
Abstract
This study aimed to compare retracted (due to misconduct) and non-retracted articles in biochemistry, in terms of proportion of positive terms, certainty score and different certainty aspects. The data set of this study composed of 662 retracted and non-retracted articles published in the time period of 2018–2020 and indexed in Scopus. These 662 articles accounted for 331 non-retracted and 331 retracted articles, which were matched using matching and covariate balancing analysis. The analysis in this article was done using several regression models. Regarding the use of positive terms, the findings showed that retracted articles were 16% less probable to use positive terms in abstracts, titles and findings presented in conclusion and discussion compared with non-retracted articles. In addition, the results regarding the analysis of certainty language, showed that retracted articles were 15% less probable to use certain language, measured by certainty score, in presenting their scientific findings. Finally, regarding the certainty aspects, the results of regression models showed that retracted articles had 11% less likelihood to present their research findings using certain probability aspect.
Keywords
1. Introduction
Research misconduct is an important ethical concern affecting the integrity of the biomedical literature [1,2]. Retractions are made for various reasons. Misconduct has been reported to account for the majority of retractions in many disciplines [3]. Retractions are a key proxy for recognising errors in research and for reconciling misconduct in scientific literature. Thus, understanding the characteristics associated with retractions can provide insight and guide policy for journal editors and authors within a discipline [2]. Characteristics of retracted articles have been studied in different biomedical and medical disciplines, such as cancer [4], surgery [5], emergency medicine [6], nursing [7] and veterinary medicine and animal health [2]. The most common characteristics that have been studied in several research works were journal impact factor [8], affiliation country or institution [2,9], reasons for retraction [2,5], accessibility of data regarding retraction notices [10] and publisher [9]. Very few studies have been conducted regarding the linguistic characteristics of retracted articles. For example, Markowitz and Hancock [11] evaluated the writing style of a single fraudulent author, social psychologist Diederik Stapel. Their finding showed that the author’s writing style differed across his fraudulent and genuine articles. In a more recent study, Markowitz and Hancock [12] compared the writing style of 253 fraudulent articles (retracted for fraudulent data) partially matched with 253 non-fraudulent articles based on year, journal and keywords. These articles were indexed in PubMed and published in the time period of 1973–2013. They used an obfuscation index to do this. Their results showed that fraudulent articles tend to demonstrate a higher rate of linguistics obfuscation. The findings also showed a lower rate of positive emotion terms and a higher rate of causal terms in fraudulent articles.
This study also follows in the same vein and expands the latter line of research by applying exact matching on year, journal and topic and covariance balancing on several important factors, such as authors’ gender, country and scientific impact. It additionally uses the weights obtained from matching and covariate balancing in different regression models, to provide a more accurate comparison between retracted and non-retracted articles in terms of language use. Language use in this article was measured from the point of view of use of positive terms and certainty language. (Un)Certainty is an essential components of science communication and presenting uncertainty in scientific works might influence reader’s perception of scientific findings and their trust in science [13,14]. In biomedical research, the certainty or uncertainty of information communicated by authors in scientific articles through a series of linguistic markers plays a significant role in determining whether that information will be translated into practice or not [15]. Given the importance of certainty in science reporting and previous research that has showed language cues vary regarding use of positive terms in retracted and non-retracted articles, this study aimed to compare these two groups of articles in biochemistry, in terms of proportion of positive terms, certainty score and different certainty aspects.
To achieve the aim of study, the two research questions have been addressed below:
Is there any difference in the proportion of positive terms used in the in abstracts, titles and findings presented in conclusion and discussion of retracted and non-retracted articles?
Is there any difference between retracted and non-retracted articles in terms of uncertainty language (certain probability aspect, certain framing, certain suggestion) when findings are reported?
2. Data collection and processing
2.1. Data set
All journal articles published in time period of 2018–2020 in the subject area of biochemistry were downloaded from Scopus. These downloaded articles accounted for 331 retracted and 806,255 non-retracted articles. These 331 articles were retracted due to scientific misconduct, either in relation to issues with data or findings. After matching and covariate balancing analysis, 331 of 806,255 non-retracted articles were matched with 331 retracted articles. This accounted for a total of 662 articles, which was used for analysis in this article. Details regarding matching and covariate balancing can be found in the ‘Data analysis’ section. The reason for choosing biochemistry was previous research that found this field to be among the subject areas with a high number of retracted articles [9,16]. Choosing this time span allowed to consider a 3-year time window for possible retraction. Previous research works conducted in biomedical literature found a varied mean range of 26 [5] and 32.91 months [17] from publication to retraction for an article.
2.2. Outcome and covariates
In this section, we provide details regarding data collection and processing of the variables used in matching and covariate balancing as well as regression analysis.
2.2.1. Outcome variables
In model 1, the proportion of positive terms for each article was calculated by dividing the sum of positive terms appearing in the abstract, title and findings presented in conclusion and discussion by the length of the abstract and title (calculated as the number of words). We only included those sentences from discussion and conclusion sections where the authors were describing their own findings. As there were only 662 articles, we manually extracted these sentences. To avoid duplication, we also removed sentences from our analysis that were already mentioned in the abstracts.
Stop words were not considered in the calculation of the length of abstracts and titles. Python was used to do the data processing for natural language processing. We used a list of 25 positive terms that previous research had identified as positive in the titles and abstracts of biomedical articles [18,19]. For each positive term, a manual check was conducted to assure that positive words were not negated. For example, encouraging can appear as ‘not encouraging’. If they were, we did not count them as positive terms and thus they were eliminated.
For models 2–5, the outcome variables were certainty score and certainty aspects (certain probability, certain framing and certain suggestion).
Certainty score and certainty aspects were calculated using the findings in the conclusion and discussion sections of the 662 articles. The Python certainty-estimator package was used to do this. Certainty-estimator is a package for estimating the certainty of scientific findings. The model in the package was trained over findings from diverse scientific domains, including biochemistry. The package provides two options to study certainty: sentence level and aspect level. The certainty score is between 1 and 6. The certainty aspects of scientific findings are categorised in: number, extent, probability, framing, condition and suggestion [20]. Table 1 shows these six different aspects, their definition and an example sentence for each aspect. The definitions are taken from Pei and Jurgens [20], whereas the examples are from the findings of the 662 studied articles.
Certainty aspect levels, their corresponding definition and an example sentence.

MM: Multiple myeloma; OA: Osteoarthritis.
Certainty score was calculated at sentence level. For each article, an average of certainty score was calculated based on all sentences reporting the findings in the conclusion section. In this article, we only compared retracted and non-retracted articles in terms of certain probability count, certain framing and certain suggestion aspects. These certainty aspects were the top 3 aspects that appeared in the findings of 662 studied articles (see ‘Results’, certainty-level aspects section).
2.2.2. Covariates
The covariates included in regression models affect both treatment and outcome and are called confounders. In this section, we have provided details regarding data collection and reasons regarding the inclusion of these covariates in the models.
To detect the gender of first and last authors, a combination of gender application programming interface (API) (https://gender-api.com/) and manual checking was carried out. First, gender API was used to conduct a search using the first name of authors. Then, in cases of gender-neutral, unknown, initials or where the accuracy was lower than 80%, the names were checked manually using Internet searches. The scientific age of first and last authors was calculated using the geometric mean of citations. Both first and last authors were divided in quartiles based on their geometric mean of citations. In the models, they were entered as two categorical variables named first author impact and last author impact. The number or log-transformed number of publications and citations of an author has previously been defined as professional or scientific age of an author [21,22]. The reason for controlling for gender was that previous research found gender differences in the writing style of scientists and scientific discourse [23,24]. In addition, in terms of retraction, previous research found different patterns in terms of retraction between female and male scholars [25].
For topic, a categorical variable was created, which grouped articles into 20 topics. To do this, we used the classification data that were provided by Sjögårde [26]. This classification is based on 19 million PubMed publications from 1995 onwards and their citation relations. Labels in the classification have been created by extracting noun phrases from titles, author keywords, medical subject headings (MeSHs), journals and author addresses. Before performing covariate balancing and matching, there were 22 topics in both sets of retracted and non-retracted articles. However, after performing it, two topics were removed. Previous research has shown that different subjects can be differentiated by their writing styles [27]. Furthermore, some subject areas, such as chemistry [1] or cellular biology [9], have been found to have a higher rate of retraction. Regarding high-impact institute, a binary variable was created, which showed whether a top rank university existed in the affiliation list on a article (1) or not (0). In this study, by top rank we mean those universities that according to the Times Higher Education ranking are ranked as group 1 (1–200). The reason for inclusion of this variable in the model, was that previous research found universities with a higher ranking tend to have a lower rate of retraction [28]. Regarding country, a binary variable was created, which showed whether authors on a article were affiliated with a country where English is the official majority language (Australia, New Zealand, United Kingdom, Ireland, Canada and the United States) or had an affiliation outside these countries. Previous research has shown differences regarding the use of positive words between authors affiliated with these two groups of authors [18]. In addition, differences have been found between English and non-English languages, such as Bulgarian, in terms of certainty language (use of boosters and hedges) in academic texts [29].
Regarding the number of authors, according to previous research, having a large number of researchers may mitigate scientific errors and result in better reporting of studies, which may therefore avoid future retraction of articles [30]. In addition, some research works have found differences in readability and language use in single authored and co-authored articles [31].
Finally, we used Scopus to determine the open access status of articles. According to previous research, higher visibility of open access articles increases their readership and consequently the probability of detection of flaws in these publications [32].
Table 2 shows the covariates, outcome and independent variables in each regression model and in covariate balancing and matching analysis.
Outcome, independent variables and covariates for matching and covariate balancing and regression analyses.
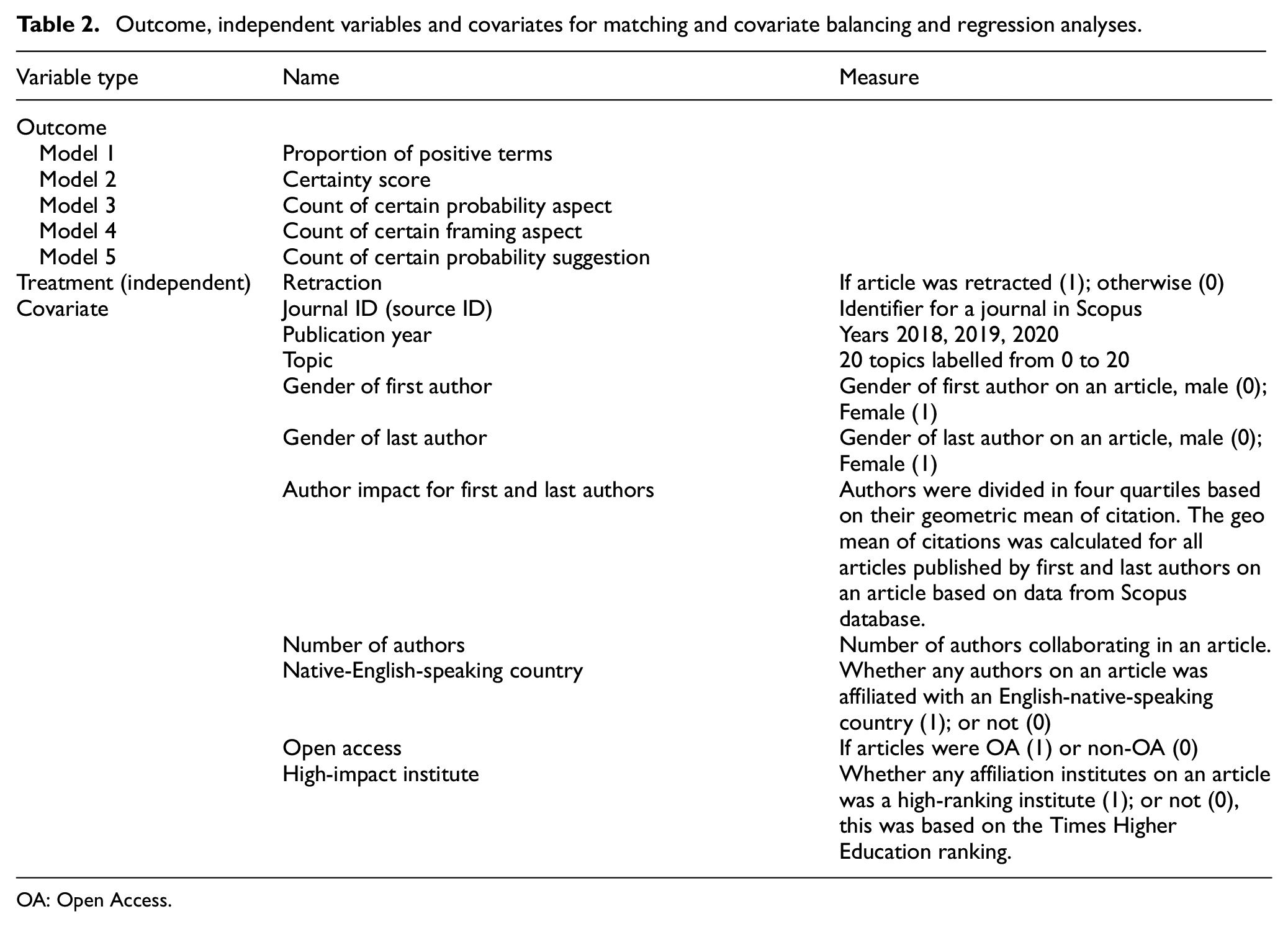
OA: Open Access.
3. Data analysis
3.1. Matching and covariate balancing
To provide a more accurate comparison between retracted and non-retracted articles in terms of language use with the current data, we combined regression analysis with propensity score matching. This approach is referred to as ‘doubly robust estimator’ [33]. This helps to isolate causal factors by removing biases associated with differences between retracted and non-retracted articles. When regression and propensity score methods are used individually to estimate a causal effect, they are unbiased only if the statistical model is correctly specified. The doubly robust estimator combines these two approaches, such that, only one of the two models needs to be correctly specified to obtain an unbiased effect estimator [33].
Using MatchIt R library, we did exact matching on three covariates of year, journal and topic. For journals, ISSN was used to do exact matching. Exact matching is a form of stratum matching that involves creating subclasses based on unique combinations of covariate values and assigning each unit into their corresponding subclass, so that, only units with identical covariate values are placed in the same subclass [34]. As an example, exact matching for a retracted article based on a journal means that a retracted article was matched to a non-retracted article, if they were both published in the same journal (using ISSN).
Exact matching on journal accounted for all level 2 variables related to a journal, such as its specialty or impact that might be correlated with the use of positive terms or certainty language. Bibliometric data have a multilevel structure. As articles are published in journals, journal is level 2 and article is level 1. Previous research has shown a positive association between the use of positive terms and being a high-impact factor clinical journal [19]. Doing exact matching on year and topic accounted for the possibility that positive presentation of research findings might vary over time or across different topics.
Covariate balancing for retracted and non-retracted was conducted on gender of first author, gender of last author, impact of first author, impact of last author, number of authors, English-native-speaking country, open access and high-impact institute. Using exact matching and covariate balancing, it was possible to gain the benefits of both exact matching and propensity score matching.
3.2. Regression models
To address the research questions of this study, five regression models were fitted. Model 1 compares retracted and non-retracted articles in terms of proportion of positive terms, whereas models 2–5 compare them in terms of certainty score and certainty aspects (certain probability, certain framing and certain suggestion).
3.2.1. Model 1: comparison of retracted and non-retracted articles in terms of proportion of positive terms used
As the dependent variable in this model is a proportion, a logistic regression with a binomial distribution was fitted. The logistic regression model is arguably the best model for proportion data when it is computed as ‘ny out of n’ with
3.2.2. Model 2: comparison of retracted and non-retracted articles in terms of certainty score
As the dependent variable in this model is a score, a linear regression was fitted. After checking the assumptions associated with linear regression models (linearity, normality of residuals, multicollinearity and heteroscedasticity), it was realised that the regression residuals suffered from heteroscedasticity (p < 0.001). According to previous research, continuous bounded outcome data that take values in a finite, typically display heteroscedasticity [37]. This is the case in our study as well, where the certainty scores take a value in the open interval of (2.68, 5.22). Beta regression has been proposed and judged suitable for modelling bounded outcome variables [38,39]. Beta distribution assumes values on the standard unit interval (0, 1), and it is flexible to model unimodal and bimodal data that are symmetric or skewed. If the variable takes on values in (a, b) (with a < b known), then the response can be transformed to the (0, 1) interval by (y−a)/(b−a), where b and a are the maximum and minimum possible scores [37,39], respectively. For details regarding model diagnostics, please see the supplementary material (Appendix 2, model 2).
3.2.3. Models 3 and 5: comparison of retracted and non-retracted articles in terms of count of certain probability aspect and certain suggestion aspect
As the dependent variables in both models are count variables, two Poisson regression models were fitted. The models fit were assessed using DHARMa package [40] in terms of dispersion, zero-inflation, outliers, collinearity and homogeneity of variances (see the supplementary material, Appendix 2, Models 3 and 5).
3.2.4. Model 4: comparison of retracted and non-retracted articles in terms certain framing aspect
As the dependent variable in this model is a count variable, a Poisson regression model was fitted. However, after checking the Poisson model using testDispersion() commands in R DHARMa package, it was realised that the model had under-dispersion. To deal with this, a quasi-Poisson model was fitted [41,42].
4. Results
4.1. Matching and covariate balancing
Figure 1 shows the absolute mean difference and Kolmogorov–Smirnov statistics for the adjusted and unadjusted case. As can be seen from the figure, the propensity scores matching weights substantially improve balance across all variables. These weights were used in the regression analyses.
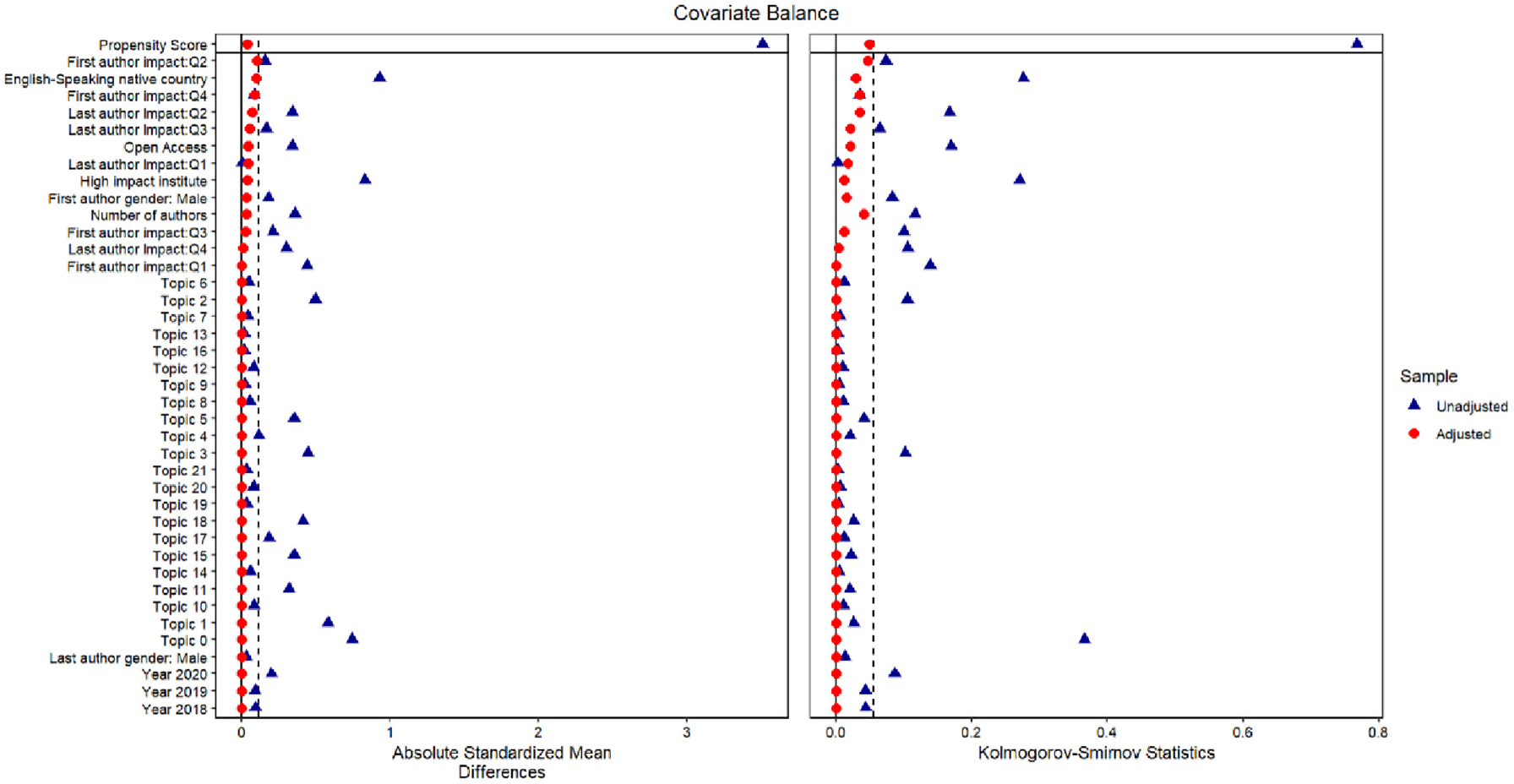
Covariate balance plot unadjusted versus adjusted mean difference and Kolmogorov–Smirnov statistic; horizontal lines mark critical values 0.1 and 0.05, respectively.
4.2. Frequency of top 5 terms in retracted and non-retracted articles
Figure 2 shows the frequency of top 5 positive terms in retracted and non-retracted articles. As can be seen from the figure, except for term ‘interesting*’ and ‘support*’, which both had very similar frequency, non-retracted articles used terms important, novel and effective more frequently in comparison with retracted articles. However, the results of two sample proportion test showed that, only terms ‘important*’ and ‘novel’ were used more significantly in non-retracted articles (p < 0.001). Among the 25 positive terms studied, the only term that had a significantly higher frequency in retracted articles was ‘remarkabl*’ (remarkable, remarkably) with frequency of 70, in comparison with 50 for non-retracted articles (p = 0.01).
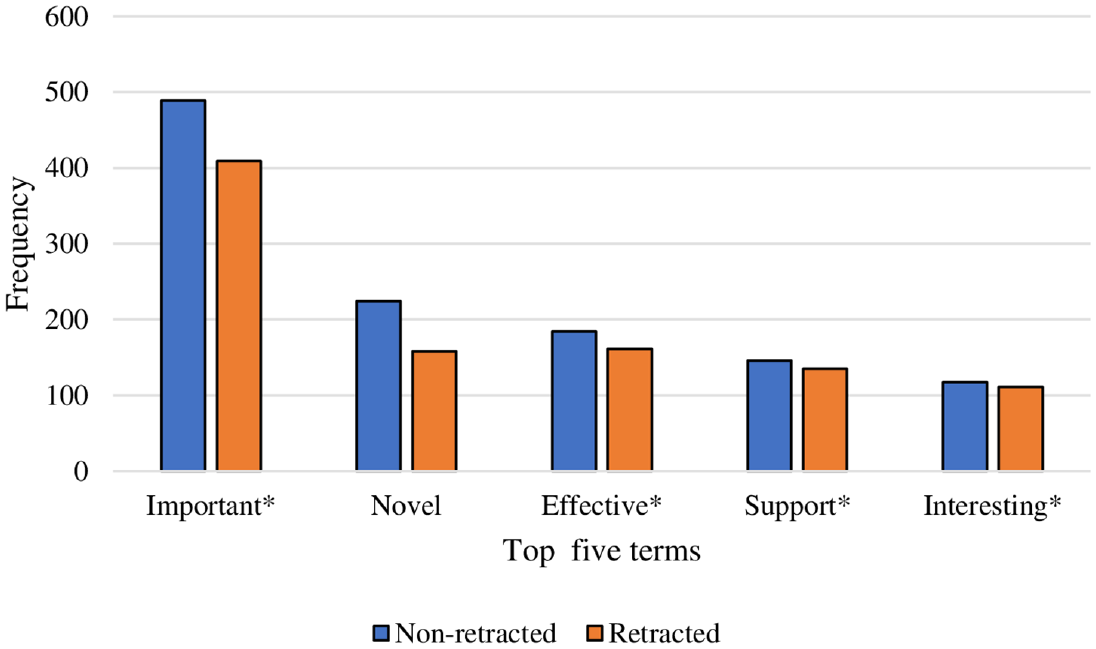
The frequency of top 5 positive terms in retracted and non-retracted articles.
4.3. Regression results
In the regression tables in this section, the results were reported only for the variable retraction. The full result of the regression analyses for all covariates can be consulted in the supplementary material, Appendix 1 (Tables S1–S5).
4.3.1. Comparison of retracted and non-retracted articles in terms of proportion of positive terms
As can be seen from the table, retracted articles were 16% less probable to use positive terms in abstracts, titles, conclusion and findings sections in comparison with non-retracted articles (Table 3).
The result of logistic regression for comparison of retracted and non-retracted articles in terms of proportion of positive terms.
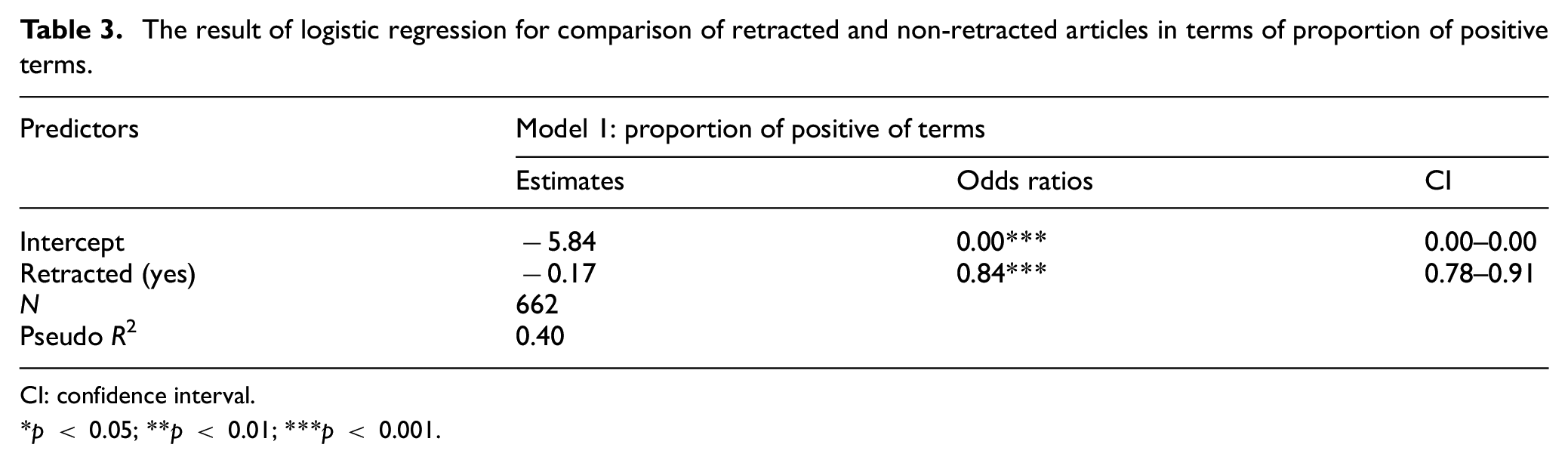
CI: confidence interval.
p < 0.05; **p < 0.01; ***p < 0.001.
4.3.2. Comparison of certainty language
Certainty score
Regarding certainty score, as can be seen from the table, the results showed that retracted articles had 15% lower odds in terms of use of certainty language, measured as certainty score, in presenting their scientific findings. As explained in the methodology section, these scientific findings were contained in the conclusion sections of the articles (Table 4).
The result of beta regression for comparison of retracted and non-retracted articles in terms of certainty score.
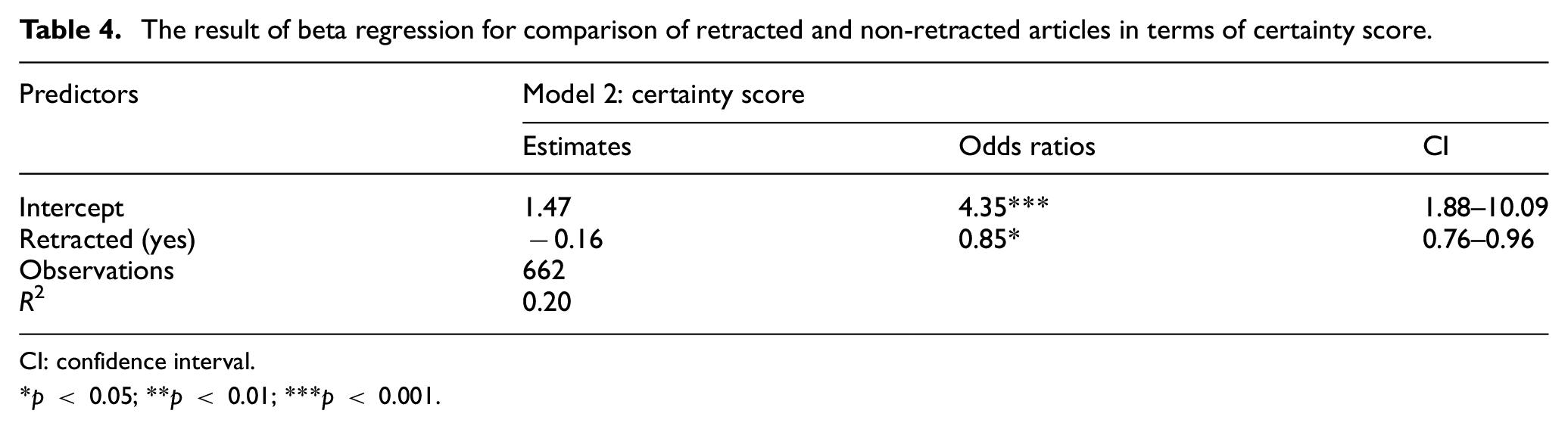
CI: confidence interval.
p < 0.05; **p < 0.01; ***p < 0.001.
4.3.2.1. Certainty aspect-levels: retracted vs non-retracted articles
Figure 3 compares retracted and non-retracted articles in terms of six certainty-level aspects. As can be seen from the figure, certain probability, certain framing and certain suggestion were the top 3 certain aspects appeared in the findings of 662 studied articles. Among these three certain aspects, except for certain probability that was used more frequently in the representation of findings of non-retracted articles, certain framing and certain suggestion were used more frequently with retracted articles. Regarding the uncertainty aspects, uncertain probability was used more frequently in the presentation of findings for retracted articles than non-retracted articles.
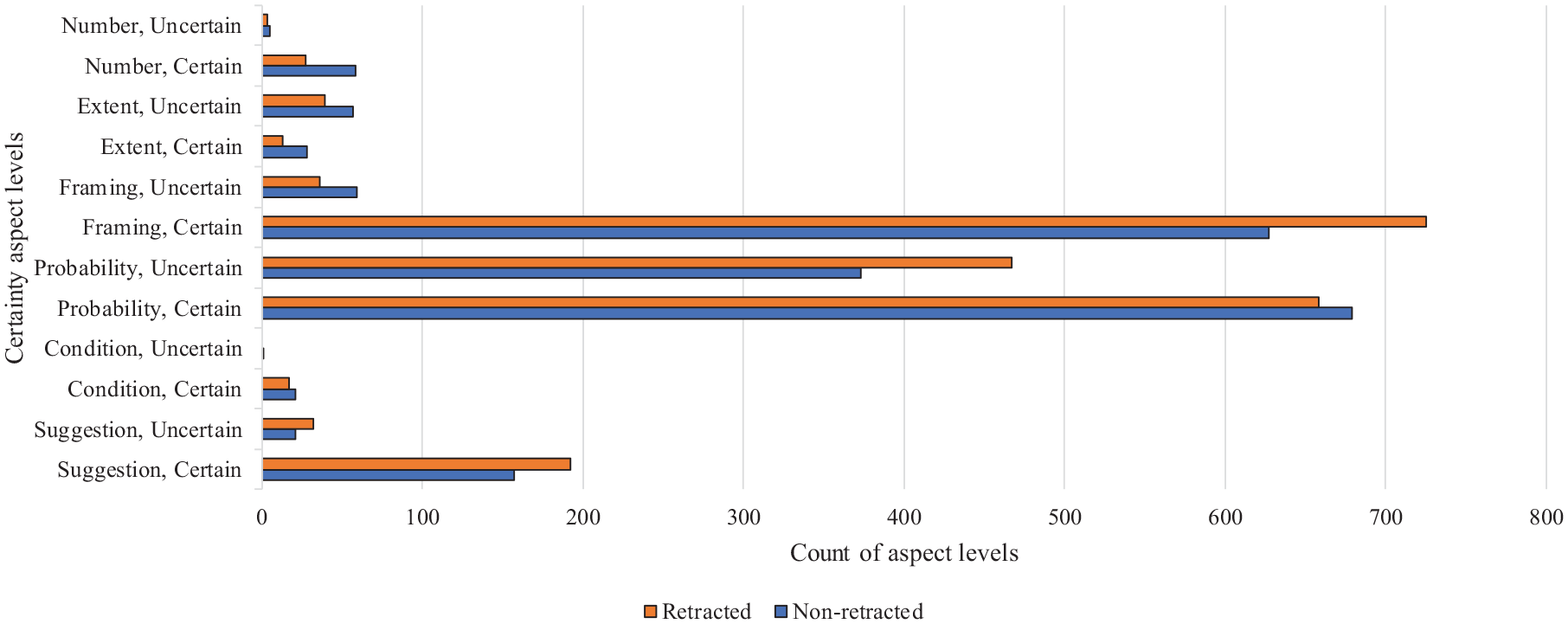
The comparison of retracted and non-retracted articles in terms of count of six certainty aspect levels.
Table 5 shows the results of Poisson regression analysis for comparison of retracted and non-retracted articles in terms of count of certain probability aspects. As can be seen from the table, being a retracted article was associated with 11% decrease in the count of certain probability aspects used to present the research findings. In other words, retracted articles had 11% less likelihood to present their research findings using certain probability aspects.
The result of Poisson regression analysis for comparison of retracted and non-retracted articles in terms of count of certain probability aspect.
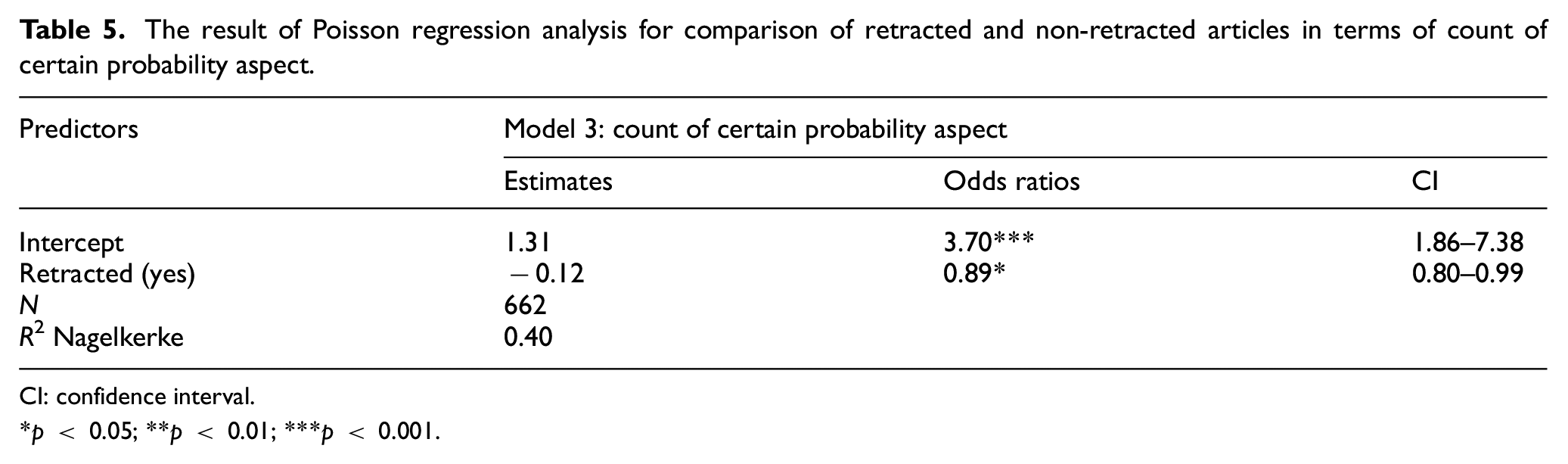
CI: confidence interval.
p < 0.05; **p < 0.01; ***p < 0.001.
Table 6 shows the results of quasi-Poisson regression analysis for comparison of retracted and non-retracted articles in terms of count of certain framing aspects. As can be seen from the table, there was no significant difference between retracted and non-retracted articles in term of use of certain framing aspect to present the research findings.
The result of quasi-Poisson regression analysis for comparison of retracted and non-retracted articles in terms of count of certain framing aspect.
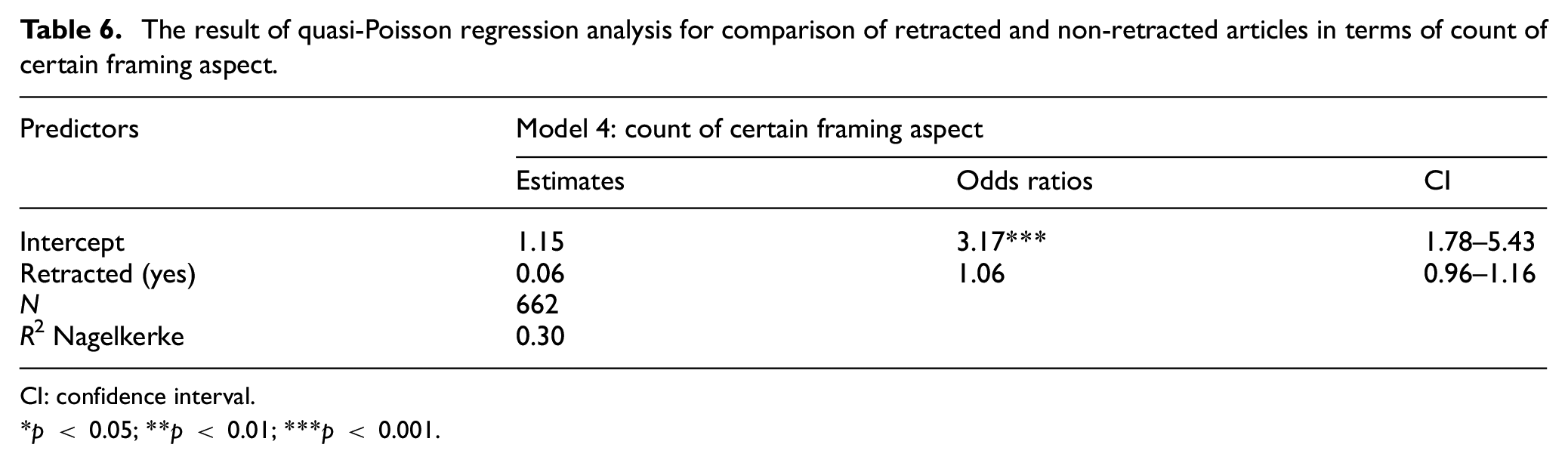
CI: confidence interval.
p < 0.05; **p < 0.01; ***p < 0.001.
Regarding count of certain suggestion aspects, as can be seen from Table 7, the results showed no significant difference between retracted and non-retracted articles in terms of count of certain suggestion aspects that were used when presenting their scientific findings.
The result of Poisson regression analysis for comparison of retracted and non-retracted articles in terms of count of certain suggestion aspect.
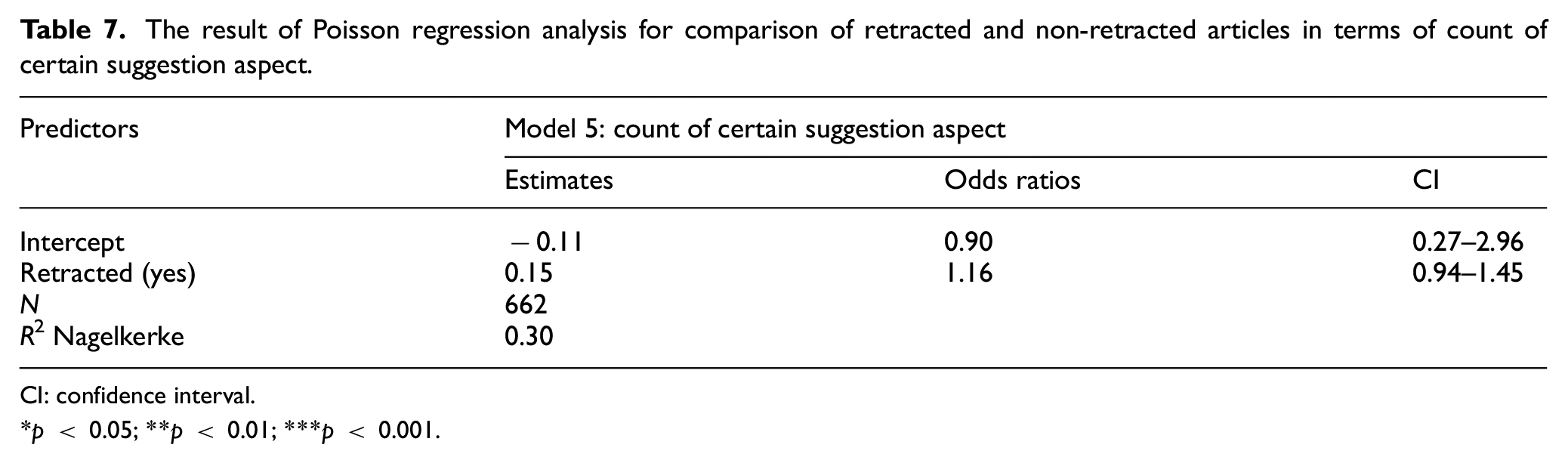
CI: confidence interval.
p < 0.05; **p < 0.01; ***p < 0.001.
5. Conclusion and discussion
The aim of this study was to compare retracted and non-retracted articles in biochemistry, in terms of proportion of positive terms, certainty score and different certainty aspects (probability, framing and suggestion). Using a combination of regression analysis and covariate balancing and matching, this study attempted to remove biases associated with differences between retracted and non-retracted articles. This technique, which was previously mentioned as a ‘doubly robust’ estimator, has been recommended in bibliometrics studies as a technique to strengthen the robustness of the results [43]. Our analyses yielded several findings that are briefly presented and discussed below.
The findings with regards to the analysis of positive terms, showed that the term ‘remarkabl*’ was the only term among the 25 studied terms, which was used more frequently in the titles, abstracts and findings presented in ‘Conclusion and discussion’ sections of retracted articles. Among the top 5 terms, ‘important*’, ‘novel’ and ‘effective*’ were more frequently used in non-retracted articles. However, only ‘important*’ and ‘novel’ were used more significantly in non-retracted articles.
The results of regression analysis regarding the proportion of positive terms showed that retracted articles had lower odds of 16% to use positive terms in abstracts and titles in comparison with non-retracted articles. This finding is in line with Markowitz and Hancock [12] study, which also found a lower rate of positive emotion terms in retracted articles. The authors of retracted articles may use fewer positive terms not to draw attention to their research, which could lead to closer investigation of their work [44].
The findings regarding the analysis of certainty language, showed that retracted articles were 15% less probable to use certain language (measured by certainty score) when presenting their scientific findings. Uncertainty is a normal and necessary characteristic of scientific work as science involves producing knowledge about what was previously unknown [45]. However, in line with previous research [12], it might be possible that authors of retracted articles used an uncertain language to make their findings less comprehensive, thereby masking their deception. Regarding the three studied certainty aspects, the findings showed that except for certain probability, which was used more frequently in the presentation of findings by non-retracted articles, certain framing and certain suggestion were used more frequently with retracted articles. The results of further analysis by regression models showed that retracted articles had 11% less likelihood to present their research findings using certain probability aspect. The reason for this could be that authors of retracted articles might lack knowledge, data, methods or consciousness of aspects of a problem and, therefore, cannot be certain and precise in presenting and interpreting their findings. In their study, Funtowicz and Ravetz [46] referred to this type of scientific uncertainty as a ‘border with ignorance’, which cannot be sufficiently quantified and expressed with statistical measures. Our findings are in line with the work of Mehta and Guzmán [47], who in a slightly different context found that news outlets used probabilistic language, such as ‘may’, ‘likely’ and ‘possible’, in an uncertain way to add nuance to statistical discussions thereby making damaging claims more authentic.
Overall, the findings from our research suggest that linguistic characteristics can serve as a tool for distinguishing between retracted and non-retracted articles. They can also assist us in better understanding of how scientific misconduct in scientific articles can affect communication and presentation of scientific findings. These findings also provide insight and guide policy for journal editors and authors within biochemistry discipline. In addition, better understanding of linguistic features of retracted and non-retracted could be helpful for classification of retracted articles (due to misconduct) and non-retracted articles using machine learning algorithms. Finally, the current research has some limitations. The findings obtained from this study are only limited to the field of biochemistry and certain time span and thus are not generalisable to other disciplines. However, it would be interesting to do a follow-up study in the future and compared those results with the ones obtained in this study. In addition, in this study we only studied certainty aspects of language and use of positive terms, other linguistic characteristics of retracted and non-retracted articles could also be studied in the future research.
Supplemental Material
sj-docx-1-jis-10.1177_01655515231176650 – Supplemental material for Use of positive terms and certainty language in retracted and non-retracted articles: The case of biochemistry
Supplemental material, sj-docx-1-jis-10.1177_01655515231176650 for Use of positive terms and certainty language in retracted and non-retracted articles: The case of biochemistry by Tahereh Dehdarirad and Marco Schirone in Journal of Information Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.