
Abstract
This paper investigates whether attitudinal measures can predict usage in two bilingual communities with radically different language policies. We compare 163 participants’ (ages 24–36) rates of spontaneous language usage to two attitudinal measures among Welsh—English and Lombard—Italian bilinguals. Usage rates are found to correlate with Matched Guise Technique status scores for Lombard and to predict solidarity scores for Welsh. A different picture emerges from the Implicit Association Test, with scores correlating with usage for Welsh but not for Lombard. We link these findings to the radically different levels of sociopolitical support associated with the regional/minority languages and the nature of the two attitudinal measures. Our findings suggest that the utility of different attitudinal measures depends partly on sociopolitical circumstances and on the type of association intrinsically addressed in each measure. These have important implications for both the study of language attitudes and research on language vitality.
Keywords
It is generally agreed that speakers’ attitudes are a fundamental barometer for the vitality of a language. The widely used UNESCO language vitality index (2003) lists speakers’ attitudes toward their own language among its nine major evaluative factors of language vitality. Further, the presence and/or development of positive attitudes has been argued to be essential to a successful language policy: in the absence of positive attitudes, many policies for the maintenance of a language are likely to be met with opposition and thus ultimately doomed to fail (e.g., Bell, 2013; Dołowy-Rybińska & Hornsby, 2021; Kircher et al., 2023a). A similar position is also echoed in Fishman's (1991) work on reversing language shift and integrated into the development of the Graded Intergenerational Disruption Scale (GIDS; Fishman, 2012), where the role of attitudes is framed around the concept of “premature goals” (2012: 428), and the notion that pursuing policies prematurely (i.e., when they do not line up with the community's attitudes toward domains of usage) can lead to societal conflict and thus to policy failure.
The mental representation of attitudes has been conceptualized in several ways by different theoretical frameworks, with an ongoing debate between proponents of what may be described as single attitude models (e.g., Olson & Fazio, 2009) and dual attitude models (e.g., Greenwald & Nosek, 2009). Broader agreement is found in relation to attitude measures, and specifically the idea that implicit measures involve the notion of automaticity (Gawronski, 2024), though it is debated whether this equates to accessing unconscious processes (e.g., Greenwald & Lai, 2020; see also the overview in McKenzie & McNeill, 2023). While important to our understanding of human cognition, these theoretical and representational debates are immaterial to the question at hand, namely, whether and to what extent attitude measures are accurate proxies for language vitality. In this case, what matters is the relationship between (1) different attitude measures and (2) their ability to predict language use as the requisite of intergenerational transmission, the core ingredients, and ultimate arbiters of language vitality. Therefore, we will follow widespread practice in using the term implicit measures to refer to those instruments that require automatic evaluative responses (typically high-speed responses) 1 and oppose these to explicit measures, while remaining agnostic as to the theoretical significance of these measures in relation to the mental representation of attitudes. Due to ongoing debate concerning a specific set of methods used in language attitudes research, namely, the Matched Guise Technique (Lambert et al., 1960), we follow McKenzie & McNeill (2023) in distinguishing between explicit measures that are direct and those that are indirect. Direct methods, such as questionnaires and self-reports, involve making participants aware of both the attitudinal nature of the task and the attitudinal object under investigation. Conversely, indirect methods may involve participants’ awareness that their attitudinal evaluation are being sought, but a lack or incomplete awareness of the exact attitudinal object being investigated. We find this distinction helpful in our exposition, though we recognize that there is disagreement as to whether the MGT may potentially be an implicit measure (e.g., Loureiro-Rodríguez & Acar, 2022).
In line with the distinctions outlined above, research has shown that different attitudinal measures can produce substantially different results (e.g., Maegaard, 2005; McKenzie & Gilmore, 2017). A discrepancy between attitudes measured via direct methods (e.g., self-reports) and an indirect method such as the MGT has emerged in a variety of regional/minority language contexts such as Welsh (Price & Tamburelli, 2016; 2020), Irish (Ó Duibhir, 2009), Catalan (Pieras-Guasp, 2002), Frisian (Jonkman, 1991), and Quechua (McGowan & Babel, 2020). Moreover, although many attitudinal studies regularly rely on explicit measures (as shown in Garrett, 2010; Price & Tamburelli, 2020), positive scores on explicit measures can and often do coexist with patterns of declining use (e.g., Cochran, 2008; Haboud, 2004). Therefore, a major challenge in the study of language attitudes is to understand the degree to which different types of attitudinal measures may predict actual speakers’ behavior in the form of language use. Indeed, it is language use, rather than language attitudes themselves, that is the ultimate goal of language policy and planning and of language maintenance and revitalization more broadly. Attitudes measures are taken to be a useful proxy for language use, with a growing body of research investigating the relationship between attitudes and self-reported use as established via questionnaires (e.g., Kircher et al., 2023b; Lasagabaster & Huguet Canalís, 2006) or interviews (e.g., Jaffe, 2015; McEwan-Fujita, 2010). However, self-reports may not provide an accurate assessment of language use, as they are prone to effects such as social desirability (e.g., Holtgraves, 2004; Oppenheim, 2000). If we are to seriously pursue the idea that attitudes toward a language are a major evaluative factor in the vitality of that language, the central question becomes: what type of attitudinal measures are most suited for such evaluation? To address this, we need to investigate the degree to which different attitudinal measures are able to predict actual language use, in the form of whether and how much the language is employed in conversation.
Drawing on recent methodological developments in language attitudes research (Kircher & Zipp, 2022; Vari & Tamburelli, 2023) as well as research on the broader question of how attitudes are linked to behavior (Karpinski & Hilton, 2001), this paper seeks to address a gap in the literature by examining whether and to what extent linguistic behavior—specifically the degree of spontaneous language use— can be predicted by different language attitude measures. While some previous studies have investigated the relationship between attitudes and within-language variation (see, e.g., Hawkey, 2020, on morphosyntactic variation in Catalan), the fundamental difference is that the present study is not concerned with within-language variation but instead aims to measure which of their two languages a bilingual chooses to employ in spontaneous conversation and to what extent. This is—to our knowledge—the first study that seeks to test the presumed link between attitudinal measures (either explicit or implicit) and actual conversational use via direct measurement of participants’ spontaneous language production.
Language Attitudes and Linguistic Behavior
Broadly speaking, language attitudes are evaluative dispositions (Ajzen, 1988), tendencies (Eagly & Chaiken, 1993), or orientations (Garrett, 2010) toward a language, but also toward some linguistic property or properties such as accent (Ladegaard & Sachdev, 2006) or diachronic as well as diatopic variation (Beard, 2004).
Recent advances in social psychology suggest that attitudes often operate outside of conscious awareness or control (Devos, 2008; Fazio & Olson, 2003). Although several models have been proposed in relation to the mental representation of attitudes and whether—as well as to what extent—implicit and explicit attitudes are manifestations of separate underlying constructs (see Pratkanis et al., 2014 for an overview), there is broad agreement that attitudes are associated with behavior, though the strength of this association is disputed (e.g., Conner & Sparks, 2002). Further, there is evidence that implicit attitudes are better predictors of habitual or spontaneous behavior (e.g., Devos, 2008; Perugini, 2005).
This relationship between attitudes and behavior is crucial to the use of language attitudes as barometers of language vitality, and hence to the successful development and implementation of language policy, whose ultimate aim is to positively affect linguistic behavior, e.g., by leading to increased language usage and subsequently intergenerational transmission. Therefore, only by basing policy on attitudinal measurements that reflect actual linguistic behavior, and specifically frequency and amount of use, can we ensure efficient allocation of resources and ultimately achieve policy success and the effective prevention of language loss.
However, it is also the case that the extent and manner in which different types of attitudinal measures are linked to institutional policy can vary (e.g., Maegaard, 2005) and that this variation is not yet understood. For example, while some studies have shown that institutional policy may have an effect on attitudes as measured by the Matched Guise Technique (e.g., Kircher, 2014; Woolard & Gahng, 1990), other studies using the same methodology reported mixed results (e.g., Hilton & Gooskens, 2013), raising the question of whether the effect is dependent on the type of institutional policy.
Moreover, the general tendency in studies on language attitudes is largely to rely on direct methods such as self-reports (see Price & Tamburelli, 2020 for an overview) or—when wishing to employ less explicit measures—on the Matched Guise Technique (Lambert et al., 1960) or its variations (e.g., Markel et al., 1967). However, although often presented as an implicit measure of attitudes (e.g., Pantos, 2019), the Matched Guise Technique is unlikely to qualify as an implicit measure due to the fact that it involves explicit instructions (Kristiansen, 2015; Pharao & Kristiansen, 2019): while participants may not be aware that the task focuses specifically on language, they are nevertheless made explicitly aware that they are required to express value judgments (Casasanto et al., 2015). For this reason, some refer to the MGT as an indirect method (or “instrument,” e.g., McKenzie & McNeill, 2023) but an explicit measure (see also Loureiro-Rodríguez & Acar, 2022).
A measure that is more widely accepted as implicit and that has been increasingly adopted in the study of language attitudes is the Implicit Association Test (Greenwald et al., 1998). This methodological choice is generally motivated by the fact that the MGT—while involving covert components and generally considered implicit in the linguistic literature (e.g., Rosseel & Grondelaers, 2019)—is nevertheless susceptible to conscious control of responses, something which the IAT is designed to minimize via its reaction time component. Hence the IAT has been used in several sociolinguistic contexts where an implicit measure was required, including in the study of attitudes toward dialectal variants of American English (Campbell-Kibler, 2012) and of Belgian-Dutch (Rosseel, 2022), non-native or foreign accents (Pantos & Perkins, 2013; Rosseel et al., 2018), and the relation between vernacular and standard varieties in minority language situations (Vari & Tamburelli, 2023).
In sum, at least four points emerge from the literature: (1) MGT is an indirect method unlikely to constitute an implicit measure due to the explicitness of its instructions; (2) IAT is generally accepted to be an implicit method; (3) there is no research to date on how measurements collected via these typologically different methods impact actual linguistic behavior; (4) there is lack of knowledge on how attitudes measured via different methods may be affected by different language policies. This paper aims to shed light on these points by investigating the following research questions:
Research Questions
RQ1: To what degree are MGT scores predictive of language behavior across bilingual communities with different language policies?
RQ2: To what degree are IAT scores predictive of language behavior across bilingual communities with different language policies?
RQ3: Does the predictive power of the MGT or IAT vary across different regional/minority language situations with different degrees of sociopolitical recognition?
The Present Study
To address the research questions, we investigated whether and to what extent MGT and IAT scores relate to behavior in the form of language choice in bilinguals in two communities: Welsh—English bilinguals in Wales and Lombard—Italian bilinguals in Italy. The choice of communities was made due to their substantially different language policy situations. In Wales, the sociopolitical status of Welsh has been steadily improving since the passing of the Welsh Language Act 1993. While official status was secured by The Welsh Language (Wales) Measure 2011, official language strategies have been implemented since at least 2003, culminating in the current language strategy Cymraeg 2050: Miliwn o siaradwyr (“Welsh 2050: A Million speakers”—Welsh Government, 2017).
The situation in Lombardy is profoundly different. While its supposed protection and promotion are mentioned in a regional law on “cultural matters” (Regional Law 2016, n. 25), Lombard is not officially recognized by the Italian state, nor does it benefit from any active or overt language policy (Coluzzi, 2007; Coluzzi et al., 2018). Further, the Italian establishment tends to contest the idea of Lombard as a language distinct from Italian (e.g., Coluzzi et al., 2021; Tamburelli, 2021), treating most Romance languages of Italy as “dialects,” and denying them any institutional recognition or support (Coluzzi, 2007; 2009).
The aim of our combined studies is therefore to establish how the MGT and IAT compare in their association with self-reported as well as actual linguistic behavior and in their potential ability to predict linguistic behavior across communities with radically different institutional policies. To collect data on actual linguistic behavior, we set out to measure participants’ spontaneous language use when they were addressed in the regional/minority language by a stranger. To achieve this, participants were asked to complete either an MGT or an IAT test, after which they were approached by an actor who attempted to engage them in a conversation in the participants’ regional/minority language. We detail each method below.
Methods
Overview
Two groups of participants were recruited in each speech community under investigation to collect data using two combinations of methods. The first combination involved collection of self-reported data on usage and proficiency via an electronic implementation of the Language and Social Background Questionnaire (LSBQe—Breit et al., 2023a; adapted from Anderson et al., 2018) followed by a Matched Guise Test (MGT—Lambert et al., 1960) and a language usage task (see below for details). The second combination also included self-reports via the LSBQe but was then followed by an auditory Implicit Association Test (IAT—Greenwald et al., 1998), before also concluding with the same language usage task. These combinations were utilized on two separate participant samples per community as part of a larger project.
Participants
All participants were aged between 24 and 36 years, as we wished to test a section of the population that is representative of the current and imminent parent generation; the average age in England and Wales is 30.9 for mothers and 33.7 for fathers (UK Government, 2023), and in Italy it is 32.5 for mothers and 35.1 for fathers (ISTAT, 2023). The decision to investigate this cross-section of the populations was made in line with the broader foundational aim of the research, namely, to investigate speakers’ attitudes as indicators of language vitality. Given the crucial role that the “child-bearing generation” (Fishman, 1991) play in intergenerational transmission, their attitudes and patterns of use are fundamental in whether a language will be passed on to the next generation. This role is built into all major language vitality assessment tools, most notably the seminal work of Fishman (1991), but also more recent developments such as the UNESCO (2003) document and the work of Lewis & Simons (2010), where the role of “the child-bearing generation [in] transmitting [the language] to their children” underlies the difference between a language being “Vigorous” as opposed to “Threatened” (Lewis & Simons, 2010) and between being “Safe” or “Definitively endangered” (UNESCO, 2003: 7–8). Similar delineations are drawn by the UNESCO Atlas of the World's Languages in Danger (Moseley, 2010) and the Ethnologue (Eberhard , 2024; Grime, 2000; Gordon, 2007).
Welsh—English Bilinguals
Forty-two Welsh—English bilinguals (17 females, 25 males, mean age = 28.3, SD = 2.99) were included in the MGT (completing LSBQe + MGT + language usage task). Forty-four participants were originally recruited, but two had to be excluded due to lacking data for the language usage task (malfunction of the recording equipment, and a case of a participant leaving before the actor could approach). A further 42 took part in the IAT (completing LSBQe + IAT + language usage task). Three IAT participants had to be excluded from the analysis due to issues with the data in the language usage task (excessive background noise and malfunction of the recording equipment). Therefore, 39 IAT participants were entered in the analysis (23 females, 16 males, 4 left-handed, mean age 29.5, SD = 3.84).
Lombard—Italian Bilinguals
As fluent Lombard speakers are in severe decline, participants were selected on the basis of either being Lombard—Italian bilinguals or being “very familiar with” and having “a good understanding of (any Bergamasque variety of) Lombard.” A total of 40 participants (23 females, 17 males, mean age 30.2, SD = 4.26) took part in the MGT (LSBQe + MGT + language usage task), and 42 (24 females, 8 males, 7 left-handed, mean age 29.9, SD = 3.67) took part in the IAT (LSBQe + IAT + language usage task). Ten of the IAT participants were re-tested approximately a week apart, as an excessive number of participants had been erroneously allocated to the block order “Italian-Positive.” On both occasions, their overall scores were moderately in favor of Italian, though slightly less so on the second testing (0.56 vs. 0.47).
Self-reported Use and Proficiency: LSBQe
Self-reported information on language use and proficiency was collected using the LSBQe delivered through the L’ART Research Assistant app (Breit et al., 2023a; Breit et al., 2024; see Figure 1 for an example). The central aim of the LSBQ is “to present a valid and reliable measurement tool […] that can be used to quantify bilingualism […] and be sensitive to the nature of bilingual profiles” (Anderson et al., 2018, p. 252). The LSBQe mainly adapts the LSBQ for use with regional and minority languages and broadens its scope for use with populations outside of the North American context (see Breit et al., 2023b for detail).
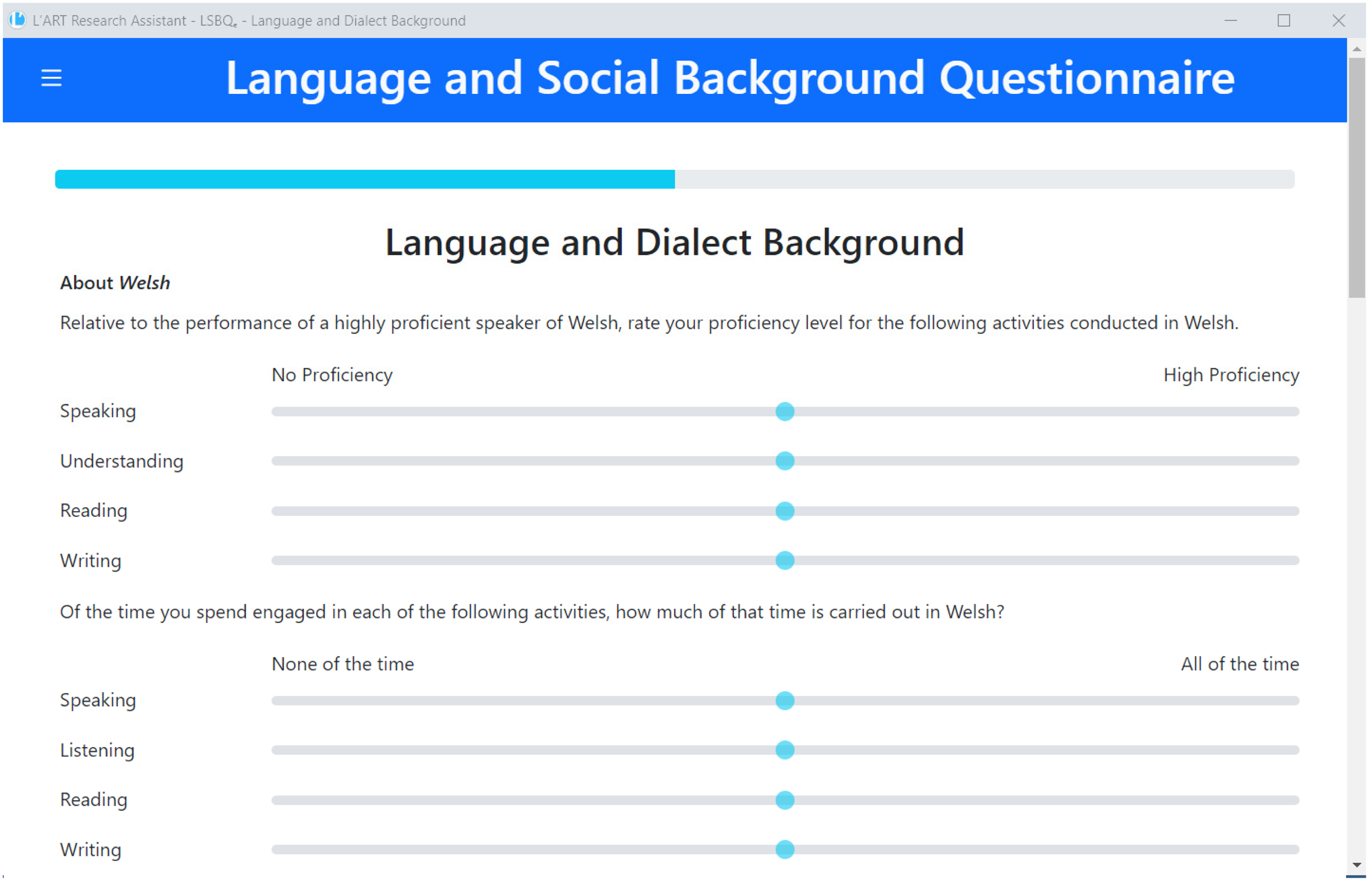
Screen showing the section on Welsh proficiency of the LSBQe, part of the self-reported use and proficiency section adapted from the LSBQ.
The Matched Guise Technique
The MGT was also delivered through the L’ART Research Assistant app (Breit et al., 2023a; Breit et al., 2024; see Figure 2), presenting participants with 12 recorded audio guises (6 in the majority language and 6 in the regional/minority language) produced by 6 bilingual speakers. In order to limit potential acquiescence effects and social desirability bias (e.g., Holtgraves, 2004; Oppenheim, 2000), participants were told that they were required to evaluate voices for podcasts and radio broadcasts. The full linguistic aim of the study was revealed to them only after they had taken part.
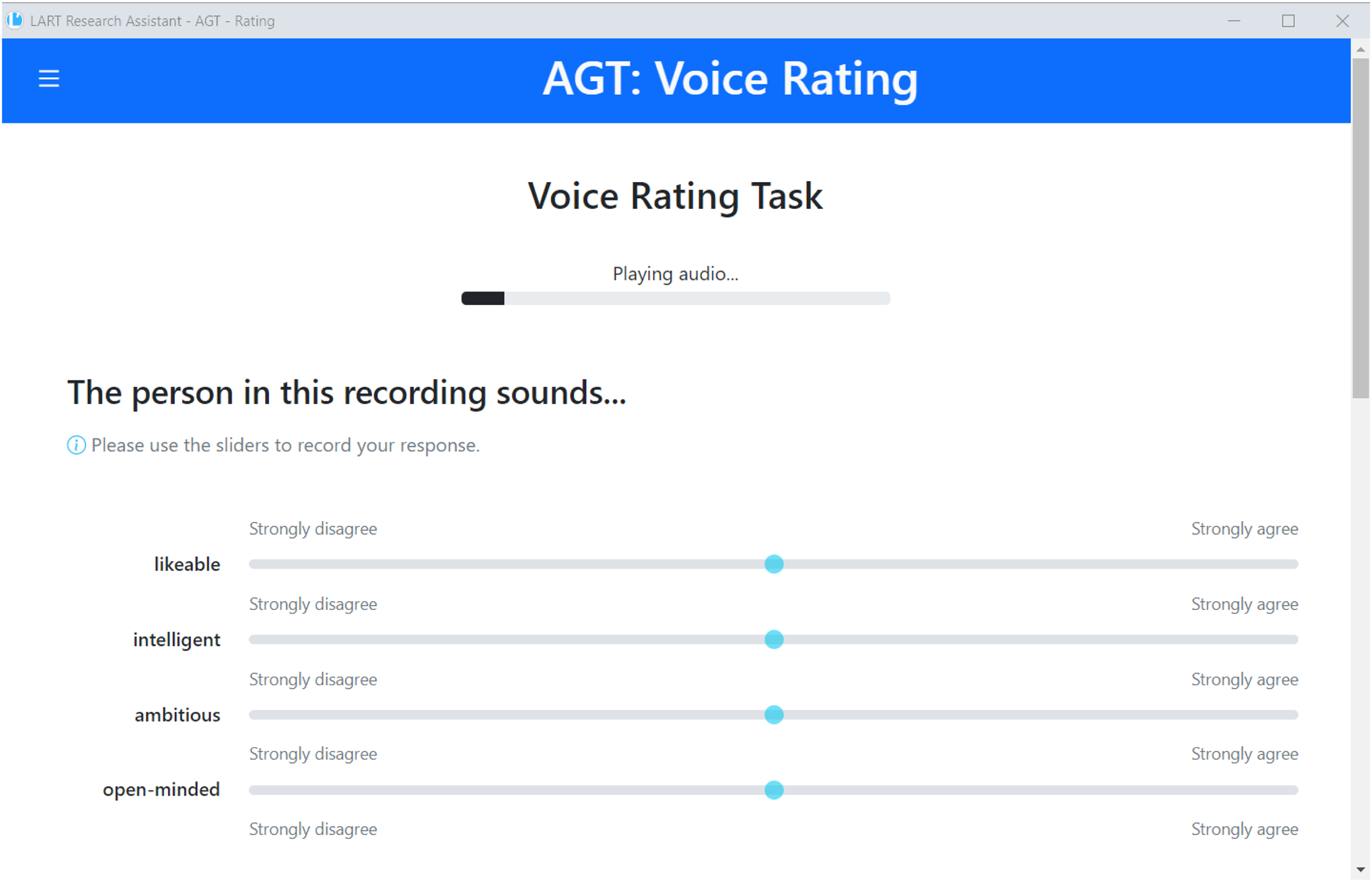
Screenshot showing the top section of the MGT, presented as a voice rating task.
Stimuli
Guises were produced through a two-step selection process. First, six fluent female bilinguals were asked to speak informally about a range of topics including hobbies and holiday experiences, in both the regional/minority and majority language. Female speakers were chosen due to the reported tendency for female voices to be more intelligible than male voices overall (e.g., Yoho et al., 2019). Given that low intelligibility has been reported to correlate with less positive attitudes (e.g., Hutchinson et al., 2019), the selection of female voices minimized the possibility of obtaining lower scores for reasons independent of the language being spoken. The decision to include only informal topics of conversation was made to comply with the more restricted sociolinguistic expectations in Lombardy. As current use of Lombard no longer extends to formal domains (Coluzzi et al., 2018), employing informal topics ensured that the guises were suitably aligned with participants’ expectations (on the importance of suitability of domains in the MGT, see Loureiro-Rodríguez & Acar, 2022).
In Wales, speakers were between 24 and 31 years old, while in Lombardy the ranged in age between 53 to 63 years old. The age difference is a consequence of the need to comply with sociolinguistic expectations, as fluent speakers of Lombard who use the language in everyday settings tend to be in their fifties or older (ISTAT, 2017). The speakers were recruited from within the same areas as the participants: the Bergamo province (Lombardy) and the “heartlands” of Gwynedd and Ynys Môn (Wales). Speakers were chosen for their being representative of the specific varieties for each language, as assessed by the research team—which included at least one member with linguistic expertise in each of the languages in question—in consultation with local native speakers.
For consistency, in terms of speed and input level, speakers were invited to talk in a natural, friendly, and calm tone while being recorded in individual sessions in a quiet room. A Rode NT1A was used for recordings in Wales, and a ZOOM H2 portable digital recorder was used in Italy. All guises were made as consistent as possible for acoustic ambience by reducing background noise and normalizing to 1.0 dB in Audacity (Audacity Team, 2014). The second and final step involved extracting excerpts of approximately 60 to 80 s long from the recordings to produce the guises. The guises produced by four of the speakers were used as stimuli, while those produced by the other two speakers were used as fillers. One further guise was produced in the majority language and presented to the participants as practice item before starting the test (see Breit et al., 2023b for details).
Traits
Eighteen traits were selected based on a combination of the original MGT (Lambert et al. 1960) and more recent lists of traits from studies that focused on minority language contexts (Echeverria 2005; Loureiro-Rodriguez et al., 2013; Price & Tamburelli, 2020; Soukup 2012). These were considered in view of the sociolinguistic characteristics of the communities under investigation and any item that did not transfer well across the communities was removed. For example, the trait “amusing” was included from Echevarria (2005) as it was thought likely to provide information on the type of attitude when describing a regional/minority language speaker, i.e., as eliciting derision or even being seen as somewhat of a curiosity. On the other hand, “cosmopolitan” was excluded due to potential ambiguity, as the connotations attached to being cosmopolitan may not be inherently positive, for instance, in the sense of relating to high society rather than having a worldwide scope or outlook. The adjective “international” was therefore preferred. Further, traits were excluded if they were not relevant to the specific population in question. For example, traits such as “goody-two-shoes” or “likes a laugh” from Price and Tamburelli (2020) were excluded, as these were specifically aimed at adolescents and hence outside our sample age group. Through this process we achieved a final list containing the following adjectives: “amusing,” “open-minded,” “attractive,” “trustworthy,” “ignorant,” “polite,” “ambitious,” “international,” “cool,” “intelligent,” “influential,” “likeable,” “educated,” “friendly,” “honest,” “competent,” “natural,” and “pretentious.”
Implicit Association Test
An auditory modification of the 7-block IAT design (see Greenwald et al., 2022; Greenwald et al., 1998) was implemented using PsychoPy 2023.1.3 open-source software (Peirce et al., 2019). The IAT relies on reaction times to capture the extent to which participants automatically associate a target category (attitude object) with an attribute category (emotional valence: positive or negative). In our studies the attitude objects’ target category was language (the regional/minority language and the majority language in each community of interest), namely, Welsh and English in Wales and Lombard and Italian in Italy. To represent the attitude objects, we used 6 words in each language (n = 12 auditory stimuli). All words were neutral in valence to ensure that any negative association that might emerge from the IAT would be traceable to the language rather than the meaning of the word itself. Due to the fact that Lombard does not have a widely agreed orthography, target stimuli were produced in audio format, ensuring consistency across language communities. The attribute category was presented through images representing the two emotional valence poles positive and negative, consisting of 6 images of flowers (representing positive valence) and 6 images of pests (representing negative valence), for a total of 12 visual stimuli. A norming study was conducted to select appropriate stimuli for both the target and attribute category, as well as to select an appropriate speaker for the auditory stimuli to be produced in both languages. Twelve bilingual raters were recruited from each community under investigation to perform the norming.
Word Norming
We compiled a list of 60 words per language (n = 120 per community) which included 30 potentially neutral words as well 15 positive and 15 negative words that served as reference points for the raters. Only disyllabic, concrete nouns were included to avoid reaction time-related differences (Reilly & Desai, 2017). Polysemic words, homophones across languages (e.g., Welsh plant “children” and English plant) and phonologically close cognates (e.g., Welsh fforest, English forest) were avoided. Pairs of direct translations across languages were also avoided, such that using the word gwyneb (“face”) as a stimulus for Welsh precluded the use of face among the English stimuli. Words beginning with /s/ + consonant sequences were also excluded, as the syllabic structure—and thus the number of syllables—of such words is disputed in the linguistic literature (e.g., Goad, 2016 for an overview).
We also controlled preselected words for token frequency, targeting between 10 and 1,000 tokens per million. English frequencies were based on the 201-million-word Subtlex corpus (van Heuven et al., 2014), Welsh frequencies on the 11-million-word CorCenCC corpus (Knight et al., 2020), while Italian and Lombard frequencies were based on the 517,564-word Subtlex corpus (Crepaldi et al., 2015).
Raters were asked to evaluate word valence on a 7-point Likert scale (1 = extremely negative, 4 = neutral, 7 = extremely positive) and to report any words they thought were unfamiliar, not widely used, strange, or that seemed artificial. Words that received more than one report for the same idiosyncrasy were discarded, as were words with extreme valence ratings. Based on the norming data, we selected 12 final words per speech community, six for each target category (minority language and majority language). The final selection of word stimuli is given in Table 1.
Final Selection of Word Stimuli After Norming.

Image Norming
A total of 30 images were included for norming: 15 preselected as potentially positive (flowers) and 15 as potentially negative (pests), all presented against a white background.
Raters scored image valence on the same a 7-point Likert scale as the word stimuli. Images were discarded if they were evaluated either as neutral or outside the valence category for which they had been preselected. Based on the norming data, 12 images were selected for each speech community, six for each attribute category: positive valence (mean score between 6.04 and 5.92) and negative valence (mean score between 2.24 and 1.82).
Procedure
To familiarize participants with the visual stimuli and their categorization into positive and negative, all images were presented on the screen under the heading of their associated category before the experiment proper (Greenwald et al., 2022). Throughout the experiment, visual stimuli were presented as 6 cm × 6 cm images centered vertically and horizontally, as illustrated in Figure 3. Audio-stimuli were presented through headphones without any accompanying visual stimulus, as illustrated in Figure 4. Participants were instructed to press the keys “E” or “I” as quickly and as accurately as possible to categorize the target categories (Welsh and English/Lombard and Italian for the audio stimuli) and attribute categories (positive and negative valence for visual stimuli).
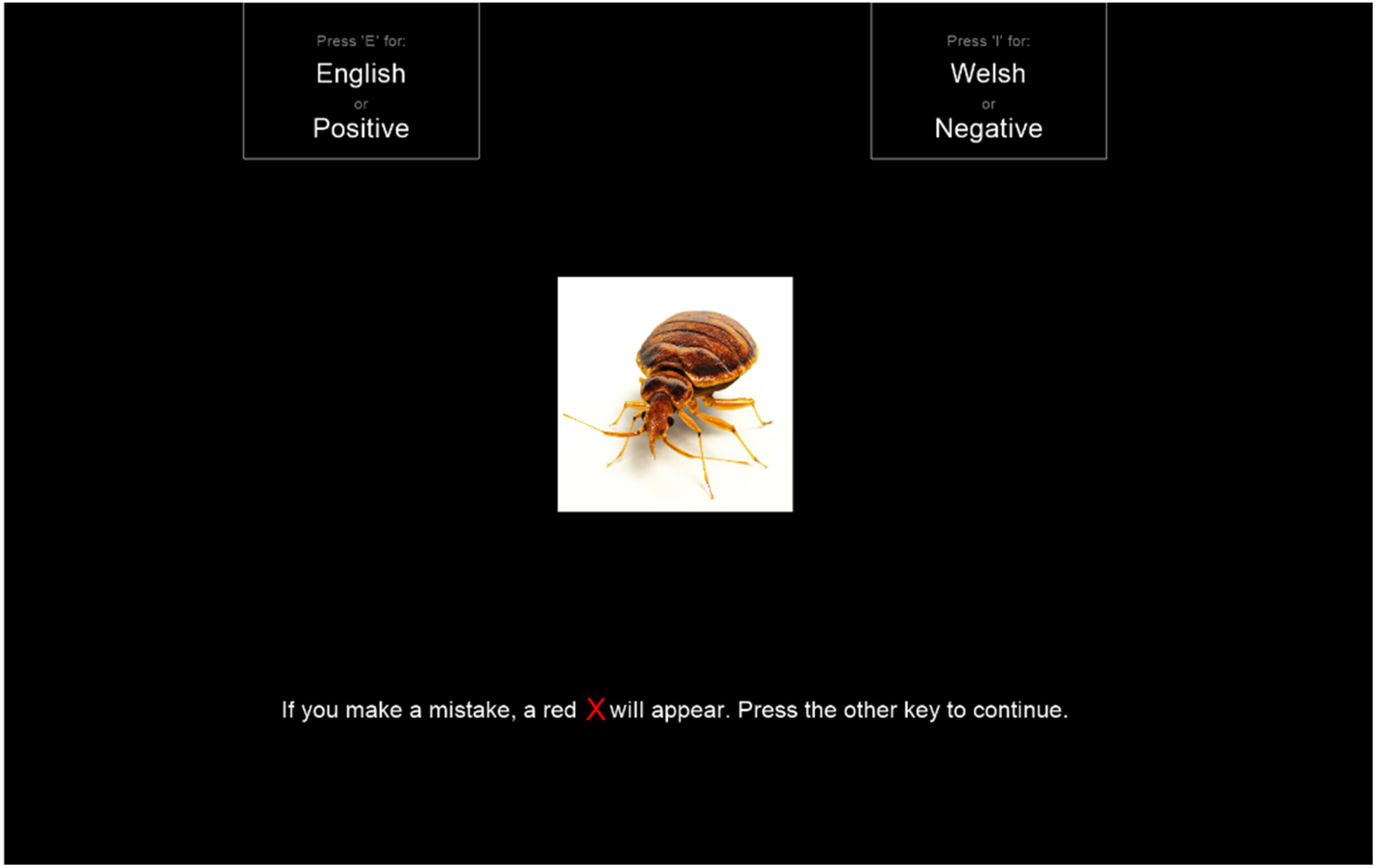
Screen displaying a critical IAT block as used with Welsh—English bilinguals, with a visual stimulus as attribute category.

Screen displaying a critical IAT block as used with Welsh—English bilinguals, where the participant must categorize target category audio stimulus.
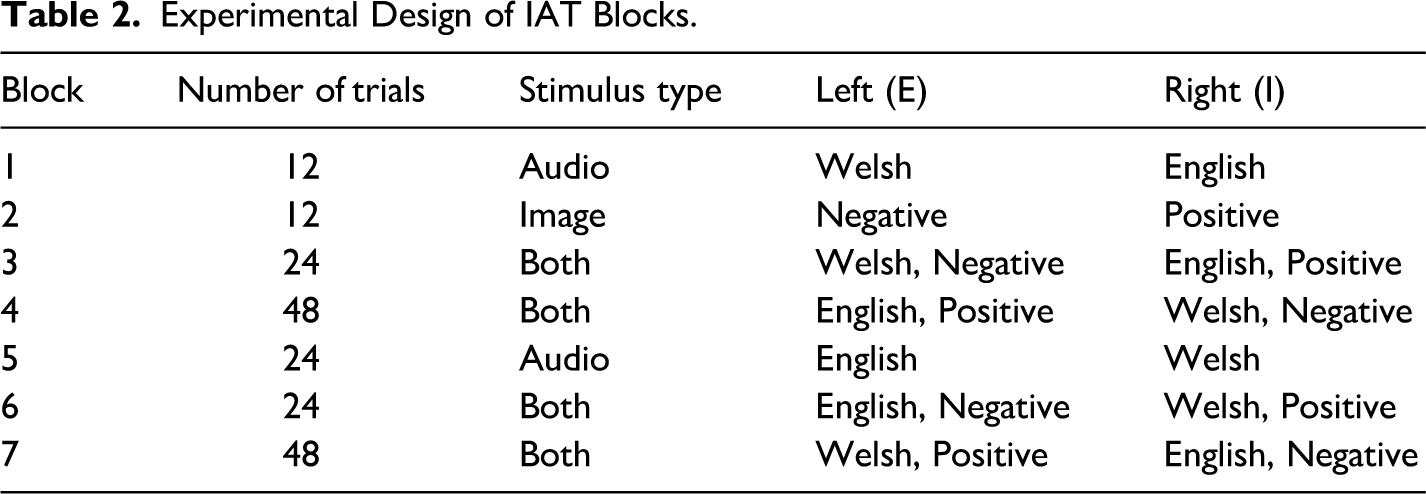
The experiment began with two practice blocks in which only the target categories or attribute categories were presented. The five blocks that followed consisted of a pair of critical blocks with an audio block as separator. In critical blocks, either of the target categories (RML or majority language audio) shared the same response key with either of the attribute categories (positive or negative image). Table 2 exemplifies the block structure using Welsh and English as a working example for the RML and majority language, respectively, showing information on number of trials, stimulus type, response key, and screen location of response key.
Experimental Design of IAT Blocks.
Each participant was assigned to one of four groups based on four predefined block orders. This was done to counterbalance experimental blocks based on two features: the order of presentation of combined blocks (e.g., Welsh-positive first or English-positive first) and the side on which each of the combined categories were shown (i.e., right or left, linked to the response keys used for categorization). Counterbalancing was implemented to reduce the extraneous influence on IAT results known as the order effect (Greenwald et al., 2022). Number of trials per block and stimulus type presented in each block remained constant across all four blocks.
All trials were randomly presented within each block. Within critical blocks, where stimulus types were combined, visual and auditory stimuli strictly alternated, such that participants were never presented with consecutive stimuli of the same type (e.g., image > image > image).
Language Usage Task
The Language Usage Task was designed to measure participants’ language choice and amount of use in a premeditated scenario aimed to replicate a real-life language exchange. The task was inspired by an idea from Karpinski and Hilton (2001), who surreptitiously presented participants with a dichotomous choice between an apple and a chocolate bar in order to study dietary choices in comparison to self-reports and attitudinal results. Karpinski and Hilton (2001) were interested in whether self-reports and experimental results would predict participant dietary behavior, e.g., whether the choice of food item was consistent with the reported preference for fruit over candy.
We developed and adapted Karpinski and Hilton (2001)'s idea to the context of regional/minority language use, with the aim of investigating the reliability of attitudinal measurements in predicting actual language use. Therefore, we introduced several adaptations and innovations that made the task suitable for the measurement of linguistic behavior. These include the use of an actor as interlocutor, the addition of an interaction component, and the measurement of choice as a continuous rather than dichotomous variable, i.e., by measuring and comparing percentages of syllables uttered and turns taken in each language.
Similar to the study presented in Karpinski and Hilton (2001), participants were faced with a choice, but in this case, it was a linguistic choice between their regional/minority language and the majority language. After taking part in the main study, each participant was approached by an actor posing as a stranger who addressed them in the regional or minority language (RML) relevant to the location of the study. This was aimed to obtain data on the participants’ linguistic behavior, and specifically on whether—and to what extent—they would choose to use the regional/minority language when prompted by someone from the same linguistic community. In other words, while Karpinski and Hilton's (2001) participants were presented with “fruit over candy,” our participants’ choice was “Welsh over English” or “Lombard over Italian.” Seeing as language choices—unlike fruit or candy—are not necessarily binary, we intended to collect data on how much of each language would be uttered by each participant, and particularly what percentage of participants’ utterances would be in the regional/minority language as opposed to the majority language. Due to logistical reasons (e.g., the changes in locations and the protracted amount of time involved in data collection), it was not always possible to use a single actor throughout the study. Nevertheless, we kept as many variables constant as possible. For example, we employed only female actors, as females are generally perceived to be more approachable than males (e.g., Campbell et al., 2010; Miles, 2009) and so gender of the actors was kept consistent across the two locations. The age of the actors varied, however, due to different sociolinguistic pressures. For example, while it is common for younger generations to speak Welsh in Wales (e.g., Welsh Government, 2022), Lombard speakers tend to be older (e.g., ISTAT, 2017; see also discussions in Coluzzi et al., 2018). Therefore, while the actors who carried out the task in Wales were within the same age range as the participants (and specifically between the age 32 and 34), their counterparts in Lombardy were older (between 48 and 60 years old). These choices were made with sociolinguistic plausibility as the main priority, to minimize the possibility that participants would suspect the experimental setup but also to ensure that a plausible sociolinguistic situation was being recreated. In line with this approach, actors were recruited within the broader local area where data was collected, and therefore spoke with an accent local to each area.
Following the spirit of the work of Karpinski and Hilton (2001) by which this method was inspired, the purpose of the Language Usage Task was to provide a comparison between the participants’ attitude scores and their actual linguistic choice in a scenario that simulates a real-life conversation. What makes the Language Usage Task novel is that it aimed at providing the comparison for linguistic purposes, thus involving a linguistic choice (while Karpinski & Hilton, 2001 involved a dietary choice).
Materials and Procedure
All actors followed a predetermined sequence illustrated by the flowchart in Figure 5, asking participants a set of open-ended questions designed to elicit free-flowing conversation and thus provide data on language choice. Both the sequence and script were kept consistent across participants and locations in order to maximize comparability of data, the main difference being the language in which the questions were delivered. Participant data was recorded via two covert recorders: a Zoom H1 concealed inside a pencil case and a voice recorder pen (SG30012).
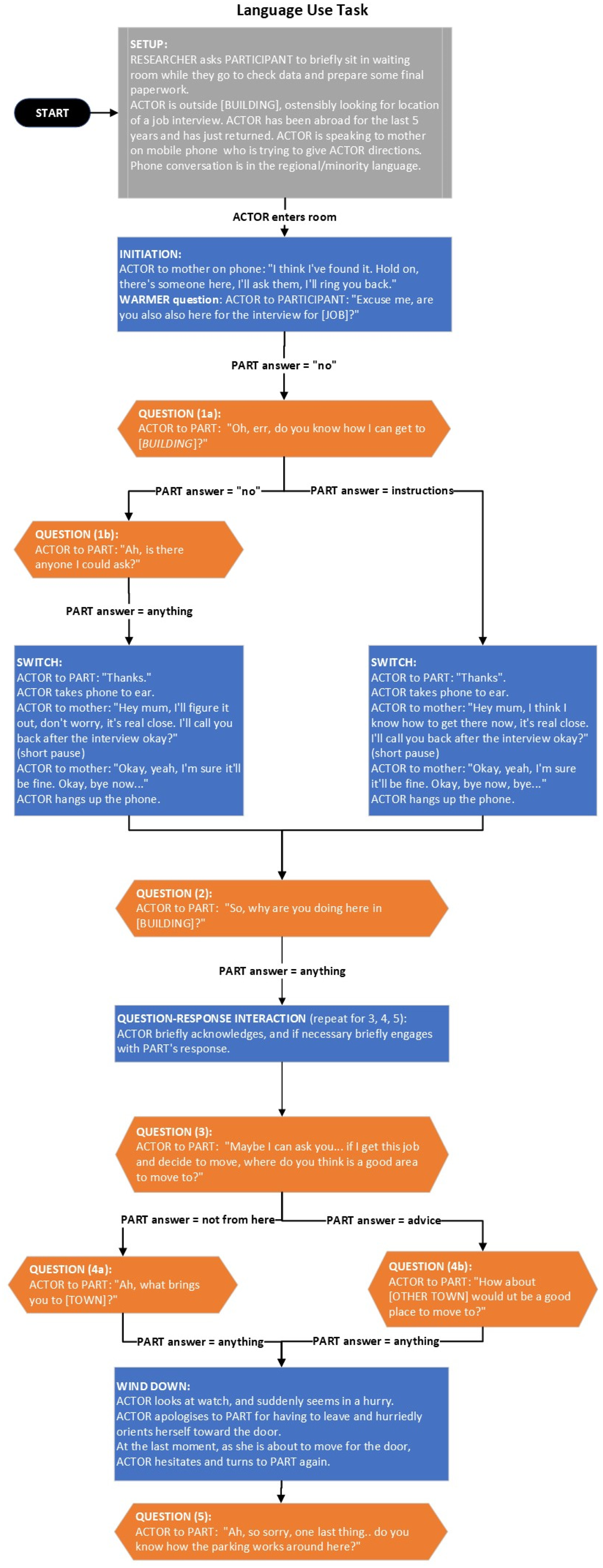
Flowchart of actor questions and conversation.
Actors were instructed to start the conversation in the RML and—in cases where the participant switched to the majority language—to follow the participant's lead in order to appear sociolinguistically plausible, in line with well-known accommodation tendencies in multilingual societies (e.g., Sachdev et al., 2012). However, actors were instructed to then attempt to encourage a switch back into the RML up to two times between questions 1b and 5 (see Figure 5 for details), depending on how many questions were left after the participant's original switch. This was done to maximally encourage participants’ use of the RML, while also ensuring that the actor behaves in a sociolinguistically plausible manner, as overly persevering in the RML after the participant has replied in the majority language may break sociolinguistic norms in a way that can raise the participant's suspicions.
Some possibility of variation was also built into the script. Specifically, actors were instructed to adapt the script according to how the conversation with the participant developed, for example, she could change the exact wordings of her questions to adapt to the participant's previous answers, but she would not diverge from the topics of the script or the order in which they were delivered. Further, actors were also advised to react plausibly to what the participant was saying, for example, by replying with additional conversation not in the script; however, variations could not involve the exclusion of any questions from the script. The full sequence of questions and the conversation structure is illustrated by the flowchart in Figure 5. The placeholders [JOB], [BUILDING], [TOWN], and [OTHER TOWN] indicate different jobs, buildings, and towns, depending on the specific location of the data collection.
Ethical Considerations
The studies were approved by the Ethics Committee of the College of Arts, Humanities and Social Sciences at Bangor university (reference: MT2-2022 and MT3-202223).
While the aims of the study required that participants be unaware that they were conversing with an actor, care was taken to ensure that participants were thoroughly debriefed and fully informed of the deception that had taken place and why it had been necessary. A debriefing protocol was followed with every participant in each location. This involved revealing the actor's identity to the participant, while also explaining that the conversation had been recorded in order to collect data on spontaneous conversational usage (note that, as part of the informed consent procedure, participants had also been informed before agreeing to taking part that recording “may take place”). After full disclosure, participants were then asked if they had any questions for the researcher about any part of the procedure. Further, they were asked whether—being now aware of the full extent of the research aims and of the data they provided—they still wished for their data to be included in the study. At this stage they were also reminded of their right to withdraw at any time and that their recordings would be immediately deleted if they decided to withdraw at this juncture. They were also informed that their withdrawal would not affect receipt of any compensation they had been promised.
Prior to this full debrief, researchers took the opportunity to gauge whether participants had suspected the involvement of an actor. They were asked if they had “anything to report,” to which all participants responded with a description of what had happened. Most participants did not give any indication that they suspected they had been engaged in conversation with an actor rather than a member of the public. In Lombardy, suspicion was expressed by 2 MGT participants and 4 IAT participants, citing what they saw as “excessive” use of Lombard as the source of their suspicion. In Wales, suspicion was expressed by 3 MGT participants and 4 IAT participants, who relied that it seemed overly coincidental to be approached by someone speaking Welsh while taking part in a study on Welsh. However, none of these participants made explicit reference toward this suspicion during the task, e.g., by either asking the actor if the situation was a ruse or refusing to engage in conversation with her. All data were therefore included in the analysis, as none of the recordings suggested anything untoward in the participant's contribution to the task.
Finally, participants were asked to keep all aspects of the research confidential, especially the fact that an actor was involved, so as to avoid spreading awareness among potential future participants.
Data Coding
In order to obtain a measure of language use, recordings of participants’ interactions with the actors underwent automatic syllable counts using Praat Script Syllable Nuclei (de Jong & Wempe, 2009). Following instructions from the developers, Ignorance Level/Intensity Median (dB) was set to 0, and Minimum dip between peaks (dB) was set to 2. A sample of the syllable counts generated by the script for four participants (two for Lombard and two for Welsh) was checked manually for accuracy by two researchers working on the project and they were found to be between 94.44% and 94.74% accurate.
Further, all recordings were manually annotated in Praat (Boersma & Weenink, 2024), specifying who was speaking (actor, participant or third person, e.g., a passerby) and which language they were speaking in (e.g., Welsh or English). Finally, syllable measures were programmatically extracted with a short Python script which calculated (i) the percentage of syllables uttered in the RML and (ii) the number of turns taken in the RML, for each participant.
These measurements provided some information on RML use and how it relates to use of the majority language. Specifically, measure (i) give us an indication of how much the participant used the RML in comparison to the majority language, while measure (ii) is an indication of the degree to which RML utterances followed switches from the majority language. For example, a higher number of turns indicates more switches from/into the RML, allowing us to distinguish between participants who tended to switch between the two languages and those who tended to keep consistently to one or the other language, but who may otherwise have uttered a similar percentage of RML syllables overall. Together, these measures give us a reasonably detailed picture of participants’ usage of the RML in relation to their usage of the majority language. In addition, working with relative measures like ratios and percentages rather than with absolute numbers minimizes the potential effect of each individual's variability in terms of utterance length.
Results
Component Analysis
A Principal Axis Factor (PAF) with a Varimax (orthogonal) rotation of the 18 MGT adjectives was conducted on data from all 82 participants for a total of 164 average ratings (82 participants x 2), with averages calculated from a total of 656 ratings (82 participants × 2 languages × 4 guises per language = 656 individual ratings). Kaiser-Meyer Olkin measure of sampling adequacy suggested that the sample was factorable (KMO = .869).
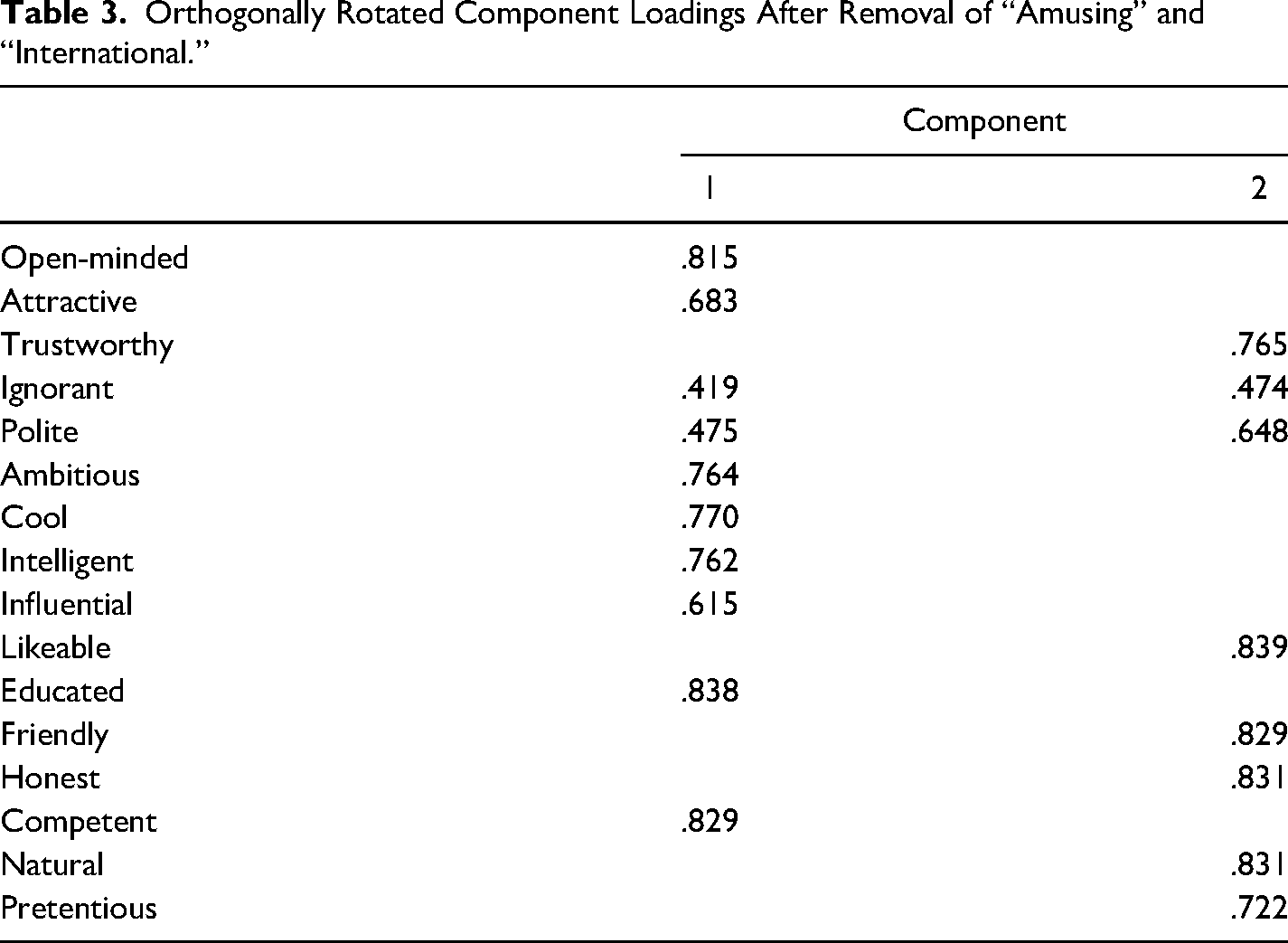
A four-factor solution emerged when loadings less than 0.40 were excluded. However, factors 3 and 4 only contained the items “amusing” and “international.” respectively, with “amusing” also showing an unexpected correlation with factor 2. This suggested that perhaps participants did not interpret these adjectives as intended. In the case of “amusing,” it appears they may have interpreted it in the sense of “humorous / light-hearted,” rather than in the intended sense of being laughable, hence departing from our reasoning for including “amusing,” i.e., the idea that a speaker is “laughable” when using the RML in a relatively high domain such as a recording in an experimental setting. Rerunning the analysis after removing “amusing” and “international” yields the two-factor solution reported in Table 3, closely aligned with the two typical sets of MGT traits: Solidarity (factor 1) and Status (factor 2).
Orthogonally Rotated Component Loadings After Removal of “Amusing” and “International.”
Welsh—English
MGT Results
To facilitate a correlation analysis between self-reported use, MGT scores, and usage scores, D-scores were calculated in order to have a single score for each measure (Solidarity and Status) that is indicative of attitudes toward the two languages.
This was achieved by subtracting the Welsh scores from the English scores in each case (i.e., once for Solidarity and once for Status). Therefore, negative D-scores indicate a preference for Welsh, while positive D-scores indicate a preference for English.
Kendall's tau-b correlations were run to determine the relationship between language usage, MGT D-scores, and LSBQe score for the usage and proficiency section (Table 4). There was a statistically significant negative correlation between usage score and solidarity D-score (τb = −.195, p = .036) (Figure 6), suggesting that usage increased as the solidarity D-score decreased (i.e., tilted in favour of Welsh), and a positive correlation between usage and the LSBQe use and proficiency score (Figure 7). A negative correlation is also present between number of turns in Welsh and the LSBQe score (τb = −.310, p = .005), while a positive correlation is present between number of turns in Welsh and solidarity D-score (τb = .218, p = .022), suggesting that switching into and from English decreased as solidarity D-score decreased (i.e., as solidarity scores were more in favor of Welsh).
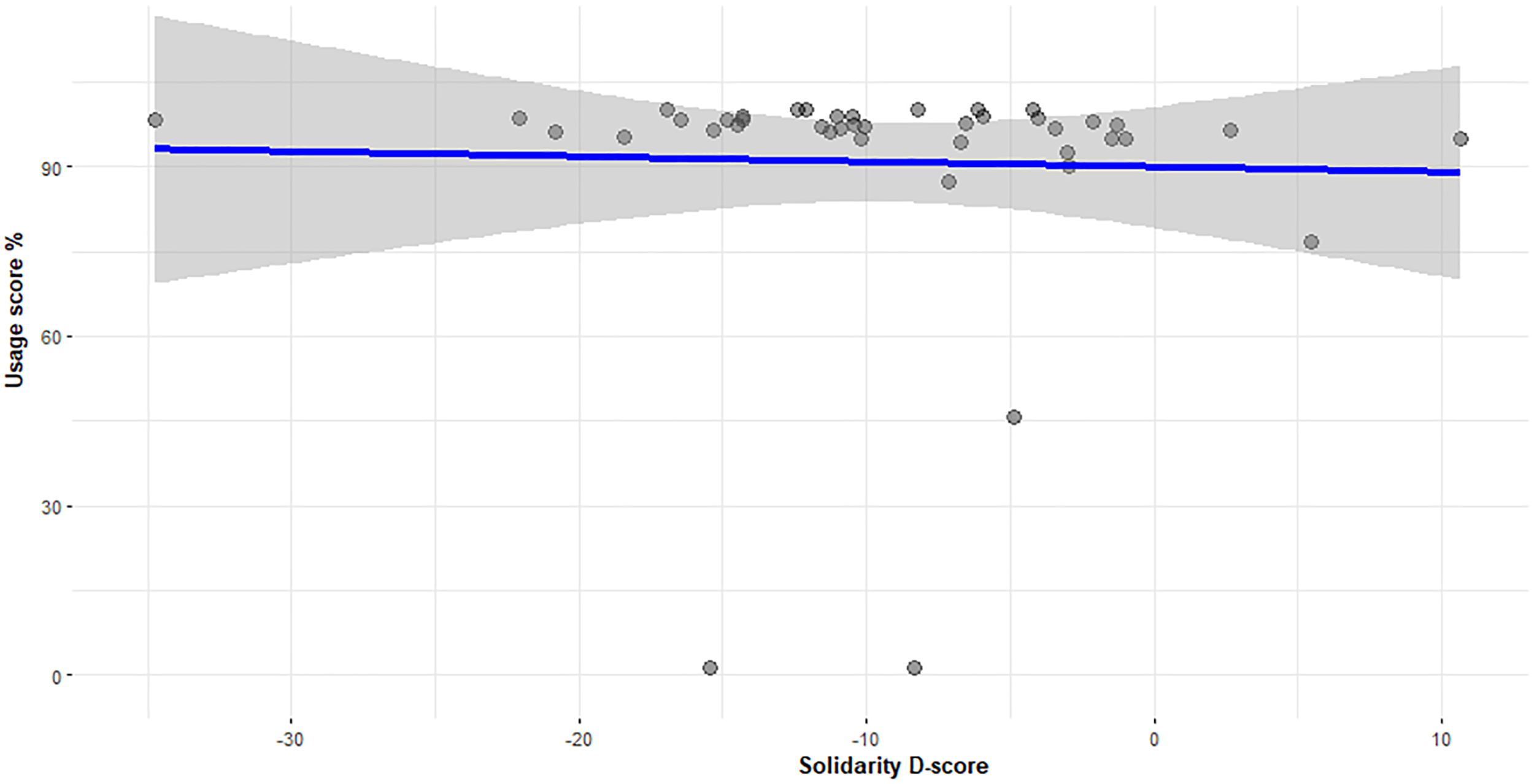
Correlation between usage score (%) for Welsh and MGT solidarity D-score.
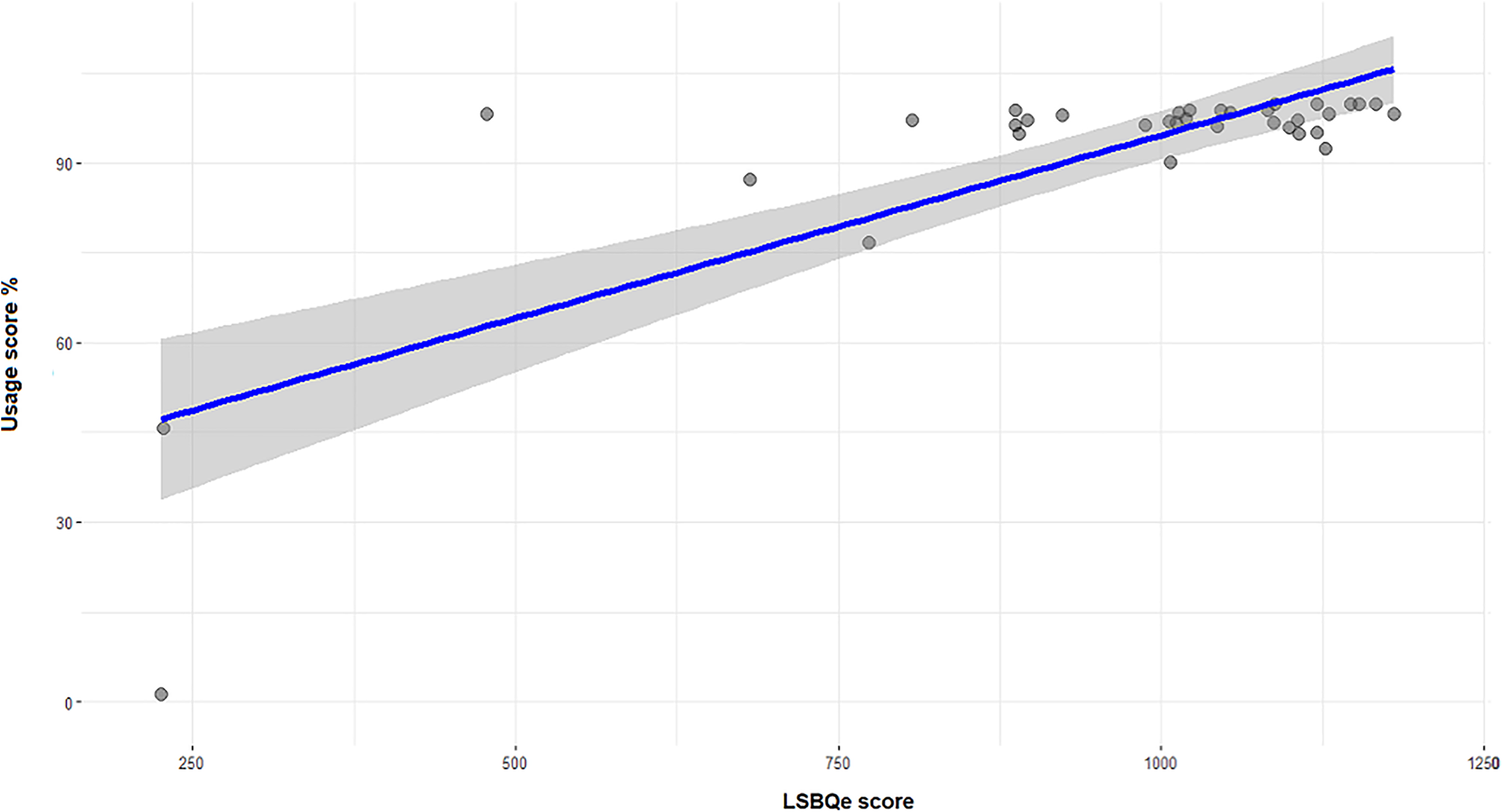
Correlation between usage score (%) for Welsh and LSBQe (self-reported) use and proficiency score.
Kendall tau-b Correlations for MGT Data, Language Usage Measures and LSBQe (Self-Reported) Usage and Proficiency Score for Welsh.

To investigate MGT scores and (self-reported) LSBQe scores as potential predictors of spontaneous usage, significant correlations were followed up with a quantile regression analysis, which showed significant positive associations between solidarity D-score and usage score at the lower (95% CI [.307, .731], p < .001) and mid quantile (95% CI [.185, .484], p < .001) (Figure 8). Significant positive associations were also found at the lower quantile between solidarity D-score and number of turns taken in the RML (95% CI [.230, 1.140], p = .004) (Figure 9) and between self-reported usage and number of turns taken in the RML at the lower quantile (95% CI [.077, .353], p = .003) (Figure 10), while negative associations were found between self-reported usage and number of turns taken in the RML at the mid (95% CI [−.425, −.039], p = .020) and higher (95% CI [−.516, −.091], p = .006) quantiles. No other association was found (p > .172).
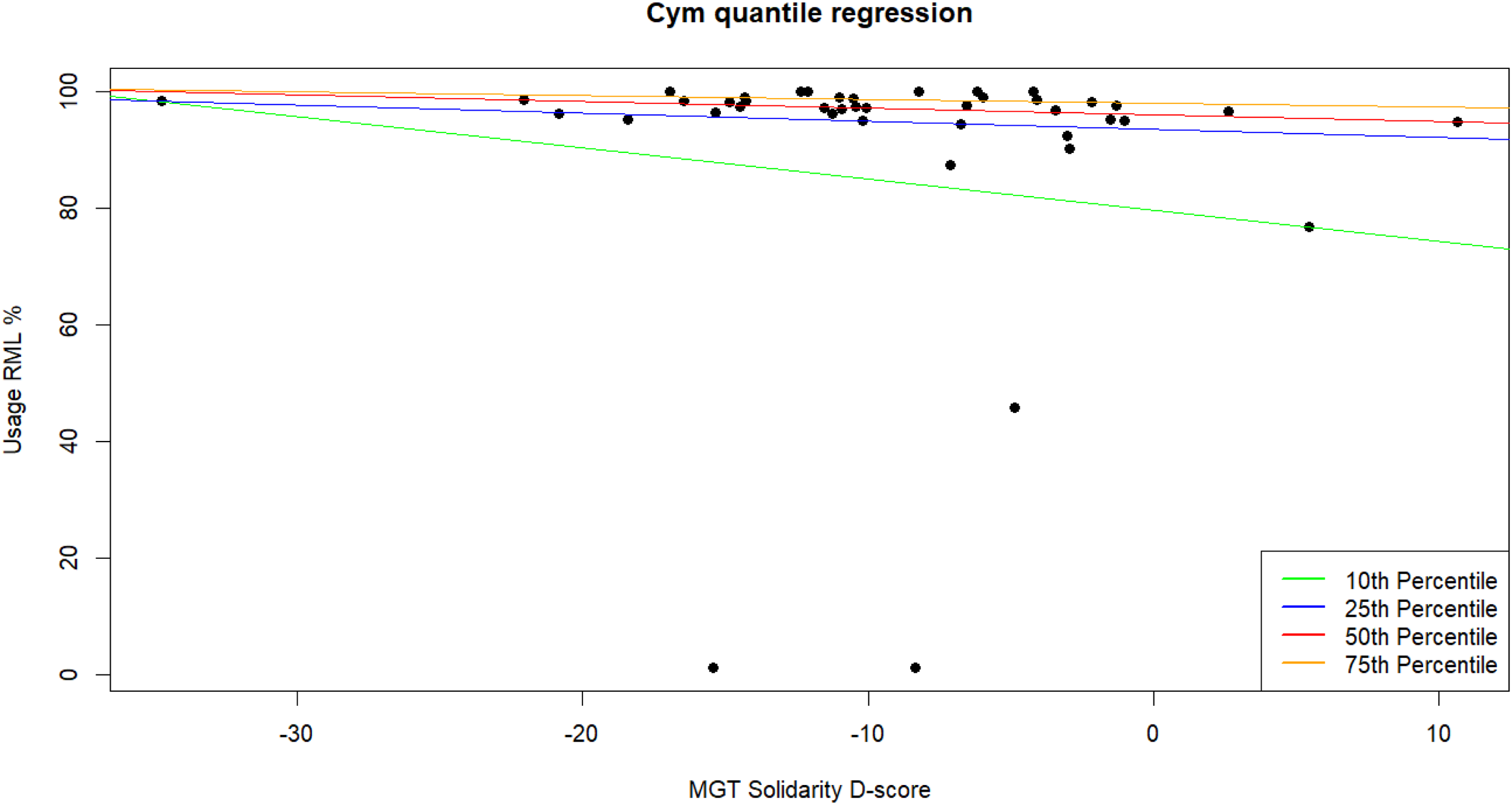
Quantile regression for solidarity D-score on percentage of RML use (Welsh).
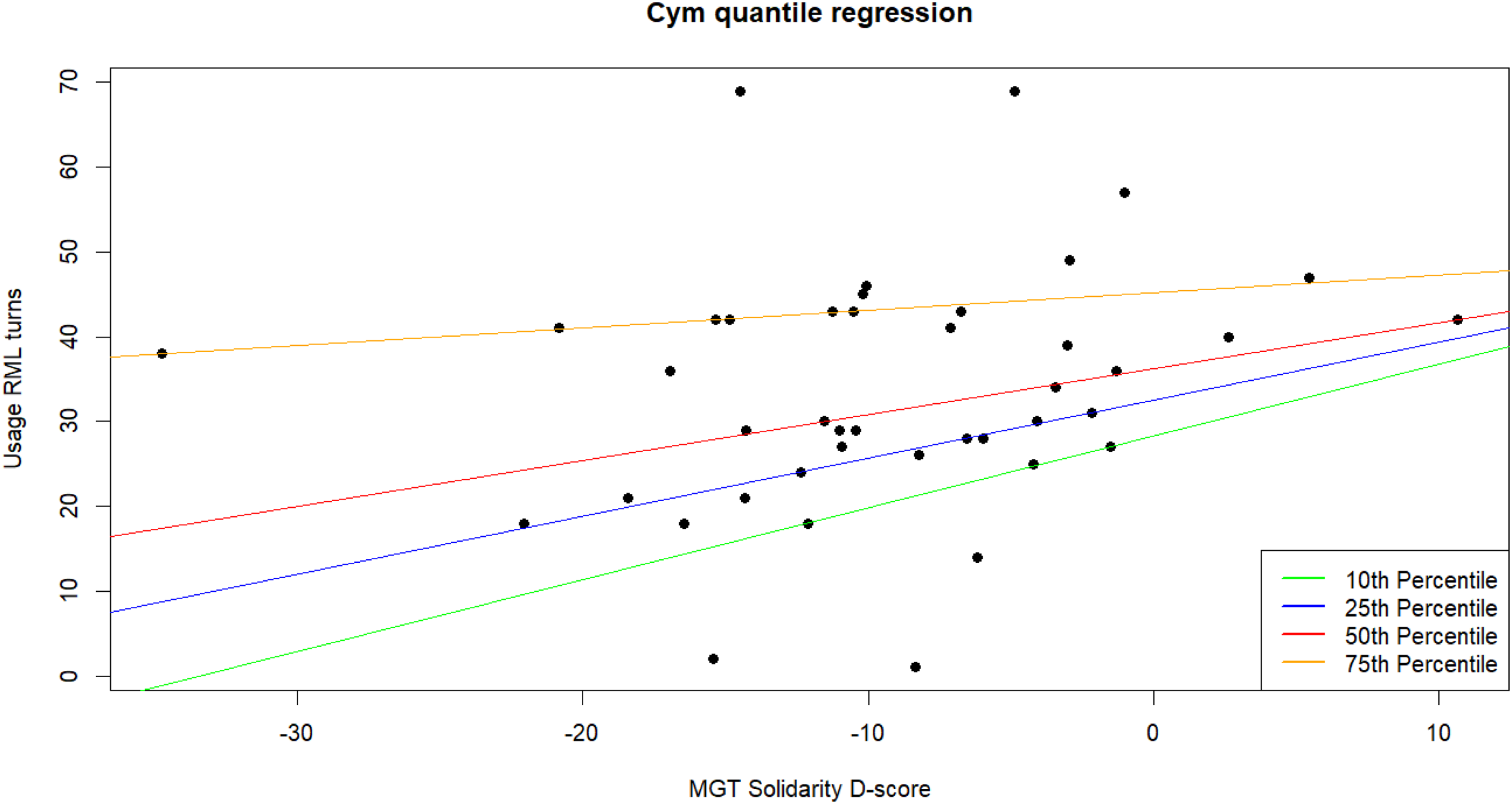
Quantile regression for solidarity D-score on number of turns taken in the RML (Welsh).
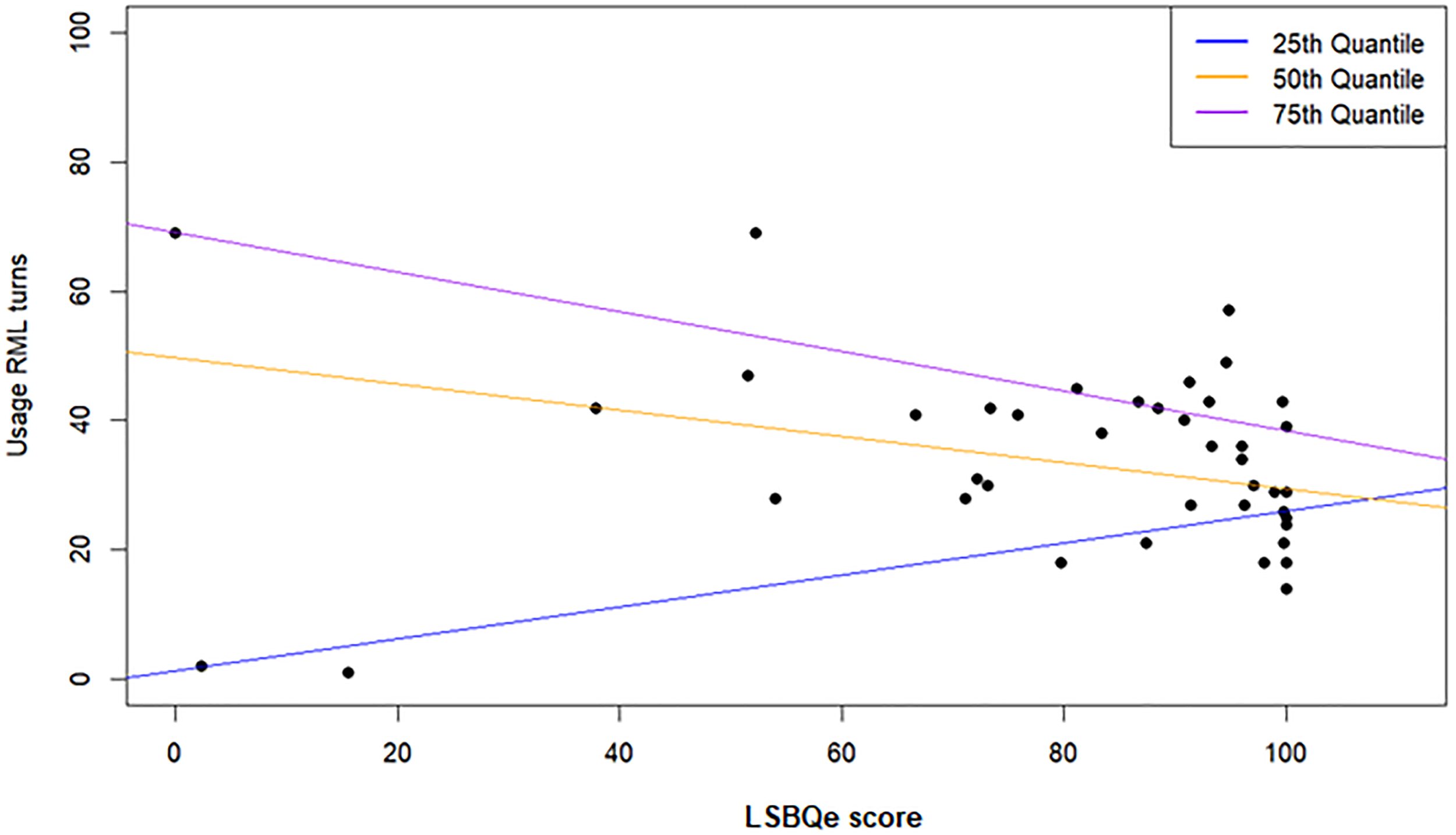
Quantile regression for LSBQe use and proficiency score (self-reported) on number of turns taken in the RML (Welsh).
Interim Discussion
A positive relationship at the lower quantile between solidarity and number of turns taken in the RML suggests that as solidarity tilts more toward English (higher D-score), participants make more attempts at using English. This is likely due to the fact that at higher quantiles, participants made hardly any switches into English, using Welsh consistently throughout the interaction. The higher number of turns at the lower quantile therefore could suggest that—for speakers who use less Welsh overall—higher solidarity with the Welsh-speaking community acts as strong motivation in their attempt to keep switching back to Welsh after adopting English in parts of the conversation.
The negative relationship found between scores on the usage and proficiency section of the LSBQe and the number of turns taken in Welsh at the mid and higher quantile suggests that participants’ daily use of Welsh is a good predictor of their likelihood to also engage in sustained use of Welsh in unfamiliar social situations. This highlights the importance of increasing opportunity for speakers to engage in everyday use of Welsh. In 2014, the language strategy Iaith Fyw: Iaith Byw–Bwrw ‘Mlaen (“A Living Language: A Language for Living–Moving Forward”—Welsh Government, 2014) saw the Welsh Government dedicate £1.25 million to supporting the development of Welsh language centers to promote the use of Welsh in communities across Wales before its dissolution with the successive Cymraeg 2050 strategy (Welsh Government, 2017). Well-renowned Iaith Gwaith orange speech bubble badges indicating that a person can speak Welsh are a well-celebrated example that remains in facilitating the use of Welsh in public or private sector institutions in Wales.
From a methodological perspective, this result also suggests that number of turns works well as a measure for frequency of code-switching at these quantiles: participants who self-report higher usage and proficiency switch less, i.e., once they begin an interaction in Welsh they tend to keep conversing in Welsh, thus producing fewer turns taken in Welsh.
Overall, MGT scores appear to be only partly predictive of language use in Wales, being limited to the lower quantile. However, this could be due to the high scores across most participants on the language usage task. Therefore, it remains at least possible that the MGT could be predictive beyond the lower quantile but that such relationship is not discernible in our data due to a ceiling effect in usage.
IAT Results
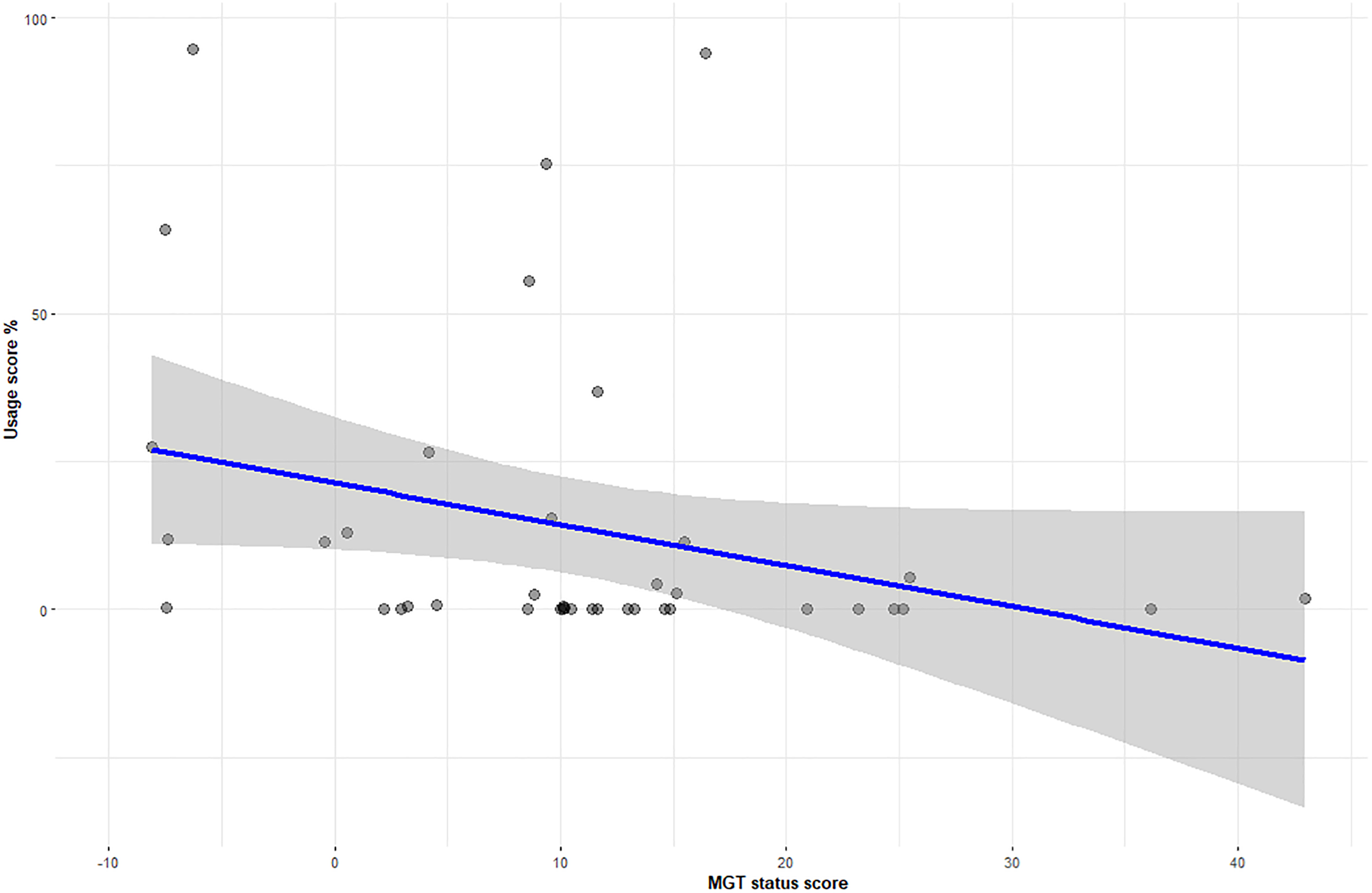
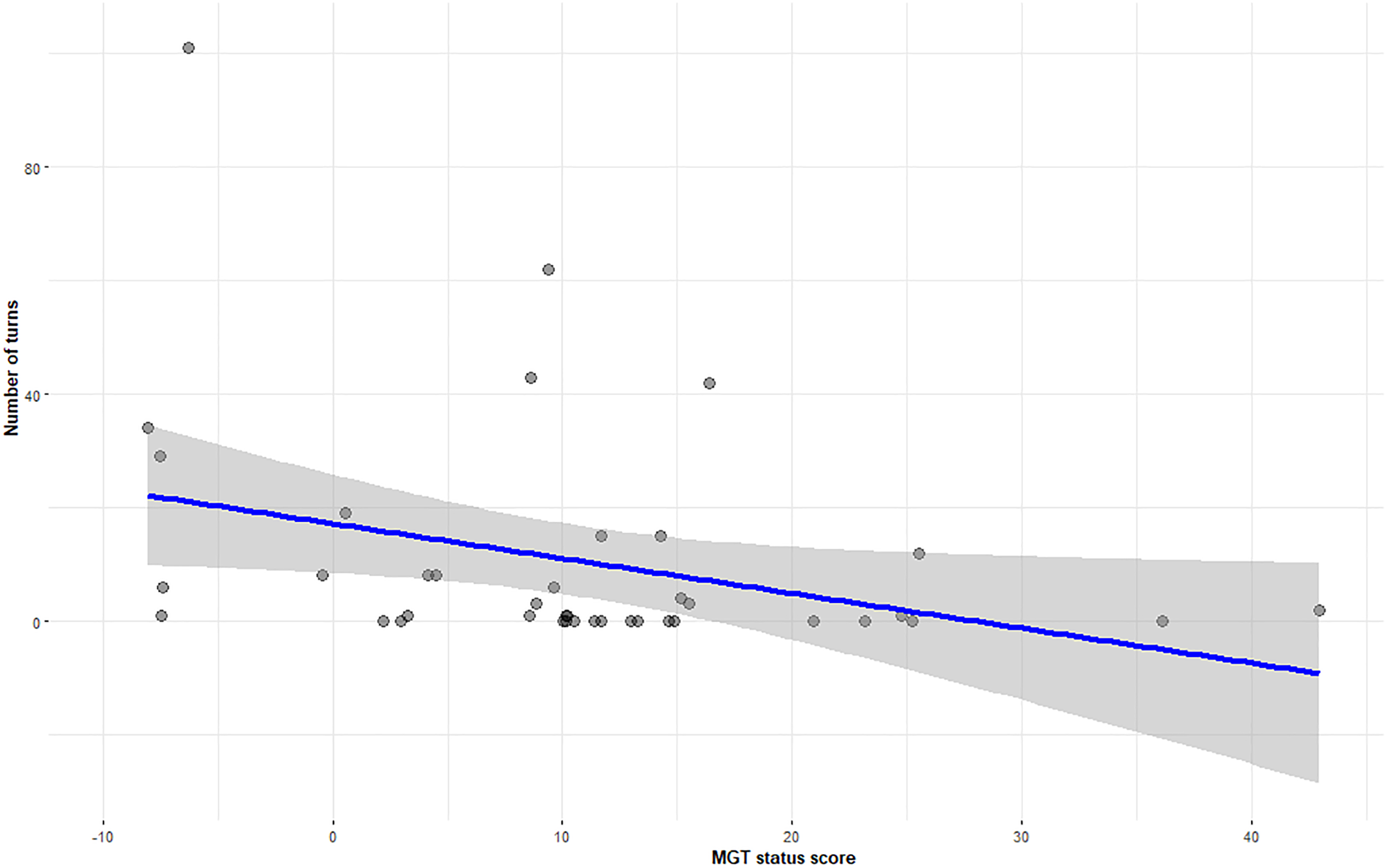
D-scores were calculated based on the Improved Scoring Algorithm (Greenwald et al., 2003). The Mean D-score across all participants was .037 ± .56 which shows almost no implicit preference for either language. Kendall's tau-b correlations were run to determine the relationship between language usage, IAT D-scores and self-reported language score from the usage and proficiency section of the LSBQe. Table 5 shows details of the statistically significant negative correlations between usage measures and IAT scores, and the positive correlations between usage scores and LSBQe scores for self-reported usage and proficiency in Welsh. Figure 11 shows correlation between usage score and the IAT D-score, while Figure 12 shows correlation between usage score and LSBQe score.
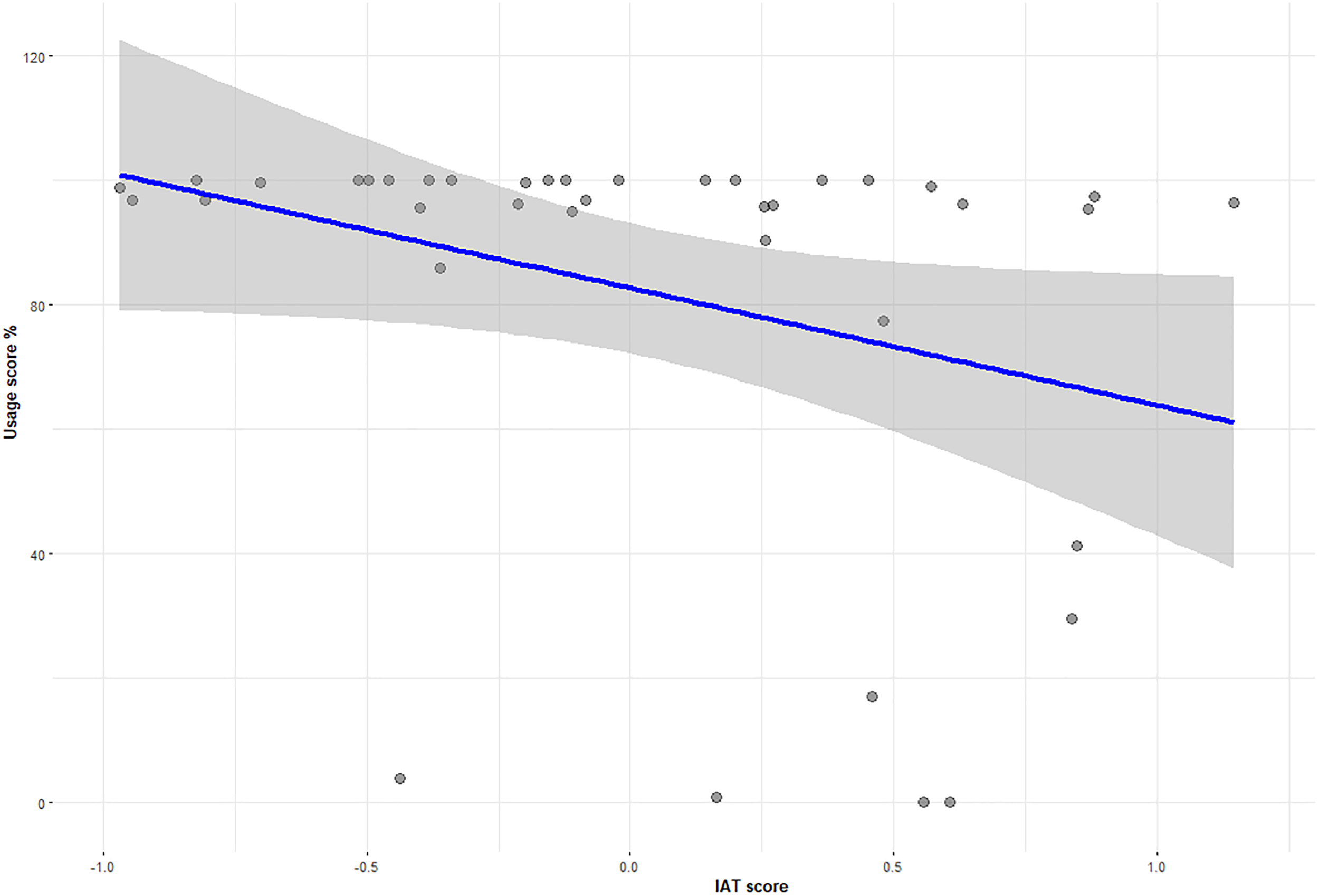
Correlation between usage score (%) for Welsh and IAT D-score.
Kendall tau-b Correlations for IAT Data, Language Usage Measures and LSBQe Score for Welsh.

Correlations were followed up with a quantile regression analysis to investigate IAT scores and LSBQe scores as potential predictors of usage. This showed a significant positive relationship between LSBQe use and proficiency score and the usage score at the higher quantile (95% CI [.307, .731], p < .001) (Figure 13). No other significant associations were found.
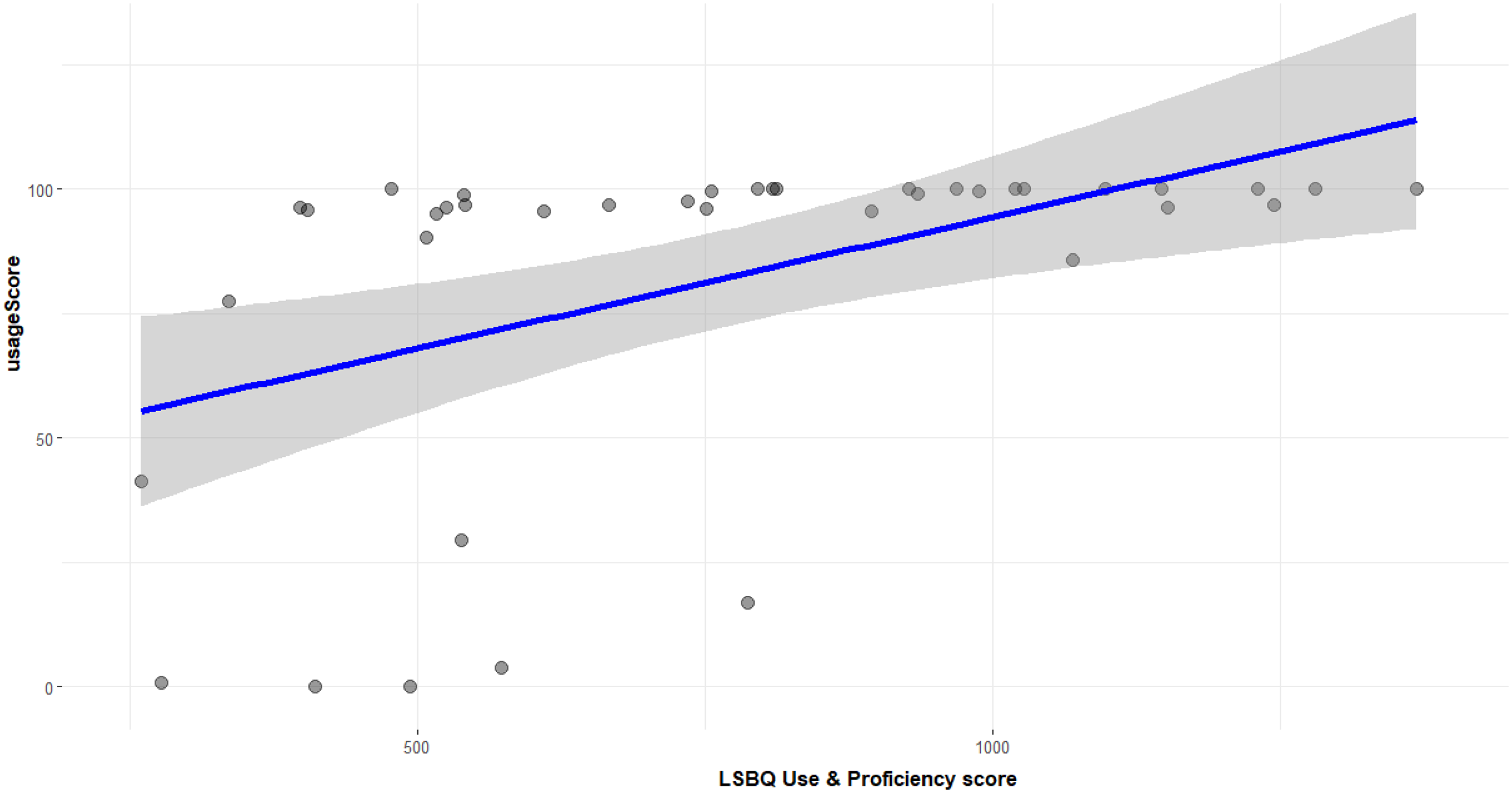
Correlation between usage score (%) for Welsh and LSBQe score.
Quantile regression for LSBQe (self-reported) use and proficiency score on usage score (%) in the RML (Welsh).
Interim Discussion
Scores from the language usage task showed a mild negative correlation with IAT D-scores, though the regression analysis failed to show a predictive relationship between IAT scores and language usage. This suggests that IAT scores may be a useful proxy for current usage and possibly how established the usage may be, but at the same time may cast some doubt on the idea that attitudes as measured by IAT may be a good predictor of future usage. Nevertheless, the consistently high scores we saw for the language usage task in the MGT were also a feature of the IAT group, and therefore failure to find a predictive relationship could in this case too be due to a ceiling effect in usage.
The positive relationship found between scores on the usage and proficiency section of the LSBQe and performance on the language usage task at the higher quantile may suggest that participants’ self-identification with the Welsh language is a good predictor of their likelihood to engage in actual use of Welsh in unfamiliar social situations.
Lombard—Italian
MGT Results
The same procedure was carried out as for the Welsh data: with calculation of D-scores for MGT Solidarity and Status by subtracting scores for the regional/minority language (in this case Lombard) from the scores for the majority language (i.e., Italian). Therefore, negative D-scores indicate a preference for Lombard, while positive D-scores indicate a preference for Italian.
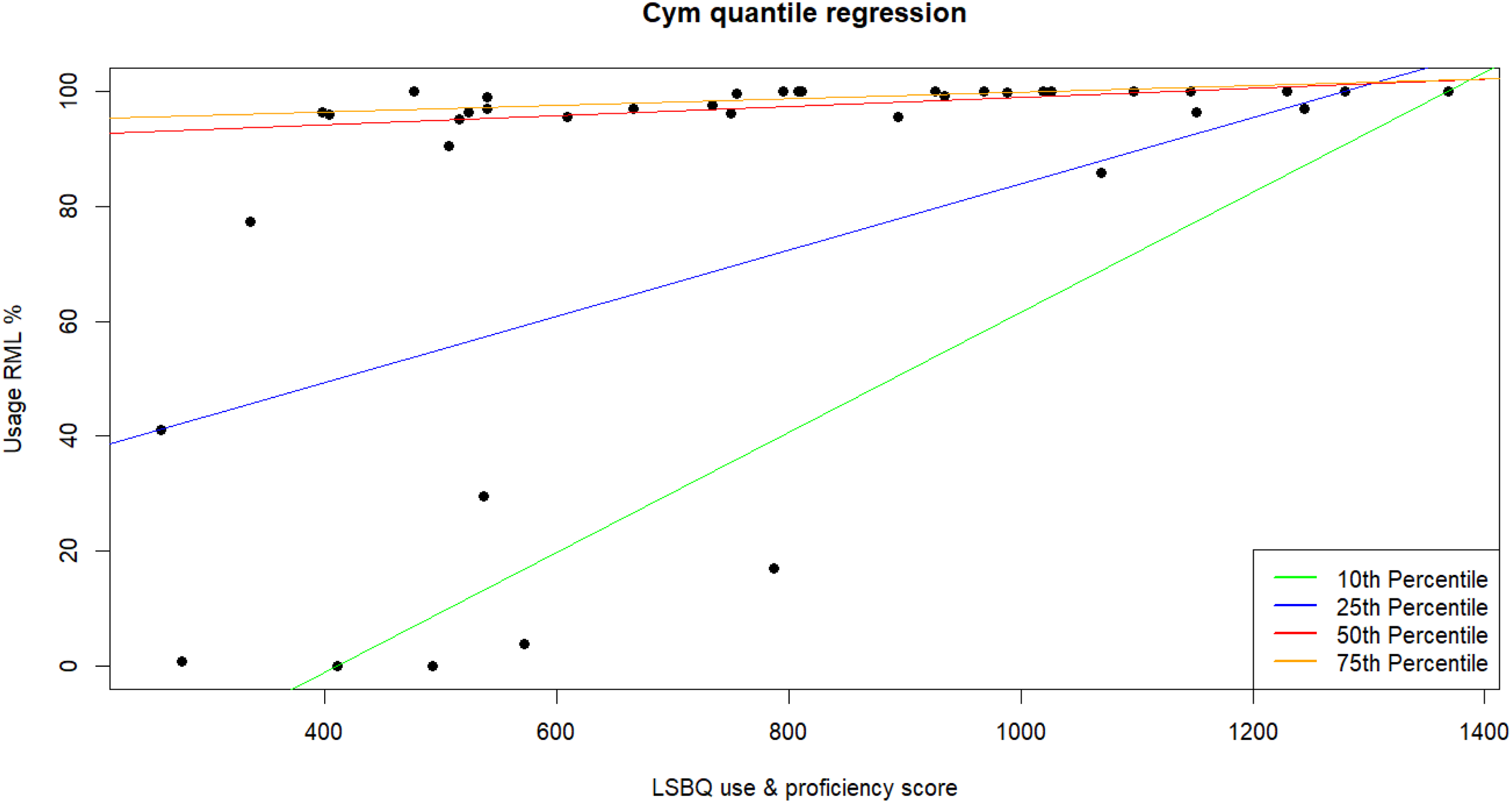
Kendall's tau-b correlations were run to determine the relationship between language usage, MGT D-scores, and LSBQe score for the usage and proficiency section. As shown in Table 6, there is a statistically significant negative correlation between usage score and status D-score, with usage scores increasing as the status D-score decreased (i.e., a stronger toward Lombard, see Figure 14), and between number of turns taken in Lombard and status D-score (Figure 15).
Correlation between usage score (%) for Lombard and MGT status D-score.
Correlation between number of turns in Lombard and MGT status D-score.
Kendall tau-b Correlations for MGT Data, Language Usage Measures and LSBQe (Self-Reported) Usage and Proficiency Score for Lombard.
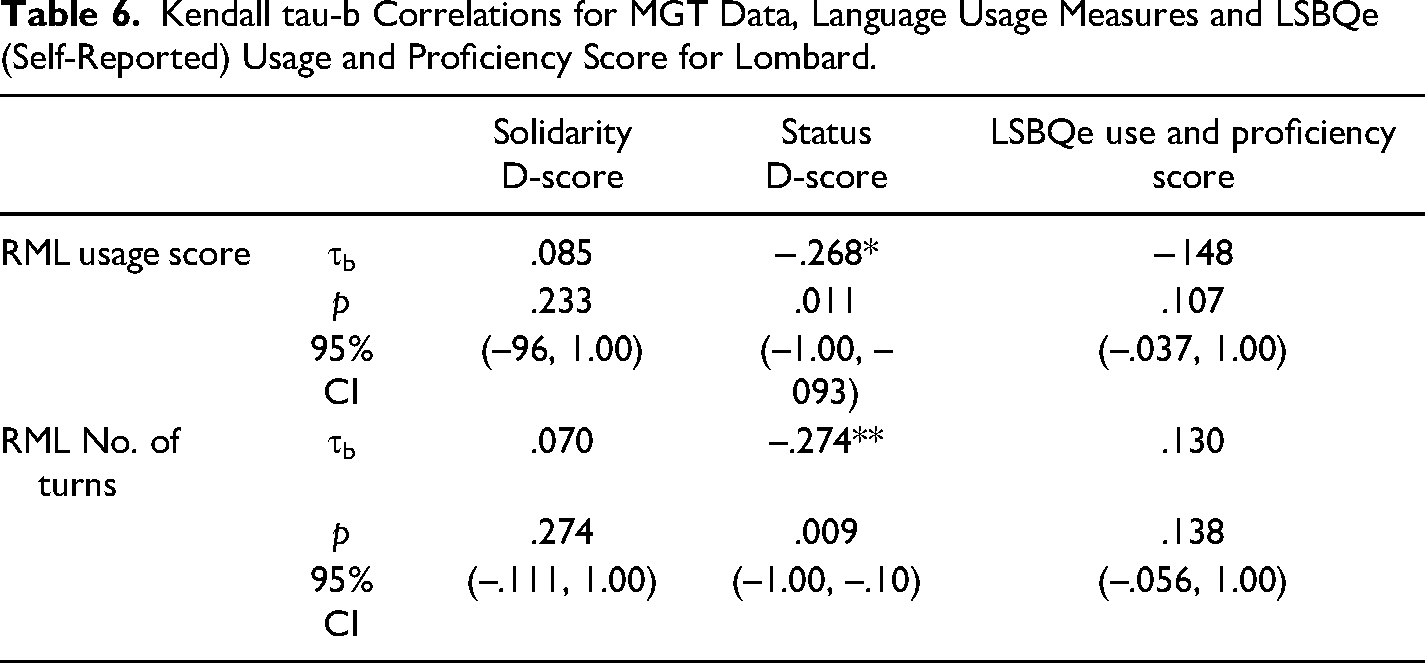
Significant correlations were followed up with a quantile regression analysis, which showed no significant associations for usage score (p ≥ .205) or number of turns taken in the RML (p ≥ .313).
Interim Discussion
Mild negative correlations between MGT status score and the two usage measures (usage percentage as well as number of turns in the RML) suggest that participants who associate Lombard with a relatively higher status (lower D-Score) make more use of Lombard (higher usage percentage scores) and make more efforts to switch back into Lombard after having drifted into Italian (higher number of turns taken in Lombard).
However, these relationships are not predictive, as shown by lack of associations in the regression analyses. This may cast some doubt on the MGT scores as predictive of language usage. Nevertheless, the consistently low scores in the language usage task for Lombard leave open the possibility that any predictive relationship may not be discernible in our data due to a floor effect in usage.
From a methodological perspective, the Lombard results reinforce the fact that number of turns may be a good measure for usage, albeit in different ways depending on the language situation: while in the case of Welsh a high number of turns meant more inconsistent use of Welsh (with usage being overall very high, more turns in Welsh meant more occasions where the participant switched back from using English), in the case of Lombard the situation is reversed: since usage is generally very low, a higher number of switches indicates more use of Lombard, with fewer instances of conversation solely in Italian.
IAT Results
The Mean D-score across all participants was .40 ± .40 which shows a moderate implicit preference for Italian. Kendall's tau-b correlations were run to determine the relationship between language usage, IAT D-scores, and self-reported language score from the usage and proficiency section of the LSBQe. Table 7 shows details of the correlation results, including a statistically significant positive correlations between number of turns taken in Lombard and LSBQe scores for self-reported usage and proficiency (Figure 16).
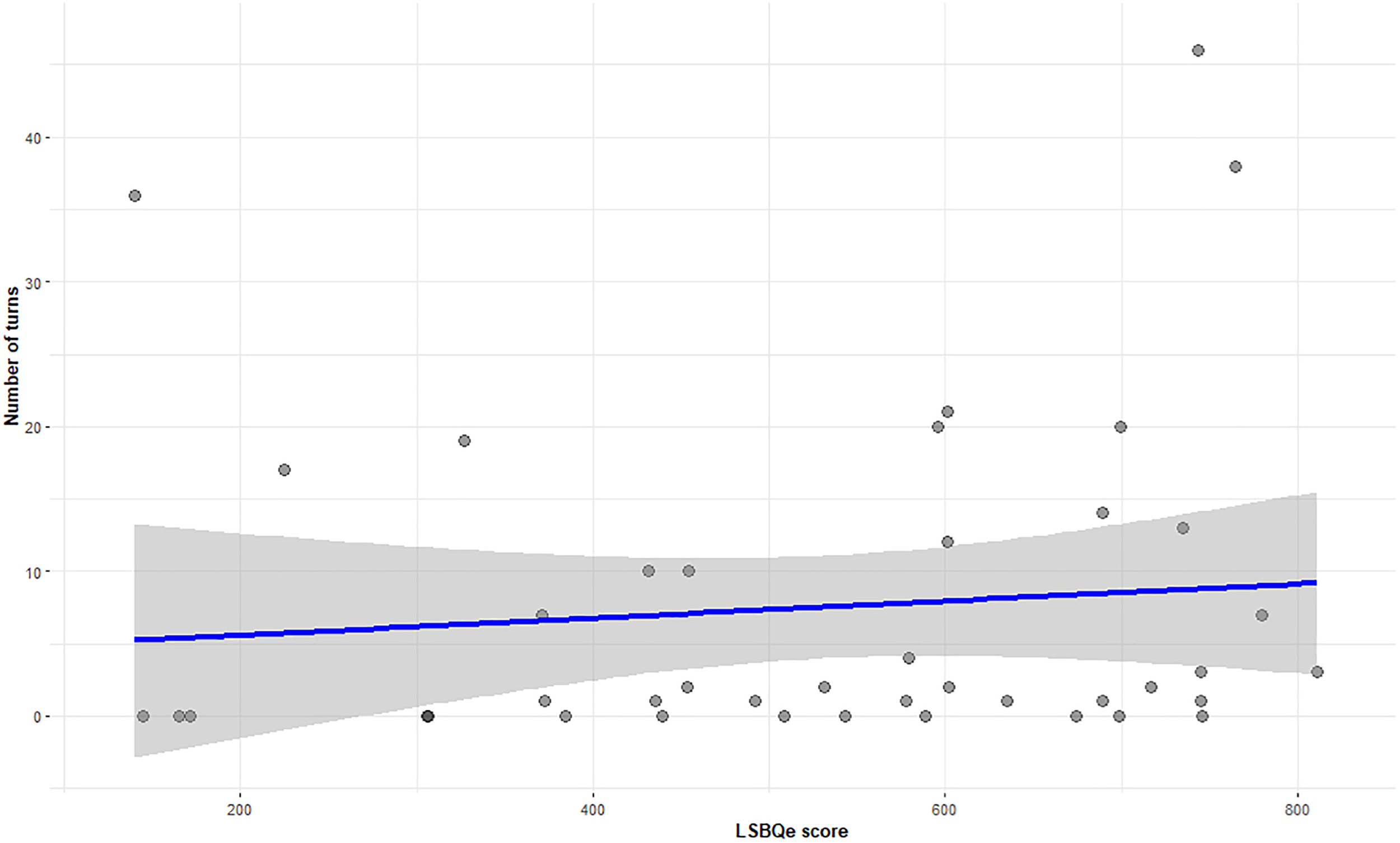
Correlation between number of turns taken in Lombard and LSBQe use and proficiency score (self-reported).
Kendall tau-b Correlations for IAT Score, Language Usage Measures and LSBQe Score for Lombard.
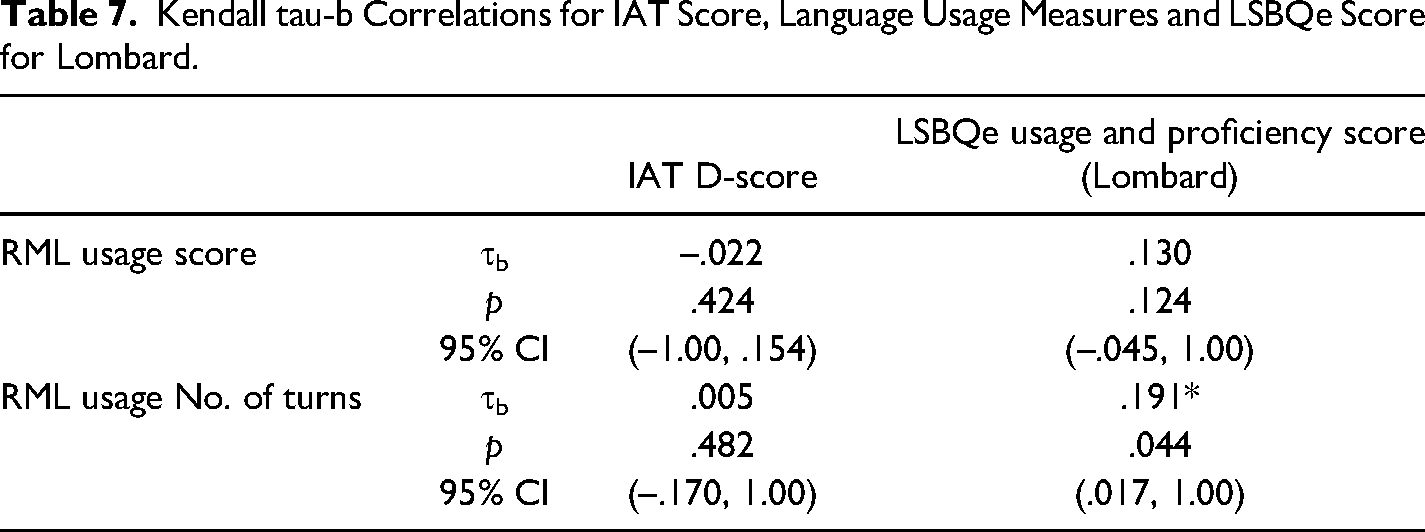
The correlation was followed up with a quantile regression analysis, which returned no significant associations (p ≥ .172).
Discussion
We investigated two bilingual communities whose regional/minority languages receive radically different degrees of sociopolitical recognition: Lombard—Italian (Italy) and Welsh—English (UK). The aim was to address three research questions:
To what degree are MGT scores predictive of language behavior across bilingual communities with different language policies? To what degree are IAT scores predictive of language behavior across bilingual communities with different language policies? Does the predictive power of the MGT or IAT vary across different regional/minority language situations with different degrees of sociopolitical recognition?
We attempted to address these questions by measuring rates of spontaneous language usage and comparing them with attitudinal results from two distinct attitudinal measures: the Matched Guise Technique and the Implicit Association Test.
Results from the MGT-based studies showed that use of Welsh correlates with and is partly predicted by stronger solidarity scores, while use of Lombard correlates with stronger status scores. This suggests that linguistic behavior may be affected differently in situations of radically different sociopolitical recognition.
The language policy of Wales, which affords equal status to English and Welsh, officially sanctions speakers to choose the language they wish to use across any and all communicative domains, thus actively promoting the equitable use of Welsh. This means that, at least insofar as status is related to and/or derived from institutional agents, Welsh language policy seeks to effectively eliminate or at least minimize the association between (institutionalized) status and language choice. Our results show that, in the case of Welsh, it is therefore solidarity with the Welsh-speaking community—rather than the established status of Welsh—which contributes to the intensity of usage.
Lombard, on the other hand, is a “contested language” (Tamburelli & Tosco, 2021), lacking institutional support and with a tendency to be perceived as low prestige (or not even “a language”, Tamburelli, 2024) among the majority of speakers (e.g., Coluzzi et al., 2018). There is little, if any scope, for activities where the use of Lombard is institutionally or even socially sanctioned, which results in usage associating more closely with status. This tallies with research on accents in second language speakers, and the finding that awareness that one's accent is perceived to be low status influences how second language speakers approach communicative interactions, shaping their behavior during the interaction (Gluszek & Dovidio, 2010; Gluszek et al., 2011). However, while a second language speaker cannot choose to “switch off” their accent, in a bilingual situation, speakers do have the option of switching away from the lower prestige language and to the higher prestige language (e.g., Rindler-Schjerve, 1998). Our data shows that such a switch is at least partly dependent on the speaker's perception of the regional language status in cases of overall low prestige. Although the overall use of Lombard was generally very low, speakers who associate the language with marginally less low status are more likely to make some attempts at using it in conversation with an unfamiliar interlocutor. In doing so, these speakers are essentially departing from the accepted relegation to the family context as the primary domain of usage common to languages in a state of advanced shift (Fishman, 1965), and which—like Lombard—have experienced loss of the diglossic equilibrium (Tamburelli, 2010) that used to ensure a degree of safety (Fishman, 1993).
Regarding the question of whether the MGT is a good predictor of language usage, results were less clear-cut. While solidarity toward Welsh was found to be predictive of number of turns taken in Welsh, this was only the case at the lower quantile, likely due to the fact that—at higher quantiles—participants tended to almost exclusively use Welsh, and therefore did not engage in switching to or from English at all. For Lombard—Italian bilinguals, MGT scores turned out not to be predictive of any language usage measures. While this may question the utility of the MGT as predictive of language usage, the lack of a predictive relationship may also be due to the consistently low scores of Lombard speakers in the language usage task. Future research may benefit from investigating bilingual communities with a wider range of variation in language choices or where language usage outside the family is not quite as limited as in Lombardy nor as widespread as in north-west Wales.
From a methodological perspective, both sets of MGT results suggest that the number of turns taken in the regional/minority language may be a good measure to evaluate spontaneous usage, albeit in different ways depending on the language situation: while a high number of turns indicates more inconsistent use in cases where overall usage is high (and hence more turns equate to more occasions in which participants switch back from using the majority language), in cases of overall low usage, a higher number of turns is a useful indicator of more sustained attempts to maintain conversation in the regional/minority language.
Self-reports, and specifically scores from the use and proficiency section of the LSBQ (Anderson et al., 2018), revealed to be relatively strong predictors of usage in the Welsh—English cohorts, but not in the Lombard—Italian cohorts. We suggest that this dichotomy is possibly linked to the recognition of the respective regional/minority languages. Whereas for speakers of a recognized language which benefits from institutional and educational use it is relatively straightforward to self-reflect on use and proficiency in that language, speakers of a contested language such as Lombard do not recognize their variety as an entity on par with other languages, which may hinder their ability to self-reflect on the use of the regional/minority language as an entity standing in contrast to the surrounding (and linguistically closely related) majority language. It seems plausible in such situations to postulate that the self-reports from Lombard speakers are more ad hoc and therefore also less accurate than those of the Welsh speakers, who are more likely to already have some preformed conception of their usage and proficiency when presented with the questionnaire.
The results from our IAT studies raise interesting methodological issues. Outside of linguistics (and linguistic attitude research more specifically), there is some evidence that IAT scores may be good predictors of spontaneous or habitual behavior. For instance, Richetin et al. (2007) have shown the IAT to be predictive of behavioral food choice (dichotomous choice between a fruit or a snack), in Maison et al. (2004) the IAT has been shown to predict performance on soft drink taste tests better than self-report measures, while Romero-Rivas et al. (2022) showed IAT results to be predictive of categorization and stereotyping behavior.
Based on such prior findings, as well as the general concern that more direct and/or explicit methods may be subject to more contextually present biases, we expected that the IAT would be, if anything, better than the MGT and the self-reported data at predicting spontaneous usage in our usage task. However, the regression analysis showed that while the MGT and the LSBQ-based self-reports have some ability to predict language usage behavior, no predictive relationship was found between the IAT scores and language use. On the one hand, this may be due to the rather extreme performances on the language usage task, approaching ceiling for the Welsh—English cohorts and floor for the Lombard—Italian cohorts, possibly indicating that the IAT is not sufficiently sensitive in cases of consistently high or consistently low performance.
A possible explanation for this finding may also be that our IAT assessed implicit attitudes toward the target languages only in the form of an association between two speaker-external entities (language ∼ valence), while both the LSBQ(e) and MGT encode at least in-part a measure touching on what is referred to as the implicit self-concept (ISC) in the attitudinal model of Greenwald et al. (2002). That is, in the MGT, the participant is at least to some extent asked to make an association between their self and the guise (where the guise is a proxy for the language), so that if a participant is asked to rate, say, a Welsh guise as relatable or not relatable, they are being indirectly queried on the association “me = Welsh speaker.” Similarly, the self-reporting in the usage and proficiency section of the LSBQ(e) ask the participant to—at least in part—represent their self-concept as a speaker of the language(s). This explanation would fit the findings of Suter et al. (2017), who investigated two types of IAT, one assessing implicit attitudes and one assessing ISC as predictors of anti-social behavior, and found that the ISC-based IAT was a better and more reliable predictor than both the Inventory of Callous-Unemotional Traits questionnaire (Essau et al., 2006) and the implicit attitude IAT, the latter failing to predict anti-social behavior altogether. If this is correct, it suggests that IATs probing the ISC as related to the target languages may offer an additional avenue of investigation where the goal is to predict usage and/or future vitality.
Independent of the attitude measures, our studies also provided insightful results on language usage itself, and thus the level of vitality of the regional/minority languages under investigation, with usage being a fundamental component of vitality (e.g., Fishman, 1991; 2012; Lewis & Simons, 2010; UNESCO, 2003, among many others). The ceiling performance across both groups of Welsh—English participants shows that—at least in North-west Wales—the Welsh language is in a strong position of vitality, as evidenced by participants’ spontaneous and sustained Welsh use with an unknown interlocutor, a sign that the language is in a situation of “relatively stable multilingualism” (Fishman, 1965: 67). For a language to be used in a context like that of our language usage task, it must be relatively well established in domains of language behavior that lie outside the intimate, familial contexts that typically limit usage in cases of ongoing or advanced language shift (Fishman, 1965; see Landry et al., 2022 for more recent work on the importance of domains of use in societal language maintenance). Therefore, the high scores on the language usage task are a very positive sign for the Welsh language and its ongoing maintenance efforts.
Conversely, the near-floor effects across two instances of the language usage task for Lombard are a reminder of the severe language shift currently experienced by this language community, in line with its status as “Definitely endangered” reported by the UNESCO Atlas (UNESCO, 2010), partly also due to its perceived low social status. The rampant monolingualist policies and the depiction of Italian as the only “language” of Italy (e.g., Coluzzi et al., 2018; Coluzzi et al., 2021; see also Brasca et al., 2024) are likely the main driver of the consistently low rates of Lombard usage in our results. The spreading of Italian into all communicative contexts has subsequently broken the diglossic equilibrium that used to safeguard its use in a variety of societal domains (Tamburelli, 2010), thus making Lombard increasingly less necessary for everyday communication, which further declined its use as well as its transmission to the younger generations. The historically contingent parallelism between increasing educational levels and increased use of Italian—being the only language of education—is likely to have driven the association between Lombard and low sociointellectual status. To break this vicious cycle, institutionally led efforts are likely to be needed in order to intervene at the level of language status, which our results showed to correlate with increased attempts at using Lombard, in order to encourage young speakers to increase engagement with the language and begin to address its endangerment.
Conclusions
These results have important implications for the study of language attitudes, particularly for the measurement of attitudes as a proxy for language vitality. Specifically, they suggest that whether attitudinal measurements can predict linguistic behavior depends partly on the social and political circumstances of the language at issue, while also possibly being affected by the rate of usage and the attitude object as operationalized in each methodological implementation.
Footnotes
Acknowledgments
We would like to thank Hamidreza Bagheri for his invaluable help with IAT design and implementation. Many thanks also to Judit Vari for her advice on IAT design and for the fruitful conversations on the measurement of language attitudes, which inspired some of the work reported in this paper. We could not have hoped to complete any of this work without the invaluable assistance of various people, who helped with conducting the experiments, producing matched voice guises, and acting for our Language Usage Task. In Wales, these were Alice Butler, Jago Williams, Abigail Ruth Price, Bethany Granton, Lois Elenid Jones, Sioned Prys Griffith, Mari Elen Jones, Moli Williams, and Gwenfair Vaughan. In Lombardy, these were Antonella Troletti, Federica Cossali, Luisa Nembrini, Cinzia Troletti, Germana Troletti, Gian Paolo Belloli, Luca Ranza, Ileana Bani, Terry Ghezzi, Luisa Mazzoleni, Daniela Moioli, Antonella Rota, and Francesca Poliani. We further thank Canolfan Ucheldre Centre in Holyhead, the Biblioteca Comunale di Albino, the Biblioteca Comunale di Seriate “Giacinto Gambriasio” and the Club Alpino Italiano (C.A.I.) section Clusone “Rino Olmo” in the Province of Bergamo for letting us use their facilities to conduct experiments. Last but not least, we want to express our gratitude to the audiences of ICLASP18 in Tallinn and other venues where work contained herein was presented and to the editors as well as the anonymous reviewers, whose feedback we found both encouraging and helpful.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was supported by the Economic and Social Research Council [grant number ES/V016377/1].