
Abstract
Social media has become a platform for information diffusion, voicing concerns of existing inequalities and raising public awareness of various social and societal issues. Despite the social good, social media has become a fertile ground for spreading misinformation, hate speech and conspiracy theories. The death of George Floyd in May 2020 triggered a series of protests worldwide in support of the Black Lives Matter (BLM) movement and triggered a debate about equity, inclusion and social justice. The purpose of this study is to examine the impact of misinformation and social noise on the original intended message of BLM using data from the Twitter hashtag ‘BLM’. Results from topic modelling have shown the strong presence of misinformation and social noise. Such information was most probably intended to influence, mislead and dilute the original intended message. However, despite the effort to distort the original message of BLM, results from sentiment analysis show that users’ opinions of the BLM movement remained positive.
Keywords
1. Introduction
Advances in information science technologies, such as mobile devices, learning technologies, publishing tools, communication and socialisation hubs, live streaming and interactive multimedia, have made it possible for people to access a wealth of information and knowledge that never existed before. While this is considered a blessing for some, for most people, it is a double-edged sword that cuts both ways. The rise of misinformation, hate speech, conspiracy theories, cyberbullying, fake news and the increased use of unethical artificial intelligence are some of the challenges that we must deal with [1]. The recent events surrounding the US elections, Black Lives Matter issues and COVID-19 have highlighted the danger of misinformation and the importance to democratic institutions, science and society [2,3]. Undermining faith in science and democratic institutions has a long-term effect on human development and progress.
When inaccurate information is spread either intentionally or unintentionally, it is referred to as misinformation [4]. The difficult part is dealing with misinformation when those who are participating in its diffusion are not aware of its existence. The influence of a user’s personal and relational characteristics on information received through social media that might confuse, distort or even modify the original message is referred to as social noise [5]. A study of social noise in misinformation cases is needed, emphasising how it affects disseminating false and harmful information. BLM stands for ‘Black Lives Matter’ and is a decentralised political and social movement that protests against police brutality and racially motivated violence against black citizens. After George Zimmerman’s acquittal in the shooting leading to the death of African American teen Trayvon Martin, the campaign started with the hashtags ‘#BlackLivesMatter’, ‘#BLM’ and so on, on social media in July 2013 [6]. During the George Floyd demonstrations in 2020, the campaign resurfaced in the national spotlight and drew even more international attention.
While certain percentages of the people participating in social media discussions can be considered advocates of social justice causes, many others are engaged in misinformation activities and social noise. The openness of social media platforms allows external parties to infiltrate the conversation and exploit social noise to influence opinion and distort the original message for political or ideological reasons. The external influence on the American elections in 2016 and 2020 is a good example of the role external players can have on social media users. This study examines how misinformation and conspiracy theories in the form of social noise impact the original intended message. We hypothesised that the existence of social noise dilutes, alters and distorts the original intended message. Expanding our understanding of social noise in the way it is generated, manipulated and spread could help identify and minimise the impact of intended and harmful misinformation generated by outside players. The study also examines the effects of misinformation and social noise on social issues, such as equity, inclusion and social justice.
In this article, data related to the BLM movement are collected from Twitter, and sentiment analysis is performed to understand the sentiments of social media users towards the BLM movement. Latent Dirichlet Allocation (LDA) and a biterm model are built and executed, and the keywords related to social noise, misinformation, equity, inclusion and many others are identified and extracted. Additionally, the associations among the words are explored in this study.
2. Literature review
The first realisation of the power of social media as a platform for protest and social justice started in 2010 with the Arab Spring and the uprising in Tunisia. People discovered that they have a bigger circle of influence, and their ideas, messages and posts have a ripple effect on others [7–9]. During the uprising, people used social media to organise protests, create awareness, share stories and, most importantly, document violence and violate people’s right to exercise freedom of speech and civic engagement. The role of social media in equity and inclusion that was demonstrated led the US supreme court to decide to legalise marriage between same-sex couples in 2015 [10]. The Human Rights Campaign (HRC) work around the #LoveWins was an effective way of using social media with more than 7 million tweets and 1.4 million photos on Instagram [11]. The Me-Too movement (or #MeToo movement) originated in 2006 has been elevated and has gained momentum in 2017 when famous actresses and high profile female musicians decided to share their experience with sexual harassment using the hashtag #MeToo [12]. This led to more awareness about sexual harassment issues and the conviction of several well-known figures in the Hollywood and the movies industry.
BLM started in 2013 with the use of hashtags, such as #BlackLivesMatter, #BLM and others, following the murder of Trayvon Martin. It aimed at protesting and combating anti-black racism and police brutality towards African Americans [6]. The movement and the hashtags got magnified after the murder of George Floyd when protests and demonstrations spread around the world calling for equity and social justice. The BLM movement, born in 2013, was indirectly created out of decades of frustration within the African American community over the legal system’s continual exoneration of those who had taken black lives [13]. Ince et al. [14] studied the social media presence in BLM. In their article, the authors analysed different hashtags related to BLM and found that the ‘hashtags mention solidarity or approval of the movement, refer to police violence, mention movement tactics, mention Ferguson or express counter-movement sentiments’. Francis [15], in his paper, mentions that the global rallying cry in the BLM protests alerts us to the urgency for transformative change in all spheres. As Brock [16] mentioned in his paper ‘twitter’s combination of brevity, multi-platform access and feedback mechanisms has enabled it to gain mindshare far out of proportion to its actual user base, including an extraordinary number of black users’.
Recent events in the United States and around the world have highlighted the danger of spreading misinformation and fake news on the Internet and social media [17]. The seriousness of the problem has prompted calls from politicians and legislators for technology companies to identify and stop the spread of misinformation. Efforts are being made by social media companies to counter the effect of misinformation by trying to introduce a combination of technical and non-technical measures. For example, Google and Facebook introduced a community-driven approach that allows users to flag false content to correct the newsfeed [18]. However, the effectiveness of such measures will depend largely on the ability to distinguish disinformation and misinformation created with the intent to harm from noise created and proliferated by users for different reasons. Misinformation in the form of social noise could occur for several reasons, including the selective and partial representation of the original information without the intent to harm [5,19]. Social media users tend to operate in groups that could foster confirmation bias, segregation and polarisation. This can also lead to the proliferation of biased narratives and unsubstantiated rumours, mistrust and paranoia that impact the quality of the information [20]. Not everyone in the group is aware of the impact of their action or the extent by which their participation is contributing to the problem of misinformation and social noise.
Social noise occurs when people interact differently with information on social media than if they encountered it privately due to the awareness of being observed by peers, colleagues, family and other members of their social network. Under the influence of social noise, a user may tamper their communication based on external cues from their social network regarding what behaviour is acceptable or desirable, consciously or unconsciously attempting to present themselves more desirably and increase their social capital within the network [19,21]. For example, if a well-respected friend posts a news article supporting a social issue that is generally in line with the users’ belief system, the user might indicate support by ‘liking’ the post without fully understanding the issues being discussed. Similarly, in an effort to maintain important relationships and avoid controversy, social media users might not indicate their true opinion in opposition to the issue, and instead, they pretend they agree on the issues [22–24]. Social noise can influence users’ behaviour and push them to participate in conversations without knowing or understanding the issues at stake.
While misinformation in the form of doctrine, denial of the truth, manipulation of historical information and propaganda is considered a problem that needs to be dealt with, social media’s role in the spread of misinformation is evident [25–27]. Recent remarks by President Joe Biden regarding ‘misinformation killing people’ referring to misinformation regarding the COVID-19 vaccine indicate the seriousness of the problem and the need for social media companies to take steps to control misinformation on their platforms [28]. Unfortunately, this is a complex problem given the openness of social media platforms and the challenges in identifying misinformation from social noise. To deal with the problem of misinformation, there is a need to understand why ordinary people might participate in the spread of misinformation. A study by the MIT lab found that false and manipulated information spread 70% faster on social media than authentic information [29]. Most people forward social media messages and retweet misinformation as a social event without realising that the information being sent might be manipulated or fake. People engaged in social noise as part of image curation, relationship management, conflict engagement or cultural agency are less probably to question the accuracy or the validity of the information they are dealing with [19].
Zimmerman [19] introduced the concept of social noise in an attempt to understand user information behaviour in social media and the type of content posted under certain circumstances that constitute social noise. She defines social noise as being made up of four constructs that could help in explaining the spread of misinformation. The four constructs are image curation, relationship management, conflict engagement and cultural agency. Image curation is defined as an attempt by social media users to knowingly or unknowingly craft their online identity and create a personal exhibition that satisfies them [30]. Relationship management refers to a user’s desire to build a community with individuals or groups with profound importance or high social value to them. This can be driven by a desire to be included as a member of a particular group (whether formal or informal) or to connect with and maintain good relationships with other people [21]. There are various reasons why people might participate in certain discussions on social media or retweet certain messages or content without understanding the broader implication of their actions. The social noise categories identified by Zimmerman are described in Table 1.
Social noise constructs identified by Zimmerman.

3. Methodology
To perform content analysis on data extracted from social media in an unstructured format, we use two methods of data analysis: sentiment analysis and topic modelling. Sentiment analysis is a popular text analysis technique that detects polarity (e.g. a positive, neutral or negative opinion) within the text, a whole document, paragraph, sentence or clause. Sometimes, it is combined with the content analysis for topic discovery and opinion mining [31]. Emotion detection is another type of sentiment analysis aimed at detecting emotions, such as happiness, sadness, anger and so on [32]. Sentiment analysis can also indicate whether the response is fact-based and the degree to which the opinion reflects the respondent’s personal opinion. Routray et al. [33] reviewed different aspects of sentiment analysis for text documents and highlighted four different research challenges: subjectivity classification, word sentiment classification, document sentiment classification and opinion extraction.
Topic modelling is one of the methods used to discover topics across various text documents. These topics are abstract in nature, that is, words related to each other form a topic. There can be multiple topics in an individual document. Topic modelling helps explore large amounts of text data, find clusters of words, the similarity between documents and discover abstract topics [34]. LDA is a topic modelling method used to identify the topics and topic keywords in a document. The basic concept is that documents are interpreted as random mixtures of latent topics, each of which is described by a word distribution [35]. Biterm is another topic modelling technique, wherein the biterm model will learn about the topics based on word co-occurrences patterns. It is a word co-occurrence-based topic model that learns topics by modelling patterns of word-to-word co-occurrences [36].
For this study, the data related to the BLM movement was collected from Twitter. Although the BLM movement has been in existence since 2013, it was the death of George Floyd on 25 May 2020 that ignited a global protest and gave momentum for the BLM discussion. Since George Floyd’s death, BLM has become one of the most discussed topics on social media platforms, such as Twitter and Facebook. For this study, the hashtag ‘BLM’ was used to collect data from 25 May 2020 to 10 June 2020. The time frame was chosen because the hashtag was trending during that time, following George Floyd’s death and the renewed interest in inequality and social justice.
The google cloud compute engine was used to build a virtual machine instance, which was then configured with a python environment. This python environment was used to run the python code that extracted the data from Twitter using Twitter APIs. A total of 104,546 records were extracted for the hashtag ‘BLM’. The data extracted included tweet content (referred to as tweets), tweet id, user id, language, tweet source, created date, retweet count, reply count, like count and quote count. Despite the fact that multiple data points about tweets were collected, this study only looked at the tweet content and the tweet creation date. The rest of the data will be used in future studies. The extracted data were imported into a local machine, and the analysis was performed. At first, Tableau Software was used to build visualisations for the data.
Figure 1 depicts the frequency of tweets related to BLM from 25 May to 10 June. Although George Floyd passed away on 25 May 2020, from the above graph, it is evident that the tweets related to BLM began to acquire traction slowly after his death. There was a peak on 31 May, which was the day when George Floyd’s second autopsy was performed. The number of tweets tweeted on 3 June grew once more because the charge against the officers responsible for George Floyd’s death was upgraded on that day. In addition, more tweets were tweeted on 8 June because George Floyd’s body was on display in his hometown for the public. It is evident from Figure 1 that anytime there was news about George Floyd’s death, users tweeted about BLM, linking George Floyd’s tragedy to the BLM movement.
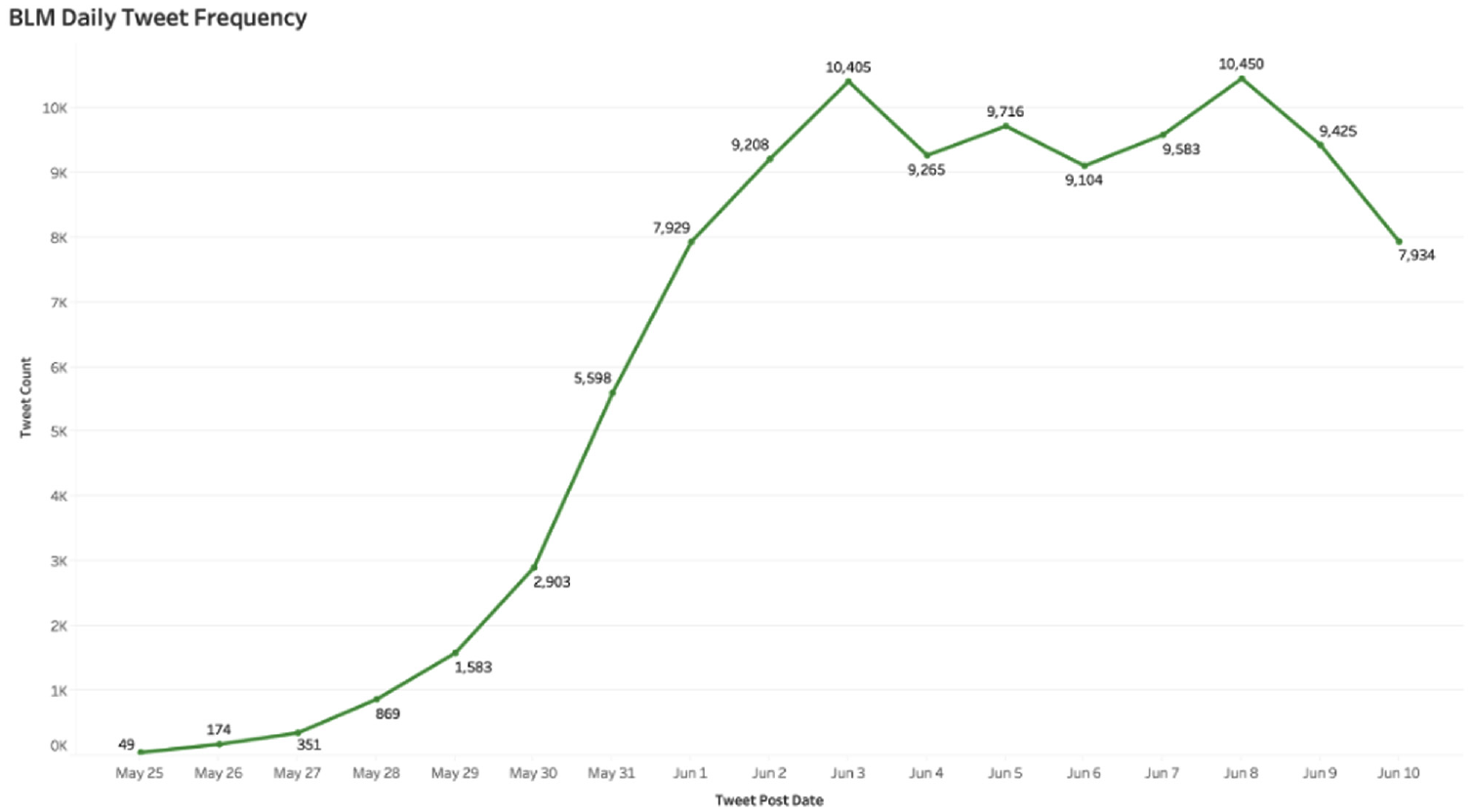
BLM daily tweet frequency chart.
Figure 2 represents the number of tweets tweeted between 25 May and 10 June on an hourly basis. Majority of the tweets were tweeted between 3 p.m. and 12 a.m., as shown in Figure 2.
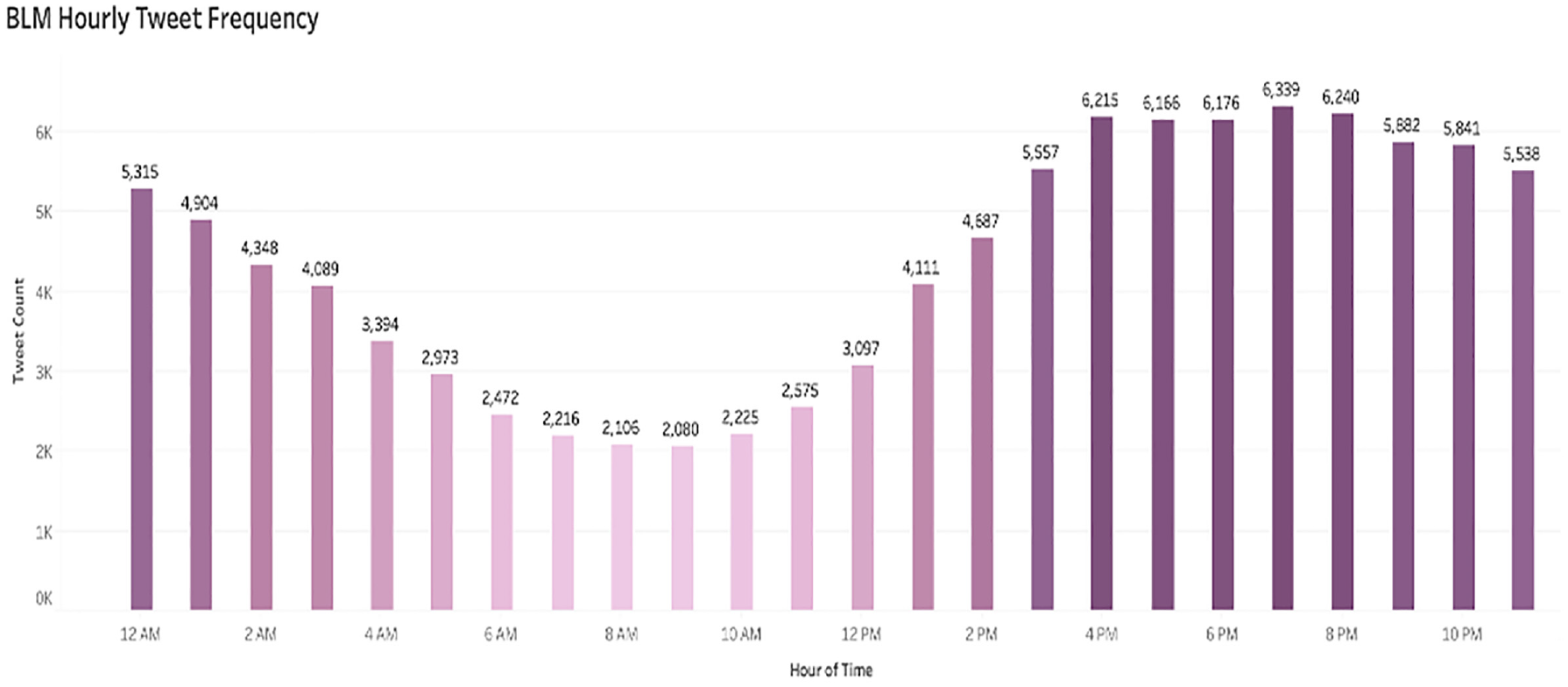
BLM hourly tweet frequency.
After creating the visualisations in Tableau, the data was cleaned by loading the data file into a python data frame and removing all the unnecessary text and symbols from the tweet content column. Exploratory data analysis was performed to analyse the dataset and summarise their main characteristics using visual methods. Furthermore, sentiment analysis was performed to identify the user’s sentiment towards the tweet. Sentiment analysis will reveal whether the social media user has a positive, negative or neutral feeling towards the tweet and whether the tweet is fact-based or influenced by the writer’s personal opinion. To perform sentiment analysis, the textblob python library was used. Textblob library is used to analyse textual data and provides an API that can be used to perform sentiment analysis. Textblob is a more reliable method because of its extensive sentiment analysis capabilities. Textblob was chosen for reasons, such as accessibility, lightweight, ease of use and a less oppressive learning curve [37]. Moreover, the Textblob library produces two outputs: subjectivity and polarity, both appropriate for this study.
Furthermore, data was preprocessed using techniques, such as tokenisation, lemmatisation, n-grams implementation and speech of tag selection.
Tokenisation refers to the process of splitting the sentences into words while lowercasing the terms, removing punctuation, ignoring tokens that are too short and dismissing letter accents.
Lemmatisation includes removing inflectional endings and returning the base or dictionary form of a word, known as the lemma. For example, terms, such as ‘used’, ‘using’, and ‘uses’, are all converted to a base word called ‘use’.
N-grams implementation is extracting sequences of ‘n’ words that frequently occur in the corpus. Bigrams and trigrams were created for this study, representing two words and three words in series, respectively.
Speech of tag selection is the process where part of the speech tag is assigned for each token. For this study, only those words, which have part of the speech tag as nouns, adjectives, verbs and adverbs, were kept for further analysis.
For topic modelling, the Gensim python library and Mallet toolkit were used to build the LDA model and extract the topics. Gensim is a python library used for topic modelling, document indexing and similarity retrieval with large text collections. Mallet toolkit is a java-based package based on machine learning for statistical natural language processing, document classification, topic modelling and other machine learning applications. The LDA model was run on the tweet data, and a total of 500 topics were extracted from 104,546 tweets. Each topic had 20 keywords related to the topic. The keywords were analysed to identify the presence of misinformation and social noise. The selected keywords were then assigned to different social noise constructs.
Another topic modelling technique, which is the biterm topic modelling (BTM), was also performed for richer results. The Biterm library was used to build a biterm model. To handle the problem of sparse word co-occurrence at the document level, the library explicitly models word co-occurrence patterns across the whole corpus [38]. The biterm model was run on 104,546 tweet data, and topics were extracted and analysed. The selected keywords were then combined with LDA keywords and assigned to different social noise constructs.
Furthermore, bigrams were built and analysed, and interesting word associations were discovered from the tweet data. Figure 3 illustrates the research workflow chart and processes used to complete this research work. The highlighted boxes represent the stages that led to the production of the results.
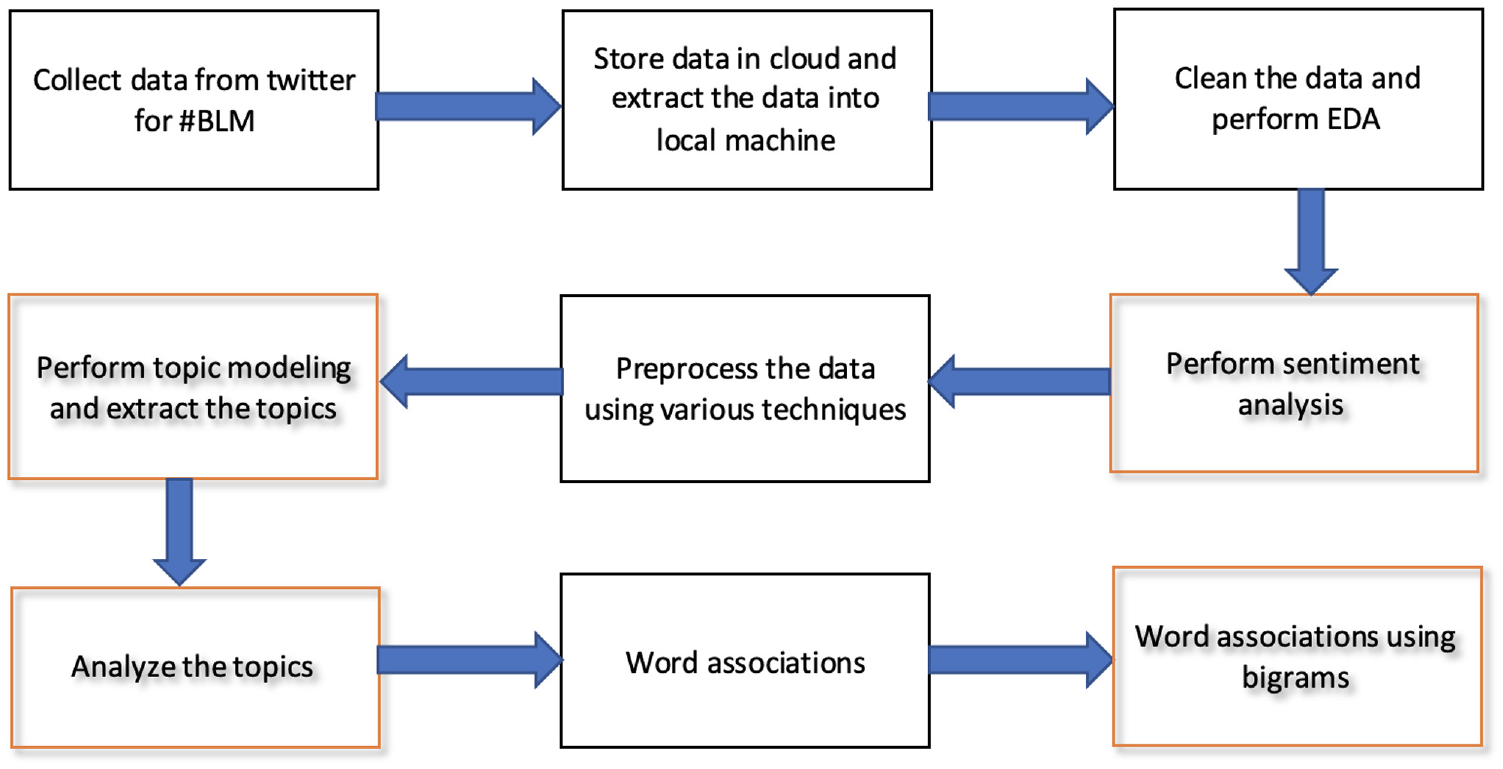
Research flow diagram.
4. Results
4.1. Contextual analysis of tweets
Sentiment analysis was carried out on 104,546 tweets. For each tweet, the subjectivity and polarity scores were calculated. A text can have a subjectivity score between 0 and 1. A text with a subjectivity score of 0 is categorised as objective or based on facts. A text with a subjectivity score of 1 is classified as subjective or based on personal opinion or motivated by emotion. The sentiment analysis of the tweets resulted in 76.12% (79,580 tweets) of the tweets being subjective, while 23.88% (24,966 tweets) being objective or focused on facts. This shows that most of the tweets were based on the personal opinion of the Twitter user. Figure 4 represents the sentiment analysis subjectivity results.
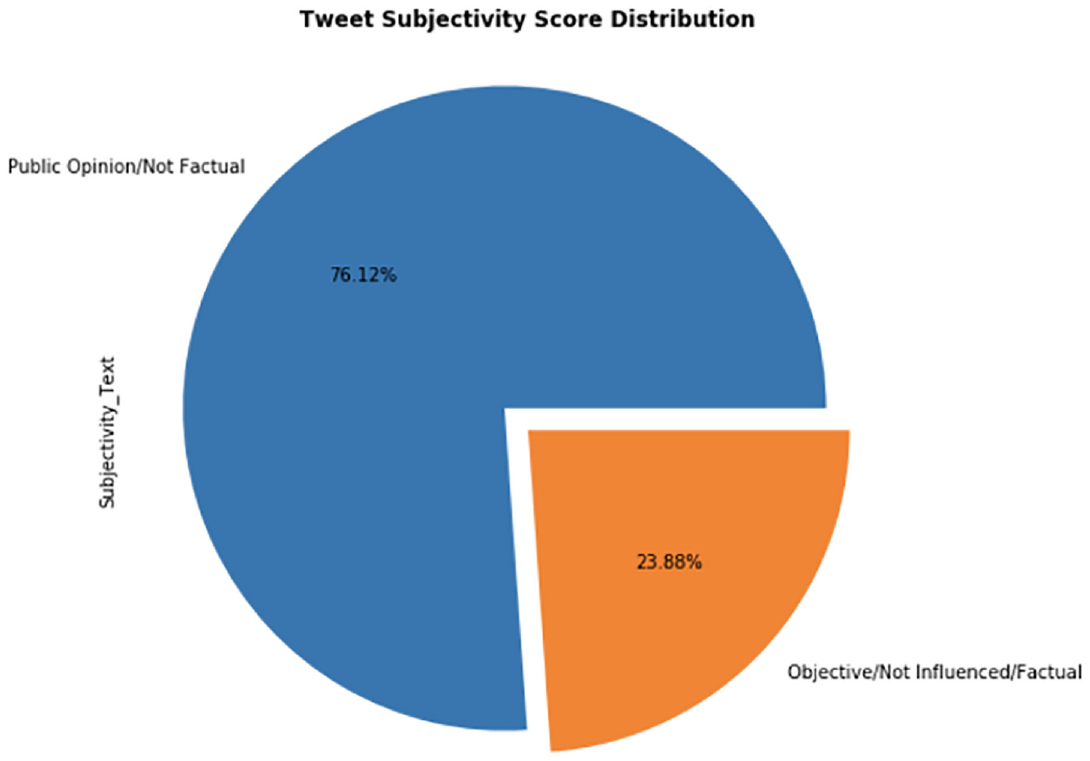
Sentiment analysis subjectivity score chart.
Using sentiment analysis on the data, the polarity score of the data was also calculated. The polarity score helps to determine the sentiment of the tweet, such as positive or negative, or neutral. For a tweet, the polarity score ranges from −1 to 1. A negative sentiment has a polarity score of −1, whereas a neutral sentiment has a polarity score of 0 and a positive sentiment has a polarity score of 1. Sentiment analysis on 104,546 tweets resulted in 42.16% (44,076 tweets) having positive sentiment, 29.60% (30,946 tweets) having neutral sentiment and 28.24% (29,524 tweets) having negative sentiment. Based on the polarity scores, it can be concluded that most of the tweets in this dataset had positive sentiment towards the BLM movement. Figure 5 represents the polarity score results.
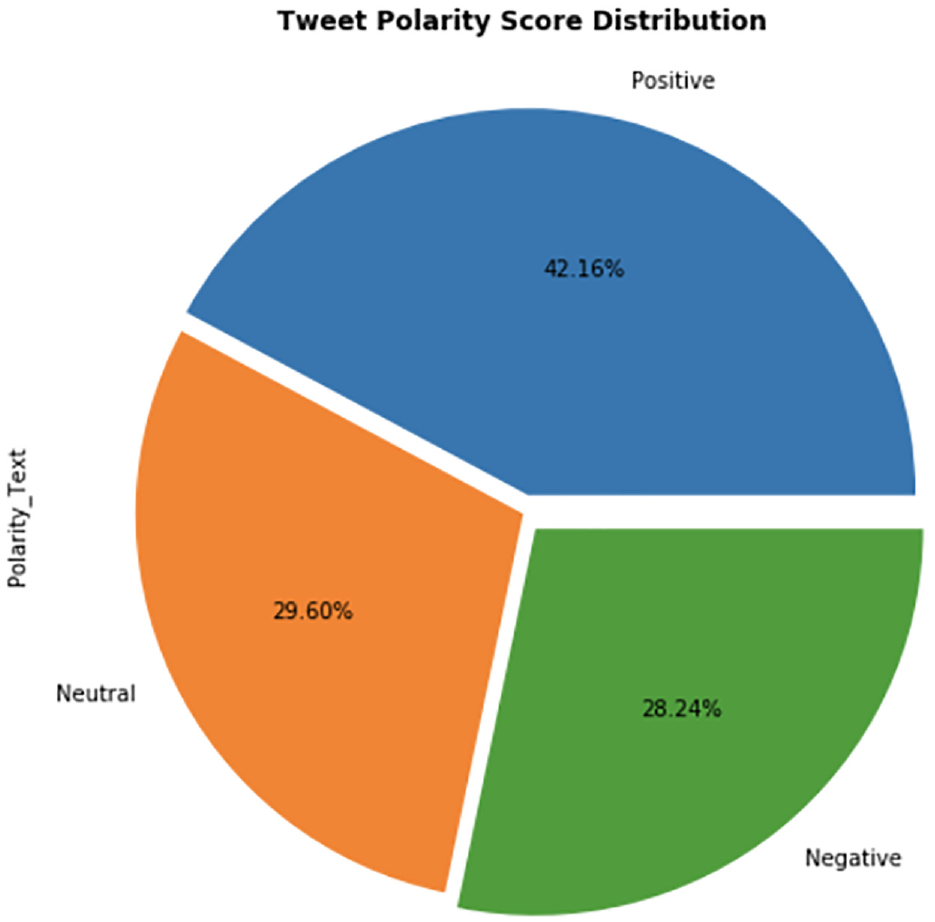
Sentiment analysis polarity score chart.
While Figure 4 shows that most of the tweets posted are based on the personal opinion of the Twitter user, Figure 5 shows that most of the tweets were positive in nature. Figure 6 depicts the positive, negative and neutral tweet rates over the data collection period. The chart shows that the number of positive tweets about BLM has always been more significant than negative and neutral tweets throughout the data collection period. At the beginning of the data collection period, the number of negative tweets about BLM was greater than the number of neutral tweets. However, between 3 June and 6 June, the number of negative tweets fell below the number of neutral tweets but subsequently increased during the remainder of the data collection period.
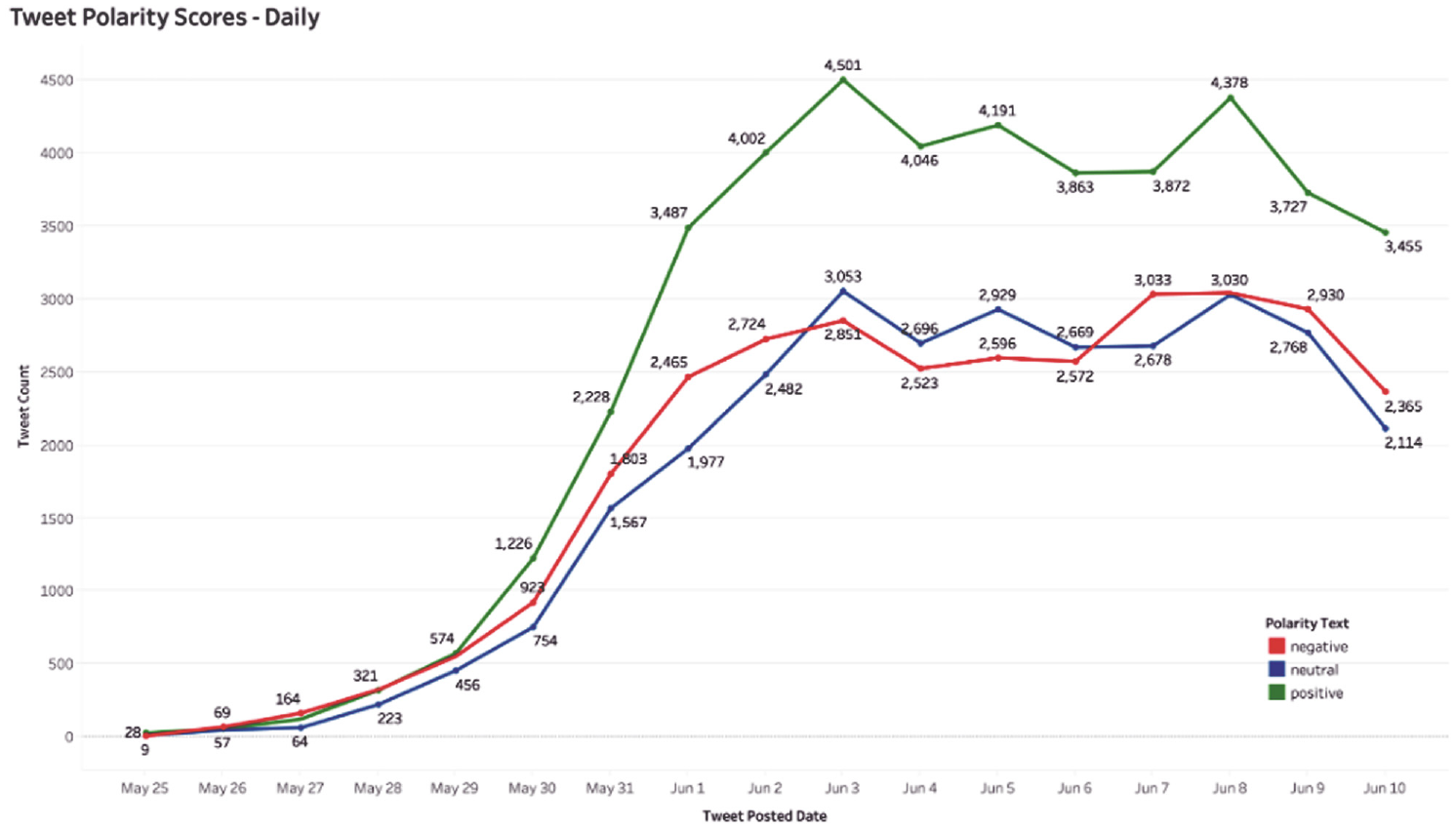
BLM tweet polarity score chart on a daily basis.
4.2. LDA topic modelling
LDA is a generative statistical model that uses an unsupervised machine learning technique. It is used to identify topics or clusters of keywords. LDA first assumes there are a ‘k’ number of topics across the documents. Documents, in this case, refer to the extracted tweets containing the BLM hashtag. LDA assigns keywords to different topics by first determining the number of keywords in the document/tweet and then estimating the probability of a given keyword assigned to a specific topic. This process is repeated until all the keywords are assigned to their respective topic. An LDA model was developed for this study and was used to analyse 104,546 tweets extracted containing the BLM hashtag from 25 May 2020 to 10 June 2020. The LDA model identified a total of 500 topics. The reason for choosing 500 topics is because the dataset is large. Another rationale for selecting 500 topics is that the LDA model’s coherence score for 500 topics is around 0.6, indicating that the topics are of good quality. Each topic consisted of 20 keywords associated with the topic. The topic and its keywords were then analysed further to determine the dominant keyword or construct representing a specific area of interest. Some of the areas identified include equity, inclusion, justice, racism, riots, violence and so on. Figure 7 shows dominant keywords that characterised the discussion on the BLM hashtag.
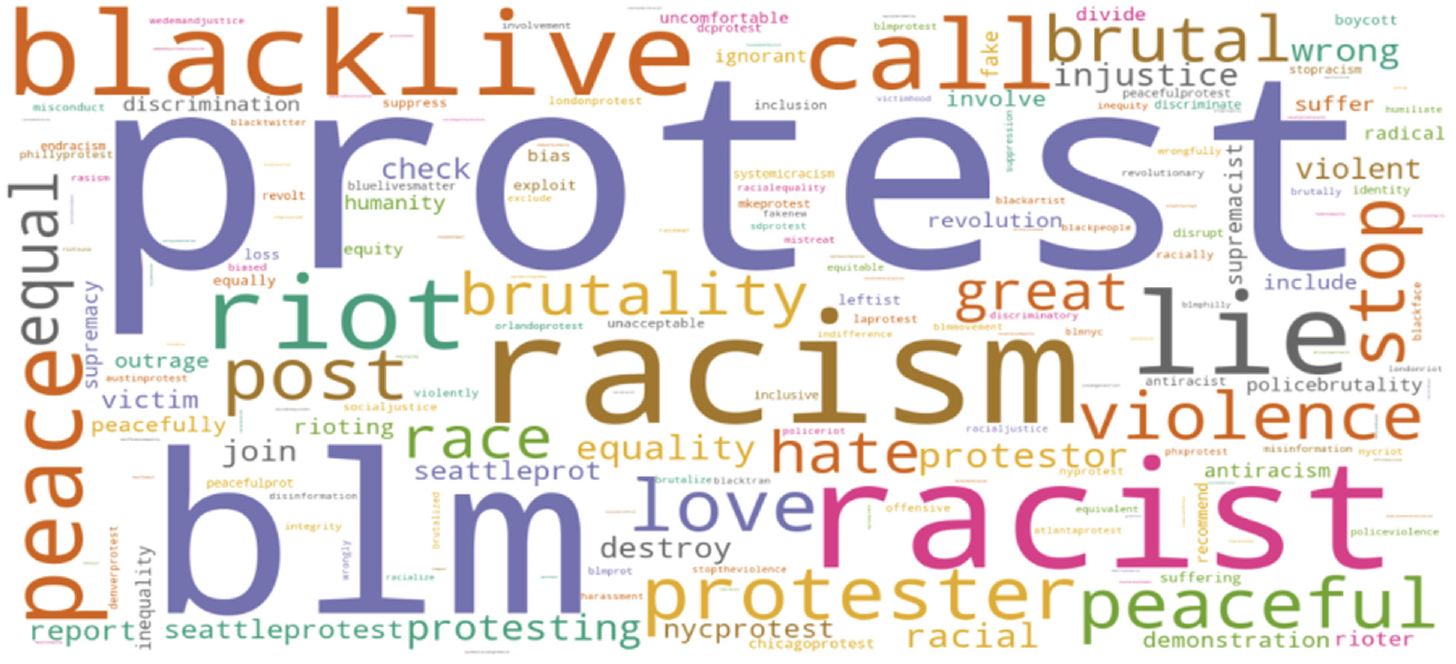
Word Cloud showing dominant keywords.
4.3. Biterm topic modelling
BTM is a form of topic modelling technique that is used to locate topics in collections of short texts. The wordco-occurrence is used by the biterm topic model to identify the topics. A BTM used word occurrences to identify topics by modelling word-to-word co-occurrences patterns commonly referred to as biterms [36]. From these patterns, it learns how to model a topic and its keywords. LDA and biterm vary in the approach and capabilities. While LDA employs word-to-document co-occurrences, biterm uses word-to-word co-occurrences. Both LDA and biterm are used to identify topics and its associated keywords that represent a specific area of interest or a category. Some of the areas identified reflect or create a positive image of ‘BLM’ as a social justice movement which is listed in Table 2.
Categories that create a positive image about BLM.

The existence of certain keywords or categories as listed in Table 3 reflects negatively and creates a negative image of BLM as a violent movement.
Categories that create a negative image about BLM.
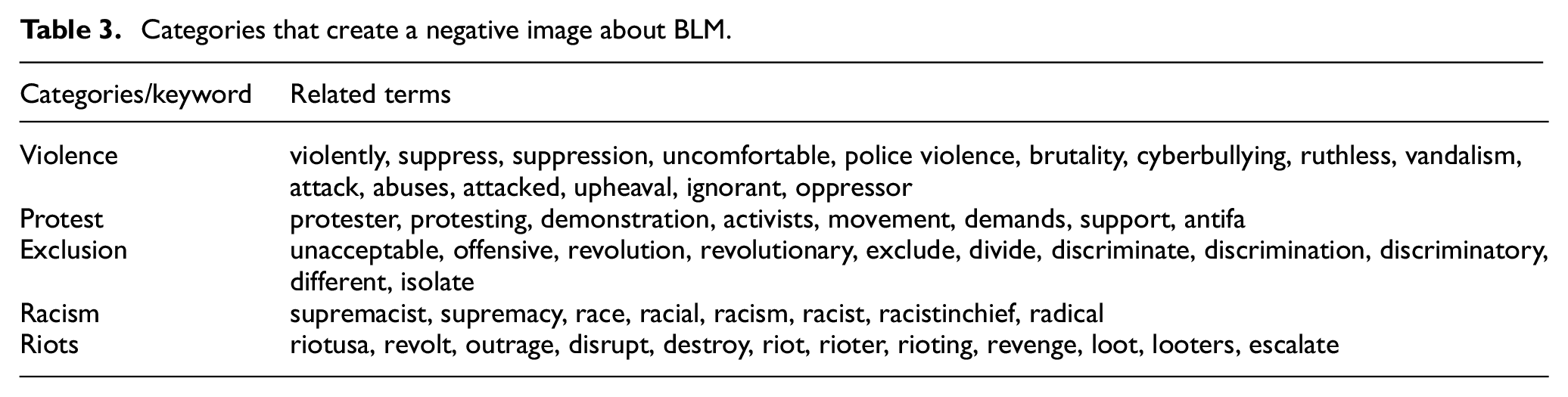
Figure 8 shows the number of tweets corresponding to each of these categories or areas. The study results show that people who were tweeting about #BLM refer to being treated unequally or differently and are asking for equity, peace and justice. However, strong terms, such as violence, riots and protest, could be linked to misinformation and social noise. While certain tweets could indicate people opposing the discussion and their role might be to spread misinformation and cause trouble. A large number of other participants going along might have other motives for being there, which can amount to social noise.
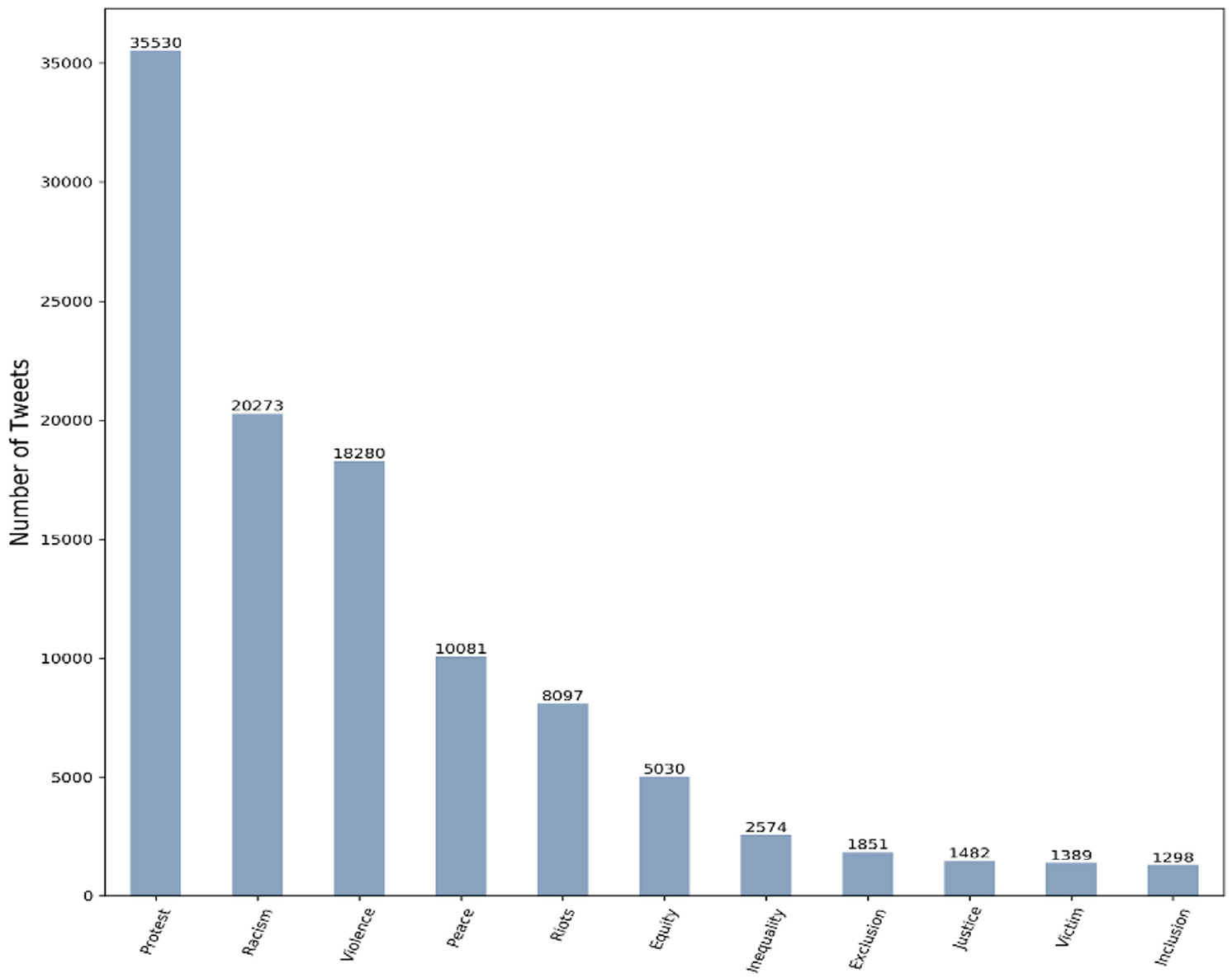
The number of tweets related to each of the categories.
4.4. Word associations
Word associations aid comprehension of the words that are linked together. Figure 9 is an example of the type of network diagram created to better understand the relationships between the dominant keywords in the BLM data. From Figure 9, it can be inferred that the word ‘blm’ is the centre of all the tweet data and this is because the data used in this research are about BLM movement. Also, the keyword ‘black’ forms the other centre of the network graph meaning the hashtag BLM was mainly used in reference to black people. It is interesting to know that the ‘black’ keyword is directly connected to the other keywords, such as justice, white, racism, violence, police and support. From Figure 9 network graph, we can see that the term police and the term white seem to be more associated with negative terms, such as racist, supremacy and brutality. Figure 9 is an interactive graph built using the pyvis library. The link to the interactive graph is https://drive.google.com/file/d/13LK4iRJKk_td7T5wSKydzkadX4X9N33H/view?usp=sharing (Note: The file needs to be downloaded to access the graph).
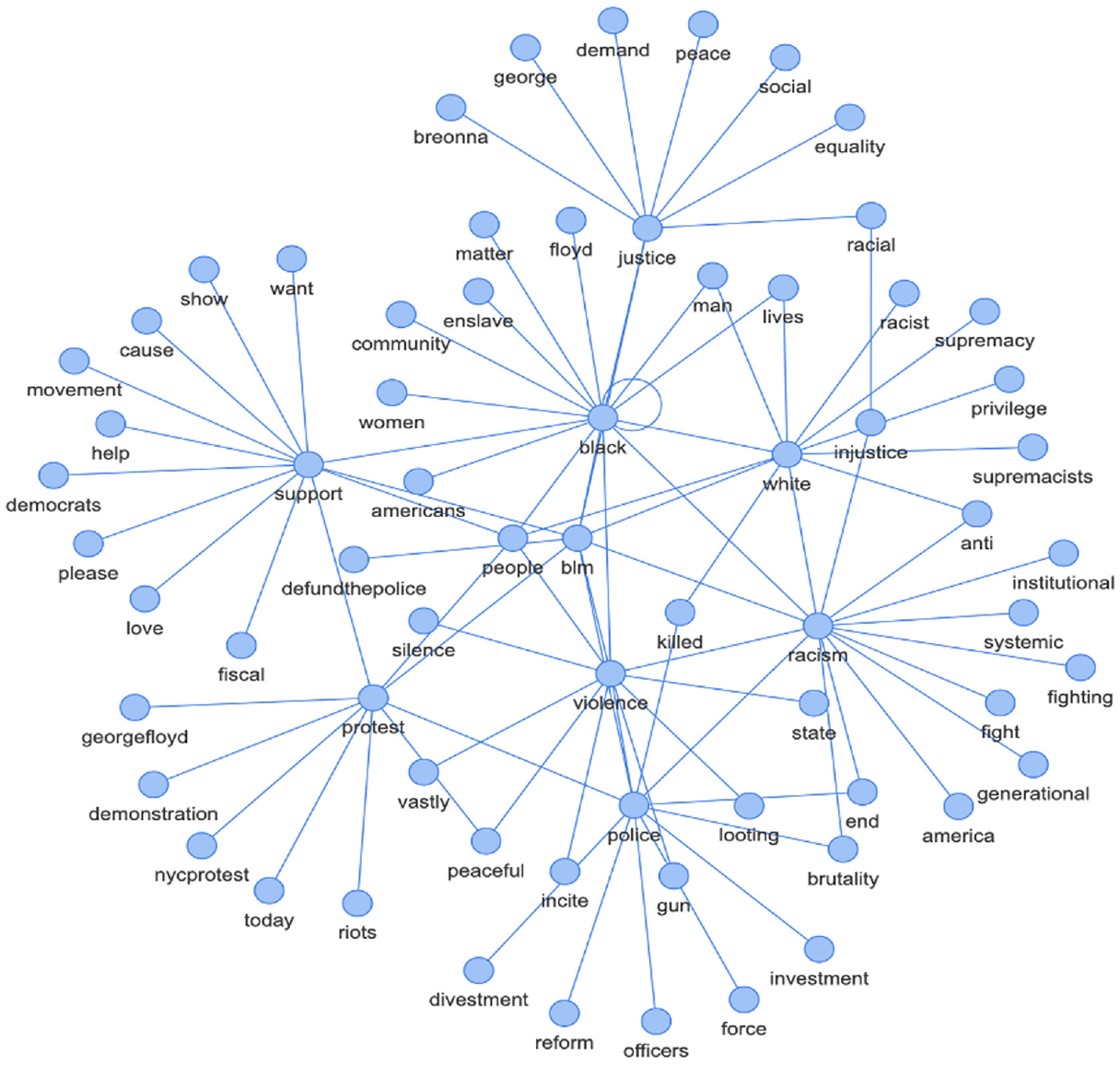
Network graph representing term association between dominantly used terms.
4.5. Word associations using Bigrams
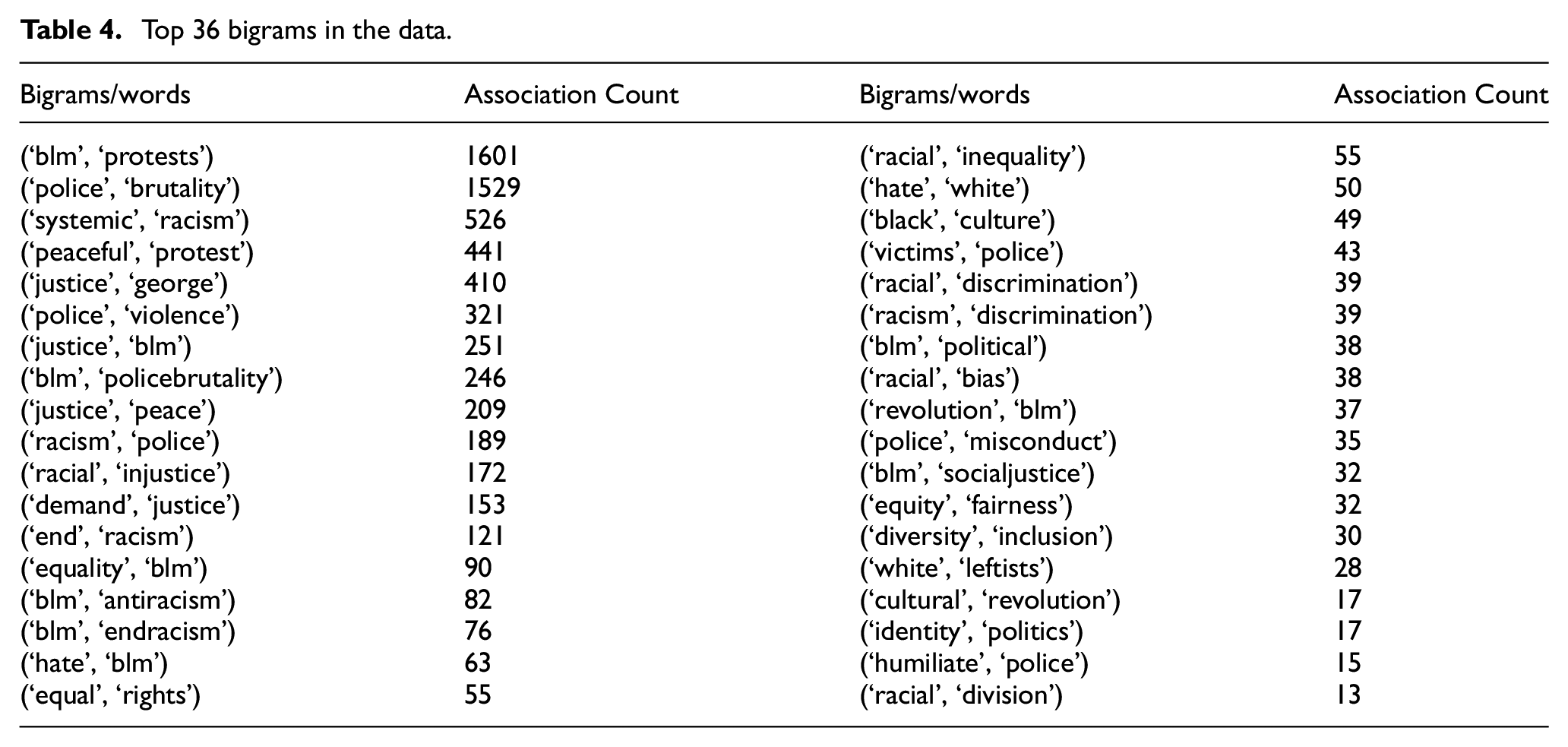
Bigrams refers to the combination of two words. As a part of further data analysis, for the entire tweet data, bigrams were constructed. The frequently occurring bigrams were then analysed, and interesting word associations of the data were made for the tweet data. Table 4 shows the top 36 bigrams in the data.
Top 36 bigrams in the data.
5. Discussion
The results have shown that the existence of social noise can affect the original message by diluting the focus or changing the subject to distort the original intended message through the spread of misinformation. From the topic modelling and data analysis techniques used in this study, we are able to identify a set of keywords that fits the four social noise constructs/categories identified originally by Zimmerman [19]. The study also identified sets of keywords that did not match the original four constructs and was initially classified as other. After a close examination of the list of keywords generated, we used the term association method to better understand the original purpose of the tweets and the context in which these tweets were generated. This led to the creation of two new social noise constructs.
Based on the analysis of the data and the relationship between various tweets, the researchers decided to create two additional social noise constructs/categories. The two additional constructs are ‘affiliation and politics’ and ‘norm and beliefs’. It is observed that most of the social noise generated around these two categories, whether the affiliation and politics category or the norms and belief category are tribal in nature. People without much thinking or further examination of the facts tend to agree and forward the original tweets. Both affiliation and politics, and norms and beliefs are deeply rooted in the culture. Table 5 shows the expanded constructs and categories representing social noise. The table provides definitions of each construct and sample keywords used to indicate or describe each construct. Further studies are needed to understand the factors that motivate people to participate in misinformation or social noise.
Social noise constructs with two additional constructs and their keywords.

On 26 May, a Twitter user tweeted, ‘How is it we are still dealing with this? How long would it take to solve the problem if a Black man did this to a cop? STOP IT! The 4 cops involved were fired. They should all be jailed for life for murder. #BLM’ This is an example of image curation and cultural agency, in which a Twitter user is constructing their online persona while also participating in social concerns to get their opinions heard. Another tweet read, ‘Joe Biden has been part of the system for 40 years. The system is broken. Which is exactly why I vote for Donald Trump. Criminal reform. More black jobs than any point in history. Record funding for black colleges. #GeorgeFloydWasMurdered #blm.’
This tweet is an example of political affiliation, in which the Twitter user declares their support for a political Party. The Twitter user, however, uses the BLM movement to promote a political Party, which is the strong proof of social noise.
The term association provides a better understanding of the context in which terms within the tweets are used. Term association and based on the repeated occurrences of the terms in the tweets measure the distance between certain concepts visually. As illustrated in Figure 9, the terms ‘blm’ and ‘black’ are located at the centre of the graph indicating that these are the two terms that have the highest occurrence in the dataset. Using bigrams to create word associations (Table 4) helps in arriving at some of the observations listed below.
From the term associations, it is evident that the term ‘BLM’ was most commonly used with the word ‘protests’. From this, it can be understood that people generally meant BLM protest when they tweeted about it. Justice, police brutality, equality, antiracism, end racism, hate, political, revolution and social justice were also frequently associated with the word ‘BLM’. These associations indicate that the term ‘BLM’ was primarily used to refer to and identify with police brutality and inequality towards black people.
The words brutality, violence, racism, victims, misconduct and humiliate were frequently associated with the word ‘police’. It is evident from this that individuals had a negative perception of the word ‘police’ and that the term ‘police’ was mainly used to refer to police aggression against black people.
The words systematic, injustice, end, inequality, discrimination, bias and division were mainly associated with words having the base word ‘race’. This demonstrates that the terms ‘racism’ and ‘racial’ were primarily used to refer to racism towards black people in this BLM dataset.
Many people used the term BLM to refer to it as a peaceful protest because the word protest was mainly connected with the word ‘peaceful’.
The words George, peace and demand were usually connected with the phrase ‘justice’. It can be concluded that the word ‘justice’ was employed to seek/demand justice for George Floyd.
Equal and equity were linked to the word’s rights and fairness, respectively, implying that BLM was employed to promote equality.
The word ‘white’ was mainly associated with the phrase’s ‘hate’ and ‘leftists’, hence many people referred to white people as ‘leftists’ and ‘haters’. The phrase ‘culture’ was associated with the word black; therefore, black was used to refer to culture.
It is also apparent from the bigrams table that the concepts of diversity and culture were linked to inclusion and revolution.
Another noteworthy finding is that the phrase ‘identity’ was commonly used in conjunction with the term ‘politics’, implying that individuals used the term politics with identity, which forms the basis for the ‘affiliation and politics’ construct.
Sentiment analysis is one of the most well-studied methods for determining the underlying sentiment, views of, attitudes towards a situation or opinions in agreeing or disagreeing. As an example, sentiment study of the US 2016 presidential election using Textblob revealed that Hillary Clinton received the most significant number of positive tweets, whereas tweets about Bernie Sanders were primarily based on the Twitter users’ personal opinions [39]. In this study, sentiment analysis helps us to better understand Twiiter users views, attitude and opinion about the BLM movement. Based on the subjectivity and polarity scores shown in the results section, we can see that most of the tweets connected to the BLM data were based on the Twitter user’s personal opinions, and many Twitter users had positive sentiments about the BLM movement. However, the existence of social noise and misinformation on social media do affect the overall sentiment. The problem with social noise is that most people are not aware of their role as participants in spreading misinformation for one or more of the reasons we listed in the social noise constructs in Table 5.
5. Conclusion
Sentiment analysis and topic modelling are interesting data analytics techniques used to process and mine large amounts of data. In this article, we examined the impact of social noise on the original intended message in the context of BLM movement data downloaded from Twitter. The study examined the notion of social noise where the participant engaged in social noise might unintentionally alter or dilute the original intended message of the movement. The sentiment analysis and topic modelling were performed on the 104,546 tweets data extracted for the ‘BLM’ hashtag from 25 May 2020 to 10 June 2020. The sentiment analysis of the tweet results shows 76.12% (79,580 tweets) of the tweets were subjective, while 23.88% (24,966 tweets) were objective or focused on facts. Further polarity scores revealed that 42.16% (44,076 tweets) were positive statements, 29.60% (30,946 tweets) were neutral statements and 28.24% (29,524 tweets) were negative statements.
The sentiment analysis results showed that most of the tweets were based on Twitter user’s personal opinions and that the majority of Twitter users had a favourable opinion about the BLM movement. Even though in the beginning of the data collection period, the number of negative tweets about BLM was more than the number of neutral tweets, during the period from 3 June to 6 June, the number of negative tweets fell below the number of neutral tweets and subsequently increased during the remainder of the data collection period. This can be attributed to possibly a decline in social noise and misinformation over time.
LDA and BTM techniques are used to identify keywords and terms that indicate the existence of social noise. The results show that the two methods used produced topics that are helpful in identifying keywords and terms that indicate the existence of social noise constructs. However, the Biterm method which is normally used for classifying short messages and consists of two word co-occurring to produce better results than the LDA. The analysis of the identified topics together with the results from term association using Bigram network graph results in identifying two additional constructs, namely ‘affiliation and politics’ and ‘norms and beliefs’. Such construct could be helpful in explaining social noise and the role that might play in diluting or altering the original intended message. This is necessary in dealing with misinformation that is generated by users who did not have the intent to create or spread misinformation. However, their unintentional participation and action in forwarding and spreading misinformation can contribute greatly to the social noise problem.
6. Limitations and further studies
While this study analysed the data related to hashtag BLM to determine misinformation and social noise, it has some limitations. For instance, images, videos and emojis were removed from the tweets during the data preprocessing stage. Furthermore, the data for this study were collected from 25 May 2020 to 10 June 2020. A more comprehensive study over a more extended period would create a richer picture and enable to dig deeper into the impact of misinformation and social noise on the intended message of movements, such as BLM.
Further studies using more advanced methods, such as natural language processing, or deep learning models using other social media platforms, such as Facebook, will help better understand the impact of social noise and misinformation. The topic modelling technique used in this article is also limited to the LDA and biterm methods. Different topic modelling techniques, such as latent semantic analysis (LSA) and k-means clustering, can be used for further study. Furthermore, emotions analysis can be applied to identify emotions, such as anger, sadness and happiness for each tweet. It is also important to note that this study is part of an ongoing research project to understand social noise and its impact on social media users.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.