
Abstract
There is little comparative research on what causes candidates in elections across the world to ‘go negative’ on their rivals – mainly because of the scarcity of large-scale datasets. In this article, we present new evidence covering over 80 recent national elections across the world (2016–2018), in which more than 400 candidates competed. For the first time in a large-scale comparative setting, we show that, ceteris paribus, negativity is more likely for challengers, extreme candidates, and right-wing candidates. Women are not more (or less) likely to go negative on their rivals than their male counterparts, but we find that higher numbers of female MPs in the country reduces negativity overall. Furthermore, women tend to go less negative in proportional systems and more negative in majoritarian systems. Finally, negativity is especially low for candidates on the left in countries with high female representation, and higher for candidates on the right in countries with proportional representation (PR).
Introduction
This article investigates the drivers of negative campaigning worldwide using a dataset of more than 80 national elections. The phenomenon of negative campaigning – that is, the use of political attacks against the program, record, policies, or persona of opponents during election campaigns – has received increased attention in recent decades. Yet, the question of whether negativity is a detrimental force for contemporary democracy is highly contested. Several studies have shown that negative messages tend to demobilize voters, negatively influence public trust (Ansolabehere and Iyengar, 1995), and increase political cynicism (Cappella and Jamieson, 1997). At the same time, other scholars suggest instead that negative campaigning has the potential to mobilize voters (Goldstein and Freedman, 2002) because it stimulates interest and participation (Geer, 2006).
Regardless of its effects, few would argue that negative campaigning is inconsequential, which is why the literature increasingly focuses also on its drivers. Why, and under what conditions, are parties and candidates more likely to go negative on their opponents? Negative campaigning is unlikely to always work as intended, and often ends up harming the sponsors more than their designated target (Roese and Sande, 1993). Also, because of this, the decision to make use of attack messages often becomes a strategic one. Little is, however, known about how the individual profiles of candidates affect this decision, especially in a comparative perspective. Most of the research on negativity in politics focuses on the American case. Outside this case, existing evidence is either on specific countries – such as Brazil (da Silveira and de Mello, 2011) or Germany (Maier and Jansen, 2015) – or, if comparative, often limited to only a handful of countries (e.g. Walter et al., 2014). A recent study (Nai, 2018) compared the use of negative campaigning by candidates who competed in 35 national elections worldwide, but mostly focused on differences among the sponsors and the targets of the attacks, and only addressed the issue of cross-country comparison marginally.
All things considered, we still know surprisingly little about (i) whether negative campaigning in elections across the world – from Albania to Zimbabwe, so to speak – follows the same logics identified in the US literature, and (ii) to what extent differences across countries drive the use of negativity in campaigns differently. Is negative campaigning a global phenomenon, driven by universal ‘rules’? To what extent do the characteristics of the context shape the use of negative campaigning strategies?
This article contributes to the emerging comparative political communication literature by looking at the use of negativity in elections worldwide. We do so by comparing the content of election campaigns of 404 ‘top’ candidates (that is, party leaders and leading candidates for office) who competed in 84 elections in 71 countries worldwide between June 2016 and December 2018, rated by selected samples of scholars (1,321 experts in total). We aim to shed light on the effects of candidate profiles and two specific contextual aspects, namely the electoral system and the proportion of female representatives in parliament. As will be discussed in the following sections, we claim that the increased need for consensus in proportional electoral systems reduces the incentives to go negative and that more female representatives lead to a convergence towards ‘kinder’ communicative norms and hence, less negativity.
All data and materials, including the full Appendix, are available for replication at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/
Why and under which conditions candidates go negative
Candidate profile
The literature claims that incumbents are less likely to go negative than challengers (Nai, 2018; Walter and Vliegenthart, 2010). Incumbents have a larger political record which they can use to promote themselves; because challengers are less likely to have this option, they need to provide good reasons as to why voters should turn against the incumbents (Kahn and Kenney, 2004). Challengers tend to receive weaker media coverage (Hopmann et al., 2011), which encourages them to find ways to increase their visibility, by, for example, attracting attention through negative rhetoric (Nai, 2018). Moreover, challengers have no office to lose, which makes it electorally less risky for them to use negativity. The first hypothesis is thus formulated:
H1: Challengers are more likely to use negativity than incumbents.
Evidence from the US further suggests that right-wing candidates have a higher tendency to use negativity than left-wing candidates (Lau and Pomper, 2001). The right-wing inclination to view ‘the world as a ruthlessly competitive jungle in which the strong win and the weak lose’ (Duckitt, 2006, p. 685) may increase the acceptance of attack messages among their electorate. This assumption is at least partially supported by studies that show that Democrats, in comparison with Republicans and Independents, exhibit less sympathy for negativity (Ansolabehere and Iyengar, 1995). Accordingly, hypothesis two goes as follows:
H2: Right-wing candidates are more likely to use negativity than left-wing candidates.
It further seems likely that parties and candidates on the extremes of the political spectrum have a higher tendency to use negative rhetoric. The more extreme a party is, the more it disagrees with other parties on political issues (Elmelund-Præstekær, 2010, p. 142), making it less likely for them to form coalitions or policy agreements. Assuming that political disagreements may lead to rhetorical attacks, we expect that the ideologically extreme are more negative in their campaigns than mainstream candidates. Results of previous studies do indeed suggest that parties far from the ideological centre are more inclined to go negative (Elmelund-Præstekær, 2010; Walter et al., 2014). This logic leads to the following hypothesis:
H3: Extreme candidates are more likely to use negativity than mainstream candidates.
It remains much debated how gender influences the choice of going negative (Grossmann, 2012). Scholars, including Fox (1997) and Kahn and Kenney (2004), find support that males are more likely to go negative. Fewer studies claim that females increasingly engage in attack behaviour (e.g. Kahn, 1993), and the preponderance of research does not find any significant gender differences in the use of negativity (Grossmann, 2012; Lau and Pomper, 2001; Panagopoulos, 2004). One rationale behind the assumption that females refrain from going negative is as simple as follows: The usage of negative rhetoric violates the female stereotype. The different attributes assigned to males and females trigger concrete expectations of ‘appropriate’ social behaviours (Ennser-Jedenastik et al., 2017) that also translate into stereotypical expectations of campaign behaviour (Dinzes et al., 1994). Women thus have to choose between dispelling or exploiting gender stereotypes while acknowledging that the disruption of the expected behaviour might have damaging electoral consequences (Trent and Friedenberg, 2008). Although plausible in theory, current research challenges this logic. The lack of consensus will be addressed in this large-scale study by testing the controversial hypothesis four on a cross-national sample:
H4: Female candidates are less likely to use negativity than male candidates.
The role of the context
Candidates do not campaign in a vacuum, and the nature of the context is likely to drive campaigning dynamics. More specifically, we could expect that the context both drives a differential use of negative campaigning and alters the incentives of competing candidates to go negative. Because of the lack of large-scale comparative data, these dynamics have not yet received the attention they deserve. In this article, we explore the direct and indirect effects of the election context by testing the assumptions that negative campaigning has a lower incidence in proportional representation (PR) systems and democracies with higher shares of female MPs.
First, as discussed in Nai (2018) we expect that elections held under PR should have lower levels of negativity. PR tends to create multiparty systems, which are likely to reduce negativity for at least two reasons. First, when multiple parties (or candidates) compete, the positive return on attacks are very uncertain. Negative campaigns might decrease support for the target, but because of the non-zero-sum nature of the political competition, this does not necessarily result in increased support for the sponsor (Nai, 2018; but see Elmelund-Præstekær and Svensson, 2014). Second, in multiparty PR systems, competing parties and candidates have enhanced incentives for cooperative behaviour, due to the possibility of coalition bargaining (e.g. Elmelund-Præstekær, 2010; Walter et al., 2014). This assumption has been addressed by Lijphart (1999), who claimed that PR systems tend to have a stronger community orientation and social consciousness and, thus, stand in contrast to self-interest and power politics. In line with this idea, PR and multiparty systems should reduce political conflicts, as the risks of alienating potential coalition allies is at odds with the systemic incentives for successful governance (Lijphart, 1999). Hence, we test the following hypothesis:
H5: Negativity is less likely in countries with proportional representation (PR).
Whereas in majoritarian elections citizens cast their ballot for specific candidates, in proportional systems voters often opt for a party list, which reduces the importance of the individual candidates (Thames and Williams, 2010, p. 1579). The diverging foci of these systems are expected to affect the relative importance of the candidate profile in so far as politicians’ personal differences become less relevant in PR systems. In other words, we expect that the influence of ideology, extremism, and gender on negativity decreases in PR systems. The expected interactions can be summarized as follows:
H6: The effect of the left–right positioning of candidates on negativity is weaker in countries with proportional than majoritarian systems.
H7: The effect of extremism on negativity is weaker in countries with proportional than majoritarian systems.
H8: The effect of gender on negativity is weaker in countries with proportional than majoritarian systems.
There is also reason to believe that negativity declines with an increase in female representation. In general, women are said to practice a kinder politics that is ‘characterized by cooperation rather than conflict, collaboration rather than hierarchy’ (Norris, 1996, p. 93). This ‘feminized’ style of politics is expected to radically transform not only institutions, and public policy, but also the political behaviour once a ‘critical mass’ of elected women is reached (Studlar and McAllister, 2002). The cited literature makes it plausible that more female representatives lead to a greater convergence of these ‘kind’ norms and political styles. Yet, one should not disregard the mixed results regarding the general attack pattern of women discussed in the preceding section. The following hypothesis, therefore, serves the purpose of investigating the gender difference on the institutional level and posits that:
H9: Negativity is less likely in countries with a higher proportion of female MPs.
In their work, Ennser-Jedenastik et al. (2017) further suggest that the candidates’ attack behaviour varies with intraparty gender balance. Although the authors do not uncover evidence for this claim, the theoretical argument that highlights the role of the social context deserves some attention. Ennser-Jedenastik et al. (2017) argue that a more equal gender distribution leaves females less ‘“conspicuous” since female politicians are naturally a more common occurrence in an environment with higher overall female representation’ (p. 88). This, in turn, may decrease women’s responsiveness to gender stereotypes and thus increase their willingness to go negative. Testing this hypothesis aims to shed light on the ongoing debate about gender effects and follows Eagly et al.’s (2004, p. 280) suggestion that it might be the social context that explains the variation in gender behaviour. The hypothesis to be tested can be formulated as follows:
H10: Female candidates are more likely to use negativity in democracies with a higher proportion of female MPs.
Data and methods
Dataset
Due to the complexity of measuring discourse comparatively, very little data exists that compares the content of election campaigns worldwide, across different cultures, languages, and political systems. In this article, we rely on the Negative Campaigning Comparative Expert Survey Dataset (Nai, 2018; Nai and Maier, 2018; Nai et al., 2019), covering all national elections held worldwide between June 2016 and December 2018. The dataset is based on a systematic survey distributed to election-specific samples of national and international scholars 1 in the weeks following each election. Experts were asked a series of questions about the campaign in general, as well as actor-specific questions. The average response rate across all elections in the dataset is just below 20%. After excluding the missing values on all relevant variables and considering only elections for which at least five different scholars rated the campaign, our models are run on 404 candidates who competed in 84 elections worldwide. The information is based on answers provided by 1,321 experts. Appendix A lists all elections and candidates in our dataset; the number of responses for each election is signalled in Table A1 (available at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/).
On average, scholars in the dataset lean to the left (M = 4.33/10, SD = 1.80), 74% are domestic (that is, have a professional appointment at a university in the country for which they were asked to evaluate the election), and 33% are female. Overall, experts declared themselves very familiar with the elections (M = 8.01/10, SD = 1.77) and estimated that the questions in the survey were relatively easy to answer (M = 6.51/10, SD = 2.38). Table C1 in Appendix C (available at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/) presents the composition of the expert samples according to these characteristics for each election in our database.
Using experts to measure the tone of the campaign might seem unorthodox, as the literature usually focuses on systematic content analysis of communication messages (e.g. Russmann, 2017). Yet, there are several advantages to using experts. There is a long tradition of using ‘expert’ knowledge to assess party dynamics and positions (e.g. Hooghe et al., 2010), and using experts is a particularly cost-effective way to obtain systematic and comparable data across a wide variety of contexts. In the case of discursive dynamics, as we study here, we could even argue that expert ratings are likely to be the most indicated approach for very large-scale comparative studies because they are able to ‘circumvent’ fundamental issues such as coding in different languages and the availability of comparable communication outputs to code in the first place. Furthermore, experts can be used to assess the campaign on the whole, independently of specific communication channels (e.g. manifestos or TV ads, which are both idiosyncratic and strongly contextual). We return to this important feature in the following when discussing the measurement. To be sure, using experts does not come without downsides, especially in terms of sample composition and profile effects (e.g. Curini, 2010; Walter and van der Eijk, 2019). Furthermore, a frequent issue with expert surveys is the complexity in assessing which information experts rely upon when providing their ratings (e.g. Budge, 2000). We address some of these issues in the following when discussing the measure of campaign tone and provide some robustness checks to exclude any major profile effects (see the following).
Case selection
The dataset includes information for all national elections (legislative and presidential) held across the globe between June 2016 and December 2018, with the exclusion of elections in microstates (e.g. the election in Palau in November 2016) or in case of flagrant violations of basic rules of free and fair elections and/or absence of competition (e.g. Somaliland, or the Egyptian election of March 2018). The elections in our database are thus not a random selection of elections and not statistically representative of all elections worldwide per se. Yet, because of their sheer number and geographical spread (Figure 1), they can be seen as providing a comprehensive image of contemporary electoral competition across the globe.
Geographical coverage.
All analyses are run on a dataset that includes measures of campaign negativity for ‘top candidates’: party leaders during legislative elections or main candidates in presidential elections. Especially during legislative elections, the focus on ‘top’ candidates is likely to yield a conservative estimate of campaign negativity. Evidence from the Austrian case shows, for instance, that a ‘division of labour’ takes place within parties, where the ‘dirty work’ of attacking the opponents is delegated to lower-level party leaders (Dolezal et al., 2015). Robustness checks will assess whether the difference between these two types of elections matters in our case (it mostly does not; see in the following).
Measuring negativity
Experts were asked to assess the ‘tone’ of the campaign (Lau and Pomper, 2001; Nai and Walter, 2015) used by competing actors, that is, to what extent they ‘talked about the opponents in the race by criticizing their programs, attacking their ideas and accomplishments, questioning their qualifications, and so on’ instead of ‘talking about one’s own accomplishments, qualifications, programs and ideas by praising them’ (quoted directly from the questionnaire). Concretely, experts had to evaluate the tone on a scale from -10 very negative to +10 very positive.
Table C2 in Appendix C (available at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/) reports, for each candidate, the number of experts which provided ratings – whose answers are aggregated into the measure of campaign tone – and the standard deviation resulting from this aggregation. The standard deviation can be seen as an indicator of how ‘consensual’ the experts were about the campaign tone of any given candidate; the average standard deviation across all candidates is approximately 3.7, which is relatively modest on a 21-point scale (from -10 to +10); there is no significant relationship between the standard deviation and number of experts, r(402) = 0.01, p = .846 nor between the standard deviation and the overall tone score, r(402) = -0.06, p = .234, as also shown in Figure C1 (Appendix C) (available at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/). In other terms, experts were not significantly more or less precise in assessing the campaign of candidates that went particularly negative or positive.
Due to the complex nature of the concept measured (Sigelman and Kugler, 2003) and because the concept itself could suffer from cross-cultural comparability issues, the questionnaire included six ‘vignettes’ – examples of campaign messages 2 that experts also had to rate using the scale for the campaign ‘tone’. We used those vignettes to ‘anchor’ the experts’ ratings, starting with the assumption that answers to these vignettes provide a useful benchmark across experts. More specifically, we ran a series of parametric adjustments (King et al., 2004) through ordered probit models (gllamm models). The models yielded an adjusted measure of campaign negativity that simultaneously takes into account the experts’ vignettes ratings plus a series of cross-sectional set parameters (an election identifier, plus the expert’s gender, domestic/international status, self-reported familiarity with the election, and left–right positioning – this latter is of particular interest in the light of research suggesting that expert ratings might be influenced by their individual orientations; e.g. Curini, 2010). The obtained variable is a continuous measure of negative tone that ranges between 1 ‘very positive’ and 7 ‘very negative’. The original and adjusted variables are very strongly correlated, r(402) = -0.97, p < .001. Nonetheless, and to err on the side of caution, we replicated all analyses also using the original expert rating (see Appendix B, Tables B7 to B9) (available at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/).
It is important to note that, because they were cued to assess the campaign ‘on the whole’ – that is, beyond idiosyncratic differences across channels or specific communication events (e.g. rallies) – experts can be expected to provide an assessment of the general negativity of the campaign. We can expect experts to pick up not only the tone of messages used by the competing candidates but also the volume of the negative messages they use (e.g. Stevens, 2009). Experts are also likely to include in their assessment the overall ‘harshness’ or incivility of the exchanges between the candidates; indeed, they tend to rate the harsher vignettes as higher on the negativity scale (Nai, 2018). Furthermore, campaign negativity, as measured by experts, strongly correlates with the use by candidates of harsher character attacks and fearmongering (Gerstlé and Nai, 2019). In this sense, using such a ‘holistic’ measure of campaign negativity could help reduce the disconnect between the ‘narrow’ scholarly definition and measurement of channel-specific negativity and the more broad, general impression of the public (Lipsitz and Geer, 2017; see also Haselmayer, 2019; Sigelman and Kugler, 2003). Table A3 (Appendix A) (available at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/) illustrates the differences in the overall campaign tone in the 71 countries in our dataset, ranked from the most ‘positive’ to the most ‘negative’ campaign (overall assessment).
Due to the large-scale scope of the dataset, and the discursive nature of the phenomenon we are dealing with, the external validity of our measures cannot be assessed by comparing them with other existing ones – quite simply, there is no other dataset that measures the tone of candidates’ campaigns across the globe. Nonetheless, as we report elsewhere (Maier and Nai, 2020), we were able to set up a triangulation check for our measures within a different context – an expert survey we ran for the 2018 US Senate election Midterms using an identical protocol and measure of campaign tone as the ones discussed here. For all candidates having competed in the 2018 US Senate Midterms we compared the ratings of our experts with two independent data sources: the tone of the candidates’ campaigns on Twitter, and the percentage of negative TV ads of competing candidates in the Midterms elections. Even controlling for covariates at the candidate and US state levels (gender, party affiliation, age, state turnout, state leaning), the expert measure is significantly and positively correlated with the negativity in Twitter and in TV ads. This triangulation suggests that experts are able to pick up the content (at least in terms of tone) of candidates’ campaigns, beyond the idiosyncrasies of different campaign channels (Walter and Vliegenthart, 2010); we have no reason to believe that this should not be the case outside of the US Midterms as well.
Candidate and country characteristics
Gender, age, and incumbency status of candidates are information easy to find, and their measure is straightforward. Less so is their left–right position; to compensate for the lack of cross-sectional datasets including information about the ideology of candidates worldwide, we use the information provided by Wikipedia. For all parties, Wikipedia includes an ‘information box’ in which demographic and biographic information of the party are presented, as well as the party’s ‘political position’. The latter is classified using a systematic series of labels, ranging from ‘far left’ to ‘far right’; sometimes, intermediate positions are presented (e.g. UKIP is currently classified as ‘right’ to ‘far right’). All of this information can be reduced to a 13-point scale (‘far left’, ‘far left/left’, ‘left’, and so forth), which we simplified into a 7-point scale ranging from 1 ‘far left’ to 7 ‘far right’. The dataset available in the OFS repository (available at https://osf.io/4vhea/) includes both versions of the measure. Although not ideal, Wikipedia can often provide quality factual information (Brown, 2011). Indeed, an external validity check discussed in Nai (2018) shows that comparing the information in Wikipedia with left–right measures in the Chapel Hill Expert Survey (CHES; Polk et al., 2017) and the data in Benoit and Laver (2007) yields very high correlations. It is also important to note that the left–right scale is an ‘amorphous vessel’ (Huber and Inglehart, 1995, p. 90) unlikely to capture ideological cleavages in exactly the same way in every context (e.g. Rohrschneider and Whitefield, 2009), and some scholars argue instead for the use of party ‘families’ (e.g. ‘social democrat’, ‘communist’, ‘liberal’, and so forth; Franzmann and Kaiser, 2006). Nonetheless, the left–right distinction still represents a clear and simple heuristic to classify parties. The fact that the information is easily available on Wikipedia also suggests, in our opinion, that the left–right distinction still has a relevant appeal for the public at large.
The left–right variable is then folded on itself to create the ‘extremism’ variable, which takes the value 0 for ‘low extremism’ (centre left to centre right), 1 for ‘moderate extremism’ (left, right) and 2 for ‘high extremism’ (far left, far right). We also used a more restrictive binary measure, differentiating only between ‘extreme parties’ (far left and far right) and all the other ones, and obtain very similar results (see robustness checks discussed in the following).
To quantify the ‘level’ of female representation, we rely on the percentage of female politicians in the national parliament, using data from the Institute for Democracy and Electoral Assistance (IDEA). 3 We use a binary variable that sorts countries with a PR electoral system from countries with a plurality/majority system. Our models are controlled, at the contextual level, by the competitiveness of the election, effective number of competing candidates, and country’s level of democracy. We measure the competitiveness of the election via a question in the expert survey that asked experts to evaluate how much they agree that ‘the race was not competitive, the winner was clearly known beforehand’. We use the formula of Laakso and Taagepera (1979) to measure the total effective number of candidates (ENC), which yields a number reflecting the number of competing candidates with a similar strength. Controlling for the ENC is important, as recent research suggests that party system fragmentation has a role to play in the overall level of negativity of the campaign (Papp and Patkós, 2019). Descriptive statistics for all variables are in Table A4 (Appendix A) (available at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/).
Results
Our main results are presented in Tables 1–3. Table 1 estimates firstly the use of negative campaigns as a function of individual and contextual determinants.
Drivers of negative campaigning, direct effects.
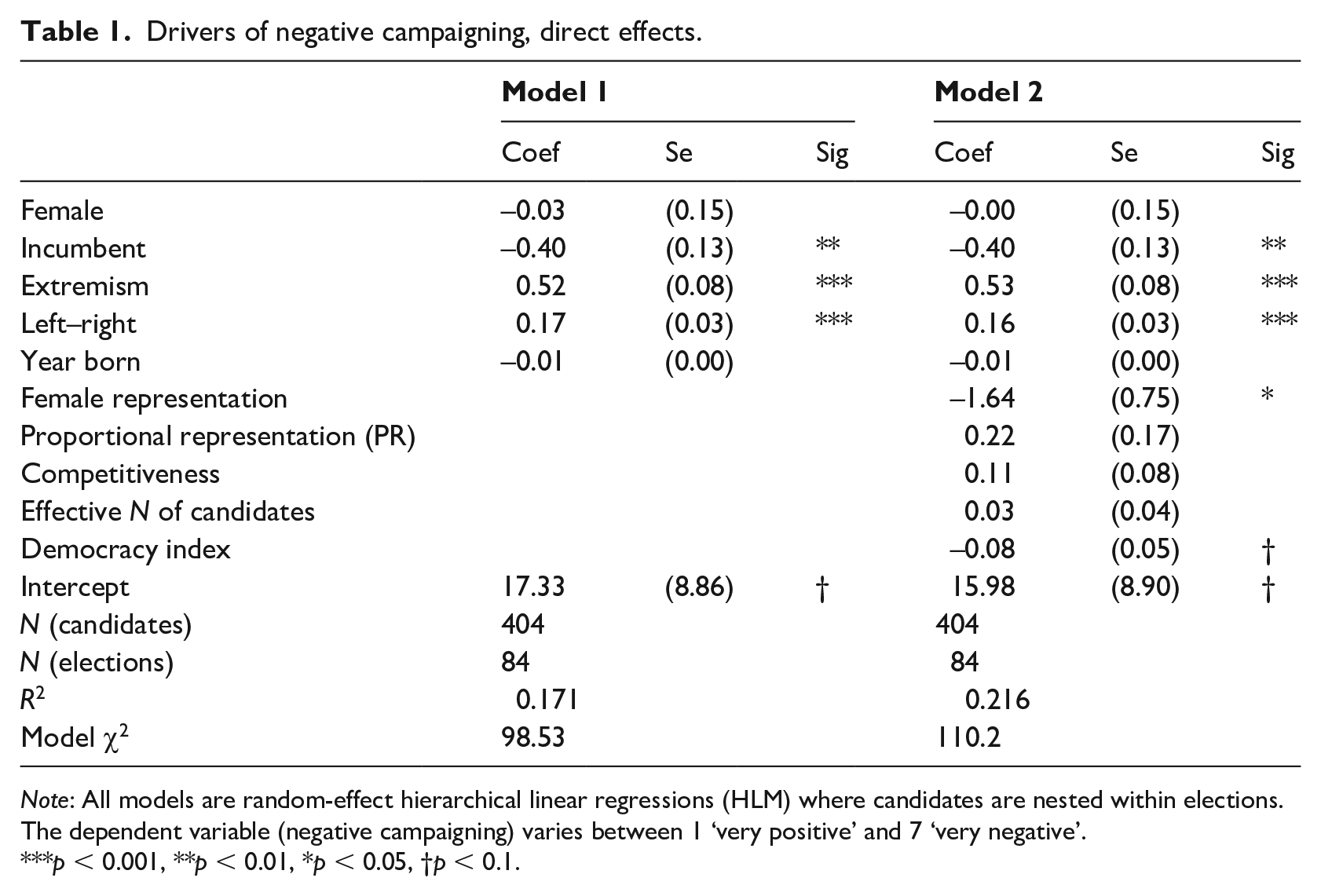
Note: All models are random-effect hierarchical linear regressions (HLM) where candidates are nested within elections. The dependent variable (negative campaigning) varies between 1 ‘very positive’ and 7 ‘very negative’.
p < 0.001, **p < 0.01, *p < 0.05, †p < 0.1.
Drivers of negative campaigning, moderated by female representation.
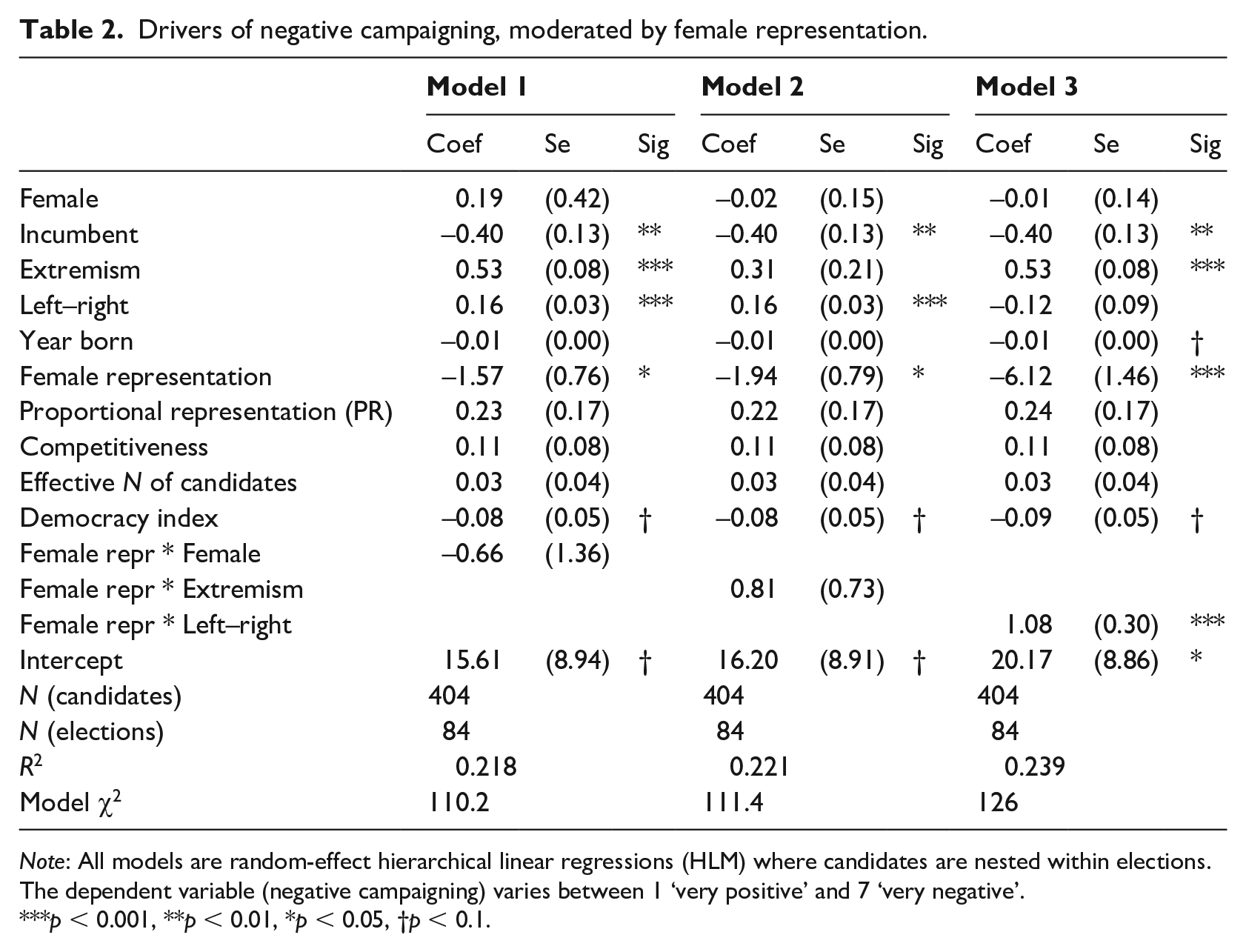
Note: All models are random-effect hierarchical linear regressions (HLM) where candidates are nested within elections. The dependent variable (negative campaigning) varies between 1 ‘very positive’ and 7 ‘very negative’.
p < 0.001, **p < 0.01, *p < 0.05, †p < 0.1.
Drivers of negative campaigning, moderated by electoral system.
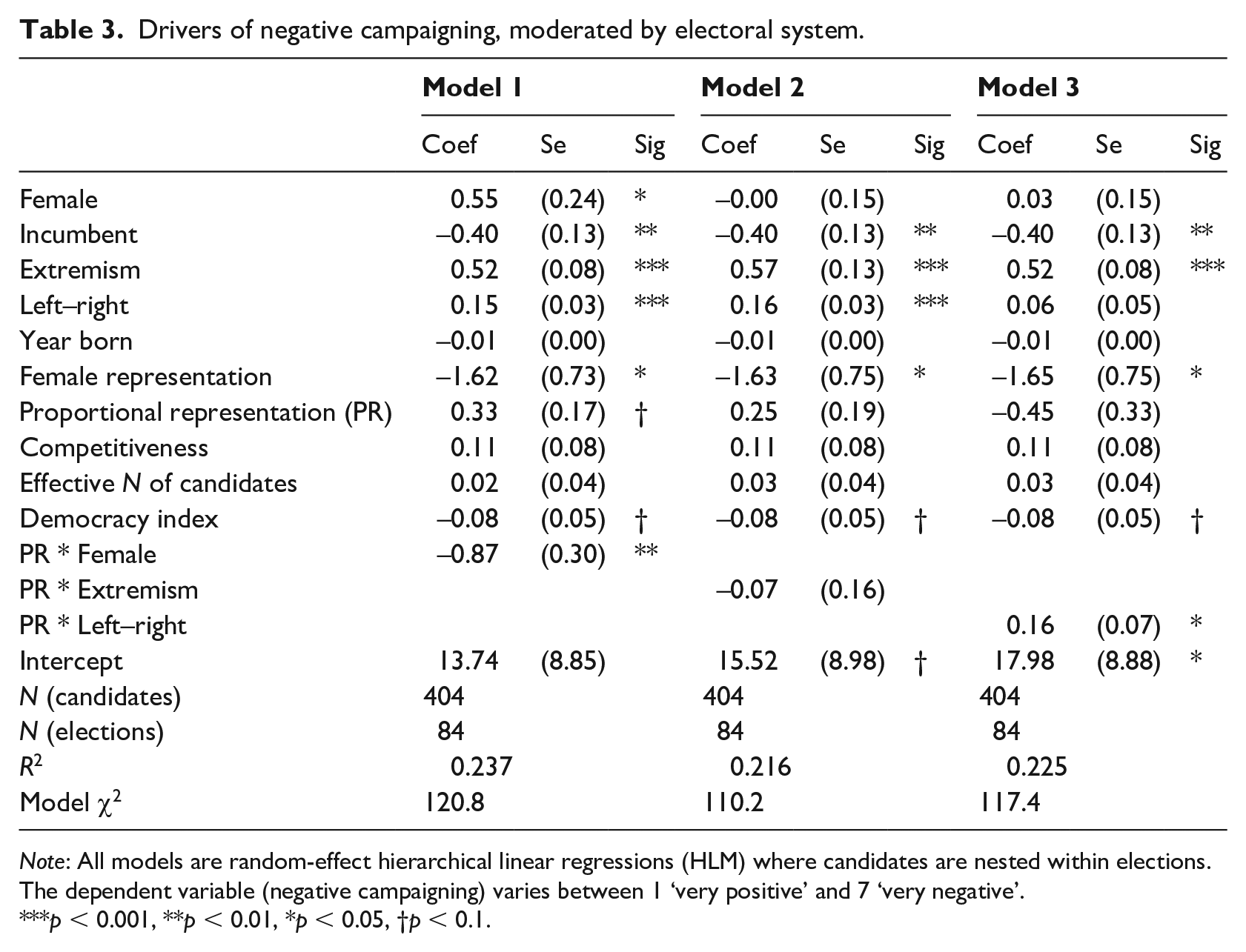
Note: All models are random-effect hierarchical linear regressions (HLM) where candidates are nested within elections. The dependent variable (negative campaigning) varies between 1 ‘very positive’ and 7 ‘very negative’.
p < 0.001, **p < 0.01, *p < 0.05, †p < 0.1.
Comparing the two models in Table 1, our results show that, even controlling for the nature of the context, individual differences across candidates drive the use of negativity quite substantially. As expected (H1), incumbents are significantly less likely to go negative on their opponents. More extreme candidates are significantly and substantially more likely to go negative and use character attacks in their campaigns (H3), and so are right-wing candidates (H2). Against our expectations (H4), but in line with the idea that gender plays a more complex role than expected, we do not find any support for the notion that female candidates are less likely to use negative elements in their campaigns.
Turning to the characteristics of the context, we find that candidates in countries with more female MPs tend to campaign more positively (H9); for each increase of 10% of female MPs in the national parliament, campaigns tend to be approximately 0.16 points (on a 1–7 scale) more positive. This being said, the difference between a PR and a majoritarian electoral system does not seem to drive a different use of campaign negativity; we thus reject H5. This lack of effect is somewhat of a surprise, especially in light of case-specific evidence. For instance, Ridout and Walter (2015) show that election campaigns in New Zealand have become more positive since the country moved away from its first-past-the-post electoral system in the mid-1990s. Our results suggest that, broadly speaking, the importance of the electoral system should not be overestimated – or, at least, that its effects are subordinate to the effects of candidates’ profile and electoral dynamics. This being said, contextual factors can alter the incentives to go negative for candidates with different profiles. Tables 2 and 3 test the moderating effect of the percentage of female MPs and the electoral system.
Results suggest that some moderation dynamics are at play for the effects of candidates’ ideological placement. Substantively, the effect of candidates’ left–right position is much stronger in countries with higher female representation or a PR electoral system, all things considered. Figure 2 substantiates the interactions in Tables 2 and 3. As Figure 2 shows, negativity is especially low for candidates on the left when female representation is high (left-hand panel), and high for candidates on the right in PR countries (right-hand panel, which rejects H6). In both cases, the effect of left–right – which was quite substantial when only direct effects are accounted for – is virtually nonexistent in countries with low female representation or a majoritarian system. We do not find any moderation effects for candidates’ extremism, rejecting H7.
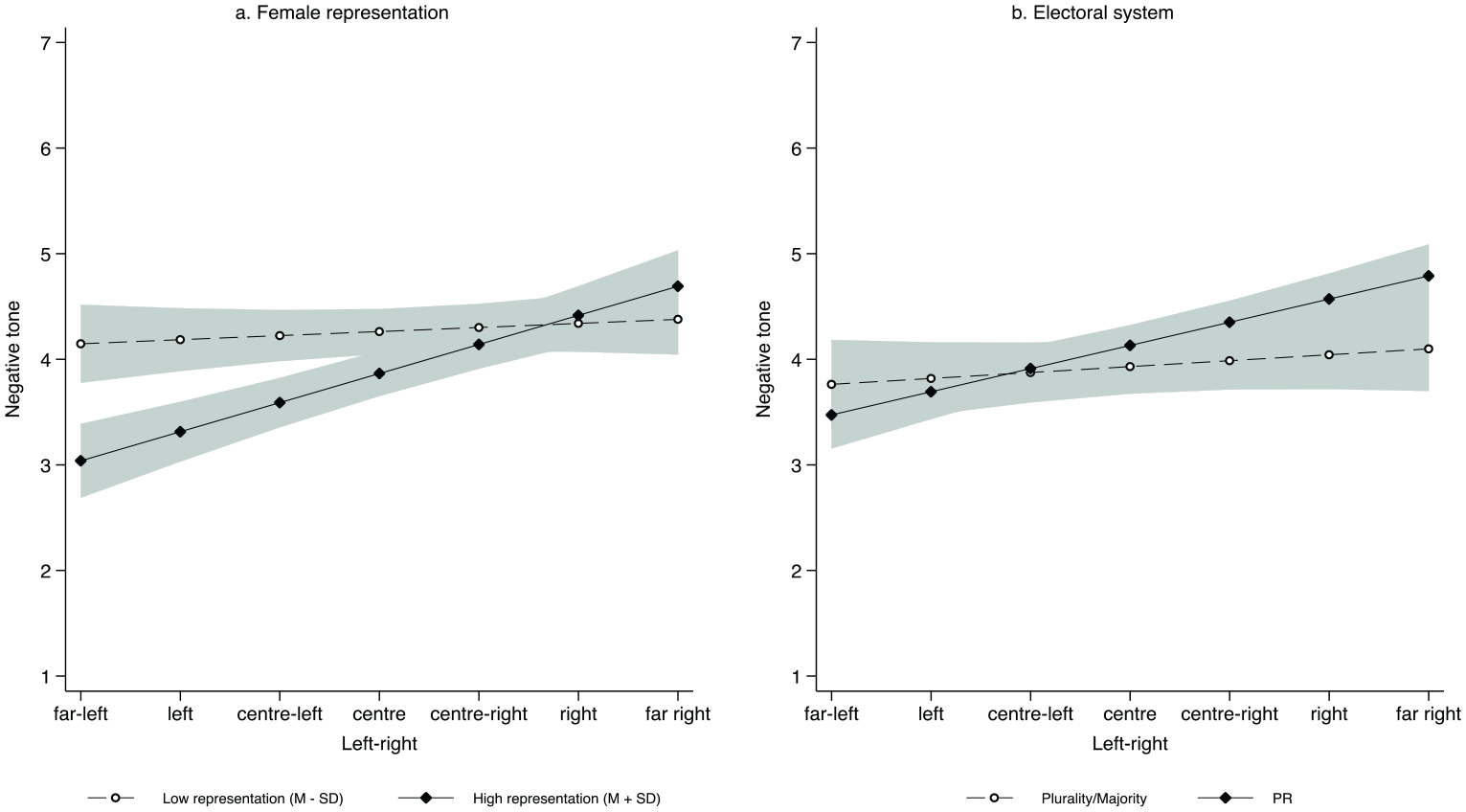
Negative tone, by left–right * female representation, electoral system.
Second, we find some evidence that male and female candidates react differently to the nature of the context. As shown in Table 3, female candidates tend to go less negative in PR systems and attack more than their male counterparts in majoritarian systems. This suggests again that the overarching expectation that female candidates adopt a gentler style of campaigning is unfounded – not only do they not do so overall, but in more competitive settings (majoritarian elections), they go even more negative than men, partially confirming H8. We, however, find no indication whatsoever that female candidates are more or, for that matter, less likely to go negative on their opponents in countries with a higher or lower percentage of female MPs. We thus reject H10.
Robustness checks
Appendix B (available at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/) includes a series of robustness checks. First, Tables B1 to B3 replicate the main analyses but use a more restrictive sample of candidates and elections, for which at least 10 experts provided ratings. Results are slightly weaker on the effects of contextual variables, but broadly in line with the main results. Second, Tables B4 to B6 are run for democracies only – that is, countries that score a minimum of 4 points out of 10 in the Economist ‘democracy index’. Results are in line with the main effects discussed in the text. Third, Tables B7 to B9 replicate the main analyses, but using the original unadjusted dependent variable; results are virtually identical in direction and magnitude. Fourth, a case is often made that expert ratings are potentially affected by the profile of the experts and the composition of expert samples (e.g. Budge, 2000; Curini, 2010; Walter and van der Eijk, 2019). With this in mind, we replicated all analyses controlling for each election’s average expert profile in terms of gender, percent of domestic experts, average familiarity with elections in the country, average simplicity in answering the questionnaire, and average position on the left–right scale. Tables B10 to B12 present the results for these additional models and show that (i) the effect of the average experts’ profile is absolutely negligible, and (ii) the main results resist such controls. We can thus confidently exclude any major profile effects. Fifth, we replicated all models using bootstrapped standard errors (300 replacements; Tables B13 to B15) and find robust results. Sixth, Table B16 shows then that the difference between legislative and presidential elections seems to influence some effects (for instance, the effects for left–right are stronger during presidential elections); to avoid any spurious effects there, we replicated all models controlling for the difference between legislative and presidential elections (Tables B17 to B19); results are not only robust, but in many cases even stronger. Similarly, seventh, the difference between Western and Non-Western countries does not seem to alter the dynamics studied here (Tables B20 to B23), beyond the fact that female candidates seem less likely to go negative in Western countries, ceteris paribus. Notably, the effect of political ideology, which has been shown to follow different dynamics in Non-Western countries (e.g. Rohrschneider and Whitefield, 2009), does not seem to differ depending on this broad geographical classification. Finally, eight, we replicated all models using a more restrictive binary measure of political extremism (Tables B24 to B26); results are robust.
Discussion and conclusion
In a nutshell, our results show that challengers, right-wing, and ideologically extreme candidates have a higher tendency to use attack messages. Females are not more likely to attack their rivals in general, but they are more negative than their male counterparts in majoritarian countries. Higher numbers of female representatives reduce negativity overall, but right-wing candidates tend to particularly go negative on their opponents in countries with higher female representation and PR electoral systems. Taken together, these results indicate that (a) the candidates’ profile matters, as expected, but also that (b) the context matters, but mostly to moderate the effects of candidates’ profile. In turn, this suggests that comparative analyses looking at contextual drivers of campaigning strategies should be careful in only assuming that the context alters the incentives to campaign in a certain fashion – it certainly does so, but not across the board.
This article is not without caveats: first, these results are likely to be conservative, especially for legislative elections. Evidence suggests that in this type of contest, the dangerous and ‘dirty work’ of attacking competitors is left to lower-level candidates (e.g. Dolezal et al., 2015), whereas our analyses are run on top candidates only. In this sense, it is likely that the dynamics at play here are even more intense when looking beyond the party leadership. This being said, as shown in Appendix D (available at the following Open Science Foundation (OSF) repository: https://osf.io/4vhea/), experts tended to rate rather consistently the negativity of top candidates and the negativity of their party overall, even if incumbents seem slightly less likely to go negative than their own party, ceteris paribus. Second, the study solely relied on ratings provided by experts, which cannot provide all the nuances of other more traditional approaches to the study of campaign content (e.g. structured content analysis). Nonetheless, relying on experts is particularly handy in large-scale comparative settings. Expert ratings provide comparability across diverse contextual settings where it is unrealistic to implement traditional comparative methodologies, due to language barriers, for example. Third, the analysis only provides a snapshot of the elections and looks at the respective campaigns as a whole. It, thereby, largely ignores temporal dynamics such as, for example, the proximity of the election day (Damore, 2002). Fourth, we did not discriminate between the different communication channels, which may influence not only the amount of negativity but also the nature of the attacks (Walter and Vliegenthart, 2010). Fifth, of course, structural differences in political systems across countries go well beyond the rather simple dichotomy between countries with PR and majoritarian systems. Recent research shows indeed that additional elements, like electoral system disproportionality or the polarization of the electorate, can have an important role to play as well (Papp and Patkós, 2019).
Despite these shortcomings, this study contributes to the literature in multiple ways: by providing evidence from a large-scale comparative dataset, we contribute to the comparative research on elections and political campaigning. The analysis of 84 elections worldwide enabled us to test prominent communication trends on a broader sample and assess to what extent these can be confirmed in cases that, up to this day, have received little to no attention from the literature. Moreover, while most articles focus on the isolated effects of either candidate characteristics or contextual factors, this article is one of the first to integrate both levels and look at them simultaneously. This provides a more realistic and comprehensive picture of why and under which conditions candidates choose to use negative rhetoric. The possibilities of extending this approach are manifold: future research could, for example, include other aspects of the political culture such as the citizens’ attitudes toward oppositional forces, or the degree of polarization. From a broader perspective, this paper deepens our knowledge of an international phenomenon, whose practical and normative implications for modern democracies are not to be underestimated.
Supplemental Material
Supplementary_File – Supplemental material for Attack politics from Albania to Zimbabwe: A large-scale comparative study on the drivers of negative campaigning
Supplemental material, Supplementary_File for Attack politics from Albania to Zimbabwe: A large-scale comparative study on the drivers of negative campaigning by Chiara Valli and Alessandro Nai in International Political Science Review
Footnotes
Acknowledgements
We are very grateful to the anonymous reviewers and IPSR editors for their support, critical assessment, and constructive suggestions during the publication process. We take, of course, full responsibility for any remaining mistakes. A previous version of this article was presented at the 2019 annual meeting of the Canadian Political Science Association (CPSA) in Vancouver. Many thanks to all participants to the panel, and in particular to Scott Matthews, for precious comments and feedback. A sincere thank you to all experts that participated over the years in the NEGex study for their time and insights.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Alex Nai acknowledges financial support from the Swiss National Science Foundation (Grant P300P1_161163), and logistic support from the Electoral Integrity Project at the University of Sydney and Harvard; thank you in particular to Pippa Norris. We also acknowledge the generous institutional and financial support from the Amsterdam School of Communication Research (ASCoR) at the University of Amsterdam.
Supplemental material
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.