
Abstract
The field of artificial intelligence (AI) is transforming almost every aspect of modern society, including medical imaging. In computed tomography (CT), AI holds the promise of enabling further reductions in patient radiation dose through automation and optimisation of data acquisition processes, including patient positioning and acquisition parameter settings. Subsequent to data collection, optimisation of image reconstruction parameters, advanced reconstruction algorithms, and image denoising methods improve several aspects of image quality, especially in reducing image noise and enabling the use of lower radiation doses for data acquisition. Finally, AI-based methods to automatically segment organs or detect and characterise pathology have been translated out of the research environment and into clinical practice to bring automation, increased sensitivity, and new clinical applications to patient care, ultimately increasing the benefit to the patient from medically justified CT examinations. In summary, since the introduction of CT, a large number of technical advances have enabled increased clinical benefit and decreased patient risk, not only by reducing radiation dose, but also by reducing the likelihood of errors in the performance and interpretation of medically justified CT examinations.
1. Introduction
Artificial intelligence (AI) was recognised as an academic discipline in the middle of the 20th century, followed by cycles of optimism and disappointment as the field progressed to its prominence today, where various elements of AI impact almost every aspect of modern technology. Much of the success of the field in recent decades can be attributed to advances in computation power, vast digital datasets, and the rise of cloud computing infrastructures, in combination with improved understanding of theoretical aspects of AI and implementable algorithms. By the early 21st century, AI was being developed in earnest by technology leaders such as IBM, Google, Microsoft, Apple, and Facebook. Today, we can use speech to direct electronic devices to perform tasks for us. Software can recognise features in images to identify individual people within photographs or, in medicine, specific pathological features in computed tomography (CT) or other images of the human body.
1.1. Introductory concepts in AI
AI is a broad discipline that contains a number of subfields, each of which approaches the overall tasks using different strategies, wherein the overall task is to develop hardware and software approaches by which a machine can perform cognitively complex tasks, including decision making. In machine learning, algorithms are trained to perform specific tasks by learning patterns from large datasets. Deep learning is a subset of machine learning whereby artificial neural networks, inspired by the design of the human brain, are used in conjunction with very large amounts of data to solve highly complex problems (Chartrand et al., 2017; Erickson et al., 2017).
1.1.1. Machine learning
In classical computer programming, the developer has a specific set of mathematical or logic rules to follow to turn input data into output answers. That is, the developer knows the rules to be applied to the data to yield the desired answers.
In machine learning, these rules are not known a priori. For example, in supervised learning, the developer has access to large amounts of input data paired with output answers. The relationship between the input and output information is highly complex, and difficult or impossible to define a priori. Machine learning is ideally suited for this task, in which the known input data/output answer pairs are fed into a machine learning framework to train the algorithm in such a way that it learns the rules to move from input data to output answers. Once trained (i.e. once the rules have been learned), inputting any future datasets into the same algorithm is expected to yield correct output answers.
1.1.2. Neural networks and deep learning
Artificial neural networks are a series of cascaded mathematical prophecies intended to loosely model the complex decision trees of the human brain. The network is composed of a number of layers, each performing one task in a long series of cascaded tasks. The phrase ‘deep learning’ is used to describe a neural network with a large number of hidden layers, in addition to the input and output layers. In CT, most deep learning applications use a type of artificial neural network known as a ‘convolutional neural network’. During the training process, input data are fed into the cascaded networks, each composed of a set of neural nodes that are connected to downstream nodes that perform various simple mathematical functions, such as convolution. Throughout the process, some nodes and node connections are cut and others are reinforced, and the weightings linking one node to another are adjusted so that at the end of the training, the weights, or parameters, of the neural network have been adjusted so that the difference between the network’s output and the output data (‘truth’) used for training for a given input are minimised. Subsequently, new data on which the network has not been trained previously can be input into the network to yield output information that is deemed to reflect anticipated truth. The overall number of weightings on a network can be in the millions, and although convolution operation is fundamentally linear, the overall process becomes highly non-linear due to the existence of non-linear activation functions. An example is provided in Fig. 1.
Subsequent to training with large amounts of data where both the input images and output labels are known with confidence, a new input image (in this case, a computed tomography image of the liver) can be fed through the network, where important features are extracted and passed to classification layers. Finally, the decision, or label, is presented to inform the user whether a lesion is present or absent at any given location.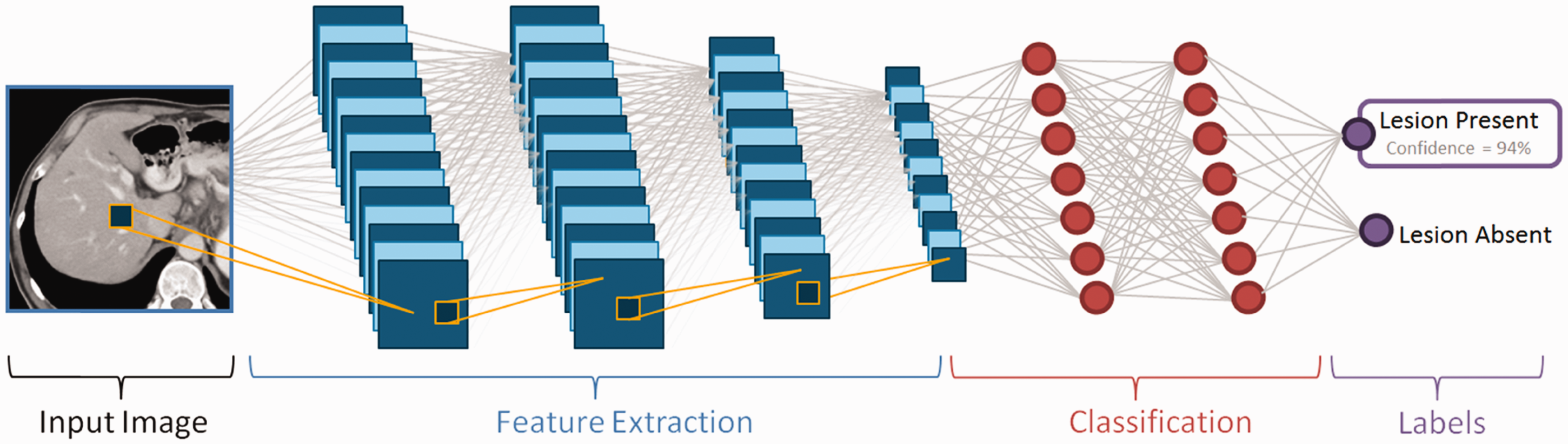
1.1.3. AI applications in medical imaging
At the current time, AI, whether in the form of traditional machine learning, or the more recent deep learning, other types of learning, has been demonstrated to successfully detect and characterise areas of pathology, accurately segment areas of pathology or organs, synthesise presented information to make a diagnosis, label types and locations of pathology and anatomy, reduce quantum noise in images, and even reconstruct cross-sectional images from multiple views (or projections) around the patient. This article describes currently available AI approaches that facilitate optimisation of patient radiation dose from CT imaging. The word ‘optimise’ is used, as opposed to the word ‘reduce’, because the goal of medical imaging is to arrive at an accurate diagnosis using the lowest dose of radiation that is reasonable to achieve. That is, the benefit (i.e. achieving an accurate diagnosis) is maximised and the potential risk (i.e. the dose of radiation or iodinated contrast media to the patient) is minimised. As will be emphasised in the concluding section of this article, reducing the dose of radiation or iodinated media to a level where an accurate diagnosis is difficult to achieve or cannot be achieved is inappropriate, because it compromises the overall care of the patient.
2. Applications Of Ai In Ct
Fig. 2 illustrates the processes involved in a CT examination, from setting up the patient on the scanner table through to reconstruction of the final images.
Illustration of the performance of a computed tomography (CT) examination. The patient is placed on the scanner table, and the anatomy of interest is positioned around the centre of the CT gantry. A CT localiser radiograph is acquired, and the operator marks the start and end locations over which the scan is to be acquired. The correct scan protocol is selected, based on the clinical indication for the examination, and then the specific scan parameters are selected to produce images of the quality required for that diagnostic task. Finally, images are reconstructed using a range of parameters that determine the characteristics of the image, such as image sharpness and FOV, field of view.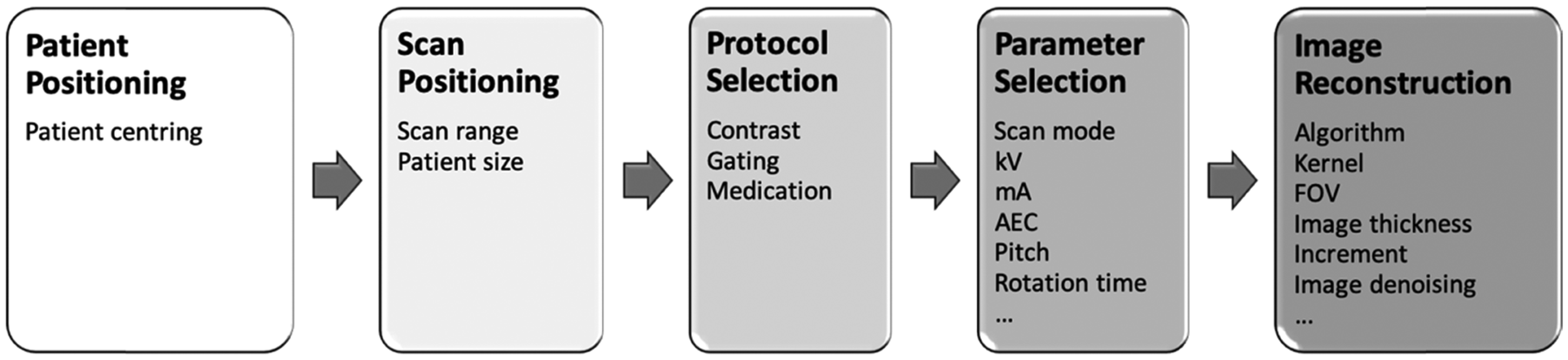
AI techniques can be incorporated into each of these steps.
2.1. Patient positioning
The geometry of the CT system is such that the x-ray tube–detector pair rotates around a fixed centre, referred to as the ‘machine isocentre’. A physical object, referred to as a ‘bow-tie filter’, is used to decrease the number of x-ray photons hitting the patient periphery, because the patient’s thickness is smaller there and fewer photons are needed. As patients are thickest at the isocentre, the filter has the lowest amount of attenuation there. The bow-tie filter is an important tool for patient dose optimisation. However, if the patient is not centred around the isocentre, there is a mismatch between the assumption used in developing the bow-tie filter and the actual patient set-up. This causes dose to be misapplied in some body locations, and image noise is increased relative to when the patient is positioned at the isocentre.
Since approximately 2000, CT systems have incorporated a feature, referred to as ‘automatic exposure control’ (AEC), which increases the tube current (i.e. increases the number of x-ray photons) for thicker body regions and decreases the tube current (i.e. decreases the number of x-ray photons) for thinner body regions. For the system to estimate the attenuation of a body region, it relies on the information provided by the CT localiser radiograph, which is essentially a digital x ray acquired on the CT scanner with the x-ray tube in a fixed position. As shown in Fig. 3 with the x-ray tube beneath the patient table, if the patient is positioned too high or too low with respect to the isocentre, the system perceives the patient as being too thin or too thick, respectively. This is because the spatial calibration of a CT system is performed at the isocentre (McCollough et al., 2006).
Illustration of the performance of automatic exposure control on a computed tomography scanner.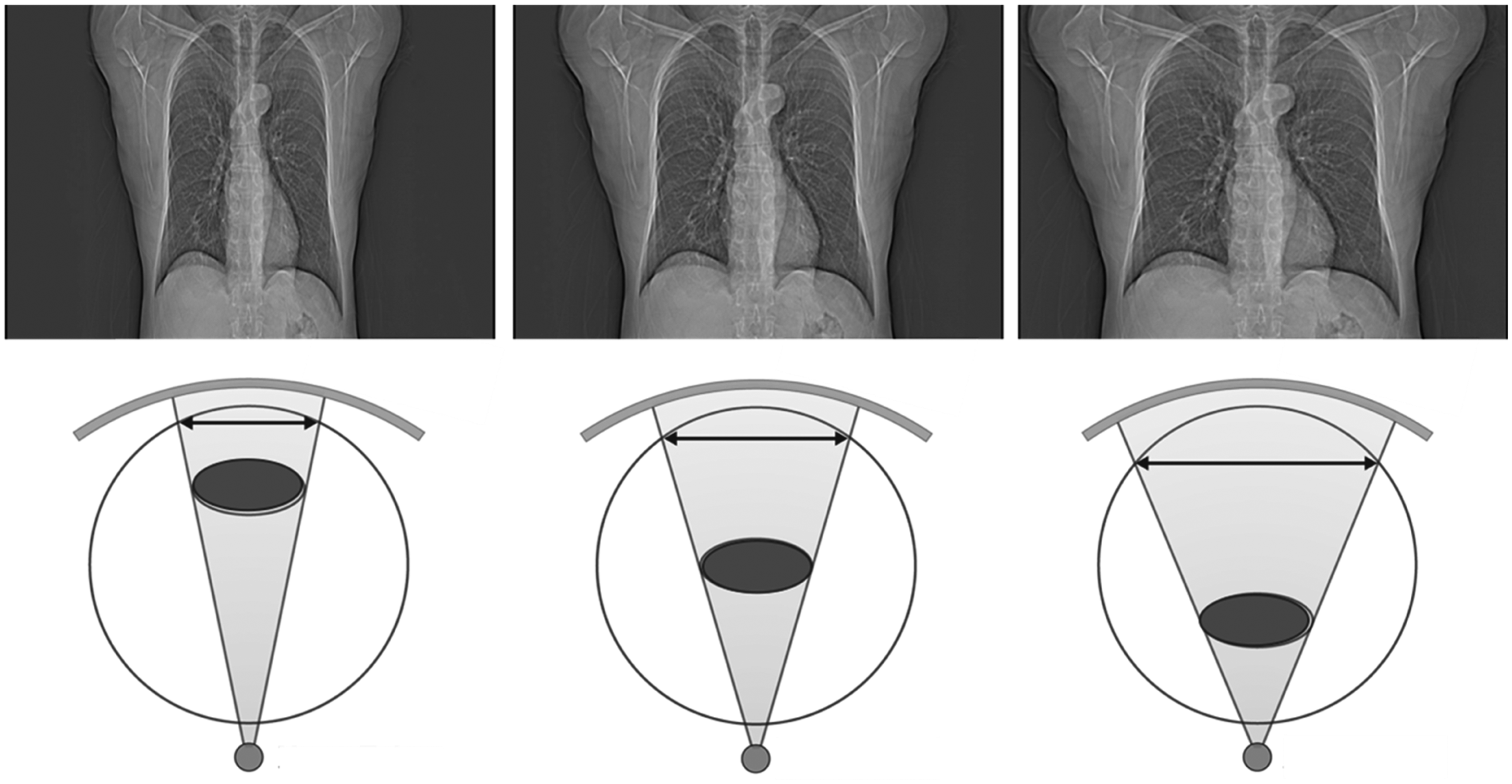
While manufacturers have implemented AEC systems somewhat differently in their commercial products, the fundamental principles remain the same, and the result is that the system automatically determines the required number of photons at every projection through the patient. For very large patients, this means that the system needs to further increase the number of photons in order to achieve the specified examination quality to accomplish the specified clinical task. As patients are not homogeneous cylinders, the end result is typically that the tube current oscillates up and down within a single rotation of the gantry, and increases, on average, through thick body regions (e.g. the shoulders and hips), and decreases, on average, through thinner body regions (e.g. the chest). For these algorithms to operate properly, it is essential that the patient is centred about the system’s isocentre. However, as patient anatomy is quite variable, this can be difficult to achieve in practice.
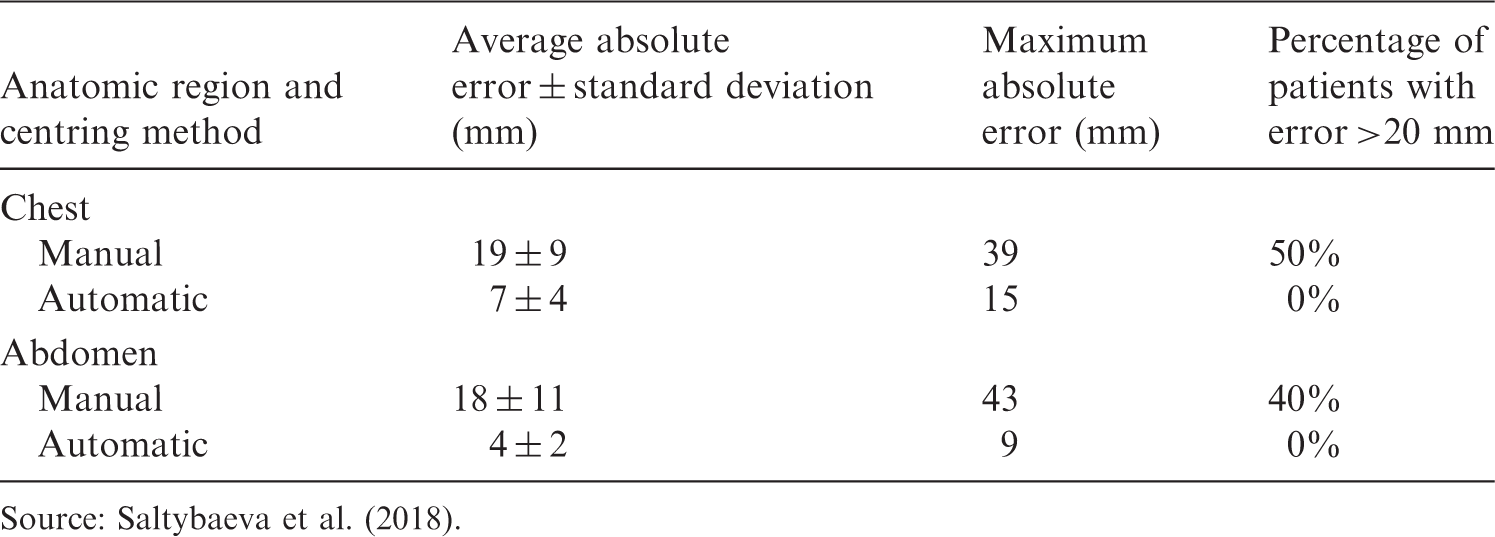
Recently, a CT manufacturer has integrated a three-dimensional infra-red camera into their system (Fig. 4). The camera is located on the ceiling above the patient table and produces a three-dimensional image of the patient’s surface with depth information. Using an AI algorithm, which was trained on over 1000 patients from three different hospitals, it detects specific landmarks on the patient’s surface; based on the portion of the body to be scanned and the current height of the table, the system automatically moves the table vertically to position the patient such that the majority of the scanned anatomy is located at the isocentre (Saltybaeva et al., 2018; Booij et al., 2019). Table 1 summarises the results of a study by Saltybaeva et al. (2018), demonstrating that the average and maximal errors are decreased substantially using this AI algorithm to centre the patient automatically. Considering an error >20 mm to be clinically unacceptable, the AI approach reduces serious errors from 40–50% to 0.
The three-dimensional camera and its location above the patient table (left). Optical image and three-dimensional depth map of the patient acquired using the overhead camera (right). Summary of errors from manual and automated positioning. Source: Saltybaeva et al. (2018).
2.2. Scan positioning
Once the patient is centred appropriately on the scanner table, the operator must prescribe the specific anatomy over which data are to be acquired. This process also uses the localiser radiograph (Fig. 5). Typically, the operator must move a line manually to the start and end positions of the desired scan. Operator-to-operator variations result in either too much or too little anatomy being covered. Operators have the tendency to be somewhat cautious; therefore, they often extend the scan range further than necessary to avoid the potential of excluding any anatomy from the scan. AI algorithms have been trained to accurately identify specific human anatomy from medical images. Based on the examination indication (and hence, the instructions selected by the operator for the examination), the system can automatically choose the scan range that is optimally centred around the required anatomical coverage.
A computed tomography localiser radiograph acquired in the anterior–posterior orientation (left) and in the lateral orientation (right). The artificial intelligence algorithm can position the scan range automatically to cover all of the lung anatomy (transparent grey box) or cardiac anatomy alone (dark grey box).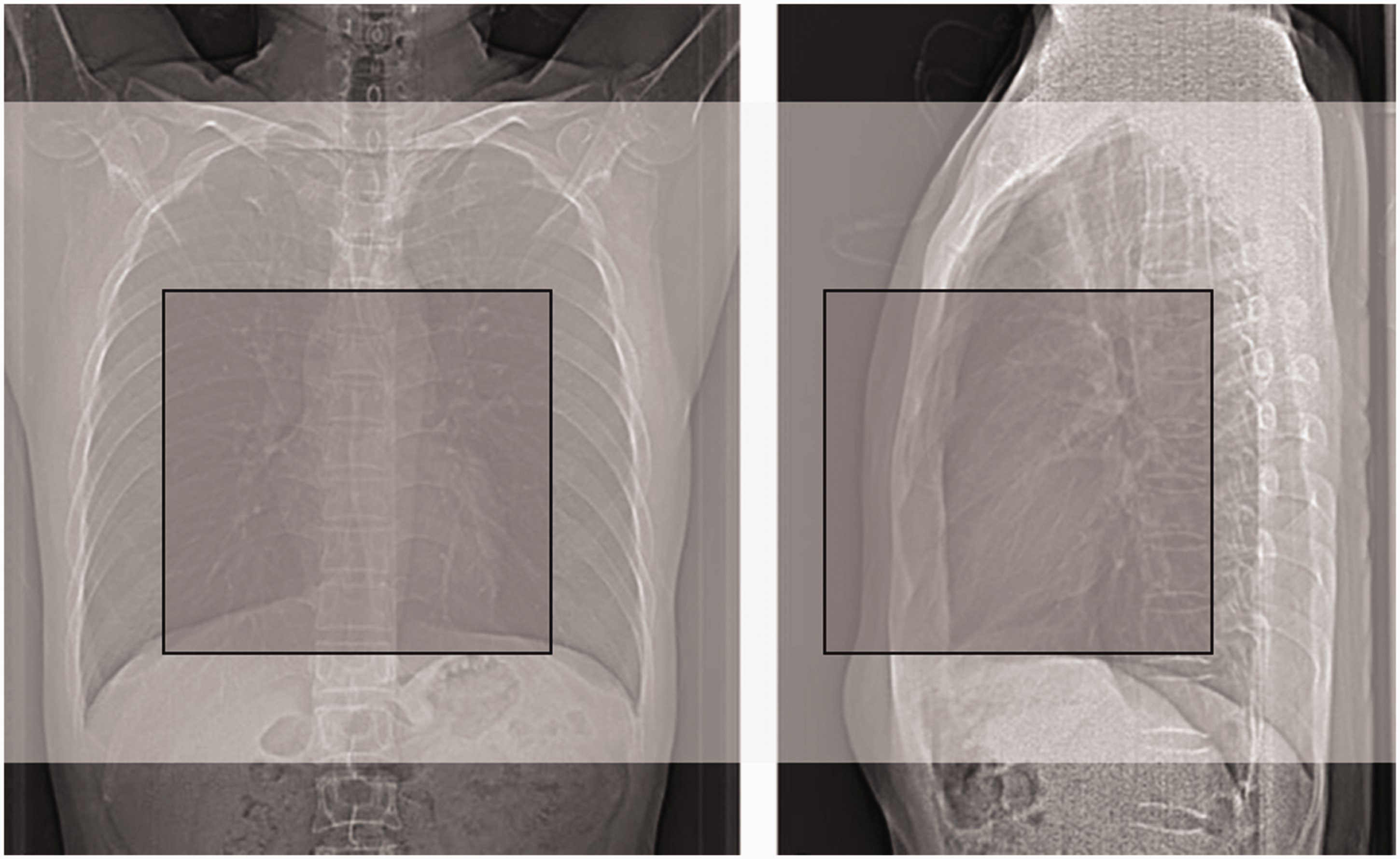
2.3. Protocol selection
Currently, selection of the scan protocol is a process that begins with the referring physician, who requests a scan to diagnose a specific condition. The radiologist then helps decide what type of medical images are most appropriate to diagnose that condition. Finally, the CT operator, who knows the specific variations of protocols programmed into the scanner for a given condition, chooses the correct protocol for the specific modality. Algorithms are under development that could lead any of these stages via a decision matrix to select the optimal protocol. However, at this time, such a system, which takes required contrast material, medication, or gating schemes into account, is not available.
2.4. Parameter selection
For a given type of scan protocol and clinical indication, many parameters need to be properly selected in order to optimise the CT examination. For data acquisition, these parameters are related to how the radiation is applied to the patient, how the patient table and x-ray tube move, and whether or not other special techniques (e.g. cardiac gating) are used. Currently, some AEC systems use simple machine learning techniques to select the optimal tube potential and tube current. One of the more complicated decisions involves setting up the contrast injection and scan acquisition time, such that the iodine enhancement is greatest over the anatomy of interest during data acquisition. To accomplish this, data at multiple time points were acquired on a large number of patients as the contrast was injected and travelled through the patient’s cardiovascular system. Based on these data, an algorithm is able to predict the ultimate height and width of the resulting contrast enhancement curve in the aorta. In subsequent patients beyond the training data, the system can predict the whole contrast enhancement curve using only a few data points on the rising edge of the curve, based upon which the optimal timing of the scan to be performed can be set as the contrast is flowing through the patient (Hinzpeter et al., 2019). Clinical studies have demonstrated better uniformity of contrast enhancement over the scan range in parallel to a reduction in the required dose of iodinated contrast media. The reduction in iodine can be accomplished by decreasing the rate of injection, which decreases the risk of damage to the vein into which the material is injected (Gutjahr et al., 2019).
2.5. Image reconstruction
The process of reconstructing a series of images from the acquired projection data requires the operator to carefully choose parameters that will impact the final characteristics of the image, including, but not limited to, the spatial resolution in the image, amount of overlap between consecutive images, thickness of anatomy represented in the image, image noise level, and magnification of the anatomy within the reconstructed image. An exciting application of AI in CT is the use of a convolutional neural network (CNN)-based deep learning approach to reduce image noise (also referred to as ‘denoising’) (Chen et al., 2017; Yang et al., 2018; Yi and Babyn, 2018). Missert et al. (2020) developed a CT image denoising technique that is trained to identify noise and not specific anatomical structures (Fig. 6), which is subsequently subtracted from the original images to improve image quality and reduce radiation dose.
A convolutional neural network (CNN)-based image denoising technique implemented using a residual network can identify image noise, which is consequently removed from the low-dose (high-noise) images to generate low-noise images.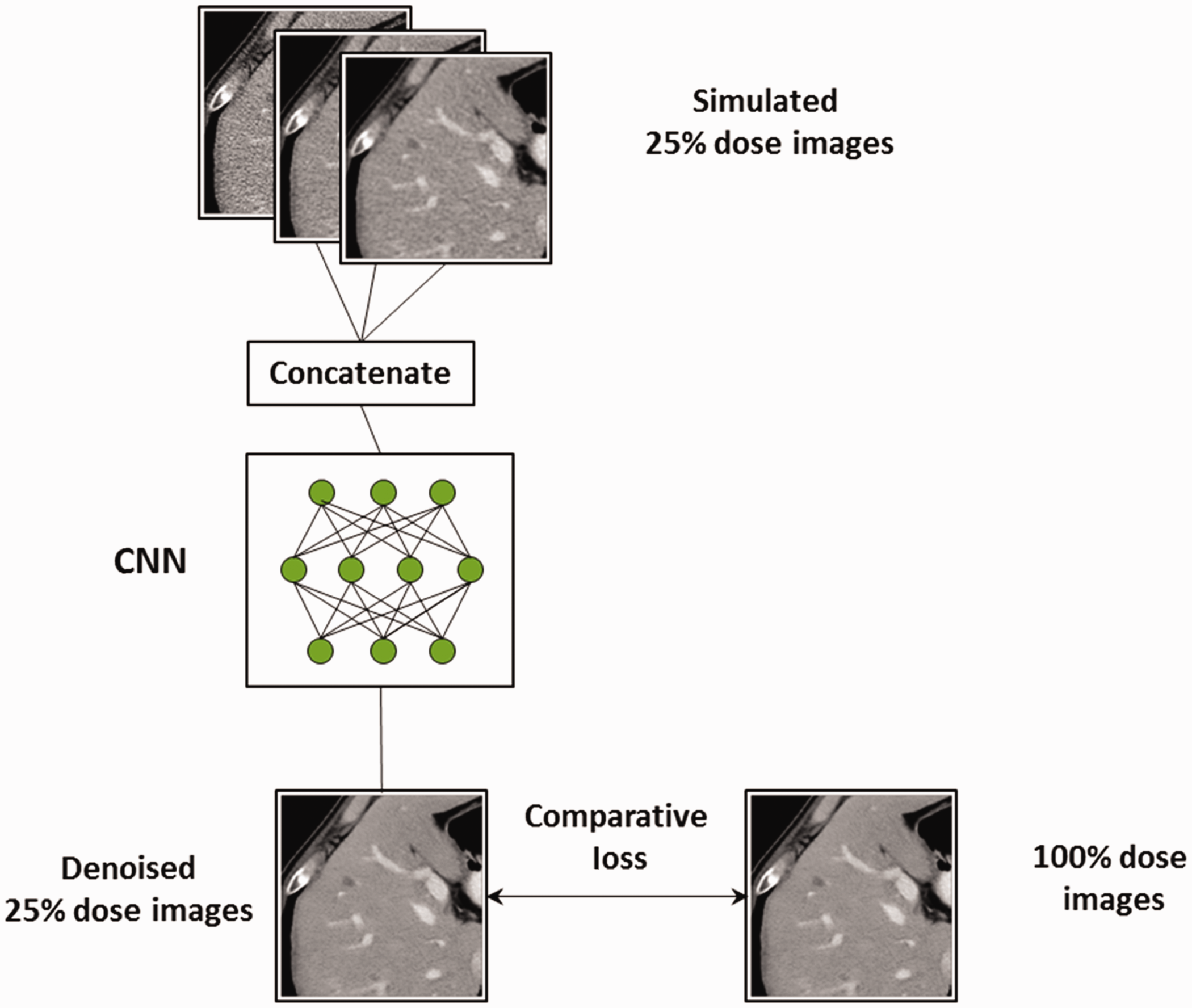
The algorithm was trained with millions of small patches from clinical patient data through the abdomen. For those patient cases, reduced dose images were simulated using a validated noise insertion technique (Yu et al., 2012; Chen et al., 2015). Thus, the training set contained simulated low-dose images (at 25% of the clinical dose level) and images acquired at the clinical dose level. From these data, the algorithm was trained to find image noise (Fig. 7). The reduction in noise is dramatic, without any loss of spatial resolution (Missert et al., 2020).
Dramatic noise reduction is achieved using a convolutional-neural-network-based denoising algorithm, evidenced by the comparison of images from simulated and denoised 25% dose.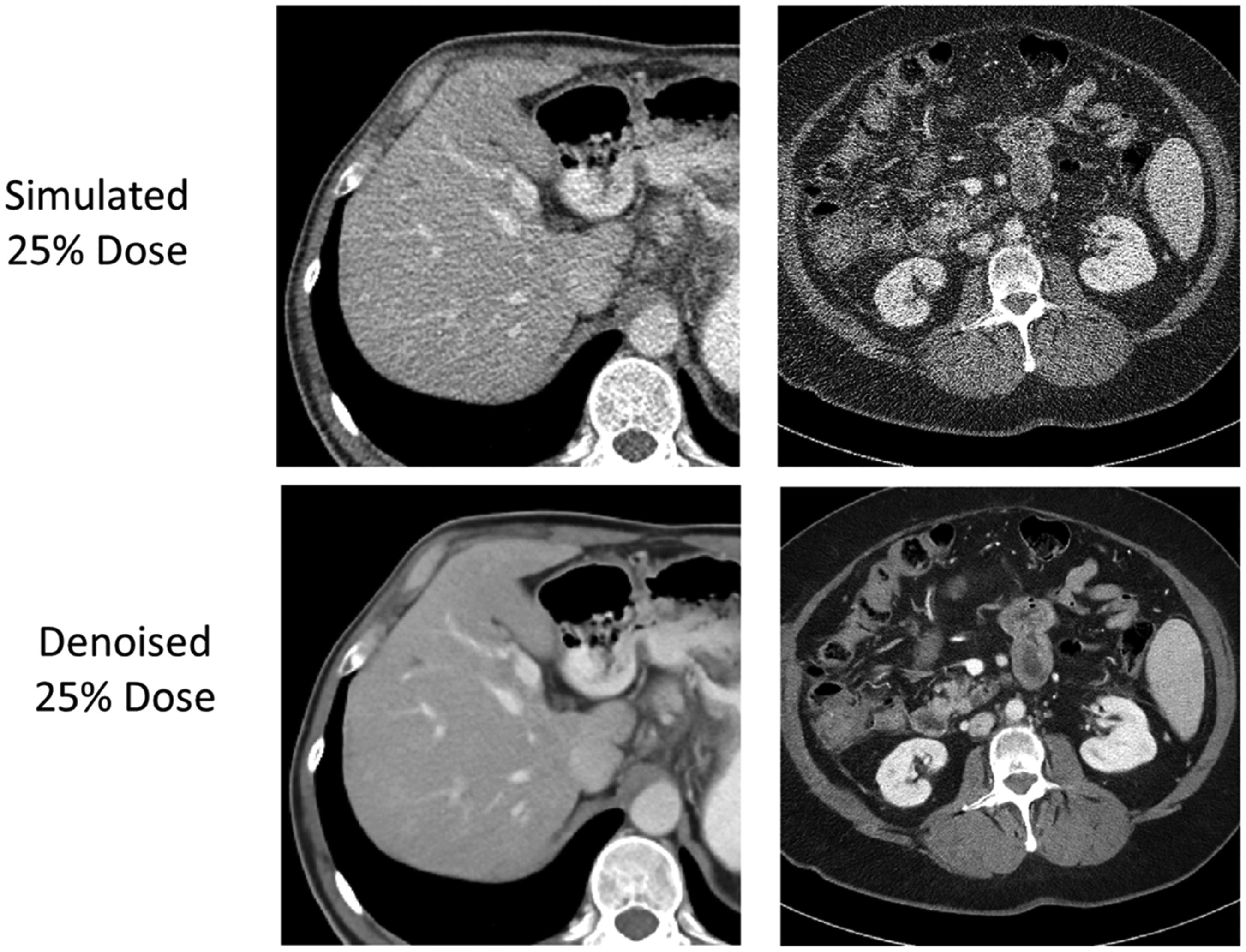
AI, particularly CNN-based deep learning, requires the use of training datasets to establish the correct weightings of the connections between various neural nodes and network layers. The network illustrated in Fig. 6, which produced the results shown in Fig. 7, was trained with low-dose (25% of full dose) and full-dose images. To assess the generalisability of the network to images from the same system having different input noise levels, we reconstructed the full-dose data, which decreased the noise of the full-dose images substantially. The network performed extremely well for that case, presumably because the datasets were so similar, and the CT image noise for that particular system was able to be modelled accurately by the network, independent of the specific noise levels. It is this ability to reduce image noise, after the data have been acquired, that allows an operator to reduce the dose during data acquisition and yet still achieve a high-quality image with an acceptable noise level.
However, AI networks are trained using specific datasets, which represent specific image characteristics; data acquired on different CT scanner models or with different acquisition or reconstruction parameters typically do not work well with networks that have been trained under different conditions. This lack of generalisability is one of the most fundamental barriers to widespread deployment of deep-learning-based image denoising.
3. Limitations
Since the widespread introduction of CT of the torso in the mid-1980s, the routine dose for an average-sized patient has decreased by approximately a factor of 4. As expressed in terms of the volume CT dose index, the routine output for a body CT examination has decreased from approximately 46 mGy in the early 1980s to approximately 11 mGy in recent years (Kanal et al., 2017). Use of AI to denoise reconstructed images, or even to perform the image reconstruction itself, will further reduce the required dose for body CT images of diagnostic quality. There is, however, a fundamental limitation regarding how low a dose can actually be achieved. The panel of images relating the number of photons needed to form the image to the ability of the observer to recognise the object contained in the image (Fig. 8), made famous by Rose (1973), demonstrates that there is a number of photons below which the statistical information needed to form a meaningful representation of the object being imaged is not present.
The panel of images relating the number of photons needed to form the image to the ability of the observer to recognise the object contained in the image. Reprinted with permission from Rose (1973).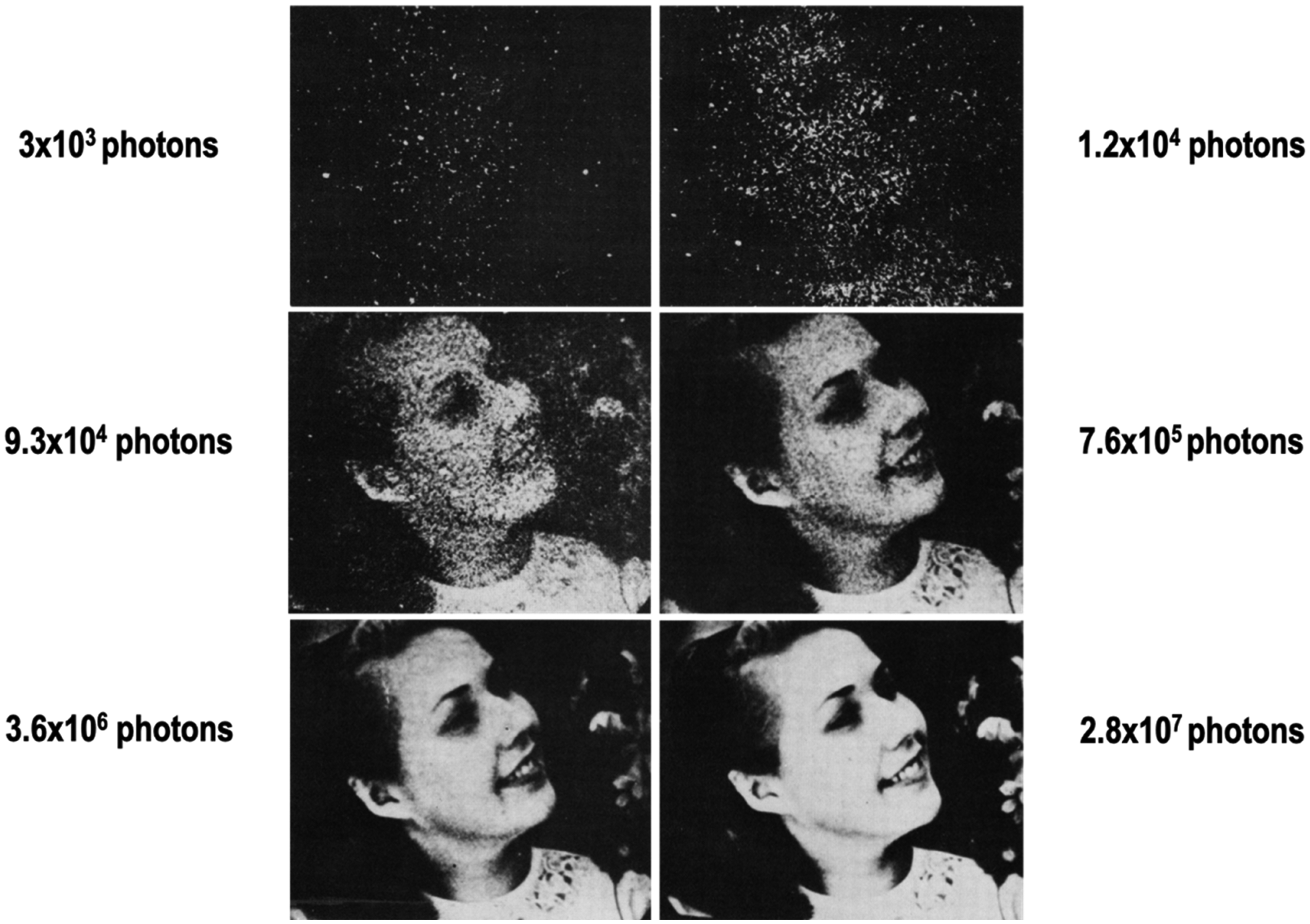
This principle has been demonstrated in recent years with the use of iterative reconstruction techniques to reduce image noise. These non-linear processes have been shown to degrade spatial resolution for objects that have low levels of signal contrast relative to background material. Favazza et al. (2017) demonstrated that although image noise is maintained, when the dose is decreased too much, subtle signals are lost. This is because the algorithm can no longer distinguish subtle features from the background, and in its effort to reduce high noise levels associated with reduced dose levels, the edges of subtle anatomy are blurred out. That is, there is a dose level at which the signal is not statistically strong enough to be maintained. For small nodules, this means that they can no longer be observed (Fig. 9).
Low contrast lesions seen in routine dose scans (post-protocol changes) are not clearly visible in low-dose previous scans (pre-protocol changes), although image noise is generally comparable among all scans. Reprinted with permission from Favazza et al. (2017).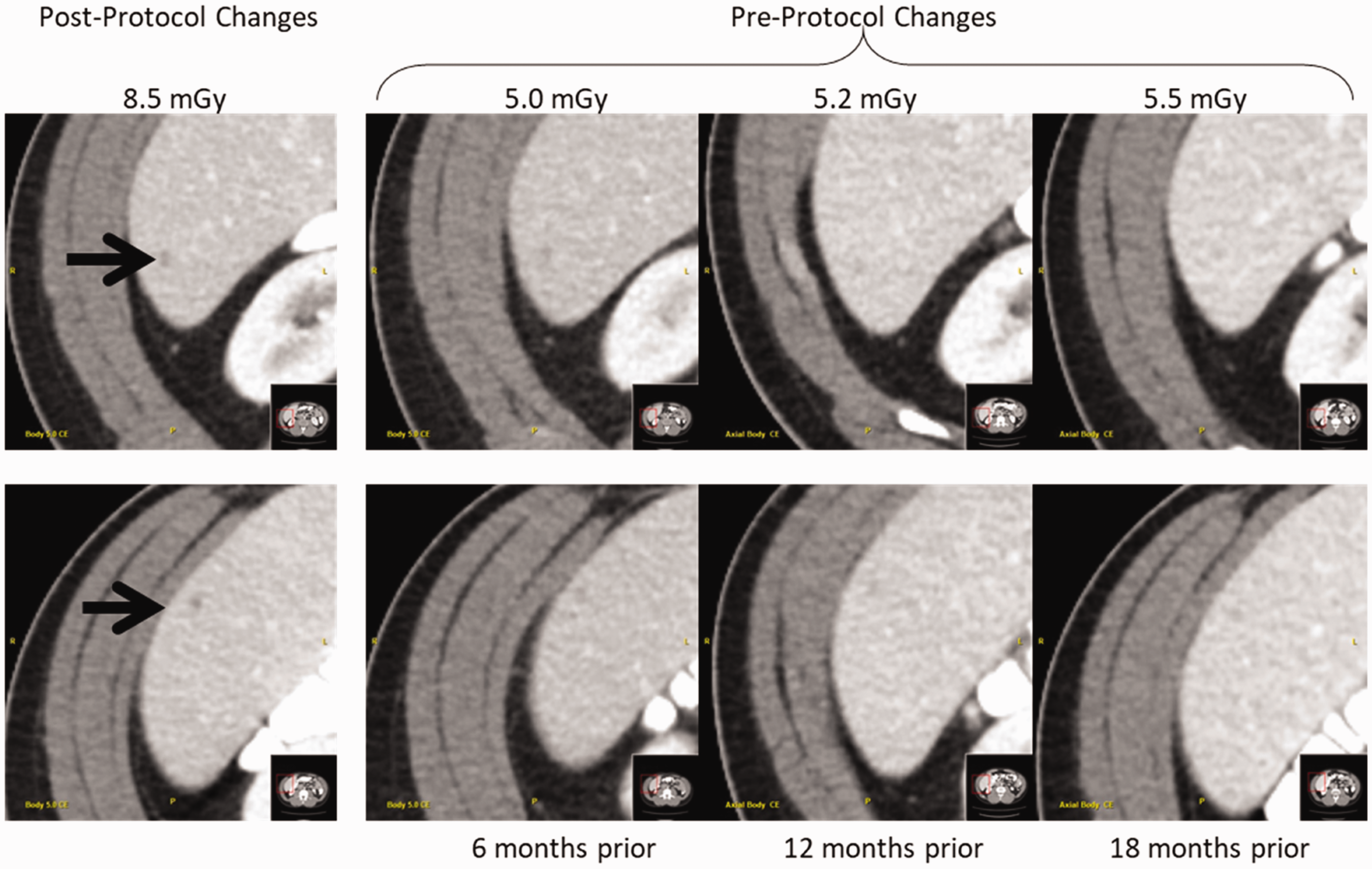
4. Summary
In summary, AI techniques can be used at every stage of a CT examination to benefit the quality of the resulting images, make the work flow more efficient for the operator and radiologist, and reduce image noise such that the radiation dose applied to the patient can be reduced during data acquisition. Currently, the use of a three-dimensional infra-red camera allows for automated positioning of the patient at the isocentre as well as automated prescription of the start and end rotations of the scan. Continued work in the field of optimising the scan acquisition and reconstruction parameters, as well as selecting optimal scan protocols, will enhance the reproducibility of CT images, improve the diagnostic value of the CT images, and reduce the dose to the patient. AI methods to reduce image artefacts, such as those caused by metal within the scan volume, are also anticipated. However, as exciting as new technology can be when first introduced, there will be limitations with how and when AI approaches are applied when first applied to practical problems. Generalisability will be one of the most challenging limitations to overcome. Thus, while it is clear that AI will be a part of medical imaging going forward, both manufacturers and users must proceed with caution, lest we repeat the mistake made with the introduction of iterative reconstruction and, as a consequence, miss important diagnosis. Further, it is not yet clear how these algorithms can be evaluated in the clinical setting, particularly for AI techniques that continuously ‘learn’ from the clinical information flowing through the network. What tests can be performed, and what datasets should be used, to confirm that a system performs as claimed by the manufacturer, and what tests and data should be used to confirm that the algorithm performs consistently at that level over time? These important questions remain to be answered.
Footnotes
Acknowledgements
We gratefully acknowledge the contributions of A.M. Missert and N.R. Huber, who learned AI, applied it to ongoing work in our laboratory, and then shared this knowledge with our team. We also appreciate the assistance of K.M. Nunez with manuscript preparation.