
Abstract
Since the arrival of ChatGPT in November 2022, many Generative AI chatbots have appeared in the marketplace. Some of these tools like Consensus, Scholar GPT and Scholar AI are specifically designed to facilitate access to research and scholarly information. Also, research database aggregators and vendors like Scopus, Clarivate and JSTOR have introduced their version of Gen AI applications for use on their databases. Will the widespread use of these tools change the ways people seek, access and use information? How can the contemporary, and future, information science research contribute to the sustainability of the Gen AI-augmented information systems and services, especially in the context of research and scholarly information? By critically analysing a diverse range of research papers, and industry and institutional reports and documents, this article discusses various issues associated with the social, economic and environmental sustainability of research and scholarly information systems and services in the era of Gen AI. It proposes a model for sustainability of the information ecosystem in the era of Gen AI, focusing particularly on access to research and scholarly information using LLM-based chatbots, and proposes a research agenda to achieve the social, economic and environmental sustainability of information.
1. Introduction
The arrival of ChatGPT, a chatbot and virtual assistant, developed by OpenAI [1], in November 2022, has brought a new wave of transformative technologies that has a profound impact on all areas of life and activities involving data, information and knowledge [2–4]. Generative AI, or Gen AI, tools are capable of generating content – text, image, audio, video, summary, presentations and so on – based on natural language interactions or prompts – and hence these tools have potential applications in every sector such as, business [5], education [6], everyday life [7], health [8] and information access [9].
Since the arrival of ChatGPT, many similar chatbots or tools like Consensus, Claude, Perplexity AI, Scholar GPT and Scholar AI have appeared in the marketplace. Gen AI tools like ChatGPT, or similar industry-specific applications, have also been embedded in various information search tools or conventional search engines like Copilot for Microsoft’s Bing, and Gemini for the Google search engine. Conventional search systems are based on indices that map lexical tokens or semantic embeddings to document identifiers, and these indices are designed for retrieving responsive documents; whereas LLM-based search systems support the integration of these documents into a holistic answer that is presented to the user in response to search queries or prompts [10]. The emergence of the Gen AI technologies has opened up new opportunities for people to find summarised information for research and scholarship as well as for everyday life [2,7,8]. Recent research and reports demonstrate that technology is catching up fast with the long-held vision where information interactions will involve personal search assistants with advanced capabilities, including natural language input, rich sensing, user/task/world models, and reactive and proactive experiences [9,11].
Many Gen AI tools such as Consensus, Scholar GPT and Scholar AI are designed specifically for promoting access to research and scholarly information. Also, research database aggregators and vendors like Scopus, Clarivate and JSTOR have introduced their version of Gen AI applications for use on their databases, for example, the Web of Science Research Assistant, ProQuest Research Assistant and Primo Research Assistant. The rapid development of LLMs and the evolving Gen AI tools, is giving rise to a new paradigm of IR (information retrieval), called Generative Information Retrieval (GenIR) or GR (Generative Retrieval), which aims to achieve IR goals through generative approaches [12].
So, what would be the impact of these LLM-driven general purpose and/or custom-built Gen AI tools on the sustainability of information systems and services, and especially the research and scholarly information services? Will the widespread use of these tools change the ways people seek, access and use information? How can the contemporary and future information science research contribute to the sustainability of the Gen AI-driven information systems and services, especially in the context of research and scholarly information that form the foundation of education and research, and progress of science and society at large?
Although there has been a huge surge in research papers on Gen AI and information access, discussing a range of general issues and topics of research [13], and in specific issues, for example, human-centred AI [14], human information behaviour [15], privacy issues [16] and information affordances in everyday life [7], there has not been any studies discussing the sustainability of information systems and services in the context of the growing use and applications of Gen AI tools for access to information, especially research and scholarly information.
Overall, research on the potential impact of Gen AI on information access and use, and its implications for the information services sector has so far been limited. This article argues that a systematic and sustainable approach to research and development in this area is needed to shape the future role of IS as a discipline and a profession, because in the absence of this, the IS discipline and profession would be in great danger of losing its importance and role, especially in education and research contexts. In order to achieve this goal, the research reported in this article takes the approach of a systematic review of relevant research and development on Gen AI and information access, discussing the implications of this research in the context of the models for sustainable information services previously reported in literature, and thereby proposing a new model for achieving socially, economically and environmentally sustainable information systems and services in the era of Gen AI.
A number of searches were conducted on Scopus, Web of Science and Google Scholar using a combination of relevant search terms like: ((AI) or (Artificial Intelligence) or (Generative AI) or (Gen AI) or (GenAI) or (LLMs) or (large language models)) and ((information retrieval) or (information access) or (IR)). Top 100 papers were selected from each of the three source databases, and the duplicates were removed, to select a set of papers and reports which were critically reviewed to identify the trends and directions of research around Gen AI and information access. Based on this, the article proposes a model for sustainability of the information ecosystem in the era of Gen AI, focusing particularly on access to information using LLMs. It proposes a research agenda to achieve sustainability in all its three pillars – social, economic and environmental.
2. Gen AI and sustainability of information
Research and scholarly information services have changed significantly over the past few decades providing seamless access to digital information and data from multiple paid as well as open access resources. While information retrieval models and technologies have improved significantly over the past seven decades, and the research and scholarly information services sector has taken several measures to facilitate access to a vast range of information resources, the process for accessing information remained more or less the same. This typically includes- the following steps: (1) the user has to select a set of search terms, often combining them using a set of Boolean operators; (2) select one or more databases to conduct the search; (3) conduct several searches using the chosen search terms; (4) read the titles, and sometimes the abstracts or brief extracts, of the retrieved items to decide whether or not they are relevant; and finally (5) select a list of retrieved items and then read those items to assimilate the information before using it to address the problem in hand. Although significant improvements have taken place to support the users at different stages of this process, giving rise to numerous books and research papers, and many sophisticated aggregator services that provide access to research output in multiple disciplines appearing in a diverse range of journals, conference papers and so on, the described search process or stages remained more or less unchanged, until the arrival of Gen AI in November 2022. These are discussed in more detail in the following sections of the article.
Figure 1 shows the output generated by the Gen AI tool Consensus, a tool specifically designed to provide access to research and scholarly information, for a simple natural language question. As shown in Figure 1, the user gets a summarised output based on 10 items. The output also provides citation details of the 10 items. The same question was submitted to another similar Gen AI tool, viz., Scholar AI, which first asks a question back: Scholar AI wants to talk to api.scholarai.io [Allow, Always Allow, Decline], and once it is allowed, it produced a summarised output based on six items, as shown in Figure 2.

Output generated by consensus for the question: what can libraries do for sustainable development?

Output from Scholar AI for the question: ‘What can libraries do for sustainable development’.
These examples, and many more shown in some recent research [2,17], demonstrate that the user gets a summarised output from both the Gen AI tools on the given search topic along with a small set of cited items. However, they don’t get a complete list of research papers relevant to the topic, nor do they get an option to filter and rank the research output to meet their specific search context. Furthermore, the user does not get an idea of which sources were searched and why, which search terms were used, and how the relevance judgement was made.
As opposed to this, when the same question was posed to the Web of Science Research Assistant, a Gen AI tool created by the database service provider Clarivate, it generated a summarised output based on eight selected items. It also provided an option: ‘View additional documents relevant to this response’. Upon selection of that option, it produced a list of all the 99 publications available on the given search topic in the Web of Science database which the user could browse using the standard features of the database, such as filtering and analytics including the publication timeline and trends, and so on.
So, what do the Gen AI tools bring to the average users in the context of finding research and scholarly information? Research shows that users face a number of challenges while using the conventional libraries and scholarly database services, like Scopus, Web of Science and so on, for finding the relevant information on a topic [2,17]. However, users do not need to face many of these challenges while using Gen AI tools for access to information (see Table 1).
Access to information through libraries/databases and Gen AI [16].

Although the quality of the output is steadily improving because of the use of multimodal, multi-agent and RAG supported Gen AI tools, and the chances of hallucinations – imaginary or fake citations – are being reduced in the new versions of tools, the output of Gen AI is not always exhaustive and specific [16]. In other words, exhaustivity and specificity – recall and precision of information – which are essential for academic and scholarly research, cannot be guaranteed, at least as of now, from the output of Gen AI tools. It is also difficult to judge the relevance of the items cited or recommended by the Gen AI tools. Relevance judgement has remained one of the most important and challenging areas of research in information retrieval since the Cranfield tests in the early 1960s [18–20]. Reproducibility is also a challenge because the Gen AI tools do not tell the users why and how the output was produced, and also the same Gen AI tool may produce different sets of output for the same question, even if those are asked on the same day. These indicate that users cannot be sure and/or confident with the output generated by the tools, especially in the context of finding information that requires confidence, reliability, reproducibility and trust.
The rest of this article discusses how information science research can contribute to addressing some of these challenges, and thus achieving the social, economic and environmental sustainability of information in the era of Gen AI.
3. The three pillars of sustainability
In the popular media and discourse, the word sustainability is often taken in a narrow context only focusing on the environmental sustainability. However, there are three pillars of sustainability, and there is a need for building systems and services that are economically, environmentally and socially sustainable [21]. The 17 UN Sustainable Development Goals (SDGs) can be grouped into 3 broad categories as follows [21]:
Access to information and data, and sustainable information practices form the foundation of sustainable development in any area [21,22], while sustainable information practices are the socially negotiated behaviour through which we create, change, share and store information [21]; and this:
Calls for the use of appropriate technologies, tools, standards, methods, policies and practices so that sustainability can be achieved throughout the lifecycle of data and information; and
Influences ‘the development and use of appropriate ICT infrastructure and digital information tools, regulations, and policies, as well as human and social/institutional behaviour in the use of data and information for sustainability in every sphere of life and activity’ [21], (pp. 22–23).
4. Social sustainability of information
Research on the social sustainability of information focuses on equitable access, user education and literacy, and strengthening of the processes in which society is transformed according to the ideals of sustainable development [23–28]. More recent research shows that social sustainability of information systems and services contribute primarily to SDG4 (Quality education), but also to several other SDGs, for example, SDG5 (Gender equality), SDG10 (Reduced inequalities), SDG11 (Sustainable cities and communities), SDG 16 (Peace and justice) and especially SDG16.10 (Access to information), and SDG17 (Partnerships) [21]. The following sections discuss how information science can contribute to achieving the social sustainability of digital information systems and services in the era of Gen AI.
4.1. Responsible use of AI
Van Wynsberghe [29] argues that sustainable AI has ‘three accompanying tensions between AI innovation and equitable resource distribution; inter and intra-generational justice; and, between environment, society, and economy’. Responsible artificial intelligence (AI) is ‘a set of principles that help guide the design, development, deployment and use of AI – building trust in AI solutions that have the potential to empower organizations and their stakeholders’ [30], and it aims to embed ‘ethical principles into AI applications and workflows to mitigate risks and negative outcomes associated with the use of AI, while maximizing positive outcomes’ [30].
Obviously Responsible AI calls for AI Governance, and countries worldwide are designing and implementing AI governance legislation and policies [31]. However, these regulations vary from country to country, as they are designed to protect the rights of the people and interests of the government and businesses in the respective country. International agencies like the OECD, UNESCO and the European Union [31] have also developed AI governance and policies.
The UK government defined 10 common principles that can guide people in the safe, responsible and effective use of AI in government organisations [32]:
Principle 1: You know what AI is and what its limitations are.
Principle 2: You use AI lawfully, ethically and responsibly.
Principle 3: You know how to use AI securely.
Principle 4: You have meaningful human control at the right stage.
Principle 5: You understand how to manage the AI life cycle.
Principle 6: You use the right tool for the job.
Principle 7: You are open and collaborative.
Principle 8: You work with commercial colleagues from the start.
Principle 9: You have the skills and expertise needed to implement and use AI.
Principle 10: You use these principles alongside your organisation’s policies and have the right assurance in place.
The US Department of Homeland Security (DHS) [33] defined five key principles for use of AI:
Lawful and Mission-Appropriate: AI use must comply with the constitution, laws and policies, protecting privacy, civil rights and civil liberties.
Mission-Enhancing: AI use must be purposeful to improve DHS’s operational, administrative and support functions.
Safe, Secure, and Responsible: AI use must address risks and benefits, protects privacy and civil rights, and is rigorously tested to avoid biases and ensure effectiveness, accuracy and security.
Trustworthy: AI use must be transparent and explainable, with public disclosures and traceable, auditable outputs.
Human-Centred: AI design and deployment must consider the impact on users and those affected, incorporating feedback from communities and stakeholders.
Both examples, shown above, take a human-centric approach to the design and deployment of AI. The same approach is taken by the European Union that pledges to ‘develop a “human-centric” approach to AI to ensure that Europeans can benefit from new technologies developed and functioning according to the EU’s values and principles’ [31].
Information professionals are clearly positioned to approach an AI-augmented world from a human-centred perspective [3]. Taking this perspective of human-centric AI, a number of issues around the sustainability challenges can be addressed by using the principles of Responsible AI for access to information systems and services.
4.2. Access to information and data
As discussed earlier in the article (see Table 1), Gen AI tools can make it easier to access information. However, the key question is: how does the benefit of easy access also meets the requirements of the exhaustivity, specificity and relevance of the retrieved or recommended information? Personalisation and recommendation have remained major areas of research for several decades [34]. More recent research on retrieval-augmented language models has attracted considerable attention in both academia and industry [35–38]. A workshop supported by the CCC (Computing Community Consortium), held in July 2024 to discuss the future of IR, identified a number of questions around user-centred IR research in the age of Gen AI [39] that can be phrased as follows:
The above list can be augmented with the following research questions that can enable the Gen AI tools to contribute to achieving the social sustainability:
4.3. Support for innovation
Research shows that Gen AI can be used for analysing a collection of research papers for creating knowledge graph, pattern recognition, hypothesis generation and testing, and so on [40]. IBM researchers and collaborators outline an ‘AI scientist’ called AI-Hilbert that ‘turns existing theories and data into new, consistent, interpretable, mathematical models. With this new tool, they hope to revolutionize the very process of scientific discovery’ [41]. Following on from such developments, future information science research should investigate:
4.4. User education and literacy
In order to be able to successfully use AI technologies, people need a new kind of literacy, called AI literacy that:
Provides ‘the basic ability to become an independent citizen in the AI era’ [42];
Provides ‘the ability to properly identify, use, and evaluate AI-related products under the premise of ethical standards’ [43];
‘Is based on competencies and purpose targeted by existing literacy education’ [42]; and
‘Includes three components: AI concepts, using AI concepts for evaluation, and using AI concepts for understanding the real world through problem solving’ [44].
Some researchers argue that Gen AI literacy is composed of four types of knowledge: theoretical knowledge, ethical knowledge, pragmatic knowledge and reflective knowledge [45], while others recommend 12 defining competencies of Gen AI literacy that offer ‘a framework for individuals, policymakers, government officials, and educators to take advantage of the potential of generative AI responsibly’ [46]. Recent research shows that ‘Prompt engineering’ aimed at creatively or iteratively designing prompts, do not always produce the desirable outcomes from LLMs, and it ‘can be turned into or aided by prompt science by introducing a multi-phase process with a human in the loop’ [47].
Given this, the following research questions may promote the use of Gen AI for information access:
4.5. Equitable access
Inequalities in higher education can be based on the gender, ethnicity, socioeconomic status and disability of students [48]. A recent report shows that researchers from smaller or underfunded institutions face significant barriers, limiting their ability to contribute to global knowledge production. From prohibitive costs to inadequate infrastructure, these challenges impede innovation, stifle collaboration, and widen the gap between institutions of different resource levels [49].
Wanti et al. [50] point out that in addition to financial support, social support influence – by peers, by family, by teachers, by university officers, and via programmes – can improve access and equity in higher education. The following research question may be able to address the challenges of equitable access to information contributing to equitable learning and research opportunities.
5. Economic sustainability
A recent MIT Technology Review Insights [51] report points out that the impact of Gen AI on economies and enterprise will be revolutionary. The McKinsey [52] Digital report estimates that Gen AI will add between $2.6 and $4.4 trillion in annual value to the global economy, and Goldman Sachs [53] predicts a 7%, or nearly $7 trillion, increase in global GDP attributable to Generative AI.
The higher education and information services sector around the world are facing severe economic hardship. Nearly three quarters (72%) of higher education providers could be in deficit by 2025–2026, and more than 50 universities have announced redundancies and course closures [54]. The same scenario prevails across the Atlantic. The economic model on which universities in the United States relied to conduct their research, to fund their students is in crisis, and the onslaught of the government funding will have a significant impact on the education and research [55]. Gen AI may contribute to the economic sustainability of education and research by building case studies focusing on the cost-benefits of Gen AI-augmented information access and use by different groups of users and institutions.
5.1. Saving user time
Gen AI tools can significantly reduce user’s time for discovering and accessing information and thus can make indirect contributions to economic sustainability. The IBM [56] Top Strategic Technology Trends for 2025 report says that autonomous AI agents (Agentic AI) ‘will dramatically upskill workers and teams, enabling them to manage complicated processes, projects and initiatives through natural language’. In the academic and research context, such agentic AI tools can significantly reduce the time of students and researchers – individuals as well as teams – which can in turn reduce the overall costs of research and education. This may be addressed through the following research question:
5.2. Reducing the cost of accessing information and data
The CCC workshop, discussed earlier, identified that that, among others, IR researchers should investigate ‘the capabilities of numerous small LLMs rather than a single monolithic approach’ and ‘the trade-offs between different sized LLMs and different sized IR systems’ [39] (p. 10). Some initial and localised studies show the potential of Gen AI for saving user time for accessing information. For example, a Clarivate Ex Libris [57] report that at the Universitat Oberta de Catalunya Library, librarians have experimented with Primo Research assistant and other AI tools to assess the impact they make on search and user experience. In just three months, library search adoption increased from 6.75% to 11.63% and user satisfaction increased to 83.7%.
However, it should be noted that many LLMs are built on unauthorised access to some content and data that may be considered unlawful, and this may lead to IP and data protection issues for the developers of Gen AI tools, which may have potential implications for the costs of these tools. Furthermore, some vendor-developed Gen AI tools do not necessarily come free with subscription to their databases, and often the tool has to be purchased separately. As an example, for a medium-sized university in the United Kingdom, the annual subscription cost of the Web of Science Research Assistant can be around £20,000 per year. Using this figure, it can be estimated that the total subscription cost of this just one Gen AI tool for all the 255 UK higher education institutions could be over £5 million; and so, the cost of subscription of multiple Gen AI tools for databases from multiple vendors, could be quite significant for the entire UK higher education sector.
An alternative, and cheaper, approach could be a joined-up initiative for the research and information sector to build their own Gen AI tools on the back of open access content accessible through institutional repositories and other open access databases such as Semantic Scholar, Google Scholar and PubMed. This can be addressed through the following research question:
5.3. Sharing resources
The CCC workshop brought together 44 experts comprising 30 academics, 5 government employees and 9 industrial researchers – 24 primarily affiliated with information retrieval, 12 with NLP and 8 with other AI topics – to discuss the key research questions to be addressed for the future of IR in the age of Gen AI [39]. A similar initiative, the LLM4Eval workshop, brought together researchers from industry and academia to discuss various aspects of LLMs for evaluation in information retrieval, including automated judgments, retrieval-augmented generation pipeline evaluation, altering human evaluation, robustness, and trustworthiness of LLMs for evaluation in addition to their impact on real-world applications [20].
Such coordinated and shared approach to research can significantly reduce the cost of research and innovation, by addressing the following question:
5.4. Providing new value-added services
Many tech companies are now developing new tools for helping researchers analyse hidden links among information resources and datasets, and generate novel hypotheses and ideas. For example, Google has recently released AI co-scientist, ‘a multi-agent AI system built with Gemini 2.0 as a virtual scientific collaborator to help scientists generate novel hypotheses and research proposals, and to accelerate the clock speed of scientific and biomedical discoveries’ [58]. AI co-Scientist uses a coalition of specialised agents to iteratively generate, evaluate and refine hypotheses. Some other such tools include: GT4SD (Generative Toolkit for Scientific Discovery) [59], SciAgents Framework [60], AutoGen framework [61] and so on. These and many other new and emerging tools can enable the researchers to develop new, inter- and multi-disciplinary, research projects that can contribute to the economic sustainability of research and innovation. This raises the following question in the context of the economic sustainability of information:
6. Environmental sustainability of Gen AI and information services
The July 2025 issue of Communications of the ACM includes a number of research papers on the theme of ‘Computing for Sustainability’, and the editors of this special issue argue that ‘“Environmental Computing as a Branch of Science” combines observation and modelling of environmental systems as a holistic endeavour worthy of consideration as a new science’ [62]. The target for environmental sustainability for digital information systems and services is to ensure reductions in the environmental impact by building appropriate tools and techniques as well as taking measures to reduce the greenhouse gas (GHG) emissions throughout their lifecycle [25,26]. Earlier research on environmental sustainability of digital information systems and services focused on print versus digital information [63,64], open access content [26], developing a sustainability model taking into account the roles played by various stakeholders like the publishers, database service providers and vendors and ICT infrastructure [62], as well as proposing some research agenda [65,66].
Using the conventional LCA (Lifecycle Analysis) approach to estimate the carbon footprint of a digital information service could be quite complex and resource-intensive [65]. An alternative approach for estimating the energy consumption of an information retrieval system or service may be taken, that involves [66]:
Identifying the computing equipment and facilities used for development and management of the IR system or service, and estimating the energy required to manufacture, and end-of-life disposal, of those equipment and facilities;
Estimating the socket energy consumption of various equipment and facilities for creation and maintenance of the IR system or service;
Estimating the energy consumptions for business, travel, office equipment and overheads in terms of office facilities, and so on used for development of the content vis-à-vis the IR system/service;
Estimating the types, number and duration of usage of different user devices for accessing the IR service and the corresponding energy requirements for manufacture, maintenance and disposal of those devices; and
Estimating the socket energy consumption of various user devices.
In addition to the above points, estimates of the environmental costs of information access using Gen AI tools and chatbots, should also be added to the energy costs associated with the building and running of the LLMs. One estimate shows that the process of training an AI model ‘can emit more than 626,000 pounds of carbon dioxide equivalent – nearly five times the lifetime emissions of the average American car (and that includes manufacture of the car itself)’ [67]. However, this estimate is based on the earlier models, like GPT3; and the energy cost for newer and more robust LLMs could be much higher.
One research [68] shows that while training a single model is relatively inexpensive, the cost of tuning a model for a new dataset quickly becomes extremely expensive. Sam Altman, CEO of OpenAI recently mentioned that a typical ChatGPT request consumes approximately [69]:
0.34 watt-hours of electricity;
0.000085 gallons of water.
So, for an estimated one billion query per day [70], ChatGPT consumes 340 megawatt of electricity and 85,000 gallons (3,86,417 litres) of water every day; or 124.1 gigawatt of electricity and 141 million litres of water per year. This is just an estimation for only one Gen AI tool handling 1 billion queries per day. To put the electricity and water consumption figures in perspective, an average household in United Kingdom consumes 2700 kWh (kilowatt-hour) of electricity and 125,925 litres of water per year.
Some estimates show that the power requirements of data centres in the United States doubled in 1 year increasing ‘from 2,688 megawatts at the end of 2022 to 5,341 megawatts at the end of 2023, partly driven by the demands of generative AI’ [71]. One estimate shows that in the third quarter of 2023, Microsoft and Meta each bought three times more NVIDIA graphics processing units (GPU) than Amazon and Google, which acquired 50,000 units each [72].
However, some researchers argue that the ‘more that Gen AI can grow both using and encouraging responsible and sustainable practices up front, the less likely a costly and difficult transformational change will be needed to address an entrenched and problematic vulnerability down the line’ [72]. Therefore, although it is predicted that the environmental costs of the growing use of Gen AI will be quite substantial, such costs should be assessed against the benefits that these technologies offer, for example, bringing in a paradigm shift in the way people access, use, interpret and utilise data and information for progress in science, health, business and multitude of societal benefits, and how search behaviour and everyday living changes over time. Zewe [71] argues that we ‘require a comprehensive consideration of all the environmental and societal costs of generative AI, as well as a detailed assessment of the value in its perceived benefits’.
Given this, it is proposed that environmental sustainability research in information should investigate:
7. Towards a sustainable AI-driven information ecosystem
Figure 3 provides a schematic view of how Gen AI technologies and sustainable practices can lead to sustainable development by addressing and achieving social, economic and environmental sustainability in education, research and progress of science and society. The research agenda, with 20 questions, can be interpreted using the prevailing models of sustainability pillars [21,24,25], but need to be interpreted in the light of the Gen AI because it brings a paradigm shift in information access [2] which call for new and coordinated research for achieving sustainability in information systems and services to support education, research and scholarly activities (Figure 3). The 20 research questions mentioned in this article cannot be addressed by any one group or discipline of research as such. Instead, as shown in Figure 4, a collaborative approach is needed to involve researchers from computer and information sciences as well as experts from other allied disciplines, and multiple stakeholders such as technology industries, content creators, publishers, database aggregators and vendors, academic and research institutions, library/web/digital library and database services, governments, international agencies and regulatory bodies.
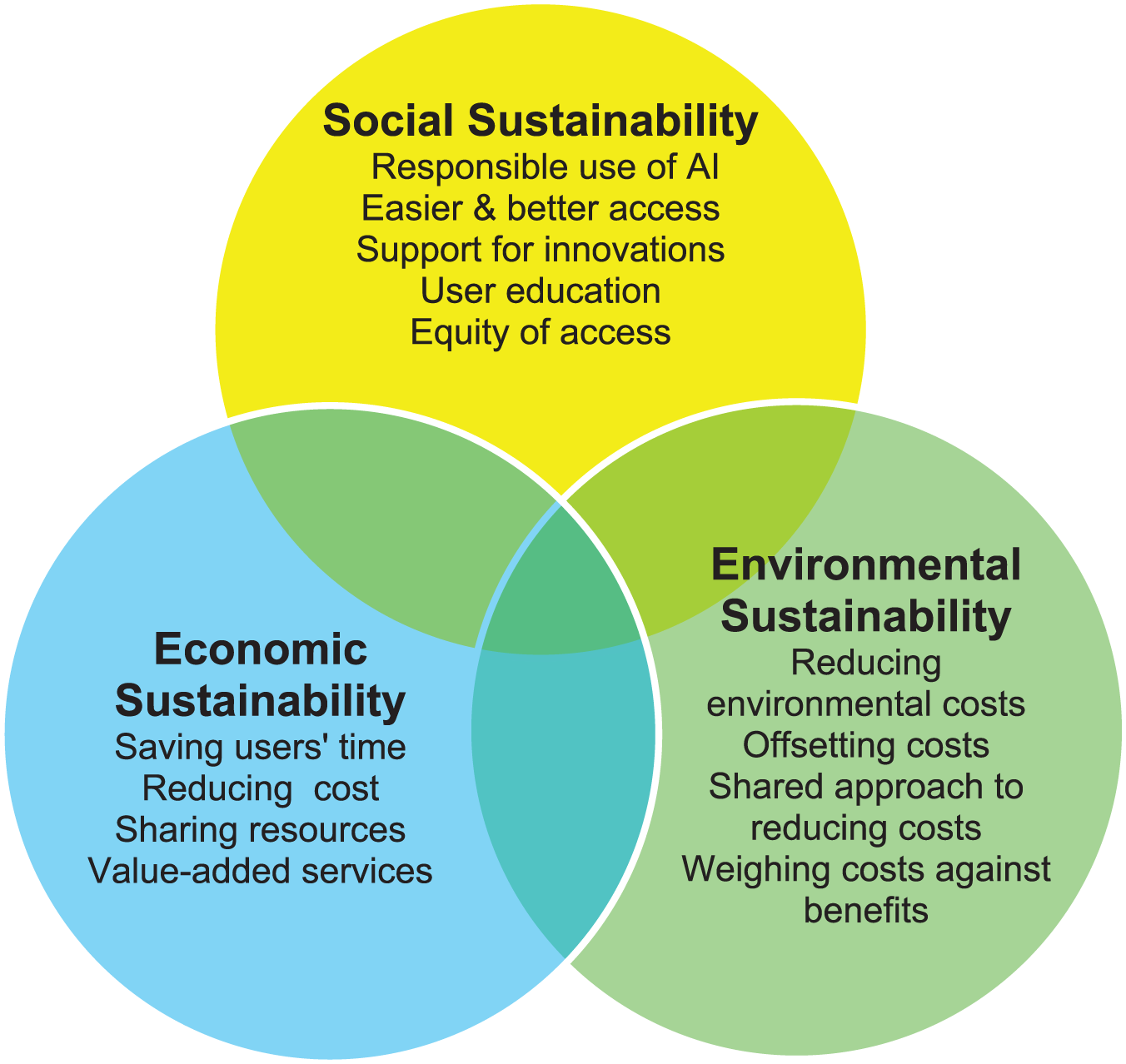
A schematic view of sustainable information in the era of Gen AI.
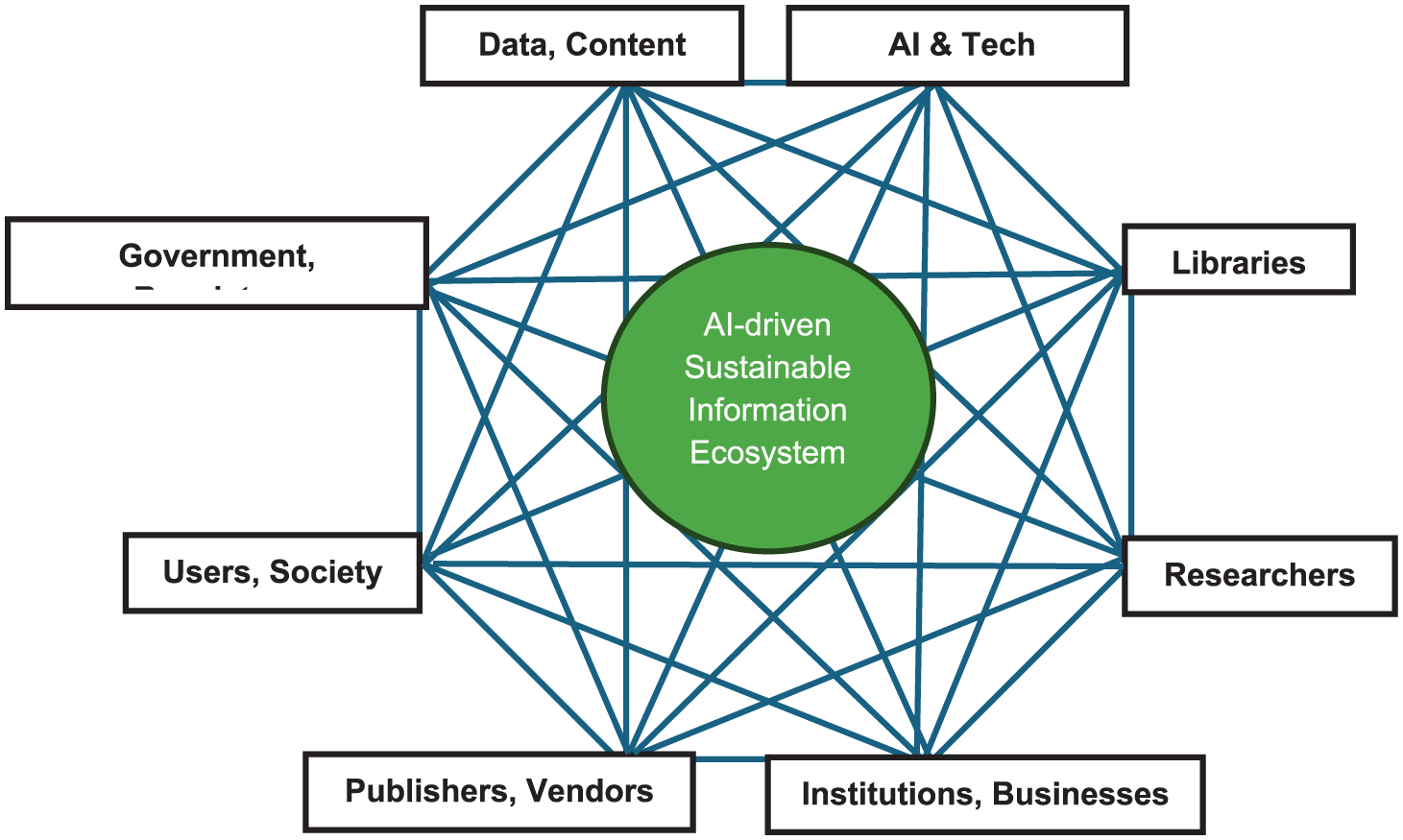
Stakeholders in an AI-driven sustainable information ecosystem.
Figure 4 provides a schematic view of various stakeholders that may have to be engaged in research and development, proposed in this article, and an equilibrium among the various actors is needed to achieve a sustainable Gen AI-driven information ecosystem. As various government and international agencies have argued, humans and society should be at the centre of Gen AI technologies and the associated research and developments. Figure 4 shows that:
8. Summary and conclusion
Based on the review of literature, reports and market scan, this article has proposed 20 research questions for the global information research community. This by no means is an exhaustive list, but together these research questions can lead to a sustainable model for access to information in the era of Gen AI.
The conceptual model shows how research in different areas can contribute to achieving sustainability in all the three pillars of sustainable development. It is argued that the proposed research and development activities cannot be achieved by the researchers alone; and instead, a coordinated effort involving multiple actors and stakeholders can help to achieve the objectives. It is expected that the proposed model and the associated research questions will contribute to the UNESCO’s vision of a human-centred approach to the use of Gen AI [73] for promoting education and research, and thus building an AI-driven sustainable information ecosystem to promote better education, research, business, government and society.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.