
Abstract
This article empirically maps and compares types of knowledge produced about people on the move by the European border security apparatus. Exploring two complementary analytical moments, the article addresses the stabilization of power and contingent practices within such apparatuses. We argue, first, that analyzing classification schemas implemented in data systems used within the European apparatus can reveal assumptions and limitations about people on the move—what we call “scripts of alterity.” Second, the comparative mapping of scripts of alterity reveals a de facto division of labor between scales of governance that would otherwise be invisible in policy. Utilizing the new Ontology Explorer software method as well as discursive analysis, we identify four scripts of alterity, which materialize relations in data systems and are thus relatively stabilized. Third, we identify as “de-inscriptions” forms of resistance specific to scripts of alterity. These can still be contested and we account for three contingent practices of de-inscription from scripts of alterity by conducting ethnographic observation of data systems’ use. Finally, we summarize three contributions that the “scripts of alterity” concept makes to the science and technology studies and to the critical security studies literature on the securitization of cross-border mobility.
Introduction
Since the late 1990s, cross-border mobility and migration have been framed as a matter of security, with people on the move being enacted as security subjects (Bigo 2001; Amoore 2006; Aradau et al. 2006). In Europe, the securitization of migration has escalated after terrorist attacks like the ones in Paris in November 2015, Brussels, Nice, and Berlin in 2016, among others. Fueled by Eurosceptic constituencies and nationalist anti-immigrant resentment (Schimmelfennig 2018), high-profile political responses followed, like hardline pushbacks against the principle of non-refoulement (Fill 2021). Securitization has had consequences for European multilevel integration as well. In the aftermath of the 2015 “crisis of solidarity on migration,” securitization has brought European member states to act unilaterally (Biermann et al., 2019), thus undermining a joint response in migration and asylum management (Pelizza and Loschi 2023).
In recent years, critical security studies (CSS) scholarship on borders and mobility has engaged with science and technology studies (STS) to investigate the apparatuses that securitize the border (Amicelle et al. 2015; Andersson 2015; Aradau 2018). Apparatuses are networks of heterogeneous elements—from policy to policy makers, from institutions to data systems—which produce diverse types of knowledge to establish what and who belongs to the realm of possibility, and what does not. Border apparatuses increasingly rely on digital components that make unknown people “legible” to European authorities (Pelizza 2020) and sort them into categories of differential risk (Dijstelbloem and Broeders 2015).
For their part, STS scholars have analyzed the political consequences of the digitization of the border (Dijstelbloem 2021; Trauttmansdorff and Felt 2021) and its logistic and temporal arrangements (Pollozek and Passoth 2019; Pollozek 2020; Olivieri 2023). In addition, scholars have described how security apparatuses enact alterity and enmity through classifications inscribed in data systems (van der Kist et al. 2019; Suchman 2020; Amelung 2021), and how the securitization of cross-border mobility has longer-term implications for the institutional order (Broeders and Dijstelbloem 2015; Pelizza 2020). Overall, these STS studies go beyond an instrumental understanding of the digital components of apparatuses and instead assume their agency.
Considering these developments, it is curious that research has not yet systematically mapped and compared the types of knowledge about people on the move produced at the border. 1 And yet mapping and comparing diverse types of knowledge can be crucial to understand the border apparatus. One tendency of CSS scholarship is their reliance on theoretical literature sources (e.g., Pötzsch 2015) or focus on individual data systems (e.g., Bellanova and Glouftsios 2022)—at the expense of empirical comparison between systems. Furthermore, while classifications have been rightly criticized as asymmetrical mechanisms of risk calculation and exclusion, the technical schemas underpinning classifications have rarely been analyzed. Nor has the STS new wave on digitized border and mobility bridged this gap yet. However, as STS early studies on infrastructures have taught us, comparing classification schemas can make visible power relations related to knowledge production (Bowker and Star 1999). This is especially so for European multilevel integration, where power relations across European Union (EU) and national governance levels might not yet be visible in policy.
This paper aims to bridge this gap by analyzing the classification schemas underpinning data systems used at the European border 2 and comparing the resulting types of knowledge about people on the move. Using the new Ontology Explorer method and software tool, we identify four types of knowledge that we call “scripts of alterity.” We drew on technical documents, system screenshots and eighteen interviews collected in Greece (twelve), Italy (four), and at the European Commission (two) since 2017, as well as on ethnographic observation at four identification and registration centers in Greece (methodological details are provided in the fourth section).
In this paper, we argue that analyzing classification schemas implemented in data systems used at the border can expose hegemonic assumptions and limitations about people on the move (third section). We compare the differences in the scripts of alterity (fifth section) and describe their implications for the European order. Notably, we spot a de facto division of labor between national and supranational governance levels (Division of Labor by Design subsection). These findings can eventually uncover tensions between member states and EU agencies—reminding us that the European order is not stabilized (Grommé and Ruppert 2020). We further develop the paper by describing how people on the move can resist scripts of alterity. Following the analogy with scripts, we identify “de-inscriptions,” three forms of resistance specific to scripts of alterity (sixth section).
We introduce the conceptualization of “scripts of alterity” in relation to security apparatuses to address one of the recurrent topics explored in this special issue of Science, Technology, & Human Values: the distinction between power stabilization and contingent practices. Drawing on actor-network theory’s (ANT) dualism between scripts and de-inscriptions, we identify two complementary moments that, taken together, encompass stabilization and contingency (fourth section). In the first moment, we analyze scripts of alterity as materializations of power-laden relations in data systems. As the outcomes of security apparatuses materialized in durable data systems, scripts of alterity are relatively stabilized. Only at certain costs can these assumptions still be contested (Bowker and Star 1999; Callon 1995). And still, the meaning of technological systems emerges contingently in being performed. In the second moment, we thus conduct ethnographic observation of data systems in use at the border. The two analytical moments are complementary: mapping the scripts of alterity designed to upkeep the border is a necessary step to explain the possibility of resistance.
The concept of “scripts of alterity” contributes to the STS and CSS literature on migration management and cross-border mobility in three respects. First, it addresses the risk of legitimizing hegemonic standpoints by reviving the concept of “de-scription,” which is useful to describe standpoints without naturalizing them. Second, thinking in terms of scripts of alterity allows researching the stabilization versus contingency tension as complementary analytical moments. Third, it questions the original STS formulation of scripts assuming intentionality.
Digital Classification Schemas: Objects of Analysis, Methodological Entry Points, and Sources of Knowledge
The conceptualization of apparatus has played an important role in studies of the securitization of cross-border mobility. Michael Foucault first introduced the term “apparatus” in the mid-1970s, and political theory has since further developed it (e.g., Agamben 2009; Perugini and Gordon 2017). For Foucault (2009, 4), the apparatus (dispositif) of security is the contemporary rationality dominant over other historical mechanisms, like the legal rationality and the disciplinary mechanism. Unlike earlier mechanisms, the security apparatus is characterized by quantification of risk and probabilistic thinking.
While Foucault (1980, 194) never provided a clear-cut definition, in a late interview, he identified a security apparatus as the network that can be established between heterogeneous human and nonhuman elements such as “discourses, institutions, architectural forms, regulatory decisions, laws, administrative measures, scientific statements, philosophical, moral, and philanthropic propositions—in short, the said as much as the unsaid.” The reference to the “the said as much as the unsaid” implies questions about how we come to know an apparatus (Agamben 2009, 2). Foucault sees a mutual relationship between apparatuses and knowledge: The apparatus is thus always inscribed into a play of power, but it is also always linked to certain coordinates of knowledge that issue from it but, to an equal degree, condition it. This is what the apparatus consists in: strategies of relations of forces supporting, and supported by, types of knowledge. (Foucault 1980, 196) I think we can speak here of a technique that is basically organized by reference to the problem of security, that is to say, at bottom, to the problem of series. … I think the management of these series that, because they are open series can only be controlled by an estimate of probabilities, is pretty much the essential characteristic of the mechanism of security. (Foucault 2009, 20)
This duality of classification schemas is becoming even more evident with the increasing digitization of contemporary life, where classification schemas are made durable in digital databases as data schemas. Noortje Marres’s (2017) work has insightfully identified the inherent duality of the digital in ethnomethodological terms. She (p. 117) has pointed out that “the digital presents both an object and a resource of social life.”
We suggest that classification schemas show this duality: they organize knowledge and action while they make these activities methodologically accessible. Classification schemas thus constitute methodological entrypoints that allow scholars to follow the production of knowledge in action. Therefore, studying the classification schemas underpinning data systems used in cross-border mobility is expected to concomitantly make types of knowledge available for analysis and provide insights on how people on the move are enacted as security subjects.
Moreover, comparing the results of the analysis provides evidence about the producers of classification schemas. In addition to the object/method duality recognized in ethnomethodology and infrastructural studies, we identify a third level of analysis: classification schemas can also reveal knowledge about those who produced them—usually an authority. Thus, comparing different schemas can spot diverse assumptions by diverse authorities active in the apparatus which produced them. In the case of the European multilevel governance of cross-border mobility, comparing classification schemas might reveal differences and similarities, or even a division of roles, between authorities.
Strangely enough, classification schemas have only marginally been conceived of as resources in CSS and STS research about apparatuses of security. More precisely, classifications have been extensively (and rightly) criticized as the mechanisms through which people are excluded and expelled, but schemas have rarely been empirically analyzed and systematically compared. This may be because Foucault did not apply the concept of apparatus to the management of migrant mobility (Walters 2011); “Apparatus” was introduced in the field only recently by CSS concerned with the datafication of security and the increasing digitization of the border (Pötzsch 2015; Allen and Vollmer 2018; Sontowski 2018).
Most of these studies adopt a performative understanding of border technologies and data systems. Kloppenburg and van der Ploeg (2018) have shown that biometrics are involved in producing and enacting gender and ethnic classifications. Amicelle et al. (2015) have pointed out that security devices are performative because they draw legal, gender, race, and class boundaries. A performative understanding of classificatory practices is a tenet of STS research concerned with the production of alterity and enmity, too. Suchman (2020, 179), for example, has proposed “apparatuses of recognition” as “apparatuses through which the architecture of enmity is put in place and into practice.” STS research in migration management has accounted for border crossers as “enacted” (Mol 2002) as security subjects (Ruppert 2013; Broeders and Dijstelbloem 2015; van Reekum 2019; Pelizza 2021).
Despite this attention to performativity, CSS and STS have paid less attention to classification schemas as methodological resources and sources of knowledge about producers. Three notable exceptions have empirically studied the classification schemas through which people are enacted as security types. First, Van der Ploeg and Sprenkels (2011) systematically analyzed the classification schemas used in the Dutch migration policy to register migrants. While the police was mandated to reduce twelve classes of subjects into five, the authors identified ninety identity categories in which people were administratively labeled in migration policy. Second, Dijstelbloem and Broeders (2015, 32) examined a broader range of European data systems to identify three risk classes: “those who are trusted in the eyes of the migration state, those who are not, and those who are suspect and/or require further scrutiny.” Third, M’charek et al. (2014) have identified racialized “phenotypic others” enacted by five different border management systems. Their empirical analysis of data-based othering comes closest to our comparative goal here: it spots different configurations of Europe “depending on the specific technologies in place and the matters of concern involved” (p. 476).
Beyond these studies, little research in CSS and STS has empirically analyzed or compared classification schemas. This article aims to bridge these gaps and compare the types of knowledge produced by the four main data systems being used at the European border. By drawing on ANT’s concept of “script,” the next section conceptualizes the types of knowledge resulting from the analysis of classification schemas as “scripts of alterity.”
Introducing Scripts of Alterity
The notion of “script” was introduced in ANT (Akrich and Latour 1992; Latour 1992) to refer to the designed instructions for action, the affordances of an artifact offered to users. For example, a beeping alarm requires car users to fasten their seat belt. Through scripts, artifacts exert normative power by prescribing instructions to users. Yet scripts have a second, correlated meaning as assumptions. In exerting normativity, scripts reveal designers’ assumptions about intended users: their expected skills, goals, interests, and limitations. While intended users are a projection, an ideal, actual users may or may not adhere to assumptions. In other words, understanding assumptions is a way to study designers’ imaginaries, more than actual users.
With “scripts of alterity,” we draw on the second meaning of scripts as assumptions. We use this term to describe assumptions about the expected skills, goals, interests, and limitations of the “others”—unknown people moving to and across Europe. For example, scripts can assume that border crossers have low education, come to Europe to increase their income, and have an interest in hiding their identity. Being assumptions, scripts of alterity do not speak so much for actual people on the move but of their producers. Scripts of alterity correspond to the types of knowledge produced by the apparatus. How can we know them?
Scripts of alterity are not immediately accessible: they are inscribed in digital data systems used at the border. As scripts can only be known through artifact analysis, so scripts of alterity can be known by analyzing the classification schemas implemented in data systems used at the border. If classification schemas are both objects of analysis and methodological resources, then by analyzing classification schemas, we can study how people on the move are enacted as intended others as security subjects. The next section discusses our mixed methods in obtaining scripts of alterity, which primarily involved analyzing classification schemas implemented in digital data systems (i.e., data schemas).
As a concept, script of alterity can be productive for CSS and STS concerned with the securitization of cross-border mobility. Firstly because scripts of alterity are analogous to policy formation: they “express in condensed terms the hegemonic forms of social order and reiterate…legitimizing narratives” (Feldman 2005, 678; see also Feldman 2012). Studying a hegemonic standpoint a well-known dilemma in CSS: should scholars analyze apparatuses’ assumptions at the risk of legitimizing and naturalizing them, or should they renounce studying hegemonic standpoints? As Trauttmansdorff (2022, 88) has put it, “[a]ny study on the inner operations of the digital border regime bears a considerable risk in reproducing and normalizing its language and logics.” In studying classification schemas, we should acknowledge and avoid the risk of normalizing and reproducing hegemonic perspectives.
At the same time, in the vocabulary of script (Akrich and Latour 1992), we find a term to help address this dilemma: “de-scription.” De-scription refers to the translation of a script from artifacts into text, words, and concepts. Translating a script from artifacts into words opens the possibility of critique: in fact, it is a preliminary condition for critique. It is in de-scribing, in translating implicit, embedded normativities into discourse that the possibility of analysis, critique, and resistance emerges. With the concept of script of alterity, we borrow from script theory the practice of making implicit normativities explicit. In de-scribing hegemonic assumptions and limitations that would otherwise remain implicit in data systems, scripts of alterity ground the preliminary conditions for critique.
Secondly, script theory provides another term to address the risk of reproducing hegemonic perspectives: “de-inscription.” De-inscriptions refer to the gap between intended and actual use. Where a script refers to instructions and assumptions about intended uses and ideal users, actual users may correspond to that ideal or not. When they act as expected by designers, actual users subscribe to the script (Akrich and Latour 1992). Alternatively, they can resist, appropriate, and subvert the script by de-inscribing, by using the artifact in ways that were not imagined by designers.
Script theory remains ambiguous about the intentionality of de-inscriptions. While for Foucault resistance as counteract is assumed as intentional, script theory is more ambivalent about whether de-inscriptions also include uses that are unintentionally different from designer’s plans. In the field of migration management and cross-border mobility, resistance, frictions, and struggles are constitutive elements of bordering (Mezzadra and Neilson 2013). Resistance is said to take multiple forms as appropriation, subversion, recalcitrance, and insubordination (Dijstelbloem et al. 2017; Scheel 2017; Mora-Gámez 2020; Schinkel 2020), but it always entails some intentionality. With the concept of “de-inscription,” we instead borrow from script theory the possibility that resistance is not necessarily intentional. Classification schemas can be unwillingly contested, data might not match the required field, officers might not enter data as expected. We thus suggest that using “de-inscription” instead of “resistance” for the time grants more pliability to our analysis. Thinking of resistance as de-inscription suggests that the agency of actual people on the move is not necessarily intentional: it can take place by being unable to reduce past living experience into skills, interests, goals, and limitations assumed by scripts of alterity. This extended definition of agency, we argue in the conclusion, redistributes responsibility from people on the move to authorities.
Two Complementary Moments to Account for Stabilization and Contingency
The distinction between scripts and de-inscriptions suggests an asymmetrical relation between scripts of alterity and de-inscriptions elicited by people on the move. While CSS scholars are more likely to frame this relation as a tension between hegemony and subjectification, from an STS perspective, we can see it as a tension between stabilization and contingency. Being distributed among various authorities (which increases the alignment labor necessary to bring about even minor modifications) and made of the durable “stuff of bits” (Dourish 2017), scripts of alterity can be seen as relatively stabilized. At the same time, de-inscriptions are always possible, at higher or lower costs (Callon 1995), because resistance practices take place mainly in the contingent encounter between people on the move and the security apparatus.
We accounted for both stabilization and contingency in our methodology by identifying two complementary moments for analysis. First, paraphrasing a well-known STS tenet, we could say that scripts of alterity are apparatuses made durable: stabilized moments in which the security apparatus materializes its power-laden relations in data systems. 3 Given the obstacles to modifying data systems that are up and running, scripts of alterity are unlikely to change in the short-term. This moment corresponds to the de-scriptive phase where embedded normativities are made explicit by analyzing and comparing classification schemas. De-scribing scripts of alterity makes it possible to recognize de-inscriptions from those scripts. So, the second moment aims to understand apparatuses by finding de-inscriptions from the scripts of alterity identified in the previous phase. This moment thus mobilizes ethnographic observation of actual use of data systems at the border.
These two analytical moments are complementary: mapping the scripts of alterity designed to uphold the border reveals stabilized relationships of power and, at the same time, is a precondition for the ensuing analysis of contingent de-inscriptions. To operationalize these moments of analysis, we compared the scripts of alterity inscribed in the three EU mandated data systems enacting the European border: European Dactyloscopy (Eurodac), the Schengen Information System II (SIS II), and the Visa Information System (VIS). In addition to these three, and in order for our comparison to include systems at different scales of governance, we analyzed the national data system used at the Greek border: the Greek Register of Foreigners (GRF).
Eurodac is an EU data system introduced in 2003 to support the application of the Dublin Regulation (Regulation No. 604/2013; also known as the Dublin III Regulation). The Dublin System sets the criteria and mechanisms for establishing which EU member state is responsible for examining asylum applications based on the principle of first entry. Eurodac was deployed to prevent asylum seekers from lodging a protection application in more than one member state. The system collects fingerprints from asylum seekers and compares those data with fingerprints already stored on its servers. When a hit occurs, it can mean the claimant has submitted an asylum request elsewhere.
Since 2011, SIS II supports intergovernmental cooperation on law enforcement and external border management among state authorities participating in the “Schengen Agreement Application Convention.” The system allows authorities to check criminal perpetrators, people denied entry into the Schengen space, missing persons, data on stolen or lost objects. Authorities use SIS II at the EU border and beyond to check the identity of third-country nationals entering Europe to sort out people with criminal records or to seize objects.
VIS is used to exchange visa data of third-country citizens temporarily traveling to Europe. It is used in European member states’ consulates outside Europe, as well as at Schengen and national borders, to check visas are valid. VIS is one of the largest biometric databases in the world, registering both granted and refused visa applications. Finally, the GRF was developed by the national information systems branch of the Greek police and is used mainly at the border to register, identify and process asylum requests.
All these four systems are in use at the (Greek) border for the purposes described above. They are not (yet) interoperable 4 and are used in variable order, depending on the situation at the point of entry—although fingerprinting on Eurodac is usually given priority.
Now to the first moment in our analysis. From 2017 to 2020, the authors collected data from the three European data systems (Eurodac, SIS II, and VIS), and the first author collected data about the GRF and its use at four Greek registration and identification centers. Data schemas are the formal classification schemas or, more precisely, they can be used to infer classification schemas. A data schema specifies categories (such as “nationality,” “country of origin,” “name”), sets of attributes (“Afghan,” “German,” “Turkish” are attributes of the category “nationality”), and relationships between database entries. As such, data schemas provide “thin” data compared to the “thickness” of ethnographic observation (Geiger and Ribes 2011).
In order to turn those thin traces into thick descriptions, for the first moment of analysis, we designed a two-step methodology. The first step utilized the Ontology Explorer method and web tool developed in the context of the Processing Citizenship project (Van Rossem and Pelizza 2022) to quantitatively analyze and compare the four data schemas. The different formats in which data schemas were made available to us (regulations, screenshots, technical documents, and interviews) were harmonized through Computer-Assisted Qualitative Data Analysis Software (CAQDAS; for more details, see Van Rossem and Pelizza 2022). Next, the Ontology Explorer software tool was used to compare the data schemas corresponding to the four data systems. In comparing the data schemas, quantitative analysis paid specific attention to the presence, absence and frequency of data categories and attributes. The guiding idea was that comparing multiple systems’ data schemas can foreground the data categories present in some but missing in others, thus bringing out assumptions and limitations about intended people on the move inscribed in a specific system. Drawing on these preliminary results, the more fine-grained discursive analysis in the second step took stock of the presence/absence comparison previously conducted to focus specifically on the categories and attributes that appeared as specific of a data system, that is, which were absent from the other data systems. Through this means, we identified the categories and attributes that characterize each script of alterity, and—most importantly—to detect differences and absences between scripts.
The resulting map of scripts of alterity informed the second analytical moment, when we tried to grasp the meaning of technological systems during their use. The first author conducted ethnographic observation of data systems in use to identify de-inscriptions from the scripts of alterity. Ethnographic observation was conducted in multiple periods for a total amount of five weeks from March 2017 to 2019 at the Greek registration centers mainland (Fylakio center) and on the islands (Samos, Chios, Leros). It involved observing all stages of cross-border management, from preregistration to asylum request lodging.
Describing Scripts of Alterity
We identified four scripts of alterity inscribed in the data schemas used in European and Greek national data systems for migration management and cross-border mobility control. While we do not expect that these scripts of alterity can be found in other security subfields, the analysis of their data schemas reveals their classificatory mechanisms and suggests an analytical method to further study scripts of alterity.
Comparative Analysis Using the Ontology Explorer Method
The comparative analyses conducted through the Ontology Explorer show that all systems collect data “native” to each individual system, like the date on which data were first recorded, system-specific identifiers, and the ID of the inputting operator. The three European systems (Eurodac, SIS II, and VIS) have only few data categories in common, namely biometric fingerprint data and gender. SIS II and VIS have slightly more data in common, like biographical data (people’s date and place of birth, nationality, and names). SIS II and VIS also include additional biometric data, such as facial photos. All three European systems collect categories unique to that system. The Eurodac data schema, for example, includes categories about the asylum procedure, such as the date of registration and the place where a person’s application was first examined. The SIS II system features various categories of data that provide supplementary and undocumented information, like different names or aliases a person might use. Also, noteworthy is the possibility of describing a person’s physical and behavioral characteristics. Finally, the VIS has the most extensive set of categories to capture a person’s biographical data and travel. Biographical information includes data about their family, occupation, residence, and education. Information about a person’s travel includes data regarding their travel documents, travel itinerary, and personal ties in Europe.
Comparing the three European data schemas with the data schema underpinning the Greek national system—the GRF—reveals some specificities of the latter. First and foremost, while the GRF collects many categories similar or closely related to those included in the European systems, some other security-related categories (e.g., data about criminal offenses, prior travel intentions) are not present. Some differences can be observed between categories common to all systems. For example, data about a person’s occupation or residence differ across systems run by national and European authorities. Whereas the VIS seems concerned with the person’s current situation, the GRF covers previous information about a person’s life. In addition, the GRF collects supplemental personal data about persons, like languages spoken, contact information, family, and marital status. Also notable is the inclusion in the GRF of data regarding a person’s ethnicity, religion, and vulnerabilities.
Figure 1 visually summarizes the findings of this comparison. 5 At the top of the network are data categories specific to EU systems. In the middle are data common to two or more systems, with data shared by all systems in the center. Color coding and grouping distinguish the systems between categorical co-occurrences. At the bottom of the figure are data specific to the GRF.
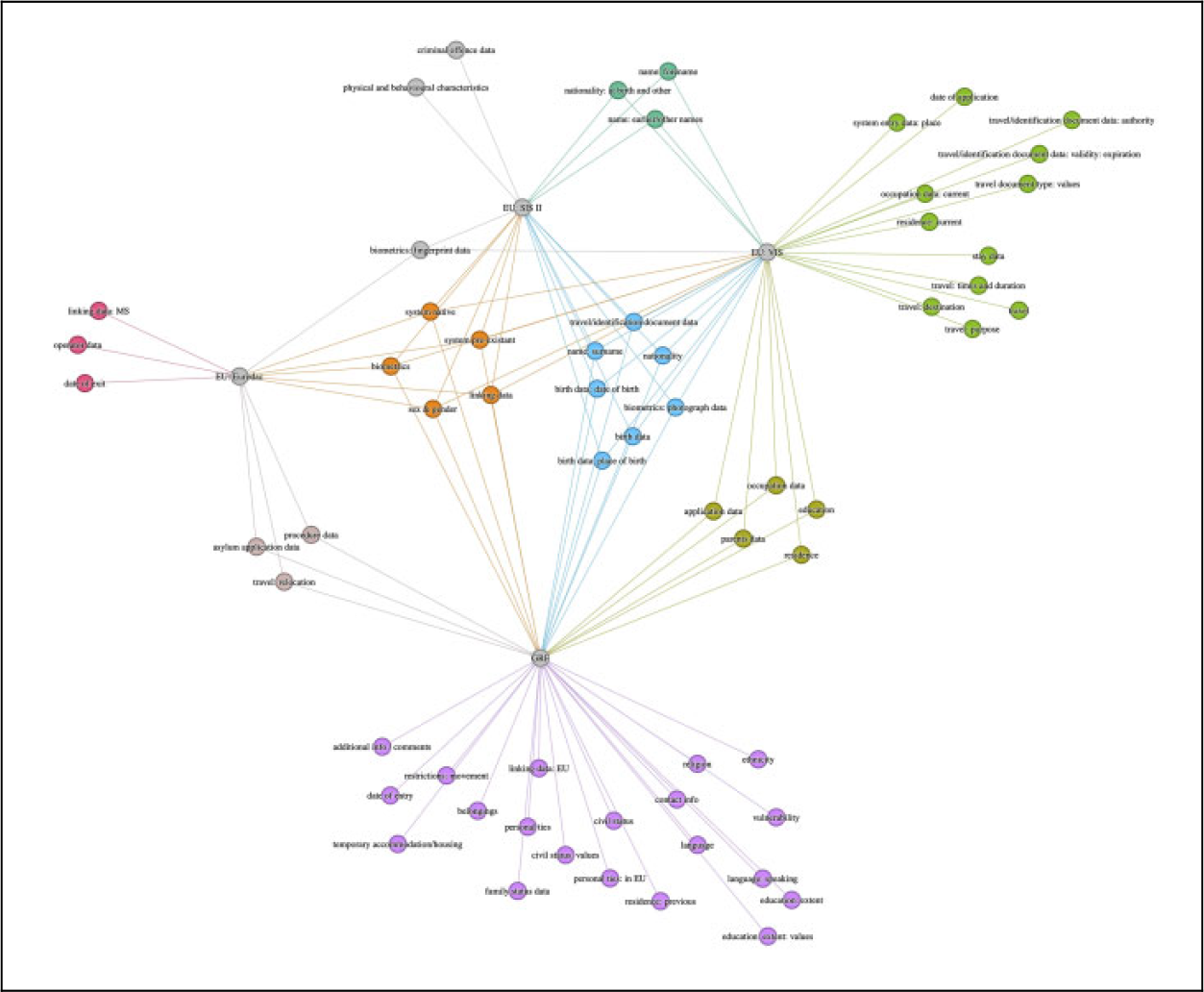
The network generated through the Ontology Explorer and visualized as a force-directed network with the help of the Gephi tool for layout and color coding.
A More Fine-grained Analysis
Drawing on this preliminary comparison, discursive analysis identified one or more scripts of alterity corresponding to each data schema. More precisely, discursive analysis focused on categories and attributes which the preliminary comparison had identified as specific to a system. As Table 1 shows, the GRF collects a range of basic data: name, nationality, gender, ID, photo and date of birth. It also includes less mundane categories, like name of father and mother, religion, ethnic group, educational level, spoken languages, profession, family situation and number of children, and sociocultural ties with Greece.
Data Categories Collected by the Greek Register of Foreigners.
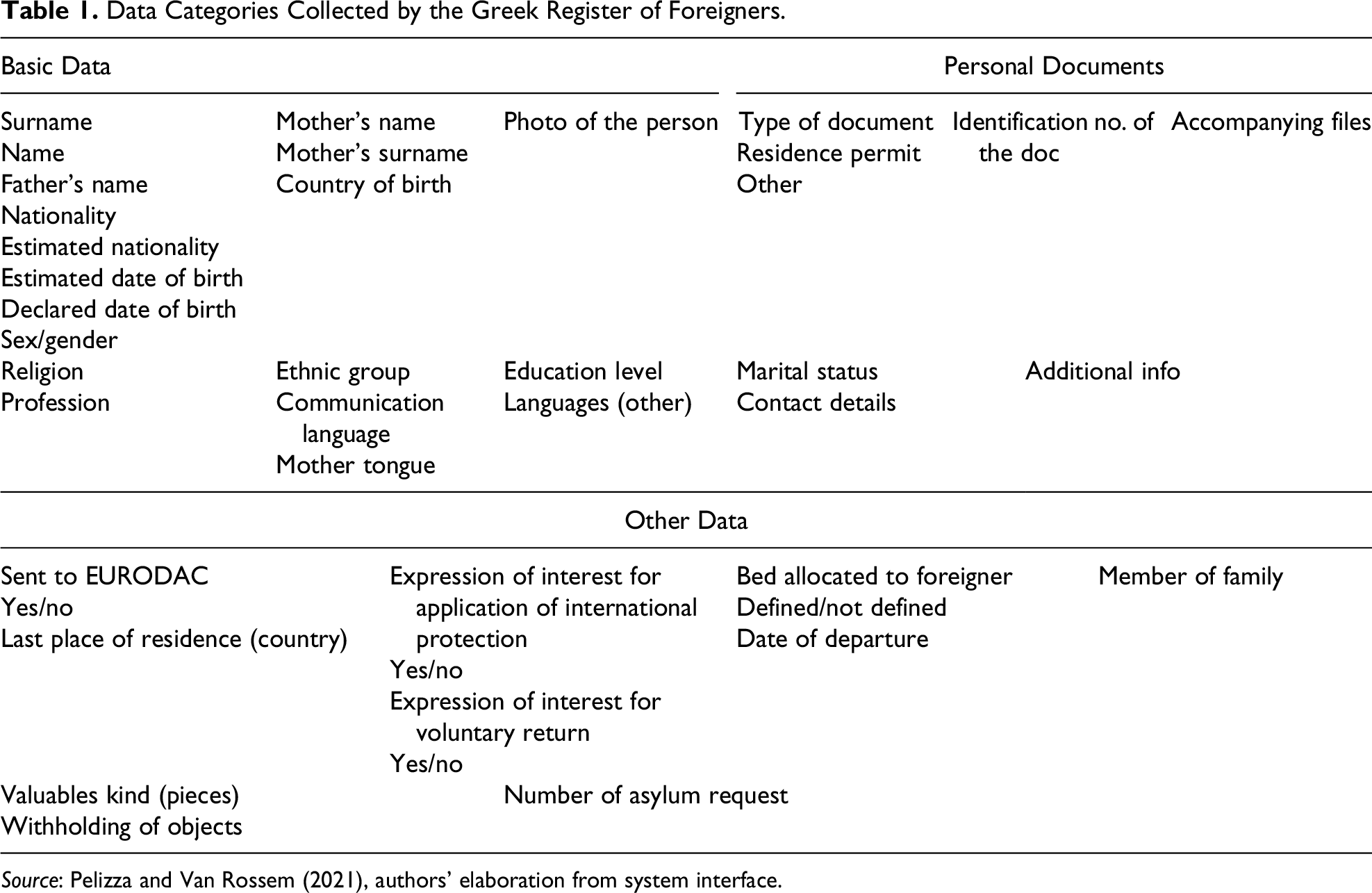
Source: Pelizza and Van Rossem (2021), authors’ elaboration from system interface.
Such a panoply of personal data are expected to be necessary to perform a broad set of functions, beyond administrative and security tasks, including accommodation, family reunification, health care, asylum, and integration in the job market. Designing integration policies without data about professional and linguistic skills would indeed be difficult. Drawing on this evidence, we suggest that the GRF enacts people on the move as long-term stayers, eligible for societal integration.
The script of alterity for Eurodac is very different. 6 Eurodac’s mission is to identify asylum seekers through their fingerprints, so that they cannot apply in more than one EU member state. It stores the digital fingerprints of people claiming asylum in one of the EU member states and alerts authorities if someone claims asylum in another member state. Table 2 shows data collected in Eurodac.
Data Categories Collected by Eurodac.

a Data collected when applicable and in compliance with relevant articles.
Source: European Regulation (EU) No 603/2013 of the European Parliament and of the Council.
The Eurodac script of alterity is composite. Many data categories included in the GRF are not collected in Eurodac, such as religion, ethnic group, educational level and languages spoken, profession, family situation, and sociocultural ties. Instead, Eurodac collects many data that are system-native: they did not exist before the person was recorded in the system (e.g., Eurodac number, place and date of registration, ID of registration officer). This characterizes Eurodac as a self-referenced index, in which information acquires meaning in the context of the system itself. More precisely, fingerprints and other personal data receive meaning from indexical data that bind them within a series of relations meaningful in the Dublin system. Furthermore, people are assumed to be unforthcoming about their previous asylum requests: their fingerprint data are collected to be compared with fingerprints collected in other places and times to avoid “asylum shopping” and also for crime detection purposes. Data are used to connect a biometric-based identity with other systems in order to devise whether an asylum application has already been lodged elsewhere. In this case, asylum seekers will be dislocated to the country of first asylum request, and their request will be there processed. This lack of trust and a broader security turn are reinforced by planned developments on the system, which may include a security flag, which officers can use to add their assessment of whether an applicant constitutes a security threat (EDRI 2022; Council of the European Union 2022).
All in all, this analysis suggests that Eurodac enacts people on the move as foreigners expected to stay only temporarily, not eligible for integration (for which those types of data would be necessary). We propose to label Eurodac’s script of alterity as a short-term irregular immigrant. Irregularity is an important feature here because it marks a turning point in the system as it becomes a genuine law enforcement instrument, gathering a large amount of data supposedly informing whether a person could be considered a “security threat” (EDRI 2022). Our findings agree with a growing body of legal scholarship on the securitization of EU large-scale IT systems (Balzacq 2008; Curtin 2017; Galli 2020).
The second European system, SIS II, collects names of people and objects previously involved in criminal activities (e.g., guns, lost documents), missing people, and witnesses. 7 Like Eurodac, SIS II collects data that are specific to the system, like Schengen ID, data/place/reason for fingerprinting, links to other alerts issued in SIS II. Most importantly, it collects data categories that assume that people may wish to hide their identity. 8 To counteract this, SIS II collects data about aliases and physical or long-term characteristics that are difficult to falsify. One category in particular reveals the script of alterity enacted by SIS II. Tick-boxes signal whether someone is armed, violent, has escaped or poses a risk of suicide. When ticking a box once, this attribute becomes permanent: being violent is conceived of as a permanent condition, a personality trait, rather than a temporary reaction to a threatening situation (very common when people are caught at the border by armed police). This evidence accords with what Suchman (2020) has described as the expanding temporal and spatial boundaries of what comprises an imminent threat. Here, the imminent threat of a person who might behave irrationally when caught at the border is temporally expanded and becomes a permanent personality trait. This qualifies one of SIS II’s scripts of alterity as a potentially threatening subject.
For the last of the EU systems, VIS, our analysis again focused on data that are system specific. On the one hand, categories such as main destination and duration of the intended stay, purpose of travel, intended date of arrival and departure, border of intended first entry or transit route, and details of the person issuing an invitation enact applicants as travelers. On the other hand, applicants are assumed to be settled individuals in their country of origin and asked to provide information on residence, current occupation, and employer. This is an apparent paradox.
The paradox reveals that travel is defined as a temporary condition: it is assumed that people will return home and will not overstay in Europe. Although the EU VIS regulations were updated in 2018 to incorporate details about long-term visas and residency permits, the script of alterity continues to assume a temporary situation. Hence, VIS’s script of alterity could be defined a resident traveler, and it reveals the double nature of VIS: travelers are assumed to be rights-holders (who can travel to Europe regularly) only insofar as they keep residence in their country of origin. It is assumed they will go back before their visa expires. If they do not, assumptions will be betrayed.
In the next section, we compare these four scripts of alterity with an eye on their consequences for the multilevel European order.
Division of Labor by Design
As anticipated in the third section, analyzing scripts of alterity promises to throw light not so much on the actual identity of people on the move, but on the security apparatus enacting the European border. 9 In particular, it allows a comparison of the assumptions and limitations by diverse authorities in charge of diverse systems. We can wonder, for example, whether diverse scripts of alterity are complementary or overlapping, and which practices they facilitate or hamper, depending on the categories and attributes information systems collect. This type of analysis appears particularly promising for European multilevel governance of cross-border mobility. Comparing different scripts of alterity might reveal differences between authorities: we may identify divisions of labor or “geographies of responsibility” (Oudshoorn 2011) among diverse authorities or governance scales involved in the security apparatus. Given scripts of alterity’s stabilized character, their comparative analysis is expected to trace divisions of labor that are unlikely to change in the short term.
In this sense, this subsection contributes to studying the stabilizing end of the stabilization-and-contingency tension. Drawing on the preliminary analysis conducted with the Ontology Explorer, a distinction between national and supranational scales of governance is notable, with clear differences in the categories and attributes collected by the three European systems on the one hand and by the Greek system on the other. Such differences were then confirmed by discursive analysis. The three European systems, and especially Eurodac and SIS II, create self-referenced digital indexes, in which personal and biometric data acquire meaning in the context of indexical data. These two data systems also focus mainly on security and biometric data, and fall short of collecting other personal data, like linguistic or professional skills. On the other hand, not all security-related categories are collected in the GRF and, most importantly, the GRF collects supplemental personal data, like linguistic skills, contact information, family, and marital status. Furthermore, the GRF collects sensitive data regarding a person’s ethnicity, religion, and vulnerabilities (see Table 1).
It is important to note that the GRF is not and will not be interoperable with the European systems. While a major interoperability strategy is being pursued by the European Commission and eu-LISA (the Commission’s agency for the operational management of large-scale IT systems in the area of freedom, security, and justice), its focus is on furthering interoperability only among European systems and does not involve national ones (see EU 2019a, 2019b). As a result, personal data collected by the GRF are not expected to be shared with other EU member states, which will continue to receive only data from European systems.
Taken together with the comparison of scripts of alterity, this clarification reveals a de facto division of labor between national and supranational scales of governance. The European systems only allow functions based on hit/no-hit queries based on biometrical data. Some functions like societal integration and job placement, which require more fine-grained personal data, can only be completed at the national level by authorities with access to data on the national system. Therefore, on the basis of data collected at the border, EU agencies and non-frontline countries are only enabled to carry on security functions.
This finding does not imply that Greek authorities are more receptive to integrating people on the move than non-frontline European authorities. It is better interpreted in light of the broader European data architecture and the origin of the GRF: designed by the police IT headquarters in Athens around 2015, the GRF was heavily subsided by the EU Commission DG HOME, which played a role in shaping the European architecture of migration management data (interview with DG HOME officer, June 2017). The difference in categories makes visible not so much the goodwill of Greek authorities but a (lack of) intergovernmental cooperation on integration by design. In this light, the comparative analysis of scripts of alterity reveals a division of labor that—while not being formalized in policy—de facto shapes the European order.
De-inscribing Scripts of Alterity
In order to account for stabilized crystallizations of power into scripts of alterity, we complemented our analysis of scripts of alterity with ethnographic observation of their use. This constitutes the second moment of the analysis, focused on the contingent contestation in practice of the security apparatus deployed at the European border. Here, we focus specifically on de-inscriptions from scripts of alterity, that is, from assumptions and limitations about people on the move.
We undertook ethnographic observation at registration centers in the Greek mainland (Fylakio center) and on the islands (Samos, Chios, and Leros) at multiple times, for a total amount of five weeks from 2017 to 2019. Our observations revealed three practices of de-inscription from scripts of alterity: alternative proofs, categorical stretching, and unmatching declarations. Of course, we do not claim that these exhaust the full analytical variety of de-inscriptions: these three practices provide an initial typology of de-inscriptions from scripts of alterity, with further research currently being conducted (e.g., Olivieri 2023).
First, “alternative proofs” relate to alternative ways of establishing one’s identity (Pelizza 2020). They are open requests made by people on the move to officers during identification and registration. It is quite common for people to ask police and registration officers to be identified neither on the basis of passports nor biometrics but by school certificates, family trees, or other documents reporting personal data and life achievements. Pelizza (2020) notes this practice is an effort to reject the standard process of identification that relies on biometric data and documents issued by police authorities and instead to assert the legitimacy of alternative forms of identification based on documents produced by other authorities. This practice can be conceived of as a form of de-inscription from hit/no-hit systems using biometric indexes. We observed its use mainly as an act of de-inscription from Eurodac’s “irregular immigrant” script of alterity. In this de-inscriptive practice, political agency unfolds as an explicit and intentional contestation of the legitimacy of policing epistemic sources (i.e., the bare body or the police issuing passports in the country of origin).
“Categorical stretching” is a second type of practice challenging the scripts of alterity (Pelizza 2020). It involves implicit contestation from people on the move to Western classifications established as global benchmarks. Pelizza (2020) reports the example of seventeen men who self-identified as siblings. Having left their village in sub-Saharan Africa together and having reached the EU border still together was sufficient, in their view, to qualify as siblings. By so doing, migrants challenged the European nuclear family model and de-inscribed themselves from a script of alterity that did not include non-European classifications of family relationships. Another example of categorical stretching happens when children try to register as adults and vice versa (FRA 2018), thus challenging the definition of adulthood. This practice de-inscribes from Eurocentric classifications and asserts alternative classifications based on lived experience. Categorical stretching can be conceived of as a means of de-inscribing mainly from data systems that contain personal information. We observed its use with the GRF script of alterity as “long-term stayer.” In this de-inscriptive practice, political agency unfolds as an implicit but intentional contestation of the legitimacy of classifications.
A third practice of de-inscription is “unmatching declarations,” unintentional mismatches between data schemas and data reported by applicants. For example, inaccurate birth date recordings often involve cases where only the birth year is known, so the date are recorded as January 1 of that year, and discrepancies can also result from variations in calendar systems (FRA 2018).
10
A telling case of unmatching declaration was observed during registration procedures at the Fylakio center in Greece: A hot day in July 2018, mosquitos and flies infest the narrow alleys and barracks at the identification and registration center in Fylakio. Amina (fictional name) crossed the border today with her family from Turkey and across the river Evros. They were caught by the police along the river and brought to the center. She has already gone through the first stage of identification in a different shed and is now being registered on the GRF as part of her asylum claim. She is sitting on one side of the desk, the Greek asylum officer sits in front of her—the desktop computer between them, the interpreter to her left, the researcher conducting ethnographic observation
11
and her translator further next, still at hearing distance. Two other asylum officers are present in the shed, attending to their own issues. Amina, the interpreter and the asylum officer are collaboratively filling the GRF through questions and answers. When asked in her language about her profession, Amina declares to be a school director. As the interpreter translates, the ethnographer notices the asylum officer’s puzzlement. The officer stops the Q&A procedure and asks for support in Greek to the two colleagues present in the shed. They seem puzzled, as well, then answer in Greek. The officer reflects about the answer and the inputs something in the GRF. Given her noninterferential mandate, the ethnographer takes advantage of a break to ask the officer and the assisting translator what had happened. Apparently, Amina’s profession did not fit the script: “school director” was not an option available on the scroll-down menu of the GRF, and neither was “teacher.” After consulting with colleagues, the asylum officer found a solution in the attribute “other profession.” At the end of the procedure, the asylum officer and the interpreter take a break. The ethnographer reaches the two other asylum officers who went smoking outside the shed. They spontaneously report that “school director” is just one case among many of data schemas that fail in providing for categories and attributes declared by applicants. Other exemplary cases are “pilot,” “flight attendant,” “teacher.”
Security apparatuses act by imposing limitations, but unmatching declarations de-inscribe from such scripts of alterity. They do not fit established assumptions and assert the irreducibility of lived experience. The practice of unmatching declarations can be understood as a form of de-inscription from all scripts of alterity that fall short of providing for the multiplicity of migrants’ life trajectories. In this de-inscriptive practice, political agency unfolds as an implicit and unintentional contestation of assumptions and limitations.
The unintentional character of unmatching declarations sets it apart from the other two forms of de-inscription we observed at the border, and from broader forms of resistance reported by the literature as above described. It challenges the Foucauldian formulation of resistance that assumes intentionality in resisting artifacts and forces us to wonder whether script theory can account for unintentional de-inscriptions. The concept of scripts of alterity can certainly account for unintentional de-inscriptions that would not normally be considered as resistance.
Furthermore, unmatching declarations involve practices of de-inscription beyond the in-situ interaction with the system (e.g., the refusal to being fingerprinted); it characterizes a longer-term relation between people on the move and scripts that do not take into account their diverse and multiple past life trajectories. Seen in this light, scripts of alterity can describe a condition that unfolds in the present in relation to the past. It is by reducing the past to scripts’ assumptions and categories that the violence of the here-and-now of the border becomes evident.
Conclusion: The Contribution of Scripts of Alterity to STS and CSS
In this article, we have analyzed classification schemas in the context of a growing securitization of cross-border mobility. Classification schemas have been mobilized as objects of analysis, methodological resources, and as sources of knowledge about their producers. We conceptualized the outcomes of the analysis as “scripts of alterity” and compared the scripts of alterity of four digital data systems used at the European border. In light of the findings, we suggest that the conceptualization of scripts of alterity contributes to the STS and CSS literature on migration management and cross-border mobility in three respects. The first contribution addresses a topical issue in CSS, namely the risk of naturalizing hegemonic standpoints. Although this risk cannot be fully avoided, by our conceptualization of scripts of alterity revitalized the notion of “de-scription” as translation of implicit normativities into discourse. Rather than a process of naturalization, de-scribing scripts of alterity is a necessary preliminary condition to critique and resist hegemonic assumptions and limitations that would otherwise remain implicit.
Second, the conceptualization of scripts of alterity contributes to the debate in STS and CSS by addressing the tension between stabilization and contingency foregrounded by this special issue of Science, Technology, & Human Values as a matter of complementary analytical moments. While we recognize the asymmetrical relations at play between apparatus and people on the move, we explain them not so much as a matter of hegemony versus subjectification (the explanans, so to say), but as a matter of stabilization and contingency (the explanandum). This choice is operationalized in our adoption of script theory: as scripts of alterity materialize the apparatus in data systems, their contestation through de-inscriptions is always contingent to the encounter with actual people on the move.
On the one hand, focusing on stabilization and comparing scripts of alterity has allowed us to spot implications for the European order that would have remained invisible if our methodological focus were only on contingency. Given the stabilized, durable character of data systems, the de facto division of labor between national and supranational scales of governance is unlikely to change in the short term. In themselves, these findings are expected to contribute to studies that look at “processing alterity” as processes of European reordering (Pelizza 2020; Pelizza and Loschi 2023). As Grommé and Ruppert (2020, 238) have established, the data grids and cubes of statistical infrastructures that enact European populations are far from coherent and unified, and produce “Europe not as a whole but as multiple spatial, temporal, social, and methodological topologies.” Our comparative analysis of classification schemas contributes to highlighting this multiplicity by spotting power relations not just between apparatus and people but across scales of governance.
On the other hand, the methodological focus on contingency has allowed us to identify forms of resistance that challenge stabilization. Practices of de-inscription are not exerted against an ungraspable security apparatus but vis-à-vis identifiable scripts of alterity. Resistance by people on the move takes place in the context of data systems and their embedded scripts of alterity that attempt to reduce past life experiences into discrete categories. Our findings suggest research on the securitization of cross-border mobility should focus not only on the future dimension of resistance as mobilized by life expectations but also on the role of the past (see also Olivieri 2023).
Third and finally, our concept of scripts of alterity also has the potential to advance STS scholarship. Scripts of alterity can account for unintentional de-inscriptions that would not normally fall under the label of resistance, which is assumed to be intentional. Although ANT has traditionally predicated the disentanglement of agency and intentionality, it is not clear whether the notion of de-inscription assumes intentionality (Akrich and Latour 1992). The evidence of unmatching declarations suggests script theory must disambiguate this issue, so as to account for unintentional de-inscriptions. Additionally, we may wonder who has the responsibility to provide people on the move with fair and just identification. When their past life cannot be changed, it is authorities who must assure that assumptions and limitations inscribed in information systems adequately match the richness of experience.
Footnotes
Authors’ Note
This article was written in the context of the “Processing Citizenship. Digital Registration of Migrants as Co-production of Citizens, Territory and Europe” project, which has received funding from the European Research Council under the EU’s Horizon 2020 research and innovation program under grant agreement No 714463. The research was conducted in conformity with the ethical plan of the Processing Citizenship project, which was approved by the European Research Council Executive Agency’s Ethics Committee (approval number 714463—ProcessCitizenship), the Ethical Committee of the Faculty of Behavioral, Management and Social Sciences of the University of Twente (approval number CvB UIT—2210), and by the Bioethical Committee of the University of Bologna (approval number 219611 on September 24, 2019). Human participants were recruited on a voluntary basis, kept anonymous, and informed about the Project’s goals; they all gave informed consent. For the sake of scientific accountability, as main author of the Ontology Explorer Wouter Van Rossem wrote the section “Comparative Analysis Using the Ontology Explorer Method,” Annalisa Pelizza wrote the other sections. The whole article was jointly revised and thoroughly discussed between the two authors.
Acknowledgment
The authors wish to thank the anonymous respondents and Ermioni Frezouli and Aristotele Tympas for their support in networking in Greece.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: H2020 European Research Council (grant agreement No 714463).