén & Takala, 2007). Although the models used in this work rely solely on transcripts and might miss acoustic cues available from audio, we chose to predict holistic scores rather than subdimensions, which can, to some extent, compensate for the missing of acoustic information. This decision was further supported by the higher inter-rater agreement for holistic scores, which makes them more reliable as training labels (Song et al., 2022). For rater agreement by dimension, please see Supplementary Appendix 3. Most of the recordings received scores from multiple raters, with an average of 2.1 ratings per recording for Finland Swedish (range: 1–14) and 2.6 for Finnish (range: 1–25). To produce a single training label per response, we averaged the holistic scores and discretized the result into one of seven equal-width bins spanning the 1–7 scale. This step transformed the continuous average into a categorical label suitable for model training.
The fold-splitting process was as follows. Each student who responded to the selected grading tasks was assigned an average holistic score based on their responses. This average score was then binned into one of seven bins, as shown in Figure 2. Finally, the four folds were created by stratifying the student levels within each bin, ensuring that each fold contained a similar distribution of proficiency levels and that speakers did not mix between different folds. This process provided a balanced representation of speakers across all proficiency levels within each fold. To divide the recordings outside the selected tasks, for students who did not respond to the selected tasks, fold assignment was done randomly. The distribution of data between the folds is reported in Supplementary Appendix 4.
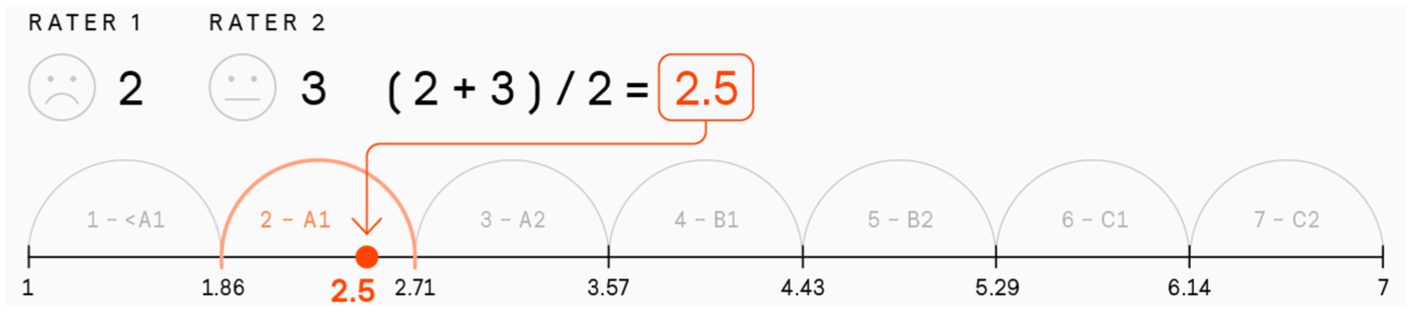
Binning averaged human scores into a single categorical label for training.
Task selection
For ASR training, we used recording–transcript pairs from all tasks, since label reliability was not a concern. For holistic scoring experiments, we limited the data to free response tasks, which provide more comprehensive evidence of language proficiency than read-aloud tasks. Among these, we selected three tasks per language: A, B, and C for Finland Swedish, and D, E, and F for Finnish. This decision was driven by the need to reduce label noise from low inter-rater agreement and to ensure more reliable training and evaluation. See Table 1 for the summary statistics for the selected tasks.
Task statistics used in ASA training.
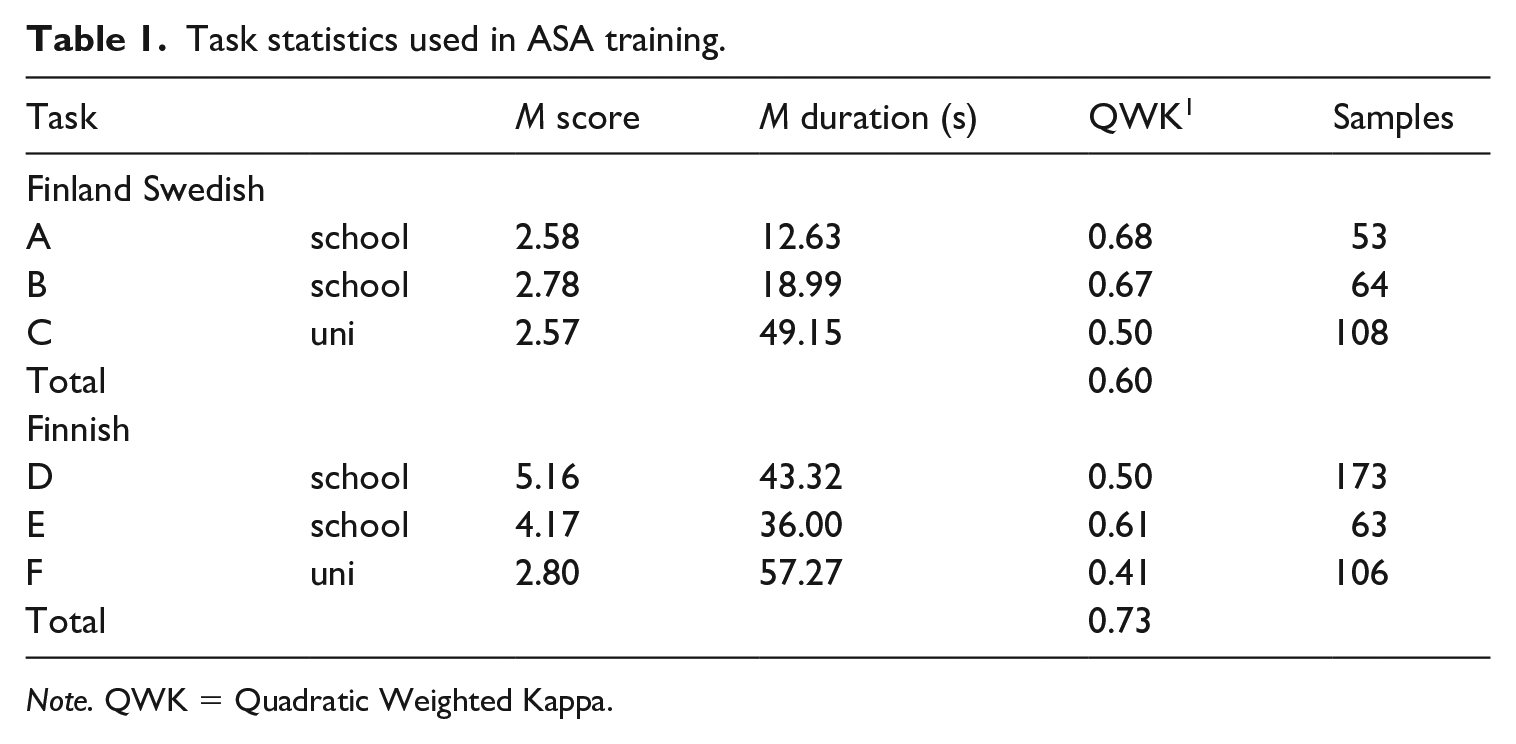
Note. QWK = Quadratic Weighted Kappa.
Tasks were selected to ensure both label reliability and diversity across student groups and response formats. For each language, we aimed to include tasks completed by both high school and university students. We also prioritized variation in response demands, selecting tasks that required both short and extended answers. To ensure label quality, we focused on tasks with high inter-rater agreement, as measured by Quadratic Weighted Kappa (QWK). Agreement was generally higher for high school tasks, likely due to more homogeneous learner backgrounds, while greater variation in university students’ accents may have contributed to inconsistent ratings (Kang et al., 2019). Within each learner group, we identified the five tasks with the highest QWK scores and selected a diverse subset from this pool. The final Finland Swedish subset reached an inter-rater agreement of 0.60, and the Finnish subset achieved 0.73 (see Supplementary Appendix 3).
Metrics for model evaluation
To analyze the performance of the models, the scores that the models produce are compared to the aggregated and binned scores. To study the difference between model and human behavior, we use the following metrics: accuracy, macro F1, macro Precision, macro Recall, QWK, and macro mean absolute error (MAE). Accuracy shows the proportion of labels produced by an automated scoring system that match human labels. F1 is the harmonic mean of precision and recall. Precision indicates how many responses graded as proficiency level X by the machine match human labels, while recall indicates how many human-graded level X responses are correctly identified by the machine. QWK measures the agreement between aggregated human scores and model labels. MAE measures the average magnitude of prediction error. Macro means the performance metrics were calculated for each proficiency level and then averaged, ensuring all proficiency levels contribute equally to the final metric. All metrics are used in Experiments 1–3 (corresponding to RQs 1–3), while Experiment 4 (RQ4) uses only macro F1, QWK, and macro MAE.
To facilitate a more detailed comparison between the models, especially across different proficiency levels, we also include plots of F1 scores by proficiency level. Each plot presents F1 scores for individual levels in a task, with levels represented as columns and models identified by row names. These scores reflect the model’s performance at specific levels, analogous to the diagonal of a confusion matrix. Higher F1 scores indicate better model predictions at the corresponding level. Additionally, the “Level Proportion” rows indicate the proportion of samples per level in a task, with higher values representing majority classes. This row allows for easier comparison of per-level performance relative to the data availability in the original dataset. Both level proportions and F1 scores use darker colors to visually emphasize majority levels and better performance.
Experiments
The initial pair of experiments aimed to assess LLMs’ understanding of holistic proficiency in L2 Finnish and Finland Swedish. The objective was to identify strategies that enhance text-based baseline performance at underrepresented proficiency levels. The third and fourth experiments focused on examining the application of LLMs for grading in real-life scenarios.
BERT as traditional ML baseline and cross-validation
To understand if LLMs are beneficial for ASA with scarce and imbalanced data, we compared them to a method that has been shownto work in a general ASA setting. Since the main modality that most LLMs operate on is text, we chose to compare their performance against a text-based solution to ensure a fair comparison. To create this baseline 1 , we selected BERT-based models (Devlin et al., 2019). This approach is a common method for text classification problems and has been shown to be effective in proficiency scoring of L2 English speech using ASR transcripts, without relying on explicit delivery features such as pronunciation and fluency (Wang et al., 2021). The Finland Swedish and Finnish models were trained on manual transcript–score pairs from tasks A–C and D–F, respectively.
To assess the performance of the system through cross-validation, we split the data into four parts, called folds. In each round of cross-validation, one fold serves as the test set, while the other three folds are used for training. This ensures that every fold is used as test data once, and the results are averaged to provide a robust evaluation of the system. To ensure that the system is reliable in the real-world conditions of transcribing speech with ASR and then scoring, each fold was designed to reflect the overall dataset. For scoring, the distribution of proficiency levels was preserved to match the overall data, while for ASR, the folds contained different speakers to ensure the system was not biased and could generalize to new individuals.
Experiment 1
To address RQ1, we used synthetic transcripts generated by the GPT-4 model (OpenAI, 2023), hosted on Azure OpenAI, to construct two training datasets: (1) a fully synthetic dataset and (2) an augmented version of the original dataset, where underrepresented proficiency levels were supplemented with synthetic responses. For each dataset, we trained a BERT-based classifier to predict holistic proficiency scores for free response tasks A–C (Finland Swedish) and tasks D–F (Finnish), and evaluated the models on original human transcripts. The goal was to assess whether LLM-generated data can improve performance, especially for rare levels, compared to the baseline. For overall performance comparison, we used macro F1, macro Precision, macro Recall, macro MAE, accuracy, and QWK. To assess how models performed at individual proficiency levels, we examined per-level F1 plots described in Metrics.
For the model to effectively generate examples of spoken responses, a well-structured prompt is crucial. The prompt was created in a zero-shot fashion, containing only system and user messages. The system message for data generation defined the task the model needed to perform: generating transcripts. It specified the proficiency level descriptors, which contain the evaluation criteria used by raters (von Zansen, 2022a; see Supplementary Appendix 5 for the translated version). Additionally, the task description and the target language were incorporated to ensure that the outputs mirror the original tasks as seen by students. Finally, we outline the format in which the model should return the answers, designed for easy automatic extraction of the generated examples. The user message outlined the targeted proficiency level, and the number of transcripts required at that level. For each task, the prompt included only the level descriptors for the proficiency levels present in the original data to save tokens. To conserve resources and ensure a diversity of responses, especially at lower proficiency levels, we prompted the model to produce five transcripts simultaneously and set the temperature parameter to 1. The complete system and user prompt templates can be seen in Supplementary Appendix 6 .
In forming the fully synthetic dataset, we aimed to maintain the same total amount of data as in the original dataset while making the proficiency level representation equal. We calculated the number of responses per task and redistributed this number evenly across all levels present in the original responses. Each level was then populated with generated responses until the predetermined quota was met. This method ensured that the sample size matched the original dataset, with each level equally represented. This balanced distribution approach is illustrated in Figure 3.
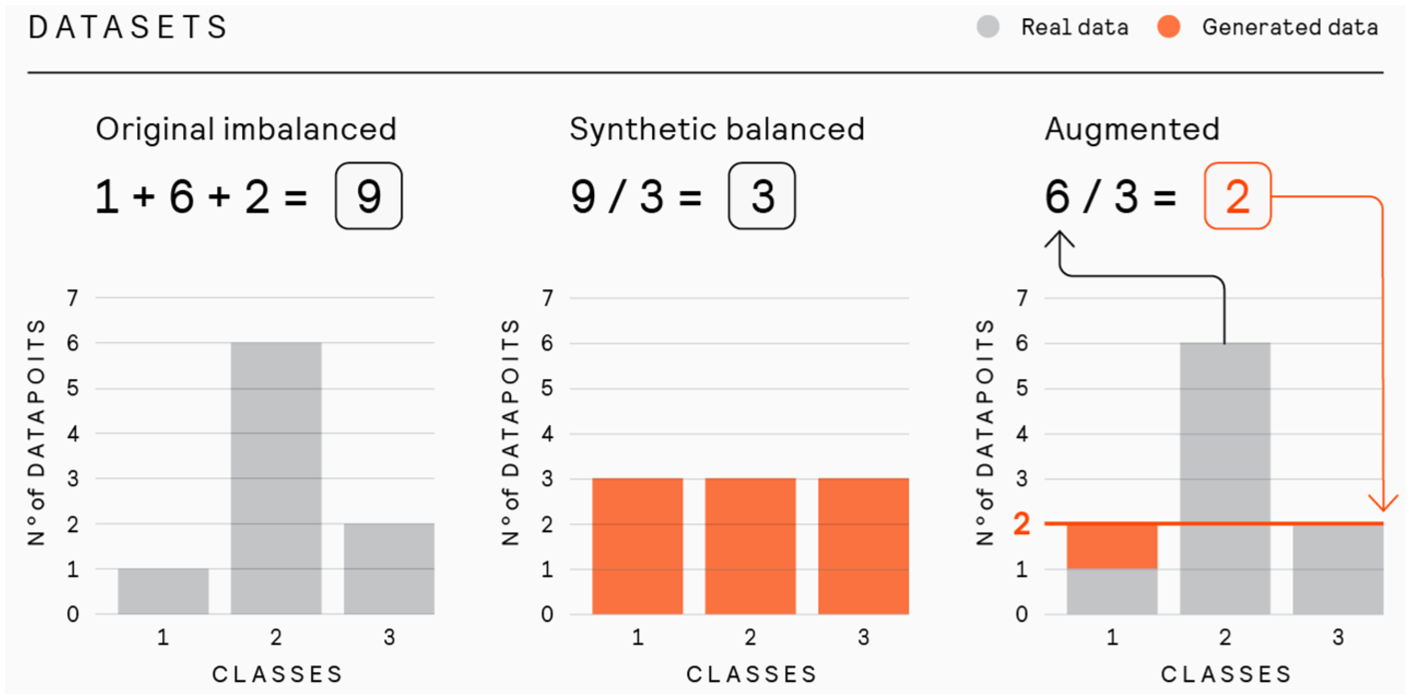
Construction of synthetic and augmented datasets.
In augmenting the underrepresented proficiency levels within the original dataset, our objective was to ensure that these levels contained at least one-third of the number of examples found in the most represented level in the task. This threshold was chosen as a practical compromise to improve balance while avoiding synthetic samples diluting the influence of authentic data, particularly in classes that would otherwise require a tenfold increase to match the majority class. To achieve this, in each task we determined the size of the most represented class, then set one-third of this number as our target for the lesser represented classes. For any level falling below this threshold, we supplemented it with generated examples until it reached the targeted one-third proportion. This process is shown in Figure 4. These augmented samples were then randomly assigned across cross-validation splits).
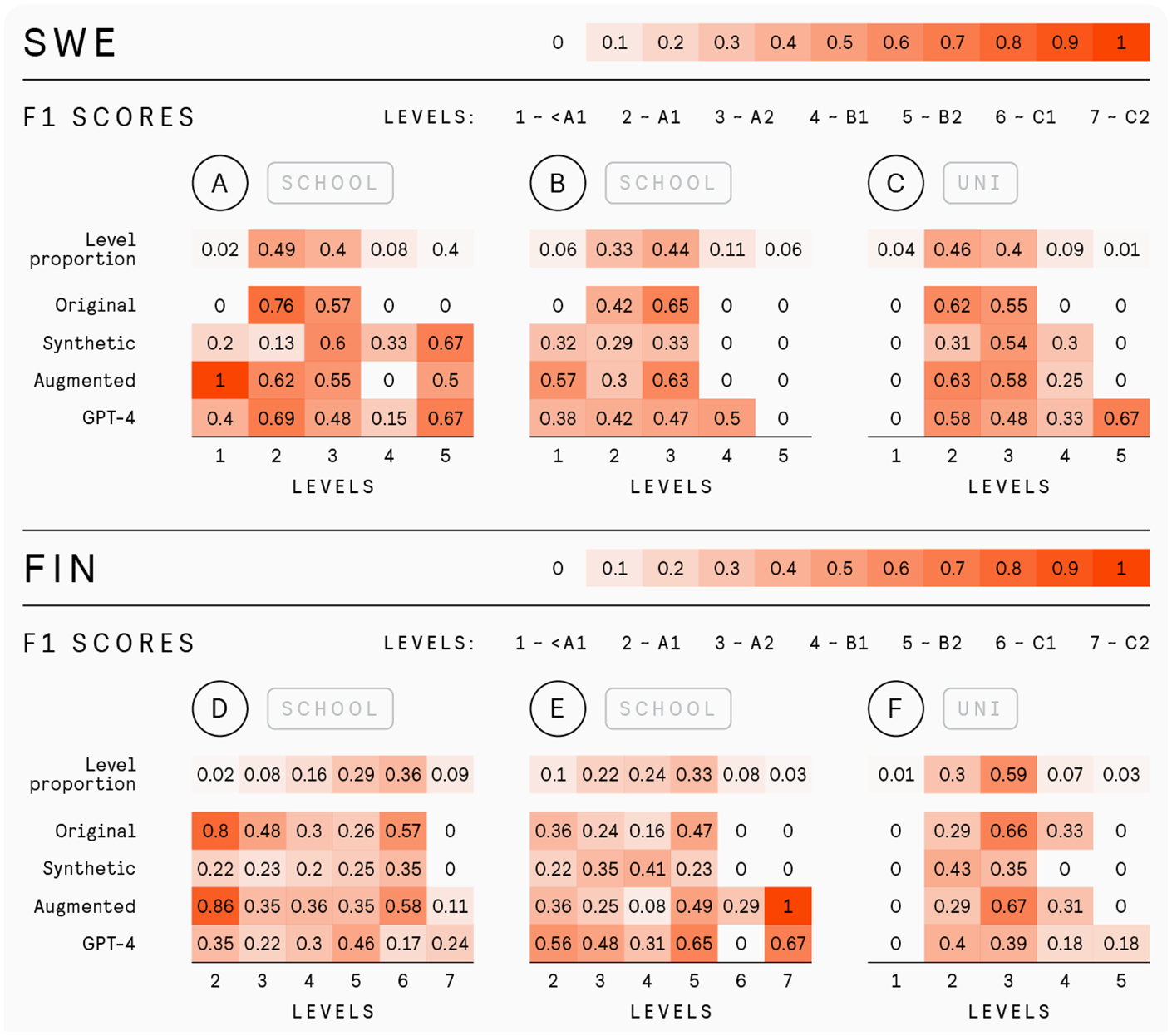
F1 (harmonic mean of precision and recall) scores across CEFR proficiency levels for the original, synthetic, augmented, and GPT-4 models.
In both data settings, we trained BERT models with the same hyperparameters as the baseline . For the fully synthetic dataset, we trained both Finnish and Finland Swedish models on the generated data only and then tested them solely on the original responses. Since the fully synthetic dataset contains no original data, cross-validation was unnecessary in this setup. With the augmented dataset, the models were trained using a fourfold cross-validation same as the baseline (see Appendix 3). Each training subset of data was a mix of original and augmented data, while testing was performed on the original data only in each of the test folds. We then aggregated the results from each fold.
Experiment 2
This experiment addresses RQ2. We evaluated GPT-4’s ability to assign holistic proficiency scores to manual transcripts from tasks A–F. Predicted scores were compared to human ratings and to baseline model predictions using macro F1, macro Precision, macro Recall, macro MAE, accuracy, and QWK. To assess how models performed at individual proficiency levels, we examined per-level F1 plots described in the Metrics subsection and compared the best-performing GPT-4 grading setup to models from Experiment 1.
Zero-shot classification. We begin our examination by assessing GPT-4’s capacity for zero-shot proficiency scoring. In this setup, the model was only provided with the instructions and the transcript, without exposure to any human scores. The prompt configuration consisted of a system message and a user message. The system message started by specifying the task: to score the holistic proficiency of a transcript. It then includeed the evaluation criteria, which were used by human raters, but only for the levels present in the task (see Supplementary Appendix 5). Additionally, we detailed the question that the transcribed response was meant to answer. We also clarified the format in which the model should deliver its response to ensure it is easy to parse. The user message includeed only the target transcript. Examples of these prompt templates can be viewed in Supplementary Appendix 6. For all scoring experiments, we maintained the temperature setting at 0, ensuring that the model consistently outputs the most probable next token.
In-context learning. In the ICL experiment, we investigated the impact of exposing the model to transcripts and their associated scores on the proficiency levels it assigns. We tested this through two approaches: one-shot and few-shot.
In the one-shot scenario, the prompt was constructed to simulate a conversation history with the assistant. It began with the system message as described in the zero-shot scenario, followed by a user message containing the transcript. Next, an assistant message provided the correct grade for that transcript. Finally, the model received another user message with a new transcript that required grading. The one-shot demonstration shown to the model was randomly chosen, but it is always selected from the same task as the transcript. By contrast, the level of the demonstration is random, with no assurance that it corresponds to the level of the new transcript that needs grading. Moreover, since it is selected at random, it is bound to frequently be an illustration of a well-represented class.
For the few-shot prompt, we simulated a more extended conversation by exposing the model to examples from all levels produced by students for the task in question. The prompt began with the system message, followed by a series of paired user messages and assistant responses. Each pair demonstrated a grade level, with one random example per level from the task. To grade a response for task B, the prompt includes five demonstrations (one for each level available), while for task D, it includes six examples. The examples were ordered randomly. The final user message contained the transcript for which the model is to produce a score.
Experiment 3
This experiment addresses RQ3 by aiming to assess whether reliable grading can be achieved in real-life scenarios where only automatic transcriptions are available. The prompts for this experiment were identical to those used in the few-shot setting of the Experiment 2, with one key modification: the final user message containing the transcript to be graded was replaced with an ASR-generated transcript. The ASR was trained using all recording-transcript pairs in the dataset. We evaluated the impact of transcript quality by comparing model predictions based on ASR transcripts to those based on manual transcripts, using macro F1, macro Precision, macro Recall, macro MAE, accuracy, and QWK.
To transform audio into text, we utilized wav2vec 2.0 models (Baevski et al., 2020) fine-tuned for ASR. Our approach involved using models trained for ASR of Finnish and Swedish and further adapting them to produce verbatim transcriptions of L2 speech in our datasets. The resulting word error and character error rates (WER/CER) were 21.08%/6.08% and 23.22%/9.41% for the Finnish and the Finland Swedish data, respectively.
Experiment 4
This experiment addresses RQ4. We investigated the grading performance of variously sized Llama 2 models fine-tuned for chat (Touvron et al., 2023) to assess the impact of model size in a low-resource language setting. Specifically, we tested models with 7 billion (7B), 13 billion (13B), and 70 billion (70B) parameters, using one- and few-shot prompting facilitated through the Transformers library (Wolf et al., 2020). Each model was prompted to score manual transcripts from Tasks A–F, following the same procedure as in Experiment 2. Performance of these models was compared to those of models from Experiments 1 and 2 using macro F1, macro MAE, and QWK.
Reflecting the advantages of ICL demonstrated in previous experiments with GPT-4, we employed similar one- and few-shot learning strategies in this study. We maintained the same demonstrations and their sequence as those used in the GPT-4 experiments to facilitate a direct comparison. For differences between Llama 2-Chat OpenAI prompt formats, see Supplementary Appendix 1.
Results
Experiment 1
BERT trained on original data
The results for the baselines are presented in Table 2 labeled as original (baseline). Across both languages, the macro F1 scores fall below 0.3, indicating limited ability to classify the full range of proficiency levels. Additionally, the macro MAE values suggest an average misclassification of approximately 1 level. Despite the relatively low accuracy and F1 scores, QWK demonstrates significant agreement for Finnish, reaching a high of 0.79, while for Finland Swedish, it stands lower at 0.41.
Performance of BERT-based models.
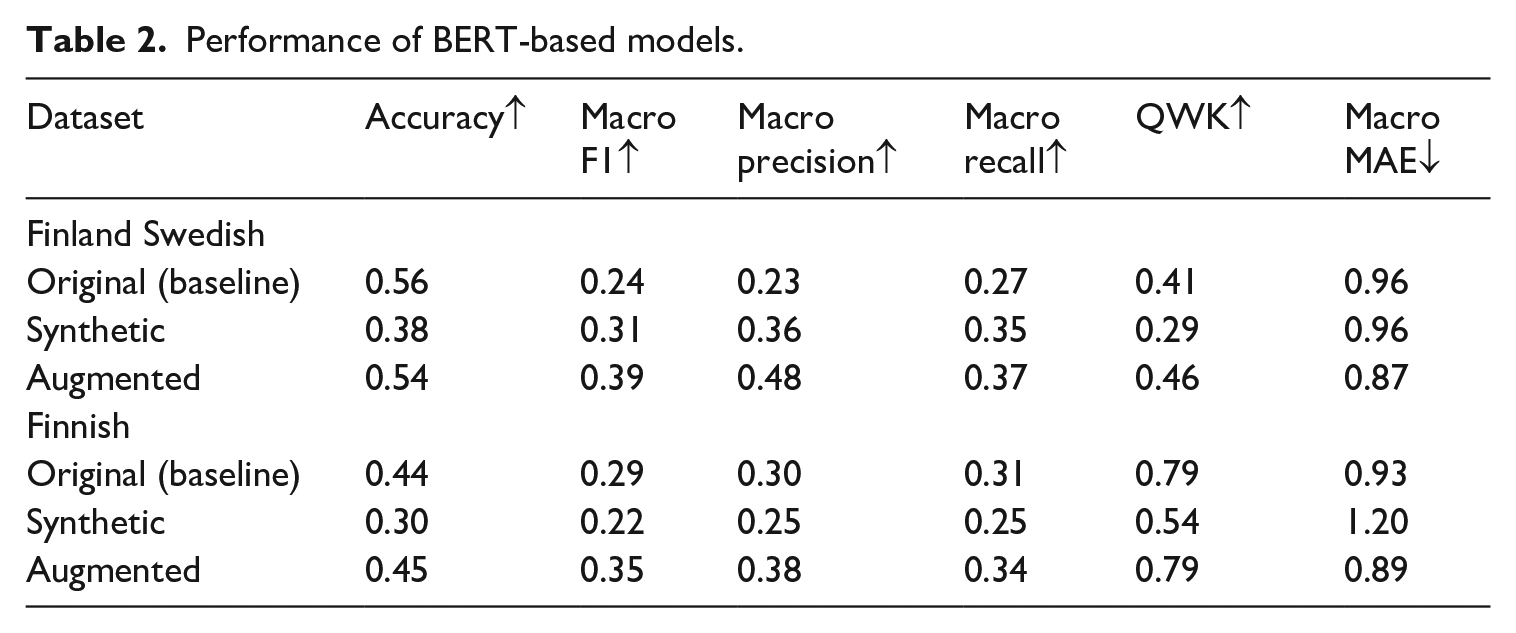
Figure 4 shows that when examining classification performance across the levels present in the tasks, it is clear that traditional ML algorithms, like our baseline, struggle to assign levels beyond those that are well represented. This is particularly noticeable in the Finland Swedish data. For Finnish, while it may appear that the baseline model can handle levels outside the most represented in specific tasks, this is partially misleading. For instance, although the underrepresented level 2 in tasks D and E is recognized, this performance is aided by its representation in task F. It is noteworthy that responses at a certain proficiency level from outside the target task can still enhance classification within that task. However, for levels that are generally underrepresented across the dataset, such as levels 1 and 7, the baseline models struggle to perform effectively.
BERT trained on synthetic and augmented data
When examining the results of using LLM-generated data to train the model for Finland Swedish presented in Table 2, it is evident that the F1 score for the synthetic dataset demonstrates an improvement over the baseline. However, QWK decreases slightly, while the MAE remains consistent. This increase in F1 suggests that the model can recognize a wider range of levels within the data. Additionally, when considering the model trained on the augmented dataset, all overall metrics but accuracy show improvement compared to both the original and the synthetic dataset.
Through a closer look at the classification performance across tasks and proficiency levels presented in Figure 4, it is evident that synthetic data enhances the model’s ability to predict levels beyond those with the highest proportions of examples (marked by the level proportion heatmaps). This suggestthat LLM-generated data is effective in recognizing underrepresented classes. Augmented data combines the strengths of the original and the synthetic data, maintaining baseline performance while leveraging augmented data for overall improvement.
For Finnish, however, the performance of the model trained solely on synthetic data falls short of the baseline, evident in the lower F1 score and higher MAE. Nevertheless, the efficacy of synthetic examples becomes apparent when examining the results of the model trained on augmented data. In this configuration, the F1 score improves and the MAE decreases, while the QWK remains consistent with the baseline.
Even though the Finnish model trained solely on the synthetic dataset underperforms compared to the baseline, it is still capable of generating transcripts that discernibly differentiate between several proficiency levels across every task, which can be noticed from plots in Figure 4. This ability of the synthetic dataset is particularly valuable when combined with real data in the augmented dataset. In this mixed setting, the synthetic data contribute to correctly assigning some responses at the underrepresented level 7, which were otherwise misclassified.
Experiment 2
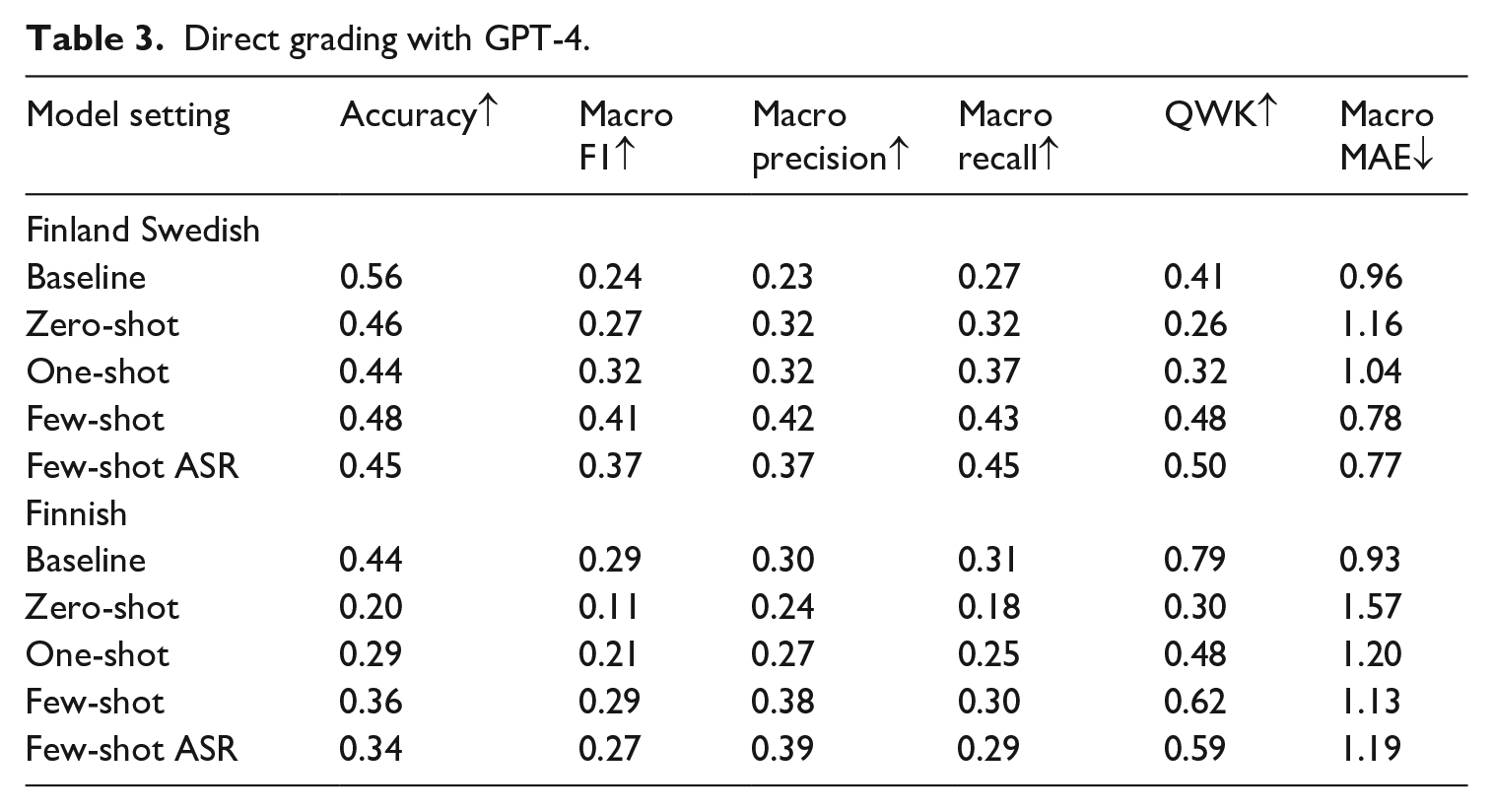
The results for the zero-shot and ICL experiments with direct grading are shown in Table 3 in the rows marked by zero-shot, one-shot, and few-shot. ICL demonstrated consistent improvement over the zero-shot setup across all metrics for both languages. Notably, even using just one random example led to a significant performance boost. The few-shot approach consistently outperformed the one-shot setup. In Finland Swedish, the few-shot prompts not only surpassed the baseline but also outperformed the model fine-tuned on the augmented dataset. As shown in Figure 5, the few-shot approached (marked GPT-4) predicted nearly all proficiency levels, including low-frequency bands. For Finnish, while the few-shot model does not exceed the overall baseline performance or the model trained on the augmented dataset, it still shows an improvement over results obtained from fully synthetic data, which is impressive since this is achieved without any parameter updates. Moreover, as shown in Figure 3, the few-shot setup successfully covers a wider range of proficiency levels than the baseline.
Direct grading with GPT-4.
Aggregated in-context learning (ICL) results.
Experiment 3
Table 3 shows the results of Experiment 3 in the rows marked as few-shot ASR. The numbers show that substituting human transcripts with ASR transcripts does not significantly degrade scoring performance, which implies that proficiency scoring with LLMs can be automated. However, it is worth noting that these results are not directly comparable to the few-shot results using human transcripts as targets. This discrepancy arises because two Finland Swedish transcripts (with a score of 1) and one Finnish transcript (with a score of 3) were not graded by the model due to being flagged by Azure’s filtering system.
Experiment 4
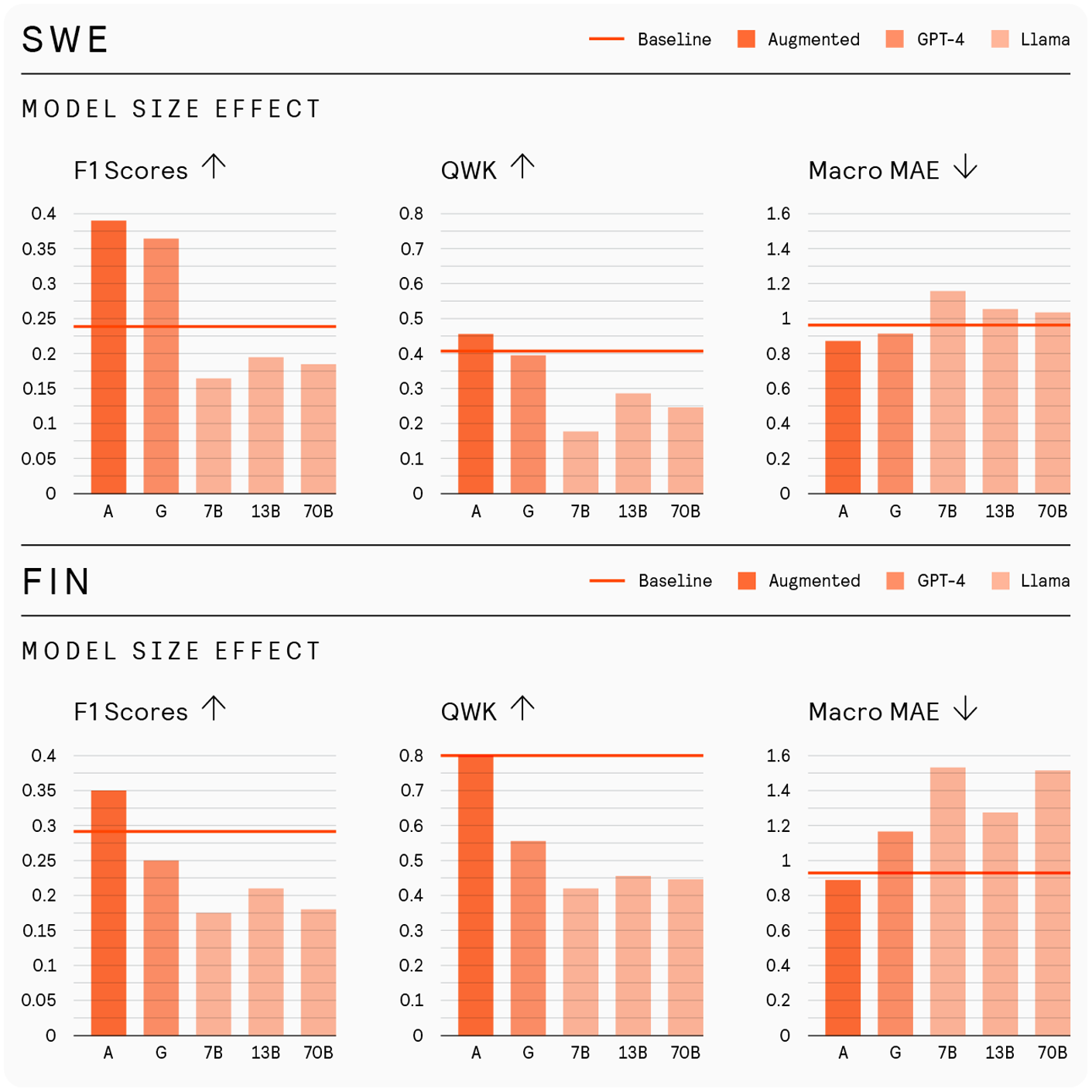
Figure 5 shows averaged metrics for both one-shot and few-shot prompts across different model sizes imarked as Llama. It also includes metrics for the baselines and the models trained on augmented data, as well as aggregated ICL scores for GPT-4 to enhance the comparison of performance across the experiments. The 13 billion parameter (13B) model demonstrated the highest performance among the tested Llama 2 models for both Finnish and Finland Swedish across all metrics. Nevertheless, it still underperformed compared to the baseline and setups utilizing GPT-4. Additionally, the models achieved slightly higher F1 scores for Finnish than for Finland Swedish, which contrasts with the results observed with GPT-4.
Discussion
This study explored whether LLMs can support automated assessment of L2 speech in Finnish and Finland Swedish, where learner data is scarce and imbalanced.To do so, we examined their potential for data augmentation and direct grading to enable more unbiased, scalable assessment in low-resource settings. To address RQ1, we investigated whether LLM-generated transcripts can help traditional ML models better score responses from underrepresented proficiency levels. ASA models rely on labeled data, and when some categories are underrepresented, the models fail to learn them. The BERT baseline achieved high F1 scores for well-represented levels but struggled on underrepresented ones: levels 1, 4, 5 for Finland Swedish, and 1, 7 for Finnish, demonstrating that data imbalance severely affected performance (Figure 4). This aligns with earlier work revealing that BERT-based classifiers exhibit low recall for rare classes (Ein-Dor et al., 2020). As a result, beginner and advanced proficiency learners who are underrepresented in our data receive less reliable scores.
To mitigate this issue, we explored training BERT models on LLM-generated transcripts. Training exclusively on synthetic data improved performance on proficiency levels that were not well represented in the dataset but led to declines in the more common proficiency levels. However, augmenting the original data with synthetic examples of underrepresented levels led to the best overall results, with improved performance, especially at the lowest and highest levels (Table 2, Figure 5). This confirms findings by Cai et al. (2023), who show that LLM-generated data can address label imbalance.
These findings suggest that even modest amounts of synthetic data can improve fairness in ASA by reducing bias against underrepresented proficiency levels. For assessment contexts where human-labeled data is sparse and costly to obtain, combining real and generated transcripts offers a practical way to train more balanced scoring systems without requiring large-scale data collection.
However, synthetic transcripts are not an adequate substitute for real learner data. Manual inspection revealed that zero-shot LLM-generated transcripts often resembled written rather than spoken language, lacking the disfluencies, hesitations, and errors typical of authentic L2 speech. As a result, they further narrow the already limited construct representation possible with text, with benefits primarily stemming from grammatical and lexical markers rather than pronunciation or fluency. These limitations point to the need for stronger LLM alignment with authentic learner data. Moving beyond zero-shot prompting through ICL or fine-tuning may help improve both construct coverage and scoring accuracy.
With respect to RQ2 on LLM grading, we reiterate that traditional BERT models learn by updating parameters solely from response–label pairs and are not exposed to grading rubrics or task instructions used by human raters, limiting their ability to align with scoring criteria or generalize across tasks. In contrast, LLMs can incorporate scoring criteria and task context directly through prompts and adapt to new tasks without retraining (Radford et al., 2019). This ability proved useful for data generation (Experiment 1), and in Experiment 2, we tested its applicability for direct grading. The zero-shot GPT-4 model, using only rubrics and task instructions, had the weakest performance. However, adding just a single human-graded example (one-shot) improved results, especially for Finnish, echoing Min et al.’s (2022) finding that even minimal supervision improves LLM-based scoring.
Few-shot prompts further improved results, especially in Finland Swedish, where it surpassed both the baseline and the BERT trained on augmented data. In Finnish, it outperformed the synthetic model but remained slightly below BERT trained with authentic data. Still, few-shot GPT-4 produced scores across nearly all proficiency levels, including rare ones (Figure 4). This broad coverage is notable given that few-shot learning requires no parameter updates and far fewer training examples compared to traditional models, which still often fail to generalize to low-frequency classes (He & Garcia, 2009). Therefore, few-shot learning with LLMs offers a compelling alternative in imbalanced, low-resource settings. It is practical and scalable, requiring no parameter updates and only a few human-graded examples, yet achieving comparable or better performance, particularly across underrepresented proficiency levels. Moreover, unlike traditional models, it supports direct integration of task instructions and scoring rubrics through prompts, facilitating rapid adaptation to new tasks (Brown et al., 2020).
For RQ3 on error rates, despite the ASR word error rate (WER) over 20%, GPT-4’s scoring accuracy dropped by only ~2% for Finnish and ~3% for Finland Swedish. This minimal drop suggestes that moderate transcription errors do not significantly degrade scoring. While the WER may seem high, ASR was fine-tuned for L2 verbatim transcription and captured key learner features. Most differences appeared in cues like disfluencies and mispronunciations that are difficult to transcribe consistently and, in some cases for pronunciation, were non-standard features. These mismatches with human transcripts still preserved the relevant signals for scoring, likely explaining the model’s stable performance.
These findings suggest that LLM-based scoring can reliably operate on ASR output, enabling scalable, real-time L2 assessment without costly human transcription. This is especially useful for classroom feedback, self-assessment, and formative testing in low-resource settings, as well as for deployment in online platforms, mobile apps, or large-scale low-stakes testing. While highly accurate ASR is not essential, transcript quality still matters. Fine-tuning models to the target learner group and task type remains important, as LLMs are sensitive to changes in prompt content such as label format and example order (Fei et al., 2023; Lu et al., 2022).
GPT-4’s proprietary nature raises concerns for fair, consistent, and privacy-compliant language assessment: its outputs may change over time due to undocumented updates, and using it requires transmitting learner data to external servers. To address both concerns, in RQ4, we evaluated open-source Llama 2 models, which support version control and local deployment. Llama 2 underperformed compared to GPT-4 and produced more severe grading errors, confirming earlier findings in Finnish language understanding (Moisio et al., 2024). Among the three tested sizes, the 13B model outperformed both 7B and 70B, consistent with Luukkonen et al. (2023), who found that scaling LLMs beyond a certain point may not necessarily improve performance for Finnish, likely due to its limited representation in training data. Unexpectedly, Llama 2 performed better on Finnish than on Finland Swedish in contrast to GPT-4 results and despite Swedish having more data in the original Llama corpus (Touvron et al., 2023). This discrepancy may reflect a mismatch between the Finland Swedish and the Swedish represented in Llama’s training data. A model unfamiliar with regional variation may misinterpret its features as deviation from standard language use, leading to distorted proficiency judgments. This raises concerns about test validity for learners of less common language varieties. These findings suggest that open-source LLM performance is sensitive to both model scale and language coverage. In low-resource settings, “larger” is not always better if the model lacks sufficient or relevant training data. Effective use of open-source LLMs in language assessment requires empirically validating model fit to the target learner populations, especially when regional varieties are involved.
Limitations
We note several limitations of the current study. First, our experiments relied on speech transcripts rather than audio. Even in the ASR-based scoring pipeline, models made decisions based solely on text. While transcripts included hesitations and mispronunciations, they lacked relevant features related to pronunciation and fluency (Luoma, 2004; Ockey & Wagner, 2018). Second, in tasks involving images, models received only textual descriptions, whereas students and raters viewed the images. These limitations stem from the fact that, at the time of our research, LLMs were primarily unimodal and could process only text.
Third, the data used in this research is nonoptimal. The tasks were not designed for speakers to fully express their proficiency: even a native speaker might fail to receive the highest score because the task does not allow them to demonstrate sufficient skills. Additionally, human ratings can vary widely within the same proficiency bin (see Figures 8 and 10 in Appendix 2). Such disagreement introduces noise into the “ground-truth” labels, limiting model consistency. The modest QWK values observed in models’ performances should be interpreted in relation to the level of agreement among human raters, which sets an approximate upper bound for model performance given the label noise. Alternative methods for averaging ratings, such as Rasch analysis, couldt be considered instead of a simple mean in data reanalysis or future research to help reduce the effect of inconsistent annotations.
Fourth, we highlight limitations in our experimental design. This study aimed to test whether LLMs can be applied to ASA for L2 Finland Swedish and Finnish in a straightforward way, without prompt engineering. Materials shown to raters and students were given to the model in the same form, resulting in multi-lingual prompts that sometimes included three languages, which may have confused the model.
Finally, we also did not tune hyperparameters: factors like the number of generated transcripts or temperature could affect results. Label choice may also matter (Fei et al., 2023): using CEFR labels instead of numerical ones could yield different outcomes. We did not explore the effect of the quality of the samples included as demonstrations in prompts or their order in ICL. Models received random-level examples with imperfect human agreement, unlike human raters who saw high-quality benchmarks. The order of few-shot examples may also affect performance (Lu et al., 2022).
Conclusion
ASA tools can widen access to speaking practice, including in lower-resource L2 learning environments, with limited teacher L2 proficiency, learning materials, or a small pool of speakers of a given world langauge (Bashori et al., 2024; Dhahbi et al., 2025; Yan et al., 2020). However, current ASA relies on data-driven ML, requiring large, balanced datasets across proficiency levels, which are scarce for languages with smaller learner populations. As a result, beginners and advanced learners are often underrepresented, biasing scoring systems toward mid-proficiency speakers. Our study demonstrates that LLMs can mitigate this issue by generating synthetic transcripts to balance datasets for traditional ML models and by grading learner responses directly via few-shot prompting, making the approach both resource- and computationally efficient.
Moreover, test developers, teachers, teacher trainers, and researchers would benefit from using LLMs to generate example responses across proficiency levels. In less commonly taught languages, there is often a lack of learner samples for training or calibration. Both teachers and learners can benefit from LLM-generated examples, which support feedback and instruction, as well as from LLM-based grading, which enables quick formative assessment in classroom settings and self-regulated learning. Few-shot prompting allows teachers to adapt grading to new tasks with minimal effort, making the system flexible and practical. Developers of spoken dialogue systems and intelligent tutoring systems could apply the same generation and grading methods to provide individualized, level-appropriate feedback in low-resource contexts. In high-stakes testing, LLM-based scoring could support human raters through preliminary assessment, tie-breaking, or rubric alignment checks, but not replace expert judgment.
Given these benefits, we recommend adopting few-shot learning, which requires only a handful of benchmark performances and no parameter updates. Our experiments show that using ASR-generated transcripts, when the ASR system is fine-tuned for L2 speakers performing the tasks to be graded, does not significantly decrease performance, making it a viable option for real-life applications. Additionally, when selecting an open-source model, bigger is not always better. It is crucial to choose a model whose training data includes the language being assessed to achieve optimal results.
As to future research, we plan to explore fine-tuning models to better align them with the specific language being assessed, particularly in capturing spoken language patterns. In our generation experiments, we observed that LLMs struggle to accurately mimic transcripts that reflect spoken data, often failing to add mispronunciations and instead generating text in a written style. We believe that aligning the models more closely with the spoken patterns of the target language could significantly enhance the performance and accuracy of the grading process. Additionally, we plan to investigate the impact of the quality of few-shot demonstrations, testing whether examples with perfect rater agreement are more beneficial for ICL. Finally, we see potential in incorporating a speech embedder into LLMs, as current assessments do not explicitly utilize pronunciation and fluency features, which are critical to language proficiency. We also aim to use LLMs to support automatic, individualized feedback for L2 learners.
Supplemental Material
sj-pdf-1-ltj-10.1177_02655322251351648 – Supplemental material for Enhancing second language speaking assessment: Integrating large language models for Finnish and Finland Swedish proficiency scoring
Supplemental material, sj-pdf-1-ltj-10.1177_02655322251351648 for Enhancing second language speaking assessment: Integrating large language models for Finnish and Finland Swedish proficiency scoring by Ekaterina Voskoboinik, Anna von Zansen, Nhan Chi Phan, Yaroslav Getman, Tamás Grósz and Mikko Kurimo in Language Testing
Footnotes
Acknowledgements
We acknowledge the use of OpenAI’s ChatGPT for assisting in text editing to improve readability.
Author contributions
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We would like to thank the following projects and funding agencies: NordForsk through the funding to Technology-enhanced foreign and second-language learning of Nordic languages (project number 103893), the Research Council of Finland through the funding to “Automatic assessment of spoken interaction in second language” (grant nos 355586, 355587), and “Digital support for training and assessing second language speaking” (grant nos 322619, 322625).
ORCID iDs
Supplemental material
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.