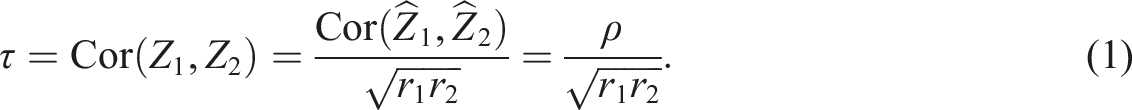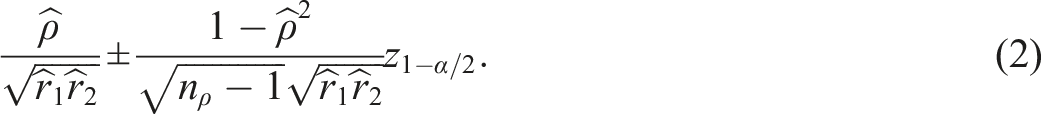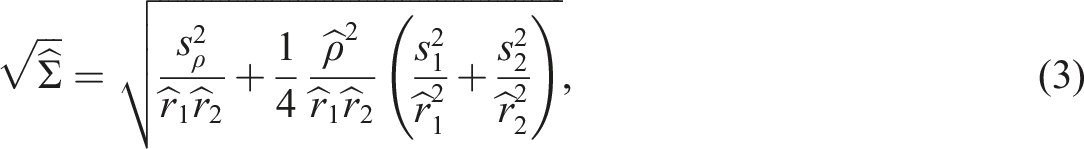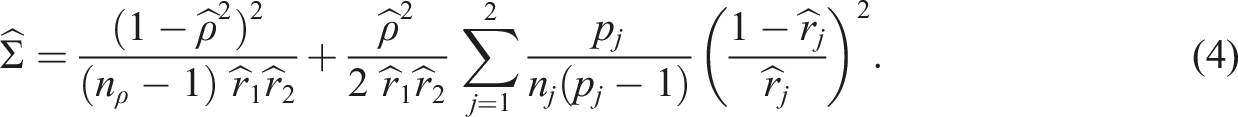When only summary statistics from published studies are available, the Hunter–Schmidt interval is the standard tool for inference on Spearman’s disattenuated correlation, but it treats reliability estimates as known constants and ignores their sampling variability. We derive a simple delta method variance that accounts for the uncertainty of all estimates while requiring nothing beyond the summaries already at hand. Under bivariate normality of scores and coefficient alpha from a normal parallel model, the corrected interval is asymptotically valid. In simulations it achieves coverage near nominal, while Hunter–Schmidt can undercover substantially when reliability is imprecisely estimated.
We are often interested in the correlation between two latent variables, and (e.g., conscientiousness and authoritarianism), which are not measured directly. Instead, they are estimated using scores, typically sum scores, derived from observed items. Denoting the scores by and and their reliabilities by and , Spearman’s formula (Spearman, 1904) gives the disattenuated correlation as
Our focus is on inference for when only summary statistics from papers are available, namely, the sample correlation , the estimated reliabilities and , their respective sample sizes , and potentially the number of items in each scale .
In this setting, the most common approach is the Hunter–Schmidt confidence interval (Hunter & Schmidt, 2004):
However, the validity of this interval is questionable. Its variance estimator, , incorrectly treats the reliabilities and as known constants, thereby failing to account for their sampling error. This known limitation (Padilla & Veprinsky, 2012, 2014), along with the strict requirement of bivariate normal data for the variance of (Fisher, 1915), motivates our goal of presenting a valid analytical confidence interval that incorporates the uncertainty of all estimates and is usable when only summary statistics are available. In practice, reliability estimates are often borrowed from an external validation study with its own, potentially small, sample size, making this source of uncertainty non-negligible, as illustrated in Example 1.
The Method
To construct our corrected interval, we first derive a standard error for the disattenuated correlation that accounts for the sampling variability of all its components. Suppose one has independent estimates , and for the correlation and reliabilities together with estimated standard errors , and . Then a valid standard error for the disattenuated correlation is
as may be found using a standard delta method argument. See the online appendix for a proof sketch.
While equation (3) provides a valid framework, its components (, and ) are not directly available from most published research. The formula applies to any reliability estimator with a known standard error, including omega or the greatest lower bound (e.g., McNeish, 2018; Sijtsma, 2009). To proceed from published summaries, however, we must adopt a model for the data that lets us calculate these standard errors from the information we do have. This requires three strong assumptions: (a) the scores are bivariate normal, (b) both reliabilities were estimated using coefficient alpha, and (c) the items follow a normal parallel model. Assumption (c) is needed not for alpha to consistently estimate reliability, as it does so under the weaker tau-equivalent model (Lord & Novick, 1968; Novick & Lewis, 1967), but for the standard error of alpha (Feldt, 1965; Kristof, 1963) to be correct. A more general standard error is available under the tau-equivalent model (van Zyl et al., 2000), but it requires the full item covariance matrix rather than the summary statistics we target here.
The utility of this approach is limited by the plausibility of these assumptions. Only assumption (b) typically holds, as coefficient alpha is still ubiquitous. However, the parallel model assumption is seldom met exactly, and psychometric data (often from Likert scales) are rarely truly normal. The substantial consequences of violating normality on the correlation are well-documented (e.g., Bishara et al., 2018; Kowalski, 1972). These effects are likely to be less pronounced here; however, since we are typically dealing with sum scores that are at least approximately marginally normal.
Under bivariate normality of scores we have , a result dating back to Fisher (1915). Under the parallel normal model we have (Feldt, 1965; Kristof, 1963), where is the number of items, and likewise for . These may be plugged into equation (3) to obtain an estimated standard error. When and are known and all our assumptions are met we have
Compared to the Hunter–Schmidt variance this formula contains an additional positive term.
Our corrected confidence interval is defined as
where is the -quantile of the standard normal distribution. The confidence intervals will be clipped to to respect the parameter space. code (R Core Team, 2025) for these confidence intervals is provided as supplementary material. For the remainder of this note, all confidence intervals discussed below have level .
From equation (3) we see that the confidence intervals can be widely different if one has small reliabilities, relatively high correlations, and small sample sizes for both the correlation and the reliabilities. For example, if , , , for , and , then the Hunter–Schmidt confidence interval will be [0.9479,1] and the corrected [0.8357,1]. But the confidence intervals can also be quite similar, as in the following example.
Neroni et al. (2022) reported a correlation of 0.38 between Self-Esteem (Rosenberg, 2016) and Perseverance of Effort (Duckworth et al., 2007) on a sample of subjects. For self-esteem, Muslih and Chung (2024) reported , , and . For Perseverance of Effort, Christensen and Knezek (2014) reported , , and . Under the parallel model, the standard errors of these reliability estimates are approximately 0.025 and 0.040, respectively. The Hunter–Schmidt interval is [0.4855, 0.5787] and the corrected interval [0.4735, 0.5907].
Papers often report reliabilities and correlations from a single data set, which by necessity makes them correlated. Consequently, equation (4) is not strictly correct. However, in the online appendix we give a heuristic argument and simulation evidence suggesting that, under our stated assumptions, using equation (4) is conservative. This still supports using the corrected interval in practice.
Marx and Winne (1978) reported correlations and alphas for three self-concept measures in one sample of sixth-graders. For Gordon versus Piers–Harris the observed score correlation was with alphas and . The Hunter–Schmidt interval is [0.9190,1] while the corrected interval is [0.8916,1]. Because the parameters are estimated on the same sample, the corrected interval is mildly conservative.
Simulations
We first simulate under the normal parallel model, matching our plug-in assumptions, then examine robustness to the tau-equivalent model. We do not consider richer factor models. Under congeneric measurement, coefficient alpha can underestimate reliability, so alpha-based disattenuation can be biased. Fisher’s variance requires normality, and dropping it can make coverage arbitrarily poor for both intervals (see Duncan & Layard, 1973, equation (1.1)).
We ran replicates with , , reliability for , correlation sample size , and reliability sample size .
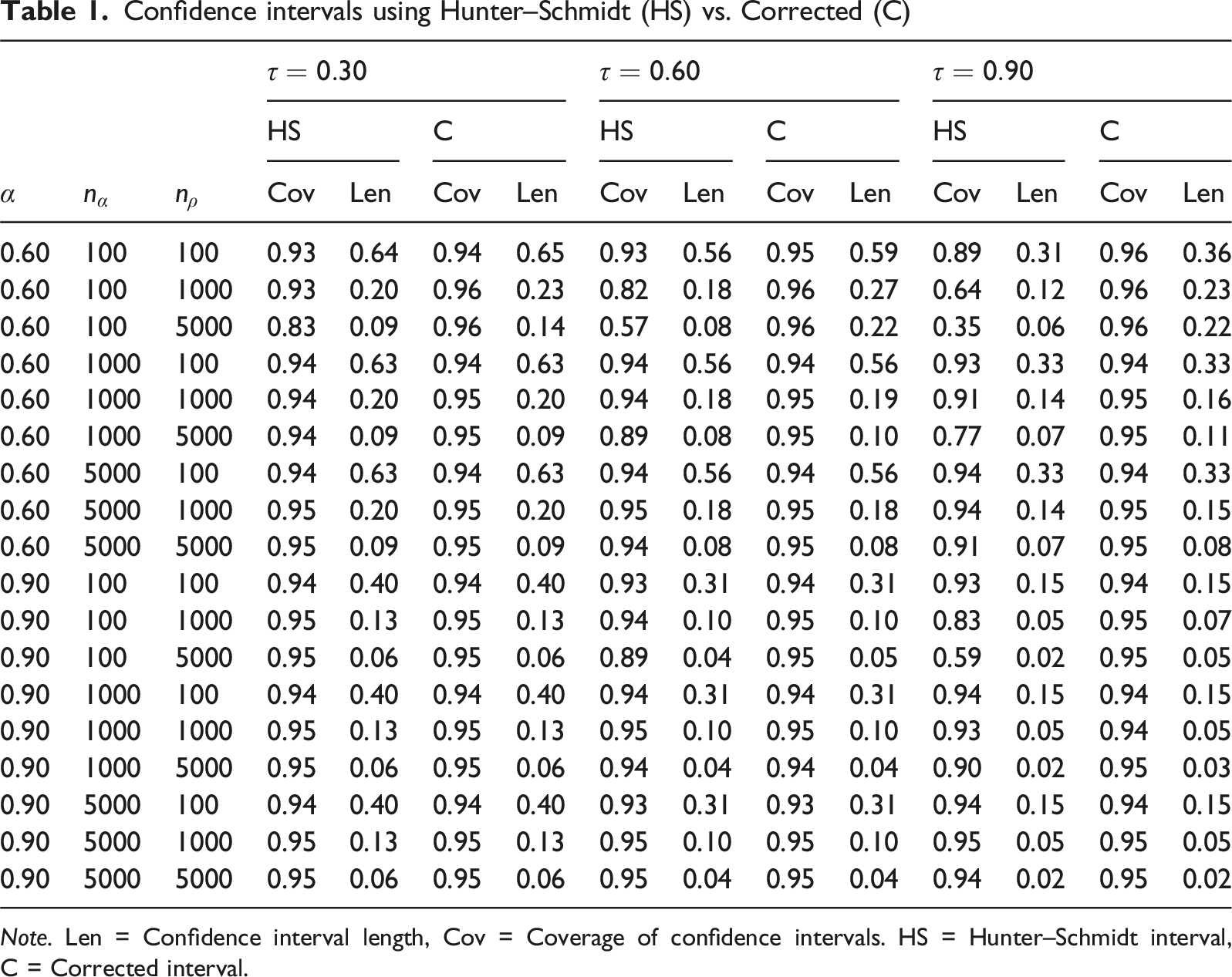
The results in Table 1 are simple. Hunter–Schmidt performs reasonably when is large relative to , but undercovers when reliability is noisy and is large. Higher exacerbates the problem. Where both intervals cover well, lengths are similar, so using the corrected interval by default sacrifices little.
Confidence intervals using Hunter–Schmidt (HS) vs. Corrected (C)
HS
C
HS
C
HS
C
Cov
Len
Cov
Len
Cov
Len
Cov
Len
Cov
Len
Cov
Len
0.60
100
100
0.93
0.64
0.94
0.65
0.93
0.56
0.95
0.59
0.89
0.31
0.96
0.36
0.60
100
1000
0.93
0.20
0.96
0.23
0.82
0.18
0.96
0.27
0.64
0.12
0.96
0.23
0.60
100
5000
0.83
0.09
0.96
0.14
0.57
0.08
0.96
0.22
0.35
0.06
0.96
0.22
0.60
1000
100
0.94
0.63
0.94
0.63
0.94
0.56
0.94
0.56
0.93
0.33
0.94
0.33
0.60
1000
1000
0.94
0.20
0.95
0.20
0.94
0.18
0.95
0.19
0.91
0.14
0.95
0.16
0.60
1000
5000
0.94
0.09
0.95
0.09
0.89
0.08
0.95
0.10
0.77
0.07
0.95
0.11
0.60
5000
100
0.94
0.63
0.94
0.63
0.94
0.56
0.94
0.56
0.94
0.33
0.94
0.33
0.60
5000
1000
0.95
0.20
0.95
0.20
0.95
0.18
0.95
0.18
0.94
0.14
0.95
0.15
0.60
5000
5000
0.95
0.09
0.95
0.09
0.94
0.08
0.95
0.08
0.91
0.07
0.95
0.08
0.90
100
100
0.94
0.40
0.94
0.40
0.93
0.31
0.94
0.31
0.93
0.15
0.94
0.15
0.90
100
1000
0.95
0.13
0.95
0.13
0.94
0.10
0.95
0.10
0.83
0.05
0.95
0.07
0.90
100
5000
0.95
0.06
0.95
0.06
0.89
0.04
0.95
0.05
0.59
0.02
0.95
0.05
0.90
1000
100
0.94
0.40
0.94
0.40
0.94
0.31
0.94
0.31
0.94
0.15
0.94
0.15
0.90
1000
1000
0.95
0.13
0.95
0.13
0.95
0.10
0.95
0.10
0.93
0.05
0.94
0.05
0.90
1000
5000
0.95
0.06
0.95
0.06
0.94
0.04
0.94
0.04
0.90
0.02
0.95
0.03
0.90
5000
100
0.94
0.40
0.94
0.40
0.93
0.31
0.93
0.31
0.94
0.15
0.94
0.15
0.90
5000
1000
0.95
0.13
0.95
0.13
0.95
0.10
0.95
0.10
0.95
0.05
0.95
0.05
0.90
5000
5000
0.95
0.06
0.95
0.06
0.95
0.04
0.95
0.04
0.94
0.02
0.95
0.02
Note. Len = Confidence interval length, Cov = Coverage of confidence intervals. HS = Hunter–Schmidt interval, C = Corrected interval.
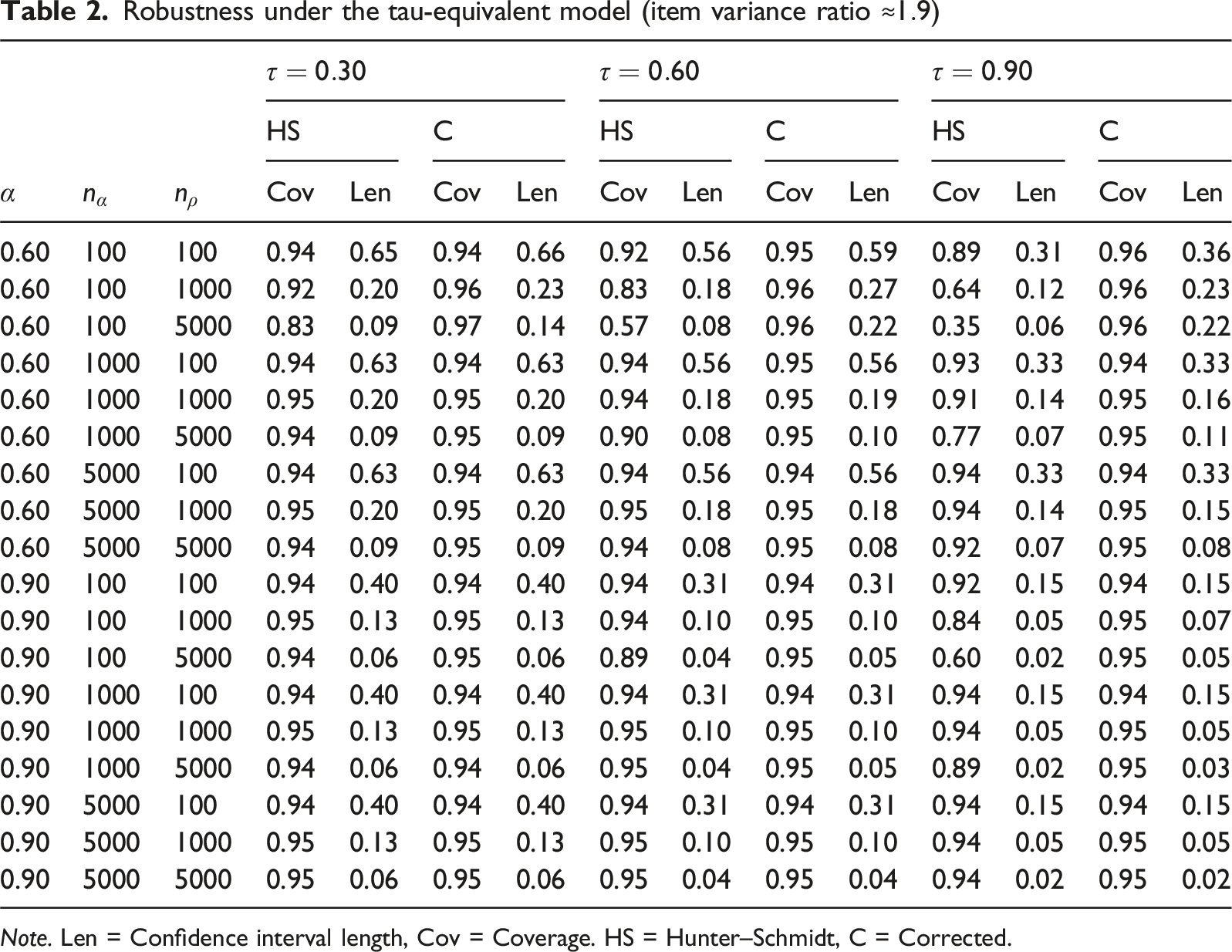
To assess sensitivity to violations of the parallel model assumption, we repeated the simulation under a tau-equivalent model (equal loadings, unequal error variances) with item variance ratios calibrated from the psych::bfi data (Revelle, 2026). Table 2 shows results for item variance ratios of approximately 1.9, representative of scales such as Openness in the BFI. A milder ratio of 1.3 gave nearly identical results (see the online appendix for details).
Robustness under the tau-equivalent model (item variance ratio )
HS
C
HS
C
HS
C
Cov
Len
Cov
Len
Cov
Len
Cov
Len
Cov
Len
Cov
Len
0.60
100
100
0.94
0.65
0.94
0.66
0.92
0.56
0.95
0.59
0.89
0.31
0.96
0.36
0.60
100
1000
0.92
0.20
0.96
0.23
0.83
0.18
0.96
0.27
0.64
0.12
0.96
0.23
0.60
100
5000
0.83
0.09
0.97
0.14
0.57
0.08
0.96
0.22
0.35
0.06
0.96
0.22
0.60
1000
100
0.94
0.63
0.94
0.63
0.94
0.56
0.95
0.56
0.93
0.33
0.94
0.33
0.60
1000
1000
0.95
0.20
0.95
0.20
0.94
0.18
0.95
0.19
0.91
0.14
0.95
0.16
0.60
1000
5000
0.94
0.09
0.95
0.09
0.90
0.08
0.95
0.10
0.77
0.07
0.95
0.11
0.60
5000
100
0.94
0.63
0.94
0.63
0.94
0.56
0.94
0.56
0.94
0.33
0.94
0.33
0.60
5000
1000
0.95
0.20
0.95
0.20
0.95
0.18
0.95
0.18
0.94
0.14
0.95
0.15
0.60
5000
5000
0.94
0.09
0.95
0.09
0.94
0.08
0.95
0.08
0.92
0.07
0.95
0.08
0.90
100
100
0.94
0.40
0.94
0.40
0.94
0.31
0.94
0.31
0.92
0.15
0.94
0.15
0.90
100
1000
0.95
0.13
0.95
0.13
0.94
0.10
0.95
0.10
0.84
0.05
0.95
0.07
0.90
100
5000
0.94
0.06
0.95
0.06
0.89
0.04
0.95
0.05
0.60
0.02
0.95
0.05
0.90
1000
100
0.94
0.40
0.94
0.40
0.94
0.31
0.94
0.31
0.94
0.15
0.94
0.15
0.90
1000
1000
0.95
0.13
0.95
0.13
0.95
0.10
0.95
0.10
0.94
0.05
0.95
0.05
0.90
1000
5000
0.94
0.06
0.94
0.06
0.95
0.04
0.95
0.05
0.89
0.02
0.95
0.03
0.90
5000
100
0.94
0.40
0.94
0.40
0.94
0.31
0.94
0.31
0.94
0.15
0.94
0.15
0.90
5000
1000
0.95
0.13
0.95
0.13
0.95
0.10
0.95
0.10
0.94
0.05
0.95
0.05
0.90
5000
5000
0.95
0.06
0.95
0.06
0.95
0.04
0.95
0.04
0.94
0.02
0.95
0.02
Note. Len = Confidence interval length, Cov = Coverage. HS = Hunter–Schmidt, C = Corrected.
In this tau-equivalent setting, the corrected interval maintains coverage near , while Hunter–Schmidt undercovers when is large relative to .
To probe the normality assumption, we also ran a reduced-design simulation with standardized latent factors and item errors (full results in the online appendix). Non-normality reduces coverage for both intervals, with neither reaching nominal at high . At and , for example, corrected coverage ranged from 0.87 to 0.92 across design conditions while Hunter–Schmidt ranged from 0.52 to 0.82.
Concluding Remarks
We propose a corrected confidence interval for disattenuated correlations that accounts for the sampling variability of the reliability estimates. It is necessarily wider than the Hunter–Schmidt interval, but its empirical coverage is close to nominal across conditions. When only summary statistics are available (e.g., in meta-analyses), the corrected interval is a sensible default. But with raw data, latent-variable models such as lavaan (Rosseel, 2012) are preferable, and bootstrap intervals for the disattenuated correlation have also performed well in prior work (Padilla & Veprinsky, 2012, 2014).
Our approach assumes bivariate normality of sum scores and a normal parallel model. Bivariate normality may be violated, which can reduce coverage (Kowalski, 1972). Under non-parallel measurement, the coefficient alpha standard error of Kristof (1963) and Feldt (1965) is typically underestimated, again hurting coverage. Although equation (3) admits alternative standard errors, robust choices require raw data and are biased in small samples (Xiao & Hau, 2022). In our summary statistics setting, these assumptions cannot be directly verified, but researchers can consult the source studies for item-level diagnostics. In practice, researchers should look for roughly symmetric sum-score distributions, no strong piling up at the lowest or highest response categories, and item variances that are not wildly different. When such diagnostics are unavailable, the interval should be viewed as the best available large-sample correction to Hunter–Schmidt under limited information. As shown in the simulation study, the corrected interval is reasonably robust to realistic tau-equivalent departures from parallelism, but non-normality can reduce coverage for both intervals. The corrected interval is not assumption-free, but it is the best that can be done without raw data.
Supplemental Material
Supplemental Material - Inference for Disattenuated Correlations
Supplemental Material for Inference for Disattenuated Correlations by Jonas Moss in Applied Psychological Measurement.
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Provided in the supplemental material.*
Supplemental Material
Supplemental material for this article is available online.
References
1.
BisharaA. J.LiJ.NashT. (2018). Asymptotic confidence intervals for the Pearson correlation via skewness and kurtosis. The British Journal of Mathematical and Statistical Psychology, 71(1), 167–185. https://doi.org/10.1111/bmsp.12113
2.
ChristensenR.KnezekG. (2014). Comparative measures of grit, tenacity and perseverance. International Journal of Learning, Teaching and Educational Research, 8(1), 1694–2116.
3.
DuckworthA. L.PetersonC.MatthewsM. D.KellyD. R. (2007). Grit: perseverance and passion for long-term goals. Journal of Personality and Social Psychology, 92(6), 1087–1101. https://doi.org/10.1037/0022-3514.92.6.1087
4.
DuncanG. T.LayardM. W. J. (1973). A Monte-Carlo study of asymptotically robust tests for correlation coefficients. Biometrika, 60(3), 551–558. https://doi.org/10.1093/biomet/60.3.551
5.
FeldtL. S. (1965). The approximate sampling distribution of Kuder-Richardson reliability coefficient twenty. Psychometrika, 30(3), 357–370. https://doi.org/10.1007/bf02289499
6.
FisherR. A. (1915). Frequency distribution of the values of the correlation coefficient in samples from an indefinitely large population. Biometrika, 10(4), 507–521. https://doi.org/10.2307/2331838
7.
HunterJ. E.SchmidtF. L. (2004). Methods of meta-analysis: Correcting error and bias in research findings (2 edition). Sage. https://doi.org/10.4135/9781412985031
8.
KowalskiC. J. (1972). On the effects of non-normality on the distribution of the sample product-moment correlation coefficient. Journal of the Royal Statistical Society. Series C, Applied Statistics, 21(1), 1. https://doi.org/10.2307/2346598
9.
KristofW. (1963). The statistical theory of stepped-up reliability coefficients when a test has been divided into several equivalent parts. Psychometrika, 28(3), 221–238. https://doi.org/10.1007/BF02289571
10.
LordF. M.NovickM. R. (1968). Statistical theories of mental test scores. Addison-Wesley.
11.
MarxR. W.WinneP. H. (1978). Construct interpretations of three self-concept inventories. American Educational Research Journal, 15(1), 99–109. https://doi.org/10.3102/00028312015001099
12.
McNeishD. (2018). Thanks coefficient alpha, we’ll take it from here. Psychological Methods, 23(3), 412–433. https://doi.org/10.1037/met0000144
13.
MuslihM.ChungM.-H. (2024). Structural validity of the Rosenberg self-esteem scale in patients with schizophrenia in Indonesia. PLOS One, 19(5), e0300184. https://doi.org/10.1371/journal.pone.0300184
14.
NeroniJ.MeijsC.KirschnerP. A.XuK. M.de GrootR. H. M. (2022). Academic self-efficacy, self-esteem, and grit in higher online education: Consistency of interests predicts academic success. Social Psychology of Education, 25(4), 951–975. https://doi.org/10.1007/s11218-022-09696-5
15.
NovickM. R.LewisC. (1967). Coefficient alpha and the reliability of composite measurements. Psychometrika, 32(1), 1–13. https://doi.org/10.1007/bf02289400
16.
PadillaM. A.VeprinskyA. (2012). Correlation attenuation due to measurement error: A new approach using the bootstrap procedure. Educational and Psychological Measurement, 72(5), 827–846. https://doi.org/10.1177/0013164412443963
R Core Team. (2025). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
19.
RevelleW. (2026). Psych: Procedures for psychological, psychometric, and personality research. Northwestern University. R package version 2.6.1. https://CRAN.R-project.org/package=psych
20.
RosenbergM. (2016). Society and the adolescent self-image. Princeton University Press.
21.
RosseelY. (2012). Lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48(2), 1–36. https://doi.org/10.18637/jss.v048.i02
SpearmanC. (1904). The proof and measurement of association between two things. The American Journal of Psychology, 15(1), 72–101. https://doi.org/10.2307/1412159
24.
van ZylJ. M.NeudeckerH.NelD. G. (2000). On the distribution of the maximum likelihood estimator of Cronbach’s alpha. Psychometrika, 65(3), 271–280. https://doi.org/10.1007/BF02296146
25.
XiaoL.HauK.-T. (2022). Performance of coefficient alpha and its alternatives: Effects of different types of non-normality. Educational and Psychological Measurement, 83(1). https://doi.org/10.1177/00131644221088240