
Abstract
In this study, we investigated whether female and male authors in the field of life sciences and biomedicine differed in their tendency for citation and citation sentiment. The data comprised two sets, cited set and citing set. Cited set comprised 17,237 articles whereas citing set comprised 115,935 articles. The cited set which is from the area Life Sciences & Biomedicine and published during 2012–2016 was retrieved from the Web of Science Medline. The citing set and its citation contexts were retrieved using the Colil database. The analysis was done using a combination of homophily analysis, regression analysis and a chi-square test. The covariates in the regression analyses were features related to authors, journal, institution, country and abstract readability. The homophily analysis showed a significant tendency for female (8%) and male (14%) authorship teams to cite papers by the same gender composition teams. In addition, the results of regression analysis (Model 1) and pairwise comparisons showed that male-authored papers received a significant higher positive sentiment compared with female-authored papers. The results of regression analysis (Model 2) showed a small significant positive association between gender similarity of cited and citing authorship teams and the sentiment score. However, further analysis using the chi-square test showed a significant lower tendency for women to use positive terms when citing the research findings of papers with the same gender composition. Men, in contrast, used significantly more positive terms when citing papers with the same gender composition. Finally, lay summary for a cited paper, country similarity and the venue of cited publication when it was a mega journal had a positive significant association with the sentiment score received.
Keywords
1. Introduction
Women are under-represented in top-ranking positions in academia, such as professorships. This is true in the biomedical disciplines [1,2]. The way in which women present their research accomplishments, in comparison to men, has been regarded as one of the factors that causes gender gaps in academic life sciences according to previous research [3]. A group of studies on gender and self-promotion have investigated the association between gender gap/implicit bias and language patterns. Lerchenmueller et al. [3] analysed the language used in more than 6 million papers in peer-reviewed articles in life sciences. Their findings showed that papers with a male first author or a male last author were up to 21% more probably to use positive framing than those with female lead authors. In mathematics, it has been shown that women are less probably to boast about their intellectual performance [4]. In a study on gender gaps in grant funding at Canadian Institutes of Health Research, Witteman et al. [5] associated the gender gap in grant funding to the unconscious use of modest, less compelling language by female applicants, when describing their accomplishments. However, in a more recent study by Franco et al. [6], no significant gender differences were found in terms of language patterns used in biomedical research grant proposal summaries in Brazil. Lewis and Lupyan [7] showed that language statistics can predict people’s implicit biases. In other words, linguistic biases may be causally related to biases in people’s implicit judgements of what can be accomplished by women.
As the notion of ‘excellence’ within audit cultures in academia implicitly reflects images of masculinity [8], the promotion of women’s research findings could be considered counter stereotypical behaviour, which may in turn cause a backlash against women [9–11]. Men’s research can be viewed as more central or important in a field (i.e. the ‘Matthew’ effect), whereas women’s work can be ignored, or worse, attributed to men in a field (i.e. the ‘Matilda’ effect) [12,13]. This can, therefore, result in implicit biases in term of authors’ tendency regarding citations [14] and citation sentiments. In a large-scale study of gender citation homophily, Ghiasi et al. [15] suggested under-recognition of women’s contribution to science, as a reason for men’s preference for citing men.
In this article, we investigated when citing a paper, whether female and male authors differed in terms of their citation tendency and framing the findings of papers that they cited, using inbreeding homophily and sentiment analyses. To the best of our knowledge, no study so far has investigated this in the field of life science and biomedicine. Inbreeding homophily refers to the ties between similar others that form over and beyond what would be expected by chance given the opportunity pool [16]. Citation sentiment analysis is a natural language processing (NLP) technique that has been used in previous research to study the sentiment of an author towards a paper that they have cited [17–20]. Citation content analysis research focuses on describing and classifying semantic relationships between the citing and cited works [21], providing a more nuanced, qualitative view of how an article is cited [22]. These classifications are based on the polarities and strengths of the opinions extracted from citances 1 [23]. In the literature, two different methods have been used for classification of citation sentiments: unsupervised (Lexicon-based) approaches and supervised (machine learning framework) approaches [17]. Most unsupervised methods rely on a sentiment lexicon to assign a sentiment score to the text. This unsupervised approach is more understandable and can easily be implemented in contrast to machine learning-based algorithms [24]. However, sentiment lexicons are largely dependent on the genre of the text being classified [17]. Studies [25-27] are example research works in life sciences and biomedince that are conducted using Lexicons. This method has also been applied in citation sentiment analysis studies in the context of co-citation analysis [28], to rank citations [29] or to measure citation quality [30]. The supervised methods represent the labelled data in the form of a set of features. The features are then used to learn a function for classification of unseen data [17]. While one advantage of learning-based methods is their ability to adapt and create trained models for specific purposes and contexts, their drawback is the availability of labelled data and hence the low applicability of the method on new data. This is because labelling data might be costly [31]. Using supervised machine learning techniques, some studies in biomedicine have been conducted on small, annotated citation corpuses from biomedical articles [32,33] or clinical trials [18,22].
This study has two objectives: (1) in general, to study whether there is a tendency towards authorship teams based on their gender, in terms of sentiment, when citing or being cited and (2) more specifically, to investigate whether there is a tendency for authorship teams, in terms of citations, sentiment score or use of positive/negative terms, when citing papers of the same gender composition teams.
To achieve these objectives, the study addressed the four below questions:
Is there any difference in terms of sentiment score among authorship teams of cited and citing papers, based on their gender?
Is there any citation homophily based on gender between citing and cited papers?
Is there any association between gender similarity of cited and citing authorship teams and the sentiment score received?
Is there any difference between authorship teams in terms of the proportion of positive/negative terms used, when citing papers of the same gender composition teams?
2. Methodology
2.1. Data sets
The data for this study comprised two sets, the cited set and the citing set. The cited set comprised 17,237 articles, whereas the citing set comprised 115,935 articles. By the citing set, we mean all of the articles that cited the 17,237 articles in the cited set.
To retrieve these data sets, several steps were taken. First, all articles in the research area of Life Sciences & Biomedicine from 2012 to 2016 were retrieved from the Web of Science Medline in June 2020. This resulted in 83,444 papers. In the next step, using the PubMed identifier (PMID) of these papers, a search was conducted in the PubMed Central Open Access Subset (PMC-OAS). As a result of this search, we identified 17,237 papers in PMC-OAS. The PMC-OAS is a part of the total collection of articles in PMC, which are made available under a Creative Commons or similar licence that generally provides users with the rights to reuse and redistribute content [34]. In the next step, citations and citation contexts for each of these 17,237 cited papers were extracted from the Colil (Comments on Literature in Literature) database. This resulted in 115,935 citing articles, which provided 210,181 citation contexts. These two data sets, citing and cited, were used for further analysis in this article.
Colil is a database and search service for citation contexts in the life sciences. Using the web-based search service, it is possible to search for a cited paper in the Colil database and retrieve a list of its citation contexts. The citation contexts in the Colil database are extracted from full-text papers of the PMC-OAS [35].
2.2. Data analysis and procedures
2.2.1. Sentiment analysis
KNIME (the Konstanz Information Miner) was used to pre-process the citation contexts obtained from the data collection process. The pre-processing step included removing stop words, special characters and numbers. It also entailed tokenisation, part of speech (PoS) tagging and lemmatisation. In this article, sentiment analysis was conducted on the four parts of speech, namely, nouns, adjectives, adverbs and verbs. The reason for this was that these parts of speech are believed to carry opinion loads in a sentence [36,37]. We also accounted for three valence shifters: amplifiers (absolutely, certainly), de-amplifiers (barely) and adversative conjunctions (although). In the case of negators (not, can’t, etc.), we applied a list of negation terms 2 that was used in Athar’s [17] study. In addition, we also added other negators such as aren’t, didn’t and has not to the list. The number of negators was very low (~ 0.5%) in our sample.
The sentiment scores were assigned to words using SentiWordNet. SentiWordNet is one of the most widely used sentiment lexicons [38] which has a wide coverage of words [39]. Furthermore, it has been previously used in the domains of medicine and biomedicine [25,26] and in citation sentiment analysis studies [29,30,40].
SentiWordNet assigns three sentiment scores to each synset of WordNet: positivity, negativity and objectivity, ranging from 0 to 1 [38]. Since every word may have different meanings, SentiWordNet has a collection of different synsets. 3 Every synset may have positive, negative and neutral scores for a given word, which sums up to one. Given the existence of several synsets for a given word, it was necessary to assign a single score to each word. To do so, we used a methodology applied by Cavalcanti et al. [29]. For a given word, within a specific PoS, all scores for its synsets were averaged, after subtracting the negative scores from the positive ones. Finally, the scores of each citation context were aggregated. In some cases, a citing article might have referenced a cited article in several places: thus, creating more than one citation context. In these cases, the sentiment score of these citation contexts was averaged.
Finally, we randomly selected 5% (~850) of the cited PMIDs. For each of these PMIDs, we then randomly selected one citing PMID and one of its corresponding citation contexts. The minimum required sample size for inter-rater agreement in this study was calculated using the methodology provided in Rotondi and Donner [41]. These contexts were then read by two experts in the field of life sciences and biomedicine, and they assigned sentiment polarity to the sample citation contexts. To measure the inter-rater agreement between each person’s polarity and the automated polarity, we used both percent agreement and Cohen’s kappa test using the irr [42] package. The latter is used to measure inter-rater reliability for qualitative (categorical) items [43]. Values range between −1 and 1. Values lower than 0 are indicative of no reliability, values between 0 and 0.4 of slight to fair, values between 0.41 and 0.6 of moderate, values between 0.61 and 0.8 of substantial and values between 0.81 and 1 of almost perfect reliability [44]. In our case, the results showed a kappa agreement of 0.68 and 0.70 (~70%), which indicates a good agreement. In addition, the percent agreement showed values of 79% and 82%. As the experts were from the field of life sciences and biomedicine, they would be less probably to guess when assigning sentiments. Thus, we believe these percent values are also reliable [43].
2.2.2. Regression and homophily analysis
Regarding questions one and three, the linear mixed model (LMM) was used to: (1) to compare the mean of sentiment scores by gender among authorship teams associated with cited and citing articles; (F (both first and last female), M (both first and last male), M-F (first male-last female), F-M (first female-last male)) (Model 1) and (2) to study the association between sentiment score and gender similarity (measured as cosine similarity between cited and citing sets based on gender), while controlling for some covariates (Model 2) (see Table 1). Using Model 2, we investigated whether there was a tendency for authors (not) to be more positive towards the authors of similar gender composition in terms of terms of sentiment score.
Dependant, independent variables and covariates for regression Models 1 and 2.
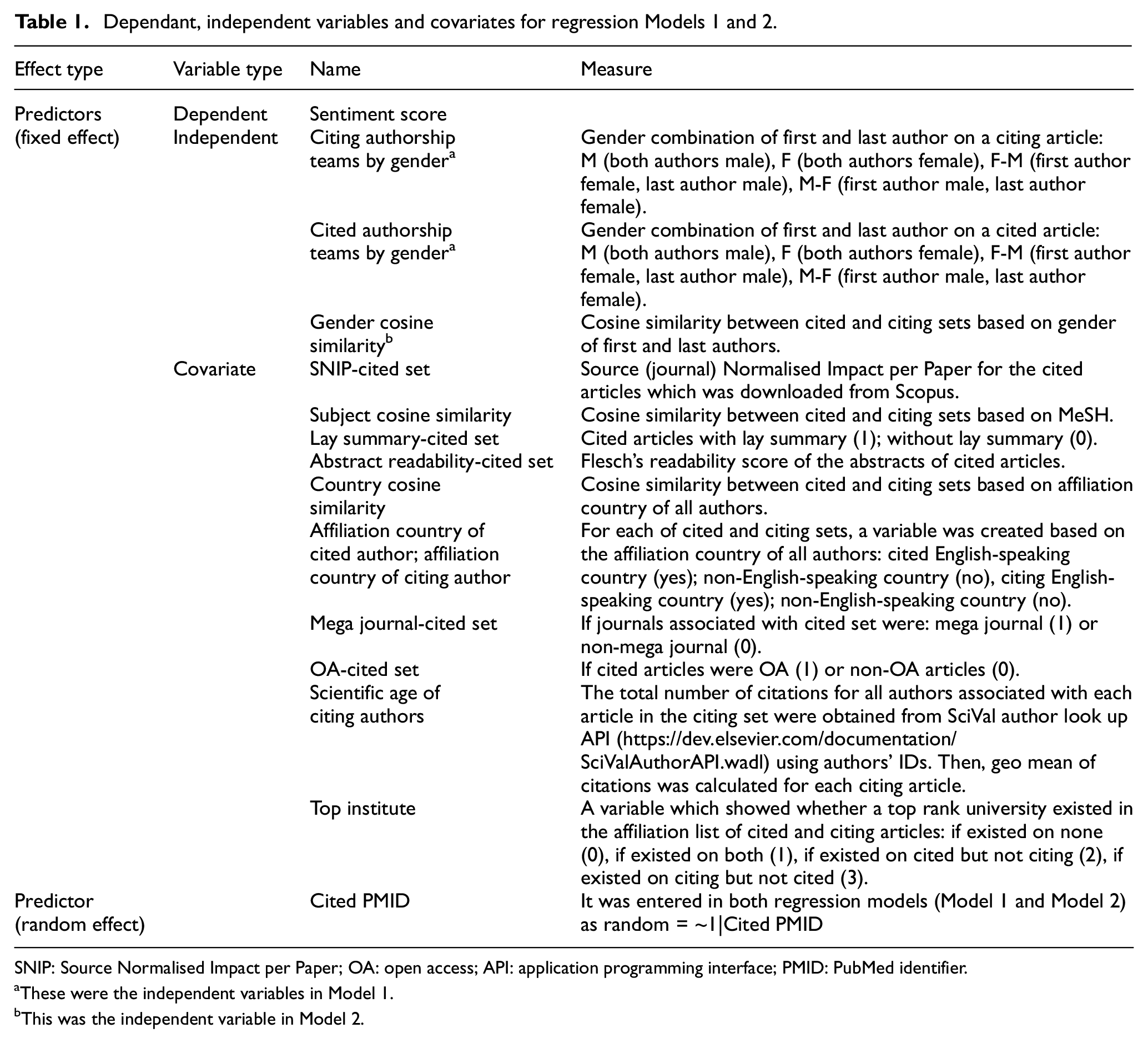
SNIP: Source Normalised Impact per Paper; OA: open access; API: application programming interface; PMID: PubMed identifier.
These were the independent variables in Model 1.
This was the independent variable in Model 2.
LMM is a generalisation of linear regression, which allows to model correlated errors. These models are called mixed effects since they combine both fixed effects and random effects. While using fixed effects, we can get an estimate of their effects on the response variable (in our case sentiment score), using random effects, we can quantify the variability in the baseline values of the response variable [45,46]. Mixed-effect models are the preferred approach for the analysis of longitudinal or clustered data [47,48]. The reason for this is flexibility of these models in modelling the correlation structure of the data and ability to account for both balanced (i.e. with the same set of observations points for each subject) and unbalanced (i.e. with different observations points for different subjects) designs. Another major advantage of LMM is how they handle missing data. Specifically, the mixed-effects approach does not require a complete set of observations on each subject, rather, it uses all available data on each subject. If a subject has intermittent missing data, or subjects/clusters that have different numbers of (repeated) observations, all available data are used [48]. The case in this study is clustered and unbalanced data design. The grouping variable is the cited articles’ PMIDs. All citing articles (citing PMIDs) are matched with their cited PMIDs. As the clusters (cited PMIDs) can be considered to have been sampled from a larger population of clusters, their effects can be modelled as random effects in an LMM [47]. Furthermore, the sentiment scores within cited PMIDs might be correlated. The reason for this is that we expect the citing PMIDs to be more homogeneous within a cited PMID, than between cited PMIDs.
In both regression models, the outcome y (sentiment scores) is a continuous variable. Furthermore, we have 13 fixed effects predictors with fixed slopes for Model 1: gender citing, gender cited, top institute, subject similarity, open access (OA) status, abstract readability, SNIP (Source Normalised Impact per Paper), lay summary, scientific age of citing authors, country similarity, affiliation country of cited author (English-speaking country or not), affiliation country of citing author (English-speaking country or not) and mega journal (see Table 1). In Model 2, we have the same fixed effect predictors except for gender-citing and gender-cited variables instead of which we used gender cosine similarity. In both models, we have a random effect associated with the intercepts for each cited PMID. As mentioned above, random effect is a way to correct statistical tests when some observations are correlated [37]. We fitted the LMM using lme () function from the R package nlme [49]. R package Emmeans [50] was also used to perform pairwise comparisons among authorship teams of different gender (F, M, M-F, F-M) associated with cited and citing articles.
When fitting the regression models: (1) we tested whether the random effects associated with the intercept for each cited PMID can be omitted from the regression Models (1, 2) and (2) we also checked to decide which covariates to include in the model. To do so, for both cases, we conducted a likelihood ratio test using the anova () function. In the first case, the result of the test (p < 0.001) for both Models (1, 2) suggested that the random-cited PMID effects should be retained in the regression Models (1, 2). Regarding covariates, after running the anova () function on the random effect models for both Models 1 and 2, we decided to remove the scientific age of cited authors from both models as it did not improve the models. The sjPlot R package [51] was used for diagnostic of both models in terms of multicollinearity, normality of residuals, normality of random effect and homoscedasticity (see Supplementary Material).
To answer the second question, we investigated whether there was an inbreeding homophily in citation tendency by gender composition of authorship teams (cited-citing). To do this, we used inbreeding homophily analysis using R. 4
Finally, to answer question 4, a chi-squared test was used to compare the proportion of positive and negative terms between the same gender authorship teams associated with both cited and citing sets (both female teams, both male teams, both F-M teams, both M-F teams).
2.2.3. Data collection and processing of the variables
In this section, we provide details regarding data collection and processing of some of the variables used in the regression analysis. We also provide reasons why we have included these variables as covariates in the regression models.
Several of the covariates used in the regression Models (1, 2) capture different aspects that might have an impact on the sentiments towards a cited work based on the previous literature. Journal aspects (SNIP and mega journal): as higher impact journals might publish more papers of higher importance, they tend to be cited with more positive sentiment [20]. Readability aspects (lay summary and abstract readability): previous research has found that easy to read posts are more liked, commented on and shared on social media [52]. Furthermore, the effect of language sentiment is more probably when readability is low than when it is high [53]. So, we expect text readability to have a positive influence on the sentiments and attitude towards cited works. Institute’s and author’s reputation (for which the proxies were top institute and scientific age): as reputation can be considered as important signal of trustworthiness and quality [54], it is expected that papers with authors and institutes with higher reputations to receive more positive sentiments. Furthermore, previous research has shown a relationship between author’s and institute’s prestige and the number of citations received [54]. Country-related aspects (measured as country similarity and author’s affiliation with a country where English is the official majority language (Australia, New Zealand, United Kingdom, Canada and the United States) and authors with affiliations outside these countries). Previous research has shown differences regarding the use of positive words between authors affiliated with these two groups of authors [55].
To detect the gender of first and last authors in both cited and citing sets, we used a combination of gender application programming interface (API) (https://gender-api.com/) and manual checking. First, gender API was used to conduct a search using the first name of authors. For each name, the API returns the gender (male, female or unknown), the number of names used to determine the gender and accuracy [56]. Then, in cases of gender-neutral, unknown, initials or where the accuracy was lower than 80%, the names were checked manually using Internet searches. The reason for choosing these two authorship positions was that in the field of biomedicine, the last position in the authors list is reserved for senior authors, whereas the first author position is for the person who fulfils the International Committee of Medical Journal Editors (ICMJE) authorship criteria to the highest level and performs the majority of the experimental and clinical work [57,58]. We calculated cosine gender similarity and cosine subject similarity between citing and cited sets using Python. The subject similarity was calculated based on MeSH. For each article in both cited and citing sets, MeSH was downloaded from Medline using Bio.Medline Python package [59]. MeSH pairs of citing/cited articles have been used in the previous literature for identifying shared medical topics between cited and citing articles and clustering of topically related articles in biomedical sciences [60,61].
The scientific age of authors on citing/cited papers was calculated using the geometric mean of citations 5 for first and last authors. The number or log-transformed number of publications and citations of an author has been previously defined as professional or scientific age of an author [62–64]. While we used the Web of Science Medline to determine the OA status of the cited articles, we used the list provided by Spezi et al. [65] to determine whether a journal was a mega journal or not.
Regarding readability we calculated ‘abstract readability’ and ‘lay summary 6 ’ for each cited article. Using a journal list provided by Shailes [66], the cited articles were divided in two groups – those with and those without a lay summary. Regarding abstract readability, the Flesch Reading Ease Score was used, as it is the most used measure of text readability, and it has been used in other bibliometric studies [67]. The R quanteda package [68] was used to calculate this score for each abstract. The highest possible score is 121.22 and there is no lower limit. Very complicated sentences can have negative scores. The higher the score, the easier the text is to understand.
3. Results
Figure 1 shows the percentage of papers for citing and cited authorships teams by gender. As can be seen from the figure, in both sets, male authorship team was the group with the highest number of papers in both cited and citing sets, whereas female authorship team was the group with the lowest number of papers in both sets.
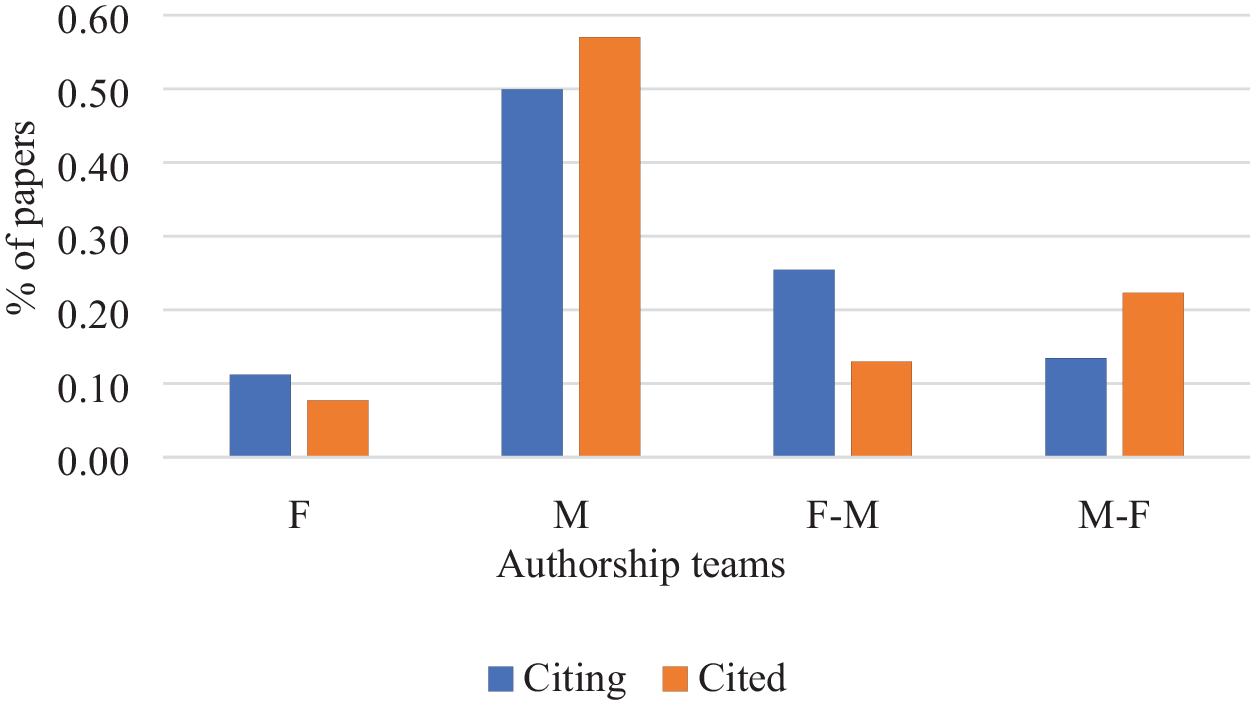
The percentage of papers for authorship teams of different gender in cited and citing sets.
The results of homophily analysis showed that there was a significant inbreeding for female and male authorship teams. This means that there is a significant tendency for female and male authorship teams to cite the papers by the same gender composition teams. As can be seen from Table 2, 14% of the times an authorship team composed entirely of male authors will cite another authorship team composed of only male authors. For female authorship teams, this means that 8% of the times, a female authorship team will cite another female authorship team.
The result of inbreeding homophily analysis for citation tendency by gender composition of authorship teams.
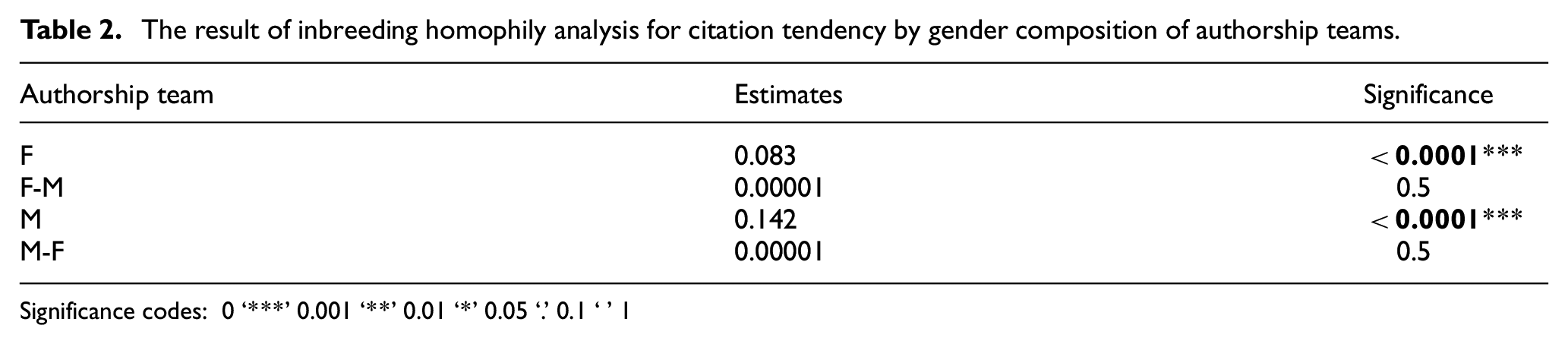
Significance codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
3.1. The results of linear mixed-effect regression analysis for Models 1 and 2
In this section, we have reported the results of regression analysis regarding Model 1 and Model 2, while controlling for several covariates. In the tables for both models, ICC is the intraclass correlation coefficient, which is calculated by dividing between-variance and the sum of between- and within-variance. In other words, ICC = τ00/(σ 2 + τ00), where σ 2 is the between-group variance and τ00 is equal to within-group variance [69]. By looking at the ICC values for both Models 1 and 2, it can be said that 20% of the variance in sentiment scores is due to variation between cited articles, whereas 80% of the variance is due to variation within cited articles (among citing articles connected to a cited article). Regarding gender, the result of regression analysis (Model 1) (Table 3) and pairwise comparisons (Table 4), showed that (1) in citing teams, female only authorship (F) teams had a significant lower positive sentiment towards the cited papers in comparison to male (M) and mixed (M-F) authorship teams. This means that female authorship teams were slightly less positive towards cited papers in comparison to male (M) and mixed authorship teams (M-F) and (2) in cited teams, male teams (M) received a significant higher positive sentiment in comparison to mixed teams (M-F). In addition, mixed authorship teams with a female last author (M-F) received a lower positive sentiment in comparison to mixed authorship teams with a male last author (F-M).
The results of linear mixed-effect analysis for Model 1.
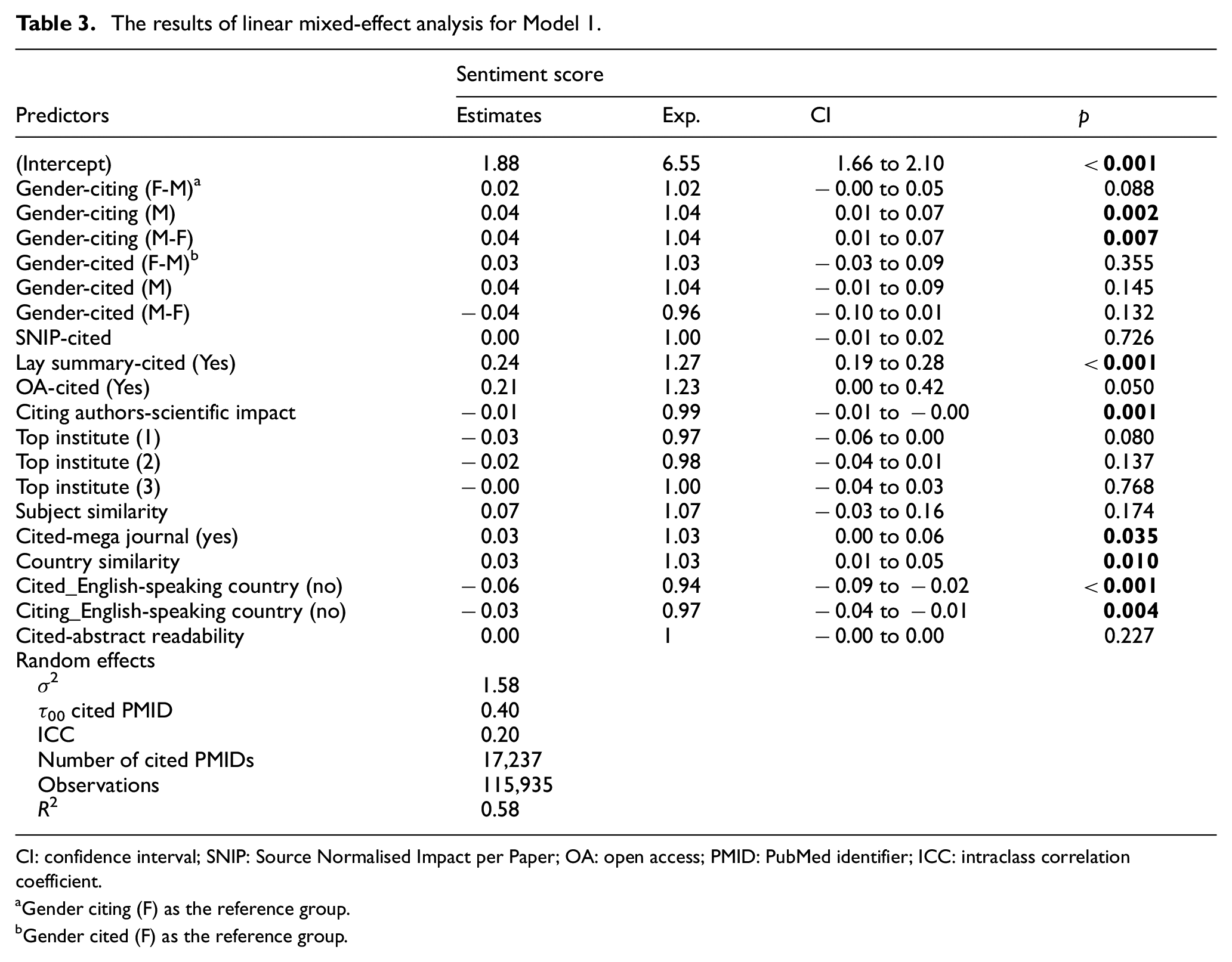
CI: confidence interval; SNIP: Source Normalised Impact per Paper; OA: open access; PMID: PubMed identifier; ICC: intraclass correlation coefficient.
Gender citing (F) as the reference group.
Gender cited (F) as the reference group.
Results of pairwise comparison based on gender among cited authorship teams (gender cited) and among citing authorship teams (gender citing).
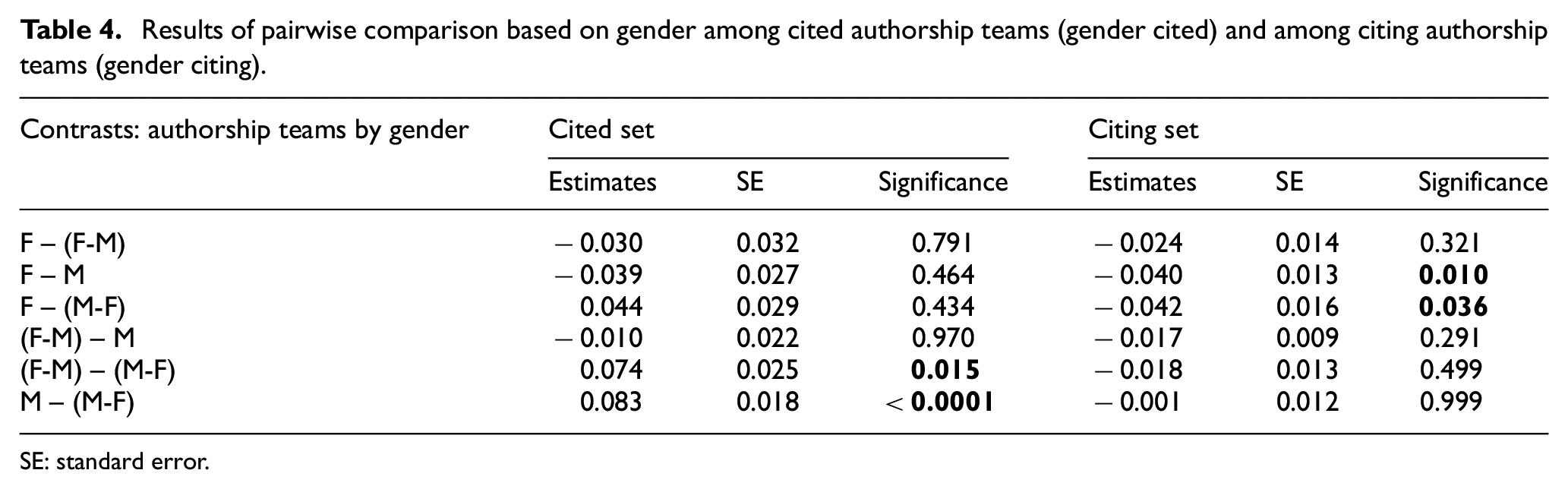
SE: standard error.
The result of regression analysis regarding gender for Model 2 (Table 5) showed a small significant positive association between gender similarity of cited and citing authorship teams and sentiment score received per cited papers. This means that as the gender similarity between cited and citing sets increased, the sentiment score increased.
The results of linear mixed-effect analysis for Model 2.
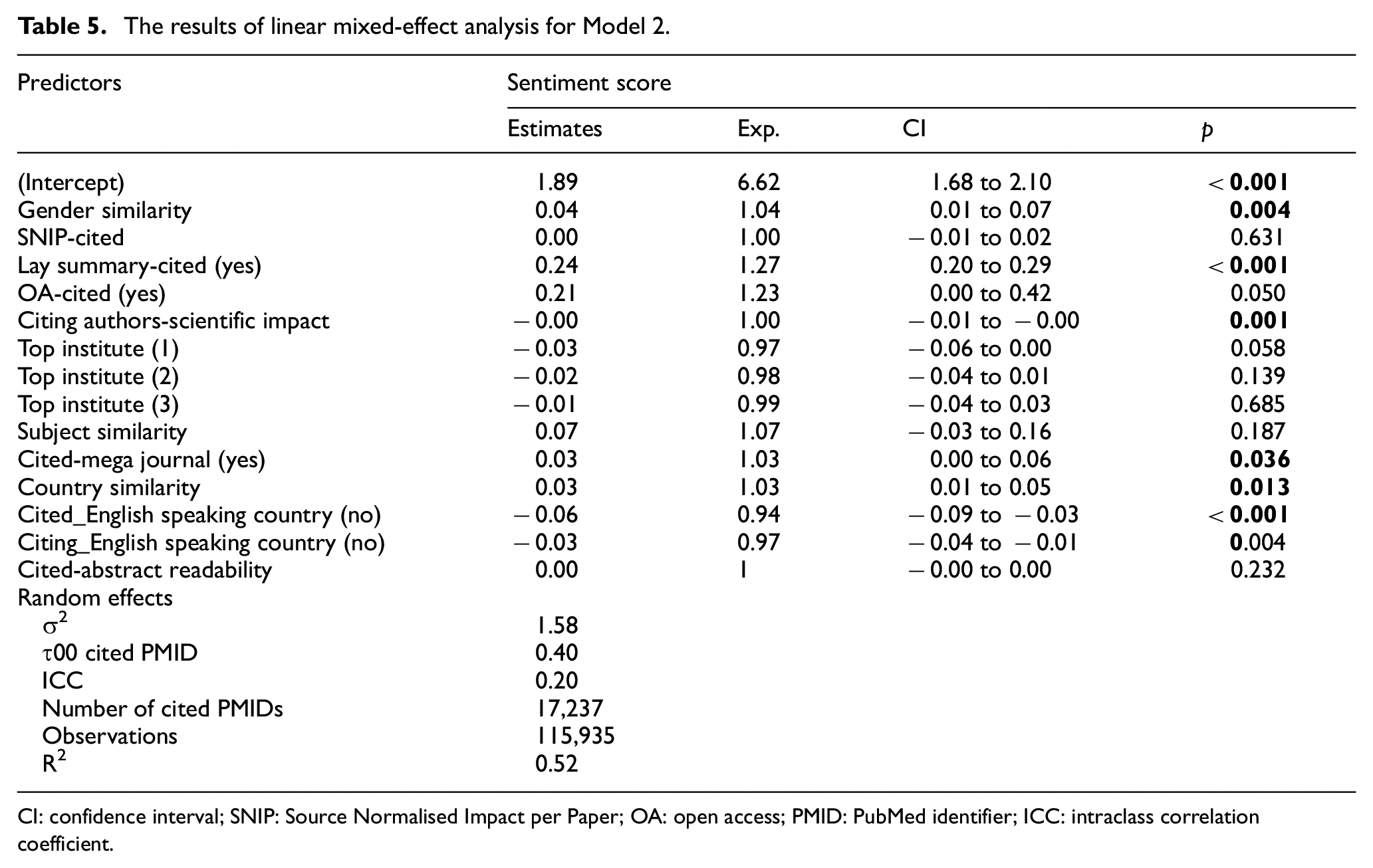
CI: confidence interval; SNIP: Source Normalised Impact per Paper; OA: open access; PMID: PubMed identifier; ICC: intraclass correlation coefficient.
As for the rest of covariates in both models, the results showed that the existence of lay summary for a cited paper had a small positive significant association with the sentiment score received. In addition, the results showed a positive association between the publication venue of a cited paper when it was a mega journal and the sentiment score revived. This means that if the publication venue of a cited paper was a mega journal, the sentiment score received was positive.
Regarding the country covariates, as can be seen from Table 5, as country similarity increased, the sentiment score increased. In addition, the results showed when authors on citing or cited papers were affiliated with non-English native speaking countries, the sentiment score decreased.
3.2. The results of chi-square test to compare the proportion of positive and negative terms
A chi-square test was used to study whether the proportion of counts of positive and negative terms between the same gender composition teams was significantly different or not. The results showed that relative proportion of positive and negative terms was significantly different in the groups (p < 0.0001). In addition, the result of post hoc test (using Bonferroni’s correction) showed that the proportion of positive terms was significantly higher than expected for male authorship teams when citing a male authorship team. Interestingly, the proportion of negative terms was significantly higher than expected for female and mixed gender (F-M and M-F) teams, when citing teams composed of the same gender.
4. Conclusion and discussion
In this study, we investigated whether female and male authors in the field of life sciences and biomedicine differed in their citation homophily and framing the findings of papers that they cited. To do this, we addressed two research objectives and four questions. The findings in relation to these are discussed below.
Regarding the first objective, whether there was a tendency towards authorship teams by gender in terms of sentiment when citing or being cited, we investigated this via question one. The results of regression analysis and pairwise comparisons for question 1 showed that when citing a paper, female only authorship (F) teams had a significant lower positive sentiment towards the cited papers in comparison to male (M) and mixed (M-F) authorship teams. In other words, female authorship teams were slightly less positive towards cited papers in comparison to male (M) and mixed authorship teams (M-F). In addition, when being cited, male teams (M) received a significant higher positive sentiment in comparison to mixed (M-F).
Regarding the second objective, we studied whether there was a tendency for authorship teams in terms of citation, sentiment score or the frequency of positive/negative terms when citing papers of the same gender composition teams. This objective was answered through questions 2, 3 and 4.
The results of the analysis from question 2 showed a significant tendency for female and male authorship teams to cite papers by the same gender composition teams. This homophily was 14% and 8% of the times for men and women, respectively. This finding makes sense, as found in previous research, networks of men are more homophilic than women’s, especially in environments in which men are dominant [70,71]. Our finding is in line with Ghiasi et al. [15], who also found a gender homophily in referencing patterns. The authors concluded that the lower number of female authorships might lead to men’s higher inclination (compared with women) to cite papers by the same gender, which in turn could contribute to the Matilda effect in science [12].
The results of regression analysis from question 3 showed a small significant positive association between the gender similarity of cited and citing authorship teams and the sentiment score received, while controlling for several covariates. In other words, as the cosine gender similarity between cited and citing papers increased, the positive sentiment score slightly increased. This finding seems to suggest that there is a slight tendency for authors to be more positive towards authorship teams with a more similar gender composition. However, further analysis (question 4) showed that the frequency of positive terms for male authorship teams was significantly higher than expected when citing a male authorship team. In contrast, the frequency of negative terms for female authorship teams was significantly higher than expected when citing a female authorship team. The findings about the use of positive and negative terms when citing same gender authorship teams is in line with Lerchenmueller et al.’s [3] study which showed that in medicine and life sciences, female first-last authored articles were 21% less probably to present their research work positively compared with articles in which the first and/or last author was male. The finding is also in line with McKinnon and O’Connell’s [11] study, which found that in STEM, women academics who publicly communicated their scientific work were probably to be negatively stereotyped, judged and held back by other women. The authors suggested the reason why women may judge other women more harshly, could be simply due to underlying implicit bias. As language statistics have been shown to predict people’s implicit gender biases [7], it could also be the case in this study that authors’ implicit biases about gender could be translated into sentiments regarding the articles they cite. Another explanation to this finding could be related to men’s higher tendency to use more boastful or authoritative language compared with women, who may also use less compelling language and be less probably to self-promote their research findings [4]. Consequently, men could be more positive regarding the work of other men, whereas women may be less positive to the work of their own gender.
When conducting regression analyses for questions 1 and 3, we controlled for several important factors that were associated with sentiment score according to previous research. Among these factors, lay summary for a cited paper, country similarity and publication venue of a cited paper (when it was a mega journal) had a positive significant association with the sentiment score received. The finding about lay summary as also indicated in Tan et al. [53] shows the importance of making the text readable (by providing a lay summary in our case) as it provides a remedy in debiasing the language sentiment effect. The finding regarding mega journal might be related to the Matthew effect of journal’s ranking – the tendency for a high-ranked journal to receive more citations to its papers [72]. In addition, our findings showed that authors affiliated to an institute in a non-English-speaking country had a lower positive sentiment when they were citing or being cited. As the use of English language in scientific papers can affect one’s judgement about the quality of a scientific paper [73], this might presumably create a bias towards authors affiliated to non-English-speaking countries. The finding with regard citing authors is in line with a study by Kourilová [74], which found that non-native English speakers often wrote in an honest, or brutal, blunt manner in their scientific reports.
Collectively, our findings showed gender differences in citation homophily and citation sentiments in the fields of in life science and biomedicine. In general, our findings seem to suggest the existence of Mathew/Matilda effect in the field of life sciences and biomedicine, where there is a higher tendency for male authors to cite papers written by the same gender. Furthermore, when being cited, male-authored papers received a significant higher positive sentiment compared with female-authored papers. Men also used significantly more positive terms when citing papers written by the same gender composition teams. However, this study seems to suggest that not only men contribute to this gender gap in this field, but also women; as our finding showed a lower tendency for women to use positive terms when citing the research findings of papers with the same gender composition. The higher tendency of men to use more positive, boastful or authoritative language compared with women as shown per pervious research [3–5] might act in two ways: men to be more positive towards their own gender and women be less positive towards their own gender. Previous research suggested the extent to which women promote their research accomplishments relative to men as one of the mechanisms that might contribute to current gender gaps in academic medicine [3]. However, it should also be considered that as the promotion of research findings for women might be considered counter stereotypical behaviour [10,75], women might be criticised for this behaviour, even sometimes by other women [4,11]. Thus, it might be the case that implicit gender biases negatively act against women in the way that their research findings are perceived by both men and women. However, further research is required to corroborate this finding.
We believe that our findings are important, as they provide awareness regarding these gender differences in tendency of authors, in terms of citation and language framing of research findings that they cited. Thus, they could serve as a basis for initial actions that can be taken to reduce the gender gap in life sciences and biomedicine.
Finally, this study has some limitations. In this study, we used SentiWordNet for sentiment analysis. Although this dictionary has a large vocabulary coverage and our results demonstrated a good reliability, this analysis could be potentially further improved using a field specific dictionary, which is not currently available [76]. Alternative algorithms such as supervised machine learning methods could also be used in future research.
Supplemental Material
sj-docx-1-jis-10.1177_01655515221074327 – Supplemental material for Gender differences in citation sentiment: A case study in life sciences and biomedicine
Supplemental material, sj-docx-1-jis-10.1177_01655515221074327 for Gender differences in citation sentiment: A case study in life sciences and biomedicine by Tahereh Dehdarirad and Maryam Yaghtin in Journal of Information Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.