
Abstract
Most existing solutions to the current replication crisis in science address only the factors stemming from specific poor research practices. We introduce a novel mechanism that leverages the experts’ predictive abilities to analyze the root causes of replication failures. It is backed by the principle that the most accurate predictor is the most qualified expert. This mechanism can be seamlessly integrated into the existing replication prediction market framework with minimal implementation costs. It relies on an objective rather than subjective process and unstructured expert opinions to effectively identify various influences contributing to the replication crisis.
Introduction
Experimental research had formed a solid basis in the natural sciences, however, its application in the social and humanitarian sciences has caused significant challenges. The feasibility and reliability of experimental research designs in these fields have been debated and scrutinized (Ioannidis, 2005b; Simmons et al., 2011). In response to the raised concerns, the scientific community has witnessed several significant large-scale replication efforts (Benjamin et al., 2018; Open Science Collaboration, 2015; Ioannidis, 2005a). These endeavors aimed to assess the reproducibility and generalizability of findings derived from prior studies. The effectiveness of these replication efforts themselves is still under discussion and requires evaluation (Laws, 2016; Nosek & Errington, 2017).
An essential portion of replication discussion revolves around the issue of “systematic error” (Schmidt, 2009). This phenomenon occurs when an effect is falsely attributed to a specific aspect of an experiment, whereas it is actually caused by another aspect (Feest, 2019). Feest, in particular, posits that there is a perpetual risk of systematic error due to the potential existence of overlooked confounding variables. Chen and Risen (2010) provide an empirical illustration of systematic error persistence in subsequent replications.
In this methodological essay, we address the claim that replication is overrated (Soler, 2011) due to the intractable systematic error and intrinsic assumptions, that “replication alone is not sufficient to establish internal validity.” We will demonstrate that, indeed, it is necessary yet perhaps insufficient to establish the internal validity of an effective successful replication. Moreover, we will show that expertise is always required in this process, because only established experts can track back the factors leading to replication failure. The problem of tracking those factors is more tricky than it looks because besides poor scientific practices and incentives issues, other factors (like effect heterogeneity) may also play a role. We will provide a taxonomy of these factors and propose a criterion for objective assessment of the current expertise level. This criterion will be founded on assessing the accuracy of predictions made by experts, enabling us to identify and trace the underlying causes of non-reproducibility.
Systematic Error is Inaccuracy in What?
Taxonomy From Campbell & Cook (1979).

Now we can restate the basic issue of systematic error in terms of validity: a high replication level would indicate a high level of statistical validity, but not a high level of internal validity.
When the replication rate is low, it becomes difficult to detect any effects, both valid and occasional, as the set of all detected valid effects is encompassed within the set of all detected effects. Therefore, a high percentage of successfully replicated studies becomes crucial for identifying valid effects.
However, it is important to note that the replication of an effect alone cannot be considered a sufficient condition to establish its internal validity, as systematic errors can still influence the results. Likewise, the replication failure cannot reliably refute the presence of an effect. Despite this, substantial number of replicated effects suggests that a significant proportion of studies showcase statistical effects, among which causal effects are likely presented. Hence, achieving a high level of replication across all studies is a necessary condition to enhance the overall internal validity of a research. In essence, without adequate replication, our ability to discover and understand effects is severely limited.
When we switch our attention to a highly coveted but challenging issue of external validity, it becomes clear that the two preceding validities are necessary conditions for its attainment: not for each particular effect, but rather in general for all the discovered effects. Statistical validity, measured by the replication level, ensures the effects detection, while internal validity ensures that these effects are accurately represented as causal relationships. Ultimately, external validity guarantees stability and generalizability of these effects.
Indeed, replication alone cannot address all research challenges. Both replication and distinguishing types of validity developed as a reaction to Fisher randomization in experiments. Since replication should provide evidence of the effect’s stability, it is interesting to track that validity topology arose to eliminate the “erroneous impression that randomization took care of all threats to validity” (Campbell, 1986). Therefore, internal validity by definition cannot be tested by replication. Nevertheless, since replication is still required in the next part, we will look into causes preventing high replication level.
Non-Reproducibility is Lack in What?
The Researchers Degrees of Freedom Checklist From Wicherts et al. (2016).

Different Scenarios of Replication Failure.
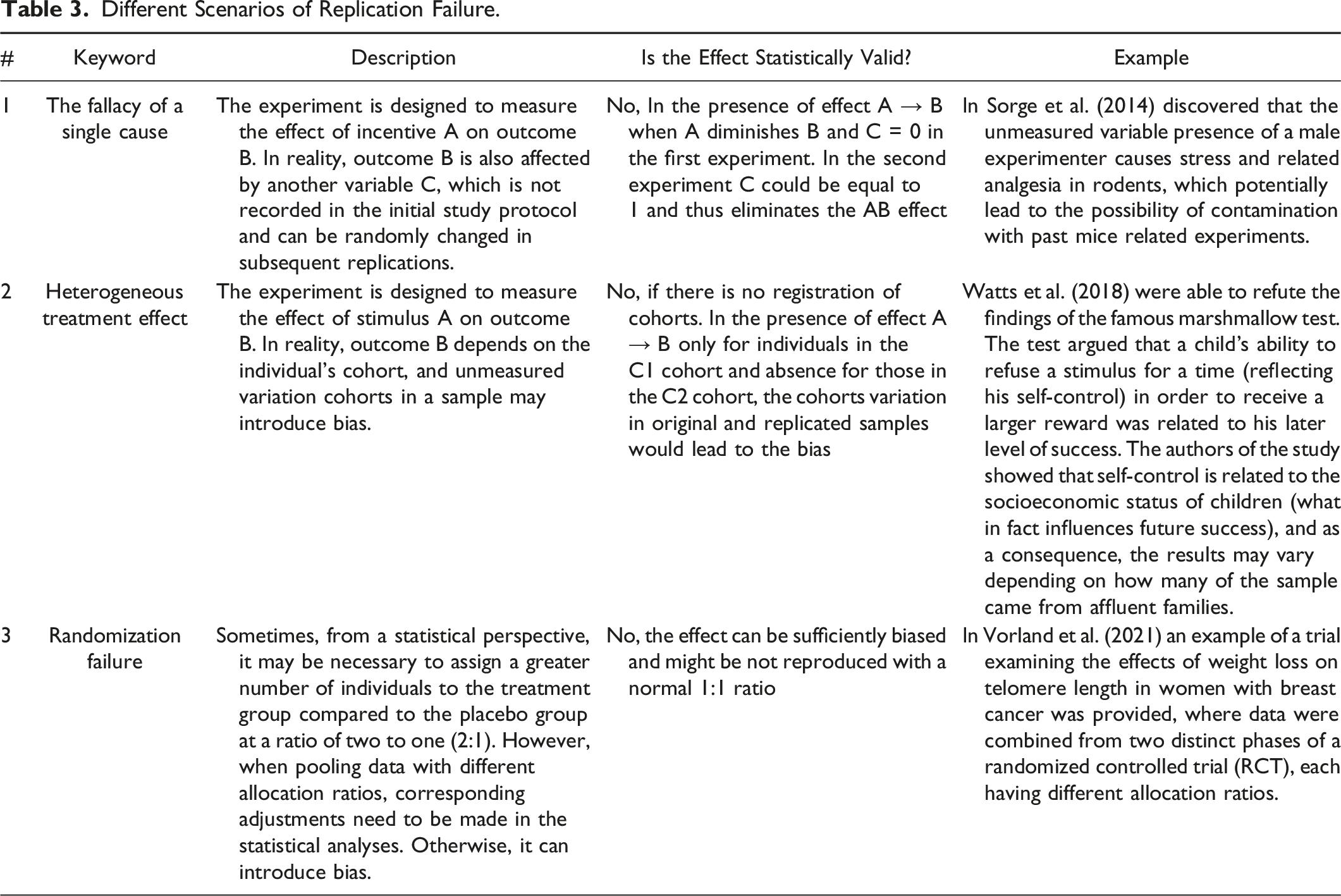
The aforementioned scenarios differ from the degrees of freedom concept as they do not involve inappropriate incentives or behavior, but rather stem from lack of expertise at the individual or domain level. Scenario 3, for instance, exemplifies a situation where an accepted standard in a given domain is not strictly implemented when needed and therefore represents a low standard example. Standards themselves can also be flawed, such as utilizing Neyman-Pearson Type I error instead of Fisherian error (Rubin, 2021), combining blocking results into a single regression (Pashley & Miratrix, 2022), or the case of a dead salmon appearing alive on tomography due to incorrect measurement aggregations (Bennett et al., 2009). These cases demonstrate that even when researchers adhere to domain-level standards, reproducibility may not be achieved.
Scenarios 1 and 2 share similarities with systematic error as they stem from an incorrect underlying experiment or measurement model. The causal structure differs from what researchers originally envisioned modeling the problem. However, unlike systematic error, problems arising from unmeasured heterogeneity, or the presence of other unmeasured causes can impede reproducibility.
Therefore, lack of reproducibility can be attributed to both the researcher’s degrees of freedom and expertise deficiency at the individual and domain levels. The varying levels of reproducibility observed across different fields within the social and cognitive sciences suggest that lack of expertise can significantly influence the outcome. Without addressing the expertise issue, significant improvements in reproducibility are unlikely to be achieved. Consequently, it becomes challenging to determine from an external standpoint whether the measures taken to counteract degrees of freedom, such as pre-registration, are ineffective in addressing the issue or if the reasons for non-reproducibility extend beyond the scope of degrees of freedom. Further, we provide a possible conceptual solution.
Prediction of Replication Outcome as Criterion
Why a Replication Outcome Prediction Could be Useful for Identifying and Tracking a Lack of Expertise
ow can expertise be measured objectively, without relying on others’ expertise (and, therefore, groupthink)? Experts may overstate or understate their expertise and it is hard to provide objective feedback. We can, however, develop such measurement through an objective process—making predictions about unknown future events, verifying whether the prediction is correct, and updating the resulting measure of expertise step-by-step. In this section, we will develop a more specific procedure starting from a highly stylized thought experiment.
Imagine several experts claiming they can color a map using three colors without neighboring countries sharing the same color, but they will not disclose either the entire coloring or their used method to make it. These experts may be incorrect or dishonest and the observer wants to test the experts to learn which of them are genuine. A simple procedure can do that with high confidence. The experts are instructed to place colors assigned to each country in separate sealed envelopes with country names on them. The observer randomly opens the expert’s envelopes for two neighboring countries, checking that the colors differ. This process is reiterated, while experts privately recolor the map with a randomized palette during each iteration (so the observer cannot reconstruct entire coloring from pieces). With each take, the observer’s confidence in identifying true experts grows. But if two envelopes contain the same colors, it suggests the expert is deceptive or erroneous. By conducting a significant number of repetitions, the observer can identify the real experts with a high level of confidence.
The main takeaway from this example is that to make a test we need to collect specific statements which, when verified at random, would enhance an expert’s credibility. To establish such test we can use the replication framework feature. Replication yields a binary outcome as a result for each study; therefore, all properties of random binary outcome processes can be used. When a certain amount of outcomes has been received, the empirical frequencies are used to approximate this random process, which is called a calibrated prediction (Foster and Vohra, 1997). This property can be inverted—an improvement over the calibrated prediction cannot be achieved without the knowledge of the data-generating process (Olszewski, 2015). In our case, it means that the prediction accuracy of a particular expert, which on average passes the threshold of the calibrated forecast, can be explained only by expertise. Consequently, we will use replication outcomes as an objective process (analog of a map with colors), and the prediction accuracy of the expert above the calibrated prediction as an analog of a test (opening envelopes).
Social Science Analog of Map Coloring Thought Experiment.
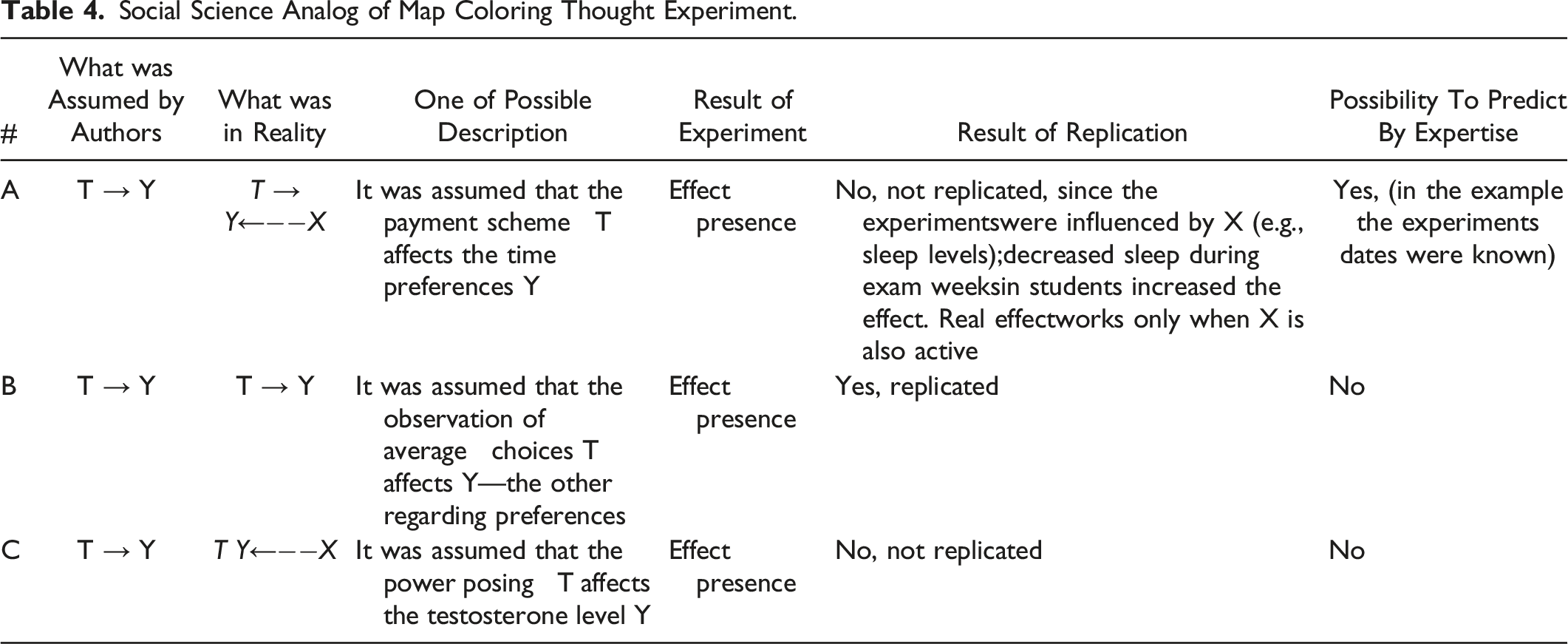
Further, let’s assume that each of these experiment types has been conducted 1000 times, and both forecasters are perfectly calibrated (the implications of this assumption will be elaborated upon in the following section). In this scenario, if the expert forecaster, who is aware of X influencing Y in experiments of type A, consistently predicts their outcomes, their average prediction accuracy will be 66%. On the other hand, the forecaster who predicts only half of them will achieve an average accuracy of 50%, which identifies the true expert.
The approach of predicting replication outcomes has been previously explored as a means to reduce replication costs (Camerer et al., 2016; Dreber et al., 2015) and assess the quality of expertise (DellaVigna & Pope, 2018). To serve as a viable test criterion, it must effectively identify genuine experts and align with the parameters employed in replication studies.
To address these replication parameters, we will employ a framework (Maniadis et al., 2014). Subsection “Forecasting Task in a Replication Framework” will delve into the detailed workings of this framework.
To ensure that the expert predictor is not merely a charlatan using calibration rules to generate seemingly accurate forecasts without possessing genuine underlying information we use Foster & Vohra (1997) criterion. In subsection “Using Calibration as a Criterion to Reveal True Expert”, we will outline how calibration can serve as a distinguishing criterion, similar to the envelope color match. By using calibration as a metric, we can evaluate the expert’s performance in detail.
Our final goal is to establish more robust scientific institutions: subsection “Default Minimal Simple Procedure” will propose a comprehensive procedure for identifying potential causes of non-reproducibility. This procedure actively leverages the principle that the most accurate predictor is the best expert for analyzing the cause. Thus, experts who successfully predict outcomes and are authorized to be true experts can also weigh in on the factors they believe to be the primary causes of non-reproducibility. By aggregating the input of genuine experts, we can compile an authoritative list of reasons behind the replication failure.
Forecasting Task in a Replication Framework
A unit of a forecasting task is an expert’s disclosure statement, which in the replication framework is a forecast for each binary outcome (will the study be reproduced or not). To ensure accurate calculations in subsequent steps it is important to include all parameters impacting the replication outcome into a forecast.
Given the sample size, type I (called α), and II (called β) errors are fixed, the probability experiments’ replication R of N experiments is equal to the number of true discovered associations divided by all the associations declared “true”: RR = TP\(TP + FP), where RR—replication rate, TP is a true positive (1 − β), and FP is a false positive (α). Thus we could separate two types of forecast for a single experiment: π
i
is given by expert subjective probability that experiment i will replicate, 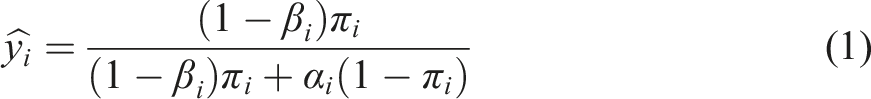
Whether a prior is taken into account when we ask an expert to make a forecast remains a question. The difference is whether we need to adjust the reported probability from π to
Using Calibration as a Criterion to Reveal True Expert
With a precise prediction in hand, we can now utilize the results of the replication to determine whether the effect is reproducible. This involves examining whether the effect magnitude falls within the confidence interval established in the initial study. By doing so, we can establish a criterion for distinguishing between genuine experts and charlatans.
The experts quality in forecasting tasks has to be evaluated by predictive metrics, so the choice of metric matters. The task organizer could use any arbitrary measure as a rule which satisfies the requirement of proper scoring rules (Gneiting & Raftery, 2007). Any proper scoring rule counts the weighted aggregate of mistakes, they differ in what aggregate is used (sum, product, or something else) and in the weighting function for those mistakes. Building upon the work of Dreber et al. (2015), we adopt the Brier score as the foundation for our analysis. The Brier score is commonly used for evaluating binary outcomes, where the response variable, denoted as y, takes values of either 0 or 1: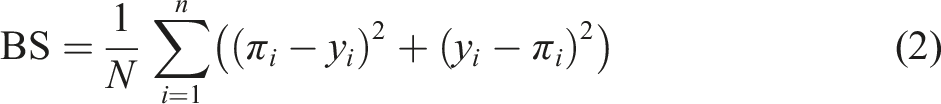
Here π is taken as a base, but it might be replaced with
To illustrate this idea, consider an example from Foster and Hart (2021). Let outcomes alternate in a deterministic way from success to failure y = {0, 1, 0, 1… 0, 1}. If we compare 3 types of predictions p1 = {0, 1… 0, 1}; p2 = {0.1, 0.9, … 0.1, 0.9}; and p3 = {0.5, 0.5, … 0.5, 0.5} we will see that while the first forecast is the ideal the rest have different properties. The third is ideally calibrated however it is not capable to distinguish between positive and negative outcomes. The second, however, is almost ideal but it isn’t calibrated. Now, from the prior replication ratio RR and empirical frequency of replication—
Let’s consider them one by one, with Brier decomposition determined as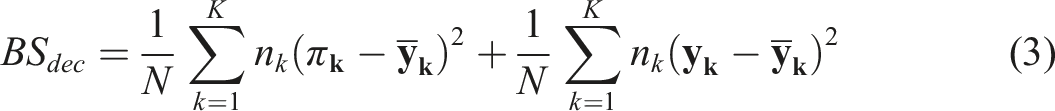
The second approach starts with a calculation of Brier skill score (BSS), which takes as a benchmark BS
ref
—some other forecast: 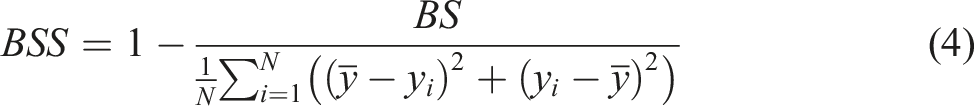
The Brier score serves as a loss function, where a lower score indicates better performance, with a perfect score of 0 being the optimal outcome. However, when considering the Brier skill score, a higher value is desirable, with 1 (or 100%) representing the best possible score. In the context of separating an expert from a calibrated model, our criterion is based on the expert’s Brier skill score going below zero. A negative Brier skill score indicates that the expert’s performance is worse than the calibrated model. Therefore, the experts can only outperform the calibrated model if they possess expertise or knowledge about the underlying process, which aligns with our objective in this study.
Default Minimal Simple Procedure
To identify the factors contributing to replication failures, we propose a straightforward procedure. First, we gather a pool of candidate studies for replication and invite researchers to participate as volunteer forecasters.
Next, the forecasters are given surveys where they allocate 100 scores across the factors. Factors include both factors from individual and domain cohorts and all factors from the Table 2. Experts are asked to distribute the scores based on the perceived importance of each factor in predicting non-replication for each study in the replication pool. Additionally, they provide replication likelihood forecasts for each hypothesis, rating the probability of replication on a scale from 0% to 100%. Participants are incentivized based on their performance using Brier skill scores, which reward accuracy in forecasting. After getting the results we can calculate a score of each factor and rank it according to its association with replication failures: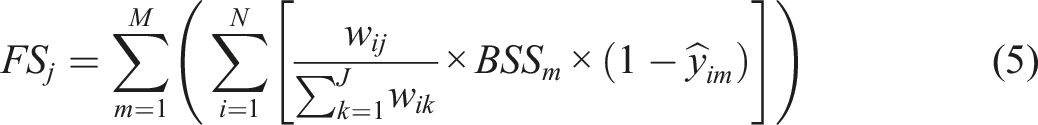
Through this procedure we aim to pinpoint and prioritize the factors that play a role in non-reproducibility within scientific studies. By assessing the Brier skill scores (BSS) of each individual, we can distinguish the true experts from the rest. This allows us to focus solely on the scores provided by those who have BSS higher than 0 and thus demonstrate the expertise in the field.
Discussion and Applications
The issue of non-reproducibility in scientific studies is a complex one, due to systematic errors and confounding variables (Crandall & Sherman, 2016; Feest, 2019). Mere success in replicating an individual study does not guarantee indisputable conclusions, challenging the benefits of replication. Recent discussions (Hudson, 2023) have focused on the concept of indirect replication as a potential solution, aiming to address internal validity concerns.
In this essay, it has been argued that replication and validity are not directly linked as various factors beyond causality can contribute to irreproducibility. A conceptual solution for tracking these factors has been proposed, along with an implementation framework. The framework is relatively simple as it utilizes existing replication prediction markets (Camerer et al., 2016; Dreber et al., 2015) with an addition of the questionnaire for participating experts.
To implement the proposed approach, it is advisable to integrate it into existing initiatives rather than create separate replication projects. If the integration of calibration exercises into standard practices within the social sciences becomes more widespread, it could usher in a significant transformation of research conduction and evaluation.
Large-scale replication projects have already been accompanied by ones that predict their outcomes. For instance, in the field of experimental economics, we have initiatives like the Experimental Economics Replication Project (EERP, Camerer et al. (2016)), the Social Science Replication Project (SSRP, Dreber et al. (2015)), and smaller-scale projects conducted by individual labs, such as WKW, DellaVigna and Pope (2018). These projects require collaboration among several labs yet not an overwhelmingly high number of participants: EERP (involving 18 authors, 18 studies, and 97 experts), SSRP (involving 8 authors, 44 studies, and 52 experts), and WKW (involving 2 authors, 15 studies, and 208 experts). The ultimate goal of these additional calibration exercises is multifaceted. Firstly, they aim to untangle the complex web of factors contributing to non-replicability, distinguishing between social and domain-specific influences. Secondly, these exercises demonstrate the potential for enhancing replication forecasts through the expertise of seasoned researchers. Lastly, they aim to provide open-source materials in the form of checklists to assist researchers in meticulously planning and executing their studies.
This is only a transitional solution, yet a necessary step that acknowledges the complexity of the issue. A deeper understanding of reproducibility reasons and establishing expert ratings may result in a protocol for full-fledged conceptual replication.
Footnotes
Acknowledgments
The author would like to thank Ivan Susin, Vladimir Starostin, and Alexander Khlebalin for valuable discussions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Author is grateful to German Academic Exchange Service (Deutscher Akademischer Austauschdienst, DAAD) for their support and funding (57507441).